This work was partly supported by the Adaptable and Seamless Technology Transfer Program through Target-driven R&D (A-STEP) from the Japan Science and Technology Agency (JST) Grant Number JPMJTR20RG and the Japan Society for the Promotion of Science by a Grant-in-Aid for Scientific Research (B) under Grant 21H01347.
Corresponding author: Sho Sakaino (e-mail: sakaino@iit.tsukuba.ac.jp).
Imitation Learning for Variable Speed Contact Motion for Operation up to Control Bandwidth
Abstract
The generation of robot motions in the real world is difficult by using conventional controllers alone and requires highly intelligent processing. In this regard, learning-based motion generations are currently being investigated. However, the main issue has been improvements of the adaptability to spatially varying environments, but a variation of the operating speed has not been investigated in detail. In contact-rich tasks, it is especially important to be able to adjust the operating speed because a nonlinear relationship occurs between the operating speed and force (e.g., inertial and frictional forces), and it affects the results of the tasks. Therefore, in this study, we propose a method for generating variable operating speeds while adapting to spatial perturbations in the environment. The proposed method can be adapted to nonlinearities by utilizing a small amount of motion data. We experimentally evaluated the proposed method by erasing a line using an eraser fixed to the tip of the robot as an example of a contact-rich task. Furthermore, the proposed method enables a robot to perform a task faster than a human operator and is capable of operating close to the control bandwidth.
Index Terms:
Imitation learning, bilateral control, motion planning, fast-forward, machine learning=-15pt
I Introduction
The utilization of machines and robots is promising; however, many processes are still performed manually, and labor is not yet fully automated because robots lack adequate environmental adaptability. Particularly, contact-rich tasks, such as grinding and peg-in-hole, are difficult for robots. Recent developments in reinforcement learning (RL) have succeeded in addressing the aforementioned tasks without precise prior knowledge of the tasks [1, 2, 3, 4]. However, this approach is impractical because the model learns with an enormous number of trials using actual machines. Given that robotic control involves interactions with the real-world environment, the time required for a single trial is constrained by the time constant of the physical phenomenon under investigation. Hence, applying RL from the onset requires an impractical trial time. If RL is performed in the simulation, this problem is greatly alleviated because there is no need to try it on actual machines. Johannink et al. showed that the number of trials required can be reduced using residual RL, and further reduced using sim2real, which transfers learning results from simulations to actual robots [5]. However, this still required several hundred to a thousand trials.
Imitation learning, which can address this problem, is gaining attention. In this process, humans provide demonstrations as teacher data, and the robots mimic human motion. This approach significantly reduces the number of trials required. Many studies have demonstrated the effectiveness of imitation learning by applying Gaussian mixture models [6][7], neural networks (NNs) [8][9], and RL [10]. Some researchers have reported visual imitation learning [11]. Imitation learning using force information has also attracted notable attention owing to its high adaptability to environmental changes [12, 13, 14, 15, 16]. It is worth noting that it may be possible to reduce the number of required motion teachings if the policy is learned in advance using simulation-based methods such as [17] before imitation learning. However, for its implementation, it is necessary to create a robot and environment simulator. Particularly, it is difficult to create an accurate simulator when there are flexible objects in the environment.
The above-mentioned imitation learning is focused on performing geometrically challenging robotic tasks and is not relevant to reproducibility over time, such as in the case of a phase delay. Consequently, the movements are often static and slower than human operations, and it is difficult to realize movements based on the dynamic interaction between robots and objects. Motion that considers friction and inertial forces, such as that described in [18], remains a challenge. Conventional imitation learning predicts the next response value of a robot and provides it as a command value. Generally, no ideal control system exists, and a delay between the command and response values occurs. Consequently, only low-speed operation, wherein control systems can be assumed to be ideal, can be achieved.
We recently showed that this problem can be solved using four-channel bilateral control [19][20]. Bilateral control is a remote operation that synchronizes two robots: a master and a slave. Furthermore, four-channel bilateral control is a structure with position and force controllers implemented on both robots [21] [22]. Using bilateral control, an operator can experience a control delay on the slave side and dynamic interaction with the environment. Thus, the operator can compensate for the control delay and dynamic interaction. There are conventional methods of imitation learning using bilateral control [23][14]. However, even if bilateral control is used, it is inadequate. We revealed that the teacher data obtained via bilateral control can be fully utilized under the following three important conditions:
-
1.
Predicting the master robot’s response
The command in the next step must be predicted when the response of a certain slave is measured. In the case of bilateral control, the response value of a master is given as the command value of the slave, and the command value can be directly measured. It should be noted that this command value includes human skills to compensate for control delays and dynamic interactions. -
2.
Having both position and force control in a slave
position control is robust against force perturbations, and force control is robust against position perturbations. Although robot control can be described as a combination of these controls [24], the predominant control is task-dependent and often not obvious. In this case, machine learning must apply a configuration that can adjust to both position and force commands. -
3.
Maintaining control gains
Research has also been conducted on adjusting control gains to achieve environmental adaptability [25]. However, if the control gains are changed, the dynamic characteristics of the control also change. Robots are then unable to mimic the skills of humans and compensate for control delays and dynamic interactions. In summary, the controllers must be consistently applied when the training data are collected and during autonomous execution.
Our method satisfies these requirements, and the control system does not need to be ideal because the operation is performed by explicitly considering the control delay by predicting the response of the master. Therefore, it is possible to realize object operation at a rate comparable to that of humans, and high adaptability to environmental changes is achieved. A detailed explanation can be found in [26][27].
Given that fast motion can be achieved using the proposed method, a generalization ability with respect to the operating speed is the next target. A basic study on achieving variable operating speed was proposed by Yokokura et al. [28], in which a robot moved autonomously by reproducing stored motion. Reproduced motion was generated using simple linear interpolation and extrapolation of the stored motion. However, this method has been evaluated only in highly transparent, single-degree-of-freedom (DOF) linear motors. In actual multi-DOF robots, dynamic forces, such as the inertial force, change significantly according to the operating speed. For example, in a line-erasing task, the required state of the end-effector differs depending on the operating speed because the pressing force on the paper surface is adjusted to utilize inertial force during high-speed operation, and the eraser is actively pressed against the paper surface during low-speed operation. The force and operating speed clearly have a nonlinear relationship. However, it should be possible to express this relationship using specific functions. Percio et al. also demonstrated variable speed operation [29]; however, this method did not effectively reproduce the operation speed. Consequently, it was not possible to operate at the frequency of the control bandwidth. The self-organization of the operation speed is realized by parametric biases, in which the physical parameters of robotic motions can be adjusted [30]. However, because this is a self-organizing process, it is not possible to precisely command the desired operating speed.
