Improving Sum-Rate of Cell-Free Massive MIMO with Expanded Compute-and-Forward
Abstract
Cell-free massive multiple-input multiple-output (MIMO) employs a large number of distributed access points (APs) to serve a small number of user equipments (UEs) via the same time/frequency resource. Due to the strong macro diversity gain, cell-free massive MIMO can considerably improve the achievable sum-rate compared to conventional cellular massive MIMO. However, the performance of cell-free massive MIMO is upper limited by inter-user interference (IUI) when employing simple maximum ratio combining (MRC) at receivers. To harness IUI, the expanded compute-and-forward (ECF) framework is adopted. In particular, we propose power control algorithms for the parallel computation and successive computation in the ECF framework, respectively, to exploit the performance gain and then improve the system performance. Furthermore, we propose an AP selection scheme and the application of different decoding orders for the successive computation. Finally, numerical results demonstrate that ECF frameworks outperform the conventional CF and MRC frameworks in terms of achievable sum-rate.
Index Terms:
Cell-free massive MIMO, expanded compute-and-forward, power control, sum rate.I Introduction
Massive multiple-input multiple-output (MIMO) is a promising physical-layer technology to keep up with the exponential traffic growth of future wireless communication systems. More specifically, massive MIMO can provide tremendous beamforming gains and spatially multiplexing gains to multiple user equipments (UEs) and increase the system achievable sum-rate [2, 3, 4]. Despite the potential performance gain brought by massive MIMO, UEs at cell-edge may experience poor channel conditions and suffer from strong inter-cell interference (ICI). To alleviate this performance bottleneck, distributed massive MIMO has been proposed to combat ICI and to improve the performance of cell-edge UEs. However, there is a fundamental performance limitation for distributed massive MIMO with full cooperation between different transmitters [5].
Recently, the authors in [6] proposed a practical network infrastructure for distributed massive MIMO, under the name of cell-free massive MIMO [7, 8, 9]. In cell-free massive MIMO systems, a large number of access points (APs) distribute in a large area and are connected to a central processing unit (CPU) via a fronthaul network. In particular, a small number of UEs are served by all APs with the same time/frequency resource [6, 10, 11]. Since there are no cells or cell boundaries, ICI does not exist. Indeed, cell-free massive MIMO is a specific realization of distributed massive MIMO [6].
The most outstanding aspect of cell-free massive MIMO is that many APs simultaneously serve a much smaller number of UEs, which yields a high degree of macro-diversity and can offer a huge spectral efficiency. Besides, some studies have reported that favorable propagation is also a potential advantage for cell-free massive MIMO which can be exploited to eliminate inter-user interference (IUI) [6]. Note that favorable propagation refers to the property that when the number of AP antennas is sufficiently large, the channels between the UEs and APs become asymptotically orthogonal [12]. However, the favorable propagation property does not always hold in practical systems. The non-negligible IUI is highly undesirable and leads to a considerable loss in achievable sum-rate. As a result, how to harness the IUI has triggered many new coding and signal processing techniques.
I-A Related Works
As a new approach of linear physical-layer network coding that allows intermediate nodes to send out functions of their received packets [13, 14, 15, 16], the compute-and-forward (CF) scheme has recently been employed in cell-free massive MIMO systems to offer protection against noise and to reduce IUI with cooperation gain [17]. For the uplink transmission, UEs employ a nested lattice coding strategy to encode data that takes values in a prime-size finite field before transmission. Then, the CF scheme enables APs to decode the integer linear equations of UEs’ codewords using the noisy linear combinations provided by the channels. Relying on nested lattice codes, the linear combination of UEs’ codewords is still a regular codeword [18, 19]. Next, each AP forwards the decoded combination to the CPU through the fronthaul link. After receiving sufficient linear combinations, the CPU could recover every UE¡¯s original data by performing AP selection and solving the received equations [20, 21, 17].
However, the CF scheme requests all UEs transmit with equal power, which is generally not the optimal strategy for improving the achievable sum-rate. Due to the different propagation conditions between APs and UEs, the performance can be improved by performing appropriate power control [12]. Moreover, with power control for UEs, the effective noise variance across all APs whose linear combinations involve the message can be reduced. Then, the achievable sum-rate can be further improved.
Motivated by the discussion above, we adopt the expanded compute-and-forward (ECF) framework which was proposed in [22] for the uplink transmission in cell-free massive MIMO systems. The ECF framework is able to distribute transmit powers unequally and retains the connection between the finite field data and the lattice codeword. We note that coordinated multiple points (CoMP) framework also can be implemented with interference alignment at the transmitter-side [23, 24, 25], however, the distinction between CoMP and ECF is that CoMP as conventionally defined does not involve CF strategy.
There are two types of ECF framework, named parallel computation and successive computation, respectively. The distinction between these schemes is that in parallel computation the CPU recovers UEs’ data independently while for successive computation the CPU decodes the linear combinations by using successive cancellation. Specifically, in successive computation, the combinations which have been decoded can be used as side information in the subsequent decoding steps to decrease both effective noise variance and the number of UEs that need to tolerate the effective noise. Applying successive computation helps improve the achievable sum-rate, however, in terms of processing delay, the parallel computation has some advantages. In other words, there is a trade-off between the parallel computation and successive computation.
Besides, there are some key aspects which dominate the performance of ECF framework: coefficient vector selection and AP selection. Since the performance of ECF is captured by the computation rate and that rate achieves the highest when the equation coefficients closely approximate the effective channel coefficients, designing the coefficient vector elaborately is beneficial for the improvement of achievable sum-rate. As for AP selection, it is performed at the CPU when recovering UEs’ original data in both parallel computation and successive computation. With the help of AP selection, the computational complexity of power optimization is reduced. Furthermore, the noise tolerance on UEs’ data can also be relaxed, which contributes to the improvement of the achievable sum-rate.
I-B Contributions
In this paper, we consider the application of ECF framework in cell-free massive MIMO systems to increase the achievable sum-rate, including both parallel computation and successive computation. The main contributions of this paper are as follows:
-
•
We apply a quadratic programming relaxation based coefficient vector selection method and a large-scale fading based low-complexity AP selection algorithm to improve the achievable sum-rate of the cell-free massive MIMO system.
-
•
We design efficient power control algorithms for parallel and successive computation schemes, respectively. For the successive computation scheme, we further derive a sub-optimal decoding order of combinations and develop three assignment algorithms to find a sub-optimal decoding order of UEs.
