Hierarchical Clustering for Smart Meter Electricity Loads based on Quantile Autocovariances
Abstract
In order to improve the efficiency and sustainability of electricity systems, most countries worldwide are deploying advanced metering infrastructures, and in particular household smart meters, in the residential sector. This technology is able to record electricity load time series at a very high frequency rates, information that can be exploited to develop new clustering models to group individual households by similar consumptions patterns. To this end, in this work we propose three hierarchical clustering methodologies that allow capturing different characteristics of the time series. These are based on a set of “dissimilarity” measures computed over different features: quantile auto-covariances, and simple and partial autocorrelations. The main advantage is that they allow summarizing each time series in a few representative features so that they are computationally efficient, robust against outliers, easy to automatize, and scalable to hundreds of thousands of smart meters series. We evaluate the performance of each clustering model in a real-world smart meter dataset with thousands of half-hourly time series. The results show how the obtained clusters identify relevant consumption behaviors of households and capture part of their geo-demographic segmentation. Moreover, we apply a supervised classification procedure to explore which features are more relevant to define each cluster.
Index Terms:
Quantile autovariances, massive time series, hierarchical clustering, smart meters.I Introduction
I-A Background and Aim
Moved by the need of improving the efficiency and sustainability of aging electrical systems, many countries worldwide are adopting new information and communication technologies, with special emphasis on the residential sector [1]. These technologies imply a new paradigm in the economical and technical operation of distribution networks, and create new business opportunities for all the companies that take part in the electricity supply chain.
It is very relevant the extended integration of advanced metering infrastructures (AMI) [2] with an special role played by households “smart meters”. These devices allow recording electricity consumption data at a very high frequency rate and instantly transmit this information to the retailing and/or distribution companies.
Furthermore, as many electricity markets worldwide are open to competition in both the generation and retailing sectors, there is a growing interest by the electrical companies in using these data to increase their profit, their market share or the consumers’ welfare. In this vein, the treatment of these new datasets require the research and implementation of novel data science techniques, with practical applications on energy fraud detention, outliers identification, consumers profiling, demand response, tariff design, load forecasting, etc. [3].
The special characteristics of the data stored by smart meters (hundreds of thousands, or even millions, of high frequency time series), and their combination with exogenous variables (meteorological, calendar, economical, etc.), open the possibility of designing specific clustering models for household consumers. Furthermore, these models can help to better understand the behavior of both aggregated and disaggregated electrical loads [4], and how this knowledge can be exploited to improve electrical system’s.
In particular, clustering households with similar consumption patterns has many potential applications. Retailing companies can be interested on grouping clients by consumption profiles to offer tailor-made tariffs. This may increase consumers utility while ensuring revenue-adequacy for the company. Moreover, clustering may help to identify the best candidate group of consumers to implement demand response policies. In this vein, system operators and distribution companies can benefit from clustering techniques to improve their load forecasting accuracy [5], with a direct impact on system reliability or predictive maintenance.
In this work we propose different hierarchical-based clustering strategies based on a set of “dissimilarity” measures: quantile auto-covariance, and simple and partial autocorrelations. These strategies summarize each consumption time series in only a few representative features so that they are highly efficient, easy to automatize and scalable to hundreds of thousands of series, i.e., can be successfully implemented in large-scale applications that make use of smart meters datasets. We test the performance of our clustering models by using a real-world dataset with thousands of electricity consumption time series. The results are promising as the obtained clusters not only identify relevant consumption patterns but also capture part of the geo-demographic segmentation of the consumers. Furthermore, we implement a multiclass supervised classification algorithm, based on decision trees, in order to characterize the most important features conditioning each cluster.
I-B Literature Review
A review of several clustering techniques to group similar electricity consumers is presented in [6]. It is shown that the overall performance of the different techniques is related to their ability to isolate outliers. Reference [7] proposes a clustering method for household consumers based on K-means and Principal Components Analysis (PCA). The resulting clusters are subject to a multiple regression analysis to identify relevant explanatory variables. The work in [8] addresses the consumer segmentation problem by normalizing the daily load shapes for each consumer, together with their total consumption, to apply an adaptive K-means algorithm. A clustering model based on K-means is proposed in [9] to, focusing on commercial and industrial electricity consumers, identify candidate users for energy efficiency policies and their businesses opening and closing hours. Reference [10] evaluates and compare three clustering techniques for smart meter data: k-medoid, K-means and Self Organizing Maps (SOM), to show that the latter presented to overall best performance. Traditional time series methods are applied in [11], like wavelets or autocorrelation analysis, to the raw smart meter data to enrich the input of a K-mean based clustering algorithm for consumers segmentation. Reference [12] proposes to use dynamic information, in terms of transitions between adjacent time periods, for consumers segmentation. The resulting clusters are used to evaluate their potential for demand response policies.
Several works seek to identify relevant features that condition the dynamic patterns of electricity consumers. For instance, a supervised ML model is proposed in [13] based on individual household consumption time series. With the same aim, [14] proposed a methodology to examine smart meter data and identify important determinants of consumers electricity load. To extend the number of features that can potentially be used for profiling consumers, [15] complement the smart meter data with door-to-door question surveys. It is shown how these new dataset improves the performance of a Ward’s hierarchical clustering algorithm. A detailed analysis of household consumption data is presented in [16] to identify those time periods from which relevant consumption features can be extracted. Based on these features, a mixture-based clustering algorithm is proposed and evaluated by bootstrap techniques. Another mixture model framework, based on linear Gaussian approximations, is used by [17] to derive relevant load profiles from individual consumption patterns.
To improve computational performance, [18] presents a two-level clustering methodology to derive representative consumptions profiles based on K-means. The first level is used to obtain local profiles that are generalized in the second level. With a similar aim, reference [19] proposes a feature construction model for time series to cluster similar consumers. The model reduces the dimensionality of the problem by using conditional filters and profile errors. An efficient frequency domain hierarchical clustering model is proposed [20] to derive adequate load profiles. Moreover, [21] studies how the temporal resolution of the consumption time series may have an strong impact on both the quality and computational performance of the clustering techniques.
Clustering techniques has been used also to improve the accuracy of forecasting models. In this vein, a K-means based algorithm is employed in [5] to derive consumption estimates and impute missing data. The cross-similarities between consumptions series is used by [22] to enhance the performance of a forecasting model, based on Long Short-term Memory (LSTM) networks. Similarly, [23], implements a K-means based clustering algorithm to group similar consumers and then adjust a Neural Network (NN) forecasting model for aggregated loads. Another clustering K-Means based algorithm is employed in [24] to household load curves to group similar consumers and enhance the performance of a nonparametric functional wavelet-kernel approach. Reference [25] also makes used of consumers segmentation through PCA and K-means clustering to identify typical daily consumption profiles that can improve the accuracy of a ML forecasting tool.
I-C Contributions
We build part of our research on the original methodology presented in [26], which proposes to cluster time series based on quantile autocovariances distances. An extensive simulation analysis and a real-world application on daily financial time series show the ability of this approach to identify different dependence models among the series.
In the present work, and by the first time to the authors knowledge, we adapt and extend part of the methodology in [26] to identify relevant clusters from massive and high frequency smart meters time series.
In particular, by considering the state of the art presented in Section I-B, the main contributions of this work are fivefold:
-
1.
To summarize each smart meter time series in an small set of meaningful features: autocorrelation coefficients, partial autocorrelation coefficients and quantile autocovariances.
-
2.
To propose three hierarchical clustering models, based on Euclidean dissimilarity measures, computed over the previous features. The models are computationally efficient and robust against outlier observations.
-
3.
