HI-GVF: Shared Control based on Human-Influenced Guiding Vector Fields for Human-multi-robot Cooperation
Abstract
Human-multi-robot shared control leverages human decision-making and robotic autonomy to enhance human-robot collaboration. While widely studied, existing systems often adopt a leader-follower model, limiting robot autonomy to some extent. Besides, a human is required to directly participate in the motion control of robots through teleoperation, which significantly burdens the operator. To alleviate these two issues, we propose a layered shared control computing framework using human-influenced guiding vector fields (HI-GVF) for human-robot collaboration. HI-GVF guides the multi-robot system along a desired path specified by the human. Then, an intention field is designed to merge the human and robot intentions, accelerating the propagation of the human intention within the multi-robot system. Moreover, we give the stability analysis of the proposed model and use collision avoidance based on safety barrier certificates to fine-tune the velocity. Eventually, considering the firefighting task as an example scenario, we conduct simulations and experiments using multiple human-robot interfaces (brain-computer interface, myoelectric wristband, eye-tracking), and the results demonstrate that our proposed approach boosts the effectiveness and performance of the task.
Index Terms:
Human-robot interaction, multi-robot systems cooperation, shared control.I Introduction
Multi-robot systems (MRS) have attracted much attention from the research community, and they are widely used in tasks such as monitoring [1], firefighting [2], search and rescue [3], source seeking [4], etc. Despite that considerable efforts have been made by researchers to enhance the autonomy of distributed multi-robot systems, there are still several challenges due to, e.g., perception inaccuracies, communication delays, and limited decision-making capabilities of robots [5]. Therefore, practical multi-robot systems often require human operators’ supervision and intervention, which can help assess and find potential targets, identify threats, react to emergencies and especially, provide intelligent guidance when planning algorithms fail. In many cases, human partners can operate remotely using the shared control technology to influence multi-robot systems, which can perform collaborative tasks with guaranteed safety autonomously when human influence is absent and thus alleviate the physical and mental workload on humans.
Shared control methods used in remote operating systems are usually based on mixed inputs [6, 7] or haptic feedback [8, 9]. There are various human-multi-robot interaction systems. For instance, a task-dependent graphical user multi-touch interface [10, 11], a gesture-based interface [12, 13] of a mobile handheld device [11], and a multi-modal interface with gesture, voice, and vision [14]. As noted in several reviews [15, 16], the effectiveness of such a team is primarily influenced by the type of information operators receive from the robots and the tools they have available to exert control. In some cases, multiple modalities are necessary for the expression of human intentions. Assume a scenario similar to Fig. 1, where an operator and a group of robots collaborate on a mission together, where the robots perform tasks in the rubble, and the operator provides a more comprehensive view via image transmission from the UAV. Humans hold remote operating equipment/tools and, therefore, need other methods to send commands to robots, such as covert hand gestures and smart helmets that can capture EEG signals as well as eye movement information. In this way, the operator can provide the robots with more information about the environment, where the target is (e.g., threats that need to be removed, trapped persons), and, if necessary, the operator even needs to be given a certain trajectory that will lead the robot to a certain area.

Based on this motivation, this paper proposes a layered shared control computing framework based on human-influenced guiding vector fields (HI-GVF) for multi-robot systems, which is shown in Fig. 2. The blocks of different colors represent different research contents. Robots acquire different world models by sensors for calculation and decision-making, as shown in Fig. 2 (gray block).
Human operators acquire the world models not based on direct observations of the environment but on a virtual environment based on remote images. This method gives humans a broader view of the situation, which is useful for integrated planning. The operator can then give human intention by plotting a trajectory for robots or selecting a priority target area, as shown in Fig. 2 (green block). Robot intention and human intention are fused through a shared control framework, as shown in Fig. 2 (blue block). The components are explained in detail in subsequent sections.
The main contributions of this paper are as follows:
-
1)
We propose a shared control framework based on HI-GVF for human-multi-robot cooperation, without requiring humans to intervene at every moment, and the operator can intuitively give a certain desired path as an input to guide robots.
-
2)
We design a layered shared control framework, where an intention field is utilized to merge the robot intention generated by the robot local controller and the human intention generated by HI-GVF in the upper layer, and a policy-blending model is used to fuse various VFs in the lower layer.
-
3)
We give a stability analysis of the proposed method and use an obstacle avoidance method based on optimization in a minimally invasive way, which ensures stability in obstacle avoidance for the whole formation.
-
4)
We conduct simulations and physical experiments using multiple human-robot interfaces (brain-computer interface, myoelectric wristband, eye-tracking) based on self-designed human-multi-robot interaction system to verify the effectiveness of the proposed method.
II preliminary: guiding vector field
In this section, we introduce preliminary knowledge about guiding vector field. Then, we utilize HI-GVF to describe human intention, which is used to influence the collective behavior of the multi-robot system. The HI-GVF is derived based on a desired path given by the human operator, who expects a robot to follow the desired path for a specified period of time according to the human intention.
II-A GVF
To derive the guiding vector field, we first suppose that the desired path can be described by an implicit function:
| (1) |
where is twice continuously differentiable, and represents the two-dimensional position. Then a guiding vector field proposed in [17] to solve the path-following problem is defined by:
| (2) |
where is the rotation matrix , is used to specify the propagation direction along the desired path, is an adjustable parameter. The first term of (2) is the tangential component, enabling the robot to move along the desired path, while the second term of (2) is the orthogonal component, assisting the robot to move closer to the desired path. Therefore, intuitively, the guiding vector field can guide the robot to move toward and along the desired path at the same time.

.
II-B HI-GVF
When the desired path is occluded by obstacles, a robot needs to deviate from the desired path to avoid obstacles, and then return to the desired path. To address this problem, we design a smooth composite vector field, consisting of vector fields generated by the desired path and obstacles and integrated with two bump functions [18].
