Inference in Spatial Experiments with Interference using the SpatialEffect Package
Abstract
This paper presents methods for analyzing spatial experiments when complex spillovers, displacement effects, and other types of “interference” are present. We present a robust, design-based approach to analyzing effects in such settings. The design-based approach derives inferential properties for causal effect estimators from known features of the experimental design, in a manner analogous to inference in sample surveys. The methods presented here target a quantity of interest called the “average marginalized response,” which is equal to the average effect of activating a treatment at an intervention node that is a given distance away, averaging ambient effects emanating from other intervention nodes. We provide a step-by-step tutorial based on the SpatialEffect package for R. We apply the methods to a randomized experiment on payments for community forest conservation in Uganda, showing how our methods reveal possibly substantial spatial spillovers that more conventional analyses cannot detect.
Inference in Spatial Experiments with Interference using the SpatialEffect Package
Keywords: spatial statistics, causal inference, interference, experiments.
1 Introduction
Spatial experiments involve interventions that are applied to points or polygons in geographic space. Such interventions have effects that transmit across space in potentially complicated ways. Figure 1 illustrates the generic structure of such experiments. The left panel illustrates a potential point-intervention experiment. The points show locations at which an intervention might be applied. An experimental design could assign half of such points to be treated with the intervention (gray shaded points), with the rest of the points remaining in the untreated, control condition (unshaded points). The shading in the background raster indicates outcome values. The right panel illustrates a similar situation, but with treatments assigned to polygons instead of points. A conventional analysis might work with outcomes within small circles surrounding the points or within the polygons, treating outcomes as independent, or at most, subject to some spatial correlation. However, such modeling assumptions may be inadequate if the interventions have effects that bleed out in space. The dashed lines illustrate possible zones into which effects may bleed out. If effects bleed out in such ways, then outcomes by a given point or polygon depend not only on the treatment assignment of that point/polygon, but also on the pattern of treatment assignments for neighboring points/polygons. Such spillover effects are examples of what statisticians, following Cox (1958), call causal “interference.” This paper discusses an approach for analyzing spatial experiments when such interference is present.

Many environmental, health, agricultural, and other social interventions can be understood in these terms. Consider, for example, “payments for ecosystem services” (PES) interventions, which typically offer money in exchange for recipients’ refraining from degrading natural resources in their vicinity. Such an intervention may displace such degradation to more distant areas (negative spillover) or the intervention may have a bandwagon effect that induces people in neighboring areas to reduce degradation too (positive spillover) (Pfaff and Robalino, 2017). Ignoring negative spillovers can lead researchers to overstate the value of an intervention, while ignoring positive spillovers can lead researchers to understate this value. Below, we analyze spillovers using data from a PES experiment due to Jayachandran et al. (2017), finding indication of positive spillovers that the original analysis could not detect.
This paper presents an introduction to design-based inference for spatial effects when interference is present, drawing on the technical results presented in Wang et al. (2022). Design-based inference is distinct from model-based inference (Särndal, Swensson and Wretman, 1992). Model-based inference is based on specifying a parametric or semi-parametric model for outcome variables, and then obtaining parameter estimates that best account for outcome variation. For spatial experiments, model-based approaches include spatial regression analysis (Arbia, 2006; Darmofal, 2015; Kelejian and Piras, 2017). Such methods are sensitive to misspecification. For example, a conventional modeling assumption is that effects are homogenous or that heterogeneity can be modeled in simple terms. When this is not valid, researchers may misinterpret the generality of an estimated effect.
Design-based inference, by contrast, focuses on how well an experimental design or sampling design produces information about a target quantity under minimal assumptions on the outcome data generating process (Rubin, 2008). A design based analysis is robust to a variety of outcome data generating processes and sources of effect heterogeneity. Design-based methods focus on carefully defined target quantities, such as average treatment effects, and the conditions for non-parametric estimation of such quantities. These quantities have immediate relevance for assessing the welfare implications of an intervention. Under the stable unit treatment value assumption (SUTVA), the average treatment effect tells us the expected effect of assigning all units to treatment, regardless of the nature of effect heterogeneity (Imbens and Rubin, 2015). Unfortunately, interference directly violates SUTVA, and so this interpretation is no longer valid (Aronow et al., 2020; Sävje, Aronow and Hudgens, 2018). Interference motivates consideration of alternative quantities of interest.
Our analysis focuses on a quantity that we call the “average marginalized response” (AMR). The AMR measures how, on average, outcomes that at a given distance from an intervention site are affected by activating treatment at that site, taking into account ambient effects emanating from other intervention sites. From a policy perspective, the AMR tells us the average value of adding an additional treated site. We can also use linear functionals of the AMR (e.g., the sum or the mean of AMRs) to characterize cumulative effects. In our illustrations below we demonstrate this. Statistically, the AMR can be reliably estimated in spatial experiments through a simple contrast. Wang et al. (2022) show that when effects are additive or homogenous, the AMR is equivalent to the “spillover” coefficient in a linear structural model. The AMR retains a meaningful interpretation when effects are heterogenous or non-additive. We note that in targeting the AMR, we are not attempting to disentangle “direct” and “indirect” effects, as in analyses by Hudgens and Halloran (2008), Zigler and Papadogeorgou (2018), and Hu, Li and Wager (2022).
The methods presented here are more agnostic about the structure of the interference than methods that specify an “exposure mapping” (Manski, 2012; Aronow and Samii, 2017). We also work with looser assumptions on the spatial extent of interference as compared to methods based on “partial interference.” See Aronow et al. (2020) for a review of approaches based on exposure mappings and partial interference.
