Heterogeneous Beliefs and Multi-Population Learning in Network Games
Abstract
The effect of population heterogeneity in multi-agent learning is practically relevant but remains far from being well-understood. Motivated by this, we introduce a model of multi-population learning that allows for heterogeneous beliefs within each population and where agents respond to their beliefs via smooth fictitious play (SFP). We show that the system state — a probability distribution over beliefs — evolves according to a system of partial differential equations. We establish the convergence of SFP to Quantal Response Equilibria in different classes of games capturing both network competition as well as network coordination. We also prove that the beliefs will eventually homogenize in all network games. Although the initial belief heterogeneity disappears in the limit, we show that it plays a crucial role for equilibrium selection in the case of coordination games as it helps select highly desirable equilibria. Contrary, in the case of network competition, the resulting limit behavior is independent of the initialization of beliefs, even when the underlying game has many distinct Nash equilibria.
1 Introduction
Smooth Fictitious play (SFP) and variants thereof are arguably amongst the most well-studied learning models in AI and game theory [2, 3, 21, 22, 9, 19, 36, 37, 42, 18, 17]. SFP describes a belief-based learning process: agents form beliefs about the play of opponents and update their beliefs based on observations. Informally, an agent’s belief can be thought as reflecting how likely its opponents will play each strategy. During game plays, each agent plays smoothed best responses to its beliefs. Much of the literature of SFP is framed in the context of homogeneous beliefs models where all agents in a given role have the same beliefs. This includes models with one agent in each player role [3, 2, 39] as well as models with a single population but in which all agents have the same beliefs [21, 22]. SFP are known to converge in large classes of homogeneous beliefs models (e.g., most 2-player games [9, 19, 3]). However, in the context of heterogeneous beliefs, where agents in a population have different beliefs, SFP has been explored to a less extent.
The study of heterogeneous beliefs (or more broadly speaking, population heterogeneity) is important and practically relevant. From multi-agent system perspective, heterogeneous beliefs widely exist in many applications, such as traffic management, online trading and video game playing. For example, it is natural to expect that public opinions generally diverge on autonomous vehicles and that people have different beliefs about the behaviors of taxi drivers vs non-professional drivers. From machine learning perspective, recent empirical advances hint that injecting heterogeneity potentially accelerates population-based training of neural networks and improves learning performance [25, 29, 44]. From game theory perspective, considering heterogeneity of beliefs better explains results of some human experiments [10, 11].
Heterogeneous beliefs models of SFP are not entirely new. In the pioneering work [12], Fudenberg and Takahashi examine the heterogeneity issue in 2-population settings by appealing to techniques from the stochastic approximation theory. This approach, which is typical in the SFP literature, relates the limit behavior of each individual to an ordinary differential equation (ODE) and has yielded significant insights for many homogeneous beliefs models [3, 2, 19, 39]. However, this approach, as also noted by Fudenberg and Takahashi, “does not provide very precise estimates of the effect of the initial condition of the system.” Consider an example of a population of agents each can choose between two pure strategies and . Let us imagine two cases: (i) every agents in the population share the same belief that their opponents play a mixed strategy choosing and with equal probability , and (ii) half of the agents believe that their opponents determinedly play the pure strategy and the other half believe that their opponents determinedly play the pure strategy . The stochastic approximation approach would generally treat these two cases equally, providing little information about the heterogeneity in beliefs as well as its consequential effects on the system evolution. This drives our motivating questions:
How does heterogeneous populations evolve under SFP? How much and under what conditions does the heterogeneity in beliefs affect their long-term behaviors?
Model and Solutions. In this paper, we study the dynamics of SFP in general classes of multi-population network games that allow for heterogeneous beliefs. In a multi-population network game, each vertex of the network represents a population (continuum) of agents, and each edge represents a series of 2-player subgames between two neighboring populations. Note that multi-population network games include all the 2-population games considered in [12] and are representation of subclasses of real-world systems where the graph structure is evident [czechowski2021poincar]. We consider that for a certain population, individual agents form separate beliefs about each neighbor population and observe the mean strategy play of that population. Taking a approach different from stochastic approximation, we define the system state as a probability measure over the space of beliefs, which allows us to precisely examine the impact of heterogeneous beliefs on system evolution. This probability measure changes over time in response to agents’ learning. Thus, the main challenge is to analyze the evolution of the measure, which in general requires the development of new techniques.
As a starting point, we establish a system of partial differential equations (PDEs) to track the evolution of the measure in continuous time limit (Proposition 1). The PDEs that we derive are akin to the continuity equations111The continuity equation is a PDE that describes the transport phenomena of some quantity (e.g., mass, energy, momentum and other conserved quantities) in a physical system. commonly encountered in physics and do not allow for a general solution. Appealing to moment closure approximation [13], we circumvent the need of solving the PDEs and directly analyze the dynamics of the mean and variance (Proposition 2 and Theorem 1). As one of our key results, we prove that the variance of beliefs always decays quadratically fast with time in all network games (Theorem 1). Put differently, eventually, beliefs will homogenize and the distribution of beliefs will collapse to a single point, regardless of initial distributions of beliefs, 2-player subgames that agents play, and the number of populations and strategies. This result is non-trivial and perhaps somewhat counterintuitive. Afterall, one may find it more natural to expect that the distribution of beliefs would converge to some distribution rather than a single point, as evidenced by recent studies on Q-learning and Cross learning [23, 24, 27].
Technically, the eventual belief homogenization has a significant implication — it informally hints that the asymptotic system state of initially heterogeneous systems are likely to be the same as in homogeneous systems. We show that the fixed point of SFP correspond to Quantual Response Equilibria (QRE)222QRE is a game theoretic solution concept under bounded rationality. By QRE, in this paper we refer to their canonical form also referred to as logit equilibria or logit QRE in the literature [14]. in network games for both homogeneous and initially heterogeneous systems (Theorem 2). As our main result, we establish the convergence of SFP to QRE in different classes of games capturing both network competition as well as network coordination, independent of belief initialization. Specifically, for competitive network games, we first prove via a Lyapunov argument that the SFP converges to a unique QRE in homogeneous systems, even when the underlying game has many distinct Nash equilibria (Theorem 3). Then, we show that this convergence result can be carried over to initially heterogeneous systems (Theorem 4), by leveraging that the mean belief dynamics of initially heterogeneous systems is asymptotically autonomous [31] with its limit dynamics being the belief dynamics of a homogeneous system (Lemma 7). For coordination network games, we also prove the convergence to QRE for homogeneous and initially heterogeneous systems, in which the underlying network has star structure (Theorem 5).
