Identity-Aware CycleGAN for Face Photo-Sketch Synthesis and Recognition
Abstract
Face photo-sketch synthesis and recognition has many applications in digital entertainment and law enforcement. Recently, generative adversarial networks (GANs) based methods have significantly improved the quality of image synthesis, but they have not explicitly considered the purpose of recognition. In this paper, we first propose an Identity-Aware CycleGAN (IACycleGAN) model that applies a new perceptual loss to supervise the image generation network. It improves CycleGAN on photo-sketch synthesis by paying more attention to the synthesis of key facial regions, such as eyes and nose, which are important for identity recognition. Furthermore, we develop a mutual optimization procedure between the synthesis model and the recognition model, which iteratively synthesizes better images by IACycleGAN and enhances the recognition model by the triplet loss of the generated and real samples. Extensive experiments are performed on both photo-to-sketch and sketch-to-photo tasks using the widely used CUFS and CUFSF databases. The results show that the proposed method performs better than several state-of-the-art methods in terms of both synthetic image quality and photo-sketch recognition accuracy.
keywords:
Convolutional neural network, generative adversarial network, photo-sketch synthesis, photo-sketch recognition, identity-aware training1 Introduction
Face photo-sketch synthesis (FPSS) has received significant interest for its various applications in both social entertainment and police enforcement [1]. For digital entertainment, people want to obtain their own face sketches immediately by taking photos to be shared with others on social media. For law enforcement, a typical application is the automatic matching of one suspect’s facial image to photos in the police’s criminal face databases. However, in many situations, the facial photo of a potential criminal may not be available because only poor-quality images under partial occlusion are captured. People have found that face sketches can be used as a substitute in searching for a suspect by constructing a mapping between a facial photo and a sketch. The common solution to this issue is performing FPSS and then implementing face photo-sketch recognition (FPSR) in a single domain. In this aspect, the tasks of FPSS and FPSR can be studied together.
There are two pathways for synthesis-based methods in implementing photo-sketch recognition: one is matching in the sketch domain by transforming photo to sketch; the other is transforming sketch to photo and then matching in the photo domain [1]. Based on model construction techniques, conventional FPSS methods can be divided into three classes [2]: subspace learning-based method such as LLE [3], sparse representation-based method such as SFS [4] and Bayesian inference-based method such as MRF [1] and MWF [5]. However, those FPSS methods mostly concentrate on making synthesized images consistent with the original images in texture, which may cause information loss for face recognition [2].
Recently, with the generative adversarial networks (GANs) [6] have become prevalent, considerable progress has been made in the image-to-image translation tasks. For a typical GAN model, the discriminator aims to decide whether the given inputs are fake or real, while the generator learns to generate sharper and more realistic samples that are indistinguishable from the real samples. For example, Pix2Pix [7] accomplishes the image style translation task in a supervised manner using conditional GAN. To alleviate the difficulty of obtaining image pairs, CycleGAN [8] preserves key attributes between the inputs and the translated images by utilizing a cycle consistency loss. However, when applied to the FPSS task, all these frameworks are only capable of learning the relations between two domains, where its discriminator focuses only on the differences between the photos and sketches but does not consider any specific optimization for the recognition purpose.
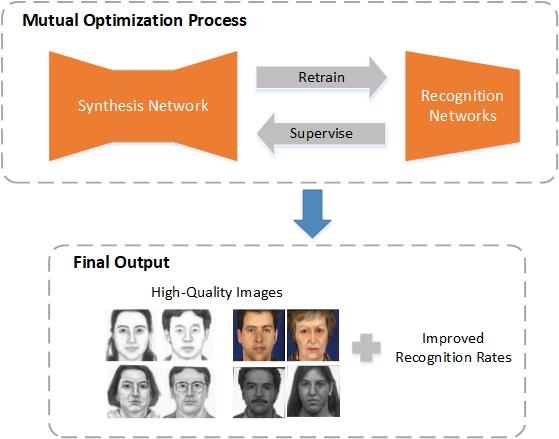
To address this problem, every facial image must contain its own ”identity-specific information” [9]. While Huang et al. [10] apply the identity preservation between the input face and the translated face for the image-video translation, we suggest to supervise the relationship between the real target and the fake image using two recognition networks. In this paper, we propose an Identity-Aware Cycle Generative Adversarial Network (IACycleGAN) that integrates the recognition model into the cross-domain image generation process. As demonstrated in Figure 1, the recognition networks, first fine-tuned by the generated sketch or photo dataset from the basic synthesis network (CycleGAN), provide a supervision to regularize the performance of the synthesis network (IACycleGAN) using a perceptual loss [11]. Then, to enhance the recognition ability for FPSR, the synthesized images from IACycleGAN can be used to retrain the recognition networks. Similarly, the newly fine-tuned recognition model can be devoted to the synthesis process once again. Finally, a mutual cyclic optimization process is formed between the recognition model and the synthesis model, from which work on FPSS and FPSR can be constantly improved.
In summary, our main contributions include the following:
-
1.
First, we propose IACycleGAN, a robust generative adversarial network that addresses the FPSS problem, from which a perceptual loss is introduced to take the face identity information into consideration between the real and synthesized images. This new loss makes our synthesis network focus on high-level features for identity recognition, rather than the average pixel features of the whole image.
-
2.
Second, we designed a feedback training method to further enhance the deep recognition model. On the one hand, IACycleGAN supervises the image generation process by the deep recognizer. On the other hand, the generated images from the synthesis network can be used to retrain the recognition model. Experimental results show that our mutual optimization method indeed improves the final recognition accuracy.
Extensive experiments are performed on two widely used datasets, CUFS and CUFSF, by evaluating both the image quality of the synthesized images and photo-sketch recognition accuracy. The results suggest that the proposed method is effective in improving both sketch-matching and photo-matching based recognition, achieving a much better result compared to state-of-the-art synthesis-based recognition methods such as LR [12], GAN [7], DR-GAN [13] and Dual-Transfer [9]. We also evaluated the fusion of these two matching methods, which can further improve the recognition results.
The remainder of the paper is organized as follows. A review of existing FPSS methods and image-to-image translation is presented in Section 2. The synthesis network, i.e. IACycleGAN, is introduced in Section 3. The mutual optimization process between the synthesis model and the recognition model is explained in Section 4. Our detailed experimental results and analyses are presented in Section 5. And Section 6 draw conclusions about our work.