In this study, we propose a method in which the operating speed is varied using imitation learning based on four-channel bilateral control. It should be noted that in the proposed method, the operating speed can exceed that of the original demonstrations and even be capable of operating at the frequency of the control bandwidth. If a robot can move quickly, its productivity can be improved. Moreover, it is also desirable to adjust the operating speed to match the production speed of other production lines. To evaluate the effectiveness of the proposed method, we performed a task in which a robot erased a line written in pencil using an eraser fixed to the robot as an example of contact-rich motions. Using the relationship between the inertial force, friction force, and operating speed is necessary to accomplish this task because a large operating force is required for fast operation to compensate for the inertial force and vice versa. Moreover, when the same task is performed, a different operating force is required depending on the operating speed because the friction characteristics change significantly with speed [31][32]. Using the proposed method, the operating speed is determined based on the peak frequency calculated using the fast Fourier transform (FFT), and the slave responses are concatenated and inputted into an NN. Variable speed operation is achieved by incorporating the operating frequency as an input. This is a further development of our imitation learning using bilateral control.
It is worth noting that it is not difficult to achieve variable-speed contact control with known dynamics or to operate faster than humans; however, it is difficult to operate up to the control bandwidth. Additionally, it is not difficult to slowly control contact with unknown dynamics. Therefore, the contributions of this study are summarized as follows:
-
•
Variable speed contact motion with unknown dynamics
-
•
Contact motion with unknown dynamics up to the control bandwidth
It is also worth noting that many previous studies on object manipulation using machine learning have mainly aimed at improving the generalization performance for space, and few of them have aimed at improving the generalization performance over time.
The remainder of this paper is organized as follows. Section 2 presents the robot control system and bilateral control used in this study. Section 3 presents the proposed learning method and detailed network structure. Section 4 details the experiment and results in addition to a description of a comparative experiment involving the proposed method and a variable-speed motion copy approach based on the study described in [28]. Finally, Section 5 presents the concluding remarks and areas of future study.
II Robot and controller
In this section, the robots and controllers used in this study are presented.
II-A Setup
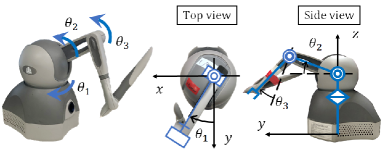
In this study, we used two Geomagic Touch haptic devices manufactured by 3D systems (Rockhill, SC, USA) as manipulators (Fig. 1, respectively. Sensors, a motor driver, and a microcomputer were built into the robot, and the robot could be controlled by connecting a USB cable to a personal computer. Detailed specifications can be found at https://www.3dsystems.com/haptics-devices/touch/specifications. Two robots were used during the data collection phase, and an autonomous operation phase using an NN model was executed using a single robot. The robot’s joints and Cartesian coordinates are defined as shown in Fig. 1. The model of the robots was assumed to be the same as that in [27]. However, the physical parameters of the robot were different and were identified on the basis of [33]. Note that in this model, we neglected the interference among the axes and treated them as three single-DOF axes. Therefore, inertia, damping, and gravity coefficients were identified as a single-DOF system.
| Joint 1 inertia [m Nm] | 3.49 | |
| Joint 2 inertia [m Nm] | 3.36 | |
| Joint 3 inertia [m Nm] | 1.06 | |
| friction compensation coefficient [m kg m2/s] | 12.1 | |
| Gravity compensation coefficient 1 [m Nm] | 124 | |
| Gravity compensation coefficient 2 [m Nm] | 51.6 | |
| Gravity compensation coefficient 3 [m Nm] | 81.6 |
Table I lists the physical parameter values used in this study. The parameters , , and are the inertia, friction compensation coefficient, and gravity compensation coefficient, respectively. The parameters with subscripts 1, 2, and 3 represent those of the first, second, and third joints, respectively.
II-B Controller
This robot can measure the joint angles of the first to third joints and calculate the angular velocity and torque response using pseudo-differentiation and a reaction force observer (RFOB) [34], respectively. Acceleration control was realized using a disturbance observer (DOB) [35], and robustness against modeling errors was guaranteed. A position controller and a force controller were implemented in the robot; these two controllers were composed of a proportional and differential position controller and a proportional force controller, respectively. Here, , , and represent the joint angle, angular velocity, and torque, respectively, and the superscripts , , and indicate the command, response, and reference values, respectively. The torque reference of the slave controller is given as follows:
| (1) |
where and are the slave variables, defined as follows:
| (8) |
In addition, . Here, is the Laplace operator. Additionally, the parameters , , and are scalar, and represent the proportional position gain, derivative position gain, and proportional force gain, respectively. We set the same control parameters in each axis. The gains were determined by trial and error so that the control bandwidth covered the motion frequencies of a human. Note that we adjusted the proportional-derivative control of the position to have the characteristics of critical damping. Table I shows the control parameters.
| Position feedback gain | 121 | |
|---|---|---|
| Velocity feedback gain | 22.0 | |
| Force feedback gain | 1.00 | |
| Cut-off frequency of pseudo derivative [rad/s] | 40.0 | |
| Cut-off frequency of DOB [rad/s] | 40.0 | |
| Cut-off frequency of RFOB [rad/s] | 40.0 |
Bilateral control is a remote operation technology between two robots. The operator first operates the master robot and then operates the slave robot directly through the master robot [21] [22]. The operation and reaction forces can be independently measured by the master and slave. This controller was implemented to imitate human object manipulation skills. A four-channel bilateral controller was implemented similar to that in [27].
