Imputation-based randomization tests for randomized experiments with interference
Abstract
The presence of interference renders classic Fisher randomization tests infeasible due to nuisance unknowns. To address this issue, we propose imputing the nuisance unknowns and computing Fisher randomization p-values multiple times, then averaging them. We term this approach the imputation-based randomization test and provide theoretical results on its asymptotic validity. Our method leverages the merits of randomization and the flexibility of the Bayesian framework: for multiple imputations, we can either employ the empirical distribution of observed outcomes to achieve robustness against model mis-specification or utilize a parametric model to incorporate prior information. Simulation results demonstrate that our method effectively controls the type I error rate and significantly enhances the testing power compared to existing randomization tests for randomized experiments with interference. We apply our method to a two-round randomized experiment with multiple treatments and one-way interference, where existing randomization tests exhibit limited power.
1 Introduction
In causal inference, the “no interference” assumption posits that potential outcomes of each unit are unaffected by assignments of other units (Cox,, 1958; Rubin,, 1980). In practice, however, interference does exist in different scenarios. For instance, whether or not other people were vaccinated against COVID-19 can affect your probability of infection. Causal inference in the presence of interference has received much attention in recent years (Rosenbaum,, 2007; Hudgens and Halloran,, 2008; Tchetgen and VanderWeele,, 2012; Liu and Hudgens,, 2014; Loh et al.,, 2020; Imai et al.,, 2021; Yu et al.,, 2022; Leung, 2022a, ; Forastiere et al.,, 2022; Vazquez-Bare,, 2023; Shirani and Bayati,, 2024).
As the golden standard for drawing causal conclusions, randomized experiments provide a solid basis for causal inference and enable Fisher randomization tests (FRTs) exactly valid in finite samples under the assumption of no interference (Fisher,, 1935). In the presence of interference, however, classic FRTs are infeasible since the null hypothesis of interest can no longer impute all potential outcomes certainly. To address this challenge, conditional randomization tests (CRTs) have been proposed to conduct causal inference for a selected subset of units (referred to as the focal units) with respect to a carefully selected subset of treatment assignments (referred to as the focal assignments) instead, so that the null hypothesis is sharp for the conditional cause inference and thus the classic FRT is still applicable (Aronow,, 2012; Athey et al.,, 2018; Basse et al.,, 2019; Puelz et al.,, 2022; Yanagi and Sei,, 2022; Owusu,, 2023; Tiwari and Basu,, 2024; Basse et al.,, 2024; Zhang and Zhao,, 2024). Although CRTs can achieve valid causal inference, they often suffer from severe power loss due to aggressive selection of focal units and assignments in conditioning (Puelz et al.,, 2022). Zhong, (2024) proposed partial null randomization tests (PNRTs), which avoid conditioning on focal assignments by conducting pairwise comparisons of the test statistic between the observed assignment and all possible assignments. This method allows distinct focal unit sets for different assignments, enhancing statistical power. While PNRTs relax the restrictions of CRT, they remain underpowered in challenging cases where the focal unit proportion is low, as demonstrated in our simulations and real data application.
Alternatively, multiple imputation (MI) pioneered by Rubin, (1977, 1978, 1996); Rubin, 2004a ; Rubin, 2004b is another popular approach to handle nuisance unknowns in causal inference, following the Bayesian idea. Examples include imputing compliance status to enable more powerful FRTs with noncompliance (Rubin,, 1998; Lee et al.,, 2017; Forastiere et al.,, 2018), imputing potential outcomes in FRTs for facilitating partially post hoc subgroup analyses (Lee and Rubin,, 2015), handling unspecified factorial effects (Espinosa et al.,, 2016), addressing missing outcomes (Ivanova et al.,, 2022), and managing disruptions (e.g., COVID-19) in clinical trials (Uschner et al.,, 2024). Noticeably, FRT with MI often leads to a posterior predictive p-value (Rubin,, 1984), enabling us to address more complex scenarios in causal inference from the Bayesian perspective (Ding and Guo,, 2023; Leavitt,, 2023; Li et al.,, 2023; Ray and van der Vaart,, 2020; Breunig et al.,, 2022).
In this paper, we follow such an imputation-based idea for implementing FRTs to propose an imputation-based randomization test (IRT) for randomized experiments with interference. Imputing unobserved potential outcomes that cannot be fully specified based on the null hypothesis of interest with respect to an appropriate imputation distribution, we come up with a series of FRT p-values, each of which comes from a FRT corresponding to a specific imputation of the unobserved potential outcomes. A working p-value, referred to as the IRT p-value, can be obtained by averaging these FRT p-values to claim statistical significance of the causal effect of interest. Retaining all units and potential treatment assignments, the proposed IRT is more powerful than CRTs and PNRTs, and can be easily applied to various challenging scenarios with interference. Theoretical analyses show that the proposed IRT controls the type I error rate at most twice the significance level asymptotically when the imputation distribution is properly specified. Furthermore, numerical results show that IRT empirically maintains the type I error rate at the nominal significance level and substantially improves power over existing methods.
2 Preliminaries
2.1 The Potential Outcome Model in Presence of Interference
Consider a finite population with units, to each of which different treatments in the treatment set can be potentially assigned. For simplicity, we mainly consider the simple case with in this study, though our approach can be easily extended to more complicated scenarios where (as demonstrated in the real data application in Section 5). Let be the binary treatment set with as control treatment and 1 as active treatment, and be the indicator of treatment assignment for the -th unit in . The collective treatment assignment for all units is represented by the binary vector . Let be the treatment assignment actually implemented in the randomized experiment. Throughout this study, we always assume that is a random sample from a known randomized design defined over .
In the presence of interference, each unit has a collection of potential outcomes, i.e., , in general, because there could be a total of distinct exposures for each unit in the most general case where interference occurs between any two units. In practice, however, interference typically occurs only among certain units. In this case, the number of distinct exposures for each unit would be much smaller than . In practice, researchers often assume that only a small exposure set is available, with the actual exposure received by unit under treatment assignment vector determined by an exposure mapping . This leads to the assumption of correct exposure mapping as outlined below (Manski,, 2013; Aronow and Samii,, 2017; Hoshino and Yanagi,, 2023). Apparently, the potential outcomes of unit reduce to a much smaller set under such an assumption.
Assumption 1 (Correct exposure mapping).
For all and , if , then we have .
Different exposure mappings define different interference mechanisms. A general framework for establishing an interference mechanism is to introduce an interference network over units of interest where units and are connected (denoted as ) if and only if interference may occur between them, and define
| (1) |
Under such an interference mechanism, we have three types of treatment exposures for each unit , i.e., , where exposure implies that unit itself is assigned to treatment, exposure implies that units is assigned to control while one of its direct neighbors is under treatment, and exposure implies that unit and all its direct neighbors are all under control. Many popular interference mechanisms can be viewed as special cases of this framework. Below are three concrete examples.
Example 1 (Clustered Interference).
Assuming that the units in the finite population of interest are grouped into disjointed clusters (such as villages), and interference occurs solely within clusters, Basse et al., (2019) considered an interference mechanism known as clustered interference where if and only if units and belong to the same cluster.
Example 2 (Spatial Interference).
Assuming that the units of interest are located in a spatial space with being the spatial distance between units and , and interference occurs only between two units whose spatial distance is shorter than a threshold , Puelz et al., (2022) considered an interference mechanism known as spatial interference where if and only if .
Example 3 (No Interference).
In case where there does not exist such that , in Eq. (1) degenerates to for all with , which can be further simplified to and after a rescaling of ’s. In this special case, the exposure unit receives is completely determined by , implying no-interference between units. This setting is a critical component of the stable unit treatment value assumption (SUTVA) proposed by Rubin, (1980).
2.2 Fisher Randomization Test
In case of no interference, a classic problem in a randomized case-control study is to test the sharp null hypothesis of no treatment effect for all units. Following the notation in Example 3,
| (2) |
where and denote the potential outcomes of unit under treatment and control, respectively. Under , define for all and . With the observed outcomes where , is fully observed. Consider a finite-population framework where potential outcomes are fixed quantities, and the only source of randomness is the treatment assignment. The classic difference-in-means test statistic under a treatment assignment is
| (3) |
Because is a fixed vector after the randomization experiment is conducted, the null distribution of is determined by the randomization distribution . Based on these facts, Fisher randomization test (FRT) can be conducted by calculating the p-value below:
| (4) |
where stands for the realized assignment, and is the probability defined by . According to Fisher, (1935), FRT is finite-sample exact in the sense that under ,
Hypothesis is commonly referred to as the sharp null hypothesis, since the reference distribution of the test statistic is fully determined under .
2.3 Conditional and Partial Null Randomization Tests
In presence of interference, however, the situation becomes more complicated. Given the treatment exposure mapping in Eq. (1), we aim to test the null hypothesis on the contrast between any two exposures and in , i.e.,
| (5) |
For example, we are often interested in testing the null hypothesis of no spillover effect, i.e., . Under , define for all and , then the classic difference-in-means test statistic under treatment assignment becomes
| (6) |
where , , , and . is well defined as long as for all .
A critical challenge in testing in a randomized experiment with interference, however, lies in the fact that even under , not all elements of are observable after the experiment is conducted with the realized assignment . To be concrete, define , the partially observed version of can be expressed as
| (7) |
where the question mark ‘’ stands for the missing values. Define . Because only elements of are observable, the null hypothesis is no longer sharp, resulting in an unknown reference distribution of the test statistic under .
To deal with this critical issue, Aronow, (2012) and Athey et al., (2018) proposed conditional randomization tests (CRTs) to substitute the classic FRT that is not applicable in this setting. The main idea is to avoid nuisance unknowns by focusing only on a subset of carefully selected units, referred to as “focal units”, and conducting randomized experiments on them with a randomization distribution restricted to a subset of treatment assignments, referred to as “focal assignments”. This approach ensures that the null hypothesis becomes sharp in the conditional inference. Because the reference distribution of the test statistic with focal units is precisely known conditional on the focal assignments and under the null hypothesis, an FRT-like testing procedure can be conducted. Basse et al., (2019) has shown that CRTs are exact both conditionally and unconditionally under mild conditions. Nonetheless, because CRTs employ only a restrictive subset of treatment assignments on a small subset of units of interest, they often suffer from severe power loss. To mitigate power loss, it is advisable to utilize as large a set of focal units associated with a set of focal assignments as possible, because a larger focal unit set often ensures a higher power, whereas a larger focal assignment set offers a higher resolution in obtaining the p-value. To achieve this, Puelz et al., (2022) proposed the concept of null exposure graph (NEG), which is a bipartite graph between units and assignments with an edge between unit and assignment if and only if unit is exposed to either or under . Encoding the impact of treatment assignments on units in terms of the observability of ’s under a given treatment assignment, NEG offers a way to better select focal units and focal assignments. For example, every biclique in NEG defines a set of appropriate focal units and focal assignments. Such an insight leads to a series of CRTs based on biclique decomposition of NEG, whose efficiency is further improved by Yanagi and Sei, (2022) via power analysis. More recently, Zhong, (2024) expanded the core concept of CRTs into a more general framework named partial null randomization tests (PNRTs), which reports an ensemble p-value by averaging multiple p-values obtained from a series of CRTs. Each CRT utilizes a small focal assignment set comprising only two focal assignments, yet incorporates an enlarged set of focal units including all focal units compatible with the specific pair of focal assignments. In PNRTs, the larger focal unit set of each individual CRT enhances testing power, while the ensemble p-value, obtained through averaging, addresses the issue of extremely low resolution in the individual p-values.
