Hierarchical Gaussian Process-Based Bayesian Optimization for Materials Discovery in High Entropy Alloy Spaces
Abstract
Bayesian optimization (BO) is a powerful and data-efficient method for iterative materials discovery and design, particularly valuable when prior knowledge is limited, underlying functional relationships are complex or unknown, and the cost of querying the materials space is significant. Traditional BO methodologies typically utilize conventional Gaussian Processes (cGPs) to model the relationships between material inputs and properties, as well as correlations within the input space. However, cGP-BO approaches often fall short in multi-objective optimization scenarios, where they are unable to fully exploit correlations between distinct material properties. Leveraging these correlations can significantly enhance the discovery process, as information about one property can inform and improve predictions about others. This study addresses this limitation by employing advanced kernel structures to capture and model multi-dimensional property correlations through multi-task (MTGPs) or deep Gaussian Processes (DGPs), thus accelerating the discovery process. We demonstrate the effectiveness of MTGP-BO and DGP-BO in rapidly and robustly solving complex materials design challenges that occur within the context of complex multi-objective optimization—carried out by leveraging the pyiron workflow manager—over FCC FeCrNiCoCu high entropy alloy (HEA) spaces, where traditional cGP-BO approaches fail. Furthermore, we highlight how the differential costs associated with querying various material properties can be strategically leveraged to make the materials discovery process more cost-efficient.
keywords:
Bayesian Materials Discovery Deep Gaussian Processes Multi-task Gaussian Processes High Entropy Alloys1 Introduction
Accelerating technological advancements often necessitates a corresponding acceleration in the materials development cycle. Central to this overarching initiative are the Integrated Computational Materials Engineering (ICME) paradigm [1] and the Materials Genome Initiative (MGI) [2]. ICME, established prior to MGI, focuses on integrating complex computational workflows to streamline the creation of new materials and processes [3, 4, 5, 6, 7, 8, 9]. Despite its advantages, ICME programs often face limitations due to the high computational cost of models and the challenges in creating explicit connections across different modeling steps [10]. In contrast, the MGI, launched in 2011, adopts a broader and more aspirational approach, advocating for the integration of advanced computational tools and data science to accelerate materials discovery [11]. This initiative has facilitated the adoption of emerging technologies, such as machine learning (ML), which has become a powerful tool for addressing limitations in traditional methods, particularly in predictive modeling for materials science.
ML excels at processing vast amounts of data, enabling the identification of patterns, the prediction of material properties, and the optimization of performance [12, 13]. By leveraging data from high-throughput simulations, fabrication processes, and characterization efforts, ML assists in identifying promising material candidates and aids in designing materials with specific functionalities [14, 15, 16]. When combined with physics-based models, ML can further enhance predictive insights, particularly for high-temperature alloys, thereby improving both material performance and resilience [17, 18, 19, 20, 21]. Beyond predictive capabilities, ML is increasingly employed to explore and optimize materials spaces, framing materials discovery as a ‘black box’ optimization problem. The objective is to optimize material properties by varying features such as chemical composition and processing conditions. Given the vast array of possible configurations and microstructures, efficient navigation of these spaces poses significant challenges. Bayesian Optimization (BO) has emerged as a key method to address this challenge [22, 23].
BO is particularly effective for optimizing functions that are expensive to evaluate and when available information is limited. It achieves this by using: (1) a surrogate model, typically a Gaussian Process (GP), to approximate the objective function while quantifying prediction uncertainty; (2) an acquisition function that strategically balances exploration and exploitation to determine the next evaluation point; and (3) an iterative process that refines the model and acquisition function with each new experiment [24, 23]. GPs are favored in BO due to their mathematical rigor, flexibility, and ability to quantify uncertainty, making them ideal for a wide range of optimization challenges [25, 26, 23]. By effectively balancing exploration and exploitation, BO accelerates the identification of materials with desired properties while minimizing the number of required experiments [26, 27, 28, 29, 30, 31, 32, 33, 34, 35].
BO’s data-efficient nature makes it an invaluable tool for the design and optimization of complex materials. Although BO has been successfully applied across various materials discovery challenges, it is particularly effective in navigating the expansive compositional spaces of high-entropy alloys (HEAs). HEAs, which incorporate five or more principal metallic elements, represent a significant advancement in alloy design by offering a broad landscape for optimizing material properties [36]. Given the vast design space, exhaustive searches are impractical, necessitating the adoption of strategic experimentation.
BO has been instrumental in advancing HEA development by enabling the creation of alloys with enhanced mechanical and functional properties, thus overcoming the limitations of conventional alloys at relatively modest computational or experimental costs [37, 38, 39, 40, 41, 42]. Its adaptability is further demonstrated through its application in exploring high-dimensional HEA design spaces using innovative approaches. These strategies include leveraging informative priors (incorporating domain expertise) [43], integrating physics-informed variants (embedding known physical laws) [44], implementing parallelized optimization (enabling batch-wise suggestions per iteration) [45], and ensuring constraint-aware optimization (adhering to specific design constraints) [46].
In practical applications, materials design always involves the consideration of multiple factors, including conflicting performance targets, design allowables, and constraints. This complexity renders single-objective BO-based materials optimization largely an academic exercise, as real-world problems require balancing trade-offs between various properties. Multi-objective BO-based materials discovery, although not as developed as single-objective BO-based materials design, has started to address these challenges [47, 45, 48, 49, 50, 51]. To date, most approaches to BO-based multi-objective materials design assume that each property target is independent, modeling the multi-objective response through independent GPs for each property. However, this approach is suboptimal, as it does not account for the fact that materials properties are often correlated to varying degrees, given their dependence on the same underlying arrangement of matter—examples of such correlations include the strength-ductility tradeoff or the positive correlation, within metallic systems, between density and electronic thermal conductivity. Unlike conventional GPs, Deep Gaussian Processes (DGPs) and Multi-Task Gaussian Processes (MTGPs) can learn correlations among multiple outputs using connected kernel structures, making them more efficient and effective in optimizing complex materials.
Multi-Task Gaussian Processes (MTGPs) are effective in learning correlations between related tasks, improving generalization by sharing information across tasks [52]. MTGPs model both positive and negative correlations, which enhances prediction quality and aids in identifying outliers [53, 54]. They use message-passing architectures to iteratively share latent information, efficiently transferring knowledge in correlated tasks [55, 56]. MTGPs have been successfully applied in fields like gene expression [56], sentiment analysis [55], and human motion modeling [57], making them powerful tools for multi-task learning. Deep Gaussian Processes (DGPs) offer a hierarchical extension of GPs, combining the flexibility of deep neural networks with the uncertainty quantification of GPs [58]. These models, equivalent to neural networks with infinitely wide hidden layers, capture complex, non-linear relationships [59]. They have proven effective in time series forecasting [60], image classification [61], and reinforcement learning [62].
The advantages of DGP and MTGP over cGP within a BO setting remains to be demonstrated for any materials design scenario with multiple objectives, however, the potential to dramatically improve the performance of Bayesian materials discovery schemes is evident: unlike cGP-BO, which models each material property independently, MTGP-BO and DGP-BO are capable of capturing correlations between multiple material properties. This capability allows these advanced BO methods to exploit shared information across different properties, leading to more efficient exploration and optimization of complex material spaces. By leveraging these correlations, MTGP-BO and DGP-BO can reduce the number of required experiments, accelerate the discovery process, and achieve more accurate predictions in multi-objective optimization tasks.
One promising application of these advanced Bayesian Optimization (BO) methods lies in the discovery of alloys that must simultaneously satisfy multiple, interrelated performance criteria. A prime example of such a discovery problem is the identification of alloys that exhibit both low thermal expansion coefficients (CTE) and high bulk moduli (BM). These alloys are highly sought after in various technologies where dimensional stability, mechanical strength, and thermal resistance are paramount. For instance, alloys such as NbTiVZr, known for its high yield strength and low CTE at elevated temperatures [63], and ZrNbAl, recognized for its low CTE and robust mechanical properties [64], are ideal for engineering applications that demand thermal dimensional stability and strength. Furthermore, the fine-tuning of CTE is crucial when considering self-compatible base alloys and thermal/environmental protection systems in turbine blade applications [65]. The extensive design space of high-entropy alloys (HEAs) offers a rich landscape for discovering new alloys with these combined properties; however, the complexity of this space necessitates intelligent and informed experimentation.
This study aims to demonstrate the superiority of Deep Gaussian Process Bayesian Optimization (DGP-BO) and Multi-task Gaussian Process Bayesian Optimization (MTGP-BO) over conventional Gaussian Process Bayesian Optimization (cGP-BO) within the FeCrNiCoCu HEA system, focusing on two specific sets of objectives. Specifically, the proposed framework will be used to explore compositions with both low CTE-high BM and high CTE-high BM in the vast HEA design space using high-throughput atomistic simulations.
Our ultimate objective is to demonstrate that advanced kernel-based Bayesian Optimization (BO) methods, such as Deep Gaussian Process BO (DGP-BO) and Multi-Task Gaussian Process BO (MTGP-BO), can effectively leverage and learn from correlated properties, thereby outperforming conventional Gaussian Process BO (cGP-BO), which lacks the ability to utilize shared information across correlated properties. Given that material properties are inherently correlated and share information among themselves, we hypothesize that methods like DGP-BO and MTGP-BO, which explicitly exploit mutual information across different properties (or ’tasks’ in the context of machine learning), will exhibit markedly superior performance compared to methods that are agnostic to these correlations. Since all realistic materials discovery problems are inherently multi-objective and properties are interrelated, the methods demonstrated in this work have broad applicability in a diverse set of problems associated with materials discovery and optimization.
2 Methods
2.1 Mathematical Basis of GP and MTGP
In materials discovery applications, GP and MTGP models offer powerful frameworks for predictive modeling and optimization. GPs are a robust tool for modeling objective functions in multi-objective BO, providing a probabilistic approach to regression that quantifies uncertainty in predictions [66]. Traditional BO algorithms often model each objective function independently using separate GPs, thus assuming no correlation between them. This independent modeling approach can overlook potential interrelationships among objective functions. In contrast, the MTGP approach models all objective functions jointly, capturing any correlations and leveraging shared information to improve predictive accuracy [67].
Consider a GP constructed for an objective function . The prediction at an unobserved location given previously observed data points denoted by , where and , is given as:
where the mean and variance are defined as:
Here, is the kernel function, is an matrix where the -th entry is , and is an vector with the -th entry being . The term represents experimental noise. The kernel function captures the correlation between observations based on their relative distances [68]—these distances may not necessarily be defined in a Euclidean space. A common choice for the kernel function is the squared exponential kernel:
where is the dimensionality of the input space, and is the characteristic length-scale determining the strength of correlation in the -th dimension.
The MTGP model extends this by jointly modeling multiple objective functions, taking into account their inter-task correlations [69]. To achieve this, we define a task-specific covariance matrix to capture the similarities between tasks. The overall covariance function for the MTGP model is constructed using the Kronecker product of the task covariance matrix and the input covariance matrix :
Here, denotes the Kronecker product. The variable in the equations is a column vector, where each task’s data is ordered in columns and stacked vertically.
This MTGP model allows us to capture the correlations between different objective functions, thereby improving the accuracy and efficiency of the optimization framework. By leveraging the shared information between tasks, the MTGP can enhance the performance of the design optimization process, leading to more accurate predictions and faster convergence to optimal solutions [70]. Inference in the MTGP model follows the standard GP equations for the mean and variance of the predictive distribution, extended to the multi-task setting. The mean prediction for a new data point for task is given by:
where selects the -th column of , is the vector of covariances between the test point and the training points, and is the combined covariance matrix given by , where is a diagonal matrix representing noise variances. Here, represents the observed data across all tasks, stacked appropriately. The use of MTGP allows for the transfer of information between tasks, leveraging the inter-task correlations to improve predictive performance, especially when data is sparse for some tasks. This joint modeling approach is particularly beneficial in materials discovery, where the properties of materials are often correlated, and exploiting these correlations can lead to more efficient and accurate predictions [71, 72].
The hyperparameters of the MTGP model, including the parameters of the kernel functions and the task covariance matrix, are learned by maximizing the marginal likelihood of the observed data [66]. This can be done using gradient-based optimization methods, ensuring the positive semi-definiteness of through parametrization such as the Cholesky decomposition [69]. Overall, the MTGP model provides a flexible and powerful approach for multi-objective optimization, capturing inter-task correlations and enhancing the efficiency of the design framework.
2.2 Mathematical Basis of DGP
Deep Gaussian Processes (DGPs) extend the concept of GP to hierarchical models, providing a more powerful and flexible approach to modeling complex data [73]. A DGP consists of multiple layers of latent variables, where each layer is modeled by a GP. This hierarchical structure allows for the representation of more abstract features at higher layers, which can improve predictive performance in tasks with complex underlying structures [74].
In a standard GP, we model a set of training input-output pairs, , using a latent function drawn from a GP prior, and we infer the distribution of given the data. Observed data points are denoted by , where and . In the case of the DGP, the inputs to the GP at each layer are governed by the outputs of the GP from the previous layer. Formally, if we consider a DGP with hidden layers, the generative process can be described as:
where are the observed data points, are the latent variables at the -th layer, and are the discrete data points used as the inputs for the highest layer in the hierarchy. Each function is modeled as a GP with an appropriate covariance function [75].
Training a DGP involves marginalizing over the latent variables in each layer, which is analytically intractable. To address this, we use a variational approach to approximate the marginal likelihood [76]. The variational distribution is introduced to approximate the true posterior distribution of the latent variables. The variational lower bound on the marginal likelihood is given by:
where is factorized as:
and are inducing variables for the -th layer, which is a smaller set of data points designed to approximate the posterior for each layer while managing computational complexity. The terms in the variational lower bound can be computed analytically, allowing for efficient optimization of the model parameters and variational distributions [77].
This Bayesian training approach not only provides a principled way to learn the model parameters but also enables automatic determination of the appropriate structure for the deep hierarchy through the use of automatic relevance determination (ARD) priors [78]. The ARD priors help in identifying the most relevant dimensions at each layer, facilitating effective model complexity control.
2.3 Mathematical Basis of Expected Hypervolume Improvement (EHVI) and Upper Confidence Bound (UCB)
In BO, acquisition functions guide the search for the optimal solution by balancing exploration and exploitation. Two popular acquisition functions are the Upper Confidence Bound (UCB) and Expected Hypervolume Improvement (EHVI).
2.3.1 Upper Confidence Bound (UCB)
The UCB acquisition function selects the next query point by maximizing a confidence interval around the prediction. It is defined as:
where is the mean prediction at point , is the standard deviation, and is a parameter that controls the trade-off between exploration (higher ) and exploitation (lower ) [80]. By considering both the predicted mean and the uncertainty, UCB ensures that regions with high uncertainty are explored, which helps in finding the global optimum efficiently [81].
2.3.2 Expected Hypervolume Improvement (EHVI)
2.3.3 Definition of Dominance and Hypervolume
Consider a multi-objective optimization problem with objectives:
| (1) |
Let be a vector of objective values. A point is said to dominate another point , denoted as , if:
| (2) |
The hypervolume of a set with respect to a reference point is defined as:
| (3) |
where is an indicator function that returns 1 if and 0 otherwise [84].
2.3.4 Improvement in Hypervolume
Given a new candidate solution with predicted objective values following an independent multivariate Gaussian distribution with mean vector and standard deviation vector , the improvement in hypervolume is measured by the increase in the hypervolume of the Pareto front when is added to the population :
| (4) |
2.3.5 Computation of EHVI
The EHVI integrates the improvement in hypervolume over the distribution of the predicted values:
| (5) |
where is the probability density function of the predicted values of [85]. To compute the EHVI, the integration region is partitioned into a set of interval boxes using a grid defined by the current Pareto front and the reference point . Each grid cell has lower and upper bounds and , respectively. The contribution of each active grid cell to the EHVI is computed by:
| (6) |
where:
| (7) |
and is given by:
| (8) |
Here, and denote the probability density function and the cumulative distribution function of the standard normal distribution, respectively [83]. Finally, the EHVI is obtained by summing the contributions of all active grid cells:
| (9) |
This formulation allows for an efficient and accurate computation of EHVI, enabling its use in multi-objective Bayesian optimization for alloy design problems [86].
Both UCB and EHVI provide robust frameworks for decision-making in Bayesian optimization, with UCB being straightforward and suitable for single-objective problems, and EHVI being powerful for multi-objective optimization by effectively balancing the exploration of the Pareto front [87].
