Integrating Multiple Sources Knowledge for Class Asymmetry Domain Adaptation Segmentation of Remote Sensing Images
Abstract
In the existing unsupervised domain adaptation (UDA) methods for remote sensing images (RSIs) semantic segmentation, class symmetry is an widely followed ideal assumption, where the source and target RSIs have exactly the same class space. In practice, however, it is often very difficult to find a source RSI with exactly the same classes as the target RSI. More commonly, there are multiple source RSIs available. And there is always an intersection or inclusion relationship between the class spaces of each source-target pair, which can be referred to as class asymmetry. Obviously, implementing the domain adaptation learning of target RSIs by utilizing multiple sources with asymmetric classes can better meet the practical requirements and has more application value. To this end, a novel class asymmetry RSIs domain adaptation method with multiple sources is proposed in this paper, which consists of four key components. Firstly, a multi-branch segmentation network is built to learn an expert for each source RSI. Secondly, a novel collaborative learning method with the cross-domain mixing strategy is proposed, to supplement the class information for each source while achieving the domain adaptation of each source-target pair. Thirdly, a pseudo-label generation strategy is proposed to effectively combine strengths of different experts, which can be flexibly applied to two cases where the source class union is equal to or includes the target class set. Fourthly, a multiview-enhanced knowledge integration module is developed for the high-level knowledge routing and transfer from multiple domains to target predictions. The experimental results of six different class settings on airborne and spaceborne RSIs show that, the proposed method can effectively perform the multi-source domain adaptation in the case of class asymmetry, and the obtained segmentation performance of target RSIs is significantly better than the existing relevant methods.
Index Terms:
Unsupervised domain adaptation, remote sensing images, semantic segmentation, class asymmetry, multiple sourcesI Introduction
Recently, the unsupervised domain adaptation (UDA) semantic segmentation of remote sensing images (RSIs) has attracted more and more attention [1, 2, 3]. Aiming to the knowledge transfer across RSIs domains, the UDA technologies can effectively improve the segmentation accuracy of unlabeled target RSIs, and greatly reduces the tedious workload of labeling RSIs. Benefiting from the development of deep learning, various UDA methods have been proposed, constantly improving the performance of RSIs domain adaptation [4, 5]. The existing methods can be roughly divided into three categories: RSIs style transfer, adversarial learning and self-supervised learning. The style transfer methods take the lead in exploring RSIs domain adaptation, which mainly align source and target RSIs in the input space [6]. Subsequently, with the continuous improvement of generative adversarial networks (GANs), it has become a popular solution to extract the domain-invariant features using adversarial learning [7]. More recently, the self-supervised learning methods have been gradually applied with the stable and efficient training process and superior performance, further improving the segmentation accuracy of target RSIs [8].
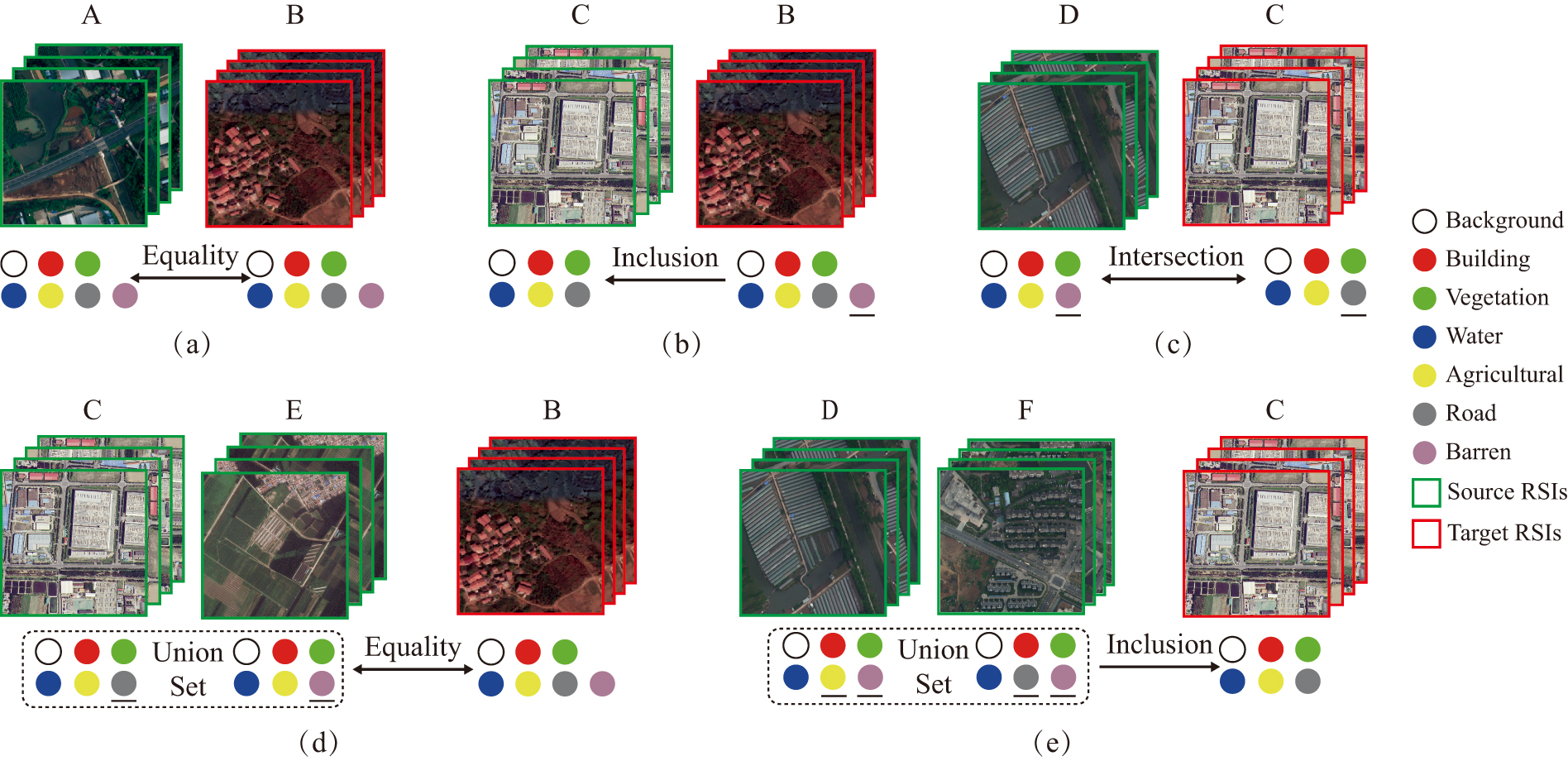
Although there have been extensive researches on UDA semantic segmentation of RSIs, the existing methods generally follow an ideal assumption that labeled source domains and unlabeled target domains have exactly the same classes [9], which can be referred to as class symmetry. As shown in Fig. 1 (a), the source class set is equal to the target class set. However, in practical application, it is often difficult and time-consuming to find a source RSI whose class set is completely consistent with that of target RSI. More commonly, the class set of available source RSIs is different from that of target RSIs, and the two have inclusion or intersection relationship. Fig. 1 (b) shows the case where the target class set includes the source class set, and the latter is actually a subset of the former. Fig. 1 (c) illustrates the intersection relationship between the source class set and target class set, where each domain has a unique class that the other does not. The above two relationships can be collectively referred to as class asymmetry, which is characterized by the fact that the target RSIs contain classes that do not appear in the source RSIs. Considering the practical application situations of RSIs domain adaptation, the class asymmetry cases are obviously more common, but also more challenging. However, the existing UDA methods following the class symmetry assumption cannot deal with the class asymmetry cases because of the inconsistency between source and target class sets.
No matter in the inclusion relationship of Fig. 1 (b) or the intersection relationship of Fig. 1 (c), the knowledge learned from source RSIs could not be well adapted and generalized to target RSIs because of the class asymmetry problem. Indeed, the necessary condition for implementing RSIs domain adaptation is that the source class set includes the target class set. In other words, any target class can be found in source domains, to ensure that the knowledge required by target RSIs can be learned from source RSIs. Therefore, a natural idea for the class asymmetry domain adaptation is to collect more source RSIs, thus ensuring that the class union of multiple source domains is exactly equal to the target class set, or, under a laxer condition, includes the target class set. Fig. 1 (d) illustrates an example of the former, in which each source class set is a subset of the target class set, and the source class union has an equality relationship with the target class set. Fig. 1 (e) illustrates an example of the latter, in which each source class set intersects the target class set, and the source class union includes the target class set. In both cases, the class spaces of different source RSIs are also different, which is close to the practical scenarios. Undeniably, the introduction of more sources can provide the necessary information for multi-source RSIs domain adaptation in the case of class asymmetry. However, in this novel and challenging experimental setup, there are still two key challenges that need to be addressed.
Challenge 1: In addition to distribution discrepancy, the class space between each source-target pair is also different, creating greater difficulties for knowledge transfer. Under this more complex condition, how to achieve the adaptation and alignment between each single source RSI and the target RSI is the first key challenge.
Challenge 2: There are distribution and class discrepancies among different source RSIs simultaneously. Therefore, how to integrate the strengths and characteristics of multiple sources, complement each other, and efficiently transfer knowledge to target RSIs is the second key challenge.
Obviously, existing UDA methods of RSIs are struggling to address the above challenges, since they require a completely symmetric class relationship between source and target RSIs. To this end, a novel Class Asymmetry Domain Adaptation method with Multiple Sources (MS-CADA) is proposed in this paper, which can not only integrate the diverse knowledge from multiple source RSIs to achieve better domain adaptation performance, but also greatly relax the strict restrictions of existing UDA methods. For challenge 1, the proposed method utilizes a novel cross-domain mixing strategy to supplement class information for each source branch, and adapts each source domain to the target domain through collaborative learning between different sources RSIs. For challenge 2, on the one hand, a multi-source pseudo-label generation strategy is proposed to provide self-supervised information for domain adaptation; on the other hand, a multiview-enhanced knowledge integration module based on the hypergraph convolutional network (HGCN) is developed for high-level relation learning between different domains, to fully fuse the different source and target knowledge and achieve better multi-source domain adaptation performance. To sum up, the main contributions include the following four points.
-
1)
A novel multi-source UDA method is proposed, which can effectively improve the performance of RSIs domain adaptation in the case of class asymmetry. To our knowledge, this is the first exploration of class asymmetry domain adaptation segmentation of RSIs.
-
2)
A collaborative learning method based on the cross-domain mixing strategy is proposed, to achieve the domain adaptation between each source-target pair through supplementing class information for each source branch.
-
3)
A pseudo-label generation strategy is proposed to deal with two different scenarios where the source class union is equal to or includes the target class set. A multiview-enhanced knowledge integration module is developed for efficient multi-domain knowledge routing and transfer by fully fusing the advantages of different branches.
-
4)
Extensive experiments are conducted on airborne and spaceborne RSIs, and the results of three different scenarios, including two-source union equality, three-source union equality and two-source union inclusion, show that the proposed method can effectively perform the class asymmetry domain adaptation of RSIs with multiple sources, and significantly improves the segmentation accuracy of target RSIs.
II Related Work
II-A RSIs domain adaptation segmentation
Accurately labeling RSIs is a very complicated and time-consuming work [10, 11, 12]. To improve the generalization ability of deep segmentation models, more and more attention has been paid to the researches of RSIs domain adaptation. From an intuitive visual perspective, the differences between RSIs mainly exist in color and other style attributes. Therefore, the initial exploration mainly focuses on RSIs translation, aiming to reduce the discrepancies between the source and target domains by unifying the styles of different RSIs. Tasar et al. present a color mapping GAN, which can generate fake images that are semantically exactly the same as real training RSIs [13]. Sokolov et al. focus on the semantic consistency and per-pixel quality [14], while Zhao et al. introduce the depth information to improve the quality of synthetic RSIs [15]. Only the implementation of style transfer in the input space often produces unstable domain adaptation performance. Therefore, obtaining the domain-invariant deep features through adversarial learning has gradually become the mainstream in RSIs domain adaptation segmentation. Cai et al. develop a novel multitask network based on the GAN structure, which possesses the better segmentation ability for low-resolution RSIs and small objects [16]. Zhu et al. embed an invariant feature memory module into the conventional adversarial learning framework, which can effectively store and memorize the domain-level context information in the training sample flow [17]. Zheng et al. improve the high-resolution network (HRNet) according to the RSIs characteristics, making it more suitable for RSIs domain adaptation. In addition, the attention mechanism [18, 19], contrastive learning [20], graph network [21] and consistency and diversity metric [22] are also integrated into the adversarial learning framework, further improving the segmentation accuracy of target RSIs. Recently, the self-supervised learning based on the mean teacher framework [23] has been gradually applied in RSIs domain adaptation due to its excellent knowledge transfer effect and stable training process. Yan et al. design a cross teacher-student network, and improve the domain adaptation performance on target RSIs through the cross consistency constraint loss [24]. Wang et al. focus on the problem of spatial resolution inconsistency in self-supervised adaptation, effectively improving the effect of knowledge transfer from airborne to spaceborne RSIs [25]. In addition, combining the above different types of methods is a common idea to further improve the performance of RSIs domain adaptation [26].
