HiDe-PET: Continual Learning via Hierarchical Decomposition of Parameter-Efficient Tuning
Abstract
The deployment of pre-trained models (PTMs) has greatly advanced the field of continual learning (CL), enabling positive knowledge transfer and resilience to catastrophic forgetting. To sustain these advantages for sequentially arriving tasks, a promising direction involves keeping the pre-trained backbone frozen while employing parameter-efficient tuning (PET) techniques to instruct representation learning. Despite the popularity of Prompt-based PET for CL, its empirical design often leads to sub-optimal performance in our evaluation of different PTMs and target tasks. To this end, we propose a unified framework for CL with PTMs and PET that provides both theoretical and empirical advancements. We first perform an in-depth theoretical analysis of the CL objective in a pre-training context, decomposing it into hierarchical components namely within-task prediction, task-identity inference and task-adaptive prediction. We then present Hierarchical Decomposition PET (HiDe-PET), an innovative approach that explicitly optimizes the decomposed objective through incorporating task-specific and task-shared knowledge via mainstream PET techniques along with efficient recovery of pre-trained representations. Leveraging this framework, we delve into the distinct impacts of implementation strategy, PET technique and PET architecture, as well as adaptive knowledge accumulation amidst pronounced distribution changes. Finally, across various CL scenarios, our approach demonstrates remarkably superior performance over a broad spectrum of recent strong baselines. Our code is available at https://github.com/thu-ml/HiDe-PET.
Index Terms:
Continual Learning, Incremental Learning, Pre-trained Models, Parameter-Efficient Tuning, Catastrophic Forgetting.1 Introduction
The proficiency of artificial intelligence (AI) in accommodating real-world dynamics is largely contingent on its capability of continual learning (CL), which has benefited significantly in recent years from the deployment of pre-trained models (PTMs). In essence, PTMs provide CL with not only positive knowledge transfer but also resilience to catastrophic forgetting [1, 2, 3, 4], which are critical to improve the performance of CL methods. Given that adapting PTMs to sequentially arriving tasks may compromise these advantages via progressive overwriting of pre-trained knowledge, numerous efforts have been devoted into implementing parameter-efficient tuning (PET) techniques for CL, i.e., keeping the pre-trained backbone frozen and introducing a few lightweight parameters to instruct representation learning. However, current advances predominantly center around empirical designs of Prompt-based PET [5, 6, 7, 8], which struggle to adequately achieve the CL objective and therefore often exhibit sub-optimal performance across different PTMs and target tasks (see Sec. 6.2). In response to this critical challenge, there is an urgent need for a more profound understanding of CL with PTMs and PET, coupled with endeavors to enhance its effectiveness and generality.
In this work, we propose a unified framework for CL with PTMs and PET, seeking to advance this direction with both theoretical and empirical insights. We initiate our explorations with an in-depth theoretical analysis of the CL objective in a pre-training context. Considering the significant impact of pre-trained knowledge on CL, this objective can be decomposed into three hierarchical components in response to sequentially arriving tasks, namely within-task prediction (WTP), task-identity inference (TII) and task-adaptive prediction (TAP). They prove to be sufficient and necessary to ensure low errors in common CL settings. Based on the theoretical analysis, we devise an innovative approach named Hierarchical Decomposition PET (HiDe-PET) to explicitly optimize WTP, TII and TAP.
The principal concept behind HiDe-PET leverages the unique strengths of PTMs for CL, with a particular focus on the effective instruction and efficient recovery of pre-trained representations. As a generic approach applicable to mainstream PET techniques (e.g., Prompt [9, 10], Adapter [11], LoRA [12], etc.), we construct an ensemble of task-specific parameters that incorporates the knowledge of each task to optimize WTP, and a set of task-shared parameters that accumulates knowledge in a task-agnostic manner to improve TII. We further recover the distribution of uninstructed and instructed representations through preserving their statistical information, so as to optimize TII and TAP, respectively. In this way, our HiDe-PET is able to adeptly predict the identity of task-specific parameters from uninstructed representations and collect appropriate instructed representations for final predictions.
The proposed framework facilitates a thorough assessment of important factors emerged in CL with PTMs and PET, including the implementation strategy, PET technique and PET architecture. For example, we dissect representative strategies for stabilizing task-shared parameters and for preserving pre-trained representations, empirically analyzing their effectiveness. Moreover, we evaluate the behaviors of different PET techniques in achieving the CL objective, where the Prompt-based PET tends to be less effective in WTP, consequently displaying lower sensitivity to TII and clearly lagging behind the LoRA/Adapter-based PET. Motivated by the inherent connections between TII and out-of-distribution (OOD) detection, we further devise a PET hierarchy tailored for adaptive knowledge accumulation, and unravel the relationship between task-specific and task-shared PET architectures in representation learning.
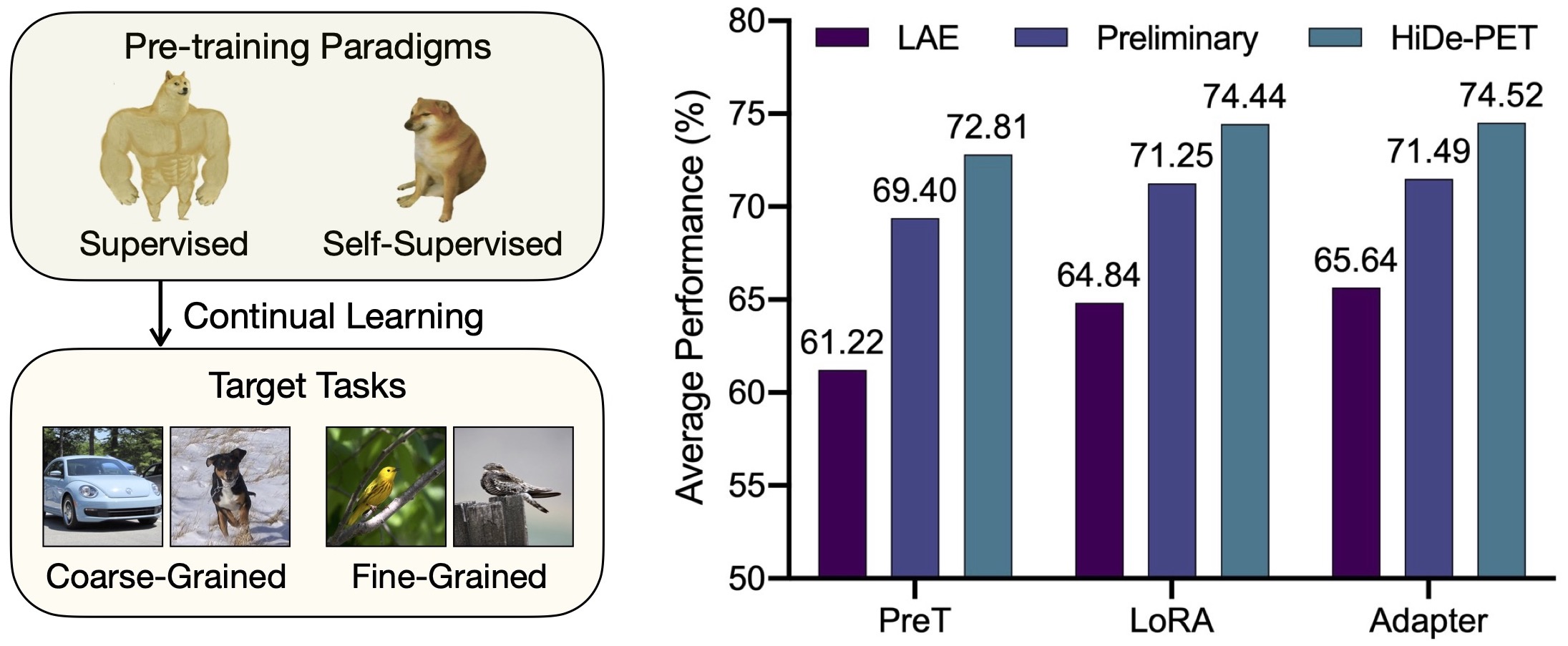
Upon extensive experiments, our HiDe-PET clearly outperforms a wide range of recent strong baselines, and demonstrates remarkable generality across a variety of PET techniques, pre-trained checkpoints and CL benchmarks (summarized in Fig. 1). We further provide empirical analysis to elucidate the respective contributions of the three hierarchical components. Note that some results have been presented in our preliminary version [13], which mainly considered a specific implementation of task-specific parameters via Prompt-based PET. In contrast, the current version presents a unified framework for CL with PTMs and PET. It incorporates substantial extensions to the implementation strategy, PET technique and PET architecture, culminating in a comprehensive analysis and improved performance.
Overall, our main contributions are as follows:
-
•
We present an in-depth theoretical analysis of the CL objective in a pre-training context, decomposing it into three hierarchical components for model design;
-
•
We propose an innovative approach that exploits mainstream PET techniques and pre-trained representations to explicitly optimize the decomposed objective;
-
•
We conduct extensive experiments to demonstrate the effectiveness and generality of our approach, coupled with a thorough assessment of important factors emerged in CL with PTMs and PET.
2 Related Work
Continual Learning (CL) is characterized by learning sequentially arriving tasks and performing well on them. The primary challenge of CL stems from the dynamic nature of data distribution, which leads to catastrophic forgetting of old tasks while acquiring new ones [3, 15]. As summarized in a recent survey [3], representative methods include selective stabilization of important parameters for old tasks [16, 17, 18], approximation and recovery of old data distributions [19, 20, 21], exploitation of robust and well-distributed representations [22, 23, 24], manipulation of optimization programs via gradient projection [25, 26, 27], construction of (relatively) dedicated parameters for each task [28, 29, 30], etc.
In the realm of CL, current efforts have predominantly centered around computer vision (CV), specifically for visual classification tasks. These efforts have progressively expanded their scope to include more complex visual tasks, as well as natural language processing (NLP), reinforcement learning (RL) and other related applications. Across various representative CL settings, especially those lacking the oracle of task identity during the testing phase, robust CL models often necessitate the storage and rehearsal of old training samples [31, 32, 21], which creates additional resource overheads and potential privacy concerns. These issues have been largely avoided through effective use of pre-trained knowledge in recent work, as discussed later.
Pre-training and Fine-tuning: Transfer learning with pre-trained models (PTMs) can significantly improve the performance of target tasks and has therefore become a prevalent paradigm in many areas of artificial intelligence (AI). Since the pre-trained knowledge is usually generalized and difficult to cover all specific domains, PTMs necessitate further fine-tuning for better adaptation. The most straightforward way is to update all model parameters, but involves keeping a separate copy of fine-tuned model parameters for each task. This leads to considerable resource overheads especially for advanced PTMs of increasing size.
In order to improve the efficiency of fine-tuning, some lightweight alternatives have been proposed that update only a few extra parameters with most of the model parameters frozen, collectively referred to as the parameter-efficient tuning (PET) techniques. These PET techniques were originally proposed for NLP and are now widely used for CV as well. Representative practices include Prompt Tuning (ProT) [9] and Prefix Tuning (PreT) [10] that prepend short prompt tokens into the original inputs or intermediate inputs, Adapter [11] that inserts small neural modules between backbone layers, Low-Rank Adaptation (LoRA) [12] that approximates the updates of model parameters with low rank matrices, etc. A recent work [33] unified these PET techniques in a similar form, corresponding to modifying specific hidden states of the PTMs.
CL with PTMs and PET: While much of the past work in CL has focused on training from scratch, a growing body of efforts have delved into the benefits of PTMs, which provide not only positive knowledge transfer but also resilience to catastrophic forgetting [1, 2]. Meanwhile, PTMs also need to improve the ability of CL to accommodate sequentially arriving tasks and to refine pre-trained knowledge from them. However, fine-tuning PTMs becomes much more difficult when considering CL, since repetitive adaptation of the same PTM may lead to progressive overwriting of pre-trained knowledge, whereas separate saving of the fine-tuned PTMs creates an additional linear increase in resource overhead on the time scale [4].
Therefore, applying PET techniques for CL has become an emerging direction in recent years, with Prompt-based PET being predominant. Many state-of-the-art methods have focused on designing appropriate prompt architectures for CL, such as task-shared prompts [6, 34, 14], task-specific prompts [6, 7, 13, 8] and their combinations [5, 6]. Since the frozen backbone with pre-trained knowledge can provide robust and well-distributed representations, these methods have almost achieved the performance pinnacle of rehearsal-free CL under adequate supervised pre-training and general tasks. However, their sub-optimality in achieving the objective of CL has been clearly exposed under the more realistic self-supervised pre-training and fine-grained tasks [4, 13], in part due to the limited fitting ability of Prompt-based PET [35, 36]. LAE [14] is a recent work that assembles a pair of task-shared parameters to be implemented with mainstream PET techniques, but exhibits only moderate improvements in CL performance.
3 Preliminaries
In this section, we first introduce the problem formulation of continual learning (CL) in a pre-training context. Then we describe representative parameter-efficient tuning (PET) techniques and PET-based CL methods.
3.1 Problem Formulation
The CL problem can be generally defined as learning sequentially arriving tasks from their respective training sets in order to perform well on their corresponding test sets. The training set and test set of each task are assumed to follow the same distribution. For supervised CL, each training set comprises multiple sample-label pairs, where and represent the sample and label elements, respectively, and denotes the size of . Let us consider a neural network model composed of a backbone with parameters , and an output layer with parameters . This model aims to learn a projection from to , so that it can correctly predict the label of an unseen test sample from observed tasks. Since are usually limited in size and distinct in distribution, learning from scratch can easily converge to an undesirable local minimum. In contrast, initialization of with a substantial quantity of training samples external to , i.e., applying adequate pre-training, helps converge to a wide low-error region and thus can greatly improve the CL performance [1, 2].
