Gradient-Free Classifier Guidance for Diffusion Model Sampling
Abstract
Image generation using diffusion models have demonstrated outstanding learning capabilities, effectively capturing the full distribution of the training dataset. They are known to generate wide variations in sampled images, albeit with a trade-off in image fidelity. Guided sampling methods, such as classifier guidance (CG) and classifier-free guidance (CFG), focus sampling in well-learned high-probability regions to generate images of high fidelity, but each has its limitations. CG is computationally expensive due to the use of back-propagation for classifier gradient descent, while CFG, being gradient-free, is more efficient but compromises class label alignment compared to CG. In this work, we propose an efficient guidance method that fully utilizes a pre-trained classifier without using gradient descent. By using the classifier solely in inference mode, a time-adaptive reference class label and corresponding guidance scale are determined at each time step for guided sampling. Experiments on both class-conditioned and text-to-image generation diffusion models demonstrate that the proposed Gradient-free Classifier Guidance (GFCG) method consistently improves class prediction accuracy. We also show GFCG to be complementary to other guided sampling methods like CFG. When combined with the state-of-the-art Autoguidance (ATG), without additional computational overhead, it enhances image fidelity while preserving diversity. For ImageNet 512512, we achieve a record FDDINOv2 of 23.09, while simultaneously attaining a higher classification Precision (94.3%) compared to ATG (90.2%).
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/56a1e948-ca5a-4f5f-8418-0dedfe0feb07/x1.png)
1 Introduction
Denoising diffusion models [11, 31, 32, 29], the latest popular generative models, have demonstrated exceptional performance across various domains[18, 21, 12, 25, 34], particularly in image generation [22, 26, 28]. By leveraging a learned denoising network, these models iteratively refine outputs to produce diverse, high-quality images. To enhance control over image generation, the denoiser is often trained with specific conditions to generate images with desired properties, commonly employing class labels [10] or text prompt embeddings [28, 22], as well as other types of image conditions [27].
Guiding an unconditional model to generate images of a specific class can be accomplished using classifier guidance (CG) [6]. During the iterative image generation process, CG steers the model towards outputs that align with a designated class by incorporating the classifier’s gradient at each step. This approach not only improves image fidelity but also applies to other attributes beyond class [23, 36, 2]. Despite its effectiveness in generating images with desired attributes, gradient-based guidance methods such as CG are computationally inefficient due to the time-consuming back-propagation required at each sampling step, often multiple times per step [35]. Although CG enhances image quality, indicated by increased precision scores when tested on synthetic images using a real classifier [6], it also compromises image diversity, as evidenced by lower FID scores [9] and decreased recall when evaluated on real images using a classifier trained on synthetic images.
Classifier-free guidance (CFG) [10] is the first gradient-free guidance method that improves image quality without requiring a classifier. This is achieved by generating an unconditional sample and using it as a bad sample to avoid. CFG experiences a similar trade-off between sample quality and diversity as CG. Autoguidance (ATG) [16], a recent gradient-free guidance method, proposes using a sample from a bad version of the model instead of the bad unconditional sample used in CFG. It guides sampling to high-probability regions of the data distribution without reducing diversity, achieving state-of-the-art performances in both FID [9] and FDDINOv2 [33] metrics. However, the trade-off in image quality as evaluated using classification metrics, is not addressed.
In this work, we propose a new gradient-free guidance method that uses the sample from a reference class () as the undesired sample to avoid. Unlike CFG, where an empty class or a separate unconditional model is fixed throughout the sampling process, a pre-trained classifier is used to adaptively determine the reference class and guidance scale based on classier predictions. Compared to gradient-based classifier guidance, the proposed gradient-free classifier guidance (GFCG) offers similar benefit of better alignment between generated images and class label conditions, without the computational expense of classifier gradient descent. Additionally, it is complementary to other guidance methods and can be combined with them to improve image quality without trade-off in diversity. We investigate two combination methods for their efficiency and effectiveness. For the mixed guidance, it combines the guidance from two methods temporally resulting in no additional overhead in the number of function evaluations (NFEs). Alternatively, the additive guidance method combines the guidance terms from two methods, achieving the best performance in both image quality and diversity at the cost of more computations, as the guidance terms are calculated separately. Extensive experiments are conducted on class-conditional and text-to-image diffusion models to demonstrate the benefits of GFCG in improving image fidelity with minimal trade-off in diversity. Extensive ablation studies are conducted to provide insights into optimal settings for GFCG alone and in combination with other methods like CFG and ATG. As shown in Figure 1, our results significantly improve classification accuracy for different models. For the bottom text-to-image generation, GFCG successfully generates the correct bird species while maintaining coherence with the detailed description.
In summary, the proposed GFCG method has the following key advantages:
-
It is the first known work of using a classifier for gradient-free guidance in diffusion sampling, leveraging a pre-trained classifier to adaptively determine both the reference class and guidance scale during sampling.
-
It significantly enhances image fidelity for both class-conditional and text-to-image models.
-
It is complementary to other gradient-free guidance methods. When combined with ATG, it establishes a new state-of-the-art performance in metrics measuring both sample image fidelity and diversity.
2 Related Works
Gradient-based Diffusion Guidance Dhariwal et al. [6] were the first to propose gradient-based guided sampling for diffusion model. In addition to the trade-off in image diversity and time-consuming classifier gradient calculation, it requires additional training of a noise-conditional classifier. For works following that, there are two main focuses, to generalize the guidance from classifier loss to any differentiable loss functions [2], and apply it through an existing differentiable target predictor without involving any additional training using noisy images [3]. Additionally, various techniques have been proposed to improve guidance effects, including guidance with multiple samples from Monte Carlo (MC) method [30], repetitive guided sampling at each time step [36], and computing the loss function gradient to the estimated denoised image [8]. Ye et al. [35] introduced a unified framework which encompass the prior works as special cases. By optimizing multiple hyperparameters in the unified framework, it is able to achieve improved performance over prior works in both FID and classification accuracy metrics. While the proposed techniques like MC sampling and recurrent guidance are shown beneficial to guidance effects, they all come with additional computational steps to different extents, making it even worse with already expensive gradient calculations.
Gradient-free Diffusion Guidance Ho et al. [10] introduced the first gradient-free guidance method, classifier-free guidance (CFG), to improve image quality in diffusion sampling without the need of a classifier. At each sampling step, it modifies the class conditional sample by enhancing the contrast between it and the corresponding unconditional sample. CFG enhances sample quality by guiding samples toward high-probability regions but suffers reduction in diversity for over-correction in class label alignment. Karras et al. [16] proposed a new method, Autoguidance (ATG), to improve sample quality with fewer loss in diversity. Using a smaller model trained from the same dataset with less learning iterations, it generates a bad reference sample for the main sample to steering away from. However, the samples are not assessed using classification accuracy so it is not clear if there is trade-off in image quality in terms of alignment with class labels. This is investigated in our work as part of a comprehensive set of experiments. There is another line of gradient-free methods which work on generating a bad reference sample by exploiting the self-attention layers of the diffusion network, including blurring pixels with high self-attention [14], adding Gaussian blur to weights of an intermediate self-attention layer [13], and replacing an intermediate self-attention map with an identity matrix [1]. There is no known comparisons between these self-attention based methods and the latest ATG. In addition to the innovative gradient-free classifier method, to our best knowledge, we are the first to conduct comparison studies for the full range of gradient-free guidance methods.
3 Methods
3.1 Diffusion Models
Diffusion models are a class of generative models that generate data following an iterative denoising process [11, 29, 32]. This involves a forward process where noise is ingested to data over a sequence of time steps to render them indistinguishable from Gaussian noise, and a backward denoising process where the noise is removed following the reverse sequence until noise-free data is recovered. The forward process is governed by the stochastic differential equation (SDE):
| (1) |
where is the data, is the time step, and and are predefined functions that govern the noise schedule, and is a standard Wiener process. The denoising process is governed by the reverse SDE:
| (2) |
where is the score function and is the standard Wiener process for the reverse steps.
In diffusion models, the score function is parameterized by a deep neural network with parameters , and represented as . Conditioning variables such as class label or text prompt, denoted as , can also be included and in this setting . During the reverse denoising process, to improve the quality of data generation, classifier-free guidance (CFG) is widely used [10]:
| (3) |
where and are the main and guidance networks, parameterized by neural network weights and , respectively. Here could be an unconditional diffusion model as in some implementations. In others, both and may be conditional neural networks where a null () class is used as the reference for CFG, replacing in Equation 3.1 with . Furthermore, is a hyperparameter referred to as the “guidance scale” where a scale of 1 means no guidance. Guided sampling improves the quality of data generation, albeit trading-off diversity [10].
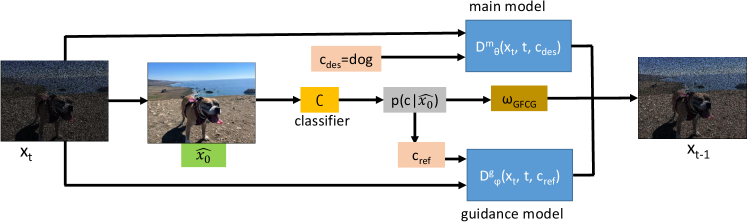
3.2 Gradient-free Classifier Guidance
Classifier guided sampling [6] from diffusion models involves the computation of gradients of classifier probabilities, and this is computationally expensive as it involves the use of autograd operators. To mitigate this issue, as explained above, CFG[10] was proposed to use an unconditional sample as a reference to increase contrast from. We extend these concepts to devise a novel formulation that utilizes a classifier, without computation of gradients, to generate an conditional sample as the reference. In what follows, we describe this methodology and refer to our method as “gradient-free classifier guidance” (GFCG). Our method is also adaptive in that it computes the guidance scale on-the-fly depending on how confused the diffusion model is during the denoising process.
In what follows, we will describe the method to a class-conditional diffusion model, where we denote the class label as for the -th class (e.g., i = 0, 1, …, 999 for ImageNet which has 1000 classes). Let refer to the desired class that we wish to generate. At each time step , the noisy sample is used to estimate the corresponding noise-free :
| (4) |
where is the noise schedule at time [11, 29]. A pre-trained classifier is used to estimate the class probabilities: . We then define an adaptive guidance scale as follows:
| (5) |
where 0, 0 and 01 are hyperparameters that need to be calibrated. When , the diffusion model is confused, necessitating the use of guidance to help the data generation. On the other hand, if , the diffusion model is confident and does not require guidance in this scenario. Thus, we adaptively determine if guidance is required at any time step and also the right magnitude. In addition, if , we identify a reference class following two criteria: (1) = the class with highest probability if does not have the highest probability; (2) = the class with second highest probability if has the highest probability. We then recast the denoising step in Equation 3.1 as follows:
| (6) |
Note that this involves two forward propagation processes, one with and another with as the conditioning class.
In summary, this method adaptively determines the guidance strength using a pre-trained classifier, and also decides when to use/not use guidance. For the classifier , we use a standard ResNet-101 pre-trained on ImageNet.

3.3 Implementation Considerations
As explained above, the proposed guidance can be applied at each sampling step using adaptively determined and . In practice, there are two additional hyperparameters, and , which can also be tuned for optimal guidance effects. Similar to the guidance interval applied to CFG [19], is the starting time step that the proposed GFCG is applied first and beyond during the denoising steps. For , it is used to determine the frequency for classifier prediction for and adaptation, i.e., the classifier is invoked only once every steps. The pseudo-code to implement the GFCG guidance method is included in Algorithm 1.
There are also two optional techniques that can be added to improve guidance effects based on the models used. First for , in place of the one step calculation as in Equation 4, a multi-step denoising process can be used to improve classifier prediction accuracy, especially in the case when is large, like classifier prediction is only used once. Additionally, in place of the deterministic reference class as explained in previous section, a stochastic reference class can be sampled at each step following Equation 7 where is the probability that is chosen as . This technique is helpful when is small, like classifier prediction is invoked for every sampling step.
| (7) |
4 Experiments
The main experiments are conducted with the EDM2 [17] code base111https://github.com/NVlabs/edm2 and pre-trained ImageNet [5] 512512 class-conditional models. Application of the proposed GFCG on text-to-image models is also investigated where the Stable Diffusion (SD) 1.5222https://huggingface.co/stable-diffusion-v1-5/stable-diffusion-v1-5 model is used for image sampling. Bird Species333https://huggingface.co/datasets/chriamue/bird-species-dataset, a fine-grained classification dataset which consists of 525 different bird species, and it’s accompanying classifier444https://huggingface.co/chriamue/bird-species-classifier are used for guided sampling and assessment of generated image quality.
