Instructed Diffuser with Temporal Condition Guidance for Offline Reinforcement Learning
Abstract
Recent works have shown the potential of diffusion models in computer vision and natural language processing. Apart from the classical supervised learning fields, diffusion models have also shown strong competitiveness in reinforcement learning (RL) by formulating decision-making as sequential generation. However, incorporating temporal information of sequential data and utilizing it to guide diffusion models to perform better generation is still an open challenge. In this paper, we take one step forward to investigate controllable generation with temporal conditions that are refined from temporal information. We observe the importance of temporal conditions in sequential generation in sufficient explorative scenarios and provide a comprehensive discussion and comparison of different temporal conditions. Based on the observations, we propose an effective temporally-conditional diffusion model coined Temporally-Composable Diffuser (TCD), which extracts temporal information from interaction sequences and explicitly guides generation with temporal conditions. Specifically, we separate the sequences into three parts according to time expansion and identify historical, immediate, and prospective conditions accordingly. Each condition preserves non-overlapping temporal information of sequences, enabling more controllable generation when we jointly use them to guide the diffuser. Finally, we conduct extensive experiments and analysis to reveal the favorable applicability of TCD in offline RL tasks, where our method reaches or matches the best performance compared with prior SOTA baselines.
1 Introduction
Diffusion probabilistic models (DPMs) have shown impressive results in photo-realistic image synthesization [24, 55, 40], text-to-image generation [30, 45], and realistic video creation [15, 28, 8]. Besides, DPMs are not limited to classical supervised learning tasks mentioned above. More broadly, diffusion-based RL methods have also shown huge potential in sequential decision-making problems [66, 27, 17], facilitating many successful attempts in RL [27]. For example, Ajay et al. [1] propose Decision Diffuser (DD), which learns policies with the return-conditioned, constraint-conditioned, or skill-conditioned diffuser and achieves better performance in many offline RL tasks.
Given the initial states, prior studies usually adopt heuristic conditions to generate behaviors by either the action-participated or non-action-participated diffusion process [35, 62]. The former generation strategy directly generates the state-action sequences, while the latter method first synthesizes state sequences and then generates actions with inverse dynamics or other models [27, 10]. However, regardless of which approach to be adopted, the condition of the diffusion model always plays a pivotal role in generating plausible sequences where inappropriate conditions will lead to sub-optimal policies [66, 1, 39]. Heuristic conditions adopted by previous studies could cause several undesirable consequences because they do not fully consider temporal information, which is critical for understanding the dynamics, dependencies, and consequences of decisions over time in sequential modeling problems. Although some existing approaches [1, 27] are conditioned on prospective information, such as future returns, they usually neglect the immediate behaviors and the historical behaviors, which are important during long sequence generation, especially in partially observable and highly stochastic environments. Since temporal dependencies are associated with the performance of diffusion models, a key question arises:
How can we further dig into the potential of DPMs by considering the
temporal properties of decision-making in RL?
In this paper, we aim to identify temporal information from experiences, systematically understand the effects of temporal dependencies, and explicitly incorporate temporal conditions into the diffusion and generation processes of diffusion models. Specifically, we identify three distinct classes: historically-conditional, immediately-conditional, and prospectively-conditional sequence generation. Any arbitrary combination of these three conditions can be integrated, which we refer to as interchangeably-conditional sequence generation. Then, we provide a unified discussion of temporal conditions about their respective advantages, disadvantages, and connections to existing works, including potential implementation approaches and corresponding experimental results. Inspired by the above discoveries, we propose a generic temporally-conditional diffusion model and observe that this Temporally-Composable Diffuser (TCD), with the diffusion model as a sequential planner and different temporal conditions as guidance, can capture the sequential distribution information and generate conditional planning trajectories. We adopt classifier-free training, where the interchangeably-temporal conditions are composed with samples together during reverse denoising process, and perform generation by considering the interactive history, statistical current action rewards, and remaining available returns. Additionally, apart from the above-mentioned temporal condition types, we also draw inspiration from recent works [9, 6, 32, 3], and incorporate them into our proposed TCD method to extend the attention of historical sequence length, perform better estimation on out-of-distribution actions, obtain radical and conservative reward estimation, and capture more useful feature information. The sufficient experiments confirm that TCD can perform better than other baselines in various offline RL tasks, coinciding with our motivations and findings.
In summary, our main contributions are four-fold:
-
•
We rethink the temporal dependencies of context sequences in diffusion models and find that current diffusion-based models with heuristic conditions can not fully dig into the potential of diffusion models and lead to sub-optimal performance.
-
•
We propose the Temporally-Composable Diffuser (TCD), which can capture the temporal dependencies of sequences when performing sequential generation. Furthermore, we provide a comprehensive discussion of the effects of temporal conditions, which reveals potential improvements and helps new algorithms discovery.
-
•
Inspired by the discussion of temporal conditions, we also consider incorporating other techniques, such as transformer-backbone, distributional RL, quantile regression, and experience replay, into our method and provide some new variants with temporal condition guidance in Appendix E.
-
•
Finally, we conduct extensive experiments and discussions in Section 6 to investigate the applicability of temporal conditions. The results show that our method can surpass or match the best performance compared with other baselines.
2 Related Work
Offline RL. Offline RL aims to learn the optimal policy from previously-collected datasets without extra interaction [36, 33, 35, 68, 22, 2, 50, 38, 52, 2]. Although offline RL technology makes it possible for avoiding expensive and risky data collection process, in practice, the distribution shift between the learned policy and the data-collected policy poses difficulties for improving performance [35, 18]. The overestimation of out-of-distribution (OOD) actions produces errors in policy evaluation, which results in poor performance [36, 46]. In order to solve this issue, recent works can be roughly divided into two categories. Model-free offline RL methods apply constraints on learned policy and value function to prevent inaccurate estimation of unseen actions or enhance the robustness of OOD actions by introducing uncertainty quantification [69, 33, 34]. Model-based RL approaches propose to learn the optimal policy through planning or RL algorithms based on synthetic experiences generated from the learned dynamics [29, 47, 43].
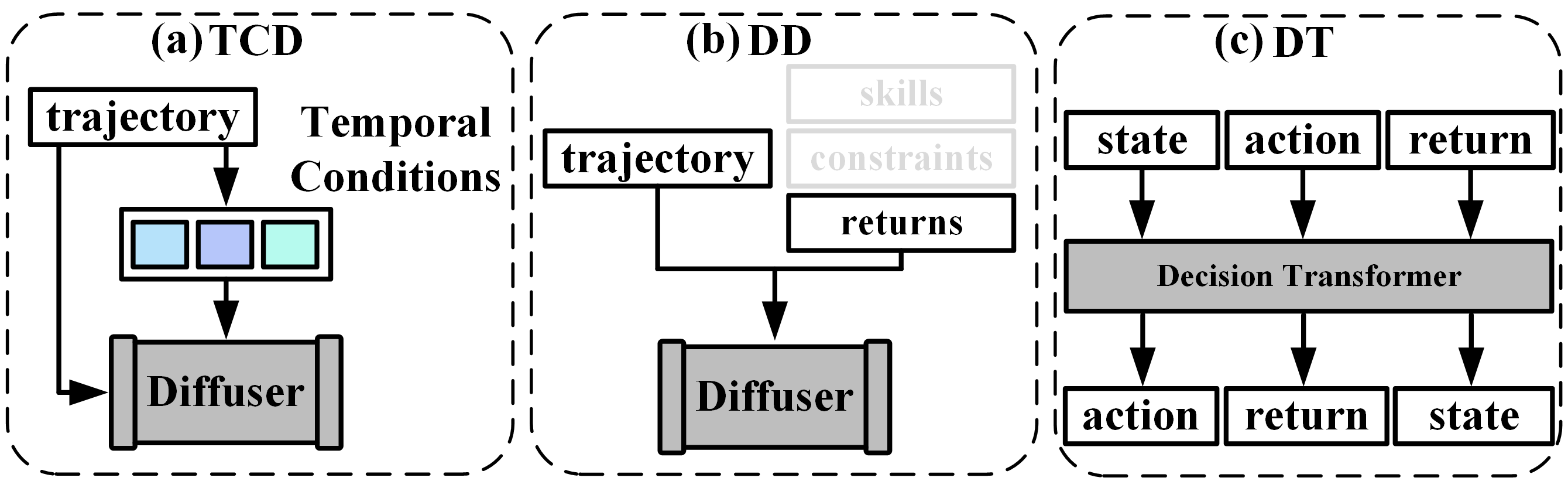
Transformers in RL. Recent works show huge potential in RL by casting the decision-making as a sequence generation problem [9, 26, 71, 20, 65, 25]. For example, given the future return as prompt, Decision Transformer (DT) orderly generates state, action, and reward tokens by considering the historical token sequence [9]. Another example is Trajectory Transformer (TT), which discretizes the state, action, and reward tokens and generates the sequences through beam search [26]. Compared with Transformer-based policies, the diffusion-based methods integrate planning and decision-making together, which leaves the value function estimation out. Besides, the conditions of diffusion models guide the whole generative sequences directly, while the prompts of transformers work iteratively.
Diffusion Probabilistic Models. Diffusion models have made big progress in image synthesis and text generation by formulating the data-generating process as an iterative denoising procedure [53, 24, 40, 48]. The denoising procedure can be derived from the posterior of the predefined diffusion process or the score matching of data distribution [55]. In order to generate samples conditioned on human-preferred information, previous works propose to perturb the denoising process with classifier-guided methods and classifier-free methods [14, 37, 23]. Though the classifier-guided method does not need retraining the diffusion model, More recent works reveal that the classifier-free guidance can generate better conditional samples [1]. In this paper, we adopt classifier-free guidance, which is formed with an unconditional model and a conditional model, as the sampling method.
Diffusion Models in RL. Recently, offline decision-making problems have been formulated from the perspective of sequential distribution modeling and conditional generation with DPMs [27, 16, 1, 10, 10, 5], where high-performance policies are recovered by training on the given return-labeled trajectories datasets. This new pattern brings more flexible control in offline RL, such as goal-based planning, composable constraint combination, scalable trajectory generation, and complex skill synthesis [1, 63]. For example, Janner et al. [27] propose to combine the learned models and the trajectory optimization methods, effectively bypassing the adversarial examples that don’t exist in the environment and reaching outstanding performance under proper condition guidance. Ajay et al. [1] investigate how constraints and skills can be used to train DPMs and show the potential in many RL tasks. Additionally, diffusion policy is proposed as a more expressive policy, which has been used in RL, computer vision, and natural language processing [66, 10, 12].
Compared with existing works (Find Figure 1 for synoptical comparison.), we are the first to consider temporal dependencies in generation with diffusion models. We identify three types of temporal conditions, i.e., historical condition, immediate condition, and prospective condition, and propose a generic temporally-composable diffuser to produce behaviors with high performance. Besides, we conduct extensive experiments and provide a comprehensive discussion of temporal conditions.
3 Preliminaries
In this section, we first present the relationship between decision-making and sequence generation. Then we review the conditional generation with diffusion models.
