HBMax: Optimizing Memory Efficiency for Parallel Influence Maximization on Multicore Architectures
Abstract.
Influence maximization aims to select most-influential vertices or seeds in a network, where influence is defined by a given diffusion process. Although computing optimal seed set is NP-Hard, efficient approximation algorithms exist. However, even state-of-the-art parallel implementations are limited by a sampling step that incurs large memory footprints. This in turn limits the problem size reach and approximation quality. In this work, we study the memory footprint of the sampling process collecting reverse reachability information in the IMM (Influence Maximization via Martingales) algorithm over large real-world social networks. We present a memory-efficient optimization approach (called HBMax) based on Ripples, a state-of-the-art multi-threaded parallel influence maximization solution. Our approach, HBMax, uses a portion of the reverse reachable (RR) sets collected by the algorithm to learn the characteristics of the graph. Then, it compresses the intermediate reverse reachability information with Huffman coding or bitmap coding, and queries on the partially decoded data, or directly on the compressed data to preserve the memory savings obtained through compression. Considering a NUMA architecture, we scale up our solution on 64 CPU cores and reduce the memory footprint by up to with average speedup (encoding overhead is offset by performance gain from memory reduction) without loss of accuracy. For the largest tested graph Twitter7 (with 1.4 billion edges), HBMax achieves compression ratio and speedup.
1. Introduction
A graph, , captures complex relationships between a set of entities represented as nodes or vertices (), through binary relations expressed as edges or links (). Graph analytics provides a set of algorithms such as centrality measures, community detection, shortest paths, and network flow to enable decision making on data presented as graphs. The ubiquity of massive data from domains such as social networks and life sciences has enabled application of graph analytics on numerous domains with varying degrees of scale. A fundamental limitation to the application of graph analytics is the massive memory requirement of algorithms. Since many graph algorithms have irregular accesses to memory and low (arithmetic) computation, the performance of memory system becomes critical.
Given a directed graph , where represents edge weights corresponding to the influence of node on node for an edge ; a diffusion model, and a budget ; the Influence Maximization (IM) problem is an optimization problem to identify a set of vertices which when activated result in a maximal number of expected activation in , where activation is defined for a given model of diffusion. The IM problem came from viral marketing, where a company tried to create a cascade of product adoption through the word-of-mouth effect by choosing a set of influential individuals and giving them free samples of the product. Now It has numerous applications (Kempe et al., 2003; Leskovec et al., 2007; Minutoli et al., 2020b) in domains such as politics, public health, bioinformatics, and sensor networks.
Finding the top influential vertices (i.e., seeds) in a graph can be formulated as a discrete optimization problem that has been shown to be NP-Hard (Kempe et al., 2003). Consequently, a few key efficient approximation solutions have been developed. For instance, Kempe et al. (Kempe et al., 2003) attempts to find an approximate solution by hill-climbing on a large number of Monte Carlo (MC) diffusion processes (typically around ). Borgs et al. (Borgs et al., 2014) greatly improves the efficiency of MC simulations by exploiting the potential overlap in the vertex space among multiple simulated paths of diffusion. Their approach enumerates random reverse reachable (RRR) sets and using them to select influential vertices that occur frequently in them. Tang et al. (Tang et al., 2015) further extend this work with a two-phase IMM algorithm (including sample estimation and seed selection) to improve the determination of the sampling effort through a martingale strategy (will be discussed in detail in Section 2). The targeted quality is a -approximation. The error factor plays an important role in the overall performance of the IMM algorithm. Smaller will produce a more accurate approximation by making the algorithm carry out more MC trials. With the growing size of social networks and the goal of getting high-quality approximation, the IMM algorithm is both computationally challenging and memory demanding. To alleviate this challenge, parallel computing has been introduced to reduce the execution time of the IMM algorithm. Ripples, proposed by Minutoli et al. (Minutoli et al., 2019) is the state-of-the-art parallel implementation of the IMM algorithm. It can solve the time-cost challenge by parallelizing the computation and scaling up in both the shared-memory and distributed-memory architectures.
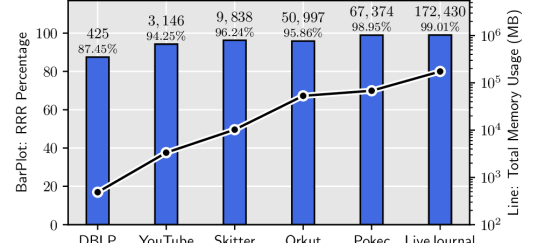
However, few studies in the literature address the memory-intensive challenge, which should have a standalone place in the research on the IMM algorithm. More specifically, the reason to address the memory challenge of the IMM algorithm is two-fold: (1) Although the aggregated memory capacity of today’s high-performance computing (HPC) systems is ever-increasing, such distributed computing resource is not readily available to most. Thus, reducing the memory usage on shared-memory systems helps to solve larger influence maximization problems with limited computational resources. (2) There is a vast difference between the input graph size and the memory footprint during the computation (Ghosh et al., 2021). This memory inflation (by the algorithm) is particularly pronounced for a stochastic graph application such as IMM. For instance, for the six graphs studied in Figure 1, the ratio of the peak memory usage to the input size varies from 30 to 165—implying a one to two orders of magnitude increase in memory requirement during the course of computation to store the intermediate results.
To this end, we propose a memory-efficient parallel influence maximization algorithm using Huffman coding and Bitmap coding (called HBMax) and implement it based on the state-of-the-art implementation Ripples (Minutoli et al., 2020a). Specifically, by profiling the memory footprint of Ripples on large real-world graphs, we identify the most demanding portion of the algorithm and different demands with different types of graphs. With these characteristics, we propose a block-based workflow that leverages the Huffman coding or bitmap coding to save the intermediate MC simulation results in a compressed format. The subsequent analysis can be performed on partially decompressed Huffman encoded data or directly performed on the bitmap encoded data: neither of the two schemes needs to fully decompress the data to the original size, so as to preserve the memory savings. To the best of our knowledge, this work represents the most space-efficient parallel IMM on very large graphs. Our main contributions are summarized as follows.
-
(1)
We conduct a comprehensive characterization and profiling of different real-world graphs to understand the impact of their features on the memory footprint based on the state-of-the-art solution for the influence maximization problem.
-
(2)
We identify the intermediate RRR sets sampled from MC simulations vary from skewed-distributed to flat-head distributed. We propose a scalable “compress-to-compute” based IMM method (called HBMax) that leverages the Huffman coding or bitmap coding to reduce the memory footprint of saving intermediate RRR sets based on these characteristics.
-
(3)
We propose two efficient seed selection approaches based on the two encoding methods. Specifically, for Huffman-encoded intermediate RRRs, we exploit data locality to query the compressed RRRs without fully decoding them; for bitmap-encoded RRRs, we directly query the compressed RRRs with bit operations. Moreover, we propose a new parallel max-reduction method for finding the vertex with the maximum frequency to improve the scalability of seed selection.
-
(4)
We evaluate our HBMax and compare it with the original Ripples implementation on eight large graphs (Ripples cannot run the largest two graphs on the tested machine with 376 GB RAM). Experiments show that HBMax reduces the memory usage by up to with speedup (the encoding overhead is offset by performance gain from memory reduction). Moreover, HBMax can reduce the overall time by up to with the same memory footprint when compared to Ripples.
The rest of this paper is organized as follows. In Section 2, we present background information about the IM problem, state-of-the-art algorithms and implementations, Huffman coding, bitmap coding and related work. In Section 3, we profile the memory footprint of Ripples with different graphs and characterize input graphs into two main categories. In Section 4, we propose our three optimizations for memory footprint reduction and performance/scalability enhancement. In Section 5, we evaluate our optimized IMM solution and compare it with the state-of-the-art method on large graphs. In Section 6, we conclude our work and discuss the future work.
2. Background and Related Work
In this section, we introduce the influence maximization problem, the RIS and IMM algorithms, Ripples software, Huffman/bitmap compression, and compressed-based graph analytics.