To evaluate the overall sample quality for various methods compared in this work, the new FDDINOv2 [33] is used in favor of the original Fréchet Inception distance (FID) [9]. According to [33], the Inception encoder used in FID is unfairly punitive to diffusion models. More importantly, it was noted in [24] that FID is sensitive to minor data domain shift like resizing kernels and lossy compression qualities. We have conducted a comparison test between FID and FDDINOv2 by compressing the same set of guided samples with different qualities, which shows FDDINOv2 is almost constant across different settings which FID is very sensitive to. Additionally, we adopt the Precision and Recall metrics used in CFG to measure image fidelity and diversity separately. The image fidelity metric Precision is computed as the percentage of generated samples that fall into the data manifold (assessed using the real image classifier), while the image diversity metric Recall is measured as the fraction of real images which is correctly classified by the classifier trained from sampled images. Recall is only reported for a subset of classes with selected experiments due to the time-consuming processes of sample generation and classifier training.
| Model | Method | FDDINOv2 | Precision | Recalla | ||||||||
| EDM2-S | NG | 68.29 | 90.0% | 71.5% | - | - | - | - | - | - | 0.190 | - |
| CFG | 51.80 | 94.9% | 70.0% | (XS,T) | - | 1.90 | - | - | - | 0.085 | 0.085 | |
| SEG | 39.45 | 89.1% | 75.0% | (XS,T/16) | - | - | 2.20 | - | - | 0.085 | 0.165 | |
| ATG | 38.50 | 90.6% | 74.1% | (XS,T/16) | 2.45 | - | - | - | - | 0.120 | 0.165 | |
| GFCG | 40.71 | 95.4% | 72.0% | (XS,T/16) | - | - | - | 0.50 | 1.25 | 0.085 | 0.165 | |
| GFCGNG | 36.93 | 93.3% | 75.1% | (XS,T/16) | - | - | - | 0.80 | 1.25 | 0.085 | 0.165 | |
| GFCGCFG | 44.17 | 95.6% | 68.8% | (XS,T/16) | - | 1.90 | - | 0.70 | 1.00 | 0.085 | 0.165 | |
| GFCGSEG | 37.99 | 93.5% | 73.2% | (XS,T/16) | - | - | 2.20 | 0.80 | 1.25 | 0.085 | 0.165 | |
| GFCGATG | 34.56 | 93.5% | 75.3% | (XS,T/16) | 2.45 | - | - | 0.80 | 1.25 | 0.085 | 0.165 | |
| GFCGATG+CFG | 33.39 | 93.8% | 72.1% | (XS,T/16) | 2.45 | 1.60 | - | 0.40 | 1.25 | 0.085 | 0.165 | |
| EDM2-XXL | NG | 42.58 | 90.8% | - | - | - | - | - | - | - | 0.150 | - |
| CFG | 32.74 | 93.7% | - | (XS,T) | - | 1.70 | - | - | - | 0.015 | 0.015 | |
| ATG | 24.83 | 90.2% | - | (M,T/3.5) | 2.30 | - | - | - | - | 0.130 | 0.205 | |
| GFCGATG | 23.09 | 94.3% | - | (M,T/3.5) | 2.10 | - | - | 0.70 | 1.25 | 0.095 | 0.205 |
-
a
1000 samples per class for 10 challenging Imagewoof [7] classes are used to train classifiers for Recall calculation on ImageNet training data.
4.1 Class-Conditional Image Generation
We implemented our proposed GFCG sampling algorithm on top of the publicly available EDM2 [17] code base and use ImageNet [5] 512512 as the main dataset. Pre-trained models of EDM2-S and EDM2-XXL with default sampling parameters: 32 deterministic steps with order Heun Sampler [15] were utilized in this work. For the classifier, we use the standard ResNet-101 pre-trained on ImageNet.
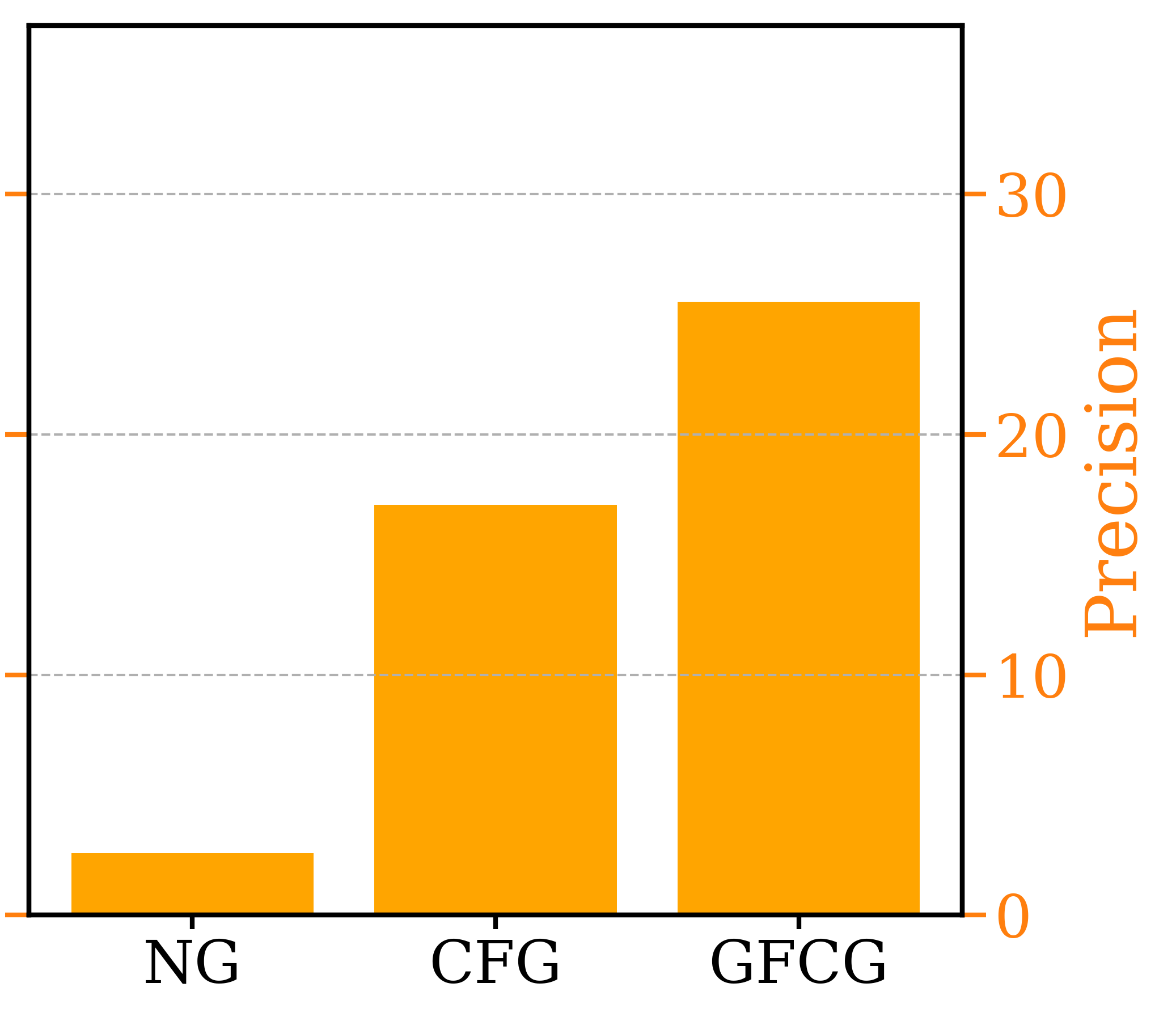
