How Does GAN-based
Semi-supervised Learning Work?
Abstract
Generative adversarial networks (GANs) have been widely used and have achieved competitive results in semi-supervised learning. This paper theoretically analyzes how GAN-based semi-supervised learning (GAN-SSL) works. We first prove that, given a fixed generator, optimizing the discriminator of GAN-SSL is equivalent to optimizing that of supervised learning. Thus, the optimal discriminator in GAN-SSL is expected to be perfect on labeled data. Then, if the perfect discriminator can further cause the optimization objective to reach its theoretical maximum, the optimal generator will match the true data distribution. Since it is impossible to reach the theoretical maximum in practice, one cannot expect to obtain a perfect generator for generating data, which is apparently different from the objective of GANs. Furthermore, if the labeled data can traverse all connected subdomains of the data manifold, which is reasonable in semi-supervised classification, we additionally expect the optimal discriminator in GAN-SSL to also be perfect on unlabeled data. In conclusion, the minimax optimization in GAN-SSL will theoretically output a perfect discriminator on both labeled and unlabeled data by unexpectedly learning an imperfect generator, i.e., GAN-SSL can effectively improve the generalization ability of the discriminator by leveraging unlabeled information.
1 Introduction
Deep neural networks have repeatedly been able to achieve results similar to or beyond those of humans on certain supervised classification tasks based on large numbers of labeled samples. In the real world, due to the limited cost of labeling and the lack of expert knowledge, the dataset we obtain usually contains large numbers of unlabeled samples and only a small number of labeled samples. Although unlabeled samples do not have label information, they originate from the same data source as the labeled data. Semi-supervised learning (SSL) strives to make use of the model assumptions of unlabeled data distributions, thereby greatly reducing the need of a task for labeled data.
Early semi-supervised learning methods include self-training, transductive learning, generative models and other learning methods. With the rapid development of deep learning in recent years, semi-supervised learning has gradually been combined with neural networks, and corresponding achievements have occurred [17, 11, 10, 3, 19]. At the same time, the deep generative model has become a powerful framework for modeling complex high-dimensional datasets [9, 7, 18]. As one of the earlier works, [8] uses the deep generative model in SSL by maximizing the lower variational bound of the unlabeled data log-likelihood and treats the classification label as an additional latent variable in the directed generative model. In the same period, the well-known generative adversarial networks (GANs) [7] were proposed as a new framework for estimating generative models via an adversarial process. The real distribution of unsupervised data can be learned by using the generator of GANs. Recently, GANs have been widely used and have obtained competitive results for semi-supervised learning [15, 17, 4, 12, 5]. The early classic GAN-based semi-supervised learning (GAN-SSL) [15] presented a variety of new architectural features and training procedures, such as feature matching and minibatch discrimination techniques, to encourage the convergence of GANs. By labeling the generated samples as a new ”generated” class, the above techniques were introduced into semi-supervised tasks, and the best results at that time were achieved.
Despite the great empirical success achieved using GANs to improve semi-supervised classification performance, many theoretical issues are still unresolved. For example, [15] observed that, compared with minibatch discrimination, semi-supervised learning with feature matching performs better, but generates images of relatively poorer quality. A basic theoretical issue of the above phenomenon is as follows: how does GAN-based semi-supervised learning work? The theoretical work of [4] claimed that good semi-supervised learning requires a ”bad” generator, which is necessary to overcome the generalization difficulty in the low-density areas of the data manifold. Thus, they further proposed a ”complement” generator to enhance the effect of the ”bad” generator. Although the complement generator is empirically helpful for improving the generalization performance, we find that their theoretical analysis was not rigorous; hence, their judgment regarding the requirement of a ”bad” generator is somewhat unreasonable. This paper re-examines this theoretical issue and obtains some theoretical observations inconsistent with that in [4].
First, we study the relationship between the optimal discriminator in GAN-SSL and the one in the corresponding supervised learning. For a fixed generator, we prove that maximizing the GAN-SSL objective is indeed equivalent to maximizing the supervised learning objective. That is, the optimal discriminator in GAN-SSL is expected to be perfect in the corresponding supervised learning, i.e., the optimal discriminator can make a correct decision on all labeled data. Thus, we can initially state that GAN-SSL can at least obtain a good performance on labeled data.
