InPTC: Integrated Planning and Tube-Following Control for Prescribed-Time Collision-Free Navigation of Wheeled Mobile Robots
Abstract
In this article, we propose a novel approach, called InPTC (Integrated Planning and Tube-Following Control), for prescribed-time collision-free navigation of wheeled mobile robots in a compact convex workspace cluttered with static, sufficiently separated, and convex obstacles. A path planner with prescribed-time convergence is presented based upon Bouligand’s tangent cones and time scale transformation (TST) techniques, yielding a continuous vector field that can guide the robot from almost all initial positions in the free space to the designated goal at a prescribed time, while avoiding entering the obstacle regions augmented with safety margin. By leveraging barrier functions and TST, we further derive a tube-following controller to achieve robot trajectory tracking within a prescribed time less than the planner’s settling time. This controller ensures the robot moves inside a predefined “safe tube” around the reference trajectory, where the tube radius is set to be less than the safety margin. Consequently, the robot will reach the goal location within a prescribed time while avoiding collision with any obstacles along the way. The proposed InPTC is implemented on a Mona robot operating in an arena cluttered with obstacles of various shapes. Experimental results demonstrate that InPTC not only generates smooth collision-free reference trajectories that converge to the goal location at the preassigned time of (i.e., the required task completion time), but also achieves tube-following trajectory tracking with tracking accuracy higher than after the preassigned time of . This enables the robot to accomplish the navigation task within the required time of .
Index Terms:
Prescribed-time control, path planning, trajectory tracking, collision avoidance, wheeled mobile robots.I Introduction
The motion control of wheeled mobile robots (WMRs) is a benchmark problem in robotics due to its key role in extensive real-world applications, such as cargo transportation, automated patrolling, and exploration of hazardous environments [1]. In these applications, WMRs typically operate in obstacle-cluttered environments, which motivates the development of safe navigation algorithms that can steer WMRs from an initial position to a desired goal location without colliding with any obstacles along the way [2]. Collision-free navigation of WMRs have garnered significant attention from the robotics and control research communities [3].
Existing solutions to the robot navigation problem can be primarily classified into two categories [4]: global (map-based) methods and local (reactive) methods. The former requires a priori information of environments (e.g., position and shape of obstacles), while the latter utilizes only local knowledge of obstacles obtained from on-board sensors. Among the global methods, a computationally efficient solution is the artificial potential field (APF)-based approach [5], which uses a field of potential forces to push the robot towards a goal position and pull it away from obstacles [6, 7, 8]. Control barrier function (CBF) combined with quadratic programming (CBF-QP) also provides an effective strategy for developing controllers that can both stabilize a system and ensure safety, making it particularly useful for autonomous vehicles operating in obstacle-cluttered environments [9, 10, 11]. Note that both the APF- and CBF-based methods often reach local minima, which hinders achieving global convergence to the designated goal, especially in topologically complex settings. Although navigation functions presented in [12] can overcome this issue, they require unknown tuning of parameters. Other global methods include heuristic approaches such as [13], rapidly exploring random tree (RRT) [14], and genetic algorithms [15]. Since these methods are search-based solutions, their performance is directly affected by the problem scale [16]. Optimization-based methods [17] provide alternatives, but typically require numerically solving constrained optimization problems, which results in high computational costs. Local methods that offer reactive solutions for collision-free robot motions are highly desirable, particularly in autonomous exploration applications, where robots often have limited access to environment information and must rely on local sensory data to detect obstacles. Bug algorithm is a simple reaction planning approaches for mobile robots [18, 19]. Arslan and Koditschek [20] proposed a reactive method based on a robot-centric spatial decomposition for collision-free navigation. Huber et al. [21] adopted contraction-based dynamical systems theory to achieve dynamic obstacle avoidance. Berkane et al. [4] proposed a sensor-based navigation algorithm that employs Nagumo’s invariance theorem to guarantee robot safety by projecting the nominal velocity onto safe velocity cones (e.g., Bouligand’s tangent cones) when the robot is close to obstacle boundaries. Although most reactive approaches offer closed-form solutions, they typically consider only the nominal robot kinematics, without accounting for disturbances that may arise, for example, from sensor noise, imperfect wheel alignment, and motor or actuator asymmetry. These unmodeled factors inevitably degrade system performance, potentially leading to deviations of the desired trajectory and compromising the robot’s safety. Furthermore, the aforementioned methods can only guarantee that WMRs reach the desired goal asymptotically, which is undesirable for time-critical missions.
There has been extensive research on the trajectory tracking control of WMRs. Zhai and Song [22] combined the adaptive and sliding mode control techniques to address the trajectory tracking problem of WMRs. Zheng et al. [23] presented an adaptive sliding mode control method for trajectory tracking of WMRs, and introduced a barrier function-like control gain to prevent input saturation. Kim and Singh[24] proposed a differential-flatness-based feedback controller to achieve the tracking of prescribed point-to-point trajectories. Recently, Zhou et al.[25] proposed a homogeneous control strategy to solve the trajectory tracking problem for perturbed unicycle mobile robots, where the convergence rate can be tuned by selecting a proper homogeneity degree. While these methods are effective in addressing stability and steady-state performance, they often do not explicitly consider the critical requirement of maintaining the WMR’s actual motion within a predefined safe tube around the reference trajectory. This actually imposes constraints on the tracking errors. Furthermore, most of these methods can only achieve asymptotic position tracking, and they typically lack the capability to preassign the convergence time according to the task requirements.
This paper examines the planning and control problems for prescribed-time collision-free navigation of WMRs in a convex workspace cluttered with static, sufficiently separated, and convex obstacles. By selecting an off-axis point as the virtual control point, the non-holonomic kinematics of WMRs is transformed into a fully-actuated system [26, Section 11.6.1]). Building upon this model, we propose a novel approach, called InPTC (Integrated Planning and Tube-Following Control), to achieve collision-free navigation of WMRs within a finite time that can be preassigned according to the task requirement, even in the presence of disturbances. Numerical simulations and experiments illustrate the effectiveness of the proposed InPTC. The main contributions of this paper are twofold:
-
1)
A reactive path planner with prescribed-time convergence is developed based on Bouligand’s tangent cones [4] and time scale transformation [27]. This planner yields a continuous vector field that can guide the WMR from almost all initial positions in the free space to reach the goal at a prescribed finite time, while avoiding entering the obstacle regions augmented by safety margins.
-
2)
By leveraging time scale transformation and barrier functions, a prescribed-time tube-following controller is derived for reference trajectory tracking. This controller guarantees that the tracking error converges to a small residual set within a prescribed finite time, whilst the WMR’s position remains within a predefined safe tube around the reference trajectory, despite the presence of disturbances.
The remainder of the paper is organized as follows: In Section II, we describe the kinematics and operating environment of WMRs, and formulate the prescribed-time safe navigation problem. In Section III, an integrated planning and control framework is proposed to address this problem. The simulation and experimental results are presented in Sections IV and V, respectively. Finally, Section VI provides concluding remarks and discusses future work.
Notations: Throughout the paper, is the -dimensonal Euclidean space, is the vector space of real matrices, and is a unit matrix. is the absolute value, and denotes either the Euclidean vector norm or the induced matrix norm. The topological interior and boundary of a subset are denoted by and , respectively, while the complement of in is denoted by . Given two non-empty subsets , denotes the distance of a point to the set , and denotes the distance between and .
II Problem Statement
II-A Kinematics of wheeled mobile robots
In this paper, we consider a nonholonomic wheeled mobile robot (WMR) with a control point located at the midpoint of the axis connecting the two driving wheels, as depicted in Fig. 1. Let be the position vector of in the global coordinate frame, and be the WMR’s heading angle. The kinematic model of the WMR is expressed as
| (1) |
where is the the control input vector with and being the linear and angular velocities of the WMR, respectively, and is the matched disturbance that may arise from sensor noise, imperfect wheel alignment, and motor or actuator asymmetry.
