High Quality Related Search Query Suggestions using Deep Reinforcement Learning
Abstract.
“High Quality Related Search Query Suggestions” task aims at recommending search queries which are real, accurate, diverse, relevant and engaging. Obtaining large amounts of query-quality human annotations is expensive. Prior work on supervised query suggestion models suffered from selection and exposure bias, and relied on sparse and noisy immediate user-feedback (e.g., clicks), leading to low quality suggestions. Reinforcement Learning techniques employed to reformulate a query using terms from search results, have limited scalability to large-scale industry applications.
To recommend high quality related search queries, we train a Deep Reinforcement Learning model to predict the query a user would enter next. The reward signal is composed of long-term session-based user feedback, syntactic relatedness and estimated naturalness of generated query. Over the baseline supervised model, our proposed approach achieves a significant relative improvement in terms of recommendation diversity (), down-stream user-engagement () and per-sentence word repetitions ().
1. Introduction
Related search query suggestions aims at suggesting queries that are related to the user’s most recent search query. For example, search query “machine learning jobs” is related to “machine learning”. These suggestions are important to improve the usability of search engines (Cao et al., 2008). We define high-quality related search query suggestions as query recommendations which are natural (i.e., entered by a real user), diverse, relevant, error-free and engaging.
Sequence-to-Sequence (Seq2Seq) encoder-decoder architectures are widely used to generate query suggestions (Wang et al., 2020; Nogueira and Cho, 2017; Yu et al., 2017; Kazi et al., 2020). Supervised autoregressive generative models trained with ground-truth labels suffer from exposure bias (Yu et al., 2017; Schmidt, 2019). Maximum Likelihood Estimation (MLE) training generates repetitive sequences (Li et al., 2016). Machine learning approaches (Kazi et al., 2020; Li et al., 2019) that are trained on immediate user feedback, such as click on recommended query, are prone to selection-bias (Wang et al., 2016). Reinforcement Learning techniques were proposed to address these limitations (Wang et al., 2020).
“Local” Deep-Reinforcement-Learning (DRL) frameworks for query reformulation (Wang et al., 2020; Nogueira and Cho, 2017) adjust a query relative to the initial search results. Reward signals used in these approaches were computed from mined search result documents. Processing search results to reformulate the query and mining entire collection of documents is not practical in large-scale real-world applications, due to rapidly changing and ever-growing user-generated content. Hence, we employ “global” DRL approaches (Nogueira and Cho, 2017), that are independent of the set of documents returned by the original query and instead depend on the actual queries entered by the users and the feedback provided by them. Furthermore, we choose the more useful approach to predict the queries a user will enter next, over simply reformulating the current query (Cao et al., 2008). We mine search sessions and corresponding co-occuring query pairs from LinkedIn search engine logs. Unlike general purpose web search, our work is focused on domain-specific-search queries (Tang et al., 2006), that users enter to search for job postings, people profiles, user-groups, company pages and industry news.
DRL text generation approaches such as policy-gradient based Sequential Generative Adversarial Networks (SeqGAN) (Yu et al., 2017) achieved excellent performance on generating creative text sequences. Most recently, on summary generation task, fine-tuning pre-trained supervised model using Proximal Policy Optimization (PPO) (Schulman et al., 2017) method outperformed supervised GPT3 (Brown et al., 2020) model 10x its size (Stiennon et al., 2020). Motivated by the performance improvements achieved by DRL techniques on text-generation problems, we solve the high quality query suggestions problem by modeling the query generator as a stochastic parametrized policy. Specifically, we fine-tune the state-of-the-practice Seq2Seq Neural Machine Translation (NMT) model (Bahdanau et al., 2015) for query generation (Kazi et al., 2020), using policy-gradient REINFORCE (Williams, 1992) algorithm. Seq2Seq NMT models are widely popular in industry applications, especially in low resource environments(Ganegedara, 2020).
