Heterogeneous Risk Minimization
Abstract
Machine learning algorithms with empirical risk minimization usually suffer from poor generalization performance due to the greedy exploitation of correlations among the training data, which are not stable under distributional shifts. Recently, some invariant learning methods for out-of-distribution (OOD) generalization have been proposed by leveraging multiple training environments to find invariant relationships. However, modern datasets are frequently assembled by merging data from multiple sources without explicit source labels. The resultant unobserved heterogeneity renders many invariant learning methods inapplicable. In this paper, we propose Heterogeneous Risk Minimization (HRM) framework to achieve joint learning of latent heterogeneity among the data and invariant relationship, which leads to stable prediction despite distributional shifts. We theoretically characterize the roles of the environment labels in invariant learning and justify our newly proposed HRM framework. Extensive experimental results validate the effectiveness of our HRM framework.
1 Introduction
The effectiveness of machine learning algorithms with empirical risk minimization (ERM) relies on the assumption that the testing and training data are identically drawn from the same distribution, which is known as the IID hypothesis. However, distributional shifts between testing and training data are usually inevitable due to data selection biases or unobserved confounders that widely exist in real data. Under such circumstances, machine learning algorithms with ERM usually suffer from poor generalization performance due to the greedy exploitation of correlations among the training data, which are not stable under distributional shifts. How to guarantee a machine learning algorithm with out-of-distribution (OOD) generalization ability and stable performances under distributional shifts is of paramount significance, especially in high-stake applications such as medical diagnosis, criminal justice, and financial analysis etc (Kukar, 2003; Berk et al., 2018; Rudin & Ustun, 2018).
There are mainly two branches of methods proposed to solve the OOD generalization problem, namely distributionally robust optimization (DRO) (Esfahani & Kuhn, 2018; Duchi & Namkoong, 2018; Sinha et al., 2018; Sagawa et al., 2019) and invariant learning (Arjovsky et al., 2019; Koyama & Yamaguchi, 2020; Chang et al., 2020). DRO methods aim to optimize the worst-performance over a distribution set to ensure their OOD generalization performances. While DRO is a powerful family of methods, it is often argued for its over-pessimism problem when the distribution set is large (Hu et al., 2018; Frogner et al., 2019). From another perspective, invariant learning methods propose to exploit the causally invariant correlations(rather than varying spurious correlations) across multiple training environments, resulting in out-of-distribution (OOD) optimal predictors. However, the effectiveness of such methods relies heavily on the quality of training environments, and the intrinsic role of environments in invariant learning remains vague in theory. More importantly, modern big data are frequently assembled by merging data from multiple sources without explicit source labels. The resultant unobserved heterogeneity renders these invariant learning methods inapplicable.
In this paper, we propose Heterogeneous Risk Minimization (HRM), an optimization framework to achieve joint learning of the latent heterogeneity among the data and the invariant predictor, which leads to better generalization ability despite distributional shifts. More specifically, we theoretically characterize the roles of the environment labels in invariant learning, which motivates us to design two modules in the framework corresponding to heterogeneity identification and invariant learning respectively. We provide theoretical justification on the mutual promotion of these two modules, which resonates the joint optimization process in a reciprocal way. Extensive experiments in both synthetic and real-world experiments datasets demonstrate the superiority of HRM in terms of average performance, stability performance as well as worst-case performance under different settings of distributional shifts. We summarize our contributions as following:
1. We propose the novel HRM framework for OOD generalization without environment labels, in which heterogeneity identification and invariant prediction are jointly optimized.
2. We theoretically characterize the role of environments in invariant learning from the perspective of heterogeneity, based on which we propose a novel clustering method for heterogeneity identification from heterogeneous data.
3. We theoretically justify the mutual promotion relationship between heterogeneity identification and invariant learning, resonating the joint optimization process in HRM.
2 Problem Formulation
2.1 OOD and Maximal Invariant Predictor
Following (Arjovsky et al., 2019; Chang et al., 2020), we consider a dataset , which is a mixture of data collected from multiple training environments , and are the -th data and label from environment respectively and is number of samples in environment . Environment labels are unavailable as in most real applications. is a random variable on indices of training environments and is the distribution of data and label in environment .
The goal of this work is to find a predictor with good out-of-distribution generalization performance, which can be formalized as:
| (1) |
where is the risk of predictor on environment , and is the loss function. is the random variable on indices of all possible environments such that . Usually, for all , the data and label distribution can be quite different from that of training environments . Therefore, the problem in Equation 1 is referred to as Out-of-Distribution (OOD) Generalization problem (Arjovsky et al., 2019).
Without any prior knowledge or structural assumptions, it is impossible to figure out the OOD generalization problem, since one cannot characterize the unseen latent environments in . A commonly used assumption in invariant learning literature (Rojas-Carulla et al., 2015; Gong et al., 2016; Arjovsky et al., 2019; Kuang et al., 2020; Chang et al., 2020) is as follow:
Assumption 2.1.
There exists random variable such that the following properties hold:
a. : for all , we have holds.
b. : .
This assumption indicates invariance and sufficiency for predicting the target using , which is known as invariant covariates or representations with stable relationships with across different environments . In order to acquire the invariant predictor , a branch of work to find maximal invariant predictor (Chang et al., 2020; Koyama & Yamaguchi, 2020) has been proposed, where the invariance set and the corresponding maximal invariant predictor are defined as:
Definition 2.1.
The invariance set with respect to is defined as:
| (2) | ||||
where is the Shannon entropy of a random variable. The corresponding maximal invariant predictor (MIP) of is defined as:
| (3) |
where measures Shannon mutual information between two random variables.
Here we prove that the MIP can can guarantee OOD optimality, as indicated in Theorem 2.1. The formal statement of Theorem 2.1 as well as its proof can be found in appendix.
Theorem 2.1.
Recently, some works suppose the availability of data from multiple environments with environment labels, wherein they can find MIP (Chang et al., 2020; Koyama & Yamaguchi, 2020). However, they rely on the underlying assumption that the invariance set of is exactly the invariance set of all possible unseen environments , which cannot be guaranteed as shown in Theorem 2.2.
Theorem 2.2.
As shown in Theorem 2.2 that , the learned predictor is only invariant to such limited environments but is not guaranteed to be invariant with respect to all possible environments .
Here we give a toy example in Table 1 to illustrate this. We consider a binary classification between cats and dogs, where each photo contains 3 features, animal feature , a background feature and the photographer’s signature feature . Assume all possible testing environments and the train environment , then while . The reason is that only tell us cannot be included in the invariance set but cannot exclude . But if and can be further divided into and respectively, the invariance set becomes .
This example shows that the manually labeled environments may not be sufficient to achieve MIP, not to mention the cases where environment labels are not available. This limitation necessitates the study on how to exploit the latent intrinsic heterogeneity in training data (like and in the above example) to form more refined environments for OOD generalization. The environments need to be subtly uncovered, in the sense of OOD generalization problem, as indicated by Theorem B.4, not all environments are helpful to tighten the invariance set.
Theorem 2.3.
Given set of environments , denote the corresponding invariance set and the corresponding maximal invariant predictor . For one newly-added environment with distribution , if for , the invariance set constrained by is equal to .
| Class 0 (Cats) | Class 1 (Dogs) | |||||
| Index | ||||||
| Cats | Water | Irma | Dogs | Grass | Eric | |
| Cats | Grass | Eric | Dogs | Water | Irma | |
| Cats | Water | Eric | Dogs | Grass | Irma | |
| Cats | Grass | Irma | Dogs | Water | Eric | |
| Mixture: 90% data from and 10% data from | ||||||
| Mixture: 90% data from and 10% data from | ||||||
2.2 Problem of Heterogeneous Risk Minimization
Besides Assumption 2.1, we make another assumption on the existence of heterogeneity in training data as:
Assumption 2.2.
