Highly Generalizable Models for Multilingual Hate Speech Detection
1. Abstract
Hate speech detection has become an important research topic within the past decade. More private corporations are needing to regulate user generated content on different platforms across the globe. In this paper, we introduce a study of multilingual hate speech classification. We compile a dataset of 11 languages and resolve different taxonomies by analyzing the combined data with binary labels: hate speech or not hate speech. Defining hate speech in a single way across different languages and datasets may erase cultural nuances to the definition, therefore, we utilize language agnostic embeddings provided by LASER and MUSE in order to develop models that can use a generalized definition of hate speech across datasets. Furthermore, we evaluate prior state of the art methodologies for hate speech detection under our expanded dataset. We conduct three types of experiments for a binary hate speech classification task: Multilingual-Train Monolingual-Test, Monolingual-Train Monolingual-Test and Language-Family-Train Monolingual Test scenarios to see if performance increases for each language due to learning more from other language data.
2. Introduction
Hate speech detection online has increasingly become an important domain of research in the past decade (Fortuna and Nunes, 2018). In the United States, hate speech is protected under the First Amendment, but many other countries including the United Kingdom, Canada, and France have laws prohibiting specific forms of hate speech (Rosenfeld, 2002). With these legal requirements, online platforms must be prepared to internally monitor the content uploaded by users and ensure that they are not enabling the spread of hate speech. The repercussions of unmoderated content could range from large fines to legal action, or even imprisonment. Facebook and Twitter have had to make public statements in response to criticism of their internal monitoring of hate speech to specify what they label as hateful conduct, and how they will be monitoring and regulating this content 111https://help.twitter.com/en/rules-and-policies/hateful-conduct-policy 222https://transparency.fb.com/policies/community-standards/hate-speech/. Previous work in machine-learning-based hate speech detection involve developing a discriminator model for a reduced linguistic taxonomy. Previous attempts at multilingual hate speech detection often translate the dataset to English and use models for single language embedding such as LSTM and BERT (Uzan and HaCohen-Kerner, 2021). In this paper, we expand upon prior work in multilingual hate speech detection by making the following contributions:
-
(1)
Compiling, preprocessing, and quality checking a hate speech dataset consisting of 11 different languages.
-
(2)
Preparing, training, and evaluating deep learning models that effectively recognize hate speech in a multilingual setting and generalize reasonably well to languages not present in the dataset.
-
(3)
Releasing the dataset and trained models to serve as a benchmark for multilingual hate speech detection.
We formalize our experiments by answering the following research questions:
-
(1)
RQ1: How does hate speech differ from normal speech in a language agnostic setting?
-
(2)
RQ2: How well do the different model architectures perform in hate speech detection when trained on multiple languages?
-
(3)
RQ3: If we trained a model on a particular language family, how well does the model perform on a language that belongs to the same family in comparison to a model trained on the entire set of languages?
3. Literature Survey/ Baselines
Corazza et al. (et.al, [n.d.]c) uses datasets for 3 different languages (English, Italian, and German) and trains different models such as LSTMs, GRUs, Bidirectional LSTMs, etc. While this work claims to have a robust neural architecture for hate speech detection across different languages, our work develops models that are far more generalizable and trained on a much larger dataset of languages. We also believe that our larger dataset along with novel techniques such as attention-based mechanisms enables us to outperform these models.
Huang et al. (et.al, [n.d.]d) constructed a multilingual Twitter hate speech corpus from 5 languages that they augmented with demographic information to study the demographic bias in hate speech classification. The demographic labels were inferred using a crowd-sourcing platform. While this study presents an excellent analysis on demographic bias in hate speech detection, it does not leverage the dataset to build a multilingual hate speech classifier, let alone perform any classification tasks.
Aluru et al. (Sai Saketh Aluru and Mukherjee, [n.d.]) use datasets from 8 different languages and obtain their embeddings using LASER (Research, [n.d.]a) and MUSE (Research, [n.d.]b). The resultant embeddings are fed in as input to different architectures based on CNNs, GRUs, and variations of Transformer models. While the paper does achieve reasonably good performance across the languages, it falls short on two fronts: 1. The paper claims that the models are generalizable, but these models do not make use of datasets of multiple other languages and lose out on a more fine-tuned set of parameters for generalization. Thus, these models are not expected to perform well outside of the 8 languages, and 2. the study focuses on models that perform well in low-resource settings while not paying much attention to how the models perform in an environment not constrained by resources. By combining datasets from 11 different languages we achieve a better performance.