2.1. Influence Maximization Problem
Let be a graph with vertices and edges. Given and a stochastic diffusion process, the influence maximization problem is one of identifying a set of top vertices in (called “seeds”) that maximizes the expected influence spread () in , measured by the number of activated vertices. Kempe et al. (Kempe et al., 2003) have shown that is a submodular function of for two simple but powerful diffusion models: the independent cascade model (IC) and the linear threshold model (LT). Submodular functions have the property of diminishing marginal gains and leads to efficient approximation algorithms (Nemhauser et al., 1978). Leveraging the submodularity framework, they propose a greedy hill-climbing algorithm that offers an approximation guarantee of (Kempe et al., 2003).
The IC and LT diffusion models are broadly studied in the literature. The IC model comes from the physics of interacting particles. In this model, each newly activated vertex has a single chance to activate its neighbors. Assuming a directed graph as an example, each edge is assigned with a probability to trigger the activation of from . When the vertex gets activated at time , then at time , the vertex gets activated with the probability .
In contrast, the LT model captures mass behaviours. Each vertex has a threshold modeling their resistance to adopting the mass behavior and each edge has a weight representing the capacity of to influence . At time , a vertex gets activated if the sum of the weights on the incoming edges from its already active neighbors exceeds its threshold. It is worth noticing that the edge weights are provided by input graphs, but they are not corresponding to the probability of activation. Thus they only affect the LT model instead of the IC model.
The LT diffusion model tends to produce very small RRR sets and more than of them end up with less than 10 vertices (Minutoli et al., 2020a). On the contrary, the sizes of RRR sets from the IC model is less skewed and tend to be of larger size. From a utility standpoint, the IC model is more generally applicable to abstract a range of diffusion processes. It can be viewed as a special case of the Susceptible-Infected-Recovered (SIR) models (Minutoli et al., 2020b) used in epidemics. However, its large memory footprint (as shown in Figure 1) limits its scalability, so we focus on the IC diffusion model in this paper.
2.2. RIS, IMM, and Ripples
Reverse Influence Sampling. Following the seminal work (Kempe et al., 2003), Borgs et al. (2014) proposed an approximation algorithm based on the idea of Reverse Influence Sampling (RIS). Their scheme attempts to find which are the most likely causes of activation for each vertex in the graph. The algorithm randomly samples vertices and simulates the diffusion model in reverse collecting sets of vertices which may cause the activation of . The seed sets is later decided by solving a maximum coverage problem over the sets collected through RIS. This approach provides the same approximation guarantee as the greedy hill-climbing algorithm (Kempe et al., 2003).
The RIS approach is the fundamental building block of the IMM algorithm from Tang et al. (2015), and its state-of-the-art parallel implementation Ripples (Minutoli et al., 2019) is the starting point for our work. In the following, we give important definitions and a high-level description of the fundamental building blocks of the IMM and Ripples algorithm. We direct the reader to the original work for a more exhaustive presentation.
Definition 2.1 (Reverse Reachable (RR) Set).
Let be the transposed graph obtained from by inverting the orientation of all the edges in . The reverse reachable set of a vertex is the set of vertices that are reachable from in .
Definition 2.2 (Random Reverse Reachable (RRR) Set).
Let be a subgraph of obtained by edge removal by retaining only the active edges during a simulation of a diffusion process on . A random reverse reachable set for a vertex is the set of vertices that are reachable from in , where is the transposed graph obtained from .
In the following discussion, we use RRR sets to refer to the collection of random reverse reachable sets. We use rr or sample to refer to one RRR. Since each RRR is a set of vertices, we refer the cardinality of an RRR as the size of RRR.
IMM and Ripples. Although the reverse reachable scheme of Borgs et al. greatly improves the efficiency of MC simulations, it could overestimate the required number of MC simulations and waste a lot of computation. The IMM algorithm proposed by Tang et al. (2015) adopts a two-phase design to algorithmically determine the sampling effort by leveraging a martingale strategy111The martingale strategy is a betting strategy in which a person doubles the bet every time they lose knowing that they must win at some point. It first samples a small number of RRR sets to calculate the achieved influence and then doubles the number of samples until the influence reaches an estimated lower bound. . This strategy greatly improves the performance so that IMM algorithm can analyze large graphs with millions of vertices.
Specifically, the two-phase design works as follows. In the Sampling phase, the algorithm will produce RRRs starting from random vertices in the input graph and simulating the diffusion model (IC or LT) in reverse. In the case of the IC and LT model, the task of generating a RRR set resembles a randomized breadth-first search (BFS) where only a subset of the neighbors of a vertex enter the next frontier. To estimate the required sampling effort () to achieve the approximation guarantee (controlled through the parameter ), the algorithm uses two important results. Borgs et al. showed that the fraction of RRR covered during the seed selection process is an unbiased estimator of the influence function while Tang et al. were able to prove a lower bound on the sampling effort using an estimation of the influence function. In Equation (1), Tang et al. shows the algorithm starts with a guess on and doubles the sampling effort at every iteration until the exit condition derived from the lower lower bound is satisfied and the final value of is computed. Here is the number of vertices, is the number of seeds, is the error factor, and is the required number of sampling. The larger and are, the larger will be. On the other hand, small error factor will increase non-linearly. This process resembles to the martingale betting strategy.
| (1) |
The Seed Selection algorithm is based on the greedy maximum coverage algorithm (Vazirani, 2001). The method iterates times over the RRR sets to select the vertex appearing most frequently. At every iteration , the RRR sets covered by one of the seeds already selected are ignored. Minutoli et al. (2019, 2020a) devise efficient parallel schemes that perform the counting by either updating the state of the previous iteration or recount from scratch when more profitable.
Ripples (Ripples, 2022) is a state-of-the-art parallel software framework that provides fast and scalable implementation for the IM problem. According to (Minutoli et al., 2019, 2020a), its CPU version provides a speedup of 580 over the best sequential baseline using 1024 nodes, and its CPU+GPU version provides a speedup of 760 over the best sequential baseline.
2.3. Huffman Coding and Bitmap Compression
Huffman coding is a classical data compression technique (Huffman, 1952). It assigns variable-length codes to encode target characters based on their relative frequency, which gets better reduction when the data has skewed distribution (Roth and Van Horn, 1993). The Huffman codes are prefix-free and are typically created as a binary tree with the encoded characters stored at the leaves. There are works that adopt Huffman coding to reduce the memory footprint. For example, Suontausta and Tian (Suontausta and Tian, 2003) applied Huffman coding for efficiently storing decision tree parameters to minimize the memory footprint. Ficara et al. (Ficara et al., 2010) adopted Huffman coding to improve counting bloom filters in terms of fast access and limited memory consumption.
Bitmap is a mapping from some domain (e.g., a range of integers) to bits (Foley et al., 1996). It not only reduces the data size but also allows efficient direct operations such as binary logic operations (Martínez-Bazan et al., 2012). Thus, many efficient bitmap compression schemes have been extensively studied in the database systems, such as BBC, WAH, EWAH, and Roaring (Wang et al., 2017). However, none of these work exploited data analytics on the Huffman or bitmap encoded data directly.
2.4. Graph Compression and Data Analytics on Compressed Data
Due to the growing sizes of graphs, researchers have been studying compression techniques for graphs. For example, Randall et al. (Randall et al., 2002) tried to compress the links of web graphs by leveraging the locality of web graphs. Ligra (Shun and Blelloch, 2013) and SlimGraph (Besta et al., 2019) focused on providing frameworks that can facilitate graph analytics with compression scheme. The Ligra framework mainly utilizes the vertex degrees and graph density to select a scheme to map vertices or edges to integer-arrays or bit-vectors, while SlimGraph focuses more on utilizing statistics of local parts in the input graph to map vertices and edges to higher hierarchies. Thus, its compression kernels can preserve some critical graph properties. However, the use of these frameworks needs to re-program the graph applications with their specific syntax and semantics. This is a non-trivial effort for most of the graph algorithms and applications in the literature.
