Improving the Hosmer-Lemeshow Goodness-of-Fit Test in Large Models with Replicated Trials
Summary
The Hosmer-Lemeshow (HL) test is a commonly used global goodness-of-fit (GOF) test that assesses the quality of the overall fit of a logistic regression model. In this paper, we give results from simulations showing that the type 1 error rate (and hence power) of the HL test decreases as model complexity grows, provided that the sample size remains fixed and binary replicates are present in the data. We demonstrate that the generalized version of the HL test by Surjanovic et al. (2020) can offer some protection against this power loss. We conclude with a brief discussion explaining the behaviour of the HL test, along with some guidance on how to choose between the two tests.
Key Words: chi-squared test, generalized linear model, goodness-of-fit test, Hosmer-Lemeshow test, logistic regression
Note: The latest version of this article is available at https://doi.org/10.1080/02664763.2023.2272223.
1 Introduction
Logistic regression models have gained a considerable amount of attention as a tool for estimating the probability of success of a binary response variable, conditioning on several explanatory variables. Researchers in health and medicine have used these models in a wide range of applications. One of many examples includes estimating the probability of hospital mortality for patients in intensive care units as a function of various covariates (Lemeshow et al., 1988).
Regardless of the application, it is always desirable to construct a model that fits the observed data well. One of several ways of assessing the quality of the fit of a model is with goodness-of-fit (GOF) tests (Bilder and Loughin, 2014). In general, GOF tests examine a null hypothesis that the structure of the fitted model is correct. They may additionally identify specific alternative models or deviations to test against, but this is not required. Global (omnibus) GOF tests are useful tools that allow one to assess the validity of a model without restricting the alternative hypothesis to a specific type of deviation.
An example of a well-known global GOF test for logistic regression is the Hosmer-Lemeshow (HL) test, introduced by Hosmer and Lemeshow (1980). The test statistic is a Pearson statistic that compares observed and expected event counts from data grouped according to ordered fitted values from the model. The decision rule for the test is based on comparing the test statistic to a chi-squared distribution with degrees of freedom that depend on the number of groups used to create the test statistic. The HL test is relatively easy to implement in statistical software, and since its creation, the HL test has become quite popular, particularly in fields such as biostatistics and the health sciences.
Despite its popularity, the HL test is known to have some drawbacks. In both experimental and observational studies, it is possible to have data for which binary observations have the same explanatory variable patterns (EVPs). In this case, responses can be aggregated into binomial counts and trials. When there are observations with the same EVP present in the data, it is possible to obtain many different p-values depending on how the data are sorted (Bertolini et al., 2000). A related disadvantage of HL-type tests is that the test statistic depends on the way in which groups are formed, as remarked upon by Hosmer et al. (1997). In this paper we will highlight a related but different problem with the HL test that does not appear to be well known.
Models for logistic regression with binary responses normally assume a Bernoulli model where the probability parameter is related to explanatory variables through a logit link. As mentioned, when several observations have the same EVP, responses can be summed into binomial counts. Other times, the joint distribution of covariates may cause observed values to be clustered into near-replicates, so that the responses might be viewed as being approximately binomially distributed. These cases present no problem for model fitting and estimating probabilities. However, it turns out that this clustering in the covariate space may materially impact the validity of the HL test applied to the fitted models.
For such data structures, a chi-squared distribution does not represent the null distribution of the HL test statistic well in finite samples, as suggested by simulation results in Section 4. This, in turn, adversely affects both the type 1 error rate and the power of the HL test. Bertolini et al. (2000) demonstrated that it is possible to obtain a wide variety of p-values and test statistics when there are replicates in the data, simply by reordering the data. Our analysis also deals with replicates in the data. However, we find a different phenomenon: as the model size grows for a fixed sample size, the type 1 error rate tends to decrease.
In this paper we show that the HL test can be improved upon by using another existing global GOF test, the generalized HL (GHL) test from Surjanovic et al. (2020). Empirical results suggest that the GHL test performs reasonably well even when applied to moderately large models fit on data with exact replicates or clusters in the covariate space. We offer a brief discussion as to why one might expect clustering in the covariate space to affect the regular HL test. A simple decision tree is offered to summarize when each test is most appropriate.
