Improved Consistency Training for Semi-Supervised Sequence-to-Sequence ASR via Speech Chain Reconstruction and Self-Transcribing
Abstract
Consistency regularization has recently been applied to semi-supervised sequence-to-sequence (S2S) automatic speech recognition (ASR). This principle encourages an ASR model to output similar predictions for the same input speech with different perturbations. The existing paradigm of semi-supervised S2S ASR utilizes SpecAugment as data augmentation and requires a static teacher model to produce pseudo transcripts for untranscribed speech. However, this paradigm fails to take full advantage of consistency regularization. First, the masking operations of SpecAugment may damage the linguistic contents of the speech, thus influencing the quality of pseudo labels. Second, S2S ASR requires both input speech and prefix tokens to make the next prediction. The static prefix tokens made by the offline teacher model cannot match dynamic pseudo labels during consistency training. In this work, we propose an improved consistency training paradigm of semi-supervised S2S ASR. We utilize speech chain reconstruction as the weak augmentation to generate high-quality pseudo labels. Moreover, we demonstrate that dynamic pseudo transcripts produced by the student ASR model benefit the consistency training. Experiments on LJSpeech and LibriSpeech corpora show that compared to supervised baselines, our improved paradigm achieves a 12.2% CER improvement in the single-speaker setting and 38.6% in the multi-speaker setting.
Index Terms: semi-supervised learning, consistency regularization, FixMatch algorithm, speech chain reconstruction, ASR, TTS
1 Introduction
In recent years, sequence-to-sequence (S2S) ASR has made significant progress thanks to the advancement of deep neural networks. S2S ASR models are designed for directly converting the input speech into transcripts [1, 2, 3]. However, a large amount of transcribed speech data is essential for training S2S ASR models to achieve state-of-the-art performance. Thus, many semi-supervised learning algorithms have been proposed to efficiently train ASR models with the help of untranscribed speech [4, 5, 6, 7, 8, 9, 10, 11].
Consistency regularization [12] is an important principle of semi-supervised learning algorithms. This principle was originally designed for semi-supervised image classification [13, 14, 15, 16] and it has recently been extended to semi-supervised S2S ASR [4, 5, 6, 7, 17]. Consistency regularization assumes that an ASR model should output similar predictions for the same input speech with various perturbations. Also, these perturbations should change the distribution of input speech without altering the corresponding transcripts[15]. In the literature, SpecAugment [18] is commonly used to perturb speech features due to its simplicity. Its time-frequency masking plays a major role in improving the robustness of ASR [17]. However, randomly removing continuous frequency bins or temporal frames may damage the semantics of the input speech. Incomplete linguistic contents will further accumulate errors in pseudo labels and thus influence ASR performance during consistency training.
Different from image classification, S2S ASR models require both input speech and prefix tokens to make the prediction at each time step. In the consistency training paradigm for S2S ASR [5, 7, 4, 6, 9, 8], a teacher model trained on transcribed speech is used to produce pseudo transcripts for untranscribed speech. The pseudo transcripts are then fed into the student ASR model as prefix tokens during consistency training. However, there exist some errors in predictions of the teacher model because of the limited training set [7]. These errors remain in the static pseudo transcripts and make pseudo labels poorer in quality. Moreover, since the static pseudo transcripts are made by original speech before consistency training, the mismatch between these transcripts and perturbed speech will further influence the student model during consistency training.
This paper presents an improved consistency training paradigm of S2S ASR. In previous work, machine speech chain [19, 20] was designed to jointly train ASR and TTS by reconstructing unlabeled speech and text data. In this work, we adopt the speech chain reconstruction as a data augmentation method and focus on the FixMatch algorithm [15] which has recently been applied on S2S ASR [5]. Our contributions are as follow:
-
•
We propose the self-transcribing scheme where the student model serves as its own teacher. Specifically, the pseudo transcripts are produced dynamically by the student model with perturbed speech as input.
-
•
We demonstrate that speech chain reconstruction is superior than SpecAugment as the weak augmentation for making pseudo labels.
-
•
We conducted constrast experiments that covers most of the factors that may have an impact on the consistency training, including number of speakers, confidence threshold, ratio of unlabeled data to labeled data, data augmentation methods, and pseudo transcript generation.
