Improve Variational AutoEncoder with
Auxiliary SOFTMAX MultiClassifier
Abstract
As a general-purpose generative model architecture, VAE has been widely used in the field of image and natural language processing. VAE maps high dimensional sample data into continuous latent variables with unsupervised learning. Sampling in the latent variable space of the feature, VAE can construct new image or text data. As a general-purpose generation model, the vanilla VAE can not fit well with various data sets and networks with different structures. Because of the need to balance the accuracy of reconstruction and the convenience of latent variable sampling in the training process, VAE often has problems known as “posterior collapse”, and images reconstructed by VAE are also often blurred. In this paper, we analyze the main cause of these problem, which is the lack of control over mutual information between the sample variable and the latent feature variable during the training process. To maintain mutual information in model training, we propose to use the auxiliary softmax multi-classification network structure to improve the training effect of VAE, named VAE-AS. We use MNIST and Omniglot data sets to test the VAE-AS model. Based on the test results, It can be show that VAE-AS has obvious effects on the mutual information adjusting and solving the posterior collapse problem.
1 INTRODUCTION
In recent years, generative model has played an important role in the field of machine learning such as natural language processing (NLP) and image processing. Compared with supervised learning for pattern recognition and classification, Unsupervised and semi-supervised generation model is used more for image synthesis, automatic text response, etc. Variational Autoencoder (VAE) (Kingma & Welling, 2013) is a typical generator model, which encodes the observed samples by an encoder, then restore the observation sample through a decoder. VAE’s feature space has good properties, compared with observed variables, the compressed latent variables encoding has the effect of dimensionality reduction and noise immunity. Latent variables capture and summarize the feature of the information better. At the same time, VAE can also generate new images or text by sampling in latent variable space and restoring by the decoder. VAE provides a good, scalable computing framework for tasks such as migration learning and more.
In the variational processing of VAE, in order to solve the problem that the posterior distribution is unintegrable, an approximation method of variational inference is used to calculate. VAE suppose a simple prior distribution of latent variables, and use KL-Divergence to compare the difference between the posterior and the prior distribution of the latent variable. For machine learning, the requirement for prior distribution can be seen as a regular term, which plays a role in simplifying calculations and optimizing the coding space. There are two contradictory aspects in VAE’s learning goals. On the one hand, we require that the code generated by the encoder can objectively and truly reflect the distribution of actual data. On the other hand, we also require the distribution of the code to be as simple as possible so that we can easily generate new samples. (Bowman et al., 2015; Chen et al., 2016) mentions the problem of the posterior latent variable collapse in VAE. The decoder tends to ignore the latent variable and generate directly. As mentioned in (Dosovitskiy & Brox, 2016), VAE tends to produce blurred images when using complex natural image datasets.
Now, the methods for solving these problems mainly include three types. The first method is to cancel hypothesis of the simple normal prior distribution in VAE and instead use a more complex and accurate distribution to describe the latent code distribution. When we know more about the actual data distribution, we can use a more explicit prior distribution, such as (Xu & Durrett, 2018) using the Mises-Fisher distribution instead of the standard normal prior distribution. The MCMC method is more accurate than variational inference but requires multiple iterations, how to combine the advantages of both and apply it to machine learning is proposed as a topic (Salimans et al., 2015; Hoffman, 2017). The second type of approach is to start with the training process of the model. In the early stages of model training, the encoder could not establish the association between the latend variable and the observed variable , this led to the occurrence of posterior latent variable collapse. In these papers (Sønderby et al., 2016; Higgins et al., 2017; Burgess et al., 2018), the weight coefficient is added before the KL-Divergence term of VAE loss function, and an annealing mechanism is used to make the KL-Divergence play a small role at the beginning. When the encoder establishes an association between and , it gradually increases the alignment requirements between the approximate posterior and the prior distribution. (He et al., 2019) changes the way VAE trains encoder and decoder at the same time, use sequence training to update the decoder and encoder parameters. The third method is to use the compensation mechanism in the original optimization goal of VAE. (Zhao et al., 2017a; Dieng et al., 2018; Ma et al., 2019) added a regular term of the mutual information to the loss function of VAE. This method is highly targeted, but the mutual information is difficult to calculate and generally depends on Monte Carlo sampling for estimation. (Tolstikhin et al., 2017; Zhao et al., 2017a) used the NMD-based penalty to calculate the difference between the two distributions. (Dieng et al., 2018) proposes a method based on skip model to optimize mutual information. (Ma et al., 2019) estimates mutual information based on the mutual KL-Divergence divergence(MPD).
In this article, (1) Based on the calculation process of VAE, we analyzed the causes of encode collapse and blurry problem in detail. (2) In the framework of vanilla VAE, we propose a novel method to estimate the mutual information and the marginal KL-Divergence by the auxiliary softmax MultiClassifier, noted as VAE-AS. (3) we test the validity of VAE-AS using MNIST and Omniglot data sets, and evaluate the quality of hidden variable space from various aspects.
