High-Order Paired-ASPP Networks for Semantic Segmentation
Abstract
Current semantic segmentation models only exploit first-order statistics, while rarely exploring high-order statistics. However, common first-order statistics are insufficient to support a solid unanimous representation. In this paper, we propose High-Order Paired-ASPP Network to exploit high-order statistics from various feature levels. The network first introduces a High-Order Representation module to extract the contextual high-order information from all stages of the backbone. They can provide more semantic clues and discriminative information than the first-order ones. Besides, a Paired-ASPP module is proposed to embed high-order statistics of the early stages into the last stage. It can further preserve the boundary-related and spatial context in the low-level features for final prediction. Our experiments show that the high-order statistics significantly boost the performance on confusing objects. Our method achieves competitive performance without bells and whistles on three benchmarks, i.e, Cityscapes, ADE20K and Pascal-Context with the mIoU of 81.6%, 45.3% and 52.9%.
Index Terms:
Semantic Segmentation, Convolutional Neural Network, Scene Parsing, High-Order Statistics, Feature Representation.I Introduction
As a fundamental and challenging task in computer vision, semantic segmentation aims at predicting labels for every pixel accurately. FCNs [1] based state-of-the-art approaches have achieved great success among several segmentation benchmarks. Currently, segmentation is widely applied to many vision-based applications such as autonomous driving [2], medical image analysis [3] and remote sensing [4]. Nonetheless, these methods are inherently limited by the lack of discriminative information and the disparity between low-level and high-level features.

Many state-of-the-art methods made great effort to address the above issues. Methods such as ASPP [5], PSP [6], Context Encoding [7] and Self-Attention mechanism [8, 9, 10, 11] are proposed to achieve global receptive fields and capture long-range context. They aggregate pixel-wise contextual information from high-level features to produce discriminative information. Besides, encoder-decoder structures [12, 13, 14, 15] are employed to retain and utilize spatial information from low-level features. They utilize feature fusion to reduce the disparity between low-level and high-level features. Although these methods improved the performance, they only focus on first-order information and high-level features. Their drawback is the neglect of high-order information and low-level features. The first-order information is coarse and insufficient to capture the semantic concepts of the confusing categories. For example, the ’electric wires’ can be easily identified as ’pole’, and the ’wall’ represents similar features with the ’building’. However, high-order statistics can provide more discriminative information than first-order ones. As shown in Figure 1, the first-order statistics contain more noise than third-order ones, which may mislead the classifier. The third-order statistics remove some noise and reserve the edge information, improving the performance on the confusing categories.
Thus, in this paper we propose the High-Order Paired-ASPP Network to exploit abstract statistical information from various level of layers. We first introduce a High-Order Representation (HR) module to extract high-order statistics from different network layers. We adopt the polynomial kernel approximation based high-order methods [16] to generate low-dimensional high-order statistics. The kernel representation can be reformulated with 1 1 convolution operation followed by element-wise product. With our HR module, the features will be mapped to a high-dimensional kernel feature space. The HR module can capture the differences between confusing categories and make features much more discriminative.
Furthermore, in order to utilize the low-level features, we propose a Paired-ASPP (PA) module in the network to bridge the semantic and spatial information gap. The low-level features contain a large amount of boundary-related information, which contributes to dense pixel prediction. The PA module respectively combines the high-order statistics of the first three stages with the last one. The combination enables us to obtain multi-scale information and embed spatial resolution clues into high-level features, and each output contains two scales features. Then we apply 3 3 atrous convolution with various rates on these outputs to fuse different scales features. In this way we can effectively capture eight scales information.
In summary, the main contributions are:
-
We propose the High-Order Representation module to generate high-order statistics from different layers. To the best our knowledge, it is the first work to apply high-order information in semantic segmentation.
-
We propose the Paired-ASPP module to fuse the high-order statistics of all levels. It takes full advantage of the low-level features and multi-scale receptive fields context.
-
We integrate the HR and PA modules to construct the High-Order Paired-ASPP Network. The network enhances the richness of semantic clues and exploits information from the high-order statistics.
-
We have conducted extensive experiments and achieved state-of-the-art performance on the Cityscapes, ADE20K and the PASCAL Context benchmarks.
The rest of this paper is organized as follows. Related work is reviewed in Part II. And we present the proposed High-order Representation module and Paired-ASPP module in Part III. Experimental results are presented in Part IV. Finally, Part V concludes this paper.
II Related Works
In recent years, the developments of deep neural networks encourage the emergence of a series of works on semantic segmentation. FCN [1] is the first approach to adopt fully convolution network for semantic segmentation. Later, state-of-the-art segmentation approaches based on FCN [1] have made great progress in semantic segmentation.