Supervised reward estimation models are commonly used to optimize text-generation policy (Wang et al., 2020; Nogueira and Cho, 2017; Stiennon et al., 2020; Yu et al., 2017). SeqGAN model used GAN (Goodfellow et al., 2014) discriminator output as reward signal. The supervised discriminator model predicted if the generated sequence is “real”. The estimated reward is passed back to the intermediate state-action steps using computationally expensive Monte Carlo search (Chaslot et al., 2008). PPO based summary generation model (Stiennon et al., 2020) used estimated annotated user feedback on generated summaries as the reward signal. Immediate implicit user feedback is sparse, asking users to provide explicit feedback is intrusive (Bodigutla et al., 2019) and reliable annotations are expensive to obtain.
In our proposed approach, the DRL future-reward is composed of three signals, which are: 1) long-term implicit user-feedback within a search-session; 2) unnatural query generation penalty; and 3) syntactic similarity between generated query and user’s most recent search query. Leveraging implicit user-feedback from search-sessions as opposed to using immediate feedback, helps in maximizing user engagement across search-sessions, addresses the reward-sparsity problem and removes the need to obtain expensive human annotations (Section 2.2.2). We design a weakly supervised context-aware-naturalness estimator model, which estimates the naturalness probability of a generated query. Similar to (Yu et al., 2017) we perform Monte Carlo search to propagate rewards. However, we reduce the computation cost considerably by performing policy roll-out only from the first time-step of the decoder (Section 2.2.1).
In summary, we employ DRL policy-gradient technique for making high-quality related-query suggestions at scale. Our proposed approach achieves improvement in-terms of recommendation diversity, down-stream user-engagement, relevance and errors per sentence. To the best of our knowledge, this is the first time a combination of long-term session-based user-feedback, un-natural sentence penalty and syntactic relatedness reward signals are jointly optimized to improve query suggestions’ quality.
2. Approach for Improving Query Suggestions
We fine-tune a weakly supervised Sequence-to-Sequence (Seq2Seq) Neural Machine Translation (NMT) model () to initialize the query generation policy. The process then consists of two steps: 1) Learn a context-aware weakly supervised naturalness estimator; and 2) Fine-tune pre-trained supervised model using REINFORCE (Williams, 1992) algorithm. The future-reward is composed of user-feedback in a search session (), syntactic similarity () and unnaturalness penalty () of the generated query given the co-occuring previous query.
2.1. Weakly Supervised Pre-Training
Variants of mono-lingual supervised models are used in industry applications for query suggestions [14]. In the pre-training step, we train the supervised model using co-occurring consecutive query pairs in a search sessions. A search-session (Cao et al., 2008) is a stream of queries entered by a user in a 5-min111Based on guidance from internal search team’s proprietary analysis. time window. N-1 Consecutive query pairs (, ) are extracted from a search session consisting of a sequence of N queries (, ,…,). Consecutive queries could be unrelated, semantically and (or) syntactically related. Our model is weakly supervised as we use all query pairs and do not filter them using sparse click data, costly human-evaluations and weak association rules. Weak supervision allows the training process to scale, minimize selection-bias and we conjecture that it improves model generalization too. For example, unlike [14], we do not apply syntactic similarity heuristics to filter query pairs, as queries could be semantically related yet syntactically dissimilar (e.g., “artificial intelligence” and “machine learning”) . The encoder-decoder framework consists of a BiLSTM (Graves et al., 2013) encoder, that encodes a batch (batch-size ) of input queries () and the LSTM (Hochreiter and Schmidhuber, 1997) decoder generates a batched sequence of words y = (,…, ). Where, is the sequence length. During training, we use teacher forcing (Williams and Zipser, 1989), i.e., use the co-occuring query () as input to the decoder. Context attention vector is obtained from the alignment model (Bahdanau et al., 2015) . Categorical cross entropy loss is minimized during training and hyper-parameters of the model are fine-tuned (see Section 3.2).
2.2. Fine-tuning using Deep Reinforcement Learning
This section describes the reward estimation and Deep Reinforcement Learning (DRL) model training steps to fine-tune and improve the policy obtained via pre-trained supervised model.
