Incentive Designs for Learning Agents to Stabilize Coupled Exogenous Systems
Abstract
We consider a large population of learning agents noncooperatively selecting strategies from a common set, influencing the dynamics of an exogenous system (ES) we seek to stabilize at a desired equilibrium. Our approach is to design a dynamic payoff mechanism capable of shaping the population’s strategy profile, thus affecting the ES’s state, by offering incentives for specific strategies within budget limits. Employing system-theoretic passivity concepts, we establish conditions under which a payoff mechanism can be systematically constructed to ensure the global asymptotic stability of the ES’s equilibrium. In comparison to previous approaches originally studied in the context of the so-called epidemic population games, the method proposed here allows for more realistic epidemic models and other types of ESs, such as predator-prey dynamics. The stability of the equilibrium is established with the support of a Lyapunov function, which provides useful bounds on the transient states.
I Introduction
Systems whose behavior depends on the strategic choices of many agents can be studied through the lens of evolutionary game theory, in particular when considering large populations of nondescript agents that repeatedly revise their strategies. Examples of systems with such dependency on the aggregate choice of a large population include models of traffic congestion [1], optimal power dispatch [2], distributed task allocation [3], building temperature control [4], and epidemic mitigation [5].
The coupling between the evolutionary dynamics, which models the population’s strategic choices, and the exogenous system (ES) dynamics, which captures the state of the system affected by the decisions of the population, makes the task of designing stabilizing policies challenging. This is especially true when we aim to design policies that not only improve the behavior of the system, but also provide performance guarantees that hold at any given time.
In our work, we generalize the design concept from [5] to a larger class of ESs which, when agents stop revising their strategies, have a Lyapunov function and satisfy some mild assumptions. We design incentives that guarantee the convergence of the population state to an equilibrium, which can be selected independently of the payoff mechanism. While our results require similar assumptions on the behavior of the population to those of [5], unlike [5, 6] we obtain a bound on the instantaneous cost of implementing our incentives.
In addition, we show that the proposed payoff mechanism is compatible with many ESs, such as the epidemic models studied by [5, 6, 7] and the Leslie-Gower model for studying the interaction between populations of hosts and parasites [8]. As an application, we use the proposed framework to devise incentives for a modified epidemic model studied in [6], while considering disease transmission rates that depend nonlinearly on the agents’ choices.
I-A Contributions
The goal of our study is to develop a new framework for designing a dynamic payoff mechanism that guarantees the convergence of both the population and the ES, whose dynamics are influenced by the strategic choices of the agents in the population, to a desirable equilibrium that can be selected independently of the payoff. The incentive we design has a bound on the instantaneous reward offered to the population, which is not guaranteed in the previous studies that use -passivity for designing policies that mitigate epidemics.
The assumptions we introduce on the learning rule employed by the agents are similar to those of [5]. However, we relax one of the assumptions on the learning rule, which is not easy to verify, and replace it with another assumption that is easier to check. The proposed mechanism works on previously studied ESs [5, 6, 7], but is not limited to epidemic models; our framework is more general and can be applied to any system satisfying the conditions identified in this paper, even when the learning rule is unknown to the policy maker. As an illustrative example, we show in §VI-A that the Leslie-Gower system studied in [8] satisfies these conditions.
II Related Works
Earlier studies showed that, for potential games, bounded-rational learning rules with the positive correlation (PC) property, where agents revise their strategies in a way that increases their payoffs, guarantee the convergence of the population state to Nash equilibria (NEs) [9]. In addition, Hofbauer and Sandholm [10] established that, for the class of contractive games, many evolutionary dynamics lead the population state to an NE. A recent study demonstrated that for certain potential and strictly contractive games, the population state converges to an NE, even when the revision rates depend explicitly on the current strategies of the agents [11, 12]. For a survey of earlier studies and the applications of population games we refer the reader to [13, 14], and the references therein.
