Graph Convolutional Network with Connectivity Uncertainty for EEG-based Emotion Recognition
Abstract
Automatic emotion recognition based on multichannel Electroencephalography (EEG) holds great potential in advancing human-computer interaction. However, several significant challenges persist in existing research on algorithmic emotion recognition. These challenges include the need for a robust model to effectively learn discriminative node attributes over long paths, the exploration of ambiguous topological information in EEG channels and effective frequency bands, and the mapping between intrinsic data qualities and provided labels. To address these challenges, this study introduces the distribution-based uncertainty method to represent spatial dependencies and temporal-spectral relativeness in EEG signals based on Graph Convolutional Network (GCN) architecture that adaptively assigns weights to functional aggregate node features, enabling effective long-path capturing while mitigating over-smoothing phenomena. Moreover, the graph mixup technique is employed to enhance latent connected edges and mitigate noisy label issues. Furthermore, we integrate the uncertainty learning method with deep GCN weights in a one-way learning fashion, termed Connectivity Uncertainty GCN (CU-GCN). We evaluate our approach on two widely used datasets, namely SEED and SEEDIV, for emotion recognition tasks. The experimental results demonstrate the superiority of our methodology over previous methods, yielding positive and significant improvements. Ablation studies confirm the substantial contributions of each component to the overall performance.
Emotion Recognition, EEG, Connectivity Uncertainty, Graph Neural Network.
1 Introduction
The superior cognition of human intelligence over artificial intelligence is not due to computational capacity but the former’s ability to comprehend emotions, a sophisticated function of the brain that mediates self-assessment [1]. This realization has galvanized efforts towards evolving artificial intelligence to discern emotions rather than mere binary judgments. Automated emotion recognition, thus, holds immense promise across varied domains like medical treatment, fatigue monitoring, and human-computer interaction (HCI) systems.
Human emotions, intricate and multi-dimensional, are conveyed through gestures, facial expressions, physiological signals, and more. Among these, physiological signals, particularly those from the brain, have emerged as potent indicators of emotional changes due to their inherent veracity [1]. Electroencephalogram (EEG), along with other physiological measures, has demonstrated to be highly reflective of an individual’s emotional states [2, 3]. To unlock this potential, multi-channel emotion EEG induction research is actively pursued, leading to the creation of open-access databases [4, 5, 6, 7].
Current research delving into brain functional connectivity, as indicated by functional magnetic resonance imaging (fMRI), points towards the potential ability of individuals to maintain attention. EEG-based emotion studies have sought to capture spatial information by transforming the three-dimensional electrode position into a two-dimensional matrix, thereby enabling the use of two-dimensional convolution [8]. While conventional models such as CNN and RNN have been employed, their precision has been questioned [9]. However, the advent of graph neural networks (GNNs) has allowed treating each EEG channel as a node and connections as edges, leading to significant advancements in EEG-based emotion classification [10, 11].
Despite their popularity, GNNs have been limited by the vanilla graph convolution network (GCN) approach, suffering from over-smoothing beyond a few layers [12]. Numerous methods to address this have emerged, some of which include dropout [13], drop-edge [14], and residual-based approaches [15]. While these have alleviated over-smoothing, they often involve computationally expensive operations.
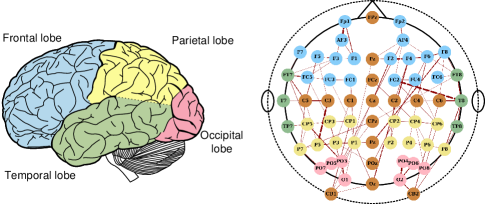
Brain connectivity characterizing emotions requires a nuanced approach. Simple construction of the adjacency matrix using distance coefficients or correlation indices have shown subpar performance in emotion recognition [11, 16, 17]. Emotion processing in the brain is an intricate activity, asynchronous across multiple regions [18]. Positive emotions, for instance, are linked with heightened activity in the left prefrontal cortex, while negative emotions involve the right prefrontal cortex [19]. This understanding underscores the need for effective brain functional connectivity construction and long-path dependencies. Current research has thus far had little to offer regarding effective brain functional connectivity construction and long-path dependencies. Figure 1 represents an example of 62-channel electrode distribution and possible connection among different brain lobes.
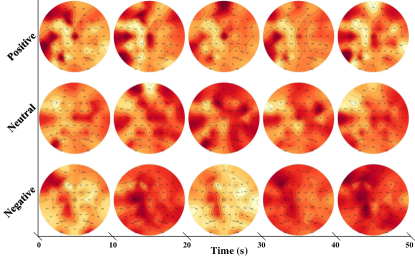
Restricted to the collection difficulties of EEG signals, all available datasets are designed in a lab environment. During trials that involve video-induced emotions, participants often encounter challenges such as insufficient stimulation or extreme variability, resulting in varying emotional states throughout the test. As depicted in Figure 2, even for the same individual, the brain activation patterns for the same emotion over continuous periods of time exhibit noticeable variations, despite maintaining some consistent activation regions. Traditionally, one-second EEG signals have been treated as individual samples, using handcrafted features for emotion categorization [11, 10, 5, 4, 20]. However, accurately labeling and identifying emotions based on these short segments pose difficulties. This issue has been overlooked by many researchers, except for Zhong et al., who introduced the concept of soft labels based on the spatial relationship between different emotions on the arousal-valence plane [11]. Their approach provides a more nuanced understanding of video-induced emotions, overcoming the limitations of traditional single-sample annotations and enhancing comprehension in this domain.
Despite the aforementioned strategies, the efficacy of GCN may be constrained in certain scenarios due to the following factors: 1) Intrinsic limitations stemming from over-smoothing issues, impeding effective long-path information acquisition; 2) Inadequate exploration of the brain’s spatial topological structure and the significance of spectral features; and 3) Insufficient induction resulting in data-label discrepancies, thereby constraining the effectiveness of strategies.
In our endeavor to address limitations in EEG emotion recognition, we have introduced an uncertainty-guided deep Graph Convolutional Network (GCN) model. Our model efficiently mitigates the challenges of over-smoothing and noisy labels by leveraging an uncertainty-guided approach for adjacency matrix generation and Bayesian techniques to estimate connectivity probability, which enhances connectivity between local and global brain regions. We have also demonstrated that the learning of connection uncertainty within our GCN parallels the PageRank algorithm, an advancement that enables the elimination of over-smoothing issues and captures a broader range of spectral information. Furthermore, we have employed a data mixing technique to address the issue of noisy labels, thus introducing potentially connected edges for robust representation. The main contributions of our work lie in the following aspects:
-
1.
We introduce an uncertainty-driven Graph Convolutional Network (UC-GCN), effectively addressing functional connectivity uncertainties and frequency band obscurities in EEG signals.
-
2.
We illustrate the role of uncertainty masks in our spectral-enhanced GCN structure, mitigating over-smoothing and augmenting high-frequency information capture.
-
3.
We innovate with a graph mixing augmentation strategy, enhancing the model’s capability to discriminate ambiguous data through potentially connected edges and soft labels.
2 Related Works
2.1 EEG based emotion classification
EEG signals are a key resource for assessing human emotional states. In the past, feature extraction for emotion categorization was primarily manual, with time domain characteristics such as statistical measures [21], higher-order correlation methods [22], and event-related potentials [23] being used. From a frequency domain perspective, features like power spectral density were used [24, 4], along with techniques such as short-time Fourier transform and discrete wavelet transform for time-frequency domain features [25, 26]. Nonlinear dynamics and chaos-based concepts have also been examined [27], with nonlinear features such as fractal dimension [28] and multifractal detrended fluctuation analysis [29] showing significant correlations with different emotional states.