Moreover, there are a few works that investigate data analytics directly on compressed data without decompression. For example, Zhang et al. proposed an approach to perform document analytics (word count, inverted index, and sequence count) directly on compressed textual data on CPUs (Zhang et al., 2021b) and GPUs (Zhang et al., 2021a; Pan et al., 2021; Liu et al., 2022). Moreover, Zhang et al. developed a new storage engine, called CompressDB, which can support data processing for databases without decompression (Zhang et al., 2022). Furthermore, Macko et al. (Macko et al., 2015) proposed LLAMA that performs graph storage and analysis on the compressed sparse row (CSR) representation and achieves performance gain on graph benchmarks (i.e., PageRank, BFS, and triangle counting) due to in-memory execution. In addition, Mofrad et al. (Mofrad et al., 2019) proposed a compression technique specifically designed for matrix-vector operations based on the compressed sparse column (CSC) representation and leverage this compression to accelerate distributed graph benchmarks (e.g., PageRank, single source shortest path, and BFS). However, no work has been done on using compression to improve memory efficiency and accelerate a real-world diffusion-based graph application such as influence maximization.
3. Memory Footprint Profiling and Graph Characterization
In this section, we characterize the memory usage of Ripples, the state-of-the-art parallel IMM implementation and discuss the potentials to reduce the memory footprint.
3.1. Memory Usage of RRR Sets
The key component of the Monte Carlo (MC) diffusion process (Tang et al., 2015; Minutoli et al., 2019) is a probabilistic Breadth First Search. The intermediate collections of vertices that may cause activation of the BFS root are saved in the form of RRR sets. We benchmark six real-world large graphs used in the literature and study the memory usages for the MC diffusion process and generating/saving the intermediate RRR sets. As shown in Figure 1, the space attributed to storing of the intermediate RRR sets dominate, consuming between 87% to 99% of the memory footprint.
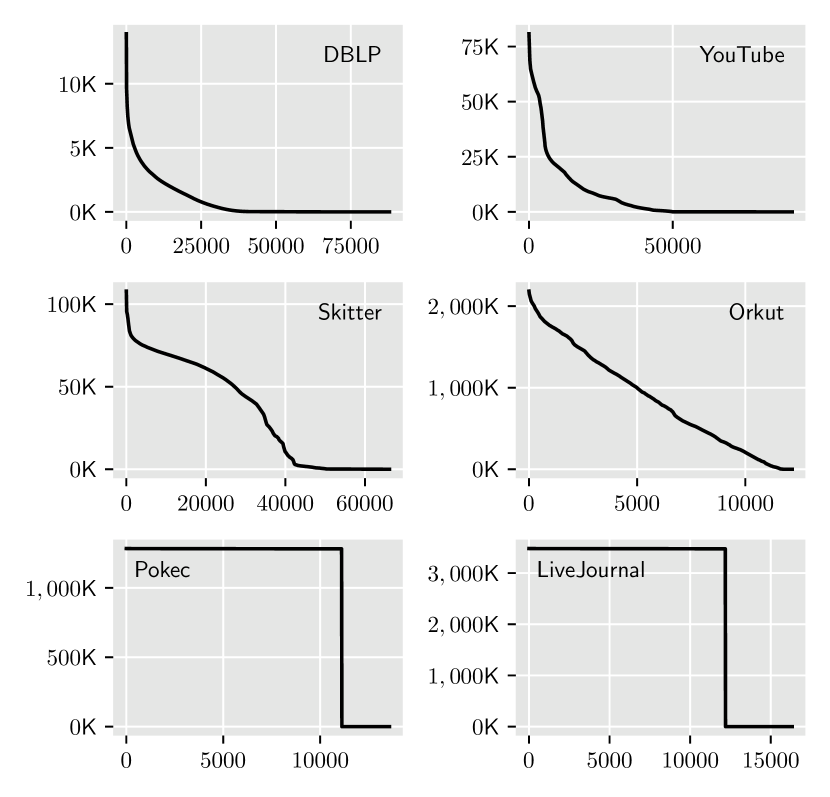
To further understand the memory footprint usage patterns in Figure 1, we studied the distribution of the RRR sets by their sizes. Figure 2 shows the sizes of RRR sets, i.e., their vertex counts, for different graphs. The figure illustrates the shapes of RRR sets’ distribution based on their sizes: (1) In the top row, the two graphs (i.e., DBLP and YouTube) have long tails, and their shapes correspond to a power-law distribution. (2) In the middle row, the shapes of the two graphs (i.e., Skitters and Orkut) show close to a linear decay without any long tails. (3) In the bottom row, the shapes of the two graphs (i.e., Pokec and LiveJournal) show a very uniform two-step (flat-head) distribution. The overall memory footprint of the RRR sets corresponds to the area under the curves in the respective plots. This well explains why the last two graphs spends much more memory in saving the RRR sets. Further, these observations raise a critical question to the design of optimizations for memory footprint reduction: What are the characteristics of the various RRR sets of the above three different categories? (see Section 3.2)
3.2. Characterize The RRR Sets
The shapes in Figure 2 roughly categorize the RRR sets’ distributions into two types: the first four graphs (i.e., DBLP, YouTube, Skitter and Orkut) have skew-distributed distribution while the last two graphs (i.e., Pokec and LiveJournal) have a uniform two-step distribution. We use two quantities, i.e., skewness and density, to characterize the shapes of RRR sets’ distributions.
| Graph | Skewness | Density |
|---|---|---|
| DBLP | ||
| Youtube | ||
| Skitter | ||
| Orkut | ||
| Pokec | ||
| LiveJournal |
The skewness score () measures how distributions are asymmetric about their mean: When , the distribution has a longer left tail; When , the distribution’s right tail is longer. Equation (2) shows the calculation of skewness score for the size of RRR sets , where each is a sample of the number of visited vertices starting from a seed vertex in a MC simulation. Thus all ’s are at least because there will be no empty resultant RRR set (it will at least contain the starting seed vertex); is the total number of sampled RRR sets; is the average RRR size, and is their standard deviation.222The standard deviation because ’s are the sizes of RRR sets, which are not all equal. Given the elements in Equation (2) are all non-zero, the skewness score and density will not overflow by dividing zeros for real-world social networks. In Table 1, we show the skewness scores of the first four graphs (i.e., DBLP, YouTube, Skitter and Orkut) are all positive, which help to distinguish them from the last two graphs (i.e., Pokec and LiveJournal) whose skewness scores are negative.
The density () measures the proportion of non-zero elements that are required to represent the sampled RRR sets if they are stored in matrix format. Although density is not correspond to the shape of distributions, it can help to select the data structure to store RRR sets. It is sufficient to use 32-bit unsigned integers to represent each vertex in the sampled RRR sets in this study. Thus we can use to be the threshold. When the density , it is more efficient to use a sparse representation of RRR sets, i.e., to explicitly store each vertex. On the other hand, when the density , it is more efficient to use a dense bitmap coding to store RRR sets. Equation (2) shows the calculation of density for the size of RRR sets (Similarly, is the total number of RRR sets; is the number of vertices in each RRR set; is the number of vertices in graph ). In Table 1, we show the last two graphs (Pokec and LiveJournal) have much higher densities () than the rest four graphs (DBLP, YouTube, Skitter, Orkut).
| (2) |
3.3. Characterize The Influence of Vertices
The different shapes of RRR sets’ distribution also characterize the influence of individual vertices which can help us to find data localities. To verify this intuition, we compare the selected seeds of each graph by varying the random starting vertex for MC samplings. Table 2 shows the Rank-Biased Overlap (RBO) scores (Webber et al., 2010) ( means highly overlapping rank positions and means no overlapping). For the graphs with skew-distributions, the same top-1 influential vertex is consistently selected from different random starting vertices. However, for the graphs with flat-head distributions, many vertices achieve the maximum influence, so the RBO score is zero.
| Graph | Activated |
|
|
||||
|---|---|---|---|---|---|---|---|
| DBLP | 0.499 | 1.0 | |||||
| YouTube | 0.554 | 0.87 | |||||
| Skitter | 0.794 | 0.50 | |||||
| Orkut | 0.967 | 0.46 | |||||
| Pokec | 0.817 | 0.0 | |||||
| LiveJournal | 0.741 | 0.0 |
From the first four graphs (DBLP, YouTube, Skitter, Orkut), the sampled RRR sets are close to power-law or linear decay distributions. Under this situation, there are only a small number vertices that influence a lot of other vertices; while many vertices only influence one or two other vertices. On the other hand, for the last two graphs (Pokec and LiveJournal), the flat-head shows that many vertices can influence many other vertices. In other words, many vertices are equally influential, which makes the flat-head distributed RRRs lack the data locality in the skew-distributed RRR sets. Thus, they need different optimization strategies to reduce their memory footprints.