II-B1 Reactive boundary and repulsive boundary
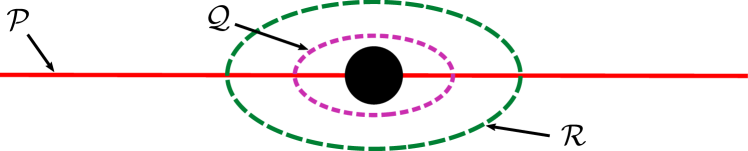
Regardless of the shapes (circle or bar) of the obstacles, we design some boundaries to enclose each obstacle, such that avoiding collisions with the obstacles is simplified as avoiding collisions with the boundaries, as shown in Fig. 4(a). The reactive boundary and the repulsive boundary around the circle obstacle or bar barrier are defined as follows:
| (3) |
| (4) |
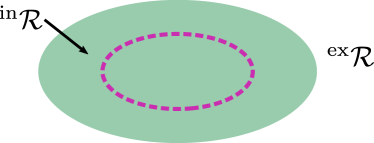
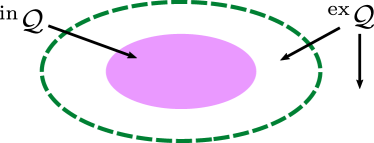
for , where represents the set of a finite number of obstacles, is a twice continuously differentiable function, and is a given constant. The reactive boundary divides the workspace into the interior, denoted by , and the exterior, denoted by , as shown in Fig. 4(b). For convenience, is also called the reactive area, and is the non-reactive area. When the robot enters the reactive area, it is able to detect and react to the obstacle. Similarly, we define and to represent the repulsive area and the non-repulsive area, respectively, as shown in Fig. 4(c). The repulsive area is a region where the robot is forbidden to enter; otherwise collision with the obstacle would happen. Besides, we use to represent the area containing the corresponding boundary (i.e., the closure of a given set). For instance, denotes the reactive area containing the reactive boundary .
II-B2 Zero-in and zero-out bump function
To smooth the motion of the robot as it passes through the reactive area where a robot is able to sense the obstacle, we use two smooth bump functions to generate a composite vector field so that the velocity does not change abruptly near the reactive boundary.
For a reactive boundary and a repulsive boundary , we can define smooth bump function , as follows:
| (5) |
| (6) |
where and are smooth functions.
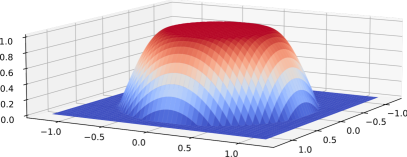
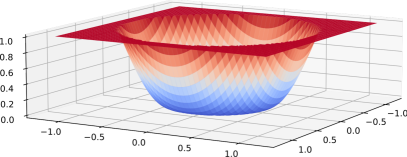
Intuitively, we call (see Fig. 5(a)) a smooth zero-out function with respect to the reactive boundary , and (see Fig. 5(b)) a smooth zero-in function with respect to the repulsive boundary . Evidently, approaches smoothly value 1 when approaches , and approaches smoothly value 0 when approaches , and the converse applies for .
II-B3 Composite vector field
Using the smooth zero-out and zero-in bump functions to blend two vector fields, we can obtain a composite vector field as follows:
| (7) |
where is the normalization notation (i.e., for a non-zero vector). In our paper, it is assumed that different reactive areas do not overlap, which is a common assumption; if they overlap, then one can redefine the reactive boundaries such that this assumption is satisfied (e.g., by shrinking the sizes of the boundaries or by merging two boundaries into a large one). Therefore, according to (5) and (6), (7) is equivalent to:
| (8) |


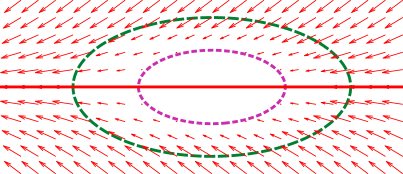
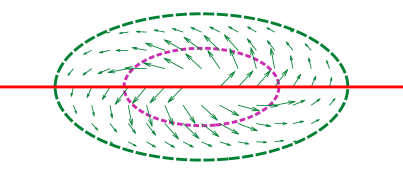

The illustration of the construction of the composite vector field is shown in Fig. 6. The red solid line represents the desired path , the green dotted line represents the reactive boundary , and the purple dotted line represents the repulsive boundary . Each arrow in the subfigures represents a vector of the corresponding vector field at the position. In Fig. 6(e), the green arrows belong to the vector field generated by the reactive boundary, and are all in . The red arrows belong to the vector field generated by the desired path, and are all in . The blue arrows belong to the mixed vector field, the sum of and , and are all in the mixed area . More discussion can be found in our previous work [18].
From this, the human intention for the -th robot is defined to be the following “zero-in” guiding vector field:
| (9) |
Notably, it is very difficult for human operators to establish stable communication with each robot because of wireless communication bandwidth limitations and environmental interference. Therefore, in this paper, we assume that the human operator influences only one of the robots in the formation, and the human intention is propagated through the communication links among the robots and thus indirectly influences the entire MRS. The human operator can intuitively draw a desired path via the mouse, the touch screen, or the eye-tracking device, etc., and can choose which robot is affected.
III methodology: multi-robot local control
Without human intervention, the robot should autonomously perform tasks through its own perception and decision-making in firefighting scenarios111In fact, our human-robot shared control approach can be used in a wide range of studies not limited to firefighting missions, and this paper uses firefighting missions as an illustrative example.. For such tasks, we assume that 1) a single robot has limited firefighting capability, and a single fire source requires multiple robots to work simultaneously to extinguish it. 2) individual robots should not leave the formation for a long period of time or long distances to maintain communication with others. In this section, we design a local controller for multi-robot coordination, including two subtasks: target selection (robot intention) and formation control, and these subtasks are accomplished by using different vector fields that will be designed in the following subsections. For convenience, we use the notation to denote the set of integers for .
