Integrating Reward Maximization and Population Estimation: Sequential Decision-Making for Internal Revenue Service Audit Selection
Abstract
We introduce a new setting, optimize-and-estimate structured bandits. Here, a policy must select a batch of arms, each characterized by its own context, that would allow it to both maximize reward and maintain an accurate (ideally unbiased) population estimate of the reward. This setting is inherent to many public and private sector applications and often requires handling delayed feedback, small data, and distribution shifts. We demonstrate its importance on real data from the United States Internal Revenue Service (IRS). The IRS performs yearly audits of the tax base. Two of its most important objectives are to identify suspected misreporting and to estimate the “tax gap” — the global difference between the amount paid and true amount owed. Based on a unique collaboration with the IRS, we cast these two processes as a unified optimize-and-estimate structured bandit. We analyze optimize-and-estimate approaches to the IRS problem and propose a novel mechanism for unbiased population estimation that achieves rewards comparable to baseline approaches. This approach has the potential to improve audit efficacy, while maintaining policy-relevant estimates of the tax gap. This has important social consequences given that the current tax gap is estimated at nearly half a trillion dollars. We suggest that this problem setting is fertile ground for further research and we highlight its interesting challenges. The results of this and related research are currently being incorporated into the continual improvement of the IRS audit selection methods.
1 Introduction
Sequential decision-making algorithms, like bandit algorithms and active learning, have been used across a number of domains: from ad targeting to clinical trial optimization (Bouneffouf and Rish 2019). In the public sector, these methods are not yet widely adopted, but could improve the efficiency and quality of government services if deployed with care. Henderson et al. (2021) provides a review of this potential. Many administrative enforcement agencies in the United States (U.S.) face the challenge of allocating scarce resources for auditing regulatory non-compliance. But these agencies must also balance additional constraints and objectives simultaneously. In particular, they must maintain an accurate estimate of population non-compliance to inform policy-making. In this paper, we focus on the potential of unifying audit processes with these multiple objectives under a sequential decision-making framework. We call our setting optimize-and-estimate structured bandits. This framework is useful in practical settings, challenging, and has the potential to bring together methods from survey sampling, bandits, and active learning. It poses an interesting and novel challenge for the machine learning community and can benefit many public and private sector applications (see more discussion in Appendix C). It is critical to many U.S. federal agencies that are bound by law to balance enforcement priorities with population estimates of improper payments (Henderson et al. 2021; Office of Management and Budget 2018, 2021).
We highlight this framework with a case study of the Internal Revenue Service (IRS). The IRS selects taxpayers to audit every year to detect under-reported tax liability. Improving audit selection could yield 10:1 returns in revenue and help fund socially beneficial programs (Sarin and Summers 2019). But the agency must also provide an accurate assessment of the tax gap (the projected amount of tax under-reporting if all taxpayers were audited). Currently, the IRS accomplishes this via two separate mechanisms: (1) a stratified random sample to estimate the tax gap; (2) a focused risk-selected sample of taxpayers to collect under-reported taxes. Based on a unique multiyear collaboration with the IRS, we were provided with full micro data access to masked audit data to research how machine learning could improve audit selection. We investigate whether these separate mechanisms and objectives can be combined into one batched structured bandit algorithm, which must both maximize reward and maintain accurate population estimates. Ideally, if information is reused, the system can make strategic selections to balance the two objectives. We benchmark several sampling approaches and examine the trade-offs between them with the goal of understanding the effects of using bandit algorithms in this high-impact setting. We identify several interesting results and challenges using historical taxpayer audit data in collaboration with the IRS.
First, we introduce a novel sampling mechanism called Adaptive Bin Sampling (ABS) which guarantees an unbiased population estimate by employing a Horvitz-Thompson (HT) approach (Horvitz and Thompson 1952), but is comparable to other methods for cumulative reward. Its unbiasedness and comparable reward comes at the cost of additional variance, though the method provides fine-grained control of this variance-reward trade-off.
Second, we compare this approach to -greedy and optimism-based approaches, where a model-based population estimate is used. We find that model-based approaches are biased absent substantial reliance on , but low in variance. Surprisingly, we find that greedy approaches perform well in terms of reward, reinforcing findings by Bietti, Agarwal, and Langford (2018) and Bastani, Bayati, and Khosravi (2021). But we find the bias from population estimates in the greedy regime to be substantial. These biases are greatly reduced even with small amounts of random exploration, but the lack of unbiasedness guarantees make them unacceptable for many public policy settings.
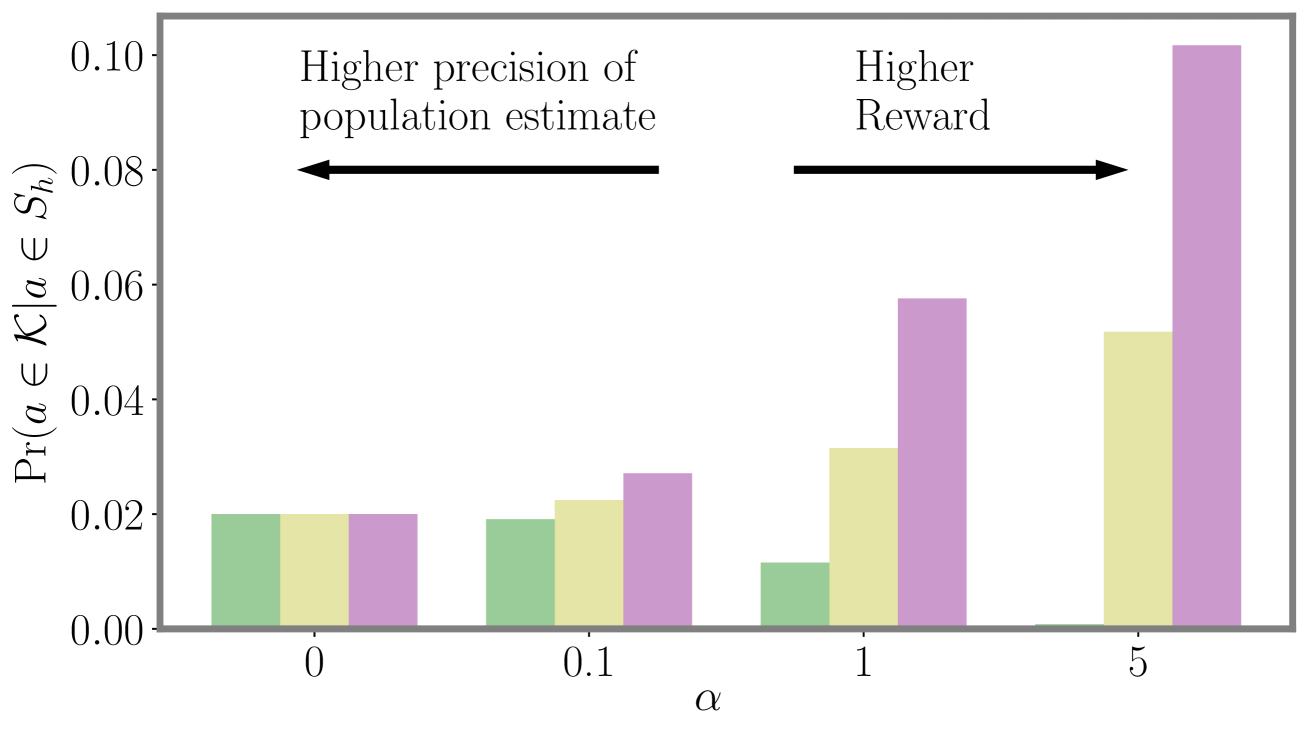
Third, we show that more reward-optimal approaches tend to sample high-income earners versus low-income earners. And more reward-optimal approaches tend to audit fewer tax returns that yield no change (a reward close to 0). This reinforces the importance of reducing the amount of unnecessary exploration, which would place audit burdens on compliant taxpayers. Appendix D details other ethical and societal considerations taken into account with this work.
Fourth, we show that model errors are heteroskedastic, resulting in more audits of high-income earners by optimism-based methods, but not yielding greater rewards.111We note that it is possible that these stem from measurement limitations in the high income space (Guyton et al. 2021).
We demonstrate that combining random and focused audits into a single framework can more efficiently maximize revenue while retaining accuracy for estimating the tax gap. While additional research is needed in this new and challenging domain, this work demonstrates the promise of applying a bandit-like approach to the IRS setting, and optimize-and-estimate structured bandits more broadly. The results of this and related research are currently being incorporated into the continual improvement of the IRS audit selection methods.
2 Background
Related Work. The bandit literature is large. To fully engage with it, we provide an extended literature review in Appendix E , but we mention several strands of related research here. The fact that adaptively collected data leads to biased estimation (whether model-based or not) is well-known. See, e.g., Nie et al. (2018); Xu, Qin, and Liu (2013); Shin, Ramdas, and Rinaldo (2021). A number of works have sought to develop sampling strategies that combat bias. See, e.g. Dimakopoulou et al. (2017). This work has been in the multi-armed bandit (MAB) or (mostly linear) contextual bandit settings. In the MAB setting, there has also been some work which explicitly considers the trade-off between reward and model-error. See, e.g, Liu et al. (2014); Erraqabi et al. (2017). In Appendix E we provide a comparison against our setting, but crucially we have volatile arms which make our setting different and closer to the linear stochastic bandit work (a form of structured bandit) (Abbasi-Yadkori, Pál, and Szepesvári 2011; Joseph et al. 2018). However, we require non-linearity and batched selection, as well as adding the novel estimation objective to this structured bandit setting. To our knowledge, ours is the first formulation which actively incorporates bias and variance of population estimates into a batched structured bandit problem formulation. Moreover, our focus is to study this problem in a real-world public sector domain, taking on the challenges proposed by Wagstaff (2012). No work we are aware of has analyzed the IRS setting in this way.
Institutional Background. The IRS maintains two distinct categories of audit processes. National Research Program (NRP) audits enable population estimation of non-compliance while Operational (Op) audits are aimed at collecting taxes from non-compliant returns. The NRP is a core measurement program for the IRS to regularly evaluate tax non-compliance (Government Accountability Office 2002, 2003). The NRP randomly selects, via a stratified random sample, 15k tax returns each year for research audits (Internal Revenue Service 2019), although this has been decreasing in recent years and there is pressure to reduce it further (Marr and Murray 2016; Congressional Budget Office 2020). These audits are used to identify new areas of noncompliance, estimate the overall tax gap, and estimate improper payments of certain tax credits. Given a recent gross tax gap estimate of $441 billion (Internal Revenue Service 2019), even minor increases in efficiency can yield large returns. In addition to its use for tax gap estimation, NRP serves as a training set for certain Op audit programs like the Discriminant Function (DIF) System (Internal Revenue Service 2022), which is based on a modified Linear Discriminant Analysis (LDA) model (Lowe 1976). DIF also incorporates other measures and policy objectives that we do not consider here. We instead focus on the stylized setting of only population estimation and reward maximization. Tax returns that have a high likelihood of a significant adjustment, as calculated by DIF, have a higher probability of being selected for Op audits.
It is important to highlight that Op data is not used for estimating the DIF risk model and is not used for estimating the tax gap (specifically, the individual income misreporting component of the tax gap). Though NRP audits are jointly used for population estimates of non-compliance and risk model training, the original sampling design was not optimized for both revenue maximization and estimator accuracy for tax non-compliance. Random audits have been criticized for burdening compliant taxpayers and for failing to target areas of known non-compliance (Lawsky 2008). The current process already somewhat represents informal sequential decision-making system. NRP strata are informed by the Op distribution, and are adjusted year-to-year. We posit that by formalizing the current IRS system in the form of a sequential decision-making problem, we can incorporate more methods to improve its efficiency, accuracy, and fairness.
Data. The data used throughout this work is from the NRP’s random sample (Andreoni, Erard, and Feinstein 1998; Johns and Slemrod 2010; Internal Revenue Service 2016, 2019), which we will treat as the full population of audits, since they are collected via a stratified random sample and represent the full population of taxpayers. The NRP sample is formed by dividing the taxpayer base into activity classes based on income and claimed tax credits, and various strata within each class. Each stratum is weighted to be representative of the national population of tax filers. Then a stratified random sample is taken across the classes. NRP audits seek to estimate the correctness of the whole return via a close to line-by-line examination (Belnap et al. 2020). This differs from Op audits, which are narrower in scope and focus on specific issues. Given the expensive nature of NRP audits, NRP sample sizes are relatively small (15k/year) (Guyton et al. 2018). The IRS uses these audits to estimate the tax gap and average non-compliance.222The IRS uses statistical adjustments to compensate naturally occurring variation in the depth of audit, and taxpayer misreporting that is difficult to find via auditing, and other NRP sampling limitations (Guyton et al. 2020; Internal Revenue Service 2019; Erard and Feinstein 2011). For the goals of this work we ignore these. Legal requirements for these estimates exist (Taxpayer Advocate Service 2018). The 2018 Office of Management and Budget (OMB) guidelines, for instance, state that these values should be “statistically valid” (unbiased estimates of the mean) and have “ or better margin of error at the 95% confidence level for the improper payment percentage estimate” (Office of Management and Budget 2018). Later OMB guidelines have provided more discretion to programs for developing feasible point estimates and confidence intervals (CIs) (Office of Management and Budget 2021). Unbiasedness remains an IRS policy priority.

Our NRP stratified random audit sample covers from 2006 to 2014. We use 500 covariates as inputs to the model which are a superset of those currently used for fitting the DIF model. The covariates we use include every value reported by a taxpayer on a tax return. For example, the amount reported in Box 9 of Form 1040 is Total income and would be included in these covariates. Table 5 , in the Appendix, provides summary statistics of the NRP research audits conducted on a yearly basis. Since NRP audits are stratified, the unweighted means represent the average adjustment made by the IRS to that year’s return for all audited taxpayers in the sample. The weighted mean takes into account stratification weights for each sample. One can think of the weighted mean as the average taxpayer misreporting across all taxpayers in the United States, while the unweighted mean is the average taxpayer misreporting in the NRP sample.
Problem Formulation. We formulate the optimize-and-estimate structured bandit problem setting in the scenario where there is an extremely large, but finite, number () of arms () to select from at every round. This set of arms is the population at timestep . The population can vary such that the set of available arms may be totally different at every step, similar to a sleeping or volatile bandit (Nika, Elahi, and Tekin 2021). In fact, it may not be possible to monitor any given arm over several timesteps.333Note the reason we make this assumption is because the NRP data does not track a cohort of taxpayers, but rather randomly samples. We are not guaranteed to ever see a taxpayer twice. To make the problem tractable, it is assumed that the reward for a given arm can be modeled by a shared function where are some set of features associated with arm at timestep , and are the parameters of the true reward function. Assume is any realizable or -realizable function. Thus, as is typical of the structured bandit setting “choosing one action allows you to gain information about the rewards of other actions” (Lattimore and Szepesvári 2020, p. 301). The agent chooses a batch of arms to: (1) maximize reward; (2) yield an accurate and unbiased estimate of the average reward across all arms – even those that have not been chosen (the population reward). Thus we seek to optimize a selection algorithm that chooses non-overlapping actions according to a selection policy () and outputs a population estimate () according to an estimation algorithm ():
| (1) | ||||
| s.t. | (2) |
where is the underlying distribution from which all taxpayers are pulled. In our IRS setting each arm () represents a taxpayer which the policy could select for a given year (). The associated features () are the 500 covariates in our data for the tax return. The reward () is the adjustment recorded after the audit. The population average reward that the agent seeks to accurately model is the average adjustment (summing together would instead provide the tax gap).
3 Methods
We focus on three methods: (1) -greedy; (2) optimism-based approaches; (3) ABS sampling (see Appendix F for reasoning and method selection criteria).
-greedy. Here we choose to sample randomly with probability . Otherwise, we select the observation with the highest predicted reward according to a fitted model , where indicates fitted model parameters. To batch sample, we repeat this process times. The underlying model is then trained on the received observation-reward pairs, and we repeat. For population estimation, we use a model-based approach (see, e.g., Esteban et al. 2019). After the model receives the true rewards from the sampled arms, the population estimate is predicted as: , where is the NRP sample weight444The returns in each NRP strata can be weighted by the NRP sample weights to make the sample representative of the overall population, acting as inverse propensity weights. We use NRP weights for population estimation. See Appendix K. from the population distribution.
Optimism. We refer readers to Lattimore and Szepesvári (2020) for a general introduction to Upper Confidence Bound (UCB) and optimism-based methods. We import an optimism-based approach into this setting as follows. Consider a random forest with trees . We form an optimistic estimate of the reward for each arm according to: , where is an exploration parameter based on the variance of the tree-based predictions, similar to Hutter, Hoos, and Leyton-Brown (2011). We select the returns with the largest optimistic reward estimates. We shorthand this approach as UCB and use the same model-based population estimation method as -greedy.
ABS Sampling. Adaptive Bin Sampling brings together sampling and bandit literatures to guarantee statistically unbiased population estimates, while enabling an explicit trade-off between reward and the variance of the estimate. In essence, ABS performs adjustable risk-proportional random sampling over optimized population strata. By maintaining probabilistic sampling, ABS can employ HT estimation to achieve an unbiased measurement of the population.
