How to Spread a Rumor: Call Your Neighbors or Take a Walk?
Abstract
We study the problem of randomized information dissemination in networks. We compare the now standard push-pull protocol, with agent-based alternatives where information is disseminated by a collection of agents performing independent random walks. In the visit-exchange protocol, both nodes and agents store information, and each time an agent visits a node, the two exchange all the information they have. In the meet-exchange protocol, only the agents store information, and exchange their information with each agent they meet.
We consider the broadcast time of a single piece of information in an -node graph for the above three protocols, assuming a linear number of agents that start from the stationary distribution. We observe that there are graphs on which the agent-based protocols are significantly faster than push-pull, and graphs where the converse is true. We attribute the good performance of agent-based algorithms to their inherently fair bandwidth utilization, and conclude that, in certain settings, agent-based information dissemination, separately or in combination with push-pull, can significantly improve the broadcast time.
The graphs considered above are highly non-regular. Our main technical result is that on any regular graph of at least logarithmic degree, push-pull and visit-exchange have the same asymptotic broadcast time. The proof uses a novel coupling argument which relates the random choices of vertices in push-pull with the random walks in visit-exchange. Further, we show that the broadcast time of meet-exchange is asymptotically at least as large as the other two’s on all regular graphs, and strictly larger on some regular graphs.
As far as we know, this is the first systematic and thorough comparison of the running times of these very natural information dissemination protocols.
1 Introduction
We investigate the problem of spreading information (or rumors) in a distributed network using randomized communication. The archetypal paradigm solution is the so-called, randomized rumor spreading protocol, where each informed node samples a random neighbor in each round, and sends the information to it. This is the push version of rumor spreading, introduced by Demers et al. in the 80’s [15], as a robust and lightweight protocol for distributed maintenance of replicated databases [15, 24].
The push-pull variant of rumor spreading, popularized by Karp et al. in 2000 [31], allows for bidirectional communication: In each round, every node calls a random neighbor and the two nodes exchange all information they have. push-pull was initially proposed as a way to reduce the message complexity of push on the complete graph [31]. It was subsequently observed that it is significantly faster than push in several families of graphs, including graph models of social networks [12, 17].
The above two protocols have been studied extensively over the past 15 years, and have also found several applications, including data aggregation [32, 8, 38], resource discovery [28], failure detection [42], and even efficient simulation of arbitrary distributed computations [10].
We compare the above well-established protocols for information spreading, with agent-based alternatives that have received almost no attention so far, even though they have very attractive properties, as we will see. These alternative protocols use a collection of agents performing independent random walks to disseminate information. In the visit-exchange protocol, both nodes and agents store information, and each time an agent visits a node, the two exchange all the information they have. In the meet-exchange protocol, only the agents store information, and exchange their information with each agent they meet.
