Hallucination Detection and Mitigation with Diffusion in Multi-Variate Time-Series Foundation Models
Abstract
Foundation models for natural language processing have many coherent definitions of hallucination and methods for its detection and mitigation. However, analogous definitions and methods do not exist for multi-variate time-series (MVTS) foundation models. We propose new definitions for MVTS hallucination, along with new detection and mitigation methods using a diffusion model to estimate hallucination levels. We derive relational datasets from popular time-series datasets to benchmark these relational hallucination levels. Using these definitions and models, we find that open-source pre-trained MVTS imputation foundation models relationally hallucinate on average up to 59.5% as much as a weak baseline. The proposed mitigation method reduces this by up to 47.7% for these models. The definition and methods may improve adoption and safe usage of MVTS foundation models.
1 Introduction
Foundation models (FMs) trained on large and diverse datasets, that can be prompted to perform many types of computation, have enjoyed rapid progress in Natural Language Processing (NLP). Examples include Llama touvron2023llama , ChatGPT achiam2023gpt , Claude min2023recent and Gemini anil2023gemini . Models with similar capabilities are now also seen in other domains including time-series modelling. Recent works have shown that pre-trained models for time-series forecasting can be used effectively on unseen forecasting domains in a zero-shot manner. This is achieved by training on large quantities of time-series data from diverse domains as in Chronos ansari2024chronos , TimesFM das2023decoder , LagLlama rasul2023lag , TimeGPT garza2023timegpt , MOIRAI woo2024unifiedtraininguniversaltime . Similar models have also been successful for time-series imputation such as MOMENT goswami2024moment , TIMER liutimer , TOTEM talukder2024totem , TimesNet wu2022timesnet and GPT4TS zhou2023one .
We argue that pre-trained models for multi-variate time-series (MVTS) imputation are closer than MVTS forecasting to what are typically referred to as FMs in NLP as these can be prompted to handle different tasks. Prompts are the provided values and responses are the imputed values. For example, forecasting can be prompted for by masking future time-steps and asking the model to fill in these masked values; while interpolation can be prompted for with data from both before and after the missing period. Imputation therefore provides an interface for arbitrary question answering in MVTS. This work will therefore focus on these models, particularly MOMENT goswami2024moment and TIMER liutimer which are the only FMs of this type that currently have open-source weights available.
For MVTS question answering to be useful in real-world cases, a measure of confidence in the model’s response is required, analogous to hallucination detection in NLP. To our knowledge, there is no literature on hallucination definition and detection in MVTS imputation, even with the advent of MVTS FMs. This is in stark contrast to NLP which has a large and active literature on defining and detecting different types of hallucination rawte2023survey ; zhang2023siren ; ye2023cognitive . We here aim to bring MVTS hallucination detection closer to parity with NLP.
The following example highlights the utility of hallucination detection for MVTS question answering. Consider a MVTS system comprising three variables: temperature, vapour pressure deficit (VPD) and plant biomass. A farm operator may want to optimise the system to increase plant growth rate. To prompt for this question, an above average plant growth curve is provided and the model imputes the temperature and VPD it believes will result in this growth curve. This response, however, cannot be used since there is no measure of whether this response should be trusted. An inherently out of distribution question will inherently result in an out of distribution response. However, the response can still be correct. In order to use the response, MVTS hallucination detection is required.
The contributions of this work include the definition of two types of hallucination in the context of MVTS imputation: distributional and relational. These are defined using analogous definitions from the NLP literature. We use diffusion models ho2020denoising for MVTS imputation and propose a method to detect and mitigate hallucination in its response. We also show that MVTS FMs hallucinate heavily using popular MVTS datasets, and that this can be detected and mitigated using our proposed methods. Source code will be provided here upon acceptance.
1.1 Diffusion Model Preliminaries
Diffusion models are probabilistic generative models that iteratively degrade data by introducing noise, then learn to reverse this process. This allows them to iteratively generate new samples by sampling from a simple prior, which is typically a Gaussian distribution yang2023diffusion . They have become well known in image generation rombach2022high and have been applied extensively to various fields including time-series generation yuan2024diffusion , forecasting meijer2024rise and imputation wang2024deep ; yang2024survey . Ever since diffusion models have been applied to time-series imputation tashiro2021csdi , there has been growing work to improve them for this use case. These include improvements to the masking criteria during training xiao2023imputation ; chen2023imdiffusion ; liu2023pristi , the architectures used alcaraz2022diffusion and the sampling process wang2023observed . Diffusion models have since become widely popular, becoming one of the best performing methods for time-series imputation zhou2024mtsci . The background on diffusion models that is directly used in this work will be explained in the following sections. This includes the mathematical notations for Denoising Diffusion Probabilistic Models (DDPM) ho2020denoising and conditioning through RePaint lugmayr2022repaint .
1.1.1 Unconditional Diffusion Models
In the forward process, samples from the training data are increasingly corrupted through the addition of Gaussian noise for time-steps to generate noisy samples :
| (1) |
| (2) |
The Gaussian noise is determined by the variance schedule which is typically linearly increasing. The forward process also admits sampling timestep directly:
| (3) |
where and
The reverse process is used to successively denoise the corrupted data by learning using a neural network with learnable parameters :
| (4) |
| (5) |
| (6) |
where is the predicted mean used to sample and is the noise predicted by a neural network at time-step . The original DDPM ho2020denoising sets , where . We will use this DDPM formulation of diffusion models in this work due to its popularity and simplicity.
1.1.2 Conditioning Diffusion with RePaint
Diffusion models as described above are referred to as unconditional diffusion models as they do not directly allow for conditioning to be applied. It is however possible to guide the unconditional diffusion model using the RePaint lugmayr2022repaint method. Here, components of the input vector are split into conditioning values and missing values to be imputed by the model. The missing values are sampled in the same way as Eq. 5:
| (7) |
The conditioning values however uses the corrupted version obtained using Eq. 3:
| (8) |
In this way, at each time-step of the reverse process, is composed of the imputed missing values obtained by denoising, and the conditioning values obtained by corrupting the actual given values to the correct noise level associated with the time-step . The predicted mean at each diffusion time-step is then computed as usual using Eq. 4.
We will use RePaint to condition an unconditional diffusion model trained on our dataset and impute missing values. This allows for arbitrary question answering using the prompt-response framework at inference without modification to the training procedure of the diffusion model.
1.2 Hallucination Detection and Mitigation in NLP
Example methods for hallucination detection and mitigation in NLP include the use of external knowledge retrieved from the web or task-specific databases to identify and correct non-factual content in responses peng2023check ; shuster2021retrieval ; lewis2020retrieval ; chen2023purr ; varshney2023stitch . However, effective knowledge retrieval can be challenging and costly to run in practice mundler2023self . It is unclear how this transfers to MVTS as there are no clear-cut facts to retrieve. There are also methods that do not use external knowledge but instead uses multiple samples from the same prompt to measure consistency of the generated information manakul2023selfcheckgpt ; elaraby2023halo ; zhang2023sac ; farquhar2024detecting . This can also be done using an ensemble of models du2023improving . Similarly to these methods, this work will mitigate hallucination through sampling. The concept of consistency, however, does not transfer to MVTS as these require clear-cut facts and contradictions. A separate hallucination detection model can also be trained to detect hallucination from the generated text chen2023hallucination ; pacchiardi2023catch ; mishra2024fine ; zha2023alignscore or the model’s internal states su2024unsupervised . This is the approach that will be adopted in this work using a diffusion model. There has also been work on scaling the generation of datasets that can be used to train these models su2024unsupervised ; gu2024anah . Hallucination mitigation can also be achieved through direct supervised finetuning gu2025mask ; tian2023fine ; lin2024flame ; zhang2024self ; chen2024grath . However, the fine-tuned model still has to be used in conjunction with hallucination detection methods since they can still hallucinate, albeit at a potentially reduced rate.
2 Defining Hallucination for Multi-Variate Time-Series Imputation
There is a large and active literature on defining, detecting and mitigating hallucination in NLP. In this context, hallucination is commonly defined as the behaviour when models generate responses with information that is false rawte2023survey ; zhang2023siren ; ye2023cognitive . In time-series however, there are no clear-cut facts as in language. Consequently, there is no absolute truth to time-series, only what is probable relative to the provided context dataset. We therefore define distributional hallucination as a type of hallucination in time-series where the combination of the prompt and the generated response is out of distribution (OOD) with respect to a target dataset. Note that if an OOD prompt is provided to a model, all responses will automatically be classified as a distributional hallucination. This is important in the context of foundation models trained on large quantities of data since it is typically unknown whether a prompt is OOD or not. In practice, distributional hallucination is a continuous concept, so a threshold must be chosen to define a prompt-response pair as distributionally hallucinating.