2.2.1. Deep Reinforcement Learning Model.
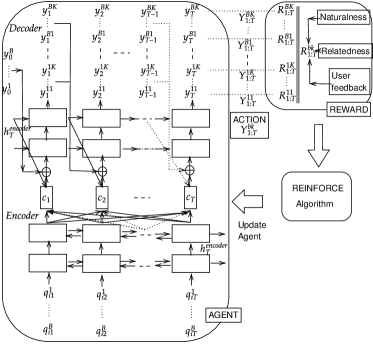
Parameters of the DRL agent are initialized with pre-trained model (Section 2.1). The initial policy is fine-tuned using the REINFORCE policy-gradient algorithm (Figure 1). ‘’ complete sentences () generated per query () constitute the action space at time-step , where is the index in a mini-batch of queries. To mitigate exposure-bias, generated words () from previous time-step are passed as input to the next time-step ‘’ of the decoder. Future-reward () computed at the end of each generated sample, is back-propagated to the encoder-decoder model. Given the start-state () comprising of the input query () and ¡START¿ token , the objective of the agent is to generate related-search query suggestions () which maximize objective:
| (1) |
Where per-sample reward is:
| (2) |
MC approximation of the gradient using likelihood ratio trick:
| (3) |
Unlike SeqGAN (Yu et al., 2017) DRL model training, where the action-value at each intermediate time-step is evaluated by generating samples (), we perform MC policy roll-out from the start state alone. queries () are generated using roll-out policy , for each input query . This modification reduces the computation cost by a factor of () per input query. is initialized with and is periodically updated during training, using a configurable schedule (see Algorithm 1). At each time-step , the state is comprised of the input query and the tokens produced so far () and the action is the next token to be selected from stochastic policy .
Details of the constituents of future-reward (, and ) are in the next section (Section 2.2.2). Since the expectation can be approximated by sampling methods, we then update the generator’s parameters with as the learning-rate as:
| (4) |
2.2.2. Reward Formulation.
This section describes the three components of the future-reward , which are session based positive user-feedback (), syntactic-similarity () and unnatural suggestion penalty ().
-
•
Long-term user-feedback in a search session (): Viewing search-results (dwell time ¿= 5 seconds 222Determined by internal domain-specific search user-behavior analysis.) or performing an engaging action such as: sending a connection request or a message; applying for a job; favoriting a group, profile or an article, constitute positive implicit user actions in a search-session. Immediate user-feedback is sparse. However, positive user action percentage increases by absolute 333Computed over a set of ~100 million query pairs extracted from search-sessions in one month window. Actual of positive user actions is not included due to confidentiality., when the remainder of the search session after the user enters is considered. In our work we maximize session-based user-feedback, as we are interested in maximizing user engagement across search sessions. For a generated query , session-based user feedback () is “1” , if a positive down-stream user action is observed in the remainder of the search-session and “0” otherwise.
-
•
Relatedness of generated query to source query (): Despite increasing the percentage of associated positive user action by considering user’s feedback across a search session, the label sparsity problem is not completely mitigated. In the search query logs, when there is no positive downstream user action associated with a generated query , we estimate the reward using a syntactic similarity measure. Reformulated queries are syntactically and semantically similar (Lee et al., 2021). We compute syntactic relatedness of generated query () with the source query () using ROUGE-1 (Lin, 2004) score.
-
•
Naturalness probability of generated query (): Users enter either natural language search queries(Borges et al., 2020) (e.g., “jobs requiring databases expertise in the bay area” ) or they just enter key-words (e.g., “bay area jobs database” ). In the context of related query suggestions, we define a “natural” query as one which a real user is likely to enter. We train a contextual-naturalness-estimation model (see Section 2.2.3) to predict naturalness probability of a generated query, given the previous query entered by the user as context. “AI jobs” is an example of a natural query after the user searched for “Google”, even though both queries are syntactically and semantically (jobs vs company) dissimilar. However, “AI AI jobs jobs” is unnatural and is unlikely to be entered by a real user. In our DRL reward formulation, we add penalty term to syntactic-relatedness () score to discourage generation of unnatural queries. Coefficient is the configurable penalty weight.