Motivated by the class of contractive games, Fox and Shamma [15] showed that certain learning rules, such as impartial pairwise comparison and excess-payoff target rules, exhibit a form of passivity which they named -passivity. The concept of -passivity was generalized in [16] to admit a large class of dynamical payoff mechanism and in [1] that introduced -dissipativity. In [17], the authors determined a sufficient condition for the interconnections of -dissipative dynamical systems to also be -dissipative.
Adapting tools from robust control, Mabrok and Shamma [18] studied the passivity properties of higher-order games and determined necessary conditions for evolutionary dynamics to be stable for all higher-order passive games. Their work also proved that replicator dynamics is lossless [18], which was later shown to be not -passive [19].
The population game framework has been used in many problems. For example, it has been used for distributed optimization [20] and distributed NE seeking [21]. Obando et al. [4] studied a temperature control problem, where the population models the heating power to be distributed in a building and is coupled to a thermal model of the building. We refer the reader to a survey [14] for additional examples.
To the best of our knowledge, [5] is the first study that used -passivity as a design tool: a dynamic payoff mechanism was designed to lessen the impact of an epidemic subject to a limit on the long-term budget available to the decision maker. This work was extended to cases with nonnegligible disease mortality rates [6] and to scenarios with noisy payoffs to agents [22]. The same framework was also used to consider two-population scenarios [7].
Our work extends the design method in [5] to a larger class of ESs, which includes epidemic models as examples. Our assumptions are similar to those of previous studies, but the proposed dynamic payoff mechanism has a provable bound on the incentives provided to the agents. We also determine conditions under which a class of ESs coupled to a population of learning agents can be stabilized to a desired equilibrium.
III Population Games and Learning Rules
We consider a population of a large number of nondescript agents, in which each agent follows a single strategy at any given time and can repeatedly revise its strategy, based on the payoffs to available strategies at the revision times. We assume that the agents have a common set of strategies available to them. The instantaneous payoff obtained by following the -th strategy at time is given by , and the payoff vector offered to the population at time is denoted as , where . The payoff perceived by agents at time is the difference between the rewards offered by the policy maker at time , which is denoted by , and the vector that contains the intrinsic costs of the strategies, which we denote by . Thus, the payoff vector at time is given by
| (1) |
These assumptions render the tools of population games well-suited for analyzing the strategic interactions among the agents. The population state at time is denoted by , with being the proportion of the population following the -th strategy at time . The vector takes values in the standard simplex
In the large-population limit, for , the population state evolves according to the Evolutionary Dynamics Model (EDM)
| (EDM) |
where . The -th element of is
| (2) |
with a learning rule (also referred to as a revision protocol) that is a Lipschitz continuous map , upper bounded by .
We consider the EDM coupled to an ES, whose state at time is denoted by . The ES state takes values in and evolves according to
| (3) |
where is locally Lipschitz continuous and the population state acts as time-varying parameters of the ES. We assume that, for any , if then (3) has a unique equilibrium denoted as .
The dynamics of rewards offered to the agents is described by the following:
| (4) | ||||
where and form a dynamic payoff mechanism to be designed by the policy maker.
Definition 1
A learning rule is said to satisfy the positive correlation (PC) condition if the following holds: for all ,
Definition 2
A learning rule is Nash Stationary (NS) if, given the best response map , where
the following holds:
Definition 3
An EDM is -passive if there exist (i) a differentiable function and (ii) a Lipschitz continuous function , which satisfy the following inequality for all , and in , and , respectively:
| (5) |
where and must also satisfy the equivalences below:
Since the EDM is determined by the learning rule, we say that the learning rule is -passive if the resulting EDM is -passive. Two well-known classes of learning rules that satisfy PC and NS conditions and lead to -passive evolutionary dynamics are the separable excess payoff target and the impartial pairwise comparison learning rules.
Example 1
A learning rule is said to be of the separable excess payoff target type [23] if, for each in , there is some such that
and satisfies for and for .
Example 2
A learning rule is said to be of the impartial pairwise comparison type [24] if, for each in , there is some such that
and satisfies for and for .
Lastly, we introduce a lemma that will be useful for proving our main result (Theorem 1) in the following section.
