[1]\fnmMarcos \surAlfaro
[1]\orgdivInstitute for Engineering Research (I3E), \orgnameMiguel Hernández University, \orgaddress\streetAv. Universidad, s/n, \cityElche, \postcode03202, \countrySpain
2]\orgnameCamí de Vera, Building 3Q, \orgaddress\streetStreet, \cityValencia, \postcode46020, \countrySpain
Hierarchical place recognition with omnidirectional images and curriculum learning-based loss functions
Abstract
This paper addresses Visual Place Recognition (VPR), which is essential for the safe navigation of mobile robots. The solution we propose employs panoramic images and deep learning models, which are fine-tuned with triplet loss functions that integrate curriculum learning strategies. By progressively presenting more challenging examples during training, these loss functions enable the model to learn more discriminative and robust feature representations, overcoming the limitations of conventional contrastive loss functions. After training, VPR is tackled in two steps: coarse (room retrieval) and fine (position estimation). The results demonstrate that the curriculum-based triplet losses consistently outperform standard contrastive loss functions, particularly under challenging perceptual conditions. To thoroughly assess the robustness and generalization capabilities of the proposed method, it is evaluated in a variety of indoor and outdoor environments. The approach is tested against common challenges in real operation conditions, including severe illumination changes, the presence of dynamic visual effects such as noise and occlusions, and scenarios with limited training data. The results show that the proposed framework performs competitively in all these situations, achieving high recognition accuracy and demonstrating its potential as a reliable solution for real-world robotic applications. The code used in the experiments is available at https://github.com/MarcosAlfaro/TripletNetworksIndoorLocalization.git.
keywords:
place recognition, omnidirectional images, deep neural networks, triplet loss, curriculum learning1 Introduction
The advancement of autonomous systems, from mobile robots to self-driving vehicles, relies on their capacity for robust and accurate localization within complex and dynamic environments. Place recognition, which involves capturing sensory information from the robot unknown position and retrieving the most similar sample among a previously stored database, is crucial for enabling this autonomy [1, 2, 3].
Among various sensing modalities, vision sensors offer a compelling balance of rich information, capturing colors, textures or shapes, at a relatively low cost [4]. However, the utility of visual data is often challenged by perceptual aliasing (i.e. different places appearing similar) or significant changes in appearance caused by variations of illumination, weather, season or viewpoint [5]. Omnidirectional cameras, which have a 360∘ field of view, constitute a particularly potent solution for Visual Place Recognition (VPR) [6]. These sensors capture complete information from the environment regardless of the robot orientation, thereby mitigating viewpoint-dependent appearance shifts and providing comprehensive scene context. Such panoramic views can be achieved through various means, including multi-camera systems [7], catadioptric setups [8] or paired fisheye cameras [9].
In recent years, deep learning tools have had a major impact on the field of mobile robotics [10]. In this context, Convolutional Neural Networks (CNNs) [11] and subsequently Vision Transformers (ViTs) [12] have demonstrated unparalleled success in learning powerful and discriminative image representations directly from data [13].
To effectively train these deep networks, specialized architectures and learning strategies are crucial. Siamese [14] and triplet [15] networks, which employ multiple weight-sharing branches, enable the generation of a vast number of training samples from a limited set of images. This is crucial for learning fine-grained similarities and differences between places. This learning is guided by a loss function, which must be carefully chosen to compare network outputs with ground truth relationships [16]. Within this context, contrastive learning has proven particularly effective [17]. It consists in training the model to map similar (positive) inputs to nearby points in an embedding space and dissimilar (negative) inputs to distant points. For VPR, positive pairs can be images from the same location, while negative pairs are from distinct locations. Triplet networks, utilizing anchor, positive, and negative samples, are especially suitable for refining descriptor spaces for high-precision retrieval.
Despite these advancements, effectively leveraging omnidirectional imagery for fine-grained, robust VPR across diverse conditions and with efficiency remains a significant challenge. Furthermore, optimizing the learning process itself is necessary for high-accuracy position retrieval.
Consequently, this paper addresses these challenges by proposing a novel hierarchical VPR framework that leverages panoramic images with deep networks, specifically fine-tuned through a two-stage process: an initial stage for coarse retrieval followed by a second stage for fine localization within the retrieved area. A key innovation of our approach lies in the introduction of novel contrastive triplet loss functions that explicitly incorporate curriculum learning principles. By strategically presenting training examples in an order of increasing difficulty, these loss functions guide the network to progressively learn more discriminative features, enhancing the final performance in the place recognition task. The experimental evaluations, conducted across challenging indoor and outdoor datasets, demonstrate that this approach, even with low-shot fine-tuning, achieves superior precision and remarkable robustness against substantial environmental changes. The main contributions of this paper are threefold:
-
•
We develop a framework to tackle hierarchical VPR with omnidirectional images and deep networks for coarse-to-fine place recognition.
-
•
We propose a set of novel contrastive triplet loss functions that integrate curriculum learning strategies, dynamically adjusting the difficulty of training triplets to optimize feature embedding for VPR.
-
•
We provide extensive experimental validation demonstrating that the proposed methodology provides a great precision and robustness against pronounced environmental changes, defying visual phenomena and different indoor and outdoor scenarios.
The rest of the manuscript is structured as follows. Section 2 reviews the state-of-the-art in VPR and relevant deep learning techniques. Section 3 presents the proposed hierarchical approach and novel loss functions. Section 4 describes the experimental setup and presents a comprehensive evaluation of the proposed framework. Finally, conclusions and future works are outlined in Section 5.
2 State of the art
Visual Place Recognition (VPR) has long been an integral part of robot navigation and scene understanding, with early efforts focusing on analytical techniques to craft global appearance descriptors from images [18]. However, these handcrafted methods often struggled with significant appearance variations and scalability. The rise of deep learning, driven by increased computational capabilities, has fundamentally reshaped the VPR landscape. Pioneer convolutional neural networks (CNNs), initially designed for tasks like object classification (e.g., LeNet [11], and later developed by deeper models such as AlexNet [19], VGG [20] and GoogLeNet [21] on datasets like ImageNet [22]), provided powerful tools for learning visual features directly from data. More recently, Vision Transformers (ViTs) [12] and their variants, including Swin-L [23] or DINOv2 [24], have emerged as highly effective feature extractors, often demonstrating superior performance and generalization in various vision tasks, including VPR.
Vision sensors are widely employed for VPR due to their versatility and low cost [25, 26, 27]. Among these, omnidirectional cameras are particularly advantageous for this task. Their 360∘ field of view ensures that, for a given robot position, the captured image contains comprehensive scene information irrespective of the robot’s orientation, inherently mitigating viewpoint-dependent appearance shifts. Consequently, numerous approaches have leveraged omnidirectional views as a primary or sole source of information for robot localization and mapping tasks, including panoramic [28, 29] and fisheye views [9]. While offering richer contextual information, effectively processing and learning from the often distorted or high-dimensional nature of panoramic imagery remains an active area of research.
Current VPR research focuses on optimizing deep learning architectures and their training processes to learn discriminative and robust place representations. Transformer-based architectures, such as AnyLoc [30], have been proposed to achieve high generalization capabilities across diverse environments. Concurrently, methods like CosPlace [31] have focused on developing efficient and scalable training strategies for large-scale VPR, utilizing modified CNN backbones (e.g., VGG16 [20]). EigenPlaces [32] further refined such CNN-based approach to enhance the robustness against viewpoint changes. Significant effort has also been invested in designing sophisticated pooling mechanisms to aggregate features into comprehensive global descriptors, as seen in MixVPR [33] and SALAD [34].
Despite their successes, many of these state-of-the-art methods demonstrate optimal performance primarily with standard, narrow field-of-view images and often require extensive fine-tuning for deployment in new environments or for achieving highly accurate localization. Furthermore, their predominant focus on single-step global localization may not be optimal for all scenarios.
In contrast to single-step global localization, hierarchical (or coarse-to-fine) strategies are often more suitable, particularly in structured environments like indoor spaces [35, 36]. These methods typically decompose the localization problem into multiple stages: first, identifying a broader area or room containing the query image, and subsequently, estimating a precise position within that retrieved area. This staged approach can improve efficiency by reducing the search space and can enhance accuracy by allowing specialized models for each stage.
Besides, learning discriminative embeddings is crucial for VPR. Siamese and triplet architectures [37, 38, 39] are widely employed for this, trained using loss functions that explicitly model similarity and dissimilarity. Triplet loss, first introduced in fields like face recognition [40, 41, 42], is particularly predominant, aiming to obtain similar embeddings of images from similar places (anchor-positive pairs) while obtaining dissimilar ones of images from different places (anchor-negative pairs).
While effective, the design of loss functions specifically tailored and optimized for VPR remains an active research direction. To further enhance the learning process, curriculum learning strategies have shown promise. Curriculum learning involves presenting training examples to the model in a structured manner, typically from easy to progressively more difficult instances. This can be achieved through strategic example selection [43] or by designing the loss function itself to adapt to the learning stage, as demonstrated by the siamese contrastive curriculum loss in [44]. Given that triplet networks often outperform siamese networks in complex metric learning tasks [45], extending curriculum learning principles to triplet loss functions for robust VPR is a compelling task.
In this paper, a novel hierarchical VPR framework is proposed, which uniquely leverages the comprehensive information from panoramic images within a two-stage deep learning pipeline. A core contribution is the introduction of a set of contrastive triplet loss functions that integrate curriculum learning principles, designed to enhance feature discriminability and training stability. By combining the strengths of omnidirectional vision, hierarchical localization and curriculum-guided deep metric learning, the proposed approach aims to deliver superior accuracy and robustness, particularly in challenging real-world environments requiring low-shot fine-tuning.
3 Methodology
3.1 Hierarchical localization
This approach leverages a place recognition framework based on omnidirectional imagery and deep neural networks, which are trained by means of a coarse-to-fine method. The input to our system consists of panoramic and equirectangular images captured by mobile robots across different indoor and outdoor environments. The datasets, along with the corresponding ground truth coordinates for each image, are partitioned into distinct training and test sets. The training images and the descriptors computed for each of them form the visual model, against which query images are compared. This supervised setup allows for precise training and evaluation of the proposed VPR pipeline.
A two-stage hierarchical localization strategy is implemented, adapting and extending concepts from [35]. Each stage utilizes a triplet network architecture, where three identical network branches that share their weights process an anchor image (), a positive image () and a negative image (), respectively, computing a descriptor for each image. During inference (validation and testing), a query image is processed by the appropriately trained model to generate a global appearance descriptor (where in the experiments). This descriptor is normalized and compared with the descriptors in the visual map using Euclidean distance or cosine similarity. The nearest neighbor in the descriptor space determines the recognized place or estimated position. The hierarchical process unfolds as follows:
3.1.1 Stage 1: Coarse Localization (Room Retrieval)
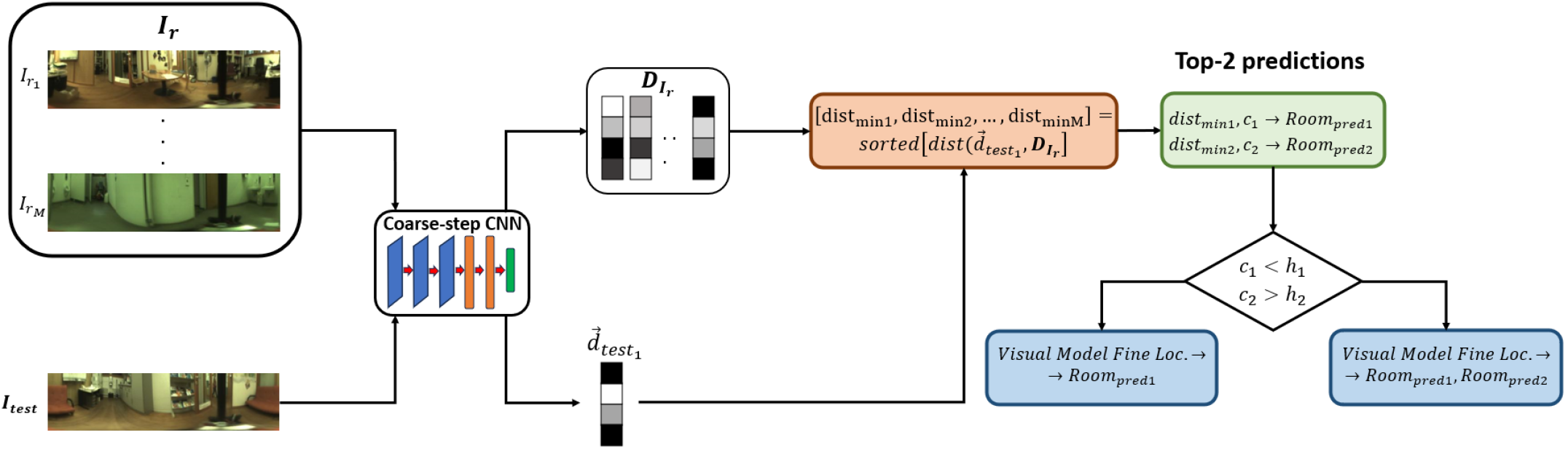
The objective of this stage is to identify the correct room or general area where the query image was captured. For this purpose, the network is trained using triplets where the anchor and positive images belong to the same room, while the negative image is from a different room. Triplet samples are chosen randomly following these criteria. This way, the network learns to produce room-discriminative descriptors. At inference, for a query image, its descriptor is compared against a set composed of one representative descriptor for each room, , where is the total number of rooms. Each is the descriptor of a pre-selected representative image for room (i.e. the image captured closest to the room’s geometric center).
