How Diffusion Models Learn to Factorize and Compose
Abstract
Diffusion models are capable of generating photo-realistic images that combine elements which likely do not appear together in the training set, demonstrating the ability to compositionally generalize. Nonetheless, the precise mechanism of compositionality and how it is acquired through training remains elusive. Inspired by cognitive neuroscientific approaches, we consider a highly reduced setting to examine whether and when diffusion models learn semantically meaningful and factorized representations of composable features. We performed extensive controlled experiments on conditional Denoising Diffusion Probabilistic Models (DDPMs) trained to generate various forms of 2D Gaussian bump images. We found that the models learn factorized but not fully continuous manifold representations for encoding continuous features of variation underlying the data. With such representations, models demonstrate superior feature compositionality but limited ability to interpolate over unseen values of a given feature. Our experimental results further demonstrate that diffusion models can attain compositionality with few compositional examples, suggesting a more efficient way to train DDPMs. Finally, we connect manifold formation in diffusion models to percolation theory in physics, offering insight into the sudden onset of factorized representation learning. Our thorough toy experiments thus contribute a deeper understanding of how diffusion models capture compositional structure in data.
1 Introduction
Large-scale text-to-image generative models can produce photo-realistic synthetic images that combine elements in a novel fashion (compositional generalization). Nonetheless, the ability of models to do so, as well as their failure modes, are not well-studied systematically in large diffusion models due to the size of the model and the complex and high-dimensional nature of their training datasets. Factorization and compositional generalization have been theoretically and empirically investigated in many deep generative models before Zhao et al. (2018); Higgins et al. (2017); Burgess et al. (2018); Montero et al. (2021); Xu et al. (2022); Okawa et al. (2023); Wiedemer et al. (2023); Bowers et al. (2016); Chaabouni et al. (2020). However, these studies have not reached a unanimous conclusion on whether factorized representations learned in the intermediate layers of the model promote compositional generalization in the model performance. Specifically, several studies Xu et al. (2022); Montero et al. (2021); Chaabouni et al. (2020) have found little correlation between factorization and compositionality, contrary to others that suggest that factorization promotes compositionality Bengio et al. (2013); Higgins et al. (2017); Burgess et al. (2018); Duan et al. (2020); Bowers et al. (2016). As a result, there is no consensus on the exact mechanism of compositionality and how models gain the ability to compositionally generalize. However, these previous studies involve data with a complex mix of discrete and continuously varying features, making it difficult to explicitly analyze the model’s learned representations beyond the disentanglement score, and thereby hindering a deeper understanding of factorization and compositionality.
Despite the remarkable compositional abilities demonstrated by diffusion-based text-to-image generative models, explicit exploration of factorization and compositional generalization of diffusion models has been relatively limited. In a recent empirical study of toy diffusion models, Okawa et. al. Okawa et al. (2023) shows that diffusion models learn to compositionally generalize multiplicatively. They too, however, did not focus on the mechanistic aspect of compositional generalization within the model or analyze the representations learned by the models. To investigate factorization and compositionality in diffusion models, we conduct extensive experiments on conditional denoising diffusion probablistic models (DDPMs) Ho et al. (2020) trained with various 2D Gaussian datasets to characterize their learned representations and generalization performance.111A preliminary version of this work was presented at the ME-FoMo and BGPT workshops at ICLR 2024 Liang et al. (2024). Drawing inspiration from traditional cognitive psychology and neuroscience studies on animals and humans, we design straightforward cognitive tasks for models to perform while analyzing both their generation output (“behavior”) and their intermediate layer representations (“neural activities”). Specifically, we evaluate the diffusion model’s ability to generalize by generating 2D Gaussian bumps centered at specified coordinates on a finite canvas. We deliberately chose a low-dimensional dataset and a simplified experimental setup to enable a clear analysis of how the model’s representation factorization relates to its generalization capabilities.
Conceptually, the models can adopt different parameterizations of the coordinates for the Gaussian bumps, each with varying implications for data efficiency. Consider a -dimensional dataset created from the composition of multiple independently varying 1-dimensional (1D) latent features (e.g. a factorizable data distribution ). Hypothetically, a model may learn either a joint representation of all dimensions or learn independent 1D representations . In the former case, if there were states per dimension, the model would need to see approximately samples during training. If the model could somehow recognize the independence of the different factors, as few as training samples might suffice. We term the former a coupled representation, while the latter is a factorized one. Factorized representations could be far more sample efficient to learn, potentially permitting better generalization, and are more robust and adaptable for downstream applications. In biological neural networks, features of independent variation are typically represented in a factorized manner. For instance, primates encode allocentric pose information in a factorized fashion, leveraging grid cells for two-dimensional location and head direction cells for orientation Lindsey and Issa (2023); Moser EI (2008); Hafting et al. (2005b); Chaudhuri et al. (2019); Taube et al. (1990); Taube (2007); Hafting et al. (2005a); Stensola et al. (2012); Burak and Fiete (2009). Further, spatial information about objects in the environment is factorized into place cells and other spatial coding cells Moser et al. (2015); Moser EI (2008).
Across three related studies, we investigate how diffusion models learn to encode independent features of the dataset, how that informs the model’s ability to generalize out-of-training-distribution in terms of composition and interpolation, and how variations in the training data could impact such generalization. To be precise, here we define compositionality as the ability to generate novel combinations of feature values that are not observed during training (e.g., given , output ). We define interpolation as the ability to linearly combine different feature values (e.g., output given and ). The failure of the model to perform the designed tasks could be due to its inability to handle composition, interpolation, or a combination of both. We train the model on 2D Gaussian data and, in some cases, explicitly include 1D Gaussian stripes with specified positions that can be combined to form the desired 2D Gaussian. We then pose the following questions:
-
1.
Do diffusion models learn factorized representations? If so, when do these emerge over training?
-
2.
Do the trained models learn to generalize beyond the training distribution, and what kind of training data is sufficient for this generalization?
-
3.
Does the inclusion of a few explicitly factorized examples in training (e.g. the 1D Gaussian data) improve sample efficiency and generalization?
Contributions. In three experiments, we find that:
-
1.
Given factorized, continuous conditional inputs, diffusion models learn “hyper-factorized” representations that are orthogonal not only for independent features but also different values of the same feature (Section 3.1).
-
2.
Models compose well but interpolate poorly. Models can compositionally generalize when they observe the full extent of each independent latent feature along with a few compositional examples (Section 3.2).
-
3.
Models trained on datasets containing isolated factors of variation require an exceptionally small number of compositional examples to compositionally generalize, showing remarkable data efficiency (Section 3.2).
-
4.
Formation of a factorized representation for each continuous dimension of variation requires a threshold amount of correlated data, related to percolation theory in physics (Section 3.3).
Our results suggest that diffusion models can learn factorized, though not fully continuous, representations of continuous features with independent variations. These models demonstrate exceptional compositionality but have limited interpolation ability, even with sufficient training and data. Our analysis offers deeper diagnostic insights into the mechanism of factorization and compositionality of diffusion models from a microscopic representation perspective. Moreover, our insights on the data efficiency of training with isolated factors of variation with few compositional examples suggest the possibility of far more data efficient methods of training diffusion models.
2 Methods
Dataset. We generate pixel grayscale images. By default, we set unless otherwise specified. Each image contains one 2D Gaussian bump (“blob”), the multiplication of a vertical and a horizontal 1D Gaussian stripe, or one 2D Gaussian addition, the sum of a vertical and a horizontal 1D Gaussian stripe (“sum of stripes (SOS’s)”), at various locations. The brightness of the pixel at position for a 2D Gaussian blob centered at with standard deviation is given as and as for a 2D Gaussian SOS with the normalized range of to be . Each image is generated with a ground truth label of , which continuously vary within unless otherwise specified. In our convention of notation, we label the top left corner of the image as while the bottom right corner of the image as . Sample images of 2D Gaussian bump and SOS centered at with are shown in Fig. 1.
A single dataset of these images consist of the enumeration of all possible Gaussians tiling the whole canvas at increment in the -direction and in the -direction. A larger or means a sparser tiling of the image space and fewer data while a smaller or result in more data with denser tiling of the total image space. Moreover, each 2D Gaussian have independent spread in the and direction given by and , with a larger spread leading to more spatial overlap of neighboring Gaussians and a smaller spread less overlap. By parameterically tuning the increments and and the spread and , we can generate datasets of various sparsities and overlaps. We provide a more detailed analysis of the various attributes of the data based on these parameters in Appendix A.5. For the majority of the experimental results we show in Sec. 3, we have chosen to fix and unless otherwise specified. A default dataset of contains 102400 images.
Models & Evaluations. We train a conditional DDPM (Ho et al., 2020; Chen et al., 2021; Saharia et al., 2023) with a standard UNet architecture as shown in Appendix Fig. 7. For each image in the training dataset, we provide an explicit ground truth label as an input to the network. For reference, we investigate the internal representation learned by the model using the output of layer 4 as labeled in Fig. 7. Since each dataset has inherently two latent dimensions, and , we use dimension reduction tools such as PCA or UMAP McInnes and Healy (2018) to reduce the internal representation of the model to a 2D/3D embedding for the ease of visualization and analysis. We defer the details of model architecture, dimension reduction, and experimentation to Appendix A.1 and A.2. Briefly, we assess the performance of the model based on the accuracy of its generated images at correctly displaying the center location of the 2D Gaussian. Further details on the precise definition of the accuracy metric can be found in Appendix A.3.
3 Results
3.1 Models learn factorized but not fully continuous representations
In this section, we aim to understand the factorization of the model’s learned representation via explicit inspection of its topology and geometry. Given a conditional DDPM trained on the 2D Gaussian bump dataset described above, we first investigate whether the model learns a coupled or factorized representation. Naïvely, a 2D Gaussian dataset with two independent features of variation, and , has a 2D plane-like latent representation. Unfortunately, simply inspecting the learned representation would not allow us to easily differentiate between a coupled versus a factorized representation since the Cartesian product of two lines is topologically and geometrically equivalent to a plane . To overcome this issue, we perform a simple modification to the Gaussian dataset. We impose periodic boundary conditions in the image space to connect the left-right and top-bottom boundaries of the image such that the latent representation of the dataset forms a torus. Mathematically, a torus is defined by the Cartesian product of two circles . A Clifford Torus is an example of a factorized representation of the torus, with each circle independently embedded in , resulting in a 4-dimensional object. However, the most efficient representation in terms of extrinsic dimensionality is the regular torus , which is embedded in , albeit unfactorized. Various 2D projections of the 3D torus and the Clifford (4D) torus are shown in Fig. 2(a). Due to geometric differences between the Clifford and the 3D torus, we can now distinguish whether the model learns a factorized representation. If the model were to represent and independently with two ring manifolds, we expect to see a Clifford torus in the neural activations, rather than a different geometry such as the 3D torus.
