Information Geometry for Maximum Diversity Distributions
Abstract
In recent years, biodiversity measures have gained prominence as essential tools for ecological and environmental assessments, particularly in the context of increasingly complex and large-scale datasets. We provide a comprehensive review of diversity measures, including the Gini-Simpson index, Hill numbers, and Rao’s quadratic entropy, examining their roles in capturing various aspects of biodiversity. Among these, Rao’s quadratic entropy stands out for its ability to incorporate not only species abundance but also functional and genetic dissimilarities. The paper emphasizes the statistical and ecological significance of Rao’s quadratic entropy under the information geometry framework. We explore the distribution maximizing such a diversity measure under linear constraints that reflect ecological realities, such as resource competition or habitat suitability. Furthermore, we discuss a unified approach of the Leinster-Cobbold index combining Hill numbers and Rao’s entropy, allowing for an adaptable and similarity-sensitive measure of biodiversity. Finally, we discuss the information geometry associated with the maximum diversity distribution focusing on the cross diversity measures such as the cross-entropy.
1 Introduction
This paper examines the application of information geometry to biodiversity measurement. Various indices, including the Simpson-Gini index, Hill numbers, and Rao’s quadratic entropy, have been developed and utilized to assess the ecological states of biological communities. In particular, Rao’s quadratic entropy has become a cornerstone of biodiversity research , which incorporates both species abundance and functional or genetic dissimilarity, see Rao (1982a, b). By combining species abundance with functional or genetic differences, Rao’s quadratic entropy offers a comprehensive tool for ecological and population genetics studies, enabling ecologists to measure and interpret diversity in ways that were not possible before. By combining species abundance with functional and genetic differences across large datasets, it provides insights into ecosystem stability, resilience, and conservation needs. As computational power and data accessibility continue to grow, Rao’s quadratic entropy will likely remain at the forefront of biodiversity assessments, driving advances in ecological understanding and environmental stewardship. Rao’s groundbreaking contributions in statistical theory and information geometry have had a profound influence on the development of diversity measures, see Rao (1945). His introduction of the Fisher-Rao information metric laid the foundation for viewing statistical models as geometric entities, an approach that has become instrumental in machine learning, ecological modeling, and data science, see Rao (1961, 1987).
We present a comprehensive review of diversity indices through the lens of information geometry. This approach highlights the deep interconnections between Rao’s information-theoretic measures and ecological resilience, revealing how the geometric properties of diversity measures can enhance our understanding of community structure. Specifically, we discuss the maximum diversity distributions under linear constraints, examining how ecological factors, such as resource limitations or habitat suitability, can be represented as geometric constraints on species distributions. We reduce the problem of finding the maximal distribution to a mathematical optimization characterized by the Karush-Kuhn-Tucker (KKT) conditions to find an optimal solution. We demonstrate that the maximum Hill-number distributions can be characterized using -geodesics, which generalize the concept of geodesic paths in the simplex and provide insightful connections between statistical estimation and ecological interpretations. This approach extends Rao’s vision of information geometry, providing ecologists and conservationists with a robust method for identifying optimal diversity configurations in response to environmental constraints. In addition, we propose practical applications for this framework, emphasizing how Rao’s contributions to information geometry continue to shape and advance biodiversity research, guiding conservation strategies and promoting a deeper understanding of ecosystem dynamics. From this information-geometric viewpoint, we offer valuable insights into ecosystem stability and resilience. Our approach not only advances theoretical understanding but also has practical implications for biodiversity conservation and environmental management.
The paper is organized as follows: Section 2 builds a mathematical framework for diversity measures, in which we overview the standard indices of diversity such as the Gini-Simpson index, the Hill number and Rao’s quadratic entropy. In Section 3 we present an idea of maximum divergence distributions under a linear constraint focusing on the Hill numbers. The approach is extended to a case of multiple constraints. The ecological interpretation is explored from the practical point of view. Section 4 gives information-geometric understanding for the maximum divergence distributions in a simplex, or a space of categorical distributions. Notably, we associate a foliation, a partitioning into submanifolds, of the simplex with the maximum divergence distribution under linear constraints. This geometric structure provides deeper insight into the behavior of diversity measures within the simplex of categorical distributions. In Section 5 we discuss the maximum divergence distribution in comprehensive perspectives.
2 Biodiversity measures
We provide an overview of common measures used to quantify the diversity of a community, cf. May (1975). Consider a community with species, where represents the relative abundance of species . The set of all possible relative abundance vectors is represented by the -dimensional simplex:
Henceforth, we will identify with the set of all -variate categorical distributions. The following measures of diversity, applied in various ecological contexts, enable various views of biodiversity, emphasizing different aspects from species evenness and dominance. The Gini-Simpson index is given by
for of , see Simpson (1949). The Gini-Simpson index represents the probability that two randomly selected individuals from a community belong to different species. This index is sensitive to species evenness and increases as species abundances become more evenly distributed. The Hill Numbers provide a general framework for diversity that is sensitive to the order , which adjusts the emphasis on species richness versus evenness. The Hill number of order is defined as:
| (1) |
where is a controlling parameter that determines the sensitivity of the index to species abundances, see Hill (1973). When , , which is simply species richness (the count of species). When goes to , the measure becomes Boltzmann-Shannon entropy, with calculated as where
This form uses the exponential of Boltzmann-Shannon entropy to remain in the Hill framework. This quantifies the uncertainty in predicting the species of a randomly chosen individual. It is maximized when all species are equally abundant, indicating high diversity, and decreases as dominance by fewer species increases. When , The measure reduces to the inverse Simpson index
which gives greater weight to common species and is particularly useful for measuring dominance. Thus, the parameter adjusts the sensitivity of the Hill number to species abundances, with higher -values emphasizing dominant species and lower values favoring rare species. The Berger-Parker index focuses on dominance by measuring the proportional abundance of the most abundant species
where is the relative abundance of each species. The Berger-Parker index is useful for identifying communities dominated by a single or few species, with higher values indicating lower diversity and higher dominance by certain species. Alternatively, the inverse Berger-Parker index can be used as a diversity measure, where higher values indicate greater diversity. When the order of the Hill number goes to infinity, it goes the inverse Berger-Parker index. This is because
which is nothing but . Alternatively, as , the Hill number converges to the inverse of the smallest relative abundance: .