We apply these methods to an experimental study of a forest-conservation PES intervention in Uganda, originally analyzed by Jayachandran et al. (2017). We offer a step-by-step demonstration of the tools in the SpatialEffect package for R (Samii and Wang, 2020), which was developed to implement the methods presented in Wang et al. (2022). The required input data include raster or geographic point data on outcomes and then either geographic point data or polygon shapefile data on experimental treatments sites.
In the next section, we provide an accessible discussion of our methods, defining the AMR and strategies for inference. Next, we describe how to implement this approach using the SpatialEffect package for R, and use a small toy simulation to illustrate. We then turn to the forest conservation experiment in Uganda.
2 Methods
This section gives an overview of design-based inference for spatial effects. For a more detailed and technical treatment, we refer the reader to Wang et al. (2022).
2.1 Setting
Our setting resembles the “bipartite causal inference” setup of Zigler and Papadogeorgou (2018), in that we have a set of observation points and then a separately indexed set of intervention nodes. As described at the outset, these intervention nodes could be points or polygons. Wang et al. (2022) show that the analysis is essentially the same, and so for illustration here we will focus on point interventions. Our application based on Jayachandran et al. (2017) illustrates with a polygon intervention. Both the observation points and intervention nodes reside in the same geographic space. Specifically, suppose that we have a set of intervention nodes indexed by , and these nodes are arrayed as points in a spatial field, . Each point in this spatial field, , equals a coordinate vector of length 2 (recording, e.g., longitude and latitude coordinates). For point interventions, the coordinates of an intervention node can be given by .
For each intervention node, we have a binary random variable that connotes whether, at node , treatment is activated () or not (). Denote the ordered vector of random treatment assignments as , with support . We define potential outcomes such that at each point , we would have outcome when the treatment assignment is such that , and these potential outcomes are defined for each . We stress that outcomes are defined at all values in , not just at the values, which makes the setting bipartite. This definition allows for the existence of interference: the potential outcome of each is decided not by the treatment status of any single intervention node (e.g., the nearest ) but the treatment assignment vector for all the nodes (i.e., ). The outcome that we observe at point , labeled , is the potential outcome associated with the realized treatment assignment vector:
where is the indicator function. Our approach does not require us to attempt to model how is affected by the assignment vector in terms of a regression or other parametric specification (i.e., we allow for effects to be nonlinear and heterogenous).
The setup is consistent with how spatial experiments operate: represents the area where the experiment occurs, for example a region, and the intervention nodes are places where the treatment could be potentially implemented, such as villages. is the outcome—for example, whether a given point in the experimental area (e.g. region) is covered by forests or not. As discussed in the introduction, treatment effects in spatial experiments can have complex forms. Imposing structural restrictions such as homogenous spatial effects can lead to mischaracterizing the effect of an intervention.
Data for points in come in various formats. We may have raster data for which the space is coarsened into raster cells. Alternatively, we may have data for only a sparse set of points in , in which case we could either limit ourselves to working with those sparse points, or we could work with values interpolated between the points.
Our analysis focuses on randomized experiments for which the distribution of the treatment assignment vector, , is known. Our inferential results are derived from the treatment assignment distribution. Extensions to observational studies would follow if the treatment assignment mechanism resembled the kind of Bernoulli process assumed in Wang et al. (2022).
2.2 The average marginalized response
For defining causal effects of interest, we rewrite the potential outcome at point as , where is the treatment status of all the intervention nodes except for node . To concentrate on the effect generated by node , we hold node to treatment value and marginalize over this variation in to define an “individualistic” average of potential outcomes at point :
where is the experimental design parameter that governs the distribution of (that is, the probabilities of different treatment assignment vectors), is a vector of treatment values at nodes other than node , and is the set of possible values that can take. The design parameter, , is an abbreviated way of capturing a variety of factors that might affect the distribution of . For example, it could index vectors of treatment assignment probabilities for the intervention nodes, where such probabilities would determine the level of treatment saturation. It could also index the correlation structure for the treatments, which would characterize potential restrictions (for example, stratification or clustering) on the profiles of possible treatment assignments.
This allows us to define the causal effect at point of intervening on node , allowing other nodes to vary as they otherwise would under :
This defines the effect on raster cell of switching node from no treatment to active treatment, averaging over possible treatment assignments to the nodes other than .
We can aggregate outcomes and effects at each intervention node as follows. First, define the “circle average” function:
where is some well-defined metric that defines whether point is within a specified distance from intervention node , which is located at , and is a suitable integration measure. In the SpatialEffect R package, the user has the possibility to define the distance metric. The default is Euclidean distance, in which case the circle average is defined in terms of the average of raster points that reside on the edge of a circle with radius , defined in terms of the geographic coordinate values. Another option that the SpatialEffect package offers is to define the circle average as points that are within a -coordinate-wide bandwidth around points that are coordinate units from the intervention node; this latter specification defines a disc or circular band (or “donut”) of intervention nodes that are between and coordinate units from the intervention node. The quantity is the average of points selected with the specified distance metric. Then,
is the potential -radius circle average around node , given that node is assigned to treatment condition and marginalizing over possible assignments to other points. The quantity is simply the circle average of the values. Finally,
is the average of individualistic responses for points along the circle of radius around node . This is the circle average of the values for outcome at distance from intervention node .
Working with these terms, our target quantity is the average marginalized response (AMR) for distance , which is simply the average -radius effect over the intervention nodes:
The interpretation of the AMR for distance is the average effect of switching a node to treatment on points at distance from that node, marginalized over possible realizations of treatment statuses in other intervention nodes. The distribution of these possible realizations of treatment statuses depends on the experimental design.