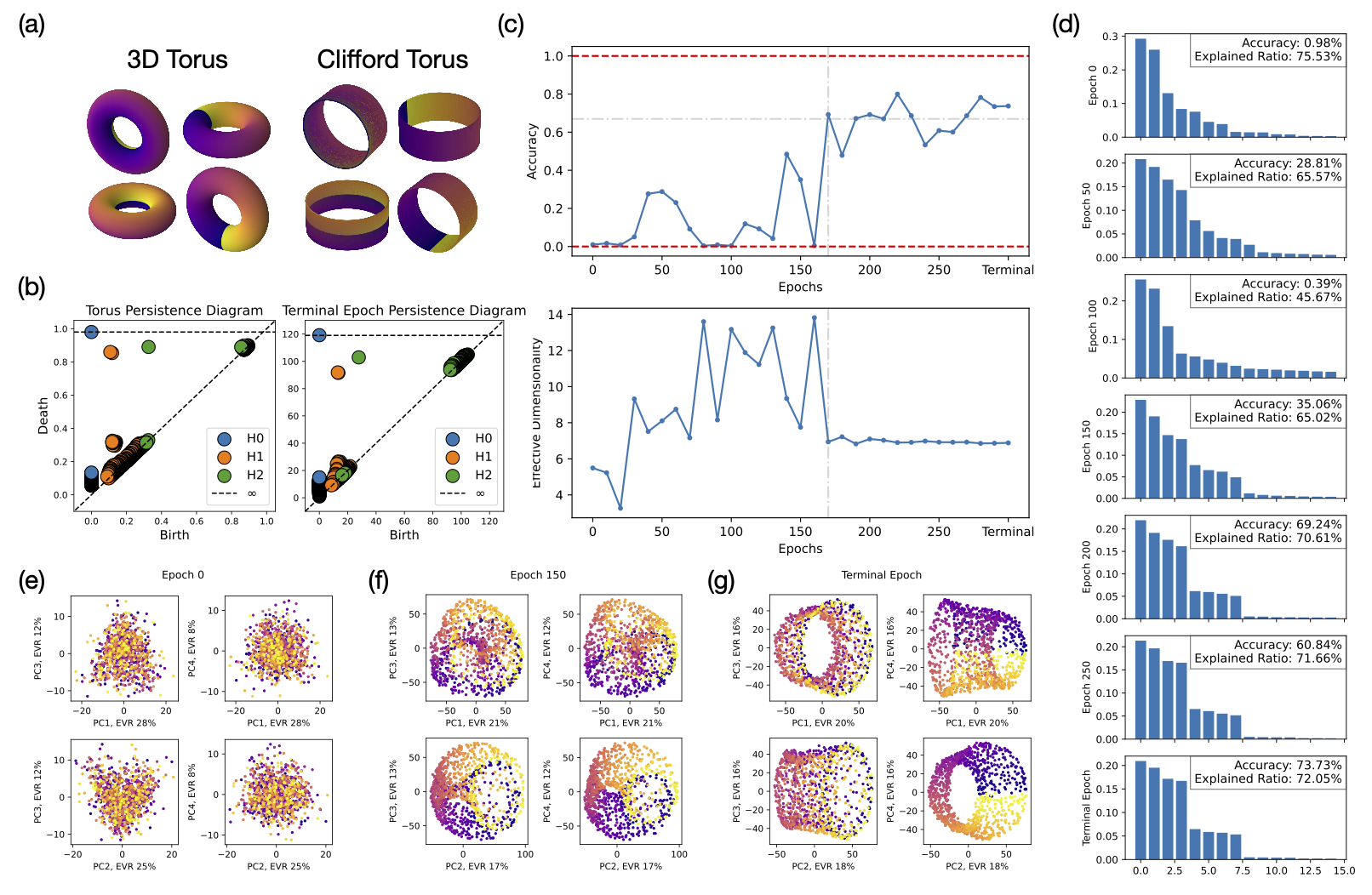
To apply the geometry tests for differentiating between the 3D and the Clifford torus, we first need to confirm that the model indeed learns a torus representation of the dataset by computing the topological features of the learned representation via persistent homology. In Fig. 2(b), we compare the persistence diagrams of a standard torus (left) with the final learned representation of the model (right). Both diagrams exhibit the similar topological features, rank-1 group, rank-2 group (with overlapping orange points on top in both diagrams), and rank-1 group, signaling that the model indeed learns a torus representation.
We then investigate when this torus representation emerges during training. In Fig. 2(c), we show the model’s performance as measured by the accuracy of its generated images (top) and the corresponding effective dimension (bottom) of the learned representations across training, as measured by the participation ratio ( given by , where is the eigenvalue of the -th principal component Gao et al. (2017)). Intuitively, the participation ratio counts the dominant eigen-components, providing a measure of the effective dimension of the geometric object of interest. A detailed inspection of the effective dimension of the learned representations over the training duration informs us of whether and how the model arrives at a factorized, 4D representation. We see in Fig. 2(c) that as training progresses, the model’s internal representation first undergoes a dimension increase then a decrease, eventually converging to around 7 dimensions after 200 epochs. While the dimensionality converged to a higher dimension than 4, the top 4 eigenvectors became notably more prominent as the training converges, as indicated in the eigenspectra in Fig. 2(d). This signals that a 4D, rather than 3D, torus representation is eventually learned. Various PCA projections of the learned representations along the training process are shown in Fig. 2(g)-(i), where the projections in the last epoch resembles those of the Clifford torus shown in (a).
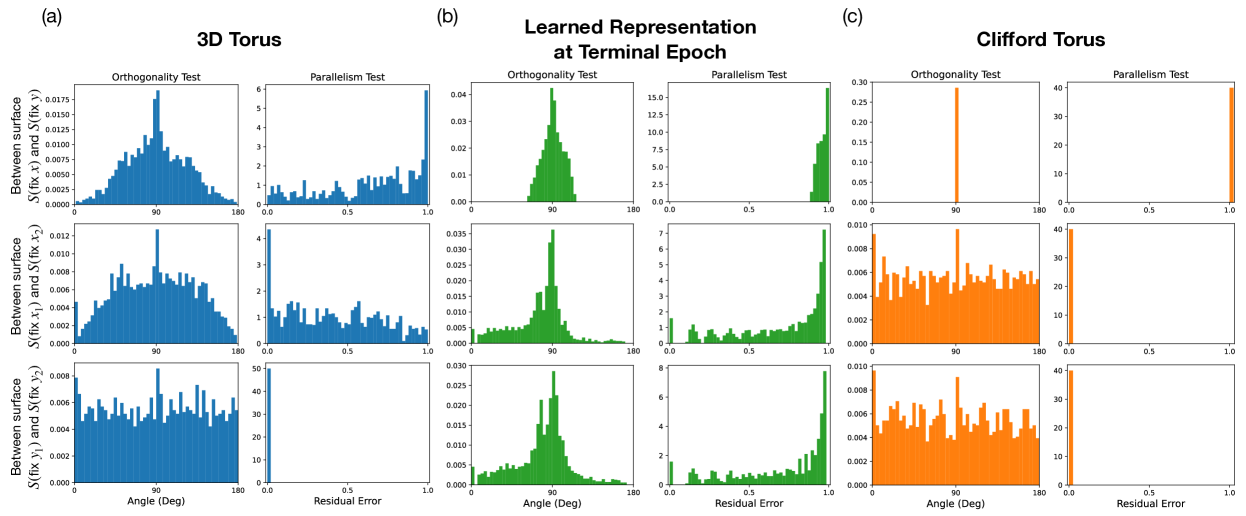
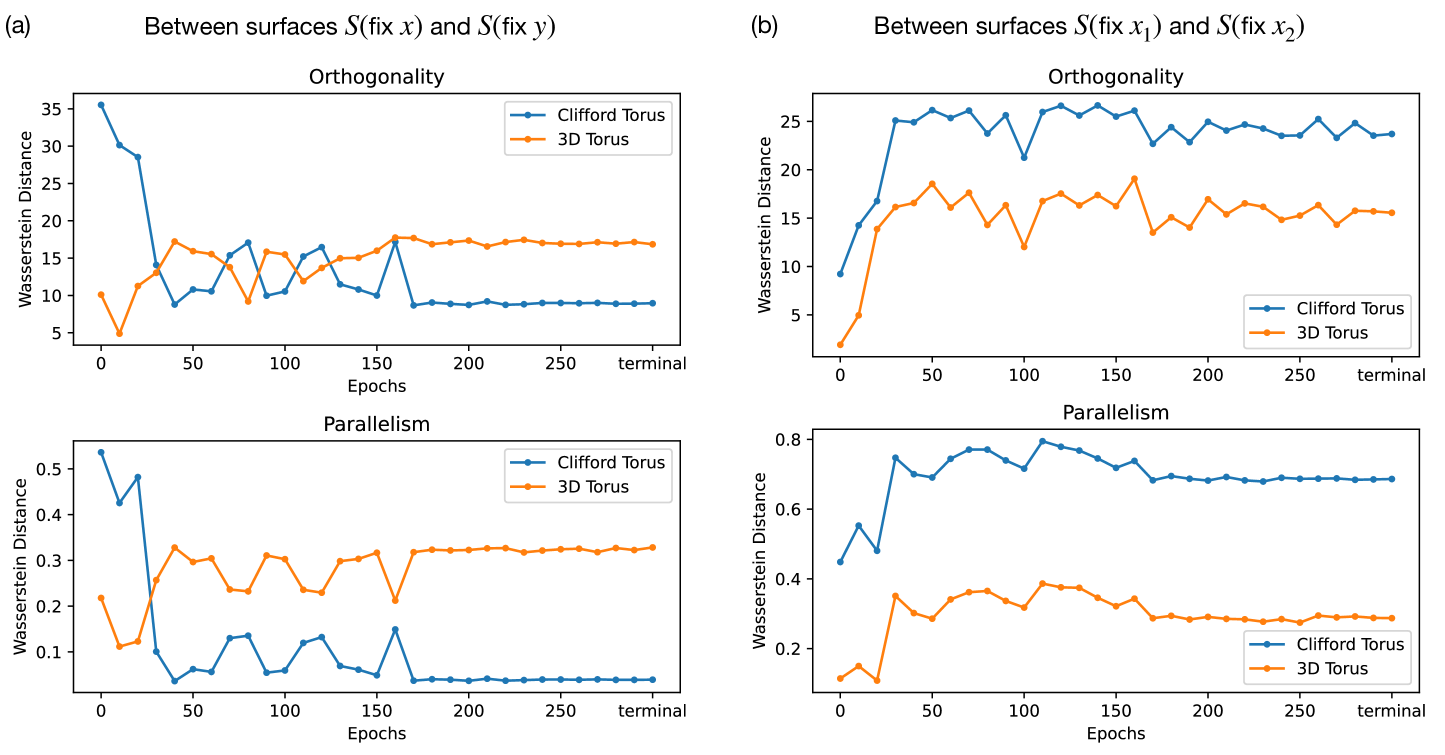
To confirm whether the model learns a Clifford torus, we employ the orthogonality and parallelism tests of tori Cueva et al. (2021b) (details found in Appendix B). In an ideal Clifford torus, the rings along the poloidal direction should be parallel with each other, and similarly for those along the toroidal direction. Moreover, the rings along the poloidal direction should be orthogonal with respect to the rings in the toroidal direction. The orthogonality and parallelism tests measure the orthogonality and parallelism of subspaces spanned by various rings on the torus. If the model learns a Clifford torus representation, the subspaces that code for and should be orthogonal, and the subspaces that code for () for any given () should be equivalent (parallel). Given a pair of and , we construct 2D subspaces of rings and spanned by fixing while varying and fixing while varying , respectively. We perform 3 sets of tests: 1) -on- tests test orthogonality and parallelism between surfaces and for all combinations of and ; 2) -on- tests test orthogonality and parallelism between and for all combinations of different ’s; 3) -on- tests test orthogonality and parallelism between and for all combinations of different ’s.
In Fig. 3, we compare the orthogonality and parallelism test statistics between an ideal 3D torus (left), the model’s learned representation at the final epoch (center), and an ideal Clifford torus (right). Comparing test 1 statistics (top row) between the model representation and the standard 3D and Clifford tori, we see that the model encodes and independently in mostly orthogonal subspaces, similar to a Clifford torus. The test 2 and 3 statistics (middle and bottom row) of the model representation, however, does not match those of either the 3D or the Clifford torus. In fact, the statistics from tests 2 and 3 of the model representation closely resemble those from test 1 of the 3D torus. This means that the model is encoding different values of in an almost orthogonal, as opposed to parallel, fashion, similarly for different values of . These observations signify that the models “hyper-factorizes” each individual factor of variation by treating them more similarly to categorical variables with nonzero overlaps between neighboring categories rather than fully-continuous variables, which explains why the effective dimension of the model’s learned representation is higher than 4 after convergence in Fig. 2(c). Although these observations are made from a model trained on a torus dataset, we expect the model to have similar encoding schemes across all variants of our Gaussian bump datasets.
