Improved Hierarchical Clustering on Massive Datasets with Broad Guarantees
Abstract
Hierarchical clustering is a stronger extension of one of today’s most influential unsupervised learning methods: clustering. The goal of this method is to create a hierarchy of clusters, thus constructing cluster evolutionary history and simultaneously finding clusterings at all resolutions. We propose four traits of interest for hierarchical clustering algorithms: (1) empirical performance, (2) theoretical guarantees, (3) cluster balance, and (4) scalability. While a number of algorithms are designed to achieve one to two of these traits at a time, there exist none that achieve all four.
Inspired by Bateni et al.’s scalable and empirically successful Affinity Clustering [NeurIPs 2017], we introduce Affinity Clustering’s successor, Matching Affinity Clustering. Like its predecessor, Matching Affinity Clustering maintains strong empirical performance and uses Massively Parallel Communication as its distributed model. Designed to maintain provably balanced clusters, we show that our algorithm achieves good, constant factor approximations for Moseley and Wang’s revenue and Cohen-Addad et al.’s value. We show Affinity Clustering cannot approximate either function. Along the way, we also introduce an efficient -sized maximum matching algorithm in the MPC model.
1 Introduction
Clustering is one of the most prominent methods to provide structure, in this case clusters, to unlabeled data. It requires a single parameter for the number of clusters. Hierarchical clustering elaborates on this structure by adding a hierarchy of clusters contained within superclusters. This problem is unparameterized, and takes in data as a graph whose edge weights represent the similarity or dissimilarity between data points. A hierarchical clustering algorithm outputs a tree , whose leaves represent the input data, internal nodes represent the merging of data and clusters into clusters and superclusters, and root represents the cluster of all data.
Obviously it is more computationally intensive to find as opposed to a flat clustering. However, having access to such a structure provides two main advantages: (1) it allows a user to observe the data at different levels of granularity, effectively querying the structure for clusterings of size without recomputation, and (2) it constructs a history of data relationships that can yield additional perspectives. The latter is most readily applied to phylogenetics, where dendrograms depict the evolutionary history of genes and species (Kraskov et al., 2003). Hierarchical clustering in general has been used in a number of other unsupervised applications. In this paper, we explore four important qualities of a strong and efficient hierarchical clustering algorithm:
-
1.
Theoretical guarantees. Previously, analysis of hierarchical clustering algorithms has relied on experimental evaluation. While this is one indicator for success, it cannot ensure performance across a large range of datasets. Researchers combat this by considering optimization functions to evaluate broader guarantees (Charikar et al., 2004; Lin et al., 2006). One function that has received significant attention recently (Charikar et al., 2018; Cohen-Addad et al., 2018) is a hierarchical clustering cost function proposed by Dasgupta (2016). This function is simple and intuitive, however, Charikar & Chatziafratis (2017) showed that it is likely not constant-factor approximable. To overcome this, we examine its dual, revenue, proposed by Moseley & Wang (2017), which considers a graph with similarity-based edge weights. For dissimilarity-based edge weights, we look to Cohen-Addad et al. (2018)’s value, another cost-inspired function. We are interested in constant factor approximations for these functions.
-
2.
Empirical performance. As theoretical guarantees are often only intuitive proxies for broader evaluation, it is still important to evaluate the empirical performance of algorithms on specific, real datasets. Currently, Bateni et al. (2017)’s Affinity Clustering remains the state-of-the-art for scalable hierarchical clustering algorithms with strong empirical results. With Affinity Clustering as an inspirational baseline for our algorithm, we strive to preserve and, hopefully, extend Affinity Clustering’s empirical success.
-
3.
Balance. One downside of algorithms like Affinity Clustering is that they are prone to creating extremely unbalanced clusters. There are a number of natural clustering problems where balanced clusters are preferable or more accurate for the problem, for example, clustering a population into genders. Some more specific applications include image collection clustering, where balanced clusters can make the database more easily navigable (Dengel et al., 2011), and wireless sensor networks, where balancing clusters of sensor nodes ensures no cluster head gets overloaded (Amgoth & Jana, 2014). Here, we define balance as the minimum ratio between cluster sizes.
-
4.
Scalability. Most current approximations for revenue are serial and do not ensure performance at scale. We achieve scalability through distributed computation. Clustering itself, as well as many other big data problems, has been a topic of interest in the distributed community in recent years (Chitnis et al., 2015, 2016; Ghaffari et al., 2019). In particular, hierarchical clustering has been studied by Jin et al. (2013, 2015), but only Bateni et al. (2017) has attempted to ensure theoretical guarantees through the introduction of a Steiner-based cost metric. However, they provide little motivation for its use. Therefore, we are interested in evaluating distributed algorithms with respect to more well-founded optimization functions like revenue and value.
For our distributed model, we look to Massively Parallel Communication (MPC), which was used to design Affinity Clustering. MPC is a restrictive, theoretical abstraction of MapReduce: a popular programming framework famous for its ease of use, fault tolerance, and scalability (Dean & Ghemawat, 2008a). In the MPC model, individual machines carry only a fraction of the data and execute individual computations in rounds. At the end of each round, machines send limited messages to each other. Complexities of interest are the number of rounds and the individual machine space. This framework has been used in the analysis for many large-scale problems in big data, including clustering (Im et al., 2017; Ludwig, 2015; Ghaffari et al., 2019). It is a natural selection for this work.
1.1 Related Work
There exist algorithms that can achieve up to two of these qualities at a time. Affinity Clustering, notably, exhibits good empirical performance and scalability using MPC. While Bateni et al. (2017) describe some minor theoretical guarantees for Affinity Clustering, we believe that proving an algorithm’s ability to optimize for revenue and value is a stronger and more well-founded result due to their popularity and relation to Dasgupta’s cost function. A simple random divisive algorithm proposed by Charikar & Chatziafratis (2017) was shown to achieve a expected approximation for revenue and can be efficiently implemented using MPC. However, it is notably nondeterministic, and we show that it does not exhibit good empirical performance. Similarly, balanced partitioning may achieve balanced clusters, but it is unclear whether it is scalable, and it has not been shown to achieve strong theoretical guarantees.
For both revenue and value, Average Linkage achieves near-state-of-the-art and -approximations respectively (Moseley & Wang, 2017; Cohen-Addad et al., 2018). Charikar et al. (2019) marginally improves these factors to for revenue and for value, through semi-definite programming (SDP, a non-distributable method). However, since value and revenue both strove to characterize Average Linkage’s optimization goal, and this was only marginally beat by an SDP, we do not expect to surpass Average Linkage in the restrictive distributed context.
After the completion of our work, a new algorithm was introduced achieving an impressive 0.585 approximation for revenue Alon et al. (2020). While this result was unknown during the course of this work, it sets a new standard to strive for in future work.
1.2 Our contributions
In this work, we propose a new algorithm, Matching Affinity Clustering, for distributed hierarchical clustering. Inspired by Affinity Clustering’s reliance on the minimum spanning tree in order to greedily merge clusters (Bateni et al., 2017), Matching Affinity Clustering merges clusters based on iterative matchings. It notably generalizes to both the edge weight similarity and dissimilarity contexts, and achieves all four desired qualities.
In Section 4, we theoretically motivate Matching Affinity Clustering by proving it achieves a good approximation for both revenue and value (the latter depending on the existence of an MPC minimum matching algorithm), nearing the bounds achieved by Average Linkage:
Theorem 1.
In the revenue context (where edge weights are data similarity), with machine space, Matching Affinity Clustering achieves (whp):
-
•
a -approximation for revenue in rounds when ,
-
•
and a -approximation for revenue in rounds in general.
Theorem 2.
Assume there exists an MPC algorithm that achieves an -approximation for minimum weight -sized matching whp in rounds and machine space. In the value context (where edge weights are data distances) and in rounds with machine space, Matching Affinity Clustering achieves (whp):
-
•
a -approximation for value when ,
-
•
and a -approximation for value in general.
Furthermore, in Theorem 3, we prove that Matching Affinity Clustering can give no guarantees with respect to revenue or value. The discussion and proof of this theorem can be found in the Appendix.
Theorem 3.
Affinity Clustering cannot achieve better than a -factor approximation for revenue or value.
We also present an efficient and near-optimal MPC algorithm for -sized maximum matching in Theorem 4 in Section 3. This is used by Matching Affinity Clustering.
To evaluate the empirical performance of our algorithm, we run Bateni et al. (2017)’s experiments used for Affinity Clustering on small-scale datasets in Section 6. We find Matching Affinity Clustering performs competitively with respect to state-of-the-art algorithms. On filtered, balanced data, we find that Matching Affinity Clustering consistently outperforms other algorithms by at least a small but clear margin. This implies Matching Affinity Clustering may be more useful on balanced datasets than Affinity Clutsering.
