Inferring the shape of data: A probabilistic framework for analyzing experiments in the natural sciences
ABSTRACT
A critical step in data analysis for many different types of experiments is the identification of features with theoretically defined shapes in N-dimensional datasets; examples of this process include finding peaks in multi-dimensional molecular spectra or emitters in fluorescence microscopy images. Identifying such features involves determining if the overall shape of the data is consistent with an expected shape, however, it is generally unclear how to quantitatively make this determination. In practice, many analysis methods employ subjective, heuristic approaches, which complicates the validation of any ensuing results—especially as the amount and dimensionality of the data increase. Here, we present a probabilistic solution to this problem by using Bayes’ rule to calculate the probability that the data has any one of several potential shapes. This probabilistic approach may be used to objectively compare how well different theories describe a dataset, identify changes between datasets, and detect features within data using a corollary method called Bayesian Inference-based Template Search (BITS); several proof-of-principle examples are provided. Altogether, this mathematical framework serves as an automated ‘engine’ capable of computationally executing analysis decisions currently made by visual inspection across the sciences.
I Introduction
Across the physical and life sciences, many experimental techniques rely upon pragmatic data analysis steps where an expert researcher is required to make scientific decisions based on their visual perception of data. This perception involves identifying and recognizing correlations between datapoints that stem from underlying physical processes, which are ideally invariant across experiments; we refer to these correlations as the latent structure of the data. Latent structure manifests visually in what we would colloquially call the ‘shape’ of the data and is the basis for inspection-driven analysis decisions. For example, an expert researcher might have to visually identify a feature of interest by recognising an expected shape in a plot of their data (e.g., a shoulder on a peak in a molecular spectrum). Alternatively, such a researcher might anticipate the location of an expected feature within their plotted data (e.g., a peak at a specific frequency in a molecular spectrum), but must then decide whether or not it is actually present at that location. In these types of determinations, the researcher must generate at least two visual models of a phenomenon, manually compare those models to the shape of their experimental data, and then choose the model that, in their expert opinion, best describes the data. To be explicit, in the first example above, the researcher visually compares both the shape of a peak and the shape of a peak with a shoulder to the experimental molecular spectrum. Similarly, in the second example, the researcher visually compares both the shape of a peak and the shape of signal-free background noise
to the experimental molecular spectrum.
A key advantage of such expert-driven analyses is the human ability to make accurate, informed decisions about the latent structure of experimental data, even in the absence of a full theoretical description of the phenomenon of interest. For instance, while the spectral line shapes of peaks in molecular spectra arise due to physical processes with well established theoretical foundations, a full quantum mechanical calculation is generally not required to determine whether a certain peak exists at a particular location, nor whether or not it has a shoulder. Instead, approximate models of the shape of a peak, guided by a researcher’s physics-based intuition and years of experience, are usually sufficient for the level of analysis required for these problems. Having considered all the models they deem appropriate, the expert researcher then decides which of those models is the best description of their data and, thus, is best supported by the available evidence.
Such researcher-dependent approaches to data analysis create major practical, quantitative, and scientific challenges. An obvious difficulty is the time required for manual data processing, which limits a researcher’s output and productivity. Another is simply the learning curve required to perform visual inspection-based analysis tasks–an extensive amount of training is required before an inexperienced researcher can build enough physics-guided intuition to accurately and reliably interpret experimental data. Yet another obstacle is the lack of a quantitative metric for assessing the confidence one should have in one’s own or someone else’s analysis decisions, especially in cases of conflicting results. The lack of such a quantitative confidence metric makes it similarly difficult to validate or replicate such visual inspection-based analyses. Most importantly, there exist fundamental barriers which inhibit precise communication of the details of these analyses: namely, the intrinsic complexity of describing in writing the exact details of a method performed within one’s mind, and conversely, of understanding the details of such a method solely by reading a description of it. All of these challenges are exacerbated as scientific research fields progress towards more quantitative, data-driven approaches, and as more techniques are developed that yield larger amounts of increasingly more complex data, as is systematically occurring with, for instance, the advent of ultrahigh-throughput methods Johnstone and Titterington (2009); Leek et al. (2010).
In contrast to such human-dependent approaches, here we have developed a computational framework designed to automate and imitate the visual inspection-based data analysis steps typically performed by expert researchers, but in manner that is quantifiable, reproducible, and precisely communicable. Inspired by the human ability to visually assess the ‘shape’ of plotted data, our approach is to use probabilistic inference-based model selection Jaynes (2003); Bishop (2006) on technique-specific sets of models in order to calculate how well the shape of each model, which we call a ‘template’, can quantitatively describe the latent structure of the data. Specifically, we apply Bayes’ rule to the probability expressions, known as evidences, which here characterise the degree to which the models under consideration can explain the observed data, in a process known as Bayesian model selection (BMS) Kinz-Thompson et al. (2021). Broadly, the advantages of adopting a Bayesian framework have led to the increased usage of Bayesian methods in recent times across the sciences Malakoff (1999). For instance, in the field of biophysics, and particularly single-molecule studies, the use of Bayesian inference has been transformative due to its intrinsic ability to handle particularly noisy data (reviewed in Kinz-Thompson et al. (2021)). However, the difficulty of deriving evidences has historically limited the extension of Bayesian inference to BMS-based analysis approaches von Toussaint (2011); Friel and Wyse (2012), except in a few specialised cases (e.g., in Cossio and Hummer (2013) and Ensign and Pande (2010)).
In this work we create a generalised BMS-based framework using closed-form expressions for evidences that can be adapted by researchers in the physical and life sciences to a variety of different applications with computational ease and efficiency (Fig. 1). Additionally, because each implementation of this framework is defined by the specific set of physics-informed models considered, our approach can be leveraged to create constrained analyses that achieve optimal balances between theoretical precision and computational efficiency. We also harness this framework to create a corollary method, called Bayesian Inference-based Template Search (BITS), that enables us to achieve a large computational speedup when identifying and localising multiple features of interest within a dataset. Altogether, our probabilistic, BMS-based framework is a radically new method for analysing data that allows researchers to computationally mimic expert-based visual analyses without needing to resort to a subjective, researcher-dependent approach.
