IB-DRR - Incremental Learning with Information-Back
Discrete Representation Replay
Abstract
Incremental learning aims to enable machine learning models to continuously acquire new knowledge given new classes, while maintaining the knowledge already learned for old classes. Saving a subset of training samples of previously seen classes in the memory and replaying them during new training phases is proven to be an efficient and effective way to fulfil this aim. It is evident that the larger number of exemplars the model inherits the better performance it can achieve. However, finding a trade-off between the model performance and the number of samples to save for each class is still an open problem for replay-based incremental learning and is increasingly desirable for real-life applications. In this paper, we approach this open problem by tapping into a two-step compression approach. The first step is a lossy compression, we propose to encode input images and save their discrete latent representations in the form of ‘codes’ that are learned using a hierarchical Vector Quantised Variational Autoencoder (VQ-VAE). In the second step, we further compress ‘codes’ losslessly by learning a hierarchical latent variable model with bits-back asymmetric numeral systems (BB-ANS). To compensate for the information lost in the first step compression, we introduce an Information Back (IB) mechanism that utilizes raw exemplars for a contrastive learning loss to regularise the training of a classifier. By maintaining all seen exemplars’ representations in the format of ‘codes’, Discrete Representation Replay (DRR) outperforms the state-of-art method on CIFAR-100 by a margin of 4% average accuracy with a much less memory cost required for saving samples. Incorporated with IB and saving a small set of old raw exemplars as well, the average accuracy of DRR can be further improved by 2%.
1 Introduction
Deep neural networks leveraging large-scale annotated datasets have been shown to be powerful in many real-world tasks such as image classification. One downside is that these data-driven methods work under the assumption that all training samples (exemplars) are simultaneously available during the training phase [11, 21, 19]. However, due to the growing need for systems that can adapt to dynamic environments and can continually learn new tasks, current deep neural networks are not adequate as they suffer from catastrophic forgetting - when a model is continuously updated using novel incoming data, the updates can override knowledge acquired from previous classes. Incremental learning, also known as continual learning, never-ending learning or life-long learning, aims to design systems that can keep learning new knowledge while maintaining the performance for the previously learned tasks.
An effective and commonly used strategy in the current incremental learning methods is replay or rehearsal, which is mixing the new data with the old data when learning new information to maintain old knowledge. This can be achieved by saving a small subset of old data [26, 42, 28, 16, 39, 15, 33]. However, the success of this strategy highly depends on how many and which exemplars to save [26, 39, 16]. Alternatively, a line of research has focused on learning a generator to produce pseudo old samples [25, 44, 34]. However, the generator needs to be updated using fake old data that may lead to a vicious cycle if some pseudo data of bad quality is produced. Recent work [25, 44, 34] has shown that image generator is unstable and unreliable in incremental learning for complex dataset such as CIFAR-100 [20] and only works on small and relatively simple datasets such as MNIST [22].
Although carefully selected exemplars or generated representative exemplars can help improve the performance up to some degree [39, 16], the larger number of exemplars a model inherits the better performance it can achieve. However, saving all available data is memory-expensive. The trade-off between model performance and the number of exemplars per class is hard to be optimised due to different applications requirement and varies among different distinctive tasks.
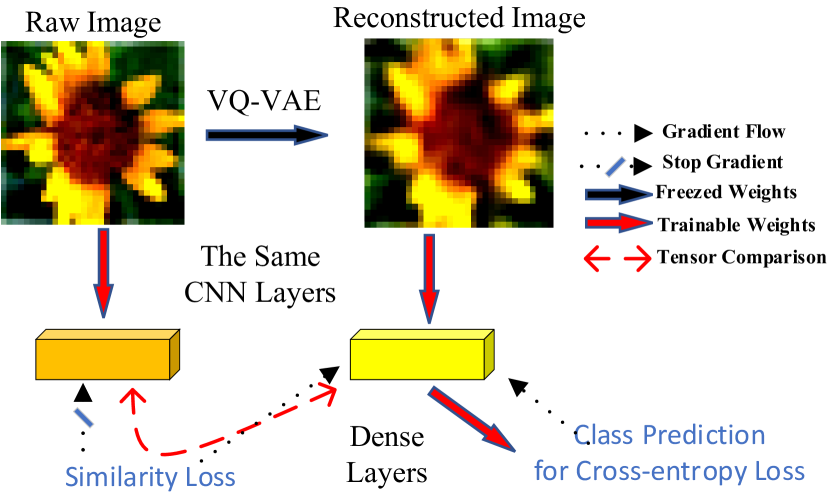
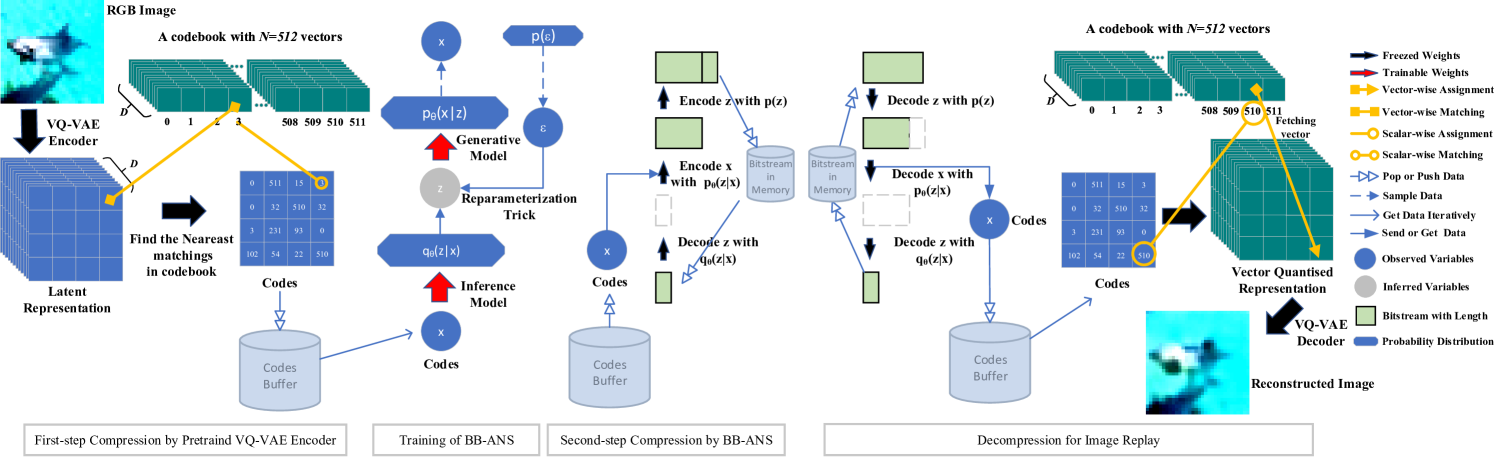
In this paper, we approach this open problem by introducing Discrete Representation Replay (DRR). The DRR module allows saving the maximum number of exemplars possible at a small memory cost with two-step compression. As shown in Figure 2, DRR benefits from a Vector-Quantised Variational Autoencoder (VQ-VAE) [31, 38] as well as a Bits-Back Asymmetric Numeral Systems (BB-ANS) that paired with hierarchical latent variables. The VQ-VAE reduces the memory required for uncompressed training exemplars on the CIFAR-100 [20] dataset from MB to MB and BB-ANS further reduces it to MB, resulting in an overall memory gain of 97%. To learn new classes, DRR combines latent representations (in the format of codes) of new training samples with those of old samples and reconstruct them back to the RGB image domain at run time. Our experiments on CIFAR-100 [20] showed that Discrete Representation Replay (DRR) outperformed the state-of-the-art replay-based method [26] in the multi-class incremental learning setting by a margin of 4% while reducing the memory size required for saving exemplars. To alleviate the loss of information caused by VQ-VAE, we design a negative-pairs-free contrastive learning component called Information Back (IB) inside our classifier that saves and uses raw images to regularize the training of the classifier, see Fig. 1. We assume the reconstruction processes of different images share similar transformation patterns as the same VQ-VAE is applied. Note that IB requires to save an additional subset of raw previously seen samples but they are not directly used for minimizing the classification loss. They serve as regularizers to force the classifier to get back some general information lost during image reconstruction. Incorporated with IB component, called IB-DRR, the testing accuracy of DRR increases by 2% on CIFAR-100. Additionally, our empirical results show that even without maintaining previously seen raw data IB-DRR can still boost performance in some settings, especially, the settings where the number of new classes to learn is large. In summary, our main contributions are as follows:
-
•
We formalize incremental learning as a representation compression problem and introduce Discrete Representation Replay (DRR) strategy for this task. More explicitly, we propose a two-step compression which allows us to save training exemplars at a competitively small memory cost. This is enabled by a VQ-VAE that is used to save and reconstruct images during new training phases and hierarchical latent variable models with BB-ANS that further reduces the memory cost.