2 Related Work
FPSS is considered as a typical image-to-image translation problem. In this section, the development of these two fields is discussed in detail.
2.1 Face Photo-Sketch Synthesis
Existing FPSS approaches can be classified into 4 categories [2]: subspace learning, sparse representation, Bayesian inference and deep-learning-based methods, where the former three categories belong to data-driven method, and the last one belongs to model-driven method [14].
Subspace-learning-based methods mainly include linear subspace-based methods, such as principal component analysis (PCA) [15], and nonlinear subspace methods such as local linear embedding (LLE) [16]. Tang and Wang [17] assume that the target sketch can be synthesized by a linear combination of training sketches, similar to the relationship within photos. Later, inspired by LLE [16], Liu et al. [3] proposed a patch-based synthesis method that aims to synthesize the target sketch patch from several training sketch patches according to the photos’. In recent years, sparse-representation-based methods have been widely used in FPSS tasks. Chang et al. [18] introduce a sparse coding technique for feature extraction, assuming that the face photo and corresponding sketch have the same sparse representation. To further consider high-frequency information, Gao et al. [4] propose a two-step process to improve the quality of synthesized sketches, during which the mapping between the high-frequency information of the photo-sketch patches is learned using the sparse coding technique. Bayesian inference-based methods explore such an area in a different way by using embedded hidden Markov model (E-HMM) or Markov random field (MRF). Wang and Tang [1] employ a multi-scale MRF model for FPSS problem to learn the relations among neighboring image patches. Zhou et al. [5] improve the basic MRF method in [1] by proposing a weighted MRF algorithm, called Markov weight fields (MWF). Wang et al. [2] propose a novel face sketch synthesis method (TFSPS) to improve the robustness of MWF based on transductive learning. Those Bayesian inference-based methods pay special attention to the relations among target image patches in the corresponding domain but may overlook the domain-to-domain transformations, which may lead to high computation costs in practical use.
The deep-learning-based method actually focuses on model-driven strategy, where the mapping function is learned in advance and then applied to execute the transformation. Zhang et al. [19] propose an end-to-end photo-sketch generation model based on a 7-layer fully convolutional network (FCN) with a joint generative-discriminative optimization process. However, the synthesized images still produce blurring, with less facial texture information obtained. With GAN attracting increased attention, the development of FPSS was spawned. Wang et al. [20] perform photo-to-sketch synthesis with a GAN-based method and demonstrate high effectiveness; however, sketch-to-photo synthesis is not considered. Recently, Wang et al. [21] applied the multi-adversarial idea to CycleGAN to generate high-resolution images. For sketch-to-photo synthesis, Kazemi et al. [22] employ an additional geometry-discriminator to distinguish based on high-level facial features. However, these approaches have only focused on adapting the architecture of GAN for an improvement on synthesizing images. Instead, our framework additionally adopts a mutual optimization process by exploring identity information of images and utilizing the relation between FPSS and FPSR. Zhang et al. [9] propose a dual-transfer FPSS framework composed of an inter-domain transfer process and an intra-domain transfer process. They get the transferred image from the combination of two transfer results, while we transform images between sketch and photo directly through a synthesis model.
2.2 Image-to-Image Translation
Many traditional algorithms have been used to address FPSS problem and achieved effectiveness results. However, these methods still have limitations in image conversion, since they may not be able to learn high-level features of target images and only address certain tasks that are generally single purpose. With the success of CNNs, many studies address image translation problems effectively. However, in some respects, traditional CNN methods may lead to blurry and conservative results because the only goal for a CNN model is to minimize the loss function, which is defined and constructed artificially such as in [19]. Under this training strategy, all reasonable outputs are averaged; this may cause indistinct outputs when only minimizing the predefined loss.
Considering these consequences, a more automated mechanism for training is needed. Generative networks, such as GANs [6] and VAEs [23], have become popular and have achieved great results. Their fundamental objective is to train a model in which output images have the same distributions as the ground truth but are separated from other domain. For image translation tasks, GANs have produced more impressive results due to their strong generative and discriminative ability compared to other generative networks. However, the selection, design and training process of the GANs are also highly uncertain, directly producing many difficulties. Specifically, the simple training requirements of GANs result in large degree of freedom with no pre-modelling necessary; thus, it may suffer performance losses when there are more pixels. Based on this concept, some explicit external information, such as extra inputs by users and category information, can then be added to the original GAN model to enhance its stability.
Isola et al. [7] propose conditional GAN (cGAN), whose generative process is constrained by extra information such as images, labels and tags. In other words, hints are given during training and play a guiding role in the data generation process for the generator. In addition, traditional GANs lack guidance, which can also be seen as a mode distortion problem since the only goal is to optimize an asymmetric KL divergence. Zhu et al. later proposed CycleGAN [8], which showed promising results on unsupervised image-to-image translation tasks based on two generators and two discriminators using unpaired image data. In addition, CycleGAN adds a new cycle consistency loss to the original loss function, which provides extra supervision between the input and cyclic output. However, facial content from CycleGAN cannot be well preserved because of the weak content constraint. Inspired by dual learning, Yi et al. [24] propose Dual-GAN with a similar unpaired training mechanism based on unsupervised performance. More recently, Mo et al. [25] design an instance-aware GAN (InstaGAN) to incorporate the instance information and improve multi-instance transfiguration, which shows no advantages in handling our problem of single face image translation.
3 Synthesis Network - IACycleGAN
In this section, we first illustrate the architecture of IACycleGAN and then introduce the objective function for training this model.
