Improved Inference for Respondent-Driven Sampling Data with Application to HIV Prevalence Estimation
Abstract
Respondent-driven sampling is a form of link-tracing network sampling, which is widely used to study hard-to-reach populations, often to estimate population proportions. Previous treatments of this process have used a with-replacement approximation, which we show induces bias in estimates for large sample fractions and differential network connectedness by characteristic of interest.
We present a treatment of respondent-driven sampling as a successive sampling process. Unlike existing representations, our approach respects the essential without-replacement feature of the process, while converging to an existing with-replacement representation for small sample fractions, and to the sample mean for a full-population sample.
We present a successive-sampling based estimator for population means based on respondent-driven sampling data, and demonstrate its superior performance when the size of the hidden population is known. We present sensitivity analyses for unknown population sizes. In addition, we note that like other existing estimators, our new estimator is subject to bias induced by the selection of the initial sample. Using data collected among three populations in two countries, we illustrate the application of this approach to populations with varying characteristics. We conclude that the successive sampling estimator improves on existing estimators, and can also be used as a diagnostic tool when population size is not known.
Key Words: link-tracing, PPSWOR, successive sampling, Markov chain, network sampling, hidden population sampling, snowball sampling, social networks
1 Background
Researchers and government officials are often interested in characteristics of human populations for which there are no practicable sampling frames for direct sampling. In some such hidden populations, members are connected through social networks. A common approach is to collect a sample using a variant of link-tracing (Thompson, 2006a, b), such as a snowball sample (Goodman, 1961), where subsequent sample members are selected based on their relations with previously sampled individuals. When the initial sample is not a probability sample, this approach does not result in a probability sample. However, most available alternatives, (Muhib et al., 2001; Peterson et al., 2008; Watters and Biernacki, 1989) also fail to produce a probability sample of the population.
Respondent-Driven Sampling (RDS, introduced by Heckathorn 1997, 2002, see also Salganik and Heckathorn, 2004, Volz and Heckathorn 2008) is a recently introduced variant of link-tracing sampling which increases the ease of sampling and produces samples which, it is argued, approach probability samples as sampling progresses. The lack of satisfactory alternatives has spurned a strong demand for RDS (Johnston et al., 2008; Lansky et al., 2007).
RDS presents two main innovations: a sampling design and a corresponding approach to estimation. The former is highly effective in many settings (Lansky et al., 2007); the respondent-driven design relies on the respondents at each wave to select the next wave by distributing uniquely identified coupons to others in the target population, who can choose to return the coupons to enroll in the study. Thus, the sampling exploits the network of social relations while also avoiding the confidentiality concerns associated with recording the names of contacts.
The key innovation for estimation is that through many waves of sampling, the dependence of the final sample on the initial sample is reduced, allowing researchers more confidence in making approximate probability statements about the resulting samples. This insight allows for statistical inference in settings where the initial sample is typically selected by a convenience mechanism. Although current inference is likely superior to the alternative non-probability methods, existing methods are sensitive to deviations from many assumptions (Goel and Salganik, 2009; Gile and Handcock, 2010; Neely, 2009). This paper offers a modification of the existing theoretical formulation of respondent-driven sampling, and corresponding inference to address what we find to be a serious conceptual weakness of existing work: the known inaccuracy of the with-replacement approximation to the sampling process.
In the next section, we begin by introducing current RDS estimation, particularly the estimator introduced by Volz and Heckathorn (2008), and illustrate the sensitivity of this estimator to the with-replacement sampling assumption in cases of substantial sample fractions. In Sections 3 and 4, we then introduce a new model for RDS sampling based on successive sampling, and introduce a new estimator based on that model. In Section 5, we use a simulation study to illustrate the superior performance of the new estimator. We also include sensitivity analyses concerning inaccurate estimation of the size of the target population and the characteristics of the initial sample. In Section 6, we apply our estimator to data collected in three populations of drug users and men who have sex with men. We conclude with a broader discussion of the method and its limitations.
2 Previous Approaches to Estimation
The basic ideas underlying estimation from RDS data are clever and important. They allow for something like valid statistical inference, in a sampling setting where the target population cannot be effectively reached using a traditional sampling frame. The original article, (Heckathorn, 1997) made very strong assumptions about the sampling procedure so as to assume that the sample proportions were representative of the population proportions. Salganik and Heckathorn (2004) introduced a Markov chain argument for population mixing, and proposed an estimator based on equating the number of cross-relations between pairs of sub-populations of interest, based on the referral patterns of each group. This estimator is currently in wide use, and is implemented in the standard RDS analysis software (Volz et al., 2007). Volz and Heckathorn (2008) connect RDS estimation to mainstream survey sampling through the use of a generalized Horvitz-Thompson estimator form. This estimator relies on the estimation of the inclusion probabilities of the sampled units, . Based on an argument for treating the sample as independent draws from the stationary distribution of a random walk on the nodes of an undirected graph, Volz and Heckathorn (2008) approximate the sampling probabilities as proportional to nodal degree, , or number of incident edges in the graph. This estimator avoids the problem of potentially unknown population size by using the generalized Horvitz-Thompson form, normalizing by an estimator of as follows:
| (1) |
where indicates that the unit has been selected for sampling, and indicates it has not been selected, and represents the variable of interest measured on the unit.
We refer to this approach as the Volz-Heckathorn (VH) estimator. Gile and Handcock (2010) illustrate that this estimator consistently out-performs the Salganik-Heckathorn estimator, and we believe it is the most principled estimator currently available for RDS. For these reasons, we use the VH estimator as the standard for comparison in this paper.
Many critical assumptions required to justify this estimator are explored in Gile and Handcock (2010) and listed in Table 2. In this paper, we focus on the reliance on a with-replacement sampling model. We present an estimator based on an alternative sampling model reflecting the without-replacement nature of the sampling process.
3 Successive Sampling for RDS
The Volz-Heckathorn estimator requires many waves of sampling to justify its reliance on a stationary distribution. In practice the number of waves is small (almost always fewer than 20, and often 5 or fewer). Also, we wish to consider a without-replacement process for which stationarity does not apply. It is therefore instructive to consider a special case when stationarity is not necessary.
Consider a graph formed in the following manner: Begin with vertices, designated by indices . Assign to each vertex a number of edge-ends according to arbitrary fixed degree distribution , where is the number of nodes of degree , and are the minimum and maximum degrees, respectively, and subject to the constraint that twice the number of edges, , is even. Now select pairs of edge-ends completely at random and assign an edge connecting each pair. This procedure results in a variant of the so-called configuration model for networks, a popular null model for networks, especially in the physics literature (Molloy and Reed, 1995). Note that this formulation does allow loops, or links to oneself as well as multiple edges between the same pair of vertices, although the rate of these events decreases with increasing population size for fixed maximum degree , such that several authors have suggested they are negligible for or , where is the mean degree of the network (Chung and Lu, 2002; Burda and Krzywicki, 2003; Boguna et al., 2004; Catanzaro et al., 2005; Foster et al., 2007).
Now consider a random walk on a set of vertices with degrees given by , such that , where is the indicator function on . Volz and Heckathorn (2008) consider the stationary distribution of this random walk for a fixed graph. Instead, we consider the transition probabilities of the corresponding walk over the distribution of all networks of fixed degree distribution constructed as above, in which the node visited, , is selected from the distribution of possible edges from node . The transition probabilities are then given by:
| (5) |
where this probability is taken over the space of all possible configuration model graphs of given degree distribution, as well as over the steps of the random walk.
