Inference of Media Bias and Content Quality Using Natural-Language Processing
Abstract
Media bias can significantly impact the formation and development of opinions and sentiments in a population. It is thus important to study the emergence and development of partisan media and political polarization. However, it is challenging to quantitatively infer the ideological positions of media outlets. In this paper, we present a quantitative framework to infer both political bias and content quality of media outlets from text, and we illustrate this framework with empirical experiments with real-world data. We apply a bidirectional long short-term memory (LSTM) neural network to a data set of more than 1 million tweets to generate a two-dimensional ideological-bias and content-quality measurement for each tweet. We then infer a “media-bias chart” of (bias, quality) coordinates for the media outlets by integrating the (bias, quality) measurements of the tweets of the media outlets. We also apply a variety of baseline machine-learning methods, such as a naive-Bayes method and a support-vector machine (SVM), to infer the bias and quality values for each tweet. All of these baseline approaches are based on a bag-of-words approach. We find that the LSTM-network approach has the best performance of the examined methods. Our results illustrate the importance of leveraging word order into machine-learning methods in text analysis.
keywords:
Research
,
1 Introduction
Mass media is a fundamental part of modern society. Media outlets provide windows to the world and influence public knowledge, attitudes, and behavior [1]. They disseminate news and information, help educate the public, provide entertainment, and influence the spread of ideologies and opinions [2]. However, media outlets have biases (including potentially very strong ones), and their influential societal roles make it important to examine such biases [3, 4]. Biased ideologies can impact people’s choices (e.g., through their attitudes on topics like abortion [5]), their sharing behavior on social media [6], and more. Additionally, media can exacerbate political polarization by intensifying or even creating ideological “echo chambers” [7, 8] and enhancing so-called “pernicious polarization” [9], which divides societies into “Us versus Them” camps along a focal dimension of difference that overshadows other similarities and differences. There is a long history of quantitative studies of voting blocs and ideological biases of politicians [10, 11, 12]. Researchers have quantitatively examined the ideological biases of politicians in a variety of situations, including in social media [13, 14, 15, 16, 17, 18] and in television interviews [19]. Media outlets help broadcast the messages of public figures (such as politicians), which, in turn, influences public biases and opinions. Moreover, the quantitative study of the ideologies of politicians also helps guide investigations of the political biases of other entities, such as private citizens and media outlets, and one can estimate the ideological positions of individuals based on the media outlets with which they engage [20].
There are a variety of approaches to quantify ideological bias. It is common to use a liberal–conservative (i.e., “Left–Right”) political spectrum as a one-dimensional (1D) spectrum when analyzing ideological biases [16, 21, 22, 23]. This places these ideological biases in the context of common political polarities. A Left–Right dimension also arises in data-driven inference of ideological positions in multiple dimensions [10, 24]. In the United States, it is traditional to place the Democratic political party on the Left and the Republican political party on the Right. Ideological views manifest in conversations and other “digital footprints” on social-media platforms [25], such as in posts by politicians on Twitter. For example, Anmol et al. [22] manually counted selected words in tweets that are related to COVID-19 and concluded that Republican politicians post more tweets that are related to business and the economy and that Democratic politicians concentrate more on public health. Xiao et al. [26] examined political polarities in textual data from social-media platforms (specifically, from Twitter and Parler) and quantified such ideological biases on tweets from politicians and media outlets by assigning polarity scores to words, hashtags, and other objects (“tokens”) in social-media posts. Waller et al. [18] introduced a multidimensional framework to summarize the ideological views, with a focus on traditional forms of identity (specifically, they considered age, gender, and political partisanship) of the posters and commenters, of Reddit posts around the time of the 2016 United States presidential election. Similarly, Gordon et al. [27] argued that one cannot fully capture political bias using a single axis with two binary ideological extremes (such as Republican and Democrat); instead, one should use multidimensional approaches. Moreover, models that aim to analyze the content of media outlets should incorporate not only measures of outlet biases but also measures of outlet quality [28, 29]. In the present paper, we use natural-language processing (NLP) [30] of textual data from tweets by media outlets to infer (Left–Right, low–high) coordinates for these outlets, where the first dimension describes the political bias of a media outlet and the second dimension represents its quality.
Neural-network models that are based on deep learning have been useful for many NLP tasks, including speech recognition [31], sentiment classification, answer selection, and textual entailment [32]. By using deep neural networks instead of traditional machine-learning (ML) approaches (such as a naive-Bayes method), one can significantly improve the performance of tasks like text classification [33]. Moreover, neural networks that exploit input word sequences can produce more accurate results than methods that rely on a bag-of-words approach [34, 35]. Recurrent neural networks (RNN) are a trendy deep-learning architecture to analyze sequential textual data. For example, Socher et al. [36] used an RNN to study binary sentiments (i.e., favorable or unfavorable) from a data set of movie reviews. In the present paper, we apply a specific type of RNN called a long short-term memory (LSTM) neural network to infer ideological and quality coordinates of media outlets based on the textual content of their tweets. We also compare the results of using an LSTM network to those from several traditional ML methods that have been used in previous sentiment analysis studies. These traditional approaches include a naive-Bayes method, a support-vector machine (SVM), an artificial neural network (ANN), a decision tree, and a random forest. All of these traditional approaches use a bag-of-words approach.
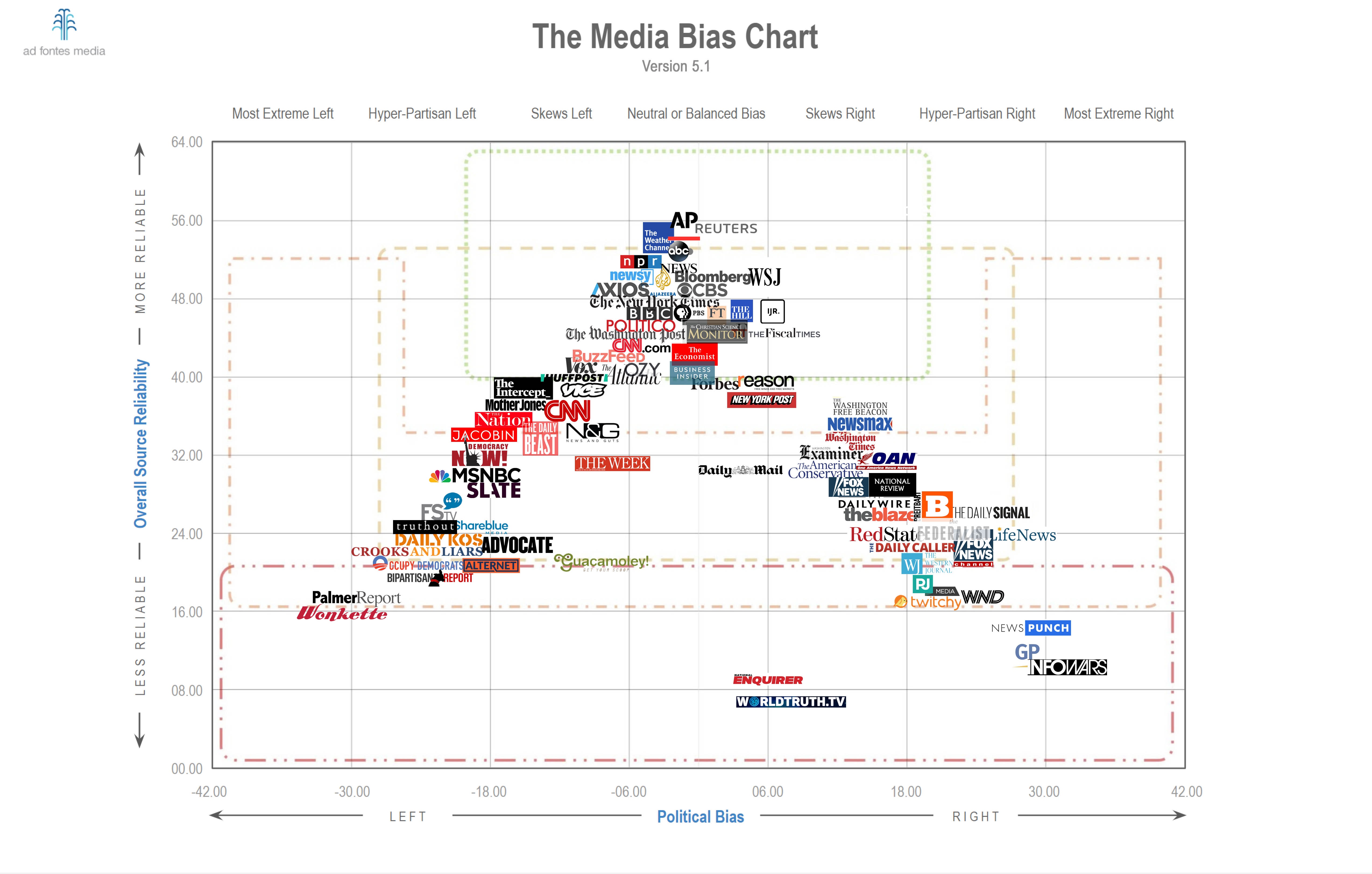
To further motivate our work, consider the Ad Fontes Media-Bias Chart (AFMBC) [37], which is a two-dimensional (2D) visualization (see Figure 1) of the political ideologies and content qualities of about 100 media outlets. The AFMBC shows the positions of media outlets with ideological biases along one axis and content qualities along the other axis. The AFMBC uses data from 1,818 online articles and 98 cable news shows, which were rated in 2019 by a politically balanced team of analysts [37]. In the AFMBC, the bias and quality scores of each media outlet are the mean scores of each rated news item. Typically, 15–20 news items were used to evaluate a media outlet; at least three analysts rated each news item.