II-A Encoder-Decoder
A encoder generally reduces the spatial size of feature maps to get semantic context information and enlarge the receptive field. Then the decoder recovers the predictions. As the first encoder-decoder approach on semantic segmentation, FCN [1] shows good performance. It discards the fully connected layer to support input of arbitrary sizes. Based on FCN [1], many works change the upsample methods to generate better results. The SegNet [17] stores the max-pooling indices of the feature maps and uses them in its decoder network to make upsample convincing. The DeconvNet [18] uses deconvolutions to perform the decoding pass. Besides, multi-level feature fusion in semantic segmentation is a hot topic, many encoder-decoder methods try to solve this problem. The U-Net [19] gradually fuses high-level low-resolution features with low-level but high-resolution features, which is helpful for decoder to generate better results. This architecture is adopted in many works [20, 21, 22]. RefineNet [22] exploits all the information available along the down-sampling process to enable high-resolution predictions using long-range residual connections. ICNet [23] incorporates multi-resolution branches under proper label guidance to address the challenge of real-time semantic segmentation. FCDenseNet [24] adjust DenseNet [25] for semantic segmentation. ExFuse [12] assigns auxiliary supervisions to all stages to force low-level features to encode more semantic concepts and high-level features to learn more spatial information. DFN [15] uses two sub-networks, one smooth network and one border network to select the more discriminative features for later segmentation. Besides, Conditional Random Field [26] can be used in encoder-decoder structures for semantic segmentation. Combining with CNNs, the methods [27, 28, 29, 30, 31] adopted this strategy, making the deep network end-to-end trainable. The encoder-decoder structure guarantees the competitive performance. However, it is difficult to discover disciminative feature and fuse the different level features using only simple encoder-decoder structure.
II-B Context Embedding
Context embedding has shown promising improvements on semantic segmentation. GCN [32] utilizes , convolution to constitude a global convolution block. ParseNet [33] uses global pooling to clarify local confusions. Both of these two methods are intended to enlarge the receptive field and capture context information. Recently, self-attention mechanism [8] is widely used for semantic segmentation to get global dependencies. The self-attention [8] is originally proposed to solve the machine translation [34], [35], and the following work [36] further proposed the non-local neural network for various tasks such as object detection, video classification and instance segmentation. DANet [9] appends two types of attention modules which model the semantic interdependencies in spatial and channel dimensions. CCNet [10] harvest the contextual information of its surrounding pixels on the criss-cross path through a novel criss-cross attention module. As variants of self-attention structure, EMANet [11] and ANN [37] present new self-attention modules to reduce the computation and memory consumption without sacrificing the performance. To extract the multi-scale information and global context efficiently, SPP [29] based methods are proposed. Deeplabv2 [30] proposes ASPP module, where parallel atrous convolution layers with different rates to capture multi-scale information, then concatenate the different scales features to fuse the local and global context. PSPNet [6] performs spatial pooling at several grid scales to aggregate global contextual information, the local and global clues together make the final prediction more reliable. The ASPP module is improved in DeepLabV3 [5] by integrating a global pooling branch. DenseASPP [38] connects a set of atrous convolutional layers in a dense way, such that it generates multi-scale features that not only cover a larger scale range, but also cover that scale range densely, besides the module doesn’t increase the computation cost too much. All of the SPP [29] variants are stacked at the top of their backbone networks for prediction, which ignores the spatial information. These works achieve great performance on semantic segmentation. However, the low-level and high-level features in these methods are first-order and lack of spatial information. Thus, we propose the High-Order Representation module and Paired-ASPP module to exploit high-order statistics and capture more discriminative spatial information.
II-C High-order statistics
Recently, some works of image classification and recognition [39, 40, 41, 42, 43] show that the integration of high-order statistics significantly improves their performance. Global high-order pooling is utilized to aggregate the information and represent whole images [41, 42, 43], in which the sum of outer product of convolutional features is firstly computed, then element-wise power normalization [42], matrix logarithm normalization [41] and matrix power normalization [43] are performed. G2DeNet [44] adds a trainable layer of one global Gaussian as an image representation into CNNs, which exploits first-order and second-order information. All these methods generate very high dimensional representations, which is not suitable for other tasks such as semantic segmentation. Some works [39, 40] adopt polynomial and Gaussian RBF Kernel functions to generate low-dimensional high-order representations. MLKP [45] proposes a location-aware kernel approximation method to exploits high-order statistics for improving performance of object detection. MHN [46] proposes the High-Order Attention module, using complex and high-order statistics to increase the discrimination of proposals. It improves the performance of person-ReID task. All these methods only extract high-order information from single scale. In this paper, we generate high-order features from different layers and fuse them. Therefore, our high-order statistics contain plenty of spatial details and semantic concepts. To the best of our knowledge, our method is the first work to apply high-order information in semantic segmentation.
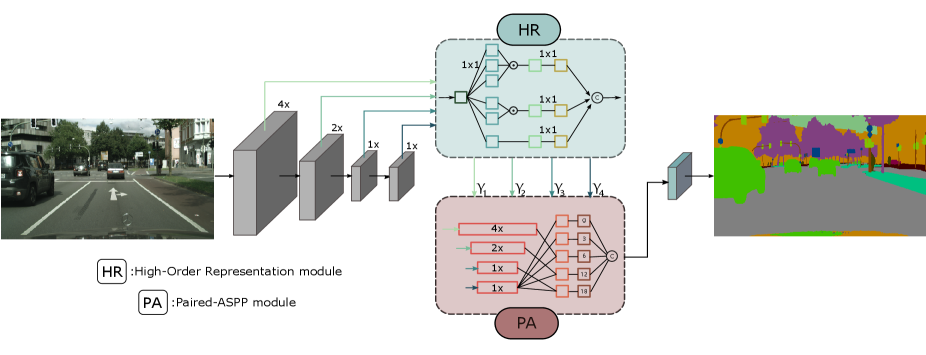
III High-Order Paired-ASPP Network
In this section, we introduce the High-Order Paired-ASPP Network. Sec III-A firstly introduces the High-Order Representation module. Then Sec III-B shows the Paired-ASPP module. Finally we illustrate the overall framework of our High-Order Paired-ASPP Network in Sec III-C.
