GQE-Net: A Graph-based Quality Enhancement Network for Point Cloud Color Attribute
Abstract
In recent years, point clouds have become increasingly popular for representing three-dimensional (3D) visual objects and scenes. To efficiently store and transmit point clouds, compression methods have been developed, but they often result in a degradation of quality. To reduce color distortion in point clouds, we propose a graph-based quality enhancement network (GQE-Net) that uses geometry information as an auxiliary input and graph convolution blocks to extract local features efficiently. Specifically, we use a parallel-serial graph attention module with a multi-head graph attention mechanism to focus on important points or features and help them fuse together. Additionally, we design a feature refinement module that takes into account the normals and geometry distance between points. To work within the limitations of GPU memory capacity, the distorted point cloud is divided into overlap-allowed 3D patches, which are sent to GQE-Net for quality enhancement. To account for differences in data distribution among different color components, three models are trained for the three color components. Experimental results show that our method achieves state-of-the-art performance. For example, when implementing GQE-Net on a recent test model of the geometry-based point cloud compression (G-PCC) standard, dB, dB and dB delta (BD)-peak-signal-to-noise ratio (PSNR), corresponding to , and BD-rate savings were achieved on dense point clouds for the Y, Cb, and Cr components, respectively.
The source code of our method is available at https://github.com/xjr998/GQE-Net.
Index Terms:
point cloud, quality enhancement, graph neural network, G-PCC.I Introduction
Point clouds are sets of 3D points given by their coordinates and attribute information such as color, reflectance, and normals. Point clouds are obtained from laser scans, multiview video cameras, or light field imaging systems [1] [2]. Due to their flexibility and powerful representation capability, they are increasingly being used in fields such as immersive communication, robotics, geographic information systems (GIS), and autonomous driving [3]. However, the large volume of data in point clouds can be a challenge for storage and transmission. Therefore, developing efficient compression technologies for point clouds is necessary.
To reduce resource consumption, the International Organization for Standardization (ISO) and the International Electrotechnical Commission (IEC) joint technical committee for “Information technology” (JTC1) / Work Group 7 (WG7) are currently developing two types of compression standards [4] for 3D point clouds: video-based point cloud compression (V-PCC) [5] and geometry-based point cloud compression (G-PCC) [6]. WG7 is also studying the potential of artificial intelligence technologies for point cloud compression, with the aim of developing a corresponding standard [7]. V-PCC projects the point cloud onto 2D planes and compresses these images using existing video coding standards, such as H.265/High Efficiency Video Coding (HEVC). G-PCC, on the other hand, is directly based on the 3D geometric structure. Compared to V-PCC, G-PCC has lower complexity and requires less memory use. However, the coding efficiency of G-PCC is usually lower than that of V-PCC when dealing with dense point clouds.

Currently, many technologies for G-PCC and V-PCC are being developed and optimized, resulting in a higher compression efficiency. However, when the bandwidth is limited, the compression bit rate may have to be reduced by increasing the quantization step size. This can result in noticeable attribute distortions in the reconstructed point cloud and negatively affect the overall visual experience.
Both geometry and attribute compression can result in a reduction in quality. Geometry distortion is typically characterized by outliers and holes, while attribute distortion is mainly caused by blurring of textures and mismatches in color. Fig. 1 shows a comparison between an original point cloud and its reconstruction after compression using the lifting transform in a lossless geometry, lossy attribute configuration in G-PCC. The reconstructed point cloud is clearly different from the original point cloud due to the significant distortion in color. Therefore, it is essential to enhance the quality after compression.
In recent years, deep learning-based methods have had significant success in image processing. However, due to the irregular distribution of points, point clouds are difficult to process using conventional neural networks for 2D images and videos. To address this challenge, various approaches have been proposed. For example, projection-based methods aim to map the point cloud into multiple 2D images, which can then be processed by convolutional neural networks [8, 9, 10]. Another approach [11, 12, 13] is to regularize the point cloud through voxelization and then apply a convolutional neural network with slight modifications to the voxels. However, the high complexity and memory consumption of these two approaches limit their applicability to some extent. As a result, many researchers have turned to working directly with 3D point clouds. Qi et al. [14] proposed PointNet, which achieves permutation invariance of points and extracts features of the point cloud. Later, recognizing that each point in PointNet is learned independently and that the local features between points are not exploited, Qi et al. [15] proposed PointNet++ to capture local geometry information using a hierarchical structure. They also used 3D sparse convolutions to process cubes directly. Graham et al. [16] introduced new sparse convolutional operations to efficiently process spatially-sparse data. Su et al. [17] proposed sparse lattice networks with sparse bilateral convolutional layers. These layers apply convolutions only on occupied parts of the lattice, enabling hierarchical and spatially-aware feature learning.
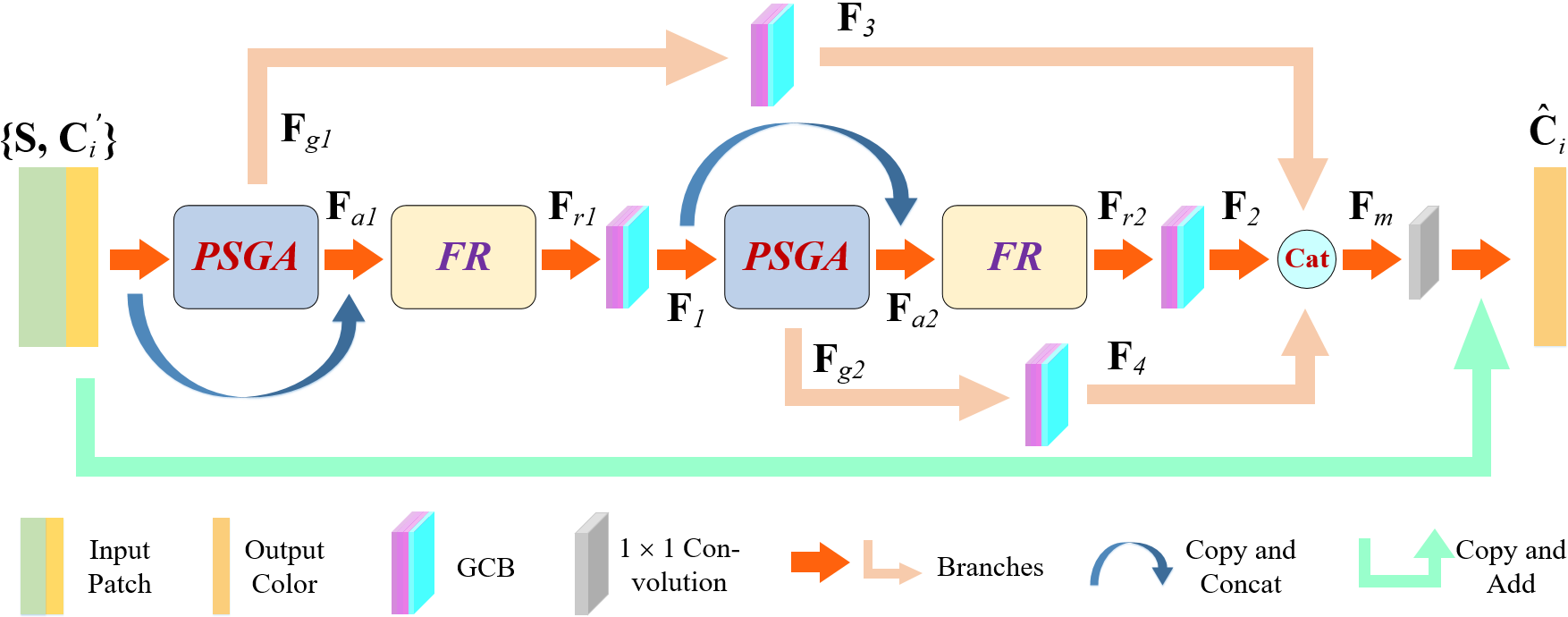
Using a graph-based neural network approach is a promising way to process point clouds. By creating a graph topological structure, points are closely related to each other, making it easy to extract local features. Building on previous successful graph-based processing techniques for point clouds [18, 19, 20, 21, 22, 23, 24], we propose a graph neural network-based method for enhancing the quality of point clouds that have been distorted by compression. Our method splits a large point cloud into smaller, overlapping 3D patches that contain both geometry and color information. These patches are then fed into a neural network, called graph-based quality enhancement network (GQE-Net), for enhancement of the color attributes.The architecture of GQE-Net is shown in Fig. 2. As can be seen, GQE-Net includes special modules, such as a parallel-serial graph attention (PSGA) module and a feature refining (FR) module. Additionally, geometry coordinates are used to build graphs and calculate normal vectors. In our method, the Luma (Y) and Chroma (Cb and Cr) components of the color information are processed separately due to their distinct data distribution. Strategies are also implemented to handle overlapping and unprocessed points when merging the patches back into a single point cloud. In summary, this paper makes the following contributions:
-
•
We introduce a parallel-serial graph attention module that uses a multi-head attention mechanism to focus on key points and points with high distortion. The module includes two parallel attention heads and one reinforcement head.
-
•
We propose a feature refining module that uses geometry information to determine the correlation between points. The module calculates normal vectors and incorporates them into the color features. Moreover, it assigns weights to the features based on the distance between points.
-
•
Our experiments show that the proposed network significantly improves the quality of distorted point clouds and enhances coding efficiency. Moreover, the proposed network is robust in the sense that it can handle point clouds with various levels of distortion using a single pre-trained model.
The remainder of this paper is organized as follows. In Section II, we review related work in the areas of graph neural network-based point cloud processing, point cloud geometry denoising, and point cloud color quality enhancement. Section III provides a detailed description of our method, including the methodology of the proposed network and the structure of each module. In Section IV, we present experimental results and an ablation study to demonstrate the effectiveness of our method. Finally, Section V concludes the paper.
II Related Works
In this section, we begin by providing a brief overview of graph neural network-based point cloud processing methods, as our proposed method is also built on this framework. Next, we review methods for geometry denoising of point clouds, as they aid in the extraction of inter-point correlation by considering the geometry structure. Finally, we discuss several quality enhancement methods for point cloud color.
II-A Graph neural network-based point cloud processing
Recently, graph-based neural networks have achieved great success in 3D point cloud processing. Notably, the EdgeConv module, a prominent graph convolution technique, was introduced by Wang et al. [18] to facilitate high-level feature extraction from point clouds. This module uses a dynamic graph across network layers, significantly enhancing the capacity to capture intricate features. Additionally, the incorporation of graph-attention mechanisms plays an important role to focus on key points within the point cloud. Chen et al. [19] introduced a graph attention-based point network layer (GAPLayer) to learn local geometric representations by multiple single head graph attention mechanisms. Wang et al. [20] proposed a graph attention convolution (GAC) that adapts its kernels to the structure of an object to capture structured features for fine-grained segmentation and avoid feature contamination between objects.
Many advancements in point cloud analysis have been achieved through the synergistic fusion of graph neural networks with classical models or mechanisms. This collaborative approach enhances the capability of these networks to tackle complex tasks effectively. Shi et al. [21] proposed a graph neural network for object detection. The network uses an auto-registration mechanism to reduce translation variance and a box merging and scoring operation to combine detections from multiple vertices accurately. Feng et al. [23] proposed a deep auto-encoder with graph topology inference and filtering to achieve compact representations of unorganized 3D point clouds in an unsupervised manner. Liang et al. [24] proposed a hierarchical depth-wise graph convolutional neural network for point cloud semantic segmentation. A customized block called depthwise graph convolution (DGConv) was designed for local feature extraction.
While these methods effectively extract correlation between points using the graph structure, they do not fully exploit the available information. The distances between points and the normals play a crucial role in determining the strength of correlation between two points. Moreover, as different points have varying importance, it is important to focus on key points and design more effective attention modules. In the field of quality enhancement, it is particularly important to capture points with high distortion or those located in key positions. Therefore, we design modules (PSGA and FR) that adaptively extract features and further exploit correlations between points.
II-B 3D point cloud geometry denoising
3D point cloud geometry denoising is crucial for various applications such as autonomous driving. The goal of point cloud denoising is to remove outliers or fill in holes to enable further processing or downstream applications. Within this context, the integration of graph Laplacian regularization (GLR) has proven effective in enhancing denoising capabilities [25][26]. Dinesh et al. [25] proposed a signal-dependent feature graph Laplacian regularizer which can be used as a signal prior. Zeng et al. [26] proposed a discrete patch distance measure to quantify the similarity between two surface patches of the same size for graph construction. Given the huge data volume in point cloud processing, manifold-based methods hold promise for features projection and dimensionality reduction. Hu et al. [27] proposed a method based on spatial-temporal graph representation that uses the temporal consistency between surface patches that correspond to the same underlying manifold. Xu et al. [28] proposed a transformer-based end-to-end network with an encoder-decoder architecture. The encoder uses a transformer, while the decoder learns the latent manifold of each sampled point. To achieve optimal denoising, multi-stage or stepwise strategies are often applied. Chen et al. [29] proposed a task-specific point cloud denoising network, RePCDNet, which consists of four key modules based on recurrent neural networks (RNNs) for feature extraction and enhancement. Jia et al. [30] proposed a two-step method for removing geometry artifacts and improving the compression efficiency of V-PCC. The first step is learning-based pseudo-motion compensation, aiming at denoising the artifacts. The second step takes advantage of the strong correlation between the near and far depth fields decomposed from geometry to further improve the results. Furthermore, within the specific context of V-PCC, the work in [31] introduced an adaptive denoising method, which applies the Wiener filter on the 2D geometry images.
The works reviewed in this section suggest that extracting effective geometry features is crucial for improving the quality of the point cloud. Techniques such as domain transformation, surface fitting, normal approximation, and distance measurement can be used to detect and eliminate noise in the point cloud. In addition, geometry features can provide important information to enhance color quality.
II-C 3D point cloud color quality enhancement
Most of the previous work in the field of point cloud quality enhancement is based on traditional algorithms. For example, Irfan and Magli [32, 33] make full use of graph transform or optimization to reduce color distortion. In [32], a point cloud quality enhancement method was proposed, which uses a spectral graph wavelet transform to jointly exploit both geometry and color in the graph spectral domain. The authors [33] later proposed a graph-based optimization method that aims to remove both geometry and color distortion simultaneously. The method assumes that the color and location of a point are related to each other. Similarly based on the graph, Yamamoto et al. [34] proposed a deblurring method for point cloud attributes, which is inspired by multi-Wiener Stein’s unbiased risk estimate-linear expansion of thresholding deconvolution of images. The blurred textures are considered as graph signals that are decomposed into sub-bands after Wiener-like filtering, and then all filtered signals are added together with the coefficients obtained from the linear equation. Another work using Wiener filter for color quality enhancement is [35], which is specifically designed for G-PCC. Optimal coefficients of the filter for each color component are calculated in the encoder and selectively written into the bit stream according to the rate-distortion cost. For V-PCC, the only color enhancement method we are aware of is the low-complexity color smoothing method [36] included as an optional mode in the V-PCC test model. In this method, the decoded points are split into 3D grids, and the color centroid of each grid is calculated and then smoothed with tri-linear filtering.
The methods discussed above often offer straightforward yet effective ways to enhance the color quality of point clouds. It becomes evident that the relationship between geometry and color is crucial for driving performance improvements. Nonetheless, these methods do have certain limitations. For instance, their objectives can sometimes be confined to specific tasks, such as G-PCC or V-PCC, resulting in a rather narrow scope. This has motivated the exploration of learning-based methods. Sheng et al. [37] proposed a multi-scale graph attention network for removing attribute compression artifacts for G-PCC. This method uses Chebyshev graph convolutions to extract features of point cloud attributes and a multi-scale scheme to capture short and long-range correlations between the current point and its neighbors. However, the applicability of the method is restricted to G-PCC geometry lossless coding. Moreover, the need for separate models trained at various bit rates imposes limitations.
In summary, while current point cloud quality enhancement methods have shown promising results, there is still room for improvement, particularly within a point cloud coding system. Enhancing quality not only improves the reconstruction quality but also increases the efficiency of the coding system. As color plays a significant role in the overall subjective quality of point clouds and has an impact on subsequent tasks [38], we propose GQE-Net as a post-processing filter for a point cloud compression system to reduce the compression artifacts.
III Proposed Method
To reduce the artifacts caused by compression, we propose a graph-based quality enhancement network as a post-processing filter for point cloud compression. The proposed method is outlined in Fig. 3.
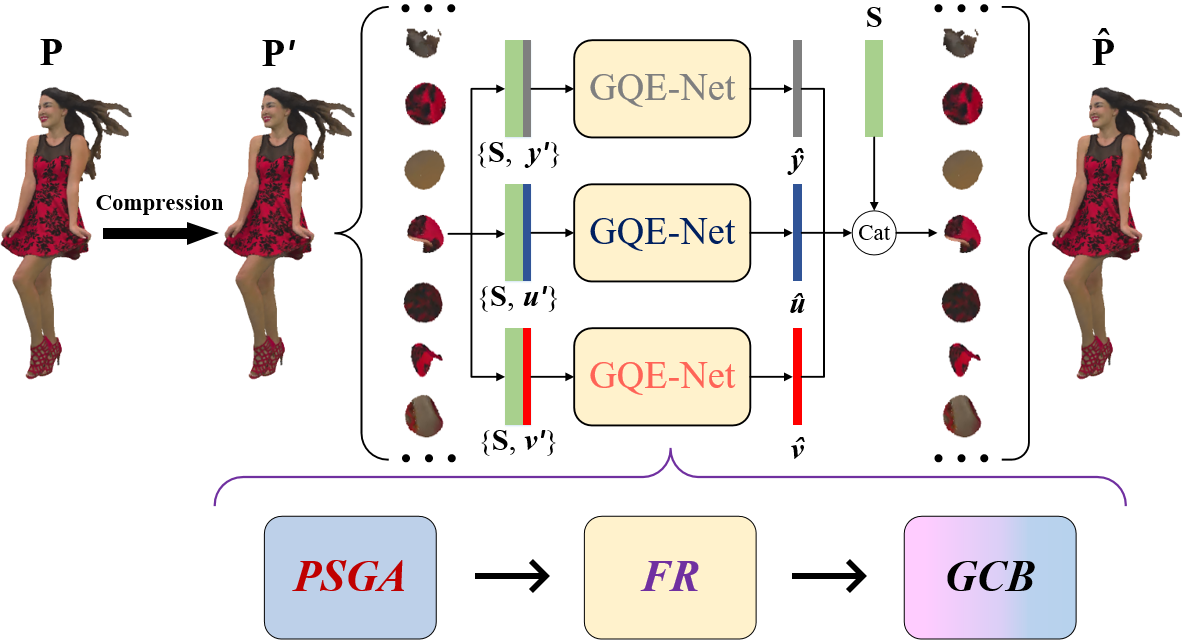
There are four main modules in GQE-Net. The first module deals with graph construction, where the importance of local information is recognized for effective feature learning. To achieve this goal, we build a graph for each individual point. The second module, the Graph Convolution Block (GCB), facilitates efficient extraction of features from the graph. By integrating a maxpooling layer, GCB contributes to the selection of the most relevant features from various channels.
The third module, Parallel-Serial Graph Attention (PSGA), concentrates on salient points. A multi-head mechanism is used to enhance feature attention. To ensure coherence among the different heads and to further amplify the attention-related features, we adopt a structure that interconnects single heads in a parallel-serial configuration.
The fourth module introduces geometric information by computing normals, which are then integrated into the existing feature framework. Notably, we introduce a geometry-distance guided weighting matrix for each feature channel, mitigating the influence of points located farther away from the key point.
III-A Problem modelling
To avoid color distortions caused by geometry losses, we assume that the compression of the geometry information is lossless, i.e., the coordinates of each point in the reconstructed point cloud remain unchanged after compression. We first convert the color space from RGB to YCbCr. We denote the original point cloud by , where is the number of points, and corresponds to the 3D geometry coordinates and three color components. After decoding, the original point cloud is denoted by . By applying the proposed method to , we obtain a quality-enhanced point cloud , as shown in Fig. 3. The aim of the proposed method is to minimize the difference between and .