Independent parallel random walks have been studied since the late 70s [1], mainly as a way to speed-up cover and hitting times and related graph problems [9, 2, 23, 21]. As far as we know, visit-exchange has not been studied before. For meet-exchange there is some limited previous work. It was studied for specific graph families, namely grids [39, 35] and random graphs [14]. Also, general bounds on the broadcast time of meet-exchange with respect to the meeting time were shown [16].
In this paper, we restrict our attention to the case where the number of agents in the network is linear in the number of nodes , and we assume that all agents start from the stationary distribution.
Under the assumption that there is a linear number of agents, the agent-based protocols have similar amount of communication as the rumor spreading protocols, both in terms of the (maximum) total number of messages sent per round, which is linear, and the total number of bits. One can think of the agents simply as tokens passed between nodes, along with the actual information (if there is any). Agents need not be labeled, so each node only needs to send a counter of the number of agents in each message.
The assumption that agents start from the stationary distribution makes sense in a setting where several pieces of information (or rumors) are generated frequently and distributed in parallel over time by the same set of agents, which execute perpetual independent random walks. As discussed later, our results for regular graphs hold also in the case where there is exactly one agent starting from each node.
One distinct advantage of the agent-based protocols is their locally fair use of bandwidth, i.e., all edges are used with the same frequency, since the random walks are independent and start from stationarity. Interestingly, the superiority of push-pull over push is commonly attributed to a similar fairness property: that nodes of larger degree contribute more to the dissemination — except that push-pull satisfies this property only for some graph topologies, and approximately, as we will see below. In the agent-based protocols, on the other hand, this property is satisfied in a very precise and exact way.
We will see that this fairness property results in a significant performance advantage of visit-exchange and meet-exchange over push and push-pull in certain families of graphs, on which the first two processes need only logarithmic time to spread an information, whereas the other two need polynomial time.
Contribution.
We compare the broadcast times of a single piece of information, originated at an arbitrary node of an -node graph , when push (or push-pull), visit-exchange, and meet-exchange are used. In the first three, the broadcast time is the time until all vertices are informed, while in meet-exchange it is the time until all agents are informed. Also, for meet-exchange, we assume that the first agent to visit the source becomes informed, and from that point on, information is exchanged only between agents.111This is a technicality used to allow for direct comparison between the protocols, and has limited effect on our results. As mentioned before, we assume a linear number of agents, each starting from the stationary distribution.
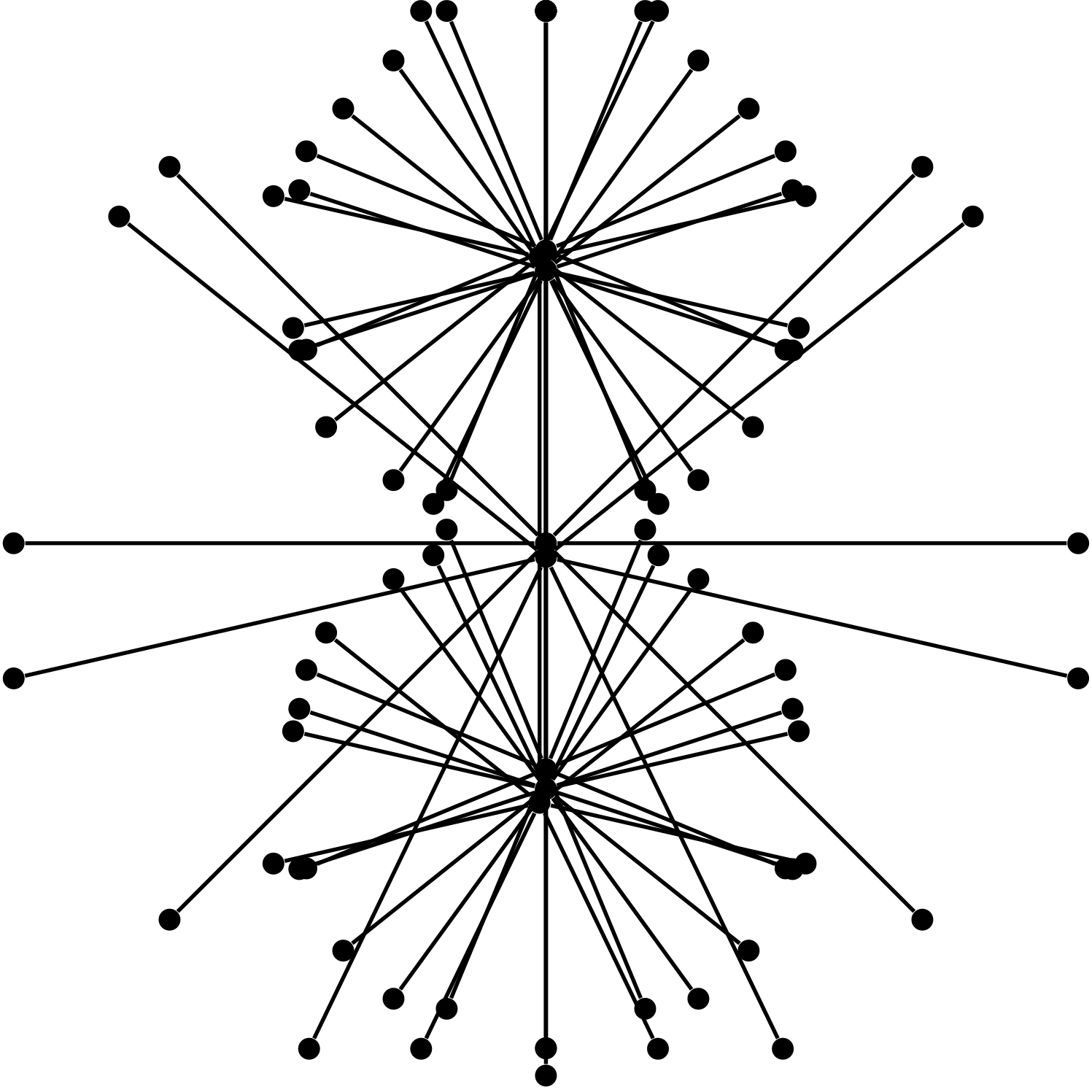
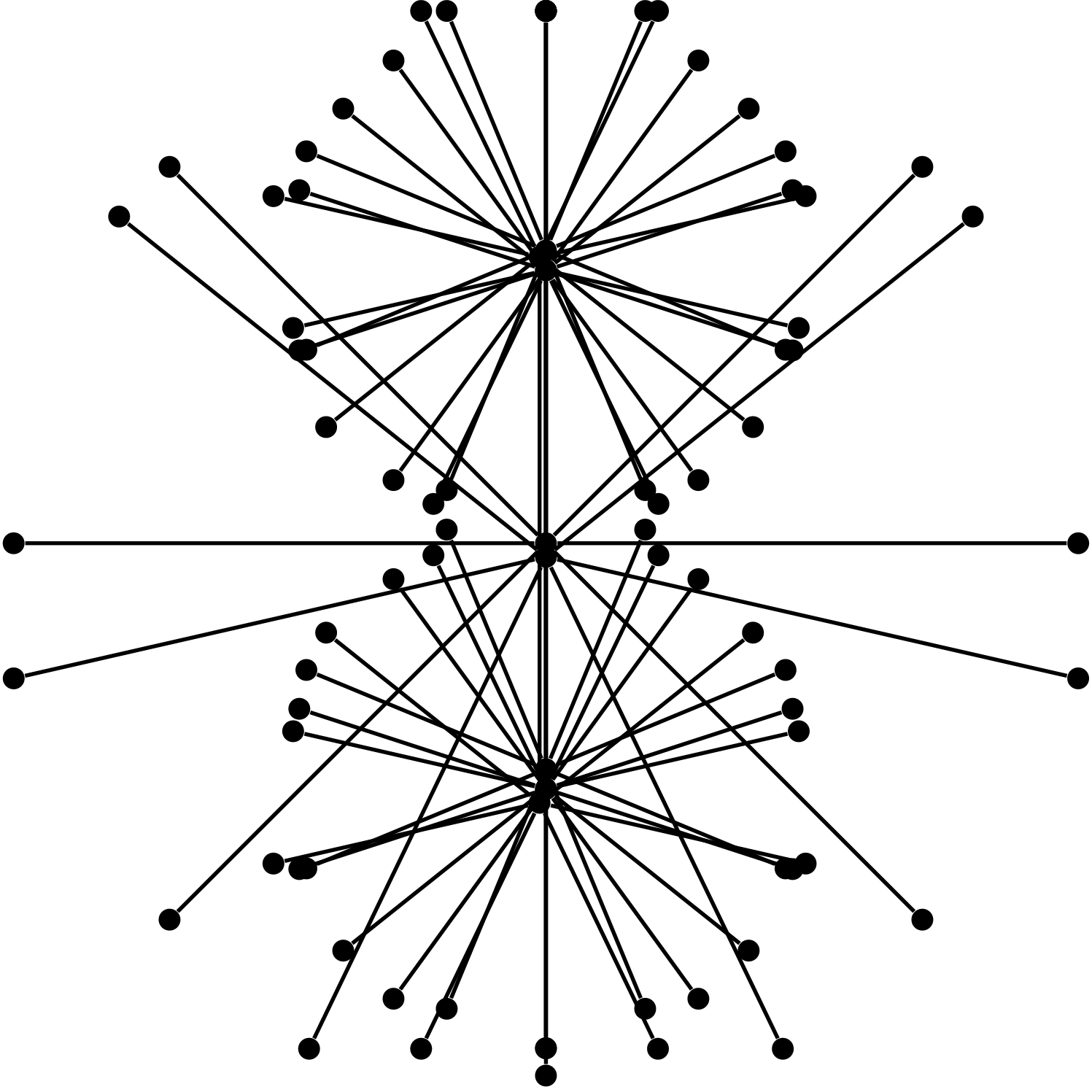
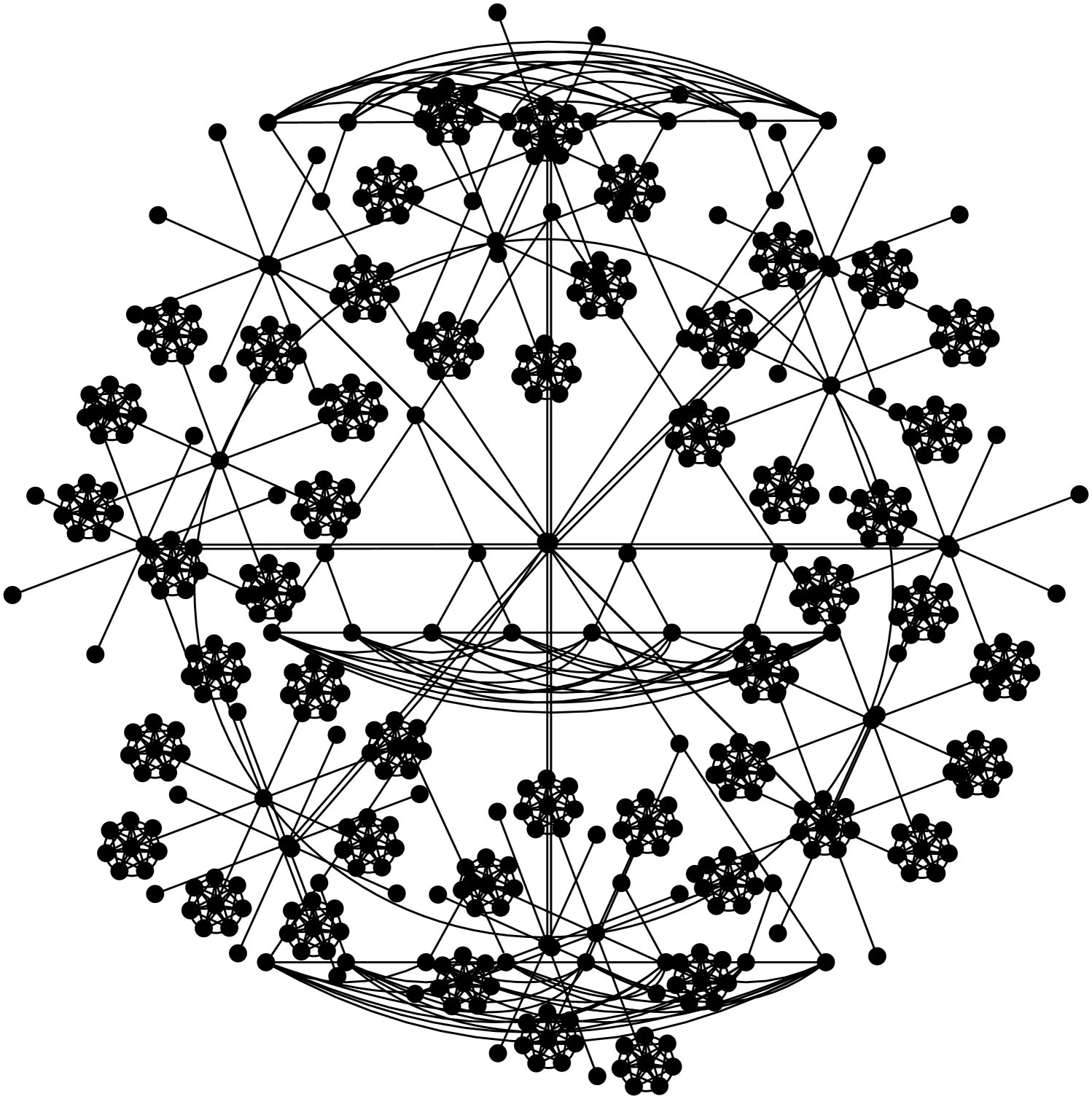
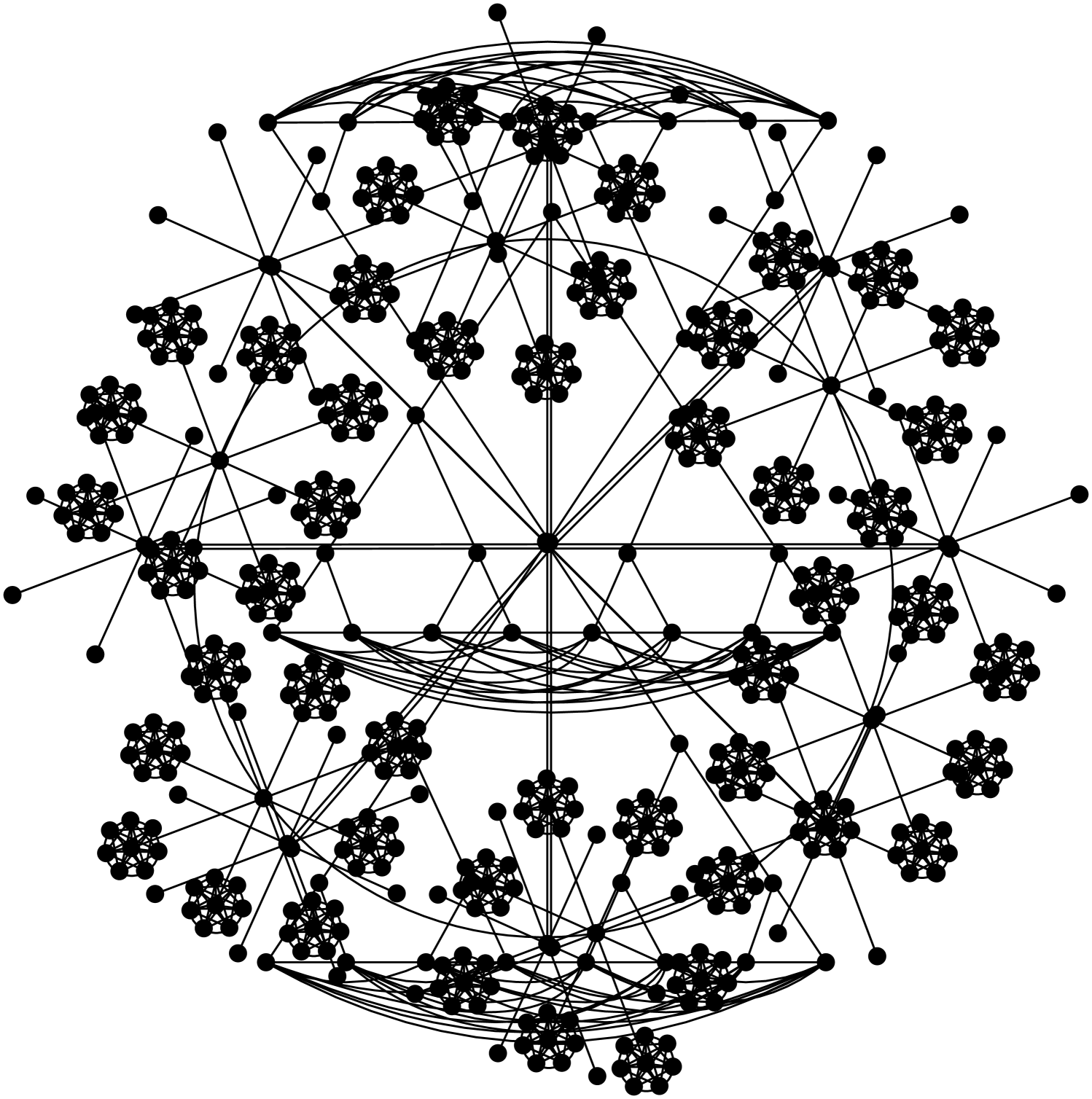
We observe that in general graphs, the broadcast times of the above protocols are incomparable: For any pair of protocols, there are examples of graphs where the first protocol is significantly faster than the other, by a polynomial factor in most cases. The examples we use, depicted in Fig. 1, are fairly simple, mainly trees or superpositions of trees with cliques.
