Improved Quick Hypervolume Algorithm
Abstract
In this paper, we present a significant improvement of the Quick Hypervolume algorithm, one of the state-of-the-art algorithms for calculating the exact hypervolume of the space dominated by a set of d-dimensional points. This value is often used as the quality indicator in the multiobjective evolutionary algorithms and other multiobjective metaheuristics and the efficiency of calculating this indicator is of crucial importance especially in the case of large sets or many dimensional objective spaces. We use a similar divide and conquer scheme as in the original Quick Hypervolume algorithm, but in our algorithm we split the problem into smaller sub-problems in a different way. Through both theoretical analysis and a computational study we show that our approach improves the computational complexity of the algorithm and practical running times.
keywords:
Multiobjective optimization , Hypervolume indicator , Computational complexity analysis1 Introduction
In this paper, we consider the problem of calculating the exact hypervolume of the space dominated by a set of d-dimensional points. This hypervolume is often used as the quality indicator in the multiobjective evolutionary algorithms (MOEAs) and other multiobjective metaheuristics (MOMHs), where the set of points corresponds to images in the objective space of the solutions generated by a MOMH. Multiple quality indicators have been proposed in the literature, however, the hypervolume indicator has the advantage of being compatible with the comparison of approximation sets based on the dominance relation (see [1] for details) and is one of the most often used indicators. The hypervolume indicator may be used a posteriori to evaluate the final set of solutions generated by a MOMH e.g. for the purpose of a computational experiment comparing different algorithms or to tune parameters of a MOMH. Some authors proposed also indicator-based MOMHs that use the hypervolume to guide the work of the algorithms [2, 3].
The exact calculation of the hypervolume may become, however, computationally demanding especially in the case of large sets in many dimensional objective spaces. Thus the exact calculation of the hypervolume obtained a significant interest from the research community [4, 5, 6, 7, 8, 9]. According to the recent study of Lacour et al. [8] the state-of-the-art algorithms for the exact calculation of the hypervolume are Quick Hypervolume (QHV) [4, 5], Hypervolume Box Decomposition Algorithm (HBDA) [8] and Walking Fish Group algorithm (WFG) [10]. From the theoretical point of view the currently most efficient algorithm in the case in terms of the worst case complexity () is by Chan [9]. To our knowledge, there is currently, however, no available implementation of this approach and no evidence of its practical efficiency [8].
In this paper, we improve QHV algorithm by modifying the way the problem is split into smaller sub-problems. This modification although may seem relatively simple significantly improves the computational complexity of the algorithm and practical running times. Since our work is based on relatively recently published results we do not give in this paper an extended overview of the applications of the hypervolume indicator and the algorithms for the hypervolume calculation. Instead we refer an interested reader to [4, 5, 6, 7, 8, 10] for recent overviews of this area.
The paper is organized in the following way. In the next section, we define the problem of the hypervolume calculation. In section 3, the improved Quick Hypervolume (QHV-II) algorithm is proposed. The computational complexity of QHV-II algorithm is analyzed and compared to QHV in section 4. In section 5, a computational study is presented. The paper finishes with conclusions and directions for further research.
2 Problem formulation
Consider a d-dimensional space that will be interpreted as the space of maximized objectives.
We say that a point dominates a point if, and only if, . We denote this relation by .
We will consider hypercuboids in parallel to the axes, defined by two extreme points and such that .
Consider a finite set of points . The hypervolume of the space dominated by within hypercuboid , denoted by is the Lebesgue measure of the set . The introduction of may seem superfluous since it does not influence the hypervolume, however, such definition will facilitate further explanation of the algorithms which are based on the idea of splitting the original problem into sub-problems corresponding to smaller hypercuboids.
3 Quick Hypervolume II algorithm
In this section we propose a modification of the QHV algorithm proposed by Russo and Francisco [4, 5]. We call this modified algorithm QHV-II. Both QHV and QHV-II are based on the following observations:
-
1.
, i.e. the hypervolume of the space dominated by is equal to the hypervolume of the hypercuboid defined by a single point and , i.e. , plus the hypervolume of the area dominated by the remaining points, i.e. excluding the area of hypercuboid .
-
2.
The region may be defined as a union of non-overlapping hypercuboids .
-
3.
Consider a point . The hypervolume of the space dominated by within is equal to the hypervolume of the space dominated by the projection of onto . The projection means that the coordinates of the projected point larger than the corresponding coordinates of are replaced by the corresponding coordinates of .
The above observations immediately suggest the possibility of calculating the hypervolume in a recursive manner with Algorithm 1. The algorithm selects a pivot point, calculates the hypervolume of the area dominated by the pivot point, and then splits the problem of calculating the remaining hypervolume into a number of sub-problems. If the number of points is sufficiently small it uses simple geometric properties to calculate the hypervolume.
Russo and Francisco [4, 5] propose to split the region into hypercuboids corresponding to each possible combination of the comparisons on each objective, where a coordinate may be or than the corresponding coordinate of the pivot point , with the exception of the two combinations corresponding to the areas dominated and dominating . Each such hypercuboid may be defined by a binary vector where at -th position means that and at -th position means that . We will call such hypercuboids basic hypercuboids.
We propose a different splitting scheme. We split the region into hypercuboids defined in the following way:
-
1.
is defined by the condition
-
2.
…
-
3.
is defined by the conditions
-
4.
…
In other words, the hypercuboids are defined not by binary vectors but by the following schemata of binary vectors:
-
1.
-
2.
…
-
3.
, with at -th position
-
4.
…
-
5.
where means any symbol either or . Each of these hypercuboids is obviously an union of a number of the basic hypercuboids.
The difference between the splitting schemes in QHV and QHV-II is graphically illustrated in Figure 1 for the 3-objective case. In this case, there are 6 basic hypercuboids. The colors describe the hypercuboids corresponding to the different sub-problems. Please note, that in the case of QHV-II the hypercuboid defined by the condition contains also the region dominating but this region does not contain any points. In addition, the arrows indicate the directions of projections of the points onto the hypercuboids.
