Improved accuracy for decoding surface codes with matching synthesis
Abstract
We present a method, called matching synthesis, for decoding quantum codes that produces an enhanced assignment of errors from an ensemble of decoders. We apply matching synthesis to develop a decoder named Libra, and show in simulations that Libra increases the error-suppression ratio by about . Matching synthesis takes the solutions of an ensemble of approximate solvers for the minimum-weight hypergraph matching problem, and produces a new solution that combines the best local solutions, where locality depends on the hypergraph. We apply matching synthesis to an example problem of decoding surface codes with error correlations in the conventional circuit model, which induces a hypergraph with hyperedges that are local in space and time. We call the matching-synthesis decoder Libra, and in this example the ensemble consists of correlated minimum-weight matching using a different hypergraph with randomly perturbed error probabilities for each ensemble member. Furthermore, we extend matching synthesis to perform summation of probability for multiple low-weight solutions and at small computational overhead, approximating the probability of an equivalence class; in our surface code problem, this shows a modest additional benefit. We show that matching synthesis has favorable scaling properties where accuracy begins to saturate with an ensemble size of 60, and we remark on pathways to real-time decoding at near-optimal decoding accuracy if one has an accurate model for the distribution of errors.
I Introduction
A fault-tolerant quantum computer requires real-time decoding of the parity checks that detect errors during the computation [1]. Accuracy of decoding is important as well, since improvements in accuracy can reduce the resource overhead for error correction [2, 3, 4, 5]. Hence decoding algorithms that achieve higher accuracy while being efficient to run in real time are desirable for making useful quantum computers.
Many works have studied accurate decoding for surface codes. If accuracy improvements are relative, then the historical baseline [6] is Edmonds’ Blossom algorithm [7] for minimum-weight perfect matching (where often the decoder itself is known as MWPM). The observation that correlations between the and lattices (or primal and dual in the original work [8]) could be exploited by edge reweighting [9] led to improved accuracy with correlated MWPM [10, 11, 12, 13]. More recently, a mapping between surface and color codes [14] converts the problem into finding a good decoder for color codes. Accuracy in matching can also be improved with belief propagation [15] or accounting for path degeneracy with multi-path summation [16].
Whereas correlated matching is heuristic with error correlations, there are other decoding algorithms that attempt to compute optimal solutions. Belief propagation [17, 18] can achieve high accuracy but sometimes fails to converge (Ref. [15] falls back to matching). Tensor-network decoders appear to approach optimal accuracy for 2D networks (noiseless syndrome measurement) [19, 20, 21], but contracting a 3D tensor network, required for fault tolerance in surface codes, is believed to be intractable beyond small code distances [22, 23, 24]. Likewise, integer-program decoders have exponential runtime in the worst case [25, 26], though the average runtime for below-threshold error rates could be more favorable; linear-program decoders [27, 28] may also enable circumventing intractable runtimes.
This work introduces a decoder called Libra that utilizes ensembling, where a collection of decoders produce differing decoding solutions, which are analyzed collectively. Ensembling for decoding has appeared in machine-learning decoders [29, 30] and matching with the Harmony decoder [13]. The Harmony decoder, developed by colleagues at the same institution, was an inspiration for how to identify improving cycles in problem-independent way, as opposed to local search that would introduce complexity that depends on problem structure. Both Harmony and Libra access an ensemble of decoders; Harmony makes fewer demands on the ensemble output (majority voting or selecting the global-minimum weight), whereas Libra can synthesize the best local solutions across the ensemble, if the ensemble can produce an assignment of errors.
We remark that the matching synthesis method appears new to the author, but the procedure seems to apply to other problems in optimization beyond decoding quantum codes. Hence this method or something similar may already appear in a different field, under a different name. It was not found in a literature search, though this would be limited by the author’s knowledge of terminology in other fields. The use of a random ensemble and combining pieces of solutions resembles local search in simulated annealing [31, 32, 33] or “crossover” in genetic algorithms [34, 35, 36], but the similarity ends there; our method is not local search or a genetic algorithm. If a closer match to this method is found in prior work, the manuscript will be updated accordingly.
II Decoding from Minimum-Weight Hypergraph Perfect Matching
The minimum-weight hypergraph perfect matching (MWHPM) problem is a generalization of the more commonly encountered minimum-weight perfect matching problem [7]. However, whereas the latter can be solved optimally in polynomial time, MWHPM is an NP-hard problem [37]. Hence the best we can hope for in a new approach to this problem is to improve the trade-off between computational time and approximation to optimal accuracy. Let us first define the MWHPM problem and describe how this problem applies to decoding quantum codes.
Define a weighted hypergraph as where is a set of vertices and is a set of hyperedges. Each hyperedge has some list of vertices , where the list size is any positive integer (contrast this with a graph, where the size must be two for every edge) and every vertex in the list is in . Furthermore, each hyperedge has weight that in general can be any real number, though we restrict our attention to in this work. Let us furthermore represent the sum of edge weights for a list of hyperedges as
| (1) |
In mapping to decoding stabilizer quantum codes [38], each vertex is a parity check, and each hyperedge corresponds to an error channel. The vertices are the parity checks that flip when the error occurs. There are different approaches to selecting the hyperedge weights, but we will motivate a typical one. If errors are independent binary channels with probability (i.e. weighted coin flip for each error occurring or not), then setting creates an equivalence between minimizing a sum of hyperedge weights and maximizing posterior probability over error events consistent with the syndrome [9, 19, 20, 13], as described below. Because each hyperedge corresponds to a specific error occurring, we will interchangeably refer to as an error as well. Likewise, we will say , a list of hyperedges, is also a configuration of errors.
The MWHPM problem, generalized for our purposes, is defined as follows. For a weighted hypergraph, one is given a “syndrome” that is a list of vertices. In decoding quantum codes, the syndrome will be parity checks that have flipped due to errors. Furthermore, let us define a syndrome function for a single hyperedge, and for a list of hyperedges
| (2) |
where means symmetric difference of the lists and , or equivalently mod-2 parity. Hence, the MWHPM optimization problem is finding that solves
| (3) |
Said in words, all configurations of hyperedges that satisfy correspond to possible Pauli-error patterns consistent with the observed parity-check violations, and we seek the error pattern that minimizes the weight sum because this event will be the most probable. For simplicity, we call any solution that satisfies a “matching for ”.
The generalization to MWHPM used here is in the meaning of “perfect matching”, implied by the in Eqn. (2). Here we take perfect matching to mean that the parity of hyperedges incident to a given vertex must be odd for and must be even for . In the traditional formulation of perfect matching for graphs [7], there is no syndrome (or one could say the syndrome is implicitly all vertices), and the number of incident edges to every vertex must be one, instead of any odd number.
To complete the connection between MWHPM and decoding for quantum codes, we additionally associate an “observable list” with every hyperedge . This does not appear in the optimization problem, but it does determine the result of decoding once a solution to the optimization problem has been chosen. For the quantum code, make some arbitrary choice of logical operators (which are Pauli strings in stabilizer codes) that propagate through the error correction circuit. For each error event, is the list of operators in that anticommutes with (i.e. error occurring would flip the observed value of ). For a set of hyperedges we can say that
| (4) |
where again means symmetric difference. Equivalently, if we track observable lists as bitstrings with a 1 in position for each , then the operation means bitwise XOR.
These logical observables are important for two reasons. First, all error patterns with the same observable list define an equivalence class [9, 19]. Second, when decoding is employed in a fault-tolerant computation, the observable list for the chosen error configuration determines the outcome of logical-qubit measurements.
III Matching Synthesis
Matching synthesis is a procedure for taking two or more solutions to the MWHPM problem, described in the previous section, and producing a new solution that is in general better than any of the inputs (and at least as good as the best input). For two distinct MWHPM solutions, the procedure is:
-
1.
compute the symmetric difference (SD) of the assigned errors,
-
2.
separate the SD into pieces with null syndrome (“cycles”),
-
3.
determine the signed weight of each cycle, and
-
4.
form a new “synthetic matching” that incorporates only the cycles that lower weight.
The rest of this section elaborates on the synthesis process, and later sections describe how this can be used in decoding quantum codes.
Following the nomenclature of Section II, suppose that for decoding a syndrome , there are candidate matchings and : . Let be the symmetric difference of these two solutions; namely, cancel out the errors assigned in both configurations and keep the errors that appear in only one configuration. By linearity, , the null syndrome.