To test the proposed methodology in a real dataset, including thousands of half-hourly load time series, to characterize relevant electricity consumption profiles.
-
4.
To make use of a supervised classification procedure (decision trees) to identify those variables (features) that have been more relevant to form the resulting clusters.
-
5.
To verify that the resulting clusters are able to capture, up to some extend, the geo-demographic segmentation of household consumers.
I-D Paper Organization
II The Clustering Methodology
Let’s assume that we observe time series, where and denotes the first and the last times where the -th time series is observed, respectively. In our dataset, the are the same for all time series but our procedures do not require this condition since they are based on extracted features from the time series. As mentioned in the previous section, there are many interesting features to consider as “clustering” variables instead of using raw data. In our case, we consider three sets of features that capture different aspects of the time series dynamic behaviour:
-
•
The set of autocorrelation coefficients of orders , that is, we calculate the correlation coefficient between the variables and for defined by
(1) -
•
The set of partial autocorrelation coefficients of orders , that is, we calculate the correlation coefficient between observations separated by periods, and , when we eliminate the linear dependence due to intermediate values. The partial autocorrelation coefficient will be denoted by .
-
•
The set of quantile autocovariances of order at quantile levels defined by
(2) where denotes the indicator function and and are the and quantiles of and , respectively.
It is interesting to realize the differences among features (1) and (2) since both involve the calculation of a covariance between observations separated by periods. In (1), the covariance term is estimated by
which involves the products that can be distorted by extreme or outlier observations. For example, two very high loads observed at a distance of periods would spuriously increase the correlation at the lag. On the other hand, the quantile autocovariance (2) is estimated by
| (3) |
The involved products are bounded which imply a negligible effect of outliers. The expression (3) can be interpreted as a mean of the number of times that values at below coincide with values at below . The term is the number of coincidences that occur completely randomly. Therefore, a positive means that the number of matches is greater (smaller) than expected by chance.
It should be noticed that the above characteristics, in general, depend on and , but if the time series are stationary, then they do not depend on , which simplifies their analysis. For this reason, we consider the (daily) seasonal difference of the smart meter load (logarithmic transformed) time series. That is, as the time series that will be used in this paper present an half-hourly frequency, then are the series to be clustered, where denotes the logarithm of the load time series of the -th smart meter. We should fix the largest lag, , in the sets of autocorrelation and partial autocorrelation coefficients. We can fit autoregressive models to all the univariate time series, selecting the order by the BIC criterion, and take , where is the selected order for -th time series. It is shown in [27] that this procedure provides an upper bound of the memory of stationary linear time series. The selected was 96. This selection allows us to captures the main linear dependencies in all time series. Also, for the set of quantile autocovariances, we should fix the lag and quantile levels. In this case, following the suggestions of [26], we use and since these values have shown that they are capable of capturing and differentiating different types of nonlinearities. Finally, the three clustering analyzes will be based on the following sets of features:
-
a)
-
b)
-
c)
, , , , , , , ,
Thus, the analysis will be based on vectors of features for autocorrelation and partial autocorrelation coefficients and based on vectors of features for quantile autocovariances. Once we have the vectors of features, we define a dissimilarity measure between time series and by the Euclidean distance of the corresponding vectors. That is:
-
a)
-
b)
-
c)
where denotes de Euclidean distance.
The distances will be obtained for all pairs with to construct the following dissimilarity matrix
| (4) |
where . The dissimilarity matrix (4) can be used in any cluster procedure which requires this kind of input. In particular, we can apply hierarchical clustering since it allows us to identify clusters as well as hierarchies among the clusters. In hierarchical cluster procedures, to decide which groups should be combined, it is necessary to choose a measure of dissimilarity (linkage criterion) between sets. It is important to emphasize that this choice will influence the shape of the groups, since some sets could be close according to one distance and far according to another. The three best known measures are minimum or single-linkage (), maximum or complete-linkage () and average linkage () defined by:
where and are two sets of observations having and elements, respectively.
In this work, we prefer to use complete linkage as it ensures that the observations in a group are “similar” to all observations of the same group in the sense that once the cut-off point in the dendrogram has been set all the distances within of a cluster are smaller than this cut-off point.
Once we obtain the groups, an interesting question is to know which variables have been the most relevant to form these groups. This question can be addressed through the use of a supervised classification procedure where the labels of the observations will be the result of the clustering methodology. That is, if we have clusters, we will assign the labels to the observations of the respective clusters. These labels and the features will be the input of the supervised classification procedure. In this work, we will use decision trees [28] for multiclass classification problem since for this procedure unbiased estimates of the predictor (feature) importance [29] are available.
III Numerical Results
In this section we use the public energy consumption dataset from [30]. It includes a sample of 5,567 households of London with their individual electricity consumption time series during 2013, in kWh (per half hour), date and time, and CACI ACORN segmentation (6 geo-demographic categories) [31]. In particular, to validate this work’s clustering methodology, we will compare the resulting clusters with the geo-demographic aggregated categories coded as “ACORN_GROUPED”, which classify households into three main groups: “Affluent”, “Comfortable” and “Adversity”. Moreover, the dataset is also divided into two subgroups of consumers:
-
i)
std tariff: Consumers whose electricity tariff is fixed (standard) to a constant price during the time of the study.
-
ii)
tou tariff: Consumers with “time of use” tariff for which the electricity price is different for each hour.
In order to better characterized the inherent consumption behavior of individual households, we have focused the following study on the std tariff consumers, as these are not influenced by a variable price signal. This initial group includes approximately 4500 time series from which some of them are discarded, due a high proportion of missing observation, rendering a final subsample of around 3200 time series (households).
The following three dendrograms, Fig. 1 - 3, are obtained using the QC, AC and PAC features and complete linkage introduced in Section II. In the three graphs we can observe some clear groups of observations (time series) and also observations that are joined to the hierarchical structure at large levels. Those observations have a dynamic “atypical” behavior and are grouped in clusters with less than 1% of the total number of time series. Once we discard the atypical observations, we find eight, six and seven large clusters for QC, AC and PAC, respectively. Moreover, the degrees of coincidence among these three clusters partitions are low as indicated by the adjusted Rand indexes (0.0941 when comparing QC and AC; 0.1432 when comparing QC and PAC and 0.2687 when comparing AC and PAC). This implies that the three approaches look at different characteristics of the time series.