The star graph in Fig. 1(a) is an example where push is known to take rounds, as the center must contact all leaves. visit-exchange and meet-exchange, on the other hand, take only logarithmic time, as roughly half of the walks visit the center in each round, and a constant number visits each leaf on average.
In the star, push-pull is also (extremely) fast. The next example, the double-star in Fig. 1(b), is a graph where push-pull (and thus also push) is slow, whereas visit-exchange and meet-exchange are still fast. This demonstrates the advantages of the local fairness property we pointed out earlier, and the impact it can have on the broadcast time: Here push-pull selects the edge between the two stars only with probability , which results in an expected broadcast time of . In visit-exchange and meet-exchange, on the other hand, the probability that some agent crosses the edge in a round is constant, resulting in a logarithmic broadcast time.
Fig. 1(c) and Fig. 1(d) illustrate examples where rumor spreading protocols have an advantage over agent-based protocols. In both examples push (and thus push-pull) has logarithmic broadcast time. For visit-exchange, at least linear time is needed: Since almost all the volume of the graph is concentrated on the leaves, it is likely that all agents are on the leaves at time zero, and then it takes linear time before the first walk reaches the root. For meet-exchange, we have that it is fast in the first example, as all walks meet quickly in the clique induced by the leaves. However, in the second example, where agents are roughly split between the two induced cliques, the broadcast times of both meet-exchange and visit-exchange is .
The above results suggest that in certain settings, agent-based information dissemination, separately or in combination with push-pull, can significantly improve the broadcast time. We stress that, even though the examples presented may seem contrived, they are intentionally simple to demonstrate the principle reasons that make the protocols perform differently, and we expect that similar result can be observed in a wide range of networks. In particular, we believe that the observations for the double-star example of Fig. 1(b), extend to more general tree-like topologies with high-degree internal nodes.
All examples we have discussed so far, involve highly non-regular graphs. Our main technical result concerns regular graphs, and can be stated somewhat informally as follows. (For the formal, stronger statements see Sections 5 and 6.)
Theorem 1.
For any -regular graph on vertices, where , and any source vertex, the broadcast times of push and visit-exchange are asymptotically the same both in expectation and w.h.p.,222By with high probability (w.h.p.) we mean with probability at least , with some constant that can be made arbitrary large, by adjusting the constants in the statement. modulo constant multiplicative factors.
Recall that push and push-pull have asymptotically the same broadcast times on regular graphs [27]. Note also that the broadcast times of push and push-pull on -regular graphs can vary from logarithmic, e.g., in random -regular graphs, to polynomial, e.g., in a path of -cliques where the broadcast time is .
The proof of Theorem 1 uses a novel coupling argument which relates the random choices of vertices in push, with the random walks in visit-exchange. Roughly speaking, for each node , we consider the list of neighbors that samples in push, and the list of neighbors to which informed agents move to in their next step after visiting in visit-exchange. Our coupling just sets the two lists to be identical for each . Even though the coupling is straightforward, its analysis is not. On the one direction of the proof, showing that the broadcast time of push is dominated by the broadcast time of visit-exchange, the main step is to bound the congestion, i.e., the number of agents encountered along a path, for all possible paths through which information travels. On the reverse direction, we focus only on the fastest path through which information reaches each node in push, and show that an equally fast path exists in visit-exchange. A useful trick we devise, to consider only every other round of visit-exchange in the coupling, simplifies the proof of this second direction. We expect that our proof ideas will be useful in other applications of multiple random walks as well.
In addition to Theorem 1, we observe that the broadcast time of meet-exchange is asymptotically at least as large as visit-exchange’s on any regular graph of at least logarithmic degree. The idea is that once all agents are informed it takes at most logarithmic time to cover the graph. It is probably surprising that the converse direction is not true, i.e., there are regular graphs where meet-exchange is strictly slower than visit-exchange. Fig. 1(e) presents one such example of a -regular graph, where , for which a logarithmic-factor gap exists between the broadcast times of the two protocols.
Road-map.
In Section 2, we survey additional related work. In Section 3, we provide a formal description of the protocols we study. In Section 4, we analyze the broadcast times for the example graphs in Fig. 1. In Section 5, we prove the first direction of Theorem 1, namely, that push is at least as fast as visit-exchange; the other direction is proved in Section 6. The result that visit-exchange is at least as fast as meet-exchange on regular graphs is provided in Section 7. Finally, some open problems are discussed in Section 9.
2 Related work
The push variant of rumor spreading was first considered in [15]. It was subsequently analyzed on various graphs in [24], where also bounds with the degree and diameter were shown for general graphs. The push-pull variant was introduced in [31], and was studied initially on the complete graph. More recently, there has been a lot of work on showing that in several settings rounds of rumor spreading suffice w.h.p. to broadcast information [18, 5, 19]. In addition, general bounds in terms of expansion parameters of the graph have been studied extensively, e.g., in [26, 11].
Another line of work compares synchronous and asynchronous versions of rumor spreading, where in the latter each node takes steps at the arrival times of an independent unit-rate Poisson process. In [41], it is shown that the asynchronous version of push has the same broadcast time as standard push on regular graphs. In [27, 4], tight bounds are given for the relation between the broadcast times of synchronous and asynchronous push-pull.
On the random walk literature, there has been some previous work on models related to meet-exchange, motivated mainly by the study of the spread of infectious diseases. The earliest work considering a process equivalent to meet-exchange is [16], which studies general graphs. It shows that the broadcast time of meet-exchange is at most times larger than the meeting time of two random walks in the graph, and that this upper bound is tight. Later, the authors of [14] studied meet-exchange for the case of random regular graphs and random walks. They showed that the expected broadcast time is . In [39], the -dimensional finite grid was studied and a broadcast time of was shown for random walks. This work was extended to -dimensional grids in [35], where a tight lower bound up to a polylogarithmic factor was also shown.
The continuous variant of meet-exchange in the infinite grid was studied in [33, 34]. In these works the initial number of agents at each vertex is a Poisson random variable, with constant mean, and initially the information is placed at the origin. The authors prove a theorem for the asymptotic shape formed by the set of informed agents. A similar process is the frog model, where only the informed agents move, while the uninformed ones stay put until they are hit by an informed agent. This process has been studied for infinite grids [40, 3] and finite -ary trees [29].
3 Protocol Descriptions
We compare four information spreading protocols. The first two, push and push-pull, are standard versions of randomized rumor spreading. The other two, visit-exchange and meet-exchange, use a system of interacting agents performing independent random walks, and are less standardized. In push and push-pull, information is communicated between adjacent vertices, whereas in visit-exchange and meet-exchange information is passed between an agent and a vertex it visits, or between two agents when they meet. All protocols proceed in a sequence of synchronous rounds. They are applied on a connected undirected graph with vertices, and the information originates from an arbitrary source vertex .
Push.
In round zero, vertex becomes informed. In each round , every vertex that was informed in a previous round samples a random neighbor to send the information to, and if is not already informed, it becomes informed in this round. We denote by the number of rounds before all vertices are informed.
Push-Pull.
As in push, vertex is informed in round zero. In each round , every vertex (informed or not) samples a random neighbor to exchange information with, and if exactly one of and was informed before round , then the other vertex becomes informed as well. The number of rounds before all vertices are informed is denoted .
Visit-Exchange.
Let be a set of agents. Every agent performs an independent simple random walk on , starting from a vertex sampled independently from the stationary distribution (i.e., each vertex is sampled with probability ). In round zero, vertex becomes informed, and every agent that is on vertex becomes informed as well. In each subsequent round , all agents do a single step of their random walk in parallel. If an agent that was informed in a previous round visits a vertex that is not yet informed, then becomes informed in this round. Also, if an agent that is not yet informed visits a vertex which got informed either in a previous round or in the current round (by some other informed agent), then becomes informed as well. We denote by the number of rounds before all vertices (and thus all agents) are informed.
Meet-Exchange.
As in visit-exchange, a set of agents perform independent random walks starting from the stationary distribution. In round zero, all agents that are on vertex become informed. If there is no agent on in round zero, then the first agent to visit after round zero becomes informed (if more than one agents visit simultaneously, they all get informed). After that point, vertex does not inform any other agent that visits . In each subsequent round , whenever two agent meet and exactly one of them was informed in a previous round, the other agent becomes informed as well. We denote by the number of rounds before all agents are informed.
If is a bipartite graph, then, depending on the initial positions of the agents, it is possible that some agents are never informed, thus . To avoid this complication we will sometimes assume that the random walks of the agents are lazy, i.e., a walk stays put in a round with probability . This ensures that , for any connected graph .
We will collectively refer to , , , and as the broadcast time of the corresponding protocol. We will sometimes omit graph and source vertex in this notation, when they are clear from the context.
4 Examples
In this section, we provide examples demonstrating that push or push-pull rumor spreading, visit-exchange, and meet-exchange can have very different broadcast times on the same graph. More precisely, we present graphs where rumor spreading takes polynomial time while visit-exchange and meet-exchange need only logarithmic time (Sections 4.1 and 4.2), and also graphs where the converse is true (Sections 4.3 and 4.4). We demonstrate a similar separation between visit-exchange and meet-exchange (Sections 4.4 and 4.5), but the gap is polynomial only in one direction, while in the other it is logarithmic. We do not know whether there exist graphs where visit-exchange is faster than meet-exchange by more than a logarithmic factor. In all examples below, we assume that the number of agents is .
4.1 Star Graph
Let denote an -leaf star, that is, a tree with one internal node (the center of the star), and leaves; see Fig. 1(a) for an illustration. This is an example of a graph where push is very slow, whereas all other processes are very fast.
Lemma 2.
For the graph described above and any source vertex , (a) , (b) , (c) , w.h.p., and (d) , w.h.p.
Proof.
(a): This bound is well-known. It follows from the observation that the center needs to sample each of the leaves (except possibly for one) before all vertices are informed. The time for that is the time needed to collect all coupons (except possibly for one) in a coupon collector’s problem, which is in expectation.
(b): This bound is also well-known (and trivial). It takes one round to inform all vertices if is the source, and two rounds if is a leaf.