2.3 Estimation and inference
Wang et al. (2022) present non-parametric estimators for the AMR. On the basis of mean square error considerations, the preferred estimator for practical purposes is the Hajek estimator (Särndal, Swensson and Wretman, 1992, pp. 182-184), given by:
where and .
With raster data, we can estimate the values using outcome values from the raster cells. That is, with raster data, the value corresponds to the value of the raster cell that lays over . For data that consist of discrete points over a spatial field, we have two options. One is to use coarsened circle averages. But if the discrete points are sparse, then another approach is to use interpolation. The SpatialEffect R package includes an approach to do this using a kriging fit.111The implementation is based on the Krig() function in the fields package for R. Then, the predicted values from the kriging fit are used for the values in the expression above. As discussed in Wang et al. (2022), we can also smooth the AMR estimates using a local regression approach.
Wang et al. (2022) show that under a set of mild regularity conditions, the Hajek estimator is consistent and asymptotically normal. Essentially, the conditions require the intervention nodes are separated from each other and there exists an upper bound on the number of nodes that interfere with each other. This allows for two types of inference for the estimated AMR. The first is a “sharp null hypothesis” permutation test. The sharp null hypothesis states that the interventions have no effects whatsover, such that , in which case all unit-level effects are also zero and the AMR is zero. If one assumes that the sharp null hypothesis holds, then the randomization distribution of the AMR can be simulated by simply permuting treatment assignment, estimating the AMR under each of these permutations, and then collecting the resulting set of estimates (Imbens and Rubin, 2015, Ch. 5). The resulting distribution is referred to as the null permutation distribution. For a two-way test of the sharp null hypothesis for a specific AMR value with an error rate of , one can evaluate the estimated AMR relative to the and quantiles of the null permutation distribution. (We use for the inferential error rate here so as not to confuse with , which is defined above to characterize the experimental design.) Such tests of the sharp null are approximately in exact finite samples, where the quality of the approximation depends the extent to the which the simulated permutations cover the full set of possible permutations. We can also use a permutation test to test linear functionals of the AMR, such as the mean or cumulative AMR within a range of distance values. To do so, one evaluates the estimated AMR functional value against the null permutation distribution of the functional values. We illustrate this approach below.
The second type of inference provides confidence intervals that combine a normal approximation with a non-parametric spatial heteroskedasticity and autocorrelation consistent (spatial-HAC) standard error estimator as proposed by Conley (1999). These intervals characterize uncertainty for the estimated AMR, and can be used to test the “weak null hypothesis” that the AMR equals zero. (The weak null is implied by the sharp null, but the reverse does not hold.) The SpatialEffect package allows one to construct confidence intervals in either a pointwise manner, for specific AMR values, or in the form of a confidence band for simultaneous inference on the entire AMR curve. Wang et al. (2022) describe conditions under which these intervals are asymptotically conservative with respect to type-I error.
3 Feature of the SpatialEffect package
We have developed an R package, SpatialEffect, to implement the methods described above. As we focus on bipartite designs, the key command in package, also called SpatialEffect(), takes two main inputs. The first is the data of the intervention nodes that records both their coordinates and treatment status. It takes the form of either a dataset with point intervention coordinates and attributes that include treatment status (Zdata) or, for polygon interventions, a shapefile or a raster object (ras_Z) with polygons giving the location of each node along with attributes that include treatment status. The second is the outcome data, which can also be either a raster object (ras) or a dataset with the location and outcome value of each outcome point (Ydata). Users need to specify the variable names of location (x_coord_Z, y_coord_Z) and treatment (treatment) in Zdata as well as location (x_coord_Y, y_coord_Y) and outcome (outcome) in the outcome data if no raster object is provided.222If neither ras nor Ydata is provided, the command will try to find outcome in Zdata and interpolate the outcome values on using kriging.
Users also need to specify the vector of distance values (dVec) at which the AMR will be estimated. It is usually helpful if users plot the data first to check the unit and range of distance in the sample. The distance metric (dist.metric) can be based on Euclidean distance or geodesic distance. Users can choose a set of points that form the edge of a circle of radius , that form a circular band (“donut”) centered at radius , or that form a sector centered at (“disk”), by altering the option cType. When ras_Z is provided, the distance will be calculated from the boundary of each polygon and we implement polygon intervention. Otherwise, it is calculated from the center of each intervention node and point intervention is implemented. There are also several parameters that allow users to control the precision when constructing the circle averages. numpts is the number of sampling points on a circle. If no value is submitted, the number will be decided by the raster object’s resolution. We sample roughly the same number of points for circles with different radius. Users can also choose whether to sample each outcome point only once by setting the value of only.unique.
As discussed in the previous section, the package provides users with two inference methods, a Fisher-style permutation test (per.se) and an asymptotic variance estimator based on Conley (1999) (conley.se). Users can change the error rate defining the level of statistical significance (conley.se). The permutation test can be adjusted to account for blocking or clustering in experimental design. For the asymptotic variance estimator, users need to specify a distance threshold (cutoff) beyond which interference dependence does not exist. This can be based on substantive judgments about the likely spatial extent of interference, and can be varied as part of a sensitivity analysis. Users have the discretion on which kernel (kernel) to use when calculating the standard errors333There are three kernels available: the uniform kernel (“uni” or “uniform”), the triangular kernel (“tri” or “triangular”) and the Epanechnikov kernel (“epa” or “epanechnikov”). and whether to apply an effective degrees of freedom adjustment (edf) as proposed by Young (2015)444The adjustment rescales the variance estimate such that its distribution is a more accurate approximation to the chi-square distribution.. If the option smooth is set to 1, the output will also contain the smoothed AMR estimates.
