Improving Responsiveness to Robots for Tacit Human-Robot Interaction
via Implicit and Naturalistic Team Status Projection
Abstract
Fluent human-human teaming is often characterized by tacit interaction without explicit communication. This is because explicit communication, such as language utterances and gestures, are inherently interruptive. On the other hand, tacit interaction requires team situation awareness (TSA) to facilitate, which often relies on explicit communication to maintain, creating a paradox. In this paper, we consider implicit and naturalistic team status projection for tacit human-robot interaction. Implicitness minimizes interruption while naturalness reduces cognitive demand, and they together improve responsiveness to robots. We introduce a novel process for such Team status Projection via virtual Shadows, or TPS. We compare our method with two baselines that use explicit projection for maintaining TSA. Results via human factors studies demonstrate that TPS provides a more fluent human-robot interaction experience by significantly improving human responsiveness to robots in tacit teaming scenarios, which suggests better TSA. Participants acknowledged robots implementing TPS as more acceptable as a teammate and favorable. Simultaneously, we demonstrate that TPS is comparable to, and sometimes better than, the best-performing baseline in maintaining accurate TSA.
I INTRODUCTION
Over the past decade, there has been accelerated growth and advancement in robotic search, making it no longer far-fetched to envision robots as part of our lives. One of the most appealing applications are teaming domains where humans and robots complement each other to achieve complex tasks [1]. Effective teaming is often characterized by tacit interaction without explicit communication111In our work, we take a more generic stance and refer to explicit communication as communication, regardless of its modality, with the intention to convey information and be perceived as conveying information. to minimize interruption. To facilitate such interaction, it is critical for the team members to maintain team situation awareness (TSA) where each member separately maintains and predicts the team status for non-interruptive and fluent teaming [2]. However, existing methods for human-robot teaming (HRT) often rely on explicit communication for maintaining TSA [3, 4, 5], creating a paradox for achieving tacit human-robot interaction (HRI). While implicit communication methods have been investigated mainly on communicative robot motion and actions [6, 7, 8], these methods would only work under the assumption of continuous observation of the robot and its actions. Hence, the challenge of maintaining TSA without explicit communication is still left unattended.
Consider a scenario in a semi-automated car assembly shop where a human worker, Mark, works along with a partner robot. Each agent has its own tasks in hand but must also collaborate occasionally to make progress. In one scenario, Mark sends the robot to fetch a hot soldering rod. However, Mark may not know exactly when the robot would return. To improve productivity, he would context switch to others tasks before the robot returns instead of idly waiting for the rod. However, focusing on the other tasks would cause him to lose track of the moving robot, resulting in the loss of TSA (e.g., whether the robot is approaching), degraded team performance, and even safety risks. Similarly, having the robot announcing its arrival can be interruptive and does not help much with continuous TSA maintenance other than providing discretized status-updates. In such situations, it would be desirable for the robot to implicitly project its status to Mark in a way that draws little attention to allow him to continuously track the robot while focusing on the other tasks. Simultaneously, we would like to encourage Mark to be responsive to the robot to reduce its waiting time as if with a human teammate, for improved team efficiency.

In this paper, we consider implicit and naturalistic Team status Projection via virtual Shadows (TPS). TPS is considered implicit communication in our work since shadows are not normally perceived as a way for conveying information. Implicit projection minimizes interruption while naturalness reduces cognitive demand, and they together improve human responsiveness to robots. In particular, the virtual shadows are created in a way to simulate the experience in proximal human-human teaming where observing the shadows of others would help us infer about their status. It has two intuitive appeals given our familiarity with shadows: 1) we can easily and implicitly interpret the shadows of others; 2) the shadows of agents around us would naturally encourage our interaction with them (and hence our responsiveness to them as well) [9]. To realize TPS, we propose to use Augmented Reality (AR) to generate virtual shadows. However, there are significant scientific and engineering challenges to address:
-
•
Realistic Shadow Projection: Shadow projection is often achieved with approximate methods such as negative shadow. However, for proximal human-robot interaction, unrealistic shadow projection can lead to misinterpretation of the shadow and hence TSA.
-
•
Naturalistic Shadow Projection: To display shadows when needed, the virtual light source must be dynamically updated to project the shadow into the human’s field of view. This can have a negative effect on the perception of the naturalness of virtual shadows, leading to misinterpretation and unwarranted distraction.
Our contributions in this work is three-fold. T First, we developed a novel engineering process for realistic shadow projection with Microsoft Hololens, which includes environment modeling and virtual shadow rendering222This part was presented as a Late-Breaking Report at HRI 2021 [10].. It generates shadows by superimposing a cutout model from 3D scan of the environment for generating the robot’s shadow onto the real-world. The result is high fidelity shadows generated according to the environment layout as with real shadows. See Fig. 1 for an illustration of a virtual shadow generated by TPS. Second, we proposed a method for naturalistic shadow projection to ensure that the shadows are informative and smooth, by integrating a virtual shadow mapping mechanism with a control method. The shadow mapping mechanism ensures that the robot status (such as its moving and rotation speeds) is “effectively” represented and the control method makes sure that shadow generation is smooth to minimize discomfort during interaction. Third, we evaluated TPS to validate our hypotheses and compared with baselines (that use explicit projection) to demonstrate its effectiveness in facilitating tacit teaming for proximal HRI.
II RELATED WORK
AR empowers us to visually perceive and interact with objects that are not present in the physical world [11]. Due to the intuitive appeal of such visual augmentation, it has been used in various domains [12] that include military [13], marketing [14], education [15], manufacturing [16], medical [17], entertainment [18], and robotics [19]. Thus far, research has been focused on making VR objects more realistic and interactable. For example, Wang et. al [20] make use of the lighting and shading of real scenes to modify AR objects to make them more lifelike. In robotics, AR objects have been used as part of the interface to facilitate human-robot interaction [21]. Anderson et al. [22] project virtual parts onto a physical object to highlight the right places to insert the parts for assembly tasks. In general, AR has been mostly used as an explicit way of visual communication, which often requires substantial human attention. Our focus in this work is to consider implicit communication with AR.
In linguistics, traditionally, explicit communication refers to information conveyed via spoken or written words. When multiple modalities are available, explicit communication may be expanded to refer to information conveyed directly through an established channel while implicit communication to information that must be inferred. Such a distinction, however, is subject to a level of ambiguity. For example, spoken words may also have implied meanings that are not directly available and must be inferred [23, 24]. In our work, we take a more generic stance and refer to explicit communication, regardless of its modality, as communication with the intention to convey information and be perceived as conveying information. Note that our definition of explicit communication is similar to that commonly adopted in HRI research [25, 26], except that we also consider it from the receiver’s perspective. While implicit communication methods have been investigated in HRI, mainly on communicative robot motion and actions [6, 7, 8], they would only work under the assumption of continuous human observation. TPS specifically addresses the challenge of maintaining TSA without explicit communication for proximal HRI using AR.