III-B Patch generation and fusion
Due to limitations in GPU memory capacity, it is challenging to input the entire point cloud directly into the neural network. As an alternative, we partition the point cloud into smaller 3D patches of fixed size . These points are obtained as follows. Let be a parameter used to control the overlap between the 3D patches and let
| (1) | |||
Using farthest point sampling (FPS), we select points from the point cloud. We call these points key points. Next, the k Nearest Neighbor (k-NN) algorithm [39] is applied to each key point to identify its closest neighbors. Each key point and its neighbors are grouped into a 3D patch represented as , where denotes the geometry coordinates and denotes the three color components of the points in the 3D patch. Thus, for each color component, the 3D patches have the same geometry but different color information. The architecture of GQE-Net for these three sets is identical, but with different parameters. For example, GQE-Net for the Luma component (denoted as Y) can be written as a function:
| (2) | |||
where represents GQE-Net, represents the learnable parameters for the Y component, represents the initial reconstructed Y component, and represents the final, quality-enhanced Y component. The final color of the patch is generated by combining the three quality-enhanced color components.
Using S, we merge the 3D patches to create a high-quality point cloud, . However, in this process, it is likely that some points will be selected multiple times across different patches, while others may not be selected at all. To address this problem, we use the following approach. For points that are processed in different patches, we take the average as the restored value. For points that are not included in any patch, we keep the same color.
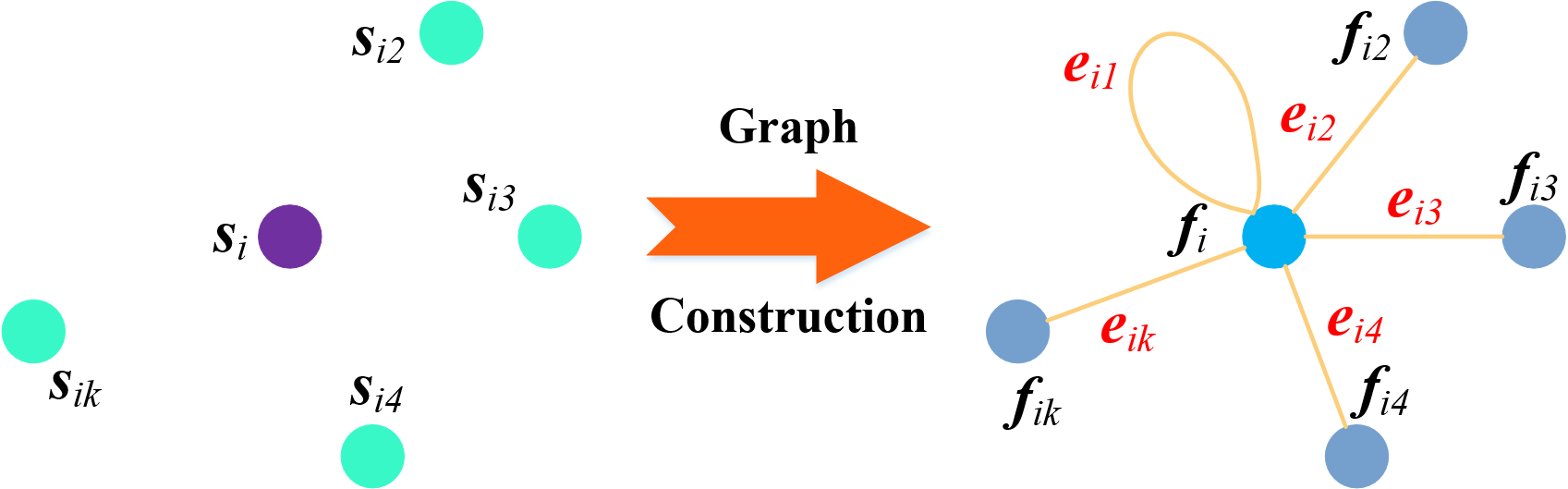
III-C Graph construction
GQE-Net is a graph-based neural network, with most of its operations carried out on the graph topology. Given points with -dimensional color features and 3D coordinates , at the beginning, the -dimensional feature is simply the corresponding color, i.e., . We construct a directed and self-loop graph , where represents the nodes and represents the edges. To exploit the relationship between features of a node and its neighbors, while also simplifying the graph, each node is only connected to its closest neighboring nodes, as well as itself. These nodes are called the neighbors of the current node in the rest of the paper. The subsequent operations are carried out on the edge features , where is the feature of the current node, is the feature of the connected node (), and . By combining the edge features of all nodes, we obtain the final features . Thus, for each node we calculate a dimensional feature based on its nearest neighbors. This graph construction is shown in Fig. 4 and can be written as
| (3) | |||
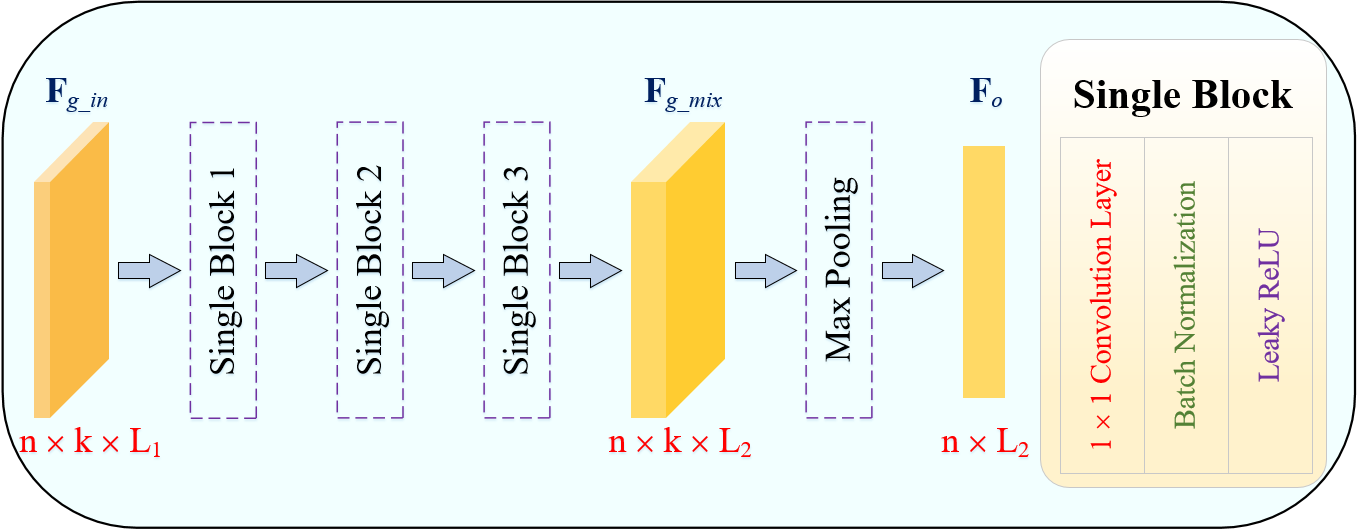
III-D Graph convolution block
The graph convolution block (GCB) is a pivotal element within GQE-Net, facilitating the efficient extraction of features from the graph (Fig. 5). By integrating a maxpooling layer, the GCB aids in the selection of the most pertinent features from various channels. The input edge feature, , has a size of , where is the number of feature channels. The input features are processed by three single blocks in series. Each single block contains a 2D convolution layer with a kernel size of , a batch normalization layer, and a Leaky ReLU for activation. After this process, the feature , whose number of feature channels is , can be obtained. At this point, the feature is still an edge feature. To capture more abstract features from , a max pooling layer is used. It is worth noting that the max pooling layer selects the most important feature from the neighboring nodes at each channel. As a result, we can obtain the output feature with a size of . In other words, the neighboring information has been embedded into the -dimensional feature, .
III-E PSGA module
Points located in different areas may experience different levels of distortion after compression. It is important to focus on points with significant artifacts or those located in areas that significantly affect the subjective quality, such as high-frequency edges. To achieve this, we propose a PSGA module based on a multi-head mechanism [19] [40], as shown in Fig. 6 (a). Unlike existing methods, it adopts a parallel-serial structure. In the first layer, two single head attention (SHA) blocks ( and ) are used in parallel to extract attention features separately. The output attention features from these two blocks are then combined and sent to a third SHA block () for feature integration and reinforcement. This design is beneficial for exploring feature correlation and further integrating attention features.
The input to PSGA is F with feature channels. The graph construction is done before each SHA block. The outputs of the parallel SHA blocks include an attention feature obtained through graph-based self-attention on the input features, and a graph feature which contains the neighboring features of each point. For the two parallel heads, the graph features and the attention features are concatenated, respectively. A third SHA block takes the concatenated attention features as input for fusion. Finally, and the output attention feature of are concatenated to get the final features , while and the output of are also concatenated to get the updated graph features .
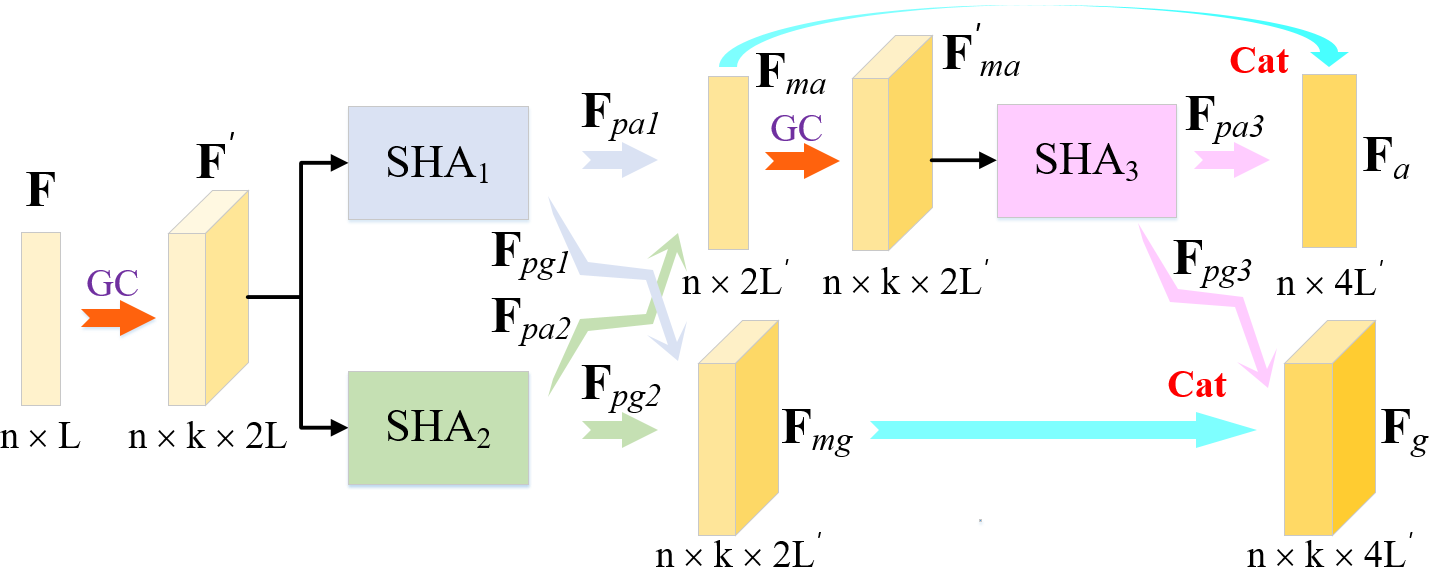
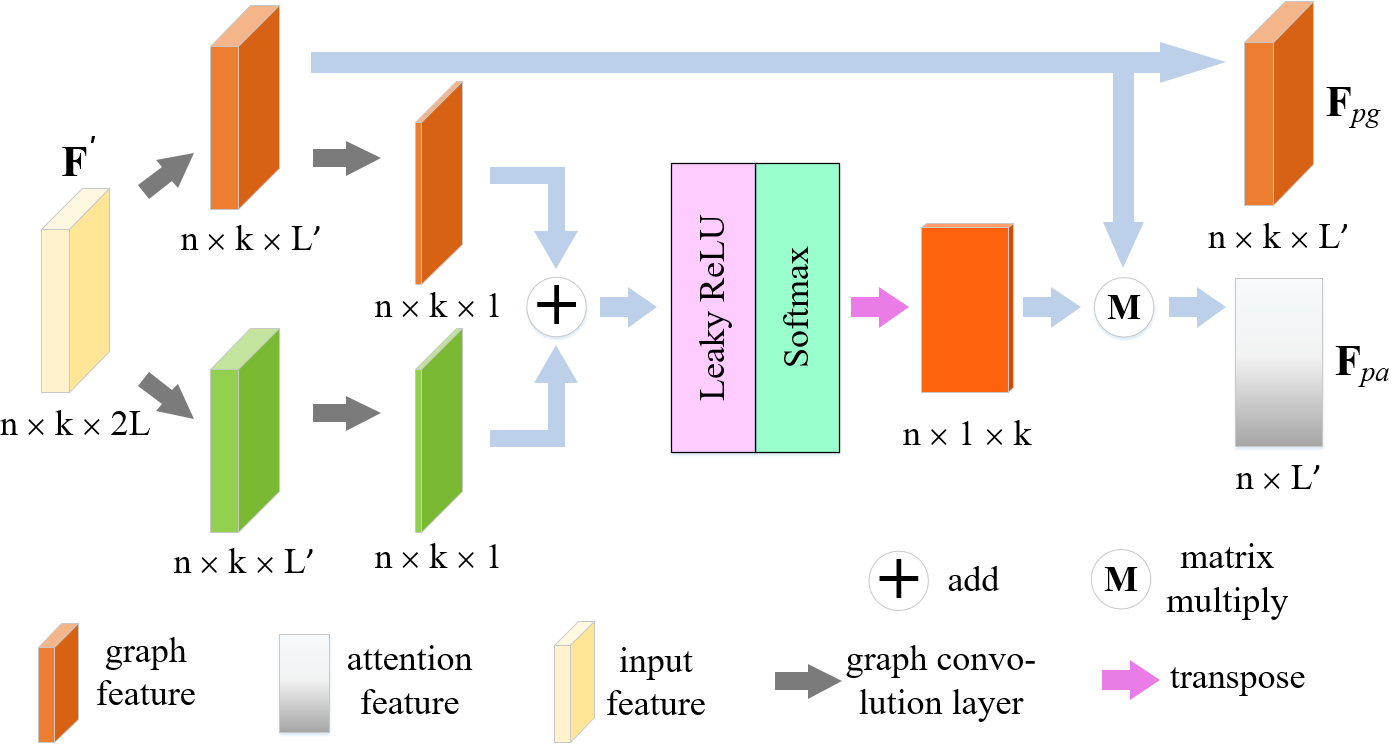
The structure of a single head attention is illustrated in Fig. 6 (b). We project the feature into a higher-dimensional space, with a dimension of , using two branches. The output of one branch is . Specifically, we apply a graph convolution on to obtain . In PSGA, the graph convolution layer uses a 2D convolution with a kernel size of , followed by batch normalization and a Leaky ReLU activation function. Next, the graph features from both branches are compressed into the dimension using a graph convolution layer without an activation function to obtain the most distinctive features of each neighboring point. We then add the features of the two branches and apply a Leaky ReLU activation function. The output, , is then normalized to weights ranging from to . We use function to each row of A:
| (4) | |||
where is the row of A, and is the feature value of . The final attention feature, , is obtained by multiplying the graph feature with the normalized attention weights. provides information about the degree of distortion and importance of each point by taking into account the local information.
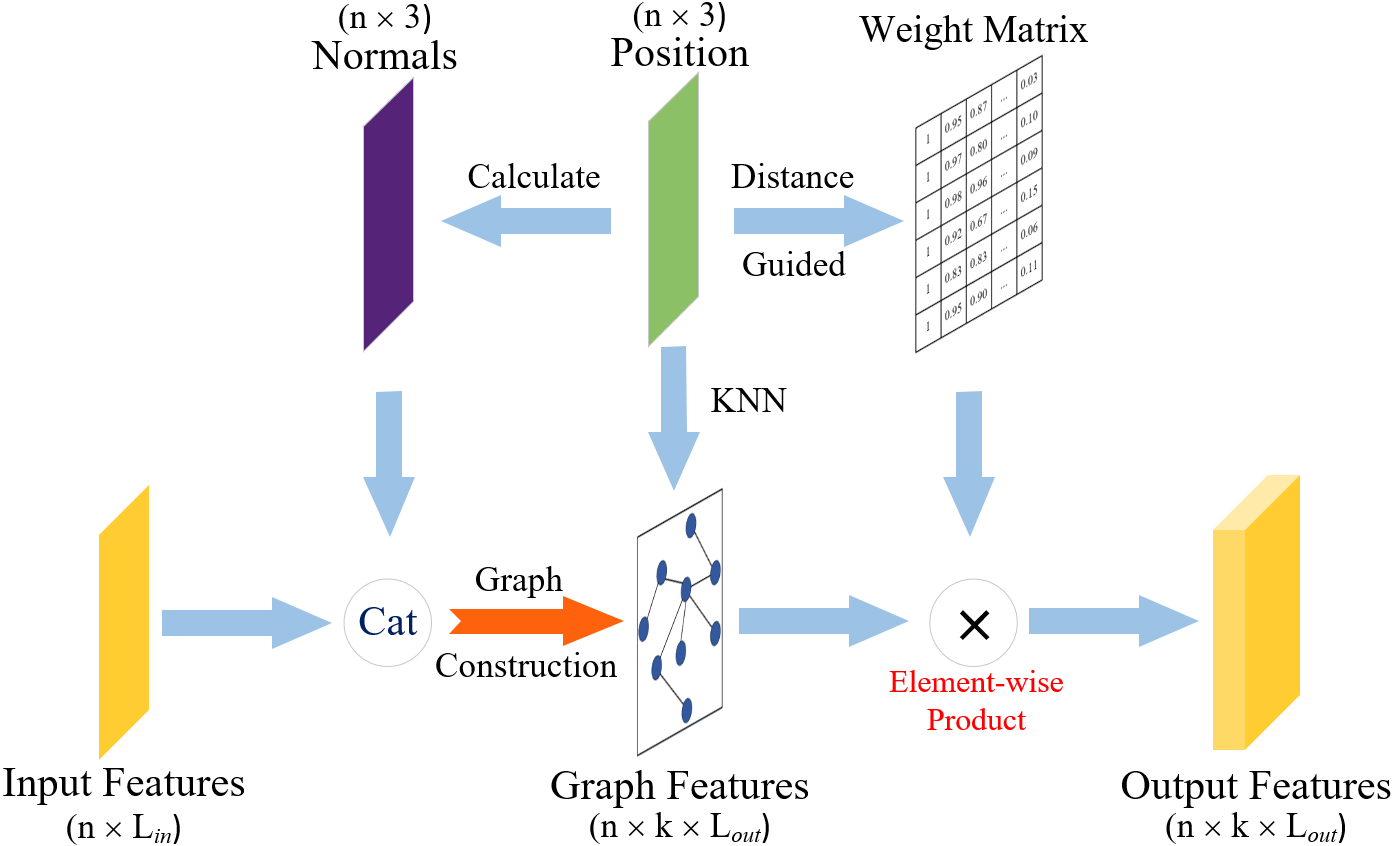
III-F FR module
The FR module is designed to effectively analyze and use the geometric information in the vicinity of each point, allowing for efficient leverage of the inter-correlation among points. The structure of the FR module is illustrated in Fig. 7. Specifically, the normal vector of each point is calculated and integrated with the input features. After constructing the graph, a weight matrix is also computed based on the distance between each point and its neighboring points, which is then multiplied by the graph feature.
The normal gives a measure of the angle of the tangent plane on which a point is located. The normals of points can reflect changes in the curvature of the surface. Both the coordinates and the normal contribute to the correlation between points. For example, if the normal discrepancy between two neighboring points is large, their color may differ greatly because they are not on the same plane and do not have similar local features. Therefore, we incorporate the normal of each point into the features, increasing the dimension of the features from to .