The Euclidean distance between the query descriptor and the nearest representative descriptor provides the room initially considered the best prediction . Let be the confidence for this top prediction. If is below a threshold (set to 0.5), the second-best prediction is also considered. If the confidence for this second prediction is above a threshold (set to 0.1), both rooms are passed to the fine localization stage. Otherwise, only the top-predicted room is considered. Success at this stage is defined as the correct identification of the room containing the query image. Figure 1 (a) displays the general outline of the coarse step.
3.1.2 Stage 2: Fine Localization (Intra-Room Positioning)
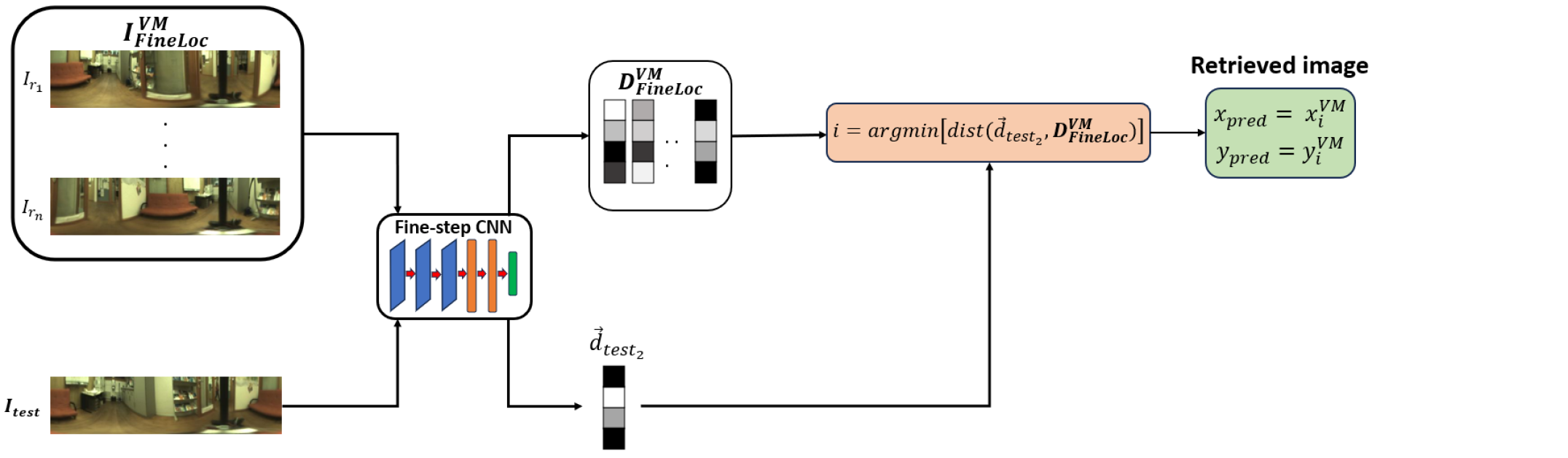
This stage aims to estimate the precise robot coordinates within the room(s) identified in the coarse step. In this stage, a unique model is trained for the entire environment. For this intra-room training, positive pairs are defined as images captured within a specified metric distance (set to 0.4m), while negative pairs are images captured further apart than the threshold (set to 0.4m). To perform inference, for a query image and a previously retrieved room (or rooms and ) from the coarse step, its descriptor is compared against all descriptors in the visual map for that room(s), where is the number of images in the visual map, built from the retrieved rooms.
The ground truth coordinates of the nearest neighbor in the visual map are taken as the estimated robot position. Recall@1 () is typically measured as the percentage of queries correctly localized within a certain distance threshold from their true positions. Figure 1 (b) contains the scheme for the fine localization stage.
3.2 Backbone selection
For both stages of the proposed hierarchical framework, we leverage the EigenPlaces [32] architecture, specifically the variant employing a VGG16 [20] backbone, which outputs a dimensional global descriptor. This choice was motivated by the fact that EigenPlaces demonstrated strong feature extraction capabilities and efficiency, with particular robustness to viewpoint changes, which is beneficial even with omnidirectional imagery. Preliminary experiments indicated its superiority over ResNet variants for this task. Transfer learning is employed by initializing the models with pre-trained weights and fine-tuning all the layers during the training process.
3.3 Triplet loss functions
| Name | Formula | Parameters |
|---|---|---|
| Triplet Margin (TL) [41] | ||
| Lifted Embedding (LE) [42] | ||
| Lazy Triplet (LT) [46] | ||
| Semi Hard (SH) [41] | ||
| Batch Hard (BH) [42] | ||
| Circle (CL) [47] | , | |
| Angular (AL) [48] | ||
| Curriculum TL+LT () | , , | |
| Curriculum TL+BH () | , , | |
| Curriculum LT+BH () | , , |
| Symbol | Description |
|---|---|
| Batch size | |
| Anchor, positive, and negative descriptors | |
| Euclidean distance between the anchor and positive descriptors in the -th triplet | |
| Euclidean distance between the anchor and negative descriptors in the -th triplet | |
| Euclidean distance between the positive and negative descriptors in the -th triplet | |
| Euclidean distances between each anchor-positive pair | |
| Euclidean distances between each anchor-negative pair | |
| Cosine similarity between the anchor and positive descriptors in the -th triplet | |
| Cosine similarity between the anchor and negative descriptors in the -th triplet | |
| Margin | |
| , , | Margin (TL,LT,BH) |
| Scale factor (CL) | |
| Angular margin (AL) | |
| Loss weight | |
| ReLU function: |
A core contribution of this paper is the exploration and proposal of novel triplet loss functions that integrate curriculum learning to enhance the training process for VPR. The standard triplet loss function aims to enforce a margin between the distance of positive pairs and negative pairs . The loss functions that we propose in this work build upon this by introducing a curriculum strategy, which typically works by modulating the difficulty of triplets considered or by adjusting the loss emphasis as training progresses. This allows the network to first learn from easier examples and gradually tackle more challenging distinctions, leading to more robust and discriminative embeddings. To achieve this progressive training, two contrastive losses of different exigence are combined by means of a weighted sum:
| (1) |
where is the weight, is the least restrictive loss and is the hardest loss.
This weight is initialized at 1 (i.e. the least restrictive loss is the only loss considered) and is modified during training, achieving a value of 0 at the end of the training process (i.e. only the hardest loss is employed). This approach permits performing a training with increasing difficulty, with the model first learning the broader features of the images from the dataset and finally adjusting to particular high-demanding examples to increase predictive accuracy.
In this paper, three different curriculum loss variants are proposed, which are built by combining the Triplet Loss () [41], which is calculated as the average error in the predictions from a batch, the Lazy Triplet () [46], which outputs the highest error from the batch (i.e. it returns the most difficult example from the batch), and the Batch Hard () [42], which returns the most difficult positive and negative examples from the batch. In terms of training exigence, . Therefore, three different combinations are possible: , and .
The specific formulations of the benchmark triplet losses and the proposed curriculum losses are detailed in Table 1. Definitions for all mathematical terms and symbols used in these loss functions are provided in Table 2. In the next section, exhaustive experiments will assess their impact on both coarse and fine localization performance.
4 Experiments
This section presents the experimental evaluation of the proposed hierarchical localization framework. Section 4.1 introduces the datasets used for training and evaluation, whereas the subsequent sections detail the experimental setup and results.
4.1 Datasets
4.1.1 Indoor dataset: COLD
The COLD database [49] is composed of omnidirectional images captured by a mobile robot that makes use of a catadioptric vision system with a hyperbolic mirror. The robot navigates various paths within several buildings, traversing different rooms such as offices, kitchens, toilets or corridors. The dataset was collected across four different scenarios — Freiburg Part A (FR-A) and B (FR-B) and Saarbrücken Part A (SA-A) and B (SA-B) — and under three different lighting conditions: cloudy, night and sunny.
Figure 2 displays sample images from the COLD database, illustrating the different lighting conditions and environments. These examples highlight challenging aspects of the dataset, such as significant appearance changes due to illumination variations (e.g. windows, shadows, etc) or pieces of furniture in different positions and perceptual aliasing arising from visually similar rooms in different locations.






4.1.2 Mixed indoor-outdoor dataset: 360Loc
The 360Loc database [50] consists of equirectangular images captured with a 360∘ camera at the Hong Kong University, which includes both indoor and outdoor areas. This dataset contains trajectories from four different locations — atrium, concourse, hall and piatrium — recorded under both day and night conditions. Figure 3 shows examples of images from two different environments of this dataset (atrium and hall) under day and night illumination.




4.2 Experiment 1. Evaluation of loss functions
In this experiment, a comparative evaluation of the different triplet loss functions described in Section 3 is conducted in the FR-A environment. For both the coarse and fine localization stages, a separate network is trained with each loss function. We have varied the parameters of each loss function to identify their optimal configurations. Each network is trained with 50000 triplet samples, using the Stochastic Gradient Descent (SGD) as optimizer algorithm, with a learning rate . Table 3 specifies the number of images used for training and testing in this experiment. Only cloudy images are used in the training. Tables 4 and 5 present the best results achieved with each loss function for coarse and fine localization, respectively. In this experiment, the threshold distance to calculate the was set to 0.5m.
| Environment |
|
|
|
|
||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| FR-A | 556 | 2595 | 2707 | 2114 |
| Loss | Parameters | N | Accuracy (%) | |||
|---|---|---|---|---|---|---|
| Cloudy | Night | Sunny | Avg. | |||
| TL | 16 | 99.27 | 97.41 | 95.70 | 97.46 | |
| LE | 4 | 99.15 | 97.38 | 95.65 | 97.39 | |
| LT | 4 | 99.19 | 97.27 | 96.03 | 97.50 | |
| SH | 16 | 99.00 | 97.19 | 95.70 | 97.30 | |
| BH | 4 | 98.96 | 97.27 | 96.12 | 97.45 | |
| CL | 4 | 98.77 | 97.45 | 95.36 | 97.19 | |
| AL | 16 | 98.96 | 97.08 | 95.79 | 97.28 | |
| 4 | 99.19 | 97.52 | 96.03 | 97.58 | ||
| 4 | 99.19 | 97.60 | 96.36 | 97.72 | ||
| 8 | 99.11 | 97.56 | 96.26 | 97.64 | ||
As shown in Table 4, for coarse localization, the standard Triplet Loss (TL) achieved the highest accuracy when the test is performed in the same lighting conditions than the training (cloudy). However, the proposed curriculum-based loss functions demonstrated superior overall retrieval accuracy, particularly under lighting conditions not encountered during training (night and sunny). Specifically, the loss variant yielded the best overall performance.
| Loss | Parameters | N | Recall@1 (%) | |||
| Cloudy | Night | Sunny | Avg. | |||
| TL | 16 | 91.91 | 94.16 | 83.07 | 89.71 | |
| LE | 4 | 92.45 | 94.50 | 83.92 | 90.29 | |
| LT | 4 | 92.14 | 95.09 | 85.48 | 90.90 | |
| SH | 16 | 93.29 | 94.68 | 84.77 | 90.91 | |
| BH | 4 | 91.75 | 94.27 | 81.03 | 89.02 | |
| CL | 4 | 92.91 | 94.50 | 84.67 | 90.69 | |
| AL | 16 | 92.18 | 94.31 | 81.08 | 89.19 | |
| 4 | 93.14 | 94.87 | 85.71 | 91.24 | ||
| 4 | 93.29 | 94.57 | 83.35 | 90.40 | ||
| 8 | 92.41 | 94.64 | 84.96 | 90.67 | ||
| Baseline (no training) | 92.22 | 93.02 | 81.41 | 88.88 | ||
Table 5 indicates that for fine localization, the loss function outperformed the other functions in terms of , demonstrating its competitive performance across varied lighting scenarios. Besides, the Semi Hard (SH) and the Lazy Triplet (LT) losses also achieved high recall under cloudy and night conditions, respectively. When compared to the baseline, i.e. single-step localization without model fine-tuning is performed, the proposed training method based on curriculum loss functions showed a substantial improvement under all conditions, confirming its robustness against illumination changes.