2 Semi-supervised consistency training for S2S ASR
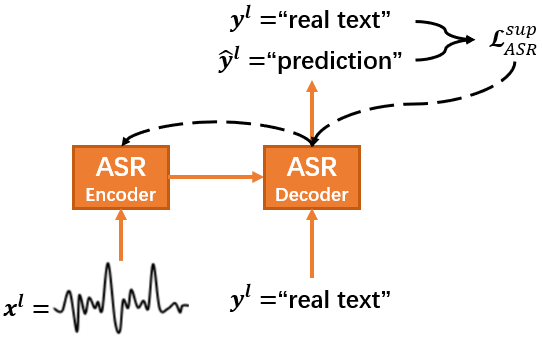
2.1 Supervised training for a base ASR model
S2S ASR models are designed to directly predict the conditional probability of a sequence of predicted tokens given a sequence of speech features . Here, represents the parameters of ASR, is the length of the input sequence, and is the length of the output sequence. Our ASR models are based on Listen-Attend-Spell (LAS) [1] which has an encoder-decoder architecture as shown in Fig.1(a).
The encoder converts the input sequence of speech features into a sequence of hidden representations . The decoder receives and outputs the token probability at time step based on the prefix tokens . The probability of the generated transcript is calculated by the product of the token probability at each time step as
| (1) |
During training, the prefix tokens are replaced with the ground-truth labels. Given a speech-text pair , a base ASR model is trained by the following supervised ASR loss:
| (2) |
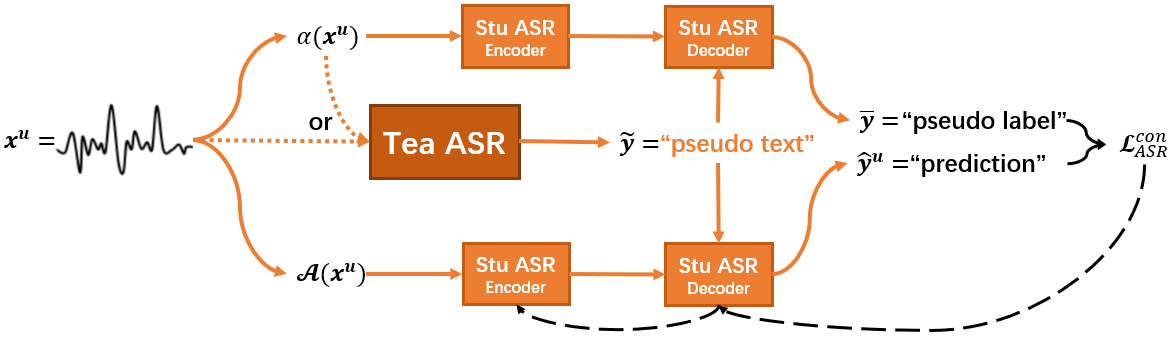
2.2 Consistency training for S2S ASR based on FixMatch algorithm [5]
FixMatch algorithm [15] is a semi-supervised algorithm for image classification that combines consistency regularization with pseudo-labeling. In its existing application to S2S ASR [5], a teacher ASR model is initialized on the parameters of the base ASR model and used to produce the pseudo transcript for the untranscribed speech as
| (3) |
As shown in Fig.1(b), untranscribed speech is separately perturbed by a weak augmentation function and a strong augmentation function . The weakly-perturbed speech is fed into the student ASR model to obtain the pseudo label at time step given as prefix tokens by
| (4) |
The consistency ASR loss is calculated on the strongly-perturbed speech and pseudo label given the same pseudo transcripts as prefix tokens by
| (5) |
where is the confidence of the student model on and is the confidence threshold.
Finally, the student model is trained by the following loss function:
| (6) |
2.3 Proposed self-transcribing scheme
On top of the existing paradigm, we made two improvements. First, the weakly-perturbed speech is used to produce the pseudo transcripts . Second, the student model is initialized by the base ASR and dynamically produces the pseudo transcripts by itself during the consistency training. Our improvements can be formualted as follow:
| (7) |
3 Speech chain reconstruction
3.1 Semi-supervised TTS based on pseudo transcribing
Sequence-to-sequence TTS models can be considered the reverse case of ASR that directly predicts the conditional probability of a sequence of speech features given a sequence of tokens . Our TTS model is based on Tacotron2 [21] which has a similar architecture to LAS. We provide the decoder of TTS with the speaker embedding extracted from the input speech, which enables TTS to synthesize speech in a multi-speaker setting. Our TTS model is trained by the loss function :
| (8) | ||||
| (9) | ||||
| (10) |
where are the predicted and ground-truth log Mel-scale spectrograms at time and are the predicted and ground-truth end-of-frame probabilities. The pseudo transcripts used for training the TTS model is produced by the base ASR model before ASR consistency training as Eq.3 does.