4. Dataset Description and Analysis
4.1. Source
We retrieved our datasets from hatespeechdata.com, a website published by Poletto et al that compiles hate speech data from 11 different languages. Data statistics for the combined datasets for each language is summarized in Table 1. The collection source and taxonomy used for each dataset is described below.
-
(1)
English: The Ousidhoum et al. (Ousidhoum et al., 2019) dataset labels tweets with five attributes (directness, hostility, target, group, and annotator.) The Davidson et al. (Davidson et al., 2017) classifies collected tweets as hate speech or not hate speech using a lexicon directory for increased labeling accuracy. Gilbert et al. (de Gibert et al., 2018) uses a text extraction tool to randomly sample posts on Stormfront, a White Supremacist forum, and label them as hate speech or not. The Basile et al. (Basile, [n.d.]) dataset categorizes tweets as hate or not hate. Waseem et al. (Waseem and Hovy, 2016) uses the Twitter API to obtain tweets, then classifies them as hate speech or not hate speech. The Founta et al. (Founta et al., 2018) dataset uses a crowd-sourcing project to compile tweets that are then labeled as hate speech or not hate speech.
-
(2)
Arabic: The Arabic Leventine Hate Speech and Abusive Language Dataset (ara, [n.d.]) consists of Syrian/Lebanese political tweets labeled as normal, abusive or hate. Ousidhoum et al. (Ousidhoum et al., 2019) dataset of tweets are labeled based on 5 attributes (directness, hostility, target, group, and annotator.)
- (3)
-
(4)
Indonesian: Ibrohim et al. (et.al, [n.d.]e) collects tweets from Indonesian Twitter for multi-label classification where labels are hate or no-hate, abuse or no-abuse, and attributes of the people targeted including race, gender, religion, etc. The Alfina et al. (et.al, [n.d.]a) tweet dataset classifies them as hate speech or not hate speech. The aforementioned datasets were both obtained using a Python Web Scraper and the Twitter API.
-
(5)
Italian: Sanguinetti et al. (Sanguinetti et al., 2018) dataset of tweets regarding certain minority groups in Italy that are labeled as hate or not hate. Bosco et al. (et.al, [n.d.]b) compiles Facebook posts and tweets about minority groups and immigrants in Italy using the Facebook and Twitter APIs.
-
(6)
Portuguese: Fortuna et al. (Fortuna and Nunes, 2019) compiles hate speech tweets in Portuguese that are labeled at two levels: a simple binary label of hate vs no hate followed by a fine-grained hierarchical multiple label scheme with 81 hate speech categories in total.
- (7)
-
(8)
French: Ousidhoum et al. (Ousidhoum et al., 2019) compiles a dataset of tweets that are labeled based on five attributes (directness, hostility, target, group, and annotator.)
-
(9)
Turkish: Coltekin et al. (Çağrı Çöltekin, [n.d.]) randomly samples Turkish blog posts from Twitter and reviews and annotates them as offensive language or not offensive language. Tweets were sampled over a period of 18 months and are regarding various issues currently prominent in Turkish culture.
-
(10)
Danish: Sigurbergsson et al. (Gudbjartur Ingi Sigurbergsson, [n.d.]) introduces dkhate, a dataset of user-generated comments from various social media platforms that are annotated as offensive or not offensive speech.
-
(11)
Hindi: Kumar et al. (Ritesh Kumar, [n.d.]) develops a dataset from Twitter and Facebook that is annotated using binary labels depending on whether or not the example exudes aggression.
4.2. Data Preprocessing
4.2.1. Unifying taxonomy of classification
One challenge while working with these datasets was different taxonomies of classification. We processed all datasets and re-labeled some to ensure all datasets had consistent binary labels: hate speech or not hate speech. For some datasets, it was relatively straightforward to derive the final binary labels since there was an explicit hate speech label column. For the remaining datasets, we considered all sub-categories of hate speech as hate speech and any categories that didn’t fall under the hate speech umbrella as not hate speech. In one special case, for the German dataset by Ross et al. (Ross et al., 2016) we had to resolve labeling between annotators. For the Ousidham et al. datasets (Ousidhoum et al., 2019) in French, English and Arabic which had multi-labeling in terms of sentiment, we considered any data point containing hateful sentiment as hate speech and any containing normal sentiment as not hate speech. Finally, the labels across datasets were mapped to integer labels of 1 for hate speech and 0 for not hate speech.