2.4 Isotopic vs. Heterotopic Data in DGP-BO
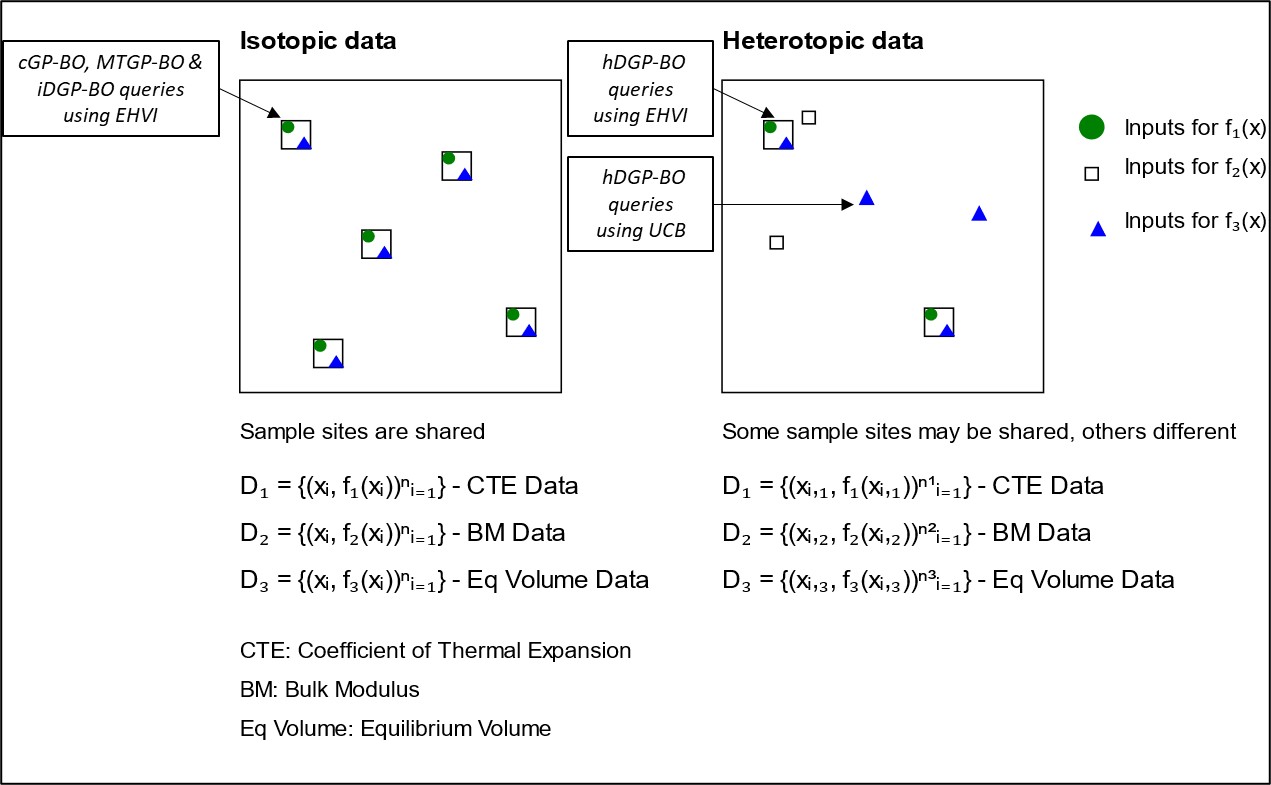
In BO with DGPs, the distinction between isotopic and heterotopic sample sites(query sites or data points) is crucial for understanding the operational differences between Isotopic DGP-BO (iDGP-BO) and Heterotopic DGP-BO (hDGP-BO)[69].
Isotopic data refers to scenarios where sample sites are shared across all tasks. This means that the same input locations are used for every task, simplifying the modeling process since the correlation structure between tasks can be more easily captured due to the shared sampling sites. This is the approach taken by iDGP-BO in this work, which assumes that the tasks are closely related and can be effectively modeled using shared sample points or query sites. While this assumption reduces complexity and improves computational efficiency, it may miss task-specific nuances that arise from differing sample sites, potentially leading to suboptimal performance in complex, real-world scenarios where such assumptions do not hold. Mathematically it can be described as,
where represents the shared sample locations, and and represent the outputs for the respective tasks at those locations.
Heterotopic data, on the other hand, allows query sites to differ between tasks, providing greater flexibility in modeling. This is the foundation of hDGP-BO , where each task has its own set of sampling sites. This approach leverages the additional flexibility provided by different query locations to better capture task-specific correlations, making it possible to exploit these for more effective optimization. By allowing for different sample sites, hDGP-BO can perform more nuanced and accurate predictions, particularly in cases where the tasks exhibit significant variability in their data distributions. This added complexity requires more sophisticated modeling but can result in superior performance, as evidenced in our experiments. It can be expressed as,
where and represent different sample locations for each task.
iDGP-BO uses a DGP that assumes all tasks share the same sampling sites. Here, all the queries across all the task are always made on same query locations based on EHVI acquisition function. This isotopic approach simplifies the correlation structure between tasks, making it easier to model but potentially less flexible in handling task-specific variations. The advantage of iDGP-BO lies in its simplicity and computational efficiency, which can be beneficial in scenarios where tasks are expected to be closely related.
hDGP-BO, however, uses a more complex framework that allows each task to have its own sampling sites (heterotopic approach). This model leverages DGP to capture more intricate correlations between tasks, which can be particularly beneficial when tasks are less related or exhibit significant individual characteristics. hDGP-BO also incorporates an acquisition strategy where less expensive tasks can be queried more frequently, using techniques like UCB to reduce uncertainty, thereby informing the sampling strategy for more expensive tasks. This makes hDGP-BO not only more flexible but also potentially more accurate in scenarios where task-specific data is critical. In our strategy, hDGP-BO makes queries using same input points one-third of the times using EHVI. During other steps, it queries only BM and volume at different input locations, based on the highest UCB of respective tasks. In this way hDGP-BO can explore or be informed about CTE at a certain location by only querying the BM or volume at that specific location. This occurs because of the correlated structure of DGP. Thus, knowing one task at a specific input location informs the GP about associated tasks at that location without explicitly querying those associated tasks.
In the workflow of this current work, hDGP-BO queries CTE, BM and volume 500 times using EHVI during the whole BO procedure (isotopic queries). In addition to that, hDGP-BO queries only BM and volume twice using UCB before each isotopic queries. So, in total hDGP-BO acquires CTE data 500 times and BM, volume data 1500 times. Whereas, models executing only isotopic queries (cGP-BO, MTGP-BO & iDGP-BO) acquires CTE, BM and volume data 500 times each. hDGP-BO leverages this additional relatively inexpensive BM and volume data to carry out the optimization task in a more efficient and robust manner.
2.5 High-throughput Bayesian Optimization Framework
As the underlying simulation platform for our BO, we employed the pyiron workflow framework [88] to conduct high-throughput screening simulations for sampling the FeCrNiCoCu high entropy alloy (HEA) space. pyiron provides workflows to calculated material properties independent of the simulation engine, including thermal expansion coefficeints (CTE), equilibrium bulk modulus (BM) and equilibrium volume (V). We calculate those with an atomic composition resolution of 3%, amounting to a total of roughly 60,000 configuration to sample the composition space. For benchmarking the BO schemes the target properties were calculated for all compositions a priori. Subsequently, the BO schemes queried from this consolidated database for optimization, which accelerates benchmarking the different BO schemes and facilitates systematic performance analysis.
We emphasize that, in a real experimental design scenario, the properties would only be evaluated at the query points in an on-the-fly fashion, a mode of operation that our workflow is designed to support. The pyiron workflow framework facilitates the seamless integration and automation of various simulation tools and workflows, significantly enhancing the efficiency and scalability of high-throughput screenings. Conceptually, pyiron functions as a high-level task-based interface to the simulation engine responsible for the material property calculations. In our case, the Large-scale Atomic/Molecular Massively Parallel Simulator (LAMMPS) [89, 90] is employed to efficiently evaluate material properties across a large number of configurations. Additionally, pyiron provides a user-friendly Python interface for setting up, executing, storing, and analyzing high-throughput molecular dynamics (MD) simulations at large computational scales on high-performance computing (HPC) resources, which is critical for the coupling with Bayesian Optimization (BO).
To efficiently sample the composition space and ensure a realistic representation of the random nature of HEAs, we utilized Special Quasirandom Structures (SQS) [91, 92] with 32 atoms, generated with the sqsgenerator package [93]. SQS are designed to mimic the perfectly random atomic arrangements of alloys in finite supercells, providing more accurate simulation results. The atomic configuration were evaluted using the embedded atom method (EAM) interatomic potential developed by Deluigi et al., which was designed for simulating FeNiCrCoCu [94]. That being said, as the purpose of this study is to quantify the performance of various multi-task BO approaches, the absolute accuracy of the physical predictions obtained from the interatomic potential is not critical, as the general statistical properties of the correlations within and between tasks is expected to control performance.
For our workflow, each simulation began with rescaling the simulation cell based on the concentration-averaged nearest neighbor distance of its end members. This is followed by a structure optimization including relaxation of the simulation cell volume and internal degrees of freedom, resulting in an equilibrated structure at 0K. For calculation of equilibrium BM, these equilibrated structures are strained from -15% to +15% with an additional equilibration of the internal degrees of freedom. The BM is then calculated as the second derivative of these energy volume curves. Starting from the same equilibrated structure at 0K the CTE is determined by varying the simulations temperature from 15K to 1500K in 5K intervals over a 6ps molecular dynamics trajectory in the NPT ensemble [95, 96] with a 1fs time step. By recording the change of volume with increasing temperature, the CTE is calculated providing insights into the thermal behavior of the alloys [97]. These MD simulations are carried out in supercells of the 32 atoms SQS cells, resulting in 864 atoms cells to ensure statistical accuracy [98, 99].The calculation of CTE differs from that of BM. The CTE require calculations of volume(along with energy minimization and NPT ensemble trajectories) at 297 different temperatures. Whereas, for calculation of equilibrium BM, there’s no dependence on temperature unlike CTE. Thus, the cost associated with BM calculations is lower than that of CTE from a computational perspective. The CTE calculations requires 29800 more force evaluations (within a NPT ensemble), compared to the cost of calculation in case of BM.
In total 3.5 billion atomic configurations were evaluated to construct the consolidated database for the roughly 60,000 compositions with over 750,000 individual simulation tasks being recorded in the pyiron database. This highlights the need of a workflow framework like pyiron for systematically evaluating the HEA composition space.
3 Results and Discussion
3.1 High-throughput Atomistics Simulation
The main objective of this work is to compare the performances of cGP-BO, MTGP-BO, iDGP-BO and hDGP-BO in two specific multi-objective optimization tasks, concerning FeCrNiCoCu HEA design space. The first optimization task is to minimize CTE and maximize BM. The second optimization task involves maximization of both CTE and BM in the vast HEA space. Both of the objectives has their respective engineering applications, which will be discussed in details afterwards.
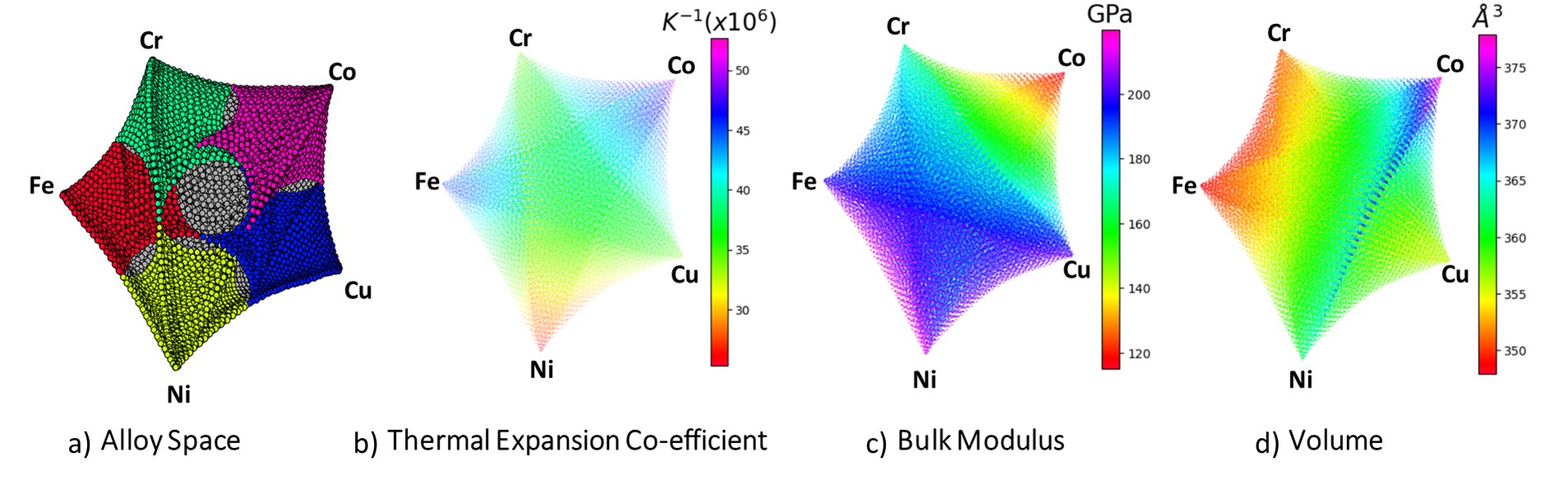
Firstly, the results of our high-throughput atomistics simulations for the FeCrNiCoCu alloy system are presented using Uniform Manifold Approximation and Projection (UMAP) representations, as shown in Figure 2 [100, 101]. UMAP, a dimension reduction technique, was chosen for its ability to preserve both local and global structure in high-dimensional data, making it particularly suited for visualizing the complex relationships in our alloy composition space.
UMAP offers several advantages over traditional dimension reduction methods [101]:
-
1.
It preserves topological structure across multiple scales, allowing for the visualization of both fine-grained local relationships and broader global patterns.
-
2.
It can handle non-linear relationships in the data, which are common in materials science datasets.
-
3.
It is computationally efficient, enabling the visualization of large datasets typical in high-throughput studies.
In our analysis, UMAP transforms the five-dimensional compositional space of the FeCrNiCoCu alloy system into a two-dimensional representation. Each point in these visualizations corresponds to a unique alloy composition, with color gradients indicating the magnitude of different material properties. This approach provides an intuitive understanding of how properties vary across the compositional landscape, allowing for rapid identification of trends, clusters, and potential high-performance regions. These plots effectively capture the complex interplay between composition and properties, offering insights that might be obscured in traditional analysis methods. The use of UMAP allows us to visually explore correlations between different properties and identify compositional regions of interest for further investigation.
Figure 2 reports the properties of the FeCrNiCoCu alloy space in UMAP scheme, calculated using the workflow described in the last section. Figure 2(a) reports the mapping of the compositional space of the FeCrNiCoCu alloy system onto a UMAP. Colors indicate region where the alloy contains an element at more than 50% concentration, while no single element reaches this threshold in grey regions. Pure materials are found at the vertices of the projection. Figure 2(b) illustrates the distribution of thermal expansion coefficients across different alloy compositions in this same projection, showing significant variation and potential candidates with low CTE. Figure 2(c) shows the bulk moduli for the same set of alloys, which is crucial for identifying compositions with high mechanical strength. Finally, Figure 2(d) depicts the equilibrium volumes, providing additional context for the structural properties of the alloys. Note that this projection does not guarantee continuity of the various properties in the 2D plane. It should therefore be taken primarily as a visualization aid.