Despite these efforts, randomization tests based on the idea of conditional inference still suffer from diminishing power. For instance, consider a scenario where a high proportion of treatment arises from ethical concerns (e.g., the treatment significantly benefits participants). This typically leads to a high proportion of exposure . If the goal is to test for no spillover effect , the proportion of units with observable potential outcomes under this null hypothesis, , tends to be small for many assignments . This results in a sparse NEG, posing significant challenges in identifying sufficiently large bicliques within the NEG to conduct a randomization test with realistic power.
2.4 Imputation-based p-value for Testing a Complex Null Hypothesis
For a parametric statistical model with as the vector of parameters, consider testing the following complex null hypothesis where is a non-empty subset of the parameter space . Given a collection of independent and identically distributed (i.i.d.) samples from model , researchers often test based on a parameter-dependent test statistics . In case that contains only one element and thus is fully specified under , the p-value for testing can be naturally established as below:
| (8) |
where the probability is derived by random sample . In case that contains more than one element and thus is not fully specified under , the most classic way to establish the p-value for is to find a proper estimate of (e.g., the MLE) first, and then replace the unspecified in (8) by its estimate , resulting in the classic plug-in p-value (PIP) .
From the Bayesian perspective, imputes the unspecified parameter with a point estimation based on the observed data, which is obviously suboptimal. A natural alternative is to impute based on its posterior distribution under . Based on this insight, Meng, (1994) and Gelman et al., (1996) proposed to test by the posterior predictive p-value (PPP) defined as:
| (9) |
where is the posterior distribution of given and a prior distribution defined over . Notably, because typically and both converge to the true parameter as the sample size approaches infinity, the PPP and the PIP often shares the same asymptotical behavior. A key advantage of PPP over PIP is its ability to address uncertainty in specifying via the posterior distribution , which makes the inference procedure more robust.
Many causal inference problems with complicated structures conform to the framework of PPP. For example, Rubin, (1998) utilized PPP to improve the power of FRT in randomized experiments with one-sided noncompliance. Under the null hypothesis of no treatment effect for compliers, the unknown compliance types of units serve as the nuisance parameter , whose value can be imputed based on its posterior predictive distribution under a parametric model with an appropriate prior distribution. Averaging the pristine p-values across the imputed datasets according to Eq. (9), PPP is obtained to summarize the observed evidence against the null hypothesis. Earlier efforts of utilizing multiple imputation based on posterior predictive distribution for Bayesian model checking were summarized in Guttman, (1967) and Rubin, (1981, 1984). In this paper, we aim to utilize the imputation idea to address the unobservable potential outcomes in randomization tests with interference.
3 Imputation-based Randomization Test
3.1 Methodology
Following the spirit of PPP, we propose the following imputation-based randomization test. First, we impute the missing elements of the partially observed according to an imputation distribution to get a complete version of referred to as hereafter, and conduct the classic FRT based on the single imputation for the p-value below:
| (10) |
with the partially observed in Eq. (4) substituted by the fully imputed . Next, we average according to the imputation distribution , which is dependent on the realized assignment and observed outcomes, to get the following ensemble p-value:
| (11) |
and reject if is smaller than a pre-specified significance level . We term the above testing procedure as imputation-based randomization test (IRT). Considering that it’s difficult to calculate exactly because the involved FRT p-values typically have no analytical form, we can approximate via Monte-Carlo simulation, as suggested by Rubin, (1998), after conducting the randomized experiment according to the realized assignment . The algorithm below summarizes the procedure of IRT. Define as the indicator function.
Apparently, the imputation distribution plays an important role in the construction of IRT. Assuming that units in are random samples from a super population with as the marginal density of for , the structure of the hypothesis testing problem defined in Eq. (5) naturally suggests the following strategy to impute , given its observed version : we set for , and we impute with a random sample from for , leading to the oracle imputation distribution
| (12) |
where is the Dirac delta function. We refer to the IRT based on as IRTo.
In practice, however, it’s often the case that distribution is unknown and needs to be estimated based on the observed subset in , namely according to Eq. (7). Let be the estimated marginal distribution of , we get the following imputation distribution in action:
| (13) |
When distribution has a parametric form with as the model parameters, we can learn from by inferring its parameter in either frequentist or Bayesian manner. We term this version of IRT as IRTp.
If no appropriate parametric model is available, we can estimate via non-parametric approaches instead. For example, we can approximate the unknown by the empirical distribution of the observed potential outcomes , i.e.,
| (14) |
Alternatively, when is known to be a continuous distribution, we can rely on the smoothed version of the empirical distribution instead as suggested by van der Vaart, (1994), i.e.,
| (15) |
where is a symmetric kernel function with bandwidth satisfying , , and . We refer to the IRTs based on and as IRTe and as IRTs, respectively.
3.2 Theoretical Results
In this section, we present the theoretical results for IRT under the null hypothesis in Eq. (5), when the oracle imputation distribution is precisely known or needs to be estimated based on the observables. Some of the results are closely related to the results for PPP in Meng, (1994). A critical difference between IRT and PPP, however, is that the imputation distribution in IRT would not converge to a point mass, as in the classic PPP, with the increase of sample size. Such a fact leads to some unique issues in the theoretical analysis of IRT, making it non-trivial to establish the validity of IRT. First, we start with the simple case where IRT is conducted with the oracle imputation distribution, i.e., IRTo.
Theorem 1.
Assume that (i) the null hypothesis in Eq. (5) holds with , (ii) are i.i.d. samples from distribution with probability density , (iii) , and (iv) the imputation of is according to the oracle imputation distribution as defined in Eq. (12). Then is stochastically less variable than a uniform distribution but with the same mean, which means that: (i) , and (ii) for all convex functions on , where is a random sample from the uniform distribution on , the expectation is taken with respect to the joint distribution of , and is taken with respect to .
Theorem 1 shows that IRTo is more centered around than when the null hypothesis holds. The proof is detailed in the Supplementary Material. The theorem immediately leads to the following corollary based on Lemma 1 in Meng, (1994).
Corollary 1.
Corollary 1 ensures that IRTo can control the type I error rate at most twice the significance level, i.e., , a result that is well-known for PPP. Although such a result cannot be further improved to more positive forms from the theoretical perspective, e.g., for all , according to the counterexample in Dahl, (2006), our empirical studies in Sections 4 and 5 show that the type I error rate of IRTo and its extensions are often well controlled at . Interestingly, such a phenomenon also occurs in other model-free, finite-sample exact inference methods, such as cross-conformal prediction, jackknife+, and CV+ (Vovk et al.,, 2018; Vovk and Wang,, 2020; Barber et al.,, 2021; Guan,, 2024). For instance, Barber et al., (2021) recommended the jackknife+ prediction interval for its typical empirical coverage of , although theoretically, it can only guarantee coverage due to certain pathological cases. These practices provide extra support for the application of IRT.
Next, we focus on the more challenging cases where IRT is conducted with the estimated imputation distribution as shown in Eq. (13). Define
as the ensemble p-value difference between the two versions of IRT with the estimated and oracle imputation distributions. Intuitively, if the distribution of , which is determined by the joint distribution of , concentrates at 0, the IRT under the estimated imputation distribution will closely resemble IRTo with similar properties. The following lemma provides a positive answer to the above intuition, ensuring that if converges to 0 in probability, the asymptotic type I error rate of IRT with the corresponding estimated imputation distribution is also bounded by twice the significance level.
Lemma 1.
Denote the sampling distribution of derived by as , and the corresponding probability mass function (p.m.f.) as
| (17) |
where is defined over . The following theorem provides sufficient conditions under which , and thus Eq. (16) holds.
Theorem 2.
Under the same assumptions in Lemma 1, if and correspond to continuous distributions, a sufficient condition for , and thus Eq. (16), is
| (18) |
where is the expectation taken with respect to i.i.d. with probability density function , and . If and correspond to discrete distributions with corresponding p.m.f. p and , the sufficient condition is
| (19) |
where is the expectation taken with respect to i.i.d. with probability density function , and .
The above sufficient conditions imply that when the likelihood ratio between the estimated distribution and the true distribution on the unobservables converges to 1 in , IRT with the estimated imputation distribution will exhibit similar performance as IRTo, whose behavior has been established previously. The corollary below shows that in a simple case where represents a normal distribution with known variance, the sufficient conditions can be theoretically validated under specific conditions.
Corollary 2.
Under the same assumptions in Lemma 1, let be i.i.d. samples from with known variance and unknown mean . Suppose the sampling distribution of is a point mass distribution, so that the missing rate of nuisance parameters, defined as , is a constant depending on . If we estimate the unknown density with its posterior predictive distribution , given the observed outcomes and a normal prior for , then (16) holds when .
For more complex cases, theoretical verification of the sufficient conditions in Theorem 2 becomes challenging, but can be approximated by numerical verification when converges to 0 at a sufficiently fast rate, e.g., . Further details are provided in the Supplementary Material.
4 Simulations
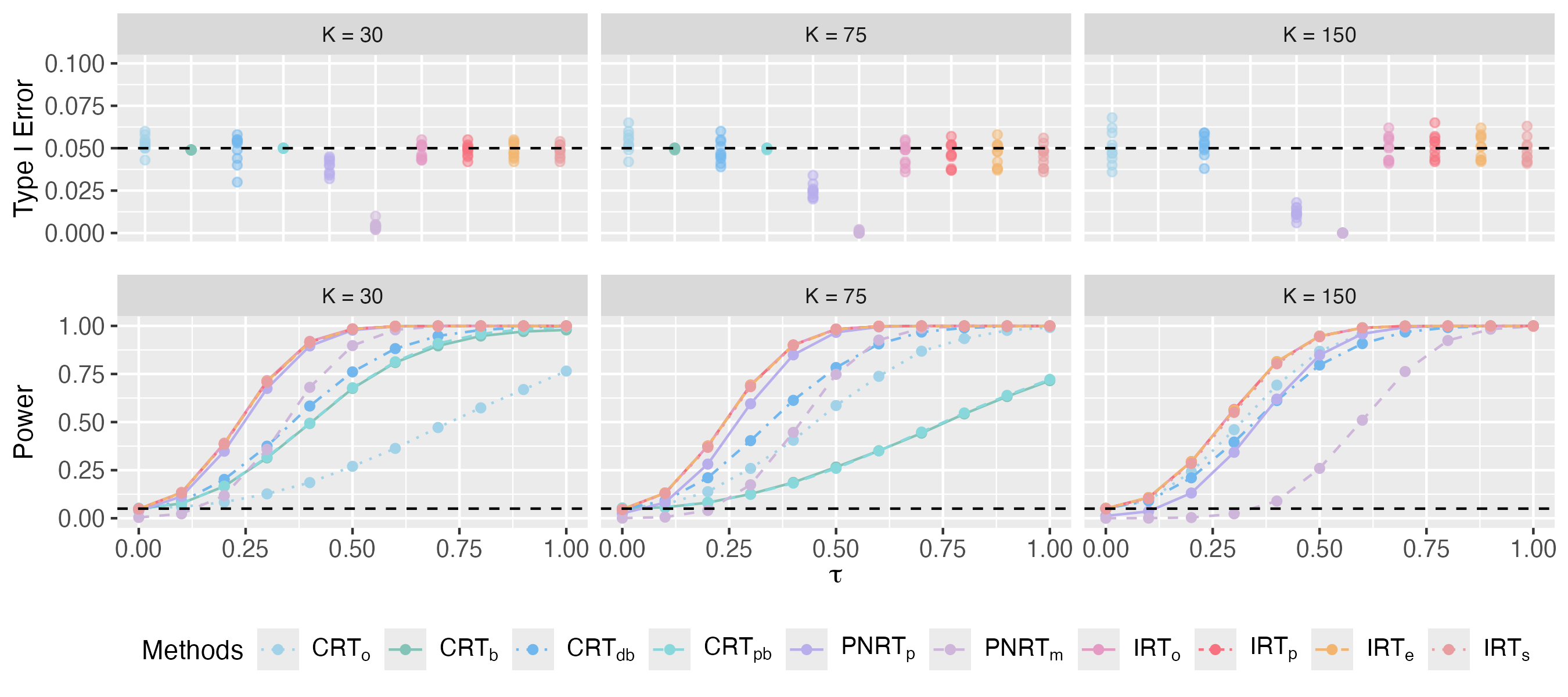
4.1 Clustered Interference
In this section, we examine the proposed method under various interference mechanisms via simulation. First, we consider the clustered interference as defined in Example 1. For a group of units equally divided into clusters, we are interested in testing the null hypothesis of no spillover effect . Since the potential outcome is irrelevant to our interest, we only generate potential outcomes and by
| (20) |
where . To identify the spillover effect under clustered interference, we consider the two-stage randomized experiment suggested by Hudgens and Halloran, (2008), where we randomly assign clusters to the treatment group and the remaining clusters to the control group in the first stage, and then randomly select one unit from each cluster in the treatment group to receive the treatment in the second stage with all the other units untreated. For each of the configurations of , we generate 10 independent datasets according to the data simulation model in Eq. (20). For each simulated dataset with a specific set of potential outcomes, we conduct 1,000 parallel randomized experiments with the treatment assignment randomly specified based on the randomized design according to the two-stage experiment.