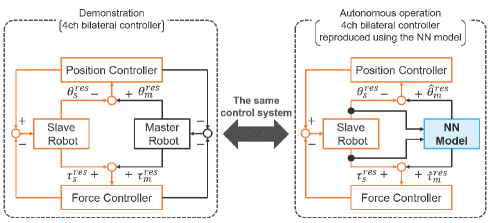
A block diagram of the four-channel bilateral controller in the demonstration (data collection phase) is shown on the left side of Fig. 2. The command values of the slave robot in the four-channel bilateral control are given as follows:
| (9) |
where and are the master variables defined as follows:
| (16) |
III Imitation Learning for Variable-Speed Operation
We propose a method for generating variable-speed motion that can exceed the speed of the original motion using imitation learning.

III-A Data collection
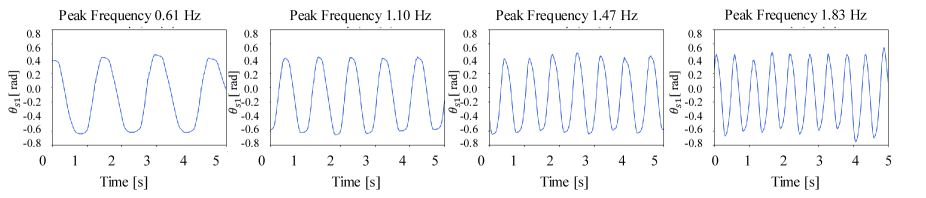
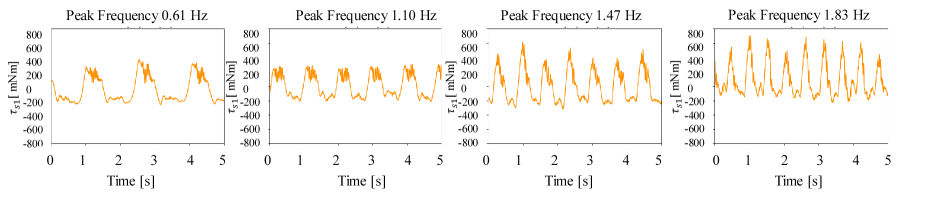
Fig. 3 shows the data collection phase. The two robots were used for data collection based on a four-channel bilateral control, as described in Section II-A. The objective was to generate motion to quickly or slowly erase a line written in pencil. This task simulated contact-rich motions, such as polishing [36], grinding [37], and wiping [38]. Therefore, the operator of the master robot erased the lines using seven different frequencies, that is, 0.61, 0.85, 1.10, 1.22, 1.47, 1.59, and 1.83 Hz. Frequency adjustments were performed using a metronome. The motions at 0.61 and 1.83 Hz were the slowest and fastest motions that the human was able to manipulate the robot, respectively, and for the other frequencies, the human was instructed to divide these frequencies into seven equal parts using a metronome. It was not exactly divided into seven equal parts, as the value was calculated based on the peak frequency of human motion. This trial was conducted three times at paper heights of 3.5, 5.6, and 6.6 cm from the surface of the desk. The height was adjusted by piling up books under a plate for placing paper. A total of 21 trials were conducted. The saved motion data points were acquired over 15 s in each case, and the joint angle, angular velocity, and torque of the master and slave data were stored at 1 kHz. Training data were obtained by augmenting the collected data 20 times by down-sampling at 50 Hz using the technique described in [39].
Additionally, Figs. 4 and 5 show some of the training data of and for a height of 5.6 cm, respectively. From these figures, when the operating speed changes, it can be confirmed that the required motion and force adjustment differ, although the trajectory is similar. When the operation is the fastest, the torque is the greatest because the inertial force is the highest, whereas the torque decreases with a decrease in the operating frequency. However, when the operation was the slowest, the torque was slightly larger to compensate for the nonlinearity of the frictional force. This is a major problem, which makes it difficult to achieve motion generation at variable speeds.
III-B Training the NN model phase
In this study, we use a network consisting of a recurrent NN (RNN). An RNN, which has a recursive structure, is a network that holds time-series information. This network has contributed significantly to the fields of natural language processing and speech processing [40][41] and has recently been widely applied to robot motion planning [42]. However, RNNs are hindered by the vanishing gradient problem, which makes it difficult to learn long-term data. Long short-term memory (LSTM) refers to an NN that can learn long-term inferences [43]. This approach was improved based on the results of numerous studies and was adopted in this study. To extract the feature values from the response variables that do not depend on time-series information, we implemented a convolutional NN (CNN) prior to the LSTM. We expected that the CNN would extract time-independent transformations, such as Jacobian matrices.
The network inputs are , , , and the frequency command of the first joint, whereas the outputs are , , and of each joint in the next step. The variables with are estimates given by the NN. The frequency command was designed based on the peak frequency values of the first joint angle of the robot, which was calculated using the FFT. Here, the next step indicates a point 20 ms later than the slave data. Autonomous operation was realized by considering the network calculation time required to generate online motion. Thus, the data had 315,000 () input-output samples. Additionally, the weights were optimized using the mean square error between the normalized master value and network output.
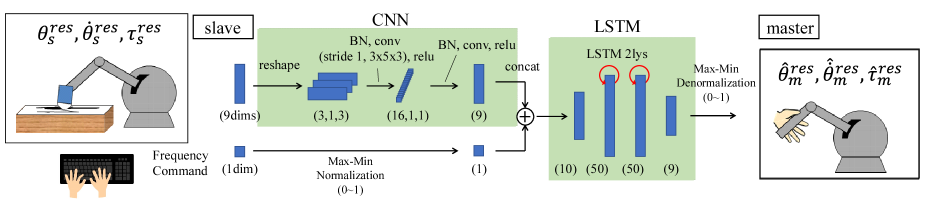
Fig. 6 shows the network. The responses , , and of each joint of the slave robot are reshaped into other channels. The reshape was designed to predict the effect of batch normalization (BN) for each unit dimension. Additionally, the mini-batch consisted of 100 random sets of 300 time-sequential samples corresponding to 6 s. The frequency command was manually provided using a keyboard and normalized using max-min normalization. Max-min denormalization was set at the output of the network. In this study, the computer used for training and autonomous operation comprised an Intel Core i7-8700K CPU, 32 GB of memory, and an nVIDIA GTX 1080 Ti GPU.