An overview of the HL and GHL tests is given in Section 2. The design of the simulation study comparing the performance of these two tests is outlined in Section 3, with the results given in Section 4. We end with a discussion of the implications of these results and offer some guidance on how to choose between the two tests in Section 5.
2 Methods
In what follows, we use the notation of Surjanovic et al. (2020). We let denote a binary response variable associated with a -dimensional covariate vector, , where the first element of is equal to one. The pairs , denote a random sample, with each pair being distributed according to the joint distribution of . The observed values of are denoted using lowercase letters as .
In a logistic regression model with binary responses, one assumes that
for some . The likelihood function is
From this likelihood, a maximum likelihood estimate (MLE), , of is obtained.
The HL Test Statistic
To compute the HL test statistic, one partitions the observed data, , into groups. Typically, the groups are created so that fitted values are similar within each group and the groups are approximately of equal size. To achieve this, a partition is defined by a collection of interval endpoints, . The often depend on the data, usually being set equal to the logits of equally-spaced quantiles of the fitted values, . We define , , , , and , where is the indicator function on a set . With this notation, the number of observations in the th group is represented by , and denotes the mean of the fitted values in this group. The HL test statistic is a quadratic form that is commonly written in summation form as
When , Hosmer and Lemeshow (1980) find that the HL test statistic is asymptotically distributed as a weighted sum of chi-squared random variables under the null hypothesis, after checking certain conditions of Theorem 5.1 in Moore and Spruill (1975). Precisely,
| (1) |
with each being a chi-squared random variable with 1 degree of freedom, and each an eigenvalue of a certain matrix that depends on both the distribution of and the vector , the true value of under the null hypothesis. Hosmer and Lemeshow (1980) conclude through simulations that the right side of (1) is well approximated by a distribution in various settings.
The HL test statistic and the corresponding p-value both depend on the chosen number of groups, . Typically, groups are used, so that observations are partitioned into groups that are associated with “deciles of risk”. Throughout this paper we use 10 groups, and therefore compare the HL test statistic to a chi-squared distribution with 8 degrees of freedom, but the results hold for more general choices of .
The GHL Test Statistic
The GHL test introduced by Surjanovic et al. (2020) generalizes several GOF tests, allowing them to be applied to other generalized linear models. Tests that are generalized by the GHL test include the HL test (Hosmer and Lemeshow, 1980), the Tsiatis (Tsiatis, 1980) and generalized Tsiatis tests (Canary et al., 2016), and a version of the “full grouped chi-square” from Hosmer and Hjort (2002) with all weights equal to one. The test statistic is a quadratic form like , but with important changes to the central matrix. The theory behind this test depends on the residual process, , , defined in Stute and Zhu (2002). In the case of logistic regression,
a cumulative sum of residuals that are ordered according to the size of their corresponding fitted values. This process is transformed into a -dimensional vector, , which forms the basis of the HL and GHL test statistics, with
In order to approximate the variance of , we need to define several matrices. Let
for , and . Also, define to be the matrix with th row given by , and let be the same as , but evaluated at the estimate of . Finally, define
| (2) |
where is the identity matrix.
For logistic regression models, the GHL test statistic is then
where is the Moore-Penrose pseudoinverse of . Under certain conditions given by Surjanovic et al. (2020),
where , with a matrix defined in their paper. Since the rank of might be unknown, they use the rank of as an estimate. We use the same approach to estimating , empirically finding that the estimated rank of is often equal to for logistic regression models.
The GHL test statistic for logistic regression models is equivalent to the Tsiatis GOF test statistic (Tsiatis, 1980) and the statistic from Hosmer and Hjort (2002) with all weights set equal to 1, when a particular grouping method is used—that is, when is the same for all methods. However, use of the GHL test is justified for a wide variety of GLMs and grouping procedures with a proper modification of , as described by Surjanovic et al. (2020). For both the HL and GHL tests, we use the grouping method proposed by Surjanovic et al. (2020), which uses random interval endpoints, , so that is roughly equal between groups. Further details of the implementation are provided in the supplementary material of their paper.