The heterogeneity among provided environments can be evaluated by the compactness of the corresponding invariance set as . Specifically, smaller leads to higher heterogeneity, since more variant features can be excluded. Based on the assumption, we come up with the problem of heterogeneity exploitation for OOD generalization.
Problem 1.
Heterogeneous Risk Minimization.
Given heterogeneous dataset without environment labels, the task is to generate environments with minimal and learn invariant model under learned with good OOD performance.
Theorem B.4 together with Assumption 2.2 indicate that, to better constrain , the effective way is to generate environments with varying that can exclude variant features from . Under this problem setting, we encounter the circular dependency: first we need variant to generate heterogeneous environments ; then we need to learned invariant as well as variant . Furthermore, there exists positive feedback between these two steps. When acquiring with tighter , more invariant predictor (i.e. a better approximation of MIP) can be found, which will further bring a clearer picture of variant parts, and therefore promote the generation of . With this notion, we propose our framework for Heterogeneous Risk Minimization (HRM) which leverages the mutual promotion between the two steps and conduct joint optimization.
3 Method
In this work, we temporarily focus on a simple but general setting, where in raw feature level and satisfy Assumption 2.1. Under this setting, Our Heterogeneous Risk Minimization (HRM) framework contains two interactive parts, the frontend for heterogeneity identification and the backend for invariant prediction. The general framework is shown in Figure 1.
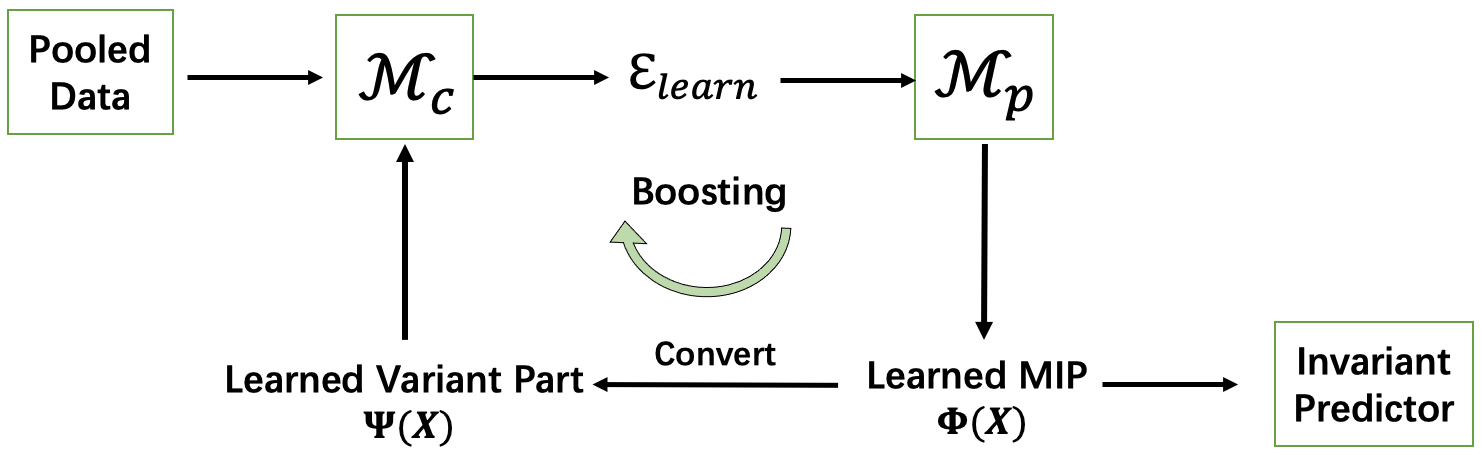
Given the pooled heterogeneous data, it starts with the heterogeneity identification module leveraging the learned variant representation to generate heterogeneous environments . Then the learned environments are used by OOD prediction module to learn the MIP as well as the invariant prediction model . After that, we derive the variant to further boost the module , which is supported by Theorem B.4. As for the ’convert’ step, under our setting, we adopt feature selection in this work, through which more variant feature can be attained when more invariant feature is learned. Specifically, the invariant predictor is generated as , and the variant part correspondingly, where is the binary invariant feature selection mask. For instance, for Table 1, , the ground truth binary mask is . In this way, the better is learned, the better can be obtained. Note that we use the soft selection which is more flexible and general in our algorithm with .
The whole framework is jointly optimized, so that the mutual promotion between heterogeneity identification and invariant learning can be fully leveraged.
3.1 Implementation of
Here we introduce our invariant prediction module , which takes multiple environments training data as input, and outputs the corresponding invariant predictor and the indices of invariant features given current environments . We combine feature selection with invariant learning under heterogeneous environments, which can select the features with stable/invariant correlations with the label across . Specifically, the former module can select most informative features with respect to the loss function and latter module ensures the selected features are invariant. Their combination ensures to select the most informative invariant features.
For invariant learning, we follow the variance penalty regularizer proposed in (Koyama & Yamaguchi, 2020) and simplify it in feature selection scenarios. The objective function of with is:
| (4) | ||||
| (5) |
However, as the optimization of hard feature selection with binary mask suffers from high variance, we use the soft feature selection with gates taking continuous value in . Specifically, following (Yamada et al., 2020), we approximate each element of to clipped Gaussian random variable parameterized by as
| (6) |
where is drawn from . With this approximation, the objective function with soft feature selection can be written as:
| (7) |
where is a random vector with independent variables for . Under the approximation in Equation 6, is simply and can be calculated as , where is the standard Gaussian CDF. We formulate our objective as risk minimization problem:
| (8) |
where
| (9) |
Further, as for linear models, we simply approximate the regularizer by . Then we obtain and when we obtain as well as . Further in Section 4, we theoretically prove that the prediction module is able to learn the MIP with respect to given environments .
3.2 Implementation of
Notation. means the learned variant part . means -dimension simplex. means the function parameterized by .
The heterogeneity identification module takes a single dataset as input, and outputs a multi-environment dataset partition for invariant prediction. We implement it with a clustering algorithm. As indicated in Theorem B.4, the more diverse for our generated environments, the better the invariance set is. Therefore, we cluster the data points according to the relationship between and , for which we use as the cluster centre. Note that is initialized as in our joint optimization.
Specifically, we assume the -th cluster centre parameterized by to be a Gaussian around as :
| (10) |
For the given empirical data samples , the empirical distribution is modeled as where
| (11) |
The target of our heterogeneous clustering is to find a distribution in to fit the empirical distribution best. Therefore, the objective function of our heterogeneous clustering is:
| (12) |
The above objective can be further simplified to:
| (13) |
As for optimization, we use EM algorithm to optimize the centre parameter and the mixture weight . After optimizing equation 13, for building , we assign each data point to environment with probability:
| (14) |
In this way, is generated by .
4 Theoretical Analysis
In this section, we theoretically analyze our proposed Heterogeneous Risk Minimization (HRM) method. We first analyze our proposed invariant learning module , and then justify the existence of the positive feedback in our HRM.
Justification of We prove that given training environments , our invariant prediction model can learn the maximal invariant predictor with respect to the corresponding invariance set .
Theorem 4.1.
Given , the learned is the maximal invariant predictor of .
Justification of the Positive Feedback The core of our HRM framework is the mechanism for and to mutual promote each other. Here we theoretically justify the existence of such positive feedback. In Assumption 2.1, we assume the invariance and sufficiency properties of the stable features and assume the relationship between unstable part and can arbitrarily change. Here we make a more specific assumption on the heterogeneity across environments with respect to and .
