History Encoding Representation Design for Human Intention Inference
Abstract
In this extended abstract, we investigate the design of learning representation for human intention inference. In our designed human intention prediction task, we propose a history encoding representation that is both interpretable and effective for prediction. Through extensive experiments, we show our prediction framework with a history encoding representation design is successful on the human intention prediction problem.
I Introduction and Setup
In this extended abstract, we investigate the selection of history encoding representation for the application of human behavior prediction in a multi-step pick and place task based on supervised learning. Prior works have shown that the reasoning of representations can significantly improve learning-based inference performance [1, 2, 3, 4, 5, 6, 7, 8, 9]. We design a novel and interpretable representation formulation to effectively recognize the scene and encode the history information so as to obtain a fast and accurate human behavior prediction module. The task is designed as follows (overview shown in Fig. 1): A human worker need to pick up two objects A, and B. The worker shall put object A onto either one of the C and E pads, and object B onto pad D. The worker has to perform each pick, place and transport operation one by one, resulting in a sequential operation strategies. We can observe the human performing the task from a third-party-view camera image stream, and the goal of the task is to infer the strategy as soon and accurately as possible.
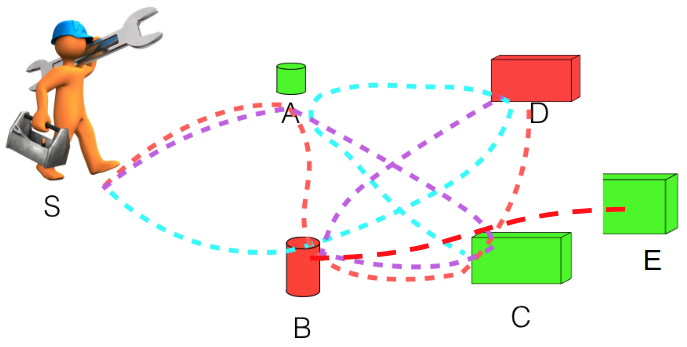
To study the behavior prediction methodology, We collect a large video dataset of a human volunteer performing the task, as shown in Fig. 2. To finish this task, the human worker has 12 strategies in total, Fig. 2 shows one of them. We decompose the whole task into a series of subtasks, such as transporting from one location to another, picking and placing an object. There are in total 22 such sub-tasks, and Fig. 3 and Fig. 4 shows two of them.














II Behavior Prediction Framework and History Encoding Representation