Depending on the split of label space and the availability of task identity, there are three representative setups for CL [37], including task-incremental learning (TIL), domain-incremental learning (DIL), and class-incremental learning (CIL). Specifically, the label space with is the same for DIL whereas disjoint for TIL and CIL. The task identity is provided at test time for TIL whereas not available for DIL and CIL. As a result, CIL is often considered more challenging and realistic. Of note, although CIL is named from classification tasks, its definition can be generalized to other task types. To avoid additional resource overhead and potential privacy issues, the CL process is further restricted to be rehearsal-free [8], i.e., the sample elements of each are available only when learning task , which particularly increases the challenge of CIL [3].
3.2 PET Techniques
The backbone of advanced pre-trained models (PTMs) often employs a transformer architecture [38] based on multi-head attention mechanisms. For example, a pre-trained vision transformer (ViT) [39] consists of multiple consecutive multi-head self-attention (MSA) layers that transform an input sample into a sequence-like output representation of sequence length and embedding dimension . Let us consider the -th layer with input and output , where is equivalent to for total layers. Since the output then becomes the input of the next layer, we omit the layer identity for the sake of clarity. Then, the input is further specified as the query , key and value , and the output of the current layer is
| (1) |
| (2) |
where , , are projection matrices, is the number of heads, and in ViT. The concatenation (Concat) and attention (Attn) functions are specified in their original papers [38, 39].
To facilitate effective transfer of pre-trained knowledge while preventing its catastrophic forgetting, the backbone parameters are usually frozen and additional lightweight parameters are introduced to instruct representation learning, referred to as the PET techniques [33]. Here we describe some representative ones (see Fig. 2):
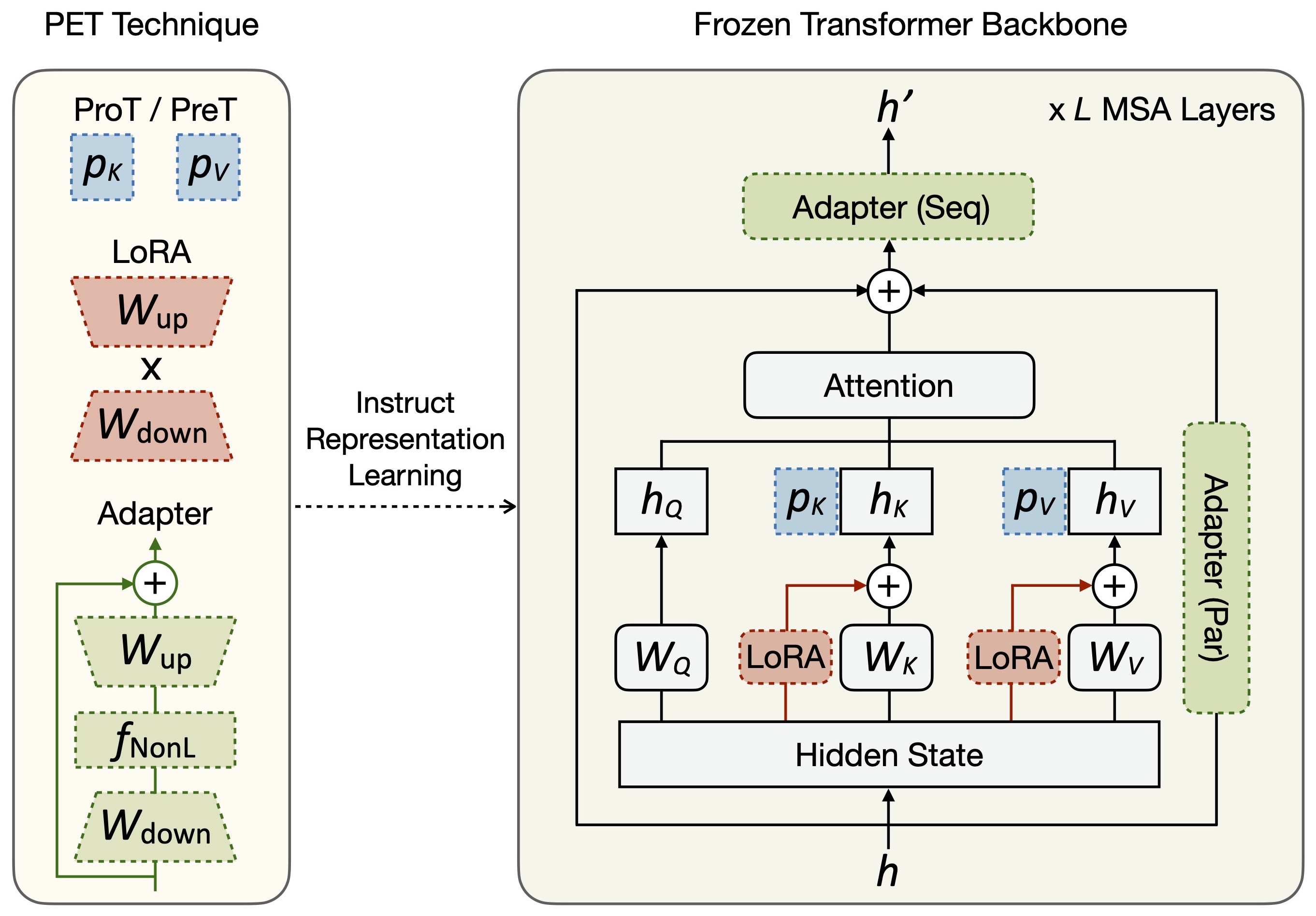
Prompt Tuning (ProT) [9] and Prefix Tuning (PreT) [10] both prepend a few learnable parameters of sequence length and embedding dimension to , collectively known as the Prompt-based PET. For ProT in ViT, an identical is prepended to , and :
| (3) |
where represents the concatenation operation along the dimension of sequence length. Since the output in has increased dimensions, ProT is often used for only the last layer in CL [5, 7]. In contrast, PreT splits into for and for :
| (4) |
where the output has the same dimension as the input , allowing PreT to be implemented in multiple layers. In particular, the output of PreT can be reframed as
| (5) |
where is the nonlinear (NonL) softmax function, and is a scalar that depends on the input [33].
Adapter [11] inserts lightweight neural modules between backbone layers, each usually composed of a down-projection matrix that reduces the dimension of with bottleneck , a nonlinear (NonL) activation function and an up-projection matrix . These modules are implemented with residual connections, acting on the output in a sequential (Seq) manner, i.e.,
| (6) |
as well as on the input in a parallel (Par) manner, i.e.,
| (7) |
LoRA [12] approximates the updates of pre-trained parameter matrix with a low-rank decomposition , where , and is the low-rank bottleneck. For ViT, LoRA is typically used to update the and of a backbone layer. As a special case, when performs linear projection of the input , the output is modified as
| (8) |
where is a scalar hyperparameter [33].
As we can see, these PET techniques all amount to modulating the (intermediate) representations of , though differing in their specific implementations.
3.3 PET-Based CL Methods
With the widespread use of PTMs in CL, there have been a variety of methods that incorporate PET techniques on a continual basis. Most of these methods have focused on designing appropriate PET architectures to formulate lightweight parameters tailored for CL, which can be conceptually summarized into task-specific parameters, task-shared parameters, and their explicit or implicit combinations. In particular, task-specific parameters require their identity to be predicted during the testing phase, while task-shared parameters need to mitigate catastrophic forgetting when learning each task. We briefly describe these methods here, with a comprehensive summary in Appendix Table VII for further comparison.
L2P [5] constructs a prompt pool of size and instructs pre-trained representations in a ProT manner. Each prompt is associated with a learnable key, optimized by the cosine distance of the top- keys to a query function . The most relevant prompt(s) can therefore be selected via uninstructed representations.
DualPrompt [6] employs the task-specific prompt and task-shared prompt to instruct respective layers in a PreT manner. The layer-wise is associated with a task-specific key, optimized by its cosine distance to , and the best-matched key is selected via uninstructed representations.
S-Prompt [7] employs only the task-specific prompt and instructs pre-trained representations in a ProT manner. The task identity is inferred from preserved task centroids with -Nearest Neighbors (NNs). S-Prompt also employs a multi-head output layer associated with the task identity.
CODA-Prompt [8] performs a weighted summation of the prompt pool, i.e., , and instructs multiple layers in a PreT manner. Each weighting factor for is associated to a learnable key, optimized by its cosine distance to . The inference of can therefore construct an appropriate prompt for each input sample.
LAE [14] employs two kinds of task-shared parameters to incorporate knowledge from more recent tasks and more remote tasks, respectively, applicable to PreT, Adapter and LoRA for multiple layers. Their update speeds are regulated via combinatorial strategies such as temporary freezing and exponential moving average (EMA).
Besides, there are several relevant methods with different focuses. For example, SLCA [4] updates the entire backbone with a reduced learning rate, and further preserves pre-trained representations via dedicated covariance matrices. RanPAC [34] projects pre-trained representations to a high-dimension space and preserves them via a shared covariance matrix. These methods are often parameter-inefficient, i.e., the parameter cost is comparable to due to a complexity much larger than , and therefore not prioritized in this work.111Our preliminary version [13] also employed dedicated covariance matrices as the main implementation to acquire better performance.
Taken together, three notable limitations have surfaced in current progress of harnessing PET techniques for CL. First, the above methods often rely on empirical designs, making it difficult to ascertain their effectiveness in achieving the objective of CL in a pre-training context. In particular, their performance exhibits significant variations across different PTMs and target tasks, as demonstrated in Sec. 6.2. Second, these methods predominantly center around Prompt-based PET, which has been shown to be less effective under self-supervised pre-training [36] and fine-grained tasks [40], leaving underexplored the particular behaviors and potential benefits of other alternatives. Third, these methods share some analogous strategies, such as stabilizing task-shared parameters and recovering pre-trained representations, without a comprehensive analysis of different implementations and assimilation of their respective strengths. Therefore, there is an urgent need to establish a unified framework that incorporates both theoretical and empirical insights for CL with PTMs and PET, which constitutes our main motivation.
4 Theoretical Analysis
In this section, we present an in-depth theoretical analysis of the CL objective in a pre-training context, so as to inspire the better design of PET-based CL methods. We first decompose this objective into three hierarchical components, which demonstrate the impact of pre-trained knowledge on CL and are both sufficient and necessary to optimize the CL performance (Sec. 4.1). This analysis motivates us to develop an innovative CL method to explicitly optimize the objective (Sec. 5.1). We then illustrate the connection of the decomposed objective to OOD detection, which is shown to play a similar role as inferring the task identity (Sec. 4.2). This analysis motivates us to adaptively accumulate knowledge with the proposed CL method to facilitate the learning of subsequent tasks (Sec. 5.2).
4.1 Three Hierarchical Components
Let us consider a CL problem for sequentially arriving tasks with training set of domain and label , where denotes the -th class of task . The goal is to learn a projection from to in order to predict the label of an unseen test sample from all observed tasks, referred to as task-adaptive prediction (TAP). As summarized in Sec. 3.1, there are many representative setups of CL, such as CIL, DIL and TIL. Here we take CIL as a typical scenario for theoretical analysis, and leave the results of DIL and TIL to Appendix A.
CL from Scratch: When training from scratch, the TAP performance is to predict across all classes without distinguishing tasks, where , denotes the ground truth label of , and denotes the domain of class . The restricted definition of CIL further posits two assumptions [41]: the domains of tasks are disjoint (i.e., , ), and the domains of classes of the same task are disjoint (i.e., , ). Through predicting which task to perform and then performing that task (i.e., there is an execution order), the CIL probability can be expressed as a hierarchical process of task-identity inference (TII) and within-task prediction (WTP):
| (9) |
Eq. (9) is exactly the main conclusion of a previous theoretical study of CL from scratch [41]. Given the assumptions of disjoint domains and the omitted impact of randomly initialized , the TAP performance is essentially equivalent to the decomposed CIL performance , where and denote the ground truth of an w.r.t. the task identity and within-task index. Here we provide a more intuitive explanation with the definition of class labels and the implementation of output heads. The decomposed CIL performance can be naturally computed in a multi-head manner with two steps: inferring the task identity , i.e., the TII performance; and predicting the within-task index , i.e., the WTP performance. In comparison, the TAP performance is computed by performing single-head prediction for global class . For CL from scratch, the decomposed CIL performance of multi-head inference & prediction is equivalent to the TAP performance of single-head prediction. In this case, the decomposed CIL performance can also be computed in a single-head manner, as many traditional continual learning methods do.
CL with Pre-training: When considering the impact of pre-trained knowledge carried by parameters , the TAP is redefined as , while the CIL probability of TII and WTP in Eq. (9) is re-written as
| (10) |
It can be seen that both the TAP performance and the CIL performance are now affected by , but in different ways. The pre-trained parameters in TAP affect simultaneously all observed classes (i.e., a large output space ), while in CIL affect separately TII and WTP (i.e., two small output spaces and ). Accordingly, the CIL performance is upper bounded by either the TII performance or the WTP performance , whereas the TAP performance is not, as the CL tasks and pre-trained knowledge are not conditionally independent from a statistical perspective. For example, an incorrectly predicted task identity results in full errors in predicting within-task index, remaining a performance gap from rectifying the predictions of inter-task classes to make them properly balanced. This also underscores the notable difference of the multi-head inference & prediction from the single-head prediction in the context of pre-training. Such difference tends to be more pronounced if the task structure is not clear (e.g., randomly split classes of the same dataset), and has been empirically validated in our preliminary experiments [13], where the multi-head inference & prediction significantly underperforms the single-head prediction in CL with PTMs.
Therefore, we propose to further optimize TAP along with the improved TII and WTP, formulating the ultimate goal of CL as a multi-objective optimization problem, i.e.,
| (11) |
where follows a similar decomposition as in Eq. (10), with TII and WTP having an execution order.