Furthermore, the performance of the best loss function with varying sizes of the training set is evaluated. Figure 4 (a) and (b) illustrate the results for each illumination condition as a function of the training set size.
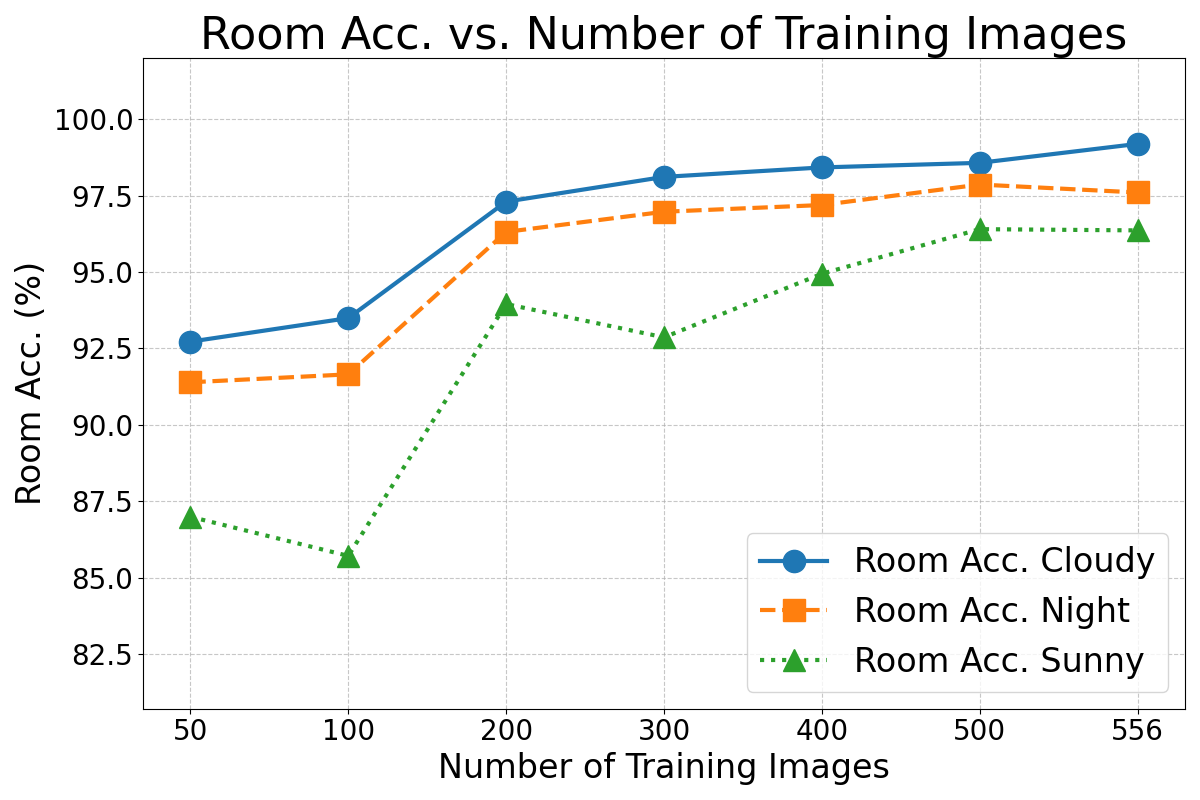
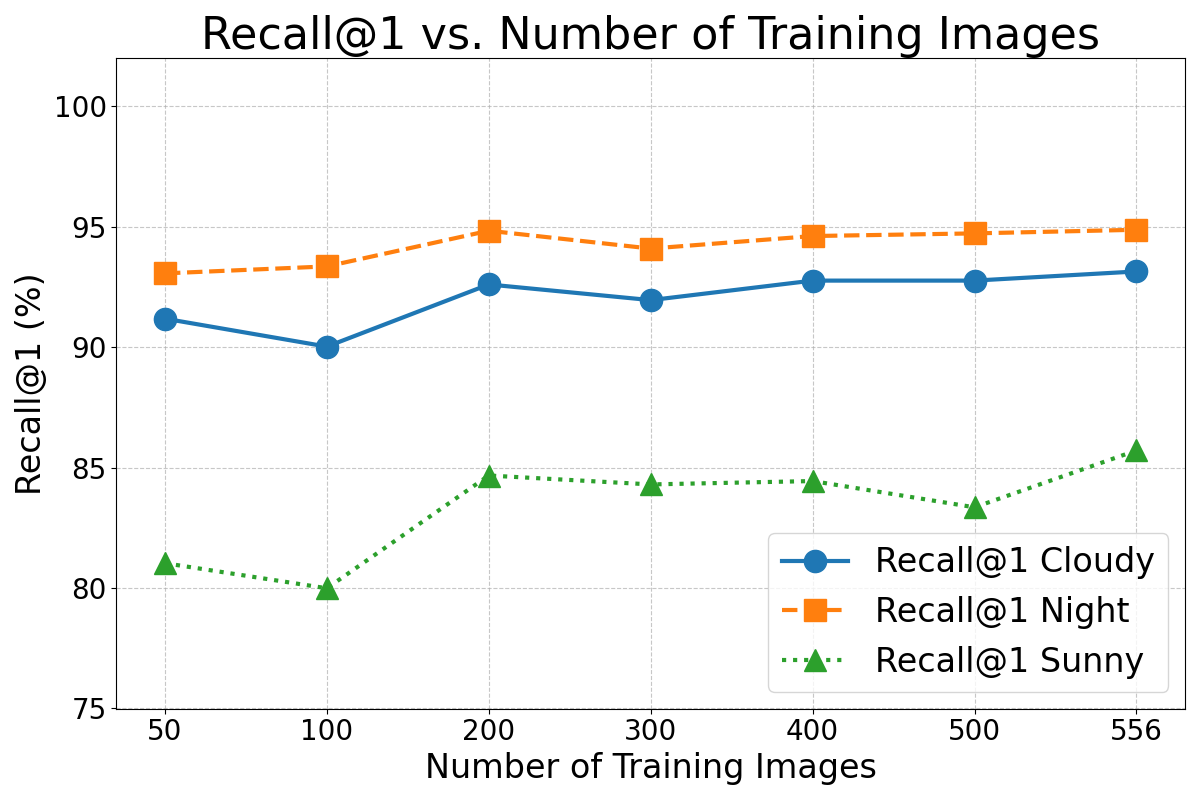
The results in Figure 4 indicate that the model performed competitively across all lighting conditions, even when trained on smaller subsets. The performance shows near-total invariance to the number of training images for sets with 200 or more images.
To better understand the method’s performance, Figure 5 presents qualitative results. The left column displays room retrieval predictions from the coarse model, where the query image locations are color-coded based on the retrieved room. The right column shows pose retrieval predictions from the fine model, where correctly localized query images are marked in green and incorrect ones in red. The Recall@1 criterium is used to consider correctly localized query images (i.e. the retrieved image must be at a distance lower than 0.5m from the query image).
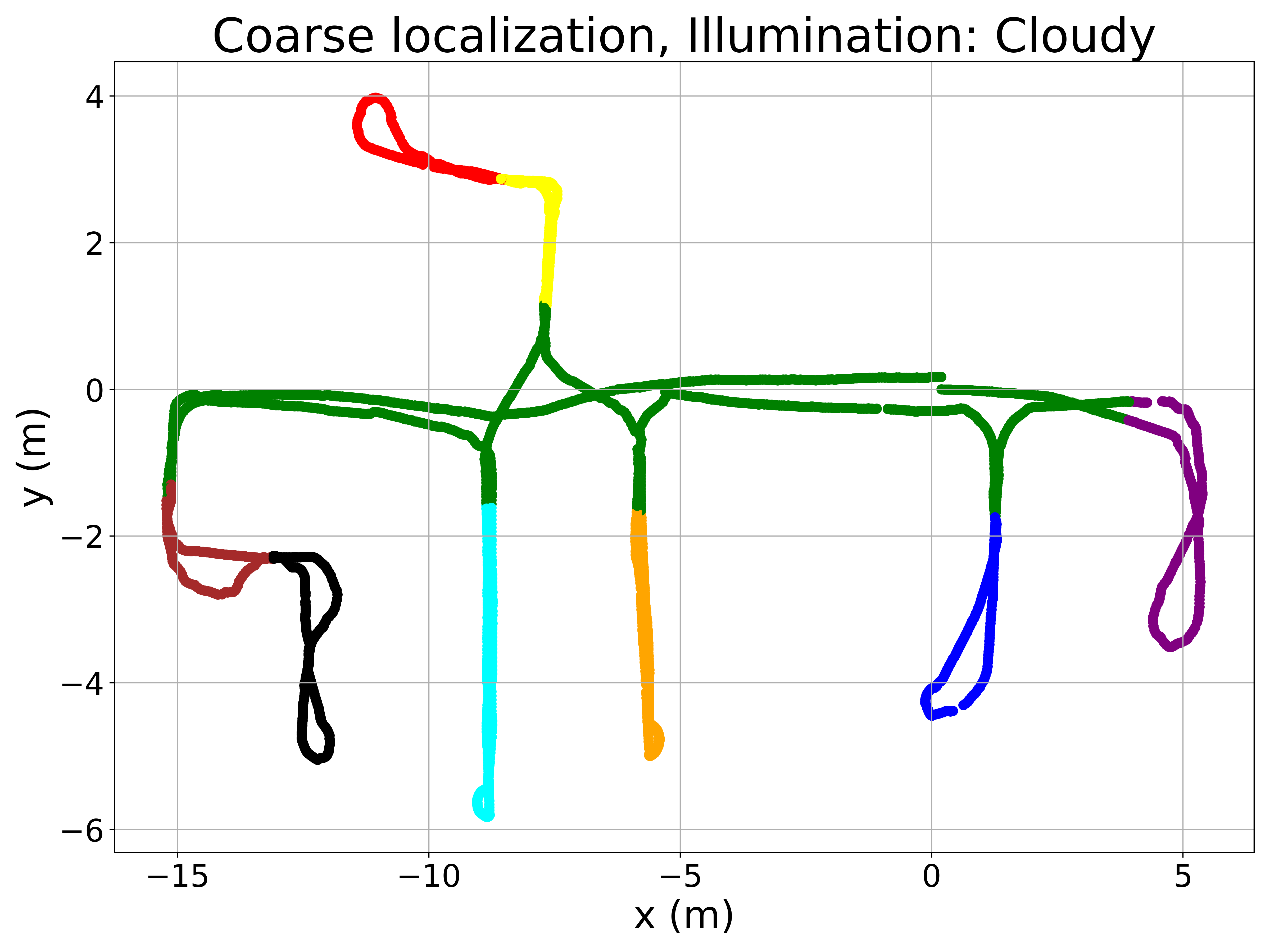