Assumption 4.1.
Assume the pooled training data is made up of heterogeneous data sources: . For any , we assume
| (15) |
where is invariant feature and the variant. represents mutual information in and represents the cross mutual information between and takes the form of and .
Here we would like to intuitively demonstrate this assumption. Firstly, the mutual information can be viewed as the error reduction if we use to predict rather than predict by nothing. Then the cross mutual information can be viewed as the error reduction if we use the predictor learned on in environment to predict in environment , rather than predict by nothing. Therefore, the R.H.S in equation 15 measures that, in environment , how much prediction error can be reduced if we further add for prediction rather than use only . And the L.H.S measures that, when using predictors trained in to predict in , how much prediction error can be reduced if we further add for prediction rather than use only . Intuitively, Assumption 4.1 assumes that invariant feature provides more information for predicting across environments than in one single environment, and correspondingly, the information provided by shrinks a lot across environments, which indicates that the relationship between variant feature and varies across environments. Based on this assumption, we first prove that the cluster centres are pulled apart as invariant feature is excluded from clustering.
Theorem 4.2.
Theorem B.6 indicates that the distance between cluster centres is larger when using variant features , therefore, it is more likely to obtain the desired heterogeneous environments, which explains why we use learned variant part for clustering. Finally, we provide the theorem for optimality guarantee for our HRM.
Theorem 4.3.
Under Assumption 2.1 and 4.1, for the proposed and , we have the following conclusions: 1. Given environments such that , the learned by is the maximal invariant predictor of .
2. Given the maximal invariant predictor of , assume the pooled training data is made up of data from all environments in , there exist one split that achieves the minimum of the objective function and meanwhile the invariance set regularized is equal to .
Intuitively, Theorem 4.3 proves that given one of the and optimal, the other is optimal, which validates the existence of the global optimal point of our algorithm.
5 Experiment
In this section, we validate the effectiveness of our method on simulation data and real-world data.
Baselines We compare our proposed HRM with the following methods:
-
•
Empirical Risk Minimization(ERM):
-
•
Distributionally Robust Optimization(DRO (Sinha et al., 2018)):
-
•
Environment Inference for Invariant Learning(EIIL (Creager et al., 2020)):
(16) -
•
Invariant Risk Minimization(IRM (Arjovsky et al., 2019)) with environment labels:
(17)
Further, for ablation study, we also compare with HRMs, which runs HRM for only one iteration without the feedback loop. Note that IRM is based on multiple training environments and we provide environment labels for IRM, while others do not need environment labels.
Evaluation Metrics To evaluate the prediction performance, we use defined as , defined as , which are mean and standard deviation error across and , which are mean error, standard deviation error and worst-case error across .
Imbalanced Mixture It is a natural phenomena that empirical data follow a power-law distribution, i.e. only a few environments/subgroups are common and the rest are rare (Shen et al., 2018; Sagawa et al., 2019, 2020). Therefore, we perform non-uniform sampling among different environments in training set.
| Scenario 1: varying selection bias rate () | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Methods | |||||||||
| ERM | 0.476 | 0.064 | 0.524 | 0.510 | 0.108 | 0.608 | 0.532 | 0.139 | 0.690 |
| DRO | 0.467 | 0.046 | 0.516 | 0.512 | 0.111 | 0.625 | 0.535 | 0.143 | 0.746 |
| EIIL | 0.477 | 0.057 | 0.543 | 0.507 | 0.102 | 0.613 | 0.540 | 0.139 | 0.683 |
| IRM(with label) | 0.460 | 0.014 | 0.475 | 0.456 | 0.015 | 0.472 | 0.461 | 0.015 | 0.475 |
| HRMs | 0.465 | 0.045 | 0.511 | 0.488 | 0.078 | 0.577 | 0.506 | 0.096 | 0.596 |
| HRM | 0.447 | 0.011 | 0.462 | 0.449 | 0.010 | 0.465 | 0.447 | 0.011 | 0.463 |
| Scenario 2: varying dimension () | |||||||||
| Methods | |||||||||
| ERM | 0.510 | 0.108 | 0.608 | 0.533 | 0.141 | 0.733 | 0.528 | 0.175 | 0.719 |
| DRO | 0.512 | 0.111 | 0.625 | 0.564 | 0.186 | 0.746 | 0.555 | 0.196 | 0.758 |
| EIIL | 0.507 | 0.102 | 0.613 | 0.543 | 0.147 | 0.699 | 0.542 | 0.178 | 0.727 |
| IRM(with label) | 0.456 | 0.015 | 0.472 | 0.484 | 0.014 | 0.489 | 0.500 | 0.051 | 0.540 |
| HRMs | 0.488 | 0.078 | 0.577 | 0.486 | 0.069 | 0.555 | 0.477 | 0.081 | 0.553 |
| HRM | 0.449 | 0.010 | 0.465 | 0.466 | 0.011 | 0.478 | 0.465 | 0.015 | 0.482 |
5.1 Simulation Data
We design two mechanisms to simulate the varying correlations among covariates across environments, named by selection bias and anti-causal effect.
| Scenario 1: | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Training environments | Testing environments | |||||||||
| Methods | ||||||||||
| ERM | 0.290 | 0.308 | 0.376 | 0.419 | 0.478 | 0.538 | 0.596 | 0.626 | 0.640 | 0.689 |
| DRO | 0.289 | 0.310 | 0.388 | 0.428 | 0.517 | 0.610 | 0.627 | 0.669 | 0.679 | 0.739 |
| EIIL | 0.075 | 0.128 | 0.349 | 0.485 | 0.795 | 1.162 | 1.286 | 1.527 | 1.558 | 1.884 |
| IRM(with label) | 0.306 | 0.312 | 0.325 | 0.328 | 0.343 | 0.358 | 0.365 | 0.374 | 0.377 | 0.392 |
| HRMs | 1.060 | 1.085 | 1.112 | 1.130 | 1.207 | 1.280 | 1.325 | 1.340 | 1.371 | 1.430 |
| HRM | 0.317 | 0.314 | 0.322 | 0.318 | 0.321 | 0.317 | 0.315 | 0.315 | 0.316 | 0.320 |
| Scenario 2: | ||||||||||
| Training environments | Testing environments | |||||||||
| Methods | ||||||||||
| ERM | 0.238 | 0.286 | 0.433 | 0.512 | 0.629 | 0.727 | 0.818 | 0.860 | 0.895 | 0.980 |
| DRO | 0.237 | 0.294 | 0.452 | 0.529 | 0.651 | 0.778 | 0.859 | 0.911 | 0.950 | 1.028 |
| EIIL | 0.043 | 0.145 | 0.521 | 0.828 | 1.237 | 1.971 | 2.523 | 2.514 | 2.506 | 3.512 |
| IRM(with label) | 0.287 | 0.293 | 0.329 | 0.345 | 0.382 | 0.420 | 0.444 | 0.461 | 0.478 | 0.504 |
| HRMs | 0.455 | 0.463 | 0.479 | 0.478 | 0.495 | 0.508 | 0.513 | 0.519 | 0.525 | 0.533 |
| HRM | 0.316 | 0.315 | 0.315 | 0.330 | 0.3200 | 0.317 | 0.326 | 0.330 | 0.333 | 0.335 |
Selection Bias In this setting, the correlations between variant covariates and the target are perturbed through selection bias mechanism. According to Assumption 2.1, we assume and and that remains invariant across environments while changes arbitrarily. For simplicity, we select data points according to a certain variable set :
| (18) |
where , and denotes the probability of point to be selected. Intuitively, eventually controls the strengths and direction of the spurious correlation between and (i.e. if , a data point whose is close to its is more probably to be selected.). The larger value of means the stronger spurious correlation between and , and means positive correlation and vice versa. Therefore, here we use to define different environments.