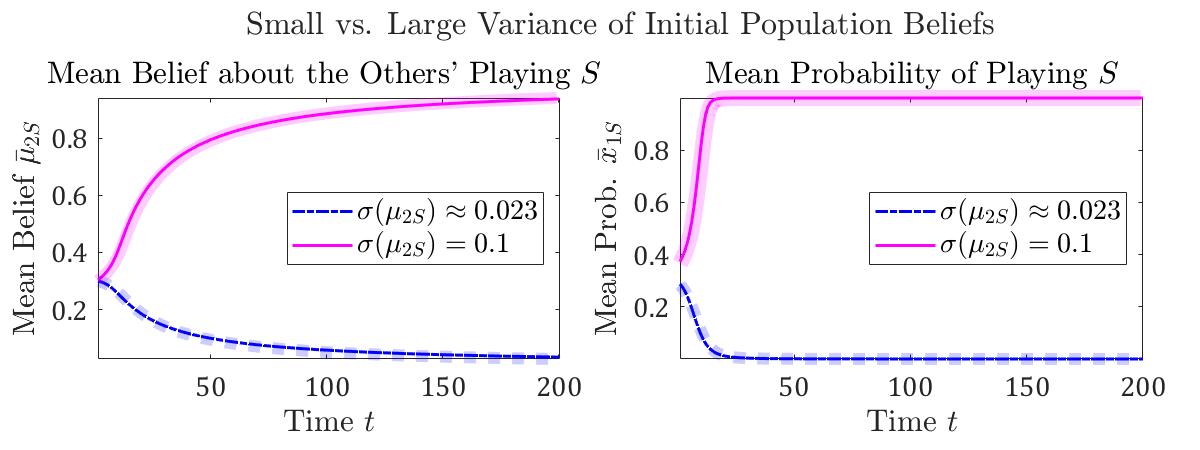
On the other hand, the eventual belief homogenization may lead to a misconception that belief heterogeneity has little effect on system evolution. Using an example of 2-population stag hunt games, we show that belief heterogeneity actually plays a crucial role in equilibrium selection, even though it eventually vanishes. As shown in Figure 1, changing the variance of initial beliefs results in different limit behaviors, even when the mean of initial beliefs remains unchanged; in particular, while a small variance leads to the less desirable equilibrium , a large variance leads to the payoff dominant equilibrium . Thus, in the case of network coordination, initial belief heterogeneity can help select the highly desirable equilibrium and provides interesting insights to the seminal thorny problem of equilibrium selection [26]. On the contrary, in the case of network competition, we prove (Theorems 3 and 4 on the convergence to a unique QRE in competitive network games) as well as showcase experimentally that the resulting limit behavior is independent of initialization of beliefs, even if the underlying game has many distinct Nash equilibria.
Related Works.
SFP and its variants have recently attracted a lot of attention in AI research [36, 37, 42, 18, 17]. There is a significant literature that analyze SFP in different models [3, 7, 21, 19], and the paper that is most closely related to our work is [12]. Fudenberg and Takahashi [12] also examines the heterogeneity issue and anticipate belief homogenization in the limit under 2-population settings. In this paper, we consider multi-population network games, which is a generalization of their setting.333The analysis presented in this paper covers all generic 2-population network games, all generic bipartite network games where the game played on each edge is the same along all edges, and all weighted zero-sum games which do not require the graph to be bipartite nor to have the same game played on each edge. Moreover, our approach is more fundamental, as the PDEs that we derive can provide much richer information about the system evolution and thus precisely estimates the temporal effects of heterogeneity, which is generally intractable in [12]. Therefore, using our approach, we are able to show an interesting finding — the initial heterogeneity plays a crucial role in equilibrium selection (Figure 1) — which unfortunately cannot be shown using the approach in [12]. Last but not least, to our knowledge, our paper is the first work that presents a systematic study of smooth fictitious play in general classes of network games.
On the other hand, networked multi-agent learning constitutes one of the current frontiers in AI and ML research [43, 30, 16]. Recent theoretical advances on network games provide conditions for learning behaviors to be not chaotic [6, 34], and investigate the convergence of Q-learning and continuous-time FP in the case of network competitions [7, 28]. However, [7, 28] consider that there is only one agent on each vertex, and hence their models are essentially for homogeneous systems.
Lahkar and Seymour [27] and Hu et al. [23, 24] also use the continuity equations as a tool to study population heterogeneity in multi-agent systems where a single population of agents applies Cross learning or Q-learning to play symmetric games. They either prove or numerically showcase that heterogeneity generally persists. Our results complement these advances by showing that heterogeneity vanishes under SFP and that heterogeneity helps select highly desirable equilibria. Moreover, methodologically, we establish new proof techniques for the convergence of learning dynamics in heterogeneous systems by leveraging seminal results (Lemmas 1 and 2) from the asymptotically autonomous dynamical system literature, which may be of independent interest.
2 Preliminaries
Population Network Games.
A population network game (PNG) consists of a multi-agent system distributed over a graph , where is the set of vertices each represents a population (continuum) of agents, and is the set of pairs, , of population . For each population , agents of this population has a finite set of pure strategies (or actions) with generic elements . Agents may also use mixed strategies (or choice distributions). For an arbitrary agent in population , its mixed strategy is a vector , where is the simplex in such that and . Each edge defines a series of two-player subgames between populations and , such that for a given time step, each agent in population is randomly paired up with another agent in population to play a two-player subgame. We denote the payoff matrices for agents of population and in these two-player subgames by and , respectively. Note that at a given time step, each agent chooses a (mixed or pure) strategy and plays that strategy in all two-player subgames. Let be a mixed strategy profile, where (or ) denotes a generic mixed strategy in population (or ). Given the mixed strategy profile , the expected payoff of using in the game is
| (1) |
The game is competitive (or weighted zero-sum), if there exist positive constants such that
| (2) |
On the other hand, is a coordination network game, if for each edge , the payoff matrices of the two-player subgame satisfy
Smooth Fictitious Play.
SFP is a belief-based model for learning in games. In SFP, agents form beliefs about the play of opponents and respond to the beliefs via smooth best responses. Given a game , consider an arbitrary agent in a population . Let be the set of neighbor populations. Agent maintains a weight for each opponent strategy of a neighbor population . Based on the weights, agent forms a belief about the neighbor population , such that each opponent strategy is played with probability
| (3) |
Let be the vector of beliefs with the -th element equals . Agent forms separate beliefs for each neighbor population, and plays a smooth best response to the set of beliefs . Given a game , agent ’s expected payoff for using a pure strategy is
| (4) |
where is a unit vector where the -th element is . The probability of playing strategy is then given by
| (5) |
where is a temperature (or the degree of rationality). We consider that agents observe the mean mixed strategy of each neighbor population. As such, at a given time step , agent updates the weights for each opponent strategy as follows:
| (6) |
where is the mean probability of playing strategy in population , i.e., with the number of agents denoted by . For simplicity, we assume the initial sum of weights to be the same for every agent in the system and denote this initial sum by . Observe that Equation 6 can be rewritten as
| (7) |
Hence, even though agent directly updates the weights, its individual state can be characterized by the set of beliefs . In the following, we usually drop the time index and agent index in the bracket (depending on the context) for notational convenience.
3 Belief Dynamics in Population Network Games
Observe that for an arbitrary agent , its belief is in the simplex . We assume that the system state is characterized by a Borel probability measure defined on the state space . Given , we write the marginal probability density function as . Note that is the density of agents having the belief about population throughout the system. Define . Since agents maintain separate beliefs about different neighbor populations, the joint probability density function can be factorized, i.e., . We make the following assumption for the initial marginal density functions.