To resolve the above WTP, TII and TAP, we derive the sufficient and necessary conditions with the widely-used cross-entropy loss. Specifically, we define
| (12) | ||||
| (13) | ||||
| (14) |
where , and are the cross-entropy values of WTP, TII and TAP, respectively. denotes the index of all observed classes. . is a one-hot encoding function.
We now present the first theorem under the CIL setting (see Appendix A for the complete proof and the corresponding extensions to DIL and TIL settings):
Theorem 1
For continual learning (CL) in a pre-training context, if , , and , we have the loss error , regardless whether the WTP predictor, TII predictor and TAP predictor are trained together or separately.
With the use of cross-entropy, the CL performance tends to be better as the bounds are tightened. In Theorem 1 we have shown that good performance of WTP, TII and TAP is sufficient to ensure good performance of CL. For completeness, we now study the necessary conditions of a well-performed CL model in Theorem 2.
Theorem 2
For CL in a pre-training context, if the loss error , then there always exist (1) a WTP predictor, s.t. ; (2) a TII predictor, s.t. ; and (3) a TAP predictor, s.t. .
Theorem 2 suggests that if a CL model is well trained (i.e., with low loss error), then the WTP error, TII error and TAP error for sequentially arriving tasks are always implied to be small. Similar to the connection between TAP and CIL under different assumptions, Theorem 1 and Theorem 2 would degenerate into the main conclusion of the previous theoretical study [41] if the pre-trained knowledge carried by is not considered. This suggests that the presented theorems are particularly directed to the impact of pre-training on CL.
4.2 Connection of TII to OOD Detection
In essence, the TII probability specifies the CL problem with task-wise input samples. Although the definition of “task” in literature can generalize to an incoming training batch of distinct distribution [3], it may not be pertinent in describing realistic data streams with apparent similarity and dissimilarity. Indeed, the CL problem is often associated with the out-of-distribution (OOD) detection [42], i.e., the ability of a model to detect an unseen input sample, which has been shown to behave similarly as task prediction when training from scratch [41]. Inspired by this, we further explore the necessary conditions to optimize TII/OOD for CL in a pre-training context, in order to facilitate adaptive knowledge accumulation from more pronounced distribution changes.
We again use cross-entropy to measure the performance of TII and OOD detection, so as to establish their connection in each task. We first define the OOD detector of the -th task as . Different from the TII probability, the OOD detection probability here is a Bernoulli distribution:
| (15) |
where is the cross-entropy value of an OOD detector of task , and can be predicted with an appropriate distance function. The TII probability can then be defined with the OOD detectors, i.e., .
Now we have the following theorem to explore the connection between TII and OOD detection in a pre-training context (see Appendix B for the complete proof):
Theorem 3
For CL in a pre-training context, if for , then we have . Likewise, if , then for .
Theorem 3 shows that the TII performance improves if the OOD detection performance improves, and vice versa. In particular, converges to 0 as converges to 0. Note that the connection between TII and OOD detection in Theorem 3 for CL with pre-training is similar in form to that for CL from scratch [41]. We further derive the sufficient and necessary conditions of improving CL with WTP, OOD detection and TAP, as detailed in Appendix B.
5 Hierarchical Decomposition PET
Based on the above analysis, we now present an innovative approach named Hierarchical Decomposition PET (HiDe-PET) to explicitly optimize the three hierarchical components tailored for CL in a pre-training context (see Fig. 3). Our HiDe-PET is applicable to mainstream PET techniques for learning sequentially arriving tasks, from which the pre-trained knowledge can also be evolved.
Input: Pre-trained transformer backbone , training sets , number of tasks , number of epochs and .
Output: Parameters , , and
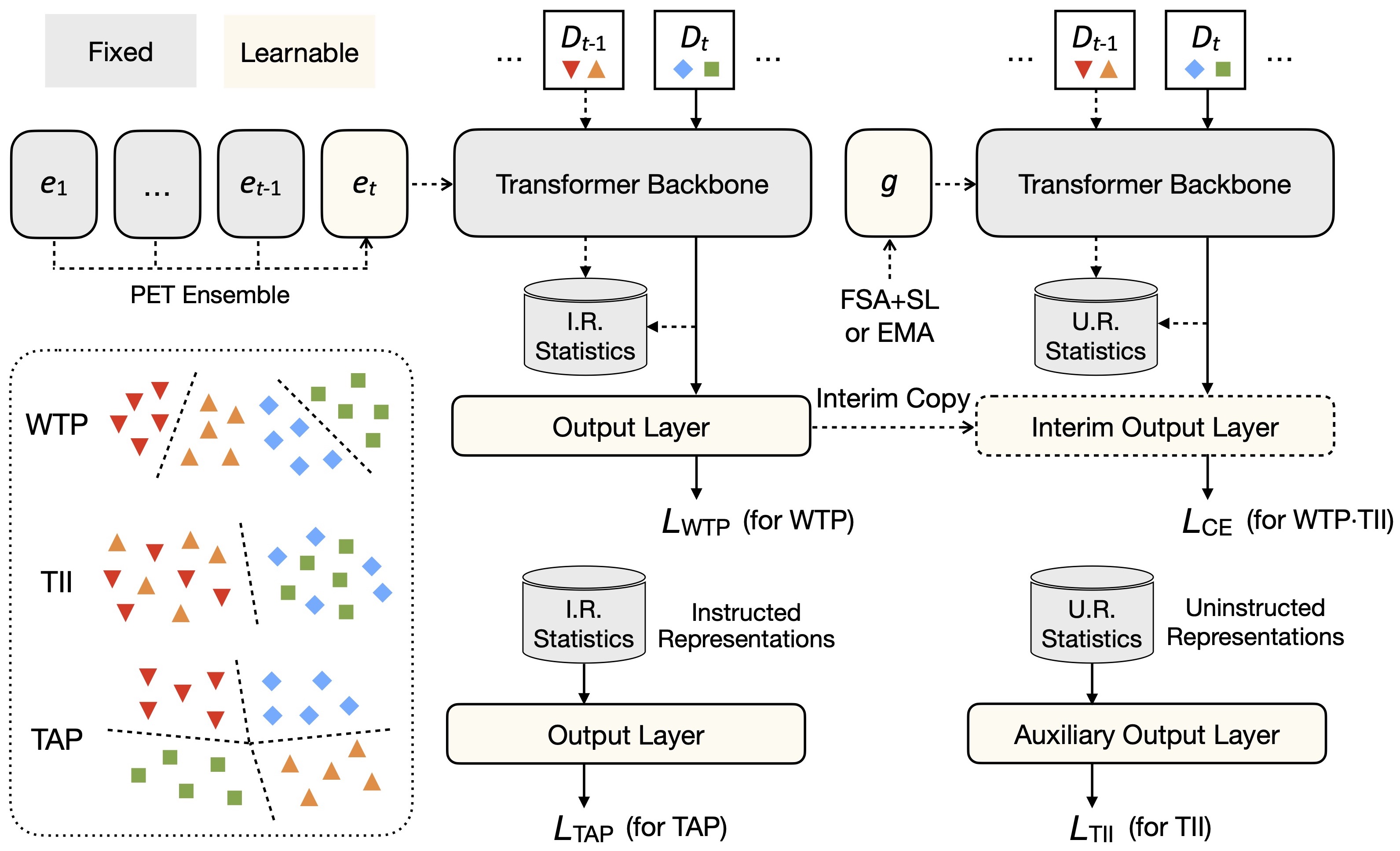
5.1 Optimization of Decomposed Objective
The principal concept behind HiDe-PET stems from two unique strengths of PTMs in CL: (1) the pre-trained representations can be effectively adapted to the distribution of target tasks through implementing PET techniques, and (2) the distribution of target tasks can be efficiently recovered through preserving statistical information of their pre-trained representations. The optimization of WTP, TII and TAP is described as below.
First, we improve WTP through incorporating task-specific knowledge from to capture the distribution of any task . Specifically, we employ multiple sets of task-specific parameters to instruct pre-trained representations, implemented via mainstream PET techniques. Their concrete forms can be defined as the prompt parameters for ProT and PreT, the projection matrices for Adapter and LoRA, etc. When learning task , we keep the previous parameters frozen to avoid catastrophic forgetting. In order to inherit knowledge obtained from CL, we employ a PET ensemble strategy that initializes with and optimizes with a weighted combination of all previous parameters , where is a hyperparameter that controls the strength of obtained knowledge that facilitates in learning task . For , we then optimize and via the cross-entropy (CE) loss:
| (16) |
Second, we improve TII and TAP through recovering the distributions of pre-trained representations to achieve the optimum over all tasks. Specifically, after learning each task , we collect the uninstructed and instructed representations, i.e., the backbone projection of with and , respectively. We then approximate the distributions of these representations with their statistical information for subsequent recovery. Taking classification tasks as an example, for each class and , we denote the approximated distributions of uninstructed and instructed representations as and , respectively.
For , we build an auxiliary output layer with parameters , learning the projection from uninstructed representations to the task identity:
| (17) |
where is a collection of uninstructed representations sampled in a class-balanced manner from for and . Therefore, we can determine the task identity via uninstructed representations and then obtain the corresponding instructed representations.
For , we use a similar strategy to optimize the final output layer with parameters , learning the projection from instructed representations to all observed classes:
| (18) |
where is a collection of instructed representations sampled in a class-balanced manner from for and .
Improvement of Uninstructed Representations: Since the TII process depends heavily on the uninstructed representations of collected from , its effectiveness tends to be severely affected by the pre-trained checkpoints and target tasks. This issue becomes particularly pronounced when implementing more advanced PET techniques, which better incorporate task-specific knowledge for WTP and are thus more sensitive to TII. To address this issue, we further deploy a set of task-shared parameters to improve TII in a task-agnostic manner. is implemented via mainstream PET techniques analogous to , while optimized with the cross-entropy to accumulate task-shared knowledge from sequentially arriving for , where is an interim copy of to avoid overwriting. We then use instead of to collect uninstructed representations222For naming consistency, we still use “uninstructed representations” to denote the projection of ., approximate each and optimize Eq. (17).
Notably, needs to overcome its own catastrophic forgetting that leads to not only the loss of information in representation learning but also the representation shift in subsequent recovery. There are many CL methods attempting to address this challenge [14, 34, 4], but their strategies remain sub-optimal in balancing sequentially arriving tasks (see Table IV). Here we propose a simple yet effective strategy by taking advantages of first-session adaptation (FSA) [34, 43] and slow learner (SL) [4, 14]. Specifically, we learn in the first task with a larger learning rate that is adequately strong for representation learning, and then in subsequent tasks with a smaller learning rate for further fine-tuning. In this way, task-shared knowledge is effectively incorporated into and accumulates over time.
Recovery of Task Distributions: Since the pre-trained representations are well-distributed in general, there are many feasible strategies to approximate and preserve their distributions and . The most straightforward option is to save randomly selected prototypes [44], yet not adequately employing the relationships between them. For classification tasks, the class-wise distribution is typically single-peaked and thus can be naturally approximated as a Gaussian with its mean and covariance [4, 13]. In order to reduce storage complexity, dedicated covariance matrices need to be further simplified for practical use, suffering from information loss to varying degrees [4, 34, 13]. Considering both storage efficiency and task-type generality, our default implementation is to obtain multiple representation centroids with -Nearest Neighbors (NNs) and add Gaussian noise to them. We also provide an empirical comparison of different implementations in Table V.
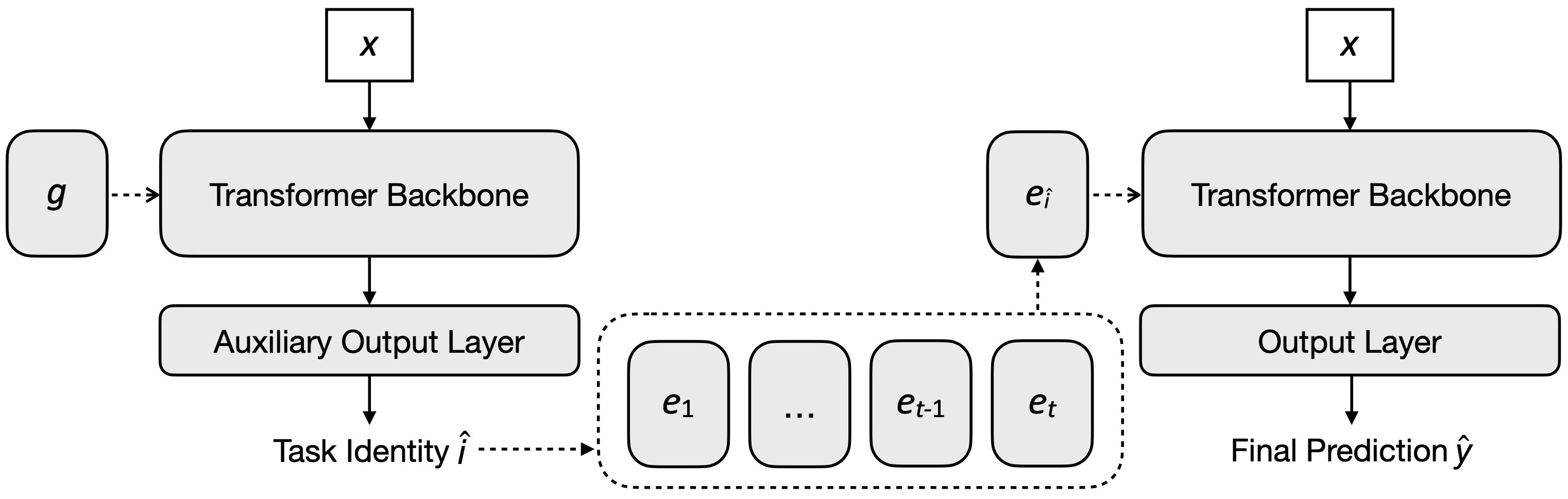
Overall, the entire HiDe-PET consists of two training stages (see Algorithm 1 and Fig. 3), corresponding to the pre-trained transformer backbone and the (auxiliary) output layer. At test time, HiDe-PET first predicts the task identity and then the overall class label (see Fig. 4). Compared to the backbone parameters , the trainable parameters , , and , as well as the representation recovery are all lightweight, thus ensuring resource efficiency.