To confirm the balance of our algorithm, we are able to prove that Matching Affinity Clustering achieves perfectly balanced clusters on datasets of size , and otherwise guarantee near balance (a cluster size ratio of at most 2). See Lemma 1. This was also confirmed in our empirical evaluation in Section 6.
Finally, we show in Section 4 that Matching Affinity Clustering is highly scalable because it was designed in the same MPC framework as Affinity Clustering. We provide similar complexity guarantees to Affinity Clustering.
Matching Affinity Clustering is ultimately a nice, simply motivated successor to Affinity Clustering that achieves all four desired qualities: empirical performance, theoretical guarantees, balance, and scalability. No other algorithm that we know of does this.
2 Background
In this section, we describe basic notation, hierarchical clustering cost functions, and Massively Parallel Communication (MPC).
2.1 Preliminaries
The standard hierarchical clustering problem takes in a set of data represented as a graph where weights on edges measure similarity or dissimilarity between data. In this paper, edge weights, denoted for a graph and may be similarities or differences as specified.
One of the most simple, serial hierarchical clustering algorithms is Average Linkage, which provides a good approximation for Moseley and Wang’s dual (Moseley & Wang, 2017). It starts with each vertex being its own cluster, and builds the next cluster by merging the two clusters and that maximize the average distance between points in the clusters:
Finally, we note that much of our results occur with high probability (whp), as is true with many MPC algorithms. This means they occur with probability , where the denominator is generally exponential in . The probabilistic aspects of the algorithm come from our use of Ghaffari et al. (2018)’s maximum matching algorithm, which finds a -approximate maximum matching with high probability. As we do not introduce a probabilistic aspect ourselves, this will not be discussed in depth in our proofs, but will be stated in the theorems and lemmas.
2.2 Optimization functions
Consider some hierarchical tree, . We say for leaves and is the least common ancestor of and . The subtree rooted at an interior vertex is , therefore the subtree representing the smallest cluster that contains both and is . Let be the set of leaves in , and be the set of all of the leaves of but not . Now we can describe Dasgupta’s function.
Definition 1 (Dasgupta (2016)).
Dasgupta’s cost function of tree on graph with similarity-based edge weights is a minimization function.
To minimize edge weight contribution, we want a small for heavy edges. This ensures that heavy edges will be merged earlier in the tree. To calculate this, it is easier to break it down into a series of merge costs for each node in . It counts the costs that accrue due to the merge at that node so that we can keep track of the cost throughout the construction of . It is defined as:
Definition 2 (Moseley & Wang (2017)).
The merge cost of a node in which merges disjoint clusters and is:
This breaks down the cost of a hierarchy tree into a series of merge costs. Consider some edge, . At each merge containing exclusively or , this edge contributes times the size of the other cluster. In the hierarchical tree, this counts how many vertices accrue during merges along the paths from and to . However, this does not account for the leaves or themselves, so we need to add two extra times in addition to each merge. This means we can derive the total cost from the merge costs as:
Next, we consider Moseley and Wang’s dual to Dasgupta’s function Moseley & Wang (2017).
Definition 3 (Moseley & Wang (2017)).
The revenue of tree on graph with similarity-based edge weights is a maximization function.
We can, in a similar fashion to Dasgupta’s cost function, break revenue down into a series of merge revenues.
Definition 4.
Moseley & Wang (2017). The merge revenue of a node in which merges disjoint clusters and is:
Note that for some and , is contributed exactly once, when and merge at , and is the number of non-leaves at that step. Therefore: . In addition, note the contribution of each pair, which is scaled by , is the number of leaves of for revenue, and the number of non-leaves of for cost. Therefore the contribution of each edge for revenue is minus the contribution for cost, scaled by . In other words: .
While cost is a popular and well-founded metric, Charikar & Chatziafratis (2017) found that it is not constant factor approximable under the Small Set Expansion Hypothesis. On the other hand, Moseley & Wang (2017) proved that revenue is, and Average Linkage achieves a -approximation. This makes it a more practical function to work with.
Our other function of interest is Cohen-Addad et al. (2018)’s value function. This was introduced as a Dasgupta-inspired optimization function where edge weights represent distances. It looks exactly like cost, except it is now a maximization function because it is in the distance context.
Definition 5 (Cohen-Addad et al. (2018)).
The value of tree on graph with dissimilarity-based edge weights is a maximization function.
Like revenue, value is constant factor-approximable. In fact, the best approximation (other than an SDP) for value is Average Linkage’s -approximation (Cohen-Addad et al., 2018). To our knowledge, there are no distributable approximations for value.
2.3 Massively Parallel Communication (MPC)
Massively Parallel Communication (MPC) is a model of distributed computation used in programmatic frameworks like MapReduce (Dean & Ghemawat, 2008b), Hadoop (White, 2009), and Spark (Zaharia et al., 2010). MPC consists of “rounds” of computation, where parts of the input are distributed across machines with limited memory, computation is done locally for each machine, and then the machines send limited messages to each other. The primary complexities of interest are machine space, which should be , and the number of rounds. Many MPC algorithms are extremely efficient. For instance, Affinity Clustering in some cases can have constantly many rounds, and otherwise may use up to rounds (Bateni et al., 2017).
3 Finding a k-sized maximum matching
The algorithm we introduce in Section 4 requires the use of a -approximation for the maximum -sized (or less) matching, where . For this we will use Ghaffari et al. (2018)’s -approximation for maximum matching in MPC, which runs in rounds with space. Inspired by the results of Hassin et al. (1997), we provide a distributed reduction between matching and -matching. To do this, we add vertices and edges of weight (which is found with a binary search) between the new and original vertices, and run the matching algorithm. The algorithm can be seen below and the proof is found in the Appendix in the full paper.
Theorem 4.
There exists an MPC algorithm for -sized maximum matching with nonnegative edge weights and max edge weight for that achieves a -approximation whp in rounds and machine space.
4 Bounds on a matching-based hierarchical clustering algorithm
We now introduce our main algorithm, Matching Affinity Clustering. For revenue, we show it achieves a -approximation for graphs with vertices, and a -approximation in general. Similarly, for value, we show it achieves a -approximation for graphs with vertices, and a -approximation in general, given an -approximation algorithm for minimum weighted -sized matching in MPC.
4.1 Matching Affinity Clustering
Matching Affinity Clustering is defined in Algorithm 2. Its predecessor, Affinity Clustering, uses the MST to select edges to merge across, which sometimes causes imbalanced clusters. This is one reason why it cannot achieve a good approximation for revenue or value (Theorem 3). We fix this by, instead, using iterated maximum matchings (for similarity edge weights) and minimum perfect matchings (for dissimilarity edge weights). This ensures that on vertices for some , clusters will always be perfectly balanced. Otherwise, we will show how to achieve at least relative balance.
The algorithm starts with one cluster per each of vertices. Let be the smallest value such that . It finds a maximum (resp. minimum) matching of size (line 8, this means it matches vertices with edges) and merges these vertices (line 12, Figure 2). Note that if , then and the first step is a perfect matching. After this step, we have clusters. We then transform the graph into a graph of clusters with edge weights equal to the Average Linkage between clusters (lines 17-21). We find a maximum (resp. minimum) perfect matching of clusters in this new graph (line 10), then iterate.
4.2 Revenue approximation
Now, we evaluate the efficiency and approximation factor of Matching Affinity Clustering with respect to revenue. In this section, edge weights represent the similarity between points. Proofs are in the Appendix in the full version of the paper. Ultimately, we will show the following.
Theorem 1.
In the revenue context (where edge weights are data similarity), with machine space, Matching Affinity Clustering achieves (whp):
-
•
a -approximation for revenue in rounds when ,
-
•
and a -approximation for revenue in rounds in general.
This will be a significant motivation for Matching Affinity Clustering’s theoretical strength. As stated previously, one of the goals of Matching Affinity Clustering is to keep the cluster sizes balanced at each level. However, in the first step, note that Matching Affinity Clustering creates clusters of size 2, and the rest of the vertices form singleton clusters. Therefore, to use this benefit of Matching Affinity Clustering, we need to ensure that cluster sizes will never deviate too much.
Lemma 1.
After the first round of merges, Matching Affinity Clustering maintains cluster balance (ie, the minimum ratio between cluster sizes) of whp.
After every matching, the algorithm creates a new graph with vertices representing clusters and edges representing the average linkage between clusters. We will call this a clustering graph.
Definition 6.