3.1 Framework
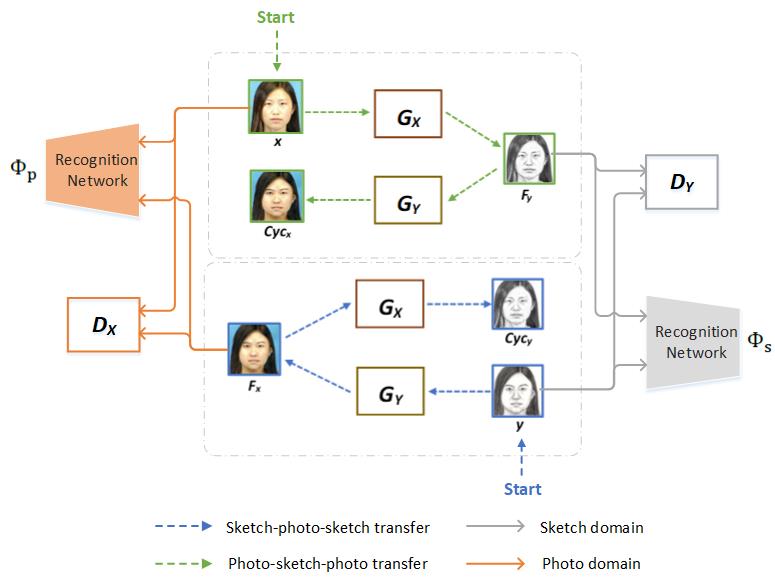
Our goal is to learn the mapping functions between the face photo and the sketch, which correspond to two sample spaces and . A dataset consisting of a number of photo-sketch pairs is needed. Given face photos and corresponding face sketches , we want to obtain two generators and . transforms the face photo into a sketch, and transforms the face sketch into a photo. The whole network framework is shown in Figure 2. The generated fake sketches from are expressed as , and the generated fake photos from are . The relationship is expressed as follows:
| (1) |
To realize the cyclic process of the full image transformation, the generated fake images are input into the other generator:
| (2) |
And the two discriminators and for two domains learn to distinguish between the real input images and the fake generated samples.
Since we have paired data in the target datasets, unsupervised training in [8, 22] is not necessary for our work. To learn the identity information of each person, high-level features of facial images are extracted from a pre-trained recognition model that is fine-tuned based on the VGGFace model [26]. With these two basic recognition networks and , respectively for photo and sketch, the most prominent facial characteristic and facial structure for identity discrimination can be captured to directly regularize the distance between the real image and the fake image.
Our IACycleGAN is adapted from the CycleGAN architecture [8]. The generators come from the style transfer network [11], which contains two stride-2 convolutions, several residual blocks [16], and two stride- convolutions. For the discriminators, a PatchGAN architecture is adopted that attempts to classify an image at the patch-level [7, 27]. Tiling artifacts can be alleviated by using a 7070 Patch-GAN, and fewer parameters are necessary, from which better results are obtained in terms of both visual quality and efficiency compared to other PatchGAN models of different sizes [7].
3.2 Objective Function
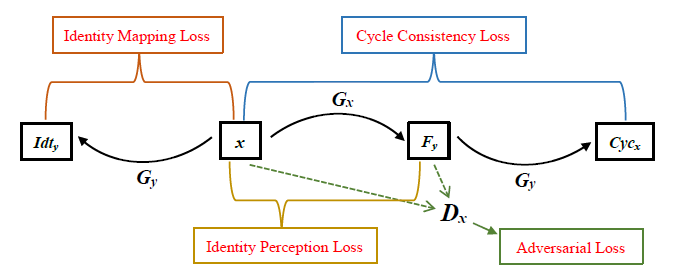
As summarized in Figure 3, the loss function we defined contains four terms: the adversarial loss that matches the distribution of the generated images to the data distribution of the target domain; the cycle consistency loss that prevents the mapping functions and from contradicting each other; the identity perception loss that aims to preserve identity information based on two recognition networks; and the identity mapping loss that favors to preserve the person texture identity between the input and output.
Adversarial Loss. The adversarial loss is applied in both mapping directions. For the mapping function and its discriminator , the adversarial loss is expressed as
| (3) |
where aims to generate a fake image that is completely indistinguishable from the images in the target domain, while tries to distinguish between the real and fake images. And for the mapping function and the discriminator , we define a similar adversarial loss: . The generators try to minimize this loss, while discriminators try to maximize it.
Cycle Consistency Loss. The key to the success of CycleGAN is using the supervision of the cycle consistency loss, which assumes that the generated images can be transformed back to the source domain. Thus, for the images in domain , we expect , and for the images in domain , we expect , from which the objective can be expressed as:
| (4) |
Note that we still adopt a pix-level loss to satisfy backward cycle consistency, different from Kazemi et al. [22] who utilize a high-level perceptual loss for the cycle-consistency definition.
Identity Perception Loss. As illustrated in [28], only using the adversarial loss may lead to artifacts and training instabilities while synthesizing high-resolution images. Specifically, to add a strong supervision between the synthesized image and ground truth, we utilize a perception loss constructed by the face features relating to the activations of the fc7-layer of the VGG-16 [29]. The identity perception loss is defined as
| (5) | |||
where and are the recognition networks for photo and sketch.
Unlike Wang et al. [21], who minimize the pixel-level difference between synthesized images and corresponding real samples, we employ a perceptual supervision for facial features for two reasons. On the one hand, real sketches drawn by artists have distortions in the facial texture information and exaggerated facial characteristics in a certain style. Therefore, synthesizing images completely based on such hand-drawn sketches does not make sense. Taking photo-to-sketch synthesis as an example, generated sketches have different texture distributions from hand-drawn sketches; using a pix-to-pix supervision of these two types of sketches is thus unreasonable. On the other hand, the training of CycleGAN requires common data augmentation techniques during data preprocessing, such as random cropping, flipping and resizing, which may cause pix-level supervision to be difficult to implement.
Identity Mapping Loss. To constraint the generator to be near an identity mapping when real samples from the target domain are provided as the input, we introduce a pixel-wise consistency between the input images and the generated images. We express this loss as:
| (6) |
Full Objective. Thus, the total objective function can be formulated as
| (7) | |||
where , and are parameters controlling the relative importance of every loss. The final objective can be expressed as a minmax problem:
| (8) |
4 Mutual Optimization between the Synthesis and the Recognition Network
Many similar studies adopting a perceptual loss use a fixed network to extract identity-specific information without a cyclic optimization [11, 22]. Considering that the final goal is identity recognition and that an image-to-image translation model already exists, we can use the generated photo-sketch dataset from the basic synthesis network to retrain recognition networks. Thus the newly fine-tuned networks can be used as an additional supervision unit in training synthesis network. Note that the generated dataset mentioned above is constructed with all fake training images obtained from the synthesis model and the corresponding real training samples from the original dataset. After training IACycleGAN with new recognition networks, we obtain new fake photo and sketch datasets that can be applied to the fine-tuning process once again, which produce a new recognition model with better identity preserving ability. As shown in Figure 4, there are two models in our optimization system: the synthesis model (), used for producing fake images, and the recognition model ( and ), which can be fine-tuned using the synthesized image dataset. Therefore, a mutual cyclic optimization process can be applied, as illustrated in Algorithm 1. Through the constant optimization between these two models, the recognition network is able to easily distinguish different subjects, and the synthesis network can be trained to generate images with more identity information.