(c): For any pair of vertices , the probability that an agent located at visits within the next two rounds is at least . Since agents do independent random walks, it follows from standard Chernoff bounds (Theorem 26) that, for any placement of the agents at round , at least one of the agents will visit a given vertex by round w.h.p. By this observation, it takes rounds w.h.p. until the first agent gets informed (by visiting ). If is not the center, then the center gets informed in the next round. After that it takes at most two rounds before all agents are informed, because an agent visits the center every other round. Finally, every leaf gets informed in an additional rounds w.h.p., by the same observation we used above.
(d): Since the graph is bipartite, we assume that the random walks are lazy (i.e., in every round, each random walk stays put with probability ). Similarly to (c), for any pair , the probability that an agent located at visits within the next two rounds is at least , thus for any placement of the agents at round , at least one agent visits by round w.h.p. It follows that it takes rounds w.h.p. until the first agent gets informed (by visiting ); let denote that agent (or one of them, if there are many). We complete the proof by arguing that within an additional rounds, w.h.p. every agent meets with at the center vertex, and thus, all agents become informed within rounds w.h.p. This follows from the observation that for any given placement of and , the probability they are both at the center vertex in the next round is exactly . Thus, a Chernoff bound yields that and will meet w.h.p. within rounds. ∎
4.2 Double Star
In the star example above only the push version of randomized rumor spreading is slow, while push-pull is extremely fast. Next we present a graph where push-pull (and thus, push) is slow, while visit-exchange and meet-exchange are fast. Let denote a double-star graph: two star graphs with vertices with their centers connected by an edge; see Fig. 1(b).
Lemma 3.
For the graph described above and any source vertex , (a) , (b) , w.h.p., and (c) , w.h.p.
Proof.
(a): Let be the centers of the two stars. For push-pull to complete, must sample or must sample , at least once. The probability of that happening in a given round is at most . Thus, the expected number of rounds until push-pull completes is at least .
(b): Let denote the event that at least agents visit vertex in round . We consider the following modification to process visit-exchange.
Modification 1: For any round and , if event does not hold, then before round we add a number of new and informed agents to the graph, at node , such that there are agents at .
In visit-exchange, at any round , the expected number of agents that visit is greater than . It follows, by a Chernoff bound. By applying a union bound for each and round , we get that, with probability at least , the modified process is identical to the original visit-exchange for the first rounds. Since our goal is to prove that w.h.p., it suffices to analyze the modified process.
In the modified process, since there is at least a linear number of agents at each before each round, it is straightforward to show that, w.h.p.: if and is adjacent, say, to , it takes rounds before gets informed (if , is informed at round zero); then in additional rounds gets informed; and finally in extra rounds all leaves are informed.
(c): We assume that the walks are lazy, as the graph is bipartite. We apply to meet-exchange the same modification we made to visit-exchange in part (b). We also make a second modification. Let denote the event that at least one of the agents at vertex stays put in round .
Modification 2: For any round and , if event does not hold, then before round we add a new and informed agent to the graph, at node .
Once again, it is easy to show that with probability at least , the modified process is identical to meet-exchange in the first rounds, thus we can analyze the modified process.
Similarly to part (b), we have that the following hold w.h.p. for the modified process. If and is adjacent, say, to , it takes rounds before some agent visits , thus gets informed, and then visits . From that point on, by our second modification, there is always some informed agent at . Then in additional rounds some informed agent visits , and again there is always an informed agent at , thereafter. Finally, in extra rounds every agent that is not already informed visits one of and thus gets informed. ∎
4.3 Heavy Binary Tree
Next we describe a graph where visit-exchange is slow, while the other processes are fast. Let denote a heavy binary tree, which is constructed by adding an edge between every pair of leaves of a balanced binary tree with vertices. Even though is not a tree, we will refer to the leaves of the original binary tree as the leaves of . The set of leaves of induces a clique of vertices. See Fig. 1(c) for an illustration.
Lemma 4.
For the graph described above and any source vertex , (a) , w.h.p., and (b) . If the source is a leaf, then (c) , w.h.p.
Proof.
(a): First, we bound the number of rounds until some internal node is informed. This is zero if is an internal node, so suppose is a leaf. The number of rounds before all leaves are informed is w.h.p. This follows from the well-known logarithmic bound on the push broadcast time on a clique, and the fact that random failures of transmission with probability (corresponding to the case when a leaf samples its parent) do not change the broadcast time asymptotically [22]. Once all leaves are informed, it takes at most additional rounds, w.h.p., until the first internal node is informed, because there are leaves and, in each round, each leaf samples its parent with probability . Once some internal node becomes informed, then all internal nodes become informed after at most rounds w.h.p. This follows from the observation that the broadcast time of push on starting from an internal node is dominated by the broadcast time on a balanced binary tree with vertices. Since the binary tree has bounded degree and logarithmic diameter, the broadcast time of push is w.h.p. [24]. Adding all these logarithmic bounds and applying a union bound proves (a).
(b): Since agents are initially distributed according to the stationary distribution, it follows that a given agent visits the root vertex with probability at any given round. Therefore, the expected number of times agents visit the root during the first rounds of visit-exchange is at most . It follows that with probability at least no agent visits the root in any of the rounds , . From this it is immediate that the expected number of rounds before the first agent visits the root is at least ; this implies (b).
(c): Let denote the event that at most agents visit internal nodes at round , where is a large enough constant. We apply the following modification to meet-exchange.
Modification: For any round , if does not hold, then before round we move all agents that are at internal nodes to leaf nodes. (It is not important to which leaves we move the agents.)
Since the random walks of the agents start from the stationary distribution, the expected number of agents that visit internal nodes at any given round is . Furthermore, since the random walks are independent, a Chernoff bound gives that event holds w.h.p. (where the probability is controlled by the choice of ). By a union bound, event holds also w.h.p. It follows that w.h.p. the modified process is identical to the original one in the first rounds. Next we analyze this modified process.
Let be the first round when some agent visits source , and let be an agent that visits in that round, and thus gets informed. We have that w.h.p., because by the modification above, there are agents on leaf nodes before each round, thus the probability at least one agent visits leaf in any given round is .
For each , we denote by the round when gets informed. In particular, . Also, let be the set of informed agents after round .
Next we show that at least agents are informed by some round .
Claim 5.
W.h.p., .
Proof.
Recall that is a constant, and let For any agent , let be the event that visits only leaf vertices in rounds . Suppose that is at a leaf before round . Then
Also,
where is the probability that and visit the same leaf at a given round, assuming that they are at different leaves before the round, and that they both visit leaves at that round. Using the fact that at least agents are on leaves before round (due to the modification above), we obtain for the number of informed agents after round ,
where the extra accounts for . We can thus apply a Chernoff bound to obtain
for large enough. From that and , it follows
| (1) |
We can amplify the above probability as follows. Suppose that . Consider the first round such that is at a leaf vertex before round . Then , w.h.p. The reason is that from any internal vertex, an agent reaches a leaf after at most rounds w.h.p., by the properties of a biased random walk on the line [25, Section 14.2], as the probability of the agent moving closer to the root in a round is , while the probability of moving closer to the leaf level is .
We can now apply the same argument as in the proof of (1), using in place of , to obtain Repeating the argument a constant number of times, we obtain that for some . ∎
Next we argue that once agents have been informed, at least half of the agents (or if ) are informed after additional rounds.
Claim 6.
There is a constant , such that if , then
Proof.
Suppose that . By the modification we have made, at least informed agents are on leaf nodes before round ; let be the set of these agents. Let be the set of leaves visited by at least one informed agent in round . By a Chernoff bound,
because for each agent among the first agents in , the probability that in round , visits a leaf that no other agents among the first agents in visit in the round, is at least .
Given , consider an agent which is at a leaf before round and is not yet informed. The probability that visits a leaf in in round , and thus gets informed, is at least . There are at least such agents, and therefore, the expected number of agents that get informed in round is at least for a sufficiently small constant . Since the agents move independently, by a Chernoff bound we obtain
The claim then follows by combining the two equations we have shown above. ∎
By applying Claim 6 repeatedly, for a logarithmic number of rounds, we obtain that if , then w.h.p,
Next we argue that once agents have been informed, the remaining agents are informed after additional rounds.
Claim 7.
If and , then w.h.p.
Proof.
We saw in the proof of Claim 5, that if is on an internal node after round , it will reach a leaf after at most rounds w.h.p. Suppose now that is at a leaf vertex before round , for some . As we saw earlier, the probability that visits leaves in all rounds , where , is at least . For a given round in which visits a leaf, let be the probability that no informed agent visits the same leaf. Since there are at least informed agents at leaf vertices before each round,
for a constant that depends on . This bound follows from the observation that is maximized when all informed agents are on the same leaf before the round. It follows
for some constant . By repeating the argument a constant number of times we obtain the claim for an arbitrary high probability. ∎
Combining all the above results we complete the proof of (c). ∎
4.4 Siamese Heavy Binary Trees
We consider now an example where both random walk based processes are slow, while rumor spreading is fast. Let denote a graph obtained by taking two copies of the graph described above and merging the two roots into a single root vertex; see Fig. 1(d).
Lemma 8.
For the graph described above and any source vertex , (a) , w.h.p., (b) , and (c) .
Proof.
Parts (a) and (b) follow from the same arguments used to prove the corresponding bounds in Lemma 4. For (c), we observe that w.h.p. at least one agent will start from each of the two trees. Then, for the information to pass from agents on the one tree to agents on the other, some agent must reach the root, which requires rounds in expectation, as we showed in the proof of Lemma 4(b). ∎
4.5 Cycle of Stars of Cliques
Finally, we present a graph on which visit-exchange is faster than meet-exchange, by a logarithmic factor. We note that this graph is (almost) regular, unlike the highly non-regular graphs we considered in the previous sections. We leave open the question whether there are graphs on which visit-exchange is asymptotically faster than meet-exchange by a polynomial factor.
Lemma 9.
There is a graph with such that for any source vertex , (a) , and (b) .
Proof Sketch.
An example of a graph with the above properties is a cycle-of-stars-of-cliques, obtained as follows: Consider a cycle graph of length , consisting of vertices , . For each consider a new set of vertices , , and connect to each . Finally, for each consider a new set of vertices , , add an edge between each pair , and also between and all . See Fig. 1(e) for an illustration of this graph. We denote by the -clique induced by the vertex set .