III-A Robot Intention
Finding and prioritizing the most threatening fire source to extinguish is the primary task for the MRS. Each robot prioritizes the fire to be extinguished based on its perception of the fire situation, and generates the robot intention , which points to the largest fire source observed by the -th robot.
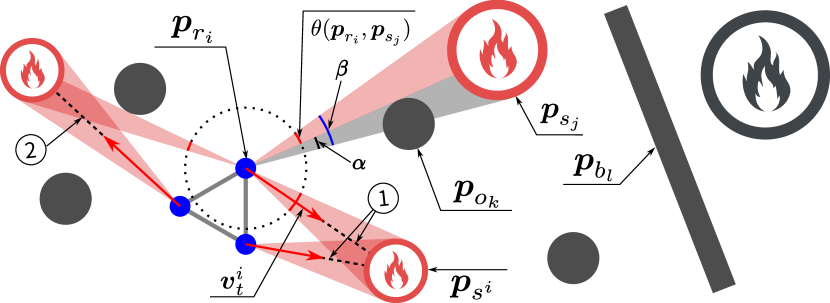
Suppose there are homogeneous omnidirectional robots, with positions denoted by , fire sources, with positions denoted by , circle obstacles, with positions denoted by , and barriers, with positions denoted by , in the two-dimensional space. In this paper, the observed severity of the -th fire source by the -th robot is described by the observed fire value . This value increases if the fire becomes more severe and decreases if obstacles obstruct the robot’s observation. It is worth emphasizing that, in practice, the observed fire value is directly measured by the onboard sensors. However, for simplicity, we use a circle centered at the fire source to represent the severity of the fire; the more severe the fire, the larger the radius. Then the observed fire value is approximated as the angle calculated by subtracting the angle of view obscured by the obstacle ( in Fig. 7) from the angle of view of the fire ( in Fig. 7) when there are no obstacles. Note that if , i.e., the fire source is totally obstructed by obstacles, then the observed fire value is zero. Fig. 7 graphically illustrates how the fire value is determined in an environment with fire sources, robots and obstacles. Therefore, the -th robot can select the most severe fire source as its prioritized target , which is defined as:
| (10) |
In some cases, robots may not choose the same target. For example, in Fig. 7, two robots choose ➀ as their prioritized target while one robot has a different target: ➁. Then, similar to method (2), we define a vector field for the -th robot based on the target :
| (11) |
where , and , represent the position and radius of the prioritized target fire source , respectively. Note that the tangential component is removed and only the orthogonal component remains. Therefore, following this vector field (11), the robot would move directly towards the fire target.
III-B Formation Control
As some robots have different intentions, it may cause them to be separated from the team for too long or too far away, thus breaking away from the formation and resulting in a failure to work together to accomplish the mission. To address this problem, we adopt the distance-based formation control method to maintain the formation of MRS while moving.
Then, using (2), we can define a composite vector field for the -th robot based on the neighbors of the -th robot:
| (12) |
where represents the desired distance between the -th and -th robot, , is the normalization notation (i.e., it normalizes the gradient ), and represents the neighbor set of the -th robot222If a robot has a (bidirectional) communication link with the -th robot, then it is a neighbor of the -th robot. For example, when a communication range is set, other robots within the range are neighbors of -th robot. Human operators can also initialize the communication connection topology among robots before the task execution.. Due to the constraints of formation control, robots with greater robot intention will dominate when each robot moves to its selected target. Therefore, the target selection of the entire MRS will eventually become consistent.
Then, similar to (9), the VF induced by the target (i.e., the robot intention), and the VF for formation control are defined respectively as follows:
| (13) |
| (14) |
IV methodology: shared control for the human-multi-robot
So far, we have obtained the VFs based on the local controller and HI-GVF. Then, using a shared control method, the human intention and the robot intention can be reasonably fused to generate more appropriate actions, which can improve the execution efficiency of the system. In this section, a layered shared control framework is proposed to propagate the human intention and blend the VFs, effectively influencing the entire MRS by controlling one robot.
IV-A Upper Layer: Intention Field Model
In the upper layer of the framework, we use an intention field model to allow the human operator to control one robot and to propagate the intention among the robots, thus affecting the whole system. As stated in the preceding sections, obtained by (13) represents the robot intention, and obtained by (9) represents the human intention received by the human-influenced robot. In each control cycle, the -th robot updates the shared intention at time step as follows333For simplicity, the notation of the shared intention at time step is simplified as ; the same simplification is used for other notation. :
| (15) | ||||
where , are weighted coefficients that regulate the degree of influence of the robot intention, the neighbor intention, and the human intention in the update process, and is an indicator function that holds when the -th robot has received the human intention and otherwise, and is a dead zone function defined as:
| (16) |
where . The intention field model can help the human operator to control effectively by abstracting the human input as an intention field value and fusing it with the robot intention. The shared intention can be viewed as a virtual control intention generated by robot intentions and human intentions. Assuming that the desired robot motion speed is , the final shared intention can be represented as
| (17) |
The model has the following properties:
-
1)
Local similarity. If the -th robot is close to the -th robot, then and have similar values.
-
2)
Space separation. If the -th robot is far from the -th robot, then variation in has little impact on .
Local similarity allows nearby robots to be controlled simultaneously by a human operator, while space separation enables different parts of the MRS to be controlled separately. With the intention field model, each robot updates itself under the influence of its neighbors and the human operator. When one robot receives the human intention, the inter-robot network implicitly propagates that intention to each robot. This result is fundamentally different from the “leader-follower” model, in which followers just react passively to the actions of their neighbors. The stability analysis of the intention field can be referred to in the Appendix-A.