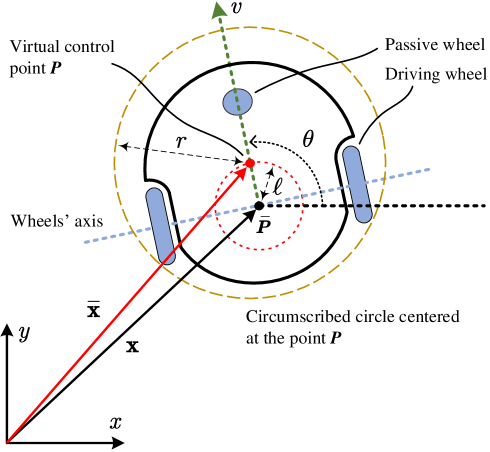
To facilitate the subsequent design and analysis, we select an off-axis point as the virtual control point, which locates at a distance away from along the longitudinal axis of the WMR [26], as shown in Fig. 1. Denote by and the position and heading angle of , respectively. We have the following change of coordinates:
| (2) |
In view of (1) and (2), the kinematics of is given by
| (3) |
where is full rank. This enables us to freely steer the WMR’s position regardless of nonholonomic constraints. By setting , it follows that .
Assumption 1.
The disturbance is bounded by an unknown constant , that is, .
Remark 1.
The kinematics given by (1) represents a general kinematic model for unicycle mobile robots, such as differential drive robots and synchro drive robots. Additionally, following the input/output linearization outlined in [26, Section 11.6.1], the nonholonomic kinematics (1) is transformed into a full-actuated system (3), via a change of coordinates given by (2). This transformed model can be rewritten in the form of a single integrator system, which has the same structure as the kinematics of omnidirectional robots with holonomic constraints. Consequently, the proposed method building upon (3) is applicable for a broad class of WMRs.
II-B Operating environment
Consider a WMR operating inside a closed compact convex workspace , punctured by a set of static obstacles , , which are represented by open balls with centers and radii . A circumscribed circle centered at with radius is constructed, which is the smallest circle enclosing the WMR (see Fig. 1). To ensure that the WMR can navigate freely between any of the obstacles in , we make the following assumption [4, 20]:
Assumption 2.
The obstacles are separated from each other by a clearance of at least
| (4) |
and from the boundary of the workspace as
| (5) |
where is a constant.
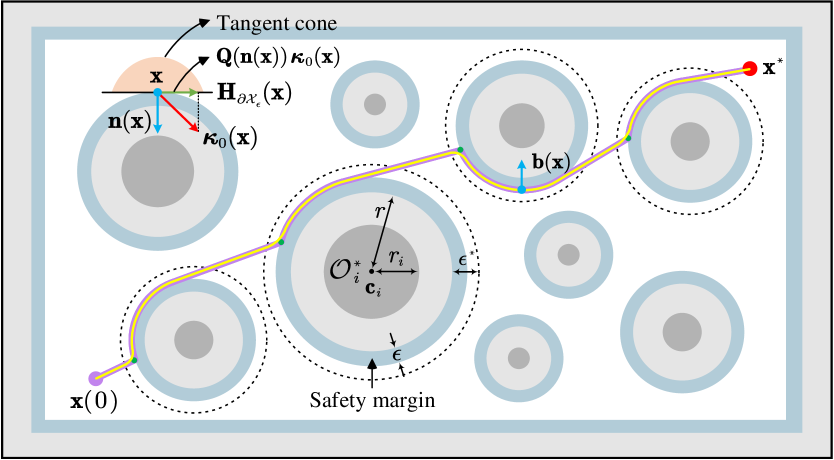
For ease of design, the WMR is considered as a point (i.e., the off-axis point ), by transferring the volume of the circumscribed circle to the other workspace entities. For the point , the workspace is , and the obstacle regions are : , where . Thus, the free space of is given by the closed set with . To enhance the safety, a safety margin of size is introduced (see the light blue regions in Fig. 2), which results in an eroded workspace and augmented obstacle regions , . Then, the free space of reduces to with .
II-C Problem formulation
The robot navigation problem is formulated as follows:
III Main Results
In this section, an approach, called InPTC, is proposed to solve Problem 1. The block diagram of this scheme is shown in Fig. 3, where the planner module generates a collision-free reference trajectory with prescribed-time convergence. In the control module, a tube-following controller is derived to achieve prescribed-time trajectory tracking within a safe tube around (with radius less than the safety margin). Under this framework, will converge to the goal within a prescribed time, without colliding with any obstacles along the way, thus achieving prescribed-time safe robot navigation.

III-A Preliminaries
Definition 1 (Bouligand’s tangent cone [28]).
Given a closed set , the tangent cone to at a point is the subset of defined by
The tangent cone is a set that contains all the vectors pointing from inside or tangent to , while for , . Since for all , we have , the tangent cone is non-trivial only on the boundary . Next, we recall the Nagumo’s invariance theorem.
Theorem 1 (Nagumo 1942 [29]).
Consider the system , which admits a unique solution in forward time for each initial condition in an open set . The closed set is forward invariant iff , .
Definition 2 (Time scale transformation function, TSTF [27]).
A smooth function is called a TSTF if 1) it is strictly increasing; 2) it is s.t. and ; 3) it is s.t. and .
A TSTF squeezes the infinite-time interval into a prescribed finite time interval , which plays a key role for achieving prescribed-time planning and control. In this work, is of the form
| (6) |
III-B Prescribed-time path planning
We neglect the disturbance in (3) and consider a control law , where is a virtual control law to be designed. Then, substituting it into (3), one gets
| (7) |
A tangent cone based control policy (vector field) is designed to achieve collision-free path planning. According to Theorem 1, we consider a nearest point problem
| (8) |
where is a nominal control law for motion-to-goal and is designed here as
| (9) |
with being a constant.
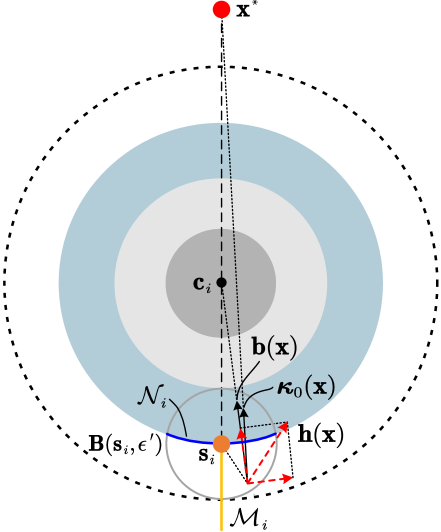
The robot workspace is a convex set, so does , which suggests that for all , points inside the free space (i.e., ) and thus is a solution to (8). Moreover, for all , is also the solution to (8). Next we check the obstacle boundary points . As is a smooth hypersurface of and is orientable, there exists a continuously differentiable map (known as Gauss map [30]) such that for all , is the outward unit normal vector to . As clearly seen in Fig. 2, the tangent cone at any is a half-space , which is a convex function. Thus, (8) has a unique solution. In summary, if or , then is a solution to (8). While if , the closest point of (8) is obtained by the orthogonal projection onto the tangent hyperplane of , defined by . Then, a general solution to (8) is as follows: if or , and if . The resulting vector field is discontinuous at some boundary points like the green points in Fig. 2. To address this issue, a continuous control law is proposed in the sequel. Following the line of [4], we specify an influence region for each obstacle (marked by the dashed line in Fig. 2), which is defined as , where and . Obstacle avoidance is activated only when the position of enters the influence regions of obstacles. To proceed, a bearing vector is defined as
| (10) |
where is a set-valued map. Since , , (referring to Assumption 2) and , there can be only one obstacle such that . With this in mind, in (10) can be computed by . Note that when , is equivalent to the Gauss map . Now the control law is modified as
| (11) |
with
| (12) |
where is a bump function that smoothly transitions from to on the interval . A simple choice of is
| (13) |
where . It is clear that the modified control law (11) is continuous and piecewise continuously differentiable on the domain .