Although various UDA methods for RSI semantic segmentation have sprung up, they all follow a common ideal assumption of class symmetry. Under the condition that the source and the target class set are different, the existing methods often fail to achieve the satisfactory performance.
II-B RSIs multi-source domain adaptation
The effective utilization of multiple RSIs sources can provide more abundant and diverse knowledge for improving RSIs domain adaptation performance. However, most of the existing UDA methods of RSIs focus on the knowledge transfer from a single source to a single target domain, and there are relatively few researches tailored for multi-source RSIs domain adaptation. The existing methods can be divided into two categories: constructing a combined source and aligning each source-target pair separately. The former usually combines several different RSIs into a single source domain and performs cross-domain knowledge transfer according to the conventional UDA mode [27, 28, 29, 30]. The obvious shortcoming is that the RSIs sources with different distribution in the combined domain will interfere with each other during domain adaptation process, thus weakening the effect of knowledge transfer [31, 32]. In contrast, the latter typically aligns each source and target RSI separately, and merges the results from different sources as the final prediction of target RSIs [33, 34, 35]. The multiple feature spaces adaptation network proposed by Wang et al. is the closest to our work, which explores the performance of multi-source UDA in crop mapping by separately aligning each source-target RSI pair [35]. However, all the above work, including literature [35], require that each source and target RSI share exactly the same class space. Obviously, meeting this requirement is even more laborious and cumbersome than the conventional UDA methods in Section II-A.
Our work focuses on the problem of RSIs class asymmetry domain adaptation. Compared with existing multi-source UDA method, the proposed method can deal with the scenario closer to practical situation, that is, performing knowledge transfer using multiple RSIs sources with different class spaces.
II-C Incomplete and partial domain adaptation
In the field of computer vision, there are two research directions related to our work, namely incomplete domain adaptation (IDA) and partial domain adaptation (PDA). The problem setting of IDA is to utilize multiple sources with incomplete class for domain adaptation, and the existing few researches mainly focus on the image classification task [36, 37]. Lu et al. and Gong et al. introduce IDA into the remote sensing field and preliminarily explore the performance of RSIs cross-domain scene classification [38, 39], and Ngo et al. further deepen the research on this issue [40]. In addition, Li et al. propose to conduct the class-incomplete model adaptation without accessing source information, and design a deep model for street scene semantic segmentation [41]. However, the performance of this method on target domain is dissatisfactory, since it abandons the source knowledge in the domain adaptation process. Different from the IDA setting, PDA is a single-source to single-target domain adaptation task. However, in the PDA setting, the number of source classes is required to be greater than the number of target classes. In the field of computer vision, various PDA methods have been developed for the image classification task [42, 43, 44]. Meanwhile, the performance of PDA methods on RSIs scene classification has begun to be studied, and the typical methods include the weight aware domain adversarial network proposed by Zheng et al. [45].
The differences between the existing IDA and PDA methods and our work can be summarized into the two aspects. First, most of the existing methods are designed for the classification task of natural images, and the performance of these methods directly applied to the RSIs domain adaptation segmentation is greatly degraded. Secondly, our work focuses on the class asymmetry domain adaptation of RSIs with multiple sources, and can simultaneously cover the two scenarios where the source class union is equal to or includes the target class set. On the one hand, our work can directly perform RSIs domain adaptation with multiple class-incomplete sources; On the other hand, compared to the single-source PDA tasks, our work is more consistent with the practical situations where multiple sources with different class sets are available.
III Methodology
III-A Problem setting
Formally, the problem setting of class asymmetry RSIs domain adaptation with multiple sources is first presented. There are labeled source domains with class sets and one unlabeled target domain with the class set . The distribution and class space of each domain are known and distinct from each other, i.e., , and . In addition, the source class union is equal to or contains the target class set, i.e., , and each source class set has an intersection with the target class set, i.e., . Given source labelled samples and target unlabelled samples , the class asymmetry domain adaptation aims to achieve knowledge transfer from multiple sources to target RSIs.
III-B Workflow
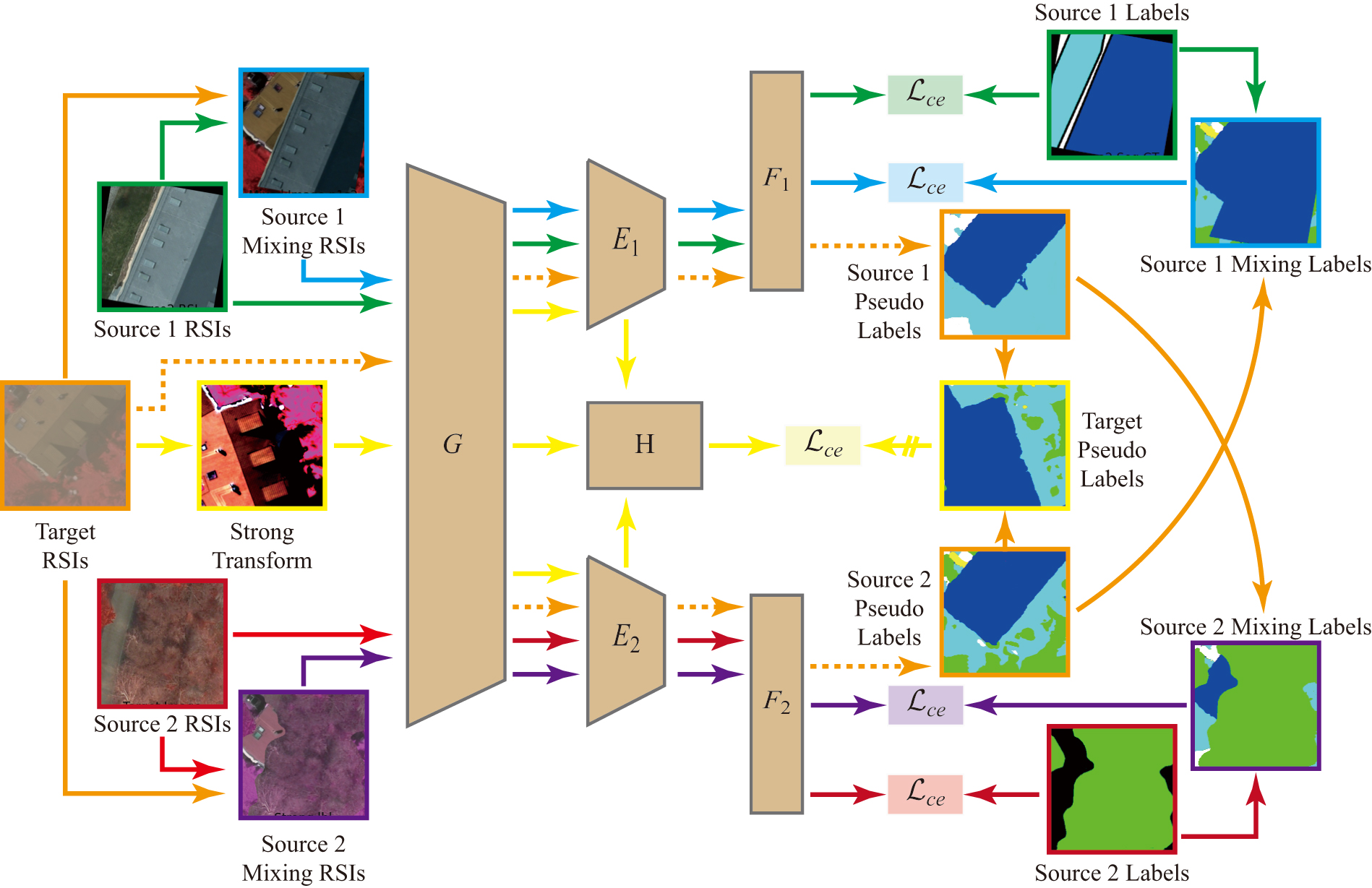
This paper proposes to integrate multiple sources knowledge for RSIs domain adaptation segmentation in the case of class asymmetry. To clearly articulate the proposed MS-CADA method, the two-source scenario is used as an example to describe its workflow, as shown in Fig. 2. The whole deep model consists of a feature extraction network and a multi-branch segmentation head. The former is shared by multiple domains for common feature extraction existing in different RSIs, while the latter includes two expert networks and , two classifiers and , and a knowledge integration module . The expert networks are used to learn the source-specific deep features, and the module is responsible for integrating knowledge from different domains and inferring target RSIs. Overall, the proposed method follows the self-supervised adaptation mode, thus in each iteration, the teacher model is established based on the exponential moving average (EMA) algorithm. Specifically in each iteration, the proposed method performs three different learning tasks simultaneously, including supervised learning, collaborative learning, multi-domain knowledge transfer.
Firstly, the source RSIs and their corresponding true labels are used for model supervised training. Due to the discrepancies in class space and data distribution, different RSIs are respectively fed into the corresponding expert networks and classifiers for loss calculation after passing through the shared . This step provides the basic supervision information for model optimization. Secondly, to supplement the class information that each source branch does not have, the mixing of true labels and target pseudo-labels is performed between each source pair. Correspondingly, the source and target RSIs are also mixed, and collaborative learning on multiple source branches is carried out according to the mixing results. This step builds on the problem setting in Section III-A, where each source most likely contains class information that the other does not. Thirdly, the predictions from different source branches in the teacher model are used to generate the final target pseudo-labels. In the student model, the module fuses the deep features from different branches and performs multi-domain knowledge transfer based on the final target pseudo-labels. In the following sections, the above learning process will be described in detail.
III-C Multi-source supervised learning
Acquiring rich and robust source knowledge is a prerequisite for realizing class asymmetry multi-source domain adaptation. Related researches have shown that simply combining different RSIs into one single source will lead to suboptimal domain adaptation effect due to the domain discrepancies [38, 39, 40]. Therefore, in each iteration, the RSIs from different sources will be fed into the corresponding expert branches, and supervised training will be conducted on the basis of learning common and source-specific features, which can be expressed as:
| (1) |
where and index different source domains and RSIs samples respectively in a training batch. Utilizing different expert branches for supervised learning can effectively avoid the interference of domain discrepancies on model training, so as to provide support for the multi-source collaborative learning and knowledge integration in the next steps.
III-D Collaborative learning with cross-domain mixing
Different source RSIs have different class sets. Therefore, the multi-source supervised learning can only enable each expert branch to learn the knowledge within its corresponding class space. In this case, the domain adaptation cannot be achieved due to the class asymmetry problem between each source-target pair. To this end, a novel cross-domain mixing strategy is proposed to supplement each expert branch with the class information that it does not possess.
Specifically, the information supplementation from source 2 to source 1 is used as an example for detailed explanation. As shown in Fig. 2, the class set of source 1 contains only Building, Low vegetation, and Impervious surface, thus during the initial phase of model training, the source 1 branch can only accurately recognize the three classes in target RSIs. In contrast, the class set of source 2 contains the Tree class that source 1 does not have, and thus the target segmentation results of the source 2 branch will contain high-quality pseudo-labels of the Tree class. Based on these observations, the proposed mixing strategy pastes part of the true label of source 1 onto the target pseudo-label generated by the source 2 branch, and the source 1 RSIs and the target RSIs are also mixed according to the same mask, which actually introduces the unseen class information into the source 1 branch. Obviously, the mixing techniques play a key role in the proposed strategy. In our work, the coarse region-level mixing [46] and fine class-level mixing [47] are adopted simultaneously. Both the two techniques belong to the local replacement approaches, so they can be uniformly formalized as:
| (2) |
where denotes the target pseudo-labels of the source 2 branch of the EMA teacher model, the symbol represents the element-wise multiplication, and M is a binary mask determining which region of pixels is cut and pasted. When the class-level mixing is performed, the mask is generated by randomly selecting partial classes in the true source labels, which delivers the inherent properties of a certain class of objects completely. When the region-level mixing is performed, the mask is obtained by randomly cutting a region patch from the true source labels, which can retain the local structure and context information. Therefore, the application of the two mixing techniques can combine different advantages at the fine class and coarse region levels, effectively improving the performance of the information supplement between different sources. In addition, the diversity of mixed samples is further enhanced, which can help to improve the robustness of the trained model.
After the mixed sample-label pairs are obtained, the source 1 branch will carry out the weighted self-supervised learning. Specifically, the confidence-based weight map is first generated as follows:
| (3) |
where and denote the height and width of RSIs samples, the operation is the Iverson bracket, and represents the pixel percentage in which the maximum softmax probability of prediction class exceeds the threshold . Then, the self-supervised loss of source 1 branch can be calculated as:
| (4) |
which actually achieves the domain adaptation from source 1 to the target domain, since the input sample contains partial target RSIs.