This procedure results in stationary distribution proportional to , and, in fact, selection probabilities at each step very nearly proportional to . Thus, for a network structure given by such a configuration model, the Volz-Heckathorn estimator constitutes a Hansen and Hurwitz (1943) estimator, without further requirement of sufficient waves for convergence.
Now consider the corresponding self-avoiding random walk . In this procedure,
| (8) |
This sampling procedure is mathematically equivalent to successive sampling (SS) or probability proportional to size without replacement sampling (PPSWOR), dating back to Yates and Grundy (1953), and typically defined by the following sampling process:
-
•
Begin with a population of units, denoted by indices with varying sizes represented by , with , for total edges .
-
•
Sample the first unit from the full population with probability proportional to size .
-
•
Select each subsequent unit with probability proportional to size from among the remaining units, such that conditional sampling probabilities are given by (8).
In the survey sampling literature, mostly based on the work of Raj (1956) and Murthy (1957), this sampling design is referred to as probability proportional to size without replacement (PPSWOR), and typically used in instances where the desired probability proportional to size (PPS) design is not feasible. In such cases, the sizes of population units are all known, the sampling design is implemented, and the main interest is in estimating the population total or mean of a variable measured on sampled units. The analytical properties of this procedure are quite difficult, as suggested by more recent work including Rao et al. (1991) and Kochar and Korwar (2001). In fact, even the marginal unit sampling probabilities are not available in closed form.
In the geological discovery literature, successive sampling is not a purposive design, but an approximation to a non-designed sampling process. Important work in this area includes Andreatta and Kaufman (1986), Nair and Wang (1989), and Bickel et al. (1992). These authors address the case of oil field discovery, in which successive fields are discovered with probabilities proportional to some measure of their size, typically taken to be their volume. This literature does not assume the full population of sizes to be known, and typically takes some function of the sizes, such as the sum of the sizes of undiscovered reserves, as the object of inference. Our application of successive sampling also assumes the unobserved sizes to be unknown, however as in Raj (1956) and Murthy (1957), our object is to use these sizes to estimate the population characteristics on another variable measured on all sampled units. To do so, we both develop a novel algorithm and leverage more recent work by Fattorini (2006).
4 Estimation of population means from RDS samples based on successive sampling
Under successive sampling, for population of sizes given by and sample size , there is a function mapping the size of a unit to its sampling probability . Our proposed estimator is based on estimated sampling weights, which are based on the given by the successive sampling procedure, applied to nodal sampling units and “sizes” given by nodal degrees. There are three key challenges for this approach. The mapping depends on first, the known population size and, second, the degree distribution, , neither of which is known in the general RDS case. Finally, given and the sample size , the mapping is not explicit. The lack of explicit mapping has been addressed by Fattorini (2006), who suggests estimating the mapping by simulation. For known and given , he simulates the successive sampling procedure, then estimates the inclusion probability associated with unit by:
| (9) |
where is the number of times unit is sampled in the trials. He proposes using these estimated probabilities in the standard Horvitz-Thompson estimator:
| (10) |
In most of this paper, we assume the population size, , is known. We evaluate the sensitivity of our results to that assumption in Section 5.2, and in the examples in Section 6.
Given the known population size, we present a novel approach to estimating the degree distribution jointly with inclusion probabilities when degrees are only observed for sampled nodes. This procedure can be applied beyond the RDS setting whenever the population distribution of unit sizes corresponding to a sample collected through successive sampling is unknown.
Our approach iteratively estimates the population distribution and the mapping . This approach relies on two key points:
We leverage these two points to propose the following procedure for the estimation of population mean in the case of nodal degrees observed only for sampled units.
Let denote expectation with respect to a sample of size sampled by successive sampling from a population with degree counts Then:
| (11) |
where is the random variable representing the number of sample units with degree , is the (common) inclusion probability of a node of degree , and is the maximum degree, . This suggests first order moment equations for the unknown true
| (12) |
where is the observed number of sample units with degree .
The algorithm is then:
-
1.
Initial estimate:
(13) that is proportional to .
-
2.
For iterate the following steps:
-
(a)
Estimate the population distribution of degrees:
(14) where is the observed number of sample units with degree .
-
(b)
Estimate inclusion probabilities:
-
i.
Simulate successive sampling samples of size from a population with composition
-
ii.
Estimate the inclusion probabilities:
(15) where is the total number of observed units of size in the simulations.
-
i.
-
(a)
-
3.
Estimate the population distribution of degrees and the corresponding inclusion probabilities via, respectively: and
-
4.
Use the resulting mapping to estimate via the generalized Horvitz-Thompson estimator:
(16)
For computational efficiency, most simulations in this paper were conducted with and , with good results. In general, we recommend at least and , and we have used these parameters for the simulations of the standard error procedure in the supplemental materials, in the application to real data, and in the extension to in the discussion. Estimation time scales with sample size, population size, and . In our simulations, with and , estimates require about seconds on a personal computer, increasing to about seconds when . In practice, these parameters can be adjusted for desired precision in the solution to (12). Higher values of are particularly helpful for more dispersed degree distributions and larger population sizes.
Simulations have shown the results of this procedure to be at least as good as those provided by a first order asymptotic approximation provided by Andreatta and Kaufman (1986). This approach is novel and its theoretical properties are not well understood. It is appealing is to consider the algorithm as a variant of an EM algorithm, such as an ECM algorithm (Meng and Rubin, 1993), with the unobserved part of the degree sequence, as the latent variable. Unfortunately, in the design-based frame, these values also fully determine the unknown parameters , resulting in a degenerate likelihood form.
4.1 Between Infinite Population and Full Population Sample
Consider the limiting case of the moment equation (12) where . In this case, this equation is only satisfied for the degree distribution given by, , resulting in , and , the sample mean.
Now consider the limit as , for fixed and fixed maximum degree. Then the step-wise selection probabilities for an unsampled node approach values proportional to degree:
| (17) |
where . Then , such that
| (18) |
for overall inclusion probabilities , and step-wise selection probabilities . Therefore, .
In either limit, or , approaches an existing estimator. Thus, it retains the professed limiting properties of , such as robustness to bias based on the initial sample, while retaining the favorable finite population characteristics of the sample mean in the case of a large sample fraction. In the next section, we use simulation studies to argue that for , the proposed estimator appropriately mediates between these two, and therefore out-performs both.
5 Comparing the New and Existing Estimators:
A Simulation Study
Our simulation study is designed to highlight the treatment of without-replacement sampling in the case of a large sample fraction. To increase the realism of the study, we chose parameters to match the characteristics of the pilot data from the CDC surveillance program (Abdul-Quader et al., 2006) wherever possible. The general procedure was as follows:
-
•
1000 networks are simulated under each test condition.
-
•
An RDS sample is simulated from each sampled network.
-
•
RDS estimators are computed from each sample.
Because the CDC’s surveillance system aims for a sample size of 500, and many RDS studies approach exhaustion of their populations of interest (Johnston, 2009; CDC, 2008), we fix all sample sizes at 500. We also consider a mean degree of 7, close to the mean of the pilot data from the CDC study (Abdul-Quader et al., 2006).
We assign a discoverable class to each member of the simulated population. In reference to studies designed to estimate the prevalence of infectious disease, we refer to this characteristic as “infection status,” assigning the “infected” status () to 20% of simulated population members in each simulation. Note that could also be applied to a continuous or categorical variable.
We consider networks sampled from models from the Exponential-family Random Graph Model (ERGM) class (Snijders et al., 2006). Here the relations are represented as a realization of the random variable with distribution:
| (19) |
where are nodal or dyadic covariates, is a -vector of network statistics, is the parameter vector, is the set of all possible undirected graphs, and is the normalizing constant (Barndorff-Nielsen, 1978). The structure of the networks represented is determined by the choice of .