Theorem 2.
Consider the kinematics defined by (7). If and the obstacles , satisfying Assumption 2, then the continuous control law (11) with given by (9) can guarantee that:
-
1.
The free space is forward invariant.
-
2.
For any , the solution of (7) admits a unique solution in forward time, which asymptotically converges to the set , where the stationary point that satisfies is locally unstable.
-
3.
The equilibrium point is almost globally asymptotically stable and locally exponentially stable.
Proof. The proof is relegated to Appendix.
To further achieve prescribed-time path planning, the TSTF defined in (6) is introduced to squeeze and map the collision-free trajectory of (7) from an infinite time interval to a prescribed finite time interval . Let and define a prescribed-time gain function (PTGF) as
| (14) |
showing that is continuously differentiable on and satisfies and . Here the prescribed-time control law is designed as , where is given by
| (15) |
Theorem 3.
Consider the kinematics given by (7) with initial conditions satisfying . Then, the closed-loop system converge to the set at , while avoiding obstacle regions , . The system under follows the same path as the closed-loop system , but goes faster within the time window .
Proof: The proof is conducted over two time intervals.
1) Consider the interval . The closed-loop system is written as
| (16) |
Let . Then, the system (16) is rewritten in the stretched infinite-time interval as
| (17) |
In view of 14 and (16), 17 becomes
| (18) |
The initial conditions satisfy and , where the facts that and have been used. As (18) has the same solution as the closed-loop system , it follows from Theorem 2 that asymptotically converges to the set . This implies that converges to the set at the prescribed time , due to and as . Additionally, Theorem 2 ensures that is collision-free on . As a result, is also collision-free on .
2) Let us consider the interval , on which the closed-loop system becomes . It can be verified that for all , no matter or as , indicating that the system states remain unchanged. This completes the proof.
Remark 2.
The proposed prescribed-time control policy (15) is discontinuous at and cannot be practically implemented due to the unboundedness of as . To remedy this, a continuous version is given as
| (19) |
with the PTGF given by
| (20) |
where , and is a sufficiently small constant. The resulting continuous vector field can guide to a small neighborhood of the set at . Since on , will asymptotically converge to the set after . It is clear from (9) that choosing a larger will increase the convergence rate of the planner during the transient-state phase. However, this comes at the expense of increased reference velocity.
Remark 3.
Although the prescribed-time path planner (19) is partially inspired by [4], there remain substantial differences in the following two aspects:
-
1.
A bump function defined in (13) is introduced into the projection function , which makes the resulting vector filed more smoother;
- 2.
Moreover, the planning algorithm offers an analytical solution without involving any numerical optimization solving, rendering it computationally efficient.
Remark 4.
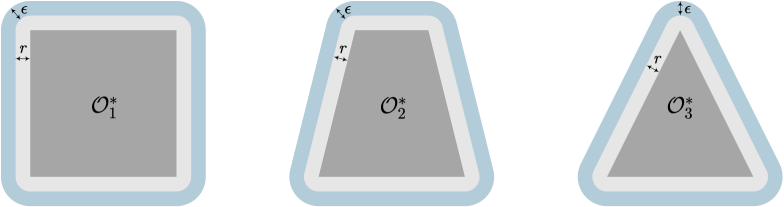
Although the path planner in (19) is proposed for environments with circular obstacles, it can be easily extended to deal with convex polygonal obstacles, such as rectangle, trapezoid, and triangle. For such obstacles, we can define the augmented obstacle regions and . The distance function ensures that the boundaries of and are smooth, as shown in Fig. 4. In practical implementation, the distance function and the bearing vector in can be obtained locally using on-board LiDARs.
III-C Prescribed-time tube-following control
To avoid conflicts of notations, the reference trajectory is denoted as , which is governed by , where is given by (19) but with replaced by . Define the position tracking error as . It follows from (3) that
| (21) |
To ensure the tracking safety, we impose the following “tube” constraint on
| (22) |
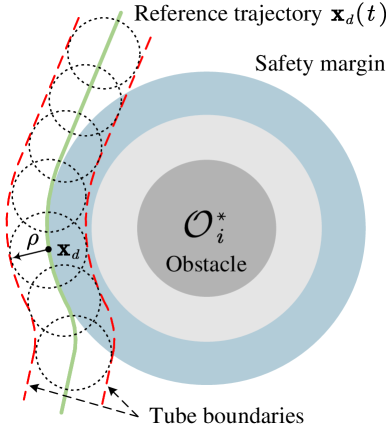
where is a user-defined constant. At each time instance, the actual position of the virtual control point is allowed to stay within a 1-sphere of radius and center . Unifying all such spheres along forms a tube around , as shown in Fig. 5. Since a safety margin is considered in the planning module, if the tube radius is taken no larger than the size of the safety margin and (22) holds for all , then the actual trajectory remains within the safe tube without colliding with any obstacles, that is, , .
In the following, a tube-following controller is developed to achieve prescribed-time trajectory tracking, while ensuring that evolves within the tube defined by (22). To this end, we define a transformed error
| (23) |
Taking the time derivative of (23), whilst using (3) and (21), one can easily get
| (24) |
Inspecting (23) reveals that is equivalent to (22), and only when . Therefore, the prescribed-time tube-following control problem boils down to achieving , while ensuring , , via a properly-designed controller.
To achieve trajectory tracking within a prescribed finite time , as per Definition 2, we introduce a TSTF , which generates the following PTGF:
| (25) |
Let us define and design the prescribed-time control law as
| (26) |
with
| (27) |
where are constant gains, and is a continuous PTGF akin to in (20), given by
| (28) |
with and being constants.
Theorem 4.
Proof. We analyze the closed-loop behavior over two time intervals and , separately.
1) We first consider the time interval . Substituting (26) into (21) yields
| (29) |
To proceed, let us define
| (30a) | ||||
| (30b) | ||||
| (30c) | ||||
Further define for notational concision. Then, the closed-loop system (29) can be rewritten in the stretched infinite time interval as
| (31) |
with and .
Consider the following logarithmic barrier function
| (32) |
Taking the derivative of w.r.t. along (III-C) yields
| (33) |
From [31, Lemma 3], it follows that holds for all . In addition, recalling Assumption 1 and the fact that , we have . As a result, (33) reduces to
| (34) |
on the set . Integrating both sides of (III-C) leads to
| (35) |
where is a constant. From (35), it is clear that is bounded, indicating that for all . As a result, holds for all . Since as , it follows from (30a) that keeps within the safe tube (22) for all .
In the following, we show that converges to a small neighborhood of origin at . It follows from (35) that . As per the definition of , one can easily deduce that as . Since , is a very large value, which renders very small. By (23) and (32), we get , which implies that converges to a small neighborhood of origin as . Since as and (see (30a)), it can be claimed that .
2) Consider the time interval , in which and the closed-loop system becomes
| (36) |
We likewise consider the barrier function in (32). Taking its derivative w.r.t. along (36) gets
| (37) |
where and are defined for notational concision. Solving (37), we get
| (38) |
indicating that is bounded on . Thus, satisfies the tube constraint (22) for all . In addition, remains within the set for all . As a result, the tracking error remains within the residual set for all .
Based on the above analyses, we conclude that the tracking error converges to a small residual set within the prescribed time , while remaining within the safe tube defined by (22) for all times. This completes the proof.
Remark 5.
Under the InPTC framework, if the radius of the tube is set less than the safety margin , whilst is set no larger than , then the actual trajectory of will converge to a small neighborhood of the goal position (if no local minima occurs) within the prescribed time , while avoiding collision with all obstacles , along the way. Therefore, the proposed InPTC can achieve prescribed-time collision-free navigation of WMRs. Furthermore, inspecting (35) and (38) reveals that choosing a smaller together with larger values for and decreases the size of residual set. However, this comes at the price of higher control gains (see (26)), particularly when selecting a very small . This, in turn, may excite the unmodeled high frequency dynamics, leading to instability of the closed system. Thus, , , and should be judiciously chosen to strike a balance between tracking accuracy and system stability.