5.2 Adaptive Knowledge Accumulation
Within HiDe-PET, the parallel organization of and facilitates the incorporation of task-specific and task-shared knowledge for many representative CL scenarios. In fact, the functions of and are usually not exclusive, depending on the similarity and dissimilarity between task distributions. Motivated by the intrinsic connection between TII and OOD detection in our theoretical analysis, we unify the task-specific and task-shared PET architectures with a hierarchy of expandable parameter sets (see Fig. 5), which may degenerate into either case of Sec. 5.1. We further explore a particular implementation of this hierarchy in order to accumulate knowledge adaptively from more pronounced distribution changes.
Let us assume the existence of multiple parameter sets that are implemented via mainstream PET techniques and are expanded or retrieved upon the input samples. For example, the sample elements of sequentially learning tasks have derived parameter sets . If the incoming is identified as OOD from the previously observed distributions of , it learns an expanded set of parameters through the task-specific loss , otherwise it retrieves and updates the most relevant one with through , where is an interim copy of the output layer parameters to avoid overwriting.
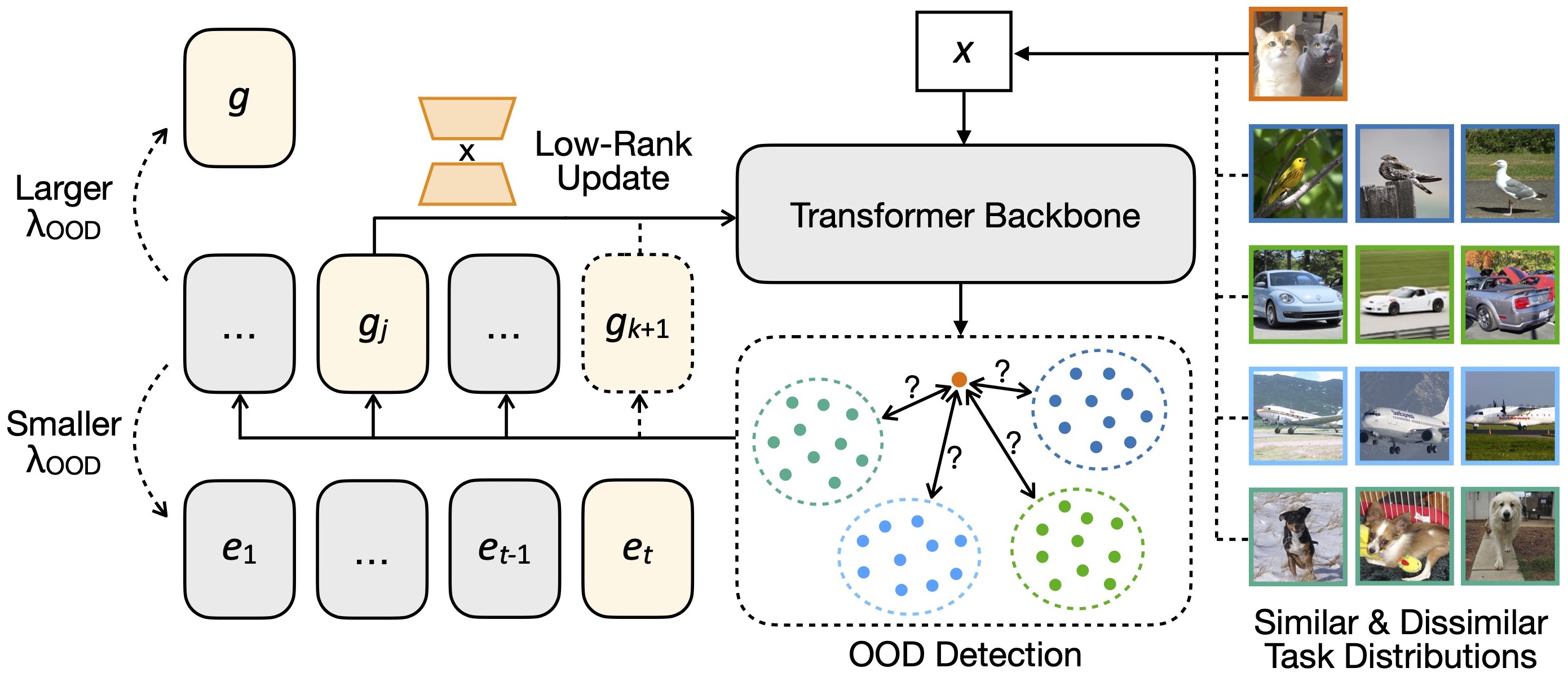
OOD Detection Strategy: Given that the previous are not available in CL to describe their distributions, we take inspirations from recent metric-based OOD detectors [45] and formulate an effective criterion with their uninstructed representations:
| (19) |
where for denotes the approximated distribution of uninstructed representations. It can be further specified as for classification tasks. denotes the OOD detection threshold. is the indicator function. measures the distance of task-wise distributions, which can be implemented via the average Euclidean distance between and . Consequently, if is identified as OOD for all tasks , then it will be associated with . Otherwise, it will retrieve the associated for corresponding to the majority of the most relevant task . To overcome catastrophic forgetting when updating , we employ the same strategy as for learning the task-shared parameters , e.g., a combination of FSA [43] and SL [4]. As a special case, we have if all input samples are identified as in-distribution, for which only exists and is equivalent to .
Connection of PET Architectures: We now extend the above discussion with the criterion of OOD detection in Eq. (19). Given a task sequence , using a larger would make and , while using a smaller would make and . Therefore, the representation learning of HiDe-PET in Sec. 5.1 is equivalent to a parallel combination of these two extreme conditions for TII and WTP, respectively. This is a reasonable choice as most CL benchmarks employ randomly split classes of the same dataset as the task sequence, i.e., there is no actual task structure.
Instead, Eq. (19) applies to the apparent similarity and dissimilarity between task distributions, which is more realistic in applications and enables adaptive knowledge accumulation from CL for enhanced utilization. Here we leverage the unique property of LoRA-based PET to construct a specialized implementation, serving as a plug-in module for Algorithm 1. Unlike the commonly-used Prompt-based PET that updates only attached tokens, the LoRA-based PET specifies as the approximated updates of , where the most relevant is selected and temporarily added to in CL. Therefore, the learning of subsequent tasks can be significantly improved from the accumulated knowledge and further contribute to it (see Fig. 5). Moreover, this allows for the flexible evolution of pre-trained knowledge with target tasks in a lifelong manner, deviating from the conventional practice of fixing it at the initial checkpoint.
6 Experiment
In this section, we perform extensive experiments to demonstrate the effectiveness and generality of our HiDe-PET. We first describe the experimental setups, and then present the experimental results with a comprehensive analysis.
6.1 Experimental Setup
To ensure the breadth and adequacy of the experiments, we consider a variety of CL benchmarks, pre-trained checkpoints, recent strong baselines, PET techniques and evaluation metrics. For the sake of comparison fairness, we follow the official implementations to reproduce all baselines.
| PTM | Method | Split CIFAR-100 | Split ImageNet-R | Split CUB-200 | Split Cars-196 | ||||
|---|---|---|---|---|---|---|---|---|---|
| FAA () | CAA () | FAA () | CAA () | FAA () | CAA () | FAA () | CAA () | ||
| Sup-21/1K | L2P [5] | 84.25 | 88.84 | 71.34 | 76.87 | 70.90 | 76.70 | 41.06 | 46.47 |
| DualPrompt [6] | 83.75 | 89.11 | 71.65 | 77.51 | 68.21 | 75.15 | 42.68 | 51.60 | |
| S-Prompt++ [7] | 82.41 | 87.68 | 71.15 | 77.16 | 68.01 | 75.04 | 39.62 | 47.85 | |
| CODA-Prompt [8] | 86.65 | 90.78 | 75.11 | 81.45 | 71.43 | 78.61 | 45.67 | 53.28 | |
| LAE-PreT [14] | 87.36 | 91.63 | 74.95 | 81.23 | 78.46 | 83.65 | 42.80 | 52.12 | |
| LAE-LoRA [14] | 88.38 | 92.45 | 76.27 | 82.99 | 80.02 | 84.47 | 50.90 | 58.38 | |
| LAE-Adapter [14] | 88.37 | 92.50 | 75.69 | 82.80 | 80.52 | 84.75 | 55.20 | 61.63 | |
| \cdashline2-10[2pt/2pt] | HiDe-PreT | 91.11 | 94.11 | 78.93 | 83.44 | 87.95 | 88.48 | 68.73 | 69.19 |
| HiDe-LoRA | 91.21 | 93.99 | 79.32 | 83.97 | 88.76 | 89.32 | 69.65 | 69.36 | |
| HiDe-Adapter | 91.23 | 94.26 | 78.65 | 83.55 | 88.49 | 89.17 | 70.98 | 71.31 | |
| iBOT-21K | L2P [5] | 79.32 | 85.13 | 61.31 | 70.05 | 45.93 | 56.02 | 45.25 | 45.75 |
| DualPrompt [6] | 78.17 | 85.15 | 61.42 | 70.06 | 41.46 | 54.57 | 34.61 | 42.28 | |
| S-Prompt++ [7] | 79.85 | 85.89 | 60.84 | 69.01 | 39.88 | 53.71 | 36.46 | 43.34 | |
| CODA-Prompt [8] | 81.58 | 87.36 | 67.15 | 76.54 | 47.79 | 59.24 | 39.50 | 43.32 | |
| LAE-PreT [14] | 82.22 | 88.05 | 65.85 | 75.34 | 45.83 | 60.31 | 49.14 | 52.59 | |
| LAE-LoRA [14] | 84.63 | 90.24 | 70.49 | 79.06 | 56.16 | 68.38 | 58.66 | 62.59 | |
| LAE-Adapter [14] | 84.68 | 90.31 | 69.93 | 79.14 | 58.04 | 70.01 | 61.76 | 65.61 | |
| \cdashline2-10[2pt/2pt] | HiDe-PreT | 88.13 | 92.17 | 70.57 | 77.89 | 70.72 | 74.09 | 63.98 | 64.18 |
| HiDe-LoRA | 89.72 | 93.34 | 74.46 | 80.89 | 76.10 | 79.99 | 67.73 | 68.64 | |
| HiDe-Adapter | 89.46 | 93.12 | 74.25 | 80.48 | 75.17 | 79.42 | 69.62 | 70.11 | |
| Sup-Weak | L2P [5] | 67.73 | 78.84 | 47.95 | 56.51 | 43.99 | 58.85 | 33.25 | 38.97 |
| DualPrompt [6] | 69.09 | 79.56 | 51.21 | 59.67 | 46.05 | 58.51 | 35.08 | 42.99 | |
| S-Prompt++ [7] | 71.05 | 81.34 | 47.87 | 56.62 | 42.91 | 57.70 | 36.20 | 43.35 | |
| CODA-Prompt [8] | 65.45 | 76.43 | 53.21 | 63.61 | 44.91 | 57.73 | 35.59 | 41.90 | |
| LAE-PreT [14] | 67.25 | 77.34 | 55.55 | 64.78 | 48.56 | 61.73 | 36.63 | 41.56 | |
| LAE-LoRA [14] | 68.43 | 78.57 | 57.40 | 66.84 | 48.99 | 61.50 | 35.35 | 39.93 | |
| LAE-Adapter [14] | 68.55 | 78.59 | 57.92 | 67.79 | 49.79 | 62.25 | 37.17 | 41.72 | |
| \cdashline2-10[2pt/2pt] | HiDe-PreT | 77.65 | 85.14 | 57.98 | 65.79 | 65.03 | 71.63 | 52.89 | 55.09 |
| HiDe-LoRA | 77.46 | 84.89 | 59.40 | 67.05 | 66.84 | 71.91 | 52.61 | 54.78 | |
| HiDe-Adapter | 76.71 | 84.55 | 58.94 | 67.53 | 66.26 | 71.24 | 54.38 | 56.23 | |
Benchmark: We focus on four datasets that are widely used in previous work to evaluate CL [5, 6, 8, 14, 4], and split each into 10 target tasks of disjoint classes for CIL experiments. The first two are general datasets, such as CIFAR-100 [46] of 100-class small-scale images that are common objects in the real world and ImageNet-R [47] of 200-class large-scale images that are hard examples of ImageNet-21K [48] or newly collected examples of different styles. The latter two are fine-grained datasets, such as CUB-200 [49] of 200-class bird images and Cars-196 [50] of 196-type car images. We mainly consider three representative pre-trained checkpoints that differ in paradigm and dataset, including Sup-21/1K, iBOT-21K and Sup-Weak. Specifically, Sup-21/1K [8] is essentially a supervised checkpoint that performs self-supervised learning on ImageNet-21K and then supervised fine-tuning on ImageNet-1K. iBOT-21K [51] is a self-supervised checkpoint that currently achieves the first-place classification performance for self-supervised learning on ImageNet-21K. Sup-Weak [52] is a supervised checkpoint on a subset of ImageNet-1K, in which 389 similar classes to subsequent CL are intentionally removed.