3.2 Models can compose but not interpolate
In this section, we examine the model’s ability to compositionally generalize. Specifically, we train the model on incomplete datasets of 2D Gaussian SOSs, in which we leave out all Gaussian SOSs centered in the red-shaded test regions (Fig. 4(f), sampling distributions shown in Fig. 4(a), (b)). We then assess the performance of the models in generating 2D Gaussian SOSs centered within and outside of the test regions. Here we choose the width of the cuts to be around 6 pixels wide, which roughly corresponds to the width of the Gaussian stripes of . We design the lesions such that we can probe the model’s ability at compositionally generalizing out of the training distribution as well as its ability to spatially interpolate in a single variable alone. There are 4 possible outcomes based on the model’s ability to compose and interpolate, and we give predictions for the model’s generalization performance in each case: 1) the model cannot compose or interpolate: here, we would see low performance across the test regions; 2) the model interpolates but cannot compose: here, we would see high performance across the test regions; 3) the model composes but cannot interpolate: here, we would see high performance in one dimension but not the other in the non-intersecting part of the test regions, low performance in the intersection; 4) the model can compose and interpolate: here, we would see higher performance across the test regions. We note that case (2) and (4) are indistinguishable via the behavior of the model.
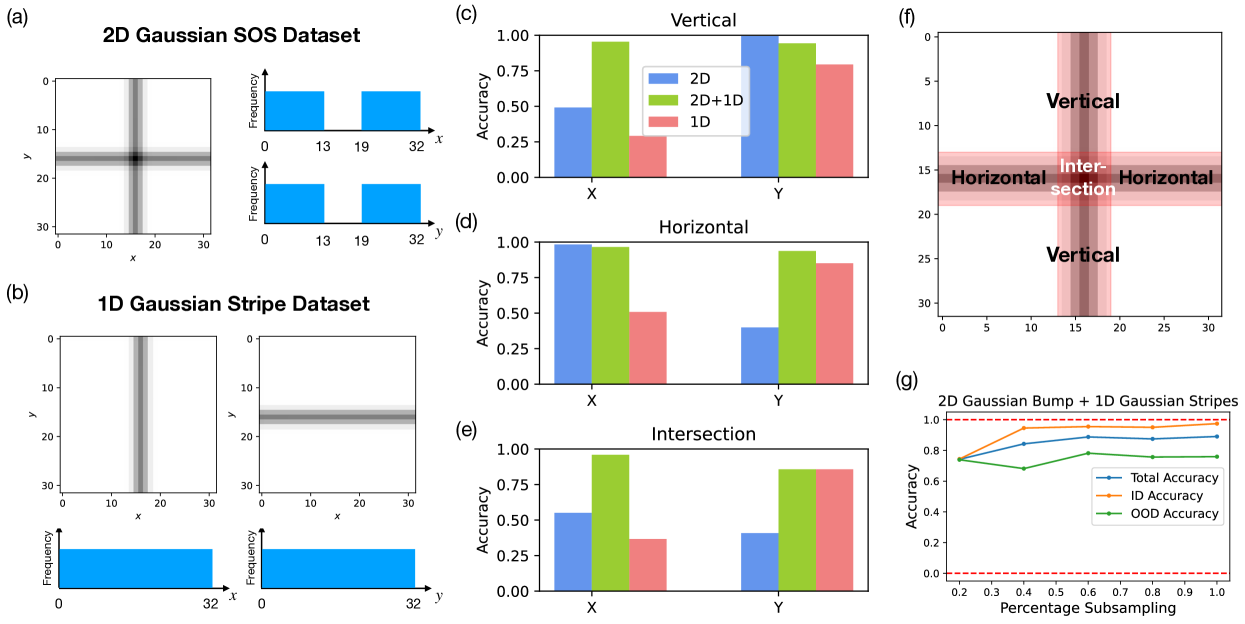
In our first experiment, we simply train our model on a 2D Gaussian SOS dataset where all data centered in the test regions are left out, i.e. excluding all as shown in Fig. 4(a). We call this model the 2D model since the model is trained on only 2D Gaussian SOS data. We then examine the terminal accuracy of the 2D model in generating Gaussian SOSs at the correct and in various parts of the test regions, which we section into a horizontal part, a vertical part, both excluding the area of their intersection, and the intersection itself (shown schematically in Fig. 4(f)). We note that the 2D model achieves high accuracy in generating while suffers low accuracy in generating in the vertical section. Similarly, the 2D model achieves high accuracy in generating while suffers low accuracy in generating in the horizontal section. The model suffers low accuracy in generating both and in the intersection region. These observations have two implications: i) the model is factorized and compositional since it is able to generate the correct or irrespective of the other; ii) the model has limited ability to spatially interpolate, which suggests that it does not learn a fully continuous manifold in its activation space (see Fig. 10(c)). These observations meet our expectation for outcome case (3), when the model can compose but not interpolate and resonates our conclusion from Sec. 3.1 that the model has learned to factorize x and y, but has not learned a consistent representation across all x’s (and likewise y’s). In Appendix C.3 Fig. 11, we quantitatively assess model’s ability to interpolate as a function of the held-out range width in the data manifold and found that model’s ability to interpolate gradually decrease as a function of the held-out region width.
To further verify our hypothesis that the model is capable of composition but not interpolation, we design an alternative dataset that includes a mixture of 2D Gaussian SOS data and 1D Gaussian stripe data (single stripes that are either horizontal or vertical). Specifically, we generate a set of 1D Gaussian stripe data across the entire range of and without any held-out regions, as shown in Fig. 4(b). Note that the 1D Gaussian stripe data respects the 2D structure of the conditional input embedding. The exact generation procedure for the 1D Gaussian stripe dataset is described in Appendix C.1. This 1D dataset is then combined with the previous 2D Gaussian SOS dataset with the same held-out test regions. The resulting 2D+1D dataset contains 1D data in all range of and but has not seen 2D data (composition of 1D) in the test regions. The model trained under this dataset, deemed the 2D+1D model, has high performance in generating both and across all of the test regions. This shows that given the necessary “ingredients" (1D Gaussian stripes of all range of and ), the model is able to compose them in a proper manner (2D Gaussian SOSs). These observations again confirm that the learned representation of the model is factorized but not consistent across a single feature, meaning that the model is able to compose independent features but not interpolate within a single feature dimension.
Finally, we test whether compositionality can be learned given no compositional examples in the training dataset. To test this, we train a 1D model on the 1D Gaussian stripe dataset as described above. Our results show that while model achieves respectable accuracy in generating the correct across the test regions, it does not simultaneously generate the correct , indicating that the model did not learn to properly compose the 1D stripes. This is also evident from the generated image samples from the 1D model shown in Fig. 10(c). Without any compositional examples, the model fails to generate the intersection of two 1D Gaussian stripes and defaults back to generating one of the stripes at the correct location. While the 1D model has also learned to factorize and as independent concepts, it is not able to generalize here due to the lack of compositional examples. Hence, based on the performance of the 1D, 2D, and 2D+1D models that we have seen above, we conclude that complete compositional generalization requires data of all range of ’s and ’s and some compositional examples of the two to be present within the dataset.

Building on our previous results, we investigate whether combining the 2D Gaussian bump dataset with 1D stripe data can impart a different form of compositionality to the model – multiplicative rather than additive. To do this, we create a dataset that mirrors the 2D+1D Gaussian SOS set, substituting the 2D Gaussian SOS data with 2D Gaussian bump data while maintaining the same test regions. The latent representation of this dataset can be found in Fig. 9(h) in the Appendix. The resulting model trained under the 2D Gaussian bump + 1D Gaussian stripe dataset is able to generate 2D Gaussian bumps within the test regions up to 70% accuracy, suggesting that the model is adept at handling an alternative form of compositionality. We further investigated whether the number of 2D Gaussian bump examples in the dataset influences compositionality by subsampling the 2D Gaussian bumps in the in-distribution regions (Fig. 9(g)). The results show that models trained on datasets with varying percentages of subsampled 2D Gaussian bumps achieve similar performance across the test regions, even with as little as 20% of the original data. These findings suggest that training for compositional generalization can be efficiently achieved by using a full range of data for each individual factor of variation, along with a few compositional examples.
To validate the benefit of training with 2D + 1D datasets, we analyzed the data efficiency scaling of models trained on 2D Gaussian bumps + 1D Gaussian stripes, comparing them to models trained solely on 2D Gaussian bumps as a function of image size . For both the baseline and augmented datasets, we excluded of the 2D Gaussian bumps from the center square region of the canvas for out-of-distribution (OOD) evaluations. The accuracy of the models are plotted against the percentage of 2D Gaussian bumps subsampled in Fig. 5(a) for the baseline dataset and (b) for the augmented dataset. The results clearly demonstrate that the model trained on the augmented dataset performs better with a significantly lower percentage of 2D Gaussian bumps in the training dataset. We then plotted the sizes of the baseline and augmented datasets required to reach a accuracy threshold as a function of on a log-log scale in Fig. 5(c). We found that models trained on the augmented datasets only require linear number of data in while those trained on the baseline datasets require quadratic number of data in . This result suggests that augmented datasets with samples of all independent factors plus a few compositional examples provide an efficient training method that has sample complexity linear in the number of factors. In Appendix C.2 and C.4, we further discuss the sample efficiency of learning compositionality from dataset of isolated factors of variation plus few compositional examples.
In summary, our findings indicate that the model excels at compositionality but struggles with interpolation. Consequently, effective generalization necessitates that the training set encompasses the full range of each individual factor of variation, alongside compositional examples. Furthermore, we discovered that models trained on datasets featuring explicitly factorized examples exhibit remarkable data efficiency and adaptability to various forms of compositionality. These results align with the observed factorization patterns in the model representation discussed in Sec. 3.1 and suggest promising strategies for developing more data-efficient training schemes that utilize tailored datasets.