A clustering graph for graph and clustering of is a complete graph with vertex set . Its edge weights are the average linkage between clusters. Specifically, for vertices and in corresponding to clusters and where , the weight of the edge between these vertices is:
The fact that the edge weights in the clustering graph are the average linkage between clusters denotes the similarities between Matching Affinity Clustering and Average Linkage. Essentially, we are trying to optimize for average linkage at each step, but instead of merging two clusters, we merge many pairs of clusters at once with a maximum matching.
Since Matching Affinity Clustering computes this graph, we must show how to efficiently transform a clustering graph at the th level, with clustering , into a clustering at the th level, with clustering .
Lemma 2.
Given and where clusters are all composed of two subclusters in , can be computed in the MPC model with machine space and one round.
This will eventually be used for our proof of efficiency of Theorem 1. For now, we return our attention to the approximation factor. Our approximation proof is going to observe the total merge cost and revenue across all merges on a single level of the hierarchy. For concision, we introduce the following notation to describe cost and revenue over a single clustering.
Definition 7.
The clustering revenue based off of some superclustering of on graph is the sum of the merge revenues of combining clusters in to create clusters in . It is denoted by .
Definition 8.
The clustering cost based off of some superclustering of on graph is the sum of the merge costs of combining clusters in to create clusters in . It is denoted by .
In order to prove an approximation for revenue, we want to compare each clustering revenue and cost. First, we must show that Matching Affinity Clustering has a large clustering revenue at any level.
Lemma 3.
Let clusters and be the th and th level clusterings found by Matching Affinity Clustering, where . Let be the indicator that is 1 if is not a power of 2. Then the clustering revenue of Matching Affinity Clustering at the th level is at least (whp):
Now we address clustering cost. This time, we must show an upper bound for clustering cost at the th level in terms of clustering revenue at the th level. Let be the matching Matching Affinity Clustering uses to merge into . Then is a -approximation of the optimum .
Lemma 4.
Let and be the th and th level clusterings found by Matching Affinity Clustering, where the th step uses matching for maximum matching and . Then the clustering cost of Matching Affinity Clustering at the th level is at most (whp):
Now we are ready to prove the approximation factor for Matching Affinity Clustering. We combine Lemma 4 with properties of revenue from Section 2.2 to obtain an expression for revenue in terms of times the sum of weights in the graph. We use this as a bound for the optimal revenue.
Lemma 5.
Matching Affinity Clustering obtains a -approximation for revenue on graphs of size , and a -approximation on general graphs whp.
Finally, the round complexity is limited by the iterations and calls to the matching algorithm. The space complexity is determined by the clustering graph construction.
Lemma 6.
Matching Affinity Clustering uses space per machine and runs in rounds on graphs of size , and rounds in general.
Lemmas 5 and 6 are sufficient to prove Theorem 1. Our algorithm achieves an approximation for revenue efficiently in the MPC model. In addition, the algorithm creates a desirably near-balanced hierarchical clustering tree.
We now prove the approximation bound tightness for Matching Affinity Clustering when . Recently, Charikar et al. (2019) proved by counterexample that Average Linkage achieves at best a -approximation on certain graphs. We find that Matching Affinity Clustering acts the same as Average Linkage on these graphs, and so has at best a -approximation.
Theorem 5.
There is a graph on which Matching Affinity Clustering achieves no better than a -approximation of the optimal revenue.
4.3 Value approximation
Now we consider Matching Affinity Clustering when edge weights represent distances instead of similarities. In this context, instead of running a -sized maximum matching and then iterative general maximum matchings, we run a -sized minimum matching and then iterative general minimum perfect matchings. Therefore, this algorithm is dependent on the existence of a -sized minimum matching algorithm in MPC. Due to its similarity to other classical problems with solutions in MPC (Ghaffari et al., 2018; Behnezhad et al., 2019), we conjecture:
Conjecture 1.
There exists an MPC algorithm that achieves a -approximation for minimum weight -sized matching whp that uses machine space.
Given such an algorithm, we can show that Matching Affinity Clustering approximates value.
Theorem 6.
Assume there exists an MPC algorithm that achieves an -approximation for minimum weight -sized matching whp in rounds and machine space. In the value context (where edge weights are data distances) and in rounds with machine space, Matching Affinity Clustering achieves (whp):
-
•
a -approximation for value when ,
-
•
and a -approximation for value in general.
The proof for this result is quite similar to the proof for the -approximation of Average Linkage by Cohen-Addad et al. (2018). Instead of focusing on single merges, however, we observed the entire set of merges across a clustering layer in our hierarchy. Then we can make the same argument about the value across an entire level of the hierarchy, and use the cluster balance from Lemma 1 to achieve our result.
If Conjecture 1 holds, then the approximation factors become and respectively. We see a similar pattern as the revenue result, where the algorithm nears the state-of-the-art -approximation achieved by Average Linkage (Cohen-Addad et al., 2018) on datasets of size , and still achieves a constant factor in general. Finally, we can additionally show the former approximation is tight. See the construction and proofs in the Appendix.
Theorem 7.
There is a graph on which Matching Affinity Clustering achieves no better than a -approximation of the optimal revenue.
4.4 Round comparison to Affinity Clustering
In this section, we only consider Matching Affinity Clustering in the similarity edge weight context. The round complexities of Matching Affinity Clustering and regular Affinity Clustering depend on graph qualities, and in certain cases one outperforms the other. On dense graphs with edges for constant , Bateni et al. (2017) showed that Affinity Clustering runs in rounds. On sparse graphs, it runs in rounds, and it runs in rounds when given access to a distributed hash table. We saw that Matching Affinity Clustering runs in rounds on graphs of size , and in general for max edge weight .
There are two situations where our algorithm outperforms Affinity Clustering. First, if the graph is sparse and the number of vertices is , then our algorithm runs in rounds, and Affinity Clustering runs in rounds. Otherwise, if the graph is sparse, Matching Affinity Clustering performs better as long as the largest edge weight is . This is strictly larger than constant. If is large, Affinity Clustering is slightly more efficient. Finally, if the graph is dense, Affinity Clustering achieves an impressive constant round complexity, and is therefore more efficient. In any case, Matching Affinity Clustering is an efficient and highly scalable algorithm.
5 Affinity Clustering approximation bounds
In this section and all following sections, we provide the proofs for all theorems and lemmas introduced in this paper. It is broken down into sections based off of the sections corresponding to sections in the paper itself.
We start by proving Theorem 3. Bateni et al. (2017) were in part motivated by the lack of theoretical guarantees for distributed hierarchical clustering algorithms. Thus, they introduced Affinity Clustering, based off of Borůvka (1926)’s algorithm for parallel MST. In every parallel round of Borůvka’s algorithm, each connected component (starting with disconnected vertices) selects the lowest-weight outgoing edge and adds that to the solution, eventually creating an MST. Affinity Clustering creates clusters of each component. Note that Affinity Clustering was evaluated on a graph with weights representing dissimilarities between vertices, as opposed to our representation where weights are similarities. It is easy to verify that Affinity Clustering functions equivalently using max spanning tree in our representation. Bateni et al. (2017) theoretically validate their algorithm by defining a cost function based off the cost of the minimum Steiner tree for each cluster in the hierarchy, however they do not motivate this metric. Therefore, it is more interesting to evaluate in terms of revenue and value. We ultimately show:
Theorem 3.
Affinity Clustering cannot achieve better than a -factor approximation for revenue or value.
We will split this into two cases for each objective function. We start with revenue. First, note that when Affinity Clustering merges clusters in common connected components, it creates one supercluster (ie, cluster of clusters) for all clusters in that component. Therefore, it may merge many clusters at once. A brief counterexample of why such a hierarchy does not work is when the max spanning tree is a star. Here, all vertices will be merged to a cluster in one round for a revenue of zero, which is not approximately optimal. To evaluate this algorithm, we must consider all possible ways Affinity Clustering might decide to resolve edges on the max spanning tree of the input graph. We propose a graph family that shows Affinity Clustering cannot achieve a good revenue approximation. The hierarchy we use for comparison is one that Matching Affinity Clustering would find, not including the -matching step. We prove the following lemma.
Lemma 7.
There exists a family of graphs on which Affinity Clustering cannot achieve better than a -factor approximation for revenue.
We now move on to value.
Lemma 8.
There exists a family of graphs on which Affinity Clustering cannot achieve better than a -factor approximation for value.