In summary, the memory required to store intermediate RRR sets is one to two order of magnitude larger than the memory footprint of the diffusion process. We observe two types of graphs with regards to their different behaviors in diffusion process and hence the data localities. Considering the observed skewed-distributed RRR sets, it is promising to leverage variable-length encoding to reduce the memory footprint of RRR sets for those graphs. On the ther hand, using bitmap coding can reduce the memory footprints for the flat-head distributed RRR sets because of their high density of non-zero elements.
4. Our Proposed Optimizations
In this section, we propose a “compress-to-compute” IMM method to reduce the memory footprint for the Ripples based on our characterization and profiling.
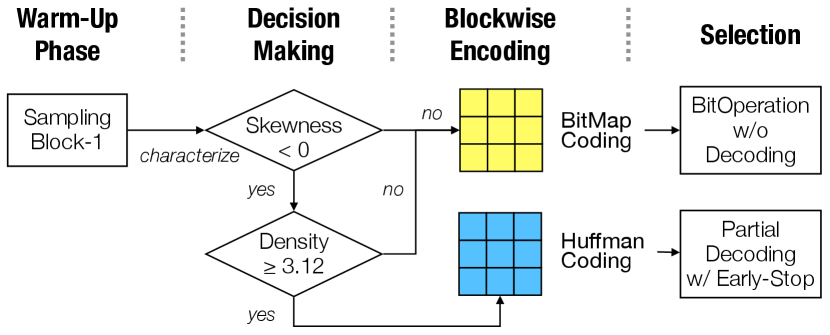
4.1. Overview of Our Proposed Workflow
The overview of the “compress-to-compute” workflow is shown in Figure 3. It contains three main phases: warm-up, sample-and-encode, and decode-and-select. Specifically, we first characterize the skewness score and the density from the distribution of the RRR sets in the warm-up phase. Based on that, we then choose an efficient compression technique to encode the intermediate RRR sets and query on the encoded RRR sets.
More specifically, we introduce a block-based sampling-and-encoding approach and an integrated selection approach. To achieve a better scalability on multicore architectures, we design two schemes - (1) Huffmax: We use Huffman coding to encode skew-distributed RRR sets, and leverage the data locality knowledge acquired from the warm-up phase to accomplish the selection without fully decoding the compressed RRR sets. (2) Bitmax: We use bitmap coding to encode flat-head distributed RRR sets. The corresponding selection can be accomplished directly on the encoded data by efficient bit operations. These two schemes are complementary to each other so that the proposed workflow does not rely on the data locality of skewed distributions. It can work with RRR sets that have non-skewed distributed sizes such as normal distributions or uniform distributions (their skewness scores are zero). In Figure 2, we show the flat-headed distributions of Pokec and Livejournal are two special cases that are close to uniform distributions. Furthermore, we use a heuristic approach to optimize the parallel reduction operation to find the vertex with the highest frequency. We use Table 3 to list the notation used in the paper.
| Notation | Description |
|---|---|
| The number of vertices in Graph | |
| RRR | Random Reverse Reachable set |
| seeds | The selected most influential vertices |
| The number of most influential vertices in seeds | |
| The number of random RRR sets to be sampled | |
| The skewness score of RRR sets | |
| The proportion of non-zero elements of sampled RRR sets | |
| The number of vertices in a sampled RRR set | |
| The approximation factor | |
| The number of blocks that consists the Sampling step | |
| A block of RRR sets | |
| One RR set from the block | |
| A block of Huffman encoded RRR sets | |
| The encoded part of one RRR | |
| A block of copied buffers | |
| The copied part of one RRR | |
| The Huffman codebook | |
| The shared vertex-frequency table | |
| A block of bitmap encoded RRR sets | |
| The current most influential vertex |
4.2. Sampling-and-Encoding
Next, we describe the proposed two encoding methods.
4.2.1. Block-based sampling-and-encoding
We adopt a block-by-block sampling strategy and use the first block as the warm-up phase. This design provides three benefits: First, as aforementioned, the warm-up phase characterizes the graph and enables us to choose between Huffman coding and bitmap coding. Second, the learned characteristics of RRR sets distribution also helps to determine whether the two encoding methods can efficiently compress RRR sets and hence reduce the memory usage of RRR sets. For RRR sets with negative skewness, using the Huffman coding will cause low compression ratio, and the decoding cannot early stop due to the lack of data localities; For RRR sets with density , the bitmap coding will even increase the memory footprints. Third, the block-by-block sampling enables us to interleave the sampling and encoding so that we can release the used memory as soon as possible to maximize the peak memory reduction.
4.2.2. Encoding of Huffmax
We simply check the skewness in the warm-up phase to enable the Huffman coding. Table 1 shows the skewness scores of our benchmark graphs. The skewed RRR sets of the first four graphs have . They will be encoded with Huffman Codes. Next, we will describe the block-based sampling-and-encoding approach where the Huffman coding method is interleaved with the sampling step. Algorithm 1 presents the block-based sampling-and-encoding method in detail.
Specifically, we split the sampling step into sub-steps. In each sub-step we get a block of RRR sets. Let be the first block. We build a Huffman codebook based on the block . We use this codebook to encode into a set of byte-strings , each of which corresponds to a RRR set. At the same time, we construct a frequency table to store the vertex frequency of the block . In the following sub-steps, we keep updating the frequencies stored in the table and encoding the RRR sets into , where . Because of the data localities of the skew-distributed RRR sets, we can keep track of the current most influential vertex and swap it to the beginning position of the encoded byte string whenever it appears in the corresponding RRR set. Note that this swap is beneficial as it enables early-stopping (will be described in Section 4.3). At the end of each sub-step, to reduce the peak memory usage, the memory for is deallocated once the encoding of the current block completes.
Ideally, the codebook built from the first block should contain the Huffman codes for all vertices in the entire RRR sets. However, in our block-based sampling-and-encoding approach, some vertices may not be sampled in but could appear in later blocks due to the skewed distributions. The more skewed distributions the RRR sets have, the more likely some vertices are missing from . For example, 0.2% of DBLP’s vertices have no Huffman-codes where the skewness score is 11.46; 0.02% vertices of Skitters have no Huffman-code where the skewness is 5.38; and 0.003% vertices of Orkut’s have no Huffman-code where the skewness is 0.75. For those vertices do not have corresponding Huffman codes in the codebook , we use an additional array to directly save those vertices without encoding. By doing this, we preserve the exact information of RRR sets by encoding and/or copying all the vertices in the original RRR sets. From our empirical studies, the vertices that do not have corresponding Huffman codes only consist of less than of the entire vertices. Thus we do not build new Huffman code book in the following steps to reduce the overhead.
4.2.3. Encoding of Bitmax
We not only check the skewness (), but also check the density () to enable the bitmap coding (as mentioned in Section 3.2). For a block of RRR sets , the encoded data is represented as a dense bit matrix , where the shape of matrix is rows by columns ( is the number of vertices in graph G, is the number of RRR sets sampled in this block). If the bit at the -th row and -th column in matrix is set to , it represents the -th vertex appears in the -th RRR set. In our implementation, we pad columns to be the multiple of so that we can save the bit matrix in byte format. Because the padded bits are all zeros, the padded columns do not affect the correctness of the method. Similar to Huffmax, we deallocate the after the bitmap encoding to reduce the peak memory usage.
4.2.4. Parallel implementation
The sampling-and-encoding computation on one sample is independent of other RRR sets. To accelerate the computation, we distribute the sampling-and-encoding workload to multiple threads/cores. For Huffmax, the bottleneck is to perform a parallel reduction to build a shared frequency table considering the NUMA effect (Lameter, 2013). Our solution is to follow the first-touch principle: we allocate a local frequency table on each thread to store the vertex frequencies and sum them to the global frequency table after the sampling-and-encoding of this block completes (the synchronization happens times as we split the sampling-and-encoding into sub-steps). For Bitmax, its encoding is embarrassingly parallel on multi-cores for high scalability.
