HyperLoRA for PDEs
Abstract
Physics-informed neural networks (PINNs) have been widely used to develop neural surrogates for solutions of Partial Differential Equations. A drawback of PINNs is that they have to be retrained with every change in initial-boundary conditions and PDE coefficients. The Hypernetwork, a model-based meta learning technique, takes in a parameterized task embedding as input and predicts the weights of PINN as output. Predicting weights of a neural network however, is a high-dimensional regression problem, and hypernetworks perform sub-optimally while predicting parameters for large base networks. To circumvent this issue, we use a low ranked adaptation (LoRA) formulation to decompose every layer of the base network into low-ranked tensors and use hypernetworks to predict the low-ranked tensors. Despite the reduced dimensionality of the resulting weight-regression problem, LoRA-based Hypernetworks violate the underlying physics of the given task. We demonstrate that the generalization capabilities of LoRA-based hypernetworks drastically improve when trained with an additional physics-informed loss component (HyperPINN) to satisfy the governing differential equations. We observe that LoRA-based HyperPINN training allows us to learn fast solutions for parameterized PDEs like Burger’s equation and Navier Stokes: Kovasznay flow, while having an 8x reduction in prediction parameters on average without compromising on accuracy when compared to all other baselines.
Introduction
Partial Differential Equations have been used to model several physical phenomenon, with applications cutting across Industries, including but not limited to Chemical, Aerospace, Automotive, Power, Pharmaceuticals and Metallurgy. However, most systems of PDEs are not amenable to analytical solutions and require numerical approximations which are very time consuming. Additionally, even the slightest change in the initial or boundary value conditions, or the coefficient values of a PDE, may require running fresh computational simulations. These limitations have spurred significant interest in applying neural networks for accelerating numerical methods (Raissi, Perdikaris, and Karniadakis 2019; Kochkov et al. 2021; Greenfeld et al. 2019).
A technique for obtaining a neural network based fast solver is to approximate the operator using data driven methods. Early approaches such as (Guo, Li, and Iorio 2016) assumed a finite dimensional fixed resolution mesh for approximating the solution. However recent advances on Neural Operators (Lu, Jin, and Karniadakis 2019; Li et al. 2020) allow for mesh-free learning by utilizing a single set of network parameters for different discretizations. Meanwhile, there is a recent trend to represent data with implicit neural representatons (INRs) and these have been used to represent images (Ha 2016), and 3D shapes (Mescheder et al. 2019). There is interest in performing deeplearning tasks on a dataset formed by such INRs (Dupont et al. 2022). Such an approach can be used for obtaining fast solvers as well, where a single solution is represented by a neural network and yet another neural network is trained by treating such INRs as data. Such Hyper-networks learn to directly predict weights of an INR for unseen conditions and PDEs. In case of PDEs the dataset of INRs can also be obtained by employing a solver which directly obtains neural surrogates for the solution of a PDE (Majumdar et al. 2022).
Hypernetwork (Ha, Dai, and Le 2016) is a form model based meta learning network that takes task descriptions as input and predicts the weights of a neural network as output. Predicting weights of a neural network however, is a high-dimensional regression problem, and hypernetworks perform sub-optimally while predicting parameters for large base networks. However, one can represent the adaptation of large network with parameter efficient tuning (Hu et al. 2021; Li and Liang 2021). Thus, a hypernetwork can be trained using just adaptation parameters rather than the entire network. Almost concurrent to our work such ideas have been used for Image Generation (Ruiz et al. 2023) and Instruction Tuning of LLMs (Ivison et al. 2023).
In this work we show the efficacy of utilizing Hypernetworks to predict low rank adaptation weights of neural surrogate for solving PDEs. We observe that hypernetworks trained purely by using INRs as data do not provide the best performance and significant performance gains can be obtained if one has access to input-output data for the neural surrogates. Such data may be available from sensors or from employing a PINN solver for each task. Further, we observed the best performance when a physics informed loss is included during hypernetwork training.
The remainder of the paper is organized as follows. First, we mathematically define the LoRA-based equations in the methodology section of the paper. We follow it up by Dataset information, training and hyperparameter details. We discuss the results and observations in the next section and summarize our findings in the conclusions.