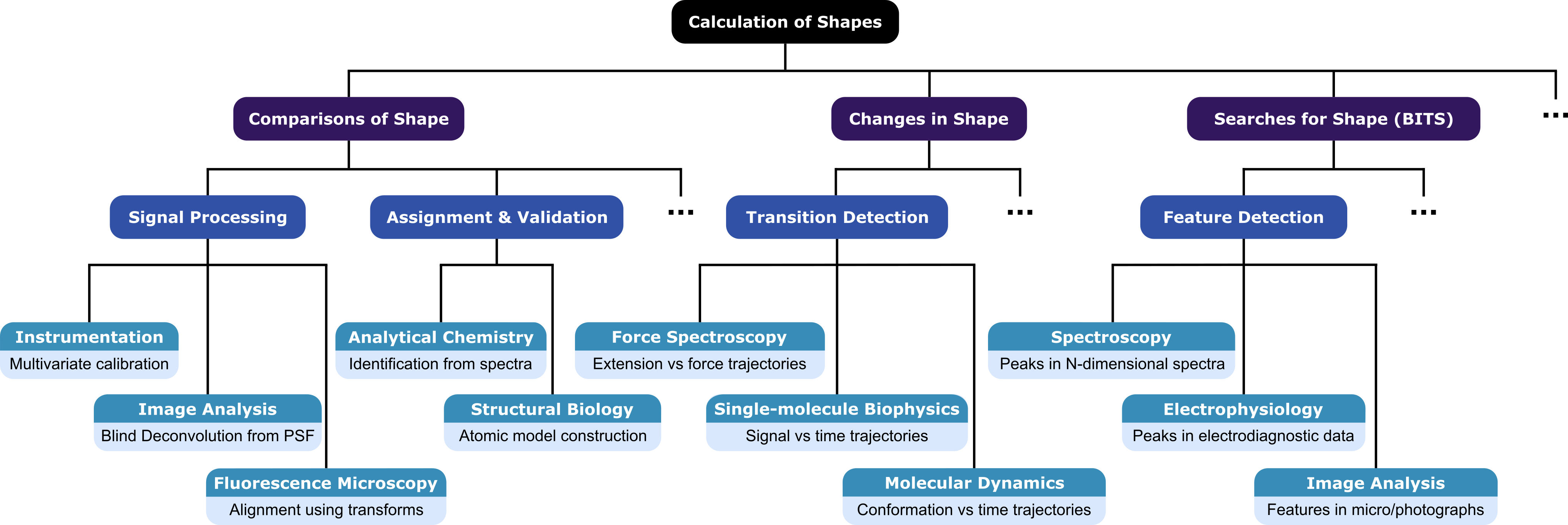
II Describing the Shape of a Dataset
In this section, we detail a mathematical framework designed to resemble the process of expert-based visual analysis. This approach uses orientation-preserving affine transformations of a template vector to map the associated model of latent structure onto the experimental data being analysed. The marginal likelihood of the data given a specific template is then calculated regardless of the scaling and translation of this transformation, or the noise present in the data. These marginal likelihoods are computed for a predefined set of templates, and are then used in BMS to calculate the posterior probabilities for each template. The shape of the data is then optimally described by the template with the highest posterior probability.
II.1 Defining a Template
To begin, we consider the problem of specifying a model of the latent structure of a dataset for the purpose of mimicking visual recognition. In our framework, a dataset, , is a tensor whose components are the individual, scalar datapoints. Regardless of the experimental relationships between those datapoints (i.e., the organisational structure of the tensor), for simplicity we can reshape into an N-dimensional vector , where are the scalar datapoints. One can imagine a dataset collected using a particular instrument, in a particular location, on a particular day, and by a particular researcher. Altogether, these specific factors might induce systematic differences in relative to an otherwise equivalent experiment. For example, an optical filter in an instrument might slowly oxidise, which could reduce the intensity of light incident upon the detector and, over a period of months, yield with different scales (i.e., units). Similarly, overhead lights might be left on accidentally when making an optical measurement, which could increase the background photons incident on the detector and yield with different relative offsets. Likewise, local vibrations might vary from day to day, which could affect the stability of an instrument and yield with different amounts of noise. Yet factors such as the scaling, offset, or amount of noise in a measurement generally do not alter the underlying physical processes that give rise to the measured data, and thus should not affect the latent structure (i.e., the shape) of . Instead, these factors often act as irregularities, or nuisances, that can limit our ability to model the shape of , hence our use of the term ‘nuisance parameters’ to describe them. With this in mind, we define a template, , as a particular N-dimensional vector of scalar quantities which is related to through the following transformation
| (1) |
In this equation, and are nuisance parameters representing changes to scale and offset, respectively, is a nuisance parameter composed of stochastic terms representing the experimental noise, and is the number of components in or . If we recall our definition of shape as correlations within data which derive from fundamental physical processes, we can conceptually understand a template, , as an ideal representation of these correlations, without noise or background.
To avoid confusion, we note that our definition of shape is distinct from those that take shape to mean a boundary or segmentation in data Dryden and Mardia (2016), and that it is this choice of definition which enables our framework and aligns it with the intuitive visual analyses performed manually by researchers.
It is important to note that the shape of , regardless of any distortions caused by the experimental nuisance parameters described above, may often be reasonably described by many different s. Indeed, there are no restrictions on what specific s one may choose as templates. Different s might depend upon different levels of theory, the particular details of the experimental setup, and even sample-to-sample variability. For example, the laws of diffraction dictate the point spread function (PSF) that describes the shape of point emissions in a fluorescence microscopy image Pawley (2006). However, for a standard microscope, the PSF can be modeled by an Airy disk; a two-dimensional circular Gaussian function; or, in order to incorporate an astigmatism correction, even a two-dimensional elliptical Gaussian function Shen et al. (2017). Each of these models of the PSF provides a distinct, theoretically valid capable of modeling the shape of with varying degrees of complexity. Alternatively, one’s s could be empirically derived from data previously recorded in other experiments. In the context of the above example, an can be created from fluorescence microscopy images of point emitter-like samples without needing to explicitly invoke a theory of diffraction, and such empirically derived s might even model the latent structure of more effectively than analytical, theory-derived s. Regardless of the complexity of or its origin, once formulated, it is directly related to a by the simple affine transformation given in Eqn. (1).