By necessity, the AFMBC uses a small number of items from each media outlet, although media outlets produce a wealth of content. By applying modern data-science techniques, one can leverage such abundant data through an algorithmic process of rating documents for both bias and quality. For example, Widmer et al. [38] applied penalized logistic regression and latent Dirichlet allocation (LDA) to a corpus of about 40,000 transcribed television episodes and examined the potential influence that national cable television can have on local newspapers. By measuring the textual similarities between the content of national television channels (specifically, Fox News, CNN, and MSNBC) and local newspaper content, they found that the content of local newspapers with more viewership of a given cable channel has greater textual similarity with the content of that cable channel than with it does with the other examined cable channels. They suggested the possibility that national cable television propagates slants and partisan biases to local newspapers and can thereby polarize local news content. In the present paper, we explore the potential to quantify the political ideologies and content qualities of media outlets based on the tweets that they posted in a specific time window. We use a data set from the Harvard GWU Libraries Dataverse [39] of more than 30 million tweets from more than 4,000 news outlets. We then remove tweets that were not posted by media outlets in the AFMBC. This leaves about 1.4 million tweets, to which we apply ML techniques to infer bias and quality coordinates for each tweet. There is no absolute truth in the numerical values of a media outlet’s bias and quality scores. Therefore, we evaluate the performance of the ML algorithms by comparing their outputs with the AFMBC. The 2D coordinates that we obtain from an algorithm can provide insight into ideological polarization and can serve as an input to opinion-dynamics models, such as the one in [40] that incorporates media outlets.
1.1 Our Contributions
As of May 2020 (based on manual inspection), 65 of the media outlets in the AFMBC maintained active Twitter accounts. The other media outlets in the AFMBC either did not have a Twitter account or had a suspended account at that time. Between 4 August 2016 and 12 May 2020, these 65 accounts generated 1.4 million tweets; these tweets are tabulated in the George Washington University (GWU) Libraries Dataverse [39] in the Harvard Dataverse. We use several existing supervised ML algorithms (a naive-Bayes method, an SVM, an ANN, a decision tree, a random forest, and an LSTM network) to infer the ideological biases and content qualities of each tweet. We then compute the bias and quality scores for each media outlet by calculating the means of the biases and qualities of their tweets. In Figure 2, we show our workflow for inferring the bias and quality scores of the tweets and media outlets.
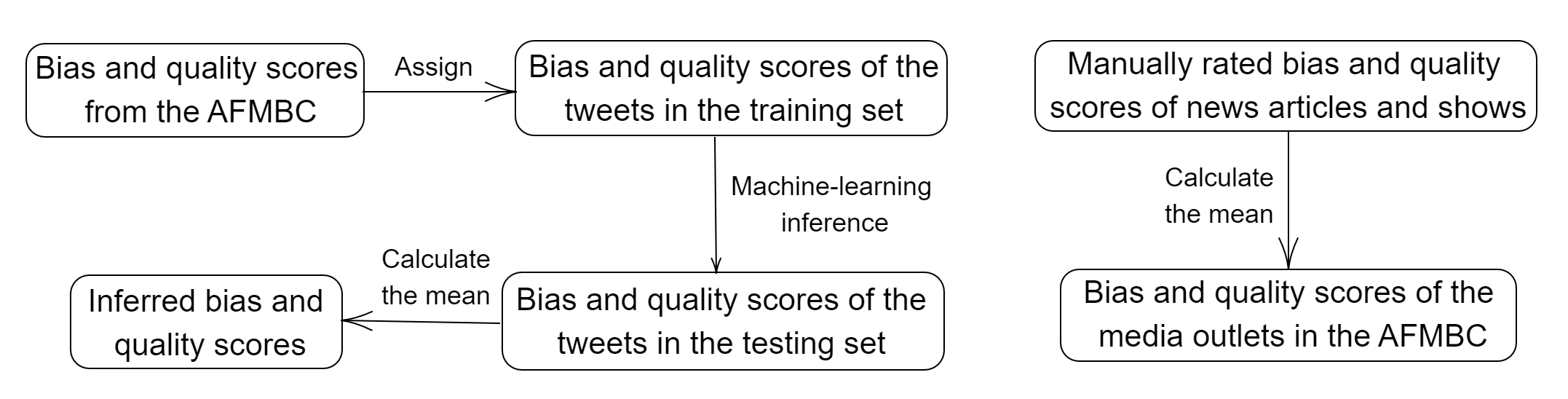
We observe a strong linear correlation between the manually rated political ideologies in the AFMBC (which plays the role of a “ground truth” in our study) and the political ideologies that are inferred by the LSTM network. We observe a similarly strong positive linear correlation between the AFMBC quality scores and the inferred quality scores. This suggests that algorithms can successfully produce reasonable (ideology, quality) scores for articles and other text from media outlets. We generate a 2D media-bias chart for the examined media outlets and compare it with the AFMBC. We then compare the results of an LSTM neural-network approach to the results of several traditional methods (a naive-Bayes method, an SVM, a decision tree, a random forest, and an ANN). We find that the LSTM approach (which considers word sequences) outperforms these baseline methods, which each use a bag-of-words approach.
1.2 Organization of our Paper
Our paper proceeds as follows. In Section 2, we discuss several ML methods that we use to infer the ideological biases and content qualities of tweets. In Section 3, we briefly describe the employed data, which includes the manually rated news articles and shows from Ad Fontes [37] and the media-outlet tweets from the GWU Libraries Dataverse [39]. In Section 4, we propose a scheme to construct a media-bias chart from the tweet content of media outlets. We also briefly describe our preprocessing of the tweets. In Section 5, we introduce how we evaluate the performance of each ML method and compare the performance of different ML methods. In Section 6, we conclude and discuss future work. In Appendix A, we list the 65 examined media outlets and the number of tweets for each of them.