III APPROACH
To maintain TSA, TPS requires the virtual shadow to be always observable to the human. To simplify the technical development, we assume that the robot would always operate behind the human (i.e., outside of the human’s field of view) and the human would not change his viewing directions. For example, this situation may occur when the human is reading off a computer. See Fig. 2 for an example of the task settings used in this paper. The relaxation of these assumptions will be discussed in future work.

III-A Shadow Mapping
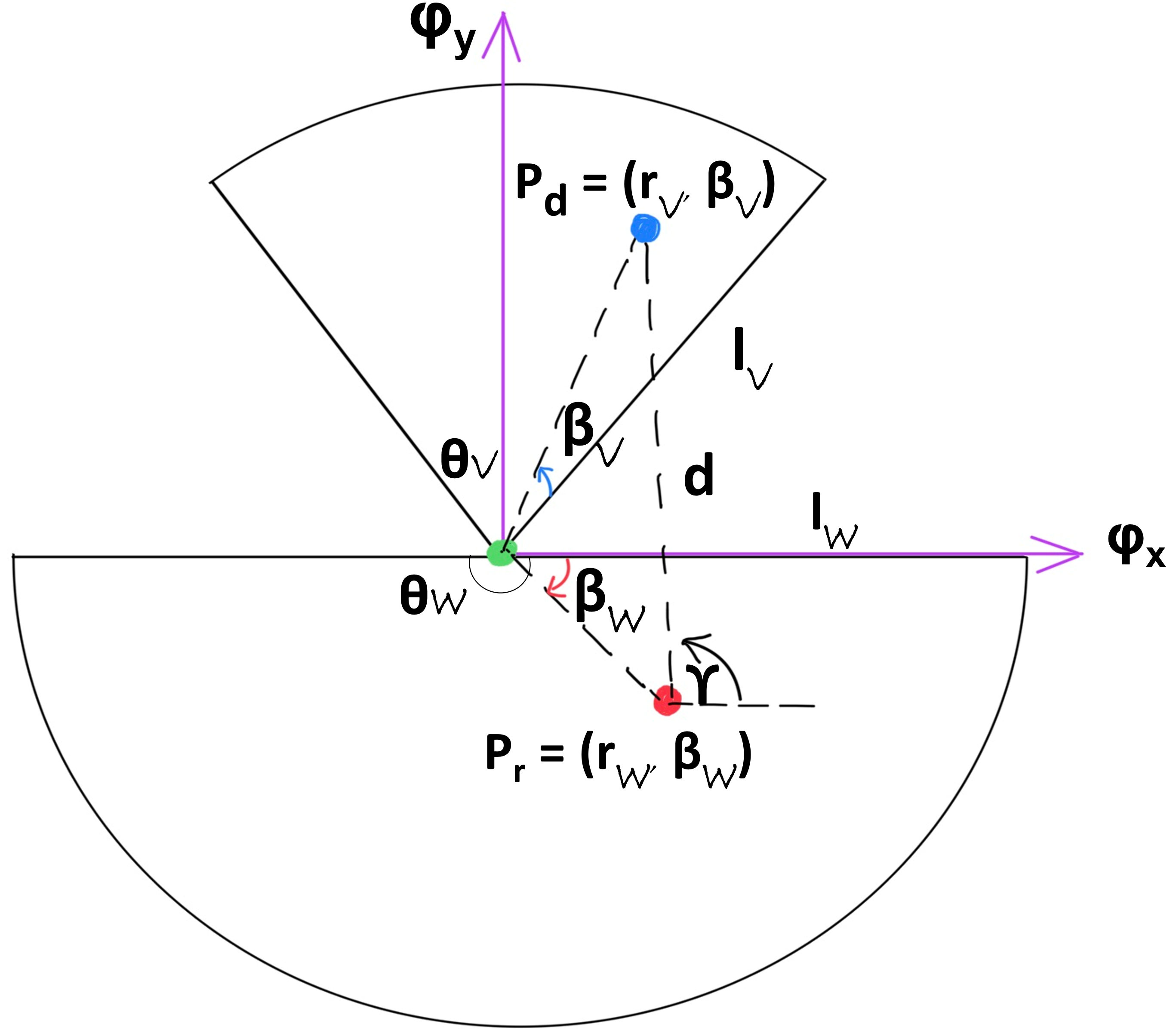
One of the challenges to render the virtual shadow always observable is that the Hololens has a small field of view (FOV) of with a maximum distance of from user to the holograms (i.e., AR objects). To achieve this, we use Shadow Mapping to project the robot’s position from outside the human’s FOV in the real-world to its desired shadow position in the virtual world within the FOV of Hololens. Furthermore, to ensure that the shadow is informative about the robot’s status, we would like the shadow movements to effectively capture the movements of the robot, given that the exactly correct mapping (as with real shadows) may not always result in a visible shadow. Intuitively, to ensure its effectiveness, when the robot moves faster (slower), the shadow should also move faster (slower); for sufficiently small enough position updates, when the robot moves left, right, up, or down, the shadow should also move likewise. To satisfy these requirements, we choose to implement a linear mapping between the robot’s position and the shadow’s position in their respective polar coordinate systems. First, we consider the real-world outside the human’s FOV to be a semi-circular area (i.e., ) with a user declared radius (i.e., the maximum distance from the human to the robot where the robot’s status is critical to the human), and the virtual world as a sector with apex angle and . The mapping is as follows:
| (1) |
where and above refer to the polar coordinates of a point in the real-world, and and refer to the polar coordinates of the corresponding point in the virtual world. Note that is a decreasing function of since more shadow should be seen when the robot moves closer to the human. Such a mapping is illustrated in Fig. 3 where the human is at the intersection of the two worlds shown as a green dot. We also introduce the global coordinate system as a Cartesian system (i.e., and ).