-
•
We introduce an Information Back (IB) mechanism that utilizes a subset of raw images for old classes and all raw images from new classes via a contrastive learning loss to alleviate the information loss and regularise the training.
-
•
Finally, we show that on the CIFAR-100 dataset [20] our DRR surpasses the state-of-the-art method [26] by a margin of 4% without saving any raw examples. And by saving a small number of raw samples, IB-DRR yields the best performance with a margin of 6% as compared to the state-of-the-art method [26]. Our preliminary results on the ImageNet [7] also indicate the viability of this approach across different datasets.
2 Related Work
There is a significant body of work on incremental learning, which can be divided into three broad categories, namely, regularization-based (e.g., [19, 50]), parameter-isolation-based (e.g., [35, 32]) and replay-based (e.g., [42, 16, 29, 4, 26, 25]). Our proposed approach falls into the category of replay-based methods. Replay, also known as rehearsal, is the most competitive and popular strategy in incremental learning and achieves state-of-the-art performance on many benchmark datasets including CIFAR-100 [20], MNIST [22] and ImageNet [43]. We summarise these replay-based methods in three categories, namely, image-level replay, feature-level replay, and compression for replay.
Image-level Replay. Storing and replaying exemplars in the memory to solve catastrophic forgetting was first introduced in 1990s [41]. Recently, Isele et al. [16] reintroduced replay strategy in incremental learning and proposed a ranking function to select and store exemplars for each class in a long-term memory called episodic memory. To control the memory required for replay, Rebuffi et al. [39] proposed a method name iCaRL that used a fixed size memory for all classes. To maintain the most important exemplars, they used a buffer-reconstruction procedure called Herding to select a number of exemplars from a new class to save and discard the least preferred exemplars from previous classes to prevent memory from growing. To address the imbalance between a small number of exemplars for old classes and substantially more samples of new classes, Hou et al. [15] proposed a method named (LUCIR) that treated both old and new classes uniformly by introducing cosine normalization on latent representations of samples of new classes and old classes. They also selected samples to save by leveraging an online mining method. Most recently, Liu et al. [26] developed a method called Mnem, where exemplars to save were considered as learnable parameters. The parameterized exemplars of old classes were optimised in an end-to-end manner during the training, and by utilizing strategies used in [15] their model achieved state-of-the-art performance as compared to existing replay-based methods on both CIFAR-100 and ImageNet. On the other hand, using exemplars directly for training classifiers may be prone to over-fitting [29, 4]. Therefore, Gradient Episodic Memory (GEM) [29] was proposed to indirectly utilize saved exemplars. Their model computed gradients given new data as well as a set of task-specific gradients using episodic memory, and it projected the gradients in the feasible region defined by task gradients. Like GEM, our Information-Back Discrete Representation Replay (IB-DRR) also used saved raw exemplars indirectly for classification. To avoid saving original inputs, a number of works [44, 34, 51] utilised a generative model such as Generative Adversarial Network (GAN) [9] or Variational Autoencoder (VAE) [17] to produce fake data that is similar to data from old classes. In this way, they aimed to transfer incremental learning problem into image generating problem. However, the generative model itself needs to maintain the ability to generate fake data for old tasks, and this approach still has to deal with catastrophic forgetting that occurs in the generative model rather than the classifier. This has been demonstrated by a recent work [24] pointing out that a GAN itself has a catastrophic forgetting problem and the training of GAN can be regarded as an incremental learning problem. In addition, fake data may not reflect the real data distribution, which can potentially lead to a vicious cycle. Therefore, training a generative model in incremental learning settings is unstable and unreliable and recent generative-replay-based methods [44, 34, 51] work on comparatively simple datasets such as MNIST [22] and SVHN [30] datasets.
Feature-level Replay. Another line of work has focused on saving the latent representations instead of saving original image data or generating fake data. Indeed, in some incremental learning scenarios [25, 1, 44, 23], training data from a certain task is no longer available after a model is trained for the task. Because saving data firstly leads to privacy and security issues and secondly results in a significant increase in the memory as the model gradually learns new classes. Pellegrini et al. [33] pretrained a classifier on ImageNet [43]. Then its low-level layers were kept and frozen to serve as a feature extractor for other datasets like Core50 [27]. They extracted and saved a small subset of latent representations (namely, the output of the feature extractor) of inputs and replayed them during new training phases. They trained and updated a classifier using both the features of new data and replayed features. Recently, Xialei et al. [25] combined a generative model with a feature-level replay strategy and used a GAN to produce fake latent representations and achieved competitive performance on the CIFAR-100. Their model called generative feature replay (GFR) consisted of a modified classifier that took latent representation as inputs, a feature extractor and a generator. The modified classifier was jointly trained using cross-entropy loss with the feature extractor which encodes original images to corresponding latent representations. After trained on new data, they were frozen and the generator was updated using latent representations produced by them given corresponding data. Besides, they applied the knowledge distillation technique to the feature extractor to avoid forgetting. Feature-level replay methods generally require less memory cost compared to image-level counterparts when used to save the same amount of samples. Our approach can also be regarded as a feature-level replay method. Because we save features rather than images and the saved features are replayed and reconstructed to the image domain by the decoder in our model for training a classifier.