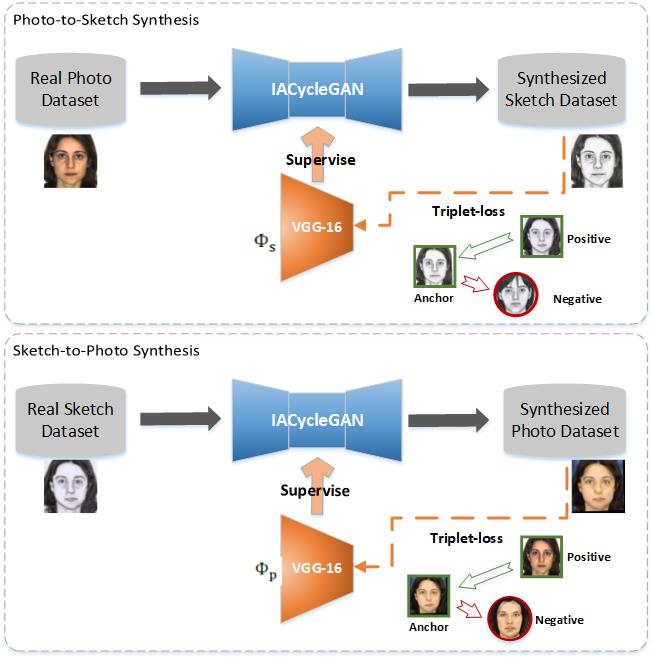
In the fine-tuning process, to make a real image closer to the corresponding fake sample from the same person and far away from the images of different people, the real image and the synthesized fake image should belong to the same class, and the labels from different people should be different. Therefore, we use a triplet loss [30] to regularize the inter-class and intra-class distances, which aims to make the anchor image close to the positive sample and far from the negative samples. For each anchor image , where is the corresponding fake or real positive image sample with the same identity and is the negative sample from the images of a different person, we want to enforce the distance between and to be greater than it between and . Thus, we add a triplet loss layer behind the fc8 layer in VGG-16 [29], and the loss is defined as
| (9) |
where is a margin enforced between positive and negative pairs and is the recognition network. Moreover, to train a more robust feature extractor, we adopt the hard negative mining method in selecting the triplet samples [31], where only the hard negatives are chosen to calculate the loss, rather than all possible negative samples. Specifically, we perform gradient descent learning for the top negatives with the highest losses calculated by the distance of the anchor image from all negative samples.
5 Experiments
In this section, we implement comparative analysis to verify the effectiveness of our proposed method for FPSS and FPSR tasks. Output images from the first synthesis task are used as the experimental datasets of our recognition work. According to Algorithm 1, our experiment was conducted by four steps: CycleGAN Synthesis 1st VGG Fine-tuning IACycleGAN Synthesis 2nd VGG Fine-tuning. The synthesis experiments and final synthesis results in Step 1 and Step 3 are introduced in Section 5.2; the fine-tuning experiments and recognition results in Step 2 and Step 4 are illustrated in Section 5.3.
5.1 Datasets
There are only limited datasets for pairs of human-drawn sketches and face photos since it requires a great effort to collect face sketches. In this paper, the source of photo-sketch pairs is collected from two popular datasets: the Chinese University of Hong Kong (CUHK) Face Sketch Database (CUFS) [1] and the CUHK Face Sketch FERET Database (CUFSF) [32].
The CUFS dataset [1] consists of 606 faces in total: 188 faces from the CUHK student database [17], in which 88 pairs are taken as the training set and the remaining 100 pairs are used as the testing set; 123 faces from the AR database [33], in which 80 pairs are used for the training and the remaining 43 pairs are used for testing; and 295 faces from the XM2VTS database [34], in which 100 pairs are chosen as the training dataset and the remaining 195 pairs are used as the testing set. Each face has one photo-sketch pair, and the sketch is drawn based on a photograph by an artist under normal lighting conditions as well as with neutral expressions. The CUFSF dataset [32] includes 1,194 faces from the FERET database [35], in which 250 faces are taken as the training set and the remaining 944 faces are taken as the testing set. Each person has a face photo with illumination changes and a face sketch drawn by an artist. This database is quite challenging since the photos are taken under different illumination conditions, and the sketches have numerous exaggerations compared to the photos. We employ the MTCNN method [36] to perform face detection and alignment. Before the training process, all images are cropped to the standard size of 256256.
5.2 Photo-sketch Synthesis
Implementation Details: For the training of CycleGAN and IACycleGAN, all these synthesis networks are trained from scratch, instance normalization is used to achieve better stability and lower noise, and Adam with and is used. We flip the images horizontally with a probability of 0.5 for data augmentation. The learning rate is set to 0.0002 for the first 100 epochs and linearly decayed down to 0 for the next 100 epochs. Training takes about 10 hours with a single NVIDIA Titan Xp GPU. We empirically set the hyperparameters of the loss functions in Eq. (7) as follows: , , . As illustrated in [8], to reduce network oscillation, an image buffer storing several generated images is adopted to update the discriminator rather than using the last image generated.
Our final results of FPSS are obtained from the IACycleGAN synthesis in the optimization process. We compare three different networks (traditional CNN, conditional GAN and CycleGAN) with our proposed model from both qualitative and quantitative perspectives, therein focusing on the quality of the synthesized images. For the qualitative research, we employ visual observations. For the quantitative aspect, two measurements, the structural similarity index metric (SSIM) [37] and the feature similarity index metric (FSIM) [38], are used to evaluate structural and feature similarity between images. In addition, we test our trained synthesis network on other unseen datasets to prove the effectiveness of our framework.