2 Background
2.1 VAE
Modeling the joint distribution of the latent variable and the observed variable , VAE calculates the margin distribution of . Consider the sample data set consisting of i.i.d. samples. Introduce the latent variable , the joint distribution of and is . The true distribution of can be obtained by computing the margin distribution . However, this integral is often intractable, so VAE uses the approximate distribution to solve the problem by variational inference.
The margin likelihood function can be written as the sum of the likelihood function for each sample point, . Combin with Jensen Inequality, for each sample ,
| (1) |
where, joint distribution is , the evidence lower bound can be written as
| (2) |
It can be seen from the equation 2 that the loss function of VAE consists of two parts. One part of the loss is the observation reconstruction error, and the other part is the difference between the posterior distribution and the prior distribution .
The prior distribution of the latent variable chosen by VAE is denoted as , General assumption is a multidimensional standard normal distribution to facilitate sampling of the model. The complete calculation of VAE includes two processes of encoding and decoding. During the encoding process, the encoder training fit a conditional posterior distribution of after is observed, noted as . We use KL-Divergence to evaluate the similarity of a prior and conditional posterior distributions of latent variable. That is, the posterior distribution generated by the encoder is required to be as close as possible to a standard normal distribution. The decoding process is to sample from the prior distribution, then use the decoder to generate a refactoring . Compare the difference between and as a loss function, calculating the gradient to update parameters .
The calculation of in VAE depends on sampling. Specifically, for each sample , VAE encoder fits the variables and , it is used to define the posterior distribution of the latent variable . Then VAE completes samples and calculates
In order to ensure the continuity of the loss calculation, enable the inverse gradient descent training process. VAE uses the technique of reparameterization during the sampling process. First sample the random variable from , then let .
2.2 Disadvantages of VAE
For VAE, the latent variable space needs to have sufficient feature coding ability to express complex real distributions. The sample space is often discrete, but the encoder needs to smooth and fill the missing parts between discrete samples to generate new pictures or text. At the same time, the coding space must be conducive to sampling and likelihood calculations, which requires that the prior distribution is simple.
The VAE encoder encodes each discrete sample of into a continuous latent random variable . It can be seen that is mapped to a continuous area of distribution defined by . Intuitively, in the calculation of the equation equation 2, VAE hopes that the difference between the distribution of generated by each encoding is large to reduce the error of reconstruction. But minimizing the KL-Divergence term pushes to a uniform standard normal distribution. These two optimization directions are contradictory, When VAE tries to reduce the reconstruction error, it is bound to increase the difference of the code distribution , then KL-Divergence will increase. When the reduced reconstruction error is smaller than the increased KL-Divergence, VAE directly reduces the KL-Divergence without the error reduction.
Design an experiment, when feeding a completely random set of images to VAE for learning, we will find that the KL-Divergence will soon tend to . Because the image does not contain any rules, the VAE reconstruction error is optimized so small that it does not start at all.
There are two cases of coding collapse. One is that in the early stage of model training, because the parameters optimization of the decoder have not been completed or because the randomness of the training samples is too strong, strong KL-Divergence constraints will result in a high optimization constraint threshold, models are easier to optimize only KL-Divergence. In a more general view, the text (He et al., 2019) rewrites the ELBO to
The first term in R.H.S can be seen as the maximum log likelihood of the decoder’s distribution. The KL-Divergence of the second term characterizes the degree of similarity between and . When the VAE is trained in the beginning, the encoder is not perfect, the correlation between and is not strong and can be regarded as an independent variable. When is simple, minimizing the KL-Divergence requires to be directly locked to , which is, is independent with , , similarly , item disappears on this element.
Another type of collapse is due to the lack of correlation in the model encoding, or the need of correlation for reconstruction is small, it also causes the fact that the feature space dimension exceeds the active number of latent variable. Image and language coding often have autocorrelation, such as the value of a pixel in an image and the value of surrounding pixels. In the case of a strong decoder, using the autocorrelation information, can be recovered without , As can be seen from the Table 1, with the increase of layers of Decoder network, the decoding ability of decoder is continuously enhanced. Encoder constructs according to , The number of dimensions with larger variances of continues to decline. This shows that the higher the complexity of the Decoder, then the less information is used in the information contained in .
| ecoder Layers | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| 23 | 21 | 17 | 12 | 8 |
From the above, in order to prevent the posterior collapse, we need to increase the correlation between and in the joint distribution to prevent independent of and . The correlation in the joint distribution is mainly controlled by mutual information. The problem of blurred images is also related to mutual information. Mentioned in the article (Zhao et al., 2017b), the optimal solution to reconstruction loss of decoder for a given is . That is to say, the reconstructed image of VAE is the expectation of a set of images, which is related to the smoothness of the latent variable distribution. The mutual information is directly related to the entropy of . We prefer to think the blurry as a trade-off rather than a problem. In the article (Shwartz-Ziv & Tishby, 2017; Alemi et al., 2016) on information bottlenecks, the neuron network will have a decrease in mutual information in the later stage of optimization training. It is actually an optimization that reduces overfitting. when the mutual information is reduced, the smoothness of the model is higher, and the anti-noise and fitting between samples is better. As the mutual information increases, the error of model reconstruction will be smaller, but the generalization performance of the model will be worse. Therefore, for mutual information, what we need more is to better control according to the model task, rather than simply increasing or decreasing.
