Graphical and numerical diagnostic tools to assess multiple imputation models by posterior predictive checking
Abstract
Missing data are often dealt with multiple imputation. A crucial part of the multiple imputation process is selecting sensible models to generate plausible values for the incomplete data. A method based on posterior predictive checking is proposed to diagnose imputation models based on posterior predictive checking. To assess the congeniality of imputation models, the proposed diagnostic method compares the observed data with their replicates generated under corresponding posterior predictive distributions. If the imputation model is congenial with the substantive model, the observed data are expected to be located in the centre of corresponding predictive posterior distributions. Simulation and application are designed to investigate the proposed diagnostic method for parametric and semi-parametric imputation approaches, continuous and discrete incomplete variables, univariate and multivariate missingness patterns. The results show the validity of the proposed diagnostic method.
Keywords
missing data, multiple imputation, model checking, posterior predictive checking
1 Introduction
Multiple imputation (MI) is a popular approach for the analysis of incomplete datasets. It involves generating several plausible imputed datasets and aggregating different results into a single inference. Missing cells are filled with synthetic data drawn from corresponding posterior predictive distributions. This procedure is repeated multiple times, resulting in several imputed datasets. The parameters of scientific interest are then estimated for each imputed dataset by complete-data analyses. Finally, different estimates are pooled into one inference using Rubin’s rule, which accounts for within and across imputation uncertainty Rubin (\APACyear1987).
The validity of post-imputation analyses relies on the congeniality of the imputation model and the analysis model (Meng, 1994; Xie & Meng, 2017; Bartlett& Hughes, 2020). If the imputation and analysis models are congenial and correctly specified, Rubin’s rules will give consistent estimates Rubin (\APACyear1987). Hence, a crucial part of the multiple imputation process is selecting sensible models to generate plausible values for the incomplete data. However, model selection is not a trivial process in practice since there can be a wide array of candidate models to check. Therefore, researchers should consider which variables, interaction terms, and nonlinear terms are included based on the scientific interest and data features.
Despite the popularity of multiple imputation, there are only a few imputation model diagnostic methodologies. One standard diagnostic method is to compare distributions of the observed with imputed data (Van Buuren, 2018; Abayomi et al., 2008). Plausible imputation models would generate imputed values that have a similar distribution to the observed data. Although missing at random (MAR) mechanisms would also induce the discrepancies between the observed and imputed data, any dramatic departures that the observed data features cannot explain are evidence of potential imputation model misspecification. Reliable interpretation of the observed and imputed data’s discrepancies could be derived from external knowledge about the incomplete variables and the missingness mechanisms (Abayomi et al., 2008).
The idea to evaluate the validity of scientific models with multiply imputed data is not new. Bondarenko and Raghunathan (2016) proposed an advanced diagnostic method to compare the distributions of the observed with imputed data conditional on the probability of missingness. Gelman et al. (1998) applied cross-validation to check the fit of a hierarchical Bayesian model in the study of 51 public opinion polls preceding the 1988 U.S. Presidential election. Gelman et al. (2005) also proposed to apply graphical posterior predictive inference on the test statistics for model checking with missing and latent data. If regression-based imputation approaches are involved, the conventional regression diagnostics, such as plots of residuals and outliers, are helpful (White et al., 2011). A comprehensive overview of model diagnostic in multiple imputation is available in Nguyen et al. (2017).
Posterior predictive checking (PPC) has been proposed as an alternative method for the imputation model diagnostic (Gelman et al., 2005; He and Zaslavsky, 2012; Nguyen et al., 2015). PPC is a Bayesian model checking approach that compares the replicated data drawn from the corresponding posterior predictive distribution to the observed data. If the model lacks fit, there could be a discrepancy between the replicated and observed data.
He & Zaslavsky (2012) and Nguyen et al. (2015) applied posterior predictive checking to assess the inadequacies of the joint imputation model with one or more test quantities relevant to the scientific interest. To evaluate the ‘usability’ of imputation models with respect to the test statistics, analysts compare the estimates for the complete data to their replicates. Comparisons of the complete data and its replicates ensure the calculation of test quantities with general missingness patterns. However, it also results in sensitivity to the amount of missingness.
This manuscript proposes and evaluates the implementation of posterior predictive checking for imputation techniques. The general idea is that if the imputation model is congenial to the substantive model, the expected value of the data (whether observed or missing) is in the centre of corresponding predictive posterior distributions. We compare the observed data to their posterior replicates generated under the imputation model and evaluate the posterior distributions of all observed data points. This distinguishes our approach from the posterior predictive checking of imputation models by applying target analyses. We demonstrate:
-
1.
that PPC can be generalised to variable-by-variable imputation techniques;
-
2.
that PPC can be used to identify the imputation model that conforms most to the true data generating model;
-
3.
that PPC can be used as a model evaluation technique to identify the better substantive analysis model;
-
4.
how to perform PPC with MICE in R on a real-life data set (Van Buuren and Groothuis-Oudshoorn, 2011);
-
5.
that this PPC approach is not sensitive to the amount of missing data.
The remainder of this manuscript is organised as follows. In section 2, we review the posterior predictive checking of the imputation model by applying the target analysis proposed by He & Zaslavsky (2012). In section 3, we provide an overview of the MICE package and the underlying imputation algorithm: fully conditional specification (FCS). We also further point out the necessity of extending the posterior predictive checking of the imputation model so that the diagnostics would apply to the MICE algorithm. In section 4, we evaluate the performance of the proposed diagnostic approach with simulation studies. In section 5, we show the results of simulation studies. In section 6, we apply the proposed diagnostic approach to the body mass index (BMI) data of Dutch adults. In section 7, we conclude with a discussion of our findings.
2 Posterior predictive checking (PPC)
2.1 Posterior predictive checking
Without incomplete variables, PPC compares the observed data with the replicated data which are simulated from the posterior predictive distribution, with parameter :
| (1) |
To detect the discrepancy between the model and the data, we define test quantities that connect the model diagnostics to the scientific interests and estimate them for both observed and replicated data. For example, if the substantive analysis is a regression analysis, the test quantities could be the regression coefficients. Misfits of the model with respect to the data could be summarised by the posterior predictive p-value, which is the probability that the replicated data are more extreme than the observed data, with respect to the selected test quantities Gelman \BOthers. (\APACyear2013):
| (2) |
where is the indicator function. An extreme p-value (close to 0 or 1) implies the suspicion on the fit of the model since a consistent discrepancy between test quantities and cannot be explained by the simulation variance.
Posterior predictive checking has been widely used for model diagnostics in applied Bayesian analysis (Gelman et al., 2013, chapter 6), and the posterior predictive distribution is usually calculated by simulation. Suppose we have draws of model parameters from its posterior distribution , we then generate a replicated data for every theta . The PPC compares test quantities based on observed data with the empirical predictive distribution of test quantities. The estimated posterior predictive p-value is the proportion of these N simulations for which . It is noticeable that PPC’s application for the imputation model diagnostic is not based on the hypothesis test perspective. Hence, there is no underlying assumed distribution for the posterior predictive p-value in this case. The posterior predictive p-value indicates whether the model would provide plausible inference based on the data with respect to the selected test quantities.
To perform multiple imputation model checking with PPC, we compare the completed data, the combination of the observed and imputed data, with its replications. Gelman et al. (2005) applied graphical PPC to visualise test quantities comparisons based on completed and replicated data. He & Zaslavsky (2012) and Nguyen et al. (2015) developed numerical posterior predictive checks as target analyses to the joint imputation model. He and Zaslavsky (2012) proposed two kinds of discrepancies, completed data discrepancy and expected completed-data discrepancy, and the approaches to calculate corresponding posterior predictive p-values. We briefly introduce these discrepancies and p-values for the completeness of PPC for MI models.
2.2 Complete data discrepancy
When there are incomplete variables, the hypothetically complete data consists of the observed data and the missing data (). To assess the completed-data discrepancy , we draw imputed values for incomplete variables and the replication of the complete data from their posterior predictive distribution:
| (3) |
To assess the model fit, we calculate the posterior predictive p value as :
| (4) |
The simulation process to estimate p-value proposed by He and Zaslavsky (2012) is:
-
1.
Simulate draws of from the corresponding posterior distribution
-
2.
For each , impute from and simulate the replicated data from
A , which is close to 0 or 1, implies the discrepancy between the model and the data with respect to the selected test quantities.
2.3 Expected complete data discrepancy
He and Zaslavsky (2012) noticed that the power of completed-data discrepancy is weakened because the variance of imputed data across complete data and replicated data increase the variance of the test quantities. He and Zaslavsky (2012) reduced the variance of completed-data discrepancy by calculating the expectation value of missing data for each model parameter draw. The modification of p-value would be:
| (5) |
where is the notation of the expected value.
Again, the nested simulation process to calculate the p-value is:
-
1.
Simulate draws of from the corresponding posterior distribution
-
2.
For each , impute from and simulate the replicated data from
-
3.
For each j-th replicate, calculate the mean discrepancy by setting and to missing and overimputing them with the same paramters over draws and . Calculate the difference : over draws and then average the difference for the j-th replicate :
-
4.
Calculate as the proportion of these estimates that are positive,
He and Zaslavsky (2012) evaluated whether the PPC could detect the uncongeniality of the imputation model. Nguyen et al. (2015) investigated the performance of PPC in other imputation model misspecification scenarios, such as ignoring the response variable and auxiliary variables or failing to transform skewed variables. The PPC approach proposed by He and Zaslavsky (2012) is based on the joint imputation model. The imputation model for diagnostic is a joint distribution for the observed data, and the test quantities depend on multiple variables and parameters.
3 MICE package
Fully conditional specification (FCS) is a popular approach for multiple imputation. It attempts to specify an imputation model for each incomplete variable conditional on all the other variables , with parameter . It generates imputations iteratively over all incomplete variables after an initial imputation, such as mean imputation or random draw from observed values. Let denote the observed and imputed values of variable at iteration and . Given the most recent imputations of the other incomplete variables at iteration , the algorithm of generating imputations for the incomplete variable consists of the following draws:
where is the prior distribution for the parameter of the imputation model . The FCS is an attractive imputation approach because of its flexibility in imputation model specification. It is known under different names: chained equations stochastic relaxation, variable-by-variable imputation, switching regression, sequential regressions, ordered pseudo-Gibbs sampler, partially incompatible MCMC, and iterated univariate imputation Van Buuren (\APACyear2007).
Multivariate Imputation by Chained Equations (MICE) is the name of software for imputing incomplete multivariate data by Fully Conditional Specification. It has developed into the de facto standard for imputation in R and is increasingly being adopted in Python (e.g., statsmodels (imputer function) & miceforest). The MICE package creates functions for three components of FCS: imputation, analysis, and pooling.