Another definition of hallucination in NLP is the generation of self-contradictory responses mundler2023self ; with incoherent explanation and reasoning zhang2023language ; or responses that are irrelevant to the prompt gallifant2024peer . These definitions will be used as the NLP analogue of what will be referred to as relational hallucination. A relation between a set of variables can be written as , where is some ground-truth function that defines the relation. The ‘relational error’ which measures the degree of which the relation is broken can then be defined as . Relational hallucination can then be defined as the case when the model returns a set of variables that has ‘high’ relational error, relative to some threshold. This occurs when the prompt and the response are incompatible, given . This is analogous to a response that is irrelevant to the prompt in the NLP case. Additionally, relational hallucination can occur when the variables returned in the response are incompatible with themselves. This case is analogous to self-contradiction in NLP hallucination. Incoherent explanations and reasoning can also be seen as a form of self-contradiction. In the same way as distributional hallucination, relational hallucination is also defined relative to a given dataset.
Examples
In contrast to distributional hallucination, an OOD prompt may not necessarily result in relational hallucination. As a concrete example, consider the following case with three variables where the ground truth relation is addition: . The training dataset consists of and . The combination of the prompt, where and , and the response , will be classified as distributionally hallucinating but not relationally hallucinating. The combination of the prompt, where and , and the response , will be classified as both distributionally hallucinating and relationally hallucinating. In this sense, relational hallucination is a subset of distributional hallucination.
Relational Hallucination is More Important
Distributional hallucination is important for detecting whether a question is OOD, which is typically not known at inference. Relational hallucination also captures all the in-distribution data, since by definition they all have correct relations between the variables. They however also extend to regions of the state space that is OOD. In this sense, relational hallucination is less restricted than distributional hallucination. Models being able to generalise to and operate in regions which are OOD is important as a large family of important question types are OOD. For example, to optimise variables to achieve better performances given the current data or to simulate a system under new conditions. This work will therefore focus on relational hallucination with the following proposed methods only applying to relational hallucination and not distributional hallucination.
Related Concepts
OOD detection aims to detect test samples that do not exist in the training distribution yang2024generalized . This is what we refer to as distributional hallucination in our work. We use the term hallucination as this is the common term used with respect to FMs in NLP. Anomaly Detection in contrast aims to detect unusual cases which may exist in the training set zamanzadeh2024deep , assuming that the majority of training data is from the ‘correct’ distribution and a minority of data is from an ‘anomalous’ distribution. Anomaly detection can therefore be seen as OOD detection but with the definition of being ‘in distribution’ replaced with being in the ‘correct distribution’. Anomaly detection in MVTS predicts which time indices within a single MVTS window correspond to anomalous values. Relational hallucination differs from these definitions, as it measures the compatibility of all the values in a MVTS window. A MVTS window can be out of distribution but still be relationally correct.
3 Relational Hallucination Detection and Mitigation using Diffusion Models
Previous works have shown that diffusion models trained to generate images can detect hallucinations in their generated outputs aithal2024understanding . They have also been successfully applied to MVTS imputation zhou2024mtsci and anomaly detection chen2023imdiffusion . We therefore consider diffusion models a promising candidate for arbitrary MVTS question answering through imputation, and the detection of relational hallucination.
Notations
To describe the prompt-response framework for MVTS imputation, we will use the following notation for each data point: , where indexes the data dimension. A prompt is defined by specifying the set of variables that will be used as the prompt and setting their values accordingly. The values for the remaining indices will be masked and imputed by the model to generate the response. As before, the predicted mean at each diffusion time-step will be denoted where . Note that denoising decrements the time-step from to . The final output (prediction) from the model () will be denoted as , where the imputed response is , and .
Conditioning
Once the prompt is defined, RePaint lugmayr2022repaint is used to condition an unconditional diffusion model trained on the dataset. The prompt is used as the conditioning in RePaint as described in Section 1.1.2. This allows diffusion models to act as a prompt-response model for general time-series question answering.

Relational Hallucination Metric
We propose the Combined Error (CE) metric that can be used to estimate the level of relational hallucination and a method to extract it from a diffusion model trained on the dataset. This metric can be computed for a given prompt-response pair obtained from some model such as a foundation model. It is computed by using RePaint to condition the diffusion model and setting the prompt as . The output of this process will be referred to as where the double hat denotes a prediction where the target is a previous prediction. The CE metric can be computed as
| (9) |
where the root mean square error is taken across the data dimension. Note that can be computed using a single denoising step (the final time-step going ). This is because RePaint allows the diffusion process to be skipped to the final step for all conditioning values, which in this case is the entire data dimension. This is done using the forward process (Eq. 8). Denoising using Eq. 4 is therefore only done on the final diffusion time-step and obtaining this metric is not computationally expensive. This process is shown in Fig. 1 (middle right).
To highlight properties of the CE metric, a diffusion model was trained on a small nonlinear 2D dataset. Fig. 1 (right) visualises the value of the CE metric for each point in this space. The CE metric is low in regions where the relations hold. This is true even in OOD regions without data. We also tested variations of metrics similar to aithal2024understanding . However, these are not effective, as shown in Appendix A.
Hallucination Detection
To use the proposed CE metric to gauge the expected level of relational hallucination, a dataset-specific scale is required to determine whether the metric is high/low relative to the dataset. We propose a simple method. Firstly, the CE metric is obtained for all the prompt-response pairs obtained from the training set, over all the imputation tasks. The quartiles of the CE metric are then computed. These quartiles are then used to classify the prompt-response pairs into classes of expected relational hallucination levels at inference: low (below the second quartile), medium (between the second and third quartile) and high (greater than the third quartile).
Hallucination Mitigation
we also propose a simple method for mitigating relational hallucination for non-deterministic models. For a given prompt, responses are sampled from the model. The CE metric can then be computed for all the obtained prompt-response pairs . The prompt-response pair with the lowest metric , where , is then selected as the response with the expected lowest relational hallucination.
4 Experiments
Why We Need New Datasets
In real-world settings, the ground-truth relation function is typically unknown. So, the ground-truth relational error cannot be computed for a given prompt-response pair. This work proposes the use of diffusion models to generate a metric for a given prompt-response pair, that can be used as an indirect measure for the relational error, and hence relational hallucination. To evaluate our proposed methods however, we require a dataset with a known that can be used to compute the ground-truth relational error. We introduce five such datasets: the relational electricity consuming load (rECL), relational weather (rWTH), relational traffic (rTraffic), relational illness (rIllness) and relational electricity transformer temperature (rETT) dataset, which are relational variations of popular MVTS datasets. We aim to demonstrate that our method can estimate relational hallucination by applying it to datasets where is known and hence the ground-truth relational error can be computed.
Datasets
The rECL dataset is derived from the electricity consuming load dataset ecldataset . In this case, the first and second variable are the electric consumption data for two different clients. The third variable is generated by taking the difference between the first two variables. The rWTH dataset is derived from the weather dataset wthdataset , another commonly used time-series dataset. Temperature and humidity is taken from this dataset and a third variable, vapour pressure deficit (VPD) is created which is a non-linear function of temperature and humidity where is the temperature in Celsius and is the relative humidity expressed as a decimal. This is a real-world example dataset that include the variables important for agriculture. rTraffic is derived from the traffic dataset trafficdataset , where the first two variables are the same as the original and the third variable is the sum of the two. rIllness is derived from the Illness dataset illnessdataset , where the first two variables are the same as the original and the third variable is the difference between the two. rETT is derived from the ETTh1 dataset zhou2021informer , where the first two variables are the ‘middle useful load’ and the oil temperature, and the third variable is the product of the two. A context length of is used for each data point, this results in each data point with since there are three variables. A schematic of this is shown in Fig. 1 (left top).
Tasks
We consider three types of prompts in this work, which will be referred to as tasks. To describe these tasks, we will split the indices of each data point using the following notation where indexes the variables and indexes the time-step within the data point. This is not the diffusion time-step and this splitting of the indices is only used in the description of the three tasks below. Illustrations of this index decomposition and the tasks are shown in the top left and middle left of Fig. 1.
-
•
Over-constrained (OC) - this task include prompts that constrain the response such that there is one correct response. For this task the indices and will be used for the prompt.