QHV QHV-II
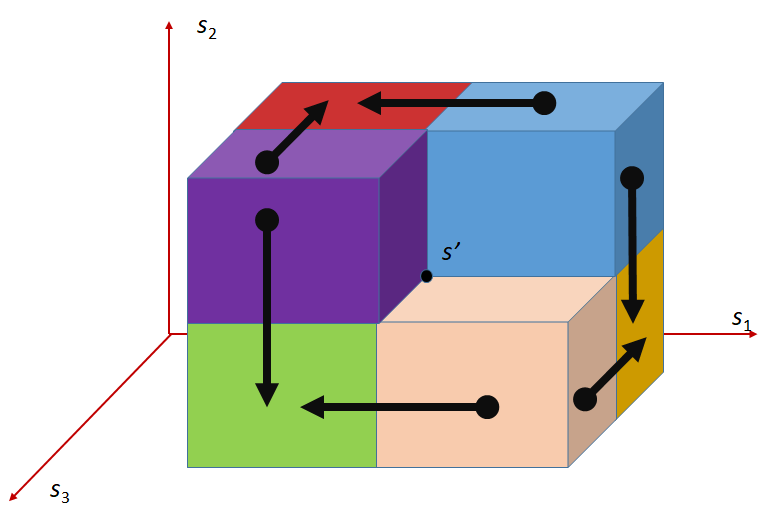
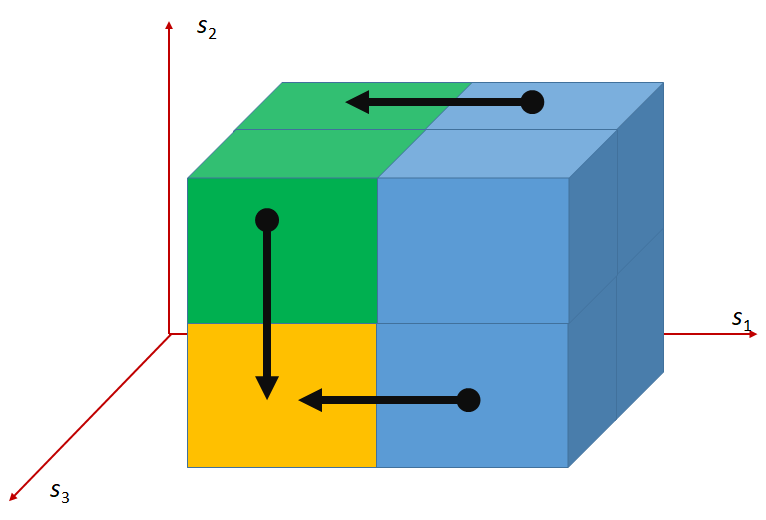
Please note, that the points projected onto a hypercuboid may become dominated since some coordinates are replaced with lower values. Russo and Francisco [4, 5] propose to explicitly remove the dominated points e.g. with the algorithm proposed in [11]. We do not use this step in QHV-II since we did not find it practically beneficial in the preliminary computational experiments. Note, however, that alike Russo and Francisco [4, 5] we implemented only a naive method for the removal of the dominated points by comparing all pairs of points. This could perhaps be improved by using more advanced methods. Please note, however, that the pivot point selected in the way described above is guaranteed to be non-dominated within . Furthermore, while assigning points to sets each point is compared to and the points dominated by may be removed. It does not guarantee an immediate removal of all dominated points but finally all dominated points will be removed by the algorithm because each of the dominated points will be dominated by one of the selected pivots or eliminated while using the simple geometric properties when the number of points is sufficiently small.
4 Theoretical Analysis
The analysis of the computational complexity of such complex algorithms like QHV or QHV-II is very difficult. Russo and Francisco [4] present a quite complex analysis of the computational complexity of QHV algorithm. However, the authors needed to make some strong assumptions like the uniform distribution of points on a hyperplane or the surface of a hypersphere to prove some main results. Furthermore their analysis in general shows that for large number of points, most of the projected points become dominated and may be removed. Thus the time needed for the removal of the dominated points has the main influence on the asymptotic behavior of the algorithm. Realistic data sets are, however, much smaller and the projected non-dominated points significantly influence running times. Indeed in our theoretical analysis we show that in the best case when all projected points are dominated and removed QHV and QHV-II have the same computational complexity. However, if all or a fraction of the projected points are preserved QHV-II starts to outperform QHV.
In this paper we use more standard tools like the recurrence solving and the Akra-Bazzi method [12] to analyze the computational complexity of QHV-II and QHV is some specific cases. We present results for the worst and the best cases. Since it is very difficult to analyze the average case behavior of such complex algorithms we analyze a number of specific intermediate cases for which we can obtain the complexity of QHV and QHV-II.
4.1 Worst case
To analyze the worst case we follow the approach proposed in [4]. The worst case is when all points except of the pivot point are assigned to each sub-problem. In this case, we can discard the time of removal of the dominated points and use the relation:
| (1) |
where is the numbers of the comparisons needed to process a set of points. Solving the above recurrence:
| (2) |
where is a constant. Thus QHV-II has the worst case time complexity
For the original QHV algorithm we get:
| (3) |
Solving the above recurrence:
| (4) |
where is a constant. Thus QHV has the worst case time complexity which is worse than the worst case time complexity of QHV-II.
4.2 Best case
In the best case points are distributed uniformly in all basic hypercuboids and all projected points become dominated and are removed. So, each of the basic hypercuboids contains points.
To analyze the complexity of the algorithm we use the Akra-Bazzi method [12] for the analysis of the divide and conquer algorithms of the form:
| (5) |
where is a constant, and are constants for all k, , and for some constants . In this case:
| (6) |
where is the unique real solution to the equation:
| (7) |
4.2.1 QHV-II
In QHV-II the problem is split into sub-problems. The -th sub-problem corresponds to the schema with positions that can be either or . Thus there are binary vectors and thus basic hypercuboids directly (i.e. without projection) assigned to the -th sub-problem, for . For we have directly assigned basic hypercuboids because we discard the basic hypercuboid corresponding to the binary vector 11…1 and containing points dominating the pivot point.
In this case, , , , , . Equation 7 has the solution . If we discard the removal of the dominated points (i.e. assume that all of them where removed through the comparison to the pivot point) then and:
| (8) |
4.2.2 QHV
In the same way we may analyze the best case behavior of the original QHV algorithm. In QHV the problem is split into classes of equivalent sub-problems. The -th class contains sub-problems with binary vectors having symbols . Each subproblem contains just one basic hypercuboid.
In this case, , , . In this case, we also get and the same time or , without or with the explicit removal of the dominated points, respectively. So, in the best case the time complexity of QHV and QHV-II is the same.
4.3 Intermediate case
Consider the case when the points are equally distributed in all basic hypercuboids but no projected points are removed. In other words each sub-problem will contain all points belonging to its hypercuboid and all projected points.
4.3.1 QHV-II
In this case, and since each sub-problem will contain half of the points better on one objective than the pivot point. Equation 7 has the solution . Since we can discard the removal of the dominated points and
| (10) |
Furthermore, since the points dominated by the pivot point may be removed without any additional comparisons QHV-II has time complexity with the considered distribution of points.
4.3.2 QHV
In the case of the original QHV algorithm , , since there are other basic hypercuboids projected onto a basic hypercuboid with symbols .
