Improved bounds for noisy group testing with constant tests per item
Abstract.
The group testing problem is concerned with identifying a small set of infected individuals in a large population. At our disposal is a testing procedure that allows us to test several individuals together. In an idealized setting, a test is positive if and only if at least one infected individual is included and negative otherwise. Significant progress was made in recent years towards understanding the information-theoretic and algorithmic properties in this noiseless setting. In this paper, we consider a noisy variant of group testing where test results are flipped with certain probability, including the realistic scenario where sensitivity and specificity can take arbitrary values. Using a test design where each individual is assigned to a fixed number of tests, we derive explicit algorithmic bounds for two commonly considered inference algorithms and thereby naturally extend the results of Scarlett & Cevher (2016) and Scarlett & Johnson (2020). We provide improved performance guarantees for the efficient algorithms in these noisy group testing models – indeed, for a large set of parameter choices the bounds provided in the paper are the strongest currently proved.
1. Introduction
1.1. Motivation and background
Suppose we have a large collection of people, a small number of whom are infected by some disease, and where only tests are available. In a landmark paper [16] from 1943, Dorfman introduced the idea of group testing. The basic idea is as follows: rather than screen one person using one test, we could mix samples from individuals in one pool, and use a single test for this whole pool. The task is to recover the infection status of all individuals using the pooled test results. Dorfman’s original work was motivated by a biological application, namely identifying individuals with syphilis. Subsequently, group testing has found a number of related applications, including detection of HIV [51], DNA sequencing [29, 37] and protein interaction experiments [35, 49]. More recently, it has been recognised as an essential tool to moderate pandemic spread [12], where identifiying infected individuals fast and at a low cost is indispensable [32]. In particular, group testing has been identified as a testing scheme for the detection of COVID-19 [2, 17, 21]. From a mathematical perspective, group testing is a prime example of an inference problem where one wants to learn a ground truth from (possibly noisy) measurements [1, 8, 15]. Over the last decade, it has regained popularity and a significant body of research was dedicated to understand its information-theoretic and algorithmic properties [9, 13, 14, 44, 45, 46]. In this paper, we provide improved upper bounds on the number of tests that guarantee successful inference for the noisy variant of group testing.
1.2. Related Work
1.2.1. Noiseless Group Testing
In the simplest version of group testing, we suppose that a test is positive if and only if the pool contains at least one infected individual. We refer to this as the noiseless case. In this setting, each negative test guarantees that every member of the corresponding pool is not infected, so they can be removed from further consideration. However, a positive test only tells us that at least one item in the test is defective (but not which one), and so requires further investigation. Dorfman’s original work [16] proposed a simple adaptive strategy where a small pool of individuals is tested, and where each positive test is followed up by testing every individual in the corresponding pool individually. Since then it has been an important problem to find the optimal way to recover the whole population’s infection status in the noiseless case (see [7] for a detailed survey). A simple counting argument (see for example [7, Section 1.4]) shows that to ensure recovery with zero error probability, since every possible defective set must give different test outcomes, the following must hold in the noiseless setting:
| (1.1) |
This can be extended to the case of recovery with small error probability, for example with the bound (see [7, Eq. (1.7)]) that the success probability
| (1.2) |
meaning that the success probability must decay exponentially with the number of tests below . Hwang [24] provided an algorithm based on repeated binary search, which is essentially optimal in terms of the number of tests required in that it requires tests, but may require many stages of testing. The question of whether non-adaptive algorithms (or even adaptive algorithms with a limited number of stages) can attain the bound (1.1) remained open until recently. [4, 14] showed that the answer depends on the prevalence of the disease, for example on the value of in a parameterisation111The result of [14] is two-fold. On the one hand, it provides a method to recover infected individuals w.h.p.as well as attaining (1.1) for a certain range of . On the other hand they show that (1.1) cannot be attained by any testing procedure for larger . One finds . where the number of infected individuals . Non-adaptive testing schemes can be represented through a binary -matrix that indicates which individual participates in which test. Significant research was dedicated to see which design attains the optimal performance, although much of the recent research analysed the performance of randomized designs. Initial research focused on the case where the matrix entries are i.i.d. [3, 5, 46], which we will refer to as Bernoulli pooling. Later work considered a constant column design where each individual is assigned to a (near-)constant number of tests [6, 13, 14, 26]. Indeed [14] showed that such a design is information-theoretically optimal in the noiseless setting and it is to be expected that this remains true for the noisy case. To recover the ground truth from the test results and the pooling scheme, this paper focuses on two non-adaptive algorithms, COMP and DD, which are relatively simple to perform and interpret in the noiseless case. We describe them in more detail below, but in brief COMP [10] simply builds a list of all the individuals who ever appear in a negative test and are hence certainly healthy, and assumes that the other individuals are infected. DD [5] uses COMP as a first stage and builds on it by looking for individuals who appear in a positive test that only otherwise contains individuals known to be healthy. While the noiseless case provides an interesting mathematical abstraction, it is clear that it may not be realistic in practice [40].
1.2.2. Noisy Group Testing
In medical applications [42] the two occurring types of noise in a testing procedure are related to sensitivity (the probability that a test containing an infected individual is indeed positive) and specificity (the probability that a test with only healthy individuals is indeed negative), and in that language we cannot assume the gold standard of tests with unit specificity and sensitivity. Thus, research attention in recent years has shifted towards the noisy version of group testing [10, 43, 44, 46, 47, 48]. On the one hand, the adaptive noisy case was considered in [43, 44]. On the other hand [10, 27, 28, 33, 46, 47, 48] looked at the non-adaptive noise case from different angles (for instance linear programming, belief propagation, and Markov Chain Monte Carlo). In [46, 47, 48] the algorithmic performance guarantees within noisy group testing under Bernoulli pooling are discussed. First of all [46] obtained a converse as well as a theoretical achievability bound, but stated the practical recovery as an direction for further research. In the following [47, 48] shed light on this question by using Bernoulli pooling.222[47] introduced an approach based on separate decoding of items for symmetric noise models. While this approach works well for small (in particular ), the performance drops dramatically for larger . For most this approach is worse off than the noisy DD discussed in [48]. Note there exist some noise levels with the very strong restriction assuming where [47] improve over our results in the very close to 0 regime. Due to the generality of our model we will from now on focus on [48] as benchmark for our results. In this paper we focus on the COMP and DD algorithms, since it is possible to deduce explicit performance guarantees for them. The original COMP and DD were designed for the noiseless case and do not automatically carry over to general noisy models. However, recent work of Scarlett and Johnson [48] showed that noisy versions of these algorithms can perform well under certain noise models using i.i.d. (Bernoulli pooling) test designs, particularly focusing on channel and reverse channel noise. As common medical tests have different values for sensitivity and specificity [31] the analysis of a generalized noise model beyond the and reverse channel is warranted.
1.2.3. Model Justification
As described for example in pandemic plans developed by the EU, US and WHO [19, 38, 39], and in COVID-specific work [36], adaptive strategies may not be suitable for pandemic prevention. For example, if a test takes one day to prepare and for the results to be known, then each stage will require an extra day to perform, meaning that adaptive group testing information can be received too late to be useful. Hence the need to perform large-scale testing to identify infected individuals fast relative to the doubling time [12, 32, 36] can make adaptive group testing unsuitable to prevent an infectious disease from spreading. Furthermore it may be difficult to preserve virus samples in a usable state for long enough to perform multi-round testing [22]. Due to its automation potential and the fact that tests can be completed in parallel (for example by the use of 96-well PCR plates [18]), the main applications of group testing such as DNA screening [11, 29, 37], HIV testing [51] and protein interaction analysis [35, 49] are non-adaptive, where all tests are specified upfront and performed in parallel. For example, while group testing strategies appear to be useful to identify individuals infected with COVID-19 (see for example [17, 21]), testing for the presence of the SARS-CoV-19 virus is not perfect [52], and so we need to understand the effect of both false positive and false negative errors in this context, with non-identical error probabilities. For this reason, we consider a general noise model in this paper. Under this model, a truly negative test is flipped with probability to display a positive test result, while a truly positive test is flipped to negative with probability (Figure 1). Its formulation is sufficiently general to accommodate the recovery of the noiseless results (), Z channel (), reverse Z channel () and the Binary Symmetric Channel (). However, our results include the case of non-zero and without having to make the somewhat artificial assumption that false negative and false positive errors are equally likely. We note that it may be unrealistic to assume that the noise parameters are known exactly, and more sophisticated models may be needed to understand the real world. Nevertheless our analysis of a generalised noise model serves as a starting point towards a full understanding of the difficulties occurring while implementing group testing algorithms in laboratories.
1.3. Contribution
This paper provides a simultaneous extension of [13] and [26, 48], by analysing noisy versions of COMP and DD under more general noise models for constant-column weight designs. In contrast to prior work [5, 26] assuming sampling with replacement, in this paper we use sampling without replacement, meaning that our designs have exactly the same number of tests for each item, rather than approximately the same as in those previous works. This makes little difference in practice, but may be closer to the spirit of LDPC codes for example.
We provide explicit bounds on the performance of these algorithms in a generalized noise model. We will prove that (noisy versions of) COMP as well as DD succeed with tests. Our analysis reveals the exact constants to ensure the recovery with these two inference algorithms. The main results will be stated formally in Theorems 2.1 and 2.2, but we would like to give the reader a first insight of what will follow. We analyze Algorithms 1 and 2 for the constant degree model, where there are tests performed and each individual chooses tests uniformly at random. Let and .
For any we find a threshold such that COMP succeeds in inferring the infected individuals if the number of tests
For any we find thresholds and such that DD succeeds in inferring the infected individuals if the number of tests
For all typical noise channels (Z, reverse Z and BSC) we compare the constant-column and Bernoulli design and find for all such instances that the required number of tests in the former is lower than the number needed in the latter thereby improving on results from [48], and providing the strongest performance guarantees currently proved for efficient algorithms in noisy group testing.
1.4. Test design and notation
To formalize our notation, we write for the number of individuals in the population, for a binary vector representing the infection status of each individual, (the Hamming weight of ) for the number of infected individuals and for the number of tests performed. We assume that is known for the purposes of matrix design, though in practice (see [7, Remark 2.3]) it is generally enough to know up to a constant factor to design a matrix with good properties. In this paper, in line with other work such as [5], we consider a scaling for some fixed , referred to in [7, Remark 1.1] as the sparse regime333Note that the analysis directly extends to as a constant factor in front does not influence the analysis.. In addition to the interesting phase transitions observed using this scaling, this sparse regime is particularly relevant as it was found suitable to model the early state of a pandemic [50].
Let us next introduce the test design. With denoting the set of individuals444 will be used as an abbreviated notation for the set . and the set of tests, the test design can be envisioned as a bipartite factor graph with variable nodes "on the left" and factor nodes "on the right". We draw a configuration , encoding the infection status of each individual, uniformly at random from vectors of Hamming weight . The set of healthy individuals will be denoted by and the set of infected individuals by . In symbols,
The lower bound from (1.1) suggests that in the noisy group testing setting it is natural to compare the performance of algorithms and matrix designs in terms of the prefactor of in the number of tests required. To be precise, we carry out tests, and each item is assigned to exactly tests chosen uniformly at random without replacement. We parameterize and as
| (1.3) |
for some suitably chosen constants .
Let denote the set of tests that individual appears in and the set of individuals assigned to test . The resulting (non-constant) collection of test degrees will be denoted by the vector . Further, let
| (1.4) |
Throughout, describes the random bipartite factor graph from this construction.
Now consider the outcome of the tests. Recall from above that a standard noiseless group test gives a positive result if and only if there is at least one defective item contained in the pool, or equivalently if . Even in the noisy case, this sum is a useful object to consider. Writing for the indicator function, we define
| (1.5) |
to be the outcome we would observe in the noiseless case using the test matrix corresponding to . We will say that test is truly positive if and truly negative otherwise.