III-A High-Order Representation Module
To get high-order representations from each stage, we first let be the feature map extracted from the given convolutional layer, where , and indicate the number of channel, height and width. Then we can define a linear predictor on the high-order statistics of , where denotes a local descriptor from .
| (1) |
where is the parameter of predictor, denotes the high-order statistics. We can reformulate Eq 1 with a homogeneous polynomial kernel as
| (2) |
The is inner product of two same-sized tensors. is the number of order, tensor comprises all the degree- monomials in , and -th order tensor determines a degree- homogenous polynomial predictor.
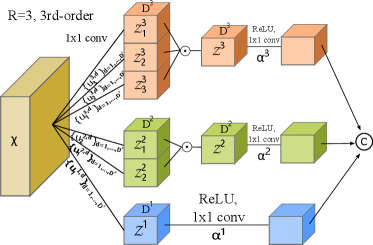
With the tensor decomposition [47], can be approximated by rank-1 tensors, i.e., in case of , where is the weight for -th rank-1 tensor, are vectors, and is the outer-product. The Eq 1 can be further rewritten as follow.
| (3) |
where is the weight vector and with .
With the Eq 3, we can calculate any arbitrary order of representation by learning the parameters of weight , and . For the , we can first deploy as a set of convolutional filters on to generate a set of feature maps of dimension . In general, the dimension of should be large enough to make a good approximation. However, in practice, we should use a relative low dimension because the high-dimension increases the computational cost and causes the over-fitting problem. The feature maps are combined by element-wise product to get . The can be regarded as a polynomial module to learn degree-r polynomial features.
Implementation: As shown in Figure 2, the HR module of can be easily implemented. At each stage of the backbone, we can get a feature map . Then we adopt as a set of convolution layers on . So we can get representations with channels , . These feature maps are combined by element-wise product to generate , and . And can also be implemented by three convolution layers. Finally we concatenate the three feature maps as the third-order statistics of this stage.
III-B Paired-ASPP Module
In a general encoder-decoder structure, high-level features of the encoder output depict the semantic information of the input images. Although the highest-level features contain much semantic information, it is also necessary to make use of the low-level features. Neglecting low-level features leads to the lack of multi-scale information and concrete spatial details. To extract discriminative information from features in shallow layers, we introduce the Paired-ASPP (PA) module. The PA module collects high-order statistics from all stages of the backbone and fuses them via a pairing manner.
The normal ASPP module applies four parallel atrous convolutions with different atrous rates on the last stage. This enable the ASPP module to extract multi-scale information and whole image context. We argue that only using the highest-level feature is inappropriate. Therefore, we combine the high-order statistics of the first three stages to the last stage in a pairing manner. In this way we can capture more scales information than normal ASPP while retaining the spatial information from low-level layers.
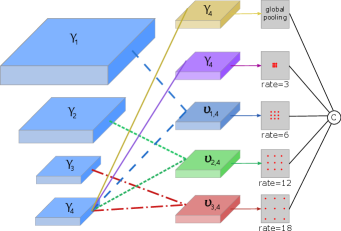
As shown in Figure 4, we get four feature maps , , , and where is the high-order representation of each stage. Then we concat the first three feature maps with in a pairing manner:
| (4) |
We can regard the as multi-view information of the scene, each of which contains two scales high-order statistics. We apply four atrous convolutions with and one global pooling on and . In this way, each atrous convolution can capture information of two scales. We want to use different atrous rates convolutions to cover the span of scales as large as possible. Therefore, we apply atrous convolution with the biggest rate 18 on since the receptive field of and is large. Meanwhile, atrous convolution with the small rates is employed on . The main reason is that low-level features need low-rate atrous convolutions to maintain their spatial information. Moreover, we apply normal convolution and global average pooling on original . The normal convolution also extracts one scale information and the global average pooling captures global context information.
| (5) |
Then we concatenate . It is followed by several convolutional layers with batch normalization and ReLU activation. Finally the fused features are fed into segmentation layer to give the prediction.
III-C Network Architecture
The architecture of our High-Order Paired-ASPP Network is shown in Figure 3. We choose the ResNet [48] as our backbone network. We remove the last two stages with atrous convolution and make both strides to 1 in order to keep the spatial information. Each stage of the ResNet has an output . The four feature maps are used as the input for four High-Order Representation modules (R=3) to capture high-order statistics . Then, all the high-order statistics are sent to the Paired-ASPP module for multi-scale feature extraction and feature fusion. All the convolutional layers are followed with batch normalization and ReLU activation. In the Paired-ASPP module, all the feature maps are concatenated finally. And we will use it for final semantic segmentation. Comparing with other methods which use segmentation heads, our proposed method models the high-order disparity between confusing objects. Besides we take full advantage of low-level features, making high-level features more comprehensive and discriminative. The entire network is trained in an end-to-end manner driving by cross-entropy loss defined on the segmentation benchmarks.
IV Experiments
In this section, we evaluate the proposed network by carrying out extensive experiments on the Cityscapes, ADE20K and the PASCAL Context datasets. Results show that the High-Order Paired-ASPP network achieves state-of-the-art performance. In following subsections we will first introduce the datasets and implementation details. Then we show the comparison results on the three datasets. At last, we carry out the ablation experiments.