Lemma 1
For any fixed and , the only vector that satisfies
| (6) |
is .
Proof.
Since , it is a solution to (6). To see that no other solution exists, rewrite (6) as
Define , and note from the inequality above
It then follows from the minimum principle that s.t. . As this is a convex problem with strictly convex objective, it has a unique solution. Since is a solution as noted above, the lemma follows. ∎
IV Main Result
Our goal is to design a dynamic payoff mechanism given by the maps and , which not only guarantees the convergence of the population state to some selected by the policy maker, but also gives bounds on the ES state and the instantaneous cost incurred by the policy maker. Our convergence result assumes that the population adopts a learning rule that is -passive, NS and PC, along with some conditions on the ES in (3). For the incentive design, we do not need to know the learning rule used by the agents as long as it satisfies the properties above.
Although our assumptions are similar to those in the previous works, we do not require the assumption in equation [5, (13)] on the storage function associated with the learning rule, but instead assume that the learning rule is PC, which is simpler to check.
Our approach to designing the dynamic payoff mechanism leverages the -passivity of the EDM, which yields a Lyapunov function for the overall system. The Lyapunov function is used to bound based on the initial condition . Moreover, the maps and , combined with the bound on , also enable us to bound the instantaneous rewards provided to the agents, as discussed in §V.
Theorem 1
Consider a payoff vector , a population state , and positive design parameters and . Suppose that the exogenous system (3) satisfies the following:
(i) There is a nonnegative continuously differentiable function such that, for any and , .
(ii) For any , is compact.
(iii) For every , the set is the largest invariant subset of .
(iv) The function satisfies for every .
In addition, assume that
(v) the learning rule is Nash stationary, -passive, and positively correlated.
Then, the dynamic payoff mechanism given by
| (7) | ||||
guarantees that, for any initial condition and in , we have .
Proof.
Define the following candidate Lyapunov function for the overall system comprised of (2), (3), and (4).
| (8) |
where is the storage function of the EDM. Due to our selection of , we have
We denote by the directional derivatives of the function (8) along the vector field defined by (2), (3), and (4) at the point :
where the inequality follows from (5). Conditions (i) and (v) imply that is nonpositive, and is a nonstrict Lyapunov function.
By condition (ii) and , is bounded. Since (7) is a bounded-input bounded-output linear system with state and bounded input , which is a continuous function of the trajectory , we obtain that is bounded.
Let denote the largest invariant subset within . From the LaSalle-Krasovskii invariance principle, converges to the -limit set , which is compact and invariant with respect to (2), (3), and (4) [25, Lemma 4.1].
For any , the trajectory will satisfy that, for all , and due to the fact that for all implies for all , and condition (iii) in Theorem 1. This, together with condition (iv), leads to
so that and
V Bounds
As proven in Theorem 1, if the ES in (3) satisfies (i)-(iv) and the learning rule satisfies (v), the payoff mechanism described in (7) can be used to stabilize the ES and the population to a desired equilibrium. Also, we are able to determine bounds for the state and the rewards offered to the population.
If at some , the storage function of the EDM is equal to zero at , as any is a best response. In particular, if , both and are equal to zero, and we have
Furthermore, because is decreasing along trajectories and for any , we obtain that, for any ,
| (9) |
This in turn can be used to bound not only and but also the policy maker’s instantaneous cost : for any ,
| (10) | |||
where the terms , and are affected by the choice of the parameters , , and .
VI Examples
In §VI-A and §VI-B we present two systems that fit our framework as the ES in (3). They meet conditions (i)-(iv) of Theorem 1, and when coupled to a population that employs a learning rule satisfying condition (v), the dynamic payoff mechanism described in Theorem 1 stabilizes the overall system to a desired equilibrium . In §VI-C we consider a modification of [6] to exemplify how our theorem can be leveraged for design: We first select a target equilibrium population state that minimizes the disease transmission rate subject to a budget constraint, and choose the parameters , and so that the peak size of the infected population is guaranteed to be below a given threshold. We then present simulation results using several different learning rules.