2.2.3. Contextual Naturalness Estimator.
Our proposed contextual-naturalness-estimator is a BiLSTM (Graves et al., 2013) supervised model, which predicts the probability a generated query is “natural” () . Concatenated with query-context (), user entered queries () serve as positive examples () to train the model. We employ four methods to generate negative examples () per each positive example, which are: 1) With as input, sample query from fine-tuned model’s decoder (Section 2.1); 2) perturb by duplicating a word in randomly selected position within the sentence; 3) replace a word with unknown word token (“¡UNK¿”) at a randomly selected position in ; and 4) generate a sentence by repeating a sampled word from a categorical distribution () for (randomly chosen) times. —V— is the size of the training data vocabulary, = , is word () frequency and . Methods , and generate hard-negative examples (Lee et al., 2021) and captures popularity-bias (Abdollahpouri, 2019), a situation where popular terms are generated more often than terms in long-tail.
To validate our hypothesis that sampled queries from are less natural than the ones provided by the user, we asked three annotators to rate randomly sampled query pairs (). Query is entered by the user and is either sampled from a supervised model () or was entered by the user () after searching for . Without revealing the source of , we asked annotators to identify if the query is “natural” (defined in Section 2.2.2) . On an average of model-generated queries and of real-user queries were identified as natural. The Inter Annotator Agreement (IAA), measured using Fleiss-Kappa (Schouten, 1986), was poor () when the users evaluated model-generated sentences. In comparison, when they evaluated queries entered by real users, IAA was better () between the three annotators’ ratings and it ranged from fair () to moderate () agreement between each pair of annotators. Higher IAA and higher percentage of queries identified as “natural” imply that real-user queries are more natural and distinguishable than queries sampled from pre-trained model.
3. Experiment Setup and Results
This section describes the experimental setup to train and evaluate the naturalness-estimator, supervised and DRL query generation models.
3.1. Data
From user search-query logs, we randomly sampled 0.61 million (90% train), 34k (5% valid) and 34k (5% test) query pairs to train the supervised and DRL models. Dataset size to train the naturalness-estimator model is 5x the aforementioned amount (See Section 2.2.3). Max-length of a query is 8 and mean-length is ~2 words. Vocabulary size is 32k and out of vocabulary words in validation and test sets are replaced with “¡UNK¿” unknown-token.
3.2. Experimental Setup
We implemented all models in Tensorflow (Abadi et al., 2015) and tuned the parameters using Ray[Tune] (Liaw et al., 2018) on Kubernetes (kubernetes.io, 2020) distributed cluster. As described in Section 2, the query suggestion policy is initialized with fine-tuned model. model parameters are updated using Adam (Kingma and Ba, 2015) optimizer and categorical-cross-entropy loss is minimized during training. During inference, six444In production environment six related queries are suggested for each user query. queries are generated per input query () using beam-search (Freitag and Al-Onaizan, 2017) decoding. Negative examples to train the two-layered BiLSTM contextual-naturalness-estimator are obtained from pre-trained model. At inference, naturalness probability ()) is obtained from the output of fully-connected layer with last time-step’s hidden state as its input.
The initial policy is fine-tuned using REINFORCE policy-gradient algorithm, using future-reward described in Section 2.2.2. During training, “K” samples for MC roll-out are generated using beam-search or from categorical distribution of inferred word probabilities at each time-step (See Figure 1). DRL model training stability is monitored using reward weighted Negative Log Likelihood convergence performance, with as the computed loss at each model training step.