IV-B Lower Layer: Policy-Blending Model
In the lower layer of the framework, a consensus network is used to blend the shared intention generated by the upper layer and VF of formation control generated by the local controller. We can obtain the final velocity as follows:
| (18) |
where , , and are obtained by (15), (14) and (17), respectively.
The weighting function need to satisfy the following conditions:
-
1)
is continuous, non-negative, and .
-
2)
Let , then is strictly increasing.
-
3)
Let , then is strictly decreasing.
-
4)
and
We design a function that satisfies these conditions
| (19) |
where are constants.
The final velocity integrates all the VFs so that with suitable policy-blending, the MRS can maintain its formation and avoid obstacles while reaching the target. The stability analysis of the consensus network can be referred to in the Appendix-B.
V collision avoidance based on safety barrier certificates
An analysis of the stability of the whole formation when human and target intentions are used as inputs has already been given in the previous section. However, when the formation performs obstacle avoidance, it is difficult to ensure the stability of the whole formation anymore. Therefore, it is very important and necessary to adopt suitable collision avoidance methods. We use a safety barrier certificates method [19] based on optimization in a minimally invasive way, which ensures stability in obstacle avoidance for formation.
V-A collision avoidance among robots
Although formation control can keep robots at a distance from each other to some extent, it does not guarantee that robots will not collide with each other at all. Therefore, we still need to consider collision avoidance within the formation. By first defining a set of safe states, we use the control barrier function (CBF) to formally guarantee forward invariance of the desired set, i.e., if the system starts in the safe set, it stays in the safe set. A CBF is similar to a Control Lyapunov Function in that they ensure certain properties of the system without the need to explicitly compute the forward reachable set.
For , we define a function
| (20) |
where is the safe distance among robots. The function reflects whether two robots maintain a safe distance. Therefore, the pairwise safe set can be defined as
| (21) |
Using , we can define a barrier function
| (22) |
We use the optimization method to adjust the final velocity so that the new velocity enables collision-avoidance. Specifically, the new velocity should subject to the constraint , where is a constant. Using (22), we can obtain , so the constraint can be rewritten as
| (23) |
In order to ensure that the main control objectives are met to the greatest extent possible, the collision avoidance strategy should modify the target velocity as little as possible. Therefore, we calculate the new velocity by the quadratic program (QP) as follows:
| (24) | ||||
| s.t. |
This optimization problem is centralized as it requires the positions and desired velocities of all robots. Further, we can improve it to a distributed form for each robot :
| (25) | ||||
| s.t. |
Therefore, robot only considers the positions of its neighbors, and does not need to get the desired velocity of other robots.
V-B Collision avoidance between robots and obstacles
Note that the safety barrier certificates can also deal with static or moving obstacles by treating obstacles as agents with no inputs. Similar to the method of collision avoidance among robots, the robot needs to maintain a safe distance between obstacles. Therefore, a function can be designed to ensure that the robot does not collide with the obstacle
| (26) |
where is the safe distance between the robot and the obstacle.
Similar to (23), we can obtain the constraint of robot avoiding obstacles:
| (27) |
where is a constant. Then, the new velocity can be calculated by the QP as follows:
| (28) | ||||
| s.t. | ||||
It is worth noting that the collision avoidance behavior may affect the convergence of the robot formation, and even deadlocks may occur at certain positions (the deadlock problem is still an intractable challenge at this point), resulting in robots not being able to move. Thus, to ensure that multi-robot cooperative tasks and collision avoidance behavior are feasible, we assume that the required parameters have been properly designed, that the initial Euclidean distances between the robots are all greater than the safe distance , and that the initial distances between robots and obstacles are all greater than the safe distance . When the robots are unable to move due to the deadlock problem, we temporarily disengage the robots from the deadlock position by increasing the human intent.
VI Validation
To verify the effectiveness of our proposed method, we designed a series of experiments based on simulation and physical MRS platforms, respectively.
Given the function and as in (4). We design the function and as follows:
| (29) |
| (30) |
where and are defined as follows:
| (31) |
where , are used to change the decaying or increasing rate.


VI-A Simulation
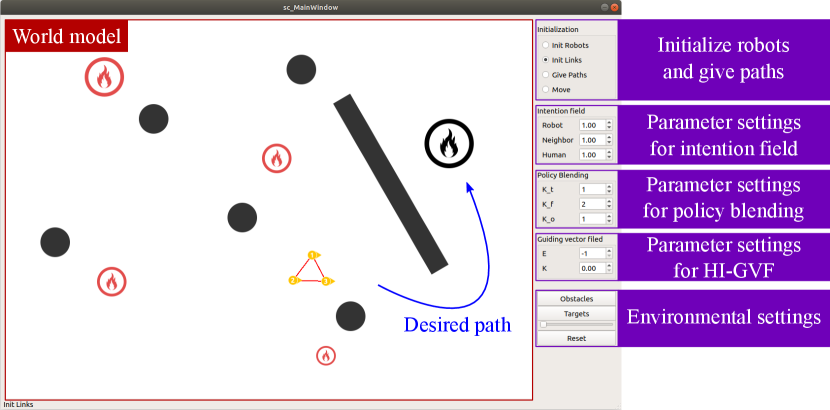
We design a human-computer interface based on QT for simulation experiments as shown in Fig. 8. The operator can arbitrarily initialize the robot position and connection, modify parameters, etc. We set up the following three types of experiments to verify the effectiveness of the algorithm.