Rao’ s quadratic entropy is a measure of diversity that accounts not only for species abundance but also for the dissimilarity between species, such as functional or genetic differences, see Rao (1982a, b). It is defined as
where represents the relative abundances, and is a measure of dissimilarity between species and satisfying and . For example, the dissimilarity matrix is often derived from a distance matrix calculated using measures such as Gower’s distance, Manhattan distance, and others, see Botta-Dukát (2005); Southwood and Henderson (2009). Rao’ s quadratic entropy increases with both the abundance of different species and their functional or genetic differences.
When for all , Rao’s quadratic entropy reduces to a form of the Gini-Simpson index. This measure is particularly useful for quantifying functional diversity in ecosystems where species differ in ecological roles or genetic traits. The Hill number is a family of diversity indices parameterized by , which controls the sensitivity of the measure to species abundances. Hill numbers are ‘effective’ numbers, meaning they give an intuitively meaningful measure of the effective number of species in a community by reflecting both species abundances and the emphasis on common versus rare species through the parameter . Rao’s quadratic entropy, on the other hand, incorporates both species abundances and a dissimilarity matrix that quantifies pairwise similarities between species, allowing it to account for the phylogenetic or functional differences between them. Mathematically, it is defined as the expected dissimilarity between two randomly chosen individuals from a community. In essence, Rao’s entropy provides a diversity measure that is sensitive not only to species abundances but also to their similarity, making it valuable for communities where species may vary significantly in terms of genetic, functional, or ecological traits. To integrate these two concepts the Leinster-Cobbold index is proposed by
where is the similarity matrix with entries representing the similarity between species and satisfying and , see Leinster and Cobbold (2012). The term is the average similarity of species to all species in the community, weighted their relative abundances. This retains the effective number interpretation of Hill numbers while incorporating a similarity matrix like Rao’s quadratic entropy. For a given community, they define a generalized diversity measure that combines both relative abundances and similarities among species. The sensitivity parameter of the Hill number framework is retained, controlling the emphasis on rare versus common species, and a similarity matrix quantifies species resemblance. Leinster and Cobbold’s index with simplifies
which, under some conditions, aligns with the inverse of Rao’s quadratic entropy when (i.e., the similarity matrix is derived from the dissimilarity matrx). This makes it a direct similarity-sensitive generalization of the Gini-Simpson index. By varying , one obtains a diversity profile that reflects different levels of sensitivity to rare and common species, while the similarity matrix ensures that closely related species contribute less to the overall diversity measure. This connection allows both Hill numbers and Rao’s entropy to be seen as part of a single framework, with converging to the traditional Hill numbers when species are maximally distinct (i.e., the similarity matrix is an identity matrix). In this unified measure, the flexibility of Hill numbers in emphasizing different aspects of species abundance combines with Rao’s consideration of species dissimilarity, providing a comprehensive and adaptable biodiversity measure that bridges the strengths of both approaches.
3 Maximum diversity distributions
This section explores the mathematical foundations of maximizing biodiversity measures, focusing on Hill numbers, Rao’s quadratic entropy, and the Leinster-Cobbold index. We present optimization results under realistic ecological constraints, such as linear resource limits, and examine their implications for understanding community dynamics. By integrating these mathematical insights with ecological interpretations, we aim to provide a robust framework for evaluating and managing biodiversity in both theoretical and applied contexts.
Hill numbers are interpreted as effective species counts, emphasizing their bounded nature and ensuring that the do not exceed the actual species count , see Hill (1973); Jost (2006). Here, we confirm the maximum of the Hill numbers within a mathematical framework.
Proposition 1.
Let be a uniform distribution, that is, for . Then, the Hill number attains its maximum value at .
Proof.
We aim to show that for all , with equality if and only if .
Case 1: .
The function is convex on when .
By Jensen’s inequality for convex functions:
| (2) |
Thus, . The equality holds when and only when .
Case 2: , The function is concave on when .
The reverse of inequality (2) holds and hence, , or we get the same inequality: due to . Similarly, the equality holds when and only when .
Thus, in both cases, the maximum Hill number is and is attained uniquely at the uniform distribution .
∎
Extending this result, over a -dimensional simplex (i.e., considering only out of species), the Hill number attains its maximum value when is the uniform distribution over those species, with for the species and for the remaining species. In this way, the Hill number satisfies . When , the community is entirely dominated by a single species, indicating. Conversely, when , the community has maximum diversity with species occurring in equal abundances. Therefore, the Hill number represents the effective number of species, providing a meaningful measure of diversity that accounts for both species richness and evenness. It is helpful to compare values of the Hill number across different ecosystems or treatments, considering both the index value and how close it is to its theoretical maximum for that number of species, see Chao (1987) for ecological perspectives.
However, in real ecosystems, perfect evenness is rare, and the maximizing may not always be ecologically desirable or feasible, see Colwell and Coddington (1994). Maximizing the Hill number might conflict with other ecological goals or constraints. To address this, we introduce a linear constraint on species distribution to reflect real-world ecological limits like resource availability, climate tolerance, and habitat capacity. We fix a linear constraint
where ’s and are fixed constants. Here, without losing generality, we assume is positive. The constant reflects a fixed ecological limit, which lies within the range to ensure the existence for feasible , where and . In practice, the value of is often set as where represents an initial estimate of species proportions based on preliminary field data or other relevant ecological information. This approach anchors in observed or estimated ecological conditions, providing a realistic basis for the constraint on species distribution. This can represent ecological factors such as resource preference, habitat suitability, or species-specific traits. For instance, in a desert ecosystem, might represent drought tolerance in plants, favoring species with high values as they better adapt to dry conditions. The distribution can reflect species’ access to shared resources under competition. Species with high values may beat others in resource acquisition, resulting in larger values.
In this context, the linear constraint model is particularly relevant for habitats where specific resources are scarce and heavily contested. Such constraints shape community structures by influencing which species thrive, based on factors such as resource efficiency or adaptability to environmental conditions. For a general value of in the Hill number framework, the maximum Hill number distribution under a linear constraint is characterized by a power-law form of as follows.
Proposition 2.
Assume a linear constraint , where ’s and are constants.
-
1.
For , the Hill number is maximized at
(3) if satisfies , where is determined by the constraint. Here
-
2.
For , the Hill number is maximized at
(4) if satisfies , where , is determined by the constraint.
Proof.
Our goal is to maximize under the constraints and .
Case 1: . Since is an increasing function of when , maximizing is equivalent to maximizing .
We construct the Lagrangian:
where , , and are Lagrange multipliers. Taking the derivative of with respect to and setting it to zero gives:
If , then , and thus . If , then is undefied because of , so all must be positive. Setting , we obtain the global maximizer in (3) since satisfies the KKT conditions.