Despite their value, these features have mostly been focused on single-channel signals, ignoring the relationships between different channels. This is a significant oversight, as research has shown that different parts of the brain can be affected differently by emotional states [30]. To address this, recent research by Shi et al. [31] used differential and rational asymmetry measures to quantify differences in hemispheric brain activity. Tao et al. [32] proposed using an attention-based convolutional recurrent neural network to extract both channel relationships and inherent similarities from EEG data. Li et al. [33] also used directed recurrent neural networks on two hemisphere areas to capture both spatial and temporal dependencies simultaneously. Graph neural networks (GNNs) have been employed by researchers to analyze intra-channel connections, with each node representing inter-channel characteristics [10, 20, 11]. While promising, these GNNs often use predetermined adjacency matrices that lack a robust clinical or psychological basis.
2.2 Graph Neural Network in EEG
Traditional neural networks like CNNs and RNNs face challenges in non-Euclidean spaces, pushing researchers to explore alternatives. Spectral methods using Laplace transformed space for convolution have been introduced but were computationally demanding [34]. This was improved with Chebyshev polynomials, enhancing graph convolutional networks (GCNs) [35]. Spatially-based methods, like defining fixed neighbor vectors for graph convolution or building adjacency matrices via randomly selected neighbors, have also been proposed [36, 37]. However, deep GCNs tend to oversmooth, leading to indistinct representations [12]. Solutions like custom PageRank matrices have been suggested to combat this issue [38].
Regarding EEG data tasks, GNNs have shown promising results in emotion categorization [11, 10, 20], epilepsy identification [39], and seizure analysis [17]. Most of the research focuses on constructing brain functional connectivity based on thresholds or constructing a graph that combines local and global regions. However, these methods often rely on a predefined graph, which may not fully capture the interconnectedness of different emotional states across individuals. Also, static connection graphs may struggle to represent brain activation patterns accurately in noisy environments. As a solution, we suggest an uncertainty-driven strategy for replacing the adjacency matrix, which integrates weighted root node features to mitigate over-smoothing and improve model performance for all emotions.
2.3 Uncertainty for graphs
While uncertainty quantification in CNNs has been extensively studied, it has received limited attention in the context of GNNs [40, 41]. Aleatoric uncertainty, arising from imprecise and noisy measurements, affects the observability of node characteristics, edge connectivity, and edge weights in a graph. Zhang et al. [42] proposed a Bayesian framework that generates graph structures and parameters using parametric random graphs to handle aleatoric uncertainty. Munikoti et al. [43] established a generic Bayesian framework and employed assumed density filtering to measure aleatoric uncertainty. Epistemic uncertainty, on the other hand, arises from the model’s limited ability to accurately represent the underlying process. Variational inference [44, 20] and sampling-based approaches [45] are commonly used to estimate posterior density functions of model parameters. Hasan et al. [46] presented an adaptive connection sampling-based stochastic regularization algorithm for GNNs, while Munikoti et al. [43] and Feng et al. [47] employed Monte-Carlo dropout during testing to quantify prediction uncertainty. Existing efforts in graph data analysis have primarily focused on feature qualification and model performance, assuming pre-defined graph structures. However, for EEG-related activities, the functional connectivity of the brain remains a challenging mystery. Our study explicitly incorporates uncertainty in graph structures into our paradigm, addressing this crucial aspect.
3 Methods
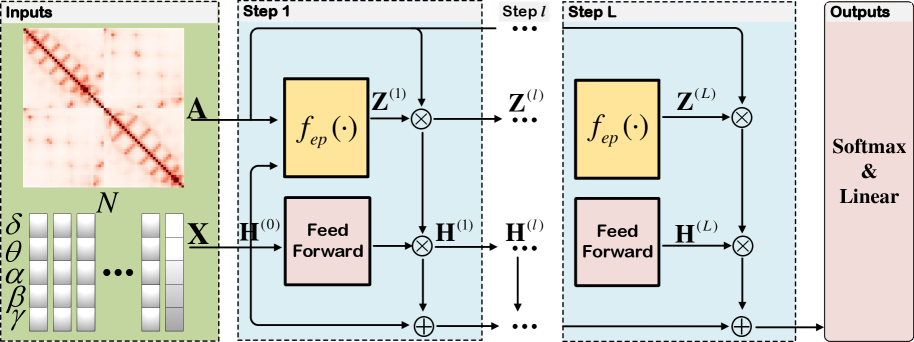
In this section, we then present our key idea of automatically learning the connections between different EEG channels to reconstruct the brain’s functional graph for emotional response, as shown in Figure 3.
3.1 Preliminaries
3.1.1 Graph Neural Networks
We represent an undirected graph with node set and edge set . The edges in the graph may be alternately represented using an adjacency matrix , where indicates that node and are not connected and is the number of nodes. Let the node attribute matrix be , where denotes the input feature dimension and each node may be endowed with a -dimensional node attribute vector . Let be the diagonal degree matrix of with .
Spectral Graph Convolution [35] - Spectral graph theory [48] study the graph topology property by means of the eigenvalues and eigenvectors of the Laplace matrix of graphs. Laplacian matrix is defined as and its normalization matrix is , which is a semi-definite matrix with eigenvalues as and eigenvectors as . Thus, . Similar to the role of CNNs in image processing, spectral convolution on graphs can be understood as a filtering operation in the spatial domain. It is achieved by performing a multiplication between the raw graph signal and the filter kernel in the spectral domain, utilizing techniques such as Fourier transform [35] or wavelet transform [49, 50]. This spectral convolution operation allows us to extract meaningful features from graph-structured data, analogous to the way CNNs extract features from images.
| (1) |
where denotes the element-wise multiplication and denotes a diagonal matrix of spectral filter coefficients. To avoid the high computation overload of matrix decomposition of , [35] approximated with -order Chebyshev polynomials :
| (2) |
and the corresponding filter coefficients , where is a scaled Laplacian normalization, denotes the largest eigenvalue of and is a learnable vector of Chebyshev coefficients, means the -th term of a -order polynomials.
Graph convolution neural network (GCN) [51] further approximate the Eq. (2) with , and , so that the convolution operation in Eq. (1) translate into . Each GCN layer transformation function is defined as:
| (3) | ||||
where is a normalized adjacency matrix, is a renormalization trick introduced in GCN, , is the convolutional parameter of each layer to realize the feature transformation, denotes a nonlinear activation function and denotes the layer number. The normalized Laplacian and its corresponding graph filter can be described as , where are eigenvalues of .
For brevity and without loss of generality, we denote as the adjacency matrix with a self-loop and as the degree matrix with a self-loop.
3.1.2 Over-smoothing in GNNs
The aggregation progress of neighborhood information can be seen as a graph filtering step over node features with a filter expressed in Eq. (2). Obviously, the preserved spectral component in is dominated by the eigenvalues of , i.e. and , which in turn represent the low to high-frequency components. Currently, practical models are usually shallow (number of layers is 2 - 4), as such a choice offers the best empirical performance which is later proved attributed to the low-pass characteristic. Besides, the transition matrix will finally collapse to an independent matrix of input without a linear interposition in Eq. (3), . And the final decision derived from such an undiscriminating, is merely determined by the -hop node attributes with denotes the total layers, provided that the graph is irreducible and aperiodic. More specifically, the learned representations will lose discriminative information provided by nodes with different topological and feature characteristics as the model goes deeper.
3.2 Uncertainty-guided GCN for Emotion Recognition from EEG Signals
3.2.1 Emotion-specific function connectivity reconstruction
In practical applications, each EEG channel is regarded as a node, with node vectors encapsulating the computed features across various frequency bands, specifically, the delta, theta, alpha, beta, and gamma bands. Our central proposition rests on leveraging the information derived from both the inherent topology of the graph in the spatial domain and the node features in the time-frequency domain to overcome prevalent challenges such as the identification of topological connections and distinct effective frequency band responses. This two-pronged approach allows us to pinpoint crucial information to be assimilated into the propagation of knowledge during the design phase of the GCN.