III-B Shadow Projection
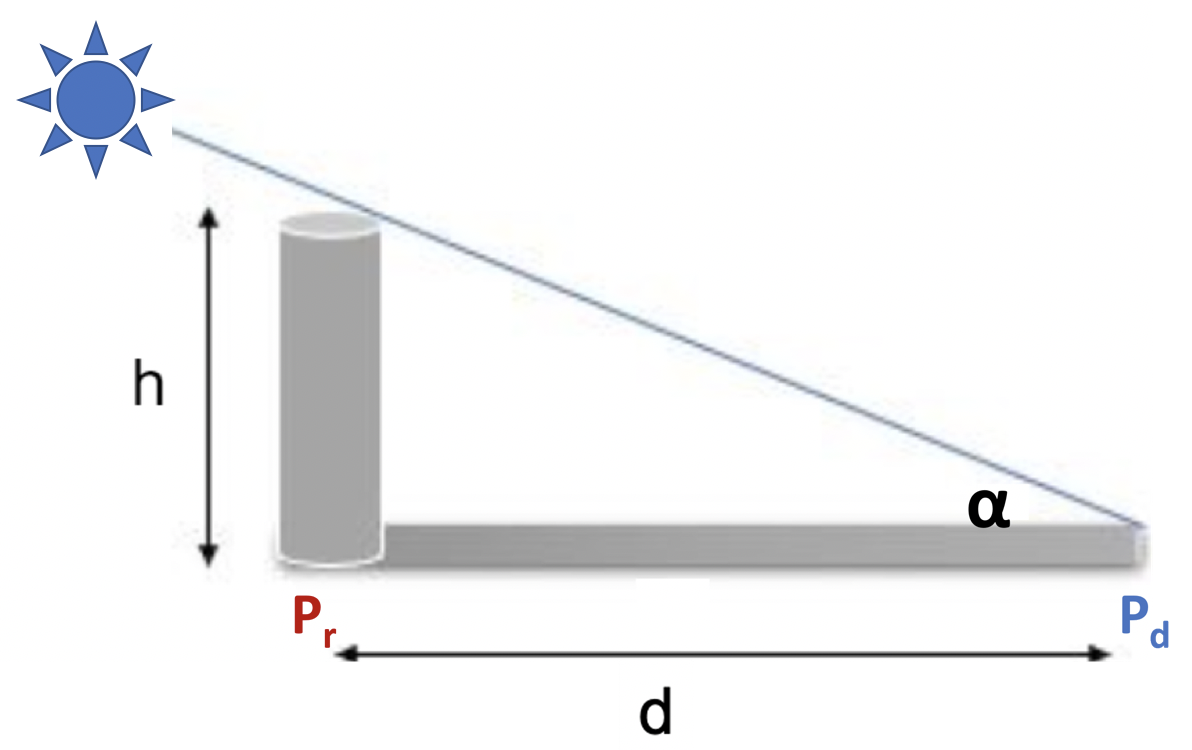
Next, we discuss how to project the robot’s position, denoted as , to its desired shadow position as expressed in Eq. (1), denoted as , by setting the tilt and pan of a directional light source. The 3D development platform (Unity) for Hololens uses a depth buffer system to keep track of all surfaces close to the light source. If any surface comes in direct line with the light source, the surface will be illuminated. The unilluminated surface therefore creates the shadow effect [27]. The benefit of using such a process is so that the shadow generated will be realistic as it naturally caters to the surface onto which the shadow is projected (see Fig. 6), assuming that the environment model is accurate. Hence, we can safely ignore the geometry of the virtual world in shadow projection by assuming that it is a flat surface. For a given and height (h) of the robot, the tilting, , of the light source to generate a shadow long enough to reach is given below and illustrated in Fig. 4:
| (2) |
Adjusting the tilt of the light source would increase or decrease the shadow length as needed. is the Euclidean distance between and :
| (3) |
We compute the pan () of the light source based on Fig. 3.
III-C Shadow Smoothing
Even though we can derive the exact tilt and pan of the light source to project the top of the robot to the desired shadow position as discussed above, the magnitudes of the updates to these angles for when the robot moves in different parts of the real world can differ substantially. This means significant variation in the angle updates. For example, for the same amount of shadow movement, the smaller the shadow-robot distance (i.e., ) is, the more the light source must update its tilt (see Eq. (2)). Users are often not accustomed to significant directional changes of the light source, which could mislead the perception of the shadow and the maintenance of TSA. We must reduce such effects by smoothing the shadow generation process.
We choose to apply a PID control method that is often used in robotics to generate smoother state transition processes [28]. It is a combination of Proportional (), Integral (), and Derivative () controls. P is proportional to the error between a set point and the observed process variable. The term I considers the past errors and integrates them over time to help correct the accumulated error. The D term estimates the future error. The control function of PID is given by:
| (4) |
where and are the coefficient matrices of , and , respectfully. For shadow smoothing, with changes to the light source angles (i.e., ) as our control inputs and given the robot’s position in the real world (i.e., ), we must drive the shadow towards the desired output . Such a model can be modeled with the plant as follow:
| (5) |
where is the virtual shadow position, and encodes changes to the tilt and pan angles of the light source that we are actively controlling. is the change in the robot’s position in the real world, which is treated as an exogenous input. In this paper, we consider as a first-order discrete-time dynamic model:
| (6) |
where , , , and are positive constants. These values are chosen to capture and ’s expected relationship with the change of the shadow position from step to . We assume that is expressed in the polar coordinate system of the real world.
Now, we can derive a simple PID controller using Eq. (5) with the setpoint at step being . This is the position we would like the shadow to be rendered. represents the shadow position actually rendered at step . We assume that both and are expressed in the polar coordinate system of the virtual world. The difference between and then leads to the error .
III-D Shadow Rendering
To generate realistic shadows in TPS, shadow rendering is composed of environment modeling, shadow generation, and shadow superimposition. Our environment modeling technique uses the semi-autonomous nature of SLAM-like modeling (provided by HoloLens). To be able to find anchoring surfaces in the real world to place virtual objects (Holograms), the HoloLens constantly maps its environment. This also ensures that when there is a change in the environment (e.g., when an object is moved in the environment), it will be updated to the new arrangement.

In order to make use of the 3D map created by the HoloLens, we use vertex-lighting technique to create a custom shadow-receiving shader. Although pixel lighting provides more details by calculating the illumination for each pixel, it is computationally expensive. In contrast, by using vertex lighting, we calculate illumination at each vertex of a model and then interpolate the resulting values over the faces of the models, resulting in a more efficient solution. We apply this shader to the exported HoloLens-generated map (see an example in Fig. 5) and enable its shadow receiving properties. This creates our transparent shadow-receiving model of the environment (see an example in Fig. 6 for the environment model in Fig. 5). Finally, this model is superimposed onto the real-world to render the shadow.

IV EXPERIMENTAL DESIGN

We are interested in verifying the benefits of implicit communication over explicit communication for maintaining TSA. The focus here is on the distinction between explicit and implicit communication from the receiver’s (human’s) perspective. hence requiring less attention to receive. In particular, TPS is considered as implicit communication since natural shadows are not normally perceived as a way of communication by the receiver (i.e., viewer of the shadow). In contrast, humans must pay substantial attention to receive explicit communication. When the human has other tasks to manage simultaneously, it would result in the loss of TSA and hence reduced responsiveness to the communicator.