4.2.2. Definition of Hate Speech
Before and during the process of re-labeling the datasets, we uncovered another major challenge: varied definitions of hate speech across datasets. We decided not to define hate speech commonly across datasets, since this may interfere with different nuanced definitions across cultural contexts. Our goal was to create a model that is able to learn a generalized definition of hate speech across all datasets and languages, and hopefully preserve the cultural differences that we are unequipped to identify ourselves.
4.2.3. General preprocessing
A few of these datasets: English (Founta et al. (Founta et al., 2018)), English (Waseem et al. (Waseem and Hovy, 2016)), Italian (Sanguinetti et al. (Sanguinetti et al., 2018)) consisted only of tweet IDs along with labels for each tweet. We retrieved the corresponding text for each tweet using a Python wrapper for the Twitter API called python-twitter (bear, [n.d.]) and appended the column to the original datasets. The Hindi and Arabic datasets were in their original scripts so we transliterated (romanized) them during preprocessing. For Arabic we used Buckwalter transliteration from the lang-trans python package (kariminf, [n.d.]), and for Hindi we used the python package indic-transliteration (vvasuki, [n.d.]) to convert the script to ITRANS romanization scheme.
General text preprocessing steps included removing carriage return and new line escape characters, removing non-ASCII words, conversion to lowercase, and removing stop words for all supported languages in the nltk python package (tomaarsen, [n.d.]). We also chose to remove emojis because of the differences in connotation, meaning, and usage across different cultures and because we decided to focus on text characteristics to classify data. We combine all datasets within a each language into a single dataset, resulting in 11 datasets for the 11 languages we considered. We outline the statistics of each language’s dataset (number of examples, class imbalance) in the table below:
| Language | #Examples | %Hate Speech |
|---|---|---|
| English | 65553 | 0.35 |
| German | 5568 | 0.26 |
| French | 1033 | 0.75 |
| Spanish | 10080 | 0.42 |
| Italian | 9692 | 0.28 |
| Danish | 2619 | 0.12 |
| Arabic | 3293 | 0.51 |
| Turkish | 27832 | 0.19 |
| Portuguese | 4534 | 0.33 |
| Hindi | 12000 | 0.36 |
| Indonesian | 11104 | 0.41 |
| Total | 157183 |
5. Experiment Settings and Baselines
5.1. The Hate Speech Classification Task
Our primary task is binary hate speech classification in a single modality, i.e., for only text data. Let be the raw input text sequence that we want to classify, be the target variable with when is not hate speech and when is hate speech. We generate a vectorized representation where is an encoding technique (for example, an embedding generated by LASER (Research, [n.d.]a) or the output of the encoder in BERT models.) Let be the model architecture that we train to perform binary hate speech classification. We state the classification problem as follows:
Given , we want our model to output where the predicted label is ideally the same as .
5.2. Evaluation Metrics
We chose to use the following evaluation metric to measure model performance:
Weighted F1 Score: The F1-score is the harmonic mean of the precision and recall of a classifier. In our case, a lot of the datasets are class-imbalanced, which makes the precision metric extremely important. Additionally, the cost of a false negative (predicting something that is hate speech as benign) is high which makes the recall equally important. The F1 score is able to capture both the precision and recall under a single, balanced evaluation metric. We also ensure that the computation of the F1-score is class-weighted, i.e., each class is weighted by the fraction of the dataset that it represents.
5.3. Experiment Parameters
The system configuration we used for experiments was as follows:
-
(1)
CPU: 2 x 2.2GHz vCPU
-
(2)
RAM: 13 GB DDR4
-
(3)
GPU: 1 x Nvidia Tesla P100
5.4. Baselines
We use the LASER + LR model architecture introduced by Aluru et al. (Aluru et al., 2021) as our baseline model. The model takes in the raw text sequence as input, generates a 1024 dimensional vector representation of the text from LASER (Research, [n.d.]a), and passes the resultant embedding into a Logistic Regression model. We utilize this model in 2 scenarios for our baseline results:
-
(1)
Monolingual-Train Monolingual-Test: We train the model on a particular language and test it on the same language.
-
(2)
Multilingual-Train Monolingual-Test: We train the model on all the languages and test it on each language separately.