2 Background and Related Work on NLP Methods
Because of the increased bounty and accessibility of machine-readable text [41], researchers have applied many supervised ML techniques to analyze and classify textual data [42]. One can categorize supervised NLP methods into (1) sequential approaches (which account for word order) and (2) non-sequential approaches (which do not). Non-sequential methods transform a document into a bag of words before subsequent analysis [43]. Such methods were the typical type of approach in early NLP studies with ML techniques [44, 45, 46], and they are still the main approach for smaller data sets (e.g., ones with fewer than 5,000 data points [47]). Importantly, sequential models (e.g., RNNs [48]) transform a document into a sequential input and use associated contextual information when mapping from an input sequence to an output sequence [49]. Therefore, we expect the inference of political ideologies to be more effective with a sequential approach than with a bag-of-words approach [36].
In this section, we briefly discuss several non-sequential approaches (which we employ as baseline methods) and a sequential approach that we use to infer a media-bias chart from the tweets of media outlets. In Table 1, we summarize our key notation.
| symbol | explanation | example or further information |
|---|---|---|
| an entire data set or a training set | example: the entire set of tweets | |
| or | an input feature vector | example: one tweet |
| the th entry of a vector | example: one word | |
| the label of the th input | example: the label of the th tweet | |
| a vector of weights | we use these in the SVM and the neural networks | |
| the bias term in | we use these in the SVM and the neural networks | |
| the index of a label | it ranges from to when there are classes in total |
2.1 Naive-Bayes Method
A naive-Bayes method is a simple approach that has been used successfully for text categorization [46, 50, 51], which is the common NLP task of assigning each text document in a corpus to a category .
We start with Bayes’ rule
Using the chain rule, we compute the probability that the current item (for example, the th tweet), with feature vector (for example, the sequence of words in the th tweet), is in category . This yields
The word “naive” appears in the method’s name because a naive-Bayes approach assumes that all words have independent probabilities of appearing in a document. That is,
In a naive-Bayes approach, one needs both and to compute the output probability . One substitutes the probability for the relative frequency of class in the training set. We obtain the conditional probability using maximum a posteriori (MAP) estimation [52].
2.2 Support-Vector Machines (SVMs)
SVMs have been employed often in classification tasks [53, 54, 55]. For example, Go et al. [50] used SVMs for sentiment classification of Twitter data. Gopi et al. [47] used an SVM approach for tweet classification using positive and negative opinions.
In a traditional SVM, one is given a training data set and seeks binary class labels, which we denote by and . One seeks the maximum-margin hyperplane that separates the data points of those two different classes. One attempts to minimize the hinge loss
| (1) |
where the parameter determines the trade-off between the margin size and the labeling accuracy, which is equal to the number of correctly assigned labels divided by the number of elements in the training set. The loss function (1) is convex, so one can use a common convex-optimization approach (e.g., gradient descent) to successfully minimize it [56].
The original SVM setting is directly applicable only to binary classification. For classification problems with three or more labels, one needs to split the classification task into multiple binary-classification tasks.
2.3 Decision Trees and Random Forests
A decision tree is a flowchart-like structure in which each node of the tree splits the flow of a procedure into two sets of classes based on the information gain , where
is the entropy of a data set and
is the conditional entropy of a data set after the split at node , where denotes the set of all possible splits at with respect to one variable.
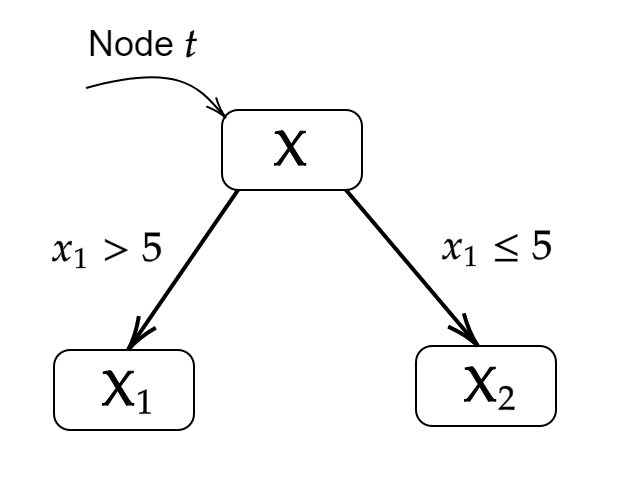
In Figure 3, we give a schematic illustration of splitting a source data set. In this example, the full data set is , the subsets and are disjoint, and . The entropy of the data set after the split at node is
The root node is always split into two new nodes (which are called “children”), and we further split any new node that has data with multiple labels. We continue the splitting process recursively (i.e., following a tree structure), using the criterion of maximum information gain at each node until we obtain a set of leaf nodes in which each node has data with a single label. See Breiman et al. [57] for other splitting strategies and stopping conditions for decision trees.
A random-forest classification approach uses a set of decision trees. It selects a random sample from a training set using some probability distribution and then fits trees to these samples [57]. A random-forest classifier consists of trees, where one specifies the value . We use to balance efficiency and performance and to avoid overfitting. To classify a new data set, we pass each sample of that data set to each of the trees. The forest chooses a class with the most votes of the possible votes; if there is a tie for the largest vote total, it uniformly randomly selects one of the classes with the most votes. In one example of sentiment analysis using a random-forest classifier, Bilal et al. [58] identified positive, negative, and neutral sentiments in a set of documents.
2.4 Artificial Neural Networks (ANNs)
Artificial neural networks (ANNs) are popular classifiers that have been used for various text-classification problems [59]. We use a fully-connected (i.e., “dense”) feedforward ANN to infer media bias and back-propagation (BP) to train this ANN. Because of the feedforward structure, the nodes are not part of any cycles. BP is an iterative gradient-based algorithm that we use to minimize the mean-squared error between the actual output and the desired output. See Schmidhuber [60] for more details about ANNs and training methods for them. ANNs have been used for a variety of tasks in sentiment analysis [61, 62, 63]. Zharmagambetov and Pak [59] used an ANN and a word-embedding model to classify a data set of movie reviews with positive and negative sentiments.
2.5 Long Short-Term Memory (LSTM) Neural Networks
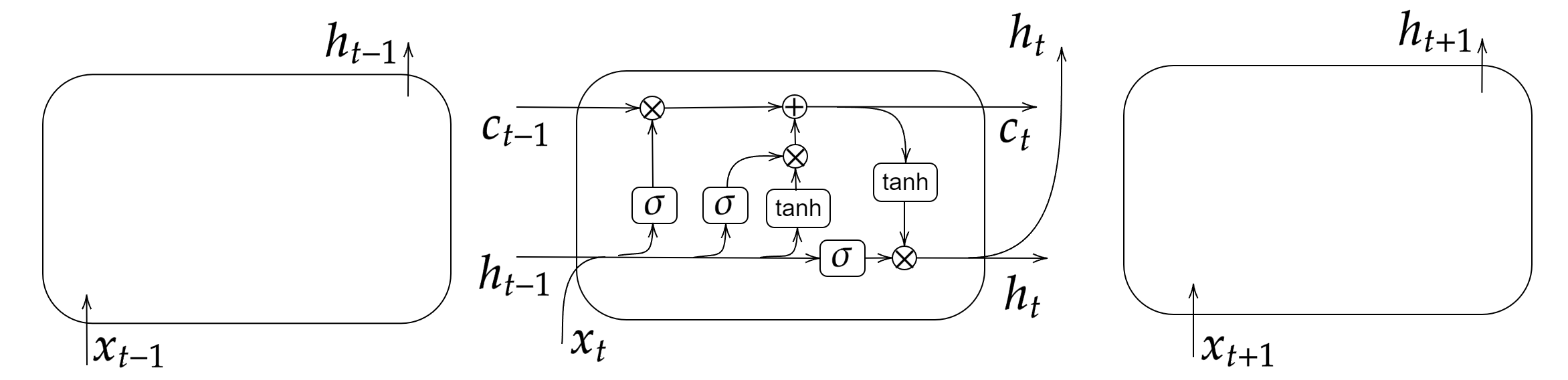
An LSTM neural network is one type of RNN architecture. Unlike a traditional RNN, an LSTM network has a “forget” gate that determines whether or not to pass information from one memory cell to the next memory cell. LSTM networks have achieved good performance on various NLP tasks, including machine translation, next-word inference, and binary sentiment classification [64, 65, 66]. In Figure 4, we show the structure of a single LSTM cell. The scalar denotes the “memory” that is passed between each cell. In the center panel (which indicates the th cell), the sigmoid activation function on the left is a forget gate. When outputs , the previous memory is “forgotten” by multiplying it by ; when outputs , one uses and passes it to the next cell. The middle sigmoid activation function is called the input gate, which decides the input value for updating the memory. The right sigmoid activation function is called the “output gate” and determines the output value. The hyperbolic tangent is another activation function, and the output is . In Section 4.2, we will explain the architecture of the bidirectional LSTM network model that we use to infer the ideological biases and content qualities of the media outlets.