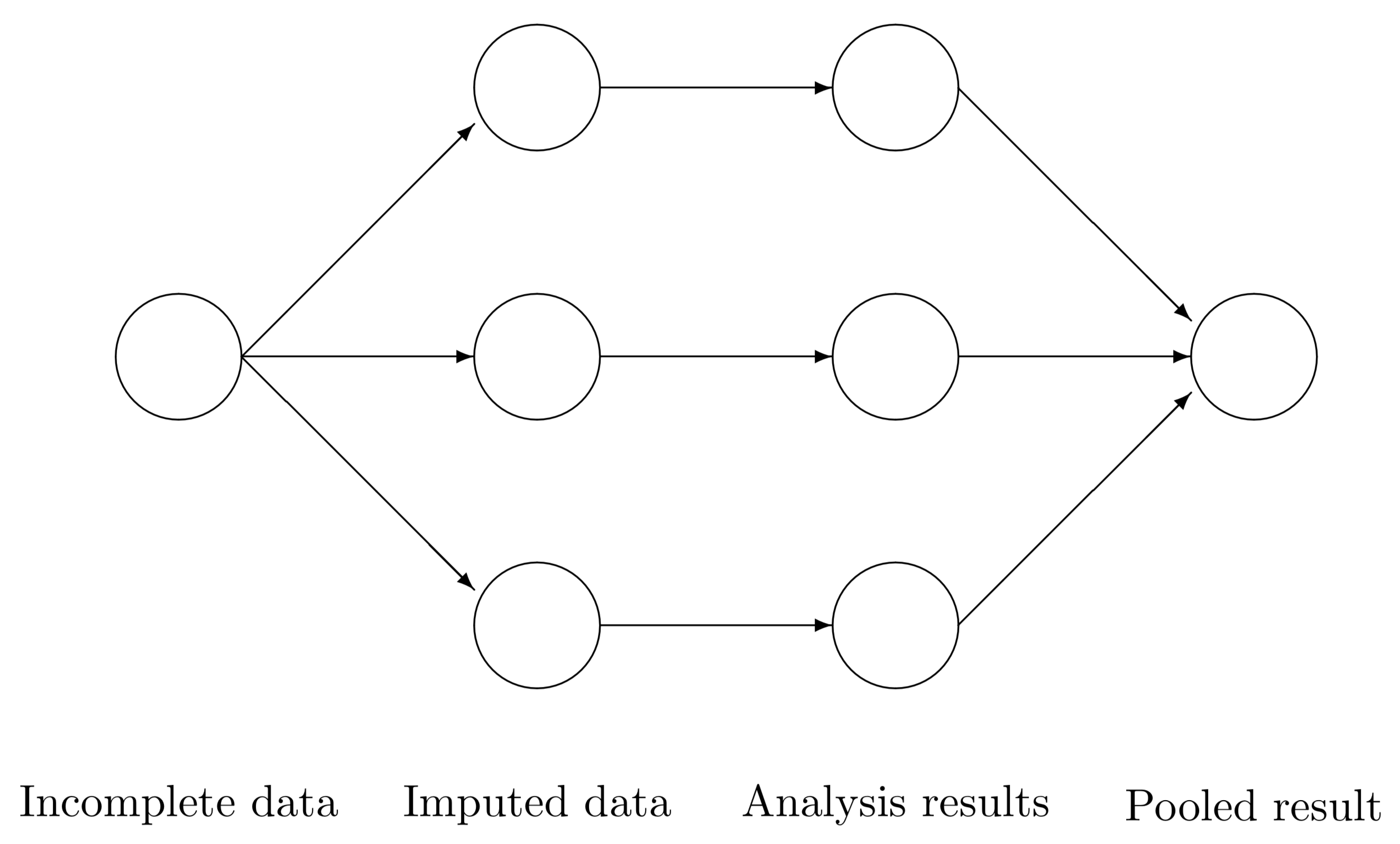
Figure 1 illustrates how MICE solves a missing data problem by generating 3 imputed datasets. Three imputed datasets are generated with function mice(). Analysis are performed on every imputed dataset by with() function and combined into a single inference with function pool(). The software stores the output of each step in a particular class: mids, mira and mipo. More details about MICE package can be found in van Buuren & Groothuis-Oudshoorn (2011).
Two features of the software motivate our research. First, the default imputation method for numerical missing data is predictive mean matching (PMM) (Little, 1988).
Ψ## age bmi hyp chl Ψ## "" "pmm" "pmm" "pmm"
It generates imputations for a missing cell from its nearest points. Predictive mean matching is a semi-parametric imputation approach that is proven to perform well in a wide range of scenarios (De Waal et al., 2011; Siddique and Belin, 2007; Su et al., 2011; Van Buuren, 2018; Van Buuren and Groothuis-Oudshoorn, 2011; Vink et al., 2014; Vink et al., 2015; White et al., 2011; Yu, Burton and Rivero-Arias, 2007). The attractive advantage of PMM is that the imputations fall consistently within the range of the observed sample space (Heeringa et al., 2001; Van Buuren, 2018; Vink et al., 2014; Vink et al., 2015; White et al., 2011; Yu et al., 2007). For instance, PMM prevents imputing negative values for data that are strictly non-negative. Second, mids only stores imputed datasets not the estimated parameters of the imputation models (Hoogland et al., 2020).
Based on the features of MICE package discussed above, it is necessary to investigate whether PPC could check the donor selection procedure of PMM and perform PPC based on the observed data itself instead of the target statistics. He and Zaslavsky (2012) briefly discussed the approach to checking imputation models for subsets of incomplete variables. However, they assumed that the imputations of the remaining variables (excluding the incomplete variables of interest in an assessment) are adequate. Therefore, we also evaluate the performance of PPC when relaxing this assumption in the application section.
The implementation of PPC in MICE (version 3.13.15) is straightforward. A new argument where is included in mice function which allows us to replace the observed data by randomly drawing values from the predictive posterior distribution Volker \BBA Vink (\APACyear2021). Here is an example to generate replications of the observed data.
The observed data pattern may not be conducive to calculating test quantities involving multiple incomplete variables. Hence, the complete data discrepancy discussed in section 2.2 calculates test quantities based on the imputed data. In such a case, the diagnosis is sensitive to the amount of missing data. However, we propose to calculate the discrepancy based on the observed data. The proposed method compares the observed data to the corresponding predictive posterior distributions generated over multiple imputations. If the imputed model fits the observed data, the observed data will appear like a random draw from the corresponding posterior distribution.
4 Simulation Study
We carried out a simulation study to investigate the performance of the proposed diagnostic approach. For illustrative purposes, the simulation study consisted of diagnostics under three analysis models: 1) a quadratic equation with an incomplete outcome 2) a quadratic equation with incomplete covariates, and 3) a generalised linear model with an incomplete binary outcome. The proposed diagnostic method natually could be applied to more generalized analysis models.
All these scenarios are designed with several factors including missingness proportion (30%, 50%, 80%), missingness mechanisms (a missing completely at random (MCAR) and a right-tailed missing at random (MARr) mechanism), nominal levels of the confidence interval (75%, 95%) and different imputation models. We evaluated whether the proposed diagnostic method could identify the congenial imputation model for continuous and discrete incomplete variables under the first and the third scenarios. We also investigated the performance of the proposed diagnostic method on the donor selection procedure of predictive mean matching under the second scenario. The sample size and the number of imputed datasets were set to be 1000 and 50 separately in all simulations.
We induced missingness with the ampute() function in the simulation study. Generally, ampute() is a convenient function in MICE package to generate missing data for simulation purposes (Schouten et al. 2018). We considered missing completely at random (MCAR) mechanism where the probability of missingness is equal for every cell as well as right-tailed missing at random (MARr) mechanism where higher values of covariates have a higher probability of being unobserved. In the algorithm of ampute() function, the probability of missingness is allocated with different logistic functions of the weighted sum score (wss), which is a linear combination of covariates correlated with the probability of missingness:
| (6) |
The weight is pre-specified to reflect the influence of the variable on the probability of missingness. For instance, if the formation of a weighted sum score is: , the probability of missingness is determined by both and with the equal effects. It is noticable that the influence of the weights is relative. will have the same effct as . More specifically, under MARr mechanism, candidates with higher values of weighted sum score have a higher probability of being unobserved when applying the ampute() function to generate missing data.
4.1 Quadratic equation with an incomplete outcome
In the first simulation study, we considered a partially observed variable and a fully observed variable . The data was generated from : , , where . The scientific model was indeed a quadratic model. Under MARr mechanism, the probability of missingness for the incomplete variable was completely determined by variable (). We considered two imputation models for the incomplete response : one is a linear regression of on , and the other is a quadratic regression of on . The linear regression impuation model is expected to be uncongenial and have a worse performance.
4.2 Quadratic equation with incomplete covariates
In the second simulation study, the response variable was generated from a normal distribution: , where and the covariate followed a standard normal distribution. In this simulation study, the response variable was completely observed while the covariate and the corresponding quadratic term were jointly missing for a fraction of the cases. There were no cases with missing cells on either or . Under MARr mechanism, the probability of missingness for jointly missingness of was completely determined by variable (). We compared two semi-parametric methods, predictive mean matching (PMM) and polynomial combination (PC) with a parametric method, the substantive model compatible fully conditional specification (SMC-FCS) (Vink and van Buuren, 2013, Bartlett et al., 2015, Cai and Vink, 2022). The PC and SMC-FCS methods are two accepted methods to impute linear regression with quadratic terms. The PC method is an extension of PMM but applies a different donor selection procedure. We expect that PC and SMC-FCS outperform PMM.
4.3 Generalized linear model for discrete variables
The final simulation study considered a partially observed binary and two complete covariates and . The model of scientific interest was : , where and . Under MARr mechanism, the weights of variables and in determining the probability of missingness for were set to be equal (). Since the logistic regression actually models the probability of assignment, we investigated the plot of deviance and calculated the sum of squared deviance divided by the sample size. There were two candidate models: a logistic regression of on and and a logistic regression of on only. The imputation model including both predictors and is expected to provide more sensible imputations.
5 Simulation results
In this section, we present the simulation results of the proposed diagnostic method under three different scenarios. We construct the nominal confidence interval for each observed data point based on the empirical distribution generated by the corresponding multiple imputed values. For numerical assessment, we estimated the rate of coverage by which the nominal confidence intervals covers the observed data points (COV), the mean of the distance between the observed data and the mean of corresponding predictive posterior distributions (Distance), and the average width of the confidence intervals (CIW). Since the incomplete variable in section 4.1 is the conditionally normal distribution and the incomplete variable in section 4.2 is the normal distribution, the mean of corresponding predictive posterior distributions is a valid representation of the centre of corresponding posterior distributions. In such a case, the selected quantities (COV, Distance and CIW) could be used to inspect the discrepancy between observed and replicated data. We expect the better-fitted imputation model to derive a smaller Distance and CIW.