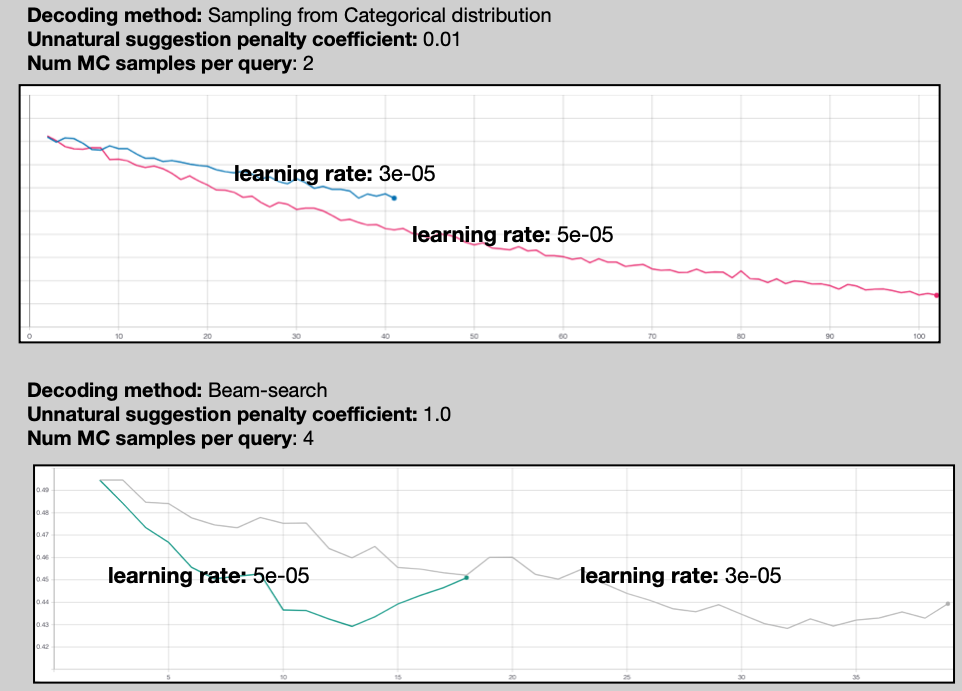
We use SGD optimizer (Kiefer and Wolfowitz, 1952) to update the weights of the agent (Equation 4). Appendix Figure 2 shows the convergence performance of the DRL model for different values of unnaturalness penalty (), number of MC samples () and choice of sampling strategy. Complete set of hyper-parameters we tuned are in Appendix Table A. Best combination of hyper-parameters are chosen are based on performance on validation set (See Appendix Table A).
3.3. Evaluation Metrics
The binary “natural/unnatural” class prediction performance of the contextual naturalness estimator is evaluated using F1555F1 = score and Accuracy666Categorical accuracy: calculates how often predictions match one-hot labels. metrics. We use the mean of the following metrics calculated on the test set, to evaluate the relevance, engagement, accuracy and diversity of generated queries.
-
•
Sessions with positive user-action (): Long-term binary engagement metric indicating if recommended queries lead to a successful session. Its value is “1”, if any of the six generated queries belong to a search-session in test-data with an associated down-stream positive user action (Section 2.2.2).
-
•
Unique@6: Diversity metric indicating the percentage of unique sentences in (six) query suggestions made per query . Queries containing unknown word token (“¡UNK¿”) are filtered out as only high-quality suggestions are presented to the end user.
-
•
Precision@6: Measures relevance with respect to the query a user would enter next. Is “1” if () is in the set of six query suggestions made for () and “0” otherwise.
-
•
Word-repetitions per sentence (): Fraction of word repetitions per generated query (). Unwanted word repetitions lead to lower quality.
-
•
Prior Sentence Probability (): , measures the prior sentence probability. is prior word probability defined in Section 2.2.3. Lower sentence probability indicates higher diversity as generated queries contain less frequent words.
3.4. Results
The contextual-naturalness-estimator achieved accuracy and F1 performance on test set. Table 1 shows the performance of supervised () and proposed DRL model on the five metrics mentioned in previous section. and use “beam-search” and “sampling from categorical distribution” MC sampling strategies respectively (see Section 3.2). In order assess the impact of applying heuristics to filter and improve quality of suggestions provided by supervised models, we analyzed the performance of , which is model with post-processing filters to remove suggestions with repeated words.