-
•
Under-constrained (UC) - this task include prompts that under-constrain the response such that there are multiple correct responses. For this task the indices and will be used for the prompt.
-
•
Forecast (FC) - this task does not separately constrain the related variables but provide the past variables as the prompt. For this task the indices will be used for the prompt.
Dataset Model Task = OC Task = UC Task = FC rECL Baseline DM (ours) MOMENT TIMER rWTH Baseline DM (ours) MOMENT TIMER rTraffic Baseline DM (ours) MOMENT TIMER rIllness Baseline DM (ours) MOMENT TIMER rETT Baseline DM (ours) MOMENT TIMER
Models
that will be evaluated on the tasks above are:
-
•
Baseline - Since each dataset will have different scales, a baseline is required to compare against. A weak baseline that returns the training set mean for each variable for all responses will be used.
-
•
Diffusion Model - The diffusion model trained on each dataset, which will be used for hallucination detection on that dataset. It can conveniently also be used for question answering. This will serve as a stronger baseline. The model uses a simple five layer MLP with 1 million parameters.
-
•
MOMENT goswami2024moment - A MVTS foundation model using a transformer encoder architecture, pre-trained on Time-Series Pile (20GB). We use the large model with 24 layers and 385M parameters. This model will be used for question answering only. MOMENT models MVTS in a channel-independent manner, a popular choice nie2022time . As shown in Fig. 1 (left bottom), we therefore provide additional context (24 time-steps) to each task to allow MOMENT to function on tasks like the OC and UC task. This makes the task easier.
-
•
TIMER liutimer - A MVTS foundation model using a transformer decoder architecture, pre-trained on the UTSD-4G dataset (1.2GB). It has 4 layers and 2M parameters. This model will be used for question answering only. Since TIMER requires at least the first token (24 time-steps) to be provided, additional context is also provided in the same way as MOMENT. This allows for a fair comparison.
Implementation
is in Python 3.11 using PyTorch. The diffusion models trained were all MLPs with five hidden layers of size 512. A linear variance schedule ranging from a value of 1e-4 to 1e-2 was used with 1000 diffusion steps. Models were trained using the ADAM optimizer diederik2014adam , one-cycle learning rate scheduler smith2019super , a maximum learning rate of 1e-3 and batch size of 1024. All models were trained up to a maximum of 8000 epochs with early stopping. The model with best validation loss was used for all subsequent experiments. The relational datasets use all the data present in the original dataset and were split into train, validation and test sets with a ratio of 5:1:1 in a chronologically increasing manner such that there is no overlap in time. Training runs on a single NVIDIA T1000 in 2-22 hours depending on the dataset.
4.1 Multi-Variate Time-Series Models Hallucinate
As the ground-truth relation is known for our datasets, the degree of relational hallucination exhibited by a model can be quantified. This is achieved by using each model to respond to all the prompts from the OC, UC and FC tasks on each dataset (test set), and then computing the relational error . The lower the average is, the better. As each dataset has different value scales, all comparisons are relative to the weak baseline. Since the diffusion model was trained on the training set of each dataset, it can be taken as a strong baseline. These values are shown in Table 1 (mean and standard deviation) for each model, task and dataset (test set). The mean values normalised by the baseline’s mean is also provided so that it is easier to compare across the datasets with different scales.
The results show that even with the handicap of being given extra context, both the pre-trained foundation models (MOMENT and TIMER) hallucinate heavily. They typically hallucinate less than the weak baseline but in some cases can match or even exceed it. The diffusion model (strong baseline) hallucinates the least, but nevertheless still hallucinates. All models relationally hallucinate the least on the FC task. This may be because there are no hard constraints on the values that must be predicted and the model is free to sample/predict values that are relationally correct. Averaging over the tasks and datasets, the relational hallucination level of the diffusion model, MOMENT and TIMER are 15.3%, 44.6% and 59.5% the values of the weak baseline. The results demonstrate that even models trained on each dataset can relationally hallucinate relative to that dataset, with this being exhibited much strongly in pre-trained foundation models.
4.2 Estimation of Hallucination Levels at Inference
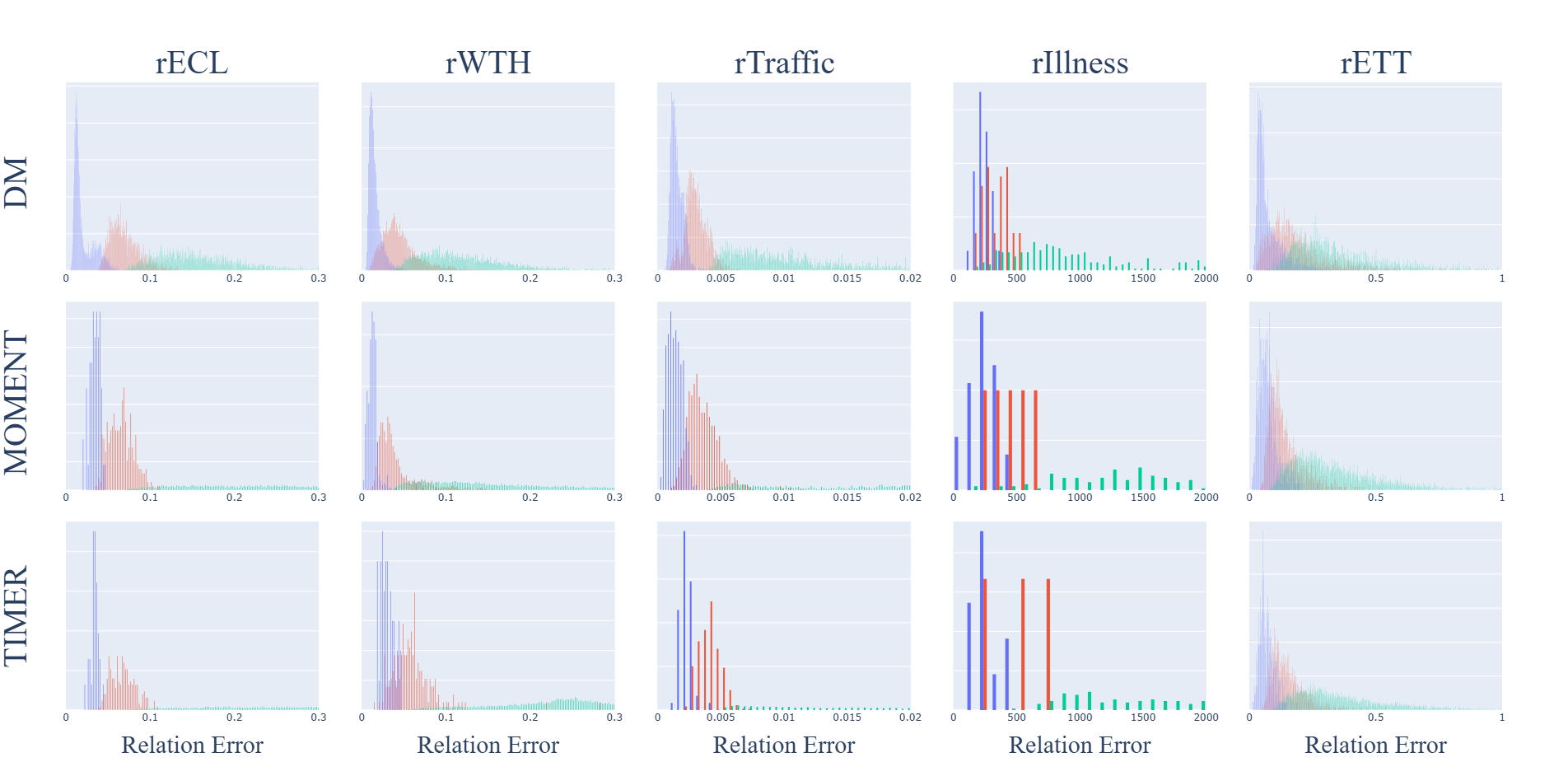
The following proposed quartile thresholding method is used to classify responses by their expected relational hallucination level: low, medium and high. This can be evaluated by computing the relational error for all the prompt-response pairs classified into each class. This gives us the distribution of for each class. The overlap coefficient between the distribution of for the low and high classes can be computed. These distributions will be referred to as and , respectively. They are of the form , where is the number of bins and the values are the probability in each bin with . The overlap coefficient between them can be computed as Lower coefficients mean better hallucination detection. A value of zero implies zero overlap, and a value of one implies that the distributions are identical. The results (mean and standard deviation) obtained for the models on each dataset averaged over five runs are shown in Table 2. The overlap coefficients are low (generally below 1%) except for the the rETT dataset which is a moderate value of around 15%.