Methodology
Physics-informed Neural Networks
We consider Partial Differential Equations of the form
| (1) |
Here, is a non-linear differential operator consisting of space and time derivatives of spatial variable and temporal variable . The neural network is trained using a loss function that consists of: 1) A supervised initial condition loss and boundary condition loss component and 2) An unsupervised physics-informed loss component.
| (2) |
Here, C represents the set of collocation points on which the Physics-loss is calculated. IC, BC represents the set of points at which Initial Conditions and Boundary Conditions are evaluated. ,, represent the initial condition and boundary condition functions respectively. represents the weights of the neural network.
Low ranked adaptation for PINNs
We follow the methodology as proposed in (Hu et al. 2021). We first train a PINN on task and represent it’s weights as . Now, we represent the weights of a task as and represent it’s update as follows:
| (3) |
Here, ,, , . Here min{}. During train time, is kept frozen and matrices contain trainable parameters which adapt from task to task .
Hypernetworks
Hypernetworks (Ha, Dai, and Le 2016) are neural networks parameterized by which accept a task-representation as input and predict weights of a neural network used to model that particular task.
| (4) |
Here is directly supplied to the main-network for evaluating the solution . We sample different values of to train the hypernetwork, and generalize to unseen values at test-time.
LoRA-based Hypernetworks
LoRA-based Hypernetworks are a combination of Hypernetworks and low-ranked adaptation of the main-network. The mathematical formulation is defined as follows:
| (5) |
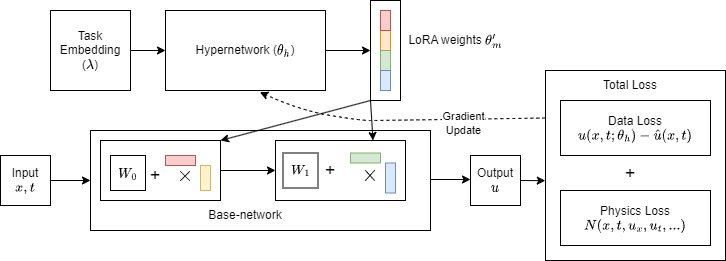
Here, refers to the weights of a pretrained main-network for a task . The Hypernetwork , instead of predicting the weights of the entire main-network , just predicts the low ranked weights represented by .
HyperPINNs
HyperPINNs are hypernetworks trained using physics-informed loss introduced in (de Avila Belbute-Peres, fan Chen, and Sha 2021) to solve parameterized differential equations.
| (6) |
HyperPINN consists of two components, a hypernetwork and a main-network . takes in task parameterization as input and outputs the weights of the main-network .
LoRA-based HyperPINNs
We combine LoRA-based adaptation and HyperPINNs to solve for parameterized PDEs while having to predict a lower number of parameters against a standard HyperPINN. The mathematical formulation of LoRA-based HyperPINN is defined as follows:
| (7) |
We provide an illustration of LoRA-based HyperPINN in figure 1.
Weight regressor hypernetwork
Instead of using supervised data or physics-informed loss to train the Hypernetwork, Majumdar et al. directly perform regression in weight-space on pretrained PINN weights.
| (8) |
Here, the hypernetwork is trained using , where refers to the task space and refers to weights of pretrained PINN for task .
Weight regressor LoRA-based hypernetwork
Instead of predicting weights of the entire network, Hypernetwork just predicts the LoRA decomposed weights. Remaining methodology follows from the previous subsection.
PDE Information
One-dimensional Burger’s equation
The governing PDE system of one-dimensional Burger’s equation is given by:
| (9) |
Here, , refers to the viscosity of the system, and refers to the initial condition sampled from where .
Two-dimensional coupled viscous Burger’s equation
The governing equations of two-dimensional coupled viscous Burger’s equation is given by:
| (10) |
The initial and boundary conditions are sampled from the true analytical solutions of the PDE, given by:
| (11) |
Here , , refers to the viscosity of the flow. We consider for our experiments.