Assumption 1.
At time , for each population , the marginal density function is continuously differentiable and has zero mass at the boundary of the simplex .
This assumption is standard and common for a “nice” probability distribution. Under this mild condition, we determine the evolution of the system state with the following proposition, using the techniques similar to those in [27, 23].
Proposition 1 (Population Belief Dynamics).
The continuous-time dynamics of the marginal density function for each population is governed by a partial differential equation
| (8) |
where is the divergence operator and is the mean mixed strategy with each -th element
| (9) |
where .
For every marginal density function , the total mass is always conserved (Corollary 1 of the supplementary); moreover, the mass at the boundary of the simplex always remains zero, indicating that agents’ beliefs will never go to extremes (Corollary 2 of the supplementary).
Generalizing the notion of a system state to a distribution over beliefs allows us to address a very specific question — the impact of belief heterogeneity on system evolution. That said, partial differential equations (Equation 8) are notoriously difficult to solve. Here we resort to the evolution of moments based on the evolution of the distribution (Equation 8). In the following proposition, we show that the characterization of belief heterogeneity is important, as the dynamics of the mean system state (or the mean belief dynamics) is indeed affected by belief heterogeneity.
Proposition 2 (Mean Belief Dynamics).
The dynamics of the mean belief about each population is governed by a system of differential equations such that for each strategy ,
| (10) |
where is the logit choice function (Equation 5) applied to strategy , and is the variance of belief in the entire system.
In general, the mean belief dynamics is under the joint effects of the mean, variance, and infinitely many higher moments of the belief distribution. To allow for more conclusive results, we apply the moment closure approximation444Moment closure is a typical approximation method used to estimate moments of population models [13, 15, 32]. To use moment closure, a level is chosen past which all cumulants are set to zero. The conventional choice of the level is , i.e., setting the third and higher cumulants to be zero. and assume the effects of the third and higher moments to be negligible.
Now, just for a moment, suppose that the system beliefs are homogeneous —- the beliefs of every individuals are the same. Hence, the mean belief dynamics are effectively the belief dynamics of individuals. The following proposition follows from Equation 7.
Proposition 3 (Belief Dynamics for Homogeneous Populations).
For a homogeneous system, the dynamics of the belief about each population is governed by a system of differential equations such that for each strategy ,
| (11) |
where is the same for all agents in each neighbor population .
Intuitively, the mean belief dynamics indicates the trend of beliefs in a system, and the variance of beliefs indicates belief heterogeneity. Contrasting Propositions 2 and 3, it is clear that the variance of belief (belief heterogeneity) plays a role in determining the mean belief dynamics (the trend of beliefs) for heterogeneous systems. It is then natural to ask: how does the belief heterogeneity evolve over time? How much does the belief heterogeneity affect the trend of beliefs? Our investigation to these questions reveals an interesting finding — the variance of beliefs asymptotically tends to zero.
Theorem 1 (Quadratic Decay of the Variance of Population Beliefs).
The dynamics of the variance of beliefs about each population is governed by a system of differential equations such that for each strategy ,
| (12) |
At given time , , where is the initial variance. Thus, the variance decays to zero quadratically fast with time.
Such quadratic decay of the variance stands no matter what 2-player subgames agents play and what initial conditions are. Put differently, the beliefs will eventually homogenize for all population network games. This fact immediately implies the system state in the limit.
Corollary 1.
As time , the density function for each population evolves into a Dirac delta function, and the variance of the choice distributions within each population also goes to zero.
Note that while the choice distributions will homogenize within each population, they are not necessarily the same across different populations. This is because the strategy choice of each population is in response to its own set of neighbor populations (which are generally different).
4 Convergence of Smooth Fictitious Play in Population Network Games
The finding on belief homogenization is non-trivial and also technically important. One implication is that the fixed points of systems with initially heterogeneous beliefs are the same as in systems with homogeneous beliefs. Thus, it follows from the belief dynamics for homogeneous systems (Proposition 3) that the fixed points of systems have the following property.
Theorem 2 (Fixed Points of System Dynamics).
For any system that initially have homogeneous or heterogeneous beliefs, the fixed points of the system dynamics is a pair that satisfy for each population and are the solutions of the system of equations
| (13) |
for every strategy and population . Such fixed points always exist and coincide with the Quantal Response Equilibria (QRE) [33] of the population network game .
Note that the above theorem applies for all population network games.
We study the convergence of SFP to the QRE under the both cases of network competition and network coordination. Due to space limits, in the following, we mainly focus on network competition and present only the main result on network coordination.
4.1 Network Competition
Consider a competitive population network game . Note that in competitive network games, the Nash equilibrium payoffs need not to be unique (which is in clear contrast to two-player settings), and it generally allows for infinitely many Nash equilibria. In the following theorem, focusing on homogeneous systems, we establish the convergence of the belief dynamics to a unique QRE, regardless of the number of Nash equilibria in the underlying game.
Theorem 3 (Convergence in Homogeneous Network Competition).
Given a competitive , for any system that has homogeneous beliefs, the belief dynamics (Equation 11) converges to a unique QRE which is globally asymptotically stable.
Proof of Sketch.
We proof this theorem by showing that the “distance” between and is strictly decreasing until the QRE is reached. In particular, we measure the distance in terms of the perturbed payoff and construct a strict Lyapunov function
| (14) |
where are the positive weights given by , and is a perturbed payoff function defined as . ∎
Next, we turn to systems with initially heterogeneous beliefs. Leveraging that the variance of beliefs eventually goes to zero, we establish the following lemma.
Lemma 1.
For ease of presentation, we follow the convention to denote the solution flows of an asymptotically autonomous system and its limit equation by and , respectively. Thieme [40] provides the following seminal result that connects the limit behaviors of and .
Lemma 2 (Thieme [40] Theorem 4.2).
Given a metric space . Assume that the equilibria of are isolated compact -invariant subsets of . The --limit set of any pre-compact -orbit contains a -equilibrium. The point , have a pre-compact -orbit. Then the following alternative holds: 1) , for some -equilibrium e, and 2) the --limit set of contains finitely many -equilibria which are chained to each other in a cyclic way.
Combining the above results, we prove the convergence for initially heterogeneous systems.
Theorem 4 (Convergence in Initially Heterogeneous Network Competition).
Given a competitive , for any system that initially has heterogeneous beliefs, the mean belief dynamics (Equation 10) converges to a unique QRE.
The following corollary immediately follows as the result of belief homogenization.
Corollary 2.
For any competitive , under smooth fictitious play, the choice distributions and beliefs of every individual converges to a unique QRE (given in Theorem 2), regardless of belief initialization and the number of Nash equilibria in .
4.2 Network Coordination
We delegate most of the results on coordination network games to the supplementary, and summarize only the main result here.
Theorem 5 (Convergence in Network Coordination with Star Structure).