Second, for the optimal discriminator, we investigate the behavior of the optimal generator of GAN-SSL. We find that the error of the optimal generator distribution relative to the true data distribution highly depends on the optimal discriminator. Given an optimal discriminator, the minimax game in GAN-SSL for the generator is equivalent to minimizing , where is the true data distribution, is the generator distribution and represents the error between the output of the perfect discriminator and its theoretical maximum. Once the optimal discriminator can not only make a correct decision on all labeled data but also cause the objective of the supervised learning part in GAN-SSL to reach its theoretical maximum (i.e., ), minimizing the generator objective is equivalent to minimizing ; hence, the optimal generator is perfect, i.e., the optimal generator distribution is indeed the true data distribution. Whereas the theoretical maximum is impossible to reach in practice, the optimal generator will always be inconsistent with the true data distribution, i.e., the optimal generator is imperfect. Notably, although our observation is that the optimal generator is imperfect in practice, it is not as ”bad” as claimed in [4]. Here, we can state that GAN-SSL will always output an imperfect generator.
Furthermore, if the labeled data can traverse all connected subdomains of the data manifold, which is a reasonable assumption in semi-supervised classification, we will additionally have that the optimal discriminator of GAN-SSL can be perfect on all unlabeled data, i.e., it can make a correct decision on all unlabeled data. Thus, we can state that GAN-SSL can also obtain a good performance on unlabeled data.
Overall, with our theoretical analysis, we can answer the above question: the optimal discriminator in GAN-SSL can be expected to be perfect on both labeled and unlabeled data by learning an imperfect generator. This theoretical result means that GAN-SSL can effectively improve the generalization ability of the discriminator by leveraging unlabeled information.
2 Related Work
Based on the classic GAN-SSL [15], the design of additional neural networks and the corresponding objectives have received much interest. The work of [13] presents Triple-GAN, which consists of three players, i.e., a generator, a discriminator and a classifier, to address the problem in which the generator and discriminator (i.e., the classifier) in classic GAN-SSL may not be optimal at the same time. Later, a more complex architecture consisting of two generators and two discriminators was developed [6], which performs better than Triple-GAN under certain conditions. To address the issue caused by incorrect pseudo labels, based on the margin theory of classifiers, MarginGAN [5], which also adopts a three-player architecture, was proposed.
As mentioned in GAN-SSL [15], feature matching works very well for GAN-SSL, but the interaction between the discriminator and the generator is not yet understood, especially from the theoretical aspect. To the best of our knowledge, few theoretical investigations on this topic exist, with one exception being the work of [4], which focused on the analysis of the optimal and . Our paper is also developed from this aspect. In addition, some theoretical works in the area of GANs regarding the design of the objective [16, 14] or the convergence of the adversarial process [1, 2], can be applied to the area of GAN-SSL. Since GAN-SSL has an additional supervised learning objective, one should further develop some theoretical techniques to handle this problem. These open aspects should be studied in the future.
3 Theoretical Analysis
We first introduce some classic notations and definitions. We refer to [15] for a detailed discussion. Consider a standard classifier for classifying a data point into one of possible classes. The output of the classifier is a -dimensional vector of logits that can be turned into class probabilities by applying softmax. The classic GAN-SSL [15] is implemented by labeling samples from the GAN generator with a new ”generated” class . We use to determine the probability that is true or fake, respectively. The model is both a discriminator and a classifier, correspondingly increasing the dimension of the output from to . Thus, the discriminator is defined as , where is a nonlinear vector-valued function, is the weight vector for class and is the -dimensional vector of the logits. Since a discriminator with outputs is over-parameterized, is fixed as a zero vector. We also denote as a discriminator. Similar to the traditional GANs, in GAN-SSL, and play the following two-player minimax game with the value function :
| (1) |
where
where is the supervised learning objective for all labeled data and is the unsupervised objective, i.e., the traditional GANs objective, in which is the true data distribution and is the generator distribution. When is fixed, the objectives and become and , respectively. After we obtain a satisfactory by optimizing , we use to determine the class of the input data . Similar to the other related works on GAN-SSL, we use as the supervised learning objective by applying only the softmax operator on the former -dimensional vector of the output of .