Navier-Stokes: Kovasznay flow
Navier-Stokes: Kovasznay flow is a two-dimensional steady state laminar flow. The governing Partial Differential equations are given by:
| (12) |
The boundary conditions for the equation are sampled from the true analytical solutions of the PDE, given by:
| (13) |
Here, , , where refers to the Reynold’s number of the system. We consider for our experiments.
Training and Hyperparameter details
We take a Multi-layer Perceptron of architecture [inputs-64*4-outputs] for training PINNs. We train a base PINN using an Adam optimizer for 30k epochs with a starting learning rate of 1e-3 for first 10k epochs and use a multiplicative decay of 0.1 with minimum learning rate of and stop when validation loss doesn’t improve for 1000 epochs. We further finetune the trained PINNs using an L-BFGS optimizer. We use the same optimizer and learning-rate schedule for LoRA-based PINNs and finetuning-PINN experiments. For 1D-Burger’s equation, we use 128 initial condition points and 10k uniformly sampled collocation points for training the PINNs. In 2D-Burger’s equation, we use 400 boundary condition points with 100 points sampled over each face of the square grid, 500 initial condition points and 10k uniformly sampled collocation points. In Navier-Stokes: Kovasznay flow, we consider a equally spaced grid domain to represent the spatial domain, and sample 2601 collocation points. We further use 320 boundary condition points, with 80 points for each face of the grid to enforce the boundary conditions.
In our Hypernetwork-based experiments, we consider an MLP of architecture [inputs- 512*2 - 256*2- 128*2 - outputs]. Here inputs refer to the dimensionality of the task representation, which is 1 for Navier-Stokes (Reynold’s number ), 1 for 2D-Burger’s (Viscosity ), and 128 for 1D burger’s (Initial condition discretized at 128 positions). Outputs refer to the number of parameters being predicted, with parameter details tabulated in Table 2. We train all the Hypernetworks using an Adam optimizer for 15k epochs, with a starting learning rate of for 5k epochs and a multiplicative decay of 0.1 every 3k epochs. Across all examples, we consider 20 validation and 20 test tasks, while we consider 100,20,20 train-tasks for 1D-Burger’s, 2D-Burger’s and Navier Stokes equations respectively. All experiments were conducted on Nvidia P100 GPU with 16 GB GPU Memory and 1.32 GHz GPU Memory clock using Pytorch framework.
Results and Observations
Rank analysis of decomposed Low-rank matrices
| 1D-Burger’s | Rank | # | Error | Time | Epochs |
|---|---|---|---|---|---|
| PINNs | 21057 | 4.54 | 0.28 | 30k | |
| F-PINNs | 21057 | 1.93 | 0.28 | 25k | |
| L-PINNs | 1 | 643 | 1.95 | 0.01 | 30k |
| 2 | 1286 | 1.54 | 0.03 | 25k | |
| 4 | 2572 | 7.00 | 0.05 | 12k | |
| 8 | 5144 | 8.89 | 0.09 | 12.5k | |
| 16 | 10288 | 1.00 | 0.12 | 20k | |
| 32 | 20576 | 1.03 | 0.16 | 20k | |
| 64 | 41152 | 1.15 | 0.28 | 30k | |
| Kovasznay | Rank | # | Error | Time | Epochs |
| PINNs | 21187 | 1.05 | 0.22 | 30k | |
| F-PINNs | 21187 | 6.36 | 0.22 | 20k | |
| L-PINNs | 1 | 645 | 8.16 | 0.02 | 30k |
| 2 | 1290 | 6.68 | 0.04 | 20k | |
| 4 | 2580 | 3.85 | 0.06 | 12k | |
| 8 | 5160 | 5.59 | 0.09 | 12.5k | |
| 16 | 10320 | 9.35 | 0.14 | 20k | |
| 32 | 20640 | 9.74 | 0.16 | 30k | |
| 64 | 41280 | 1.18 | 0.22 | 30k | |
| 2D-Burger’s | Rank | # | Error | Time | Epochs |
| PINNs | 21187 | 3.25 | 0.33 | 30k | |
| F-PINNs | 21187 | 2.69 | 0.33 | 25.5k | |
| L-PINNs | 1 | 645 | 3.81 | 0.02 | 30k |
| 2 | 1290 | 7.02 | 0.04 | 25k | |
| 4 | 2580 | 1.17 | 0.05 | 12k | |
| 8 | 5160 | 2.73 | 0.10 | 13k | |
| 16 | 10320 | 2.89 | 0.14 | 20k | |
| 32 | 20640 | 2.94 | 0.17 | 20k | |
| 64 | 41280 | 3.01 | 0.36 | 30k |
In this subsection, we analyze how the performance varies by changing the rank of our decomposed matrices of Neural network used for low-ranked adaptation. We tabulate the results of our Low-ranked adaptation experiments in Table 1. Our experimental design is as follows: Across all PDE examples, we first train an independent PINN on a task . Then we perform Low-ranked adaptation for a new task using the trained PINN for task as our base model. Lower the rank of the decomposed tensors, the fewer the number of parameters involved in adapting to the newer task.