4.3. Optimized Selection
Lastly, we describe two selection approaches for efficiently querying in Huffmax and Bitmax, respectively. The selection iterates two core computations for times to select the most influential seeds. The first computation is to locate and remove the RRR sets which contain the current most frequent vertex . The second computation is to reconstruct the frequency table after every RRR set that contains the previous is removed. After that, a new is selected based on the updated frequency table .
4.3.1. Selection of Huffmax
For RRR sets encoded by Huffman coding, we leverage the data locality to swap the most frequent vertex to the beginning position during the Huffmax encoding steps (described in Section 4.2.2). This enables us to partially decode an encoded RRR set (i.e., where ) and stop early whenever it contains . Due to the skew-distributed RRR sets, we only need to decode a small number of encoded RRR sets. As aforementioned in Table 1, graphs of greater skewness scores (DBLP/11.46, YouTube/9.01) also have longer tails than graphs of smaller skewness scores(Skitter/5.38, Orkut/0.75). However, the difference of tails does not affect the selection efficiency: even graph with small positive skewness (Orkut/0.75) still has the data locality that enables Huffmax to early-stop in the selection step. Note that when we decode back to a temporary buffer , it implies that the current does not appears in the encoded part of this RRR set; otherwise, we would have early stopped decoding. In this case, we will search the corresponding copied array .
To reconstruct the new frequency table , we only need to count the vertices in the fully decoded buffer and the corresponding copied array if is not found. At this point, the temporary buffer is safely deallocated to reduce memory footprints. Algorithm 2 describes this Huffmax selection in detail.
4.3.2. Selection of Bitmax
Unlike Huffmax’s selection, where we leverage the data localities to partially decode the compressed data, the selection in Bitmax directly operate on the encoded data without decoding. The selection is accomplished by efficient bit operations. Note that the shape of bitmap encoded is different from the Huffman encoded ; we will use an example to illustrate the two core selection computations (i.e., locate and remove RRR sets which contains , reconstruct frequency table to find the new ).
| (3) |
Equation (3) shows a simple example that has vertices and RRR sets. The frequency table is computed by row-wise POPCOUNT operation (i.e., find the sum of ones in each row). Given their frequencies, is selected as the current most frequent . We do not need to locate the RRR sets because their locations are explicitly represented by the s in ’s row (for simplicity, we use the notation to represent the ’s row). To remove these RRR sets, we subtract row from all the other rows. We use two bit operations to accomplish the SUBTRACT operation on the bitmap-encoded data. Specifically, we use to subtract row from row .
After SUBTRACT, we use row-wise POPCOUNT again on the updated bitmap matrix to reconstruct the updated frequency table . Algorithm-3 describes the selection of Bitmax in detail.
4.3.3. Parallel implementation
The above example in Equation (3) demonstrates the bit operations of POPCOUNT, AND, and XOR on each row of vertices. However, the bit-columns of the encoded bitmap are distributed across different threads according to the first touch principle (as described in Section 4.2.4). It is important to consider the NUMA effect to parallelize the selection step of Bitmax along the bit-column direction instead of iteratively applying bit operations on each row. More concretely, each thread keeps track of a local frequency table and these local frequency tables are reduced to the global frequency table after each iteration. The next section describes our solution to address the scalability challenge on getting the global most frequent vertex without reducing the entire global frequency table .
4.3.4. Parallel merge
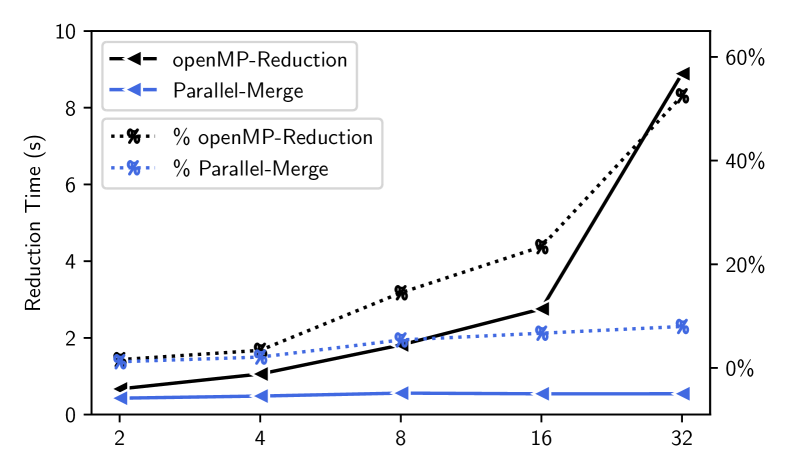
Both selections in Huffmax and Bitmax need to find the new most influential vertex after reconstructing the frequency table. However, we note that to generate the overall reconstructed frequency table from multiple threads, a parallel reduction with times of synchronizations is needed to sum local frequencies for all vertices. This reduction introduces high time overhead, as shown in Figure 4. The reduction times are measured on the Skitter graph. The dashed line shows the runtime of the OpenMP reduction function with 232 threads/cores. It illustrates that the original OpenMP reduction would become the performance bottleneck as the number of threads increases. The reduction time takes upto of the entire time-to-solution.
To solve this issue, we propose to use the following approach to greatly decrease the number of reductions so as to make the selection step more efficient and scalable: (1) Select the locally most frequent vertex from each thread (these are local maxima); (2) Perform reductions to get the global frequencies for these locally selected vertices (the local maxima); and (3) Select the vertex with the maximum global frequency from the locally selected vertices ( get the global maximum from these local maxima). Note that the total number of reduction operations in (2) is instead of , where is the number of threads and is the number of vertices in graph (). Figure 4 illustrates that our proposed parallel-merge-based reduction is highly efficient and scalable with almost constant time cost. In this example, the number of vertices of Skitter is about 1.6 millions. With 32 threads, the OpenMP reduction needs to reduce 650 MB data, whereas our approach only needs to reduce 12.5 KB data333In the skitter example (n=1.6M, k=100), each frequency needs 4 bytes (one float), the baseline reduction needs to sum 1.6M*100*4=650MB data; and with 32 threads, our proposed method sums 321004=12.5 KB data.. This explains why our approach is more efficient with the constant computation time of about 0.5 seconds.
The heuristic is based on the fact that (1) The global RRR sets is the collection of local RRR sets from each thread. The local RRR sets on each thread is independent because the MC simulations are uniformly sampled. (2) Let be the distribution of vertex ’s frequency in the global RRR sets. Then, the distribution of vertex ’s frequency on each thread is . (3) Given two vertices , the corresponding distributions of their frequencies are if they are measured from the global RRR sets. Let , without loss of generality, we also have on each thread. (4) Thus the globally most frequent vertex is among the locally most frequent vertices from each thread.
5. Experimental Evaluation
In this section, we first present our experimental setup. We then demonstrate the effectiveness of our “compress-to-compute” method. After that, we show the performance of HBMax in memory usage and computation time. Finally, we show that our method has strong scalability on the multicore architectures.
