Holistic Autonomous Driving Understanding by Bird’s-Eye-View Injected
Multi-Modal Large Models
Abstract
The rise of multimodal large language models (MLLMs) has spurred interest in language-based driving tasks. However, existing research typically focuses on limited tasks and often omits key multi-view and temporal information which is crucial for robust autonomous driving. To bridge these gaps, we introduce NuInstruct, a novel dataset with 91K multi-view video-QA pairs across 17 subtasks, where each task demands holistic information ( e.g., temporal, multi-view, and spatial), significantly elevating the challenge level. To obtain NuInstruct, we propose a novel SQL-based method to generate instruction-response pairs automatically, which is inspired by the driving logical progression of humans. We further present BEV-InMLLM, an end-to-end method for efficiently deriving instruction-aware Bird’s-Eye-View (BEV) features, language-aligned for large language models. BEV-InMLLM integrates multi-view, spatial awareness, and temporal semantics to enhance MLLMs’ capabilities on NuInstruct tasks. Moreover, our proposed BEV injection module is a plug-and-play method for existing MLLMs. Our experiments on NuInstruct demonstrate that BEV-InMLLM significantly outperforms existing MLLMs, e.g. improvement on various tasks. We plan to release our NuInstruct for future research development.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/12d4a686-a473-48cd-a153-603eb4418e95/x1.png)
Tasks Information Dataset Perception Prediction Risk P w/ R Multi-view Temporal Multi-object Distance Position Road Scale BDD-X [19] ✗ ✗ ✗ ✔ ✗ ✔ ✗ ✗ ✗ ✗ K Talk2Car [9] ✔ ✗ ✗ ✗ ✗ ✔ ✗ ✗ ✗ ✗ K DRAMA [33] ✔ ✗ ✔ ✗ ✗ ✔ ✗ ✗ ✗ ✗ K DRAMA-ROLISP [11] ✔ ✗ ✔ ✔ ✗ ✔ ✗ ✗ ✗ ✗ K DriveGPT4 [48] ✔ ✗ ✔ ✗ ✗ ✔ ✔ ✗ ✗ ✔ K Talk2BEV [10] ✔ ✔ ✗ ✔ ✗ ✗ ✔ ✔ ✔ ✗ K Nuscenes-QA [41] ✔ ✗ ✗ ✗ ✔ ✗ ✔ ✔ ✔ ✗ K NuPrompt [47] ✔ ✗ ✗ ✗ ✔ ✔ ✔ ✗ ✗ ✗ K NuInstruct (Ours) ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔ K
1 Introduction
Witnessing the success of multimodal large language models (MLLMs) [50, 7, 5, 27, 39, 49, 25, 15], language-based driving is one of the trends in various autonomous driving tasks [33, 11, 48, 10]. For instance, some researchers ground the instruction prompts to single or multiple objects for 2D or 3D object detection and tracking [9, 45, 46, 47, 51]. Nuscenes-QA [41] offers numerous question-answer pairs for multi-view perception tasks in driving scenes. Some advancements, e.g., DRAMA [33] and HiLM-D [11], generating text descriptions for localizing risk objects. Except for perception tasks, DriveGPT4 [48] and GPT-Driver [34] leverage LLMs for interpreting vehicle actions and planning, respectively. Talk2BEV [10] formulate BEV into a JSON file and input it into ChatGPT [35] to conduct autonomous driving understanding.
Although remarkable progress has been achieved, current language-based driving research still exhibits two main shortcomings as shown in Table 1. (i) Partial tasks. Existing benchmarks only cover a subset of autonomous driving tasks. However, autonomous driving comprises a series of interdependent tasks, each indispensable to the system’s overall functionality [2]. For instance, it is challenging to make reliable predictions when lacking accurate perception. (ii) Incomplete information. The information utilized by existing methods for executing these tasks is often incomplete. Specifically, existing datasets [11, 48] usually consist of single-view-based images, without considering temporal and multi-view information. However, safe driving decisions require a holistic understanding of the environment, e.g., only concerning on the front may neglect an overtaking vehicle in the left [43].
To address the above two problems, we first create NuInstruct, a comprehensive language-driving dataset with K multi-view video-QA pairs across subtasks (Fig. 4). Our dataset presents more complex tasks than existing benchmarks, demanding extensive information like multi-view, temporal, distance and so on, as shown in Fig. 1 and Table 4. To obtain NuInstruct, we introduce a SQL-based method for the automated generation of instruction-response pairs. This method transforms instruction-response creation into a process utilizing structured query languages (SQLs) [8] from a database. Our rationale for the tasks and their corresponding SQL design follows the logical progression of human drivers: ❶ initially observing surrounding objects (Perception), ❷ predicting their behavior (Prediction), ❸ assessing potential threats such as overtaking vehicles (Risk), and ❹ ultimately using the previous information to plan a safe route with justified reasoning (Planning with Reasoning). Finally, to ensure the quality of our NuInstruct, we conduct human or GPT-4 [35] verification to eliminate the erroneous instruction-response pairs. Compared with other data generation methods, e.g., ChatGPT-based [35] or human-based [10], this structured design ensures the generation of instruction-response pairs is both reliable and scalable.
To address the challenging tasks of the proposed NuInstruct, we further extend the current MLLMs to receive more holistic information. Existing MLLMs are constrained by their design for single-view inputs. To overcome this, we provide a Multi-View MLLM (MV-MLLM) with a specialized Multi-view Q-Former capable of processing multi-view video inputs. Although MV-MLLM allows for the capture of Multi-view temporal appearance features, they often miss out on critical information (e.g., distance, spatial) as well as suffer from occlusions. BEV’s feature, a formulation of multi-view inputs, has been widely adopted in traditional autonomous driving models since they can clearly represent object locations and scales (essential for distance/spatial-sensitive tasks) [17, 3, 4]. Leveraging this, we integrate BEV into MV-MLLM to create BEV-InMLLM, enhancing perception and decision-making in autonomous driving by capturing a comprehensive information spectrum. Inspired by this, we integrate BEV into MV-MLLM, obtaining BEV-InMLLM to capture a full spectrum of information for reliable perception and decision-making in autonomous driving. BEV-InMLLM uses a BEV injection module to effectively obtain BEV features aligned with language features for LLMs. This approach is more resource-efficient than training a BEV extractor from scratch with visual-language data like CLIP [42, 21]. Notably, our BEV injection module serves as a plug-and-play solution for existing MLLM
Overall, our contributions can be summarized as follows:
-
•
We curate NuInstruct, a new language-driving dataset with K multi-view video-instruction-response pairs across 17 subtasks, using a novel SQL-based method. NuInstruct is currently the most holistic language-driving dataset, to our knowledge. We plan to release our NuInstruct for future research development.