However, we do not observe the values of directly, but rather see what we will refer to as the displayed test outcomes – the outcomes of sending the true outcomes independently through the channel of Figure 1. Since in this model a truly positive test remains positive with probability and a truly negative test is displayed as positive with probability we can write
| (1.6) |
where denotes a Bernoulli random variable with parameter independent of all other randomness in the model. For models with binary outputs, this is the most general channel satisfying the noisy defective channel property of [7, Definition 3.3], though more general models are possible under the only defects matter property [7, Definition 3.2], where the probability of a test being positive depends on the number of infected individuals it contains.
Note that if , we can preprocess the outputs from (1.6) by flipping them, i.e. setting and , where . Hence without loss of generality we will assume throughout that . In the case , the test outcomes are independent of the inputs, and we cannot hope to find the infected individuals – see Corollary 2.3.
With being the number of truly negative tests, let be the number of truly negative tests that are flipped to display a positive test result and be the number of truly negative tests that are unflipped. Similarly, define as the number of truly positive tests, of which are flipped to a negative test result and of which are unflipped. For reference, for we write
Here we use bold letters to indicate random variables. Throughout the paper, we use the standard Landau notation and define . Furthermore we say that a property holds with high probability ( w.h.p.), if as . In order to quantify the performance of our algorithms, for any , we write
| (1.7) |
for the relative entropy of a Bernoulli random variable with parameter to a Bernoulli random variable with parameter , commonly referred to as the Kullback–Leibler divergence. Here and throughout the paper we use to denote the natural logarithm. For or equal to or we define the value of (possibly infinite) on grounds of continuity, so for example .
2. Main results
With the test design and notation in place, we are now in a position to state our main results. Theorems 2.1, 2.2 are the centerpiece of this paper, featuring improved bounds for the noisy group testing problem for the general model. We follow up in Section 2.2 with a discussion of the combinatorics underlying both algorithms, and provide a converse bound in Section 2.3. Subsequently, in Section 2.4 we show how the bounds simplify when we consider the special cases of the Z, the reverse Z and Binary Symmetric Channel. Finally, in Section 2.5 we derive sufficient conditions under which DD requires fewer tests than the COMP algorithm and compare the bounds of our constant-column design against the Bernoulli design employed in prior literature.
2.1. Bounds for Noisy Group Testing
We will consider two well-known algorithms from the noiseless setting to identify infected individuals in this paper. First, we study a noisy variant of the COMP algorithm, originally introduced in [10].
Note that for the formulation of Algorithm 1 coincides with the standard algorithm where an individual is classified as healthy if it appears in at least one displayed negative test which constitutes a sufficient condition in the noiseless case. We now state the first main result of this paper.
Theorem 2.1 (Noisy COMP).
Let , . Suppose that and let
If for some , noisy COMP will recover w.h.p. given test design and test results .
Note that the formulation of Algorithm 2 reduces to the noiseless version of DD introduced in [5] by taking . This is because in the noiseless setting a single negative test or a single positive test with just individuals already classified as uninfected is sufficient in the noiseless case. Furthermore note that for noisy DD and noisy COMP are the same. From now on we assume . The proof of Theorem 2.1 can be found in Appendix B. We now state the second main result of the paper.
Theorem 2.2 (Noisy DD).
Let , and and define . Suppose that and let
If for some , then noisy DD will recover w.h.p. given test design and test results .
The proof of Theorem 2.2 can be found in Appendix C. While the bounds appear cumbersome at first glance, the optimization is of finite dimension and for every specific value of and can be efficiently solved to arbitrary precision yielding explicit values for and . For illustration purposes, we will calculate those bounds for several values of and .
2.2. The combinatorics of the noisy group testing algorithms
In the following, we outline the combinatorial structures that Algorithm 1 and 2 take advantage of.
We start with defining the three types of tests that are relevant for the classification of an individual while using COMP and DD.
In the first stage we find
-
•
Type DN: Displayed negative tests
-
•
Type DP: Displayed positive tests
Note that the only available information during the first stage of the algorithms is the test result and the pooling structure – no information about the individuals’ infection status is available. We give an illustration on the left hand side of Figure 2. After this step COMP terminates by declaring all remaining individuals as infected.
The DD algorithm continues with a second step which considers just the displayed positive tests. From the first step of the algorithm one receives the estimate of the set of non-infected individuals obtained in the first round. Now distinguish the following two types, illustrated on the right hand side in Figure 2:
-
•
Type Displayed-Positive-Single (DP-S): Displayed positive tests in which all other individuals are already declared as uninfected.
-
•
Type Displayed-Positive-Multiple (DP-M): Displayed positive tests with at least one other individual that is not contained in the estimated set of uninfected individuals.
2.2.1. The noisy COMP algorithm
To get started, let us shed light on the combinatorics of noisy COMP (Algorithm 1). For the noiseless case, the COMP algorithm classifies each individual that appears in at least one negative test as healthy and all other individuals as infected, since the participation in a negative test is a sufficient condition for the individual to be healthy.
For the noisy case, the situation is not as straightforward, since an infected individual might appear in displayed negative tests that were flipped when sent through the noisy channel. Thus, a single negative test is not definitive evidence that an individual is healthy. Yet, we can use the number of negative tests to tell the infected individuals apart from the healthy individuals.
Clearly, noisy COMP (Algorithm 1) using a threshold succeeds if no healthy individual appears in fewer than displayed negative tests and no infected individual appears in more than displayed negative tests. To this end, we define
| (2.1) |
for the number of displayed negative tests that item appears in. In terms of Figure 2, the algorithm determines the infection status by counting the number of tests of Type DN.
2.2.2. The noisy DD algorithm
As in the prior section, let us first consider the noiseless DD algorithm. The first step is identical to COMP classifying all individuals that are contained in at least one negative test as healthy. In a second step, the algorithm checks each individual to see if it is contained in a positive test as the only remaining unclassified individual after the first step of the algorithm and thus must be infected.
Again, the situation is more intricate when we add noise, since neither a single negative test gives us confidence that an individual is healthy nor does a positive test where the individual is the single remaining unclassified individual after the first step of the algorithm inform us that this individual must be infected. Instead we count and compare the number of such tests. The first step of the noisy DD algorithm is identical to noisy COMP, but we are not required to identify all healthy individuals in the first step (we are able to keep some unclassified for the second round). Thus, after the first step, we are left with all infected individuals (as the algorithm did not try to classify any individual as infected in the first step) and a set of yet unclassified healthy individuals (as some of them might exhibit a first neighbourhood that is not sufficient for a clear first round classification) which we will denote by .These are healthy individuals who did not appear in sufficiently many displayed negative tests to be declared healthy with confidence in the first step555Note that the bounds are taken in a way such that no infected individual is classified as uninfected in the first round.. In symbols, for some
To tell and apart, we consider the number of displayed positive tests where the individual appears on its own after removing the individuals , which were declared healthy already, from the first step, i.e.
| (2.2) |
Referring to Figure 2, the second step of the algorithm is based on counting tests of Type DP-S. Tests of Type DP-M contain another remaining unclassified individual after the first step of the algorithm from . The noisy DD algorithm takes advantage of the fact that it is less likely for an individual to appear as the only yet unclassified individual in a displayed positive test than it is for an individual in . For such a test would be truly negative and would have been flipped (which occurs with probability ) to display a positive test result. Conversely, an individual renders any of its tests truly positive and thus the only requirement is that the test otherwise contains only individuals which were declared healthy already, and is not flipped (which occurs with probability ). For this reason, we will see that the distribution of differs between and , and the difference helps determine the size of this difference. The second step of DD exploits this observation by counting tests of Type DP-S.
2.3. The Channel Perspective of noisy group testing
Motivated by (1.1), we can describe the bounds in terms of rate, in a Shannon-theoretic sense. That is, we follow the common notion to define the rate (bits learned per test) of an algorithm in this setting (for instance as in [9]) to be
(Recall that we take logarithms to base throughout this paper). For example the fact that Theorems 2.1 and 2.2 show that noisy COMP and DD respectively can succeed w.h.p. ; with tests for some is equivalent to the fact that is an achievable rate in a Shannon-theoretic sense.
We now give a counterpart to these two theorems by stating a universal converse for the channel below, improving on the universal counting bound from (1.1). The starting observation (see [7, Theorem 3.1]) is that no group testing algorithm can succeed w.h.p. with rate greater than , the Shannon capacity of the corresponding noisy communication channel. Thus, we cannot hope to succeed w.h.p. with tests where . Hence as a direct consequence of the value of the channel capacity of the channel, we deduce the following statement.
Corollary 2.3.
Let , and , write for the binary entropy in nats (logarithms taken to base ) and . If we define
then for no algorithm can recover w.h.p. for any matrix design.
Remark 2.4.
This result follows from Lemma F.1 derived in Appendix F below. As discussed there, this derivation (combined with the fact that each test is negative with probability ) suggests a choice of density for the matrix:
While a choice of is not necessarily optimal, it may be regarded as a sensible heuristic that provides good rates for a range of and values.
2.4. Applying the results to standard channels
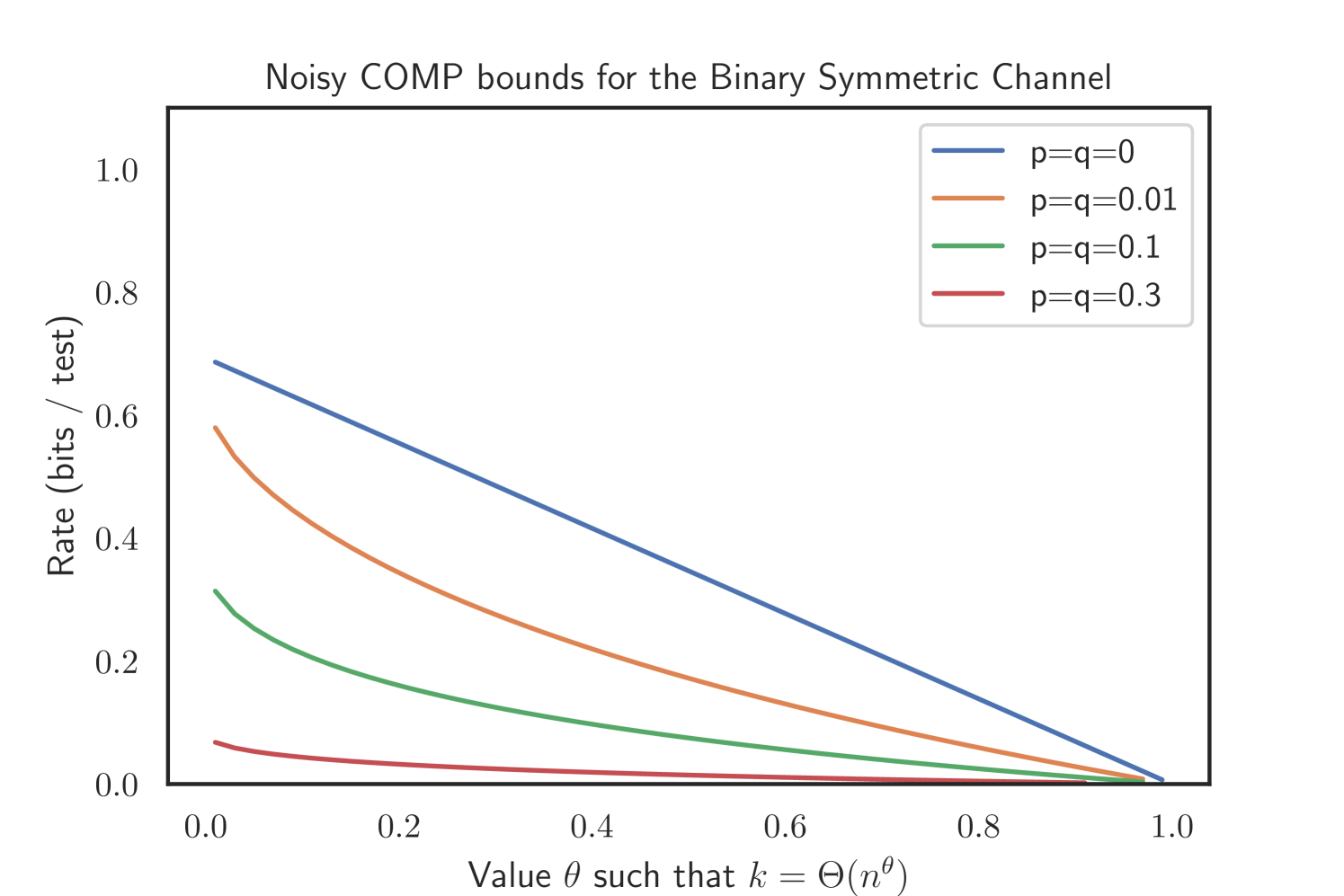
With Theorem 2.1 and Theorem 2.2 we derived achievable rates for the generalized p-q-model (see Figure 1). Prior research considered the Z channel where and , the Reverse Z channel where and and the Binary Symmetric Channel with . These channels are common models in coding theory [41], but are also often considered in medical applications [30, 31] concerned with taking imperfect sensitivity (), specificity () or both ( and ) into account. As a consequence we also compare our results with the most recent results of Johnson and Scarlett [48]. In the following section we will demonstrate how performance guarantees on these channels can directly be obtained from our main theorems.