Similar to the theoretical analysis of GANs, we consider a nonparametric setting, e.g., we represent a model with infinite capacity and study the optimal discriminator and generator in the space of probability density functions. The theoretical proofs, including Proposition 1 - Proposition 3, are provided in the supplementary material. We show the proof of Lemma 1, since it is the key point of our paper.
3.1 Optimal discriminator on labeled data
First, we consider the optimal discriminator for any given generator . Motivated by the proof of Proposition 1 in [4], this subsection proves that for fixed , if the discriminator has infinite capacity, then regardless of whether the generator is perfect, i.e., or , maximizing the above GAN-SSL objective is equivalent to maximizing the supervised learning objective . We first introduce a basic Lemma 1 and give its proof.
Lemma 1.
For any given generator , if the discriminator has infinite capacity, then for any solution of the GAN-SSL objective , there exists another solution such that and .
Proof.
For any given generator and any solution of the GAN-SSL objective , because the discriminator has infinite capacity, there exists such that for all and ,
For all ,
Then , and
For the following unsupervised objective function
when is fixed, it is easy to verify that can maximize it. Therefore, and . This completes the proof. ∎
Lemma 1 states that for any given generator and due to the infinite capacity of the discriminator, under the condition that the supervised objective remains unchanged, we can always increase the unsupervised objective until the extreme value is reached. Then, based on Lemma 1, we can present the theoretical results of the optimal discriminator for any given generator .
Proposition 1.
Given the conditions in Lemma 1, we can obtain the following:
(1) for any optimal solution of the supervised learning objective , there exists such that maximizes the GAN-SSL objective and that, for all ,
(2)
for any optimal solution of the above GAN-SSL objective , is an optimal solution of the supervised objective .
(3) the optimal discriminator of the above GAN-SSL objective is
Proposition 1 (1) and (2) jointly indicate that given a fixed generator, optimizing the discriminator of GAN-SSL is equivalent to optimizing that of supervised learning. Thus, the optimal discriminator in GAN-SSL is expected to be perfect on labeled data. We should note that Proposition of [4] gives a similar theoretical result, claiming only that the optimal discriminator of can lead to an optimal discriminator of GAN-SSL, i.e., the first claim of the above Proposition 1, but given the condition that . Actually, our theoretical investigation instead shows that the condition is unnecessary and that the optimal discriminator of GAN-SSL is an optimal discriminator of supervised learning.
By carefully checking the statements in Proposition of [4] and comparing their results with ours, one may realize that their results are not rigorous. They claimed that good semi-supervised learning requires a bad generator because they observed that the semi-supervised objective shares the same generalization error with the supervised objective given a perfect generator. First, from our theoretical results, a perfect generator is not necessary for the observation, such that the requirement of a bad generator in their claim is unreasonable. Moreover, the fact that the semi-supervised objective shares the same generalization error with the supervised objective is insufficient for claiming that GAN-SSL will reduce the generalization ability of supervised learning. In addition, if we can claim only that the optimal discriminator of can lead to the optimal discriminator of GAN-SSL, one would not expect to obtain a perfect discriminator on labeled data by GAN-SSL such that the Assumption (1) of [4] is over-assumed. Our result, i.e., the Proposition 1 (2), can overcome their shortcoming, such that our later Assumption 1 (1) is indeed reasonable.
3.2 Optimal generator
Next, for a fixed optimal discriminator, we discuss the behavior of the optimal generator of GAN-SSL. By the definition of the discriminator , we have . Based on Proposition 1 (3), . Namely,
implying that . Now, the objective of becomes , with
The aim of the discriminator is to classify the labeled samples into the correct class, the unlabeled samples into the ”true” class (any of the first classes) and the generated samples into the ”fake” class, i.e., the -th class. In this paper, the so-called perfect discriminator means that for any , , i.e., the discriminator can make a correct decision on labeled data. We say that the discriminator reaches its theoretical maximum given that and, for any other class , . Obviously, it is impossible to reach the theoretical maximum in practice, i.e., can only be close to , and for any other class , . That is, because the discriminator has an infinite capacity, we can expect that there exists such that for any other class . Here, represents the error between the output of the perfect discriminator and its theoretical maximum. Now, we show the relationship between the true data distribution and the generator distribution in GAN-based semi-supervised tasks through the following Proposition 2.