A crucial step in this procedure is the introduction of an edge predictor (EP), which computes the connection probabilities between any two nodes, paving the way for node feature learning. The edge predictor can be formally expressed as , where denotes an edge existence mask. We leverage the mask matrix to establish deterministic links to high-scoring non-edges and remove poorly scored linked edges. The propagation procedure is then reformulated as the following metric:
| (4) |
It is easy to observe that implementing node-wise and feature-wise uncertainty quantization leads to different probabilistic interpretations. To provide a comprehensive measure of model uncertainty, we further extend as a 3-dimensional matrix, where denotes the connection of any two nodes , and denotes the mask vector of layer on features of each node. We can rewrite and reorganize Eq. 4 in a feature-wise view as
| (5) |
where
| (6) |
that means we allocate each frequency component with a different topological connection strategy for a better group of useful information. is a binary mask sampled from a Bernoulli distribution with a success rate as for each layer. The success rate is adaptive for different representations, guaranteeing the effectiveness of topology construction.
3.2.2 Uncertainty Learning With Bayesian Approximation
To generate an uncertain binary mask , we endeavor to leverage the power of Bayesian inference to train our predictor, using the predictive posterior derived from training data. Intriguingly, we illustrate in the context of this study that the dynamic process of adaptive connection learning can be elegantly transposed from the realm of output feature space to the more abstract parameter space, thereby casting it as a credible Bayesian process encapsulated within the Graph Convolutional Network (GCN) framework.
To further clarify our approach, we revisit Eq. 4 and reinterpret it from a node-wise perspective of a GCN layer, which can be described as:
| (7) |
where
| (8) | ||||
In this context, we introduce the notation , thereby facilitating the transference of the learning process for the uncertainty-based edge predictor to the acquisition of a weighted adjacency matrix along the edges for each respective layer.
The model parameters that require optimization are denoted as , with serving as the weight set for the -th edge. Here, represents the number of edges. Initially, each row of is assigned a distribution according to . Moreover, we postulate a vector of dimensions for each layer. Consequently, the predictive probability of the deep GNN model can be expressed as:
| (9) |
3.2.3 Variational Interpretation
However, the posterior distribution proves intractable. In light of this, we adopt a variational interpretation, where a binary mask (each row of ) can be viewed as an approximate distribution that approximates the posterior distribution . We define as follows:
| (10) | ||||
Here, represents the variational parameters, and denotes the mean weight matrices. The variable corresponds to the removal of features, leading to the omission of nodes in layer as connected neighbors within the graph , solely when the entire set of features is eliminated.
To optimize the aforementioned model, we introduce the Kullback-Leibler (KL) divergence in order to minimize the discrepancy between the approximate posterior and the prior distribution . The discrete quantized Gaussian prior distribution is commonly employed to analytically evaluate this intractable KL divergence. Considering the distribution of the edges, we have . By approximating each edge distribution as , we can express the general KL term as:
| (11) |
Consequently, the edge predictor loss can be approximated as:
| (12) |
where denotes the entropy of a Bernoulli random variable with success rate , defined as:
| (13) |
Given a fixed edge connection probability , the entropy term remains unaffected by model weights and can be viewed as a constant regularization term during optimization, thereby rendering it negligible. However, the connectivity sampling probability inherently relies on the specific functional structure of each frequency component. The minimization of the KL divergence term equates to maximizing the entropy term with a probability of , which is optimally achieved when approximates 0.5. It becomes apparent that constant proportion sampling fails to meet the requirements for intricate functional connections and may introduce extraneous information. In order to train during the model training process, we must compute the derivative of the entropy objective, which presents a formidable challenge.
Several commonly used estimators, such as Reinforce [52] or pathwise derivative re-parametrization methods [53, 44, 54], are inapplicable due to the discrete nature of the masks. Rather than sampling the random variable from a discrete Bernoulli distribution, we employ an approximation by substituting the discrete distribution with its continuous relaxation. This can be seen as a relaxation of the ”max” function in the Gumbel-max trick to a ”softmax” function. The transition from a discrete Bernoulli random variable to a continuous variable is reparametrized as , where represents the model parameters and is a random variable independent of . Assuming that follows a uniform distribution, i.e., , we utilize the Sigmoid function to constrain the continuous value within the interval [0, 1]:
| (14) |
where is a temperature parameter. This distribution assigns most of its mass to the boundaries of the interval 0 and 1. With this concrete relaxation of the adjacency masks, we can now optimize the connection probability.
3.3 Alleviating Over-smoothing and Enhance Spectral Filter
Long path information, known as the high-frequency component among the graph, was demonstrated to have strong discriminative power for graph-level classification. Hence a natural research direction of research regarding GNNs is to investigate how to leverage long paths over graphs without over-smoothing the vertex features. Generalized PageRank (GPR) values [55, 56] enable more accurate characterizations of hidden state distance and similarities and hence lead to improved performance of various graph learning techniques. Given a seed feature and another deeper hidden feature in the graph, the GPR value is defined as , for some GPR weight sequence . We rewrite the multi-step propagation with a truncated polynomial based on Eq 4:
| (15) | ||||
noted that the task of learning GPR score for graph classification can be reformulated as learning a flexible factor over the adjacency matrix in different propagation steps, thus could be learned with , i.e., . That means the long-path learning could be realized with the uncertainty learning on each step. Thus, learning the optimal uncertainty mask is equivalent to learning the optimal polynomial graph filter. As any graph filter could be approximated with a polynomial graph filter and increasing allows one to better approximate the underlying feature extractor. The uncertainty-guided GNN is able to leverage long-path topological structure information and with an adaptive learned GPR weight, one can enhance the beneficial middle state while suppressing the harmful.
Augmented Spectral Filters. More specifically, corresponds to a polynomial graph filter of order over . Wherein the is a multiplier factor derived from ranged in (0, 1) as proved in Eq. 14. The corresponding polynomial graph filter equals to . As proved in [51, 57], the eigenvalues of renormalized GCN range in [0, 1.5]. When , the amplitude of vanilla GCN is equal to robust GCN, i.e. . Hence, the robust GCN retains the low-pass filter ability. However, when , , which provides the model more high frequency components. Besides, as is less than 1 and will be smaller with the stacking of the convolution layer, will hardly get a negative value, which is previously proved harmful for the model performance [57], thus enhance the robustness of such a model. We refer to the proposed model as Enhanced Graph Convolutional Network (eGCN).
3.4 Implicit adversarial training strategy
In section 3.2.3, we sparsify adjacency with Bernoulli-based uncertainty sampling to get the graph variant adjacency . However, the generated adjacency matrix is able to keep the most class-specific connections but weak in adding global emotion-effective connections, which we argue should be generally existing edges for all emotional states. Besides, existing methods generate samples by segmenting raw data with a non-overlapping 1-s window, ignoring the fact that participants may not always be effectively stimulated when watching an induced material due to self-resistance or insufficient stimulation. Unwanted data are adversarial samples that are harmful to robust model training.
We propose a data-agnostic augmentation method to add latent connected edges and alleviate the mismatching problem (noisy label) by leveraging information from other positive samples of the same mini-batch. In a nutshell, we use mixup [58] to construct virtual training examples. Given a pair of graph samples , with the embedding , initial adjacency matrix and its corresponding label , we interpolate contextual information by
| (16) | ||||
with controlling the strength of interpolation between feature-target pairs. We sample the mixup weight from the Beta distribution with as a hyper-parameter [58, 59, 60]. With such an augmentation technique, the converted graph data tend to be close to its intrinsic distribution and labeled with a more convicting soft label. Let denote the graph embedding and the optimization objective of graph classification can be written as:
| (17) |
Consequently, our emotion recognition method was designed by optimizing both the classification loss and uncertainty edge predictor loss in Eq. (12)
| (18) |
4 Experiments and Results Analysis
In this section, we provide details about the datasets used in our experiments and describe the experimental settings, as well as comparisons with state-of-the-art.