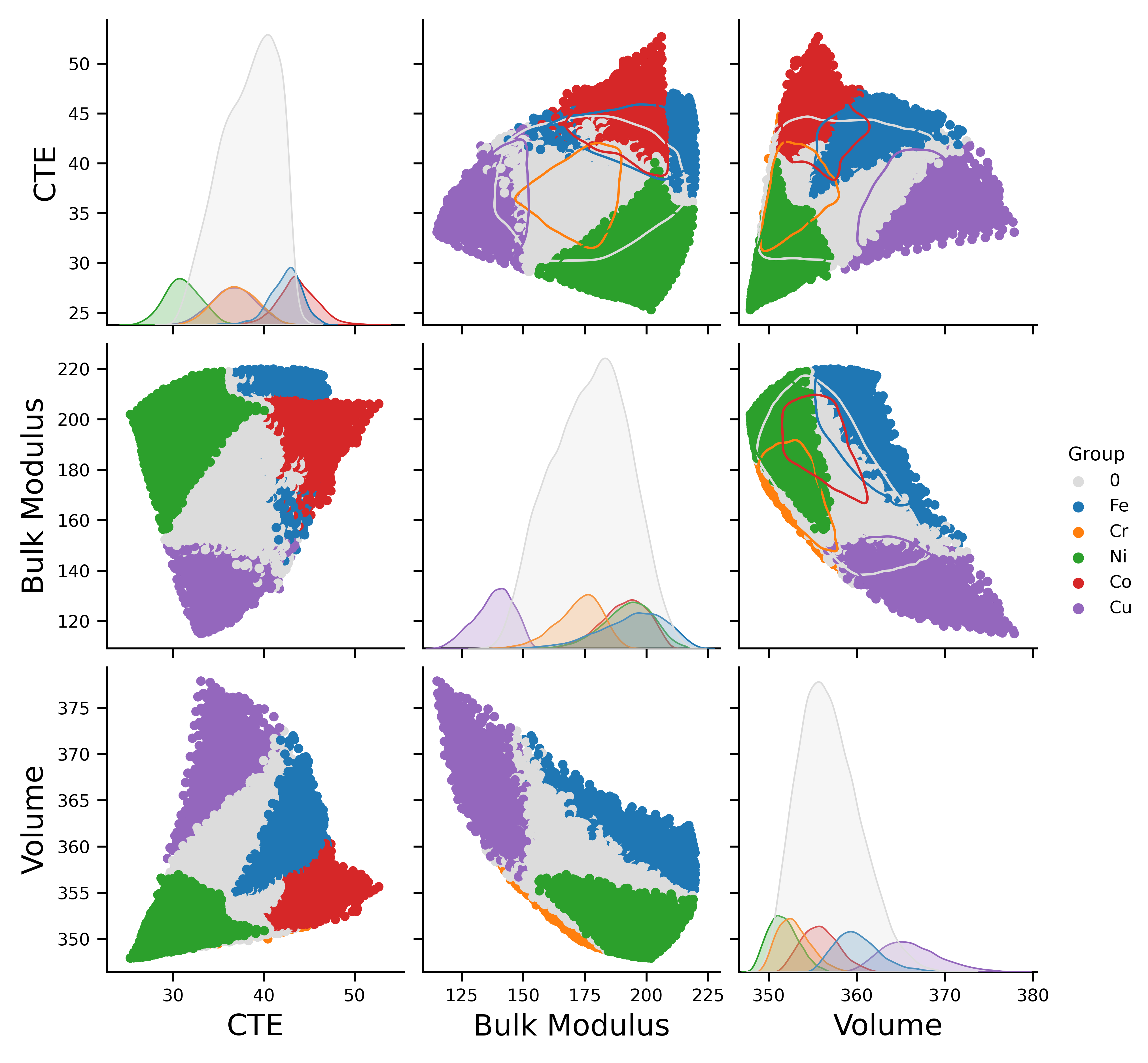
In addition to having UMAP plots for the properties individually, attempts have been made to understand the inter-relationship between the properties. The pairwise plots in Figure 3 and the correlation table in Table 1 provide a deeper understanding of the inter-dependencies between thermal expansion coefficients, bulk moduli, and volumes. Table 1 reports a statistical correlation analysis, including Pearson correlation coefficients, Spearman coefficients, and mutual information between CTE, BM, and volume. The Pearson and Spearman coefficients provide insights into the linear and monotonic relationships between the properties, respectively, while mutual information captures both linear and non-linear dependencies [102].
The weak correlations observed between these properties suggest the possibility of complex non-linear relationships [102, 103]. It is important to note that while weak linear correlations can indicate non-linear relationships, they are not definitive proof [104]. Nonetheless, the presence of weak correlations in our high-dimensional materials data motivates the exploration of more sophisticated analysis techniques [105]. Thus, the potential for using multi-task learning models to exploit these potentially complex non-linear relationships is a motivating factor for our subsequent analysis [67, 106, 107].
These correlations arise from the underlying physical mechanisms governing the behavior of HEAs, such as the complex interplay between atomic size mismatch, lattice distortion, and chemistry [108, 109]. Empirical models to predict the thermal expansion based on the equilibrium volume, equilibrium bulk modulus and its derivative like proposed by Moruzzi et al. [110] fail for these HEAs, which highlights the need for improved regression surrogates capable of learning complex relationship like MTGP or DGP for HEAs. Finally, leveraging these correlations can lead to more efficient exploration and optimization of the HEA design space.
| Name | TEC | BM | Volume | ||||||
| Pearson | Spearman | MI | Pearson | Spearman | MI | Pearson | Spearman | MI | |
| TEC | 1 | 1 | 1 | 0.13 | 0.15 | 0.12 | 0.32 | 0.37 | 0.20 |
| BM | 0.13 | 0.15 | 0.12 | 1 | 1 | 1 | -0.66 | -0.56 | 0.37 |
| Volume | 0.32 | 0.37 | 0.20 | -0.66 | -0.56 | 0.37 | 1 | 1 | 1 |
3.2 Multi-objective Bayesian Optimization with Auxiliary Tasks in FeCrNiCoCu Alloy Space: Minimization of TEC - Maximization of BM
In this section, we characterize and compare the relative efficiency of four multi-task BO approaches: cGP-BO, MTGP-BO, iDGP-BO and hDGP-BO. We apply these approaches to multi-objective material design tasks within the FeCrNiCoCu HEA space, focusing on the simultaneous minimization of CTE and maximization of BM (also, maximization of both as a case study in the next subsection), while using equilibrium volume as an auxiliary task.
This optimization scenario is particularly relevant for advanced technological applications requiring materials with exceptional dimensional stability under varying thermal conditions while maintaining high mechanical strength. Such materials are crucial in industries like aerospace, where components must withstand extreme temperature fluctuations without compromising structural integrity. For instance, in the design of next-generation aircraft engines or hypersonic vehicles, alloys with low CTE and high BM are essential for maintaining precise geometries and resisting deformation under high-stress, high-temperature environments [108, 111].
Our investigation aims to demonstrate how advanced BO techniques, particularly MTGP-BO and DGP-BO, can leverage inter-task correlations and complex, non-linear relationships in the material property space to accelerate the discovery of HEAs with these desired characteristics. By comparing these methods against cGP-BO, we seek to quantify the potential improvements in optimization efficiency and highlight the advantages of multi-task learning approaches in navigating the vast and complex design space of HEAs. Among all the different variants of BO, our novel hDGP-BO has demonstrated the most significant improvements over all other BO variants. The primary objective in this scenario was to minimize the CTE while maximizing the BM.
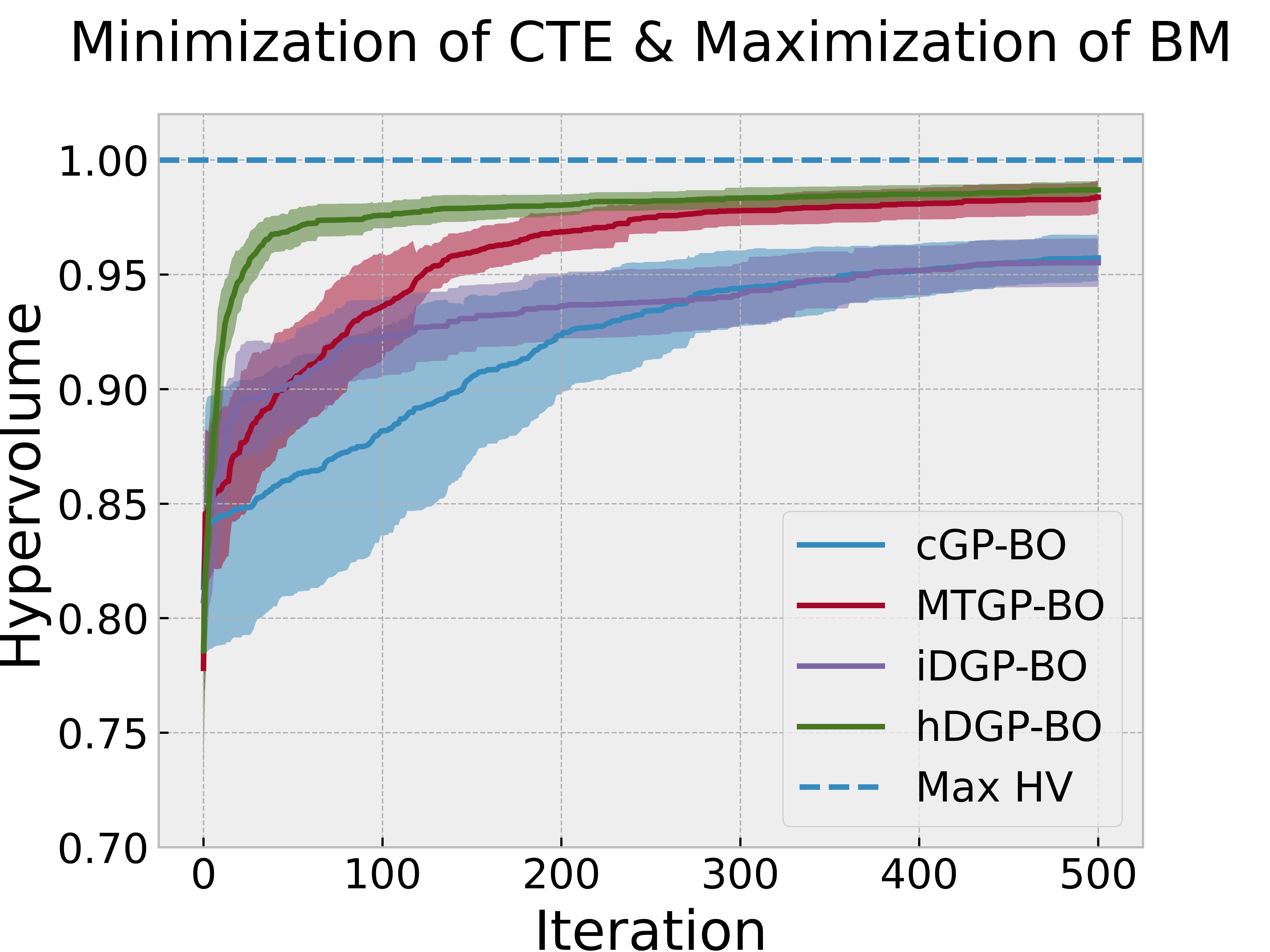
Figure 4 reports the evolution of the hypervolume during an iterative BO procedure based on different models, where an iteration is defined by a single query to all tasks using EHVI, except for the heterotopic DGP-BO (hDGP-BO) model where one iteration of hDGP-BO comprises of two steps of queries to BM and volume using UCB, and one step of query to CTE, BM and volume using EHVI. So, during 500 iteration, hDGP-BO acquired 500 CTE, 1500 BM and 1500 volume data points, whereas, cGP-BO, MTGP-BO & iDGP-BO acquired 500 datapoints of CTE, BM and volume each. One of the objectives is to investigate whether hDGP-BO can use these extra to accelerate the mapping of the Pareto front with respect to isotopic BO variants.
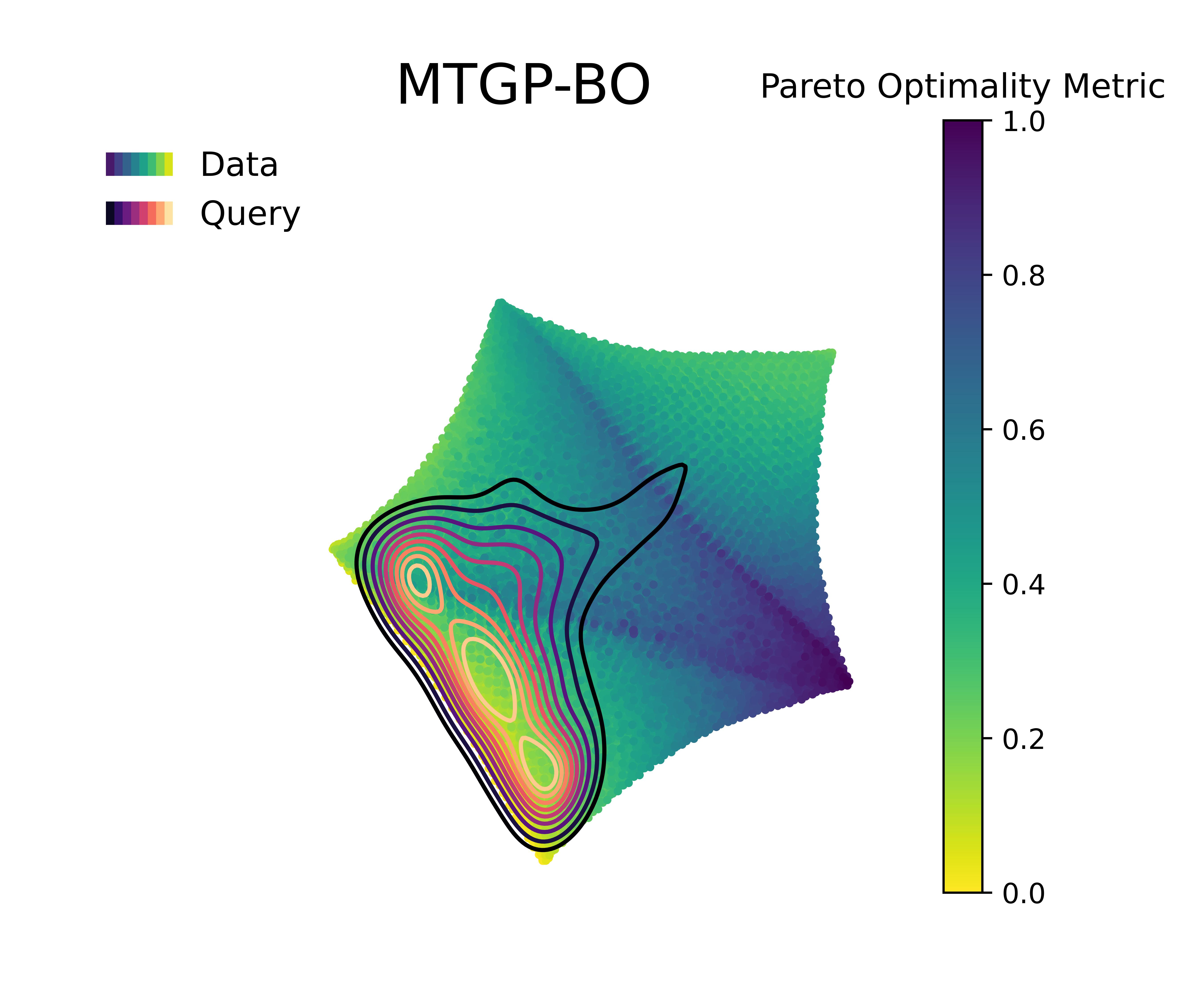
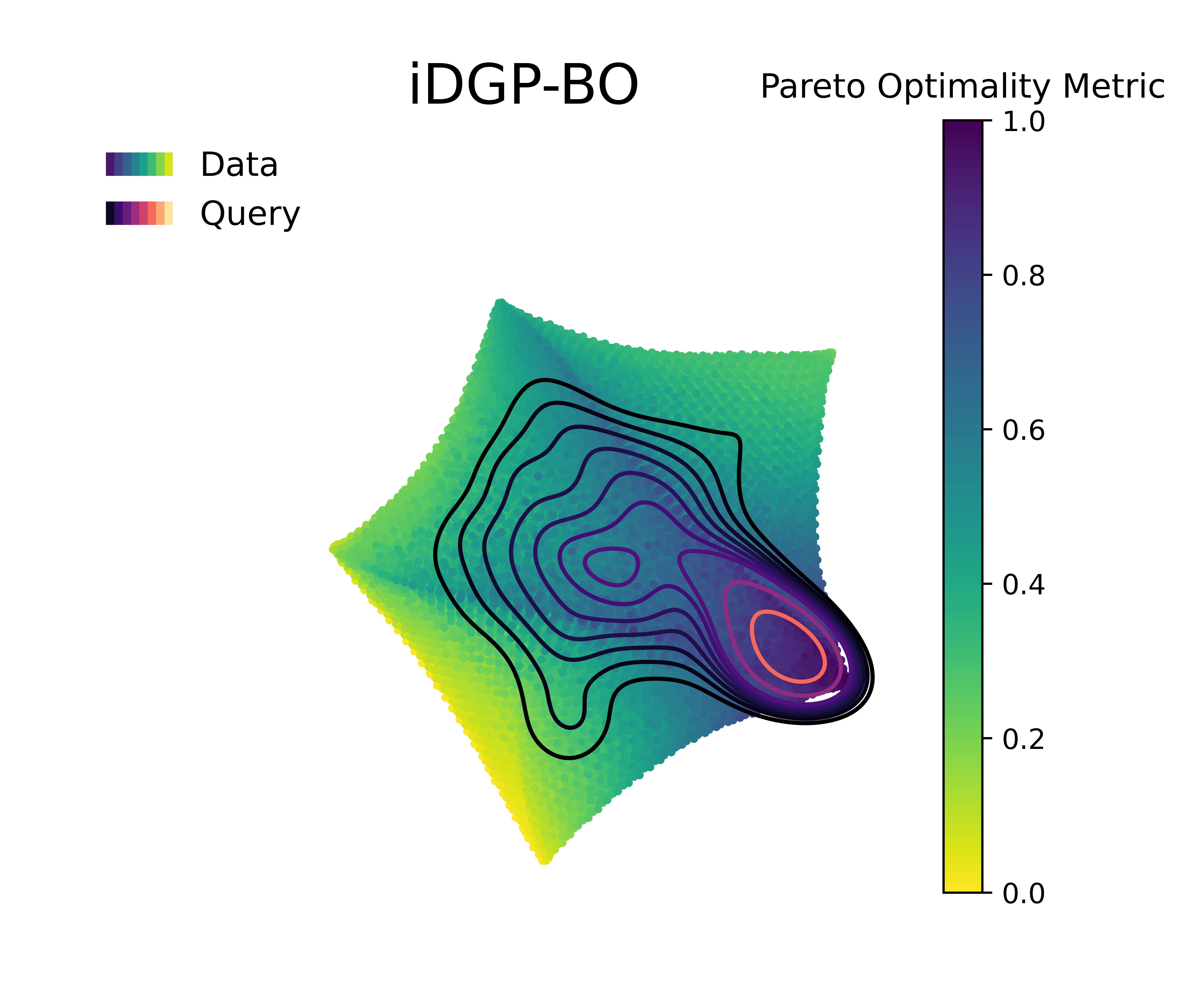
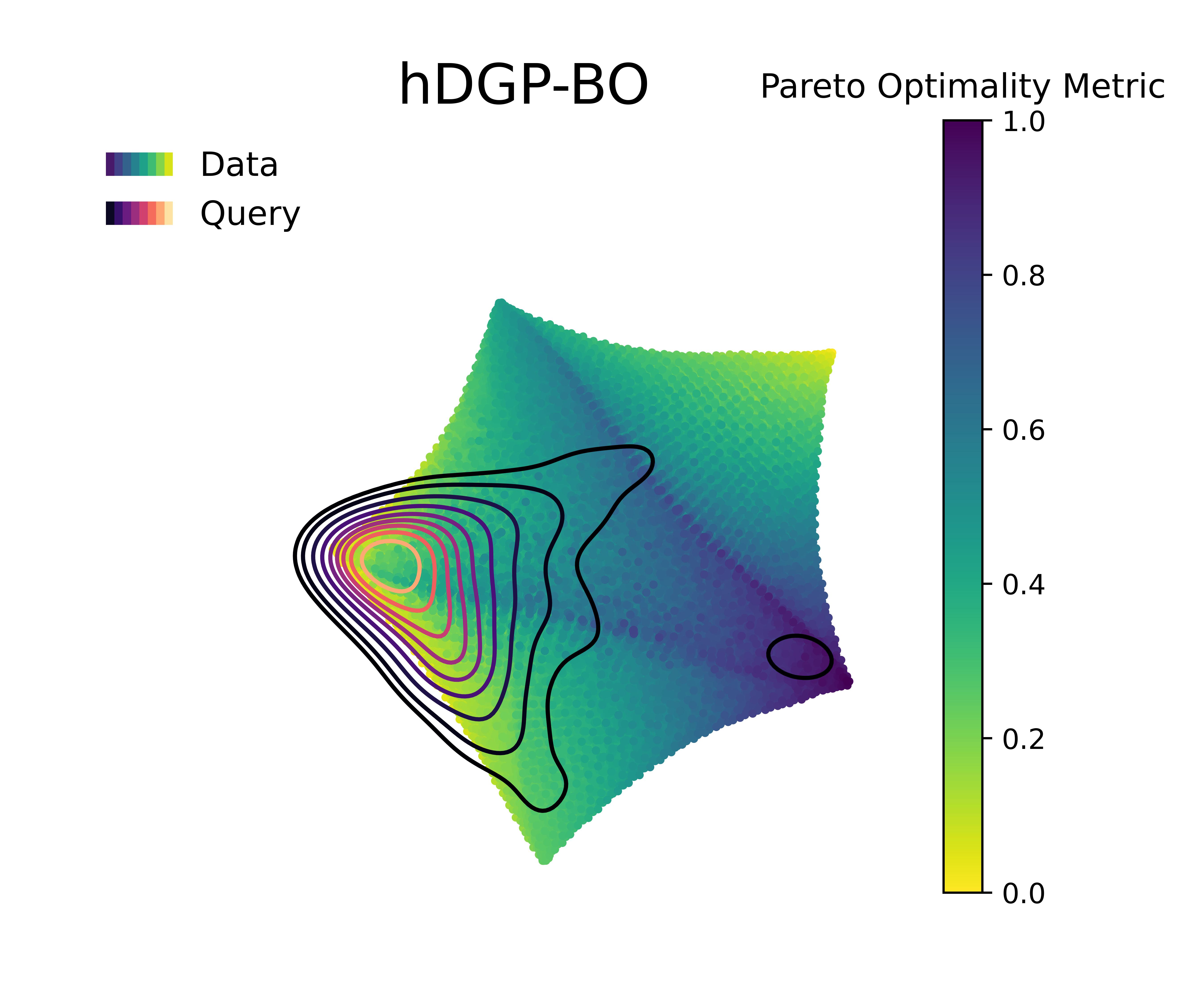
Figure 5 &
Figure 6 visualizes the queries in the objective space and design space for the first 100 queries, and the Pareto optimality metric across the query space, respectively. The Pareto optimality metric is defined by the euclidean distance to the nearest Pareto point, scaled between 0 and 1, where 1 implies being farthest from the nearest Pareto optimal points and 0 indicate the Pareto set itself. The KDE (kernel density estimation) contounrs represent the distribution of queries made by 20 independent replications of the whole BO loop.