In training, we generate data points, where points from environment with a predefined and points from with . In testing, we generate data points for 10 environments with . is set to 1.0. We compare our HRM with ERM, DRO, EIIL and IRM for Linear Regression. We conduct extensive experiments with different settings on , and . In each setting, we carry out the procedure 10 times and report the average results. The results are shown in Table 4.
From the results, we have the following observations and analysis: ERM suffers from the distributional shifts in testing and yields poor performance in most of the settings. DRO surprisingly has the worst performance, which we think is due to the over-pessimism problem (Frogner et al., 2019). EIIL has the similar performance with ERM, which indicates that its inferred environments cannot reveal the spurious correlations between and . IRM performs much better than the above two baselines, however, as IRM depends on the available environment labels to work, it uses much more information than the other three methods. Compared to the three baselines, our HRM achieves nearly perfect performance with respect to average performance and stability, especially the variance of losses across environments is close to 0, which reflects the effectiveness of our heterogeneous clustering as well as the invariant learning algorithm. Furthermore, our HRM does not need environment labels, which verifies that our clustering algorithm can mine the latent heterogeneity inside the data and further shows our superiority to IRM.
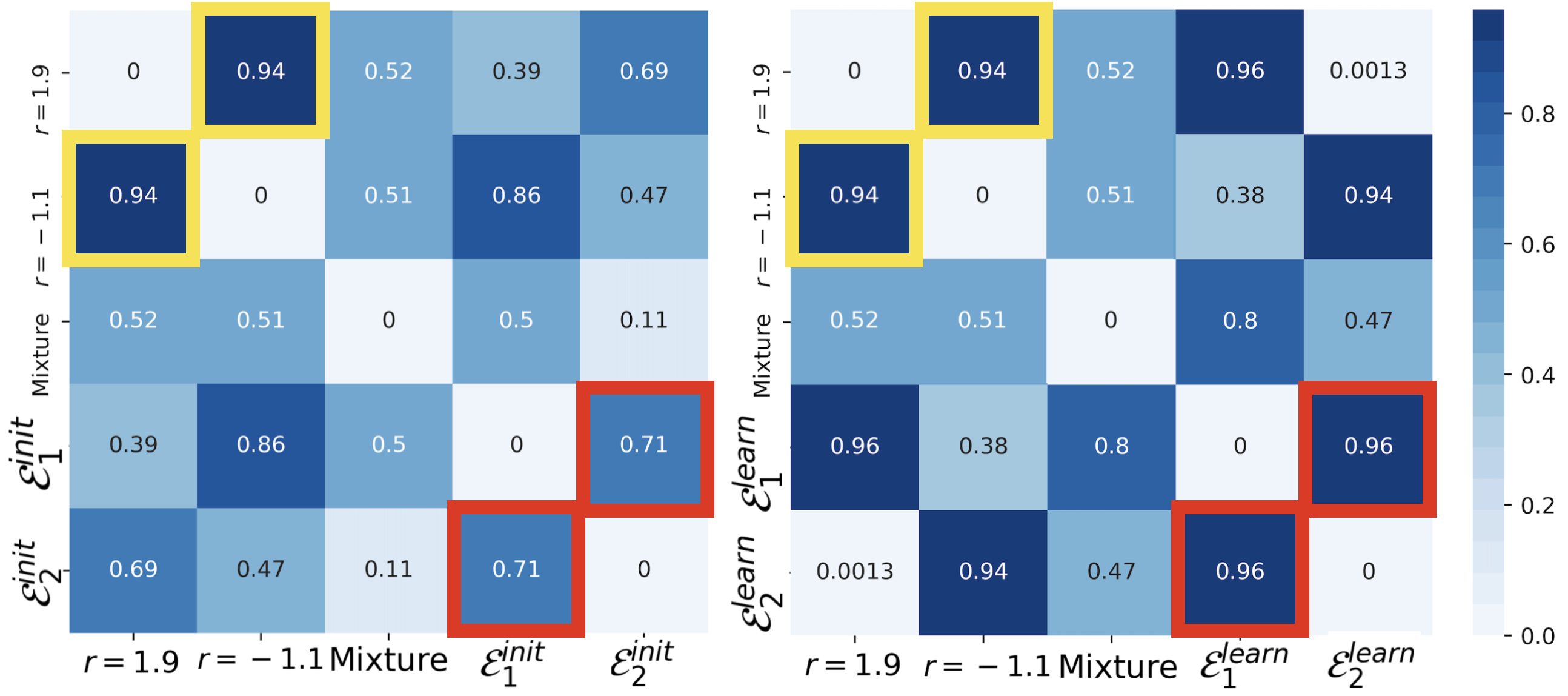
Besides, we visualize the differences between environments using Task2Vec (Achille et al., 2019) in Figure 2, where larger value means the two environments are more heterogeneous. The pooled training data are mixture of environments with and , the difference between whom is shown in yellow box. And the red boxes show differences between learned environments by HRMs and HRM. The big promotion between and verifies our HRM can exploit heterogeneity inside data as well as the existence of the positive feedback. Due to space limitation, results of varying as well as experimental details are left to appendix.
Anti-causal Effect Inspired by (Arjovsky et al., 2019), we induce the spurious correlation by using anti-causal relationship from the target to the variant covariates . In this experiment, we assume and firstly sample from mixture Gaussian distribution characterized as and the target . Then the spurious correlations between and are generated by anti-causal effect as
| (19) |
where means the Gaussian noise added to depends on which component the invariant covariates belong to. Intuitively, in different Gaussian components, the corresponding correlations between and are varying due to the different value of . The larger the is, the weaker correlation between and . We use the mixture weight to define different environments, where different mixture weights represent different overall strength of the effect on .
In this experiment, we set and build 10 environments with varying and the dimension of , the first three for training and the last seven for testing. We run experiments for 10 times and the averaged results are shown in Table 3. EIIL achieves the best training performance with respect to prediction errors on training environments , , , while its performances in testing are poor. ERM suffers from distributional shifts in testing. DRO seeks for over-considered robustness and performs much worse. IRM performs much better as it learns invariant representations with help of environment labels. HRM achieves nearly uniformly good performance in training environments as well as the testing ones, which validates the effectiveness of our method and proves its excellent generalization ability.
5.2 Real-world Data
We test our method on three real-world tasks, including car insurance prediction, people income prediction and house price prediction.