The computation of the normal vector is achieved through principal component analysis (PCA) [41], a method that uses the k nearest neighbors of a given point to approximate the underlying plane. By extracting a specific direction from this plane, the distribution of all points projected onto this direction becomes the most concentrated, effectively revealing the least significant vector in PCA. This calculated normal vector subsequently enriches the feature set, enabling a more comprehensive characterization of each point.
Then, we also extract local correlation based on the distances between points. Since points that are farther away from the current point may have less structural similarity, we aim to reduce the influence of features from distant neighboring points. To do this, we first calculate the distance , , between the node and each of its neighboring nodes in the graph. This defines a weight matrix , where
| (5) | |||
and
| (6) | |||
Note that is close to when is close to , while is close to when is large. Since the number of channels in the current graph features is , we replicate matrix W times to generate a tensor with dimension to deal with each channel of the graph features. Finally, we calculate an element-wise product between and the graph features to generate the output features.
III-G Architecture of GQE-Net
Fig. 2 shows the architecture of GQE-Net. The input of the network is divided into two parts: distorted color and geometry coordinates S. The PSGA module is applied to the input color to focus on important points or points with large distortions. The output of the PSGA module is graph features and attention features :
| (7) | |||
The number of feature channels of and is . In the FR module, the attention features are fused with the input color . The normals and distance are taken into account, and the neighbors are weighted by the geometry distance. The output of the FR module is the refined features
| (8) | |||
where represents concatenation. To effectively fuse and extract features, the proposed GCB is applied to the graph feature :
| (9) | |||
where denotes the graph convolution block. This operation changes the number of feature channels to . To further extract features point-by-point, another PSGA module is applied:
| (10) | |||
where the number of feature channels for and is . The normals and neighbors are also combined for further feature refinement:
| (11) | |||
where aggregates two features ( and ) and incorporates distance and normal information, resulting in channels. Then, another GCB is applied for feature fusion and to select the most important neighbor in each feature channel.
| (12) | |||
This results in feature channels for . Graph features are crucial for obtaining local information of each point. Therefore, we use the graph features generated by the PSGAs and process them through GCBs to generate and :
| (13) | |||
The features obtained through this process have incorporated information from the neighborhood through graph convolution and also emphasized important details. Moreover, the features are fused through skip connections to enhance the representation capabilities of the network. In this way, the features from different layers can be fully exploited:
| (14) | |||
Finally, by using an convolution layer without batch normalization and activation, the mixed features are restored, and residual learning is also used to speed up convergence and ensure the performance of the proposed network:
| (15) | |||
where is a convolution layer with kernel size of .
III-H Loss function
The loss function needs to reflect the distance between the quality-enhanced patch and the ground truth for each color component. Therefore, we use the mean squared error (MSE) as the loss function of GQE-Net:
| (16) | |||
where is the loss of the color component, C and represent the true color and the restored color, respectively. Note that the loss is calculated in the YCbCr color space.
IV Experimental Results
We conducted a series of experiments to assess the objective and subjective quality of the point clouds when our method is used. We also compared the coding efficiency before and after incorporating our method into the coding system. Additionally, we carried out several ablation studies to study the impact of each component of GQE-Net on the overall performance.
IV-A Experimental configuration
We evaluated the performance of our method on point clouds encoded with G-PCC Test Model Category 13 version 14.0 (TMC13v14.0) using a computer with an Intel i7-7820X CPU and 64GB of memory. The encoding process was conducted under the Common Test Condition (CTC) C1 [42], which involves lossless geometry compression and lossy attribute compression. We used the lifting transform [6] in the coding procedure.
We trained two GQE-Net models, one for dense point clouds and one for sparse point clouds. To train each model, we used point clouds compressed at various bit rates. Training was carried out on an NVIDIA GeForce RTX3090 GPU, using PyTorch v1.10. The experimental details, results, and analysis for each case are presented in the following sections.
IV-A1 GQE-Net for dense point clouds
To train our first GQE-Net model, we first selected point clouds with color information from the Waterloo point cloud sub-dataset (WPCSD) [9]. The training data set is shown in the supplemental materials. As can be seen, the point clouds have rich color and texture. During training, we set the number of points in a patch to , and the overlapping ratio to . In the k-NN-based graph construction, we set to . We collected a total of patches for training. We ran a total of epochs, during which we started with an initial learning rate of and decreased it by every epochs. The batch size was . We used the Adam optimizer [43] with a momentum of .
We assessed the performance of GQE-Net on point clouds from the Cat_A dataset. We selected several representative point clouds provided by MPEG [44]. The test data set is shown in the supplemental materials. Each point cloud was compressed with G-PCC using the quantization parameters (QP) , , , , , , which correspond to the six bit rates R01, R02, …, R06. During the test, the number of points in a patch was set to , and the overlapping ratio was set to . This ensures that the percentage of unprocessed points is less than .
IV-A2 GQE-Net for sparse point clouds
To train our second GQE-Net model, we selected point clouds of the “building” type from the MPEG Cat_B dataset [44]. For testing, we used a different set of point clouds from the same dataset. The training data set and the test data set are shown in the supplemental materials. As in Section IV-A-1), we encoded the point clouds with G-PCC at the six bit rates R01, R02, …, R06 and set the number of points in each patch to , with overlapping ratio .
IV-B Objective quality evaluation
To evaluate both the objective quality and coding efficiency, we used the commonly used BD-PSNR and BD-rate [45] metrics. The BD-rate measures the average bit rate reduction in bits per input point (bpip) at the same PSNR. A negative BD-rate indicates better performance compared to the test model. In addition to calculating the PSNR for each color component, we used YCbCr-PSNR [46] to evaluate the overall color quality gains brought by our method to the point cloud. The results for Cat_A and Cat_B are shown in Table I and Table II, respectively. More results can be found in the supplemental materials.
| Sequence | BD-PSNR [dB] | BD-rate [%] | |||||
|---|---|---|---|---|---|---|---|
| Luma | Cb | Cr | YCbCr | Luma | Cb | Cr | |
| basketball | 0.381 | 0.171 | 0.413 | 0.359 | -13.5 | -8.5 | -20.4 |
| dancer | 0.399 | 0.181 | 0.415 | 0.374 | -13.5 | -8.3 | -18.6 |
| exercise | 0.255 | 0.141 | 0.281 | 0.244 | -11.2 | -8.2 | -21.6 |
| longdress | 0.449 | 0.375 | 0.374 | 0.431 | -12.4 | -10.7 | -12.0 |
| loot | 0.472 | 0.428 | 0.479 | 0.467 | -13.9 | -11.7 | -16.7 |
| model | 0.375 | 0.194 | 0.438 | 0.360 | -12.5 | -7.7 | -15.8 |
| queen | 0.242 | 0.417 | 0.489 | 0.289 | -8.0 | -12.2 | -13.8 |
| redandblack | 0.449 | 0.242 | 0.498 | 0.429 | -14.1 | -8.6 | -14.5 |
| soldier | 0.550 | 0.375 | 0.480 | 0.519 | -15.2 | -10.0 | -15.7 |
| Andrew | 0.584 | 0.179 | 0.120 | 0.476 | -20.5 | -8.4 | -6.1 |
| David | 0.335 | 0.169 | 0.266 | 0.305 | -12.2 | -8.8 | -15.9 |
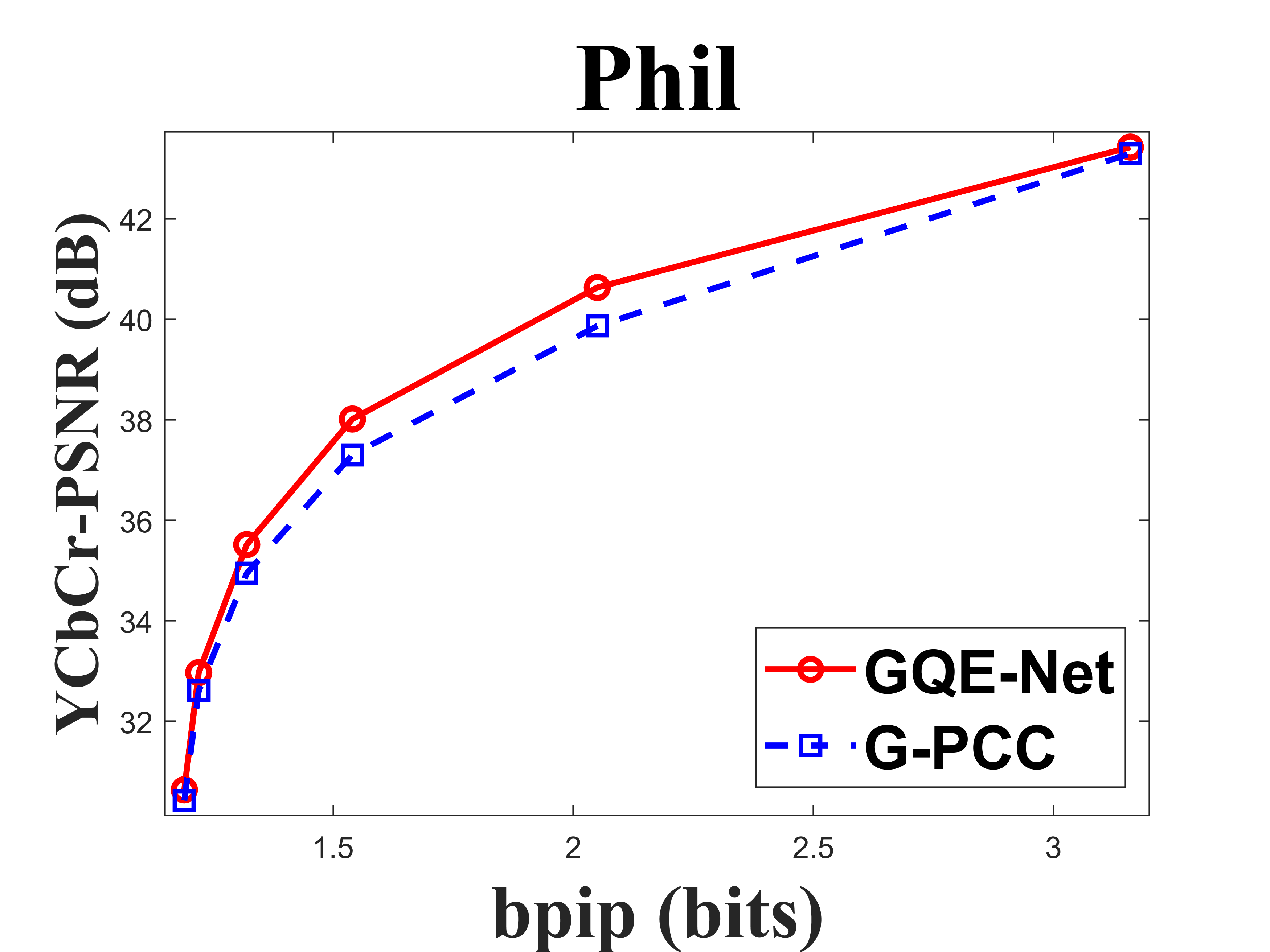
| Phil | 0.558 | 0.165 | 0.159 | 0.459 | -17.8 | -7.0 | -6.3 |
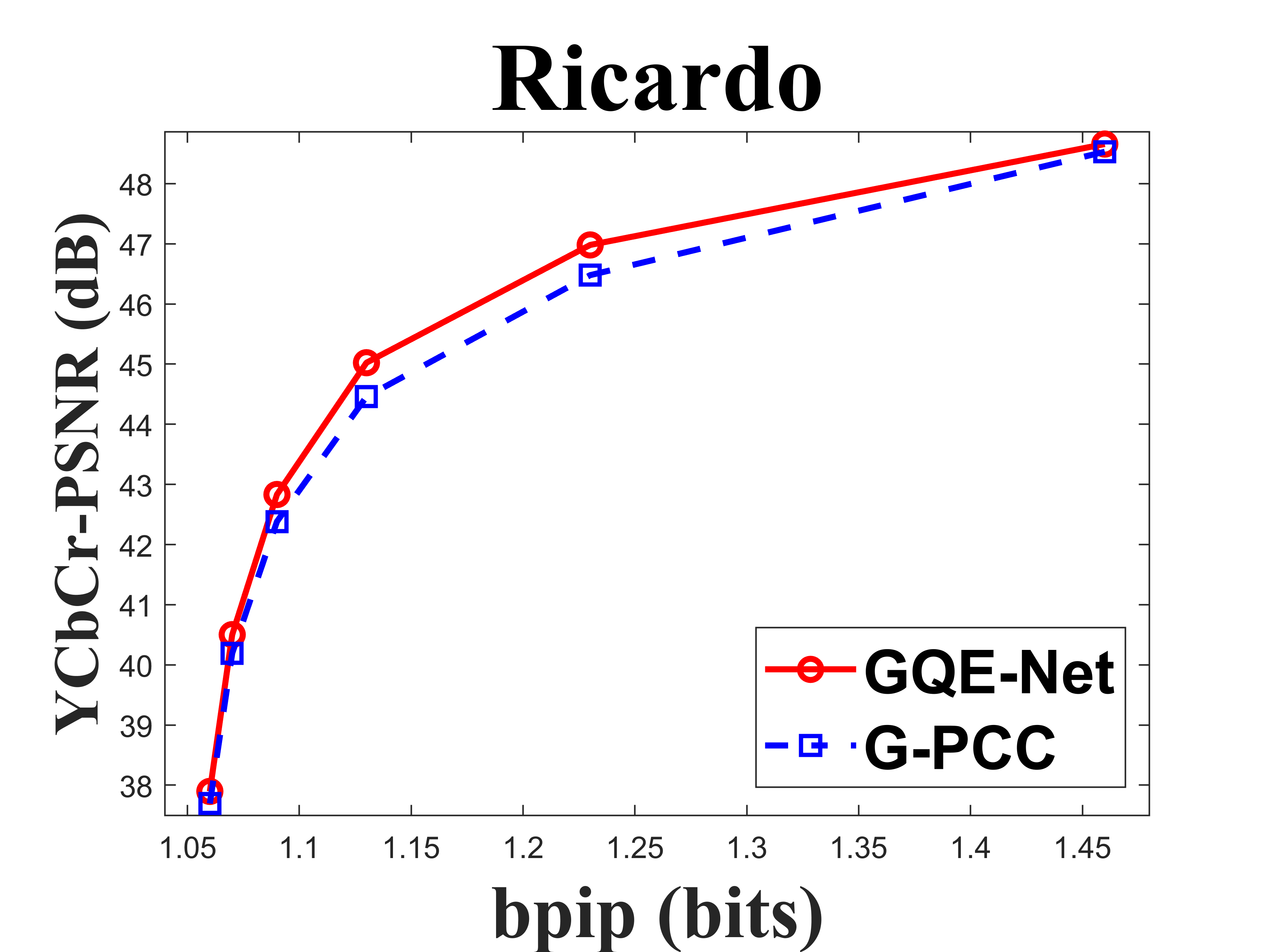
| Ricardo | 0.390 | 0.240 | 0.299 | 0.360 | -14.2 | -10.1 | -14.1 |
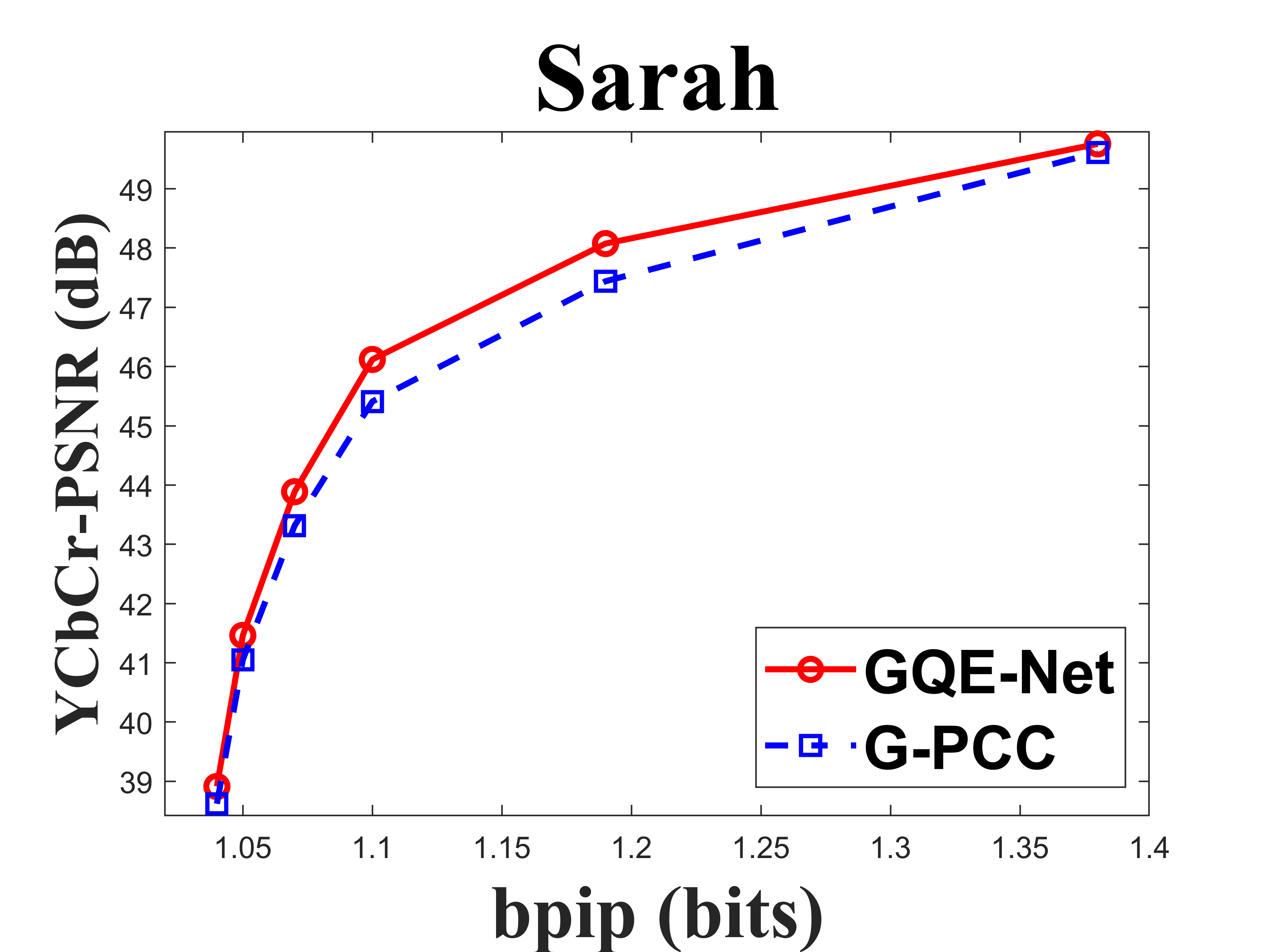
| Sarah | 0.535 | 0.227 | 0.249 | 0.461 | -17.4 | -9.8 | -11.3 |
| Average | 0.427 | 0.253 | 0.355 | 0.395 | -14.0 | -9.3 | -14.5 |
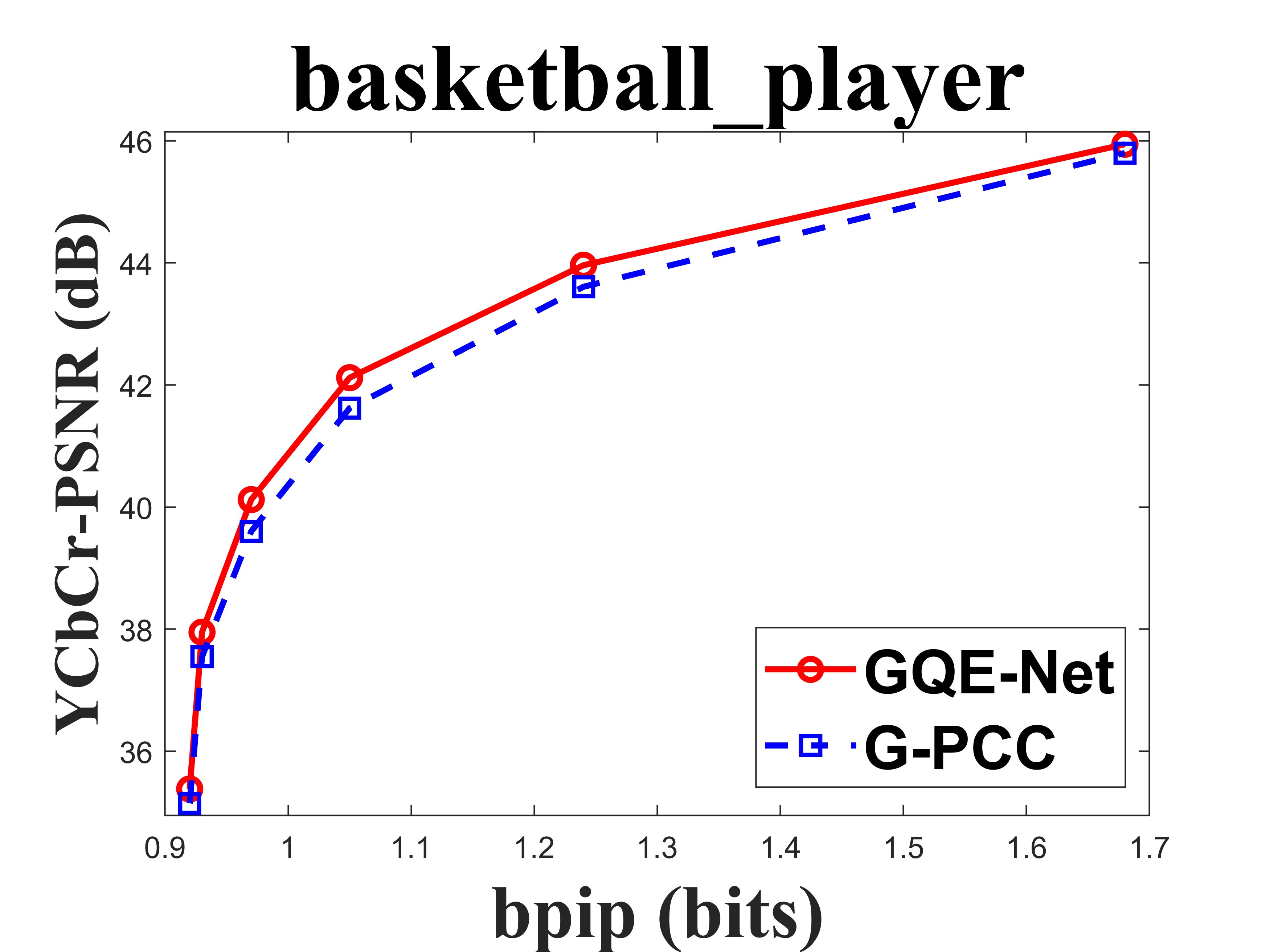
From Table I, we can see that for Cat_A point clouds GQE-Net achieved an average improvement of dB, dB and dB for the Y, Cb, and Cr components, respectively, corresponding to -, -, - BD-rates. The largest PSNR gains were dB (Luma component of Andrew at R05), dB (Cb component of soldier at R06), and dB (Cr component of soldier at R06). We observed that the performance gains were limited at the high bitrates. This is due to two reasons. First, since the quality of the point clouds at high bitrates is already high, the room for improvement is smaller than at low bitrates. Second, since we trained GQE-Net with point clouds compressed at various bitrates, the training process is likely to have geared the network towards minimizing large distortions. Such large distortions typically correspond to low bitrates. Fig. 8 compares the rate-PSNR curves for Cat_A point clouds. It can be seen that the coding efficiency can be greatly improved by incorporating the proposed method into the coding system, particularly at medium and high bit rates.