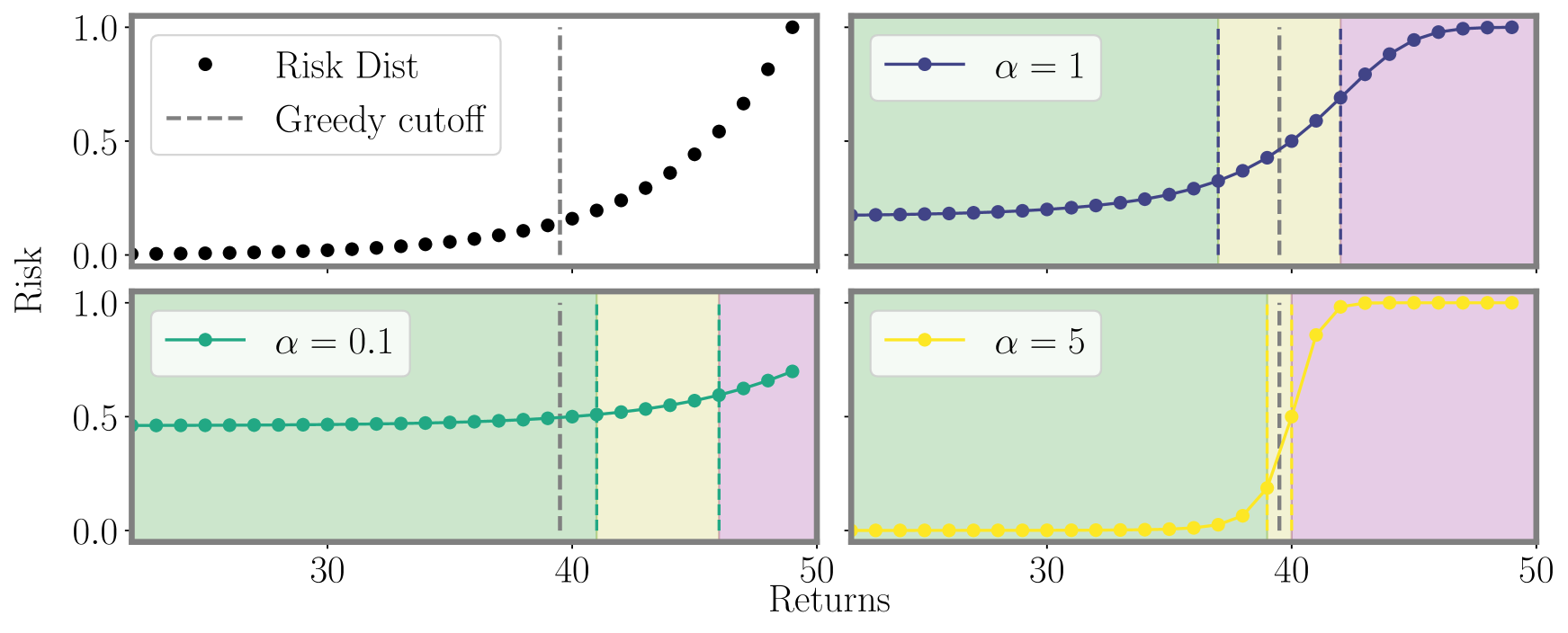
Pseudocode is given in Algorithm 1. Fix timestep and let be our budget. Let be the predicted risk for return . First we sample the top returns. To make the remaining selections, we parameterize the predictions with a mixing function intended to smoothly transition focus between the reward and variance objectives, but whose only requirement is that it be monotone (rank-preserving). For our empirical exploration we examine two such mixing functions, a logistic function, and an exponential function . is the value of the -th largest value amongst reward predictions . As decreases, approaches a uniform distribution which results in lower variance for but lower reward. As increases, the variance of increases but so too does the reward. Figure 1 provides a visualization of this.
The distribution of transformed predictions is then stratified into non-intersecting strata . We choose strata in order to minimize intra-cluster variance, such that there are at least points per bin:
| (3) |
where is the average value of the points in bin . We place a distribution over the bins by averaging the risk in each bin:
| (4) |
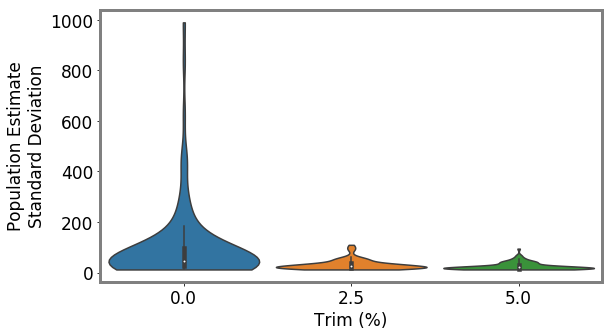
To make our selection, we sample times from to obtain a bin, and then we sample uniformly within that bin to choose the return. We do not recalculate after each selection, so while we are sampling without replacement at the level of returns (we cannot audit the same taxpayer twice), we are sampling with replacement at the level of bins. The major benefit of ABS is that by sampling according to the distribution , we can employ HT estimation to eliminate bias. Indeed, if is the set of arms sampled during an epoch, is an unbiased estimate of the true population, where is the probability that arm was selected (i.e., ) and is the NRP weight. Like with other HT-based methods (Potter 1990; Alexander, Dahl, and Weidman 1997), to reduce variance we also add an option for a minimum probability of sampling a bin, which we call the trim %. See Appendix N for more details, proof of unbiased estimation, and estimator variance. See Appendix U for regret bounds.
Reward Structure Models. As the data is highly non-linear and high-dimensional, we use Random Forest Regression (RFR) for our reward model. We exclude linear models from our suite of algorithms after verifying that they consistently underperform RFR (Appendix M). We do not include neural networks in this analysis as the data regime is too small. Future approaches might build on this work using pretraining methods suited for a few-shot context (Bommasani et al. 2021). We do compare to an LDA baseline (Appendix T.3). This is included both as context to our broad modeling decisions, and as an imperfect stylized proxy for one component of the current risk-based selection approach used by the IRS.
4 Evaluation Protocol
We evaluate according to three metrics: cumulative reward, percent difference of the population estimate, and the no-change rate. More details in Appendix L.2 and L.3.
Cumulative reward () is simply the total reward of all arms selected by the agent across the entire time series . It represents the total amount of under-reported tax revenue returned to the government after auditing. This is averaged across seeds and denoted as .
Percent difference (, ) is the difference between the estimated population average and the true population average: . is absolute mean percent difference across seeds (bias). is the standard deviation of the percent difference across random seeds.
No-change rate () is the percent of arms that yield no reward where we round down such that any reward $200 is considered no change . NR is of some importance. An audit that results in no adjustment can be perceived as unfair, because the taxpayer did not commit any wrongdoing (Lawsky 2008). It can have adverse effects on future compliance (Beer et al. 2015; Lederman 2018). is the average NR across seeds.
Experimental Protocol. Our evaluation protocol for all experiments follows the same pattern. For a given year we offer 80% of the NRP sample as arms for the agent to select from. We repeat this process across 20 distinct random seeds such that there are 20 unique subsampled datasets that are shared across all methods, creating a sub-sampled bootstrap for Confidence Intervals (more in Appendix S). Comparing methods seed-to-seed will be the same as comparing two methods on the same dataset. Each year, the agent has a budget of 600 arms to select from the population of 10k+ arms (description of budget selection in Appendix R). We delay the delivery of rewards for one year. This is because the majority of audits are completed and returned only after such a delay (DeBacker et al. 2018). Thus, the algorithm in year 2008 will only make decisions with the information from 2006. Because of this delay the first two years are randomly sampled for the entire budget (i.e., there is a warm start). After receiving rewards for a given year, the agent must then provide a population estimate of the overall population average for the reward (i.e., the average tax adjustment after audit). This process repeats until 2014, the final year available in our NRP dataset (diagram in Appendix O).
Best Reward Settings Policy Unbiased ABS-1 $41.5M∗ 0.4 ✓ 31.0 37.6% -only $41.3M∗ 4.3✓ 37.4 38.3% ABS-2 $40.5M∗ 0.6✓ 24.5 38.3% Random $12.7M 1.5✓ 14.7 53.1% Biased Greedy $43.6M∗ 16.4 ✗ 8.8 36.5% UCB-1 $42.4M∗ 15.3 ✗ 9.4 38.6% -Greedy $41.3M∗ 6.1 ✗ 7.5 38.3% UCB-2 $40.7M∗ 15.6 ✗ 10.21 40.7%
5 Results
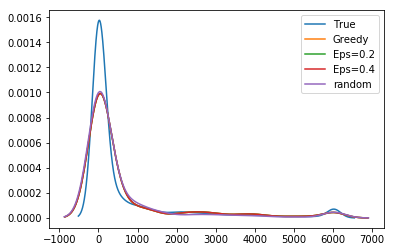
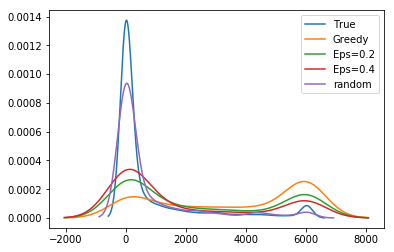
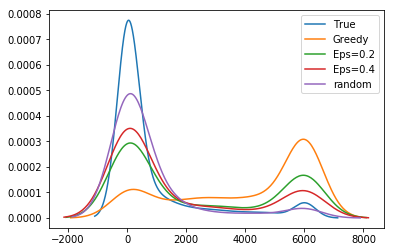
We highlight several key findings with additional results and sensitivity analyses in Appendix T.
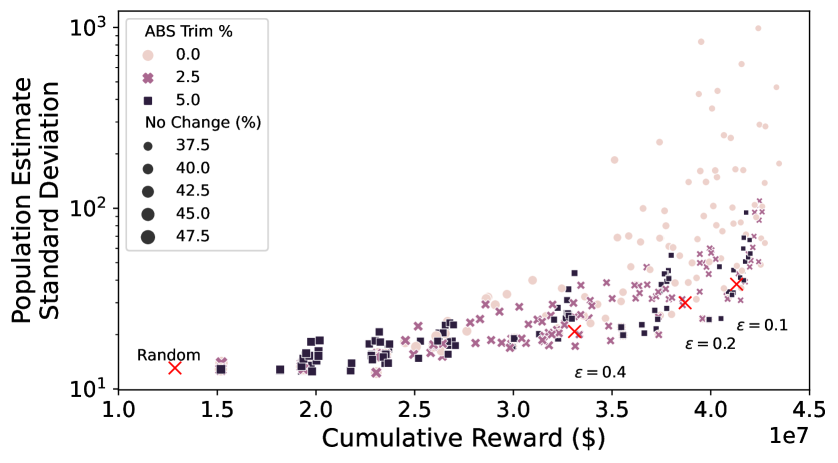
Unbiased population estimates are possible with little impact to reward. ABS sampling can achieve similar returns to the best performing methods in terms of audit selection, while yielding an unbiased population estimate (see Table 1). Conversely, greedy, -greedy, and UCB approaches – which use a model-based population estimation method – do not achieve unbiased population estimates. Others have noted that adaptively collected data can lead to biased models (Nie et al. 2018; Neel and Roth 2018). In many public sector settings provably unbiased methods like ABS are required. For -greedy, using the -sample only would also achieve an unbiased estimate, yet due to its small sample size the variance is prohibitively high. ABS reduces variance by 16% over the best -only method, yielding even better reward. Trading off $1M over 9 years improves variance over -Greedy (-only) by 35%. It is possible to reduce this variance even further at the cost of some more reward (see Figure 2). Note, due to an extremely small sample size, though the sample is unbiased in theory, we see some minor bias in practice. Model-based estimates are significantly lower variance, but biased. This may be because models re-use information across years, whereas ABS does not. Future research could re-use information in ABS to reduce variance, perhaps with a model’s assistance. Nonetheless, we emphasize that model-based estimates without unbiasedness guarantees are unacceptable for many public sector uses from a policy perspective.
ABS allows fine-grained control over variance-reward trade-off. We sample a grid of hyperparameters for ABS (see Appendix P). Figure 2 shows that more hyperparameter settings close to optimal rewards have higher variance in population estimates. We can control this variance with the trimming mechanism. This ensures that each bin of the risk distribution will be sampled some minimum amount. Figure 2 also shows that when we add trimming, we can retain large rewards and unbiased population estimates. Top configurations (Table 1) can keep variance down to only 1.7x that of a random sample, while yielding 3.2x reward. While -greedy with the random sample only does surprisingly well, optimal ABS configurations have a better Pareto front. We can fit a function to this Pareto front and estimate the marginal value of the reward-variance trade-off (see Appendix T.2).
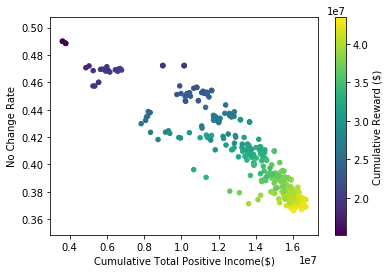
Greedy is not all you need. Greedy surprisingly achieves more optimal reward compared to all other methods (see Table 1). This aligns with prior work suggesting that a purely greedy approach in contextual bandits might be enough to induce sufficient exploration under highly varied contexts (Bietti, Agarwal, and Langford 2018; Kannan et al. 2018; Bastani, Bayati, and Khosravi 2021). Here, there are several intrinsic sources of exploration that may cause this result: intrinsic model error, covariate drift (see Appendix Table 5), differences in tax filing compositions, and the fact that our population of arms already come from a stratified random sample (changing in composition year-to-year).
Figure 2 (bottom) demonstrates greedy sampling’s implicit exploration for one random seed. As the years progress, greedy is (correctly) more biased toward sampling arms with high rewards. Nonetheless, it yields a large number of arms that are the same as a random sample would yield. This inherent exploration backs the hypothesis that the test sample is highly stochastic, leading to implicit exploration. It is worth emphasizing that in a larger population and with a larger budget, greedy’s exploration may not be sufficient and more explicit exploration may be needed. The key difference from our result and prior work showing greedy’s surprising performance (Bietti, Agarwal, and Langford 2018; Kannan et al. 2018; Bastani, Bayati, and Khosravi 2021) is our additional population estimation objective. The greedy policy has a significant bias when it comes to model-based population estimation. This bias is similar – but not identical – to the bias reported in other adaptive data settings (Thrun and Schwartz 1993; Nie et al. 2018; Shin, Ramdas, and Rinaldo 2021; Farquhar, Gal, and Rainforth 2021). Even a 10% random sample – significantly underpowered for typical sampling-based estimation – can reduce this bias by more than 2.5 (see Table 1). Even if greedy can be optimal for a high-variance contextual bandit, it is not optimal for the optimize-and-estimate setting. -greedy achieves a compromise between variance that may be more acceptable in settings when some bias is permitted, but bias is not desirable in most public sector settings. We also show that RFR regressors significantly outperform LDA and that incorporating non-random data helps (Appendix T.3). This is a stylized proxy of the status quo system that uses a small -only sample (NRP) for population estimates and an LDA-like algorithm (DIF) for selection.
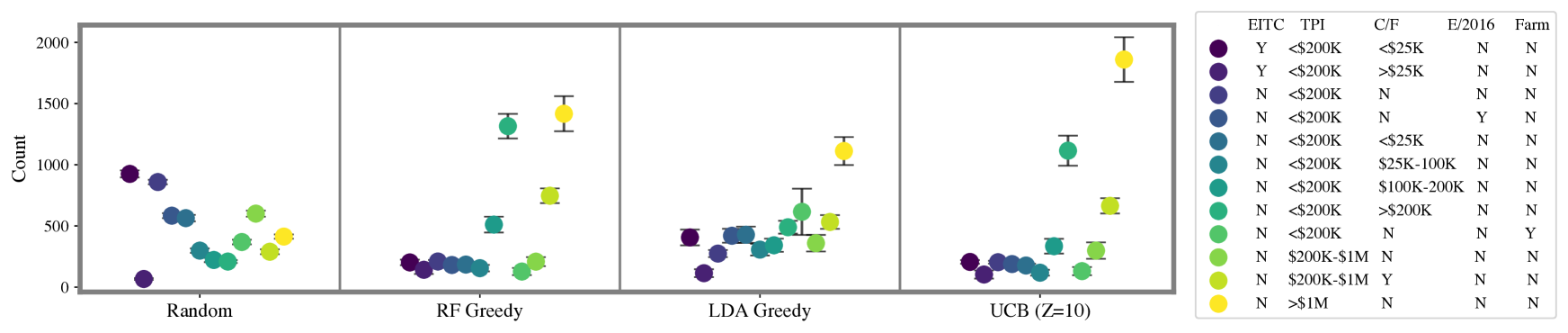
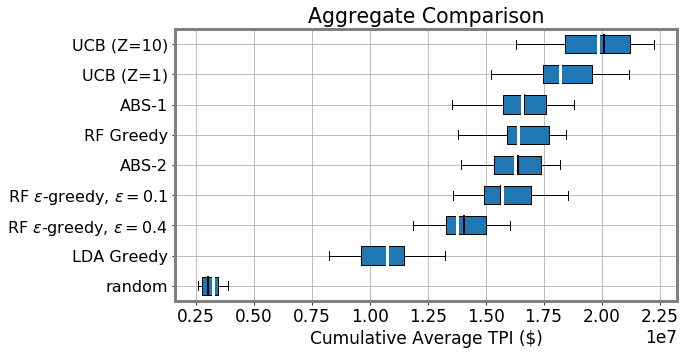
A more focused approach audits higher cumulative total positive income. A key motivator for our work is that inefficiently-allocated randomness in audit selection will not only be suboptimal for the government, but could impose unnecessary burdens on taxpayers (Lawsky 2008; Davis-Nozemack 2012). An issue that has received increasing attention by policymakers and commentators in recent years concerns the fair allocation of audits by income (Kiel 2019; Internal Revenue Service 2021; Treasury 2021). Although we do not take a normative position on the precise contours of a fair distribution of audits, we examine how alternative models shape the income distribution of audited taxpayers.