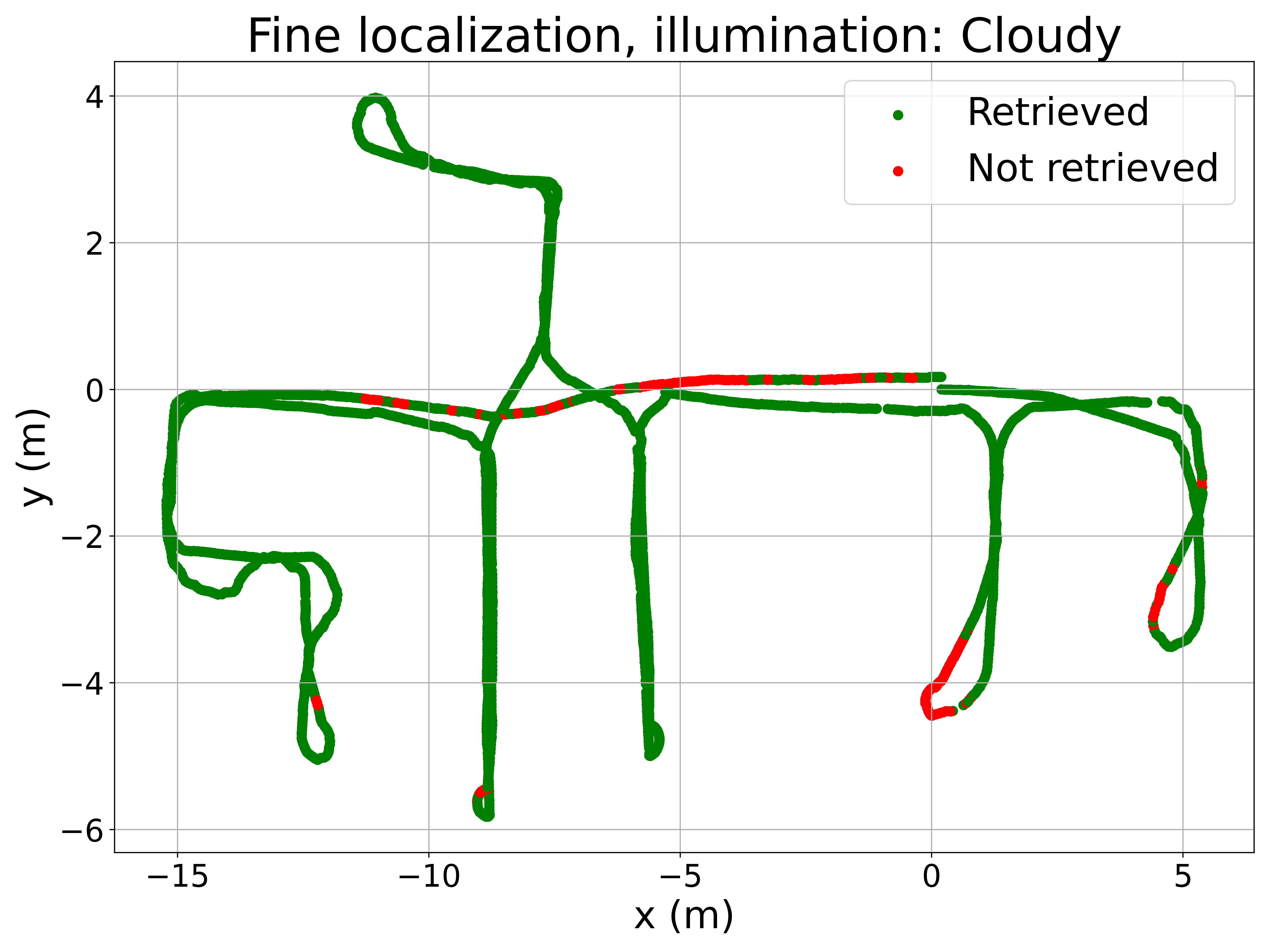
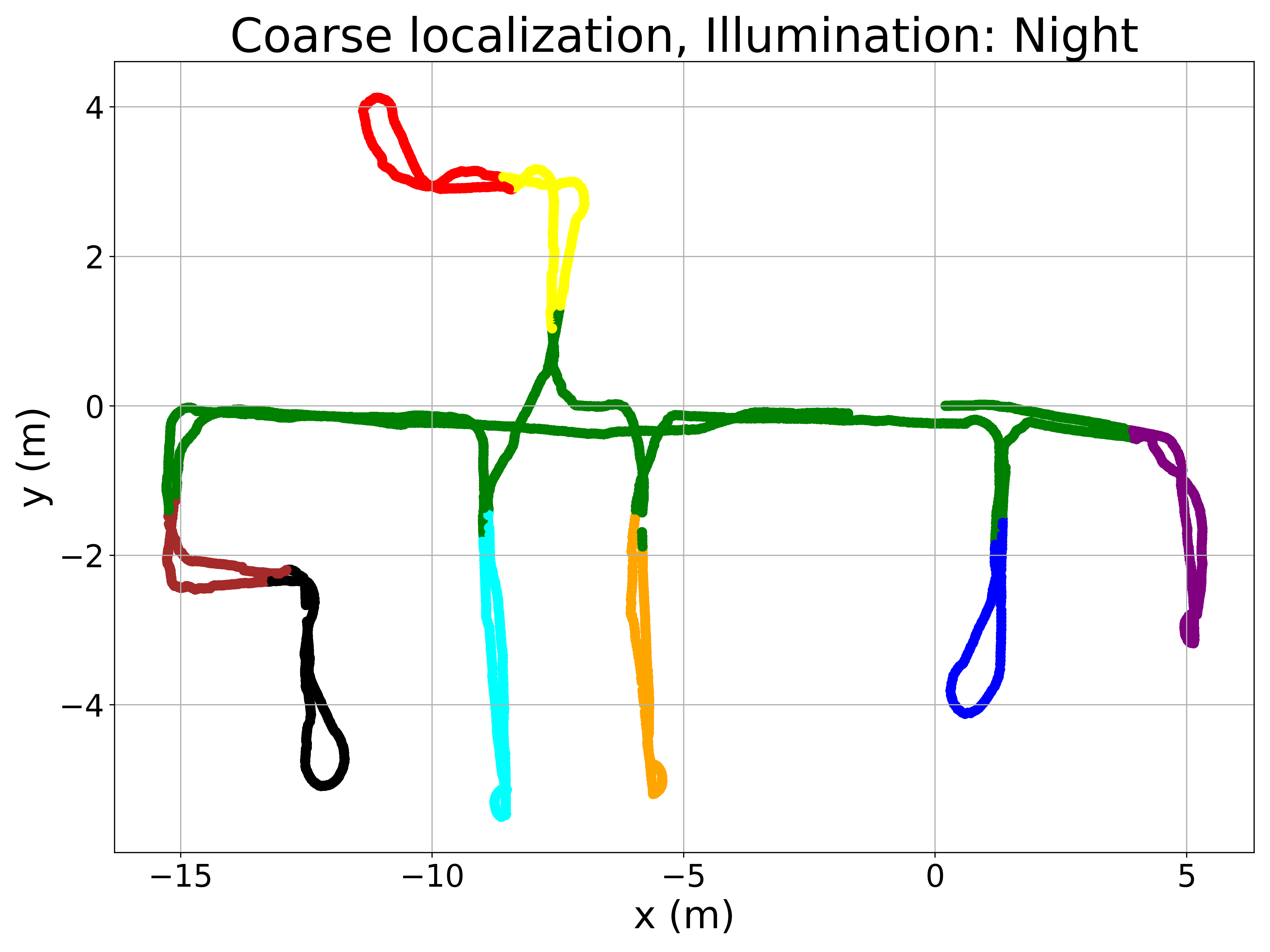
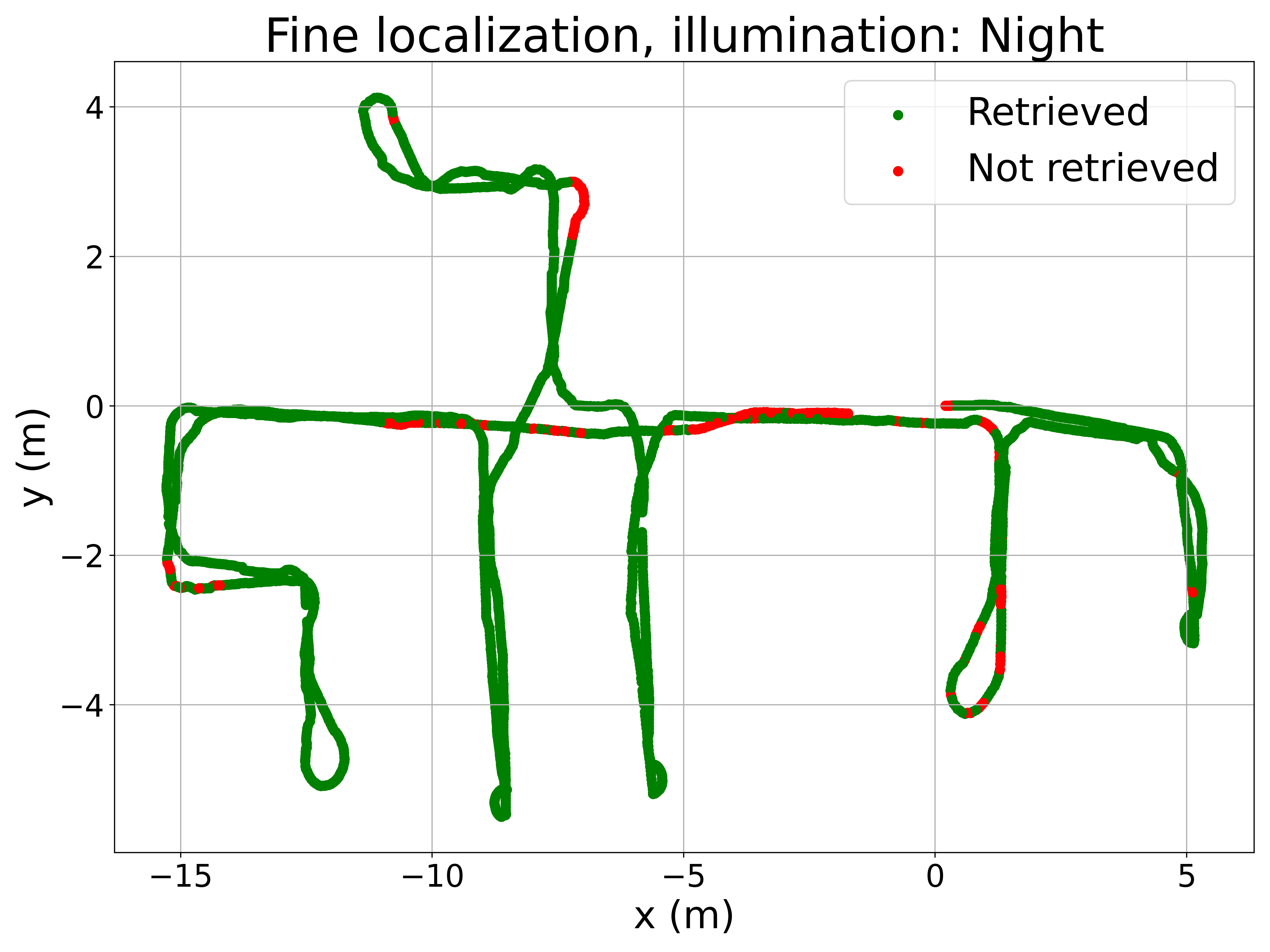
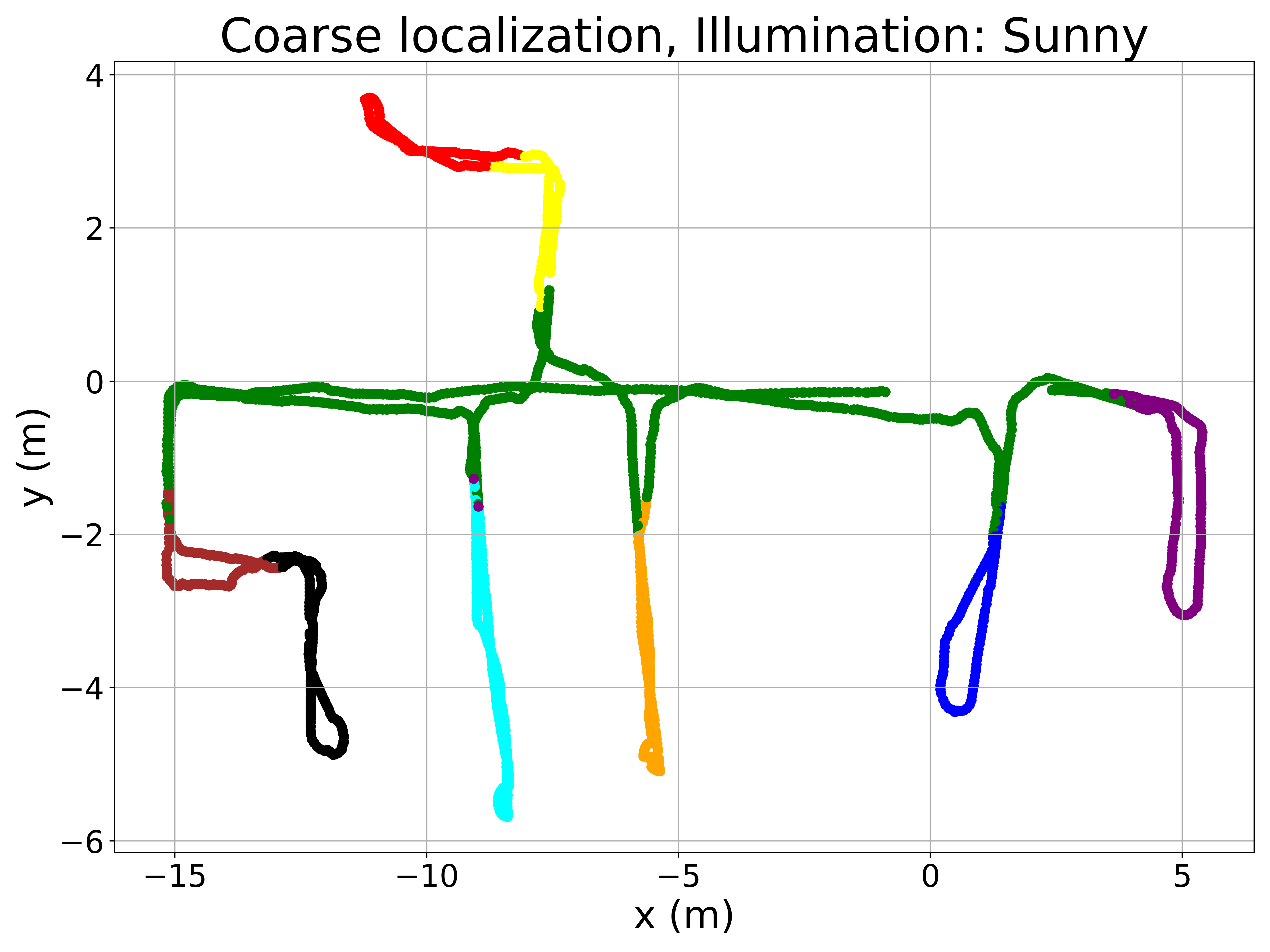
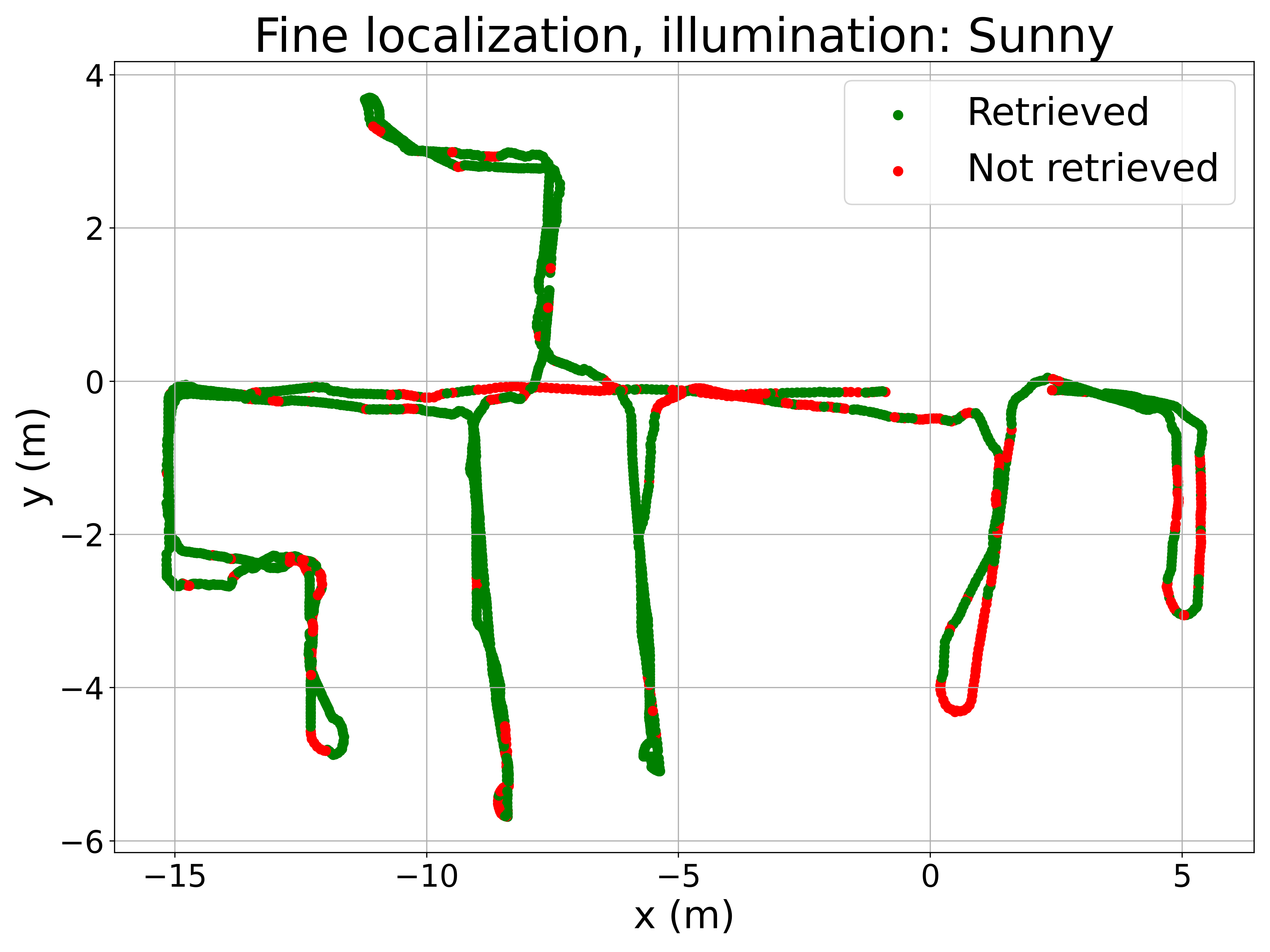
The maps in Figure 5 reveal a very low proportion of errors in room retrieval, considering that this is a challenging problem because of the visual similarity between different rooms. Errors between non-adjacent rooms are anecdotic, occurring only under sunny conditions. For fine localization, pose retrieval errors are concentrated in specific areas, such as the corridor, which is prone to perceptual aliasing. Some rooms with large windows also exhibit a higher number of errors under sunny conditions due to extreme illumination changes. Nevertheless, the proposed method demonstrates competitive performance across all lighting conditions, given the inherent difficulty of the task.
Regarding the computational cost, the localization time of the proposed hierarchical method, defined as the interval from image capture to the final pose retrieval, is approximately 7 ms. The memory requirement, which includes the descriptors for the