Baseline: We compare our HiDe-PET with a range of recent strong baselines as described in Sec. 3.3, including L2P [5], DualPrompt [6], S-Prompt [7], CODA-Prompt [8] and LAE [14]. In brief, these baselines cover different PET architectures, but mainly target the Prompt-based PET. LAE [14] is the most recent baseline among them, and is also the most relevant one to ours as it applies to a variety of mainstream PET techniques. Similar to the previous work [13], we modify the implementation of S-Prompt [7] by inserting task-specific prompts into multiple MSA layers in a PreT manner and using a single-head output layer, in order to evaluate the impact of PET architecture and better adapt to the CIL experiments. The modified S-Prompt is referred to as S-Prompt++. Following LAE [14], we consider three kinds of mainstream PET techniques in our HiDe-PET and our preliminary version [13], including PreT [10], LoRA [12] and Adapter [11].
Evaluation: We use to denote the prediction accuracy on task after learning task (with single-head evaluation for CIL), and define the average accuracy of all seen tasks as . After learning all tasks, we report both the final average accuracy that serves as the primary metric to evaluate CL performance, and the cumulative average accuracy that further reflects the historical performance. Moreover, we evaluate the behaviors of different PET techniques with the average learning accuracy for learning plasticity and the final forgetting measure for memory stability, as well as evaluate the TII performance in our HiDe-PET.
Implementation: We follow similar implementations as previous work.333The training regime and supervised checkpoints are identical to those in CODA-Prompt [8], which are slightly different from those in our preliminary version [13] and lead to some performance differences. Specifically, we employ a pre-trained ViT-B/16 backbone with an Adam optimizer (, ), a batch size of 128, and a cosine-decaying learning rate of 0.001. We train Split CIFAR-100 for 20 epochs and other benchmarks for 50 epochs to ensure convergence on each task. The image inputs are resized to and normalized to . The PET architecture of each baseline is also similar to its original paper, which has been shown to yield strong performance. Specifically, L2P [5] is implemented with the prompt pool size , the prompt length and the Top-5 keys. DualPrompt [6] is implemented with the prompt length of task-shared prompts inserted into layers 1-2 and the prompt length of task-specific prompts inserted into layers 3-5. S-Prompt++ [7] is implemented similarly to DualPrompt but replaces all task-shared prompts with task-specific prompts, inserted into layers 1-5 with the prompt length . CODA-Prompt [8] is implemented with the prompt pool size and the prompt length , inserted into layers 1-5. LAE [14] and our HiDe-PET are implemented with the prompt length for PreT, and the low-dimension bottleneck for Adapter and LoRA, inserted into layers 1-5. We insert the Adapter modules in both sequential and parallel manners, while employ LoRA to update both and . Therefore, the extra parameter costs of PreT, Adapter and LoRA are identical [14]. Note that, our HiDe-PET and our preliminary version [13] adopt a similar PET architecture as S-Prompt++, but replace the task-specific keys with an auxiliary output layer to predict the task identity and further preserve statistical information of pre-trained representations.444We consider a lightweight implementation in terms of the auxiliary output layer and representation recovery, which slightly compromise the performance but largely improve resource efficiency.
6.2 Experimental Result
Now we present the results of our empirical investigation, including the overall performance of all methods, an ablation study of the three hierarchical components, the distinct impacts of implementation strategy, PET technique and PET architecture, as well as the adaptive knowledge accumulation over similar and dissimilar tasks.
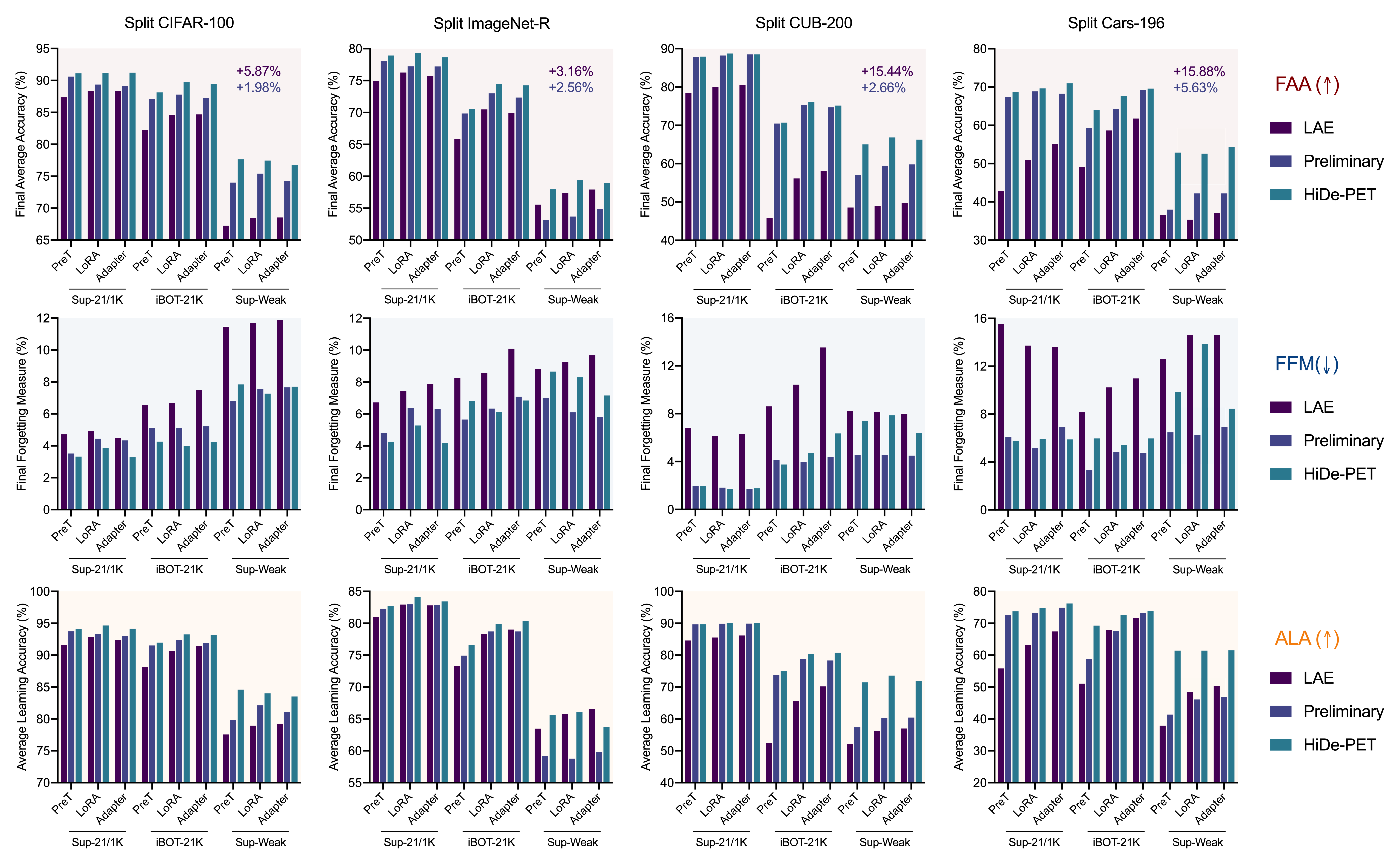
Overall Performance: Table I summarizes the results of all methods across various pre-trained checkpoints and CL benchmarks. It can be seen that our HiDe-PET implemented with three mainstream PET techniques achieves consistently the highest performance, and the performance lead tends to be more pronounced under the more challenging scenarios. Specifically, the performance of all methods is affected to varying degrees when considering fine-grained tasks (i.e., CUB-200 and Cars-196) and weakened pre-training in terms of self-supervised paradigm (i.e., iBOT-21K) and reduced pre-training samples (i.e., Sup-Weak). Among these competitors, the sub-optimality of Prompt-based PET in CL is clearly exposed, which underperforms LoRA/Adapter-based PET within and across methods. The LoRA/Adapter version of LAE [14] is the strongest competitor but still severely affected by the double challenges of pre-trained checkpoints and CL benchmarks. In contrast, our HiDe-PET adapts to them effectively with strong generality.
| Setup | Method | Split ImageNet-R | Split Cars-196 | ||
|---|---|---|---|---|---|
| FAA () | CAA () | FAA () | CAA () | ||
| DINOv2 LVD-142M | LAE-PreT [14] | 78.98 | 85.26 | 45.53 | 58.19 |
| LAE-LoRA [14] | 79.13 | 86.04 | 52.48 | 61.92 | |
| LAE-Adapter [14] | 77.43 | 83.98 | 57.30 | 67.08 | |
| \cdashline2-6[2pt/2pt] | HiDe-PreT | 85.68 | 87.70 | 85.65 | 82.20 |
| HiDe-LoRA | 86.26 | 89.14 | 85.53 | 84.95 | |
| HiDe-Adapter | 86.03 | 90.05 | 83.48 | 84.11 | |
It is noteworthy that self-supervised pre-training is often considered more practical than supervised pre-training, owing to the expense of annotating massive pre-training samples [13, 4]. Meanwhile, Sup-Weak avoids potential overlap between PTMs and target tasks, providing a more restrictive scenario for CL [52]. Sup-Weak is also more analogous to the widely used setting of CIL experiments in literature, i.e., the model first learns half of the classes and then learns the other classes in multiple incremental phases, where the baselines of Prompt-based PET have been shown to perform poorly on it [54]. These considerations underscore more profound advantages of our HiDe-PET in CL. We further evaluate CL under DINOv2 of ViT-B/14 [53], a state-of-the-art self-supervised checkpoint that largely improves iBOT-21K with additional training tricks and more pre-training data, and HiDe-PET consistently outperforms LAE [14] by a wide margin (see Table II).
| Setup | Method | Split ImageNet-R | Split Cars-196 | ||
|---|---|---|---|---|---|
| FAA () | CAA () | FAA () | CAA () | ||
| Sup-21/1K PreT | Naive | 69.77 | 76.36 | 46.08 | 53.59 |
| WTP | 73.01 | 78.20 | 48.23 | 54.11 | |
| WTP+TII | 75.68 | 80.95 | 52.89 | 54.18 | |
| WTP+TAP | 78.06 | 82.69 | 61.38 | 64.46 | |
| WTP+TII+TAP | 78.93 | 83.44 | 68.73 | 69.19 | |
| Sup-21/1K LoRA | Naive | 74.54 | 80.66 | 45.39 | 54.28 |
| WTP | 75.59 | 81.31 | 48.01 | 53.85 | |
| WTP+TII | 76.03 | 81.69 | 49.62 | 57.29 | |
| WTP+TAP | 78.33 | 83.68 | 63.28 | 65.87 | |
| WTP+TII+TAP | 79.32 | 83.97 | 69.65 | 69.36 | |
| Sup-21/1K Adapter | Naive | 75.17 | 81.46 | 47.20 | 55.69 |
| WTP | 76.10 | 82.23 | 53.12 | 59.35 | |
| WTP+TII | 76.80 | 82.60 | 55.93 | 60.89 | |
| WTP+TAP | 76.98 | 82.73 | 64.65 | 67.38 | |
| WTP+TII+TAP | 78.65 | 83.55 | 70.98 | 71.31 | |
| iBOT-21K PreT | Naive | 63.78 | 73.47 | 41.54 | 47.96 |
| WTP | 64.98 | 73.54 | 52.99 | 56.31 | |
| WTP+TII | 66.33 | 74.98 | 53.89 | 57.01 | |
| WTP+TAP | 69.84 | 77.02 | 59.75 | 61.28 | |
| WTP+TII+TAP | 70.57 | 77.89 | 63.98 | 64.18 | |
| iBOT-21K LoRA | Naive | 67.07 | 77.07 | 53.13 | 59.07 |
| WTP | 68.06 | 77.39 | 56.03 | 61.18 | |
| WTP+TII | 68.54 | 77.60 | 59.48 | 63.36 | |
| WTP+TAP | 72.60 | 79.95 | 61.50 | 64.88 | |
| WTP+TII+TAP | 74.46 | 80.89 | 67.73 | 68.64 | |
| iBOT-21K Adapter | Naive | 68.17 | 77.57 | 53.58 | 59.69 |
| WTP | 69.11 | 77.29 | 57.71 | 62.21 | |
| WTP+TII | 69.65 | 77.90 | 62.12 | 65.66 | |
| WTP+TAP | 71.32 | 79.17 | 62.78 | 65.59 | |
| WTP+TII+TAP | 74.25 | 80.48 | 69.62 | 70.11 | |
Ablation Study: Table III presents an ablation study to validate the effectiveness of optimizing the three hierarchical components in HiDe-PET. Specifically, we progressively incorporate the designs of within-task prediction (WTP), task-identity inference (TII) and task-adaptive prediction (TAP) on the top of a naive architecture, which consists of only task-specific parameters implemented via mainstream PET techniques. In general, the optimization of each component all contributes to the strong performance of HiDe-PET. Although their contributions are relatively comparable under supervised pre-training and general tasks, the improvement of TAP becomes more significant under self-supervised pre-training and fine-grained tasks, demonstrating the necessity of TAP within the CL objective. Besides, the improvement of TII often becomes more apparent with WTP+TAP rather than with WTP alone, suggesting that WTP, TII and TAP operate in concert rather than in isolation.