The intuition behind this model is to use LASER as a method of capturing semantic and syntactic relationships of each language and use the representation it outputs to tune the parameters of the logistic regression model.
6. Proposed Method
6.1. Novelty/Improvements
So far, research in multilingual hate speech detection, suffers from some overarching issues: (1) The lack of generalizable models due to hyper-focused set of languages or insufficient training examples in certain languages, and (2) The lack of creativity in leveraging certain properties of each language to their own advantage (for instance, the similarity of languages within a certain family.) We attempt to overcome these shortcomings by:
-
(1)
Combining the benefits of an enriched multilingual dataset, cross-lingual representation methods, and/or complex model architectures to learn parameters using higher-quality representations.
-
(2)
Training complex model architectures on different language families to leverage each family’s semantic tendencies and achieve relevant parameter learning.
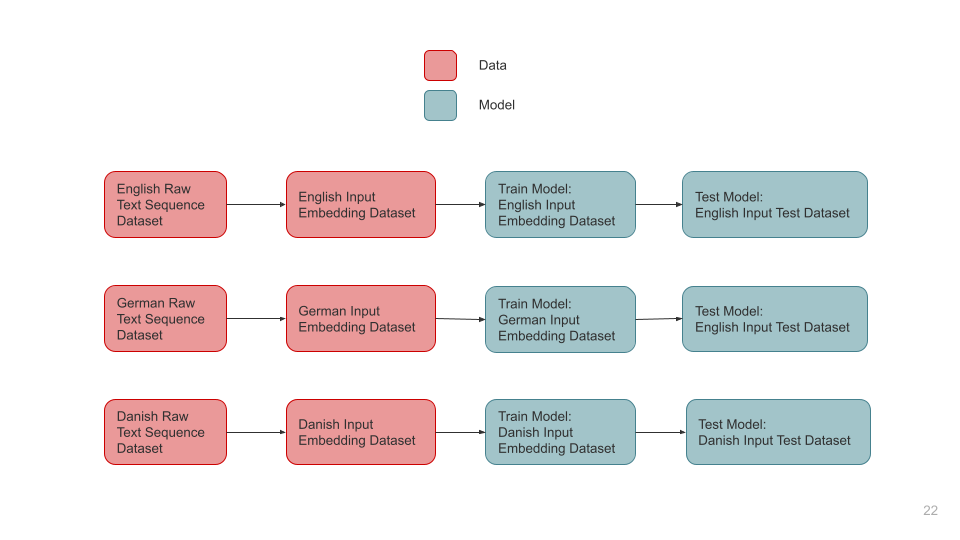
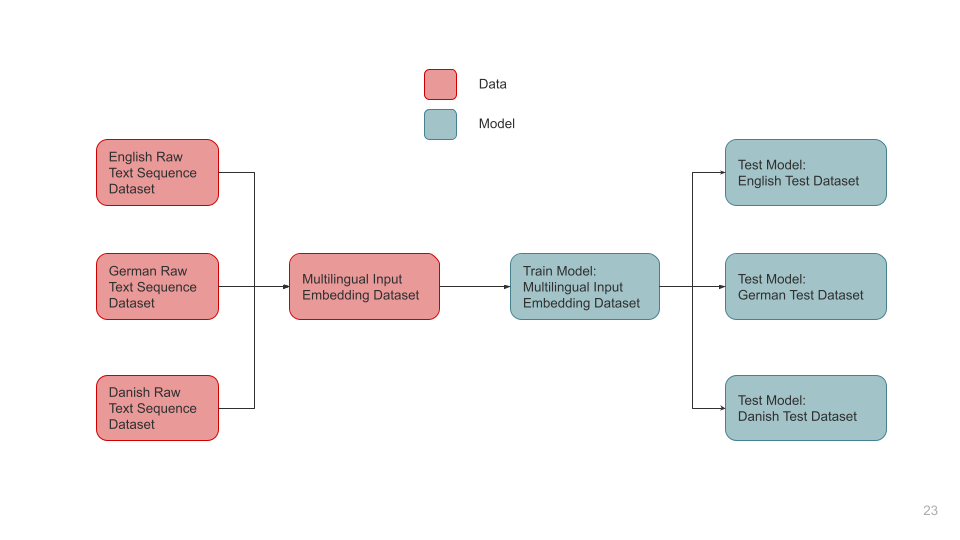
Formally, we attempt to introduce two novel scenarios as part of our experiments:
-
(1)
Multilingual-Train Monolingual-Test: We train the model on all available languages and test model performance on each language.