query image and the visual map, as well as the two CNN models, is 1.72 GB. All experiments were conducted on a desktop computer equipped with an NVIDIA GeForce GTX 3090 GPU with 24 GB of RAM.
4.3 Experiment 2. Analysis of the robustness against dynamic effects
In this experiment, the robustness of the proposed hierarchical localization approach against common visual artifacts encountered in mobile robotics is assessed: occlusions, noise, and motion blur. Figure 6 provides examples of these effects applied to panoramic images from the FR-A environment. For this evaluation, the models trained for Experiment 1 are employed without any further training. The best-performing model from the coarse localization step and the best model from the fine localization step are used.









4.3.1 Noise effect
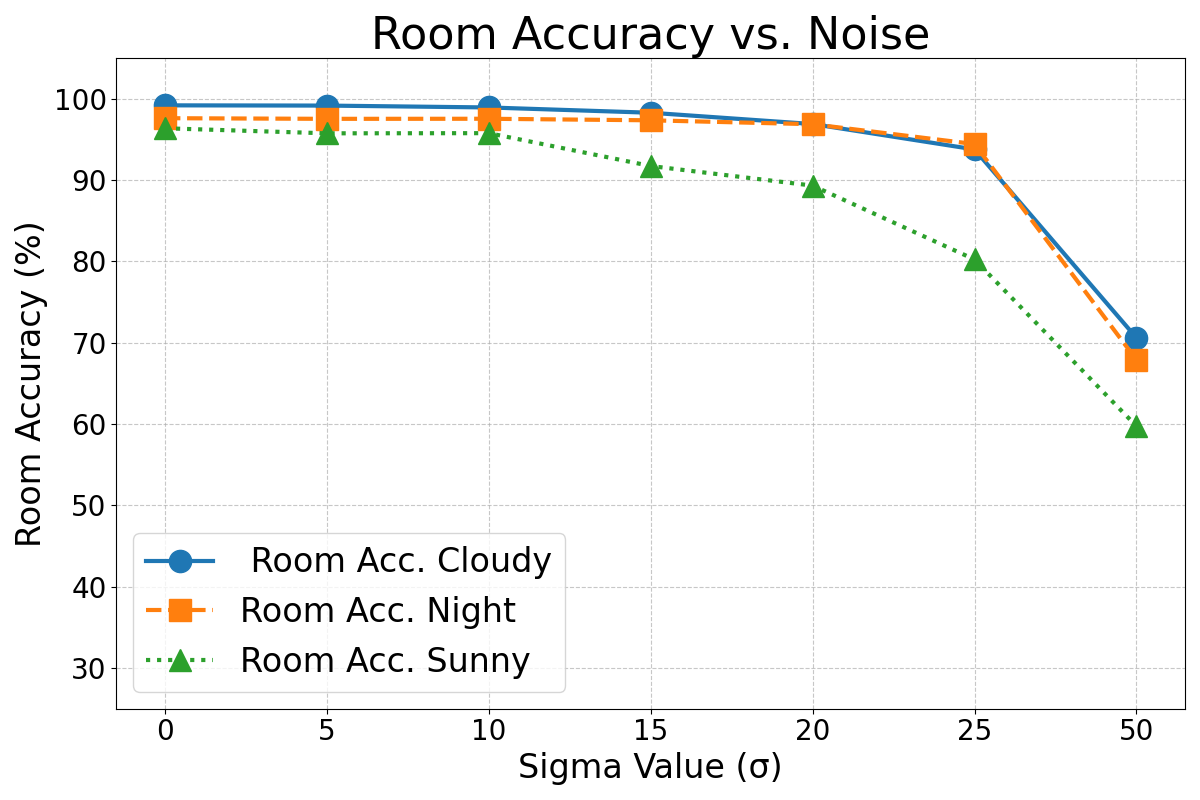
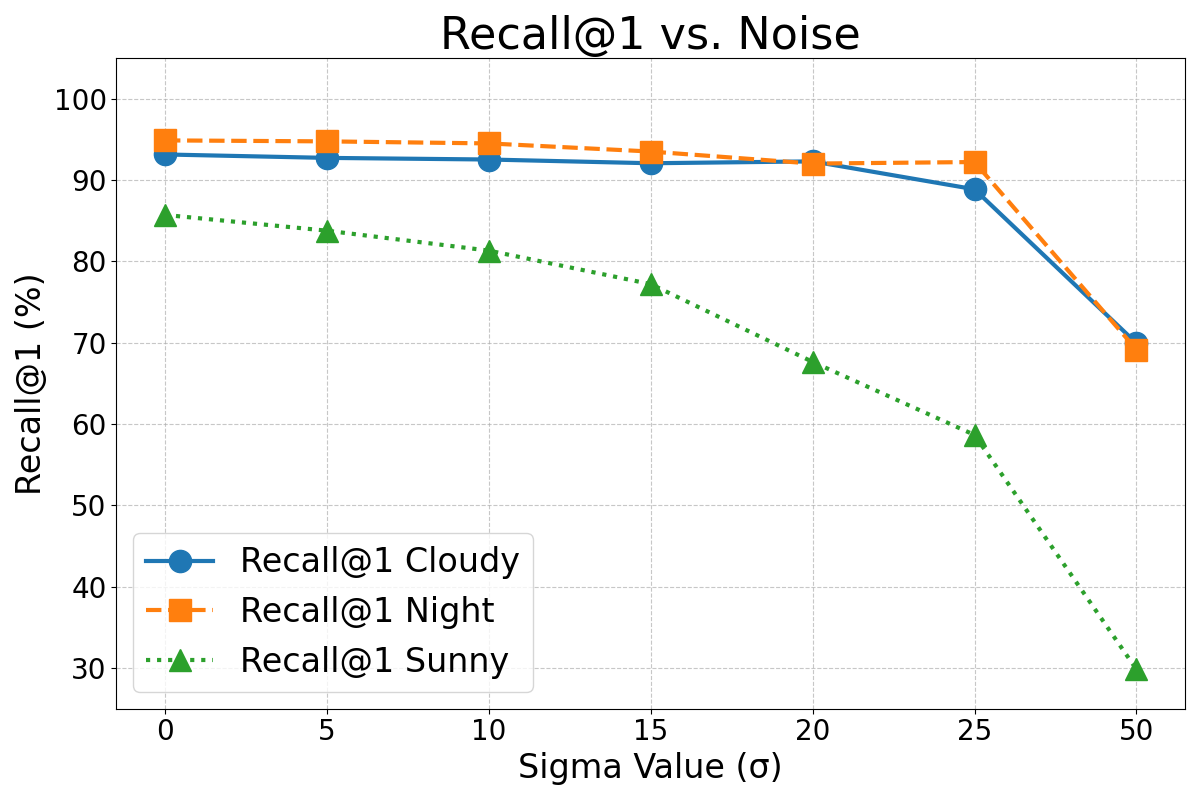
Image noise is a frequent artifact in robotic vision. To simulate this, Gaussian noise of standard deviation is added to the test images and the images composing the visual map. Figure 7 shows the average performance degradation for different levels of noise.