Unfortunately, we were not able to solve analytically equation 7 in this case. In Table 1 we present values of obtained numerically for different numbers of objectives . However, we can consider an approximate model assuming that points are uniformly distributed among all basic hypercuboids including the two hypercuboids dominated and dominating the pivot point . For larger values of the differences between the exact and the approximate models become very small as illustrated in Table 1 and since the approximate model differs in only two among basic hypercuboids it asymptotically converges to the exact model with growing . Please note, that although Table 1 suggest that is always higher for the approximate model we do not have a formal proof of this fact. For the approximate model , , and equation 7 is expressed as:
| (11) |
and has solution:
| (12) |
thus:
| (13) |
Theorem 1.
, i.e. the time complexity of QHV-II in the considered case is lower than the time complexity of QHV assuming the approximate model.
This theorem is the direct consequence of Lemma 1.
Lemma 1.
Proof 1.
| (14) |
Using Laurent series extension
| (15) |
| exact model | approximate model | |
|---|---|---|
| 2 | 1 | 1.2715 |
| 4 | 2.2942 | 2.4019 |
| 6 | 2.9920 | 3.0295 |
| 8 | 3.4543 | 3.4658 |
| 10 | 3.7971 | 3.8004 |
| 12 | 4.0709 | 4,0718 |
4.4 Constant fraction of the removed points
In practice some of the projected points are removed. The fraction of the preserved (not removed) projected points depends in general on the number of points and the number of projected objectives. We may consider, however, a simplified model where the fraction of the preserved points is a constant . Please note, that for we get the best case considered above, and for the intermediate case considered above. In this case:
| (16) |
for QHV-II, and:
| (17) |
for QHV. Unfortunately, we did not manage to solve equation 7 in these cases analytically. Numerical analysis with the use of non-linear solvers suggests that the following hypothesis is true:
Hypothesis 1.
is lower for QHV-II than for QHV, i.e. the time complexity of QHV-II is lower than the time complexity of QHV in the considered case, for any .
Namely, we used a non-linear solver to solve the following optimization problem:
| (18) |
with variables . The optimum solution was always , , for any starting solution tested. Furthermore, in Table 2 we present some exemplary values of for various numbers of objectives and values of obtained by solving equation 7 numerically. Of course, this is still not a formal proof of Hypothesis 1.
| 4 | 0,9 | 1,8635 | 2,0928 |
|---|---|---|---|
| 4 | 0,5 | 1,4279 | 1,5071 |
| 4 | 0,1 | 1,0837 | 1,0957 |
| 12 | 0,9 | 3,1897 | 3,6731 |
| 12 | 0,5 | 2,0706 | 2,5321 |
| 12 | 0,1 | 1,2548 | 1,5445 |
| 20 | 0,9 | 3,8092 | 4,3628 |
| 20 | 0,5 | 2,3820 | 3,0746 |
| 20 | 0,1 | 1,3563 | 1,9701 |
4.5 Average case with no removal of the dominated points
In QHV-II each of the sub-problems corresponds to a split based on the value of one objective in the pivot point which allows us to follow the analysis of well-known algorithms like the binary search or Quicksort. Assuming that the pivot point is selected at random with the uniform probability and that the ranks of a given point according to particular objectives are independent variables:
| (19) |
Multiplying both sides by :
| (20) |
Assuming that :
| (21) |
Subtracting equations 20 and 21:
| (22) |
Simplifying:
| (23) |
The above recurrence has the solutions:
| (24) |
where:
| (25) |
(with being an arbitrary constant), which can be shown by substituting and with 24 in 23
Since
| (26) |
thus
| (27) |
| (28) |
This analysis was based on the assumption that the pivot point is selected at random while in QHV and QHV-II we select a point with maximum . This increases the chance of selecting points with a good balance of the values of all objectives with ranks closer to on each objective which may improve the practical behavior of the algorithms.
Similar analysis of QHV is much more difficult, we can prove however that under the same assumptions the following relation holds:
Theorem 2.
, where and are the numbers of comparisons in QHV and QHV-II algorithms, respectively.
Proof 2.
In QHV each node is split into sub-problems. Among them are the sub-problems corresponding to the basic hypercuboids with only one objective better or equal to the corresponding value in the pivot point. Consider one of such basic hypercuboids better or equal to the corresponding value in the pivot point only on objective . All points with equal or better values on objective either belong to or are projected on this hypercuboid. Thus, each these sub-problems is equivalent to one of the sub-problems used in QHV-II. In result:
| (29) |
where is the number of comparisons needed to process the remaining sub-problems other than the sub-problems discussed above.
4.6 Discussion
We have shown that the worst case time complexity of QHV-II is better than of QHV. On the other hand, the best case time complexity of the two algorithms is equal. We have analyzed also a number of intermediate cases each time showing that the time complexity of QHV-II is better than of QHV which supports the hypothesis that in practical cases QHV-II performs better than QHV.
5 Computational experiment
In order to test the proposed method we used the test instances proposed in [8]. The set of instances includes linear, concave, convex, and hard instances with up to 10 objectives and up to 1000 points. In addition we used also instances with points uniformly distributed over a multi-dimensional spherical surface generated by us in a way proposed by Russo and Francisco [4]. Among the hard instances there is just one instance of each size. In other cases, there are 10 instances of each size. The presented results are the average values over 10 instances of each type and size in all cases with the exception of the hard instances. All test instances used in this experiment, as well as the source code and the detailed numerical results, are available at https://sites.google.com/view/qhv-ii/qhv-ii.
The main goal of the computational experiment is to show that QHV-II performs less operations than QHV. Please note, that our goal is not to present a very efficient code for calculation of the hypervolume. We have developed only a simple implementation of QHV-II in C++. In the same programming language we have implemented also QHV algorithm. Both implementations share majority of the code. We compare it also to the implementation of QHV available at http://web.tecnico.ulisboa.pt/luis.russo/QHV/ developed by the authors of the algorithm. We call this implementation oQHV (the original implementation of QHV). oQHV implementation is much faster than our implementation of QHV (and thus of QHV-II) because of several reasons:
-
1.
oQHV is implemented in C and the code is highly optimized for efficiency. Our implementation is made in C++ and is relatively simple. In particular, we do not use any low level code optimizations used in oQHV, and we use object-oriented techniques, e.g. classes from the STL library, which are very convenient, but can make the code less efficient.
- 2.