5.1. Experimental Setup
Test datasets
For evaluation purpose, we use the five largest graphs tested in the Ripples software and three large graphs not tested by Ripples444Tested graphs are from the the SNAP collection (Leskovec and Krevl, 2014), the UFL sparse matrix collection (Davis and Hu, 2011), and Laboratory for Web Algorithms (LAW) (Boldi et al., 2011; Boldi and Vigna, 2004).. Table 4 shows the main features of these widely studied networks. In detail, (1) DBLP (Yang and Leskovec, 2015) describes a co-authorship network of researchers in computer science; (2) YouTube (Mislove et al., 2007) is a social network of friendship and groups on the video-sharing web site; (3) Skitter (CAIDA UCSD, 2008) is an internet topology graph by depicting the forward paths that actual packets traversed to a destination; (4) Orkut (Mislove et al., 2007) is generated from an on-line social networking site where its primary purpose is to finding and connecting new users; (5) Pokec (Takac and Zabovsky, 2012) is an on-line social network in Slovakia and Czech Republic; (6) LiveJournal (Backstrom et al., 2006) is a graph from a social networking and blogging site, with explicit user-defined communities; (7) Arabic-2005 (Boldi and Vigna, 2004; Boldi et al., 2011, 2004) crawls web pages written in Arabic; and (8) Twitter7 (Yang and Leskovec, 2011) contains the graph of Twitter posts covering a 7-month period. The first six graphs are characterized (as shown in Figure 2) to help us design HBMax, while the last two are not characterized beforehand. We use these two graphs as a test set to verify the effectiveness of HBMax. For the Arabic graph, , , and for the Twitter7 graph, , . Thus, these two graphs use Bitmax. Note that the input data of the two largest graphs uses large amount of storage. Specifically, Arabic has over 22.7 million vertices and 639.9 million edges (requiring more than 11 GB storage overhead), while Twitter7 has 41.6 million vertices and 1.46 billion edges (requiring more than 23 GB storage overhead). These two largest graphs cannot be run by Ripples on our tested platforms due to memory overflow.
| Network | #Vertices | #Edges | Avg Deg | Max Deg |
|---|---|---|---|---|
| DBLP | 317,080 | 1,049,866 | 3.31 | 306 |
| YouTube | 1,134,890 | 2,987,624 | 2.63 | 28,576 |
| Skitter | 1,696,415 | 11,095,298 | 6.54 | 35,387 |
| Orkut | 3,072,441 | 117,185,083 | 76.28 | 33,313 |
| Pokec | 1,632,803 | 30,622,564 | 37.51 | 20,518 |
| LiveJournal | 4,847,571 | 68,993,773 | 28.47 | 22,889 |
| arabic-2005 | 22,744,080 | 639,999,458 | 28.14 | 575,618 |
| twitter7 | 41,652,230 | 1,468,365,182 | 35.25 | 770,155 |
Evaluation platforms
We evaluate our proposed method and compare it with the baseline on two platforms. The first platform is a local workstation which has 4 Intel Xeon Gold 6238R CPUs, 376 GB RAM and 1 TB NVMe SSD storage. This local workstation is used to make a fair comparison with Ripples because it has larger memory. The second platform is a Regular Memory (RM) compute node from the Bridges-2 supercomputer (Bridge-2 system, 2020) at PSC, which has 2 AMD EPYC 7742 CPUs (64 cores per CPU) and 256 GB RAM. The Bridges-2 compute node is used for scalability study because it has more CPU cores. We use GCC-8.3.1 for compilation.
Parameter setup
We choose for all the graphs. We use for DBLP, YouTube, and Skitter, for Orkut, Pokec, and LiveJournal, and for Arabic and Twitter based on the sizes of these graphs. Note that it takes 24+ hours to run Twitter7 using 2 cores on Bridges2.
Our implementation and comparison baseline
We use HBMax to denote our solution; specifically, we use Huffmax to denote our solution using the Huffman encoding with partial decoding for selection and Bitmax to denote our solution using the bitmap encoding with non-decoding selection. We compare HBMax with the original Ripples v.2.1. We implement our optimization in parallel based on this version of Ripples by using OpenMP-4.1.1. Note that Ripples provides a flexibility to configure the number of threads for sampling and selection phases separately. In our evaluation, HBMax uses the same number of threads for both phases, while Ripples can use different number of threads in the selection phase to get the best performance.
| Graph | HBMax | Ripples | Reduced Page Faults |
|---|---|---|---|
| DBLP | 0.45 | 0.50 | |
| YouTube | 4.30 | 5.78 | |
| Skitter | 13.43 | 17.56 | |
| Orkut | 196.02 | 245.25 | |
| Pokec | 196.79 | 257.96 | |
| LiveJournal | 612.60 | 761.59 | |
| arabic-2005 | 1297.60 | NA | NA |
| twitter7 | 11219.10 | NA | NA |
| Graph | DBLP | YouTube | Skitter | Orkut | Pokec | Journal | Arabic | Twitter7 |
|---|---|---|---|---|---|---|---|---|
| Ripples | 424 (1.00) | 3,143 (1.00) | 9,838 (1.00) | 46,506 (1.00) | 55,682 (1.00) | 163,745 (1.00) | 348,606(1.00) | 1,193,006(1.00) |
| Huffmax | 316 (1.34) | 1,722 (1.83) | 5,293 (1.86) | 30,130 (1.54) | - | - | - | - |
| Bitmax | - | - | - | - | 10,661 (5.22) | 29,329 (5.58) | 81,504(4.28) | 200,250(5.96) |
| Graph | DBLP | YouTube | Skitter | Orkut | Pokec | Journal | Arabic | Twitter7 |
|---|---|---|---|---|---|---|---|---|
| Ripples | 0.95 (1.0) | 6.95 (1.0) | 20.46 (1.0) | 249.35 (1.0) | 262.66 (1.0) | 775.58 (1.0) | NA | NA |
| Huffmax | 1.10 (1.16) | 6.31 (0.91) | 17.93 (0.88) | 235.14 (0.94) | - | - | - | - |
| Bitmax | - | - | - | - | 222.63 (0.85) | 692.70 (0.89) | 1,608.48 | 12,098.30 |
| Graph | DBLP | YouTube | Skitter | Orkut | Pokec | Journal | Arabic | Twitter7 |
|---|---|---|---|---|---|---|---|---|
| Ripples | 1.68 (1.0) | 20.69 (1.0) | 85.95 (1.0) | 669.85 (1.0) | 998.85 (1.0) | 1930.60 (1.0) | 5463.62(1.0) | 26825.60(1.0) |
| HBMax | 1.10 (0.66) | 6.31 (0.30) | 17.93 (0.21) | 235.14 (0.35) | 222.63 (0.22) | 692.70 (0.36) | 1608.48 (0.29) | 12098.30 (0.45) |

5.2. Performance Evaluation
In this section, we evaluate the performance of our proposed HBMax. We first evaluate on the local workstation to compare the memory usage and time-to-solution of HBMax with Ripples because it has larger memory (376 GBs). The experiment results are measured with 16 cores. For a fair comparison, we repeat the experiments on each tested graph for five times and take the averages to compare memory usage and time-to-solution of HBMax with Ripples. We show the averaged experiment results in Table 6, 7 and 8. We then use Bridges-2 to study the scalability of HBMax because its compute node has more CPU cores (i.e., 64 cores per CPU). We show the scalability results in Figure 5 and 6.
5.2.1. Memory Reduction Evaluation
Table 6 shows the memory footprint and memory reduction ratio of our proposed solution compared with Ripples. The reduction ratio is computed as the ratio of our memory usage to Ripples’s memory usage. With the proposed “compress-to-compute” techniques, Huffmax achieves an average of 1.6 memory reduction on four skew-distributed RRR sets (i.e., reduces memory footprint); Bitmax achieves an average of 5.3 memory reduction (i.e., reduces memory footprint)on two flat-head distributed RRR sets. Note that the memory usage of Ripples are colored to grey for the last two graphs (Arabic and Twitter7). The numbers are projected from accumulation. The original Ripples cannot finish due to out-of-memory (OOM) error.
5.2.2. Time-to-Solution Evaluation
Table 5 shows HBMax has better performance than Ripples in the sampling phase. This is because, although the sampling phases of HBMax and Ripples are identical (HBMax only optimizes the storage of intermediate RRR sets in the seed selection phase), reducing memory footprint can decrease the page faults for the sampling phase (the average reduced percentile of page faults is 555the reduced page fault percentile ) and hence shorten the sampling time and the overall time-to-solution. In other words, the encoding/decoding overheads are offset by the performance gain from the improved sampling phase.
Table 7 shows the time-to-solution of our proposed solution compared with Ripples. We calculate the overhead (in ratio) as . When our time-to-solution is longer than that of Ripples, the overhead is greater than ; otherwise, it is less than . The table shows that Huffmax achieves an average overhead of for the four skew-distributed RRR sets, while the Bitmax achieves an average overhead of for the two flat-head distributed RRR sets. In other words, Huffmax reduces the time-to-solution and the memory footprints at the same time. More concretely, the average reduction on peak memory usage is with speedup on time-to-solution on all the tested graphs (not including the last two graphs that Ripples gets OOM error). Our solution reduces the peak memory usage by up to (on LiveJournal) and the time-to-solution by up to (on Pokec).