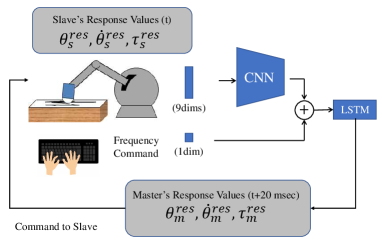
III-C Autonomous operation phase
The right part of Fig. 2 shows a block diagram of the slave robot conducting autonomous execution using the trained NN. In the autonomous operation phase, the demonstrator, master robot, and master controllers are substituted by the trained NN. In this case, the command values are not the true response values of the master, but the estimated values provided by the NN. Fig. 7 shows its detailed schematic. The NNs predict responses of the master in the next step (20 ms after) from the responses of the slave and frequency commands. Then, the master’s responses are commanded to the slave.
| (17) |
It is worth noting that the control system in the autonomous execution phase is the same as that in the data collection phase. Although the input interval into the network was 20 ms, the control period of the position and force controller was 1 ms. Therefore, the control input was updated during every control period.
IV Experiment
This section presents the experimental evaluation of the proposed method.
IV-A Control bandwidth
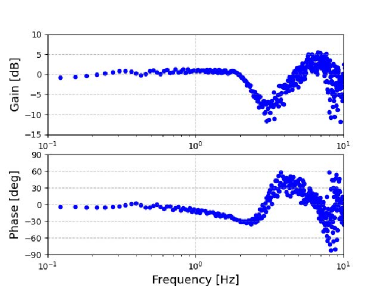
First, the control bandwidth of the robot was tested. Fig. 8 shows a Bode diagram of the angle response of the first joint () in free motion with zero torque commands. As can be observed from this figure, the control bandwidth where the gain is -3 dB was approximately 2.3 Hz. It should be noted that operations over the control bandwidth are extremely difficult, and motion over the control bandwidth is not a subject of interest in the research field of control engineering.
IV-B Preliminary experiment
Prior to performing the main experiment, one of the three conditions described in the introduction was tested. The validity of the predicting command value of the slave, that is, the predicting master response, was evaluated. In this case, the environment was not changed from the data collection phase, the NN was not used, and motion at 2.17 Hz was simply replayed as a command value. The following two command values for the next step were given for comparison:
-
1.
the master’s response during the training data (our approach); , and
-
2.
the slave’s response during the training data; .
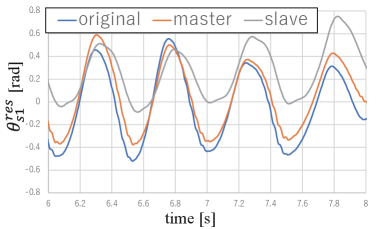
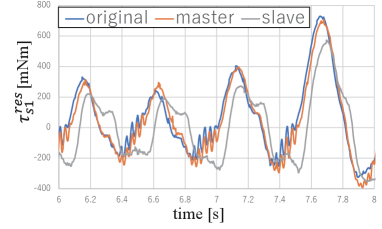
The variables with superscript indicate the training data. Figs. 9 and 10 show the experimental results for and , where the blue lines represent the original slave responses in the training data. The orange and gray lines represent the responses reproduced using the master and slave responses in the training data, respectively. The orange lines indicate that the response was almost identical to that of the data collection when the master’s next response was used as a command value. However, based on the gray lines, when the next response of the slave was given as a command value, the shape of the response differed significantly from that in the training data. It is evident that the amplitude was smaller than that in the original slave response, and a large phase delay occurred. Given that the motion was rapid, and it was very close to the control bandwidth, the transfer function from the command to the response cannot be 1.
These results clearly show that predicting the master’s response is important for reproducing fast motion. It should be noted that kinesthetic teaching cannot satisfy this condition, nor does conventional imitation learning using bilateral control [23]. As such, temporal reproducibility at high speeds can only be achieved using our approach. Hence, variable-speed imitation learning with precise reproducibility has been made possible for the first time.
IV-C Comparative experiment
The results of the experiment conducted to change the operating speed based on the training data were compared with the results of a motion copying system [28]. In the latter, the data collected at a frequency of 1.22 Hz and height of 5.6 cm were used to reproduce the operation. Given that the motion copying system simply rescales the time axis, it only requires one time series of data for reproduction. To convert the operating speed, the original data were rescaled to fit the target speed data. The training data were rescaled along the time axis of the data using linear interpolation with a zero-order hold.

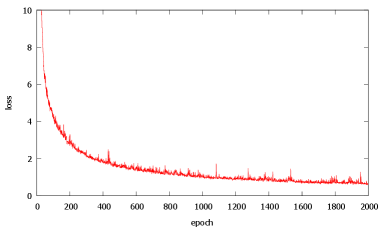
First, nine and 16 convoluted channels were compared for the implementation of the CNN. The variable-speed range for the 16 channels was wider than that for the nine channels. Hence, the proposed method was implemented using 16 channels. Fig. 12 shows the training loss versus epochs for the 16-channel network. We then selected the model of the 1500 epochs because the loss almost settled down. The learning time was approximately 40 min.
IV-D Results and Discussion
The success rate of the operation was then evaluated. Fig. 11 shows the working area. Given that this robot was not equipped with a camera, it was not possible to completely erase the entire area. In contrast, it is easy to erase the entire area by combining the proposed method with conventional methods using a camera. However, when several methods are combined, it is difficult to evaluate the effectiveness of the proposed method. Therefore, we investigated whether we could erase the arc-shaped area through which the end-effector of the robot passed. When the robot erased more than 90 % of the area inside the red lines, this was defined as successful, and it was inferred by a human. Note that because it is a cyclic motion, it can gradually erase all the lines as time goes by if it could keep operating with stable contact.