IV Simulation Results
In this section, we demonstrate the proposed InPTC scheme in a rectangular workspace cluttered with 8 circular obstacles, denoted as , whose centers and radii are listed in Table I. The distance between the virtual and actual control points is , the radius of the circumscribed circle around is . The safety margin and influence region of obstacles are set to and , respectively. The desired goal is , and the task completion time is . The disturbance is modeled as . The simulation duration is , and the sample step is .
| Index | Configuration | Index | Configuration | ||
|---|---|---|---|---|---|
| Center (m) | Radius (m) | Center (m) | Radius (m) | ||
We begin by illustrating the effectiveness of the proposed prescribed-time planner (19) (denoted as “PTP”). For comparison purposes, the APF-based planner presented in [32] (denoted as “APF”) and the CBF-based planner presented in [9] (denoted as “CBF”) are also simulated. The attractive and repulsive potentials of the APF planner are designed as , , where and are positive weights, and is a smooth repulsive function defined as if , and , if . Then, the vector field generated by the APF planner is
| (39) |
We consider a CBF together with the safe set , where (for workspace boundaries), and , . The CBF planner is obtained by quadratic programming
| (CBF-QP) | ||||
| s.t. |
where is a user-defined constant. The CBF-QP has an explicit solution of the form
| (40) |
where , and is determined by
with . As dictated by [9], the CBF planner (40) ensures that the set is forward invariant. The APF planner parameters are chosen as and , while the CBF planner parameter is chosen as . It is important to note that these three planners have the same motion-to-goal control law. Their design parameters are listed in Table II.
| Method | Parameter |
|---|---|
| PTP in (19) | , , |
| TFC in (26) | , , , , |
| APF in [32] | , |
| CBF in [9] |
The planned trajectories starting at a set of initial positions (purple points) are plotted in Fig. 6, where the dense arrows denote the magnitude and direction of the resulting vector field from the prescribed-time planner (19) at various points. These vector arrows are directly obtained as per (19). As shown in Fig. 6, all three planners successfully guide the WMR from different initial positions to the goal (red point), while avoiding all obstacle regions. The comparison results of and are depicted in Fig. 7, from which we find that both the APF and CBF converge slower than the proposed PTP; moreover, their convergence times become longer as the path is longer. However, the PTP always converges at , regardless of initial positions. We further provide quantitative comparison results in Table III, where the 3rd initial position is considered as a case study. Although all the three planners offer analytical solutions and have an almost identical time consumption (average time of 100 runs), the convergence time differs greatly. The PTP converges at the prescribed time , while the APF and CBF take significantly longer, converging in . The path length metric also differs, with CBF covering a shorter path compared to the other two methods. The maximum and standard deviation (std) of the velocity norm provide additional insights, with PTP exhibiting higher values than APF and CBF in both measures, due to its faster convergence rate.
| Method | Time consumption | Convergence time | Path length | Maximum of | std of | Obstacle avoidance | Prescribed time |
|---|---|---|---|---|---|---|---|
| PTP in (19) | 0.3136 s | 200 s | 6.4411 m | 0.0548 | 0.0148 | ✓ | ✓ |
| APF in [32] | 0.3196 s | 950 s | 6.7394 m | 0.0548 | 0.0096 | ✓ | ✗ |
| CBF in [9] | 0.3474 s | 950 s | 6.3976 m | 0.0479 | 0.0102 | ✓ | ✗ |
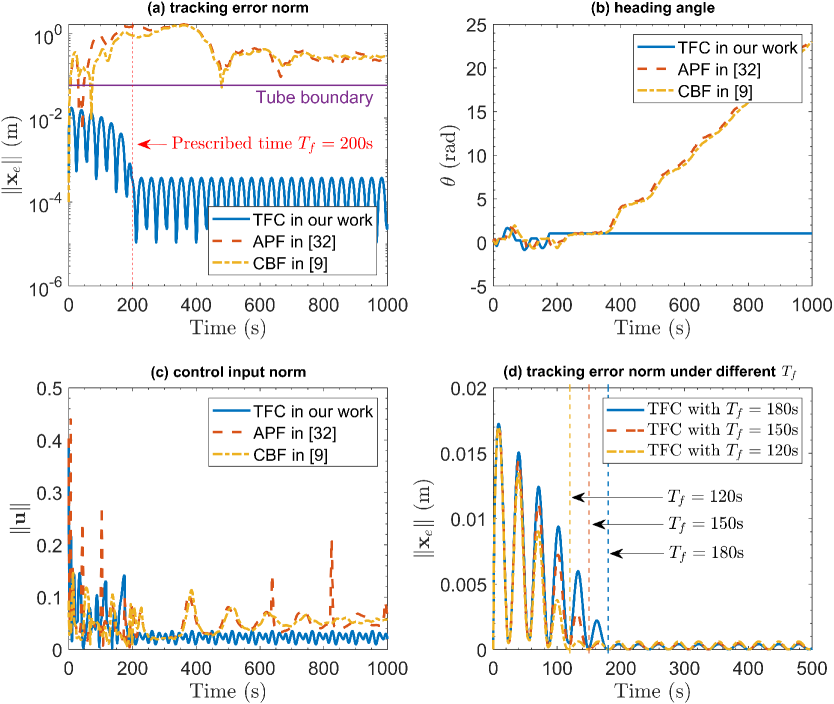
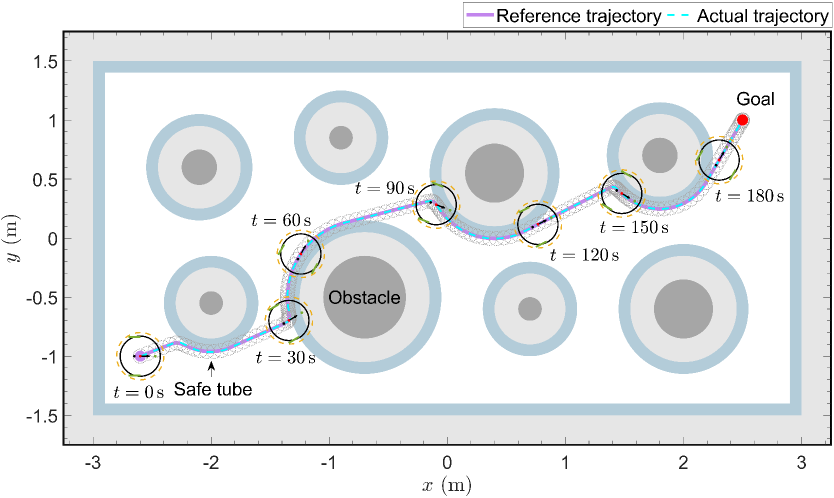
In the following, we show the effectiveness and performance of the proposed tube-following controller (26) (denoted as “TFC”) with parameters given in Table II. As a case study, the planned trajectory starting from the 3rd initial position is selected as the reference trajectory. To verify the robustness of the APF and CBF planners, we execute them in the presence of disturbances and define the difference between the reference and actual trajectories as the position tracking error . The closed-loop tracking responses of three controllers are shown in Fig. 8. In Fig. 8(a), the tracking error under the proposed TFC is shown to converge to a residual set of after the prescribed time , while complying with the tube constraint defined by (22). In contrast, the APF and CBF controllers exhibit larger stead-state errors of and , respectively, whilst violate the tube constraint, leading to an increased risk of collision. The WMR’s heading angle is provided in Fig. 8(b), from which it is clear that under the TFC is bounded and converges to a nearly constant value, while under the APF and CBF, continuously increases. This implies that both the APF and CBF controllers are susceptible to disturbances. The control norm is shown in Fig. 8(c). To further show the prescribed-time convergence property of the proposed TFC, the tracking error norm under different prescribed time is given in Fig. 8(d). As illustrated, the proposed controller can precisely and flexibly set the convergence time in advance. The position tracking trajectory of the proposed TFC is shown in Fig. 9. Intuitively, accurately tracks the reference trajectory, while remaining within the safe tube. This implies that, under the proposed InPTC, the WMR reaches the goal within the prescribed time , while avoiding collision with any obstacles (dark gray balls).