We also provided graphical analyses with scatterplots, density plots, and distribution plots, which show observed values, upper and lower bounds of confidence intervals for each observed data point. The proposed diagnostic approach is performed on a variable-by-variable basis. Sometimes a single plot or summarised statistic is inadequate to arrive at a conclusion. Conducting PPC with various tools would provide a more comprehensive evaluation of the imputation model.
5.1 Quadratic equation with an incomplete outcome
Table 1 shows the results of the simulation study when the substantive model is a quadratic equation with an incomplete outcome. Since we only generated one incomplete dataset and repeated imputing it 50 times, all coverage rates were close to the pre-specified nominal level. However, when the imputation model was misspecified as a linear regression model, the average distance was larger than the average distance under the correct specification of the imputation model (linear regression with a quadratic term). It conforms to our intuitive idea that the data would be close to the centre of predictive posterior distributions if the model fits. The variance of the incomplete variable was set as 1, which implied that the width of 95% nominal confidence interval is approximate 3.92 (1.96 2) and the width of 75% nominal confidence interval is approximate 2.3 (1.15 2). When the imputation model was correctly specified, the estimated average width of the confidence interval was unbiased. However, the variance of was overestimated when the imputation model was linear.
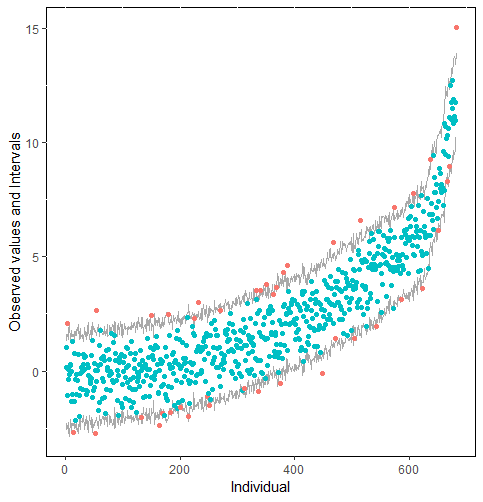
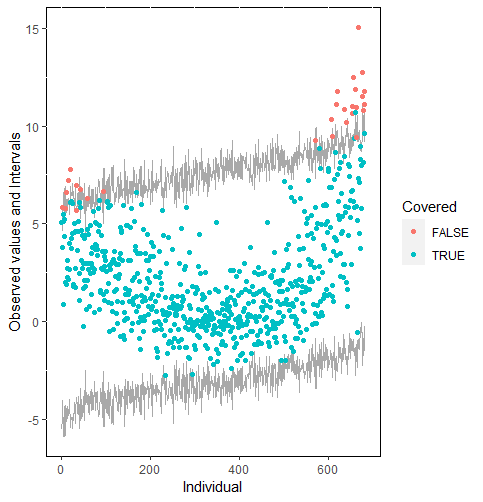
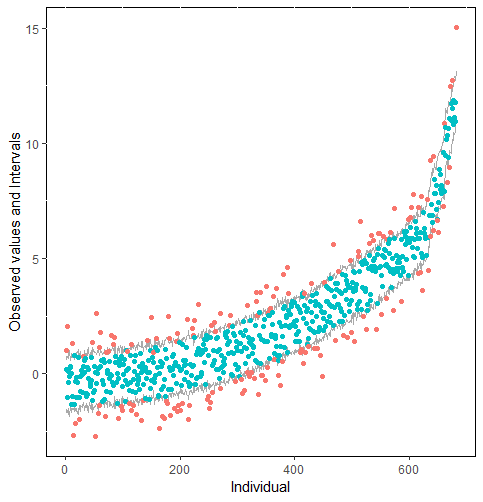
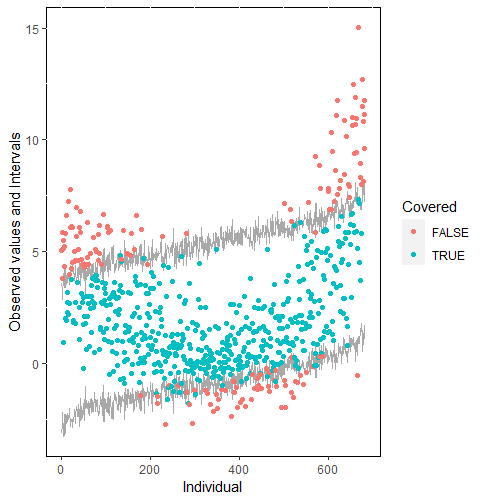
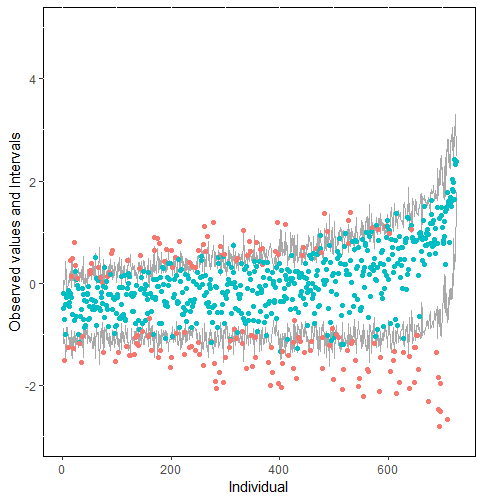
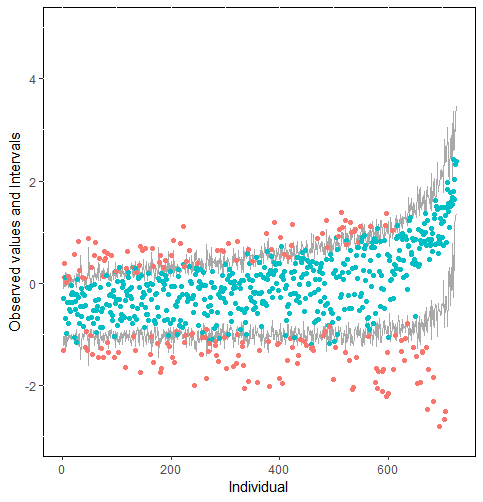
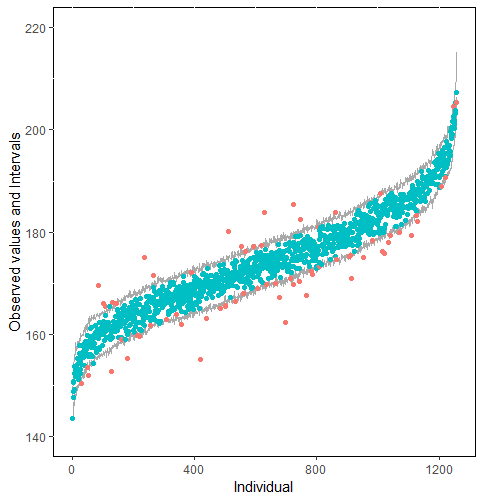
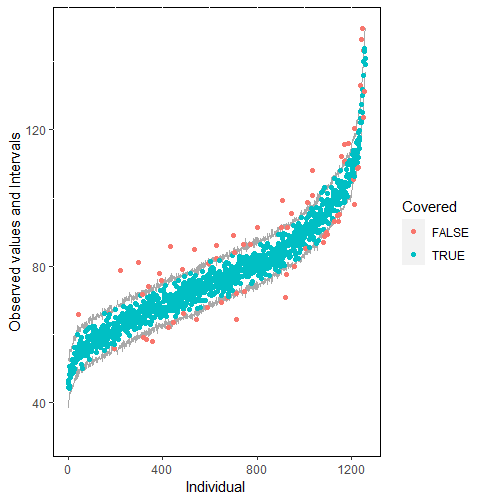
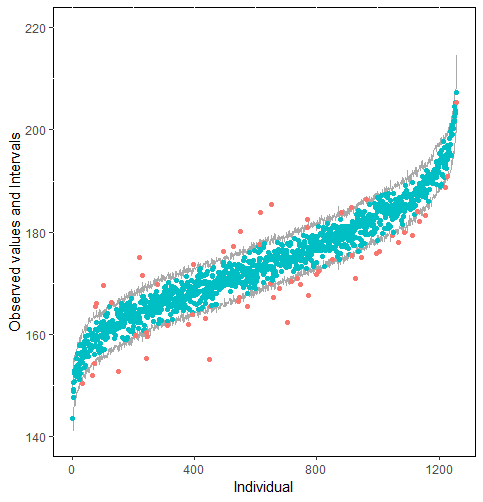
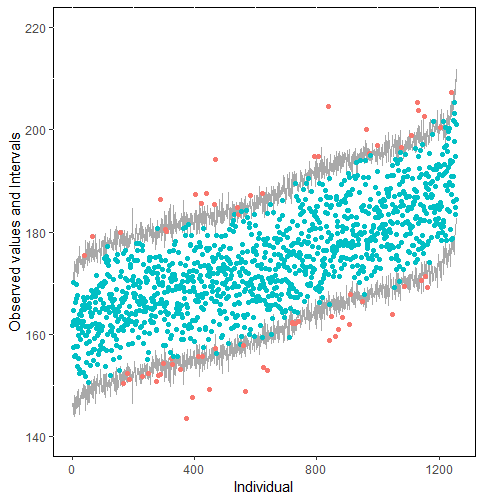
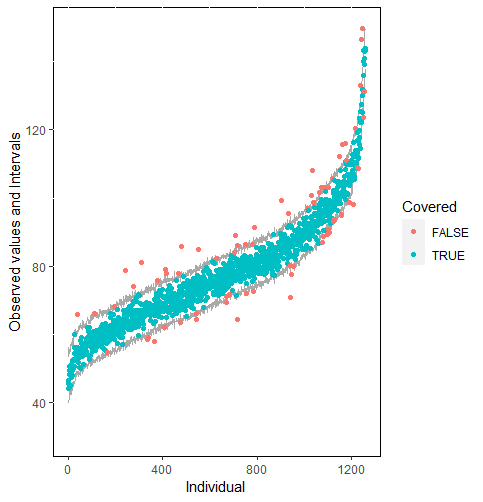
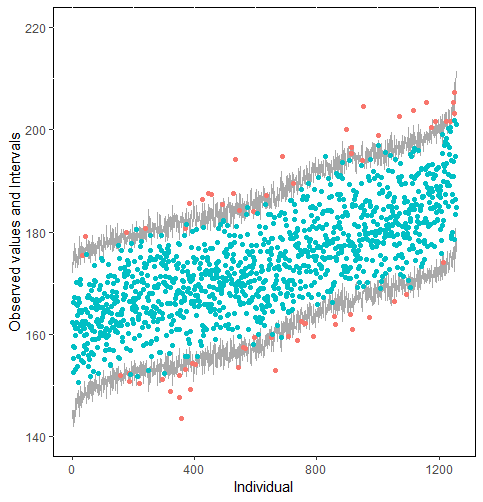
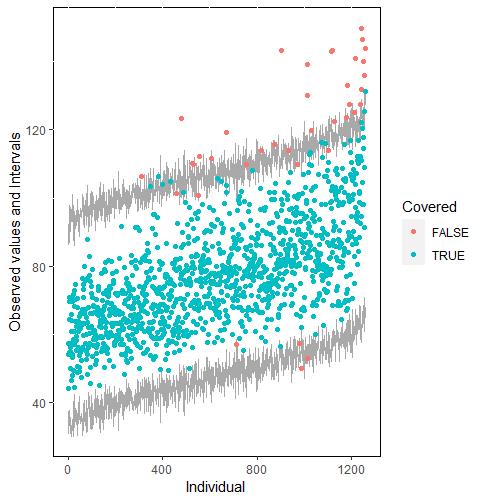
The same result could also be derived from the graphical analysis. Figure 2 shows distribution plots under the scenario of 30% missing cases and MARr missing mechanism. This plot provides upper and lower bounds of the posterior predictive distribution for all observed in ascending order of the mean of the posterior distribution. Blue points imply the corresponding observed value falls in the interval, while red points imply the corresponding observed value falls outside the interval.