Any set of hyperedges with null syndrome has a property that is key to this work. Let us label any such a “cycle”, where we will refine the definition below after motivating its use. For any error configuration and any cycle , then . Hence, given one decoding solution , we can use cycles to generate other solutions. If we are clever about which cycles to incorporate, then we can produce new solutions with lower weight, and improve our approximate solution to MWHPM.
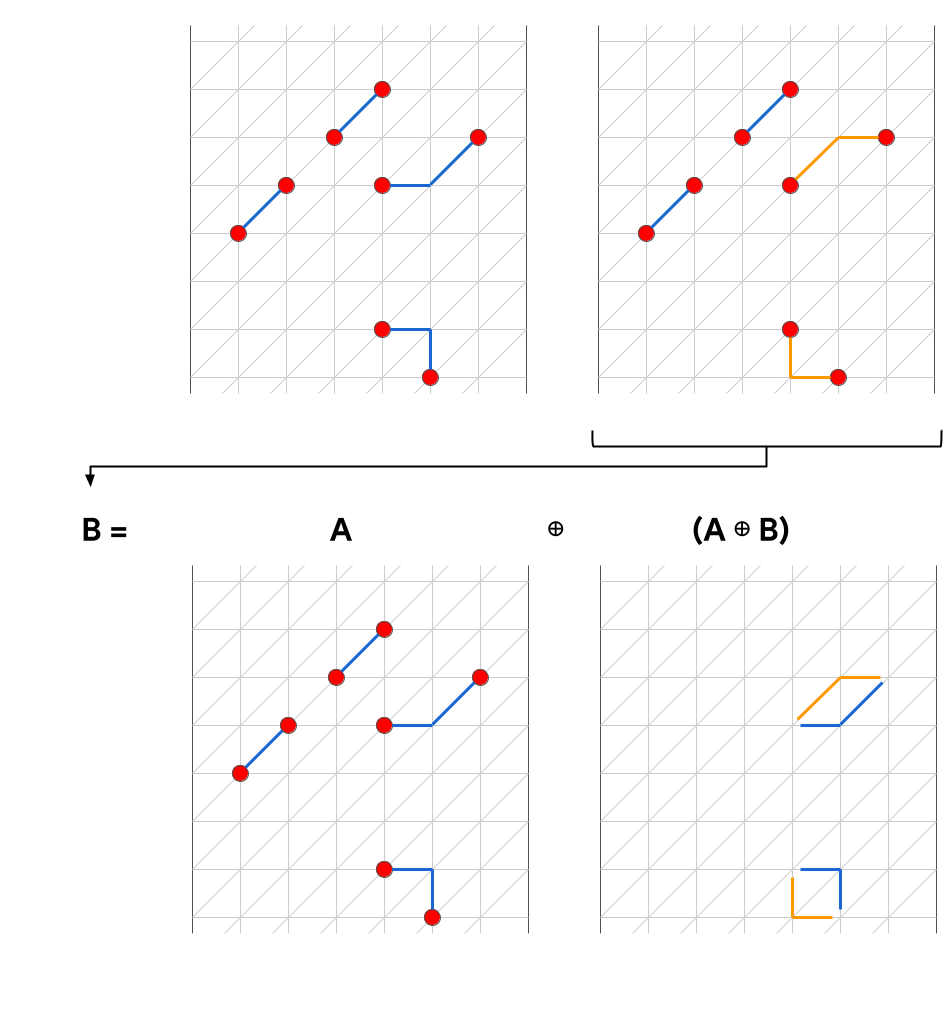
Let us be explicit about what we mean by “cycle” in our extended version of a hypergraph. For our purposes, a cycle is any hyperedge list such that and . Setting aside logical observables, this definition subsumes the traditional meaning of cycles on graph. It also includes any configuration of hyperedges such every vertex has an even number of incident hyperedges. The logical observables are furthermore necessary because they define equivalence classes, and we require that given a cycle , for all , such that incorporating a cycle does not change the equivalence class for a given solution. An example using edges in a normal graph, which is easier to visualize than a hypergraph, is shown in Fig. 1.
We want to make the best (i.e. lowest weight) matching that we can for a given syndrome , and our approach will be to improve an initial solution by combining with one or more cycles. To proceed, we define a “relative weight” function for cycles:
| (5) |
While it might seem like we are going in circles, this relative weight can be expressed as
| (6) |
where means “hyperedges in and not in ” and is the interection, “hyperedges in both and ”. The interpretation is straightforward: in going from , we remove the hyperedges in and subtract their summed weight, and we we add the hyperedges in and add their weight. The formulation in Eqn. (6) shows that we can compute the relative weight of the cycle with complexity that scales with the cycle size, not the size of the matching as one might think from Eqn. (5). The relative weight is useful because it tells us how much a matching solution improves by combining with a cycle.
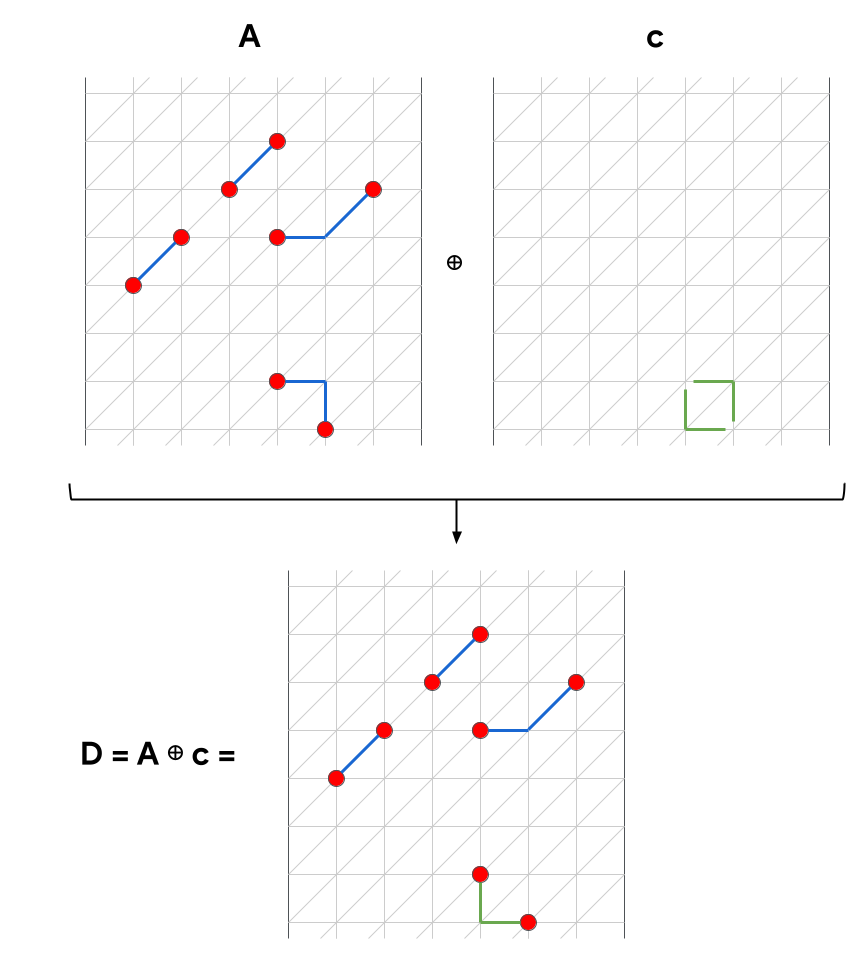
So we want to find cycles with negative relative weight, , because this would mean . If we take two matchings and , compute the symmetric difference , and compute , we are left with the uninspiring result that we are just picking the lower weight matching of the two. Now we reach the core result of matching synthesis. Instead of computing the weight of the entire symmetric difference, we break into smaller cycles where possible,
| (7) |
where each is a subset of . We then compute for each subset, and filter out the ones that have or . What remains are cycles of negative relative weight. We can produce a new matching
| (8) |
where the set of negative-relative-weight cycles is . Matching is derived from and , and it will equal when and equal when . However, something interesting happens when contains some of, but not all of, the cycles in : in this case, is an entirely new “synthetic” matching, and it has lower weight than either or . This is depicted with a visual example in Fig. 2.