5.2.1 Visual Observations
Typical comparative results of P2S on the CUFS and CUFSF datasets are shown in Figure 5. As observed from (a) and (b), the CUFSF dataset is significantly more challenging than CUFS because of the illumination changes of the photos and the over-exaggerated features of the sketches. The traditional CNN method in the fast style transfer network [11] leads to blurred results, where the synthesized images are not realistic and result in minimal information being learned from the sketch style. The other three methods can solve such problems due to the principles of adversarial loss. The results of cGAN (Pix2Pix) have some unacceptable distortions around the mouth and nose, whereas CycleGAN can produce clearer images. With the identity perception loss, some fuzzy edges near the eyes and nose can be eliminated, and the overall images seem to be clearer. Specifically, the facial details of the synthesized sketches in IACycleGAN tend to be nearer to the sketch style. For example, as shown in Figure 6, the eyes produced by IACycleGAN are more distinct and acceptable, and the glasses have been perfectly recovered. Moreover, the fringe and short hair around the forehead appears to be more similar to those of a hand-drawn sketch with fewer distortions in the representations of hair.
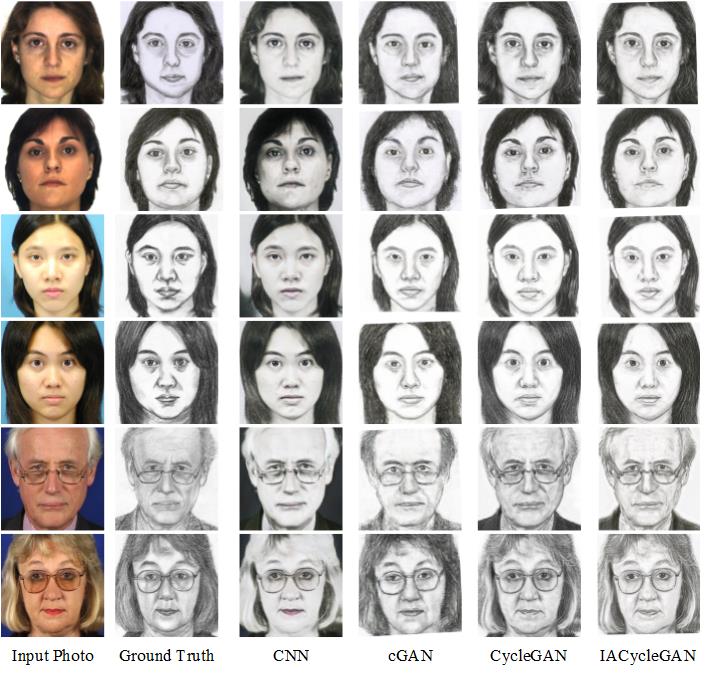


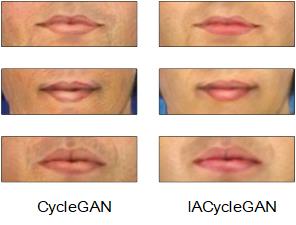
Figure 7 shows the results of S2P on the two datasets. The synthesized photos produced by the CNN method are still not realistic, and suffer color distortions a lot on the CUFS dataset. CGAN produces highly blurred images compared to other GAN methods. The CycleGAN model seems effective but introduces undesirable artifacts around the nose. Compared to the results of CycleGAN, IACycleGAN generates images with more real facial details, such as details about the eyes and lips, which make the fake image look more like a face photo rather than a sketch. Although these artifacts cannot be completely eliminated with the identity perception loss, the overall quality of the images is improved, and some lightness distortions of CUFSF are partially corrected. Similarly, the facial details of the synthesized photos are shown in Figure 8. Our IACycleGAN model can effectively generate red and real lips, while CycleGAN produces some local texture of the pencil drawing around the edges of the lips.


5.2.2 Quantitative Measurements
The SSIM (structural similarity index) [37] is an index for measuring the perceptual metric difference between a synthesized image and its corresponding ground-truth image. It defines the structure information as an attribute in a scene that is independent of brightness and contrast with respect to image composition. The FSIM (feature similarity index) [38] is a type of image quality assessment that evaluates the image denoising performance and has a similar function to SSIM. Thus, these two measurements can be used to produce a better estimation of the quality of synthesized images as well as the performance of different synthesis methods.
| cGAN[7] | CycleGAN[8] | IACycleGAN | ||
|---|---|---|---|---|
| sketch | CUFS() | 63.72 | 64.52 | 64.95 |
| CUFSF() | 49.39 | 57.05 | 57.64 | |
| photo | CUFS() | 69.26 | 70.70 | 71.22 |
| CUFSF() | 57.09 | 61.50 | 62.50 | |
| cGAN[7] | CycleGAN[8] | IACycleGAN | ||
|---|---|---|---|---|
| sketch | CUFS() | 73.22 | 73.74 | 74.01 |
| CUFSF() | 69.41 | 68.67 | 70.05 | |
| photo | CUFS() | 75.77 | 76.24 | 76.52 |
| CUFSF() | 70.21 | 72.41 | 75.47 | |
The result images from the three GAN-based methods are tested using these two measurements. Table 1 shows the comparative results of the SSIM, and Table 2 presents the results of the FSIM. From these two tables, we can see that IACycleGAN provides higher scores compared to the baseline GAN models in terms of both criteria. Simultaneously, Table 3 shows comparison results of the average SSIM scores (%) of the LLE [3], SFS [4], SSD [39], MRF [1], MWF [5], Fast-RSLCR [40], FCN [19], LR [12], and IACycleGAN models on the two datasets. We can observe that our proposed method outperforms all other competing models. In general, by fusing the perceptual-level supervision in the baseline model based on two recognition networks, the proposed method can learn a more discriminative feature representation in terms of both qualitative and quantitative aspects.
| LLE | SFS | SSD | MRF | MWF | Fast-RSLCR | FCN | LR | IACycleGAN | |
|---|---|---|---|---|---|---|---|---|---|
| CUFS | 52.58 | 51.90 | 54.20 | 51.32 | 53.93 | 55.42 | 52.14 | 54.20 | 64.95 |
| CUFSF | 41.79 | 42.11 | 44.09 | 37.24 | 42.99 | 44.55 | 36.22 | 36.65 | 57.64 |
5.2.3 Results on Unseen Datasets
To validate the effectiveness of this method, we test our trained IACycleGAN on other unseen datasets without prior knowledge from testing data. We utilize the network trained on CUFS, since the images of this dataset look more common and have no special condition compared to others. For photo-to-sketch synthesis, we tested the photos from RaFD [41], and for sketch-to-photo synthesis, we tested the viewed sketches from the IIIT-D Sketch Database [42]. Figure 9 shows some example results, where the synthesized images look quite acceptable though no training on input datasets.

