Integration of Skyline Queries into Spark SQL
Abstract.
Skyline queries are frequently used in data analytics and multi-criteria decision support applications to filter relevant information from big amounts of data. Apache Spark is a popular framework for processing big, distributed data. The framework even provides a convenient SQL-like interface via the Spark SQL module. However, skyline queries are not natively supported and require tedious rewriting to fit the SQL standard or Spark’s SQL-like language.
The goal of our work is to fill this gap. We thus provide a full-fledged integration of the skyline operator into Spark SQL. This allows for a simple and easy to use syntax to input skyline queries. Moreover, our empirical results show that this integrated solution by far outperforms a solution based on rewriting into standard SQL.
1. Introduction
Skyline queries are an important tool in data analytics and decision making to find interesting points in a multi-dimensional dataset. Given a set of data points, we can compute the skyline (also called Pareto front) using the skyline operator (Börzsönyi et al., 2001). Intuitively, a data point belongs to the skyline if it is not dominated by any other point. For a given set of dimensions, a data point dominates (denoted ) if is better in at least one dimension while being at least as good in every other dimension. More formally, the skyline is obtained as .
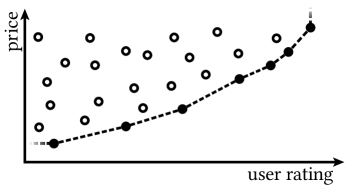
A common example for skyline queries in the literature can be found in Figure 1. Suppose that we want to find the perfect hotel for our holiday stay. Each hotel has multiple properties that express its quality such as the price per night or the distance to the beach among others. In this example, we limit ourselves to the price per night (y-axis) and the user rating (x-axis) for simplicity. Such attributes relevant to the skyline are called skyline dimensions. A hotel dominates another hotel if it is strictly better in at least one skyline dimension and not worse in all others. For the price per night, minimization is desirable while we want the rating to be as high as possible (maximization). Figure 1 depicts the skyline of the hotels according to these two dimensions. In this simple (two-dimensional) example, it is immediately visible that for each hotel not part of the skyline there exists a “better” (dominating) alternative. In practice, things get more complex as skyline queries usually handle a larger number of skyline dimensions.
Skyline queries have a wide range of applications, including recommender systems to propose suitable items to the user (Börzsönyi et al., 2001) and location-based systems to find “the best” routes (Kriegel et al., 2010; Huang and Jensen, 2004). Skyline queries have also been used to improve the quality of (web) services (Alrifai et al., 2010) and they have applications in privacy (Chen et al., 2007), authentication (Lin et al., 2011), and DNA searching (Chen and Lian, 2008). Many further use cases for skyline queries are given in these surveys: (Kalyvas and Tzouramanis, 2017; Hose and Vlachou, 2012; Chomicki et al., 2013). Skyline queries are particularly useful when dealing with big datasets and filtering the relevant data items. Indeed, in data science and data analytics, we are typically confronted with big data, which is stored in an optimized and distributed manner. We thus need a processing engine that is capable of efficiently operating on such data.
Apache Spark (Zaharia et al., 2016) is a unified framework that is specifically designed for distributed processing of potentially big data and has gained huge popularity in recent years. It works for a wide range of applications, and it can interoperate with a great variety of data sources. Conceptually, it is similar to the MapReduce framework, where instead of map-combine-reduce nodes, there are individual nodes in an execution plan for each processing step. Spark also provides a multitude of modular extensions such as MLlib, PySpark, SparkR, and others, built on top of its core functionality. Another important extension is Spark SQL, which provides relational query functionality and comes with the powerful Catalyst optimizer.
Hence, Apache Spark would be the perfect fit for executing skyline queries over big, distributed data. Despite this, to date, the skyline operator has not been integrated into Spark SQL. Nevertheless, it is possible to formulate skyline queries using “plain” SQL. Listing 2 shows the “plain” skyline query for our hotel example.
There are several drawbacks to such a formulation of skyline queries in plain SQL. First of all, as more skyline dimensions are used, the SQL code gets more and more cumbersome. Hence, such an approach is error-prone, and readability and maintainability will inevitably be lost. Moreover, most SQL engines (this also applies to Spark SQL) are not optimized for this kind of nested SELECTs. Hence, also performance is of course an issue. Therefore, a better solution is called for. This is precisely the goal of our work:
-
•
We aim at an integration of skyline queries into Spark SQL with a simple, easy to use syntax, e.g., the skyline query for our hotel example should look as depicted in Listing 2.
-
•
We want to make use of existing query optimizations provided by the Catalyst optimizer of Spark SQL and extend the optimizer to also cover skyline queries.
-
•
At the same time, we want to make sure that our integration of the skyline operator has no negative effect on the optimization and execution of other queries.
-
•
Maintainability of the new code is an issue. We aim at a modular implementation, making use of existing functionality and making future enhancements as easy as possible.
-
•
Spark and Spark SQL support many different data sources. The integration of skyline queries should work independently of the data source that is being used.
Our contribution
The main result of this work is a full-fledged integration of skyline queries. This includes the following:
-
•
Virtually every single component involved in the query optimization and execution process of Spark SQL (see Figure 2) had to be extended: the parser, analyzer, optimizer, etc.
-
•
While a substantial portion of new code had to be provided, at the same time, we took care to make use of existing code as much as possible and to keep the extensions modular for easy maintenance and future enhancements.
-
•
For the optimization of skyline queries, the specifics of distributed query processing had to be taken into account. Apart from incorporating new rules into the Catalyst optimizer of Spark SQL, we have extended the skyline query syntax compared with previous proposals (Börzsönyi et al., 2001; Eder, 2009) to allow the user to control further skyline-specific optimization.
-
•
We have carried out an extensive empirical evaluation which shows that the integrated version of skyline queries by far outperforms the rewritten version in the style of Listing 1.
Structure of the paper
In Section 2, we discuss relevant related work. The syntax and semantics of skyline queries are introduced in Section 3. A brief introduction to Apache Spark and Spark SQL is given in Section 4. In Section 5, we describe the main ideas of our integration of the skyline operator into Spark SQL. We report on the results of our empirical evaluation in Section 6. In Section 7, we conclude and identify some lines of future work.
The source code of our implementation is available here: https://github.com/Lukas-Grasmann/skyline-queries-spark. Further material, comprised of the binaries of our implementation, all input data, and queries from our empirical evaluation is provided at (Grasmann et al., 2022).
2. Related Work
Since the original publication of the skyline operator by Börzsönyi, Kossmann, and Stocker (Börzsönyi et al., 2001), various algorithms and approaches to skyline queries have been proposed. In this section, we give an overview of the relevant related work. We limit ourselves to, broadly, the “original” definition of skyline queries and exclude related query types like reverse skyline queries (Dellis and Seeger, 2007).
The main cost factor of skyline computation is the time spent on dominance testing, which in turn depends on how many dominance tests between tuples need to be performed. A simple, straightforward algorithm runs in quadratic time w.r.t. the size of the data. It checks for each pair of tuples whether one of them is dominated and, therefore, not part of the resulting skyline. This basic idea of pairwise dominance tests is realized in the Block-Nested-Loop skyline algorithm (Börzsönyi et al., 2001), which performs well especially when the resulting output is not too big, and the input dataset fits in memory.
In the most recent algorithms, there are two main approaches that are used to either decrease the total number of dominance checks or to increase the parallelism of these checks.
- (1)
-
(2)
Partitioning (and distributing) the skyline computation by first independently computing the skyline of partitions (local skylines) before proceeding to the computation of the final skyline (global skyline) (Kim and Kim, 2018; Cui et al., 2008; Tang et al., 2019; Gulzar et al., 2019). This does not necessarily decrease the total number of dominance checks but speeds up the algorithm through parallelism.
Most of these approaches are centered around special data structures and indexes, which are provided by the respective database system. This makes them less suitable for Spark, which currently has no internal support for building and maintaining indexes. Such algorithms include Index (Tan et al., 2001) which uses a bitmap index to compute the skyline. Many algorithms of this class also make use of presorting, i.e., sorting the tuples from the dataset according to a monotone scoring function. Such scoring can, by definition, rule out certain dominance relationships between tuples such that fewer comparisons become necessary. This includes the algorithms SFS (Chomicki et al., 2003, 2005), LESS (Godfrey et al., 2005, 2007), SALSA (Bartolini et al., 2006, 2008), and SDI (Liu and Li, 2020).
A simple partition-based algorithm is the Divide-and-Conquer algorithm presented in the original skyline paper (Börzsönyi et al., 2001). Its working principle is to recursively divide the data into partitions until the units are small enough such that the skyline can be computed efficiently. The resulting (local) skylines are then merged step by step until the entire recursion stack has been processed. Related approaches include the nearest-neighbor search (Kossmann et al., 2002) as well as other similar algorithms (Papadias et al., 2003, 2005; Morse et al., 2007; Zhang et al., 2009; Sheng and Tao, 2012).
The algorithm BSkyTree (Lee and Hwang, 2010a, b) supports both a sorting-based and a partition-based variant. These make use of an index tree-structure to increase performance. Alternatively, there also exist tree structures based on quad-trees (Park et al., 2013). Here, the data is partitioned dynamically and gradually into smaller and smaller “rectangular” chunks until the skylines can be computed efficiently.
There are also newer algorithms specifically targeted towards the MapReduce framework (Kim and Kim, 2018; Lee et al., 2007; Tang et al., 2019). MapReduce approaches use mappers to generate partitions by assigning keys to each tuple while the reducers are responsible for computing the actual skylines for all tuples with the same key. Each intermediate skyline for a partition is called a local skyline. This approach usually employs two or more rounds of map and reduce operations (stages) where each stage first (re-)partitions the data and then computes skylines. The final result is then derived by the last stage which generates only one partition and computes the global skyline.
The success of MapReduce approaches relies on keeping the intermediate results as small as possible and maximizing parallelism (Kim and Kim, 2018). To achieve this, multiple different partitioning schemes exist such as random, grid-based, and angle-based partitioning (Kim and Kim, 2018). Keeping the last local skylines before the global skyline computation small is especially desirable since the global skyline computation cannot be fully parallelized. Indeed, this is usually the bottleneck which slows the skyline computation down (Kim and Kim, 2018). This approach is not suitable for our purposes since it requires data from different partitions to be passed along with meta-information about the partitions. Spark does not currently support such functionality and adding it would be beyond the scope of this work.