The choice of which (or set of s) one uses to model the shape of depends not only on the experimental technique but also on the level of precision required for that particular analysis. When using this mathematical framework to analyse experimental data from the natural sciences, one can invoke prior knowledge of the physics governing the experiment which gave rise to the data to constrain the choice of templates used in the analysis. Thus, while templates with higher complexities (e.g., an Airy disk as a model for a PSF) may be required for certain applications, in other cases, a less complex template (e.g., a 2D Gaussian as model for a PSF) can perform just as effectively while greatly reducing the computational cost of the analysis. The flexibility in choice of templates enabled by our framework can greatly increase the efficiency and effectiveness of an analysis method (see Sec. III), however, determining which of the chosen s, if any, is the optimal template requires that we first compute how well the shape of is explained by a given .
II.2 Deriving Probabilistic Expressions for Shape
After defining an , we quantify the degree to which it describes the latent structure of , regardless of the nuisance parameters described above in Eqn. (1). For the th template, , in a set of templates, , this means calculating a marginalised likelihood probability called the evidence, . Here, the conditional represents all of the details of the experiment, previous knowledge about the system, and particulars of the analysis method(s)—including which templates have been incorporated into the chosen . The expression for the evidence of is the marginalisation of the joint probability, which is given by
| (2) |
In Eqn. (2), is called the likelihood, and it represents the probability density of observing for a given and given values of the nuisance parameters; is called the prior, and it represents the joint probability density of those particular nuisance parameter values based on the prior knowledge specified by .
In this work, we have used combinations of different likelihoods and priors to derive a set of evidences, expressed in closed-form, that are particularly useful for calculating the shape of data in a variety of experimental situations. For all of the cases presented here, we have assumed in our that the are uncorrelated, such that = 0, and = , where is a constant called the precision and is the Kronecker delta. While this assumption is not a requirement of our approach, this noise model is often experimentally reasonable, and it has allowed us to present analytical solutions to evidence integrals in many general situations (see Supplemental Materials, Section 2 for other noise models). Together with Eqn. (1), this assumption yields the following likelihood function:
| (3) |
Very similar likelihood functions arise with this noise model when is known to be 0 or 1, and/or is 0.
Specifying the probability expression for the prior–the second term in the integrand in Eqn. (2)–requires that we mathematically represent our previous knowledge of how , , and are distributed in the experiments of interest Jaynes (2003). In particular, the prior dictates the integration bounds of Eqn. (2) by determining the values that are possible for these parameters to assume (i.e., regions where the prior probability is non-zero). For the results derived here, we have used so-called ‘maximum entropy’ priors, which allow us to encode information and constraints into our prior probability expressions, without dictating their functional form in an ad hoc manner Jaynes (2003). If we assume in that we only know that , , and are within some range and that we do not know the magnitude of (i.e., the amount of noise we expect), then the corresponding maximum entropy priors are a uniform distribution for and , and a uniform distribution over the logarithm of (see Supplemental Materials, Section 1). If we further assume that , , and are independent, then the corresponding joint prior of these parameters within the given ranges is
| (4) |
where the shorthand defines the range of a parameter.
In order to analytically integrate Eqn. (2), the integration bounds in the prior must be explicitly defined. We note that a positive transformation of an () can have a distinct physical interpretation from a negative transformation (). Thus, in order to differentiate between these two cases and properly model the underlying shape of , we impose that and be oriented in the same direction. This constraint can be encoded into the calculation by only considering orientation-preserving (i.e., positive scaling) affine transforms of the in Eqn. (1). To explicitly include this information in the prior, and thus in our , we therefore use rather than some . In the case that the negative transformation () is of interest, we note that with is equivalent to with . Closed-form expressions for the evidence derived using other integration bounds are also provided in the Supplemental Materials. Additionally, to keep the prior normalised and avoid using a so-called ‘improper’ prior, the minimum and maximum values must be chosen such that , , and are not infinite. For the purposes of a tractable integration Gradshteyn et al. (2014); Ng and Geller (1969), we have used such large negative and positive values that the integration bounds in Eqn. (2) can be approximated as , , and . While the exact values of the bounds are important and should be chosen judiciously, we note that the resulting prior normalisation terms end up canceling in subsequent steps during BMS (see below). Using the integration bounds discussed above, the closed-form probability expression for the evidence calculated using Eqn. (2) is
| (5) |
where , , , is the arithmetic mean, is the gamma function, and is the regularised incomplete beta function. This evidence is the probability that the shape of corresponds to a specific template , regardless of the particular values of the (positive) scale, offset, and noise parameters used in the affine transformation that relates to (Eqn. (1)). At first glance, the appearance of the term suggests that two s that are equivalent up to a multiplicative constant would have different abilities to explain the same . However, that constant must also be accounted for in the prior term , where it can cancel this effect. Thus, choosing the range for in the prior is intimately related to setting the of the and, unless one has a reason to believe different models have different ranges of , the within a should be normalised such that their are equivalent.
While the evidence expression in Eqn. (5) is very general in the sense that it can be used for almost all choices of templates, it is not applicable to the special, ‘null’ case in which a template is absent (i.e., where is flat and/or is only zero). This case is very useful in our approach for validating the presence or absence of a shape in experimental data, as we will show in following section. The corresponding evidence expression for this case is
| (6) |
where represents the case that the model lacks a template. This evidence expression represents the probability that the experimental data is featureless (i.e., lacking any latent structure) beyond the presence of a constant background offset and noise, regardless of the exact values of these parameters. Together, the evidence expressions in Eqns. (5) and (6) enable us to quantitatively express how well the shape of experimental data agrees with candidate templates, independent of extraneous details and nuisance parameters that may change from experiment to experiment.