5.3 Photo-sketch Recognition
Implementation Details: The fine-tuning process is implemented on Caffe. All networks are trained using . For first fine-tuning on the basic VGGFace, we adopt learning policy with , and 600 iterations are used for photo recognition network and 1600 iterations for sketch recognition network. For second fine-tuning on the last fine-tuned VGG, we adopt training policy with , and 2000 iterations are used for both photo and sketch recognition networks. We set and for the parameters of triplet loss layer. Training takes about 30 hours with a single NVIDIA Titan Xp GPU.


As seen from Figure 10, there are two approaches to retrieving real face photos based on a query sketch: photo matching method and sketch matching method. In the photo matching method, sketch-to-photo synthesis (S2P) is first implemented on the query sketch; then, the generated photo is used for matching on the real photo dataset, where the photo matching rate needs to be computed. In the sketch matching method, all photos in the dataset will first be transformed into sketches, and then, the query sketch is matched to the generated fake samples; at last, the sketch matching rate is computed. In our experiment, we implement both two matching methods and compare the results with other synthesis-based recognition techniques.
5.3.1 Recognition for GAN-Based Methods
Table 4 shows the recognition results of three GAN-based synthesis models, while the recognition model is VGG-Face [26]. We also implement a non-synthesis-based method, which means directly matching between two domains without any synthesis process. It can be observed that synthesis-based methods show a better recognition ability, and our IACycleGAN performs better than other baseline models for both photo and sketch recognition on the two datasets. Moreover, by using score fusion to combine the recognition rates of two matching methods, the performance can be further improved.
| Synthesis model | none | cGAN | CycleGAN | IACycleGAN | |
| Recognition model | VGG-Face | ||||
| CUFS | sketch-matching | 94.97 | 97.63 | 98.82 | 100.00 |
| photo-matching | 81.95 | 96.45 | 98.82 | ||
| fusion | 94.97 | 99.41 | 98.82 | 100.00 | |
| CUFSF | sketch-matching | 57.94 | 41.21 | 68.75 | 70.87 |
| photo-matching | 28.07 | 59.00 | 64.94 | ||
| fusion | 57.94 | 57.94 | 73.52 | 81.36 | |
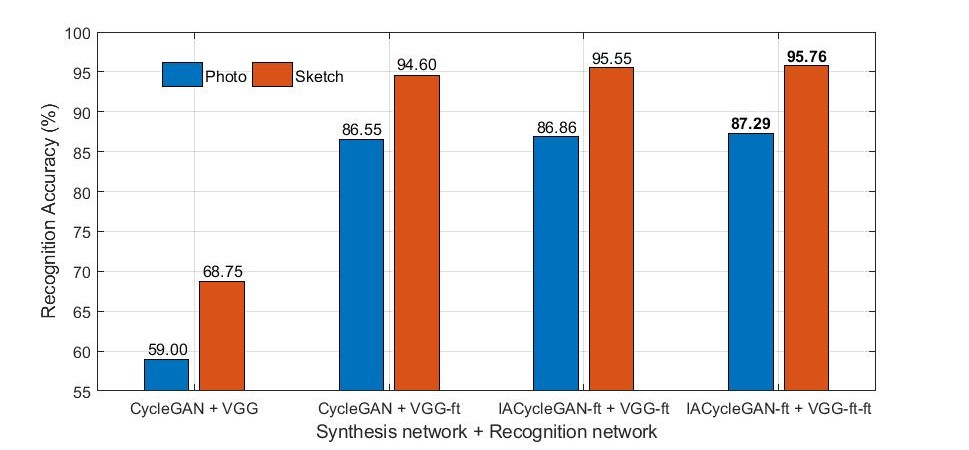
In our optimization model, every new synthesized dataset can be tested directly or used to fine-tune the last recognition network and then compute matching rates on the new recognition network. Thus, two recognition results are obtained for one synthesis model with these two recognition model, as shown in Figure 11. We can also observe that with further optimization of this cyclic system, higher recognition accuracy is obtained, validating the efficiency and effectiveness of the proposed cyclic optimization process. Specifically, due to the simplicity of the CUFS dataset, the recognition accuracy approaches 100% for the first fine-tuned result, as shown in Table 4. In other words, image data may be somewhat distorted on CUFS by multiple iterations and over-sampling; thus, further cyclic fine-tuning is only applied to the CUFSF dataset in our experiment.
5.3.2 Comparisons to Other Methods
In addition, we compare our final recognition results with several state-of-the-art FPSR methods using conventional face recognition algorithms. For the CUFS dataset, 150 synthesized images with corresponding ground truth are randomly selected for classifier training, and the testing set contains the remaining 188 image pairs. And for CUFSF, 300 fake-real image pairs are selected for training, and the remaining 644 pairs are used for testing. For sketch-matching method, we adopt nullspace linear discriminant analysis (NLDA) [43] as the basic recognition technique. The comparison results for sketch-matching are shown in Table 5, therein referring to [14], who uses the same training protocols as our experiment. Meanwhile, Zhang et al. [9] adopt the eigenface recognition technique to compare several synthesis models based on photo-matching. Since we have similar evaluation settings as their experiment, we implement eigenface recognition for photo matching method, the results of which are summarized in Table 6.