-
•
We propose BEV-InMLMM to integrate instruction-aware BEV features with existing MLLMs, enhancing them with a full suite of information, including temporal, multi-view, and spatial details. Notably, our BEV injection module serves as a plug-and-play solution for existing MLLM.
-
•
Our experiments with NuInstruct demonstrate our proposed methods significantly boost MLLM performance in various tasks, notably outperforming state-of-the-art by 9% on various tasks. Ablation studies show that MV-MLLM enhances multi-view tasks, and BEV-InMLLM is vital for most tasks, emphasizing the importance of spatial information.
2 Related Work
Language-driving datasets and models. CityScapes-Ref [45], Talk2Car [9] perform language-grounding tasks. ReferKITTI [46] and NuPrompt [41] leverage temporal data for 2D or 3D referring object detection and tracking. Nuscenes-QA [41] offers numerous question-answer pairs for multi-view perception tasks in driving scenes. Some advancements, e.g., DRAMA [33] and HiLM-D [11], generating text descriptions for localizing risk objects. Beyond perception, DriveGPT4 [48] and GPT-Driver [34] leverage LLMs for interpreting vehicle actions and planning, respectively. Talk2BEV [10] formulate BEV into a JSON file and input it into ChatGPT [35] to conduct autonomous driving understanding. Despite these advancements, a common limitation persists: most datasets and models address only part of the autonomous driving tasks with incomplete information. As shown in Table 1 and Fig. 1, in this paper, we propose a challenging dataset containing various tasks that require holistic information, i.e., temporal, multi-view, spatial and so on, to address.
Multimodal Large Language Models. Leveraging the capabilities of pre-trained LLMs like LLaMA [44] and Vicuna [6], Multimodal LLMs (MLLMs) are expanding their application spectrum, handling inputs from images [39, 23, 24, 40, 13, 50, 1, 5], videos [49, 25, 22], and 3D data [15, 18] to medical data [20]. In the domain of autonomous driving, DriveGPT4 [48] and Talk2BEV [10] have integrated MLLMs for comprehension. However, these approaches have limitations; DriveGPT4 is confined to single-view inputs, and Talk2BEV lacks temporal dynamics and an end-to-end framework. Addressing these gaps, our BEV-InMLLM model assimilates comprehensive temporal, multi-view, and spatial data, for reliable decisions.
3 NuInstruct
In this section, we will illustrate the details of our constructed NuInstruct dataset. In Section 3.1, we will discuss the process of data generation. We will then go deeper and provide statistics on our dataset in Section 3.2. Finally, Section 3.3 shows the evaluation metrics to evaluate the performance of different models on the new NuInstruct.
3.1 Instruction Data Generation
Our NuInstruct is built on one of the most popular datasets, i.e., Nuscenes [2]. There are six view records for samples of Nuscenes, i.e., Front, Front Left, Front Right, Back Right, Back Left, and Back. These views have some areas of overlap with one another. In NuScenes, the collected data is annotated with a frequency of Hz, and each annotated frame is referred to as a keyframe with annotations.
In our research, we propose an SQL-based approach for the automated generation of four types of instruction-follow data, namely: Perception, Prediction, Risk, and Planning with Reasoning. This methodology aligns with the sequential decision-making stages of human drivers, categorized as follows: 1. Perception: The initial stage of recognizing surrounding entities. 2. Prediction: Forecasting the future actions of these entities. 3. Risk: Identifying imminent dangers, such as vehicles executing overtaking manoeuvres. 4. Planning with Reasoning: Developing a safe travel plan grounded in logical analysis.
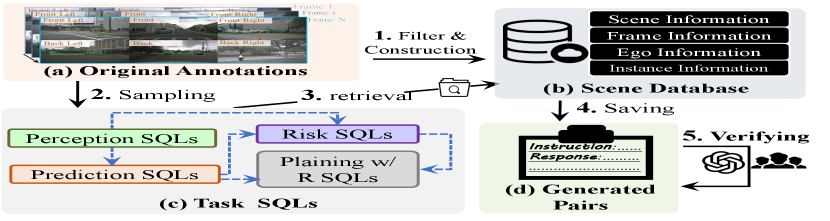
The detailed process is shown in Fig. 2. Specifically, 1). The filter & construction step leverages the (a) original annotations to generate the scene information database (see Fig. 2 (b)). 2). The sampling step first samples three keyframes from the original dataset. Then, as shown in Fig. 2 (c)), we construct a series of pre-defined task SQLs. Each task SQL consists of several subtasks, each of them consisting of a subtask function and an instruction prompt. 3). The retrieval step uses the instruction prompt and the task SQL to retrieve the corresponding response from the scene database. 4). The saving step saves all instruction-response pairs (see Fig. 2 (d)). 5). The verifying step employs either human analysis or LLM-based methods (e.g., GPT-4 [35]) to eliminate erroneous instruction-response pairs, thereby guaranteeing the quality of NuInstruct. Our task SQL design is logically sequenced, and based on the inherent relational flow of autonomous driving tasks, i.e., ‘Perception Prediction, (Perception, Prediction) Risk, (Risk, Prediction) Planing with Reasoning’, where indicates the SQL is derived from the SQL (blue dashed arrows in Fig. 2 (c)).
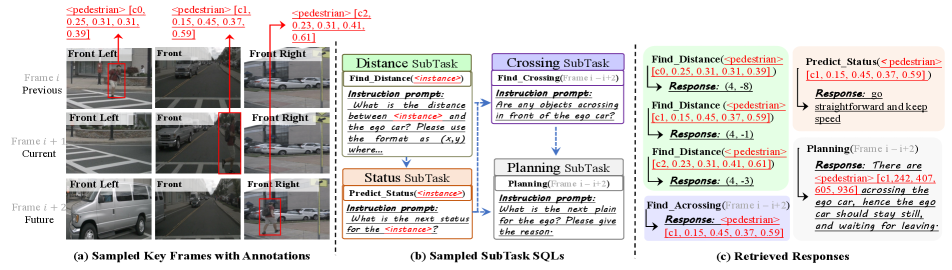
We show a more detailed example for Step 2 and Step 3 in Fig. 3. Specifically, three keyframes (i.e., from frame to frame ) with annotations are randomly sampled from the original dataset, and we only select one instance, i.e., the pedestrian (box) for clarity (Fig. 3 (a)). In this case, we choose distance, status, crossing, and planning subtask SQLs from the perception, prediction, risk, and planning with reasoning task SQLs, respectively (shown in Fig. 3 (b)). The status subtask is based on the distance task, since the next status (e.g., speed, direction) for the instance is computed based on the distances of previous, current, and future frames. Each subtask SQL consists of two parts, i.e., the subtask function and the instruction prompt. For example, the distance subtask SQL has Find_Distance(instance) function and the instruction prompt is ”What is the distance between instance and the ego car? Please use the format as (x,y) where..”, where instance is the input. Finally, as shown in Fig. 3 (c), we use the instance information or frame information as the input for different subtask functions to retrieve the response from the scene database. Compared with other data generation methods, e.g., ChatGPT-based [48] or human-based [10], this structured design ensures the generation of instruction-response pairs is both reliable and scalable.