To make sure that our understanding of QHV is correct we modified the code of oQHV. We call this modified implementation oQGHV-s (oQHV simplified). In oQGHV-s we do not use the additional methods (HSO and IEX) for the sub-problems with small numbers of points. In other words, oQGHV-s implements the same algorithm as our implementation of QHV. We have compared the numbers of visited nodes in the recursive tree in both our implementation of QHV and oQHV-s. The numbers of visited nodes were the same for smaller instances and differed slightly (only in once case above 0.1%) for larger instances. These small differences where probably caused by small numerical perturbations since in both implementations the objective values are stored as the floating point numbers. On the other hand the running times of our implementation of QHV were on average 3 times higher due to the differences in the programming languages and code optimization. Of course, we have also checked that our implementations of QHV-II and QHV returns the same values of the hypervolume that the other tested algorithms.
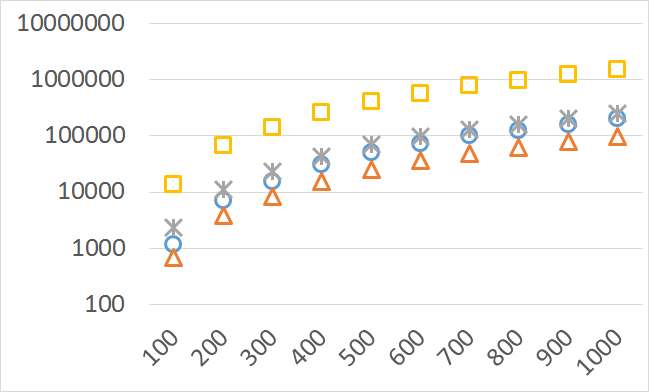
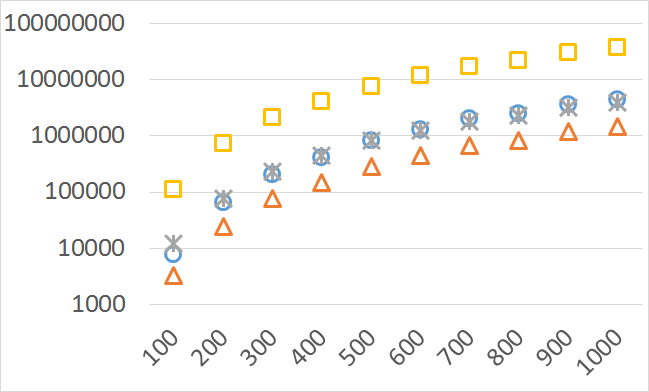
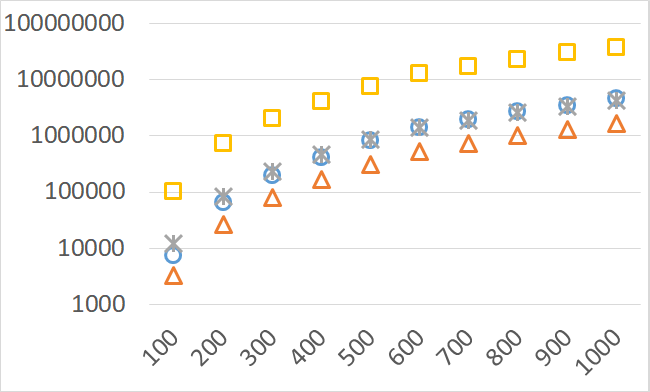
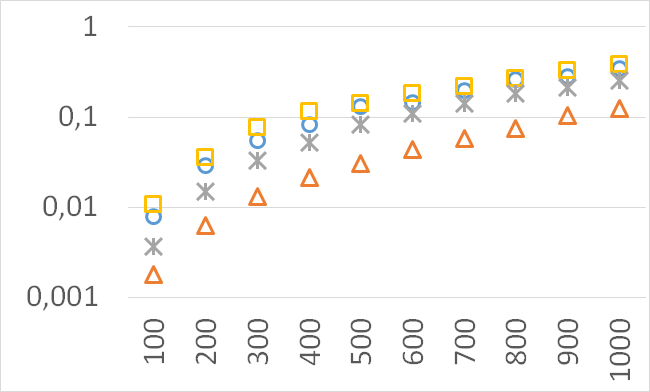
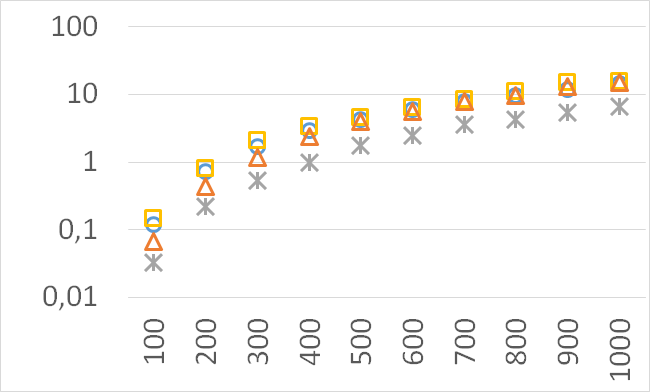
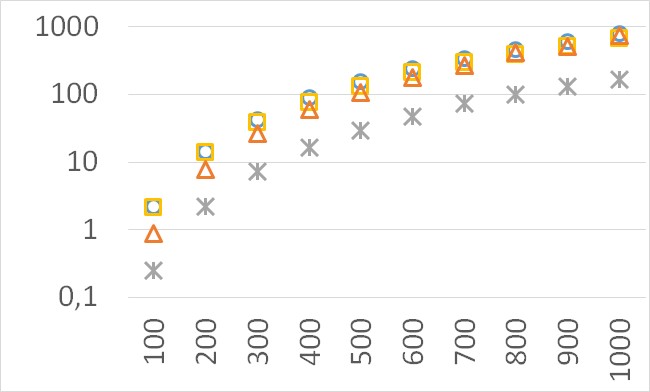
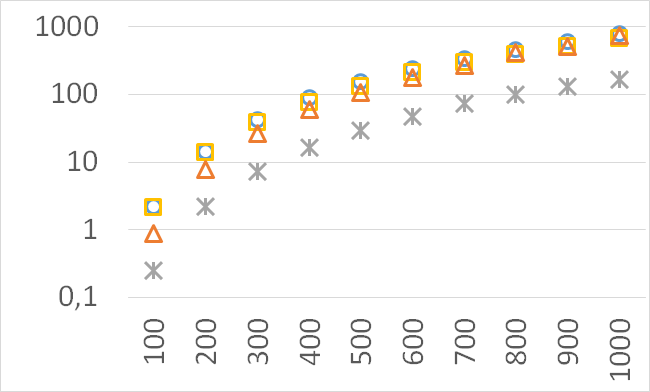
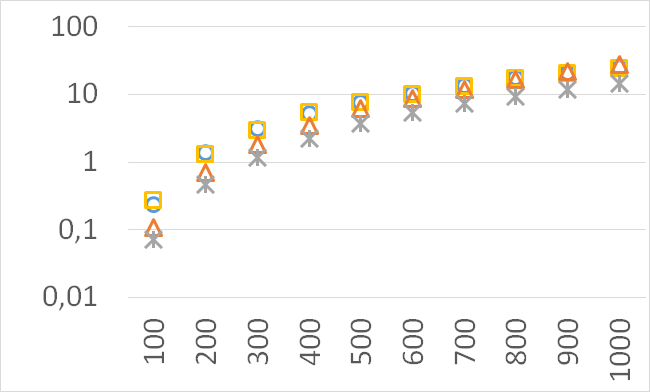
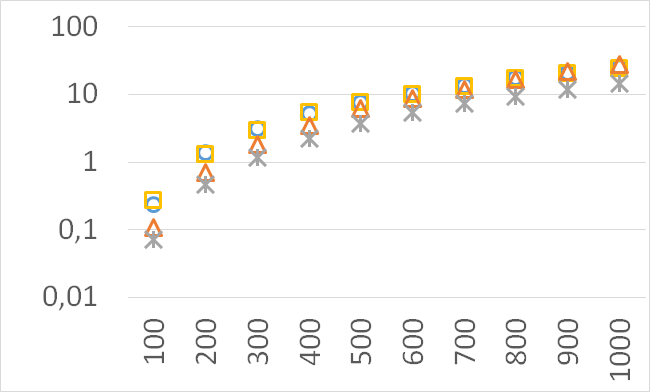
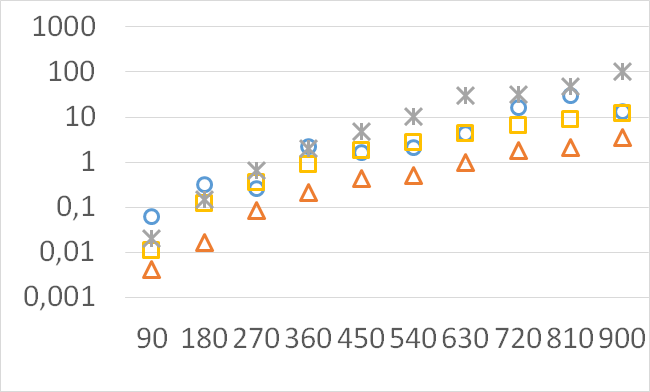
The numbers of visited nodes in the case of QHV-II and oQHV are not directly comparable since oQHV cuts the recursive tree at some levels and applies the additional methods (HSO or IEX) for the small sub-problems. To make a fair comparison in Figures 2 to 6 we compare the original implementation of QHV and our implementation of QHV-II with the recursive trees cut in both cases at the level at which the original implementation of QHV would use the additional methods. In other words, the sub-problems for which the original implementation of QHV would solve with the additional methods were completely skipped. We call these methods oQHV-cut and QHV-II-cut. We report the numbers of visited (internal) nodes and the number of leafs, i.e. the number of calls to the additional methods (HSO or IEX). The number of visited nodes was on average 2,21 (33,5 maximum) times higher in oQHV-cut