Next, we address the existence in such that satisfies the linear constraint. Let . Then,
where Hence,
If , then
This implies , or equivalently , and hence is monotone increasing in . Therefore, noting . This ensures that is in such that satisfies the linear constraint.
Case 2: . Similarly, by the monotonicity argument, the Lagrangian is the same as , and we can observe the similar argument for the KKT conditions. If , then , and thus . If , then the stationarity condition yields . This yields the equilibrium distribution is given by in (4), which satisfies the KKT conditions. Since is monotone increasing, coverges to as goes to . Therefore, , which ensures the existence in such that satisfies the linear constraint. The proof is complete. ∎
We note that, if , then the equilibrium is well-known as the maximum entropy distribution:
in which the equilibrium distribution can be defined for any of the fully feasible interval . This is referred to as a softmax function that is widely utilized in the field of Machine Learning. It also closely related to MaxEnt model that is important as a species distribution model, see Phillips et al. (2004).
To illustrate the application of Proposition 2, we consider a community with species, where the trait for species is given by
This trait distribution creates two peaks, representing species with higher ecological advantages. We compute the maximum distributions under this linear constraint with and for and , respectively. The results are shown in Fig. 1. The left panel of Fig. 1displays the trait values against species . The right panel shows the optimized species distribution for (squares) and (circles). For , the distribution assigns zero probability to species with indices between and , indicating that these species are excluded from the optimal distribution due to the emphasis on common species. For , the distribution includes all species with non-zero probabilities, promoting evenness across the species. Indeed, for , the Hill number is more sensitive to rare species, resulting in a more uniform distribution of probabilities among the species. We note that this numerical study can be conducted by solving only a one-parameter equation for to satisfy the linear constraint thanks to the result of Proposition 2. Thus, the optimization problem with 101 variables is drastically reduced to such a simplified one.
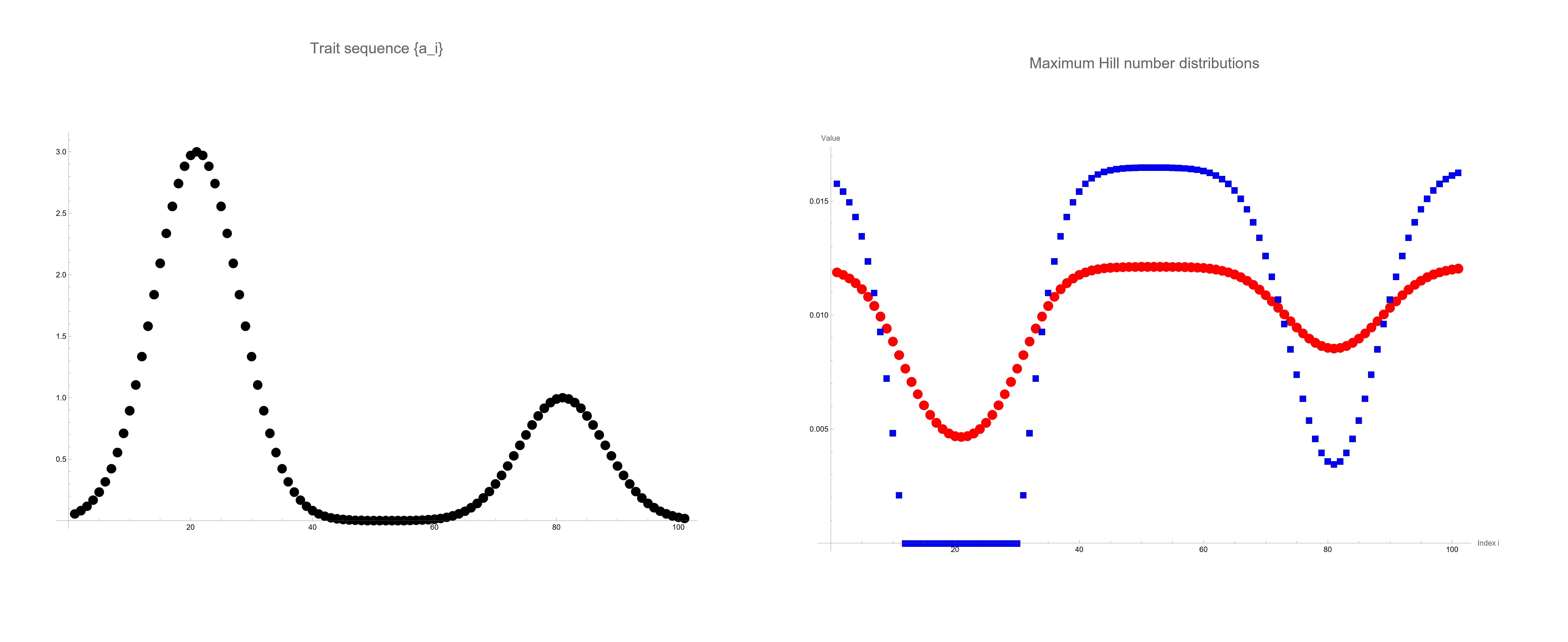
We discuss ecological meaning for , which represents a critical value in the linear constraint. If satisfy for a case of , then the optimal distribution becomes degenerate, meaning that it assigns zero probability to some species. This occurs because the resource constraint is too restrictive to allow for a distribution where all species have positive abundances. Ecologically, this reflects situations where only species with certain trait values can survive under the given constraints, leading to competitive exclusion and reduced diversity. Thus, the ecosystem cannot sustain all species at non-zero abundances without violating resource constraints. Fig. 2 gives a 3-D plot of the Hill number against of a -dimensional simplex with . In the surface, the curve has the centered point that attains the global maximum of .