3 Data Sets
We use tweets from media outlets to examine the ideological biases and content qualities of those outlets. Tweets by media outlets are more readily available and larger in number than shows and articles from these outlets. We use data from the NewsOutletTweet data set of media tweets from Littman et al. [39]. This data set has a list of tweet IDs from the Twitter accounts of 9,636 news outlets. The tweets from these media outlets were collected between 4 August 2016 and 12 May 2020. The tweet IDs are 18-digit integers that provide access (with twitter.com/ as the prefix) to the corresponding tweets. We use the Hydrator application [67] to extract the content of all 39,695,156 tweets in NewsOutletTweet; we refer to these tweets as the “hydrated NewsOutletTweet” data set. For each of the 102 media outlets in the AFMBC, we manually search for their official Twitter account and check if it is in the account list in NewsOutletTweet. If one media outlet has multiple official Twitter accounts — e.g., The New York Times has several Twitter accounts, such as @NYTSports and @nytopinion — we manually determine its primary Twitter account and keep only this account. (For example, we use @nytimes for The New York Times.) This yields 65 media outlets that are part of both the AFMBC and NewsOutletTweet. We list these media outlets and the associated Twitter accounts in Appendix A.
We select the tweets in the hydrated NewsOutletTweet data set that were posted by the 65 media outlets. There are 1,417,030 such tweets in total. Except for Bloomberg (for which there are 127 tweets), the numbers of tweets of the media outlets range from about 1,000 to about 100,000. We obtain bias and quality scores for each media outlet using the bias and quality scores of articles and shows in the MediaSourceRatings data set [37]. For each article, the ideological bias lies in one of seven categories: most extreme Left, hyperpartisan Left, skews Left, neutral, skews Right, hyperpartisan Right, and most extreme Right. Each category spans 12 rating units (except for the neutral category, which spans 13 units from to ), so the numerical scale consists of all integers between and . The seven categories of bias were defined by analysts, and the 12 units within each category allow nuanced distinctions in the amount of bias [37]. The overall reliability of each article by each media outlet was divided by the analysts into eight categories, with eight units each. This yields a numerical scale that consists of all integers between (the least reliable) and (the most reliable) [37]. The number of rating units was selected because it is convenient for the aspect ratio of visual displays.
Each media outlet in the AFMBC has between 15 and 25 reviewed articles and shows (in total, including both types of media) in the MediaSourceRatings data set. For each media outlet, we use the mean of the bias scores and the mean of the quality scores as representative quality and bias scores.
4 Generation of a Media-Bias Chart
We preprocess the tweet data from [39] and input it into an LSTM neural network to generate a bias score and a quality score for each tweet.111Our code for filtering the tweets from NewsOutletTweet and applying ML algorithms to this data set is available at https://gitlab.com/zchao3/MediaSentiment.git. Using the (bias, quality) scores of the tweets (in the testing set), we generate a media-bias chart — with coordinates for both ideological bias and content quality — for the media outlets and then interpret it. The numbers of tweets of the media outlets range between 127 (for Bloomberg) and 93,259 (for Reuters); see Figure 5. For our data preprocessing, we select 10,000 tweets uniformly at random with replacement (so we do bootstrap sampling, and the sampled tweets can contain duplicates, especially for media outlets with smaller numbers of tweets) for each media outlet. With this procedure, our sample data set has 65 10,000 tweets. The training set (a uniformly random subset) consists of a fixed proportion of the sampled tweets, to which we assign bias and quality scores that are equal to the bias and quality scores of the corresponding media outlets in the AFMBC. The media outlets thereby contribute equally to our training set regardless of how often they tweeted.
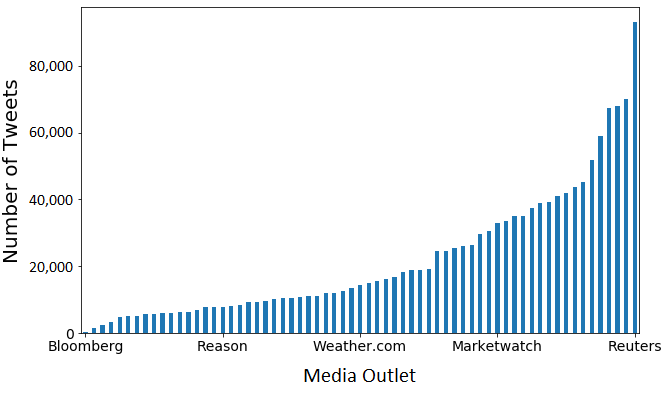
4.1 Text Preprocessing
We apply the following text-preprocessing scheme to our data set. We remove all stop words (“and”, “you”, “to”, and so on) in the built-in list of stop words in the Python package nltk, and we then remove all hyperlinks. We build a vocabulary using the 5,000 words (where we treat hashtags as words) with the highest frequencies in the sampled data set using the CountVectorizer function in the Python package sklearn. Each word that remains in a tweet is a token. We convert all words that are not in the vocabulary into “OOV” tokens and add “PAD” tokens at the end of each tweet so that all tweets have the same length (i.e., the same number of tokens) as the longest tweet.
4.2 Bidirectional LSTM Neural Network
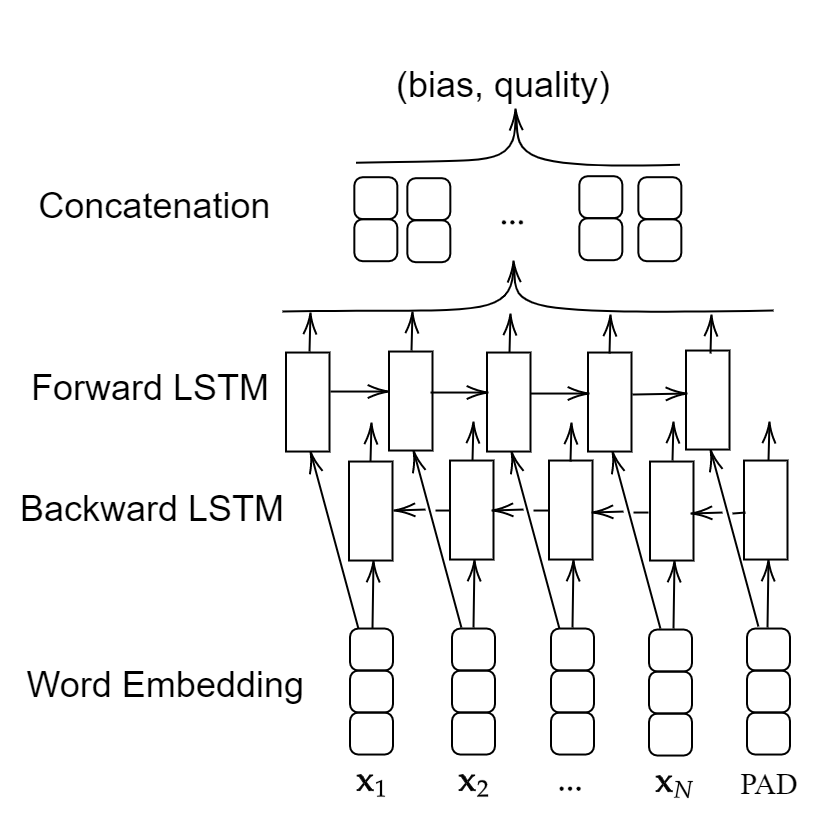
We input the processed tweets (which are sequences of tokens) into a bidirectional LSTM neural network to infer their bias and quality scores. The LSTM network that we use has three layers, which have different purposes. Each layer transforms an input sequence into another sequence of scalars or into a sequence of vectors. The first layer is a fully-connected word-embedding layer [68] that transforms each word into a vector of a user-selected length. The second layer is a bidirectional LSTM layer that consists of a forward LSTM and a backward LSTM. The number of memory cells (see Section 2.5) in each LSTM is equal to the length of the input sequence. Each LSTM layer transforms an input sequence of vectors into a sequence of scalars. For each cell in the LSTM layer, we apply the following transition functions:
Following common practice, we refer to , , , , and as a forget gate, an input gate, an output gate, a memory-cell state, and a hidden state, respectively [69, 70, 71]. (The difference between a “state” and a “gate” is that the value of the former is passed to the next cell, but that is not the case for the latter.) The sigmoid function and function are the activation functions. Finally, we append a fully-connected concatenation layer [72] that transforms the outputs from the bidirectional LSTM into a pair of scalars in that encode a tweet’s bias score and quality score. Both the embedding layer and the concatenation layer use a matrix–vector product and a rectified linear unit (ReLU) as an activation function. We use the standard ReLU activation function [73]
In Figure 6, we show a schematic illustration of the bidirectional LSTM architecture and the workflow in our computational experiments. We initialize all parameters — including the parameters in the embedding layer, the concatenation layer, and the weight vectors , , , and — with independent uniform random real numbers in . As a loss function, we use the mean-square error (MSE) , where denotes the th training label and denotes the th inferred label, and we train the weight vectors with the Adams optimizer [74] to minimize the loss function.