VI-A1 MRS follows the desired path without robot intention
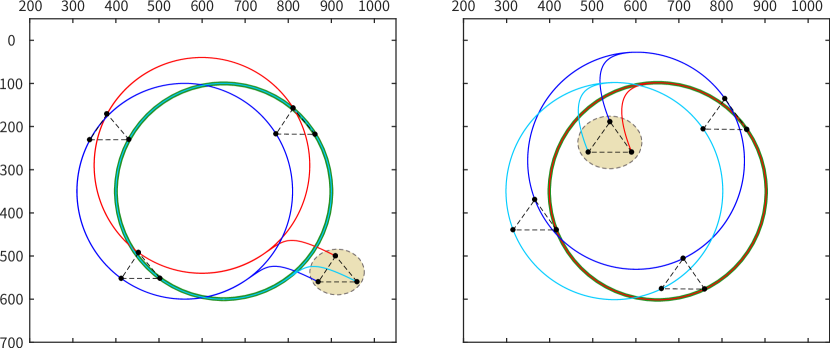
Given the desired path as a circle with center (250,300) and radius 250, the initial positions of the three robots are (590,260), (540,190), (490,260), and (910,500), (870,560), (960,560), which are located inside and outside the circle, respectively.
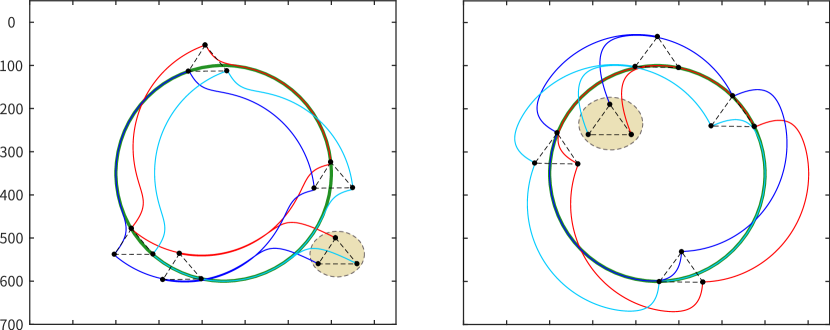
Case 1: MRS follows the desired path. Selecting a certain robot to be affected, this affected robot is able to follow the desired path from inside or outside the circle. Besides, the other robots can keep moving in formation, thus generating similar trajectories, as shown in Fig. 9(a).
Case 2: MRS follows the desired path with changing affected robots. When the MRS follows the desired path, the human can choose any robot affected. Thanks to the influence of the intention field, the entire MRS can respond quickly and continue to follow the desired path, as shown in Fig. 9(b).
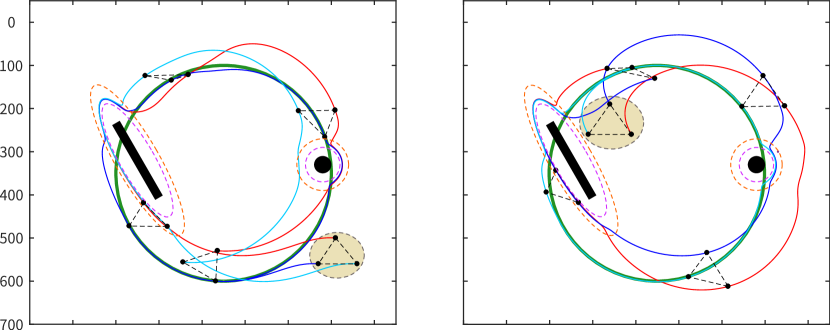
Case 3: MRS follows the desired path when encountering obstacles. In this case, there are bar barriers and circle obstacles in the environment. The robots will temporarily deviate from the desired path and change formation to avoid obstacles, which can be irregularly shaped, as shown in Fig. 9(c).
VI-A2 Shared control of human intervention
For firefighting tasks, we consider the following scenario where human intervention can make the MRS more efficient to reduce the damage caused by fire. There are five fire sources, several circle obstacles, and a bar barrier in the environment. The initial setup of these experiments is shown in TABLE I. The fire source radius increases with time (1m/s), and the time required to extinguish the fire is proportional to the size of the fire; the area covered by the -th fire source is denoted by the loss area . The ultimate goal of the MRS in extinguishing the fire is to minimize the total loss area.
| Robot(Position) | (700,300) (670,350) (730,350) | ||
|---|---|---|---|
| Fire source(Position)[Size] |
|
||
| Obstacles(Position)[Size] |
|
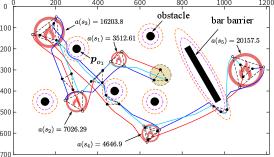
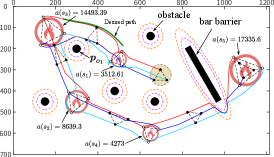
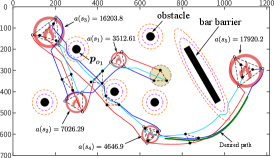
Case 1: MRS changes target priority with human intervention. The robots choose the next priority fire to be extinguished based on their observations. The MRS will maintain the formation and make adjustments when one robot encounters obstacles while performing the task. During the firefighting process, the robots are distributed to the appropriate locations according to the size of the fire. After extinguishing fire source 1, the robots choose fire source 2 over the actual more threatening fire source 3 due to the obstruction caused by obstacle 1. When humans intervene, the robot will be guided to change its trajectory to discover and select the fire source 3, as shown in Fig. 10. The results in Table II show that the area of damage caused by the fire is reduced after human intervention.