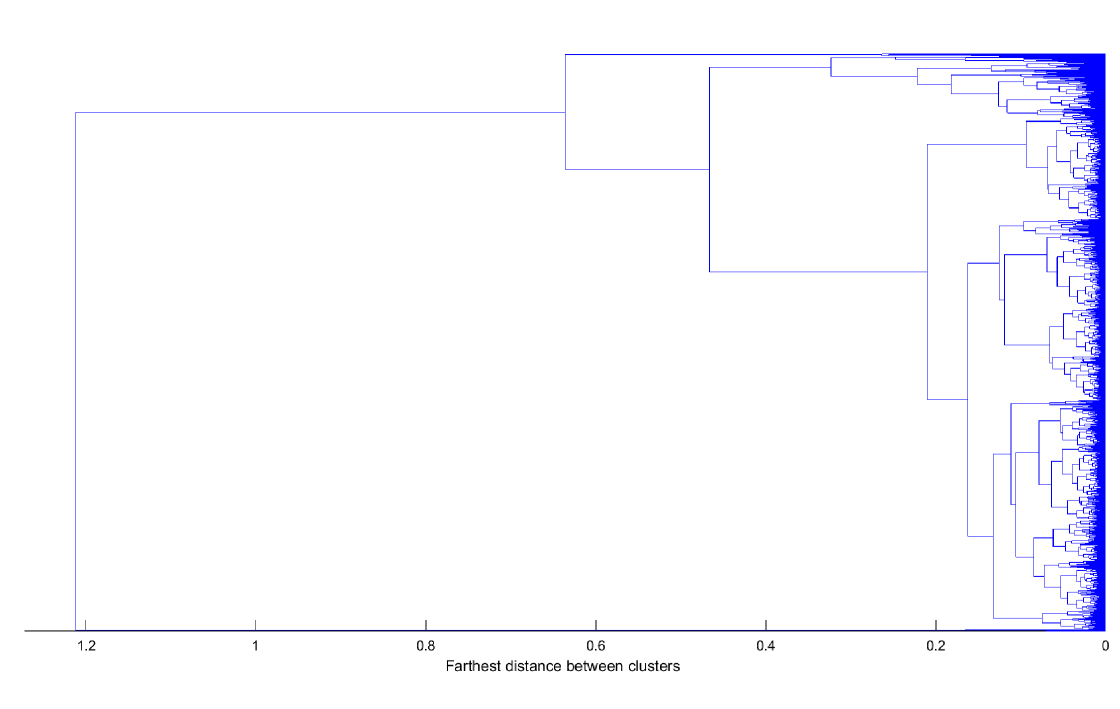
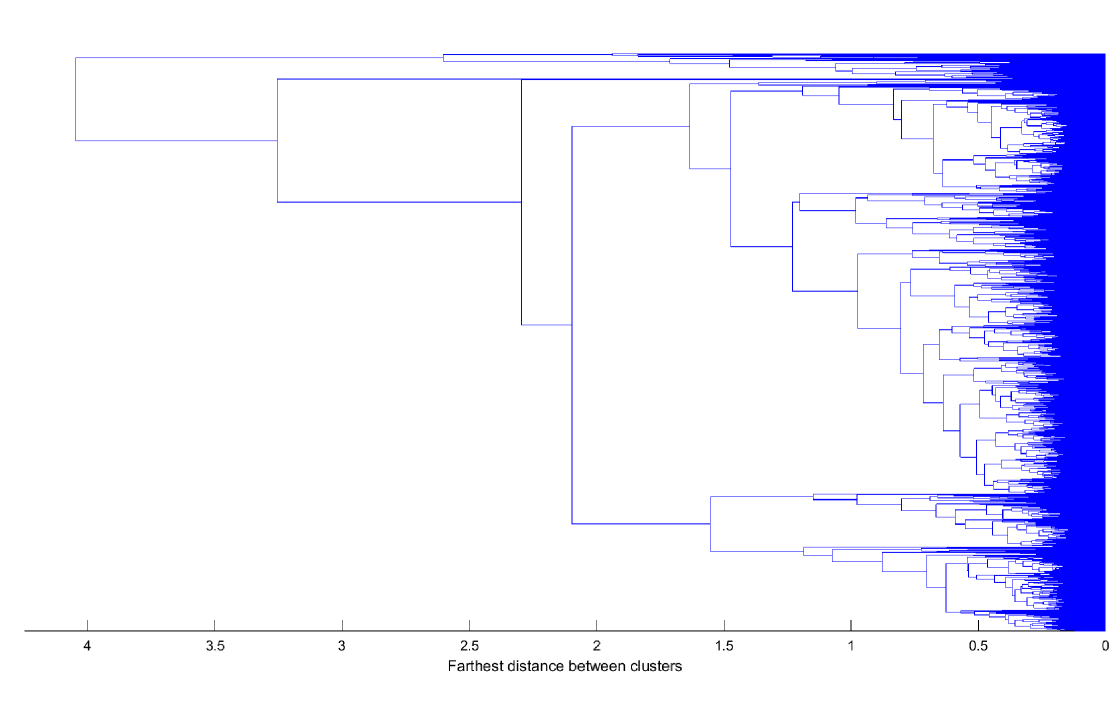
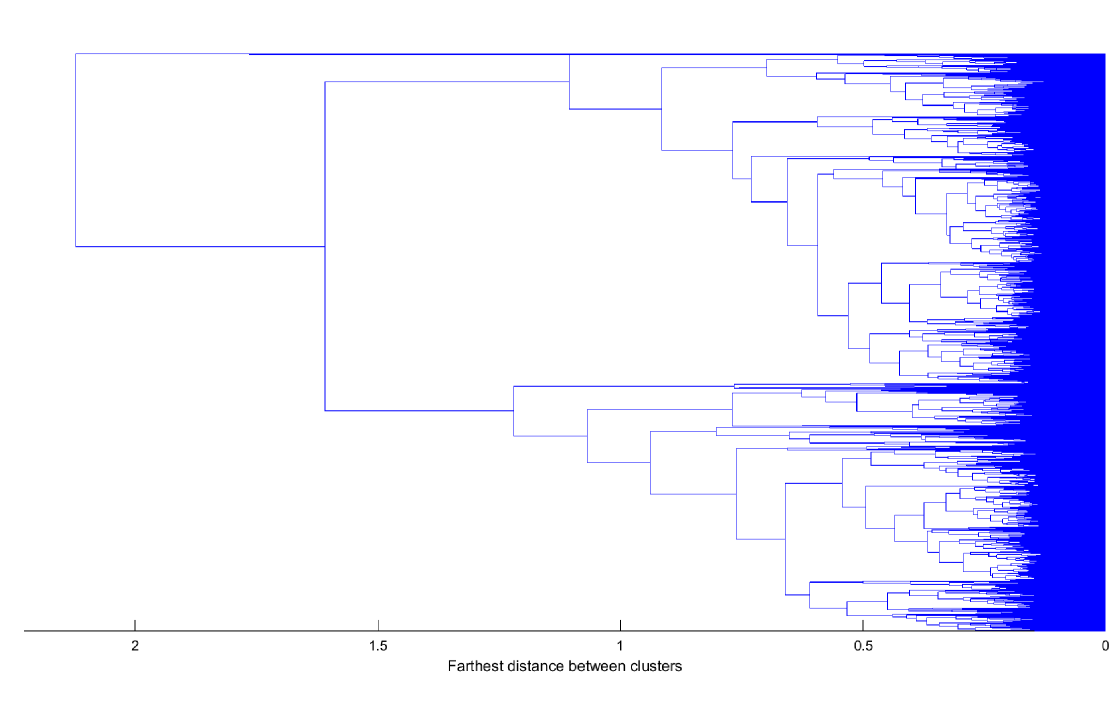
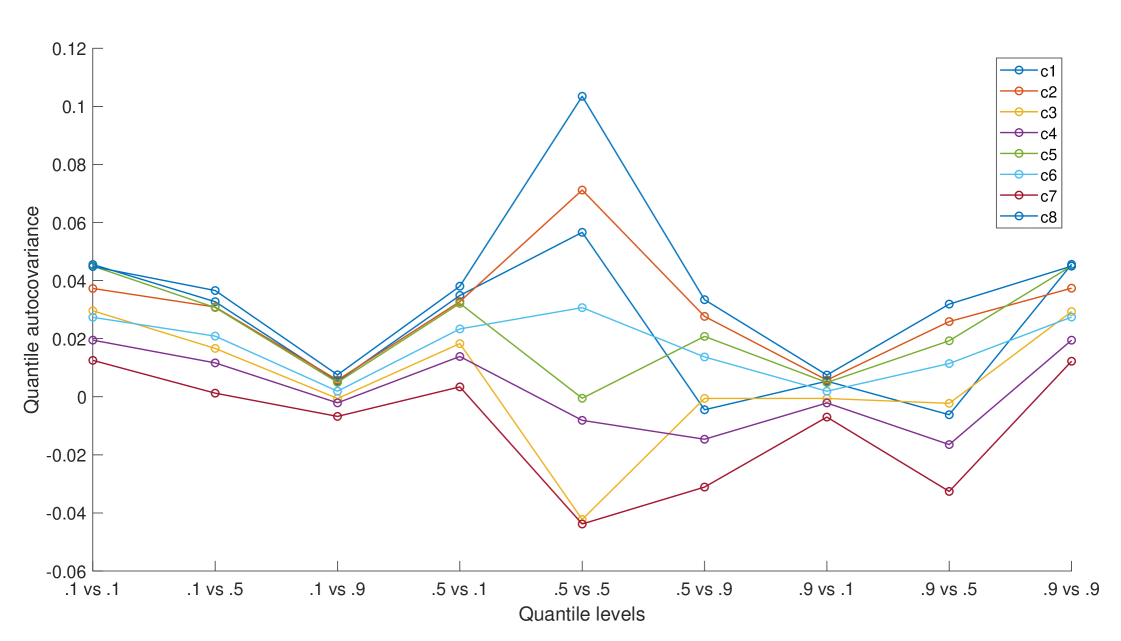
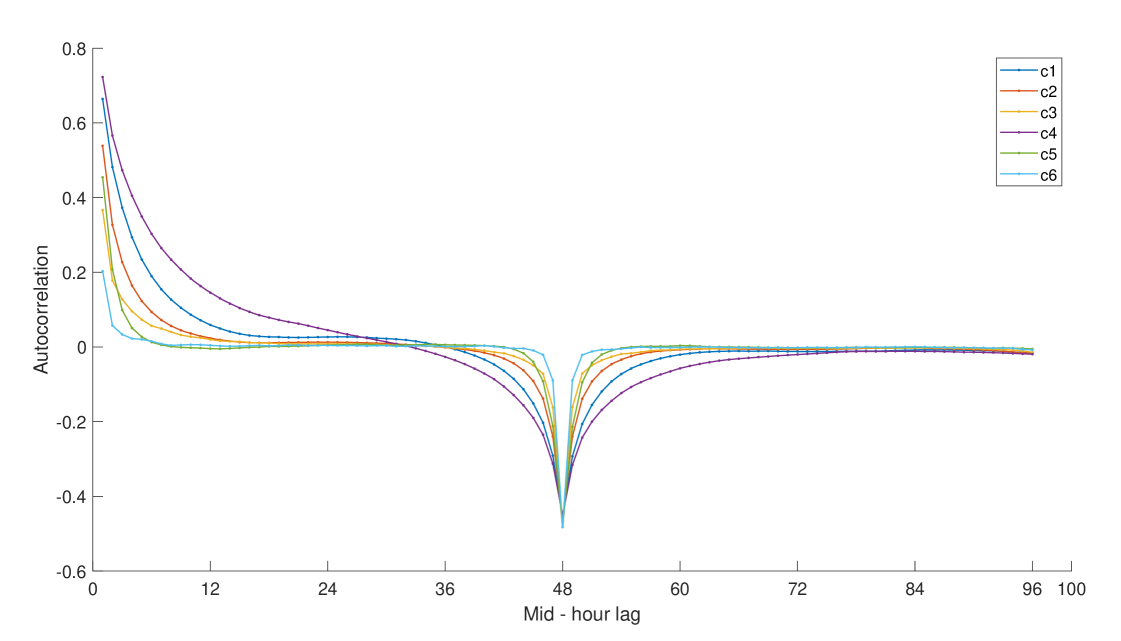
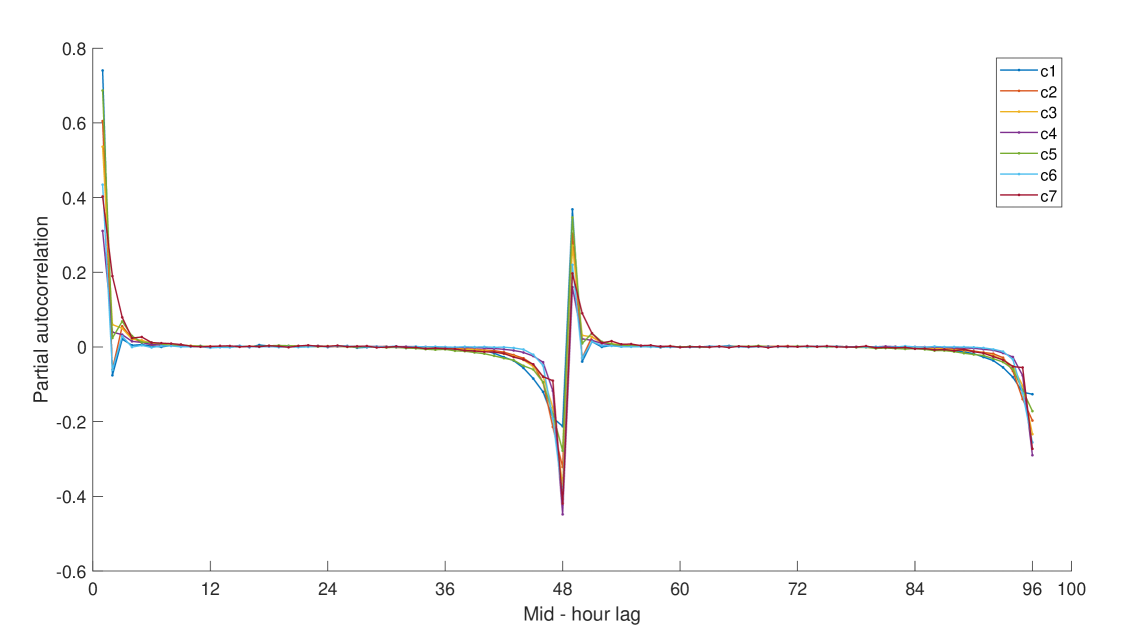
Figures 4 - 6 illustrate these large clusters obtained with QC, AC and PAC, respectively. In the figures, we represent the mean of the features used to obtain the clusters. There are nine features, in the case of QC, corresponding to the covariance of quantiles 10%, 50% and 90%. In the case of AC and PAC, we use the first 96 simple and partial autocorrelations, respectively. The clusters based on QC reveals differences in the median consumptions (.5 versus .5) and highest versus median consumptions (.9 versus .5). For instance, it is remarkable the difference between c3 and c7 versus c1, c2, c4, c6 and c8 at the median consumptions. The c3 and c7 have negative covariances and the c1, c2, c4, c6 and c8 have positive ones. That is, in the first group, a consumption below the median tends to be followed by consumption above the median, while the second group tends to maintain their consumption below the median. The groups by SAC and PAC show differences in the short range dependencies but also in the way they are around the lag 48 (one day). We can focus on the first correlations coefficients that show different degrees of persistency in the consumptions. For instance, in the AC clusters, there is a clear order from high dependency at c4, c1 and c2, medium at c3 and c5 and to low dependency at c6. At the PAC clusters, we can differentiate between clusters with negative second partial autocorrelation (c1, c2 and c6), medium (c3, c4, and c5) and hight positive (c7). That is, once we eliminate the first order correlation, there are negative (or positive) direct effects on the consumption at the 2-step ahead period.