The histogram of the relational error for each class of hallucination level is shown in Fig. 2. The results show that quartile thresholding is a simple and effective way to classify responses into their expected relational hallucination levels where the distributions with high and low hallucination have low overlap.
Dataset Model Overlap Coefficient (OC) (UC) (FC) rECL DM (ours) MOMENT TIMER rWTH DM (ours) MOMENT TIMER rTraffic DM (ours) MOMENT TIMER rIllness DM (ours) MOMENT TIMER rETT DM (ours) MOMENT TIMER
4.3 Mitigation of Hallucination at Inference
The proposed filtering method for mitigating relational hallucination can be evaluated using the ground-truth relation that is available for the proposed datasets used in this work. This can be achieved by computing the relational error for the response selected by filtering and comparing it to the mean relational error for the sampled responses . The relative change in relational error can then be computed . The lower is the better, with meaning there is no improvement. Since the foundation models (MOMENT and TIMER) are deterministic, a simple way make them non-deterministic and sample from them is to activate the dropout layers used for their training. The sample with the lowest CE is then selected. Instead of computing relative to the mean of the ensemble, it should be relative to the response from the model with deactivated dropout.
The relative change in relational error for each dataset averaged over 20 runs is given in Table 2 (mean and standard deviation). The average relative change is always less than unity, which means that the filtering method is effective, even when the pre-trained foundation models with dropout. The proposed method can on average reduce the relational error by up to 55.0% for the diffusion model and 47.7% for the pre-trained foundation models. This demonstrates that filtering using CE is a simple and effective method for mitigating relational hallucination.
5 Conclusion
Hallucination in MVTS imputation has been defined using analogies from established definitions in NLP. Pre-trained open-source MVTS foundation models are seen to hallucinate in this manner. By training a diffusion model on data in a target domain and extracting the proposed CE metric, it is possible to detect and mitigate MVTS hallucination, being able to on average reduce the hallucination of pre-trained FMs by up to 47.7%. This work encourages the responsible use of MVTS FMs by formally defining, detecting and mitigation MVTS hallucination.
Limitations and Further Work
While our work shows promising results, it is largely intuition-driven and empirical. For instance, our mitigation method statistically improves responses, but is not guaranteed to always do so. This can be improved through further work on methods with stronger theoretical guarantees. Additionally, the MLP architecture used for the diffusion model is simple, and hence does not naturally support variable length responses. Switching to other architectures such as the transformer will address this issue. Since we stack each variable into one time series as the input to the model, the simple MLP architecture does not scale well to a high number of variables or long windows. Exploring the use of latent diffusion or tokenisation may address this issue. There is, however, currently no consensus on the best architectures for MVTS and hence further work is required. Although the current method used to convert deterministic pre-trained MVTS foundation models into non-determinstic ones that can be sampled works, it is very simple. Exploring decoding strategies and methods from NLP for sampling responses that can be applied to MVTS is another promising direction.
References
- (1) Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv:2307.09288, 2023.
- (2) Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. GPT-4 technical report. arXiv:2303.08774, 2023.
- (3) Bonan Min, Hayley Ross, Elior Sulem, Amir Pouran Ben Veyseh, Thien Huu Nguyen, Oscar Sainz, Eneko Agirre, Ilana Heintz, and Dan Roth. Recent advances in natural language processing via large pre-trained language models: A survey. ACM Computing Surveys, 56(2):1–40, 2023.
- (4) Rohan Anil, Sebastian Borgeaud, Yonghui Wu, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: A family of highly capable multimodal models. arXiv preprint arXiv:2312.11805, 1, 2023.
- (5) Abdul Fatir Ansari, Lorenzo Stella, Caner Turkmen, Xiyuan Zhang, Pedro Mercado, Huibin Shen, Oleksandr Shchur, Syama Sundar Rangapuram, Sebastian Pineda Arango, Shubham Kapoor, et al. Chronos: Learning the language of time series. arXiv:2403.07815, 2024.
- (6) Abhimanyu Das, Weihao Kong, Rajat Sen, and Yichen Zhou. A decoder-only foundation model for time-series forecasting. arXiv:2310.10688, 2023.
- (7) Kashif Rasul, Arjun Ashok, Andrew Robert Williams, Arian Khorasani, George Adamopoulos, Rishika Bhagwatkar, Marin Biloš, Hena Ghonia, Nadhir Vincent Hassen, Anderson Schneider, et al. Lag-llama: Towards foundation models for time series forecasting. arXiv:2310.08278, 2023.
- (8) Azul Garza and Max Mergenthaler-Canseco. TimeGPT-1. arXiv:2310.03589, 2023.
- (9) Gerald Woo, Chenghao Liu, Akshat Kumar, Caiming Xiong, Silvio Savarese, and Doyen Sahoo. Unified training of universal time series forecasting transformers, 2024.
- (10) Mononito Goswami, Konrad Szafer, Arjun Choudhry, Yifu Cai, Shuo Li, and Artur Dubrawski. Moment: A family of open time-series foundation models. arXiv:2402.03885, 2024.
- (11) Yong Liu, Haoran Zhang, Chenyu Li, Xiangdong Huang, Jianmin Wang, and Mingsheng Long. Timer: Generative pre-trained transformers are large time series models. In Forty-first International Conference on Machine Learning, 2024.
- (12) Sabera Talukder, Yisong Yue, and Georgia Gkioxari. Totem: Tokenized time series embeddings for general time series analysis. arXiv:2402.16412, 2024.
- (13) Haixu Wu, Tengge Hu, Yong Liu, Hang Zhou, Jianmin Wang, and Mingsheng Long. Timesnet: Temporal 2D-variation modeling for general time series analysis. arXiv:2210.02186, 2022.
- (14) Tian Zhou, Peisong Niu, Liang Sun, Rong Jin, et al. One fits all: Power general time series analysis by pretrained LM. Advances in neural information processing systems, 2023.
- (15) Vipula Rawte, Amit Sheth, and Amitava Das. A survey of hallucination in large foundation models. arXiv:2309.05922, 2023.
- (16) Yue Zhang, Yafu Li, Leyang Cui, Deng Cai, Lemao Liu, Tingchen Fu, Xinting Huang, Enbo Zhao, Yu Zhang, Yulong Chen, et al. Siren’s song in the AI ocean: a survey on hallucination in large language models. arXiv:2309.01219, 2023.
- (17) Hongbin Ye, Tong Liu, Aijia Zhang, Wei Hua, and Weiqiang Jia. Cognitive mirage: A review of hallucinations in large language models. arXiv:2309.06794, 2023.
- (18) Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. Advances in neural information processing systems, 33:6840–6851, 2020.
- (19) Ling Yang, Zhilong Zhang, Yang Song, Shenda Hong, Runsheng Xu, Yue Zhao, Wentao Zhang, Bin Cui, and Ming-Hsuan Yang. Diffusion models: A comprehensive survey of methods and applications. ACM Computing Surveys, 56(4):1–39, 2023.
- (20) Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. In Proc. IEEE/CVF conference on computer vision and pattern recognition, 2022.
- (21) Xinyu Yuan and Yan Qiao. Diffusion-TS: Interpretable diffusion for general time series generation. arXiv:2403.01742, 2024.
- (22) Caspar Meijer and Lydia Y Chen. The rise of diffusion models in time-series forecasting. arXiv:2401.03006, 2024.
- (23) Jun Wang, Wenjie Du, Wei Cao, Keli Zhang, Wenjia Wang, Yuxuan Liang, and Qingsong Wen. Deep learning for multivariate time series imputation: A survey. arXiv:2402.04059, 2024.
- (24) Yiyuan Yang, Ming Jin, Haomin Wen, Chaoli Zhang, Yuxuan Liang, Lintao Ma, Yi Wang, Chenghao Liu, Bin Yang, Zenglin Xu, et al. A survey on diffusion models for time series and spatio-temporal data. arXiv:2404.18886, 2024.
- (25) Yusuke Tashiro, Jiaming Song, Yang Song, and Stefano Ermon. Csdi: Conditional score-based diffusion models for probabilistic time series imputation. Advances in Neural Information Processing Systems, 2021.
- (26) Chunjing Xiao, Zehua Gou, Wenxin Tai, Kunpeng Zhang, and Fan Zhou. Imputation-based time-series anomaly detection with conditional weight-incremental diffusion models. In Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 2742–2751, 2023.