3.2 Speech chain reconstruction for untranscribed speech
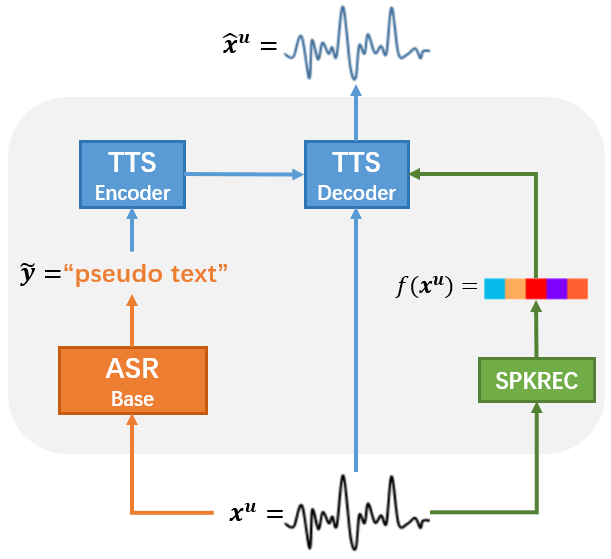
Different from our previous work that generates synthetic speech from real texts for semi-supervised ASR training [19, 20], this work applied the speech chain reconstruction as a data augmentation method for the untranscribed speech by the teacher-forcing technique. This technique prevents TTS decoding from mispronunciation and early stopping, thus protecting the linguistic contents. Fig.2 shows the process of our proposed speech chain reconstruction that can be considered as a frame-level speech transformation.
Untranscribed speech is utilized three times before generating reconstructed speech . First, the base ASR model converts into pseudo transcripts as the input of our TTS encoder. Then, the speaker embedding is extracted from to provide our TTS decoder with the speaker information. Finally, our TTS decoder generates the reconstructed speech with original speech as the prefix speech features at each time step. The reconstructed speech is treated as the weakly-perturbed speech during the subsequent ASR consistency training.
4 Experiments
4.1 Datasets
We conducted experiments in both single-speaker and multi-speaker settings. We use the LJSpeech corpus [22] for the single-speaker setting. We take 12,600 utterances as the training set, 250 utterances as the development set and 250 utterances as the test set. There is no overlap in the division of data. We treat the first 50% of the training set as labeled data and the last 50% as unlabeled data. In the multi-speaker setting, we use the LibriSpeech corpus [23]. We take the “train-clean-100” set as the training set, the “dev-clean” set as the development set and the “test-clean” set as the test set. We treat the first 75 speakers (8,570 utts) of the training set as labeled data and the last 176 speakers (19,968 utts) as unlabeled data.
As for acoustic features, we used 80-dimensional log Mel-spectrograms extracted at a 50-ms frame length and a 12.5-ms frame shift. The English letters in the transcripts of all utterances are normalized into their lowercase forms. All transcripts are mapped into a 29-token set: 26 (a-z) letters of the alphabet, apostrophes, space, and “sos/eos” 111We combined sos and eos into one token..
4.2 Model configuration
4.2.1 ASR
In the single-speaker setting, our ASR encoder is composed of three bidirectional LSTM layers with 256 hidden units for each direction (totally 512 hidden units for each Bi-LSTM layer). Hierarchical sub-sampling [1, 2] was used on the last two layers to reduce the sequence length by a factor of four. In the multi-speaker setting, we added two extra Bi-LSTM layers at the beginning of the encoder. On the decoder sides, the single-speaker and multi-speaker settings shared the same configuration: an embedding layer followed by a unidirectional LSTM layer with 512 hidden units. We selected Additive Attention [24] as the attention module of our ASR models. The beam searching technique was adopted to generate pseudo transcripts during the consistency training and the beam size was set to 4.
AdaDelta [25] was adopted to train our ASR models. During the base training, the initial learning rate was set to 1.0 and the decay rate was set to 0.1. During the consistency training, we set a smaller initial learning rate of 0.5 and a larger decay rate of 0.2. The learning rate decay was based on the accuracy calculated on the development set during training and the minimal learning rate was set to 1% of the initial value. We used early stopping to prevent the models from overfitting. The weight of the consistency loss is set to 0.1.