6 Experiments
We now empirically validate these results to further motivate Matching Affinity Clustering. The algorithm is implemented as a sequence of maximum or minimum perfect matchings, and the testing software is provided in supplementary material. The software as well as the five UCI datasets Dua & Graff (2017) ranging between 150 and 5620 data points are exactly the same as those that were used for small-scale evaluation of Affinity Clustering Bateni et al. (2017). The data is represented by a vector of features. Similarity-based edge weights are the cosine similarity between vectors, and dissimilarity-based edge weights are the L2 norm. Most data and algorithms are deterministic and thus have consistent outcomes, but for any randomness, we run the experiment 50 times and take the average. Just like the evaluation of Affinity Clustering, our evaluation runs hierarchical clustering algorithms on -clustering problems until we find a -clustering within the hierarchy. This was compared to the ground truth clustering for the dataset.
We evaluate performance using the Rand index, which was designed by Rand (1971) to be similar to accuracy in the unsupervised context. This is an established and commonly used metric for evaluating clustering algorithms and was used in the evaluation of Affinity Clustering.
Definition 9 (Rand (1971)).
Given a set of points and two clusterings and of , we define:
-
•
: the number of pairs in that are in the same cluster in and in the same cluster in .
-
•
: the number of pairs in that are in different clusters in and in different clusters in .
The Rand index is . By having the ground truth clustering of a dataset, we define the Rand index score of a clustering to be .
6.1 Comparison with Affinity Clustering
In addition, we are interested in evaluating the balance between cluster sizes in the clusterings, which indicates how good our algorithms are at evaluating balanced data. We use the cluster size ratio of a clustering, which was observed in Bateni et al. (2017). For a clustering , the size ratio is .
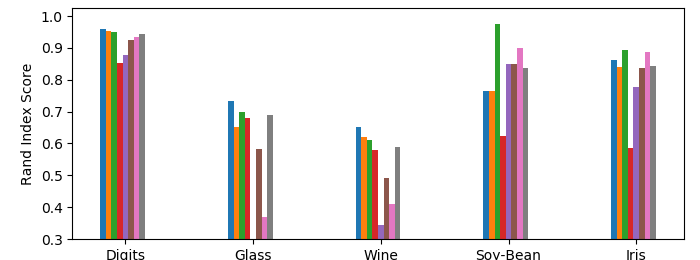
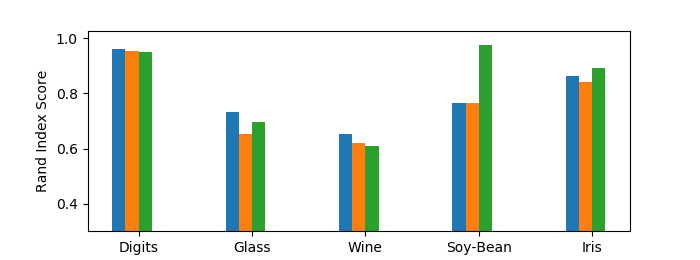
In Figure 3(a), we see the Rand indices of Max Matching Affinity Clustering (ie, in the similarity context), Min Matching Affinity Clustering (ie, in the distance context), and Affinity Clustering. A Rand index is between 0 and 1, where higher scores indicate the clustering is more similar to the ground truth. Matching Affinity Clustering performs similarly to state of the art algorithms like Affinity Clustering on all data except the Soy-Bean dataset. A full evaluation on other algorithms (see the Appendix) illustrates that Matching Affinity Clustering outperforms other algorithms like Random Clustering and Average Linkage.
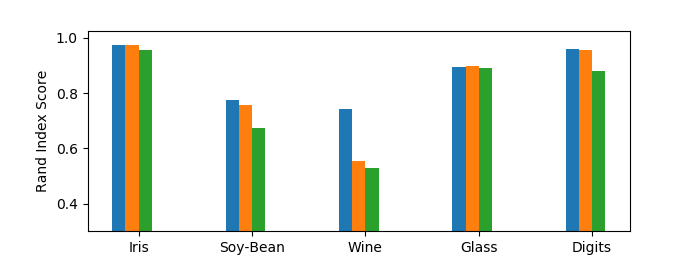
Figure 3(b) depicts the same information but on a slightly modified dataset. Here, we randomly remove data until (1) the dataset is of size , and (2) ground truth clusters are balanced. We did this 50 times and took the average results. This is motivated by Matching Affinity Clustering’s stronger theoretical guarantees on datasets of size and ensured cluster balance. As expected, Matching Affinity Clustering performs consistently better than Affinity Clustering on filtered data, albeit by a a small margin in many cases. This shows that, experimentally, Matching Affinity Clustering performs better on balanced datasets of size .
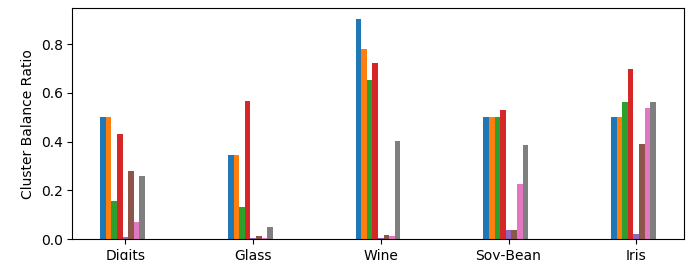
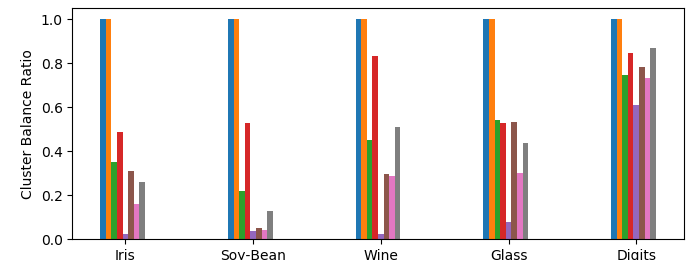
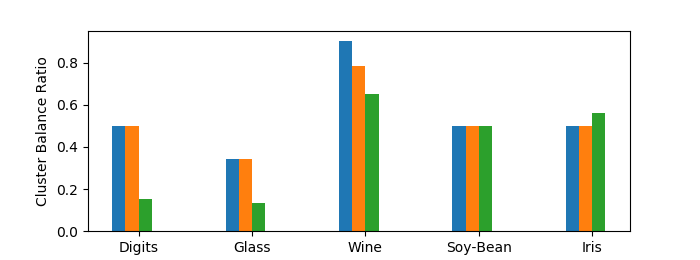
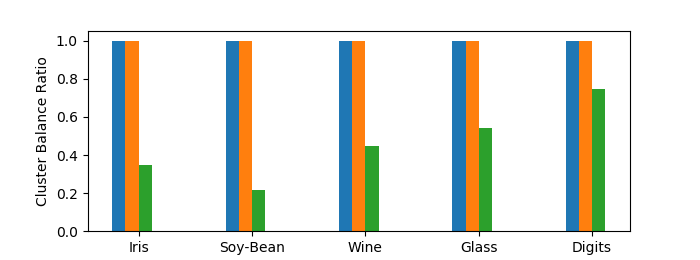
Finally, Figures 3(c) and 3(d) depict the cluster size ratios on the raw and filtered data respectively. In theory, at every level in the hierarchy of Matching Affinity Clustering, no cluster can be less than half as small as another (Lemma 1). However, in our evaluation, we are comparing a single -clustering, which may not precisely correspond to a level in the hierarchy. In this case, we take some clusters from the first level with fewer than clusters and the last level with more than clusters. Therefore, since cluster sizes double at each level, the lower bound for the cluster size ratio is now . This is reflected Figure 3(c), where Matching Affinity Clustering stays consistently above this minimum, and often exceeds it by quite a bit. On the filtered data (Figure 3(d)), Matching Affinity Clustering maintains perfect balance in every instance, whereas Affinity Clustering performs much worse. Thus, Matching Affinity Clustering has proven empirically successful on small datasets.
6.2 Comparison with other algorithms
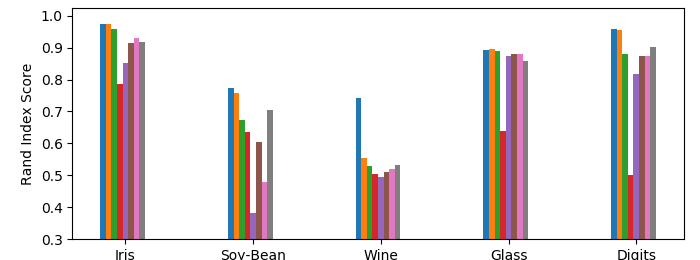
Here we include more complete visualizations of the performance of all tested algorithms. Like in the main body of text, we find the rand index and cluster size ratio on balanced and filtered data. These tests were run in the same way as the tests in the main body, we just present results on other common algorithms for completeness. The results are presented in Figure 4 in the Appendix.