It is important to note that is a non-diagonal matrix that standardizes and accounts for correlations between the grouped residuals in the vector . This can be seen from (2), which shows that contains a generalized hat matrix for logistic regression. In contrast, when written as a quadratic form, the central matrix of the HL test statistic is diagonal and does not account for the number of parameters in the model, , when standardizing the grouped residuals. We expect this standardization to be very important when exact replicates are present, as the binomial responses might be more influential than sparse, individual binary responses.
It is extremely common to fit logistic regression models to data where multiple Bernoulli trials are observed at some or all EVPs, even when the underlying explanatory variables are continuous. As with any fitted model, a test of model fit would be appropriate, and the HL test would likely be a candidate in a typical problem. It is therefore important to explore how the HL and GHL tests behave with large models when exact or near-replicates are present in the data.
3 Simulation Study Design
We compare the performance of the HL and GHL tests by performing a simulation study. Of particular interest is the rejection rate under the null, when the tests are applied to moderately large models that are fit to data with clusters or exact replicates in the covariate space.
In all settings, the true regression model is
| (3) |
with in . Here, represents the intercept term. To produce replicates in the covariate space, unique EVPs are drawn randomly from a -dimensional spherical normal distribution with marginal mean 0 and marginal variance for each simulation realization. At each EVP, replicate Bernoulli trials are then created, with probabilities determined by (3). In our simulation study, we fix and select so that the number of replicates at each EVP, , is 10, 5, or 1, respectively.
We set and . This results in fitted values that rarely fall outside the interval , regardless of the number of parameters in the model, so that the number of expected counts in each group is sufficiently large for the use of the Pearson-based test statistics.
We also perform some simulations with , using smaller values of and than for . However, we focus on results for because we are then able to increase the number of replicates per EVP, , while still maintaining large enough so that it is possible to create ten viable groupings. In each simulation setting, 10,000 realizations are produced. All simulations are performed using R.
4 Simulation Results
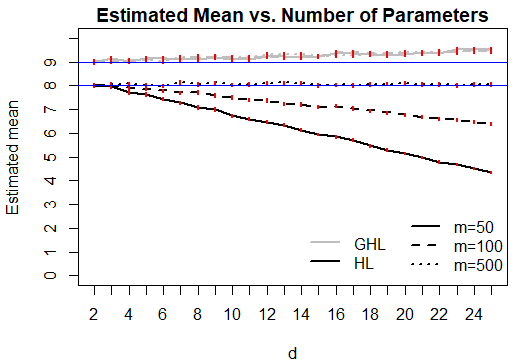
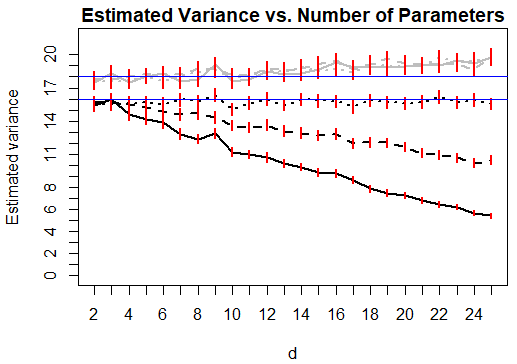
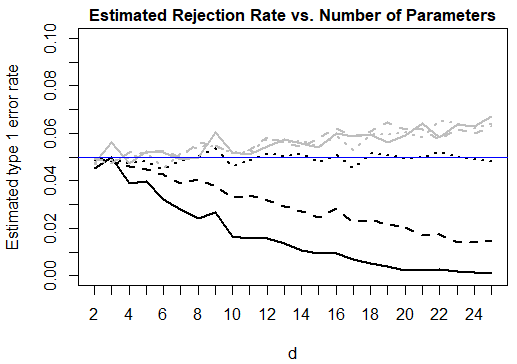
Figure 1 presents plots of the sample mean and variance of the HL and GHL test statistics against the number of variables in the model, separately for each . An analogous plot of the estimated type 1 error rate of the tests against the number of variables is also presented. For the HL test, all three statistics show a clear decreasing pattern with increasing model size when replicates are present, with a sharper decrease when the number of replicates per EVP is larger. Since the estimated variance is not always twice the size of the mean, we can infer that the chi-squared approximation to the null distribution of the HL test statistic is not adequate in finite samples for these data structures. Simulation results with a sample size of are not displayed, but are quite similar.