4.3 Training and Results
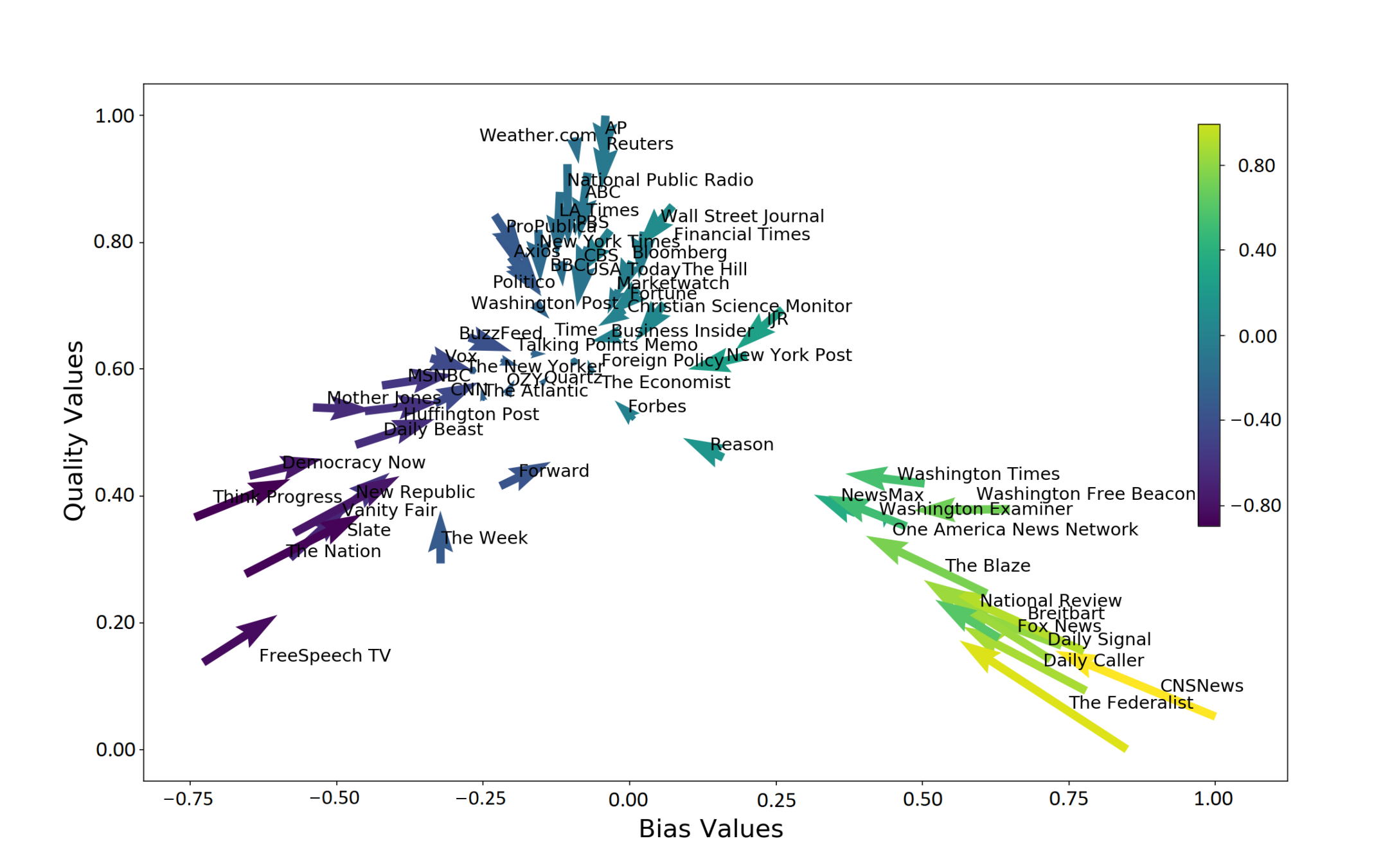
We use a tweet-level split of testing and training data. We split the 650,000 tweets uniformly at random with 80% of them in the training set and 20% in the testing set. We apply the trained model to the testing tweets and assign bias scores and quality scores to each of these tweets. We group the testing set by media outlet, and we then compute the mean bias score and mean quality score of each group and assign this pair of scores to the corresponding media outlet. We normalize the bias scores to , and we normalize the quality scores to . In Figure 7, we plot these scores along with the normalized bias and quality scores from the AFMBC.
5 Evaluation of the LSTM Network’s Performance
We examine the performance of inferring a 2D media-bias chart of (bias, quality) coordinates for each media outlet using a variety of approaches (see Section 2). As we will see, the LSTM network (which incorporates sequential data) outperforms the other approaches, which use only non-sequential information.
In the output of each method, we observe that many tweets do not have a strong ideological bias. This is the case even for many tweets from media outlets with a strong ideological bias (e.g., with an absolute value of at least in the interval ) in the AFMBC. Therefore, it is sensible that the mean bias scores of the tweets of the media outlets tend to be closer to the center of the ideological spectrum than their bias scores from the AFMBC (see Figure 7).
We calculate Pearson correlation coefficients, which are invariant under scaling and shifting of its arguments, to examine linear correlations between the inferred bias and quality scores and the AFMBC bias and quality scores. We use these coefficients to evaluate the performance of each method; a large Pearson correlation coefficient suggests that a method yields a spectrum with a reasonable ordering of the scores. For example, a large Pearson correlation coefficient for the bias score indicates a good performance at inferring the relative locations of media outlets on a Left–Right ideological spectrum. The Pearson correlation coefficient of two vectors and is
where consists of the media-outlet bias or quality coordinates from the AFMBC and consists of the algorithmically inferred media-outlet coordinates from tweets.
5.1 Computational Experiments
In addition to the LSTM-network approach on which we focus, we examine results from five other methods: a naive-Bayes (NB) method, a support-vector machine (SVM), a decision tree (DT), a random forest (RF), and an artificial neural network (ANN) with fully-connected layers.