4.2.2 TTS
The hyperparameters for our TTS model were generally the same as those for the original Tacotron2, except we concatenated the encoder hidden representations with the speaker embedding vectors in the multi-speaker experiments. We extracted X-vectors [26] from the input speech as the speaker embedding vectors and the extraction was done using SpeechBrain [27].
Adam [28] was adopted to train our TTS model with an initial learning rate of 0.001 and a decay rate of 0.1. The learning rate decay was based on the loss calculated on the development set during training and the minimal learning rate was set to 1% of the initial value. Early stopping was also used to avoid overfitting. For each time-step, our model generated two consecutive frames to reduce the number of steps in the decoding process.
4.3 Experimental setting
ESPNET2 [29, 30] was used to perform our experiments. Our supervised baselines were the base ASR models trained using only the labeled data. We designed four scenarios and conducted contrast experiments where the weak augmentation was either SpecAugment or speech chain reconstruction. For all experiments, the strong augmentation was implemented by SpecAugment. Our weak SpecAugment applied one time of time-frequency masking while the strong SpecAugment applied two times. Maximal frequency masking width was 5 bins for and 20 bins for . For the LJSpeech corpus, maximal time masking width was 10 frames for and 50 frames for . For LibriSpeech corpus, maximal time masking width was 20 frames for and 100 frames for .
| LJSpeech | LibriSpeech | |||||||
| =0.5 | =0.6 | =0.7 | =0.8 | =0.9 | =0.5 | =0.7 | =0.9 | |
| Supervised Baseline | ||||||||
| – | 8.2 | 8.2 | 8.2 | 8.2 | 8.2 | 28.0 | 28.0 | 28.0 |
| Static produced by (the existing paradigm [5]) | ||||||||
| Weak SpecAugment | 8.3 | 7.8 | 7.7 | 7.5 | 7.7 | 18.3 | 19.6 | 20.8 |
| Speech Chain Reconstruction | 7.9 | 7.6 | 7.4 | 7.5 | 7.8 | 18.2 | 19.8 | 18.5 |
| Static produced by | ||||||||
| Weak SpecAugment | 7.8 | 7.7 | 7.7 | 7.8 | 7.6 | 18.8 | 19.6 | 20.3 |
| Speech Chain Reconstruction | 7.9 | 7.7 | 7.2 | 7.2 | 7.6 | 17.2 | 18.4 | 18.3 |
| Dynamic produced by | ||||||||
| Weak SpecAugment | 7.9 | 7.9 | 7.6 | 7.4 | 7.6 | 19.1 | 19.1 | 19.9 |
| Speech Chain Reconstruction | 8.2 | 7.2 | 7.5 | 7.4 | 7.6 | 18.1 | 18.4 | 18.4 |
| Dynamic produced by | ||||||||
| Weak SpecAugment | 7.5 | 7.4 | 8.1 | 7.6 | 8.0 | 19.8 | 20.5 | 18.9 |
| Speech Chain Reconstruction | 7.7 | 7.7 | 7.6 | 7.4 | 7.2 | 20.0 | 19.1 | 18.5 |
5 Results and analysis
5.1 Single-speaker experiments
In the single-speaker setting, the ratio of labeled data to unlabeled data was set to 1:1. From Tab.1, we observed that speech chain reconstruction outperforms the weak SpecAugment in all scenarios. Our consistency training paradigm achieved the best CER performance of 7.2%, which has a 12.2% CER improvement on the supervised baseline. This showcases how speech chain reconstruction keeps more linguistic information than SpecAugment, and thus it is more suitable to be the weak augmentation.
In the single-speaker setting, dynamic pseudo transcripts produced by the student model achieved a 2.7% CER improvement on the existing paradigm. This indicates that the student model gradually corrects the errors in the pretrained base model during consistency training. It can be seen that the pseudo transcripts produced by the weakly-perturbed input speech also resulted in a 2.7% CER improvement. It supports our idea that prefix tokens should match the input speech during ASR consistency training. As for the reason why the relative improvements on the existing paradigm were not large in scale, we hypothesized that the base model is already good enough to produce understandable transcripts because 50% of the training set was used as the labeled data.
5.2 Multi-speaker experiments
In the multi-speaker setting, we simulated a harsher condition where the ratio of labeled data to unlabeled data is 3:7. From Tab.1, speech chain reconstruction still outperformed the weak SpecAugment in all scenarios. With more unlabeled data, the improvement of our paradigm over the supervised baseline surged to 38.6%, which indicates that our paradigm benefits from a large amount of untranscribed speech.