In this study, we vary the structure of the networks in three ways: First, we consider populations of sizes (i.e. numbers of nodes) 1000, 835, 715, 625, 555, and 525, such that samples of size 500 constitute about 50%, 60%, 70%, 80%, 90%, and 95% of the target population. We focus on this range of sample fractions because it highlights settings in which we might expect to see finite population biases such as those is intended to address. Another critical feature is the activity ratio , equal to the ratio of the mean degree of infected nodes to the mean degree of uninfected nodes,
| (20) |
This measures the differential tendency for the groups to be socially connected in the population. We consider .
We also induce homophily on infection status in these simulations, parameterized as the relative probability of an edge between two infected nodes, and an edge between an infected and an uninfected node. This is an intuitive parameterization, also used in Gile and Handcock (2010), but differs from that used in other analyses of RDS. Except in Section 5.3, the edge probability between the two infected nodes is fixed at five times that of the mixed dyad. For , this, along with the 20% infected, implies that an edge between two uninfected nodes is twice as likely as an edge in a mixed dyad. We consider several other levels of homophily, and in Section 5.3 we show that this feature has important implications for the bias induced by biased initial samples, however for the case of initial samples at random with respect to , as in most of the simulations presented here, bias was not affected by level of homophily, although increasing homophily does increase the variance of both and , and is therefore important to consider in standard error estimation.
These features are represented in the ERGM by choosing network statistics to represent the mean degree, the activity ratio , and homophily (based on using the “infected” status as a nodal covariate). These three values were specified using the “nodemix” statnet model term, which includes three parameters corresponding to the three cells of the mixing matrix on infection. The parameter was chosen so the expected values of the statistics were equal to the values given above (van Duijn et al., 2009). Samples from the resulting models were taken using the statnet R package (Handcock et al., 2003, 2008).
The RDS sampling mechanism is again designed to mimic that of the CDC’s pilot study. Ten initial sample nodes were chosen for each sample, selected sequentially with probability proportional to degree, (i.e. by successive sampling). In the sensitivity analysis, we also consider initial sample selection regimes dependent on . Subsequent sample waves were selected without-replacement by sampling up to two nodes at random from among the un-sampled alters of each sampled node. Exactly two alters were sampled whenever possible. This process typically resulted in the sampling of four complete waves and part of a fifth wave, stopping when a sample size of 500 was attained.
We augment our basic results with two sub-studies evaluating the sensitivity of the estimator to assumptions not required for : the accuracy of the assumed population size and the dependence on the initial sample.
5.1 Results
The Volz-Heckathorn estimator exhibits substantial bias in cases of non-unity activity ratio, and more so for larger sample fractions. This result was noted in Gile and Handcock (2010), and is illustrated in Figure 1(a). The bias can be understood as follows: in the case of higher mean degree among infected nodes , and large sample fraction, the higher-degree infected samples will be down-weighted proportional to their degrees. The true without-replacement sampling probabilities are closer to uniform than would be suggested by the proportional-to-degree estimates, such that these higher-degree nodes are excessively down-weighted, leading to negative bias in the estimated proportion infected. The corresponding mappings from degree to sampling weight are illustrated in Figure 2.


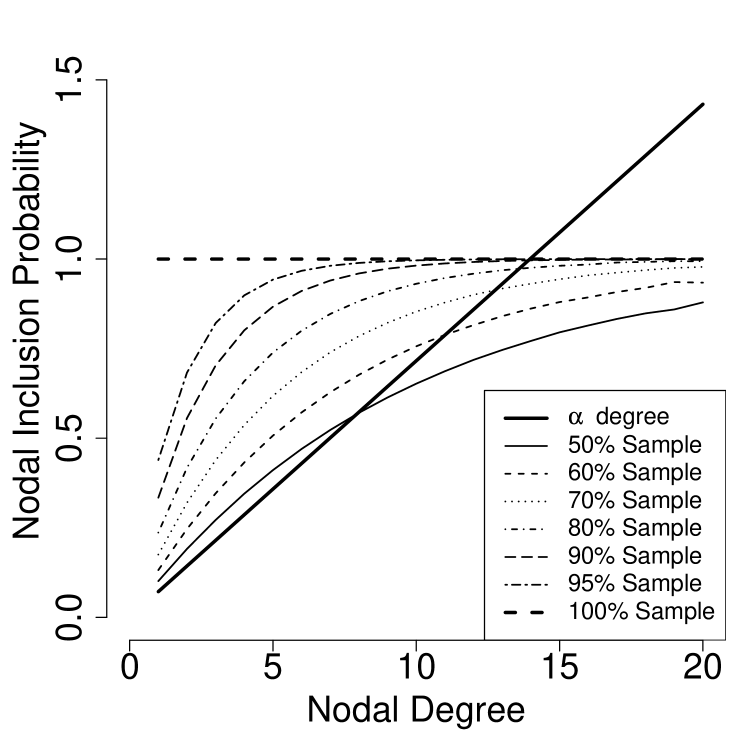
The SS estimator, however, is not subject to this type of bias, as illustrated in Figure 1(b). This is the main contribution of the proposed estimatior. In this plot, the bias is negligible, with the exception of the case in which . At least two factors, related to the strong homophily and the smaller size of the infected group contribute to this exception. First, the homophily-induced dependence implies the initial sample has greater influence on the final sample than in standard successive sampling. As this sample is selected first, its selection probabilities are closer to proportional to degree than the final successive sampling inclusion probabilities, contributing to a resulting sample slightly over-representing high-degree uninfected nodes. Furthermore, because the infected nodes have low degrees and high homophily, they more often fail to produce both possible recruits. The relative group sizes contribute to the difference in the magnitude of this effect for and .
The variance of is also consistently lower than that of , combining with the lower bias to yield substantially lower mean squared error, often massively so. The mean squared error of is less than that of for the full parameter space of Figure 1. The combination of bias and variance effects is visible in Figures 3(a) and 3(b).
5.2 Sensitivity to Population Size Estimate
It is important to note that the performance of in Figure 1(b) is dependent on knowledge of the true population size . This is often unrealistic in practice. Therefore, we evaluate the performance of in the case of over and under estimation of . In particular, we consider small () and large () estimates of given by:
| (21) |
Figure 3 depicts the results of these simulations for the case of . Each sub-plot gives the distribution of the estimator over 1000 samples from each of the 6 population proportions. The four sub-plots represent (top left), (top right), (bottom left) and (bottom right).