-
•
We quantitatively compare the performance of conventional combining and ECF frameworks under practical channel model and scenarios, which proves that the ECF framework is an effective approach for the fronthaul reduction. In particular, the successive computation scheme outperforms the parallel computation scheme with a larger fronthaul load.
Compared with our related conference paper [1], which focused only on parallel computation with power control based on uplink-downlink duality, in this paper, we provide a thorough analysis for the successive computation scheme with power control for improving the achievable sum rate. Besides, the problem-solving methodology for determining the suboptimal decoding order of combinations and UEs are investigated. Furthermore, the results from [1] are not applicable to the case considered in this paper due to different power control method and additional AP selection algorithm are applied. More importantly, we also provide practice insights into the performance of MRC, CF, centralized MMSE, parallel computation, and successive computation schemes in achievable sum rate.
The rest of this paper is organized as follows. In Section II, we describe the cell-free massive MIMO system model. A detailed introduction for ECF framework is given in Section III. Furthermore, AP selection methods and power control algorithm for parallel computation are introduced in Section III-B. In Section III-C, we investigate different decoding order methods of combinations for successive computation. Finally, numerical results and discussions are given in Section IV while Section V concludes the paper.
Table I shows the notations. Unless further specified, plain letters, boldface letters, and boldface uppercase letters denotes scalars, column vectors, and matrices respectively.
| A prime number | |||||
| , , |
|
||||
| Element in | |||||
|
|
|
||||
|
|||||
| Addition over the finite field | |||||
|
|||||
| 2-norm of vector | |||||
| , |
|
||||
| Floor function of | |||||
| I | Identity matrix | ||||
| Expectation of | |||||
|
II System Model
We consider an uplink cell-free massive MIMO system. single-antenna APs and () single-antenna UEs are randomly distributed in a wide geographical area [6, 10, 11]. APs provide services for UEs via the same time/frequency resource. In particular, each AP exchanges information with the CPU via fronthaul link. As the practical number of APs is finite, we assume that the IUI can still have significant impact on the achievable sum-rate.
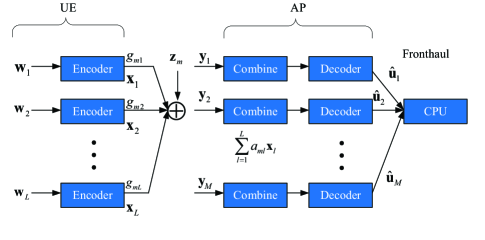
First, we will provide some necessary definition on nested lattice codes. An -dimensional lattice, , is a set of points in such that if , then and if , then . Note that a lattice can always be written in terms of a lattice generator matrix , i.e., . Besides, a lattice is said to be nested in a lattice if . As shown in Fig. 1, without loss of generality, the th UE maps the original length- data into a length- complex-valued lattice codeword with encoder . The specific choices of and are studied in [22, Theorem 8]. For creating generation matrices to encode the original data into nested lattice codeword, the blocklength needs to be large enough. Therefore, the longer blocklength, i.e., , is better. Note that is the number of symbols carrying information. The remaining symbols are set to zero to meet the power constraint and the effective noise tolerance. The lattice codeword is subject to the power constraint , where is the transmit power of the th UE.
Let represent the channel coefficient between the th AP and th UE, which is given by
| (1) |
where denotes the large-scale fading and denotes the small-scale fading. With the help of [11, Eq. (17)], the propagation is given as
| (2) |
where represents the distances between the th AP and the th UE and is the shadow fading. We assume that , are independent and identically distributed (i.i.d.) random variables (RV)s.
The length- vector received signal at the th AP is
| (3) |
where the thermal noise is elementwise independent and identically distributed (i.i.d.) .
The ECF framework manipulates the algebraic structure such that any Gaussian integer combination of lattice codewords is still a lattice point. In cell-free massive MIMO, each AP endeavours to represent the received length- signal vector with a Gaussian integer linear combination of UEs’ codewords. By applying an equalization factor and selecting the coefficient vector , the scaled received signal can be expressed as
| (4) |
Each AP is equipped with a decoder, . Then, AP decodes the received signal into the finite field as , where is an estimation of the linear combination of original data . 111If the codeword spacing for a given data from the th UE can tolerate the maximum effective noise across the APs whose linear combinations involve that data, the probability of decoding error is given as , where represents the number of APs whose combinations contain the data and is a small positive number that tends to zero. The specific procedure for recovering messages for UEs is stated in [18]. Given linear combinations of messages with real and imaginary coefficient matrices , , the CPU can recover message if there exists a vector such that
| (5) |
where denotes a unit column vector with 1 in the th entry and 0 elsewhere. 222The two decoders adopted at APs and the CPU, respectively, have different functionalities. Indeed, decoders at the APs are used for decoding the received signal into the linear combination of the UEs’ original data. Then, these decoded linear combinations are transmitted from APs to CPU. In contrast, the decoder at the CPU is responsible for recovering each UE’s data from those combinations. Specifically, when applying it with successive computation, the interference cancellation procedure takes place at the decoder at the CPU. For the traditional multiuser MIMO systems, where , data recovery is a major challenge due to the high probability of rank deficiency. However, the number of APs is far larger than that of the UEs in cell-free massive MIMO systems. Since when the number of APs increases the probability of selecting APs that provides independent linear combinations also increases [17], the extra APs can ensure a much higher probability for avoiding rank deficiency, so as to improve the probability to recover the desired message.
III Expanded Compute-and-Forward
One of the major challenges in cell-free massive MIMO is the IUI in the uplink. In particular, CF scheme can achieve large gain through decoding linear functions of transmitted signals with nested lattice codes. The performance of CF scheme for cell-free massive MIMO has been compared with MRC in [17], which shows that with equal power transmission at all UEs, the CF scheme can offer a throughput improvement. Furthermore, the ECF framework can improve the achievable sum-rate utilizing the characteristic of optimal power control.
In this section, two practical ECF frameworks are considered for cell-free massive MIMO systems. The first one is parallel computation, which refers to that the CPU decodes each of the integer linear combinations independently. Furthermore, successive computation decodes received combinations one-by-one and employing the side information to reduce the effective noise. We begin with the parallel computation.
III-A Coefficient Vector Selection
The goal of this paper is to evaluate the performance of the ECF framework for cell-free massive MIMO systems by deriving its computation rate region [22], which is defined as the set of achievable rate ensuring successful data recovery:
| (6) |
where refers to the effective noise at the th AP and is the diagonal matrix with the power constraint for UEs. In order to maximize the computation rate region, we need to find the optimal coefficient vector and equalization factor .