We only describe the overview of the data generation in this section. Please refer to the supplementary material for more details about the scene information database, the task SQLs, and the retrieval process.
3.2 Data Statistics
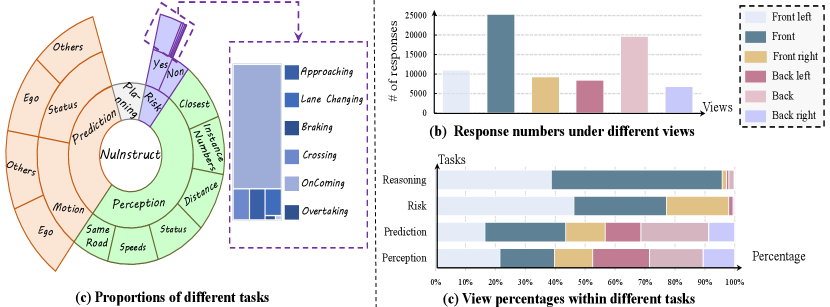
To construct our NuInstruct, we sampled a total of keyframes from videos within the NuScenes dataset [2]. Subsequent filter yields unique instances, which collectively appear times across all keyframes. This culminates in an average of approximately instances per keyframe. By employing our SQL-based method (Section 3.1), we generated a total of instruction-response pairs, encompassing four primary tasks—namely, Perception, Prediction, Risk, and Planning with Reasoning. These tasks are further delineated into sub-tasks. The quantities of task categories are statistically presented in Fig. 4 (a).
Compared with other single-view benchmarks, our dataset covers multi-view information. Hence, we also conduct a statistical analysis of the relations of different views and constructed instruction-response pairs. Fig. 4 (b) shows the distribution of the numbers of the responses based on the views, i.e., for a given view, we record how many responses are derived from information from the view. Through such statistics, we find that to answer the instructions, the system needed to look at multiple views, instead of just a single one. In Fig. 4 (c), for each task, the proportions of responses obtained based on different views are calculated. We find two observations: (i) in the case of perception and prediction tasks, the distribution across views is relatively even, showing that our data generation method produces balanced multi-view information; (ii) When it comes to reasoning and risk tasks, the responses predominantly draw on information from the front, left-front, and right-front views. This is reasonable since drivers normally base their ahead or sides to decide the next actions, seldom needing to look behind.
Task SubTask Metrics Perception Distance, Speeds, Instance Number MAE Closest, Status, Same Road Accuracy Prediction Motion Ego, Motion Others MAE Status Ego, Status Others Accuracy Risk All MAP Reasoning All BLEU [37]
3.3 Evaluation Protocols
Evaluation Metrics. Our NuInstruct consists of diverse tasks, making it hard to evaluate the different tasks using one metric. We summarize the evaluation metrics for different tasks in Table 2. For tasks evaluated by MAE, we use the regular expression [12] to obtain values. More detailed computations for different metrics please refer to the supplementary material.
Data Split. Our NuInstruct contains a total of videos from NuScenes [2]. We split the all videos into training/validation/testing sets (7.5:1.5:1.5). We train all models in the training set and select the model with the best performance in the validation set to report its results on the test set.
4 Method
In Section. 4.1, we first give a preliminary for our framework, i.e., input, output, task definition and notations. Then, in Section 4.2, we provide Multi-view MLLM (MV-MLLM), a baseline that extends current multimodal large language models (MLLMs) for processing multi-view video inputs. Finally, in Section 4.3, we propose BEV-InMLLM, which injects the bird’s-eye-view (BEV) representations into current MLLMs for better panorama understanding for NuInstruct.
4.1 Preliminaries
Different from current MLLMs, the visual inputs for our model are the multi-view videos , where is the total number of camera views, , is the -th frame in and is the total number of frames. Instead of the predefined several tasks, we give a specific language instruction, we use a unified model to obtain its corresponding language response, as shown in Fig. 1. For clarity in the following, we use and to denote the language instruction tokens and the response tokens respectively, which are generated by the language tokenizer [44]. / and / are numbers of tokens and dimensions for the instruction/response.
4.2 Multi-View MLLM
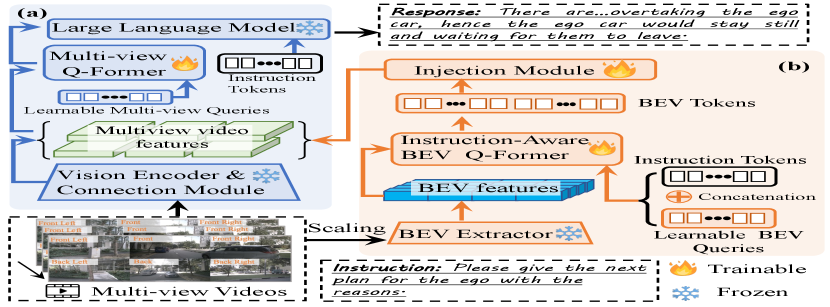
Existing MLLMs [50, 23, 7, 25] generally consist of three parts: a vision encoder to receive the visual input; a connection module (e.g., Q-Former [24]) to transfer the visual representations to the visual tokens aligned with the language; a large language model (LLM) to receive visual and language instruction tokens to generate the response. Since they can only receive single-view input, we propose a baseline model named Multi-view MLLM (MV-MLLM) to enable the current MLLMs to process the multi-view videos, as shown in Fig. 5 (a). Specifically, for a video from a specific view, i.e., , we feed it into the vision encoder followed by the connect module to obtain the visual tokens, which can be formulated as:
| (1) |
where and are the numbers of the visual tokens and the dimensions respectively. Then, we introduce a multi-view Q-Former (similar to BLIP-2 [23]) to capture the MV visual semantics from . We concatenate along the view dimension to obtain . The input to the multi-view Q-Former contains a set of learnable multi-view queries , which interact with through the cross attention, formulated as follows:
| (2) |
The output then goes through a linear projection (omitted in Fig. 5), and is fed to the LLM. Note that in our MV-MLLM, only the MV Q-Former is trainable and other parameters are frozen to fully retain the knowledge of the pre-trained models.