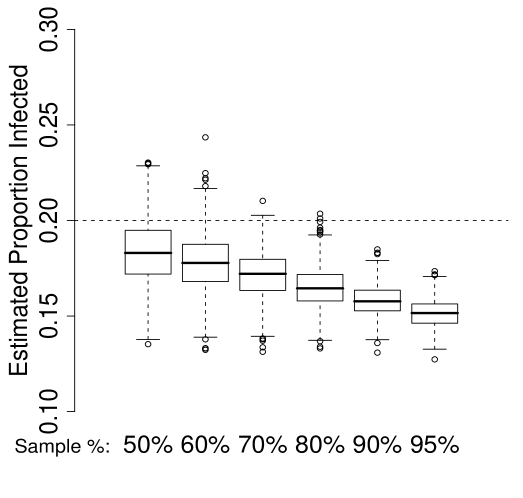
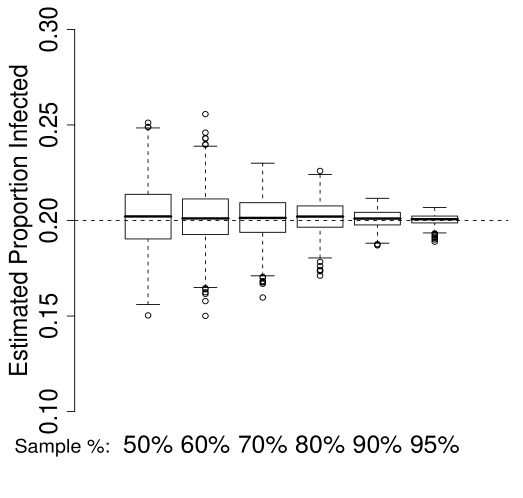
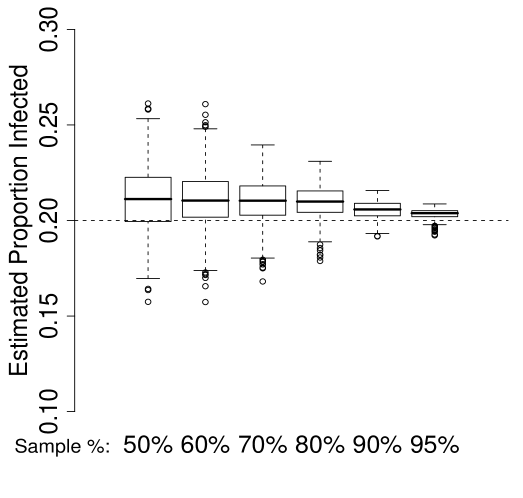
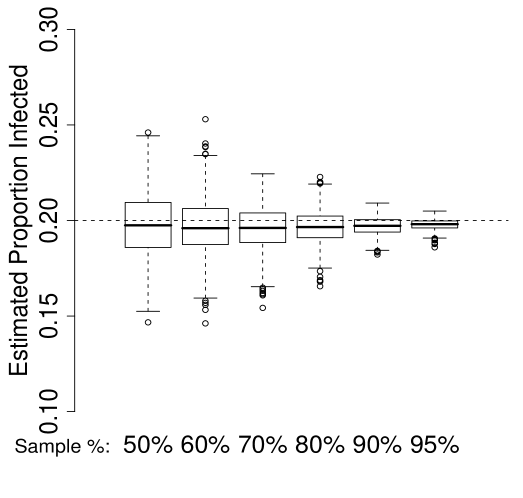
In this case, the underestimation of results in a small positive bias, due to the over-estimation of the curvature of . A small negative bias is also present in the case of , due to the under-estimation of the curvature or . In both cases, the bias induced by inaccurate is less than the bias of , and the resulting new estimators clearly out-perform the existing estimator.
Figure 4 presents mean point estimates for other values of activity ratio . The middle set of plots, , corresponds to a case of moderately lower mean degree among infected nodes. In this case, the biases introduced by under and over estimation of change sign, but remain small in magnitude. The remaining plots illustrate the greater bias possible for extreme values of . While the biases become larger, they are generally smaller than those exhibited by , with the exception for the two cases where the negative bias of due to small , as described in Section 5.1 is compounded by negative bias due to (, sample). The mean squared error of is still smaller than that of in these cases. Although the performance of is less robust to in cases of extreme , also performs more poorly in these cases.
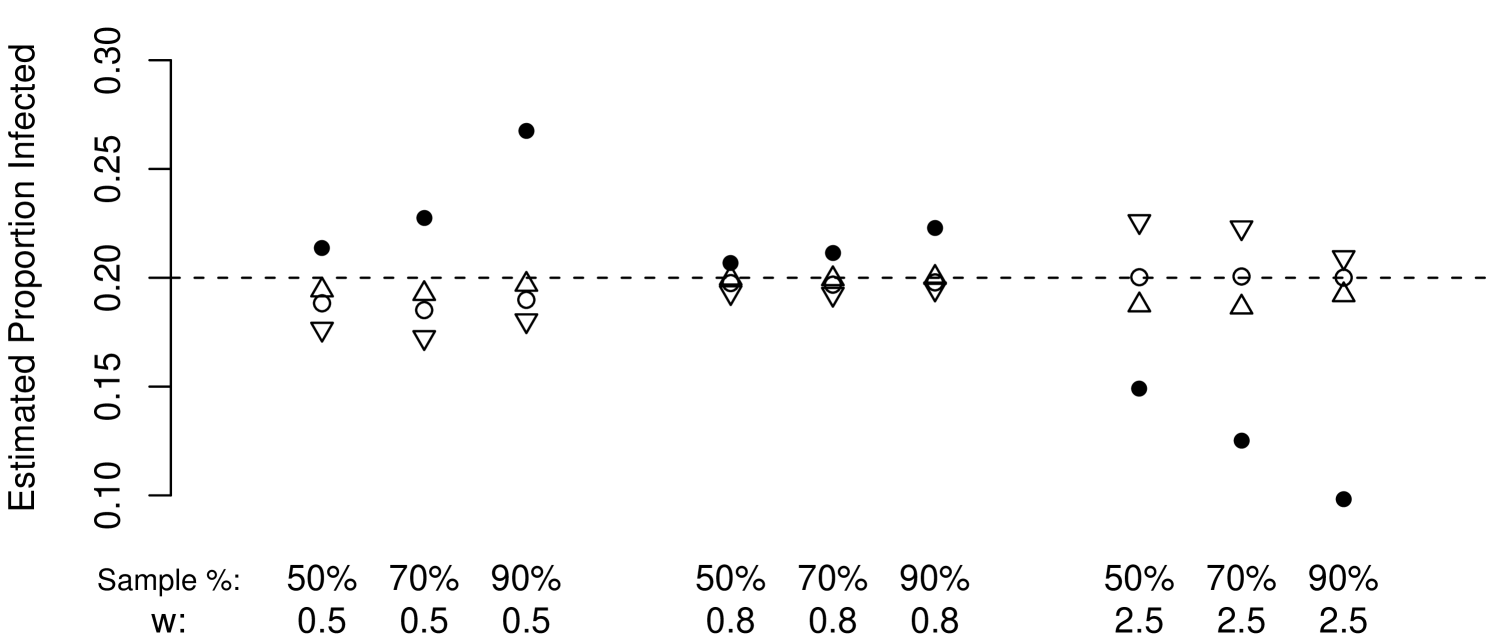
The behavior we see in these plots is typical of other simulations not shown here. With the more extreme values of activity ratio , the bias induced by the inaccurate estimation of is increased, but typically not so much as to cause performance of worse than that of .
5.3 Sensitivity to Initial Sample and Homophily
The estimator requires sufficiently many sample waves to overcome the effect of an initial convenience sample and step-wise sampling probabilities not proportional to degree due to the particular network structure. The estimator , not based on a stationary distribution, does not allow for such an argument. We therefore argue only that it is not worse than in this respect. In Section 5.1, we illustrate that in the simulated networks, bias induced by deviations from the configuration model are is no worse for than for . We focus here on bias induced by the initial sample. Gile and Handcock (2010) show that exhibits considerable bias in the case of a biased initial sample and network homophily. We expect to exhibit similar sensitivity, and here compare its performance to that of .
We consider three regimes for the selection of the initial sample: all uninfected, random with respect to infection, and all infected. We also consider five levels of homophily, measured by the ratio defined by:
| (22) |
The standard level of homophily used in this paper corresponds to . To present a comparison most favorable to , we treat a population size of 1000, (a sample), and activity ratio .