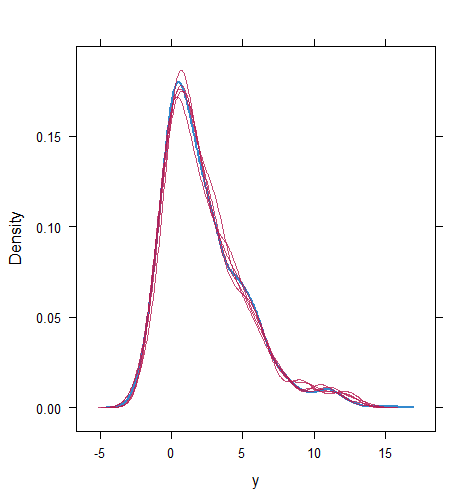
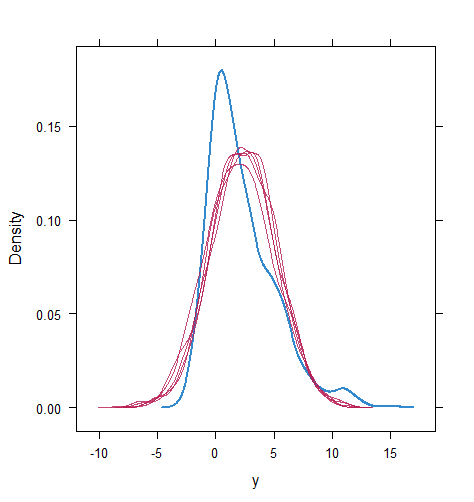
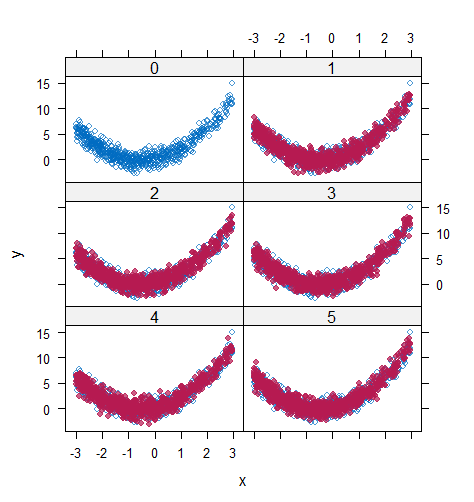
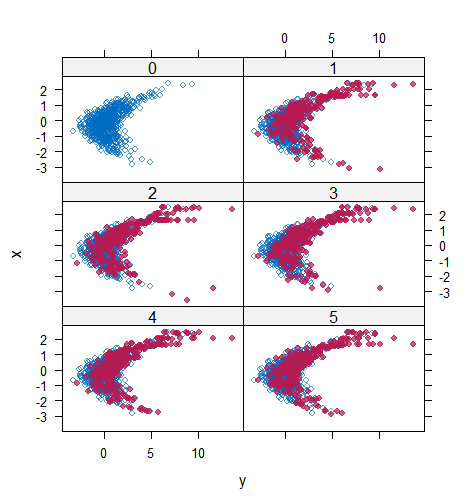
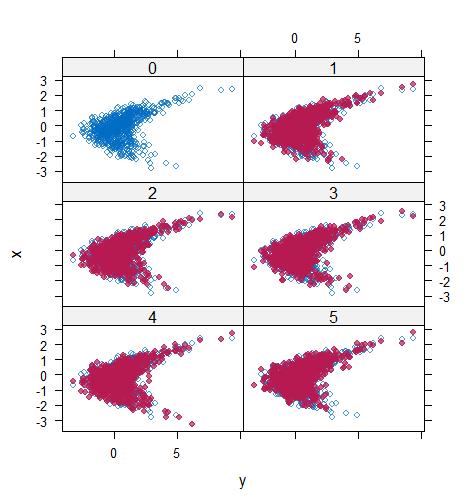
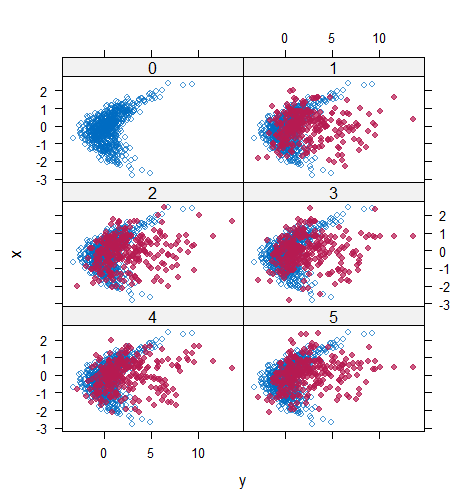
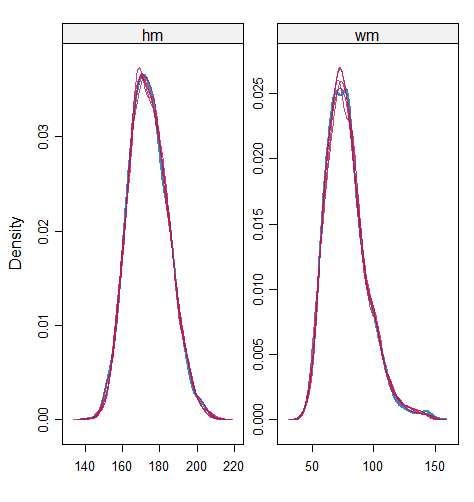
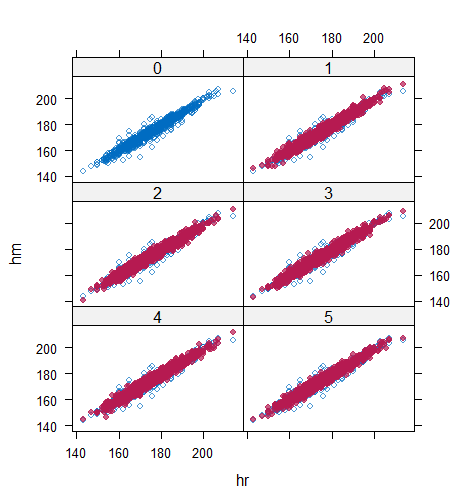
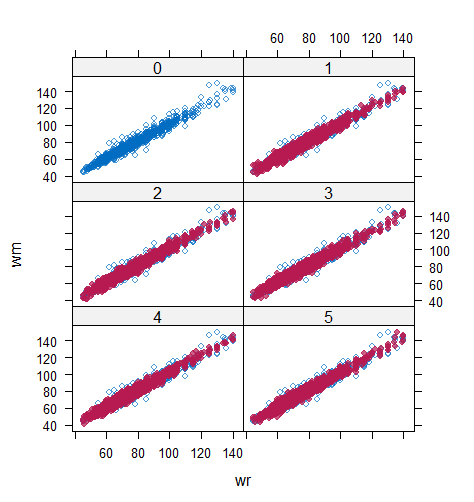
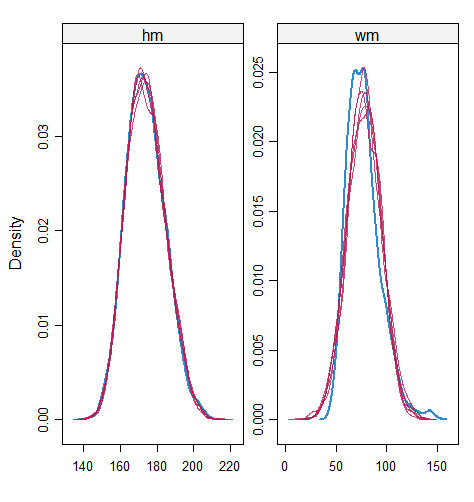
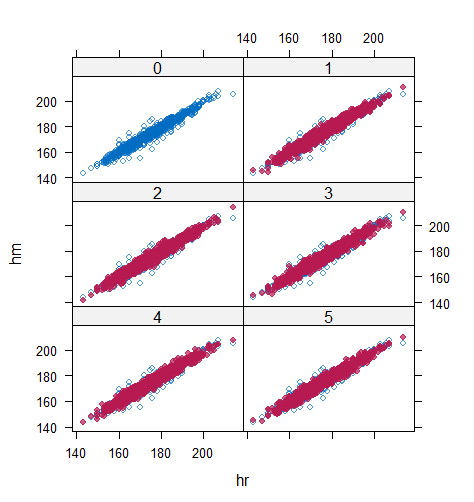
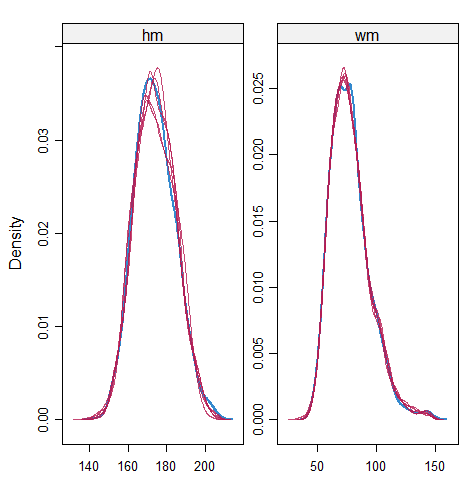
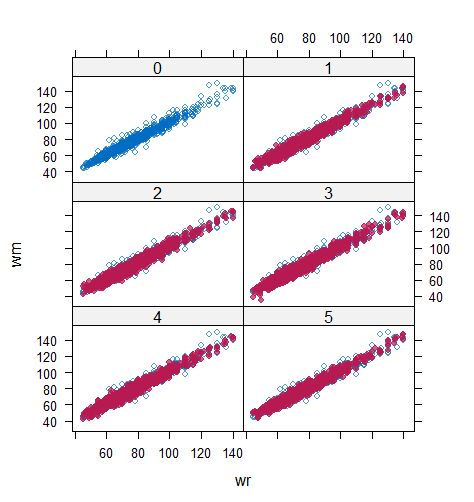
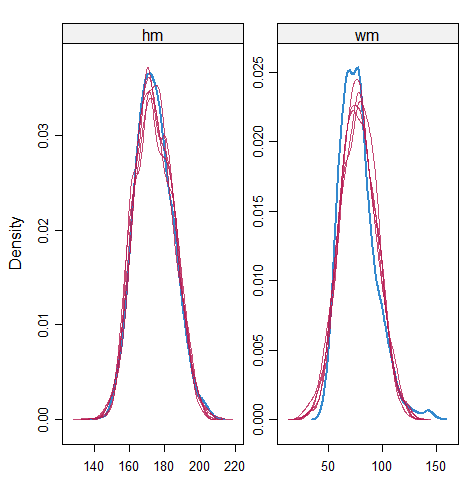
When the imputation model was correctly specified, the red points were randomly spread over the sample space without any patterns. However, when the imputation model was incorrectly specified as the linear regression model, the red points are shown at tails with lower and higher expectations of the posterior distribution. Moreover, the width of the intervals was generally narrower when the model was correct. The density plot and the scatter plot of the observed and replicated data generated with function densityplot() and xyplot() in MICE also show the evidence that the quadratic regression is preferable than the linear model (see figure 3). The scatter plot of the quadratic regression imputation model shows that replicated data overlapped the observed data. The density plot shows that the replicated data shared the same distribution as the observed data. This evidence illustrates the congeniality of the quadratic regression imputation model. However, the linear regression model performed worse than the quadratic regression model. First, the replicated data did not cover the observed data in two extreme regions in the scatter plot. Second, the empirical density of the replicated data and observed data were different.