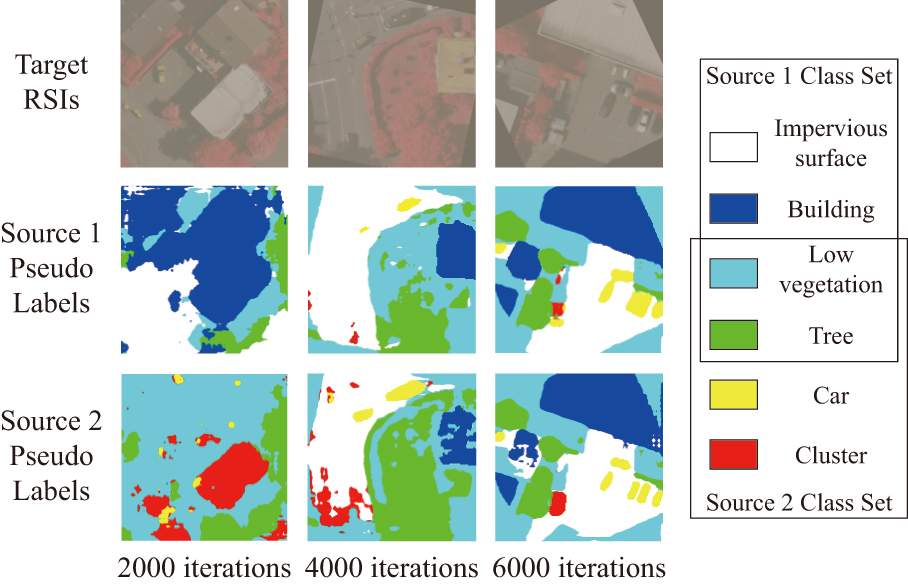
At this point, the process of class information supplementation from source 2 to source 1 has been completed. Conversely, the information supplementation from source 1 to source 2 is similar to the above process. To intuitively observe the effectiveness of the proposed cross-domain mixing strategy, the target pseudo-labels generated by different source experts are visualized, as shown in Fig. 3. Obviously, at the initial training stage, each source expert can only segment the target RSIs within its own class space. For example, in the first column of Fig. 3, the source 1 expert could not accurately identify the Car class, while the source 2 expert wrongly classifies the objects of impervious surface and building into the Cluster and Low vegetation classes. With the continuous training, however, the class information among multiple source domains is supplemented with each other, and all the expert branches can identify all source classes more accurately.
When more source RSIs are adopted, the Equation 2 will be extended to more forms including multiple mixed results of pairwise source combinations. Summarily, in the proposed mixing strategy, each source can provide additional class information for other sources, which is actually the collaborative learning process between different experts. As a result, each expert can learn all the class knowledge contained in the source union, thus effectively solving the class asymmetry problem during the domain adaptation process of each source-target pair.
III-E Knowledge integration for multi-domain transfer
As stated in challenge 2, discrepancies between source RSIs domains can give different expert branches the strengthes of focusing on different feature knowledge. After each source domain is adapted to the target domain separately, the advantages of different source experts should be combined to further improve the performance of multi-domain transfer. Therefore, a multi-source pseudo-label generation strategy is proposed, which can deal with both cases where the source class union is equal to or includes the target class set. And a multiview-enhanced knowledge integration module is developed for target inference through learning the high-level relations between different domains.
III-E1 Multi-source pseudo-label generation
As shown in Fig. 2, in each iteration, the target RSIs will be fed into different expert branches of the EMA teacher model, which will output different predictions according to their respective ability of learning features. Therefore, the final target pseudo-labels can be obtained:
| (5) |
where the operation selects the class corresponding to the maximum softmax probability of the results of the two source branches. And denotes the class filter operation, which is determined according to the relationship between the prediction class and target class set:
| (6) |
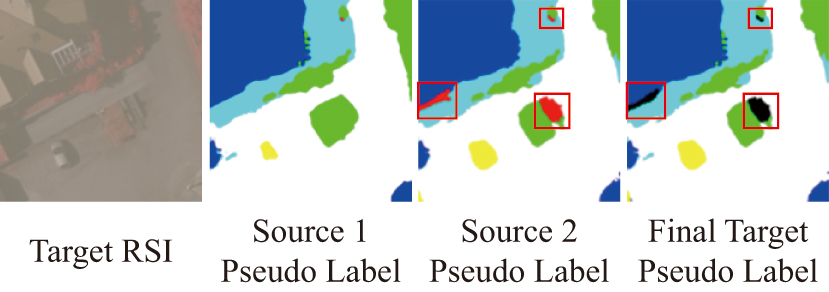
In short, the proposed multi-source pseudo-label generation strategy has two effects. (1) Equation 5 can flexibly select the predictions of expert who is better at a certain class by comparing the confidence probabilities, which actually combines the advantages of different source branches. (2) When the source class union contains the outlier classes that do not exist in the target RSIs, Equation 6 discards these classes by assigning them the value of 255 (pixels with the value of 255 are not used for loss calculation). Actually, considering that the target RSIs do not contain the objects belonging to the outlier class, there will be a few target pixels classified into this class, which are often located in the boundary region between objects in target RSIs. Therefore, the removal of these pixels from the final predictions can play a positive role in selectively preserving the high-quality pseudo-labels. Fig. 4 shows an example to visually explain the proposed strategy.
III-E2 Multiview-enhanced high-level relation learning
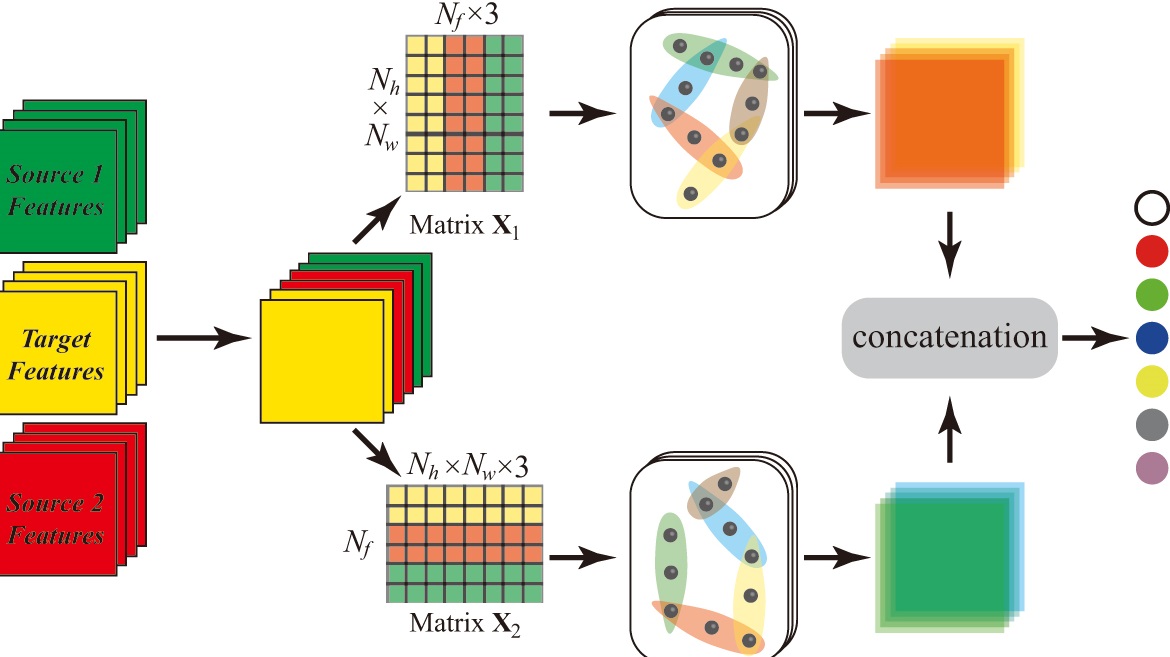
As shown in Fig. 2, for the input target RSIs after strong transformation, the features with source 1 bias learned by , features with source 2 bias learned by and features learned by are fed into the module simultaneously, to realize the multi-domain knowledge transfer. Theoretically, any network structure can act as the role of . Inspired by the recent development of HGCN in the computer vision field [48, 49, 50], a multiview-enhanced knowledge integration module based on HGCN is developed, as shown in Fig. 5. In the hypergraph structure where is the vertice set and is the hyperedge set, a hyperedge can connect arbitrary number of vertices simultaneously. Therefore, superior to the abstraction of GCN on the pairwise connections or the modeling of CNN on the local features, the HCGN can better describe the high-level relations [51, 52], which provides an effective solution for expressing the knowledge routing from different domains to the target predictions.
Firstly, the features learned by are compressed by a network with the same structure as and , to ensure that the features from different branches have the same dimension . Then, the features of different branches are directly concatenated in the channel dimension. Next, the high-level relation learning based on HGCN is carried out from two different views of space and feature. The former refers to reshaping the obtained feature map into the matrix , where corresponds to the number of pixels in the spatial dimension, and represents the richness of feature channels. Consequently, the constructed hypergraph contains vertices, each of which has the feature vector of dimension. In this case, the hyperedges mainly describe the global contextual relation in the spatial dimension of feature maps. And so on, based the matrix of , the latter will produce a hypergraph with nodes, each of which possessing the feature vectors. The hyperedges model the high-level relation between different feature channels. Finally, the outputs of hypergraphs with different views are concatenated and the target predictions are generated through a linear classification layer. Obviously, implementing the high-level relation learning from the views of space and feature can more fully model the knowledge routing relation between different branches and target predictions, and effectively improve the effect of multi-source domain adaptation in the case of class asymmetry.
Next, the formal description of the above learning process and loss calculation is given. For each vertex in the matrix or , the nearest neighbor vertices are selected to build the hyperedge , which can be denoted as:
| (7) |
where is actually the neighbor set containing vertices. Specifically, the k-neighbor algorithm based on the Euclidean distance is used for generating the set . After all possible hyperedges are built, the incidence matrix can be obtained:
| (8) |
where each entry describes the connection between vertices and hyperedges, and thus the matrix can represent the whole topological structure of hypergraph. Then, the hypergraph convolution operation is performed on the matrices and :
| (9) |
where is the output results of hypergraph convolution, is the ReLU activation function, is the hyperedge weight matrix, and is the trainable parameter matrix. In addition, and denote the diagonal matrices of the vertex degrees and the edge degrees respectively, with each vertex degree calculated as and each edge degree calculated as .
After the high-level learning by hypergraph convolution, the outputs of different hypergraph branches are reshaped into the feature maps with the spatial size of , and the channel concatenation and classification operations are performed to produce the prediction results of target RSIs. Therefore, the self-supervised loss for multi-domain knowledge transfer can be calculated as:
| (10) |
where the operation represents the same spatial transformation as in the strong transformation of input target RSIs.
III-F Optimization objective
By combining the losses of multi-source supervised learning, collaborative learning and multi-domain knowledge transfer, the final optimization objective can be obtained:
| (11) |
where and both contains the sum of the losses of different source branches, and and denote the weight coefficients. In addition, Algorithm 1 summarizes the pseudo code of the proposed MS-CADA method, to clearly show the entire workflow of class asymmetry RSIs domain adaptation in the two-source scenario.
IV Experimental Results
IV-A Datasets description and experimental setup
| Datasets | Subsets | Types | Coverage | Resolution | Bands |
| ISPRS | VH | Airborne | 1.38 | 0.09 m | IRRG |
| ISPRS | PD | Airborne | 3.42 | 0.05 m | RGB IRRG RGBIR |
| LoveDA | Rural Urban | Spaceborne | 536.15 | 0.3 m | RGB |
| BLU | Tile 1, Tile 2 Tile 3, Tile 4 | Spaceborne | 150 | 0.8 m | RGB |
The four public RSIs datasets, including ISPRS Potsdam (PD), ISPRS Vaihingen (VH), LoveDA [53] and BLU [54], are used for experiments, and the details are listed in Table I.
| Class | Setting 1 | Setting 2 | Setting 3 | ||||||
| PD1 | PD2 | VH | PD1 | PD2 | VH | PD1 | PD2 | VH | |
| Impervious surface | |||||||||
| Building | |||||||||
| Low vegetation | |||||||||
| Tree | |||||||||
| Car | |||||||||
| Clutter | |||||||||
The VH and PD datasets contain the same six classes: Impervious surface, Building, Low vegetation, Tree, Car and Cluster. Referring to relevant researches, the target VH dataset contains 398 samples for domain adaptation training and 344 samples for evaluation, while the source PD dataset contains 3456 samples for training [21, 55]. The space size of each sample is . In the two-source union equality scenario of airborne RSIs, the whole PD training set is divided into two groups, i.e., the PD1 subset with 1728 RGB samples and the PD2 subset with 1728 IRRG samples. As listed in Table. II, the first two settings are obtained by discarding part of the classes in PD1 and PD2 respectively. In addition, the class symmetry two-source setting is also used for experiments.
| Class | Setting 1 | Setting 2 | ||||||
| BLU1 | BLU2 | BLU3 | Urban | BLU1 | BLU2 | BLU3 | Urban | |
| Background | ||||||||
| Building | ||||||||
| Vegetation | ||||||||
| Water | ||||||||
| Agricultural | ||||||||
| Road | ||||||||
The class space merge is first performed on the LoveDA dataset by referring to [54], so that LoveDA and BLU datasets have the same six classes: Background, Building, Vegetation, Water, Agricultural and Road. The Urban dataset used as the target domain contains 677 training samples and 1156 testing samples, and the first three tiles in the BLU dataset are used for different source domains, each of which contains 196 samples for domain adaptation training. Each sample is cropped to the size of . Similar to the scenario of airborne RSIs, the two three-source union equality scenarios are established, as listed in Table. III.
| Class | Setup 1 | ||
| PD1 | PD2 | Partial VH | |
| Impervious surface | |||
| Building | |||
| Low vegetation | |||
| Tree | |||
| Car | |||
| Clutter | |||
In addition, the two-source union inclusion scenario is established on the airborne RSIs, as shown in Table. IV. Through discarding the RSIs containing the Clutter class of the VH dataset, the partial VH subset is obtained, where the number of training and testing samples is reduced to 350 and 319 respectively.