There are efforts to eliminate multiple data points at once and make the global skyline computation step distributed by partitioning the data. In the case of grid-based-partitioning it is possible to eliminate entire cells of data if they are dominated by another (non-empty) cell (Tang et al., 2019). It is then also possible to cut down the number of data points which each tuple must be compared against in the global skyline since some cells can never dominate each other according to the basic properties of the skyline (if a tuple is better in at least one dimension then it cannot be dominated) (Kim and Kim, 2018; Tang et al., 2019).
There have been two past efforts to implement skyline computation in Spark. The first one is the system SkySpark (Kanellis, 2020) which uses Spark as the data source and realizes the skyline computation on the level of RDD operations (see Section 4 for details on Spark and RDDs). A similar effort was made in the context of the thesis by Ioanna Papanikolaou (Papanikolaou, 2018), which uses the map-reduce functionality of RDDs in Spark to compute the skyline. Both systems thus realize skyline computation as standalone Spark programs rather than as part of Spark SQL, which would make, for instance, a direct performance comparison with our fully integrated solution difficult (even though it might still provide some interesting insights). However, the most important issue is that these implementations are not ready to use: SkySpark (Kanellis, 2020), with the last source code update in 2016, implements skyline computation for an old version of Spark. The code has been deprecated and archived by the author with a note that the code does not meet his standards anymore. For the system reported in (Papanikolaou, 2018), there is no runnable code provided since it is only available as code snippets in the PDF document.
As will be detailed in Section 5, we have chosen the Block-Nested-Loop skyline algorithm (Börzsönyi et al., 2001) for our integration into Spark SQL due to its simplicity. By the modular structure of our implementation, replacing this algorithm by more sophisticated ones in the future should not be too difficult. We will come back to suggestions for future work in Section 7. Partitioning also plays an important role in our distributed approach (see Section 5 for limits of distributed processing in the case of incomplete data though). However, to avoid unnecessary communication cost, we refrain from overriding Spark’s partitioning mechanism.
3. Skyline Queries
In this section, we take a deeper look into the syntax and semantics of skyline queries. Skyline queries can be expressed in a simple extension of SELECT-FROM-WHERE queries in SQL. This syntax was proposed together with the original skyline operator in (Börzsönyi et al., 2001) and can be found in Listing 3. The skyline dimensions out of total dimensions are denoted as through (where ). The DISTINCT keyword defines that we only return a single tuple if there are tuples with the same values in the skyline dimensions. If there are multiple possibilities, the exact tuple that is returned is chosen arbitrarily. The keyword COMPLETE is an extension compared to (Börzsönyi et al., 2001) that we have introduced. It allows the user to inform the system that the dataset is complete in the sense that no null occurs in the skyline dimensions. The system can, therefore, safely choose the complete skyline algorithm, which is more efficient than the incomplete one. This will be discussed in more detail in Section 5.
In Section 1, we have already introduced the dominance relationship and the skyline itself in a semi-formal way. Below, we provide formal definitions of both concepts.
Definition 3.1 (Dominance relationship between tuples (Börzsönyi et al., 2001; Kim and Kim, 2018)).
Given a set of tuples , two -ary tuples and a set of skyline dimensions which always consists of four (potentially empty) disjoint subsets , we define and as the value of the tuple and in dimension respectively. The subsets of the dimensions correspond to the skyline dimensions () and “extra” (non-skyline) dimensions (). Then dominates () if and only if:
In words, the above definition means that a tuple dominates another tuple if and only if:
-
•
The values in all DIFF dimensions are equal and
-
•
is at least as good in all MIN/MAX skyline dimensions and
-
•
is strictly better in at least one MIN/MAX skyline dimension
The dominance relationships are transitive, i.e., if dominates and dominates then also dominates .
Given this formal definition of the dominance relationship, we can now also formally define the skyline itself.
Definition 3.2 (Skyline (Börzsönyi et al., 2001)).
Given a set of skyline dimensions , let be a set of tuples. The skyline (denoted ) is a set of tuples defined as follows:
Note that the above definitions apply to complete datasets. For incomplete datasets (if null may occur in some skyline dimension), we need to slightly modify the definition of dominance in that the comparison of two tuples is always restricted to those dimensions where both are not null. Hence, the above definition for the complete case is modified as follows (Gulzar et al., 2019):
-
•
The values in all DIFF dimensions where and are not null are equal and
-
•
is at least as good in all MIN/MAX skyline dimensions where and are not null and
-
•
is strictly better in at least one MIN/MAX skyline dimension where and are not null
Given the modified dominance relationship, we now run into the problem that for incomplete datasets the transitivity property of skyline dominance is lost and there may be cyclic dominance relationships. For instance, assume a dataset similar to the one given in (Gulzar et al., 2019) consisting of three tuples , where is a placeholder for a missing value. If all three dimensions are skyline dimensions, then, given the definition of dominance in incomplete datasets, it follows that since for the first dimension. Similarly, we have since on the second dimension. Lastly, we note that since but since for the third dimension. Under the assumption of transitivity, it would follow from and that holds, which is not the case. In other words, for incomplete data, the transitivity property gets lost (Gulzar et al., 2019). Since , , and , the dominance relationship forms a cycle and can therefore be referred to as a cyclic dominance relationship (Gulzar et al., 2019). Hence, when computing the skyline of a potentially incomplete dataset, prematurely deleting dominated tuples may lead to erroneous results. Indeed, this is the trap into which the skyline algorithm proposed in (Gulzar et al., 2019) fell. For details, see Appendix A.
As already mentioned in Section 1, skyline queries can be formulated in plain SQL without the specialized skyline syntax from Listing 3. A general schema of rewriting skyline queries in plain SQL is given in Listing 4. A first version of this rewriting was informally described in (Börzsönyi et al., 2001). The full details and the corresponding syntax used here were introduced in (Eder, 2009): First, the outer query selects all tuples from some relation (which may itself be the result of a complex SELECT-statement) and then we use a subquery with WHERE NOT EXISTS to eliminate all dominated tuples.
4. Apache Spark
Apache Spark is a unified and distributed framework for processing large volumes of data. The framework can handle many different data sources. Through various specialized modules on top of its core module, it supports a wide range of processing workloads. The central data structure of the Spark Core are resilient distributed datasets (RDDs). An RDD is a collection of elements distributed over the nodes of the cluster. Working with Spark comes down to defining transformations and actions on RDDs, while data distribution, parallel execution, synchronization, fault-tolerance, etc. are taken care of by the system and are largely hidden from the user.
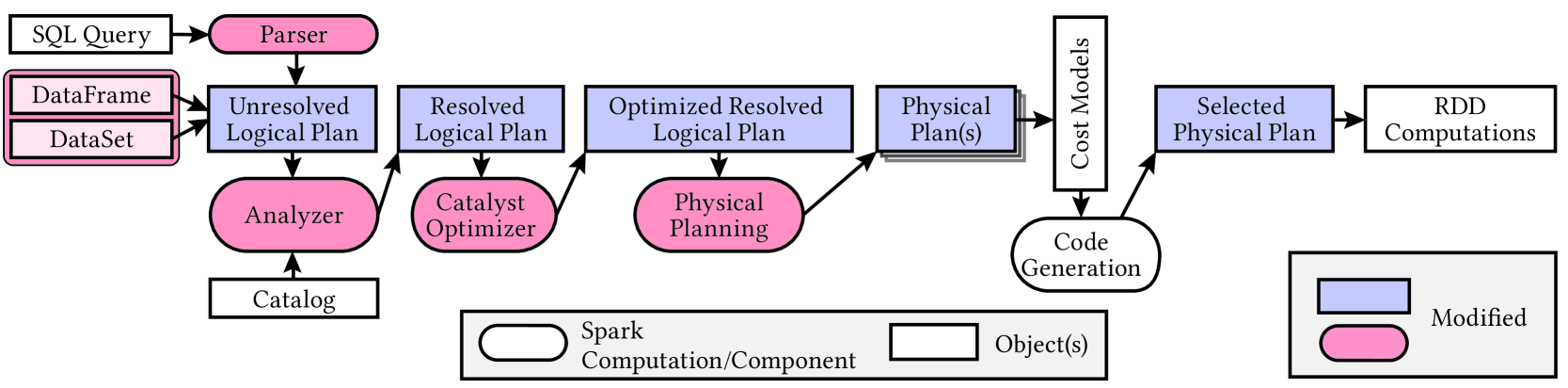
The focus of our work lies on the Spark SQL module, which extends the Spark Core by providing an SQL interface. Queries can be formulated either via query strings or using an API. This API is based on specialized data structures called DataFrame and DataSet. They are (meanwhile) closely related in that every DataFrame is also a DataSet, with the only difference being that DataSets are strongly typed while DataFrames are not. The processing and execution of input queries follows a well-defined schema with multiple steps that are depicted in Figure 2.
First, the queries are formulated either via SQL query strings or via APIs. In the case of query strings, it is necessary to parse them first. Both methods produce a logical execution plan that contains the information which operations the plan consists of. For instance, filtering is represented as a specific node in the plan and can be used for both WHERE and HAVING clauses in the query. The references to tables or columns are not yet assigned to actual objects in the database in this step. To solve this, the Analyzer takes each identifier and translates it using the Catalog. The result returned by the Analyzer is the resolved logical plan where all placeholders have been replaced by actual references to objects in the database.
The Catalyst Optimizer is a crucial part for the success of Spark SQL. It is a powerful rule-based optimizer that can be extended to include new rules for specific (newly introduced) nodes. Optimizations are applied to the resolved logical plan.
To actually execute the query, the logical execution plan must first be translated into a physical execution plan, which contains information about how the various operations are to be realized. For example, Spark provides different join implementations, which are each represented by different nodes in the physical plan and one of them is selected during the physical planning phase. There may be more than one physical plan generated during this step. Based on the physical plan(s), one specific plan must be selected, and Code Generation is carried out according to the chosen physical plan. In Spark, the generated code is a computation based on RDDs.
It will turn out that, for a full-fledged integration of skyline queries into Spark SQL, virtually all of the components of query processing and execution mentioned above have to be extended or modified. This will be the topic of the next section.