3.1 Reinforcement Learning as Sequence Generation
In classical reinforcement learning, the sequential decision-making problem is formulated via the Markov Decision Process (MDP), which is defined as the tuple where and represent the state and action space, respectively, denotes the Markovian transition probability, is the reward function, is the initial state distribution, and is the discount factor. At each time step , the agent receives a state from the environment and produces an action with a stochastic or deterministic policy . Then a reward from the environment serves as the feedback to the executed action of the agent. After the interactive interaction with the environment in a whole episode, we will obtain the state, action, and reward sequence . In RL, our goal is to find a policy that can maximize the discounted return [57, 58].
Each trajectory can be regarded as a data point sampled from trajectory distribution according to certain policy . Then we can use diffusion models to learn the data distribution with a predefined forward diffusion process and a trainable generative process , where is preassigned, , , and . Finally, the decision-making problem can be formulated as a sequential generation problem by learning a noising model of the trajectory denoising process to capture the trajectory distribution and generate the offline datasets samples when a start state is given [53, 24]. The simplified objective for training the diffusion model is defined by
where is the diffusion time step in the inverse diffusion process, denotes uniform distribution, denotes the multivariant Gaussian noise, is sampled from the replay buffer , and is the parameters of model .
3.2 Conditional Diffusion Probabilistic Models
There are two methods, classifier-guided and classifier-free, to train conditional diffusion models , i.e., generating data under perturbed variable and condition [14, 37]. The former method enables us to first train an unconditional diffusion model, which can be used to perform conditional generation under the gradient guidance of an additional classifier. For the stochastic sampling process, such as DDPM [24], indicates that the classifier guidance information is , where the condition should be the label of data and is the parameters. Applying Taylor expansion on at , we can obtain the perturbed noise that is added during the generation process. Then we have . For the deterministic sampling process, such as DDIM [54], the score function of joint distribution is defined by . The perturbed noise is , where is the guidance scale.
The classifier-free method builds the correlation between the samples and conditions in the training phase by learning unconditional noise and conditional noise , where we usually choose zero vector as in practice [1]. Then the perturbed noise at each diffusion time step is calculated by . In this paper, we adopt the classifier-free guidance because it can usually bring more controllable generation and higher performance.
4 Rethink the Temporal Dependencies in Sequential Generation
In this section, we rethink the temporal dependencies of sequences when regarding decision-making as the sequential generation with diffusion models and discuss the limitations of existing diffusers.
What is the difference of generation between supervised learning and decision-making? Classical generation tasks, such as image synthesization, possess one-step property, where each picture does not have temporal dependencies. But in decision-making tasks, each sequence contains temporal dependencies among the context transitions in it. Roughly assimilating trajectory with image neglects the characteristics of multi-step interaction and temporal correlation of RL. Besides, episodic returns are continuous values while the classes of figures are discrete values, which presents challenges for the generation when we only use one coarse-grained condition to guide the diffusion model. Thus, in order to learn policies from the sequential data, we must extract temporal information and utilize it to guide the generation process of diffusion models.
How temporal conditions enhance the performance in state sequence generation? To answer this question, we try to visualize the effects of temporal dependencies in sequential generation by conducting three types of environments (Figure 2), which correspond to the temporal conditions. In the historical condition env (Figure 2 (a)), the state sequences behind the junction state are strongly related to historical states, e.g., the green triangle trajectories only exist when the historical state sequence meets the condition of state incidence at the angle to the junction state. In Figure 2 (b), we fix the historical sequences but just modify the action reward of different actions under the junction state, where the red square trajectories possess high rewards while low rewards arise in green triangle trajectories. We fix the total reward the same in Figure 2 (c) by either masking the reward of the front part of trajectories with 0 or masking the latter part of trajectories with 0. Refer to Appendix C.1 for the detailed environmental description.
The generation sequences of DD and our method (TCD) under temporal conditions are shown in Figure 2 (d)-(f), where each below result is evaluated on the corresponding upper environment. Taking Figure 2 (d) as an example, losing the capacity to capture temporal dependencies makes DD fail to generate homologous sequences based on historical states, while TCD distinguishes the diverse samples and achieves controllable generation. Although we may only need behaviors with high rewards in practice (Figure 2 (e)), the ability of subtle discernibility and diverse generations are as important as high performance. Finally, in the results of Figure 2 (f), we can also see that the return-to-go (RTG) with remaining available time step can help diffusion model recognize different trajectories. But the DD can not recover all types of trajectories when the prospective returns are the same. More discussion can be found in Appendix D.1.
5 Temporally-Composable Diffuser
In this section, we introduce the Temporally-Composable Diffuser (TCD), as shown in Figure 3, which contains three types of temporal conditions from the perspective of temporal condition guidance (), and provide a unified discussion on these temporal conditions. Due to the discrepancy across environments, various trajectory length makes it hard to train diffusion models, which need fixed sequence length. Following previous works [27, 1], the trajectories are split into equaling sequences (i.e., fragments of trajectory), where is the sequence length. We use the a hat symbol to represent the generative sequence in the following parts.
During training, we use the diffusion model to capture the joint distribution of temporal condition guidance () and the sequences. During generation, we search the temporal conditions from previously-collected experiences and interactive sequences. The universal training objective and generation process is given below
| (1) |
| (2) |
where represents the mixture of prospective condition , historical condition , and immediate condition . , , , and . Next, we introduce these temporal conditions successively.
Prospective Condition . For each sequence to be waiting for generation, the prospective condition information can be provided as guidance, such as expected discounted return of state value or state-action value, RTG, and target goal state. Compared with previous diffusion-based methods that estimate the action value function Q or state value function V, the advantage of RTG is that modeling one RTG bypasses inaccurate estimation on OOD samples. Besides, RTG relates the remaining available time step with the historical best performance in one episode, which can not be reflected by Q or V function.
In this paper, we adopt the RTG, which indicates the future desired returns when preestablishing the initial returns. In the generation process, we select the maximal return value in the datasets as the initial returns. Statistically, we first calculate the episode returns from the replay buffer and then obtain the maximal return value and minimum return value . After that, the RTG information from state is normalized by . Finally, we use as the condition during training, i.e., . Furthermore, we find that our model can extrapolate to behavior sequences with higher returns when given a higher initial return offset. More discussion can be found in Section 6.4. Similar to the processing way in Diffuser, where they apply the condition by replacing the denoised sequence with , we can also substitute the final generative state with goal state , i.e., .
Historical Condition . Classical diffusion model structure utilizes the U-net backbone and one-dimensional convolution to process sequence data, so the most straightforward method to consider historical information is conditioning on preceding experiences. Specifically, based on the U-net backbone, we add the historical information by replacing the incipient generative state segments of sequences with at each generative step. Previous methods, like DD, generate state sequence conditioning only on current state , which may omit important information that appears in history, especially for environments with partial observability. Even for environments without partial observability, the historical conditions can be regarded as an argumentation method, and the experiments show they can still provide improvements.
Immediate Condition . Though we can use the diffusion model to plan a long-term sequence, only the first two states, and , are adopted to produce actions with inverse dynamics . Consequently, the direct influencing factor in obtaining rewards from the environment is the quality of the generated states . This enlightens us that we should pay more attention to the current generative state , which is the meaning of immediate condition .
The immediate condition works through two stages. During the training stage, the first action reward and the corresponding sequence are bound together for training. Then in the evaluation stage, we select the trajectories with top- returns and extract the reward sequences as the immediate condition. For each time step in evaluation, we use the that associates and to instruct generation. Thus, is the immediate condition.
6 Experiments
In this section, we investigate the effects of different temporal conditions on a variety of different decision-making tasks [17, 19, 44]. We first introduce environmental settings in Section 6.1. Then in Section 6.2 and Appendix C.3, we report the performance of TCD on various tasks. Next, we provide the discussion of temporal conditions in Section 6.3 and Appendix E. Finally, we conduct parameter sensitivity analysis in Section 6.4.
6.1 Environment Settings
Environments. Gym-MuJoCo is a widely used benchmark of D4RL that provides offline datasets (HalfCheetah, Hopper, Walker2d) collected from single policy (-random (-r), -medium (-m), and -expert (-e)) or multi-policies (-medium-replay (-mr), -medium-expert (-me), and -full-replay (-fr)) [17]. The Maze2D is a 2D navigation task that requires the agent to reach the destination under sparse and dense reward functions [19]. See Appendix C.3 for more description.
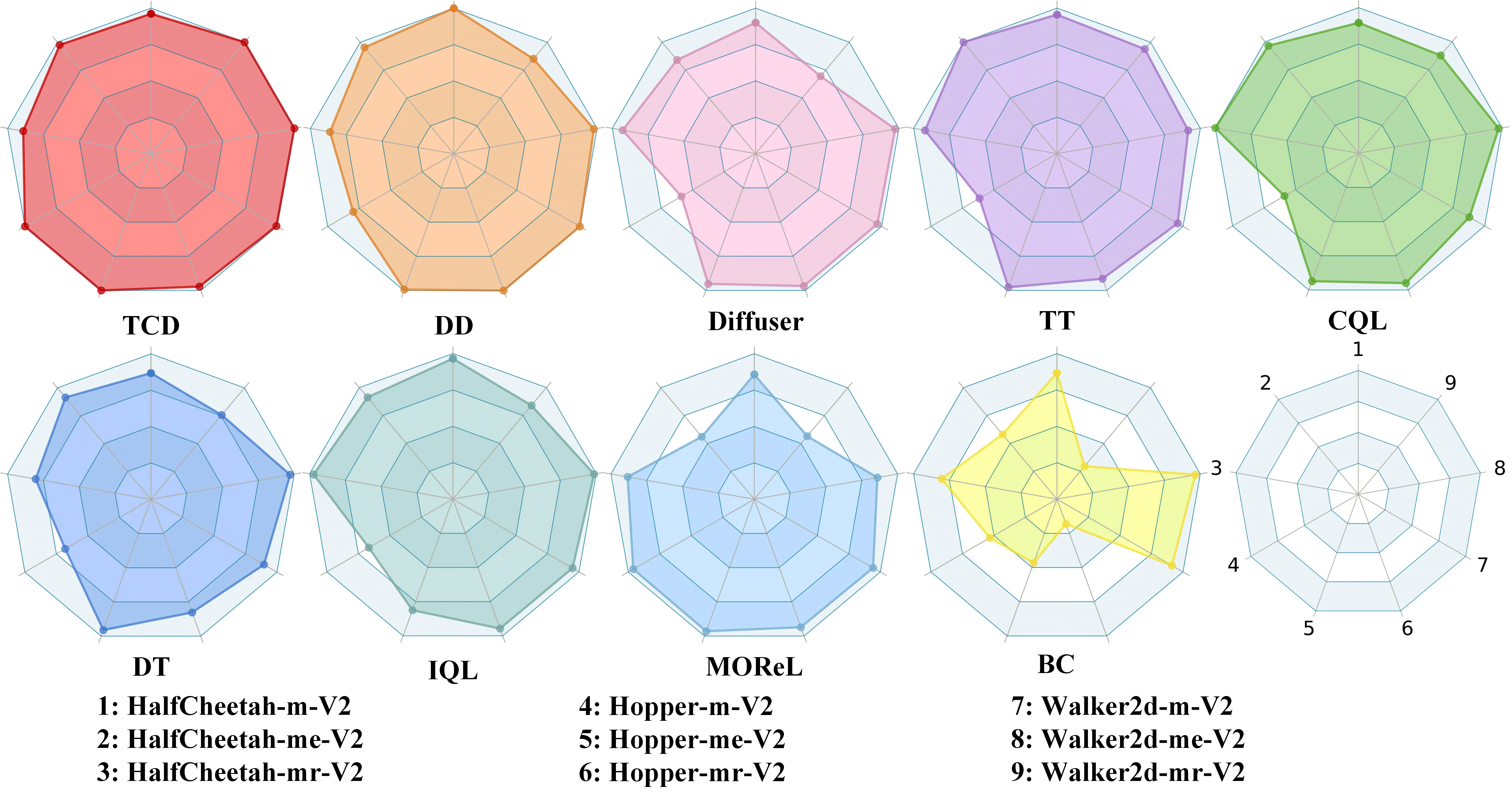
Baselines. We compare our method with recent representative offline RL baselines (Figure 4), including model-based methods MOReL [29], model-free methods CQL [35], IQL [33], BC, and sequential modeling methods DT [9], TT [26], Diffuser [27], and DD [1]. In the analysis of temporal conditions, we also provide many other temporally-composable algorithms, such as diffuser with transformer-backbone (TFD), diffuser with state-reward sequence modeling (SRD), diffuser with distributional Q estimation (DQD), TCD with reward estimation (RR-TCD and RQR-TCD) and other TCD variants that remove certain temporal conditions. Refer to Appendix D.2 for more description.