4.3 BEV-Injected MLLM
The BEV approach has become pivotal in autonomous driving for its precise depiction of object positioning, essential for tasks like perception and planning [32, 26]. Integrating BEV into our MV-MLLM offers enhanced visual-spatial analysis for autonomous driving. While BEV can be constructed from the multi-view features by physical transformations such as LSS [38], similar to NuScenes-QA [41], the plain of ViTs in current MLLMs limits their perception capabilities [36]. Replacing the VIT with BEV-specific backbones, e.g., ResNet [14] or Swin Transformer [28], diminishes visual-language alignment [11]. Furthermore, the limited input resolutions generate small feature maps, which are hard to scale up to the high-resolution BEV representation.
To address the above problems, we propose the BEV-injected MLLM (BEV-InMLLM), which uses a BEV injection module (BEV-In) to obtain the BEV information aligned with LLMs in a data-efficient and resource-light way. As shown in Fig. 5 (b), we obtain the high-quality BEV features from the pre-trained BEV extractor [38, 17], where , and denote the width, height and dimensions. The following are two key components of BEV-In, i.e., an instruction-aware BEV Q-Former and an injection module.
Instruction-aware BEV Q-Former. We introduce the instruction-aware BEV Q-Former to ignore the redundant and irrelevant to the given instructions from . The input queries for the instruction-aware BEV Q-Former blend two parts: the instruction tokens for instruction-related aspects, and the learnable BEV queries for extracting the useful information pertinent to the instruction from . The process of the instruction-aware BEV Q-Former is defined as:
| (3) |
where indicates the concatenation, and indicates and the BEV queries and their the numbers, are the instruction-aware BEV tokens.
Injection module. Our injection module fuses multi-view features with instruction-aware BEV tokens through cross-attention:
| (4) |
where the enhanced contains both (i) temporal multi-view cues for scene comprehension and (ii) spatial-aware BEV information for precise perception and planning tasks. We keep our BEV-In module efficient by making only two components trainable: the BEV Q-Former and the injection module, while the BEV feature extractor remains frozen to maintain feature quality.
Perception Prediction Risk Method Dis Sped # Ins Clos Sta SameR Mot Sta App LaneC Onco Cro Over Brak Planning with Reasoning BLIP-2∗ [23] 29.3 5.6 4.4 18.5 15.9 23.8 8.7 38.7 6.1 10.6 15.4 16.7 3.7 21.5 24.9 MV-MLLM 26.8 5.3 3.9 28.2 17.7 31.5 6.8 43.6 15.2 19.3 18.4 22.7 9.6 22.7 30.1 BEV-InMLLM 23.3 3.6 3.2 33.6 18.9 31.6 3.8 45.2 16.8 21.0 19.7 23.9 10.5 27.5 33.3 MiniGPT-4∗ [50] 30.2 6.2 6.3 20.2 17.3 24.2 8.7 39.6 7.8 12.5 16.9 18.7 4.8 21.8 26.3 MV-MLLM 28.6 4.7 4.1 27.5 18.5 30.7 7.2 44.2 15.5 18.9 19.1 23.3 8.2 23.1 32.3 BEV-InMLLM 23.6 3.1 3.8 32.9 19.2 31.5 4.2 46.5 17.3 20.5 21.5 24.5 9.4 26.8 35.6 Video-LLama [49] 29.9 6.5 5.4 22.3 16.7 20.9 9.3 39.3 6.2 10.9 16.2 18.4 4.1 21.3 25.3 MV-MLLM 28.9 6.2 2.4 27.9 19.6 30.9 9.3 44.3 16.5 18.7 19.9 23.0 6.5 26.6 31.4 BEV-InMLLM 24.5 3.5 4.2 31.6 19.0 34.6 4.1 44.7 17.7 22.5 21.4 26.1 8.7 27.9 35.2
5 Experiments
Implementation and training details. We experiment on three base MLLMs, i.e.We evaluated our MV-MLLM and BEV-InMLLM on three base MLLMs: BLIP2 [24], Video-LLama [49], and MiniGPT-4 [50]. To adapt BLIP2 and MiniGPT-4, which are image-centric, for video input, we used the spatiotemporal adapter (ST-Adapter)[36], following[11], while preserving their pre-trained parameters. We initialized all MLLMs with their official pre-trained weights 111https://github.com/salesforce/LAVIS/;https://github.com/Vision-CAIR/MiniGPT-4; https://github.com/DAMO-NLP-SG/Video-LLaMA, freezing these during training and only training the parameters of ST-Adapters and our additional modules (MV Q-Former, BEV Q-Former, and injection module). We choose LSS [38] and BEVFormer [26] as our BEV extractors, and and are both set to . , , are set to , and respectively. The dimensions, i.e., and are both set to , the same as the dimension of the same as EVA_CLIP hidden feature dim used by BLIP-2. The input is resized and cropped to the spatial size of , and each video is uniformly sampled frames. We use AdamW [31] as the optimizer and cosine annealing scheduler [30] as the learning rate scheduler with an initial learning rate of -. We train all models in a total of epochs.
5.1 State-of-the-art Comparison
We select three advanced MLLMs, i.e., BLIP-2 [24], MiniGPT-4 [50] and Video-LLama [49] as our base models. For each MLLM, we apply our proposed modules to obtain MV-MLLM and BEV-InMLLM. All models are finetuned in the same setting. We report our results on NuInstruct test set in Table 3. To conserve space, we aggregate the reporting of two subtasks, ‘motion ego’ and ‘motion others’. A similar approach is adopted for ‘status ego’ and ‘status others’.
From Table 3, we observe that equipped with our proposed modules, there is a significant increase in the evaluation metrics on all tasks, demonstrating its effectiveness. More specifically, the integration of temporal and multi-view information (MV-MLLM) substantially improves risk and planning tasks by and , respectively. Furthermore, injecting BEV into MV-MLLM, i.e., BEV-InMLLM, benefits tasks sensitive to distance and position, e.g., perception and prediction.