2.4.1. Recovery of the noiseless model
Note that the bounds Corollary 2.5 and Corollary 2.6 are already known [10, 26]. We would like to give the reader an idea of how one can see that our cumbersome looking bounds relate to the more accessible bounds given for the noiseless case. First, we show the noiseless bounds can be simply recovered by letting . In the noiseless setting, it is sufficient, by definition of the algorithm, to set both and . To see why, observe that in the absence of noise a single negative test is sufficient evidence that an individual is healthy. Conversely, a single positive test where the individual only appears with individuals , which were declared healthy already, implies that particular individual must surely be infected. As shown in [13] the optimal parameter choice for the density parameter in the constant-column design in the noiseless setting is . Applying these values to Theorem 2.1 we recover the noiseless bound for COMP.These bounds were first stated in [10].
Corollary 2.5 (COMP in the noiseless setting).
Proof.
We start by taking the bounds and . To see how this boils down to , we start with using the well-known fact that within the near constant column design is the optimal choice [13]. Now by taking both one realizes that vanishes as as . Turning our focus to the second bound we see that it boils down to
On the one hand we realize that is negative for all . This leads to
On the other hand we realize that in the noiseless case a single negative test is sufficient for a classification as uninfected. Therefore we may choose sufficiently small. One indeed realizes that for each we can choose appropriately, such that the bounds given in Theorem 2.1 recover the noiseless case. ∎
We also recover the noiseless bounds for the DD algorithm as stated in [26].
Corollary 2.6 (DD in the noiseless setting).
Proof.
We start with taking and as defined in Theorem 2.2. First of all we take . By assumption we find and therefore the indicator is 1 as soon as we let . Furthermore for we get and find . Second of all we take . With a similar argument as before we see that for as in this case we find . Therefore we are left with and . Again, we use the well known fact that in the noiseless case is the optimal choice. Therefore with the two remaining bounds read as follows:
Again we see that is negative for . Therefore we find
Now as as before in this case again a single negative test as well as a single test with only already classified uninfected individuals is sufficient. Therefore we can choose sufficiently small. One indeed realizes that for each one can choose appropriately such that the bounds of Theorem 2.2 recover the noiseless case. ∎
2.4.2. The Z channel
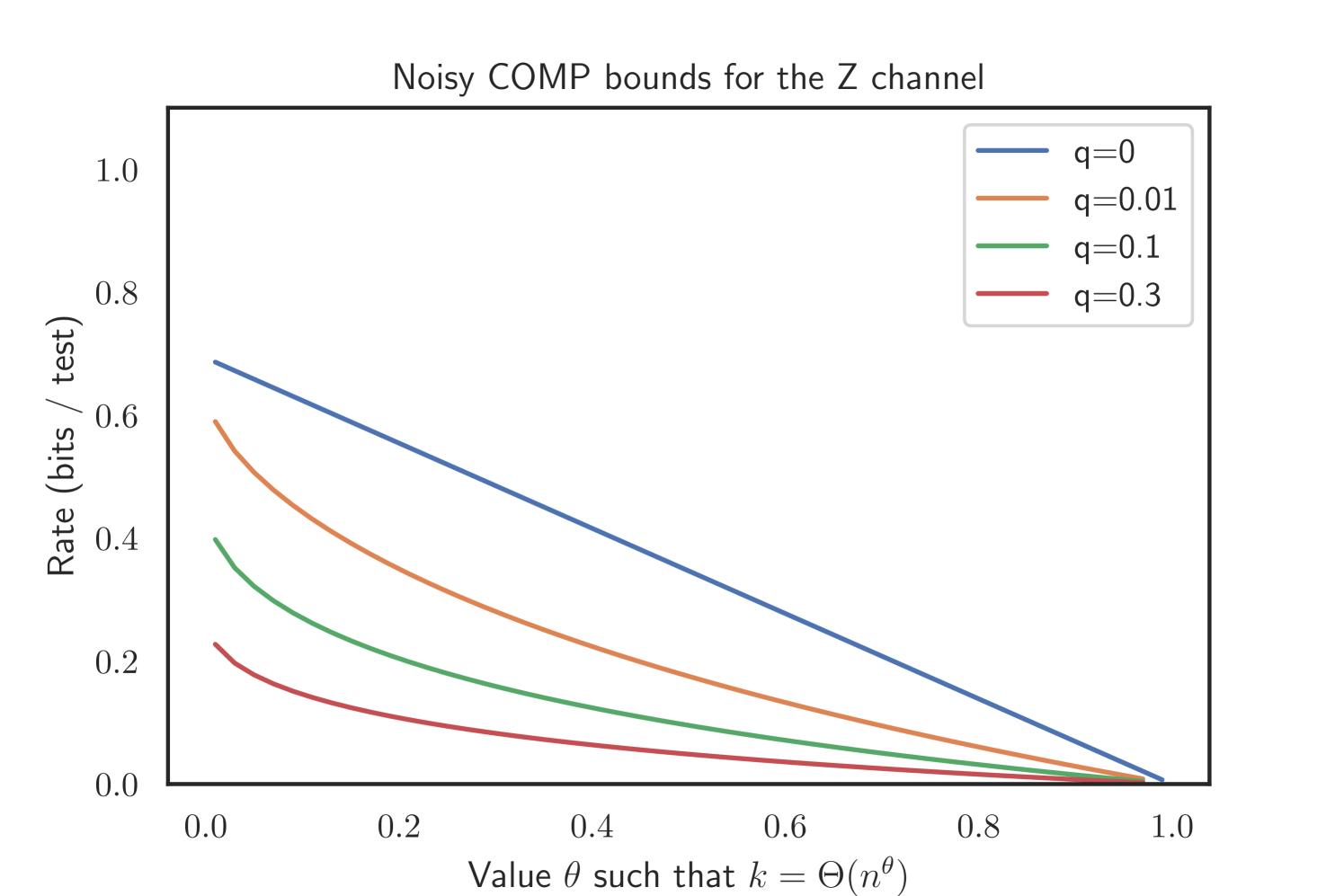
In the Z channel, we have and , i.e. no truly negative test displays a positive test result. Thus, in this case finding one positive test with only one unclassified individual is a clear indication, therefore we again can choose sufficiently small and remain agnostic about and . The bounds for COMP and DD thus read as follows.
Corollary 2.7 (Noisy COMP for the Z channel).
Let and . Further, let
If , noisy COMP will recover w.h.p. given .
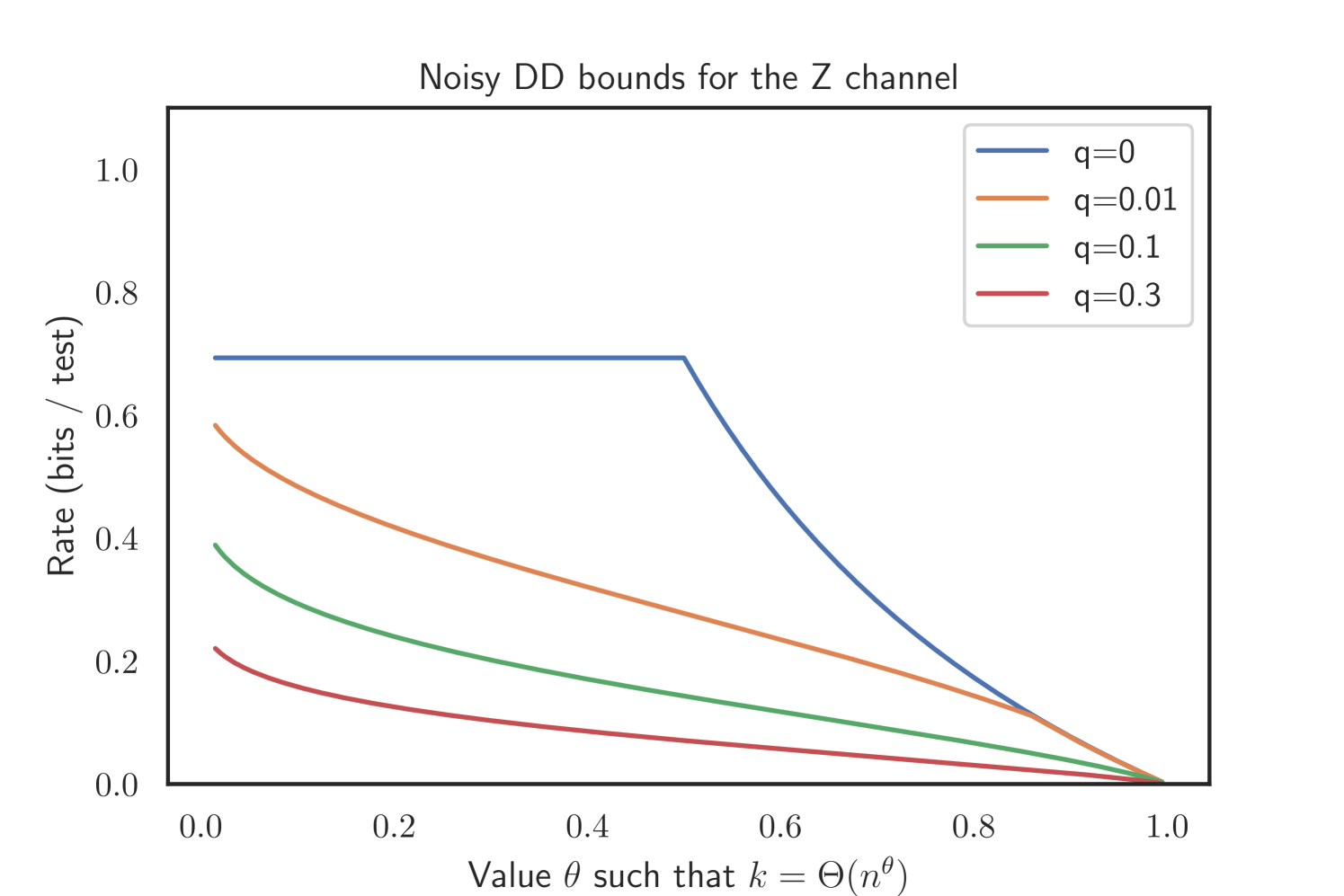
Corollary 2.8 (Noisy DD for the Z channel).