Proposition 2.
Given the conditions in Proposition 1, for a fixed optimal discriminator , suppose there exists such that the other logit output () of satisfies . Then, the generator objective .
Proposition 2 indicates that minimizing the generator objective is equivalent to minimizing and maximizing simultaneously. To minimize , we need to train close to ; however, to maximize , we need to increase the difference between and . If the optimal solution of GAN-SSL for the supervised objective can reach the theoretical maximum, i.e., , then minimizing is equivalent to minimizing . Since the Jensen-Shannon divergence between two distributions is always non-negative and zero iff they are equal, then is the global minimum of , and the only solution is , i.e., the generator distribution perfectly replicates the true data distribution such that the optimal generator is perfect. Whereas, it is impossible to reach the theoretical maximum, then . If we assume that is sufficiently small, i.e., , the optimal generator will not be . Otherwise, if , can reach its minimum, and becomes very small, which is in contrast to maximizing in the objective .
Different from the theoretical result of [4] that good semi-supervised learning requires a bad generator, Proposition 2 shows that the error of the optimal generator distribution relative to the true data distribution largely depends on the optimal discriminator. First, when the perfect discriminator for the supervised objective can reach its theoretical maximum, the global optimal generator of GAN-SSL is , i.e., the optimal generator is perfect. However, since the theoretical maximum cannot be reached in practice, one cannot expect to learn a perfect generator, i.e., the optimal generator is imperfect. In addition, we note that although the optimal generator is imperfect in actual situations, it can be similar to the original data distribution. As shown in the work of [15], samples generated by the excellent GAN-SSL generator are not perfect but not completely different from the original data distribution, which is apparently inconsistent with the requirement of a ”bad” generator in [4].
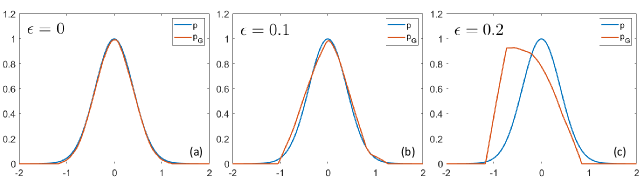
Case Study on Synthetic Data. To obtain a more intuitive understanding of Proposition 2, we conduct a case study based on a 1D synthetic dataset, where we can easily verify our theoretical analysis by visualizing the model behaviors. The training dataset is sampled from the Gaussian distribution . Based on Proposition 2, we study the relationship between the original data distribution and the generator distribution obtained by directly training the following generator objective function . We use the generator architecture of a fully connected neural network with ReLU activations: 1-100-100-1. We give the results of comparing and when , and in Figure 1, respectively. As theoretically analyzed above, for a constant , minimizing is equivalent to minimizing , and the optimal solution is (as shown in Figure 1 (a)). As shown in Figure 1 (b) and (c), when , is imperfect and the greater is, the larger the gap between and . Although there is a certain gap between the generator distribution and the data distribution, is similar to , and most of their supports overlap. Therefore, in this case, different from GANs, the optimal generator cannot be used to generate samples.
3.3 Optimal discriminator on unlabeled data
Finally, to study the behavior of the optimal discriminator of GAN-SSL on unlabeled data, we first present the assumption on the convergence conditions of the optimal discriminator and generator and the manifold conditions on the dataset. Let be the set of labeled data. Let , be the data manifold and generated data manifold, respectively. Obviously, we have , and the unlabeled data should be sampled from . Denote , where is the data manifold of class . Denote , where is a connected subdomain.
Assumption 1.
Suppose are optimal solutions of the GAN-SSL objective (1). We assume that:
(1) for any , we have for any other class ;
(2) for any , ; for any , ;
(3) each contains at least one labeled data point;
(4) for any and , there exists a connected subdomain , a labeled data point ,
a generated data point , and , such that .
The Reasonableness of Assumption 1 (1). According to the theoretical analysis for the optimal discriminator (Proposition 1), we found that optimizing the discriminator of GAN-SSL is equivalent to optimizing that of supervised learning. Because is an optimal solution of the GAN-SSL objective, is an optimal solution of the supervised learning objective. Naturally, Assumption 1 (1) holds, i.e., the discriminator has a correct decision boundary for labeled data given that the discriminator has infinite capacity.