Task Temporal Multi-view Spatial Holistic SubTask Sped, Mot, Sta # Ins, SameR Dis, Mot, Sta, Clos Risk, Planning
Temporal Multi-view Spatial Model Whole (a) Full 3.7 32.8 3.8 31.5 13.9 32.9 22.2 (b) w/o Video 7.4 28.5 4.2 30.4 14.2 30.8 21.0 -3.7 -4.3 -0.4 -1.1 -0.3 -1.1 -1.2 (c) w/o MV 5.2 31.2 6.0 28.3 14.4 32.5 21.6 -1.5 -1.6 -2.2 -3.2 -0.5 -0.4 -0.6 (d) w/o BEV 6.0 31.4 4.1 30.7 18.0 30.0 20.1 -2.3 -1.4 -0.3 -0.8 -4.1 -2.9 -2.1 (e) Base 10.3 25.8 6.7 22.7 20.8 27.6 12.4 -6.6 -7.0 -2.9 -8.8 -6.9 -5.3 -9.8
| Spatial | Whole | |
| w/o | 15.3 | 20.1 |
| w/ | 13.9 | 21.5 |
| Spatial | Whole | |
| 16 | 14.5 | 21.0 |
| 32 | 13.9 | 21.5 |
| 64 | 13.9 | 21.6 |
| feature | Spatial | Whole |
| 15.1 | 20.8 | |
| 13.9 | 21.5 |
5.2 Ablation Study
In this section, we conduct experiments to evaluate the effect of different proposed modules and different input information. Here, we use MiniGPT-4 [50] as our baseline model. To better analyze the impact of each module on autonomous driving tasks, we reclassify the sub-tasks into four main tasks based on their dependency on different types of information. These are categorized as temporal-related (temporal), multi-view-related (multi-view), spatial-related (Spatial), and holistic-related tasks, as shown in Table 4. ‘Temporal’ indicates subtasks related to temporal cues, e.g., the vehicle’s status is determined based on its positions at various times, and so do others. Note that some subtasks may be classified into different tasks, e.g., the status task is in both temporal and spatial tasks. We will report the results of different models under the reclassified tasks in the following.
5.2.1 Effect of different proposed modules
In our study, we explore different modules to capture different information for autonomous driving tasks: ST-Adapter accepts videos for temporal, MV-Q Former for multi-view, and BEV Injection module for location, distance, and spatial information in BEV features. We use BEV-InMLLM as a full model including comprehensive information types, then sequentially remove each module to derive the following distinct models: (a) The full model, i.e., BEV-InMLLM introduced in Section 4.3. (b) BEV-InMLLM without temporal cues, i.e., the input is image. (c) BEV-InMLLM without multi-view information, i.e., only single-view input. (d) BEV-InMLLM without BEV information, i.e., without BEV injection module. (e) The baseline model, i.e., MiniGPT-4 [50].
We report the results of different models in Table 5. From the table, we observe the following findings: (i) Compared with (a) and (b), without temporal information, the performance of tasks highly dependent on temporal cues would degrade clearly, proving the importance of video input. We can also observe a similar phenomenon when comparing the results with (a) and (c). (ii) Information contained in BEV is very important for most of autonomous driving tasks, since it clearly presents the surroundings of the ego vehicle, thus aiding the model in making informed decisions.
5.2.2 Analysis of BEV Injection Module
We ablate our BEV injection module (BEV-In) (Fig. 5 (b)) using the default settings in Table 6 (see caption). Several intriguing properties are observed.
BEV extractor.
We compare the performance of different BEV extractors in Table LABEL:tab:bevextractor. Our results show that more strong extractor, e.g., BEVDet [17], outperforms the weak one LSS [38]. Furthermore, BEVFusion [29] uses RGB and lidar modality for best performance. Here, we use RGB images for efficiency.
Intruction tokens in BEV-In.
Table LABEL:tab:instructiontoken studies the effect of in Eq. 3. ‘w/o’ indicate only using to interact with . Results show that using instruction tokens can capture more related BEV features, thus improving the performance by for both spatial tasks and holistic tasks.
BEV query number
. In Table LABEL:tab:querynumber, we study the influence of BEV query numbers, i.e., in (Eq. 3). As the number increases, the performance would be improved, e.g., on the spatial performance with arise from to . Considering setting to only brings a small improvement, we use as the default settings for computation efficiency.
Injection feature
. The key design of our BEV-InMLLM is to inject instruction-aware BEV features ( i.e., in Eq. 4) to the MV-MLLM. In Table LABEL:tab:injectfeat, we compare the performance of different features to inject with the . Specifically, the multi-view visual semantics (Section 4.2) and the output of multi-view Q-Former (Eq. 2). We find injecting into achieves better, improvement over on the holistic tasks. The reason is that is the filtered visual tokens, losing much spatial information.
6 Conclusion
In this study, we investigate language-based driving for autonomous drivingtasks. We introduce NuInstruct, featuring 91K multi-view video-instruction-response pairs across 17 subtasks, created via a novel SQL-based method. Our proposed BEV-InMLMM integrates instruction-aware BEV features into MLLMs, enhancing temporal, multi-view, and spatial detail processing. BEV-InMLMM, as a plug-and-play enhancement, boosts MLLM performance on autonomous drivingtasks. Our empirical results on NuInstruct confirm our method’s efficacy.
Limitations. The current dataset lacks traffic light information and tasks related to 3D object detection, which we plan to address in future work.
References
- Alayrac et al. [2022] Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning. Advances in Neural Information Processing Systems, 35:23716–23736, 2022.
- Caesar et al. [2020] Holger Caesar, Varun Bankiti, Alex H Lang, Sourabh Vora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom. nuscenes: A multimodal dataset for autonomous driving. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11621–11631, 2020.
- Chen et al. [2022] Chaoqi Chen, Jiongcheng Li, Hong-Yu Zhou, Xiaoguang Han, Yue Huang, Xinghao Ding, and Yizhou Yu. Relation matters: foreground-aware graph-based relational reasoning for domain adaptive object detection. IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(3):3677–3694, 2022.
- Chen et al. [2023a] Chaoqi Chen, Luyao Tang, Yue Huang, Xiaoguang Han, and Yizhou Yu. Coda: Generalizing to open and unseen domains with compaction and disambiguation. In Thirty-seventh Conference on Neural Information Processing Systems, 2023a.
- Chen et al. [2023b] Keqin Chen, Zhao Zhang, Weili Zeng, Richong Zhang, Feng Zhu, and Rui Zhao. Shikra: Unleashing multimodal llm’s referential dialogue magic. arXiv preprint arXiv:2306.15195, 2023b.
- Chiang et al. [2023] Wei-Lin Chiang, Zhuohan Li, Zi Lin, Ying Sheng, Zhanghao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yonghao Zhuang, Joseph E Gonzalez, et al. Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023), 2023.
- Dai et al. [2023] Wenliang Dai, Junnan Li, Dongxu Li, AnthonyMeng Huat, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, and Steven Hoi. Instructblip: Towards general-purpose vision-language models with instruction tuning. 2023.
- Date [1989] Chris J Date. A Guide to the SQL Standard. Addison-Wesley Longman Publishing Co., Inc., 1989.
- Deruyttere et al. [2019] Thierry Deruyttere, Simon Vandenhende, Dusan Grujicic, Luc Van Gool, and Marie Francine Moens. Talk2car: Taking control of your self-driving car. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 2088–2098, 2019.