-
(2)
Language Family Train-Test: We train the model on a particular language family and test model performance on each language in that family.
We train the following model architectures for each scenario in our experiment:
-
(1)
LASER + LR: We generate sentence-level LASER embeddings and pass them as input to a Logistic Regression model. The model is expected to outperform the SoTA as its trained on our enriched dataset.
-
(2)
MUSE + CNN-GRU: We generate word-level MUSE embeddings for each input word and pass them as input to the CNN-GRU architecture.
-
(3)
mBERT: Multilingual-BERT is a variation of BERT pretrained on 104 languages without their respective language IDs. It can generalize to most of the langauges we consider. We use the raw sentences from each language to fine-tune the mBERT model.
All 3 of the candidate models use a batch size of 16 and are optimized using the AdamW optimizer and Cross Entropy loss. The model-specific hyperparameters are tabulated below:
| Hyperparameter | Value |
|---|---|
| Epochs | 20 |
| Learning Rate | 0.001 |
| Hyperparameter | Value |
|---|---|
| Epochs | 5 |
| Learning Rate | 5 x |
| # Encoder Layers | 16 |
| Max. Length | 512 |
| Hyperparameter | Value |
|---|---|
| Epochs | 20 |
| Learning Rate | 1 x |
| # Conv. Layers | 3 |
| # Conv. Filters | 300 |
| Kernel Sizes | 2x2, 3x3, 4x4 |
7. Experiments and Results
7.1. Monolingual-Train Monolingual-Test
Idea: Given languages, we train models for each langauge and test the performance of model on language for .
| Language | LASER + LR | MUSE + CNN-GRU | mBERT |
|---|---|---|---|
| English | 0.641 | 0.851 | 0.748 |
| German | 0.563 | 0.881 | 0.702 |
| French | 0.596 | 0.653 | 0.723 |
| Spanish | 0.588 | 0.724 | 0.642 |
| Italian | 0.686 | 0.805 | 0.633 |
| Danish | 0.599 | 0.853 | 0.808 |
| Arabic | 0.501 | 0.844 | 0.898 |
| Turkish | 0.562 | 0.790 | 0.729 |
| Portuguese | 0.645 | 0.838 | 0.864 |
| Hindi | 0.697 | 0.807 | 0.734 |
| Indonesian | 0.683 | 0.775 | 0.536 |
MUSE + CNN-GRU significantly outperforms LASER+LR and mBERT for 8/11 languages. mBERT in particular performs worse than both the other models in languages with heavy class imbalances such as Indonesian and Italian. Since mBERT requires a significant amount of data to fine-tune a specific task, it appears from the Monolingual-Train-Tests results that there is not enough data available for each language to properly fine-tune the model. The Arabic dataset has the highest absolute difference in performance, where the LASER+LR F1-score is approximately 60% lower than the other two models. It is curious that LASER+LR does no better than random guessing for this language while MUSE+CNN-GRU and mBERT are able to achieve a much higher F1 score with only 3300 training examples.
7.2. Multilingual-Train Monolingual-Test
Idea: Given languages, we train a single model on all languages and test the model’s performance on each langauge for .
| Language | LASER + LR | MUSE + CNN-GRU | mBERT |
|---|---|---|---|
| English | 0.672 | 0.854 | 0.857 |
| German | 0.577 | 0.893 | 0.747 |
| French | 0.590 | 0.721 | 0.769 |
| Spanish | 0.573 | 0.669 | 0.732 |
| Italian | 0.691 | 0.824 | 0.661 |
| Danish | 0.569 | 0.864 | 0.812 |
| Arabic | 0.509 | 0.848 | 0.896 |
| Turkish | 0.565 | 0.722 | 0.774 |
| Portuguese | 0.619 | 0.770 | 0.887 |
| Hindi | 0.612 | 0.798 | 0.739 |
| Indonesian | 0.687 | 0.705 | 0.578 |
mBERT and MUSE+CNN-GRU perform equally well, with mBERT narrowly beating out the latter in 6/11 languages. This is likely because mBERT requires more data to achieve good performance, and with the multilingual dataset, it has access to a richer dataset consisting of 11 languages.