According to [22, Lemma 2], the equalization factor that minimizes the effective noise variance from (4) is the MMSE projection. Then, we have
| (7) |
Hence, the effective noise is given by
| (8) |
where represents the codeword matrix. For the th AP, the aim is to find its optimal coefficient vector that maximizes the computation rate region as
| (9) |
Since the channel coefficient between the th AP and the th UE is complex-valued, the received signal can be divided into the real part and the imaginary part:
Therefore, we can transform the complex-valued network with UEs and APs into a real-valued network with UEs and APs. It is convenient to calculate the real and imaginary parts of the coefficient vector , respectively. 333Reducing the problem of developing coefficient algorithms for complex channels to an equivalent real-only channel is generally suboptimal. Some solutions of finding the optimal solution in polynomial time over complex integer based lattices and complex channels were proposed in [26], however, they require a substantially higher complexity. Therefore, the investigation of explicitly addresses the complex channel with low complexity is one of our future work. Without loss of generality, we only consider for a given real-valued channel coefficient in the following.
For each coefficient vector , we can find a signed permutation matrix S, which is unimodular and orthogonal such that is nonnegative and its elements are in nondecreasing order [27, Lemma 1]. Suppose is the optimal coefficient vector with the specifical power constraint P and channel coefficient , we have [27, Lemma 3]. Define as the nonnegative and non-decreasing-ordered vector, e.g., . Therefore, we can recover the desired coefficient vector through .
In the following, we concentrate on acquiring for by relaxing the optimization problems stated in (III-A) based on the quadratic programming (QP) method [28]. Recall that is in nondecreasing order, therefore, the maximum element should be . According to [22], the searching space for can be restricted with
| (10) |
where denotes the maximum eigenvalue of . Then, the problem stated in (III-A) can be rewritten as a series of QP problems
| (11) |
where and . Let represent the solution to the problem of (III-A) with the constraint . solutions can be obtained by utilizing . With the Lagrange multiplier method [28], we have
| (12) |
where . With the help of [27, ALgorithm 1], real-valued solutions to the problem in (III-A), , can be quantized to integer-valued . We select a sub-optimal coefficient vector for with
Finally, the optimal coefficient vector correlated with the channel coefficient is recovered with . Following a similar line of reasoning, the imaginary part of the coefficient vector can be derived.
III-B Parallel Computation
For parallel computation, the integer linear combinations of UEs’ data are decoded independently. On this basis, we first introduce the computation rate region. Then, we provide a detailed description of the proposed power control algorithm which improves the achievable sum-rate. For reducing the effective noise variance and computation complexity, we further propose an AP selection algorithm based on large-scale fading.
III-B1 Computation Rate Region
Let us suppose that all APs have full channel state information. To obtain the estimation of the integer combination with UEs’ original data , the th AP multiplies the received signal by an equalization factor by the received signal to obtain the effective channel as
| (13) |
After choosing to be the minimum mean-square error (MMSE) coefficient adopted at the th AP, the minimum effective noise variance for parallel computation is given by
| (14) |
We denote as the matrix of the coefficient vectors, . Specifically, if the th column of is a null vector, the th AP does not serve any UE; if the th row of is a zero vector, the th UE is not served by any AP. When we remove such columns and rows from , we obtain , where and refers to the number of effective UEs and APs. Due to the array gain, the sum-rate increases along with the value of increase. However, there is a trade-off between the values of and sum-rate performance, since the growth of effective UEs does not always lead to the increase in sum-rate [6]. According to the discussion of coefficient vector selection in Section III-A, the values of and are determined by the location of APs and UEs, therefore and can take the optimal value when the location of APs and UEs is optimal. Define the rank of by . According to [18], all effective UEs’ data can be recovered if . Therefore, we only need integer linear combinations among the whole combinations. In other words, only APs need to transmit signals to the CPU through fronthaul links. The computation rate region for the parallel computation is given by
| (15) |
where means the th AP doesn’t serve the th UE.
III-B2 Power Optimization
If , the computed achievable rate for the th UE at the th AP is given as
| (16) |
However, when recovering the data of the th UE, the codeword spacing for that data should tolerate the maximum effective noise variance across APs, whose linear combinations involve that data. Therefore, the actual achievable rate of the th UE is
| (17) |
Hence, the achievable sum-rate of UEs is
| (18) |
Recall that all UEs transmit with equal power in CF scheme. For fairness, we compare the performance of CF and ECF with the constraint of equal total transmit power. We aim at optimizing the power allocation to maximize the achievable sum-rate under the constraints on the total power consumption . The optimization problem is formulated as follows:
| (19) |
UEs can share a total power budget which is the upper bound performance of each UE’s power constraint as their total maximum allowable transmit power [29]. Besides, (19) is handled at the CPU since the global information and are required.
As mentioned above, each AP decodes as one regular codeword due to the lattice algebraic structure. All UEs served by the th AP need to tolerate the same effective noise. If the linear integer combinations can tolerate the effective noise variance , then all UEs served by the th AP, which means can be successfully recovered from the linear combination with integer coefficient vector . In cell-free massive MIMO, we always emphasize a good quality-of-service for all users. However, directly improving the achievable sum rate cannot achieve a good balance of quality-of-service for all users [12]. Therefore, the goal of minimizing the maximum effective noise variance that can generally improve the achievable rate for most UEs is more suitable for our model. In other words, we could minimize the maximum effective noise variance as
| (20) |
According to (14), (III-B2) is equivalent to
| (21) |
According to [12, Lemma B. 4], the matrix inversion can be equivalently represented by
| (22) |
Therefore, the effective noise variance for the th AP is
| (23) |
Aa a result, (III-B2) can be rewritten as
| (24) |
However, (III-B2) is NP-hard. To tackle this challenge, we first introduce three auxiliary variables. On this basis, we can build the following optimization problem by introducing three auxiliary variables , , and :
| (25) |
In particular, variables and have limited searching space, respectively. For a given value of , the variable should be smaller than . Therefore, we employ a two-dimension of brute force search on these two scalars. For fixed and , the optimization problem in (25) can be rewritten as a feasibility problem
| (26) |
where , . is a matrix whose th element is given as . Clearly, is a positive semi-definite matrix. Consequently, (26) can be solved efficiently by performing a brute force search on two scalars. In each step, a feasibility problem needs to be solved. Since transforming a nonconvex problem into its equivalent convex form is quite difficult if not possible, an off-the-shelf optimization solver, e.g. fmincon in Matlab, is adopted to obtain a suboptimal solution. Besides, simulations show that solving a nonconvex problem also brings obvious performance improvement, the computation cost is tolerable. Besides, actually (III-B2) is equal to (25) only if the two terms in the objective of (III-B2) are independent. However, at the optimal point, we only care about minimize the final maximum term. More specifically, Algorithm 1 can solve (25). The parameters in Step 1, e.g., and , can be determined by solving another two feasibility problems:
| (27) |
respectively. When the search is completed, all APs achieve the same minimal effective noise variance . The corresponding values of and can be denoted as and . Finally, utilizing (18) and (23), the achievable sum-rate can be obtained. In Algorithm 1, there are at most
| (28) |
feasibility problems that need to be solved, where and refer to the step size for searching and , respectively.