Metrics. For all methods considered, we report the performance under different offline RL datasets. In order to compare the holistic capacity of all methods, the performance normalization based on all methods is considered because the value of performance in different scenarios varies considerably. For example, if we have evaluation results of three methods, then the normalized performance is defined by , where and enables us to distinguish the differences of methods appropriately. In the experiments, we set . Note that we also report the normalized score on environments in Appendix D.
6.2 Evaluation on the Effectiveness of TCD
Evaluation on Temporal Condition Envs. We briefly introduce the environments in Section 4, report the experimental results in Figure 2, and postpone more discussion in Appendix C.1 and D.1.
Evaluation on Gym-MuJoCo. Results for the Gym-MuJoCo domains are shown in Figure 4 and Table 1. The results for the baselines are based on the numbers reported in [1], [27], and [26]. On the datasets generated from single policy and multi policies, TCD surpasses or matches the best prior methods in 8 of 9 environments under successful comparison, i.e., the evaluation time step is equal to the time limit of environments, and the agent is still capable of gaining more rewards. Previous diffusion-based models (i.e., Diffuser and DD) do not realize the temporal dependencies among prospective, immediate, and historical decisions. In comparison, our method guides generation with these temporal conditions and outperforms baselines by large margins in Walker2d-mr and Hopper-m.
Evaluation on Maze2D. In this experiment, we report the performance (Table 4) of our method (TCD) and baselines in the sparse and dense reward setting. The sparse reward setting makes it hard for the agent to explore successful trajectories, especially in offline RL tasks, where the agent can not explore novel experiences through interaction with the environment. As shown in Table 4, in the Maze2D sparse setting, our method under temporal conditions guidance is consistently better than prior diffusion methods [1], such as DD, which generates sequences without temporal conditions guidance. The reason is that the expected return estimation is almost zero for most states when the agent never or seldom observes successful trajectories, which results in restricted capacity in solving these sparse tasks. In comparison, our method considers historical information, which provides wise decision reference when future instruction is relatively useful. With difficulty increasing from umaze to large under the Maze2D dense setting, the performance of DD degrades significantly, forming a sharp contrast that our method even reaches higher returns in larger size of environments.
6.3 Ablation Study of Temporal Conditions
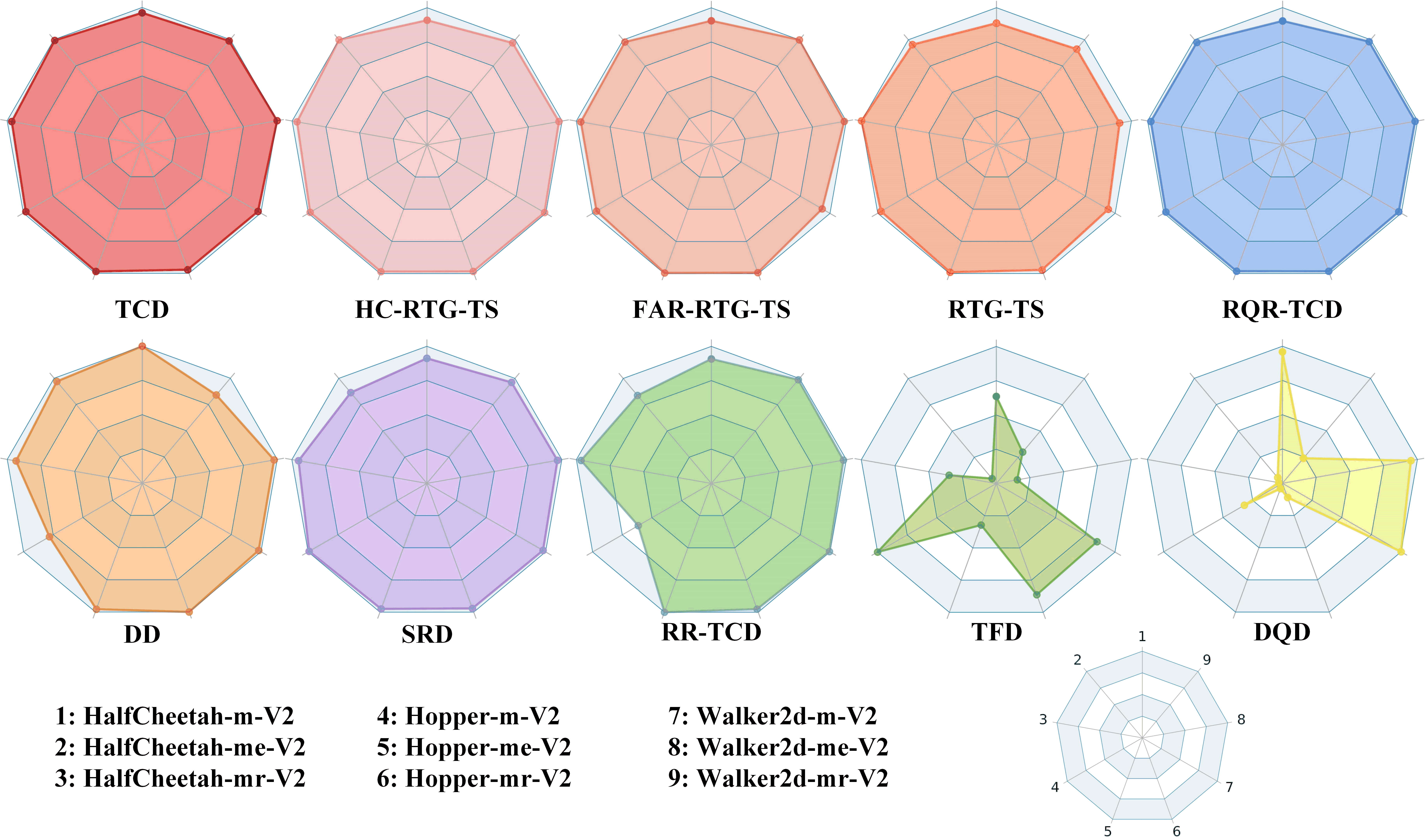
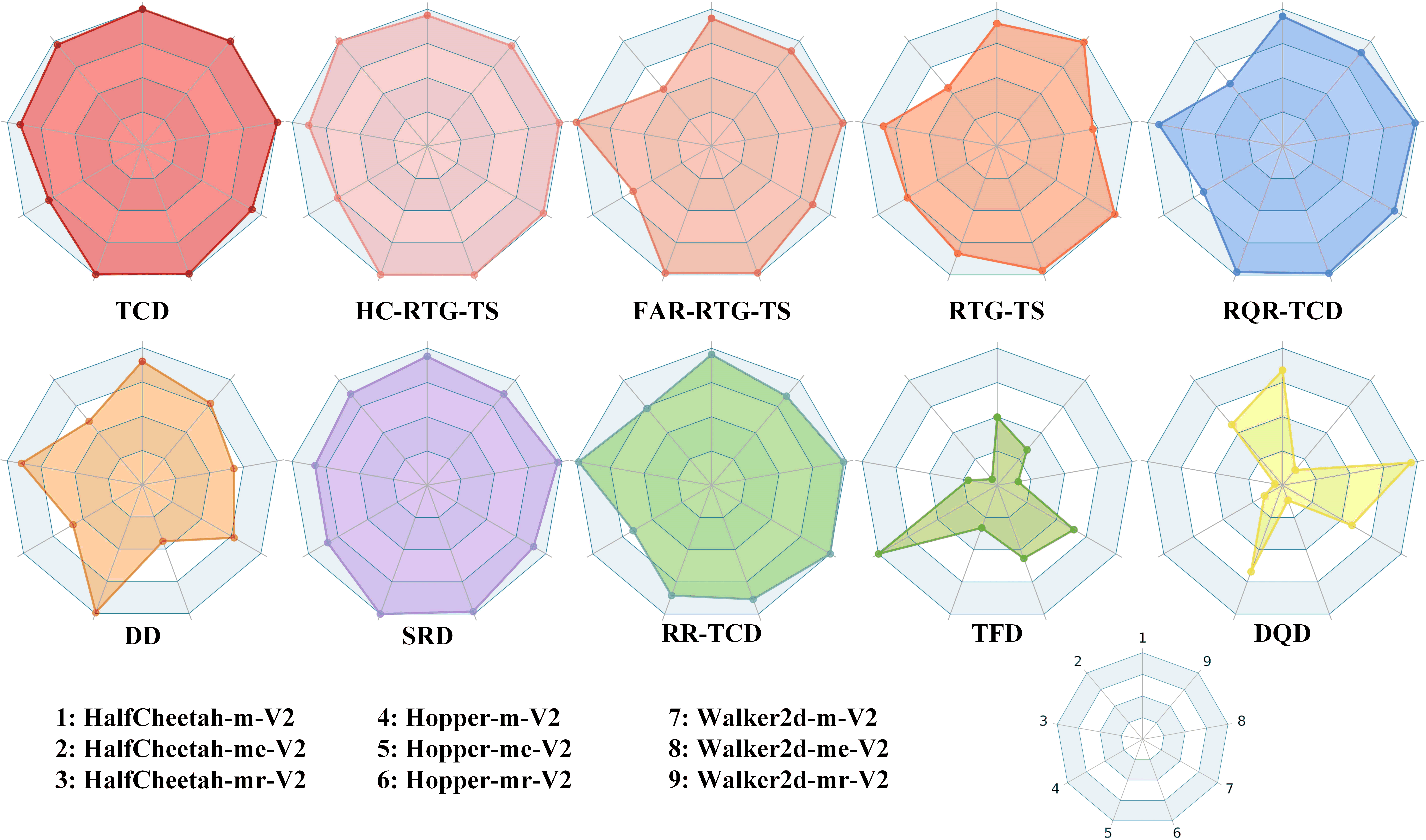
To investigate the effects of different temporal conditions, we report the performance of TCD when removing certain temporal conditions. Specifically, RTG-TS denotes that we remove the historical condition and immediate condition during training and evaluation. HC-RTG-TS denotes TCD without immediate condition guidance, while FAR-RTG-TS means that we cut the historical condition guidance. We conduct the experiments on Gym-MuJoCo tasks under successful comparison. As shown in Table 2, each type of temporal condition contributes positive effects in the sequential generation. Besides, the historical condition leads to greater performance gain compared with the immediate condition when considering the performance difference between HC-RTG-TS and FAR-RTG-TS. The reason can be attributed to the fact that historical condition provides multi-step information while immediate condition only contains one-step information. More extensively, we consider other types of temporal conditions, including explicit and implicit. The overall performance is shown in Figure 6. The concrete values are summarized in Table 7. More discussion of the temporal conditions ranging from architecture backbone to training mode can be found in Appendix E.