Case 2: MRS finds undetected target with human intervention. After the robots extinguish fire source 2, there is still a fire source left in the environment. Because of the barriers, the robot could not detect the fire until the fire spreads further, which would cause more damage. At this point, human intervention can guide the robot to detect the target early and reduce the damage, as shown in Table II.
| Loss area | Without human | With human | |||||||
|---|---|---|---|---|---|---|---|---|---|
|
|
|
|||||||
| 3512.61 | 3512.61 | 3512.61 | |||||||
| 7026.29 | 8639.3 | 7026.29 | |||||||
| 16203.8 | 14491.39 | 16203.8 | |||||||
| 4646.9 | 4273 | 4646.9 | |||||||
| 20157.5 | 17335.6 | 17920.2 | |||||||
| Sum | 51547.1 | 48253.9 | 49309.8 | ||||||
VI-B Human-computer interaction methods
As we mentioned earlier, we assume that in a scenario of human-multi-robot collaboration, humans obtain a global view through the UAV, thus guiding the robots to accomplish the task together using multiple human-robot interactions. We briefly overview the brain-computer interfaces, myoelectric wristbands, and eye-tracking devices used.
VI-B1 brain-computer interface
The brain-computer interface (BCI) is a unique form of human-computer interaction that uses brain activity to communicate with the external world [20]. Researchers typically capture brainwave signals using non-invasive electrodes placed on the scalp. Unlike traditional methods, BCI generates commands directly from EEG signals, reflecting users’ choices and uncertainties [21]. Therefore, BCI is ideal for controlling intelligent robots.
Our experiment uses the NeuSen W wireless EEG system, which is portable, stable, and well-shielded, equipped with a nine-axis motion sensor for both controlled and natural experiments. The hardware includes a 64-channel EEG cap and an amplifier, with electrodes positioned according to the international 10-20 system.
VI-B2 myoelectric wristbands
The EMG interface captures electromyography signals from the skin to interpret human intent. Surface-measured muscle contractions range from tens to hundreds of microvolts. Although weak and prone to noise, EMG signals directly reflect body activity, making them an advanced HCI for predicting user intentions [22]. Extensive research has utilized EMG to control robots [23, 24, 25, 13].
We have developed an EMG acquisition device that contains an array of standard medical snap buttons compatible with dry Ag/AgCl and gel electrodes. These snap buttons are arranged longitudinally in pairs along the arm to detect distinct muscle activities. Our wristband supports eight channels for surface EMG acquisition. This multi-channel design improves sensitivity and fidelity, enabling the detection of subtle hand gestures and fine motions.
VI-B3 eye-tracking device
The eye-tracker monitors and records human eye movements using infrared light and camera technology. This data can be analyzed to understand users’ intentions, predict future actions, and gain insights into their cognitive states [26]. Eye-tracking techniques have been widely used to recognize human intentions for indirect input or task assistance [27, 28, 29].
Intent prediction through eye movements is natural and seamless, serving as an efficient interface. Our system uses a simple Tobii eye-tracker to capture eye movements. The eye-tracker captures gaze positions over time, allowing us to derive gaze trajectories and construct heat maps that illustrate attention distribution and estimate cognitive workload.
VI-C Physical Multi-robot Experiment
Based on our self-designed human-multi-robot interaction system, we conduct physical robotics experiments. All participants were provided with written informed consent to participate in the experiment in accordance with the Declaration of Helsinki. We consider the following two scenarios: (1) The desired path is given in advance, and the robot moves along the path motion and deviates from the path when the target is found. (2) While the robot is executing the task, a human intervenes to change the execution sequence.
VI-C1 case 1
When the robot cannot directly observe the target, it is slow to search for it by directly exploring the environment. At this point, the human operator can utilize the information provided by the UAV to guide the robot’s movement, given the trajectory, which can improve the efficiency of the task. Consider a scenario like the one in Fig. 11, where the environment has circular and bar-shaped obstacles, simulating objects such as general obstacles and walls in real situations.The robot should avoid collisions with obstacles as well as other robots at all times during the task. Besides, it is assumed that the robot has a limited perceptual range and can only detect the target when it is close to it. The red line is the human’s given path. When the robots find the target, they break away from the path, and when the task is completed, the robots can still be guided to the given path.
The experimental result is shown in Fig. 12. The robots achieve the obstacle avoidance requirement throughout, even when the desired path crosses barriers. Besides, The robots are able to follow the desired path and reach the target position for operation.
VI-C2 case 2
A human operator intervenes online in real-time with a robot based on a human-multi-robot interaction interface. In this case, the eye-tracker is used to capture the gaze to draw a desired path, the BCI interface is used to select the robot to be guided, and gestures are used to switch the task progress. The experimental equipment is shown in Fig. 13. Although the operator in the picture is holding the drone remote control in his hand, it is only to simulate that the operator can use tiny gestures for ground robot control even though his hands are manipulating the drone. In fact, we do not use the remote control for the whole experiment. It is worth noting that the entire task process does not require using traditional interaction methods such as mouse and keyboard, which provides a flexible and feasible solution for human-multi-robot collaboration.