Figure 4 along with Figure 5 & Figure 6 compare the performance and querying behavior of cGP-BO, MTGP-BO, isotopic DGP-BO (iDGP-BO), and heterotopic DGP-BO (hDGP-BO). DGP-BO and MTGP-BO models, in general, exhibit a more thorough exploration of the objective space, efficiently identifying regions with low CTE and high BM. The superior performance of MTGP-BO and DGP-BO can be attributed to their ability to exploit correlations between different objectives, as noted by prior works [112, 70, 113]. This leads to fewer iterations to identify optimal solutions, thereby reducing computational costs and time.
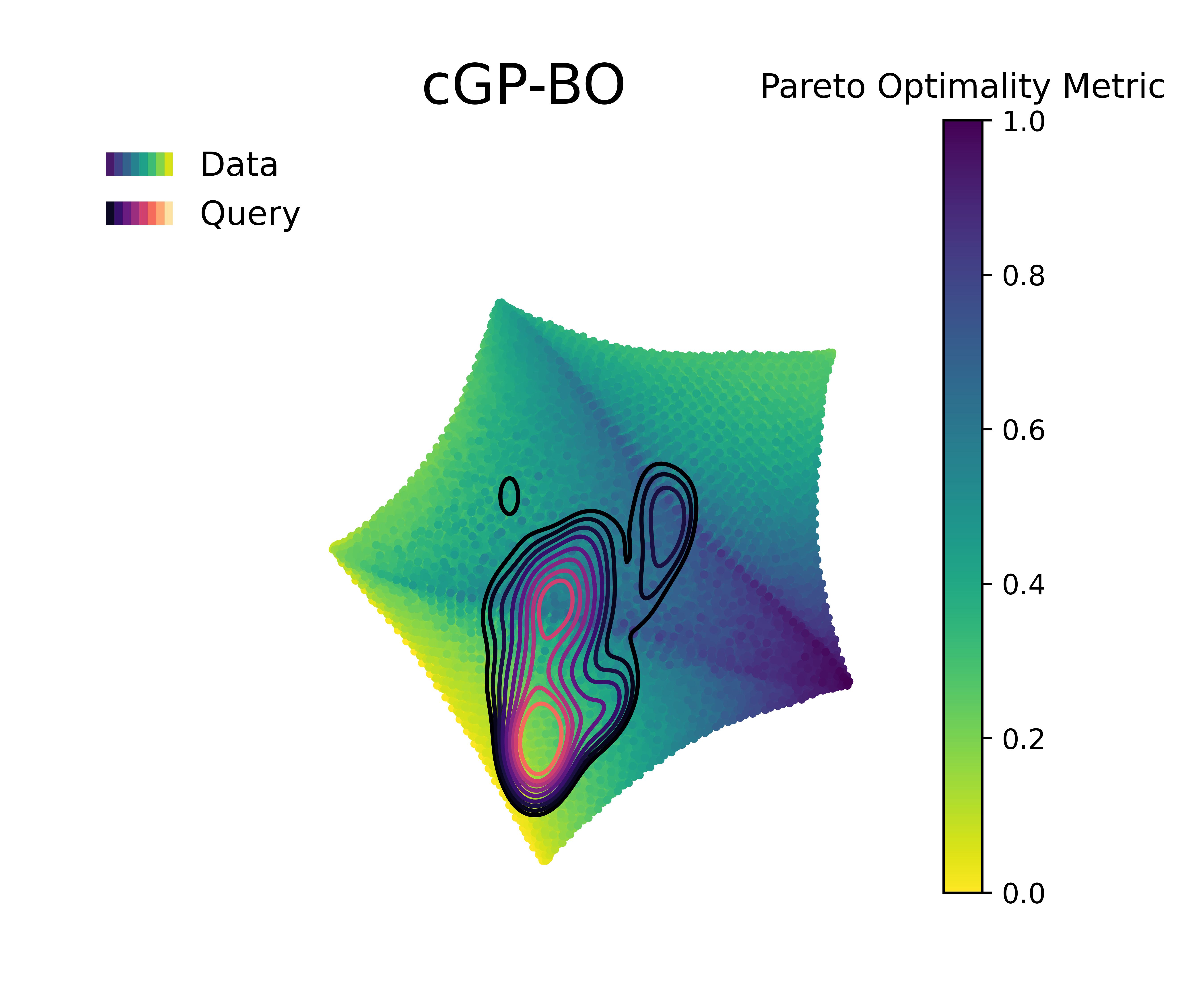
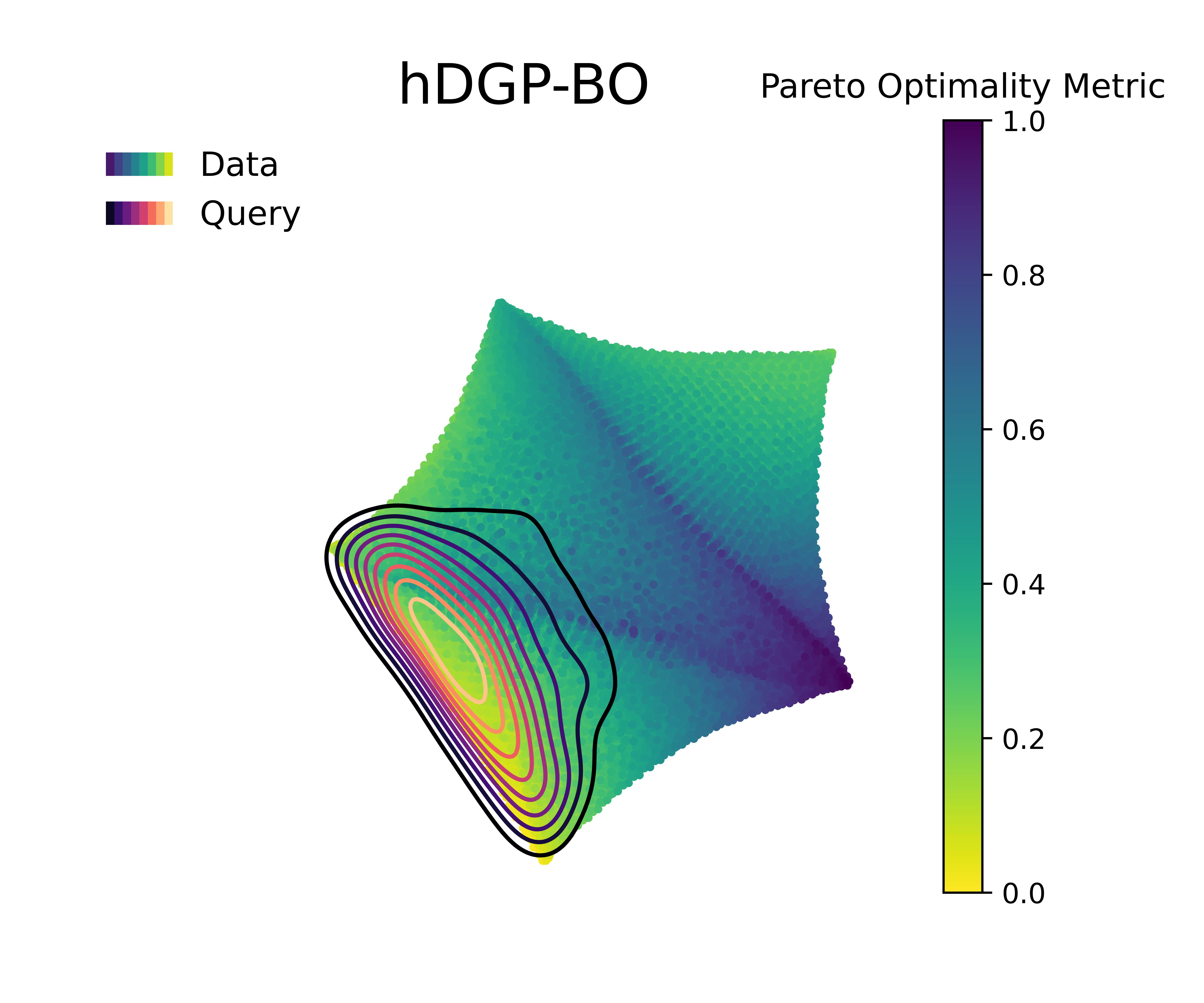
A careful examination of Figure 4 along with Figure 5 & Figure 6 further highlights differences between iDGP-BO, hDGP-BO & MTGP-BO. The hDGP-BO was by far performing best, showing excellent hypervolume improvements compared to others, covering more than 95% of the actual maximum hypervolume within the first 50 iterations. In comparison, MTGP-BO (the second best model) required more than 100 iterations to achieve the same coverage. The performance bounds obtained in multiple replications of hDGP-BO was also narrower, demonstrating a lower sensitivity to initial conditions, presumably due to the additional information gained from the additional interleaved queries of BM and volume using UCB.
This interpretation is supported by the fact that iDGP-BO failed to match the performance of hDGP-BO, while sharing the same architecture. iDGP-BO was also performing worse than MTGP-BO in latter stages. This suggests that UCB-based uncertainty-minimization improves the performance of DGP. The query pattern in Figure 4 & Figure 5 indicates that iDGP-BO made queries roughly randomly, showing no clear sign of systematic exploration. MTGP-BO was able to perform better than iDGP-BO and ultimately reached the hypervolume attained by hDGP-BO at latter stages. But, it was not able to achieve that as fast as hDGP-BO. Figure 4 & Figure 5 indicates the querying pattern of MTGP-BO is less concentrated around the Pareto front compared to hDGP-BO, leading to lower performance.
This phenomenon may be related to the simpler linear relationship assumed between tasks by the MTGP’s structure.
This more efficient exploration and exploitation of the design space by hDGP-BO corroborates findings by Hernandez-Lobato et al. (2016) [114], who demonstrated the effectiveness of advanced BO models in multi-objective optimization tasks through the use of acquisition functions based on information-theoretic approaches. Our obsevations indicate that the combination of an UCB heterotopic sampling strategy and of the non-linear cross-task representation lead to the superior performance of hDGP-BO.
3.3 Multi-objective Bayesian Optimization with Auxiliary Tasks in FeCrNiCoCu Alloy Space: Maximization of TEC - Maximization of BM
In the second optimization scenario, the objective was to maximize both the CTE and the BM. Finding an alloy with both high BM and high CTE is generally challenging due to the typical inverse relationship between these properties in most materials [115], since i) still interatomic interactions tend to oppose thermal expansion [116, 117] and an empirically-observed inverse correlation between anharmonicity (which is the driving force for CTE) and bond strength [118, 119].
Materials possessing both high BM and high CTE simultaneously, while relatively rare, find valuable applications in specific engineering contexts. In thermal management systems for electronics, they can provide structural stability while allowing for thermal expansion to match surrounding components. This property combination is particularly useful in electronic packaging, where managing thermal stresses is crucial [120]. High-temperature sensors operating in extreme temperature environments also benefit from materials that maintain structural integrity while being sensitive to temperature changes. The high bulk modulus ensures the sensor’s structural stability under pressure, while the high CTE allows for enhanced sensitivity to temperature variations [121]. In the field of thermal energy storage, materials that can withstand high pressures and exhibit significant volume changes with temperature are desirable. These properties are particularly relevant for phase change materials and other advanced thermal storage systems, where the ability to maintain structural integrity under varying thermal conditions is critical [122]. Micro-electro-mechanical systems (MEMS) and certain types of actuators also benefit from materials combining high stiffness with high thermal responsiveness. The high bulk modulus provides the necessary structural rigidity, while the high CTE allows for thermally-driven actuation. This combination is particularly valuable in the development of advanced MEMS devices and smart materials for various applications, including aerospace and robotics [123]. It’s important to note that the specific requirements for ”high” values of these properties can vary depending on the application context. The development of materials that optimize both properties simultaneously remains an active area of research in materials science and engineering, driving innovation in various technological fields.