6.4 Parameter Sensitivity Analysis
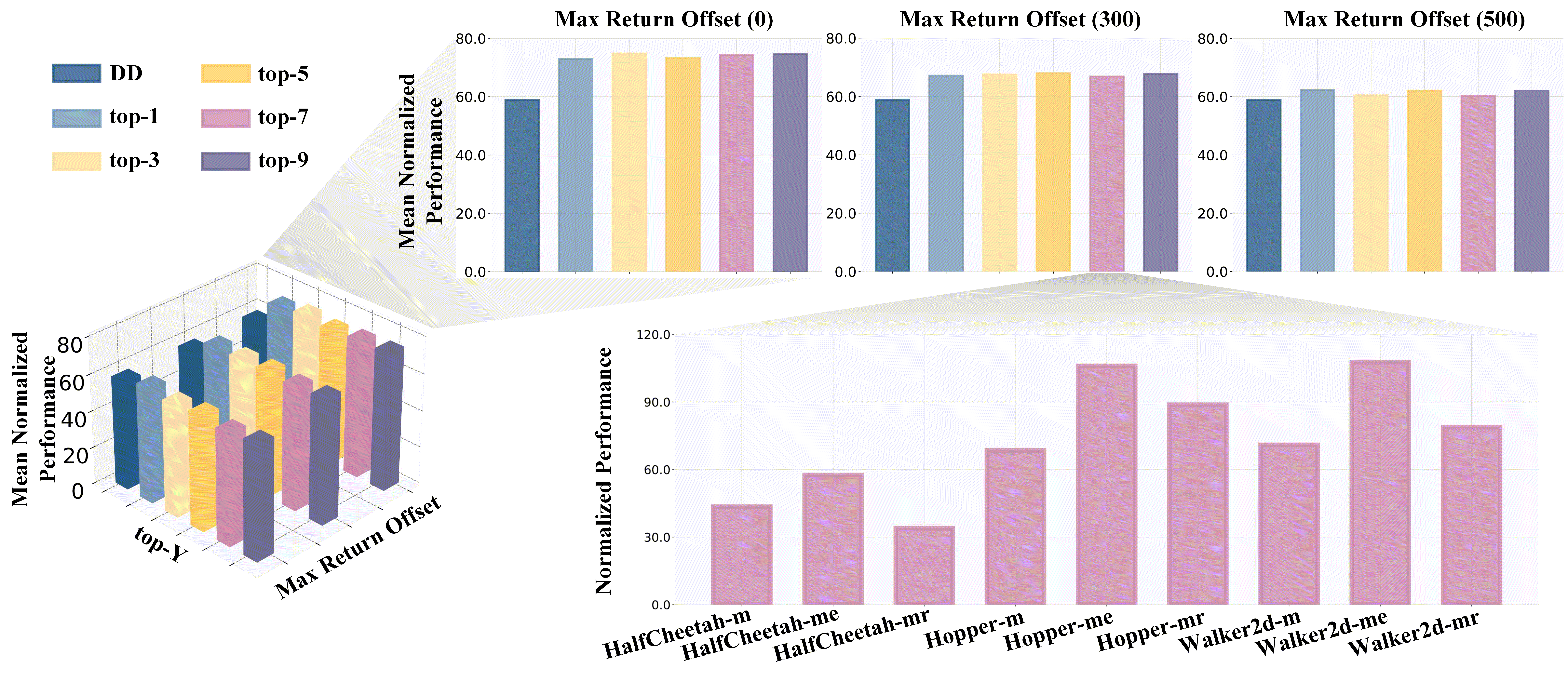
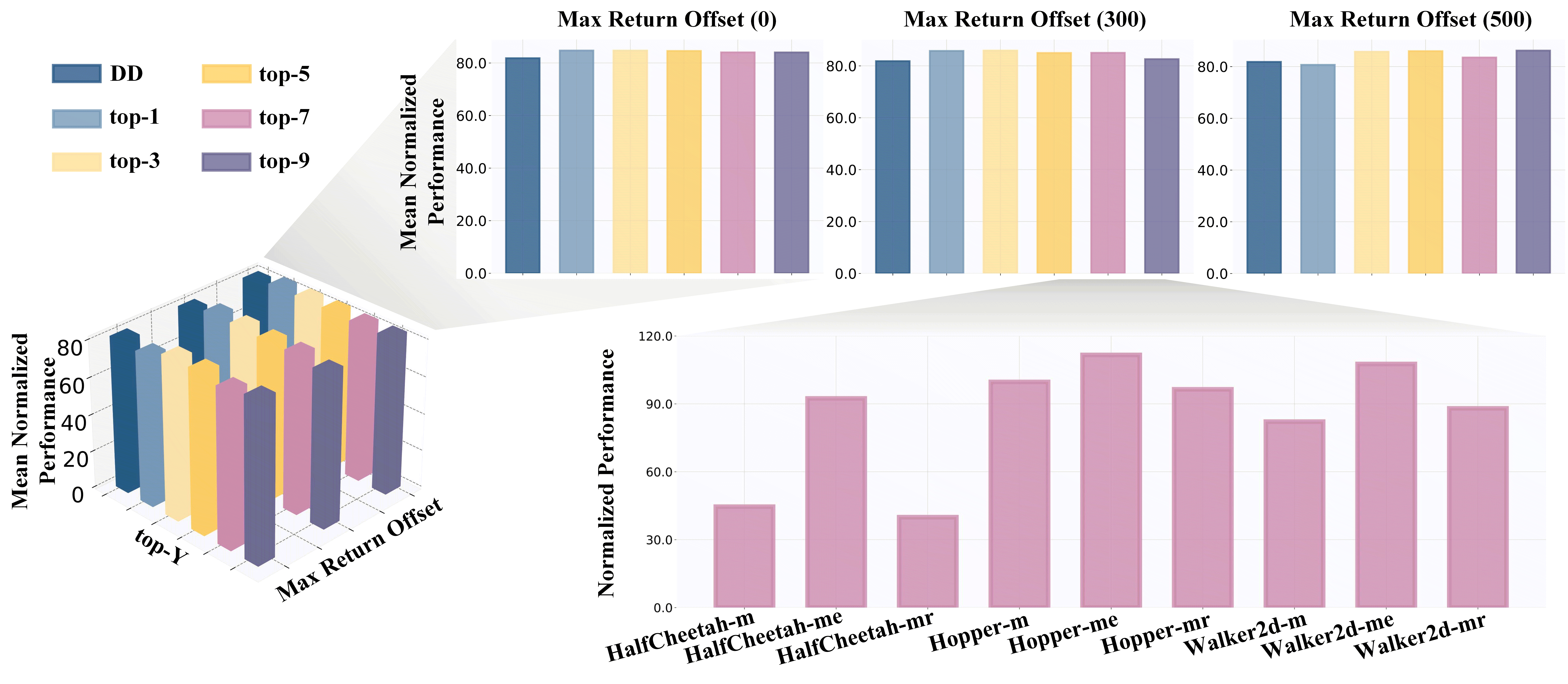
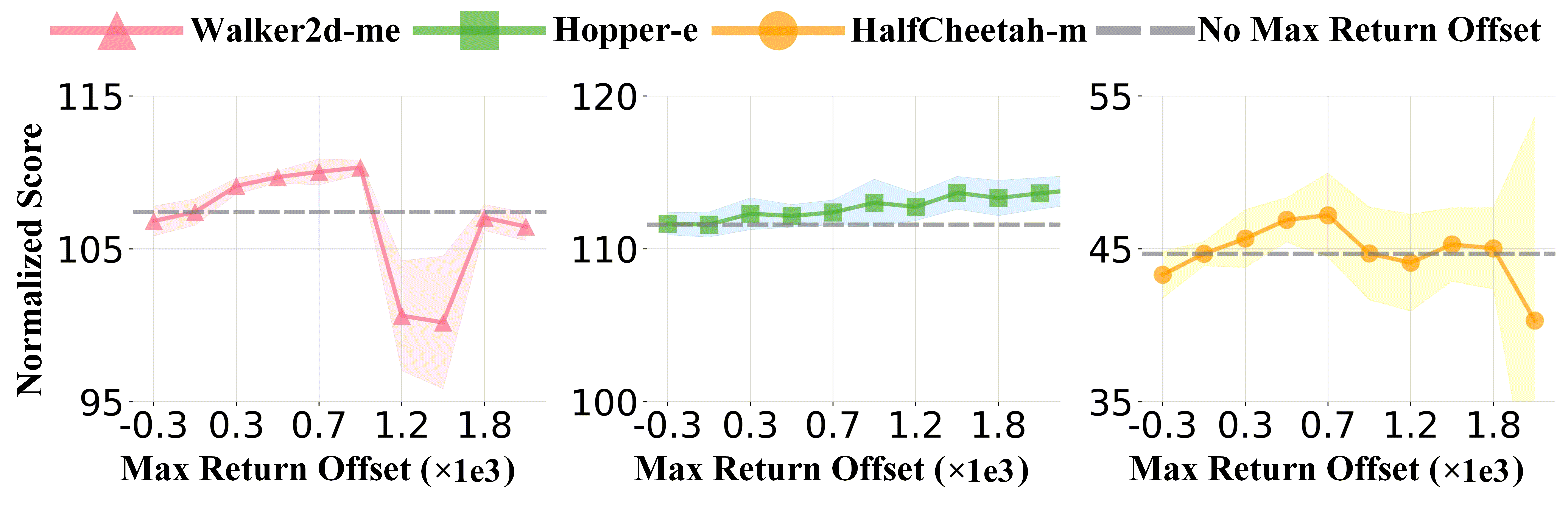
In this experiment, we investigate several hyper-parameters that may influence the performance of temporal conditions. Specifically, we investigate the impacts of top- and max return offset. Top- denotes that the action-instructed reward sequence is selected from the trajectories of top- expected return, while the max return offset represents the value that we add into the initial RTG setting during the evaluation stage. As shown in Figure 5, small , such as , is good enough for generating plausible sequences, but due to poor robustness to deflected situations, small may result in low performance in Walker2d-m. When we set a larger value of max return offset, the model may show over-optimistic to future return and weaken the effects of the current situation and historical behaviors, thus leading to performance decay. But the above phenomenon also relates to the quality of datasets where relatively increasing the value of max return offset will bring higher performance. For more discussion and experiments, please refer to Appendix D.4.