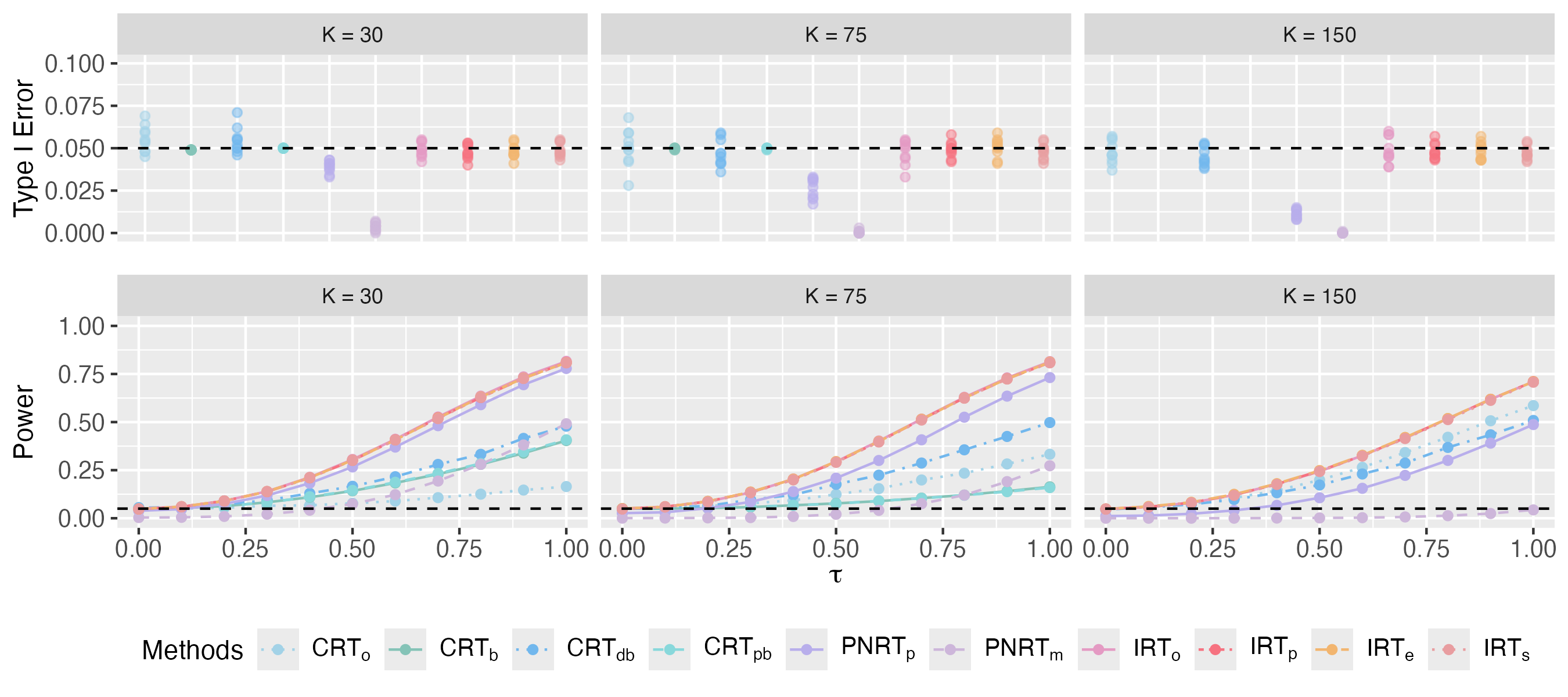
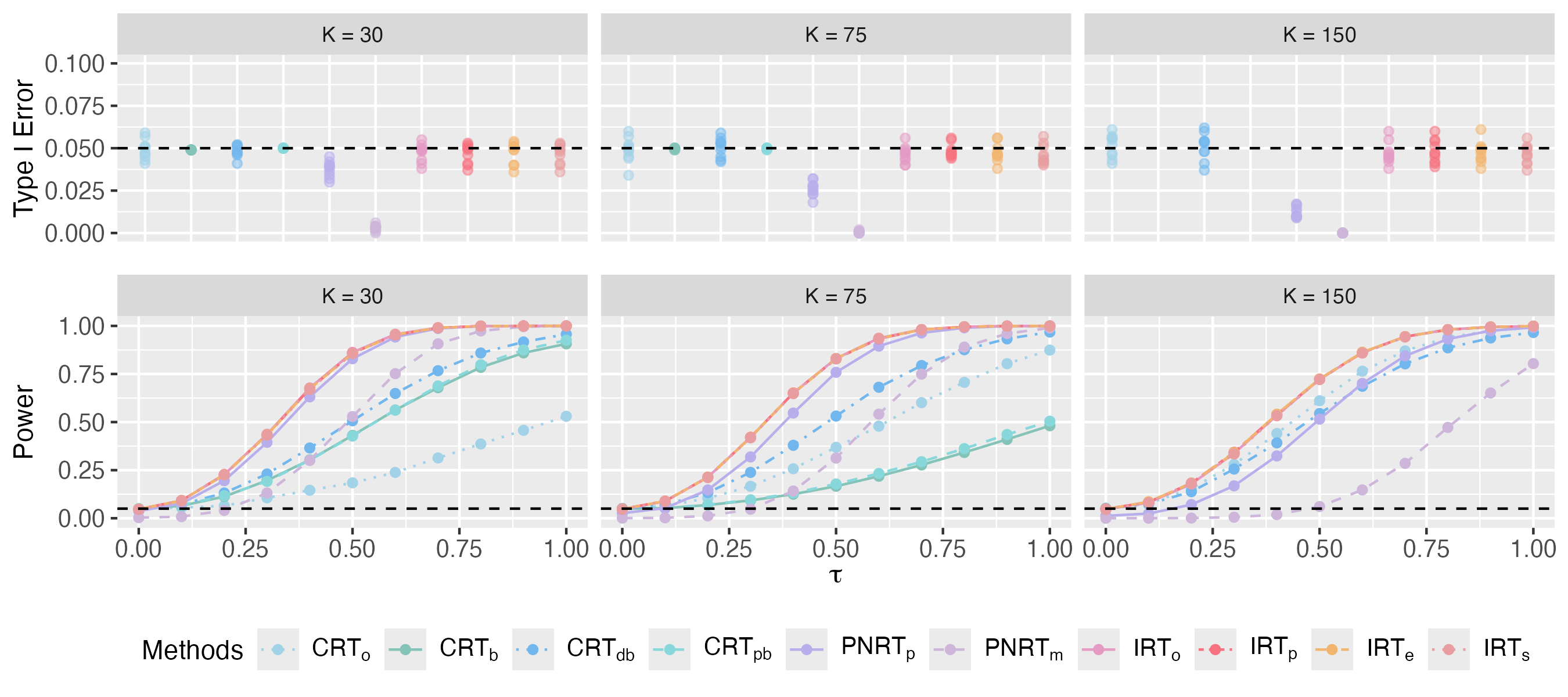
Using the difference-in-means in Eq. (6) as the test statistic with the significance level to reject the null hypothesis set to , we compare the proposed IRT methods, including IRTo, IRTp, IRTe and IRTs, to a group of CRT methods with focal units and assignments selected by various algorithms (including CRTo, CRTb, CRTdb and CRTpb) and two PNRT methods (namely PNRTp and PNRTm). Detailed configurations of the 10 involved competing methods can be found in Table 1. For each of these competing randomization tests, we measure its type I error rate via simulated datasets with , and power via simulated datasets with .
| Methods | Description | Interference Type | |
| Clustered | Spatial | ||
| CRTo | CRT with one focal unit per cluster (Basse et al.,, 2019) | ✓ | ✗ |
| CRTb | CRT with general biclique decomposition (Puelz et al.,, 2022) | ✓ | ✓ |
| CRTdb | CRT with design-assisted biclique decomposition (Puelz et al.,, 2022) | ✓ | ✗ |
| CRTpb | CRT with power-analysis-assisted biclique decomposition (Yanagi and Sei,, 2022) | ✓ | ✓ |
| PNRTp | The pairwise comparison-based PNRT (Zhong,, 2024) | ✓ | ✓ |
| PNRTm | The minimization-based PNRT (Zhong,, 2024) | ✓ | ✓ |
| IRTo | IRT imputed with the oracle distribution | ✓ | ✓ |
| IRTp | IRT imputed with a parametric model | ✓ | ✓ |
| IRTe | IRT imputed with the empirical distribution | ✓ | ✓ |
| IRTs | IRT imputed with a smooth kernel density function | ✓ | ✓ |
We present the type I error rate across 10 datasets and the average power of the 10 competing methods in Fig. 1. For cases where , however, the results of CRTb and CRTpb are absent because these two methods become infeasible in these cases. When , the average missing rate of reaches up to 25%, leading to a null exposure graph with a density lower than 0.75. Consequently, it is impractical to find a biclique decomposition that meets the minimum size requirements established by Puelz et al., (2022) and Yanagi and Sei, (2022), which specify at least 20 focal assignments and 20 focal units, rendering CRTb and CRTpb infeasible. From the results, we make the following observations. First, while IRT and CRT methods successfully control the type I error rate around 0.05 across all 10 datasets, the two PNRT methods fail to do so and tend to yield type I error rates that are much smaller than 0.05 in all cases. Although our theory guarantees only a bound of the type I error rate for IRT methods asymptotically, these simulation results suggest that IRT can often successfully control the type I error rate below in practice. Second, the IRT methods demonstrate significantly higher power than CRT and PNRT methods across all cases, especially for cases with a large number of clusters . Although CRTo and CRTdb also yield competitively high power in these cases, they are specifically designed for clustered interference only and can not be extended to other settings. Third, the IRT methods based on estimated distribution – namely IRTe, IRTp and IRTs – exhibit performance similar to IRTo, even though the missing rate of nuisance parameters is far from 0. These results confirm that the proposed IRTs are powerful tools for casual inference in presence of cluster interference.