To show such an effect, we compare TPS against two baselines that use explicit communication with AR. AR is also adopted for the baselines to avoid the impact due to differences in communication modalities. For maintaining TSA, we assume that each method is required to continuously project team status information to the human. TPS and the baselines using explicit communication are described below:
-
1.
Map shows the environment using a map. It displays a real-time view of the robot and its movements on the map (Fig. 7 (left)). The pink sphere indicates the position of the human and the robot is shown in black.
-
2.
Arrow uses an arrow that points to the position of the robot in real-time (Fig. 7 (right)). The arrow only pans in a plane (hence encodes no depth information).
-
3.
TPS uses a virtual shadow of the robot to communicate real-time status information (Fig. 7 (middle)).
Map is chosen due to its frequent use in real life, which makes it less cognitively demanding. It should alleviate the issue with explicit communication. Arrow, on the other hand, is chosen as a “novel” method that the human may be less familiar with. We chose a task scenario that is similar to the one shown in Fig. 2 and our motivating example. In this task scenario, a human is supposed to work with a robotic partner that occasionally delivers objects to or for the human. The human, on the other hand, has his own tasks (e.g., reading some documents) besides collaborating with the robot, i.e., picking up the object delivered or sending an object to be delivered. We used Kinova Movo in this study.
To prepare for the study, each participant was given a printed copy of the room in a discretized form for location identification (see Fig. 8). We deployed all three methods onto Hololens and placed the robot outside the participant’s FOV. To evaluate the methods for maintaining TSA, the participants were told they were work partners of a robot and must complete all tasks together in the least amount of time. The tasks included providing the robot with objects to deliver and receiving objects delivered by the robot. They were asked to attend to the robot when the robot arrived to deliver or pick up an object. At the same time, participants were asked to work on some other tasks (i.e., reading or solving simple puzzles). Participants were advised to not turn to observe the robot during the study and could only access the team status via Hololens. As a secondary aim to evaluate how accurately each method maintains TSA, we broke a session for each method into two parts. The first part involved delivery tasks as discussed and the second part involved asking the participants to identify the robot’s location and predict its destination (i.e., estimation tasks).

