Group Spike and Slab Variational Bayes
Abstract
We introduce Group Spike-and-slab Variational Bayes (GSVB), a scalable method for group sparse regression. A fast co-ordinate ascent variational inference (CAVI) algorithm is developed for several common model families including Gaussian, Binomial and Poisson. Theoretical guarantees for our proposed approach are provided by deriving contraction rates for the variational posterior in grouped linear regression. Through extensive numerical studies, we demonstrate that GSVB provides state-of-the-art performance, offering a computationally inexpensive substitute to MCMC, whilst performing comparably or better than existing MAP methods. Additionally, we analyze three real world datasets wherein we highlight the practical utility of our method, demonstrating that GSVB provides parsimonious models with excellent predictive performance, variable selection and uncertainty quantification.
Keywords: High-dimensional regression, Group sparsity, Generalized Linear Models, Sparse priors, Bayesian Methods
1 Introduction
Group structures arise in various applications, such as genetics (Wang et al., 2007; Breheny and Huang, 2009), imaging (Lee and Cao, 2021), multi-factor analysis of variance (Meier et al., 2008), non-parametric regression (Huang et al., 2010), and multi-task learning, among others. In these settings, -dimensional feature vectors, , for observations can be partitioned into groups of features. Formally this means that we can construct sub-vectors, for , where the groups are disjoint sets of indices satisfying . Typically, these group structures are known beforehand, for example in genetics where biological pathways (gene sets) are known, or they are constructed artificially, for example, through a basis expansion in non-parametric additive models.
In the regression setting incorporating these group structures is crucial, as disregarding them can result in sub-optimal models (Huang and Zhang, 2010; Lounici et al., 2011). In this manuscript, we focus on the general linear regression model (GLM) where, for each observation , the response, can be modelled by
| (1) |
where represents the link function, denotes the model coefficient vector with . Beyond incorporating the group structure, it is often of practical importance to identify the groups of features that are associated with the response. This holds particularly true when there are a large number of them. To address this, various methods have been proposed over the years, with one of the most popular being the group LASSO (Yuan and Lin, 2006), which applies an norm to groups of coefficients. Following Yuan and Lin (2006) there have been numerous extensions, including the group SCAD (Wang et al., 2007), the group LASSO for logistic regression (Meier et al., 2008), the group bridge (Huang et al., 2009), group LASSO with overlapping groups (Jacob et al., 2009), and the sparse group LASSO (Breheny and Huang, 2009; Simon et al., 2013), among others (see Huang et al. (2012) for a detailed review of frequentist methods).
In a similar vein, Bayesian group selection methods have arisen. The earliest of which being the Bayesian group LASSO (Raman et al., 2009; Kyung et al., 2010), which uses a multivariate double exponential distribution prior to impose shrinkage on groups of coefficients. Notably, the maximum a posteriori (MAP) estimate under this prior coincides with the estimate under the group LASSO. Other methods include Bayesian sparse group selection (Xu and Ghosh, 2015; Chen et al., 2016) and the group spike-and-slab LASSO (Bai et al., 2020) which approach the problem via stochastic search variable selection (Mitchell and Beauchamp, 1988; Chipman, 1996). Formally, these methods utilize a group spike-and-slab prior, a mixture distribution of a multivariate Dirac mass on zero and a continuous distribution over , where is the size of the th group. Such priors have been shown to work excellently for variable selection as they are able to set coefficients exactly to zero, avoiding the use of shrinkage to enforce sparsity. For a comprehensive review see Lai and Chen (2021) and Jreich et al. (2022).
However, a serious drawback of these methods is that most use Markov Chain Monte Carlo (MCMC) to sample from the posterior (Raman et al., 2009; Xu and Ghosh, 2015; Chen et al., 2016). In general, MCMC approaches are known to be computationally expensive when there are a large number of variables, and within the group setting they can result in poor mixing when group sizes are large (Chen et al., 2016). To circumvent these issues, some authors proposed computing MAP estimates (Kyung et al., 2010; Bai et al., 2020), by relaxing the form of the prior, replacing the multivariate Dirac mass with a continuous distribution concentrated at zero (Ročková and George, 2018). Although these algorithms are fast to compute, they come at the sacrifice of interpretability, as posterior inclusion probabilities no longer guarantee the coefficient is zero but rather concentrated at zero. Beyond this, these algorithms only return a point estimate for and therefore do not provide uncertainty quantification – a task at the heart of Bayesian inference.
To bridge the gap between scalability and uncertainty quantification several authors have turned to variational inference (VI). An approach to inference wherein the posterior distribution is approximated by a tractable family of distributions known as the variational family (see Zhang et al. (2019) for a review). In the context of high-dimensional Bayesian inference, VI has proven particularly successful, and has been employed in linear regression (Carbonetto and Stephens, 2012; Ormerod et al., 2017; Ray and Szabó, 2022), logistic regression (Ray et al., 2020) and survival analysis (Komodromos et al., 2022) to name a few. Within the context of Bayesian group regression, to our knowledge only the Bayesian group LASSO has seen a variational counterpart (Babacan et al., 2014).
In this manuscript we examine the variational Bayes (VB) posterior arising from the group spike-and-slab prior with multivariate double exponential slab and Dirac spike, referring to our method as Group Spike-and-slab Variational Bayes (GSVB). We provide scalable variational approximations to three common classes of generalized linear models: the Gaussian with identity link function, Binomial with logistic link function, and Poisson with exponential link function. We outline a general scheme for computing the variational posterior via co-ordinate ascent variational inference. We further show that for specific cases, the variational family can be re-parameterized to allow for more efficient updates.
Through extensive numerical experiments we demonstrate that GSVB achieves state-of-the-art performance while significantly reducing computation time by several orders of magnitude compared to MCMC. Moreover, through our comparison with MCMC, we highlight that the variational posterior provides excellent uncertainty quantification through marginal credible sets with impressive coverage. Additionally, the proposed method is compared against the spike-and-slab group LASSO (Bai et al., 2020), a state-of-the-art Bayesian group selection algorithm that returns MAP estimates. Within this comparison our method demonstrates comparable or better performance in terms of group selection and effect estimation, whilst carrying the added benefit of providing uncertainty quantification, a feature not available by other scalable methods in the literature.
To highlight the practical utility of our method, we analyse three real datasets, demonstrating that our method provides excellent predictive accuracy, while also achieving parsimonious models. Additionally, we illustrate the usefulness of the VB posterior by showing its ability to provide posterior predictive intervals, a feature not available to methods that provide MAP estimates, and computationally prohibitive to compute via MCMC.
Theoretical guarantees for our method are provided in the form of posterior contraction rates, which quantify how far the posterior places most of its probability from the ‘ground truth’ generating the data for large sample sizes. This approach builds on the work of Castillo et al. (2015) and Ray and Szabó (2022), and extends previous Bayesian contraction rate results for true posteriors in the group sparse setting (Ning et al., 2020; Bai et al., 2020) to their variational approximation.
Concurrent to our work, Lin et al. (2023) proposed a similar spike-and-slab model for group variable selection in linear regression, which appeared on arXiv shortly after our preprint.
Notation. Let denote the realization of the random vector . Further, let denote the design matrix, where for a group let . Similarly, for , denote where , and . Wherein, without loss of generality we assume that the elements of the groups are ordered such that . Finally, the Kullback-Leibler divergence is defined as , where and are probability measures on , such that is absolutely continuous with respect to .
2 Prior and Variational family
To model the coefficients , we consider a group spike-and-slab prior. For each group , the prior over consists of a mixture distribution of a multivariate Dirac mass on zero and a multivariate double exponential distribution, , whose density is given by,
where and is the -norm. In the context of sparse Bayesian group regression the multivariate double exponential has been previously considered by Raman et al. (2009) and Kyung et al. (2010) as part of the Bayesian group LASSO and by Xu and Ghosh (2015) within a group spike-and-slab prior.
Formally the prior, which we consider throughout, is given by , where each has the hierarchical representation,
| (2) | ||||
for , where is the multivariate Dirac mass on zero with dimension . In conjunction with the log-likelihood, for a dataset , we write the posterior density under the given prior as,
| (3) |
where is a normalization constant known as the model evidence.
The posterior arising from the prior (2) and the dataset assigns probability mass to all possible sub-models, i.e. each subset , such that and otherwise. As using MCMC procedures to sample from this complex posterior distribution is computationally prohibitive, even for a moderate number of groups, we resort to variational inference to approximate it. This approximation is known as the variational posterior which is an element of the variational family given by
| (4) |
For our purposes the variational family we consider is a mean-field variational family,
| (5) |
where with , with , . denotes the multivariate Normal distribution with mean parameter and covariance . Notably, under , the vector of coefficients for each group is a spike-and-slab distribution where the slab consists of the product of independent Normal distributions,
meaning the structure (correlations) between elements within the same group are not captured. To mitigate this, a second variational family is introduced, where the covariance within groups is unrestricted. Formally,
| (6) |
where is a covariance matrix for which , for and denotes the covariance matrix of the th group. Notably, should provide greater flexibility when approximating the posterior, because unlike , it is able to capture the dependence between coefficients in the same group. The importance of which is highlighted empirically in Section 5 wherein the two families are compared.
Note that the posterior does not take the form or , as the use of these variational families replaces the model weights by VB group inclusion probabilities, , thereby introducing substantial additional independence. For example, information as to whether two groups of variables are selected together or not is lost. However, the form of the VB approximation retains many of the interpretable features of the original posterior such as the inclusion probabilities of particular groups.
3 Computing the Variational Posterior
Computing the variational posterior defined in (4) relies on optimizing a lower bound on the model evidence, , known as the evidence lower bound (ELBO). The ELBO follows from the non-negativity of the Kullback-Leibler divergence and is given by . Intuitively, the first term evaluates the model’s fit to the data, while the second term acts as a regularizer, ensuring the variational posterior is “close” to the prior distribution.
Various strategies exist to tackle the minimization of the negative ELBO,
| (7) |
with respect to (Zhang et al., 2019). One popular approach is co-ordinate ascent variational inference (CAVI), where sets of parameters of the variational family are optimized in turn while the remainder are kept fixed. Although this strategy does not (in general) guarantee the global optimum, it is easy to implement and often leads to scalable inference algorithms. In the following subsections we detail how this algorithm is constructed, noting that derivations are presented under the variational family , as the equations for follow by restricting to be a diagonal matrix.
3.1 Computing the Evidence lower bound
To compute the negative ELBO, note that the KL divergence between the prior and the variational distribution, is constant regardless of the form of the likelihood. To evaluate an expression for this quantity the group independence structure between the prior and variational distribution is exploited, allowing for the log Radon-Nikodym, , to be expressed as,
where . Subsequently, it follows that,
| (8) | ||||
where we have used the fact that . Notably, there is no closed form for , meaning is not tractable and optimization over this quantity would require costly Monte Carlo methods.
To circumvent this issue, a surrogate objective is constructed and used instead of the negative ELBO. This follows by applying Jensen’s inequality to , giving,
| (9) |
Thus, can be upper-bounded by,
| (10) | ||||
and in turn, . Via this upper bound, we are able to construct a tractable surrogate objective. Formally, this objective is denoted by, , where we introduce to parameterize additional hyperparameters, specifically those introduced to model the variance term under the Gaussian family, and those introduced to bound the Binomial likelihood. Under this parametrization we define,
| (11) |
where and (which is an inequality under non-tractable likelihoods). To this end, what remains to be computed is an expression for the expected negative log-likelihood and the term where appropriate. In the following three subsections we provide derivations of the objective function for the Gaussian, Binomial and Poisson likelihoods taking the canonical link functions for each.
3.1.1 Gaussian
Under the Gaussian family with identity link function, for all , the -likelihood is given by . To model an inverse Gamma prior is considered due to its popularity among practitioners, i.e. which has density where . The prior is therefore given by , and the posterior density by , where and is the observed data.