As shown in Figure 3, we find that as methods become more optimal we see an increase in the total positive income (TPI) of the individuals selected for audit (RF Greedy selects between $1.8M and $9.4M more cumulative TPI than LDA Greedy, effect size 95% CI matched by seed). We also show the distribution of ABS hyperparameter settings we sampled. As the settings are more likely to increase reward and decrease no change rates, the cumulative TPI increases. This indicates that taxpayers with lower TPI are less likely to be audited as models are more likely to sample in the higher range of the risk distribution. We confirm this in Figure 3 (top) which shows the distribution of activity classes sampled by different approaches. These classes are used as strata in the NRP sample. The UCB and RF Greedy approaches are more likely to audit taxpayers with more than $1M in TPI (with UCB sampling this class significantly more, likely due to heteroskedasticity). More optimal approaches also significantly sample those with $200K in TPI, but more than $200K reported on their Schedule C or F tax return forms (used to report business and farm income, respectively).
Errors are heteroskedastic, causing difficulties in using model-based optimism methods. Surprisingly, our optimism-based approach audits tax returns with higher TPI more often ($1.2M to $5.8M million cumulative TPI more than RF Greedy) despite yielding similar returns as the greedy approach. We believe this is because adjustments and model errors are heteroskedastic. Though TPI is correlated with the adjustment amount (Pearson ), all errors across model fits were heteroskedastic according to a Breusch–Pagan test (). A potential source of large uncertainty estimates in the high income range could be because: (1) there are fewer datapoints in that part of the feature space; (2) NRP audits may not give an accurate picture of misreporting at the higher part of the income space, resulting in larger variance and uncertainty (Guyton et al. 2021); or (3) additional features are needed to improve precision in part of the state space. This makes it difficult to use some optimism-based approaches since there is a confound between aleatoric and epistemic uncertainty. As a result, optimism-based approaches audit higher income individuals more often, but do not necessarily achieve higher returns. This poses another interesting challenge for future research.
6 Discussion
We have introduced the optimize-and-estimate structured bandit setting. The setting is motivated by common features of public sector applications (e.g., multiple objectives, batched selection), where there is wide applicability of sequential decision making, but, to date, limited understanding of the unique methodological challenges. We empirically investigate the use of structured bandits in the IRS setting and show that ABS conforms to IRS specifications (unbiased estimation) and enables parties to explicitly trade off population estimation variance and reward maximization. This framework could help address longstanding concerns in the real-world setting of IRS detection of tax evasion. It could shift audits toward tax returns with larger understatements (correlating with more total positive income) and recover more revenue than the status quo, while maintaining an unbiased population estimate. Though there are other real-world objectives to consider, such as the effect of audit policies on tax evasion, our results suggest that unifying audit selection with estimation may help ensure that processes are as fair, optimal, and robust as possible. We hope that the methods we describe here are a starting point for both additional research into sequential decision-making in public policy and new research into optimize-and-estimate structured bandits.
Acknowledgements
We would like to thank Emily Black, Jason DeBacker, Hadi Elzayn, Tom Hertz, Andrew Johns, Dan Jurafsky, Mansheej Paul, Ahmad Qadri, Evelyn Smith, and Ben Swartz for helpful discussions. This work was supported by the Hoffman Yee program at Stanford’s Institute for Human-Centered Artificial Intelligence and Arnold Ventures. PH is supported by the Open Philanthropy AI Fellowship. This work was conducted while BA was at Stanford University. The findings, interpretations, and conclusions expressed in this paper are entirely those of the authors and do not necessarily reflect the views or the official positions of the U.S. Department of the Treasury or the Internal Revenue Service. Any taxpayer data used in this research was kept in a secured Treasury or IRS data repository, and all results have been reviewed to ensure no confidential information is disclosed.
References
- Abbasi-Yadkori, Pál, and Szepesvári (2011) Abbasi-Yadkori, Y.; Pál, D.; and Szepesvári, C. 2011. Improved algorithms for linear stochastic bandits. Advances in Neural Information Processing Systems, 24.
- Abe and Long (1999) Abe, N.; and Long, P. M. 1999. Associative reinforcement learning using linear probabilistic concepts. In ICML, 3–11. Citeseer.
- Agarwal et al. (2021) Agarwal, R.; Schwarzer, M.; Castro, P. S.; Courville, A. C.; and Bellemare, M. 2021. Deep reinforcement learning at the edge of the statistical precipice. Advances in Neural Information Processing Systems, 34.
- Agrawal and Devanur (2015) Agrawal, S.; and Devanur, N. R. 2015. Linear contextual bandits with knapsacks. arXiv preprint arXiv:1507.06738.
- Alexander, Dahl, and Weidman (1997) Alexander, C. H.; Dahl, S.; and Weidman, L. 1997. Making estimates from the american community survey. In Annual Meeting of the American Statistical Association (ASA), Anaheim, CA.
- Andreoni, Erard, and Feinstein (1998) Andreoni, J.; Erard, B.; and Feinstein, J. 1998. Tax compliance. Journal of Economic Literature, 36(2): 818–860.
- Ash, Galletta, and Giommoni (2021) Ash, E.; Galletta, S.; and Giommoni, T. 2021. A Machine Learning Approach to Analyze and Support Anti-Corruption Policy.
- Bastani, Bayati, and Khosravi (2021) Bastani, H.; Bayati, M.; and Khosravi, K. 2021. Mostly exploration-free algorithms for contextual bandits. Management Science, 67(3): 1329–1349.
- Beer et al. (2015) Beer, S.; Kasper, M.; Kirchler, E.; and Erard, B. 2015. Audit Impact Study. Technical report, National Taxpayer Advocate.
- Belnap et al. (2020) Belnap, A.; Hoopes, J. L.; Maydew, E. L.; and Turk, A. 2020. Real effects of tax audits: Evidence from firms randomly selected for IRS examination. SSRN.
- Bertomeu et al. (2021) Bertomeu, J.; Cheynel, E.; Floyd, E.; and Pan, W. 2021. Using machine learning to detect misstatements. Review of Accounting Studies, 26(2): 468–519.
- Biecek (2018) Biecek, P. 2018. DALEX: explainers for complex predictive models in R. The Journal of Machine Learning Research, 19(1): 3245–3249.
- Bietti, Agarwal, and Langford (2018) Bietti, A.; Agarwal, A.; and Langford, J. 2018. A contextual bandit bake-off. arXiv preprint arXiv:1802.04064.
- Bommasani et al. (2021) Bommasani, R.; Hudson, D. A.; Adeli, E.; Altman, R.; Arora, S.; von Arx, S.; Bernstein, M. S.; Bohg, J.; Bosselut, A.; Brunskill, E.; et al. 2021. On the Opportunities and Risks of Foundation Models. arXiv preprint arXiv:2108.07258.
- Bouneffouf and Rish (2019) Bouneffouf, D.; and Rish, I. 2019. A survey on practical applications of multi-armed and contextual bandits. arXiv preprint arXiv:1904.10040.
- Bouthillier et al. (2021) Bouthillier, X.; Delaunay, P.; Bronzi, M.; Trofimov, A.; Nichyporuk, B.; Szeto, J.; Mohammadi Sepahvand, N.; Raff, E.; Madan, K.; Voleti, V.; et al. 2021. Accounting for variance in machine learning benchmarks. Proceedings of Machine Learning and Systems, 3.
- Caria et al. (2020) Caria, S.; Kasy, M.; Quinn, S.; Shami, S.; Teytelboym, A.; et al. 2020. An adaptive targeted field experiment: Job search assistance for refugees in Jordan.
- Chugg et al. (2022) Chugg, B.; Henderson, P.; Goldin, J.; and Ho, D. E. 2022. Entropy Regularization for Population Estimation. arXiv preprint arXiv:2208.11747.
- Chugg and Ho (2021) Chugg, B.; and Ho, D. E. 2021. Reconciling Risk Allocation and Prevalence Estimation in Public Health Using Batched Bandits. NeurIPS workshop on Machine Learning in Public Health.
- Congressional Budget Office (2020) Congressional Budget Office. 2020. Trends in the Internal Revenue Service’s Funding and Enforcement.
- Davis-Nozemack (2012) Davis-Nozemack, K. 2012. Unequal burdens in EITC compliance. Law & Ineq., 31: 37.
- de Roux et al. (2018) de Roux, D.; Perez, B.; Moreno, A.; Villamil, M. d. P.; and Figueroa, C. 2018. Tax fraud detection for under-reporting declarations using an unsupervised machine learning approach. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, 215–222.
- DeBacker, Heim, and Tran (2015) DeBacker, J.; Heim, B. T.; and Tran, A. 2015. Importing corruption culture from overseas: Evidence from corporate tax evasion in the United States. Journal of Financial Economics, 117(1): 122–138.
- DeBacker et al. (2018) DeBacker, J.; Heim, B. T.; Tran, A.; and Yuskavage, A. 2018. The effects of IRS audits on EITC claimants. National Tax Journal, 71(3): 451–484.
- Deliu, Williams, and Villar (2021) Deliu, N.; Williams, J. J.; and Villar, S. S. 2021. Efficient Inference Without Trading-off Regret in Bandits: An Allocation Probability Test for Thompson Sampling. arXiv preprint arXiv:2111.00137.
- Dickey, Blanke, and Seaton (2019) Dickey, G.; Blanke, S.; and Seaton, L. 2019. Machine Learning in Auditing. The CPA Journal, 16–21.
- Dimakopoulou et al. (2017) Dimakopoulou, M.; Zhou, Z.; Athey, S.; and Imbens, G. 2017. Estimation considerations in contextual bandits. arXiv preprint arXiv:1711.07077.
- Drugan and Nowé (2014) Drugan, M. M.; and Nowé, A. 2014. Scalarization based Pareto optimal set of arms identification algorithms. In 2014 International Joint Conference on Neural Networks (IJCNN), 2690–2697. IEEE.
- Dularif et al. (2019) Dularif, M.; Sutrisno, T.; Saraswati, E.; et al. 2019. Is deterrence approach effective in combating tax evasion? A meta-analysis. Problems and Perspectives in Management, 17(2): 93–113.
- Erard and Feinstein (2011) Erard, B.; and Feinstein, J. S. 2011. The individual income reporting gap: what we see and what we don’t. In IRS-TPC Research Conference on New Perspectives in Tax Administration.
- Erraqabi et al. (2017) Erraqabi, A.; Lazaric, A.; Valko, M.; Brunskill, E.; and Liu, Y.-E. 2017. Trading off rewards and errors in multi-armed bandits. In Artificial Intelligence and Statistics, 709–717. PMLR.
- Esteban et al. (2019) Esteban, J.; McRoberts, R. E.; Fernández-Landa, A.; Tomé, J. L.; and Næsset, E. 2019. Estimating forest volume and biomass and their changes using random forests and remotely sensed data. Remote Sensing, 11(16): 1944.
- Farquhar, Gal, and Rainforth (2021) Farquhar, S.; Gal, Y.; and Rainforth, T. 2021. On statistical bias in active learning: How and when to fix it. arXiv preprint arXiv:2101.11665.
- Foster and Rakhlin (2020) Foster, D. J.; and Rakhlin, A. 2020. Beyond UCB: Optimal and efficient contextual bandits with regression oracles. arXiv preprint arXiv:2002.04926.
- Foster et al. (2020) Foster, D. J.; Rakhlin, A.; Simchi-Levi, D.; and Xu, Y. 2020. Instance-dependent complexity of contextual bandits and reinforcement learning: A disagreement-based perspective. arXiv preprint arXiv:2010.03104.
- Government Accountability Office (2002) Government Accountability Office. 2002. New Compliance Research Effort Is on Track, but Important Work Remains. https://www.gao.gov/assets/gao-02-769.pdf. United States General Accounting Office: Report to the Committee on Finance, U.S. Senate. Online; Accessed Jan 10, 2022.
- Government Accountability Office (2003) Government Accountability Office. 2003. IRS Is Implementing the National Research Program as Planned. https://www.gao.gov/assets/gao-03-614.pdf. United States General Accounting Office: Report to the Committee on Finance, U.S. Senate. Online; Accessed Jan 10, 2022.
- Guo et al. (2021) Guo, W.; Agrawal, K. K.; Grover, A.; Muthukumar, V.; and Pananjady, A. 2021. Learning from an Exploring Demonstrator: Optimal Reward Estimation for Bandits. arXiv preprint arXiv:2106.14866.
- Guyton et al. (2020) Guyton, J.; Langetieg, P.; Reck, D.; Risch, M.; and Zucman, G. 2020. Tax Evasion by the Wealthy: Measurement and Implications. In Measuring and Understanding the Distribution and Intra/Inter-Generational Mobility of Income and Wealth. University of Chicago Press.
- Guyton et al. (2021) Guyton, J.; Langetieg, P.; Reck, D.; Risch, M.; and Zucman, G. 2021. Tax Evasion at the Top of the Income Distribution: Theory and Evidence. Technical report, National Bureau of Economic Research.
- Guyton et al. (2018) Guyton, J.; Leibel, K.; Manoli, D. S.; Patel, A.; Payne, M.; and Schafer, B. 2018. The effects of EITC correspondence audits on low-income earners. Technical report, National Bureau of Economic Research.
- Henderson et al. (2021) Henderson, P.; Chugg, B.; Anderson, B.; and Ho, D. E. 2021. Beyond Ads: Sequential Decision-Making Algorithms in Law and Public Policy. arXiv preprint arXiv:2112.06833.
- Henderson et al. (2020) Henderson, P.; Hu, J.; Romoff, J.; Brunskill, E.; Jurafsky, D.; and Pineau, J. 2020. Towards the systematic reporting of the energy and carbon footprints of machine learning. Journal of Machine Learning Research, 21(248): 1–43.
- Henderson et al. (2018) Henderson, P.; Islam, R.; Bachman, P.; Pineau, J.; Precup, D.; and Meger, D. 2018. Deep reinforcement learning that matters. In Proceedings of the AAAI conference on artificial intelligence, volume 32.
- Ho and Xiang (2020) Ho, D. E.; and Xiang, A. 2020. Affirmative algorithms: The legal grounds for fairness as awareness. U. Chi. L. Rev. Online, 134.
- Horvitz and Thompson (1952) Horvitz, D. G.; and Thompson, D. J. 1952. A generalization of sampling without replacement from a finite universe. Journal of the American statistical Association, 47(260): 663–685.
- Howard et al. (2020) Howard, B.; Lykke, L.; Pinski, D.; and Plumley, A. 2020. Can Machine Learning Improve Correspondence Audit Case Selection?
- Huang and Lin (2016) Huang, K.-H.; and Lin, H.-T. 2016. Linear upper confidence bound algorithm for contextual bandit problem with piled rewards. In Pacific-Asia Conference on Knowledge Discovery and Data Mining, 143–155. Springer.
- Hutter, Hoos, and Leyton-Brown (2011) Hutter, F.; Hoos, H. H.; and Leyton-Brown, K. 2011. Sequential model-based optimization for general algorithm configuration. In International conference on learning and intelligent optimization, 507–523. Springer.
- Internal Revenue Service (2016) Internal Revenue Service. 2016. Federal tax compliance research: Tax gap estimates for tax years 2008–2010.
- Internal Revenue Service (2019) Internal Revenue Service. 2019. Federal tax compliance research: Tax gap estimates for tax years 2011–2013.
- Internal Revenue Service (2021) Internal Revenue Service. 2021. IRS Update on Audits. https://www.irs.gov/newsroom/irs-update-on-audits. Online; Accessed Jan 10, 2022.
- Internal Revenue Service (2022) Internal Revenue Service. 2022.
- Järvelin and Kekäläinen (2002) Järvelin, K.; and Kekäläinen, J. 2002. Cumulated gain-based evaluation of IR techniques. ACM Transactions on Information Systems (TOIS), 20(4): 422–446.
- Johns and Slemrod (2010) Johns, A.; and Slemrod, J. 2010. The distribution of income tax noncompliance. National Tax Journal, 63(3): 397.
- Joseph et al. (2018) Joseph, M.; Kearns, M.; Morgenstern, J.; Neel, S.; and Roth, A. 2018. Meritocratic fairness for infinite and contextual bandits. In Proceedings of the 2018 AAAI/ACM Conference on AI, Ethics, and Society, 158–163.
- Kannan et al. (2018) Kannan, S.; Morgenstern, J. H.; Roth, A.; Waggoner, B.; and Wu, Z. S. 2018. A smoothed analysis of the greedy algorithm for the linear contextual bandit problem. Advances in Neural Information Processing Systems, 31.