Model\Metric Unique@6 Precision@6 0.1108 0.002 5.8244 0.0045 0.0456 0.0025 2.21% 0.04% -6.4442 0.0149 0.1101 0.001 5.5595 0.0075 0.0456 0.0025 0.00% 0.00% -6.4875 0.0151 0.1155 0.002 5.9606 0.0023 0.0468 0.0025 1.10% 0.03% -6.4897 0.0140 0.1149 0.002 5.9956 0.0007 0.0467 0.0024 0.40% 0.02% -6.3932 0.0141
On offline test data set, in comparison to the baseline model, removed query suggestions with repeated words completely, however the heuristics-based model performed poorly in-terms of diversity (4.5% relative drop in mean Unique@6) and average number of successful sessions (0.6% relative drop in mean ). On the other hand, both versions of our proposed DRL models outperformed the baseline model on all metrics. DRL variants achieved significant relative improvement in-terms of user-engagement (mean ) up to 4.2% (), query suggestions’ diversity (mean Unique@6) up to 3% (), sentence-level diversity (mean Prior Sentence Probability) up to 0.7% () and reduction in errors per sentence up to 82% (). Non significant improvement in relevance (mean Precision@6) is not surprising as the supervised model is also trained with consecutive query pairs.
4. Conclusions
In this paper, we proposed a Deep Reinforcement Learning (DRL) framework to improve the quality of related-search query suggestions. Using long-term user-feedback, syntactic relatedness and estimated unnaturalness penalty as reward signals, we fine-tuned the supervised text-generation policy at scale with REINFORCE policy-gradient algorithm. We showed significant improvement in recommendation diversity (), query correctness (), user-engagement () over industry-baselines. For future work, we plan to include semantic relatedness as reward. Since the proposed DRL framework is agnostic to the choice of an encoder-decoder architecture, we plan to fine-tune different state-of-the-art language models using our proposed DRL framework.
Acknowledgements.
Thanks to Cong Gu, Ankit Goyal and LinkedIn Big Data team for their help in setting up DRL experiments on Kubernetes. Thanks to Souvik Ghosh and RL Foundations team for your valuable feedback.References
- (1)
- Abadi et al. (2015) Martín Abadi, Ashish Agarwal, Paul Barham, Eugene Brevdo, Zhifeng Chen, Craig Citro, Greg S. Corrado, Andy Davis, Jeffrey Dean, Matthieu Devin, Sanjay Ghemawat, Ian Goodfellow, Andrew Harp, Geoffrey Irving, Michael Isard, Yangqing Jia, Rafal Jozefowicz, Lukasz Kaiser, Manjunath Kudlur, Josh Levenberg, Dan Mané, Rajat Monga, Sherry Moore, Derek Murray, Chris Olah, Mike Schuster, Jonathon Shlens, Benoit Steiner, Ilya Sutskever, Kunal Talwar, Paul Tucker, Vincent Vanhoucke, Vijay Vasudevan, Fernanda Viégas, Oriol Vinyals, Pete Warden, Martin Wattenberg, Martin Wicke, Yuan Yu, and Xiaoqiang Zheng. 2015. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. http://tensorflow.org/ Software available from tensorflow.org.
- Abdollahpouri (2019) Himan Abdollahpouri. 2019. Popularity Bias in Ranking and Recommendation. https://doi.org/10.1145/3306618.3314309
- Bahdanau et al. (2015) Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. 2015. Neural Machine Translation by Jointly Learning to Align and Translate. CoRR abs/1409.0473 (2015).