IV-B Environment and hyperparameters
All algorithms are developed based on Python 3.8 and relevant machine learning libraries. A computer equipped with an Intel Xeon Gold 6152 CPU and an Nvidia A100 PCIE GPU provides hardware support for programs running.
Referring to most relevant researches, the ResNet-101 network pretrained on ImageNet dataset is used as the shared backbone . Each expert branch actually contains a improved atrous spatial pyramid pooling (ASPP) module as and a convolution classification layer as . The number of output channels of , and is 2048, 64 and respectively, where is the number of all source classes. The HGCN in the knowledge integration module contains two hypergraph convolution layers. In the view of space, the number of neighbor vertices used for building hypergraph is 64, and the number of channels of two layers is and 64 respectively, while in the view of feature, the above values are changed to 8, and respectively. In the multi-source union equality scenario, the liner classifier in outputs the classes, while in the multi-source union inclusion scenario, it outputs the classes.
During the domain adaptation training, the batchsize is set to 4, which means that there are source samples and target samples in a training batch. For each source domain, half of the samples are mixed using the coarse region-level strategy, and the other half are mixed using the fine class-level strategy. More specifically, in each source labeled sample, half of the classes or 40% of the region is pasted to the target sample. In the process of multi-domain transfer, the strong transformation of target RSIs containing flipping, rotation, cropping, color jitter and gaussian blur, and only the pixels with the prediction probability larger than 0.968 are used for loss calculation. In addition, the Adam algorithm is used for model optimization, the training iteration is set to 40,000, and the learning rates of the backbone and multi-branch segmentation head are set to and respectively. The weight coefficients and are both set to 1. Other related hyperparameter optimization techniques are consistent with [56].
IV-C Methods and measures for comparison
To verify the effectiveness of the proposed MS-CADA method, four conventional single-source UDA methods including Li’s [57], DAFormer [56], HRDA [58] and PCEL [55], and four multi-source UDA methods including UMMA [41], DCTN [36], He’s [32] and MECKA [40], are used for performance comparison.
The UDA method presented by Li et al. introduces the two strategies of gradual class weights and local dynamic quality into the process of self-supervised learning, which can achieve better performance than most adversarial learning methods. DAFormer is a simple and efficient UDA method, which can improve the target segmentation accuracy to a certain extent, by improving the training strategies of class sampling, feature utilization and learning rate. HRDA is an improvement method over DAFormer, which can effectively combine the advantages of high-resolution fine segmentation and low-resolution long-range context learning. PCEL is an advanced UDA method for RSIs segmentation, which can significantly improve the domain adaptation performance through the enhancement of prototype and context. The above methods take the simple combination of different RSIs domains as the singe source, which can be referred to as "Combined source" for short.
Considering that there is no existing method that can exactly fit the problem setting of class asymmetry domain adaptation segmentation of RSIs, several multi-source UDA methods designed for related problems are modified appropriately and used for comparison. UMMA is an advanced model adaptation method for street scene segmentation, which can achieve the adaptation to target domains using multiple models trained on different sources. DCTN is an adversarial-based UDA method for natural images classification. It can utilize different discriminators to generate the weights of different sources and combine different classifiers to achieve multi-source adaptation. The method proposed by He et al. is actually a multi-source UDA method for street scene segmentation, and MECKA is a multi-source UDA method for RSIs scene classification based on the consistency learning between different domains. Among them, only the methods UMMA and He’s are capable of dealing with the multi-source union equality scenario of RSIs segmentation. Therefore, appropriate modifications are imposed on the methods DCTN and MECKA. Specifically, the classifiers of DCTN is replaced by the ASPP module, and the complete predictions are obtained through casting the results of different classifiers over the target class space and calculating the weighted results. And the cross-domain mixing strategy proposed in Section III-D is integrated into different branches of MECKA. In addition, in the multi-source union inclusion scenario, for the above four methods, the outlier class that target RSIs do not contain will be discarded to re-form the multi-source union equality scenario, which is significantly different from the proposed MS-CADA method. Consequently, the above methods can utilize multiple separated sources for class asymmetry UDA of RSIs, which can be referred to as "Separated multiple sources" for short.
All the above methods utilize the ResNet-101 trained on the ImageNet dataset as the backbone network, and perform domain adaptation training with the random seed of 0. In addition, to fairly compare the performance of different methods, the three widely used measures including IoU per class, mIoU and mF1, are selected for quantitative comparisons.
IV-D Results of the two-source union equality scenario of airborne RSIs
| Type | Method | Imp. surf. | Build. | Low veg. | Tree | Car | Clu. | mIoU | mF1 | |
| Combined source | Li’s | 64.22 | 88.06 | 55.64 | 75.60 | 27.77 | 29.22 | 56.75 | 69.74 | |
| DAFormer | 67.75 | 82.15 | 50.40 | 61.03 | 60.00 | 15.73 | 56.18 | 69.33 | ||
| HRDA | 72.39 | 83.78 | 50.26 | 66.46 | 50.23 | 44.48 | 61.27 | 73.08 | ||
| PCEL | 71.12 | 87.62 | 54.89 | 66.62 | 47.07 | 45.78 | 62.18 | 73.91 | ||
| Separated multiple sources | UMMA | 55.63 | 59.80 | 46.41 | 48.38 | 40.30 | 8.83 | 43.23 | 56.89 | |
| DCTN | 76.84 | 87.65 | 49.52 | 44.36 | 38.22 | 7.71 | 50.72 | 63.95 | ||
| He’s | 72.45 | 79.15 | 43.50 | 62.94 | 44.35 | 10.41 | 52.13 | 65.05 | ||
| MECKA | 82.36 | 87.56 | 53.81 | 54.46 | 48.14 | 7.95 | 55.71 | 67.32 | ||
| MS-CADA | 77.39 | 89.47 | 56.45 | 67.34 | 51.94 | 47.06 | 64.94 | 76.26 |
| Type | Method | Imp. surf. | Build. | Low veg. | Tree | Car | Clu. | mIoU | mF1 |
| Combined source | Li’s | 78.98 | 88.39 | 62.26 | 74.57 | 9.83 | 24.00 | 56.34 | 69.13 |
| DAFormer | 69.28 | 84.88 | 51.16 | 62.50 | 59.97 | 40.75 | 61.42 | 75.20 | |
| HRDA | 69.62 | 88.94 | 54.44 | 70.34 | 57.52 | 59.06 | 66.65 | 78.17 | |
| PCEL | 72.98 | 88.64 | 53.82 | 71.91 | 54.06 | 60.41 | 66.97 | 78.32 | |
| Separated multiple sources | UMMA | 52.73 | 56.17 | 40.59 | 55.20 | 37.30 | 10.23 | 42.04 | 55.91 |
| DCTN | 79.42 | 87.54 | 50.28 | 44.96 | 38.57 | 7.66 | 51.41 | 64.54 | |
| He’s | 78.07 | 85.17 | 52.81 | 53.07 | 48.00 | 17.58 | 55.78 | 67.88 | |
| MECKA | 81.54 | 86.27 | 53.28 | 56.20 | 52.00 | 15.88 | 57.53 | 69.96 | |
| MS-CADA | 80.25 | 89.68 | 55.02 | 66.24 | 55.59 | 75.20 | 70.33 | 81.39 |
| Type | Method | Imp. surf. | Build. | Low veg. | Tree | Car | Clu. | mIoU | mF1 |
| Single source | DAFormer (PD1) | 64.13 | 87.36 | 27.63 | 30.48 | 64.53 | 1.52 | 45.94 | 57.14 |
| DAFormer (PD2) | 82.56 | 89.81 | 55.83 | 65.16 | 64.45 | 47.34 | 67.53 | 79.71 | |
| PCEL (PD1) | 76.97 | 88.28 | 56.74 | 75.73 | 65.21 | 8.16 | 61.85 | 72.56 | |
| PCEL (PD2) | 81.51 | 89.55 | 59.40 | 72.32 | 57.96 | 59.45 | 70.03 | 81.07 | |
| Combined source | Li’s | 81.95 | 88.75 | 55.77 | 65.38 | 58.99 | 40.34 | 65.20 | 77.83 |
| DAFormer | 79.04 | 89.71 | 51.79 | 61.83 | 65.94 | 39.00 | 64.55 | 77.18 | |
| HRDA | 81.25 | 88.94 | 57.29 | 78.70 | 58.34 | 44.98 | 68.25 | 80.03 | |
| PCEL | 79.03 | 89.80 | 59.23 | 66.84 | 58.88 | 60.04 | 68.97 | 80.54 | |
| Separated multiple sources | UMMA | 68.37 | 70.19 | 47.26 | 56.71 | 45.63 | 16.38 | 50.76 | 64.82 |
| DCTN | 79.31 | 88.12 | 53.85 | 65.29 | 62.85 | 15.05 | 60.75 | 73.26 | |
| He’s | 79.58 | 86.16 | 55.79 | 62.48 | 56.46 | 36.28 | 62.79 | 76.05 | |
| MECKA | 79.51 | 88.65 | 54.72 | 67.81 | 64.75 | 50.26 | 67.62 | 79.13 | |
| MS-CADA | 83.73 | 90.08 | 60.15 | 68.40 | 59.89 | 70.93 | 72.20 | 83.36 |
Tables V-VII list the segmentation results of different methods in the two-source union equality scenario of airborne RSIs, which correspond to the three different class settings in Table II respectively. Observations and analysis can be obtained from the following four aspects.
Firstly, simply combining different RSIs and implementing domain adaptation based on the single-source UDA methods will weaken the segmentation performance of target RSIs. According to the results of DAFormer and PCEL in Table VII, the mIoU based on the combined source decreases to different degrees, compared with the mIoU based on the best single source. This is not difficult to understand that, different RSIs with domain discrepancies interfere with each other, resulting in the suboptimal domain adaptation performance.
Secondly, the performance of the four conventional single-source UDA methods with the combined source is obviously inferior to that of the proposed method. Specifically, in the three different class settings, the mIoU of the proposed method is 2.76%, 3.36% and 3.23% higher than that of the conventional UDA method with the best performance, respectively. Correspondingly, the mF1 value of the proposed method is increased by 2.35%, 3.07% and 2.82% respectively. These observations directly verify the effectiveness of the knowledge integration and transfer with multiple separated sources, which effectively avoids the negative transfer problem in the combined source.
Thirdly, the results of four improved multi-source UDA methods and the proposed MS-CADA method are compared. Specifically, UMMA can only utilize the models pretrained on different sources for domain adaptation without feature alignment between source and target RSIs, resulting in the relatively poor results. DCTN can simply combine the advantages of different classifiers to some extent by weighted calculation, and its performance is better than UMMA. The two methods He’s and MECKA can perform the consistency learning and knowledge supplement between different source domains, and thus their domain adaptation performance is further improved. The proposed method always performs better than the other four methods, wether in the class asymmetry case or the class symmetry case. Compared to the second place, the proposed method improved by 9.23%, 12.80% and 4.58% in mIoU and 8.94%, 11.43% and 4.23% in mF1, in the three different class settings. This demonstrates the superiority of the proposed methods in airborne RSIs domain adaptation segmentation in the two-source union equality scenario.
Fourthly, the performance of the proposed method in the class asymmetry scenario is still better than that of some advanced methods in the class symmetry scenario. For example, the proposed method can achieve the higher mIoU and mF1 in class setting 2 than the other eight methods do in class setting 3, which fully demonstrates the effectiveness of the proposed method in integrating and transferring multi-source knowledge in the case of class asymmetry.