- (27) Yuhang Chen, Chaoyun Zhang, Minghua Ma, Yudong Liu, Ruomeng Ding, Bowen Li, Shilin He, Saravan Rajmohan, Qingwei Lin, and Dongmei Zhang. Imdiffusion: Imputed diffusion models for multivariate time series anomaly detection. arXiv:2307.00754, 2023.
- (28) Mingzhe Liu, Han Huang, Hao Feng, Leilei Sun, Bowen Du, and Yanjie Fu. Pristi: A conditional diffusion framework for spatiotemporal imputation. In 2023 IEEE 39th International Conference on Data Engineering (ICDE), 2023.
- (29) Juan Miguel Lopez Alcaraz and Nils Strodthoff. Diffusion-based time series imputation and forecasting with structured state space models. arXiv:2208.09399, 2022.
- (30) Xu Wang, Hongbo Zhang, Pengkun Wang, Yudong Zhang, Binwu Wang, Zhengyang Zhou, and Yang Wang. An observed value consistent diffusion model for imputing missing values in multivariate time series. In Proc. 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2023.
- (31) Jianping Zhou, Junhao Li, Guanjie Zheng, Xinbing Wang, and Chenghu Zhou. Mtsci: A conditional diffusion model for multivariate time series consistent imputation. arXiv:2408.05740, 2024.
- (32) Andreas Lugmayr, Martin Danelljan, Andres Romero, Fisher Yu, Radu Timofte, and Luc Van Gool. Repaint: Inpainting using denoising diffusion probabilistic models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11461–11471, 2022.
- (33) Baolin Peng, Michel Galley, Pengcheng He, Hao Cheng, Yujia Xie, Yu Hu, Qiuyuan Huang, Lars Liden, Zhou Yu, Weizhu Chen, et al. Check your facts and try again: Improving large language models with external knowledge and automated feedback. arXiv:2302.12813, 2023.
- (34) Kurt Shuster, Spencer Poff, Moya Chen, Douwe Kiela, and Jason Weston. Retrieval augmentation reduces hallucination in conversation. arXiv:2104.07567, 2021.
- (35) Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in Neural Information Processing Systems, 33:9459–9474, 2020.
- (36) Anthony Chen, Panupong Pasupat, Sameer Singh, Hongrae Lee, and Kelvin Guu. Purr: Efficiently editing language model hallucinations by denoising language model corruptions. arXiv:2305.14908, 2023.
- (37) Neeraj Varshney, Wenlin Yao, Hongming Zhang, Jianshu Chen, and Dong Yu. A stitch in time saves nine: Detecting and mitigating hallucinations of llms by validating low-confidence generation. arXiv preprint arXiv:2307.03987, 2023.
- (38) Niels Mündler, Jingxuan He, Slobodan Jenko, and Martin Vechev. Self-contradictory hallucinations of large language models. arXiv:2305.15852, 2023.
- (39) Potsawee Manakul, Adian Liusie, and Mark JF Gales. Selfcheckgpt: Zero-resource black-box hallucination detection for generative large language models. arXiv:2303.08896, 2023.
- (40) Mohamed Elaraby, Mengyin Lu, Jacob Dunn, Xueying Zhang, Yu Wang, and Shizhu Liu. Halo: Estimation and reduction of hallucinations in open-source weak large language models. arXiv:2308.11764, 2023.
- (41) Jiaxin Zhang, Zhuohang Li, Kamalika Das, Bradley A Malin, and Sricharan Kumar. Sac3: Reliable hallucination detection in black-box language models via semantic-aware cross-check consistency. arXiv:2311.01740, 2023.
- (42) Sebastian Farquhar, Jannik Kossen, Lorenz Kuhn, and Yarin Gal. Detecting hallucinations in large language models using semantic entropy. Nature, 630(8017):625–630, 2024.
- (43) Yilun Du, Shuang Li, Antonio Torralba, Joshua B Tenenbaum, and Igor Mordatch. Improving factuality and reasoning in language models through multiagent debate. arXiv:2305.14325, 2023.
- (44) Yuyan Chen, Qiang Fu, Yichen Yuan, Zhihao Wen, Ge Fan, Dayiheng Liu, Dongmei Zhang, Zhixu Li, and Yanghua Xiao. Hallucination detection: Robustly discerning reliable answers in large language models. In Proceedings of the 32nd ACM International Conference on Information and Knowledge Management, pages 245–255, 2023.
- (45) Lorenzo Pacchiardi, Alex J Chan, Sören Mindermann, Ilan Moscovitz, Alexa Y Pan, Yarin Gal, Owain Evans, and Jan Brauner. How to catch an ai liar: Lie detection in black-box llms by asking unrelated questions. arXiv:2309.15840, 2023.
- (46) Abhika Mishra, Akari Asai, Vidhisha Balachandran, Yizhong Wang, Graham Neubig, Yulia Tsvetkov, and Hannaneh Hajishirzi. Fine-grained hallucination detection and editing for language models. arXiv preprint arXiv:2401.06855, 2024.
- (47) Yuheng Zha, Yichi Yang, Ruichen Li, and Zhiting Hu. Alignscore: Evaluating factual consistency with a unified alignment function. arXiv preprint arXiv:2305.16739, 2023.
- (48) Weihang Su, Changyue Wang, Qingyao Ai, Yiran Hu, Zhijing Wu, Yujia Zhou, and Yiqun Liu. Unsupervised real-time hallucination detection based on the internal states of large language models. arXiv preprint arXiv:2403.06448, 2024.
- (49) Yuzhe Gu, Ziwei Ji, Wenwei Zhang, Chengqi Lyu, Dahua Lin, and Kai Chen. Anah-v2: Scaling analytical hallucination annotation of large language models. arXiv preprint arXiv:2407.04693, 2024.
- (50) Yuzhe Gu, Wenwei Zhang, Chengqi Lyu, Dahua Lin, and Kai Chen. Mask-dpo: Generalizable fine-grained factuality alignment of llms. arXiv preprint arXiv:2503.02846, 2025.
- (51) Katherine Tian, Eric Mitchell, Huaxiu Yao, Christopher D Manning, and Chelsea Finn. Fine-tuning language models for factuality. In The Twelfth International Conference on Learning Representations, 2023.
- (52) Sheng-Chieh Lin, Luyu Gao, Barlas Oguz, Wenhan Xiong, Jimmy Lin, Scott Yih, and Xilun Chen. Flame: Factuality-aware alignment for large language models. Advances in Neural Information Processing Systems, 37:115588–115614, 2024.
- (53) Xiaoying Zhang, Baolin Peng, Ye Tian, Jingyan Zhou, Lifeng Jin, Linfeng Song, Haitao Mi, and Helen Meng. Self-alignment for factuality: Mitigating hallucinations in llms via self-evaluation. arXiv preprint arXiv:2402.09267, 2024.
- (54) Weixin Chen, Dawn Song, and Bo Li. Grath: Gradual self-truthifying for large language models. arXiv preprint arXiv:2401.12292, 2024.
- (55) Muru Zhang, Ofir Press, William Merrill, Alisa Liu, and Noah A Smith. How language model hallucinations can snowball. arXiv:2305.13534, 2023.
- (56) Jack Gallifant, Amelia Fiske, Yulia A Levites Strekalova, Juan S Osorio-Valencia, Rachael Parke, Rogers Mwavu, Nicole Martinez, Judy Wawira Gichoya, Marzyeh Ghassemi, Dina Demner-Fushman, et al. Peer review of GPT-4 technical report and systems card. PLOS Digital Health, 3(1):e0000417, 2024.
- (57) Jingkang Yang, Kaiyang Zhou, Yixuan Li, and Ziwei Liu. Generalized out-of-distribution detection: A survey. International Journal of Computer Vision, 132(12):5635–5662, 2024.
- (58) Zahra Zamanzadeh Darban, Geoffrey I Webb, Shirui Pan, Charu Aggarwal, and Mahsa Salehi. Deep learning for time series anomaly detection: A survey. ACM Computing Surveys, 57(1):1–42, 2024.
- (59) Sumukh K Aithal, Pratyush Maini, Zachary C Lipton, and J Zico Kolter. Understanding hallucinations in diffusion models through mode interpolation. arXiv:2406.09358, 2024.
- (60) Artur Trindade. ElectricityLoadDiagrams20112014. UCI Machine Learning Repository, 2015. DOI: https://doi.org/10.24432/C58C86.