3 Method
3.1 Mutual Information
According to (Hoffman & Johnson, 2016; Dieng et al., 2018), the KL-Divergence term in the ELBO of the VAE can be expressed as (See the appendix for details).
where is the mutual information between and , measure the correlation between and . And is the KL-Divergence between code marginal distribution and prior distribution .
In order to control the mutual information and the marginal KL-Divergence more precisely, rewrite the ELBO:
| (3) |
Where and are Lagrange multiplier, By adjusting , , we can adjust the performance of VAE-AS to meet different optimization requirements.
The calculation of mutual information and marginal KL-Divergence involves solving the margin distributions of . For research objects such as images and texts, the dimensions are often large and the probability of the samples are both small. Select sample each time, the distribution of the sample can be considered as a discrete Categorical distribution , where . We note this category distribution as . Since , the empirical distribution can be derived as . is called aggregated posterior distribution (Makhzani et al., 2015), which is difficult to obtain analytical solutions. Sampling to calculate the estimate of mutual information and marginal KL-Divergence is generally (Hoffman & Johnson, 2016; Dieng et al., 2018).
We explore mutual information from the perspective of empirical distribution. According to the definition of mutual information, the mutual information can be rewritten as:
| (4) |
For the integral term in the form equation 4, since . we can select sample to approximate in each training batch, . But unfortunately, this method of estimation is biased, we will use another method to calculate mutual information.
3.2 MINE
Theorem 3.1 (Donsker-Varadhan representation).
The KL divergence between any two distributions and , with , admits the following dual representation (Donsker & Varadhan, 1983)
| (5) |
where the supremum is taken over all functions such that the two expectations are finite.
From Theorem 3.1, MINE (Belghazi et al., 2018) has been proposed as a method for estimating mutual information using a neural network. If are the density functions of respectively, given any subclass of such functions, then have
| (6) |
where can be fitted with a neuron network parameterized . The expectations in the above lower-bound can then be estimated by Monte-carlo sampling. After sampling, we can get
| (7) |
then we obtain the Mutual Information Neural Estimator (MINE):
| (8) |
3.3 Auxiliary SOFTMAX multiclassifier
In this paper, we add an auxiliary softmax multi-classifier based on VAE to solve the mutual information , which is called VAE-AS. For mutual information, we can write
| (9) |
In order to calculate the mutual information, we need to solve and the entropy of . According to Bayes’ theorem, , and , , we know,
| (10) |
As can be seen from the discussion in the previous section, it is still difficult to directly calculate equation 10. We use the auxiliary softmax multi-classifier to fit . First number each sample, let . Equivalent to determining a label for each sample , Where is the one-hot variable with a 1 at position . i.e.
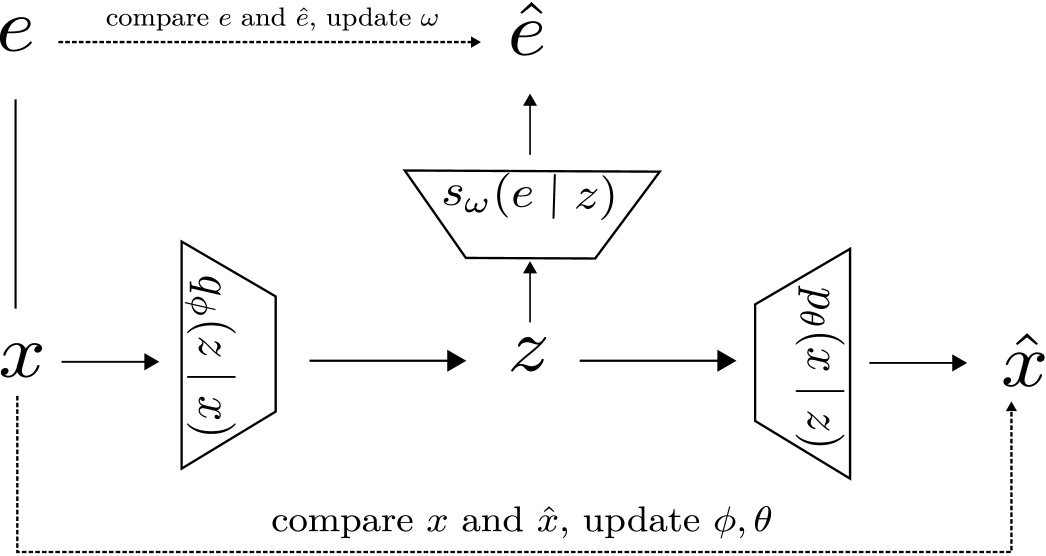
Based on the structure of VAE, we add a multi layer neural network to fit the distribution . The network is trained in a supervised manner, we use the one-hot variable as label, the activation function of the network is the softmax function.