We consider 1000 samples from each homophily and sampling scenario, and summarize performance in terms of absolute bias, variance, and mean squared error, the last of which is depicted in Table 1. We find that the variance of always exceeds that of , as does bias in all but a few cases of small differences. The MSE of always exceeds that of . Table 1 illustrates this relation for the case of an all-infected initial sample. The patterns for the other two sampling conditions are similar.
| Homophily () | 1 | 2 | 3 | 5 | 13 |
|---|---|---|---|---|---|
| MSE | 0.00029 | 0.00036 | 0.00054 | 0.00150 | 0.01525 |
| MSE | 0.00026 | 0.00032 | 0.00052 | 0.00140 | 0.01449 |
| Efficiency: MSE /MSE | 1.12 | 1.12 | 1.04 | 1.07 | 1.05 |
6 Application to HIV Prevalence in High-Risk
Populations
6.1 Background
The United Nations requires countries to measure and monitor key indicators related to their HIV epidemics (UNAIDS and World Health Organization, 2007; UNAIDS, 2008). In particular, countries with epidemics concentrated in high-risk groups are required to report on several features of key populations such as (injecting) drug users ((I)DU), men who have sex with men (MSM), and sex workers (SW). Such features include HIV prevalence, risk behaviors, and population sizes. Because these populations are typically hard-to-reach, many countries rely on respondent-driven sampling to estimate HIV prevalence and risk behaviors. In this section, we evaluate data collected on IDU and MSM in cities from two different countries in 2007 and 2008.
6.2 Injecting Drug Users in an East European City
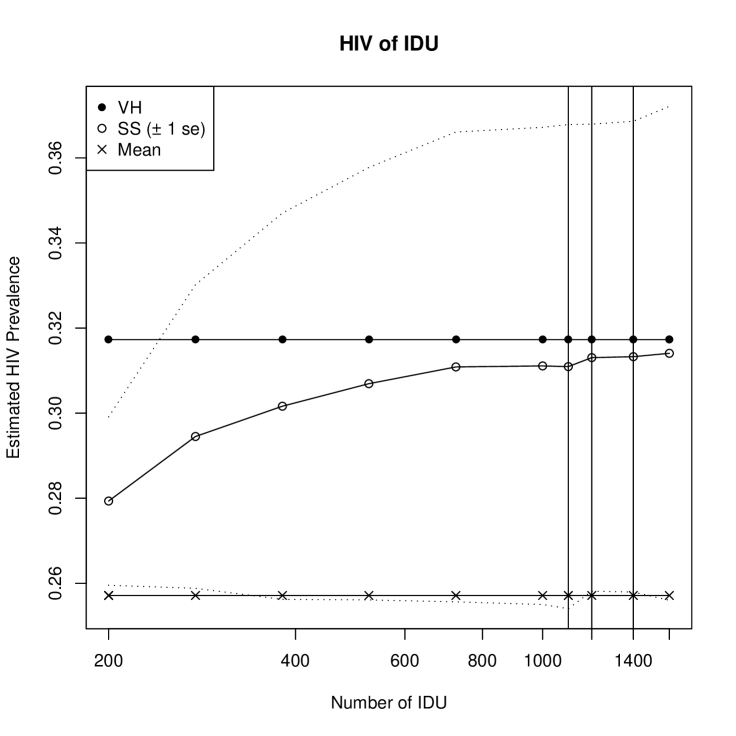
The first example is based on a 2007 survey of IDU in major cities in a former Soviet block country. The HIV epidemic in this country is largely driven by IDU, where prevalence levels are over 50% in many cities, and RDS is used to study this population, as well as MSM and SW in several larger cities. This country also invests heavily in producing estimates of the size of the hidden population through scale-up and multiplier methods (Kruglov et al., 2008; UNAIDS/WHO, 2003). We focus here on the results for one city. Because in very large populations we expect to be nearly identical to , we consider a city with one of the smaller estimates for the size of the hidden population. In this city, the number of IDU is estimated at 1200, with confidence interval 1100-1400. The RDS sample began with 6 initial samples, and distributed 3 coupons per respondent. The sample size was 175, all with full degree and HIV data. The two longest sample chains ended at wave 9, with 4 total respondents from wave 9.
We estimate the HIV prevalence using for several population sizes including 1100, 1200, and 1400, and also report the corresponding estimates of and the sample mean. These results are summarized in Figure 5(a). We find that the prevalence estimate based on is very close to that based on for population sizes in this range, and well within the uncertainty of the estimate, according to the estimator in the supplemental materials. This pattern is consistent across the cities we have considered in this country. This is partly due to the policy in this country of using RDS only in cities with larger estimated population sizes, opting for strategies of institutional sampling or attempted complete enumeration in areas with smaller populations.
6.3 Drug Users in a Caribbean City
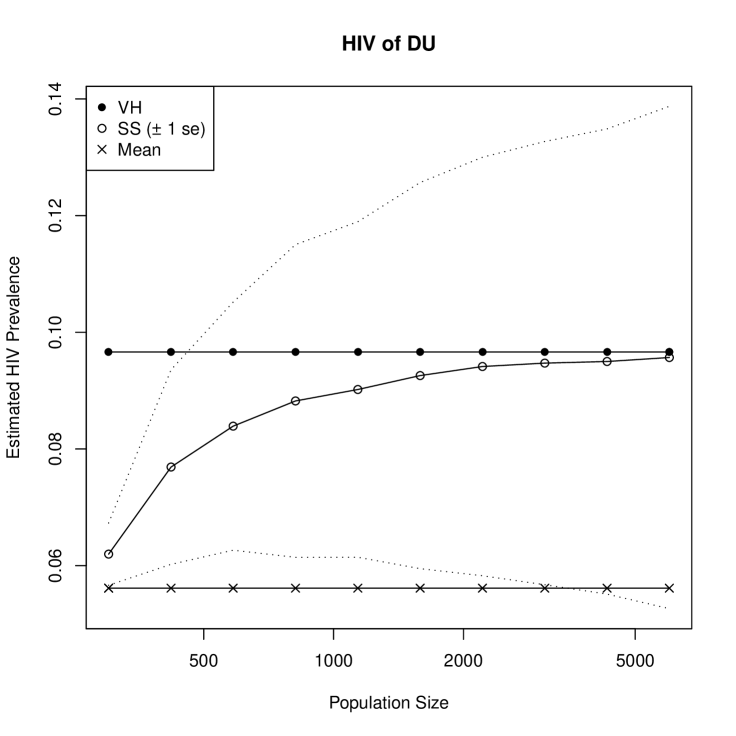
The second example is taken from a small Caribbean country, which has conducted RDS studies of drug users (DU), MSM, and SW in four main cities in 2008 (note that this study did not limit participation to injecting drug users). We focus here on the study of DU in one of the cities with smaller total population. In this study, there were 7 initial samples, resulting in a sample of size 301, of which we include here only the 285 with full degree and HIV information. Again three coupons were distributed to most respondents, although this number was reduced as the sample size approached the target of 300. The two longest sample chains reached wave 11, with 6 respondents from this wave.
In this city, the number of DU is unknown. Therefore, we use the successive sampling estimator to produce a sensitivity analysis for the effect of population size on the HIV prevalence estimate. The results of this analysis are shown in Figure 5(b). Here the point estimate varies from 6.2% for a population size of 301 to 9.6% for a population size of 6000, with . In absolute and relative terms, this is more variation than in the previous example, (3.4% or about 15% of ). Although these differences are still well within the uncertainty of the estimator, in many cases RDS point estimates are important in themselves. It is also possible that a sensitivity analysis such as this one will be of interest with respect to a particular prevalence threshold, such at the threshold on which UNAIDS bases national epidemic classifications. In this example, the point estimate of prevalence is above for all population sizes, while a nominal 90% confidence interval includes 5% for all population sizes.