- (61) Max Planck Institute for Biogeochemistry. Weather data. https://www.bgc-jena.mpg.de/wetter/, 2024. Accessed: 2025-01-16.
- (62) California Department of Transportation. Performance measurement system (pems). http://pems.dot.ca.gov/, 2024. Accessed: 2025-01-16.
- (63) Centers for Disease Control and Prevention. Fluview: Flu activity & surveillance. https://gis.cdc.gov/grasp/fluview/fluportaldashboard.html, 2024. Accessed: 2025-01-16.
- (64) Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang. Informer: Beyond efficient transformer for long sequence time-series forecasting. In Proc. AAAI conference on Artificial Intelligence, 2021.
- (65) Yuqi Nie, Nam H Nguyen, Phanwadee Sinthong, and Jayant Kalagnanam. A time series is worth 64 words: Long-term forecasting with transformers. arXiv:2211.14730, 2022.
- (66) P Kingma Diederik. Adam: A method for stochastic optimization. arXiv:1412.6980, 2014.
- (67) Leslie N Smith and Nicholay Topin. Super-convergence: Very fast training of neural networks using large learning rates. In Artificial intelligence and machine learning for multi-domain operations applications, volume 11006, pages 369–386. SPIE, 2019.
Appendix A Other Metrics
It has been shown on a computer vision and toy Gaussian dataset that a measure of hallucination can be extracted from unconditional diffusion models during the generation process [59]. This measure will be referred to as the the trajectory variance (TV), which is the variance of the predicted mean with respect to the diffusion time-step. The predicted mean at each diffusion time-step (Eq. 4) is obtained from the generation process and will be written as , where indexes the data dimension and indexes the diffusion time-step. The TV metric is calculated as
| (10) |
where variance is taken across the diffusion time-step and mean across the data dimension. A schematic example of this is shown in Fig. 3. This measures the variation in the trajectory of the variables during the diffusion process.
TV however only applies to unconditional generation and does not apply to the prompt-response framework using imputation. This is because in the prompt-response framework, the subset of the data dimension that is used for the prompt is not unconditionally generated. Three modifications to the TV metric that address this are proposed. These are response trajectory spread (RTS), prompt trajectory spread (PTS) and combined trajectory spread (CTS) metrics. We also propose two additional metrics that use the magnitude of the noise returned by the diffusion model as a metric to detect hallucination. These are prompt error (PE) and combined error (CE). The combined error is the metric presented in the main text as this is the most effective metric and the other metrics fail at detecting relational hallucination.

Response Trajectory Spread (RTS)
Since TV is computed for unconditional generation, the simplest generalisation to the prompt-response framework is to compute this metric for the response only, as this is the part which is generated in a similar manner. Instead of using the variance however, this work uses the standard deviation since it is simpler and is more interpretable. The response trajectory spread (RTS) can be computed as
| (11) |
where standard deviation is taken across the diffusion time-step, and mean across the data dimension. This is illustrated in Fig. 3 but with standard deviation instead of variance.
Prompt Trajectory Spread (PTS)
As we are using RePaint [32] to condition the diffusion model, all predicted means of the prompt are clamped to the values provided by the prompt. The values provided by the prompt can therefore be used as the mean that is required to compute the standard deviation. The prompt trajectory spread (PTS) can be computed as
| (12) |
where the root mean square error is taken across the diffusion time-step and the mean across the data dimension.
Combined Trajectory Spread (CTS)
The final output from the model which combines both the prompt and the response can also be used to compute the trajectory spread. The full diffusion process can be computed one more time by setting the prompt as . The combined trajectory spread (CTS) can then be computed for this as
| (13) |
where the root mean square error is taken across the diffusion time-step and the mean is taken across the data dimension. Since the full diffusion process has to be computed completely an additional time, this metric is computationally expensive. CTS is like PTS but includes both the prompt and response.
Prompt Error (PE)
The previous metrics are all based on the trajectory variance [59]. This work proposes two additional simple metrics based on the reconstruction error of the final output of the model. The first considers the reconstruction error of the output with respect to the prompt. Only indices are used since as are the only values where ground-truth is available through the values provided by the prompt. PE can be computed as
| (14) |
where the RMSE is taken across the data dimension.
Combined Error (CE)
The PE metric can be extended to also include the response indices in the same way as the CTS metric, which leads to the CE metric of Eqn. 9.
A.1 Sensitivity to Relational Hallucination
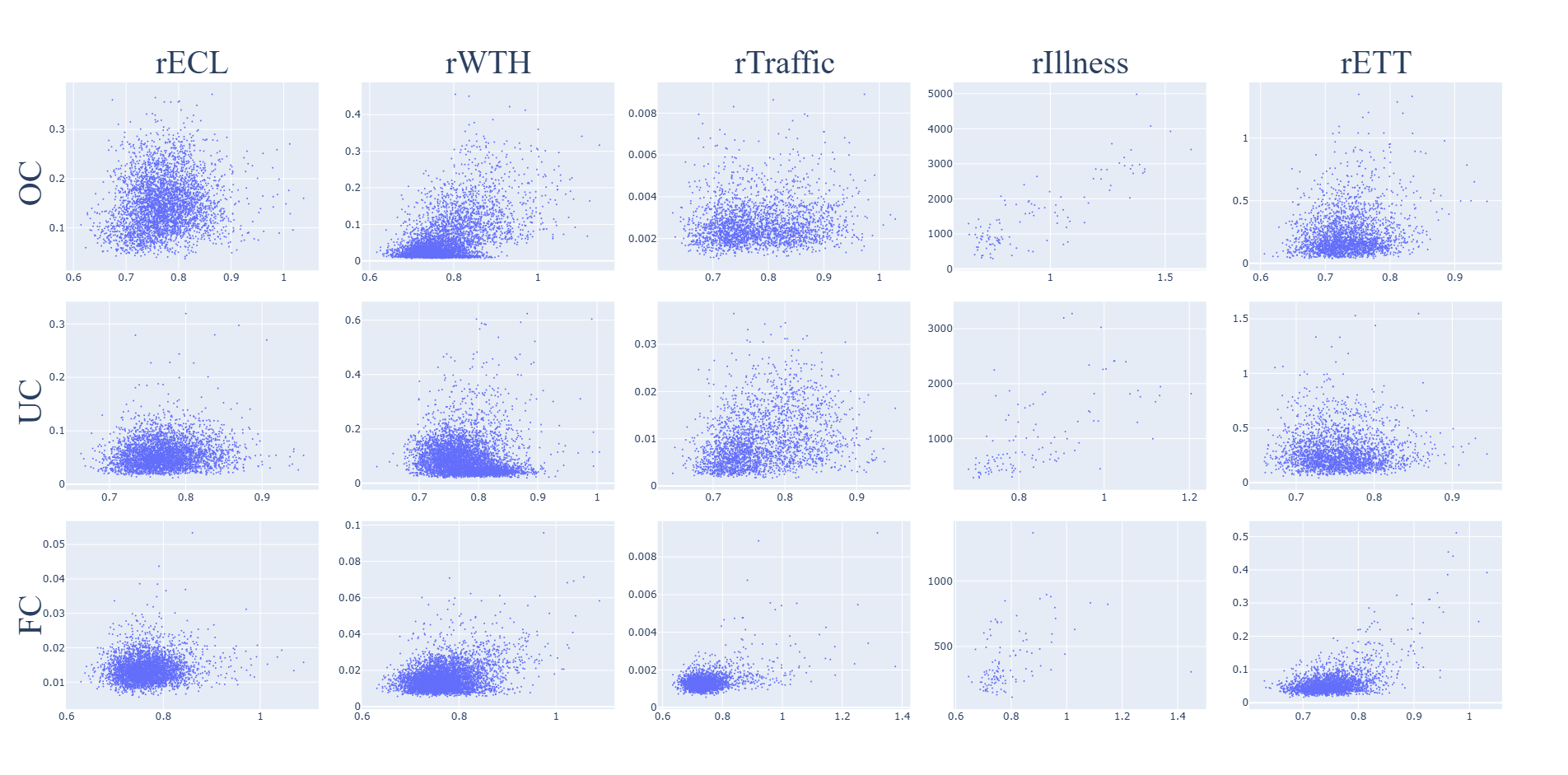
RTS
The sensitivity of the RTS metric to the relational error on the test set for each task and dataset is shown in Fig. 4. The metric is not sensitive to the relational error.