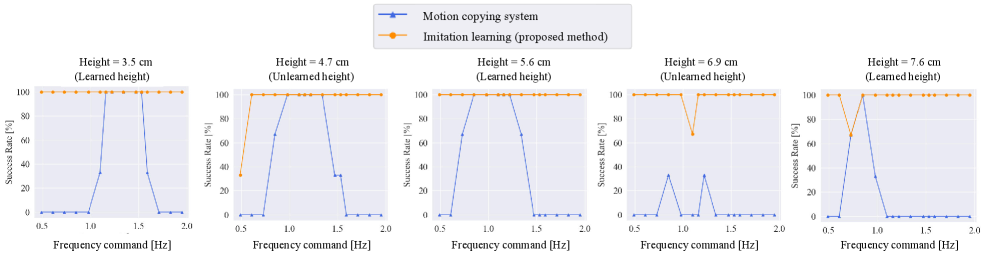
Evaluation was conducted using 15 frequency commands: 0.49, 0.61, 0.73, 0.85, 0.98, 1.10, 1.16, 1.22, 1.34, 1.47, 1.53, 1.59, 1.71, 1.83, and 1.95 Hz, for five heights of 3.5, 4.7, 5.6, 6.9, and 7.6 cm from the surface of the desk. Three trials were conducted for each condition, for a total of 225 trials (15 [frequencies] 5 [heights] 3 [trials]). It should be noted that height information from the desk surface was not given to the robot. Given that the robot was not equipped with a camera, it needed to adapt to the perturbation of the height using only the angle, angular velocity, and torque information. The experiments can be viewed using the following link to a video: (https://youtu.be/2XjbauSGu0s).
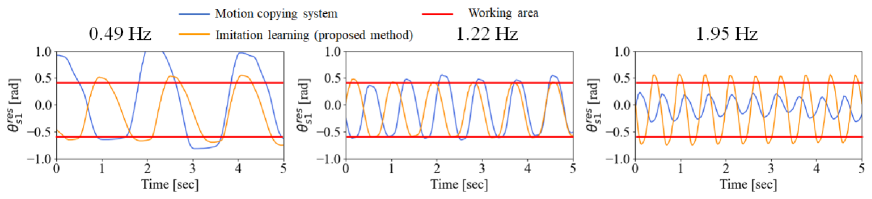
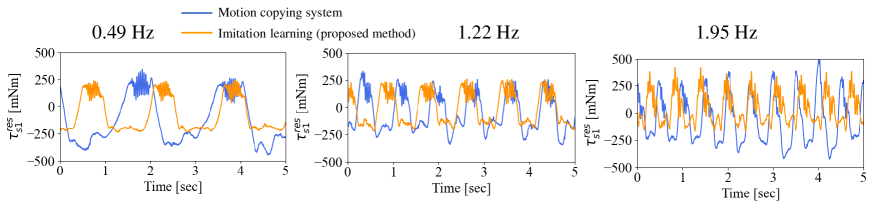
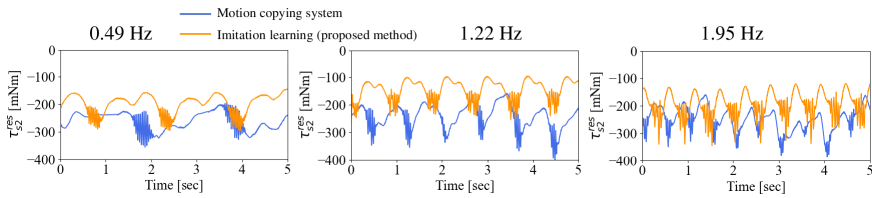
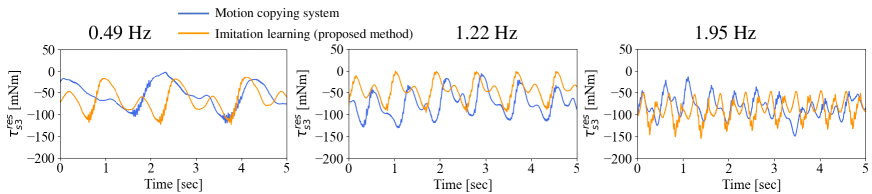
Fig. 13 shows the success rate for each height. The blue lines show the success rates of the motion copying system, whereas the orange lines represent the rates of the proposed method. As shown in the figure, the motion copying system performs its task under limited frequencies and heights, whereas the proposed method can adapt to variations in both the speed and height. The success rate was the same or higher than that of the motion-copying system under all conditions. Particularly, given that the motion copying system does not have an adaptation mechanism against a height perturbation, it was significantly less effective at heights of 6.6 and 7.6 cm. Figs. 14-17 show the angular responses of and the torque responses of , , and for a height of 5.6 cm. The blue lines represent the responses of the motion-copying system, whereas the orange lines show the responses of the proposed method. The red lines indicate the working area. In the motion copying system, within a high-speed range, the amplitude of was too small to meet the conditions shown in Fig. 11. In the low-speed range, the amplitude was too large to remain within the desk. In contrast, in the proposed method, the angular response was almost constant in amplitude and independent of frequency, indicating that it could operate properly within the working range. However, the amplitudes of the torque varied adaptively for different frequencies in the proposed method. These figures clearly demonstrate that the proposed method could achieve almost the same angular trajectory regardless of the frequency, whereas the motion copying system exhibited a strong dependency on the frequency; simultaneously, the proposed method could give adaptive force command values with dependencies on the frequency. Thus, the proposed method can effectively handle frequency-dependent physical phenomena, such as inertial force and friction. It is also worth noting that the reason why the response of the proposed method and the motion copying system differed at 1.22Hz is that the proposed method generated trajectories in real time, then the motion changed according to subtle changes in the environments and the states of the robot. For example, a typical example is that the contact force changed according to the change of the shape of the eraser between the data collection and autonomous operation. The overall success rate of the proposed method was 98.2 %.