Let and . Further, let
| with | |||
| and |
If , noisy DD will recover w.h.p. given .
Proof.
The bounds and follow directly from Theorem 2.2 by letting . An immediate consequence of is that due to the fact that and one finds that , thus being trivial in this case. For we use the fact that we can choose sufficiently small we find for . Note that by definition of the noise model, we may choose an arbitrary very close to zero and as a consequence leading to . The assertion follows as for each we may choose such that . ∎
2.4.3. Reverse Z channel
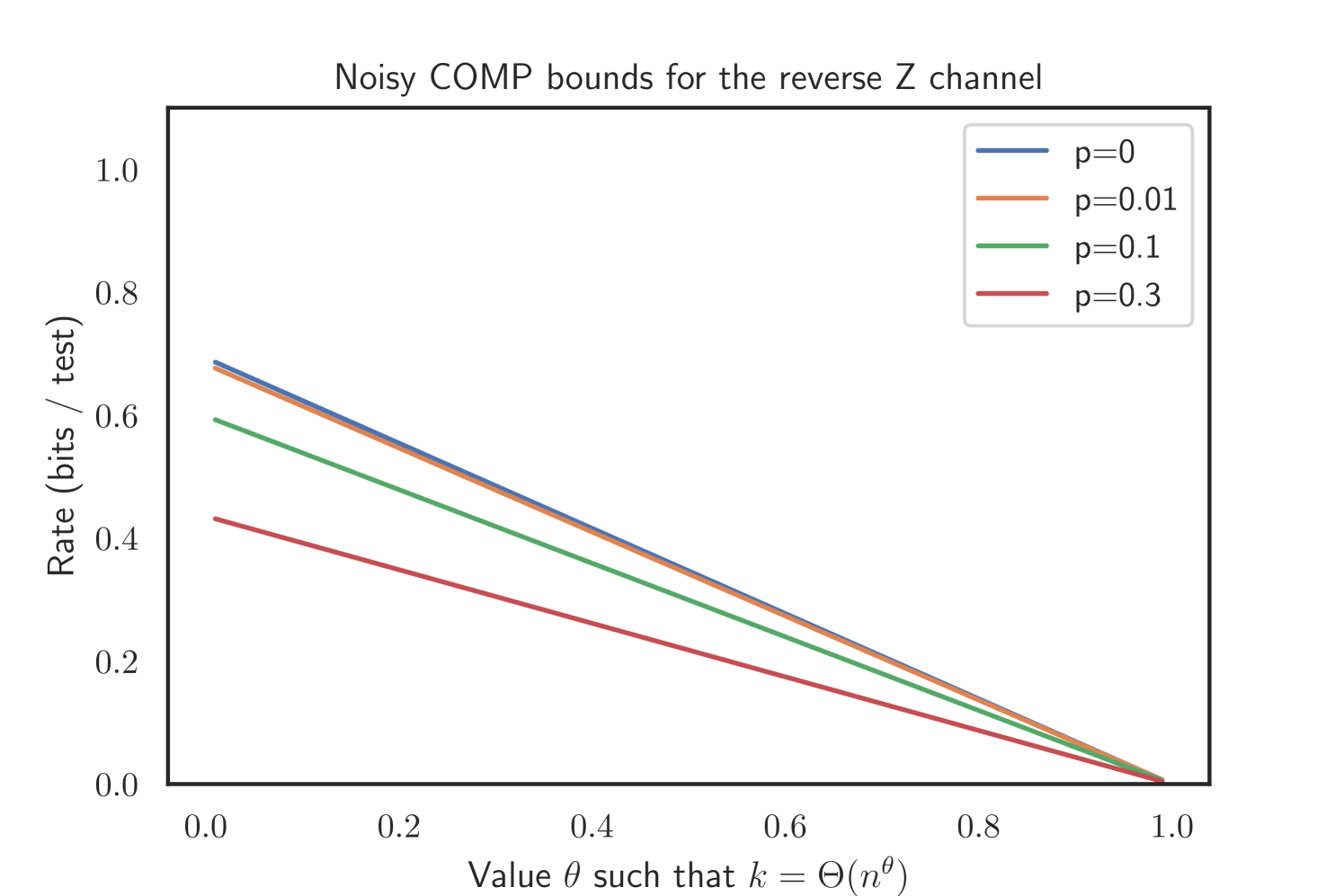
In the reverse Z channel, we have and , i.e. no truly positive test displays a negative test result. Thus, we may choose sufficiently small and remain agnostic about and . The bounds for the noisy COMP and DD thus read as follows.
Corollary 2.9 (Noisy COMP for the Reverse Z channel).
Let and . Further, let
If , noisy COMP will recover w.h.p. given .
Proof.
The corollary follows from Theorem 2.1 and the fact that for one finds that diverges, Thereby just gives a trivial bound in this case. Furthermore for sufficiently small we get . Due to the noise assumption, we may choose an arbitrary very close to zero and which leads to . The assertion follows by choosing such that . ∎
Note that Corollary 2.9 does not yield an immediate closed form expression for the optimal value of .
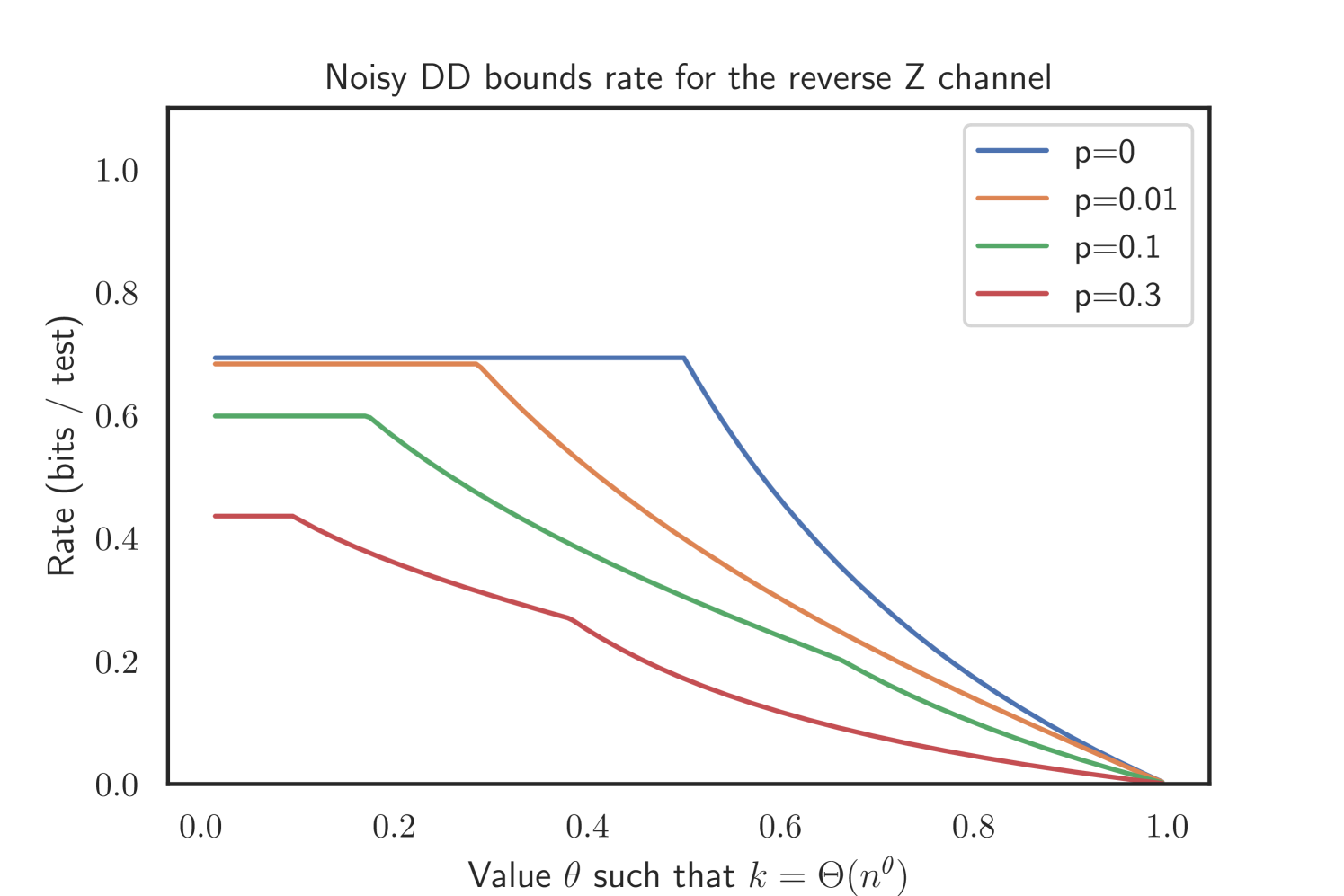
Corollary 2.10 (Noisy DD in the Reverse Z channel).
Let and . Further, let
| with | |||
| and |
If , noisy DD will recover w.h.p. given .
Proof.
First of all we assume . Therefore we find as . The bounds follow from Theorem 2.2 and the same manipulations as above. For , we again see that by definition of the noise model we may choose as close to zero as we like. Therefore we get close to 1, which leads to . The assertion follows as for each we can choose such that .∎
2.4.4. Binary Symmetric Channel
In the Binary Symmetric Channel (BSC), we set . Even though information-theoretic arguments would suggest setting , we formulate the expression below with general . We also keep the threshold parameters and . The bounds for the noisy DD and COMP only simplify slightly.
Corollary 2.11 (Noisy COMP in the Binary Symmetric Channel).
Let and . Further, let
| with |
If , noisy COMP will recover w.h.p. given .
Corollary 2.12 (Noisy DD in the Binary Symmetric Channel).
Let and and define . Further, let
| with | |||
| and | |||
| and |
If , noisy DD will recover w.h.p. given .
2.5. Comparison of noisy COMP and DD
An obvious next question is to find conditions under which the noisy DD algorithm requires fewer tests than the noisy COMP. For the noiseless setting, it can be easily shown that DD provably outperforms COMP for all . For the noisy case, matters are slightly more complicated.
Recall that noisy COMP classifies all individuals appearing in less than displayed negative tests as infected while noisy DD additionally requires such individuals to appear in more than displayed positive tests as the only yet unclassified individual. Thus, it might well be that an infected individual is classified correctly by noisy COMP, while it is missed by the noisy DD algorithm.