Our examples focus on systems that are naturally coupled to a population of agents and are affected by the strategic choices of the agents. The system considered in [5, 6] is a compartmental model of an epidemic disease, and the population state affects the transmission rate of the disease. Similarly, [7] considers an epidemic model with two interacting populations, with the transmission rates of each population being affected by its agents’ current strategies. Korobeinikov [8] studied a Host-Parasite model, and by finding a nonstrict Lyapunov function he proved the convergence to the unique equilibrium of the model. We modify this model so that some of its parameters change according to the population state. We choose a desirable equilibrium of this modified model to reduce the number of parasites at the equilibrium, and then use (7) to stabilize the equilibrium.
VI-A Leslie-Gower predator-prey model
Korobeinikov [8] studies the Leslie-Gower model that captures the interaction of populations of hosts and parasites. Let and denote the number of hosts and parasites, respectively, at time . The population sizes evolve according to the following differential equations:
| (11a) | ||||
| (11b) | ||||
where , and are positive, and is nonnegative. The intrinsic population growth rates of the hosts and parasites are and , respectively. The parameter relates to a growth limit on the hosts without parasites, while relates to a decrease of hosts due the parasites, and relates to a population limit on the parasites due to the number of hosts. The unique co-existing equilibrium, where , is
The following is a nonstrict Lyapunov function of (11) on :
| (12) |
where
with . The directional derivatives of (12) along the vector field defined by (11) is
with positive and nonnegative . This confirms that (12) is a Lyapunov function of (11).
Suppose that and are functions of the population state, i.e., , and . Such scenarios could arise when the agents are the farmers who breed and raise livestock, which are the hosts affected by parasites. The strategic choices of the agents could include, for example, how many animals to breed or which measures to take to reduce the spread of parasites, e.g., diagnosing, isolating, and treating infected hosts. In this case, the Leslie-Gower model as the ES in (3) is described by
with the equilibrium
Suppose , and are continuously differentiable so that the equilibrium map is also continuously differentiable.
Define
Note that (a) for any , and (b) for any , if , then . Thus, it satisfies conditions (i) and (iii). As a continuous function, the sublevel sets of are closed, and we can verify that they are also bounded so that condition (ii) is satisfied. Lastly, satisfies (iv):
because
VI-B Epidemic Population Games (EPG)
Previous studies on EPG [5, 6, 7] examined epidemic compartmental models coupled to a population, with the epidemic model being the ES. Here we show that the model used in [6] satisfies the conditions in Theorem 1, even for a more general dependency of the transmission rates on the agents’ strategies than that considered in [6]. The epidemic model satisfies conditions (i)-(iv) and, when coupled to a population employing a learning rule that satisfies (v), we can use Theorem 1 to drive them to a desirable equilibrium. A similar analysis shows that the epidemic models in [5, 7] also satisfy conditions (i)-(iv).
We first briefly describe the normalized susceptible-infectious-recovered-susceptible (SIRS) model, which is the ES we aim to stabilize. Let , and denote the proportions of infected agents and recovered agents, respectively, in the population at time . Suppose that is the population size at time . The population size changes according to , where is the difference between the birth rate and the natural death rate , and is the disease death rate. The disease recovery rate and the rate at which a recovered individual becomes susceptible again due to waning immunity are denoted by and , respectively.
Since the model is normalized, and at any time . The ES state is given by and evolves according to
| (13a) | ||||
| (13b) | ||||
where is the average transmission rate at time , , , , , and is the mean infectious period for an affected individual (till recovery or death). The adopted time unit is one day, and newborns are assumed susceptible. As in [6], we assume but moderate such that . Also, for all so that there is a unique endemic equilibrium.
For fixed , the endemic equilibrium of (13) is given by the differentiable functions of :
where , and the discriminant is .
Now, suppose , where is a continuously differentiable function, and let and . For a fixed , the following is a strict Lyapunov function for (13) on :
| (15) |
where
and . The derivative of (15) along trajectories is
and it is negative for any .