On top of the existing paradigm, a 5.5% CER improvement was achieved when the input speech used to produce the pseudo transcripts was changed from the original speech to weak-perturbed speech . On the other hand, only a 0.5% CER improvement was observed when we set the teacher model in the existing paradigm to the student model itself during consistency training. This indicates that the mismatch between the input speech and pseudo transcripts has a stronger influence on our ASR models than the errors in the pretrained base model.
According to the right part of Tab.1, our ASR models performed better when we set the confidence threshold to a smaller value. Since we only used the first 30% of “train-clean-100” as the labeled data to train the base model, our student ASR models are not very confident on the untranscribed speech and thus output relatively lower token probability at each time step. With a higher confidence threshold, only a small fraction of untranscribed speech is utilized to calculate the final ASR loss, hence seriously restricting the potential of consistency training for improving ASR performance.
6 Conclusions
In this work, we proposed an improved consistency training paradigm for S2S ASR. We took the FixMatch algorithm as the proving ground and presented comprehensive constrast experiments covering most of the factors in the semi-supervised ASR training. Our results show that speech chain reconstruction protects more linguistic contents than SpecAugment and produces pseudo labels with higher quality. Moreover, the proposed self-transcribing method helps the student model correct the errors in the pretrained base model and eliminate the mismatch between the input speech and prefix tokens. Our future work involves applications of other semi-supervised algorithms on S2S ASR with various data augmentation methods for speech data.
7 Acknowledgements
Part of this work is supported by JSPS KAKENHI Grant Number JP21H05054 and JP21H03467.
References
- [1] W. Chan, N. Jaitly, Q. Le, and O. Vinyals, “Listen, attend and spell: A neural network for large vocabulary conversational speech recognition,” in 2016 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, 2016, pp. 4960–4964.
- [2] D. Bahdanau, J. Chorowski, D. Serdyuk, P. Brakel, and Y. Bengio, “End-to-end attention-based large vocabulary speech recognition,” in 2016 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, 2016, pp. 4945–4949.
- [3] J. K. Chorowski, D. Bahdanau, D. Serdyuk, K. Cho, and Y. Bengio, “Attention-based models for speech recognition,” Advances in neural information processing systems, vol. 28, 2015.
- [4] Z.-q. Zhang, Y. Song, J.-s. Zhang, I. V. McLoughlin, and L.-r. Dai, “Semi-supervised end-to-end asr via teacher-student learning with conditional posterior distribution.” in INTERSPEECH, 2020, pp. 3580–3584.
- [5] F. Weninger, F. Mana, R. Gemello, J. Andrés-Ferrer, and P. Zhan, “Semi-supervised learning with data augmentation for end-to-end asr,” in INTERSPEECH, 2020.
- [6] R. Masumura, M. Ihori, A. Takashima, T. Moriya, A. Ando, and Y. Shinohara, “Sequence-level consistency training for semi-supervised end-to-end automatic speech recognition,” in ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020, pp. 7054–7058.
- [7] Z. Chen, A. Rosenberg, Y. Zhang, H. Zen, M. Ghodsi, Y. Huang, J. Emond, G. Wang, B. Ramabhadran, and P. J. M. Mengibar, “Semi-supervision in asr: Sequential mixmatch and factorized tts-based augmentation,” in INTERSPEECH, 2021.
- [8] J. Kahn, A. Lee, and A. Hannun, “Self-training for end-to-end speech recognition,” in ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020, pp. 7084–7088.
- [9] D. S. Park, Y. Zhang, Y. Jia, W. Han, C.-C. Chiu, B. Li, Y. Wu, and Q. V. Le, “Improved noisy student training for automatic speech recognition,” in INTERSPEECH, 2020.
- [10] Y. Higuchi, N. Moritz, J. L. Roux, and T. Hori, “Momentum pseudo-labeling for semi-supervised speech recognition,” in INTERSPEECH, 2021.
- [11] A. Xiao, C. Fuegen, and A. Mohamed, “Contrastive semi-supervised learning for asr,” in ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2021, pp. 3870–3874.
- [12] P. Bachman, O. Alsharif, and D. Precup, “Learning with pseudo-ensembles,” Advances in neural information processing systems, vol. 27, 2014.