V Experiments
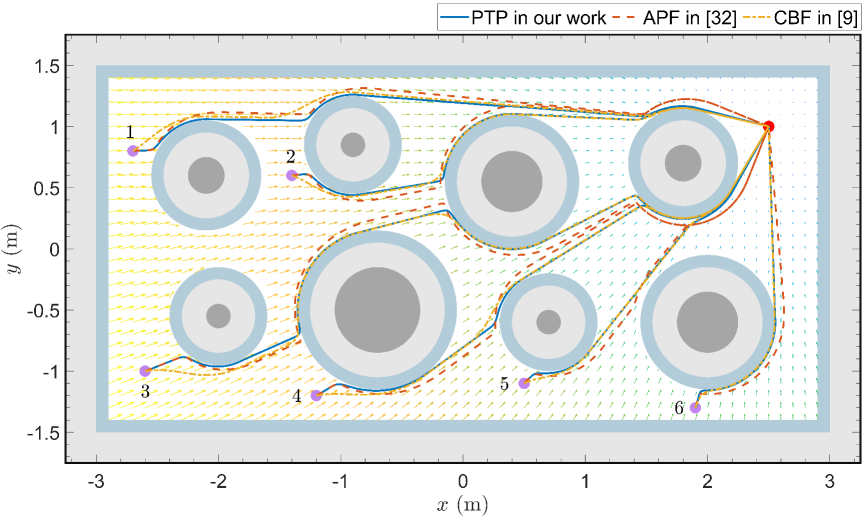
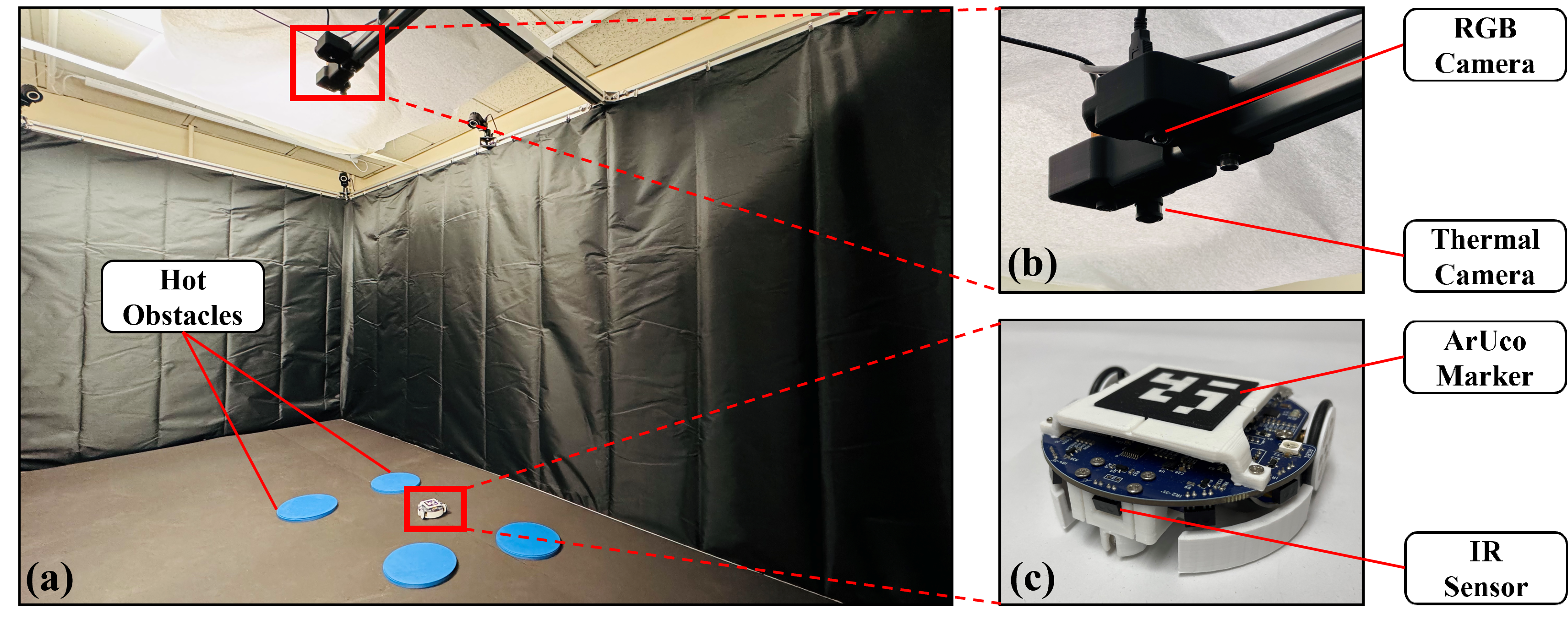
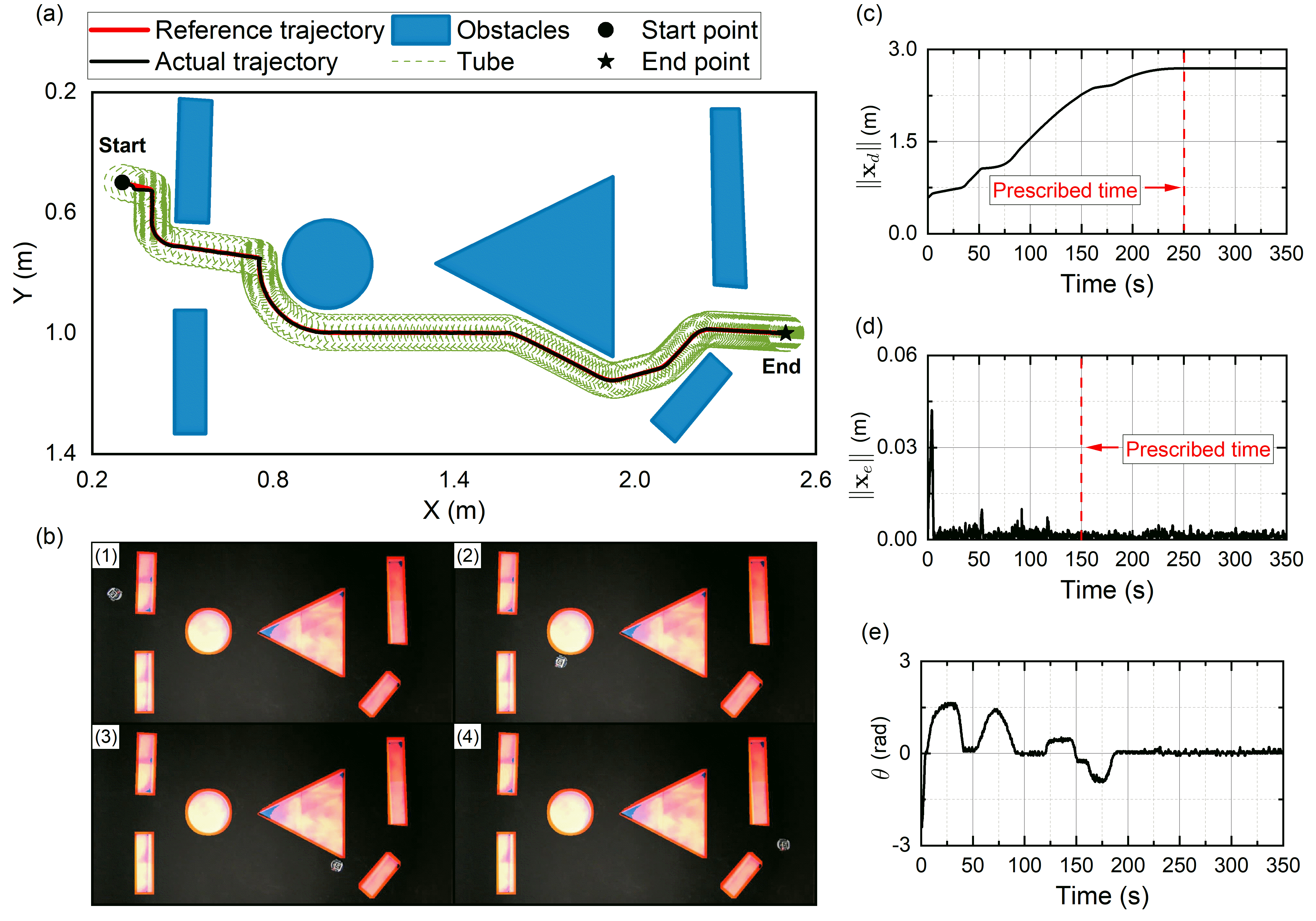
The experimental platform is shown in Fig. 10, which consists of a Mona robot [33] with nonholonomic dynamics, several hot obstacles containing iron powders that can heat up themselves, a RGB camera to observe the pose and location of the WMR, a thermal camera to obtain the size and location of the hot obstacles, and a control PC to collect feedback data and send motion commands. The Wi-Fi communication (at a rate of ) between the control PC and robot is built by ROS. All experiments are performed in a arena. Since the Mona robot has a very limited onboard sensing capability, the distance between the robot and obstacle boundary is obtained in real-time from the RGB and thermal cameras. The radius of the circle surrounding the robot is set to , the parameter for the change of coordinates is . The design parameters of the InPTC are listed in Table IV. In experiments, the disturbances could come from measurement noises, communication delay, imperfect wheel alignment, motor or actuator asymmetry, etc. In the following, we report the results of two representative experiments, where the extracted thermal image and the RGB image are merged to record the experimental process.