Compression for Replay. There are three most related continual learning works [2, 3, 40] similar to our DRR. Ayub et al. [2] used a pretrained autoencoder structure that saved compressed latent representations of previous samples and reconstructed them back to image-domain for replaying.
Caccia et al. [3] used stacked VQ-VAEs and updated the codebooks to control drifting representations during the incremental learning whereas our DRR used a hierarchical VQ-VAE and our codebooks were frozen after the VQ-VAE was pretrained. Caccia et al.reported that saving more samples might degrade the image quality due to the drift that occurred in their VQ-VAE. Thus, in their approach storing more samples did not necessarily improve classification performance. Our results showed that our VQ-VAE with frozen codebooks did not suffer from data shift problem much.
Matthew et al. [40] used a discrete VAE model with a ‘codes’ buffer. However, unlike our DRR whose latent space was able to represent infinite latent representations of samples, their latent space had a restricted size that was proportional to the VAE capacity (VAE capacity was a major hyperparameter in their work). As shown in their work, the smaller capacity their VAE had, the higher compression it could achieve but the fewer maximum samples they could save. Besides, to make their discrete VAE fit new data, the VAE was updated using reconstructed images via codes in the buffer as well as real images from new tasks. It potentially transferred the problem of catastrophic forgetting from classifiers into generators like other generative models we discussed before. In contrast, our trained DRR has a stable high compression rate with generally good reconstructed image quality and can be generalized to other datasets (see Appendix for reconstructed images via DRR).
3 Background
3.1 Vector Quantised Variational AutoEncoder
Vector Quantised Variational AutoEncoder (VQ-VAE) [31] was originally designed for reducing the computation workload in PixelCNN [49] for the task of image generation. PixelCNN-based methods [49, 6] can generate high-quality fake images, however, due to the nature of auto-regressive models, they need to be trained over each pixel leading to a considerably high computation cost. The VQ-VAE encodes an RGB image into a ‘codes’ matrix with a smaller size. Instead of original images, the codes are then used as an input to auto-regression models, resulting in a significant computation reduction. The VQ-VAE relies on vector quantisation that encodes inputs into discrete representations rather than continuous ones and as a compressor it has been shown to be effective in image generation and image compression [31, 38]. Similarly, in this paper, we benefit from the VQ-VAE not only as a good feature extractor but also as a powerful compressor. Considering that a PixelCNN is also a generative model that has to deal with incremental learning as we discussed in Section 2, instead of generating fake images using an auto-regressive generator, our model reconstructs the images via saved codes using the VQ-VAE only. The VQ-VAE defines a discrete embedding space called ‘codebook’ , where is the size of codebook and is the dimension of each embedding vector . The encoder learns a non-linear mapping that encodes the input to the latent representation , where . Then vector quantisation is applied over and, given the codebook (the prototype set), is replaced with a set of embedding vectors in the codebook using nearest neighbor search as formalised by
| (1) |
The quantised output is then fed into the decoder to obtain the reconstructed data. The objective of VQ-VAE can be defined as
| (2) | ||||
| (3) | ||||
| (4) |
where the term in Eq. 2 is the reconstruction error of a typical autoencoder (e.g., mean squared error). And refers to the decoder of the VQ-VAE. The term in Eq. 3 is called codebook loss, which brings the selected embedding vectors close to . Besides, the gradients produced by Eq. 3 are applied to the codebook only. The last term in Eq. 4, called commitment loss, enables encoder to produce similar values to the chosen embedding vectors and it is only applied to the encoder weights.
A hyperparatmer is used to balance the learning rates of different terms and , namely stop-gradient, is an operation that prevents gradients to propagate to its argument. For example, in Eq. 3 blocks the gradients calculated by this loss term from flowing into the weights of the encoder . The visualized vector quantisation operation can be found in Fig. 2.
3.2 Bits-Back Asymmetric Numeral Systems
Asymmetric Numeral Systems (ANS) is used to compress sequences of discretely distributed symbols (a ‘symbol’ is a one dimension data point) into a sequence of bits and can recover those bits back to symbols.
Bits-back with ANS (BB-ANS) [47, 48, 18] tries to approximate true data distribution by and encode datapoint into a number of bits equal to its negative log probability assigned by a latent variable model.
BB-ANS models use latent variable models with a marginal distribution defined by , and they utilize an inference model of variational autoencoders (VAE) [17] to approximate the posterior . The marginal likelihood is rewritten as:
| (5) |
where the first term in Eq. 5 is the Evidence Lower BOund (ELBO) that is jointly optimized using the reparameterization trick with the inference model and generative model of VAE. However, for latent variable models, to encode , it is necessary to encode as well, inducing an extra message length for the prior equals to . To get those extra bits back, BB-ANS firstly initializes ANS with a bit-stream of random bits. Then it performs three steps (denoted as S1,S2,S3) as follows: S1 Decode from bit-stream using the inference model ; S2 Encode using generative model ; S3 Encode to bit-stream using the prior . The S2 and S3 add bits and respectively, but BB-ANS gets bits back from the S1. The net message length then becomes , which is on average equal to the negative ELBO. The cost of initial random bits is negligible for encoding long sequences. A visualized BB-ANS in shown in Fig. 2.
4 Discrete Representation Replay (DRR)
In this section, we formalize the incremental learning as a representation compression problem, and propose Discrete Representation Replay (DRR) by a two-step compression as shown in Fig. 2.
Lossy Compression by VQ-VAE.