To include this term within the inference procedure, the variational families and are extended by and respectively. Under the extended variational family , the negative ELBO is given by
where the second term follows from the independence of and in the prior and variational family and is given by,
| (12) |
where . The expectation of the negative log-likelihood is given by,
| (13) | ||||
where,
| (14) |
Substituting (12) and (13) into (11) gives under the Gaussian family.
3.1.2 Binomial
Under the Binomial family with logistic link, for all where . The log-likelihood is given by where with .
Unlike the Gaussian family, variational inference in this setting is challenging because of the intractability of the expected log-likelihood under the variational family. To overcome this issue several authors have proposed bounds or approximations to maintain tractability (see Depraetere and Vandebroek (2017) for a review). Here we employ a bound introduced by Jaakkola and Jordan (1996), given as
| (15) |
where and , and is an additional parameter that must be optimized to ensure tightness of the bound.
3.1.3 Poisson
Finally, under the Poisson family with exponential link function, for all with . The log-likelihood is given by, , whose (negative) expectation is tractable and given by,
| (18) |
where is the moment generating function under the variational family, with being the moment generating function for the th group and . Unlike the previous two families the Poisson family, does not require any additional variational parameters, therefore and .
3.2 Coordinate ascent algorithm
Recall the aim is to approximate the posterior by a distribution from a given variational family. This approximation is obtained via the minimization of the objective derived in the previous section. To achieve this a CAVI algorithm is proposed (Murphy, 2007; Blei et al., 2017) as outlined in Algorithm 1.
In this context, the objective introduced in (11) is written as , highlighting the fact that optimization over the variational parameters occurs group-wise. Further, for each group , while the optimization of the objective function over the inclusion probability, , can be done analytically, we use the Limited memory Broyden–Fletcher–Goldfarb–Shanno optimization algorithm (L-BFGS) to update at each iteration of the CAVI procedure. Details for the optimization with respect to are presented in Section 3.2.1. The hyper-parameters, , are updated using L-BFGS for the Gaussian family and analytically for those under the Binomial family.
To assess convergence, the total absolute change in the parameters is tracked, terminating when this quantity falls below a specified threshold, set to in our implementation. Other methods involve monitoring the absolute change in the ELBO, however we found this prohibitively expensive to compute for this purpose.
3.2.1 Re-parameterization of
Our focus now turns to the optimization of w.r.t. . By using similar ideas to those of Seeger (1999) and Opper and Archambeau (2009), it can be shown that only one free parameter is needed to describe the optimum of under the Gaussian (see below) and Binomial family (see Section A of the Supplementary material). The objective w.r.t under the Gaussian family, is given by,
| (19) |
where is a constant that does not depend on . Differentiating (19) w.r.t. , setting to zero and re-arranging gives,
| (20) |
where . Thus, substituting where into the objective and optimizing over is equivalent to optimizing over , and carries the added benefit of requiring one free parameter to perform rather than . Note that under this re-parametrization the inversion of an matrix is required which can be a time consuming operation for large .
For the Poisson family the same re-parameterization cannot be used, so is parameterized by where is an upper triangular matrix. Optimization is then performed on the upper triangular elements of .
3.2.2 Initialization
As with any gradient-descent based approach, our CAVI algorithm is sensitive to the choice of initial values. We suggest to initialize using the group LASSO from the package gglasso using a small regularization parameter. This ensures many of the elements are non-zero. The covariance matrix can be initialised by using the re-parametrization outlined in Section 3.2.1 with an initial value of for for both the Gaussian and the Binomial families. For the Poisson family we propose the use of an initial covariance matrix . Finally, the inclusion probabilities are initialised as . For the additional hyper-parameters are used: and for all .
4 Theoretical results for grouped linear regression
4.1 Notation and assumptions
This section establishes frequentist theoretical guarantees for the proposed VB approach in sparse high-dimensional linear regression with group structure. The full proofs of the following results are provided in the Supplementary Material.
To simplify technicalities, the variance parameter is taken as known and equal to 1, giving model with , and . Under suitable conditions, contraction rates for the variational posterior are established, which quantify its spread around the ‘ground truth’ parameter generating the data as .
Recall that the covariates are split into pre-specified disjoint groups of size with and maximal group size . The above model can then be written as
| (21) |
with and . Let denote the law of under (21), be the set containing the indices of the non-zero groups in . For a vector and set , we also write for its vector restriction to . We write for the ground truth generating the data, and for its group-sparsity. For a matrix , let be the Frobenius norm and define the group matrix norm of by
If all the groups are singletons, reduces to the same norm as in Castillo et al. (2015). We further define the -norm of a vector by . We assume that the prior slab scale satisfies
| (22) |
mirroring the situation without grouping (Castillo et al., 2015; Ray and Szabó, 2022).
The parameter in (21) is not estimable without additional assumptions on the design matrix , for instance that is invertible for sparse subspaces of . These notions of invertibility can be precise via the following definitions, which are the natural adaptations of compatibility conditions to the group sparse setting (Bühlmann and van de Geer, 2011; Castillo et al., 2015).
Definition 1.
A model has compatibility number
Compatibility considers only vectors whose coordinates are small outside , and hence is a (weaker) notion of approximate rather than exact sparsity. For all in the above set, it holds that , which can be interpreted as a form of continuous invertibility of for approximately sparse vectors in the sense that changes in lead to sufficiently large changes in that can be detected by the data. The number 7 is not important and is taken in Definition 2.1 of Castillo et al. (2015) to provide a specific numerical value; since we use several of their techniques, we employ the same convention. We next consider two further notions of invertibility for exact group sparsity.
Definition 2.
The compatibility number for vectors of dimension is
Definition 3.
The smallest scaled sparse singular value of dimension is
While is not generally invertible in the high-dimensional setting, these last two definitions weaken this requirement to sparse vectors. These are natural extensions of the definitions in Castillo et al. (2015) to the group setting, and similar interpretations and relations to the usual sparse setting apply also here, see Bühlmann and van de Geer (2011) or Section 2.2 in Castillo et al. (2015) for further discussion.
The interplay of the group structure and individual sparsity can lead to multiple regimes see for instance Lounici et al. (2011) and Bühlmann and van de Geer (2011). To make our results more interpretable, we restrict to the main case of practical interest where the group sizes are not too large, and hence the group sparsity drives the estimation rate.
Assumption (K).
There exists such that
While related works make similar assumptions (Bai et al., 2020), introducing an explicit constant above allows us to clarify the uniformity in our results.
4.2 Asymptotic results
We now state our main result on variational posterior contraction for both prediction loss and the usual -loss. Our results are uniform over vectors in sets of the form
| (23) |
where , and (arbitrarily slowly).
Theorem 1 (Contraction).
Contraction rates for the full posterior based on a group spike and slab prior were established in Ning et al. (2020), as well as for the spike and slab group LASSO in Bai et al. (2020). Our proofs are instead based on those in Castillo et al. (2015) and Ray and Szabó (2022). We have extended their theoretical results from the coordinate sparse setting to the group sparse setting. This approach permits more explicit proofs and allows us to consider somewhat different assumptions from previous group sparse works (Ning et al., 2020; Bai et al., 2020), for instance removing the boundedness assumption for the parameter spaces.
Remark 1.
The optimization problem (4) is in general non-convex, and hence there is no guarantee that CAVI (or any other algorithm) will converge to the global minimizer . However, an inspection of the proofs shows that the conclusions of Theorems 1 and 2 apply also to any element in the variational families for which
where is the true group sparsity and is the negative ELBO. Thus, as long as the ELBO is within of its maximum, the resulting variational approximation will satisfy the above conclusions, even if it is not the global optimum.
The next result shows that the variational posterior puts most of its mass on models of size at most a multiple of the true number of groups, meaning that it concentrates on sparse sets.
5 Numerical experiments
In this section a numerical evaluation of our method, referred to as Group Spike-and-slab Variational Bayes (GSVB), is presented111Scripts to reproduce our results can be found at https://github.com/mkomod/p3. Where necessary we distinguish between the two families, and , by the suffix ‘–D’ and ‘–B’ respectively, i.e. GSVB–D denotes the method under the variational family . Notably, throughout all our numerical experiments the prior parameters are set to , , , and for the inverse-Gamma prior on under the Gaussian family.
This section begins with a comparison of GSVB222 An R package is available at https://github.com/mkomod/gsvb. against MCMC to assess the quality of the variational posterior in terms of variable selection and uncertainty quantification. Following this, a large-scale comparison with the Spike-and-Slab Group LASSO (SSGL) proposed by Bai et al. (2020), a state-of-the-art MAP Bayesian group selection method described in detail in Section 5.3, is performed.
5.1 Simulation set-up
Data is simulated for observations each having a response and continuous predictors . The response is sampled independently from the respective family with mean given by where is the link function (and variance applicable to the Gaussian family of ). The true coefficient vector consists of groups each of size i.e. . Of these groups, are chosen at random to be non-zero and have each of their element values sampled independently and uniformly from where and for the Gaussian, Binomial and Poisson families respectively. Finally, the predictors are generated from one of four settings:
-
•
Setting 1:
-
•
Setting 2: where for .
-
•
Setting 3: where is a block diagonal matrix where each block is a square matrix such that and otherwise.
-
•
Setting 4: where with and is a block diagonal matrix of blocks, where each block , for , is an matrix given by ; we let so that predictors within groups are more correlated than variables between groups.
To evaluate the performance of the methods four different metrics are considered: (i) the -error, , between the true vector of coefficients and the estimated coefficient defined as the posterior mean where applicable, or the maximum a posteriori (MAP) estimate if this is returned, (ii) the area under the curve (AUC) of the receiver operator characteristic curve, which compares true positive and false positive rate for different thresholds of the group posterior inclusion probability, (iii) the marginal coverage of the non-zero coefficients, which reports the proportion of times the true coefficient is contained in the marginal credible set , (iv) and the size of the marginal credible set for the non-zero coefficients, given by the Lebesgue measure of the set. The last two metrics can only be computed when a distribution for is available i.e. via MCMC or VB. The marginal credible sets for each variable for are given by:
where and is the quantile function of the standard Normal distribution.
5.2 Comparison to MCMC
Our first numerical study compares GSVB to the posterior obtained via MCMC, often considered the gold standard in Bayesian inference. The details of the MCMC sampler used for this comparison are outlined in Section C of the Supplementary material333An implementation is available at https://github.com/mkomod/spsl.. The MCMC sampler is ran for iterations taking a burn-in period of iterations.