IV-A Datasets and Evaluation Metrics
Cityscapes [49] is a large-scale dataset to train and test approaches for semantic and instance segmentation, which contains 5000 high quality pixel-level annotations and 20000 coarse annotations. All the images come from a set of video sequences recorded in the streets from 50 different cities and the image size is resolution. The fine data contains 2975 training, 500 validation and 1525 test images. And there are 30 classes in the dataset but only 19 classes are used for evaluation.
ADE20K [50] is a challenging scene parsing benchmark covering a wide range of scenes and object categories with dense and detailed annotations. The dataset contains 150 classes and all images are divided into 20K/2K/3K for training, validation and testing. Besides the dataset parses the scene into stuff, objects, and object parts, bringing more difficulties for semantic segmentation methods.
PASCAL Context [51] labels every pixel of PASCAL VOC 2010 detection challenge with a semantic category, containing 4998 images for training and 5105 images for validation. We use 60 categories (59 object categories and background) for evaluation.
Evaluation Metric. Our evaluation metric is mean of class-wise intersection over union (mIoU).
IV-B Implementation Details
Network Structure. Our baseline network is ResNet-based FCN with dilated convolution module incorporated at stage 4 and 5. Following [5], we remove the last two down-sample operation in the ResNet, so that the last stage feature map is smaller than the input image. To get the final semantic labels for each pixel, we use bilinear interpolation to upsample the feature map to the target size. Besides, we use our own PyTorch implementation of DeepLabV3 [5].
Training Settings. We use the PyTorch framework and replace normal batch normalization with cross-GPU synchronize batch normalization for better mean/variance estimation. We adopt Stochastic Gradient Descent (SGD) with warm-up poly learning rate policy to optimize our network. Different initial learning rates, weight decays, batch sizes, crop sizes and training iterations are applied to different datasets. For Cityscapes and PASCAL Context, we train our network for 60K/28K iterations with the initial learning rate 0.01. And we choose the momentum of 0.9 and a weight decay of 0.0005, the batch size of 8/16 and the crop size of / . For ADE20K, we train our network for 150K iterations with the initial learning rate of 0.02, the momentum of 0.9 and a weight decay of 0.001, the batch size is 16 and crop size is . For all the datasets, we adopt random scaling in the range of [0.5, 2.0], random horizontal flip and random brightness as additional data augmentation methods. All the experiments are conducted on RTX 2080Ti GPUs.
Inference Settings For inference, following other state-of-the-art methods, we apply multi-scale and horizontal flip testing for the Cityscapes, ADE20K and the PASCAL Context. The scales is in the range of [0.5, 1.75] with .
| Method | Backbone | MS_F | mIoU(%) |
| DeepLabV3+ [52] | Xception-65 | 79.1 | |
| DFN [15] | ResNet-101 | 79.9 | |
| ANN [37] | ResNet-101 | 80.1 | |
| DPC [53] | Xception-71 | 80.8 | |
| Ours | ResNet-101 | 80.7 | |
| DeepLabV3 [5] | ResNet-101 | 79.3 | |
| DFN [15] | ResNet-101 | 80.1 | |
| CCNet [10] | ResNet-101 | 81.3 | |
| Ours | ResNet-101 | 81.8 |
IV-C Comparison with State-of-the-art Methods
IV-C1 Cityscapes Dataset
We first illustrate the performance of our method on Cityscapes dataset. We directly train our High-Order Paired-ASPP Network for 60K iterations without coarse data. The comparison results of our method and the state-of-the-art methods on Cityscapes validation set are summarized in Table I.
Among these approaches, DeepLabV3+ and DPC use more stronger backbone than ours, and DPC utilizes COCO dataset for training. As shown in Table I, the results show that our network outperforms others in validation set.
In addition, we also train our network with both training-fine and val-fine sets, and evaluate on test set by submitting the results to the official evaluation server. Most of the methods use the same backbone ResNet-101 as ours. ResNet-38 and DenseASPP [54, 38] use stronger backbones than others. Besides DeepLabV3 [5] uses both fine and coarse sets for training. As shown in Table II, our network achieves mIoU, which outperforms the others. DeepLab [30, 5] and PSPNet [6] adopt multi-scale context fusion module to aggregate contextual information. CCNet [10] and ANN [37] utilize self-attention mechanism to obtain long-range dependencies. These methods also achieve great performance on the Cityscapes dataset. However, these methods only utilize the first-order information. In contrast, our High-Order Paired-ASPP Network adopts high-order statistics for semantic segmentation and achieves the highest performance.