The core-idea is that since vertices are not informed in meet-exchange, the information advances from to its neighboring ring vertices and slower than in visit-exchange. Below we give a sketch of the analysis. To make it rigorous, one needs to use techniques similar to those in the other proofs of the paper, namely, bounding above and below the number of agents at subgraphs of . The number of rounds we refer to below are all in expectation.
(a): Suppose that the source vertex is in clique . Then it takes rounds until all vertices of the clique are informed. After that, vertex gets informed in additional rounds, which is the average time it takes for the first agent to cross the edge from to , since a constant number of agents visit each vertex on average. From , the information passes to and in rounds after is informed. Thus, it takes rounds before all ring nodes are informed. Once is informed, it takes rounds (by coupon collector’s) until all cliques are informed. It follows that the total broadcast time is .333Alternatively, one can prove the statement assuming push instead of visit-exchange, and then apply Theorem 1, since graph is (almost) regular.
(b): Suppose again that the source is in clique . We first lower bound the number of rounds until at least informed agents visit , which is the average number of agents until one of them moves to either or . It takes rounds until the first informed agent visits . This agent will move to another clique with probability . After that, the next informed agent visiting can come from or , and, therefore, the expected number of rounds until such a visit is halved. In general once of the cliques have received an informed agent, is visited by informed agents at the rate of once every rounds. It follows that it takes rounds before has been visited by informed agents, and therefore, at least that many rounds are necessary until an informed agent moves to either or . Therefore, it takes rounds before all nodes on the ring are informed. ∎
5 Bounding by on Regular Graphs
In this section, we prove the following theorem, which upper bounds the broadcast time of push in a regular graph by the broadcast time of visit-exchange.
Theorem 10.
For any constants , there is a constant , such that for any -regular graph with and , and for any source vertex , the broadcast times of push and visit-exchange, with agents, satisfy
for any .
From Theorem 10, it is immediate that if w.h.p., then w.h.p. Moreover, using Theorem 10 and the known upper bound on which holds w.h.p. [24], one can easily obtain that .
Proof Overview of Theorem 10.
The proof uses the following coupling of processes push and visit-exchange: For each vertex , let be the sequence of neighbors that samples in push after getting informed. Similarly, for visit-exchange, consider all moves of informed agents from to its neighbor vertices in chronological order, and let be the destination vertices in those moves (we order moves in the same round by, say, agent ID). We couple the two processes by setting , for all .
The intuition for this coupling is that in visit-exchange, at most a constant number of agents in expectation visits each vertex in a round (since the graph is regular and ), and thus the same number of agents leaves per round in expectation. The coupling ensures that for each informed agent that moves from to a neighbor , vertex samples the same neighbor in push. Thus, if we had a constant upper bound on the actual number (rather than the expected number) of visits to each vertex on each round, then the coupling would immediately yield for the coupled processes. In reality, however, a super-constant number of agents may visit a vertex in a round, and, moreover, the number of visits depends on the past history of the process.
An basic idea we use to tackle dependencies on the past history is to consider a tweaked version of visit-exchange, called t-visit-exchange. The only difference between this process and visit-exchange, is that it arbitrarily removes some agents after each round to ensure that the neighborhood of any vertex contains at most agents. For and , we have that in the first rounds the two processes are identical w.h.p. Therefore, we can consider t-visit-exchange in our proofs. The benefit we get is that since the neighborhood of any vertex contains agents in round , at round the number of agents that visit will be bounded by the binomial distribution , independently of the past.
To prove the theorem is suffices to show that under our coupling, with probability at least , if then . Further, we will assume that is at least ; for the theorem is obtained by showing that w.h.p.
To show that w.h.p. implies , we consider all possible paths of length through which information travels in visit-exchange, and for each path we count the total number of (non-distinct) agents encountered along this path, called the congestion of the path. Formally, we use the notion of a canonical walk , which is represented by a sequence of vertices starting from : In each round , the walk either stays put and , or it follows one of the agents that leave in round , and, in that case, is the new vertex that moves to. For any round , we count the agents that are in . The sum of these counts, for is the congestion of the walk .
The congestion of a canonical walk is used to bound the time needed for information to travel along the same path in the coupled push process. Intuitively, larger congestion implies longer travel time for push, for the following reason. Suppose there are agents in at some round after it is informed by visit-exchange. The coupled push process, using the same random decisions for the choice of neighbors as visit-exchange, will take rounds to “go through” these agents.
To relate the congestion of canonical walks with the time it takes for information to spread in push, we introduce C-counters: For each vertex , we maintain a counter . The counter is initialized in the round in which becomes informed in visit-exchange. Its initial value is the value of the C-counter of the neighbor from which the first informed agent arrived to . In each subsequent round , increases by the number of agents that visited in round . C-counters have the following two properties: If is the round when gets informed in push then ; and for any , there is a canonical walk of length such that . Therefore, to show that w.h.p. implies , it suffices to show that the maximum congestion of all canonical walks of length is at most w.h.p.
We can bound the congestion of a single canonical walk of length using the property of t-visit-exchange that the number of agents at a node is bounded by a binomial distribution with constant mean. This results in the desired bound of for a single walk with probability at least , for some constant . We would like to take a union bound over all canonical walks, which would give the desired result. For this to work, however, we should also bound the total number of canonical walks of length by at most .
We bound the number of canonical walks of length by introducing a set of descriptors for these walks. A descriptor is represented by a matrix, which, together with a given execution of visit-exchange, uniquely defines a canonical walk. Additionally, the set of descriptors suffices to encode all canonical walks, and therefore, it is at least as large as the set of all walks. Thus, we can use a bound on the number of descriptors that can be computed by a simple combinatorial argument involving the number of elements used in the matrix, and the values they can take. A naive construction of descriptors, however, is too wasteful giving us a much larger bound than the we need. A key idea here is that the majority of the descriptors represent walks only in executions that happen with low probability. So, we construct a set of concise descriptors that can describe all canonical walks in a random execution w.h.p. We show that the size of the set of concise descriptors can be bounded by , as desired. Next we give the details of the proof.
5.1 Notation and Coupling Description
For each vertex , we denote by the round when gets informed in push. For , let be the th vertex that samples, i.e., the vertex it samples in round . Note that . In visit-exchange, we denote by the round when vertex gets informed. For any agent and , we denote by , the vertex that visits in round . Thus, is a random walk on . Let be the set of all agents that visit in round , i.e.,
Thus, is also the set of agents that depart from in round . Consider all visits to in rounds , in chronological order, ordering visits in the same round with respect to a predefined total order over agents. For each , consider the agent that does the th such visit, and let be the vertex that visits next. Formally, let and order its elements such that if , or and . If is the th smallest element in , then .
Coupling.
We couple processes push and visit-exchange by setting . Formally, let , be a collection of independent random variables, where takes a uniformly random value from the set of ’s neighbors. Then, for every and , we set
5.2 Upper Bound on Agents and Tweaked Visit-Exchange
We will use the next simple bound on the number of agents that visit a given set of vertices in some round of visit-exchange. The proof is by a simple Chernoff bound, and relies on the assumption that agents execute independent walks starting from stationarity.
Lemma 11.
For any , , and ,
Proof.
Since each random walk starts from stationarity, and is a regular graph, it follows that for any agent , . Thus, the expected number of agents that visit in round is Then, by the independence of the random walks, we can use a standard Chernoff bound to show that the number of agents that visit at is at most with probability at least . ∎
We remark that Lemma 11 holds also in the case where and exactly one walk starts from each vertex. This implies that Theorem 10 holds in the above case as well, because the rest of the proof does not require any assumptions about the initial distribution of agents.
In parts of the analysis, we will use a “tweaked” variant of visit-exchange, called t-visit-exchange, defined as follows. Let
| (2) |
be a (sufficiently large) constant to be specified later. If in some round , there is a vertex for which the following condition does not hold:
| (3) |
then before round , we remove a minimal set of agents from the graph in such a way that the above condition holds for all vertices , when counting just the remaining agents.
It follows from Lemma 11 that if constant is large enough, and , then w.h.p. the modified process is identical to the original in the first polynomial number of rounds.
Lemma 12.
The probability that Eq.(3) holds simultaneously for all and is at least .
Proof.
The claim follows by applying Lemma 11, for each and each pair , where and , and then combining the results using a union bound. ∎
We use the same definitions and notations for both visit-exchange and t-visit-exchange.
5.3 C-Counters
Recall that is the round when vertex gets informed in visit-exchange. If , this is the first round when some informed agent visits . We are interested in the neighbor of from which that agent arrived. Note that . Note also that there may be more than one such neighbors , if more than one informed agent visit at round . For each , let
i.e., contains all neighbors of for which some informed agent moved from to in round . Next, for each , we define the counter variable
| (4) |
That is, is initialized in round to the minimum counter value of the neighbors in (or to zero if ), and is the number of visits to from round until round , or equivalently, the number of departures of agents from in rounds up to .
Lemma 13.
For any , .
Proof.
Consider the following path through which information reaches in visit-exchange. The path is , where , , and for each , we have and . We prove by induction on that
| (5) |
This holds for , because , , and . Let , and suppose that ; we will show that . We have
Let , let be the agent that does the th visit to since round , and let be the round when that visit takes place, thus and . By the minimality of , is the first round when some informed agent moves to from . Since , it follows that . Then
Also, from the coupling, , which implies
Combining all the above we obtain completing the inductive proof of (5). Applying (5) for , we obtain . ∎
5.4 Canonical Walks and Congestion
Let , where and for , be a walk on constructed from visit-exchange as follows. We start from vertex in round zero, and in each round , we either stay put, in which case , or we choose one of the agents , which visited in the previous round, and move to the same vertex as in round , i.e., . We call a canonical walk of length . A labeled canonical walk is a canonical walk that specifies also the agent that the walk follows in each step , if . Formally, a labeled canonical walk corresponding to is , where if , and if . Note that different labeled canonical walks may correspond to the same (unlabeled) canonical walk. We define the congestion of a canonical walk as the total number of agents encountered along the walk,444The same agents is counted more than once if encountered in multiple rounds. not counting the last step, i.e.,
The congestion of a labeled canonical walk is the same as the congestion of the corresponding unlabeled walk.