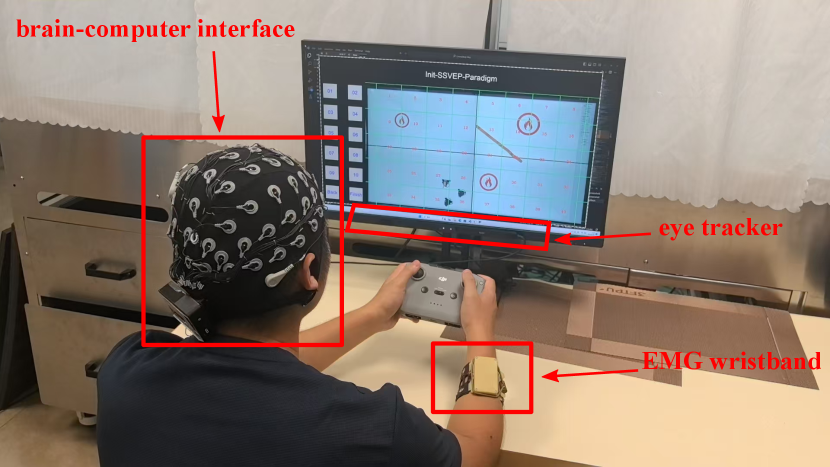
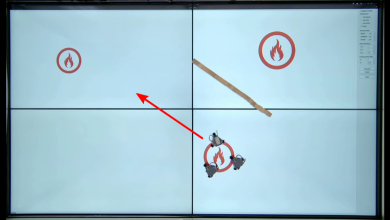
The experimental scenario is shown in Fig. 14. In this case, the robots are not able to observe targrt 3, which has the highest threat level, due to the occlusion of the barrier. The robots operate autonomously with an execution sequence target 2 target 1 target 3, which leads to great damage. At this point, the human operator guides the robot around the obstacle to prioritize the elimination of target 3. Fig. 15(a)-(f) show the motion of the robot in sequence. The direction of the red arrow in the figure represents the robot’s current direction of motion. In Fig. 15(a), the robots are close to target 2, and target 2 is a greater threat than target 1, so the robots prioritize movement toward target 2. When target 2 is eliminated, the robots can only observe target 1 due to the obstacles, so the robots autonomously move towards target 1 (see Fig. 15(b)). However, in reality, the threat level of target 3 is greater. At this point, the human operator guides the robot along the desired path by first pausing the robot’s motion through hand gestures, giving the desired path through eye movements, and selecting the affected robot through a brain-computer interface (see Fig. 15(c)). When the robots move to the end of the desired path, the robots move toward target 2 (see Fig. 15(d)), and later move towards target 1 avoiding obstacles. The robot trajectories are show in Fig. 16.





VII Conclusion
Multi-robot teams can robustly accomplish large-scale complex missions. However, robots often need human involvement to solve tough dilemmas. In this context, a shared control method integrating human intentions within a multi-robot team can improve the execution capabilities of multi-robot systems. In this paper, a novel shared control method is proposed that allows humans to use desired paths (or certain areas) as inputs without requiring real-time human involvement in the motion control of robots, thus reducing the burden on human operators. In our method, with human-influenced guiding vector fields utilized to describe human intentions, a hierarchical shared control framework is proposed to propagate and merge the robot and human intentions. In addition, a novel human-multi-robot interaction system based on multi-touch screens is built for a physical demonstration to validate the proposed algorithm. Besides, we use a variety of human-robot interactions (brain-computer interface, myoelectric wristband, eye-tracking) to intervene in the robot’s task progression. The results in different scenarios show that our method promotes the effectiveness and efficiency for completing the tasks.
Appendix
VII-A The stability analysis of the intentional field
Consider the robot as a first-order model, i.e., . Equation (15) can be rewritten as follows:
| (32) | ||||
For the whole robot formation, the state can be represented as . Let , , , , , where is the Kronecker product. Then, (32) becomes
| (33) |
where , D is the incidence matrix. We use the Lyapunov method for stability analysis of the intention field model.
Theorem 1.
The intention field model with and as the input, and as the state, is input-to-state stable. Moreover, let , , and , we can obtain
| (34) |
VII-B The stability analysis of the consensus network
According to the consensus theory [30], the system dynamics of the consensus network can be represented as
| (39) |
| (40) |
where is the state set; , ; , is the Laplacian matrix; is the consensus error. And we can easily obtain Lemma 1.
Lemma 1.
Given a connected graph , is positive definite on space . Therefore, for , such that .
For the designed function in (19), we have Lemma 2.
Lemma 2.
For , there exists , when such that ,
| (41) |
Proof.
Let , then we can easily obtain that is strictly decreasing in , and , . Therefore, for , there exists such that , and for , . ∎
Theorem 2.
The consensus network with as the input, and as the state, is input-to-state stable. Moreover, let , , we can obtain
| (42) |
Proof.
From (17), we can obtain . Since , we obtain that
| (44) |
From Lemma 2, it follows that ,
| (45) |
Let , then . Then it follows that . Since , from (43) and Lemma 1, we have
| (46) | ||||
Thus the system is input-to-state stable, with a bound that ∎
Combining Theorem 1 and Theorem 2, we obtain corollary:
Corollary 1.
The hierarchical control system with inputs human intention and robot intention and state consensus error is input-state stable and satisfies
| (47) |
References
- [1] S. L. Smith and D. Rus, “Multi-robot monitoring in dynamic environments with guaranteed currency of observations,” in 49th IEEE Conference on Decision and Control (CDC), 2010, pp. 514–521.
- [2] J. Saez-Pons, L. Alboul, J. Penders, and L. Nomdedeu, “Multi-robot team formation control in the guardians project,” Industrial Robot: An International Journal, vol. 37, no. 4, pp. 372–383, 2010.
- [3] Y. Liu and G. Nejat, “Robotic urban search and rescue: A survey from the control perspective,” Journal of Intelligent and Robotic Systems, vol. 72, no. 2, pp. 147–165, 2013.
- [4] R. Fabbiano, F. Garin, and C. Canudas-de Wit, “Distributed source seeking without global position information,” IEEE Transactions on Control of Network Systems, vol. 5, no. 1, pp. 228–238, 2018.
- [5] W. Dai, H. Lu, J. Xiao, and Z. Zheng, “Task allocation without communication based on incomplete information game theory for multi-robot systems,” Journal of Intelligent and Robotic Systems, vol. 94, no. 3, pp. 841–856, 2019.
- [6] L. Saleh, P. Chevrel, F. Claveau, J.-F. Lafay, and F. Mars, “Shared steering control between a driver and an automation: Stability in the presence of driver behavior uncertainty,” IEEE Transactions on Intelligent Transportation Systems, vol. 14, no. 2, pp. 974–983, 2013.
- [7] R. Krzysiak and S. Butail, “Information-based control of robots in search-and-rescue missions with human prior knowledge,” IEEE Transactions on Human-Machine Systems, vol. 52, no. 1, pp. 52–63, 2022.