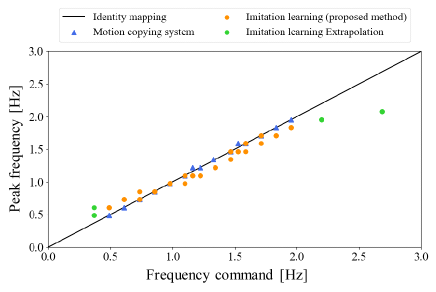
Fig. 18 shows the reproducibility of the frequency at a height of 5.6 cm. The horizontal axis shows the frequency command, whereas the vertical axis shows the peak frequency measured using the FFT. Given that the proposed method was 100 % successful, all the peak frequencies of are plotted. Moreover, four additional experiments were conducted to further evaluate the extrapolation performance of the proposed method. In contrast, given that the conventional method had few successful samples, the behaviors that did not meet the conditions in Fig. 11 are plotted. The blue, orange, and green plots show the peak frequencies of the motion copying system, the proposed method, and the proposed method applied during the additional experiment, respectively. The solid line indicates the identity mapping. When the plots are along the line, the reproducibility of the frequency is ideal. In the motion copying system, the operating frequency was adjusted by the designer, and the reproducibility of the operating frequency was consequently high. However, the proposed method could also operate at the command frequency, although there were more variations compared to the motion copying system. When extrapolation was far from the training data, the reproducibility was reduced, although the peak frequency tended to increase with an increase in the frequency command. It is worth noting that the operation at 2.08 Hz was achieved using a 2.69 Hz command, indicating that the operation was faster than the fastest training data at 1.83 Hz. Thus, the proposed method could not only change the operating frequency, but it could also perform the task faster than a human. Additionally, the control bandwidth of the robot was approximately 2.3 Hz, and it was very difficult to operate at frequencies beyond the control bandwidth. It is also worth noting that the proposed method can achieve behaviors close to such a limit even when using imitation learning, which has no explicit dynamic model. To the best of the authors’ knowledge, there is no other imitation learning that can operate at a frequency almost at the limit of the control bandwidth.
In general imitation learning, the objective is to reproduce the teacher data, thus, the evaluation is mostly based on the success rate of the task, and whether a specific physical quantity can be controlled is not the main issue. However, the proposed method not only imitates the motions but also has a frequency command, thus, the actual frequency can be compared with the frequency command during autonomous operation. Therefore, by labeling the actual frequency as a frequency command and storing it with the motion data, the autonomous motion data can be regarded as new teacher data. If online learning, such as Bayesian optimization, is applied to the new teacher data, the accuracy of motion generation can be further improved iteratively. In addition, although it is not the subject of this paper, it is expected that generalization performance against modeling errors of the robot’s parameters can also be treated as the perturbation of environments.
IV-E Untrained Object Demonstration
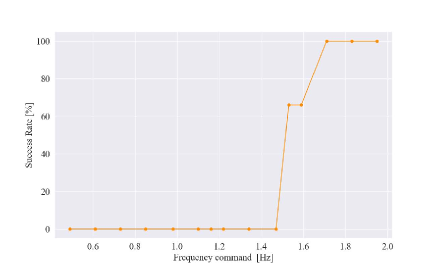
To further demonstrate the generalization performance of the proposed method, a task of slicing a cucumber was conducted using the same NN model and controller. No parameter was changed from the previous experiments. The height of the surface of the slicer was 5.6 cm from the desk surface. A cucumber was fixed at the tip of the robot, and the cucumber was sliced using a slicer. Fig. 19 shows a snapshot of the experiment. As shown in the figure, the robot continued to slice the cucumber. The success rates versus frequency commands are shown in Fig. 20. The evaluation was conducted using 15 frequency commands: 0.49, 0.61, 0.73, 0.85, 0.98, 1.10, 1.16, 1.22, 1.34, 1.47, 1.53, 1.59, 1.71, 1.83, and 1.95 Hz, and three trials were performed for each command. This result shows that fast motions were required to slice the cucumber because it was rigid and required a lot of force for slicing. In other words, the robot had to move quickly and exploit its own inertial force to slice them. In conventional force control theories, the inertial forces of robots are often treated as disturbances. However, using the proposed method, it was possible to realize motions that exploited inertial forces. Particularly, it is very effective to use the inertial force of a robot with a small maximum output torque, such as the robot used in this experiment. Additionally, to make the most effective use of the inertial force, a high-frequency motion is required for high acceleration. It would have been difficult to slice a cucumber without using our method, which can operate the robot to the limit of the control bandwidth.

V Conclusion
In this study, we proposed a method for generating variable-speed motion while adapting to perturbations in the environment. Given that there is a nonlinear relationship between the operating speed and frictional or inertial forces, the operating force changes with the work speed. Therefore, we confirmed that a variable-speed operation could not be achieved using simple interpolation and extrapolation. To solve this problem, we proposed a method to imitate human motion using four-channel bilateral control, a CNN, and an LSTM. Based on the experimental results, it was determined that the motion varied with the interpolation of the operating speed of the training data as well as the high speed of the extrapolation. Furthermore, the proposed method can complete a given task faster than a human operator and achieves operations close to the control bandwidth. The high generalization performance of the proposed method was confirmed by the fact that it was able to acquire the motion of slicing cucumbers from the teacher data of erasing lines with an eraser. In particular, the success rate of the task was highly dependent on the operating frequency because the cucumber slicing required the explicit use of inertia forces. The fact that we were able to achieve this operation shows the remarkable characteristics of the proposed method in being able to operate at high speed. In addition, imitation learning has been evaluated only for generalization performance over space in conventional methods, but this study has made it possible to discuss generalization performance over time. The approach of analyzing the behavior of the system according to the operating frequency is compatible with the design of ordinary control systems, and the development of a control system design theory that integrates imitation learning and control system design theory is expected.
Note that if the operation is periodic, such that the frequency can be measured in FFT, then this method should be applicable. In the future, we will demonstrate the practicality of the proposed method for other periodic motions. In addition, our another future goal is to improve the reproducibility of the frequency during extrapolation.
References
- [1] T. Zhang, M. Xiao, Y. Zou, and J. Xiao, “Robotic constant-force grinding control with a press-and-release model and model-based reinforcement learning,” CThe International Journal of Advanced Manufacturing Technology, vol. 106, pp. 589–602, 2020.
- [2] S. L. Chen Lu, Jing Wang, “Surface following using deep reinforcement learning and a gelsighttactile sensor,” arXiv:1912.00745, 2019.
- [3] X. Zhang, L. Sun, Z. Kuang, and M. Tomizuka, “Learning variable impedance control via inverse reinforcement learning for force-related tasks,” IEEE Robotics and Automation Letters, vol. 6, no. 2, pp. 2225–2232, 2021.