| Method | Parameter |
|---|---|
| Planner in (19) | , , |
| Controller in (26) | , , , , |
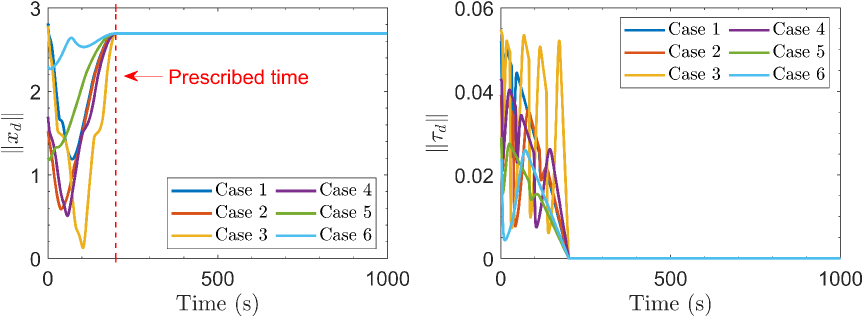
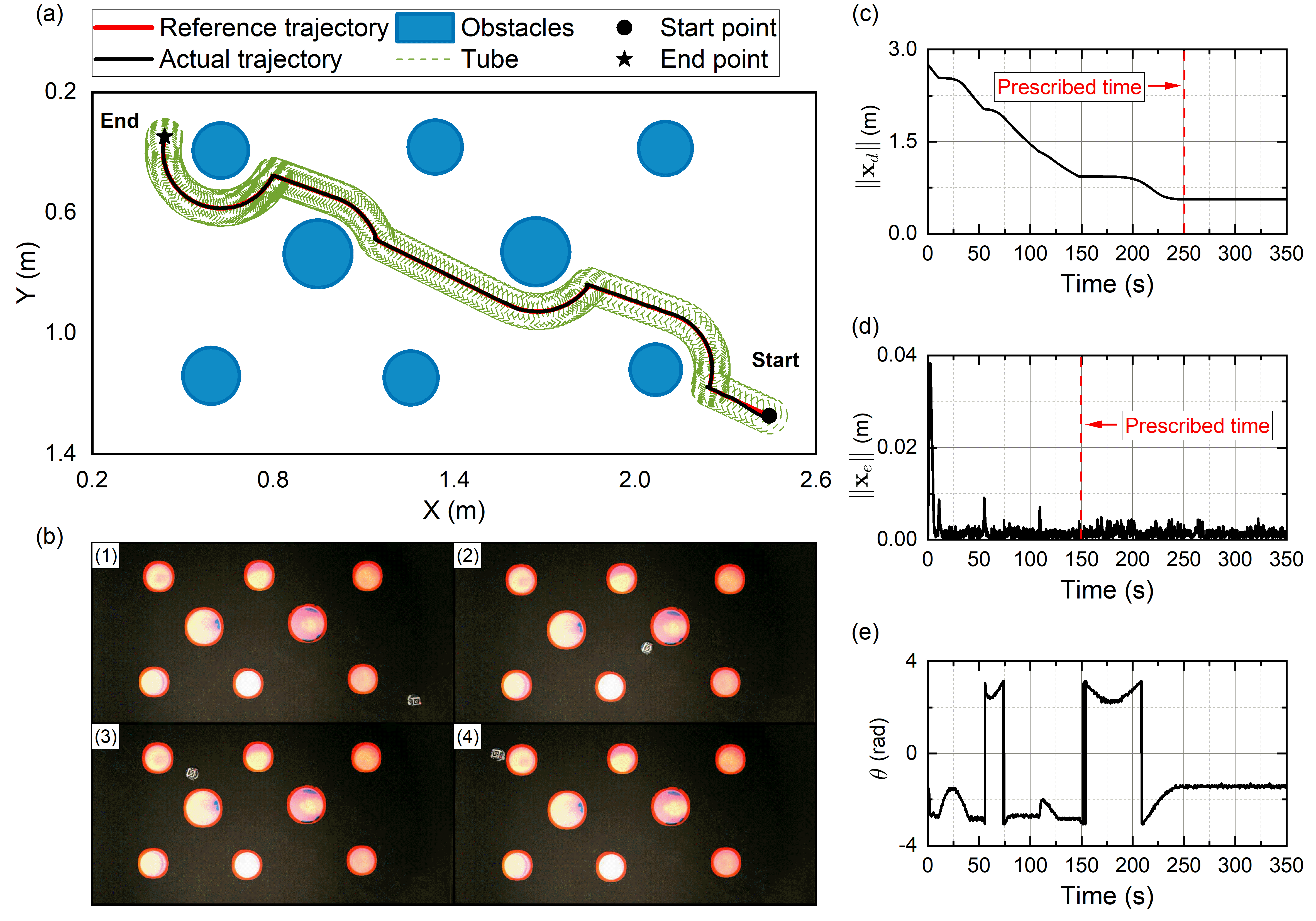
In the first experiment, eight circular obstacles are placed in the arena, and the safety margin and influence region of obstacles are set to and , respectively. The WMR starts from the right side of the arena (coordinates: ), and is tasked with reaching the goal located on the right side (coordinates: ). The task is required to be completed within . The results are shown in Fig. 11, from which it is clear that the proposed planner in (19) generates a smooth, collision-free reference trajectory that converges to the goal at the preassigned time (i.e., the red line in Fig. 11(a)). While the proposed controller in (26) achieves trajectory tracking along with the safe tube (see Fig. 11(c)), with a tracking accuracy higher than after the preassigned time (see Fig. 11(d)). As seen in Fig. 11(e), the robot’s heading angle remains nearly constant after the task completion time . The above results demonstrate that the proposed InPTC scheme enables the WMR to safely accomplish the navigation task within the required time of .