The command returns a list of objects. The first element in the list, AMR_est, is a data frame that contains each value of dVec and the corresponding estimate of the AMR at that distance value. If per.se is set to be 1, then the list includes an element named Per.CI. For a specified error rate of (e.g., ), it is the and percentiles of the sharp null distribution generated by permutation. At each distance , the sharp null hypothesis of no effect is rejected if the AMR estimate is smaller than the percentile or larger than the percentile. Conley.SE and Conley.CI are in the list if conley.se equals 1. For an error rate , they are the spatial HAC standard errors and the corresponding confidence intervals for the AMR estimate at each distance , respectively. The smoothed AMR estimates (called AMR_est_smoothed) is in the list if the option smooth is turned on. Depending on the values of aforementioned options, the list may also include measures of their uncertainties (smoothed.Conley.SE and smoothed.Conley.CI).
Another command in the package, SpatialEffectTest(), helps researchers evaluate the significance of linear functionals of the estimated AMR effects via a Fisher-style permutation test. It takes the output from SpatialEffect() as an input and needs users to decide the distance range on which the effects are aggregated in the form of a linear functional (i.e., scaled sum) of the AMR estimates. This can be used to estimate a mean effect or a cumulative effect, in the form of a Riemann sum approximation of the area under the AMR curve. The SpatialEffectTest() function generates the null permutation distribution of the sum of the AMR estimates within the specified range. One can then use this null distribution to test the statistical significance of the linear functional estimate.
We also have display functions summary() and print(). Both take the output of SpatialEffect() as the input and print estimates within the distance range specified by the user (dVec.range).
4 A toy example
We now illustrate concepts discussed above using a toy simulated example based on point interventions. We offer a full-fledged application with polygon interventions in the next section. The toy example includes 4 intervention nodes in a spatial field where outcomes are recorded in a 4-by-4 raster (left plot of Figure 2). We construct a hypothetical effect function by mixing two gamma-distribution kernels. This yields a non-monotonic effect emanating from each intervention node, which is presented on the right plot of Figure 2.
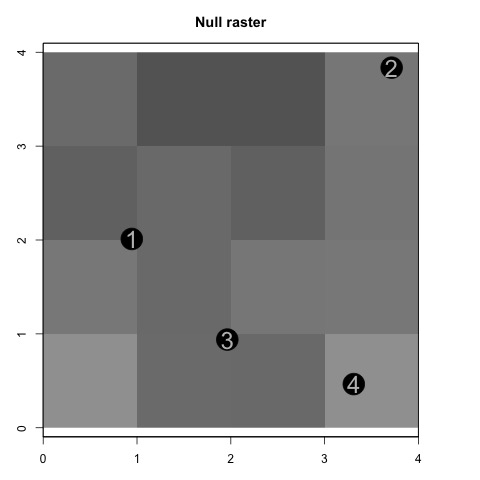
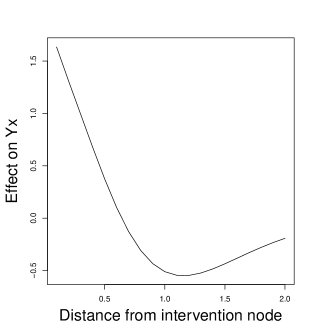
To get the true AMR, we need to marginalize over all of the ways that treatment could be applied. We suppose Bernoulli random assignment of the nodes to treatment, in which case there are 16 ways treatment could be applied, all with equal probability. We then simulate the potential outcomes that would correspond to each treatment assignment and view the result.

We can construct the causal quantities using outcomes under the sixteen assignments. First are the values of (the node-and-point-specific effects). For each grid cell, there will be a separate value corresponding to the effect of switching treatment status of each intervention node, averaging over possible assignments at other nodes. This corresponds to the difference in mean potential outcomes when node is in treatment versus in control, where these means are taken with respect to the set of assignments in the assignment matrix ( in the formal analysis). So, to compute the values, we go through each assignment and take differences in means for outcome values corresponding to treatment status with 1 minus those with 0. For example, to calculate , we take the average over outcome values in graphs where node 1 is treated and subtract from it the the average over outcome values in graphs where node 1 is under control.
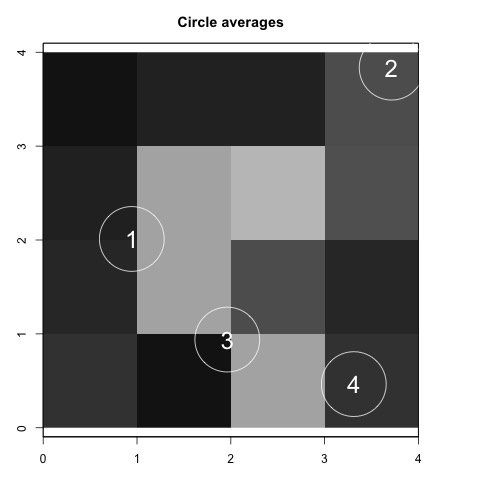
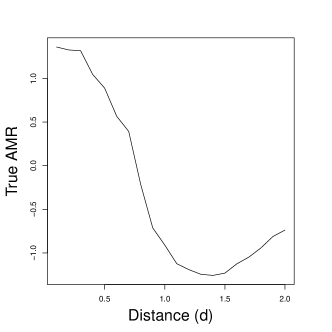
We then obtain the -specific values for each of the intervention nodes by drawing circles with radius around them. The left plot of Figure 4 shows how the circle averages are constructed when the distance metric is Euclidean distance and . For this particular , the circle average for node uses four grid cells while that of node only uses one. Finally, we aggregate these values to get the vector of -specific AMR. The true AMR values reflect the non-monotonicity of the effect function (the right plot of Figure 4).