As shown in Table 1, EDM2-S was used as the main model for most experiments. GFCG was first compared with other gradient-free guidance methods. ATG still enjoys the best score in FDDINOv2 but it comes with a significant cost in Precision. Comparing to ATG, our proposed GFCG is able to increase Precision significantly with some trade-off in FDDINOv2 . To maintain the same computational efficiency, the same guidance model as in ATG is applied for GFCG and SEG. The second group includes mixed guidance methods which combines GFCG with other guidance methods sequentially, i.e., GFCG, following other methods, is applied to steps after . In the case of GFCGNG, it is similar to applying guidance interval [19] to GFCG. All mixed methods improve both FDDINOv2 and Precision metrics comparing to the corresponding method which GFCG is mixed with, and GFCGATG gets the best FDDINOv2 out of all four. The best FDDINOv2 of all is achieved when the additive guidance of GFCG and CFG, setting a SOTA performance of 33.39 while beating ATG in Precision by a 3.2% margin. Experiments in EDM2-XXL shows similar benefits of GFCG. A subset of 10 classes are also chosen for Recall assessment, which is a good indicator for sample diversity. Individually, SEG and ATG have the two highest values. The mixed guidance of GFCGATG has the best recall overall while leading ATG in both FDDINOv2 and Precision too. While assessed only on 10 classes, it shows GFCG is able to improve image fidelity while preserving diversity. Note that the FDDINOv2 metric for ATG is a little worse than the published value [16]. The same random seed setting was used for all methods for fair comparison.
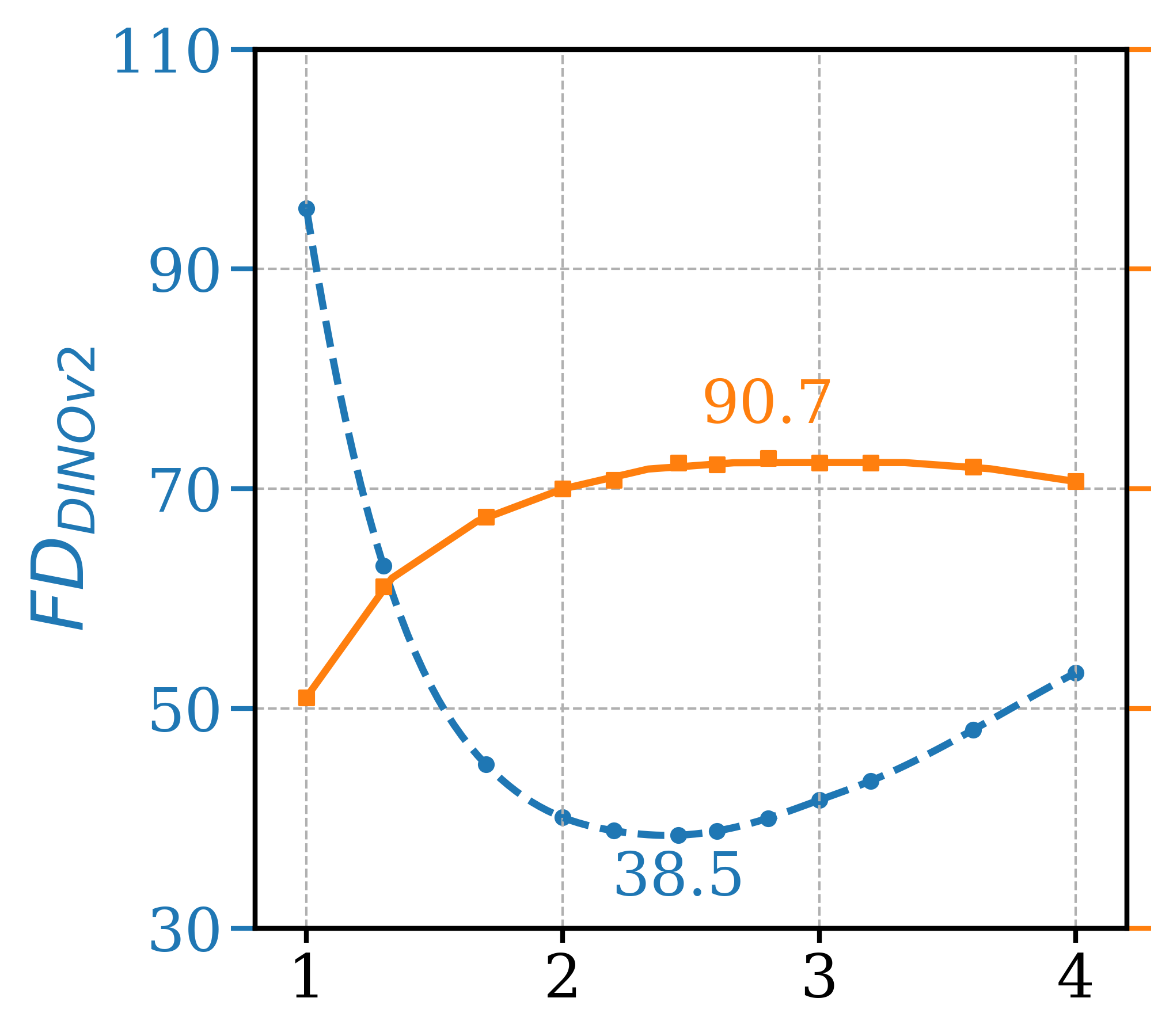
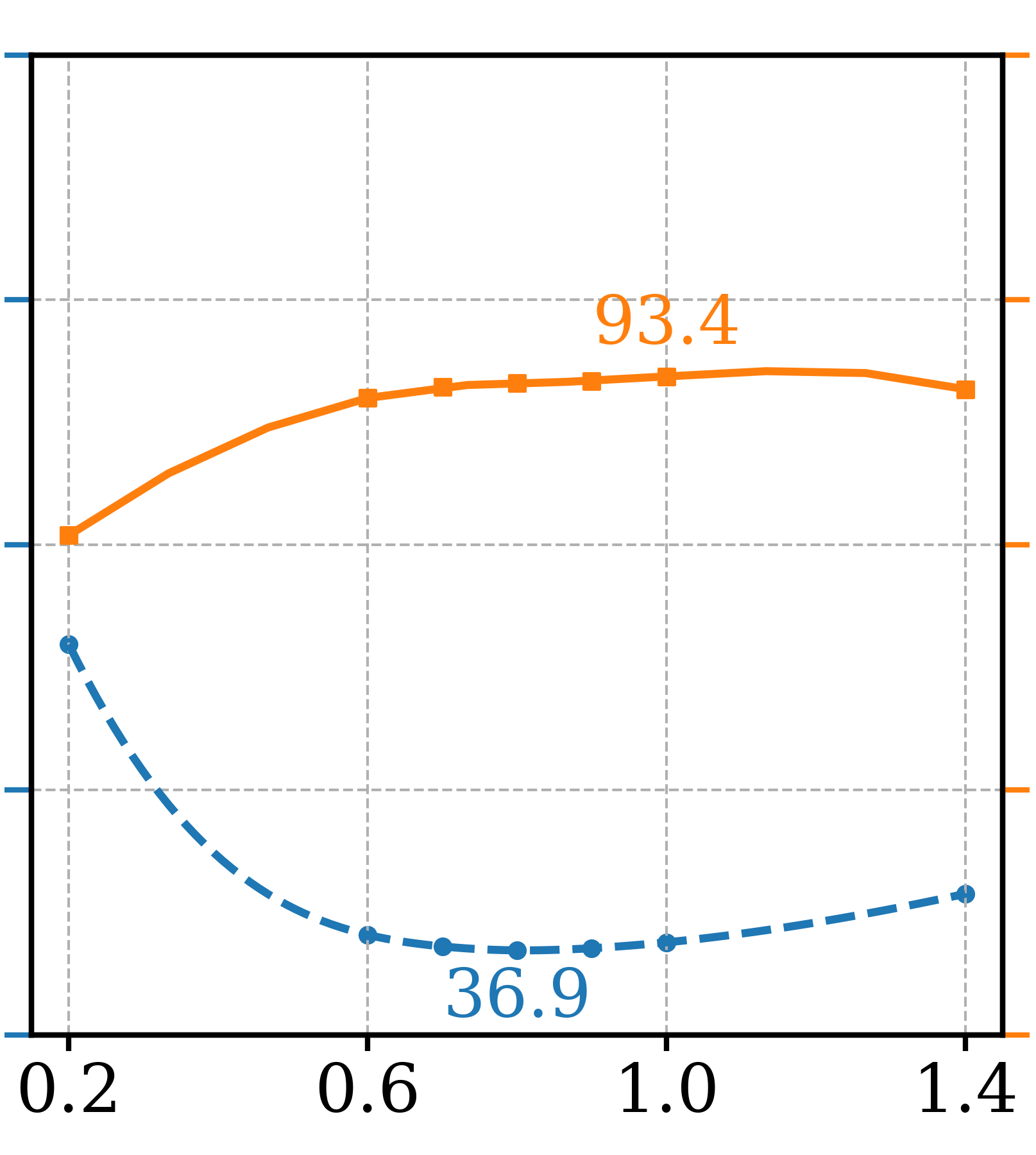
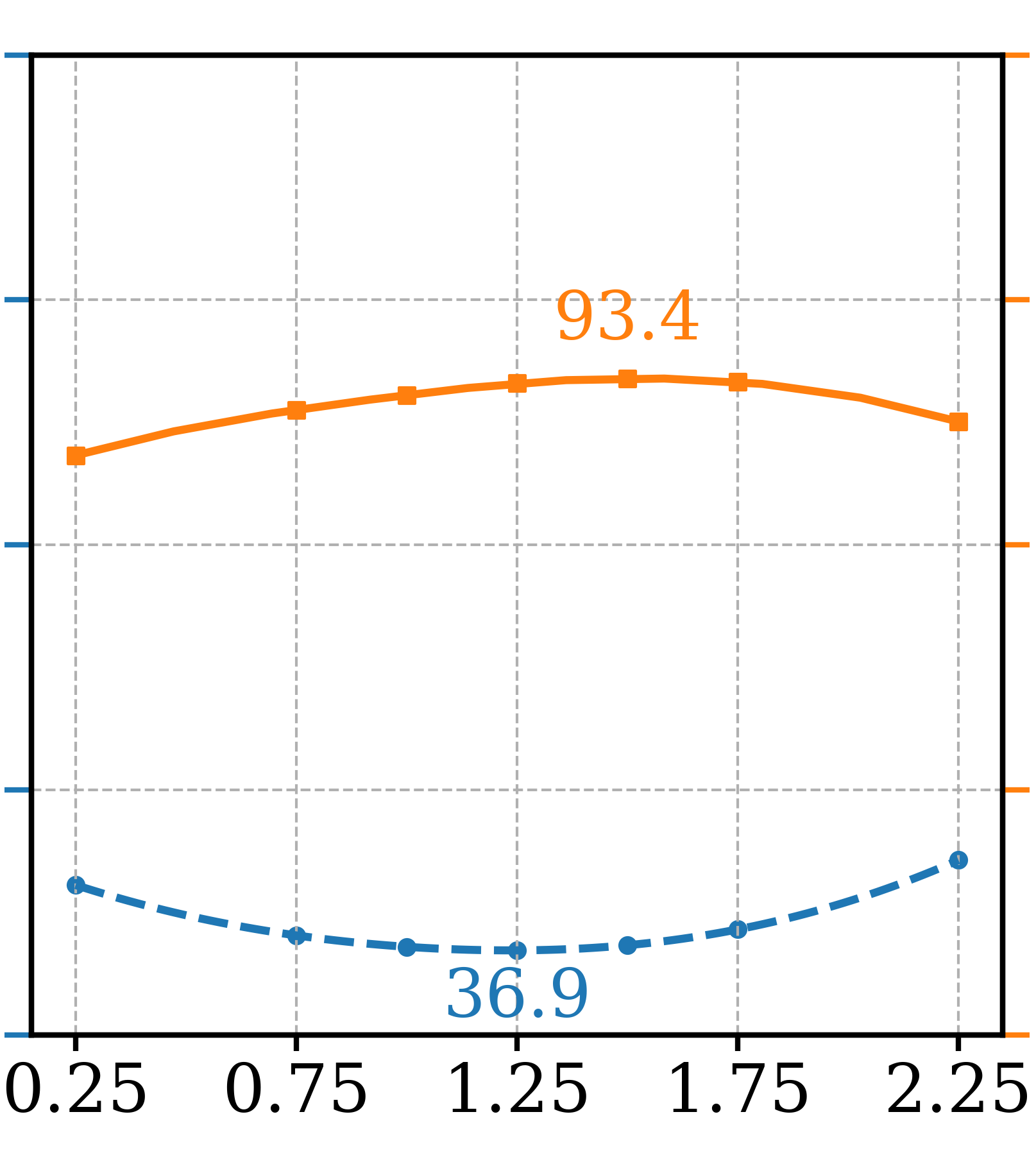
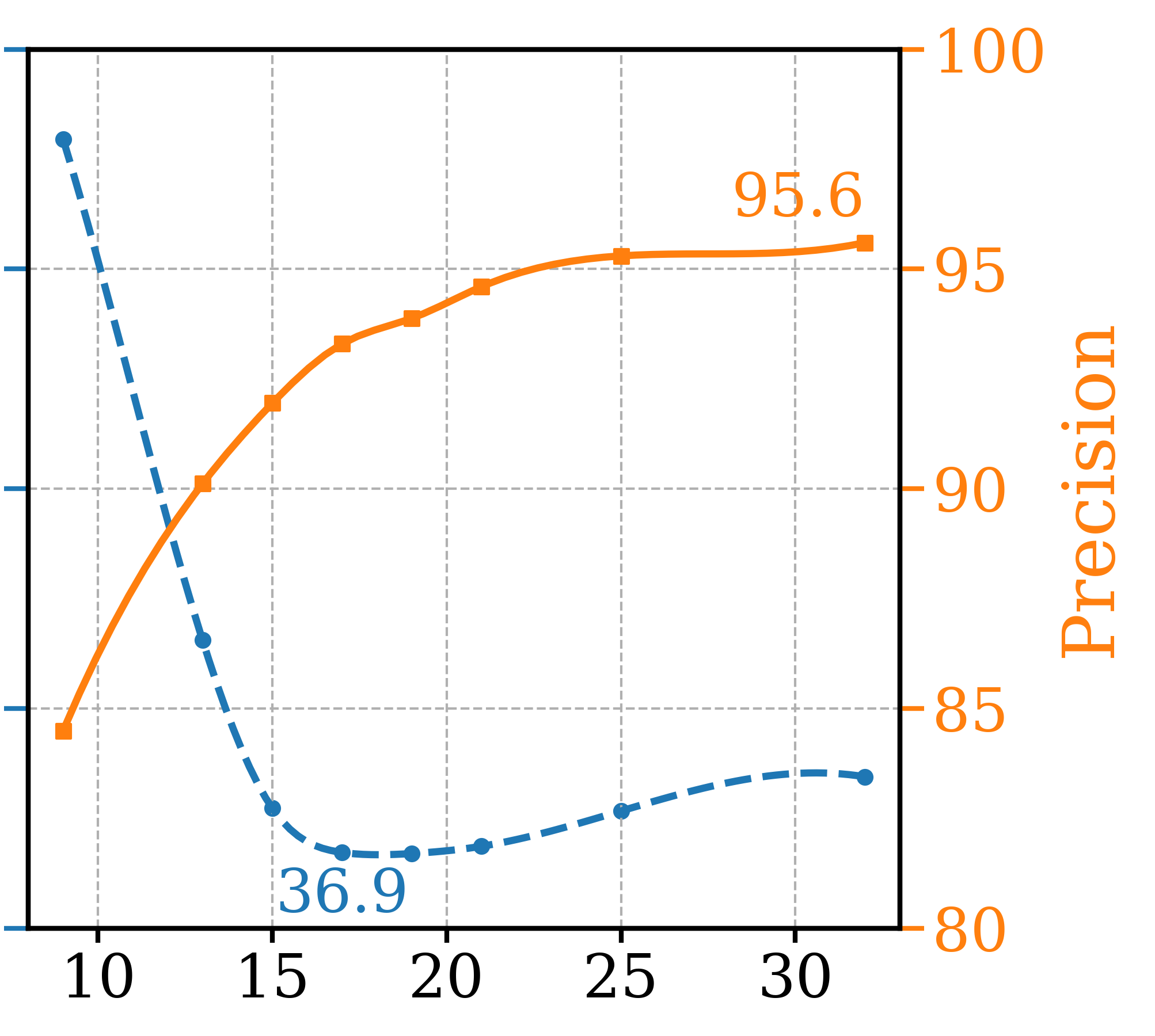
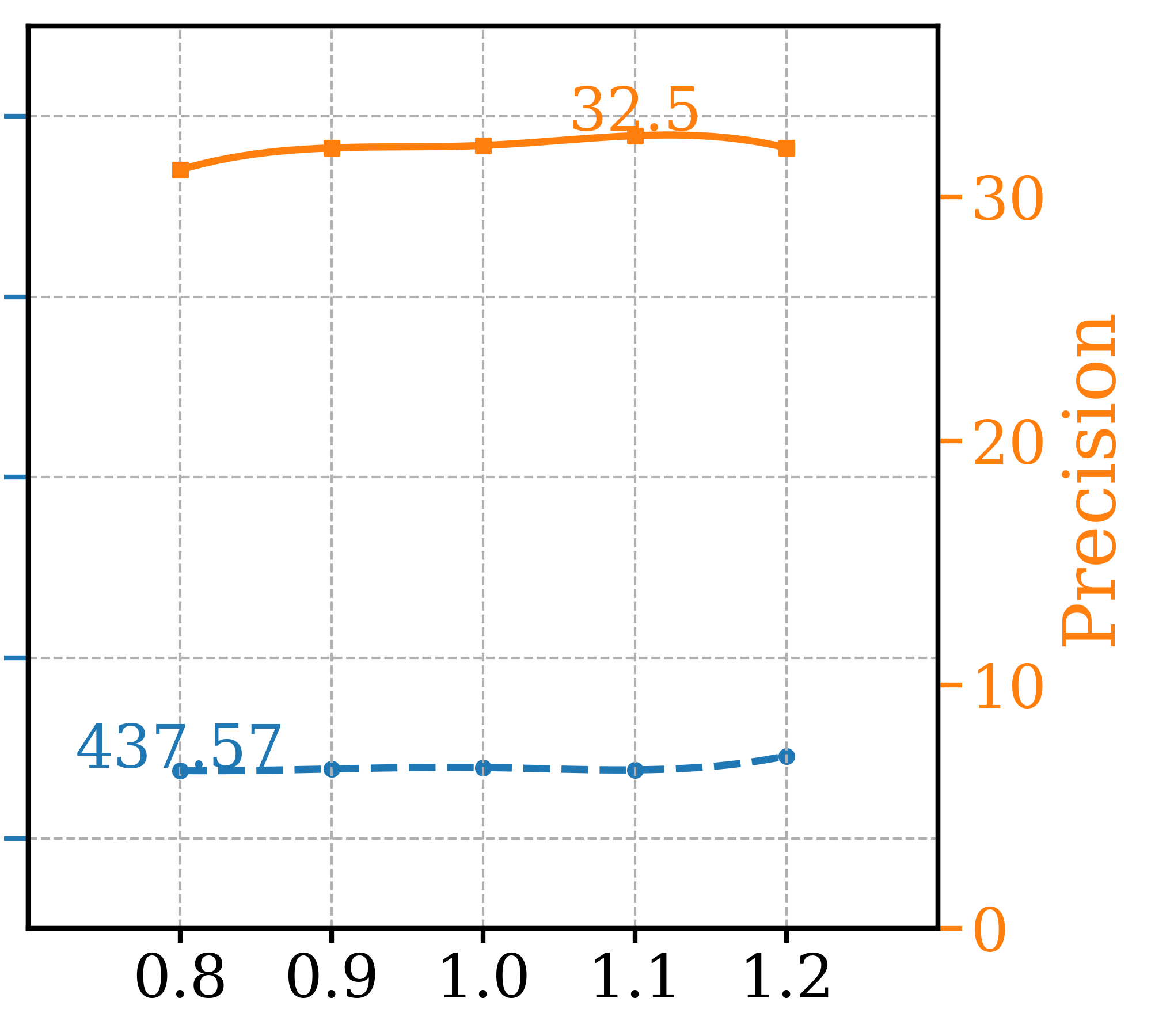
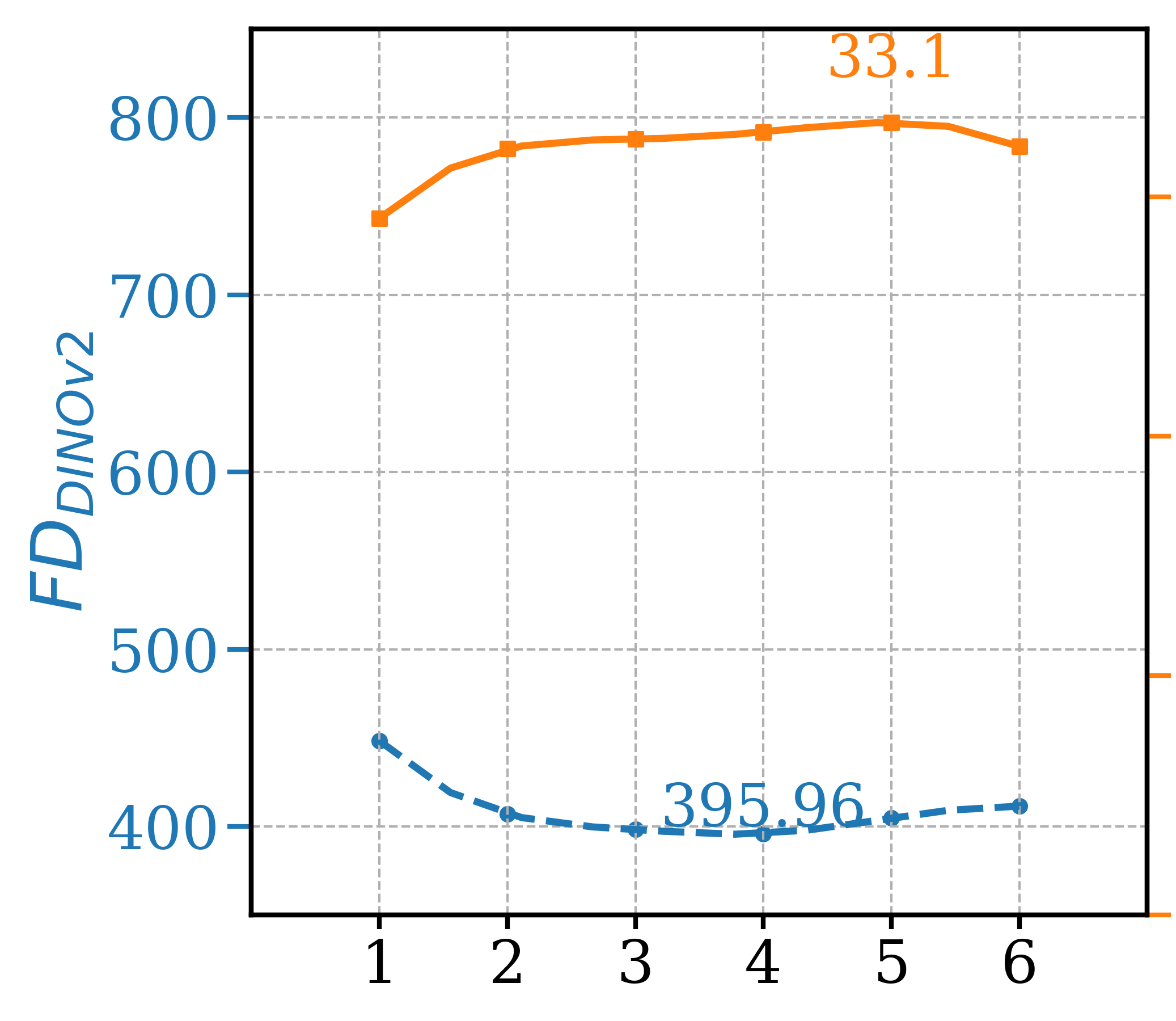
To determine the optimal setting for different hyperparameters, a series of ablation tests were conducted and three most critical ones are presented in Figure 4, leaving the remaining ones to the supplementary section. Note that other than the varying parameter, other settings are fixed as GFCGNG (XS,T/16) in Table 1. The first is study the trade-off in image fidelity (lower Precision) for different ATG guidance scale, which is not reported in the original paper. It shows that the optimal setting for FDDINOv2 is also in range of optimal Precision, as further increased scale doesn’t increase Precision. For GFCG tests, both and are used to determine guidance scale where is responsible for the overall strength while controls the relative strength in regards to classification confidence. While increasing improves both metrics initially, FDDINOv2 starts to get worse after passes 0.8 and Precision also decreases after 1.2. For , there is a similar trend and the optimal range is around 1.25 to 1.50. Lastly, out of the total of 32 sampling steps, earlier the application of guidance (larger ) is better for Precision, but there is a trade-off for worse FDDINOv2 . The optimal range is around 17. For , it is better set to the maximum so that only one classifier prediction is used for all mixed and additive GFCG methods included in Table 1. Based on that, a multi-step denoising process is used for estimation. This adds a few NFEs but not significant as the multi-step estimation is needed one time. For example, for GFCGATG, it is a 4-step estimation.
Visual examples are included in Figure 3 to demonstrate the effects of transitioning from ATG to GFCG, where intermediate results are from mixed guidance of ATG and GFCG, before and after respectively. It shows image fidelity () increases when GFCG starts earlier. In the second example, GFCG has better but looses details in the background, a concern of trade-off in diversity. The mixed guidance for results in increased while preserving the background details.