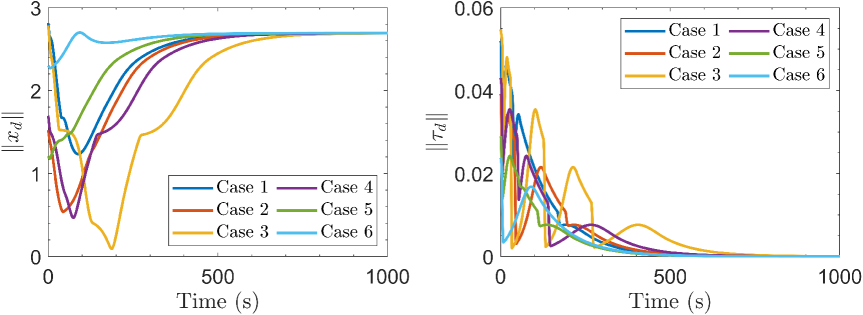
In the second experiment, we consider a more complex environment with six obstacles of various shapes. The safety margin and influence region of obstacles are set to and , respectively. The WMR starts from the left side of the arena (coordinate: ) and is required to reach a goal location at the right side (coordinate: ). The results are depicted in Fig. 12, hich shows outcomes analogous to those observed in the initial experiment. In this case, the proposed InPTC still generates a smooth and safe reference trajectory with prescribed-time convergence (see Fig. 12(c)). It also achieves prescribed-time tube-following control with an accuracy of (see Fig. 12(d)), thus enabling the WMR to accomplish the navigation task within the prescribed time (see Fig. 12(a)).
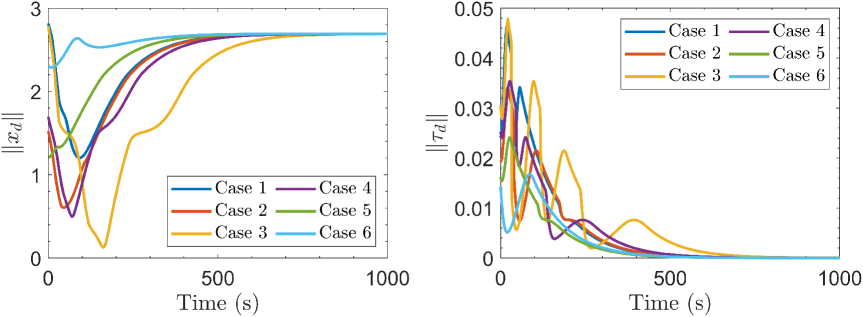
Furthermore, we perform multiple trials with different initial and goal locations to further test the proposed InPTC. From these experiments, we consistently observe the effectiveness of InPTC in achieving tracking accuracy higher than and task completion time less than . More details are provided in the supplementary video (https://vimeo.com/895801720).
VI Conclusion
In this article, we propose a prescribed-time path planning algorithm for wheeled mobile robots (WMRs) to generate a collision-free reference trajectory that can converge to the goal location at a prescribed finite time. The derived planner is then paired with a tube-following controller that allows WMRs to achieve high-precision trajectory tracking within a prescribed time, while remaining within a predefined “safe tube” around the reference trajectory. The resulting integrated planning and tube-following control (InPTC) scheme achieves prescribed-time collision-free navigation of WMRs, despite the presence of disturbances. The salient features of the proposed InPTC are two-fold: 1) it enables WMRs to accomplish safe navigation within a finite time that can be flexibly preassigned according to the mission requirements; and 2) it enhances the navigation safety of WMRs in practical implementations. Simulation and experimental results show the effectiveness of InPTC. Future work will focus on extending the proposed method to achieve prescribed-time safe navigation of WMRs in environments with dynamic or intersecting obstacles.
[Proof of Theorem 2]
From (11) and (12), it follows that for all , which according to Theorem 1 suggests that the free space is forward invariant.
As previously stated, is piecewise continuously differentiable, indicating that it is locally Lipschitz on its domain [34]. Moreover, the free space , as a compact subset of , is forward invariant. Then, it follows from [35, Theorem 3.3] that the closed-loop kinematics (7) under with has a unique solution that is defined for all . We next show that the unique solution converges to a set of stationary points. To this end, we consider the following LFC:
| (41) |
For ease of analysis, (11) is rewritten as
| (42) |
with
| (43) |
Taking the time derivative of along (7) and noting (9) and (42), one gets
| (44) |
Since and is positive semidefinite, one has
| (45) |
indicating that is a stable equilibrium of (7). From LaSalle’s invariance principle, it follows that the solution of (7) asymptotically converges to the set , i.e., a set of stationary points. One can infer from (12) and (44) that the stationary points correspond to either or the points satisfying . Therefore, for any , the solution of (7) converges to the set . The set contains stationary points, all of which are isolated due to Assumption 2. Geometrically, the undesired stationary point (on the boundary of ) and are collinear with , but located on the opposite sides of , as seen in Fig. 13. As per (44), the analytical form of is obtained as follows:
| (46) |
with .
The isolated stationary points , may prevent us from achieving the objective (motion-to-goal). To check the stability of , we define a small neighborhood of , i.e., an open ball with , such that holds for all . When restricted on , the feasible set of initial configurations is , and evolves according to
| (47) |
Further define two sets
| (48) | ||||
| (49) |
Geometrically speaking, all elements of form a radial line extending outward from the stationary point along (see the yellow line in Fig. 13), while all elements of form a curve, which is a portion of the boundary (see the blue curve in Fig. 13). In the following, three cases are considered: 1) ; 2) ; and 3) .
Case 1): . Note that for all , holds, whereby (47) reduces to
| (50) |
From (13) and (48), it is evident that on the set and only when . Hence, for all , the velocity vector (i.e., the right-hand side of (50)) points directly towards and becomes zero when , indicating that the set is forward invariant. Consider the following LFC:
| (51) |
The time derivative of along (50) is given by
| (52) |
Since for all , one can conclude from (52) that on the set and only occurs at . This implies that is a stable manifold of and any initial state on it will converge to . Thus, all will converge to .
Case 2): . For all , we have and . As such, (47) becomes
| (53) |
where is defined for notational brevity. Consider again the LFC in (51). Then, taking the time derivative of along (53) and noting (46) and the fact that , we get
| (54) |
where is the angle between the vectors and and satisfies for all . Further consider the following LFC:
| (55) |
whose time derivative along (53) is given by
| (56) |
showing that for all , the control vector is tangent to the boundary of , thus directing the robot to move along . In view of (VI) and (56), we can conclude that if , then will keep away from along until it leaves the set .
Case 3): . Actually, for any , it holds that , and and are not collinear. Moreover, we can decompose into two components: the component parallel to and the component perpendicular to , as shown in Fig. 13. With (12) in mind, one can verify that
| (57) |
which implies that and the bearing vector have the same direction, causing to point towards . A straightforward calculation yields , which allows us to express . Under , (47) turns to be (53), which results in as seen in (VI). Thus, generates a velocity component tangent to , causing to move away from . Since and the vector are situated on opposite sides of (see Fig. 13), cannot move toward on the set . From Fig. 13, one can intuitively observe that guides towards the boundary of (attributed to , while simultaneously keeping away from the manifold (attributed to ). Therefore, for any , the solution of (7) will either directly leaves the ball , or first converges to the set and then leaves the ball along (as shown in Case 2).
The three cases above demonstrate that each stationary point () is an unstable fixed point, but there exists one line of initial conditions, namely the stable manifold , that is attracted to . Note that is a 1-dimensional manifold with boundary and thus has zero measure [36]. As such, is an almost globally asymptotically stable equilibrium, with a basin of attraction consisting of the free space , except for a set of measure zero. Furthermore, as , there certainly exists such that for all . On the ball , the kinematics reduces to
| (58) |
indicating that the local exponential stability of .