| Method | Backbone | mIoU(%) |
|---|---|---|
| DeepLabV2 [30] | ResNet-101 | 70.4 |
| RefineNet [22] | ResNet-101 | 73.6 |
| GCN [32] | ResNet-101 | 76.9 |
| DUC [55] | ResNet-101 | 77.6 |
| SAC [56] | ResNet-101 | 78.1 |
| ResNet-38 [54] | WiderResNet-38 | 78.4 |
| PSPNet [6] | ResNet-101 | 78.4 |
| BiSeNet [57] | ResNet-101 | 78.9 |
| AAF [58] | ResNet-101 | 79.1 |
| DFN [15] | ResNet-101 | 79.3 |
| PSANet [59] | ResNet-101 | 80.1 |
| DenseASPP [38] | DenseNet-161 | 80.6 |
| PSPNet [6] | ResNet-101 | 81.2 |
| ANN [37] | ResNet-101 | 81.3 |
| DeepLabV3 [5] | ResNet-101 | 81.3 |
| CCNet [10] | ResNet-101 | 81.4 |
| Ours | ResNet-101 | 81.6 |
IV-C2 ADE20K dataset
We conduct experiments on the ADE20K dataset to further prove the effectiveness of our proposed network. We compare our network to the previous state-of-the-art methods in Table III. We can see that our method boosts the performance to . EncNet [7] achieves good performance among the methods by using global pooling and image-level supervision to capture the global semantic context of scenes. However, our High-Order Paired-ASPP Network provides a new way of obtaining multi-scale contextual information and achieve better performance than EncNet [7].
| Method | Backbone | mIoU(%) |
|---|---|---|
| RefineNet [22] | ResNet-152 | 40.70 |
| UperNet [60] | WiderResNet-38 | 42.66 |
| PSPNet [6] | ResNet-101 | 43.29 |
| DSSPN [61] | ResNet-101 | 43.68 |
| PSANet [59] | ResNet-101 | 43.77 |
| SAC [56] | ResNet-101 | 44.30 |
| EncNet [7] | ResNet-101 | 44.65 |
| CCNet [10] | ResNet-101 | 45.22 |
| Ours | ResNet-101 | 45.30 |

IV-C3 PASCAL Context dataset
PASCAL Context dataset provides dense semantic labels for the whole scene. We also conduct experiments on the PASCAL Context dataset to verify the generalization of our proposed network. We follow the prior work to use the most frequent 59 object classes plus background as semantic labels. We report the comparison results with the state-of-the-art methods in Table IV. With deep pre-trained ResNet-101, our model achieves Mean IoU , which outperforms previous methods by a large margin.
| Method | Backbone | mIoU(%) |
|---|---|---|
| FCN-8s [1] | - | 37.8 |
| Piecewise [62] | - | 43.3 |
| DeepLabV2 [30] | ResNet-101 | 45.7 |
| RefineNet [22] | ResNet-152 | 47.3 |
| PSPNet [6] | ResNet-101 | 47.8 |
| CCL [63] | ResNet-101 | 51.6 |
| EncNet [7] | ResNet-101 | 51.7 |
| DANet [9] | ResNet-101 | 52.6 |
| Ours | ResNet-101 | 52.9 |
IV-D Ablation Study
In this section, we analyze the High-Order Representation module and High-Order Paired-ASPP module. Ablation experiments are conducted on the validation set of Cityscapes with only single scale testing if not specified.
| Orders | Memory(M) | mIoU(%) |
|---|---|---|
| R=1 | 0 | 79.74 |
| R=2 | 58 | 80.15 |
| R=3 | 136 | 80.73 |
High-Order Representation module. In this section we mainly discuss the effect of -th order on network performance. All experiments are conducted with Paired-ASPP module and without multi-scale method. We train our network with various orders in the HR module to find the best implementation. Table V shows the results of our network on Cityscapes validation set by using various orders in the HR module. The input image is , resulting in the size of input feature maps of HR module are , and . The increment of Memory usage is estimated when . We can observe that the performance gets better with the increase of the orders. Therefore, we choose as the default settings in all the following experiments. By increasing the order from to (donated as and ), it improves the performance of . Results effectively demonstrate the significance of High-Order Representation module. Furthermore, increasing the order from 1 to 2 can improve the performance by . So it can be seen that high-order information is useful for contextual capturing. Finally, increasing from 2 to 3 improves the performance by . These results prove that the proposed High-Order Representation module can significantly improve the performance by utilizing high-order statistics.
We provide the visualization of results in Figure 5 to further illustrate the effectiveness of the High-Order Representation module. We choose some challenging region (the in the images) to illustrate that the confusing regions can be progressively corrected with the order increased. It proves the effectiveness of high-order statistics for semantic segmentation.
| Orders | mIoU(%) |
|---|---|
| Baseline | 75.35 |
| combination-1 | 79.74 |
| combination-2 | 79.45 |
Paired-ASPP module. In this section we give experiments to verify the effectiveness of the High-Order Paired-ASPP module. The experiments are conducted without High-Order Representation module. Table VI illustrates the results of two combination modes in the Paired-ASPP module. In combination-1, we apply atrous convolution with the biggest rate 18 on and the smallest rate 6 on . On the contrary, we apply atrous convolution with the smallest rate 6 on and the biggest rate 18 on in the combination-2. The combination-1 achieves a good improvement () and is better than the combination-2. We suppose that combination-1 can capture much contextual information by providing comprehensive coverage of all scales.

In Figure 6, we visualize the scales coverage of combination-1 and combination-2. The receptive field becomes larger when the network goes deeper and feature map becomes smaller. Therefore, if we apply atrous convolution with rate 18 on , we can not obtain the smallest scale information as shown in combination-2 of Figure 6. In combination-2, some similar scales information are repeatedly captured. By adopting the combination-1, we can cover the span of scales as large as possible, making features more comprehensive and discriminative.