Given a coordination where the network structure consists of a single or disconnected multiple stars, each orbit of the belief dynamics (Equation 11) for homogeneous systems as well as each orbit of the mean belief dynamics (Equation 10) for initially heterogeneous systems converges to the set of QRE.
Note that this theorem applies to all 2-population coordination games, as network games with or without star structure are essentially the same when there are only two vertices. We also remark that pure or mixed Nash equilibria in coordination network games are complex; as reported in recent works [5, 4, 1], finding a pure Nash equilibrium is PLS-complete. Hence, learning in the general case of network coordination is difficult and generally requires some conditions for theoretical analysis [34, 35].
5 Experiments: Equilibrium Selection in Population Network Games
In this section, we complement our theory and present an empirical study of SFP in a two-population coordination (stag hunt) game and a five-population zero-sum (asymmetric matching pennies) game. Importantly, these two games both have multiple Nash equilibria, which naturally raises the problem of equilibrium selection.
| (1, 1) | (2, 0) | |
| (0, 2) | (4, 4) |

5.1 Two-Population Stag Hunt Games
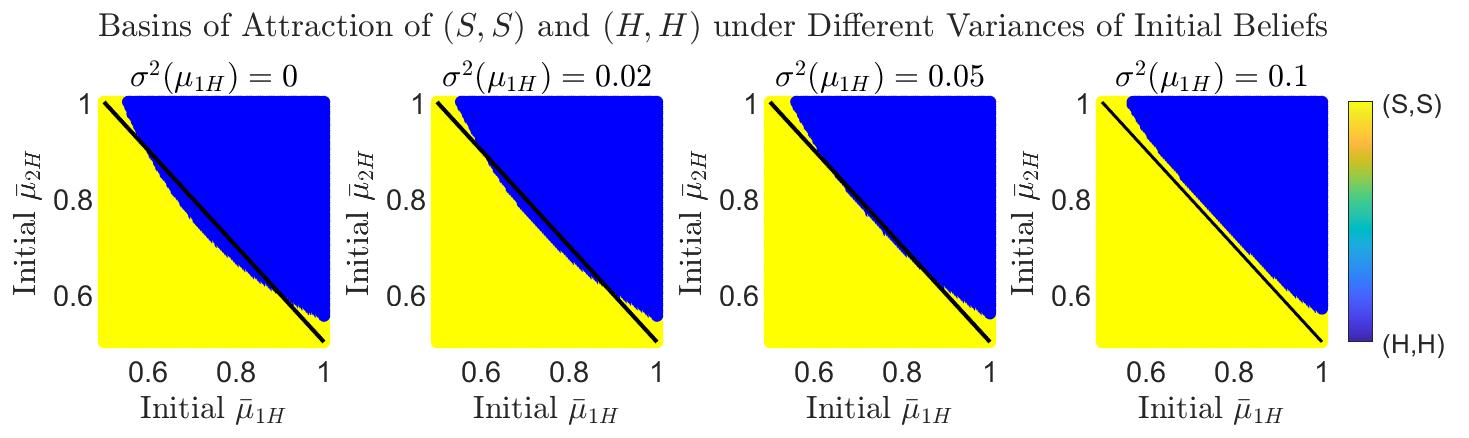
We have shown in Figure 1 (in the introduction) that given the same initial mean belief, changing the variances of initial beliefs can result in different limit behaviors. In the following, we systematically study the effect of initial belief heterogeneity by visualizing how it affects the regions of attraction to different equilibria.
Game Description. We consider a two-population stag hunt game, where each player in populations and has two actions . As shown in the payoff bi-matrices (Table 1), there are two pure strategy Nash equilibria in this game: and . While is risk dominant, is indeed more desirable as it is payoff dominant as well as Pareto optimal.
Results. In this game, population 1 forms beliefs about population 2 and vice versa. We denote the initial mean beliefs by a pair . We numerically solve the mean belief dynamics for a large range of initial mean beliefs, given different variances of initial beliefs. In Figure 3, for each pair of initial mean beliefs, we color the corresponding data point based on which QRE the system eventually converges to. We observe that as the variance of initial beliefs increases (from the left to right panel), a larger range of initial mean beliefs results in the convergence to the QRE that approximates the payoff dominant equilibrium . Put differently, a higher degree of initial belief heterogeneity leads to a larger region of attraction to . Hence, belief heterogeneity eventually vanishes though, it provides an approach to equilibrium selection, as it helps select the highly desirable equilibrium.
5.2 Five-Population Asymmetric Matching Pennies Games
We have shown in Corollary 2 that SFP converges to a unique QRE even if there are multiple Nash equilibria in a competitive . In the following, we corroborate this by providing empirical evidence in agent-based simulations with different belief initialization (the details of simulations are summarized in the supplementary).
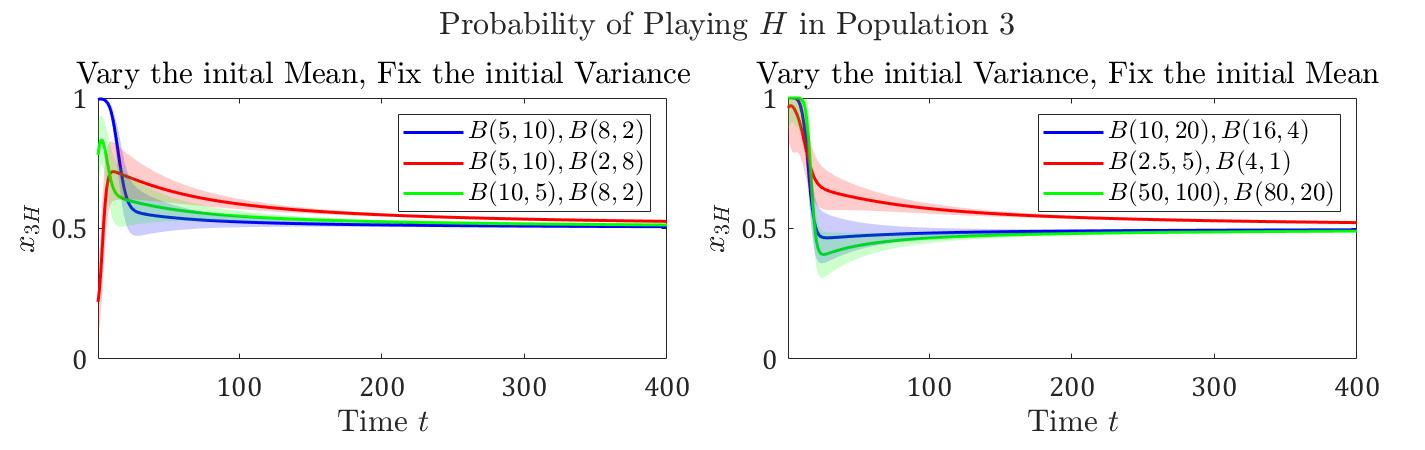
Game Description. Consider a five-population asymmetric matching pennies game [28], where the network structure is a line (depicted in Figure 2). Each agent has two actions . Agents in populations and do not learn; they always play strategies and , respectively. For agents in populations to , they receive if they match the strategy of the opponent in the next population, and receive if they mismatch. On the contrary, they receive if they mismatch the strategy of the opponent in the previous population, and receive if they match. Hence, this game has infinitely many Nash equilibria of the form: agents in populations and play strategy , whereas agents in population are indifferent between strategies and .