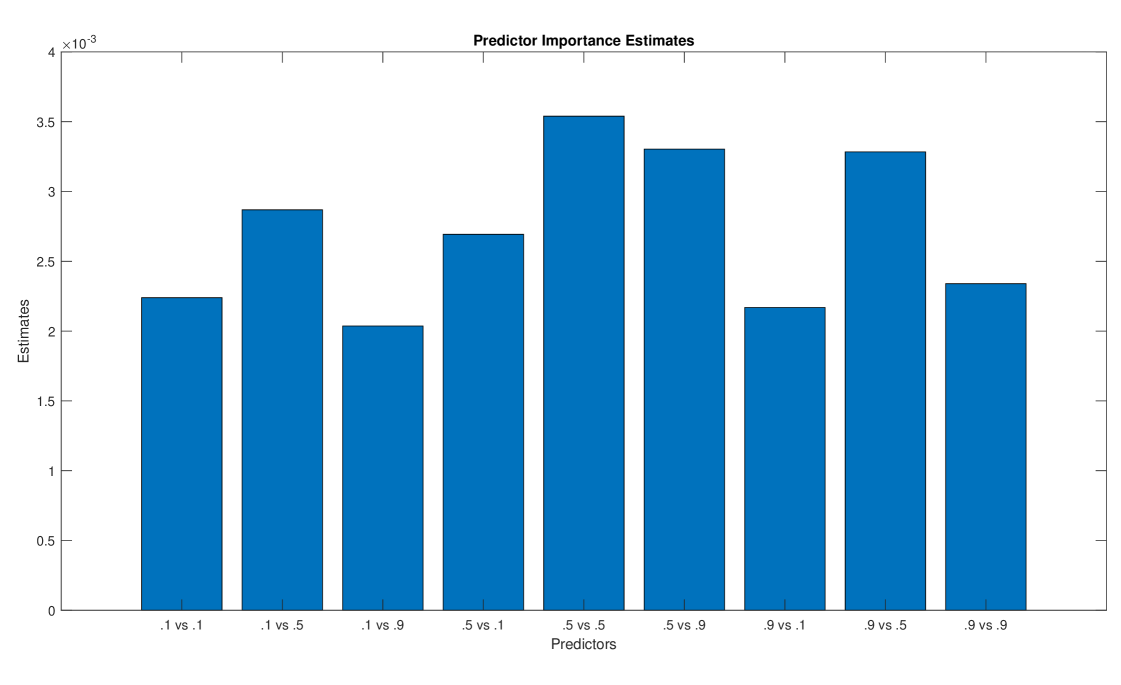
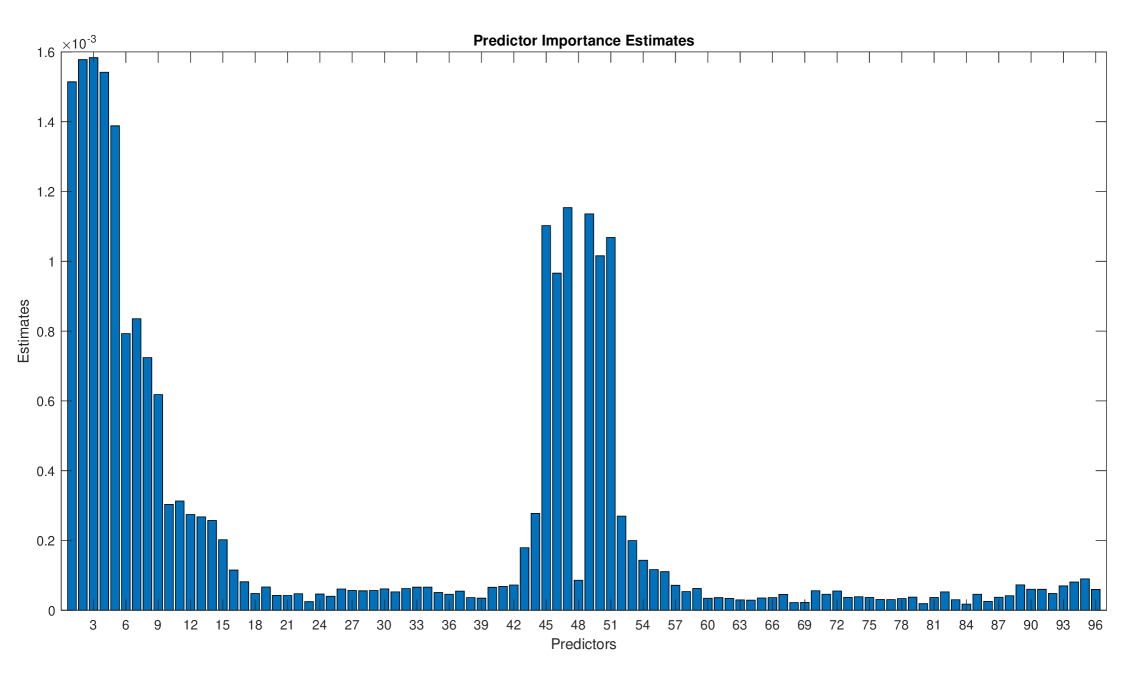
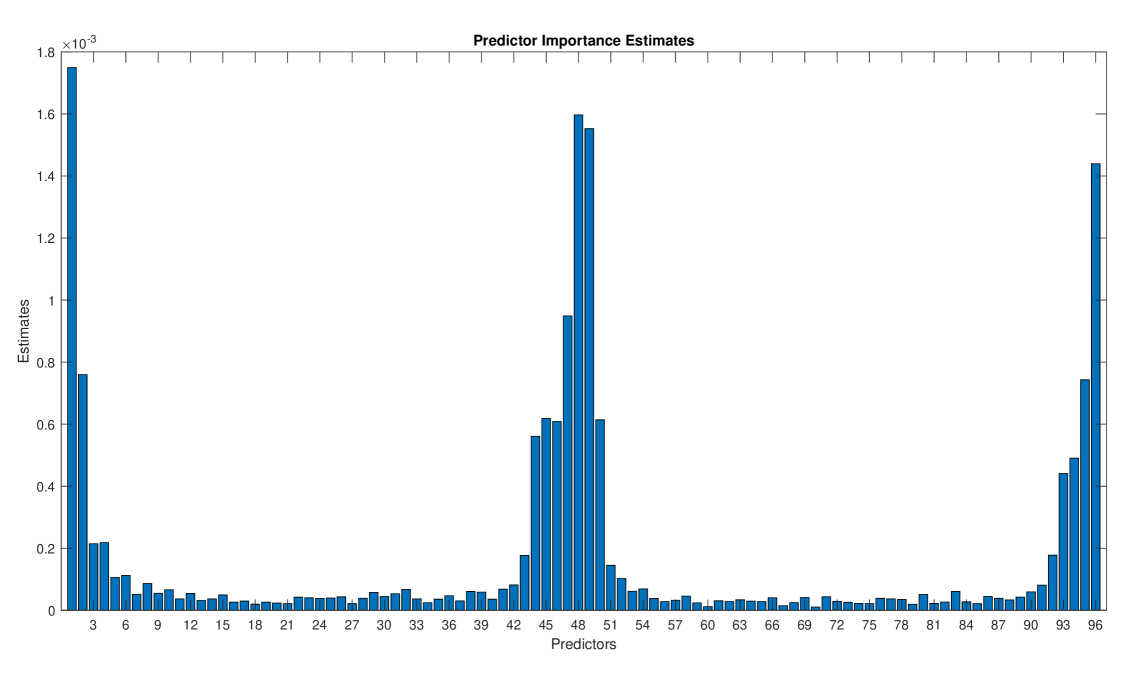
Figures 7 - 9 provide the estimates of the predictor importance. It is clear that all features are relevant in the clustering based on QC but we can make a selection of features in the clusterings based on SAC and PAC. In particular, for SAC, the first fifteen lags and the four lags around the 48–lag appear to be relevant and, for PAC, the first four lags and the four lags before and two lags after the 48– and 96–lags as well as those daily “seasonal” lags. It is interesting to notice that the 48–lag is not relevant in the SAC but this is due to the (daily) seasonal difference. However, there are still stationary seasonal behavior as reflected by relevant predictors/lags around the 48–lag. For PAC, the daily lags are highly relevant. The misclassification rates estimated by cross–validation for the three trained decision trees were 9.9%, 23.3% and 21.4% when using QC, SAC and PAC, respectively. These low rates point out that the obtained trees are good approximations to the clustering mechanism. Of course, other supervised classification procedures such as random forest or neural networks can be used in order to obtain better approximations.