References
- [1] G. Klancar, A. Zdesar, S. Blazic, and I. Skrjanc, Wheeled mobile robotics: from fundamentals towards autonomous systems. Butterworth-Heinemann, 2017.
- [2] X. Chu, R. Ng, H. Wang, and K. W. S. Au, “Feedback control for collision-free nonholonomic vehicle navigation on SE (2) with null space circumvention,” IEEE/ASME Transactions on Mechatronics, vol. 27, no. 6, pp. 5594–5604, 2022.
- [3] V. J. Lumelsky, Sensing, intelligence, motion: how robots and humans move in an unstructured world. John Wiley & Sons, 2005.
- [4] S. Berkane, “Navigation in unknown environments using safety velocity cones,” in 2021 American Control Conference (ACC). IEEE, 2021, pp. 2336–2341.
- [5] O. Khatib, “Real-time obstacle avoidance for manipulators and mobile robots,” The International Journal of Robotics Research, vol. 5, no. 1, pp. 90–98, 1986.
- [6] J.-O. Kim and P. Khosla, “Real-time obstacle avoidance using harmonic potential functions,” IEEE Transactions on Robotics and Automation, vol. 8, no. 3, pp. 338–349, 1992.
- [7] L. Valbuena and H. G. Tanner, “Hybrid potential field based control of differential drive mobile robots,” Journal of Intelligent & Robotic Systems, vol. 68, pp. 307–322, 2012.
- [8] H. Li, W. Liu, C. Yang, W. Wang, T. Qie, and C. Xiang, “An optimization-based path planning approach for autonomous vehicles using the dynefwa-artificial potential field,” IEEE Transactions on Intelligent Vehicles, vol. 7, no. 2, pp. 263–272, 2021.
- [9] A. Singletary, K. Klingebiel, J. Bourne, A. Browning, P. Tokumaru, and A. Ames, “Comparative analysis of control barrier functions and artificial potential fields for obstacle avoidance,” in 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2021, pp. 8129–8136.
- [10] M. Srinivasan and S. Coogan, “Control of mobile robots using barrier functions under temporal logic specifications,” IEEE Transactions on Robotics, vol. 37, no. 2, pp. 363–374, 2021.
- [11] Y. Chen, A. Singletary, and A. D. Ames, “Guaranteed obstacle avoidance for multi-robot operations with limited actuation: A control barrier function approach,” IEEE Control Systems Letters, vol. 5, no. 1, pp. 127–132, 2020.
- [12] E. Rimon and D. Koditschek, “Exact robot navigation using artificial potential functions,” IEEE Transactions on Robotics and Automation, vol. 8, no. 5, pp. 501–518, 1992.
- [13] S. Erke, D. Bin, N. Yiming, Z. Qi, X. Liang, and Z. Dawei, “An improved A-star based path planning algorithm for autonomous land vehicles,” International Journal of Advanced Robotic Systems, vol. 17, no. 5, p. 1729881420962263, 2020.
- [14] I. Noreen, A. Khan, and Z. Habib, “Optimal path planning using rrt* based approaches: a survey and future directions,” International Journal of Advanced Computer Science and Applications, vol. 7, no. 11, pp. 97–107, 2016.
- [15] J. Tu and S. X. Yang, “Genetic algorithm based path planning for a mobile robot,” in 2003 IEEE International Conference on Robotics and Automation (Cat. No. 03CH37422), vol. 1. IEEE, 2003, pp. 1221–1226.
- [16] M. M. Costa and M. F. Silva, “A survey on path planning algorithms for mobile robots,” in 2019 IEEE International Conference on Autonomous Robot Systems and Competitions (ICARSC). IEEE, 2019, pp. 1–7.
- [17] Y. Yan, L. Peng, J. Wang, H. Zhang, T. Shen, and G. Yin, “A hierarchical motion planning system for driving in changing environments: Framework, algorithms, and verifications,” IEEE/ASME Transactions on Mechatronics, vol. 28, no. 3, pp. 1303–1314, 2023.
- [18] V. J. Lumelsky and T. Skewis, “Incorporating range sensing in the robot navigation function,” IEEE Transactions on Systems, Man, and Cybernetics, vol. 20, no. 5, pp. 1058–1069, 1990.
- [19] K. N. McGuire, G. C. de Croon, and K. Tuyls, “A comparative study of bug algorithms for robot navigation,” Robotics and Autonomous Systems, vol. 121, p. 103261, 2019.
- [20] O. Arslan and D. E. Koditschek, “Sensor-based reactive navigation in unknown convex sphere worlds,” The International Journal of Robotics Research, vol. 38, no. 2-3, pp. 196–223, 2019.
- [21] L. Huber, A. Billard, and J.-J. Slotine, “Avoidance of convex and concave obstacles with convergence ensured through contraction,” IEEE Robotics and Automation Letters, vol. 4, no. 2, pp. 1462–1469, 2019.
- [22] J.-Y. Zhai and Z.-B. Song, “Adaptive sliding mode trajectory tracking control for wheeled mobile robots,” International Journal of Control, vol. 92, no. 10, pp. 2255–2262, 2019.
- [23] Y. Zheng, J. Zheng, K. Shao, H. Zhao, H. Xie, and H. Wang, “Adaptive trajectory tracking control for nonholonomic wheeled mobile robots: A barrier function sliding mode approach,” IEEE/CAA Journal of Automatica Sinica, vol. 11, no. 4, pp. 1007–1021, 2024.
- [24] Y. Kim and T. Singh, “Energy-time optimal trajectory tracking control of wheeled mobile robots,” IEEE/ASME Transactions on Mechatronics, vol. 29, no. 2, pp. 1283–1294, 2024.
- [25] Y. Zhou, H. Ríos, M. Mera, A. Polyakov, G. Zheng, and A. Dzul, “Homogeneity-based control strategy for trajectory tracking in perturbed unicycle mobile robots,” IEEE Transactions on Control Systems Technology, vol. 32, no. 1, pp. 274–281, 2024.
- [26] B. Siciliano, L. Sciavicco, L. Villani, and G. Oriolo, Robotics: Modelling, Planning and Control. Springer, 2009.
- [27] D. Tran and T. Yucelen, “Finite-time control of perturbed dynamical systems based on a generalized time transformation approach,” Systems & Control Letters, vol. 136, p. 104605, 2020.
- [28] G. Bouligand, “Introduction à la géométrie infinitésimale directe,” (No Title), 1932.
- [29] M. Nagumo, “Über die lage der integralkurven gewöhnlicher differentialgleichungen,” Proceedings of the Physico-Mathematical Society of Japan. 3rd Series, vol. 24, pp. 551–559, 1942.
- [30] J. M. Lee, Manifolds and Differential Geometry. American Mathematical Society, 2022, vol. 107.
- [31] X. Shao, Q. Hu, Y. Shi, and Y. Zhang, “Fault-tolerant control for full-state error constrained attitude tracking of uncertain spacecraft,” Automatica, vol. 151, p. 110907, 2023.
- [32] M. Wang and A. Tayebi, “Hybrid feedback for affine nonlinear systems with application to global obstacle avoidance,” IEEE Transactions on Automatic Control, vol. 69, no. 8, pp. 5546–5553, 2024.
- [33] F. Arvin, J. Espinosa, B. Bird, A. West, S. Watson, and B. Lennox, “Mona: an affordable open-source mobile robot for education and research,” Journal of Intelligent & Robotic Systems, vol. 94, pp. 761–775, 2019.
- [34] R. W. Chaney, “Piecewise functions in nonsmooth analysis,” Nonlinear Analysis: Theory, Methods & Applications, vol. 15, no. 7, pp. 649–660, 1990.
- [35] H. K. Khalil, Nonlinear Systems (3rd edn). NJ: Prentice Hall, 2002.
- [36] J. W. Milnor and D. W. Weaver, Topology from the differentiable viewpoint. Princeton University Press, 1997.