4.2 Text-to-Image Generation
While the proposed method fits well with class-conditional diffusion models naturally as it uses classifier for guided sampling, it can also help to improve sample quality for general text-to-image diffusion models like SD 1.5 [4]. As explained earlier, a classifier trained from the Bird Species dataset was used for guided sampling and the samples were evaluated against the same training dataset. As the output resolution for SD 1.5 is 512512, they were resized to the same resolution of 224224 of the dataset before assessed for FDDINOv2 , Precision and Recall metrics. All samples were generated in 50 steps using PNDM [20]. This fine-grained generation task is challenging as many of the bird species are long-tailed classes in SD 1.5. The only other known generation test for such fine-grained classes was reported in the unified training-free classifier guidance (TFG) work [35]. Only unconditional generation using gradient classifier guidance was investigated and the best Precision score is only 2.24%. In this work, we focus on conditional generation using different guidance methods. For a given target bird species [bird #1], generic prompts like a close up bird photo, [bird #1] were used to generate diverse images of said species. In the case of GFCG, when a different bird species [bird #2] was identified as the reference class, the [bird #1] phrase in the target prompt was replaced by [bird #2] to get .



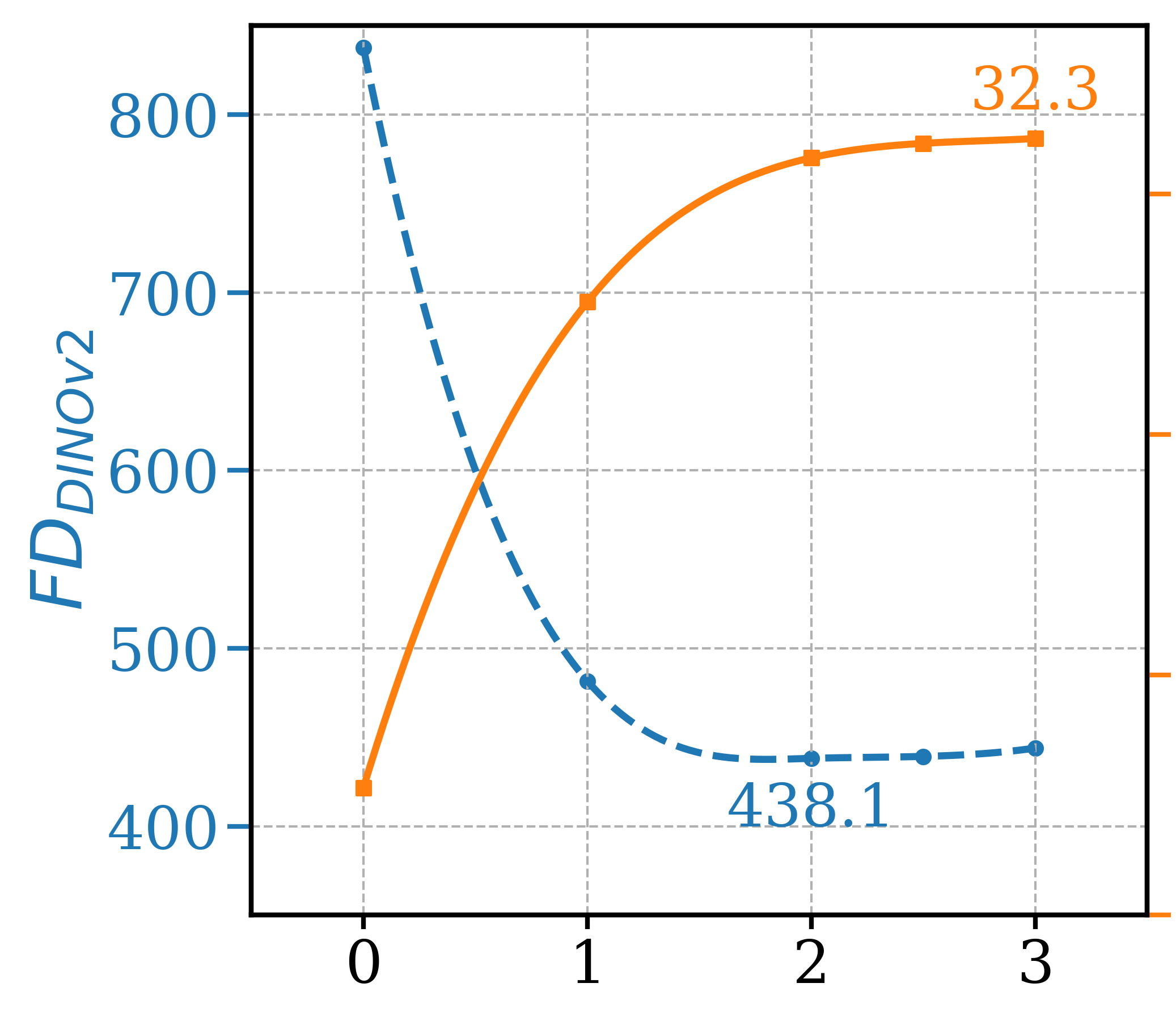
GFCG was first compared with three gradient-free guidance methods: CFG, PAG and SEG. ATG is not included as training a bad version of SD 1.5 with the optimal settings is not trivial. For experiment results shown in Table 2, 80 samples were generate for each of the 525 species and the same random seed settings were kept across different methods for fair comparison. Among all four, CFG has the best FDDINOv2 metric while our GFCG has a clear advantage in Precision score. PAG and SEG don’t perform well for this challenging task, likely due to lack of reliable self-attention weights for long-tailed classes. Experiments were also conducted for mixed guidance GFCGCFG, where CFG was used exclusively before applying GFCG after . Without additional NFEs, it is able to match FDDINOv2 of CFG while maintaining advantage in Precision. The best results are additive guidance of GFCG+CFG, both FDDINOv2 and Precision metrics are improved significantly though at the cost of double NFEs. Comparing to ImageNet experiments where it is beneficial to start applying GFCG midway through sampling and predict confused class only once, here it was consistently found advantageous to start applying GFCG from the beginning and conduct classifier prediction more frequently. Consequently, the stochastic selection of is also included to improve performance. This is likely due to the challenging case of fine-grained classification as there are multiple confused classes, so that adjusting confused class using classifier prediction more often is desired. As SD 1.5 is trained on a large general dataset, GFCG based on the Bird Species classifier can only provide guidance inside the bird related region of the overall data distribution, while CFG adds guidance from other parts of the data distribution. This could be the cause that GFCG+CFG has the best in both metrics.