Lemma 14.
For any and , there is a canonical walk of length with .
Proof.
We consider the same path as in the proof of Lemma 13, where , , and for each , and . Consider the canonical walk obtained from this path by adding between each pair of consecutive vertices and , copies of , and also appending after a number of copies of . It is then easy to show by induction that . ∎
5.5 Concise Descriptors of Canonical Walks
In this section, we bound the number of distinct labeled canonical walks of a given length . For that, we present a concise description for such walks, and bound the total number of the walks by the total number of different possible descriptions.
We start with a rather wasteful way to describe labeled canonical walks, which we then refine in two steps. Let denote the set of all matrices , where . Let us fix the first rounds of visit-exchange, and consider a labeled canonical walk . For each , let
be the number of agents that visit in round , and thus also the number of agents that depart from in round . Let if , otherwise, is equal to the rank of in set , i.e., . We describe walk by a matrix with the following entries: For each , if , then , for , i.e., value is stored in the first unused entry of row . At most of the entries of are specified that way; the remaining entries can have arbitrary values. We call a non-concise descriptor of .
For any given realization of visit-exchange, each describes exactly one labeled canonical walk of length , and any labeled canonical walk of length has at least one non-concise descriptor (in fact, several ones). The total number of different non-concise descriptors is , which is too large for our purposes.
A simple improvement is to use only entries in rows for which is a power of 2 (we assume w.l.o.g. that is also a power of 2). Roughly speaking, if is between and then is stored in raw . Formally, let be a (large enough) constant, to be specified later, which is a power of 2. The matrix we use to describes has the following entries. For each :
-
1.
If , where , and , then
-
(a)
if , we have ,
-
(b)
if , can take any value in .
-
(a)
-
2.
If and , then
-
(a)
if , we have ,
-
(b)
if , can take any value in .
-
(a)
The purpose of subcases (b) is to maintain the property that every describes a labeled canonical walk, which would not be the case if we just set or , since values greater than would not correspond to a walk. We call the matrix above a semi-concise descriptor of .
A second modification we make is based on the observation that, even in the logarithmic number of ’ rows used in the above scheme, most entries are very unlikely to be actually used. For each row , we specify a threshold index , such that the first entries in each row suffice w.h.p. to describe all labeled canonical walks of length , in a random realization of visit-exchange. Let be a subset of defined as follows. Let
and recall that is a constant power of 2. The set consists of all such that
| if and | |||
A concise descriptor of a labeled canonical walk of length is any semi-concise descriptor of that belongs to set .
Next we compute an upper bound on the number of all possible concise descriptors of length .
Lemma 15.
.
Proof.
From the definition of , we have
where in the second-last line we used , , and ; and in the last line we used that . ∎
For any realization of visit-exchange, each is a concise descriptor of some labeled canonical walk of length . However it is not always the case that a labeled canonical walk has a concise descriptor. The next lemma shows that w.h.p. all labeled canonical walks of length have concise descriptors for an appropriate choice of constant parameter . Note that the lemma assumes the t-visit-exchange process. The proof is given in Section 5.6.
Lemma 16.
If then, with probability at least , all labeled canonical walks of length in a random realization of t-visit-exchange have concise descriptors.
5.6 Proof of Lemma 16
First, we bound the number of steps in which more than agents are encountered in a canonical walk of length .
Lemma 17.
Fix any , and let be the labeled canonical walk with semi-concise (or non-concise) descriptor in t-visit-exchange. For any and ,
Proof.
Recall that is the number of agents that visit vertex in round , and thus also the number of agents that depart from in round . We argue that for any , conditioned on , variable is stochastically dominated by the binomial random variable : From (3), applied for vertex and round , we get
thus, there are at most agents in the neighborhood of before round . If , then each one of those at most agents will visit in round independently with probability . If (thus ), then each of the at most agents will visit in round independently with probability , except for agent who visits with probability 1. In both cases, the number of agents that visit is dominated by . It follows that for any and ,
Similarly, for we have
Let It follows from the above that for any ,
| (6) |
For and ,
We proceed now to the proof of the main claim. For any , and for the labeled canonical walk with semi-concise descriptor , let denote the event:
Applying Lemma 17, for and , for each , and then using a union bound, we obtain
By another union bound and Lemma 15,
| (7) |
where the last inequality holds if . Next we show that event implies that every labeled canonical walk has a concise descriptor . From this and (5.6), the lemma follows.
Fix a realization of t-visit-exchange conditioned on the event . Suppose, for contradiction, that there is some labeled canonical walk that does not have a concise descriptor. Let be a labeled canonical walk that does have a concise descriptor , and shares a maximal common prefix with . Consider the first element where and are different. We first argue that this element is not a vertex: Suppose, for contradiction, that and , for some . Then , as . Moreover, if , then by definition, implies , contradicting our assumption. Thus, the first element where and are different must be an agent. Suppose and , for some . Then, by the maximal prefix assumption, the labeled canonical walk , which stays put at vertex in rounds up to , has no concise descriptor. This can only be true if for some . But this contradicts event . Therefore, there exists no labeled canonical walk of length such that has no concise descriptor.
5.7 Upper Bound on Congestion
The next lemma gives un upper bound on the congestion of a single canonical walk of length .
Lemma 18.
Fix any , and let be the labeled canonical walk with concise descriptor in t-visit-exchange. Then, for any ,
Proof.
Let . Then where . By the same reasoning as in the proof of Lemma 17, is stochastically dominated by , where are independent binomial random variables, such that and, for , . It follows that and
by a Chernoff bound, since . ∎
5.8 Putting the Pieces Together – Proof of Theorem 10
We consider first the case where is at most logarithmic. In Theorem 24, we show that w.h.p., by arguing that some vertices are not visited by any agent (informed or not) during the first logarithmic number of rounds. Thus, there is some constant such that if , . From this, the theorem’s statement follows for . In the rest of the proof, we assume that .
We have and from Lemma 13,
Since for any fixed realization of visit-exchange and any , is a non-decreasing function of , and since , it follows
By Lemma 14, for any , there is a canonical walk of length with congestion . Thus, there is also a labeled canonical walk of length with . It follows
| (8) |
where denotes the set of all labeled canonical walks of length in visit-exchange.
Next we bound . Consider t-visit-exchange, and for any , let be the labeled canonical walk with concise descriptor in t-visit-exchange. From Lemma 18, for any and , Then
by Lemma 15. Choosing constant large enough so that , yields
From Lemma 16, the probability that all labeled canonical walks of length have concise descriptors is at least , if . It follows
where is the set of all labeled canonical walks of length in t-visit-exchange. By Lemma 12, however, we can couple visit-exchange and t-visit-exchange, by using the same collection of random walks for both, such that the two processes are identical until round with probability at least . Thus
Combining the last three inequalities above, we obtain
Since and , for any given constant we can choose constants large enough such that
| (9) |
This completes the proof of Theorem 10.
6 Bounding by on Regular Graphs
The following theorem upper bounds the broadcast time of visit-exchange in a regular graph by the broadcast time of push.
Theorem 19.
For any constants with sufficiently large, there is a constant , such that for any -regular graph with and , and for any source , the broadcast times of push and visit-exchange, with agents, satisfy
for any .
From Theorem 19, it is immediate that if w.h.p., then w.h.p. Moreover, using Theorem 19 and the well-known upper bound w.h.p. on the cover time for a single random walk on a regular graph, which also applies to , one can easily obtain that .
Proof Overview Of Theorem 19.
We use a coupling which is similar to that in the proof of the converse result, stated in Theorem 10, but with a twist (which we describe momentarily). Unlike in the proof of Theorem 10, where we essentially consider all possible paths through which information travels, here we focus on the first path by which information reaches each vertex. Let be such a path for vertex in push, where each vertex in the path gets informed by . Let be the number of rounds it takes for to sample (and inform) in push. We consider the same path in visit-exchange, and compare with the number of rounds until some informed agent moves from to , counting from the round when becomes informed. Note that is precisely the round when is informed in push, while is an upper bound on the round when is informed in visit-exchange.
The coupling from Section 5 seems suitable for this setup. Recall, in that coupling we let the list of neighbors that a vertex samples in push, be identical to the list of neighbors that informed agents visit in their next step after visiting , in visit-exchange. The same intuition applies, namely, that on average each vertex is visited by agents per round, which suggests that should be close to . We can even apply a similar trick as in Section 5 to avoid some dependencies: In each round, the number of agents in the neighborhood of a vertex is bounded below by , w.h.p. This should imply that the number of agents that visit a vertex in a round is bounded below by a geometric distribution with constant expectation. Let denote the event that the above bound holds for all , for polynomially many rounds.
There is, however, a problem with this proof plan. By fixing path in advance, to be the first path to inform in push, we introduce dependencies from the future. So, when we analyse and , we must condition on the event that the -prefix of the path we have considered so far will indeed be a prefix of the first path to reach . These kind of dependencies seem hard to deal with.
We use the following neat idea to overcome this problem. We only consider the odd rounds of visit-exchange in the coupling, i.e., we match the list of neighbors that a vertex samples in push (in all rounds), to the list of neighbors that informed agents visit in round after visiting in round , for all . In even rounds, agents take steps independently of the coupled push process.
Under this coupling, we proceed as follows. We condition on the high probability event defined earlier (formally, we modify visit-exchange to ensure holds). We then fix all random choices in push, and thus the information path to . For each even round of visit-exchange, we have that vertex in is visited by at least one agent with constant probability, independently of the past and of the fixed choices in future odd rounds. If indeed some vertex visits in an even round, then in the next round it will visit a vertex dictated by the coupling. This allows us to show that under this coupling, , w.h.p. We get rid of the term in the final bound, by using that w.h.p.
6.1 Coupling Description
We use mostly the same notation as in Section 5.1. For each vertex , we denote by the round when vertex gets informed in push. For , let be the th the vertex that samples (in round ). We denote by the round when vertex gets informed in visit-exchange. For an agent and round , let be the vertex that visits in round . Let be the set of agents that visit in round , i.e.,
The next definition differs from the corresponding one in Section 5.1, as it distinguishes between even and odd rounds. Fix a vertex , and consider all visits to in even rounds , in chronological order, ordering visits in the same round with respect to a predefined total order over all agents. We call these visits even visits to vertex . For each , consider the agent that performs the th even visit and let be the vertex that visits in the next (odd) round. Formally, let
where is the set of non-negative even integers. Order the elements of such that if , or and . If is the th smallest element in , then .