Across all three PDE systems, we notice the average accuracy across the test-tasks first increases with increase in rank, reaches an optimal rank, which happens to be 4, and then slightly deteriorates as the rank is further increased to the full rank of the original matrix. The best LoRA-based PINN is on average 3.98 better than PINNs, while requiring fewer parameters, fewer epochs while yielding faster training time per epoch (due to training fewer parameters). Additionally, the best LoRA-based PINN is on average better than a finetuned-PINN, while requiring fewer parameters, fewer epochs yielding faster training time per epoch.
Improvement of performance due to initial rank increase can be attributed to improved representation capacity of the finetuned task due to higher number of parameters. We see a 2.78% improvement in 1D-Burger’s, 2.11% improvement in Navier-Stokes, and 32.56% improvement in 2D-Burger’s on increasing the rank from 1 to 4. We additionally notice, while the training-time per epoch is lower for LoRA-based PINNs with ranks 1 and 2, as the representation capacity is restricted, these take a higher time to converge as compared to LoRA-based PINNs with rank 4. Further increase in rank leads to drop in performance, and we speculate overfitting and increased in variance to be reasons for it due to increase in # parameters. In addition, very high ranked LoRA-based PINNs require higher training time to converge, as against the best-ranked LoRA-based PINN.
Hypernetworks for Low-ranked adaptation
| Rank | # Parameters | Train | Valid | Test | Time per epoch | ||
|---|---|---|---|---|---|---|---|
| 1 | 645 | 2.19 | 1.39 | 1.87 | 0.16 | ||
| 2 | 1290 | 4.45 | 9.16 | 8.31 | 0.21 | ||
| Hypernetwork+LoRA | 4 | 2580 | 4.08 | 5.16 | 5.23 | 0.29 | |
| 8 | 5160 | 6.46 | 6.99 | 7.75 | 0.37 | ||
| * | 21187 | 4.38 | 3.60 | 2.66 | 2.15 | ||
| 1 | 645 | 4.17 | 3.29 | 3.22 | 0.05 | ||
| 2 | 1290 | 3.95 | 3.59 | 3.49 | 0.07 | ||
| Hypernetwork+LoRA | 4 | 2580 | 2.95 | 3.06 | 3.19 | 0.101 | |
| (Weight Regression) | 8 | 5160 | 4.04 | 5.19 | 7.72 | 0.12 | |
| Navier-Stokes | * | 21187 | 1.17 | 2.18 | 1.95 | 0.73 | |
| Kovasznay flow | 1 | 645 | 2.19 | 1.39 | 1.91 | 0.16 | |
| 2 | 1290 | 4.28 | 9.03 | 8.29 | 0.21 | ||
| Hypernetwork+LoRA | 4 | 2580 | 4.11 | 5.04 | 5.26 | 0.29 | |
| (PINN generated) | 8 | 5160 | 6.28 | 7.15 | 7.64 | 0.37 | |
| * | 21187 | 4.47 | 3.66 | 2.82 | 2.15 | ||
| 1 | 645 | 2.22 | 1.35 | 1.80 | 0.63 | ||
| 2 | 1290 | 4.36 | 9.15 | 8.25 | 0.84 | ||
| HyperPINN+LoRA | 4 | 2580 | 4.15 | 5.52 | 4.84 | 1.15 | |