Most of these results are as expected and simply reproduce the results from Bateni et al. (2017). However, we add one more algorithm: random clustering. Again, this is the clustering that randomly recursively partitions the data into a hierarchy. In our experiments, random clustering had surprisingly good cluster balance ratios (see Figure 4(d)). In fact, on raw data, it on average had more balanced clusters than Matching Affinity Clustering on three of the datasets.
There are three main observations about why Matching Affinity Clustering is still clearly more empirically successful than random clustering. First, notice that on filtered data in Figure 4(e), Matching Affinity Clustering has more balanced clusters than Random clustering by a very wide margin. Second, it is clear in Figures 4(b) and 4(c) that Matching Affinity Clustering consistently and significantly outperforms random clustering. Third, random clustering is nondeterministic, whereas Matching Affinity Clustering is works with high probability. Therefore, Matching Affinity Clustering’s theoretical strengths and empirical performances are much stronger assurances than that of random clustering. Therefore, while an argument can be made that random clustering seems to empirically balance clusters well, Matching Affinity Clustering still does better in a number of respects, and thus is a more useful algorithm.
7 Conclusion
Matching Affinity Clustering is the first hierarchical clustering algorithm to simultaneously achieve our four desirable traits. (1) Theoretically, it guarantees state-of-the-art approximations for revenue and value (given an approximation for MPC minimum perfect matching) when , and good approximations for revenue and value in general. Affinity Clustering cannot approximate either function. (2) Compared to Affinity Clustering, our algorithm achieves similar empirical success on general datasets and performs even better when datasets are balanced and of size . (3) Clusters are theoretically and empirically balanced. (4) It is scalable.
These attributes were proved through theoretical analysis and small-scale evaluation. While we were unable to perform the same large-scale tests as Bateni et al. (2017), our methods still establish several advantages to the proposed approach. Matching Affinity Clustering simultaneously attains stronger broad theoretical guarantees, scalability through distribution, and small-scale empirical success. Therefore, we believe that Matching Affinity Clustering holds significant value over its predecessor as well as other state-of-the-art hierarchical clustering algorithms, particularly with its niche capability on balanced datasets.
References
- Alon et al. (2020) Alon, N., Azar, Y., and Vainstein, D. Hierarchical clustering: A 0.585 revenue approximation. In Conference on Learning Theory, COLT, Proceedings of Machine Learning Research, pp. 153–162, 2020.
- Amgoth & Jana (2014) Amgoth, T. and Jana, P. K. Energy efficient and load balanced clustering algorithms for wireless sensor networks. IJICT, 6(3/4):272–291, 2014.
- Bateni et al. (2017) Bateni, M., Behnezhad, S., Derakhshan, M., Hajiaghayi, M., Kiveris, R., Lattanzi, S., and Mirrokni, V. S. Affinity clustering: Hierarchical clustering at scale. In Guyon et al. (2017), pp. 6867–6877.
- Behnezhad et al. (2019) Behnezhad, S., Hajiaghayi, M., and Harris, D. G. Exponentially faster massively parallel maximal matching. In 60th IEEE Annual Symposium on Foundations of Computer Science, FOCS 2019, Baltimore, Maryland, USA, November 9-12, 2019, pp. 1637–1649, 2019.
- Borůvka (1926) Borůvka, O. O jistém problému minimálním. Práce Moravské přírodovědecké společnosti. Mor. přírodovědecká společnost, 1926.
- Charikar & Chatziafratis (2017) Charikar, M. and Chatziafratis, V. Approximate hierarchical clustering via sparsest cut and spreading metrics. In Klein, P. N. (ed.), Proceedings of the Twenty-Eighth Annual ACM-SIAM Symposium on Discrete Algorithms, SODA 2017, Barcelona, Spain, Hotel Porta Fira, January 16-19, pp. 841–854. SIAM, 2017.
- Charikar et al. (2004) Charikar, M., Chekuri, C., Feder, T., and Motwani, R. Incremental clustering and dynamic information retrieval. SIAM J. Comput., 33(6):1417–1440, 2004.
- Charikar et al. (2018) Charikar, M., Chatziafratis, V., Niazadeh, R., and Yaroslavtsev, G. Hierarchical clustering for euclidean data. CoRR, abs/1812.10582, 2018.
- Charikar et al. (2019) Charikar, M., Chatziafratis, V., and Niazadeh, R. Hierarchical clustering better than average-linkage. In Chan, T. M. (ed.), Proceedings of the Thirtieth Annual ACM-SIAM Symposium on Discrete Algorithms, SODA 2019, San Diego, California, USA, January 6-9, 2019, pp. 2291–2304. SIAM, 2019.
- Chitnis et al. (2016) Chitnis, R., Cormode, G., Esfandiari, H., Hajiaghayi, M., McGregor, A., Monemizadeh, M., and Vorotnikova, S. Kernelization via sampling with applications to finding matchings and related problems in dynamic graph streams. In Krauthgamer, R. (ed.), Proceedings of the Twenty-Seventh Annual ACM-SIAM Symposium on Discrete Algorithms, SODA 2016, Arlington, VA, USA, January 10-12, 2016, pp. 1326–1344. SIAM, 2016.
- Chitnis et al. (2015) Chitnis, R. H., Cormode, G., Hajiaghayi, M. T., and Monemizadeh, M. Parameterized streaming: Maximal matching and vertex cover. In Indyk, P. (ed.), Proceedings of the Twenty-Sixth Annual ACM-SIAM Symposium on Discrete Algorithms, SODA 2015, San Diego, CA, USA, January 4-6, 2015, pp. 1234–1251. SIAM, 2015.
- Cohen-Addad et al. (2018) Cohen-Addad, V., Kanade, V., Mallmann-Trenn, F., and Mathieu, C. Hierarchical clustering: Objective functions and algorithms. In Czumaj, A. (ed.), Proceedings of the Twenty-Ninth Annual ACM-SIAM Symposium on Discrete Algorithms, SODA 2018, New Orleans, LA, USA, January 7-10, 2018, pp. 378–397. SIAM, 2018.
- Dasgupta (2016) Dasgupta, S. A cost function for similarity-based hierarchical clustering. In Wichs, D. and Mansour, Y. (eds.), Proceedings of the 48th Annual ACM SIGACT Symposium on Theory of Computing, STOC 2016, Cambridge, MA, USA, June 18-21, 2016, pp. 118–127. ACM, 2016.
- Dean & Ghemawat (2008a) Dean, J. and Ghemawat, S. Mapreduce: simplified data processing on large clusters. Commun. ACM, 51(1):107–113, 2008a.
- Dean & Ghemawat (2008b) Dean, J. and Ghemawat, S. Mapreduce: simplified data processing on large clusters. Commun. ACM, 51(1):107–113, 2008b.
- Dengel et al. (2011) Dengel, A., Althoff, T., and Ulges, A. Balanced clustering for content-based image browsing. In German Computer Science Society, Informatiktage, 03 2011.
- Dua & Graff (2017) Dua, D. and Graff, C. UCI machine learning repository, 2017. URL http://archive.ics.uci.edu/ml.
- Ghaffari et al. (2018) Ghaffari, M., Gouleakis, T., Konrad, C., Mitrovic, S., and Rubinfeld, R. Improved massively parallel computation algorithms for mis, matching, and vertex cover. In Newport, C. and Keidar, I. (eds.), Proceedings of the 2018 ACM Symposium on Principles of Distributed Computing, PODC 2018, Egham, United Kingdom, July 23-27, 2018, pp. 129–138. ACM, 2018.
- Ghaffari et al. (2019) Ghaffari, M., Lattanzi, S., and Mitrovic, S. Improved parallel algorithms for density-based network clustering. In Proceedings of the 36th International Conference on Machine Learning, ICML 2019, 9-15 June 2019, Long Beach, California, USA, pp. 2201–2210, 2019.
- Guyon et al. (2017) Guyon, I., von Luxburg, U., Bengio, S., Wallach, H. M., Fergus, R., Vishwanathan, S. V. N., and Garnett, R. (eds.). Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, 4-9 December 2017, Long Beach, CA, USA, 2017.
- Hassin et al. (1997) Hassin, R., Rubinstein, S., and Tamir, A. Approximation algorithms for maximum dispersion. Oper. Res. Lett., 21(3):133–137, 1997.
- Im et al. (2017) Im, S., Moseley, B., and Sun, X. Efficient massively parallel methods for dynamic programming. In Hatami, H., McKenzie, P., and King, V. (eds.), Proceedings of the 49th Annual ACM SIGACT Symposium on Theory of Computing, STOC 2017, Montreal, QC, Canada, June 19-23, 2017, pp. 798–811. ACM, 2017.