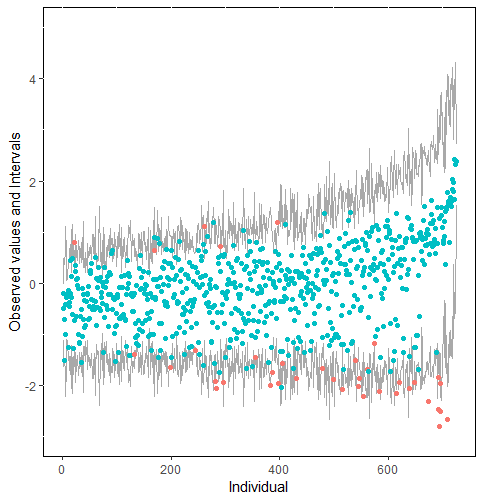
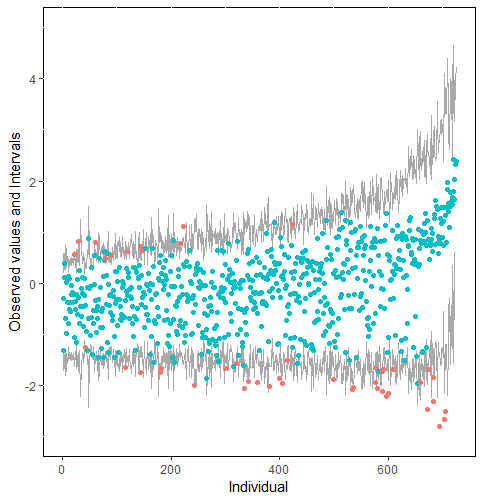
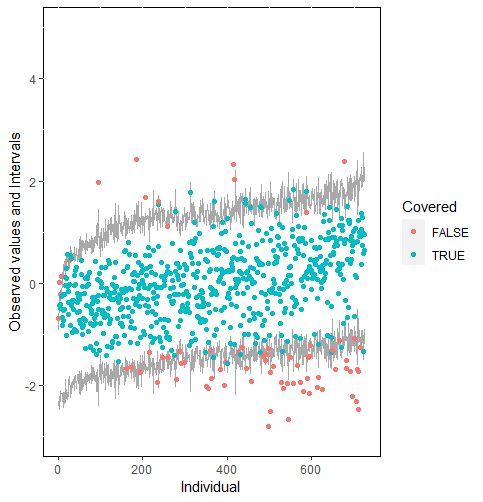
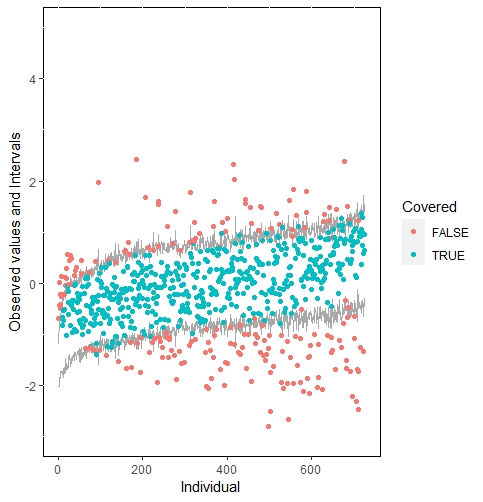
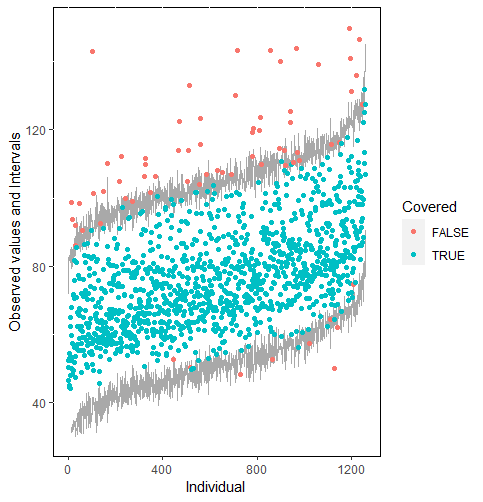
Furthermore, our proposed PPC approach for imputation models is robust against the different percentages of missing cases, missingness mechanisms, and the confidence interval’s nominal levels. The nominal level of the confidence interval is determined by the extent to which we could undertake the outliers when the imputation model is not congenial with the data generating process. For instance, there were more outliers in the plot of means and 75% confidence intervals than the plot of mean and 95% confidence intervals. (See figure 4).
5.2 Quadratic equation with incomplete covariates
Tables 2 and 3 show the result of the simulation for the quadratic equation with incomplete covariates. Based on the numerical results, the performance of these three methods, PC, SMC-FCS, and PMM, was the same, despite the slightly reduced coverage rate of PMM. In fact, when the missingness mechanism is MCAR (to bypass the problem of the sparse observed region for PMM), PMM would also provide a valid inference of the regression parameters (see Table 4) (Vink & van Buuren, 2013).
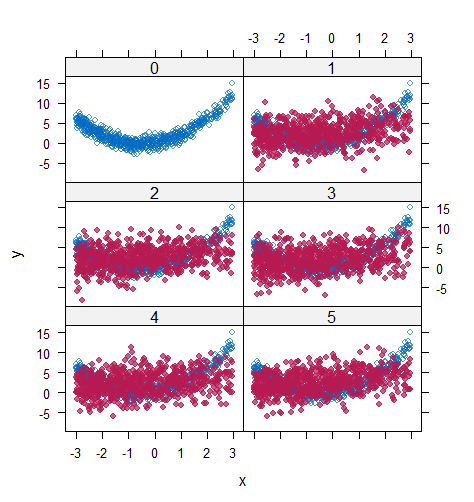
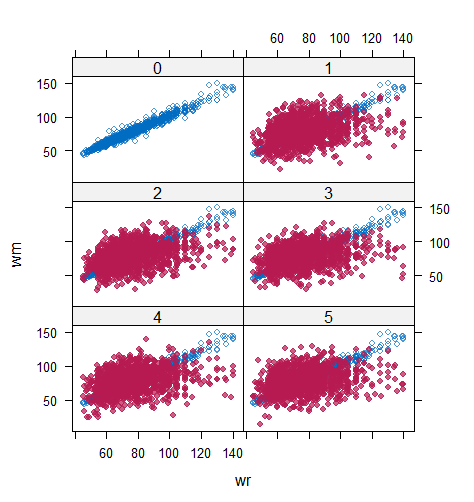
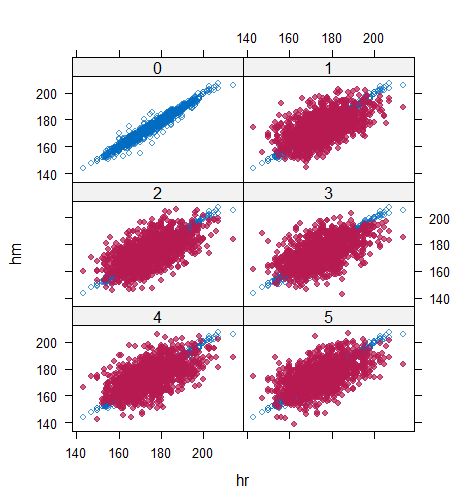
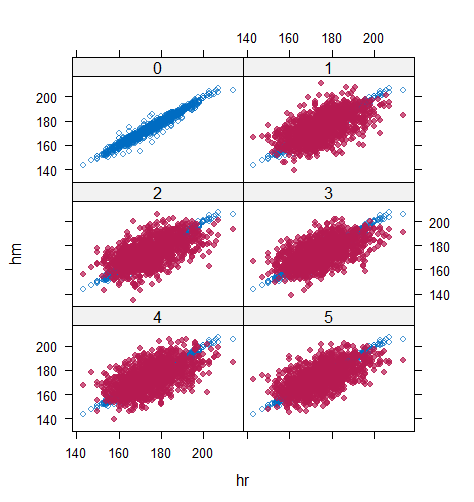
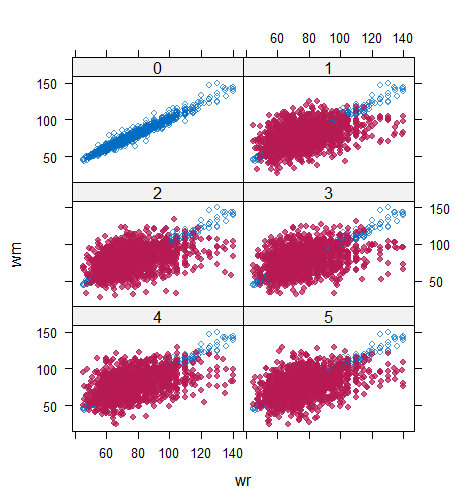
However, when it comes to graphical diagnostics, the misfit of PMM appears. The distribution plot (figure 5 and 6) show that PC and SMC-FCS generated the same posterior predictive distribution of the observed data. There were more outliers with a larger value of . It is sensible since the density function of based on is not monotone. Thus, it is unavoidable to impute the missing cell on the opposite arm of the parabolic function. Although in such a case, the imputed value was not the same as the true value, the replicated data still overlapped the observed data in the scatter plot (see Figures 7). The distribution plot of PMM with a 95% nominal level in Figure 5 did not show more outliers than these of PC and SMF-FCS. However, when the nominal level was set to 75%, more outliers appeared in the sub-plot of PMM (Figure 6). The reason is that there are more observed data closed to the centre in the plots of PC and SMC-FCS, which implies the superiority of PC and SMC-FCS. The scatter plot also shows the discrepancy between the distribution of the replicated and the observed data with respect to PMM (Figures 7). The result is robust against various percentages of missing cases and over the studied missing mechanisms.