3.3 Connection between manifold learning and percolation theory
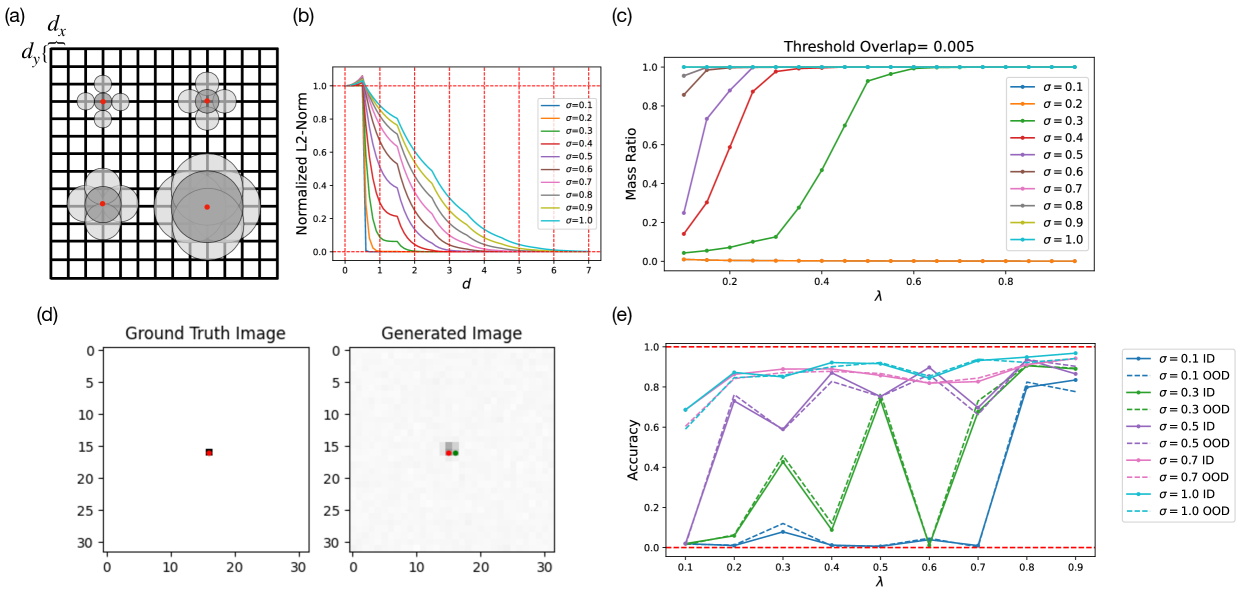
We have established that the model learns factorized (but not fully continuous) and compositional representations. Next, we identify a potential connection between manifold learning in diffusion models and percolation theory in physics, which provides a normative explanation as to how factorization (or compositional generalization) emerges. To start, we note that our Gaussian bump datasets can be approximated as a simple Poisson Boolean (Gilbert’s disk) model Gilbert (1961); Hanisch (1980), a well-studied system in continuum percolation theory. Fig. 6(a) shows a schematic illustration of our dataset of Gaussian bumps approximated as disks of various widths on a 2D lattice of grid spacings and . In percolation theory, the quantity of interest is the critical fraction of nodes that need to have non-zero overlaps in order for the entire system to be interconnected with high probability. For most systems (finite- and infinite-sized), there exist a phase transition that occurs at the critical fraction that can be either analytically derived or numerically estimated, with the transition becoming sharper as the system size scales. In our context, since the Gaussian bump images are pixelated, overlaps between neighboring Gaussian bumps are not smooth. In Fig. 6(b), we plot the normalized L2-norm of the neighboring distance--separated Gaussian bumps with various spread ’s. We note that since the L2-norm measure of overlap is normalized to 1 between a given Gaussian bump and itself, the overlap between a given Gaussian bump and a slightly offset Gaussian bump temporarily goes beyond 1 due to the discrete nature of the data.
We hypothesize that below a threshold amount of training data, the diffusion model cannot construct a faithful representation of the training dataset. From the percolation perspective, if there does not exist a large enough interconnected component within the dataset, the model will fail to learn the relative spatial location of the data points, making it hard to learn a faithful 2D representation. To test this hypothesis, we first simulated the mass ratio of largest interconnected components as a function of the unit area data density with our 2D Gaussian bump datasets. For simulation, we use a dataset of 1024 data points, corresponding to on a lattice. We then randomly sample points on the lattice to compute the size of the largest interconnected cluster of Gaussian bumps. Here, we define a hyperparameter of threshold overlap beyond which we consider two Gaussian bumps as overlapping. In Fig. 6(c), we show the simulation results. averaged over 5 runs, with the chosen threshold overlap of 0.005 for datasets with various ’s. Additional simulation results with various chosen overlap thresholds can be found in Appendix D.
Next, we quantify the connection between percolation theory and manifold formation in diffusion models. To account for the stochasticity in sampling the datasets and avoid significant overhead in model training, we choose a fix set of grid points on the lattice and generate datasets of varying ’s from this fixed set of grid points. Moreover, we choose each sampled fraction of the dataset to be a strict superset of the smaller sampled fractions of the dataset. For example, dataset at contains all of dataset at , and dataset at contains all of dataset at and hence all of , so on and so forth. For datasets of different ’s, we chose the same grid points such that the only difference between datasets of different ’s is just the itself. This procedure eliminates all the stochasticity due to the probabilistic nature of percolation, and ensures that differences in training are only due to the differences in and . To ensure fair comparison, we proportionally add training time to each model trained with fewer data such that the total amount of training batches are constant across all models.
In Fig. 6(e), we display the accuracy of models trained with different fractions of a training dataset of a total size of 1024 for various ’s. We note that there are high variances in the model performance, especially for . This is due to stochasticity in model training itself as well as the gradual as opposed to a sharp phase transition, as shown in simulation Fig. 6(c). In addition, we notice that based on the simulation, will not forge any connected cluster due to its minuscule spread. In Fig. 6(d), an sample image of Gaussian bumps of is shown on the left, where it is a mere pixel centered at . Nonetheless, in experiment Fig. 6(e), we see that the model is able to learn the dataset at . This is partially due to the fact that the noising process in diffusion training smears out the Gaussian bump of to give it a larger effective width, as shown in the generated bump image in Fig. 6(d). In general, our experimental results agree with the percolation theory prediction that smaller similarities between the samples makes it harder for the models to learn meaningful representations, despite the same quanitity of data. The portraits of the learned representations by the models generating Fig. 6(e) is shown in Fig. 15 of Appendix D.2.
4 Discussion
In the previous section, we have shown that diffusion models are capable of learning factorized and semi-continuous representations. This allows for compositional generalization across factors that have appeared in the training dataset, even given only a small number of compositional examples. While we studied a toy system, our results imply that the diffusion model architecture has some inductive biases favoring factorization and compositionality, as seen in astonishing compositional text-to-image generation examples such as an “astronaut riding a horse on the moon". Our results demonstrate further that if the training data include isolated factors of independent variation and some compositional examples, diffusion models are capable of attaining high performance in OOD compositional generalization. While it is true that natural images are much more complex, and there can be numerous forms of compositionality within a single image, the datasets and modes of composition we studied were not trivial. Nonetheless, further investigation is necessary to understand the compositionality and factorization of models when multiple forms of compositionality are at play.
Furthermore, we showed a connection between the models’ performance, as related to its ability to learn a faithful representation of the dataset, and percolation theory in physics. Percolation theory provides a plausible mechanistic interpretation of the observed sudden emergence in the model’s capability beyond a threshold number of data points. Further work is needed to characterize the precise connection between percolation theory and manifold formation, in both toy settings and realistic settings. In realistic datasets, mutual information or cosine similarity between data points can serve as abstract forms of overlap. Moreover, the idea of percolation can be further extended to study alternative observations of phase transitions in deep learning, such as percolation of the chain-of-knowledge in large language models.
5 Conclusion
We have shown that diffusion models are capable of learning factorized representations that can compositionally generalize OOD, given data containing the full range of each independent factor of variation and a small amount of compositional examples. Our study suggests that diffusion models have the inductive bias for factorization and compositionality, which are believed to be key ingredients for scalability. We identified that the diffusion models fail to generalize out-of-distribution when 1) there are unseen values of a given factor of variation for the composition, 2) there are no compositional examples in the training dataset, 3) there is an insufficient quantity of data, and 4) there is an insufficient amount of overlaps between data. Together, our results imply that a more efficient training dataset can be constructed by incorporating samples that feature explicit factorized examples along with a few compositional examples that have substantial overlap. By optimizing the training data in this manner, we can enhance the data efficiency scaling of diffusion-based models. Future investigations should consider controlled experiments with data optimization for improving data efficiency of diffusion models using more realistic data.
References
- Bengio et al. (2013) Yoshua Bengio, Aaron C. Courville, and Pascal Vincent. Representation learning: A review and new perspectives. IEEE Trans. Pattern Anal. Mach. Intell., 35(8):1798–1828, 2013. doi: 10.1109/TPAMI.2013.50. URL https://doi.org/10.1109/TPAMI.2013.50.
- Bowers et al. (2016) Jeffrey S. Bowers, Ivan I. Vankov, Markus F. Damian, and Colin J. Davis. Why do some neurons in cortex respond to information in a selective manner? insights from artificial neural networks. Cognition, 148:47–63, 2016. ISSN 0010-0277. doi: https://doi.org/10.1016/j.cognition.2015.12.009. URL https://www.sciencedirect.com/science/article/pii/S0010027715301232.
- Burak and Fiete (2009) Yoram Burak and Ila R Fiete. Accurate path integration in continuous attractor network models of grid cells. PLoS Comput. Biol., 5(2):e1000291, February 2009. ISSN 1553-734X, 1553-7358. doi: 10.1371/journal.pcbi.1000291.
- Burgess et al. (2018) Christopher P. Burgess, Irina Higgins, Arka Pal, Loïc Matthey, Nick Watters, Guillaume Desjardins, and Alexander Lerchner. Understanding disentangling in -vae. CoRR, abs/1804.03599, 2018. URL http://arxiv.org/abs/1804.03599.
- Chaabouni et al. (2020) Rahma Chaabouni, Eugene Kharitonov, Diane Bouchacourt, Emmanuel Dupoux, and Marco Baroni. Compositionality and generalization in emergent languages. In Dan Jurafsky, Joyce Chai, Natalie Schluter, and Joel R. Tetreault, editors, Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL 2020, Online, July 5-10, 2020, pages 4427–4442. Association for Computational Linguistics, 2020. doi: 10.18653/V1/2020.ACL-MAIN.407. URL https://doi.org/10.18653/v1/2020.acl-main.407.
- Chaudhuri et al. (2019) Rishidev Chaudhuri, Berk Gerçek, Biraj Pandey, Adrien Peyrache, and Ila Fiete. The intrinsic attractor manifold and population dynamics of a canonical cognitive circuit across waking and sleep. Nat. Neurosci., 22(9):1512–1520, September 2019. ISSN 1097-6256, 1546-1726. doi: 10.1038/s41593-019-0460-x.
- Chen et al. (2021) Nanxin Chen, Yu Zhang, Heiga Zen, Ron J. Weiss, Mohammad Norouzi, and William Chan. Wavegrad: Estimating gradients for waveform generation. In 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. OpenReview.net, 2021. URL https://openreview.net/forum?id=NsMLjcFaO8O.
- Cueva et al. (2021a) Christopher J Cueva, Adel Ardalan, Misha Tsodyks, and Ning Qian. Recurrent neural network models for working memory of continuous variables: activity manifolds, connectivity patterns, and dynamic codes. arXiv preprint arXiv:2111.01275, 2021a.
- Cueva et al. (2021b) Christopher J. Cueva, Adel Ardalan, Misha Tsodyks, and Ning Qian. Recurrent neural network models for working memory of continuous variables: activity manifolds, connectivity patterns, and dynamic codes. CoRR, abs/2111.01275, 2021b. URL https://arxiv.org/abs/2111.01275.
- Duan et al. (2020) Sunny Duan, Loic Matthey, Andre Saraiva, Nick Watters, Chris Burgess, Alexander Lerchner, and Irina Higgins. Unsupervised model selection for variational disentangled representation learning. In 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, April 26-30, 2020. OpenReview.net, 2020. URL https://openreview.net/forum?id=SyxL2TNtvr.
- Gao et al. (2017) Peiran Gao, Eric Trautmann, Byron Yu, Gopal Santhanam, Stephen Ryu, Krishna Shenoy, and Surya Ganguli. A theory of multineuronal dimensionality, dynamics and measurement. bioRxiv, 2017. doi: 10.1101/214262. URL https://www.biorxiv.org/content/early/2017/11/12/214262.
- Gilbert (1961) E. N. Gilbert. Random plane networks. Journal of the Society for Industrial and Applied Mathematics, 9(4):533–543, 1961. doi: 10.1137/0109045. URL https://doi.org/10.1137/0109045.
- Hafting et al. (2005a) Torkel Hafting, Marianne Fyhn, Sturla Molden, May-Britt Moser, and Edvard I Moser. Microstructure of a spatial map in the entorhinal cortex. Nature, 436(7052):801–806, August 2005a. ISSN 0028-0836, 1476-4687. doi: 10.1038/nature03721.