II.3 Describing the Shape of a Dataset using Bayesian Model Selection (BMS)
We compare the performance of different templates by using BMS Jaynes (2003); Bishop (2006); Kinz-Thompson et al. (2021) in order to calculate the probability that each is the best description of the shape of the data, . This calculation is conditionally dependent on the assumptions in , which define the specifics of the analysis method, including the composition of . Multiple distinct analysis methods can consequently be developed by using different s to tailor their effectiveness to individual experimental situations and systems. For any chosen , an appropriate template prior probability for , , must then be assigned, for example, by: (i) using an equal a priori assignment of , where represents the number of templates in ; (ii) learning prior values from separate experiments; or even (iii) using a Dirichlet process or hierarchical Dirichlet process Teh et al. (2006) for a non-parametric ‘infinite’ set of templates. Once all of the have been assigned, Bayes’ rule can be used to perform BMS and compute the template posterior probability as
| (7) |
This expression represents the probability of an given the observed data and, thus, may be used to identify the in that most optimally describes the latent structure of (for a specific choice of ). Using Eqn. (7) is therefore a quantitative means by which the underlying shape of experimental data may be determined. Furthermore, by considering a ‘background’-shaped and/or just the presence of noise (i.e., Eqn. (6)) in the BMS process, this approach can also validate whether using the most probable to describe the shape of is justified, or whether the shape of can be better explained as just noise in the data. Altogether, this BMS process sets up an objective, quantitative, researcher-independent metric for not only determining the shape of experimental data, but also validating such shape assignments.
The shape-calculation equations we report above describe a relationship between ideal distributions (i.e., ) and noisy signals (i.e., ) that is independent of many experimental details which would otherwise complicate the analysis being performed. The only requirements are that both and exist in the same data-space and are vectors of the same size. Practically, however, most templates are generated from some underlying model that exists in a separate ‘model-space’ distinct from the data-space of and . Relating such a model-space to data-space requires that a set of parameters, , be used to map the model to an . For example, a model of a three-dimensional object being projected onto a two-dimensional image may use the Euler angles of the object to generate s with different orientations in the two-dimensional image data-space.
Generally, when using such a model to generate s for identifying the shape of , the template posterior probabilities for an entire group of model-associated s must be calculated to account for the many possible ways that the single model could have been mapped into data-space. Having performed all of those calculations, it is then possible to marginalise out the dependence upon some of the from the model. In the example above, marginalising out the Euler angles would yield the posterior probability that the shape of corresponds to a two-dimensional image of the model, regardless of not knowing the true orientation of the three-dimensional object being projected into the image. Thus, this type of marginalisation in data-space enables our framework to provide objective measures for shape assignment in model-spaces as well. We note that the map between model-space and data-space used in these shape-calculations should be explicitly acknowledged and defined in order to mitigate unintentional mis-estimations of the weight of particular models in data-space during the change of variables. Finally, it is worth mentioning that such model-spaces almost always exist for scientific analyses, even if they are only implicitly invoked within .
The most complete implementations of these BMS-based shape calculations occur when using s that specify every physically appropriate . However, this approach may not always be theoretically possible nor computationally feasible if an effectively infinite number of s exist. In such situations, it is worth noting that, depending on the precision required by a particular analysis method, the full set of templates may not be required to obtain effective results. Importantly, a major benefit of BMS is that we can determine which among a set of approximate templates best describes the shape of , even if none are ‘exact’. Additionally, the BMS expression in Eqn. (7) can be rearranged into a function of the log difference of evidence expressions (i.e., a Bayes’ factor) between a test and an appropriate control (or a ‘null’ model), which yields an effective cost function for the direct optimisation of a single (see Supplemental Materials, Section 3). Overall, the most powerful aspect of the BMS-based shape calculations described here is that by considering different s, an analysis method can be optimised for completeness (where all appropriate templates are enumerated) or efficiency (where only a test and a control template are considered), or for a trade-off between the two (using only a restricted set of templates), as the situation demands. This flexibility is a large reason why our framework can be effectively adapted to mimic nearly any of the subjective, expert-based analysis methods that it is meant to replace. Furthermore, the ability to easily disseminate the used in an analysis means that methods can be readily shared, critiqued, and reproduced. Together, these especially powerful aspects of our framework make it extremely straightforward to implement tailor-made, shape-based analysis methods for new experiments and applications.
III Searching for Shapes: Bayesian Inference-based Template Search (BITS)
While the practical scientific applications of shape calculations are numerous (see Fig. 1 and Sec. IV), the flexibility of our framework leads to a corollary of this approach that can be used to search for the presence of particular ’local’ features in the data. Experimental examples of this kind of analysis include finding the location of peaks in molecular spectra, puncta in fluorescence microscopy images, or stepping behavior in time-series. In all of these situations, an underlying physical relationship exists between the datapoints in (e.g., emission wavelength, Cartesian position on a substrate, or measurement time). In the previous section we considered as an -dimensional vector in a manner that largely ignored the relationships between datapoints. Because is a tensor, however, we can reshape it to fundamentally account for these relationships. For instance, if is a fluorescence microscopy image, then each datapoint might correspond to a pixel of spectral colour with an associated position (, , ) in the sample-space of the experiment. Thus, it would be useful to reshape from a first-order tensor (i.e., a vector) of scalar datapoints into a more natural representation as a fourth-order tensor with one dimension each for , , , and . Because , , and exist in a Euclidean metric space, we can also calculate a distance, , between any two datapoints in this example. With such a distance metric for at least one of the tensor dimensions of , a local neighbourhood around the position of can be defined as the subset of datapoints, , for which , where is a specified distance cutoff. Notably, this neighbourhood contains datapoints, and may be orders of magnitude smaller depending on the choice of . Thus, for a fixed value of , can be thought of as a composite of approximately unique -neighbourhoods of size (i.e., distinct subsets ).
We can then define the local, latent structure of by performing the BMS-based shape assignment described in Sec. II separately within each of these unique neighbourhoods using a set of templates, , where each is also of size . Intuitively, this process can be understood as ‘scanning’ a small region through along the dimensions of the tensor and assessing the shape of the data at each site. Whenever one of the is found to be an appropriate description for the data in a particular neighbourhood, a feature (i.e., ) is effectively ‘localised’ at that site. Therefore, we call this local analysis approach ‘Bayesian inference-based template search’ (BITS), because it localises the templates in within by traversing the unique neighbourhoods of and determining the latent structure of the data in each using the BMS approach described above. As the name BITS suggests, this approach is conceptually similar to traditional template matching calculations (e.g., via normalised cross correlation Briechle and Hanebeck (2001)), and in fact incredible mathematical similarities, as seen in the cross-correlation term between and in Eqn. (5), have naturally arisen from our probabilistic approach. As such, we believe many strategies used for template matching (e.g., fast Fourier transforms) might be adapted with future work. Regardless, as discussed below, by casting the template matching process into a probabilistic framework BITS enables powerful extensions facilitated by model selection, such as model comparison and automatic feature localisation.