Splitting a given with into pieces with can be done in more than one way. The method we employ here is to simply to break into connected components, where two hyperedges are connected when they touch a common vertex. This can be computed efficiently using standard techniques in graph search. It results in subsets that satisfy Eqn. (7) by being non-overlapping; note however than Eqn. (7) does not require to be non-overlapping. Using connected components does not guarantee the pieces are as small as possible; for example, if there are two cycles that touch at one mutual vertex, they will form a single connected component. We find that isolating cycles by connected components works well for decoding surface codes, as shown in Section V, and we leave the more general problem of cycle decomposition, which can be done with cycle-finding algorithms, to future work.
There is one final step to close the loop on matching synthesis, and that is addressing the observable lists associated with hyperedges. When we separate a symmetric difference into pieces according to Eqn. (7), such as by connected components, sometimes pieces in will be logical operators. Using our previous definitions, any with and is a logical operator. Although they are not cycles, logical operators will be useful in two ways for improving our decoding solutions. First, using one solution , we can generate another solution in a different equivalence class via , because . Second, for two pieces and with and , we can make a cycle , because . In some cases, adding cycles from a pair of equivalent logical operators, which may not be found by the connected-components method, can yield an improving cycle.
While matching synthesis improves a solution to the MWHPM problem by incorporating cycles of negative relative weight, what can we make of cycles with positive relative weight? One application, which will we show can improve decoding for surface codes, is to record cycles with small positive (or zero) relative weight. Each cycle can generate a new matching, and if the relative weight is small, this will be another approximate solution, with weight that is not the best known, but close to it. Of course, if there are cycles with relative weight zero, they produce alternative solutions with smallest weight found. If these small-weight cycles are non-overlapping, they generate many good solutions to the MWHPM problem: non-overlapping cycles encodes distinct solutions. We show later that the Libra decoder can efficiently compute the sum of probability over all configurations in time linear in , and also describe how it handles cases where these small-positive cycles overlap. This is reminiscent of multi-path summation [16] or the way Markov-chain [9], tensor-network [19, 20, 13] or belief-propagation [17, 15, 18] decoders account for multiple error configurations in an equivalence class.
IV Libra decoder
We apply matching synthesis to make a new decoder that we call Libra. Libra works by using an ensemble of decoders to generate multiple distinct matchings, and synthesize from them better matchings. Libra iteratively improves two or more matchings, one for each equivalence class represented. For example, in the simulations of Section V, there are two equivalence classes for a logical memory experiment (e.g. in an -basis memory experiment, logical operators act trivially, so there are two equivalence classes and not four).
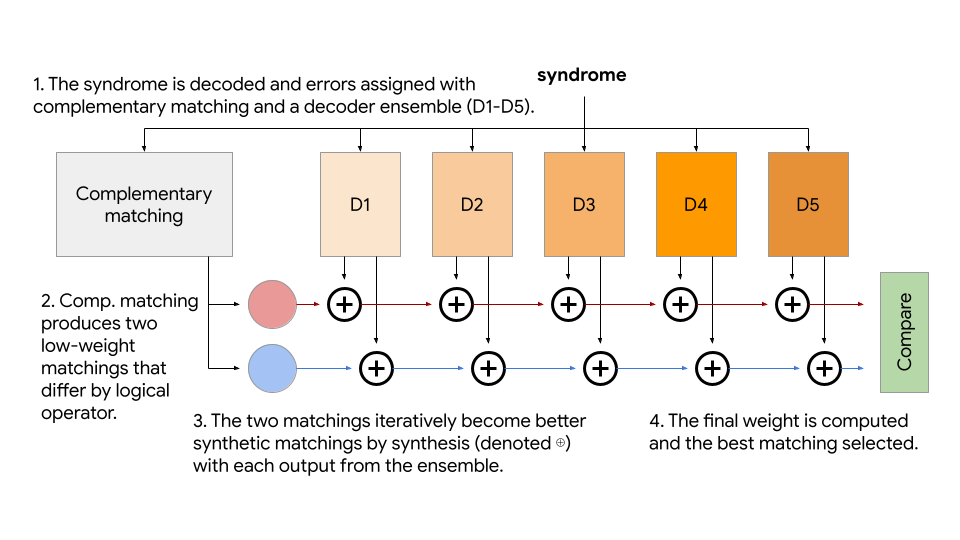
The architecture of Libra as implemented in this work is shown in Fig. 3. To initialize a representative for each equivalence class, we first perform complementary matching [9, 39, 40, 41, 42], using correlated MWPM on the unperturbed error hypergraph. Correlated MWPM returns two “edge” matchings for the and graphs, which can be converted to the most-probable assignment of hyperedges within the original hypergraph that contain these matched and edges using the assignment method in Ref. [13]. There are other ways of producing representatives, such as relying on an ensemble to stochastically generate matchings in more than one equivalence class [13]. However, the complementary matching also provides the “complementary gap”, the difference in weight between the two matchings found, which is very predictive of the probability of logical error for a given syndrome [39]. We use the gap to only invoke the ensemble on a small fraction of “hard” cases (where the gap is small), which happens sufficiently rarely (and with likelihood that decreases exponentially with code distance when below threshold) that the average runtime of Libra is dictated by complementary matching, and the cost of running an ensemble of 100 decoders becomes insignificant to the average runtime. Another option would be to use a small ensemble first, where we invoke the larger ensemble if there are least two equivalence classes for the matchings in the first ensemble [13].
There are many ways to choose an ensemble, but we opt for using correlated minimum-weight perfect matching (MWPM) [10, 11, 12, 13] with randomly perturbed hyperedge weights. This is simple to implement (via Stim [43], one can edit DEM files) and is similar to the ensemble in Harmony [13], though not the same. The perturbation is to multiply the probability for each error channel by a log-normally distributed random variable: , where is equivalent to for . For example, if , then the perturbations will have a standard deviation of a factor-of-2, normally distributed in the logarithm of probability. This will ensure that probabilities are normalized, and zero-probability events (if present) remain zero. Furthermore, since hyperedge weights are typically the logarithm of probability, this is effectively adding a normally distributed perturbation to hyperedge weights. To be explicit, we only use these randomly perturbed hypergraph weights to induce an ensemble of correlated-MWPM decoders to give different matching solutions; when we evaluate the weight of a matching or cycle (such as Eqn. (6), we use the unperturbed weights.
For the comparison step in Fig. 3, one could compare the weights of the best solution for each equivalence class (e.g. two for a logical memory experiment) after matching synthesis across the ensemble. One can also use small-positive cycles found during synthesis to generate multiple configurations in each equivalence class, sum the probabilities for each equivalence class, and compare the probabilities for the equivalence classes, in a manner described below. Libra is configured to do both (the first is necessary, and the second comes at negligible additional cost), and Section V reports the results for decoding the surface code.
We describe here the algorithm currently employed for using the small-positive cycles to estimate probabilities for equivalence classes, though many variations are possible. As cycles with nonnegative relative weight are discovered, they are stored in a max-heap of fixed size (in the simulations of Section V, the size is 30). When an improving cycle (one with negative relative weight) is found, the heap is cleared, because the stored positive cycles were relative to a hyperedge configuration that has changed with the improving cycle. Alternatively, one could iterate through the cycles in the heap and only modify or discard as necessary for those overlapping the improving cycle. Because clearing the heap could happen in any synthesis step, Libra currently performs the synthesis procedure twice, where negative cycles are rarely discovered in the second pass, which mostly functions to discover small-positive cycles.
After all matching-synthesis operations are performed, we have a “best matching” for each of the equivalence classes being considered by Libra (e.g. two for the memory experiment). We also have the small-positive cycles that were discovered, from which we can generate many other configurations. For example, if we store 30 such cycles, we could generate as many as configurations. The number could be less than if the cycles stored are not linearly independent (e.g. if the combination of two cycles is another stored cycle). Computing all such configurations generated by these cycles would be impractical. However, at least for surface codes, they tend to be small cycles from disparate parts of the hypergraph, so instead we split the cycles into connected components. For this step, two cycles are connected if they overlap in at least one edge. For each connected component of cycles , we compute a relative probability:
| (9) |
where is the set of all unique cycles generated by and the relative probability for a single cycle is
| (10) |
i.e. the ratio of probability of the configuration using the cycle to the “base” synthetic matching . We emphasize relative, because the “null” cycle is always an element of any , corresponding to the synthetic matching itself, and it has a relative probability of 1. If probability is the logarithm of weight, then relative probability can be computed directly from the relative weight of the cycle, which is much faster than a computation over the entire matching. Finally, two implementation notes. First, as we are generating , we may encounter a generating set from the connected component that is not linearly independent. To guard against this, we use a hash table to store the elements of as they are produced, and skip redundant entries. An alternative would be to compute an independent vector basis such as by Gaussian elimination over binary vectors. Second, it is possible that is very large because it is exponential in the size of . For speed, we truncate the sum by only considering a low-order approximation to the exponentially large number of combinations (e.g. use as the set to sum over, or all combinations of two elements of ). In the simulations, we make this approximation if cycles. Finally, the estimated probability of the equivalence class is
| (11) |
where is the relative probability for the connected component in the small-positive cycles.