- Hafting et al. (2005b) Torkel Hafting, Marianne Fyhn, Sturla Molden, May-Britt Moser, and Edvard I. Moser. Microstructure of a spatial map in the entorhinal cortex. Nature, 436:801–806, 2005b. URL https://api.semanticscholar.org/CorpusID:4405184.
- Hanisch (1980) Karl-Heinz Hanisch. On classes of random sets and point process models. J. Inf. Process. Cybern., 16(8/9):498–502, 1980.
- Higgins et al. (2017) Irina Higgins, Loïc Matthey, Arka Pal, Christopher P. Burgess, Xavier Glorot, Matthew M. Botvinick, Shakir Mohamed, and Alexander Lerchner. beta-vae: Learning basic visual concepts with a constrained variational framework. In 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017, Conference Track Proceedings. OpenReview.net, 2017. URL https://openreview.net/forum?id=Sy2fzU9gl.
- Ho et al. (2020) Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. In Hugo Larochelle, Marc’Aurelio Ranzato, Raia Hadsell, Maria-Florina Balcan, and Hsuan-Tien Lin, editors, Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual, 2020. URL https://proceedings.neurips.cc/paper/2020/hash/4c5bcfec8584af0d967f1ab10179ca4b-Abstract.html.
- Liang et al. (2024) Qiyao Liang, Ziming Liu, and Ila R Fiete. Do diffusion models learn semantically meaningful and efficient representations? In ICLR 2024 Workshop on Mathematical and Empirical Understanding of Foundation Models, 2024. URL https://openreview.net/forum?id=pAAMFQiAuD.
- Lindsey and Issa (2023) Jack W. Lindsey and Elias B. Issa. Factorized visual representations in the primate visual system and deep neural networks. April 2023. doi: 10.1101/2023.04.22.537916. URL http://dx.doi.org/10.1101/2023.04.22.537916.
- McInnes and Healy (2018) Leland McInnes and John Healy. UMAP: uniform manifold approximation and projection for dimension reduction. CoRR, abs/1802.03426, 2018. URL http://arxiv.org/abs/1802.03426.
- McInnes et al. (2018) Leland McInnes, John Healy, Nathaniel Saul, and Lukas Grossberger. Umap: Uniform manifold approximation and projection. The Journal of Open Source Software, 3(29):861, 2018.
- Montero et al. (2021) Milton Llera Montero, Casimir J. H. Ludwig, Rui Ponte Costa, Gaurav Malhotra, and Jeffrey S. Bowers. The role of disentanglement in generalisation. In 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. OpenReview.net, 2021. URL https://openreview.net/forum?id=qbH974jKUVy.
- Moser et al. (2015) May-Britt Moser, David C. Rowland, and Edvard I. Moser. Place cells, grid cells, and memory. Cold Spring Harbor Perspectives in Biology, 7(2), Feb 2015. doi: 10.1101/cshperspect.a021808.
- Moser EI (2008) Moser MB. Moser EI, Kropff E. Place cells, grid cells, and the brain’s spatial representation system. 2008. doi: 10.1146/annurev.neuro.31.061307.090723. URL https://pubmed.ncbi.nlm.nih.gov/18284371/.
- Okawa et al. (2023) Maya Okawa, Ekdeep Singh Lubana, Robert P. Dick, and Hidenori Tanaka. Compositional abilities emerge multiplicatively: Exploring diffusion models on a synthetic task. CoRR, abs/2310.09336, 2023. doi: 10.48550/ARXIV.2310.09336. URL https://doi.org/10.48550/arXiv.2310.09336.
- Saharia et al. (2023) Chitwan Saharia, Jonathan Ho, William Chan, Tim Salimans, David J. Fleet, and Mohammad Norouzi. Image super-resolution via iterative refinement. IEEE Trans. Pattern Anal. Mach. Intell., 45(4):4713–4726, 2023. doi: 10.1109/TPAMI.2022.3204461. URL https://doi.org/10.1109/TPAMI.2022.3204461.
- Stensola et al. (2012) Hanne Stensola, Tor Stensola, Trygve Solstad, Kristian Frøland, May-Britt Moser, and Edvard I Moser. The entorhinal grid map is discretized. Nature, 492(7427):72–78, December 2012. ISSN 0028-0836, 1476-4687. doi: 10.1038/nature11649.
- Taube et al. (1990) J S Taube, R U Muller, and J B Ranck, Jr. Head-direction cells recorded from the postsubiculum in freely moving rats. i. description and quantitative analysis. J. Neurosci., 10(2):420–435, February 1990. ISSN 0270-6474. doi: 10.1523/JNEUROSCI.10-02-00420.1990.
- Taube (2007) Jeffrey S Taube. The head direction signal: origins and sensory-motor integration. Annu. Rev. Neurosci., 30:181–207, 2007. ISSN 0147-006X. doi: 10.1146/annurev.neuro.29.051605.112854.
- Wiedemer et al. (2023) Thaddäus Wiedemer, Prasanna Mayilvahanan, Matthias Bethge, and Wieland Brendel. Compositional generalization from first principles. In Alice Oh, Tristan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey Levine, editors, Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023, 2023. URL http://papers.nips.cc/paper_files/paper/2023/hash/15f6a10899f557ce53fe39939af6f930-Abstract-Conference.html.
- Xu et al. (2022) Zhenlin Xu, Marc Niethammer, and Colin Raffel. Compositional generalization in unsupervised compositional representation learning: A study on disentanglement and emergent language. In Sanmi Koyejo, S. Mohamed, A. Agarwal, Danielle Belgrave, K. Cho, and A. Oh, editors, Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022, 2022. URL http://papers.nips.cc/paper_files/paper/2022/hash/9f9ecbf4062842df17ec3f4ea3ad7f54-Abstract-Conference.html.
- Zhao et al. (2018) Shengjia Zhao, Hongyu Ren, Arianna Yuan, Jiaming Song, Noah D. Goodman, and Stefano Ermon. Bias and generalization in deep generative models: An empirical study. In Samy Bengio, Hanna M. Wallach, Hugo Larochelle, Kristen Grauman, Nicolò Cesa-Bianchi, and Roman Garnett, editors, Advances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems 2018, NeurIPS 2018, December 3-8, 2018, Montréal, Canada, pages 10815–10824, 2018. URL https://proceedings.neurips.cc/paper/2018/hash/5317b6799188715d5e00a638a4278901-Abstract.html.
Appendix A Experimental Details
A.1 Architecture
We train a conditional denoising diffusion probabilistic model (DDPM) Ho et al. [2020] with a standard UNet architecture of 3 downsampling and upsampling blocks, interlaced self-attention layers, and skip connections as shown in Fig. 7. Each down/up-sampling blocks consist of max pooling/upsampling layers followed by two double convolutional layers made up by convolutional layers, group normalization, and GELU activation functions.
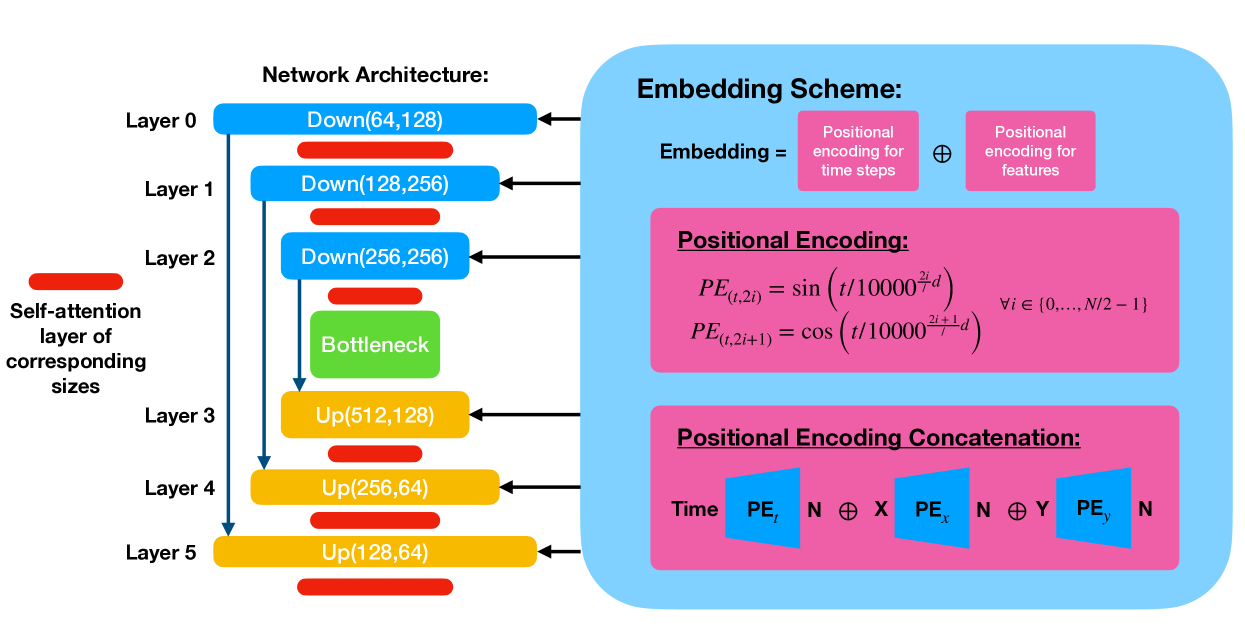
The conditional information is passed in at each down/up-sampling block as shown in the schematic drawing. In our experiments, we choose to preserve the continuity of the Gaussian position labels passed into the model via explicit positional encoding rather than using a separate trainable embedding MLP at each block. Each embedding vector is made by concatenating equal-length vectors of the positional encodings of the timestep, the -position, and the -position.
In our experiments, we visualize the outputs of layer 4 as the internal representation of the diffusion model. We have chosen not to use the output of the bottleneck layer for our study of the learned latent manifold, as we have observed that the bottleneck layers have diminishing signals in most of our experiments. This is likely due to the presence of the skip connections. This choice does not affect the validity of our main results, as we are focused on the factorization of the model’s learned representation.
A.2 Dimension Reduction
We primarily use the dimension reduction technique Uniform Manifold Approximation and Projection for Dimension Reduction (UMAP) McInnes and Healy [2018] to study and visualize the learned representation of the model. Specifically, we collect image samples and their corresponding internal representations (outputs of layer 4 from the architecture described in Sec. A.1). We then transform the high-dimensional internal representations into a 3D embedding as a sample of the learned representation, which we visualize and analyze. For an implementation of UMAP, we used the Python package McInnes et al. [2018].
A.3 Evaluation
We assess the performance of the model using two primary criteria: 1) the quality of the denoised images and 2) the quality of the learned representation.
At a given time during or after training, we generate 1024 denoised images and their corresponding internal representations of sampled labels based on grid points. We predict the label corresponding to each generated image based on the - and -positions of the generated Gaussian bump/SOS in the image. We then compute the accuracy of predicted labels from the ground-truth labels averaged over 1024 samples as
| (1) |
where is an indicator function that returns 1 if the expression within holds true, 0 otherwise. Similarly, we can modify this expression to only assess the accuracy of generated -positions or -positions separately. Here we estimate the center of the Gaussian bump/SOS and by finding the location of the darkest pixel in the image. In the cases where there are no Gaussian bumps/SOS’s or more than one bump/SOS, the algorithm defaults back to finding the centroid of the image. We then construct the learned representation of the model based on the neural activations of layer 4 corresponding to the 1024 sampled images collected at the terminal diffusion generation timestep. We note that we have investigated neural activations collected at alternative diffusion generation timesteps and found that they do not noticeably differ from timestep to timestep.