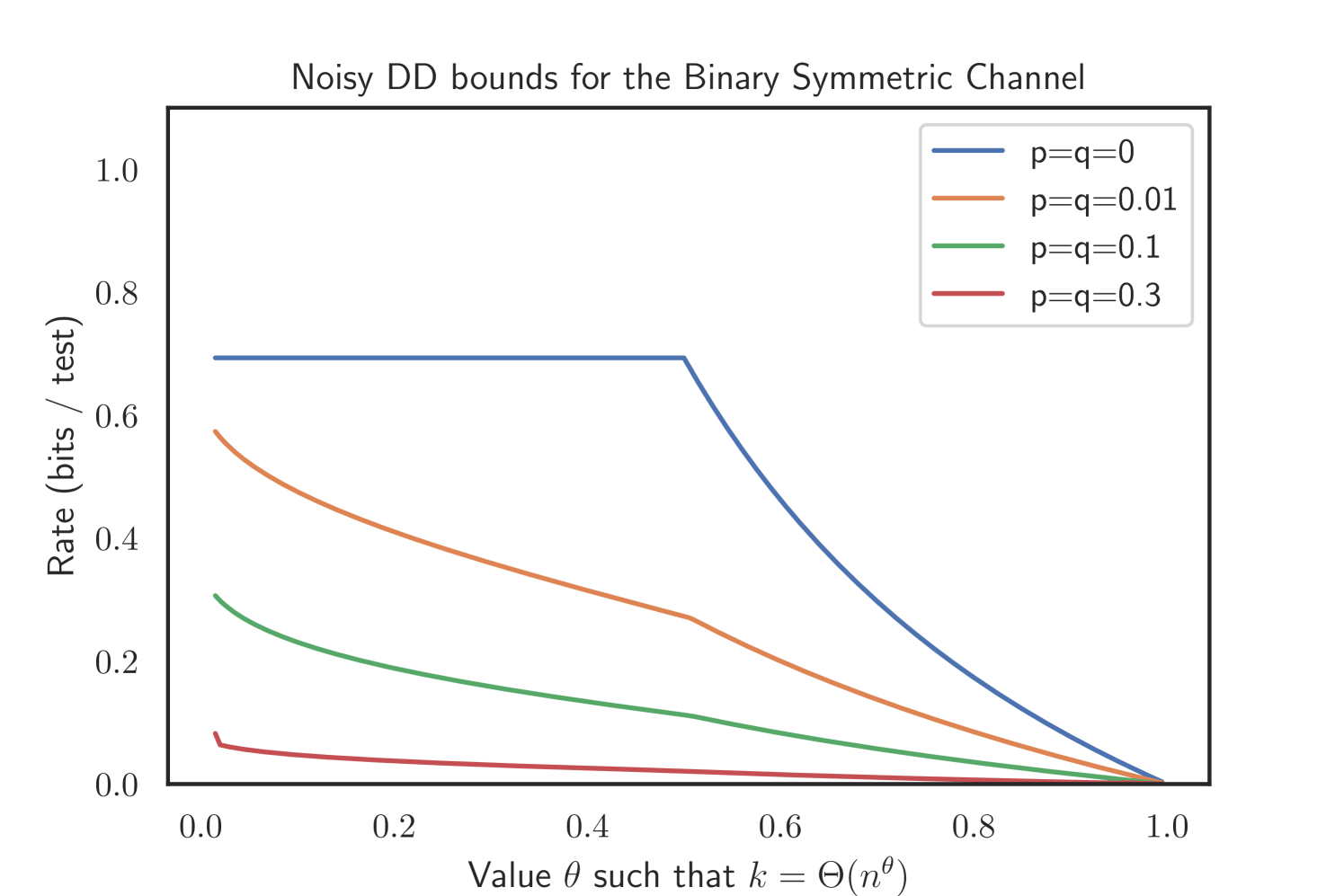
That being said, our simulations indicate that noisy DD generally requires fewer tests than noisy COMP, but for the reason mentioned above we can only prove that for the reverse Z channel while remaining agnostic about the Z channel and the Binary Symmetric Channel, as the next proposition evinces.
Proposition 2.13.
For all with there exists a such that as long as .
In terms of the common noise channels Proposition 2.13 gives the following corollary.
Corollary 2.14.
In the reverse Z channel, .
The proof can be found in Appendix D. Our simulations suggest that this superior performance of noisy DD holds as well for the Z channel and Binary Symmetric Channel. Please refer to Figure 3 for an illustration.
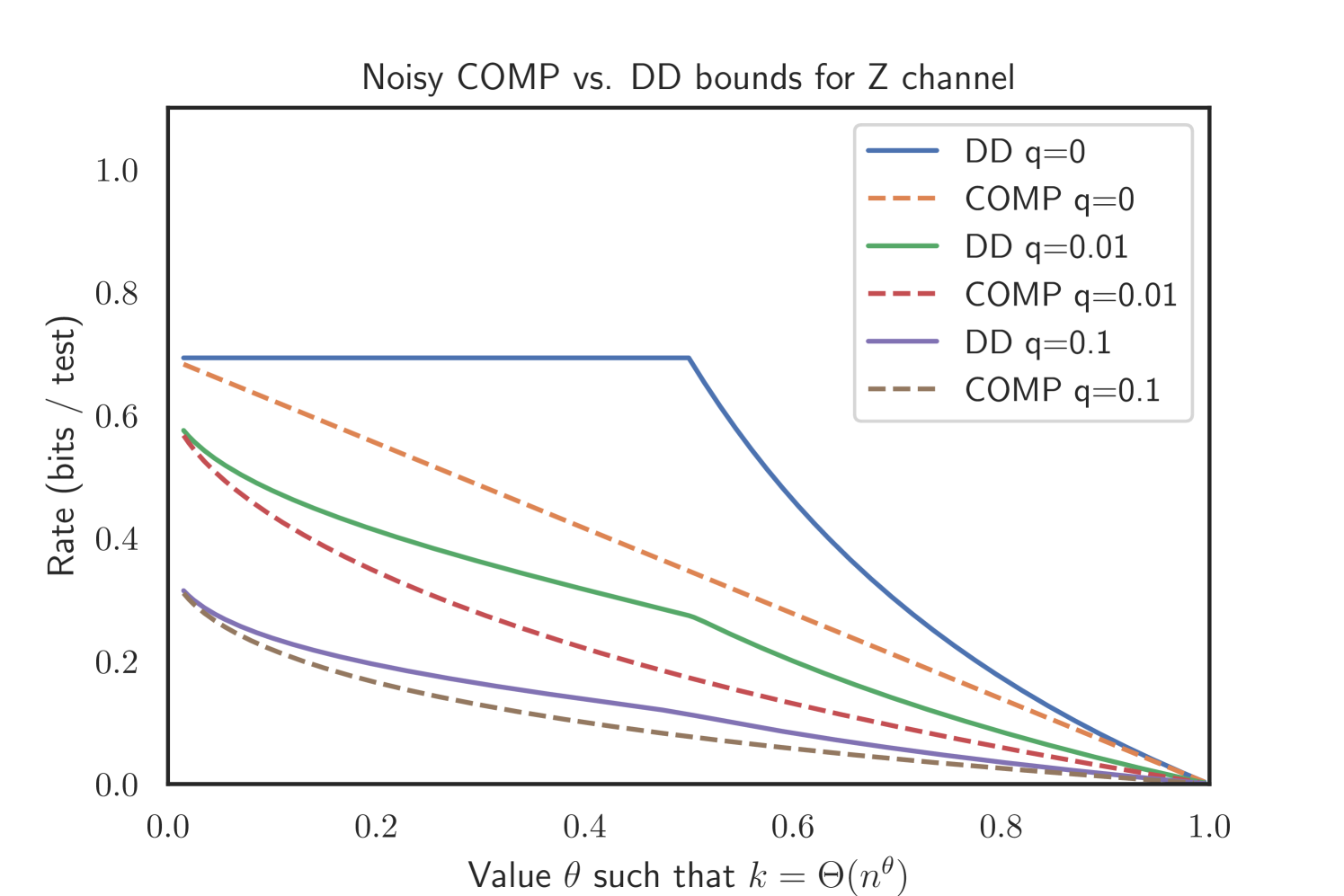
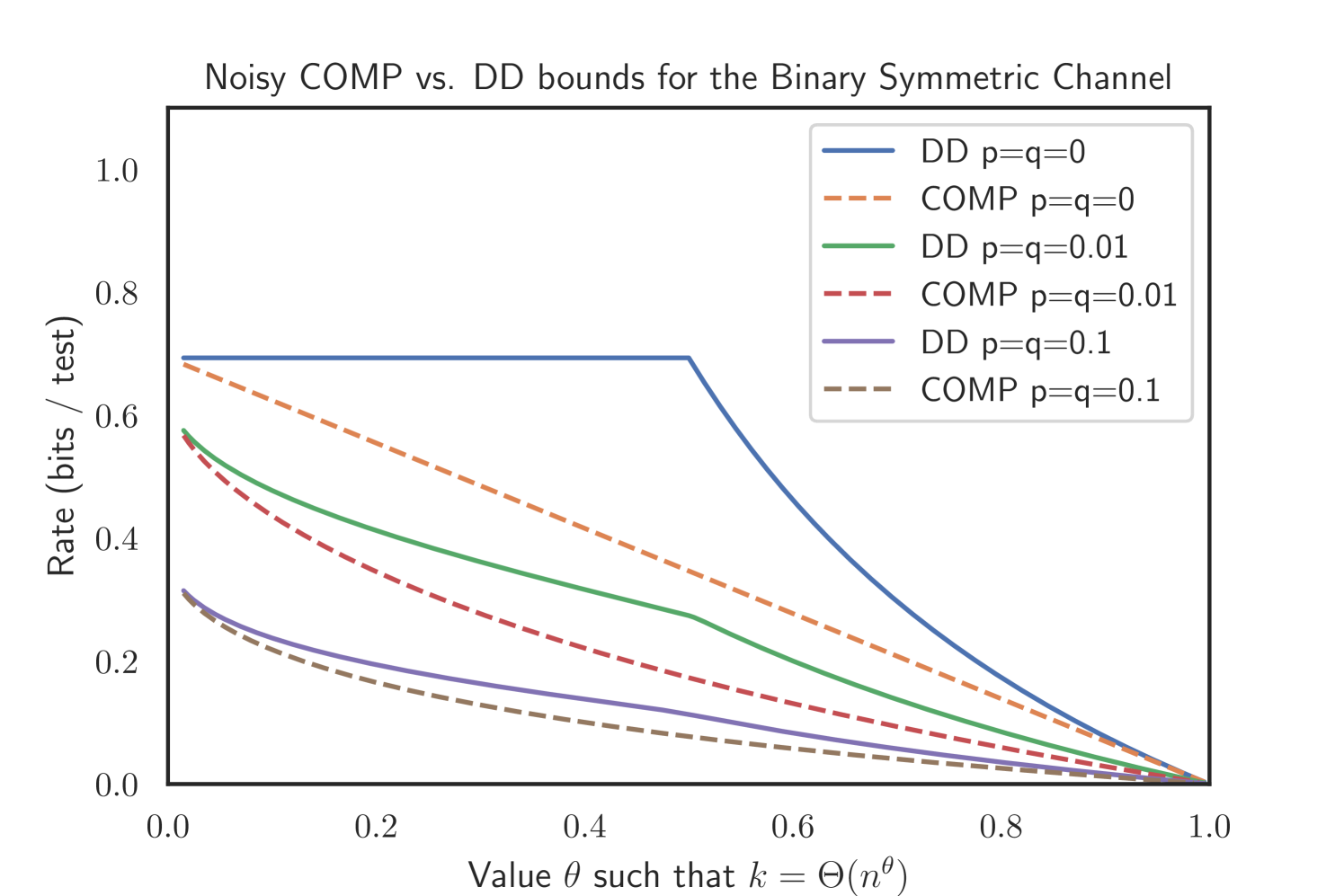
2.6. Relation to Bernoulli testing
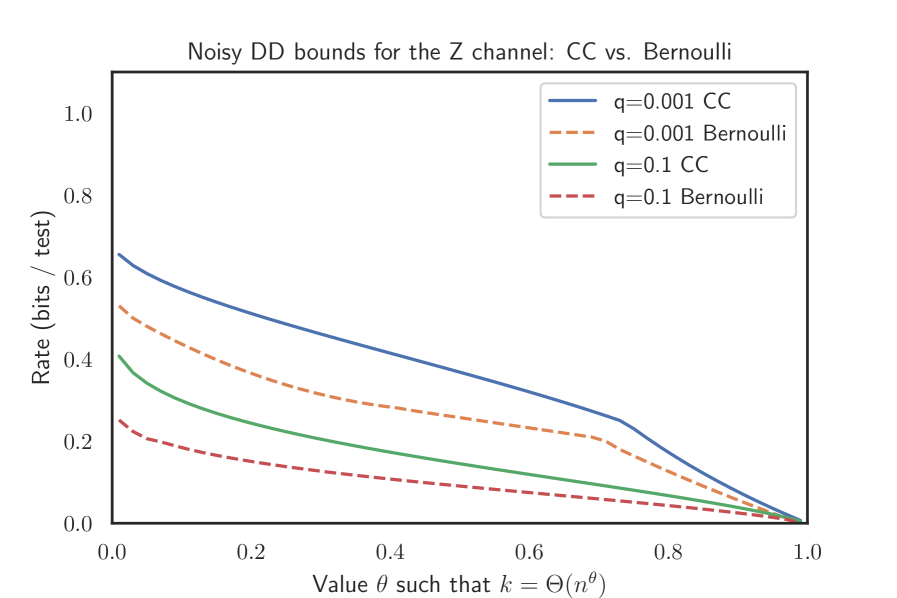
In [48] sufficient bounds for noisy group testing and a Bernoulli test design where each individual joins every test independently with some fixed probability were derived. Thus, the variable degrees fluctuate and we end up with some individuals assigned only to few tests. In contrast, we work under a model in this paper where each individual joins an equal number of tests chosen uniformly at random without replacement. For the noiseless case, it is by now clear that the near-constant-column design better facilitates inference than the Bernoulli test design [13, 26]. We find that the same holds true for the noisy variant of the COMP algorithm. Let us denote by the number of tests required for the noisy COMP to succeed under a Bernoulli test design.