We propose a two stage behavior prediction framework that is shown in Fig. 5. First, the camera image is fed into a VGG convolutional neural network [10] classifier to extract a feature for the current operation. We choose the features to be the sub-task that the human is operating at the current frame, resulting in a 22 dimensional one-hot vector encoding the 22 possible sub-task at the current video frame. We then run a steady state Kalman filter to smooth the feature vectors from the CNN. Then the feature history is encoded into a history encoding representation, which is defined as follows.
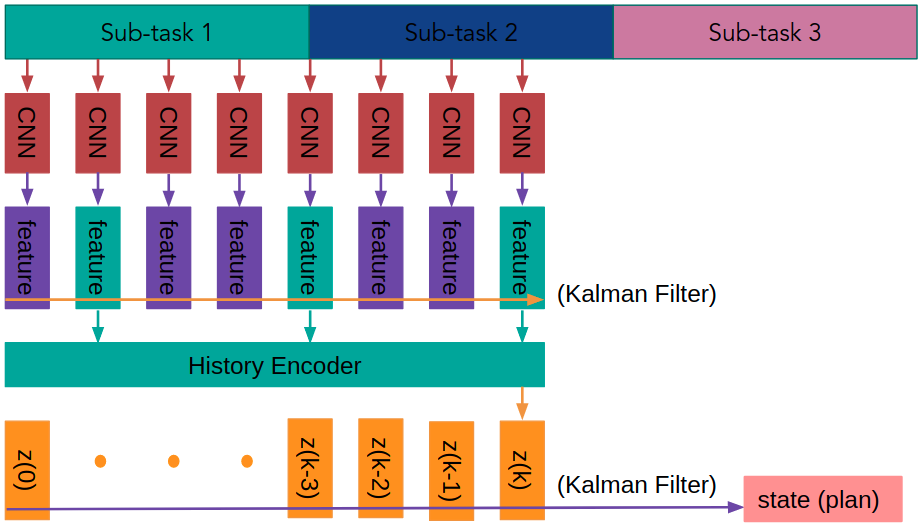
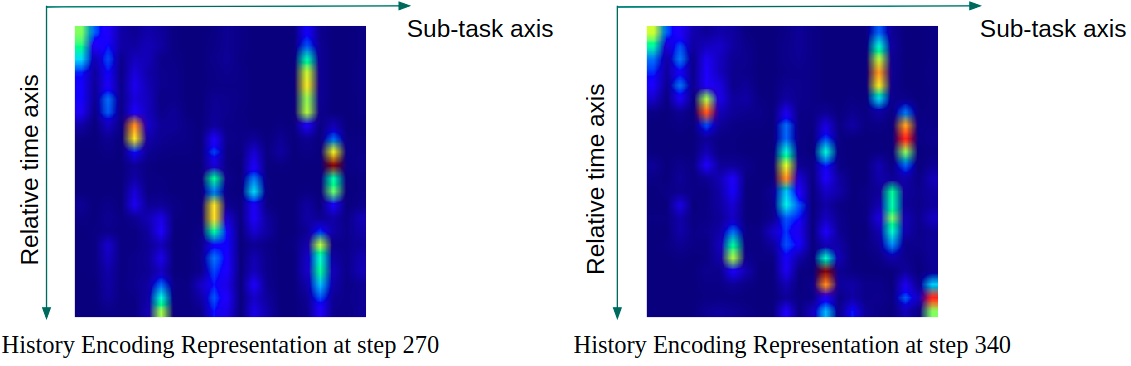
The history encoding representation uniformly (sampling time length can be different) select a fixed number of history features to form the information vector. The fixed number of history features is chosen to be 22, which is the same as the the dimension of the feature vector. Therefore, the history encoding representations can be rendered using 22 by 22 square figures, as shown in Fig. 6. In Fig. 6, the history encoding representations can be interpreted according to a relative time axis and a sub-task axis. Concretely, for each row vector with same relative time, the heat map represents the probability that the human worker is performing one of the sub-tasks at the relative time. Finally, this history encoding representation is fed into a final neural network to produce the strategy that the human is taking with ground truth strategy label supervision. After acquiring a series of estimations, we run a steady state Kalman filter to calculate the posterior state estimate. The initial state of the Kalman filter is assumed to be a discrete uniform distribution over all 12 plans.
III Performance and Discussions
We collect a large dataset of 50987 frames of 256 by 256 rgb images recording a human volunteer performing the task. Sample images can be found in Fig. 2, 3, and 4. We randomly separate the dataset into a training set of 46737 images and 4250 testing images. We finetune a VGG classification network pre-trained on ImageNet [11] (with the first 4 convolutional layers fixed) on the training set (with data augmentation of randomly cropping the images to size of 224 by 224), and evaluated the results on the testing set. We obtain a classification accuracy on the test set of 51% top 1 accuracy, and 75% and 93% top 2 and top 4 accuracy. The history encoding representations shown in Fig. 6 also show clear and contingent sub-task classification performance.