- Dewangan et al. [2023] Vikrant Dewangan, Tushar Choudhary, Shivam Chandhok, Shubham Priyadarshan, Anushka Jain, Arun K Singh, Siddharth Srivastava, Krishna Murthy Jatavallabhula, and K Madhava Krishna. Talk2bev: Language-enhanced bird’s-eye view maps for autonomous driving. arXiv preprint arXiv:2310.02251, 2023.
- Ding et al. [2023] Xinpeng Ding, Jianhua Han, Hang Xu, Wei Zhang, and Xiaomeng Li. Hilm-d: Towards high-resolution understanding in multimodal large language models for autonomous driving. arXiv preprint arXiv:2309.05186, 2023.
- Friedl [2006] Jeffrey EF Friedl. Mastering regular expressions. ” O’Reilly Media, Inc.”, 2006.
- Gao et al. [2023] Jiahui Gao, Renjie Pi, Jipeng Zhang, Jiacheng Ye, Wanjun Zhong, Yufei Wang, Lanqing Hong, Jianhua Han, Hang Xu, Zhenguo Li, and Lingpeng Kong. G-llava: Solving geometric problem with multi-modal large language model, 2023.
- He et al. [2016] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
- Hong et al. [2023] Yining Hong, Haoyu Zhen, Peihao Chen, Shuhong Zheng, Yilun Du, Zhenfang Chen, and Chuang Gan. 3d-llm: Injecting the 3d world into large language models. arXiv preprint arXiv:2307.12981, 2023.
- Hu et al. [2023] Yihan Hu, Jiazhi Yang, Li Chen, Keyu Li, Chonghao Sima, Xizhou Zhu, Siqi Chai, Senyao Du, Tianwei Lin, Wenhai Wang, et al. Planning-oriented autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 17853–17862, 2023.
- Huang et al. [2021] Junjie Huang, Guan Huang, Zheng Zhu, Yun Ye, and Dalong Du. Bevdet: High-performance multi-camera 3d object detection in bird-eye-view. arXiv preprint arXiv:2112.11790, 2021.
- Huang et al. [2023] Tianyu Huang, Bowen Dong, Yunhan Yang, Xiaoshui Huang, Rynson WH Lau, Wanli Ouyang, and Wangmeng Zuo. Clip2point: Transfer clip to point cloud classification with image-depth pre-training. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 22157–22167, 2023.
- Kim et al. [2018] Jinkyu Kim, Anna Rohrbach, Trevor Darrell, John Canny, and Zeynep Akata. Textual explanations for self-driving vehicles. In Proceedings of the European conference on computer vision (ECCV), pages 563–578, 2018.
- Li et al. [2023a] Chunyuan Li, Cliff Wong, Sheng Zhang, Naoto Usuyama, Haotian Liu, Jianwei Yang, Tristan Naumann, Hoifung Poon, and Jianfeng Gao. Llava-med: Training a large language-and-vision assistant for biomedicine in one day. arXiv preprint arXiv:2306.00890, 2023a.
- Li et al. [2023b] Guozhang Li, De Cheng, Xinpeng Ding, Nannan Wang, Xiaoyu Wang, and Xinbo Gao. Boosting weakly-supervised temporal action localization with text information. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), page 106, 2023b.
- Li et al. [2023c] Guozhang Li, Xinpeng Ding, De Cheng, Jie Li, Nannan Wang, and Xinbo Gao. Etc: Temporal boundary expand then clarify for weakly supervised video grounding with multimodal large language model. arXiv preprint arXiv:2312.02483, 2023c.
- Li et al. [2022a] Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. In International Conference on Machine Learning, pages 12888–12900. PMLR, 2022a.
- Li et al. [2023d] Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. arXiv preprint arXiv:2301.12597, 2023d.
- Li et al. [2023e] KunChang Li, Yinan He, Yi Wang, Yizhuo Li, Wenhai Wang, Ping Luo, Yali Wang, Limin Wang, and Yu Qiao. Videochat: Chat-centric video understanding. arXiv preprint arXiv:2305.06355, 2023e.
- Li et al. [2022b] Zhiqi Li, Wenhai Wang, Hongyang Li, Enze Xie, Chonghao Sima, Tong Lu, Yu Qiao, and Jifeng Dai. Bevformer: Learning bird’s-eye-view representation from multi-camera images via spatiotemporal transformers. In European conference on computer vision, pages 1–18. Springer, 2022b.
- Liu et al. [2023a] Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. arXiv preprint arXiv:2304.08485, 2023a.
- Liu et al. [2021] Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF international conference on computer vision, pages 10012–10022, 2021.
- Liu et al. [2023b] Zhijian Liu, Haotian Tang, Alexander Amini, Xinyu Yang, Huizi Mao, Daniela L Rus, and Song Han. Bevfusion: Multi-task multi-sensor fusion with unified bird’s-eye view representation. In 2023 IEEE International Conference on Robotics and Automation (ICRA), pages 2774–2781. IEEE, 2023b.
- Loshchilov and Hutter [2016] Ilya Loshchilov and Frank Hutter. Sgdr: Stochastic gradient descent with warm restarts. arXiv preprint arXiv:1608.03983, 2016.
- Loshchilov and Hutter [2017] Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101, 2017.
- Ma et al. [2022] Yuexin Ma, Tai Wang, Xuyang Bai, Huitong Yang, Yuenan Hou, Yaming Wang, Yu Qiao, Ruigang Yang, Dinesh Manocha, and Xinge Zhu. Vision-centric bev perception: A survey. arXiv preprint arXiv:2208.02797, 2022.
- Malla et al. [2023] Srikanth Malla, Chiho Choi, Isht Dwivedi, Joon Hee Choi, and Jiachen Li. Drama: Joint risk localization and captioning in driving. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 1043–1052, 2023.
- Mao et al. [2023] Jiageng Mao, Yuxi Qian, Hang Zhao, and Yue Wang. Gpt-driver: Learning to drive with gpt. arXiv preprint arXiv:2310.01415, 2023.
- OpenAI [2023] OpenAI OpenAI. Gpt-4 technical report. 2023.
- Pan et al. [2022] Junting Pan, Ziyi Lin, Xiatian Zhu, Jing Shao, and Hongsheng Li ST-Adapter. Parameter-efficient image-to-video transfer learning for action recognition. Preprint at https://arxiv. org/abs/2206.13559, 2022.
- Papineni et al. [2002] Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. Bleu: a method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics, pages 311–318, 2002.
- Philion and Fidler [2020] Jonah Philion and Sanja Fidler. Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XIV 16, pages 194–210. Springer, 2020.