- [4] M. Oikawa, T. Kusakabe, K. Kutsuzawa, S. Sakaino, and T. Tsuji, “Reinforcement learning for robotic assembly using non-diagonal stiffness matrix,” IEEE Robotics and Automation Letters, vol. 6, no. 2, pp. 2737–2744, 2021.
- [5] T. Johannink, S. Bahl, A. Nair, J. Luo, A. Kumar, M. Loskyll, J. A. Ojea, E. Solowjow, and S. Levine, “Residual reinforcement learning for robot control,” in 2019 International Conference on Robotics and Automation (ICRA), pp. 6023–6029, 2019.
- [6] S. Calinon, F. Guenter, and A. Billard, “On learning, representing, and generalizing a task in a humanoid robot,” IEEE Transactions on Systems, Man, and Cybernetics, Part B: Cybernetics, vol. 37, no. 2, pp. 286–298, 2007.
- [7] M. Kyrarini, M. A. Haseeb, D. Ristic-Durrant, and A. G. P. Graeser, “Robot learning of industrial assembly task via human demonstrations,” Autonomous Robots, vol. 43, pp. 239–257, 2019.
- [8] P.-C. Yang, K. Sasaki, K. Suzuki, K. Kase, S. Sugano, and T. Ogata, “Repeatable folding task by humanoid robot worker using deep learning,” IEEE Robotics and Automation Letters, vol. 2, no. 2, pp. 397–403, 2016.
- [9] T. Zhang, Z. McCarthy, O. Jow, D. Lee, X. Chen, K. Goldberg, and P. Abbeel, “Deep imitation learning for complex manipulation tasks from virtual reality teleoperation,” in Proceedings of 2018 IEEE International Conference on Robotics and Automation (ICRA), pp. 5628–5635, 2018.
- [10] A. Gupta, V. Kumar, C. Lynch, S. Levine, and K. Hausman, “Relay policy learning: Solving long-horizon tasks via imitation and reinforcement learning,” arXiv:1910.11956, 2019.
- [11] J. Jiny, L. Petrichy, M. Dehghany, and M. Jagersand, “A geometric perspective on visual imitation learning,” in Proceedings of the INternational Conference on Intelligent Robots and Systems, pp. 5194–5200, 2020.
- [12] A. X. Lee, H. Lu, A. Gupta, S. Levine, and P. Abbeel, “Learning force-based manipulation of deformable objects from multiple demonstrations,” in 2015 IEEE International Conference on Robotics and Automation, pp. 177–184, 2015.
- [13] P. Kormushev, S. Calinon, and D. G. Caldwell, “Imitation learning of positional and force skills demonstrated via kinesthetic teaching and haptic input,” Advanced Robotics, vol. 25, no. 5, pp. 581–603, 2011.
- [14] H. Ochi, W. Wan, Y. Yang, N. Yamanobe, J. Pan, and K. Harada, “Deep learning scooping motion using bilateral teleoperations,” in Proceedings of 2018 3rd International Conference on Advanced Robotics and Mechatronics (ICARM), pp. 118–123, 2018.
- [15] L. Rozo, “Interactive trajectory adaptation through force-guided baysian optimization,” in Proceedings of 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), p. 7603, 2019.
- [16] T. Osa, N. Sugita, and M. Mitsuishi, “Online trajectory planning and force control for automation of surgical tasks,” IEEE Transactions on Automation Science and Engineering, vol. 15, no. 2, pp. 675–691, 2018.
- [17] A. A. Shahid, L. Roveda, D. Piga, and F. Braghin, “Learning continuous control actions for robotic grasping with reinforcement learning,” in Proceedings of 2020 IEEE International Conference on Systems, Man, and Cybernetics (SMC), pp. 4066–4072, 2020.
- [18] T. Tsuji, J. Ohkuma, and S. Sakaino, “Dynamic Object Manipulation Considering Contact Condition of Robot with Tool,” IEEE Transactions on Industrial Electronics, vol. 63, no. 3, pp. 1972–1980, 2016.
- [19] T. Adachi, K. Fujimoto, S. Sakaino, and T. Tsuji, “Imitation learning for object manipulation based on position/force information using bilateral control,” in Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems, pp. 3648–3653, 2018.
- [20] K. Fujimoto, S. Sakaino, and T. Tsuji, “Time series motion generation considering long short-term moiton,” in Proceedings of 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 6842–6848, 2019.
- [21] S. Sakaino, T. Sato, and K. Ohnishi, “Multi-dof micro macro bilateral controller using oblique coordinate control,” IEEE Transacsions on Industrial Informatics, vol. 7, pp. 446–454, July 2011.
- [22] S. Sakaino, T. Furuya, and T. Tsuji, “Bilateral control between electric and hydraulic actuators using linearization of hydraulic actuators,” IEEE Transactions on Industrial Electronics, 2017.
- [23] L. Rozo, P. Jimenez, and C. Torras, “A robot learning from demonstration framework to perform force-based manipulation tasks,” Intel Serv Robotics, vol. 6, pp. 33–51, 2013.
- [24] S. Sakaino, T. Sato, and K. Ohnishi, “A novel motion equation for general task description and analysis of mobile-hapto,” IEEE Transactions on Industrial Electronics, vol. 60, no. 7, pp. 2673–2680, 2013.
- [25] L. Rozo, D. Bruno, S. Calinon, and D. G. Caldwell, “Learning optimal controllers in human-robot cooperative transportation tasks with position and force constraints,” in Proceedings of IEEE/RSJ International Conference on Intelligent Robots and Systems, pp. 1024–1030, 2015.
- [26] A. Sasagawa, K. Fujimoto, S. Sakaino, and T. Tsuji, “Imitation learning based on bilateral control for human-robot cooperation,” IEEE Robotics and Automation Letters, vol. 5, no. 4, pp. 6169–6176, 2020.
- [27] A. Sasagawa, S. Sakaino, and T. Tsuji, “Motion generation using bilateral control-based imitation learning with autoregressive learning,” IEEE Access, vol. 9, pp. 20508–20520, 2021.