Ablation Study for HR and PA modules. To further verify the performance of the HP and PA modules, we conduct experiments with different settings in Table VII.
| Backbone | ASPP | PA | HR | mIoU(%) |
|---|---|---|---|---|
| ResNet-50 | 73.24 | |||
| ResNet-50 | 77.91 | |||
| ResNet-50 | 79.11 | |||
| ResNet-50 | 79.88 | |||
| ResNet-101 | 75.35 | |||
| ResNet-101 | 78.90 | |||
| ResNet-101 | 79.74 | |||
| ResNet-101 | 80.73 |
As shown in Table VII, the two modules improve the performance remarkably. Compared with the DeepLabV3 (ResNet-50), employing PA module yields a result of in mIoU, which brings improvement. Meanwhile, employing HR module further improve the performance by . Moreover, when we adopt the deeper pre-trained ResNet-101, the network with two modules significantly improves the segmentation performance over the DeepLabV3 by . Results show that PA and HR modules bring great benefit to scene segmentation.
At last, we show the experiments results with different settings in Table VIII. We can see that the network with two modules significantly improves the segmentation performance over the DeepLabV3 module by . The results demonstrate the efficacy of the proposed High-Order Representation module and High-Order Paired-ASPP module.
| Method | ASPP | HP | MS | Flip | mIoU(%) |
|---|---|---|---|---|---|
| Baseline | 75.35 | ||||
| DeepLabV3 [5] | 78.90 | ||||
| HPNet | 80.73 | ||||
| HPNet | 81.60 | ||||
| HPNet | 81.88 |
V Conclusion
In this paper, we propose the High-Order Paired-ASPP networks, which is a new CNN architecture for semantic segmentation by exploiting high-order statistics and enhancing the feature fusion. This approach can generate low-dimensional high-order statistics from different layers. The high-order representation is driven by convolutional activations, via high-order polynomial predictor, we capture discriminative features. Unlike existing methods, we make full use of the low-level features and extract high-order spatial information for later feature fusion. In Paired-ASPP module, we fuse the high-order information with a novel paired manner to get multi-scale information. The Paired-ASPP can capture more scales information than normal ASPP module, thus showing higher mIoU than DeepLabV3 and other state-of-the-art methods.
To evaluate the proposed method, this study conducted experiments on three benchmarks, Cityscapes, ADE20K and Pascal-Context, in which the highest mIoU is shown when using 3-th order and ResNet-101 as the backbone. Particularly, we’ve already conducted the experiments of 4-th order in HR module. Compare to 3-th order, it brings only small improvement but huge computation cost. To balance the performance and resource usage, we choose 3-th order as our default settings. Our experiments show that high-order statistics contain more discriminative information and can correct the confusing regions. Our network achieves state-of-the-art results on three challenging datasets (81.6% with Cityscapes, 45.30% with ADE20K and 52.9% with Pascal-Context.)
Our work suggests promising future directions of exploiting relationships between low-level features and high-order statistics to advance the state-of-the-art in segmentation tasks.
References
- [1] E. Shelhamer, J. Long, and T. Darrell, “Fully convolutional networks for semantic segmentation,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 39, pp. 640–651, 2014.
- [2] H. Xu, Y. Gao, F. Yu, and T. Darrell, “End-to-end learning of driving models from large-scale video datasets,” 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 3530–3538, 2016.
- [3] G. J. S. Litjens, T. Kooi, B. E. Bejnordi, A. A. A. Setio, F. Ciompi, M. Ghafoorian, J. van der Laak, B. van Ginneken, and C. I. Sánchez, “A survey on deep learning in medical image analysis,” Medical image analysis, vol. 42, pp. 60–88, 2017.
- [4] M. Kampffmeyer, A.-B. Salberg, and R. Jenssen, “Semantic segmentation of small objects and modeling of uncertainty in urban remote sensing images using deep convolutional neural networks,” in Proceedings of the IEEE conference on computer vision and pattern recognition workshops, 2016, pp. 1–9.
- [5] L.-C. Chen, G. Papandreou, F. Schroff, and H. Adam, “Rethinking atrous convolution for semantic image segmentation,” ArXiv, vol. abs/1706.05587, 2017.
- [6] H. Zhao, J. Shi, X. Qi, X. Wang, and J. Jia, “Pyramid scene parsing network,” 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 6230–6239, 2016.
- [7] H. Zhang, K. J. Dana, J. Shi, Z. Zhang, X. Wang, A. Tyagi, and A. Agrawal, “Context encoding for semantic segmentation,” 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 7151–7160, 2018.
- [8] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,” in NIPS, 2017.
- [9] J. Fu, J. Liu, H. Tian, Z. Fang, and H. Lu, “Dual attention network for scene segmentation,” ArXiv, vol. abs/1809.02983, 2018.
- [10] Z. Huang, X. Wang, L. Huang, C. Huang, Y. Wei, and W. Liu, “Ccnet: Criss-cross attention for semantic segmentation,” ArXiv, vol. abs/1811.11721, 2018.
- [11] X. Li, Z. Zhong, J. Wu, Y. Yang, Z. Lin, and H. Liu, “Expectation-maximization attention networks for semantic segmentation,” ArXiv, vol. abs/1907.13426, 2019.
- [12] Z. Zhang, X. Zhang, C. Peng, X. Xue, and J. Sun, “Exfuse: Enhancing feature fusion for semantic segmentation,” in Proceedings of the European Conference on Computer Vision (ECCV), 2018, pp. 269–284.