5 Spatial effects in the toy example
The first step in the analysis is to prepare Zdata. We extract the location and treatment status of our four intervention nodes under a particular assignment. We name the variables x, y, and Z. We also name the raster object in the toy example ras_sim. Based on the plot, we choose dVec to be a sequence from to with an interval length of 0.1. The cutoff point for the spatial HAC variance is set to be 0.4 and the number of permutations is set to be 1000.555The number doesn’t make any difference here as there are in total 6 assignments.
We use the SpatialEffect() function to estimate the AMR as follows:
dVec = seq(from=.1,to=2, by=.1)
AMRest <- SpatialEffect(ras = ras_sim, Zdata = Zdata, x_coord_Z = "x",
y_coord_Z = "y", treatment = "Z", dVec = dVec,
cutoff = .4, nPerms = 1000, smooth = 1)
Next, we summarize the estimates when the distance values are between 0.1 and 1 with either summary() and print(). Conley.CI.l and Conley.CI.u refer to the lower and upper bounds of the confidence intervals based on the spatial HAC variance estimator. Per.CI.l and Per.CI.u are bounds of the confidence intervals under the null distribution.
summary(AMRest, dVec.range = c(0.1, 1))
dVec AMR_est Conley.CI.l Conley.CI.u Per.CI.l Per.CI.u
[1,] 0.1 1.491 -0.277 3.259 -1.566 1.566
[2,] 0.2 1.550 -0.242 3.343 -1.626 1.626
[3,] 0.3 1.550 -0.242 3.343 -1.626 1.626
[4,] 0.4 1.691 -0.050 3.431 -1.666 1.666
[5,] 0.5 1.714 -0.020 3.448 -1.684 1.684
[6,] 0.6 1.700 -0.038 3.438 -1.673 1.673
[7,] 0.7 1.678 -0.066 3.422 -1.657 1.657
[8,] 0.8 1.002 -0.067 2.071 -1.005 1.005
[9,] 0.9 -0.816 -2.424 0.791 -1.328 1.328
[10,] 1.0 -0.791 -2.295 0.714 -1.307 1.307
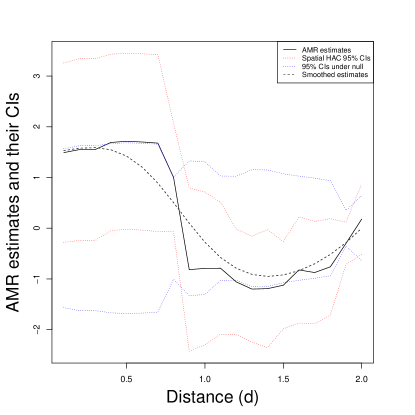
The results are also presented in Figure 5. The black solid line in the graph is the AMR estimate for each of the distance values . The red dotted line is the 95% confidence interval based on the spatial-HAC standard errors. The blue dotted line shows the 0.025 and .975 percentiles of the sharp null permutation distribution. The black dashed line is the smoothed AMR estimates. The results suggest that the AMR estimates are marginally significant when is small, where the estimates are slightly larger than the .975 percentile of the sharp null permutation distribution and the red line on the bottom is close to be positive. We also see that the estimated AMR corresponds to the shape of the AMR in Figure 4.
To further test this initial inference regarding effects at small values of , we use SpatialEffectTest() to examine whether the cumulative effect is statistically significant on the interval :
testResult <- SpatialEffectTest(AMRest, c(0.1, 0.5))
The 0.025 and .975 percentiles of the sharp null permutation distribution of the cumulative effect are and , respectively, while the actual cumulative effect is . Based on an error rate of , we would reject the sharp null hypothesis that there is no cumulative effect on the distance interval of .
Wang et al. (2022) present simulation studies to show how finite sample inference converges toward expected asymptotic performance in the number of intervention nodes. Computation time depends on whether one is smoothing the AMR curve, and if so whether one uses cross-validation to calibrate the smoother bandwidth, whether one is working with point interventions or polygon interventions, and then the resolution of the spatial polygons or rasters. For example, on a MacBook with a 2.4 GHz dual-core processor, with point interventions, an outcome raster resolution of 100 cells per intervention node, and sample sizes of 16, 64, and 144 intervention nodes, run time is approximately 12, 54, and 78 seconds without cross-validation-calibrated smoothing, and 17, 79, and 238 seconds with cross-validation-calibrated smoothing. For the forest conservation application that we present below, which uses polygon interventions, high resolution spatial data, and cross-validation-calibrated smoothing, the run time is approximately 2.5 hours.
6 An experiment on payments for forest conservation
We demonstrate the utility of the SpatialEffect package by evaluating a payments for ecosystems services (PES) conservation program in Uganda. PES programs are a form of environmental governance that financially renumerate landowners for environmental performance, such as reduced forest loss, and have become a cornerstone of international climate policies aimed at reducing emission from forest loss (Agrawal, Nepstad and Chhatre, 2011; Ferraro, 2011; Ferraro and Kiss, 2002). Prior assessments of PES programs used quasi-experimental methods to estimate the effects but have found divergent results based on selected designs and control strategies (Alix-Garcia, Sims and Yanez-Pagans, 2015; Arriagada et al., 2012; Pattanayak, Wunder and Ferraro, 2010; Samii et al., 2014). While evaluation methods of conservation programs have increased in recent years, the knowledge of potential spillover effects beyond the immediate location of intervention sites remains scarce (Pfaff and Robalino, 2017).