- Kasy and Sautmann (2021) Kasy, M.; and Sautmann, A. 2021. Adaptive treatment assignment in experiments for policy choice. Econometrica, 89(1): 113–132.
- Katerenchuk and Rosenberg (2018) Katerenchuk, D.; and Rosenberg, A. 2018. RankDCG: Rank-ordering evaluation measure. arXiv preprint arXiv:1803.00719.
- Kato et al. (2020) Kato, M.; Ishihara, T.; Honda, J.; and Narita, Y. 2020. Efficient Adaptive Experimental Design for Average Treatment Effect Estimation.
- Kiel (2019) Kiel, P. 2019. It’s Getting Worse: The IRS Now Audits Poor Americans at About the Same Rate as the Top 1%. https://www.propublica.org/article/irs-now-audits-poor-americans-at-about-the-same-rate-as-the-top-1-percent. Online; Accessed Jan 10, 2022.
- Kotsiantis et al. (2006) Kotsiantis, S.; Koumanakos, E.; Tzelepis, D.; and Tampakas, V. 2006. Predicting fraudulent financial statements with machine learning techniques. In Hellenic Conference on Artificial Intelligence, 538–542. Springer.
- Lacoste et al. (2019) Lacoste, A.; Luccioni, A.; Schmidt, V.; and Dandres, T. 2019. Quantifying the Carbon Emissions of Machine Learning. arXiv preprint arXiv:1910.09700.
- Lansdell, Triantafillou, and Kording (2019) Lansdell, B.; Triantafillou, S.; and Kording, K. 2019. Rarely-switching linear bandits: optimization of causal effects for the real world. arXiv preprint arXiv:1905.13121.
- Lattimore and Szepesvári (2020) Lattimore, T.; and Szepesvári, C. 2020. Bandit algorithms. Cambridge University Press.
- Lawsky (2008) Lawsky, S. B. 2008. Fairly random: On compensating audited taxpayers. Conn. L. Rev., 41: 161.
- Lederman (2018) Lederman, L. 2018. Does enforcement reduce voluntary tax compliance. BYU L. Rev., 623.
- Li et al. (2010) Li, L.; Chu, W.; Langford, J.; and Schapire, R. E. 2010. A contextual-bandit approach to personalized news article recommendation. In Proceedings of the 19th international conference on World wide web, 661–670.
- Liu et al. (2014) Liu, Y.-E.; Mandel, T.; Brunskill, E.; and Popovic, Z. 2014. Trading Off Scientific Knowledge and User Learning with Multi-Armed Bandits. In EDM, 161–168.
- Lowe (1976) Lowe, V. L. 1976. Statement Before the Subcommittee on Oversight House Committee on Ways and Means on How the Internal Revenue Service Selects and Audits Individual Income Tax Returns.
- Marr and Murray (2016) Marr, C.; and Murray, C. 2016. IRS funding cuts compromise taxpayer service and weaken enforcement. http://www. cbpp. org/sites/default/files/atoms/files/6-25-14tax. pdf. Last accessed August, 29: 2016.
- Matta et al. (2016) Matta, J. C. D. L.; Guyton, J.; Hodge II, R.; Langetieg, P.; Orlett, S.; Payne, M.; Qadri, A.; Rupert, L.; Schafer, B.; Turk, A.; and Vigil, M. 2016. Understanding the Nonfi ler/Late Filer: Preliminary Findings. 6th Annual Joint Research Conference on Tax Administration Co-Sponsored by the IRS and the Urban-Brookings Tax Policy Center.
- Mersereau, Rusmevichientong, and Tsitsiklis (2009) Mersereau, A. J.; Rusmevichientong, P.; and Tsitsiklis, J. N. 2009. A structured multiarmed bandit problem and the greedy policy. IEEE Transactions on Automatic Control, 54(12): 2787–2802.
- Mittal, Reich, and Mahajan (2018) Mittal, S.; Reich, O.; and Mahajan, A. 2018. Who is bogus? using one-sided labels to identify fraudulent firms from tax returns. In Proceedings of the 1st ACM SIGCAS Conference on Computing and Sustainable Societies, 1–11.
- Mukherjee, Tripathy, and Nowak (2020) Mukherjee, S.; Tripathy, A.; and Nowak, R. 2020. Generalized Chernoff Sampling for Active Learning and Structured Bandit Algorithms. arXiv preprint arXiv:2012.08073.
- Neel and Roth (2018) Neel, S.; and Roth, A. 2018. Mitigating bias in adaptive data gathering via differential privacy. In International Conference on Machine Learning, 3720–3729. PMLR.
- Nie et al. (2018) Nie, X.; Tian, X.; Taylor, J.; and Zou, J. 2018. Why adaptively collected data have negative bias and how to correct for it. In International Conference on Artificial Intelligence and Statistics, 1261–1269. PMLR.
- Nika, Elahi, and Tekin (2021) Nika, A.; Elahi, S.; and Tekin, C. 2021. Contextual Combinatorial Volatile Bandits via Gaussian Processes. arXiv preprint arXiv:2110.02248.
- Office of Management and Budget (2018) Office of Management and Budget. 2018. Requirements for Payment Integrity Improvement. https://www.whitehouse.gov/wp-content/uploads/2018/06/M-18-20.pdf. Executive Office of the President. Online; Accessed Jan 10, 2022.
- Office of Management and Budget (2021) Office of Management and Budget. 2021. Requirements for Payment Integrity Improvement. https://www.whitehouse.gov/wp-content/uploads/2021/03/M-21-19.pdf. Executive Office of the President. Online; Accessed Jan 10, 2022.
- Pandey and Olston (2006) Pandey, S.; and Olston, C. 2006. Handling advertisements of unknown quality in search advertising. Advances in Neural Information Processing Systems, 19.
- Politis, Romano, and Wolf (1999) Politis, D.; Romano, J. P.; and Wolf, M. 1999. Subsampling.
- Politis (2003) Politis, D. N. 2003. The impact of bootstrap methods on time series analysis. Statistical science, 219–230.
- Politis and Romano (1994) Politis, D. N.; and Romano, J. P. 1994. Large sample confidence regions based on subsamples under minimal assumptions. The Annals of Statistics, 2031–2050.
- Potter (1990) Potter, F. J. 1990. A study of procedures to identify and trim extreme sampling weights. In Proceedings of the American Statistical Association, Section on Survey Research Methods, volume 225230. American Statistical Association Washington, DC.
- Qin and Russo (2022) Qin, C.; and Russo, D. 2022. Adaptivity and confounding in multi-armed bandit experiments. arXiv preprint arXiv:2202.09036.
- Rafferty, Ying, and Williams (2018) Rafferty, A. N.; Ying, H.; and Williams, J. J. 2018. Bandit assignment for educational experiments: Benefits to students versus statistical power. In International Conference on Artificial Intelligence in Education, 286–290. Springer.
- Sarin and Summers (2019) Sarin, N.; and Summers, L. H. 2019. Shrinking the tax gap: approaches and revenue potential. Technical report, National Bureau of Economic Research.
- Sen et al. (2021) Sen, R.; Rakhlin, A.; Ying, L.; Kidambi, R.; Foster, D.; Hill, D. N.; and Dhillon, I. S. 2021. Top-k extreme contextual bandits with arm hierarchy. In International Conference on Machine Learning, 9422–9433. PMLR.
- Sener and Savarese (2018) Sener, O.; and Savarese, S. 2018. Active Learning for Convolutional Neural Networks: A Core-Set Approach. In International Conference on Learning Representations.
- Settles (2009) Settles, B. 2009. Active learning literature survey.
- Shao and Wu (1989) Shao, J.; and Wu, C. J. 1989. A general theory for jackknife variance estimation. The annals of Statistics, 1176–1197.
- Shin, Ramdas, and Rinaldo (2021) Shin, J.; Ramdas, A.; and Rinaldo, A. 2021. On the Bias, Risk, and Consistency of Sample Means in Multi-armed Bandits. SIAM Journal on Mathematics of Data Science, 3(4): 1278–1300.
- Sifa et al. (2019) Sifa, R.; Ladi, A.; Pielka, M.; Ramamurthy, R.; Hillebrand, L.; Kirsch, B.; Biesner, D.; Stenzel, R.; Bell, T.; L”ubbering, M.; et al. 2019. Towards automated auditing with machine learning. In Proceedings of the ACM Symposium on Document Engineering 2019, 1–4.
- Simchi-Levi and Xu (2020) Simchi-Levi, D.; and Xu, Y. 2020. Bypassing the Monster: A Faster and Simpler Optimal Algorithm for Contextual Bandits under Realizability. Available at SSRN.
- Slemrod (2019) Slemrod, J. 2019. Tax compliance and enforcement. Journal of Economic Literature, 57(4): 904–54.
- Snow and Warren Jr (2005) Snow, A.; and Warren Jr, R. S. 2005. Tax evasion under random audits with uncertain detection. Economics Letters, 88(1): 97–100.
- Soemers et al. (2018) Soemers, D.; Brys, T.; Driessens, K.; Winands, M.; and Nowé, A. 2018. Adapting to concept drift in credit card transaction data streams using contextual bandits and decision trees. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 32.
- Taxpayer Advocate Service (2018) Taxpayer Advocate Service. 2018. Improper Earned Income Tax Credit Payments: Measures the IRS Takes to Reduce Improper Earned Income Tax Credit Payments Are Not Sufficiently Proactive and May Unnecessarily Burden Taxpayers. https://www.taxpayeradvocate.irs.gov/wp-content/uploads/2020/07/ARC18˙Volume1˙MSP˙06˙ImproperEarnedIncome.pdf. 2018 Annual Report to Congress — Volume One. Online; Accessed Jan 10, 2022.
- Tekin and Turğay (2018) Tekin, C.; and Turğay, E. 2018. Multi-objective contextual multi-armed bandit with a dominant objective. IEEE Transactions on Signal Processing, 66(14): 3799–3813.
- Thrun and Schwartz (1993) Thrun, S.; and Schwartz, A. 1993. Issues in using function approximation for reinforcement learning. In Proceedings of the Fourth Connectionist Models Summer School, 255–263. Hillsdale, NJ.
- Treasury (2021) Treasury, U. 2021. The American Families Plan Tax Compliance Agenda. Department of Treasury, Washington, DC.
- Turgay, Oner, and Tekin (2018) Turgay, E.; Oner, D.; and Tekin, C. 2018. Multi-objective contextual bandit problem with similarity information. In International Conference on Artificial Intelligence and Statistics, 1673–1681. PMLR.
- United States Census Bureau (2018) United States Census Bureau. 2018. Public Use Microdata Sample. https://www2.census.gov/programs-surveys/acs/data/pums/2018/5-Year/csv˙hca.zip.
- United States Census Bureau (2019) United States Census Bureau. 2019. 2019 Annual Social and Economic Supplements. https://www.census.gov/data/datasets/2019/demo/cps/cps-asec-2019.html.
- Wagstaff (2012) Wagstaff, K. 2012. Machine learning that matters. arXiv preprint arXiv:1206.4656.
- Webb et al. (2016) Webb, G. I.; Hyde, R.; Cao, H.; Nguyen, H. L.; and Petitjean, F. 2016. Characterizing concept drift. Data Mining and Knowledge Discovery, 30(4): 964–994.
- Wortman et al. (2007) Wortman, J.; Vorobeychik, Y.; Li, L.; and Langford, J. 2007. Maintaining equilibria during exploration in sponsored search auctions. In International Workshop on Web and Internet Economics, 119–130. Springer.
- Xiang (2020) Xiang, A. 2020. Reconciling legal and technical approaches to algorithmic bias. Tenn. L. Rev., 88: 649.
- Xu, Qin, and Liu (2013) Xu, M.; Qin, T.; and Liu, T.-Y. 2013. Estimation bias in multi-armed bandit algorithms for search advertising. Advances in Neural Information Processing Systems, 26.
- Zhang, Janson, and Murphy (2020) Zhang, K.; Janson, L.; and Murphy, S. 2020. Inference for batched bandits. Advances in Neural Information Processing Systems, 33: 9818–9829.
- Zheng et al. (2020) Zheng, S.; Trott, A.; Srinivasa, S.; Naik, N.; Gruesbeck, M.; Parkes, D. C.; and Socher, R. 2020. The AI economist: Improving equality and productivity with AI-driven tax policies. arXiv preprint arXiv:2004.13332.
- Zhu et al. (2022) Zhu, Y.; Foster, D. J.; Langford, J.; and Mineiro, P. 2022. Contextual Bandits with Large Action Spaces: Made Practical. In International Conference on Machine Learning, 27428–27453. PMLR.
Appendix A Software and Data
We are unable to publish even anonymized data due to statutory constraints. 26 U.S. Code § 6103. All code, however, is available at https://github.com/reglab/irs-optimize-and-estimate. We also provide datasets that can act as rough proxies to the IRS data for running the code, including the Public Use Microdata Sample (PUMS) (United States Census Bureau 2018) and Annual Social and Economic Supplement (ASEC) of the Current Population Survey (CPS) (United States Census Bureau 2019). These two datasets are provided by the U.S. Census Bureau. In this case, we use the proxy goal of identifying high-income earners with non-income-based features while maintaining an estimate of total population average income.
Appendix B Carbon Impact Statement
As suggested by Lacoste et al. (2019), Henderson et al. (2020), and others, we report the energy and carbon impacts of our experiments. While we are unable to calculate precise carbon emissions from hardware counters, we give an estimate of our carbon emissions. We estimate roughly 12 weeks of CPU usage total, including hyperparameter optimization and iteration on experiments, on two Intel Xeon Platinum CPUs with a TDP of 165 W each. This is equal to roughly 665 kWh of energy used and 471 kg CO2eq at the U.S. National Average carbon intensity.
Appendix C Importance and Relevance of the Optimize-and-Estimate Setting
We note that the optimize-and-estimate setting is essential to many real-world tasks. First, we highlight that many Federal Agencies are bound by law to estimate improper payments under the Improper Payments Information Act of 2002 (IPIA), as amended by the Improper Payments Elimination and Recovery Act of 2010 (IPERA) and the Improper Payments Elimination and Recovery Improvement Act of 2012 (IPERIA). “An improper payment is any payment that should not have been made or that was made in an incorrect amount under statutory, contractual, administrative, or other legally applicable requirements.”555https://www.ignet.gov/sites/default/files/files/19%20FSA%20IPERA%20Compliance%20Slides.pdf OMB guidance varies year-to-year on how improper payments should be estimated, but generally they must be “statistically valid” (unbiased estimate of the mean) (Office of Management and Budget 2018). In past years OMB has also required tight confidence intervals on estimates (Office of Management and Budget 2018).
Generally this means that agencies will need to conduct audits, as the IRS does described in this paper, to determine if there was misreporting or improper payments were made. Effectively, the optimize-and-estimate problem that we highlight here can apply more broadly to any federal agency that falls under the laws listed above.
We also highlight that the optimize-and-estimate structured bandit setting is not uniquely important to the public sector. Private sector settings also have all the qualities of an optimize-and-estimate problem. We consider one such application below: content moderation.
During some time period, a platform will have a large set of content that might violate their policies. They will have a set of moderators who will audit content that should be taken down. There will likely be more content in need of moderation than there are moderators. As a result, it is important to take down the most egregious cases of policy-violating content, while assessing an overall estimate of prevalence on the platform. To optimize this process the platform could construct an optimize-and-estimate problem as we do here. In this case, each arm would be a piece of content that needs review. Reward is a rating on how offensive or egregious the content policy violation was. The population estimate would then give an estimate of prevalence and valence of content policy violations on the platform. Note, here unbiasedness is likely equally important to the platform since a heavy bias will incorrectly affect policy decisions about content moderation.
Appendix D Society/Ethics Statement
As part of the initial planning of this collaboration, the project proposal was presented to an Ethics Review Board and was reviewed by the IRS. While the risks of this retrospective study – which uses historical data – are minimal, we are cognizant of distributive effects that targeted auditing may have. In this work we examine the distribution of audits across income, noting that more optimal models audit higher income taxpayers – in line with current policy proposals for fair tax auditing (Treasury 2021). Our collaboration will also be investigating other notions of fairness in separate follow-on and concurrent work as they require a more in-depth examination than can be done in this work alone.
There are multiple important (and potentially conflicting) goals in selecting who to audit, including maximizing the detection of under-reported tax liability, maintaining a population estimate, avoiding the administrative and compliance costs associated with false positive audits, and ensuring a fair distribution of audits across taxpayers of different incomes and other groups. It is important to note that the IRS and Treasury Department will ultimately be responsible for the policy decision about how to balance these various objectives. We see an important contribution of our project as understanding these trade-offs and making them explicit to the relevant policy-makers. We demonstrate how to quantify and incorporate these considerations into a multi-objective model. We also formalize an existing de facto sequential decision-making (SDM) problem to help identify relevant fairness frameworks and trade-offs for policymakers (Henderson et al. 2021). We note, however, that we do not consider a number of other objectives important to the IRS, including deterring tax evasion.