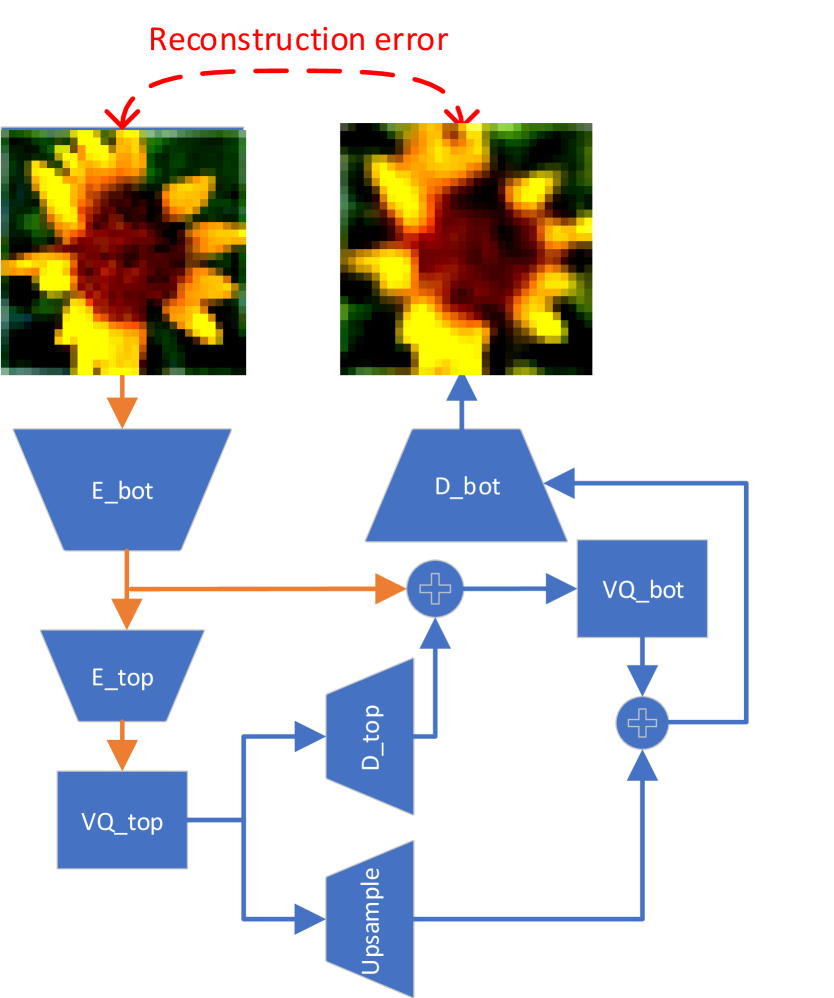
In the first step of compression, we utilise a VQ-VAE to process the inputs and save their discrete latent representations in a format called ‘codes’ that can be later used to reconstruct the original inputs. The VQ-VAE provides a lossy compression where ‘reconstructed’ images in our approach are a blurrier version of the original ones - naturally caused by an undercomplete autoencoder that gradually reduces the dimensionality of its intermediate layers and results in a smaller size of latent representation compared to the original input. This lossy compression contributes to the majority of the total compression rate of DRR. In our proposed model, we use a hierarchical VQ-VAE introduced in [38] (see Appendix for the network structure). Because our preliminary results have shown that the original VQ-VAE [31] cannot reconstruct the images adequately for our task. In our hierarchical VQ-VAE, vector quantisation is applied times after different intermediate layers. It aims to learn hierarchical discrete latent representations such that a top-level representation models global information while a bottom-level representation captures local details. Two levels are trained jointly inside the hierarchical VQ-VAE and two independent codebooks are used respectively. Additionally, we adopt a fully convolutional design for our VQ-VAE, i.e., all of the layers are either convolutional or element-wise functions. In this way, the VQ-VAE is able to process images with arbitrary sizes. Our experiments show that our VQ-VAE trained on CIFAR-100 can reconstruct images with a higher resolution well for classification like images from ImageNet.
After we pretrain the VQ-VAE, we freeze and use it as a feature extractor and save the resulting latent representations in the form of codes, which significantly decreases the memory cost.
Lossless Compression by BB-ANS.
In the second step, we utilize a BB-ANS with hierarchical latent variables called Bit-Swap introduced in [18] that is more expressive than original BB-ANS [47], i.e., can more closely model real data distribution. Instead of using a fixed prior for , Bit-Swap assumes that is generated by a latent variable , and is generated by another latent variable and so on. In this way, the sampling process of both the generative model and the inference model obeys a Markov chain dependency between the stochastic variables [18]. In a lossless manner, we use Bit-Swap to compress ‘codes’ produced by the VQ-VAE. We train from scratch a Bit-Swap model at first and keep fine-tuning it for future new data distribution of codes.
In DRR, a new classifier is trained with reconstructed images both from new classes and old classes. Our preliminary results show that training from scratch the classifier every time it is required to learn new classes always performs better than fine-tuning the previously learned classifier. Though it is widely accepted that the learned model weights contain information of old data and the learned weights are an unwritten definition for the concept ‘past knowledge’ in the increment learning domain, intuitively, if given access to old distribution, training the model from scratch is more flexible, leading a better fit to the new data distribution (a mixture of old and new data). In fact, He et al. [12] show that in some cases training from scratch is more robust and usually converges a solution on par with or even better than the fine-tuning counterpart.
5 Information-Back DRR (IB-DRR)
The pseudo data distribution produced by either generative models or reconstruction models has a drift towards original real data distribution. In our DRR, we lose the information of real data because of the nature of under-complete autoencoders as well as vector quantisation operations. This causes a considerably large decrease in classification score as compared to using original data, e.g., around an overall 12% decrease for our DRR on the CIFAR-100 dataset. We can regard the reconstructed images as augmented data that is transformed by some blurring transformation, though this kind of augmentation may not necessarily be a good augmentation for classification. To remedy this problem, we propose to utilize contrastive learning by treating an image and its reconstructed version as a positive pair. Inspired by a recent negative-pairs-free contrastive learning contrastive learning method called SimSiam [5], we propose an Information Back (IB) mechanism for DRR, see Fig. 1. Specifically, our IB-DRR maximizes the cosine similarity of the latent representations (produced by the classifier) of real images and their reconstructed views produced by VQ-VAE. We denote the convolution layers of a classifier before its dense layers (fully connected layers) as , and the output of , i.e., latent representations of raw input and its reconstructed view as and , respectively. The objective of IB is to minimize the negative cosine similarity between and :
where prevents gradients to propagate to its argument. Then IB-DRR jointly optimises the and a cross-entropy loss , i.e., where is a scalar used to balance the two loss terms. Note that IB-DRR requires maintaining two memory set, one is codes of all old training samples, the other is a small subset of raw training exemplars of old classes. Like GEM [29, 4], the saved raw old exemplars are not directly used for minimizing the classification loss. They serve as regularizers to force the classifier to get back some lost information that is important for classification. More explicitly, it forces the classifier to treat reconstructed images and the real ones in a similar way. The general training process of IB-DRR is similar to DRR except that IB-DRR jointly optimises the two losses as follows: (1) the contrastive learning loss between raw exemplars and their reconstructed views; and (2) the cross-entropy loss computed using reconstructed images from new exemplars and old codes.
6 Experiments
Our experiments are designed for class-incremental classification and we consider the single-headed classifier scheme where there is only a single unified output layer. In other words, a unified classifier learns novel classes and classifies all the classes that it has seen so far. We compare our approach with baseline methods and the state-of-the-art methods that use the replay strategy.