Additional experiments where values are generated from heavier tail distributions, such as or distributions, but still modeled as a normal distribution, are reported in the Supplementary Materials, showing that IRTp is robust to model mis-specification.
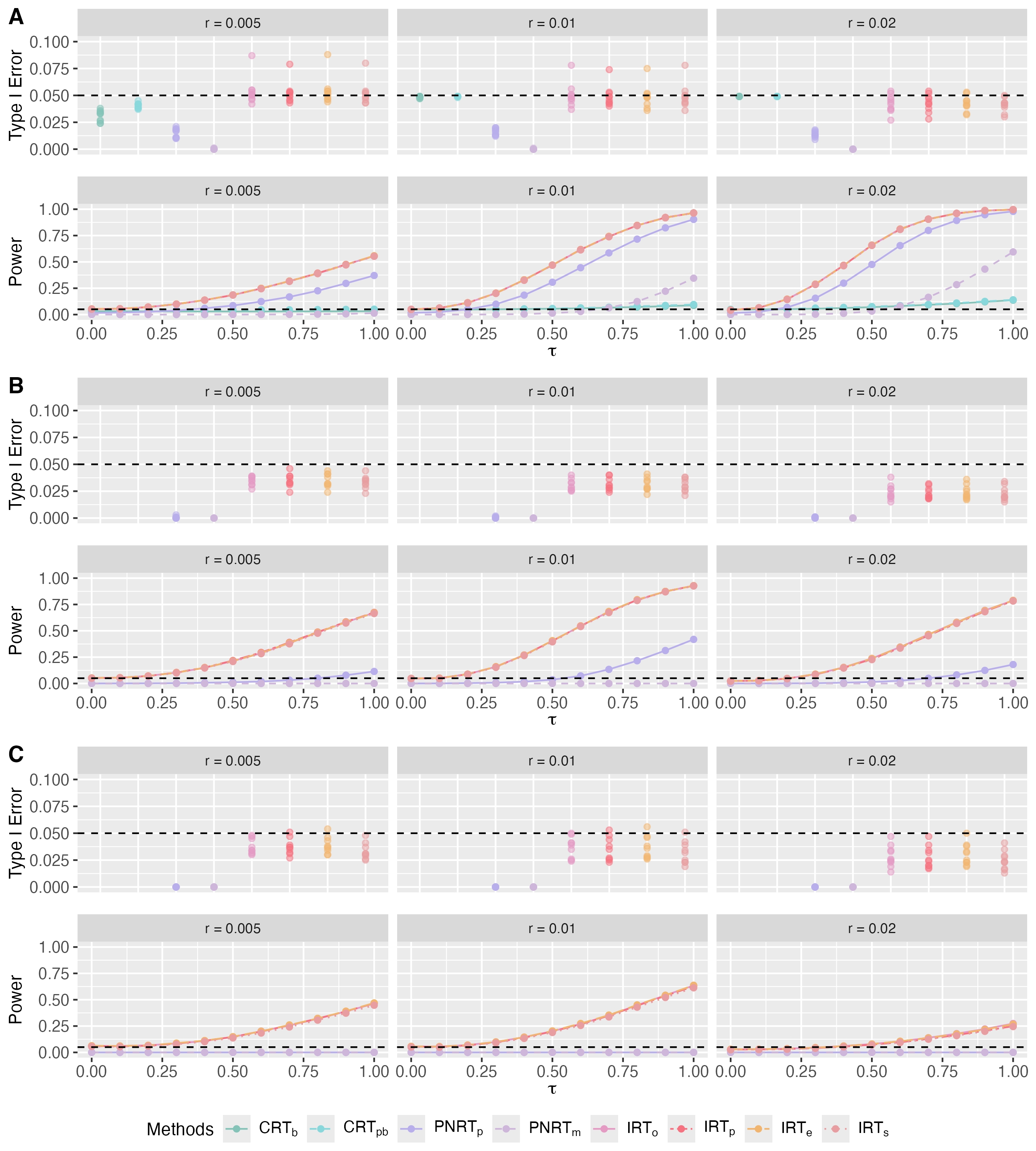
4.2 Spatial Interference
Next, we consider the spatial interference as defined in Example 2. For a group of units with spatial interference, the potential outcomes are simulated according to Eq. (20). We adopt the similar setting as in Yanagi and Sei, (2022) to specify the interference mechanism: each unit is associated with a 2-dimensional coordinate according to
where denotes the identity matrix, and allow interference to occur between two unit and if and only if their Euclidean distance , with the distance of interference . For each configuration of , we generate 10 independent datasets of sample size according to Eq. (20). For each simulated dataset, the treatment assignment is sampled randomly for 1,000 times according to an independent Bernoulli trial where for with .
Using the difference-in-means in Eq. (6) as the test statistic, we aim to test the null hypothesis of no spillover effect, i.e., , with a significance level of . The type I error rate and average power across 10 datasets for the methods described in Section 4.1 are measured for comparison. The results are presented in Fig. 2, where CRTo and CRTdb are not included due to their inapplicability under spatial interference. In this figure, subfigures A, B, and C depict the type I error rate and power for , , and , respectively. For and , the results of CRTb and CRTpb are absent due to the high average missing rate of nuisance parameters, which can reach up to 50% and 80%.
These results show that the proposed IRTs outperform existing methods significantly under spatial interference as well as under clustered interference. First, the proposed IRT methods effectively control the type I error rate and exhibit significantly higher power compared to CRTs and PNRTs, especially in the case of , where CRTs are not applicable and PNRTs have almost no power at all. Second, similar to the results under clustered interference, the other IRT methods exhibit similar performance to IRTo even with a large missing rate of nuisance parameters. Additional results for generated from and are detailed in the Supplementary Material, which show that IRT methods remain robust across different distributions in the case of spatial interference as well.
Because all simulation results show that IRTs based on different estimated imputation distributions perform similarly to IRTo, we recommend using IRTe in practice for its ease of implementation and independence from additional assumptions for the marginal distribution of .
5 Real Data Application
5.1 The Insurance Purchase Data
We re-analyze the insurance purchase data collected from a two-round randomized experiment with multiple treatments conducted by Cai et al., (2015) to study the influence of social network among farmers on their decisions to purchase a new weather insurance product. In this experiment, households of rice farmers were randomly assigned to the first or the second rounds of insurance introduction sessions. The households assigned to both rounds were randomized to receive either a simple or an intensive introduction to the insurance product. The households assigned to the second round, however, were further divided into three random groups and informed additional information about the purchase decisions of the first-round in three different ways: no additional information at all (NoInfo), summary information in terms of the overall purchase rate (Overall), or detailed information on concrete purchase decisions of all households in the first round (Indiv). At the end, all involved households were randomized into treatment groups, as summarized in Fig 3. A stratified randomized experiment was conducted to randomly assign the 8 treatments to households.
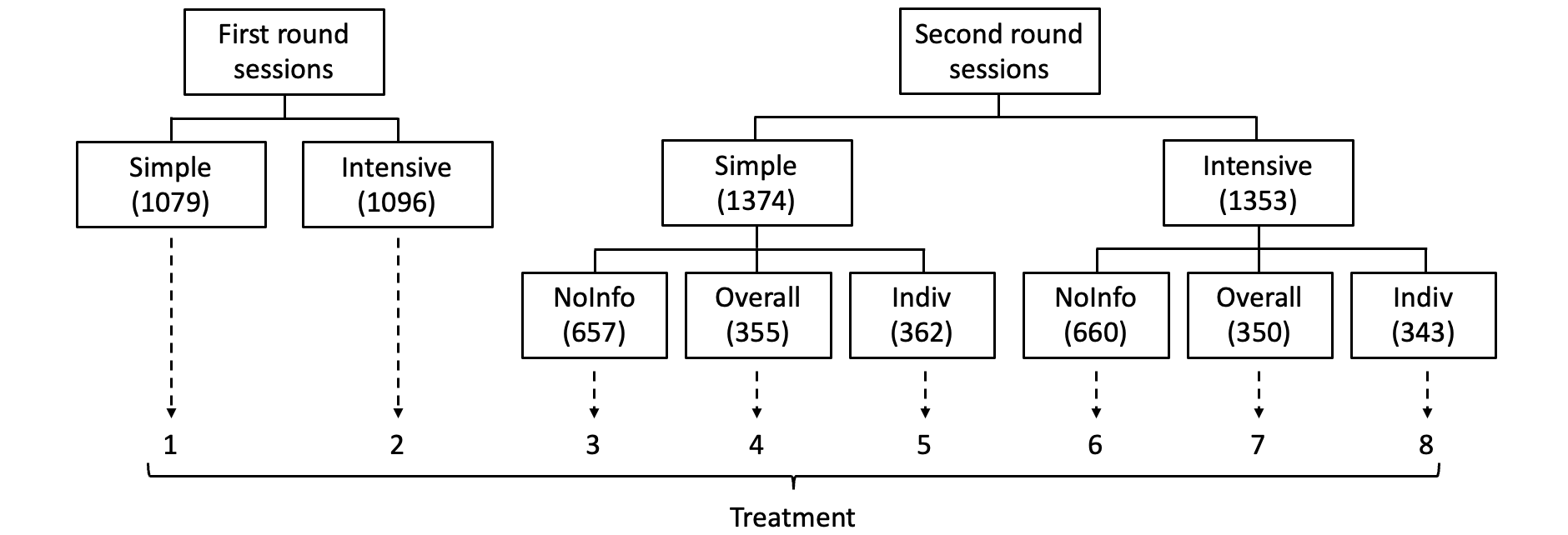
Households were asked to make a purchase decision immediately after the insurance introduction sessions, making sure that there was no interference between households in the same round. However, there was a 3-day gap between the two rounds to allow households from the first round to personally discuss the insurance with their friends in the second round, implying a one-way interference from the first round to the second round. The social network of the 4,902 households was known in the experiment. Let be the adjacent matrix of the social network. We have if two households and are friends, and otherwise. The purchase decisions of all households, i.e., ’s, were recorded as the output of the experiment, where if household made purchase and otherwise.
5.2 Testing the Spillover Effect by IRTs
Containing rich ingredients, the insurance purchase data can be analyzed in different ways to answer different scientific questions. Here, we are interested in testing the spillover effect from the first-round households to the second-round households. To be concrete, let be the households of interest, be the treatment set showed in Fig. 3, be the observed treatment assignment of household and . Due to the possible interference between households through their social network, a household assigned to treatment may receive distinct exposures depending on how much prior information its friend households can bring to it before treatment: if some of its friend households get access to the intensive introduction of the insurance product a priori in the first stage, treatment would be conducted with strong prior information, leading to exposure ; if some of its friend households get access to the simple introduction a priori only, treatment would be conducted with weak prior information, leading to exposure ; if none of its friend households get access to the simple or intensive introduction a priori, treatment would be conducted with no prior information at all, leading to exposure . Although we allow insurance content to spill over through social networks, for simplicity, we assume that households cannot obtain information about the first-round purchase decisions from social networks; they can only obtain this information from the experimenter as intended. Based on these insights, we work on the following exposure mapping from to exposure set :
| (21) |
where indicator takes value in set highlighting the level of prior information household receives before treatment. Note that because ’s are fully determined by the treatment assignment and the social network of the households, in Eq. (21) is a well defined exposure mapping.