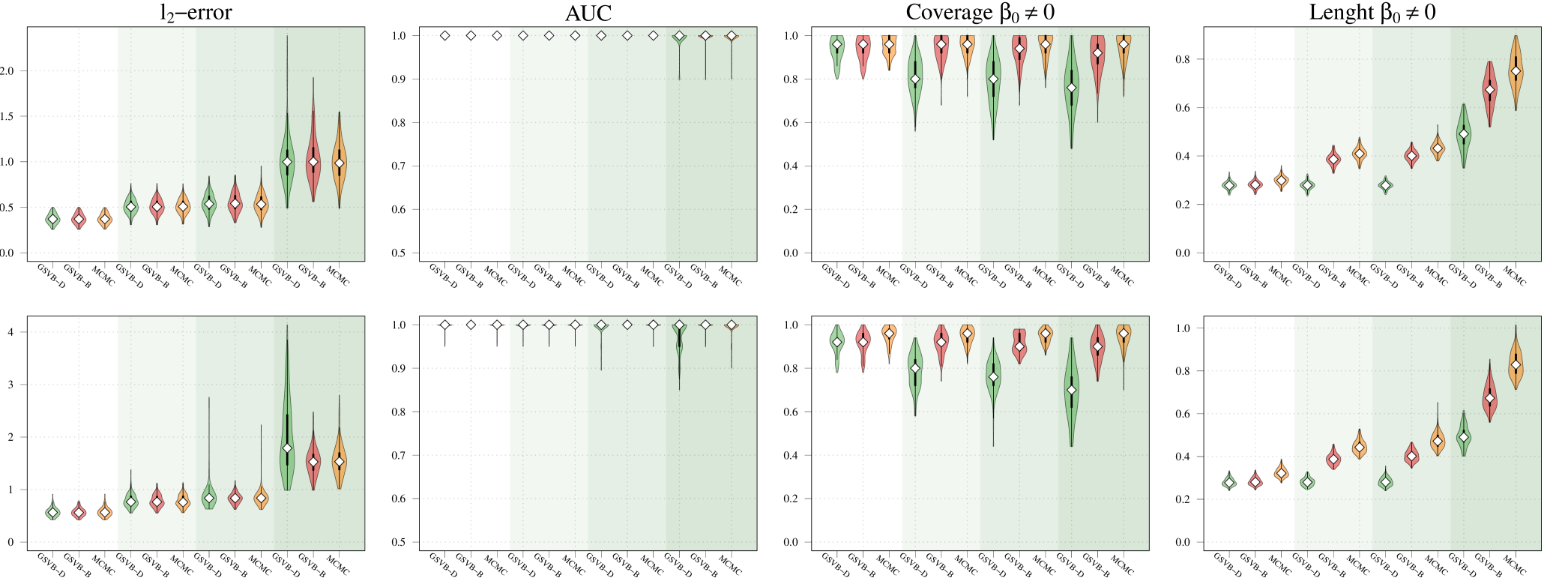
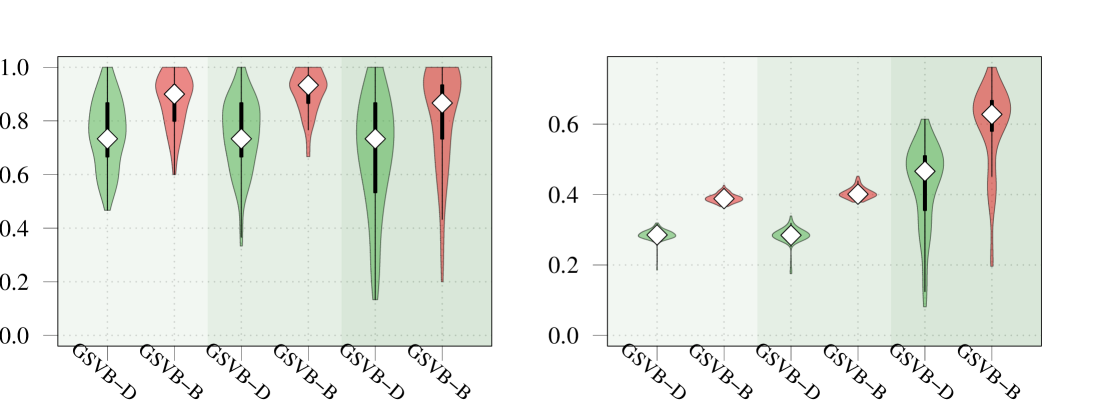
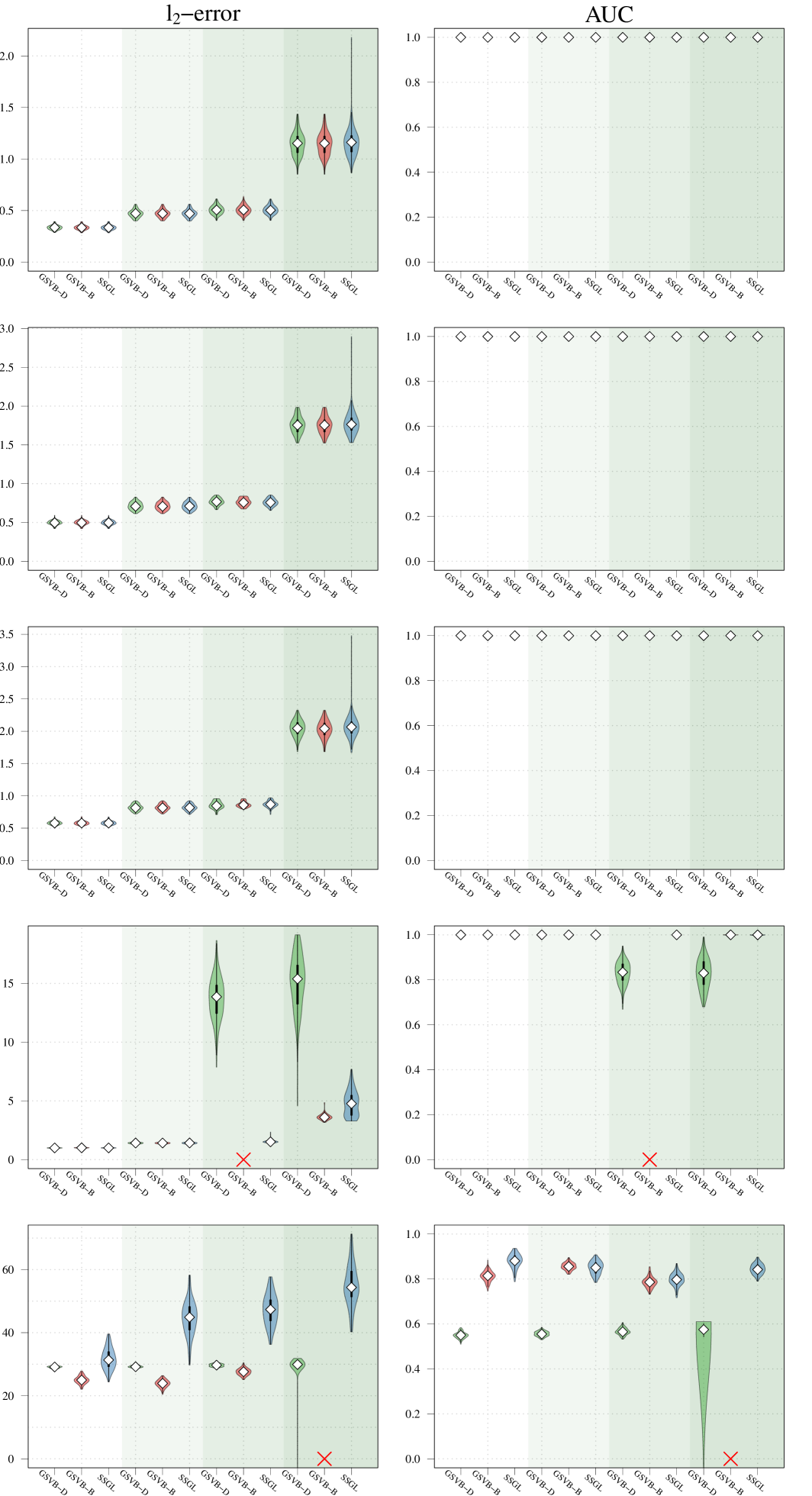
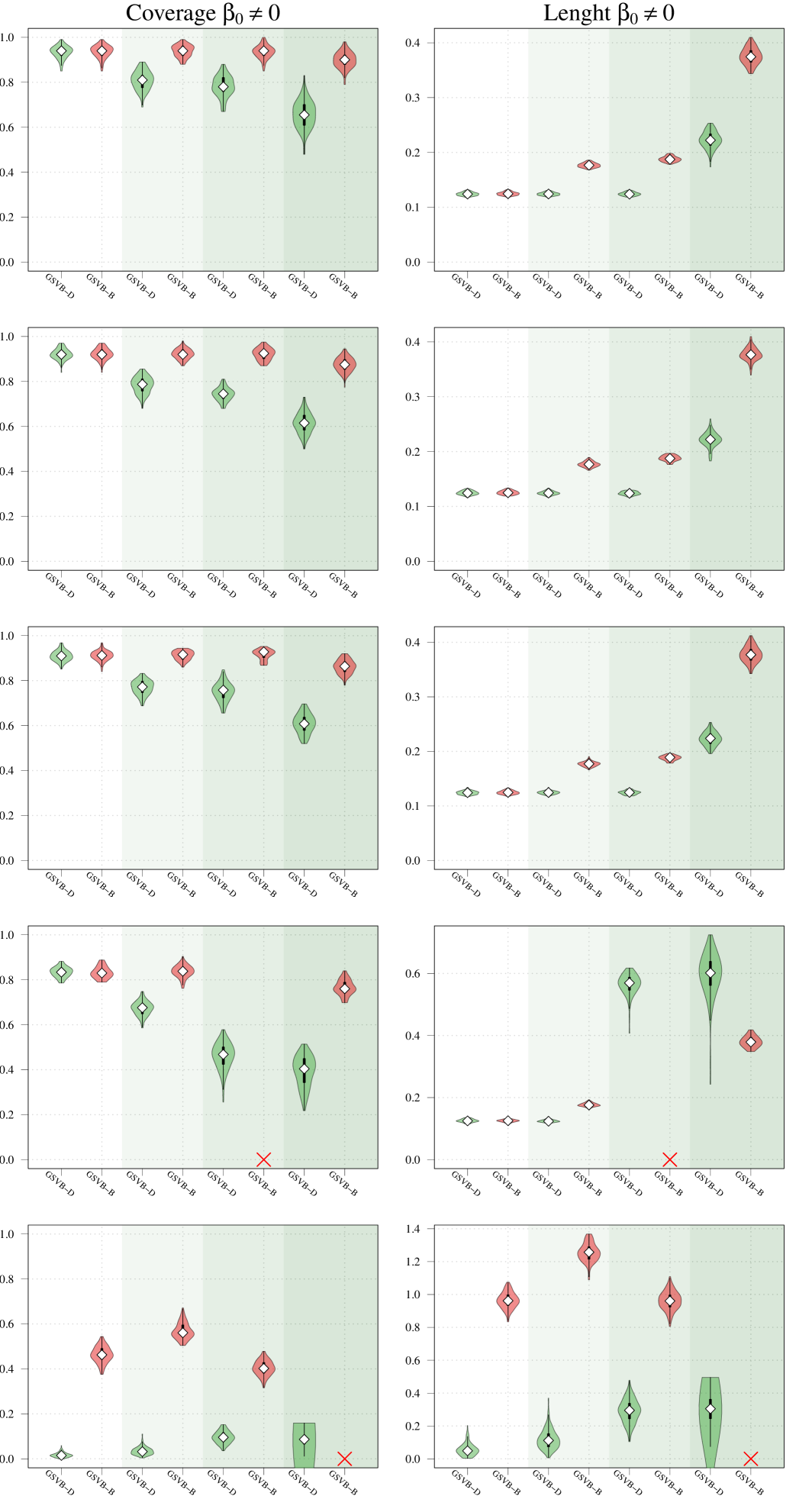
Within this comparison we set , , and vary the number of non-zero groups, . As highlighted in Figure 1 GSVB-B performs excellently in nearly all settings, demonstrating comparable results to MCMC in terms of -error and AUC. This indicates that GSVB-B exhibits similar characteristics to MCMC, both in terms of the selected groups and the posterior mean. As anticipated, all the methods exhibit better performance in simpler settings and show a decline in performance as the problem complexity increases.

 Setting 1
Setting 2
Setting 3
Setting 4
Setting 1
Setting 2
Setting 3
Setting 4
GSVB-D GSVB-B MCMC
Regarding coverage, whilst MCMC shows slightly better performance compared to GSVB, the proposed method still provides credible sets that capture a significant portion of the true non-zero coefficients (particularly GSVB-B). However, the credible sets of the variational posterior are sometimes not large enough to capture the true non-zero coefficients. This observation is further supported by the size of the marginal credible sets, with MCMC producing the largest sets, followed by GSVB-B and GSVB-D. These findings confirm the well-known fact that VB tends to underestimate the posterior variance (Carbonetto and Stephens, 2012; Blei et al., 2017; Zhang et al., 2019; Ray et al., 2020).