| Dataset | Med-Expert | Medium | Med-Replay | score | ||||||
| Env | HalfCheetah | Hopper | Walker2d | HalfCheetah | Hopper | Walker2d | HalfCheetah | Hopper | Walker2d | |
| BC | 55.2 | 52.5 | 107.5 | 42.6 | 52.9 | 75.3 | 36.6 | 18.1 | 26.0 | 51.9 |
| MOReL | 53.3 | 108.7 | 95.6 | 42.1 | 95.4 | 77.8 | 40.2 | 93.6 | 49.8 | 72.9 |
| DT | 86.8 | 107.6 | 108.1 | 42.6 | 67.6 | 74.0 | 36.6 | 82.7 | 66.6 | 74.7 |
| Diffuser | 79.8 | 107.2 | 108.4 | 44.2 | 58.5 | 79.7 | 42.2 | 96.8 | 61.2 | 75.3 |
| IQL | 86.7 | 91.5 | 109.6 | 47.4 | 66.3 | 78.3 | 44.2 | 94.7 | 73.9 | 77.0 |
| CQL | 91.6 | 105.4 | 108.8 | 44.0 | 58.5 | 72.5 | 45.5 | 95.0 | 77.2 | 77.6 |
| TT | 95 | 110.0 | 101.9 | 46.9 | 61.1 | 79.0 | 41.9 | 91.5 | 82.6 | 78.9 |
| DD | 90.61.3 | 111.81.8 | 108.81.7 | 49.11.0 | 79.33.6 | 82.51.4 | 39.34.1 | 1000.7 | 754.3 | 81.8 |
| TCD | 92.673.37 | 112.601.03 | 111.310.73 | 47.200.74 | 99.370.60 | 82.061.83 | 40.571.39 | 97.202.39 | 88.041.92 | 85.67 |
| Dataset | Med-Expert | Medium | Med-Replay | score | ||||||
| Env | HalfCheetah | Hopper | Walker2d | HalfCheetah | Hopper | Walker2d | HalfCheetah | Hopper | Walker2d | |
| RTG-TS | 89.114.47 | 113.131.55 | 101.609.90 | 43.581.26 | 98.661.03 | 79.233.09 | 42.011.23 | 97.270.00 | 81.264.30 | 82.87 |
| FAR-RTG-TS | 91.562.80 | 113.631.98 | 109.620.66 | 44.480.72 | 98.052.00 | 78.553.65 | 40.611.58 | 99.211.59 | 89.182.65 | 84.98 |
| HC-RTG-TS | 93.441.62 | 112.510.46 | 108.750.31 | 44.630.63 | 99.910.35 | 83.161.70 | 40.491.42 | 98.341.61 | 86.572.11 | 85.31 |
| TCD | 92.673.37 | 112.601.03 | 111.310.73 | 47.200.74 | 99.370.60 | 82.061.83 | 40.571.39 | 97.202.39 | 88.041.92 | 85.67 |
7 Conclusion, Limitations, and Broader Impact
In this paper, we propose Temporally-Composable Diffuser (TCD), a generic temporally-conditional diffusion model that can extract temporal dependencies of sequences and achieve better controllable generation in sequential modeling. We identify the historical conditions, immediate conditions, and prospective conditions from sequences and provide a comprehensive discussion and comparison of different temporal conditions. We evaluate TCD on extensive experiments, including several self-designed tasks and the D4RL datasets, where experiments demonstrate the superiority of our method compared with other sequential modeling methods and non-sequential modeling methods.
In terms of limitations, the mechanism of the generation process makes it slower than other models, such as Transformer-based models and MLP-based agents, even though we can use recent breakthroughs [40] to accelerate this process. More recent studies have brought hope for the efficient generation. Thus we may be able to improve the efficiency based on the current models [56]. Refer to Appendix F for more discussions of limitations and future work. Regarding societal impacts, we do not anticipate any negative consequences from using our method in practice.
References
- Ajay et al. [2022] Anurag Ajay, Yilun Du, Abhi Gupta, Joshua Tenenbaum, Tommi Jaakkola, and Pulkit Agrawal. Is conditional generative modeling all you need for decision-making? arXiv preprint arXiv:2211.15657, 2022.
- An et al. [2021] Gaon An, Seungyong Moon, Jang-Hyun Kim, and Hyun Oh Song. Uncertainty-based offline reinforcement learning with diversified q-ensemble. Advances in neural information processing systems, 34:7436–7447, 2021.
- Andrychowicz et al. [2017] Marcin Andrychowicz, Filip Wolski, Alex Ray, Jonas Schneider, Rachel Fong, Peter Welinder, Bob McGrew, Josh Tobin, OpenAI Pieter Abbeel, and Wojciech Zaremba. Hindsight experience replay. Advances in neural information processing systems, 30, 2017.
- Bao et al. [2022] Fan Bao, Chongxuan Li, Yue Cao, and Jun Zhu. All are worth words: a vit backbone for score-based diffusion models. arXiv preprint arXiv:2209.12152, 2022.
- Beeson and Montana [2023] Alex Beeson and Giovanni Montana. Balancing policy constraint and ensemble size in uncertainty-based offline reinforcement learning. arXiv preprint arXiv:2303.14716, 2023.
- Bellemare et al. [2017] Marc G Bellemare, Will Dabney, and Rémi Munos. A distributional perspective on reinforcement learning. In Proceedings of International conference on machine learning, pages 449–458. PMLR, 2017.
- Bengio et al. [2009] Yoshua Bengio, Jérôme Louradour, Ronan Collobert, and Jason Weston. Curriculum learning. In Proceedings of the 26th annual international conference on machine learning, pages 41–48, 2009.
- Ceylan et al. [2023] Duygu Ceylan, Chun-Hao Paul Huang, and Niloy J Mitra. Pix2video: Video editing using image diffusion. arXiv preprint arXiv:2303.12688, 2023.
- Chen et al. [2021] Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Misha Laskin, Pieter Abbeel, Aravind Srinivas, and Igor Mordatch. Decision transformer: Reinforcement learning via sequence modeling. Advances in neural information processing systems, 34:15084–15097, 2021.
- Chi et al. [2023] Cheng Chi, Siyuan Feng, Yilun Du, Zhenjia Xu, Eric Cousineau, Benjamin Burchfiel, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion. arXiv preprint arXiv:2303.04137, 2023.
- Cobbe et al. [2019] Karl Cobbe, Oleg Klimov, Chris Hesse, Taehoon Kim, and John Schulman. Quantifying generalization in reinforcement learning. In International Conference on Machine Learning, pages 1282–1289. PMLR, 2019.
- Dai et al. [2023] Yilun Dai, Mengjiao Yang, Bo Dai, Hanjun Dai, Ofir Nachum, Josh Tenenbaum, Dale Schuurmans, and Pieter Abbeel. Learning universal policies via text-guided video generation. arXiv preprint arXiv:2302.00111, 2023.
- Devlin et al. [2018] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018.
- Dhariwal and Nichol [2021] Prafulla Dhariwal and Alexander Nichol. Diffusion models beat gans on image synthesis. Advances in Neural Information Processing Systems, 34:8780–8794, 2021.
- Esser et al. [2023] Patrick Esser, Johnathan Chiu, Parmida Atighehchian, Jonathan Granskog, and Anastasis Germanidis. Structure and content-guided video synthesis with diffusion models. arXiv preprint arXiv:2302.03011, 2023.
- Fontanesi et al. [2019] Laura Fontanesi, Sebastian Gluth, Mikhail S Spektor, and Jörg Rieskamp. A reinforcement learning diffusion decision model for value-based decisions. Psychonomic bulletin & review, 26(4):1099–1121, 2019.
- Fu et al. [2020] Justin Fu, Aviral Kumar, Ofir Nachum, George Tucker, and Sergey Levine. D4rl: Datasets for deep data-driven reinforcement learning. arXiv preprint arXiv:2004.07219, 2020.
- Fujimoto and Gu [2021] Scott Fujimoto and Shixiang Shane Gu. A minimalist approach to offline reinforcement learning. Advances in neural information processing systems, 34:20132–20145, 2021.
- Fujimoto et al. [2019] Scott Fujimoto, David Meger, and Doina Precup. Off-policy deep reinforcement learning without exploration. In International conference on machine learning, pages 2052–2062. PMLR, 2019.
- Furuta et al. [2021] Hiroki Furuta, Yutaka Matsuo, and Shixiang Shane Gu. Generalized decision transformer for offline hindsight information matching. arXiv preprint arXiv:2111.10364, 2021.
- Geman et al. [1992] Stuart Geman, Elie Bienenstock, and René Doursat. Neural networks and the bias/variance dilemma. Neural computation, 4(1):1–58, 1992.
- Ghosh et al. [2022] Dibya Ghosh, Anurag Ajay, Pulkit Agrawal, and Sergey Levine. Offline rl policies should be trained to be adaptive. In International Conference on Machine Learning, pages 7513–7530. PMLR, 2022.
- Ho and Salimans [2022] Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance. arXiv preprint arXiv:2207.12598, 2022.
- Ho et al. [2020] Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. Advances in Neural Information Processing Systems, 33:6840–6851, 2020.
- Hu et al. [2022] Shengchao Hu, Li Shen, Ya Zhang, Yixin Chen, and Dacheng Tao. On transforming reinforcement learning by transformer: The development trajectory. arXiv preprint arXiv:2212.14164, 2022.
- Janner et al. [2021] Michael Janner, Qiyang Li, and Sergey Levine. Offline reinforcement learning as one big sequence modeling problem. Advances in neural information processing systems, 34:1273–1286, 2021.
- Janner et al. [2022] Michael Janner, Yilun Du, Joshua B Tenenbaum, and Sergey Levine. Planning with diffusion for flexible behavior synthesis. arXiv preprint arXiv:2205.09991, 2022.
- Khachatryan et al. [2023] Levon Khachatryan, Andranik Movsisyan, Vahram Tadevosyan, Roberto Henschel, Zhangyang Wang, Shant Navasardyan, and Humphrey Shi. Text2video-zero: Text-to-image diffusion models are zero-shot video generators. arXiv preprint arXiv:2303.13439, 2023.
- Kidambi et al. [2020] Rahul Kidambi, Aravind Rajeswaran, Praneeth Netrapalli, and Thorsten Joachims. Morel: Model-based offline reinforcement learning. Advances in neural information processing systems, 33:21810–21823, 2020.
- Kim et al. [2022] Gwanghyun Kim, Taesung Kwon, and Jong Chul Ye. Diffusionclip: Text-guided diffusion models for robust image manipulation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2426–2435, 2022.
- Kingma and Ba [2014] Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
- Koenker and Hallock [2001] Roger Koenker and Kevin F Hallock. Quantile regression. Journal of economic perspectives, 15(4):143–156, 2001.