| Datasets | CUFS | CUFSF |
|---|---|---|
| LLE [3] | 90.61 | 61.09 |
| SFS [4] | 89.60 | 72.48 |
| SSD [39] | 90.00 | 70.68 |
| MRF [1] | 87.34 | 45.26 |
| MWF [5] | 92.10 | 74.05 |
| Fast-RSLCR [40] | 98.43 | 72.77 |
| FCN [19] | 96.49 | 69.80 |
| LR [12] | 91.67 | 25.93 |
| GAN [7] | 93.48 | 71.44 |
| IACycleGAN (ours) | 98.40 | 74.53 |
| Mutual Optimization (Algorithm 1) | 100.00 | 95.76 |
| Datasets | CUFS | CUFSF |
|---|---|---|
| LLE [3] | 85.0 | – |
| MRF [1] | 85.7 | – |
| MWF [5] | 86.3 | – |
| SNS-SVR [44] | 85.0 | – |
| TFSPS [2] | 84.3 | – |
| DR-GAN [13] | 83.7 | – |
| Dual-Transfer [9] | 86.3 | – |
| IACycleGAN (ours) | 93.62 | 42.55 |
| Mutual Optimization (Algorithm 1) | 98.82 | 87.29 |
In addressing the challenges facing photo matching method on the CUFSF dataset, minimal recognition data can be obtained in this direction. Accordingly, a summary of other photo-matching-based results is only provided on the CUFS dataset, as summarized in Table 6. From the comparison results in Table 5 and Table 6, our synthesis model, IACycleGAN, outperforms all other competitors with the same recognition algorithm. We can observe that the recognition results of CUFS are much better than CUFSF and approach to 100% when using the basic recognition method on IACycleGAN. Thus, there remains enough upside for the recognition results of CUFSF, which accordingly realized a significant increase compared to CUFS. Moreover, we can also observe that the proposed recognition method (IACycleGAN + VGG) achieves the best matching accuracy by using a mutual optimization technique between the IACycleGAN synthesis model and the recognition model.
6 Conclusion
In this paper, we propose Identity-aware CycleGAN IACycleGAN for achieving photo-sketch synthesis with better identity preserving ability and apply a mutual optimization method to explore FPSS and FPSR problems simultaneously. For FPSS, the proposed IACycleGAN adopts a new perceptual supervision which is constructed with the deep facial features from a pre-trained recognition network. This synthesis model shows better performance compared to some recent popular image-to-image translation models for both visual observations and two quantitative measurements (SSIM and FSIM). For FPSR, the recognition network can be re-trained using the feedback from FPSS, a newly synthesized image dataset from IACycleGAN; the synthesis process can then be trained with the fine-tuned recognition model once again. Thus, a mutual cyclic optimization process is formed between the synthesis model and the recognition model, improving both FPSS and FPSR. This method is proven to greatly enhance the recognition accuracy compared to baseline models and other state-of-the-art methods for both sketch and photo matching. All results are evaluated on two popular datasets, CUFS [1] and CUFSF [32], and the proposed method achieved considerable improvements in terms of both image quality and photo-sketch matching accuracy. Our work explores the relation between the synthesis model and the recognition model, from which we plan to improve the FPSS and FPSR on a more common dataset by strengthening and stabilize the connection.
7 Acknowledgements
This work was partially supported by the National Natural Science Foundation of China under Grant Nos. 61573068 and 61871052.
8 References
References
- [1] X. Wang and X. Tang, “Face photo-sketch synthesis and recognition,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 31, no. 11, pp. 1955–1967, Nov 2009.
- [2] N. Wang, D. Tao, X. Gao, X. Li, and J. Li, “Transductive face sketch-photo synthesis,” IEEE Transactions on Neural Networks and Learning Systems, vol. 24, no. 9, pp. 1364–1376, Sep. 2013.
- [3] Q. Liu, X. Tang, H. Jin, H. Lu, and S. Ma, “A nonlinear approach for face sketch synthesis and recognition,” in 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), vol. 1, June 2005, pp. 1005–1010 vol. 1.
- [4] X. Gao, N. Wang, D. Tao, and X. Li, “Face sketch-photo synthesis and retrieval using sparse representation,” IEEE Trans. Cir. and Sys. for Video Technol., vol. 22, no. 8, pp. 1213–1226, Aug. 2012.
- [5] H. Zhou, Z. Kuang, and K. K. Wong, “Markov weight fields for face sketch synthesis,” in 2012 IEEE Conference on Computer Vision and Pattern Recognition, June 2012, pp. 1091–1097.
- [6] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio, “Generative adversarial nets,” in Advances in Neural Information Processing Systems 27, Z. Ghahramani, M. Welling, C. Cortes, N. D. Lawrence, and K. Q. Weinberger, Eds. Curran Associates, Inc., 2014, pp. 2672–2680.
- [7] P. Isola, J. Zhu, T. Zhou, and A. A. Efros, “Image-to-image translation with conditional adversarial networks,” in 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), vol. 00, July 2017, pp. 5967–5976.
- [8] J.-Y. Zhu, T. Park, P. Isola, and A. A. Efros, “Unpaired image-to-image translation using cycle-consistent adversarial networks,” IEEE International Conference on Computer Vision, Oct 2017.
- [9] M. Zhang, R. Wang, X. Gao, J. Li, and D. Tao, “Dual-transfer face sketch–photo synthesis,” IEEE Transactions on Image Processing, vol. 28, no. 2, pp. 642–657, Feb 2019.
- [10] Z. Huang, B. Kratzwald, D. P. Paudel, J. Wu, and L. V. Gool, “Face translation between images and videos using identity-aware cyclegan,” CoRR, vol. abs/1712.00971, 2017.
- [11] J. Johnson, A. Alahi, and L. Fei-Fei, “Perceptual losses for real-time style transfer and super-resolution,” in Computer Vision – ECCV 2016, B. Leibe, J. Matas, N. Sebe, and M. Welling, Eds. Cham: Springer International Publishing, 2016, pp. 694–711.
- [12] N. Wang, M. Zhu, J. Li, B. Song, and Z. Li, “Data-driven vs. model-driven: Fast face sketch synthesis,” Neurocomputing, vol. 257, pp. 214 – 221, 2017, machine Learning and Signal Processing for Big Multimedia Analysis.
- [13] L. Tran, X. Yin, and X. Liu, “Disentangled representation learning gan for pose-invariant face recognition,” in 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), July 2017, pp. 1283–1292.
- [14] A. Akram, N. Wang, J. Li, and X. Gao, “A comparative study on face sketch synthesis,” IEEE Access, vol. 6, pp. 37 084–37 093, 2018.
- [15] I. Jolliffe, Principal Component Analysis. Berlin, Heidelberg: Springer Berlin Heidelberg, 2011, pp. 1094–1096.
- [16] S. T. Roweis and L. K. Saul, “Nonlinear dimensionality reduction by locally linear embedding,” Science, vol. 290, no. 5500, pp. 2323–2326, 2000.