To intuitively compare the segmentation results of different methods, Fig. 6 shows the segmentation maps of several examples in the target RSIs. Specifically, the results of the three representative methods including PCEL, MECKA and MS-CADA in class settings 2 and 3 are visualized, from which the three main points can be drawn. (1) The quality of the segmentation maps of the proposed method is superior to that of PCEL using the combined source. Specifically, the segmentation maps of the proposed method possess the more complete context structure and less noise. (2) Compared with MECKA, the proposed method can produce the more accurate segmentation maps, which is especially obvious for the minority class and small objects. For example, in line 3, the proposed method can recognize the Clutter class accurately, and in line 5, the proposed method can locate the objects of the Car class more precisely. (3) The segmentation maps in the setting 3 of class symmetry are superior to those in the setting 2 of class asymmetry, which can be clearly observed from Fig. 6 (d)-(g). Implementing RSIs domain adaptation with completely consistent class space can provide more class information and labeled samples for finely segmenting objects, so as to produce the segmentation maps with better quality.
IV-E Results of the three-source union equality scenario of spaceborne RSIs
| Type | Method | Back. | Build. | Veg. | Water | Agri. | Road | mIoU | mF1 |
| Combined source | Li’s | 27.37 | 47.97 | 18.79 | 10.69 | 21.12 | 42.79 | 28.12 | 42.75 |
| DAFormer | 32.49 | 44.65 | 18.44 | 14.93 | 11.26 | 42.09 | 27.31 | 41.23 | |
| HRDA | 27.16 | 50.24 | 18.90 | 44.20 | 20.04 | 45.40 | 34.32 | 49.75 | |
| PCEL | 29.90 | 48.10 | 17.35 | 48.77 | 26.08 | 40.95 | 35.19 | 50.23 | |
| Separated multiple sources | UMMA | 19.55 | 30.98 | 13.13 | 13.76 | 2.86 | 20.51 | 16.80 | 29.37 |
| DCTN | 25.96 | 43.54 | 16.95 | 19.31 | 14.30 | 35.20 | 25.88 | 39.04 | |
| He’s | 24.30 | 47.75 | 12.31 | 46.67 | 16.60 | 34.26 | 30.32 | 44.69 | |
| MECKA | 29.83 | 50.21 | 18.82 | 49.89 | 15.19 | 44.61 | 34.76 | 49.86 | |
| MS-CADA | 30.82 | 52.76 | 23.48 | 43.29 | 22.36 | 46.70 | 36.57 | 51.69 |
| Type | Method | Back. | Build. | Veg. | Water | Agri. | Road | mIoU | mF1 |
| Single source | PCEL (BLU1) | 30.83 | 47.76 | 20.68 | 56.25 | 29.11 | 45.12 | 38.22 | 53.37 |
| PCEL (BLU2) | 27.03 | 37.81 | 18.72 | 62.74 | 26.64 | 44.55 | 36.25 | 51.04 | |
| PCEL (BLU3) | 31.49 | 47.27 | 19.21 | 54.32 | 30.06 | 48.08 | 38.41 | 53.63 | |
| Combined source | Li’s | 40.83 | 46.77 | 17.50 | 30.95 | 23.88 | 51.33 | 35.21 | 50.94 |
| DAFormer | 31.20 | 46.20 | 18.88 | 42.80 | 18.10 | 49.79 | 34.50 | 49.93 | |
| HRDA | 29.20 | 52.93 | 18.73 | 45.73 | 23.25 | 52.59 | 37.07 | 52.28 | |
| PCEL | 30.17 | 46.30 | 20.06 | 54.18 | 29.75 | 46.52 | 37.83 | 53.06 | |
| Separated multiple sources | UMMA | 18.70 | 32.22 | 13.71 | 27.60 | 5.04 | 31.89 | 21.53 | 35.65 |
| DCTN | 26.52 | 44.68 | 18.38 | 27.91 | 18.66 | 42.22 | 29.73 | 34.92 | |
| He’s | 21.03 | 48.71 | 17.48 | 42.38 | 14.02 | 49.32 | 32.16 | 37.47 | |
| MECKA | 23.40 | 50.40 | 18.88 | 54.68 | 21.55 | 50.04 | 36.49 | 51.59 | |
| MS-CADA | 31.82 | 48.34 | 20.95 | 58.04 | 26.23 | 54.26 | 39.94 | 55.36 |
The segmentation results of different methods in the three-source union equality scenario of spaceborne RSIs are given in Tables. VIII-IX. Compared with airborne RSIs, the domain adaptation of large-scale spaceborne RSIs is more difficult, especially knowledge integration and transfer using multiple class asymmetry sources. It can be seen that, there is a general decline in the segmentation performance of different methods, however, several observations similar to the airborne RSIs scenario can be obtained.
Firstly, according to the results of PCEL in Table IX, the performance based on the combined source is still inferior to that based on the best single source. Although the expansion of training samples from three sources effectively reduces the decline range, the discrepancies between different RSIs sources still damage the segmentation performance in the target domain to some extent. Secondly, in the two different class settings, the proposed method performs better than the best UDA method PCEL with the combined source, with the increase of 1.38% and 2.11% in mIoU, and 1.46% and 2.30% in mF1. Thirdly, the segmentation results of the proposed method are better than those of other improved multi-source UDA methods. Specifically, the proposed method improves mIoU by at least 1.81% and 3.45%, and mF1 by at least 1.83% and 3.77%. It can be seen from the above statistics that, the proposed method can achieve better results than existing advanced single-source and multi-source UDA methods, whether in the class symmetry case or the class asymmetry case.
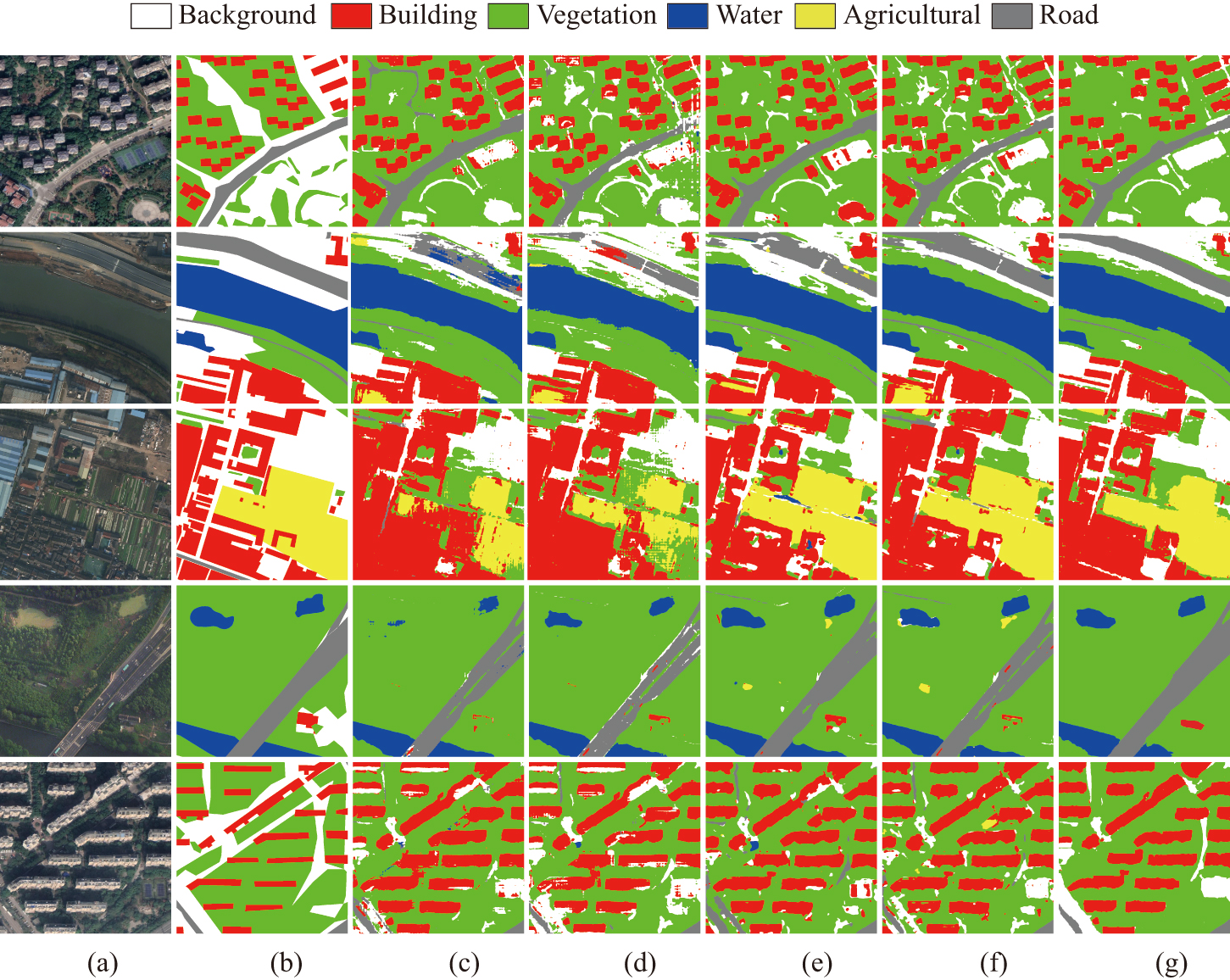
Fig. 7 shows the segmentation maps of PCEL, MECKA and MS-CADA. Compared with other methods, the segmentation maps of the proposed method in class setting 2 have the best visual effect and are closest to the ground truth. Specifically, the recognition of the Building objects is more accurate and complete, and the edge of the segmentation results of linear objects is smoother. In addition, under the same class setting, the segmentation maps of the proposed method are better than those of MECKA, which is mainly reflected in the less misclassification and noise. This verifies the advantages of the proposed method in the three-source union equality scenario of spaceborne RSIs from the perspective of visualization.
IV-F Results of the two-source union inclusion scenario of airborne RSIs
| Type | Method | Imp. surf. | Build. | Low veg. | Tree | Car | mIoU | mF1 |
| Combined source | Li’s | 68.75 | 87.57 | 54.71 | 63.54 | 19.38 | 58.79 | 67.78 |
| DAFormer | 73.58 | 86.38 | 53.76 | 59.68 | 58.05 | 66.29 | 78.91 | |
| HRDA | 75.52 | 90.40 | 60.66 | 76.30 | 49.42 | 70.46 | 81.85 | |
| PCEL | 71.50 | 88.77 | 57.28 | 74.35 | 59.17 | 70.21 | 81.62 | |
| Separated multiple sources | UMMA | 63.26 | 68.12 | 27.02 | 56.91 | 22.92 | 47.65 | 60.13 |
| DCTN | 67.61 | 80.73 | 47.75 | 58.36 | 42.71 | 59.43 | 70.55 | |
| He’s | 79.97 | 85.91 | 50.03 | 44.04 | 57.94 | 63.58 | 75.84 | |
| MECKA | 81.91 | 88.27 | 53.40 | 52.05 | 62.45 | 67.62 | 79.76 | |
| MS-CADA | 82.25 | 90.90 | 57.54 | 65.67 | 62.85 | 71.84 | 83.37 |

In addition to the multi-source union equality scenario, this section verifies the effectiveness of the proposed method in the two-source union inclusion scenario, and the results are listed in Table X. It should be pointed out that, for the eight UDA methods for comparison, the pixels corresponding to the Clutter class of the PD2 dataset in Table IV are discarded. In other words, the eight UDA methods actually still perform domain adaptation in the two-source union equality scenario, because they cannot handle the source outlier classes that the target RSIs do not contain.
As listed in Table X, the proposed method achieves the highest mIoU and mF1, which increase by 1.63% and 1.75% respectively compared with PCEL, and 4.22% and 3.61% respectively compared with MECKA. It is believed that, such improvement benefits from the proposed multi-source pseudo-label generation strategy, which can effectively filter out the low-quality pseudo-labels located at the boundary between objects, and improves the performance of knowledge transfer in the self-supervised learning process. In addition to the statistics, the segmentation maps of different methods are visualized, as shown in Fig. 8. Compared with PCEL and MECKA, the proposed method can produce more fine segmentation maps. For example, the segmentation results of small targets of the Car class and the edge of the Building objects are more accurate and detailed.