We compare the (bias, quality) coordinates that we obtain for each media outlet from these methods. For each tweet, we remove the stop words and hyperlinks (see Section 4.1), and we use the 5,000 most-frequent words (see Section 4.2) to build a vocabulary. Our results vary slightly (with the Pearson correlation differing within about in our experiments) when we use vocabularies with 2,000 and 10,000 words. We apply an 80–20 train–test split of the data (see Section 4) and generate (bias, quality) coordinates for each media outlet by calculating the mean of each method’s output for the tweets from the same media outlet. We also test each method with train–test splits that we base on the media outlets themselves. In this media-outlet split, we select 52 media outlets (i.e., 80% of them) uniformly at random. We train each method using all of the tweets from these 52 media outlets and apply the trained method to the tweets of the remaining 13 media outlets to infer (bias, quality) coordinates of all remaining media outlets.
5.2 Results
We now compare and discuss our results from the various approaches for inferring (bias, quality) coordinates. We consider both a media-level split (see Section 5.1) and a tweet-level split (see Section 4.3).
For the media-outlet split, we uniformly randomly split the media outlets into five groups of 13 media outlets each, and we apply 5-fold cross-validation to generate the coordinates for all media outlets. That is, using each of the five groups as a withheld testing group, we train each method with the tweets from the other four groups and then evaluate the method with the tweets from the withheld group. We then compute the media bias and quality scores by calculating means of the scores of the tweets (see Section 4.3) and compute the Pearson correlation coefficients from these results. We show the mean Pearson correlation (which we average over five trials) for the media-outlet split in Table 2.
| Method | Bias-Score Correlation | Quality-Score Correlation |
|---|---|---|
| NB | 0.662 | 0.713 |
| SVM | 0.652 | 0.736 |
| DT | 0.665 | 0.684 |
| RF | 0.780 | 0.779 |
| MLP | 0.809 | 0.811 |
| LSTM | 0.832 | 0.825 |
We also use 5-fold cross validation for the tweet-level split. We uniformly randomly split all tweets into five equal-sized groups. Using each of the five groups as a withheld testing group, we train each method using the other four groups and then evaluate the method using the withheld group. We show the mean Pearson correlation (which we average over five different train–test splits) for the tweet-level split in Table 3.
| Method | Bias-Score Correlation | Quality-Score Correlation |
|---|---|---|
| NB | 0.861 | 0.805 |
| SVM | 0.909 | 0.898 |
| DT | 0.856 | 0.861 |
| RF | 0.925 | 0.907 |
| MLP | 0.916 | 0.949 |
| LSTM | 0.977 | 0.964 |
From Table 2 and Table 3, we see that the LSTM-network approach that incorporates word sequences in its input performs better than the other five methods, which all use a bag-of-words approach. This demonstrates that it is advantageous to account for sequential information. We also observe that all methods perform better on the tweet-level split than they do on the media-outlet split. One possible reason is that different media outlets use different word choices for different tweets. Moreover, media outlets with similar ideological biases and quality scores on the AFMBC may tend to post about different topics. For example, Weather.com and The Economist have the same ideological-bias score (of ) on the AFMBC, but one expects posts by Weather.com to be related to weather forecasts, which one does not expect to see in many posts by The Economist.
6 Conclusions and Discussion
Media outlets have a significant and multifaceted impact on public discourse [75]. It is thus important to examine their ideological biases and heterogeneous quality levels. It can be very insightful to infer ideological positions and sentiments from the textual data of entities [16, 22], such as for media outlets. In our paper, we used a bidirectional long short-term memory (LSTM) neural network and several other machine-learning approaches to infer ideological biases and quality levels of media outlets based on tweets from their Twitter accounts. For both biases and qualities, we found a large correlation between the scores that we inferred from tweets and the scores in the Ad Fontes Media-Bias Chart (AFMBC). We compared a variety of ML approaches that use a bag-of-words approach with the LSTM-network approach, which incorporates word sequences, and we found that the LSTM approach outperforms the others. We thus conclude that the information from word order is a significant contributor to our natural-language-processing (NLP) task. We expect that this is also true for many other NLP tasks.
In our paper, we demonstrated that ML methods can successfully infer ideological biases and quality levels of textual data from media outlets. However, our study has several limitations. For example, we used only Twitter data and we only considered that data from a particular time window. It is essential to integrate different types of news sources, such as long articles and videos, to better infer the ideological biases and content quality of a media outlet. Additionally, we only inferred a single point in a 2D (bias, quality) space for each media outlet, but it is more realistic to represent the bias and quality of a media outlet using a probability distribution. It is also desirable to extend the analysis of ideological bias to multiple dimensions (e.g., with different dimensions for different political issues, such as social and economic issues) and to develop better approaches to evaluate inferred (bias, quality) coordinates and associated media-bias charts. Our paper provides a proof of concept for such studies, and it is important to explore these extensions.
Appendix A List of Media Outlets and the Number of Tweets of Each Outlet
In LABEL:list_of_media, we list the 65 media outlets that we use in our experiments. We also indicate the number of tweets from each media outlet. The tweets were collected by Littman et al. [39] between 4 August 2016 and 12 May 2020. In Section 3, we described our process of manually selecting a Twitter account for each media outlet. In LABEL:list_of_media, we also give each media outlet’s bias and quality scores from Ad Fontes [37].
| Outlet | Ideological Bias | Content Quality | Number of Tweets |
| ABC | 49.87 | 39243 | |
| AP | 52.19 | 35132 | |
| Axios | 47.30 | 10647 | |
| BBC | 46.27 | 5685 | |
| Bloomberg | 47.52 | 148 | |
| Breitbart | 18.99 | 30.64 | 9335 |
| Business Insider | 43.28 | 58868 | |
| BuzzFeed | 43.17 | 16214 | |
| CBS | 46.84 | 39004 | |
| CNN | 40.49 | 68014 | |
| CNSNews | 25.75 | 27.75 | 5570 |
| Christian Science Monitor | 44.27 | 24660 | |
| Daily Beast | 38.80 | 18088 | |
| Daily Caller | 20.06 | 28.80 | 25948 |
| Daily Signal | 19.97 | 30.41 | 7812 |
| Democracy Now | 37.54 | 8132 | |
| Financial Times | 0.62 | 47.47 | 14966 |
| Fiscal Times | 1.52 | 44.54 | 3250 |
| Forbes | 0.20 | 39.84 | 19143 |
| Foreign Policy | 41.69 | 10496 | |
| Fortune | 0.43 | 45.09 | 18971 |
| Forward | 37.12 | 8247 | |
| Fox News | 18.50 | 30.08 | 67254 |
| FreeSpeech TV | 29.95 | 10970 | |
| Huffington Post | 40.17 | 18679 | |
| IJR | 6.72 | 44.31 | 4867 |
| LA Times | 49.09 | 29475 | |
| MSNBC | 41.21 | 25312 | |
| Marketwatch | 45.11 | 32766 | |
| Mother Jones | 40.32 | 11903 | |
| National Public Radio | 50.22 | 16591 | |
| National Review | 16.23 | 30.95 | 11012 |
| New Republic | 36.03 | 6097 | |
| New York Post | 5.15 | 42.42 | 30435 |
| New York Times | 47.54 | 43772 | |
| NewsMax | 9.94 | 36.02 | 5016 |
| OZY | 40.80 | 5991 | |
| One America News Network | 11.26 | 35.88 | 6128 |
| PBS | 47.79 | 5046 | |
| Politico | 46.45 | 51742 | |
| ProPublica | 48.14 | 1430 | |
| Quartz | 41.26 | 12646 | |
| Reason | 4.12 | 38.28 | 7849 |
| Reuters | 51.79 | 93120 | |
| Slate | 34.20 | 37344 | |
| Talking Points Memo | 42.24 | 6739 | |
| The Atlantic | 40.59 | 10146 | |
| The Blaze | 15.70 | 32.76 | 9091 |
| The Economist | 42.19 | 34927 | |
| The Federalist | 21.86 | 26.42 | 7767 |
| The Hill | 0.09 | 46.26 | 70065 |
| The Nation | 33.54 | 2462 | |
| The New Yorker | 41.83 | 13520 | |
| The Week | 33.98 | 9579 | |
| Think Progress | 35.85 | 10546 | |
| Time | 42.50 | 40979 | |
| USA Today | 46.12 | 24613 | |
| Vanity Fair | 35.22 | 6064 | |
| Vox | 42.33 | 15497 | |
| Wall Street Journal | 1.89 | 48.52 | 41903 |
| Washington Examiner | 12.17 | 35.48 | 33592 |
| Washington Free Beacon | 16.71 | 36.19 | 12062 |
| Washington Post | 44.57 | 45178 | |
| Washington Times | 12.97 | 37.23 | 26358 |
| Weather.com | 51.30 | 14345 |
Acknowledgements
MAP acknowledges financial support from the National Science Foundation (grant number 1922952) through the Algorithms for Threat Detection (ATD) program. DN acknowledges financial support from the National Science Foundation (grant number 2011140 and 2108479) under the Division of Mathematical Sciences (DMS).