Coupling.
We couple processes push and visit-exchange by setting . Formally, let , be a collection of independent random variables each taking a uniformly random value from the set of ’s neighbors in . For all and , we set
6.2 Lower Bound on Agents and Re-Tweaked Visit-Exchange
We will use the following simple lower bound on the number of agents visiting a given set of vertices in a round of visit-exchange. The proof is almost the same as its counterpart Lemma 11.
Lemma 20.
For any and ,
Proof.
Since each agent’s walk starts from the stationary distribution and is a regular graph, we have that for any given agent and round , . Therefore the expected number of agents visiting in round is
By the independence of the walks, we can use a standard Chernoff bound to show that , with probability at least . ∎
Re-Tweaked Visit-Exchange Process.
Similar to the analysis in Section 5, it is convenient to work with a slightly modified version of visit-exchange. We call the new process r-visit-exchange and is identical to visit-exchange except for the following modification. If in some odd round , there is a vertex for which the next condition is not true,
| (10) |
then before round , we add a minimal set of new agents to the graph such that the above condition holds for all vertices . An agent added to vertex adopts the state (informed or non-informed) of at the end of round .
Recall that . The next lemma allows us to consider the r-visit-exchange process in the rest of the proof, and argue that the results also hold for visit-exchange.
Lemma 21.
The probability that Eq.(10) holds simultaneously for all and is at least .
6.3 Proof of Theorem 19
We first compare the times until a given vertex gets informed in push and in r-visit-exchange.
Lemma 22.
The coupling described in Section 6.1, when applied to push and r-visit-exchange, yields the following property. For any constant , there is a constant such that for any ,
where and are the rounds when is informed in the coupled processes push and in r-visit-exchange, respectively.
Proof.
In this proof, we will use the same notation for r-visit-exchange as those defined for visit-exchange. (We used instead of in the lemma’s statement to avoid confusion when we apply the lemma, but in the proof there is no such fear, because only r-visit-exchange is used.)
As described in the proof overview, we consider a path from the source to vertex that push uses to inform , and count the number of rounds visit-exchange takes to traverse the same path. First, we consider a single edge such that is informed by in a realization of push that we fix. We also fix the first rounds of r-visit-exchange, i.e., until becomes informed. Let be the number of rounds of push that it takes to inform counting from when gets informed. Similarly, we define for r-visit-exchange. We will bound in terms of .
Recall that we have defined a natural total order over the set of even visits to vertex . For , let be the th element of in that order. By the coupling, at the odd round , agent will move to the neighbor of that is sampled by push in round . In particular, since for , vertex gets informed after even visits to in r-visit-exchange (possibly earlier).
Formally, let be the number of r-visit-exchange rounds between even visits and (when , is the number of rounds until the first even visit since ). can be , if two agents visit at the same even round. With this definition,
By condition (10) and assumption , there are at least agents in the neighborhood of at any round of r-visit-exchange. Let and recall that, for an even , the agents move independently from push, and therefore, some agent visits in round with probability at least . For , when agents are placed according to the stationary distribution, some agent is placed at with probability . It follows that the number of rounds between two even visits to , namely for , is stochastically dominated by , where is a collection of independent geometric random variables with success probability . The coefficient appears because we have to take into account both odd and even rounds. In other words, for any and ,
Using Lemma 28, we get that, given is informed, is stochastically dominated by :
We apply the above result to all edges on the path from to through which push informed . Let be a path in such that, in push, is informed from , for all . By definition of , samples its neighbor at round . Define and for . From our result above for a single edge it follows that
By Lemma 28 and the fact that , we have that is stochastically dominated by , i.e., for any ,
The random variable is a sum of exactly independent and identical geometrically distributed random variables, hence, . Thus, for any constant , by Lemma 27,
Choosing large enough so that , completes the proof. ∎
We can now complete the proof of our main result. Recall that and are the rounds when vertex gets informed in push, visit-exchange, and r-visit-exchange, respectively. From Lemma 22, and a union bound over all vertices, we obtain that for any constant , there is a constant such that
Thus,
It follows that for any ,
From Lemma 21, it follows
Combining the last two inequalities above we obtain
Substituting and , and using , yields
This implies the theorem for . For larger , the theorem follows from the known polynomial upper bound on the cover time on regular graphs. For smaller , it follows from the fact that , w.h.p.
7 Bounding by on Regular Graphs
The next theorem bounds the broadcast time of visit-exchange on a regular graph by the broadcast time of meet-exchange.
Theorem 23.
For any constants with sufficiently large, there is a constant , such that for any -regular graph with and , and any source , the broadcast times of visit-exchange and meet-exchange, both with agents, satisfy
for any .
Proof.
Let be the number of rounds until all agents are informed in visit-exchange. Under the natural coupling of visit-exchange and meet-exchange, that uses the same random walks for both processes, it is immediate that
| (11) |
Let for constant to be determined later. Next we show that in rounds of visit-exchange, every vertex is visited by at least one agent, with probability at least . For that we consider the process r-visit-exchange from Section 6.2, which ensures that for every vertex and round ,
where is the set of agents visiting in round .
Fix a vertex . In any round of r-visit-exchange, the probability that no agent visits in that round is at most , since the neighborhood of contains at least agents before round . This holds for every round independently, hence is visited by some agent in rounds with probability at least . By a union bound, with probability at least , every vertex is visited by some agent in rounds . By Lemma 21, r-visit-exchange and visit-exchange are identical in the first rounds of their execution with probability at least . The last two statements together imply that
Together with (11), this implies the theorem for , since we can take and sufficiently large, depending on . For smaller , the theorem follows from the fact that w.h.p. (Theorem 25). For larger , it follows from the fact that w.h.p., by a known polynomial upper bound on the cover time of a random walk in a graph. ∎
8 Logarithmic Lower Bounds for & on Regular Graphs
Theorem 24.
For any -regular graph with and , and any source vertex , the broadcast time of visit-exchange with agents is w.h.p.
Proof.
We argue that w.h.p. some vertices are not visited by any agent (informed or not) during the first logarithmic number of rounds of visit-exchange. We only count the visits starting from round , since the initial placement of agents cannot inform any vertex. The formal argument follows next.
For a sufficiently large constant , that will be fixed later, we consider the process t-visit-exchange defined in Section 5.2. Recall that in t-visit-exchange, for every vertex ,
where is the set of agents that visit in round . In the rest of the proof we use t-visit-exchange and use the fact that it is equivalent to visit-exchange w.h.p. for the first logarithmic rounds of the process.
Let represent all random choices of t-visit-exchange up to (and including) round , and let be the set of vertices that have not been visited by any agent (either informed, or not) in any round up to . Denote the event that by . We will show that for any ,
| (12) |
for any constant . By the definition of t-visit-exchange, for each , the total number of agents in before round is at most . Each of these agents visits in round with probability , independently from one another. Let be the indicator random variable that . Then, for ,
which implies that
We observe that, conditioned on the history , the random variables are negatively associated [20, Example 3.1]. Thus, we can apply standard Chernoff bounds on their sum to obtain
which implies (12).
Let , and for , define . We prove that by induction. The case is exactly the statement of inequality (12) since . For ,
Observe that implies that there are at least vertices that have not been visited by any agent, and thus at least vertices that are uninformed (the other one may be the source). Therefore, with probability at least , there is an uninformed vertex in t-visit-exchange after round . By Lemma 12, t-visit-exchange and visit-exchange are identical in the first rounds of their execution, with probability at least . Combining the two statements, we get that there is an uninformed vertex in visit-exchange after round , with probability at least . By choosing a sufficiently large and using the fact that , we can make this probability to be at least , while , completing the proof. ∎
Theorem 25.
For any -regular graph with and , and any source vertex , the broadcast time of meet-exchange with agents is w.h.p.
Proof.
The proof follows the same line of logic as the proof of Theorem 24. We show that, w.h.p., there is an agent that has not started its walk at the source, and that has not met any other agent (informed or not) in the first logarithmic number of rounds of meet-exchange.
First observe that we can consider a tweaked process t-meet-exchange, which has the same modification as t-visit-exchange in Theorem 24 that ensures that the neighborhood of every vertex contains at most agents at any round. Recall that is the history of t-meet-exchange until round . Let be the set of agents that have not met another agent in the first rounds, and let be the event that is a constant fraction of . The next inequality, which is analogous to (12), is the key step of the proof and is proved next:
| (13) |
For every agent , consider the vertex that visits in round . With constant probability no agent other than visits in round , therefore, there is a constant such that . Unlike in Theorem 24, we do not have negative association of the events that agents in are also in , and therefore cannot use Chernoff bound directly.
Instead, we split round into two sub-rounds: In the first sub-round, only the agents in make a step, and in the second one all other agents. Consider the set , which contains agents that do not meet another agent from in the first sub-round. We have that . Additionally, is a function of the independent steps taken by the agents in , and changing the step of one of them changes by at most . It implies that, by the Method of Bounded Difference [20, Corollary 5.2],
Consider the set of vertices where agents in are located after the first sub-round. We can now use the negative association argument from Theorem 24 to show that, with probability at least , a constant fraction of vertices in do not receive any agent in the second sub-round. Hence, with the same probability, a constant fraction of agents in do not meet a new agent. Combining the above arguments, we prove (13).
Applying (13) for rounds, we get that, w.h.p., at least agents have not met any other agent after the first rounds. Of these agents, at most get informed in rounds , w.h.p. This follows from a standard bound on the largest bin in the balls-and-bins problem. Additionally, at most one such agent could be the first one to visit , while still contains the information. Therefore, the broadcast time of t-meet-exchange and thus also meet-exchange is at least . ∎
9 Open Problems
This work is the first systematic and thorough comparison of the running times of the standard push and push-pull rumor spreading protocols with some very natural agent-based alternatives. Several open problems remain. The most obvious question to ask is whether our results for regular graphs hold also when the graph degree is sub-logarithmic. Another question is whether there are graphs where meet-exchange is slower than visit-exchange by more than logarithmic factors. In this paper we assumed a linear number of agents. It would be interesting to study the performance of the protocols when a sub-linear number of agents is available.