A.4 Training Loss
Diffusion models iteratively denoise a Gaussian noisy image into a noisefree image over diffusion timesteps given the forward distribution by learning the reverse distribution . Given a conditional cue , a conditional diffusion model [Chen et al., 2021, Saharia et al., 2023] reconstructs an image from a source distribution . Specifically, we train our neural network (UNet) to predict the denoising direction at a given timestep with conditional cue with the goal of minimizing the mean squared loss (MSE) between the predicted and the ground truth noise as follows
| (2) |
where we assume each noise vector to be sampled from a Gaussian distribution I.I.D. at each timestep .
A.5 Datasets
The datasets we used for training the models generating the results in Sec. 3 have various increments and . Here we briefly comment on the interplay between increments and sigmas, and how they affect dataset densities and overlaps. The ultimate goal of our task of interest is to learn a continuous 2D manifold of all possible locations of the Gaussian bumps/SOS’s. Intuitively, the spatial information necessary for an organized, continuous, and semantically meaningful representation to emerge is encoded in the overlap of the neighboring Gaussian bumps/SOS’s, which is tuned via the parameters and . As we increase , the size of the dataset gets scaled quadratically, resulting in denser tilings of the Gaussian bumps/SOS’s.
As we scale up , the dataset size remains fixed while the overlaps with neighbors are significantly increased. In Fig. 6(b), we plot the normalized L2-norm of the product image of neighboring Gaussian bumps as a function of increments for various spreads. Specifically, given two inverted grayscale Gaussian bump images, and , the normalized L2-norm of their product is given by the formula , where is element-wise multiplication and is the L2-norm. This quantity should give a rough measure of the image overlap with the exception at increment around 0.5 due to the discrete nature of our data. Moreover, we note that the cusps in the curves occur for the same reason. As we can see, the number of neighbors that a given Gaussian bump has non-trivial overlaps with grows roughly linearly to sub-linearly with the spread. Since the model constructs non-parallel representation encodings of different values of ’s and ’s, more neighbor information results in more overlaps between different values of ’s and ’s and hence better representation learned, as shown in the percolation results in Fig. 6 in Sec. 3.3. Overlaps in Gaussian SOS data can be similarly analyzed, albeit the differences in overlaps of neighboring Gaussian SOS’s of various spread ’s is not as pronounced due to the large coverage area of each Gaussian stripe.
A.6 Training Details
We train the models on a quad-core Nvidia A100 GPU, and an average training session lasts around 6 hours (including intermediate sampling time). Each model is given an inversely proportional amount of training time as a function of the size of the dataset that it is trained on such that there is sufficient amount of training for the models to converge. For each model, we sample 1024 samples corresponding to the 3232 grid points of and pairs tiling the entire image space. The model is trained with the AdamW optimizer with built-in weight decay, and we employ a learning rate scheduler from Pytorch during training. We did not perform any hyperparameter tuning, although we would expect our observations to hold regardless.
Appendix B Orthogonality and Parallel Test
B.1 Motivation for the Analysis
To better identify whether the diffusion models learn to factorize its representations, we choose to study periodic representations of Gaussian bumps, which we expect to form toroidal manifolds in the latent space as opposed to planar manifolds. This is because toroidal manifolds have multiple standard realizations which vary based on their degree of entanglement in the two rings. In particular, the standard torus embeds the rings in three dimensions that couple the two periodic variables, whereas the Clifford Torus embeds each ring in its own orthogonal subspace. This difference in geometry motivates the two analyses that we implemented to identify which geometry the diffusion model learned.
B.2 Computation of the Tests
We implement the orthogonality and parallelism tests as in Cueva et al. [2021a]. Briefly, the orthogonality test asks whether the rings that code for each variable lie in orthogonal subspaces–if so, this indicates that the torus has a Clifford-like geometry. The parallelism test asks whether rings in one variable are aligned in the other variable. If so, this also indicates that the torus has a Clifford-like geometry.
The analysis first requires identifying each ring–surprisingly, we found that when the rings formed, the top four Principal Components comprised them. In particular, the first ring were consistently spanned by PCs 1 and 3, and the second was spanned by PCs 2 and 4 (Fig. 2(f) and (g)). Thus, we confirmed that we could use PCA for our analysis.
For each analysis, we identify the ring subspaces by fixing one variable of the input, and sweeping the other variable. We do so for each index, arriving at 32 different subsets of the data for variable and 32 different points for variable . Next, we compute the top two Principal Components for each subset of the data, thereby identifying the ring.
For the orthogonality test, we randomly draw pairs of rings that are fixed in and and compute the pairwise angles between each rings’ Principal Components via cosine similarity. For the parallelism test, we compute the randomly drawn pairs of rings that are fixed in the same variable. Next, we create a projection matrix from the subspaces defined by one of the rings, and calculate the reconstruction error of the second ring’s projection onto that subspace:
| (3) |
In each test, we aggregate histograms of the respective metric. To identify the similarity between our data and either toroidal embedding, we compute the same histograms for both the Clifford and standard torus (based on a simulation with similar spacing in and samples), and compute the Wasserstein distance between the data and these simulations. The Wasserstein distances between the orthogonality and parallelism test statistics of the model’s learned representation and those of an ideal Clifford torus and 3D torus are shown in Fig. 8 as a function of the training epochs. We note that the model’s learned representations at smaller training epochs are not necessarily a torus, hence the metric comparison at those points has less significance.
Appendix C Composition and Interpolation
C.1 Gaussian Stripe/SOS Dataset Generation
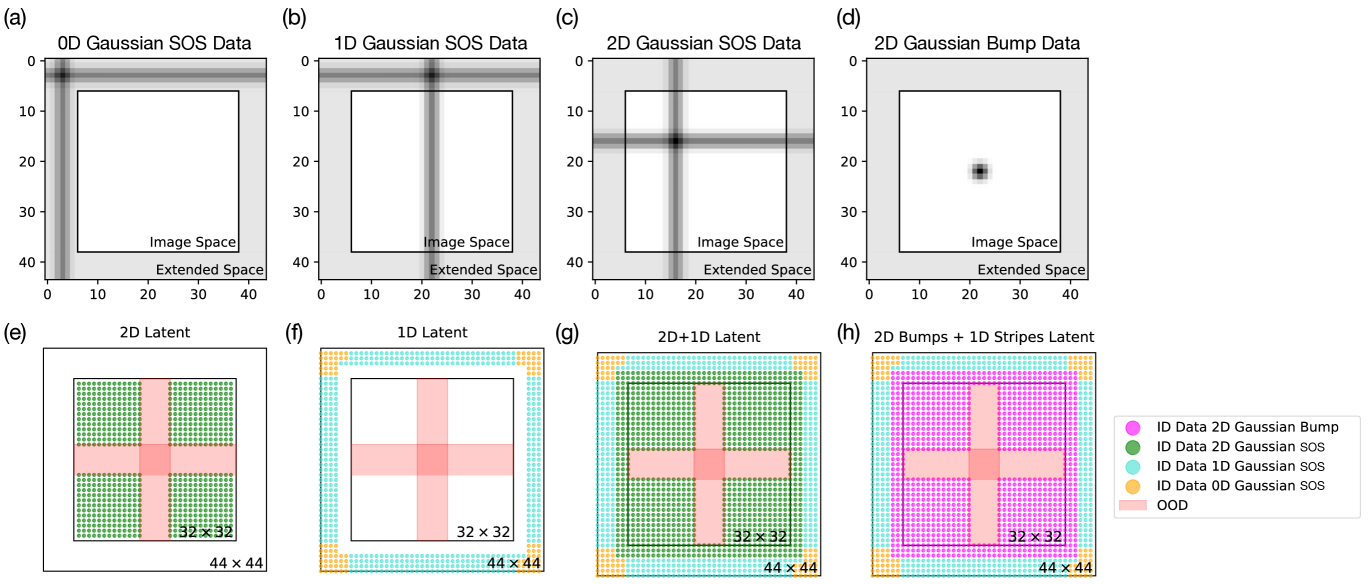
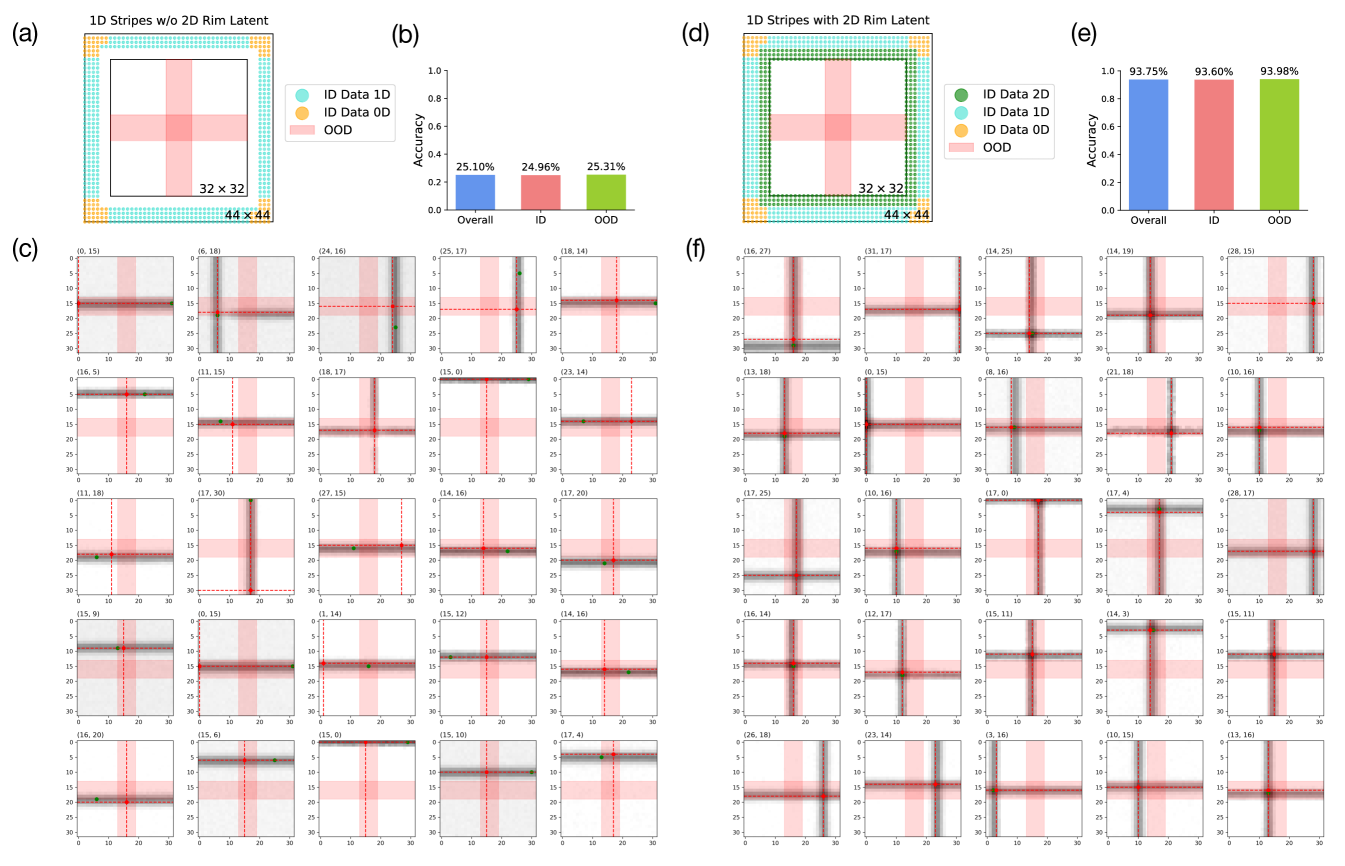
To generate 1D Gaussian stripe dataset shown in Fig. 4(b) while maintaining the structure of the 2D conditional embeddings, we embed the data latent space into an extended latent space while maintaining the image pixel size to be . Functionally, this allows us to mix into the 2D Gaussian SOS datasets 1D (and 0D) Gaussian data, as defined by the portion of the Gaussian that is actually visible to the model in the pixels. Examples of 0D, 1D, and 2D Gaussian SOS data are shown in Fig. 9(a)-(c), respectively. Fig. 9(e)-(g) then show the actual data latent representations of the 2D, 1D, and 2D+1D datasets that we use to train 2D, 1D, and 2D+1D models described in Sec. 3.2. Here, the green points represent each individual 2D Gaussian SOS data, the blue points represent the 1D Gaussian SOS data, and the yellow points the 0D Gaussian SOS data. In all three datasets, we leave out the all Gaussian SOS data centered in the red shaded regions. We note that due to the nature of our data generation scheme, the 2D data only exist within the image space (and some spillover) and the 1D (and 0D) data only exist in the extended data latent space. Because of the nonzero width of the Gaussian stripes, a portion of the data along the rim of the image space is actually 2D with a portion of the overlaps between the horizontal and the vertical stripes visible within the image frame. In training the 1D model shown in Fig. 4, we have removed the rim where any overlap between the horizontal and vertical Gaussian stripes is partially visible within the image, as shown in Fig. 9(f). The model trained on such a 1D dataset without any compositional example is, as discussed in Sec. 3.2, not able to handle the conjunction of the 2 Gaussian stripes, as shown in Fig. 10(a)-(c).