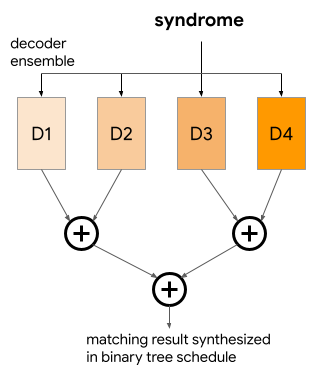
Another generalization of the procedure is the freedom of how to synthesize members of the ensemble. Figure 3 illustrates a sequential procedure where the current synthesized matching updates iteratively with each ensemble member. Alternatively, one could synthesize matchings from the ensemble in a logarithmic-depth binary tree, as shown in Fig. 4, which could have advantages for parallelization of the algorithm. Since synthesis can be performed between two matchings, any binary tree with number of leaves equal to ensemble size can describe a synthesis sequence.
V The surface code with Pauli errors in the circuit model
For our simulations, we simulate a surface code memory experiment, which consists of initializing in a basis ( or ) by direct initialization of data qubits, repeatedly measuring the stabilizers with a circuit of Clifford gates for some number of cycles, and then measuring the logical qubit in the same basis as initialization, by direct measurement of the data qubits. Noise in the simulation consists of a depolarizing channel after every operation, with a 1-qubit channel for 1-qubit gates (and reset) or a 2-qubit channel for the 2-qubit gate, which is controlled-Z (CZ) in our circuits. Measurement error is modeled as a binary symmetric channel on the classical bit (i.e. flip the classical bit with some probability). The depolarizing channels and measurement error have different probabilities according to the SI-1000 model [44], which is representative of error rates in superconducting qubits [45, 23]. The weighting also captures features seen in other qubit platforms [46, 47], such as 1-qubit gates being more reliable than 2-qubit gates, and measurement being less reliable than coherent operations. In this model, the channel probabilities are only determined by the operation and there is not inhomogeneity in space or time; e.g. all CZ gates have the same depolarizing probability.
The simulations here use a simple ensemble for Libra. As described in Section IV, each ensemble member is correlated-MWPM [10, 11, 12, 13] configured with the hypergraph for the circuit (i.e. DEM file [43]), but with the error probabilities randomly perturbed by . Half of the members have and the other half . In testing, we found such an inhomogeneous ensemble to lead to a small improvement over a homogeneous ensemble, which may be due to different values of enabling the ensemble to discover a greater variety of cycles. Future work will explore alternative ways to construct an ensemble. Libra also includes a complementary matcher (Fig. 3) with unperturbed hypergraph, as described in Section IV.
The simulations are a surface-code memory experiment, in the logical basis, using CZ and Hadamard gates, with SI-1000 depolarizing model with parameter . The parameters swept in the simulations are code distance (), syndrome rounds (), and ensemble size ():
-
•
,
-
•
,
-
•
.
For every combination of we perform correlated MWPM as a baseline, and complementary matching to determine a complementary gap and initialize two equivalence classes in Libra. If the complementary gap is less than 20 dB (i.e. ratio of probability between the two matchings is ), then we run the ensemble; this conditional execution [48, 13] significantly reduces computation time since the fraction of problems where the ensemble is run scales with the logical error rate [39], decreasing with distance. With the ensemble, we produce three decoder predictions:
-
•
“global” ensembling, which is using the minimum-total-weight error configuration found by an ensemble member [13];
-
•
Libra using matching synthesis to make improved configurations;
-
•
Libra “degeneracy” using small-positive cycles to estimate the probability of equivalence classes.
Each of these three ensembled methods use exactly the same ensemble (described above), so they demonstrate the effects of matching synthesis and using small-positive cycles. However, it is important to note that different ensembles (e.g. distributions of weight perturbations for matching) may be better suited to each of the ensembling methods listed above. The size of the heap for smallest-relative-weight cycles is 30 in all cases. When the ensemble is not run because the complementary gap is large, all decoders default to the prediction of correlated MWPM.
We use correlated MWPM as the baseline decoder, which yields error suppression factor [23] for SI-1000(). We quantify accuracy as the ratio of improvement relative to the correlated-MWPM baseline:
| (12) |
We calculate logical error rate for a memory experiment of rounds as
| (13) |
where is total number of samples and is number of simulated failures. For all values of , we simulate to at least 1000 failures for every decoder. For a fixed combination, all decoders for all values of see the same sampled shots.
| Decoder | |||
|---|---|---|---|
| MWPM-corr | 3.68 | 3.64 | 3.52 |
| global ens. | |||
| ens=20 | 3.70 | 3.61 | 3.45 |
| ens=40 | 3.75 | 3.64 | 3.43 |
| ens=60 | 3.76 | 3.62 | 3.37 |
| ens=80 | 3.78 | 3.65 | 3.41 |
| ens=100 | 3.80 | 3.67 | 3.44 |
| Libra | |||
| ens=20 | 3.95 | 3.97 | 3.78 |
| ens=40 | 4.00 | 4.03 | 3.85 |
| ens=60 | 4.01 | 4.03 | 3.84 |
| ens=80 | 4.02 | 4.04 | 3.86 |
| ens=100 | 4.01 | 4.02 | 3.83 |
| Libra degen. | |||
| ens=20 | 3.99 | 4.01 | 3.84 |
| ens=40 | 4.05 | 4.10 | 3.96 |
| ens=60 | 4.03 | 4.04 | 3.83 |
| ens=80 | 4.04 | 4.06 | 3.85 |
| ens=100 | 4.05 | 4.05 | 3.85 |
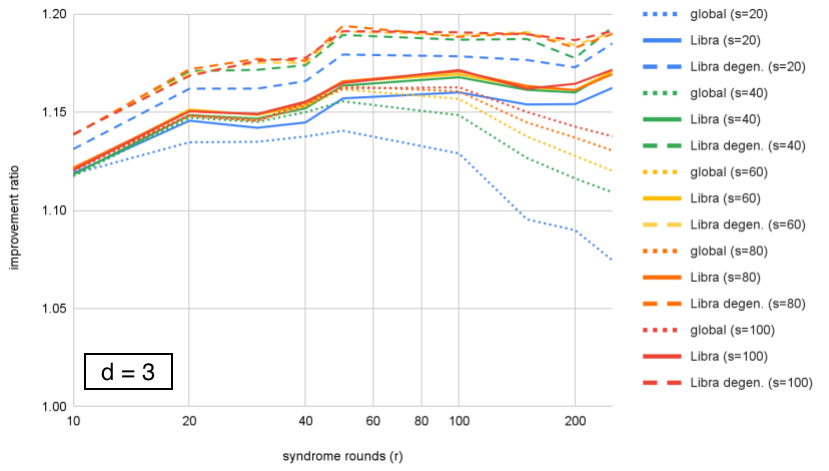
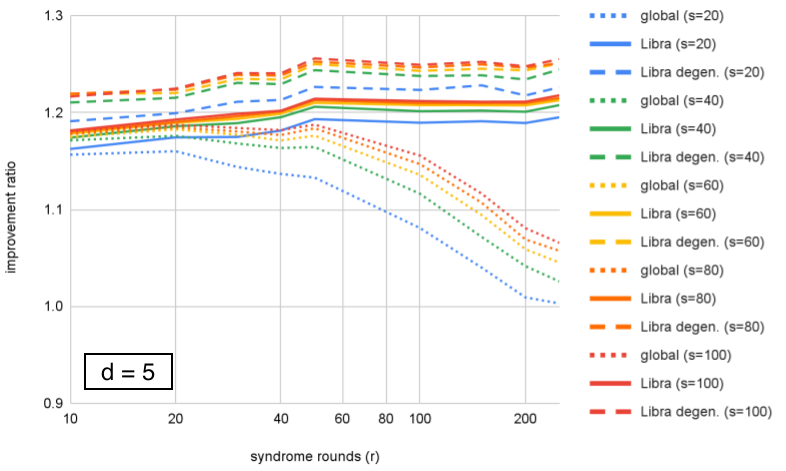
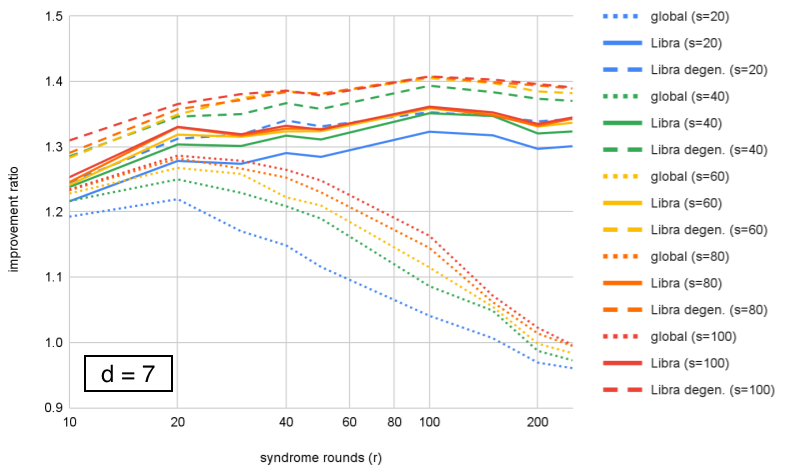
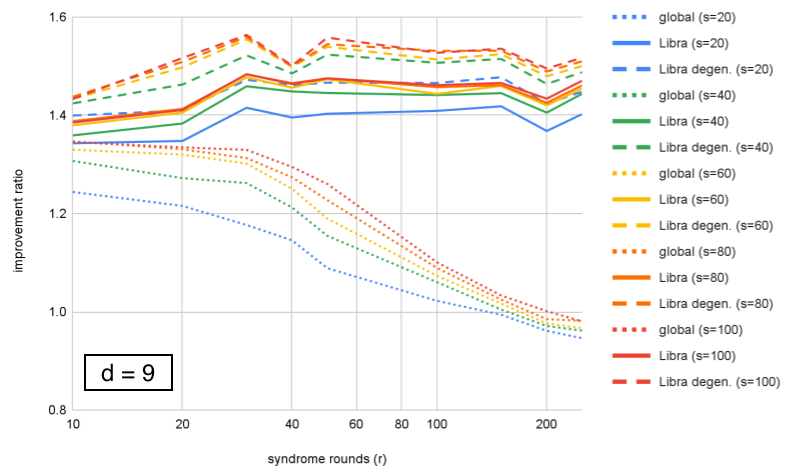
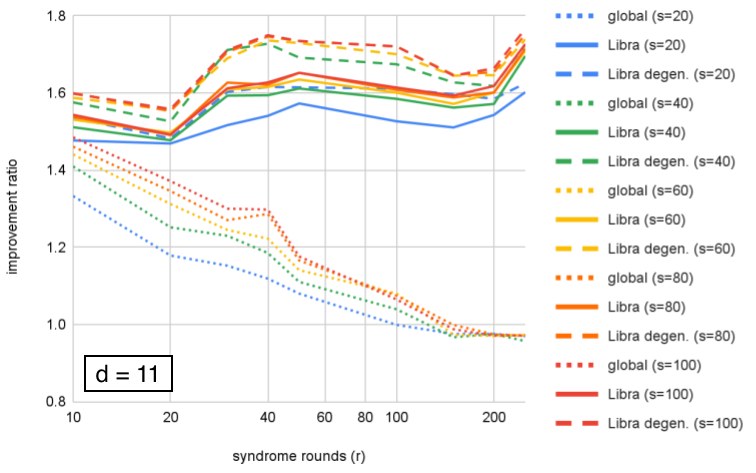
We compare performance of the ensembled decoders at each , showing improvement over correlated-MWPM as a function of . In Figs. 5–8, we see two effects. First, Libra maintains performance (or improves slightly) with number of rounds, while global ensembling decreases; the onset of the decrease becomes earlier with increasing , showing that both and affect performance of global ensembling. Second, including degeneracy by using small-positive cycles to compute probabilities for equivalence classes shows an additional modest benefit over using the best single matching.
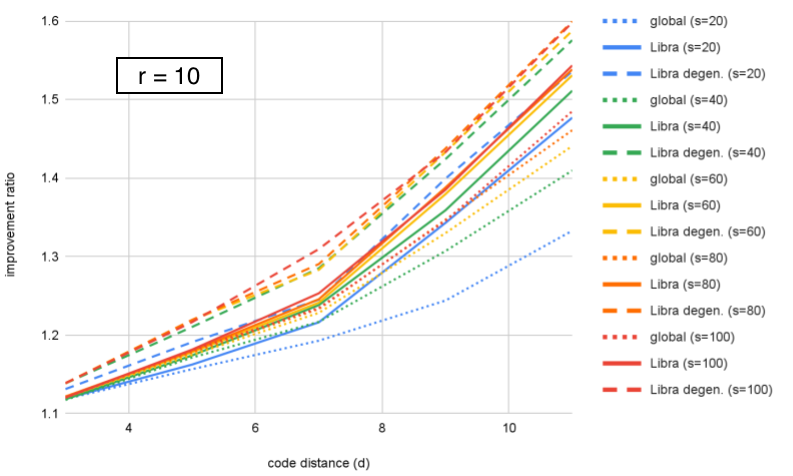
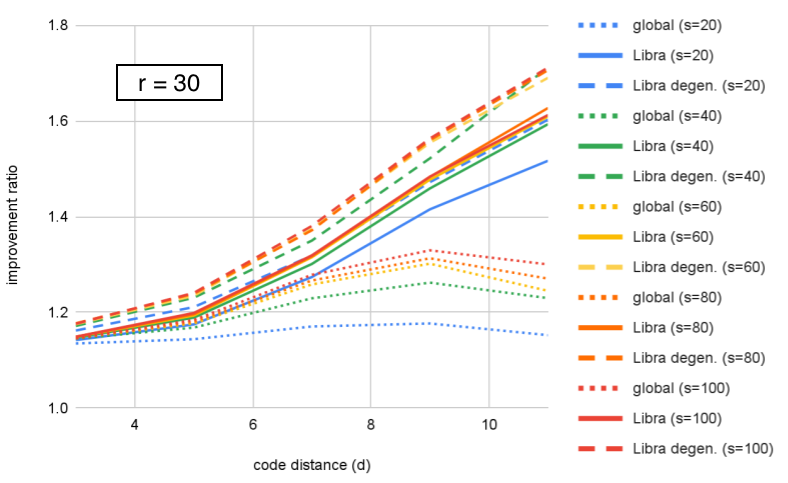
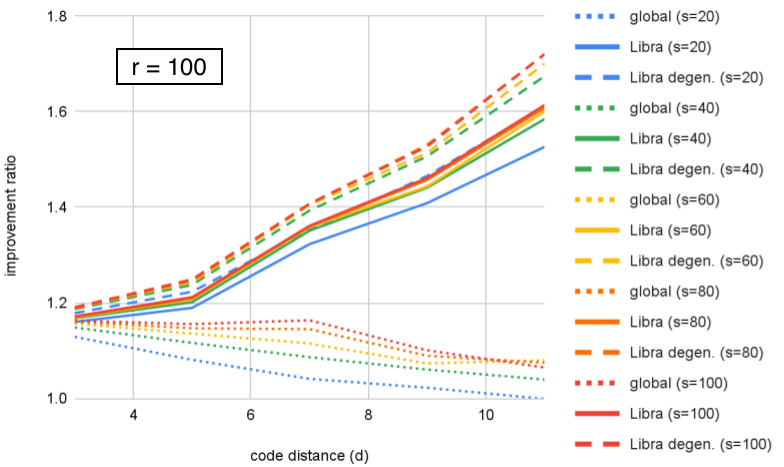
We can look at the same data organized differently, by grouping by fixed value and plotting improvement as a function of distance. This is plotted for in Figures 10–12. We can see that Libra shows increasing improvement ratio with distance for all cases. For global ensembling, there is improvement for with , some slowing of improvement for , and a decrease with distance for . Section VI proposes an explanation for this. If we take as an example, we see that both Libra and Libra-degen. appear to saturate in performance around ensemble size .