We note that each local calculation is technically performed over all but, by splitting the likelihood into two regions, one within modeled by and one without modeled by (i.e., non-local data is ‘noise’), the evidence contribution from without the local region is the same for each and cancels in the Bayes’ factors of Eqn. (7). Thus, the entire calculation can be simplified, and only the local region within needs to be addressed. Of course, rather than use the local BITS approach described here, a composite template simultaneously containing all of the features being localised could be used to describe the shape of the entire , however, as we will show, BITS is much more computationally efficient. For instance, a of size that contains unique features of size that are to be localised with datapoint-resolution would require distinct templates be tested. Both constructing each template and calculating the evidence for a template are , so such a full-sised shape calculation has computational scaling of . Clearly, this approach has severe scaling issues for any number of features. Fortunately, the equivalent BITS calculation that interrogates localisation sites, and where we have chosen so that the are the size of the features, , has a computational scaling of . In the context of shape-based analyses, template searching with BITS greatly reduces the computational burden of localising features down from a geometric to a linear scaling.

The BITS process is demonstrated in Fig. 2 with an illustrative example of the analysis of an image of a cellular environment. The data-space to be analysed in this example consists of a second-order tensor of pixel intensities where the two tensor dimensions correspond to Cartesian coordinates in the cellular environment. While the image is coloured to differentiate and visualise different cellular components with the human eye, we note that, for simplicity, our illustrative example is dealing with the total intensity value of each pixel. Three-dimensional atomic-resolution structural models for these molecules are used to generate a corresponding set of two-dimensional s that represent each biomolecule in a particular orientation in the image of the cellular environment (shown in the figure in grey boxes). Given the number of templates, and that the size of these templates is much smaller than the total size of the image, BITS can be used very efficiently in this analysis.
Along with a null template (), the biomolecular model templates are ‘scanned’ through the image , and the BMS calculation of Eqn. (7) is performed on the at each site. The white square on the image shows the specific local neighbourhood currently being interrogated using BMS, and in subsequent steps BMS calculations are performed on the adjacent local neighbourhoods (‘scanning’ order denoted by the white arrow). The biomolecular orientation dependence of the s is marginalised out of this calculation by combining the template posterior probabilities of the s derived from the same biomolecular model. This yields the model posterior probability that each biomolecule of interest is localised at a particular position in the image regardless of its orientation. The specific neighbourhood being analysed in Fig. 2 highlights the advantages of including a in a BITS analysis. While this region of the image contains some latent structure, we can visually see that it is not explained by any of the biomolecular model templates. Corresponding to this visual analysis, BITS finds that the null template has the highest posterior probability, and thus, no feature is localised. This stipulation, that a feature is only localised if the shape of the data is better explained by a model template than random noise, provides critical protection against over-fitting, which is a distinct advantage of BITS over other template searching methods.
Notably, in Fig. 2, only a small sample of biomolecular model orientations are used, and we assume that if a particular neighbourhood contains a biomolecule of interest in a similar orientation as one of the chosen templates, there is sufficient overlap of shape between the two for it to be detected in the BMS calculation. The exact amount of similarity required for this correspondence depends only upon how well the other templates can account for the local shape of this neighbourhood. Thus, while the number of sampled orientations may need to be optimised for different applications depending on the desired outcome, with sparse samples of a model’s orientations may still be used to effectively localise features.
Overall, the BITS algorithm can be understood as a method that quantifies the degree to which the latent structure in the data of each neighbourhood of is correlated with an . This correlation is maximised when BITS reaches the ‘true’ location of a feature of interest in the data and the is perfectly aligned with the feature. When misaligned by even one data-point, however, the positive correlation can be negligible, and immediately another (e.g., a null template) or even no particular can dominate the BMS calculation. The effect of this behavior is that only the location in corresponding to the center of a feature of interest (i.e., perfectly overlapped by ) is identified with a high . Interestingly, this means BITS inherently protects against multiple localisations of the same feature while simultaneously facilitating localisation of multiple, closely spaced features.
Perhaps the most important and unique aspect of the BITS algorithm is that it enables s acquired under different experimental conditions to be directly compared within a single, common reference frame. Specifically, since BITS uses evidence expressions that are based only upon agreement of an with the latent structure of , it is independent of many experimental nuisances that would otherwise obstruct direct comparisons. For example, while different background levels in two experiments can render the use of a common threshold value to localise features completely ineffective, BITS remains invariant under changes in background and thus yields two sets of feature localisations that can be directly compared. Moreover, by setting a pre-defined posterior probability threshold and/or by including a model of the background or simply noise as s in , BITS can automatically identify and localise features for a wide range of experimental techniques without human intervention or advanced knowledge about the experimental situation (e.g., exposure times for a detector).