| Sequence | BD-PSNR [dB] | BD-rate [%] | |||||
| Luma | Cb | Cr | YCbCr | Luma | Cb | Cr | |
| arco_valentino | -0.15 | 0.091 | 0.086 | -0.09 | -0.2 | -4.4 | -5.0 |
| egyptian_mask | 0.062 | 0.133 | 0.070 | 0.072 | -2.9 | -5.4 | -3.8 |
| facade_00009 | -0.09 | 0.070 | 0.034 | -0.05 | -0.5 | -2.3 | -2.0 |
| staue_klimt | 0.002 | 0.105 | -0.03 | 0.011 | -1.7 | -3.9 | -0.7 |
| Average | -0.04 | 0.100 | 0.038 | -0.02 | -1.3 | -4.0 | -2.8 |
| Average_low | 0.119 | 0.103 | 0.071 | 0.111 | -3.1 | -4.6 | -4.9 |
-
*
Average_low shows the average performance at the low bitrates (R01, R02, R03, R04).
Table II shows the performance of our second GQE-Net model. The average BD-rates for the Y, Cb, Cr components were -, - and -, respectively. This is because the relationship between the points in these sparse point clouds is more challenging to capture. Moreover, the correlation between points is also relatively low, making it difficult to improve the quality of the current point using its neighbors. Furthermore, the inherent noise present in Cat_B point clouds may also have a negative impact on performance. If we consider the low bitrates only (i.e., R01, R02, R03, R04), the BD-rates can improve, achieving -, - and -, for Y, Cb, Cr, respectively.
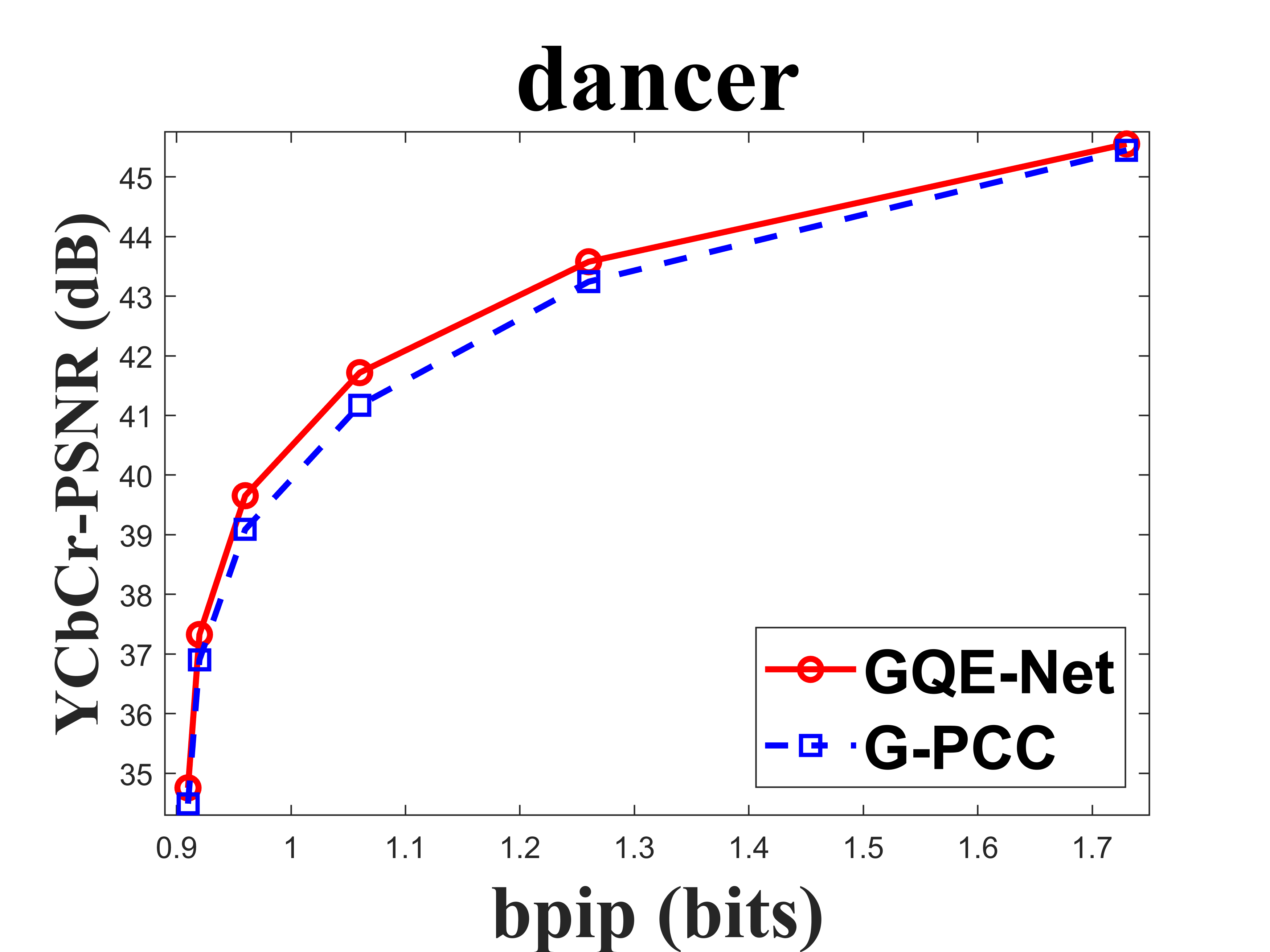
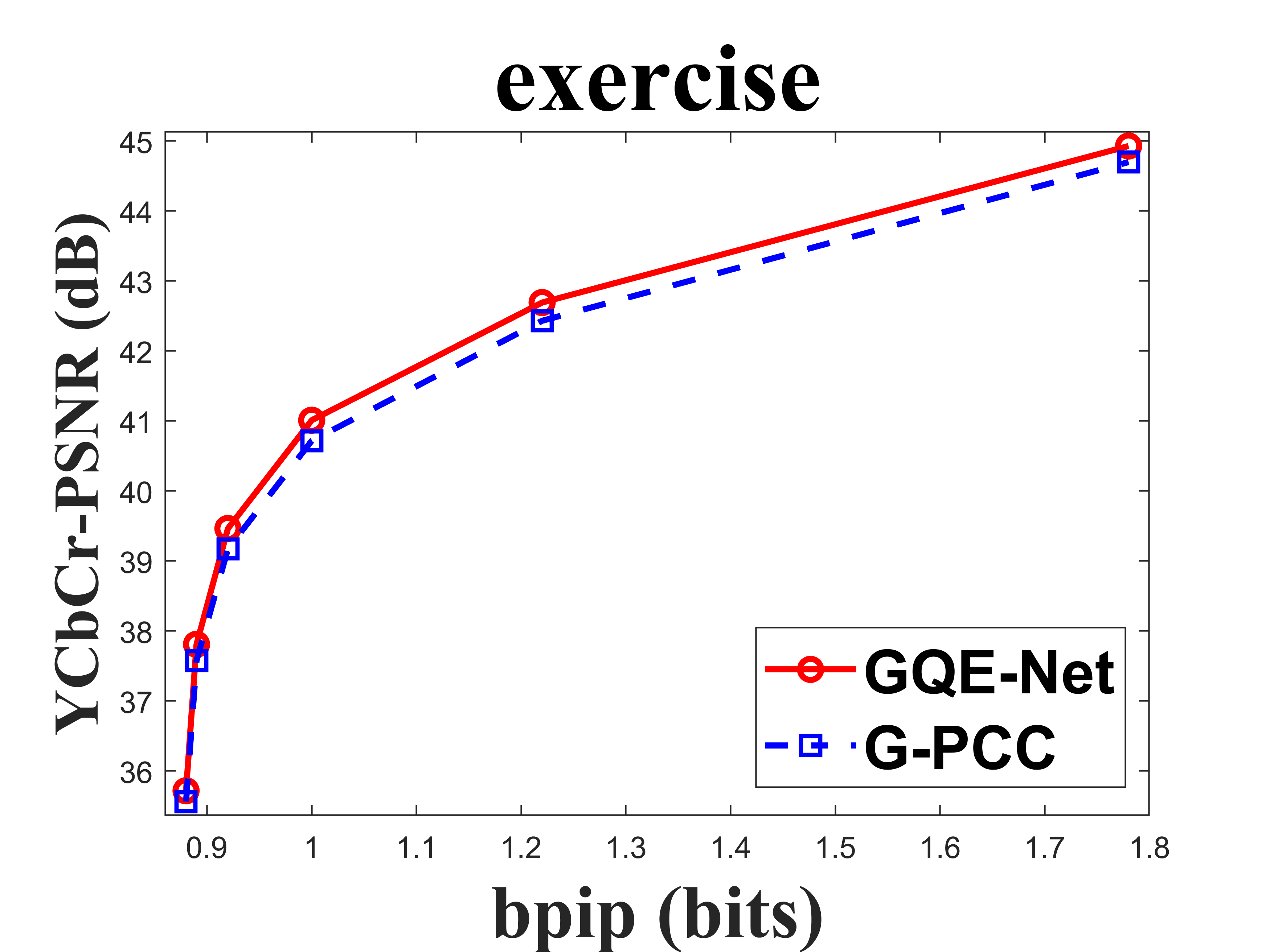
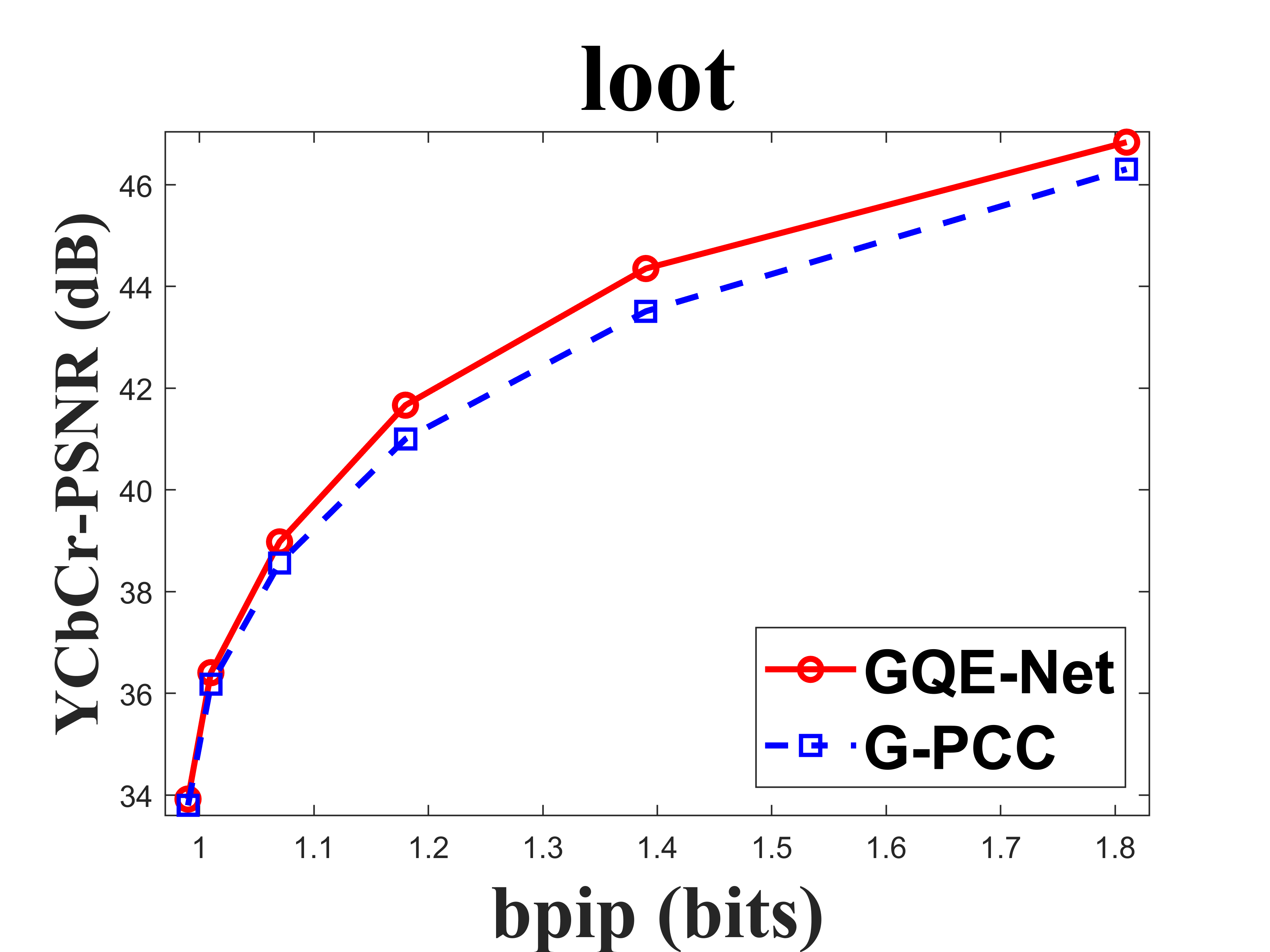
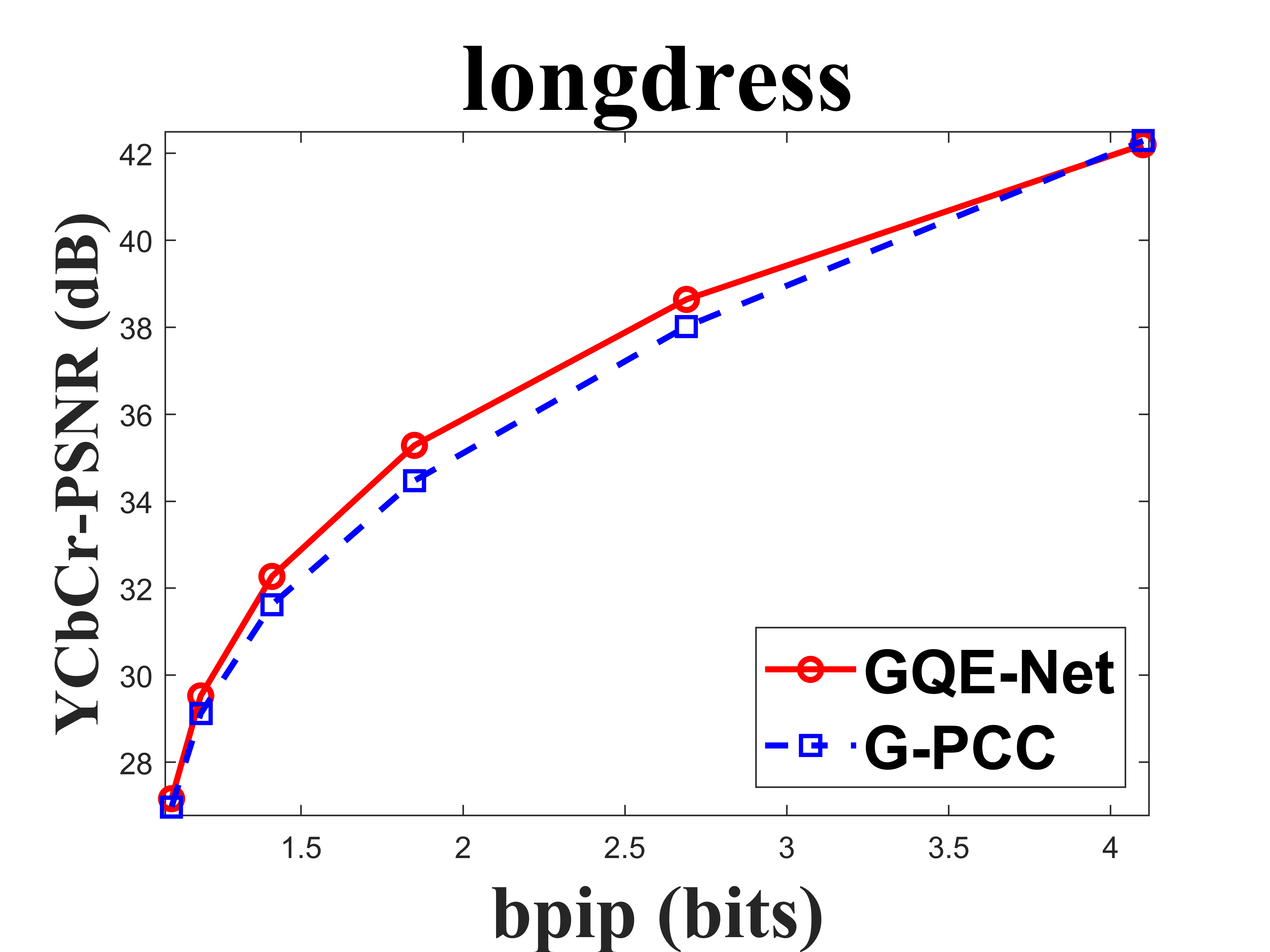
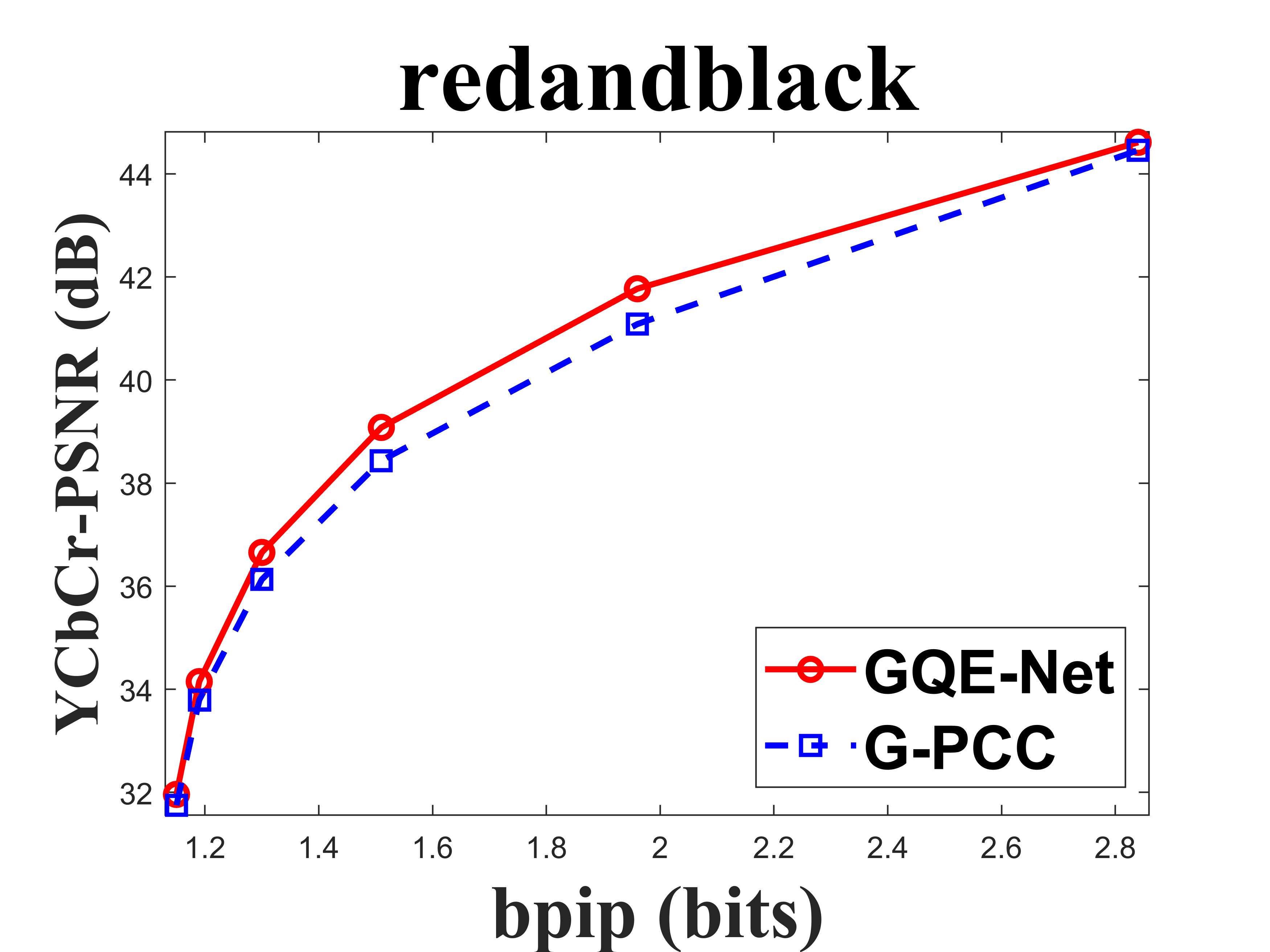
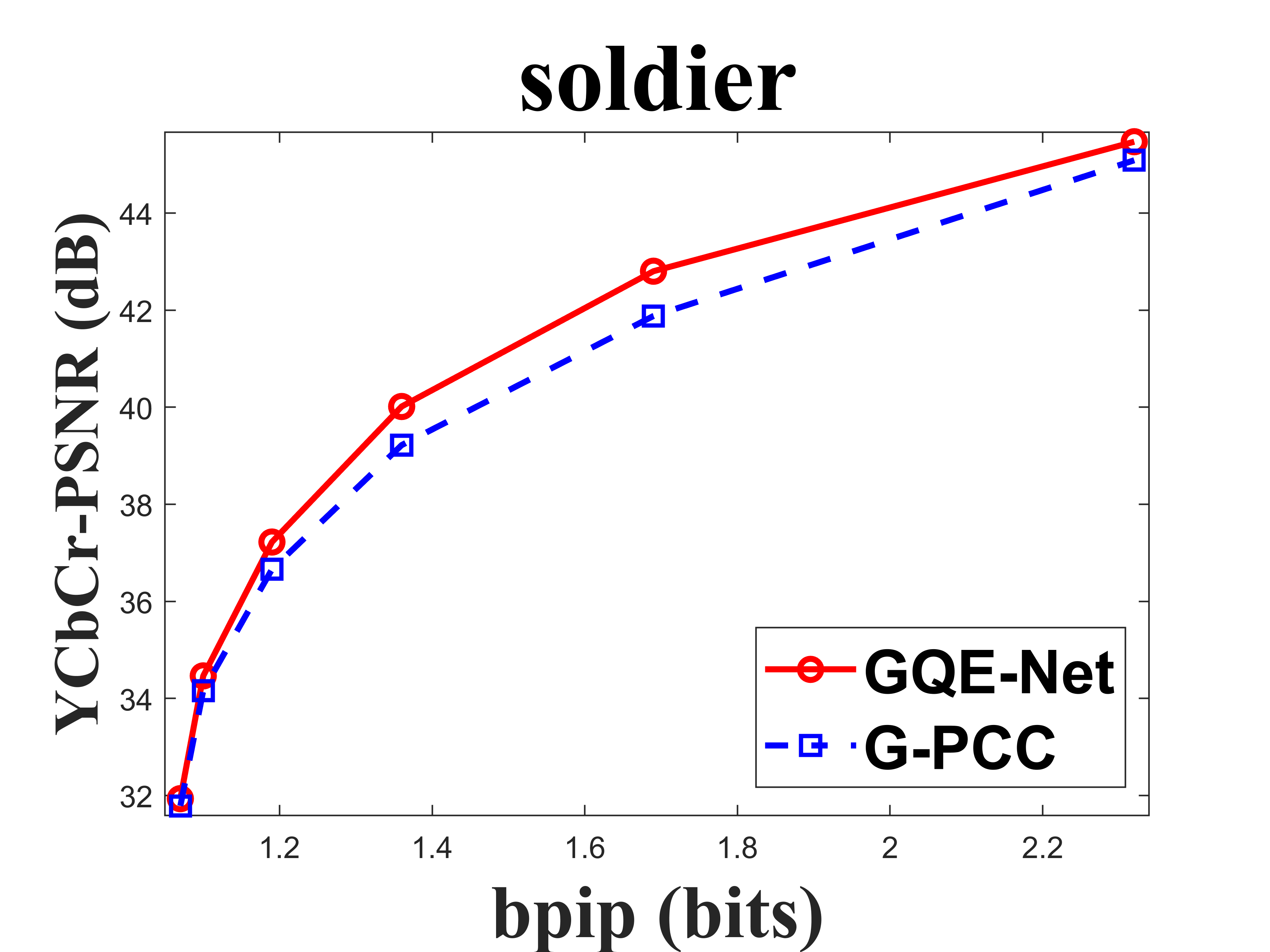
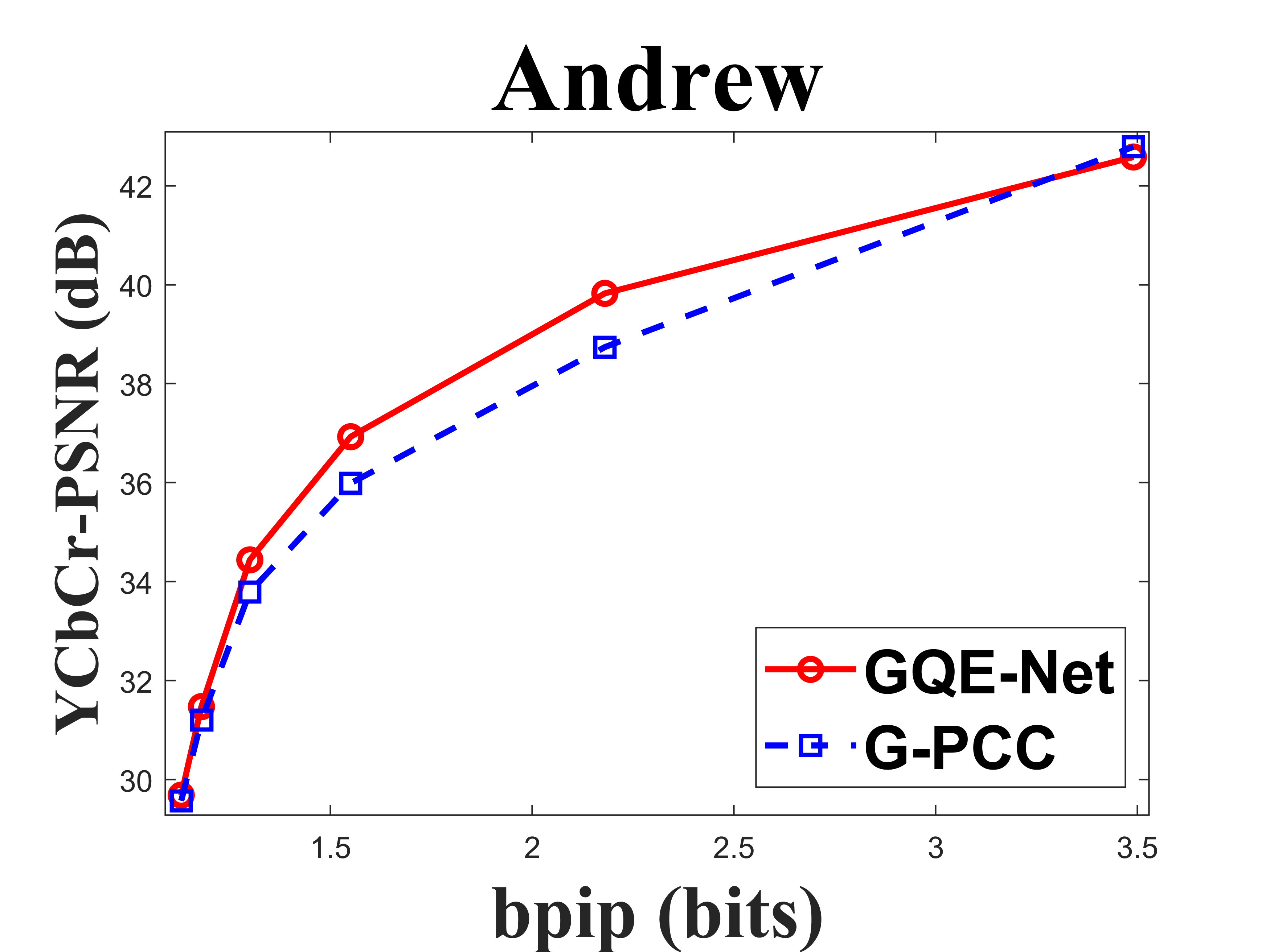
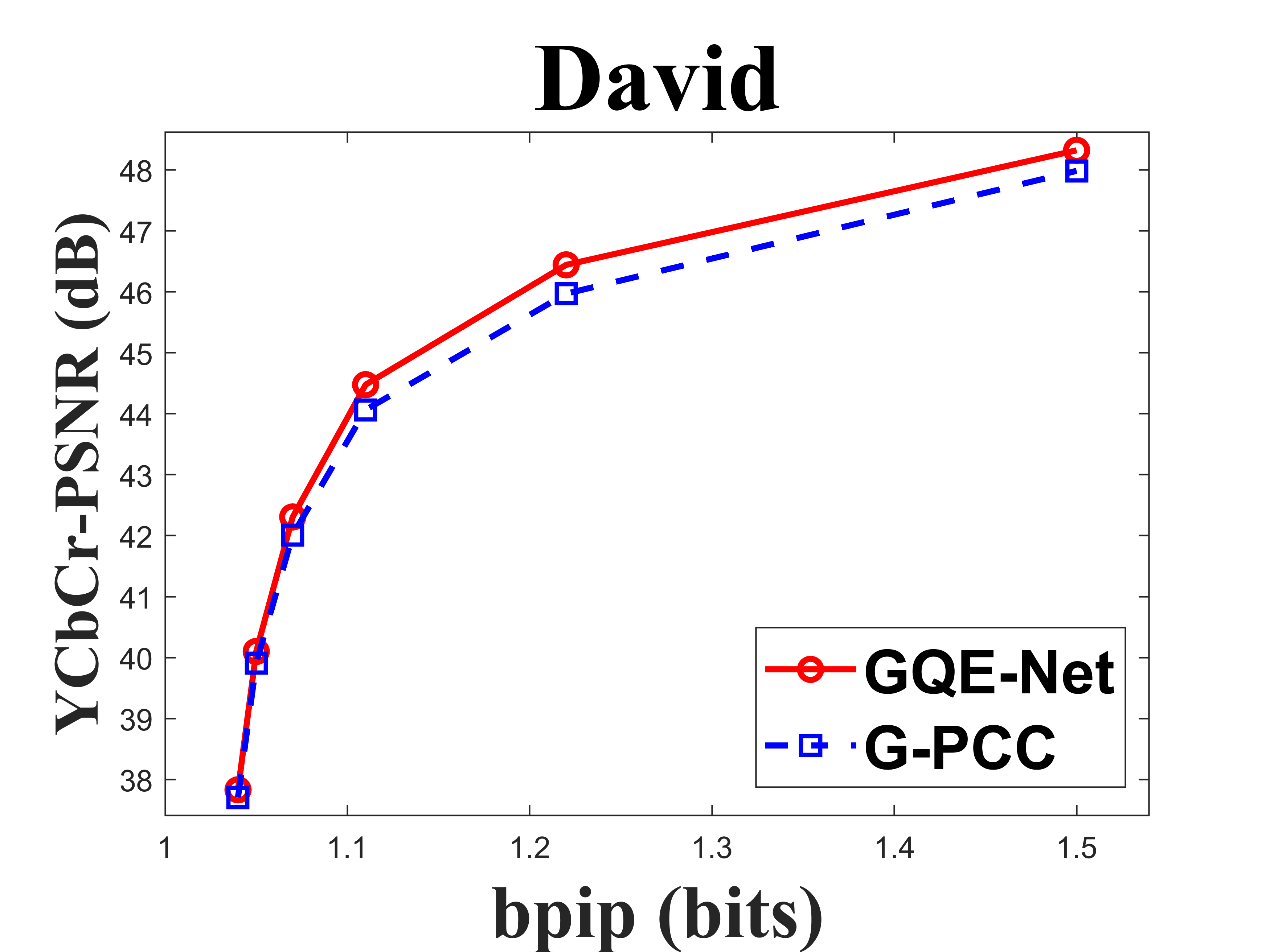

IV-C Subjective quality evaluation
Fig. 9 compares the original point clouds (ground truth), the point clouds reconstructed without any enhancement, and the point clouds processed by GQE-Net. The texture of the point clouds processed by GQE-Net is clearer and the color transitions are smoother, resulting in a better overall visual experience.
IV-D Results for RAHT
To further demonstrate the effectiveness of GQE-Net, we applied the trained GQE-Net models directly to the point clouds in Cat_A encoded under the G-PCC lossless geometry, lossy attribute and RAHT configuration. The BD-PSNR and BD-rate results are presented in Table III. More results are available in the supplemental materials.
It can be seen that competitive results can be achieved at all bit rates. Compared with G-PCC TMC13v14.0, GQE-Net achieved dB, dB, and dB BD-PSNR, corresponding to -, -, and - BD-rates. Moreover, the PSNR gain was up to dB (Cr component of redandblack at R04). We believe that the performance could be improved if GQE-Net is fine-tuned or retrained based on point clouds compressed with RAHT.
| Sequence | BD-PSNR [dB] | BD-rate [%] | |||||
|---|---|---|---|---|---|---|---|
| Luma | Cb | Cr | YCbCr | Luma | Cb | Cr | |
| basketball | 0.298 | 0.180 | 0.402 | 0.297 | -9.8 | -11.1 | -18.0 |
| dancer | 0.399 | 0.181 | 0.415 | 0.374 | -10.6 | -12.7 | -17.9 |