Finally, as is also well-known, there is no single solution for remedying fairness – different fairness definitions are contested and mutually incompatible. For this reason, our plan is not to adopt a single, fixed performance measure. Rather, we seek to show how the optimal algorithm varies based on the relative importance one attaches to the alternative goals. For example, in this work we examine how reward-optimal models shift auditing resources toward higher incomes or particular NRP audit classes. We also note that there are some challenges in examining sub-group fairness, however, including that the IRS may not collect or possess information about protected group status (e.g., race / ethnicity). If such data were available, now-standard bias assessments and mitigation could be implemented. We note that the legality of bias mitigation remains uncertain (Xiang 2020; Ho and Xiang 2020). Overcoming these challenges requires its own examination.
With thorough additional evaluation and safeguards, as part of our ongoing collaboration with the IRS, the results of this and related research are currently being incorporated into the continual improvement of the IRS audit selection method. However, we note that all models used by the IRS go through extensive internal review processes with robustness and generalizability checks beyond the scope of our work here. No model in this work will be directly used in any auditing mechanism. There are strict statutory rules that limit the use and disclosure of taxpayer data. All work in this manuscript was completed under IRS credentials and federal government security and privacy standards. All authors that accessed data have undergone a background check and been onboarded into the IRS personnel system under the Intergovernmental Personnel Act or the student analogue. That means all data-accessing authors took all trainings on security and privacy related to IRS data and were bound by law to relevant privacy standards (e.g., The Privacy Act of 1974, The Taxpayer Browsing Protection Act, and IRS Policy on Accessing Tax Information). Consent for use of taxpayer data by IRS for tax administration purposes is statutorily provided for under 26 U.S.C. §6103(h)(1), which grants authority to IRS employees to access data for tax administration purposes. This manuscript and associated data was cleared under privacy review. All work using taxpayer data was done on a secure system with separate hardware. No taxpayer names were associated with the features used in this work.
Appendix E Related Work
Please see Table 2 for a brief summary on what sets apart our setting from others and a description of related work below.
| Setting | Papers | Batched | Estimation | Volatile Arms | Per-arm Context | Non-linear |
|---|---|---|---|---|---|---|
| Multi-armed Bandit | Deliu, Williams, and Villar (2021) | N | Y | N | N | N |
| Caria et al. (2020) | N | Y | N | N | N | |
| Kasy and Sautmann (2021) | N | Y | N | N | N | |
| Pandey and Olston (2006) | Y | Y | N | N | N | |
| Xu, Qin, and Liu (2013) | N | Y | N | N | N | |
| Guo et al. (2021) | N | Y | N | N | N | |
| Contextual Bandit | Dimakopoulou et al. (2017) | N | Y | N | N | N |
| Qin and Russo (2022) | N | Y | N | N | N | |
| Sen et al. (2021) | Y | N | N | N | Y | |
| Simchi-Levi and Xu (2020) | N | N | N | N | Y | |
| Huang and Lin (2016) | Y | N | N | N | N | |
| Structured Bandit | Abbasi-Yadkori, Pál, and Szepesvári (2011) | N | N | Y | Y | N |
| Joseph et al. (2018) | Y | N | Y | Y | N | |
| Ours | - | Y | Y | Y | Y | Y |
E.1 Similar Applications
There is growing interest in the application of ML to detecting fraudulent financial statements (Dickey, Blanke, and Seaton 2019; Bertomeu et al. 2021). Previous methods have included unsupervised outlier detection (de Roux et al. 2018), decision trees (Kotsiantis et al. 2006), and analyzing statements with NLP (Sifa et al. 2019). Closer to our methodology is a bandit approach is used by Soemers et al. (2018) to detect fraudulent credit card transactions. Meanwhile, Zheng et al. (2020) propose reinforcement learning to learn optimal tax policies, but do not focus on enforcement. Finally, some work has investigated the use of machine learning for improved audit selection in various settings (Howard et al. 2020; Ash, Galletta, and Giommoni 2021; Mittal, Reich, and Mahajan 2018). None of these approaches takes into account population estimation and some do not use sequential decision-making.
E.2 Multi-objective Decision-making
Some prior work has investigated general multi-objective optimization in the context of bandits (Drugan and Nowé 2014; Tekin and Turğay 2018; Turgay, Oner, and Tekin 2018). Most work in this vein generalizes reward scalars to vectors, and seeks pareto optimal solutions. These techniques do not extend readily to our setting, which has a secondary objective of a particular form (unbiased estimation).
E.3 Batch Selection
Other works have examined similar batched selection mechanisms such as the linear structured bandit (Mersereau, Rusmevichientong, and Tsitsiklis 2009; Abbasi-Yadkori, Pál, and Szepesvári 2011; Joseph et al. 2018), top-k extreme contextual bandit (Sen et al. 2021), or contextual bandit with piled rewards (Huang and Lin 2016).
An alternative view of this problem is as a contextual bandit problem with no shared context, but rather a per arm context. This is similar to the setup to the contextual bandit formulation of Li et al. (2010) used for news recommendation systems. However, unlike in Li et al. (2010), rewards here would have to be delivered after rounds of selection (where is the budget of audits that can be selected in a given year). Since the IRS does not conduct audits on a rolling basis, the rewards are delayed and updated all at once. This is similar to the “piled-reward” variant of the contextual bandit framework discussed by Huang and Lin (2016) or possibly a variant of contextual bandits with knapsacks (Agrawal and Devanur 2015).
Notably a large difference in our setting is the scale of the problem (there are 200M+ arms per timestep in the fully scaled problem), the non-linearity of the structure. In other batched settings, it is typically to select K actions given one context, not a per-arm context as is the case for our setting.
E.4 Inference
Due to the well-known bias exhibited by data collected by bandit algorithms (Shin, Ramdas, and Rinaldo 2021; Nie et al. 2018; Xu, Qin, and Liu 2013), a large body of work seeks to improve hypothesis testing efficiency and accuracy via an active learning or structured bandit process (Kato et al. 2020; Mukherjee, Tripathy, and Nowak 2020; Deliu, Williams, and Villar 2021). There is also a body of work that seeks to improve estimation and inference properties in bandit settings (Kasy and Sautmann 2021; Wortman et al. 2007; Zhang, Janson, and Murphy 2020; Lansdell, Triantafillou, and Kording 2019). For instance, Dimakopoulou et al. (2017) consider balancing techniques to improve inference in non-parametric contextual bandits. Chugg and Ho (2021) seek to give unbiased population estimates after data has been sampled with a MAB algorithm. Guo et al. (2021) study how to develop estimation strategies when given the learning process of another low-regret algorithm. Some of this work can be classified as click-through-rate estimation (Pandey and Olston 2006; Wortman et al. 2007; Xu, Qin, and Liu 2013). Like other adaptive experimentation literature, these works are in the multi-armed bandit (MAB) or contextual bandit settings which do not neatly map onto our own setting. Our work deals with the unique challenges of the IRS setting, requiring the use of optimize-and-estimate structured bandits, discussed below.
Some work, similarly to our approach, explicitly considers trading off maximizing reward with another objective (Liu et al. 2014; Rafferty, Ying, and Williams 2018). Caria et al. (2020) develop a Thompson sampling algorithm which trades off estimation of treatment effects with estimation accuracy. Erraqabi et al. (2017) develop an objective function to trade off rewards and model error. Deliu, Williams, and Villar (2021) develop a similar approach for navigating such trade-offs. But all of these works occur in the MAB setting, however, and are difficult to apply to our structured bandit setting. That is because we are not selecting between several treatments, but rather we are selecting a batch of arms to pull which correspond to their own context. Additionally arms are volatile, we do not necessarily know which arm corresponds to an arm in a previous timestep. Finally, arms must be selected in batches with potentially delayed reward. For example, take the Thompson sampling approach of Caria et al. (2020). In that setting the authors selected among three treatments and examined the treatment effects among them given some context. Yet, in our setting we can never observe any effect for unselected arms so our setting must instead be formulated as a structured bandit.
E.5 Active Learning
We also note that there are some similarities between our formulation and the active learning paradigm (Settles 2009). For instance, the tax gap estimation requirement could be formulated as a pool-based active learning problem, wherein the model chooses each subsequent point in order to improve its estimation of the tax gap. This also coincides somewhat with the bandit exploration component since a better model will allow the agent to select the optimal arm more frequently. However, the revenue maximization objective we introduce corresponds with the exploit component of the bandit problem and is not found in the active learning framework.
E.6 Discussion
Overall, to our knowledge the optimize-and-estimate structured bandit setting has not been proposed as we describe it here. And, more importantly, no one work has examined the unique challenges of the audit selection application in the IRS in as an optimize-and-estimate structured bandit. The assumptions we make (essential to most policy contexts including the IRS) differ from each of these other contexts: (1) arms are volatile and cannot necessarily be linked across timesteps;666Note the reason we make this assumption is because the NRP data does not track a cohort of taxpayers, but rather randomly samples. We are not guaranteed to ever see a taxpayer twice. (2) decisions are batched; (3) contexts are per arm; (4) the underlying reward structure is highly non-linear; (5) an unbiased population estimate must be retained. These key features also distinguish the optimize-and-estimate structured bandit from past work handling dual optimization and estimation objectives. To simplify things, one might think of our work as a top- contextual bandit, but the key difference is that arms are volatile in our case (you may never see the same arm twice). Thus, we must formulate our setting in a different way: a structured bandit. Thus, perhaps closest to our own is the work of Joseph et al. (2018) and Abbasi-Yadkori, Pál, and Szepesvári (2011). However, we require non-linearity and batched selection, as well as adding the novel estimation objective to this selection setting. These features differentiate it from prior MAB or even contextual bandit work. To our knowledge, this is unlike any of the prior work that handles estimation trade-offs and is the reason why we call the novel domain an optimize-and-estimate structured bandit. Perhaps closest to our own is the work of Joseph et al. (2018) and Abbasi-Yadkori, Pál, and Szepesvári (2011). But we extend this work to the batched non-linear setting with a unique estimation objective.
Appendix F Baseline Methods Selection
In determining which baselines to use we surveyed existing literature on what methods might be directly applicable. First, we noticed that existing literature that handles estimation problems, such as the adaptive RCT literature (Caria et al. 2020), do not neatly map onto our setting. We do not have multiple treatments and we never see reward for unselected arms. This ruled out simple methods related to multi-armed bandits. Instead, the closest literature is the structured bandit or linear bandit literature where each arm is assumed to have a context and the policies selects arms as such. Few sampling methods guarantee unbiased estimation in the structured bandit setting, so we turn to a simple -greedy baseline for unbiasedness. In many ways this is similar to the current IRS setting. The sample can be thought of as the NRP sample and then the greedy sample can be thought of as Op audits. This is a natural baseline to compare against. Then, we selected one optimism based approach (UCB) which has proven regret bounds in the linear bandit setting (Lattimore and Szepesvári 2020). We show in another setting that a formulation of Thompson sampling does not appear to work well in this structured bandit setting, as seen in Appendix G. We do not select more such approaches because model-based approaches are not guaranteed to be unbiased. Thus, while we include one such approach for comparison and analysis, we instead focused our efforts elsewhere instead of adding additional methods that do not meet our optimization criteria. Note, in many ways ABS sampling bears a resemblance to Thompson sampling and we encourage future work to explore more direct mappings of existing literature to the optimize-and-estimate structured bandit setting. For convenience, we make a comparison of this in Table 2.
Appendix G Evaluation on Other Datasets
We provide a small ablation study on the additional Current Population Survey (CPS) dataset. We perform the same preprocessing as Chugg et al. (2022) and have a goal of predicting the income of a person based on 122 other features. We reuse the optimal ABS hyperparameters from the IRS setting and find similar results on this new dataset. Since CPS is more stationary than the IRS data, the reward-optimal method changes from greedy to UCB. This flows naturally from Bastani, Bayati, and Khosravi (2021), since IRS data is more stochastic, greedy is more optimal. CPS is less stochastic, so UCB is more optimal. ABS remains unbiased and yields high reward. We also implement a version of Thompson sampling where we estimate the standard deviation and mean of the random forest as with the UCB setting, but then sample randomly from a Gaussian distribution with these parameters. We run all permutations for 20 random seeds. We also find that if we try to back out propensity weights for the Thompson sampling approach via Monte Carlo simulations, they are not well-formed. We rolled out 1000 times per timestep and found that even under this regime roughly 75.3% of the propensity scores were 0. As such, Thompson sampling cannot maintain unbiasedness on its own with an HT-like estimator.
| Method | Reward | Bias | Variance |
|---|---|---|---|
| UCB-1 | 473 | 13.4 | 14.4 |
| ABS-2 | 444 | -1.3 | 26.3 |
| ABS-1 | 431 | 0.2 | 26.1 |
| Thompson | 427.2 | 9.7 | 12.8 |
| E-greedy, e=0.4 (Model-based) | 313.5 | 7.25 | 10.6 |
| E-greedy, e=0.2 (Model-based) | 243.9 | 7.46 | 10.0 |
Appendix H Limitations
While we have already expressed several limitations throughout this work, we gather them here as they are fertile ground for research in the optimize-and-estimate setting. First, the ABS approach does not re-use information year-to-year for population estimation. There may be better ways to re-use information in a mixed model-based and model-free mechanism, that retains unbiasedness. Second, we focus heavily on empirical analysis as we believed it was essential for a setting as important as the IRS. However, future work can delve into theoretical aspects of the problem, potentially examining whether there are lower-variance model-based approaches that retain unbiasedness guarantees. Third, we note that our evaluations may scale differently to larger datasets. For example, with more data, utilizing the entirety of all audit outcomes, more complicated models might be more feasible.
As an initial work introducing a highly relevant setting and application, we focused more on analysis of different approaches. We have one initial approach, ABS, that meets policy requirements and outperforms baselines. Future work may seek to improve on the performance of this method, focusing more on one novel method rather than analysis, which is our goal.
H.1 Deterrence
We make several observations about deterrence. First, we do not formally take into account deterrence in this setting, as that would require economic modeling that we believe is outside the scope of this work. We note, however, that economic models of deterrence generally impose relatively strong assumptions about taxpayer knowledge of the audit rate and conventional deterrence models trade off the probability of detection and sanction as policy levers. See, e.g., Slemrod (2019); Snow and Warren Jr (2005). There is relatively limited evidence about the taxpayer knowledge of audit probabilities and existing empirical literature remains mixed about the deterrence impact of audits (Dularif et al. 2019). This leads to questions like whether the optimal approach is to use tax rates, and not audits, as policy levers for deterrence, and this is what makes direct incorporation of deterrence particularly challenging but subject to much fruitful future work. Second, broad based deterrence requires some stochasticity to create uncertainty, as otherwise one part of the population might know they will not be audited and stop complying. Indeed, this is in part why the IRS has historically withheld details of previous algorithmic approaches. We note that the ABS trim parameter ensures coverage of the population and that every part of the population has some chance of being audited (though it is minimized to the extent possible for low-risk parts of the distribution). In that sense, the additional weight on exploration induced by ABS / population estimation could promote general deterrence. In short, the explore-exploit tradeoff is quite relevant for deterrence, but the economic modeling required is beyond the scope of this work.
Appendix I Covariate Drift
We also characterize the covariate drift year to year. We calculate the average per-covariate drift via the non-intersection distance, as is done by the drifter R package (Biecek 2018), using 20 bins to calculate distributions. This provides the difference between any two given years on a per-covariate basis, which we then average and report in Table 5.
For example, we may expect some shift in total positive income year to year based on inflation. The non-intersection distance bins any continuous covariates and then provides a distance metric:
| (5) |
Other distance metrics have been used for such purposes, like the Hellinger Distance or Total Variation Distance (Webb et al. 2016), but for our purposes NID is adequate to characterize drift. The year over year drift, as seen in Table 5, is mostly constant except for 2011-2013, which has a much higher year-over-year average per-covariate drift.
Appendix J More Data Details
Figure 4 is a figure representing the current audit process at the IRS.
Table 4 is a table of notation correspondence to the IRS equivalent in our structured bandit.
Table 5 is an extended table of summary statistics, including the no change rate in the population NRP sample and the sum of sample weights (equal to the population from which NRP was sampled).
Table 6 shows the number of taxpayers in each NRP audit class, as well as provides a description of those audit classes. Table 7 provides a description of those audit classes.