V Analysis and Discussion
V-A Ablation studies
V-A1 The cross-domain mixing strategy
| Scenario | Class setting | Baseline | Class-level | Region-level | Ours |
| Two-source union equality | Setting 1 | 42.79 | 63.85 | 64.13 | 64.94 |
| Setting 2 | 41.55 | 69.80 | 68.94 | 70.33 | |
| Setting 3 | 51.49 | 71.36 | 71.87 | 72.20 | |
| Three-source union equality | Setting 1 | 21.38 | 35.51 | 35.79 | 36.57 |
| Setting 2 | 27.56 | 39.04 | 39.33 | 39.94 | |
| Two-source union inclusion | Setting 1 | 49.87 | 71.06 | 70.95 | 71.84 |
The proposed cross-domain mixing strategy can supplement the class information existing in other sources for each source branch, which is the key to achieve the collaborative learning among different branches and the adaptation from each source to the target RSIs. The results of the ablation studies are presented in Table XI, where the Baseline method means that there is no mixing operation between different source branches. As can be seen, the performance of the Baseline method is far behind that of other methods, since it can only implement multi-source domain adaptation using the pseudo-labels generated by the results with severe class bias. In contrast, the performance brought by the class-level or region-level mixing strategy alone is significantly improved. It is worth noting that, the region-level mixing can lead to higher mIoU in settings where class differences between sources are small, and the class-level mixing can lead to higher mIoU in settings where class differences between sources are large, such as the class setting 2 in the two-source union equality scenario. The proposed strategy can absorb different advantages of class-level and region-level mixing, and simultaneously enhances the learning of fine inherent properties of objects and coarse local context structure. Therefore, in the three different scenarios, the proposed strategy can enable the MS-CADA method to achieve the best performance.
V-A2 The multi-source pseudo-label generation strategy
| Scenario | Class setting | Best expert | Summation | Ensemble | Ours |
| Two-source union equality | Setting 1 | 63.54 | 64.06 | 64.33 | 64.94 |
| Setting 2 | 68.87 | 69.73 | 69.61 | 70.33 | |
| Setting 3 | 70.83 | 71.74 | 71.79 | 72.20 | |
| Three-source union equality | Setting 1 | 35.02 | 35.63 | 35.86 | 36.57 |
| Setting 2 | 38.75 | 39.27 | 39.43 | 39.94 |
How to generate the target pseudo-labels for multi-source adaptation based on the results of different expert branches is also a very key link in the proposed method. The comparison of different pseudo-label generation strategies is shown in Table XII. The Best expert method means that, only the results of the best expert branch are used for self-supervised training, without any integration operation on the different results of multiple experts. In the Summation method, the logit results of different experts are firstly summed at the element level, and then the pseudo-labels are obtained through the softmax activation. The Ensemble method comes from the research of Li et al. [41], and actually performs the selective average calculation on different results. Through comparison, it is found that the self-supervised training with only the results of one source expert will produce the suboptimal performance. Obviously, different experts will focus on different feature representation when performing supervised learning on different sources. Therefore, integrating different strengths of source experts can effectively improve the performance of target tasks. Compared with other methods, the proposed strategy can achieve the higher mIoU, which verifies its effectiveness in combining the advantages of different source experts in the process of multi-source domain adaptation. In addition, it can deal with the scenario where the source class union includes the target class set, which other methods do not handle well.
V-A3 The multiview-enhanced knowledge integration module
| Scenario | Class setting | CNN | Transformer | GCN | HGCN | Ours |
| Two-source union equality | Setting 1 | 62.36 | 63.39 | 63.16 | 64.10 | 64.94 |
| Setting 2 | 68.14 | 68.67 | 68.72 | 69.26 | 70.33 | |
| Setting 3 | 69.90 | 70.55 | 70.64 | 71.58 | 72.20 | |
| Three-source union equality | Setting 1 | 35.18 | 35.82 | 35.07 | 35.75 | 36.57 |
| Setting 2 | 37.52 | 37.49 | 38.03 | 38.96 | 39.94 | |
| Two-source union inclusion | Setting 1 | 69.87 | 70.47 | 70.32 | 71.05 | 71.84 |
As described in the challenge 2 in the section I, it is very important to fully fuse the feature information existing in different domains and realize efficient knowledge transfer in the process of class asymmetry RSIs domain adaptation. This subsection explores the influence of different module on the domain adaptation performance, and the results are presented in Table XIII. The four typical deep models, CNN, Transformer, GCN and HGCN, are used for comparison. They all have two layers, and the channel dimension of each layer is consistent with that of the designed module in the spatial view. Except for the designed module, the other four models all perform feature learning based on the concatenation results of multi-domain features in the channel dimension. Compared with CNN, Transformer and GCN, the HGCN model can obtain higher mIoU in target RSIs. This validates the greater representation ability of the HGCN model, which is obtained by modeling the global many-to-many context relations. The designed multiview-enhanced knowledge integration module can simultaneously perform the high-level relation learning in the views of space and feature, so it can realize better knowledge routing and transfer from different domains to target predictions. According to the mIoU value, in the three different scenarios, the proposed multiview enhancement strategy brings at least 0.62% improvement.
V-B Feature visualization
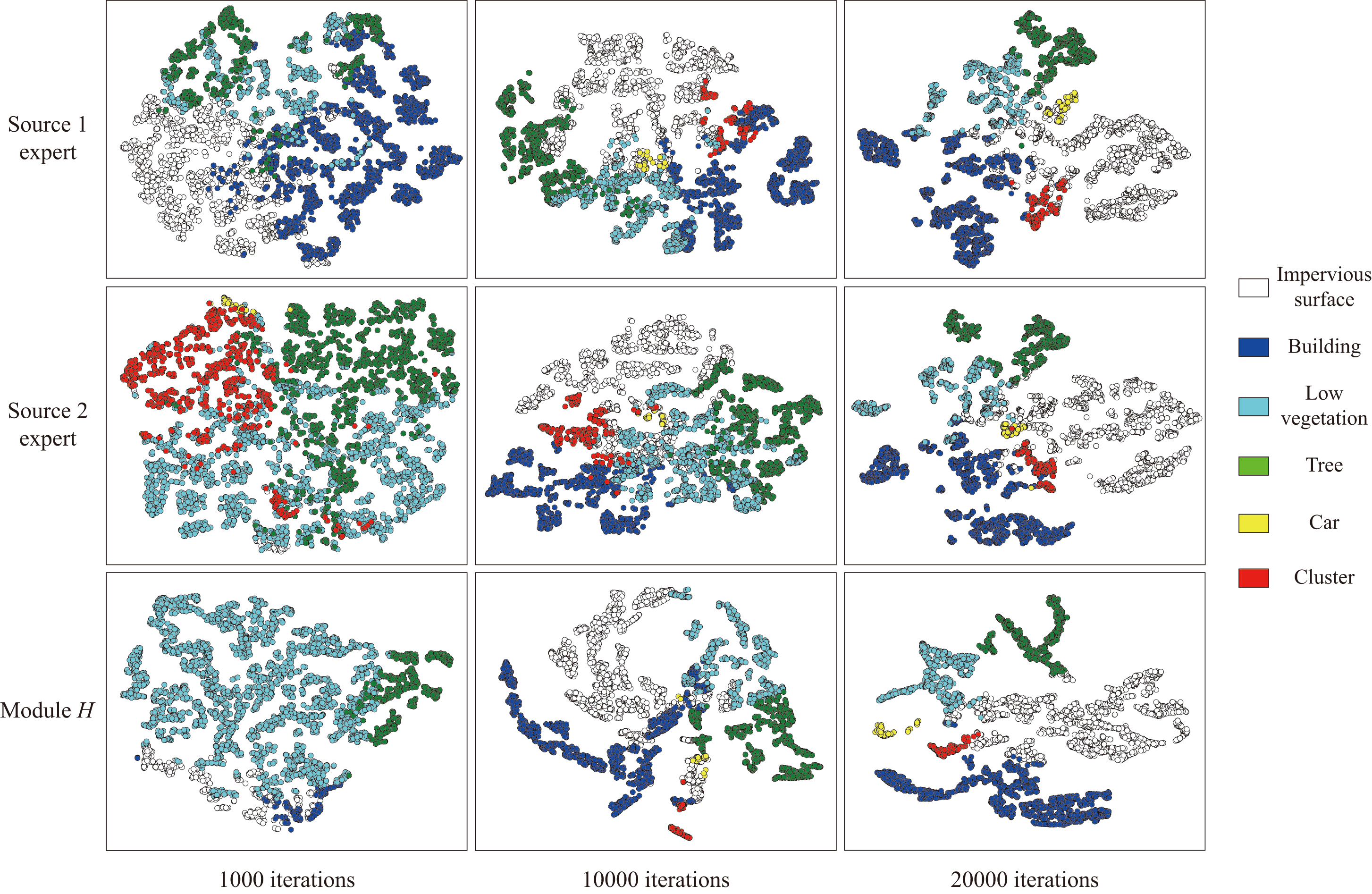
To intuitively verify the effectiveness of the proposed method in the class asymmetry RSIs domain adaptation and better understand the process of class information supplement and multi-domain knowledge transfer, the visualization analysis is carried out for the deep features generated by different branches at different training iterations. Fig. 9 shows the distribution of features after the t-SNE dimension reduction [59]. Specifically, the same target RSI sample in the class setting 2 of the two-source union equality scenario is used as an example for analysis, and the features used for visualization are all derived from the stage before the classifiers in the source branches or in the module . Next, the detailed comparison and analysis are given from three different domain adaptation stages.
V-B1 1000 iterations
As shown in the first column, in the initial training stage, each source branch maps the same target RSI into its own class space. Therefore, the features produced by the source 1 expert are limited to the first four classes, while those produced by the source 2 expert are limited to the last four classes. Such a mapping is bound to contain a lot of errors, and the ability of the module learned from these results is also relatively poor. It can be seen that, there is a serious class bias problem in the feature distribution map of the module .
V-B2 10000 iterations
With the progress of domain adaptation training, the proposed cross-domain mixing strategy gradually comes into play. As we can see, each source branch is supplemented with the initially unavailable class information, and thus it can more accurately map the target RSI sample into the full class space. At the same time, the module can utilize the more accurate pseudo-labels for knowledge integration and transfer, and the class bias problem in the feature maps of different branches could be solved effectively.
V-B3 20000 iterations
The whole model has been fully trained, and each source branch has a better ability to identify all classes. Moreover, compared with the first two columns, the separability and discriminability of the features generated by source branches are significantly improved. However, the mapping results of different source branches are still different, indicating that they have respective emphasis on different feature information. Therefore, the model can draw complementary advantages from different domains, making the features belonging to the same class more clustered and the features belonging to different classes more separated.
From the variation of feature distribution with the process of domain adaptation training, it can be seen that the proposed cross-domain mixing strategy can complete the class information supplement, and achieve the domain adaptation of each source-target pair. Moreoever, the designed module can effectively realize the knowledge transfer and class asymmetry multi-source adaptation based on the full utilization of different source features.
V-C Hyperparameters discussion
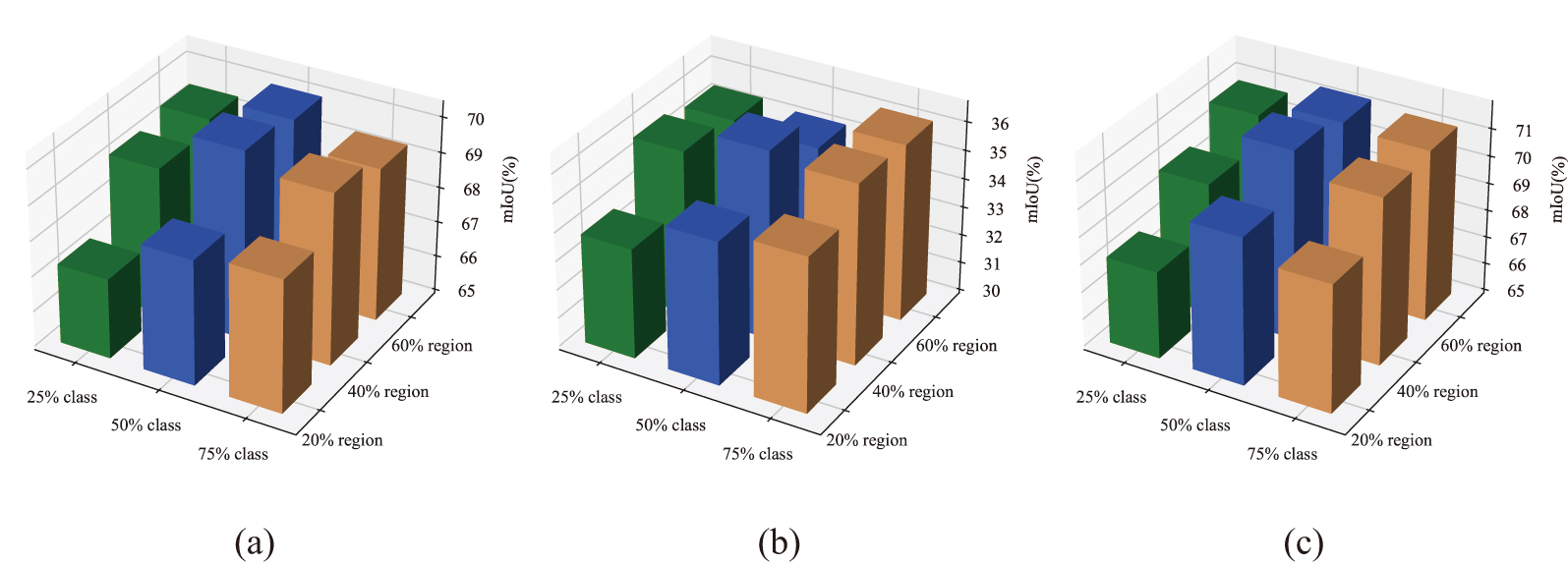
In this section, the influence of three important hyperparameters on segmentation results is analyzed, to explore the sensitivity of the proposed method. Firstly, the optimal combination of class mixing ratio and region mixing ratio in the proposed cross-domain mixing strategy is explored, and the results are shown in Fig. 10. As we can see, when one ratio is too small, increasing the other ratio can lead to a significant improvement. However, when one ratio is large enough, endlessly increasing the other ratio results in a slight decline in performance. The purpose of constructing the mixed samples and labels is to supplement the feature information of other sources to a certain source branch and realize the domain adaptation of each source-target pair. Therefore, the appropriate mixing ratios can better play the advantages of the proposed strategy. Obviously, the best combination is "50% class + 40% region".