Moreover, the memory reduction also brings performance benefits to resource-constrained systems. To simulate such an environment, we simply limit the amount of available memory for Ripples to be the same as the memory usage by HBMax. We modify Ripples to let it write the exceeded RRR sets during the sampling step to external SSD storage and read them back for the seed selection step. Table 8 shows the performance gain of HBMax over Ripples with the same limited memory capacity. The in-memory compression technique increases the overall performance on the eight skewed-distributed graphs. The average performance gain is , which equals 3.17 speed-up. This is obviously because Ripples increases I/O time due to insufficient memory, while our solution saves RRR sets in a compressed format to avoid data movement.
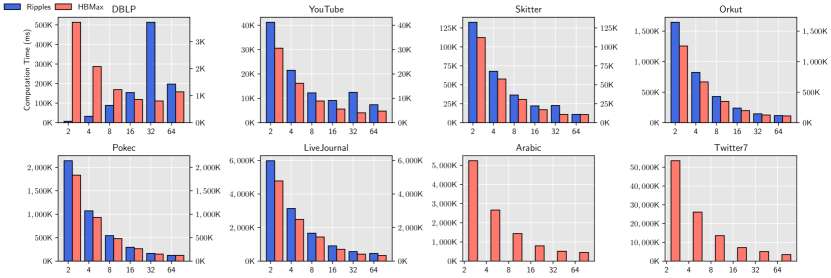
5.3. Strong Scalability Evaluation
We now present the strong scaling result of HBMax with up to 64 CPU cores, as shown in Figure 6. We break down HBMax into four operations: (1) sampling the RRR sets with MC diffusion process, (2) encoding the RRR sets with Huffmax, (3) encoding the RRR sets with Bitmax method, and (4) selecting the most influential seeds. We analyze their impacts to the overall scalability separately.
First, Figure 5 shows that the parallel sampling step is the dominant part on all evaluated graphs (takes an average of of the total time) and has a strong scalability due to the independent nature of each sampling operation; thus, the scalability of HBMax is affected by the encoding step and selection step.
Second, for Huffmax, we note that building the Huffman codebook does not affect the overall scalability. This is because we only build up the codebook once during the warm-up phase, which takes an average of of the total time. Also, the Huffman encoding takes an average of of the total time as it only includes a small number of synchronizations to build frequency table. Thus, Huffmax’s encoding shows a strong scalability up to 64 cores.
Third, for all the large graphs (Pokec, LiveJournal, Arabic, Twitter7), the encoding of Bitmax shows a strong scalability up to 64 cores due to its independent nature. The bitmap encoding takes an average of of the total time.
Fourth, the selection operation in both Huffmax and Bitmax does not affect the overall scalability. First, our optimized reduction with parallel merge plays an important role, as shown in Figure 4, to minimize the synchronization between threads. Without this optimization, the selection operation would become the bottleneck due to the original non-scalable parallel reduction. Second, both the selection operations of Huffmax and Bitmax are parallelized considering the NUMA effect so that each thread can maintain its local frequency table by only accessing the locally encoded data. Note that selection of Bitmax scales better than Huffmax because it does not have a decoding step.
Finally, we note that for the two small graphs DBLP and YouTube, Ripples does not scale well. This is because of the highly imbalanced workload between vertices in the seed-selection step, which can be also reflected in its high skewness score. While HBMax achieves better scalability (can scale up to 32 cores) thanks to the proposed parallel merge and the consideration of NUMA effect. The performance starts to degrade from 64 cores due to the relatively small workload. For the other six larger graphs, HBMax can scale up to 64 cores and achieve an average speedup of 12.98 on 64 cores.
6. Conclusions and Future Work
Graph analytics has emerged as an important class of data analytics tools. The ubiquity of data from a wide variety of sources has necessitated the development of scalable graph analytics tools. Influence Maximization (IM) is an important graph problem with many applications. Wide use of IM is currently limited due to the limitations from memory and computation requirements. In this paper, we presented a “compress-to-compute” approach to use Huffman or bitmap coding to encode the sampled RRR sets. By exploiting the data locality and leveraging the efficient bit operations, our method is able to reduce the peak memory usage by up to and reduce computation by up to without noticeable loss of accuracy.
Future research includes: i) establishing analytical bounds on the loss of information so that approximation guarantees of IM algorithms can be established; ii) extension to distributed platforms with GPU accelerators, and iii) extension of compression techniques to other key graph algorithms (with large memory footprints) that address fundamental graph problems such as triangle counting, community detecting, and network alignment, which can potentially benefit from our proposed vertex-encodings.
Acknowledgments
The research is supported by the U.S. DOE ExaGraph project at Pacific Northwest National Laboratory (PNNL) and by the NSF awards OAC-2034169, OAC-2042084, OAC-1910213, and CCF-1815467 at Washington State University. This work used the Bridges-2 system, which is supported by the NSF award OAC-1928147, at Pittsburgh Supercomputing Center.
References
- (1)
- Backstrom et al. (2006) Lars Backstrom, Dan Huttenlocher, Jon Kleinberg, and Xiangyang Lan. 2006. Group formation in large social networks: membership, growth, and evolution. In Proceedings of the 12th ACM SIGKDD international conference on Knowledge discovery and data mining. 44–54.
- Besta et al. (2019) Maciej Besta, Simon Weber, Lukas Gianinazzi, Robert Gerstenberger, Andrey Ivanov, Yishai Oltchik, and Torsten Hoefler. 2019. Slim graph: Practical lossy graph compression for approximate graph processing, storage, and analytics. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis. 1–25.
- Boldi et al. (2004) Paolo Boldi, Bruno Codenotti, Massimo Santini, and Sebastiano Vigna. 2004. UbiCrawler: A Scalable Fully Distributed Web Crawler. Software: Practice & Experience 34, 8 (2004), 711–726.
- Boldi et al. (2011) Paolo Boldi, Marco Rosa, Massimo Santini, and Sebastiano Vigna. 2011. Layered Label Propagation: A MultiResolution Coordinate-Free Ordering for Compressing Social Networks. In Proceedings of the 20th international conference on World Wide Web, Sadagopan Srinivasan, Krithi Ramamritham, Arun Kumar, M. P. Ravindra, Elisa Bertino, and Ravi Kumar (Eds.). ACM Press, 587–596.
- Boldi and Vigna (2004) Paolo Boldi and Sebastiano Vigna. 2004. The WebGraph Framework I: Compression Techniques. In Proc. of the Thirteenth International World Wide Web Conference (WWW 2004). ACM Press, Manhattan, USA, 595–601.
- Borgs et al. (2014) Christian Borgs, Michael Brautbar, Jennifer Chayes, and Brendan Lucier. 2014. Maximizing social influence in nearly optimal time. In Proceedings of the twenty-fifth annual ACM-SIAM symposium on Discrete algorithms. SIAM, 946–957.
- Bridge-2 system (2020) Bridge-2 system. 2020. https://www.psc.edu/resources/bridges-2/. (Accessed on 12/22/2021).
- CAIDA UCSD (2008) CAIDA UCSD. 2008. The CAIDA UCSD Macroscopic Skitter Topology Dataset. https://www.caida.org/catalog/software/skitter [Online; accessed 24-January-2022].
- Davis and Hu (2011) Timothy A Davis and Yifan Hu. 2011. The University of Florida sparse matrix collection. ACM Transactions on Mathematical Software (TOMS) 38, 1 (2011), 1–25.
- Ficara et al. (2010) Domenico Ficara, Andrea Di Pietro, Stefano Giordano, Gregorio Procissi, and Fabio Vitucci. 2010. Enhancing counting Bloom filters through Huffman-coded multilayer structures. IEEE/ACM Transactions On Networking 18, 6 (2010), 1977–1987.
- Foley et al. (1996) James D Foley, Foley Dan Van, Andries Van Dam, Steven K Feiner, John F Hughes, and J Hughes. 1996. Computer graphics: principles and practice. Vol. 12110. Addison-Wesley Professional.