5. Integrating Skylines into Apache Spark
Below, we give an overview of the required modifications and extensions of each component of the query processing flow depicted in Figure 2. An important aspect of integrating skyline queries into Spark SQL is the algorithm selection for the actual computation of the skyline. Here, we will discuss in some detail the challenges arising from potentially incomplete data and our solution.
5.1. Skyline Query Syntax in Spark SQL
The parser is the first step of processing a Spark SQL query. It uses the ANTLR parser grammar generator to generate a lexer and subsequent parser which take query strings as input to obtain nodes in a logical plan. We modify both parts to extend Spark’s SQL-like syntax such that it also includes skyline queries.
The grammar corresponding to the syntax introduced in Listing 3 is shown in Listing 5. Given a “regular” SELECT statement, note that a skyline always comes after the HAVING clause (if any) but before any ORDER BY clause. Each skyline clause consists of the SKYLINE OF keyword (line 2), an optional DISTINCT (line 3) and COMPLETE (line 4), as well as an arbitrary number of skyline dimensions (line 5 and 8 - 9) where the “type” MIN/MAX/DIFF is given separately for each dimension (line 9). The ordering of skyline dimensions in this syntax has no bearing on the outcome of the query (except for potential ordering). It may, however, have a slight effect on the performance of dominance checks since it determines the order in which the skyline dimensions of two tuples are compared.
5.2. Extending the Logical Plan
Each node in the logical plan stores the details necessary to choose an algorithm for the specific operator and to derive a physical plan. In the case of the skyline operator, we use a single node with a single child in the logical plan. This node contains information such as the skyline dimensions SkylineDimension as well as other vital information like whether the skyline should be DISTINCT or not. The child node of the skyline operator node provides the input data for the skyline computation.
Each SkylineDimension extends the default Spark Expression such that it stores both the reference to the database dimension and the type (i.e., MIN/MAX/DIFF). The database dimension is usually a column but can also be a more complex Expression (e.g., an aggregate) in Spark. It is stored as the child of the SkylineDimension which allows us to make use of the generic functionality responsible for resolving Expressions in the analyzer.
5.3. Extending the Analyzer
The analyzer of Spark already offers a wide range of rules which can be used to resolve the expressions. Since the skyline dimensions used by our skyline operator as well as their respective children are also expressions, they will be resolved automatically by the existing rules in most cases. We have to ensure that all common queries also work when the skyline operator is used. To achieve this, we have to extend the existing rules from the Analyzer to also incorporate the skyline operator. Such rules mainly pertain to the propagation of aggregates across the (unresolved) logical execution plan of Spark.
First, we ensure that we are also able to compute skylines which include dimensions not present in the final projection (i.e., the attributes specified in the SELECT clause). To achieve this, we expand the function ResolveMissingReferences by adding another case for the SkylineOperator. The code is shown in Listing 6. The rule is applied if and only if the SkylineOperator has not yet been resolved, has missing input attributes, and the child is already fully resolved (line 1 - 3). Then, we resolve the expressions and add the missing attributes (line 4 - 5) which are then used to generate a new set of skyline dimensions (line 6 - 7). If no output was added, we simply replace the skyline dimensions (line 8 - 9). Otherwise, we create a new skyline with the newly generated child (line 10 - 11) and add a projection to eliminate redundant attributes (line 12).
Next, we need to take care that aggregate attributes are also propagated to the skyline properly. The code to accomplish this is given in Listing 7. We will only explain it briefly since it was modified from existing Spark code for similar nodes.
To do this, we match the skyline operator which is a parent or ancestor node of an Aggregate (line 3). Then we try to resolve the skyline dimensions using the output of the aggregate as a basis (line 5 - 6). This will also introduce missing aggregates in the Aggregate node which is necessary, for example, if the output of the query only contains the sum but the skyline is based on the count (line 7 - 13). Using the output of the resolution, we (re-)construct the skyline operator (line 14 - 17). Additionally, we introduce analogous rules for other similar cases like plans where there is a Filter node introduced by a HAVING clause between the Aggregate and the skyline operator node among others.
Note that the correct handling of Filter and Aggregate nodes is non-trivial in general – not only in combination with the skyline operator. Indeed, when working on the integration of skyline queries into Spark SQL, we noticed that aggregates are in some cases not resolved correctly by the default rules of Spark. This is, for example, the case when Sort nodes are resolved in combination with Filters and Aggregates. Such cases may be introduced by a HAVING clause in the query. For a more detailed description of this erroneous behavior of Spark SQL together with a proposal how to fix this bug, see Appendix B.
5.4. Additional Optimizations
Given a resolved logical plan, the Catalyst Optimizer aims at improving the logical query plan by applying rule-based optimizations (see Figure 2). The default optimizations of Spark also apply to skyline queries – especially to the ones where the data itself is retrieved by a more complex query. Skyline queries integrated into Apache Spark thus benefit from existing optimizations, which can be further improved by adding the following specialized rules.
If a skyline query contains a single MIN or MAX dimension, then this is equivalent to selecting the tuples with the lowest or highest values for the skyline dimension respectively. In other words, the Pareto optimum in a single dimension is simply the optimum. There are two possibilities to rewrite the skyline. We can either first sort the values according to the skyline dimension and then only select the top results or find the lowest or highest value in a scalar subquery (i.e., a subquery that yields a single value) and then select the tuples which have the desired value. Given that, for a relation with tuples, sorting and selecting exhibits a worst-case runtime of while the scalar subquery and selection can, when optimized, be done in time, we opt for the latter.
A more sophisticated optimization is taken from (Börzsönyi et al., 2001), where (Carey and Kossmann, 1997) is referenced for the correctness of this transformation. It is applicable if the skyline appears in combination with a Join node in the tree. If the output of the join serves as the input to the skyline operator, then we can check whether it is possible to move the skyline into one of the “sides” of the join. This is applicable if the join is non-reductive (Börzsönyi et al., 2001) which is defined in (Carey and Kossmann, 1997). Intuitively, non-reductiveness in our case means that due to the constraints in the database, it can be inferred that for every tuple in the first table joined there must exist at least one “partner” in the other join table if the tuple is part of the skyline. The main benefit of this optimization is that computing the skyline before the join is likely to reduce the input size for both the skyline operator and the (now subsequent) join operation, which typically reduces the total query execution time.
5.5. Algorithm Selection
Given the problems that arise with skyline queries on incomplete datasets as mentioned in Section 3, we have to take extra care which algorithm is used for which dataset. The decision is mainly governed by whether we can assume the input dataset to be complete or not. If the dataset is (potentially) incomplete, we have to select an algorithm that is capable of handling incomplete data since otherwise, the computation may not yield the correct results.
As will be explained in Section 5.7 (and it will also be observed in the empirical evaluation in Section 6), skyline algorithms that are able to handle incomplete datasets are lacking in performance compared to their complete counterparts. Given that Spark can handle multiple different data sources and cannot always detect the nullability of a column, it is desirable to provide an override that decides whether a complete algorithm is used regardless of the detected input columns. We do this by introducing the optional COMPLETE keyword in the skyline query syntax. This gives the user the possibility to enforce the use of the complete algorithms also on datasets that can technically be incomplete but are known to be complete. The correctness of the algorithm only depends on whether null values actually appear in the data.
We implement the algorithm selection using the nodes in the physical execution plan. Which algorithm is selected depends on which physical nodes are chosen during translation of the (resolved and optimized) logical execution plan. In a minimally viable implementation, it is possible to implement the skyline operator in a single physical node. This has, however, the disadvantage that Spark’s potential of parallelism would be lost for the skyline computation. We therefore split the computation into two steps, represented by two separate nodes in the physical plan. The pseudocode of the algorithm selection is shown in Listing 8.
The main decision to be made (line 1, 2) is if we may use the complete algorithm. This is the case when the SKYLINE clause contains the COMPLETE keyword or when the skyline dimensions are recognized as not nullable by the system. Note that the local skylines use the same basic nodes both in the complete and incomplete cases, while the nodes for the global skyline differ.
The first node in the physical plan corresponds to the local skyline computation, which can be done in a distributed manner (line 3 and 6). This means that there may exist multiple instances of the node which can exist distributed across the cluster on which Spark runs. For the actual distribution of the data, we can use multiple different schemes provided by Spark or leave it as-is from the child in the physical plan. When left at standard distribution (UnspecifiedDistribution), Spark will usually try to distribute the data equally given the number of available executors. For example, if there are 10 executors available for 10.000.000 tuples in the original dataset, then each executor will receive roughly 1 million tuples each. For the algorithms that can handle incomplete datasets, we have to use a specialized distribution scheme, which will be discussed in more detail in Section 5.7.
The output of the local skyline computation is used as input for calculating the global skyline (line 4 and 7). This means that, in the physical execution plan, we create a global skyline node whose only child is the local skyline. In contrast to the local skyline, we may not freely choose the distribution but must instead ensure that all tuples from the local skyline are handled by the same executor for the global skyline computation. This is enforced by choosing the AllTuples distribution provided by Spark.
To keep our solution modular, we encapsulate the dominance check in a new utility that we introduce in Spark. It takes as input the values and types of the skyline dimensions of two tuples and checks if one tuple dominates the other. For every skyline dimension, we match the data type to avoid costly casting and (in the case of casting to floating types) potential loss of accuracy.
With our approach to algorithm selection in the physical plan and the modular structure of the code, it is easy to incorporate further skyline algorithms if so desired in the future. Choosing a different algorithm mainly entails replacing the local and/or global skyline computation nodes in the physical plan by new ones.
5.6. Skylines in Complete Datasets
For complete datasets, we adapt the Block-Nested-Loop skyline algorithm (Börzsönyi et al., 2001). The main idea is to keep a window of tuples in which the skyline of all tuples processed up to this point is stored. We iterate through the entire dataset, and, for each tuple, we check which dominance relationships exist with the tuples in the current window. If tuple is dominated by a tuple in the window, then is eliminated. Here, it is not necessary to check against the remaining tuples since it cannot dominate any tuples in the window due to transitivity. If tuple dominates one or more tuples in the window, then the dominated tuples are eliminated. In this case, is inserted into the window since, by transitivity, cannot be dominated by other tuples in the window. Tuple is also inserted into the window if it is found incomparable with all tuples in the current window.
We can use the same algorithm for both the local and the global skyline computation. The only necessary difference is the distribution of the data, where we let Spark handle the distribution for the local skyline while we force the AllTuples distribution for the global skyline computation. This has the additional advantage that partitioning done in prior processing steps can be kept, which increases the locality of the data for the local skyline computation and may thus help to further improve the overall performance.