Interestingly, the set size is larger under , highlighting the fact that the mean field variational family () lacks the necessary flexibility to accurately capture the underlying structure in the data. Furthermore, this result indicates that the full marginal credible quantity improves through the consideration of the interactions within the group.
5.3 Large scale simulations
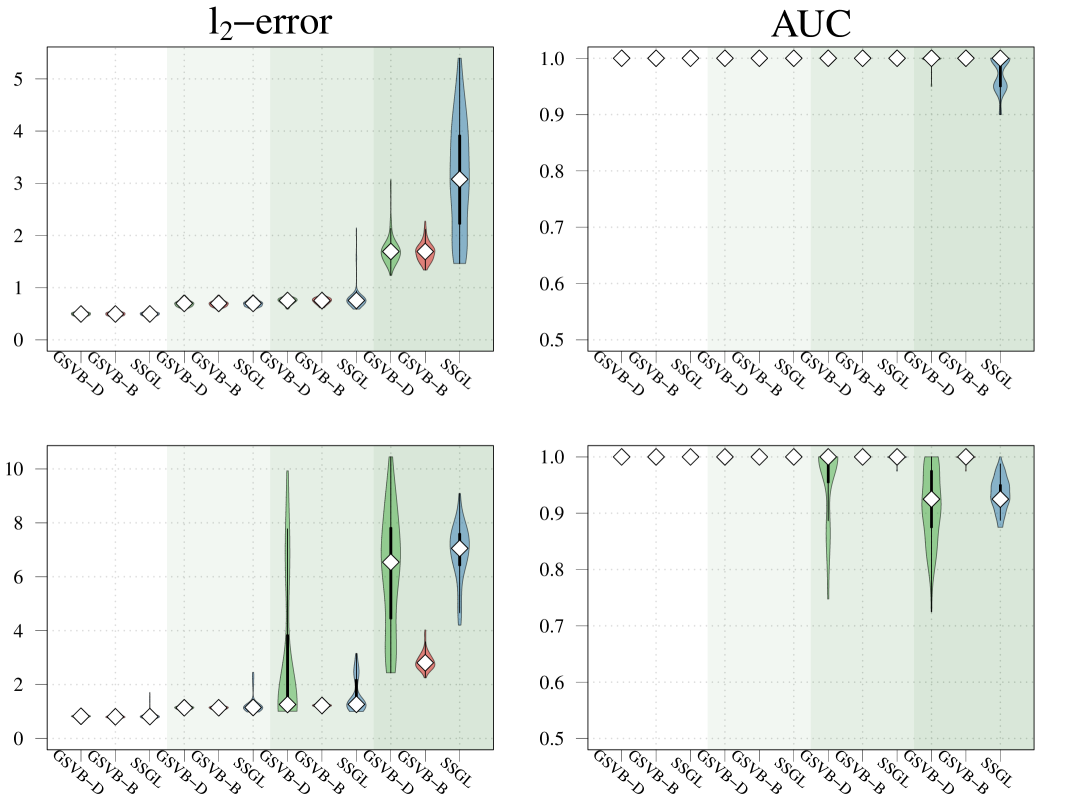
In this section, our proposed approach is compared against SSGL (Bai et al., 2020) a state-of-the-art Bayesian method. Notably, SSGL employs a similar prior to that introduced in (2), however the multivariate Dirac mass on zero is replaced with a multivariate double exponential distribution, giving a continuous mixture with one density acting as the spike and the other as the slab, parameterized by and respectively. Under this prior Bai et al. (2020) derive an EM algorithm, which allows for fast updates, however, only MAP estimates are returned, meaning a posterior distribution for is not available. In addition, the performance of the proposed method is evaluated on larger datasets. As both methods are scalable with , in this section it is increased to . Both the sample size and the number of active (non-zero) groups, are varied as illustrated in Figure 2.
In this comparison, we set for SSGL meaning the slab is identical between the two methods. For the spike for SSGL we took a value of for the Gaussian and Poisson family and under the Binomial family. These values were selected to ensure that sufficient mass is concentrated about zero without turning to cross validation to select the value. Finally, we let and for both methods.
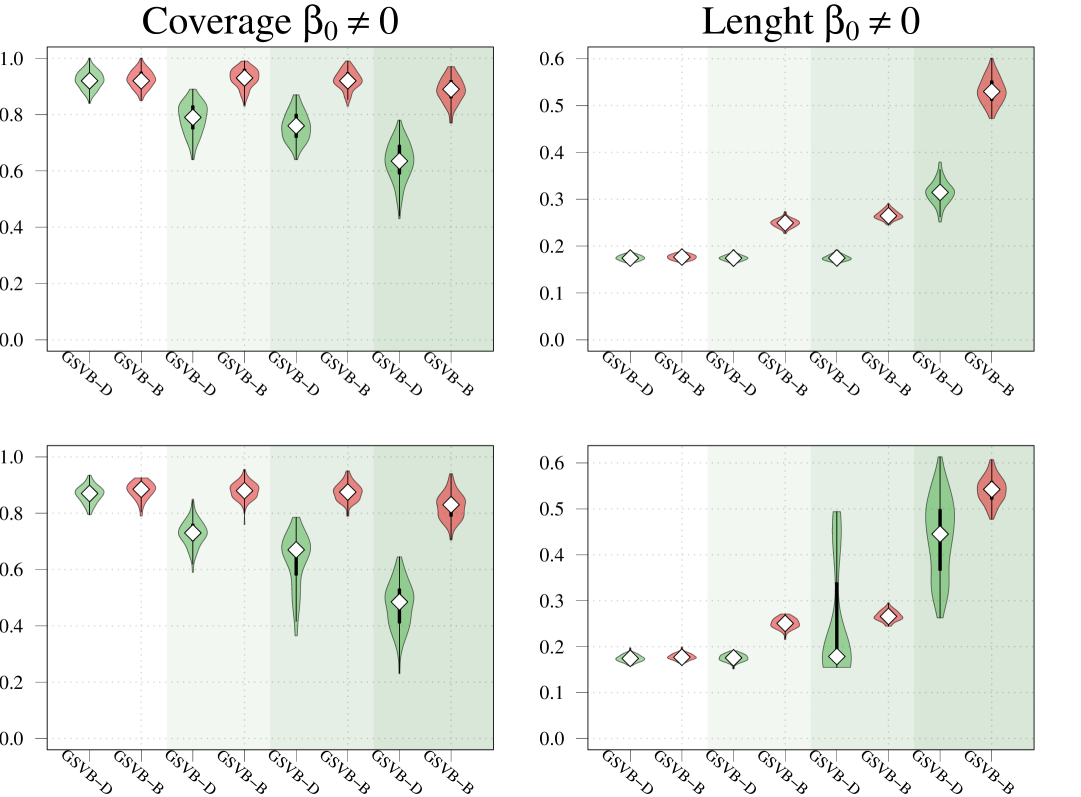
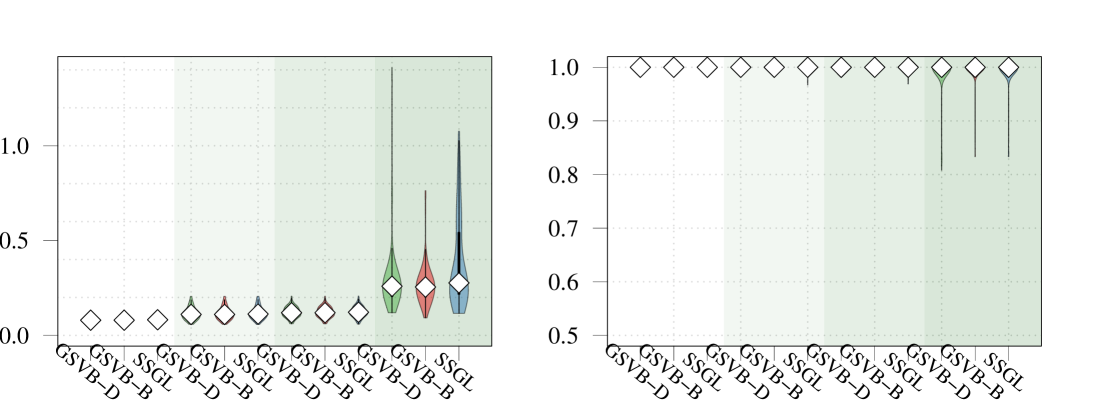
Given that SSGL only returns a point estimate for the vector of coefficients , the methods are compared in terms of -error between the estimated coefficient and the true one, as well as in terms of AUC using the group inclusion probabilities. Overall GSVB performs comparatively or better than SSGL in most settings, obtaining a lower -error and higher AUC (Figure 2). As expected, across the different methods there is a decrease in performance as the difficulty of the setting increases, meaning all methods perform better when there is less correlation in the design matrix. We note that the runtime of SSGL is marginally faster than our method in Settings 1-3, and faster in Settings 4. This is explained by the fact that SSGL only provides point estimate for , rather than the full posterior distribution. A full breakdown of the runtimes is presented in Section D.2 of the Supplementary Material. Within this large scale simulation our method provides excellent uncertainty quantification. In particular, GSVB–B provides better coverage of the non-zero coefficients than GSVB–D, which can be justified by the set size. As in our comparison to MCMC we notice that there is an increase in the posterior set size as the difficulty of the setting increases, i.e. when there is an increase in the correlation of the design matrix.
 Setting 1
Setting 2
Setting 3
Setting 4
Setting 1
Setting 2
Setting 3
Setting 4
GSVB-D GSVB-B SSGL
6 Real data analysis
This section presents the analysis of two real world datasets with a third dataset analysis included in the Supplementary Material444 R scripts used to produce these results are available at https://github.com/mkomod/p3 . The first problem is a linear regression problem wherein for which GSVB and SSGL are applied. The second is a logistic regression problem where , for which the logistic group LASSO is applied in addition to GSVB and SSGL. As before, , and GSVB was ran with a value of . For SSGL, we let and was chosen via five fold cross validation on the training set.
Overall, our results highlight that GSVB achieves state-of-the-art performance, producing parsimonious models with excellent predictive accuracy. Furthermore, in our analysis of the two datasets, variational posterior predictive distributions are constructed. These highlight the practical utility of GSVB, demonstrating how uncertainty in the predictions is quantified – an added benefit otherwise not available via MAP methods such as SSGL.
6.1 Bardet-Biedl Syndrome Gene Expression Study
The first dataset we examine is of microarray data, consisting of gene expression measurements for 120 laboratory rats555available at ftp://ftp.ncbi.nlm.nih.gov/geo/series/GSE5nnn/GSE5680/matrix/. Originally the dataset was studied by Scheetz et al. (2006) and has subsequently been used to demonstrate the performance of several group selection algorithms (Huang and Zhang, 2010; Breheny and Huang, 2015; Bai et al., 2020). Briefly, the dataset consists of normalized microarray data harvested from the eye tissue of 12 week old male rats. The outcome of interest is the expression of TRIM32 a gene known to cause Bardet-Biedl syndrome, a genetic disease of multiple organs including the retina.
To pre-process the original dataset, which consists of probe sets (the predictors), we follow Breheny and Huang (2015) and select the probe sets which exhibit the largest variation in expression on the log scale. Further, following Breheny and Huang (2015) and Bai et al. (2020) a non-parametric additive model is used, wherein, with and . Here, corresponds to the expression of TRIM32 for the th observation, and the expression of the th probe set for the th observation. To approximate a three term natural cubic spline basis expansion is used. The resulting processing gave a group regression problem with and groups of size . Denoting by the th basis for , we have
| (24) |
The performance of the methods is evaluated a ten-fold cross validation, where the methods are fit to the validation set and the test set is used for evaluation. More details about the computation of the metrics used to assess method performance can be found in the Supplementary Material.Overall, GSVB performed excellently, in particular GSVB–D obtained a smaller 10-fold cross validated MSE and model size than SSGL, meaning the models produced are parsimonious and comparably predictive to those of SSGL (Table 1). Furthermore, the PP coverage is excellent, particularly for GSVB–D which has a larger PP coverage than GSVB–B, whilst also having a smaller PP interval length.