Proposition 2.15.
For all , we have
We see the same effect for the noisy variant of the DD algorithm for all simulations, but for technical reasons only prove it for the Z channel.
Proposition 2.16.
For the Z channel where and , we have
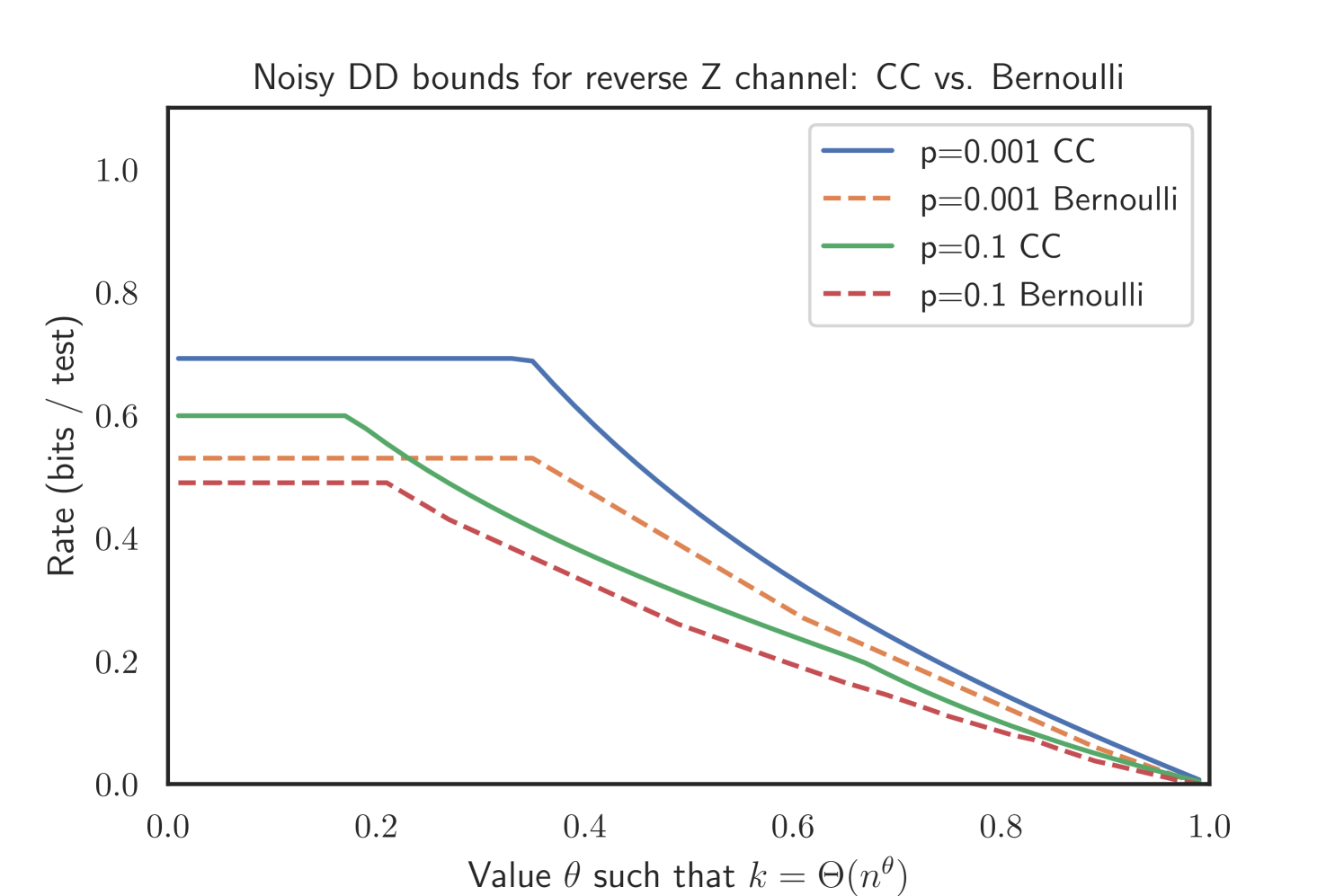
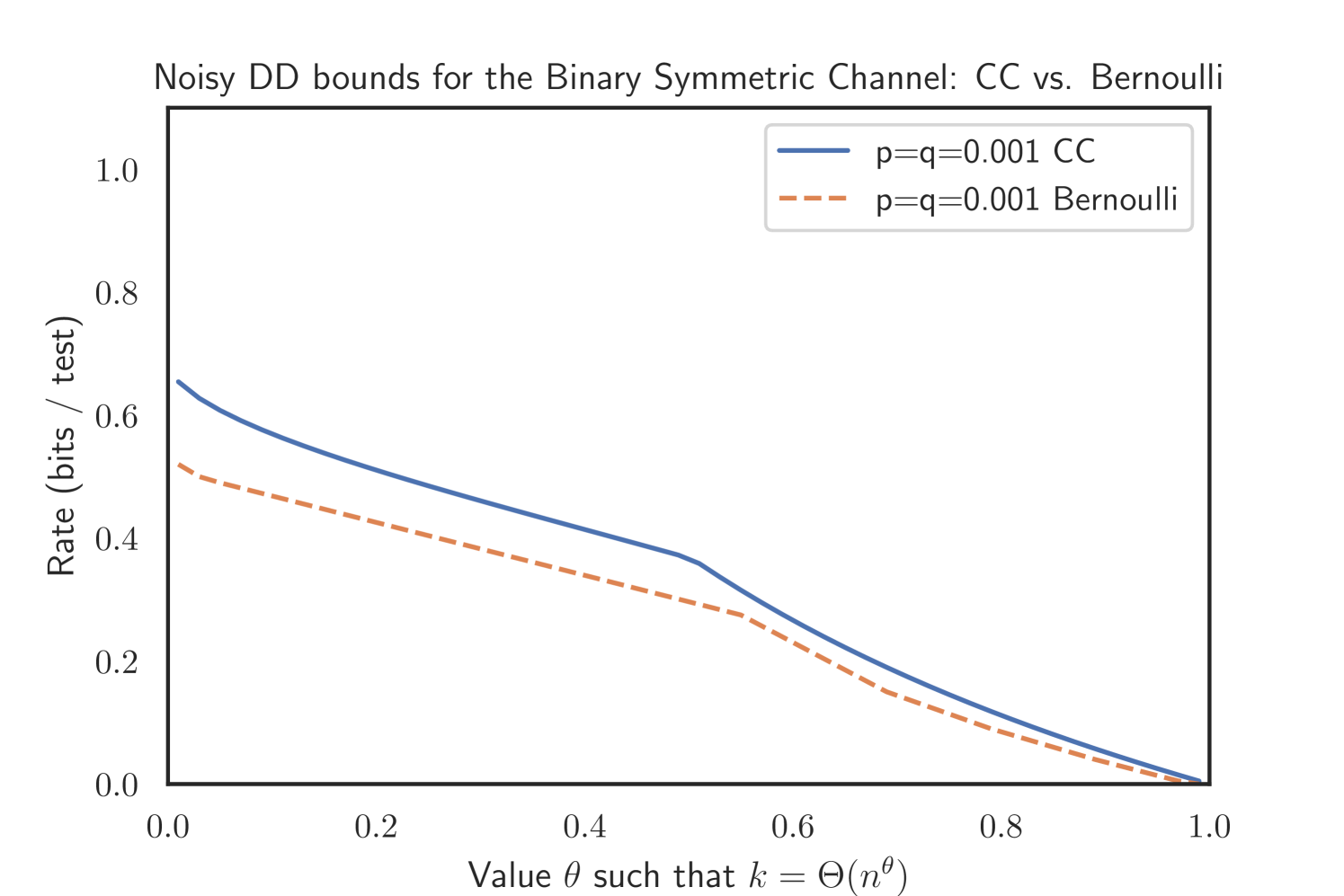
Appendix
The core of the technical sections is the proof of Theorems 2.1 and Theorem 2.2. Some groundwork with standard concentration bounds and group testing properties can be found in Section A. We continue with the proof of Theorems 2.1 and 2.2 in Sections B and C, respectively. The structure of the proofs follows a similar logic. First, we derive the distributions for the number of displayed positive and negative tests for infected and healthy individuals. Second, we threshold these distributions using sharp Chernoff concentration bounds to deduce the bounds stated in Theorem 2.1 and Theorem 2.2. Thereafter, we proceed to the proof of Proposition 2.13 in Section D, while the proofs of Propositions 2.15 and 2.16 follow in Section E. The proof of Corollary 2.3 can be found in Section F. Additional illustrations of our results for the different channels can be found in Section G.
Appendix A Groundwork
For starters, let us recall the Chernoff bound for binomial and hypergeometric distributions.
Lemma A.1 (Chernoff bound for the binomial distribution [25]).
Let and be a binomially distributed random variable. Then
Lemma A.2 (Chernoff bound for the hypergeometric distribution [23]).
Let and be a hypergeometrically distributed random variable. Further, let . Then
The next lemma provides that the test degrees, as defined in (1.4) above, are tightly concentrated. Recall from (1.3) that the number of tests and each item appears in tests.
Lemma A.3.
With probability we have
Proof.
The probability that an individual is assigned to test is given by
| (A.1) |
Since each individual is assigned to tests independently, the total number of individuals in a given test follows the binomial distribution . The assertion now follows from applying the Chernoff bound for this binomial distribution at the expectation (Lemma A.1). ∎
Next, we show that the number of truly negative tests (and thus the number of truly positive tests ) is tightly concentrated.
Lemma A.4.
With probability we have .
Proof.
Recall from (A.1) that
Since infected individuals are assigned to tests mutually independently, we find for a test that
Consequently, . Finally, changing the set of tests for a specific infected individual shifts the total number of negative tests by at most . Therefore, the McDiarmid inequality (Lemma 1.2 in [34]) yields
The lemma follows from setting . ∎
With the concentration of and at hand, we readily obtain estimates for and . We remind ourselves that these are the number of flipped, unflipped negative tests and the number of flipped, unflipped positive tests as defined in Sec. 1.4.
Corollary A.5.
With probability we have
-
(i)
-
(ii)
-
(iii)
-
(iv)
Proof.