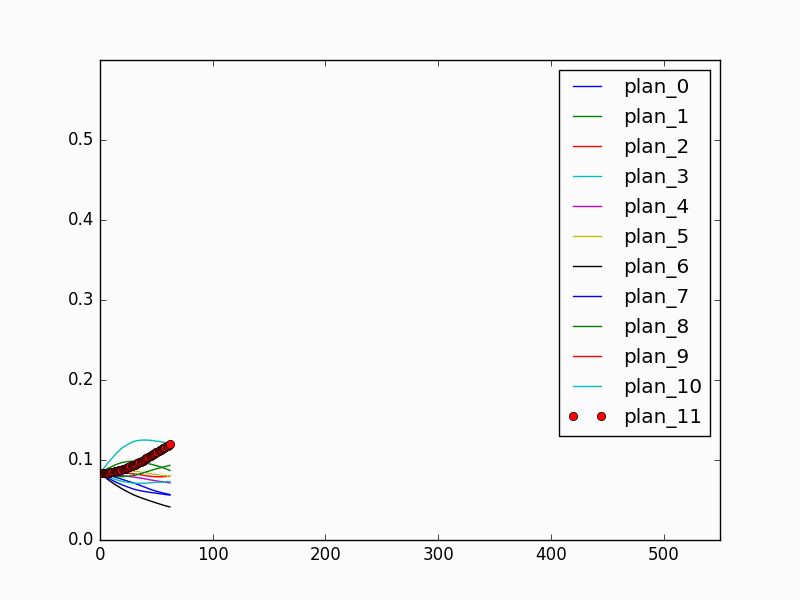
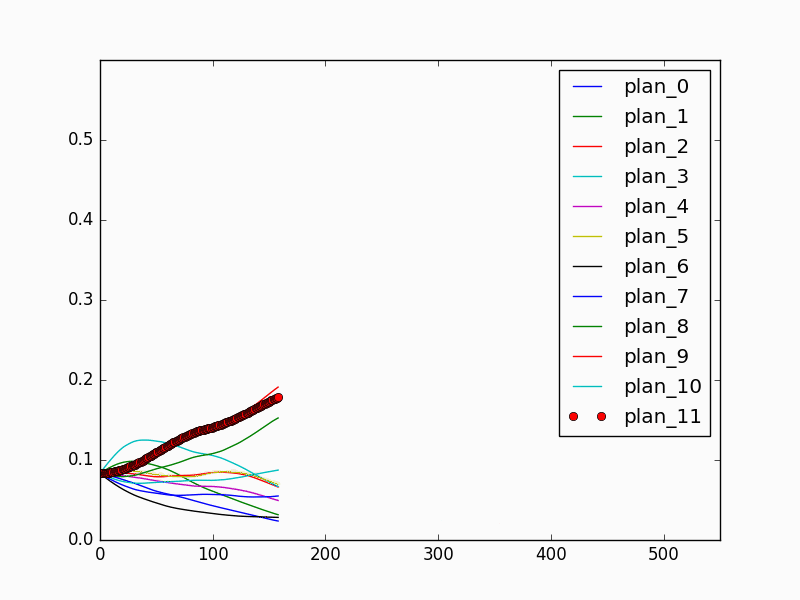
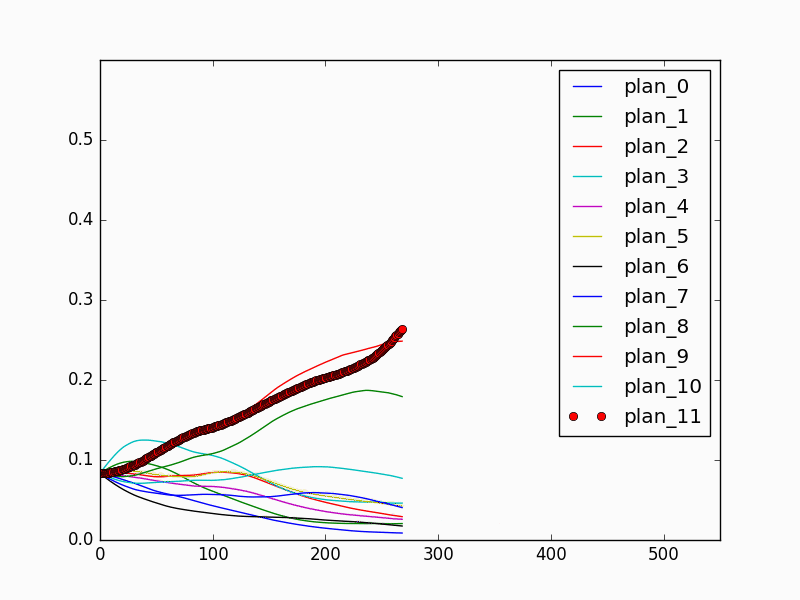
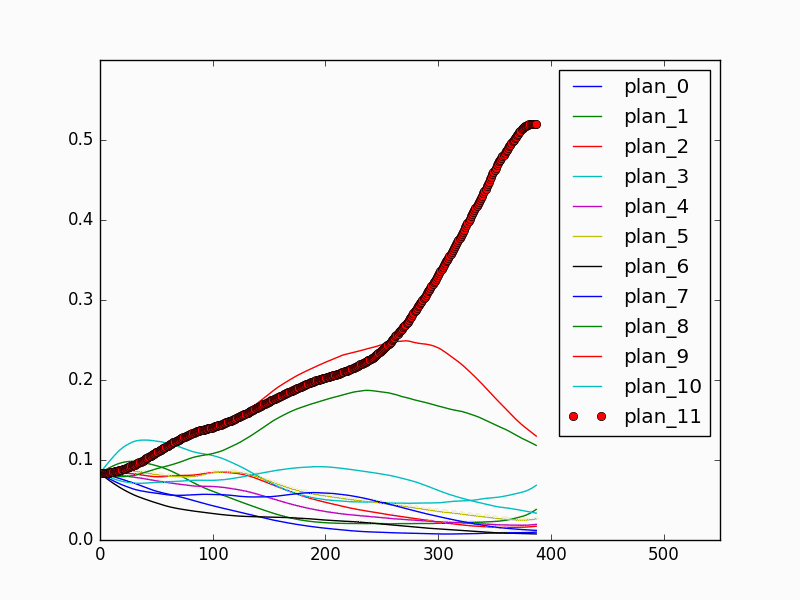
The fully connected network that maps from the history encoding representation to the strategy estimation is trained using 12 episodes (1 for each strategy) with 4250 frames of images, and tested on another 12 episodes (1 for each strategy) with 4047 frames. We result with a 32.4% top 1 classification accuracy and a 85.6% top 5 classification accuracy. The relatively low classification accuracy is due to that in the early stage of the episode, it is not possible to identify the correct strategy. For prediction performance, the model achieves 100% final classification success rate. During online prediction, the model can achieve human-level performance by converging quickly to the correct strategy once enough evidence is observed. Fig 7 and Fig. 8 show the behavior prediction model performance in an online episode. It is shown that in the first half of the episode (Fig 7) when the human volunteer picks the red object and the yellow object, the prediction model cannot determine which object the human is placing first, or which strategy the human is taking. Therefore, the thick red probability curve which corresponds to the correct strategy is similarly as high as the thin red curve, which corresponds to a wrong but indistinguishable strategy. In the second half of the episode (Fig 8), as the human approaches the right white pad and places the red object, the model is able to correctly identify the strategy, and the thick red curve rises above the thin red curve, and finally reaches to far above all other curves. The experiments show that the history encoding representation and the prediction model are able to capture the history information and achieve satisfying prediction performance.




References