The main attractive properties of standard rumor spreading protocols are simplicity, scalability, and robustness to failures [24]. Arguably, visit-exchange and meet-exchange share the first two properties, but probably not the robustness property. In particular, it seems that faulty nodes or links can result in agents getting lost. It would be interesting to explore fault tolerant variants of these protocols. For example, it seems likely that the protocols could tolerate some number of lost agents, if a dynamic set of agents were used, where agents age with time and die, while new agents are born at a proportional rate.
10 Acknowledgments
We would like to thank Thomas Sauerwald and Nicolás Rivera for helpful discussions. This research was undertaken, in part, thanks to funding from the ANR Project PAMELA (ANR-16-CE23-0016-01), the NSF Award Numbers CCF-1461559, CCF-0939370 and CCF-18107, the Gates Cambridge Scholarship programme, and the ERC grant DYNAMIC MARCH.
References
- [1] R. Aleliunas, R. M. Karp, R. J. Lipton, L. Lovász, and C. Rackoff. Random walks, universal traversal sequences, and the complexity of maze problems. In Proc. 20th IEEE Symposium on Foundations of Computer Science, FOCS, pages 218–223, 1979.
- [2] N. Alon, C. Avin, M. Koucký, G. Kozma, Z. Lotker, and M. R. Tuttle. Many random walks are faster than one. Combinatorics, Probability & Computing, 20(4):481–502, 2011.
- [3] O. S. M. Alves, F. P. Machado, and S. Y. Popov. The shape theorem for the frog model. The Annals of Applied Probability, 12(2):533–546, May 2002.
- [4] O. Angel, A. Mehrabian, and Y. Peres. The string of diamonds is tight for rumor spreading. In Proc. Approximation, Randomization, and Combinatorial Optimization. Algorithms and Techniques, APPROX/RANDOM, pages 26:1–26:9, 2017.
- [5] P. Berenbrink, R. Elsässer, and T. Friedetzky. Efficient randomised broadcasting in random regular networks with applications in peer-to-peer systems. Distributed Computing, 29(5):317–339, 2016.
- [6] P. Berenbrink, G. Giakkoupis, A. Kermarrec, and F. Mallmann-Trenn. Bounds on the voter model in dynamic networks. In Proc. 43rd International Colloquium on Automata, Languages, and Programming, ICALP, pages 146:1–146:15, 2016.
- [7] P. Berenbrink, G. Giakkoupis, and P. Kling. Tight bounds for coalescing-branching random walks on regular graphs. In Proc. 29th ACM-SIAM Symposium on Discrete Algorithms, SODA, pages 1715–1733, 2018.
- [8] S. P. Boyd, A. Ghosh, B. Prabhakar, and D. Shah. Randomized gossip algorithms. IEEE Trans. Information Theory, 52(6):2508–2530, 2006.
- [9] A. Z. Broder, A. R. Karlin, P. Raghavan, and E. Upfal. Trading space for time in undirected s-t connectivity. SIAM J. Comput., 23(2):324–334, 1994.
- [10] K. Censor-Hillel, B. Haeupler, J. A. Kelner, and P. Maymounkov. Rumor spreading with no dependence on conductance. SIAM J. Comput., 46(1):58–79, 2017.
- [11] F. Chierichetti, G. Giakkoupis, S. Lattanzi, and A. Panconesi. Rumor spreading and conductance. J. ACM, 65(4):17:1–17:21, 2018.
- [12] F. Chierichetti, S. Lattanzi, and A. Panconesi. Rumor spreading in social networks. Theor. Comput. Sci., 412(24):2602–2610, 2011.
- [13] C. Cooper. Random walks, interacting particles, dynamic networks: Randomness can be helpful. In Proc. Structural Information and Communication Complexity - 18th International Colloquium, SIROCCO, pages 1–14, 2011.
- [14] C. Cooper, A. M. Frieze, and T. Radzik. Multiple random walks in random regular graphs. SIAM J. Discrete Math., 23(4):1738–1761, 2009.
- [15] A. J. Demers, D. H. Greene, C. Hauser, W. Irish, J. Larson, S. Shenker, H. E. Sturgis, D. C. Swinehart, and D. B. Terry. Epidemic algorithms for replicated database maintenance. Operating Systems Review, 22(1):8–32, 1988.
- [16] T. Dimitriou, S. E. Nikoletseas, and P. G. Spirakis. The infection time of graphs. Discrete Applied Mathematics, 154(18):2577–2589, 2006.
- [17] B. Doerr, M. Fouz, and T. Friedrich. Social networks spread rumors in sublogarithmic time. In Proc. 43rd ACM Symposium on Theory of Computing, STOC, pages 21–30, 2011.
- [18] B. Doerr, M. Fouz, and T. Friedrich. Social networks spread rumors in sublogarithmic time. In Proc. 43rd ACM Symposium on Theory of Computing, STOC, pages 21–30. ACM, 2011.
- [19] B. Doerr, T. Friedrich, and T. Sauerwald. Quasirandom rumor spreading. ACM Trans. Algorithms, 11(2):9:1–9:35, 2014.
- [20] D. P. Dubhashi and A. Panconesi. Concentration of Measure for the Analysis of Randomized Algorithms. Cambridge University Press, 2009.
- [21] K. Efremenko and O. Reingold. How well do random walks parallelize? In Proc. Approximation, Randomization, and Combinatorial Optimization. Algorithms and Techniques, 12th International Workshop, APPROX, and 13th International Workshop, RANDOM, pages 476–489, 2009.
- [22] R. Elsässer and T. Sauerwald. On the runtime and robustness of randomized broadcasting. Theoretical Computer Science, 410(36):3414–3427, 2009.
- [23] R. Elsässer and T. Sauerwald. Tight bounds for the cover time of multiple random walks. Theor. Comput. Sci., 412(24):2623–2641, 2011.
- [24] U. Feige, D. Peleg, P. Raghavan, and E. Upfal. Randomized broadcast in networks. Random Struct. Algorithms, 1(4):447–460, 1990.
- [25] W. Feller. An Introduction to Probability Theory and its Applications. Vol. 1. Wiley, 2009.
- [26] G. Giakkoupis. Tight bounds for rumor spreading with vertex expansion. In Proc. 25th ACM-SIAM Symposium on Discrete Algorithms, SODA, pages 801–815, 2014.
- [27] G. Giakkoupis, Y. Nazari, and P. Woelfel. How asynchrony affects rumor spreading time. In Proc. 35th ACM Symposium on Principles of Distributed Computing, PODC, pages 185–194, 2016.
- [28] M. Harchol-Balter, F. T. Leighton, and D. Lewin. Resource discovery in distributed networks. In Proc. 18th ACM Symposium on Principles of Distributed Computing, PODC, pages 229–237, 1999.
- [29] J. Hermon. Frogs on trees? Electron. J. Probab., 23, 2018.
- [30] V. Kanade, F. Mallmann-Trenn, and T. Sauerwald. On coalescence time in graphs: When is coalescing as fast as meeting? In Proc. 30th ACM-SIAM Symposium on Discrete Algorithms, SODA, pages 956–965, 2019.
- [31] R. M. Karp, C. Schindelhauer, S. Shenker, and B. Vöcking. Randomized rumor spreading. In Proc. 41st IEEE Symposium on Foundations of Computer Science, FOCS, pages 565–574, 2000.
- [32] D. Kempe, A. Dobra, and J. Gehrke. Gossip-based computation of aggregate information. In Proc. 44th IEEE Symposium on Foundations of Computer Science FOCS, pages 482–491, 2003.
- [33] H. Kesten and V. Sidoravicius. The spread of a rumor or infection in a moving population. The Annals of Probability, 33(6):2402–2462, Nov 2005. Zbl: 1111.60074.
- [34] H. Kesten and V. Sidoravicius. A shape theorem for the spread of an infection. Annals of Mathematics, 167(3):701–766, May 2008.
- [35] H. Lam, Z. Liu, M. Mitzenmacher, X. Sun, and Y. Wang. Information dissemination via random walks in d-dimensional space. In Proc. 23rd ACM-SIAM Symposium on Discrete Algorithms, SODA, pages 1612–1622, 2012.
- [36] M. Mitzenmacher, R. Rajaraman, and S. T. Roche. Better bounds for coalescing-branching random walks. TOPC, 5(1):2:1–2:23, 2018.
- [37] M. Mitzenmacher and E. Upfal. Probability and Computing. Cambridge University Press, second edition, 2017.
- [38] D. Mosk-Aoyama and D. Shah. Fast distributed algorithms for computing separable functions. IEEE Trans. Information Theory, 54(7):2997–3007, 2008.
- [39] A. Pettarin, A. Pietracaprina, G. Pucci, and E. Upfal. Infectious random walks. CoRR, abs/1007.1604, 2010.
- [40] S. Y. Popov. Frogs and some other interacting random walks models. In Proc. Discrete Random Walks, DRW, pages 277–288, 2003.
- [41] T. Sauerwald. On mixing and edge expansion properties in randomized broadcasting. Algorithmica, 56(1):51–88, 2010.
- [42] R. van Renesse, Y. Minsky, and M. Hayden. A gossip-style failure detection service. In Proc. IFIP International Conference on Distributed Systems Platforms and Open Distributed Processing, Middleware ’98, pages 55–70, 1998.
APPENDIX
Appendix A Concentration Bounds
Below we state some standard bounds we use in our analysis.
Theorem 26 (Chernoff bounds, [37, Theorems 4.2, 4.3]).
Let be independent 0/1 random variables. Let and . Then,
-
(a)
, for .
-
(b)
, for .
-
(c)
, for .
Lemma 27.
Let be independent and identical geometrically distributed random variables with parameter , i.e., for any integer , Let and . Then for any ,
Proof.
We define a coupling between random variables and a sequence of Bernoulli trials with parameter . Let and for , let , i.e., is the index of th 1 in . We set . With this coupling, implies . Therefore,
which we can bound using standard Chernoff bounds from Theorem 26. We have that , and . Then,
Lemma 28.
Let be (dependent) integer random variables, and be mutually independent random variables, such that for any and ,
Then, for any ,
Proof.
Follows from a simple coupling argument. ∎