III-B3 AP Selection
As mentioned above, recovering UEs’ original data only requires integer linear combinations. Therefore, we propose a low-complexity AP selection algorithm for two purposes. First, only effective noise variance participant in the brute force search leads to a reduction in computational complexity. Second, the noise tolerance on UEs’ data can be relaxed, which contributes to the improvement of the achievable sum-rate. Recall that (10) restricts the maximum value in the coefficient vector and the search space is generally small. Hence, for different APs, it is the difference on the second term in (23) that leads to a significant deviation on the effective noise variance.
Note that the average channel gain is -70 dB while the noise power is -130 dBW. Therefore, the denominator of that term is close to 1 and is several orders of magnitude smaller than the numerator. Consequently, the main factor that affects the effective noise variance across different APs is the sum of all elements in . In other words, decoding the estimations of APs with a high sum value of will obtain a higher achievable sum-rate. Therefore, we prefer selecting APs with a high sum value of . Furthermore, according to (1), is a function of . Then, we propose an algorithm for AP selection based on large-scale fading coefficient , which generally stays constant for several coherence intervals.
We construct matrix for each AP by replacing the channel coefficient with . For each , we first sum all the elements and sort the sum values in ascending order. Then, we apply the greedy AP selection for message recovery stated in [17, Algorithm 1]. Compared with the AP selection in [17], we sort the APs by firstly replacing the channel coefficient with , and then calculating the sum value of all the elements in the matrix , which is independent of the power allocation. According to [17], we check the columns of one by one, where , until rank requirement satisfied, therefore the computational complexity of the proposed AP selection method is no more than .
III-C Successive Computation
It is beneficial to remove the codewords which have been decoded successfully from the channel observation. In that case, subsequent decoding stages will encounter less interference. This well-known technique is referred to as successive interference cancellation (SIC). In ECF framework, we apply an analog of that for cell-free massive MIMO, which is named successive computation and can be viewed as the combination of ECF and successive interference cancellation. Compared with parallel computation, successive computation reduces the effective noise variance and the number of users that need to tolerate that effective noise in each decoding step [22]. Hence, it can further improve the system performance. The SIC technique also applied in [30], which proposes a hybrid deep reinforcement learning (DRL) model to design the IUI-aware receive diversity combining scheme. Compared with [30], our successive computation scheme benefits from applying the nested lattice coding strategy which can effectively reduce the fronthaul load. In this subsection, the expression of the computation rate region for successive computation is introduced firstly. Since the decoding order of integer linear combinations and UEs both have a significant impact on the performance of successive computation, we present different methods to find the sub-optimal decoding orders with power control.
III-C1 Computation Rate Region
In successive computation, AP sends the received signal and the integer linear combinations of codewords to the CPU, instead of decoding the received signal into the combinations of UEs’ original data 444When applying with successive computation, the interference cancellation procedure takes place at the decoder equipped at the CPU. Note that the signaling exchanges occurred per coherent interval and the fronthaul load are and with parallel computation and successive computation, respectively. Besides, the data of UEs are conveyed from the CPU to the APs through fronthaul links and then distributed to the UEs with precoding.. Define , the CPU applies equalization factor and vector to the th combination as
| (29) |
where . (III-C1) shows that the decoded linear combinations can be used as side information for reducing the effective noise experienced in the latter decoding stages for other UEs.
After choosing and c to be the MMSE projection scalar and vector, the minimum effective noise variance with transmit power matrix P is given by
| (30) |
where
| (31) |
and
| (32) |
Then, the computation rate region for successive computation is given as
| (33) |
III-C2 Searching Decoding Order for Combinations
Among APs, we first select the effective UEs and APs that participate in the uplink transmission. Then, we try to find the candidate integer combinations with small effective noise utilizing the AP selection algorithm. The detailed procedure has been introduced in Section III-B3. According to (III-C1), the effective noise variance is related to the decoding order of integer linear combinations. Therefore, we propose an efficient method for determining the side information matrix with power control.
The main idea of successive computation is to utilize the side information and the decoded integer linear combinations to reduce the effective noise. Note that the integer linear combination decoded firstly does not have any side information to exploit. Hence, the effective noise expression for the first decoding step is similar to that of parallel computation, which is given by
| (34) |
where denotes the decoding order. As the remaining combinations can reduce their effective noise with the help of side information, we can select the integer linear combination which has the minimum effective noise to decode firstly. To determine , we solve the following optimization problem to obtain its local sub-optimal power allocation. As the problem (III-C2) is non-convex and translate it into non-convex is quite difficult, an off-the-shelf optimization solver, e.g. fmincon in Matlab, is adopted to obtain a suboptimal solution. Note that although the obtained solution is suboptimal, the performance of the proposed framework is still superior compared with CF and MRC, which will be verified in the simulation section. Such that, for each , , we have
| (35) |
Then, we calculate the effective noise for each with its own power allocation matrix and select the combination which has the minimal effective noise as .