The Block-Nested-Loop approach is most efficient if the window fits into main memory. Note that also Spark, in general, performs best if large portions of the data fit into the main memory available. Especially in cloud-based platforms, there is typically sufficient RAM available (in the order of magnitude of terabytes or even petabytes). At any rate, if RAM does not suffice, Spark will swap data to disk like any other program – with the usual expected performance loss.
5.7. Skylines in Incomplete Datasets
When computing the local skyline for an incomplete dataset, we must take care that no potential cyclic dominance relationships are lost such that tuples may appear in the result even though they are dominated by another tuple. To combat this, we use a special form of a bitmap-based skyline algorithm (Gulzar et al., 2019).
Given a set of tuples, we can assign each tuple a bitmap (an index in binary format) such that each bit in corresponds to a skyline dimension. If a tuple has a null value in a skyline dimension, then the corresponding bit in bitmap is set to ; otherwise, it is set to . Then, subsequently, the data is partitioned according to the bitmap indexes such that all tuples with a specific bitmap are assigned to the same subset (partition) of . We can then calculate the local skyline for each set of tuples without losing the transitivity property or running into issues with cyclic dominance relationships.
In Spark, this sort of partitioning is done via the integrated distribution of the nodes. We craft an expression for the distribution which uses the predefined IsNull() method to achieve this effect.
For the global skyline computation, we cannot use the standard Block-Nested-Loop approach since cyclic dominance relationships may occur and the transitivity of the skyline operator is not guaranteed. We therefore opt for the less efficient approach where we compare all tuples against each other. Even if a tuple is dominated, we may not immediately delete it since it may be the only tuple that dominates another tuple . In such a case, by prematurely deleting , tuple would be erroneously added to the skyline. This is a subtle point which was, for instance, overlooked in the algorithm proposed in (Gulzar et al., 2019). In Appendix A. we illustrate the error resulting from premature deletion of dominated tuples in detail.
The following lemma guarantees that our skyline computation in case of a potentially incomplete dataset yields the correct result:
Lemma 5.1.
Let a dataset be partitioned according to the null values and let denote the resulting union of local skylines. Then it holds for every tuple not part of the global skyline that either or there exists with .
Proof.
Let be a tuple that is not part of the global skyline , i.e., there exists some tuple with . If both and belong to the same partition during local skyline computation, then this dominance relation will be detected in this step and will be deleted. Hence, in this case, .
Now suppose that and belong to different partitions. If , then is the desired tuple in with .
It remains to consider the case that . This means that gets deleted during the local skyline computation. In other words, there exists a tuple in the same partition as with such that . The latter property is guaranteed by the fact that, inside each partition, all tuples have nulls at the same positions and there can be no cyclic dominance relationships.
By the assumption and the definition of skylines in incomplete datasets, is at least as good as in all non-missing skyline dimensions and strictly better in at least one. Since and both tuples have the same set of missing dimensions due to being in the same partition, it follows that also is at least as good as in all non-missing skyline dimensions and strictly better in at least one. That is, is the desired tuple in with . ∎
Selecting an algorithm which can handle incomplete datasets yields the correct result also for a complete dataset (while the converse is, of course, not true). There is, however, a major drawback to always using an incomplete algorithm. Since the partitioning in the incomplete algorithm is done according to which values of a tuple are null, only limited partitioning is possible. The worst case occurs when the algorithm for incomplete datasets is applied to a complete dataset. In this case, since there are no null values, there is only a single partition which all tuples belong to. This means that any potential of parallelism gets lost. Hence, in the case of a complete dataset, the algorithm for incomplete data performs even worse than a strictly non-distributed approach which immediately proceeds to the global skyline computation by a single executor.
5.8. Extending the User Interfaces
In addition to our extension of the SQL string-interface of Spark SQL, we integrate the skyline queries also into the basic DataFrame API provided in Java and Scala by adding new API functions. Here, the data about the skyline dimensions can either be passed via pairs of skyline dimension and associated dimension type or by using the columnar definition of Spark directly. For the latter purpose, we define the functions smin(), smax(), and sdiff(), which each take a single argument that provides the skyline dimension in Spark columnar format as input. The API calls bypass the parsing step and directly create a new skyline operator node in the logical plan.
We also integrate skyline queries into Python and R via PySpark and SparkR, respectively – two of the most popular languages for analytical and statistical applications. Rather than re-implementing skyline queries in these languages, we build an intermediate layer that calls the Scala-implementation of the DataFrame API.
In Python, this method relies on the external, open-source library Py4J (https://www.py4j.org/). Its usage requires the skyline dimensions and skyline types to first be translated into Java objects, which can then be passed on using Py4J. A slight complication arises from the fact that Python is a weakly typed language, which imposes restrictions on the method signatures. Skyline dimensions and their types are therefore passed as separate lists of strings. The first dimension is then matched to the first type of skyline dimension and so forth. Passing the skyline dimensions via Columns (i.e., Expressions) works similarly to the Scala/Java APIs.
In R, the integration is simpler since R allows for tuples of data to be entered more easily. Hence, in addition to the column-based input analogous to the Python interface, the R interface also accepts a list of pairs of skyline dimension plus type.
5.9. Ensuring Correctness
As far as the impact of the skyline handling on the overall behavior of Spark SQL is concerned, we recall from Sections 5.2 and 5.3 that, in the logical plan, the skyline operator gives rise to a single node with a single input (from the child node) and a single output (to the parent node). When translating the logical node to a physical plan, this still holds since, even if there are multiple physical nodes in the plan, there is only a single input and output.
Therefore, the main concern of ensuring correctness of our integration of skyline queries into Spark SQL is the handling of skyline queries itself. There are no side effects whatsoever of the skyline integration on the rest of query processing in Spark SQL. This also applies to potential effects of the skyline integration on the performance of Spark SQL commands not using the skyline feature at all. In this case, the only difference in the query processing flow is an additional clause in the parser. The additional cost is negligible.
We have intensively tested the skyline handling to provide evidence for its correctness. Unit tests are provided as part of our implementation in the GitHub repository. Additionally, for a significant portion of the experiments reported in Section 6, we have verified that our integrated skyline computation yields the same result as the equivalent “plain” SQL query in the style of Listing 4.
6. Empirical Evaluation
In this section, we take a closer look at how our integration performs based on a series of benchmarks executed on a cluster. We will first provide information about the experimental setup as well as the input data and the queries which are executed on them. Following that, we will provide an overview of the outcomes of the benchmark. To round off the section, we will give a brief summary of the performance measurements and draw some conclusions.
6.1. Experimental Setup
We have implemented the integration of skyline queries into Apache Spark, and provide our implementation as open-source code at https://github.com/Lukas-Grasmann/skyline-queries-spark. Our implementation uses the same languages as Apache Spark, which include Java, Scala, Python, and R. The bulk of the main functionality was written in Scala, which is also the language in which the core functionalities of Spark are implemented. The experiments can be easily reproduced by using the provided open-source software. The binaries, benchmark data, queries, and additional scripts can be found at (Grasmann et al., 2022).
All tests were run on a cluster consisting of 2 namenodes and 18 datanodes. The latter are used to execute the actual program. Every node consists of 2 Xeon E5-2650 v4 CPUs by Intel that provide 24 cores each, which equals 48 cores per node and up to 864 cores across all worker nodes in total. Each node provides up to 256GB of RAM and 4 hard disks with a total capacity of 4TB each.
The resource management of the cluster is entirely based on Cloudera and uses YARN to deploy the applications. It provides the possibility to access data stored in Hive, which we found convenient for storing and maintaining the test data in our experiments. And it is also a common way how Apache Spark is used in practice.
For fine-tuning the parameters, we use the command line arguments provided by Spark to deploy the applications to YARN. In these tests, we tell Spark how many executors are to be spawned. The actual resource assignment is then left to Spark to provide conditions as close to the real-world setting as possible.
6.2. Test Data and Queries
For our tests with a real-world dataset, we use the freely available subset of the Inside Airbnb dataset as input, which contains accommodations from Airbnb over a certain timespan. The time span chosen is 30 days and contains approximately 1 million tuples. The tuples were downloaded from the Inside Airbnb website (Airbnb, 2022) and then subsequently merged while eliminating duplicates and string-based columns. For the complete variant of the dataset, we have eliminated all tuples containing a null value in at least one skyline dimension. Content-wise, this dataset is similar to the hotel example provided in Section 1. The use cases considered here are also similar and encompass finding the “best” listings according to the chosen dimensions. The relevant key (identifying) dimension and the 6 skyline dimensions can be found in Table 1. From this relation, we constructed skyline queries with 1 dimension, 2 dimensions, …, 6 dimensions by selecting the dimensions in the same order as they appear in Table 1, i.e., the one-dimensional skyline query only uses the first skyline dimension (price) in the table, the two-dimensional query uses the first two dimensions (price, accommodates), etc.
| Dimension | Type | Description |
|---|---|---|
| id | KEY | identification number |
| price | MIN | price for renting |
| accommodates | MAX | (max) number of accommodated people |
| bedrooms | MAX | number of bedrooms |
| beds | MAX | number of beds |
| number_of_reviews | MAX | number of reviews |
| review_scores_rating | MAX | total review score ratings (all categories) |
We also carried out tests on a synthetic dataset, namely the store_sales table from the benchmark DSB (Ding et al., 2021). The skyline dimensions used in the benchmarks can be found in Table 2. The table has 2 identifying key dimensions and, again, 6 skyline dimensions. The selection of skyline dimensions to derive 6 skyline queries (with the number of skyline dimensions ranging from 1 to 6) is done exactly as described above for the Airbnb test case.
As far as the test data is concerned, we randomly generated data such that the total size of the table is approximately 15,000,000 tuples (note that data generation in DSB works by indicating the data volume in bytes not tuples; in our case, we generated 1.5 GB of data). For the tests with varying data size, we simply select the first tuples from the table until the desired size of the dataset is reached. For the complete dataset, we only select the tuples which are not null in all six potential skyline dimensions.
| Dimension | Type | Description |
|---|---|---|
| ss_item_sk | KEY | stock item identifier |
| ss_ticket_number | KEY | ticket number identifier |
| ss_quantity | MAX | quantity purchased in sale |
| ss_wholesale_cost | MIN | wholesale cost |
| ss_list_price | MIN | list price |
| ss_sales_price | MIN | sales price |
| ss_ext_discount_amt | MAX | total discount given |
| ss_ext_sales_price | MIN | sum of sales price |
For both datasets, there exists a complete as well as an incomplete variant. The difference between them is that for the complete dataset all tuples that contain null values in at least one skyline dimension have been removed. For the real-world dataset, this means that the incomplete dataset is bigger than the complete variant while for the synthetic dataset, both variants have the same size.