Method MSE Num. selected groups PP. coverage PP. length GSVB-D 0.017 (0.019) 1.10 (0.316) 0.983 (0.035) 0.5460 (0.100) GSVB-B 0.018 (0.013) 1.50 (0.527) 0.950 (0.070) 0.5673 (0.091) SSGL 0.019 (0.001) 2.30 (1.060) – –
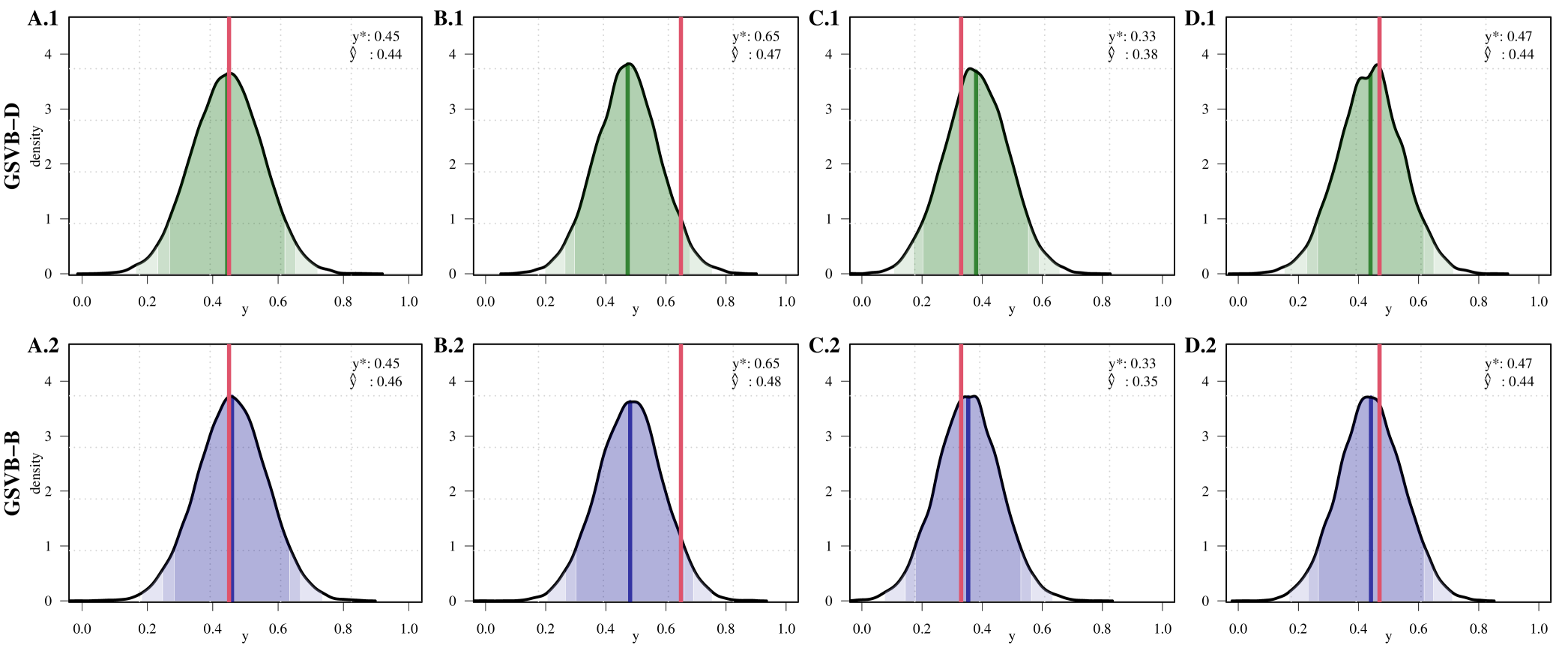
To identify genes associated with TRIM32 expression, GSVB was ran on the full dataset. Both methods identify one gene each, with GSVB–D identifying Clec3a and GSVB–B identifying Slc25a34. Interestingly, the MSE was and for each method, suggesting Slc25a34 is more predictive of TRIM32 expression. Further, the PP coverage was for both methods and the PP interval length was and for GSVB–D and GSVB–B, reflecting there is less uncertainty in the prediction under GSVB–B.
6.2 MEMset splice site detection
The following application is based on the prediction of short read DNA motifs, a task which plays an important role in many areas of computational biology. For example, in gene finding, wherein algorithms such as GENIE (Burge and Karlin, 1997) rely on the prediction of splice sites (regions between coding and non-coding DNA segments).
The MEMset donor data has been used to build predictive models for splice sites and consists of a large training and test set666available at http://hollywood.mit.edu/burgelab/maxent/ssdata/. The original training set contains 8,415 true and 179,438 false donor sites and the test set 4,208 true and 89,717 false donor sites. The predictors are given by 7 factors with 4 levels each (A, T, C, G), a more detailed description is given in Yeo and Burge (2004). Initially analyzed by Yeo and Burge (2004), the data has subsequently been used by Meier et al. (2008) to evaluate the logistic group LASSO.
To create a predictive model we follow Meier et al. (2008) and consider all rd order interactions of the 7 factors, which gives a total of groups and predictors. To balance the sets we randomly sub-sampled the training set without replacement, creating a training set of 1,500 true () and 1,500 false donor sites. Regarding the test set a balanced set of 4,208 true and 4,208 false donor sites was created.
In addition to GSVB, we fit SSGL and group LASSO (used in the original analysis), for which we performed 5-fold cross validation to tune the hyperparameters. To assess the different methods, we use the test data, dividing it into 10 folds, and reporting the: (i) precision , (ii) recall , (iii) F-score , (iv) AUC, and (v) the maximum correlation coefficient between true class membership and the predicted membership over a range of thresholds, , as used in Yeo and Burge (2004) and Meier et al. (2008). In addition we report (vi) the number selected groups, which for the group LASSO is given by the number which have a non-zero norm.
Method Precision Recall F-score AUC Num. selected groups GSVB–D 0.915 (0.013) 0.951 (0.011) 0.933 (0.009) 0.975 (0.004) 0.870 (0.016) 10 GSVB–B 0.916 (0.011) 0.958 (0.013) 0.936 (0.008) 0.975 (0.004) 0.875 (0.016) 12 SSGL 0.921 (0.012) 0.950 (0.011) 0.935 (0.009) 0.977 (0.004) 0.879 (0.015) 48 Group LASSO 0.924 (0.013) 0.952 (0.010) 0.938 (0.010) 0.977 (0.004) 0.882 (0.016) 60
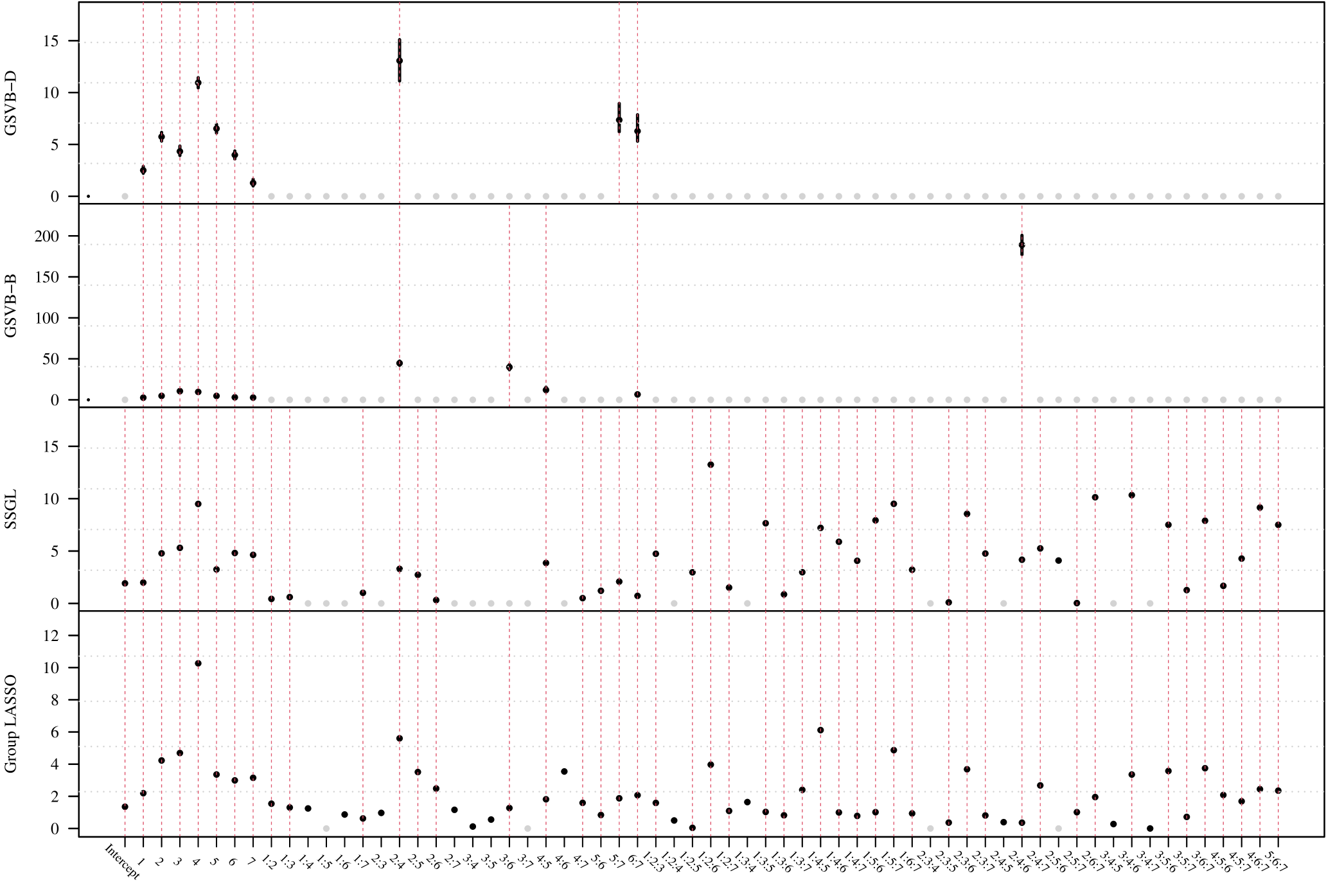
Overall the methods performed comparably. With GSVB–D obtaining the largest recall and the group LASSO the largest precision, F-score, AUC, and by a small margin (Table 2). However, GSVB returned models that were of smaller size and therefore more parsimonious than those of SSGL and the group LASSO. This is further highlighted in Figure 5 (found in the Supplementary Material), which showcases the fact that the models obtained by GSVB are far simpler, selecting groups 1–7 as well as the interactions between groups 2:4 and 6:7 for both methods, with GSVB–D selecting 5:7 and GSVB–B selecting 2:6, 4:6 and 2:4:6 in addition to these. Further, Figure 5 showcases the fact that uncertainty is available about the norms of the groups.
7 Discussion
In this manuscript we have introduced GSVB, a scalable method for group sparse general linear regression. We have shown how a fast co-ordinate ascent variational inference algorithms can be constructed and used to compute the variational posterior. We have provided theoretical guarantees for the proposed VB approach in the setting of grouped spare linear regression by extending the theoretical work of Castillo et al. (2015) and Ray and Szabó (2022) for group sparse settings. Through extensive numerical studies we have demonstrated that GSVB provides state-of-the-art performance, offering a computationally inexpensive substitute to MCMC, whilst also performing comparably or better than MAP methods. Additionally, through our analysis of real world datasets we have highlighted the practical utility of our method. Demonstrating, that GSVB provides parsimonious models with excellent predictive performance, and as demonstrated in Section E.1, selects variables with established biological significance. Finally, different to MAP and frequentist methods, GSVB provides scalable uncertainty quantification, which serves as a powerful tool in several application areas.