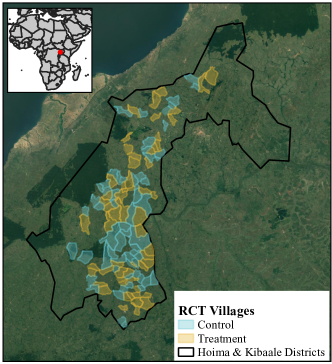
The PES case study that we examine in Uganda was previously evaluated by Jayachandran et al. (2017) with a randomized control trial design, a rarity in conservation policy evaluation (Wiik et al., 2019). The PES program was designed and implemented by a local nonprofit—Chimpanzee Sanctuary and Wildlife Conservation Trust (CSWCT)—in Hoima and northern Kibaale districts of Uganda (Figure 6). The study was carried out in 121 villages, 60 of which were randomly assigned to treatment (Figure 6). In treatment villages, the PES program was advertised to private forest owners (PFOs) to enroll in a 2-year conservation program from 2011 to 2013. Enrollees could receive 70,000 Ugandan shillings (UGX), or $28 in 2012 US dollars, per hectare of forest per year. The PES program achieved a low-level of enrollment with 180 private forest owners (32%) participating but a high-level of compliance with 88% of enrollees meeting the requirements to preserve forested land Jayachandran et al. (2017). Individual behavioral changes were found to aggregate to village level landscape differences. In treatment villages, tree cover, estimated using high-resolution satellite imagery, declined 4.2% over the study period compared to 9.1% in control villages.
A common concern of PES programs is whether conservation in one region may accelerate deforestation elsewhere due to equilibrium effects or non-compliant participants who shift to deforesting beyond regulated forest boundaries—so-called “leakage.” Jayachandran et al. (2017)’s main analyses take the villages in the study to be independent, assuming no spillover. They address the possibility of spillover only to a limited extent. First, they perform an indirect test by studying whether the effects of PES were larger in areas adjacent to forest reserves, given that such locations are places where displacement might be more likely. They do not find such effect heterogeneity to be present. Second, they look at whether forest loss in control villages varied in terms of the number of treated villages within 5km, finding no evidence for such a pattern. As the authors recognize, these two tests still allow for the possibility for spillover effects in the broader forest system outside the treated and control villages themselves, a possibility that is visibly apparent in looking at how the villages are situated in Figure 6. Moreover, the result with regard to the number of nearby treated villages could be sensitive to the choice of 5km bandwidth. (For a related discussion, see Clemens and Sandefur (2015).)
To characterize spillovers in a more robust manner, we extend the analysis to include forest raster data from the entire region (not just within the treated and control villages) and apply the methods described above to estimate the AMR curve.
The data used for our reanalysis includes the treatment and control village boundaries from the original Jayachandran et al. (2017) study.
The boundaries were not publicly available and thus hand digitized from available spatial data and published maps.666The original data repository can be found at:
https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/MGMDYN
The data is stored as a shapefile named ras_Z.
The forest cover data available from Jayachandran et al. (2017) was limited to village boundaries.
Therefore we use the Hansen et al. (2013) forest cover dataset for years 2012 and 2013 with greater than 25% tree cover over the study area.
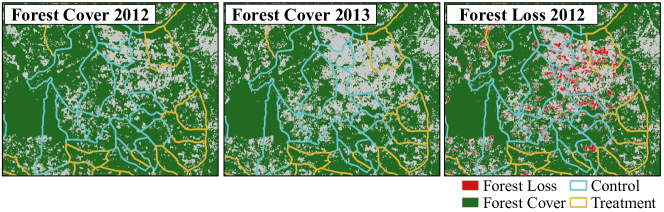
Figure 6 shows our reconstructed map of the study area, and Figure 7 zooms in to a subset of the study area to show forest cover values from Hansen et al. (2013) that we used in the analysis.
The data is stored as a raster object named ras.
We set the range of distance values to be between 0 kilometer and 20 kilometers. We consider the experiment as an example of polygon interventions. Therefore, the starting point at 0 corresponds to the area within the boundary of each village. It is worth noting that the distance unit in the raster of forests is decimal degrees. Since 1 decimal degree is approximately 111 km, the distance values we select are between 0 and , with a step size of . The cutoff is set at 10 km = 10,000 m. We specify the SpatialEffect() function as follows:
dVec = seq(from=0, to=20/111, by=5/111)
AMRest <- SpatialEffect(ras = ras, ras_Z = ras_Z, treatment = "treatment",
dVec = dVec, smooth = 1, cutoff = 10000,
dist.metric = "Geodesic")
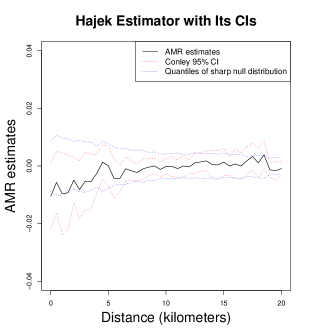
We display the estimates for distance values between 0 and 20 kilometers in Figure 8. Similar to the analysis of the toy example, the black solid lines in Figure 8 are the AMR estimate for each distance value from the Hajek estimator. We estimate that the PES intervention generates effects that transmit outward from the treated villages. The effects gradually diminish in distance, and disappear when the distance to a treated village is larger than 10 kilometers. We find the same pattern in non-smoothed and smoothed estimates. We show how the confidence intervals for the smoothed estimates vary with the selected value of the cutoff. When cutoff equals 0, the confidence intervals ignore the uncertainties caused by interference. Hence, they are much narrower compared to the others. The bottom graph shows 2km “donut” estimates: we estimate the AMR using outcome raster outcomes within 2km bands, rather than values precisely at the edge of the circle. The results show a similar pattern as the two graphs above.