References
- [1] Gerber, A.S., Karlan, D., Bergan, D.: Does the media matter? A field experiment measuring the effect of newspapers on voting behavior and political opinions. American Economic Journal: Applied Economics 1(2), 35–52 (2009)
- [2] Amedie, J.: The impact of social media on society. Pop Culture Intersections 2 (2015). Available at https://scholarcommons.scu.edu/engl_176/2
- [3] South, T., Smart, B., Roughan, M., Mitchell, L.: Information flow estimation: A study of news on Twitter. Online Social Networks and Media 31, 100231 (2022)
- [4] Tien, J.H., Eisenberg, M.C., Cherng, S.T., Porter, M.A.: Online reactions to the 2017 ‘Unite the Right’ rally in charlottesville: Measuring polarization in Twitter networks using media followership. Applied Network Science 5(1), 10 (2020)
- [5] Rye, B.J., Underhill, A.: Pro-choice and pro-life are not enough: An investigation of abortion attitudes as a function of abortion prototypes. Sexuality & Culture 24, 1829–1851 (2020)
- [6] Cicchini, T., Del Pozo, S.M., Tagliazucchi, E., Balenzuela, P.: News sharing on Twitter reveals emergent fragmentation of media agenda and persistent polarization. European Physical Journal — Data Science 11(1), 48 (2022)
- [7] Schober, M.F., Pasek, J., Guggenheim, L., Lampe, C., Conrad, F.G.: Social media analyses for social measurement. Public Opinion Quarterly 80(1), 180–211 (2016)
- [8] Bail, C.A., Argyle, L.P., Brown, T.W., Bumpus, J.P., Chen, H., Hunzaker, M.F., Lee, J., Mann, M., Merhout, F., Volfovsky, A.: Exposure to opposing views on social media can increase political polarization. Proceedings of the National Academy of Sciences of the United States of America 115(37), 9216–9221 (2018)
- [9] McCoy, J., Rahman, T.: Polarized democracies in comparative perspective: Toward a conceptual framework. In: International Political Science Association Conference, vol. 26. Poznan, Poland, pp. 16–42 (2016)
- [10] Poole, K.T., Rosenthal, H.: Congress: A Political-Economic History of Roll Call Voting. Oxford University Press, Oxford, United Kingdom (1997)
- [11] Rice, S.A.: The identification of blocs in small political bodies. American Political Science Review 21(3), 619–627 (1927)
- [12] Sirovich, L.: A pattern analysis of the second Renquist U.S. Supreme Court. Proceedings of the National Academy of Sciences of the United States of America 100(13), 7432–7437 (2003)
- [13] Huberman, B.A., Romero, D.M., Wu, F.: Social networks that matter: Twitter under the microscope. First Monday 14(1–5) (2009). Available at https://doi.org/10.5210/fm.v14i1.2317
- [14] Maynard, D., Funk, A.: Automatic detection of political opinions in tweets. In: García-Castro, R., Fensel, D., Antoniou, G. (eds.) Extended Semantic Web Conference, pp. 88–99 (2011)
- [15] DiGrazia, J., McKelvey, K., Bollen, J., Rojas, F.: More tweets, more votes: Social media as a quantitative indicator of political behavior. PloS ONE 8(11), 79449 (2013)
- [16] Preoţiuc-Pietro, D., Liu, Y., Hopkins, D., Ungar, L.: Beyond binary labels: Political ideology prediction of Twitter users. In: Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 729–740. Association for Computational Linguistics, Vancouver, Canada (2017)
- [17] Lai, M., Tambuscio, M., Patti, V., Ruffo, G., Rosso, P.: Stance polarity in political debates: A diachronic perspective of network homophily and conversations on Twitter. Data & Knowledge Engineering 124, 101738 (2019)
- [18] Waller, I., Anderson, A.: Quantifying social organization and political polarization in online platforms. Nature 600, 264–268 (2021)
- [19] Huls, E., Varwijk, J.: Political bias in TV interviews. Discourse & Society 22(1), 48–65 (2011)
- [20] Kozitsin, I.V.: Opinion dynamics of online social network users: A micro-level analysis. The Journal of Mathematical Sociology (2021). doi:10.1080/0022250X.2021.1956917
- [21] Dixit, A.K., Weibull, J.W.: Political polarization. Proceedings of the National Academy of Sciences of the United States of America 104(18), 7351–7356 (2007)
- [22] Panda, A., Siddarth, D., Pal, J.: COVID, BLM, and the polarization of US politicians on Twitter. ArXiv:2008.03263 (2020)
- [23] Prior, M.: Media and political polarization. Annual Review of Political Science 16, 101–127 (2013)
- [24] Boche, A., Lewis, J.B., Rudkin, A., Sonnet, L.: The new Voteview.com: Preserving and continuing Keith Poole’s infrastructure for scholars, students and observers of Congress. Public Choice 176(1–2), 17–32 (2018)
- [25] Kitchener, M., Anantharama, N., Angus, S.D., Raschky, P.A.: Predicting political ideology from digital footprints. ArXiv:2206.00397 (2022)
- [26] Xiao, Z., Zhu, J., Wang, Y., Zhou, P., Lam, W., Porter, M.A., Sun, Y.: Detecting political biases of named entities and hashtags on Twitter. ArXiv:2209.08110 (2022)
- [27] Gordon, J., Babaeianjelodar, M., Matthews, J.: Studying political bias via word embeddings. In: Companion Proceedings of the Web Conference 2020, pp. 760–764 (2020)
- [28] Pennycook, G., Rand, D.G.: Fighting misinformation on social media using crowdsourced judgments of news source quality. Proceedings of the National Academy of Sciences of the United States of America 116(7), 2521–2526 (2019)
- [29] Allen, J., Howland, B., Mobius, M., Rothschild, D., Watts, D.J.: Evaluating the fake news problem at the scale of the information ecosystem. Science Advances 6(14), 3539 (2020)
- [30] Ferrario, A., Naegelin, M.: The art of natural language processing: Classical, modern and contemporary approaches to text document classification (2020). Available at https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3547887
- [31] Mikolov, T., Deoras, A., Povey, D., Burget, L., Černocky, J.: Strategies for training large scale neural network language models. In: 2011 IEEE Workshop on Automatic Speech Recognition & Understanding, pp. 196–201 (2011). Institute of Electrical and Electronics Engineers
- [32] Yin, W., Kann, K., Yu, M., Schütze, H.: Comparative study of CNN and RNN for natural language processing. ArXiv:1702.01923 (2017)
- [33] Sze, V., Chen, Y.-H., Yang, T.-J., Emer, J.S.: Efficient processing of deep neural networks: A tutorial and survey. Proceedings of the IEEE 105(12), 2295–2329 (2017)
- [34] Iyyer, M., Enns, P., Boyd-Graber, J., Resnik, P.: Political ideology detection using recursive neural networks. In: Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 1113–1122 (2014)
- [35] Salehinejad, H., Sankar, S., Barfett, J., Colak, E., Valaee, S.: Recent advances in recurrent neural networks. ArXiv:1801.01078 (2017)
- [36] Socher, R., Perelygin, A., Wu, J., Chuang, J., Manning, C.D., Ng, A.Y., Potts, C.: Recursive deep models for semantic compositionality over a sentiment treebank. In: Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, pp. 1631–1642 (2013)
- [37] Otero, V.: Interactive Media Bias Chart. Available at https://adfontesmedia.com/interactive-media-bias-chart/ [accessed 26 September 2020]. Accessed 26 September 2020 (2022)