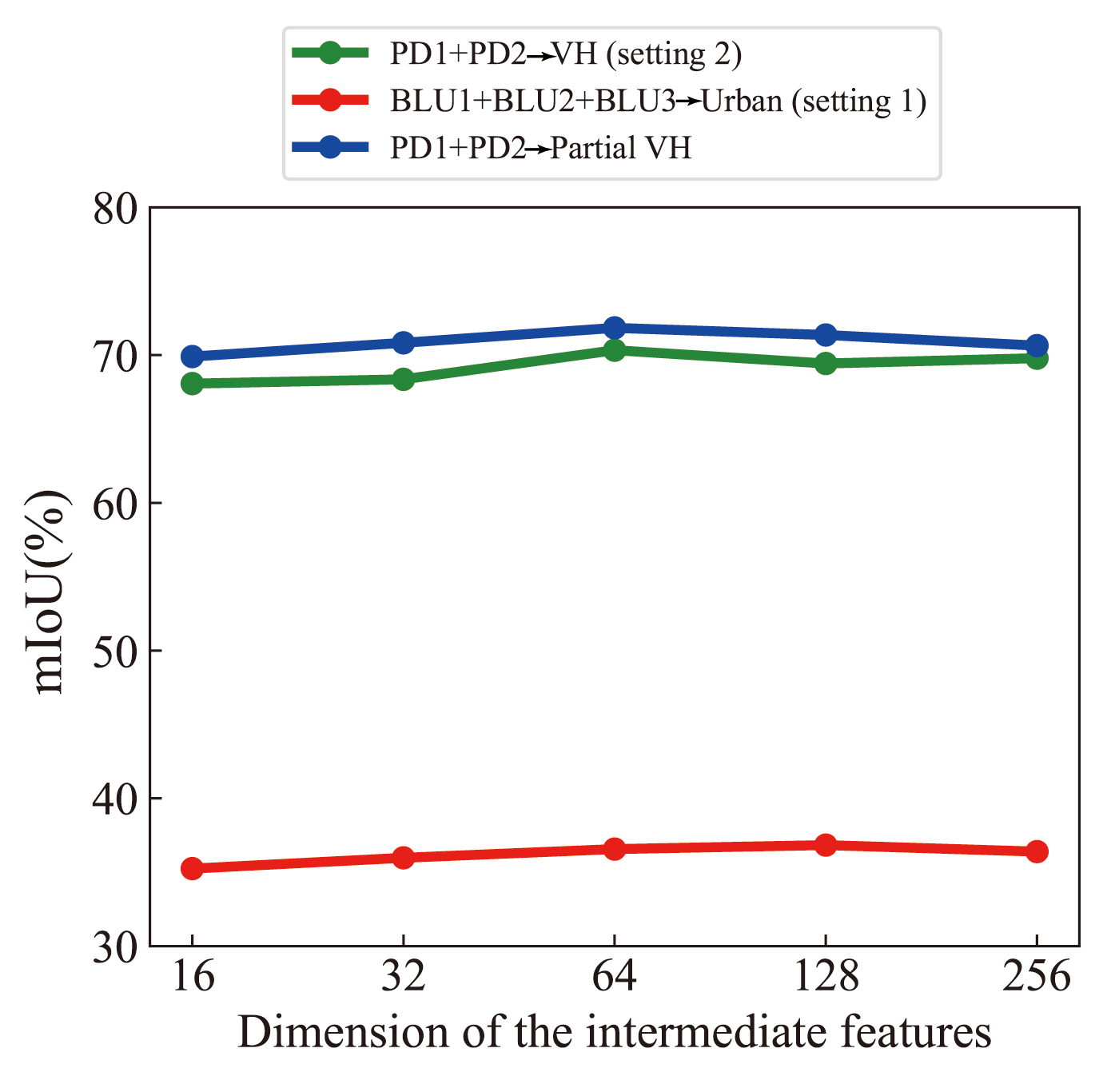
The channel dimension of the intermediate features determines the richness of information in the process of knowledge transfer from multiple domains to target predictions. Specifically, the value of directly affects the structure and size of the constructed hypergraphes. Fig. 11 shows the influence of on the segmentation results of target RSIs. On the whole, the curves corresponding to the three different scenarios show a trend of first rising and then stabilizing or even slightly declining. Therefore, considering the performance and cost simultaneously, setting to 64 is a better choice for the experimental settings in this paper.
| Scenario | Class setting | , | , | , | , | , |
| Two-source union equality | Setting 2 | 70.33 | 65.66 | 65.00 | 68.76 | 69.08 |
| Three-source union equality | Setting 1 | 36.57 | 34.19 | 33.96 | 35.73 | 36.04 |
| Two-source union inclusion | Setting 1 | 71.84 | 66.83 | 66.96 | 70.46 | 71.13 |
Last but no least, the influence of the weight coefficients of different losses on the domain adaptation performance is analysed. By observing the performance when and are set to different values, the contribution of different components to the obtained results can be analyzed. When one of or is set to 0.5, the segmentation results of target RSIs are significantly worse, which indicates that the proposed collaborative learning method and the multi-domain knowledge integration module are very important for the proposed method to achieve excellent performance. When one of A or B is set to 2, the performance is suboptimal, while setting both A and B to 1 can lead to the optimal performance. This indicates that, it is better to treat and equally, because they respectively achieve the adaptation of each source-target pair and the knowledge aggregation of multiple domains, which together contribute to the significant improvement in the performance of class asymmetry RSIs domain adaptation with multiple sources.
VI Conclusion
Class symmetry is an ideal assumption that the existing UDA methods of RSIs generally follow, but it is actually difficult to be satisfied in practical situations. Therefore, this paper proposes a novel class asymmetry RSIs domain adaptation method with multiple sources, to further improve the segmentation performance of target RSIs. Firstly, a multi-branch segmentation network is built to conduct supervised learning of different source RSIs separately, which can effectively avoid the interference of domain discrepancies while learning the basic and rich source knowledge. Then, the labels and RSIs samples are mixed simultaneously between different branches to supplement each source with the class information it does not originally have, and the collaborative learning among multiple branches is used to further promote the domain adaptation performance of each source to the target RSIs. Next, the different advantages of source branches are combined for generating the final target pseudo-labels, which provides the self-supervised information for multi-source RSIs domain adaptation in the equality or inclusion scenario. Finally, the knowledge aggregation module performs the multi-domain knowledge routing and transfer simultaneously from the views of feature and space, to achieve the better performance of multi-source RSIs domain adaptation. The three scenarios and six class settings are established with the widely used airborne and spaceborne RSIs, where the experimental results show that the proposed method can achieve effective multi-source RSIs domain adaptation in the case of class asymmetry, and its segmentation performance in target RSIs is significantly better than the existing relevant methods.
Although the proposed method preliminarily explores the problem of RSIs domain adaptation with multiple class asymmetry sources, it is still limited to the transfer and adaptation of one target RSI domain. In future work, the domain generalization, meta-learning and other related techniques will be introduced, to improve the adaptability of the proposed method in multiple target RSIs domains.
References
- [1] P. Dias, Y. Tian, S. Newsam, A. Tsaris, J. Hinkle, and D. Lunga, “Model assumptions and data characteristics: Impacts on domain adaptation in building segmentation,” IEEE Transactions on Geoscience and Remote Sensing, vol. 60, pp. 1–18, 2022.
- [2] L. Zhang and L. Zhang, “Artificial intelligence for remote sensing data analysis: A review of challenges and opportunities,” IEEE Geoscience and Remote Sensing Magazine, vol. 10, no. 2, pp. 270–294, 2022.
- [3] R. Qin and T. Liu, “A review of landcover classification with very-high resolution remotely sensed optical images mdash; analysis unit, model scalability and transferability,” Remote Sensing, vol. 14, no. 3, 2022.
- [4] S. Zhou, Y. Feng, S. Li, D. Zheng, F. Fang, Y. Liu, and B. Wan, “Dsm-assisted unsupervised domain adaptive network for semantic segmentation of remote sensing imagery,” IEEE Transactions on Geoscience and Remote Sensing, vol. 61, pp. 1–16, 2023.
- [5] H. Ni, Q. Liu, H. Guan, H. Tang, and J. Chanussot, “Category-level assignment for cross-domain semantic segmentation in remote sensing images,” IEEE Transactions on Geoscience and Remote Sensing, pp. 1–1, 2023.
- [6] M. Luo and S. Ji, “Cross-spatiotemporal land-cover classification from vhr remote sensing images with deep learning based domain adaptation,” ISPRS Journal of Photogrammetry and Remote Sensing, vol. 191, pp. 105–128, 2022.
- [7] S. Ji, D. Wang, and M. Luo, “Generative adversarial network-based full-space domain adaptation for land cover classification from multiple-source remote sensing images,” IEEE Transactions on Geoscience and Remote Sensing, vol. 59, no. 5, pp. 3816–3828, 2021.
- [8] L. Wu, M. Lu, and L. Fang, “Deep covariance alignment for domain adaptive remote sensing image segmentation,” IEEE Transactions on Geoscience and Remote Sensing, vol. 60, pp. 1–11, 2022.
- [9] M. Xu, M. Wu, K. Chen, C. Zhang, and J. Guo, “The eyes of the gods: A survey of unsupervised domain adaptation methods based on remote sensing data,” Remote Sensing, vol. 14, no. 17, 2022.
- [10] C. Liang, B. Cheng, B. Xiao, Y. Dong, and J. Chen, “Multilevel heterogeneous domain adaptation method for remote sensing image segmentation,” IEEE Transactions on Geoscience and Remote Sensing, vol. 61, pp. 1–16, 2023.
- [11] K. Gao, B. Liu, X. Yu, and A. Yu, “Unsupervised meta learning with multiview constraints for hyperspectral image small sample set classification,” IEEE Transactions on Image Processing, vol. 31, pp. 3449–3462, 2022.
- [12] K. Gao, B. Liu, X. Yu, J. Qin, P. Zhang, and X. Tan, “Deep relation network for hyperspectral image few-shot classification,” Remote Sensing, vol. 12, p. 923, Mar 2020.
- [13] O. Tasar, S. L. Happy, Y. Tarabalka, and P. Alliez, “Colormapgan: Unsupervised domain adaptation for semantic segmentation using color mapping generative adversarial networks,” IEEE Transactions on Geoscience and Remote Sensing, vol. 58, no. 10, pp. 7178–7193, 2020.
- [14] M. Sokolov, C. Henry, J. Storie, C. Storie, V. Alhassan, and M. Turgeon-Pelchat, “High-resolution semantically consistent image-to-image translation,” IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, vol. 16, pp. 482–492, 2023.
- [15] Z. Yang, P. Guo, H. Gao, and X. Chen, “Depth-assisted residualgan for cross-domain aerial images semantic segmentation,” IEEE Geoscience and Remote Sensing Letters, vol. 20, pp. 1–5, 2023.
- [16] Y. Cai, Y. Yang, Y. Shang, Z. Shen, and J. Yin, “Dasrsnet: Multitask domain adaptation for super-resolution-aided semantic segmentation of remote sensing images,” IEEE Transactions on Geoscience and Remote Sensing, vol. 61, pp. 1–18, 2023.
- [17] J. Zhu, Y. Guo, G. Sun, L. Yang, M. Deng, and J. Chen, “Unsupervised domain adaptation semantic segmentation of high-resolution remote sensing imagery with invariant domain-level prototype memory,” IEEE Transactions on Geoscience and Remote Sensing, vol. 61, pp. 1–18, 2023.
- [18] X. Ma, X. Zhang, Z. Wang, and M.-O. Pun, “Unsupervised domain adaptation augmented by mutually boosted attention for semantic segmentation of vhr remote sensing images,” IEEE Transactions on Geoscience and Remote Sensing, vol. 61, pp. 1–15, 2023.