| exercise | 0.255 | 0.141 | 0.281 | 0.244 | -9.5 | -13.3 | -22.0 |
| longdress | 0.180 | 0.320 | 0.354 | 0.219 | -6.7 | -8.8 | -10.2 |
| loot | 0.327 | 0.383 | 0.477 | 0.353 | -9.2 | -13.4 | -15.8 |
| model | 0.297 | 0.194 | 0.418 | 0.299 | -10.0 | -9.8 | -15.2 |
| queen | 0.242 | 0.417 | 0.439 | 0.289 | -6.9 | -12.2 | -12.8 |
| redandblack | 0.320 | 0.228 | 0.344 | 0.312 | -8.7 | -7.9 | -9.8 |
| soldier | 0.343 | 0.353 | 0.423 | 0.354 | -9.6 | -13.3 | -15.9 |
| Andrew | 0.209 | 0.160 | 0.119 | 0.192 | -10.8 | -9.0 | -6.9 |
| David | 0.315 | 0.225 | 0.316 | 0.304 | -10.6 | -11.6 | -15.3 |
| Phil | 0.245 | 0.151 | 0.192 | 0.227 | -9.3 | -7.3 | -7.9 |
| Ricardo | 0.306 | 0.300 | 0.351 | 0.314 | -10.0 | -13.6 | -14.2 |
| Sarah | 0.405 | 0.295 | 0.378 | 0.388 | -11.3 | -9.9 | -12.6 |
| Average | 0.284 | 0.255 | 0.355 | 0.290 | -9.5 | -11.0 | -13.9 |
| Sequence | BD-PSNR [dB] | BD-rate [%] | |||||
|---|---|---|---|---|---|---|---|
| Luma | Cb | Cr | YCbCr | Luma | Cb | Cr | |
| basketball | 0.119 | 0.121 | 0.239 | 0.134 | -4.9 | -10.3 | -11.2 |
| dancer | 0.142 | 0.144 | 0.260 | 0.157 | -5.6 | -11.4 | -12.6 |
| exercise | 0.100 | 0.135 | 0.206 | 0.118 | -4.8 | -13.7 | -15.0 |
| longdress | 0.139 | 0.151 | 0.1614 | 0.143 | -5.2 | -6.4 | -7.4 |
| loot | 0.220 | 0.443 | 0.426 | 0.273 | -6.1 | -19.6 | -18.4 |
| model | 0.099 | 0.126 | 0.235 | 0.119 | -4.9 | -9.0 | -10.3 |
| queen | 0.310 | 0.205 | 0.150 | 0.277 | -15.1 | -11.0 | -9.0 |
| redandblack | 0.228 | 0.204 | 0.241 | 0.227 | -6.8 | -11.3 | -8.7 |
| soldier | 0.282 | 0.342 | 0.332 | 0.296 | -8.2 | -16.1 | -15.3 |
| Andrew | 0.135 | 0.065 | 0.008 | 0.111 | -6.3 | -5.8 | -1.9 |
| David | 0.118 | 0.300 | 0.270 | 0.159 | -3.5 | -17.0 | -14.5 |
| Phil | 0.184 | 0.156 | 0.079 | 0.167 | -6.8 | -16.5 | -15.8 |
| Ricardo | 0.243 | 0.386 | 0.354 | 0.274 | -9.8 | -11.1 | -18.0 |
| Sarah | 0.201 | 0.451 | 0.403 | 0.2744 | -5.6 | -15.6 | -15.5 |
| Average | 0.180 | 0.230 | 0.240 | 0.194 | -6.5 | -12.4 | -11.5 |
IV-E Application to V-PCC
To further demonstrate the effectiveness of GQE-Net, we used it to improve the quality of point clouds in Cat_A, which were compressed with V-PCC TCM2v18.0 under the lossy geometry and lossy attribute configuration. The quantization parameters for the geometry coding were set to , , , , and . Since the coding structure of V-PCC is different from that of G-PCC, we retrained GQE-Net using the WPCSD dataset. The results, shown in Table IV, indicate that an average BD-PSNR of dB, dB, and dB can be achieved for the Y, Cb, and Cr components, respectively, corresponding to , and BD-rate savings. The performance of GQE-Net for V-PCC was slightly reduced compared to G-PCC. This is because the geometry of the reconstructed point cloud is lossy, making the FR module unable to extract the correct distance and normal information. A comprehensive comparison of rate-distortion and rate-PSNR performance with V-PCC is provided in the supplemental materials.