For visual examples in Figure 5, the benefits of GFCG is obvious in terms of image fidelity, like the yellow head in the second one. The mixed guidance of GFCGCFG keeps the general structure as in CFG, but improves image details which results in improved Precision comparing to CFG. The best results are from additive guidance of GFCG+CFG, which improves the image fidelity in both overall composition as well as fine details.
| FDDINOv2 | Precision | ||||||
|---|---|---|---|---|---|---|---|
| NG | 816.3 | 5.3% | 1.0 | - | - | - | - |
| CFG | 394.0 | 27.3% | 5.5 | - | - | - | - |
| PAG | 562.3 | 12.5% | - | 3.5 | - | - | - |
| SEG | 676.4 | 8.0% | - | - | 10.0 | - | - |
| GFCG | 418.8 | 32.3% | - | - | - | 2.5 | 50 |
| GFCGCFG | 392.2 | 30.2% | 5.5 | - | - | 2.5 | 20 |
| GFCG+CFG | 377.6 | 32.4% | 4.0 | - | - | 1.5 | 50 |
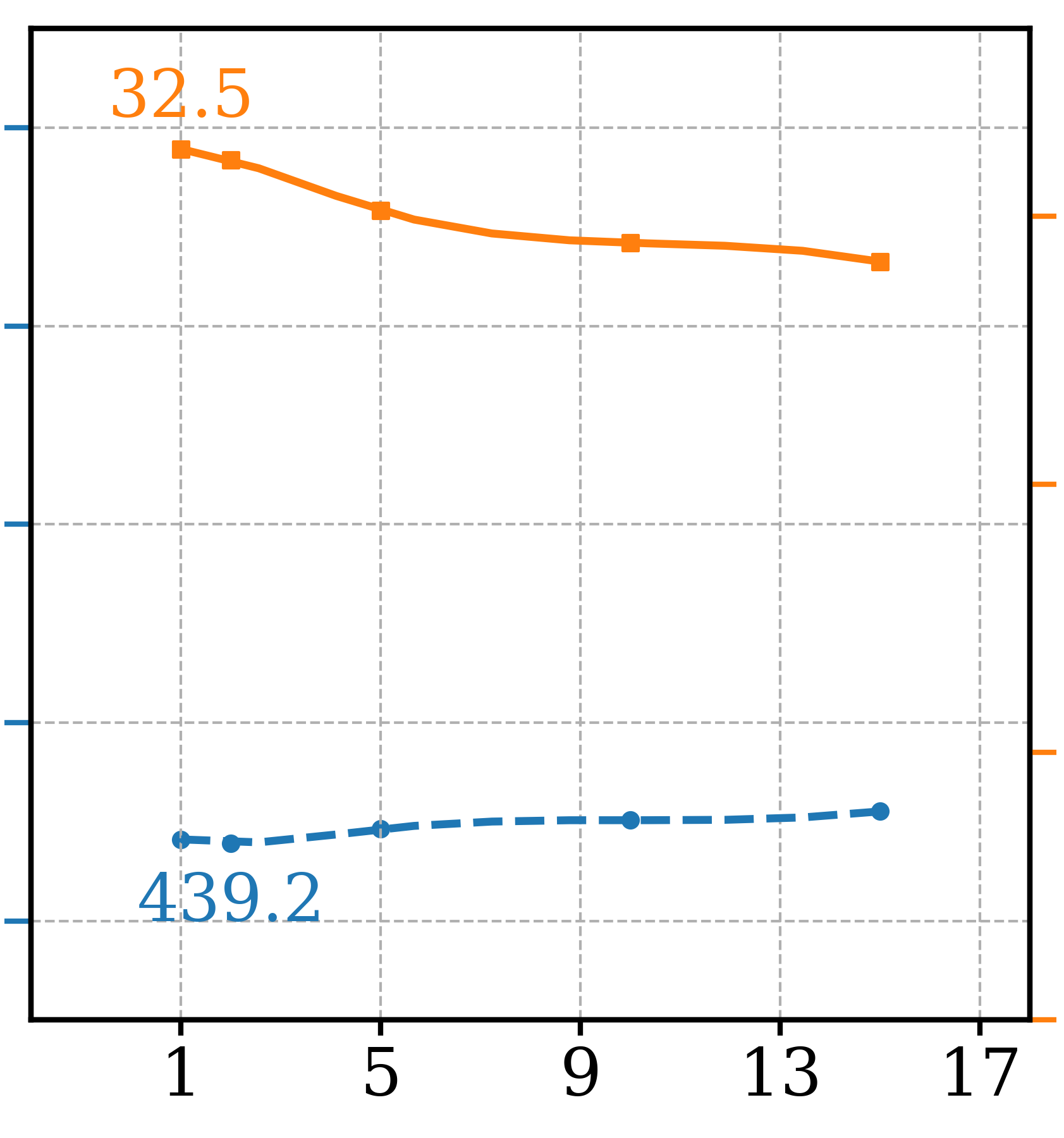
A set of ablation studies were conducted to determine the optimal settings for GFCG based sampling and three are shown in Figure 6. For GFCG, increasing improves Precision consistently but FDDINOv2 starts to worsen when it is beyond 2. For , from every 10 to 2 steps, there is significant gain in Precision with FDDINOv2 also improved. For the mixed guidance of GFCGCFG, where GFCG is applied after time step , later application of GFCG improves FDDINOv2 at a cost of lower Precision. Two other settings, and , were both kept as 1 without fine-tuning. Note that similar ablation studies were also conducted for compared methods like CFG, PAG and SEG for fair comparisons in Table 2 and results are included in the supplementary section. As shown in Figure 6(d), a set of detailed prompts, like the one in Figure 1, were also designed to compare different guided sampling for their ability to maintain classification accuracy. In this challenging case, the advantage of GFCG is more significant than the main tests of generic prompts.
5 Conclusions and Limitations
In this work, we have shown that our method generates high fidelity images without incurring the additional computational costs associated with classifier guidance or requiring the training of an extra unconditional model, as seen with classifier-free guidance. By leveraging an off-the-shelf classifier, GFCG can be seamlessly integrated with existing sampling methods without additional NFEs, thereby enhancing both FDDINOv2 and Precision metrics without loss in Recall. Moreover, we further demonstrated that it can be extended to text-to-image diffusion models, achieving high class accuracy, particularly for long-tailed and fine-grained classes. This flexibility and efficiency make GFCG a robust and adaptable approach, offering significant improvements without extra training efforts or computational resources. These results underscore the potential of GFCG to optimize overall image quality, Precision in particular, across various models and applications, paving the way for further innovations in image generation and related fields.
Limitations: While it is applicable to general text-to-image models which learn from a huge dataset, the proposed GFCG is most beneficial to generation of images which are in distribution of the pre-trained classifier. For the Bird Species experiments, as the classifier training dataset consists of close-up shots mostly, guided sampling of bird images in other layouts would be less effective. Ethical considerations: We acknowledge that this guidance method could potentially benefit creation of inappropriate materials. Deployments of such methods should apply appropriate safeguards to prevent malicious and illegal uses.
References
- Ahn et al. [2024] Donghoon Ahn, Hyoungwon Cho, Jaewon Min, Wooseok Jang, Jungwoo Kim, SeonHwa Kim, Hyun Hee Park, Kyong Hwan Jin, and Seungryong Kim. Self-rectifying diffusion sampling with perturbed-attention guidance. arXiv preprint arXiv:2403.17377, 2024.
- Bansal et al. [2023] Arpit Bansal, Hong-Min Chu, Avi Schwarzschild, Soumyadip Sengupta, Micah Goldblum, Jonas Geiping, and Tom Goldstein. Universal guidance for diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 843–852, 2023.
- Chung et al. [2022] Hyungjin Chung, Jeongsol Kim, Michael T Mccann, Marc L Klasky, and Jong Chul Ye. Diffusion posterior sampling for general noisy inverse problems. arXiv preprint arXiv:2209.14687, 2022.
- Crowson et al. [2022] Katherine Crowson, Maxwell Ingham, Adam Letts, and Alex Spirin. Stable diffusion. https://github.com/CompVis/stable-diffusion, 2022.
- Deng et al. [2009] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. ImageNet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009.
- Dhariwal and Nichol [2021] Prafulla Dhariwal and Alexander Nichol. Diffusion models beat GANs on image synthesis. Advances in Neural Information Processing Systems, 34:8780–8794, 2021.
- fast.ai [2022] fast.ai. A smaller subset of 10 easily classified classes from imagenet, and a little more french. https://github.com/fastai/imagenette, 2022.
- He et al. [2023] Yutong He, Naoki Murata, Chieh-Hsin Lai, Yuhta Takida, Toshimitsu Uesaka, Dongjun Kim, Wei-Hsiang Liao, Yuki Mitsufuji, J. Zico Kolter, Ruslan Salakhutdinov, and Stefano Ermon. Manifold preserving guided diffusion. ArXiv, abs/2311.16424, 2023.
- Heusel et al. [2017] Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. GANs trained by a two time-scale update rule converge to a local nash equilibrium. Advances in neural information processing systems, 30, 2017.
- Ho and Salimans [2021] Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance. In NeurIPS 2021 Workshop on Deep Generative Models and Downstream Applications, 2021.
- Ho et al. [2020] Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. Advances in Neural Information Processing Systems, 33:6840–6851, 2020.
- Ho et al. [2022] Jonathan Ho, Tim Salimans, Alexey A Gritsenko, William Chan, Mohammad Norouzi, and David J Fleet. Video diffusion models. In ICLR Workshop on Deep Generative Models for Highly Structured Data, 2022.
- Hong [2024] Susung Hong. Smoothed energy guidance: Guiding diffusion models with reduced energy curvature of attention. arXiv preprint arXiv:2408.00760, 2024.
- Hong et al. [2023] Susung Hong, Gyuseong Lee, Wooseok Jang, and Seungryong Kim. Improving sample quality of diffusion models using self-attention guidance. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 7462–7471, 2023.
- Karras et al. [2022] Tero Karras, Miika Aittala, Timo Aila, and Samuli Laine. Elucidating the design space of diffusion-based generative models. Advances in neural information processing systems, 35:26565–26577, 2022.
- Karras et al. [2024a] Tero Karras, Miika Aittala, Tuomas Kynkäänniemi, Jaakko Lehtinen, Timo Aila, and Samuli Laine. Guiding a diffusion model with a bad version of itself. arXiv preprint arXiv:2406.02507, 2024a.
- Karras et al. [2024b] Tero Karras, Miika Aittala, Jaakko Lehtinen, Janne Hellsten, Timo Aila, and Samuli Laine. Analyzing and improving the training dynamics of diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 24174–24184, 2024b.
- Kong et al. [2021] Zhifeng Kong, Wei Ping, Jiaji Huang, Kexin Zhao, and Bryan Catanzaro. Diffwave: A versatile diffusion model for audio synthesis. In International Conference on Learning Representations, 2021.
- Kynkäänniemi et al. [2024] Tuomas Kynkäänniemi, Miika Aittala, Tero Karras, Samuli Laine, Timo Aila, and Jaakko Lehtinen. Applying guidance in a limited interval improves sample and distribution quality in diffusion models. arXiv preprint arXiv:2404.07724, 2024.
- Liu et al. [2022] Luping Liu, Yi Ren, Zhijie Lin, and Zhou Zhao. Pseudo numerical methods for diffusion models on manifolds. arXiv preprint arXiv:2202.09778, 2022.
- Luo and Hu [2021] Shitong Luo and Wei Hu. Diffusion probabilistic models for 3d point cloud generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2837–2845, 2021.
- Nichol et al. [2022] Alex Nichol, Prafulla Dhariwal, Aditya Ramesh, Pranav Shyam, Pamela Mishkin, Bob McGrew, Ilya Sutskever, and Mark Chen. GLIDE: Towards photorealistic image generation and editing with text-guided diffusion models. arXiv preprint arXiv:2112.10741, 2022.
- Pan et al. [2023] Zhihong Pan, Xin Zhou, and Hao Tian. Arbitrary style guidance for enhanced diffusion-based text-to-image generation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 4461–4471, 2023.
- Parmar et al. [2022] Gaurav Parmar, Richard Zhang, and Jun-Yan Zhu. On aliased resizing and surprising subtleties in gan evaluation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11410–11420, 2022.
- Ren et al. [2023] Zhiyuan Ren, Zhihong Pan, Xin Zhou, and Le Kang. Diffusion motion: Generate text-guided 3d human motion by diffusion model. In ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE, 2023.
- Rombach et al. [2022] Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10684–10695, 2022.
- Saharia et al. [2021] Chitwan Saharia, William Chan, Huiwen Chang, Chris A Lee, Jonathan Ho, Tim Salimans, David J Fleet, and Mohammad Norouzi. Palette: Image-to-image diffusion models. In NeurIPS 2021 Workshop on Deep Generative Models and Downstream Applications, 2021.
- Saharia et al. [2022] Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, et al. Photorealistic text-to-image diffusion models with deep language understanding. Advances in neural information processing systems, 35:36479–36494, 2022.
- Song et al. [2021] Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. In International Conference on Learning Representations, 2021.
- Song et al. [2023] Jiaming Song, Qinsheng Zhang, Hongxu Yin, Morteza Mardani, Ming-Yu Liu, Jan Kautz, Yongxin Chen, and Arash Vahdat. Loss-guided diffusion models for plug-and-play controllable generation. In International Conference on Machine Learning, pages 32483–32498. PMLR, 2023.
- Song and Ermon [2019] Yang Song and Stefano Ermon. Generative modeling by estimating gradients of the data distribution. Advances in Neural Information Processing Systems, 32, 2019.
- Song et al. [2020] Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. In International Conference on Learning Representations, 2020.
- Stein et al. [2024] George Stein, Jesse Cresswell, Rasa Hosseinzadeh, Yi Sui, Brendan Ross, Valentin Villecroze, Zhaoyan Liu, Anthony L Caterini, Eric Taylor, and Gabriel Loaiza-Ganem. Exposing flaws of generative model evaluation metrics and their unfair treatment of diffusion models. Advances in Neural Information Processing Systems, 36, 2024.