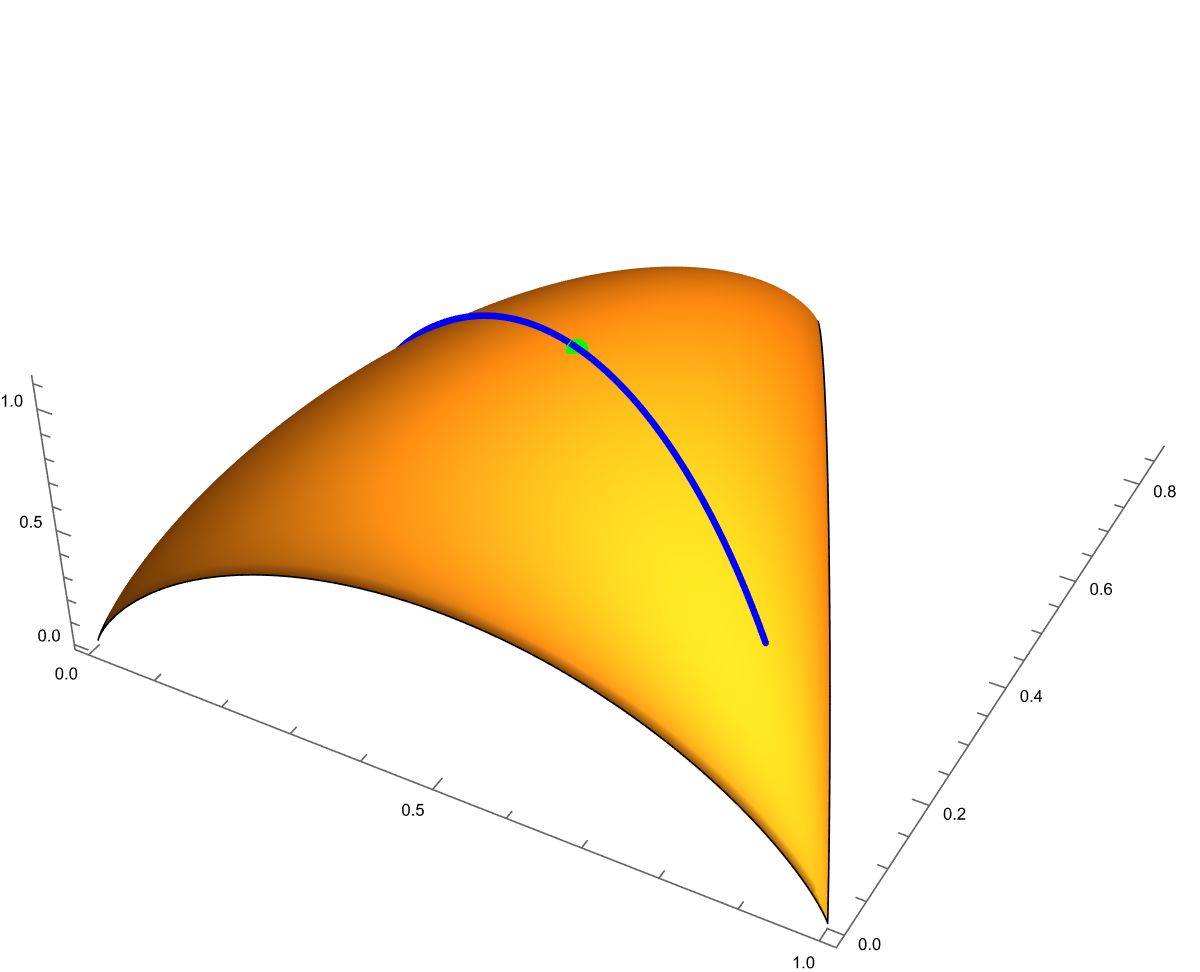
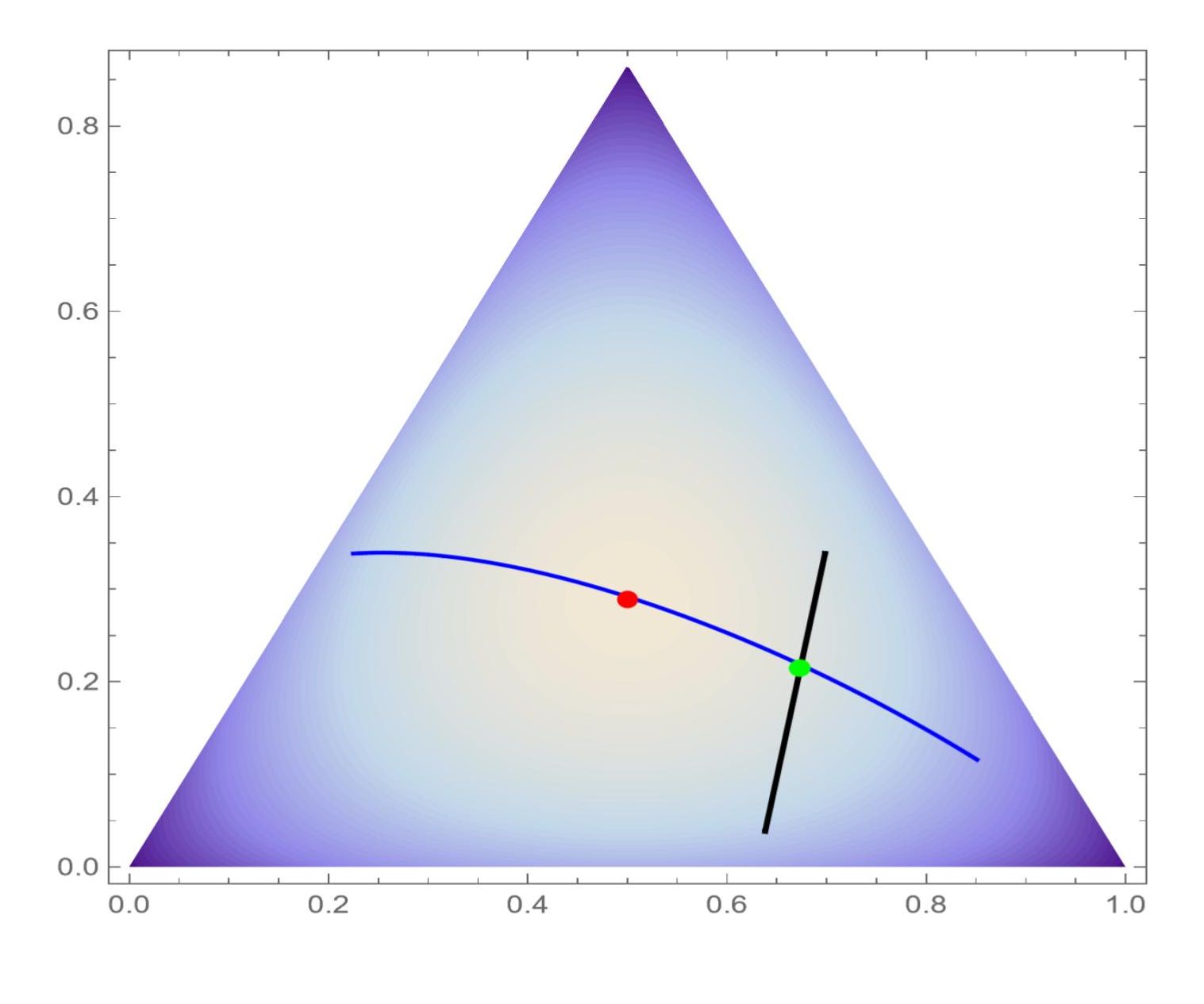
Fig. 3 gives a contour plot of the Hill number against of a -dimensional simplex with . In the simplex, the curve represents the model intersects the line defined by the linear constrain at the point with the conditional maximum; the centered point attains the global maximum of .