5.2.1 Settings
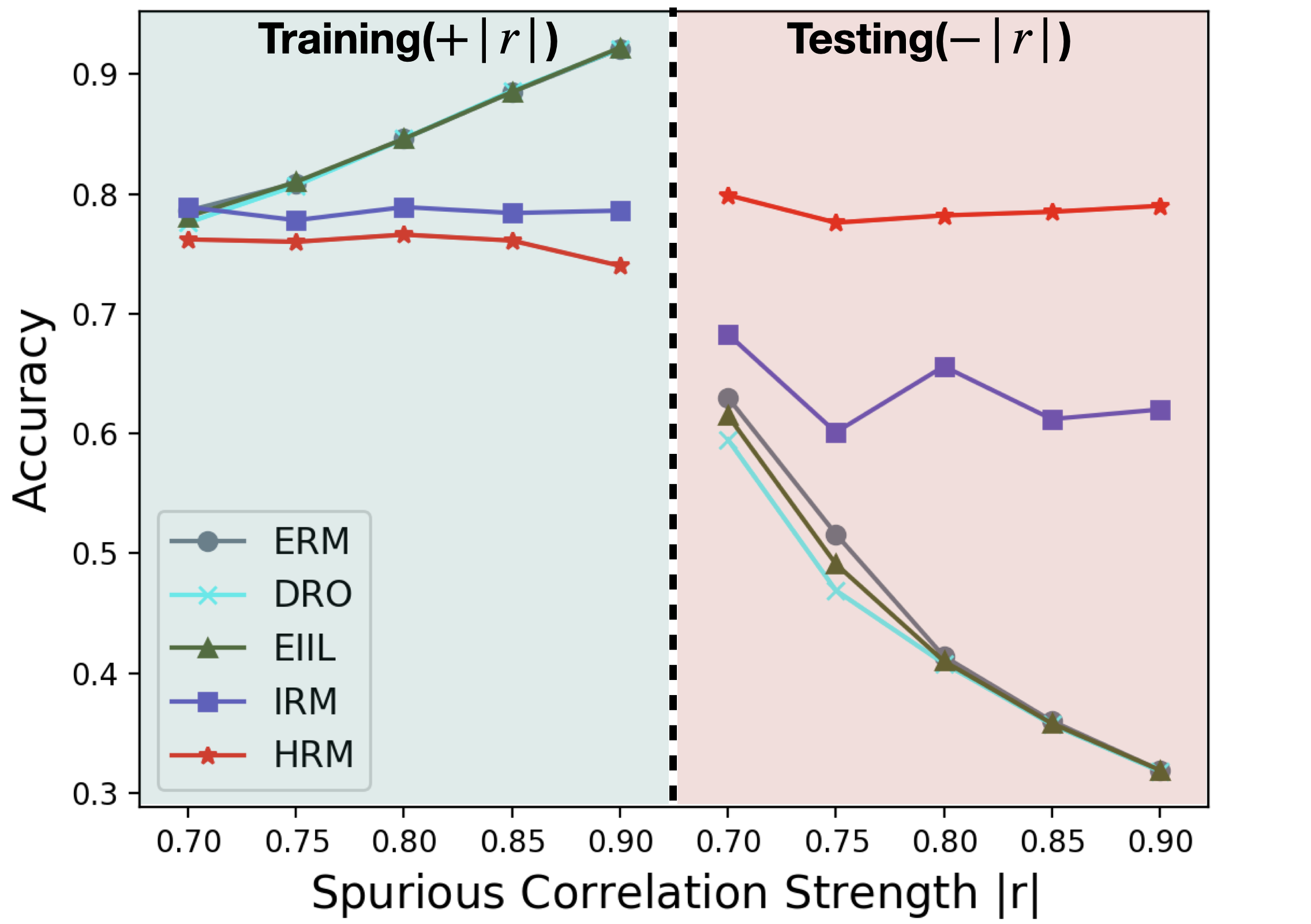
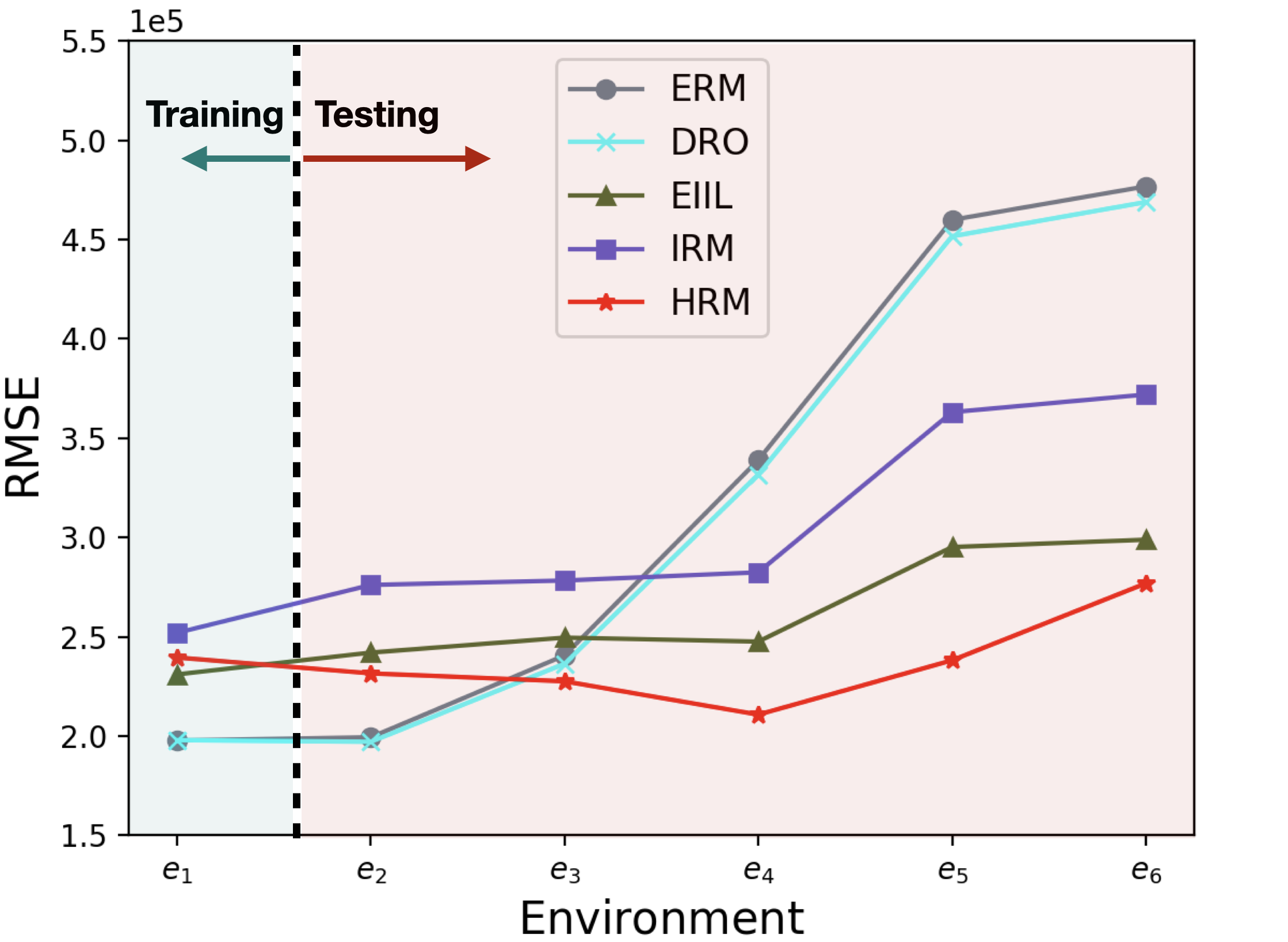
Car Insurance Prediction In this task, we use a real-world dataset for car insurance prediction (Kaggle). It is a classification task to predict whether a person will buy car insurance based on related information, such as vehicle damage, annual premium, vehicle age etc111https://www.kaggle.com/anmolkumar/health-insurance-cross-sell-prediction. We impose selection bias mechanism on the correlation between the outcome (i.e. the label indicating whether buying insurance) and the sex attribute to simulate multiple environments. Specifically, we simulate different strengths of the spurious correlation between sex and target in training, and reverse the direction of such correlation in testing( in training and in testing). For IRM, in each setting, we divide the training data into three training environments with , and different overall correlation corresponds to different numbers of data in . We perform 5 experiments with varying and the results in both training and testing are shown in Figure 3(a).