- Xu et al. [2023] Minkai Xu, Alexander S Powers, Ron O Dror, Stefano Ermon, and Jure Leskovec. Geometric latent diffusion models for 3d molecule generation. In International Conference on Machine Learning, pages 38592–38610. PMLR, 2023.
- Ye et al. [2024] Haotian Ye, Haowei Lin, Jiaqi Han, Minkai Xu, Sheng Liu, Yitao Liang, Jianzhu Ma, James Zou, and Stefano Ermon. TFG: Unified training-free guidance for diffusion models. arXiv preprint arXiv:2409.15761, 2024.
- Yu et al. [2023] Jiwen Yu, Yinhuai Wang, Chen Zhao, Bernard Ghanem, and Jian Zhang. FreeDoM: Training-free energy-guided conditional diffusion model. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 23174–23184, 2023.
Supplementary Material
6 Evaluation Metrics
We have explained the reasoning for choosing FDDINOv2 over FID as the overall image quality metric in the main paper. To further validate this choice, we also conducted a lossy compression test as in [24] to compare FID and FDDINOv2 . As shown in Table 3, For the same 42000 images sampled from SD 1.5, comparing to the original uncompressed output, multiple JPEG compressions are applied with different quality settings. For FDDINOv2 , the metric remains relatively consistent for original ouput as well as different compression. In contrast, as the Bird Species dataset used for assessment consists of JPEG images, FID benefits from applying similar JPEG compression to the original outputs. In fact, FID improves (lower value) continuously with loss of image quality until it reaches the lowest around 80% quality. Lastly, it is shown in Autoguidance [16] that the model and sample settings need to be tuned for optimal FID and FDDINOv2 separately. As a result, FDDINOv2 is chosen as the primary sample quality metric for experiments in this work to determine optimal settings.
| Original | JPEG Compression Quality | ||||||
|---|---|---|---|---|---|---|---|
| Output | 100% | 95% | 90% | 85% | 80% | 75% | |
| FID | 13.29 | 14.20 | 12.87 | 10.57 | 6.48 | 6.47 | 6.52 |
| FDDINOv2 | 401.5 | 400.5 | 399.2 | 397.0 | 397.3 | 397.6 | 398.0 |
7 Additional Implementation Details
7.1 Class-Conditional Generation: Pseudo Code
For Algorithm 1, specifics like timestep , noise schedule and sampling method are illustrated using DDIM as the example. In implementations, GFCG is applicable to different models and sampling methods and we’ve conducted class-conditional experiments using EDM2 with 2nd order Heun’s solver and text-to-image ones using SD 1.5 with PNDM sampling. Besides, some implementation details are omitted in Algorithm 1, including multi-step denoising for and mixed guidance of GFCG and other base methods like ATG. To present the detailed pseudo code for class-conditional generation, we first generalize Algorithm 1 to be compatible for both EDM2 and SD 1.5 experiments, as shown in Algorithm 2. In the case of DDIM sampling, is in line 6, Equation 4 is used for line 4 and the following equation is used for line 20:
| (8) |
For our class-conditional experiments, we used the 2nd order deterministic sampler from EDM (i.e., Algorithm 1 in [15]) in all experiments with and . We used the default settings , , and . Note that we use and for EDM to avoid confusion as and are also used in our formulations. To follow the terminology in Algorithm 2, in original EDM is denoted as , sampling steps is denoted as and noise schedule is denoted as and the noise schedule is calculated as follows:
| (9) |
Equation 4 for estimation is replaced by a multi-step denoising process, as also discussed in Section 4.1. This modification is detailed in Algorithm 3. Although this introduces a few additional NFEs, the impact is minimal since the multi-step estimation is only required once. For instance, in the case of GFCGATG, the parameters in Algorithm 3 are set as , , and . As for , it is set to the maximum so that only one classifier prediction is used for all mixed and additive GFCG methods included in Table 1.
7.2 Text-to-Image Generation: Text Prompts
For the main quantitative experiments of text-to-image generations using GFCG and other gradient-free guidance methods, a set of generic prompts are used based on the realistic distribution of the Birds Species dataset. This is designed to minimize the bias between the real and generated images so the FDDINOv2 metric could be more reliable in quantitative assessment. Each of the Set of following 8 generic text prompts was used to generate 10 samples for each bird species and quantitative results are reported in Table 2.
-
a close up photo of a bird, [bird species]
-
a close up bird photo, [bird species]
-
a close up picture of a bird, [bird species]
-
a close up bird picture, [bird species]
-
a full body photo of a bird, [bird species]
-
a full body bird photo, [bird species]
-
a full body picture of a bird, [bird species]
-
a full body bird picture, [bird species]
A set of detailed text prompts was used to generate samples, 5 per prompt for each species, for the ablation study reported in Figure 6(d). These detailed prompts are not realistic for all species, as the roadrunner in Figure 1 doesn’t perch on tree branches in real life. Besides, the descriptions below only cover part of all natural habitats. As FDDINOv2 is not applicable for this test given these biases between two distributions, only Precision scores are reported.
-
a photo of a bird perching on a tree branch with flowers blooming around it, [bird species]
-
a close up photo of a flying bird with fish in its claws, [bird species]
-
a photo of a bird eating red berry when standing on a rock, [bird species]
-
a photo of a bird walking on the beach on a raining day, [bird species]
-
a photo of a bird, [bird species], perching on a tree branch with flowers blooming around it
-
a close up photo of a flying bird, [bird species], with fish in its claws
-
a photo of a bird, [bird species], eating red berry when standing on a rock
-
a photo of a bird, [bird species], walking on the beach on a raining day
7.3 SEG implementation details
For the implementation of SEG in the EDM2 codebase, we consider = 100 for the Gaussian Blur. This is applied in the EDM2 UNet’s following blocks in the guidance network:
8x8_block1 8x8_block2 8x8_in0 8x8_block0
Other values of (=10 and 1e6) were also considered but the observations are very similar.
The SEG implementation in SD is similar to [13].
8 More Experimental Results
8.1 Effects of Random Seed Variation
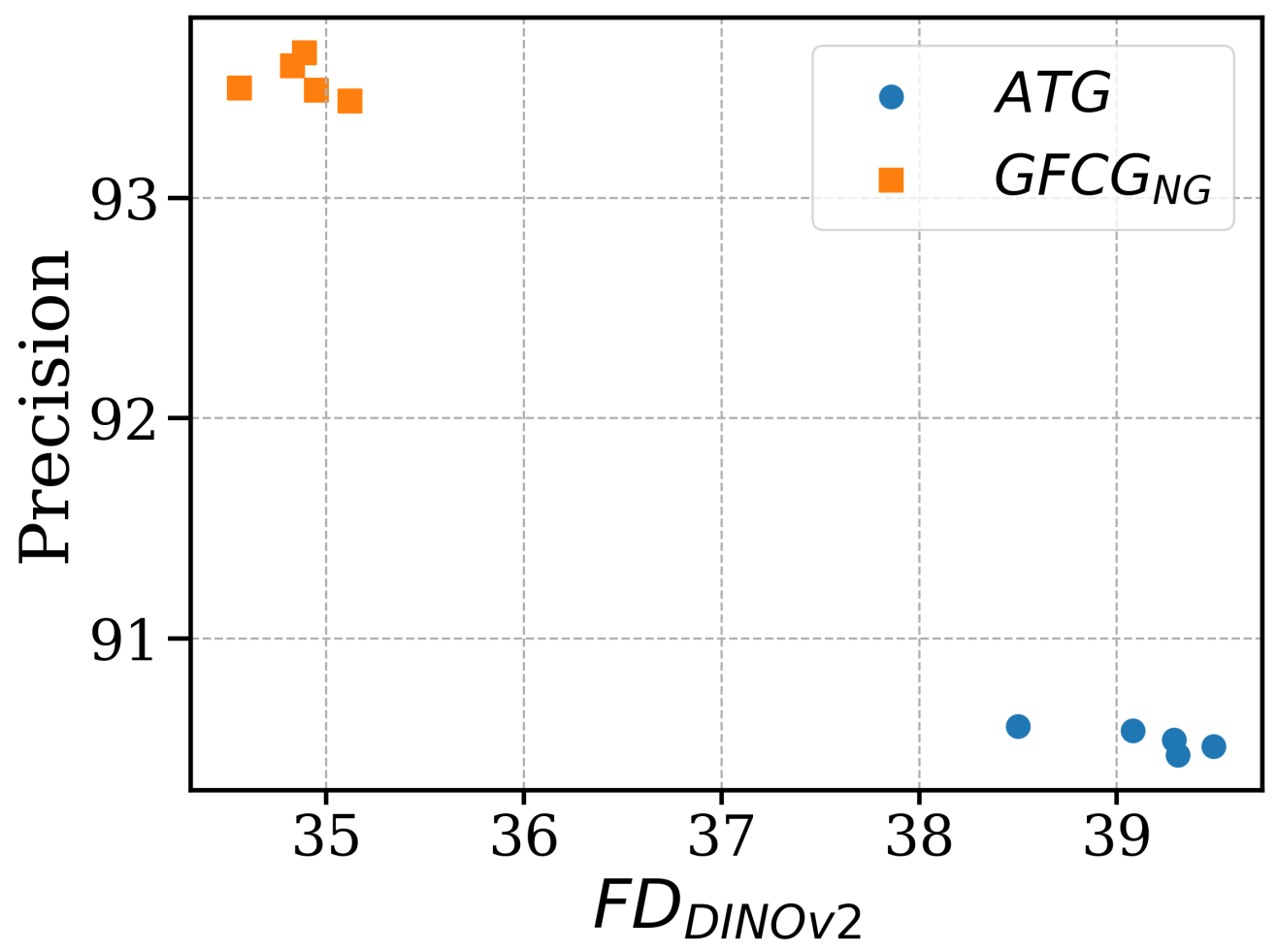
The results presented in Table 1 of the main paper were generated using the same random seed for image generation. As the random seeds used in the ATG study [16] were not disclosed, we were unable to exactly replicate the reported FDDINOv2 metric. To demonstrate that the improvement in the FDDINOv2 metric is independent of random seed choice, we have illustrated the variation in FDDINOv2 and Precision with random seeds for both ATG and GFCGNG methods in Figure 7. The results show a clear distinction between the two methods in terms of Precision and FDDINOv2 metrics, indicating that GFCGNG consistently outperforms ATG, regardless of the random seed used.