After determining , we begin to determine the remaining decoding order. For the th step, we determine depending on the effective noise and the rank of the side information matrix. More specifically, we first calculate the effective noise variance for each of the remaining integer linear combinations according to (30) and sort them in ascending order. Then, in line with the order, in each turn add the corresponding coefficient vector to the side information matrix , which is known from step 1 through , to form , . Finally, we select the integer linear combination which meets the constraint
| (36) |
to update the side information matrix. The procedure for finding terminates when all integer linear combinations find themselves decoding orders. The detailed procedure for searching the decoding order of combinations in successive computation is summarized in Algorithm 2. To determine , we need to solve the optimization problem in (III-C2) for times. Then, for searching the decoding order for the left combinations in terms of the number of complex multiplications is
| (37) |
III-C3 Searching Decoding Order for UEs
In successive computation, the effective noise of UEs whose data is decoded in the latter decoding stages can be reduced. At the th decoding step, it is possible to use the side information matrix to reduce some known individual codewords and remove them from the integer linear information without changing the effective noise variance. In particular, if the th UE’s data has been recovered at the th step, the data only need to tolerate the maximum effective noise among . Therefore, the decoding order of UEs also has an effect on the achievable sum-rate. Searching the decoding order has been studied in some works [31], [32] with SIC. However, our problem is generally intractable and the use of convex optimization for obtaining the optimal solution is not possible. Therefore, we propose several methods to determine the decoding order of UEs and select the best one as a suboptimal solution.
Received-Power-Based Algorithm
In general successive interference cancellation, the decoding order of UEs is determined by their received power. We calculate the received power of the th UE with respect to the th integer linear combination with . Then, we can obtain the achievable rate for each UE with with
| (38) |
and sort them in descending order based on the received power. The signal from UE whose rate with respect to the combination is in the first place of the order is decoded at the step.
Channel-Coefficient-Based Algorithm
As stated in Section III-B3, a better channel condition leads to the less effective noise variance. Therefore, UEs with good channel condition contributes to the small effective noise of selected APs. These UEs can be decoded first to relax their effective noise tolerance and then have a large achievable rate. For the th UE, let us define as the channel coefficients with integer linear combinations . We calculate the 2-norm of for all UEs and sort them in descending order.
Hungarian Algorithm
With the effective noise variance for integer linear combinations and the power allocation for UEs, we can find the assignment for each UE with . It has been shown in [33] that the Hungarian algorithm may be the best solution to the combinational optimization problem. Therefore, we first construct a matrix , whose element in the th row and th column represents the achievable rate of the th UE with the th integer linear combination from (38), such as . The conventional Hungarian algorithm aims to find element which are set in different rows and columns of . The sum of these element is minimum. However, we need to obtain the maximum value of the achievable sum-rate. Therefore, we first find the maximum value in and replace each element with . The detailed procedure of the Hungarian algorithm is summarized in Algorithm 3.
To determine which UE’s data should be recovered at the th decoding step, we need to compute UEs’ achievable rate. Therefore, the computational complexity for the received-power-based algorithm and the channel-coefficient-based algorithm is . Besides, the complexity of the Hungarian algorithm is [34]. After determining the decoding order of integer linear combinations and UEs, the achievable sum-rate can be obtained. Using (38) for calculating the achievable rate for th UE whose data is recovered with , and the sum achievable rate is given as .
IV Numerical Results
IV-A Parameters Setup
We adopt the similar parameters setting in [6] as the basis to establish our simulation system model. More specifically, all UEs and APs are randomly located within a square of 1 1 km. In each simulation setup, the APs and UEs are uniformly distributed at random locations within the simulation area. The square is wrapped around at the edges to avoid boundary effects. Hata-COST231 model is employed to characterize the large-scale propagation.
IV-B Results and Discussion
IV-B1 Parallel Computation
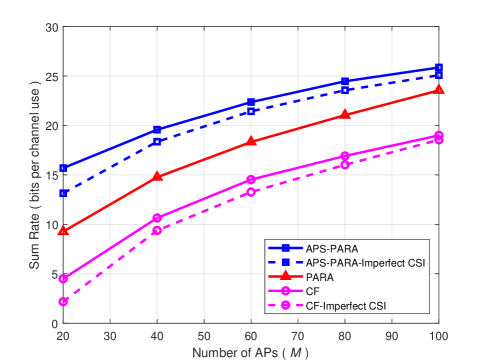
First, we evaluate the performance of the proposed parallel computation (PARA) scheme in terms of the achievable sum-rate with power control. The APS-PARA scheme refers to the PARA with AP selection. Fig. 2 shows the achievable sum-rate obtained via CF, PARA, and APS-PARA schemes versus the number of APs with and mW. Owing to the array again, the system performance of all considered schemes increases as the number of APs increasing. Moreover, the PARA scheme with the proposed power control method outperforms the conventional CF scheme. For example, compared with the CF scheme, both PARA and APS-PARA schemes improve the achievable sum-rate by factors more than 1.24 and 1.36 for the case of , respectively. This is due to the fact that the ECF framework enables optimal transmit power of UEs which facilitates the exploitation of performance gain. Furthermore, it can be seen from Fig. 2 that APS-PARA scheme is better than the PARA scheme. This is contributed to the low IUI brought by the proposed AP selection. Due to the effective noise variance which UEs’ data need to tolerate decreases considerably, it is beneficial to utilize AP selection for improving the achievable sum-rate. Besides, the computational complexity has also been reduced with AP selection. For recovering UEs’ original information, only integer linear combinations instead of need to be used in the power control. Besides, when the number of APs is 60, compared with imperfect CSI estimated by MMSE estimation method [12] known at APs, the performance degradation caused by imperfect CSI is only 4%.
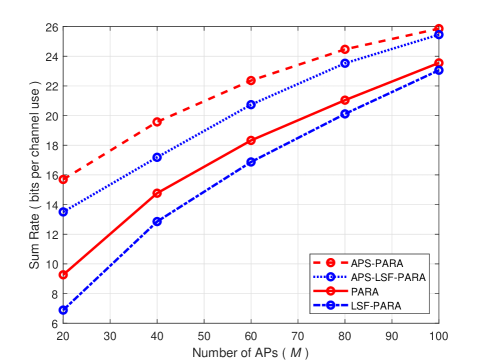
Assuming that the power control is utilized at the CPU based on the large-scale fading, we need to replace with for solving the optimization problem (III-B2). The PARA scheme using power control based on the large-scale fading is referred to as LSF-PARA scheme. Fig. 3 shows the achievable sum-rate obtained with PARA, LSF-PARA, APS-PARA, and APS-LSF-PARA schemes against the number of APs. As expected, the achievable sum-rate of all schemes improves as the number of APs increases, and applying AP selection does help enhance the performance. Furthermore, the impact on achievable sum-rate of neglecting the small-scale fading is not critical, especially when the ratio of APs to UEs becomes large. In particular, the performance gap due to ignoring the small-scale fading vanishes for . This is due to the property of channel hardening [12]. As the number of antennas is sufficiently large, the variance of the channel gain reduces and the fading becomes almost as a deterministic channel.