- Kostrikov et al. [2021] Ilya Kostrikov, Ashvin Nair, and Sergey Levine. Offline reinforcement learning with implicit q-learning. arXiv preprint arXiv:2110.06169, 2021.
- Kumar et al. [2019] Aviral Kumar, Justin Fu, Matthew Soh, George Tucker, and Sergey Levine. Stabilizing off-policy q-learning via bootstrapping error reduction. Advances in Neural Information Processing Systems, 32, 2019.
- Kumar et al. [2020] Aviral Kumar, Aurick Zhou, George Tucker, and Sergey Levine. Conservative q-learning for offline reinforcement learning. Advances in Neural Information Processing Systems, 33:1179–1191, 2020.
- Levine et al. [2020] Sergey Levine, Aviral Kumar, George Tucker, and Justin Fu. Offline reinforcement learning: Tutorial, review, and perspectives on open problems. arXiv preprint arXiv:2005.01643, 2020.
- Liu et al. [2023] Xihui Liu, Dong Huk Park, Samaneh Azadi, Gong Zhang, Arman Chopikyan, Yuxiao Hu, Humphrey Shi, Anna Rohrbach, and Trevor Darrell. More control for free! image synthesis with semantic diffusion guidance. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 289–299, 2023.
- Liu et al. [2019] Yao Liu, Adith Swaminathan, Alekh Agarwal, and Emma Brunskill. Off-policy policy gradient with state distribution correction. arXiv preprint arXiv:1904.08473, 2019.
- Lu et al. [2023] Cong Lu, Philip J Ball, and Jack Parker-Holder. Synthetic experience replay. arXiv preprint arXiv:2303.06614, 2023.
- Nichol and Dhariwal [2021] Alexander Quinn Nichol and Prafulla Dhariwal. Improved denoising diffusion probabilistic models. In International Conference on Machine Learning, pages 8162–8171. PMLR, 2021.
- Ouyang et al. [2022] Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35:27730–27744, 2022.
- Radford et al. [2018] Alec Radford, Karthik Narasimhan, Tim Salimans, Ilya Sutskever, et al. Improving language understanding by generative pre-training. 2018.
- Rafailov et al. [2021] Rafael Rafailov, Tianhe Yu, Aravind Rajeswaran, and Chelsea Finn. Offline reinforcement learning from images with latent space models. In Learning for Dynamics and Control, pages 1154–1168. PMLR, 2021.
- Rajeswaran et al. [2017] Aravind Rajeswaran, Vikash Kumar, Abhishek Gupta, Giulia Vezzani, John Schulman, Emanuel Todorov, and Sergey Levine. Learning complex dexterous manipulation with deep reinforcement learning and demonstrations. arXiv preprint arXiv:1709.10087, 2017.
- Ramesh et al. [2022] Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:2204.06125, 2022.
- Rezaeifar et al. [2022] Shideh Rezaeifar, Robert Dadashi, Nino Vieillard, Léonard Hussenot, Olivier Bachem, Olivier Pietquin, and Matthieu Geist. Offline reinforcement learning as anti-exploration. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 36, pages 8106–8114, 2022.
- Rigter et al. [2022] Marc Rigter, Bruno Lacerda, and Nick Hawes. Rambo-rl: Robust adversarial model-based offline reinforcement learning. arXiv preprint arXiv:2204.12581, 2022.
- Rombach et al. [2022] Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10684–10695, 2022.
- Ronneberger et al. [2015] Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, October 5-9, 2015, Proceedings, Part III 18, pages 234–241. Springer, 2015.
- Ross et al. [2011] Stéphane Ross, Geoffrey Gordon, and Drew Bagnell. A reduction of imitation learning and structured prediction to no-regret online learning. In Proceedings of the fourteenth international conference on artificial intelligence and statistics, pages 627–635. JMLR Workshop and Conference Proceedings, 2011.
- Shang and Ryoo [2021] Jinghuan Shang and Michael S Ryoo. Starformer: Transformer with state-action-reward representations. arXiv preprint arXiv:2110.06206, 2021.
- Siegel et al. [2020] Noah Y Siegel, Jost Tobias Springenberg, Felix Berkenkamp, Abbas Abdolmaleki, Michael Neunert, Thomas Lampe, Roland Hafner, Nicolas Heess, and Martin Riedmiller. Keep doing what worked: Behavioral modelling priors for offline reinforcement learning. arXiv preprint arXiv:2002.08396, 2020.
- Sohl-Dickstein et al. [2015] Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics. In International Conference on Machine Learning, pages 2256–2265. PMLR, 2015.
- Song et al. [2020] Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. arXiv preprint arXiv:2010.02502, 2020.
- Song and Ermon [2019] Yang Song and Stefano Ermon. Generative modeling by estimating gradients of the data distribution. Advances in neural information processing systems, 32, 2019.
- Song et al. [2023] Yang Song, Prafulla Dhariwal, Mark Chen, and Ilya Sutskever. Consistency models. arXiv preprint arXiv:2303.01469, 2023.
- Sun et al. [2022] Yanchao Sun, Ruijie Zheng, Parisa Hassanzadeh, Yongyuan Liang, Soheil Feizi, Sumitra Ganesh, and Furong Huang. Certifiably robust policy learning against adversarial communication in multi-agent systems. arXiv preprint arXiv:2206.10158, 2022.
- Sun et al. [2023] Yanchao Sun, Shuang Ma, Ratnesh Madaan, Rogerio Bonatti, Furong Huang, and Ashish Kapoor. Smart: Self-supervised multi-task pretraining with control transformers. arXiv preprint arXiv:2301.09816, 2023.
- Tian et al. [2023] Yu Tian, Chengwei Zhang, Qing Guo, Kangjie Zheng, Wanqing Fang, Xintian Zhao, and Shiqi Zhang. Optimistic exploration based on categorical-dqn for cooperative markov games. In Distributed Artificial Intelligence: 4th International Conference, DAI 2022, Tianjin, China, December 15–17, 2022, Proceedings, pages 60–73. Springer, 2023.
- Touvron et al. [2023] Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023.
- Vaswani et al. [2017] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017.
- Walke et al. [2023] Homer Rich Walke, Jonathan Heewon Yang, Albert Yu, Aviral Kumar, Jędrzej Orbik, Avi Singh, and Sergey Levine. Don’t start from scratch: Leveraging prior data to automate robotic reinforcement learning. In Conference on Robot Learning, pages 1652–1662. PMLR, 2023.
- Wang et al. [2023a] Hanlin Wang, Yilu Wu, Sheng Guo, and Limin Wang. Pdpp: Projected diffusion for procedure planning in instructional videos. arXiv preprint arXiv:2303.14676, 2023a.
- Wang et al. [2023b] Huiqiang Wang, Jian Peng, Feihu Huang, Jince Wang, Junhui Chen, and Yifei Xiao. Micn: Multi-scale local and global context modeling for long-term series forecasting. In The Eleventh International Conference on Learning Representations, 2023b.
- Wang et al. [2022a] Kerong Wang, Hanye Zhao, Xufang Luo, Kan Ren, Weinan Zhang, and Dongsheng Li. Bootstrapped transformer for offline reinforcement learning. arXiv preprint arXiv:2206.08569, 2022a.
- Wang et al. [2022b] Zhendong Wang, Jonathan J Hunt, and Mingyuan Zhou. Diffusion policies as an expressive policy class for offline reinforcement learning. arXiv preprint arXiv:2208.06193, 2022b.
- Wu et al. [2021] Haixu Wu, Jiehui Xu, Jianmin Wang, and Mingsheng Long. Autoformer: Decomposition transformers with auto-correlation for long-term series forecasting. Advances in Neural Information Processing Systems, 34:22419–22430, 2021.
- Wu et al. [2019] Yifan Wu, George Tucker, and Ofir Nachum. Behavior regularized offline reinforcement learning. arXiv preprint arXiv:1911.11361, 2019.
- Xie et al. [2021] Tengyang Xie, Ching-An Cheng, Nan Jiang, Paul Mineiro, and Alekh Agarwal. Bellman-consistent pessimism for offline reinforcement learning. Advances in neural information processing systems, 34:6683–6694, 2021.
- Zhang et al. [2021] Chiyuan Zhang, Samy Bengio, Moritz Hardt, Benjamin Recht, and Oriol Vinyals. Understanding deep learning (still) requires rethinking generalization. Communications of the ACM, 64(3):107–115, 2021.
- Zhang et al. [2023] Qin Zhang, Linrui Zhang, Haoran Xu, Li Shen, Bowen Wang, Yongzhe Chang, Xueqian Wang, Bo Yuan, and Dacheng Tao. Saformer: A conditional sequence modeling approach to offline safe reinforcement learning. arXiv preprint arXiv:2301.12203, 2023.
Appendix
Appendix A Pseudocode of Temporally-Composable Diffuser (TCD)
The pseudocode for TCD training is shown in Algorithm 1.
As shown in lines , we first process the sequences in the replay buffer to obtain the temporal conditions. Then during the training stage (lines ), we use the diffusion model to model the joint distribution between the sequences and the temporal conditions . After getting the well-trained diffusion model, we select the top- trajectories and extract and (lines ). We construct during the evaluation. Finally, during the evaluation stage (lines ), we leverage the temporally-composable condition to guide the sequence generation.
Appendix B Experimental Details
B.1 Computational Resource Description
Experiments are carried out on NVIDIA GeForce RTX 3090 GPUs and NVIDIA A10 GPUs. Besides, the CPU type is Intel(R) Xeon(R) Gold 6230 CPU @ 2.10GHz. Each run of the experiments spanned about 24-48 hours, depending on the hyperparameters setting and the complexity of the environments.
B.2 Hyperparameters
Appendix C Detailed Environment Description
C.1 Temporal Condition Scenarios
In order to show the temporal dependencies in sequential modeling and investigate whether the previous methods with prospective discounted returns, such as DD, and whether TCD can generate satisfactory sequences, we design three types of RL environments, which are shown in Figure 2.
In the first scenario (historical condition env in Figure 2 (a)), we define that the collected state sequences are generated according to three different historical state sequences. We further avoid the diffusion model distinguishing state sequences only from the current state by letting these three types of historical sequences converge to the same junction state (blue circle). The green triangle trajectories can only be unlocked when the historical state sequence meets the condition of state incidence at the angle to the junction state.
We fix the historical sequences as the same circumstance but modify the action reward under the junction state in the second scenario (immediate condition env) in Figure 2 (b). We set the low-reward trajectory samples and high-reward trajectory samples on the action reward of the junction state. Besides, we hold the total returns of trajectories the same for these two types of trajectory samples. As described in Section 5, we will obtain the generative sequences from the diffusion model, but we will not use the entire sequence for decision-making. Instead, we will make decisions based on and . Given the above settings, we can evaluate whether the diffusion model can focus on immediate behaviors that are most related to the current interaction step with the environment.