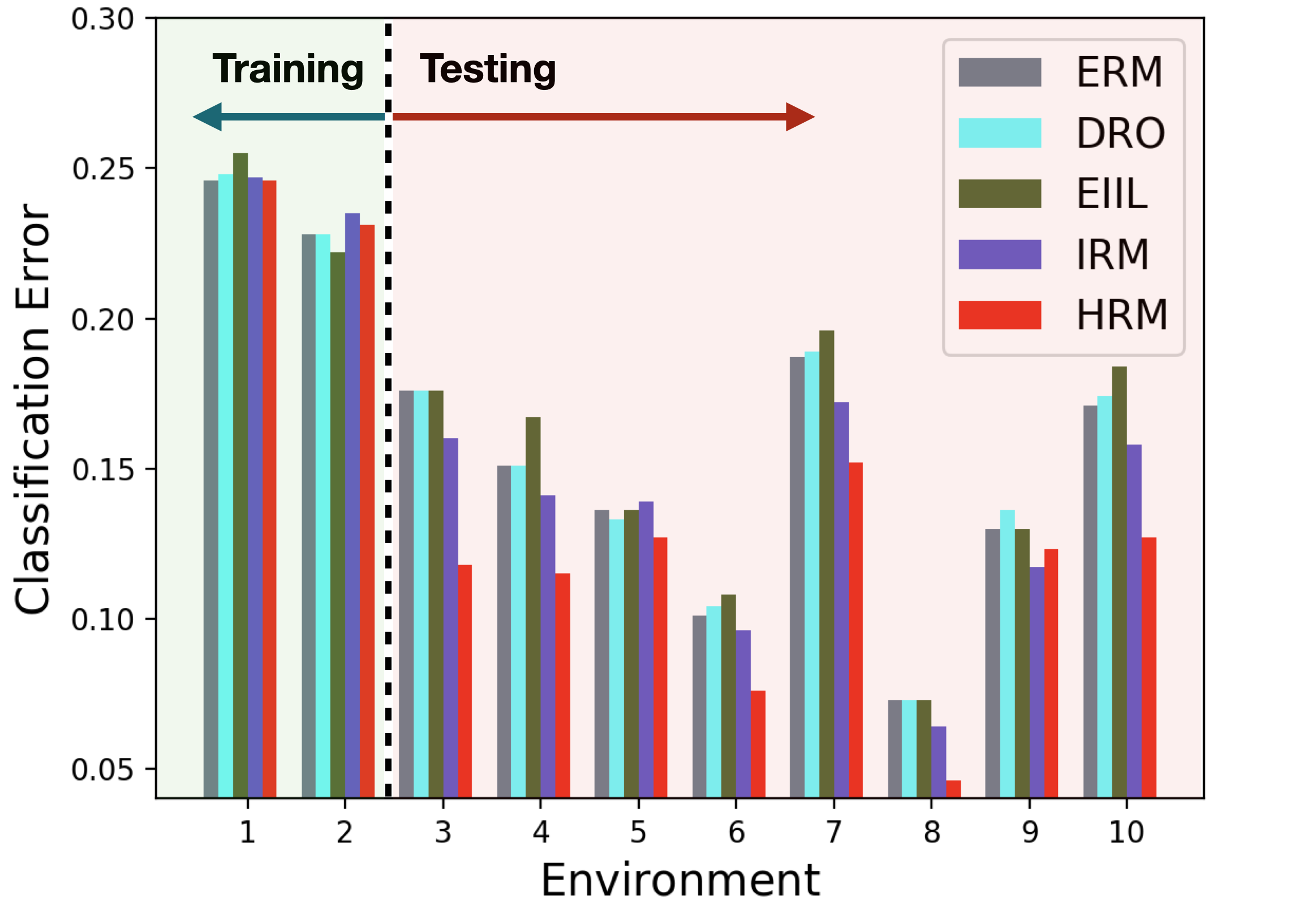
People Income Prediction In this task we use the Adult dataset (Dua & Graff, 2017) to predict personal income levels as above or below $50,000 per year based on personal details. We split the dataset into 10 environments according to demographic attributes and . In training phase, all methods are trained on pooled data including 693 points from environment 1 and 200 from environment 2, and validated on 100 sampled from both. For IRM, the ground-truth environment labels are provided. In testing phase, we test all methods on the 10 environments and report the mis-classification rate on all environments in Figure 3(b).
House Price Prediction In this experiment, we use a real-world regression dataset (Kaggle) of house sales prices from King County, USA222 https://www.kaggle.com/c/house-prices-advanced-regression- techniques/data. The target variable is the transaction price of the house and each sample contains 17 predictive variables such as the built year of the house, number of bedrooms, and square footage of home, etc. We simulate different environments according to the built year of the house, since it is fairly reasonable to assume the correlations among covariates and the target may vary along time. Specifically, we split the dataset into 6 periods, where each period approximately covers a time span of two decades. All methods are trained on data from the first period() and test on the other periods. For IRM, we further divide the training data into two environments where and respectively. Results are shown in Figure 3(c).
5.2.2 Analysis
From the results of three real-world tasks, we have the following observations and analysis: ERM achieves high accuracy in training while performing much worse in testing, indicating its inability in dealing with OOD predictions. DRO’s performance is not satisfactory, sometimes even worse than ERM. One plausible reason is its over-pessimistic nature which leads to too conservative predictors. Comparatively, invariant learning methods perform better in testing. IRM performs better than ERM and DRO, which shows the usefulness of environment labels for OOD generalization and the possibility of learning invariant predictor from multiple environments. EIIL performs inconsistently across different tasks, possibly due to its instability of the environment inference method. In all tasks and almost all testing environments (16/18), HRM consistently achieves the best performances. HRM even outperforms IRM significantly in a unfair setting where we provide perfect environment labels for IRM. One one side, it shows the limitation of manually labeled environments. On the other side, it demonstrates that, relieving the dependence on environment labels, HRM can effectively uncover and fully leverage the intrinsic heterogeneity in training data for invariant learning.
6 Related Works
There are mainly two branches of methods for the OOD generalization problem, namely distributionally robust optimization (DRO) (Esfahani & Kuhn, 2018; Duchi & Namkoong, 2018; Sinha et al., 2018; Sagawa et al., 2019) and invariant learning (Arjovsky et al., 2019; Koyama & Yamaguchi, 2020; Chang et al., 2020; Creager et al., 2020). DRO methods propose to optimize the worst-case risk within an uncertainty set, which lies around the observed training distribution and characterizes the potential testing distributions. However, in real scenarios, to better capture the testing distribution, the uncertainty set should be pretty large, which also results in the over-pessimism problem of DRO methods(Hu et al., 2018; Frogner et al., 2019).
Realizing the difficulty of solving OOD generalization problem without any prior knowledge or structural assumptions, invariant learning methods assume the existence of causally invariant relationships between some predictors and the target . (Arjovsky et al., 2019) and (Koyama & Yamaguchi, 2020) propose to learning an invariant representation through multiple training environments. (Chang et al., 2020) also proposes to select features whose predictive relationship with the target stays invariant across environments. However, their effectiveness relies on the quality of the given multiple training environments, and the role of environments remains vague theoretically. Recently, (Creager et al., 2020) improves (Arjovsky et al., 2019) by relaxing its requirements for multiple environments. Specifically, (Creager et al., 2020) proposes a two-stage method, which firstly infers the environment division with a pre-provided biased model, and then performs invariant learning on the inferred environments. However, the two stages cannot be jointly optimized, and the environment division relies on the given biased model and lacks theoretical guarantees.
7 Discussions
In this work, we theoretically analyze the role of environments in invariant learning, and propose our HRM for joint heterogeneity identification and invariant prediction, which relaxes the requirements for environment labels and opens a new direction for invariant learning. To our knowledge, this is the first work to both theoretically and empirically analyze how the equality of multiple environments affects invariant learning. This paper mainly focuses on the raw variable level with the assumption of , which is able to cover a broad spectrum of applications, e.g. healthcare, finance, marketing etc, where the raw variables are informative enough.