6.3. Tested Algorithms
In total, we run our tests on up to four skyline algorithms:
-
(1)
The distributed algorithm for complete datasets (described in Section 5.6), which splits the skyline computation into local and global skyline computation; strictly speaking, only the local part is distributed (whence, parallelized).
-
(2)
The non-distributed complete algorithm, which completely gives up on parallelism, skips the local skyline computation and immediately proceeds to the global skyline computation from the previous algorithm.
-
(3)
The distributed algorithm for incomplete datasets described in Section 5.7. Recall, however, that here, distribution is based on the occurrence of nulls in skyline dimensions, which severely restricts the potential of parallelism.
-
(4)
As the principal reference algorithm for our skyline algorithms, we run our tests also with the rewriting of skyline queries into plain SQL as described in Listing 4.
In our performance charts, we refer to these 4 algorithms as “distributed complete”, “non-distributed complete”, “distributed incomplete”, and “reference”. In all tests with complete datasets, we compare all four algorithms against each other. For incomplete datasets, the complete algorithms are not applicable; we thus only compare the remaining two algorithms in these cases.
6.4. Experimental Results
In our experimental evaluation, we want to find out how the following parameters affect the execution time:
-
•
number of skyline dimensions;
-
•
number of input tuples in the dataset;
-
•
number of executors used by Spark.
For the number of skyline dimensions, we have crafted queries with 1 – 6 dimensions. The number of executors used by Spark is chosen from 1, 2, 3, 5, 10. For the size of the dataset, we distinguish between the real-world (Airbnb) and synthetic dataset (DSB): all tests with the real-world dataset are carried out with all tuples contained in the data, i.e., ca. 1,200,000 tuples if nulls are allowed and ca. 820,000 tuples after removing all tuples with a null in one of the skyline dimensions. In contrast, the synthetic dataset is randomly generated and we choose subsets of size , , , and both, for the complete and the incomplete dataset.
We have carried out tests with virtually all combinations of the above mentioned value ranges for the three parameters under investigation, resulting in a big collection of test cases: complete vs. incomplete data, 1 – 6 skyline dimensions, “all” tuples (for the Airbnb data) vs. varying between , , , and tuples (for the DSB data), and between 1 and 10 executors. In all these cases, we ran 4 algorithms (in the case of complete data) or 2 algorithms (for incomplete data) as explained in Section 6.3. Below we report on a representative subset of our experiments. The runtime measurements are shown in Figures 3 – 7. Further performance charts are provided in Appendix C.
In our experiments, we have defined a timeout of seconds. Timeouts are “visualized” in our performance charts by missing data points. Actually, timeouts did occur quite frequently – especially with incomplete data and here, in particular, with the “reference” algorithm. Therefore, in Figures 3 – 7, for the case of incomplete data (always the plot on the right-hand side), we only show the results for datasets smaller than tuples. In contrast, for complete data (shown in the plots on the left-hand side) we typically scale up to the max. size of tuples.
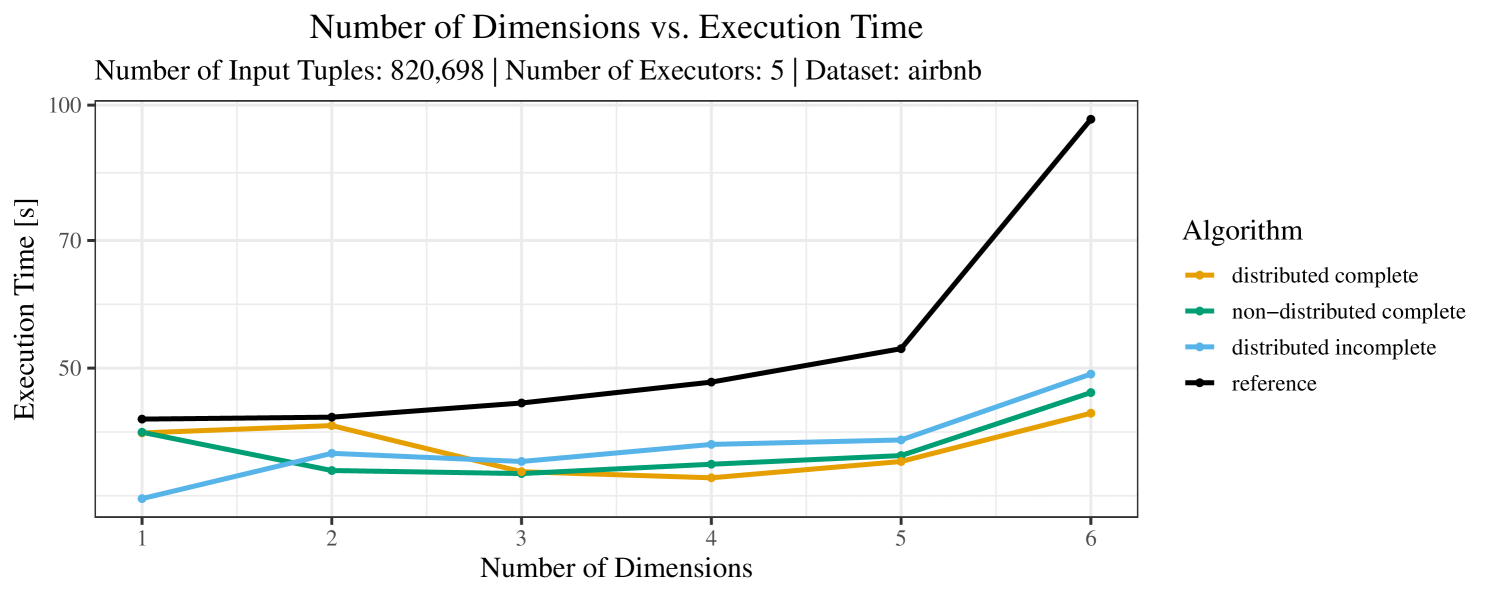
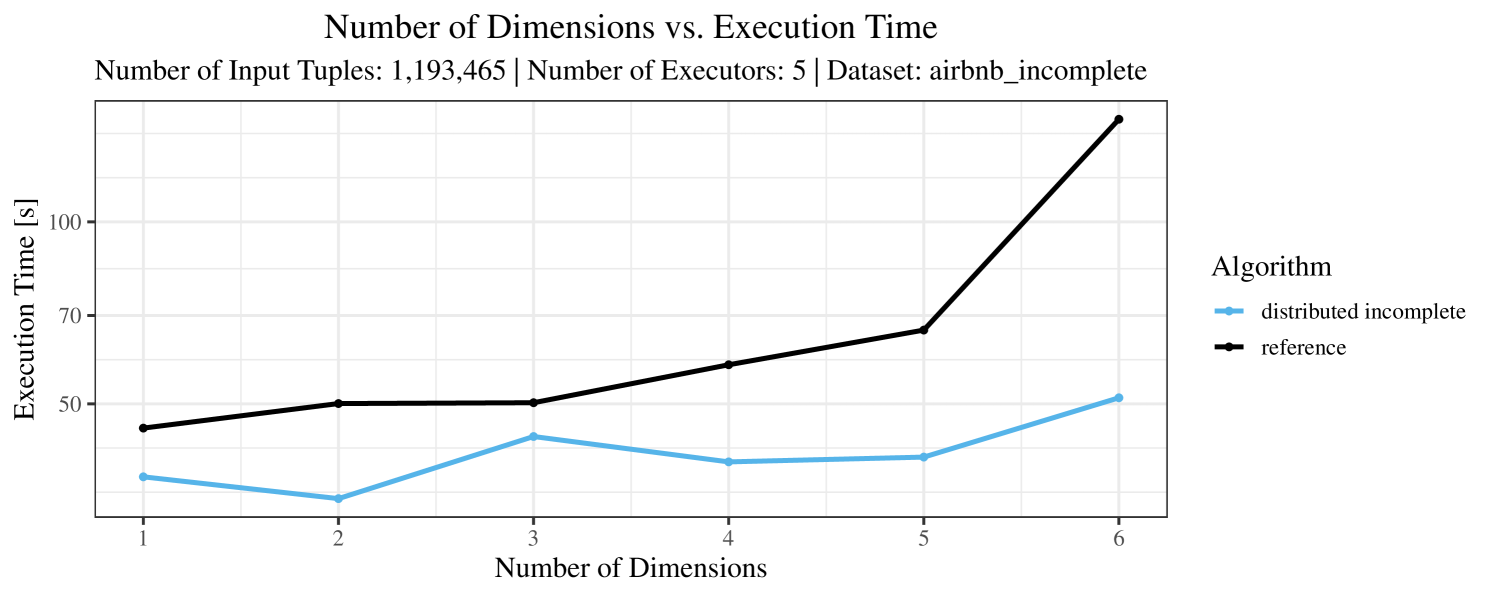