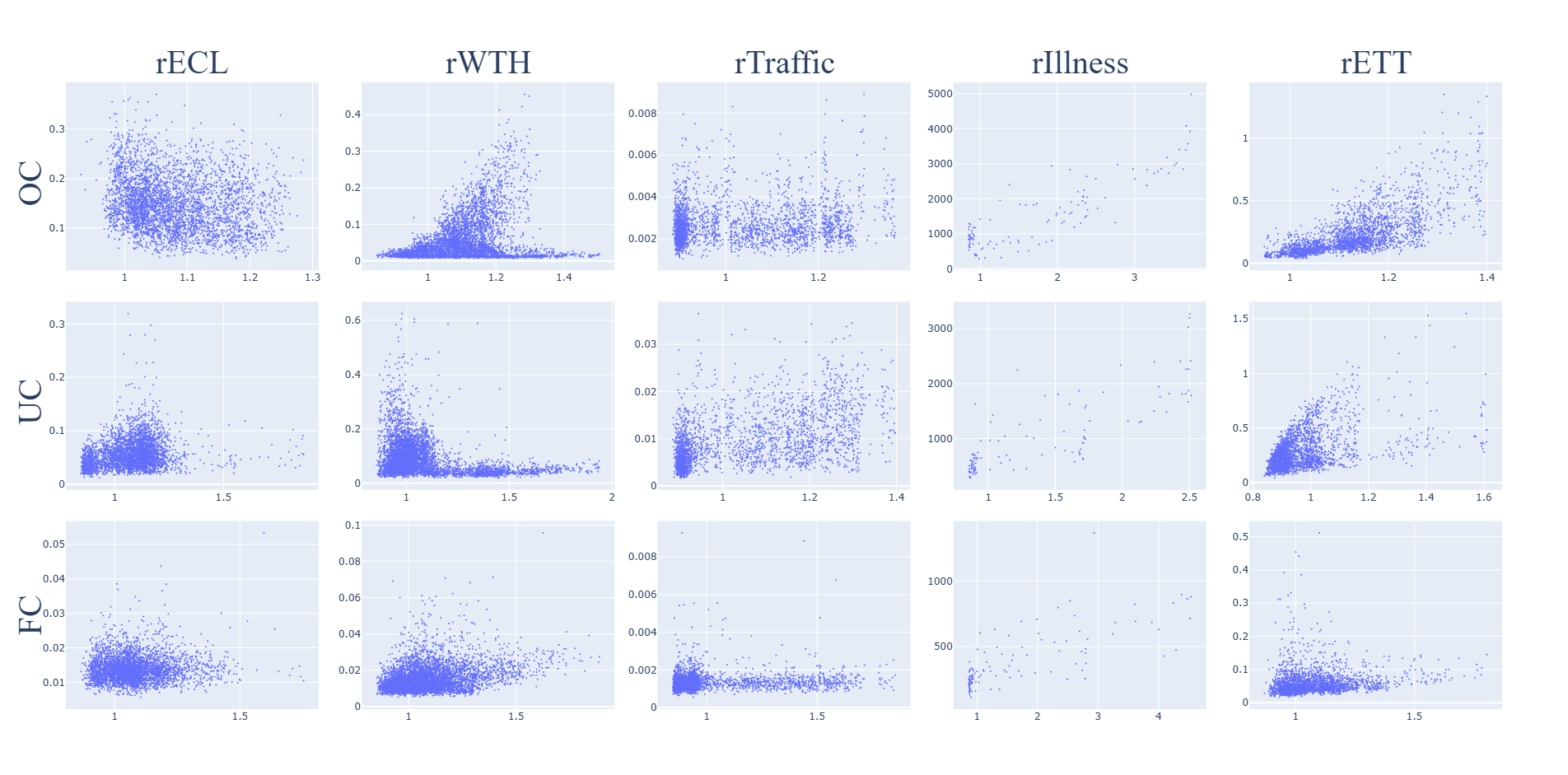
PTS
The sensitivity of the PTS metric to the relational error on the test set for each task and dataset is shown in Fig. 5. The metric is not sensitive to the relational error.
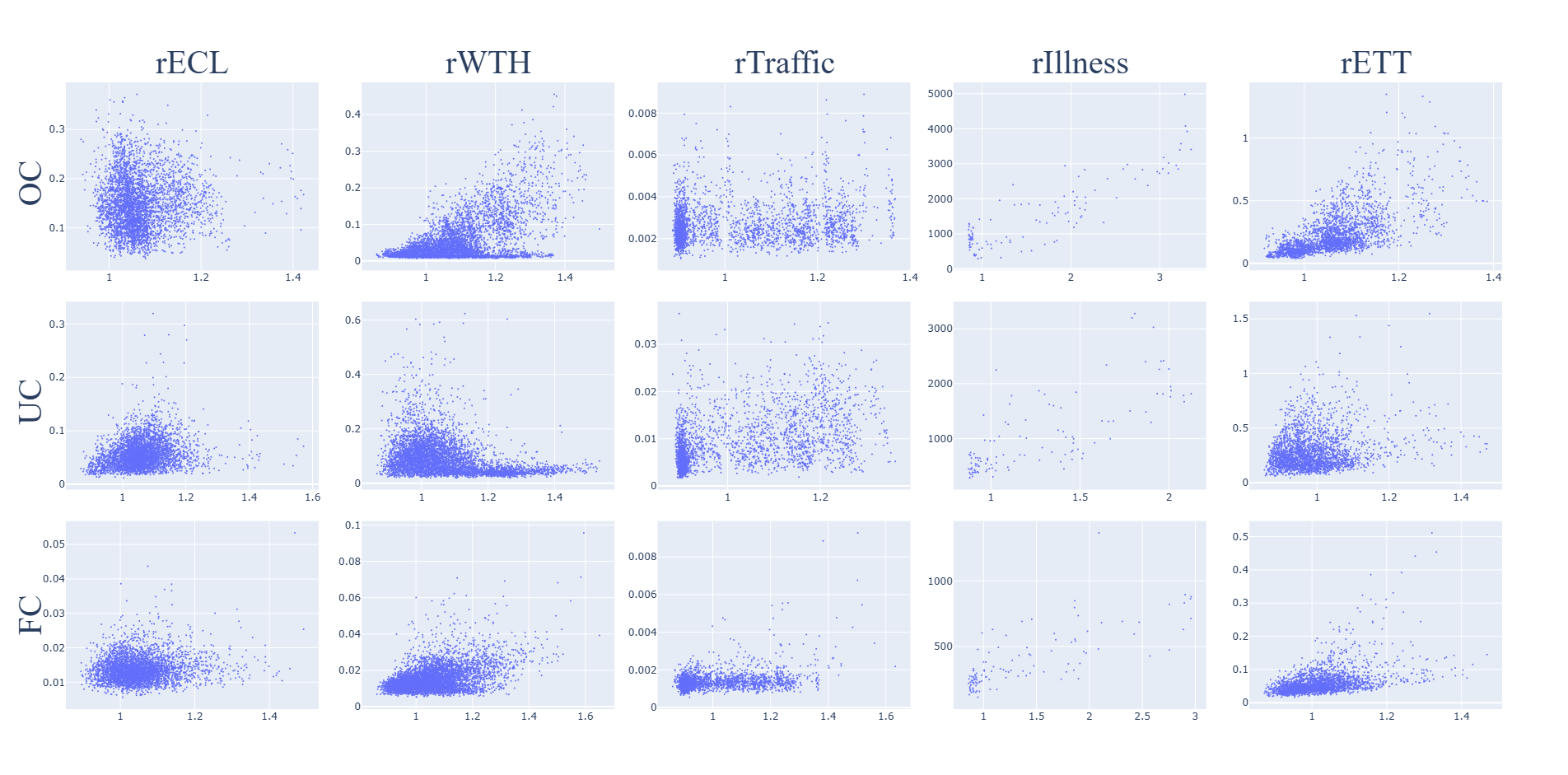
CTS
The sensitivity of the CTS metric to the relational error on the test set for each task and dataset is shown in Fig. 6. The metric is not sensitive to the relational error.