Figures 10–12 show that the improvement ratio is increasing with in both versions of Libra. The rate of improvement can be quantified with , and values for the different decoders are calculated in Table 1 for . If we take ensemble size for example, we find that increases from 3.64 to 4.02 (+10%) for Libra or to 4.05 (+11%) when including “degeneracy” from small-positive cycles.
However, we remark that is not the only figure of merit – being a ratio of logical error rates, it increases if the numerator (a smaller code) has higher logical error rate. For example, in Table 1, we see that at , Libra has = 3.86 and Libra-degen. has = 3.84 (as a reminder, these are decoding exactly the same samples of a memory experiment). Conversely, from Fig. 11, we see that Libra-degen. achieves higher improvement ratio (hence lower logical error rate) for and .
We see overall that Libra is improving by by about 10% for the range of parameters studied here, but generalizing to higher distance or different error rates is a matter for future study.
VI Interpretation of Libra
In this section, we conjecture on the mechanism that enables Libra to work well for surface-code decoding. The key concept in Libra is identifying improving cycles. How well this works will depend on the structure of the weighted hypergraph and the nature of the ensemble. In some informal sense, the ensemble needs some “entropy” (yielding a diversity of solutions) but not too much (for a local neighborhood of the hypergraph, one of the ensemble members needs to find a good local solution).
In our simulations with the surface code (Section V), we found that Libra improved accuracy over correlated MWPM [10, 11, 12, 13]. We attribute this to 3D locality of the hypergraph and the fact that the decoders in the ensemble produce a diversity of reasonably good solutions. The surface code is a topological code [8, 1] and the error model is local to each operation, so the hypergraph is local in three dimensions (every hyperedge is contained within a ball of some finite radius, independent of the code distance). Moreover, correlated MWPM is a “pretty good” decoder for the surface code, in the sense that high-accuracy decoders have demonstrated only modestly better performance [23, 30, 13], meaning increases by about . Hence the members of the ensemble tend to produce solutions that are good in a local neighborhood. We speculate that Libra will show benefit with other topological codes, such as color codes [26, 49], provided suitably “good” approximate decoders for the ensemble. Similarly, we expect Libra to generalize naturally to surface-code logical operations [50, 4, 51, 52], since these also have the properties of the error hypergraph being 3D-local and being amenable to matching.
We give some intuition for how Libra improves accuracy of decoding, though we preface that this story will be studied more carefully in future work. When operating below the threshold for error correction, which is the domain of interest for decoding, errors tend to be sparsely distributed [6, 53]. In matching synthesis, this leads to small, local cycles.
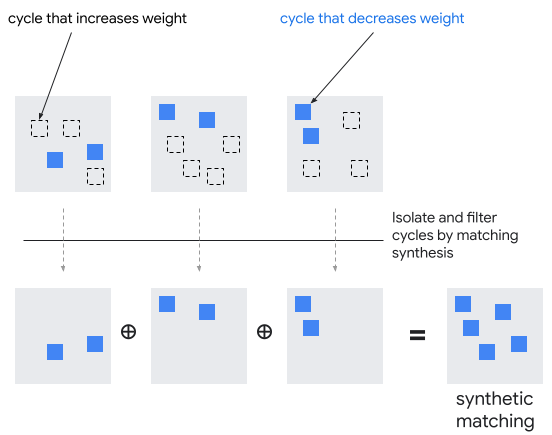
As a frame of reference, let us use the matching result produced by correlated MWPM as the baseline configuration of errors, and we can represent any other configuration as the collection of cycles and logical operators produced by symmetric difference between the two. We observe that with randomly perturbed error probabilities, the cycles discovered in matching synthesis have an average weight that is positive. This means that the majority are not improving cycles. Hence, if we were to take whole matchings from the ensemble and only consider their total weight [13], then we find a better solution than the baseline only when an ensemble member gets lucky enough to sample enough improving cycles to be in the tail of the distribution. In contrast, Libra is able to select the improving cycles individually, shown in Fig. 13.
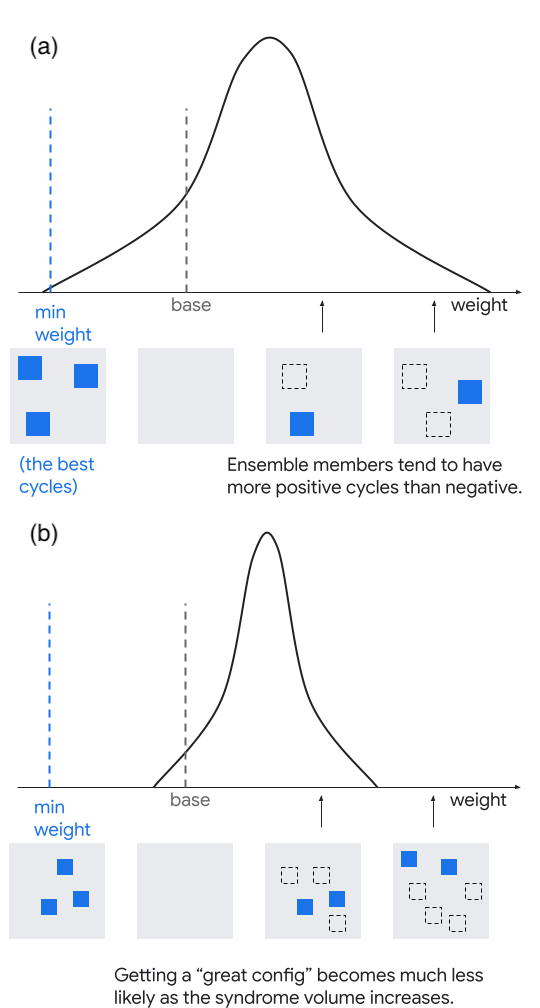
One might expect that there will be some density distribution of cycles that is independent of code distance (i.e. diameter of the hypergraph), owing to the local structure of the hypergraph described above. We caution that this is a conjecture, since we have not yet studied this carefully. This distribution could also be correlated with other observed values, such as there being more improving cycles when the complementary gap is small.
If the relative weight of each cycle can be modeled as a real-valued random variable with positive average value, then the “global” difference in weight between an ensemble member and the correlated-MWPM baseline, which is the sum over the cycle relative weights, will also have positive average value. Moreover, by the Central Limit Theorem, the ratio of the average and standard deviation for this global weight difference will shrink if the number of cycles increases (i.e. sample mean converges to distribution mean). We conjecture that the number of cycles will increase with size of the hypergraph (i.e. volume of syndrome, which in a memory experiment is for code distance and number of syndrome cycles ), as depicted in Fig. 14. In such circumstances, using the global lowest-weight configuration in the ensemble as the solution [13] will require the size of the ensemble to increase with the syndrome volume, in order to sample from the tail of the distribution for global weight. In contrast, Libra would be insensitive to this globally imposed Central Limit Theorem because it can select the best local cycles individually. The data in Section V supports this interpretation, where we see that Libra performance is insensitive to and , whereas global-weight ensembling is sensitive to both and recovers by increasing the size of the ensemble. However, we do not propose a functional form for this dependence. Techniques like windowing [54, 55] or graph partitioning [56] are important for parallelization of decoding, as well as streaming for real-time operation. If ensembling is applied to increase accuracy, windowing and/or partitioning the hypergraph would limit the size of the syndrome volume in the cut-out region, mitigating the volume-dependent effects described above. However, we expect that the minimum size of the syndrome volume will scale for the surface code, since logical operators of length can be oriented in any of the three cardinal directions in 3D. Hence, these considerations become important as quantum error correction scales to large .
VII Generalizations to other problems
This work focuses on solving a particular variant of MWHPM (Section II) that is relevant to decoding quantum codes, but the methods appear to be more general. If one is performing constrained optimization where solutions can be decomposed into pieces and evaluated individually, such as Eqn. (3), then it could be possible to synthesize two distinct solutions and keep the best pieces. In contrast to local search in stochastic algorithms [31, 32, 9], this could avoid becoming trapped in local minima [33].
Using small-positive cycles (from Section III) as generators of multiple “good” solutions could also be of interest in optimization. For example, suppose one is optimizing routing in a distribution network, and that there is a formulation of this problem to which matching synthesis or a generalization thereof can be applied. An optimal solution that has no small cycles could be interpreted as “brittle”, because if the real-world circumstances that inform the cost function change, the single solution could become a poor one. In contrast, if there is a solution with many small-positive cycles, it means there are many almost-best solutions that could be generated. In the example, we might say this is a “robust” solution because there are many options to make changes to routing, while still being a pretty good solution. Whether these conjectures can be applied usefully in optimization problems is left for future work.