Appendix B Proof of COMP bound, Theorem 2.1
Recall from (2.1) that we write for the number of displayed negative tests that item appears in (as illustrated by the right branch of Fig. 2). The proof of Theorem 2.1 is based on two pillars. First, Lemmas B.1 and B.2 provide the distribution of for healthy and infected individuals, respectively. We will see that these distributions differ according to the infection status of the individual. Second, we will derive a suitable threshold via Lemma B.3 and B.4 to tell healthy and infected individuals apart w.h.p. We start by analysing individuals in the infected set . Throughout the section, we assume .
Lemma B.1.
Given , its number of displayed negative tests is distributed as .
Proof.
Any test containing an infected individual is truly positive because of the presence of the infected individual. Since an infected individual is assigned to different tests and each such test is flipped with probability independently, the lemma follows immediately. ∎
Next, we consider the distribution for healthy individuals. Recall that denotes the event that the bounds from Lemma A.4 and Corollary A.5 hold.
Lemma B.2.
Given and conditioned on , the total variation distance of the distribution of and that is distributed as tends to zero with , that is
Proof.
Since is healthy, the outcome of all the tests remains the same if it is removed from consideration (if we perform group testing with items and the corresponding reduced matrix).
Thus, given , we find that with removed the still satisfy the bounds from Corollary A.5. As a result the number of displayed negative tests (which consist of unflipped truly negative tests and flipped truly positive tests) is given by
| (B.1) |
Now, adding back into consideration: chooses tests without replacement independently of this. Hence, given that the random quantity , the (the number of displayed negative tests that item appears in) is distributed as . Hence, a conditioning argument shows that the linear combination of distribution functions
tends to the distribution function of in total variation distance, due to the concentration of as obtained in Corollary A.5. ∎
Moving to the second pillar of the proof, we need to demonstrate that no infected individual is assigned to more than displayed negative tests as shown by the following lemma.
Lemma B.3.
If for some small , for all w.h.p.
Proof.
We have to ensure that . By Lemma B.1 and the union bound, we thus need to have
by the Chernoff bound for the binomial distribution (Lemma A.1). Since and the following must hold
The lemma follows from rearranging terms and the fact that if we choose the number of tests slightly above the required number of tests (larger by a factor of for ), the assertion holds w.h.p. as . ∎
We proceed to show that no healthy individual is assigned to less than displayed negative tests.
Lemma B.4.
If for some small , for all w.h.p.
Proof.
We need to ensure that . Since occurs w.h.p. by Lemma A.4 and Corollary A.5, we need to have by Lemma B.2 and the union bound that
| (B.2) |
We remind ourselves that and together with the Chernoff bound for the hypergeometric distribution (Lemma A.2) this leads to the following condition666Note that the additive rule of the logarithm allows us to move the error term from inside the KL-divergence to outside
in a similar way to the proof of Lemma B.3. The lemma follows from rearranging terms and the fact that if we choose the number of tests slightly above the required number of tests (larger by a factor of for ), the assertion holds w.h.p. as . ∎
Appendix C Proof of DD bound, Theorem 2.2
The proof of Theorem 2.2 follows a similar two-step approach as the proof of Theorem 2.1 by first finding the distribution of (the number of displayed positive tests where individual appears on its own after removing the individuals, which were declared healthy already, , illustrated by DP-S in Fig. 2). We then threshold the distributions for healthy and infected individuals. To get started, we revise the second bound from Theorem 2.1 to allow healthy individuals to not be classified yet after the first step of DD. Recall that, we assume and .
Lemma C.1.
If
for some small , we have w.h.p.
Proof.
The lemma follows immediately by replacing the r.h.s. of (B.2) with for some small , rearranging terms and applying Markov’s inequality. ∎
For the next lemmas, we need an auxiliary notation denoting the number of tests that only contain individuals from . In symbols,
Lemma C.2.
If
for some small , we have with probability .
Proof.
As in the proof of Lemma B.2 above, we consider the graph in two rounds: in the first round we consider the tests containing infected individuals. Since each healthy individual does not impact the number of positive and negative tests, we know by Lemma A.4 that with probability we find that the number of truly negative tests after the first round. Furthermore the presence of a healthy individual has no impact on the number of displayed negative tests, as unflipped negative tests remain unflipped and flipped positive tests remain flipped. In the second round, we consider the effect of adding healthy individuals into the tests. Knowing the number of negative tests w.h.p. we can think of the participation of individuals in these tests as a balls into bins experiment. Starting with the number of truly negative tests (given by the first round) we conduct a worst case analysis to see how many of those tests may include one of the . Consider some particular truly negative test . We are interested in the probability that none of the elements of is contained. The probability that a given individual (knowing that it participates in displayed negative tests, which is of lower order than ) is assigned to this test is given by777We refer the reader to [20] for two results we use while obtaining (C.3) (apply Claim 7.3 to the binomial coefficients) as well as (C.4)(apply Claim 7.4 as error corrected version of Bernoulli’s inequality).Please note that these bounds in particular hold for and .
| (C.1) | ||||
| (C.2) | ||||
| (C.3) | ||||
| (C.4) |
We can now calculate the probability that no individual is assigned to , bearing in mind that the size of is random, and that each such individual is assigned to tests mutually independently. Using (C.4), and decomposing the sum into two parts, this is given by (for a given )
By Lemma C.1, we can choose such that is arbitrarily close to 1, and knowing that we find
By combining this with the findings of Lemma A.4 we find . The lemma follows by a similar application of the McDiarmid inequality as used in the proof of Lemma A.4.
∎
Note that, changing the set of tests for a specific individual shifts by at most . Thus, such an individual choosing from this set is not affecting the order of .
Let be the event that . By Lemma C.2, if
for some small . With Lemma C.2 at hand, we are in a position to describe the distribution of for healthy and infected individuals (recall the definition of in (2.2)). Let us start with infected individuals.
Lemma C.3.
Given and conditioned on , the total variation distance between and , a random variable with hypergeometric distribution , tends to zero with , that is
Proof.
We are interested in the neighborhood structure of one given infected individual , and we check how the remaining individuals influence the test types. In particular we are interested in the number of tests such that are contained in the neighborhood of an infected individual . Knowing the total number of tests and fixed degree , for a given value of the random quantity , we find that this quantity of interest follows a -distribution. Given , Lemma C.2 gives that is highly concentrated,
with high probability. Hence a conditioning argument, similar to Lemma B.2, shows that the linear combination of distribution functions
tends to the distribution function of in total variation distance, due to the concentration result obtained in Lemma C.2. Since each test featuring will truly be positive (as we assume to be infected) and will be displayed positive with probability independently, the lemma follows immediately. ∎
To describe the distribution of for healthy individuals, let us introduce the random variable , which is conditioned on the individual appearing in displayed positive tests, as follows:
Then, we find for healthy individuals the following conditional distribution.
Lemma C.4.
Given ,conditioned on and , the total variation distance between and
tends to zero with . That is
Proof.
We proceed with the same exposition and reasoning as in the proof of Lemma C.3. Due to the fact that is healthy we can remove it without affecting the test result. Therefore we can analyse its neighborhood structure induced by the pooling graph while excluding it. Since by assumption individual is assigned to exactly displayed positive and the total number of displayed positive test is given by , we see that is -distributed. Due to the fact that the event pinpoints the amount of displayed positive and negative tests we can derive the distribution of neighbors the individual may choose from. Recalling the results of Corollary A.5, we see that w.h.p.
Furthermore we get from Lemma C.2 that w.h.p.
Now we apply the concentration results obtained in Corollary A.5 and Lemma C.2 to obtain a linear combination of distribution functions
that tends to . The lemma follows since truly negative tests get flipped independently with probability . ∎
Having derived the distributions for for and for we can now determine a threshold of displayed positive tests where the individual appears only with individuals from the set such that we can tell and apart and thus recover . Let us start with infected individuals.
Lemma C.5.
As long as
for some small , we have for all w.h.p.
Proof.
We need to ensure that . For the bound on from the lemma, we know that occurs w.h.p. by Lemma C.2. In combination with Lemma C.3 and the union bound we need to ensure that
| (C.5) |
where as before is a random variable with hypergeometric distribution . Using the Chernoff bound for the hypergeometric distribution (Lemma A.2), the following condition for (C.5) to hold arises
| (C.6) |
The lemma follows from rearranging terms in (C.6) and the fact that if we choose the number of tests slightly above the required number of tests (larger by a factor of for ), the assertion holds w.h.p. as . ∎
We proceed with the set of individuals .
Lemma C.6.
As long as
for some small , we have for all w.h.p.
Proof.
We need to ensure that . For the bound on from the lemma, we know that occurs w.h.p. by Lemma C.2. Moreover, occurs w.h.p. by Lemma A.4 and Corollary A.5. We write for brevity. Combining this fact with Lemma B.2 and C.4 we need to ensure
| (C.7) | ||||
| (C.8) |
We remind ourselves that
Now by the Chernoff bound for the hypergeometric distribution (Lemma A.2) and setting , we establish the following two bounds for the probability terms:
| (C.9) |
| (C.10) |
(Note that the indicator in (C.10) appears due to the condition given by Lemma A.2) We reformulate the left-hand-side of (C.8) to
where the second equality follows since the sum consists of many summands. Since for our choice of by Lemma C.2 rearranging terms readily yields that the expression in (C.7) is indeed of order .
To see this, we remind ourselves that by definition . Furthermore we plug in the definition for . In the end we have to ensure that
We solve this inequality for . As we are only interested in a worst case bound, the assertion follows from the non-negativity of .
∎
Appendix D Comparison of the noisy DD and COMP bounds
The following section is intented to provide sufficient conditions under which the DD algorithm attains reliable performance requiring fewer tests than the COMP. However, these conditions are not necessary and DD might (and for all performed simulations does) require fewer tests than COMP for even wider settings.
Proof of Proposition 2.13.
In order to prove the proposition, we need to find conditions under which
We write and for the values that minimise the maximum of the two terms at the LHS, at which point we know that . Then it is sufficient to show that there exists such that
By inspection for any and and since .
Next, we will show that for any in the respective bounds and . Writing , and recalling that by assumption that (or ) we readily find that
| (D.1) |
where the first equality follows since and for any . The bound follows. Note that (D.1) indeed holds for any choice of and in the respective bounds stated in the theorem.
Finally, we need to demonstrate that . Since is not an optimisation parameter in and the bound in (D.1) holds for any value of , we can simply set it to the value that minimizes which is and for which we find
Thus, to obtain the desired inequality we need to ensure that for the optimal choice from COMP
Using the bound
which is obtained by setting , we find that if
∎
As mentioned before, due to bounding the result is not sharp. However, one immediate consequence of Proposition 2.13 is that DD is guaranteed to require fewer tests than COMP for the reverse Z channel.
Appendix E Relation to Bernoulli testing
In the noiseless case [26] shows that the constant column weight design (where each individual joins exactly different tests) requires fewer tests to recover than the i.i.d. (Bernoulli pooling) design (where each individual is included in each test with a certain probability independently). In this section we show that in the noisy case, the COMP algorithm requires fewer tests for the constant column weight design than for the i.i.d. design, and derive sufficient conditions under which the same is true for the noisy DD algorithm.
To get started, let us state the relevant bounds for the Bernoulli design, taken from [48, Theorem 5] and rephrased in our notation.
Proposition E.1 (Noisy COMP under Bernoulli).
Let , , , . Suppose that and and let
If , COMP will recover under the Bernoulli test design w.h.p. given .
Proposition E.2 (Noisy DD under Bernoulli).
Let , , , and . Suppose that and and let
If , DD will recover under the Bernoulli test design w.h.p. given .
To compare the bounds of the Bernoulli and constant-column test design we employ the following handy observation.
Lemma E.3.
Let and be constants independent of . As
with
| (E.1) |
Proof.