5.3 Generalized linear model for discrete variables
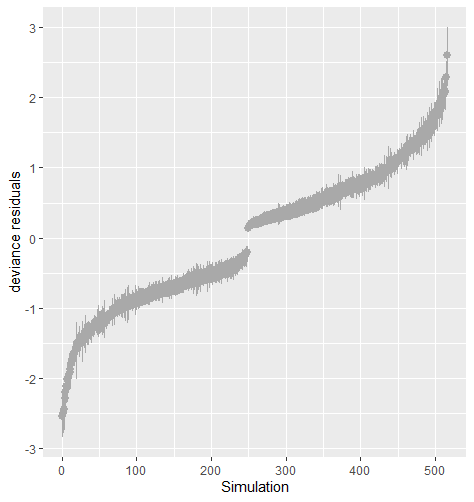
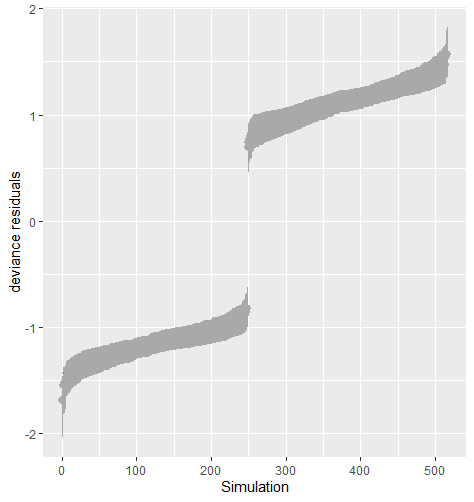
Table 5 shows the average sum of squared deviance for two different logistic regression models. The value of the average sum of squared deviance was smaller when the imputation model was correctly specified with logistic regression on both and . The result is robust against the percentage of missing cases and missingness mechanisms. Figure 8 shows that the residuals tend to zero when the imputation model fits the observed data better. The distribution of the observed data was more extreme than the empirical posterior distributions of replicated data generated under the logistic model with only variable .
6 Application
6.1 Background
We illustrate the application of the proposed PPC for multiple incomplete variables with the data from the body mass index (BMI) of the Dutch adults. This application is to study whether the proposed PPC works for a sequence of imputation models. More specifically, we aim to investigate whether the incorrect imputation model for one incomplete variable would disturb the proposed PPC for other variables. BMI is defined as the body weight divided by the square of the body height, which is broadly applied to categorise a person into underweight, normal, overweight, and obese. Since measuring a person’s weight and height is costly, an alternative is to ask people to report their weight and height. However, such self-report data is systematically biased. People are used to overestimating their height and underestimating their weight, leading to a lower self-report BMI compared with measured BMI (van Buuren, 2018, section 9.3). The goal of the study is to estimate unbiased BMI from the self-report data. We apply the multiple imputation approach to fill the unobserved measured weight and height.
The data we analyze is named selfreport in MICE package. The data consists of two components. One is the calibration dataset that contains data on 1257 Dutch individuals with both self-report and measured height and weight which was taken from Krul, Daanen, and Choi (2010). The original survey included 4459 adults from either Italy, Netherlands, or North America aged 18-65 years in 1999 or 2000. The second part is a survey dataset that includes data from 803 Dutch adults aged 18-75 years with only self-reported data. The survey data were collected in November 2007, either online or using paper-and-pencil methods (van Buuren 2018, section 9.3). Six variables are included in the application: age (years), sex (male or female), hm denoting measured height (cm), hr denoting self-reported height (cm), wm denoting measured weight (kg), and wr denoting self-reported weight (kg).
To fit the aim of this application study, we design two linear regression imputation models for hm: one includes all the other variables, and the other includes all the other variables except the variable hr. Similarly, there are two linear regression imputation models for wm: one includes all the other variables, and the other includes all the other variables except the variable wr. In such a case, we have four imputation strategies to evaluate:
-
1.
Case 1: include hr in the imputation model of hm and wr in the imputation model of wm.
-
2.
Case 2: include hr in the imputation model of hm and exclude wr from the imputation model of wm.
-
3.
Case 3: exclude hr from the imputation model of hm and include wr in the imputation model of wm.
-
4.
Case 4: exclude hr from the imputation model of hm and wr from the imputation model of wm.
Although it is evident that hr and wr are significant covariates for the imputation of hm and wm, we deliberately ignore these two variables in some cases to evaluate whether incorrect imputation model for hm (wm) influences PPC for wm (hm). If the target of analysis is BMI, one could apply passive imputation to include BMI in the imputation process (van Buuren 2018, section 6.4). In such a case, BMI is still not considered as the predictor of hm and hm because of linear dependencies.
6.2 Results
Table 6 shows that the best imputation model among these four is the one that includes both wr and hr. The average distance and the width of confidence intervals for the observed data were the smallest for both hm and wm. No matter the imputation model of hm was correctly specified, the linear regression imputation model for wm should be based on all the other variables. When fixing the imputation model for the hm (no matter including hr or not), the average distance and the average width of the confidence interval of hm derived under the linear model included hr was remarkably less than the result taken under the linear model excluded the covariate hr. The graphical results (Figure 9-12) show the same conclusion. When the linear regression imputation model for wm or hm was correctly specified, the imputed data overlapped the observed data in the scatter plot. The observed data would be closer to the centre of the confidence interval, and the width of confidence intervals was relatively small. However, the result of wr in case 3 was slightly larger than that in case 1. Similarly, the result of wr in case 4 was slightly larger than that in case 2. A similar result could be found in fixing the imputation model for the wm (no matter the imputation model includes wr or not). The average distance and the average confidence interval of wm derived under the linear model had wr was remarkably less than the result taken under the linear model excluded the covariate wr.
The findings imply that incorrect specification of the imputation models for other incomplete variables would influence the target variable for which we perform the PPC because densities of the imputed variables are different from the ‘true’ densities. However, we can still select the correct model for . Our application scenario is relatively simple: the linear model is sufficient to reflect the data generating process of incomplete variables. However, we do not rule out the possibility that under extreme and complicated cases, incorrect specification of the imputation models for other incomplete variables would prevent us from selecting the most suitable imputation model for the incomplete variable .
7 Discussion
The proposed imputation model diagnostic procedure based on PPC involves numerical assessment and graphical analysis. It is noteworthy that applying both numerical and graphical tools benefits a thorough understanding of model selection. For numerical assessment, the evidence of a fitted imputation model is less deviation between the observed value and the expectation of corresponding predictive posterior distribution and narrower width of confidence intervals of predictive posterior distributions for the observed data. For graphical analysis, we provide the distribution plot, the scatter plot and the density plot. The more suitable imputation models are, the more similar the replicated data to the observed data in the density and scatter plots. The distribution plot shows posterior distributions of all observed data. It allows the researcher to identify the regions where the imputation model misfits. Furthermore, the graphical analysis could be applied to evaluate whether a specific imputation model is adequate to provide plausible imputations.
The simulation study demonstrates that the proposed imputation model diagnostic procedure works on continuous and discrete variables under parametric and hot-deck multiple imputation approaches. For continuous variables, the distribution plots can be used to derive information to improve the imputation model. For example, we may identify that although the imputation model is incorrect, it would provide valid imputations in the focused regions. In such a case, we could still apply the suboptimal imputation model. Moreover, we could also adjust the imputation model in the misfitted regions and develop a piecewise imputation model. The PPC for categorical data or ordered categorical data is limited, since the predictor of the imputation model is the probability of assignment rather than the observed data itself. We currently investigate residual deviance as the indicator to select the model for categorical data and ordered categorical data.
For hot-deck imputation approaches, what PPC diagnoses is the donor-selection procedure. As the result shown in section 5.2, selecting donors for the composition performed better than only solving for the incomplete variable . SMC-FCS was treated as the baseline in our simulation since it is proven as a reliable imputation method when the substantive model is known (Bartlett et al., 2015). The PC performs as well as the SMC-FCS which implies the donor selection process of PC reflects the data generating process in our simulation scenarios. However, based on the features of predictive mean matching, the appropriate donor selection does not ensure plausible imputations. Extra analysis of the observed data and the imputed data would then be necessary.
The application example shows that the PPC works on the multivariate incomplete datasets. When the imputed covariate deviates from the actual distribution because of the mis-specified imputation models, the imputation model for the predictor could also be selected by PPC. In our case study, the misspecification of one incomplete variable slightly influences the other incomplete variable’s numerical results. However, in more extreme situations, such as a large number of incomplete variables and more ridiculous imputation models for covariates, the result may be influenced seriously, so as to result in a sub-optimal model selection. Therefore, it is more reasonable to perform the numerical analysis of all incomplete variables and make the model selection for those variables with remarkably different results under different candidate imputation approaches first.
Existing PPC proposed by He and Zaslavsky (2012) and Gelman et al. (2005) measured the posterior predictive p-value to indicate the discrepancies of summarised statistics between the observed and replicated data. The close to 0 or 1 p-value implies the inadequacy of the imputation model with respect to the target quantities. The target quantities should be calculated with the completed data, which consists of the observed and the imputed data because it allows the researcher to calculate the target quantities requiring a complete data matrix. Both He and Zaslavsky (2012) and Nguyen et al. (2015) found that the existing PPC for multiple imputation model is sensitive to the percentage of missing cases. Since the imputed and replicated data are generated from the same posterior predictive distribution, evaluation becomes more difficult with an increasing proportion of missing data.
Unlike the existing PPC approach, the PPC discussed in the paper checks the imputation model for each incomplete variable under the FCS framework. We diagnose the distribution of the observed data so that the result would also be reliable with a large proportion of missing cases. The simulation study also shows that the proposed PPC works for different missingness mechanisms.