- [17] X. Tang and X. Wang, “Face photo recognition using sketch,” in Proceedings. International Conference on Image Processing, vol. 1, Sept 2002, pp. I–I.
- [18] L. Chang, M. Zhou, Y. Han, and X. Deng, “Face sketch synthesis via sparse representation,” in 2010 20th International Conference on Pattern Recognition, Aug 2010, pp. 2146–2149.
- [19] L. Zhang, L. Lin, X. Wu, S. Ding, and L. Zhang, “End-to-end photo-sketch generation via fully convolutional representation learning,” in Proceedings of the 5th ACM on International Conference on Multimedia Retrieval, ser. ICMR ’15. New York, NY, USA: ACM, 2015, pp. 627–634.
- [20] N. Wang, W. Zha, J. Li, and X. Gao, “Back projection: An effective postprocessing method for gan-based face sketch synthesis,” Pattern Recognition Letters, vol. 107, pp. 59 – 65, 2018, video Surveillance-oriented Biometrics.
- [21] L. Wang, V. Sindagi, and V. Patel, “High-quality facial photo-sketch synthesis using multi-adversarial networks,” in 2018 13th IEEE International Conference on Automatic Face Gesture Recognition (FG 2018), May 2018, pp. 83–90.
- [22] H. Kazemi, F. Taherkhani, and N. M. Nasrabadi, “Unsupervised facial geometry learning for sketch to photo synthesis,” in 2018 International Conference of the Biometrics Special Interest Group (BIOSIG), Sep. 2018, pp. 1–5.
- [23] D. P. Kingma and M. Welling, “Auto-Encoding Variational Bayes,” ArXiv e-prints, Dec. 2013.
- [24] Z. Yi, H. Zhang, P. Tan, and M. Gong, “Dualgan: Unsupervised dual learning for image-to-image translation,” in 2017 IEEE International Conference on Computer Vision (ICCV), vol. 00, Oct. 2018, pp. 2868–2876.
- [25] S. Mo, M. Cho, and J. Shin, “Instagan: Instance-aware image-to-image translation,” CoRR, vol. abs/1812.10889, 2018.
- [26] O. M. Parkhi, A. Vedaldi, and A. Zisserman, “Deep face recognition,” in Proceedings of the British Machine Vision Conference (BMVC), 2015.
- [27] C. Li and M. Wand, “Precomputed real-time texture synthesis with markovian generative adversarial networks,” in Computer Vision – ECCV 2016, B. Leibe, J. Matas, N. Sebe, and M. Welling, Eds. Cham: Springer International Publishing, 2016, pp. 702–716.
- [28] H. Zhang, T. Xu, H. Li, S. Zhang, X. Wang, X. Huang, and D. Metaxas, “Stackgan: Text to photo-realistic image synthesis with stacked generative adversarial networks,” in 2017 IEEE International Conference on Computer Vision (ICCV), vol. 00, Oct. 2018, pp. 5908–5916.
- [29] K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” CoRR, vol. abs/1409.1556, 2014.
- [30] F. Schroff, D. Kalenichenko, and J. Philbin, “Facenet: A unified embedding for face recognition and clustering,” CoRR, vol. abs/1503.03832, 2015.
- [31] X. Wang and A. Gupta, “Unsupervised learning of visual representations using videos,” in The IEEE International Conference on Computer Vision (ICCV), December 2015.
- [32] W. Zhang, X. Wang, and X. Tang, “Coupled information-theoretic encoding for face photo-sketch recognition,” in CVPR 2011, June 2011, pp. 513–520.
- [33] A. M. MARTINEZ, “The ar face database,” CVC Technical Report24, 1998.
- [34] K. Messer, J. Matas, J. Kittler, J. Luettin, and G. Maître, “Xm2vtsdb: The extended m2vts database,” Proc. Second International Conference on Audio- and Video-based Biometric Person Authentication (AVBPA’99), 1999.
- [35] P. Phillips, H. Wechsler, J. Huang, and P. J. Rauss, “The feret database and evaluation procedure for face-recognition algorithms,” Image and Vision Computing, vol. 16, no. 5, pp. 295 – 306, 1998.
- [36] K. Zhang, Z. Zhang, Z. Li, and Y. Qiao, “Joint face detection and alignment using multi-task cascaded convolutional networks,” CoRR, vol. abs/1604.02878, 2016.
- [37] Z. Wang, A. C. Bovik, H. R. Sheikh, and E. P. Simoncelli, “Image quality assessment: from error visibility to structural similarity,” IEEE Transactions on Image Processing, vol. 13, no. 4, pp. 600–612, April 2004.
- [38] L. Zhang, L. Zhang, X. Mou, and D. Zhang, “Fsim: A feature similarity index for image quality assessment,” IEEE Transactions on Image Processing, vol. 20, no. 8, pp. 2378–2386, Aug 2011.
- [39] Y. Song, L. Bao, Q. Yang, and M.-H. Yang, “Real-time exemplar-based face sketch synthesis,” in Computer Vision – ECCV 2014, D. Fleet, T. Pajdla, B. Schiele, and T. Tuytelaars, Eds. Cham: Springer International Publishing, 2014, pp. 800–813.
- [40] N. Wang, X. Gao, and L. Jie, “Random sampling and locality constraint for face sketch,” Pattern Recognition, vol. 76, 2017.
- [41] O. Langner, R. Dotsch, G. Bijlstra, D. H. J. Wigboldus, S. T. Hawk, and A. van Knippenberg, “Presentation and validation of the radboud faces database,” Cognition and Emotion, vol. 24, no. 8, pp. 1377–1388, 2010.
- [42] H. S. Bhatt, S. Bharadwaj, R. Singh, and M. Vatsa, “Memetic approach for matching sketches with digital face images,” 2012.
- [43] L.-F. Chen, H.-Y. M. Liao, M.-T. Ko, J.-C. Lin, and G.-J. Yu, “A new lda-based face recognition system which can solve the small sample size problem,” Pattern Recognition, vol. 33, no. 10, pp. 1713 – 1726, 2000.
- [44] N. Wang, X. Gao, D. Tao, and X. Li, “Face sketch-photo synthesis under multi-dictionary sparse representation framework,” in 2011 Sixth International Conference on Image and Graphics, Aug 2011, pp. 82–87.