4.1 Experimental Setting
4.1.1 Datasets
Our investigation enlisted two established EEG datasets, the SJTU emotion EEG dataset (SEED) [4] and its successor SEEDIV dataset [5], in the execution of emotion recognition tasks. These datasets encompass EEG recordings from 15 youthful participants, evenly distributed by gender. The data, collected via a 62-channel ESI NeuroScan System as the subjects viewed emotionally charged film clips, were gathered over three sessions held on different days under uniform conditions to ensure data integrity. The raw EEG signals were then preprocessed, down-sampled from 1000 Hz to 200 Hz, and cleansed of artifacts stemming from eye movements (EOG) and muscle activity (EMG).
The SEED dataset comprises 15 film clips of around 4 minutes each, carefully crafted by psychologists to evoke specific emotional states - Positive, Neutral, or Negative. Hence, each participant in the SEED dataset produced 45 distinct EEG signal trials. The SEEDIV dataset, following a similar data acquisition procedure, increased the number of trials by featuring 24 film clips that lasted roughly 2 minutes each and elicited four types of emotions: Neutral, Sad, Fear, and Happy. This resulted in each participant contributing 72 EEG recording trials in the SEEDIV dataset.
| Feature | Method | band | band | band | band | band | All bands |
| DE | SVM [4] | 60.50 / 14.14 | 60.95 / 10.20 | 66.64 / 14.41 | 80.76 / 11.56 | 79.56 / 11.38 | 83.99 / 09.72 |
| DBN [4] | 64.32 / 12.45 | 60.77 / 10.42 | 64.01 / 15.97 | 78.92 / 12.48 | 79.19 / 14.58 | 86.08 / 08.34 | |
| Bi-DANN [61] | 76.97 / 10.95 | 75.56 / 07.88 | 81.03 / 11.74 | 89.65 / 09.59 | 88.64 / 09.46 | 92.38 / 07.04 | |
| R2G-STNN [62] | 77.76 / 09.92 | 76.17 / 07.43 | 82.30 / 10.21 | 88.35 / 10.52 | 88.90 / 09.57 | 93.38 / 05.96 | |
| BiHDM [63] | - | - | - | - | - | 85.40 / 07.53 | |
| vGCN [35] | 72.75 / 10.85 | 74.40 / 08.23 | 73.46 / 12.17 | 83.24 / 09.93 | 83.36 / 09.43 | 87.40 / 09.20 | |
| DGCNN [10] | 74.25 / 11.42 | 71.52 / 05.99 | 74.43 / 12.16 | 83.65 / 10.17 | 85.73 / 10.64 | 90.40 / 08.49 | |
| RGNN [11] | 76.17 / 07.91 | 72.26 / 07.25 | 75.33 / 08.85 | 84.25 / 12.54 | 89.23 / 08.90 | 94.24 / 05.95 | |
| GCB-net+BLS [64] | 79.98 / 08.93 | 76.51 / 09.56 | 81.97 / 11.05 | 89.06 / 08.69 | 89.10 / 09.55 | 94.24 / 06.70 | |
| V-IAG [20] | 81.14 / 09.46 | 82.37 / 07.44 | 84.51 / 09.68 | 92.15 / 08.90 | 92.96 / 06.19 | 95.64 / 05.08 | |
| CU-GCN | 82.01 / 08.76 | 80.62 / 08.33 | 84.92 / 10.32 | 92.56 / 09.17 | 93.32 / 05.94 | 95.70 / 05.32 | |
| PSD | SVM [4] | 58.03 / 15.39 | 57.26 / 15.09 | 59.04 / 15.75 | 73.34 / 15.20 | 71.24 / 16.38 | 59.60 / 15.93 |
| DBN [4] | 60.05 / 16.66 | 55.03 / 13.88 | 52.79 / 15.38 | 60.68 / 21.31 | 63.42 / 19.66 | 61.90 / 16.65 | |
| vGCN [35] | 69.89 / 13.83 | 70.92 / 09.18 | 73.18 / 12.74 | 76.21 / 10.76 | 76.15 / 10.09 | 81.31 / 11.26 | |
| DGCNN [10] | 71.23 / 11.42 | 71.20 / 08.99 | 73.45 / 12.25 | 77.45 / 10.81 | 76.60 / 11.83 | 81.73 / 09.94 | |
| GCB-net+BLS [64] | 72.90 / 13.19 | 74.48 / 09.03 | 76.99 / 10.36 | 83.30 / 10.73 | 83.12 / 11.95 | 84.32 / 10.61 | |
| V-IAG [20] | - | - | - | - | - | 86.71 / 10.25 | |
| CU-GCN | 74.10 / 09.78 | 73.84 / 07.35 | 77.00 / 09.53 | 84.56 / 10.49 | 85.49 / 09.17 | 87.21 / 09.81 | |
| DASM | SVM [4] | 48.87 / 10.49 | 53.02 / 12.76 | 59.81 / 14.67 | 75.03 / 15.72 | 73.59 / 16.57 | 72.81 / 16.57 |
| DBN [4] | 48.79 / 09.62 | 51.59 / 13.98 | 54.03 / 17.05 | 69.51 / 15.22 | 70.06 / 18.14 | 72.73 / 15.93 | |
| vGCN [35] | 57.07 / 06.75 | 54.80 / 09.09 | 62.97 / 13.43 | 74.97 / 13.40 | 73.28 / 13.67 | 76.00 / 13.32 | |
| DGCNN [10] | 55.93 / 09.14 | 56.12 / 07.86 | 64.27 / 12.72 | 73.61 / 14.35 | 73.50 / 16.60 | 78.45 / 11.84 | |
| GCB-net+BLS [64] | 62.36 / 10.66 | 65.00 / 10.31 | 70.91 / 10.84 | 85.55 / 11.39 | 86.04 / 10.85 | 82.09 / 13.14 | |
| V-IAG [20] | - | - | - | - | - | 90.10 / 08.73 | |
| CU-GCN | 64.56 / 08.81 | 68.77 / 10.34 | 73.11 / 09.62 | 87.77 / 10.69 | 87.43 / 10.09 | 91.04 / 09.16 | |
| RASM | SVM [4] | 47.75 / 10.59 | 51.40 / 12.53 | 60.71 / 14.57 | 74.59 /16.18 | 74.61 / 15.57 | 74.74 / 14.79 |
| DBN [4] | 48.05 / 10.37 | 50.62 / 14.02 | 56.15 / 15.28 | 70.31 / 15.62 | 68.22 / 18.09 | 71.30 / 16.16 | |
| vGCN [35] | 59.70 / 05.65 | 55.91 / 08.82 | 59.97 / 14.27 | 79.45 / 13:32 | 79.73 / 13.22 | 84.06 / 12.86 | |
| DGCNN [10] | 57.79 / 06.90 | 55.79 / 08.10 | 61.58 / 12.63 | 75.79 / 13.07 | 82.32 / 11.54 | 85.00 / 12.47 | |
| GCB-net+BLS [64] | 62.56 / 08.83 | 62.22 / 11.12 | 71.43 / 10.83 | 87.03 / 11.16 | 85.59 / 11.18 | 87.73 / 10.19 | |
| V-IAG [20] | - | - | - | - | - | 90.53 / 09.22 | |
| CU-GCN | 63.98 / 07.21 | 64.52 / 08.79 | 72.70 / 11.32 | 88.82 / 09.92 | 86.56 / 10.72 | 89.77 / 09.68 |
4.1.2 Data Splits
In the pursuit of equitable comparisons, we conducted both subject-dependent and subject-independent classifications on the SEED and SEED-IV datasets, in adherence with protocols laid out in previous investigations [65, 4, 10, 11, 20, 8]. In the subject-dependent trials on the SEED dataset, we designated the initial 3 trials from each emotional category (making up a total of 9 trials) for training purposes, while the residual 6 trials were assigned to the testing set, thereby ensuring an even distribution across categories. Notably, these experiments drew upon two sessions from each subject. We reported the final outcome as the mean accuracy across all 15 subjects.