IV-B2 Successive Computation
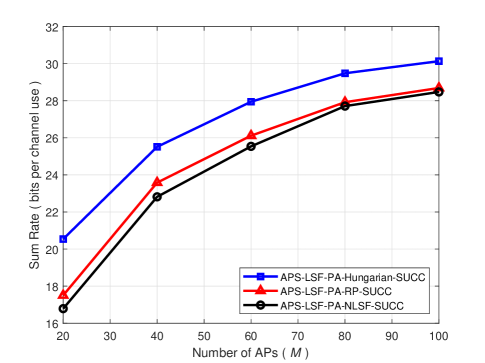
Next, we examine the performance of successive computation (SUCC) schemes. Let us denote the successive computation scheme based on large-scale fading applied with AP selection, power allocation, and Hungarian algorithm by APS-LSF-PA-Hungarian-SUCC. Fig. 4 shows the performance of APS-LSF-PA-SUCC schemes with different algorithms on determining the decoding order of UEs, Hungarian algorithm, received-power-based (RP) algorithm, and channel-coefficient-based algorithm. As we assume that the power control is employed at the CPU, which means that the channel coefficient is replaced with the large-scale fading coefficient, the APS-LSF-PA-SUCC scheme with searching the decoding order of UEs through 2-norm of large-scale fading coefficients is named as APS-LSF-PA-NLSF-SUCC scheme. As shown in Fig. 4, the APS-LSF-PA-Hungarian-SUCC scheme achieves the best result compared to other schemes. Furthermore, the performance of APS-LSF-PA-RP-SUCC scheme is similar to that of APS-LSF-PA-NLSF-SUCC. This is due to the fact that the denominator of the second term in (23) is several orders of magnitude smaller than the numerator, as the transmit power normalized by the noise power is huge. Note that the effect of the first term in (23) on effective noise variance is not significant. Therefore, according to (23), UEs with good channel state should be allocated with more transmit power for reducing the effective noise and finally the system can obtain a larger achievable sum-rate. In this way, using RP and NLSF algorithms leads to the same result.
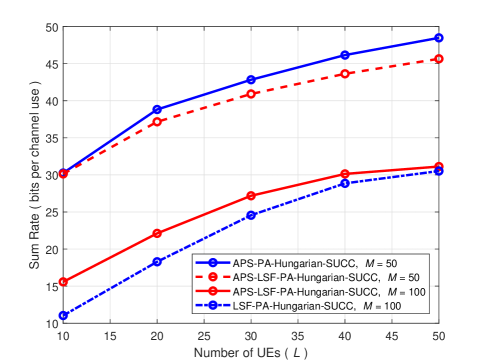
In previous simulation results, we have shown that the instantaneous channel state information can help the parallel computation scheme to improve the achievable sum-rate while with higher complexity. In successive computation, the conclusion is similar. In Fig. 5, we compare the achievable sum-rate of APS-PA-Hungarian-SUCC and APS-LSF-PA-Hungarian-SUCC schemes. Although the performance gap induced by the replacement of channel coefficient becomes large along with the increase of the number of UEs, it is still very small. At the same time, transmitting instantaneous channel state information yields a great growth load in fronthaul load. Noted that the small-scale fading coefficient is only static during one coherence block while the large-scale fading coefficient stays constant for a duration of at least 40 small-scale fading coherence intervals [6]. Therefore, using the statistical channel state information works well for successive computation schemes. Besides, the benefit of employing AP selection is also obvious in successive computation. During searching the decoding order of combinations (36), in the th step we only need to calculate times to find the minimal effective noise which increases the rank of the side information matrix. Furthermore, we can use to eliminate certain symbols from the combination and thus remove the constraint on them. For determining the total decoding order of combinations, the computational complexity is while abandoning the selection needs . Therefore, utilizing AP selection not only improves the performance but also decrease the computational complexity when the number of APs is larger than UEs.
IV-B3 Comparison of centralized MMSE, ECF, CF, and MRC scheme
In Fig. 6, we compare the achievable sum-rate of APS-LSF-PA-Hungarian-SUCC, APS-LSF-PARA, CF, and MRC schemes. MRC scheme is the simple linear strategy in cell-free massive MIMO, which has been widely used in previous works [6]. In the uplink data transmission, the received signal at the th AP can be expressed as . Then, the th AP multiplies the received signal with the conjugate of its channel coefficient vector and then forwards to the CPU. The CPU combines signals from all APs. Therefore, the achievable rate of the th UE is given by
| (39) |
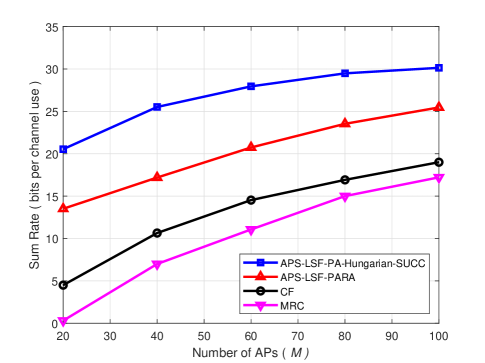
It is clear to see that the IUI limits the achievable sum-rate. However, employing CF and ECF schemes can harness and even exploit the interference for cooperative gain, which leads to an increase in the achievable sum-rate. This can be verified from Fig. 6. When the number of APs is not very large, which means the IUI affects the performance significantly, the advantage of applying CF and ECF schemes is self-evident. For example, compared with MRC scheme, the achievable sum-rate of CF and ECF schemes improves by factors more than 1.5 and 2.5 when , respectively.