- [13] L. Samuli and A. Timo, “Temporal ensembling for semi-supervised learning,” in International Conference on Learning Representations (ICLR), vol. 4, no. 5, 2017, p. 6.
- [14] M. Sajjadi, M. Javanmardi, and T. Tasdizen, “Regularization with stochastic transformations and perturbations for deep semi-supervised learning,” Advances in neural information processing systems, vol. 29, 2016.
- [15] K. Sohn, D. Berthelot, N. Carlini, Z. Zhang, H. Zhang, C. A. Raffel, E. D. Cubuk, A. Kurakin, and C.-L. Li, “Fixmatch: Simplifying semi-supervised learning with consistency and confidence,” Advances in Neural Information Processing Systems, vol. 33, pp. 596–608, 2020.
- [16] D. Berthelot, N. Carlini, I. Goodfellow, N. Papernot, A. Oliver, and C. A. Raffel, “Mixmatch: A holistic approach to semi-supervised learning,” Advances in Neural Information Processing Systems, vol. 32, 2019.
- [17] G. Wang, A. Rosenberg, Z. Chen, Y. Zhang, B. Ramabhadran, Y. Wu, and P. Moreno, “Improving speech recognition using consistent predictions on synthesized speech,” in ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020, pp. 7029–7033.
- [18] D. S. Park, W. Chan, Y. Zhang, C.-C. Chiu, B. Zoph, E. D. Cubuk, and Q. V. Le, “Specaugment: A simple data augmentation method for automatic speech recognition,” Proc. Interspeech 2019, pp. 2613–2617, 2019.
- [19] A. Tjandra, S. Sakti, and S. Nakamura, “Listening while speaking: Speech chain by deep learning,” in 2017 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU). IEEE, 2017, pp. 301–308.
- [20] ——, “Machine speech chain,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 28, pp. 976–989, 2020.
- [21] J. Shen, R. Pang, R. J. Weiss, M. Schuster, N. Jaitly, Z. Yang, Z. Chen, Y. Zhang, Y. Wang, R. Skerrv-Ryan et al., “Natural tts synthesis by conditioning wavenet on mel spectrogram predictions,” in 2018 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, 2018, pp. 4779–4783.
- [22] K. Ito and L. Johnson, “The lj speech dataset,” https://keithito.com/LJ-Speech-Dataset/, 2017.
- [23] V. Panayotov, G. Chen, D. Povey, and S. Khudanpur, “Librispeech: an asr corpus based on public domain audio books,” in 2015 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, 2015, pp. 5206–5210.
- [24] D. Bahdanau, K. H. Cho, and Y. Bengio, “Neural machine translation by jointly learning to align and translate,” in 3rd International Conference on Learning Representations, ICLR 2015, 2015.
- [25] M. D. Zeiler, “Adadelta: an adaptive learning rate method,” arXiv preprint arXiv:1212.5701, 2012.
- [26] D. Snyder, D. Garcia-Romero, G. Sell, D. Povey, and S. Khudanpur, “X-vectors: Robust dnn embeddings for speaker recognition,” in 2018 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, 2018, pp. 5329–5333.
- [27] M. Ravanelli, T. Parcollet, P. Plantinga, A. Rouhe, S. Cornell, L. Lugosch, C. Subakan, N. Dawalatabad, A. Heba, J. Zhong, J.-C. Chou, S.-L. Yeh, S.-W. Fu, C.-F. Liao, E. Rastorgueva, F. Grondin, W. Aris, H. Na, Y. Gao, R. D. Mori, and Y. Bengio, “SpeechBrain: A general-purpose speech toolkit,” 2021, arXiv:2106.04624.
- [28] D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980, 2014.
- [29] S. Watanabe, T. Hori, S. Karita, T. Hayashi, J. Nishitoba, Y. Unno, N. Enrique Yalta Soplin, J. Heymann, M. Wiesner, N. Chen, A. Renduchintala, and T. Ochiai, “ESPnet: End-to-end speech processing toolkit,” in Proceedings of Interspeech, 2018, pp. 2207–2211. [Online]. Available: http://dx.doi.org/10.21437/Interspeech.2018-1456
- [30] T. Hayashi, R. Yamamoto, K. Inoue, T. Yoshimura, S. Watanabe, T. Toda, K. Takeda, Y. Zhang, and X. Tan, “Espnet-TTS: Unified, reproducible, and integratable open source end-to-end text-to-speech toolkit,” in Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020, pp. 7654–7658.