C.2 Generalization with Few Compositional Examples
In Sec. 3.2, we have seen that the models are sufficiently data efficient in learning the compositionality given a few 2D examples. Here we compare the performance of models trained on a pure 1D Gaussian stripe dataset versus a 1D Gaussian stripe dataset + a small amount 2D compositional examples along the image rim, where the conjunction of the stripes are only partially visible within the data images. Here we name the pure 1D Gaussian stripe dataset as 1D stripes without 2D rim and the alternative as 1D stripes with 2D rim. The data latent representations of both datasets are shown in Fig. 10(a), (d) and the overall, in-distribution, and out-of-distribution sampled image accuracy of models trained on these datasets are shown in (b) and (e). We note from the generation behavior that the model trained without the 2D rim has a hard time generating the portion of the images where the vertical and horizontal stripes overlap. However, given a small set of examples of partial overlaps, the model has completely gained the ability to properly compose the stripes. Specifically, the model trained with the 2D rim achieves the same level of accuracy, if not better accuracy, than the 2D + 1D model shown in Fig. 4 with ample of 2D compositional examples. This suggests that models can learn compositional structure efficiently from merely a few compositional examples. Moreover, we have shown in Sec. 3.2 Fig. 4 (g) that this type of sample efficiency is transferable to an alternative type of compositionality.
C.3 Model’s Ability to Interpolate
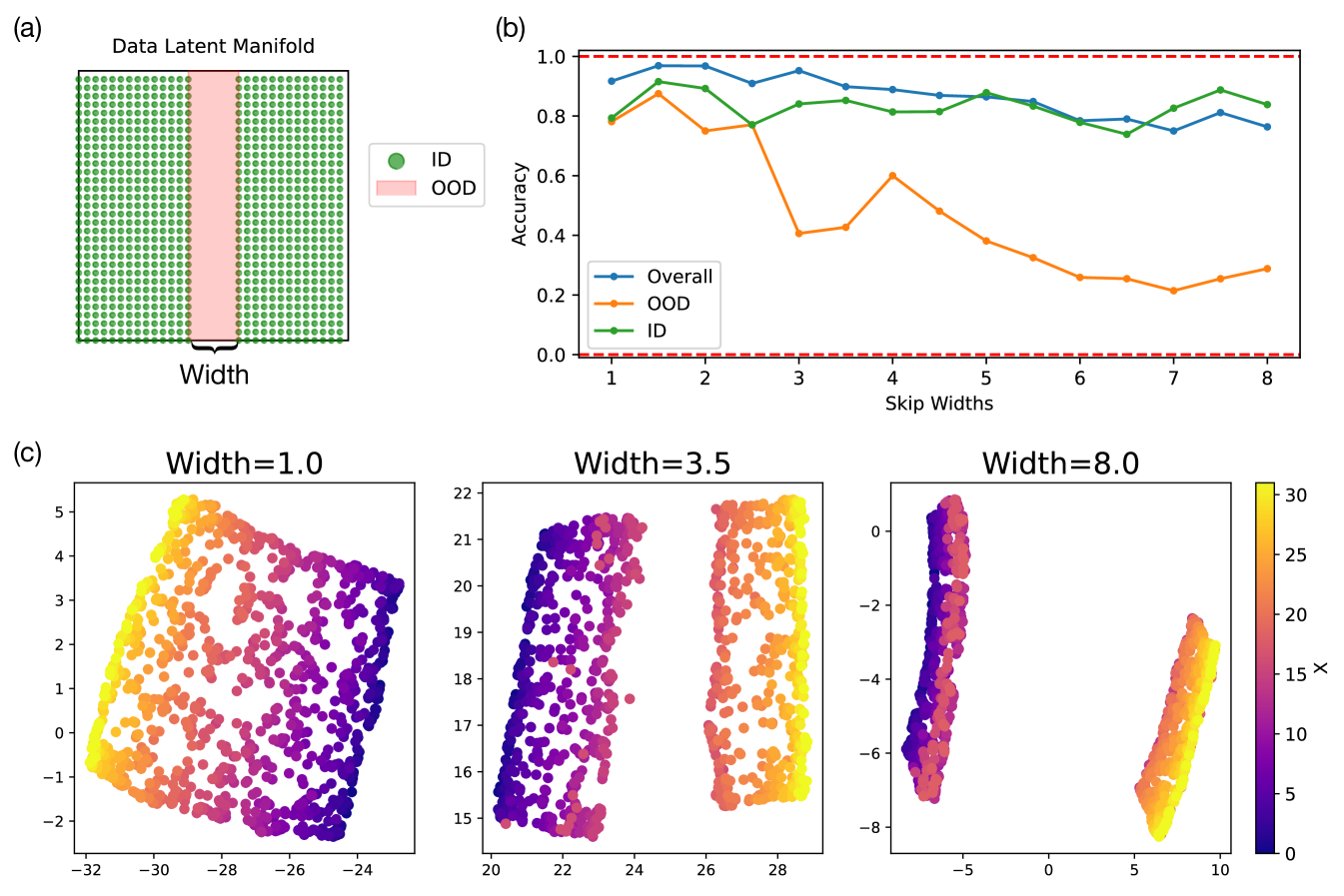
As discussed in Sec. 3.2, the models have poor ability to interpolate as evident from the fact that models cannot generalize to unseen values of and in the OOD experiments where an entire range of and are removed from the training dataset (Fig. 4). This is because the model learned non-parallel representations of different values of ’s and ’s, hence treating and similar to categorical values where there are non-zero overlaps between neighboring categories. We have established in Sec. 3.2 Fig. 4 that the 2D model trained on the 2D Gaussian SOS datasets with the red held-out test regions can indeed compose but not interpolate. Here we quantitatively investigate the model’s ability to interpolate when trained on 2D Gaussian SOS datasets of varying widths in the held-out range, as illustrated in Fig. 11(a). In Fig. 11(b), we show the trained models’ overall, in-distribution, and out-of-distribution image-generation accuracy as a function of the held-out range widths. We notice that the accuracy in generating images in the OOD region degrades gradually as function the held-out range width. This is likely due to the fact that the models learn parallel encodings of different values of ’s and ’s that have nontrivial overlaps with each other based on the spatial overlap of the Gaussian SOS data. Similarly the learned representations by the model become increasingly disconnected as a function of the width sizes, which is in agreement with the macroscopic generation behavior of the model.
C.4 Model’s Ability to Compose
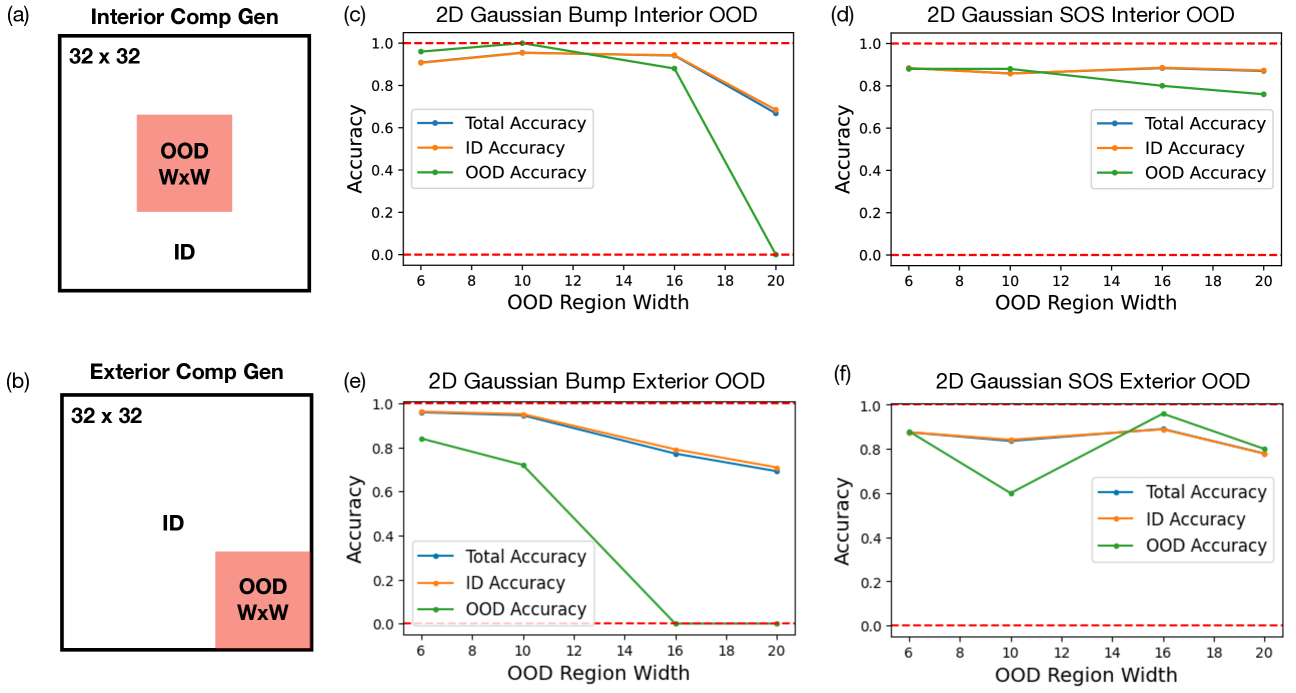
In this section, we investigate model’s ability to compositionally generalize when we cut out an out-of-distribution square region of size in the image data manifold. Specifically, we are interested in two scenario: 1) interior compositional generalization where the OOD cut is in the center of the data manifold, and 2) exterior compositional generalization where the OOD cut is at the corner of the data manifold. In either case, we want to test out diffusion model’s ability to generalize to the OOD regions as a function of the OOD region width . We test models under both settings of interior and exterior compositional generalization when trained using a 2D Gaussian bump dataset or a 2D Gaussian SOS dataset. The results show that for the Gaussian bump dataset, the model’s ability to compositionally generalize in interior regions slowly decay while in exterior regions quickly decay as a function of the OOD region width. On the other hand, the model’s performance remains relatively high for all tested OOD region widths in both interior and exterior compositional generalization when trained on the Gaussian SOS dataset. These results show that the Gaussian SOS dataset indeed allows the model to acquire compositionality in a more robust as well as sample efficient manner.