4.3.2 Occlusions effect
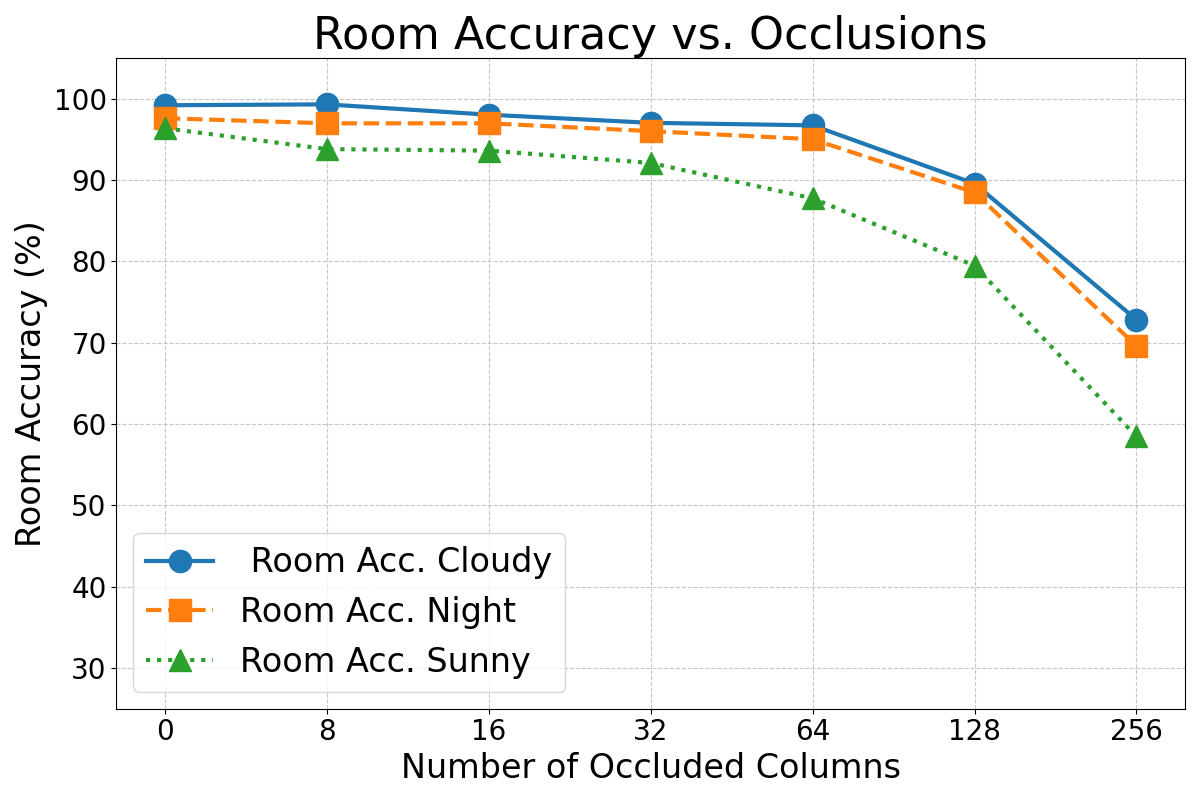
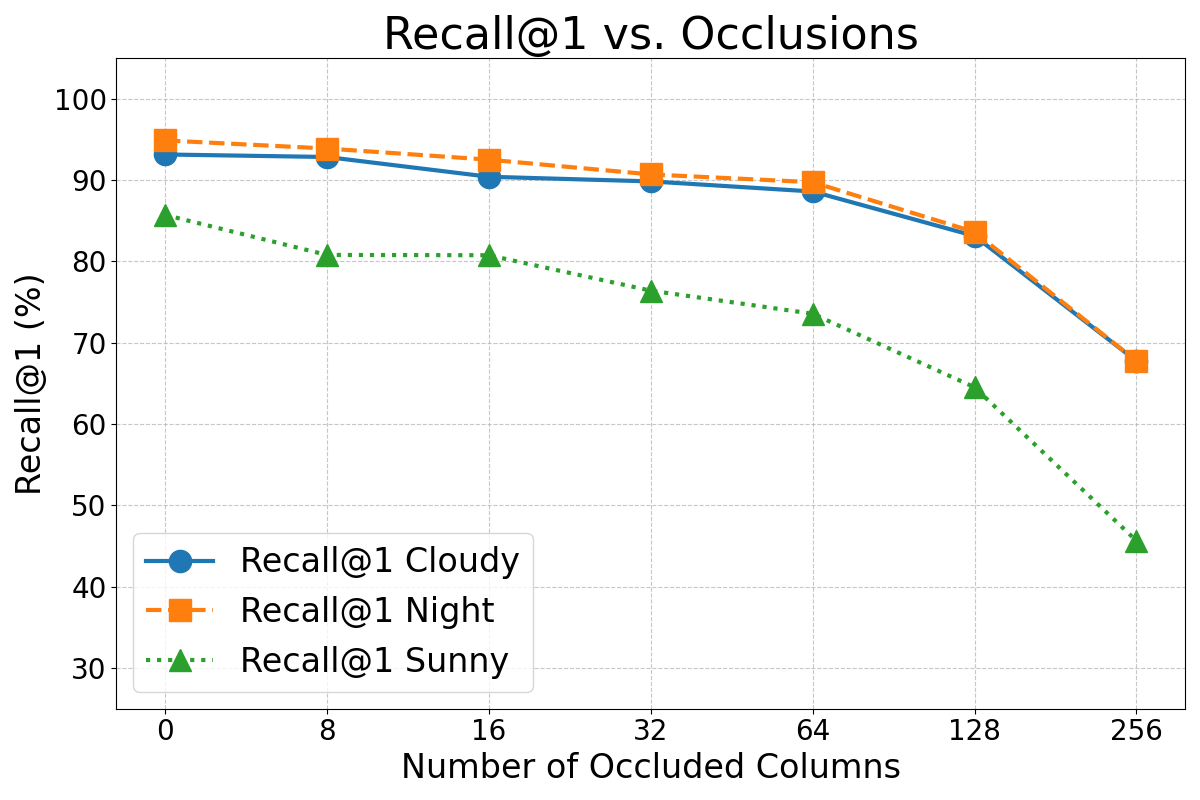
Mobile robots often encounter scenes where parts of the view are occluded by other objects or people, or even by parts of the robot itself. Occlusions have been simulated by setting a varying number of panoramic image columns to black. Figure 8 illustrates the impact of increasing occlusion on localization performance.
4.3.3 Motion blur effect
Motion blur occurs when images are captured while the robot is moving or turning. When this happens, the objects of the scene appear blurred. This effect has been simulated by applying a horizontal convolution mask to the images. The severity of the blur was controlled by the size of the mask. Figure 9 shows the influence of motion blur on the CNN’s performance.
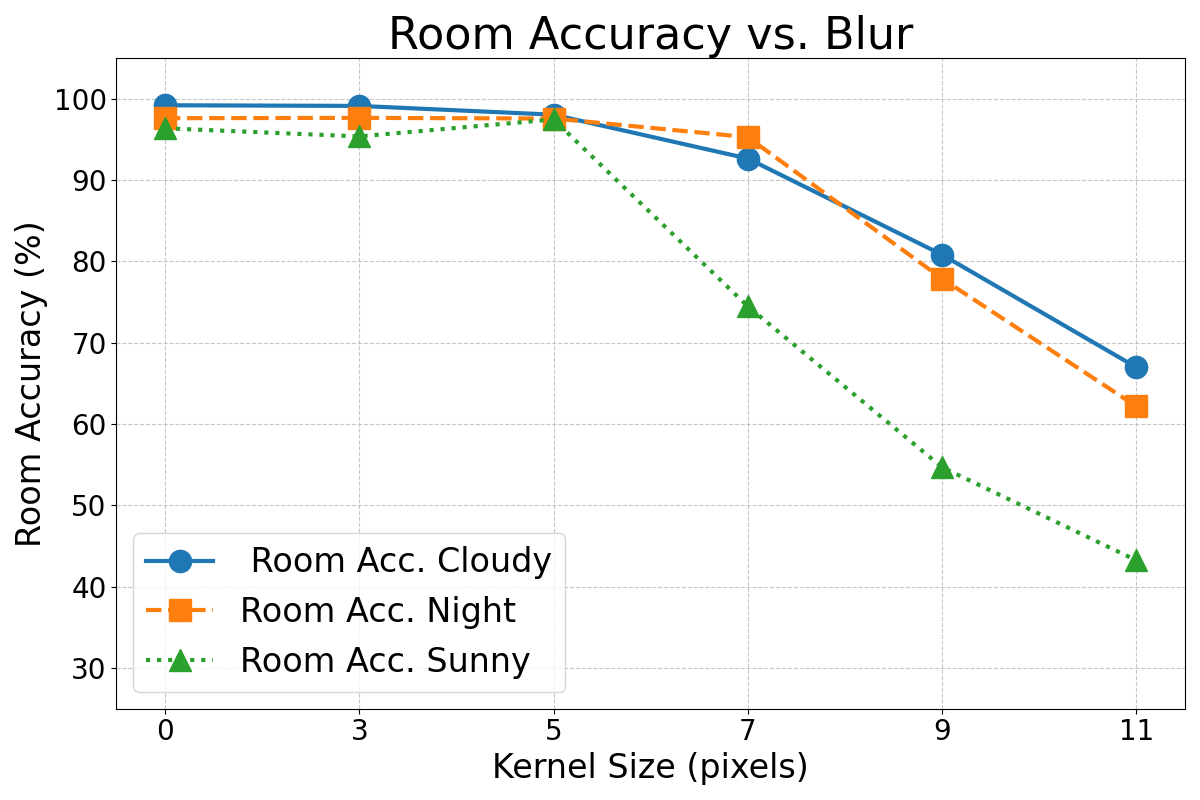
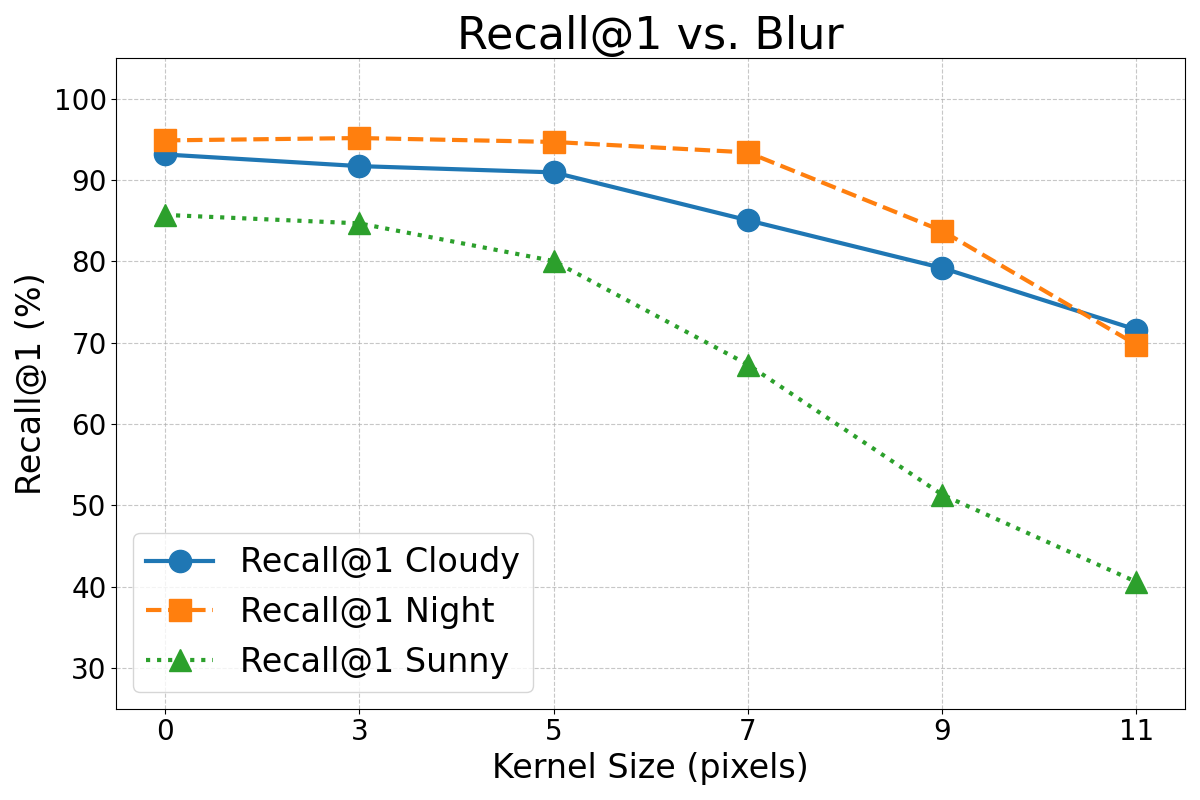
As expected, Figures 7, 8, and 9 show that the performance of this method degraded as the intensity of these effects increased. However, in general terms, the error rates did not increase substantially until the effects became very pronounced. It is important to note that the magnitude of the simulated effects in this experiment was much larger than the typical variations that may happen in real operation condition and the variations present in the original dataset (see Figure 6). For instance, the occlusion caused by the mirror’s support structure is a constant and noticeable feature in the images, yet the results from Experiment 1 demonstrate that it does not significantly impair the VPR performance.