On the other hand, Rao’s quadratic entropy stands out for its ability to incorporate not only species abundance but also functional and genetic dissimilarities. Let us look into the distribution maximizing Rao’s quadratic entropy.
Proposition 3.
Assume that is invertible and that in Rao’s quadratic entropy , where denotes a copy vector of ’s. Then, is maximized at
| (5) |
Proof.
We introduce the Lagrangian function with the multipliers and for to be in :
The stationarity condition yields . If , then , and we have Therefore, Solving for , we get The positivity of ensures that and the KKT conditions are satisfied. ∎
We discuss a case where entries of have positive and negative signs. The optimal distribution would be in the boundary of , however any closed form is not solved here. For example, consider the following examples of a dissimilarity matrix:
Then, we find , which satisfies the assumption Proposition 3. The maximum of Rao’s entropy defined by is at the optimal distribution . On the other hand, , which violates the assumption Proposition 3. Indeed, the optimal distribution is given by in the boundary, at which Roa’s entropy has a maximum . These species with zero probabilities are effectively excluded from the ecosystem’s diversity under the entropy maximization principle, meaning they ”cannot survive” within the model’s framework.
If all species are equally dissimilar, then the global maximum distribution equals the even distribution . In effect, consider the case where , where denotes the identity matrix. Then, and hence, equals the even distribution . This is the same as the maximizer of noting that Rao’s quadratic entropy is reduced to the Gini-Simpson index. However, in most realistic scenarios, species differ in their functional or genetic traits, leading to variations in dissimilarities. Therefore, typically differs from , giving higher probabilities to species more dissimilar to others. Next, consider another simple case where for a fixed of , where denotes the diagonal matrix. Thus,
and hence . This yields that, if , then , or the probability of species is a zero in the maximum distribution. Further, assume , where and is the one-copy vector of dimension. Then, a straightforward calculus yields that, if
then defined in (5) is in . This situation is quite near the case of , or the equally-dissimilar case . In general, it is difficult to get a closed form of the maximum distribution without the assumption . However, we can use efficient algorithms to find numerically the maximizer, in which the optimization problem is reduced a a standard quadratic programming problem. Fast solvers like interior-point methods, active set methods, or alternating direction method of multipliers can handle this formulation. Tools such as quadprog in R and Python or specialized libraries like Gurobi or CVXPY provide robust implementations for high-dimensional problems. See Dostál (2009) for quadratic programming algorithms.
Next, consider a linear constraint: , where and are fixed constants. Then, under the linear constraint, Similarly, we introduce the Lagrangian function:
The stationarity equation is given by which yields the solution form:
| (6) |
Here is determined by the linear constraint, so that
If we assume , then is properly the distribution maximizing Rao’s entropy due to the discussion similar to the proof of Proposition 3.
Let us examine the maximum Leinster-Cobbold index distribution. This index is integrated the Hill number with Rao’s quadratic entropy, providing a unified framework for measuring biodiversity that accounts for both species abundances and similarities.. We can find the maximizing distribution by combining arguments in Propositions 2 and 3.
Proposition 4.
Assume that is invertible and that in the Leinster-Cobbold index:
where is defined as the vector for a vector . Then, the distribution maximizing in is given by
| (7) |
Proof.
The Lagrangian function with the multipliers and is given by
which leads to the stationarity equation,
where denotes the Hadamar product. If , then by the complementary slackness. Let , where . Then, the stationarity equation becomes
which implies is a candidate of the solution. Therefore, the maximum distribution is given by (7).
∎
It is worthwhile to note that is independent of , and is the same form as the maximum Rao’s entropy distribution defined in (5). The distribution maximizing under a linear constraint is given by
| (8) |
where is determined by . We confirm that, if , then is reduced to defined in (6) by a re-parameterized ; if , then this is reduced to in (3). Thus, this effectively integrates both maximum distributions. Then, the stationarity condition is written by
This gives , which concludes the solution form (8).
The Leinster-Cobbold index serves as a unifying framework that encompasses both the Hill numbers and Rao’s quadratic entropy. The inverse similarity matrix adjusts species abundances based on their functional or phylogenetic relationships. High values focus on dominant species or those with higher contributions to similarity; low values emphasize rare species or those with unique traits.
The maximum diversity distribution derived under the linear constraint has ecological interpretations that bridge mathematical optimization and real-world ecological dynamics. The coefficients represent species-specific traits or environmental tolerances that directly influence each species’ ability to thrive under certain ecological conditions. For instance, in ecosystems where a specific resource is limited, could represent each species’ efficiency in utilizing that resource. Species with higher values are more efficient and thus have a competitive advantage, leading to higher abundances . Maximizing the Leinster-Cobbold index under this constraint does not lead to perfect evenness, which is rarely observed in natural ecosystems. Instead, it yields a distribution that balances diversity with ecological realism, reflecting the natural dominance of certain species due to their advantageous traits. This mathematical optimization highlights the trade-offs between achieving maximum diversity and adhering to ecological constraints, demonstrating that the most diverse community under a given constraint proportionally represents species according to their ecological roles and advantages. This approach offers a quantitative framework to model and analyze community structures under various ecological scenarios. By adjusting and , ecologists can simulate different environmental conditions and assess their impact on diversity and species distributions.
4 Information geometry on a simplex
In this section, we explore the general properties of a simplex within the framework of information geometry. Information geometry provides a powerful way to study statistical models by viewing them as Riemannian manifolds endowed with the Fisher-Rao metric Rao (1945). The Fisher-Rao metric provides the Cramér-Rao lower bound for unbiased estimators. This perspective allows us to examine geometric structures such as geodesics, divergence measures, and metric tensors, which have profound implications in statistical inference and diversity measurement.