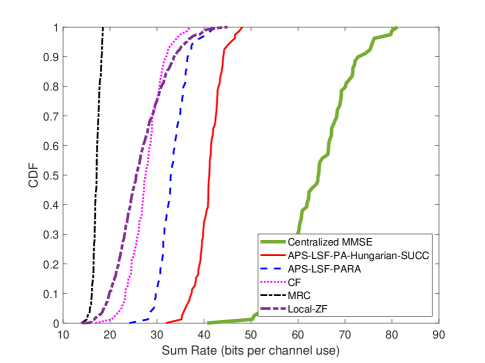
Although utilizing the ECF framework can effectively improve the system performance, it is not the optimal choice for maximizing the achievable rate. Fig. 7 shows the cumulative distribution function (CDF) of achievable sum-rate for centralized MMSE, APS-LSF-PA-Hungarian-SUCC, APS-LSF-PARA, CF, and MRC schemes with , . From Fig. 7, we can first observe that our parallel ECF scheme with power control method that solves (26) outperforms both CF and MRC. Second, when comparing the ECF framework with local MR and zero-forcing (ZF) schemes using quantized signals under the same fronthaul limit, our proposed ECF schemes including parallel and successive computation have superior performance. Specifically, compared with the local ZF, applying the successive computation scheme leads to 60.4% improvement in terms of the average achievable sum-rate. Besides, the performance gap between the APS-LSF-PA-Hungarian-SUCC scheme and the centralized MMSE scheme is obvious. It is attributed to the fact that the centralized MMSE adopts the optimal combining scheme for maximizing the instantaneous signal-to-interference-and-noise ratio [12]. Specifically, applying the centralized MMSE scheme leads to 55% improvement in terms of average achievable sum-rate. However, compared with centralized MMSE, ECF is also an efficient approach for fronthaul reduction and hence a largely achievable sum-rate still can be realized even if the fronthaul capacity is limited. In particular, each AP decodes the received signal into the finite field by applying the equalization factor and then forwards an integer combination of the transmitted symbols of all UEs. The cardinality of signals transmitted in the fronthaul link is the same as the cardinality of UEs original data, this is the theoretical minimum fronthaul load required to achieve lossless transmission [17]. When the fronthaul capacity restricted as , the actual achievable rate is [35], where represents the achievable sum-rate without considering the fronthaul load constraint.
IV-B4 Trade-off between the performance and the complexity of ECF schemes
| Schemes | Computation Complexity | Sum rate [bits per channel use] | |||||
| AP Selection |
|
Searching Decoding Order | |||||
|
N/A | 19.57 | |||||
| Successive Computation | Using Received-power-based algorithm | 23.58 | |||||
| Using Channel-coefficient-based algorithm | 22.82 | ||||||
| Using Hungarian algorithm | 25.51 | ||||||
In Table II, we summarize the performance in terms of sum-rate and the computational complexity of various versions of successive computation and parallel computation. It can be observed that there is a trade-off between performance and computational complexity. Specifically, the successive computation with the Hungarian algorithm for searching decoding order of UEs has the higher computational complexity and superior performance compared with the other two methods, i.e., received-power-based algorithm and channel-coefficient-based algorithm.
IV-B5 Scalable Issue
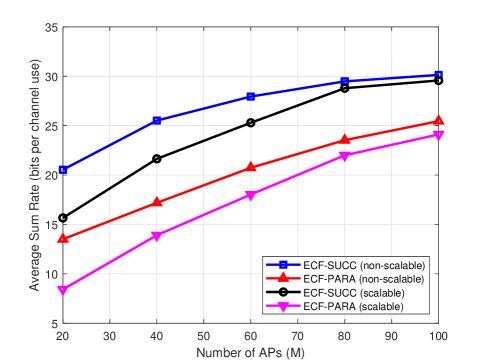
In order to realize scalability [36], [37], our ECF framework needs to control the number of UEs each AP serves. Specifically, according to the large-scale-fading-based AP selection criterion proposed in [38], APs are first selected to form UE-centric clusters for each UE. Then, each AP sorts the UEs that need to be served according to the large-scale fading information, and then selects only the first several UEs with the best channel quality to serve. Fig. 8 shows the performance comparison between the original non scalable ECF and the scalable ECF schemes. We can observe that the performance loss is small and decreases with the increase of the number of APs.
V Conclusions
In this work, we investigate the achievable sum-rate of ECF framework for cell-free massive MIMO systems. Two types of ECF framework including parallel computation and successive computation to improve the achievable sum-rate in cell-free massive MIMO are proposed. An AP selection scheme is proposed to reduce the effective noise tolerance of UEs to further improve the performance and reduce the computation complexity. We prove that the proposed power control algorithm for parallel computation and successive computation with AP selection can improve the achievable sum-rate significantly. For obtaining better system performance, methods for determining the decoding order of combinations and UEs are also presented. Numerical results show that compared with CF and MRC schemes, the ECF framework remarkably improves the achievable sum-rate of cell-free massive MIMO systems.
References
- [1] J. Zhang, J. Zhang, J. Zheng, S. Jin, and B. Ai, “Expanded compute-and-forward for backhaul-limited cell-free massive MIMO,” in Proc. IEEE ICC Wkshps, 2019, pp. 1–6.
- [2] T. L. Marzetta, “Noncooperative cellular wireless with unlimited numbers of base station antennas,” IEEE Trans. Wireless Commun., vol. 9, no. 11, pp. 3590–3600, Nov. 2010.
- [3] J. Zhang, E. Björnson, M. Matthaiou, D. W. K. Ng, H. Yang, and D. J. Love, “Prospective multiple antenna technologies for beyond 5G,” IEEE J. Sel. Areas in Commun., vol. 38, no. 8, pp. 1637–1660, Aug. 2020.
- [4] X. Chen, D. W. K. Ng, W. Yu, E. G. Larsson, N. Al-Dhahir, and R. Schober, “Massive access for 5G and beyond,” IEEE J. Sel. Areas in Commun., vol. 39, no. 3, pp. 615–637, Mar. 2021.
- [5] A. Lozano, R. W. Heath, and J. G. Andrews, “Fundamental limits of cooperation,” IEEE Trans. Inf. Theory, vol. 59, no. 9, pp. 5213–5226, Sep. 2013.
- [6] H. Q. Ngo, A. Ashikhmin, H. Yang, E. G. Larsson, and T. L. Marzetta, “Cell-free massive MIMO versus small cells,” IEEE Trans. Wireless Commun., vol. 16, no. 3, pp. 1834–1850, Mar. 2017.
- [7] E. Nayebi, A. Ashikhmin, T. L. Marzetta, H. Yang, and B. D. Rao, “Precoding and power optimization in cell-free massive MIMO systems,” IEEE Trans. Wireless Commun., vol. 16, no. 7, pp. 4445–4459, Jul. 2017.
- [8] M. Karlsson, E. Björnson, and E. G. Larsson, “Techniques for system information broadcast in cell-free massive MIMO,” IEEE Trans. Commun., vol. 67, no. 1, pp. 244–257, Jan. 2019.
- [9] M. Bashar, K. Cumanan, A. G. Burr, M. Debbah, and H. Q. Ngo, “On the uplink max¨cmin SINR of cell-free massive MIMO systems,” IEEE Trans. Wireless Commun., vol. 18, no. 4, pp. 2021–2036, Apr. 2019.