6.1 Experimental Setup
Following [15, 26, 25, 39], we evaluate our proposed strategies on the CIFAR-100 dataset [20], and we train three variants for ablation study: 1) DRR: discrete representation replay with saving latent representations (in the format of codes) of all seen exemplars; 2) IB-DRR: information back discrete representation replay with an extra requirement of saving a small set of raw original exemplars of previously seen classes; and 3) IB-DRR∗: a variant of IB-DRR without saving raw data, so it can only utilize raw (original) exemplars of new coming classes for IB. More explicitly, IB-DRR∗ is IB-DRR without saving raw samples for old classes; and DRR is obtained by ablating Information Back mechanism from IB-DRR∗.
Dataset. The CIFAR-100 dataset contains classes and each class has training samples and test samples with the image size of .
Architecture. For our hierarchical VQ-VAE, we use two codebooks (two level of codes) each with a size of (number of codes) and set the embedding dimension to . We use a Bit-Swap with hierarchical latent variables with a Markov chain structure for each level of codes. In our preliminary experiments, we find the Resnet-32 used in previous replay-based methods [26, 36, 39] causes underfitting of our DRR in some cases. We use a ResNet-18 [13] used in [25] as a classifier (see Appendix for further discussion).
Hyperparameters and Configuration. Following the class incremental settings introduced in [15, 26, 25], our VQ-VAE and Bit-Swap are pretrained given the half of the classes from CIFAR-100 at the initial training phase and the rest of the classes are added gradually in the future phases. That is, the training has initial phase for the classification of the first classes and incremental phases for the remaining classes. We freeze the VQ-VAE but keep fine-tuning the Bits-Swap for future phases. Note that our classifier is trained with reconstructed images but tested with raw images. Our preliminary results show that training the classifier with the mixture of raw images of new classes and reconstructed images of old classes degrades the classification results.
We evaluate the performance of our incremental learning method by setting to , and , meaning that , , and classes are gradually added at each incremental phase, respectively.
The VQ-VAE is trained by an Adam optimizer with a constant learning rate for epochs. We train or fine-tune the Bit-Swap by an Adam optimizer with a constant learning rate until its loss no longer decreases.
For DRR, IB-DRR and IB-DRR∗, we train the classifier with the image replay strategy as explained in Section 4. We use a stochastic gradient descent (SGD) optimizer with momentum and weight decay parameters for the classifier. The initial learning rate is set to and divided by after , , and epochs. A warmup scheduler [10] is applied for the first epochs. The classifier is trained from scratch during a new training phase for epochs. If IB is used, we set the hyperparameter for the contrastive learning loss .
Memory Budget. For DRR and IB-DRR∗ we only save codes for seen classes. For IB-DRR, we follow [26, 36, 39] and save additionally raw exemplars per class for seen classes.
Baselines. We compare our methods with the following 5 baseline methods: LWF [23], GFR [25], iCaRL [39], LUCIR [15], Mnem [26] and a Upper Bound (UB). The first two baselines do not require to save exemplars while others (including ours) need to save old exemplars. iCaRL, LUCIR and Mnem save samples per class while UB saves all (50,000) samples. We follow their original implementation settings (see Appendix for further information).
6.2 Evaluation Metrics
For each new training phase , we evaluate the performance of the model on the test set from the new classes and old classes (henceforth, phase-wise accuracy). We use two evaluation metrics. Following the previous work [15, 25, 39], the first metric is the average overall accuracy that computes the mean of phase-wise accuracy over all training phases, namely from the initial phase to phase . However, in the initial phase , there is no catastrophic forgetting; therefore, we exclude the test accuracy of the initial phase from the average overall accuracy. Let be the performance of the model on the held-out test set of phase , the average overall accuracy is then defined as: where is the total number of phases (in our experiments , and ). The second metric is the last phase accuracy that reports the phase-wise accuracy of the last training phase only. Please note that, in the last phase, all classes in the dataset are encountered, thus the accuracy is given for all classes.
| Method | 25 phases | 10 phases | 5 phases |
|---|---|---|---|
| UB | 78.60 | 78.92 | 78.86 |
| GFR [25] | 54.01 | 60.14 | 60.18 |
| Mnem [26] | 60.96 | 60.78 | 60.76 |
| DRR | 64.37 | 64.04 | 64.00 |
| IB-DRR∗ | 62.90 | 64.85 | 65.36 |
| IB-DRR | 65.65 | 66.40 | 66.71 |
| Method | 25 phases | 10 phases | 5 phases |
|---|---|---|---|
| UB | 77.91 | 77.91 | 77.91 |
| GFR [25] | 40.39 | 51.29 | 53.34 |
| Mnem [26] | 50.78 | 51.53 | 54.32 |
| DRR | 60.87 | 60.87 | 60.87 |
| IB-DRR∗ | 60.50 | 62.29 | 62.83 |
| IB-DRR | 62.86 | 63.65 | 63.97 |
6.3 Results and Analyses
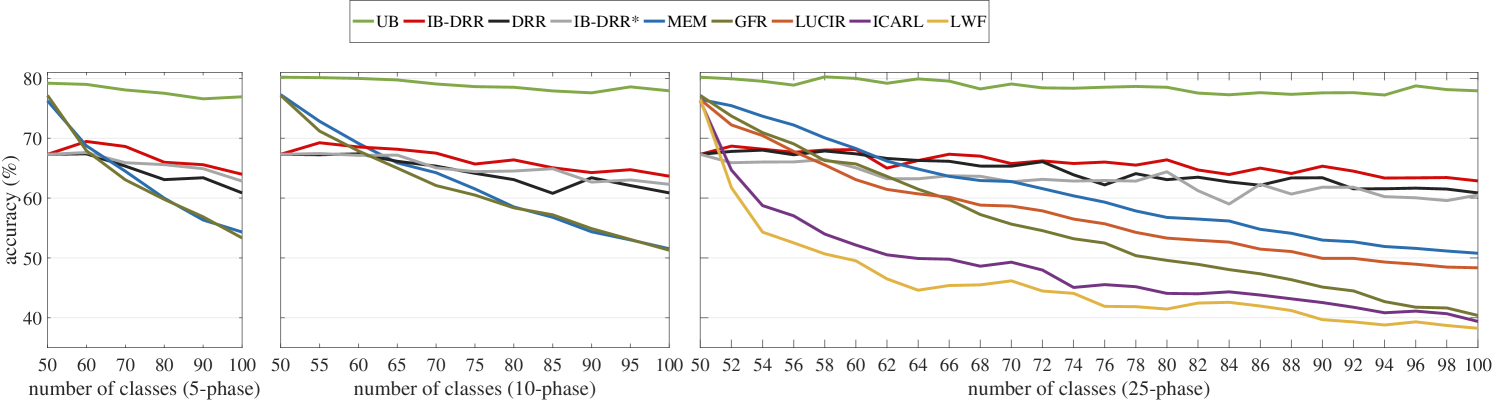
In Figure 3, we compare our methods with the state-of-the-art replay-based methods that use image-level replay [26] and feature-level replay [25] as well as other baseline methods [39, 23, 15] in terms of phase-wise accuracy. It is obvious that methods using replay have better performance than LwF [23] which is one of the most competitive methods without replay, demonstrating the superiority of replay-based methods. IB-DRR outperforms others except for the upper bound (UB) in all experimental settings.