Tables I - III show the number of households on each cluster that are classified in the three ACORN_GROUPED categories. Note that they are unevenly distributed across clusters. Indeed, we have performed chi-squared tests in those tables and the results are highly significant in the three cases revealing that clustering is related to ACORN_GROUPED classification. This shows that the proposed clustering methodology is able to, up to some representative extend, provide insights on the geo-demographic characteristics of a household (Acorn groups), just by studying the time series dependencies.
| Cluster | Adversity | Comfortable | Affluent |
|---|---|---|---|
| c1 | 24 | 24 | 44 |
| c2 | 293 | 278 | 360 |
| c3 | 42 | 23 | 36 |
| c4 | 52 | 40 | 37 |
| c5 | 28 | 22 | 55 |
| c6 | 482 | 343 | 358 |
| c7 | 18 | 9 | 16 |
| c8 | 146 | 160 | 258 |
| Cluster | Adversity | Comfortable | Affluent |
|---|---|---|---|
| c1 | 70 | 83 | 161 |
| c2 | 426 | 404 | 544 |
| c3 | 252 | 171 | 179 |
| c4 | 16 | 23 | 59 |
| c5 | 120 | 79 | 99 |
| c6 | 214 | 140 | 120 |
| Cluster | Adversity | Comfortable | Affluent |
|---|---|---|---|
| c1 | 27 | 16 | 61 |
| c2 | 66 | 67 | 111 |
| c3 | 397 | 376 | 501 |
| c4 | 454 | 305 | 261 |
| c5 | 39 | 51 | 129 |
| c6 | 83 | 54 | 68 |
| c7 | 18 | 29 | 39 |
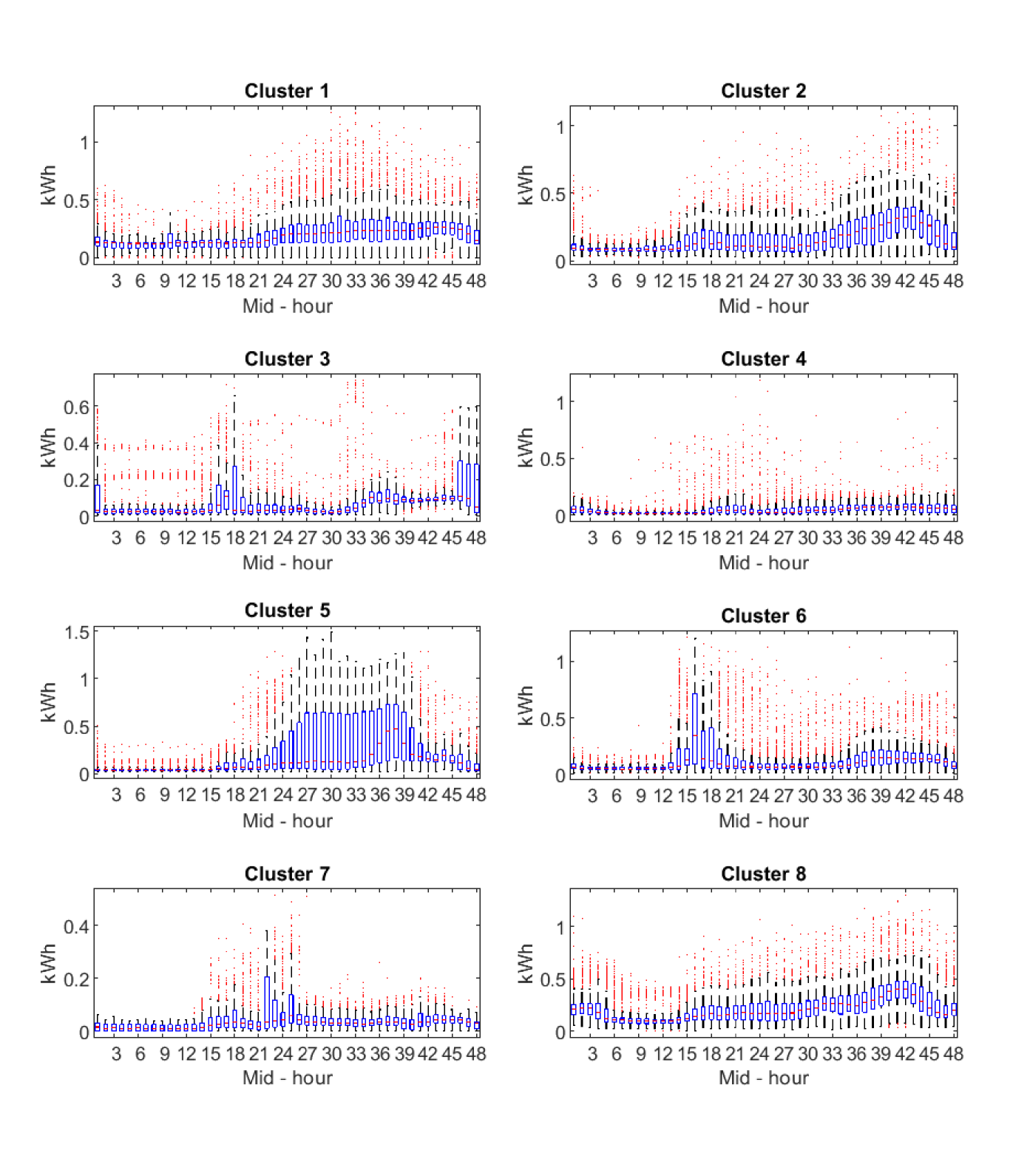
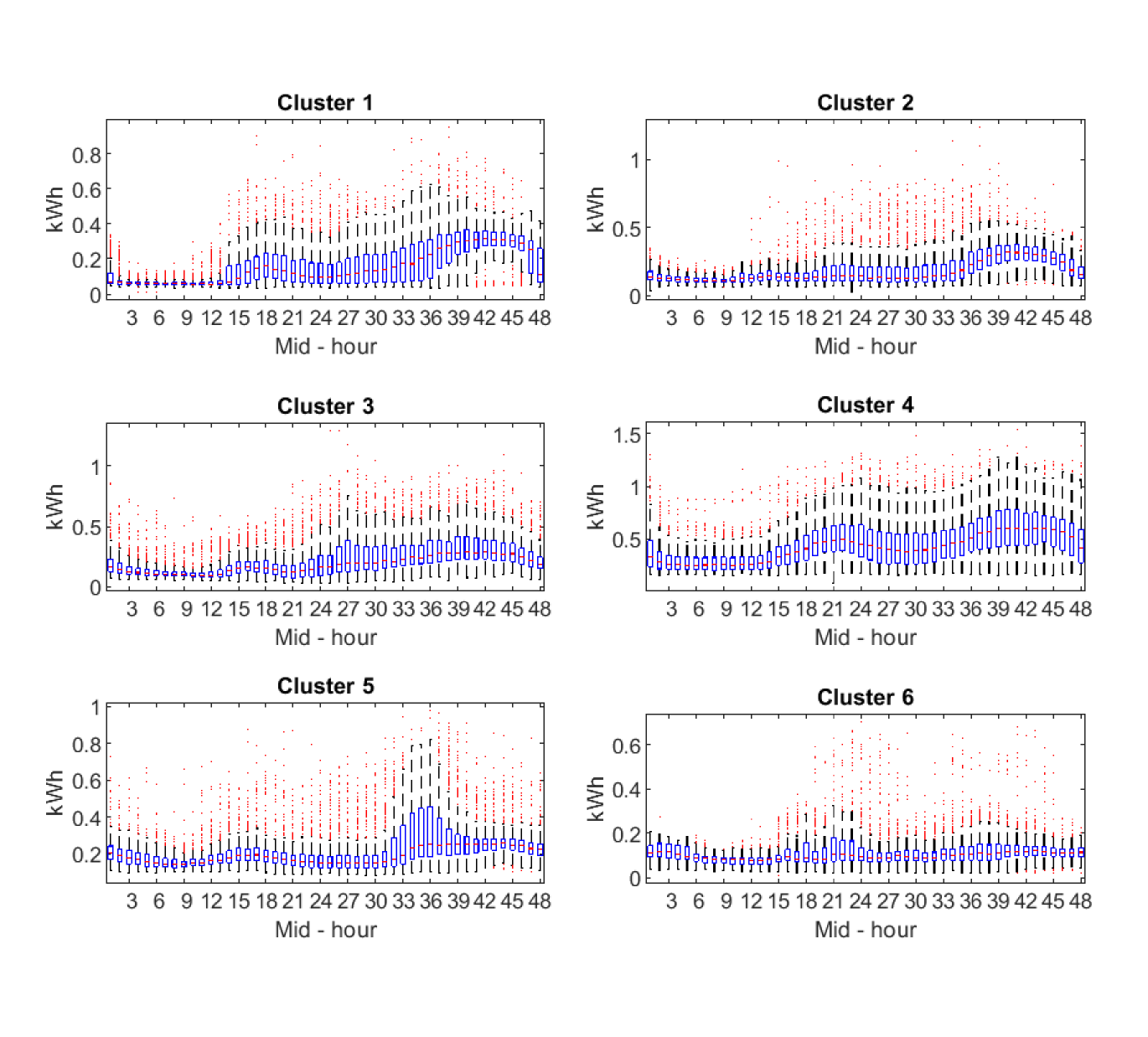