- [28] Y. Yokokura, S. Katsura, and K. Ohishi, “Motion copying system based on real-world haptics in variable speed,” in Proceedings of 2008 13th International Power Electronics and Motion Control Conference, pp. 1604–1609, 2008.
- [29] C. V. Perico, J. de Schutter, and E. Aertbeliën, “Learning robust manipulation tasks involving contact using trajectory parameterized probabilistic principal component analysis,” in Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 8336–8343, 2020.
- [30] J. Tani and M. Ito, “Self-organization of behavioral primitives as multiple attractor dynamics: A robot experiment,” IEEE Transactions on Systems, Man, and Cybernetics - Part A: Systems and Humans, vol. 33, no. 4, pp. 481–488, 2003.
- [31] M. Ruderman and M. Iwasaki, “Sensorless torsion control of elastic-joint robots with hysteresis and friction,” IEEE Transactions on Industrial Electronics, vol. 63, no. 3, pp. 1889–1899, 2016.
- [32] L. Mostefai, M. Denaï, and Y. Hori, “Robust tracking controller design with uncertain friction compensation based on a local modeling approach,” IEEE/ASME Transactions on Mechatronics, vol. 15, no. 5, pp. 746–756, 2010.
- [33] T. Yamazaki, S. Sakaino, and T. Tsuji, “Estimation and kinetic modeling of human arm using wearable robot arm,,” Electrical Enginnering in Japan, vol. 199, no. 3, pp. 57–67, 2017.
- [34] T. Murakami, F. Yu, and K. Ohnishi, “Torque sensorless control in multidegree-of-freedom manipulator,” IEEE Transactions on Industrial Electronics, vol. 40, no. 2, pp. 259–265, 1993.
- [35] K. Ohnishi, M. Shibata, and T. Murakami, “Motion control for advanced mechatronics,” IEEE/ASME Transactions on Mechatronics, vol. 1, no. 1, pp. 56–67, 1996.
- [36] J. Li, Y. Guan, H. Chen, B. Wang, T. Zhang, X. Liu, J. Hong, D. Wang, and H. Zhang, “A high-bandwidth end-effector with active force control for robotic polishing,” IEEE Access, vol. 8, pp. 169122–169135, 2020.
- [37] W.-L. Li, H. Xie, G. Zhang, S.-J. Yan, and Z.-P. Yin, “Hand–eye calibration in visually-guided robot grinding,” IEEE Transactions on Cybernetics, vol. 46, no. 11, pp. 2634–2642, 2016.
- [38] A. C. Dometios, Y. Zhou, X. S. Papageorgiou, C. S. Tzafestas, and T. Asfour, “Vision-based online adaptation of motion primitives to dynamic surfaces: Application to an interactive robotic wiping task,” IEEE Robotics and Automation Letters, vol. 3, no. 3, pp. 1410–1417, 2018.
- [39] R. Rahmatizadeh, P. Abolghasemi, A. Behal, and L. Bölöni, “From virtual demonstration to real-world manipulation using lstm and mdn,” Proceedings of the AAAI Conference on Artificial Intelligence, vol. 32, no. 1, 2018.
- [40] M. Sundermeyer, H. Ney, and R. Schluter, “From feedforward to recurrent lstm neural networks for language modeling,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 23, no. 3, pp. 517–529, 2015.
- [41] Y. Zhang, G. Chen, D. Yu, K. Yaco, S. Khudanpur, and J. Glass, “Highway long short-term memory rnns for distant speech recognition,” in Proceedings of 2016 IEEE International Conference on Acoustics, Speech and Signal Processing, pp. 5755–5759, 2016.
- [42] Z. Zhang, L. Zheng, J. Yu, Y. Li, and Z. Yu, “Three recurrent neural networks and three numerical methods for solving a repetitive motion planning scheme of redundant robot manipulators,” IEEE/ASME Transactions on Mechatronics, vol. 22, no. 3, pp. 1423–1434, 2017.
- [43] S. Hochreiter and J. Schmidhuber, “Long short-term memory,” Neural Computation, vol. 9, no. 8, pp. 1735–1780, 1997.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/ad9ec15a-d296-49b3-86fe-f66964dcc002/x21.png) |
Sho Sakaino Sho Sakaino received the B.E. degree in system design engineering and the M.E. and Ph.D. degrees in integrated design engineering from Keio University, Yokohama, Japan, in 2006, 2008, and 2011, respectively. He was an assistant professor at Saitama University from 2011 to 2019. Since 2019, he has been an associate professor at University of Tsukuba. His research interests include mechatronics, motion control, robotics, and haptics. He received the IEEJ Industry Application Society Distinguished Transaction Paper Award in 2011 and 2020. He also received the RSJ Advanced Robotics Excellent Paper Award in 2020. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/ad9ec15a-d296-49b3-86fe-f66964dcc002/x22.png) |
Kazuki Fujimoto received the B.E. and M.E. degrees in electrical and electronic system engineering from Saitama University, Saitama, Japan, in 2018 and 2020, respectively. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/ad9ec15a-d296-49b3-86fe-f66964dcc002/x23.png) |
Yuki Saigusa received the B.E. degree in electrical and electronic system engineering from Saitama University, Saitama, Japan, in 2020. He is currently working toward M.E. degrees in the Graduate School of Science and Technology, and degree programs in intelligent and mechanical interaction systems at University of Tsukuba, Japan. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/ad9ec15a-d296-49b3-86fe-f66964dcc002/x24.png) |
Toshiaki Tsuji received the B.E. degree in system design engineering and the M.E. and Ph.D. degrees in integrated design engineering from Keio University, Yokohama, Japan, in 2001, 2003, and 2006, respectively. He was a Research Associate in the Department of Mechanical Engineering, Tokyo University of Science, from 2006 to 2007. He is currently an Associate Professor in the Department of Electrical and Electronic Systems, Saitama University, Saitama, Japan. His research interests include motion control, haptics, and rehabilitation robots. Dr. Tsuji received the FANUC FA and Robot Foundation Original Paper Award in 2007 and 2008. He also received the RSJ Advanced Robotics Excellent Paper Award and the IEEJ Industry Application Society Distinguished Transaction Paper Award in 2020. |