For each sampled , after a multi-layered neuron network transformation, let , , where is activation function, such as or . The output , where is dimensions vector, The element of is . The auxiliary softmax multi-classifier can be written as:
| (11) |
Since the serial number can be seen as a random tag allocated for each sample , The loss function is the cross entropy of the softmax function, i.e.
| (12) |
Minimizing the cross entropy loss function, We hope will gradually converge to . After completing the fitting of the distribution , we can calculate the entropy .
| (13) |
then we can calculate the mutual information with equation 9.
For Calculating , we need calculate , and then estimate with Monte Carlo Sampling. After using the auxiliary softmax to estimate , we can estimate by Bayesian formula.
| (14) |
After estimating the mutual information and the marginal divergence we can calculate ELBO as equation 3.
3.4 VAE-AS and MINE
Theorem 3.2.
VAE-AS and MINE are equivalent in the optimization goal and estimation of mutual information.
Proof.
Step 1: prove that VAE’s optimization goal is equivalent to MINE’s optimization goal. The output variable of classifier is dimensions vector. its component corresponds to the observation vector , can be thought as a function of and , , then from equation 12 the optimization goal can be written:
Decomposing the log function and adding the constant does not affect optimization, the optimization goal is equivalent to
Since sample from , the first term will converge to . For the second term, about , we need to calculate for each , so is independent of , the second term will converge to .
Step 2: When , can be seen as fit of . From equation 9,
where the first item will converge to , the rest is converged to .
∎
3.5 VAE-AS optimization
Calculating mutual information by the formula equation 13 requires traversal of all samples, which is computationally burdensome. The following proposition will give an approximate estimate.
Theorem 3.3.
For each , Note the probability of multi-classifier prediction error as , let . For VAE-AS, let
be an estimate of . There is
.
Proof.
According to the network structure, constitutes a Markov chain. From Fano’s Inequality we know, for each ,
where,
. From equation 9 we can get,
∎
Intuitively, Theorem prop-1 simplifies the entropy calculation in a Multinomial distribution by using the part of the error probability as a whole. Therefore, a bias of will be generated. With optimization, the predicted error rate will gradually decrease, The gap between and will be gradually reduced to .
When the sample size is large, the cost of softmax multi-classification calculation is large. needs to calculate the sum of all categories probability, i.e. the normalized part of the denominator of the softmax function. To reduce the computational load of the softmax function, similar to the Huffman tree method used in (Morin & Bengio, 2005), we uses bianry tree.
For each we define tags , is one-hot random vector, w.r.t. sampling , the output vector of classifier network is . Construct a layers binary tree, each leaf node, representing a component of the one-hot vector, every two child node has one parent node, finally shrink to the root node. Each layer before the leaf node is noted as , let , where is parameter matrix. The vector length is increased layer by layer, with up to nodes per layer. It can be seen that for samples, . Except for leaf nodes, each node component has one left and one right child nodes (edge nodes maybe has one child). The path from the parent node to the child node is denoted as , and when , the node select the path to left child, select right child when .
using the sigmoid activation function to calculate the probability of two paths.
correspondingly we know . For an one-hot vector , there is a unique path on the binary tree pointing to its corresponding leaf node. The node through which the path passes is , The path of the selected child node for each node is . Then the fit probability of the classifier is
where is or . Compare and to construct the loss function, the parameters in the binary tree are optimized to fit the softmax function.
Using the softmax function approximation, the computational complexity is , where is the classifier output feature number. Based on multidimensional binary labels, the computational complexity is optimized to .
In the structure of VAE, when the distributions mapped by one sample and another sample are far away in the latent variable space, i.e. and are quite different, Even if the identity of the two is same, it will not affect the system’s fit of . In other words, the number of label categories we randomly select for the sample can be smaller than the actual number of samples. If we select the number of tag categories as , refer to the entropy for equation 13, The maximum entropy of the fitted distribution is , which is the case where the fitting distribution is completely indistinguishable from the uniform probability value of . From (see Appendix for details), The maximum value of the mutual information and the maximum value of is same, i.e. . The maximum mutual information that we can provide by using the tag category through the auxiliary softmax multi-classifier is . Since the log function grows very slowly, selecting categories smaller than will not affect the VAE-AS’s mutual information so much.
4 Related Work
The method for reducing the collapse of latent variables given in (Dieng et al., 2018) is also developed around adding the model’s mutual information . The method is divided into two steps, First, the Skip Network is used to make the latent variables participate in the calculation of each hidden layer output of the subsequent decoder. Then the author also adds constraints of mutual information in the loss function. The author discusses that the mutual information of Skip Network is greater than the mutual information of VAE, i.e.
The text (Ma et al., 2019) optimizes the learning of the feature layer by adding regularization regular terms to the ELBO of the variation. The author proposed mutual KL-Divergence between a pair of data to measure the diversity of posteriors.