Implementation Strategy: Now we evaluate the implementation strategy of task-shared parameters and representation recovery, which are both important for the optimization of our HiDe-PET and potentially shared by many recent methods. In contrast to task-specific parameters discussed above, task-shared parameters aim to improve pre-trained representations in a task-agnostic manner, demanding effective strategies to mitigate catastrophic forgetting. Various strategies have been employed in previous work, including (1) fix-and-tuning (F&T) [14], which updates the output layer with frozen in earlier epochs and then updates for representation learning in later epochs; (2) first-session adaptation (FSA) [43], which updates for representation learning exclusively from the first task and then fixes in subsequent tasks; (3) slow learner (SL) [4], which reduces the learning rate of in all tasks; and (4) exponential moving average (EMA) [14], which employs an interim copy of to learn each task and then updates with a small momentum.
| Setup | Method | Split ImageNet-R | Split Cars-196 | ||
|---|---|---|---|---|---|
| TII () | FAA-U () | TII () | FAA-U () | ||
| Sup-21/1K PreT | F&T [14] | 76.45 | 74.50 | 59.46 | 52.94 |
| FSA [43] | 75.85 | 73.76 | 68.42 | 58.85 | |
| SL [4] | 77.06 | 74.68 | 66.13 | 56.67 | |
| EMA [14] | 76.17 | 73.93 | 68.35 | 58.99 | |
| FSA+SL | 77.15 | 75.02 | 69.43 | 59.32 | |
| Sup-21/1K LoRA | F&T [14] | 71.90 | 69.85 | 64.65 | 57.68 |
| FSA [43] | 77.74 | 75.72 | 70.90 | 61.37 | |
| SL [4] | 77.26 | 75.41 | 68.68 | 59.33 | |
| EMA [14] | 78.33 | 76.51 | 71.20 | 61.87 | |
| FSA+SL | 78.43 | 76.35 | 71.92 | 62.89 | |
| Sup-21/1K Adapter | F&T [14] | 75.45 | 73.88 | 57.16 | 52.11 |
| FSA [43] | 78.15 | 76.30 | 72.75 | 63.51 | |
| SL [4] | 77.52 | 75.98 | 63.20 | 56.16 | |
| EMA [14] | 78.29 | 76.30 | 73.59 | 64.46 | |
| FSA+SL | 80.09 | 78.52 | 73.71 | 64.93 | |
However, most of these strategies have their own limitations. Both F&T and SL impose restrictions on the extent of updates, sacrificing the effectiveness of representation learning and suffering from potential representation shifts in subsequent recovery. FSA adeptly integrates knowledge from the first task and completely avoids representation shifts, but is unable to perform subsequent representation learning. Considering their complementary properties, we propose a simple but effective strategy that employs FSA for learning the first task and SL for learning subsequent tasks, which clearly outperforms other strategies (see Table IV). Notably, EMA can be seen as a coarse implementation of FSA+SL and indeed achieves the second-highest performance. Therefore, the task-shared parameters in HiDe-PET may also be implemented with EMA by updating from each for , offering a slight compromise in performance but reducing a half of the training cost.
On the other hand, we evaluate effective strategies for representation recovery. For classification tasks, the pre-trained representations of each class tend to be single-peaked and therefore can be modeled as a Gaussian with dedicated mean and covariance. Although the covariance achieves considerable performance as shown in Table V, it requires a storage complexity for embedding dimension , which is comparable to the MSA layer of the backbone. There are three alternatives that reduces the storage complexity to , such as simplifying the covariance to variance, preserving randomly selected prototypes, and obtaining multiple representation centroids with NNs. Among them, the multi-centroid demonstrates superior performance and is applicable to different task types, which therefore becomes our default implementation. Interestingly, the variance achieves comparable performance as the covariance and the multi-centroid under general tasks (i.e., Split ImageNet-R) and supervised pre-training (i.e., Sup-21/1K) while requires negligible parameter costs. This further strengthens the advantages of our HiDe-PET in such scenarios targeted by previous work.
Besides, we note that the proposed PET ensemble of task-specific parameters ensures efficiency and scalability due to the lightweight nature of mainstream PET techniques. As described in Sec. 3.2, ProT and PreT employ with , while Adapter and LoRA employ and with . In our default implementation, the additional parameter costs of PreT, Adapter, and LoRA for learning each task are kept the same, i.e., for PreT, and for Adapter and LoRA, inserted into layers 1-5. Therefore, the additional parameter cost is 0.073M with embedding dimension . Even though the model needs to learn a sufficiently long task sequence, e.g., 100 tasks, the total parameter cost is only 7.3M (around 8.5% of the ViT-B/16 backbone).
PET Technique: While mainstream PET techniques universally amount to modulating specific hidden states of the PTMs [33], their potential differences in CL are noteworthy. As mentioned above, Prompt-based PET usually lags behind LoRA/Adapter-based PET for both LAE and HiDe-PET (see Table I and Fig. 6). The performance gap tends to be more pronounced under the more challenging scenarios of pre-trained checkpoints and CL benchmarks. A major cause is the limited capacity of Prompt-based PET (i.e., updating attached tokens) in representation learning compared to LoRA/Adapter-based PET (i.e., updating network parameters), especially when handling self-supervised pre-training [36] and fine-grained tasks [40], as validated in our results on both task-specific parameters (see WTP in Table III) and task-shared parameters (see FSA+SL in Table IV).
Beyond the overall performance, the choice of PET technique also exerts distinct influences on the three hierarchical components. Compared to Prompt-based PET, LoRA/Adapter-based PET excels in WTP performance through more effectively incorporating task-specific knowledge, but reveals a heightened sensitivity to TII performance, manifested in the errors of predicting an inappropriate set of task-specific parameters (i.e., mismatched representations for each task lead to more errors in the final prediction). This effect is further compensated by learning a robust TAP function. As shown in Table III, the effectiveness of TII is remarkably pronounced when coupled with WTP+TAP for LoRA/Adapter-based PET, whereas diminishes for either Prompt-based PET or WTP alone. Moreover, our HiDe-PET outperforms its preliminary version [13] especially in LoRA/Adapter-based PET and the more challenging scenarios (see Fig. 6), thanks to the improved TII performance with task-shared parameters.
| Setup | Method | Split ImageNet-R | Split Cars-196 | ||
|---|---|---|---|---|---|
| FAA () | #Param () | FAA () | #Param () | ||
| Sup-21/1K PreT | No Recovery | 75.68 | 0 | 52.89 | 0 |
| Prototype | 76.88 | 10 | 62.65 | 10 | |
| Variance | 77.54 | 1 | 57.04 | 1 | |
| Covariance | 77.58 | 73.14 | |||
| Multi-Centroid | 78.93 | 9.5 | 68.73 | 8.0 | |
| iBOT-21K PreT | No Recovery | 58.88 | 0 | 41.89 | 0 |
| Prototype | 67.08 | 10 | 46.34 | 10 | |
| Variance | 70.55 | 1 | 48.27 | 1 | |
| Covariance | 68.85 | 66.42 | |||
| Multi-Centroid | 70.57 | 9.5 | 63.98 | 8.7 | |
| Sup-Weak PreT | No Recovery | 54.63 | 0 | 44.35 | 0 |
| Prototype | 55.06 | 10 | 46.91 | 10 | |
| Variance | 55.49 | 1 | 47.77 | 1 | |
| Covariance | 57.46 | 56.06 | |||
| Multi-Centroid | 57.98 | 9.1 | 52.89 | 8.7 | |
| PTM | Method | Split Dogs-120 | Split CUB-200 | Split Cars-196 | Split Aircraft-102 | CL of Mixture | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Full () | Few () | Full () | Few () | Full () | Few () | Full () | Few () | FAA () | CAA () | ||
| Sup-21/1K | w/o AKA | 92.32 | 88.36 | 89.51 | 81.26 | 83.77 | 57.04 | 77.98 | 55.56 | 77.32 | 81.14 |
| w/ AKA | 92.50 | 88.92 | 91.39 | 84.91 | 89.46 | 64.30 | 83.38 | 62.37 | 83.27 | 86.78 | |
| iBOT-21K | w/o AKA | 81.70 | 54.08 | 74.66 | 45.79 | 79.27 | 38.15 | 79.24 | 53.97 | 68.38 | 74.57 |
| w/ AKA | 84.41 | 65.10 | 82.95 | 62.30 | 88.32 | 56.12 | 85.06 | 62.76 | 74.99 | 81.55 | |
| Sup-Weak | w/o AKA | 88.14 | 80.88 | 71.10 | 47.46 | 59.03 | 36.51 | 62.68 | 35.78 | 53.23 | 58.54 |
| w/ AKA | 88.17 | 81.38 | 77.50 | 56.92 | 77.42 | 50.37 | 72.64 | 46.32 | 65.48 | 70.41 | |
PET Architecture: The generality of our HiDe-PET is also reflected in its PET architecture, which strategically exploits both task-specific and task-shared parameters for representation learning. These two kinds of parameters are used to acquire knowledge with different levels of differentiation and need to overcome their respective challenges as described in Sec. 3.3. Within HiDe-PET, they both contribute to the outstanding performance in Table I and complement each other (see WTP in Table III and FSA+SL in Table IV). In contrast, our preliminary version [13] and LAE [14] exclusively engage either task-specific or task-shared parameters, missing out on fully harnessing the benefits of PTMs and PET. We further present an extensive comparison of our HiDe-PET, our preliminary version and LAE in terms of the overall performance, memory stability and learning plasticity, so as to better demonstrate the respective contributions of different PET architectures (see Fig. 6). It can be seen that the use of task-shared parameters in HiDe-PET can largely improve ALA of new tasks and FAA of all tasks, but probably results in a slight increase in FFM of old tasks due to the ongoing updates in our default implementation (i.e., FSA+SL). This trend is comparably more pronounced under Sup-Weak that is more demanding to update the pre-trained representations, with FAA, ALA and FFM increasing on average by 6.83%, 9.64% and 2.21%, respectively. We further evaluate alternative implementations of task-shared parameters in Table IV, where FSA has no extra forgetting but performs less well than FSA+SL. The users may select appropriate implementations according to their customised requirements of evaluation metrics.
It is noteworthy that previous work such as L2P [5] and DualPrompt [6] also explicitly or implicitly exploit both task-specific and task-shared prompts, but in a sequential manner to instruct representation learning of each task (corresponding to WTP in our framework). In contrast, our HiDe-PET optimizes these two kinds of parameters in a parallel manner to improve the three hierarchical components, allowing for a more adequate differentiation of the acquired knowledge. Interesting, using only task-shared parameters coupled with representation recovery within HiDe-PET (i.e., FSA+SL in Table IV) has already achieved better performance than these methods (see Sec. 7 for a conceptual explanation), serving as a strong baseline to evaluate current progress. The inherent connections of task-specific and task-shared parameters will be further explored below with a PET hierarchy inspired by OOD detection.
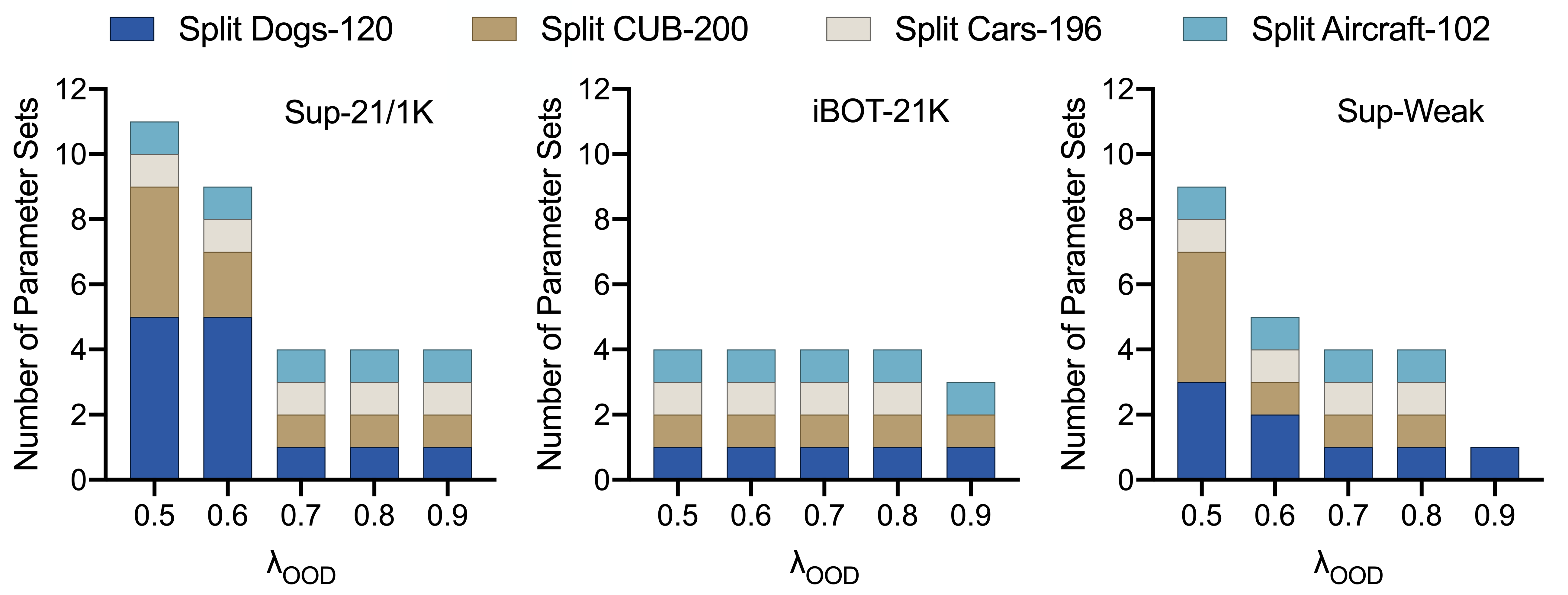
Adaptive Knowledge Accumulation: As analyzed in Sec. 5.2, the use of and can be seen as a special case tailored for target tasks randomly split from the same dataset, i.e., there is no actual task structure. When considering more realistic CL scenarios with apparent similarity and dissimilarity between task distributions, we devise a hierarchy of expandable parameter sets upon OOD detection to achieve adaptive knowledge accumulation (AKA), and focus on the LoRA-based PET to examine if the pre-trained knowledge can evolve flexibly with target tasks in CL. Here we construct such scenario with the two fine-grained datasets (i.e., CUB-200 [49] and Cars-196 [50]) and another two (i.e., Dogs-120 [55] and Aircraft-102 [56]), which cover both natural and artificial objects. Each dataset is randomly split into 10 tasks. We collect 5 tasks per dataset and mix then as a task sequence (20 tasks in total) for CL, while leaving the rest 5 tasks per dataset for validation.