However, our work has some limitations, which we hope to improve in the future. Firstly, in order to achieve the mutual promotion, we should use the variant features for heterogeneity identification rather than the invariant ones. However, the process of invariant prediction continuously discards the variant features (for invariant features or representation), which makes it quite hard to recover the variant features. To overcome this, we focus on the simple setting where , since we can directly obtain the variant features when having invariant features . To further extend the power of HRM, we will consider to incorporate representation learning from in future work. Secondly, our clustering algorithm in lacks theoretical guarantees for its convergence. To the best of our knowledge, in order to theoretically analyze the convergence of a clustering algorithm, it is necessary to measure the distance between data points. However, our clustering algorithm takes models’ parameters as cluster centers and aims to cluster data points according to their relationships between and , whose dissimilarity cannot be easily measured, since the relationship is statistical magnitude and cannot be calculated individually. How to theoretically analyze the convergence property of such clustering algorithms remains unsolved.
8 Acknowledgements
This work was supported in part by National Key R&D Program of China (No. 2018AAA0102004, No. 2020AAA0106300), National Natural Science Foundation of China (No. U1936219, 61521002, 61772304), Beijing Academy of Artificial Intelligence (BAAI), and a grant from the Institute for Guo Qiang, Tsinghua University. Bo Li’s research was supported by the Tsinghua University Initiative Scientific Research Grant, No. 2019THZWJC11; Technology and Innovation Major Project of the Ministry of Science and Technology of China under Grant 2020AAA0108400 and 2020AAA01084020108403; Major Program of the National Social Science Foundation of China (21ZDA036).
References
- Achille et al. (2019) Achille, A., Lam, M., Tewari, R., Ravichandran, A., Maji, S., Fowlkes, C. C., Soatto, S., and Perona, P. Task2vec: Task embedding for meta-learning. In 2019 IEEE/CVF International Conference on Computer Vision, ICCV 2019, Seoul, Korea (South), October 27 - November 2, 2019, pp. 6429–6438. IEEE, 2019. doi: 10.1109/ICCV.2019.00653. URL https://doi.org/10.1109/ICCV.2019.00653.
- Arjovsky et al. (2019) Arjovsky, M., Bottou, L., Gulrajani, I., and Lopez-Paz, D. Invariant risk minimization. arXiv preprint arXiv:1907.02893, 2019.
- Berk et al. (2018) Berk, R., Heidari, H., Jabbari, S., Kearns, M., and Roth, A. Fairness in criminal justice risk assessments: The state of the art. Sociological Methods & Research, pp. 0049124118782533, 2018.
- Chang et al. (2020) Chang, S., Zhang, Y., Yu, M., and Jaakkola, T. S. Invariant rationalization. In Proceedings of the 37th International Conference on Machine Learning, ICML 2020, 13-18 July 2020, Virtual Event, volume 119 of Proceedings of Machine Learning Research, pp. 1448–1458. PMLR, 2020. URL http://proceedings.mlr.press/v119/chang20c.html.
- Creager et al. (2020) Creager, E., Jacobsen, J.-H., and Zemel, R. Environment inference for invariant learning. In ICML Workshop on Uncertainty and Robustness, 2020.
- Dua & Graff (2017) Dua, D. and Graff, C. UCI machine learning repository, 2017. URL http://archive.ics.uci.edu/ml.
- Duchi & Namkoong (2018) Duchi, J. and Namkoong, H. Learning models with uniform performance via distributionally robust optimization. arXiv preprint arXiv:1810.08750, 2018.
- El Gamal & Kim (2011) El Gamal, A. and Kim, Y.-H. Network information theory. Network Information Theory, 12 2011. doi: 10.1017/CBO9781139030687.
- Esfahani & Kuhn (2018) Esfahani, P. M. and Kuhn, D. Data-driven distributionally robust optimization using the wasserstein metric: performance guarantees and tractable reformulations. Math. Program., 171(1-2):115–166, 2018. doi: 10.1007/s10107-017-1172-1. URL https://doi.org/10.1007/s10107-017-1172-1.
- Frogner et al. (2019) Frogner, C., Claici, S., Chien, E., and Solomon, J. Incorporating unlabeled data into distributionally robust learning. arXiv preprint arXiv:1912.07729, 2019.
- Gong et al. (2016) Gong, M., Zhang, K., Liu, T., Tao, D., Glymour, C., and Schölkopf, B. Domain adaptation with conditional transferable components. In Balcan, M. and Weinberger, K. Q. (eds.), Proceedings of the 33nd International Conference on Machine Learning, ICML 2016, New York City, NY, USA, June 19-24, 2016, volume 48 of JMLR Workshop and Conference Proceedings, pp. 2839–2848. JMLR.org, 2016. URL http://proceedings.mlr.press/v48/gong16.html.
- Hu et al. (2018) Hu, W., Niu, G., Sato, I., and Sugiyama, M. Does distributionally robust supervised learning give robust classifiers? In Dy, J. G. and Krause, A. (eds.), Proceedings of the 35th International Conference on Machine Learning, ICML 2018, Stockholmsmässan, Stockholm, Sweden, July 10-15, 2018, volume 80 of Proceedings of Machine Learning Research, pp. 2034–2042. PMLR, 2018. URL http://proceedings.mlr.press/v80/hu18a.html.
- Koyama & Yamaguchi (2020) Koyama, M. and Yamaguchi, S. Out-of-distribution generalization with maximal invariant predictor. CoRR, abs/2008.01883, 2020. URL https://arxiv.org/abs/2008.01883.
- Kuang et al. (2020) Kuang, K., Xiong, R., Cui, P., Athey, S., and Li, B. Stable prediction with model misspecification and agnostic distribution shift. In The Thirty-Fourth AAAI Conference on Artificial Intelligence, AAAI 2020, The Thirty-Second Innovative Applications of Artificial Intelligence Conference, IAAI 2020, The Tenth AAAI Symposium on Educational Advances in Artificial Intelligence, EAAI 2020, New York, NY, USA, February 7-12, 2020, pp. 4485–4492. AAAI Press, 2020. URL https://aaai.org/ojs/index.php/AAAI/article/view/5876.
- Kukar (2003) Kukar, M. Transductive reliability estimation for medical diagnosis. Artificial Intelligence in Medicine, 29(1-2):81–106, 2003.
- Rojas-Carulla et al. (2015) Rojas-Carulla, M., Schlkopf, B., Turner, R., and Peters, J. Invariant models for causal transfer learning. Stats, 2015.
- Rudin & Ustun (2018) Rudin, C. and Ustun, B. Optimized scoring systems: Toward trust in machine learning for healthcare and criminal justice. Interfaces, 48(5):449–466, 2018.
- Sagawa et al. (2019) Sagawa, S., Koh, P. W., Hashimoto, T. B., and Liang, P. Distributionally robust neural networks for group shifts: On the importance of regularization for worst-case generalization. arXiv preprint arXiv:1911.08731, 2019.
- Sagawa et al. (2020) Sagawa, S., Raghunathan, A., Koh, P. W., and Liang, P. An investigation of why overparameterization exacerbates spurious correlations. 2020.
- Shen et al. (2018) Shen, Z., Cui, P., Kuang, K., Li, B., and Chen, P. Causally regularized learning with agnostic data selection bias. In 2018 ACM Multimedia Conference, 2018.
- Sinha et al. (2018) Sinha, A., Namkoong, H., and Duchi, J. Certifying some distributional robustness with principled adversarial training. International Conference on Learning Representations, 2018.