Since (15) is a strict Lyapunov function when is constant, it satisfies conditions (i) and (iii). As is a continuous function, its sublevel sets are closed. Moreover, because the sublevel sets are also contained in , which is a bounded set, they are also bounded and, hence, condition (ii) holds. Lastly, we can verify condition (iv) as follows.
where the second equality follows from .
VI-C Designing an Intervention Policy for Epidemics with Nonlinear Infection Rate
We consider a modification of the EPG studied in [6], which was described in §VI-B, as an application of Theorem 1 to a dynamic payoff design problem. We aim to mitigate an epidemic outbreak and reduce the endemic level of infected agents while guaranteeing that the long-term cost of the policy maker does not exceed some available budget .
The study in [6] considers the average transmission rate that depends linearly on the population state, with , where . Such dependency on is consistent with the choices of the susceptible agents determining the likelihood of contracting the disease when exposed, e.g., choosing to wear masks or getting vaccinated. In their model, the proportion of susceptible agents following the -th strategy at time is , and for those agents the rate of new infections is equal to .
Suppose that we allow the average transmission rate to depend on both the choices of the susceptible agents and those of the infected agents. For example, an infected agent that takes no preventive measures is more likely to transmit the disease than another infected agent that does take preventive measures. In this case, the rate of new infections among susceptible agents following strategy due to the exposure to infected agents adopting strategy would be . Therefore, the average transmission rate is given by
with being a positive matrix with the elements . We assume that the disease is too infectious to be eradicated so that for all .
We aim to select a target population equilibrium that minimizes the transmission rate subject to a budget constraint. In order to find we solve
where is the vector of intrinsic costs of the strategies, and is the long-term budget available to the policy maker.
After determining , we select and use the payoff mechanism described in Theorem 1 to lead the population and epidemic states to the selected equilibrium.
Example 3
Consider a disease with parameters: , , , (mean recovery period 10 days) and (mean immunity period 91 days). Agents have three available strategies with
The initial conditions are and for the epidemic, for the EDM, and for the payoff dynamics. The long-term budget of the policy maker is , and we select , which yields and . Our goal is to design and so that for all .
For simplicity, we select and and , as does not affect the bound on if . Based on (9), we look for values of and that meet our requirement that for all , by solving
| (16) |
where and affect constraint (16).
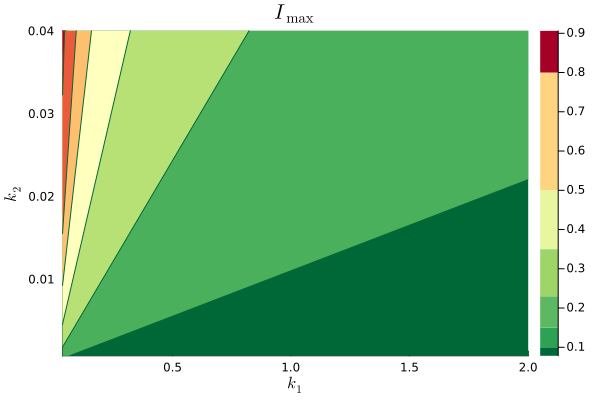
We solve numerically the optimization above for several values of and , and show the results in Fig. 1. The requirement that is met for in the region on the bottom right of the plot, and we select and . We then use the reward mechanism given by Theorem 1 to guide the population to the desired equilibrium.