References
- Babacan et al. (2014) Babacan, S. D., S. Nakajima, and M. N. Do (2014). Bayesian group-sparse modeling and variational inference. IEEE Transactions on Signal Processing 62(11), 2906–2921.
- Bai et al. (2020) Bai, R. et al. (2020). Spike-and-Slab Group Lassos for Grouped Regression and Sparse Generalized Additive Models. Journal of the American Statistical Association, 1–41.
- Blake et al. (2021) Blake, J. A. et al. (2021). Mouse Genome Database (MGD): Knowledgebase for mouse-human comparative biology. Nucleic Acids Research 49(D1), D981–D987.
- Blei et al. (2017) Blei, D. M., A. Kucukelbir, and J. D. McAuliffe (2017). Variational Inference: A Review for Statisticians. Journal of the American Statistical Association 112(518), 859–877.
- Breheny and Huang (2009) Breheny, P. and J. Huang (2009). Penalized methods for bi-level variable selection. Statistics and Its Interface 2(3), 369–380.
- Breheny and Huang (2015) Breheny, P. and J. Huang (2015). Group descent algorithms for nonconvex penalized linear and logistic regression models with grouped predictors. Statistics and Computing 25(2), 173–187.
- Bühlmann and van de Geer (2011) Bühlmann, P. and S. van de Geer (2011). Statistics for high-dimensional data. Springer Series in Statistics. Springer, Heidelberg. Methods, theory and applications.
- Burge and Karlin (1997) Burge, C. and S. Karlin (1997). Prediction of complete gene structures in human genomic DNA11Edited by F. E. Cohen. Journal of Molecular Biology 268(1), 78–94.
- Carbonetto and Stephens (2012) Carbonetto, P. and M. Stephens (2012). Scalable variational inference for bayesian variable selection in regression, and its accuracy in genetic association studies. Bayesian Analysis 7(1), 73–108.
- Castillo et al. (2015) Castillo, I., J. Schmidt-Hieber, and A. van der Vaart (2015). Bayesian linear regression with sparse priors. Ann. Statist. 43(5), 1986–2018.
- Chen et al. (2016) Chen, R. B., C. H. Chu, S. Yuan, and Y. N. Wu (2016). Bayesian Sparse Group Selection. Journal of Computational and Graphical Statistics 25(3), 665–683.
- Chipman (1996) Chipman, H. (1996). Bayesian variable selection with related predictors. Canadian Journal of Statistics 24(1), 17–36.
- Depraetere and Vandebroek (2017) Depraetere, N. and M. Vandebroek (2017). A comparison of variational approximations for fast inference in mixed logit models. Computational Statistics 32(1), 93–125.
- Huang et al. (2012) Huang, J., P. Breheny, and S. Ma (2012). A selective review of group selection in high-dimensional models. Statistical Science 27(4), 481–499.
- Huang et al. (2010) Huang, J., J. L. Horowitz, and F. Wei (2010). Variable selection in nonparametric additive models. Annals of Statistics 38(4), 2282–2313.
- Huang et al. (2009) Huang, J., S. Ma, H. Xie, and C. H. Zhang (2009). A group bridge approach for variable selection. Biometrika 96(2), 339–355.
- Huang and Zhang (2010) Huang, J. and T. Zhang (2010). The benefit of group sparsity. Annals of Statistics 38(4), 1978–2004.
- Jaakkola and Jordan (1996) Jaakkola, T. S. and M. I. Jordan (1996). A variational approach to Bayesian logistic regression models and their extensions.
- Jacob et al. (2009) Jacob, L., G. Obozinski, and J. P. Vert (2009). Group lasso with overlap and graph lasso. ACM International Conference Proceeding Series 382.
- Jreich et al. (2022) Jreich, R., C. Hatte, and E. Parent (2022). Review of Bayesian selection methods for categorical predictors using JAGS. Journal of Applied Statistics 49(9), 2370–2388.
- Komodromos et al. (2022) Komodromos, M., E. O. Aboagye, M. Evangelou, S. Filippi, and K. Ray (2022, aug). Variational Bayes for high-dimensional proportional hazards models with applications within gene expression. Bioinformatics 38(16), 3918–3926.
- Kyung et al. (2010) Kyung, M., J. Gilly, M. Ghoshz, and G. Casellax (2010). Penalized regression, standard errors, and Bayesian lassos. Bayesian Analysis 5(2), 369–412.
- Lai and Chen (2021) Lai, W. T. and R. B. Chen (2021). A review of Bayesian group selection approaches for linear regression models. Wiley Interdisciplinary Reviews: Computational Statistics 13(4), 1–22.
- Lee and Cao (2021) Lee, K. and X. Cao (2021). Bayesian group selection in logistic regression with application to MRI data analysis. Biometrics 77(2), 391–400.
- Lin et al. (2023) Lin, B., C. Ge, and J. S. Liu (2023). A variational spike-and-slab approach for group variable selection. arXiv:2309.16855.
- Lounici et al. (2011) Lounici, K., M. Pontil, S. Van De Geer, and A. B. Tsybakov (2011). Oracle inequalities and optimal inference under group sparsity. Annals of Statistics 39(4), 2164–2204.
- Matsui et al. (2010) Matsui, M. et al. (2010, dec). Activation of LDL Receptor Expression by Small RNAs Complementary to a Noncoding Transcript that Overlaps the LDLR Promoter. Chemistry & Biology 17(12), 1344–1355.
- Meier et al. (2008) Meier, L., S. Van De Geer, and P. Bühlmann (2008). The group lasso for logistic regression. Journal of the Royal Statistical Society. Series B: Statistical Methodology 70(1), 53–71.
- Mitchell and Beauchamp (1988) Mitchell, T. J. and J. J. Beauchamp (1988). Bayesian variable selection in linear regression. Journal of the American Statistical Association 83(404), 1023–1032.
- Murphy (2007) Murphy, K. P. (2007). Conjugate bayesian analysis of the gaussian distribution.
- Ning et al. (2020) Ning, B., S. Jeong, and S. Ghosal (2020). Bayesian linear regression for multivariate responses under group sparsity. Bernoulli 26(3), 2353–2382.
- Opper and Archambeau (2009) Opper, M. and C. Archambeau (2009, 03). The variational gaussian approximation revisited. Neural Computation 21(3), 786–792.
- Ormerod et al. (2017) Ormerod, J. T., C. You, and S. Müller (2017). A variational bayes approach to variable selection. Electronic Journal of Statistics 11(2), 3549–3594.
- Pinelis and Sakhanenko (1986) Pinelis, I. F. and A. I. Sakhanenko (1986). Remarks on inequalities for large deviation probabilities. Theory of Probability & Its Applications 30(1), 143–148.
- Raman et al. (2009) Raman, S. et al. (2009). The bayesian group-lasso for analyzing contingency tables. ACM International Conference Proceeding Series 382, 881–888.
- Ray and Szabó (2022) Ray, K. and B. Szabó (2022). Variational Bayes for high-dimensional linear regression with sparse priors. J. Amer. Statist. Assoc. 117(539), 1270–1281.
- Ray et al. (2020) Ray, K., B. Szabo, and G. Clara (2020). Spike and slab variational Bayes for high dimensional logistic regression. In Advances in Neural Information Processing Systems, Volume 33, pp. 14423–14434. Curran Associates, Inc.
- Ročková and George (2018) Ročková, V. and E. I. George (2018). The Spike-and-Slab LASSO. Journal of the American Statistical Association 113(521), 431–444.
- Scheetz et al. (2006) Scheetz, T. E. et al. (2006). Regulation of gene expression in the mammalian eye and its relevance to eye disease. Proceedings of the National Academy of Sciences of the United States of America 103(39), 14429–14434.
- Seeger (1999) Seeger, M. (1999). Bayesian methods for support vector machines and Gaussian processes. Master’s thesis, University of Karlsruhe.
- Silverman et al. (2016) Silverman, M. G. et al. (2016). Association between lowering LDL-C and cardiovascular risk reduction among different therapeutic interventions: A systematic review and meta-analysis. Journal of the American Medical Association 316(12), 1289–1297.
- Simon et al. (2013) Simon, N., J. Friedman, T. Hastie, and R. Tibshirani (2013). A sparse-group lasso. Journal of Computational and Graphical Statistics 22(2), 231–245.
- Wang et al. (2007) Wang, L., G. Chen, and H. Li (2007). Group SCAD regression analysis for microarray time course gene expression data. Bioinformatics 23(12), 1486–1494.
- Xu and Ghosh (2015) Xu, X. and M. Ghosh (2015). Bayesian variable selection and estimation for group lasso. Bayesian Analysis 10(4), 909–936.
- Yeo and Burge (2004) Yeo, G. and C. B. Burge (2004). Maximum entropy modeling of short sequence motifs with applications to RNA splicing signals. Journal of Computational Biology 11(2-3), 377–394.
- Yuan and Lin (2006) Yuan, M. and Y. Lin (2006). Model selection and estimation in regression with grouped variables. Journal of the Royal Statistical Society. Series B: Statistical Methodology 68(1), 49–67.
- Zhang et al. (2019) Zhang, C. et al. (2019). Advances in Variational Inference. IEEE Transactions on Pattern Analysis and Machine Intelligence 41(8), 2008–2026.
SUPPLEMENTARY MATERIAL
Appendix A Co-ordinate ascent algorithms
Derivations are presented for the variational family , noting that , hence the update equations under follow directly from those under . Recall, the family is given as,
| (25) |
where is a covariance matrix for which , for (i.e. there is independence between groups) and denotes the covariance matrix of the th group.
A.1 Gaussian Family
Under the Gaussian family, , and the -likelihood is given by,
Recall, we have chosen to model by an inverse-Gamma prior which has density,
where and in turn we extend to .
Under this variational family, the expectation of the negative log-likelihood is given by,
| (26) |
where the expectation
A.2 Binomial Family Re-parameterization
To re-parametrization of we follow the same process as in Section 3.2.1. Formally, we have,
| (27) |
where is the free parameter to be optimized and . Notably, this result follows due to the quadratic nature of the bound employed. Meaning we are able to re-parameterize .
Appendix B Derivation of Variational Posterior Predictive
To compute the variational posterior predictive distribution for the Binomial and Poisson model, we sample and then sample from the respective distribution with mean given by where and is the link function. To sample from we sample and then if otherwise we set .
For the Gaussian family we are able to simplify the process by integrating out the variance . Following Murphy (2007), substituting and recalling the independence of and in our variational family, we have,
Recognizing that the expression within the integral has the same functional form as a generalized -distribution, whose density is denoted as , yields,
| (28) |
As (28) is intractable we instead sample from , by
-
1.
Sampling .
-
2.
Sampling from where and , where denotes a t-distribution with degrees of freedom.
Appendix C Gibbs Sampler
We present a Gibbs sampler for the Gaussian family of models, noting that the samplers for the Binomial and Poisson family use the same principles. We begin by considering a slight alteration of the prior given in (2). Formally,
| (29) | ||||
for and . Under this prior writing the likelihood as,
| (30) |
where is the density of the Normal distribution with mean and variance , and is the link function (which in this case is the identity), yields the posterior
| (31) |
Notably, the posterior is equivalent to our previous formulation.