Figures 10 - 12 show the prototype’s hourly profile for each cluster. The prototype is the medoid of each cluster, that is, the element in the cluster with minimal average dissimilarity to all objects in the cluster. We can observe different characteristic consumption patterns associated to different types of consumers. For instance, the eight clusters obtained with quantile autocovariance and complete linkage in Figure 10 allow distinguishing between consumers with morning (clusters 3, 6 and 7) and evening (clusters 1, 2, 5 and 8) peak loads, and those with a more constant consumption pattern (cluster 4). This is also appreciated in the 6 clusters obtained with autocorrelation coefficients and complete linkage in Figure 11. In this case, clusters 1 and 4 capture those consumers with two intermediate peak loads in the morning and in the evening. Cluster 5 represents consumers with a single peak consumption in the afternoon, and clusters 2, 3 and 5, present consumers with less volatility.
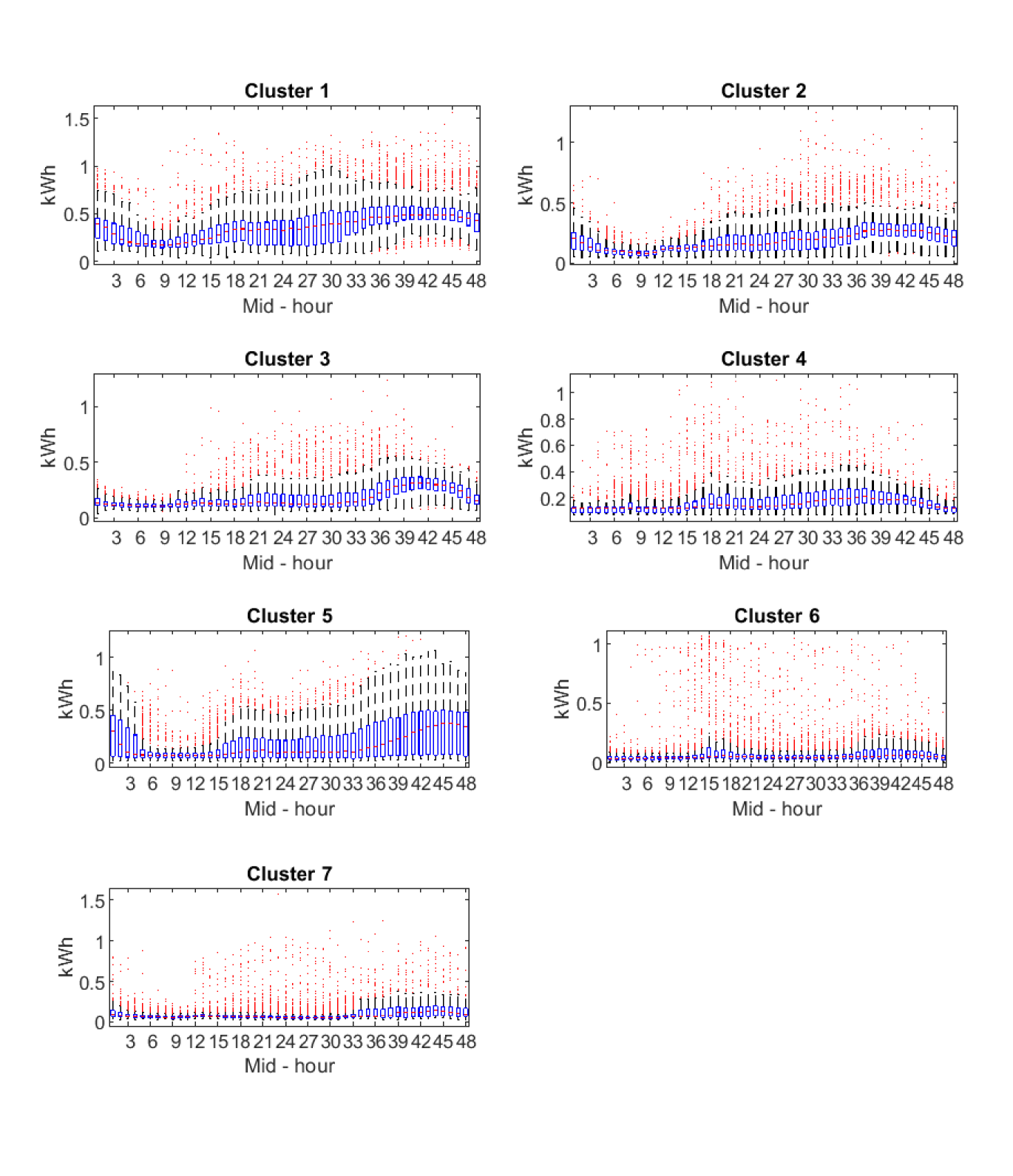
Similarly, Figure 12 shows the clusters obtained with partial autocorrelation coefficients and complete linkage. Clusters 1, 2 and 5 characterize consumers with a steady increasing load that reach its maximum at midnight, while clusters 3, 4, 6 and 7, represent consumers with two intermediate peaks in the morning and evening. In this case clusters from each type are mainly differentiated by the average load consumption levels.