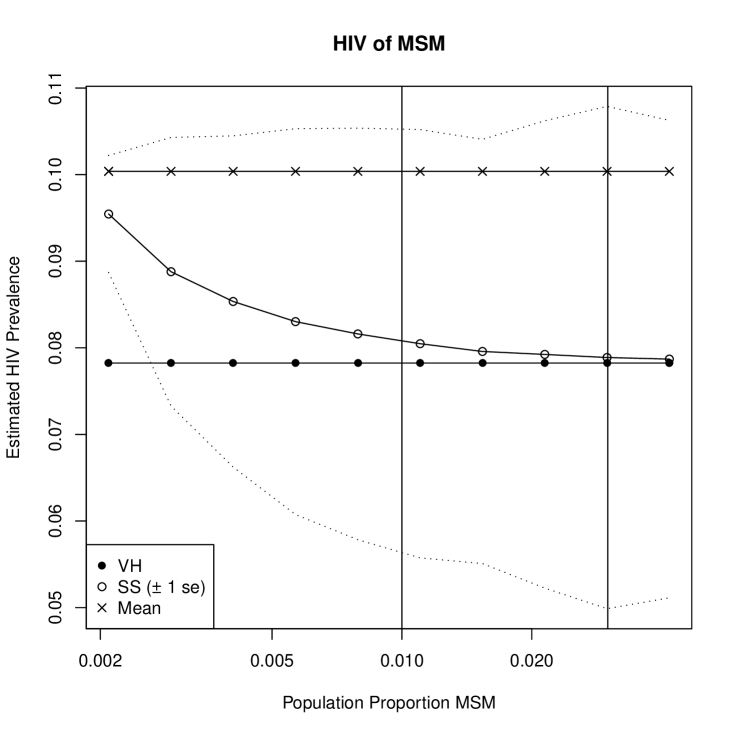
6.4 Men who have Sex with Men in a Caribbean City
Finally, we consider a population of MSM in the same Caribbean city. This study design was very similar to the corresponding DU study, with 7 initial samples, and a maximum of 3 coupons distributed. Here, the sample size was 270, with complete information for 269. One chain in this sample reached wave 12, with two respondents in that wave.
Figure 5(c) illustrates the sensitivity of the prevalence estimate to the number of MSM in this city. For comparison, the horizontal axis corresponds to the same population sizes as in 5(b), although here it is labeled in proportions. The prevalence estimate changes by about 1.6 percentage points over this range of possible population sizes (9.5% for 301 or .2% of the population are MSM, to 7.9% for 6000 or 4.2% of the population are MSM) . There are no additional studies available to provide population size estimates, however this problem is less severe for populations of MSM, as a rule-of-thumb is often applied, estimating the number of MSM at about 1%-3% of the general population, corresponding to the two vertical bars on Figure 5(c). In this case, however, further information is available. This sample did not reach its desired sample size (300), because no more coupons were returned, and the research team was not able to find additional MSM to sample. Thus the sample neared exhaustion of the portion of the population available for sampling, suggesting that although the population of MSM might be 1-3% of the city population, a smaller portion of those may be connected to the giant component of the social network of MSM and willing to participate in such a study. Therefore, if we restrict our inference to the reachable portion of the target population, the relevant population size is likely much closer to the sample size, suggesting a value of the estimate over 1.5 percentage ponts higher than . Note that among the 12 RDS studies in this country, three samples exhibited this near exhaustion behavior.
It is also of interest to note that in this example, unlike the previous two, is consistently higher than . This result is consistent with the expectation that is typically between and the sample mean. In this case, the degree-based weights of reduced the overall weight given to infected nodes, and the more moderate weights used in reduced this effect.
7 Discussion
The key insight of this paper is the recognition that the true mapping from nodal degree to inclusion probability, under Respondent-Driven Sampling is better approximated by successive sampling than by the linear mapping assumed by Volz and Heckathorn (2008). In addition, we introduce a novel approach to estimating the unit size (or degree) distribution in the population, based on the population size and sizes of observed units under successive sampling. Combining this insight and estimation strategy, we present a new estimator for population proportions based on an RDS sample.
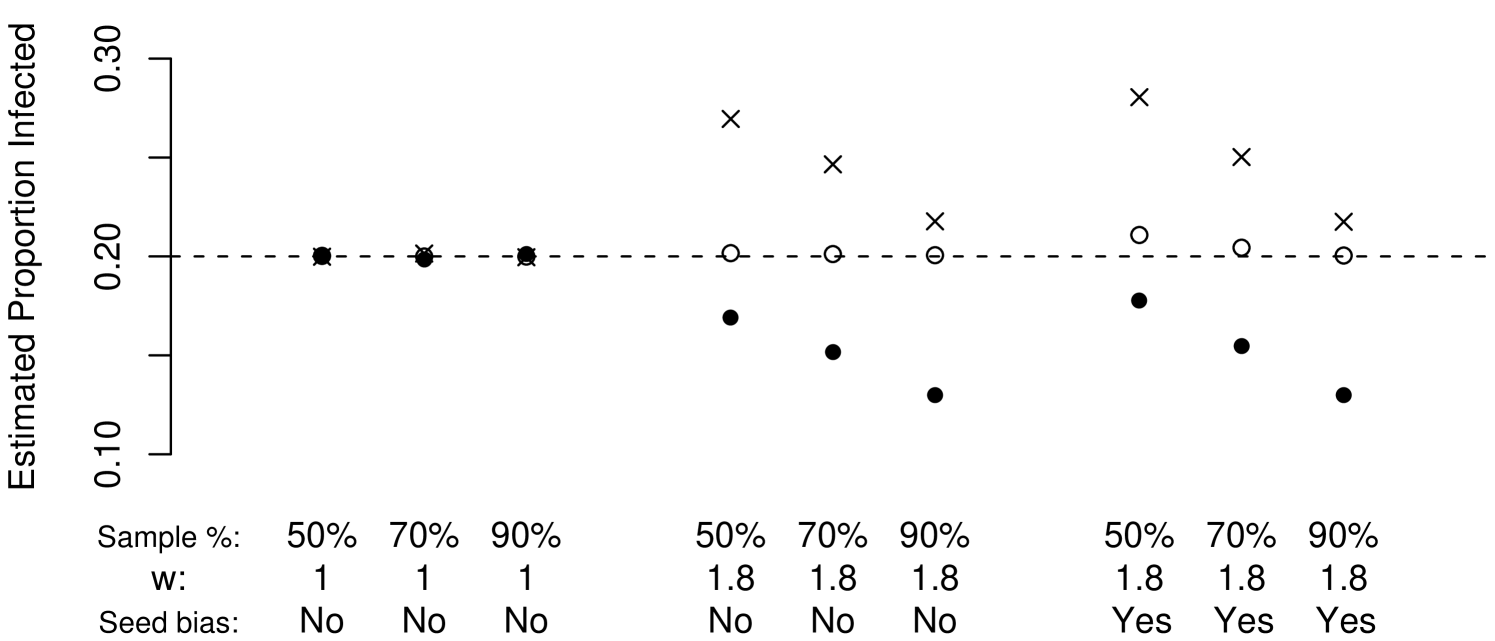
The contribution of this new estimator is illustrated in Figure 6. In cases with no correlation between degree and quantity of interest (), and initial sample selected at random with respect to infection status, the naive sample mean, is an unbiased estimator of the population mean, as are existing estimators such as and the proposed estimator . This is illustrated in the first three columns of the figure.