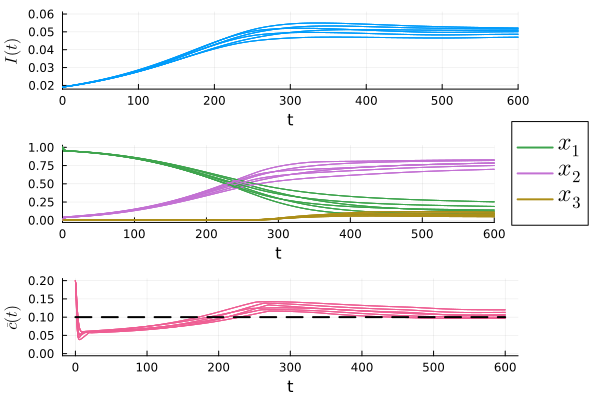
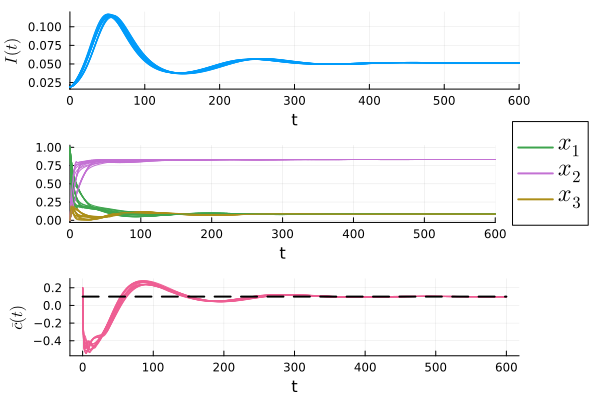
The simulation results for several different learning rules that satisfy condition (iv) in Theorem 1 are shown in Fig. 2.111See the simulation code at github/jcert/incentive-design-coupled-dynamics for more details on the learning rules that were used. It is clear that they all converge and satisfy the requirement that for all . Had we not used the bound, , to determine the parameters of the reward mechanism, the bound on the peak of infections may have been violated, as shown in Fig. 3. In both figures we observe that the instantaneous cost, , converges to , which is represented as a dashed black line in the plots.
VII Conclusion
We studied a large population of learning agents whose strategic choices influence the dynamics of an ES we seek to stabilize at a desired equilibrium. Our framework can be used to design a dynamic payoff mechanism that guarantees the convergence of both the population and the ES (Theorem 1). When the conditions on the ES stated in the theorem are met, the designed incentives can stabilize more general systems than previously considered.
We also presented example systems that satisfy the conditions of our main result (§VI-A and §VI-B) and applied our framework to design incentives that mitigate an epidemic with nonlinear infection rates subject to long-time budget constraints (§VI-C). Unlike the incentives designed in the previous studies of EPG, our payoff mechanism is guaranteed to have a bound on the instantaneous reward offered to the population.
In future research we plan to extend the results by relaxing the assumptions on the ES to be only local and to allow the EDM to depend on the ES states. Another direction we are interested in pursuing is to examine design problems where the payoff of certain strategies can only be partially designed.
References
- [1] M. Arcak and N. C. Martins, “Dissipativity Tools for Convergence to Nash Equilibria in Population Games,” IEEE Control Netw. Syst., vol. 8, no. 1, pp. 39–50, Mar. 2021.
- [2] A. Pantoja and N. Quijano, “A population dynamics approach for the dispatch of distributed generators,” IEEE Transactions on Industrial Electronics, vol. 58, no. 10, pp. 4559–4567, Oct. 2011.
- [3] S. Park, Y. D. Zhong, and N. E. Leonard, “Multi-Robot Task Allocation Games in Dynamically Changing Environments,” in 2021 IEEE International Conference on Robotics and Automation (ICRA). Xi’an, China: IEEE, May 2021, pp. 8678–8684. [Online]. Available: https://ieeexplore.ieee.org/document/9561809/
- [4] G. Obando, A. Pantoja, and N. Quijano, “Building temperature control based on population dynamics,” IEEE transactions on Control Systems Technology, vol. 22, no. 1, pp. 404–412, Jan. 2014.
- [5] N. C. Martins, J. Certório, and R. J. La, “Epidemic population games and evolutionary dynamics,” Automatica, vol. 153, p. 111016, Jul. 2023. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S0005109823001711
- [6] J. Certório, N. C. Martins, and R. J. La, “Epidemic Population Games With Nonnegligible Disease Death Rate,” IEEE Control Systems Letters, vol. 6, pp. 3229–3234, 2022.