IV Conclusions
In this work we have presented three different hierarchical-based clustering strategies based on a set “dissimilarity” measures computed over: quantile auto-covariances, and simple and partial autocorrelations. The main advantage of this approach is that we can summarize each series in only a set of representative features which makes them very easy to implement (highly efficient), easy to automatize and scalable to hundreds of thousands of series, i.e., valid for real-world applications with large datasets of time series, as the ones obtained from smart meters. We evaluate the performance of these clustering models with thousands of electricity consumption time series. The results are promising: we are able to obtain highly representative clusters capturing different electricity load consumption patterns and identifying the level of influence of each of the models’ features. Moreover, we have seen how the proposed clustering scheme can provide meaningful insights on the geo-demographic level of a household (Acorn groups), just by analyzing its time series dependencies (autocorrelations).
Acknowledgment
The authors gratefully acknowledge the financial support from the Spanish government through project MTM2017-88979-P and from Fundación Iberdrola through “Ayudas a la Investigación en Energía y Medio Ambiente 2018”.
References
- [1] R. Hierzinger, M. Albu, H. Van Elburg, A. J. Scott, A. Łazicki, L. Penttinen, F. Puente, and H. Sæle, “European smart metering landscape report 2012,” SmartRegions Deliverable, vol. 2, 2012.
- [2] S. S. S. R. Depuru, L. Wang, V. Devabhaktuni, and N. Gudi, “Smart meters for power grid—challenges, issues, advantages and status,” in 2011 IEEE/PES Power Systems Conference and Exposition. IEEE, 2011, pp. 1–7.
- [3] B. Yildiz, J. Bilbao, J. Dore, and A. Sproul, “Recent advances in the analysis of residential electricity consumption and applications of smart meter data,” Applied Energy, vol. 208, pp. 402–427, 2017.
- [4] Y. Wang, Q. Chen, T. Hong, and C. Kang, “Review of smart meter data analytics: Applications, methodologies, and challenges,” IEEE Transactions on Smart Grid, vol. 10, no. 3, pp. 3125–3148, 2018.
- [5] A. Al-Wakeel, J. Wu, and N. Jenkins, “K-means based load estimation of domestic smart meter measurements,” Applied energy, vol. 194, pp. 333–342, 2017.
- [6] G. Chicco, “Overview and performance assessment of the clustering methods for electrical load pattern grouping,” Energy, vol. 42, no. 1, pp. 68–80, 2012.
- [7] M. Koivisto, P. Heine, I. Mellin, and M. Lehtonen, “Clustering of connection points and load modeling in distribution systems,” IEEE Transactions on Power Systems, vol. 28, no. 2, pp. 1255–1265, 2012.
- [8] J. Kwac, J. Flora, and R. Rajagopal, “Household energy consumption segmentation using hourly data,” IEEE Transactions on Smart Grid, vol. 5, no. 1, pp. 420–430, 2014.
- [9] A. Lavin and D. Klabjan, “Clustering time-series energy data from smart meters,” Energy efficiency, vol. 8, no. 4, pp. 681–689, 2015.
- [10] F. McLoughlin, A. Duffy, and M. Conlon, “A clustering approach to domestic electricity load profile characterisation using smart metering data,” Applied energy, vol. 141, pp. 190–199, 2015.
- [11] A. Tureczek, P. Nielsen, and H. Madsen, “Electricity consumption clustering using smart meter data,” Energies, vol. 11, no. 4, p. 859, 2018.
- [12] Y. Wang, Q. Chen, C. Kang, and Q. Xia, “Clustering of electricity consumption behavior dynamics toward big data applications,” IEEE transactions on smart grid, vol. 7, no. 5, pp. 2437–2447, 2016.
- [13] C. Beckel, L. Sadamori, T. Staake, and S. Santini, “Revealing household characteristics from smart meter data,” Energy, vol. 78, pp. 397–410, 2014.
- [14] A. Kavousian, R. Rajagopal, and M. Fischer, “Determinants of residential electricity consumption: Using smart meter data to examine the effect of climate, building characteristics, appliance stock, and occupants’ behavior,” Energy, vol. 55, pp. 184–194, 2013.
- [15] J. P. Gouveia and J. Seixas, “Unraveling electricity consumption profiles in households through clusters: Combining smart meters and door-to-door surveys,” Energy and Buildings, vol. 116, pp. 666–676, 2016.
- [16] S. Haben, C. Singleton, and P. Grindrod, “Analysis and clustering of residential customers energy behavioral demand using smart meter data,” IEEE transactions on smart grid, vol. 7, no. 1, pp. 136–144, 2015.
- [17] B. Stephen, A. J. Mutanen, S. Galloway, G. Burt, and P. Järventausta, “Enhanced load profiling for residential network customers,” IEEE Transactions on Power Delivery, vol. 29, no. 1, pp. 88–96, 2013.
- [18] O. Y. Al-Jarrah, Y. Al-Hammadi, P. D. Yoo, and S. Muhaidat, “Multi-layered clustering for power consumption profiling in smart grids,” IEEE Access, vol. 5, pp. 18 459–18 468, 2017.
- [19] R. Al-Otaibi, N. Jin, T. Wilcox, and P. Flach, “Feature construction and calibration for clustering daily load curves from smart-meter data,” IEEE Transactions on industrial informatics, vol. 12, no. 2, pp. 645–654, 2016.
- [20] S. Zhong and K.-S. Tam, “Hierarchical classification of load profiles based on their characteristic attributes in frequency domain,” IEEE Transactions on Power Systems, vol. 30, no. 5, pp. 2434–2441, 2014.
- [21] R. Granell, C. J. Axon, and D. C. Wallom, “Impacts of raw data temporal resolution using selected clustering methods on residential electricity load profiles,” IEEE Transactions on Power Systems, vol. 30, no. 6, pp. 3217–3224, 2014.
- [22] K. Bandara, C. Bergmeir, and S. Smyl, “Forecasting across time series databases using recurrent neural networks on groups of similar series: A clustering approach,” arXiv preprint arXiv:1710.03222, 2017.
- [23] F. L. Quilumba, W.-J. Lee, H. Huang, D. Y. Wang, and R. L. Szabados, “Using smart meter data to improve the accuracy of intraday load forecasting considering customer behavior similarities,” IEEE Transactions on Smart Grid, vol. 6, no. 2, pp. 911–918, 2014.
- [24] M. Chaouch, “Clustering-based improvement of nonparametric functional time series forecasting: Application to intra-day household-level load curves,” IEEE Transactions on Smart Grid, vol. 5, no. 1, pp. 411–419, 2013.
- [25] B. Yildiz, J. I. Bilbao, J. Dore, and A. Sproul, “Household electricity load forecasting using historical smart meter data with clustering and classification techniques,” in 2018 IEEE Innovative Smart Grid Technologies-Asia (ISGT Asia). IEEE, 2018, pp. 873–879.
- [26] B. Lafuente-Rego and J. A. Vilar, “Clustering of time series using quantile autocovariances,” Advances in Data Analysis and classification, vol. 10, no. 3, pp. 391–415, 2016.
- [27] A. M. Alonso and D. Peña, “Clustering time series by linear dependency,” Statistics and Computing, vol. 29, no. 4, pp. 655–676, 2019.
- [28] L. Breiman, J. Friedman, C. Stone, and R. Olshen, Classification and Regression Trees, ser. The Wadsworth and Brooks-Cole statistics-probability series. Taylor & Francis, 1984.
- [29] H. Ishwaran, “Variable importance in binary regression trees and forests,” Electronic Journal of Statistics, vol. 1, pp. 519–537, 2007.
- [30] [Online]. Available: https://data.london.gov.uk/dataset/smartmeter-energy-use-data-in-london-households
- [31] [Online]. Available: https://acorn.caci.co.uk/downloads/Acorn-User-guide.pdf