and the number of leafs was on average 5,39 (46 maximum) times higher. These numbers were almost always lower for QHV-II-cut expect of 4 hard instances with 6 objectives were the numbers of visited nodes were slightly higher for QHV-II-cut. The relative differences were generally higher for instances with higher number of objectives. These results confirm that QHV-II constructs smaller recursive trees and allows to predict that a more advanced implementation of QHV-II, i.e. with a more optimized code and with the use of the additional methods for small sub-problems, could be several times faster than the original implementation of QHV for the tested instances.
Please note also, that QHV-II behaves much more predictably than QHV on hard instances. The number of visited nodes and leafs in QHV-II grows gradually with the growing number of points, while in QHV it is sometimes higher for smaller sets.
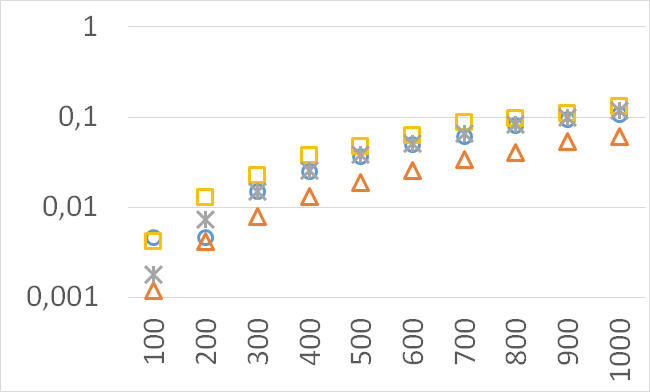
Although our goal is not to develop a very efficient implementation of QHV-II our simple code is already competitive to the state-of-the-art implementations in some cases. In Figures 7 to 11 we present running times of our implementation of QHV-II, the original implementation of QHV (oQHV), as well as of the non-incremental version of HBDA (HBDA-NI) [8] and WFG [10] algorithms. oQHV and QHV-II were run by ourselves on Intel Core i7-5500U CPU at 2.4 GHz. For HBDA-NI and WFG, in the case of the linear, concave, convex, and hard instances, we used results obtained in [8]. Since a slower CPU was used in that experiment we re-scaled the running times by a factor of 2,5 obtained by comparing the running times in a number of test runs. For uniform spherical instances, we run ourselves WFG algorithm using the code available at http://www.wfg.csse.uwa.edu.au/hypervolume/. Unfortunately, because of some technical problems, we were not able run the code of HBDA-NI, thus for these instances this method was not used. These results confirm that even our simple implementation of QHV-II is already competitive to the state-of-the-art codes in some cases, especially for hard instances with 10 objectives. Let us remind, that the results presented above suggest that the implementation of QHV-II could be further significantly improved by adding a low level code optimization, and using the additional methods for the small sub-problems.