| 8 | 5160 | 5.93 | 6.64 | 7.22 | 1.45 | ||
| * | 21187 | 3.17 | 2.91 | 4.42 | 9.43 | ||
| 1D Burger’s | 1 | 643 | 7.25 | 1.09 | 8.78 | 1.19 | |
| 2 | 1286 | 2.69 | 4.67 | 4.98 | 1.56 | ||
| Hypernetwork+LoRA | 4 | 2572 | 3.02 | 3.47 | 3.22 | 1.84 | |
| 8 | 5144 | 5.69 | 6.11 | 6.37 | 2.25 | ||
| * | 21057 | 1.96 | 3.70 | 3.14 | 17.26 | ||
| 1 | 643 | 8.82 | 8.54 | 9.13 | 0.81 | ||
| 2 | 1286 | 6.19 | 6.15 | 6.15 | 1.05 | ||
| Hypernetwork+LoRA | 4 | 2572 | 4.24 | 4.43 | 4.17 | 1.36 | |
| (Weight regression) | 8 | 5144 | 5.43 | 5.94 | 5.56 | 1.74 | |
| * | 21057 | 3.64 | 4.90 | 5.12 | 10.14 | ||
| 1 | 643 | 7.18 | 1.12 | 8.89 | 1.19 | ||
| 2 | 1286 | 2.86 | 4.75 | 5.05 | 1.56 | ||
| Hypernetwork+LoRA | 4 | 2572 | 3.12 | 3.55 | 3.35 | 1.84 | |
| (PINN generated) | 8 | 5144 | 5.58 | 6.16 | 6.44 | 2.25 | |
| * | 21057 | 2.02 | 3.84 | 3.26 | 17.26 | ||
| 1 | 643 | 9.64 | 1.45 | 1.17 | 3.15 | ||
| 2 | 1286 | 4.02 | 6.22 | 6.64 | 4.35 | ||
| HyperPINN+LoRA | 4 | 2572 | 3.67 | 4.82 | 4.74 | 5.75 | |
| 8 | 5144 | 7.19 | 8.19 | 8.23 | 8.45 | ||
| * | 21057 | 2.58 | 4.29 | 3.97 | 67.6 | ||
| 2D Burger’s | 1 | 644 | 3.05 | 4.44 | 9.52 | 0.093 | |
| 2 | 1288 | 2.97 | 3.26 | 2.55 | 0.131 | ||
| Hypernetwork+LoRA | 4 | 2576 | 1.46 | 1.50 | 1.16 | 0.171 | |
| 8 | 5152 | 1.81 | 1.66 | 1.52 | 0.241 | ||
| * | 21122 | 1.34 | 2.15 | 3.97 | 1.91 | ||
| 1 | 644 | 3.17 | 3.22 | 2.68 | 0.031 | ||
| 2 | 1288 | 2.12 | 2.15 | 2.36 | 0.044 | ||
| Hypernetwork+LoRA | 4 | 2576 | 1.40 | 1.57 | 2.15 | 0.059 | |
| (Weight Regression) | 8 | 5152 | 2.66 | 2.36 | 2.94 | 0.082 | |
| * | 21122 | 1.06 | 3.32 | 1.00 | 2.95 | ||
| 1 | 644 | 3.12 | 4.63 | 9.58 | 0.093 | ||
| 2 | 1288 | 2.88 | 3.32 | 2.57 | 0.131 | ||
| Hypernetwork+LoRA | 4 | 2576 | 1.49 | 1.61 | 1.19 | 0.171 | |
| (PINN generated) | 8 | 5152 | 1.85 | 1.58 | 1.48 | 0.241 | |
| * | 21122 | 1.34 | 2.14 | 3.88 | 1.91 | ||
| 1 | 644 | 5.52 | 8.26 | 7.35 | 0.375 | ||
| 2 | 1288 | 6.14 | 7.66 | 8.22 | 0.525 | ||
| HyperPINN+LoRA | 4 | 2576 | 2.89 | 4.26 | 4.19 | 0.69 | |
| 8 | 5152 | 2.72 | 4.31 | 4.18 | 0.975 | ||
| * | 21122 | 4.52 | 1.91 | 2.05 | 7.85 |
In this subsection, we study the results for our experiments for LoRA-based HyperPINNs. Hypernetwork-based PINN architectures have faster inference time than PINN-based counterparts, and allows for generalization to parameterized PDE systems. We tabulate the results in Table 2. Across all examples, * refers to the case where we don’t perform LoRA, and hypernetwork predicts the entire neural network.