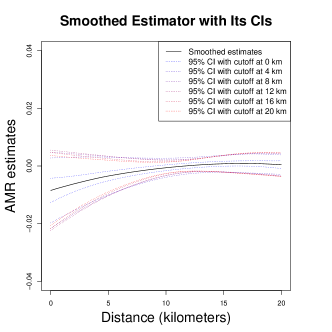

We test whether the cumulative effect between 1 and 2.5 kilometers are statistically significant using the SpatialEffectTest() function:
testResult <- SpatialEffectTest(AMRest, test.range = c(1/111, 2.5/111))
For the cumulative effect between 1 km and 2.5 km, the 0.025 and .975 percentiles of the sharp null permutation distribution are and (that is, a 3.04 percentage point reduction to a 3.36 percentage point increase in the cumulative probability of forest loss), respectively. The estimated cumulative effect between 1 km and 2.5 km is (i.e., a 3.21 percentage point reduction). The cumulative effect between 1 km and 2.5 km is thus significant with . Beyond 2.5 km, spillover effects of the PES program appear to be negligible.
Thus, we find evidence for a spatial bandwagon effect that emanates up to 2.5 km outward beyond the intervention sites. These results are somewhat at odds with what Jayachandran et al. (2017) conclude regarding spillover effects, although they did not attempt to estimate precisely the kind of spatial effect that is captured by the AMR. The closest test that they conduct is to analyze whether there was less forest loss in control areas on the basis of the number of treated villages within 5 km. The key reason for why we find more compelling evidence is that our analysis is not restricted to forest loss within the village boundaries per se, which was that case for Jayachandran et al. (2017). Our analysis extends to forest areas that are outside the study villages too. An implication of our findings is that the between-village differences Jayachandran et al. (2017) use to estimate the effect of the program may understate the overall impact of the PES intervention.
7 Conclusion
This paper presents a robust, design-based approach to inference for effects in spatial experiments in environmental, health, agricultural, and other social applications. Spatial experiments often exhibit complex displacement, bandwagon, and other spillover effects. These are forms of “interference,” which means that effects at a given point depend not only on the treatment of the nearest intervention site, but on the distribution of treatments over all intervention sites. Ignoring interference can result in mistaken conclusions. Mistakes can also result from relying on overly simplified models of spatial effects. The approach presented here makes careful use of the experimental design to make reliable inferences while remaining agnostic as to the precise nature of the outcome data generating process.
The presentation here follows Wang et al. (2022) and focuses on randomized experiments. Extensions to observational studies are possible in principle, so long as the treatment assignment mechanism abides by a process that is equivalent to what is described in Wang et al. (2022). We plan to extend the SpatialEffect package to include covariate-conditional analyses that could broaden the range of possible observational applications.
We also offer detailed examples for applying the methods we present. These methods are encoded in the SpatialEffect package for R, and we offer a step-by-step tutorial above on its use. We then apply these tools to reanalyzing the spatial effects of an intervention that offered payments to promote forest conservation in Uganda. We uncover spatial effects that were not appreciated in the original analysis. These effects suggest that the original analysis may have understated the overall impact of the program, and offer an example for why it can be crucial to account for interference in analyzing spatial experiments.
References
- (1)
-
Agrawal, Nepstad and Chhatre (2011)
Agrawal, Arun, Daniel Nepstad and Ashwini Chhatre. 2011.
“Reducing Emissions from Deforestation and Forest Degradation.”
Annual Review of Environment and Resources 36(1):373–396.
https://doi.org/10.1146/annurev-environ-042009-094508 -
Alix-Garcia, Sims and Yanez-Pagans (2015)
Alix-Garcia, Jennifer M., Katharine R. E. Sims and Patricia
Yanez-Pagans. 2015.
“Only One Tree from Each Seed? Environmental Effectiveness and
Poverty Alleviation in Mexico’s Payments for Ecosystem Services Program.”
American Economic Journal: Economic Policy 7(4):1–40.
https://www.aeaweb.org/articles?id=10.1257/pol.20130139 - Arbia (2006) Arbia, Giuseppe. 2006. Spatial econometrics: statistical foundations and applications to regional convergence. New York: Springer.
- Aronow and Samii (2017) Aronow, Peter M. and Cyrus Samii. 2017. “Estimating Average Causal Effects Under General Interference, with Application to a Social Network Experiment.” Annals of Applied Statistics 11(4):1912–1947.
- Aronow et al. (2020) Aronow, Peter M., Dean Eckles, Cyrus Samii and Stephanie Zonszein. 2020. “Spillover Effects in Experimental Data.” arXiv 2001.05444 [stat.AP].
-
Arriagada et al. (2012)
Arriagada, Rodrigo A., Paul J. Ferraro, Erin O. Sills, Subhrendu K. Pattanayak
and Silvia Cordero-Sancho. 2012.
“Do Payments for Environmental Services Affect Forest Cover? A
Farm-Level Evaluation from Costa Rica.” Land Economics 88(2):382–399.
http://le.uwpress.org/content/88/2/382.abstract - Chernozhukov, Chetverikov and Kato (2013) Chernozhukov, Victor, Denis Chetverikov and Kengo Kato. 2013. “Gaussian approximations and multiplier bootstrap for maxima of sums of high-dimensional random vectors.” The Annals of Statistics 41(6):2786–2819.
- Clemens and Sandefur (2015) Clemens, Michael and Justin Sandefur. 2015. “Mapping the worm wars: What the public should take away from the scientific debate about mass deworming.” Center for Global Development Blog .