IV Discussion
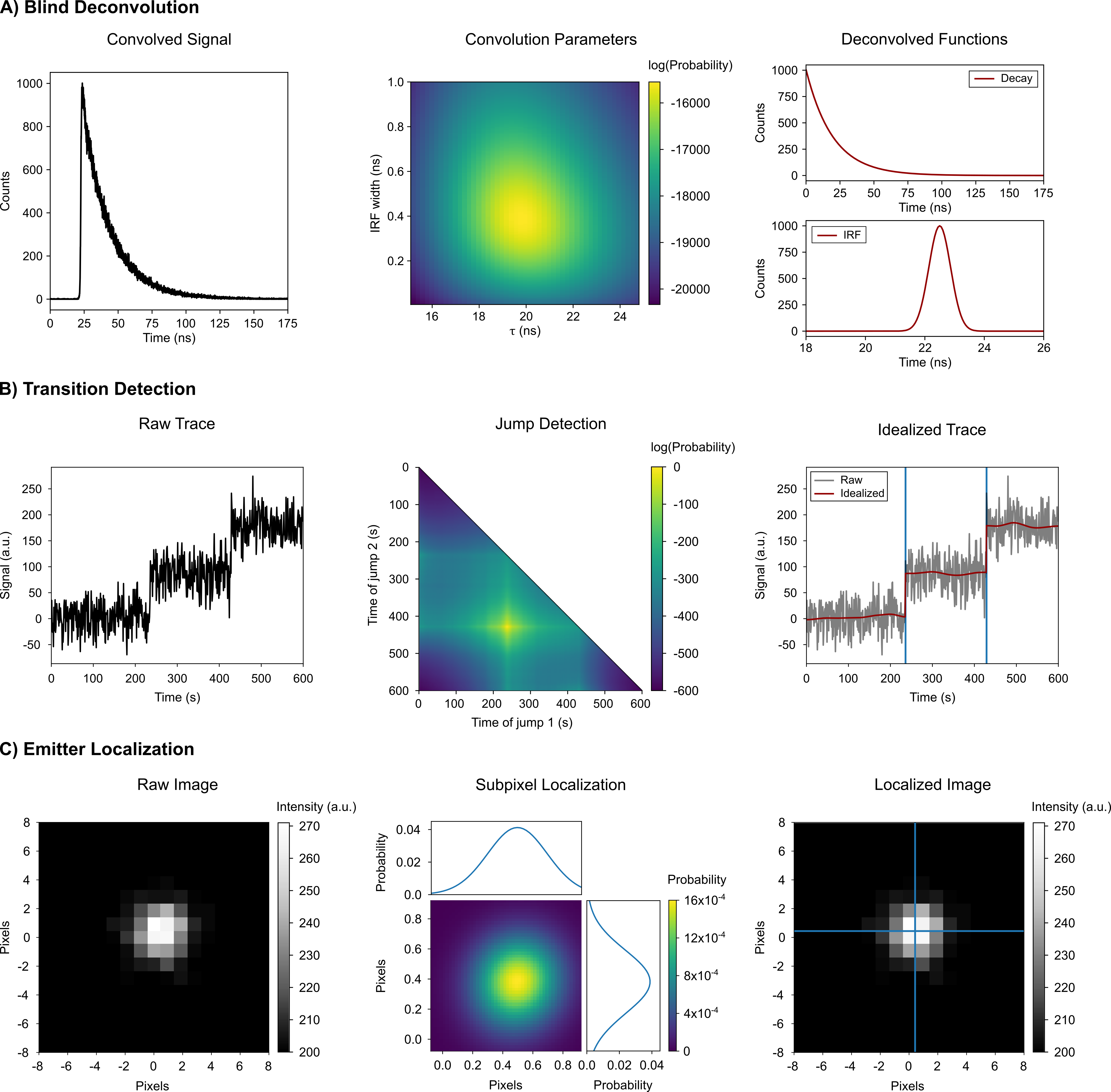
The ability to describe the latent structure of experimental data can readily be leveraged for many different techniques and analyses in the physical and life sciences (Fig. 1). Here, we consider several examples, and briefly demonstrate and discuss some of their implementations. We begin with experiments in which raw data is pre-processed in a manner according to its shape. For instance, in signal processing-based analyses, the shape-based framework presented here can be used to: (i) perform multivariate calibration transfer Workman (2018) (e.g., in optical spectroscopy techniques) by comparing the shapes of responses for standardised samples across multiple instruments; (ii) perform blind deconvolution Levin et al. (2009) (e.g., in atomic force-, optical-, or electron microscopy) by comparing the convolution of possible instrument response functions and deconvolved signals to the shape of the recorded data (Fig. 3A) ; or (iii) to align distinct measurements of the same object or sample (e.g., the same field-of-view in different colour channels Friedman and Gelles (2015) or multiple image planes Juette et al. (2008) of a fluorescence microscope) by finding the optimal polynomial transform to create an interpolated measurement that matches the shape of another measurement.
In analytical chemistry experiments that are used to identify the contents of an experimental sample based on the characteristics, or ‘fingerprints’, of known standards, the framework presented here can be used to compare the shape of the signal of an experimental sample against databases of standard experimental and/or theoretical templates of the possible contents. Examples of this kind of analysis include identification of chemicals from characteristic infrared (IR) spectra Luinge (1990), or 1H nuclear magnetic resonance (NMR) spectra Napolitano et al. (2013), and identification of proteins from fragmentation patterns in mass spectrometry data Domon and Aebersold (2006). Similarly, a shape assignment-based approach would enable the automated identification of sample contents from the noisy measurements typically obtained in analyses involving small sample concentrations. Additionally, shape comparisons can be used to construct and validate atomic- or near-atomic resolution models in structural biology experiments by comparing the: (i) structure factors from different molecular models to the diffraction pattern for an X-ray crystallography experiment Brünger (1992), (ii) electrostatic potential maps from different molecular models to the reconstructed density in a cryogenic electron microscopy (cryo-EM) experiment Scheres and Chen (2012), or even (iii) predicted electron scattering patterns from different atomic models to the raw electron microscopy micrographs in a cryo-EM experiment. In fact, in the last example, a similar Bayesian approach has been pioneered by Cossio and Hummer to analyse cryo-EM micrographs Cossio and Hummer (2013). Despite differences in the priors, scaling parameter, and specific use of BMS, our generalised shape-based analysis framework otherwise readily maps onto this approach, and could thus be used
to develop a specialised method that achieves effectively the same results.