Turning to the subject-dependent trials on the SEED-IV dataset, we allocated the first 4 trials from each emotional category (a total of 16 trials) for training, whereas the remaining 8 trials served as the testing set. All three sessions were incorporated into the evaluation of model performance. As with the SEED dataset, we reported accuracy over all 15 subjects. Regarding the subject-independent trials, we espoused the leave-one-out methodology. Specifically, cross-validation was performed by excluding one session from each subject in the case of the SEED dataset, and all sessions from each subject in the case of the SEED-IV dataset. We evaluated model performance across all 15 trials.
| Feature | Method | band | band | band | band | band | All bands |
| DE | SVM [5] | 57.58 / 12.64 | 57.98 / 12.30 | 61.22 / 16.46 | 66.66 / 18.80 | 66.34 / 17.49 | 70.58 / 17.01 |
| DBN [4] | - | - | - | - | - | 66.77 / 07.38 | |
| BiDANN [61] | - | - | - | - | - | 70.29 / 12.63 | |
| BiHDM [63] | - | - | - | - | - | 74.35 / 14.09 | |
| vGCN† [35] | 60.23 / 12.47 | 58.07 / 12.21 | 61.97 / 10.06 | 68.87 / 09.12 | 66.50 / 14.01 | 70.81 / 11.56 | |
| DGCNN† [10] | 61.84 / 11.62 | 63.44 / 13.91 | 63.74 / 13.15 | 67.28 / 12.82 | 64.77 / 12.38 | 70.47 / 15.29 | |
| RGNN† [11] | 64.23 / 09.83 | 62.33 / 10.14 | 65.98 / 08.52 | 72.47 / 09.35 | 71.66 / 09.51 | 75.90 / 12.11 | |
| CU-GCN | 66.21 / 07.71 | 64.81 / 08.12 | 65.92 / 09.69 | 75.93 / 08.77 | 73.44 / 10.10 | 77.39 / 09.24 |
-
1
indicates the experiment results obtained are based on our own implementation.
| Method | SEED | SEEDIV | |||||
| band | band | band | band | band | All bands | All bands | |
| SVM [4] | 43.06 / 08.27 | 40.07 / 06.50 | 43.97 / 10.89 | 48.63 / 10.29 | 51.59 / 11.83 | 56.73 / 16.29 | 37.99 / 12.52 |
| BiDANN-S [61] | 63.01 / 07.49 | 63.22 / 07.52 | 63.50 / 09.50 | 73.59 / 09.12 | 73.72 / 08.67 | 84.14 / 06.87 | 65.59 / 10.39 |
| DANN [66] | 56.66 / 06.48 | 54.95 / 10.45 | 59.37 / 10.57 | 67.14 / 07.10 | 71.30 / 10.84 | 75.08 / 11.18 | - |
| R2G-STNN [62] | 63.34 / 05.31 | 63.78 / 07.53 | 64.27 / 10.88 | 74.85 / 08.02 | 74.54 / 08.41 | 84.16 / 07.63 | - |
| BiHDM [63] | - | - | - | - | - | 85.40 / 07.53 | 69.03 / 08.66 |
| DGCNN [10] | 49.79 / 10.94 | 46.36 / 12.06 | 48.29 / 12.28 | 56.15 / 14.01 | 54.87 / 17.53 | 79.95 / 09.02 | 52.82 / 09.23 |
| RGNN [11] | 64.88 / 06.87 | 60.69 / 05.79 | 60.84 / 07.57 | 74.96 / 08.94 | 77.50 / 08.10 | 85.30 / 06.72 | 73.84 / 08.02 |
| V-IAG [20] | - | - | - | - | - | 88.38 / 04.80 | - |
| CU-GCN | 64.72 / 05.99 | 64.04 / 07.57 | 64.50 / 09.46 | 76.92 / 07.76 | 79.38 / 09.03 | 87.10 / 05.44 | 74.50 / 07.88 |
-
1
indicates the experiment results obtained are based on our own implementation.
4.1.3 Model Training
We conducted our experiments using the PyTorch Geometric toolbox and trained the models on a single NVIDIA Tesla A100 GPU, utilizing the Adam optimizer. To determine the optimal hyperparameters, we performed a search on the validation set, exploring the following ranges: (a) initial learning rate within the range [1e-3, 3e-2]; (b) the number of convolutional layers within range {2, 4, 6, 8} and hidden feature dimension within range {32, 64, 128}. We set the temperature parameter in the concrete distribution as 0.67, the Beta distribution weight as 2, and the batch size as 32. The hyper-parameters were hand-tuned with the best performance over the validation set. A cosine annealing learning rate scheduler was adopted for all experiments. We adopt an early stopping strategy when the validation loss did not decrease for ten consecutive epochs.
4.2 Experimental Results
We report the mean accuracy (Acc) and standard deviation (Std) as the main evaluation metrics for emotion recognition. This choice aligns with recent studies in the field [65, 4, 10, 11, 20, 8], ensuring consistency in the evaluation of our results.
4.2.1 Subject-dependent Test
Following the procedure of Algorithm 1, we compare the proposed model with a quantity of popular used models: (1) traditional machine learning classifying models, e.g. SVM [5], DBN [4]; (2) non-topological deep learning methods, e.g. CNN alone or combined with RNN, such as BiDANN [61], BiHDM [63] and R2G-STNN [62]; (3) recently proposed GNN models: vanilla GCN (vGCN) [51], DGCNN [10], RGNN [11], GCB-net with BLS [64] and V-IAG [20]. To further explore the relation of spectral information and emotion state, we conduct these experiments from the separate and total five frequency bands, known as band (1-4 Hz), band (4-8 Hz), band (8-14 Hz), band (14-30 Hz) and band (30-50 Hz). For a fair comparison, we adopt the pre-extracted DE, PSD, DASM and RASM features after linear dynamic systems (LDS) as our input source data.
Table 1 shows the performance of our model and the SOTA methods. In view of the DE feature is more effective in emotion recognition, we only take experiments with DE feature on SEEDIV, with results shown in Table 2. Our model performs on par or better than other methods both on separate and total frequency bands on all features. We analyze the results from three aspects: (1) input source - DE feature are experimentally proved as the most effective metric; (2) classifier - deep learning methods among which CNN is used to acquire spatial attention and RNN is used to learn temporal relation, outperformed traditional machine learning methods for a lot. While GCN-based methods utilize the EEG topological structure and make a more reasonable channel grouping, finally present the best performance; (3) spectral effectiveness: leverage features on and band alone are more effective for emotion activation but greatly under-performed than using features on whole bands, somehow indicating that high-frequency information is more active with emotional activities. Our model obtained the best performance on both datasets. We attribute such a performance gain to the leverage of uncertainty-guided instance-wise adjacency matrix and the improvement of model ability on the spectral richness and alleviation to over-smoothing.