In addition to optimizing the ELBO of the VAE, the optimization goal also requires maximizing . In the article (Ma et al., 2019), the author gives the proof. The mutual posterior diversity (MPD) is actually a symmetric version of the mutual information . Therefore, the method of (Ma et al., 2019) is the same as (Dieng et al., 2018), both of them add regular items of mutual information based on VAE to improve the optimization effect.
(Tolstikhin et al., 2017; Zhao et al., 2017a) mentions the use of Maximum Mean Discrepancy (MMD) to estimate the distance between distributions and , the focus remains on the estimate of . MMD uses a kernel function to estimate the distance between different sample points, which is similar in form to the softmax’s solution.
All of the above methods require the calculation of in the training batch. If the batch_size of the training batch is too small, the estimated bias of the mutual information will be larger. When the number of batches is large, such as estimating the distribution difference by MMD, if all samples are used as batch calculations, The calculation of the kernel function is required, and the cost of the calculation is relatively large.
In this paper, VAE-AS removes the batch constraints by constructing a softmax classification network, and uses the parameters of the classification network to save the differences between different sample codes. Through the calculation of Hierarchical Softmax, we can effectively reduce the number of complex exponential operations.
5 Empirical Results
5.1 Dataset
To test the actual effect of VAE-AS, we selected two reference data sets of image, MNIST (LeCun et al., 1998) and Omniglot (Lake et al., 2013; Burda et al., 2015). The MNIST data set includes 70,000 binary black and white handwritten digital images, for MNIST, 55,000 for training and 10,000 for testing. The Omniglot data set contains different handwritten characters from 50 different alphabets. The training set has samples, and test set has samples. Each characters was drawn online by different people. The image size of both data sets is
5.2 Estimate Mutual Information and Marginal Divergence
Firstly, we use of VAE-AS to estimate mutual information and marginal divergence . For the dataset MNIST (LeCun et al., 1998), Construct encoders, decoders and classifiers using MLP, the number of layers is , , , the number of hidden layers is chosen to be , the dimension of is set to , the mini-batches is set to and the iteration epochs is set to .
From the model, for each sample , and is generated, Using Monte Carlo method to estimate and , the method is same as (Hoffman & Johnson, 2016). Set sample number of Monte Carlo to , sampling to estimate mutual information and marginal divergence.
Set the number of softmax labels to the full sample size of training set of MNIST , using VAE-AS to estimate mutual information and marginal divergence . The test is notted as . To compare the results, we set the number of softmax labels to , performe a comparision test . The test results are shown in Figure 2:
From the Figure 2 we can see, for the Monte Carlo method, as the number of samples drops, whether the mutual information or marginal divergence , will produce large bias. And in the case of a small sample, there are a lot of fluctuations in the curve, which shows that Monte Carlo method will introduce a large variance due to sampling. Generally limited by computing resources, we can’t choose too much for mini-batch size during training. Using VAE-AS to fit , then estimate mutual information and marginal divergence . The estimated results are close to the large sample size Monte Carlo method. Since VAE-AS only needs a large vocabulary, the dimension of the classification label is small, the demand for computation space can generally be satisfied.
The third figure depicts the sum of mutual information and marginal divergence , compare with KL-Divergence . It can be seen that the sum of mutual information and marginal divergence has a good convergence to the mean of KL-Divergence, where SC is softmax cross-entropy.
5.3 Results
We tested the results of different parameters and on VAE-AS optimization. The encoder inference network , the decoder generation network and the classifier network are both constructed using multiple hidden layer neural networks MLP, the number of layers is , , . The number of hidden layers is chosen to be . the dimension of is set to , the mini-batches is set to and iteration epochs is set to . No other regular constraints are set.
In the test metrics, NLLtest is a non-negative likelihood based on the test set evaluation. Using the method described in (Burda et al., 2015), the number of samples is . KLtest is the KL-Divergence based on the test set. AU is the number of active units of the latent variable , for this indicator we use the definition in (Burda et al., 2015):
Where is the indicator function, is the dimension of the latent variable , is the element of , is the judgment threshold and is set to . NNLtrain, KLtrain is the reconstruction error and KL-Divergence based on the training set. MI is mutual information , MD is marginal divergence , estimated by VAE-AS during training. SC is softmax cross-entropy.