- [10] G. Interdonato, E. Björnson, H. Q. Ngo, P. Frenger, and E. G. Larsson, “Ubiquitous cell-free massive MIMO communications,” EURASIP J. Wireless Commun. Netw., vol. 2019, no. 1, p. 197, Dec. 2019.
- [11] E. Bjornson and L. Sanguinetti, “Making cell-free massive MIMO competitive with MMSE processing and centralized implementation,” IEEE Trans. Wireless Commun., vol. 19, no. 1, pp. 77–90, Jun. 2020.
- [12] E. Björnson, J. Hoydis, L. Sanguinetti et al., “Massive MIMO networks: Spectral, energy, and hardware efficiency,” Foundations and Trends® in Signal Processing, vol. 11, no. 3-4, pp. 154–655, 2017.
- [13] R. Ahlswede, N. Cai, S.-Y. Li, and R. W. Yeung, “Network information flow,” IEEE Trans. Inf. Theory, vol. 46, no. 4, pp. 1204–1216, Apr. 2000.
- [14] S.-Y. Li, R. W. Yeung, and N. Cai, “Linear network coding,” IEEE Trans. Inf. Theory, vol. 49, no. 2, pp. 371–381, Feb. 2003.
- [15] T. Yang and I. B. Collings, “On the optimal design and performance of linear physical-layer network coding for fading two-way relay channels,” IEEE Trans. Wireless Commun., vol. 13, no. 2, pp. 956–967, May 2014.
- [16] B. Nazer and M. Gastpar, “Reliable physical layer network coding,” Proc. IEEE, vol. 99, no. 3, pp. 438–460, Mar. 2011.
- [17] Q. Huang and A. Burr, “Compute-and-forward in cell-free massive MIMO: Great performance with low backhaul load,” in Proc. IEEE ICC Wkshps, May 2017, pp. 601–606.
- [18] B. Nazer and M. Gastpar, “Compute-and-forward: Harnessing interference through structured codes,” IEEE Trans. Inf. Theory, vol. 57, no. 10, pp. 6463–6486, Oct. 2011.
- [19] S.-N. Hong and G. Caire, “Compute-and-forward strategies for cooperative distributed antenna systems,” IEEE Trans. Inf. Theory, vol. 59, no. 9, pp. 5227–5243, Sep. 2013.
- [20] C. Feng, D. Silva, and F. R. Kschischang, “An algebraic approach to physical-layer network coding,” IEEE Trans. Inf. Theory, vol. 59, no. 11, pp. 7576–7596, Nov. 2013.
- [21] M. Nokleby and B. Aazhang, “Lattice coding over the relay channel,” in Proc. IEEE ICC, 2011, pp. 1–5.
- [22] B. Nazer, V. R. Cadambe, V. Ntranos, and G. Caire, “Expanding the compute-and-forward framework: Unequal powers, signal levels, and multiple linear combinations,” IEEE Trans. Inf. Theory, vol. 62, no. 9, pp. 4879–4909, Sep. 2016.
- [23] Z. Li, J. Chen, L. Zhen, S. Cui, K. G. Shin, and J. Liu, “Coordinated multi-point transmissions based on interference alignment and neutralization,” IEEE Trans. Wireless Commun., vol. 18, no. 7, pp. 3347–3365, Jul. 2019.
- [24] P. Marsch and G. P. Fettweis, Coordinated Multi-Point in Mobile Communications: from theory to practice. Cambridge University Press, 2011.
- [25] V. V. Veeravalli and A. El Gamal, Interference management in wireless networks: Fundamental bounds and the role of cooperation. Cambridge University Press, 2018.
- [26] Q. Huang and A. Burr, “Low complexity coefficient selection algorithms for compute-and-forward,” IEEE Access, 2017, pp. 19 182–19 193.
- [27] B. Zhou and W. H. Mow, “A quadratic programming relaxation approach to compute-and-forward network coding design,” in Proc. IEEE ISIT, Jun. 2014, pp. 2296–2300.
- [28] S. Boyd and L. Vandenberghe, Convex Optimization. Cambridge University Press, 2004.
- [29] W. He, B. Nazer, and S. S. Shitz, “Uplink-downlink duality for integer-forcing,” IEEE Trans. Inf. Theory, vol. 64, no. 3, pp. 1992–2011, Mar. 2018.
- [30] Y. Al-Eryani, M. Akrout, and E. Hossain, “Multiple access in cell-free networks: Outage performance, dynamic clustering, and deep reinforcement learning-based design,” IEEE J. Sel. Areas in Commun., vol. 39, no. 4, pp. 1028–1042, 2020.
- [31] W. Mesbah and H. Alnuweiri, “Joint rate, power, and decoding order optimization of MIMO-MAC with MMSE-SIC,” in Proc. IEEE Globecom Wkshps, 2009.
- [32] Z. Zhou, T. Jiang, H. Bai, S. Sun, and H. Long, “Joint optimization of power and decoding order in CDMA based cognitive radio systems with successive interference cancellation,” in Proc. IEEE ICCT, 2011, pp. 187–191.
- [33] R. R. Patel, T. T. Desai, and S. J. Patel, “Scheduling of jobs based on hungarian method in cloud computing,” in Proc. IEEE ICICCT, 2017, pp. 6–9.
- [34] B.-L. Xu and Z.-Y. Wu, “A study on two measurements-to-tracks data assignment algorithms,” Inf. Sci., vol. 177, no. 19, pp. 4176–4187, 2007.
- [35] B. Nazer, A. Sanderovich, M. Gastpar, and S. Shamai, “Structured superposition for backhaul constrained cellular uplink,” in Proc. IEEE ISIT, 2009, pp. 1530–1534.
- [36] E. Björnson and L. Sanguinetti, “Scalable cell-free massive MIMO systems,” IEEE Trans. Commun., vol. 68, no. 7, pp. 4247–4261, Jul. 2020.
- [37] G. Interdonato, P. Frenger, and E. G. Larsson, “Scalability aspects of cell-free massive MIMO,” in Proc. IEEE ICC, 2019, pp. 1–6.
- [38] H. Q. Ngo, L.-N. Tran, T. Q. Duong, M. Matthaiou, and E. G. Larsson, “On the total energy efficiency of cell-free massive MIMO,” IEEE Trans. Green Commun. Netw., vol. 2, no. 1, pp. 25–39, Mar. 2018.