Applying the definition of the Kullback-Leibler divergence and Taylor expanding the logarithm we obtain
We can bound from above by writing the final term as , using the standard linearisation of the logarithm. ∎
Proof of Proposition 2.15.
Appendix F Notes on Corollary 2.3
Lemma F.1.
If the Shannon capacity of the channel of Figure 1 measured in nats is
| (F.1) |
where . This is achieved by taking
| (F.2) |
Please note that the proof might be a standard result for readers from some research communities, but for others it might be less standard. Therefore we state it here to prevent the interested (but unfamiliar) reader from a long textbook search.
Proof.
Write and . Then since the mutual information
| (F.3) |
we can find the optimal by solving
which implies that the optimal . We can solve for this for to find the expression above. As it is indeed a maximum. Substituting this in (F.3) we obtain that the capacity is given by
as claimed in the first expression in (F.1) above. We can see that the second expression in (F.1) matches the first by writing the corresponding expression as , which is equal to (F) by the definition of . ∎
Note that this result suggests a choice of density for the matrix: since each test is negative with probability , equating this with (F.2) suggests that we take
This is unlikely to be optimal in a group testing sense, since we make different inferences from positive and negative tests, but gives a closed form expression that may perform well in practice. For the noiseless and BSC case observe that , and we obtain .
Appendix G Illustration of bounds for Z, reverse Z channel and the BSC
Acknowledgment
The authors would like to thank two anonymous referees for their detailed reading of this paper and for the suggestions they made to improve its presentation. Oliver Gebhard and Philipp Loick are supported by DFG CO 646/3.
References
- [1] E. Abbe, A. Bandeira, and G. Hall. Exact recovery in the stochastic block model. IEEE Transactions on Information Theory, 62:471–487, 2016.
- [2] B. Abdalhamid, C. Bilder, E. McCutchen, S. Hinrichs, S. Koepsell, and P. Iwen. Assessment of specimen pooling to conserve SARS-CoV-2 testing resources. American Journal of Clinical Pathology, 153:715–718, 2020.
- [3] M. Aldridge. The capacity of Bernoulli nonadaptive group testing. IEEE Transactions on Information Theory, 63:7142–7148, 2017.
- [4] M. Aldridge. Individual testing is optimal for nonadaptive group testing in the linear regime. IEEE Transactions on Information Theory, 65:2058–2061, 2019.
- [5] M. Aldridge, L. Baldassini, and O. Johnson. Group testing algorithms: bounds and simulations. IEEE Transactions on Information Theory, 60:3671–3687, 2014.
- [6] M. Aldridge, O. Johnson, and J. Scarlett. Improved group testing rates with constant column weight designs. Proceedings of 2016 IEEE International Symposium on Information Theory (ISIT’16), pages 1381–1385, 2016.
- [7] M. Aldridge, O. Johnson, and J. Scarlett. Group testing: an information theory perspective. Foundations and Trends in Communications and Information Theory, 15(3–4):196–392, 2019.
- [8] E. Arıkan. Channel polarization: A method for constructing capacity-achieving codes for symmetric binary-input memory-less channels. IEEE Transactions on Information Theory, 55:3051––3073, 2009.
- [9] L. Baldassini, O. Johnson, and M. Aldridge. The capacity of adaptive group testing. Proceedings of 2013 IEEE International Symposium on Information Theory (ISIT’13), 1:2676–2680, 2013.
- [10] C. Chan, P. Che, S. Jaggi, and V. Saligrama. Non-adaptive probabilistic group testing with noisy measurements: near-optimal bounds with efficient algorithms. Proceedings of 49th Annual Allerton Conference on Communication, Control, and Computing, 1:1832–1839, 2011.
- [11] H. Chen and F. Hwang. A survey on nonadaptive group testing algorithms through the angle of decoding. Journal of Combinatorial Optimization, 15:49–59, 2008.
- [12] I. Cheong. The experience of South Korea with COVID-19. Mitigating the COVID Economic Crisis: Act Fast and Do Whatever It Takes (CEPR Press), pages 113–120, 2020.
- [13] A. Coja-Oghlan, O. Gebhard, M. Hahn-Klimroth, and P. Loick. Information-theoretic and algorithmic thresholds for group testing. IEEE Transactions on Information Theory, DOI: 10.1109/TIT.2020.3023377, 2020.
- [14] A. Coja-Oghlan, O. Gebhard, M. Hahn-Klimroth, and P. Loick. Optimal group testing. Proceedings of 33rd Conference on Learning Theory (COLT’20), 2020.
- [15] D. Donoho. Compressed sensing. IEEE Transactions on Information Theory, 52:1289–1306, 2006.
- [16] R. Dorfman. The detection of defective members of large populations. Annals of Mathematical Statistics, 14:436–440, 1943.
- [17] S. Ciesek E. Seifried. Pool testing of SARS-CoV-02 samples increases worldwide test capacities many times over, 2020. https://www.bionity.com/en/news/1165636/pool-testing-of-sars-cov-02-samples-increases-worldwide-test-capacities-many-times-over.html, last accessed on 2020-11-16.
- [18] Y. Erlich, A. Gilbert, H. Ngo, A. Rudra, N. Thierry-Mieg, M. Wootters, D. Zielinski, and O. Zuk. Biological screens from linear codes: theory and tools. bioRxiv, page 035352, 2015.
- [19] European Centre for Disease Prevention and Control. Surveillance and studies in a pandemic in Europe, 2009. https://www.ecdc.europa.eu/en/publications-data/surveillance-and-studies-pandemic-europe (last accessed on 2020-11-16).
- [20] Oliver Gebhard, Max Hahn-Klimroth, Olaf Parczyk, Manuel Penschuck, Maurice Rolvien, Jonathan Scarlett, and Nelvin Tan. Near optimal sparsity-constrained group testing: improved bounds and algorithms. Arxiv-Preprint, 2021.
- [21] Y. Gefen, M. Szwarcwort-Cohen, and R. Kishony. Pooling method for accelerated testing of COVID-19, 2020. https://www.technion.ac.il/en/2020/03/pooling-method-for-accelerated-testing-of-covid-19/ (last accessed on 2020-11-16).
- [22] E. Gould. Methods for long-term virus preservation. Mol Biotechnol, 13:57–66, 1999.
- [23] W. Hoeffding. Probability inequalities for sums of bounded random variables. Journal of the American Statistical Association, 58:301:13–30, 1963.
- [24] F. Hwang. A method for detecting all defective members in a population by group testing. Journal of the American Statistical Association, 67:605–608, 1972.
- [25] S. Janson, T. Luczak, and A. Rucinski. Random Graphs. John Wiley and Sons, 2011.
- [26] O. Johnson, M. Aldridge, and J. Scarlett. Performance of group testing algorithms with near-constant tests per item. IEEE Transactions on Information Theory, 65:707–723, 2018.
- [27] O. Johnson and D. Sejdinovic. Note on noisy group testing: Asymptotic bounds and belief propagation reconstruction. Proceedings of 48th Allerton Conference on Communication, Control, and Computing, 2010.
- [28] E. Knill, A. Schliep, and D. Torney. Interpretation of pooling experiments using the Markov chain Monte Carlo method. Journal of Computational Biology, 3:395–406, 1996.
- [29] H. Kwang-Ming and D. Ding-Zhu. Pooling designs and nonadaptive group testing: important tools for dna sequencing. World Scientific, 2006.
- [30] A. Lalkhen. Clinical tests: sensitivity and specificity. Continuing Education in Anaesthesia Critical Care & Pain, 8, 2008.
- [31] S. Long, C. Prober, and M. Fischer. Principles and practice of pediatric infectious diseases. Elsevier, 2018.
- [32] N. Madhav, B. Oppenheim, M. Gallivan, P. Mulembakani, E. Rubin, and N. Wolfe. Pandemics: Risks, impacts and mitigation. The World Bank:Disease control priorities, 9:315–345, 2017.
- [33] D. M. Malioutov and M. Malyutov. Boolean compressed sensing: Lp relaxation for group testing. Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing, 2012.
- [34] C. McDiarmid. On the method of bounded differences. Surveys in Combinatorics, 1989: Invited Papers at the 12th British Combinatorial Conference, page 148–188, 1989.
- [35] R. Mourad, Z. Dawy, and F. Morcos. Designing pooling systems for noisy high-throughput protein-protein interaction experiments using Boolean compressed sensing. IEEE/ACM Transactions on Computational Biology and Bioinformatics, 10:1478–1490, 2013.
- [36] L. Mutesa, P. Ndishimye, Y. Butera, J. Souopgui, A. Uwineza, R. Rutayisire, E. Musoni, N. Rujeni, T. Nyatanyi, E. Ntagwabira, M. Semakula, C. Musanabaganwa, D. Nyamwasa, M. Ndashimye, E. Ujeneza, I. Mwikarago, C. Muvunyi, J. Mazarati, S. Nsanzimana, N. Turok, and W. Ndifon. A strategy for finding people infected with SARS-CoV-2: optimizing pooled testing at low prevalence. Nature, 589:276–280, 2021. doi:10.1038/s41586-020-2885-5.
- [37] H. Ngo and D. Du. A survey on combinatorial group testing algorithms with applications to DNA library screening. Discrete Mathematical Problems with Medical Applications, 7:171–182, 2000.
- [38] U.S. Department of Health and Human Services. Pandemic influenza plan, 2017. https://www.cdc.gov/flu/pandemic-resources/pdf/pandemic-influenza-implementation.pdf (last accessed on 2020-11-16).
- [39] World Health Origanisation. Global surveillance during an influenza pandemic, 2009. www.who.int/csr/resources/publications/swineflu (last accessed on 2020-11-16).
- [40] M. Plebani. Diagnostic errors and laboratory medicine – causes and strategies. Electronic Journal of the International Federation of Clinical Chemistry and Laboratory Medicine, 26:7–14, 2015.
- [41] T. Richardson and R. Urbanke. Modern coding theory. Cambridge University Press, 2007.
- [42] C. Sammut and G. Webb. Encyclopedia of machine learning. Springer, 2011.
- [43] J. Scarlett. Noisy adaptive group testing: Bounds and algorithms. IEEE Transactions on Information Theory, 65:3646–3661, 2018.
- [44] J. Scarlett. An efficient algorithm for capacity-approaching noisy adaptive group testing. Proceedings of 2019 IEEE International Symposium on Information Theory (ISIT’19), pages 2679–2683, 2019.
- [45] J. Scarlett and V. Cevher. Converse bounds for noisy group testing with arbitrary measurement matrices. Proceedings of 2016 IEEE International Symposium on Information Theory (ISIT’16), pages 2868–2872, 2016.
- [46] J. Scarlett and V. Cevher. Phase transitions in group testing. Proceedings of the 27th Annual ACM-SIAM Symposium on Discrete Algorithms(SODA’16), 1:40–53, 2016.
- [47] J. Scarlett and V. Cevher. Near-optimal noisy group testing via separate decoding of items. IEEE Journal of Selected Topics in Signal Processing, 2017.
- [48] J. Scarlett and O. Johnson. Noisy non-adaptive group testing: A (near-)definite defectives, approach. IEEE Transactions on Information Theory, 66(6):3775–3797, 2020.
- [49] N. Thierry-Mieg. A new pooling strategy for high-throughput screening: the shifted transversal design. BMC Bioinformatics, 7:28, 2006.
- [50] L. Wang, X. Li, Y. Zhang, and K. Zhang. Evolution of scaling emergence in large-scale spatial epidemic spreading. Public Library of Science ONE, 6, 2011.
- [51] L. Wein and S. Zenios. Pooled testing for HIV screening: Capturing the dilution effect. Operations Research, 44:543–569, 1996.
- [52] S. Woloshin, N. Patel, and A. Kesselheim. False negative tests for SARS-CoV-2 infection — challenges and implications. New England Journal of Medicine, 2020.