However, when the variable of interest is related to nodal degree, classes with higher degrees are over-represented in the population mean, resulting in the positive bias in the sample mean in the second three columns of Figure 6. This bias shrinks as the sample fraction increases. The existing estimator adjusts reasonably well for this effect when the sample fraction is small, however for larger sample fractions, this estimator over-compensates for the effect of degree distribution, resulting in bias opposite that of . The contribution of the proposed estimator, is that it correctly adjusts for the joint effects of varying degree distributions and large sample fractions.
The last three columns of Figure 6 illustrate a shortcoming of all three of these estimators. In this case, all initial samples, or seeds, are selected from among the infected nodes. This results in increased positive bias in all three of these estimators. All three estimators are also subject to other sources of bias discussed in Gile and Handcock (2010), including bias induced by the systematically biased passing of RDS coupons.
Because RDS is in wide usage, and often in cases where the sample fraction is large, this new estimator may improve estimation in many contexts. Its applicability is limited, however, by the requirement that the population size is known. Figures 3 and 4 illustrate that inaccurate estimates of can introduce bias into , although this new estimator still out-performs with the level of inaccuracy considered in this study.
While most of our simulation study has focused on sample fractions consistent with the finite population effects that is intended to address, it is of interest to note that is nearly identical to for small sample fractions. We have replicated much of the simulation study here with population size . We find no significant differences between and in these simulations, over a full range of values of . When using inaccurate estimates of as in (21), we found only one case of significant difference between and , corresponding to a dramatic under-estimate of population size, , and for high activity ratio, . In this case, had bias and had bias . The difference in mean squared error was not significant. Thus, the proposed estimator is helpful in correcting for finite population biases when they exist, and sensitive to the estimated population size in these cases. In cases where finite population effects are not present, the proposed estimator nearly coincides with existing estimator , and, unless the inaccurate population size estimate is small enough to transition to the region of finite population sensitivity, is insensitive to population size estimates in these cases.
Known population size and random mixing are key assumptions of the estimator . Additional assumptions required by are listed in Table 2. The assumptions with strikethrough are necessary for but not for , and the italic text indicates additional assumptions required by but not . In these terms, the key contribution of is to remove the dependence on a known inaccurate random walk model for estimating sampling probabilities. In return, sacrifices the theoretical robustness to the initial sample promised by the Markov chain model, although this robustness was not truly present in either, and the proposed estimator performs no worse than the former in this respect (Table 1). More critically, relies on the assumption of known population size. The estimator is also sensitive to the degree of non-random mixing, or homophily in the network, although no more sensitive than (Table 1), as well as to other assumptions such as accurate self-reported degree and an undirected network. Gile and Handcock (2010) illustrate the sensitivity of to deviations from some other assumptions in Table 2. We do not expect to be more robust to such deviations than .
| Network Structure | Sampling Assumptions | |
| Assumptions | ||
| Random Walk | Population size large () | Sampling with replacement |
| Model | Single non-branching chain | |
| Remove Initial | Homophily weak enough | Sufficiently many sample waves |
| Sample | Connected graph | Initial sample unbiased |
| Dependence | ||
| To Estimate | All ties reciprocated | Degree accurately measured |
| Probabilities | Known population size | Random referral |
Our application to HIV prevalence estimation in Section 6 illustrates several uses for . First, when the population size is known, provides a better estimate of population proportions than the other available methods. This can also be done when only a range of population sizes is known. In particular, in the case of MSM, officials are often willing to assume that the population ranges between 1% and 3%. When no information is available on population size, can be used to perform a sensitivity analysis. Finally, other information from the sampling process, such as the exhaustion of the population available for sampling, may suggest that the sample fraction is large. Additional information may also be gathered by asking respondents about their exposure to others who have been sampled.
Intuition suggests that in the case of a large sample fraction, an RDS estimator should negotiate between the infinite-population assumption of the Volz-Heckathorn estimator and the full-population sample assumption of the naive sample mean. In this paper, we provide an estimator based on a successive sampling model that appropriately negotiates between these two extremes. Whenever the hidden population size is known, it will be preferable to use this estimator. When the hidden population size is not known, this estimator still provides a helpful diagnostic check on the other available estimators.
Beyond the estimator itself, this paper contributes a new theoretical framework for understanding the sampling process in respondent-driven sampling. Previous understandings have relied on a with-replacement or infinite population assumption, an assumption known to be inaccurate, and critically so in some populations. The introduction of a sampling model appropriately accommodating the true without-replacement nature of the sampling process opens new possibilities for future research on respondent-driven sampling. We intend to make code available for these procedures in the R package RDS on CRAN.
References
- Abdul-Quader et al. (2006) Abu S. Abdul-Quader, Douglas D. Heckathorn, Courtney McKnight, Heidi Bramson, Chris Nemeth, Keith Sabin, Kathleen Gallagher, and Don C. Des Jarlais. Effectiveness of respondent-driven sampling for recruiting drug users in New York City: Findings from a pilot study. Journal of Urban Health, 83:459–476, 2006.
- Andreatta and Kaufman (1986) Giovanni Andreatta and Gordon M. Kaufman. Estimation of finite population properties when sampling is without replacement and proportional to magnitude. Journal of the American Statistical Association, 81(395):657–666, 1986.
- Barndorff-Nielsen (1978) Ole E. Barndorff-Nielsen. Information and Exponential Families in Statistical Theory. Wiley, New York, 1978.
- Bickel et al. (1992) Peter J. Bickel, Vijayan N. Nair, and Paul C. C. Wang. Nonparametric inference under biased sampling from a finite population. The Annals of Statistics, 20(2):853–878, 1992.
- Boguna et al. (2004) Marian Boguna, Romualdo Pastor-Satorras, and Alessandro Vespignani. Cut-offs and finite size effects in scale-free networks. European Physical Journal B, 38(2):205–209, 2004.
- Burda and Krzywicki (2003) Zdzislaw Burda and Andre Krzywicki. Uncorrelated random networks. Physical Review E, 67(4):046118, April 2003.
- Catanzaro et al. (2005) Michele Catanzaro, Marian Boguna, and Romualdo Pastor-Satorras. Generation of uncorrelated random scale-free networks. Physical Review E, 71(2, Part 2), 2005.
- CDC (2008) CDC. Consultation on the analysis of data collected through respondent driven sampling. Discussion session, February 12-14, 2008. Atlanta, GA, Keith Sabin, Organizer.
- Chung and Lu (2002) Fan Chung and Linyuan Lu. Connected components in random graphs with given expected degree sequences. Annals of Combinatorics, 6:125–145, 2002.
- Fattorini (2006) Lorenzo Fattorini. Applying the Horvitz-Thompson criterion in complex designs: A computer-intensive perspective for estimating inclusion probabilities. Biometrika, 93(2):269–278, 2006.
- Foster et al. (2007) Jacob G. Foster, David V. Foster, Peter Grassberger, and Maya Paczuski. Link and subgraph likelihoods in random undirected networks with fixed and partially fixed degree sequences. Physical Review E, 76(4, Part 2), 2007.
- Gile and Handcock (2010) Krista J. Gile and Mark S. Handcock. Respondent-driven sampling: An assessment of current methodology. Sociological Methodology, 40:forthcoming, 2010. URL http://www3.interscience.wiley.com/journal/120121482/issue.