Compared to the Monolingual-Train, Monolingual-Test scenario, the F1 score on the Monolingual-test scenario with the Multilingual-Train model is better for almost all languages because the model is able to incorporate the semantics of multiple languages to enhance its performance. The F1 score goes down for a few languages which might be due to an undue influence from other languages that are dissimilar and have a large number of examples.
7.3. Language Families: Germanic and Romance Languages
Idea: Given languages, we take a subset of the languages that form a language family . We train a model on all languages in and test the model’s performance on each language .
| Language | Monolingual | Multilingual | Language Family |
|---|---|---|---|
| English | 0.641 | 0.682 | 0.664 |
| German | 0.563 | 0.577 | 0.572 |
| Danish | 0.569 | 0.603 | 0.567 |
| Language | Monolingual | Multilingual | Language Family |
|---|---|---|---|
| English | 0.851 | 0.854 | 0.842 |
| German | 0.881 | 0.893 | 0.811 |
| Danish | 0.853 | 0.864 | 0.836 |
| Language | Monolingual | Multilingual | Language Family |
|---|---|---|---|
| English | 0.748 | 0.857 | 0.783 |
| German | 0.702 | 0.747 | 0.744 |
| Danish | 0.808 | 0.812 | 0.815 |
| Language | Monolingual | Multilingual | Language Family |
|---|---|---|---|
| French | 0.596 | 0.590 | 0.592 |
| Spanish | 0.588 | 0.573 | 0.591 |
| Italian | 0.686 | 0.691 | 0.688 |
| Portuguese | 0.645 | 0.619 | 0.652 |
| Language | Monolingual | Multilingual | Language Family |
|---|---|---|---|
| French | 0.653 | 0.721 | 0.746 |
| Spanish | 0.724 | 0.669 | 0.694 |
| Italian | 0.805 | 0.824 | 0.749 |
| Portuguese | 0.838 | 0.770 | 0.780 |
| Language | Monolingual | Multilingual | Language Family |
|---|---|---|---|
| French | 0.723 | 0.769 | 0.776 |
| Spanish | 0.642 | 0.732 | 0.718 |
| Italian | 0.633 | 0.661 | 0.684 |
| Portuguese | 0.864 | 0.887 | 0.894 |
From Table 6 and 7, it is evident that for all three model architectures, the Multilingual or Language-Family Train scenarios outperform the Monolingual-Train scenario in most cases. This demonstrates that the richer dataset across all languages allows for better classification performance due to a better generalized idea of hate speech and language semantics. What is interesting to note is: although the Multilingual train scenario tends to outperform the Language Family scenario in most cases, the F1 scores for the Monolingual Test cases are very similar. This indicates that despite having less data, the Language Family model is able to capture more relevant semantic information within a family of languages to achieve a performance close to that of the model trained on all languages. When compared to Germanic languages, the Romance Languages seem to achieve better performance in this scenario. Possible explanations for this could be that the Romance language group has more generalizability between languages compared to the Germanic group. However, we suspect that the lower performance in the Germanic language group can be attributed to the heavy bias of the model towards English with around 80% of the dataset consisting of English examples. In the future, one could investigate using a sub-sample of the English dataset to identify if this improves performance of the Germanic-language-family-trained model on other languages in the family.
8. Conclusion
8.1. Limitations
Although we outperform the current SoTA for multilingual hate speech detection models, our work has the following limitations:
-
(1)
Severe Imbalances in the Dataset: The datasets we use for each language suffers from two major types of imbalances that bias model performance: (1) textbfInter-Language Imbalance: There is a significant difference in the number of examples for each language in our dataset, which biases models towards the semantic tendencies of languages with lots of examples, and (2) Class Imbalance: A number of languages’ dataset consists mostly of examples that are not hate speech, which may strongly bias neural models.
-
(2)
Limited Explainability in Model Performance: While we have performed a significant number of experiments using various models, our work fails to provide concrete explainability on the model’s performance and why one architecture outperforms another for a certain language or scenario.
8.2. Extensions
Multilingual Hate speech detection is an extremely important area of research with lots of potential for improvement. We believe the following to be the most effective extensions to our work:
-
(1)
Data Augmentation to Low-Resource/Imbalanced Languages: Future work could utilize techniques such as back-translation introduced in Markus et al. (Bayer et al., 2021) to augment examples and improve model performance in low-resource/imbalanced languages.
-
(2)
Novel Candidate Architectures: Future work could test different architectures such as LASER + CNN-GRU and XLM-RoBERTa to compare performances across models.