- [38] Widmer, P., Galletta, S., Ash, E.: Media slant is contagious. ArXiv:2202.07269 (2022)
- [39] Littman, J., Wrubel, L., Kerchner, D., Bromberg Gaber, Y.: News Outlet Tweet IDs. Harvard Dataverse (2017). doi:10.7910/DVN/2FIFLH
- [40] Brooks, H.Z., Porter, M.A.: A model for the influence of media on the ideology of content in online social networks. Physical Review Research 2, 023041 (2020)
- [41] van Loon, A.: Three families of automated text analysis. SocArXiv. Available at osf.io/preprints/socarxiv/htnej (2022). doi:10.31235/osf.io/htnej
- [42] Kowsari, K., Jafari Meimandi, K., Heidarysafa, M., Mendu, S., Barnes, L., Brown, D.: Text classification algorithms: A survey. Information 10(4), 150 (2019)
- [43] Cambria, E., White, B.: Jumping NLP curves: A review of natural language processing research. IEEE Computational Intelligence Magazine 9(2), 48–57 (2014)
- [44] Bakliwal, A., Arora, P., Patil, A., Varma, V.: Towards enhanced opinion classification using NLP techniques. In: Proceedings of the Workshop on Sentiment Analysis Where AI Meets Psychology (SAAIP 2011), pp. 101–107 (2011)
- [45] Kanakaraj, M., Guddeti, R.M.R.: Performance analysis of ensemble methods on Twitter sentiment analysis using NLP techniques. In: Proceedings of the 2015 IEEE 9th International Conference on Semantic Computing (IEEE ICSC 2015), pp. 169–170 (2015). Institute of Electrical and Electronics Engineers
- [46] Troussas, C., Virvou, M., Espinosa, K.J., Llaguno, K., Caro, J.: Sentiment analysis of Facebook statuses using naive Bayes classifier for language learning. In: IISA 2013, pp. 1–6 (2013). doi:10.1109/IISA.2013.6623713
- [47] Gopi, A.P., Jyothi, R.N.S., Narayana, V.L., Sandeep, K.S.: Classification of tweets data based on polarity using improved RBF kernel of SVM. International Journal of Information Technology (2020). Available at https://doi.org/10.1007/s41870-019-00409-4
- [48] Mikolov, T., Karafiát, M., Burget, L., Cernocky, J., Khudanpur, S.: Recurrent neural network based language model. In: Interspeech, vol. 2. Makuhari, Chiba, Japan, pp. 1045–1048 (2010)
- [49] Kawakami, K.: Supervised sequence labelling with recurrent neural networks. PhD thesis, Technical University of Munich (2008)
- [50] Go, A., Bhayani, R., Huang, L.: Twitter sentiment classification using distant supervision. CS224N Project Report, Stanford University (2009). Available at https://www-cs.stanford.edu/people/alecmgo/papers/TwitterDistantSupervision09.pdf
- [51] Manning, C., Schutze, H.: Foundations of Statistical Natural Language Processing. MIT Press, Cambridge, MA, USA (1999)
- [52] Zhang, H.: The optimality of naive bayes. In: Proceedings of the Seventeenth International Florida Artificial Intelligence Research Society Conference, pp. 562–567 (2004)
- [53] Bhavsar, H., Panchal, M.H.: A review on support vector machine for data classification. International Journal of Advanced Research in Computer Engineering & Technology (IJARCET) 1(10), 185–189 (2012)
- [54] Sheykhmousa, M., Mahdianpari, M., Ghanbari, H., Mohammadimanesh, F., Ghamisi, P., Homayouni, S.: Support vector machine versus random forest for remote sensing image classification: A meta-analysis and systematic review. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing 13, 6308–6325 (2020)
- [55] Toledo-Perez, D.C., Rodriguez-Resendiz, J., Gomez-Loenzo, R.A., Jauregui-Correa, J.C.: Support vector machine-based EMG signal classification techniques: A review. Applied Sciences 9(20), 4402 (2019)
- [56] Rennie, J.D.M., Srebro, N.: Loss functions for preference levels: Regression with discrete ordered labels. In: IJCAI-05 Multidisciplinary Workshop on Advances in Preference Handling (2005)
- [57] Breiman, L., Friedman, J.H., Olshen, R.A., Stone, C.J.: Classification and Regression Trees. Routledge, New York, NY, USA (2017)
- [58] Bilal, M., Israr, H., Shahid, M., Khan, A.: Sentiment classification of roman-urdu opinions using naive Bayesian, decision tree and KNN classification techniques. Journal of King Saud University-Computer and Information Sciences 28(3), 330–344 (2016)
- [59] Zharmagambetov, A.S., Pak, A.A.: Sentiment analysis of a document using deep learning approach and decision trees. In: 2015 Twelve International Conference on Electronics Computer and Computation (ICECCO), pp. 1–4 (2015). doi:10.1109/ICECCO.2015.7416902
- [60] Schmidhuber, J.: Deep learning in neural networks: An overview. Neural Networks 61, 85–117 (2015)
- [61] Ghiassi, M., Skinner, J., Zimbra, D.: Twitter brand sentiment analysis: A hybrid system using n-gram analysis and dynamic artificial neural network. Expert Systems with applications 40(16), 6266–6282 (2013)
- [62] Sharma, A., Dey, S.: An artificial neural network based approach for sentiment analysis of opinionated text. In: Proceedings of the 2012 ACM Research in Applied Computation Symposium, pp. 37–42 (2012)
- [63] Sharma, A., Dey, S.: A document-level sentiment analysis approach using artificial neural network and sentiment lexicons. ACM SIGAPP Applied Computing Review 12(4), 67–75 (2012)
- [64] Wang, Y., Huang, M., Zhu, X., Zhao, L.: Attention-based LSTM for aspect-level sentiment classification. In: Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pp. 606–615 (2016)
- [65] Young, T., Hazarika, D., Poria, S., Cambria, E.: Recent trends in deep learning based natural language processing [review article]. IEEE Computational Intelligence Magazine 13(3), 55–75 (2018)
- [66] Tang, D., Qin, B., Feng, X., Liu, T.: Target-dependent sentiment classification with long short term memory. ArXiv:1512.01100 (2015)
- [67] DocNow: Hydrator. Available at https://github.com/docnow/hydrator (accessed 26 September 2022) (2020)
- [68] Gulli, A., Pal, S.: Deep Learning with Keras. Packt Publishing, Birmingham, United Kingdom (2017)
- [69] Rao, G., Huang, W., Feng, Z., Cong, Q.: LSTM with sentence representations for document-level sentiment classification. Neurocomputing 308, 49–57 (2018)
- [70] Yu, Y., Si, X., Hu, C., Zhang, J.: A review of recurrent neural networks: LSTM cells and network architectures. Neural Computation 31(7), 1235–1270 (2019)
- [71] Zhao, Z., Chen, W., Wu, X., Chen, P.C., Liu, J.: LSTM network: A deep learning approach for short-term traffic forecast. IET Intelligent Transport Systems 11(2), 68–75 (2017)
- [72] Huang, G., Liu, Z., Van Der Maaten, L., Weinberger, K.Q.: Densely connected convolutional networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 4700–4708 (2017)
- [73] Agarap, A.F.: Deep learning using rectified linear units (ReLU). ArXiv:1803.08375 (2018)
- [74] Kingma, D.P., Ba, J.: Adam: A method for stochastic optimization. ArXiv:1412.6980 (2014)
- [75] Chaudhuri, M.: Ethics in the new media, print media and visual media landscape. Journal of Global Communication 7(1), 84–95 (2014)