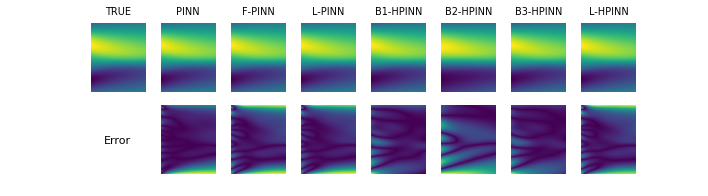
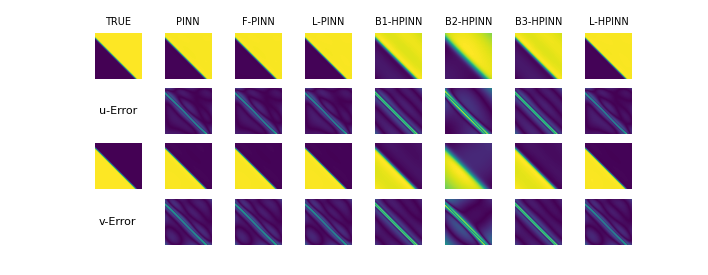
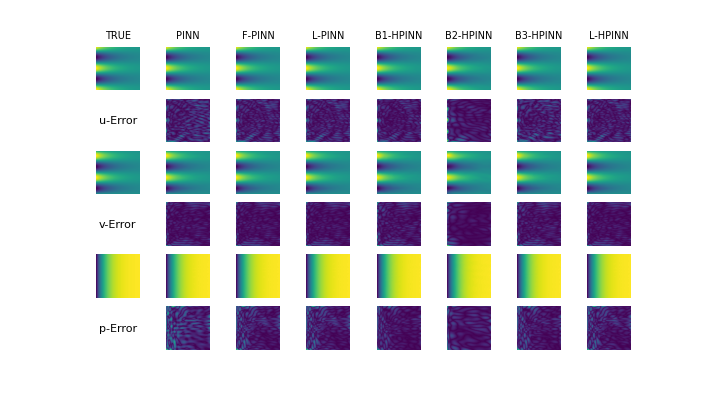
As our first benchmark, we train a LoRA-based hypernetwork using the true simulation data and solutions of the PDE as ground-truth. Similar to our analysis in previous subsection, we observe, across all PDE examples, the Hypernetwork performance improves till LoRA of rank 4, and then starts deteriorating. The reason for improved performance for rank 4 over lower ranks is higher representation capacity of base-networks. The reason for drop in performance for Hypernetworks beyond rank 4 is inability of Hypernetworks to predict very high dimensional weights in a regression setting. However, on test tasks, Rank-4 LoRA-based hypernetworks are just worse than Rank-4 LoRA-based PINNs on Kovasznay flow, but are and worse on 2D-Burger’s and 1D-Burger’s respectively. Thus, this benchmark has two issues. First, this benchmark requires pre-existing simulation data for multiple solved PDE instances which may not be available in practice, and second, the generalization is poor and physics is violated as seen in Figures 2, 3, 4.
We mitigate the data availability drawback by training multiple instances of PINNs and use the weights of the data generated by trained-PINNs as supervised labels for benchmark 2. In our second benchmark, we use the hypernetwork to predict the weights of the base-network and use weights of the pre-trained PINNs as regression loss following motivations from the paper (Majumdar et al. 2022). While the rank analysis remains similar and the hypernetwork has lower training time, the performace across all test-examples is quite poor. Reason: Weight-spaces are extremely sensitive to slight perturbations, thus leading to very complex manifolds being learnt. The complexity of generalizing the output manifold to test-examples is increased, thus leading to poor performance. Weight-regressor hypernetworks typically perform 2-3 orders worse than LoRA-based PINNs and benchmark 1.