| Sequence | BD-PSNR [dB] | BD-rate [%] | |||||
|---|---|---|---|---|---|---|---|
| Luma | Cb | Cr | YCbCr | Luma | Cb | Cr | |
| basketball | 0.352 | 0.042 | 0.121 | 0.285 | -13.4 | -2.6 | -6.4 |
| dancer | 0.265 | 0.063 | 0.079 | 0.217 | -12.1 | -4.3 | -4.8 |
| exercise | 0.175 | 0.056 | 0.060 | 0.146 | -9.4 | -4.2 | -5.1 |
| longdress | 0.124 | 0.094 | 0.079 | 0.115 | -5.8 | -5.4 | -5.9 |
| loot | 0.127 | 0.252 | 0.140 | 0.144 | -6.1 | -9.7 | -6.0 |
| model | 0.282 | 0.061 | 0.100 | 0.231 | -10.8 | -3.2 | -4.9 |
| queen | 0.182 | 0.339 | -0.012 | 0.177 | -8.6 | -12.2 | -3.8 |
| redandblack | 0.202 | 0.095 | 0.161 | 0.184 | -9.4 | -5.3 | -7.5 |
| soldier | 0.141 | 0.137 | 0.073 | 0.132 | -6.5 | -7.0 | -4.5 |
| Andrew | 0.134 | 0.026 | -0.014 | 0.102 | -6.3 | -2.9 | -0.5 |
| David | 0.044 | 0.103 | 0.044 | 0.051 | -3.0 | -6.3 | -1.7 |
| Phil | 0.214 | 0.031 | 0.006 | 0.165 | -10.4 | -2.8 | -1.7 |
| Ricardo | 0.108 | 0.143 | 0.059 | 0.107 | -5.1 | -6.9 | -3.5 |
| Sarah | 0.180 | 0.152 | 0.078 | 0.164 | -6.1 | -6.4 | -3.8 |
| Average | 0.181 | 0.114 | 0.070 | 0.159 | -8.1 | -5.7 | -4.3 |
IV-F Results for lossy geometry and lossy attribute condition
Table V compares GQE-Net to G-PCC TMC13 for a lossy geometry, lossy attribute condition. More results are provided in the supplemental materials. The results show that GQE-Net remains capable of enhancing performance, although to a lesser extent compared to the lossless geometry, lossy attribute condition.
IV-G Ablation study
In this section, we evaluate the effectiveness of the PSGA module and FR module. We also study the effect of patch overlap on the performance of GQE-Net.
| Sequence | GQE-Net w/o FR | Only Normal | Only Distance | Parallel | GQE-Net | |||||
| BD-PSNR | BD-rate | BD-PSNR | BD-rate | BD-PSNR | BD-rate | BD-PSNR | BD-rate | BD-PSNR | BD-rate | |
| basketball | 0.266 | -10.2 | 0.312 | -11.4 | 0.320 | -11.8 | 0.260 | -10.2 | 0.381 | -13.5 |
| dancer | 0.310 | -10.9 | 0.337 | -11.6 | 0.353 | -12.4 | 0.301 | -10.9 | 0.399 | -13.5 |
| exercise | 0.182 | -8.5 | 0.205 | -9.1 | 0.213 | -9.7 | 0.180 | -8.2 | 0.255 | -11.2 |
| longdress | 0.348 | -9.3 | 0.325 | -9.3 | 0.290 | -11.7 | 0.206 | -10.6 | 0.449 | -12.4 |
| loot | 0.296 | -9.4 | 0.292 | -9.7 | 0.411 | -12.7 | 0.332 | -11.1 | 0.472 | -13.9 |
| model | 0.325 | -10.8 | 0.348 | -11.5 | 0.329 | -11.5 | 0.292 | -10.7 | 0.375 | -12.5 |
| queen | 0.213 | -7.1 | 0.196 | -6.9 | 0.112 | -5.4 | 0.128 | -5.8 | 0.242 | -8.0 |
| redandblack | 0.350 | -10.8 | 0.347 | -11.1 | 0.380 | -12.6 | 0.373 | -12.1 | 0.449 | -14.1 |
| soldier | 0.475 | -12.7 | 0.418 | -12.0 | 0.531 | -14.7 | 0.423 | -12.8 | 0.550 | -15.2 |
| Andrew | 0.505 | -15.6 | 0.532 | -16.6 | 0.534 | -19.6 | 0.452 | -17.7 | 0.584 | -20.5 |
| David | 0.109 | -4.9 | 0.152 | -6.7 | 0.295 | -11.5 | 0.143 | -6.5 | 0.335 | -12.2 |
| Phil | 0.520 | -15.8 | 0.519 | -16.2 | 0.544 | -17.7 | 0.478 | -16.5 | 0.558 | -17.8 |
| Ricardo | 0.276 | -10.3 | 0.298 | -11.2 | 0.340 | -13.1 | 0.148 | -7.4 | 0.390 | -14.2 |
| Sarah | 0.423 | -13.6 | 0.424 | -14.0 | 0.471 | -15.8 | 0.148 | -7.7 | 0.535 | -17.4 |
| Average | 0.328 | -10.7 | 0.336 | -11.2 | 0.365 | -12.8 | 0.276 | -10.6 | 0.427 | -14.0 |
| Time [ms] | 25.82 | 25.94 | 26.52 | 25.80 | 26.67 | |||||
| Paras | 476,186 | 477,338 | 476,186 | 440,610 | 477,338 | |||||
| Sequence | Sequential selection | GQE-Net () | ||||||
| BD-PSNR | BD-rate | BD-PSNR | BD-rate | BD-PSNR | BD-rate | BD-PSNR | BD-rate | |
| basketball | 0.377 | -13.5 | 0.161 | -6.0 | 0.293 | -10.7 | 0.381 | -13.5 |
| dancer | 0.411 | -13.9 | 0.167 | -5.9 | 0.307 | -10.7 | 0.399 | -13.5 |
| exercise | 0.233 | -10.6 | 0.117 | -5.3 | 0.203 | -9.0 | 0.255 | -11.2 |
| longdress | 0.261 | -11.1 | 0.119 | -5.4 | 0.251 | -9.9 | 0.449 | -12.4 |
| loot | 0.398 | -12.5 | 0.200 | -6.4 | 0.368 | -11.3 | 0.472 | -13.9 |
| model | 0.387 | -12.6 | 0.151 | -5.4 | 0.286 | -9.8 | 0.375 | -12.5 |
| queen | 0.177 | -6.9 | 0.097 | -3.4 | 0.174 | -5.9 | 0.242 | -8.0 |
| redandblack | 0.392 | -12.8 | 0.183 | -6.2 | 0.345 | -11.3 | 0.449 | -14.1 |
| soldier | 0.496 | -14.2 | 0.220 | -6.6 | 0.416 | -12.0 | 0.550 | -15.2 |
| Andrew | 0.598 | -19.9 | 0.210 | -8.6 | 0.419 | -16.1 | 0.584 | -20.5 |
| David | 0.309 | -11.5 | 0.117 | -4.6 | 0.230 | -8.9 | 0.335 | -12.2 |
| Phil | 0.641 | -19.5 | 0.208 | -7.2 | 0.392 | -13.1 | 0.558 | -17.8 |
| Ricardo | 0.426 | -15.3 | 0.132 | -5.1 | 0.264 | -10.1 | 0.390 | -14.2 |
| Sarah | 0.542 | -17.6 | 0.200 | -7.1 | 0.363 | -12.4 | 0.535 | -17.4 |
| Average | 0.403 | -13.7 | 0.163 | -5.9 | 0.308 | -10.8 | 0.427 | -14.0 |
| Gen [s] | 5.45 | 9.45 | 14.83 | 29.67 | ||||
| Pro [s] | 138.72 | 59.50 | 130.19 | 291.29 | ||||
| Fus [s] | 4.93 | 22.17 | 31.36 | 43.98 | ||||
IV-G1 Influence of PSGA
The proposed parallel-serial multi-head mechanism is designed to enhance the fusion and reinforcement of the attention features. Compared to a standard multi-head attention module, it establishes a stronger relationship and interaction between each single head attention layer. To evaluate the performance of the PSGA module, we replaced the parallel-serial structure with four parallel single heads [19] (referred to as Parallel) in which each head operates independently. In this test, we only evaluated the performance on the Y component.