VIII Discussion
We have presented a method for high-accuracy decoding of surface codes called matching synthesis, and demonstrated improvements in accuracy with a decoder called Libra. We showed that the method makes efficient use of ensembling, reaching saturation around an ensemble size of 60 when using correlated MWPM. Our interpretation of the algorithm and these results is that each matching in the ensemble can be characterized as differing from the optimal solution by some random distribution of cycles on the hypergraph. If the hypergraph has “local structure” whereby these cycles tend to be confined to local neighborhoods, then matching synthesis quickly approaches optimality when the ensemble finds a good solution in each neighborhood with high probability, which is more favorable than requiring an ensemble member to find a good global solution.
A question not answered here is how close Libra comes to optimal decoding, which we will investigate in future work. In the case of surface codes, while it is theoretically interesting to wonder how close one can get to optimal accuracy with a computationally efficient algorithm, what is the practical benefit? If Libra (or any other decoder) increases by 10%, then the practical benefit is to reduce the code distance required to achieve a target logical error rate according to the approximate formula [4, 5]. For example, if the target is per syndrome round and the baseline decoder (e.g. correlated MWPM) achieves , then the benefit of an improved decoder with is to reduce required code distance from to , reducing qubit overhead by about .
Besides chasing diminishing returns in accuracy, another avenue to applying these results is real-time decoding. An advantage inherent in ensembled decoding [13] is the ability to do most of the decoding in parallel. Furthermore, matching synthesis with a logarithmic-depth tree lends itself to short-depth computation. Instead of making an ensemble out of the already-pretty-good correlated MWPM decoder, one could instead use simpler algorithms for the ensemble like uncorrelated matching [6], Union-Find [57], clustering decoders [58], or renormalization group decoders [59, 60]. Being less accurate, these might require a larger ensemble; however, if they can run in parallel on massively parallel hardware (e.g. FPGAs or GPUs) and be synthesized in a logarithmic-depth tree, the execution depth might actually be shorter than MWPM.
Finally, the matching synthesis method is not restricted to surface codes. We expect that the technique will translate well to other topological codes, such as color codes [61, 26, 62, 63, 14, 64, 49]. Whether it offers a benefit for other families of codes, such as quantum LDPC codes [65, 66, 67], is not clear at this time. We leave these investigations to future work.
Acknowledgements.
We thank Michael Newman, Dave Bacon, Oscar Higgott, and Noah Shutty for feedback on the matching synthesis procedure.References
- Terhal [2015] B. M. Terhal, Quantum error correction for quantum memories, Rev. Mod. Phys. 87, 307 (2015).
- Steane [2003] A. M. Steane, Overhead and noise threshold of fault-tolerant quantum error correction, Phys. Rev. A 68, 042322 (2003).
- Aliferis et al. [2006] P. Aliferis, D. Gottesman, and J. Preskill, Quantum accuracy threshold for concatenated distance-3 codes, Quantum Info. Comput. 6, 97–165 (2006).
- Fowler et al. [2012] A. G. Fowler, M. Mariantoni, J. M. Martinis, and A. N. Cleland, Surface codes: Towards practical large-scale quantum computation, Phys. Rev. A 86, 032324 (2012).
- Jones et al. [2012] N. C. Jones, R. Van Meter, A. G. Fowler, P. L. McMahon, J. Kim, T. D. Ladd, and Y. Yamamoto, Layered architecture for quantum computing, Phys. Rev. X 2, 031007 (2012).
- Dennis et al. [2002] E. Dennis, A. Kitaev, A. Landahl, and J. Preskill, Topological quantum memory, Journal of Mathematical Physics 43, 4452 (2002).
- Edmonds [1965] J. Edmonds, Paths, trees, and flowers, Can. J. Math. 17, 449 (1965).
- Bravyi and Kitaev [1998] S. B. Bravyi and A. Y. Kitaev, Quantum codes on a lattice with boundary, (1998), Preprint arXiv:quant-ph/9811052.
- Hutter et al. [2014] A. Hutter, J. R. Wootton, and D. Loss, Efficient markov chain monte carlo algorithm for the surface code, Phys. Rev. A 89, 022326 (2014), Preprint arXiv:1302.2669.
- Fowler [2013] A. G. Fowler, Optimal complexity correction of correlated errors in the surface code, arXiv:1310.0863 (2013).
- Paler and Fowler [2023] A. Paler and A. G. Fowler, Pipelined correlated minimum weight perfect matching of the surface code, Quantum 7, 1205 (2023).
- Higgott et al. [2023a] O. Higgott, T. C. Bohdanowicz, A. Kubica, S. T. Flammia, and E. T. Campbell, Improved decoding of circuit noise and fragile boundaries of tailored surface codes, Physical Review X 13, 031007 (2023a).
- Shutty et al. [2024] N. Shutty, M. Newman, and B. Villalonga, Efficient near-optimal decoding of the surface code through ensembling, arXiv:2401.12434 (2024).
- Benhemou et al. [2023] A. Benhemou, K. Sahay, L. Lao, and B. J. Brown, Minimising surface-code failures using a color-code decoder, (2023), Preprint arXiv:2306.16476.
- Higgott et al. [2023b] O. Higgott, T. C. Bohdanowicz, A. Kubica, S. T. Flammia, and E. T. Campbell, Improved decoding of circuit noise and fragile boundaries of tailored surface codes, Phys. Rev. X 13, 031007 (2023b).
- Criger and Ashraf [2018] B. Criger and I. Ashraf, Multi-path Summation for Decoding 2D Topological Codes, Quantum 2, 102 (2018).
- Old and Rispler [2023] J. Old and M. Rispler, Generalized Belief Propagation Algorithms for Decoding of Surface Codes, Quantum 7, 1037 (2023).
- Chen et al. [2024] J. Chen, Z. Yi, Z. Liang, and X. Wang, Improved belief propagation decoding algorithms for surface codes, (2024), Preprint arXiv:2407.11523.
- Bravyi et al. [2014] S. Bravyi, M. Suchara, and A. Vargo, Efficient algorithms for maximum likelihood decoding in the surface code, Physical Review A 90, 032326 (2014).
- Chubb and Flammia [2021] C. T. Chubb and S. T. Flammia, Statistical mechanical models for quantum codes with correlated noise, Annales de l’Institut Henri Poincaré D 8, 269 (2021).
- Chubb [2021] C. T. Chubb, General tensor network decoding of 2d pauli codes, arXiv preprint arXiv:2101.04125 (2021).
- Piveteau et al. [2023] C. Piveteau, C. T. Chubb, and J. M. Renes, Tensor network decoding beyond 2d, arXiv preprint arXiv:2310.10722 (2023).
- AI [2023] G. Q. AI, Suppressing quantum errors by scaling a surface code logical qubit, Nature 614, 676 (2023).
- Bohdanowicz [2022] T. C. Bohdanowicz, Quantum Constructions on Hamiltonians, Codes, and Circuits, Ph.D. thesis, California Institute of Technology (2022).
- Feldman et al. [2005] J. Feldman, M. J. Wainwright, and D. R. Karger, Using linear programming to decode binary linear codes, IEEE Transactions on Information Theory 51, 954 (2005).
- Landahl et al. [2011] A. J. Landahl, J. T. Anderson, and P. R. Rice, Fault-tolerant quantum computing with color codes, arXiv preprint arXiv:1108.5738 (2011).
- Li and Vontobel [2018] J. X. Li and P. O. Vontobel, LP Decoding of Quantum Stabilizer Codes, in 2018 IEEE International Symposium on Information Theory (ISIT) (IEEE Press, 2018) p. 1306–1310.
- Fawzi et al. [2021] O. Fawzi, L. Grouès, and A. Leverrier, Linear programming decoder for hypergraph product quantum codes, in IEEE ITW 2020 - IEEE Information theory workshop 2020 (Riva del Garda / Virtual, Italy, 2021).
- Sheth et al. [2020] M. Sheth, S. Z. Jafarzadeh, and V. Gheorghiu, Neural ensemble decoding for topological quantum error-correcting codes, Physical Review A 101, 032338 (2020).