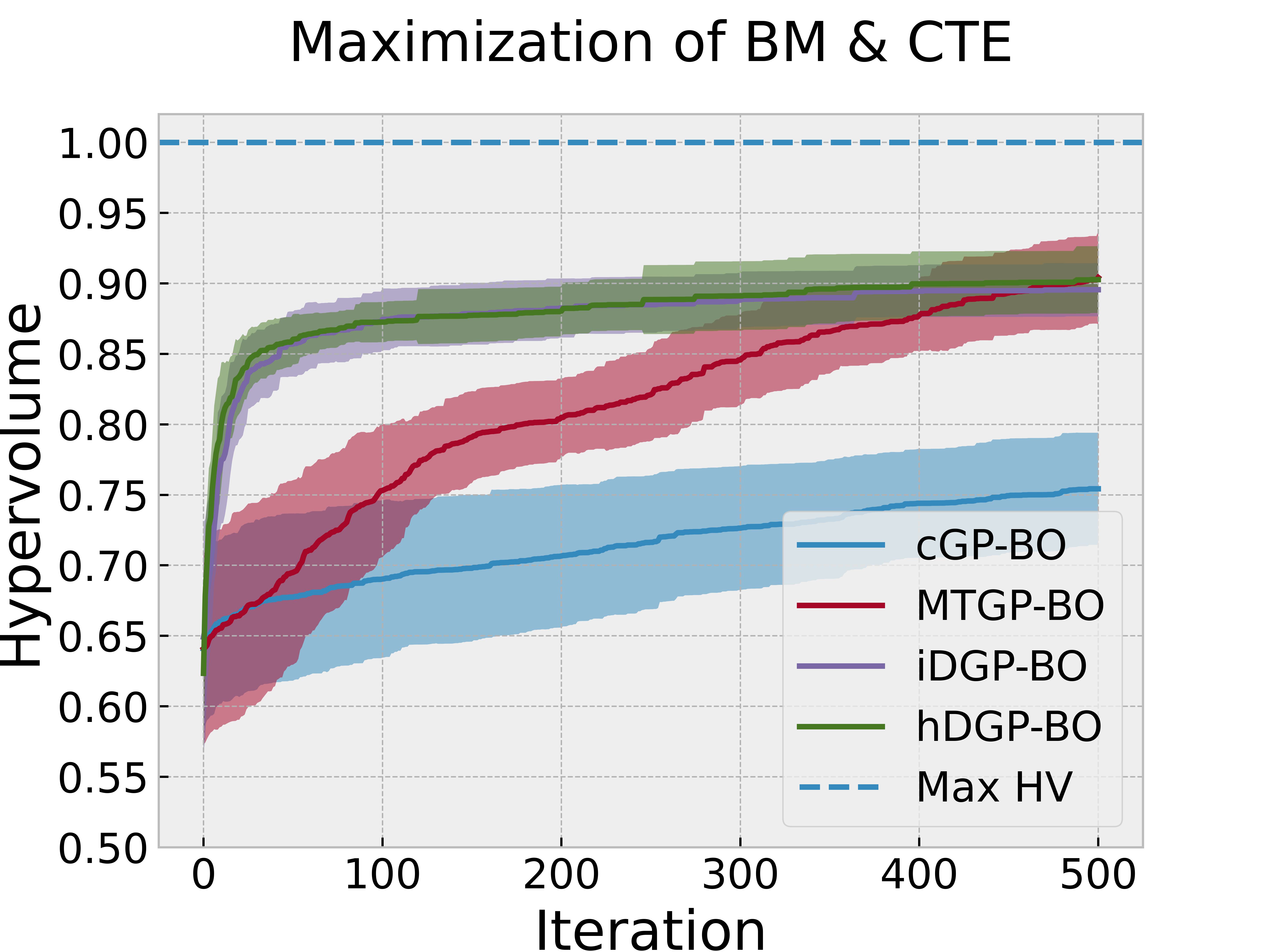
Following the structure of the previous section, Figure 7 reports the evolution of the hypervolume during an iterative BO procedure based on the four different models. Figure 8 & Figure 9 visualizes the queries in the objective space and design space for the first 100 queries. Figure 8 also displays the Pareto optimal points for reference, whereas Figure 9 reports the corresponding Pareto optimally metric, defined as described above.
Figure 7 along with Figure 8 & Figure 9 displays the difference in performance and querying behavior of cGP-BO, MTGP-BO, iDGP-BO, and hDGP-BO in this specific scenario. As in the previous problem, DGP-BO and MTGP-BO outperform cGP-BO, generating a more systemic exploration of the objective space, efficiently identifying regions with high CTE and high BM. Figure 7 indicates that MTGP-BO and both variants of DGP-BO (heterotopic and isotropic) outperform cGP-BO in terms of hypervolume improvement per iteration.
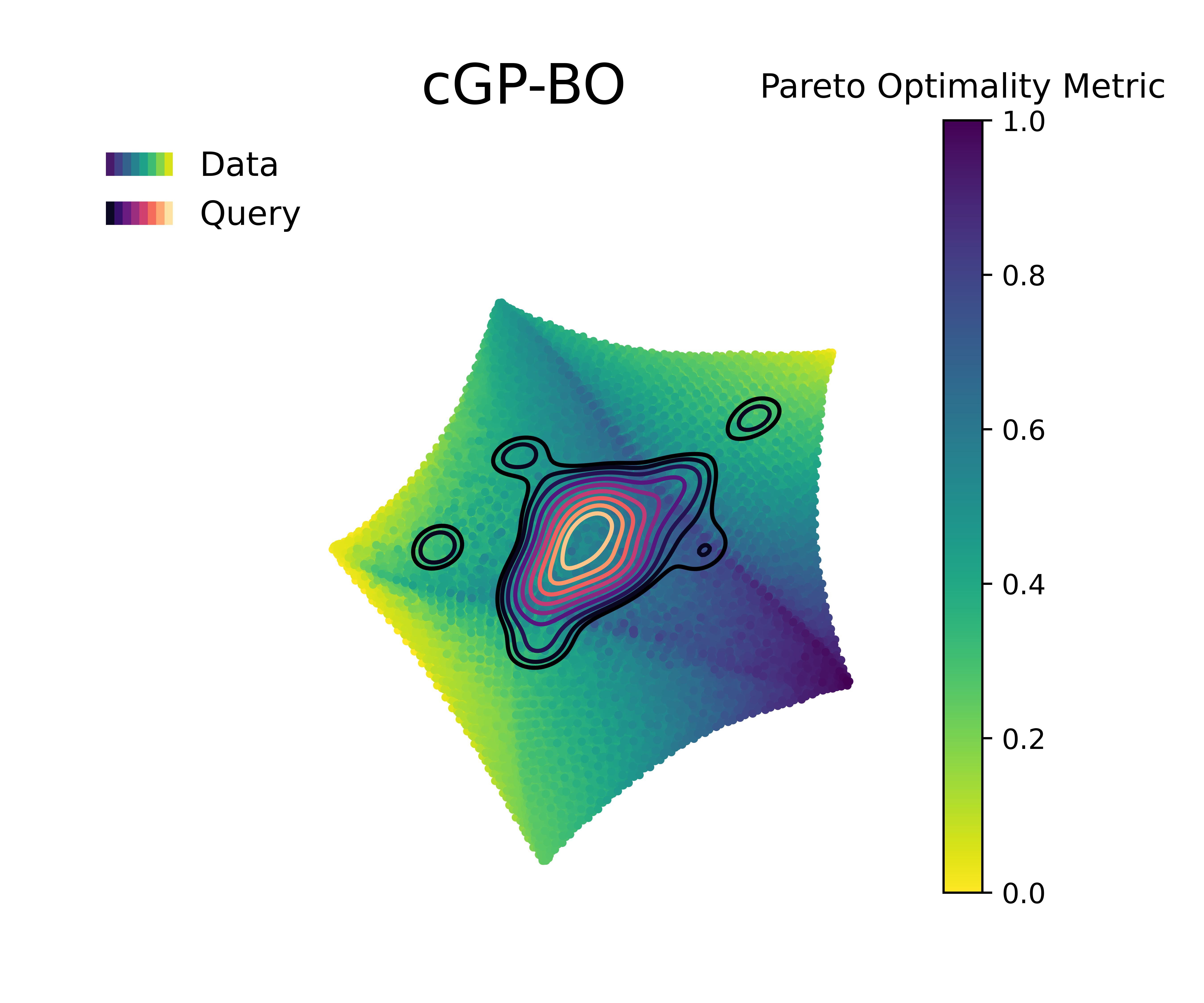
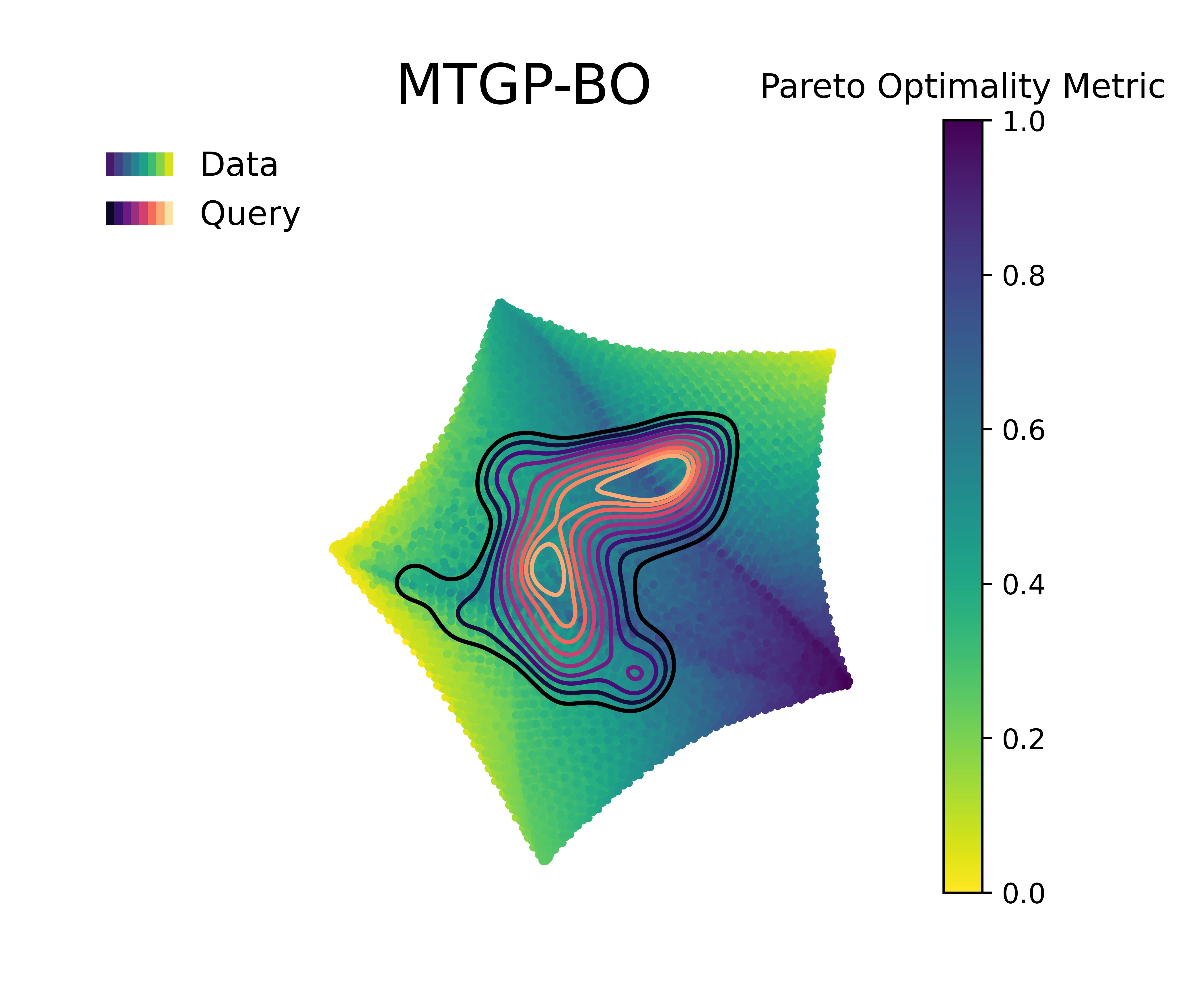
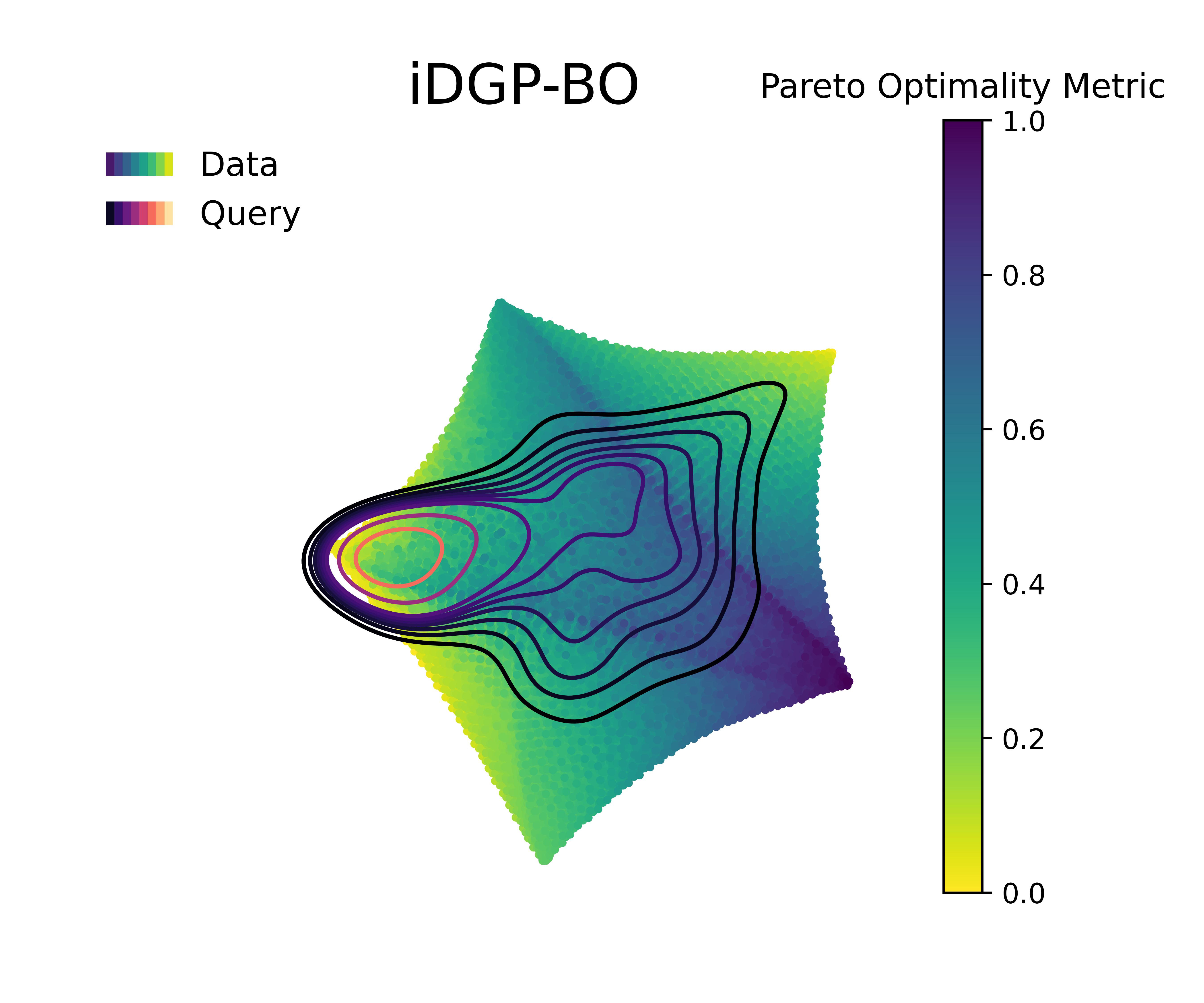
A closer scrutiny of Figure 7 along with Figure 8 &
Figure 9 reveals that, unlike the first case, iDGP-BO no longer performs worse than MTGP-BO, but instead performs better, on par with hDGP-BO.
The difference in performance between both DGP methods on the one hand and MTGP-BO and cGP-BO on the other hand is now even wider compared to the previous scenario (c.f., Figure 7 vs Figure 4 )
Both DGP methods systematically hone in to the optimal region, while the queries from MTGP-BO & cGP-BO are more diffuse and less systematic, leading to a poor exploration of Pareto-optimal solutions, which is consistent with the poor performance exhibited in Figure 7.
The superior exploration and search capability of hDGP-BO can be attributed to the same reasons as stated in the previous scenario. But, improvement of iDGP-BO performance over MTGP-BO along with overall decrease in performance of cGP-BO and MTGP-BO points to the difficulty of the current optimization goals. It can be inferred that, as the problem became harder, the simple linear assumption of MTGP-BO falters during earlier iterations. It demonstrated slower convergence to maximum attainable hypervolume compared to iDGP-BO and hDGP-BO. But, at latter stages, when MTGP-BO was able to explore enough data points, it slowly achieved the same level of coverage as that of DGP based BOs. So, at latter stages MTGP-BO matches the performance with that of DGP based BOs. But, during earlier iterations (within the first 50 iterations) DGP based BOs showed exceptional performance in covering close to 90% of the maximal hypervolume, compared to MTGP-BO which achieved only 75% coverage after 100 iterations. Additionally, cGP-BO performs even worse due to the enhanced difficulty of this problem. The difficulty faced by MTGP-BO and cGP-BO is also reflected in the querying pattern( Figure 8 & Figure 9). In both of the cases, the hDGP-BO proposed in this paper is the most robust.