In analyses in which transitions between different signal values need to be identified, our approach can be extended to locate change points by comparing s with and without a discrete change of any arbitrary magnitude in shape (Fig. 3B). This could be used to locate changes in the: (i) efficiency of fluorescence resonance energy transfer (EFRET) in the EFRET vs. time trajectories reporting on the (un)folding or conformational dynamics of a biomolecule in single-molecule FRET (smFRET) experiments Tinoco and Gonzalez (2011), (ii) extension in the force vs. extension or extension vs. time trajectories reporting on the (un)folding or conformational dynamics of a biomolecule in single-molecule force spectroscopy experiments Tinoco and Gonzalez (2011); Bustamante et al. (2021), (iii) position in the position vs. time trajectories reporting on the directional stepping of a biomolecular motor in single-molecule fluorescence experiments H. Park and Selvin (2007), (iv) conductance in the conductance vs. time trajectories reporting on the (un)folding or conformational dynamics of a biomolecule in single-molecule field effect transistor (smFET) experiments Bouilly et al. (2016), or even (v) conformation in the conformation vs. time trajectories reporting on (un)folding or conformational dynamics of a biomolecule in molecular dynamics simulations. Indeed, such a BMS-based method to detect transition in time-series data has been pioneered by Ensign and Pande Ensign and Pande (2010). Despite minimal differences in noise models, our generalised shape-based analysis framework can be mapped onto the approach of Ensign and Pande, thus facilitating the development of a specialised method that can effectively arrive at the same results. This general approach to analysing time-series extends the use of Bayesian inference-based techniques for the detection of change points in a time-dependent signal to any sequential data with arbitrary signal properties, thereby enabling the accurate estimation of kinetics from a wide range of experimental techniques.
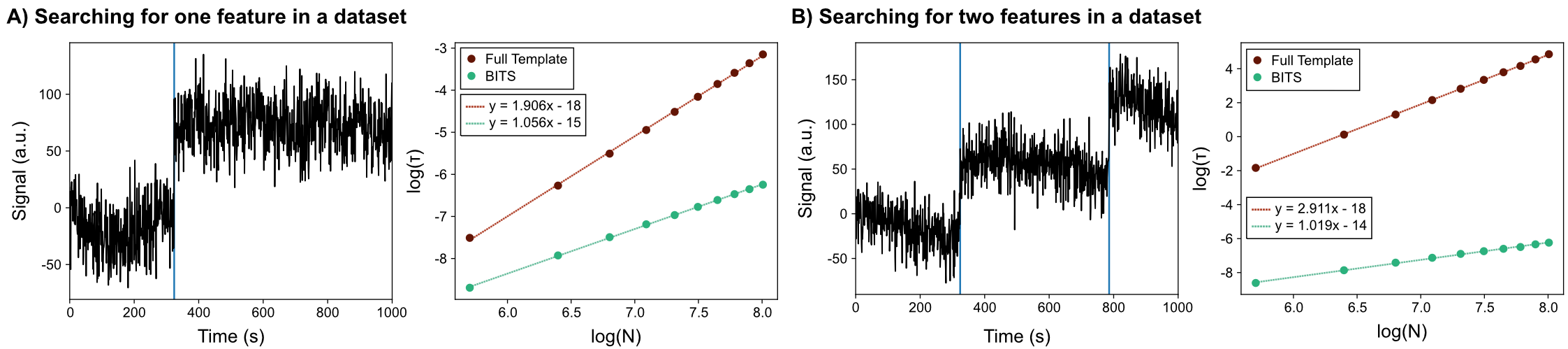
In addition to the full shape-based methods discussed above, we expect that BITS is poised to have a large impact on a number of more specialised situations–particularly analyses that require localisation of well-defined signals or image features. For example, given a particular spectral line shape (e.g., a Lorentzian function), BITS can be used to find peaks in multidimensional NMR spectra S. Hiller and Wider (2005). Similarly, BITS can be used to identify particles of interest and their orientations in cryo-EM Frank (2006a) and cryogenic electron tomography (cryo-ET) Frank (2006b) micrographs in a manner similar to that shown in Fig. 2. This is also readily extended to localising and identifying individual molecules and molecular structures in atomic force microscopy (AFM) Dufrêne et al. (2017) and super-resolution fluorescence microscopy images Khater et al. (2020) (Fig. 3C). Methods using traditional template matching for such analysis tasks can be easily adapted into our BITS framework, thereby enabling comparison across disparate datasets (e.g., Amyot and Flechsig (2020), Shi et al. (2019)). In the case of the analysis of time-series (e.g., single-molecule fluorescence, molecular dynamics), BITS can be used to detect transitions or change points between states, even when those transitions are more diffusive than instantaneous, as is a typical requirement for analysis using hidden Markov models. Additionally, as discussed in Sec. III, BITS makes this type of time-series analysis much more efficient than when analysing the shape of a whole time-series at once (Fig. 4).
The range of examples provided above are broad, but not exhaustive. Nonetheless, they highlight the versatility of our approach, and we hope they will inspire others to adopt this framework for their experiments and analysis methods. Although the development, optimisation, bench-marking, and in-depth discussion of each of the individual scientific applications described above is necessarily very specialised, and, thus, beyond the scope of the current work, we have created a gallery of illustrative, proof-of-principle examples that are open-source and written in Python to demonstrate and enable the use of our framework; they can be accessed at https://bayes-shape-calc.github.io.
V Conclusion
To the best of our knowledge, the use of probabilities to determine the latent structure of data as discussed above is a radically new approach to analysing experiments in the physical and life sciences. The framework we present here is the quantitative extension of a very intuitive approach to data analysis in which expert researchers visually determine whether their data is the shape that they expect it to be. Rather than develop heuristic approaches to emulate this subjective process, our method provides a quantitative metric based only on probability that is free from human intervention and experimental considerations. Among other things, the ability to determine the shape of data enables researchers to objectively pre-process data; identify fingerprints and validate assignments; detect change points; and identify and localise features using BITS (Figs. 1 and 2). Additionally, the shape-based framework we present here can be readily applied to analyse large, high-dimensional datasets that are difficult to visualise and would be nearly impossible to analyse manually. As can be seen from the breadth of potential applications listed above (Fig. 1), the overall methodology described in this work transcends individual fields and techniques, and indeed represents a new quantitative lens through which countless experiments in many different areas of the physical and life sciences may be analysed.
Acknowledgements.
This work was supported by funds to R.L.G. from the National Institutes of Health (NIH) (R01 GM 084288, R01 GM 137608, R01 GM 128239, and R01 GM 136960) and the National Science Foundation (NSF) (CHE 2004016) as well as funds to C.D.K. from the NIH (Training Grant in Molecular Biophysics to Columbia University, T32 GM008281), the Department of Energy (DOE) (Office of Science Graduate Fellowship, DE-AC05-06OR23100), and the NSF (CHE 2137630).References
- Johnstone and Titterington (2009) I. M. Johnstone and D. M. Titterington, Phil. Trans. R. Soc. A 367, 4237–4253 (2009).