- Jin et al. (2013) Jin, C., Patwary, M. M. A., Hendrix, W., Agrawal, A., Liao, W.-k., and Choudhary, A. Disc: A distributed single-linkage hierarchical clustering algorithm using mapreduce. International Workshop on Data Intensive Computing in the Clouds (DataCloud), 11 2013.
- Jin et al. (2015) Jin, C., Liu, R., Chen, Z., Hendrix, W., Agrawal, A., and Choudhary, A. N. A scalable hierarchical clustering algorithm using spark. In First IEEE International Conference on Big Data Computing Service and Applications, BigDataService 2015, Redwood City, CA, USA, March 30 - April 2, 2015, pp. 418–426. IEEE Computer Society, 2015.
- Kraskov et al. (2003) Kraskov, A., Stögbauer, H., Andrzejak, R. G., and Grassberger, P. Hierarchical clustering using mutual information. CoRR, q-bio.QM/0311037, 2003.
- Lin et al. (2006) Lin, G., Nagarajan, C., Rajaraman, R., and Williamson, D. P. A general approach for incremental approximation and hierarchical clustering. In Proceedings of the Seventeenth Annual ACM-SIAM Symposium on Discrete Algorithms, SODA 2006, Miami, Florida, USA, January 22-26, 2006, pp. 1147–1156. ACM Press, 2006.
- Ludwig (2015) Ludwig, S. A. Mapreduce-based fuzzy c-means clustering algorithm: implementation and scalability. Int. J. Machine Learning & Cybernetics, 6(6):923–934, 2015.
- Moseley & Wang (2017) Moseley, B. and Wang, J. Approximation bounds for hierarchical clustering: Average linkage, bisecting k-means, and local search. In Guyon et al. (2017), pp. 3097–3106.
- Rand (1971) Rand, W. M. Objective criteria for the evaluation of clustering methods. Journal of the American Statistical Association, 66(336):846–850, 1971. ISSN 01621459.
- White (2009) White, T. Hadoop - The Definitive Guide: MapReduce for the Cloud. O’Reilly, 2009. ISBN 978-0-596-52197-4.
- Zaharia et al. (2010) Zaharia, M., Chowdhury, M., Franklin, M. J., Shenker, S., and Stoica, I. Spark: Cluster computing with working sets. In Nahum, E. M. and Xu, D. (eds.), 2nd USENIX Workshop on Hot Topics in Cloud Computing, HotCloud’10, Boston, MA, USA, June 22, 2010. USENIX Association, 2010.
Appendix A Distributed maximum -sized matching
In this section, we prove our results for distributed -sized matching and additionally provide the pseudocode.
Theorem 4.
There exists an MPC algorithm for -sized maximum matching with nonnegative edge weights and max edge weight for that achieves a -approximation whp in rounds and machine space.
Proof.
Let us define by a binary search on values 1 through to find the minimum that satisfies a halting condition: that the resulting the algorithm finds satisfies and (line 5) where is the largest weight in . First we transform the graph. Create a vertex set of dummy vertices, add them to our vertex set, and connect them to all vertices in with edge weights (lines 1 to 1). Then we run Ghaffari et al. (2018)’s algorithm (line 1) on this new graph with error being the minimum of the value satisfying and itself, and . Find the portion of this matching in , and use this to check our halting condition.
We must start by showing that if is a -approximate -matching in , then when , our algorithm finds a -matching with a -approximate weight. Assume there is such a matching, and consider when our algorithm selects for this value. Consider the matching the algorithm finds in the transformed graph. Assume for contradiction that some is not matched to any , and every edge in the matching from has weight over . Because is not connected to any vertex in , that means it isn’t matched at all. And since is connected to all with a positive edge, for to not have been matched, all must have been matched. Since , a perfect matching on has at least edges. Thus the weight of the algorithm’s matching in , , is bounded below by edges of weight greater than .
But OPTG,k for -sized matching in must be at least as large as this, so then , which is a contradiction on the assumption of . Otherwise, if there is some that is not matched to any where one of the edges in the matching from has weight or less, removing that match and pairing one of those vertices with can only improve the matching. Thus we can add a processing step afterwards to ensure all new vertices are matched, while not decreasing the value of the matching.
Thus our algorithm matches all vertices in to vertices in , and the remaining vertices in create a matching for a total size of or less. Thus the algorithm outputs an at most -sized matching in , so this selection of will make the halting condition true.
Let be the matching our algorithm finds in the transformed graph. Then the total weight is,
By the same argument as before, but without the factor, there is an OPT in the transformed graph that matches all vertices in to vertices in . Thus the expression for OPT is similar, where OPTG,k is the optimum for a -sized matching in .
We know is a -approximation for OPT, so we can combine these two equations.
We are interested in the portion of the solution in , or .
Recall that , and is a -sized matching in . Therefore . We can apply this to our inequality and simplify.
Since , then is bounded above by some constant. Then the approximation factor is . So for any approximation factor , we can select some to run Ghaffari et al. (2018)’s algorithm such that our algorithm gives a -approximation.
The algorithm searches for the minimum that satisfies this, so all that’s left to prove is that a selection of yields a -sized matching where still is a -approximation. If this is true, it must have matched all vertices in with vertices in and selected edges from . The value of this, where we sub in our value for , is:
Therefore, the approximation factor on the transformed graph is equivalent to the approximation factor on . Since we ran Ghaffari et al. (2018)’s algorithm on the transformed graph with error where , this yields a matching within error of OPTG,k.
Therefore, our algorithm returns the desired approximation. This algorithm requires iterations for the binary search on . In each iteration, the only significant computation in both round and space complexity is the use of the Ghaffari et al. (2018) algorithm that uses rounds and machine space. Thus our algorithm runs in rounds and .
∎
Appendix B Revenue approximation
Lemma 1.
After the first round of merges, Matching Affinity Clustering maintains cluster balance (ie, the minimum ratio between cluster sizes) of whp.
Proof.
After the first round of merges, note that any duplicated vertex must be merged with its duplicate. This is because the edge weight between these vertices is essentially infinite (for the purposes of this paper, we will say it is arbitrarily large). Thus no duplicates will be matched with another duplicate, so each of the 2-sized clusters has at least one real vertex. In any subsequent merges, this property will hold. Thus it holds for all clusters beyond the initial singleton clusters. ∎
Lemma 2.
Given and where clusters are all composed of two subclusters in , can be computed in the MPC model with machine space and one round.
Proof.
We start by constructing the vertex set, , which corresponds to the clusters at the new th level. So for every , create a vertex and put it in vertex set . It must be a complete graph, so we can add edges between all pairs of vertices.
Consider two vertices and . Since we merge sets of two clusters at each round, these must have come from two clusters in each. Say they merged clusters from vertices and respectively. Note that these vertices are from the previous clustering graph, . Then the edges have weights that are the average distances between corresponding -level clusters (because they were from the previous clustering graph, ). Since the clusters in all have the same size, we can calculate the weight as follows.
This is true because the weights in are already the average weights in the th level clusters, so they are normalized for the clusters size, which is th of the cluster size at the next level. So when we sum together the four edge weights, we account for all the edges that contribute to the edge weight in the next level, then we only need to divide by 4 to find the average.
Matching Affinity Clustering can utilize one machine per -level cluster . Each machine needs to keep track of the distance between its subclusters and all other subclusters at level . It can then do this calculation to capture edge weights in one round with space. ∎
Lemma 3.
Let clusters and be the th and th level clusterings found by Matching Affinity Clustering, where . Let be the indicator that is 1 if is not a power of 2. Then the clustering revenue of Matching Affinity Clustering at the th level is at least (whp):
Proof.
First, we want to break down the clustering revenue into the sum of its merge revenues. Since each match in our matching defines a cluster in the next level of the hierarchy, we can view each merge as a match in . Then we apply the definition of merge revenue.
Because we start with a power of two vertices after padding, each step can find a perfect matching, thus yielding a power of two many clusters of equal size at each level. Then since cluster size doubles each round, the cluster size at the th iteration is . Even though some of the vertices may not contribute to the revenue, this is an upper bound on the size. So in this formula is at least . This is the work done in (1) below.
| (1) | ||||
| (2) | ||||
| (3) | ||||
| (4) |
In (2), we simply substitute in place of the sum of the edge weights between and in . By definition, the edge weight between and in the clustering graph is the average of the same edge edge weights in . Thus if we just scale that by , we can substitute it in for the sum of those edge weights. In (3), we simply pull out . These contain total vertices, and by Lemma 1, they contain at least that contribute to the revenue for a total factor of . If there were vertices to start, then all clusters contain only real vertices, so the factor is . With the indicator, this is . We then simplify in (4). ∎
Lemma 4.