Results. In this game, agents in each population form two beliefs (one for the previous population and one for the next population). We are mainly interested in the strategies of population , as the Nash equilibria differ in the strategies in population . For validation, we vary population ’s beliefs about the neighbor populations and , and fix population ’s beliefs about the other populations. As shown in Figure 4, given differential initialization of beliefs, agents in population converge to the same equilibrium where they all take strategy with probability . Therefore, even when the underlying zero-sum game has many Nash equilibria, SFP with different initial belief heterogeneity selects a unique equilibria, addressing the problem of equilibrium selection.
6 Conclusions
We study a heterogeneous beliefs model of SFP in network games. Representing the system state with a distribution over beliefs, we prove that beliefs eventually become homogeneous in all network games. We establish the convergence of SFP to Quantal Response Equilibria in general competitive network games as well as coordination network games with star structure. We experimentally show that although the initial belief heterogeneity vanishes in the limit, it plays a crucial role in equilibrium selection and helps select highly desirable equilibria.
Appendix A: Corollaries and Proofs omitted in Section 3
Proof of Proposition 1
It follows from Equation 7 in the main paper that the change in between two discrete time steps is
| (15) |
Lemma 3.
Under Assumption 1 (in the main paper), for an arbitrary agent in population , its belief about a neighbor population will never reach the extreme belief (i.e., the boundary of the simplex ).
Proof.
Assumption 1 ensures that is in the interior of the simplex . Moreover, the logit choice function (Equation 5 in the main paper) also ensures that stays in the interior of afterwards for a finite temperature . Hence, from Equation 15, one can see that for every time step will stay in the interior of . ∎
In the following, for notation convenience, we sometimes drop the agent index and the time index depending on the context. Consider a population . We rewrite the change in the beliefs about this population as follows.
| (16) |
Suppose that the amount of time that passes between two successive time steps is . We rewrite the above equation as
| (17) |
Next, we consider a test function . Define
| (18) |
Applying Taylor series for at , we obtain
| (19) |
where denotes the Hessian matrix. Hence, the expectation is
| (20) |
Moving the term to the left hand side and dividing both sides by , we recover the quantity , i.e.,
| (21) |
Taking the limit of with , the contribution of the second term on the right hand side vanishes, yielding
| (22) | ||||
| (23) |
Apply integration by parts. We obtain
| (24) |
where we have leveraged that the probability mass at the boundary remains zero as a result of Lemma 1. On the other hand, according to the definition of ,
| (25) |
Therefore, we have the equality
| (26) |
As is a test function, this leads to
| (27) |
Rearranging the terms, we obtain Equation 8 in the main paper. By the definition of expectation given a probability distribution, it is straightforward to obtain Equation 9 in the main paper. Q.E.D.
Remarks: The PDEs we derived are akin to the continuity equation commonly encountered in physics in the study of conserved quantities.The continuity equation describes the transport phenomena (e.g., of mass or energy) in a physical system. This renders a physical interpretation for our PDE model: under SFP, the belief dynamics of a heterogeneous system is analogously the transport of the agent mass in the simplex .
Corollaries of Proposition 1
Corollary 3.
For any population , the system beliefs about this population never go to extremes.
Proof.
This is a straightforward result of Lemma 1. ∎
Corollary 4.
For any population , the total probability mass always remains conserved.
Proof.
Consider the time derivative of the total probability mass
| (28) |
Apply the Leibniz rule to interchange differentiation and integration,
| (29) |
Substitute with Equation 8 in the main paper,
| (30) | |||
| (31) | |||
| (32) |
Apply integration by parts,
| (33) |
where we have leveraged that the probability mass at the boundary remains zero. Hence, the terms within the bracket of Equation 32 cancel out, and
| (34) |
∎
Proof of Proposition 2
Lemma 4.
The dynamics of the mean belief about each population is governed by a differential equation
| (35) |
Proof.
The time derivative of the mean belief about strategy is
| (36) |
We apply the Leibniz rule to interchange differentiation and integration, and then substitute with Equation 8 in the main paper.
| (37) | |||
| (38) | |||
| (39) | |||
| (40) | |||
| (41) |
where . Apply integration by parts to the first term in Equation 41.
| (42) |
where we have leveraged that the probability mass at the boundary remains zero. Hence, it follows from Equation 41 that
| (43) | |||
| (44) | |||
| (45) | |||
| (46) | |||
| (47) |
∎
We repeat the mean probability , which has been given in Equation 9 in the main paper, as follows:
| (48) |
where . Define and
| (49) |
Applying the Taylor expansion to approximate this function at the mean belief , we have
| (50) |
where denotes the Hessian matrix. Hence, we can rewrite Equation 48 as
| (51) | ||||
| (52) |
Observe that in Equation 52, the second and the third term can be canceled out. Moreover, for any two neighbor populations , the beliefs about these two populations are separate and independent. Hence, the covariance of these beliefs are zero. We apply the moment closure approximation [32, 13] with the second order and obtain
| (53) |
Hence, substituting in Lemma 4 with the above approximation, we have the mean belief dynamics
| (54) |
Q.E.D.
Remarks: the use of the moment closure approximation (considering only the first and the second moments) is for obtaining more conclusive results. Strictly speaking, the mean belief dynamics also depend on the third and higher moments. However, we observe in the experiments that these moments in general have little effects on the mean belief dynamics. To be more specific, given the same initial mean beliefs, while the variance of initial beliefs sometimes can change the limit behaviors of a system, we do not observe similar phenomena for the third and higher moments.
Proof of Proposition 3
Consider a population . It follows from Equation 7 in the main paper that the change in the beliefs about this population can be written as follows.
| (55) |
Suppose that the amount of time that passes between two successive time steps is . We rewrite the above equation as
| (56) |
Move the term to the right hand side and divide both sides by ,
| (57) |
Assume that the amount of time between two successive time steps goes to zero. we have
| (58) |
Note that for continuous-time dynamics, we usually drop the time index in the bracket, yielding the belief dynamics (Equation 11) in Proposition 3. Q.E.D.
Proof of Theorem 1
Without loss of generality, we consider the variance of the belief about strategy of population . Note that
| (59) |
Hence, we have
| (60) |
Consider the first term on the right hand side. We apply the Leibniz rule to interchange differentiation and integration, and then substitute with Equation 8 in the main paper.
| (61) | |||
| (62) | |||
| (63) | |||
| (64) |
where . Applying integration by parts to the first term in Equation 64 yields
| (65) |
where we have leveraged that the probability mass at the boundary remains zero. Combining the above two equations, we obtain
| (66) | |||
| (67) | |||
| (68) | |||
| (69) |
Next, we consider the second term in Equation 60. By Lemma 4, we have
| (70) |
Combining Equations 69 and 70, the dynamics of the variance is
| (71) | ||||
| (72) | ||||
| (73) |
Q.E.D.