8.2 Effects of Guidance Model
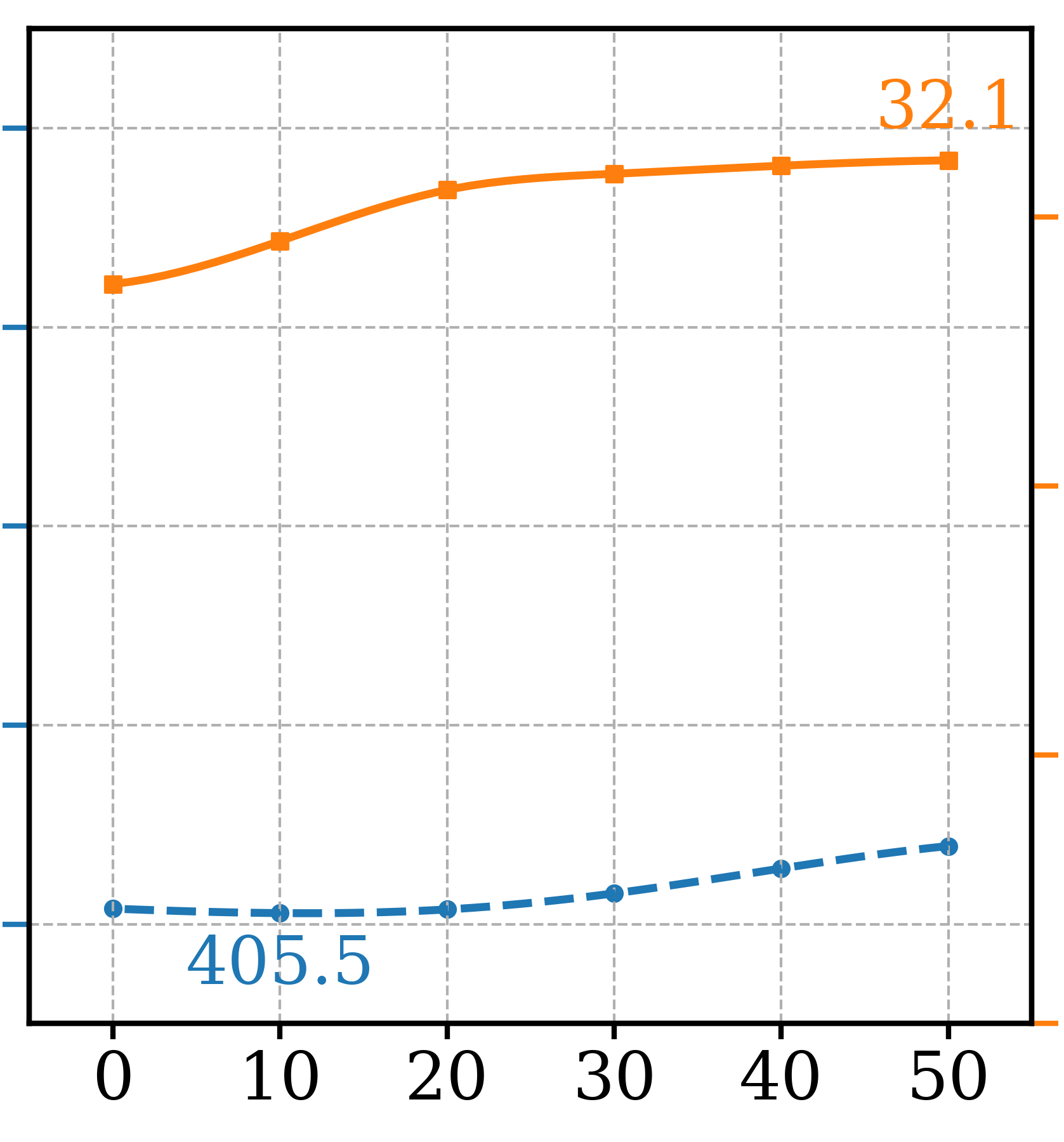
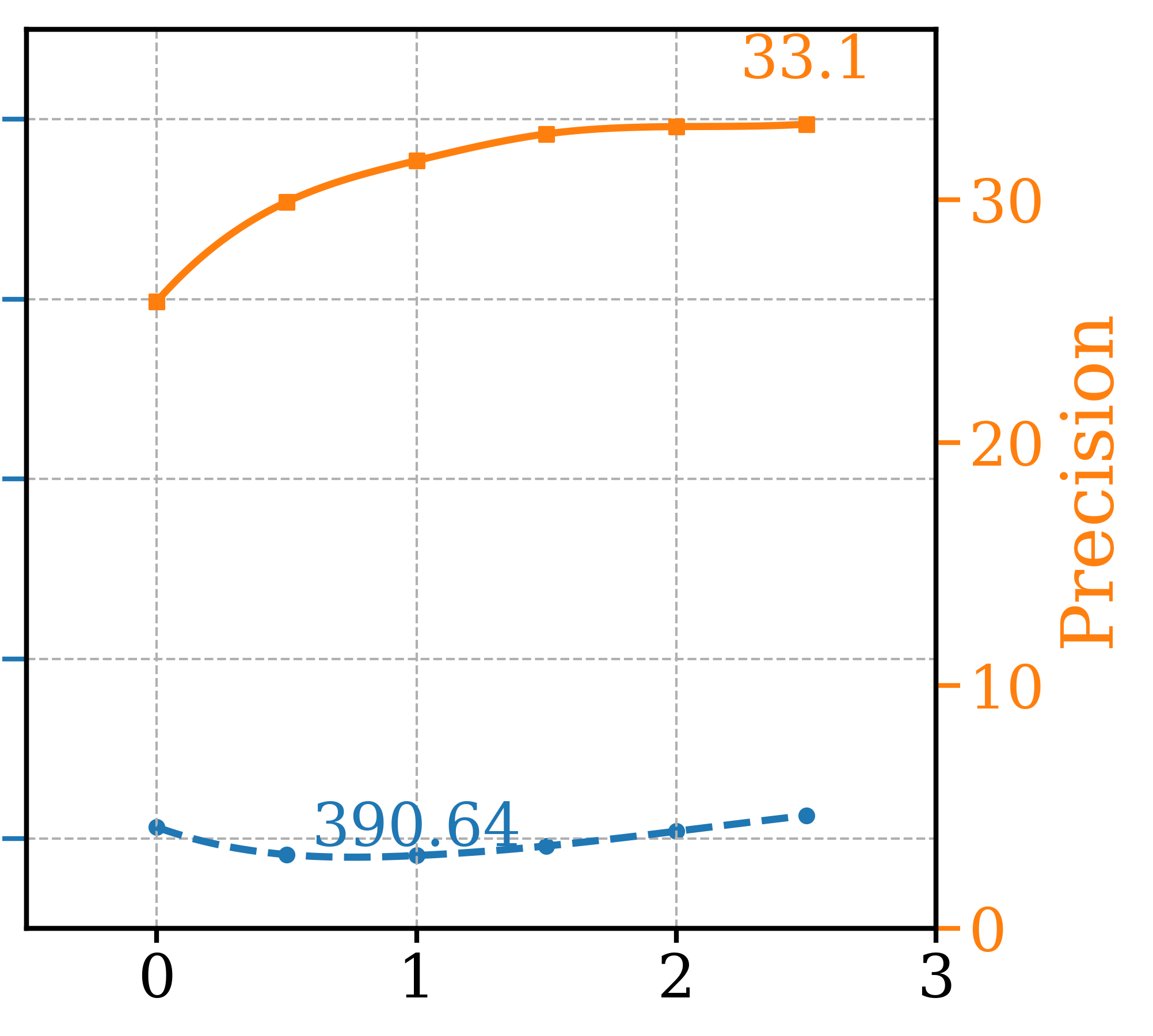
The experiments detailed in the main paper involving the EDM2-S and EDM2-XXL models utilize guidance models (XS, T/16) and (M, T/3.5) respectively for the GFCG and SEG experiments, similar to ATG [16]. These guidance models, with reduced capacity and training, are readily accessible thanks to the publicly available EDM2 codebase [17]. However, this availability may not extend to other class-conditional or text-to-image generation diffusion models. Table 5 presents the FDDINOv2 and Precision metrics for the GFCGNG method, based on the capacity and training of the guidance model. The hyperparameters for GFCG, , , and , are set to , , and , respectively. Similar to ATG, reducing training significantly impacts the FDDINOv2 metric, while reducing capacity only results in the worst performance. The highest precision is achieved when using the same guidance model as the main model with some degradation in FDDINOv2 metric.
| FDDINOv2 | Precision | ||||
|---|---|---|---|---|---|
| Reduce capacity | 51.21 | 93.3% | (XS,T) | 0.085 | 0.085 |
| Reduce training | 39.36 | 93.6% | (S,T/16) | 0.085 | 0.170 |
| Same both | 47.79 | 94.0% | (S,T) | 0.085 | 0.085 |
| Reduce both | 36.93 | 93.3% | (XS,T/16) | 0.085 | 0.165 |
8.3 Effects of Classifier Model
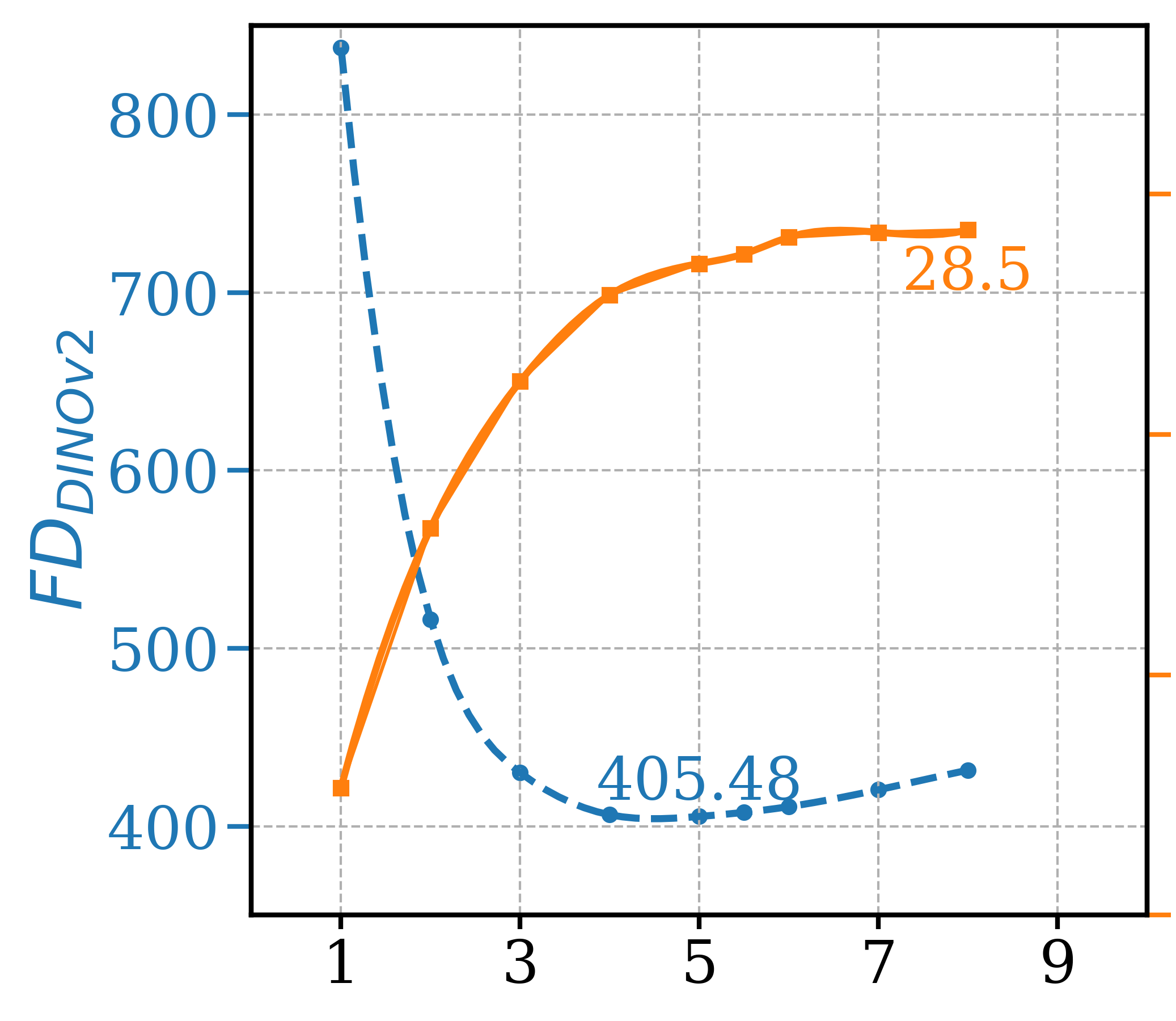
Different classifier models, with varying sizes and top-1 and top-5 accuracies on ImageNet-1k (acc@1 and acc@5 in Table 5), were considered in the ablation study for classifier predictions in GFCG-based methods. ResNet-18, which is one-fourth the size of ResNet-101 used in the main tests, achieved a high precision of 93% compared to ATG’s 90.6%, while maintaining a similar FDDINOv2 to ATG. ResNet-101 exhibited comparable FDDINOv2 and precision metrics to ResNet-152, as shown in Table 5, but with a smaller model size, and was thus selected for the main experiments in the paper.
8.4 Effects of Estimation Methods
For all the mixed and additive GFCG methods presented in Table 1, is set to its maximum value and is set to 4 for estimation. Although this introduces 7 additional NFEs, which is minimal compared to the 63 NFEs, it results in a significant boost in precision and some improvement in FDDINOv2 as well (see Table 1). We explore two methods to further reduce the NFEs. The first method is to reduce the number of steps for estimation. The second method is to use a smaller and lower-trained guidance model as the main model for estimation. For instance, the guidance model used in the majority of the EDM2-S experiments is EDM2-XS, trained for T/16. If , then line 32 in Algorithm 3 would change to , and , which essentially applies the NG method using the guidance model only for estimation. As a smaller model is used for estimation, we ignore the NFEs added by this method. The results of these two methods compared to the main paper results are presented in Table 6.