The Reasonableness of Assumption 1 (2). Proposition 2 implies that the optimal generator we obtain in practice is not a perfect generator such that we assume . We ignore the case of since it is almost impossible to ensure that our optimal generator can output only true data but with different probabilities in practice, unless we obtain the worst model with model collapse. Similar to [4], we also make a strong assumption regarding the true-fake correctness of the true data () and fake data (). In other words, we assume that the sampling of unlabeled data is good enough to achieve the best generalization ability on the true data manifold.
The Reasonableness of Assumption 1 (3). Intuitively, one cannot expect to achieve a good classification performance on a connected subdomain with no label information, since we can optionally set this connected subdomain to any class but with no influence on the objective.
The Reasonableness of Assumption 1 (4). Apparently, Assumption 1 (3) is a sufficient condition for this assumption. In addition, since the optimal generator is imperfect and we need only its existence, one can expect to be able to achieve this condition.
Now, based on Assumption 1, we give the main result of this subsection.
Proposition 3.
Given the conditions in Assumption 1, for all classes , for all data space points , we have for any .
We remark that the proof of Proposition 3 is similar to that in [4] but with different conditions; see the supplementary material for more details. Proposition 3 guarantees that given the convergence conditions of the optimal discriminator and generator, which are induced by Proposition 1 and 2, respectively, if the labeled data can traverse all subdomains of the data manifold, then the discriminator will be perfect on the data manifold, i.e., it can also learn correct decision boundaries for all unlabeled data. Now, we discuss the difference between our Assumption 1 and Assumption in [4].
- 1.
- 2.
-
3.
Unlike [4], we additionally give a reasonable assumption on the data manifold, i.e, Assumption 1 (3). By a careful check, one can find that the authors of [4] ignore this assumption because they implicitly assume that after embedding , the feature space of each class is a connected domain. Otherwise, the proof of their Proposition is not correct, since one can set a connected subdomain of the feature space without label information to any class by a similar contradiction proof.
-
4.
Similar to our Assumption 1 (4), [4] make a stronger assumption before the definition of their Assumption by setting as a complement generator. Given a complement generator, our Assumption 1 (4) can clearly be satisfied. Note that under their definition, if the optimal generator is a complementary one, the feature space of the generated data will fill the complement set of the feature space of the true data. In other words, they hope that the ”bad” generator can not only generate fake data but also generate all the existing fake data. Apparently, this assumption is too strong and requires the generator to offer a high representation ability, since our true data manifold is always low-dimensional. However, we need only the existence of a generated fake data point such that its feature can be linearly represented by that of two true data points with at least one labeled data point. This existence has a high probability to be satisfied given only a connected subdomain and an imperfect generator. Here, we actually release the requirement for a complement generator.
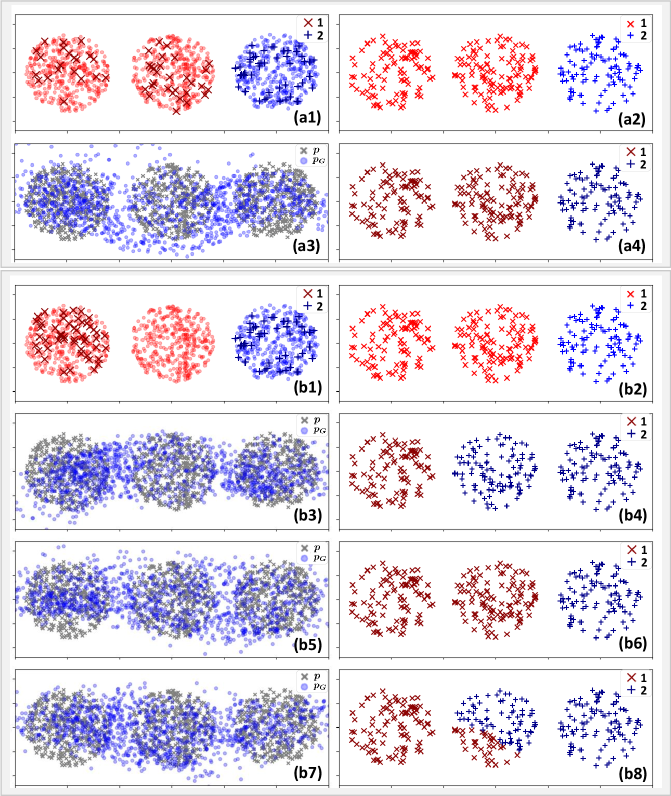