Let and be the th and th level clusterings found by Matching Affinity Clustering, where the th step uses matching for maximum matching and . Then the clustering cost of Matching Affinity Clustering at the th level is at most (whp):
Proof of Lemma 4.
As in Lemma 3, we want to break apart the clustering cost at the th level into a series of merge costs. Again, we know the merge costs can be defined through the matching .
| (1) | ||||
| (2) | ||||
| (3) |
At this step, we broke the clustering cost into merge costs of the matching (1), applied the definition of merge cost (2), and pulled out (3). Consider the inner clusters. Instead of selecting , we can consider being in any other cluster from . Let be all clusters other than or (i.e., ). Then we can define as an element in any cluster for . After, we simply rearrange the indices of summation.
Recall that the edge weights in are the average edge weights between clusters in on graph . Again, to turn this into just the summation of the edge weights, we must scale by and .
For each iteration of the outer summation, we are taking all the edges with one endpoint as and all edges with one as (besides the edge from to itself) and adding their weights. Since the only edge in with an endpoint at or is the edge from to , the summation covers all edges with one endpoint as either or that are not in . Consider an edge from some to that isn’t in . In every iteration besides possibly the first, matches everything, so we will consider and in separate iterations of the sum. In both of these iterations, we add the weight . Thus, each edge in outside of is accounted for twice, and no edge in is accounted for.
Consider a multigraph with vertex set and an edge set that contains all edges except those in twice over. Note since was a complete graph, must be a -regular graph. Thus, we could find a perfect matching in with a maximal matching algorithm, remove those edges to decrease all degrees by 1, and repeat on the new regular graph. Do this until all vertices have degree 0. Since each degree gets decremented by 1 each iteration, there must be a total of matchings . Thus the clustering cost can be alternatively thought of as the sum of the weights of these alternate matchings in clustering graph .
| (4) | |||
| (5) | |||
| (6) |
In (4), we viewed the summations as the sum of weights of the alternative matchings described earlier. Step (5) utilizes the fact that is a maximum matching, so the weight of any is bounded above by the weight of . Finally, in (6), we note that the summation does not depend on , and so we remove the summation.
Since is an approximation of the maximum matching on , we know . We can substitute this in and then rewrite it as the summation of edge weights in .
The total number of vertices in (ie, the total number of clusters at the th level) is just the total number of vertices over the cluster sizes: . Plugging that in gives the desired result.
| (7) | ||||
| (8) |
The first steps consist of plugging in the cluster sizes and performing algebraic simplifications. Finally, Step (8) refers to Lemma 3 for the clustering revenue. Recall this is an upper bound for the clustering cost in , and so the proof is complete.
So far, we have covered most of the lemma’s claim. Now we just need to account for the first step, when we utilize the -sized matching. Note the argument is dependent on being a perfect matching, where may only be a maximum matching on vertices. The proof structure here will function similarly. In this case, we still construct a multigraph as described on the subset of containing vertices matching in , then we add double copies of all the edges between vertices in the matching that aren’t matched to each other for a max degree of and thus create matchings on the vertices to cover these edges. However, the cost also accounts for edges from the matched vertices to the unmatched vertices. We can construct a bipartite graph with all these edges once. Then all vertices on one side of the bipartition have degree , and the vertices on the other side have degree . So we can construct matchings with edges in this graph that cover all edges. Alternatively, this can be viewed as matchings on vertices. In this case, we have a bunch of sized matchings on vertices, . The rest of the arguments hold. Since , step (7) becomes the following.
| (9) | ||||
| (10) | ||||
| (12) |
This mirrors the computation in steps (7) through (8). In (9), we substitute in for (7), and also replace the number of matchings with the new number of matchings (though recall at this point, we have already halved that value). Step (10) applies the fact that . Finally, in (11), we substitute in the clustering revenue. In the analysis for revenue, note that there do not exist unreal vertices yet, so we can consider when we refer to the Lemma 3. However, for this Lemma proof, this is the case where we do eventually duplicate vertices, so we analyze it along with other clusterings where , so it only needs to meet the condition when .
| (13) |
Thus concludes our proof.
∎
Lemma 5.
Matching Affinity Clustering obtains a -approximation for revenue on graphs of size , and a -approximation on general graphs whp.
Proof.
We prove this by constructing Matching Affinity Clustering. Our algorithm starts by allocating one machine to each cluster. Run Algorithm 1 for either the desired - or -matching, which finds our approximate matching, to create clusters of two vertices each, then apply the algorithm from Lemma 2 to construct the next clustering graph based off this clustering. Repeat this process until we have a single cluster.
From Lemma 4, we see that at each round, the cumulative cost is bounded above by times the revenue. Then we utilize the definition of the cost of an entire hierarchy tree to get bounds.
| (1) | ||||
| (2) | ||||
| (3) | ||||
| (4) |
Step (1) simply break down the total cost into merge costs, and then step (2) consolidates merge costs in each level of the hierarchy into clustering costs. Note that every iteration halves the number of clusters, so there must be iterations. In (3), we apply the result from Lemma 4, and finally in (4), we add up all the clustering revenues into the total hierarchy revenue. We can then examine hierarchy revenue.
The above simply utilizes the duality of revenue and cost, and then substitution from step (4). Next we only require algebraic manipulation to isolate .
Then we know the optimal solution can’t have more than non-leaves, which means that each edge will only contribute at most times its weight to the revenue. Thus, . In addition, since can be arbitrarily close to , we rewrite it as . Apply all these to our most recent inequality to get the desired results.
For an input of size , we have and get a approximation for revenue. For all other inputs, , and we get a approximation. We note that these applications of cost and revenue properties are heavily inspired by Moseley and Wang’s proof for the approximation of Average Linkage Moseley & Wang (2017). ∎
Lemma 6.
Matching Affinity Clustering uses space per machine and runs in rounds on graphs of size , and rounds in general.
Proof.
First, we use Algorithm 1 to obtain a -sized matching, which runs in rounds and machine space. After this, there are iterations, and at each iteration, we use Ghaffari et al. (2018)’s matching algorithm Algorithm, which finds our -approximate matching in rounds and machine space Ghaffari et al. (2018). We also transform the graph as in Lemma 2, which adds no round complexity, but requires space. Thus in total, this requires rounds and space per machine. However, note that when , we can just run Ghaffari et al. (2018)’s algorithm directly, and achieve a slightly better bound of rounds and space per machine. ∎
Theorem 5.
There is a graph on which Matching Affinity Clustering achieves no better than a -approximation of the optimal revenue.
Proof of Theorem 5.
The graph consists of vertices. We divide the vertices into “columns” to make large cliques. In every column, make a clique with edge weights of 1. In addition, enumerate all vertices in each column. For some index , we take all th vertices in each column and make a “row” (so there are rows that are essentially orthogonal to the columns). Rows become cliques as well, with edge weights of . All non-edges are assumed to have weight zero.
This is the graph described by Charikar et al. (2019) to show Average Linkage only achieves a -approximation, at best, for revenue. They are able to achieve this because Average Linkage will greedily select all the edges to merge across first. We can then leverage these results by showing that Matching Affinity Clustering, too, merges across these edges first.
In our formulation, we assume for some . Then there are columns and rows with and vertices respectively. Additionally, our algorithm skips the -matching steps (ie, all vertices are real). In the first round, we can clearly find a maximum perfect matching by simply matching within the rows, and we can assure this for our approximate matching by selecting a small enough error. In the next clustering graph, since edge weights are the average linkage between nodes, note that the highest edge weights are still going to be within the rows. Therefore, this matching will continue occurring until it can no longer find perfect matchings within the rows. Since the rows are cliques of vertices, this will happen until all each row is merged into a single cluster. This is then sufficient to refer to the results of Charikar et al. (2019) to get a bound. ∎
Appendix C Value approximation
Our goal in this section is to prove Theorem 6.
Theorem 6.
Assume there exists an MPC algorithm that achieves an -approximation for minimum weight -sized matching whp in rounds and machine space. In the value context (where edge weights are data distances) and in rounds with machine space, Matching Affinity Clustering achieves (whp):
-
•
a -approximation for value when ,
-
•
and a -approximation for value in general.
Since this is effectively the same algorithm as the revenue context, we can the analysis of Lemma 6 and simplify it to show the complexity of the algorithm. All that is left to do is prove the approximation. Our proof will be quite similar to that of Cohen-Addad et al. (2018), however we will require some clever manipulation to handle many merges at a time. Fortunately, the fact that we merge based off a minimum matching with respect to Average Linkage makes the analysis still follow the Cohen-Addad et al. (2018) proof quite well. We start with a lemma.
Lemma 9.