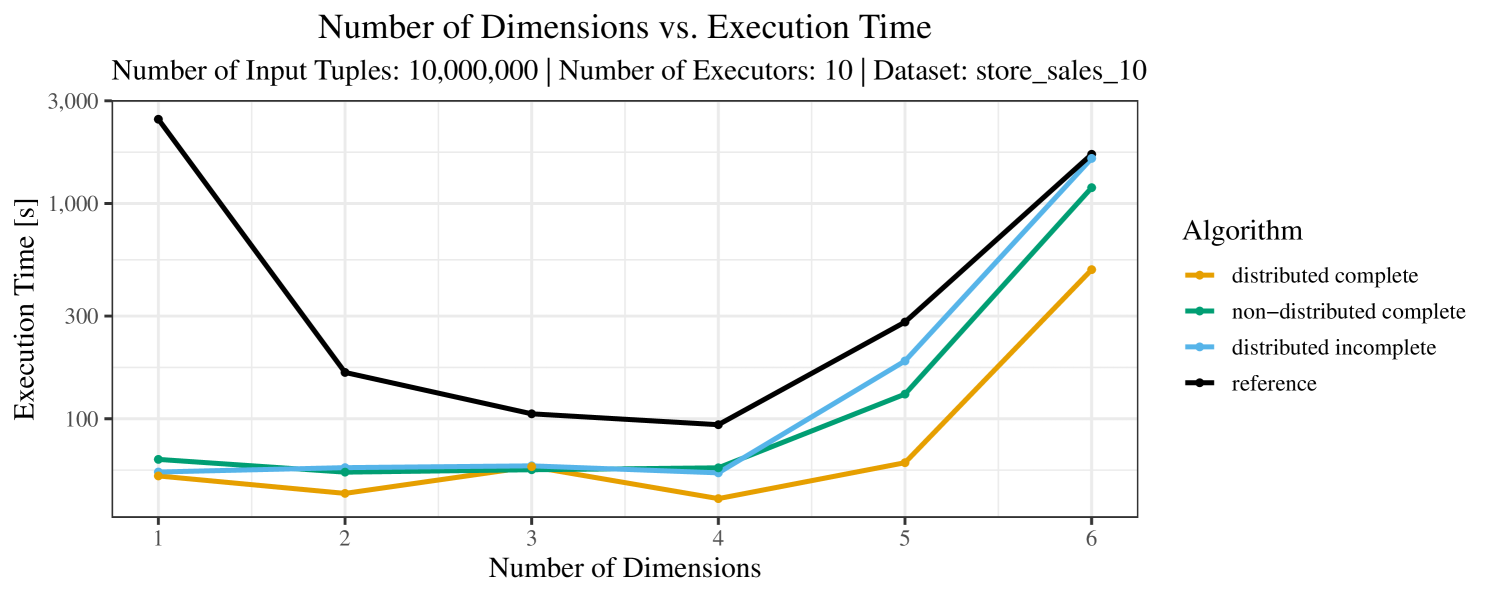
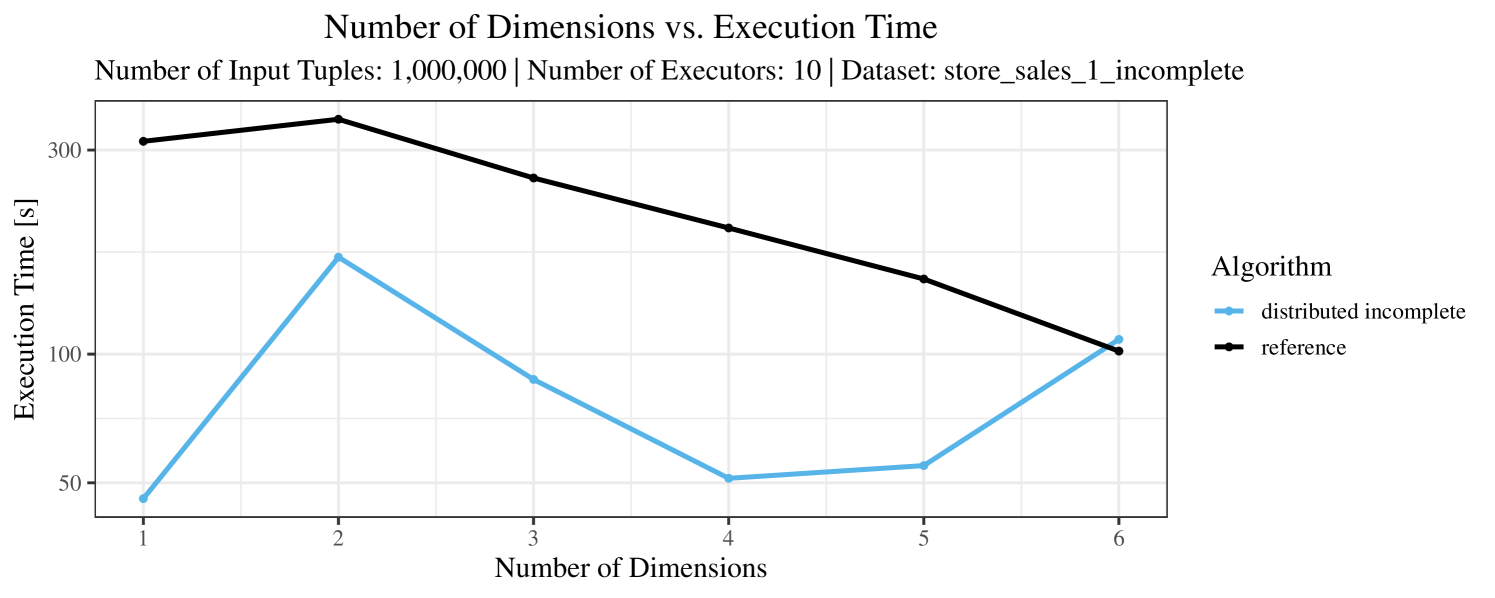
The plots for the impact of the number of skyline dimensions on the execution time can be found in Figure 3 for the real-world dataset and Figure 4 for the synthetic dataset. Of course, if the number of dimension increases, the dominance checks get slightly more costly. But the most important effect on the execution time is via the size of the skyline (in particular, of the intermediate skyline in the window).
Increasing the number of dimensions can have two opposing effects. First, adding a dimension can make tuples incomparable, where previously one tuple dominated the other. In this case, the size of the skyline increases due to the additional skyline dimension. Second, however, it may also happen that two tuples had identical values in the previously considered dimensions and the additional dimension introduces a dominance relation between these tuples. In this case, the size of the skyline decreases.
For the real-world data (Figure 3), the execution time tends to increase with the number of skyline dimensions. This is, in particular, the case for the reference algorithm. In other words, here we see the first possible effect of increasing the number of dimensions. In contrast, for the synthetic dataset, we also see the second possible effect. This effect is best visible for the reference algorithm in the left plot in Figure 4. Apparently, there are many tuples with the maximal value in the first dimension (= ss_quantity), which become distinguishable by the second dimension (= ss_wholesale_cost). For the right plot in Figure 4, it should be noted that the tests were carried out with a 10 times smaller dataset to avoid timeouts, which makes the test results less robust. The peak in the case of two dimensions is probably due to “unfavorable” partitioning of tuples causing some of the local skylines to get overly big.
At any rate, when comparing the algorithms, we note that the specialized algorithms are faster in almost all cases and scale significantly better than the “reference” algorithm (in particular, in case of the real-word data). For complete data, the “distributed complete” algorithm performs best. The discrepancy between the best specialized algorithm and the reference algorithm is over 50% in most cases and can get up to ca. 80% (complete synthetic data, 5 dimensions) and even over 95% (complete synthetic data, 1 dimension).
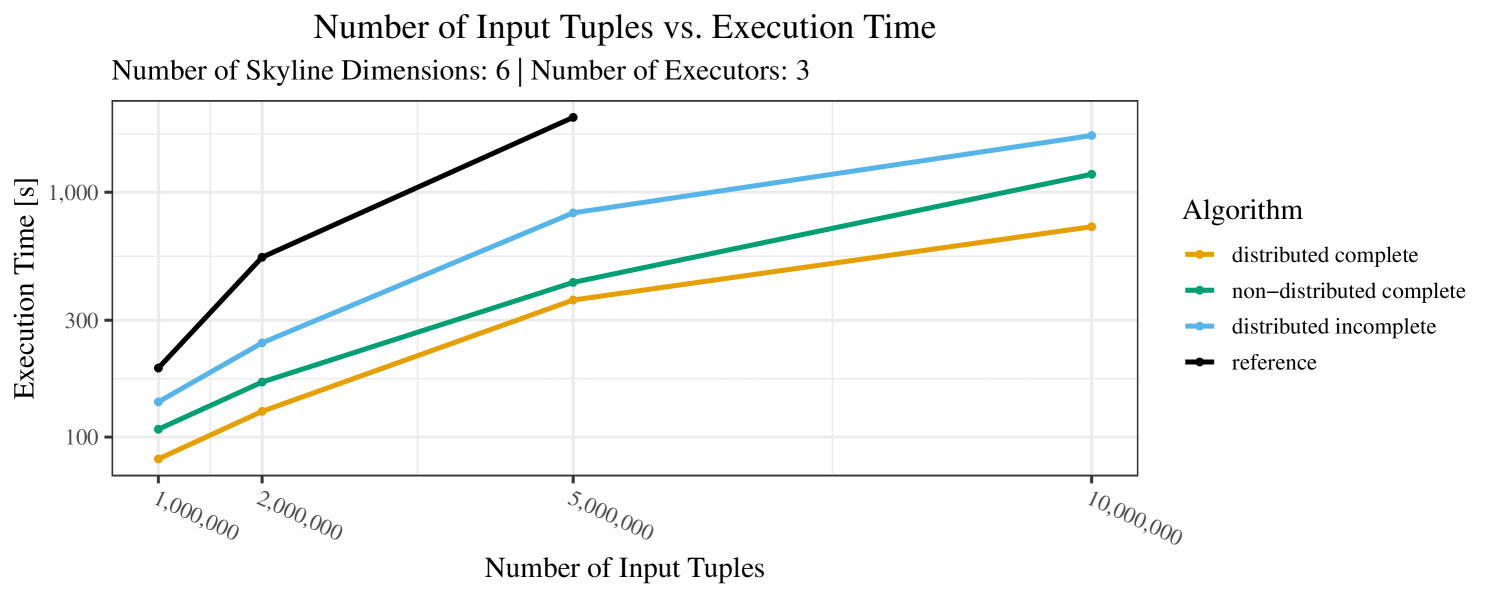
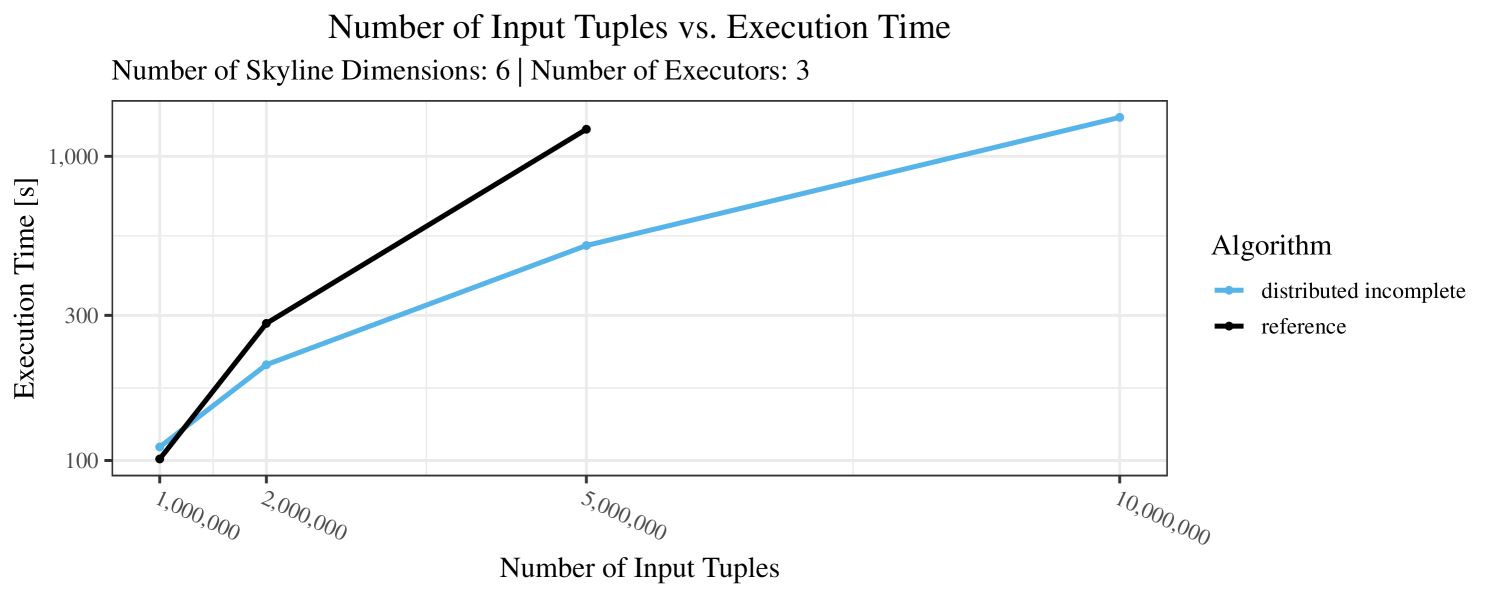
The impact of the size of the dataset on the execution time is shown in Figure 5. Recall that we consider the size of the real-world dataset as fixed. Hence, the experiments with varying data size were only done with the synthetic data. Of course, the execution time increases with the size of the dataset, since a larger dataset also increases the number of dominance checks needed. The exact increase depends on the used algorithm; it is particularly dramatic for the “reference” algorithm, which even reaches the timeout threshold as bigger datasets are considered. Again, the “distributed complete” algorithm, when applicable, performs best and, in almost all cases, all specialized skyline algorithms outperform the “reference” algorithm. The discrepancy between the best specialized algorithm and the reference algorithm reaches ca. 60% for incomplete data and over 80% for complete data (for tuples). For the biggest datasets ( tuples), the reference algorithm even times out.