The Reasonableness of Assumption 1 (3) on Synthetic Data. We design a binary classification problem with , where and , and are three bounded 2D circles with no interaction. The unlabeled data are uniformly sampled from . If Assumption 1 (3) is satisfied, each connected domain contains at least one labeled data point, as shown in Figure 2 (a1). Then, as shown in Figure 2 (a4), we can easily train the discriminator to learn the correct decision boundary. However, if Assumption 1 (3) is not satisfied, for the data in class , we sample only the labeled data in subdomain , as shown in Figure 2 (b1). At this time, it is difficult for the discriminator to learn a correct decision boundary. As shown in Figure 2 (b4), (b6), and (b8), we choose three kinds of results under several training processes. For the unlabeled data in subdomain , the classification results are uncertain. Hence, a comparison between Figure 2 (a4), (b4), (b6), and (b8) can show that the condition of Assumption 1 (3) is necessary to obtain a perfect discriminator on unlabeled data. Furthermore, as shown in Figure 2 (a3), (b3), (b5) and (b7), a comparison of the generated samples shows that there is indeed a certain gap between the generator distribution and the data distribution, while the optimal generator is not a complementary one, as claimed in [4].
4 Conclusions
Via a theoretical analysis, this paper answers the question of how GAN-SSL works. In conclusion, semi-supervised learning based on GANs will yield a perfect discriminator on both labeled (Proposition 1) and unlabeled data (Proposition 3) by learning an imperfect generator (Proposition 2), i.e., GAN-SSL can effectively improve the generalization ability in semi-supervised classification. In the future, the theoretical problems of more complex models, such as Triple-GAN and other methods, will be studied. In addition, the existence of Assumption 1 (4) will undergo further theoretical and empirical investigations.
Acknowledgements
This work was supported in part by the Innovation Foundation of Qian Xuesen Laboratory of Space Technology, and in part by Beijing Nova Program of Science and Technology under Grant Z191100001119129.
References
- [1] Sanjeev Arora, Rong Ge, Yingyu Liang, Tengyu Ma, and Yi Zhang. Generalization and equilibrium in generative adversarial nets (GANs). In International Conference on Machine Learning, pages 224–232, 2017.
- [2] Yu Bai, Tengyu Ma, and Andrej Risteski. Approximability of discriminators implies diversity in GANs. In International Conference on Learning Representations, 2019.
- [3] David Berthelot, Nicholas Carlini, Ian Goodfellow, Nicolas Papernot, Avital Oliver, and Colin A Raffel. MixMatch: A holistic approach to semi-supervised learning. In Neural Information Processing Systems, pages 5049–5059, 2019.
- [4] Zihang Dai, Zhilin Yang, Fan Yang, William W. Cohen, and Ruslan Salakhutdinov. Good semi-supervised learning that requires a bad GAN. In Neural Information Processing Systems, 2017.
- [5] Jinhao Dong and Tong Lin. MarginGAN: Adversarial training in semi-supervised learning. In Neural Information Processing Systems, pages 10440–10449, 2019.
- [6] Zhe Gan, Liqun Chen, Weiyao Wang, Yuchen Pu, Yizhe Zhang, Hao Liu, Chunyuan Li, and Lawrence Carin. Triangle generative adversarial networks. In Neural Information Processing Systems, pages 5247–5256, 2017.
- [7] Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. In Neural Information Processing Systems, pages 2672–2680, 2014.
- [8] Diederik P. Kingma, Danilo J. Rezende, Shakir Mohamed, and Max Welling. Semi-supervised learning with deep generative models. In Neural Information Processing Systems, pages 3581–3589, 2014.
- [9] Diederik P Kingma and Max Welling. Auto-encoding variational bayes. In International Conference on Learning Representations, 2014.