4.2.2 Subject-independent Test
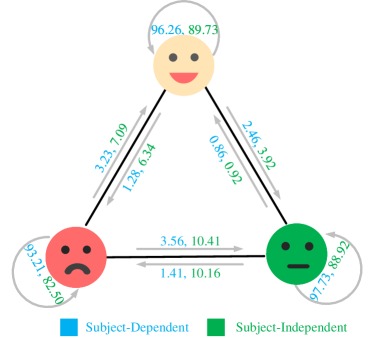
Physiological signals, such as EEG, present severe individual variation and greatly hinder the model generalization. Thus, we conduct the subject-independent emotion classification to further verify our model stability. We use DE feature as the exclusive input for its remarkable discriminating property. Table 3 shows the performance of three categorical classifiers on SEED and SEEDIV. Note that for brief comparison, we conduct the test using features from all five bands on SEEDIV following previous literature settings. Not surprisingly, despite numerical value presenting a similar tendency as subject-dependent experiments in the view of all three analysis aspects, all accuracy suffered a great decrease. Our method achieves the best performance in SEEDIV and comparable results in the SEED datasets, which verifies the generalization of CU-GCN with subject-independent EEG emotion recognition. R2G-STNN leveraged a bidirectional long short term memory (BiLSTM) to learn the region to global spatial-temporal information. BiHDM proposed a four-directed RNN based on two spatial orientations to obtain the discrepancy information between two separate brain regions and used a domain discriminator to generate the domain-invariant feature. RGNN eliminates the individual invariant by introducing a similar domain adversarial training pattern. V-IAG was believed to promote cross-subject performance by designing a more reasonable adjacency matrix that contains an instance adaptive branch and a variational branch to learn the deterministic graphs and an uncertain graph. All these methods solve the subject-independent problem by designing a data-driven node connection graph from both regional and global space. It indicates that the key point of emotion recognition should lie in the precise combination of EEG channels.

| Method | SEED | SEEDIV |
| proposed | 87.10 / 05.44 | 74.50 / 07.88 |
| - eGCN GCN(2) | 83.82 / 07.33 | 72.13 / 09.41 |
| - eGCN SGC(2) | 83.43 / 07.18 | 72.59 / 10.26 |
| - Dist adjacency matrix | 85.66 / 06.73 | 71.37 / 09.01 |
| - Coh adjacency matrix | 85.10 / 07.13 | 72.35 / 08.20 |
| - Random adjacency matrix | 85.29 / 07.03 | 71.93 / 08.77 |
| - w/o Data-aug | 85.47 / 05.82 | 72.61 / 08.50 |
| Method | Layers () | |||
| 2 | 4 | 6 | 8 | |
| vGCN | 77.85 / 10.18 | 76.12 / 10.33 | 71.00 / 12.53 | 65.96 / 09.51 |
| SGC | 76.11 / 11.92 | 75.48 / 11.72 | 70.32 / 11.02 | 63.58 / 15.58 |
| CU-GCN | 84.12 / 05.72 | 84.58 / 05.33 | 85.71 / 05.53 | 84.66 / 05.98 |
4.3 Ablation Studies and Discussions
We conducted ablation studies to analyze and discuss the components of our CU-GCN model and their impact on subject-independent emotion recognition.
4.3.1 Graph Neural Network Performance
GCN-based methods from Table 1, 2, 3, including DGCNN, RGNN, and V-IAG, have demonstrated superior performance in EEG-based emotion recognition tasks compared to other approaches. DGCNN pioneered the utilization of two-layer vanilla GCN to process EEG signals by leveraging graph structure. Building upon this, RGNN further emphasized the importance of node aggregation in graph structure learning and employed a two-layer Spectral Graph Convolution (SGC) as the backbone. However, both vanilla GCN and SGC suffer from the over-smoothing problem, which arises as the network depth increases, leading to the loss of local information. V-IAG employed an eight-layer GCN architecture that preserved features from local to global regions by aggregating the outputs of each layer for the final decision.
In light of our previous theoretical analysis, our enhanced GCN (eGCN) is designed to address the over-smoothing problem while enhancing spectral information. In this subsection, we perform ablation studies by replacing eGCN with SGC and GCN to validate our hypothesis. Table 4 presents the results, where ”eGCN GCN(2)” indicates the replacement of eGCN with a two-layer GCN, and similarly for SGC. As shown in Table 4, it is evident that eGCN achieves significantly better results than the common benchmark methods.
Furthermore, we conduct additional experiments by varying the number of layers ( corresponding to the number of aggregated filters in CU-GCN). The results in Table 5 consistently demonstrate that our method outperforms others, with the best performance achieved when , equivalent to six layers. These findings indicate that eGCN effectively mitigates the over-smoothing problem as the network depth increases. Notably, the aggregation of information from six-hops neighborhoods performs optimally, potentially due to ensuring the global connection between two hemisphere brain regions, as the relative node distance in a 2D squared matrix is nine. Overall, these results highlight the superior ability of CU-GCN to aggregate information over larger neighborhoods compared to other methods.
4.3.2 Comparison Between Graph Structures
To compare the effectiveness of our uncertainty-guided edge predictor (EP) with commonly used graph construction approaches, we trained CU-GCN for subject-independent emotion recognition on the SEED and SEEDIV datasets. The second part of Table 5 presents the performance of CU-GCN with and without EPM using different adjacency matrices: distance-based (Dist), coherence-based (Coh), and random adjacency matrices. We observed that the inclusion of EP consistently yielded better results compared to other methods. Interestingly, traditional graph construction methods did not exhibit significant differences, suggesting that EEG signals in emotion recognition possess unique characteristics. Our method offers several distinct advantages: (a) It can be applied even when the physical locations of electrodes are unknown, providing flexibility in practical scenarios. (b) It captures dynamic brain connectivity patterns instead of relying solely on spatial sensor information, which is particularly desirable for emotion recognition tasks. (c) It enables adaptive selection of spectral features in EEG, facilitating precise categorization.
4.3.3 What Is The Effect of Concrete Bernoulli Distribution?
In our study, we conducted an investigation into the impact of using a learnable Bernoulli prior distribution compared to a constant edge dropout method. The learnable Bernoulli success rate in our CU-GCN model is adaptively optimized during training. The results presented in Table 6 provide compelling evidence for the effectiveness and necessity of this approach, as CU-GCN with the learnable Bernoulli prior consistently outperforms the constant value method in terms of classification accuracy. Moreover, it is worth noting that even without the learnable Bernoulli prior, our CU-GCN approach still achieves competitive performance, often surpassing the results obtained by state-of-the-art methods. This highlights the robustness and effectiveness of CU-GCN in capturing important graph structure information and achieving accurate emotion classification, even in the absence of the learnable prior distribution. Overall, these findings emphasize the significance of incorporating the learnable Bernoulli prior distribution in CU-GCN, as it contributes to improved classification accuracy and enhances the model’s ability to leverage graph structure for emotion recognition tasks.
| p | 0.3 | 0.5 | 0.7 | 0.9 | Adaptive |
| Accuracy (%) | 85.11 | 85.73 | 85.92 | 85.64 | 87.10 |
4.3.4 Is the Graph Data mixup Method Effective?
In our CU-GCN framework, we employ the graph mixup data augmentation technique to enhance the probability confidence and facilitate the learning process in the presence of noisy labels. We conducted experiments to evaluate the effectiveness of this approach, and the results are presented in Table 4. The findings indicate that training with graph mixup leads to an improvement of 0.20.3% in performance compared to training with the original dataset alone. Furthermore, the confusion matrices depicted in Figure 4 for the SEED and SEEDIV datasets demonstrate the substantial enhancement achieved by our data augmentation methods in addressing the challenges posed by noisy labels.
5 Conclusion
In summary, our proposed method, which combines uncertainty-guided graph modeling and spectral-enhanced message aggregation, along with a noisy label learning approach, has achieved significant advancements in EEG-based emotion recognition. We have established new state-of-the-art performance in both subject-dependent and subject-independent emotion classification tasks using two publicly available datasets. Our method demonstrates improved robustness and generalization capabilities. Notably, we have observed that instance adaptive graph learning methods yield more accurate recognition of emotional states compared to simply considering channel mutual relationships. Moreover, our extensive visualization experiments provide valuable support for distributionist theories in brain neuroscience. Looking ahead, our study opens up exciting possibilities for applying graph-based representations in multi-modal emotion recognition applications, as our methods are not limited to EEG alone.
Acknowledgments
This research was funded by the National Natural Science Foundation of China (62171123, 62001105, 62211530112, and 62071241), the China Postdoctoral Science Foundation (2023M730585), the National Key Research and Development Program of China (2022YFC2405600), the Natural Science Foundation of Jiangsu Province (BK20192004), the Jiangsu Funding Program for Excellent Postdoctoral Talent (2023ZB812) and the Postgraduate Research & Practice Innovation Program of Jiangsu Province (KYCX20 0088).