4.4 Experiment 3. Performance study in different environments
The objective of this experiment is to evaluate the generalization capability of the triplet network-based approach in larger and more varied scenarios with significant environmental changes. For this purpose, the procedure from Experiment 1 is replicated for three additional environments from the COLD indoor database (FR-B, SA-A and SA-B) and four environments from the 360Loc dataset (atrium, concourse, hall and piatrium). The models are trained using the optimal loss configurations identified in Experiment 1. For the more unstructured outdoor scenarios, which are not composed of rooms, we employed a conventional single-step place recognition approach.
Tables 6 and 7 detail the number of images in the training and evaluation sets for this experiment. Figure 10 (a) and (b) show the Recall@1 results for the COLD and 360Loc environments, respectively. In this experiment, was set to 5m for the concourse scenario from the 360Loc database and to 10m for the rest of scenarios from the 360Loc database.
| Environment |
|
|
|
|
||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| FR-B | 560 | 2008 | - | 1797 | ||||||||
| SA-A | 586 | 2774 | 2267 | - | ||||||||
| SA-B | 321 | 836 | 870 | 872 |
| Environment |
|
|
|
||||||
|---|---|---|---|---|---|---|---|---|---|
| atrium | 581 | 875 | 1219 | ||||||
| concourse | 491 | 593 | 514 | ||||||
| hall | 540 | 1123 | 1061 | ||||||
| piatrium | 632 | 1008 | 697 |
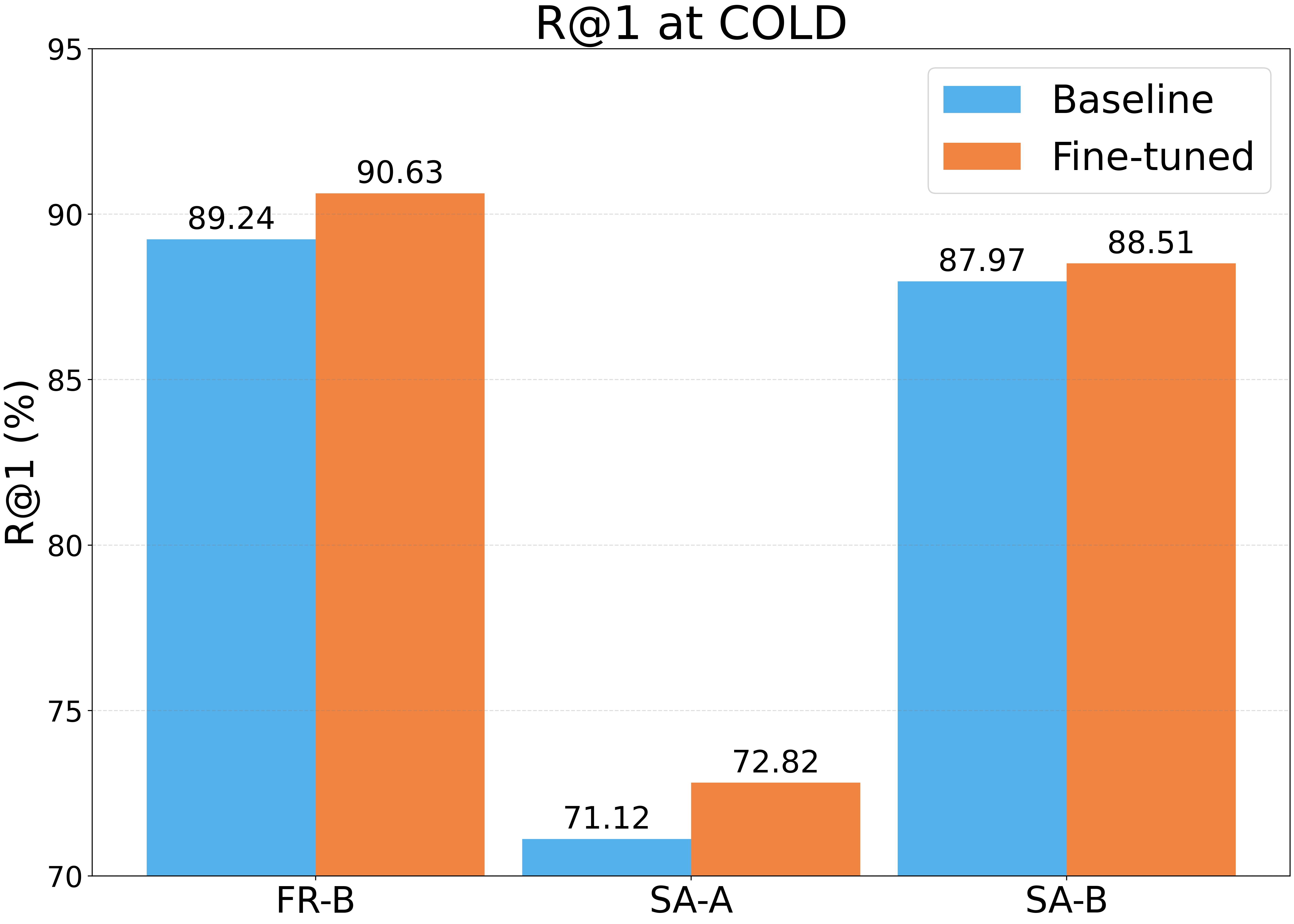
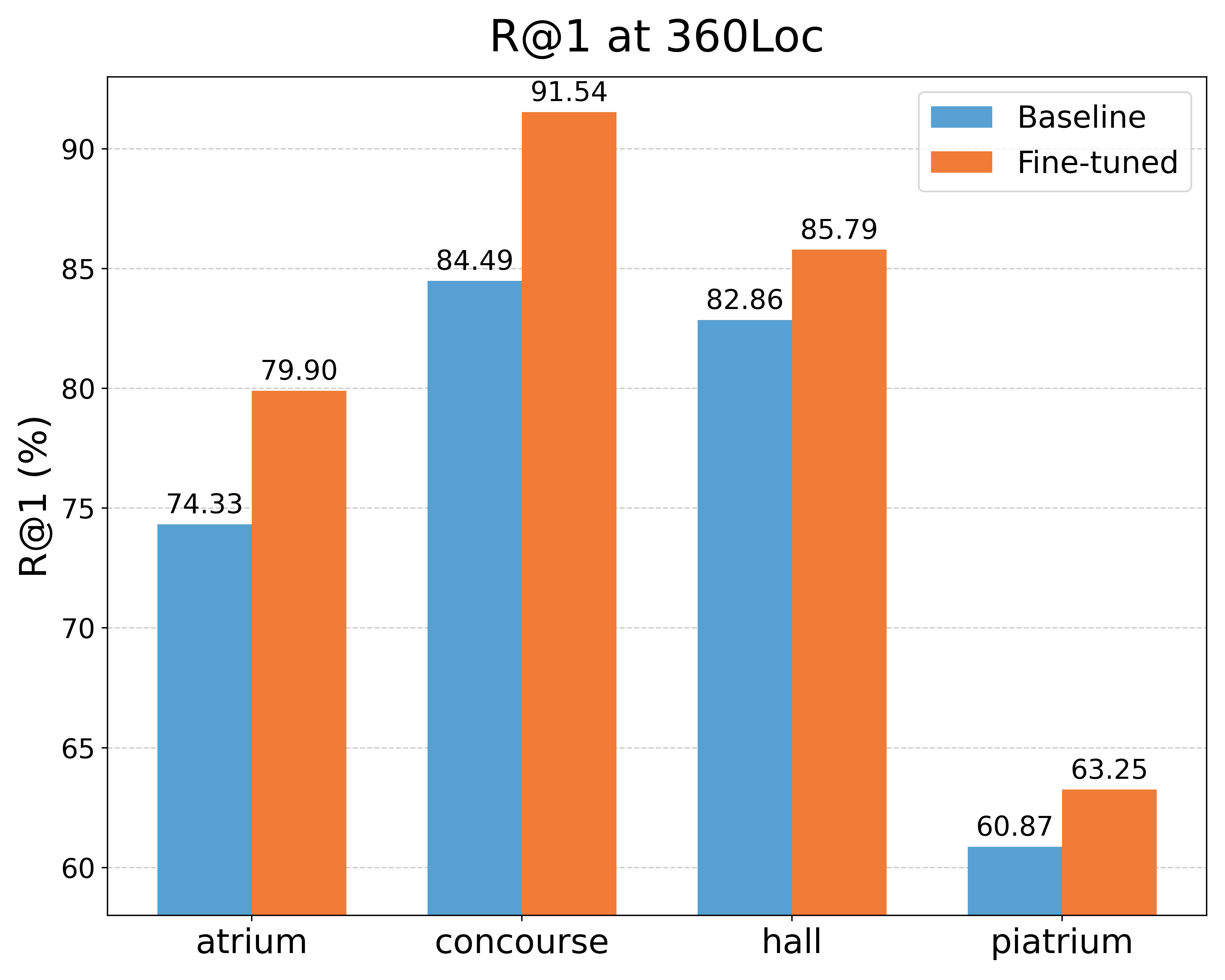
As observed in Figure 10, the proposed method achieves a notable improvement in performance across all tested scenarios and lighting conditions. Notably, a substantial improvement is observed in the outdoor environments, considering the low number of images used during training. These results underscore the importance of fine-tuning models with omnidirectional images for robust localization in diverse and challenging conditions.
5 Conclusions
This manuscript introduces a hierarchical VPR framework that leverages deep learning models and panoramic images. A central component of our work is an exhaustive evaluation of contrastive triplet loss functions for training these models. The results demonstrate that the proposed loss functions, which incorporate a curriculum learning strategy, significantly outperform existing triplet-based losses at both VPR stages (coarse and fine).
Furthermore, the proposed method was rigorously evaluated under a variety of challenging conditions. It demonstrated robust performance even with a limited number of training images and in the presence of significant visual degradations, including noise, occlusions, and motion blur. Furthermore, its effectiveness was validated across diverse indoor and outdoor environments. In all test cases, this method performed competitively, establishing itself as an accurate, efficient and robust solution for VPR.
Future research will focus on extending the hierarchical approach to large-scale and complex outdoor environments. Additionally, we plan to investigate the integration of other sensory modalities to further enhance place recognition performance and robustness.
Declarations
-
•
Funding
The Ministry of Science, Innovation and Universities (Spain) has funded this work through FPU23/00587 (M. Alfaro) and FPU21/04969 (J.J. Cabrera). This research work is part of the project PID2023-149575OB-I00 funded by MICIU/AEI/10.13039/501100011033 and by FEDER, UE. It is also part of the project CIPROM/2024/8, funded by Generalitat Valenciana, Conselleria de Educación, Cultura, Universidades y Empleo (program PROMETEO 2025).
-
•
Conflict of interest/Competing interests
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
-
•
Ethics approval and consent to participate
Not applicable
-
•
Consent for publication
Not applicable
-
•
Data availability
The COLD and 360Loc datasets are public and can be downloaded from their official websites https://www.cas.kth.se/COLD/, https://github.com/HuajianUP/360Loc.
-
•
Materials availability
Not applicable
-
•
Code availability
The code used in the experiments is available at https://github.com/MarcosAlfaro/TripletNetworksIndoorLocalization.git.