In the prospective condition env (Figure 2 (c)), we first separate the trajectories into two parts of equal length. Next, we set the reward of the front part of the upper trajectories (green triangle) as 0 and the reward of the latter part as 1 for each action. In contrast, the below trajectories (red square) have the opposite of the reward setting, i.e., 1 for the front part and 0 for the latter part. The setting of same returns of trajectories and different action reward distributions in trajectories makes it suitable for us to test the difference between the return-guided diffusion model and the RTG-guided diffusion model.
| model | BC | DD | TCD | ||
| Maze2D | Maze2D sparse | umaze | -5.4013.59 | 17.1638.96 | 39.9939.61 |
| medium | 12.3517.57 | -3.106.99 | 28.185.28 | ||
| large | 3.8312.35 | -14.196.25 | 7.6814.64 | ||
| Maze2D dense | umaze | -14.5611.42 | 83.2337.63 | 29.7721.17 | |
| medium | 16.3127.76 | 78.1783.91 | 41.449.45 | ||
| large | 17.0934.82 | 22.9740.06 | 75.5116.26 | ||
| score | 4.49 | 30.71 | 37.10 | ||
| Hand Manipulation | Pen | human | 7.4513.59 | 7.4513.59 | 49.8863.92 |
| expert | 69.6761.85 | 8.9929.77 | 35.6060.74 | ||
| cloned | 6.6331.32 | 55.1266.20 | 73.3066.48 | ||
| Relocate | human | 0.060.02 | 0.070.23 | 0.351.20 | |
| expert | 57.1246.42 | 80.3141.05 | 59.6438.35 | ||
| cloned | 0.050.04 | 0.070.15 | 0.150.34 | ||
| score | 23.46 | 30.47 | 36.49 | ||
| total mean score | 13.98 | 30.59 | 36.80 | ||
C.2 Gym-MuJoCo
Apart from the environments that we introduce in Section 6.2, we also evaluate our method in other scenarios, including -random (-r), -expert (-e), and -full-replay (-fr). The version of all the Gym-MuJoCo environments is -v2.
C.3 Maze2D
The Maze2D is a 2D navigation task where the agent needs to reach the specific location. The goal is finding the shortest path to the evaluation location by training on a previously-collected dataset. There are three difficulty settings, -umaze (-u), -medium (-m), and -large (-l), about Maze2D according to the size of the maze layouts. The trajectories are constructed with waypoint sequences that are generated by a PD controller [17]. Apart from the above-introduced difficulty settings, there are also two reward settings: sparse reward setting and dense reward setting. Thus we can obtain six scenarios by permutation and combination: Maze2D-sparse-u, Maze2D-sparse-m, Maze2D-sparse-l, Maze2D-dense-u, Maze2D-dense-m, and Maze2D-dense-l. The version of Maze2D is -v1.
C.4 Hand Manipulation
Hand Manipulation (i.e., Adroit) contains several sparse-reward, high-dimensional robotic manipulation tasks where the datasets are collected under three types of situations (-human (-h), -expert (-e), and -cloned (-c)) [44]. For example, Relocate scenario requires the agent to pick up a ball and move it to a specific location, and Pen is a scenario where the agent needs to get rewards by twirling a pen. The datasets with -h difficulty contain a small number of trajectories, while the datasets with -e and -c include abundant trajectories for training. Compared with Maze2D and Gym-MuJoCo, Hand Manipulation possesses a higher state dimension, harder exploration, more real expert demonstration, and more sparse reward feedback. The version of Hand Manipulation is -v1.
| Dataset | Random | Expert | Full-Replay | score | ||||||
| Env | HalfCheetah | Hopper | Walker2d | HalfCheetah | Hopper | Walker2d | HalfCheetah | Hopper | Walker2d | |
| DD | 1.960.11 | 5.811.25 | 12.845.66 | 17.4024.55 | 110.872.81 | 103.6717.73 | 45.6411.35 | 99.6022.30 | 82.065.52 | 53.32 |
| TCD | 3.980.61 | 2.140.82 | 6.501.78 | 36.3828.70 | 112.651.06 | 108.110.94 | 25.6514.66 | 106.270.82 | 96.161.27 | 55.32 |
| Dataset | Med-Expert | Medium | Med-Replay | score | ||||||
| Env | HalfCheetah | Hopper | Walker2d | HalfCheetah | Hopper | Walker2d | HalfCheetah | Hopper | Walker2d | |
| RTG-TS | 42.6824.25 | 92.9820.20 | 79.223.08 | 41.815.58 | 71.2418.78 | 79.223.08 | 32.7610.07 | 91.018.92 | 77.9710.03 | 66.45 |
| FAR-RTG-TS | 41.8129.01 | 109.7910.28 | 108.260.46 | 43.615.46 | 62.3118.39 | 68.0820.13 | 38.974.89 | 92.699.54 | 71.4919.91 | 72.33 |
| HC-RTG-TS | 76.9225.81 | 111.155.08 | 108.750.31 | 44.630.63 | 71.4816.27 | 77.927.96 | 34.248.85 | 94.156.49 | 75.3314.99 | 77.17 |
| TCD | 74.3029.52 | 110.948.99 | 111.310.73 | 46.731.93 | 74.4819.95 | 73.6113.26 | 35.2910.60 | 93.328.37 | 78.8313.01 | 77.65 |
Appendix D Additional Experiment Results
D.1 Discussion of Temporal Conditions Scenarios
The results of Temporal Conditions Scenarios are shown in the below part of Figure 2. (Refer to Section C.1 for environmental description.) We select the DD with prospective returns as a comparison. For the historical condition env (Figure 2 (d)), the generation process of DD needs the current state as the condition. When we give junction state as the condition, DD can not generate the corresponding sequences because it does not consider the temporal dependencies between history and immediate state. Our method (TCD) can produce the adequate trajectories that meet the historical sequence condition because of the guidance of . In the immediate condition env (Figure 2 (e)), we can see that TCD can distinguish different action reward trajectories under the same trajectory returns with immediate condition guidance. Thus it is obvious that TCD can generate the action with high rewards during evaluation. Although DD can also generate the sequence with high action reward, the single mode of generative samples reveals poor discernibility and hinders DD from applications such as diverse trajectories generation. Finally, in the prospective condition env (Figure 2 (f)), we can also see that the RTG with the remaining available time step can help the diffusion model recognize different trajectories. However, the DD can not recover all types of trajectories when the prospective returns are the same.
D.2 Additional Exploration about Temporal Conditions
RTG-TS. Compared with previous diffusion-based methods that estimate the action value function Q or state value function V, we can obtain the RTG instruction easily from the experiences rather than suffering from inaccurate estimation on OOD samples. Besides, RTG relates the remaining available time step with the historical best performance in one episode, which can not be reflected by the Q or V function. Statistically, we first calculate the episode returns from the replay buffer and then obtain the maximal return value and minimum return value . After that, the RTG information from state is normalized by . Finally, we use as the condition during training, i.e., when .
HC-RTG-TS. Based on the U-net backbone, we add the historical information by replacing the incipient generative state segments of sequences with at each generative step. Previous methods, like DD, generate state sequence conditioning only on current state , which may omit important information that appears in history, especially for environments with partial observability. Even for environments without partial observability, the historical conditions can be regarded as an argumentation method, and the experiments show they can still provide improvements. We also use RTG and remaining time steps as additional information during training. Then the historical condition is defined as .
FAR-RTG-TS. During the inference stage, though we will generate a state sequence under current state , only state is used to produce action , which inspires us to focus on the generative quality of the current action. Thus we adopt the first action reward that associates and to instruct generation, where is calculated from top- trajectories in the replay buffer. Mathematically, is used for training, and is used for evaluation, where and are normalized according to maximal and minimum single-step reward.
| Dataset | Med-Expert | Medium | Med-Replay | score | ||||||
| Env | HalfCheetah | Hopper | Walker2d | HalfCheetah | Hopper | Walker2d | HalfCheetah | Hopper | Walker2d | |
| DQD | 5.051.92 | 4.790.33 | 106.031.39 | 47.092.00 | 32.550.04 | 84.070.63 | 1.160.91 | 11.060.19 | 21.350.09 | 34.79 |
| TFD | 4.472.28 | 36.7829.13 | 17.315.17 | 31.238.36 | 101.420.85 | 71.362.85 | 14.685.06 | 86.372.01 | 26.6911.49 | 43.37 |
| RR-TCD | 78.3128.93 | 114.231.09 | 108.890.23 | 44.600.93 | 62.4613.15 | 83.601.44 | 40.551.75 | 97.591.27 | 88.052.24 | 79.81 |
| RTG-TS | 89.114.47 | 113.131.55 | 101.609.90 | 43.581.26 | 98.661.03 | 79.233.09 | 42.011.23 | 97.270.00 | 81.264.30 | 82.87 |
| SRD | 80.7925.59 | 111.400.62 | 107.720.72 | 44.810.77 | 100.580.02 | 82.292.11 | 39.951.33 | 97.141.52 | 85.762.74 | 83.38 |
| FAR-RTG-TS | 91.562.80 | 113.631.98 | 109.620.66 | 44.480.72 | 98.052.00 | 78.553.65 | 40.611.58 | 99.211.59 | 89.182.65 | 84.98 |
| RQR-TCD | 90.972.88 | 112.221.23 | 109.240.20 | 44.341.13 | 99.710.97 | 82.242.32 | 41.012.28 | 98.301.40 | 87.543.07 | 85.06 |
| HC-RTG-TS | 93.441.62 | 112.510.46 | 108.750.31 | 44.630.63 | 99.910.35 | 83.161.70 | 40.491.42 | 98.341.61 | 86.572.11 | 85.31 |
| TCD | 92.673.37 | 112.601.03 | 111.310.73 | 47.200.74 | 99.370.60 | 82.061.83 | 40.571.39 | 97.202.39 | 88.041.92 | 85.67 |
Diffuser with Transformer-Backbone (TFD). For the implicit line about historical condition, we try to replace the U-net backbone with the transformer backbone to focus on longer history information [60]. We call this method diffuser with transformer-backbone (TFD), which has lower memory consumption and shorter run time because it does not use the convolution operation.
Diffuser with State-Reward Sequence Modeling (SRD). For the implicitly immediate or prospective condition, we propose modeling the distribution of state sequences and the joint distribution of state sequences and the reward sequences. For the state of current time step, we use SRD to generate several candidate sequences and select the sequence with max reward (implicitly immediate condition) or max returns (implicitly prospective condition).
Diffuser with Distributional Q Estimation (DQD). We also conduct other explorations about explicitly-temporal conditions. In order to obtain better approximation by preserving the multimodality of action value function, we explore fitting the Q function on offline datasets with distributional RL techniques [6]. Specifically, we separate the discounted returns into 201 bins and use two networks to predict the bin values and the bin distribution, respectively. Then the expected bin values weighted by the probabilities of bin selection are adopted as prospective returns to guide the diffusion model.
TCD with Reward Estimation (RR-TCD and RQR-TCD). Directly utilizing statistical rewards from the replay buffer can not reflect the reward situation of all collected states. Thus we hope to improve the prediction accuracy by introducing reward estimation. In practice, directly estimating reward values conditioning on states requires learning a mapping from states to rewards, which we call that TCD with linear reward regression (RR-TCD). Another method, TCD with reward quantile regression (RQR-TCD), gives us a chance to roughly identify the radical and conservative actions through the reward distribution on each state.