In CL, the OOD detection threshold determines the expansion of parameter sets. As shown in Fig. 7, using a larger tends to expand fewer parameter sets, and vice versa. In particular, the choice of is relatively insensitive and can consistently construct one parameter set for each dataset (with or ) under different pre-trained checkpoints. Then we validate the effectiveness of AKA in Table VI. Inspired by a recent work [57], we evaluate the improvements of pre-trained knowledge through the average accuracy of learning the validation tasks under large-shot or few-shot setting. Through selecting the most relevant and adding it to , the pre-trained backbone is able to learn each task more effectively. With the improved , the overall performance of CL (i.e., FAA and CAA) for the mixed task sequence is also significantly enhanced.
Interestingly, the idea of updating the pre-trained backbone with a mixture of LoRA experts [58] has been shown effective to accumulate knowledge from multi-task learning, which is consistent with our results. In contrast, the design of the OOD detection, FSA+SL, and representation recovery enables our HiDe-PET to achieve this purpose in a lifelong manner. Besides, our HiDe-PET can also adapt to task-agnostic CL [3] through expanding upon the OOD detection. We leave it as a further work.
7 Discussion and Conclusion
In this work, we present a unified framework for CL with PTMs and PET, in order to advance this direction with improved effectiveness and generality. Our framework features a profound integration of theoretical and empirical insights, a broad coverage of relevant techniques, as well as a robust adaptation to different scenarios. Considering the particular impact of pre-trained knowledge on CL, we decompose the CL objective into three hierarchical components, i.e., WTP, TII and TAP, and devise an innovative approach to explicitly optimize them with mainstream PET techniques. During the optimization process, pre-trained representations are effectively instructed via task-specific and task-shared PET architectures, and are efficiently recovered through preserving their statistical information.
Our framework allows for a comprehensive evaluation of various technical elements inherent in CL with PTMs and PET. Through an extensive empirical investigation, we demonstrate the better performance of LoRA/Adapter-based PET over Prompt-based PET within both task-specific and task-shared PET architectures, which tends to be more evident under the more challenging scenarios in terms of pre-trained checkpoints and CL benchmarks. We also unravel the distinct behaviors of different PET techniques in response to the three hierarchical components, as well as the respective challenges and complementary effects of different PET architectures. These technical elements are potentially shared by many recent methods, making it possible to dissect their specific implementations and incorporate the most appropriate ones. Owning to the above extensive explorations, our approach achieves remarkably superior performance across various CL scenarios over a wide range of recent strong baselines.
Intriguingly, the correspondence of our approach to the three hierarchical components suggests a more profound connection between existing methods. As discussed in Sec. 3.3, the use of task-specific parameters [5, 6, 8, 7, 13] necessitates learning to predict their identities, equivalent to optimizing the decomposed WTP performance and TII performance . In contrast, the use of task-shared parameters [5, 6, 34, 14, 4] needs to overcome catastrophic forgetting, equivalent to optimizing the pre-decomposed performance . On the top of representation learning, the use of representation recovery [34, 4, 44] to rectify the output layer further improves the TAP performance . This connection is summarized by the multi-objective optimization problem in Eq. (32), and also demonstrates why our approach clearly outperforms other baselines and why the use of only task-shared parameters and representation recovery (i.e., FSA+SL in Table IV) is powerful enough. Subsequent efforts in CL with PTMs and PET could employ this as a theoretical reference to develop more advanced methods.
Moreover, the hierarchical decomposition along with the design of our approach showcase a close relationship with the mechanisms of robust biological CL. In the mammalian brain, the memory of an experience is consolidated with the interplay of hippocampus and neocortex, known as the complementary learning system theory [59, 60] that has been widely used to inspire CL of AI. The hippocampus-depended and neocortex-depended memories tend to be more specific and more generalized, respectively [61, 62], and the retrieval of these two memory paths is adaptively switched from the concrete scenarios [63]. Within hippocampus, the activation of distinct populations of memory cells also undergoes adaptive switching [64], and the neural representations of previous experiences are frequently recovered [65]. The entire process is consistent with the parallel organization of task-specific and task-shared parameters, the exclusive selection of the former and the representation recovery of task distributions.
In the era of large-scale PTMs, we would emphasize the pressing need for these adaptive algorithms that are designed with machine learning fundamentals and real-world considerations. By leveraging the power of PTMs and the adaptability of CL, we can customize solutions to address the unique challenges posed by specific domains, and envision extending our approach to numerous areas such as healthcare, robotics and industrial manufacturing. Such an elevated goal requires extending the target of CL from homogeneous to heterogeneous tasks, which also provides novel opportunities to explore generalizable knowledge behind them. Taken together, we expect this work to not only facilitate direct applications but also set the stage for the robustness, adaptability and reliability of future AI systems, as a general purpose of CL research.
Acknowledgments
This work was supported by the NSFC Projects (Nos. 62406160, 62350080, 62106123, 62106120, 92370124, 92248303), Beijing Natural Science Foundation L247011, Tsinghua Institute for Guo Qiang, and the High Performance Computing Center, Tsinghua University. L.W. is also supported by the Postdoctoral Fellowship Program of CPSF under Grant Number GZB20230350 and the Shuimu Tsinghua Scholar. J.Z. is also supported by the XPlorer Prize.
References
- [1] V. V. Ramasesh, A. Lewkowycz, and E. Dyer, “Effect of scale on catastrophic forgetting in neural networks,” in ICLR, 2021.
- [2] S. V. Mehta et al., “An empirical investigation of the role of pre-training in lifelong learning,” arXiv preprint arXiv:2112.09153, 2021.
- [3] L. Wang et al., “A comprehensive survey of continual learning: Theory, method and application,” IEEE TPAMI, 2024.
- [4] G. Zhang et al., “Slca: Slow learner with classifier alignment for continual learning on a pre-trained model,” in ICCV, 2023.
- [5] Z. Wang et al., “Learning to prompt for continual learning,” in CVPR, 2022.
- [6] Z. Wang et al., “Dualprompt: Complementary prompting for rehearsal-free continual learning,” in ECCV, 2022.
- [7] Y. Wang, Z. Huang, and X. Hong, “S-prompts learning with pre-trained transformers: An occam’s razor for domain incremental learning,” NeurIPS, 2022.
- [8] J. S. Smith et al., “Coda-prompt: Continual decomposed attention-based prompting for rehearsal-free continual learning,” in CVPR, 2023.
- [9] B. Lester, R. Al-Rfou, and N. Constant, “The power of scale for parameter-efficient prompt tuning,” in EMNLP, 2021.
- [10] X. L. Li and P. Liang, “Prefix-tuning: Optimizing continuous prompts for generation,” in ACL-IJCNLP, 2021.
- [11] S.-A. Rebuffi, H. Bilen, and A. Vedaldi, “Learning multiple visual domains with residual adapters,” NeurIPS, 2017.
- [12] E. J. Hu et al., “Lora: Low-rank adaptation of large language models,” arXiv preprint arXiv:2106.09685, 2021.
- [13] L. Wang et al., “Hierarchical decomposition of prompt-based continual learning: Rethinking obscured sub-optimality,” NeurIPS, 2023.
- [14] Q. Gao et al., “A unified continual learning framework with general parameter-efficient tuning,” in ICCV, 2023.
- [15] G. I. Parisi et al., “Continual lifelong learning with neural networks: A review,” Neur. Netw., 2019.
- [16] J. Kirkpatrick et al., “Overcoming catastrophic forgetting in neural networks,” PNAS, 2017.
- [17] L. Wang et al., “Afec: Active forgetting of negative transfer in continual learning,” NeurIPS, 2021.
- [18] R. Aljundi et al., “Memory aware synapses: Learning what (not) to forget,” in ECCV, 2018.
- [19] S.-A. Rebuffi et al., “icarl: Incremental classifier and representation learning,” in CVPR, 2017.
- [20] H. Shin et al., “Continual learning with deep generative replay,” NeurIPS, 2017.
- [21] L. Wang et al., “Memory replay with data compression for continual learning,” in ICLR, 2021.
- [22] Q. Pham, C. Liu, and S. Hoi, “Dualnet: Continual learning, fast and slow,” NeurIPS, 2021.
- [23] H. Cha, J. Lee, and J. Shin, “Co2l: Contrastive continual learning,” in ICCV, 2021.
- [24] O. Ostapenko et al., “Foundational models for continual learning: An empirical study of latent replay,” in CoLLAs, 2022.
- [25] D. Lopez-Paz and M. Ranzato, “Gradient episodic memory for continual learning,” NeurIPS, 2017.
- [26] S. Wang et al., “Training networks in null space of feature covariance for continual learning,” in CVPR, 2021.
- [27] G. Saha, I. Garg, and K. Roy, “Gradient projection memory for continual learning,” in ICLR, 2020.
- [28] J. Serra et al., “Overcoming catastrophic forgetting with hard attention to the task,” in ICML, 2018.
- [29] L. Wang et al., “Coscl: Cooperation of small continual learners is stronger than a big one,” in ECCV, 2022.
- [30] L. Wang et al., “Incorporating neuro-inspired adaptability for continual learning in artificial intelligence,” Nat. Mach. Intell., 2023.
- [31] Y. Wu et al., “Large scale incremental learning,” in CVPR, 2019.
- [32] J. Knoblauch, H. Husain, and T. Diethe, “Optimal continual learning has perfect memory and is np-hard,” in ICML, 2020.
- [33] J. He et al., “Towards a unified view of parameter-efficient transfer learning,” in ICLR, 2021.
- [34] M. D. McDonnell et al., “Ranpac: Random projections and pre-trained models for continual learning,” NeurIPS, 2023.
- [35] M. Jia et al., “Visual prompt tuning,” in ECCV, 2022.
- [36] S. Yoo et al., “Improving visual prompt tuning for self-supervised vision transformers,” in ICML, 2023.
- [37] G. M. Van de Ven and A. S. Tolias, “Three scenarios for continual learning,” arXiv preprint arXiv:1904.07734, 2019.
- [38] A. Vaswani et al., “Attention is all you need,” NeurIPS, 2017.
- [39] A. Dosovitskiy et al., “An image is worth 16x16 words: Transformers for image recognition at scale,” in ICLR, 2020.
- [40] X. Ma et al., “When visual prompt tuning meets source-free domain adaptive semantic segmentation,” NeurIPS, 2023.
- [41] G. Kim et al., “A theoretical study on solving continual learning,” NeurIPS, 2022.
- [42] J. Yang et al., “Generalized out-of-distribution detection: A survey,” arXiv preprint arXiv:2110.11334, 2021.
- [43] A. Panos et al., “First session adaptation: A strong replay-free baseline for class-incremental learning,” arXiv preprint arXiv:2303.13199, 2023.
- [44] Q. Tran et al., “Koppa: Improving prompt-based continual learning with key-query orthogonal projection and prototype-based one-versus-all,” arXiv preprint arXiv:2311.15414, 2023.
- [45] Y. Sun et al., “Out-of-distribution detection with deep nearest neighbors,” in ICML, 2022.
- [46] A. Krizhevsky, G. Hinton et al., “Learning multiple layers of features from tiny images,” Tech. Rep., 2009.
- [47] D. Hendrycks, S. Basart et al., “The many faces of robustness: A critical analysis of out-of-distribution generalization,” in ICCV, 2021.
- [48] T. Ridnik et al., “Imagenet-21k pretraining for the masses,” arXiv preprint arXiv:2104.10972, 2021.
- [49] C. Wah et al., “The caltech-ucsd birds-200-2011 dataset,” 2011.
- [50] J. Krause et al., “3d object representations for fine-grained categorization,” in ICCVW, 2013.
- [51] J. Zhou et al., “Image bert pre-training with online tokenizer,” in ICLR, 2021.
- [52] G. Kim, B. Liu, and Z. Ke, “A multi-head model for continual learning via out-of-distribution replay,” in CoLLAs, 2022.
- [53] M. Oquab et al., “Dinov2: Learning robust visual features without supervision,” TMLR.
- [54] Y.-M. Tang, Y.-X. Peng, and W.-S. Zheng, “When prompt-based incremental learning does not meet strong pretraining,” in ICCV, 2023.
- [55] A. Khosla et al., “Novel dataset for fine-grained image categorization: Stanford dogs,” in CVPRW, 2011.
- [56] S. Maji et al., “Fine-grained visual classification of aircraft,” arXiv preprint arXiv:1306.5151, 2013.
- [57] W. Liao et al., “Does continual learning meet compositionality? new benchmarks and an evaluation framework,” NeurIPS, 2023.
- [58] X. Wu, S. Huang, and F. Wei, “Mole: Mixture of lora experts,” in ICLR, 2023.
- [59] D. Kumaran, D. Hassabis, and J. L. McClelland, “What learning systems do intelligent agents need? complementary learning systems theory updated,” Trends Cogn. Sci., 2016.
- [60] J. L. McClelland, B. L. McNaughton, and R. C. O’Reilly, “Why there are complementary learning systems in the hippocampus and neocortex: insights from the successes and failures of connectionist models of learning and memory.” Psychol. Rev., 1995.
- [61] P. W. Frankland and B. Bontempi, “The organization of recent and remote memories,” Nature Rev. Neurosci., 2005.
- [62] L. Wang et al., “Triple-memory networks: A brain-inspired method for continual learning,” IEEE TNNLS, 2021.
- [63] I. Goshen et al., “Dynamics of retrieval strategies for remote memories,” Cell, 2011.
- [64] B. Lei et al., “Social experiences switch states of memory engrams through regulating hippocampal rac1 activity,” PNAS, 2022.
- [65] D. Kudithipudi et al., “Biological underpinnings for lifelong learning machines,” Nat. Mach. Intell., 2022.