To sample from (31), we construct a Gibbs sampler as outlined in Algorithm 2. Ignoring the superscript for clarity, the distribution is conditionally independent of and . Therefore, is sampled from , which has a distribution. Regarding , the conditional density
| (32) |
As is discrete, evaluating the RHS of (C) for and , gives the unnormalised conditional probabilities. Summing gives the normalisation constant and thus we can sample from a Bernoulli distribution with parameter
| (33) |
Finally, regarding we use a Metropolis-Hastings within Gibbs step, wherein a proposal is sampled from a random-walk proposition kernel , where in our implementation . The proposal is then accepted with probability or rejected with probability , in which case , where is given by,
Appendix D Numerical Study
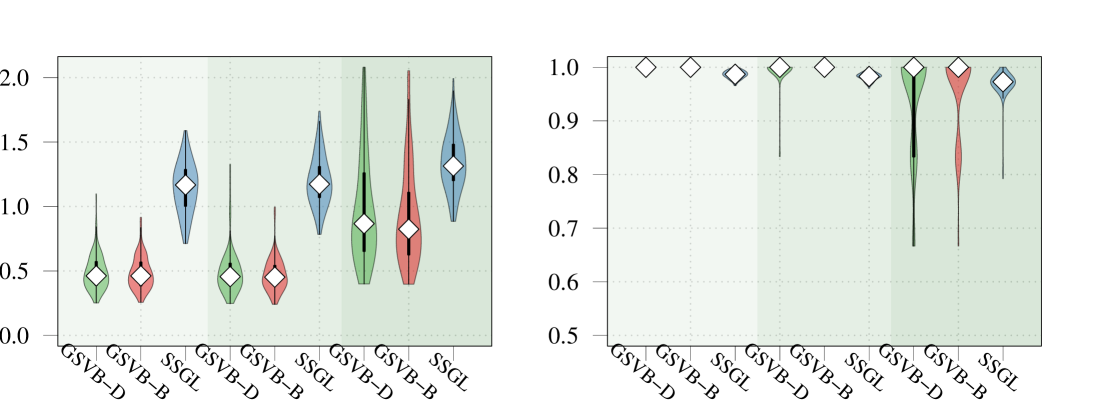
D.1 Performance with large groups
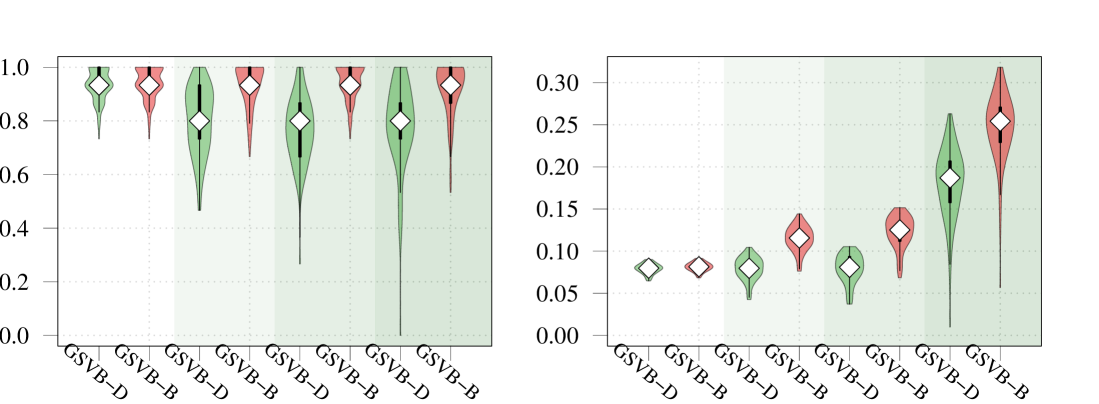
The performance of GSVB with large groups is examined. For this we fix and vary the group size to be . The results, presented in Figure 3 highlight that the performance of the method is excellent for groups of size , and begins to suffer when groups are of size and , particularly in settings 3 and 4 wherein GSVB–B did not run.
 Setting 1
Setting 2
Setting 3
Setting 4
Setting 1
Setting 2
Setting 3
Setting 4
95+ runs did not converge GSVB-D GSVB-B SSGL
D.2 Runtime
Runtimes for the experiments presented in Section 5 are presented in Table 3 and Table 4. Notably, the runtime for GSVB over MCMC is orders of magnitudes faster. The runtime of GSVB in comparison to SSGL is slower in Settings 4, but marginally slower in the remaining settings. Note all simulations were ran on AMD EPYC 7742 CPUs (128 core, 1TB RAM).
Method Setting 1 Setting 2 Setting 3 Setting 4 Gaus. s=5 GSVB–D 2.1s (1.6s, 3.0s) 1.8s (1.1s, 2.9s) 3.5s (1.6s, 8.0s) 2.2s (1.6s, 5.2s) GSVB–B 1.8s (1.2s, 2.9s) 2.0s (1.3s, 3.1s) 3.4s (1.7s, 7.3s) 2.6s (1.8s, 6.7s) MCMC 7m 53s (7m 31s, 8m 12s) 7m 55s (7m 34s, 8m 2s) 7m 44s (7m 20s, 7m 48s) 8m 14s (7m 49s, 8m 17s) Gaus. s=10 GSVB–D 2.3s (1.7s, 3.8s) 2.6s (1.9s, 3.9s) 7.4s (2.9s, 9.7s) 4.2s (2.4s, 12.1s) GSVB–B 2.9s (1.8s, 4.5s) 2.6s (2.2s, 3.2s) 9.5s (4.8s, 13.9s) 4.3s (2.7s, 14.0s) MCMC 9m 55s (9m 45s, 10m 8s) 10m 13s (9m 48s, 10m 30s) 9m 19s (9m 24s, 9m 33s) 10m 11s (9m 46s, 10m 27s) Binom. s=3 GSVB–D - 5.5s (3.5s, 9.3s) 7.7s (3.7s, 12.0s) 5.2s (2.7s, 8.0s) GSVB–B - 7.2s (6.0s, 11.9s) 7.8s (5.6s, 14.4s) 6.0s (3.7s, 9.5s) MCMC - 16m 45s (16m, 17m 15s) 16m 45s (15m 45s, 17m) 15m 45s (14m 49s, 16m 30s) Pois. s=2 GSVB–D 3.6s (3.3s, 4.1s) 3.3s (2.9s, 3.7s) 3.1s (2.9s, 5.2s) 3.4s (2.4s, 4.1s) GSVB–B 12.5s (10.0s, 18.0s) 10.1s (7.9s, 14.5s) 15.5s (10.1s, 41.6s) 13.3s (10.5s, 24.0s) MCMC 15m 45s (14m 49s, 16m 45s) 15m 45s (15m 15s, 16m 30s) 16m (14m 59s, 18m) 18m 30s (16m 45s, 19m 45s)
Method Setting 1 Setting 2 Setting 3 Setting 4 Gaus. m=10, s=10 GSVB–D 59.1s (47.2s, 1m 16s) 54.3s (47.5s, 1m 8s) 2m 53s (1m 4s, 6m 35s) 8m 7s (4m 30s, 25m 36s) GSVB–B 57.7s (50.7s, 1m 18s) 57.0s (49.5s, 1m 14s) 2m 51s (1m 7s, 6m 38s) 9m 45s (4m 53s, 25m 40s) SSGL 1m 3s (59.5s, 1m 13s) 50.8s (41.6s, 59.5s) 1m 1s (58.1s, 1m 16s) 1m 24s (1m 11s, 2m 3s) Gaus. m=10, s=20 GSVB–D 3m 7s (3m 46s, 4m 31s) 3m 13s (3m 42s, 4m 39s) 9m 42s (3m 56s, 14m 54s) 20m 48s (6m 38s, 39m 23s) GSVB–B 3m 29s (3m 6s, 4m 20s) 3m 23s (3m 57s, 4m 48s) 12m 18s (4m 59s, 16m 20s) 34m 59s (12m 54s, 45m 2s) SSGL 2m 42s (1m 23s, 2m 3s) 1m 16s (59.2s, 2m 40s) 2m 6s (2m 37s, 2m 30s) 2m 16s (2m 31s, 6m 32s) Binom. m=5, s=5 GSVB–D - 3m 43s (2m 54s, 4m 54s) 2m 26s (2m 34s, 4m 5s) 2m 50s (1m 16s, 3m 30s) GSVB–B - 4m 32s (3m 40s, 5m 8s) 3m 26s (2m 20s, 5m 26s) 2m 25s (2m 47s, 5m 18s) SSGL - 2m 54s (2m 44s, 3m 42s) 3m 33s (2m 57s, 3m 26s) 2m 40s (2m 31s, 2m 3s) Pois. m=5, s=3 GSVB–D 16.3s (9.8s, 21.5s) 11.2s (8.2s, 20.8s) 16.0s (10.4s, 43.0s) 12.9s (8.6s, 48.7s) GSVB–B 2m 26s (2m 59s, 3m 20s) 2m 55s (1m 29s, 3m 20s) 3m 53s (2m 49s, 9m 25s) 3m 33s (2m 4s, 9m 11s) SSGL 4m 11s (3m 49s, 8m 38s) 4m 34s (2m 11s, 13m 4s) 2m 29s (2m 56s, 16m 33s) 2m 32s (1m 25s, 3m 2s)
Appendix E Real data analysis
E.1 Genetic determinants of Low-density Lipoprotein in mice
Here we analyze a dataset from the Mouse Genome Database (Blake et al., 2021) and consists of single nucleotide polymorphisms (SNPs) collected from laboratory mice. Notably, each SNP, for and , takes a value of 0, 1 or 2. This value indicates how many copies of the risk allele are present. Alongside the genotype data, a phenotype (response) is also collected. The phenotype we consider is low-density lipoprotein cholesterol (LDL-C), which has been shown to be a major risk factor for conditions like coronary artery disease, heart attacks, and strokes (Silverman et al., 2016).
To pre-process the original dataset SNPs with a rare allele frequency, given by for , below the first quartile were discarded. Further, due to the high colinearity, covariates with for , , were removed. After pre-processing, SNPs remained. These were used to construct groups by coding each , in turn giving groups of size .
To evaluate the methods ten fold cross validation is used. Specifically, methods are fit to the validation set and the test set is used for evaluation. This is done by computing the: (i) MSE between the true and predicted value of the response, given by where is the size of the test set, (ii) posterior predictive (PP) coverage, which measures the proportion of times the response is included in the 95% PP set, and (iii) the average size of the 95% PP set. In addition, (iv) the number of groups selected, given by is also reported.
Importantly the PP distribution is available for GSVB, and given by, where is a feature vector (see Section B of the Supplementary material for details). In genetics studies, , is referred to as the polygenic risk score and is commonly used to evaluate genetic risk. While frequentist or MAP methods offer only point estimates, Figure 4 demonstrates that GSVB can offer a distribution for this score, highlighting the uncertainty associated with the estimate.