The PPC for multiple imputation models based on target analysis would be more informative for “one-goal” studies. The imputer is also the analyst with a specific scientific interest in such a case. The diagnosis procedure aims to select imputation models to produce imputations that could support the particular post-imputation analyses. However, the diagnostic method proposed in this paper is designed for “multiple-goals” studies. The imputer may not know the potential research on the imputed data. Our approach aims to select congenial imputation models to ensure that Rubin’s rule will provide a valid inference. The imputed data generated by selected imputation models could be used for more general downstream analysis and different scientific interests.
When the sample size is tremendous, it is better to choose some representative data to check the imputation model so that the scatter plot or the distribution plot would not be too crowded. A clustered procedure could be applied to gather the observed data with closed values and choose one subset in each cluster to check the model. Further investigation is necessary to set the rule to select the observed data when the sample size is too large.
References
- Abayomi \BOthers. (\APACyear2008) \APACinsertmetastarabayomi2008diagnostics{APACrefauthors}Abayomi, K., Gelman, A.\BCBL \BBA Levy, M. \APACrefYearMonthDay2008. \BBOQ\APACrefatitleDiagnostics for multivariate imputations Diagnostics for multivariate imputations.\BBCQ \APACjournalVolNumPagesJournal of the Royal Statistical Society: Series C (Applied Statistics)573273–291. \PrintBackRefs\CurrentBib
- Bartlett \BBA Hughes (\APACyear2020) \APACinsertmetastarbartlett2020bootstrap{APACrefauthors}Bartlett, J\BPBIW.\BCBT \BBA Hughes, R\BPBIA. \APACrefYearMonthDay2020. \BBOQ\APACrefatitleBootstrap inference for multiple imputation under uncongeniality and misspecification Bootstrap inference for multiple imputation under uncongeniality and misspecification.\BBCQ \APACjournalVolNumPagesStatistical methods in medical research29123533–3546. \PrintBackRefs\CurrentBib
- Bartlett \BOthers. (\APACyear2015) \APACinsertmetastarbartlett2015multiple{APACrefauthors}Bartlett, J\BPBIW., Seaman, S\BPBIR., White, I\BPBIR., Carpenter, J\BPBIR.\BCBL \BBA Initiative*, A\BPBID\BPBIN. \APACrefYearMonthDay2015. \BBOQ\APACrefatitleMultiple imputation of covariates by fully conditional specification: Accommodating the substantive model Multiple imputation of covariates by fully conditional specification: Accommodating the substantive model.\BBCQ \APACjournalVolNumPagesStatistical methods in medical research244462–487. \PrintBackRefs\CurrentBib
- Bondarenko \BBA Raghunathan (\APACyear2016) \APACinsertmetastarbondarenko2016graphical{APACrefauthors}Bondarenko, I.\BCBT \BBA Raghunathan, T. \APACrefYearMonthDay2016. \BBOQ\APACrefatitleGraphical and numerical diagnostic tools to assess suitability of multiple imputations and imputation models Graphical and numerical diagnostic tools to assess suitability of multiple imputations and imputation models.\BBCQ \APACjournalVolNumPagesStatistics in medicine35173007–3020. \PrintBackRefs\CurrentBib
- Cai \BBA Vink (\APACyear2022) \APACinsertmetastarcai2022note{APACrefauthors}Cai, M.\BCBT \BBA Vink, G. \APACrefYearMonthDay2022. \BBOQ\APACrefatitleA note on imputing squares via polynomial combination approach A note on imputing squares via polynomial combination approach.\BBCQ \APACjournalVolNumPagesComputational Statistics1–17. \PrintBackRefs\CurrentBib
- De Waal \BOthers. (\APACyear2011) \APACinsertmetastarde2011handbook{APACrefauthors}De Waal, T., Pannekoek, J.\BCBL \BBA Scholtus, S. \APACrefYear2011. \APACrefbtitleHandbook of statistical data editing and imputation Handbook of statistical data editing and imputation (\BVOL 563). \APACaddressPublisherJohn Wiley & Sons. \PrintBackRefs\CurrentBib
- Gelman \BOthers. (\APACyear2013) \APACinsertmetastargelman2013bayesian{APACrefauthors}Gelman, A., Carlin, J\BPBIB., Stern, H\BPBIS., Dunson, D\BPBIB., Vehtari, A.\BCBL \BBA Rubin, D\BPBIB. \APACrefYear2013. \APACrefbtitleBayesian data analysis Bayesian data analysis. \APACaddressPublisherCRC press. \PrintBackRefs\CurrentBib
- Gelman \BOthers. (\APACyear1998) \APACinsertmetastargelman1998not{APACrefauthors}Gelman, A., King, G.\BCBL \BBA Liu, C. \APACrefYearMonthDay1998. \BBOQ\APACrefatitleNot asked and not answered: Multiple imputation for multiple surveys Not asked and not answered: Multiple imputation for multiple surveys.\BBCQ \APACjournalVolNumPagesJournal of the American Statistical Association93443846–857. \PrintBackRefs\CurrentBib
- Gelman \BOthers. (\APACyear2005) \APACinsertmetastargelman2005multiple{APACrefauthors}Gelman, A., Van Mechelen, I., Verbeke, G., Heitjan, D\BPBIF.\BCBL \BBA Meulders, M. \APACrefYearMonthDay2005. \BBOQ\APACrefatitleMultiple imputation for model checking: completed-data plots with missing and latent data Multiple imputation for model checking: completed-data plots with missing and latent data.\BBCQ \APACjournalVolNumPagesBiometrics61174–85. \PrintBackRefs\CurrentBib
- He \BBA Zaslavsky (\APACyear2012) \APACinsertmetastarhe2012diagnosing{APACrefauthors}He, Y.\BCBT \BBA Zaslavsky, A\BPBIM. \APACrefYearMonthDay2012. \BBOQ\APACrefatitleDiagnosing imputation models by applying target analyses to posterior replicates of completed data Diagnosing imputation models by applying target analyses to posterior replicates of completed data.\BBCQ \APACjournalVolNumPagesStatistics in medicine3111–18. \PrintBackRefs\CurrentBib
- Heeringa (\APACyear2001) \APACinsertmetastarheeringa2001multivariate{APACrefauthors}Heeringa, S\BPBIG. \APACrefYearMonthDay2001. \BBOQ\APACrefatitleMultivariate imputation of coarsened survey data on household wealth. Multivariate imputation of coarsened survey data on household wealth.\BBCQ \PrintBackRefs\CurrentBib
- Hoogland \BOthers. (\APACyear2020) \APACinsertmetastarhoogland2020handling{APACrefauthors}Hoogland, J., van Barreveld, M., Debray, T\BPBIP., Reitsma, J\BPBIB., Verstraelen, T\BPBIE., Dijkgraaf, M\BPBIG.\BCBL \BBA Zwinderman, A\BPBIH. \APACrefYearMonthDay2020. \BBOQ\APACrefatitleHandling missing predictor values when validating and applying a prediction model to new patients Handling missing predictor values when validating and applying a prediction model to new patients.\BBCQ \APACjournalVolNumPagesStatistics in medicine39253591–3607. \PrintBackRefs\CurrentBib
- Krul \BOthers. (\APACyear2011) \APACinsertmetastarkrul2011self{APACrefauthors}Krul, A\BPBIJ., Daanen, H\BPBIA.\BCBL \BBA Choi, H. \APACrefYearMonthDay2011. \BBOQ\APACrefatitleSelf-reported and measured weight, height and body mass index (BMI) in Italy, the Netherlands and North America Self-reported and measured weight, height and body mass index (bmi) in italy, the netherlands and north america.\BBCQ \APACjournalVolNumPagesThe European Journal of Public Health214414–419. \PrintBackRefs\CurrentBib
- Little (\APACyear1988) \APACinsertmetastarLittle1988{APACrefauthors}Little, R\BPBIJ\BPBIA. \APACrefYearMonthDay1988jul. \BBOQ\APACrefatitleMissing-Data Adjustments in Large Surveys Missing-data adjustments in large surveys.\BBCQ \APACjournalVolNumPagesJournal of Business & Economic Statistics63287–296. {APACrefDOI} \doi10.1080/07350015.1988.10509663 \PrintBackRefs\CurrentBib
- Meng (\APACyear1994) \APACinsertmetastarmeng1994multiple{APACrefauthors}Meng, X\BHBIL. \APACrefYearMonthDay1994. \BBOQ\APACrefatitleMultiple-imputation inferences with uncongenial sources of input Multiple-imputation inferences with uncongenial sources of input.\BBCQ \APACjournalVolNumPagesStatistical Science538–558. \PrintBackRefs\CurrentBib
- Nguyen \BOthers. (\APACyear2017) \APACinsertmetastarnguyen2017model{APACrefauthors}Nguyen, C\BPBID., Carlin, J\BPBIB.\BCBL \BBA Lee, K\BPBIJ. \APACrefYearMonthDay2017. \BBOQ\APACrefatitleModel checking in multiple imputation: an overview and case study Model checking in multiple imputation: an overview and case study.\BBCQ \APACjournalVolNumPagesEmerging themes in epidemiology1418. \PrintBackRefs\CurrentBib
- Nguyen \BOthers. (\APACyear2015) \APACinsertmetastarnguyen2015posterior{APACrefauthors}Nguyen, C\BPBID., Lee, K\BPBIJ.\BCBL \BBA Carlin, J\BPBIB. \APACrefYearMonthDay2015. \BBOQ\APACrefatitlePosterior predictive checking of multiple imputation models Posterior predictive checking of multiple imputation models.\BBCQ \APACjournalVolNumPagesBiometrical Journal574676–694. \PrintBackRefs\CurrentBib