- [10] Thomas N. Kipf and Max Welling. Semi-supervised classification with graph convolutional networks. In International Conference on Learning Representations, 2017.
- [11] Samuli Laine and Timo Aila. Temporal ensembling for semi-supervised learning. In International Conference on Learning Representations, 2017.
- [12] Bruno Lecouat, Chuan Sheng Foo, Houssam Zenati, and Vijay Chandrasekhar. Manifold regularization with GANs for semi-supervised learning. arXiv preprint arXiv:1807.04307, 2018.
- [13] Chongxuan Li, Taufik Xu, Jun Zhu, and Bo Zhang. Triple generative adversarial nets. In Neural Information Processing Systems, pages 4088–4098, 2017.
- [14] Lars Mescheder, Andreas Geiger, and Sebastian Nowozin. Which training methods for GANs do actually converge? International Conference on Machine Learning, 2018.
- [15] Tim Salimans, Ian Goodfellow, Wojciech Zaremba, Vicki Cheung, Alec Radford, and Chen Xi. Improved techniques for training GANs. In Neural Information Processing Systems, 2016.
- [16] Tim Salimans, Han Zhang, Alec Radford, and Dimitris Metaxas. Improving GANs using optimal transport. In International Conference on Learning Representations, 2018.
- [17] Jost Tobias Springenberg. Unsupervised and semi-supervised learning with categorical generative adversarial networks. In International Conference on Learning Representations, 2016.
- [18] Aäron van den Oord, Sander Dieleman, Heiga Zen, Karen Simonyan, Oriol Vinyals, Alexander Graves, Nal Kalchbrenner, Andrew Senior, and Koray Kavukcuoglu. Wavenet: A generative model for raw audio. SSW, page 125, 2016.
- [19] Qizhe Xie, Zihang Dai, Eduard Hovy, Minh-Thang Luong, and Quoc V. Le. Unsupervised data augmentation for consistency training. arXiv preprint arXiv:1904.12848, 2019.
Appendix
Proof of Proposition
Proof.
Proof of Proposition (1). Similar to the proof of Lemma , given an optimal solution of the supervised objective , due to the discriminator has infinite capacity, there exists such that for all and ,
| (2) |
For all ,
Then . Based on the definition and given Eq. (2), we can obtain
By the proof of Lemma , is an optimal solution of . Because maximizes , also maximizes . It follows that maximizes .
Proof of Proposition (2). First, we should note that if maximizes the GAN-SSL objective , then maximizes . Otherwise, based on Lemma , there exists another solution such that and , i.e., , leading to contradiction. That is to say, for any optimal solution of the GAN-SSL objective , reaches the extreme value; then, is also an optimal solution of . Otherwise, due to the infinite capacity of the discriminator, there exists an optimal solution of the supervised objective . Thus, based on Proposition (1), there exists such that and . Therefore, , leading to contradiction, i.e., for any optimal solution of , is an optimal solution of .
Based on Proposition (1) and (2), we can obtain that maximizing is equivalent to maximizing the quantity and , simultaneously. Then, the optimal solution of must also be the optimal solution of . Similar to the theoretical results of [Goodfellow et al. 2014], for fixed, the optimal discriminator of the GAN-SSL objective is
and
This completes the proof. ∎
Proof of Proposition
Proof.
By the definition of the discriminator , , and based on Proposition (3), , then for the optimal discriminator , , such that
For a fixed optimal discriminator , suppose there exists such that the other logit output () of satisfies , then, . If the minimum can be achieved, i.e., , therefore,
Then,
This completes the proof. ∎
Proof of Proposition
Proof.
First, if is a labeled data point, based on Assumption (1), we have for any . Then, we consider is an unlabeled data point. Without loss of generality, suppose . Now, we prove it by contradiction.
Suppose there exists a data space point and a class , such that
| (3) |
By Assumption (3) and Assumption (4), there exists a connected subdomain , a labeled data point , and a generated data point , such that with . Based on Assumption (2), . Thus,
By Assumption (1) and Assumption (2), for any , . Moreover, by Eq. (3) and Assumption (2), for any , . Then, , leading to contradiction. In summary, for all data space points , we have for any . ∎