We have a concise review of the information geometric natures on a simplex. Let be a simplex of dimension , or
Henceforth, we identify with the space of all -variate categorical distributions. The Fisher-Rao metric on is given by the information matrix:
| (9) |
where . The Fisher-Rao metric captures the intrinsic geometry of the probability simplex, reflecting the sensitivity of probability distributions to parameter changes. The metric induces geodesics that can be expressed using trigonometric functions, specifically the arcsine function. The Fisher-Rao distance between two points and on the simplex is given by:
The Riemannian geodesic connecting and under the Fisher-Rao metric can be expressed parametrically using trigonometric functions:
for , where represents the angle between and on the sphere. This geodesic provides the shortest path between two probability distributions under the Fisher-Rao metric and is characterized by trigonometric functions arising from the geometry of the unit sphere.
In information geometry, two types of affine connections–the mixture and exponential connections–lead to dualistic interpretations between statistical models and inference, see Amari (1982); Amari and Nagaoka (2000), Nielsen (2021). These connections give rise to m-geodesics and e-geodesics: For any distinct points and of , the m-geodesic connecting and is given by
the e-geodesic connecting and is given by
where denotes the vector of logarithms of . The e-geodesic corresponds to linear interpolation in the natural parameter space of the exponential family. It is noted that the range of for can be extended to a closed interval including ; the range of for can be extended to as , see appendix for detailed discussion for the enlarged interval. We observe an important example of the mixture geodesic in Rao’s quadratic entropy. In effect, the maximum quadratic entropy distribution in (6) under the linear constraint is written as
This is a mixture geodesic connecting and , where . Thus, becomes a global maximum at ; it becomes a constrained maximum at determined by the linear constraint. If we take distinct points , then the e-geodesic family is given by
where is in a simplex . In general, such a family is referred to as an exponential family. By definition, the e-geodesic connecting any points and of is included in . Under an assumption of an exponential family, the Cramer-Rao inequality provides insight into the efficiency of estimators, making it clear when estimators are at or near this lower bound. It is shown that MLEs within the exponential family have optimal properties, often achieving the Cramer-Rao lower bound under regularity conditions, see Rao (1961). Further, in a curved model in , Rao (1961) gives an insightful proof for the maximum likelihood estimator to be second-order efficient, see also Efron (1975); Eguchi (1983).
As a generalized geodesic, we consider the -geodesic connecting with defined by
where is a fixed real number and is the normalizing constant, cf. Eguchi et al. (2011). We will observe a close relation to the maximum Hill-number distributions discussed in Section 3. By definition, the family of the -geodesics includes the mixture geodesic and the exponential geodesic as
We note that the feasible range for can be extended from to a closed interval, see Appendix for the exact form.
Similarly, for distinct points , then the -geodesic family is given by , where
The -geodesic connecting between any points and of is included in the -geodesic family.
Consider a linear constraint: in . Then, the maximum Hill-number distribution
with under the linear constraint lies along the -geodesic connecting between and , where and Indeed, by the definition of the -geodesic,
which can be written as
where . Therefore, if is defined by The -geodesic provides a path of distributions that transition smoothly from maximum evenness to a distribution that fully incorporates the constraint .
Consider a one-parameter family of probability distributions defined as:
| (10) |
and a subset of of constrained by a linear condition:
Geometrically, this implies that the simplex can be foliated into a family of hyperplanes , where each hyperplane intersects the one-parameter family at a single point:
where satisfies the condition . This foliation provides a geometric perspective on the simplex: each hyperplane forms a ”leaf,” and the distribution of these leaves varies smoothly over . At every point within a leaf, the tangent space of the leaf aligns with a smoothly varying distribution over the simplex. Fig. 4 gives a 3D plot of the foliation in a -dimensional simplex . We observe that the curve represents the ray that intersects the leaves ’s at the conditional maximum points, in which the leaves are parallel to each other.
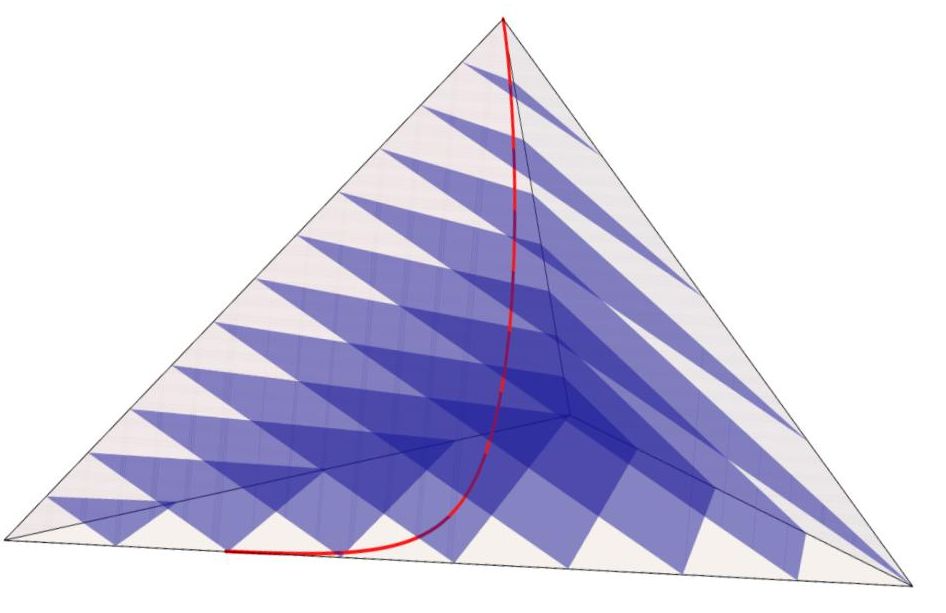
The concepts for divergence have been well discussed in statistics, see Burbea and Rao (1982); Basu et al. et al. (1998); Eguchi and Komori (2022). The -power cross-entropy between community distributions and can be given by
with a power parameter of and the (diagonal) entropy is given by
equating with , see Fujisawa and Eguchi (2008); Eguchi (2024). When , is the Boltzmann-Shannon entropy; when , is the geometric mean, ; when , is the harmonic mean, or . In essence, the -power entropy is equivalent to the Hill number with a relation of in relation to . A fundamental inequality holds: , where the difference is referred as the -power divergence
In general, any statistical divergence is associated with the Riemannian metric and a pair of affine connections, see Eguchi (1992). The power cross-entropy has the empirical form for regression and classification model, in which the minimization problem gives a robust estimation in a context of machine learning. When equals , then , and are reduced to the Boltzmann-Shannon entropy, the cross-entropy and Kullback-Leibler divergence, respectively. The empirical form of the cross-entropy under a parametric model is nothing but the negative log-likelihood function, see Eguchi and Copas (2006) for detailed discussion. We explore statistical properties for estimation methods for the maximum Hill-number model defined in (10).