- [7] J. Certório, R. J. La, and N. C. Martins, “Epidemic Population Games for Policy Design: Two Populations with Viral Reservoir Case Study,” in Proc. IEEE conf. decis. control (CDC), 2023, pp. 7667–7674. [Online]. Available: https://ieeexplore.ieee.org/document/10383665
- [8] A. Korobeinikov, “A Lyapunov function for Leslie-Gower predator-prey models,” Appl. Math. Lett., vol. 14, no. 6, pp. 697–699, Aug. 2001. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S089396590180029X
- [9] W. H. Sandholm, “Potential games with continuous player sets,” Journal of economic theory, vol. 97, pp. 81–108, 2001.
- [10] J. Hofbauer and W. H. Sandholm, “Stable games and their dynamics,” Journal of Economic Theory, vol. 144, no. 4, pp. 1665–1693.e4, Jul. 2009.
- [11] S. Kara, N. C. Martins, and M. Arcak, “Population games with erlang clocks: Convergence to nash equilibria for pairwise comparison dynamics,” in Proc. IEEE conf. decis. control (CDC), 2022, pp. 7688–7695.
- [12] S. Kara and N. C. Martins, “Excess Payoff Evolutionary Dynamics With Strategy-Dependent Revision Rates: Convergence to Nash Equilibria for Potential Games,” IEEE Control Systems Letters, vol. 7, pp. 1009–1014, 2023.
- [13] W. H. Sandholm, Population games and evolutionary dynamics. MIT Press, 2010.
- [14] N. Quijano, C. Ocampo-Martinez, J. Barreiro-Gomez, G. Obando, A. Pantoja, and E. Mojica-Nava, “The Role of Population Games and Evolutionary Dynamics in Distributed Control Systems: The Advantages of Evolutionary Game Theory,” IEEE Control Syst., vol. 37, no. 1, pp. 70–97, 2017. [Online]. Available: https://ieeexplore.ieee.org/document/7823106/
- [15] M. J. Fox and J. S. Shamma, “Population games, stable games, and passivity,” Games, vol. 4, pp. 561–583, 2013.
- [16] S. Park, N. C. Martins, and J. S. Shamma, “Payoff dynamics model and evolutionary dynamics model: Feedback and convergence to equilibria,” 2020.
- [17] K. S. Schweidel and M. Arcak, “Compositional Analysis of Interconnected Systems Using Delta Dissipativity,” IEEE Control Systems Letters, vol. 6, pp. 662–667, 2022.
- [18] M. A. Mabrok and J. S. Shamma, “Passivity analysis of higher order evolutionary dynamics and population games,” in Proc. IEEE conf. decis. control (CDC), 2016, pp. 6129–6134. [Online]. Available: https://ieeexplore.ieee.org/abstract/document/7799211
- [19] S. Park, J. S. Shamma, and N. C. Martins, “Passivity and evolutionary game dynamics,” in Proc. IEEE conf. decis. control (CDC), 2018, pp. 3553–3560.
- [20] J. Martinez-Piazuelo, N. Quijano, and C. Ocampo-Martinez, “A Payoff Dynamics Model for Equality-Constrained Population Games,” IEEE Control Systems Letters, vol. 6, pp. 530–535, 2022.
- [21] J. Martinez-Piazuelo, C. Ocampo-Martinez, and N. Quijano, “On Distributed Nash Equilibrium Seeking in a Class of Contractive Population Games,” IEEE Control Systems Letters, pp. 1–1, 2022.
- [22] S. Park, J. Certório, N. C. Martins, and R. J. La, “Epidemic population games and perturbed best response dynamics,” 2024.
- [23] W. H. Sandholm, “Excess payoff dynamics and other well-behaved evolutionary dynamics,” Journal of Economic Theory, vol. 124, no. 2, pp. 149–170, Oct. 2005. [Online]. Available: https://linkinghub.elsevier.com/retrieve/pii/S0022053105000554
- [24] ——, “Pairwise comparison dynamics and evolutionary foundations for Nash equilibrium,” Games, vol. 1, no. 1, pp. 3–17, 2010.
- [25] H. K. Khalil, Nonlinear systems. Prentice Hall, 1995.