- Bausch et al. [2023] J. Bausch, A. W. Senior, F. J. Heras, T. Edlich, A. Davies, M. Newman, C. Jones, K. Satzinger, M. Y. Niu, S. Blackwell, et al., Learning to decode the surface code with a recurrent, transformer-based neural network, (2023), Preprint arXiv:2310.05900.
- Lin [1965] S. Lin, Computer solutions of the traveling salesman problem, The Bell System Technical Journal 44, 2245 (1965).
- Lin and Kernighan [1973] S. Lin and B. W. Kernighan, An Effective Heuristic Algorithm for the Traveling-Salesman Problem, Operations Research 21, 498 (1973), https://doi.org/10.1287/opre.21.2.498 .
- Martin et al. [1991] O. Martin, S. W. Otto, and E. W. Felten, Large-step markov chains for the traveling salesman problem, Complex Systems 5, 299 (1991).
- Mahfoud and Goldberg [1995] S. W. Mahfoud and D. E. Goldberg, Parallel recombinative simulated annealing: A genetic algorithm, Parallel Computing 21, 1 (1995).
- Mühlenbein et al. [1988] H. Mühlenbein, M. Gorges-Schleuter, and O. Krämer, Evolution algorithms in combinatorial optimization, Parallel Computing 7, 65 (1988).
- Manzoni et al. [2020] L. Manzoni, L. Mariot, and E. Tuba, Balanced crossover operators in genetic algorithms, Swarm and Evolutionary Computation 54, 100646 (2020), Preprint arXiv:1904.10494.
- Håstad [1999] J. Håstad, Clique is hard to approximate within , Acta Mathematica 182, 105 (1999).
- Gottesman [1998] D. Gottesman, The Heisenberg Representation of Quantum Computers, (1998), Preprint arXiv:quant-ph/9807006.
- Gidney et al. [2023] C. Gidney, M. Newman, P. Brooks, and C. Jones, Yoked surface codes, arXiv:2312.04522 (2023).
- Bombín et al. [2024] H. Bombín, M. Pant, S. Roberts, and K. I. Seetharam, Fault-tolerant postselection for low-overhead magic state preparation, PRX Quantum 5, 010302 (2024).
- Meister et al. [2024] N. Meister, C. A. Pattison, and J. Preskill, Efficient soft-output decoders for the surface code, (2024), Preprint arXiv:2405.07433.
- Smith et al. [2024] S. C. Smith, B. J. Brown, and S. D. Bartlett, Mitigating errors in logical qubits, (2024), Preprint arXiv:2405.03766.
- Gidney [2021] C. Gidney, Stim: a fast stabilizer circuit simulator, Quantum 5, 497 (2021).
- Gidney et al. [2021] C. Gidney, M. Newman, A. Fowler, and M. Broughton, A fault-tolerant honeycomb memory, Quantum 5, 605 (2021).
- Krinner et al. [2022] S. Krinner, N. Lacroix, A. Remm, A. D. Paolo, E. Genois, C. Leroux, C. Hellings, S. Lazar, F. Swiadek, J. Herrmann, G. J. Norris, C. K. Andersen, M. Müller, A. Blais, C. Eichler, and A. Wallraff, Realizing repeated quantum error correction in a distance-three surface code, Nature 605, 669 (2022).
- Bluvstein et al. [2024] D. Bluvstein, S. J. Evered, A. A. Geim, S. H. Li, H. Zhou, T. Manovitz, S. Ebadi, M. Cain, M. Kalinowski, D. Hangleiter, J. P. B. Ataides, N. Maskara, I. Cong, X. Gao, P. S. Rodriguez, T. Karolyshyn, G. Semeghini, M. J. Gullans, M. Greiner, V. Vuletić, and M. D. Lukin, Logical quantum processor based on reconfigurable atom arrays, Nature 626, 58 (2024).
- da Silva et al. [2024] M. P. da Silva, C. Ryan-Anderson, J. M. Bello-Rivas, A. Chernoguzov, J. M. Dreiling, C. Foltz, F. Frachon, J. P. Gaebler, T. M. Gatterman, L. Grans-Samuelsson, D. Hayes, N. Hewitt, J. Johansen, D. Lucchetti, M. Mills, S. A. Moses, B. Neyenhuis, A. Paz, J. Pino, P. Siegfried, J. Strabley, A. Sundaram, D. Tom, S. J. Wernli, M. Zanner, R. P. Stutz, and K. M. Svore, Demonstration of logical qubits and repeated error correction with better-than-physical error rates, (2024), Preprint arXiv:2404.02280.
- Delfosse [2020] N. Delfosse, Hierarchical decoding to reduce hardware requirements for quantum computing, (2020), Preprint arXiv:2001.11427.
- Gidney and Jones [2023] C. Gidney and C. Jones, New circuits and an open source decoder for the color code, (2023), Preprint arXiv:2312.08813.
- Horsman et al. [2012] D. Horsman, A. G. Fowler, S. Devitt, and R. V. Meter, Surface code quantum computing by lattice surgery, New Journal of Physics 14, 123011 (2012).
- Fowler and Gidney [2018] A. G. Fowler and C. Gidney, Low overhead quantum computation using lattice surgery, (2018), Preprint arXiv:1808.06709.
- Gidney [2024] C. Gidney, Inplace Access to the Surface Code Y Basis, Quantum 8, 1310 (2024).
- Higgott and Gidney [2023] O. Higgott and C. Gidney, Sparse blossom: correcting a million errors per core second with minimum-weight matching, arXiv preprint arXiv:2303.15933 (2023).
- Skoric et al. [2023] L. Skoric, D. E. Browne, K. M. Barnes, N. I. Gillespie, and E. T. Campbell, Parallel window decoding enables scalable fault tolerant quantum computation, Nat Commun 14, 7040 (2023), Preprint arXiv:2209.08552.
- Tan et al. [2023] X. Tan, F. Zhang, R. Chao, Y. Shi, and J. Chen, Scalable surface-code decoders with parallelization in time, PRX Quantum 4, 040344 (2023).
- Wu and Zhong [2023] Y. Wu and L. Zhong, Fusion Blossom: Fast MWPM Decoders for QEC, in 2023 IEEE International Conference on Quantum Computing and Engineering (QCE), Vol. 01 (2023) pp. 928–938, Preprint arXiv:2305.08307.
- Delfosse and Nickerson [2021] N. Delfosse and N. H. Nickerson, Almost-linear time decoding algorithm for topological codes, Quantum 5, 595 (2021), Preprint arXiv:1709.06218.
- Bravyi and Haah [2013] S. Bravyi and J. Haah, Quantum self-correction in the 3d cubic code model, Phys. Rev. Lett. 111, 200501 (2013).
- Duclos-Cianci and Poulin [2010a] G. Duclos-Cianci and D. Poulin, Fast decoders for topological quantum codes, Phys. Rev. Lett. 104, 050504 (2010a).
- Duclos-Cianci and Poulin [2010b] G. Duclos-Cianci and D. Poulin, A renormalization group decoding algorithm for topological quantum codes, in 2010 IEEE Information Theory Workshop (2010) pp. 1–5.
- Bombin and Martin-Delgado [2008] H. Bombin and M. A. Martin-Delgado, Statistical mechanical models and topological color codes, Phys. Rev. A 77, 042322 (2008).
- Delfosse [2014] N. Delfosse, Decoding color codes by projection onto surface codes, Phys. Rev. A 89, 012317 (2014).
- Sahay and Brown [2022] K. Sahay and B. J. Brown, Decoder for the triangular color code by matching on a möbius strip, PRX Quantum 3, 010310 (2022).
- Kubica and Delfosse [2023] A. Kubica and N. Delfosse, Efficient color code decoders in dimensions from toric code decoders, Quantum 7, 929 (2023).
- Kovalev and Pryadko [2013] A. A. Kovalev and L. P. Pryadko, Fault tolerance of quantum low-density parity check codes with sublinear distance scaling, Phys. Rev. A 87, 020304 (2013).
- Breuckmann and Eberhardt [2021] N. P. Breuckmann and J. N. Eberhardt, Quantum low-density parity-check codes, PRX Quantum 2, 040101 (2021).
- Bravyi et al. [2024] S. Bravyi, A. W. Cross, J. M. Gambetta, D. Maslov, P. Rall, and T. J. Yoder, High-threshold and low-overhead fault-tolerant quantum memory, Nature 627, 778 (2024).