For treatment , we consider testing the following null hypothesis of no spillover effect, which is the contrast between and within treatment group :
| (22) |
For this purpose, we use the difference-in-means between the exposure group and the exposure group as the estimator of the spillover effect and the test statistic for testing for treatment , and establish two-sided p-value of the test via various randomization tests. For IRTs, we consider IRTe and IRTp with the following Beta-Binomial model for ’s: , For PNRTs, we try both PNRTp and PNRTm under the default setting. For CRTs, however, we find that all members in this method family are not applicable to this real data example: CRTo and CRTdb cannot be applied to two-round experiments with multiple treatments and one-way interference, and CRTb and CRTpb are infeasible because the low density (e.g., 0.107 when ) of the null exposure graph makes the biclique decomposition infeasible. Therefore, we only compare the performance of IRTe and IRTp versus PNRTp and PNRTm here.
| Treatment | Estimated | p-values reported by different randomization tests | ||||
| spillover effect | CRT | PNRTp | PNRTm | IRTe | IRTp | |
| 1 | -0.009 | 0.560 | 1.000 | 0.805 | 0.796 | |
| 2 | -0.019 | 0.470 | 1.000 | 0.600 | 0.593 | |
| \cdashline1-7 3 | 0.133 | 0.423 | 1.000 | 0.002 | 0.006 | |
| 4 | -0.022 | 0.590 | 1.000 | 0.739 | 0.749 | |
| 5 | 0.113 | 0.503 | 1.000 | 0.085 | 0.080 | |
| 6 | 0.011 | 0.564 | 1.000 | 0.795 | 0.829 | |
| 7 | 0.138 | 0.504 | 1.000 | 0.038 | 0.035 | |
| 8 | 0.128 | 0.510 | 1.000 | 0.048 | 0.059 | |
Table 2 summarizes the spillover effect for and the corresponding p-values obtained by different methods. From the table, we can see the following facts. First, IRTs, as well as PNRTs, suggest that spillover effects are not significant for treatment and , which is consistent with the domain knowledge of no interference within the same round. Second, both IRT methods reveal significant spillover effects for treatment 3 and treatment 7, although only the spillover effect for treatment 3 is significant after considering the Bonferroni adjustment for multiple testing. Since households in the treatment 3 group received only a simple introduction with no additional information on the purchase decision in the first round, it’s reasonable that leaked information from the social network would significantly influence their purchase decision. However, both PNRT methods miss these signals, with all p-values from PNRTm far from 0.05.
5.3 Simulation Based on Real Data
To further assess the performance of the proposed methods in practice, we train a predictive regression model for the potential outcomes based on the real data and generate simulated data from the fitted model for performance evaluation and comparison. To achieve this goal, we select 9 relevant covariates of the households according to Cai et al., (2015) as predictors to build a logistic regression model for the binary potential outcomes, resulting in a covariate matrix . Because 6 of the 9 columns in have missing values, we would like to impute these missing values for convenient model training and data simulation. Here, we follow the strategy suggested by Zhao and Ding, (2024) to impute all missing values in with 0, and include the binary missing data indicators (1 for missing elements and 0 otherwise) of the 6 incomplete covariates as additional covariates, resulting in an extra covariate matrix . Moreover, dummy variables recording actual exposures received by households in the experiment, i.e., , are also included in the model as covariates, where if household received exposure in the experiment. With these covariates, we fit the logistic model for the observed outcomes as our base model for data generation: Simulation datasets can be generated based on the above base model to evaluate the performance of various methods for testing spillover effects. For illustrative purpose, we focus on testing with , which examines the spillover effect between exposures and . To be specific, let coef and coef be the coefficients of dummy variables and obtained in the fitted base model, and be their difference. We modify the base model by resetting coef coef for some , and generate potential outcomes and of the same sample size as the original experiment according to the modified model. If , coef coef in the modified model, and holds; if , fails. Here, we adjust to align the differences in means of the generated and (denoted as ) to eight different values, ranging from 0 to 0.27, to simulate scenarios with varying signal strengths.
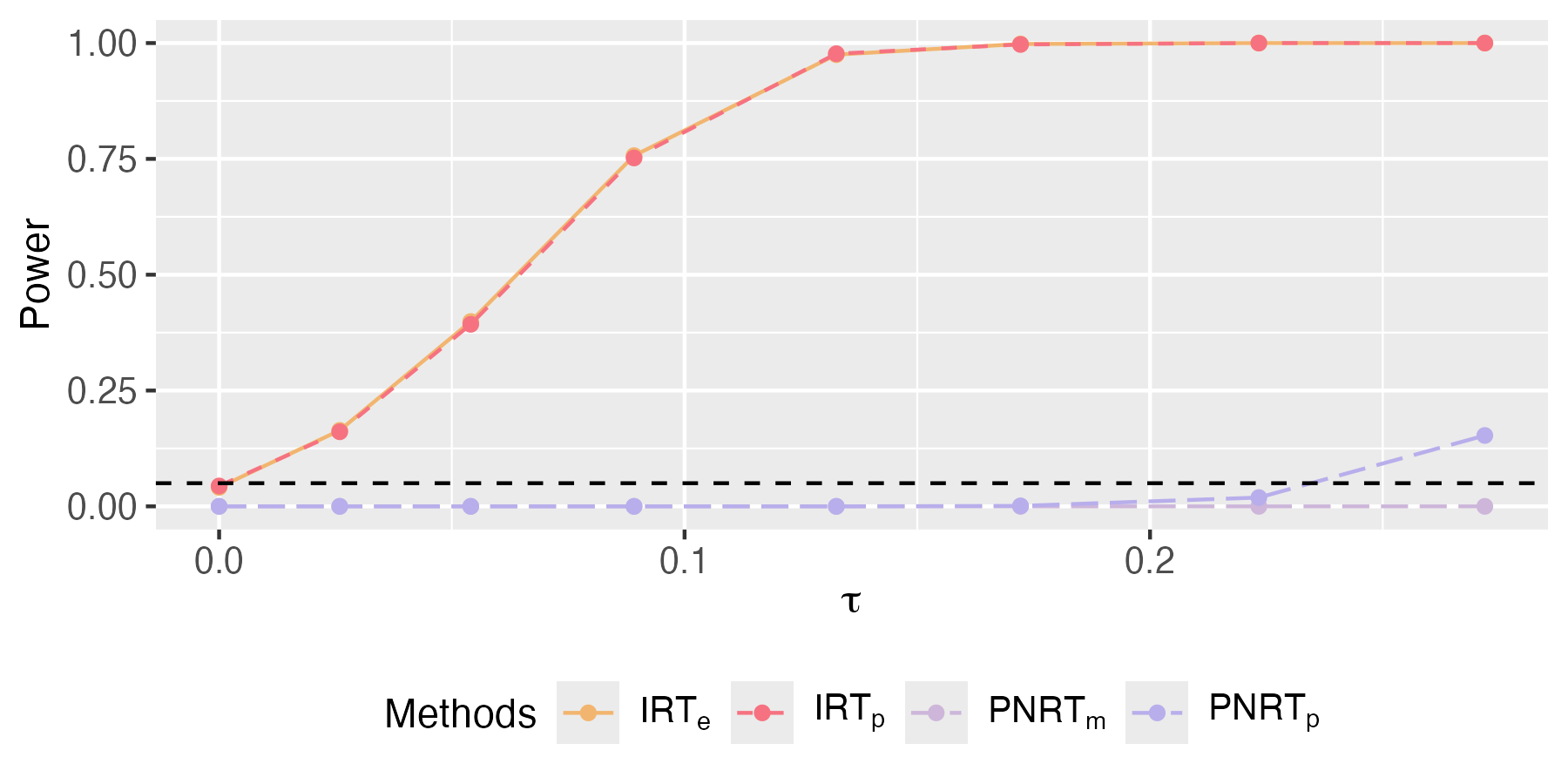
We apply PNRTp, PNRTm, IRTe, and IRTp to this simulated dataset, and visualize their type I error rate (for cases with ) and power (for cases with ) in Fig. 4. The results indicate that IRTs can effectively control the type I error rate and has high power to detect spillover effects, while PNRTs have almost no power at all.
6 Discussion
In this paper, we proposed the IRT method, which imputes unknown nuisance parameters and computes the average of pristine p-values. Theoretically, this method can bound the type I error rate at twice the significance level asymptotically when the missing rate of nuisance parameters converges to 0 in probability. Simulation results show that even when the missing rate of nuisance parameters is relatively high, the IRT method demonstrates good empirical control of type I error rate. Compared to CRTs and PNRTs, IRT methods significantly improve power and maintain robust performance regardless of the true distribution, particularly when the proportion of imputable outcomes under the null hypothesis is small. Overall, we recommend IRTe, which imputes unknowns using the empirical distribution of the observed nuisance parameters, as it is easy to implement and free from the model specification.
Our IRT framework could be extended in the following directions. First, covariates could be incorporated into IRT to further improve power, including using covariate information and machine learning methods to impute unobserved potential outcomes, and employing covariate-adjusted test statistics (Zhao and Ding,, 2024). Second, studentized test statistics could be used to construct asymptotic valid tests for weak null hypotheses (Wu and Ding,, 2021; Cohen and Fogarty,, 2022). Third, we could construct randomization-based confidence intervals by extending the analytical inversion approach of FRT to IRT (Zhu and Liu,, 2023; Fiksel,, 2024). Finally, the IRT framework could be applied to other complex network experiments and complex interference structures (Basse and Airoldi,, 2018; Leung, 2022b, ; Airoldi and Christakis,, 2024; Liu et al.,, 2024).
7 Funding
This work was supported by the National Natural Science Foundation of China (12371269 & 12071242).
Supplementary Material
Supplementary Material available online includes proofs and additional simulation results. An R package implementing the proposed methods is available at https://github.com/htx113/imprt.
References
- Airoldi and Christakis, (2024) Airoldi, E. M. and Christakis, N. A. (2024). Induction of social contagion for diverse outcomes in structured experiments in isolated villages. Science, 384(6695):eadi5147.
- Aronow, (2012) Aronow, P. M. (2012). A general method for detecting interference between units in randomized experiments. Sociological Methods & Research, 41(1):3–16.
- Aronow and Samii, (2017) Aronow, P. M. and Samii, C. (2017). Estimating average causal effects under general interference, with application to a social network experiment. The Annals of Applied Statistics, 11(4):1912 – 1947.
- Athey et al., (2018) Athey, S., Eckles, D., and Imbens, G. W. (2018). Exact p-values for network interference. Journal of the American Statistical Association, 113(521):230–240.
- Barber et al., (2021) Barber, R. F., Candes, E. J., Ramdas, A., and Tibshirani, R. J. (2021). Predictive inference with the jackknife+. The Annals of Statistics, 49(1):486–507.
- Basse et al., (2024) Basse, G., Ding, P., Feller, A., and Toulis, P. (2024). Randomization tests for peer effects in group formation experiments. Econometrica, 92(2):567–590.
- Basse and Airoldi, (2018) Basse, G. W. and Airoldi, E. M. (2018). Model-assisted design of experiments in the presence of network-correlated outcomes. Biometrika, 105(4):849–858.
- Basse et al., (2019) Basse, G. W., Feller, A., and Toulis, P. (2019). Randomization tests of causal effects under interference. Biometrika, 106(2):487–494.
- Breunig et al., (2022) Breunig, C., Liu, R., and Yu, Z. (2022). Double robust Bayesian inference on average treatment effects. arXiv preprint, arXiv:2211.16298.
- Cai et al., (2015) Cai, J., Janvry, A. D., and Sadoulet, E. (2015). Social networks and the decision to insure. American Economic Journal: Applied Economics, 7(2):81–108.