- [66] Y. Zuo et al., “Hierarchical prompts for rehearsal-free continual learning,” arXiv preprint arXiv:2401.11544, 2024.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/ef76af7d-7248-463e-add4-e1ad15fe7b80/Liyuan_Wang_Photo.jpg) |
Liyuan Wang is currently a postdoctoral researcher in Tsinghua University, working with Prof. Jun Zhu at the Department of Computer Science and Technology. Before that, he received the B.S. and Ph.D. degrees from Tsinghua University. His research interests include continual learning, incremental learning, lifelong learning and brain-inspired AI. His work in continual learning has been published in major conferences and journals in related fields, such as Nature Machine Intelligence, IEEE TPAMI, IEEE TNNLS, NeurIPS, ICLR, CVPR, ICCV, ECCV, etc. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/ef76af7d-7248-463e-add4-e1ad15fe7b80/Jingyi_Xie_Photo.jpg) |
Jingyi Xie is currently a researcher engineer in Prof. Jun Zhu’s group. She received the B.Sc. and M.Sc. degree with the Department of Mathematics and Statistics, Wuhan University, Wuhan, China. Her current research interests include representation learning, continual learning, and deep learning. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/ef76af7d-7248-463e-add4-e1ad15fe7b80/Xingxing_Zhang_Photo.jpeg) |
Xingxing Zhang received the Ph.D. degree from the Institute of Information Science, Beijing Jiaotong University in 2020 and B.E. degree in 2015. She was also a visiting student with the Department of Computer Science, University of Rochester, USA, from 2018 to 2019. She was a postdoc in the Department of Computer Science, Tsinghua University, from 2020 to 2022. Her research interests include continual learning and zero/few-shot learning. She has received the excellent Ph.D. thesis award from the Chinese Institute of Electronics in 2020. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/ef76af7d-7248-463e-add4-e1ad15fe7b80/Hang_Su_Photo.jpg) |
Hang Su , IEEE member, is an associated professor in the department of computer science and technology at Tsinghua University. His research interests lie in the adversarial machine learning and robust computer vision, based on which he has published more than 50 papers including CVPR, ECCV, TMI, etc. He has served as area chair in NeurIPS and the workshop co-chair in AAAI22. he received “Young Investigator Award” from MICCAI2012, the “Best Paper Award” in AVSS2012, and “Platinum Best Paper Award” in ICME2018. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/ef76af7d-7248-463e-add4-e1ad15fe7b80/Jun_Zhu_Photo.jpeg) |
Jun Zhu received his B.S. and Ph.D. degrees from the Department of Computer Science and Technology in Tsinghua University, where he is currently a Bosch AI professor. He was an adjunct faculty and postdoctoral fellow in the Machine Learning Department, Carnegie Mellon University. His research interest is primarily on developing machine learning methods to understand scientific and engineering data arising from various fields. He regularly serves as senior Area Chairs and Area Chairs at prestigious conferences, including ICML, NeurIPS, ICLR, IJCAI and AAAI. He was selected as “AI’s 10 to Watch” by IEEE Intelligent Systems. He is a Fellow of the IEEE and an associate editor-in-chief of IEEE TPAMI. |
Appendix A Theoretical Foundation I
In this section, we present the complete proof of our hierarchical decomposition under different CL scenarios.
A.1 Class-Incremental Learning (CIL)
Proof of Theorem 1
For CIL with pre-training, assume , , and .
Let be the ground truth of an , where and denote the task identity and within-task index, respectively.
As we defined,
| (20) | ||||
| (21) | ||||
| (22) | ||||
Then, we have
| (23) | ||||
Taking expectations on Eq. (22), we have
| (24) | ||||
Taking expectations on both sides of Eq. (23), we have
| (25) | ||||
Considering the multi-objective optimization problem in Eq. (32), we have the loss error
| (26) | ||||
This finishes the proof.
Proof of Theorem 2
For CIL with pre-training, its loss error . Assume .
According to the proof of Theorem 1, we have
| (27) | ||||
Likewise, we have
| (28) | ||||
Considering the multi-objective optimization problem in Eq. (32), each component must guarantee the loss error less than , i.e.,
| (29) | ||||
This finishes the proof.
A.2 Domain-Incremental Learning (DIL)
For DIL, let each “task”555For naming consistency, here we still use “task” to denote the sequentially arriving “domain” in DIL. consist of domain and label , where denotes the -th class in task , and for . Similar to the analysis of CIL, the goal is to learn a projection from to so as to achieve TAP. When training from scratch, the TAP performance is to predict across all classes without distinguishing tasks, where , denotes the ground truth label of , and denotes the domain of class . Given the assumptions of disjoint domains, the DIL probability can be expressed as a hierarchical process of TII and WTP:
| (30) |
In this case, the TAP performance is essentially equivalent to the DIL performance , where denotes the ground truth of an w.r.t. the within-task index.
When considering the pre-trained knowledge carried by parameters , the TAP is redefined as , while the DIL probability of TII and WTP is re-written as
| (31) |
It can be seen that both the TAP performance and the DIL performance are now affected by , but in different ways. Therefore, we propose to further optimize TAP along with the improved TII and WTP, formulating the ultimate goal of DIL as a multi-objective optimization problem, i.e.,
| (32) |
We further derive the following theorems in terms of the sufficient and necessary conditions for improving CL.
Theorem 4
For DIL with pre-training, if , , and , we have the loss error , regardless whether the WTP predictor, TII predictor and TAP predictor are trained together or separately.
Proof of Theorem 4
As similarly defined in CIL, here
| (33) | ||||
| (34) | ||||
| (35) | ||||
where represents the possibility of belonging to each observed domain, and .
Then, for any simplex , we have
| (36) | ||||
Taking expectations on Eq. (35), we have
| (37) | ||||
Taking expectations on both sides of Eq. (36), we have
| (38) | ||||
Considering the multi-objective optimization problem , we have the loss error
| (39) | ||||
This finishes the proof.
Theorem 5
For DIL with pre-training, if the loss error , then there always exist (1) a WTP predictor, s.t. ; (2) a TII predictor, s.t. ; and (3) a TAP predictor, s.t. .
Proof of Theorem 5
For DIL with pre-training, its loss error .
Assume .
According to the proof of Theorem 4, if we define
, we have
| (40) | ||||
Likewise, if we define and for , we have
| (41) | ||||
Considering the multi-objective optimization problem , each component must guarantee the loss error less than , i.e.,
| (42) | ||||
This finishes the proof.
A.3 Task-Incremental Learning (TIL)
For task-incremental learning (TIL), let each task consist of domain and label , where denotes the -th class in task . Unlike CIL and DIL, TIL has the task identity provided during the testing phase. Whether or not the impact of pre-trained parameters is taken into account, the TAP objective is to learn or , where , , and . In fact, this is equivalent to WTP alone. For completeness, we further derive the following theorems in terms of the sufficient and necessary conditions for improving CL.
Theorem 6
For TIL with pre-training, , and TAP is degraded into WTP. If , we have the loss error .
Proof of Theorem 6
For TIL with pre-training, assume .
Given an with the task identity , let be the ground truth of w.r.t. the within-task index, and be the ground truth label of .
As similarly defined in CIL, here
| (43) | ||||
| (44) | ||||
| (45) | ||||
Then, we have
| (46) | ||||
Taking expectations on both sides of Eq. (46), we have
| (47) | ||||
Considering the TIL objective , we have the loss error . This finishes the proof.
Theorem 7
For TIL with pre-training, if the loss error , then there always exists a WTP predictor, s.t. .
Appendix B Theoretical Foundation II
In this section, we first present the complete proof of connecting TII to OOD detection, and then derive the sufficient and necessary conditions of improving CL with WTP, OOD detection and TAP.
B.1 TII to OOD Detection
Proof of Theorem 3
For CL in a pre-training context, define the TII probability as .
If for , then we have
| (49) |
This means for , and (i.e., ) for .
Let denote the task identity of , then we have
| (50) | ||||
The last inequation holds due to for .
Now, let us move on the proof of adequacy for TII and OOD detection. If , then we have
| (51) |
Further, for , we have
| (52) |
The last inequation holds due to .
Likewise, for , we have
| (53) |
This finishes the proof.
B.2 Sufficient and Necessary Conditions
Now we discuss the upper bound of CIL in relation to WTP, OOD detection and TAP.
Theorem 8
For CIL with pre-training (i.e., ), define the TII probability as . If , , and for , then we have the loss error
As shown in Theorem 8, the good performance of WTP, TAP, and OOD detection are sufficient to guarantee a good CIL performance. Now we further study the necessary conditions of a well-performed CIL model.
Theorem 9
For CIL with pre-training (i.e., ), define the TII probability as . If the loss error , then there always exist (1) a WTP predictor, s.t. ; (2) a TII predictor, s.t. ; (3) a TAP predictor, s.t. ; and (4) an OOD detector for each task, s.t. for .
This theorem shows that if a good CIL model is trained, then a good WTP, a good TII, a good TAP, and a good OOD detector for each task are always implied.
Proof of Theorem 8
For CIL with pre-training (i.e., ), define TII as .
If , , and
for , then using Theorem 8 we have .
Further, using Theorem 1 we have the loss error
| (54) |
This finishes the proof.
Proof of Theorem 9
For CIL with pre-training (i.e., ), define the TII probability as . If the loss error , then using Theorem 2 there always exist (1) a WTP predictor, s.t. ; (2) a TII predictor, s.t. ; and (3) a TAP predictor, s.t. .
Furthermore, if , using Theorem 3, we always have an OOD detector for each task, s.t. for . This finishes the proof.
| Method | Year | Avenue | PET Technique | Task-Specific Parameters | Task-Shared Parameters | Representation Recovery |
|---|---|---|---|---|---|---|
| L2P [5] | 2022 | CVPR | ProT | ✓ | ✓ | N/A |
| DualPrompt [6] | 2022 | ECCV | PreT | ✓ | ✓ | N/A |
| S-Prompt [7] | 2022 | NeurIPS | ProT | ✓ | N/A | N/A |
| CODA-Prompt [8] | 2023 | CVPR | PreT | ✓ | N/A | N/A |
| SLCA [4] | 2023 | ICCV | Full | N/A | ✓ | |
| FSA [43] | 2023 | ICCV | Full | N/A | ✓ | |
| LAE [14] | 2023 | ICCV | General | N/A | ✓ | N/A |
| RanPAC [34] | 2023 | NeurIPS | PreT | N/A | ✓ | |
| KOPPA [44] | 2023 | arXiv | PreT | ✓ | N/A | |
| H-Prompt [66] | 2024 | arXiv | PreT | ✓ | ✓ | |
| \cdashline1-7[2pt/2pt] HiDe-Prompt [13] | 2023 | NeurIPS | PreT | ✓ | N/A | |
| HiDe-PET | 2024 | Current | General | ✓ | ✓ |
Appendix C Implementation Details
Here we describe the supplementary implementation details of the empirical investigation.
Comparison with Preliminary Version: The major technical difference between our HiDe-PET and our preliminary version [13] lies in the use of task-shared parameters to improve TII, which is critical for LoRA/Adapter-based PET that is sensitive to the TII errors. To mitigate catastrophic forgetting in , we set a cosine-decaying learning rate of 0.01 for FSA, a cosine-decaying learning rate of 0.001 for SL, and a momentum of 0.1 for EMA. The PET ensemble strategy sets in all cases. To ensure generality and resource efficiency, the specific implementations are slightly modified in three aspects. First, our preliminary version [13] followed the implementation of L2P [5] and DualPrompt [6], which employed a constant learning rate of 0.005 and a supervised checkpoint of ImageNet-21K (i.e., Sup-21K). We notice that many recent methods followed the implementation of CODA-Prompt [8], which employed a cosine-decaying learning rate of 0.001, a self-supervised/supervised checkpoint on ImageNet-21/1K (i.e., Sup-21/1K) and a different split of ImageNet-R. Considering that a smaller learning rate with cosine decay has been more commonly used for fine-tuning large-scale PTMs, we reproduce all baselines with the implementation of CODA-Prompt [8] in the current manuscript. This consideration further ensures the generality of our HiDe-PET in adapting to different experimental settings. Second, our preliminary version [13] devised a contrastive regularization (CR) term to balance the instructed representations for WTP and TAP, which brings some benefits to the performance of Prompt-based PET. In subsequent explorations, we observe that the CR term cannot improve the performance of LoRA/Adapter-based PET, and therefore remove it in the current manuscript to ensure generality in adapting to different PET techniques. Third, our preliminary version [13] employed dedicated covariance matrices (additional parameters for each class) in representation recovery and a two-layer MLP (additional parameters for the first layer) in , in order to acquire better performance. In contrast, the current manuscript employs multi-centroid (additional parameters for each class) in representation recovery and a one-layer MLP in , which slightly compromise the performance but largely improve resource efficiency.
Adaptive Knowledge Accumulation: In Sec. 5.2, we devise a PET hierarchy inspired by OOD detection to demonstrate the connections between task-specific and task-shared PET architecture. We further consider a specialized implementation of for HiDe-PET in Algorithm 1, serving as a plug-in module to achieve adaptive knowledge accumulation from pronounced distribution changes. As described in Sec. 5.2, are adaptively expanded or retrieved upon the distance to each previous task . The learning of each for is identical to the learning of , i.e., a combination of FSA and SL. As for the exploitation of , before learning each task , the most relevant is first retrieved upon the current training samples and then temporarily added to the backbone parameters to better incorporate task-specific knowledge (the improved is denoted as ). The improved backbone is used to obtain , i.e., Step 10 in Algorithm 1. Whereas, the original backbone is still used to obtain , i.e., Step 9 in Algorithm 1. At the testing phase, the most relevant is retrieved upon the current testing samples and temporarily added to .