| Method | NNLtest | KLtest | AU | NNLtrain | KLtrain | MI | MD | SC | ||
| VAE | - | - | 100.99 | 18.39 | 8 | 73.45 | 18.57 | - | - | - |
| VAE-AS | 1.0 | 1.0 | 96.32 | 21.84 | 11 | 71.66 | 21.22 | 10.78 | 10.66 | 0.35 |
| VAE-AS | 1.0 | 0.1 | 116.61 | 64.70 | 36 | 58.39 | 65.70 | 10.86 | 54.89 | 0.11 |
| VAE-AS | 1.0 | 0.2 | 106.92 | 46.99 | 25 | 61.16 | 45.14 | 10.87 | 34.35 | 0.12 |
| VAE-AS | 1.0 | 0.5 | 96.63 | 29.52 | 18 | 65.64 | 29.40 | 10.83 | 18.71 | 0.22 |
| VAE-AS | 1.0 | 2.0 | 101.34 | 15.68 | 7 | 81.61 | 15.87 | 10.58 | 5.78 | 0.82 |
| VAE-AS | 1.0 | 5.0 | 141.38 | 5.35 | 2 | 145.04 | 5.56 | 3.34 | 2.27 | 7.62 |
| VAE-AS | 0.1 | 1.0 | 97.22 | 21.53 | 11 | 72.13 | 21.22 | 10.80 | 10.63 | 0.31 |
| VAE-AS | 0.2 | 1.0 | 97.51 | 21.23 | 10 | 71.84 | 20.92 | 10.81 | 10.32 | 0.31 |
| VAE-AS | 0.5 | 1.0 | 98.23 | 21.57 | 10 | 72.23 | 20.91 | 10.80 | 10.32 | 0.33 |
| VAE-AS | 2.0 | 1.0 | 96.56 | 21.13 | 11 | 71.85 | 20.99 | 10.75 | 10.48 | 0.41 |
| VAE-AS | 5.0 | 1.0 | 97.33 | 20.38 | 10 | 75.94 | 19.79 | 10.44 | 9.80 | 0.93 |
| VAE-AS | 10.0 | 1.0 | 104.69 | 21.84 | 10 | 93.05 | 20.28 | 9.00 | 12.60 | 3.23 |
The test results are shown in the Table 2. The test is divided into two phases. We fixed and tested the effect of adjustment on model training and testing. In the second phase, fix , test the effect of the change of .
In VAE, the marginal divergence controls the overall shape of the latent variable distribution. The larger , the more scattered the latent variable distribution of , i.e. the larger the variance of the latent variable distribution, more conducive to the training of the model. From Table 2 we can see, if the mutual information is close, Increasing is more advantageous for optimizing the reconstruction error. But if the difference between the encoder marginal distribution and the prior distribution is far away, Sampling and Calculating based prior distribution is poor quality.
When is fixed to , it can be seen from the Table 2 that the change in affects the performance of the model generalization. As can be seen from the equation 9, the size of the mutual information depends on entropy , and depends on degree of overlap between two encoding conditional distribution and . The overlap is more directly related to the variance of the encoder output . The smaller the , the smaller the degree of overlap, the greater the mutual information. So in the Table 2, if is close. The larger the mutual information , the smaller the reconstruction error of the training. But the decrease in training error caused by the increase of is only for one single sample. Then it can’t be reproduced on the test set, which is actually a case of overfitting. If is small, The model is more inclined to remember the appearance of each training sample than to observe the common law in the sample. This is due to small overlap of the latent variable distribution caused by mutual information is large, the decoder can not abstract and summarize the rules. According to the information bottleneck theory (Alemi et al., 2016), we should minimize the mutual information to optimize model generalization while achieving the optimization goal. However, the larger value, the mutual information included in the latent variable space is smaller, and the number of active encodings is smaller, the problem of posterior collapse is more likely to occur. This is because the strong mutual information constraint limits the optimization threshold of the encoder.






The effect of on the model can also be seen in the Figure 4. The smaller has less restriction on mutual information, for training set samples, the model tends to reconstruct more accurate images. Compared with the original image (e), the training reconstruction errors of and are both small, but the graph (d) shows more subtle differences in handwritten fonts than in graph (f). But obviously it will cause more test error, so the clarity of Figure (a) is higher than that of Figure (c), but there are some obvious errors. This is because when the mutual information is large, the generated by different sample codes overlaps very little, and the model tends to restore the closest sample in the training set. The reconstruction details that can be expressed in the training set are not reproducible in the test set, which is obviously an over-fitting situation. Thus, a smaller value will result in a sharper picture, avoiding the problem of the VAE model blurry. However, it will result in poor generalization performance of the model. This can be seen as a trade-off. If the continuity of ground-truth distribution is poor, then the model should choose a smaller to get more mutual information in the latent variable space. If the continuity of ground-truth distribution is better, or if we need to interpolate in the discrete sampling training set, then we need mutual information to be given more restrictions.
In the training process of VAE-AS, the values of and have mutual influence. As can be seen from the Table 2, if , The constraint requires that the latent variable distribution is closer to , which is generally a standard normal distribution. Often the overall shape of the data distribution will be more concentrated. Then the overlap of latent variable distribution is increased due to the extrusion of the latent variable space, mutual information is thus reduced. With the decline of mutual information, the accuracy of decoder reconstruction will also decrease. And with decrease of , the contraint of marginal divergence is gradually relaxed. The distribution of is more likely to be optimized according to the decoder’s requirement to reduce the reconstruction error. There will also be an increase in mutual information in the training.