In benchmark 3, we use the data generated by trained-PINNs as supervised labels and train a hypernetwork. We observe, the rank analysis to be similar as in the past sections, and the best-ranked hypernetwork performs comparably ( worse) to the best-ranked hypernetwork in benchmark 1, and is 3-4 orders superior in performance as compared to weight-regressor hypernetworks. However, this benchmark like benchmark 1 performs similarly worse (, and ) than LoRA-based PINNs of rank 4 on Kovasznay flow, 2D Burger’s and 1D Burger’s respectively. As a summary, this benchmark has 2 issues: 1) Training multiple PINNs can be costly 2) Poor generalization and violation of physics constraints, as seen in Figure 2, 3, 4.
We mitigate both the issues in benchmark 3 by using LoRA-based HyperPINNs. HyperPINNs take in a task embedding as input, and learn the hypernetworks in a physics-informed manner, instead of taking pre-trained data as a supervision signal. This eradicates the need of having ground-truth samples or neural surrogate samples like in benchmark 3. We observe the performance of Rank 4 LoRA-based HyperPINN is 3 and 2 orders of magnitude better in 1D-Burger’s equation and 2D-Burger’s equation respectively, and is less-than an order () worse than LoRA-based PINNs on test-examples. This indicates LoRA-based HyperPINNs have the capability to generalize across test-tasks at an inference-time advantage, compared to traditional PINNs and LoRA-based PINNs, while respecting the physics constraints observed in Figures 2, 3, 4.
We tabulate the inference time for our architectures in Table 3. Across all examples, we observe LoRA-based HyperPINNs to be around 2-3 orders of magnitude faster than vanilla architectures, as the entire computational cost is transferred to one-time train cost, and we simply predict the weights for a test-time, without having to finetune. The best-ranked LoRA-based PINNs are faster than finetuned PINNs and faster than vanilla-PINNs, due to training lower number of parameters and incorporating pre-trained information from an already trained base-task.
| Architecture | Time | |
| (sec) | ||
| 1D-Burger’s | PINN | 8400 |
| Finetuned PINN | 7000 | |
| LoRA-based PINN | 600 | |
| LoRA-based HyperPINN | 1.1 | |
| PINN | 6600 | |
| Navier-Stokes | Finetuned PINN | 4400 |
| (Kovasznay flow) | LoRA-based PINN | 720 |
| LoRA-based HyperPINN | 1.2 | |
| 2D-Burger’s | PINN | 9900 |
| Finetuned PINN | 8415 | |
| LoRA-based PINN | 602 | |
| LoRA-based HyperPINN | 1.2 |
Conclusions
We use Low-ranked adaptation for PINNs to quickly adapt solutions of parameterized PDEs from one instance to another. We investigate the importance of choice of rank of decomposed tensors, and conclude there exists an optimal rank for tensor decomposition, lowering which leads to reduced representation capacity and larger training time for the newer PDE instance. Increasing the rank leads to overfitting and a slight drop in performance at test-time. We note, the optimal low-rank adapted PINN converges faster and outperforms PINNs trained from random initialization or finetuned PINNs. Next, we scale LoRA-based PINNs to HyperLoRA-based PINNs to further reduce inference time. Rank analysis of LoRA-based PINNs extend to LoRA-based Hypernetworks as well. Benchmark LoRA-based hypernetworks have the drawback of requiring pre-existing ground-truth data which is scarce, and have inferior generalization as the underlying physics isn’t captured. Utilizing a physics-loss to train the LoRA-based Hypernetworks leads to improved generalization and comparable performance with instance-wise LoRA-based PINNs, while retaining the advantage in inference-time.
Limitations and future work
One of the limitations of LoRA-based PINNs, is the manual search involved in determining the best rank of the matrix decomposition. Efficiently determining the best rank alongside theoritical guarantees will considerably help reduce manual experimentation. Second drawback, PINNs fail to model long temporal flows simply using an unsupervised physics loss, and thus we speculate LoRA-based HyperPINNs will also have difficulties modeling long temporal flows. We seek to analyze how LoRA-based HyperPINNs will scale to these complex examples where the complex loss-landscape of physics-loss will play a big factor during convergence at training time.