- Ghosh et al. (2021) Sayan Ghosh, Nathan R Tallent, Marco Minutoli, Mahantesh Halappanavar, Ramesh Peri, and Ananth Kalyanaraman. 2021. Single-node partitioned-memory for huge graph analytics: cost and performance trade-offs. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis. 1–14.
- Huffman (1952) David A Huffman. 1952. A method for the construction of minimum-redundancy codes. Proceedings of the IRE 40, 9 (1952), 1098–1101.
- Kempe et al. (2003) David Kempe, Jon Kleinberg, and Éva Tardos. 2003. Maximizing the spread of influence through a social network. In Proceedings of the ninth ACM SIGKDD international conference on Knowledge discovery and data mining. 137–146.
- Lameter (2013) Christoph Lameter. 2013. An overview of non-uniform memory access. Commun. ACM 56, 9 (2013), 59–54.
- Leskovec et al. (2007) Jure Leskovec, Lada A Adamic, and Bernardo A Huberman. 2007. The dynamics of viral marketing. ACM Transactions on the Web (TWEB) 1, 1 (2007), 5–es.
- Leskovec and Krevl (2014) Jure Leskovec and Andrej Krevl. 2014. SNAP Datasets: Stanford Large Network Dataset Collection. http://snap.stanford.edu/data.
- Liu et al. (2022) Jiesong Liu, Feng Zhang, Hourun Li, Dalin Wang, Weitao Wan, Xiaokun Fang, Jidong Zhai, and Xiaoyong Du. 2022. Exploring Query Processing on CPU-GPU Integrated Edge Device. IEEE Transactions on Parallel and Distributed Systems (2022).
- Macko et al. (2015) Peter Macko, Virendra J Marathe, Daniel W Margo, and Margo I Seltzer. 2015. Llama: Efficient graph analytics using large multiversioned arrays. In 2015 IEEE 31st International Conference on Data Engineering. IEEE, 363–374.
- Martínez-Bazan et al. (2012) Norbert Martínez-Bazan, M Ángel Águila-Lorente, Victor Muntés-Mulero, David Dominguez-Sal, Sergio Gómez-Villamor, and Josep-L Larriba-Pey. 2012. Efficient graph management based on bitmap indices. In Proceedings of the 16th International Database Engineering & Applications Sysmposium. 110–119.
- Minutoli et al. (2020a) Marco Minutoli, Maurizio Drocco, Mahantesh Halappanavar, Antonino Tumeo, and Ananth Kalyanaraman. 2020a. cuRipples: Influence maximization on multi-GPU systems. In Proceedings of the 34th ACM International Conference on Supercomputing. 1–11.
- Minutoli et al. (2019) Marco Minutoli, Mahantesh Halappanavar, Ananth Kalyanaraman, Arun Sathanur, Ryan Mcclure, and Jason McDermott. 2019. Fast and scalable implementations of influence maximization algorithms. In 2019 IEEE International Conference on Cluster Computing (CLUSTER). IEEE, 1–12.
- Minutoli et al. (2020b) Marco Minutoli, Prathyush Sambaturu, Mahantesh Halappanavar, Antonino Tumeo, Ananth Kalyananaraman, and Anil Vullikanti. 2020b. Preempt: scalable epidemic interventions using submodular optimization on multi-GPU systems. In SC20: International Conference for High Performance Computing, Networking, Storage and Analysis. IEEE, 1–15.
- Mislove et al. (2007) Alan Mislove, Massimiliano Marcon, Krishna P Gummadi, Peter Druschel, and Bobby Bhattacharjee. 2007. Measurement and analysis of online social networks. In Proceedings of the 7th ACM SIGCOMM conference on Internet measurement. 29–42.
- Mofrad et al. (2019) Mohammad Hasanzadeh Mofrad, Rami Melhem, Yousuf Ahmad, and Mohammad Hammoud. 2019. Efficient distributed graph analytics using triply compressed sparse format. In 2019 IEEE International Conference on Cluster Computing (CLUSTER). IEEE, 1–11.
- Nemhauser et al. (1978) George L Nemhauser, Laurence A Wolsey, and Marshall L Fisher. 1978. An analysis of approximations for maximizing submodular set functions—I. Mathematical programming 14, 1 (1978), 265–294.
- Pan et al. (2021) Zaifeng Pan, Feng Zhang, Yanliang Zhou, Jidong Zhai, Xipeng Shen, Onur Mutlu, and Xiaoyong Du. 2021. Exploring data analytics without decompression on embedded GPU systems. IEEE Transactions on Parallel and Distributed Systems 33, 7 (2021), 1553–1568.
- Randall et al. (2002) Keith H Randall, Raymie Stata, Rajiv G Wickremesinghe, and Janet L Wiener. 2002. The link database: Fast access to graphs of the web. In Proceedings DCC 2002. Data Compression Conference. IEEE, 122–131.
- Ripples (2022) Ripples. 2022. https://github.com/pnnl/ripples. (Accessed on 4/20/2022).
- Roth and Van Horn (1993) Mark A Roth and Scott J Van Horn. 1993. Database compression. ACM Sigmod Record 22, 3 (1993), 31–39.
- Shun and Blelloch (2013) Julian Shun and Guy E Blelloch. 2013. Ligra: a lightweight graph processing framework for shared memory. In Proceedings of the 18th ACM SIGPLAN symposium on Principles and practice of parallel programming. 135–146.
- Suontausta and Tian (2003) Janne Suontausta and Jilei Tian. 2003. Low memory decision tree method for text-to-phoneme mapping. In 2003 IEEE Workshop on Automatic Speech Recognition and Understanding (IEEE Cat. No. 03EX721). IEEE, 135–140.
- Takac and Zabovsky (2012) Lubos Takac and Michal Zabovsky. 2012. Data analysis in public social networks. In International scientific conference and international workshop present day trends of innovations, Vol. 1.
- Tang et al. (2015) Youze Tang, Yanchen Shi, and Xiaokui Xiao. 2015. Influence maximization in near-linear time: A martingale approach. In Proceedings of the 2015 ACM SIGMOD international conference on management of data. 1539–1554.
- Vazirani (2001) Vijay V Vazirani. 2001. Approximation algorithms. Vol. 1. Springer.
- Wang et al. (2017) Jianguo Wang, Chunbin Lin, Yannis Papakonstantinou, and Steven Swanson. 2017. An experimental study of bitmap compression vs. inverted list compression. In Proceedings of the 2017 ACM International Conference on Management of Data. 993–1008.
- Webber et al. (2010) William Webber, Alistair Moffat, and Justin Zobel. 2010. A similarity measure for indefinite rankings. ACM Transactions on Information Systems (TOIS) 28, 4 (2010), 1–38.
- Yang and Leskovec (2011) Jaewon Yang and Jure Leskovec. 2011. Patterns of temporal variation in online media. In Proceedings of the fourth ACM international conference on Web search and data mining. 177–186.
- Yang and Leskovec (2015) Jaewon Yang and Jure Leskovec. 2015. Defining and evaluating network communities based on ground-truth. Knowledge and Information Systems 42, 1 (2015), 181–213.
- Zhang et al. (2021a) Feng Zhang, Zaifeng Pan, Yanliang Zhou, Jidong Zhai, Xipeng Shen, Onur Mutlu, and Xiaoyong Du. 2021a. G-TADOC: Enabling efficient GPU-based text analytics without decompression. In 2021 IEEE 37th International Conference on Data Engineering (ICDE). IEEE, 1679–1690.
- Zhang et al. (2022) Feng Zhang, Weitao Wan, Chenyang Zhang, Jidong Zhai, Yunpeng Chai, Haixiang Li, and Xiaoyong Du. 2022. CompressDB: Enabling Efficient Compressed Data Direct Processing for Various Databases. In Proceedings of the 2022 International Conference on Management of Data. 1655–1669.
- Zhang et al. (2021b) Feng Zhang, Jidong Zhai, Xipeng Shen, Dalin Wang, Zheng Chen, Onur Mutlu, Wenguang Chen, and Xiaoyong Du. 2021b. TADOC: Text analytics directly on compression. The VLDB Journal 30, 2 (2021), 163–188.