| Bandit Framework | IRS Equivalent |
|---|---|
| arm () | tax return or taxpayer |
| context () | reported information to IRS, in our data 500 covariates constituting mostly of information reported in a tax return |
| reward () | adjustment amount ($) after audit |
| timestep () | the selection year |
| Year | # Audits | -uw | -w | Cov. Drift | No Change | |
|---|---|---|---|---|---|---|
| 2006 | 13403 | $2258.07 | $963.93 | - | 54.8% | 133M |
| 2007 | 14220 | $2213.64 | $920.35 | 0.0143 | 55.1% | 137M |
| 2008 | 14656 | $2442.33 | $938.11 | 0.0141 | 55.7% | 137M |
| 2009 | 12756 | $2159.62 | $989.06 | 0.0197 | 55.5% | 135M |
| 2010 | 13481 | $2177.26 | $1034.47 | 0.0143 | 53.8% | 138M |
| 2011 | 13902 | $3047.39 | $1038.69 | 0.0315 | 53.7% | 140M |
| 2012 | 15635 | $3921.93 | $1041.12 | 0.0306 | 49.9% | 140M |
| 2013 | 14505 | $3617.64 | $1173.87 | 0.0211 | 49.4% | 141M |
| 2014 | 14357 | $5024.25 | $1218.01 | 0.0144 | 47.3% | 143M |
| NRP Class | 270 | 271 | 272 | 273 | 274 | 275 | 276 | 277 | 278 | 279 | 280 | 281 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Year | ||||||||||||
| 2006 | 1972 | 139 | 2311 | 2060 | 1861 | 641 | 427 | 350 | 870 | 1500 | 605 | 667 |
| 2007 | 2445 | 138 | 2440 | 1792 | 1762 | 683 | 436 | 414 | 944 | 1680 | 543 | 943 |
| 2008 | 2631 | 173 | 2505 | 1797 | 1809 | 658 | 385 | 429 | 943 | 1816 | 603 | 907 |
| 2009 | 2688 | 162 | 2143 | 1878 | 1617 | 605 | 335 | 259 | 899 | 1239 | 464 | 467 |
| 2010 | 2380 | 163 | 2093 | 1830 | 1722 | 625 | 414 | 349 | 1005 | 1623 | 523 | 754 |
| 2011 | 2364 | 164 | 2090 | 965 | 1001 | 761 | 591 | 618 | 1289 | 1589 | 982 | 1488 |
| 2012 | 2416 | 214 | 2189 | 1067 | 971 | 1051 | 966 | 962 | 906 | 1726 | 1190 | 1977 |
| 2013 | 2540 | 187 | 2211 | 1072 | 1136 | 1002 | 950 | 823 | 914 | 1446 | 1033 | 1191 |
| 2014 | 2361 | 215 | 2144 | 1086 | 1067 | 947 | 870 | 832 | 918 | 1449 | 949 | 1519 |
| NRP Activity Code | Description |
|---|---|
| 270 | Form 1040 EITC present & TPI $200k and Sch. C/F Total Gross Receipts (TGR) $25k |
| 271 | Form 1040 EITC present & TPI $200,000 and Sch. C/F TGR $25,000 |
| 272 | Form 1040 TPI $200,000 and No Sch. C, E, F or 2106 |
| 273 | Form 1040 TPI $200,000 and No Sch. C or F, but Sch. E or 2106 OKAY |
| 274 | Form 1040 Non-farm Business with Sch. C/F TGR $25,000 and TPI $200,000 |
| 275 | Form 1040 Non-farm Business with Sch. C/F TGR $25,000 - $100,000 and TPI $200,000 |
| 276 | Form 1040 Non-farm Business with Sch. C/F TGR $100,000 - $200,000 and TPI $200,000 |
| 277 | Form 1040 Non-farm Business with Sch. C/F TGR $200,000 or More and TPI $200,000 |
| 278 | Form 1040 Farm Business Not Classified Elsewhere and TPI $200,000 |
| 279 | Form 1040 No Sch. C or F present and TPI $200,000 and $1,000,000 |
| 280 | Form 1040 Sch. C or F present and TPI $200,000 and $1,000,000 |
| 281 | Form 1040 TPI $1,000,000 |
Appendix K NRP Weights
A key complication in our investigation is that the NRP sample used by IRS is a stratified random sample and NRP weights must be used to estimate the population. This makes evaluation on the NRP sample more difficult. As such, we only use NRP weights for the population estimate. However, taking a random sample (as in the exploration sample) means that the sample is not evenly distributed across the population, but rather it matches the distribution of the NRP sample. We weighed alternative designs, such as synthetically replicating features in proportion to NRP weights and then discarding the NRP weights. However, we felt this was not realistic enough. As such, our evaluation might be thought to scale to a larger system in the following way. First a very large NRP sample would be selected. Then, within that larger sample, our methods would select sub-samples that are in line with the true budget.
For all methods we run both a weighted and an unweighted fit using NRP weights for the model fit. We found that ABS was the only method to have reduced variance from an unweighted fit, whereas other methods improved from a weighted fit. This is likely because for non-ABS methods the population estimation mechanism is model-based and the model benefits from having more fine-grained splitting criteria in areas that are up-weighted later on.
The composition of the NRP sample may also add sources of drift and stochasticity to our sample. Each year the NRP sample weights are re-calculated according to changing priorities and improvements to the program. As such, later years have a different composition of samples across NRP activity codes (Table 7) than earlier years.
We note that the NRP sample weights are base weights, reflecting the sampling probability, not adjusted for final outcome.
Appendix L Extended Metrics Descriptions
L.1 Choice of cumulative versus average Reward and Total Positive Income
Note, we report cumulative reward as is standard for bandit settings. Average reward can be recovered by dividing by the number of timesteps. We also note that in early years, where no selection has been made, the selection probability is the same across all algorithms, therefore cumulative reward reflects late-stage differences more clearly. We report cumulative average TPI for similar reasons. Cumulative average TPI is calculated as the average TPI for a selected batch in a given year, then summed over years.
L.2 Extended Percent Difference Explanation
The percent difference is the difference between the estimated population average and the true population average: . We denote to be the standard deviation of the population estimate percent difference across random seeds. That is, we measure the variation across random seeds on a per year basis, resulting in a standard deviation per year, then we present the average of these standard deviation values. This is in line with current recommendations in the ML community which recommend showing variation across seeds (Henderson et al. 2018; Agarwal et al. 2021). This provides insight into the variation of the method across slightly different populations draw from the same distribution.
is absolute mean percent difference across seeds. is the root mean squared percent difference across every prediction (year and seeds). That is, the percent difference for every prediction is squared, averaged, and the square root is taken. This is a scalar point metric and gives some indication as the a combined error rate due to both bias and variance. Note, this takes into account variance inherent to subsampling of NRP (the 80% sample used to simulate different populations) as well as variance in sampling across seeds. As such, non-model-based methods are at an inherent disadvantage since they do not re-use data from prior years. Though, this may be an interesting direction for future work.
L.3 RARE Score
It can be thought of as a modification of discounted cumulative gain (DCG) (Järvelin and Kekäläinen 2002) or RankDCG (Katerenchuk and Rosenberg 2018). In those methods, the distance between the predicted rank and true rank of a data point is discounted based on the rank position (and in the case of RankDCG, normalized and accounts for ties). Similar to other related metrics (Järvelin and Kekäläinen 2002; Katerenchuk and Rosenberg 2018), the RARE metric takes into account the magnitude of the error in estimate revenue potential as well as the rank. It is effectively the distance from the maximum revenue under the correct ranking, or the percentage of the maximum area under the ranked cumulative reward potential. We consider the true area under the cumulative reward curve where rewards are ordered by magnitude of the true reward of the arm: , where is the size of the total population.
The ranking algorithm’s area under the predicted reward curve is denoted by and the minimum area under the reward curve is the area under the reverse ordering of the reward . is the sampling weight in case the training sample is not uniformly drawn (as is the case in NRP). The RARE metric thus gives an approximation of a magnitude-adjusted distance to optimal ranking: . After a working group discussion with IRS stakeholders, we found that RARE seemed to capture many key dimensions of interest more than other conventional measures.
Appendix M Function Approximator Selection
We examine which function approximator might be best suited overall if the sample is purely an unbiased random sample. We fit random forests, OLS, and Ridge regression on a purely random sample. We evaluate the ability of the function approximator to rank correctly as well as estimate the population mean. For example, for year 2008, we train on a random sample of 2006 and evaluate the model population estimate and ranking accuracy. For year 2009, we train on a random sample of 2006 and 2007, and so on.
We find that non-linear estimators consistently achieve significantly higher RARE scores and more accurate population estimates than linear equivalents. As seen in Figure 5. As such, for the remaining experiments, we do not use any linear function approximation methods.
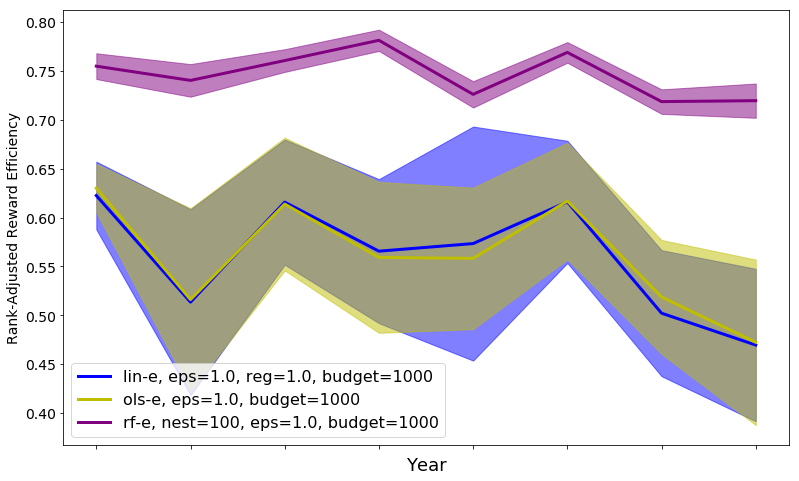
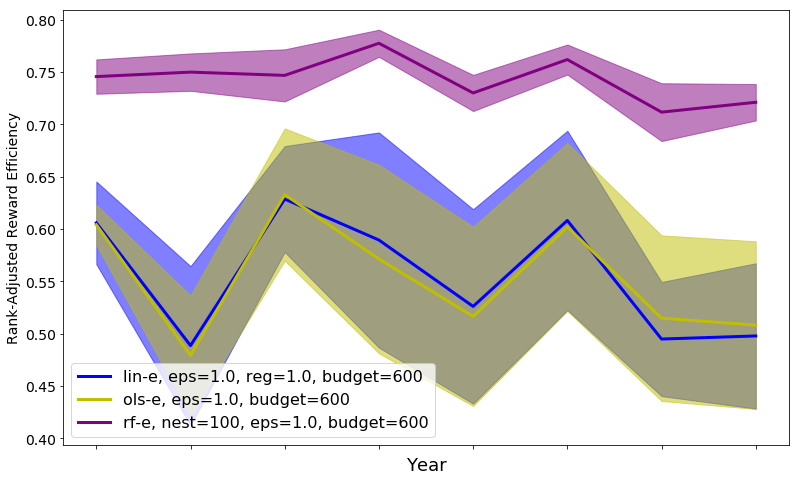
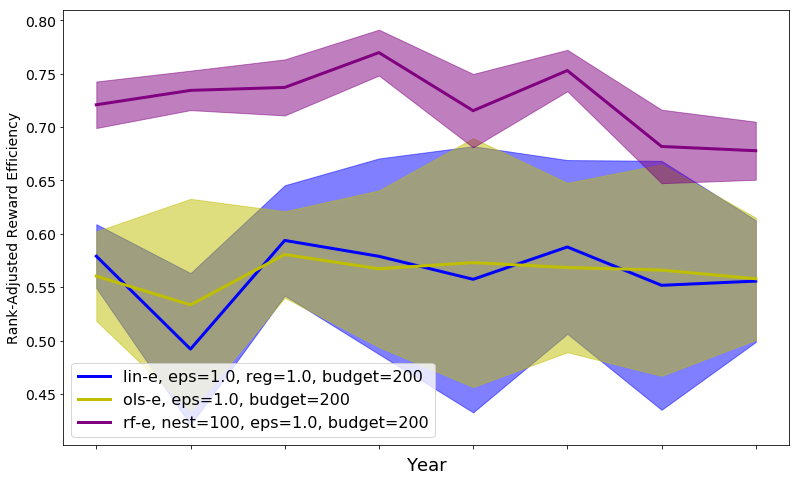
Appendix N ABS Sampling
In this section we provide further details on ABS, verify that the populate estimate is unbiased, and make some general remarks on the effects of various parameters on the variance of the estimate. Algorithm 2 gives an overview of ABS with logistic smoothing.
Fix a timestep and let be our budget. Let be the predicted risk for return . First we sample the top returns. To make the remaining selections, we parameterize the predictions with a logistic function,
or an exponential function
is the value of the -th largest value amongst reward predictions . For the logistic we normalize such that , and for the exponential. The distribution of transformed predictions is then stratified into non-intersecting strata . We choose the strata in order to minimize intra-cluster variance, subject to the constraint of having at least points per bin:
| (6) |
where is the average value of the points in bin . Note that , so the quadratic program (3) is indeed minimizing intra-cluster variance.
We place a distribution over the bins by averaging the risk in each bin, i.e,
| (7) |
To make our selection, we sample times from to obtain a bin, and then we sample uniformly within that bin to choose the return. We do not recalculate after each selection, so while we are sampling without replacement at the level of returns (we cannot audit the same taxpayer twice), we are sampling with replacement at the level of bins. This is (i) because of computational feasibility, and (ii) in order to obtain an unbiased estimate of the mean via HT Sampling (Horvitz and Thompson 1952).
In particular, note that the probability that arm in stratum is sampled is (see the next subsection for a derivation), where is the size of .
Theorem 1.
If is the set of returns chosen for auditing and contains those points first sampled, then
is an unbiased estimator of the true mean
Proof.
To see this, let be the random variable indicating whether arm is sampled. Since , linearity of expectation gives
∎
N.1 Variance of Population Estimate
Write the HT estimator as
where is the set of selected arms and is arm ’s inclusion probability in . Then
where is the joint inclusion probability of arms and . Note that for the arms in stratum , and . Therefore, all terms involving such arms are zero and they do not contribute to the variance.
We can make this expression more specific to our case by rewriting the inclusion probabilities as functions of the strata. Fix an arm and suppose it’s in stratum . Let be the number of returns we’re randomly sampling (i.e., discarding those points greedily chosen from the top of the risk distribution). The law of total probability over the trials gives
The first term in the product is the probability that is chosen as one of elements in a bucket of size . The second term is the probability that was selected precisely times and is distributed as a binomial. Therefore,
Now consider for distinct arms . Let . Conditioning on gives if since there are now trials to select . If , then since there are trials to select from a bin of size . Thus
Rewriting the variance as a summation over the strata, we see that the variance is the difference of two terms and where as a sum across all strata and includes cross-terms dependent on the relationship between strata.
where
and
We make a few remarks on the variance here, but leave a full analysis to future work. If the budget is small relative to the strata sizes (as is the case here), then , and reduces to which is independent of the strata. As grows and we place more weight on those returns deemed higher risk by the model, for lower risk arms. This results in many arms clustered in a few strata with high and low , which increases . Also, as grows and we perform more greedy sampling, decreases and the variance increases roughly proportionally.
Appendix O Experimental Setup
Figure 6 provides a visual aid to help understand the problem setting.
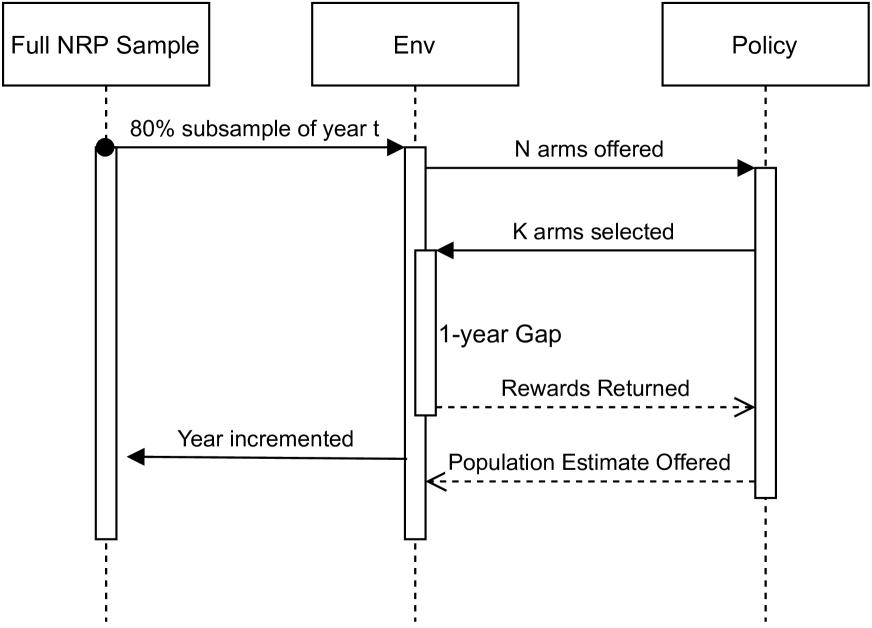
Appendix P Hyperparameter Tuning
The ideal approach would tune the hyperparameters for function approximators using cross-validation every time the model is fit in the active learning process. However, we found this approach to be extremely computationally expensive, a small grid of experiments requiring over a week to run. In the interest of reducing energy consumption – see, for example, discussion by Henderson et al. (2020) – we instead opt for a less computationally expensive proxy. We take train our function approximators on 2006 and then evaluate their RARE score and population estimate for the 2008 year, using 5-fold cross-validation across both years. We then run a grid search for all function approximators used. Finally we find the top point on the smoothed Pareto frontier between RARE and population estimation to find the optimal hyperparameters. To do this we rank the reward and population estimation criteria based on Since there is concept drift from year to year, we expect that these hyperparameters are sub-optimal and results may be even further improved with careful per-year hyperparameter tuning. However, this approach is sufficient for the purposes of our experiments.