- [8] Y. Zhu, C. Yang, Z. Tu, Y. Ling, and Y. Chen, “A haptic shared control architecture for tracking of a moving object,” IEEE Transactions on Industrial Electronics, vol. 70, no. 5, pp. 5034–5043, 2023.
- [9] D. Sieber, S. Musić, and S. Hirche, “Multi-robot manipulation controlled by a human with haptic feedback,” in 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2015, pp. 2440–2446.
- [10] N. Ayanian, A. Spielberg, M. Arbesfeld, J. Strauss, and D. Rus, “Controlling a team of robots with a single input,” in 2014 IEEE International Conference on Robotics and Automation (ICRA), 2014, pp. 1755–1762.
- [11] J. Patel, Y. Xu, and C. Pinciroli, “Mixed-granularity human-swarm interaction,” in 2019 International Conference on Robotics and Automation (ICRA), 2019, pp. 1059–1065.
- [12] G. Podevijn, R. O’Grady, Y. S. G. Nashed, and M. Dorigo, “Gesturing at subswarms: Towards direct human control of robot swarms,” in Towards Autonomous Robotic Systems, 2014, pp. 390–403.
- [13] A. Suresh and S. Martínez, “Human-swarm interactions for formation control using interpreters,” International Journal of Control, Automation and Systems, vol. 18, no. 8, pp. 2131–2144, 2020.
- [14] B. Gromov, L. M. Gambardella, and G. A. Di Caro, “Wearable multi-modal interface for human multi-robot interaction,” in 2016 IEEE International Symposium on Safety, Security, and Rescue Robotics (SSRR), 2016, pp. 240–245.
- [15] J. Y. Chen and M. J. Barnes, “Human–agent teaming for multirobot control: A review of human factors issues,” IEEE Transactions on Human-Machine Systems, vol. 44, no. 1, pp. 13–29, 2014.
- [16] A. Kolling, P. Walker, N. Chakraborty, K. Sycara, and M. Lewis, “Human interaction with robot swarms: A survey,” IEEE Transactions on Human-Machine Systems, vol. 46, no. 1, pp. 9–26, 2015.
- [17] Y. A. Kapitanyuk, A. V. Proskurnikov, and M. Cao, “A guiding vector-field algorithm for path-following control of nonholonomic mobile robots,” IEEE Transactions on Control Systems Technology, vol. 26, no. 4, pp. 1372–1385, 2017.
- [18] W. Yao, B. Lin, B. D. O. Anderson, and M. Cao, “Guiding vector fields for following occluded paths,” IEEE Transactions on Automatic Control, vol. 67, no. 8, pp. 4091–4106, 2022.
- [19] L. Wang, A. D. Ames, and M. Egerstedt, “Safety barrier certificates for collisions-free multirobot systems,” IEEE Transactions on Robotics, vol. 33, no. 3, pp. 661–674, 2017.
- [20] J. R. Wolpaw, N. Birbaumer, D. J. McFarland, G. Pfurtscheller, and T. M. Vaughan, “Brain–computer interfaces for communication and control,” Clinical Neurophysiology, vol. 113, no. 6, pp. 767–791, 2002.
- [21] F. Lotte, L. Bougrain, A. Cichocki, M. Clerc, M. Congedo, A. Rakotomamonjy, and F. Yger, “A review of classification algorithms for eeg-based brain–computer interfaces: a 10 year update,” Journal of Neural Engineering, vol. 15, no. 3, p. 031005, 2018.
- [22] M. Atzori, A. Gijsberts, C. Castellini, B. Caputo, A.-G. M. Hager, S. Elsig, G. Giatsidis, F. Bassetto, and H. Müller, “Electromyography data for non-invasive naturally-controlled robotic hand prostheses,” Scientific Data, vol. 1, no. 1, p. 140053, 2014.
- [23] M. T. Wolf, C. Assad, M. T. Vernacchia, J. Fromm, and H. L. Jethani, “Gesture-based robot control with variable autonomy from the jpl biosleeve,” in 2013 IEEE International Conference on Robotics and Automation, 2013, pp. 1160–1165.
- [24] A. S. Kundu, O. Mazumder, P. K. Lenka, and S. Bhaumik, “Hand gesture recognition based omnidirectional wheelchair control using imu and emg sensors,” Journal of Intelligent & Robotic Systems, vol. 91, no. 3, pp. 529–541, 2018.
- [25] J. Luo, Z. Lin, Y. Li, and C. Yang, “A teleoperation framework for mobile robots based on shared control,” IEEE Robotics and Automation Letters, vol. 5, no. 2, pp. 377–384, 2020.
- [26] F. Koochaki and L. Najafizadeh, “Predicting intention through eye gaze patterns,” in 2018 IEEE Biomedical Circuits and Systems Conference (BioCAS), 2018, pp. 1–4.
- [27] S. B. Shafiei, S. Shadpour, F. Sasangohar, J. L. Mohler, K. Attwood, and Z. Jing, “Development of performance and learning rate evaluation models in robot-assisted surgery using electroencephalography and eye-tracking,” npj Science of Learning, vol. 9, no. 1, p. 3, 2024.
- [28] R. M. Aronson, T. Santini, T. C. Kübler, E. Kasneci, S. Srinivasa, and H. Admoni, “Eye-hand behavior in human-robot shared manipulation.” ACM/IEEE International Conference on Human-Robot Interaction, pp. 4–13, 2018.
- [29] H. Chien-Ming and B. Mutlu, “Anticipatory robot control for efficient human-robot collaboration.” ACM/IEEE International Conference on Human-Robot Interaction, pp. 83–90, 2016.
- [30] F. L. Lewis, H. Zhang, K. Hengster-Movric, and A. Das, Cooperative control of multi-agent systems: optimal and adaptive design approaches. Springer Science & Business Media, 2013.