In the Table 2, when is in the range of values from to , due to the constraint of mutual information upper bound, the change of mutual information is small. When the is small, although the mutual information is already close to the upper limit bound , But because the constraints are looser, encoder easily reduces the output variance . VAE-AS can maintain mutual information while reducing marginal divergence. However, VAE-AS needs to be optimized for training in a smaller encoding space, so the training will be more difficult and the number of iterations of training will be more.
From the test results, we can see that the marginal KL-Divergence controls the overall distribution shape of the code distribution, which determines the upper limit precision that the model can achieve. Mutual information determines the degree of overlap between different latent variable, or the degree of smoothness of distribution between latent variable, to a certain extent it controls the degree of overfitting.
6 Conclusion
This paper analyzes the reasons why VAE has a posterior collapse problem during training in detail. A method of randomly assigning labels to samples and identifying labels by auxiliary softmax multi-classifiers is proposed to control mutual information of models.
Compared with image processing, posterior collapse is more likely to appear in the field of natural language process. In NLP processing, decoding networks such as RNN are more widely used. Therefore we will further test the effect of VAE-AS on NLP and RNN. VAE-AS is able to accurately estimate mutual information and marginal divergence in training batches, this facilitates many other machine learning tasks. The information bottleneck theory discusses in detail the optimization process of mutual information. VAE is often used for disentanglement, which requires fine control of mutual information. Subsequent we will use VAE-AS to conduct further research in these areas.
References
- Alemi et al. (2016) Alexander A Alemi, Ian Fischer, Joshua V Dillon, and Kevin Murphy. Deep variational information bottleneck. arXiv preprint arXiv:1612.00410, 2016.
- Belghazi et al. (2018) Mohamed Ishmael Belghazi, Aristide Baratin, Sai Rajeshwar, Sherjil Ozair, Yoshua Bengio, Devon Hjelm, and Aaron Courville. Mutual information neural estimation. In International Conference on Machine Learning, pp. 530–539, 2018.
- Bowman et al. (2015) Samuel R Bowman, Luke Vilnis, Oriol Vinyals, Andrew M Dai, Rafal Jozefowicz, and Samy Bengio. Generating sentences from a continuous space. arXiv preprint arXiv:1511.06349, 2015.
- Burda et al. (2015) Yuri Burda, Roger Grosse, and Ruslan Salakhutdinov. Importance weighted autoencoders. arXiv preprint arXiv:1509.00519, 2015.
- Burgess et al. (2018) Christopher P Burgess, Irina Higgins, Arka Pal, Loic Matthey, Nick Watters, Guillaume Desjardins, and Alexander Lerchner. Understanding disentangling in -vae. arXiv preprint arXiv:1804.03599, 2018.
- Chen et al. (2016) Xi Chen, Diederik P Kingma, Tim Salimans, Yan Duan, Prafulla Dhariwal, John Schulman, Ilya Sutskever, and Pieter Abbeel. Variational lossy autoencoder. arXiv preprint arXiv:1611.02731, 2016.
- Dieng et al. (2018) Adji B Dieng, Yoon Kim, Alexander M Rush, and David M Blei. Avoiding latent variable collapse with generative skip models. arXiv preprint arXiv:1807.04863, 2018.
- Donsker & Varadhan (1983) Monroe D Donsker and SR Srinivasa Varadhan. Asymptotic evaluation of certain markov process expectations for large time. iv. Communications on Pure and Applied Mathematics, 36(2):183–212, 1983.
- Dosovitskiy & Brox (2016) Alexey Dosovitskiy and Thomas Brox. Generating images with perceptual similarity metrics based on deep networks. In Advances in neural information processing systems, pp. 658–666, 2016.
- He et al. (2019) Junxian He, Daniel Spokoyny, Graham Neubig, and Taylor Berg-Kirkpatrick. Lagging inference networks and posterior collapse in variational autoencoders. arXiv preprint arXiv:1901.05534, 2019.
- Higgins et al. (2017) Irina Higgins, Loic Matthey, Arka Pal, Christopher Burgess, Xavier Glorot, Matthew Botvinick, Shakir Mohamed, and Alexander Lerchner. -vae: Learning basic visual concepts with a constrained variational framework. In International Conference on Learning Representations, volume 3, 2017.
- Hoffman (2017) Matthew D Hoffman. Learning deep latent gaussian models with markov chain monte carlo. In Proceedings of the 34th International Conference on Machine Learning-Volume 70, pp. 1510–1519. JMLR. org, 2017.
- Hoffman & Johnson (2016) Matthew D Hoffman and Matthew J Johnson. Elbo surgery: yet another way to carve up the variational evidence lower bound. In Workshop in Advances in Approximate Bayesian Inference, NIPS, 2016.
- Kingma & Welling (2013) Diederik P Kingma and Max Welling. Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114, 2013.
- Lake et al. (2013) Brenden M Lake, Ruslan R Salakhutdinov, and Josh Tenenbaum. One-shot learning by inverting a compositional causal process. In Advances in neural information processing systems, pp. 2526–2534, 2013.