- Bodigutla et al. (2019) Praveen Kumar Bodigutla, Longshaokan Wang, Kate Ridgeway, Joshua Levy, Swanand Joshi, Alborz Geramifard, and Spyros Matsoukas. 2019. Domain-Independent turn-level Dialogue Quality Evaluation via User Satisfaction Estimation. arXiv:cs.LG/1908.07064
- Borges et al. (2020) F. Borges, Georgios Balikas, Marc Brette, Guillaume Kempf, A. Srikantan, Matthieu Landos, Darya Brazouskaya, and Qianqian Shi. 2020. Query Understanding for Natural Language Enterprise Search. ArXiv abs/2012.06238 (2020).
- Brown et al. (2020) Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. 2020. Language Models are Few-Shot Learners. arXiv:cs.CL/2005.14165
- Cao et al. (2008) Huanhuan Cao, Daxin Jiang, Jian Pei, Qi He, Zhen Liao, Enhong Chen, and Hang Li. 2008. Context-Aware Query Suggestion by Mining Click-through and Session Data. In Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD ’08). Association for Computing Machinery, New York, NY, USA, 875–883. https://doi.org/10.1145/1401890.1401995
- Chaslot et al. (2008) Guillaume Chaslot, Sander Bakkes, Istvan Szita, and Pieter Spronck. 2008. Monte-Carlo Tree Search: A New Framework for Game AI. In Proceedings of the Fourth AAAI Conference on Artificial Intelligence and Interactive Digital Entertainment (AIIDE’08). AAAI Press, 216–217.
- Freitag and Al-Onaizan (2017) Markus Freitag and Yaser Al-Onaizan. 2017. Beam Search Strategies for Neural Machine Translation. CoRR abs/1702.01806 (2017). arXiv:1702.01806 http://arxiv.org/abs/1702.01806
- Ganegedara (2020) Thushan Ganegedara. 2020. Is the race over for Seq2Seq models? https://towardsdatascience.com/is-the-race-over-for-seq2seq-models-adef2b24841c
- Goodfellow et al. (2014) Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. 2014. Generative Adversarial Nets. In Proceedings of the 27th International Conference on Neural Information Processing Systems - Volume 2 (NIPS’14). MIT Press, Cambridge, MA, USA, 2672–2680.
- Graves et al. (2013) Alex Graves, Navdeep Jaitly, and Abdel-rahman Mohamed. 2013. Hybrid speech recognition with Deep Bidirectional LSTM. In 2013 IEEE Workshop on Automatic Speech Recognition and Understanding. 273–278. https://doi.org/10.1109/ASRU.2013.6707742
- Hochreiter and Schmidhuber (1997) Sepp Hochreiter and Jürgen Schmidhuber. 1997. Long Short-Term Memory. Neural Comput. 9, 8 (Nov. 1997), 1735–1780. https://doi.org/10.1162/neco.1997.9.8.1735
- Kazi et al. (2020) Michaeel Kazi, Weiwei Guo, Huiji Gao, and Bo Long. 2020. Incorporating User Feedback into Sequence to Sequence Model Training. In CIKM ’20: The 29th ACM International Conference on Information and Knowledge Management, Virtual Event, Ireland, October 19-23, 2020, Mathieu d’Aquin, Stefan Dietze, Claudia Hauff, Edward Curry, and Philippe Cudré-Mauroux (Eds.). ACM, 2557–2564. https://doi.org/10.1145/3340531.3412714
- Kiefer and Wolfowitz (1952) J. Kiefer and J. Wolfowitz. 1952. Stochastic Estimation of the Maximum of a Regression Function. The Annals of Mathematical Statistics 23, 3 (1952), 462–466. http://www.jstor.org/stable/2236690
- Kingma and Ba (2015) Diederik P. Kingma and Jimmy Ba. 2015. Adam: A Method for Stochastic Optimization. CoRR abs/1412.6980 (2015).