- Cohen and Fogarty, (2022) Cohen, P. L. and Fogarty, C. B. (2022). Gaussian prepivoting for finite population causal inference. Journal of the Royal Statistical Society Series B: Statistical Methodology, 84(2):295–320.
- Cox, (1958) Cox, D. R. (1958). Planning of Experiments. New York: John Wiley & Sons.
- Dahl, (2006) Dahl, F. A. (2006). On the conservativeness of posterior predictive p-values. Statistics & Probability Letters, 76(11):1170–1174.
- Ding and Guo, (2023) Ding, P. and Guo, T. (2023). Posterior predictive propensity scores and p-values. Observational Studies, 9(1):3–18.
- Espinosa et al., (2016) Espinosa, V., Dasgupta, T., and Rubin, D. B. (2016). A Bayesian perspective on the analysis of unreplicated factorial experiments using potential outcomes. Technometrics, 58(1):62–73.
- Fiksel, (2024) Fiksel, J. (2024). On exact randomization-based covariate-adjusted confidence intervals. Biometrics, 80(2):ujae051.
- Fisher, (1935) Fisher, R. A. (1935). The Design of Experiments. Oliver and Boyd, Edinburgh, London, 1st edition edition.
- Forastiere et al., (2018) Forastiere, L., Mealli, F., and Miratrix, L. (2018). Posterior predictive p-values with Fisher randomization tests in noncompliance settings: Test statistics vs discrepancy measures. Bayesian Analysis, 13(3):681 – 701.
- Forastiere et al., (2022) Forastiere, L., Mealli, F., Wu, A., and Airoldi, E. M. (2022). Estimating causal effects under network interference with Bayesian generalized propensity scores. Journal of Machine Learning Research, 23(289):1–61.
- Gelman et al., (1996) Gelman, A., Meng, X.-L., and Stern, H. (1996). Posterior predictive assessment of model fitness via realized discrepancies. Statistica Sinica, 6:733–760.
- Guan, (2024) Guan, L. (2024). A conformal test of linear models via permutation-augmented regressions. The Annals of Statistics, in press.
- Guttman, (1967) Guttman, I. (1967). The use of the concept of a future observation in goodness-of-fit problems. Journal of the Royal Statistical Society: Series B (Methodological), 29(1):83–100.
- Hoshino and Yanagi, (2023) Hoshino, T. and Yanagi, T. (2023). Randomization test for the specification of interference structure. arXiv preprint, arXiv:2301.05580.
- Hudgens and Halloran, (2008) Hudgens, M. G. and Halloran, M. E. (2008). Toward causal inference with interference. Journal of the American Statistical Association, 103(482):832–842.
- Imai et al., (2021) Imai, K., Jiang, Z., and Malani, A. (2021). Causal inference with interference and noncompliance in two-stage randomized experiments. Journal of the American Statistical Association, 116(534):632–644.
- Ivanova et al., (2022) Ivanova, A., Lederman, S., Stark, P. B., Sullivan, G., and Vaughn, B. (2022). Randomization tests in clinical trials with multiple imputation for handling missing data. Journal of Biopharmaceutical Statistics, 32(3):441–449.
- Leavitt, (2023) Leavitt, T. (2023). Randomization-based, Bayesian inference of causal effects. Journal of Causal Inference, 11(1):20220025.
- Lee et al., (2017) Lee, J. J., Forastiere, L., Miratrix, L., and Pillai, N. S. (2017). More powerful multiple testing in randomized experiments with non-compliance. Statistica Sinica, 27:1319–1345.
- Lee and Rubin, (2015) Lee, J. J. and Rubin, D. B. (2015). Valid randomization-based p-values for partially post hoc subgroup analyses. Statistics in Medicine, 34(24):3214–3222.
- (30) Leung, M. P. (2022a). Causal inference under approximate neighborhood interference. Econometrica, 90(1):267–293.
- (31) Leung, M. P. (2022b). Rate-optimal cluster-randomized designs for spatial interference. The Annals of Statistics, 50(5):3064–3087.
- Li et al., (2023) Li, F., Ding, P., and Mealli, F. (2023). Bayesian causal inference: a critical review. Philosophical Transactions of the Royal Society A, 381(2247):20220153.
- Liu and Hudgens, (2014) Liu, L. and Hudgens, M. G. (2014). Large sample randomization inference of causal effects in the presence of interference. Journal of the American Statistical Association, 109(505):288–301.
- Liu et al., (2024) Liu, Y., Zhou, Y., Li, P., and Hu, F. (2024). Cluster-adaptive network a/b testing: From randomization to estimation. Journal of Machine Learning Research, 25(170):1–48.
- Loh et al., (2020) Loh, W. W., Hudgens, M. G., Clemens, J. D., Ali, M., and Emch, M. E. (2020). Randomization inference with general interference and censoring. Biometrics, 76(1):235–245.
- Manski, (2013) Manski, C. F. (2013). Identification of treatment response with social interactions. The Econometrics Journal, 16(1):S1–S23.
- Meng, (1994) Meng, X.-L. (1994). Posterior predictive -values. The Annals of Statistics, 22(3):1142–1160.
- Owusu, (2023) Owusu, J. (2023). Randomization inference of heterogeneous treatment effects under network interference. arXiv preprint, arXiv:2308.00202.
- Puelz et al., (2022) Puelz, D., Basse, G., Feller, A., and Toulis, P. (2022). A graph-theoretic approach to randomization tests of causal effects under general interference. Journal of the Royal Statistical Society Series B: Statistical Methodology, 84(1):174–204.
- Ray and van der Vaart, (2020) Ray, K. and van der Vaart, A. (2020). Semiparametric Bayesian causal inference. The Annals of Statistics, 48(5):2999–3020.
- Rosenbaum, (2007) Rosenbaum, P. R. (2007). Interference between units in randomized experiments. Journal of the American Statistical Association, 102(477):191–200.
- Rubin, (1977) Rubin, D. B. (1977). Formalizing subjective notions about the effect of nonrespondents in sample surveys. Journal of the American Statistical Association, 72(359):538–543.
- Rubin, (1978) Rubin, D. B. (1978). Multiple imputations in sample surveys-a phenomenological Bayesian approach to nonresponse. In Proceedings of the Survey Research Methods Section of the American Statistical Association, volume 1, pages 20–34. American Statistical Association Alexandria, VA.
- Rubin, (1980) Rubin, D. B. (1980). Randomization analysis of experimental data: The Fisher randomization test comment. Journal of the American Statistical Association, 75(371):591–593.
- Rubin, (1981) Rubin, D. B. (1981). Estimation in parallel randomized experiments. Journal of Educational Statistics, 6(4):377–401.
- Rubin, (1984) Rubin, D. B. (1984). Bayesianly justifiable and relevant frequency calculations for the applied statistician. The Annals of Statistics, 12(4):1151–1172.
- Rubin, (1996) Rubin, D. B. (1996). Multiple imputation after 18+ years. Journal of the American Statistical Association, 91(434):473–489.
- Rubin, (1998) Rubin, D. B. (1998). More powerful randomization-based p-values in double-blind trials with non-compliance. Statistics in Medicine, 17(3):371–385.
- (49) Rubin, D. B. (2004a). The design of a general and flexible system for handling nonresponse in sample surveys. The American Statistician, 58(4):298–302.
- (50) Rubin, D. B. (2004b). Multiple Imputation for Nonresponse in Surveys, volume 81. John Wiley & Sons.
- Shirani and Bayati, (2024) Shirani, S. and Bayati, M. (2024). Causal message-passing for experiments with unknown and general network interference. Proceedings of the National Academy of Sciences, 121(40):e2322232121.
- Tchetgen and VanderWeele, (2012) Tchetgen, E. J. T. and VanderWeele, T. J. (2012). On causal inference in the presence of interference. Statistical Methods in Medical Research, 21(1):55–75.
- Tiwari and Basu, (2024) Tiwari, S. and Basu, P. (2024). Quasi-randomization tests for network interference. arXiv preprint, arXiv:2403.16673.
- Uschner et al., (2024) Uschner, D., Sverdlov, O., Carter, K., Chipman, J., Kuznetsova, O., Renteria, J., Lane, A., Barker, C., Geller, N., Proschan, M., et al. (2024). Using randomization tests to address disruptions in clinical trials: A report from the niss ingram olkin forum series on unplanned clinical trial disruptions. Statistics in Biopharmaceutical Research, 16(4):405–413.
- van der Vaart, (1994) van der Vaart, A. (1994). Weak convergence of smoothed empirical processes. Scandinavian Journal of Statistics, 21(4):501–504.
- Vazquez-Bare, (2023) Vazquez-Bare, G. (2023). Identification and estimation of spillover effects in randomized experiments. Journal of Econometrics, 237(1):105237.
- Vovk et al., (2018) Vovk, V., Nouretdinov, I., Manokhin, V., and Gammerman, A. (2018). Cross-conformal predictive distributions. In Conformal and Probabilistic Prediction and Applications, pages 37–51. PMLR.
- Vovk and Wang, (2020) Vovk, V. and Wang, R. (2020). Combining p-values via averaging. Biometrika, 107(4):791–808.
- Wu and Ding, (2021) Wu, J. and Ding, P. (2021). Randomization tests for weak null hypotheses in randomized experiments. Journal of the American Statistical Association, 116(536):1898–1913.
- Yanagi and Sei, (2022) Yanagi, M. and Sei, T. (2022). Improving randomization tests under interference based on power analysis. arXiv preprint, arXiv:2203.10469.
- Yu et al., (2022) Yu, C. L., Airoldi, E. M., Borgs, C., and Chayes, J. T. (2022). Estimating the total treatment effect in randomized experiments with unknown network structure. Proceedings of the National Academy of Sciences, 119(44):e2208975119.
- Zhang and Zhao, (2024) Zhang, Y. and Zhao, Q. (2024). Multiple conditional randomization tests for lagged and spillover treatment effects. Biometrika, in press.
- Zhao and Ding, (2024) Zhao, A. and Ding, P. (2024). To adjust or not to adjust? Estimating the average treatment effect in randomized experiments with missing covariates. Journal of the American Statistical Association, 119(545):450–460.
- Zhong, (2024) Zhong, L. (2024). Unconditional randomization tests for interference. arXiv preprint, arXiv:2409.09243.
- Zhu and Liu, (2023) Zhu, K. and Liu, H. (2023). Pair-switching rerandomization. Biometrics, 79(3):2127–2142.
Supplementary Material
Appendix A Proofs
A.1 Proof of Theorem 1
By the law of iterated expectation, we have
By definition, when oracle imputation distribution is known,
For any convex function on ,
Since is bounded on , Fubini’s theorem implies that
By definition,
Hence, conditional on ,
and we have
Hence,
where . Moreover, when , we have
We complete the proof. ∎
A.2 Proof of Corollary 1
Lemma A1.
Let be the c.d.f. of a random variable on . If is stochastically less variable than but with the same mean, then ,
| (A1) |
The first or second inequality becomes equality for all if and only if .
By Theorem 1, the IRTo p-value is stochastically less variable than but with the same mean when and are i.i.d. with density known. Denote the c.d.f. of as . Then Lemma A1 gives the lower and upper bounds of , and we have
where is the probability taken with respect to (w.r.t.) and i.i.d. with density . ∎
A.3 Proof of Lemma 1
Denote the p-value of IRTo as , then for the p-value of IRT with imputation function (13), we have
and
Since , then for any , we have
Therefore,
Letting , we obtain
We complete the proof. ∎
A.4 Proof of Theorem 2
By definition, is determined by . In the following, we denote the expectation with respect to the joint distribution of for , i.i.d., and as .