- [1] Z. Xu, C. Tang, and M. Tomizuka, “Zero-shot deep reinforcement learning driving policy transfer for autonomous vehicles based on robust control,” in 2018 21st International Conference on Intelligent Transportation Systems (ITSC), pp. 2865–2871, IEEE, 2018.
- [2] C. Tang, Z. Xu, and M. Tomizuka, “Disturbance-observer-based tracking controller for neural network driving policy transfer,” IEEE Transactions on Intelligent Transportation Systems, 2019.
- [3] Z. Xu, H. Chang, and M. Tomizuka, “Cascade attribute learning network,” arXiv preprint arXiv:1711.09142, 2017.
- [4] D. Ho, K. Rao, Z. Xu, E. Jang, M. Khansari, and Y. Bai, “Retinagan: An object-aware approach to sim-to-real transfer,” 2020.
- [5] Z. Xu, H. Chang, C. Tang, C. Liu, and M. Tomizuka, “Toward modularization of neural network autonomous driving policy using parallel attribute networks,” in 2019 IEEE Intelligent Vehicles Symposium (IV), pp. 1400–1407, IEEE, 2019.
- [6] Z. Xu, W. Yu, A. Herzog, W. Lu, C. Fu, M. Tomizuka, Y. Bai, C. K. Liu, and D. Ho, “Cocoi: Contact-aware online context inference for generalizable non-planar pushing,” arXiv preprint arXiv:2011.11270, 2020.
- [7] Z. Xu, J. Chen, and M. Tomizuka, “Guided policy search model-based reinforcement learning for urban autonomous driving,” arXiv preprint arXiv:2005.03076, 2020.
- [8] J. Chen, Z. Xu, and M. Tomizuka, “End-to-end autonomous driving perception with sequential latent representation learning,” arXiv preprint arXiv:2003.12464, 2020.
- [9] H. Chang, Z. Xu, and M. Tomizuka, “Cascade attribute network: Decomposing reinforcement learning control policies using hierarchical neural networks,” arXiv preprint arXiv:2005.04213, 2020.
- [10] K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” arXiv preprint arXiv:1409.1556, 2014.
- [11] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,” in 2009 IEEE conference on computer vision and pattern recognition, pp. 248–255, Ieee, 2009.