3.4 Mutual Information Analysis
To further analyze the differences in performance among multiple variants of BO, an analysis based on mutual information(MI) is carried out. The prediction of the four BOs were recorded in each iteration at 5000 points(sampled through dirchlet distribution) for each tasks. Then, the mutual information between the two objectives were calculated from the predicted 5000 points. This was done at each iteration.
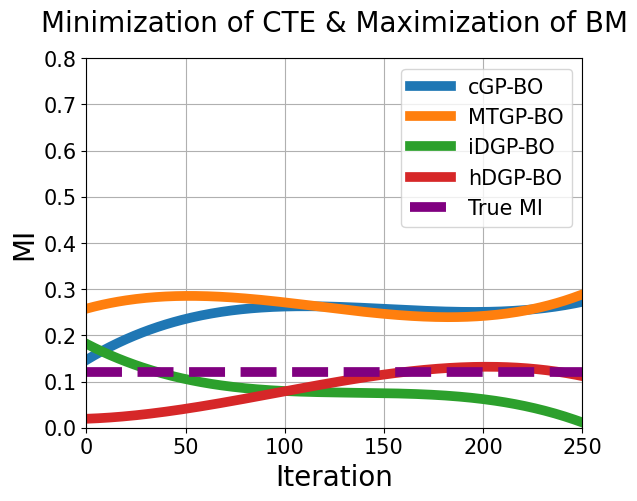
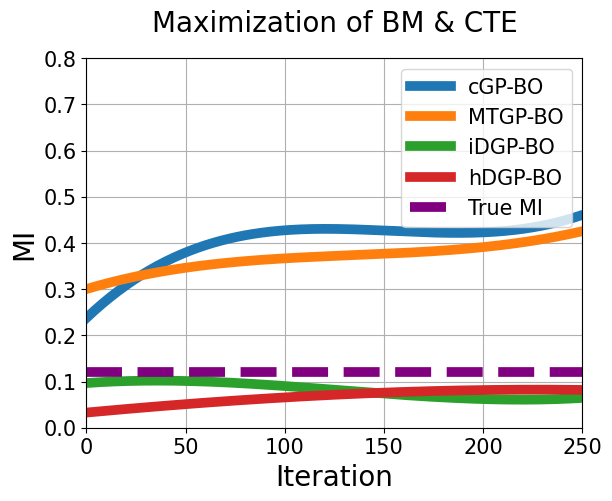
In the first scenario, Figure 10(a) shows that, only the predicted MI of hDGP-BO gets close to the true MI. Whereas, iDGP-BO struggles to achieve any significant MI due to its unsystematic query pattern(Figure 6(c)). MTGP-BO display high predicted MI due to the fact that they assume linear correlation between tasks. High MI translates into simpler and linear relationship. The cGP-BO also shows high MI without having correlated kernel.It’s because the different tasks start out with same prior, making the tasks highly correlated at unexplored regions. The agreement between predicted and true MI translates into the performance difference(Figure 4). The BO having the best agreement(hDGP-BO) shows the best performance.
The second scenario(Figure 10(b)) reaffirms the hypothesis ”ability to achieve correct predicted MI translates into better optimization performance”. Here, it is observed that iDGP-BO is able to capture the correct predicted MI(unlike first scenario). As a result, the iDGP-BO also performs better(Figure 7), unlike the first case. Moreover, the predicted MI from cGP-BO and MTGP-BO shows significant deviation from true MI in this second case. As a result, their optimization performance also deteriorates compared to the first scenario(Figure 7).
In this work, predicted MI per iteration has been demonstrated to be useful in quantifying performance for optimization problems having multiple correlated tasks. Further research is warranted to investigate the use of predicted MI in different multi-objective optimization problems having multiple correlated tasks. It can be proposed as a metric of the degree to which a model can exploit correlations.
3.5 Addition of Random Gaussian Field Noise
In this subsection, we analyze the impact of adding random Gaussian field noise to the Bayesian optimization process. The addition of noise is essential for evaluating the robustness and stability of the optimization algorithms under real-world conditions, where measurements and simulations are often subject to various sources of uncertainty [124, 125].
Gaussian field noise is characterized by its mean and covariance structure, which can be defined as:
where is the covariance function of the noise, typically chosen to be a squared exponential kernel:
Here, represents the noise variance, and is the length scale of the noise [125]. In this work, The lengthscale is chosen to be 0.20. The variance is selected such that, the third standard deviation does not exceed more than half of the spread for each tasks. As a result, CTE and BM have variances of 20 and 100 respectively. This implies uncertainty in CTE data having 4.5 K-1 standard deviation and in BM having 10 GPa standard deviation.
To assess the influence of this noise on the optimization performance, we conducted experiments by adding random Gaussian field noise to the objective functions during the Bayesian optimization process. The performance of the optimization algorithms was evaluated both before and after the addition of noise [126].
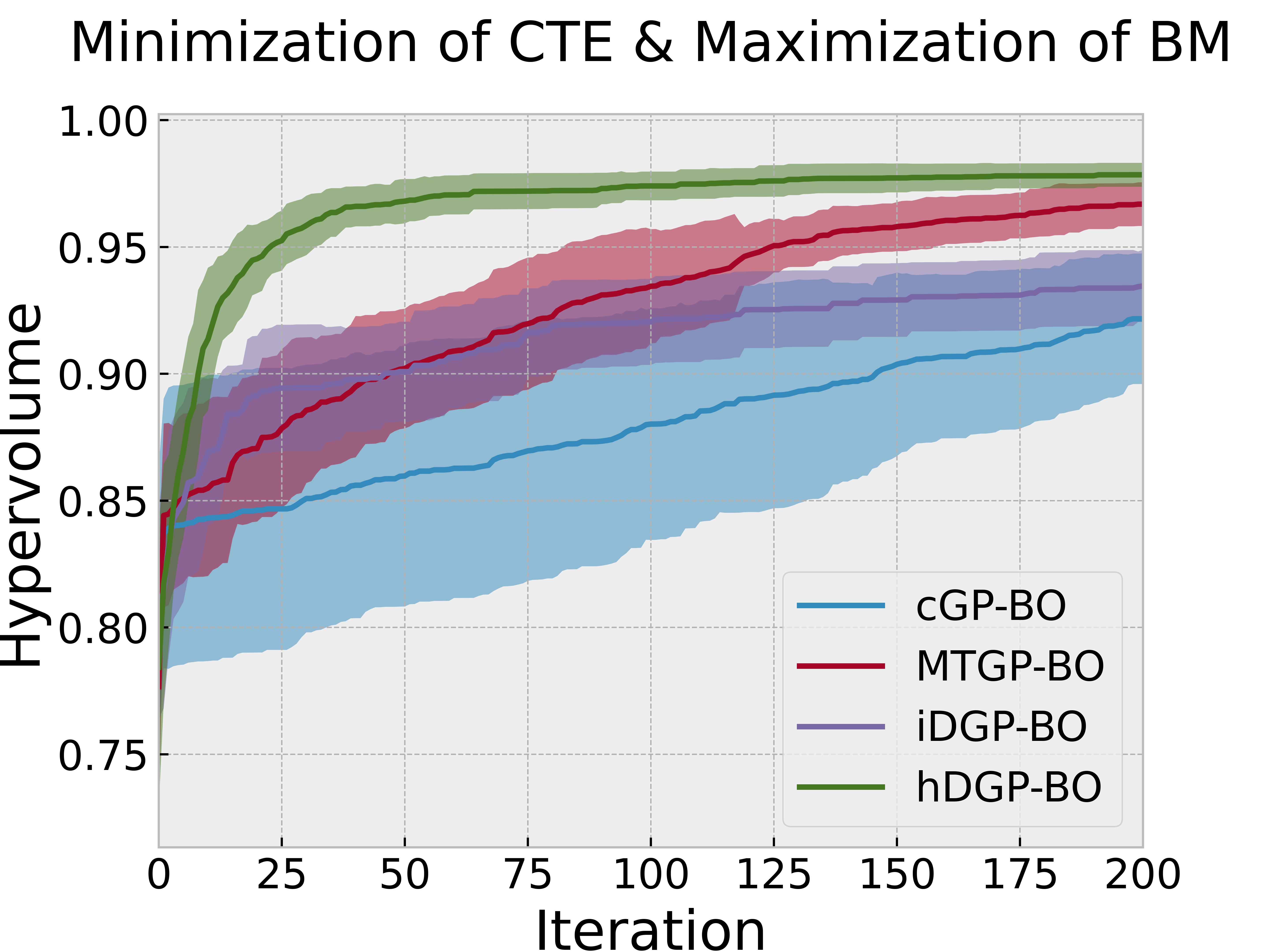
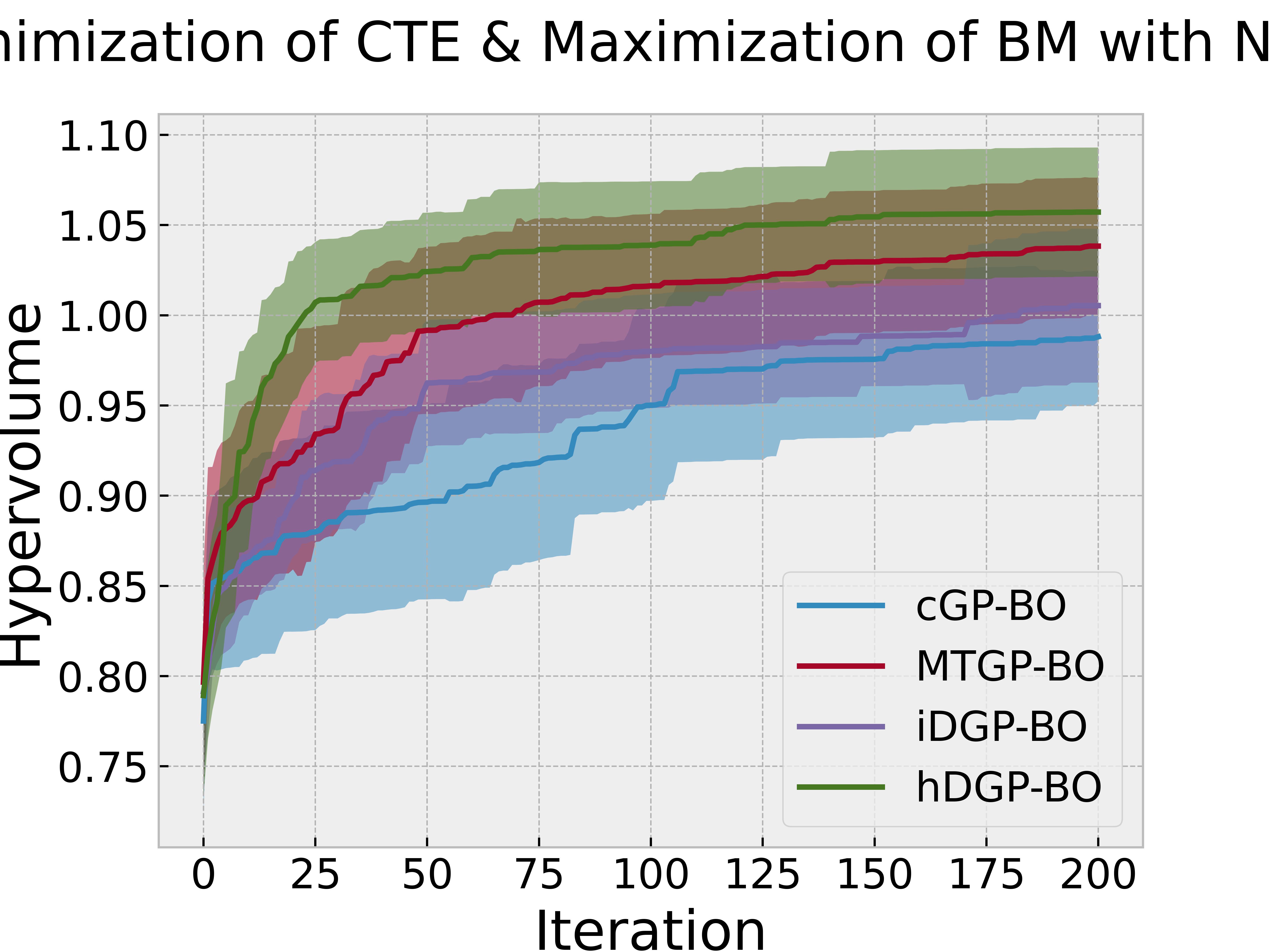
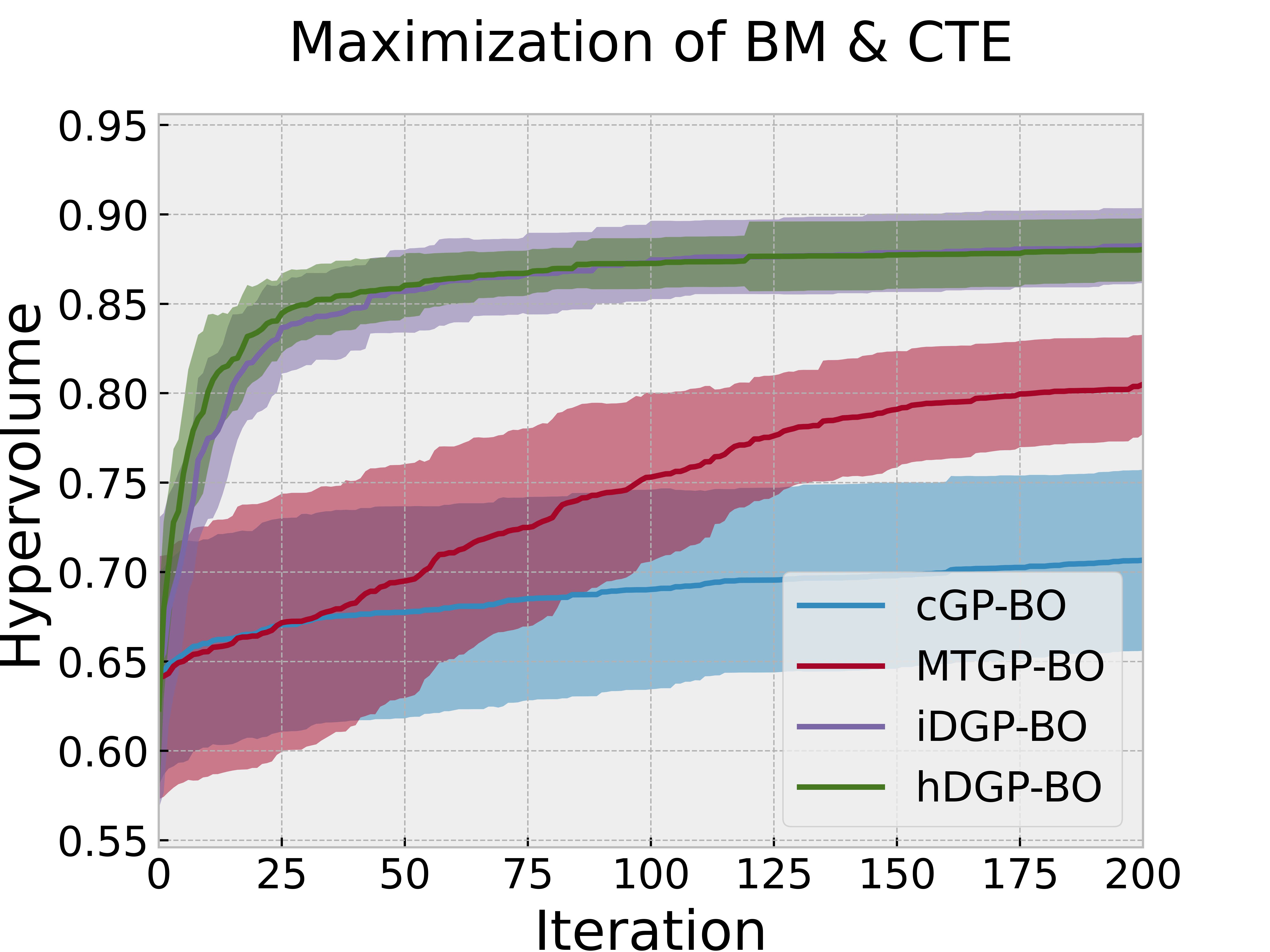
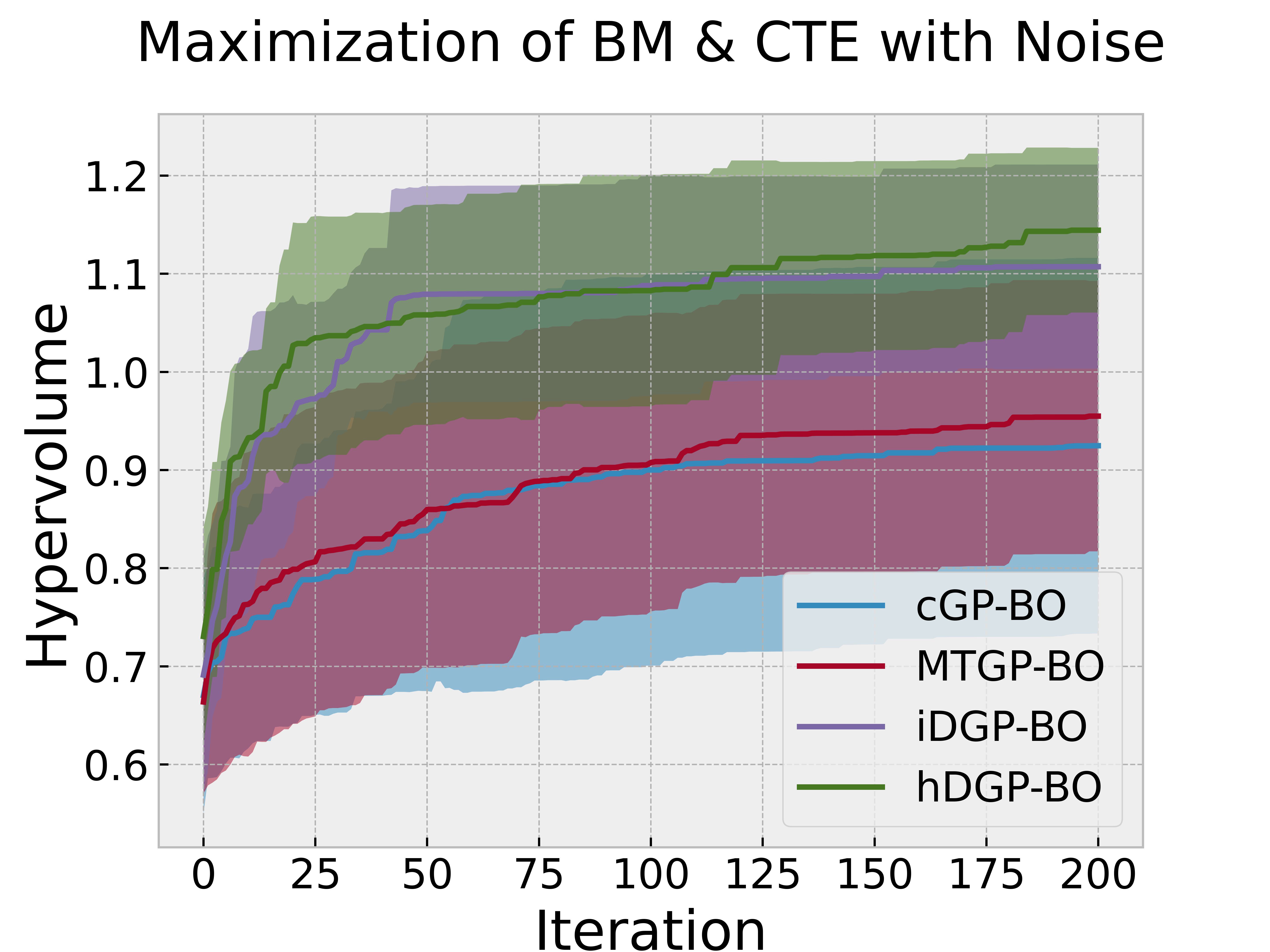
Figure 11 and Figure 12 illustrate the hypervolume improvement per iteration for the two optimization scenarios: minimization of TEC with maximization of BM, and maximization of both TEC and BM, respectively. The figures compare the performance of the optimization algorithms before and after the addition of random Gaussian field noise.