The results are shown in Fig. 10. Since we used a four-head attention mechanism in parallel, the number of learnable parameters in this module remained almost unchanged. However, we can see that the parallel-serial structure (used in GQE-Net) led to the best performance, particularly at high bit rates. The detailed statistics are given in Table VI.
| Sequence | MSGAT | GQE-Net_1 | GQE-Net_2 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Y [%] | Cb [%] | Cr [%] | Y [%] | Cb [%] | Cr [%] | Y [%] | Cb [%] | Cr [%] | |
| Longdress | -12.73 | 0.15 | -2.73 | -14.7 | -8.7 | -13.1 | -15.9 | -6.5 | -7.1 |
| Redandblack | -8.008 | 1.06 | -3.04 | -13.2 | -5.9 | -14.8 | -17.6 | -8.8 | -4.2 |
| Soldier | -11.72 | -1.28 | -1.45 | -13.4 | -5.5 | -10.7 | -16.3 | -12.6 | -6.1 |
| Dancer | -13.18 | -2.26 | -1.71 | -16.2 | -5.1 | -12.9 | -23.0 | -13.5 | -9.3 |
| Model | -13.23 | -3.87 | -4.40 | -15.9 | -5.3 | -10.7 | -20.6 | -12.4 | -9.6 |
| Andrew | -7.02 | -4.37 | -5.66 | -16.3 | -5.3 | -5.2 | -19.9 | -6.3 | -3.8 |
| David | -8.33 | -3.37 | -2.12 | -9.0 | -5.9 | -10.8 | -12.7 | -11.2 | -5.1 |
| Phil | -13.73 | -0.53 | 0.68 | -16.3 | -4.4 | -3.9 | -25.2 | -6.7 | -4.7 |
| Sarah | -12.75 | -3.52 | -3.16 | -15.2 | -7.6 | -7.8 | -16.3 | -9.4 | -3.8 |
| Ricardo | -8.93 | -3.05 | -4.55 | -12.7 | -5.4 | -8.8 | -17.4 | -14.7 | -6.9 |
| Average | -10.97 | -2.10 | -2.81 | -14.3 | -5.9 | -9.9 | -18.5 | -10.2 | -6.1 |
| Sequence | G-PCC lifting | [35] | GQE-Net | ||||||||||
| Enc [s] | Dec [s] | Y [%] | Cb [%] | Cr [%] | Enc [s] | Dec [s] | Y [%] | Cb [%] | Cr [%] | Gen [s] | Pro [s] | Fus [s] | |
| basketball | 2.85 | 1.62 | -3.3 | -2.2 | 0.5 | 9.59 | 7.56 | -13.5 | -8.5 | -20.4 | 72.47 | 550.90 | 121.16 |
| dancer | 2.51 | 1.42 | -4.1 | -2.7 | -0.9 | 8.31 | 6.67 | -13.5 | -8.3 | -18.6 | 115.68 | 489.89 | 105.01 |
| exercise | 2.57 | 1.54 | -3.1 | -2.8 | -0.4 | 7.67 | 6.26 | -11.2 | -8.2 | -21.6 | 105.91 | 472.03 | 106.02 |
| longdress | 0.79 | 0.48 | -7.5 | -4.9 | -6.3 | 2.67 | 2.03 | -12.4 | -10.7 | -12.0 | 4.72 | 166.61 | 38.55 |
| loot | 0.74 | 0.45 | -6.9 | 0.2 | 0.1 | 2.50 | 1.93 | -13.9 | -11.7 | -16.7 | 4.14 | 157.71 | 38.25 |
| model | 2.65 | 1.62 | -3.6 | -1.5 | -0.3 | 8.15 | 6.27 | -12.5 | -7.7 | -15.8 | 58.81 | 508.13 | 116.69 |
| queen | 0.87 | 0.52 | -1.7 | -0.7 | -0.3 | 3.22 | 2.51 | -8.0 | -12.2 | -13.8 | 17.39 | 185.46 | 41.05 |
| redandblack | 0.70 | 0.43 | -5.3 | -0.9 | -8.7 | 2.28 | 1.90 | -14.1 | -8.6 | -14.5 | 3.67 | 147.80 | 34.39 |
| soldier | 1.03 | 0.67 | -8.1 | 0.6 | 0.5 | 4.16 | 3.04 | -15.2 | -10.0 | -15.7 | 7.51 | 216.59 | 50.17 |
| Andrew | 1.53 | 1.06 | -7.2 | -2.7 | -3.0 | 3.92 | 3.27 | -20.5 | -8.4 | -6.1 | 30.38 | 242.67 | 52.52 |
| David | 1.37 | 0.83 | -5.5 | 0.5 | 0.6 | 4.02 | 3.22 | -12.2 | -8.8 | -15.9 | 29.86 | 245.34 | 53.46 |
| Phil | 1.56 | 1.07 | -6.5 | -2.6 | -1.8 | 4.48 | 3.40 | -17.8 | -7.0 | -6.3 | 36.61 | 273.72 | 59.65 |
| Ricardo | 0.98 | 0.55 | -2.8 | 0.2 | 0.2 | 2.75 | 2.31 | -14.2 | -10.1 | -14.1 | 15.33 | 174.58 | 37.38 |
| Sarah | 1.03 | 0.70 | -4.5 | 0.9 | 0.7 | 3.36 | 2.73 | -17.4 | -9.8 | -11.3 | 20.54 | 205.13 | 43.42 |
| arco_valentino | 5.94 | 3.88 | -3.2 | 1.7 | -1.3 | 5.65 | 4.38 | -1.3 | -6.2 | -9.2 | 19.17 | 300.56 | 57.51 |
| egyptian_mask | 1.09 | 0.76 | 0.0 | 0.2 | 0.3 | 0.91 | 0.17 | -4.7 | -4.4 | -3.7 | 0.54 | 49.95 | 10.90 |
| facade_00009 | 6.10 | 4.27 | -7.3 | -1.9 | -0.2 | 5.33 | 4.26 | -3.6 | -2.7 | -3.8 | 20.82 | 304.85 | 66.92 |
| staue_klimt | 2.03 | 1.42 | -2.6 | -1.6 | 0.1 | 1.54 | 1.20 | -2.9 | -5.0 | -3.1 | 1.71 | 99.04 | 22.18 |
| Average | 2.02 | 1.18 | -4.6 | -1.1 | -1.1 | 4.44 | 3.48 | -11.6 | -8.3 | -12.4 | 31.40 | 266.44 | 58.62 |
IV-G2 Influence of FR module
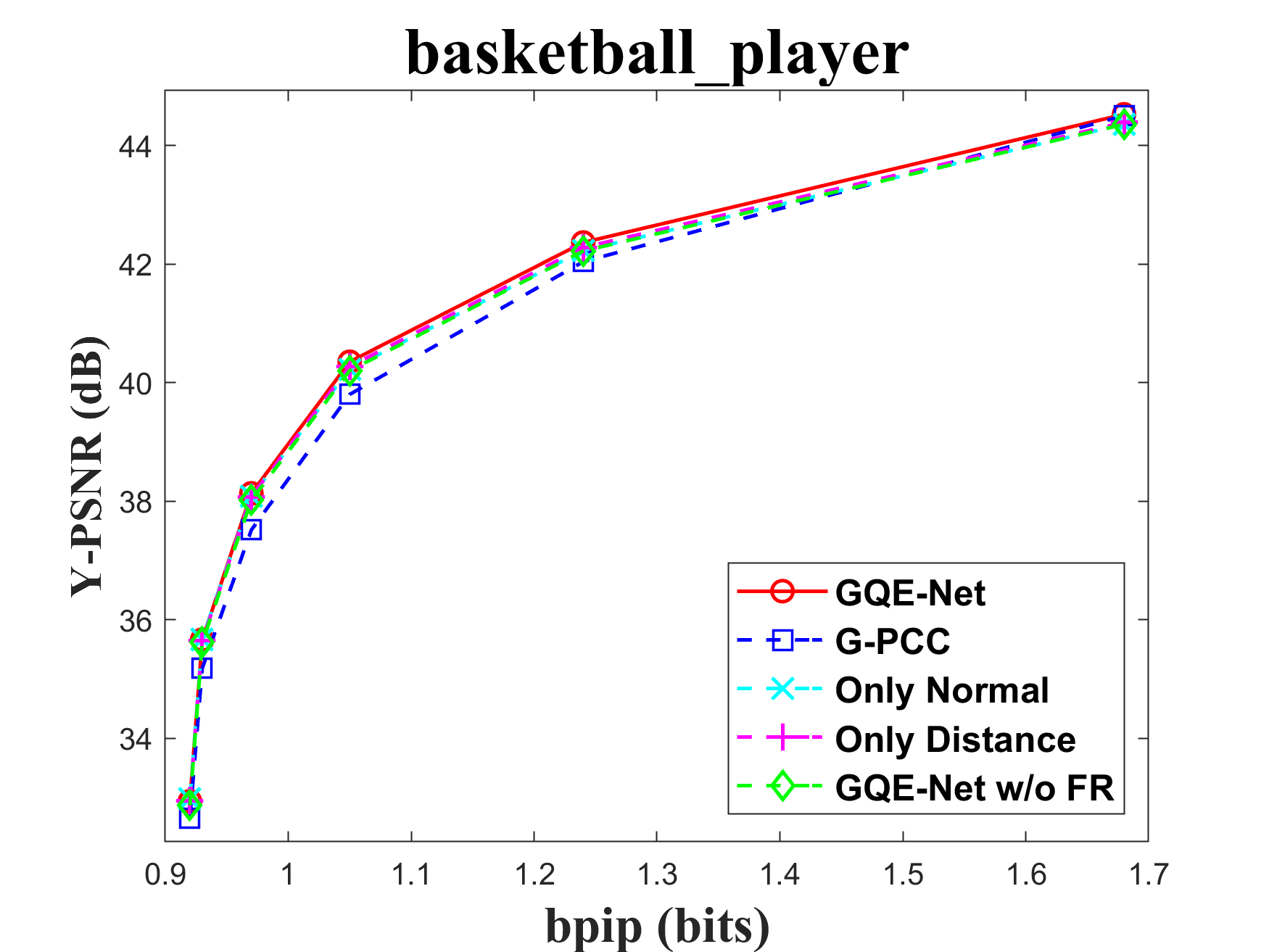
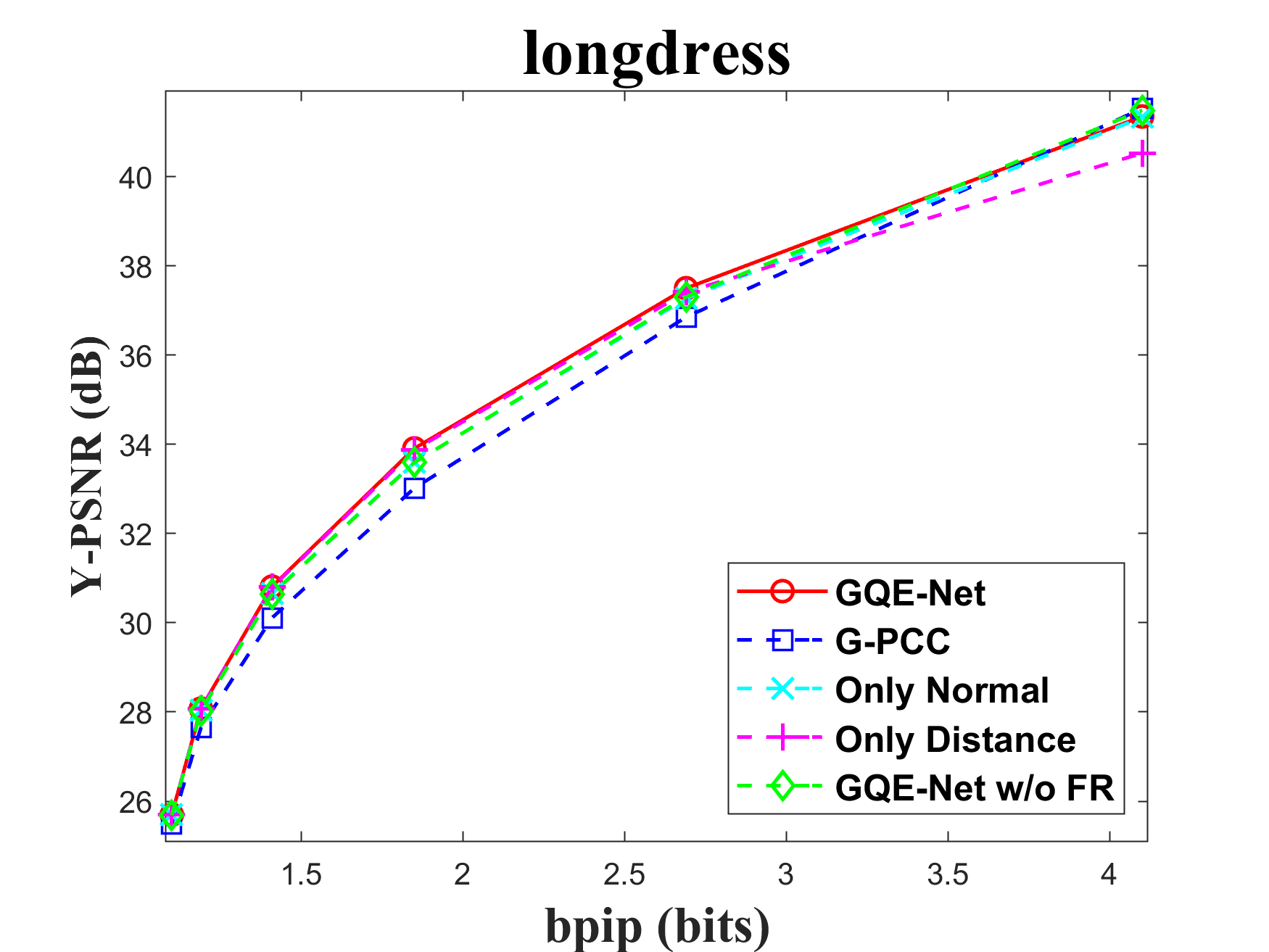
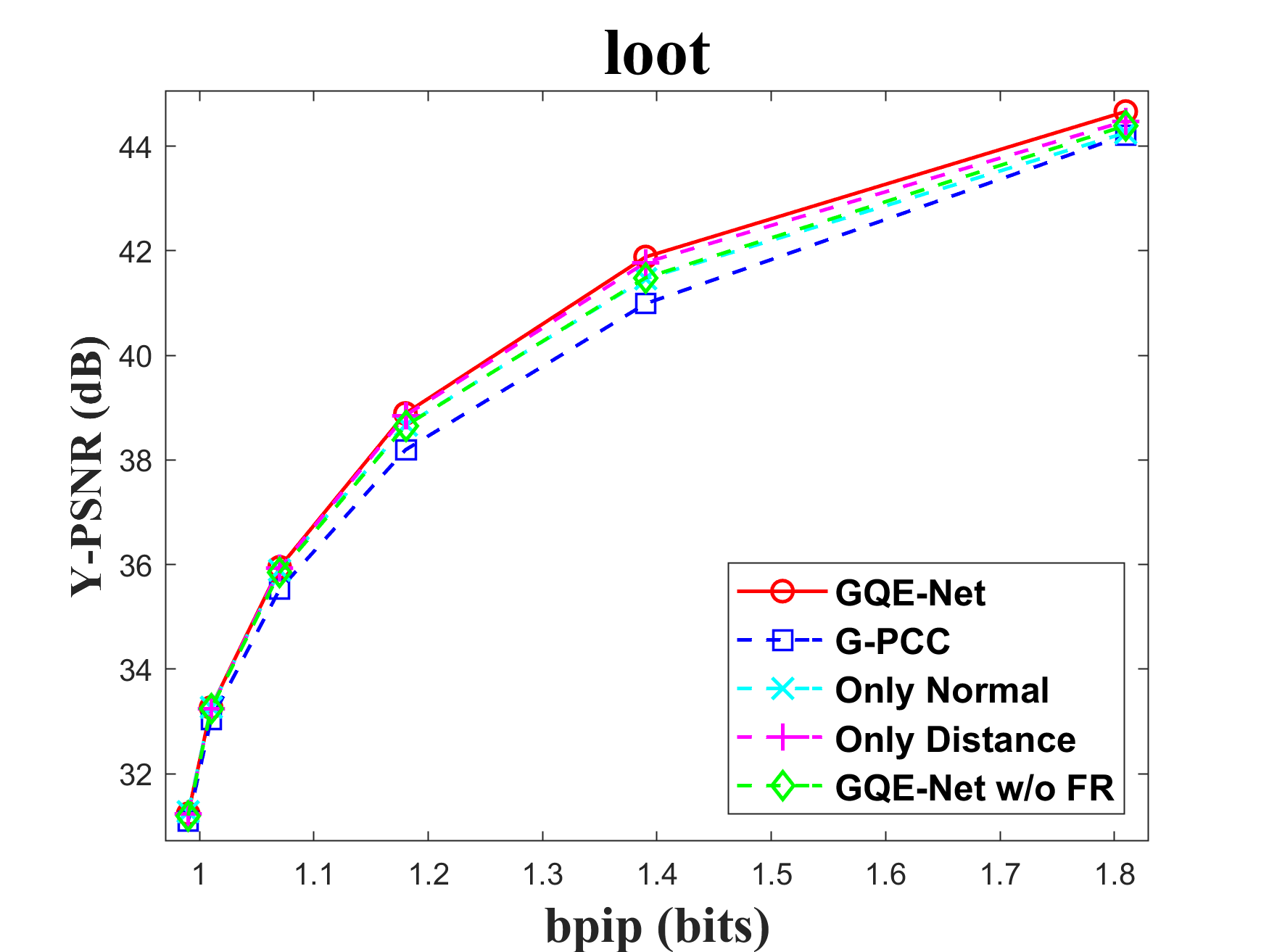
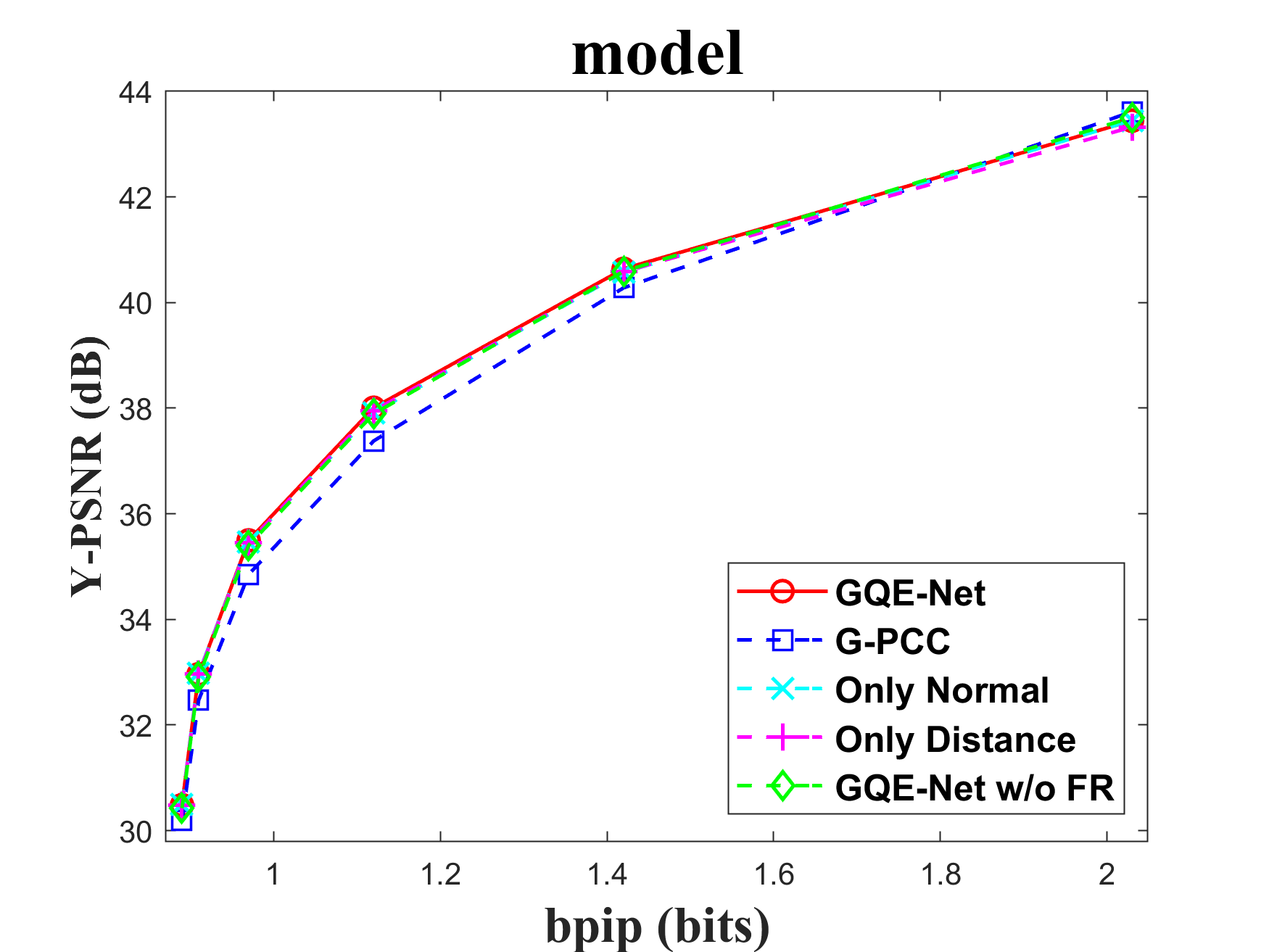
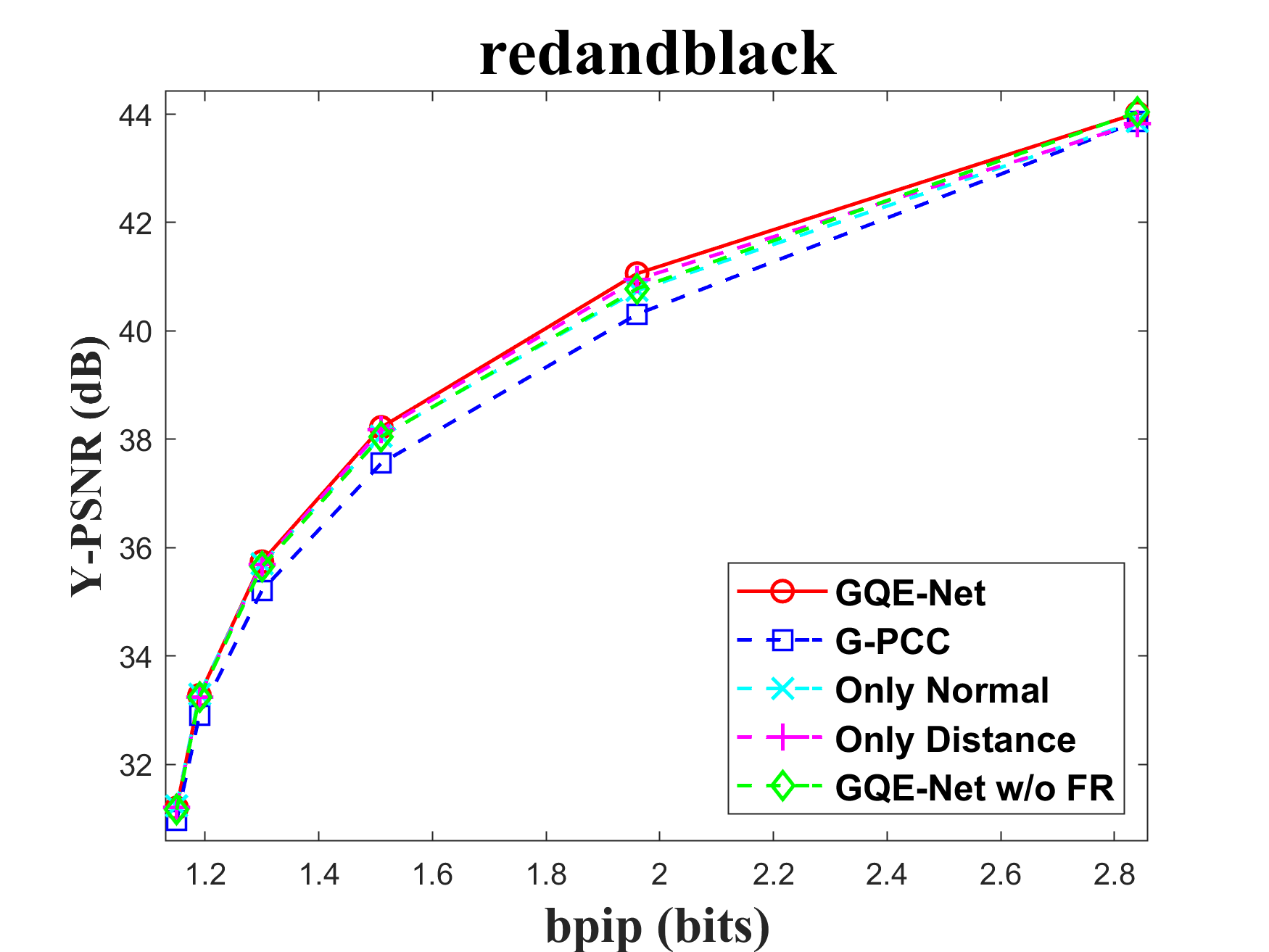
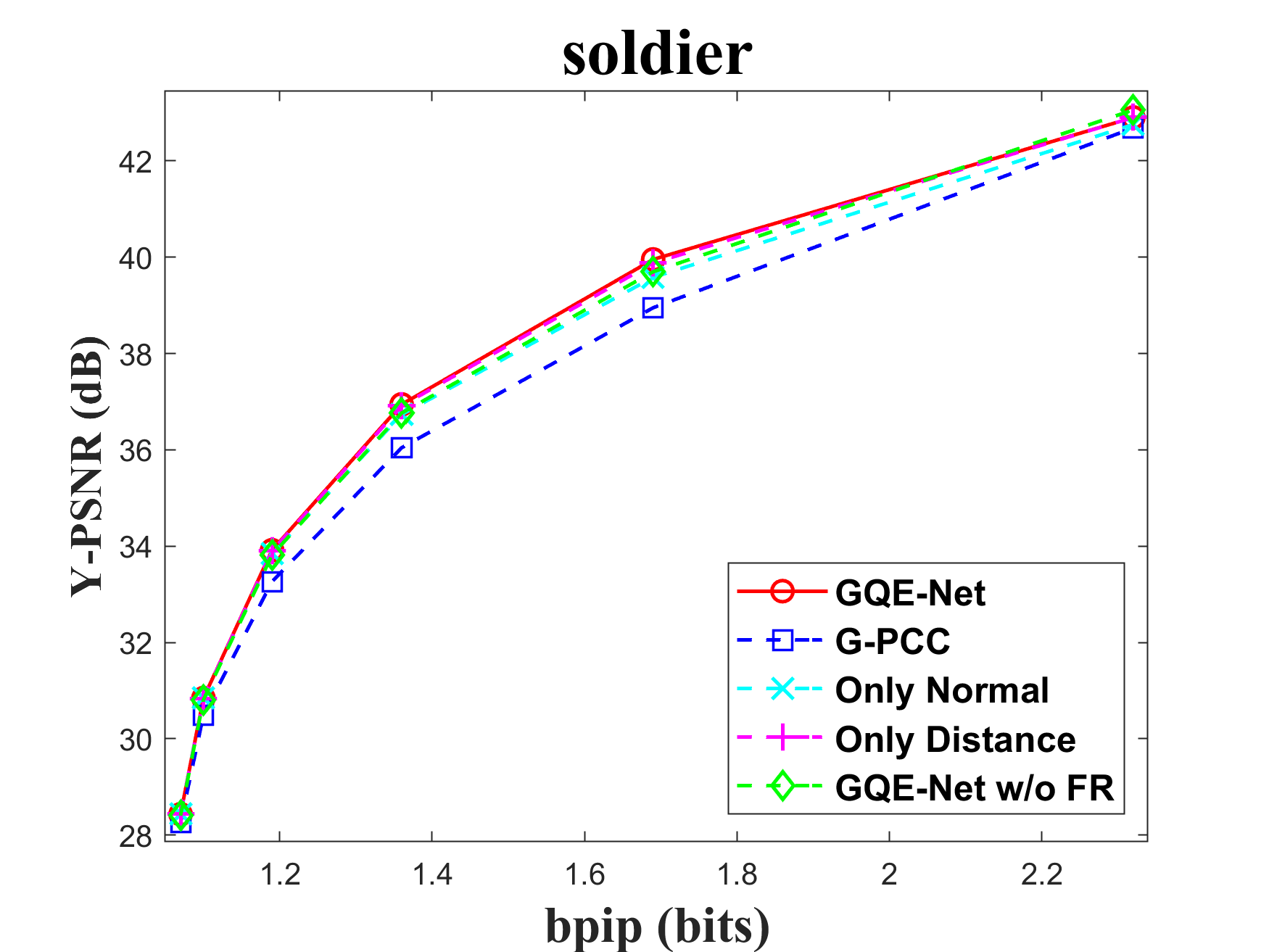
The FR module is crucial for integrating geometry information into color features. To assess the impact of the FR module, we tested the performance of GQE-Net both with and without it. There are two key components in this module: normal calculation and distance-based feature weighting. Normals aid in identifying the similarity between the central point and its neighbors, while the weighting matrix reinforces features that are geometrically close to each other and weakens features that are geometrically far apart. We tested versions of GQE-Net that fully use the FR module, only use normal information (denoted as Only Normal), only use feature weighting (denoted as Only Distance), and use none of them (denoted as GQE-Net w/o FR). The corresponding rate-PSNR curves are compared in Fig. 11. We can observe that the GQE-Net version that fully uses the FR module leads to the best performance for all tested point clouds, demonstrating the efficiency of the FR module. Similar conclusions can also be seen in Table VI.
In Table VI, we also compare time and space complexity of GQE-Net in each case. We evaluate time complexity by the processing time of one patch and space complexity by the number of learnable parameters in the network. It can be seen that with a small increase in complexity, the FR and PSGA modules provided significant performance gains for GQE-Net.