References
References
- [1] J. T. Cacioppo, G. G. Berntson, J. T. Larsen, K. M. Poehlmann, T. A. Ito et al., “The psychophysiology of emotion,” Handbook of emotions, vol. 2, no. 01, p. 2000, 2000.
- [2] M. Ullsperger, A. G. Fischer, R. Nigbur, and T. Endrass, “Neural mechanisms and temporal dynamics of performance monitoring,” Trends in Cognitive Sciences, vol. 18, no. 5, pp. 259–267, 2014.
- [3] N. Naseer and K.-S. Hong, “fnirs-based brain-computer interfaces: a review,” Frontiers in Human Neuroscience, vol. 9, p. 3, 2015.
- [4] W.-L. Zheng and B.-L. Lu, “Investigating critical frequency bands and channels for eeg-based emotion recognition with deep neural networks,” IEEE Transactions on Autonomous Mental Development, vol. 7, no. 3, pp. 162–175, 2015.
- [5] W.-L. Zheng, W. Liu, Y. Lu, B.-L. Lu, and A. Cichocki, “Emotionmeter: A multimodal framework for recognizing human emotions,” IEEE Transactions on Cybernetics, vol. 49, no. 3, pp. 1110–1122, 2018.
- [6] T. Zhang, W. Zheng, Z. Cui, Y. Zong, and Y. Li, “Spatial–temporal recurrent neural network for emotion recognition,” IEEE transactions on cybernetics, vol. 49, no. 3, pp. 839–847, 2018.
- [7] X. Zhang, J. Liu, J. Shen, S. Li, K. Hou, B. Hu, J. Gao, and T. Zhang, “Emotion recognition from multimodal physiological signals using a regularized deep fusion of kernel machine,” IEEE transactions on cybernetics, vol. 51, no. 9, pp. 4386–4399, 2020.
- [8] Z. Jia, Y. Lin, X. Cai, H. Chen, H. Gou, and J. Wang, “Sst-emotionnet: Spatial-spectral-temporal based attention 3d dense network for eeg emotion recognition,” in Proceedings of the 28th ACM International Conference on Multimedia (ACM MM), 2020, pp. 2909–2917.
- [9] J. C. Britton, K. L. Phan, S. F. Taylor, R. C. Welsh, K. C. Berridge, and I. Liberzon, “Neural correlates of social and nonsocial emotions: An fmri study,” Neuroimage, vol. 31, no. 1, pp. 397–409, 2006.
- [10] T. Song, W. Zheng, P. Song, and Z. Cui, “Eeg emotion recognition using dynamical graph convolutional neural networks,” IEEE Transactions on Affective Computing, vol. 11, no. 3, pp. 532–541, 2018.
- [11] P. Zhong, D. Wang, and C. Miao, “Eeg-based emotion recognition using regularized graph neural networks,” IEEE Transactions on Affective Computing, 2020.
- [12] Q. Li, Z. Han, and X.-M. Wu, “Deeper insights into graph convolutional networks for semi-supervised learning,” in Thirty-Second AAAI Conference on Artificial Intelligence, 2018.
- [13] N. Srivastava, G. Hinton, A. Krizhevsky, I. Sutskever, and R. Salakhutdinov, “Dropout: a simple way to prevent neural networks from overfitting,” The Journal of Machine Learning Research, vol. 15, no. 1, pp. 1929–1958, 2014.
- [14] Y. Rong, W. Huang, T. Xu, and J. Huang, “Dropedge: Towards deep graph convolutional networks on node classification,” in International Conference on Learning Representations (ICLR), 2020.
- [15] L. Chen, L. Wu, R. Hong, K. Zhang, and M. Wang, “Revisiting graph based collaborative filtering: A linear residual graph convolutional network approach,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, no. 01, 2020, pp. 27–34.
- [16] A. Demir, T. Koike-Akino, Y. Wang, M. Haruna, and D. Erdogmus, “Eeg-gnn: Graph neural networks for classification of electroencephalogram (eeg) signals,” in 2021 43rd Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC). IEEE, 2021, pp. 1061–1067.
- [17] S. Tang, J. Dunnmon, K. K. Saab, X. Zhang, Q. Huang, F. Dubost, D. Rubin, and C. Lee-Messer, “Self-supervised graph neural networks for improved electroencephalographic seizure analysis,” in International Conference on Learning Representations (ICLR), 2021.
- [18] J. LeDoux, “Rethinking the emotional brain,” Neuron, vol. 73, no. 4, pp. 653–676, 2012.
- [19] M. Palmiero and L. Piccardi, “Frontal eeg asymmetry of mood: A mini-review,” Frontiers in Behavioral Neuroscience, vol. 11, p. 224, 2017.
- [20] T. Song, S. Liu, W. Zheng, Y. Zong, Z. Cui, Y. Li, and X. Zhou, “Variational instance-adaptive graph for eeg emotion recognition,” IEEE Transactions on Affective Computing, 2021.
- [21] C. Tang, D. Wang, A.-H. Tan, and C. Miao, “Eeg-based emotion recognition via fast and robust feature smoothing,” in International Conference on Brain Informatics. Springer, 2017, pp. 83–92.
- [22] Z. Lan, O. Sourina, L. Wang, and Y. Liu, “Real-time eeg-based emotion monitoring using stable features,” The Visual Computer, vol. 32, no. 3, pp. 347–358, 2016.
- [23] J. K. Olofsson, S. Nordin, H. Sequeira, and J. Polich, “Affective picture processing: an integrative review of erp findings,” Biological Psychology, vol. 77, no. 3, pp. 247–265, 2008.
- [24] Y.-P. Lin, C.-H. Wang, T.-P. Jung, T.-L. Wu, S.-K. Jeng, J.-R. Duann, and J.-H. Chen, “Eeg-based emotion recognition in music listening,” IEEE Transactions on Biomedical Engineering, vol. 57, no. 7, pp. 1798–1806, 2010.
- [25] Y.-J. Liu, M. Yu, G. Zhao, J. Song, Y. Ge, and Y. Shi, “Real-time movie-induced discrete emotion recognition from eeg signals,” IEEE Transactions on Affective Computing, vol. 9, no. 4, pp. 550–562, 2017.
- [26] M. M. Sorkhabi, “Emotion detection from eeg signals with continuous wavelet analyzing,” Am. J. Comput. Res. Repos, vol. 2, no. 4, pp. 66–70, 2014.
- [27] T. Van Gelder, “The dynamical hypothesis in cognitive science,” Behavioral and Brain Sciences, vol. 21, no. 5, pp. 615–628, 1998.
- [28] P. Li, C. Liu, K. Li, D. Zheng, C. Liu, and Y. Hou, “Assessing the complexity of short-term heartbeat interval series by distribution entropy,” Medical Biological Engineering Computing, vol. 53, no. 1, pp. 77–87, 2015.
- [29] S. Paul, A. Mazumder, P. Ghosh, D. Tibarewala, and G. Vimalarani, “Eeg based emotion recognition system using mfdfa as feature extractor,” in 2015 International Conference on Robotics, Automation, Control and Embedded Systems (RACE). IEEE, 2015, pp. 1–5.
- [30] N. A. Jones and N. A. Fox, “Electroencephalogram asymmetry during emotionally evocative films and its relation to positive and negative affectivity,” Brain and Cognition, vol. 20, no. 2, pp. 280–299, 1992.
- [31] L.-C. Shi, Y.-Y. Jiao, and B.-L. Lu, “Differential entropy feature for eeg-based vigilance estimation,” in 2013 35th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC). IEEE, 2013, pp. 6627–6630.