In Appendix E, we review previous studies and discuss the advantages and disadvantages of the above methods, TCD, and other baselines.
| Dataset | Med-Expert | Medium | Med-Replay | score | ||||||
| Env | HalfCheetah | Hopper | Walker2d | HalfCheetah | Hopper | Walker2d | HalfCheetah | Hopper | Walker2d | |
| DQD | 4.432.49 | 4.790.33 | 106.031.39 | 39.2815.12 | 14.448.13 | 46.6818.69 | 2.222.45 | 11.060.19 | 11.516.50 | 26.77 |
| TFD | 4.472.28 | 36.7829.13 | 17.315.17 | 23.279.48 | 94.4712.93 | 51.5527.52 | 8.386.24 | 53.4330.23 | 26.6911.49 | 35.62 |
| RTG-TS | 42.6824.25 | 92.9820.20 | 79.223.08 | 41.815.58 | 71.2418.78 | 79.223.08 | 32.7610.07 | 91.018.92 | 77.9710.03 | 66.45 |
| RR-TCD | 56.3525.84 | 95.3325.74 | 108.890.23 | 44.600.93 | 62.4613.15 | 79.749.77 | 38.386.52 | 83.3617.77 | 66.9625.99 | 70.73 |
| RQR-TCD | 45.8824.32 | 108.8712.84 | 109.240.20 | 44.341.13 | 62.9316.79 | 75.1514.39 | 35.7310.20 | 92.8411.92 | 70.3525.78 | 71.70 |
| FAR-RTG-TS | 41.8129.01 | 109.7910.28 | 108.260.46 | 43.615.46 | 62.3118.39 | 68.0820.13 | 38.974.89 | 92.699.54 | 71.4919.91 | 72.33 |
| SRD | 66.8531.52 | 111.400.62 | 107.720.72 | 43.964.64 | 79.1718.36 | 71.5016.40 | 32.3810.09 | 92.3310.20 | 68.6117.20 | 74.88 |
| HC-RTG-TS | 76.9225.81 | 111.155.08 | 108.750.31 | 44.630.63 | 71.4816.27 | 77.927.96 | 34.248.85 | 94.156.49 | 75.3314.99 | 77.17 |
| TCD | 74.3029.52 | 110.948.99 | 111.310.73 | 46.731.93 | 74.4819.95 | 73.6113.26 | 35.2910.60 | 93.328.37 | 78.8313.01 | 77.65 |
D.3 Additional Evaluation on Various Scenarios
In this section, we report the additional evaluation on many environments, such as Pen-{h, e, c}-v1, Relocate-{h, e, c}-v1, HalfCheetah-{r, e, fr}-v2, Hopper-{r, e, fr}-v2, and Walker2d-{r, e, fr}-v2. From the results that are shown in Table 4 and Table 5, we can see that our method (TCD) achieves a 20% overall performance gain compared with DD and reaches the best mean performance in Pen and Relocate environments. In the HalfCheetah-{r, e, fr}-v2, Hopper-{r, e, fr}-v2, and Walker2d-{r, e, fr}-v2 environments, the performance of our method surpasses DD in 5 of 6 datasets with countable modality (i.e., expert and full-replay) and 6 of 9 on all datasets. The reason for poor performance in {HalfCheetah, Hopper, Walker2d} random datasets is that samples with random interaction do not possess primary modality on data distribution, thus leading to random update direction when we use the diffusion model to capture the data distribution. Finally, the diffusion model can not learn to generate good behaviors that align with certain behavior policies according to experiences.
Besides, we also realize several algorithms, such as DQD, TFD, RR-TCD, RQR-TCD, and SRD, by considering other types of temporal conditions, and the corresponding results on classical Gym-MuJoCo datasets are shown in Figure 6 and Figure 7. Although distributional Q estimation can alleviate the influence of OOD actions, the results show that directly adopting the distributional Q value as the instruction on conditional diffusion models may hurt the performance, which stimulates us to find a better way to combine the distributional techniques and diffusion models. We can lightweight the memory overhead and reduce the time consumption of training diffusion models with transformer backbone, but we should realize that the position embedding and diffusion process will introduce two different time encoding vectors, which may conflict with each other and impact the model learning. As shown in Table 7 and Table 8, TFD (diffuser with transformer backbone) performs poorly in most tasks, where the only difference is the Hopper-m task. The reason is that the time encoding vectors may associate with the data distribution and exactly make a positive effect on the Hopper-m task. Considering the methods, RR-TCD, RQR-TCD, and SRD, that estimate the action rewards, we find that modeling the distribution of reward sequence (SRD) is better than learning a mapping from state space to reward space (RR-TCD). Reward quantile regression (RQR-TCD) performs better than RR-TCD and SRD because quantile regression is insensitive to certain extreme reward values that refer to radical actions and conservative actions. Thus, more likely, we can recover the behavior policies and reach better performance conditioning on the median reward values.
| Dataset | Med-Expert | Medium | Med-Replay | score | ||||||
| Env | HalfCheetah | Hopper | Walker2d | HalfCheetah | Hopper | Walker2d | HalfCheetah | Hopper | Walker2d | |
| TCD (5) | 92.673.37 | 112.601.03 | 111.310.73 | 47.200.74 | 99.370.60 | 82.061.83 | 40.571.39 | 97.202.39 | 88.041.92 | 85.67 |
| TCD (10) | 85.7413.68 | 110.710.50 | 109.060.59 | 44.500.92 | 99.601.03 | 82.531.32 | 39.241.57 | 97.171.56 | 85.065.10 | 83.73 |
D.4 Additional Experiment Results about Parameter Sensitivity
We report the additional experiments of parameter sensitivity from two dimensions, i.e., top- and max return offset, in Figure 8, where the results show that our method performs better than DD in most settings of hyperparameters. Besides, we also conduct experiments of parameter sensitivity on performance extrapolation and historical sequence length.
Performance Extrapolation with Max Return Offset. During the evaluation stage, we add max return offset to the initial RTG, where the bigger values of max return offset denote more optimism about future returns, and smaller values of max return offset indicate more pessimism about available returns. When the condition aligns well with the training data, we can appropriately increase the condition, thereby encouraging the model to discover better decision sequences from historical experiences. In several scenarios, We see the corresponding extrapolated phenomena that are shown in Figure 9. The results show that we can obtain higher performance by slightly increasing the initial RTG, which inspires us to investigate adaptive methods for selecting the max return offset.
Historical Sequence Length . We first probe the impacts of historical sequence length , which represents how long the previous sequence is considered for generation when we adopt the U-net backbone. The results are shown in Table 9, where we can see that a relatively longer length of historical sequence can provide further improvements in Hopper-m and Walker2d-m. While mother scenarios, the longer historical sequence () provides negative improvements because the historical sequence may introduce useful information and extra noise concurrently, where the useless noise makes it hard for learning control.
Appendix E More Discussion about Temporal Conditions
Prospectively-Conditional Sequence Generation. For each sequence to be waiting for generation, the prospective condition information can be provided as guidance, such as expected discounted return of state value or state-action value, RTG, and target goal state. For example, Diffuser [27] trains a Q value function separately and adds the gradient with respect to state action pairs to guide the generation, where the stochastic sampling process is . is the gradient scale and . Limited by the restricted experiences and overestimation problem, direct Q value estimation can not provide a better approximation, while distributional RL technologies may be useful to capture the multimodal Q distribution, which leads to more stable learning [6, 59].
The RTG, as another prospective condition form, indicates the future desired returns when preestablishing the initial returns, which is different from the Q value function because we obtain the Q value function through temporal difference (TD) learning while the initial returns are defined according to prior knowledge of environments. In addition to the prospective conditions, goal state (GS) or goal feature (GF) can also be used to guide generation. Similar to the processing way in Diffuser, where they apply condition by replacing the denoised sequence with , we can also substitute the final generative state with goal state , i.e., . Further to say, the goal state can also be embedded in latent space, so we can use as a general function that represents feature mapping or identity function, i.e., and .
Most previous studies adopt prospective conditions, and the general objective function is defined as
where and is a sequence processing function, which can represent state sequence, state-action sequence, state-reward sequence, or the state-action-reward sequence.
Historically-Conditional Sequence Generation. When we regard the decision-making problem as a sequence modeling problem, generating sequences based on is similar to long-term series forecasting, which motivates us to add historical information into sequence generation or preprocess the sequence data, such as extracting trend variables and seasonal variables firstly [67, 64]. Classical diffusion model structure utilizes the U-net backbone and one-dimensional convolution to process sequence data, so the most straightforward method to consider historical information is conditioning on preceding experiences. From another view, the U-net backbone disregards the temporal information between consecutive transitions in a sequence, treating them as a single entity. In this context, if the sequence is considered as an image, the generation process with the U-net backbone can be likened to image inpainting.
In addition to the aforementioned methods that explicitly consider historical sequences, we can also implicitly take into account historical information. Transformers employ a novel self-attention mechanism that captures long-range dependencies and global context more effectively, leading to the widespread adoption in machine translation, sentiment analysis, question-answering, and more [61, 13, 42, 41]. Inspired by this, we can utilize the transformer backbone to preserve longer history information rather than the U-net backbone [4, 51]. When utilizing a Transformer backbone, we observe that the model is comparatively more lightweight than a U-net backbone, with reduced training time and memory overhead. However, it is worth noting that since the Transformer requires positional encoding for sequences, and the training process of the diffusion model necessitates the inclusion of diffusion time step information, there may be interference between these two temporal aspects.
Immediately-Conditional Sequence Generation. Though we can use the diffusion model to plan a long-term sequence, only the first two states and are adopted to produce actions with inverse dynamics . Consequently, the direct influencing factor in obtaining rewards from the environment is the quality of the generated states . This enlightens us that we should pay more attention to the current generative state .
Immediate conditions are further categorized into two distinct types: those based on post-hoc filtering and those based on prior guidance. For the post-hoc filtering method, we can use state-reward sequences and filtrate high-quality sequences on the basis of multi-candidate sequences, while most previous works choose state sequences or state-action sequences for training. Prior guidance methods require reward sequence as guidance so as to instruct the generation process, i.e., reward sequence statistic from replay buffer is the most straightforward idea. Alternatively, reward regression (linear regression and quantile regression) is another choice. Although reward regression methods can offer a degree of extrapolation capabilities, they may also be prone to overfitting, resulting in large estimation biases for OOD actions [21, 70]. On the other hand, statistical reward methods directly utilize historical experience for guidance, which may, to some extent, constrain the model’s performance [7, 11].
Appendix F More Discussion about Limitations and Future Work
In terms of limitations, the mechanism of generation process makes it slower than other models, such as Transformer-based models and MLP-based models, even though we can use recent breakthroughs [40] to accelerate this process. More recent studies have brought hope for efficient generation. Thus we may be able to improve the efficiency based on the current models [56]. Another limitation is the restricted application on static datasets such as offline RL tasks because, in these static datasets, the joint distribution of samples is fixed. While in online learning, the update of behavior policies influences the data distribution collected from the environment.