Appendix D Manifold formation and Percolation Theory
D.1 Percolation Theoretical Simulation
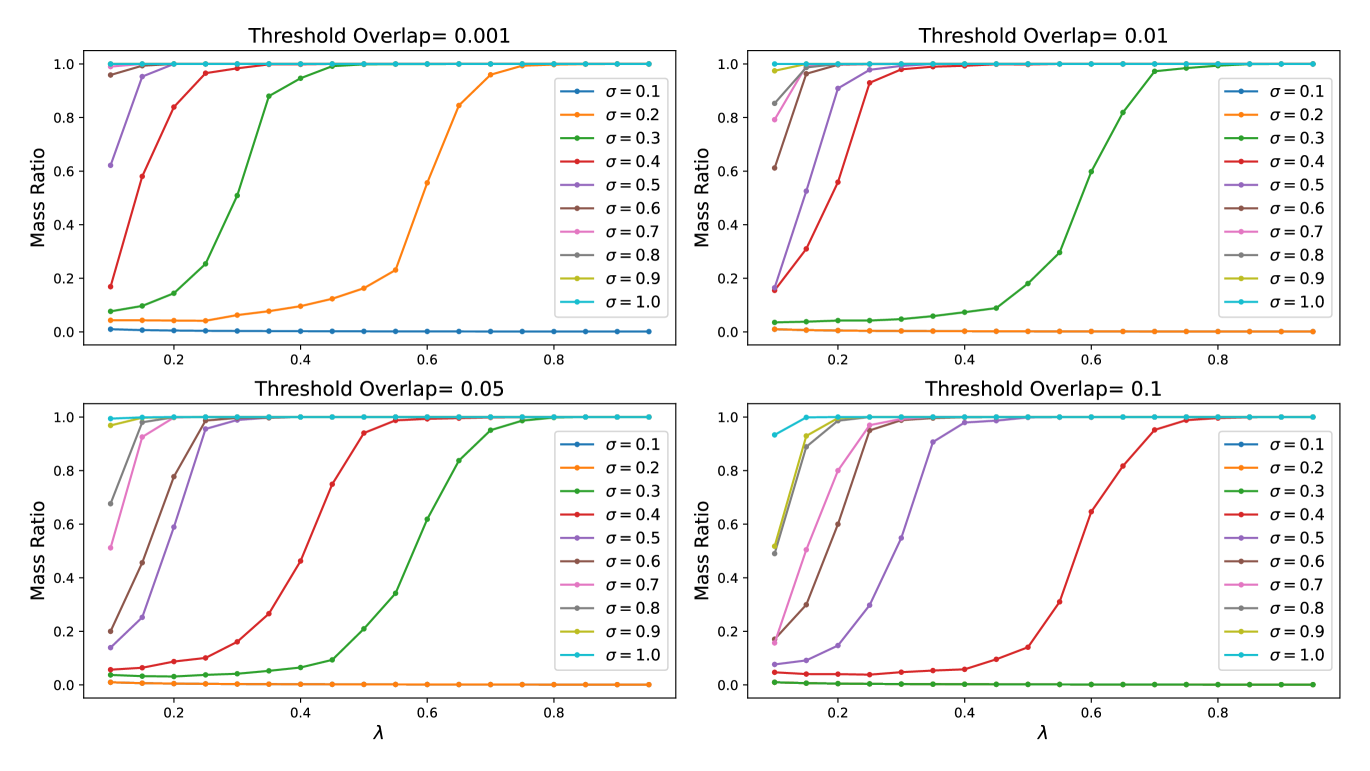
In Sec. 3.3, we have shown simulation results on percolation Fig. 6(c) to match with our experimental data in (e). Specifically, we perform the simulation on actual 2D Gaussian bump datasets generated in the same way as those used to train the models generating the experimental results. Here we employ a neighborhood-finding algorithm that recursively iterates through and find all island of connected clusters within a given sample of a dataset of and size . In the neighborhood-finding algorithm, we define a given set of two 2D Gaussian bumps to be connected if the normalized L2 metric (introduced in Appendix A.5 and plotted in Fig. 6(b)) is beyond a given threshold, which becomes a hyper-parameter in our simulation. A higher threshold overlap means that the neighborhood-finding algorithm has a more stringent standards for judging which set of bumps are connected, and that it is harder to percolate given the same amount of data. The simulation results averaged over 5 sample datasets per point are shown in Fig. 13 for various ’s and threshold overlaps. As we increase the threshold overlap in the simulation, the percolation thresholds of datasets of various ’s become delayed. Given a large enough threshold overlap, some of the datasets with small ’s never percolates. Moreover, we notice that in simulation never percolates due to its width of a pixel wide. Nonetheless, the model has learned to generated the Gaussian bumps with a larger effective width such that the model is able to construct a faithful manifold of the dataset at large . In Fig. 6(c), we have chosen to display the simulation results with threshold overlap of 0.005 to best match with the observed experimental data. Such a low threshold overlap signifies that the model is sensitive to relative spatial overlaps among data images.
D.2 Percolation Experimental Details
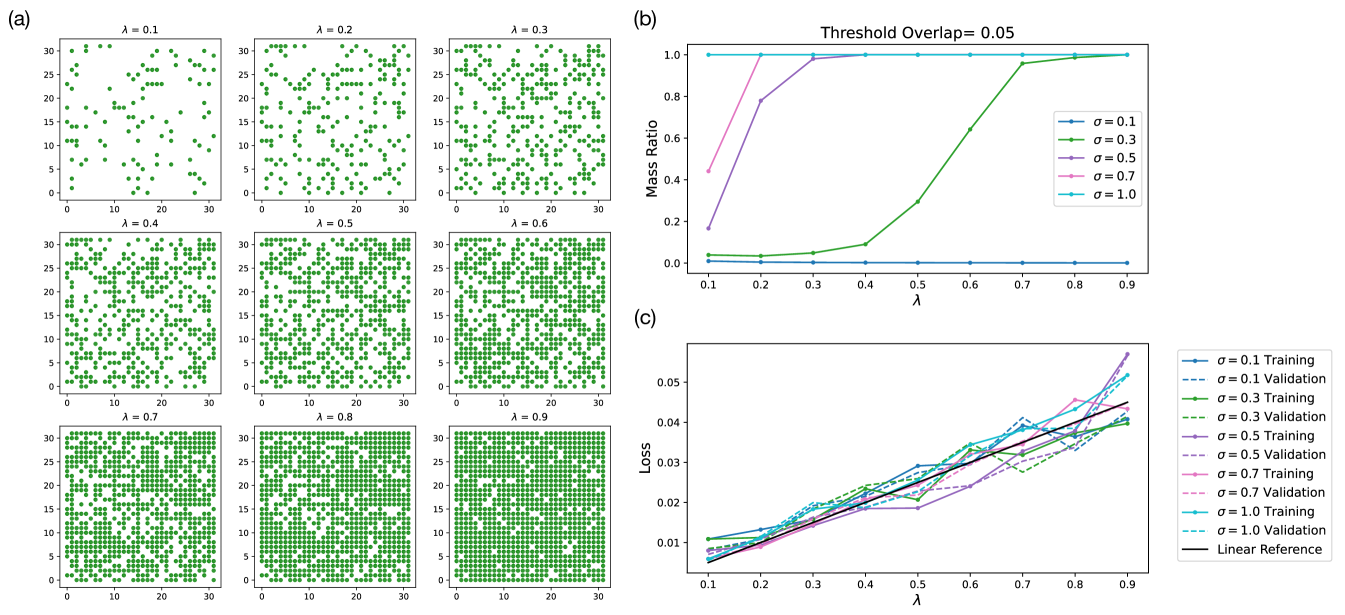
In testing out percolation theory in experiment, we relied on a specific data generation procedure to eliminate much of the stochasticity in sampling datasets to avoid having to train a large number of models. In Fig. 6(d), the datasets used to train model of different for different ’s are the same across all ’s except for the ’s. The shared underlying latent representations of the datasets are shown in Fig. 14(a) for different ’s. Moreover, we show an example simulation of the largest connected mass ratio of these specific datasets with threshold overlap of 0.05 in Fig. 14(b).
Note that here, as described in Sec. 3.3, each subsequent dataset of a larger is a superset of all preceding datasets of smaller ’s. As a result, we know that if the dataset with percolates at a given , then it automatically percolates at any . This is an important establishment since the models trained with datasets of small ’s seem to have high variance in the outcome training accuracy for different ’s, as shown in Fig. 6(d). Given the fact that all models trained on datasets with larger have a superset of information than those trained on datasets with smaller ’s, we can attribute the variance in the experimental outcome partially to the instability in the training itself rather than percolation theory.
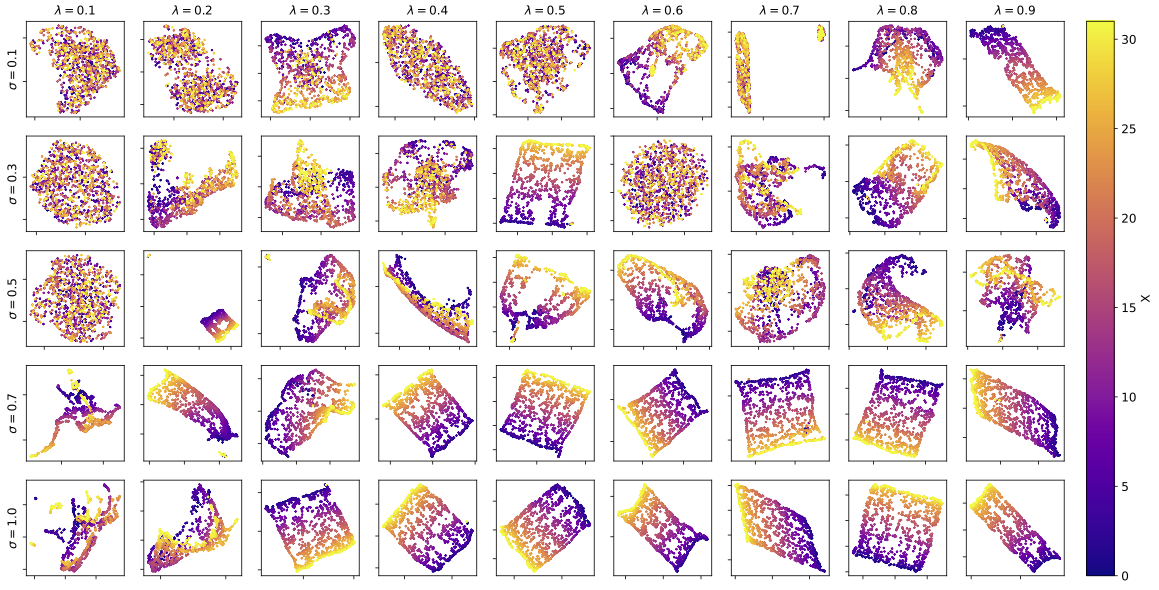
One hypothesis for the observed instability in models trained on datasets with smaller values is that the small interconnected components within the dataset lead to an unstable learned representation, making it more sensitive to fluctuations during optimization. The learned representation of the model corresponding to each data point shown in Fig. 6(d) are plotted in Fig. 15. As we can see, with fewer data points (smaller ) and smaller , the learned representation has a less rigid structure as compared to those learned with more data and larger ’s. Furthermore, we notice that the training and validation loss of the model grows linearly as a function of the number of training data, as shown in Fig. 14(c). This suggest that with a larger set of data, the model has less confidence in its learned representation due to the vast number of data it has to accommodate despite learning a higher-quality representation. Given a smaller dataset, the model can easily accommodate all data with relatively small training/validation losses despite learning a low-quality representation.