- Goel and Salganik (2009) Sharad Goel and Mathew J. Salganik. Respondent driven sampling as Markov Chain Monte Carlo. Statistics in Medicine, 28:2202–2229, 2009.
- Goodman (1961) Leo A Goodman. Snowball sampling. Annals of Mathematical Statistics, 32:148–170, 1961.
- Handcock et al. (2003) Mark S. Handcock, David R. Hunter, Carter T. Butts, Steven M. Goodreau, and Martina Morris. statnet: Software Tools for the Statistical Modeling of Network Data. Statnet Project http://statnetproject.org/, Seattle, WA, 2003. URL http://CRAN.R-project.org/package=statnet. R package version 2.0.
- Handcock et al. (2008) Mark S. Handcock, David R. Hunter, Carter T. Butts, Steven M. Goodreau, and Martina Morris. ergm: A package to fit, simulate and diagnose exponential-family models for networks. Journal of Statistical Software, 24(3), 2008. URL http://www.jstatsoft.org/v24/i03/.
- Hansen and Hurwitz (1943) Morris H. Hansen and William N. Hurwitz. On the theory of sampling from finite populations. The Annals of Mathematical Statistics, 14(4):333–362, 1943.
- Heckathorn (1997) Douglas D. Heckathorn. Respondent-driven sampling: A new approach to the study of hidden populations. Social Problems, 44:174–199, 1997.
- Heckathorn (2002) Douglas D. Heckathorn. Respondent-driven sampling II: Deriving valid population estimates from chain-referral samples of hidden populations. Social Problems, 49(1):11–34, 2002.
- Johnston (2009) Lisa Johnston. personal communication, 2009.
- Johnston et al. (2008) Lisa G. Johnston, Moshen Malekinejad, Carl Kendall, Irene M. Iuppa, and George W. Rutherford. Implementation challenges to using respondent-driven sampling methodology for HIV biological and behavioral surveillance: Field experiences in international settings. AIDS and Behavior, 12:131–141, 2008.
- Kochar and Korwar (2001) Subhash C. Kochar and Ramesh Korwar. On random sampling without replacement from a finite population. Annals of the Institute of Statistical Mathematics, 53(3):631–646, 2001.
- Kruglov et al. (2008) Y. V. Kruglov, Y. V. Kobyshcha, T. Salyuk, O. Varetska, A. Shakarishvili, and V. P. Saldanha. The most severe HIV epidemic in Europe: Ukraine’s national HIV prevalence estimates for 2007. Sexually Transmitted Infections, 84(Suppl 1):i37–41, 2008.
- Lansky et al. (2007) Amy Lansky, Abu S. Abdul-Quader, Melissa Cribbin, Tricia Hall, Teresa J. Finlayson, Richard S. Garfein, Lillian S. Lin, and Patrick S. Sullivan. Developing an HIV behavioral surveillance system for injecting drug users: the National HIV Behavioral Surveillance System. Technical Report Public Health Reports 2007; 122 Suppl 1: 48-55 17354527, Division of HIV/AIDS Prevention, National Center for HIV, STD, and TB Prevention, Centers for Disease Control and Prevention, 2007.
- Meng and Rubin (1993) Xiao-Li Meng and Donald B. Rubin. Maximum likelihood estimation via the ECM algorithm: A general framework. Biometrika, 80(2):267–278, 1993.
- Molloy and Reed (1995) Michael S. Molloy and Bruce A. Reed. A critical point for random graphs with a given degree sequence. Random Structures and Algorithms, 6:161–179, 1995.
- Muhib et al. (2001) Farzana B. Muhib, Lillian S. Lins, Ann Stueve, Robin L. Miller, Wesley L. Ford, Wayne D. Johnson, and Philip J. Smith. A venue-based method for sampling hard-to-reach populations. Technical Report Public Health Reports 2001; 116 Suppl 1: 216222, Association of Schools of Public Health, Washington, DC, 2001.
- Murthy (1957) M. N. Murthy. Ordered and unordered estimators in sampling without replacement. Sankhya: The Indian Journal of Statistics, 18:379–390, 1957.
- Nair and Wang (1989) Vijayan N. Nair and Paul C. C. Wang. Maximum likelihood estimation under a successive sampling discovery model. Technometrics, 31(4):423–436, 1989.
- Neely (2009) W. Whipple Neely. Bayesian methods for data from respondent driven sampling. Dissertation in-progress, Department of Statistics, University of Wisconsin, Madison, 2009.
- Peterson et al. (2008) James A. Peterson, Heather S. Reisinger, Robert P. Schwartz, Shannon G. Mitchell, Sharon M. Kelly, Barry S. Brown, and Michael H. Agar. Targeted sampling in drug abuse research: A review and case study. Field Methods, 20(2):155–170, May 2008.
- Raj (1956) Des Raj. Some estimators in sampling with varying probabilities without replacement. Journal of the American Statistical Association, 51(274):269–284, 1956.
- Rao et al. (1991) T. J. Rao, S. Sengupta, and B. K. Sinha. Some order relations between selection and inclusion probabilities for PPSWOR sampling scheme. Metrika, 38:335–343, 1991.
- Salganik and Heckathorn (2004) Matthew J. Salganik and Douglas D. Heckathorn. Sampling and estimation in hidden populations using respondent-driven sampling. Sociological Methodology, 34:193–239, 2004.
- Snijders et al. (2006) Tom A. B. Snijders, Philippa Pattison, Garry L. Robins, and Mark S. Handcock. New specifications for exponential random graph models. Sociological Methodology, 36:99–153, 2006.
- Thompson (2006a) Steven K. Thompson. Adaptive web sampling. Biometrics, 62(4):1224–1234, 2006a.
- Thompson (2006b) Steven K. Thompson. Targeted random walk designs. Survey Methodology, 32(1):11–24, 2006b.
- UNAIDS (2008) UNAIDS. 2008 Guidance and Specifications for Additional Reecommended Indicators. Technical report, UNAIDS - Joint United Nations Programme on HIV/AIDS, 2008. URL http://www.unaids.org.
- UNAIDS and World Health Organization (2007) UNAIDS and World Health Organization. Guidelines on Construction of Core Indicators. 2008 Reporting. Technical report, UNAIDS - Joint United Nations Programme on HIV/AIDS, 2007. URL http://www.unaids.org.
- UNAIDS/WHO (2003) UNAIDS/WHO. Estimating the size of populations at risk for HIV: Issues and methods. Technical report, UNAIDS/WHO Working Group on HIV/AIDS, 2003. URL http://www.unaids.org.
- van Duijn et al. (2009) Marijtje A. J. van Duijn, Mark S. Handcock, and Krista J. Gile. A framework for the comparison of maximum pseudo likelihood and maximum likelihood estimation of exponential family random graph models. Social Networks, 31:52–62, 2009.
- Volz and Heckathorn (2008) Erik Volz and Douglas D. Heckathorn. Probability based estimation theory for respondent driven sampling. Journal of Official Statistics, 24(1):79–97, 2008.
- Volz et al. (2007) Erik Volz, Cyprian Wejnert, Ismail Degani, and Douglas D. Heckathorn. Respondent-Driven Sampling Analysis Tool (RDSAT) Version 5.6, 2007. Cornell University, Ithaca, NY.
- Watters and Biernacki (1989) John K. Watters and Patrick Biernacki. Targeted sampling: Options for the study of hidden populations. Social Problems, 36(4):416–430, 1989.
- Yates and Grundy (1953) Frank Yates and P. Michael Grundy. Selection without replacement from within strata with probability proportional to size. Journal of the Royal Statistical Society. Series B (Methodological), 15(2):253–261, 1953.