- LeCun et al. (1998) Yann LeCun, Léon Bottou, Yoshua Bengio, Patrick Haffner, et al. Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11):2278–2324, 1998.
- Ma et al. (2019) Xuezhe Ma, Chunting Zhou, and Eduard Hovy. Mae: Mutual posterior-divergence regularization for variational autoencoders. arXiv preprint arXiv:1901.01498, 2019.
- Makhzani et al. (2015) Alireza Makhzani, Jonathon Shlens, Navdeep Jaitly, Ian Goodfellow, and Brendan Frey. Adversarial autoencoders. arXiv preprint arXiv:1511.05644, 2015.
- Morin & Bengio (2005) Frederic Morin and Yoshua Bengio. Hierarchical probabilistic neural network language model. In Aistats, volume 5, pp. 246–252. Citeseer, 2005.
- Salimans et al. (2015) Tim Salimans, Diederik Kingma, and Max Welling. Markov chain monte carlo and variational inference: Bridging the gap. In International Conference on Machine Learning, pp. 1218–1226, 2015.
- Shwartz-Ziv & Tishby (2017) Ravid Shwartz-Ziv and Naftali Tishby. Opening the black box of deep neural networks via information. arXiv preprint arXiv:1703.00810, 2017.
- Sønderby et al. (2016) Casper Kaae Sønderby, Tapani Raiko, Lars Maaløe, Søren Kaae Sønderby, and Ole Winther. How to train deep variational autoencoders and probabilistic ladder networks. In 33rd International Conference on Machine Learning (ICML 2016), 2016.
- Tolstikhin et al. (2017) Ilya Tolstikhin, Olivier Bousquet, Sylvain Gelly, and Bernhard Schoelkopf. Wasserstein auto-encoders. arXiv preprint arXiv:1711.01558, 2017.
- Xu & Durrett (2018) Jiacheng Xu and Greg Durrett. Spherical latent spaces for stable variational autoencoders. arXiv preprint arXiv:1808.10805, 2018.
- Zhao et al. (2017a) Shengjia Zhao, Jiaming Song, and Stefano Ermon. Infovae: Information maximizing variational autoencoders. arXiv preprint arXiv:1706.02262, 2017a.
- Zhao et al. (2017b) Shengjia Zhao, Jiaming Song, and Stefano Ermon. Towards deeper understanding of variational autoencoding models. arXiv preprint arXiv:1702.08658, 2017b.
7 Appendix
7.1 ELBO Rewrite
For the sample , consider .
7.2 Mutual information value range
When is independent with , , 所以. When is mapped one-to-one with , , , . Thus,
7.3 Results for Omniglot
| Method | NNLtest | KLtest | AU | NNLtrain | KLtrain | MI | MD | SC | ||
| VAE | - | - | 147.21 | 9.33 | 3 | 133.70 | 9.25 | - | - | - |
| VAE-AS | 1.0 | 0.1 | 158.54 | 81.14 | 40 | 61.31 | 82.70 | 10.10 | 72.61 | 0.00 |
| VAE-AS | 1.0 | 0.2 | 144.05 | 61.90 | 34 | 63.96 | 61.59 | 10.10 | 51.50 | 0.01 |
| VAE-AS | 1.0 | 0.5 | 133.44 | 37.22 | 21 | 70.27 | 37.59 | 10.09 | 27.52 | 0.02 |
| VAE-AS | 1.0 | 1.0 | 140.08 | 22.81 | 10 | 83.91 | 22.56 | 10.07 | 12.53 | 0.07 |
| VAE-AS | 1.0 | 2.0 | 146.47 | 8.38 | 3 | 135.03 | 8.56 | 6.17 | 2.56 | 4.10 |
| VAE-AS | 1.0 | 5.0 | 161.17 | 2.35 | 1 | 161.56 | 2.66 | 1.83 | 0.84 | 8.28 |
| VAE-AS | 1.0 | 10.0 | 174.49 | 1.46 | 0 | 177.22 | 2.09 | 0.59 | 1.55 | 9.56 |
| VAE-AS | 0.1 | 1.0 | 136.82 | 23.23 | 11 | 82.03 | 23.45 | 10.07 | 13.41 | 0.06 |
| VAE-AS | 0.2 | 1.0 | 140.38 | 21.17 | 9 | 86.22 | 21.49 | 10.07 | 11.45 | 0.06 |
| VAE-AS | 0.5 | 1.0 | 137.52 | 21.57 | 10 | 84.68 | 22.13 | 10.07 | 12.10 | 0.07 |
| VAE-AS | 2.0 | 1.0 | 140.60 | 21.16 | 9 | 86.02 | 21.27 | 10.06 | 11.25 | 0.08 |
| VAE-AS | 5.0 | 1.0 | 133.10 | 20.97 | 10 | 86.42 | 21.31 | 10.04 | 11.35 | 0.13 |
| VAE-AS | 10.0 | 1.0 | 175.63 | 41.15 | 7 | 145.96 | 39.76 | 4.22 | 36.84 | 7.18 |