- [13] H. Li, P. Xiong, H. Fan, and J. Sun, “Dfanet: Deep feature aggregation for real-time semantic segmentation,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2019, pp. 9522–9531.
- [14] T. Takikawa, D. Acuna, V. Jampani, and S. Fidler, “Gated-scnn: Gated shape cnns for semantic segmentation,” arXiv preprint arXiv:1907.05740, 2019.
- [15] C. Yu, J. Wang, C. Peng, C. Gao, G. Yu, and N. Sang, “Learning a discriminative feature network for semantic segmentation,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 1857–1866.
- [16] S. Cai, W. Zuo, and L. Zhang, “Higher-order integration of hierarchical convolutional activations for fine-grained visual categorization,” 2017 IEEE International Conference on Computer Vision (ICCV), pp. 511–520, 2017.
- [17] V. Badrinarayanan, A. Kendall, and R. Cipolla, “Segnet: A deep convolutional encoder-decoder architecture for image segmentation,” IEEE transactions on pattern analysis and machine intelligence, vol. 39, no. 12, pp. 2481–2495, 2017.
- [18] H. Noh, S. Hong, and B. Han, “Learning deconvolution network for semantic segmentation,” in Proceedings of the IEEE international conference on computer vision, 2015, pp. 1520–1528.
- [19] O. Ronneberger, P. Fischer, and T. Brox, “U-net: Convolutional networks for biomedical image segmentation,” in International Conference on Medical image computing and computer-assisted intervention. Springer, 2015, pp. 234–241.
- [20] G. Ghiasi and C. C. Fowlkes, “Laplacian pyramid reconstruction and refinement for semantic segmentation,” in European Conference on Computer Vision. Springer, 2016, pp. 519–534.
- [21] M. Amirul Islam, M. Rochan, N. D. Bruce, and Y. Wang, “Gated feedback refinement network for dense image labeling,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 3751–3759.
- [22] G. Lin, A. Milan, C. Shen, and I. Reid, “Refinenet: Multi-path refinement networks for high-resolution semantic segmentation,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 1925–1934.
- [23] H. Zhao, X. Qi, X. Shen, J. Shi, and J. Jia, “Icnet for real-time semantic segmentation on high-resolution images,” in Proceedings of the European Conference on Computer Vision (ECCV), 2018, pp. 405–420.
- [24] S. Jégou, M. Drozdzal, D. Vazquez, A. Romero, and Y. Bengio, “The one hundred layers tiramisu: Fully convolutional densenets for semantic segmentation,” in Proceedings of the IEEE conference on computer vision and pattern recognition workshops, 2017, pp. 11–19.
- [25] G. Huang, Z. Liu, and K. Q. Weinberger, “Densely connected convolutional networks,” 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 2261–2269, 2016.
- [26] J. Lafferty, A. McCallum, and F. C. Pereira, “Conditional random fields: Probabilistic models for segmenting and labeling sequence data,” 2001.
- [27] S. Chandra and I. Kokkinos, “Fast, exact and multi-scale inference for semantic image segmentation with deep gaussian crfs,” in European Conference on Computer Vision. Springer, 2016, pp. 402–418.
- [28] L.-C. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. L. Yuille, “Semantic image segmentation with deep convolutional nets and fully connected crfs,” CoRR, vol. abs/1412.7062, 2014.
- [29] K. He, X. Zhang, S. Ren, and J. Sun, “Spatial pyramid pooling in deep convolutional networks for visual recognition,” IEEE transactions on pattern analysis and machine intelligence, vol. 37, no. 9, pp. 1904–1916, 2015.
- [30] L.-C. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. L. Yuille, “Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs,” IEEE transactions on pattern analysis and machine intelligence, vol. 40, no. 4, pp. 834–848, 2017.
- [31] R. Vemulapalli, O. Tuzel, M.-Y. Liu, and R. Chellapa, “Gaussian conditional random field network for semantic segmentation,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 3224–3233.
- [32] C. Peng, X. Zhang, G. Yu, G. Luo, and J. Sun, “Large kernel matters — improve semantic segmentation by global convolutional network,” 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 1743–1751, 2017.
- [33] W. Liu, A. Rabinovich, and A. C. Berg, “Parsenet: Looking wider to see better,” arXiv preprint arXiv:1506.04579, 2015.
- [34] T. Shen, T. Zhou, G. Long, J. Jiang, S. Pan, and C. Zhang, “Disan: Directional self-attention network for rnn/cnn-free language understanding,” in Thirty-Second AAAI Conference on Artificial Intelligence, 2018.
- [35] Z. Lin, M. Feng, C. N. d. Santos, M. Yu, B. Xiang, B. Zhou, and Y. Bengio, “A structured self-attentive sentence embedding,” arXiv preprint arXiv:1703.03130, 2017.
- [36] X. Wang, R. Girshick, A. Gupta, and K. He, “Non-local neural networks,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 7794–7803.
- [37] Z. Zhu, M. Xu, S. Bai, T. Huang, and X. Bai, “Asymmetric non-local neural networks for semantic segmentation,” arXiv preprint arXiv:1908.07678, 2019.
- [38] M. Yang, K. Yu, C. Zhang, Z. Li, and K. Yang, “Denseaspp for semantic segmentation in street scenes,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 3684–3692.