The results indicate that the addition of noise generally leads to a decrease in the optimization performance advantages between the models. The DGP-BO models still show better performance compared to the cGP-BO & MTGP-BO model. But, the performance advantages of DGP-BOs decrease. The inherent uncertainty between multiple replications also increases. This happens due to the fact that, addition of gaussian field noise obscures the complex non-linear relationship between tasks. Thus, it becomes harder for DGPs or MTGPs to take advantage of the inter-relationship between tasks. This further proves that the DGPs and MTGPs performs better then cGP-BO by exploiting correlations. Otherwise, obscuring the correlation through noise addition would not have affected the performance difference between them.
The hDGP-BO still demonstrates robustness to obscured correlation between tasks. This robustness can be attributed to the sophisticated kernel structure and uncertainty reduction steps using UCB. In the context of HEA design, the presence of noise is a common challenge due to the complexity of the systems and the limitations of experimental and computational methods [111]. The robustness of hDGP-BO to noise makes them particularly suitable for handling the uncertainties inherent in HEA property data, ensuring more reliable optimization results. The incorporation of random Gaussian field noise in the optimization process serves as a valuable test for evaluating the robustness of Bayesian optimization algorithms. The findings underscore the advantages of using advanced models hDGP-BO in scenarios with inherent uncertainties, which are common in real-world materials discovery tasks [127].
4 Conclusions
Our study demonstrates that both DGP and MTGP variants of BO have significant advantages in high-throughput materials discovery involving multiple objectives. Moreover, the novel hDGP-BO in particular(proposed in this study) is the most robust and efficient in all of the cases. Utilizing hDGP-BO, we can accelerate the discovery of materials with specific properties by exploiting correlations between auxiliary properties. The superior performance of these models is attributed to their ability to capture complex, non-linear relationships, exploit correlations between objectives, and adaptively learn the inter-dependencies in the data. MTGP-BO has also demonstrated superior performance compared to iDGP-BO in specific cases, proving its importance. The robustness of hDGP-BO and MTGP-BO to random Gaussian field noise further highlights their suitability for real-world materials discovery tasks, where uncertainties are inherent in experimental and computational data [128, 125].
The correlation analysis presented in this study underscores the importance of considering property inter-dependencies in the optimization of HEAs and validates the effectiveness of hDGP-BO or MTGP-BO in leveraging these relationships to accelerate materials discovery [129]. By exploiting the correlations between thermal, mechanical, and structural properties, these advanced models can guide the search more effectively towards optimal compositions [130].
Future work includes parallelizing hDGP-BO and MTGP-BO and developing acquisition functions tailored to these models to further enhance performance. Additionally, integrating physics-based models and domain knowledge into the optimization framework can provide a more comprehensive understanding of the underlying mechanisms governing the behavior of HEAs and guide the discovery of novel compositions with targeted properties.
In conclusion, this study demonstrates the potential of advanced Bayesian optimization models like MTGP-BO and hDGP-BO in accelerating the discovery of high-performance HEAs. By exploiting property correlations, adapting to complex relationships, and robustly handling uncertainties, these models can significantly streamline the materials discovery process. The insights gained from this research can be extended to other materials systems and optimization challenges, paving the way for more efficient and targeted exploration of vast design spaces.
References
- [1] N. R. Council, D. on Engineering, P. Sciences, N. M. A. Board, C. on Integrated Computational Materials Engineering, Integrated computational materials engineering: a transformational discipline for improved competitiveness and national security, National Academies Press, 2008.
- [2] N. Science, T. C. (US), Materials genome initiative for global competitiveness, Executive Office of the President, National Science and Technology Council, 2011.
- [3] W. Y. Wang, J. Li, W. Liu, Z.-K. Liu, Integrated computational materials engineering for advanced materials: A brief review, Computational Materials Science 158 (2019) 42–48.
- [4] R. Cang, Y. Xu, S. Chen, Y. Liu, Y. Jiao, M. Y. Ren, Microstructure representation and reconstruction of heterogeneous materials via deep belief network for computational material design, Journal of Mechanical Design (2017). doi:10.1115/1.4036649.
- [5] W. Xiong, Calphad-based integrated computational materials engineering research for materials genomic design, Jom (2015). doi:10.1007/s11837-015-1514-5.
- [6] N. Chopra, Integrated computational materials engineering: A multi-scale approach, Jom (2014). doi:10.1007/s11837-014-1260-0.
- [7] Z. Liang, J.-M. Miao, A. K. Sachdev, J. C. Williams, A. A. Luo, Titanium alloy design and casting process development using an integrated computational materials engineering (icme) approach, Matec Web of Conferences (2020). doi:10.1051/matecconf/202032110013.
- [8] A. A. Luo, Material design and development: From classical thermodynamics to calphad and icme approaches, Calphad (2015). doi:10.1016/j.calphad.2015.04.002.
- [9] M. L. Green, C. Choi, J. Hattrick‐Simpers, A. Joshi, I. Takeuchi, S. C. Barron, E. M. Campo, T. Chiang, S. A. Empedocles, J. M. Gregoire, A. G. Kusne, J. W. Martin, A. Mehta, K. A. Persson, Z. Trautt, J. v. Duren, A. Zakutayev, Fulfilling the promise of the materials genome initiative with high-throughput experimental methodologies, Applied Physics Reviews (2017). doi:10.1063/1.4977487.
- [10] X. Liu, D. Furrer, J. Kosters, J. Holmes, Vision 2040: a roadmap for integrated, multiscale modeling and simulation of materials and systems, Tech. rep. (2018).
- [11] J. Pablo, N. E. Jackson, M. Webb, L. Chen, J. E. Moore, D. Morgan, R. Jacobs, T. M. Pollock, D. G. Schlom, E. S. Toberer, J. Analytis, I. Dabo, D. M. DeLongchamp, G. A. Fiete, G. M. Grason, G. Hautier, Y. Mo, K. Rajan, E. J. Reed, E. E. Rodriguez, V. Stevanović, J. Suntivich, K. Thornton, J. Zhao, New frontiers for the materials genome initiative, NPJ Computational Materials (2019). doi:10.1038/s41524-019-0173-4.
- [12] A. Agrawal, A. Choudhary, Perspective: Materials informatics and big data: Realization of the “fourth paradigm” of science in materials science, Apl Materials (2016). doi:10.1063/1.4946894.
- [13] H. Zhu, J. Mao, Y. Li, J. Sun, Y. Wang, Q. Zhu, G. Li, Q. Song, J. Zhou, Y. Fu, et al., Discovery of tafesb-based half-heuslers with high thermoelectric performance, Nature communications 10 (1) (2019) 270.
- [14] Y. Iwasaki, A. G. Kusne, I. Takeuchi, Comparison of dissimilarity measures for cluster analysis of x-ray diffraction data from combinatorial libraries, NPJ Computational Materials (2017). doi:10.1038/s41524-017-0006-2.
- [15] Y. Liu, Z. Yang, X. Zou, S. Ma, D. Liu, M. Avdeev, S. Shi, Data quantity governance for machine learning in materials science, National Science Review (2023). doi:10.1093/nsr/nwad125.
- [16] P. Sungphueng, Thermoelectric prediction from material descriptors using machine learning technique, Current Applied Science and Technology (2023). doi:10.55003/cast.2023.06.23.014.
- [17] J. Peng, Y. Yamamoto, J. A. Hawk, D. Shin, Coupling physics in machine learning to predict properties of high-temperatures alloys, NPJ Computational Materials (2020). doi:10.1038/s41524-020-00407-2.
- [18] D. M. Reitz, E. Blaisten‐Barojas, Simulating the nak eutectic alloy with monte carlo and machine learning, Scientific Reports (2019). doi:10.1038/s41598-018-36574-y.
- [19] M. E. Amine Seghier, Application of machine learning approaches for modelling crack growth rates, Ce/Papers (2023). doi:10.1002/cepa.2639.
- [20] P. Negi, Application of machine learning in predicting the fatigue behaviour of materials using deep learning, Turkish Journal of Computer and Mathematics Education (Turcomat) (2018). doi:10.17762/turcomat.v9i2.13858.
- [21] D. Verma, Multiscale modelling and characterization of coupled damage-healing for materials in concurrent computational homogenization approach using machine learning, Turkish Journal of Computer and Mathematics Education (Turcomat) (2018). doi:10.17762/turcomat.v9i2.13863.
- [22] P. I. Frazier, J. Wang, Bayesian optimization for materials design, in: Information Science for Materials Discovery and Design, Springer, 2016, pp. 45–75.
- [23] J. Snoek, H. Larochelle, R. P. Adams, Practical bayesian optimization of machine learning algorithms, Advances in neural information processing systems 25 (2012) 2951–2959.
- [24] P. I. Frazier, A tutorial on bayesian optimization, arXiv preprint arXiv:1807.02811 (2018).
- [25] Z. Ceylan, Estimation of municipal waste generation of turkey using socio-economic indicators by Bayesian optimization tuned Gaussian process regression, Waste Management & Research 38 (8) (2020) 840–850.
- [26] A. Iyer, Y. Zhang, A. Prasad, S. Tao, Y. Wang, L. Schadler, L. C. Brinson, W. Chen, Data-centric mixed-variable Bayesian optimization for materials design, in: International Design Engineering Technical Conferences and Computers and Information in Engineering Conference, Vol. 59186, American Society of Mechanical Engineers, 2019, p. V02AT03A066.
- [27] A. Talapatra, S. Boluki, T. Duong, X. Qian, E. Dougherty, R. Arróyave, Autonomous efficient experiment design for materials discovery with Bayesian model averaging, Physical Review Materials 2 (11) (2018) 113803.
- [28] S. Ju, T. Shiga, L. Feng, Z. Hou, K. Tsuda, J. Shiomi, Designing nanostructures for phonon transport via Bayesian optimization, Physical Review X 7 (2) (2017) 021024.
- [29] S. F. Ghoreishi, A. Molkeri, A. Srivastava, R. Arroyave, D. Allaire, Multi-information source fusion and optimization to realize icme: Application to dual-phase materials, Journal of Mechanical Design 140 (11) (2018) 111409.
- [30] D. Khatamsaz, A. Molkeri, R. Couperthwaite, J. James, R. Arróyave, D. Allaire, A. Srivastava, Efficiently exploiting process-structure-property relationships in material design by multi-information source fusion, Acta Materialia 206 (2021) 116619.
- [31] S. F. Ghoreishi, A. Molkeri, R. Arróyave, D. Allaire, A. Srivastava, Efficient use of multiple information sources in material design, Acta Materialia 180 (2019) 260–271.
- [32] Y. Liu, J.-M. Wu, M. Avdeev, S.-Q. Shi, Multi-layer feature selection incorporating weighted score-based expert knowledge toward modeling materials with targeted properties, Advanced Theory and Simulations 3 (2) (2020) 1900215.
- [33] J. P. Janet, H. J. Kulik, Resolving transition metal chemical space: Feature selection for machine learning and structure–property relationships, The Journal of Physical Chemistry A 121 (46) (2017) 8939–8954.
- [34] R. Ramprasad, R. Batra, G. Pilania, A. Mannodi-Kanakkithodi, C. Kim, Machine learning in materials informatics: recent applications and prospects, npj Computational Materials 3 (1) (2017) 1–13.
- [35] P. Honarmandi, M. Hossain, R. Arroyave, T. Baxevanis, A top-down characterization of niti single-crystal inelastic properties within confidence bounds through Bayesian inference, Shape Memory and Superelasticity 7 (1) (2021) 50–64.
- [36] L. Du, Deformation behaviour and microstructural evolution of high-entropy cofemnni alloy at hot deformation condition with low strain rate (2023). doi:10.21741/9781644902615-29.
- [37] J. K. Pedersen, C. M. Clausen, O. A. Krysiak, B. Xiao, T. A. Batchelor, T. Löffler, V. A. Mints, L. Banko, M. Arenz, A. Savan, et al., Bayesian optimization of high-entropy alloy compositions for electrocatalytic oxygen reduction, Angewandte Chemie 133 (45) (2021) 24346–24354.
- [38] V. Torsti, T. Mäkinen, S. Bonfanti, J. Koivisto, M. J. Alava, Improving the mechanical properties of cantor-like alloys with bayesian optimization, APL Machine Learning 2 (1) (2024).
- [39] E. Halpren, X. Yao, Z. W. Chen, C. V. Singh, Machine learning assisted design of bcc high entropy alloys for room temperature hydrogen storage, Acta Materialia 270 (2024) 119841.
- [40] X. Liu, J. Zhang, Z. Pei, Machine learning for high-entropy alloys: Progress, challenges and opportunities, Progress in Materials Science 131 (2023) 101018.
- [41] J. Qian, Y. Li, J. Hou, S. Wu, Y. Zou, Accelerating the development of fe–co–ni–cr system heas with high hardness by deep learning based on bayesian optimization, Journal of Materials Research (2024) 1–16.
- [42] G. A. Sulley, J. Raush, M. M. Montemore, J. Hamm, Accelerating high-entropy alloy discovery: efficient exploration via active learning, Scripta Materialia 249 (2024) 116180.
- [43] B. Vela, D. Khatamsaz, C. Acemi, I. Karaman, R. Arróyave, Data-augmented modeling for yield strength of refractory high entropy alloys: A bayesian approach, Acta Materialia 261 (2023) 119351.
- [44] D. Khatamsaz, R. Neuberger, A. M. Roy, S. H. Zadeh, R. Otis, R. Arróyave, A physics informed bayesian optimization approach for material design: application to niti shape memory alloys, npj Computational Materials 9 (1) (2023) 221.