-
(3)
Zero-Shot/All-but-one Hate Speech Detection: Another useful extension would be to train models in a multilingual (all-but-one or language families) to detect how well they can generalize to unseen languages.
9. Contributions
All of our team members have contributed an equal amount of effort towards making this project successful.
References
- (1)
- ara ([n.d.]) [n.d.]. L-HSAB: A Levantine Twitter Dataset for Hate Speech and Abusive Language.
- Aluru et al. (2021) Sai Saketh Aluru, Binny Mathew, Punyajoy Saha, and Animesh Mukherjee. 2021. A Deep Dive into Multilingual Hate Speech Classification. In Machine Learning and Knowledge Discovery in Databases. Applied Data Science and Demo Track: European Conference, ECML PKDD 2020, Ghent, Belgium, September 14–18, 2020, Proceedings, Part V. Springer International Publishing, 423–439.
- Basile ([n.d.]) et.al Basile. [n.d.]. SemEval2019-Task5: Multilingual Detection of Hate (hatEval). https://github.com/msang/hateval/tree/master/SemEval2019-Task5
- Bayer et al. (2021) Markus Bayer, Marc-André Kaufhold, and Christian Reuter. 2021. A Survey on Data Augmentation for Text Classification. CoRR abs/2107.03158 (2021). arXiv:2107.03158 https://arxiv.org/abs/2107.03158
- bear ([n.d.]) bear. [n.d.]. A Python wrapper around the Twitter API. https://github.com/bear/python-twitter
- Bretschneider ([n.d.]) R Bretschneider, U.; Peters. [n.d.]. Detecting Offensive Statements towards Foreigners in Social Media. http://www.ub-web.de/research/
- Davidson et al. (2017) Thomas Davidson, Dana Warmsley, Michael Macy, and Ingmar Weber. 2017. Automated Hate Speech Detection and the Problem of Offensive Language. In Proceedings of the 11th International AAAI Conference on Web and Social Media (Montreal, Canada) (ICWSM ’17). 512–515.
- de Gibert et al. (2018) Ona de Gibert, Naiara Perez, Aitor García-Pablos, and Montse Cuadros. 2018. Hate Speech Dataset from a White Supremacy Forum. In Proceedings of the 2nd Workshop on Abusive Language Online (ALW2). Association for Computational Linguistics, Brussels, Belgium, 11–20. https://doi.org/10.18653/v1/W18-5102
- et.al ([n.d.]a) Alfina et.al. [n.d.]a. Hate Speech Detection in Indonesian.
- et.al ([n.d.]b) Bosco et.al. [n.d.]b. Hate Speech Detection Tasks. https://github.com/msang/haspeede
- et.al ([n.d.]c) Corazza et.al. [n.d.]c. A Multilingual Evaluation for Online Hate Speech Detection.
- et.al ([n.d.]d) Huang et.al. [n.d.]d. Multilingual Twitter Corpus and Baselines for Evaluating Demographic Bias in Hate Speech Recognition.
- et.al ([n.d.]e) Ibrohim et.al. [n.d.]e. Multi Label Hate Speech and Abusive Language Detection in Indonesian Twitter. https://github.com/okkyibrohim/id-multi-label-hate-speech-and-abusive-language-detection
- Fortuna and Nunes (2019) João Rocha da Silva Juan Soler-Company Leo Wanner Fortuna, Paula and Sérgio Nunes. 2019. A Hierarchically-Labeled Portuguese Hate Speech Dataset. In Proceedings of the 3rd Workshop on Abusive Language Online (ALW3).
- Fortuna and Nunes (2018) Paula Fortuna and Sérgio Nunes. 2018. A Survey on Automatic Detection of Hate Speech in Text. ACM Comput. Surv. 51, 4, Article 85 (July 2018), 30 pages. https://doi.org/10.1145/3232676
- Founta et al. (2018) Antigoni-Maria Founta, Constantinos Djouvas, Despoina Chatzakou, Ilias Leontiadis, Jeremy Blackburn, Gianluca Stringhini, Athena Vakali, Michael Sirivianos, and Nicolas Kourtellis. 2018. Large Scale Crowdsourcing and Characterization of Twitter Abusive Behavior. In 11th International Conference on Web and Social Media, ICWSM 2018. AAAI Press.