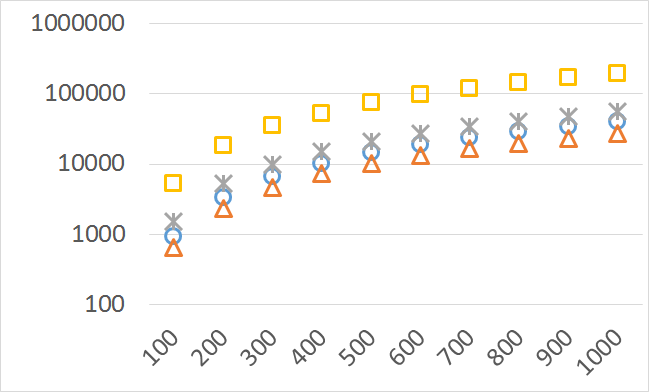
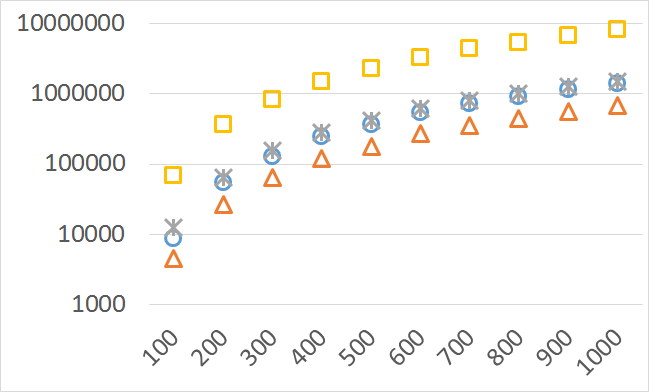
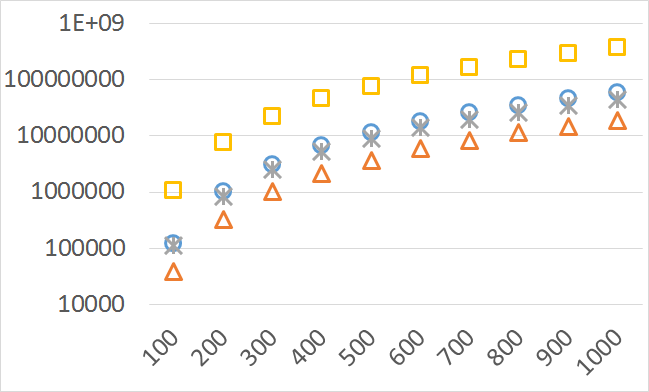

Number of operations
Number of points
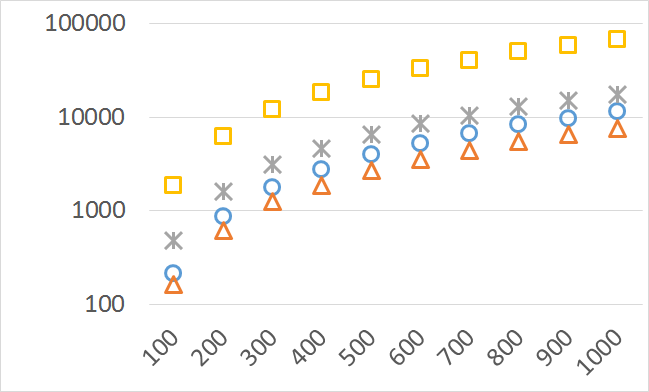
Number of operations
Number of points
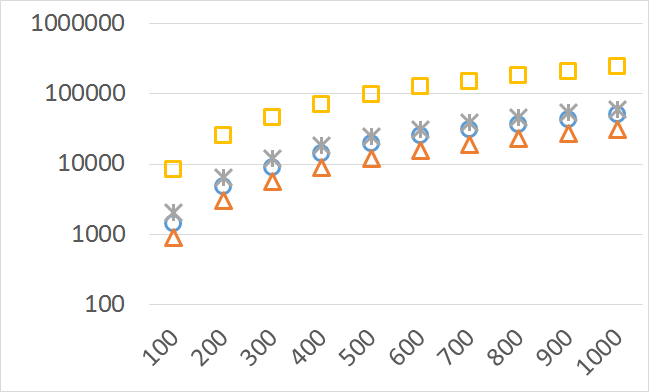
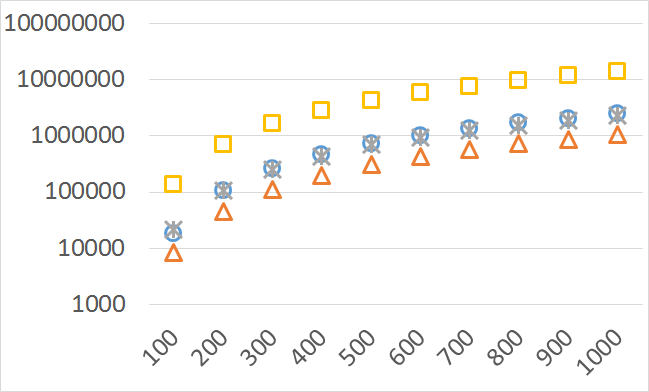
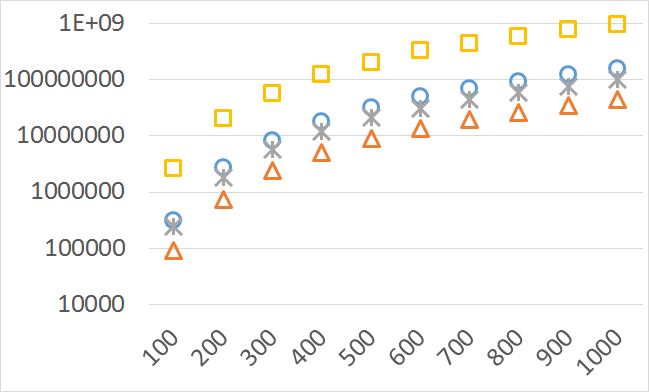
Number of operations
Number of points
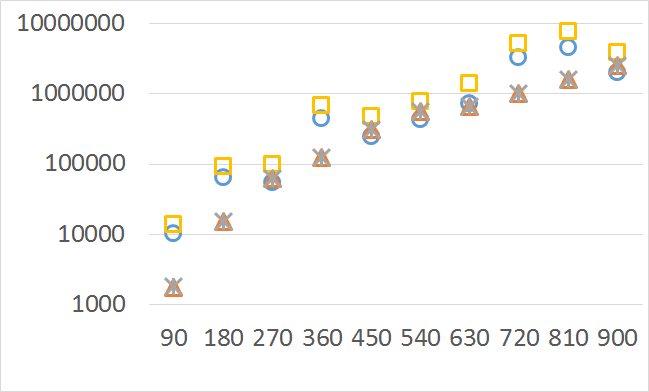
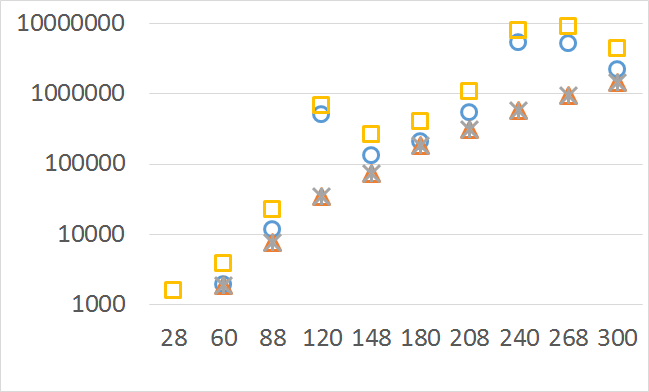
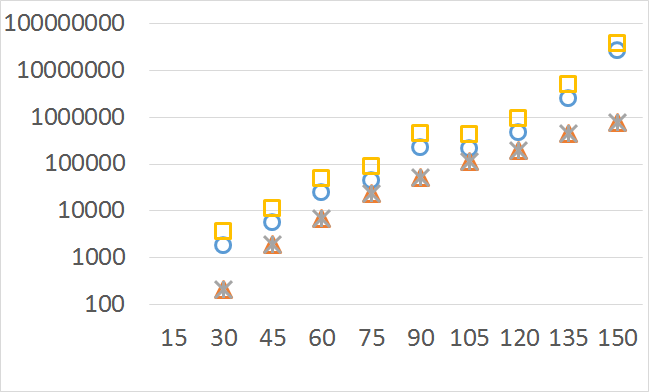
Number of operations
Number of points
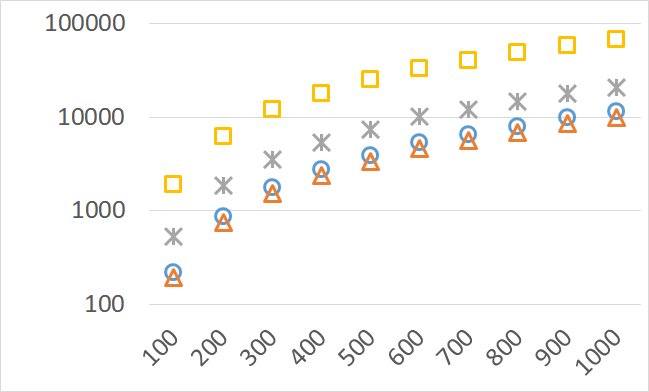
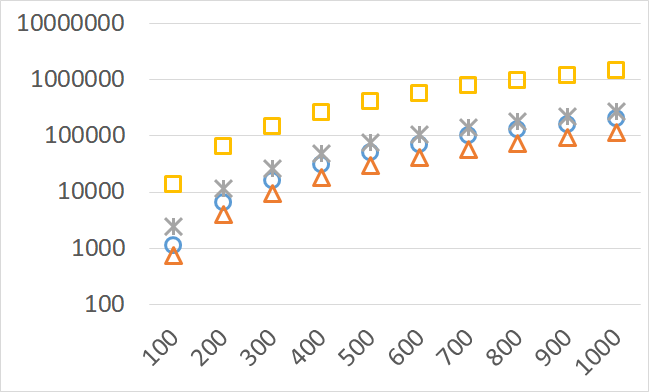
Number of operations
Number of points
CPU time [s]
Number of points
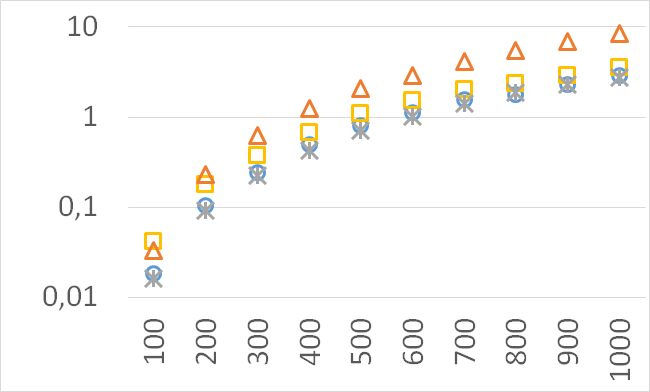
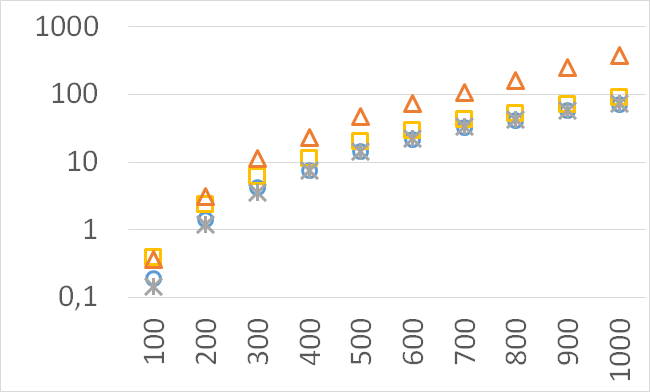
CPU time [s]
Number of points
CPU time [s]
Number of points
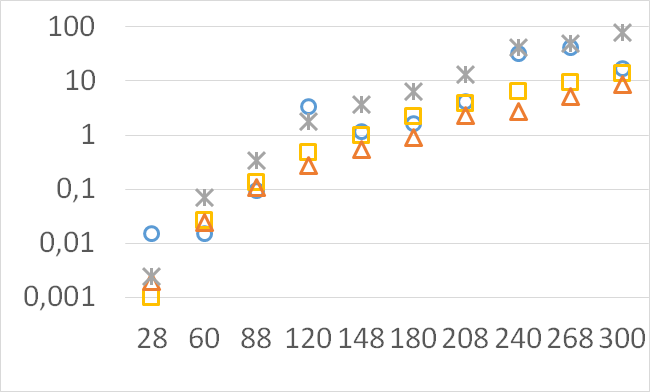
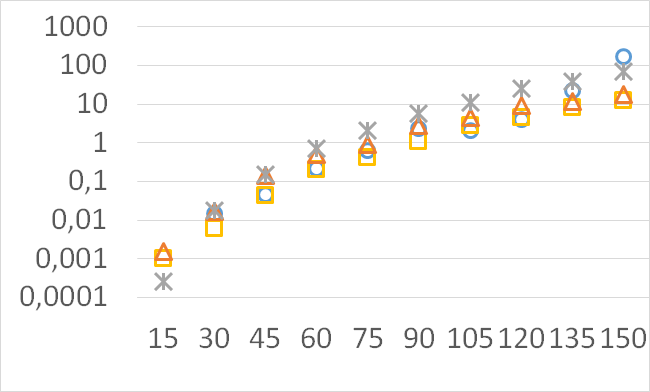
CPU time [s]
Number of points
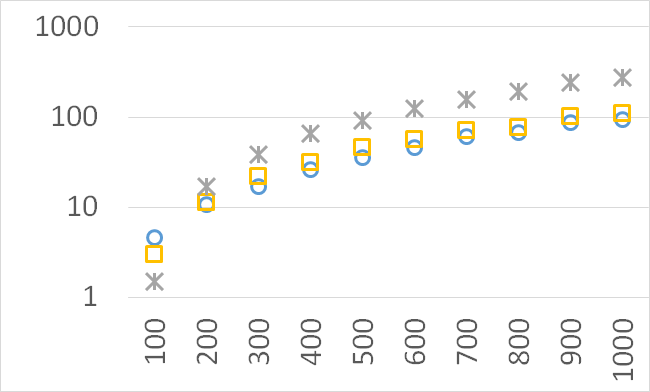
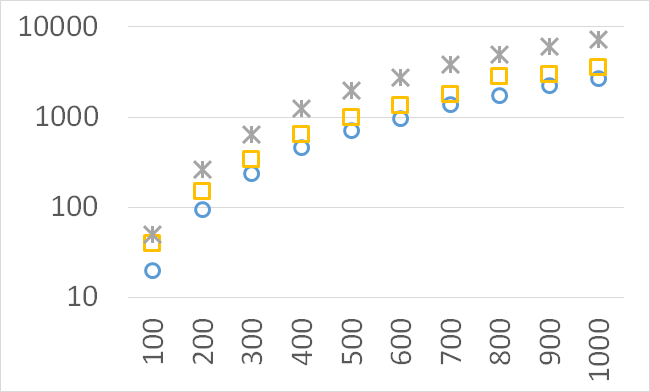
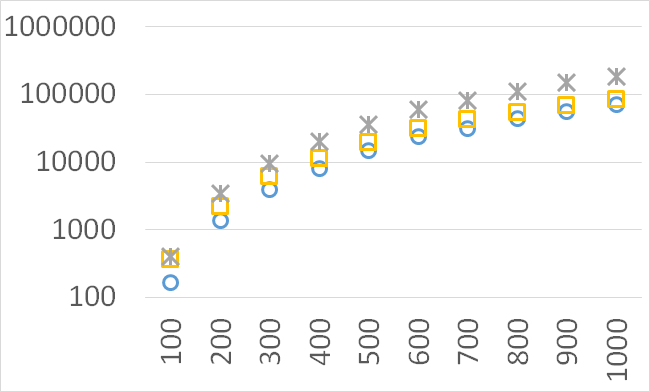
CPU time [s]
Number of points
6 Conclusions and Further Work
We have presented a modified version of QHV divide and conquer algorithm for calculating the exact hypervolume. Namely, we have modified the scheme of splitting the original problem into smaller sub-problems. Through both theoretical analysis and computational experiments we have shown that the modified version constructs smaller recursive trees and reduces the CPU time.
We have not developed a very efficient implementation of QHV-II but we believe that the we have provided a sufficient evidence that an efficient implementation of QHV-II (i.e. implementation comparable to the efficient implementation of QHV - oQHV) would run several times faster than oQHV for the considered instances.