- [45] T. Hastings, M. Mulukutla, D. Khatamsaz, D. Salas, W. Xu, D. Lewis, N. Person, M. Skokan, B. Miller, J. Paramore, et al., An interoperable multi objective batch bayesian optimization framework for high throughput materials discovery, arXiv preprint arXiv:2405.08900 (2024).
- [46] D. Khatamsaz, B. Vela, P. Singh, D. D. Johnson, D. Allaire, R. Arróyave, Bayesian optimization with active learning of design constraints using an entropy-based approach, npj Computational Materials 9 (1) (2023) 49.
- [47] A. Solomou, G. Zhao, S. Boluki, J. K. Joy, X. Qian, I. Karaman, R. Arr’oyave, D. C. Lagoudas, Multi-objective bayesian materials discovery: Application on the discovery of precipitation strengthened niti shape memory alloys through micromechanical modeling, Materials & Design 160 (2018) 810–827.
- [48] G. Zhao, R. Arroyave, X. Qian, Fast exact computation of expected hypervolume improvement, arXiv preprint arXiv:1812.07692 (2018).
- [49] A. M. Gopakumar, P. V. Balachandran, D. Xue, J. E. Gubernatis, T. Lookman, Multi-objective optimization for materials discovery via adaptive design, Scientific reports 8 (1) (2018) 3738.
- [50] R. Arróyave, D. Khatamsaz, B. Vela, R. Couperthwaite, A. Molkeri, P. Singh, D. D. Johnson, X. Qian, A. Srivastava, D. Allaire, A perspective on bayesian methods applied to materials discovery and design, MRS communications 12 (6) (2022) 1037–1049.
- [51] A. Biswas, Y. Liu, M. Ziatdinov, Y.-C. Liu, S. Jesse, J.-C. Yang, S. Kalinin, R. Vasudevan, A multi-objective bayesian optimized human assessed multi-target generated spectral recommender system for rapid pareto discoveries of material properties, in: International Design Engineering Technical Conferences and Computers and Information in Engineering Conference, Vol. 87318, American Society of Mechanical Engineers, 2023, p. V03BT03A058.
- [52] Y. Zhang, Q. Yang, A survey on multi-task learning (2017). doi:10.48550/arxiv.1707.08114.
- [53] Y. Zhang, D. Yeung, A regularization approach to learning task relationships in multitask learning, Acm Transactions on Knowledge Discovery From Data (2014). doi:10.1145/2538028.
- [54] O. Koyejo, C. Liu, J. Ghosh, The trace norm constrained matrix-variate gaussian process for multitask bipartite ranking (2013). doi:10.48550/arxiv.1302.2576.
- [55] R. He, W. S. Lee, H. T. Ng, D. Dahlmeier, An interactive multi-task learning network for end-to-end aspect-based sentiment analysis (2019). doi:10.18653/v1/p19-1048.
- [56] K. G. Dizaji, W. Chen, H. Huang, Deep large-scale multitask learning network for gene expression inference, Journal of Computational Biology 28 (5) (2021) 485–500.
- [57] J. Wang, D. J. Fleet, A. Hertzmann, Gaussian process dynamical models for human motion, Ieee Transactions on Pattern Analysis and Machine Intelligence (2008). doi:10.1109/tpami.2007.1167.
- [58] V. Kumar, Deep gaussian processes with convolutional kernels (2018). doi:10.48550/arxiv.1806.01655.
- [59] C.-K. Lu, Conditional deep gaussian processes: Empirical bayes hyperdata learning (2021). doi:10.48550/arxiv.2110.00568.
- [60] A. K. Pandey, H. D. Meulemeester, B. D. Moor, J. A. K. Suykens, Multi-view kernel pca for time series forecasting (2023). doi:10.48550/arxiv.2301.09811.
- [61] V. Dutordoir, M. Wilk, A. Artemev, J. Hensman, Bayesian image classification with deep convolutional gaussian processes, in: International Conference on Artificial Intelligence and Statistics, PMLR, 2020, pp. 1529–1539.
- [62] J. Xuan, J. Lu, Z. Yan, G. Zhang, Bayesian deep reinforcement learning via deep kernel learning, International Journal of Computational Intelligence Systems (2018). doi:10.2991/ijcis.2018.25905189.
- [63] Y. Jia, L. Zhang, P. Li, X. Ma, L. Xu, S. Wu, Y. Jia, G. Wang, Microstructure and mechanical properties of nb–ti–v–zr refractory medium-entropy alloys, Frontiers in Materials (2020). doi:10.3389/fmats.2020.00172.
- [64] Y. Zhou, X. Zhang, M. Ma, R. Liu, High performance zrnbal alloy with low thermal expansion coefficient, Chinese Physics Letters (2018). doi:10.1088/0256-307x/35/8/086501.
- [65] A. C. Karaoglanli, K. M. Doleker, Y. Ozgurluk, State of the art thermal barrier coating (tbc) materials and tbc failure mechanisms, Properties and Characterization of Modern Materials (2017) 441–452.
- [66] C. E. Rasmussen, C. K. Williams, Gaussian processes for machine learning, MIT press, 2006.
- [67] E. V. Bonilla, K. M. Chai, C. Williams, Multi-task gaussian process prediction, in: Advances in neural information processing systems, Vol. 20, 2008.
- [68] D. Duvenaud, Automatic model construction with gaussian processes, Ph.D. thesis, University of Cambridge (2014).
- [69] M. A. Alvarez, L. Rosasco, N. D. Lawrence, Kernels for vector-valued functions: A review, Foundations and Trends® in Machine Learning 4 (3) (2012) 195–266.
- [70] K. Swersky, J. Snoek, R. P. Adams, Multi-task bayesian optimization, Advances in neural information processing systems 26 (2013).
- [71] E. V. Bonilla, K. Chai, C. Williams, Multi-task gaussian process prediction, Advances in neural information processing systems 20 (2007).
- [72] D. Khatamsaz, B. Vela, R. Arróyave, Multi-objective bayesian alloy design using multi-task gaussian processes, Materials Letters 351 (2023) 135067.
- [73] A. Damianou, N. D. Lawrence, Deep gaussian processes, in: Artificial intelligence and statistics, PMLR, 2013, pp. 207–215.
- [74] H. Salimbeni, M. Deisenroth, Doubly stochastic variational inference for deep gaussian processes, in: Advances in Neural Information Processing Systems, Vol. 30, 2017.
- [75] T. Bui, D. Hernández-Lobato, J. Hernandez-Lobato, Y. Li, R. Turner, Deep gaussian processes for regression using approximate expectation propagation, in: International conference on machine learning, PMLR, 2016, pp. 1472–1481.
- [76] M. Titsias, Variational learning of inducing variables in sparse gaussian processes, Artificial intelligence and statistics (2009) 567–574.
- [77] J. Hensman, N. Fusi, N. D. Lawrence, Gaussian processes for big data, arXiv preprint arXiv:1309.6835 (2013).
- [78] R. M. Neal, Bayesian learning for neural networks, Springer Science & Business Media, 2012.
- [79] A. C. Damianou, N. D. Lawrence, Deep gaussian processes, arXiv preprint arXiv:1511.02759 (2015).
- [80] J. Wilson, F. Hutter, M. Deisenroth, Maximizing acquisition functions for bayesian optimization, in: Advances in Neural Information Processing Systems, Vol. 31, 2018.
- [81] N. Srinivas, A. Krause, S. M. Kakade, M. Seeger, Gaussian process optimization in the bandit setting: No regret and experimental design, arXiv preprint arXiv:0912.3995 (2009).
- [82] M. Emmerich, J.-w. Klinkenberg, The computation of the expected improvement in dominated hypervolume of pareto front approximations, Rapport technique, Leiden University 34 (2008) 7–3.
- [83] K. Yang, M. Emmerich, A. Deutz, T. Bäck, Multi-objective bayesian global optimization using expected hypervolume improvement gradient, Swarm and evolutionary computation 44 (2019) 945–956.
- [84] E. Zitzler, L. Thiele, M. Laumanns, C. M. Fonseca, V. G. Da Fonseca, Performance assessment of multiobjective optimizers: An analysis and review, IEEE Transactions on evolutionary computation 7 (2) (2003) 117–132.
- [85] M. T. Emmerich, A. H. Deutz, A tutorial on multiobjective optimization: fundamentals and evolutionary methods, Natural computing 10 (1) (2011) 197–215.
- [86] M. T. Emmerich, A. H. Deutz, Multicriteria optimization and decision making, LIACS, Leiden University, 2016.
- [87] D. Hernández-Lobato, J. Hernandez-Lobato, A. Shah, R. Adams, Predictive entropy search for multi-objective bayesian optimization, in: International Conference on Machine Learning, PMLR, 2016, pp. 1492–1501.
- [88] J. Janssen, S. Surendralal, Y. Lysogorskiy, M. Todorova, T. Hickel, R. Drautz, J. Neugebauer, pyiron: An integrated development environment for computational materials science, Computational Materials Science 163 (2019) 24–36.
- [89] S. Plimpton, Fast parallel algorithms for short-range molecular dynamics, Journal of Computational Physics 117 (1) (1995) 1–19.
- [90] A. P. Thompson, H. M. Aktulga, R. Berger, D. S. Bolintineanu, W. M. Brown, P. S. Crozier, P. J. in ’t Veld, A. Kohlmeyer, S. G. Moore, T. D. Nguyen, R. Shan, M. J. Stevens, J. Tranchida, C. Trott, S. J. Plimpton, LAMMPS - a flexible simulation tool for particle-based materials modeling at the atomic, meso, and continuum scales, Comp. Phys. Comm. 271 (2022) 108171. doi:10.1016/j.cpc.2021.108171.
- [91] A. Zunger, S.-H. Wei, L. G. Ferreira, J. E. Bernard, Special quasirandom structures, Physical Review Letters 65 (3) (1990) 353.
- [92] S.-H. Wei, L. G. Ferreira, J. E. Bernard, A. Zunger, Electronic properties of random alloys: Special quasirandom structures, Physical Review B 42 (15) (2008) 9622.
-
[93]
D. Gehringer, M. Friák, D. Holec, Models of configurationally-complex alloys made simple, Computer Physics Communications 286 (2023) 108664.
doi:https://doi.org/10.1016/j.cpc.2023.108664.
URL https://www.sciencedirect.com/science/article/pii/S0010465523000097 - [94] O. R. Deluigi, R. C. Pasianot, F. Valencia, A. Caro, D. Farkas, E. M. Bringa, Simulations of primary damage in a high entropy alloy: Probing enhanced radiation resistance, Acta Materialia 213 (2021) 116951.
- [95] S. Nosé, A unified formulation of the constant temperature molecular dynamics methods, The Journal of chemical physics 81 (1) (1984) 511–519.
- [96] W. G. Hoover, Canonical dynamics: equilibrium phase-space distributions, Physical review A 31 (3) (1985) 1695.
- [97] P. Schapotschnikow, R. Pool, T. J. Vlugt, Molecular simulations of interacting nanocrystals, Nano letters 8 (8) (2009) 2930–2934.
- [98] M. P. Allen, D. J. Tildesley, Computer simulation of liquids, Oxford university press, 2017.
- [99] D. Frenkel, B. Smit, Understanding molecular simulation: from algorithms to applications, Elsevier, 2001.
- [100] L. McInnes, J. Healy, J. Melville, Umap: Uniform manifold approximation and projection for dimension reduction, arXiv preprint arXiv:1802.03426 (2018).
- [101] B. Vela, T. Hastings, R. Arróyave, Visualizing high entropy alloy spaces: Methods and best practices, arXiv preprint arXiv:2408.07681 (2024).
- [102] T. M. Cover, J. A. Thomas, Elements of information theory, John Wiley & Sons, 2012.
- [103] J. B. Kinney, G. S. Atwal, Equitability, mutual information, and the maximal information coefficient, Proceedings of the National Academy of Sciences 111 (9) (2014) 3354–3359.
- [104] N. Simon, R. Tibshirani, Comment on ”detecting novel associations in large data sets” by reshef et al, science dec 16, 2011, arXiv preprint arXiv:1401.7645 (2014).
- [105] L. M. Ghiringhelli, J. Vybiral, S. V. Levchenko, C. Draxl, M. Scheffler, Big data of materials science: critical role of the descriptor, Physical review letters 114 (10) (2015) 105503.
- [106] H. Liu, K. Wu, Y.-S. Ong, C. Bian, X. Jiang, X. Wang, Learning multitask gaussian process over heterogeneous input domains, IEEE Transactions on Systems, Man, and Cybernetics: Systems 53 (10) (2023) 6232–6244.
- [107] A. Damianou, N. D. Lawrence, Deep gaussian processes, Artificial Intelligence and Statistics (2013) 207–215.
- [108] D. B. Miracle, O. N. Senkov, A critical review of high entropy alloys and related concepts, Acta Materialia 122 (2017) 448–511.
- [109] Y. Zhang, et al., Microstructures and properties of high-entropy alloys, Progress in Materials Science 61 (2014) 1–93.
-
[110]
V. L. Moruzzi, J. F. Janak, K. Schwarz, Calculated thermal properties of metals, Phys. Rev. B 37 (1988) 790–799.
doi:10.1103/PhysRevB.37.790.
URL https://link.aps.org/doi/10.1103/PhysRevB.37.790 - [111] O. N. Senkov, D. B. Miracle, K. J. Chaput, J.-P. Couzinie, Development of a refractory high entropy superalloy, Entropy 20 (3) (2018) 177.
- [112] A. Hebbal, L. Brevault, M. Balesdent, E.-G. Talbi, N. Melab, Multi-objective optimization using deep gaussian processes: Application to aerospace vehicle design, in: AIAA Scitech 2019 Forum, 2019, p. 1973.
- [113] Z. Wang, F. Hutter, M. Zoghi, D. Matheson, N. De Feitas, Bayesian optimization in a billion dimensions via random embeddings, Journal of Artificial Intelligence Research 55 (2016) 361–387.
- [114] J. M. Hernandez-Lobato, M. A. Gelbart, R. P. Adams, M. W. Hoffman, Z. Ghahramani, Predictive entropy search for multi-objective bayesian optimization with constraints, Neurocomputing 379 (2016) 237–247.
- [115] M. F. Ashby, Materials Selection in Mechanical Design, Butterworth-Heinemann, 2005.
- [116] S. F. Pugh, Xcii. relations between the elastic moduli and the plastic properties of polycrystalline pure metals, The London, Edinburgh, and Dublin Philosophical Magazine and Journal of Science 45 (367) (1954) 823–843.
- [117] C. Kittel, Introduction to Solid State Physics, Wiley, 2004.
- [118] T. H. K. Barron, G. K. White, Heat Capacity and Thermal Expansion at Low Temperatures, Springer, 1999.
- [119] B. Fultz, Vibrational thermodynamics of materials, Progress in Materials Science 55 (4) (2010) 247–352.
- [120] S.-C. Chen, C.-H. Huang, Y.-C. Chen, R.-D. Chien, Thermal management in electronic packaging: Challenges and selected applications, Microelectronics Reliability 56 (2016) 188–200.
- [121] C. Wang, J. Lee, Y. Yun, High-temperature sensors based on ceramic materials, Journal of Materials Science 53 (3) (2018) 1580–1599.
- [122] K. Pielichowska, K. Pielichowski, Phase change materials for thermal energy storage, Progress in materials science 65 (2014) 67–123.
- [123] X. Wu, J.-P. Kruth, J. Nobre, J. Pou, A. Rinaldi, V. Sufiiarov, I. V. Shishkovsky, M. Agarwala, W. Binder, Additively manufactured hierarchical stainless steels with high strength and ductility, Nature materials 18 (11) (2019) 1229–1234.
- [124] C. K. Williams, C. E. Rasmussen, Gaussian processes for machine learning, MIT press Cambridge, MA (2006).
- [125] C. E. Rasmussen, Gaussian processes to speed up hybrid monte carlo for expensive bayesian integrals, in: Bayesian statistics 7: proceedings of the seventh Valencia International Meeting, June 2-6, 2002, Oxford University Press, USA, 2003, pp. 651–659.
- [126] J. Hermans, Z. Wang, H. J. Kulik, K. Eggensperger, M. Feurer, F. Hutter, Overfitting in bayesian optimization: an empirical study and early-stopping solution, arXiv preprint arXiv:2111.11250 (2021).
- [127] T. Chen, C. Guestrin, D. Hal, Y. Rubanova, J. Sheng, A. G. Wilson, E. P. Xing, Practical evaluation of dgp models on real-world datasets, Journal of Machine Learning Research 17 (2016) 1805–1845.
- [128] J. Chen, H. Bai, W. Chen, Practical assessment of the state of the art in gaussian process regression, Neurocomputing 193 (2016) 78–90.
- [129] Q. Wang, K. Rajan, Multi-task learning in materials science: An application to property predictions and new material discovery, Computational Materials Science 172 (2020) 109246.
- [130] X. Liu, K. Goebel, P. I. Frazier, Q. Wang, Multi-objective bayesian materials discovery: Application on the discovery of precipitation strengthened niti shape memory alloys through micromechanical modeling, Materials & Design 10 (2018) 014.