- Pi et al. [2023a] Renjie Pi, Jiahui Gao, Shizhe Diao, Rui Pan, Hanze Dong, Jipeng Zhang, Lewei Yao, Jianhua Han, Hang Xu, Lingpeng Kong, and Tong Zhang. Detgpt: Detect what you need via reasoning, 2023a.
- Pi et al. [2023b] Renjie Pi, Lewei Yao, Jiahui Gao, Jipeng Zhang, and Tong Zhang. Perceptiongpt: Effectively fusing visual perception into llm, 2023b.
- Qian et al. [2023] Tianwen Qian, Jingjing Chen, Linhai Zhuo, Yang Jiao, and Yu-Gang Jiang. Nuscenes-qa: A multi-modal visual question answering benchmark for autonomous driving scenario. arXiv preprint arXiv:2305.14836, 2023.
- Radford et al. [2021] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748–8763. PMLR, 2021.
- Simons-Morton and Ehsani [2016] Bruce Simons-Morton and Johnathon P. Ehsani. Learning to drive safely: Reasonable expectations and future directions for the learner period. Safety, 2(4), 2016.
- Touvron et al. [2023] Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023.
- Vasudevan et al. [2018] ArunBalajee Vasudevan, Dengxin Dai, and LucVan Gool. Object referring in videos with language and human gaze. Cornell University - arXiv,Cornell University - arXiv, 2018.
- Wu et al. [2023a] Dongming Wu, Wencheng Han, Tiancai Wang, Xingping Dong, Xiangyu Zhang, and Jianbing Shen. Referring multi-object tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14633–14642, 2023a.
- Wu et al. [2023b] Dongming Wu, Wencheng Han, Tiancai Wang, Yingfei Liu, Xiangyu Zhang, and Jianbing Shen. Language prompt for autonomous driving. arXiv preprint arXiv:2309.04379, 2023b.
- Xu et al. [2023] Zhenhua Xu, Yujia Zhang, Enze Xie, Zhen Zhao, Yong Guo, Kenneth KY Wong, Zhenguo Li, and Hengshuang Zhao. Drivegpt4: Interpretable end-to-end autonomous driving via large language model. arXiv preprint arXiv:2310.01412, 2023.
- Zhang et al. [2023] Hang Zhang, Xin Li, Lidong Bing, and at al. Video-llama: An instruction-tuned audio-visual language model for video understanding. arXiv preprint arXiv:2306.02858, 2023.
- Zhu et al. [2023] Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mohamed Elhoseiny. Minigpt-4: Enhancing vision-language understanding with advanced large language models. arXiv preprint arXiv:2304.10592, 2023.
- Zou et al. [2023] Jian Zou, Tianyu Huang, Guanglei Yang, Zhenhua Guo, and Wangmeng Zuo. Unim2ae: Multi-modal masked autoencoders with unified 3d representation for 3d perception in autonomous driving. arXiv preprint arXiv:2308.10421, 2023.
Supplementary Material
7 More details about NuInstruct
| Field | Scene ID | Frame ID List |
| Type | string | string list |
| Field | Frame ID | Ego Information ID List | Instance Information ID List |
| Type | string token | string list | string list |
| Field | Information ID | Pose | Rotation | Velocity | Road Information | Camera Information |
| Type | string | float list | float list | float | dictionary | dictionary |
| Field | Information ID | Instance ID | Category | Attribute | Global-T | Global-R | Local-T | Local-R | Velocity | Road Information | Camera Pos |
| Type | string | string | string | string | float list | float list | float list | float list | float | dictionary | dictionary |
.
.
In this section, we give more information about our NuInstruct. In Section 7.1, we show the detailed information of the scene database. Then, we give the definition of Algorithms 1-17 for all task SQLs in Section 7.2. Finally, the computation for different metrics is presented in Section 7.3.
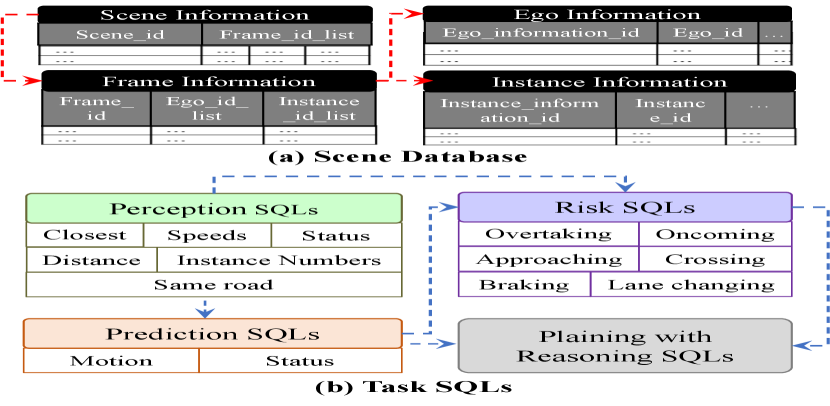
7.1 Scene Database
Based on the information of the ego car and important instances, we construct a scene database as shown in Fig. 6 (a). The scene information database includes four tables:
-
•
Scene Information: consists of the scene dictionary list. The key for each dictionary is the scene ID, which is the unique identifier of the scene in NuScenes [2]. The value is a frame ID list, consisting of IDs of frames in the current scene. The details for each frame are referred to the Frame Information table.
-
•
Frame Information: consists of the frame dictionary list. The key for each dictionary is the unique ID for a specific frame. The value contains the details for the frame, including the ego-car-information ID and instance-information ID list. The details for the information of the ego car and instances in the frame are referred to the Ego Information and Instance Information tables respectively.
-
•
Ego Information: consists of the ego-car information dictionary list. The key for each dictionary is the unique ID for the information of the ego-car in one specific frame. The values include the information: e.g., ego car pose, ego car rotation, velocity, road information, camera information, and so on.
-
•
Instance Information: consists of the instance information dictionary list. The key for each dictionary is the unique ID for the information of one instance in one specific frame. The values include the information: e.g., instance ID (the unique identifier for one instance, e.g., a car, across different frames in one scene), instance global and local translations and rotations, velocity, road information, etc.
The relations between different tables in the database are shown in Fig. 6 (b) (red dashed arrows), i.e., Scene Information and Frame Information, Frame Information and Ego Information, Frame Information and Instance Information are all one-to-many mappings. The detailed fields and their corresponding types for each table are shown in Table 7(d).
7.2 Task SQLs
As shown in Fig. 6 (b), we define four types of SQL sets (i.e., perception, prediction, risk, and planning with reasoning), which are used for generating different types of instruction-response pairs. Each type of task SQL set consists of several subtask SQLs. For example, the perception SQL set contains six subtask SQLs, e.g., Closest focuses on finding the objects closest to the ego car, and the other subtasks are similar. Note that some high-level SQLs may be inherited from low-level ones following the relational flow of autonomous driving tasks [16], as shown in blue dashed arrows in Fig. 6 (b). For instance, the prediction SQLs are based on the perception ones, the risk SQLs are based on both prediction and perception SQLs, and the planning with reasoning SQL is inherited from prediction and risk ones.