(1) Continuous distribution: When and correspond to continuous distributions, let
Then
The distribution of depends on , and it suffices to show that
where the expectation is taken with respect to the joint distribution of , and
Therefore,
where denotes the expectation with respect to the joint distribution of for , i.i.d., and . Therefore, a sufficient condition for is
| (A2) |
By definition,
and . For a given , the set is determined. Denote and , and their union is . Then the conditional expectation of given is
We make the following variable substitution: for , and for . Then we have
which is equal to the conditional expectation of
with respect to i.i.d. with probability density given . Hence,
where is the p.m.f. of , and the last expectation is with respect to i.i.d. with probability density , and . Thus, sufficient condition (A2) is equivalent to:
| (A3) |
where the expectation is taken with respect to i.i.d. with probability density and .
(2) Discrete distribution: When and correspond to discrete distributions, we denote their corresponding probability mass function as and , i.e.,
where is the set of all the s.t. . Then for any function ,
where . Similarly, we have
Hence,
where . Let
then
| (A4) |
Similar to the case of continuous distribution, the target is
where the expectation is taken with respect to the joint distribution of , and
Therefore,
and the following is a sufficient condition for :
| (A5) |
Similarly, the conditional expectation of given is
which is equal to the conditional expectation of
with respect to i.i.d. with probability density given . Hence, we can similarly prove that
where the last expectation is with respect to i.i.d. with probability density , and . Thus, sufficient condition (A5) is equivalent to:
| (A6) |
where the expectation is taken with respect to i.i.d. with probability density and . We complete the proof. ∎
A.5 Proof of Corollary 2
Denote and . Suppose i.i.d. with known, and conjugate prior . Let be the p.d.f. of . For , define the average as . Then the posterior distribution of is , where
and the posterior predictive distribution of is
Hence, for ,
and
It suffices to show that
Given , are i.i.d. for . Since is a point mass, then and are deterministic for each , and
where
Hence,
As implies that and , then there exists s.t. for any , we have , and . Let , then
and
Let
then for , we have , , and
Hence, for ,
and
As , then
i.e.,
Since ,
we have and
Moreover,
Therefore,
and thus,
We complete the proof. ∎
A.6 Numerical verification of sufficient conditions in Theorem 2
For complex cases, theoretically verifying the sufficient conditions outlined in Theorem 2 is challenging. Therefore, we provide numerical verifications for two distributions used in the simulation and real data analyses. Hereafter, we denote and . We assume that is a point mass distribution, and thus, and are deterministic.
1. Normal distribution with both mean and variance unknown. Consider the case where i.i.d. with unknown. The probability denisty is .
1.1. IRTp. We use the conjugate prior: , and . Then the posterior distribution is
where
and , . Then the posterior predictive distribution is a noncentral t-distribution:
Let , then
In the following, we verify that
holds for through simulations. For changing from 100 to 100000, let for . We generate i.i.d. from the true distribution , set and , and compute
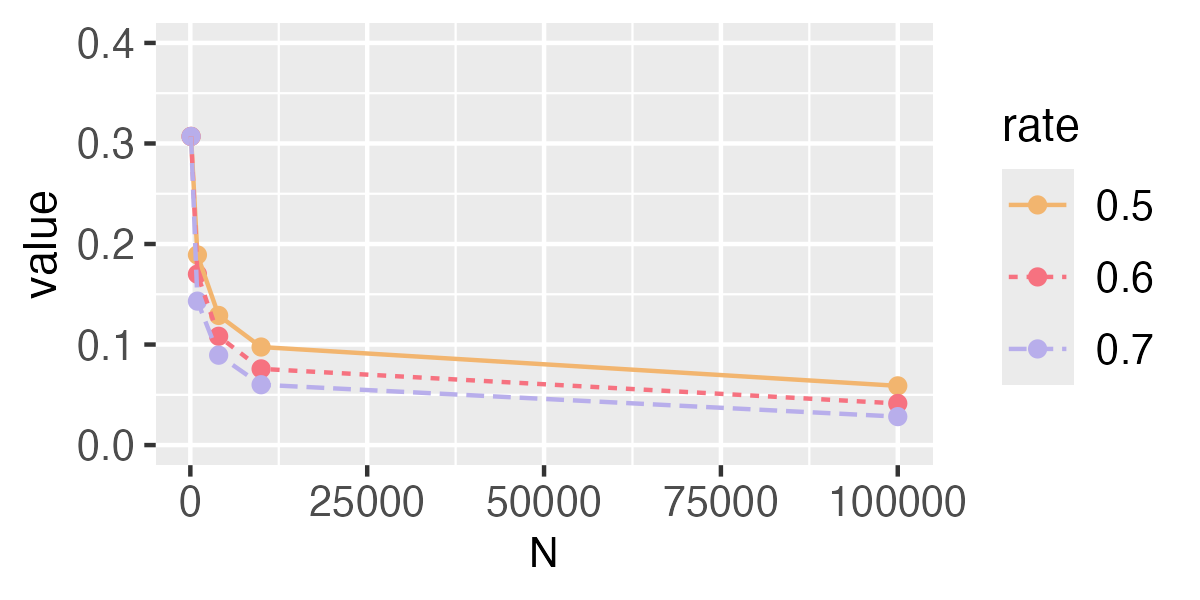
Repeat the above procedure 1000 times and the average of the obtained 1000 values is an approximation of
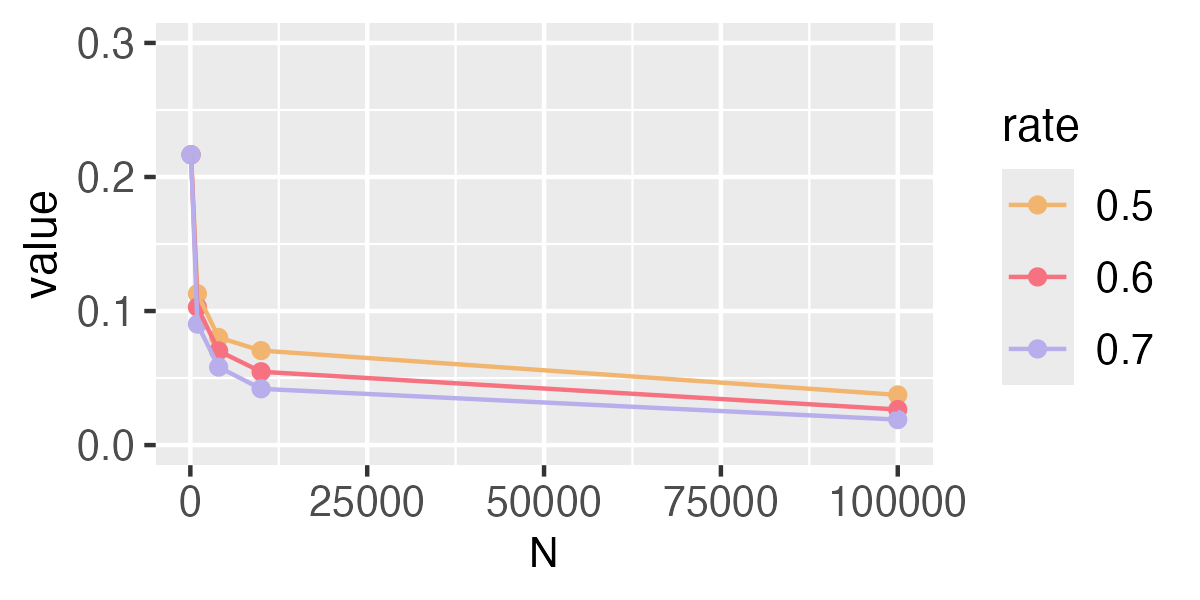
Values of the approximation are shown in Fig. A1. The results imply that when converges to 0 faster, will converge to 0 more quickly.
1.2. IRTs. When is known to be continuous, let
| (A7) |
where the kernel satisfies , , and . IRT with imputation function (A7) can be seen a smoothed version of IRTe and we denote this method as IRTs. Let be a Gaussian kernel and corresponds to normal distribution. We choose via a plug-in method, and verify that
holds for through simulations. For changing from 100 to 100000, let for . We generate i.i.d. from the true distribution , set and , and compute
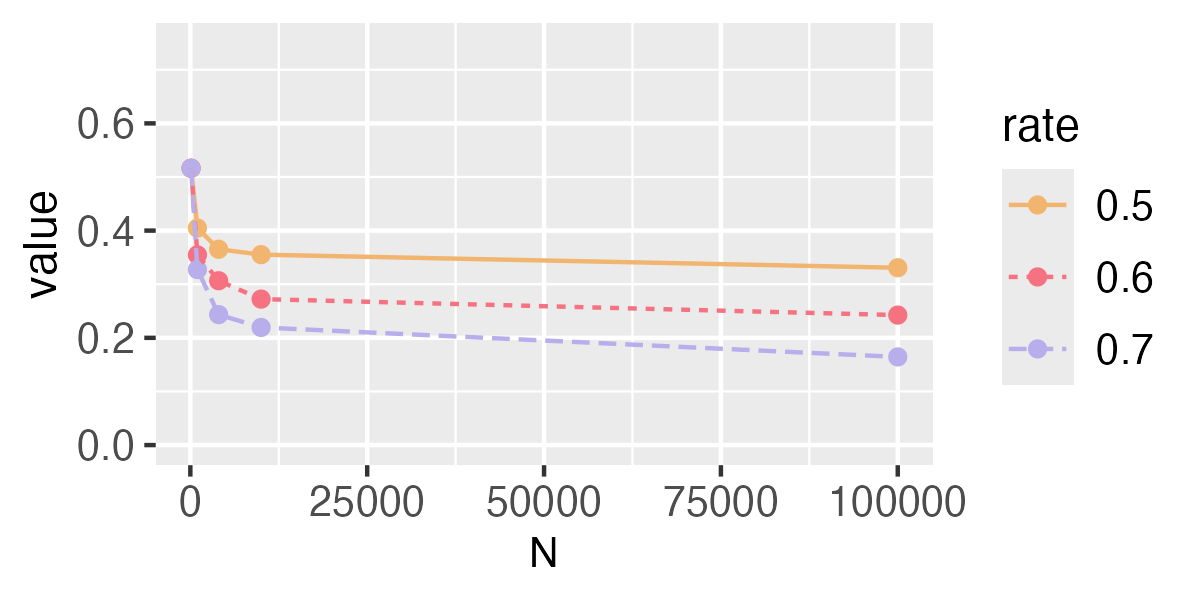
Repeat the above procedure 1000 times and the average of the obtained 1000 values is an approximation of
Values of the approximation are shown in Fig. A2. The results imply that when converges to 0 faster, will converge to 0 more quickly.
2. Binomial distribution. Consider the case where with known and unknown. The corresponding probability mass is .
2.1. IRTp. We use prior , where . Then the posterior distribution is , where
Then the posterior predictive distribution is
Denote the p.m.f. of this posterior predictive distribution as . In the following, we assume that the sequence of is deterministic for and verify that
holds for through simulations. For changing from 100 to 100000, let for . We generate i.i.d. from the true distribution Binomial, set , and compute
Repeat the above procedure 1000 times and the average of the obtained 1000 values is an approximation of
Values of the approximation are shown in Fig. A3. The results imply that when converges to 0 faster, will converge to 0 more quickly.