Using the different methods, we are interested in studying how responsive the participants were to the robot (directly related to the maintenance of TSA), how accurately their TSA was maintained, and how they viewed the sessions and robot after completion. CS students in their senior year participated in a within-subjects study. They were made up of female and male students. Each participant participated in three sessions, one for each method. We recorded a video for each part of a session (with parts in each session). The first video for the delivery tasks is used to measure the waiting time between the robot’s arrival and the participant’s response. The second video is recorded for the estimation tasks. This resulted in videos per participant and a total of videos recorded. However, due to objects and robot blocking the camera, or participants turning to observe the robot during the study, we discarded the data from participants, which left us with the remaining participants for result analysis. Participant were given a survey at the end of their sessions. It included an AttrakDiff survey and their preference towards the robot as a work partner in the different methods and the methods themselves w.r.t. their naturalness and user friendliness. In the AttrakDiff survey, the participants were asked to rate the methods based on different qualitative metrics on a scale of to . Overall, the study is designed to verify the following hypotheses:
-
•
H1. TPS improves responsiveness to the robot compared to baselines using explicit communication.
-
•
H2. TPS maintains accurate TSA that is comparable to the baselines using explicit communication.
-
•
H3. Robot with TPS is viewed more favorably as a work partner than baselines using explicit communication.
V RESULTS AND ANALYSES
An alpha level of is used for all statistical tests.
V-1 Responsiveness to Robot
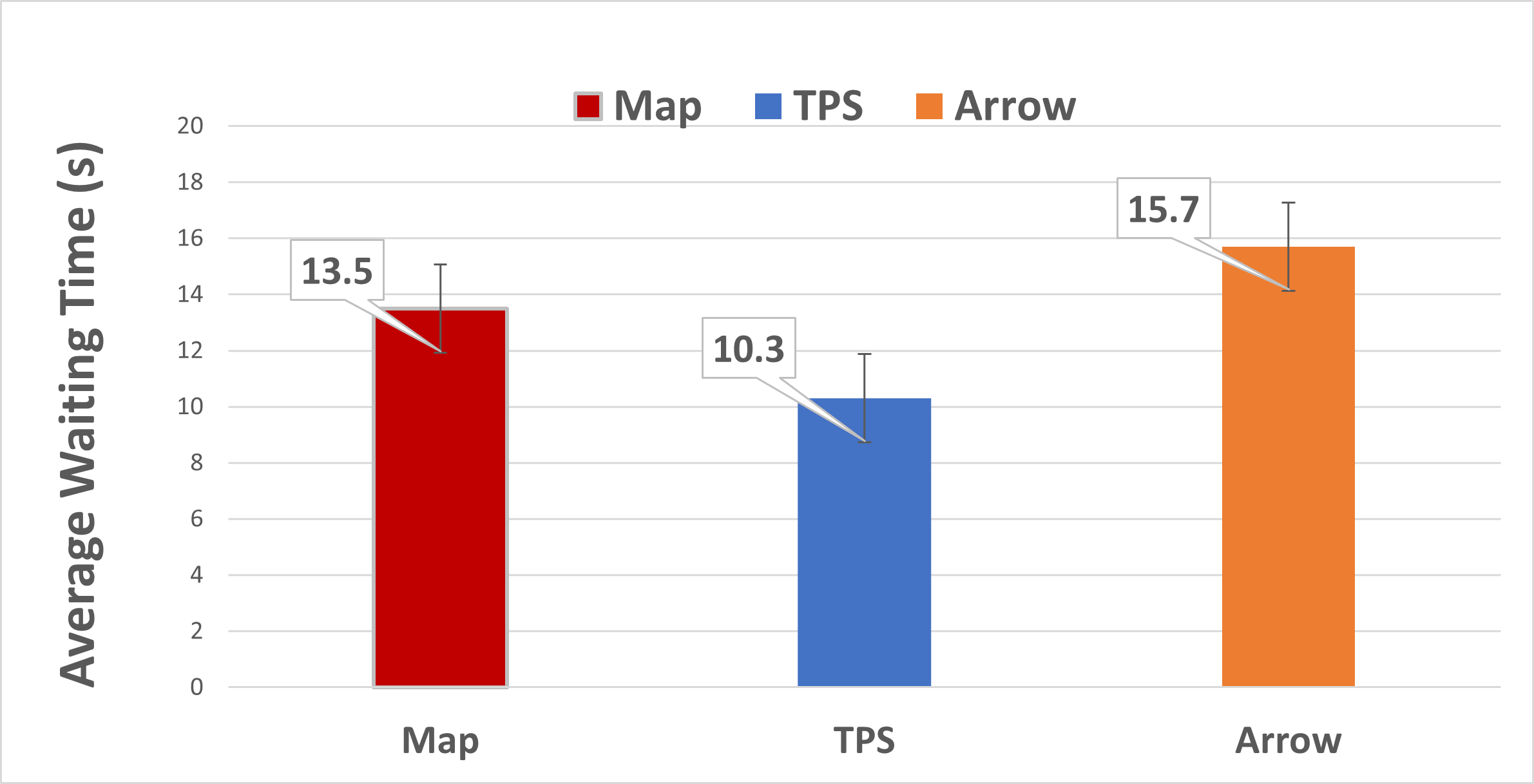
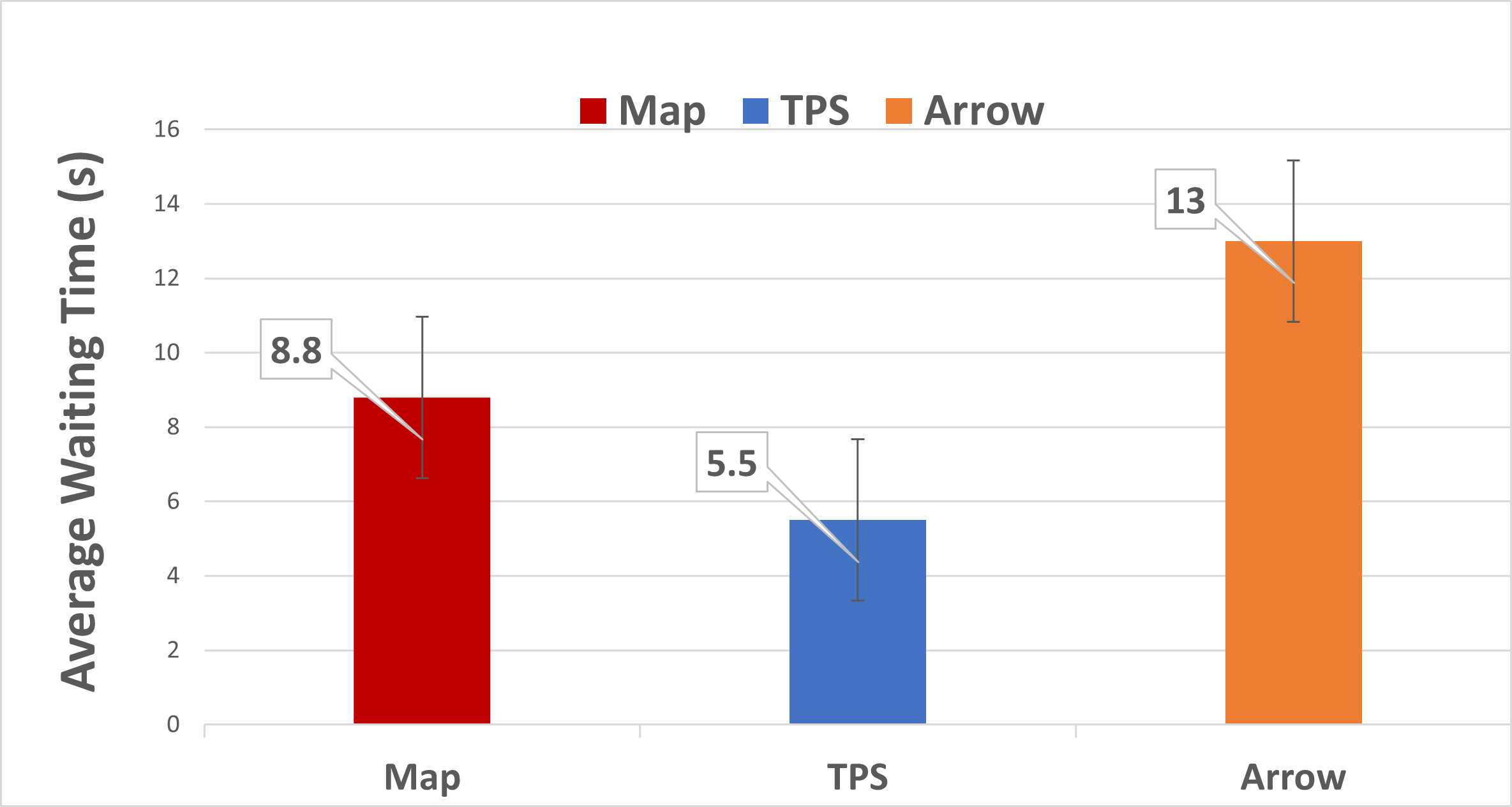
Fig. 9 presents the results for the waiting time of the robot between when it arrived at the delivery location and when the participant responded. We observe that participants were much faster to react to the robot when TPS was used. Paired Student’s t-tests gave t(16)=2.12, p=.003 between TPS (M=10.3, SD=9.18) and Map (M=13.5, SD=7.9) and t(16)=2.12, p=.002 between TPS (M=10.3, SD=9.18) and Arrow (M=15.7, SD=8.8). Fig. 10 presents the results for the waiting time of the robot between when it arrived at the pickup location on the participant’s request for a delivery and when the participant responded. Similar results were observed. T-tests resulted in between TPS (M=5.50, SD=2.11) and Map (M=8.80, SD=3.62), and t(16)=1.75, p .001 between TPS (M=5.50, SD=2.11) and Arrow (M=13.04, SD=4.66). These results verify that the participants are more responsive to the robot in TPS than the baselines ().