-
•
Author contribution
Conceptualization: O.R., L.P.; Methodology: J.J., M.F.; Software: M.A.; Validation: J.J., M.F.; Formal analysis: J.J., M.F.; Investigation: M.A., J.J.; Resources: O.R.; Data curation: M.F.; Writing – original draft: M.A., J.J.; Writing – review & editing: O.R., L.P.; Visualization: M.A., M.F., Supervision: L.P.; Project administration: O.R., L.P.; Funding acquisition: O.R.; L.P.
References
- [1] Yin, P., Jiao, J., Zhao, S., Xu, L., Huang, G., Choset, H., … & Han, J. (2025). General place recognition survey: Towards real-world autonomy. IEEE Transactions on Robotics, https://doi.org/10.1109/TRO.2025.3550771.
- [2] Ullah, I., Adhikari, D., Khan, H., Anwar, M. S., Ahmad, S., & Bai, X. (2024). Mobile robot localization: Current challenges and future prospective. Computer Science Review, 53, 100651, https://doi.org/10.1016/j.cosrev.2024.100651.
- [3] Bachute, M. R., & Subhedar, J. M. (2021). Autonomous driving architectures: insights of machine learning and deep learning algorithms. Machine Learning with Applications, 6, 100164, https://doi.org/10.1016/j.mlwa.2021.100164.
- [4] Masone, C., & Caputo, B. (2021). A survey on deep visual place recognition. IEEE Access, 9, 19516-19547, https://doi.org/10.1109/ACCESS.2021.3054937.
- [5] Yadav, R., Pani, V., Mishra, A., Tiwari, N., & Kala, R. (2023). Locality-constrained continuous place recognition for SLAM in extreme conditions. Applied Intelligence, 53(14), 17593-17609, https://doi.org/10.1109/ACCESS.2021.3054937.
- [6] Amorós, F., Payá, L., Mayol-Cuevas, W., Jiménez, L. M., & Reinoso, O. (2020). Holistic descriptors of omnidirectional color images and their performance in estimation of position and orientation. IEEE Access, 8, 81822-81848, https://doi.org/10.1109/ACCESS.2020.2990996.
- [7] Kneip, L., Furgale, P., & Siegwart, R. (2013, May). Using multi-camera systems in robotics: Efficient solutions to the NPNP problem. In 2013 IEEE International Conference on Robotics and Automation (pp. 3770-3776). IEEE, https://doi.org/10.1109/ICRA.2013.6631107.
- [8] Lin, H. Y., Chung, Y. C., & Wang, M. L. (2021). Self-localization of mobile robots using a single catadioptric camera with line feature extraction. Sensors, 21(14), 4719, https://doi.org/10.3390/s21144719.
- [9] Flores, M., Valiente, D., Gil, A., Reinoso, O., & Payá, L. (2022). Efficient probability-oriented feature matching using wide field-of-view imaging. Engineering Applications of Artificial Intelligence, 107, 104539, https://doi.org/https://doi.org/10.1016/j.engappai.2021.104539.
- [10] Mumuni, F., Mumuni, A., & Amuzuvi, C. K. (2022). Deep learning of monocular depth, optical flow and ego-motion with geometric guidance for UAV navigation in dynamic environments. Machine Learning with Applications, 10, 100416, https://doi.org/10.1016/j.mlwa.2022.100416.
- [11] LeCun, Y., Bottou, L., Bengio, Y., & Haffner, P. (1998). Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11), 2278-2324, https://doi.org/10.1109/5.726791.
- [12] Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., … & Houlsby, N. (2020). An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929, https://doi.org/10.48550/arXiv.2010.11929.
- [13] Arandjelovic, R., Gronat, P., Torii, A., Pajdla, T., & Sivic, J. (2016). NetVLAD: CNN architecture for weakly supervised place recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 5297-5307), https://doi.org/10.48550/arXiv.1511.07247.
- [14] Yin, H., Wang, Y., Ding, X., Tang, L., Huang, S., & Xiong, R. (2019). 3D LiDAR-based global localization using siamese neural network. IEEE Transactions on Intelligent Transportation Systems, 21(4), 1380-1392, https://doi.org/10.1109/TITS.2019.2905046.
- [15] Liu, Y., & Huang, C. (2017). Scene classification via triplet networks. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 11(1), 220-237, https://doi.org/10.1109/JSTARS.2017.2761800.
- [16] Musgrave, K., Belongie, S., & Lim, S. N. (2020). PyTorch metric learning. arXiv preprint arXiv:2008.09164, https://doi.org/10.48550/arXiv.2008.09164.
- [17] Ren, H., Zheng, Z., Wu, Y., & Lu, H. (2023). DaCo: domain-agnostic contrastive learning for visual place recognition. Applied Intelligence, 53(19), 21827-21840, https://doi.org/10.1007/s10489-023-04629-x.
- [18] Payá, L., Peidró, A., Amorós, F., Valiente, D., & Reinoso, O. (2018). Modeling environments hierarchically with omnidirectional imaging and global-appearance descriptors. Remote sensing, 10(4), 522, https://doi.org/10.3390/rs10040522.
- [19] Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2017). ImageNet classification with deep convolutional neural networks. Communications of the ACM, 60(6), 84-90, https://doi.org/10.1145/3065386.
- [20] Simonyan, K., & Zisserman, A. (2014). Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556, https://doi.org/10.48550/arXiv.1409.1556.
- [21] Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S., Anguelov, D., … & Rabinovich, A. (2015). Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 1-9), https://doi.org/10.48550/arXiv.1409.4842.
- [22] Deng, J., Dong, W., Socher, R., Li, L. J., Li, K., & Fei-Fei, L. (2009, June). ImageNet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition (pp. 248-255). Ieee, https://doi.org/10.1109/CVPR.2009.5206848.
- [23] Liu, Z., Hu, H., Lin, Y., Yao, Z., Xie, Z., Wei, Y., … & Guo, B. (2022). Swin Transformer v2: Scaling up capacity and resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 12009-12019), https://doi.org/10.48550/arXiv.2111.09883.
- [24] Oquab, M., Darcet, T., Moutakanni, T., Vo, H., Szafraniec, M., Khalidov, V., … & Bojanowski, P. (2023). DINOv2: Learning robust visual features without supervision, https://doi.org/10.48550/arXiv.2304.07193.
- [25] Zhang, X., Wang, L., & Su, Y. (2021). Visual place recognition: A survey from deep learning perspective. Pattern Recognition, 113, 107760, https://doi.org/10.1016/j.patcog.2020.10776.
- [26] Schubert, S., Neubert, P., Garg, S., Milford, M., & Fischer, T. (2023). Visual Place Recognition: A Tutorial [Tutorial]. IEEE Robotics & Automation Magazine, 31(3), 139-153, https://doi.org/10.1109/MRA.2023.3310859.
- [27] Kazerouni, I. A., Fitzgerald, L., Dooly, G., & Toal, D. (2022). A survey of state-of-the-art on visual SLAM. Expert Systems with Applications, 205, 117734, https://doi.org/10.1016/j.eswa.2022.117734.
- [28] Rostkowska, M., & Skrzypczyński, P. (2023). Optimizing Appearance-Based Localization with Catadioptric Cameras: Small-Footprint Models for Real-Time Inference on Edge Devices. Sensors, 23(14), 6485, https://doi.org/10.3390/s23146485.
- [29] Cabrera, J. J., Román, V., Gil, A., Reinoso, O., & Payá, L. (2024). An experimental evaluation of Siamese Neural Networks for robot localization using omnidirectional imaging in indoor environments. Artificial Intelligence Review, 57(8), 198, https://doi.org/10.1007/s10462-024-10840-0.
- [30] Keetha, N., Mishra, A., Karhade, J., Jatavallabhula, K. M., Scherer, S., Krishna, M., & Garg, S. (2023). AnyLoc: Towards universal visual place recognition. IEEE Robotics and Automation Letters, 9(2), 1286-1293, https://doi.org/10.1109/LRA.2023.3343602.
- [31] Berton, G., Masone, C., & Caputo, B. (2022). Rethinking visual geo-localization for large-scale applications. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 4878-4888), https://doi.org/10.48550/arXiv.2308.10832.
- [32] Berton, G., Trivigno, G., Caputo, B., & Masone, C. (2023). EigenPlaces: Training viewpoint robust models for visual place recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 11080-11090), https://doi.org/10.48550/arXiv.2308.10832.
- [33] Ali-Bey, A., Chaib-Draa, B., & Giguere, P. (2023). MixVPR: Feature mixing for visual place recognition. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (pp. 2998-3007), https://doi.org/10.48550/arXiv.2303.02190.
- [34] Izquierdo, S., & Civera, J. (2024). Optimal transport aggregation for visual place recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 17658-17668), https://doi.org/10.48550/arXiv.2311.15937.
- [35] Cebollada, S., Payá, L., Jiang, X., & Reinoso, O. (2022). Development and use of a convolutional neural network for hierarchical appearance-based localization. Artificial Intelligence Review, 1-28, https://doi.org/10.1007/s10462-021-10076-2.
- [36] Cabrera, J. J., Cebollada, S., Céspedes, O., Cebollada, S., Reinoso, O. & Payá, L. (2024). An evaluation of CNN models and data augmentation techniques in hierarchical localization of mobile robots. Evolving Systems, 1–13, Springer, https://doi.org/10.1007/s12530-024-09604-6.
- [37] Chen, X., Läbe, T., Milioto, A., Röhling, T., Behley, J., & Stachniss, C. (2022). OverlapNet: A siamese network for computing LiDAR scan similarity with applications to loop closing and localization. Autonomous Robots, 1-21, https://doi.org/10.1007/s10514-021-09999-0.
- [38] Aftab, S., & Ramampiaro, H. (2024). Improving top-n recommendations using batch approximation for weighted pair-wise loss. Machine Learning with Applications, 15, 100520, https://doi.org/10.1016/j.mlwa.2023.100520.
- [39] Leyva-Vallina, M., Strisciuglio, N., & Petkov, N. (2021). Generalized contrastive optimization of siamese networks for place recognition. arXiv preprint arXiv:2103.06638, https://doi.org/10.48550/arXiv.2103.06638.
- [40] Wu, H., Xu, Z., Zhang, J., Yan, W., & Ma, X. (2017, October). Face recognition based on convolution siamese networks. In 2017 10th international congress on image and signal processing, BioMedical engineering and informatics (CISP-BMEI) (pp. 1-5). IEEE, https://doi.org/10.1109/CISP-BMEI.2017.8302003.
- [41] Schroff, F., Kalenichenko, D., & Philbin, J. (2015). FaceNet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 815-823), https://doi.org/10.1109/CVPR.2015.7298682.
- [42] Hermans, A., Beyer, L., & Leibe, B. (2017). In defense of the triplet loss for person re-identification. arXiv preprint arXiv:1703.07737, https://doi.org/10.48550/arXiv.1703.07737.
- [43] Büyüktaş, B., Erdem, Ç. E., & Erdem, T. (2021, January). Curriculum learning for face recognition. In 2020 28th European Signal Processing Conference (EUSIPCO) (pp. 650-654). IEEE.
- [44] Zhang, D., Chen, N., Wu, M., & Lam, S. K. (2024, October). CurricularVPR: Curricular Contrastive Loss for Visual Place Recognition. In 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) (pp. 7916-7921). IEEE, https://doi.org/10.1109/IROS58592.2024.10802279.
- [45] Olid, D., Fácil, J. M., & Civera, J. (2018). Single-view place recognition under seasonal changes. arXiv preprint arXiv:1808.06516, https://doi.org/10.48550/arXiv.1808.06516.
- [46] Uy, M. A., & Lee, G. H. (2018). Pointnetvlad: Deep point cloud based retrieval for large-scale place recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 4470-4479).
- [47] Sun, Y., Cheng, C., Zhang, Y., Zhang, C., Zheng, L., Wang, Z., & Wei, Y. (2020). Circle loss: A unified perspective of pair similarity optimization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 6398-6407), https://doi.org/10.48550/arXiv.2002.10857.
- [48] Wang, J., Zhou, F., Wen, S., Liu, X., & Lin, Y. (2017). Deep metric learning with angular loss. In Proceedings of the IEEE International Conference on Computer Vision (pp. 2593-2601), https://doi.org/10.48550/arXiv.1708.01682.
- [49] Pronobis, A., & Caputo, B. (2009). COLD: The CoSy Localization Database. The International Journal of Robotics Research, 28(5), 588-594, https://doi.org/10.1177/0278364909103912.
- [50] Huang, H., Liu, C., Zhu, Y., Cheng, H., Braud, T., & Yeung, S. K. (2024). 360Loc: A dataset and benchmark for omnidirectional visual localization with cross-device queries. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 22314-22324). https://doi.org/10.48550/arXiv.2311.17389.