2.2. IRTe. When corresponds to a discrete distribution, it takes the form of
| (A8) |
where is the set of all the s.t. . Suppose we estimate with the empirical distribution
| (A9) |
Then the empirical distribution can be written as
i.e.,
In the following, we verify that
holds for through simulations. For changing from 100 to 100000, let for . We generate i.i.d. from the true distribution Binomial, set , and compute
Repeat the above procedure 1000 times and the average of the obtained 1000 values is an approximation of
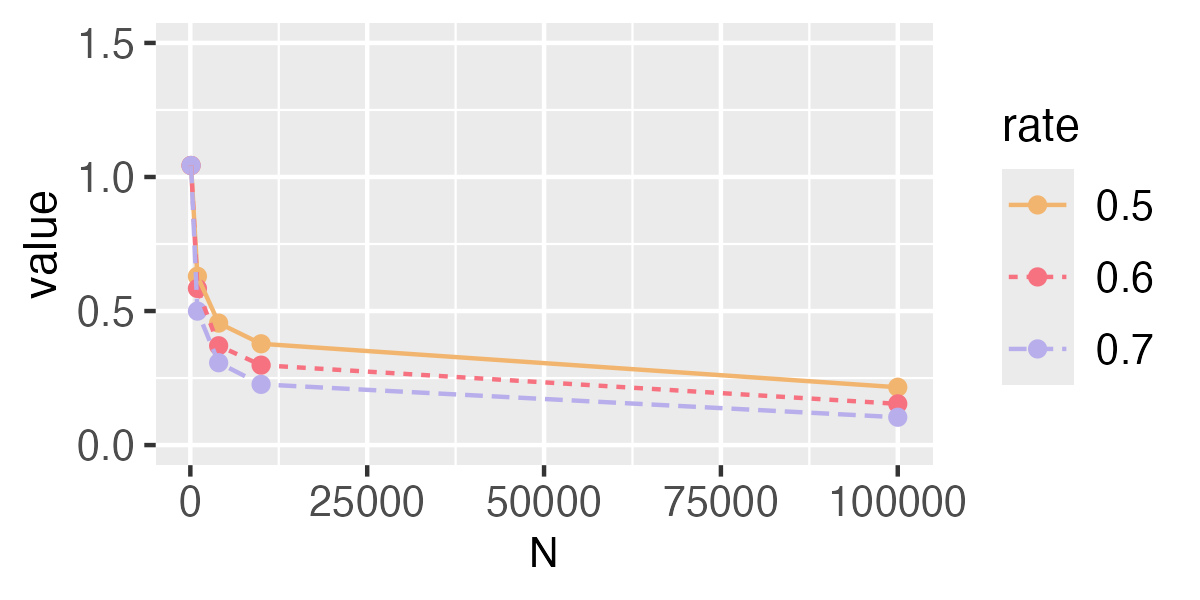
Values of the approximation are shown in Fig. A4. The results imply that when converges to 0 faster, will converge to 0 more quickly.
Appendix B Additional simulation results
B.1 Clustered Interference
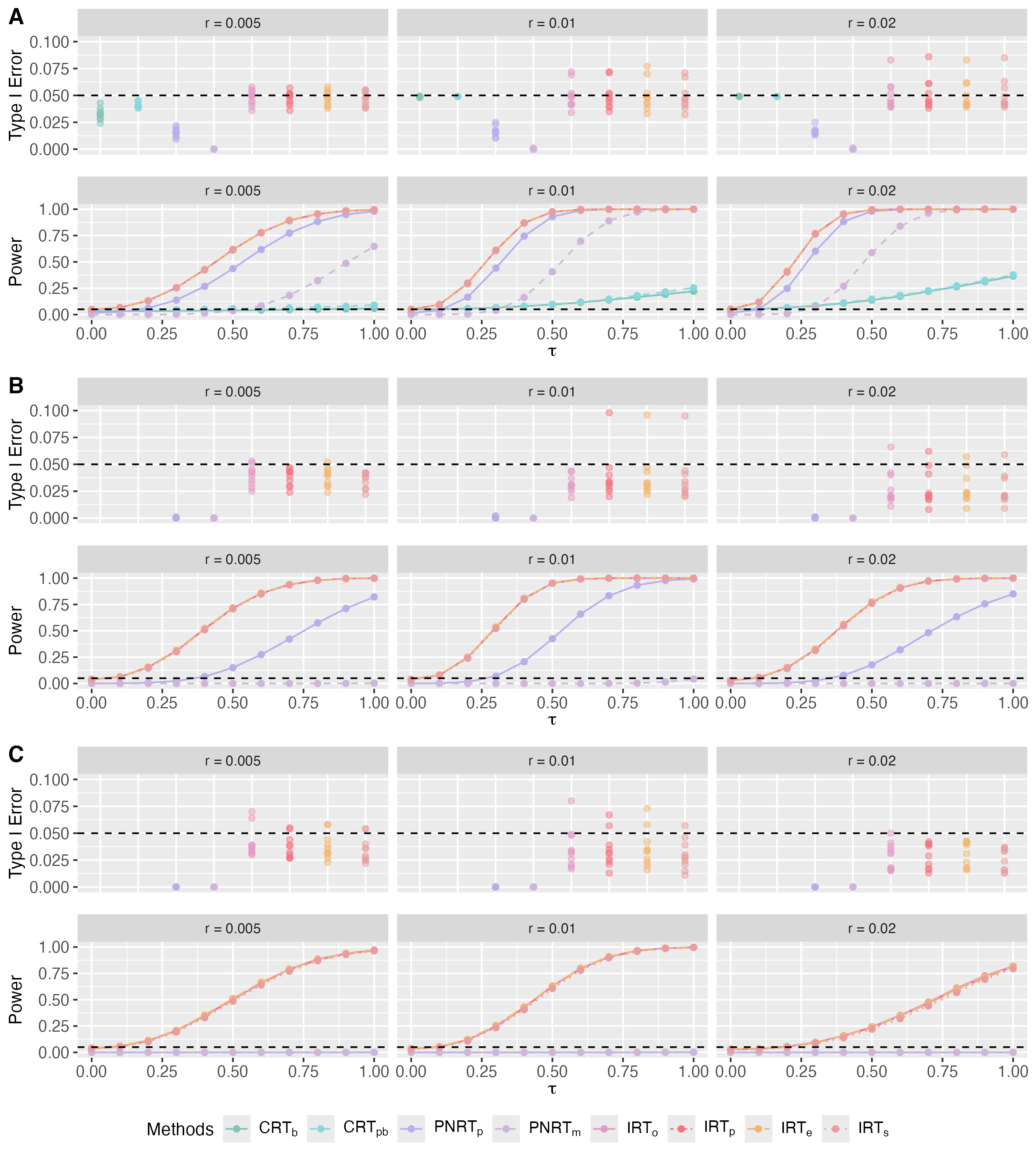
For simulations in Section 4.1, the type I error across 10 datasets and average power over these datasets with and are shown in Fig. B1 and Fig. B2. In these scenarios, the prior for IRTp is still set to be a normal distribution. Similar to the observations in Section 4.1, all methods control the type I error well and our IRT methods outperform CRTs and PNRTs with respect to the power when or . These results show that although the models used in IRTp (i.e., normal) and IRTe are different from the true distribution, their performances are robust. Moreover, all IRTs under the estimated imputation distribution are close to IRTo. Additionally, when corresponds to a continuous distribution, IRTe and IRTs are particularly close to each other in each case, which means that IRTe can also work well when the real distribution is continuous.
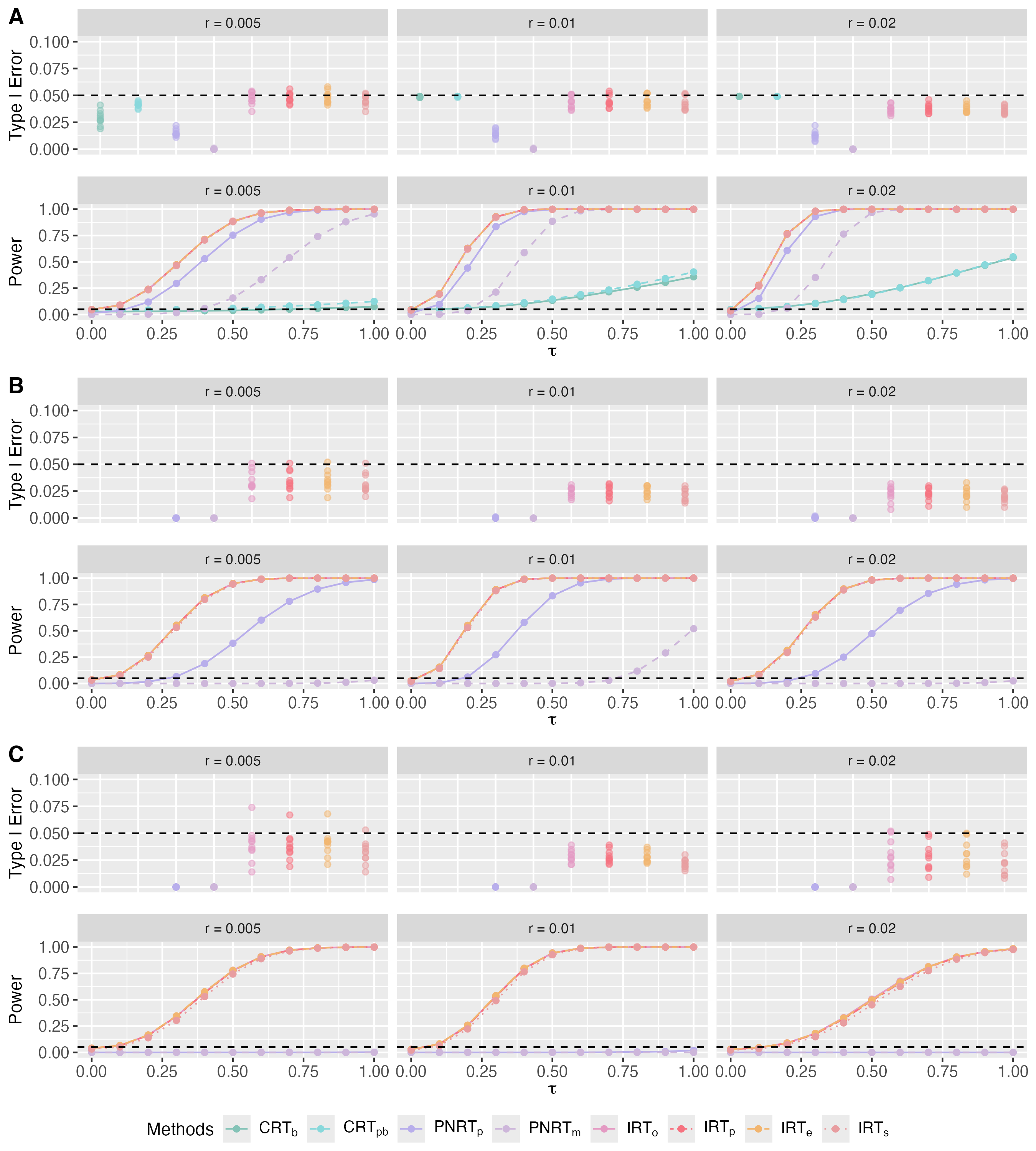
B.2 Spatial Interference
For simulations in Section 4.2, the type I error across 10 datasets and the average power when and are present in Fig. B3 and Fig. B4. The observations are similar to those in Section 4.2, and this implies that our IRT methods outperform CRTs and PNRTs, especially in the case when , where the missing rate of imputable outcomes is large. Moreover, the results show that IRT methods are robust when model is mis-specified.