Let be an observed frequency vector in derived from ecological research or auxiliary information, such as prior field surveys, species inventories, or environmental modeling outputs. Then, the linear constraint is fixed by , where . In general, the maximum likelihood method is recognized as a universal method for estimating a general parametric model. Consider the standard maximum entropy model
Then, the log-likelihood function leads to the likelihood equation: In effect, the maximum likelihood estimation is equivalent to the maximum Hill number method. However, other estimation methods are not associated with such equivalence. In general, we would like to consider the minimum -power method by fixing the power parameter as for the order of the Hill number. For an application to ecological studies, we consider the cross Hill number of -order as
| (11) |
If , then , or the cross Hill number is reduced to the Hill number, or . Hence, since , and hence we define the Hill divergence
Assume and . Then, we result
that is, is the maximum Hill number distribution. This is because
due to . In this way, we can show Proposition 2 from .
We propose the maximum -order estimator defined by
| (12) |
We will observe that the maximum -order estimation is equivalent to the method of the maximum Hill number distribution.
Proposition 5.
Let be the maximum -order estimator defined in (12). Then, the estimator satisfies the linear constraint , where . Furthermore,
Proof.
The -order cross Hill number (11) is simplified at , noting the definition of :
Hence, the gradient is given by
which is written as
due to the definition of , where . Equating the gradient to is equivalent to . The linear constraint is exactly satisfied at since, by definition, is the solution of the gradient equation. Further, if , then , so that
This is nothing but Hill number that attains the maximum at under the linear constraint. This completes the proof. ∎
In the proof, we observe a surprising property: . This directly shows the equivalence between the maximum -order estimation and the maximum distribution for the Hill number of the order . Thus, the maxim -order estimation naturally introduce the maximum Hill number of the order .
We consider a more general setting of linear constraint that allows multiple linear constraints. Let be a matrix of size with full rank and
| (13) |
where is a constant vector of dimension. This means constraints , where is the th row vector of . Consider the maximum Hill-number distribution under such linear constraints. We have an argument similar to that for one-dimensional constraint as discussed above. Thus, we introduce Lagrange multipliers , and to incorporate the constraints, and form the Lagrangian function:
The stationarity condition gives the solution form:
combining both cases of and . It is necessary to define a region of feasible values to ensure that satisfies the linear constraints. However, we omit this discussion as it closely parallels the proof of Proposition 2. The gradient of the -order risk function for the model satisfies
Hence, the maximum -order estimator satisfies the linear constraints Let us consider the asymptotic distribution of under an assumption: the observed frequency vector is randomly sampled from a categorical distribution with a frequency vector with size . Then, asymptotically converges to a normal distribution with mean and covariance , where is the Fisher-Rao information matrix as defined in (9). Hence, converges to a normal distribution with mean and covariance
where is the Jacobian matrix of the model , or
Finally, we note that, if , the Hill number of order become equivalent to the Boltzmann-Shannon entropy, and the minimum -order estimator is reduced the maximum likelihood estimator.
This section demonstrates how the framework of information geometry, particularly through the concept of -geodesics, enriches our understanding of diversity measures on the simplex . By connecting statistical divergences, geodesic paths, and maximum diversity distributions, we establish a geometric interpretation of the Hill numbers and related diversity indices. The foliation of the simplex into hyperplanes corresponding to linear constraints further illustrates the interplay between geometric structures and ecological considerations. These insights not only deepen the theoretical foundations but also provide practical tools for analyzing and optimizing biodiversity under various constraints.
5 Discussion
The maximum diversity distribution under a linear constraint embodies the interplay between species-specific ecological traits and the overall diversity of the community. It provides valuable insights into how ecological factors shape community composition and offers practical implications for biodiversity conservation and ecosystem management. By considering both the mathematical optimum and ecological principles, ecologists can better interpret diversity patterns, predict ecological dynamics, and set informed conservation goals that align with the inherent constraints of natural ecosystems. By selecting different values of , ecologists can focus on different aspects of biodiversity (dominance or rarity), making this a powerful tool for assessing community dynamics, resource competition, and conservation strategies in response to environmental constraints. For conservation applications, comparing observed abundance distribution to the theoretical maximal Hill number distributions offers a valuable diagnostic tool. Alignment with the maximal distribution suggests that the community may have reached an optimal diversity configuration for its specific ecological context, whereas deviations indicate potential imbalances or stresses, such as dominance by invasive species or suppression of keystone species. This comparison helps identify conservation needs and highlights areas for intervention, guiding efforts to maintain a balanced, resilient ecosystem. Monitoring these deviations over time can also track how community structure responds to environmental pressures, providing insights into resilience and adaptation.
Species Distribution Modeling (SDM) is a statistical approach used to predict the geographic distribution of species based on their known occurrences and environmental conditions. SDMs relate species presence-absence or presence-only data to environmental variables (e.g., temperature, precipitation, habitat features) to estimate the probability of species occurrence or abundance across spatial landscapes. These models are widely applied in ecology for biodiversity assessments, habitat suitability mapping, and predicting the impacts of environmental changes, such as climate change, on species distributions, see Southwood and Henderson (2009); Elith and Leathwick (2009); Komori and Eguchi (2019); Saigusa et al. (2024). We discuss a potential framework and its implications for incorporating SDM into the approach of maximum diversity distributions represents. SDMs naturally account for environmental covariates (temperature, precipitation, habitat types), providing realistic constraints for diversity maximization. Using the predicted relative abundances from SDMs, the observed diversity can be directly compared to the maximum diversity, offering insights into the extent to which ecological constraints influence community assembly, see Kusumoto et al. (2023). In areas with significant deviation from maximum diversity distributions, SDMs can provide insights into which species are missing or disproportionately abundant, suggesting specific restoration or management interventions.
Maximum diversity distributions offer a powerful framework that can extend beyond ecology to other domains like economics and engineering, providing insights into resource allocation, system robustness, and optimization under constraints. In portfolio planning, maximum diversity principles can balance risk and return by distributing investments across assets. In control problems, diversity-based strategies enhance robustness by distributing control efforts or resources across system components. Applications include energy management in networks, feedback control in complex systems, and adaptive control for dynamic environments (e.g., autonomous systems, smart grids). By adapting maximum diversity distributions to these fields,we can address challenges in resource optimization, system stability, and risk management.
References
- Amari (1982) Amari, S. I. Differential geometry of curved exponential families: curvatures and information loss. The Annals of Statistics, 10(2):357–385, 1982.