- [39] S. Cai, W. Zuo, and L. Zhang, “Higher-order integration of hierarchical convolutional activations for fine-grained visual categorization,” in Proceedings of the IEEE International Conference on Computer Vision, 2017, pp. 511–520.
- [40] Y. Cui, F. Zhou, J. Wang, X. Liu, Y. Lin, and S. Belongie, “Kernel pooling for convolutional neural networks,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 2921–2930.
- [41] C. Ionescu, O. Vantzos, and C. Sminchisescu, “Matrix backpropagation for deep networks with structured layers,” in Proceedings of the IEEE International Conference on Computer Vision, 2015, pp. 2965–2973.
- [42] T.-Y. Lin, A. RoyChowdhury, and S. Maji, “Bilinear cnn models for fine-grained visual recognition,” in Proceedings of the IEEE international conference on computer vision, 2015, pp. 1449–1457.
- [43] P. Li, J. Xie, Q. Wang, and W. Zuo, “Is second-order information helpful for large-scale visual recognition?” in Proceedings of the IEEE International Conference on Computer Vision, 2017, pp. 2070–2078.
- [44] Q. Wang, P. Li, and L. Zhang, “G2denet: Global gaussian distribution embedding network and its application to visual recognition,” 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 6507–6516, 2017.
- [45] H. Wang, Q. Wang, M. Gao, P. Li, and W. Zuo, “Multi-scale location-aware kernel representation for object detection,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 1248–1257.
- [46] B. Chen, W. Deng, and J. Hu, “Mixed high-order attention network for person re-identification,” arXiv preprint arXiv:1908.05819, 2019.
- [47] T. G. Kolda and B. W. Bader, “Tensor decompositions and applications,” SIAM review, vol. 51, no. 3, pp. 455–500, 2009.
- [48] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778.
- [49] M. Cordts, M. Omran, S. Ramos, T. Rehfeld, M. Enzweiler, R. Benenson, U. Franke, S. Roth, and B. Schiele, “The cityscapes dataset for semantic urban scene understanding,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 3213–3223.
- [50] B. Zhou, H. Zhao, X. Puig, S. Fidler, A. Barriuso, and A. Torralba, “Scene parsing through ade20k dataset,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 633–641.
- [51] R. Mottaghi, X. Chen, X. Liu, N.-G. Cho, S.-W. Lee, S. Fidler, R. Urtasun, and A. Yuille, “The role of context for object detection and semantic segmentation in the wild,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2014, pp. 891–898.
- [52] L.-C. Chen, Y. Zhu, G. Papandreou, F. Schroff, and H. Adam, “Encoder-decoder with atrous separable convolution for semantic image segmentation,” in Proceedings of the European conference on computer vision (ECCV), 2018, pp. 801–818.
- [53] L.-C. Chen, M. Collins, Y. Zhu, G. Papandreou, B. Zoph, F. Schroff, H. Adam, and J. Shlens, “Searching for efficient multi-scale architectures for dense image prediction,” in Advances in Neural Information Processing Systems, 2018, pp. 8699–8710.
- [54] Z. Wu, C. Shen, and A. Van Den Hengel, “Wider or deeper: Revisiting the resnet model for visual recognition,” Pattern Recognition, vol. 90, pp. 119–133, 2019.
- [55] P. Wang, P. Chen, Y. Yuan, D. Liu, Z. Huang, X. Hou, and G. Cottrell, “Understanding convolution for semantic segmentation,” in 2018 IEEE winter conference on applications of computer vision (WACV). IEEE, 2018, pp. 1451–1460.
- [56] R. Zhang, S. Tang, Y. Zhang, J. Li, and S. Yan, “Scale-adaptive convolutions for scene parsing,” in Proceedings of the IEEE International Conference on Computer Vision, 2017, pp. 2031–2039.
- [57] C. Yu, J. Wang, C. Peng, C. Gao, G. Yu, and N. Sang, “Bisenet: Bilateral segmentation network for real-time semantic segmentation,” in Proceedings of the European Conference on Computer Vision (ECCV), 2018, pp. 325–341.
- [58] T.-W. Ke, J.-J. Hwang, Z. Liu, and S. X. Yu, “Adaptive affinity fields for semantic segmentation,” in Proceedings of the European Conference on Computer Vision (ECCV), 2018, pp. 587–602.
- [59] H. Zhao, Y. Zhang, S. Liu, J. Shi, C. Change Loy, D. Lin, and J. Jia, “Psanet: Point-wise spatial attention network for scene parsing,” in Proceedings of the European Conference on Computer Vision (ECCV), 2018, pp. 267–283.
- [60] T. Xiao, Y. Liu, B. Zhou, Y. Jiang, and J. Sun, “Unified perceptual parsing for scene understanding,” in Proceedings of the European Conference on Computer Vision (ECCV), 2018, pp. 418–434.
- [61] X. Liang, H. Zhou, and E. Xing, “Dynamic-structured semantic propagation network,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 752–761.
- [62] G. Lin, C. Shen, A. Van Den Hengel, and I. Reid, “Efficient piecewise training of deep structured models for semantic segmentation,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 3194–3203.
- [63] H. Ding, X. Jiang, B. Shuai, A. Qun Liu, and G. Wang, “Context contrasted feature and gated multi-scale aggregation for scene segmentation,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 2393–2402.