- Gudbjartur Ingi Sigurbergsson ([n.d.]) Leon Derczynski Gudbjartur Ingi Sigurbergsson. [n.d.]. Offensive Language and Hate Speech Detection for Danish. http://www.derczynski.com/papers/danish_hsd.pdf
- kariminf ([n.d.]) kariminf. [n.d.]. Transliteration Library for Non-Latin Languages like Arabic, Japanese. https://github.com/kariminf/lang-trans
- Ousidhoum et al. (2019) Nedjma Ousidhoum, Zizheng Lin, Hongming Zhang, Yangqiu Song, and Dit-Yan Yeung. 2019. Multilingual and Multi-Aspect Hate Speech Analysis. In Proceedings of EMNLP. Association for Computational Linguistics.
- Pereira ([n.d.]) et.al Pereira. [n.d.]. HaterNet a system for detecting and analyzing hate speech in Twitter. https://zenodo.org/record/2592149#.YVSAg55KidY
- Poletto (2021) Basile V. Sanguinetti M. Poletto, F. 2021. Resources and benchmark corpora for hate speech detection: a systematic review.. In Lang Resources and Evaluation 55, 477–523. Association for Computational Linguistics. https://doi.org/10.1007/s10579-020-09502-8
- Research ([n.d.]a) Facebook Research. [n.d.]a. LASER: Language-Agnostic SEntence Representations. https://github.com/facebookresearch/LASER
- Research ([n.d.]b) Facebook Research. [n.d.]b. MUSE: Multilingual Unsupervised and Supervised Embeddings. https://github.com/facebookresearch/MUSE
- Ritesh Kumar ([n.d.]) Akshit Bhatia Tushar Maheshwari Ritesh Kumar, Aishwarya N. Reganti. [n.d.]. Aggression-annotated Corpus of Hindi-English Code-mixed Data. https://arxiv.org/pdf/1803.09402.pdf
- Rosenfeld (2002) Michel Rosenfeld. 2002. Hate speech in constitutional jurisprudence: a comparative analysis. Cardozo L. Rev. 24 (2002), 1523.
- Ross et al. (2016) Björn Ross, Michael Rist, Guillermo Carbonell, Benjamin Cabrera, Nils Kurowsky, and Michael Wojatzki. 2016. Measuring the Reliability of Hate Speech Annotations: The Case of the European Refugee Crisis. In Proceedings of NLP4CMC III: 3rd Workshop on Natural Language Processing for Computer-Mediated Communication (Bochumer Linguistische Arbeitsberichte, Vol. 17), Michael Beißwenger, Michael Wojatzki, and Torsten Zesch (Eds.). Bochum, 6–9.
- Sai Saketh Aluru and Mukherjee ([n.d.]) Punyajoy Saha Sai Saketh Aluru, Binny Mathew and Animesh Mukherjee. [n.d.]. Deep Learning Models for Multilingual Hate Speech Detection.
- Sanguinetti et al. (2018) Manuela Sanguinetti, Fabio Poletto, Cristina Bosco, Viviana Patti, and Marco Stranisci. 2018. An Italian Twitter Corpus of Hate Speech against Immigrants. In Proceedings of the 11th Conference on Language Resources and Evaluation (LREC2018), May 2018, Miyazaki, Japan. 2798–2895. https://github.com/msang/hate-speech-corpus
- tomaarsen ([n.d.]) tomaarsen. [n.d.]. Natural Language Toolkit (NLTK). https://github.com/nltk/nltk
- Uzan and HaCohen-Kerner (2021) Moshe Uzan and Yaakov HaCohen-Kerner. 2021. Detecting Hate Speech Spreaders on Twitter using LSTM and BERT in English and Spanish - Notebook for PAN at CLEF 2021 Keywords. (09 2021).
- vvasuki ([n.d.]) vvasuki. [n.d.]. Indic Transliteration Tools. https://github.com/indic-transliteration/indic_transliteration_py
- Waseem and Hovy (2016) Zeerak Waseem and Dirk Hovy. 2016. Hateful Symbols or Hateful People? Predictive Features for Hate Speech Detection on Twitter. In Proceedings of the NAACL Student Research Workshop. Association for Computational Linguistics, San Diego, California, 88–93. http://www.aclweb.org/anthology/N16-2013
- Çağrı Çöltekin ([n.d.]) Çağrı Çöltekin. [n.d.]. A Corpus of Turkish Offensive Language on Social Media. https://coltekin.github.io/offensive-turkish/troff.pdf