- Leek et al. (2010) J. T. Leek, R. B. Scharpf, H. C. Bravo, D. Simcha, B. Langmead, W. E. Johnson, D. Geman, K. Baggerly, and R. A. Irizarry, Nat. Rev. Genet. 11, 733–739 (2010).
- Jaynes (2003) E. Jaynes, Probability theory: the logic of science (Cambridge University Press, Cambridge, UK; New York, NY, 2003).
- Bishop (2006) C. Bishop, Pattern recognition and machine learning (Springer, New York, NY, 2006).
- Kinz-Thompson et al. (2021) C. D. Kinz-Thompson, K. K. Ray, and R. L. Gonzalez, Annu. Rev. Biophys. 50, 191–208 (2021).
- Malakoff (1999) D. Malakoff, Science 286, 1460 (1999).
- von Toussaint (2011) U. von Toussaint, Rev. Mod. Phys. 83, 943–999 (2011).
- Friel and Wyse (2012) N. Friel and J. Wyse, Stat. Neerl. 66, 288–308 (2012).
- Cossio and Hummer (2013) P. Cossio and G. Hummer, J. Struct. Biol. 184, 427–437 (2013).
- Ensign and Pande (2010) D. L. Ensign and V. S. Pande, J. Phys. Chem. B 114, 280–292 (2010).
- Dryden and Mardia (2016) I. L. Dryden and K. V. Mardia, Statistical shape analysis with applications in R, 2nd ed. (John Wiley & Sons, Chichester, UK; Hoboken, NJ, 2016).
- Pawley (2006) J. B. Pawley, ed., Handbook of biological confocal microscopy, 3rd ed. (Springer, New York, NY, 2006).
- Shen et al. (2017) H. Shen, L. J. Tauzin, R. Baiyasi, W. Wang, N. Moringo, B. Shuang, and C. F. Landes, Chem. Rev. 117, 7331–7376 (2017).
- Gradshteyn et al. (2014) I. S. Gradshteyn, I. M. Ryzhik, D. Zwillinger, and V. Moll, Table of integrals, series, and products; 8th ed. (Academic Press, Amsterdam, 2014).
- Ng and Geller (1969) E. W. Ng and M. Geller, J. Res. Natl. Bur. Stand., Section B: Mathematical Sciences 73B (1969).
- Teh et al. (2006) Y. W. Teh, M. I. Jordan, M. J. Beal, and D. M. Blei, J. Am. Stat. Assoc. 101, 1566–1581 (2006).
- Briechle and Hanebeck (2001) K. Briechle and U. D. Hanebeck, in Optical Pattern Recognition XII, Vol. 4387, edited by D. P. Casasent and T.-H. Chao, International Society for Optics and Photonics (SPIE, 2001) pp. 95 – 102.
- Workman (2018) J. J. Workman, Appl. Spectrosc. 72, 340–365 (2018).
- Levin et al. (2009) A. Levin, Y. Weiss, F. Durand, and W. T. Freeman, 2009 IEEE Conference on Computer Vision and Pattern Recognition , 1964–1971 (2009).
- Friedman and Gelles (2015) L. J. Friedman and J. Gelles, Methods 86, 27–36 (2015).
- Juette et al. (2008) M. F. Juette, T. J. Gould, M. D. Lessard, M. J. Mlodzianoski, B. S. Nagpure, B. T. Bennett, S. T. Hess, and J. Bewersdorf, Nat. Methods 5, 527–529 (2008).
- Luinge (1990) H. J. Luinge, Vib. Spectrosc. 1, 3–18 (1990).
- Napolitano et al. (2013) J. G. Napolitano, D. C. Lankin, J. B. McAlpine, M. Niemitz, S.-P. Korhonen, S.-N. Chen, and G. F. Pauli, J. Org. Chem. 78, 9963–9968 (2013).
- Domon and Aebersold (2006) B. Domon and R. Aebersold, Science 312, 212–217 (2006).
- Brünger (1992) A. T. Brünger, Nature 355, 472–475 (1992).
- Scheres and Chen (2012) S. H. W. Scheres and S. Chen, Nat. Methods 9, 853–854 (2012).
- Tinoco and Gonzalez (2011) I. Tinoco and R. L. Gonzalez, Genes Dev. 25, 1205–1231 (2011).
- Bustamante et al. (2021) C. J. Bustamante, Y. R. Chemla, S. Liu, and M. D. Wang, Nat. Rev. Methods Primers 1, 25 (2021).
- H. Park and Selvin (2007) E. T. H. Park and P. R. Selvin, Quart. Rev. Biophys. 40, 87–111 (2007).
- Bouilly et al. (2016) D. Bouilly, J. Hon, N. S. Daly, S. Trocchia, S. Vernick, J. Yu, S. Warren, Y. Wu, R. L. Gonzalez, K. L. Shepard, and C. Nuckolls, Nano Lett. 16, 4679–4685 (2016).
- S. Hiller and Wider (2005) K. W. S. Hiller, F. Fiorito and G. Wider, Proc. Natl. Acad. Sci. 102, 10876–10881 (2005).
- Frank (2006a) J. Frank, Three-dimensional electron microscopy of macromolecular assemblies: visualization of biological molecules in their native state, 2nd ed. (Oxford University Press, New York, NY, 2006).
- Frank (2006b) J. Frank, ed., Electron tomography: methods for three-dimensional visualization of structures in the cell, 2nd ed. (Springer, New York, NY; London, UK, 2006).
- Dufrêne et al. (2017) Y. F. Dufrêne, T. Ando, R. Garcia, D. Alsteens, D. Martinez-Martin, A. Engel, C. Gerber, and D. J. Müller, Nat. Nanotechnol. 12, 295–307 (2017).
- Khater et al. (2020) I. M. Khater, I. R. Nabi, and G. Hamarneh, Patterns 1, 100038 (2020).
- Amyot and Flechsig (2020) R. Amyot and H. Flechsig, PLOS Computational Biology 16, 1 (2020).
- Shi et al. (2019) X. Shi, G. Garcia, III, Y. Wang, J. F. Reiter, and B. Huang, PLOS ONE 14, 1 (2019).