References
- de Avila Belbute-Peres, fan Chen, and Sha (2021) de Avila Belbute-Peres, F.; fan Chen, Y.; and Sha, F. 2021. HyperPINN: Learning parameterized differential equations with physics-informed hypernetworks. arXiv:2111.01008.
- Dupont et al. (2022) Dupont, E.; Kim, H.; Eslami, S. M. A.; Rezende, D.; and Rosenbaum, D. 2022. From data to functa: Your data point is a function and you can treat it like one. arXiv:2201.12204.
- Greenfeld et al. (2019) Greenfeld, D.; Galun, M.; Basri, R.; Yavneh, I.; and Kimmel, R. 2019. Learning to optimize multigrid PDE solvers. In International Conference on Machine Learning, 2415–2423. PMLR.
- Guo, Li, and Iorio (2016) Guo, X.; Li, W.; and Iorio, F. 2016. Convolutional Neural Networks for Steady Flow Approximation. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’16, 481–490. New York, NY, USA: Association for Computing Machinery. ISBN 9781450342322.
- Ha (2016) Ha, D. 2016. Generating Large Images from Latent Vectors. blog.otoro.net.
- Ha, Dai, and Le (2016) Ha, D.; Dai, A.; and Le, Q. V. 2016. HyperNetworks. arXiv:1609.09106.
- Hu et al. (2021) Hu, E. J.; Shen, Y.; Wallis, P.; Allen-Zhu, Z.; Li, Y.; Wang, S.; Wang, L.; and Chen, W. 2021. LoRA: Low-Rank Adaptation of Large Language Models. arXiv:2106.09685.
- Ivison et al. (2023) Ivison, H.; Bhagia, A.; Wang, Y.; Hajishirzi, H.; and Peters, M. 2023. HINT: Hypernetwork Instruction Tuning for Efficient Zero- Few-Shot Generalisation. arXiv:2212.10315.
- Kochkov et al. (2021) Kochkov, D.; Smith, J. A.; Alieva, A.; Wang, Q.; Brenner, M. P.; and Hoyer, S. 2021. Machine learning–accelerated computational fluid dynamics. Proceedings of the National Academy of Sciences, 118(21): e2101784118.
- Li and Liang (2021) Li, X. L.; and Liang, P. 2021. Prefix-Tuning: Optimizing Continuous Prompts for Generation. arXiv:2101.00190.
- Li et al. (2020) Li, Z.; Kovachki, N.; Azizzadenesheli, K.; Liu, B.; Bhattacharya, K.; Stuart, A.; and Anandkumar, A. 2020. Fourier neural operator for parametric partial differential equations. arXiv preprint arXiv:2010.08895.
- Lu, Jin, and Karniadakis (2019) Lu, L.; Jin, P.; and Karniadakis, G. E. 2019. Deeponet: Learning nonlinear operators for identifying differential equations based on the universal approximation theorem of operators. arXiv preprint arXiv:1910.03193.
- Majumdar et al. (2022) Majumdar, R.; Jadhav, V.; Deodhar, A.; Karande, S.; Vig, L.; and Runkana, V. 2022. Real-time Health Monitoring of Heat Exchangers using Hypernetworks and PINNs. arXiv:2212.10032.
- Mescheder et al. (2019) Mescheder, L.; Oechsle, M.; Niemeyer, M.; Nowozin, S.; and Geiger, A. 2019. Occupancy Networks: Learning 3D Reconstruction in Function Space. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).
- Raissi, Perdikaris, and Karniadakis (2019) Raissi, M.; Perdikaris, P.; and Karniadakis, G. 2019. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. Journal of Computational Physics, 378: 686–707.
- Ruiz et al. (2023) Ruiz, N.; Li, Y.; Jampani, V.; Wei, W.; Hou, T.; Pritch, Y.; Wadhwa, N.; Rubinstein, M.; and Aberman, K. 2023. HyperDreamBooth: HyperNetworks for Fast Personalization of Text-to-Image Models. arXiv preprint arXiv:2307.06949.