Each subtask SQL consists of a subtask function and an instruction prompt. We illustrate the detailed algorithms for subtask SQLs in Algorithm 1-17. In these algorithms, ‘query(, *args)’ indicates querying the information from the table with the arguments *args. After obtaining the results from the task SQLs, we transfer them into the language descriptions by template or GPT-4 [35]. Regard the planning with reasoning task as the example, after obtaining the queried results , where , and are the risk instance dictionary, the future speed and the future motion of the ego car. Then, the response is formulated as ‘There are the ego car. Hence the ego car should be and move to .’
7.3 Evaluation Details
In this section, we show the computation details for different evaluation metrics, i.e., MAE, accuracy, MAP, and BLEU.
MAE.
For tasks measured by MAE, we first use the regular expression to obtain the values from the predicted response, e.g., . Then the MAE is computed by , where indicates the absolute value.
Accuracy.
There are three kinds of subtasks measured by the accuracy, i.e., Closest, Status, and Same Road. Since the predictions of the Closest subtask are the instance categories, we formulate the Closest subtask to the classification tasks. Similarly, for the Status subtask, there are totally two different statuses ( i.e., moving and stationary) for the ego car, while other instances have different statuses for different kinds of objects, e.g., for vehicles, there are moving, stopped and parked; for pedestrians, there are moving, standing and sitting. Hence, the Status subtask can also be regarded as the classification task. Finally, the responses to the Same Road task are ‘yes’ or ‘no’, which is a binary classification task.
MAP.
We evaluate all subtasks in the risk task by the mean average precision (MAP). Since risk tasks aim to find the objects that may have a risk influence on the ego car driving. Hence, we can transfer them to the object detection tasks, which are generally evaluated by MAP.
BLEU.
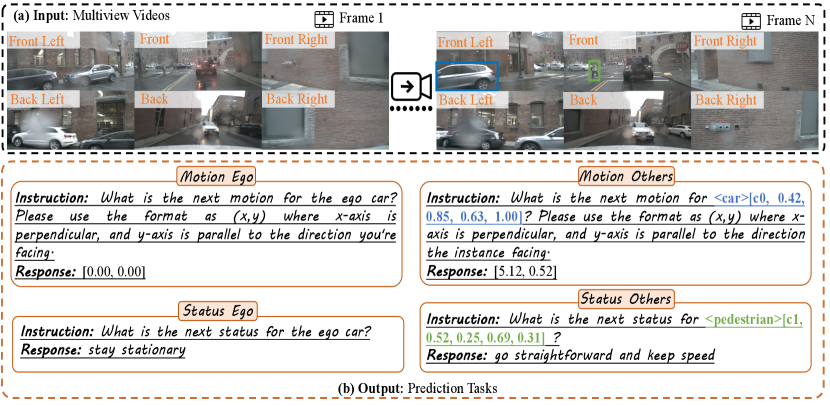
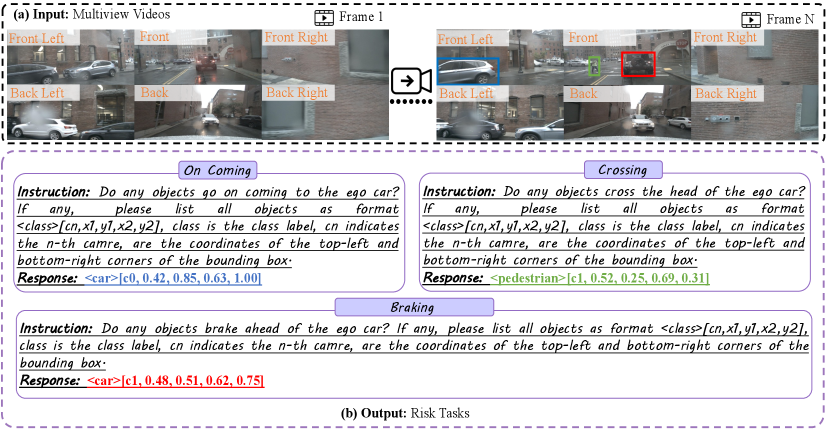
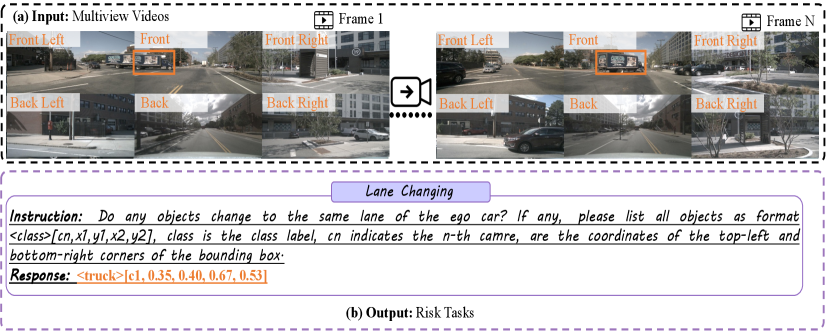
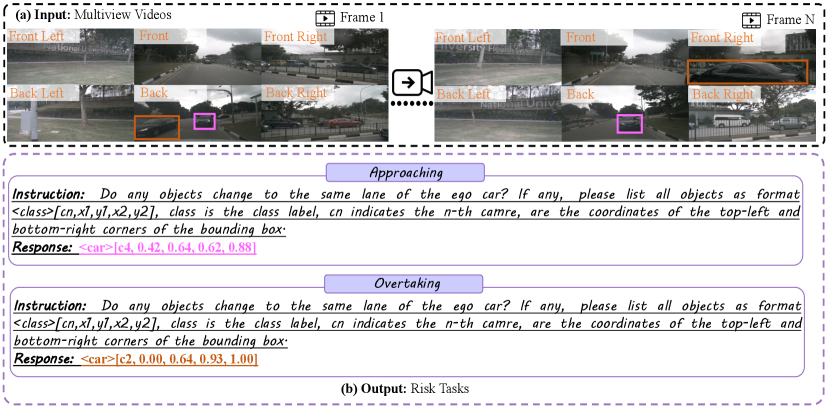
8 More Qualitative Examples
We show more visualization examples for all subtasks in Fig. 7 (perception tasks), Fig. 8 (Prediction tasks), Fig. 9-11 (risk tasks) and Fig. 12 (planning with reasoning tasks).