Looking at the most challenging -phase setting, our models start with a lower phase-wise accuracy at the initial training phase (with classes) due to the fact that reconstructed images are of low quality as compared to original images. However, despite the fact it is trained with reconstructed, low-quality images, our models can maintain the knowledge over old classes when learning new classes with improvement in the average accuracy by a margin of and by IB-DRR and DRR respectively (see Table 1). In addition, IB-DRR and DRR surpass other baselines by a margin of at least and according to the last phase accuracy (see Table 2). In -phase and -phase settings, IB-DRR∗ performs better than DRR while in -phase setting we see the opposite situation. Recall that, both of them only save codes for previously seen classes. Intuitively, the Information Back (IB) mechanism benefits more diverse raw samples from more new classes to regularize the classifier to get back some information that is useful for classification. From this point of view, in -phase or -phase IB-DRR∗ has a large enough number of new classes to utilize. As IB-DRR also saves old raw samples, it can perform well in all the settings we tested. Moreover, our methods behave similarly to the upper bound with a relatively ‘constant’ decrease in accuracy.
| Method | Exemplar cost (MB) | Assistant model cost (MB) |
|---|---|---|
| UB | 148 (50,000 exemplars) | NA |
| GFR [25] | NA | 4.5 (GAN) |
| Mnem [26] or LUCIR [15] | 6.2 (2,000 exemplars) | NA |
| DRR or IB-DRR∗ | 4.24 (50,000 exemplars) | 5.81 (VQ-VAE) + 13.4 (Bit-Swap) |
| IB-DRR | 6.2 + 4.24 | 5.81 (VQ-VAE) + 13.4 (Bit-Swap) |
6.3.1 Comparison of Memory Cost
Table 3 provides the memory required for saving extra exemplars as well as assistant model weights on the CIFAR-100. Saving discrete latent representations in codes costs less memory while saving 25 times more exemplars as compared to other replay-based methods [26, 15].
Please note that we are not able to compare the cost of assistant models. Because many incremental learning methods (especially those that use knowledge distillation techniques) save a copy of old models. For example, Mnem [26] saves the model weights after the phase and uses knowledge distillation loss to encourage and to maintain the same prediction ability on old classes. GFR [25], LUCIR [15] and Mnem [26] all need to save a copy for the latest model and train a new model with the help of the old model copy, therefore, each of them should be part of the total memory cost of assistant models.
6.4 Can DRR generalise to other datasets?
To validate that our VQ-VAE trained on CIFAR-100 has a good generalization ability when applied to a different dataset even with a higher resolution, we presented preliminary quantitative results on Subset-ImageNet that contained random classes from ImageNet-1K. For our method, we used the pretrained VQ-VAE on CIFAR-100 as described previously in Section 6.1 to process images from ImageNet. We compared our DRR with Mnem [26] which is the SOTA method. Both approaches used images with the size of as inputs and Resnet-18 as the classifier. Mnem saved raw samples per class ( MB in total) while DRR saved codes of all samples. Results of the -phase setting showed DRR and Mnem achieved an average overall accuracy of and respectively. In addition, DRR resulted in a memory cost of MB for saving raw exemplars which originally cost MB.
7 Conclusion
In this paper, we formalised incremental learning as a representation compression problem and proposed a novel approach to this problem. Our proposed approach, Discrete Representation Replay (DRR), performs a two-step compression using a Vector-Quantised Variational Autoencoder (VQ-VAE) and a Bits-back Asymmetric Numeral Systems with hierarchical latent variables (Bit-Swap). Our experimental results showed that DRR outperforms the state-of-the-art approaches on the CIFAR-100 dataset in terms of accuracy and memory size required for saving exemplars. In addition, we introduced an Information Back (IB) mechanism that utilized raw exemplars to regularize the training of the classifier and IB further boosted the performance of the DRR by saving a small set of raw exemplars of previously seen classes. Our preliminary results showed implications that our approach could be generalised to other datasets such as ImageNet. As future work, we will extend IB-DRR by introducing extra network components for contrastive learning to alleviate information loss caused by the VQ-VAE.
Acknowledgement
The work of Jian Jiang has been supported by the King’s China Scholarship Council (K-CSC) PhD Scholarship programme.
References
- [1] Rahaf Aljundi. Continual learning in neural networks. arXiv preprint arXiv:1910.02718, 2019.
- [2] Ali Ayub and Alan R Wagner. Eec: Learning to encode and regenerate images for continual learning. arXiv preprint arXiv:2101.04904, 2021.
- [3] Lucas Caccia, Eugene Belilovsky, Massimo Caccia, and Joelle Pineau. Online learned continual compression with adaptive quantization modules. In International Conference on Machine Learning, pages 1240–1250. PMLR, 2020.
- [4] Arslan Chaudhry, Marc’Aurelio Ranzato, Marcus Rohrbach, and Mohamed Elhoseiny. Efficient lifelong learning with a-gem. arXiv preprint arXiv:1812.00420, 2018.
- [5] Xinlei Chen and Kaiming He. Exploring simple siamese representation learning. arXiv preprint arXiv:2011.10566, 2020.
- [6] Xi Chen, Nikhil Mishra, Mostafa Rohaninejad, and Pieter Abbeel. PixelSNAIL: An Improved Autoregressive Generative Model. 35th International Conference on Machine Learning, ICML 2018, 2:1364–1372, dec 2017.
- [7] Patryk Chrabaszcz, Ilya Loshchilov, and Frank Hutter. A Downsampled Variant of ImageNet as an Alternative to the CIFAR datasets. arXiv, jul 2017.
- [8] Ekin D Cubuk, Barret Zoph, Dandelion Mane, Vijay Vasudevan, and Quoc V Le. Autoaugment: Learning augmentation strategies from data. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 113–123, 2019.
- [9] Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. In Advances in neural information processing systems, pages 2672–2680, 2014.
- [10] Priya Goyal, Piotr Dollár, Ross Girshick, Pieter Noordhuis, Lukasz Wesolowski, Aapo Kyrola, Andrew Tulloch, Yangqing Jia, and Kaiming He. Accurate, large minibatch sgd: Training imagenet in 1 hour. arXiv preprint arXiv:1706.02677, 2017.
- [11] Yanming Guo, Yu Liu, Ard Oerlemans, Songyang Lao, Song Wu, and Michael S Lew. Deep learning for visual understanding: A review. Neurocomputing, 187:27–48, 2016.