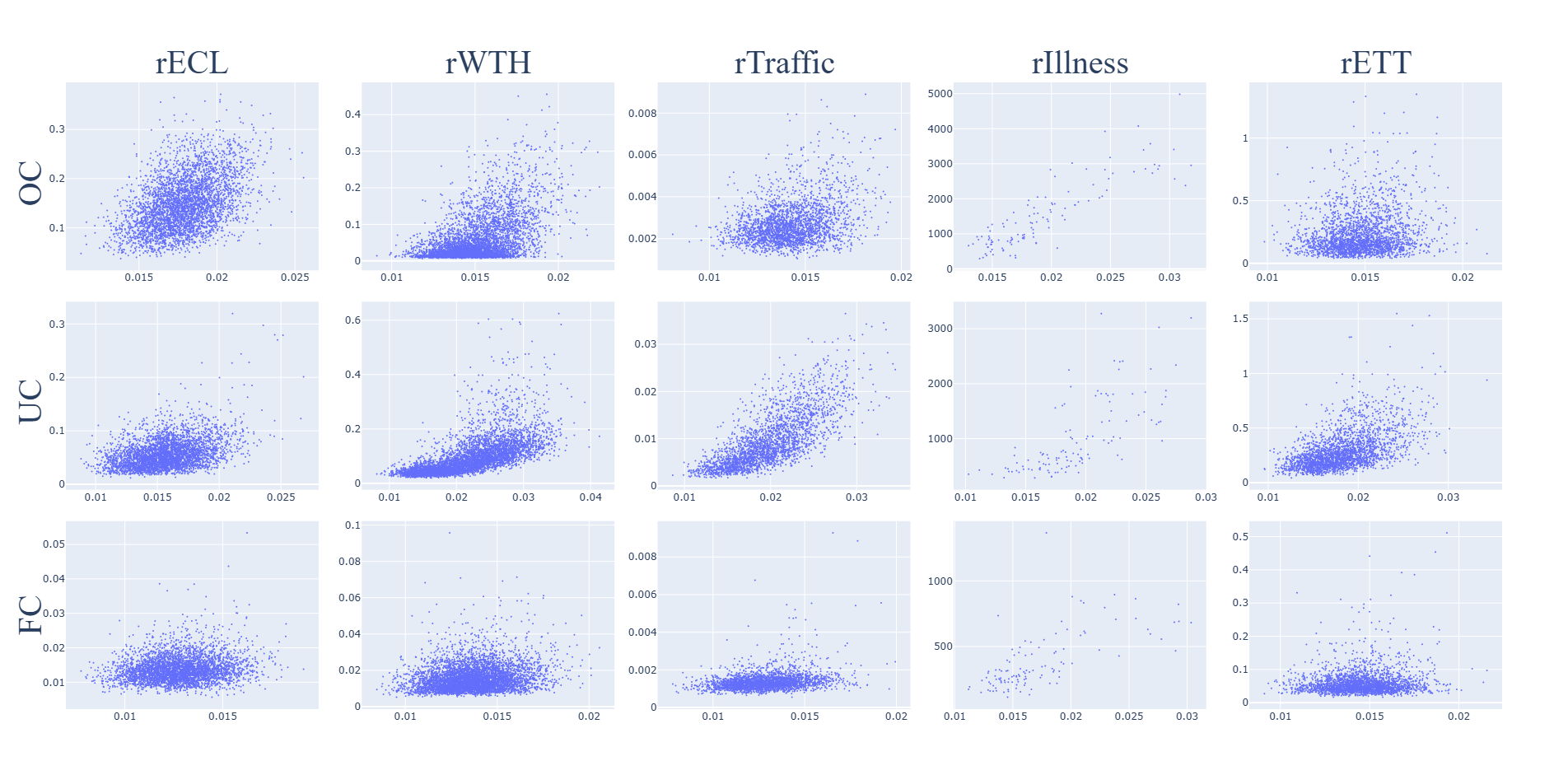
PE
Sensitivity of PE to relational error on the test set for each task and dataset is shown in Fig. 7. PE is not as robustly and consistently sensitive to the relational error as the CE metric, which is shown in Fig. 8. This may be because PE only includes the prompt, and since relational hallucination is the inconsistency of a prompt-response pair, it is expected that a metric including both the prompt and response such as CE would perform better.
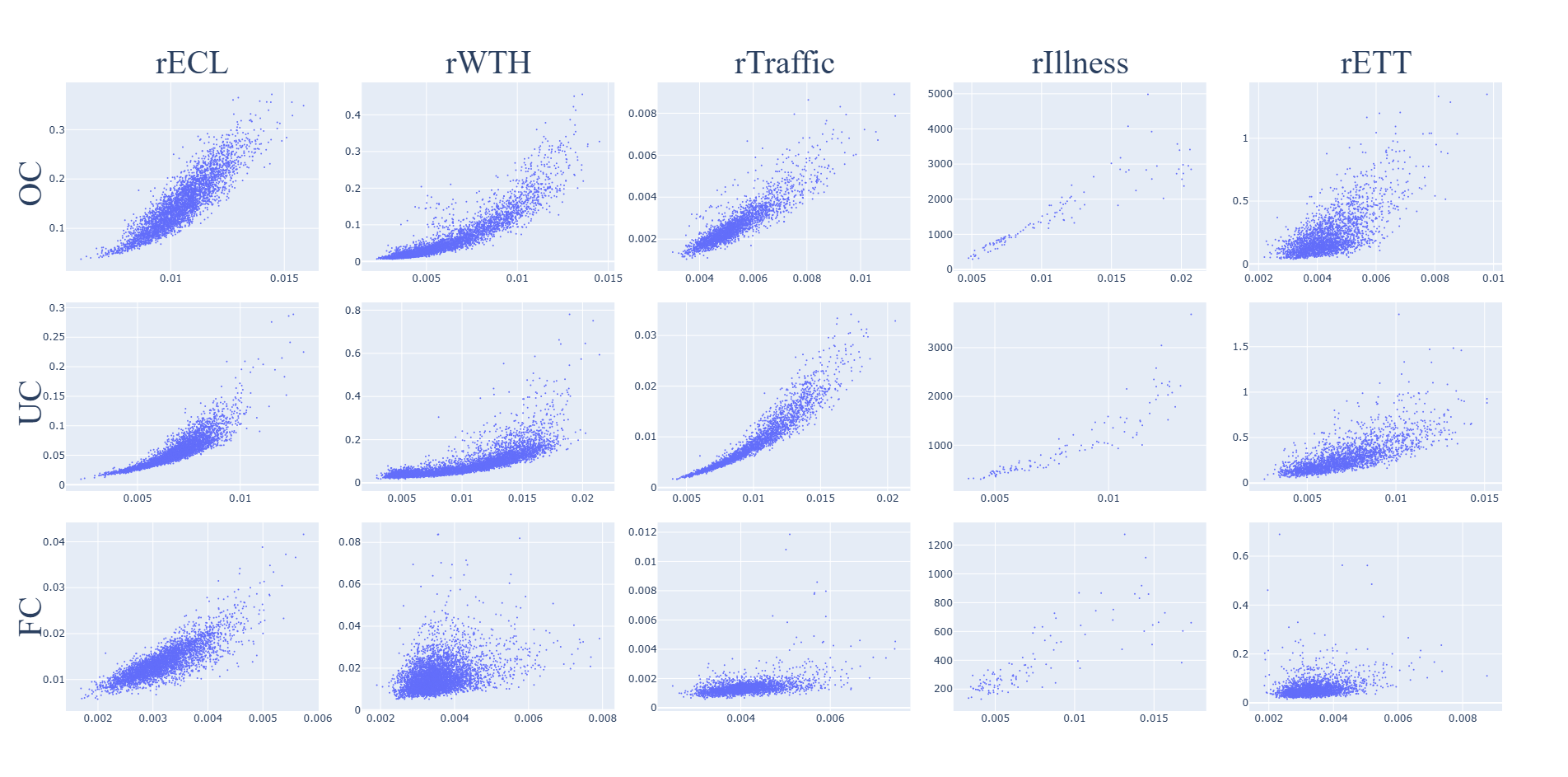
CE
Sensitivity of CE to relational error on the test set for each task and dataset is shown in Fig. 8. The CE metric is sensitive to the relational error.
Appendix B Licenses for Existing Assets
B.1 Datasets
The datasets are commonly used MVTS time-series datasets and can be accessed from the Autoformer repository (https://github.com/thuml/Autoformer) which is under MIT license.
-
•
ECL - CC BY 4.0
-
•
WTH - N/A
-
•
Traffic - CC BY 4.0
-
•
Illness - N/A
-
•
ETT - CC BY-ND 4.0
B.2 Models
-
•
MOMENT - MIT (https://github.com/moment-timeseries-foundation-model/moment)
-
•
TIMER - MIT (https://github.com/thuml/Large-Time-Series-Model)