| Classifier | FDDINOv2 | Precision | Mparams | Gflops | acc@1 | acc@5 |
|---|---|---|---|---|---|---|
| ResNet-18 | 39.54 | 93.0% | 11.7 | 1.81 | 69.8% | 89.1% |
| ResNet-34 | 40.70 | 93.0% | 21.8 | 3.66 | 73.3% | 91.4% |
| ResNet-50 | 37.08 | 93.2% | 25.6 | 4.09 | 80.9% | 95.4% |
| ResNet-101 | 36.93 | 93.3% | 44.5 | 7.80 | 81.9% | 95.8% |
| ResNet-152 | 36.90 | 93.3% | 60.2 | 11.51 | 82.3% | 96.0% |
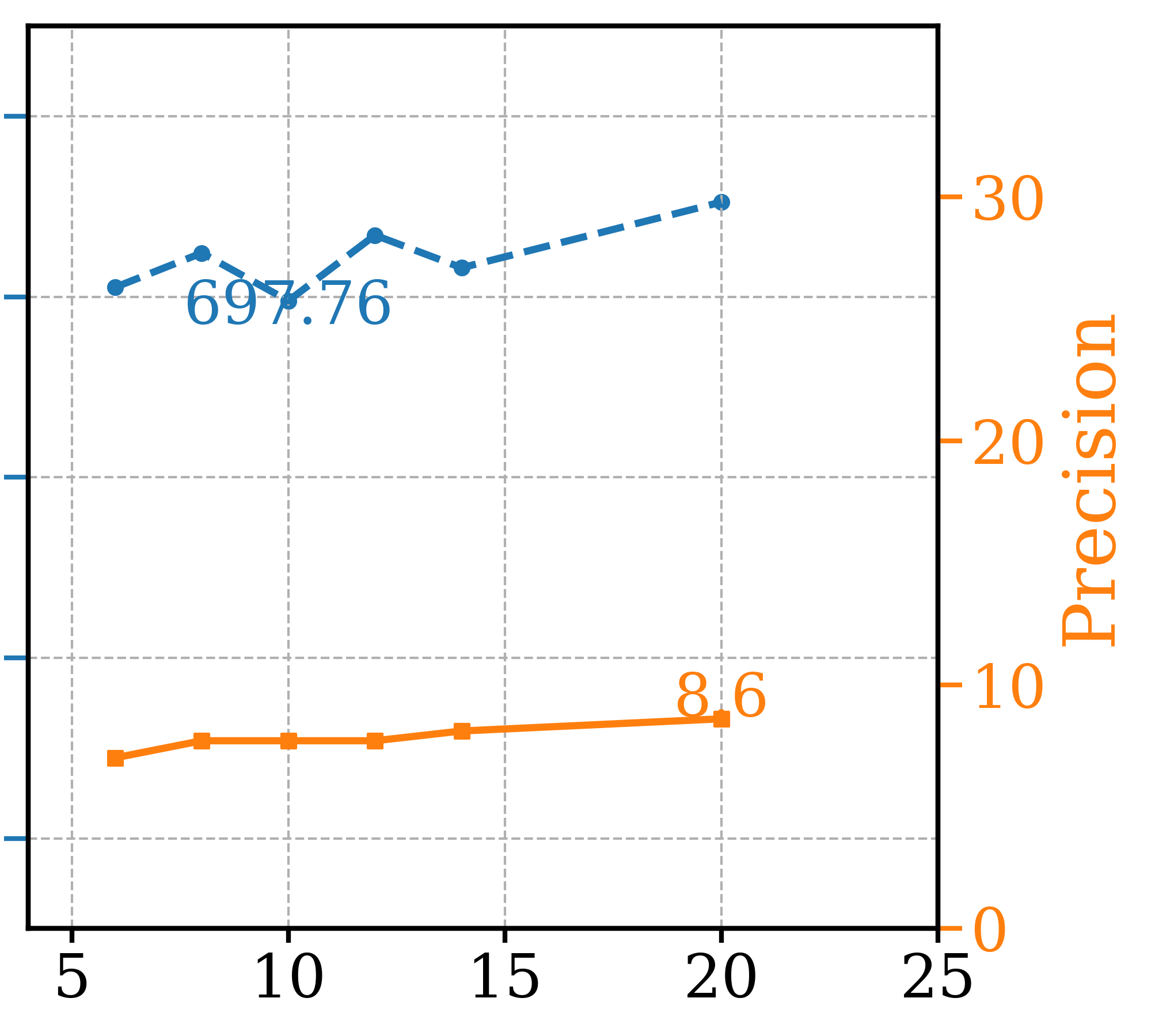
| FDDINOv2 | Precision | NFEs | |||
|---|---|---|---|---|---|
| Method 1 | 39.11 | 92.7% | - | 1 | 64 |
| 37.84 | 93.1% | 1.0 | 2 | 66 | |
| Method 2 | 36.05 | 92.5% | 0.002 | 4 | 63 |
| Main Paper | 36.93 | 93.3% | 0.002 | 4 | 70 |
8.5 Stochastic Reference Class Sampling
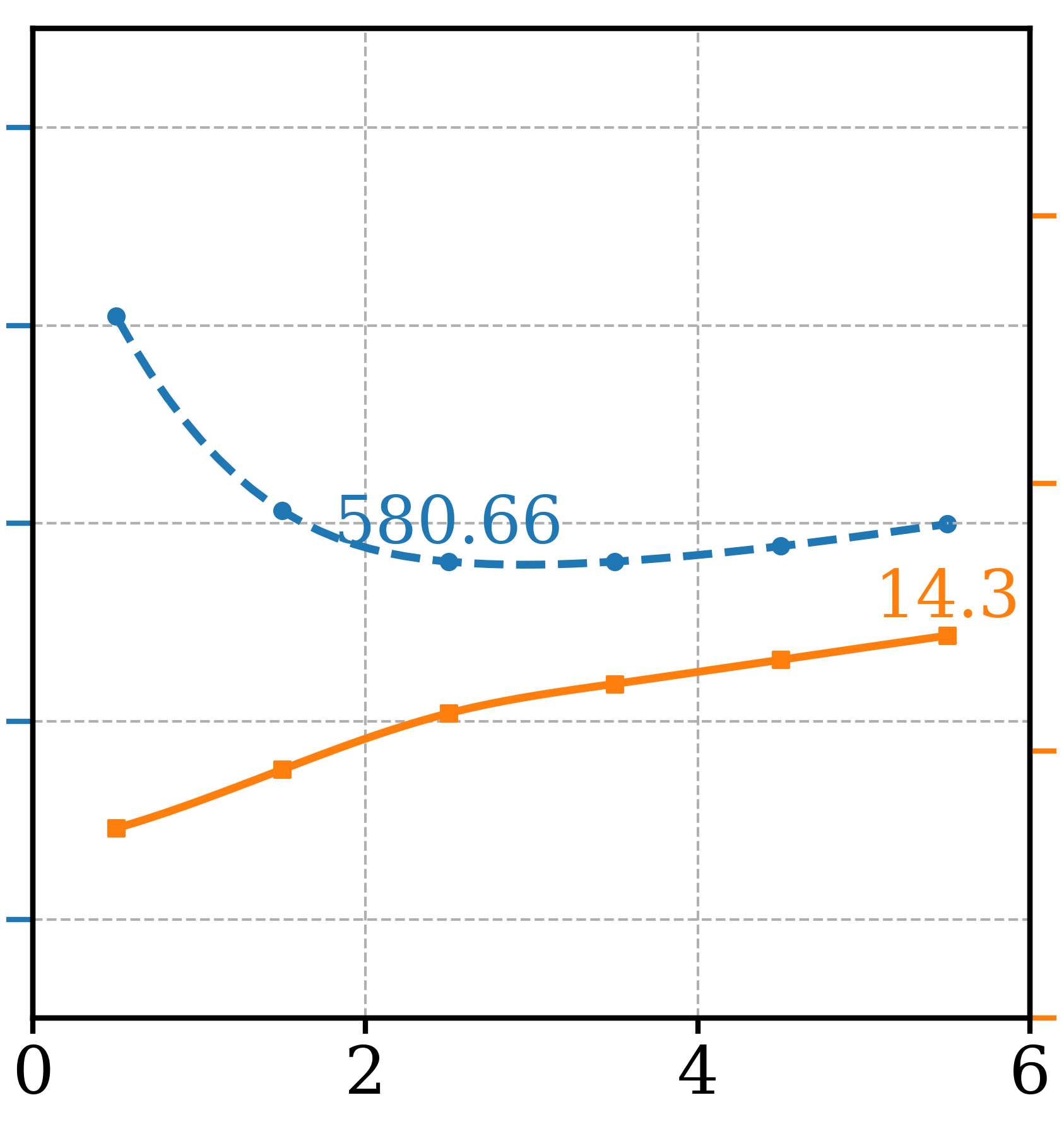
As explained in Equation 7, a stochastic reference class can be sampled each time a classifier prediction is applied. It improves sample quality when there are frequent classifier predictions, i.e., is small. Based on that, the experimental results of text-to-image generations in Table 2 are conducted with this enabled. For comparison, we compare GFCG methods with stochastic reference class sampling to their counterparts with determinist reference class and the quantitative results are included in Table 7. It shows that the stochastic methods are better than their deterministic counterparts in overall performance considering both FDDINOv2 and Precision.
| Method | FDDINOv2 | Precision | |
|---|---|---|---|
| GFCG | Stochastic | 418.8 | 32.3% |
| Deterministic | 428.8 | 32.4% | |
| GFCGCFG | Stochastic | 392.3 | 30.2% |
| Deterministic | 394.7 | 29.1% | |
| GFCG+CFG | Stochastic | 379.2 | 32.4% |
| Deterministic | 377.6 | 31.6% |
8.6 Additional Ablation Studies: Text-to-Image
A full range of ablation studies were conducted for text-to-image experiments using SD, including GFCG and other guidance methods. Three main ones are included in the main paper. All three key settings of GFCG, , and included in Figure 6, and the additional , are plotted together in Figure 8 for full comparison. As evident, has the highest impact and the least. For , the Precision value is the highest when it is set as the minimum of 1, while achieving the lowest FDDINOv2 too.
For the mixed GFCGCFG method, the only key variable is as for CFG and for GFCG are using the same optimal setting of each respectively. The results for is already included in Figure 6. For the additive method of GFCG+CFG, and are investigated to find the optimal settings. As shown in Figure 9, the optimal values are around 4.0 and 1.5, lower than the settings of 5.5 and 2.0 when optimized for CFG and GFCG individually.
For fair comparison, we also study the effect of the guidance scale for CFG, PAG and SEG in Figure 10. For CFG, has a significant role in terms of the FDDINOv2 and Precision of the generated images. For PAG, has a lesser influence, and for SEG the impact is the least. Among these three guidance methods, CFG is much superior than PAG and SEG in terms of FDDINOv2 and Precision.
9 Class-Conditional Visual Examples
Visual examples from class-conditional image generation using existing guidance methods (refer to Table 1) are compared with our GFCG method in EDM2-S sampling, as illustrated in Figure 11. Additionally, we compare GFCG to the additive method GFCGATG+CFG, which achieves state-of-the-art performance in FDDINOv2 for EDM2-S. Further visual examples can be found in Figure 18. The visual results corroborate the quantitative metrics for Precision, with GFCG-generated images demonstrating a strong alignment with class labels in most cases. This is evident in the examples of mushroom and collie in Figure 11, where other guidance methods often confuse mushroom with agaric and collie with border collie. However, this precise alignment does result in a slight trade-off in diversity, as seen in the orange class example, where GFCG generates a zoomed-in image of a single orange. The additive method GFCGATG+CFG mitigates this issue by balancing diversity and class accuracy, as illustrated in the orange class example in Figure 11, where it generates a bunch of oranges in a basket.

To further explore the differences in diversity between GFCG and mixed methods, we compare GFCG with GFCGATG, which achieves state-of-the-art FDDINOv2 for EDM2-XXL. We present visual examples displaying 10 images per class for selected classes in Figure 12, with additional examples in Figure 19. Figure 12 shows that while GFCG-generated samples align closely with class labels (notably in the collie and orange cases, which other methods confuse with border collie and lemon), there is a modest reduction in diversity. For instance, in the orange class, GFCG tends to zoom in on the oranges or exclude other fruits, compared to the mixed method. GFCG may also remove or modify background objects which may cause confusion with the target class, as seen in the pizza and valley classes in Figure 12. Mixed methods, particularly with ATG, help preserve diversity while enhancing class accuracy.

10 Text-to-Image Visual Examples
For text-to-image generations, the results presented in the main paper were all based on samples from SD 1.5 and more visual examples are included here. Additionally, we also conducted experiments using another popular model, DeepFloyd IF model555https://github.com/deep-floyd/IF from Stability AI. Some examples are included in Section 10.3.





10.1 Generic Text Prompts
Some visual examples from text-to-images generation using the set of generic prompts are included in Figure 13. The probability of classifying each generated sample as the target class is also included for reference. In general, the GFCG results have the best class accuracy. The gained accuracy could be caused by compositional change in the first example, as well as correct anatomic features like feather color in the second. For GFCGCFG, it often maintains the overall composition of CFG and is possible to improve class accuracy even when the changes are negligible with untrained eyes like the first example. In the case of the last example, minor changes like chest patterns in GFCGCFG result in significantly increased probability too.
As shown in Figure 14, GFCG results may end up worse than other methods too. For the first example of TIT MOUSE, the text-to-image model obviously has misunderstood MOUSE without recognizing its context as a bird specie. In the case of CFG, as it is guided away from an unconditional model, it will enhance the wrong features associated with MOUSE, as well as correct features associate with other keywords like bird. For GFCG, as the enhancement is in the reference to a photo of another bird species, the difference will be focused between TIT MOUSE and another bird species which results in more prominent mouse features. Similar failure happens in the second example where color features related to TEAL is magnified.
More visual examples using generic text prompts are shown in Figure 20 at the end.





10.2 Detailed Text Prompts
Some visual examples using the set of detailed prompts are included in Figure 15. Note that the hyperparameters like and for GFCG related methods were optimized for the generic prompts and adopted for detailed prompts without further tuning. It shows that GFCG has the best class accuracy while preserving the overall accuracy of the full text prompt, including improving large features like the first example, or small details like the last one. It is noted that, all method including CFG, have difficulty in depicting some details in the prompts like fish in its claws and eating red berry. As shown in Figure 16, for failure cases of GFCG where class probabilities of GFCG results are lower than those of CFG, certain features of the species, e.g. white feather of BALD EAGLE, are excessively enhanced. This could be caused by improper guidance scales. More visual examples using detailed text prompts are shown in Figure 21 at the end.




10.3 Text-to-image Generation in Pixel Space
We also explored using GFCG in the pixel space alone, without using latent diffusion like SD 1.5 used above. In this test, GFCG is integrated into the DeepFloyd IF model from Stability AI, whose diffusion mechanism is implemented in the pixel level. The IF model is able to generate high definition images in size of based on given text prompts. We assessed the performance on the Bird Species dataset, and showed some visual examples in Figure 17. The probability of classifying each generated sample as the target class is also included for reference. On multiple bird species, much higher class accuracy was achieved by GFCG over other guidance schemes. The gained accuracy is largely because of enhanced visual quality of the bird, which is more aligned to the actual appearance of corresponding species. Some additional examples are shown in Figure 22 at the end.
