- [12] Kaiming He, Ross Girshick, and Piotr Dollár. Rethinking imagenet pre-training. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 4918–4927, 2019.
- [13] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016.
- [14] Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the Knowledge in a Neural Network. 2015.
- [15] Saihui Hou, Xinyu Pan, Chen Change Loy, Zilei Wang, and Dahua Lin. Learning a unified classifier incrementally via rebalancing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 831–839, 2019.
- [16] David Isele and Akansel Cosgun. Selective experience replay for lifelong learning. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 32, 2018.
- [17] Diederik P. Kingma and Max Welling. Auto-encoding variational bayes. 2nd International Conference on Learning Representations, ICLR 2014 - Conference Track Proceedings, (Ml):1–14, 2014.
- [18] Friso Kingma, Pieter Abbeel, and Jonathan Ho. Bit-swap: Recursive bits-back coding for lossless compression with hierarchical latent variables. In International Conference on Machine Learning, pages 3408–3417. PMLR, 2019.
- [19] James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, Demis Hassabis, Claudia Clopath, Dharshan Kumaran, and Raia Hadsell. Overcoming catastrophic forgetting in neural networks. Proceedings of the National Academy of Sciences of the United States of America, 114(13):3521–3526, 2017.
- [20] Alex Krizhevsky et al. Learning multiple layers of features from tiny images. 2009.
- [21] Yann LeCun, Yoshua Bengio, and Geoffrey Hinton. Deep learning. nature, 521(7553):436–444, 2015.
- [22] Yann LeCun, Corinna Cortes, and CJ Burges. Mnist handwritten digit database. ATT Labs [Online]. Available: http://yann.lecun.com/exdb/mnist, 2, 2010.
- [23] Zhizhong Li and Derek Hoiem. Learning without Forgetting. IEEE Transactions on Pattern Analysis and Machine Intelligence, 40(12):2935–2947, jun 2018.
- [24] Kevin J Liang, Chunyuan Li, Guoyin Wang, and Lawrence Carin. Generative adversarial network training is a continual learning problem. arXiv preprint arXiv:1811.11083, 2018.
- [25] Xialei Liu, Chenshen Wu, Mikel Menta, Luis Herranz, Bogdan Raducanu, Andrew D Bagdanov, Shangling Jui, and Joost van de Weijer. Generative feature replay for class-incremental learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, pages 226–227, 2020.
- [26] Yaoyao Liu, Yuting Su, An-An Liu, Bernt Schiele, and Qianru Sun. Mnemonics training: Multi-class incremental learning without forgetting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12245–12254, 2020.
- [27] Vincenzo Lomonaco and Davide Maltoni. Core50: a new dataset and benchmark for continuous object recognition. In Conference on Robot Learning, pages 17–26. PMLR, 2017.
- [28] David Lopez-Paz and Marc’Aurelio Ranzato. Gradient episodic memory for continual learning. In Advances in Neural Information Processing Systems, volume 2017-Decem, pages 6468–6477, 2017.
- [29] David Lopez-Paz and Marc’Aurelio Ranzato. Gradient episodic memory for continual learning. In Advances in Neural Information Processing Systems, volume 2017-Decem, pages 6468–6477, 2017.
- [30] Yuval Netzer, Tao Wang, Adam Coates, Alessandro Bissacco, Bo Wu, and Andrew Y Ng. Reading digits in natural images with unsupervised feature learning. 2011.
- [31] Aaron van den Oord, Oriol Vinyals, and Koray Kavukcuoglu. Neural discrete representation learning. arXiv preprint arXiv:1711.00937, 2017.
- [32] German I. Parisi, Jun Tani, Cornelius Weber, and Stefan Wermter. Lifelong learning of spatiotemporal representations with dual-memory recurrent self-organization. Frontiers in Neurorobotics, 12(November), may 2018.
- [33] Lorenzo Pellegrini, Gabriele Graffieti, Vincenzo Lomonaco, and Davide Maltoni. Latent Replay for Real-Time Continual Learning. dec 2019.
- [34] Jason Ramapuram, Magda Gregorova, and Alexandros Kalousis. Lifelong generative modeling. arXiv preprint arXiv:1705.09847, 2017.
- [35] Amal Rannen, Rahaf Aljundi, Matthew B. Blaschko, and Tinne Tuytelaars. Encoder based lifelong learning. In The IEEE International Conference on Computer Vision (ICCV), Oct 2017.
- [36] Dushyant Rao, Francesco Visin, Andrei A Rusu, Yee Whye Teh, Razvan Pascanu, and Raia Hadsell. Continual unsupervised representation learning. arXiv preprint arXiv:1910.14481, 2019.
- [37] Dushyant Rao, Francesco Visin, Andrei A Rusu, Yee Whye Teh, Razvan Pascanu, and Raia Hadsell. Continual unsupervised representation learning. arXiv preprint arXiv:1910.14481, 2019.
- [38] Ali Razavi, Aaron van den Oord, and Oriol Vinyals. Generating diverse high-fidelity images with vq-vae-2. arXiv preprint arXiv:1906.00446, 2019.
- [39] Sylvestre-Alvise Rebuffi, Alexander Kolesnikov, Georg Sperl, and Christoph H Lampert. icarl: Incremental classifier and representation learning. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, pages 2001–2010, 2017.
- [40] Matthew Riemer, Tim Klinger, Djallel Bouneffouf, and Michele Franceschini. Scalable recollections for continual lifelong learning. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 33, pages 1352–1359, 2019.
- [41] Anthony Robins. Catastrophic forgetting, rehearsal and pseudorehearsal. Connection Science, 7(2):123–146, 1995.
- [42] David Rolnick, Arun Ahuja, Jonathan Schwarz, Timothy P Lillicrap, and Greg Wayne. Experience replay for continual learning. arXiv preprint arXiv:1811.11682, 2018.
- [43] Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, et al. Imagenet large scale visual recognition challenge. International journal of computer vision, 115(3):211–252, 2015.
- [44] Hanul Shin, Jung Kwon Lee, Jaehong Kim, and Jiwon Kim. Continual learning with deep generative replay. In Advances in Neural Information Processing Systems, volume 2017-Decem, pages 2991–3000, 2017.
- [45] Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556, 2014.
- [46] Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jon Shlens, and Zbigniew Wojna. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2818–2826, 2016.
- [47] James Townsend, Tom Bird, and David Barber. Practical lossless compression with latent variables using bits back coding. arXiv preprint arXiv:1901.04866, 2019.
- [48] James Townsend, Thomas Bird, Julius Kunze, and David Barber. Hilloc: Lossless image compression with hierarchical latent variable models. arXiv preprint arXiv:1912.09953, 2019.
- [49] Aaron Van den Oord, Nal Kalchbrenner, Lasse Espeholt, Oriol Vinyals, Alex Graves, et al. Conditional image generation with pixelcnn decoders. In Advances in neural information processing systems, pages 4790–4798, 2016.