- Amari and Nagaoka (2000) Amari, S. I., & Nagaoka, H. Methods of information geometry (Vol. 191). American Mathematical Soc., 2000.
- Basu et al. et al. (1998) Basu, A., Harris, I. R., Hjort, N. L. and Jones, M. C. Robust and efficient estimation by minimising a density power divergence. Biometrika, 85(3):549–559, 1998.
- Botta-Dukát (2005) Botta-Dukát, Z. Rao’s quadratic entropy as a measure of functional diversity based on multiple traits. Journal of vegetation science, 16(5), 533-540, 2005.
- Burbea and Rao (1982) Burbea, J. & Rao, C. R. On the convexity of some divergence measures based on entropy functions. IEEE Transactions on Information Theory, 28(3):489–495, 1982.
- Chao (1987) Chao, A. Estimating the population size for capture-recapture data with unequal matchability. Biometrics 43, 783-791, 1987.
- Colwell and Coddington (1994) Colwell, R. K. & Coddington, J. A. Estimating terrestrial biodiversity through extrapolation. Philosophical Transactions of the Royal Society of London. Series B: Biological Sciences, 345, 101-118, 1994.
- Dostál (2009) Dostál, Zdenek Optimal quadratic programming algorithms: with applications to variational inequalities,23, 2009, Springer Science & Business Media.
- Efron (1975) Efron, B. Defining the curvature of a statistical problem (with applications to second order efficiency). The Annals of Statistics, pages 1189–1242, 1975.
- Eguchi (1983) Eguchi, S. Second order efficiency of minimum contrast estimators in a curved exponential family. The Annals of Statistics, 793-803, 1983.
- Eguchi (1992) Eguchi, S. Geometry of minimum contrast. Hiroshima Mathematical Journal, 22(3):631–647, 1992.
- Eguchi and Copas (2006) Eguchi, S. and Copas, J. Interpreting Kullback–Leibler divergence with the Neyman–Pearson lemma. Journal of Multivariate Analysis, 97(9):2034–2040, 2006.
- Eguchi (2024) Eguchi, S. Minimum Gamma Divergence for Regression and Classification Problems. arXiv preprint arXiv:2408.01893, 2024.
- Eguchi and Komori (2022) Eguchi, S. and Komori, O. Minimum divergence methods in statistical machine learning: From an Information Geometric Viewpoint. Springer Japan KK, 2022.
- Eguchi et al. (2011) Eguchi, E., Komori, O. and Kato, S. Projective power entropy and maximum tsallis entropy distributions. Entropy, 13(10):1746–1764, 2011.
- Elith and Leathwick (2009) Elith, J. and Leathwick, J. R. Species distribution models: ecological explanation and prediction across space and time. Annual review of ecology, evolution, and systematics, 40(1):677–697, 2009.
- Fujisawa and Eguchi (2008) Fujisawa, H. and Eguchi, S. Robust parameter estimation with a small bias against heavy contamination. Journal of Multivariate Analysis, 99:2053–2081, 2008.
- Hill (1973) Hill, M. O. Diversity and evenness: a unifying notation and its consequences. Ecology 54, 427-432, 1973.
- Jost (2006) Jost, L. Entropy and diversity. Oikos, 113(2), 363-375, 2006.
- Komori and Eguchi (2019) Komori, O. and Eguchi, S. Statistical Methods for Imbalanced Data in Ecological and Biological Studies. Springer, Tokyo, 2019.
- Kusumoto et al. (2023) Kusumoto, B., Chao, A., Eiserhardt, W. L., Svenning, J. C., Shiono, T., & Kubota, Y. Occurrence-based diversity estimation reveals macroecological and conservation knowledge gaps for global woody plants. Science Advances, 9(40), eadh9719, 2023.
- May (1975) May, R. M. Patterns of species abundance and diversity. In Ecology and Evolution of Communities (ed. M. L. D. Cody, J. M.). Cambridge, Mass.: Harvard University Press, 1975.
- Leinster and Cobbold (2012) Leinster, T., & Cobbold, C. A. Measuring diversity: the importance of species similarity. Ecology, 93(3), 477-489, 2012.
- Nielsen (2021) Nielsen, F. On geodesic triangles with right angles in a dually flat space. In Progress in Information Geometry: Theory and Applications, pages 153–190. Springer, 2021.
- Phillips et al. (2004) Phillips, S. J., Dudík, M. and Schapire, R. E. A maximum entropy approach to species distribution modeling. In Proceedings of the twenty-first international conference on Machine learning, page 83, 2004.
- Rao (1945) Rao, C. R. Information and accuracy attainable in the estimation of statistical parameters. Bulletin of the Calcutta Mathematical Society, 37(3), 81-91, 1945.
- Rao (1961) Rao, C. R. Asymptotic efficiency and limiting information. In Proceedings of the Fourth Berkeley Symposium on Mathematical Statistics and Probability, Volume 1: Contributions to the Theory of Statistics, 4, 531-546, 1961. University of California Press.
- Rao (1982a) Rao, C. R. Diversity and dissimilarity coefficients: a unified approach. Theoretical population biology, 21(1), 24-43, 1982.
- Rao (1982b) Rao, C. R. Diversity: Its measurement, decomposition, apportionment and analysis. Sankhyā: The Indian Journal of Statistics, Series A, 1-22, 1982.
- Rao (1987) Rao, C. R. Differential metrics in probability spaces. Differential geometry in statistical inference, 10:217–240, 1987.
- Saigusa et al. (2024) Saigusa, Y., Eguchi, S. and Komori, O. Robust minimum divergence estimation in a spatial Poisson point process. Ecological Informatics, 81:102569, 2024.
- Simpson (1949) Simpson, E. H. Measurement of diversity. Nature 163, 688, 1949.
- Southwood and Henderson (2009) Southwood, T. R. E., & Henderson, P. A. Ecological methods. John Wiley & Sons, 2009.
Appendix
We explore the ranges of for defining a mixture geodesic and -geodesic in .
Proposition 6.
Consider a mixture geodesic connecting and in the interior of , where . The range of is enlarged to a closed interval
where
Proof.
By definition,
| (14) |
If , then
This implies
| (15) |
Similarly, if , then
| (16) |
Hence, this yields the closed interval combining inequalities (15) and (16).
∎
We next focus on a case of the -geodesic.
Proposition 7.
Consider a -geodesic
connecting and in in the interior of , where and is the normalizing constant. The range of is enlarged to a closed interval
| (17) |
where