- [19] J. Chen, J. Zhu, Y. Guo, G. Sun, Y. Zhang, and M. Deng, “Unsupervised domain adaptation for semantic segmentation of high-resolution remote sensing imagery driven by category-certainty attention,” IEEE Transactions on Geoscience and Remote Sensing, vol. 60, pp. 1–15, 2022.
- [20] L. Bai, S. Du, X. Zhang, H. Wang, B. Liu, and S. Ouyang, “Domain adaptation for remote sensing image semantic segmentation: An integrated approach of contrastive learning and adversarial learning,” IEEE Transactions on Geoscience and Remote Sensing, vol. 60, pp. 1–13, 2022.
- [21] A. Zheng, M. Wang, C. Li, J. Tang, and B. Luo, “Entropy guided adversarial domain adaptation for aerial image semantic segmentation,” IEEE Transactions on Geoscience and Remote Sensing, vol. 60, pp. 1–14, 2022.
- [22] A. Ma, C. Zheng, J. Wang, and Y. Zhong, “Domain adaptive land-cover classification via local consistency and global diversity,” IEEE Transactions on Geoscience and Remote Sensing, pp. 1–1, 2023.
- [23] A. Tarvainen and H. Valpola, “Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results,” in ADVANCES IN NEURAL INFORMATION PROCESSING SYSTEMS 30 (NIPS 2017) (I. Guyon, U. Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, eds.), vol. 30 of Advances in Neural Information Processing Systems, 2017. 31st Annual Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, DEC 04-09, 2017.
- [24] L. Yan, B. Fan, S. Xiang, and C. Pan, “Cmt: Cross mean teacher unsupervised domain adaptation for vhr image semantic segmentation,” IEEE Geoscience and Remote Sensing Letters, vol. 19, pp. 1–5, 2022.
- [25] J. Wang, A. Ma, Y. Zhong, Z. Zheng, and L. Zhang, “Cross-sensor domain adaptation for high spatial resolution urban land-cover mapping: From airborne to spaceborne imagery,” Remote Sensing of Environment, vol. 277, p. 113058, 2022.
- [26] J. Chen, P. He, J. Zhu, Y. Guo, G. Sun, M. Deng, and H. Li, “Memory-contrastive unsupervised domain adaptation for building extraction of high-resolution remote sensing imagery,” IEEE Transactions on Geoscience and Remote Sensing, vol. 61, pp. 1–15, 2023.
- [27] T. Lasloum, H. Alhichri, Y. Bazi, and N. Alajlan, “Ssdan: Multi-source semi-supervised domain adaptation network for remote sensing scene classification,” Remote Sensing, vol. 13, p. 3861, Sep 2021.
- [28] O. Tasar, A. Giros, Y. Tarabalka, P. Alliez, and S. Clerc, “Daugnet: Unsupervised, multisource, multitarget, and life-long domain adaptation for semantic segmentation of satellite images,” IEEE Transactions on Geoscience and Remote Sensing, vol. 59, no. 2, pp. 1067–1081, 2021.
- [29] A. Elshamli, G. W. Taylor, and S. Areibi, “Multisource domain adaptation for remote sensing using deep neural networks,” IEEE Transactions on Geoscience and Remote Sensing, vol. 58, no. 5, pp. 3328–3340, 2020.
- [30] X. Wang, Y. Li, C. Lin, Y. Liu, and S. Geng, “Building damage detection based on multi-source adversarial domain adaptation,” Journal of Applied Remote Sensing, vol. 15, no. 3, p. 036503, 2021.
- [31] S. Zhao, B. Li, X. Yue, Y. Gu, P. Xu, R. Hu, H. Chai, and K. Keutzer, “Multi-source domain adaptation for semantic segmentation,” in ADVANCES IN NEURAL INFORMATION PROCESSING SYSTEMS 32 (NIPS 2019) (H. Wallach, H. Larochelle, A. Beygelzimer, F. d’Alche Buc, E. Fox, and R. Garnett, eds.), vol. 32 of Advances in Neural Information Processing Systems, 2019. 33rd Conference on Neural Information Processing Systems (NeurIPS), Vancouver, CANADA, DEC 08-14, 2019.
- [32] J. He, X. Jia, S. Chen, and J. Liu, “Multi-source domain adaptation with collaborative learning for semantic segmentation,” in 2021 IEEE/CVF CONFERENCE ON COMPUTER VISION AND PATTERN RECOGNITION, CVPR 2021, IEEE Conference on Computer Vision and Pattern Recognition, pp. 11003–11012, IEEE; IEEE Comp Soc; CVF, 2021. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), ELECTR NETWORK, JUN 19-25, 2021.
- [33] M. M. Al Rahhal, Y. Bazi, T. Abdullah, M. L. Mekhalfi, H. AlHichri, and M. Zuair, “Learning a multi-branch neural network from multiple sources for knowledge adaptation in remote sensing imagery,” Remote Sensing, vol. 10, no. 12, 2018.
- [34] M. M. Al Rahhal, Y. Bazi, H. Al-Hwiti, H. Alhichri, and N. Alajlan, “Adversarial learning for knowledge adaptation from multiple remote sensing sources,” IEEE Geoscience and Remote Sensing Letters, vol. 18, no. 8, pp. 1451–1455, 2021.
- [35] Y. Wang, L. Feng, W. Sun, Z. Zhang, H. Zhang, G. Yang, and X. Meng, “Exploring the potential of multi-source unsupervised domain adaptation in crop mapping using sentinel-2 images,” GISCIENCE & REMOTE SENSING, vol. 59, pp. 2247–2265, DEC 31 2022.
- [36] R. Xu, Z. Chen, W. Zuo, J. Yan, and L. Lin, “Deep cocktail network: Multi-source unsupervised domain adaptation with category shift,” in 2018 IEEE/CVF CONFERENCE ON COMPUTER VISION AND PATTERN RECOGNITION (CVPR), IEEE Conference on Computer Vision and Pattern Recognition, pp. 3964–3973, IEEE; CVF; IEEE Comp Soc, 2018. 31st IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, JUN 18-23, 2018.
- [37] Z. Ding, M. Shao, and Y. Fu, “Incomplete multisource transfer learning,” IEEE TRANSACTIONS ON NEURAL NETWORKS AND LEARNING SYSTEMS, vol. 29, pp. 310–323, FEB 2018.
- [38] X. Lu, T. Gong, and X. Zheng, “Multisource compensation network for remote sensing cross-domain scene classification,” IEEE Transactions on Geoscience and Remote Sensing, vol. 58, no. 4, pp. 2504–2515, 2020.
- [39] T. Gong, X. Zheng, and X. Lu, “Cross-domain scene classification by integrating multiple incomplete sources,” IEEE Transactions on Geoscience and Remote Sensing, vol. 59, no. 12, pp. 10035–10046, 2021.
- [40] B. H. Ngo, J. H. Kim, S. J. Park, and S. I. Cho, “Collaboration between multiple experts for knowledge adaptation on multiple remote sensing sources,” IEEE Transactions on Geoscience and Remote Sensing, vol. 60, pp. 1–15, 2022.
- [41] Z. Li, R. Togo, T. Ogawa, and M. Haseyama, “Union-set multi-source model adaptation for semantic segmentation,” in COMPUTER VISION, ECCV 2022, PT XXIX (S. Avidan, G. Brostow, M. Cisse, G. Farinella, and T. Hassner, eds.), vol. 13689 of Lecture Notes in Computer Science, pp. 579–595, 2022. 17th European Conference on Computer Vision (ECCV), Tel Aviv, ISRAEL, OCT 23-27, 2022.
- [42] Z. Cao, M. Long, J. Wang, and M. I. Jordan, “Partial transfer learning with selective adversarial networks,” in 2018 IEEE/CVF CONFERENCE ON COMPUTER VISION AND PATTERN RECOGNITION (CVPR), IEEE Conference on Computer Vision and Pattern Recognition, pp. 2724–2732, IEEE; CVF; IEEE Comp Soc, 2018. 31st IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, JUN 18-23, 2018.
- [43] Z. Cao, K. You, Z. Zhang, J. Wang, and M. Long, “From big to small: Adaptive learning to partial-set domains,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 2, pp. 1766–1780, 2023.
- [44] A. Sahoo, R. Panda, R. Feris, K. Saenko, and A. Das, “Select, label, and mix: Learning discriminative invariant feature representations for partial domain adaptation,” in 2023 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pp. 4199–4208, IEEE; CVF; amazon; Airis; Google; kitware; NSF Arkansas EPSCoR; 3dMD; Grainger; WACV, 2023 2023. 2023 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2-7 Jan. 2023, Waikoloa, HI, USA.
- [45] J. Zheng, Y. Zhao, W. Wu, M. Chen, W. Li, and H. Fu, “Partial domain adaptation for scene classification from remote sensing imagery,” IEEE Transactions on Geoscience and Remote Sensing, vol. 61, pp. 1–17, 2023.
- [46] V. Olsson, W. Tranheden, J. Pinto, and L. Svensson, “Classmix: Segmentation-based data augmentation for semi-supervised learning,” in 2021 IEEE WINTER CONFERENCE ON APPLICATIONS OF COMPUTER VISION (WACV 2021), IEEE Winter Conference on Applications of Computer Vision, pp. 1368–1377, IEEE; IEEE Comp Soc; Adobe; Amazon; iRobot; Kitware; Verisk, 2021. IEEE Winter Conference on Applications of Computer Vision (WACV), ELECTR NETWORK, JAN 05-09, 2021.
- [47] S. Yun, D. Han, S. Chun, S. J. Oh, Y. Yoo, and J. Choe, “Cutmix: Regularization strategy to train strong classifiers with localizable features,” in 2019 IEEE/CVF International Conference on Computer Vision (ICCV). Proceedings, pp. 6022–31, 2019 2019. 2019 IEEE/CVF International Conference on Computer Vision (ICCV), 27 Oct.-2 Nov. 2019, Seoul, South Korea.
- [48] J. Lim, S. Yun, S. Park, and J. Y. Choi, “Hypergraph-induced semantic tuplet loss for deep metric learning,” in 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 212–222, 2022.
- [49] Q. He, X. Sun, W. Diao, Z. Yan, F. Yao, and K. Fu, “Multimodal remote sensing image segmentation with intuition-inspired hypergraph modeling,” IEEE Transactions on Image Processing, vol. 32, pp. 1474–1487, 2023.
- [50] Z. Ma, Z. Jiang, and H. Zhang, “Hyperspectral image classification using feature fusion hypergraph convolution neural network,” IEEE Transactions on Geoscience and Remote Sensing, vol. 60, pp. 1–14, 2022.
- [51] S. Bai, F. Zhang, and P. H. S. Torr, “Hypergraph convolution and hypergraph attention,” PATTERN RECOGNITION, vol. 110, FEB 2021.
- [52] Y. Gao, Y. Feng, S. Ji, and R. Ji, “Hgnn+: General hypergraph neural networks,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 3, pp. 3181–3199, 2023.
- [53] J. Wang, Z. Zheng, A. Ma, X. Lu, and Y. Zhong, “Loveda: A remote sensing land-cover dataset for domain adaptive semantic segmentation,” CoRR, vol. abs/2110.08733, 2021.
- [54] L. Ding, D. Lin, S. Lin, J. Zhang, X. Cui, Y. Wang, H. Tang, and L. Bruzzone, “Looking outside the window: Wide-context transformer for the semantic segmentation of high-resolution remote sensing images,” IEEE Transactions on Geoscience and Remote Sensing, vol. 60, pp. 1–13, 2022.
- [55] K. Gao, A. Yu, X. You, C. Qiu, and B. Liu, “Prototype and context-enhanced learning for unsupervised domain adaptation semantic segmentation of remote sensing images,” IEEE Transactions on Geoscience and Remote Sensing, vol. 61, pp. 1–16, 2023.
- [56] L. Hoyer, D. Dai, and L. Van Gool, “Daformer: Improving network architectures and training strategies for domain-adaptive semantic segmentation,” in 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 9914–9925, 2022.
- [57] W. Li, H. Gao, Y. Su, and B. M. Momanyi, “Unsupervised domain adaptation for remote sensing semantic segmentation with transformer,” Remote Sensing, vol. 14, p. 4942, Oct 2022.
- [58] L. Hoyer, D. Dai, and L. Van Gool, “Hrda: Context-aware high-resolution domain-adaptive semantic segmentation,” in COMPUTER VISION - ECCV 2022, PT XXX (S. Avidan, G. Brostow, M. Cisse, G. Farinella, and T. Hassner, eds.), vol. 13690 of Lecture Notes in Computer Science, pp. 372–391, 2022. 17th European Conference on Computer Vision (ECCV), Tel Aviv, ISRAEL, OCT 23-27, 2022.
- [59] L. van der Maaten and G. Hinton, “Viualizing data using t-sne,” Journal of Machine Learning Research, vol. 9, pp. 2579–2605, 11 2008.