- Rubin (\APACyear1987) \APACinsertmetastarRubinD1987{APACrefauthors}Rubin, D\BPBIB. \APACrefYear1987. \APACrefbtitleMultiple Imputation for Nonresponse in Surveys Multiple imputation for nonresponse in surveys. \APACaddressPublisherNew YorkJohn Wiley and Sons. \PrintBackRefs\CurrentBib
- Schouten \BOthers. (\APACyear2018) \APACinsertmetastarSchouten2018{APACrefauthors}Schouten, R\BPBIM., Lugtig, P.\BCBL \BBA Vink, G. \APACrefYearMonthDay2018. \BBOQ\APACrefatitleGenerating missing values for simulation purposes: a multivariate amputation procedure Generating missing values for simulation purposes: a multivariate amputation procedure.\BBCQ \APACjournalVolNumPagesJournal of Statistical Computation and Simulation88152909–2930. \PrintBackRefs\CurrentBib
- Siddique \BBA Belin (\APACyear2008) \APACinsertmetastarsiddique2008multiple{APACrefauthors}Siddique, J.\BCBT \BBA Belin, T\BPBIR. \APACrefYearMonthDay2008. \BBOQ\APACrefatitleMultiple imputation using an iterative hot-deck with distance-based donor selection Multiple imputation using an iterative hot-deck with distance-based donor selection.\BBCQ \APACjournalVolNumPagesStatistics in medicine27183–102. \PrintBackRefs\CurrentBib
- Su \BOthers. (\APACyear2011) \APACinsertmetastarsu2011multiple{APACrefauthors}Su, Y\BHBIS., Gelman, A\BPBIE., Hill, J.\BCBL \BBA Yajima, M. \APACrefYearMonthDay2011. \BBOQ\APACrefatitleMultiple imputation with diagnostics (mi) in R: Opening windows into the black box Multiple imputation with diagnostics (mi) in r: Opening windows into the black box.\BBCQ \PrintBackRefs\CurrentBib
- Van Buuren (\APACyear2007) \APACinsertmetastarvan2007multiple{APACrefauthors}Van Buuren, S. \APACrefYearMonthDay2007. \BBOQ\APACrefatitleMultiple imputation of discrete and continuous data by fully conditional specification Multiple imputation of discrete and continuous data by fully conditional specification.\BBCQ \APACjournalVolNumPagesStatistical methods in medical research163219–242. \PrintBackRefs\CurrentBib
- van Buuren (\APACyear2018) \APACinsertmetastarBuuren2018{APACrefauthors}van Buuren, S. \APACrefYear2018. \APACrefbtitleFlexible Imputation of Missing Data, Second Edition Flexible imputation of missing data, second edition. \APACaddressPublisherChapman and Hall/CRC. \PrintBackRefs\CurrentBib
- Van Buuren \BBA Groothuis-Oudshoorn (\APACyear2011) \APACinsertmetastarvan2011mice{APACrefauthors}Van Buuren, S.\BCBT \BBA Groothuis-Oudshoorn, K. \APACrefYearMonthDay2011. \BBOQ\APACrefatitlemice: Multivariate imputation by chained equations in R mice: Multivariate imputation by chained equations in r.\BBCQ \APACjournalVolNumPagesJournal of statistical software4511–67. \PrintBackRefs\CurrentBib
- Vink \BOthers. (\APACyear2014) \APACinsertmetastarvink2014predictive{APACrefauthors}Vink, G., Frank, L\BPBIE., Pannekoek, J.\BCBL \BBA Van Buuren, S. \APACrefYearMonthDay2014. \BBOQ\APACrefatitlePredictive mean matching imputation of semicontinuous variables Predictive mean matching imputation of semicontinuous variables.\BBCQ \APACjournalVolNumPagesStatistica Neerlandica68161–90. \PrintBackRefs\CurrentBib
- Vink \BOthers. (\APACyear2015) \APACinsertmetastarvink2015partioned{APACrefauthors}Vink, G., Lazendic, G.\BCBL \BBA van Buuren, S. \APACrefYearMonthDay2015. \BBOQ\APACrefatitlePartioned predictive mean matching as a large data multilevel imputation technique. Partioned predictive mean matching as a large data multilevel imputation technique.\BBCQ \APACjournalVolNumPagesPsychological Test and Assessment Modeling574577–594. \PrintBackRefs\CurrentBib
- Vink \BBA van Buuren (\APACyear2013) \APACinsertmetastarVink2013{APACrefauthors}Vink, G.\BCBT \BBA van Buuren, S. \APACrefYearMonthDay2013sep. \BBOQ\APACrefatitleMultiple Imputation of Squared Terms Multiple imputation of squared terms.\BBCQ \APACjournalVolNumPagesSociological Methods & Research424598–607. {APACrefDOI} \doi10.1177/0049124113502943 \PrintBackRefs\CurrentBib
- Volker \BBA Vink (\APACyear2021) \APACinsertmetastarvolker2021anonymiced{APACrefauthors}Volker, T\BPBIB.\BCBT \BBA Vink, G. \APACrefYearMonthDay2021. \BBOQ\APACrefatitleAnonymiced Shareable Data: Using mice to Create and Analyze Multiply Imputed Synthetic Datasets Anonymiced shareable data: Using mice to create and analyze multiply imputed synthetic datasets.\BBCQ \APACjournalVolNumPagesPsych34703–716. \PrintBackRefs\CurrentBib
- White \BOthers. (\APACyear2011) \APACinsertmetastarwhite2011multiple{APACrefauthors}White, I\BPBIR., Royston, P.\BCBL \BBA Wood, A\BPBIM. \APACrefYearMonthDay2011. \BBOQ\APACrefatitleMultiple imputation using chained equations: issues and guidance for practice Multiple imputation using chained equations: issues and guidance for practice.\BBCQ \APACjournalVolNumPagesStatistics in medicine304377–399. \PrintBackRefs\CurrentBib
- Xie \BBA Meng (\APACyear2017) \APACinsertmetastarxie2017dissecting{APACrefauthors}Xie, X.\BCBT \BBA Meng, X\BHBIL. \APACrefYearMonthDay2017. \BBOQ\APACrefatitleDissecting multiple imputation from a multi-phase inference perspective: what happens when God’s, imputer’s and analyst’s models are uncongenial? Dissecting multiple imputation from a multi-phase inference perspective: what happens when god’s, imputer’s and analyst’s models are uncongenial?\BBCQ \APACjournalVolNumPagesStatistica Sinica1485–1545. \PrintBackRefs\CurrentBib
- Yu \BOthers. (\APACyear2007) \APACinsertmetastaryu2007evaluation{APACrefauthors}Yu, L\BHBIM., Burton, A.\BCBL \BBA Rivero-Arias, O. \APACrefYearMonthDay2007. \BBOQ\APACrefatitleEvaluation of software for multiple imputation of semi-continuous data Evaluation of software for multiple imputation of semi-continuous data.\BBCQ \APACjournalVolNumPagesStatistical Methods in Medical Research163243–258. \PrintBackRefs\CurrentBib
| COV | Average Distance | Average CIW | |||||||||||
| linear model | quadratic model | linear model | quadratic model | linear model | quadratic model | ||||||||
| 75%CI | 95%CI | 75%CI | 95%CI | 75%CI | 95%CI | 75%CI | 95%CI | 75%CI | 95%CI | 75%CI | 95%CI | ||
| missingness | |||||||||||||
| 30 | 0.76 | 0.96 | 0.75 | 0.93 | 2.41 | 2.41 | 0.79 | 0.79 | 6.64 | 11.32 | 2.27 | 3.87 | |
| MCAR | 50 | 0.72 | 0.96 | 0.76 | 0.94 | 2.44 | 2.44 | 0.77 | 0.77 | 6.61 | 11.27 | 2.25 | 3.83 |
| 80 | 0.77 | 0.95 | 0.78 | 0.94 | 2.25 | 2.25 | 0.87 | 0.87 | 6.53 | 11.13 | 2.51 | 4.28 | |
| 30 | 0.75 | 0.95 | 0.74 | 0.94 | 2.28 | 2.28 | 0.8 | 0.8 | 6.26 | 10.66 | 2.31 | 3.94 | |
| MARr | 50 | 0.76 | 0.95 | 0.73 | 0.95 | 2.21 | 2.21 | 0.81 | 0.81 | 6.3 | 10.73 | 2.3 | 3.91 |
| 80 | 0.8 | 0.96 | 0.77 | 0.92 | 1.8 | 1.8 | 0.83 | 0.83 | 5.43 | 9.25 | 2.38 | 4.05 | |
| COV | Average distance | Average CIW | ||||||||
| missingness | PC | SMC-FCS | PMM | PC | SMC-FCS | PMM | PC | SMC-FCS | PMM | |
| 30 | 0.94 | 0.94 | 0.91 | 0.62 | 0.62 | 0.68 | 3.02 | 3.1 | 3.03 | |
| MCAR | 50 | 0.94 | 0.93 | 0.9 | 0.61 | 0.61 | 0.67 | 3.03 | 3.06 | 2.97 |
| 80 | 0.96 | 0.94 | 0.91 | 0.61 | 0.64 | 0.65 | 3.06 | 3.14 | 3 | |
| 30 | 0.94 | 0.94 | 0.89 | 0.59 | 0.59 | 0.64 | 2.93 | 2.84 | 2.84 | |
| MARr | 50 | 0.93 | 0.94 | 0.89 | 0.57 | 0.58 | 0.62 | 2.74 | 2.7 | 2.68 |
| 80 | 0.93 | 0.97 | 0.93 | 0.56 | 0.56 | 0.61 | 2.61 | 2.64 | 2.69 | |
| COV | Average distance | Average CIW | ||||||||
| missingness | PC | SMC-FCS | PMM | PC | SMC-FCS | PMM | PC | SMC-FCS | PMM | |
| 30 | 0.76 | 0.75 | 0.7 | 0.62 | 0.62 | 0.68 | 1.77 | 1.82 | 1.78 | |
| MCAR | 50 | 0.75 | 0.75 | 0.73 | 0.61 | 0.61 | 0.67 | 1.78 | 1.8 | 1.74 |
| 80 | 0.78 | 0.76 | 0.75 | 0.61 | 0.64 | 0.65 | 1.8 | 1.84 | 1.76 | |
| 30 | 0.76 | 0.74 | 0.71 | 0.59 | 0.59 | 0.64 | 1.72 | 1.66 | 1.67 | |
| MARr | 50 | 0.74 | 0.72 | 0.69 | 0.57 | 0.58 | 0.62 | 1.61 | 1.58 | 1.57 |
| 80 | 0.75 | 0.73 | 0.7 | 0.56 | 0.56 | 0.61 | 1.53 | 1.55 | 1.58 | |
| True value | Estimates value | Coverage rate | |
| 1 | 1.008 | 0.934 | |
| 1 | 1 | 0.958 |
| mean of residual deviance | |||
| missingness | with x | without x | |
| 30 | 0.83 | 1.25 | |
| MCAR | 50 | 0.85 | 1.27 |
| 80 | 0.95 | 1.3 | |
| 30 | 0.9 | 1.34 | |
| MARr | 50 | 0.94 | 1.35 |
| 80 | 0.98 | 1.28 | |
| hm | wm | |||||
|---|---|---|---|---|---|---|
| cov | average distance | average CIW | cov | average distance | average CIW | |
| strategy 1 | 0.95 | 1.57 | 8.27 | 0.95 | 2.28 | 12.46 |
| strategy 2 | 0.95 | 1.65 | 8.89 | 0.94 | 10.9 | 54.38 |
| strategy 3 | 0.95 | 5.58 | 26.89 | 0.94 | 2.35 | 12.83 |
| strategy 4 | 0.95 | 5.56 | 27.88 | 0.97 | 9.84 | 59.57 |
 |
 |
 |
| (a) | (b) | (c) |
 |
 |
| (d) | (e) |
 |
 |
 |
| (a) | (b) | (c) |
 |
 |
| (d) | (e) |
 |
 |
 |
| (a) | (b) | (c) |
 |
 |
| (d) | (e) |
 |
 |
 |
| (a) | (b) | (c) |
 |
 |
| (d) | (e) |