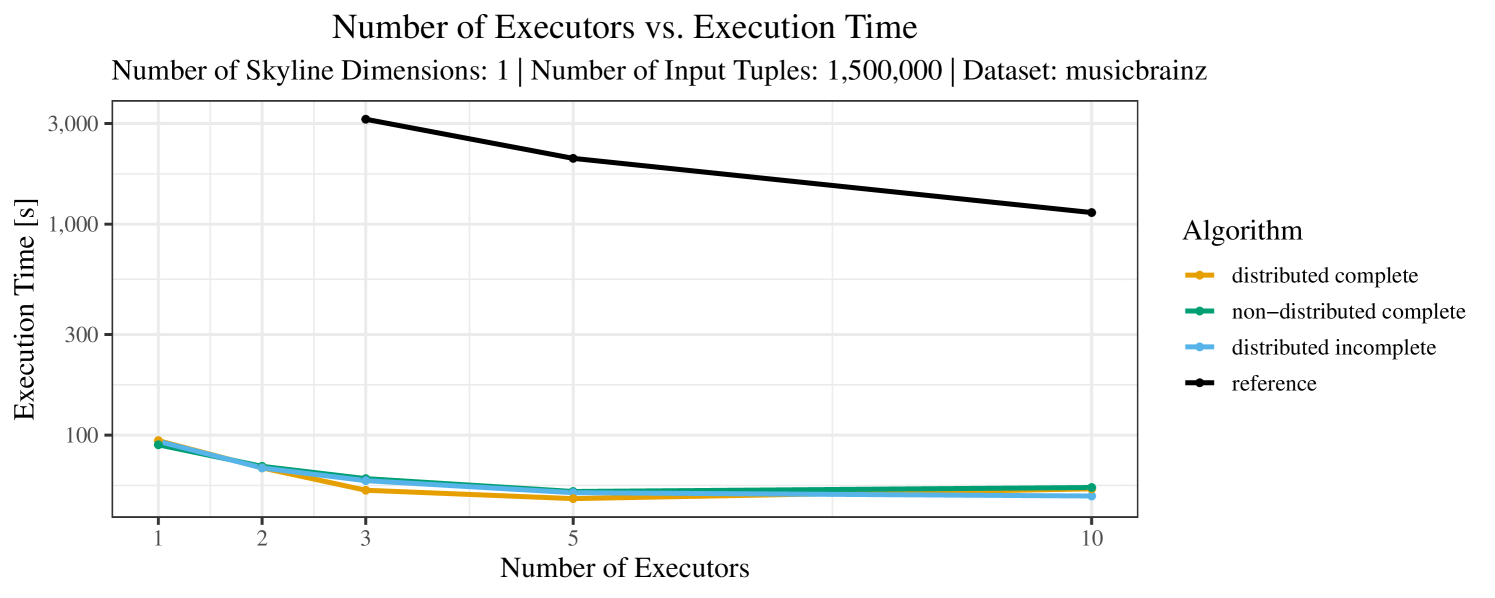
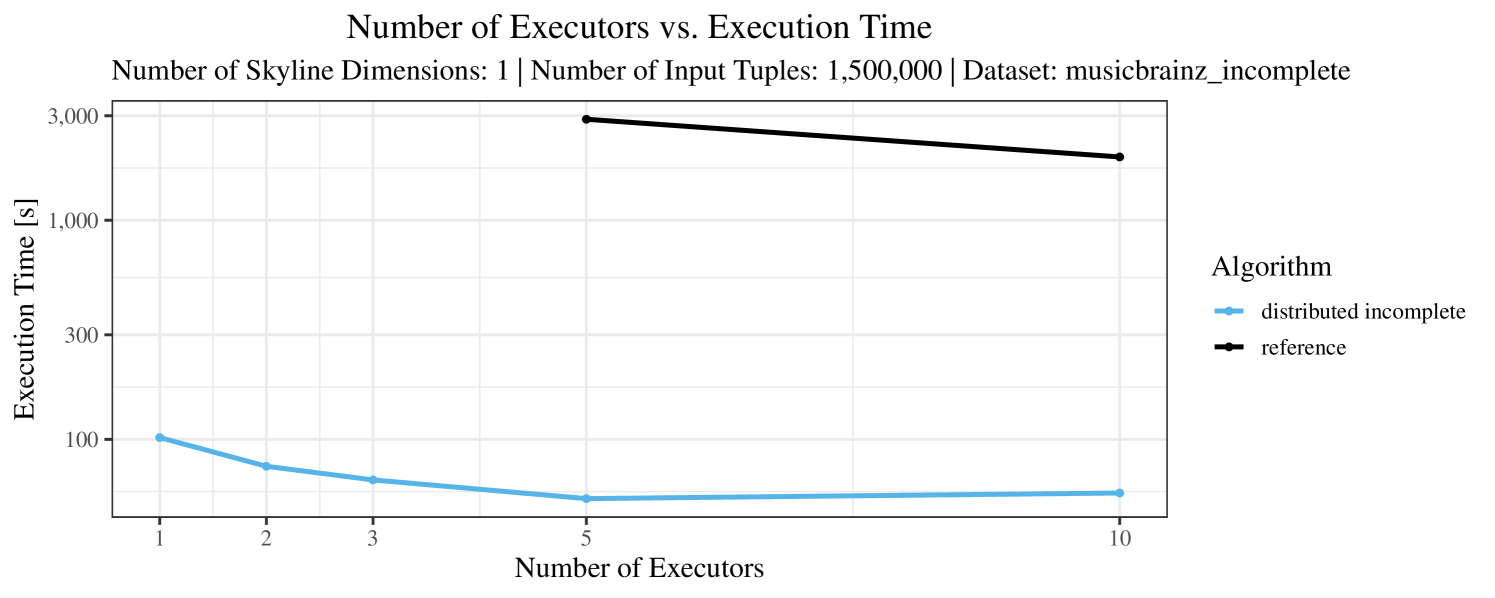
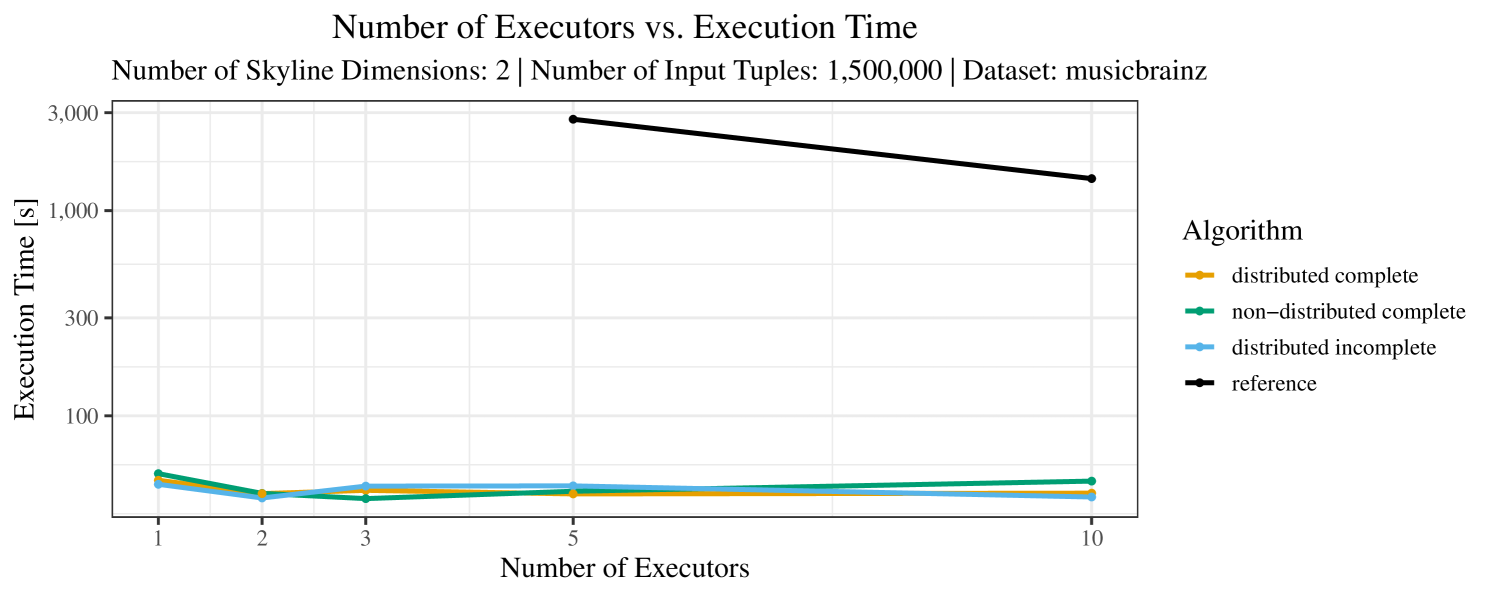