V-2 Accurate TSA
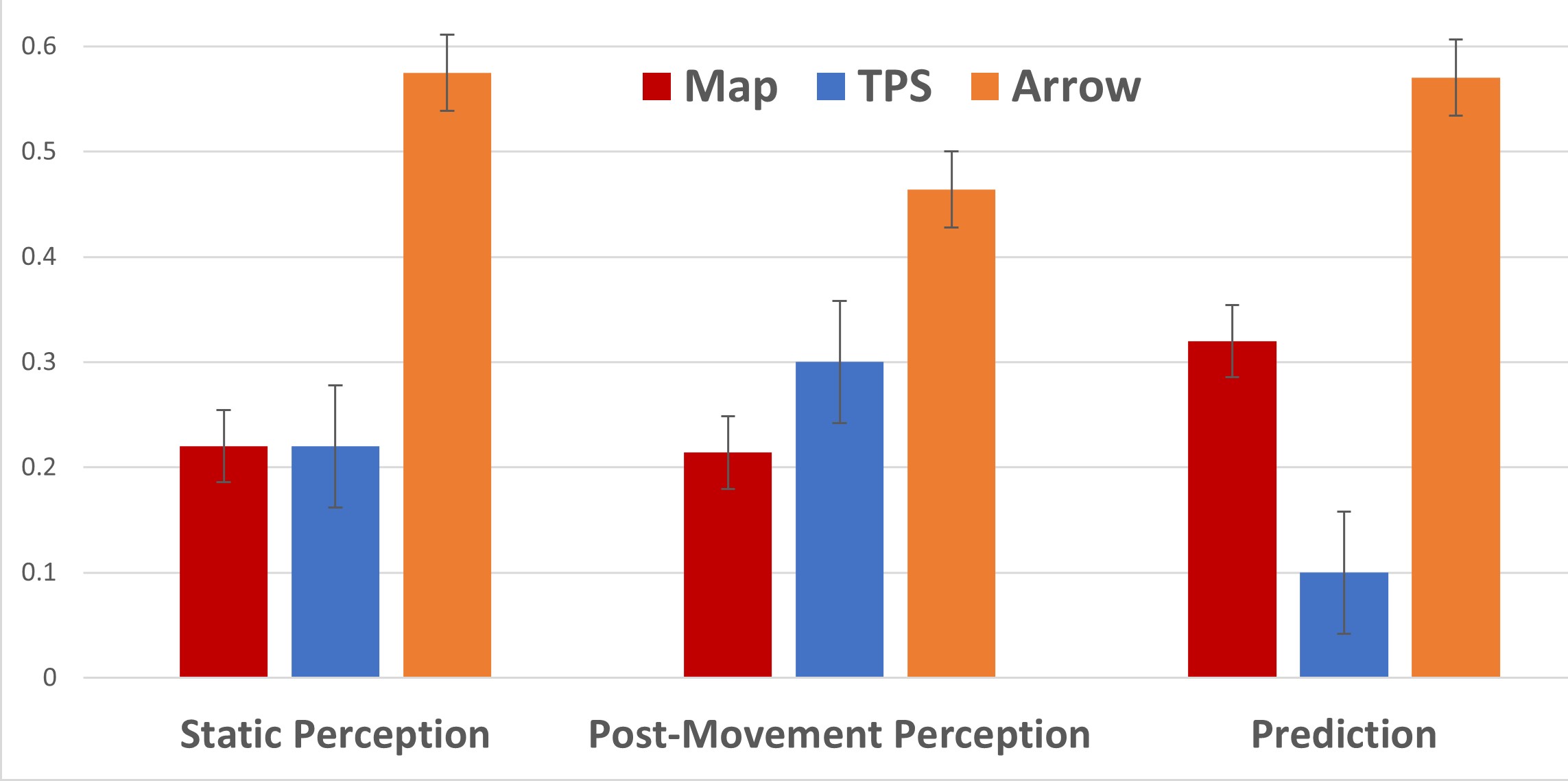
Fig. 11 presents the results w.r.t. how accurately each method maintained TSA via the estimation tasks. They included asking the participant to estimate where the robot’s current position was (static perception), where the robot was after some movement (post-movement perception), and where they expected the destination of the robot to be (prediction). We consider the accuracy as the Manhattan distance between the participant’s estimation and the ground truth. Hence, the lower the value, the more accurate the estimation. Generally, TPS did better than Arrow and was on a par with Map. Map did well, which was likely due to the fact that participants were generally familiar with maps in one form or another in real life. Arrow performed the worst as expected since it offered no depth information, which made it difficult for the participants to accurately estimate the robot’s position and change in position. It can be seen from Fig. 11 that TPS performed comparably with Map in perceptions, with Map having a slight edge in post-movement perception. T-tests reveal no significant differences between TPS and Map (H2). It is however interesting to note that TPS proved to provide more context information for TSA in prediction and did much better there than the other methods. For our prediction values (as shown on Fig. 11, We attributed such performance to better TSA since prediction required the participants to maintain the context of movements (i.e., which direction the robot was heading), instead of solely its position. Student’s paired t-tests on only prediction resulted in t(16)=2.19, between TPS (M =0.24, SD =0.42) and Arrow (M =0.57, SD =1.08)), and t(16)=2.12, p .001 between TPS and Map (M =0.32, SD =0.55).
V-3 Attractiveness
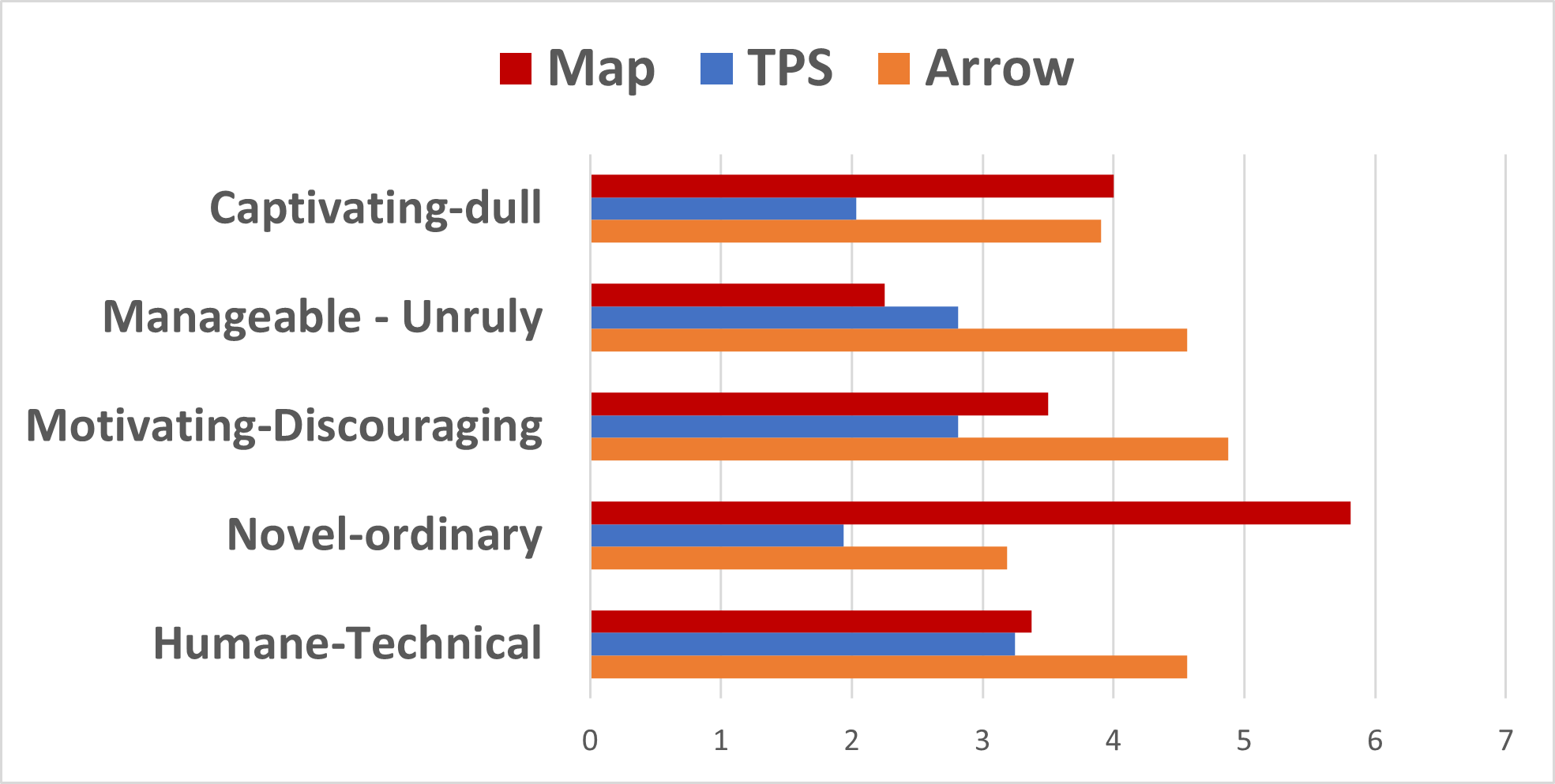
AttrakDiff evaluated the attractiveness of the robot in different methods. The result is presented in Fig. 12. Results indicate that the robot in TPS was viewed as more attractive than the robot in the baselines (). It is observed that TPS obtained the best ratings among almost all features, although participants indicated that TPS was slightly less manageable than Map. We averaged the values for a Student’s paired t-test. The results are t(16)=2.12, p .001 between TPS (M=2.59, SD=0.84) and Map (M=3.76, SD=0.60), and t(16)=2.13, p .001 between TPS (M=2.59, SD=0.84) and Arrow (M=4.31, SD=0.79).
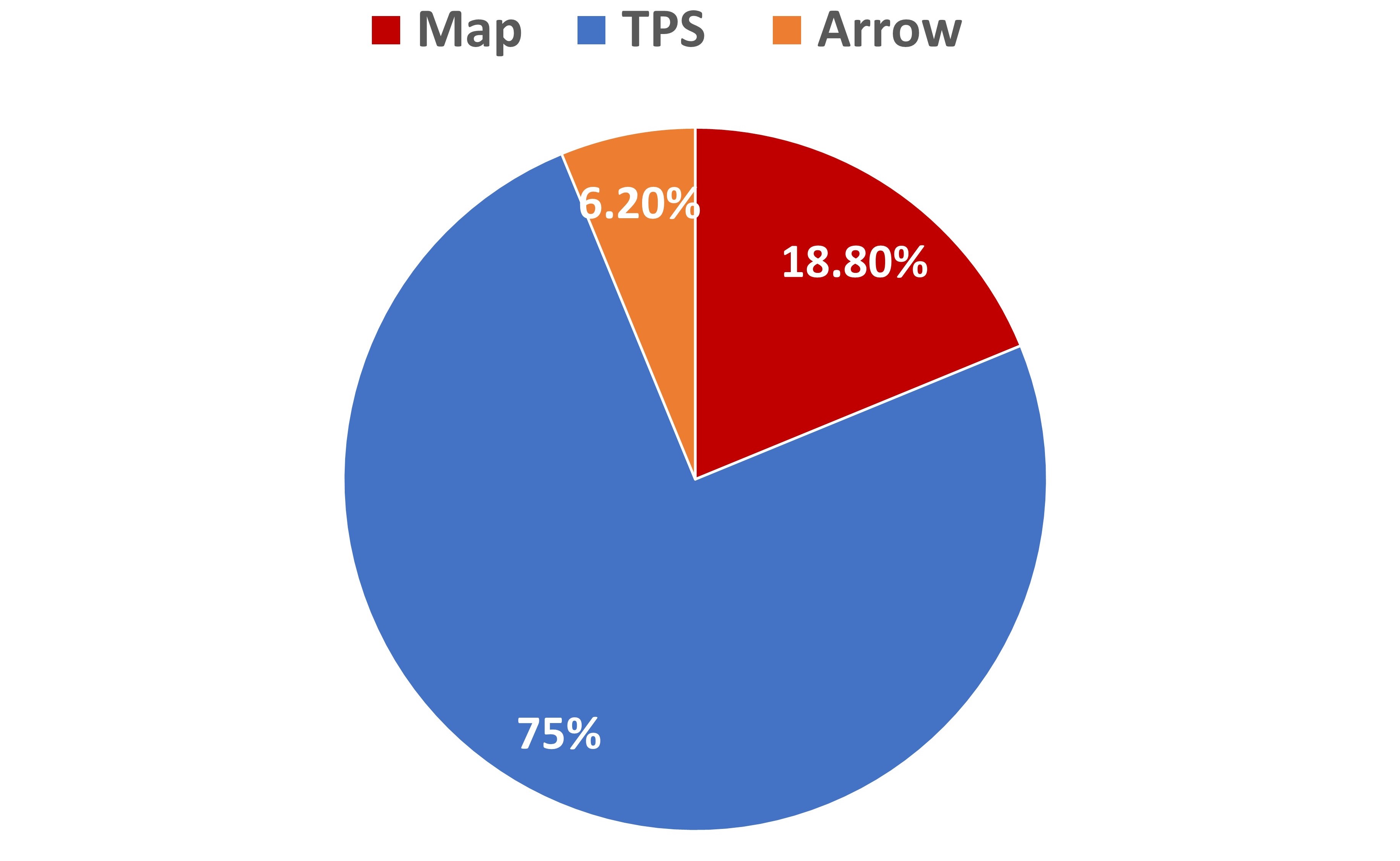
V-4 Partnership and Naturalness
We explicitly asked the participants to indicate which of the three methods gave them a feeling of partnership. of the participants indicated that TPS gave them the feeling that the robot was a work partner. felt towards Map and only towards Arrow. Fig. 13 shows the results. This result verifies that the robot with TPS would be viewed more favorably as a work partner (). Finally, we asked the participants to indicate which methods they felt the most natural. answered Map while the remaining felt towards TPS.