- Conley (1999) Conley, Timothy G. 1999. “GMM estimation with cross sectional dependence.” Journal of Econometrics 92:1–45.
- Cox (1958) Cox, D. R. 1958. Planning of Experiments. Wiley.
- Darmofal (2015) Darmofal, David. 2015. Spatial Analysis for the Social Sciences. Cambridge: Cambridge University Press.
-
Ferraro (2011)
Ferraro, Paul J. 2011.
“The Future of Payments for Environmental Services.” Conservation Biology 25(6):1134–1138.
https://conbio.onlinelibrary.wiley.com/doi/abs/10.1111/j.1523-1739.2011.01791.x -
Ferraro and Kiss (2002)
Ferraro, Paul J. and Agnes Kiss. 2002.
“Direct Payments to Conserve Biodiversity.” Science
298(5599):1718–1719.
https://science.sciencemag.org/content/298/5599/1718 -
Hansen et al. (2013)
Hansen, M. C., P. V. Potapov, R. Moore, M. Hancher, S. A. Turubanova, A.
Tyukavina, D. Thau, S. V. Stehman, S. J. Goetz, T. R. Loveland, A.
Kommareddy, A. Egorov, L. Chini, C. O. Justice and J. R. G.
Townshend. 2013.
“High-Resolution Global Maps of 21st-Century Forest Cover Change.”
Science 342(6160):850–853.
https://science.sciencemag.org/content/342/6160/850 - Hu, Li and Wager (2022) Hu, Yuchen, Shuangning Li and Stefan Wager. 2022. “Average direct and indirect causal effects under interference.” Biometrika .
- Hudgens and Halloran (2008) Hudgens, Michael G. and M. Elizabeth Halloran. 2008. “Toward causal inference with interference.” Journal of the American Statistical Association 103(482):832–842.
- Imbens and Rubin (2015) Imbens, Guido W. and Donald B. Rubin. 2015. Causal Inference for Statistics, Social, and Biomedical Sciences: An Introduction. Cambridge: Cambridge University Press Press.
-
Jayachandran et al. (2017)
Jayachandran, Seema, Joost de Laat, Eric F. Lambin, Charlotte Y. Stanton, Robin
Audy and Nancy E. Thomas. 2017.
“Cash for carbon: A randomized trial of payments for ecosystem
services to reduce deforestation.” Science 357(6348):267–273.
https://science.sciencemag.org/content/357/6348/267 - Kelejian and Piras (2017) Kelejian, Harry and Gianfranco Piras. 2017. Spatial Econometrics. New York: Elsevier.
- Manski (2012) Manski, Charles F. 2012. “Identification of treatment response with social interactions.” The Econometrics Journal (In press).
-
Pattanayak, Wunder and Ferraro (2010)
Pattanayak, Subhrendu K., Sven Wunder and Paul J. Ferraro. 2010.
“Show Me the Money: Do Payments Supply Environmental Services in
Developing Countries?” Review of Environmental Economics and Policy
4(2):254–274.
https://doi.org/10.1093/reep/req006 -
Pfaff and Robalino (2017)
Pfaff, Alexander and Juan Robalino. 2017.
“Spillovers from Conservation Programs.” Annual Review of
Resource Economics 9(1):299–315.
https://doi.org/10.1146/annurev-resource-100516-053543 - Rubin (2008) Rubin, Donald B. 2008. “For Objective Causal Inference, Design Trumps Analysis.” The Annals of Applied Statistics 2(3):808–840.
- Samii et al. (2014) Samii, Cyrus, Matthew Lisiecki, Parashar Kulkarni, Laura Paler, Larry Chavis, Birte Snilstveit, Martina Vojtkova and Emma Gallagher. 2014. “Effects of payment for environmental services (PES) on deforestation and poverty in low and middle income countries: a systematic review.” Campbell Systematic Reviews 10(1):1–95.
-
Samii and Wang (2020)
Samii, Cyrus and Ye Wang. 2020.
SpatialEffect: An R package for Design-Based Inference in
Spatial Experiments.
R package version 0.1.
https://github.com/cdsamii/spatial/package/SpatialEffect - Särndal, Swensson and Wretman (1992) Särndal, Carl-Erik, Bengt Swensson and Jan Wretman. 1992. Model Assisted Survey Sampling. New York: Springer.
- Sävje, Aronow and Hudgens (2018) Sävje, Fredrik, Peter M. Aronow and Michael G. Hudgens. 2018. “Average treatment effects in the presence of unknown interference.” arXiv:1711.06399 [math.ST] .
- Wang et al. (2022) Wang, Ye, Cyrus Samii, Haoge Chang and P. M. Aronow. 2022. “Design-Based Inference for Spatial Experiments with Interference.” arxiv 2010.13599 [stat.ME].
-
Wiik et al. (2019)
Wiik, Emma, Rémi d’Annunzio, Edwin Pynegar, David Crespo, Nigel Asquith
and Julia P. G. Jones. 2019.
“Experimental evaluation of the impact of a payment for
environmental services program on deforestation.” Conservation Science
and Practice 1(2):e8.
https://conbio.onlinelibrary.wiley.com/doi/abs/10.1111/csp2.8 - Young (2015) Young, Alwyn. 2015. “Improved, Nearly Exact, Statistical Inference with Robust and Clustered Covariance Matrices using Effective Degrees of Freedom Corrections.” Unpublished Manuscript, London School of Economics.
- Zigler and Papadogeorgou (2018) Zigler, Corwin M. and Georgia Papadogeorgou. 2018. “Bipartite Causal Inference with Interference.” arXiv 1807.08660 [stat.ME].