From the same figure, we see that the GHL test performs well in the settings considered. The estimated mean and variance of the test statistic stay close to the desired values of and . We note that the GHL test can have an inflated type 1 error rate, particularly when it is applied to highly complex models. The models considered here are only moderately large, with . If one wishes to use the GHL test to assess the quality of fit of larger models with only a moderate sample size, one should be wary of an inflated type 1 error rate that can become considerably large for complex models. A possible explanation for this is that estimating the off-diagonal elements of the matrix can potentially introduce a considerable amount of variance into the test statistic in small samples.
Recall from (1) that the asymptotic distribution for the HL test proposed by Hosmer and Lemeshow (1980) is based on a sum of chi-squares, where one has degrees of freedom. We investigated whether maintaining while increasing contributes to the phenomena we have observed. We set and performed a similar simulation study. The adverse behavior of the HL statistic still persists despite this modification.
We also investigated the effect of near-replicate clustering in the covariate space. We fixed and as in Section 3, but added a small amount of random noise with marginal variance to each replicate within the sampled vectors. The amount of clustering was controlled by varying , as shown in Figure 2. As expected, increasing reduces the severity of the decreasing mean, variance and type 1 error rate for the HL test statistic. However, the pattern remains evident while remains small.
5 Discussion
The original HL test, developed by Hosmer and Lemeshow (1980), is a commonly-used test for logistic regression among researchers in biostatistics and the health sciences. Although its performance is well documented (Lemeshow and Hosmer, 1982; Hosmer et al., 1997; Hosmer and Hjort, 2002), we have identified an issue that does not seem to be well known. For moderately large logistic regression models fit to data with clusters or exact replicates in the covariate space, the null distribution of the HL test statistic can fail to be adequately represented by a chi-squared distribution in finite samples. Using the original chi-squared distribution with degrees of freedom can result in a reduced type 1 error rate, and hence lower power to detect model misspecifications. Based on the results of the simulation study, the GHL test can perform noticeably better in such settings, albeit with a potentially inflated type 1 error rate.
Similar behaviour of the HL test was observed in Surjanovic et al. (2020), where the regular HL test was naively generalized to allow for it to be used with Poisson regression models. In their setup, even without the presence of clusters or exact replicates in the covariate space, as the number of model parameters increased for a fixed sample size, the estimated type 1 error rate decreased. The central matrix in the GHL test statistic, , makes a form of correction to the HL test statistic by standardizing and by accounting for correlations between the grouped residuals that comprise the quadratic form in both the HL and GHL tests. This is evident from (2), which shows that contains the generalized hat matrix subtracted from an identity matrix. To empirically assess the behaviour of , we varied in the setup with replicates and added noise, described at the end of Section 4. For large and moderate , both fixed, we found that the diagonal elements of tend to shrink, on average, as decreases. In contrast, the elements of the HL central matrix remain roughly constant. Therefore, the GHL statistic seems to adapt to clustering or replicates in , whereas the HL test statistic does not.
In logistic regression with exact replicates, grouped binary responses can be viewed as binomial responses that can be more influential. In this scenario, as increases for a fixed sample size , the distribution of the regular HL test statistic diverges from a single chi-squared distribution, suggesting that the standardization offered by the central GHL matrix becomes increasingly important.
The real-life implications of the reduced type 1 error rate and power of the regular HL test are that in models with a considerable number of variables—provided that the data contains clusters or exact replicates—the HL test has limited ability to detect model misspecifications. Failure to detect model misspecification can result in retaining an inadequate model, which is arguably worse than rejecting an adequate model due to an inflated type 1 error rate, particularly when logistic regression models are used to estimate probabilities from which life-and-death decisions might be made.