Remarks: We believe that the rationale behind such a phenomenon is twofold: 1) agents apply smooth fictitious play, and 2) agents respond to the mean strategy play of other populations rather than the strategy play of some fixed agents. Regarding the former, we notice that under a similar setting, population homogenization may not occur if agents apply other learning methods, e.g., Q-learning and Cross learning. Regarding the latter, imagine that agents adjust their beliefs in response to the strategies of some fixed agents. For example, consider two populations; one contains agents A and C, and the other one contains agents B and D. Suppose that agents A and B form a fixed pair such that they adjust their beliefs only in response to each other; the same applies to agents C and D. Belief homogenization may not happen.
Appendix B: Proofs omitted in Section 4.1
Proof of Theorem 2
Belief homogenization implies that the fixed points of systems with initially heterogeneous beliefs are the same as in systems with homogeneous beliefs. Thus, we focus on homogeneous systems to analyze the fixed points. It is straightforward to see that
| (74) |
Denote the fixed points of the system dynamics, which satisfies the above equation, by for each population . By the logit choice function (Equation 5 in the main paper), we have
| (75) |
Leveraging that at the fixed points, we can replace with . Q.E.D.
Proof of Theorem 3
Consider a population . The set of neighbor populations is , the set of beliefs about the neighbor populations is , and the choice distribution is . Given a population network game , the expected payoff is given by . Define a perturbed payoff function
| (76) |
where . Under this form of , the maximization of yields the choice distribution from the logit choice function [8]. Based on this, we establish the following lemma.
Lemma 5.
For a choice distribution of SFP in a population network game,
| (77) |
Proof.
This lemma immediately follows from the fact that the maximization of will yield the choice distribution from the logit choice function [8]. ∎
The belief dynamics of a homogeneous populations can be simplified after time-reparameterization.
Lemma 6.
Given , the belief dynamics of homogeneous systems (given in Equation 11 in the main paper) is equivalent to
| (78) |
Proof.
From , we have
| (79) |
By the chain rule, for each dimension ,
| (80) | ||||
| (81) | ||||
| (82) | ||||
| (83) |
∎
Next, we define the Lyapunov function as
| (84) |
where is the set of positive weights defined in the weighted zero-sum . The function is non-negative because for every , maximizes the function . When for every , , the function reaches the minimum value .
Rewrite as
| (85) |
We observe that is convex in by Danskin’s theorem, and is strictly convex in . Moreover, by the weighted zero-sum property given in Equation 2 in the main paper, we have
| (86) |
since for every Therefore, the function is a strictly convex function and attains its minimum value at a unique point ,
Consider the function . Its time derivative is
| (87) | ||||
Note that the partial derivative equals by Lemma 5. Thus, we can rewrite this as
| (88) | ||||
| (89) | ||||
| (90) |
where from Equation 89 to 90, we apply Lemma 5 to substitute with . Hence, summing over all the populations, the time derivative of is
| (91) |
The summation in the second line is equivalent to
| (92) | |||
| (93) |
By the weighted zero-sum property given in Equation 2 in the main paper, this summation equals , yielding
| (94) |
Note that the function is strictly concave such that its second derivative is negative definite. By this property, with equality only if , which corresponds to the QRE. Therefore, is a strict Lyapunov function, and the global asymptotic stability of the QRE follows. Q.E.D.
Remarks: Intuitively, the Lyapunov function defined above measures the distance between the QRE and a given set of beliefs. The idea of measuring the distance in terms of entropy-regularized payoffs is inspired from the seminal work [19]. However, different from the network games considered in this paper, Hofbauer and Hopkins [19] consider SFP in two-player games. To our knowledge, so far there has been no systematic study on SFP in network games.
Proof of Theorem 4
The proof of Theorem 4 leverages the seminal results of the asymptotically autonomous dynamical system [31, 40, 41] which conventionally is defined as follows.
Definition 1.
A nonautonomous system of differential equations in
| (95) |
is said to be asymptotically autonomous with limit equation
| (96) |
if where the convergence is uniform on each compact subset of . Conventionally, the solution flow of Eq. 95 is called the asymptotically autonomous semiflow (denoted by ) and the solution flow of Eq. 96 is called the limit semiflow (denoted by ).
Based on this definition, we establish Lemma 1 in the main paper, which is repeated as follows.
Lemma 7.
For a system that initially has heterogeneous beliefs, the mean belief dynamics is asymptotically autonomous [31] with the limit equation
| (97) |
which after time-reparameterization is equivalent to the belief dynamics for homogeneous systems.
Proof.
We first time-reparameterize the mean belief dynamics of heterogeneous systems. Assume . By the chain rule and Equation 54, for each dimension ,
| (98) | ||||
| (99) | ||||
| (100) | ||||
| (101) |
Observe that decays to zero exponentially fast and that both and are bounded for every in the simplex . Hence, Equation 101 converges locally and uniformly to the following equation:
| (102) |
Note that for homogeneous systems, and the above equation is algebraically equivalent to Equation 97. Hence, by Definition 1, Equation 101 is asymptotically autonomous with the limit equation being Equation 97. ∎
By the above lemma, we can formally connect the limit behaviors of initially heterogeneous systems and those of homogeneous systems. Recall that Theorem 3 in the main paper states that under SFP, there is a unique rest point (QRE) for the belief dynamics in a weighted zero-sum network game ; this excludes the case where there are finitely many equilibria that are chained to each other. Hence, combining Lemma 2 in the main paper, we prove that the mean belief dynamics of initially heterogeneous systems converges to a unique QRE. Q.E.D.
Appendix C: Results and Proofs omitted in Section 4.2
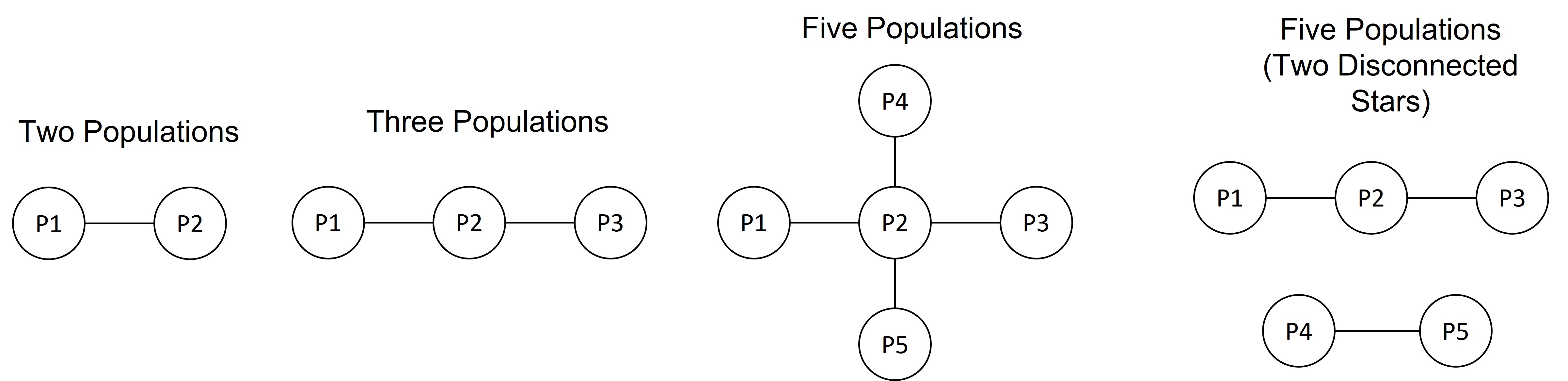
For the case of network coordination, we consider networks that consist of a star or disconnected multiple stars due to technical reasons. In Figure 1, we present examples of the considered network structure with different numbers of nodes (populations).