Interesting directions for further research are:
-
1.
The use of the concepts of QHV-II for the incremental calculation of the hypervolume, i.e. the calculation of the change of the hypervolume after adding new point(s). Similar adaptation of the original QHV algorithm has been proposed in [5]. We can reasonably expect that the splitting scheme resulting in a faster static algorithm would also reduce the time of the incremental calculation of the hypervolume.
-
2.
Parallelization of QHV-II which may further improve practical running times. This issue was also considered in the case of the original QHV in [5].
-
3.
Adaptation of QHV-II for the approximate calculation of the hypervolume with a guaranteed maximum approximation error.
Acknowledgment
The research of Andrzej Jaszkiewicz was funded by the the Polish National Science Center, grant no. UMO-2013/11/B/ST6/01075.
We would like to thank Renaud Lacour, Kathrin Klamroth, and Carlos M. Fonseca for providing us detailed results of the computational experiment reported in [8].
References
References
- Zitzler et al. [2003] E. Zitzler, L. Thiele, M. Laumanns, C. Fonseca, V. da Fonseca, Performance assessment of multiobjective optimizers: An analysis and review, IEEE Transactions on Evolutionary Computation 7 (2003) 117–132.
- Zitzler and Künzli [2004] E. Zitzler, S. Künzli, Indicator-Based Selection in Multiobjective Search, Springer Berlin Heidelberg, Berlin, Heidelberg, pp. 832–842.
- Jiang et al. [2015] S. Jiang, J. Zhang, Y. S. Ong, A. N. Zhang, P. S. Tan, A simple and fast hypervolume indicator-based multiobjective evolutionary algorithm, IEEE Transactions on Cybernetics 45 (2015) 2202–2213.