 GSVB-D:
PP mean: Mass%:
90%
95%
99%
Observed response
GSVB-B:
PP mean: Mass%:
90%
95%
99%
GSVB-D:
PP mean: Mass%:
90%
95%
99%
Observed response
GSVB-B:
PP mean: Mass%:
90%
95%
99%
Regarding the performance of each method results are presented in Table 5, these highlight that GSVB performs excellently obtaining parsimonious models with a comparable MSE to SSGL. In addition, GSVB provides impressive uncertainty quantification, yielding a coverage of and for GSVB–D and GSVB–B respectively. The SNPs selected by GSVB–D and GSVB-B are similar and reported in Table 6 of the Supplementary material. When the methods are fit to the full dataset, the SNPs selected by both method are: rs13476241, rs13477968, and rs13483814, with GSVB–B selecting rs13477939 in addition. Notably, rs13477968 corresponds to the Ago3 gene, which has been shown to play a role in activating LDL receptors, which in turn regulate LDL-C (Matsui et al., 2010).
| Method | MSE | Num. selected groups | PP. coverage | PP. length |
|---|---|---|---|---|
| GSVB-D | 0.012 (0.002) | 3.50 (0.527) | 0.945 (0.027) | 0.425 (0.005) |
| GSVB-B | 0.012 (0.002) | 4.00 (0.667) | 0.941 (0.029) | 0.421 (0.005) |
| SSGL | 0.012 (0.002) | 57.40 (5.481) | - | - |
| RSID (or probe ID) | Freq. GSVB-D | Freq. GSVB-B |
| rs13476279 | 6 | 6 |
| rs13483823 | 6 | 5 |
| CEL.4_130248229 | 5 | 3 |
| rs13477968 | 3 | 5 |
| rs13476241 | 4 | 3 |
| CEL.X_65891570 | 2 | 4 |
| rs13477903 | 2 | 2 |
| rs3688710 | 2 | 1 |
| rs13477939 | 1 | - |
| rs3157124 | 1 | - |
| rs13478204 | - | 3 |
| rs6186902 | - | 2 |
| rs13483814 | - | 1 |
| rs4222922 | - | 1 |
| rs6187266 | - | 1 |
| UT_4_128.521481 | - | 1 |
E.2 Bardet-Biedl Syndrome Gene Expression Study
| Probe ID | Gene Name | Freq. GSVB-D | Freq. GSVB-B | Freq. SSGL |
| 1383183_at | 1 | 1 | 8 | |
| 1386237_at | 1 | 1 | - | |
| 1397359_at | 4 | 2 | - | |
| 1386552_at | - | 1 | - | |
| 1378682_at | - | 1 | - | |
| 1385926_at | - | - | 2 | |
| 1396814_at | - | - | 3 | |
| 1386811_at | Hacd4 | 1 | 2 | - |
| 1386069_at | Sp2 | 4 | 2 | - |
| 1371209_at | RT1-CE5 | - | 1 | - |
| 1391624_at | Sec14l3 | - | 1 | - |
| 1383829_at | Bbx | - | 2 | - |
| 1389274_at | Dcakd | - | - | 1 |
| 1373995_at | Abcg1 | - | - | 1 |
| 1375361_at | Snx18 | - | - | 1 |
| 1368915_at | Kmo | - | - | 7 |
E.3 MEMset splice site detection
 Groups selected by more than one method
Groups for which
Groups selected by more than one method
Groups for which
Groups for which 95% credible intervals for where available
Appendix F Proofs of asymptotic results
F.1 A general class of model selection priors and an overview of the proof
Our theoretical results apply to a wider class of model selection priors than the group spike and slab prior (2) underlying our variational approximation. In this section, we thus consider this more general class of model selection priors Castillo et al. (2015); Ning et al. (2020); Ray and Szabó (2022) defined hierarchically via:
| (34) |
where is a prior on , is the uniform distribution on subsets of size and
| (35) |
is a density on with . This can be concisely written as
| (36) |
Following Castillo et al. (2015); Ning et al. (2020); Ray and Szabó (2022), we assume as usual that
| (37) |
We further recall the assumption (38) made on the scale parameter:
| (38) |
The group spike and slab prior fits within this framework by taking , and hence the following results immediately imply Theorems 1 and 2. Recall the parameter set
defined in (23).
Theorem 3 (Contraction).
Theorem 4 (Dimension).
To prove Theorems 3 and 4, we use the following result which relates the VB probability of sets having exponentially small probability under the true posterior.
Lemma 1 (Theorem 5 of Ray and Szabó (2022)).
Let be a subset of the parameter space, be events and be distributions for . If there exists and such that
then
The proof thus reduces to finding events with on which:
-
1.
The true posterior places only exponentially small probability outside , that is for some rate ,
-
2.
The -divergence between the VB posterior and the full posterior is .
In our setting, we shall take . Full posterior results are dealt with in Section F.2, the -divergence in Section F.3 and the proofs of Theorems 3 and 4 are completed in Section F.4.
F.2 Asymptotic theory for the full posterior
We now establish contraction rates for the full computationally expensive posterior distribution, keeping track of the exponential tail bounds needed to apply Lemma 1. While the proofs in this section largely follow those in Castillo et al. Castillo et al. (2015), the precise arguments adapting these results to the group sparse setting are rather technical and hence we provide them for convenience. We first establish a Gaussian tail bound in terms of the group structure.
Lemma 2.
The event
| (39) |
satisfies .
Proof.
Since under , applying a union bound over the group structure yields . Recall that for a multivariate normal , we have by Corollary 3 of Pinelis and Sakhanenko (1986). Since , this implies
and hence for any . Substituting this bound with into the above union bound thus yields
∎
Let denote the log-likelihood of the -distribution. For any , we have log-likelihood ratio
| (40) |
The next result establishes an almost sure lower bound on the denominator of the Bayes formula. It follows Lemma 2 of Castillo et al. (2015), but must be adapted to account for the uneven prior normalizing factors coming from the group structure.
Lemma 3.
Suppose Assumption (K) holds and that satisfies for . Then it holds that with -probability one,
where depend only on .
The mild condition , which will be assumed throughout, relates the true sparsity with the maximal group size. As in Assumption (K), the constant is used to provide uniformity, but this can be ignored at first reading.
Proof.
The bound trivially holds true for , hence we assume . Write to be maximal number of non-zero coefficients in . In an abuse of notation, we shall sometimes interchangeably use for both the vector in and the vector in with the entries in set to zero. Using the form (36) of the prior,
By the change of variable and the form of the log-likelihood (40), the last display is lower bounded by
Define the measure on by . Let denote the normalized probability measure with corresponding expectation . Defining , Jensen’s inequality implies , since as is a symmetric probability distribution about zero. Thus the last display is lower bounded by , which equals
| (41) |
Using the group structure, since . Using the form (35) of the density and recalling that
by (6.2) in Castillo et al. (2015), the integral in the last display is bounded below by
| (42) |
Deviating from Castillo et al. (2015), we must now take careful account of the normalizing constants .
Recall the form of the normalized constants . The non-asymptotic upper bound in Stirling’s approximation for the Gamma function gives for : Taking for ,
| (43) |
where we have used that since the function in the limit is strictly increasing on . One can directly verify that the upper bound (43) also holds for . Using (43),
for some universal constant . Using this last display, we lower bound (42) by a constant multiple of
Using (38), if , then , while if , then since by assumption. Since also , the last display is lower bounded by under the lemma’s hypotheses. The result then follows by substituting this lower bound for the integral in (41) and using that . ∎
The next result follows Theorem 10 of Castillo et al. (2015).
Lemma 4 (Dimension).
Proof.
Using Bayes formula with likelihood ratio (40) and Lemma 3, for any measurable set ,
| (44) |
for the event defined in (39). Applying Cauchy-Schwarz on the event gives
| (45) |
Therefore, since under , on , the integrand in the second last display is bounded by
and hence
Arguing exactly as on p. 2007-8 in Castillo et al. (2015),
and hence
| (46) |
Setting now with , the integral in the last display is bounded by
Using the prior condition (37), this is then bounded by
Since by the lemma hypothesis, the last sum is bounded by 2 and hence the first term in (46) is bounded by
where depend only on . Taking , using the lemma hypotheses and that , the last display is bounded by
For large enough that , this is then bounded by
∎
We next obtain a contraction rate for the full posterior underlying the variational approximation. The proof follows that of Theorem 3 of Castillo et al. (2015), modified for the group setting.
Lemma 5 (Contraction).
Proof.
Consider the set , which satisfies
| (47) |
by Lemma 4. Recall that by (38). Using this, for any set and , (44) and (45) give
Note that for any , . Using Definition 2 of the uniform compatibility ,
Thus for any ,
Note that by (37), . For , the last display implies
The last integral is upper bounded by
Using (37) and (38), the last display is bounded by , since by the lemma hypothesis. Setting for a constant , the second last display is bounded by
where we have used that . Taking large enough depending on and using again that , the last display can be made smaller than (47), which is thus the dominant term in the tail probability bound.
For the -loss, using Definition 2 of the uniform compatibility, for any ,
The result then follows from the first assertion for the prediction loss .
For the -loss, note that for any . Since for all by Lemma 1 of Castillo et al. (2015) (which extends to the group setting), the result follows. ∎
F.3 -divergence between the variational and true posterior
We next bound the KL-divergence between the variational family and the true posterior on the following event:
| (48) |
where . The proof largely follows Section B.2 of Ray and Szabó (2022), again modified to the group sparse setting, which we produce in full for completeness.
Lemma 6.
If , then there exists an element of the variational families such that
If Assumption (K) also holds, then
Proof.
The full posterior takes the form
| (49) |
with weights satisfying and where denotes the posterior for in the restricted model . Arguing exactly as in the proof of Lemma B.2 of Ray and Szabó (2022), one has that on and for , there exists a set such that
| (50) |
Writing , consider the element of the variational family
| (51) |
where are diagonal matrices to be defined below. This is the distribution that assigns mass one to the model and then fits an independent normal distribution with diagonal covariance on each of the groups in . Since is only absolutely continuous with respect to the component of the posterior (49),
| (52) |
On , the first term is bounded by by (50), so that it remains to bound the second term in (52).
Define
| (53) |
where , , is the diagonal matrix with entries
Writing for the expectation under the distribution ,
| (54) |
We next deal with each term separately.
Term (I) in (54). Using the formula for the Kullback-Leibler divergence between two multivariate Gaussian distributions,
where denotes the determinant of a square matrix . Further define the matrix
which is a block-diagonalization of . Let for . By considering multiplication along the block structure, has -block equal to , . Furthermore, is a block-diagonal matrix with -block , . Thus, by considering the block-diagonal terms,
and hence . Using (53),
Let and denote the largest and smallest eigenvalues, respectively, of a matrix . Arguing as in equation (B.12) in Ray and Szabó (2022), for any ,
| (55) |
Therefore,
and hence using (50).
Term (II) in (54). One can check that the distribution has density function proportional to for . Therefore,
where and are the normalizing constants for the densities. Arguing exactly as in the proof of Lemma B.2 of Ray and Szabó (2022), one can show that on the event is holds that if . On , the second term in the last display is bounded by
| (56) |
using Cauchy-Schwarz.
Under , so that , and using (53),
Arguing for this term as in Lemma B.2 of Ray and Szabó (2022), one can show that the first term is bounded by on . Using that the -operator norm of is bounded by by (55), the second term in the last display is bounded by . But on ,
Combining the above bounds thus yields
on , thereby controlling the first term in (56).
It remains only to bound the second term in (56). Let denote the unit vector in , , and let denote its extension to with unit entry in the coordinate of group . Then for . Therefore,
Putting together of all the above bounds yields
using that , and for .
F.4 Proofs of Theorems 3 and 4
To complete the proofs, we apply Lemma 1 with the event defined in (48) for suitably chosen constants .
Lemma 7.
Proof.
We consider each of the sets in individually. In what follows, and will be constants that may change line-by-line but which will not depend on other parameters.
Applying Lemma 4 with , where are the constants in that lemma, we have for large enough. Setting , the second event in is thus a subset of for and all in the infimum in the lemma.
For the third event in , we apply Lemma 5 with , where now are the constants in Lemma 5, to obtain
Setting and shows that the third event in is also contained in for these choices and all in the infimum in the lemma. It thus suffices to control the probability of , with tends to one uniformly in by Lemma 2. Lastly, note that for large enough. ∎
Proof of Theorem 3.
Write for the parameter set and let
for the constant in Lemma 5. Let be the event (48) with parameters (57), so that Lemma 7 gives , uniformly over .
Applying Lemma 5 with gives that for large enough, , where depend only on . We can then use Lemma 1 with event and to obtain
Since and is by definition the KL-minimizer of the variational family to the posterior, we obtain that for any ,
where the term is uniform over . But by Lemma 6, there exists an element of the variational family such that
where is uniform over and have dependences specified in Lemma 7. But since are bounded under the hypothesis of the present theorem and , we have for large enough and hence . Using this and the last two displays, we thus have
as , thereby establishing the first assertion. The second two assertions follow similarly for using the corresponding results in Lemma 5. ∎