VI CONCLUSIONS
In this paper, we introduced implicit and naturalistic team status projection via virtual shadows (TPS), with the motivation to improve TSA and responsiveness to robots in proximal HRI. We addressed the challenges in realizing TPS in four steps: shadow mapping, shadow projection, shadow smoothing, and shadow rendering, resulting in a framework that can be leveraged to use virtual shadows to communicate critical information. TPS differs from explicit communication methods since the receiver would not normally consider such shadows as a way of communication, resulting in less cognitive and attention demands and better TSA. We evaluated TPS with two baselines that use explicit communication to demonstrate the effectiveness of our approach.
References
- [1] Harley Oliff, Ying Liu, Maneesh Kumar, Michael Williams, and Michael Ryan. Reinforcement learning for facilitating human-robot-interaction in manufacturing. Journal of Manufacturing Systems”, 56:326 – 340, 2020.
- [2] Nancy J. Cooke, Jamie C. Gorman, Christopher W. Myers, and Jasmine L. Duran. Interactive team cognition. Cognitive Science, 37(2):255–285, 2013.
- [3] Nikolaos Mavridis. A review of verbal and non-verbal human–robot interactive communication. Robotics and Autonomous Systems, 63:22–35, 2015.
- [4] Brian Gleeson, Karon MacLean, Amir Haddadi, Elizabeth Croft, and Javier Alcazar. Gestures for industry intuitive human-robot communication from human observation. In 2013 8th ACM/IEEE International Conference on Human-Robot Interaction (HRI), pages 349–356. IEEE, 2013.
- [5] Terrence Fong, Charles Thorpe, and Charles Baur. Collaboration, dialogue, human-robot interaction. In Robotics research, pages 255–266. Springer, 2003.
- [6] Philip R Cohen and Hector J Levesque. Communicative actions for artificial agents. In ICMAS, volume 95, pages 65–72. Citeseer, 1995.
- [7] Anca D Dragan, Kenton CT Lee, and Siddhartha S Srinivasa. Legibility and predictability of robot motion. In 2013 8th ACM/IEEE International Conference on Human-Robot Interaction (HRI), pages 301–308. IEEE, 2013.
- [8] Yu Zhang, Sarath Sreedharan, Anagha Kulkarni, Tathagata Chakraborti, Hankz Hankui Zhuo, and Subbarao Kambhampati. Plan explicability and predictability for robot task planning. In 2017 IEEE international conference on robotics and automation (ICRA), pages 1313–1320. IEEE, 2017.
- [9] Harry T Reis, Michael R Maniaci, Peter A Caprariello, Paul W Eastwick, and Eli J Finkel. Familiarity does indeed promote attraction in live interaction. Journal of personality and social psychology, 101(3):557, 2011.
- [10] Andrew Boateng and Yu Zhang. Virtual shadow rendering for maintaining situation awareness in proximal human-robot teaming. In Companion of the 2021 ACM/IEEE International Conference on Human-Robot Interaction, pages 494–498, 2021.
- [11] Igor Baranovski, Stevan Stankovski, Gordana Ostojic, Sabolč Horvat, and Srdjan Tegeltija. Augmented reality support for self-service automated systems. Journal of graphic engineering and design, 11:63–68, 06 2020.
- [12] Mehdi Mekni and Andre Lemieux. Augmented reality: Applications, challenges and future trends. Applied computational science, 20:205–214, 2014.
- [13] M. A. Livingston. An augmented reality system for military operations in urban terrain. I/ITSEC2002, Dec., 2002.
- [14] Julien Pilet, Vincent Lepetit, and Pascal Fua. Fast non-rigid surface detection, registration and realistic augmentation. International Journal of Computer Vision, 76, 02 2008.
- [15] Mustafa Sirakaya and Didem Alsancak Sirakaya. Trends in educational augmented reality studies: A systematic review. Malaysia online journal of educational technology, 6(2):60–74, 2018.
- [16] S.J Henderson and S Feiner. Evaluating the benefits of augmented reality for task localization in maintenance of an armored personnel carrier turret. ISMAR, pages 135–144, 2009.
- [17] Carolien Kamphuis, Esther Barsom, Marlies Schijven, and Noor Christoph. Augmented reality in medical education? Perspectives on medical education, 3(4):300—311, September 2014.
- [18] Yolanda Vazquez-Alvarez, Ian Oakley, and Stephen A Brewster. Auditory display design for exploration in mobile audio-augmented reality. Personal and Ubiquitous Computing, 16:987–999, 2012.
- [19] George Michalos, Panagiotis Karagiannis, Sotiris Makris, Önder Tokçalar, and George Chryssolouris. Augmented reality (ar) applications for supporting human-robot interactive cooperation. Procedia CIRP, 41:370 – 375, 2016. Research and Innovation in Manufacturing: Key Enabling Technologies for the Factories of the Future - Proceedings of the 48th CIRP Conference on Manufacturing Systems.
- [20] Yang Wang and Dimitris Samaras. Estimation of multiple directional light sources for synthesis of augmented reality images. Graphical Models, 65(4):185 – 205, 2003.
- [21] Ayoung Hong, Burak Zeydan, Samuel Charreyron, Olgac Ergeneman, Salvador Pane, M. Toy, Andrew Petruska, and Brad Nelson. Real-time holographic tracking and control of microrobots. IEEE Robotics and Automation Letters, 2:1–1, 01 2017.
- [22] R. S. Andersen, O. Madsen, T. B. Moeslund, and H. B. Amor. Projecting robot intentions into human environments. In 2016 25th IEEE International Symposium on Robot and Human Interactive Communication (RO-MAN), pages 294–301, 2016.
- [23] Robyn Carston. Thoughts and utterances: The pragmatics of explicit communication. John Wiley & Sons, 2008.
- [24] Robyn Carston. The explicit/implicit distinction in pragmatics and the limits of explicit communication. International review of pragmatics, 1(1):35–62, 2009.
- [25] Cynthia Breazeal, Cory D Kidd, Andrea Lockerd Thomaz, Guy Hoffman, and Matt Berlin. Effects of nonverbal communication on efficiency and robustness in human-robot teamwork. In 2005 IEEE/RSJ international conference on intelligent robots and systems, pages 708–713. IEEE, 2005.
- [26] Yuhang Che, Allison M Okamura, and Dorsa Sadigh. Efficient and trustworthy social navigation via explicit and implicit robot–human communication. IEEE Transactions on Robotics, 36(3):692–707, 2020.
- [27] Microsoft. Unity - manual: Shadows. 2015.
- [28] Manuel Beschi, Riccardo Adamini, Alberto Marini, and Antonio Visioli. Using of the robotic operating system for pid control education. IFAC-PapersOnLine, 48(29):87–92, 2015. IFAC Workshop on Internet Based Control Education IBCE15.