For handling hyperparameters of the sampling algorithms, we rely on sensitivity analyses rather than hyperparameter searches. This is in line with recent work that promotes reporting results over ranges of hyperparameters and random seeds, particularly for sequential decision-making systems (Henderson et al. 2018; Bouthillier et al. 2021; Agarwal et al. 2021). Hyperparameter grids were run as follows in Table 8.
| Method | Hyperparameter Grid |
|---|---|
| -Greedy | |
| weighted, unweighted fit | |
| UCB | |
| weighted, unweighted fit | |
| ABS | mixing=exponential, logistic |
| trim=0%, 2.5%, 5% | |
| weighted, unweighted fit |
For Table 1, the only place where we display single hyperparameter settings, we use the following selection protocol from the grid of hyperparameters above. Given the lack of longitudinal data, we rely on intra-year data sub-sampling for validation sets. We select 5 random seeds, corresponding to different validation subsampled datasets. First, we identify the top reward band by finding methods with overlapping confidence intervals on reward. See Joseph et al. (2018) for discussion on meritocratic fairness given overlapping confidence intervals. Then, we order results by root mean squared error and select the top hyperaparameters for each method according to these validation seeds. We then use results from all train seeds to get results displayed in the paper.
Appendix Q Winsorization
We winsorize the rewards returned such that the top 1% of highest values is set to the top 99th percentile’s value. Negative values were truncated to 0. This is in line with recommendations for existing models within the IRS (Matta et al. 2016) and other research on audit data (DeBacker, Heim, and Tran 2015). This helps to stabilize predictions, protecting against unusually large outlier adjustments, but may bias the model.
Appendix R Budget Selection
At each timestep the IRS can select a limited budget of samples – for example the NRP sample in 2014 was 14,357 audits. This is a tiny fraction of audits as compared to the general population of taxpayers – and thus impossible to replicate when using the NRP sample to evaluate selection mechanisms. The goal of the NRP sample is to select a large enough sample to approximate the taxpayer base. The parallel in our experiments would be to ensure we select a sample which is smaller than the coreset needed to model the entire data.
Another way of thinking about the size of the budget allowed per year to approximate the NRP mechanism is by determining what is the minimum random sample to achieve a 3% margin of error with 95% confidence of the NRP sample population, per the 2018 OMB requirements for IPERIA reporting. Using an 80% (from subsampling) sample of the per-year average of 14102 NRP yearly samples, we are left with an average of 11282 arms per year. We should need about a 975 arm budget for a random sampling mechanism (ignoring stratification) to achieve OMB specifications.
We then use the approach of Sener and Savarese (2018) to find a minimal coreset which a model could use to achieve a reasonable fit. We first fit a random forest to the entire dataset for a given year and calculate the residuals (or the mean squared error across the dataset). We then iteratively select batches of 25 samples according to the method presented by Sener and Savarese (2018). We use only the raw features to compute distance (contrasting the embedding space used by the authors). We refit a random forest with the same hyperparameters as the optimal fit on the smaller coreset sampler. Then we calculate the ratio of the mean squared error on the entire year’s data to the optimal mean squared error. We find that the mean squared error is reduced to roughly 2x the overfit model at around 600 coreset samples, reducing very slowly after that point. We find that around 600 samples is the absolute minimum number required to reduce the mean squared error to a stable level at 2 times the optimal mean squared error. To simulate the small sample sizes of the NRP selection, we select this smaller budget of 600 as our main evaluation budget size, corresponding to roughly 4% of the 2014 NRP sample.
Note that in practice, IRS faces heterogeneous costs for audits. For the purposes of this work, we assume a fixed budget of arm/tax returns rather than a fixed budget of auditor hours.
Appendix S Confidence Intervals on the Time Series
Since arms within a year are randomly sampled, this is close to the subsampled bootstrap mechanism used for time-series as described by Politis and Romano (1994); Politis, Romano, and Wolf (1999); Politis (2003). We consider the year-by-year NRP sample as a stationary time series with each year of arms as an identically distributed sample, though year-to-year the samples are not necessarily independent. The subsample boostrap provides a mechanism to estimate confidence intervals for such a time series (approximately). This is also similar to the delete- where jackknife as described in (Politis, Romano, and Wolf 1999; Shao and Wu 1989). Because of the computational complexity of running experiments on the time-series, we keep low at 20 bootstrap samples with distinct random seeds (and thus the setting is not identical to the delete- jackknife).
Appendix T Results
First, we provide an extended graph with hyperparameter details for the main settings presented in Table 1. ABS-1 is a hyperparameter configuration that focuses slightly more on reward at the cost of population estimation variance. -Greedy uses an of 0.1, UCB-1 has , UCB-2 has a larger exploration factor of . ABS-1 uses an exponential mixing function with 80% greedy sample, , and a 2.5% trim factor. ABS-2 uses a logistic mixing function, , a 5% trim, and 80% greedy sample. Both ABS methods use an unweighted fit while all other approaches saw improved results with a weighted fit.
Best Reward Settings
Policy
Greedy
36.5%
16.4
21.5
0.70
$43.6M*
$760k
UCB-1
38.6%
15.3
20.9
0.70
$42.4M*
$853k
ABS-1
37.6%
0.4
34.2
0.70
$41.5M*
$796k
-Greedy
38.3%
6.1
10.5
0.73
$41.3M*
$772k
UCB-2
40.7%
15.6
22.2
0.70
$40.7M*
$1.2M
ABS-2
38.3%
0.6
26.8
0.71
$40.5M*
$672k
Random
53.1%
1.5
13.1
-
$12.7M
$493k
T.1 -Greedy, Random Sample-Only for Population Estimation
It may be tempting to use only the random sample of the -Greedy methods for population estimation, but we note that in the constrained budget setting we investigate here the variance of these estimates becomes much higher than ABS settings with comparable rewards. This demonstrates the utility of re-using information to navigate the bias-variance-reward trade-off problem. For a budget of 600, for example, Table 10 demonstrates this. Though the relationship is somewhat non-linear, ABS always has the potential for pareto improvement, yielding higher reward for the same variance. For example, though ABS-2 has 4 more standard deviations higher it yields over $7M extra in revenue. And though ABS-1 yields similar rewards to , it is 6.4 standard deviations lower in variance.
| 0.1 | 37.4 | 40.8 | $41.3M |
| 0.2 | 29.9 | 32.2 | $38.7M |
| 0.4 | 20.6 | 22.04 | $33.1M |
| ABS-1 | 31.0 | 34.2 | $41.5M |
| ABS-2 | 24.5 | 26.8 | $40.5M |
T.2 Price-for-variance Trade-offs and Policy Implications
Using our sampling mechanism we can roughly fit a function to roughly approximate the Pareto front which helps understand the “price-for-variance” trade-off. First, we take the Pareto front from ABS sampled hyperparameters in Figure 2. Then, we fit a cubic to this Pareto front as seen in Figure 7.
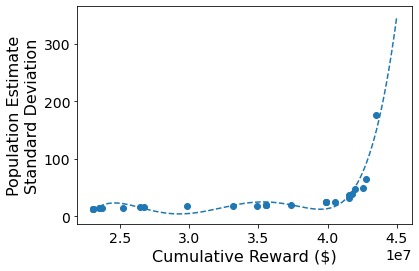
Note this should be interpreted with caution since different algorithms may have different Pareto fronts and population drift may change things. Additionally fitting polynomials or exponential to this front can have its own inference challenges. But this gives a rough understanding that under ABS (and even under -Greedy which has a slightly worse navigation of this pareto frontier), it is worth giving up some reward initially to cut variance in half, but beyond a certain point it is not worth the trade-off (at least for ABS which is able to navigate the frontier more closely.) Note the fit above yields this polynomial.
Since ABS allows for some empirical examination of these trade-offs, this provides some information for policymakers to understand what are the trade-offs for increasing the amount of random samples. For example, when OMB specifies some guidelines for estimation, our experimental exploration here provides a foundation for future work in examining this reward-variance trade-off and navigating policy implications.
T.3 Using RFR significantly outperforms LDA and incorporating non-random data helps
For the LDA baseline rather than regressing a predicted reward value for selection, we predict whether the true reward is $200 (our no-change cutoff). Arms are selected based on increasing likelihood that they are part of the $200+ reward class. This is included both as context to our broad modeling decisions, and as an imperfect stylized proxy for one component of the current risk-based selection approach used by the IRS.
Figure 8 shows that the cumulative return of -greedy sampling strategies using RFR-based approaches are significantly higher than LDA-based approaches. We emphasize again that the LDA model we use here is a stylized approximation of the current risk-based selection process and does not incorporate other policy objectives and confidential mechanisms of DIF. We note that while it serves as a rough baseline model, it demonstrates again that regression-based and globally non-linear models are needed for optimal performance in complex administrative settings such as this.
Fitting to only the random data, even with the RFR approach, reduces the ability of the model to make comparable selections and increases the variance across selection strategies. This can be seen in Figure 8, where fitting to random only leads to between $6.2M and $1.3M less reward cumulatively (95% CIs on effect size) and standard deviation across seeds is increased by $700k. Since the current risk-selection approach mainly uses the NRP model, this suggests that future work on incorporating Op audits into the model training mechanism could improve overall risk-selection. This of course bears the risk of exacerbating biases and should be done with careful correction for data imbalances.
In Figure 8 we show where LDA fits in terms of reward maximization, achieving significantly less reward than RF-based methods.
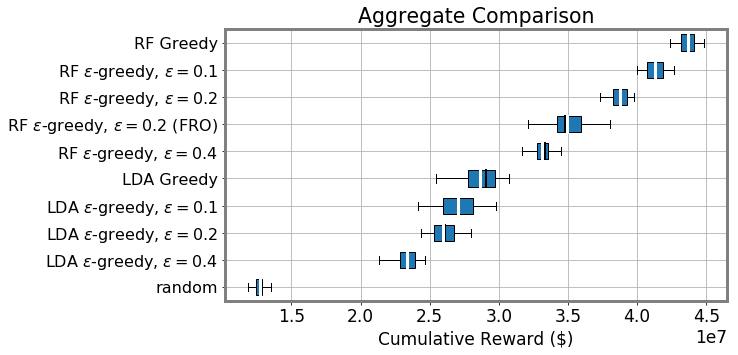
T.4 Fine-grained Kernel Density
Figure 9 shows the kernel density plots for every year in the time series on one random seed.
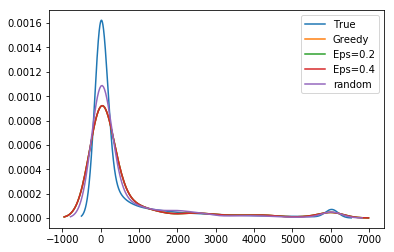
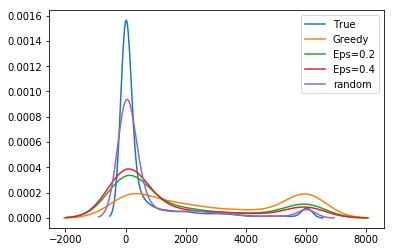
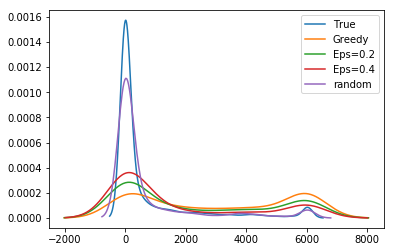
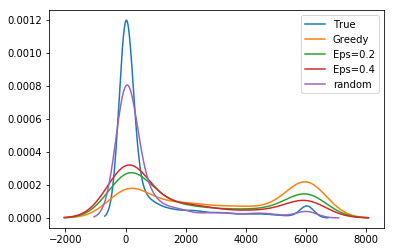
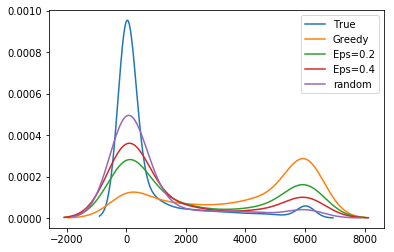
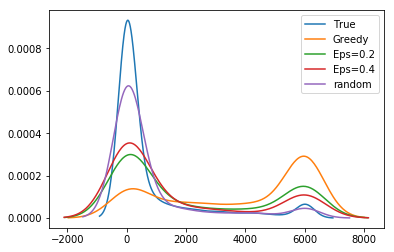
T.5 Ablation of ABS
Here, we plot the effect of various hyperparameters for each model. Figures 10 illustrate the effect of model parameters on cumulative reward, population estimation (mean), population estimation (variance), no change rate, and RARE score. For each parameter and each metric, we plot the results of all runs with the same parameter as it varies across its range. We use violin plots to demonstrate the density of the values.
ABS



T.6 Larger Budget
Results stay similar if we increase the budget to 1000 arms per timestep. This can be seen in Figures 11 and 12.
ABS



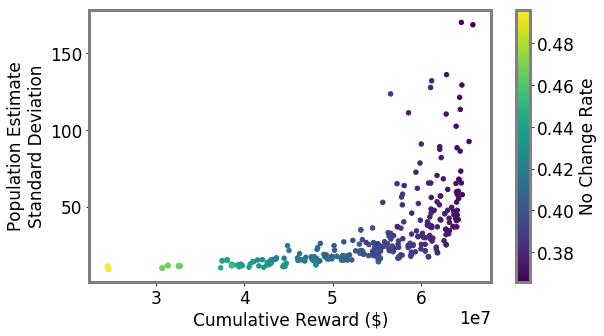
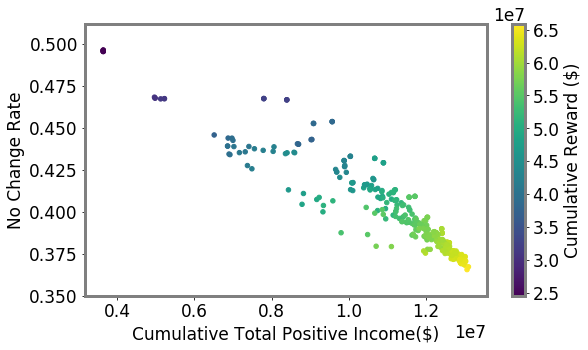
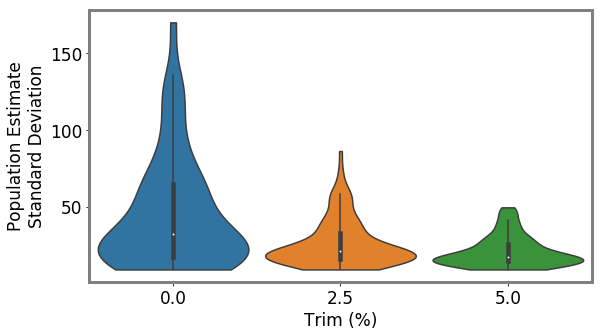
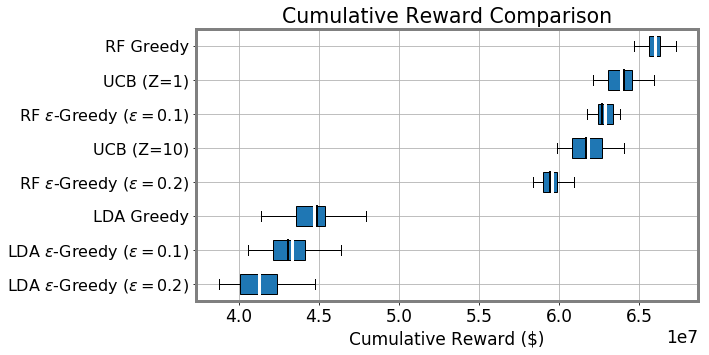
T.7 Sampling breakdown by classes
Figure 13 breaks down ABS and other methods in terms of audit classes.


T.8 Expanded Figure
To ensure that both a log scale and non-log scale version of Figure 2 are available, we include both of those in Figure 14.