- kubernetes.io (2020) kubernetes.io. 2020. Cluster Architecture. https://kubernetes.io/docs/concepts/architecture/
- Lee et al. (2021) Seanie Lee, Dong Bok Lee, and Sung Ju Hwang. 2021. Contrastive Learning with Adversarial Perturbations for Conditional Text Generation. arXiv:cs.CL/2012.07280
- Li et al. (2016) Jiwei Li, Will Monroe, Alan Ritter, Michel Galley, Jianfeng Gao, and Dan Jurafsky. 2016. Deep Reinforcement Learning for Dialogue Generation. CoRR abs/1606.01541 (2016). arXiv:1606.01541 http://arxiv.org/abs/1606.01541
- Li et al. (2019) Ruirui Li, Liangda Li, Xian Wu, Yunhong Zhou, and Wei Wang. 2019. Click Feedback-Aware Query Recommendation Using Adversarial Examples. In The World Wide Web Conference (WWW ’19). Association for Computing Machinery, New York, NY, USA, 2978–2984. https://doi.org/10.1145/3308558.3313412
- Liaw et al. (2018) Richard Liaw, Eric Liang, Robert Nishihara, Philipp Moritz, Joseph E Gonzalez, and Ion Stoica. 2018. Tune: A Research Platform for Distributed Model Selection and Training. arXiv preprint arXiv:1807.05118 (2018).
- Lin (2004) Chin-Yew Lin. 2004. ROUGE: A Package for Automatic Evaluation of Summaries. In Text Summarization Branches Out. Association for Computational Linguistics, Barcelona, Spain, 74–81. https://www.aclweb.org/anthology/W04-1013
- Nogueira and Cho (2017) Rodrigo Nogueira and Kyunghyun Cho. 2017. Task-Oriented Query Reformulation with Reinforcement Learning. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, Copenhagen, Denmark, 574–583. https://doi.org/10.18653/v1/D17-1061
- Schmidt (2019) Florian Schmidt. 2019. Generalization in Generation: A closer look at Exposure Bias. In Proceedings of the 3rd Workshop on Neural Generation and Translation. Association for Computational Linguistics, Hong Kong, 157–167. https://doi.org/10.18653/v1/D19-5616
- Schouten (1986) Hubert J. A. Schouten. 1986. Nominal scale agreement among observers. Psychometrika 51, 3 (1986), 453–466. https://doi.org/10.1007/BF02294066
- Schulman et al. (2017) John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. 2017. Proximal Policy Optimization Algorithms. CoRR abs/1707.06347 (2017). arXiv:1707.06347 http://arxiv.org/abs/1707.06347
- Stiennon et al. (2020) Nisan Stiennon, Long Ouyang, Jeff Wu, Daniel M. Ziegler, Ryan Lowe, Chelsea Voss, Alec Radford, Dario Amodei, and Paul F. Christiano. 2020. Learning to summarize from human feedback. CoRR abs/2009.01325 (2020). arXiv:2009.01325 https://arxiv.org/abs/2009.01325
- Tang et al. (2006) Thanh Tin Tang, Nick Craswell, David Hawking, Kathy Griffiths, and Helen Christensen. 2006. Quality and relevance of domain-specific search: A case study in mental health. Information Retrieval 9, 2 (2006), 207–225. https://doi.org/10.1007/s10791-006-7150-5
- Wang et al. (2016) Xuanhui Wang, Michael Bendersky, Donald Metzler, and Marc Najork. 2016. Learning to Rank with Selection Bias in Personal Search. In Proc. of the 39th International ACM SIGIR Conference on Research and Development in Information Retrieval. 115–124.
- Wang et al. (2020) Xiao Wang, Craig Macdonald, and Iadh Ounis. 2020. Deep Reinforced Query Reformulation for Information Retrieval. arXiv:cs.IR/2007.07987
- Williams (1992) Ronald J. Williams. 1992. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Machine Learning 8, 3 (1992), 229–256. https://doi.org/10.1007/BF00992696
- Williams and Zipser (1989) Ronald J. Williams and David Zipser. 1989. A Learning Algorithm for Continually Running Fully Recurrent Neural Networks.
- Yu et al. (2017) Lantao Yu, W. Zhang, J. Wang, and Y. Yu. 2017. SeqGAN: Sequence Generative Adversarial Nets with Policy Gradient. In AAAI.
Appendix A Appendices