- Yamada et al. (2020) Yamada, Y., Lindenbaum, O., Negahban, S., and Kluger, Y. Feature selection using stochastic gates. In Proceedings of the 37th International Conference on Machine Learning, ICML 2020, 13-18 July 2020, Virtual Event, volume 119 of Proceedings of Machine Learning Research, pp. 10648–10659. PMLR, 2020. URL http://proceedings.mlr.press/v119/yamada20a.html.
Appendix A Additional Simulation Results and Details
Selection Bias In this setting, the correlations among covariates are perturbed through selection bias mechanism. According to assumption 2.1, we assume and is independent from while the covariates in are dependent with each other. We assume and remains invariant across environments while can arbitrarily change.
Therefore, we generate training data points with the help of auxiliary variables as following:
| (20) | ||||
| (21) | ||||
| (22) |
To induce model misspecification, we generate as:
| (23) |
where , and . As we assume that remains unchanged while can vary across environments, we design a data selection mechanism to induce this kind of distribution shifts. For simplicity, we select data points according to a certain variable set :
| (24) | |||
| (25) | |||
| (26) |
where and . Given a certain , a data point is selected if and only if (i.e. if , a data point whose is close to its is more probably to be selected.)
Intuitively, eventually controls the strengths and direction of the spurious correlation between and (i.e. if , a data point whose is close to its is more probably to be selected.). The larger value of means the stronger spurious correlation between and , and means positive correlation and vice versa. Therefore, here we use to define different environments.
In training, we generate data points, where points from environment with a predefined and points from with . In testing, we generate data points for 10 environments with . is set to 1.0.
Apart from the two scenarios in main body, we also conduct scenario 3 and 4 with varying and respectively.
| Scenario 3: varying ratio and sample size () | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Methods | |||||||||
| ERM | 0.477 | 0.061 | 0.530 | 0.510 | 0.108 | 0.608 | 0.547 | 0.150 | 0.687 |
| DRO | 0.480 | 0.107 | 0.597 | 0.512 | 0.111 | 0.625 | 0.608 | 0.227 | 0.838 |
| EIIL | 0.476 | 0.063 | 0.529 | 0.507 | 0.102 | 0.613 | 0.539 | 0.148 | 0.689 |
| IRM(with label) | 0.455 | 0.015 | 0.471 | 0.456 | 0.015 | 0.472 | 0.456 | 0.015 | 0.472 |
| HRM | 0.450 | 0.010 | 0.461 | 0.447 | 0.011 | 0.465 | 0.447 | 0.010 | 0.463 |
| Scenario 4: varying variant dimension () | |||||||||
| Methods | |||||||||
| ERM | 0.510 | 0.108 | 0.608 | 0.468 | 0.110 | 0.583 | 0.445 | 0.112 | 0.567 |
| DRO | 0.512 | 0.111 | 0.625 | 0.515 | 0.107 | 0.617 | 0.454 | 0.122 | 0.577 |
| EIIL | 0.520 | 0.111 | 0.613 | 0.469 | 0.111 | 0.581 | 0.454 | 0.100 | 0.557 |
| IRM(with label) | 0.456 | 0.015 | 0.472 | 0.432 | 0.014 | 0.446 | 0.414 | 0.061 | 0.475 |
| HRM | 0.447 | 0.011 | 0.465 | 0.413 | 0.012 | 0.431 | 0.402 | 0.057 | 0.462 |
Anti-Causal Effect Inspired by (Arjovsky et al., 2019), in this setting, we introduce the spurious correlation by using anti-causal relationship from the target to the variant covariates .
We assume and , Data Generation process is as following:
| (27) | ||||
| (28) | ||||
| (29) |
where is the mixture weight of Gaussian components, means the Gaussian noise added to depends on which component the invariant covariates belong to and . Intuitively, in different Gaussian components, the corresponding correlations between and are varying due to the different value of . The larger the is, the weaker correlation between and . We use the mixture weight to define different environments, where different mixture weights represent different overall strength of the effect on . In this experiment, we set and build 10 environments with varying and the dimension of , the first three for training and the last seven for testing. Specifically, we set , , and . are randomly sampled from and respectively. We run experiments for 10 times and average the results.
Appendix B Proofs
B.1 Proof of Theorem 2.1
First, we would like to prove that a random variable satisfying assumption 2.1 is MIP.
Theorem B.1.
A representation satisfying assumption 2.1 is the maximal invariant predictor.
Proof.
: To prove . If is not the maximal invariant predictor, assume . Using functional representation lemma, consider , there exists random variable such that and . Then .
: To prove the maximal invariant predictor satisfies the sufficiency property in assumption 2.1.
The converse-negative proposition is :
| (30) |
Suppose and , and suppose where . Then we have:
| (31) |
Therefore, ∎
Then we provide the proof of theorem 2.1.
Theorem B.2.
Let be a strictly convex, differentiable function and let be the corresponding Bregman Loss function. Let is the maximal invariant predictor with respect to , and put . Under assumption 2.2, we have:
| (32) |
Proof.
Firstly, according to theorem B.1, satisfies assumption 2.1. Consider any function , we would like to prove that for each distribution (), there exists an environment such that:
| (33) |
For each with density , we construct environment with density that satisfies: (omit the superscript of and for simplicity)
| (34) |
Note that such environment exists because of the heterogeneity property assumed in assumption 2.2. Then we have:
| (35) | |||
| (36) | |||
| (37) | |||
| (38) | |||
| (39) | |||
| (40) | |||
| (41) |
∎
B.2 Proof of Theorem 2.2
Theorem B.3.
Proof.
Since , then for any , . ∎
B.3 Proof of Theorem 2.3
Theorem B.4.
Given set of environments , denote the corresponding invariance set and the corresponding maximal invariant predictor . For one newly-added environment with distribution , if for , the invariance set constrained by is equal to .
Proof.
Denote the invariance set with respect to as , it is easy to prove that , we have , since the newly-added environment cannot exclude any variables from the original invariance set. ∎
B.4 Proof of Theorem 4.1
Theorem B.5.
Given , the learned is the maximal invariant predictor of .
Proof.
The objective function for is
| (43) |
Here we prove that the minimum of objective function can be achieved when is the maximal invariant predictor. According to theorem B.1, satisfies assumption 2.1, which indicates that stays invariant.
From the proof in C.2 in (Koyama & Yamaguchi, 2020), indicates that .
Further, from the sufficiency property, the minimum of is achieved with . Therefore, reaches the minimum with being the MIP.() ∎
B.5 Proof of Theorem 4.2
Theorem B.6.
For , assume that satisfying Assumption 2.1, where is invariant and variant. Then under Assumption 4.1, we have
Proof.
| (44) | |||
| (45) | |||
| (46) |
Therefore, we have
| (47) | |||
| (48) | |||
| (49) | |||
| (50) |
Therefore, we have
| (51) |
∎
B.6 Proof of Theorem 4.3
Theorem B.7.
Under Assumption 2.1 and 2.2, for the proposed and , we have the following conclusions: 1. Given environments such that , the learned by is the maximal invariant predictor of . 2. Given the maximal invariant predictor of , assume the pooled training data is made up of data from all environments in , then the invariance set regularized by learned environments is equal to .
Proof.
For 1, according to theorem B.5, the learned by is the maximal invariant predictor of . Therefore, if , is the real maximal invariant predictor.
For 2, assume that , we would like to prove that reaches minimum when the components in the mixture distribution corresponds to distributions for . Since the learned by is the maximal invariant predictor of , the corresponding is exactly the . Then taking , we have ,
| (52) |
Therefore, the components in correspond to for , which makes approaches to . ∎