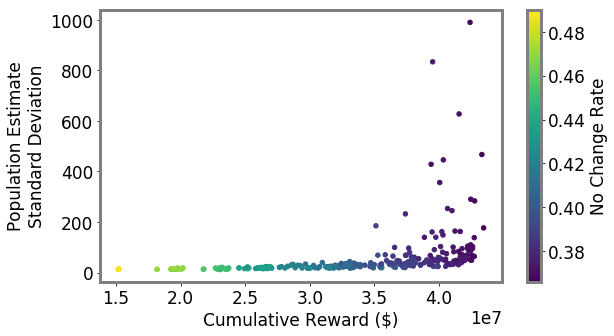
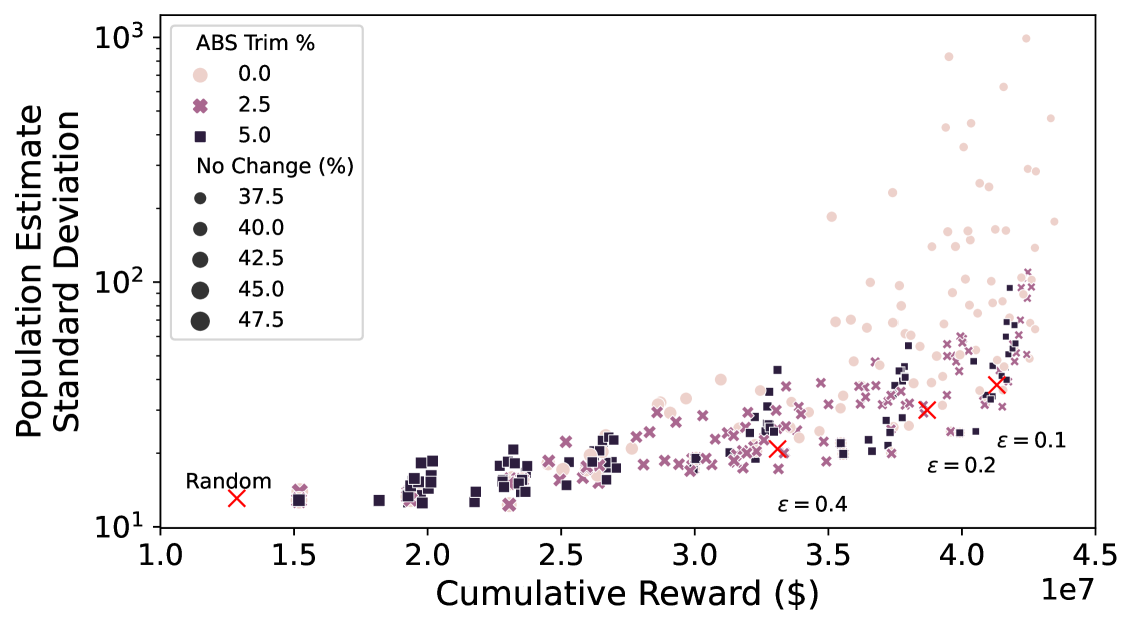
Appendix U Regret
Proving regret bounds in the non-linear batched optimize-and-estimate structured bandit poses a significant challenge and sets the ground for exciting new theoretical research. Nonetheless, we identify an initial mechanism to provide some level of bounded regret for ABS. We ground our work upon that of Sen et al. (2021) and Simchi-Levi and Xu (2020). In the setting of Sen et al. (2021) there are an extremely large, but finite, number of arms. During each epoch, the agent is presented with a single context (), drawn i.i.d. from a distribution . Using this context the agent must select arms. Sen et al. (2021) use an Inverse Gap Weighting (IGW) strategy to select these arms. IGW was introduced by (Abe and Long 1999) and has been leveraged to prove regret bounds in realizable settings with general function classes (Foster and Rakhlin 2020; Simchi-Levi and Xu 2020; Foster et al. 2020; Sen et al. 2021; Zhu et al. 2022). In this setting, given a set of arms , an estimate of the reward function, and a context , there is a distribution over arms assigned:
where , is a scaling factor, and where is the total number of arms in an epoch . In the algorithm proposed by Sen et al. (2021), for a -armed bandit the top arms are chosen greedily while arms are chosen according to this probability distribution.
Crucially, and why the IGW algorithm does not apply to the optimize-and-estimate setting, the IGW algorithm used in that case cannot be trivially used for unbiased population estimates. To select arms, the bandit incrementally recalculates probabilities after selecting each arm. This dynamic re-calculation makes ensuring unbiasedness difficult, because determining the true (or even approximate) inclusion probabilities quickly becomes non-trivial. ABS instead leverages stratification to keep exact probabilities and ensure unbiasedness.
Conveniently, however, we can reduce the ABS and optimize-and-estimate setting to a variant of the top- contextual bandit and IGW algorithm. This allows us to leverage the tools of Sen et al. (2021) and Simchi-Levi and Xu (2020) to prove bounded regret for a particular instantiation of ABS. We note that we demonstrate effectiveness in other settings empirically, as others like Sen et al. (2021) do.
Note that in the -armed contextual bandit setting it is assumed that there is one context per epoch as opposed to a per-arm context (). To make the proof tractable, we assume that arms are not volatile and that the context vector contains taxpayer information for all arms. That is, we reduce the optimize-and-estimate structured bandit to a contextual bandit with some additional constraints. Thus we assume a fixed number of arms available year over year () and a fixed budget () over the time period ending in timestep . We assume for convenience that the context is drawn i.i.d. from the distribution of possible populations that could be drawn year over year. That is, we have some global distribution and every timestep, observations are drawn i.i.d from . And can be thought of as a vector representing information about all taxpayers, to simplify the proof. The goal is then to estimate the population conditional on the draw. This of course, is a simplification of the true setting, and we note future theoretical work can tackle the more complicated dependent population draw.
Assume for the sake of our reduction proof, that we too, like Sen et al. (2021) update in epochs. That is, we have an epoch at which we have updated our regression model. For steps we then re-use this regression model year over year. This is not too far off from reality. Since we receive delayed rewards, we would not update our model for several years anyways, aligning with the epoch structure. Note, then that, aligning with the notation of Sen et al. (2021), we have epochs . Thus, and timestep is simply where is the number of steps between updating the model at epoch .
Effectively, we decompose our problem into accumulation steps before doing a regression update, like our reward delay does in reality. Assume that our functional structure is such that all non-informative parts of the context (taxpayer information not indexed by ) is masked out. Thus for action we denote the context as indicating a masked and indexed portion of the full context. For notational convenience, we let denote both the selection algorithm itself (i.e., ABS) as well as the set of selected actions in a given step. That is, we will write to denote the arm sampled by at time and would be the context associated with that arm (e.g., tax return covariates for a selected filer). If is clear from context, we drop it from the notation for clarity.
Next, we continue the reduction of ABS to the IGW setting to leverage the tools required to prove regret bounds. Recall that ABS has the distribution , for the selection probability of one exploratory arm (we only prove this case, keeping in line with Sen et al. (2021)):
| (8) |
where is a function class mapping the risk/reward distribution that is monotone (order preserving). And noticing that uniform selection of one arm (for the single exploratory arm case) is uniform over the selected stratum. Assume now that for the purposes of this analysis is the function:
| (9) |
where again , is a scaling factor, and where is the total number of arms available at epoch . This is, trivially, a monotonic function that fits into the ABS framework since, as Sen et al. (2021) do, we assume all .
Lemma 1 (ABS Minimum Probability Bound).
For ABS at epoch , we have
| (10) |
where is the maximum number of observations in any stratum, is the maximum distance between rewards in a bin, and H is the number of strata.
Proof.
and re-arranging terms and settings
Consider that if we assume that the maximal distance for any pair of points in any cluster is then this value is:
and assuming that and then at its largest (and hence the probability at its smallest) is . This is because the number of clusters is each with a maximal average of if .
Thus
Putting it together we have:
For , this bound resolves to
∎
Note that as the number of strata goes to and the intrastratum variation shrinks, the probability converges to the top- bandit, but provable unbiased population estimates become difficult.
Under this functional form for the mixture function, we can bound that regret as follows. As is the case for Sen et al. (2021), we examine only the case for exploratory arm. Nonetheless, our experiments focus on proxies that nonetheless perform well, as Sen et al. (2021) do in their setting as well. Note that it is likely that, unlike for the IGW method, our ABS regret bound may hold for . This is because, again, we do not need to re-calculate probabilities throughout an epoch, but rather they are fixed throughout the entirety of the epoch. However, we leave this as a challenge for future theoretical research in this area.
In order to prove our main theorem, we assume that the true reward mapping is a member of the family of estimators. This is Assumption 1 from Sen et al. (2021).
Assumption 1 (Realizability).
At every time , there exists an such for all ,
| (11) |
where is the class of reward functions.
As in Sen et al. (2021), we assume that is a finite class of functions.
Note that Sen et al. (2021) make an assumption on partial feedback (their Assumption 3) such that there is a factor that governs that minimum probability that you will get feedback for a given selected arm. For our case since we always receive feedback. Thus, we remove constants by setting them to 1 throughout.
Theorem 2.
As in Sen et al. (2021), under the previously stated assumptions, and assuming function form in Eq. 9, when run with parameters
has regret bound
with probability at least , for a finite function class where is the maximal distance between predicted reward in any ABS stratum and is a chosen constraint, for simplicity we also assume that strata have equal numbers of arms , that there is one exploratory arm (), and that the number of steps between reward function updates is where is an epoch.
Notice that both regret bounds increase with the width of the strata in ABS. So keeping the strata constrained (as with the nearest neighbor clustering we employ in practice), keeps the regret bound constrained as well. We note that it is likely possible to give tighter PAC bounds for strata under some other assumptions, but we leave this to future work as the focus of our work is not theoretical but rather the introduction of the optimize-and-estimate structured bandit setting and the IRS study. Finally, we note that there is some minimal strata size that is required to preserve unbiasedness. We cannot use the method of Sen et al. (2021) directly for the optimize-and-estimate structured setting because we require unbiasedness guarantees. ABS provides the required changes to remain unbiased while minimizing regret.
To prove this regret bound, we closely follow the proof structure of Sen et al. (2021). For clarity, when portions of the proof structure do not change, we will refer and reproduce their Lemmas without reproducing full proofs. Where we must make modifications for our setting we provide the full modification here.
Let be the budget. Let be the natural filtration at time .
Thus, we can borrow the following combined Lemma from Sen et al. (2021, supplemental page 3,10-12),
Lemma 2.
For any , the event
holds with probability at least . Where the event holds if
under the realizability assumption and otherwise holds under the -realizability assumption if
Proof.
See Sen et al. (2021, supplemental page 3,10-12) for proofs. ∎
Lemma 3.
Fix epoch . Consider the set of arms selected by an arbitrary policy such that arms are unique (non-overlapping) in the set. Let be the set of observations selected greedily by . If event in Eq. 2 holds, then:
Proof.
For the sake of brevity, let . Notice that since all observations are drawn iid from which does not change, we can average over timesteps and write
Recalling that is all timesteps up to a given epoch . Splitting the sum into those observations in and those not in , we get
Note that the probabilities are functions of the epoch and for any individual timestep we can map back to the epoch using .
Recall that by Cauchy-Schwarz you have:
Apply this as follows:
Trivially moving the square in by one:
Then by Cauchy-Schwarz and trivially moving the square inside so that we have :
Applying Cauchy-Schwarz again:
Which reduces to:
For the second, Cauchy-Schwarz gives:
Combining the previous two inequalities, and noticing ,
Notice that for any realization of , by construction, so the rightmost sum has at least one non-zero term. Moreover, since , , so this sum is at least 1. It follows that
where the second inequality follows since for .
Now, by Lemma 1 and noticing that we only sample from arms after greedy arms are chosen, so our population for sampling shrinks. For this case is the -th arm that is selected under the predictive policy as compared to a general strategy set .
For simplicity, let us assume that each bin has a uniform number of arms . We note that this creates a very loose downstream regret bound, but helps us avoid complications from an extra multiplicative term. Since these regret bounds are not a core function of this work, future work might tighten the regret bound. We have
Define . Then,
Then by Lemma 3 from Sen et al. (2021, supplemental p.5) (noting the change from -index to index for the top value):
Recall Lemma 2, using this for the first term of Eq. LABEL:eq:twoparthing (see also Sen et al. (2021, suppelemental p.5)), we can move into the equation and create a new bound:
from which the result follows.
∎
Now we modify the induction hypothesis of Sen et al. (2021) such that we take into account the width of the ABS strata. First, recall the induction hypothesis from Sen et al. (2021) (modified for ABS) is as follows.
Induction hypothesis ():
For any epoch , let denote the action with the -th highest reward. Let denote the observation with the estimated -th highest reward, according to the model . For any set of selected actions , let
be the regret of selecting the actions , and
the estimated regret according the where is the current epoch and the model fit to that point. The following result bounds the difference between the true regret and estimated regret.
For any set of distinct actions and any , we have
and
where
Now using this induction hypothesis, we get the following.
Proof.
Again, with our main modifications in place for our reduction to the setting of Sen et al. (2021), we can rely on their proof for this induction step. See Sen et al. (2021, supplemental p. 5) for the base case which holds for the case. We then seek to show that under the induction hypothesis the bound holds for .
For simplicity, we omit the dependence on . Introducing extra terms which cancel out, decompose into three sums:
| (13) |
For the first sum, notice that by definition of , we have:
Therefore,
As Sen et al. (2021) do, for the second sum in Eq. 13, we apply Lemma 4 to obtain:
noting that the regret term drops out since the action referenced is the same optimal action.
Putting the above together and propagating our ABS dependency on the strata parameters through the rest of the induction proof of Sen et al. (2021), we get:
and thus
Now completing the complementary inequality for in an identical fashion.
| (14) |
Continuing to follow Sen et al. (2021) and propagate our modified bound, the third sum in Eq. 14 is bounded by Lemma 4 as follows:
The, again following Sen et al. (2021), we bound the middle term of Eq. 14. Note now :
Putting it all together, we can now bound the model regret:
And as Sen et al. (2021) point out, is arbitrary so the induction step follows.
∎
Lemma 4.
Then assuming the induction hypothesis means, if are non-decreasing, that
Proof.
See Sen et al. (2021, supplemental p. 5) for details. We omit the proof for brevity, but note that there is only a minor difference for proving this Lemma, swapping out for the modified term. ∎
Proof for Theorem 2..
Finally, we can leverage Sen et al. (2021, supplemental p. 7-8) to prove a regret bound incorporating our ABS characteristics.
Under the same assumptions as Sen et al. (2021), including that the event in Lemma 2 holds and Lemma 4 holds, as well as the inductive statements hold. Then we can bound the regret as follows. Let be greedily chosen arms, and the randomly chosen -th arm. The inductive hypothesis gives
| (15) |
For brevity, let’s set aside the first term for one moment and focus on the second:
Since is bounded , like Sen et al. (2021) we note that:
| (16) |
if and .
Thus we can bound the regret gap as:
Now, we find a bound for . Recall that, if ,
| (17) |
Then, since again the maximum gap between rewards is :
| (18) |
And thus:
| (19) |
Returning to the previous bound:
Now, recalling that for simplicity we assume that strata are evenly sized and thus . Thus everything cancels out and we are left with a constant.
Recall that the event in Lemma 2 holds with probability at least under realizability if we set
We note that Sen et al. (2021) set . We note however, that in practice our due to our reward gap. Thus our true regret bound is strictly smaller by a factor that disappears in the asymptotic. As such, for clarity we keep the step size the same in the bound. Recall that we set . We find that the cumulative regret is bounded with probability at least by
And recalling that the number of epochs
∎
Reproducibility Checklist
-
•
Includes a conceptual outline and/or pseudocode description of AI methods introduced. Yes, see algorithm box in main text. We also include extended discussion in the appendix and code in the supplemental.
-
•
Clearly delineates statements that are opinions, hypothesis, and speculation from objective facts and results. Yes.
-
•
Provides well marked pedagogical references for less-familiar readers to gain background necessary to replicate the paper. Yes.
-
•
Does this paper make theoretical contributions? Yes, though they are mainly relegated to the appendix.
-
•
All assumptions and restrictions are stated clearly and formally. Yes.
-
•
All novel claims are stated formally (e.g., in theorem statements). Yes.
-
•
Proofs of all novel claims are included. Yes.
-
•
Proof sketches or intuitions are given for complex and/or novel results. Yes.
-
•
Appropriate citations to theoretical tools used are given. Yes.
-
•
All theoretical claims are demonstrated empirically to hold. Yes.
-
•
All experimental code used to eliminate or disprove claims is included. Yes.
-
•
Does this paper rely on one or more datasets? Yes.
-
•
A motivation is given for why the experiments are conducted on the selected datasets. Yes.
-
•
All novel datasets introduced in this paper are included in a data appendix. No. We are unable to publish even anonymized data due to statutory constraints related to IRS data. 26 U.S. Code § 6103.
-
•
All novel datasets introduced in this paper will be made publicly available upon publication of the paper with a license that allows free usage for research purposes. No. See above.
-
•
All datasets drawn from the existing literature (potentially including authors’ own previously published work) are accompanied by appropriate citations. N/A
-
•
All datasets drawn from the existing literature (potentially including authors’ own previously published work) are publicly available. N/A
-
•
All datasets that are not publicly available are described in detail, with explanation why publicly available alternatives are not scientifically satisficing. This paper is aimed at the specific IRS application, which is tied to the data that cannot be released by law.
-
•
Does this paper include computational experiments? Yes.
-
•
Any code required for pre-processing data is included in the appendix. Yes.
-
•
All source code required for conducting and analyzing the experiments is included in a code appendix. Yes.
-
•
All source code required for conducting and analyzing the experiments will be made publicly available upon publication of the paper with a license that allows free usage for research purposes. Yes.
-
•
All source code implementing new methods have comments detailing the implementation, with references to the paper where each step comes from. Yes.
-
•
If an algorithm depends on randomness, then the method used for setting seeds is described in a way sufficient to allow replication of results. Yes.
-
•
This paper specifies the computing infrastructure used for running experiments (hardware and software), including GPU/CPU models; amount of memory; operating system; names and versions of relevant software libraries and frameworks. Yes, some information included in code, rest in Appendix.
-
•
This paper formally describes evaluation metrics used and explains the motivation for choosing these metrics. Yes.
-
•
This paper states the number of algorithm runs used to compute each reported result. Yes.
-
•
Analysis of experiments goes beyond single-dimensional summaries of performance (e.g., average; median) to include measures of variation, confidence, or other distributional information. Yes.
-
•
The significance of any improvement or decrease in performance is judged using appropriate statistical tests (e.g., Wilcoxon signed-rank). We use significance testing in some places, but in most places we give treatment effects and confidence intervals on those effects, which is the new recommended norm.
-
•
This paper lists all final (hyper-)parameters used for each model/algorithm in the paper’s experiments. Yes.
-
•
This paper states the number and range of values tried per (hyper-) parameter during development of the paper, along with the criterion used for selecting the final parameter setting. Yes.