- [32] W. Tao, C. Li, R. Song, J. Cheng, Y. Liu, F. Wan, and X. Chen, “Eeg-based emotion recognition via channel-wise attention and self attention,” IEEE Transactions on Affective Computing, 2020.
- [33] Y. Li, L. Wang, W. Zheng, Y. Zong, L. Qi, Z. Cui, T. Zhang, and T. Song, “A novel bi-hemispheric discrepancy model for eeg emotion recognition,” IEEE Transactions on Cognitive and Developmental Systems, vol. 13, no. 2, pp. 354–367, 2021.
- [34] J. B. Estrach, W. Zaremba, A. Szlam, and Y. LeCun, “Spectral networks and deep locally connected networks on graphs,” in International Conference on Learning Representations (ICLR), vol. 2014, 2014.
- [35] M. Defferrard, X. Bresson, and P. Vandergheynst, “Convolutional neural networks on graphs with fast localized spectral filtering,” Advances in Neural Information Processing Systems (NeurIPS), vol. 29, 2016.
- [36] M. Niepert, M. Ahmed, and K. Kutzkov, “Learning convolutional neural networks for graphs,” in International Conference on Machine Learning (ICML). PMLR, 2016, pp. 2014–2023.
- [37] W. Hamilton, Z. Ying, and J. Leskovec, “Inductive representation learning on large graphs,” Advances in Neural Information Processing Systems (NeurIPS), vol. 30, 2017.
- [38] J. Gasteiger, A. Bojchevski, and S. Günnemann, “Predict then propagate: Graph neural networks meet personalized pagerank,” in International Conference on Learning Representations (ICLR), 2019.
- [39] Y. Li, Y. Liu, Y.-Z. Guo, X.-F. Liao, B. Hu, and T. Yu, “Spatio-temporal-spectral hierarchical graph convolutional network with semisupervised active learning for patient-specific seizure prediction,” IEEE transactions on cybernetics, vol. 52, no. 11, pp. 12 189–12 204, 2021.
- [40] M. Abdar, F. Pourpanah, S. Hussain, D. Rezazadegan, L. Liu, M. Ghavamzadeh, P. Fieguth, X. Cao, A. Khosravi, U. R. Acharya et al., “A review of uncertainty quantification in deep learning: Techniques, applications and challenges,” Information Fusion, vol. 76, pp. 243–297, 2021.
- [41] C. Gao, J. Zhu, F. Zhang, Z. Wang, and X. Li, “A novel representation learning for dynamic graphs based on graph convolutional networks,” IEEE Transactions on Cybernetics, 2022.
- [42] Y. Zhang, S. Pal, M. Coates, and D. Ustebay, “Bayesian graph convolutional neural networks for semi-supervised classification,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 33, no. 01, 2019, pp. 5829–5836.
- [43] S. Munikoti, D. Agarwal, L. Das, and B. Natarajan, “A general framework for quantifying aleatoric and epistemic uncertainty in graph neural networks,” arXiv preprint arXiv:2205.09968, 2022.
- [44] D. P. Kingma, T. Salimans, and M. Welling, “Variational dropout and the local reparameterization trick,” Advances in Neural Information Processing Systems (NeurIPS), vol. 28, 2015.
- [45] Y. Gal and Z. Ghahramani, “Dropout as a bayesian approximation: Representing model uncertainty in deep learning,” in International Conference on Machine Learning (ICML). PMLR, 2016, pp. 1050–1059.
- [46] A. Hasanzadeh, E. Hajiramezanali, S. Boluki, M. Zhou, N. Duffield, K. Narayanan, and X. Qian, “Bayesian graph neural networks with adaptive connection sampling,” in International Conference on Machine Learning (ICML). PMLR, 2020, pp. 4094–4104.
- [47] B. Feng, Y. Wang, and Y. Ding, “Uag: Uncertainty-aware attention graph neural network for defending adversarial attacks,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 35, no. 8, 2021, pp. 7404–7412.
- [48] F. R. Chung and F. C. Graham, Spectral graph theory. American Mathematical Soc., 1997, vol. 92.
- [49] B. Xu, H. Shen, Q. Cao, Y. Qiu, and X. Cheng, “Graph wavelet neural network,” in International Conference on Learning Representations (ICLR), 2019.
- [50] X. Zheng, B. Zhou, J. Gao, Y. G. Wang, P. Lió, M. Li, and G. Montúfar, “How framelets enhance graph neural networks,” arXiv preprint arXiv:2102.06986, 2021.
- [51] T. N. Kipf and M. Welling, “Semi-supervised classification with graph convolutional networks,” International Conference on Learning Representation (ICLR), 2017.
- [52] R. J. Williams, “Simple statistical gradient-following algorithms for connectionist reinforcement learning,” Machine Learning, vol. 8, no. 3, pp. 229–256, 1992.
- [53] D. P. Kingma and M. Welling, “Auto-encoding variational bayes,” arXiv preprint arXiv:1312.6114, 2013.
- [54] M. Titsias and M. Lázaro-Gredilla, “Doubly stochastic variational bayes for non-conjugate inference,” in International Conference on Machine Learning (ICML). PMLR, 2014, pp. 1971–1979.
- [55] P. Li, I. Chien, and O. Milenkovic, “Optimizing generalized pagerank methods for seed-expansion community detection,” Advances in Neural Information Processing Systems, vol. 32, 2019.
- [56] E. Chien, J. Peng, P. Li, and O. Milenkovic, “Adaptive universal generalized pagerank graph neural network,” in International Conference on Learning Representations (ICLR), 2020.
- [57] F. Wu, A. Souza, T. Zhang, C. Fifty, T. Yu, and K. Weinberger, “Simplifying graph convolutional networks,” in International Conference on Machine Learning (ICML). PMLR, 2019, pp. 6861–6871.
- [58] H. Zhang, M. Cisse, Y. N. Dauphin, and D. Lopez-Paz, “mixup: Beyond empirical risk minimization,” in International Conference on Learning Representations (ICLR), 2018.
- [59] Y. Wang, W. Wang, Y. Liang, Y. Cai, and B. Hooi, “Mixup for node and graph classification,” in Proceedings of the Web Conference 2021, 2021, pp. 3663–3674.
- [60] A. K. Gupta and S. Nadarajah, Handbook of beta distribution and its applications. CRC press, 2004.
- [61] Y. Li, W. Zheng, Y. Zong, Z. Cui, T. Zhang, and X. Zhou, “A bi-hemisphere domain adversarial neural network model for eeg emotion recognition,” IEEE Transactions on Affective Computing, vol. 12, no. 2, pp. 494–504, 2018.
- [62] Y. Li, W. Zheng, L. Wang, Y. Zong, and Z. Cui, “From regional to global brain: A novel hierarchical spatial-temporal neural network model for eeg emotion recognition,” IEEE Transactions on Affective Computing, vol. 13, no. 2, pp. 568–578, 2022.
- [63] Y. Li, L. Wang, W. Zheng, Y. Zong, L. Qi, Z. Cui, T. Zhang, and T. Song, “A novel bi-hemispheric discrepancy model for eeg emotion recognition,” IEEE Transactions on Cognitive and Developmental Systems, vol. 13, no. 2, pp. 354–367, 2020.
- [64] T. Zhang, X. Wang, X. Xu, and C. P. Chen, “Gcb-net: Graph convolutional broad network and its application in emotion recognition,” IEEE Transactions on Affective Computing, vol. 13, no. 1, pp. 379–388, 2019.
- [65] X.-W. Wang, D. Nie, and B.-L. Lu, “Emotional state classification from eeg data using machine learning approach,” Neurocomputing, vol. 129, pp. 94–106, 2014.
- [66] Y. Ganin, E. Ustinova, H. Ajakan, P. Germain, H. Larochelle, F. Laviolette, M. Marchand, and V. Lempitsky, “Domain-adversarial training of neural networks,” The Journal of Machine Learning Research, vol. 17, no. 1, pp. 2096–2030, 2016.