- Russo and Francisco [2014] L. M. S. Russo, A. P. Francisco, Quick Hypervolume, IEEE Transactions on Evolutionary Computation 18 (2014) 481–502.
- Russo and Francisco [2016] L. M. S. Russo, A. P. Francisco, Extending quick hypervolume, Journal of Heuristics 22 (2016) 245–271.
- Beume et al. [2009] N. Beume, C. M. Fonseca, M. Lopez-Ibanez, L. Paquete, J. Vahrenhold, On the Complexity of Computing the Hypervolume Indicator, IEEE Transactions on Evolutionary Computation 13 (2009) 1075–1082.
- While and Bradstreet [2012] L. While, L. Bradstreet, Applying the WFG algorithm to calculate incremental hypervolumes, in: 2012 IEEE Congress on Evolutionary Computation, pp. 1–8.
- Lacour et al. [2017] R. Lacour, K. Klamroth, C. M. Fonseca, A box decomposition algorithm to compute the hypervolume indicator, Computers & Operations Research 79 (2017) 347 – 360.
- Chan [2013] T. M. Chan, Klee’s measure problem made easy, in: 2013 IEEE 54th Annual Symposium on Foundations of Computer Science, pp. 410–419.
- While et al. [2012] L. While, L. Bradstreet, L. Barone, A fast way of calculating exact hypervolumes, IEEE Transactions on Evolutionary Computation 16 (2012) 86–95.
- Bentley [1980] J. L. Bentley, Multidimensional divide-and-conquer, Commun. ACM 23 (1980) 214–229.
- Akra and Bazzi [1998] M. Akra, L. Bazzi, On the solution of linear recurrence equations, Computational Optimization and Applications 10 (1998) 195–210.
- While et al. [2006] L. While, P. Hingston, L. Barone, S. Huband, A faster algorithm for calculating hypervolume, IEEE Transactions on Evolutionary Computation 10 (2006) 29–38.
- Wu and Azarm [2001] J. Wu, S. Azarm, Metrics for quality assessment of a multiobjective design optimization solution set, Journal of Mechanical Design 123 (2001) 18–25.