Let be the tree returned by Matching Affinity Clustering in the distance context. Consider any clustering at some iteration of Matching Affinity Clustering above the first level. Let be the th cluster which merged clusters and in the previous iteration. Say there are clusters in . Then whp, given an -approximation MPC algorithm for minimum weight -sized matching whp:
Proof.
Let and . Let and . Using these, one can see that the average edge weight of all edges contained in any or cluster is:
These edges were all merged across at some point lower in the hierarchy. This means that the edge set between ’s and ’s are the union of all edges merged across in lower clusterings in the hierarchy. Therefore, by averaging, we can say there exists a clustering (with ) below in the hierarchy, with clusters and splits similarly defined as , and respectively, such that:
Now we would like to build a similar expression for the edges between all and . The average of these edge weights is the following expression:
Consider the iteration that formed . Notice because is a higher level of the hierarchy, every cluster and must be a subset of some or . Fix some , and consider all the edges that cross from some to some such that . The union of all these edges precisely makes up the set of edges between and . Do this for every , and we can see this makes up all the edges of interest. We can decompose this into a set of matchings across the entire dataset. By another averaging argument, we can say there exists another alternate clustering (as opposed to ) which only matches clusters and that are descendants of and respectively such that:
Note that this was a valid matching, and therefore a valid clustering, at the same time that was selected. Also, note that either both and were perfect matchings, or they were both restricted to the same size in the first step of the algorithm. Thus, since was an -approximate minimum (-sized) matching in the graph where edges are the average edge weights between clusters, we know:
Putting this all together, we find the desired result:
∎
And we can use this to prove our theorem, similar to the results of Cohen-Addad et al. (2018).
Proof of Theorem 6.
We prove this by induction on the level of the tree. At some level, with clustering , consider truncating the entire tree at that level, and thus only consider the subtrees below , ie with roots in . Call this tree . We will consider the aggregate value accumulated by this level. Trivially, the base case holds. Then we can split the value of into the value accumulated at the most recent clustering step and value one step below . We use induction on the latter value. Since the approximation ratio is for and for , we can write the ratio as .
Now we would like to apply Lemma 1 to modify the first term in a similar manner to Cohen-Addad et al. Specifically, we want to extract terms of the form and . We will find this is harder to do with our formulation of Lemma 1, and therefore we have to rely on Lemma x that says that the cluster balance is at least . Let be the minimum cluster size. This and our cluster balance ratio implies that for all . Note that when , we have perfect cluster balance, so . Thus for our indicator , . Now we can manipulate our Lemma 1 result. Start by isolating the numerator on the left.
Note now that and and similarly for .
To get the correct term on the left, we see that . So we can multiply this result by , and then plug it into a portion of the first term. To preserve the ratio for both and , we multiply it by .
Next, note . This can be used on the second term.
Therefore, this captures of the weight of each subtree at height when , and more generally. ∎
Finally, we can show Theorem 7, which shows the tightness of the stronger approximation factor.
Theorem 7.
There is a graph on which Matching Affinity Clustering achieves no better than a -approximation of the optimal revenue.
Proof.
Consider which is almost a bipartite graph between partitions and (with ), except with a single perfect matching removed. For instance, if we enumerate and , we have for all and . And since it’s bipartite, for all .
Consider the removed perfect matching to get clusters . Matching Affinity Clustering could start by executing these merges, as this is a zero weight (and thus minimum) matching.
Now consider , the remaining graph after these merges with a vertex for each cluster and edges representing the total edge weight between clusters. This is a complete graph of size with 2-weight edges. By Dasgupta (2016)’s results, we know the value (with is calculated the same as cost) of any hierarchy on is . However, this ignores the fact that clusters are size 2, so the contribution of this part to the hierarchy on yields a revenue of .
Now let’s consider the obvious good hierarchy, where we simply merge all of , then all of , then merge and together. Thus all edges will be merged into a cluster of size for a total value of .
Asymptotically, then, Matching Affinity Clustering only achieves a ratio of on this graph.
∎
Appendix D Affinity Clustering approximation bounds
We now formally prove our bounds on the theoretical performance of Affinity Clustering.
Theorem 3.
Affinity Clustering cannot achieve better than a -factor approximation for revenue or value.
Recall that this is shown with the following two lemmas:
Lemma 7.
There exists a family of graphs on which Affinity Clustering cannot achieve better than a -factor approximation for revenue.
Proof.
Consider a complete bipartite graph with vertices such that each partition, and , has vertices, and all edges have weight 1. To make it a complete graph, we simply fill in the rest of the graph with 0 weight edges. We first consider how Affinity Clustering might act on . To start, each vertex reaches across one if its highest weight adjacent edges, a weight one edge, and merges with that vertex. Therefore, a vertex in will merge with a vertex in , and vice versa. There are many ways this could occur. We consider one specific possibility.
Take vertices and from and respectively. It is possible that every vertex in will merge with and every vertex in will merge with . It doesn’t matter which vertices and try to merge with. Then is divided into two subgraphs, both of which are stars centered at and respectively. The spokes of the stars have unit edge weights, and all other edges have weight 0. In the next step, the two subgraphs will merge into one cluster. Since there are no non-leaves at that point, it contributes nothing to the total revenue. Therefore, all revenues are encoded in the first step.
Since the subgraphs are identical, they will contribute the same amount to the hierarchy revenue. Recall that we are trying to prove a bound for whatever method Affinity Clustering might choose to break down a merging of a large subgraph into a series of independent clusters. Notice, however, due to the symmetries of the subgraphs, it does not matter in what order the independent merges occur. Therefore, we consider an arbitrary order. Let be the hierarchy of Affinity Clustering with this arbitrary order. We must break it down into individual merges, and let be the portion of the hierarchy contributing to one of the stars. We only need to sum over the merges of nonzero weight edges.
At each step of merging the star subgraph, we merge a single vertex across a unit weight edge into the cluster containing the star center. Call this growing cluster at the th merge. Let be the vertex that gets merged with at the th step. Then we can break this down into total merges.
| (1) | ||||
| (2) | ||||
| (3) |
In step (1), we simply break a single star’s merging into a series of individual merges in temporal order. Step (2) uses the fact that there are total vertices and and 1 vertices in the groups being merged to apply the definition of merge revenue. Finally, in (3), we simply evaluate the summation.
Now we consider how Matching Affinity Clustering will act on this graph. It simply finds the maximum matching. In the first iteration, it must match across unit weight edges, and therefore is a perfect matching on the bipartite graph. After this, due to symmetry, it simply finds any perfect matching at each iteration until all clusters are merged. Since the number of vertices is , it can always find such a perfect matching. Let be Matching Affinity Clustering’s hierarchy on . We will break this down into clusterings at each level, as we did in Section 4. Note there are total clusterings required in the hierarchy. And at each clustering, we have a matching that we merge across, so we can break it down into merges across matches. Let any be the usual clustering at the th level of this algorithm.
Note that by symmetry, each merge on a level contributes the same amount to the revenue. Therefore, we can simply count the number of merges and their contributions. At the th level, there are total merges. The size of each cluster being merged is , so the number of non-leaves is . Finally, the number of edges being merged across at each merge, since the graph is bipartite, is just .
Therefore, if we take the ratio of the revenues in the long run, we find the following.
So by cleverly selecting , we can make the clustering found by Affinity Clustering arbitrarily worse. If the size of the graph is , then Affinity Clustering can only achieve at best a approximation for this graph.
∎
Lemma 8.
There exists a family of graphs on which Affinity Clustering cannot achieve better than a -factor approximation for value.
Proof.
Consider simply a graph that is a matching (ie, each vertex is connected to exactly one other vertex with edge weight 1) with vertices. Again, recall that Affinity Clustering must match along the edges of a minimum spanning tree.
Partition the vertices into sets of four, which consist of two pairs. Consider one such set: is matched to and is matched to . Most of the edges here are zero. Therefore, a potential component of the minimum spanning tree is the line . If we do this for all sets, we can then simply pick an arbitrary root for each set (ie, ), make some arbitrary order of sets, and connect the roots in a line. All of these added edges are weight 0, so this is clearly a valid MST.
However, note that each edge is contained within some set of four. So if Affinity Clustering merges across these edges first, then the largest cluster the 1-weight edges can be merged in has four vertices. Say the tree returned by Affinity Clustering is . Note that we have edges.
We now observe the optimal solution. Since this is bipartite, we can simply merge each side of the partition first. Then we can merge the two partitions together at the top of the hierarchy. This means all edges are merged into the final, -sized cluster. Call this .
Thus . Thus, Affinity Clustering cannot achieve better than a approximation on this family of graphs. ∎
D.1 Experiments
Here we provide the full depiction of all experiments.