In the following theorem, focusing on homogeneous systems, we establish the convergence of the belief dynamics to the set of QRE.
Theorem 6 (Convergence in Homogeneous Network Coordination with Star Structure).
Given a coordination where the network structure consists of a single or disconnected multiple stars, each orbit of the belief dynamics for homogeneous systems converges to the set of QRE.
Proof.
Consider a root population of a star structure. Its set of leaf (neighbor) populations is , the set of beliefs about the leaf populations is , and the choice distribution is . Given the game , the expected payoff is . Define a perturbed payoff function
| (103) |
where . Under this form of , the maximization of yields the choice distribution from the logit choice function [8].
Consider a leaf population of the root population . It has only one neighbor population, which is population . Thus, given the game , the expected payoff is . Define a perturbed payoff function
| (104) |
where . Similarly, the maximization of yields the choice distribution from the logit choice function [8]. Based on this, we establish the following lemma.
Lemma 8.
For choice distributions of SFP in a population network game with start structure,
| if is a root population, | (105) | |||
| if is a leaf population. | (106) |
Proof.
This lemma immediately follows from the fact that the maximization of and , respectively, yield the choice distributions and from the logit choice function [8]. ∎
For readability, we repeat the belief dynamics of a homogeneous population after time-reparameterization, which has been proved in Lemma 4 in Appendix B, as follows:
| (107) |
Let be the set of all root populations. We define
| (108) |
Consider the function . Its time derivative is
| (109) | |||
| (110) |
Since is a coordination game, we have . Hence, applying Lemma 8, we can substitute with , and with , yielding
| (111) | |||
| (112) |
Note that the function is strictly concave such that its second derivative is negative definite. By this property, with equality only if and . Thus, the time derivative of the function , i.e., with equality only if . ∎
We generalize the convergence result to initially heterogeneous systems in the following theorem.
Theorem 7 (Convergence in Initially Heterogeneous Network Coordination with Star Structure).
Given a coordination where the network structure consists of a single or disconnected multiple stars, each orbit of the mean belief dynamics for initially heterogeneous systems converges to the set of QRE.
Proof.
The proof technique is similar to that for initially heterogeneous competitive network games. By Lemma 1 in the main paper, we show that the mean belief dynamics of initially heterogeneous systems is asymptotically autonomous with the belief dynamics of homogeneous systems. Therefore, it follows from Lemma 2 in the main paper that the convergence result for homogeneous systems can be carried over to the initially heterogeneous systems. ∎
Remarks: The convergence of SFP in coordination games and potential games has been established under the 2-player settings [19] as well as some n-player settings [20, 39]. Our work differs from the previous works in two aspects. First, our work allows for heterogeneous beliefs. Moreover, we consider that agents maintain separate beliefs about other agents, while in the previous works agents do not distinguish between other agents. Thus, even when the system beliefs are homogeneous, our setting is still different from (and more complicated) than the previous settings.
Appendix D: Omitted Experimental Details
Numerical Method for the PDE model.
Agent-based Simulations.
The presented simulation results are averaged over 100 independent simulation runs to smooth out the randomness. For each simulation run, there are agents in each population. For each agent, the initial beliefs are sampled from the given initial probability distribution.
Detailed Experimental Setups for Figure 1.
In the case of small initial variance, the initial beliefs and are distributed according to the distribution . On the contrary, in the case of large initial variance, the initial beliefs and are distributed according to the distribution . Thus, initially, the mean beliefs in these two cases are both and . In both cases, the initial sum of weights and the temperature .
Detailed Experimental Setups for Figure 3.
We visualize the regions of attraction of different equilibria in stag hunt games by numerically solving the mean belief dynamics (Equation 10 in the main paper). The initial variances have been given in the title of each panel. In all cases, the initial sum of weights and the temperature .
Detailed Experimental Setups for Figure 4.
We let the initial beliefs about populations 1, 3 and 5 remain unchanged across different cases, and vary the initial beliefs about populations 2 and 4. The initial beliefs about populations 1, 3 and 5, denoted by , and , are distributed according to the distributions , , and , respectively. The initial beliefs about populations 2 and 4 have been given in the legends of Figure 4. In all cases, the initial sum of weights and the temperature . Note that for all populations
Source Code and Computing Resource.
We have attached the source code for reproducing our main experiments. The Matlab script finitedifference.m numerically solves our PDE model presented in Proposition 1 in the main paper. The Matlab script regionofattraction.m visualizes the region of attraction of different equilibria in stag hunt games, which are presented in Figure 3. The Python scripts simulation(staghunt).py and simulation(matchingpennies).py correspond to the agent-based simulations in two-population stag hunt games and five-population asymmetric matching pennies games, respectively. We use a laptop (CPU: AMD Ryzen 7 5800H) to run all the experiments.
References
- [1] Yakov Babichenko and Aviad Rubinstein. Settling the complexity of nash equilibrium in congestion games. In Proceedings of the 53rd Annual ACM SIGACT Symposium on Theory of Computing, pages 1426–1437, 2021.
- [2] Michel Benaïm and Mathieu Faure. Consistency of vanishingly smooth fictitious play. Mathematics of Operations Research, 38(3):437–450, 2013.
- [3] Michel Benaım and Morris W Hirsch. Mixed equilibria and dynamical systems arising from fictitious play in perturbed games. Games and Economic Behavior, 29(1-2):36–72, 1999.
- [4] Shant Boodaghians, Rucha Kulkarni, and Ruta Mehta. Smoothed efficient algorithms and reductions for network coordination games. arXiv preprint arXiv:1809.02280, 2018.
- [5] Yang Cai and Constantinos Daskalakis. On minmax theorems for multiplayer games. In Proceedings of the twenty-second annual ACM-SIAM symposium on Discrete algorithms, pages 217–234. SIAM, 2011.
- [6] Aleksander Czechowski and Georgios Piliouras. Poincar’e-bendixson limit sets in multi-agent learning. 2022.
- [7] Christian Ewerhart and Kremena Valkanova. Fictitious play in networks. Games and Economic Behavior, 123:182–206, 2020.
- [8] Drew Fudenberg, Fudenberg Drew, David K Levine, and David K Levine. The theory of learning in games, volume 2. MIT press, 1998.
- [9] Drew Fudenberg and David M Kreps. Learning mixed equilibria. Games and economic behavior, 5(3):320–367, 1993.