IV-G3 Study of patch overlap
The way in which the point cloud is partitioned into patches has a significant impact on both performance and efficiency. In this section, we study the effect of the overlapping ratio . We also compare our patch generation approach to an alternative method [47] that leads to non-overlapped patches. This method sequentially partitions the point cloud into non-overlapping patches of the same size.
Table VII shows the results for the proposed patch generation method for , , and . It also shows the results for the method used in [47] when the number of points in each patch was set to .
Doubling the overlapping ratio improved the rate-distortion performance as it decreased the number of unprocessed points (about for , for , and for ). At the same time, it significantly increased the time complexity. For this reason, a further increase in the overlapping ratio is not recommended.
The time complexity of the method in [47] was lower than that of the proposed method. However, except for one point cloud, its rate-distortion performance was worse.
IV-H Comparison with the state-of-the-art
In this section, we first compare GQE-Net to the multi-scale graph attention network (MSGAT) [37], which was the first neural network used for enhancing the color quality of point clouds. Note that MSGAT trained separate models for the Y, Cb, and Cr components with bit rates ranging from R01 to R04. This means that MSGAT is only suitable for point clouds at specific bit rates, limiting its applicability. For a comprehensive comparison, we considered two versions of GQE-Net. The first one, which we call GQE-Net_1, consists of a single model for all bit rates, which was trained on the WPCSD training set for the corresponding color channel. The second one, which we call GQE-Net_2, consists of several models, where each model was trained on the training set in [37] for one target bit rate and color channel. In both cases, the training and test point clouds were compressed using G-PCC TMC13v12.0 with the lifting transform according to the configuration adopted in [37]. Table VIII gives the BD-rates of MSGAT, GQE-Net_1, and GQE-Net_2 on the test set in [37]. The results confirm the superiority of our approach.
Next, we compare the proposed method and a Wiener filter-based point cloud color quality enhancement method [35], in which the optimal coefficients of a Wiener filter are calculated in the encoder and transmitted to the decoder. We used G-PCC TMC13v14.0 with the lifting transform for compression. Table IX shows the BD-rates and the time complexity of the encoding and decoding for Cat_A and Cat_B point clouds. We can observe that the proposed method performed better no matter which category of point clouds was used.
| Sequence | Smoothing | GQE-Net | ||||
|---|---|---|---|---|---|---|
| Y [%] | Cb [%] | Cr [%] | Y [%] | Cb [%] | Cr [%] | |
| basketball | 0.5 | -0.5 | -0.5 | -4.9 | -10.3 | -11.2 |
| dancer | -10.8 | 1.3 | 12.2 | -5.6 | -11.4 | -12.6 |
| exercise | -7.2 | 2.6 | -1.0 | -4.8 | -13.7 | -15.0 |
| longdress | 1.5 | 0.1 | 0.4 | -5.2 | -6.4 | -7.4 |
| loot | 1.4 | -1.6 | -1.6 | -6.1 | -19.6 | -18.4 |
| model | 1.1 | -0.4 | -0.5 | -4.9 | -9.0 | -10.3 |
| queen | 1.3 | -0.8 | -0.8 | -15.1 | -11.0 | -9.0 |
| redandblack | 1.3 | -0.6 | 1.7 | -6.8 | -11.3 | -8.7 |
| soldier | 2.1 | -0.6 | 1.7 | -8.2 | -16.1 | -15.3 |
| Andrew | 15.3 | 3.8 | 1.9 | -6.3 | -5.8 | -1.9 |
| David | 2.3 | 0.5 | -1.8 | -3.5 | -17.0 | -14.5 |
| Phil | 18.9 | 4.0 | 5.0 | -6.8 | -16.5 | -15.8 |
| Ricardo | 10.3 | -0.9 | 1.7 | -9.8 | -11.1 | -18.0 |
| Sarah | 18.6 | 1.2 | 0.9 | -5.6 | -15.6 | -15.5 |
| Average | 4.0 | 0.5 | 1.2 | -6.5 | -12.4 | -11.5 |
In Table IX, we provide the processing time of G-PCC, the additional processing time of Wiener filtering, and the additional processing time of the proposed method in different stages (patch generation, GQE-Net, and patch fusion). We can see that the time complexity of the proposed method was higher than that of G-PCC and the Wiener filter-based method. It is a common problem that neural network-based methods consume more computational resources.
Finally, we compared the performance of GQE-Net to that of V-PCC TMC2v18.0’s low-complexity color smoothing method [36]. Table X compares the BD-rates. As can be seen, our method was more stable and provided clear BD-rate gains over the V-PCC test model color smoothing method.
V Conclusion
We proposed GQE-Net, a graph-based quality enhancement network to restore the true colors of distorted point clouds. GQE-Net includes two novel modules: PSGA and FR. PSGA, which consists of three single-head attention layers, extracts, integrates and reinforces attention features. FR efficiently uses local information through normal fusion and distance-guided feature weighting. GQE-Net can be applied to point clouds encoded at various quantization parameters, making it flexible in practical applications. GQE-Net achieved BD-PSNR gains of dB, dB, dB with corresponding BD-rates of -, - and - for the Luma, Cb, and Cr components of dense point clouds (Cat_A) coded by G-PCC with the lifting transform. For sparse point clouds (Cat_B), the BD-rate gains were -, - and -. We also showed that GQE-Net is effective for other coding configurations, such as G-PCC RAHT and V-PCC.
As future work, we will focus on improving our method for sparse point clouds. We will also build a lightweight version of our model to reduce its time complexity.
References
- [1] K. Guo, F. Xu, T. Yu, X. Liu, Q. Dai, and Y. Liu, “Real-time geometry, albedo, and motion reconstruction using a single rgb-d camera,” ACM Transactions on Graphics (ToG), vol. 36, no. 4, pp. 1, 2017.
- [2] C. Perra, F. Murgia, and D. Giusto, “An analysis of 3D point cloud reconstruction from light field images,” in 2016 Sixth International Conference on Image Processing Theory, Tools and Applications (IPTA). IEEE, 2016, pp. 1–6.
- [3] Q. Wang and M.-K. Kim, “Applications of 3D point cloud data in the construction industry: A fifteen-year review from 2004 to 2018,” Advanced Engineering Informatics, vol. 39, pp. 306–319, 2019.
- [4] D. Graziosi, O. Nakagami, S. Kuma, A. Zaghetto, T. Suzuki, and A. Tabatabai, “An overview of ongoing point cloud compression standardization activities: Video-based (V-PCC) and geometry-based (G-PCC),” APSIPA Transactions on Signal and Information Processing, vol. 9, 2020.
- [5] “V-PCC codec description,” Document ISO/IEC JTC1/SC29/WG11 N19332, April, 2020.
- [6] “G-PCC codec description,” Document ISO/IEC JTC1/SC29/WG11 N19331, April, 2020.
- [7] “Material for the preparation of the CfP for AI-based graphics coding,” Document ISO/IEC JTC 1/SC 29/WG 7 N684, July, 2023, Geneva.
- [8] J. Yang, C. Lee, P. Ahn, H. Lee, E. Yi, and J. Kim, “PBP-Net: Point projection and back-projection network for 3D point cloud segmentation,” in 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2020, pp. 8469–8475.
- [9] Q. Liu, H. Yuan, H. Su, H. Liu, Y. Wang, H. Yang, and J. Hou, “PQA-Net: Deep no reference point cloud quality assessment via multi-view projection,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 31, no. 12, pp. 4645–4660, 2021.
- [10] X. Liu, X. Liu, Y. Liu, and Z. Han, “Spu-net: Self-supervised point cloud upsampling by coarse-to-fine reconstruction with self-projection optimization,” IEEE Transactions on Image Processing, vol. 31, pp. 4213–4226, 2022.
- [11] Y. Zhou and O. Tuzel, “Voxelnet: End-to-end learning for point cloud based 3d object detection,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 4490–4499.
- [12] X. Roynard, J.-E. Deschaud, and F. Goulette, “Classification of point cloud scenes with multiscale voxel deep network,” arXiv preprint arXiv:1804.03583, 2018.
- [13] H. Kuang, B. Wang, J. An, M. Zhang, and Z. Zhang, “Voxel-FPN: Multi-scale voxel feature aggregation for 3D object detection from LIDAR point clouds,” Sensors, vol. 20, no. 3, pp. 704, 2020.
- [14] C. R. Qi, H. Su, K. Mo, and L. J. Guibas, “Pointnet: Deep learning on point sets for 3d classification and segmentation,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 652–660.
- [15] C. R. Qi, L. Yi, H. Su, and L. J. Guibas, “Pointnet++: Deep hierarchical feature learning on point sets in a metric space,” Advances in neural information processing systems, vol. 30, 2017.
- [16] B. Graham, M. Engelcke, and L. Van Der Maaten, “3d semantic segmentation with submanifold sparse convolutional networks,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 9224–9232.
- [17] H. Su, V. Jampani, D. Sun, S. Maji, E. Kalogerakis, M.-H. Yang, and J. Kautz, “Splatnet: Sparse lattice networks for point cloud processing,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 2530–2539.
- [18] Y. Wang, Y. Sun, Z. Liu, S. E. Sarma, M. M. Bronstein, and J. M. Solomon, “Dynamic graph cnn for learning on point clouds,” Acm Transactions On Graphics (tog), vol. 38, no. 5, pp. 1–12, 2019.
- [19] C. Chen, L. Z. Fragonara, and A. Tsourdos, “GAPointNet: Graph attention based point neural network for exploiting local feature of point cloud,” Neurocomputing, vol. 438, pp. 122–132, 2021.
- [20] L. Wang, Y. Huang, Y. Hou, S. Zhang, and J. Shan, “Graph attention convolution for point cloud semantic segmentation,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 10296–10305.
- [21] W. Shi and R. Rajkumar, “Point-gnn: Graph neural network for 3d object detection in a point cloud,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 1711–1719.
- [22] G. Te, W. Hu, A. Zheng, and Z. Guo, “Rgcnn: Regularized graph cnn for point cloud segmentation,” in Proceedings of the 26th ACM international conference on Multimedia, 2018, pp. 746–754.
- [23] S. Chen, C. Duan, Y. Yang, D. Li, C. Feng, and D. Tian, “Deep unsupervised learning of 3d point clouds via graph topology inference and filtering,” IEEE transactions on image processing, vol. 29, pp. 3183–3198, 2019.
- [24] Z. Liang, M. Yang, L. Deng, C. Wang, and B. Wang, “Hierarchical depthwise graph convolutional neural network for 3d semantic segmentation of point clouds,” in 2019 International Conference on Robotics and Automation (ICRA). IEEE, 2019, pp. 8152–8158.
- [25] C. Dinesh, G. Cheung, and I. V. Bajić, “Point cloud denoising via feature graph laplacian regularization,” IEEE Transactions on Image Processing, vol. 29, pp. 4143–4158, 2020.
- [26] J. Zeng, G. Cheung, M. Ng, J. Pang, and C. Yang, “3D point cloud denoising using graph Laplacian regularization of a low dimensional manifold model,” IEEE Transactions on Image Processing, vol. 29, pp. 3474–3489, 2019.
- [27] W. Hu, Q. Hu, Z. Wang, and X. Gao, “Dynamic point cloud denoising via manifold-to-manifold distance,” IEEE Transactions on Image Processing, vol. 30, pp. 6168–6183, 2021.
- [28] X. Xu, G. Geng, X. Cao, K. Li, and M. Zhou, “TDNet: transformer-based network for point cloud denoising,” Applied Optics, vol. 61, no. 6, pp. C80–C88, 2022.
- [29] H. Chen, Z. Wei, X. Li, Y. Xu, M. Wei, and J. Wang, “RePCD-Net: Feature-Aware Recurrent Point Cloud Denoising Network,” International Journal of Computer Vision, vol. 130, no. 3, pp. 615–629, 2022.
- [30] W. Jia, L. Li, Z. Li, and S. Liu, “Deep Learning Geometry Compression Artifacts Removal for Video-Based Point Cloud Compression,” International Journal of Computer Vision, vol. 129, no. 11, pp. 2947–2964, 2021.
- [31] J. Xing, H. Yuan, C. Chen, and T. Guo, “Wiener Filter-Based Point Cloud Adaptive Denoising for Video-based Point Cloud Compression,” in Proceedings of the 1st International Workshop on Advances in Point Cloud Compression, Processing and Analysis, 2022, pp. 21–25.
- [32] M. A. Irfan and E. Magli, “Joint geometry and color point cloud denoising based on graph wavelets,” IEEE Access, vol. 9, pp. 21149–21166, 2021.
- [33] M. A. Irfan and E. Magli, “Exploiting color for graph-based 3d point cloud denoising,” Journal of Visual Communication and Image Representation, vol. 75, pp. 103027, 2021.
- [34] K. Yamamoto, M. Onuki, and Y. Tanaka, “Deblurring of point cloud attributes in graph spectral domain,” in 2016 IEEE International Conference on Image Processing (ICIP). IEEE, 2016, pp. 1559–1563.
- [35] J. Xing, H. Yuan, C. Chen, and W. Gao, “Wiener filter-based color attribute quality enhancement for geometry-based point cloud compression,” in 2022 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC). IEEE, 2022, pp. 1208–1212.
- [36] M. B. Hossein Najaf-Zadeh, “Low complexity color smoothing,” Document ISO/IEC JTC1/SC29/WG11 m46277, January, 2019.
- [37] X. Sheng, L. Li, D. Liu, and Z. Xiong, “Attribute Artifacts Removal for Geometry-Based Point Cloud Compression,” IEEE Transactions on Image Processing, vol. 31, pp. 3399–3413, 2022.
- [38] Q. Liu, H. Yuan, R. Hamzaoui, H. Su, J. Hou, and H. Yang, “Reduced reference perceptual quality model with application to rate control for video-based point cloud compression,” IEEE Transactions on Image Processing, vol. 30, pp. 6623–6636, 2021.
- [39] L. E. Peterson, “K-nearest neighbor,” Scholarpedia, vol. 4, no. 2, pp. 1883, 2009.
- [40] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” Advances in neural information processing systems, vol. 30, 2017.
- [41] H. Abdi and L. J. Williams, “Principal component analysis,” Wiley interdisciplinary reviews: computational statistics, vol. 2, no. 4, pp. 433–459, 2010.
- [42] S. Schwarz, G. Martin-Cocher, D. Flynn, and M. Budagavi, “Common test conditions for point cloud compression,” Document ISO/IEC JTC1/SC29/WG11 w17766, Ljubljana, Slovenia, 2018.
- [43] D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980, 2014.
- [44] S. Schwarz, M. Preda, V. Baroncini, M. Budagavi, P. Cesar, P. A. Chou, R. A. Cohen, M. Krivokuća, S. Lasserre, Z. Li, et al., “Emerging MPEG standards for point cloud compression,” IEEE Journal on Emerging and Selected Topics in Circuits and Systems, vol. 9, no. 1, pp. 133–148, 2018.
- [45] G. , “Calculation of average PSNR differences between RD-curves,” VCEG-M33, 2001.
- [46] E. M. Torlig, E. Alexiou, T. A. Fonseca, R. L. de Queiroz, and T. Ebrahimi, “A novel methodology for quality assessment of voxelized point clouds,” in Applications of Digital Image Processing XLI. SPIE, 2018, vol. 10752, pp. 174–190.
- [47] X. Sheng, L. Li, D. Liu, Z. Xiong, Z. Li, and F. Wu, “Deep-pcac: An end-to-end deep lossy compression framework for point cloud attributes,” IEEE Transactions on Multimedia, vol. 24, pp. 2617–2632, 2021.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/57bbc2b6-f9c9-4f1e-b7c7-b7b8cd272e8c/xjr.jpg) |
Jinrui Xing received the B.E. degree in automation with the Department of Control Science and Engineering from Shandong University, Ji’nan, China, in 2021. He is now pursuing the M.E. degree in control science and engineering from Shandong University, Ji’nan, China. His research interests include 3D point cloud compression and post processing. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/57bbc2b6-f9c9-4f1e-b7c7-b7b8cd272e8c/YH.png) |
Hui Yuan (Senior Member, IEEE) received the B.E. and Ph.D. degrees in telecommunication engineering from Xidian University, Xi’an, China, in 2006 and 2011, respectively. In April 2011, he joined Shandong University, Ji’nan, China, as a Lecturer (April 2011–December 2014), an Associate Professor (January 2015-August 2016), and a Professor (September 2016). From January 2013 to December 2014, and from November 2017 to February 2018, he worked as a Postdoctoral Fellow (Granted by the Hong Kong Scholar Project) and a Research Fellow, respectively, with the Department of Computer Science, City University of Hong Kong. From November 2020 to November 2021, he worked as a Marie Curie Fellow (Granted by the Marie Skłodowska-Curie Actions Individual Fellowship under Horizon2020 Europe) with the School of Engineering and Sustainable Development, De Montfort University, Leicester, U.K. From October 2021 to November 2021, he also worked as a visiting researcher (secondment of the Marie Skłodowska-Curie Individual Fellowships) with the Computer Vision and Graphics group, Fraunhofer Heinrich-Hertz-Institut (HHI), Germany. His current research interests include 3D visual coding and communication. He served as an Associate Editor for IET Image Processing (from 2023), an Area Chair for IEEE ICME 2023, ICME 2022, ICME 2021, IEEE ICME 2020, and IEEE VCIP 2020, and Senior Area Chair for PRCV 2023. He also serves as a member of IEEE CTSoc Audio/Video Systems and Signal Processing Technical Committee (AVS TC), IEEE CASSoc Visual Signal Processing and Communication Technical Committee (VSPC TC), and APSIPA Image, Video, and Multimedia Technical Committee (IVM TC). His research interest is 3D visual media coding, processing, and communication. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/57bbc2b6-f9c9-4f1e-b7c7-b7b8cd272e8c/Raouf.jpg) |
Raouf Hamzaoui (Senior Member, IEEE) received the MSc degree in mathematics from the University of Montreal, Canada, in 1993, the Dr.rer.nat. degree from the University of Freiburg, Germany, in 1997 and the Habilitation degree in computer science from the University of Konstanz, Germany, in 2004. He was an Assistant Professor with the Department of Computer Science of the University of Leipzig, Germany and with the Department of Computer and Information Science of the University of Konstanz. In September 2006, he joined DMU where he is a Professor in Media Technology and Head of the Signal Processing and Communications Systems Group in the Institute of Engineering Sciences. He was a member of the Editorial Board of the IEEE Transactions on Multimedia and IEEE Transactions on Circuits and Systems for Video Technology. He has published more than 100 research papers in books, journals, and conferences. His research has been funded by the EU, DFG, Royal Society, and industry and received best paper awards (ICME 2002, PV’07, CONTENT 2010, MESM’2012, UIC-2019). |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/57bbc2b6-f9c9-4f1e-b7c7-b7b8cd272e8c/LH.jpg) |
Hao Liu received the B.E. degree in telecommunication engineering from Shandong Agricultural University, Taian, China, in 2017, and the Ph.D. degree in information science and engineering from Shandong University, Qingdao, China, in 2022. From July 2022, he works a Lecturer with the School of Computer Science and Control Engineering, Yantai University. His research interests include 3D point cloud compression and processing. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/57bbc2b6-f9c9-4f1e-b7c7-b7b8cd272e8c/HJH.jpg) |
Junhui Hou is an Associate Professor with the Department of Computer Science, City University of Hong Kong. He holds a B.Eng. degree in information engineering (Talented Students Program) from the South China University of Technology, Guangzhou, China (2009), an M.Eng. degree in signal and information processing from Northwestern Polytechnical University, Xi’an, China (2012), and a Ph.D. degree from the School of Electrical and Electronic Engineering, Nanyang Technological University, Singapore (2016). His research interests are multi-dimensional visual computing. Dr. Hou received the Early Career Award (3/381) from the Hong Kong Research Grants Council in 2018. He is an elected member of IEEE MSATC, VSPC-TC, and MMSP-TC. He is currently serving as an Associate Editor for IEEE Transactions on Visualization and Computer Graphics, IEEE Transactions on Circuits and Systems for Video Technology, IEEE Transactions on Image Processing, Signal Processing: Image Communication, and The Visual Computer. |