Our advice for choosing between the two GOF tests is displayed as a simple decision tree in Figure 3. The advice should be interpreted for groups, the most commonly used number of groups. With large samples, provided that is sufficiently large compared to , it should generally be safe to use the GHL test. Our simulations explored models with , so some caution should be exercised if the GHL test is to be used with larger models. For small or moderate samples, such as when or , it is important to identify whether there are clusters or exact replicates in the covariate space. One can compute the number of unique EVPs, , and compare this number to the sample size, . If , say, then there is a considerable amount of “clustering”. For data without exact replicates, clusters can still be detected using one of many existing clustering algorithms, and the average distances between and within clusters can be compared. Informal plots of the projected onto a two- or three-dimensional space can also be used as an aid in this process.
If there is no evidence of clustering or replicates, the HL test should not be disturbed by this phenomenon. On the other hand, if there is a noticeable amount of clustering, and the regression model is not too large, say , where also represents the number of estimated clusters, then one can use the GHL test. In the worst-case scenario with a small sample size, clustering, and a large regression model, one can use both tests as an informal aid in assessing the quality of the fit of the model, recognizing that GHL may overstate the lack of fit, while HL may understate it. If the two tests agree, then this suggests that the decision is not influenced by the properties of the tests. When they disagree, conclusions should be drawn more tentatively.
Acknowledgements
We acknowledge the support of the Natural Sciences and Engineering Research Council of Canada (NSERC), [funding reference number RGPIN-2018-04868]. Cette recherche a été financée par le Conseil de recherches en sciences naturelles et en génie du Canada (CRSNG), [numéro de référence RGPIN-2018-04868].
References
- Bertolini et al. (2000) G Bertolini, Roberto D’amico, D Nardi, A Tinazzi, and G Apolone. One model, several results: the paradox of the Hosmer-Lemeshow goodness-of-fit test for the logistic regression model. Journal of Epidemiology and Biostatistics, 5(4):251–253, 2000.
- Bilder and Loughin (2014) Christopher R. Bilder and Thomas M. Loughin. Analysis of categorical data with R. Chapman and Hall/CRC, 2014.
- Canary et al. (2016) Jana D. Canary, Leigh Blizzard, Ronald P. Barry, David W. Hosmer, and Stephen J. Quinn. Summary goodness-of-fit statistics for binary generalized linear models with noncanonical link functions. Biometrical Journal, 58(3):674–690, 2016.
- Hosmer and Hjort (2002) David W. Hosmer and Nils L. Hjort. Goodness-of-fit processes for logistic regression: simulation results. Statistics in Medicine, 21(18):2723–2738, 2002.
- Hosmer and Lemeshow (1980) David W. Hosmer and Stanley Lemeshow. Goodness of fit tests for the multiple logistic regression model. Communications in Statistics - Theory and Methods, 9(10):1043–1069, 1980.
- Hosmer et al. (1997) David W. Hosmer, Trina Hosmer, Saskia Le Cessie, and Stanley Lemeshow. A comparison of goodness-of-fit tests for the logistic regression model. Statistics in Medicine, 16(9):965–980, 1997.
- Lemeshow and Hosmer (1982) Stanley Lemeshow and David W. Hosmer. A review of goodness of fit statistics for use in the development of logistic regression models. American Journal of Epidemiology, 115(1):92–106, 1982.
- Lemeshow et al. (1988) Stanley Lemeshow, Daniel Teres, Jill Spitz Avrunin, and Harris Pastides. Predicting the outcome of intensive care unit patients. Journal of the American Statistical Association, 83(402):348–356, 1988.
- Moore and Spruill (1975) David S. Moore and Marcus C. Spruill. Unified large-sample theory of general chi-squared statistics for tests of fit. The Annals of Statistics, pages 599–616, 1975.
- Stute and Zhu (2002) Winfried Stute and Li-Xing Zhu. Model checks for generalized linear models. Scandinavian Journal of Statistics, 29(3):535–545, 2002.
- Surjanovic et al. (2020) Nikola Surjanovic, Richard Lockhart, and Thomas M. Loughin. A generalized Hosmer-Lemeshow goodness-of-fit test for a family of generalized linear models. arXiv preprint arXiv:2007.11049, 2020.
- Tsiatis (1980) Anastasios A. Tsiatis. A note on a goodness-of-fit test for the logistic regression model. Biometrika, 67(1):250–251, 1980.