- [10] Drew Fudenberg and David K Levine. Steady state learning and nash equilibrium. Econometrica: Journal of the Econometric Society, pages 547–573, 1993.
- [11] Drew Fudenberg and David K Levine. Measuring players’ losses in experimental games. The Quarterly Journal of Economics, 112(2):507–536, 1997.
- [12] Drew Fudenberg and Satoru Takahashi. Heterogeneous beliefs and local information in stochastic fictitious play. Games and Economic Behavior, 71(1):100–120, 2011.
- [13] Colin S Gillespie. Moment-closure approximations for mass-action models. IET systems biology, 3(1):52–58, 2009.
- [14] Jacob K Goeree, Charles A Holt, and Thomas R Palfrey. Quantal response equilibrium. In Quantal Response Equilibrium. Princeton University Press, 2016.
- [15] Leo A Goodman. Population growth of the sexes. Biometrics, 9(2):212–225, 1953.
- [16] Shubham Gupta, Rishi Hazra, and Ambedkar Dukkipati. Networked multi-agent reinforcement learning with emergent communication. In Proceedings of the 19th International Conference on Autonomous Agents and MultiAgent Systems, pages 1858–1860, 2020.
- [17] Jiequn Han and Ruimeng Hu. Deep fictitious play for finding markovian nash equilibrium in multi-agent games. In Mathematical and Scientific Machine Learning, pages 221–245. PMLR, 2020.
- [18] Erik Hernández, Antonio Barrientos, and Jaime Del Cerro. Selective smooth fictitious play: An approach based on game theory for patrolling infrastructures with a multi-robot system. Expert Systems with Applications, 41(6):2897–2913, 2014.
- [19] Josef Hofbauer and Ed Hopkins. Learning in perturbed asymmetric games. Games and Economic Behavior, 52(1):133–152, 2005.
- [20] Josef Hofbauer and William H Sandholm. On the global convergence of stochastic fictitious play. Econometrica, 70(6):2265–2294, 2002.
- [21] Josef Hofbauer and William H Sandholm. Evolution in games with randomly disturbed payoffs. Journal of economic theory, 132(1):47–69, 2007.
- [22] Ed Hopkins. A note on best response dynamics. Games and Economic Behavior, 29(1-2):138–150, 1999.
- [23] Shuyue Hu, Chin-wing Leung, and Ho-fung Leung. Modelling the dynamics of multiagent q-learning in repeated symmetric games: a mean field theoretic approach. In Advances in Neural Information Processing Systems, pages 12102–12112, 2019.
- [24] Shuyue Hu, Chin-Wing Leung, Ho-fung Leung, and Harold Soh. The dynamics of q-learning in population games: A physics-inspired continuity equation model. In Proceedings of the 21st International Conference on Autonomous Agents and Multiagent Systems, page 615–623, 2022.
- [25] Max Jaderberg, Valentin Dalibard, Simon Osindero, Wojciech M Czarnecki, Jeff Donahue, Ali Razavi, Oriol Vinyals, Tim Green, Iain Dunning, Karen Simonyan, et al. Population based training of neural networks. arXiv preprint arXiv:1711.09846, 2017.
- [26] KG Binmore AP Kirman et al. Frontiers of game theory. Mit Press, 1993.
- [27] Ratul Lahkar and Robert M Seymour. Reinforcement learning in population games. Games and Economic Behavior, 80:10–38, 2013.
- [28] Stefanos Leonardos and Georgios Piliouras. Exploration-exploitation in multi-agent learning: Catastrophe theory meets game theory. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 35, pages 11263–11271, 2021.
- [29] Chin-Wing Leung, Shuyue Hu, and Ho-Fung Leung. Self-play or group practice: Learning to play alternating markov game in multi-agent system. In 2020 25th International Conference on Pattern Recognition (ICPR), pages 9234–9241. IEEE, 2021.
- [30] Yiwei Liu, Jiamou Liu, Kaibin Wan, Zhan Qin, Zijian Zhang, Bakhadyr Khoussainov, and Liehuang Zhu. From local to global norm emergence: Dissolving self-reinforcing substructures with incremental social instruments. In International Conference on Machine Learning, pages 6871–6881. PMLR, 2021.
- [31] L Markus. Asymptotically autonomous differential systems. contributions to the theory of nonlinear oscillations iii (s. lefschetz, ed.), 17-29. Annals of Mathematics Studies, 36, 1956.
- [32] Timothy I Matis and Ivan G Guardiola. Achieving moment closure through cumulant neglect. The Mathematica Journal, 12:12–2, 2010.
- [33] Richard D McKelvey and Thomas R Palfrey. Quantal response equilibria for normal form games. Games and economic behavior, 10(1):6–38, 1995.
- [34] Sai Ganesh Nagarajan, David Balduzzi, and Georgios Piliouras. From chaos to order: Symmetry and conservation laws in game dynamics. In International Conference on Machine Learning, pages 7186–7196. PMLR, 2020.
- [35] Gerasimos Palaiopanos, Ioannis Panageas, and Georgios Piliouras. Multiplicative weights update with constant step-size in congestion games: Convergence, limit cycles and chaos. Advances in Neural Information Processing Systems, 30, 2017.
- [36] Julien Perolat, Bilal Piot, and Olivier Pietquin. Actor-critic fictitious play in simultaneous move multistage games. In International Conference on Artificial Intelligence and Statistics, pages 919–928. PMLR, 2018.
- [37] Sarah Perrin, Julien Pérolat, Mathieu Laurière, Matthieu Geist, Romuald Elie, and Olivier Pietquin. Fictitious play for mean field games: Continuous time analysis and applications. Advances in Neural Information Processing Systems, 33:13199–13213, 2020.
- [38] Gordon Dennis Smith. Numerical solution of partial differential equations: finite difference methods. Clarendon Press, 1985.
- [39] Brian Swenson and H Vincent Poor. Smooth fictitious play in n 2 potential games. In 2019 53rd Asilomar Conference on Signals, Systems, and Computers, pages 1739–1743. IEEE, 2019.
- [40] Horst R Thieme. Convergence results and a poincaré-bendixson trichotomy for asymptotically autonomous differential equations. Journal of mathematical biology, 30(7):755–763, 1992.
- [41] Horst R Thieme. Asymptotically autonomous differential equations in the plane. The Rocky Mountain Journal of Mathematics, pages 351–380, 1994.
- [42] Qiaomin Xie, Zhuoran Yang, Zhaoran Wang, and Andreea Minca. Provable fictitious play for general mean-field games. arXiv preprint arXiv:2010.04211, 2020.
- [43] Kaiqing Zhang, Zhuoran Yang, Han Liu, Tong Zhang, and Tamer Basar. Fully decentralized multi-agent reinforcement learning with networked agents. In International Conference on Machine Learning, pages 5872–5881. PMLR, 2018.
- [44] Rui Zhao, Jinming Song, Hu Haifeng, Yang Gao, Yi Wu, Zhongqian Sun, and Yang Wei. Maximum entropy population based training for zero-shot human-ai coordination. arXiv preprint arXiv:2112.11701, 2021.