- [50] Friedemann Zenke, Ben Poole, and Surya Ganguli. Continual learning through synaptic intelligence. In Proceedings of the 34th International Conference on Machine Learning-Volume 70, pages 3987–3995. JMLR. org, 2017.
- [51] Mengyao Zhai, Lei Chen, Frederick Tung, Jiawei He, Megha Nawhal, and Greg Mori. Lifelong gan: Continual learning for conditional image generation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 2759–2768, 2019.
Appendix A Qualitative Results of VQ-VAE in CIFAR-100 and ImageNet
In this section, we show the qualitative results of reconstructed images by the hierarchical VQ-VAE pretrained given half classes of CIFAR-100 (the one used in our main paper). Fig. 4 shows the model architecture of the hierarchical VQ-VAE.
Example reconstructed images from CIFAR-100 are provided in Fig. 5-(a). And those from ImageNet with resolution 32, 64, 224 are in Fig. 5-(b), Fig. 5-(c)), Fig. 5-(d)) respectively. Looking at the qualitative results presented in Fig. 5, we argue that our VQ-VAE is capable of reconstructing varying sizes of images adequately, despite being applied to a dataset (ImageNet) that is different from the training dataset (CIFAR-100). To answer why the VQ-VAE has such a good generalization ability, intuitively, a VQ-VAE is just a pixel reconstructor and the data (50 classes from CIFAR-100) used for pretraining contains diverse images that provides a considerably good pixel distribution for learning.
Appendix B Compression for Codes via Bit-Swap
Because we use the codebook size of , the discrete value of a code ranges from . Theoretically, a code can be saved using 9 bits (), but in practice, a system saves codes data in the least unit of byte, so it causes 2 bytes, i.e., 16 bits to save an uncompressed code. According to entropy coding scheme, the entropy of a certain data distribution , defined by , is the lower bound on how many average bits (called ‘message length’) a lossless compression method can achieve to encode data points coming from this distribution. Table 4 shows the entropy of top-level and bottom-level codes obtained by compressing a certain dataset via the VQ-VAE (the one used in our main paper). For example, the entropy of top codes and bottom codes of samples of classes from CIFAR-100 are bits and bits respectively. And Bit-Swap models trained by epochs for each of them could achieve or average bits cost for compressing them respectively. We originally expected the more codes data (from classes to classes) can reveal a better distribution with less entropy in terms of a certain dataset. In contrast to our expectation, the entropy of codes distribution changed a little (less than 0.1) during the incremental setting on CIFAR-100, i.e., more new codes did not decrease the average overall entropy. Moreover, if we mixed the top and bottom codes, the entropy increased. We also ran preliminary results on Subset-ImageNet that contained random 100 classes ( training samples) from ImageNet-1K with an image resolution of . We obtained codes of ImageNet using the VQ-VAE pretrained on CIFAR-100 as discussed in the main paper. For all top-level codes of Sub-ImageNet, after trained for epochs, a Bit-Swap cost average bits to encode one top-level code. As for bot-level codes, another Bit-Swap trained for epochs cost average bits to encode one bottom-level code. Our preliminary results showed that more iterations (epochs) could further improve the compression performance.
| Dataset | top | bottom | top & bottom | |
|---|---|---|---|---|
| CIFAR-100 | 8.6032 | 8.6404 | 8.7482 | |
| SubImg 224x224 | 6.7936 | 7.1016 | 7.4683 |
 |
| (a) Reconstructed images from CIFAR-100 with resolution |
 |
| (b) Reconstructed images from down-sampled ImageNet with resolution |
 |
| (c) Reconstructed images from down-sampled ImageNet with resolution |
 |
| (d) Reconstructed images from original ImageNet with resolution |
Appendix C Implementation details of compared methods
We compare our methods with the following baseline methods and state-of-the-art methods with their original implementation settings on CIFAR-100:
-
•
Upper Bound (UB) saves all (50,000) exemplars and trains from scratch a Resnet-18 for each new training phase. For training UB, we use the same hyperparameters as our DRR.
-
•
GFR [25] requires no exemplar to be stored. It has a two-stage training: The first stage jointly trains a feature extractor and a classifier for epochs, where they use a Resnet-18 and treat the former layers as the feature extractor. They save a copy of the old model after a training phase and initialize the new model with the weights of the old ones. The second stage trains a GAN used a frozen feature extractor and the classifier for epochs.
-
•
iCaRL [39] saves exemplar per class and in total. It uses a rank function to select samples to be reserved, and a Resnet-32 is trained or fine-tuned for epochs.
- •
-
•
Mnemonics [26] is built upon LUCIR while it saves trainable exemplars per class instead. Two-level training includes model-level training for a Resnet-32 and exemplar-level training for exemplars. The classifier and learnable exemplars are fine-tuned in the training phase.
-
•
LWF [23] is one of the most representative non-replay-based methods and no exemplar is saved. It incorporates knowledge distillation technique [14] as an extra regularisation term to consolidate previous knowledge when learning new knowledge. We also use the setup of LWF as presented in [26] where a Resnet-32 is used and is fine-tuned for epochs in new training phases.
Appendix D The Choice of Resnet for CIFAR-100
Residual Network (Resnet) was proposed by He et al. [13] in 2015. Resnet-18 was also proposed in [13], which had 18 layers with a hyperparameter ‘in-planes’ set to 64. The ‘in-planes’ was used to control the number of filters in layers. For example, with ‘in-planes = 64’, the layers in ResBlock had filters. There were many variants of Resnet with a different number of layers and different ‘in-planes’. In recent incremental learning works researchers prefer a Resnet-32 [26, 39, 37] with ‘in-planes = 16’ that had more layers but lower capacity than original Resnet-18 with ‘in-planes = 64’. In our preliminary experiments, we found that Resnet-32 with ‘in-planes = 16’ resulted in underfitting of our models in some cases, e.g., if a strong Data Augmentation was applied. Our further experiments showed that if we increased the number of filters in Resnet-32, i.e., setting the hyper-parameter ‘inplanes’ from to , our method performed even slightly better as compared to that used Resnet-18 with ‘inplanes=64’. We conjectured that Resnet-32 with ‘inplanes =16’ was adequate only for replaying (low resolutions) samples per class. However, for replaying more samples like ours and [40] or generated sample models (like GFR [25]), Resnet-18 or Resnet-32 with ‘inplanes=64’ was more suitable for CIFAR-100. Note that we only used simple data augmentation like ‘horizontal flip’ and ‘random crop’ for the experiments in the main paper, but our previous studies showed that DRR could benefit from a strong data augmentation strategy [8] as well as test-time augmentation strategy [45, 46]. We will further test IB-DRR with the above data augmentation strategies in the future.