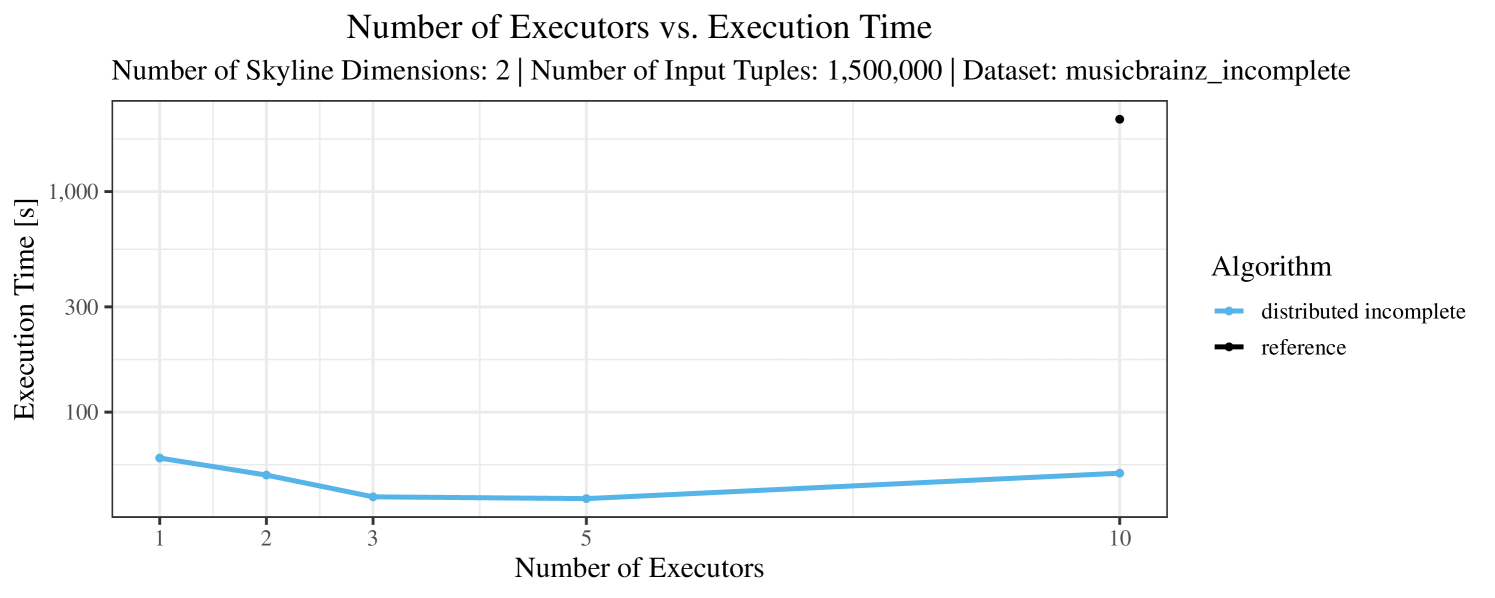
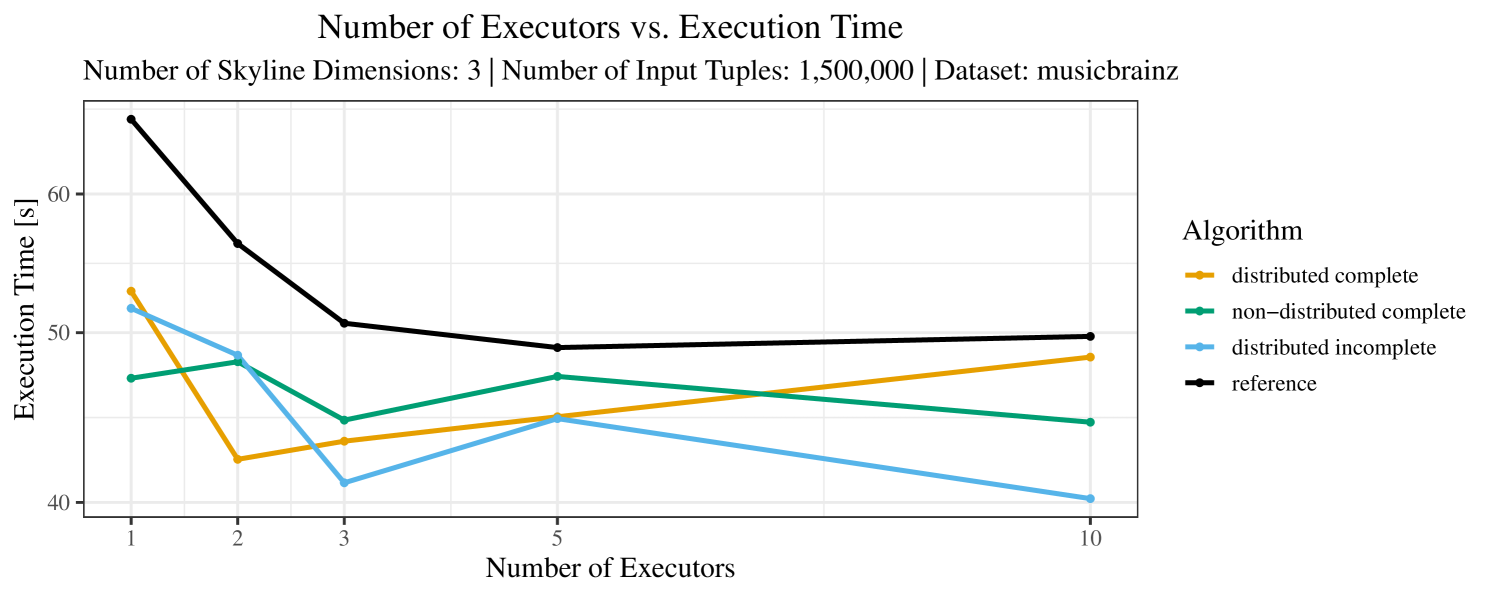
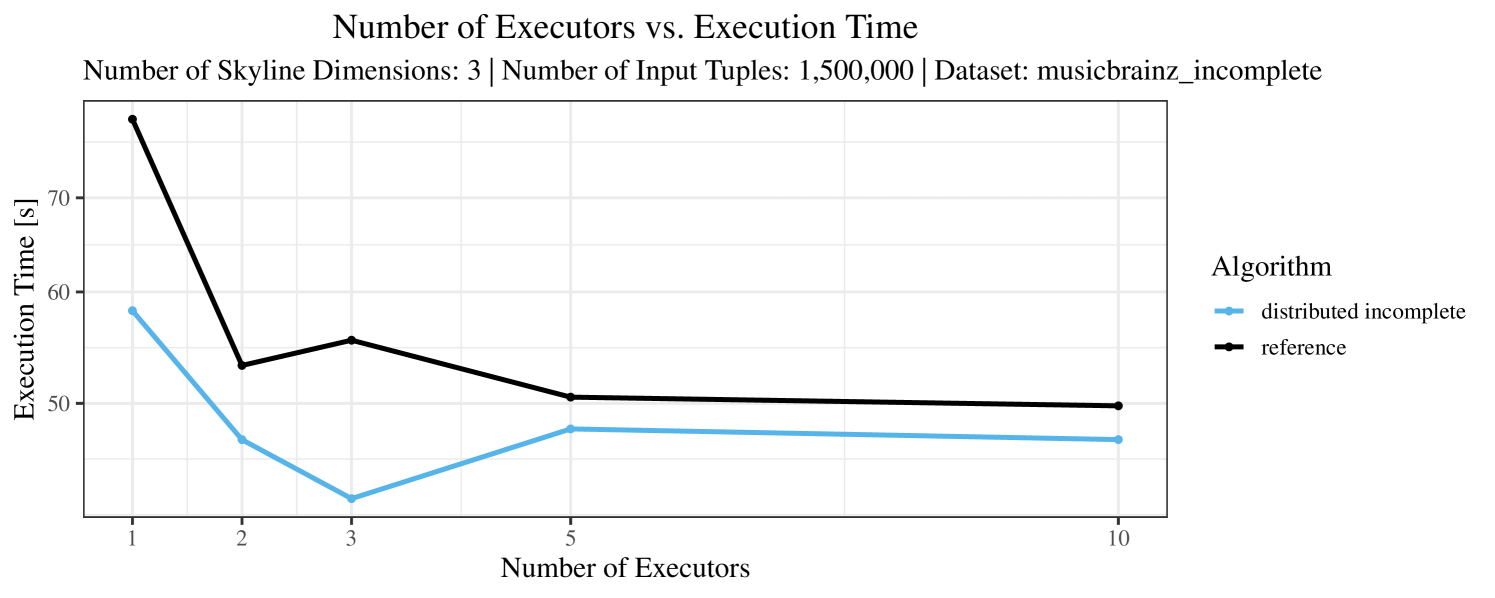
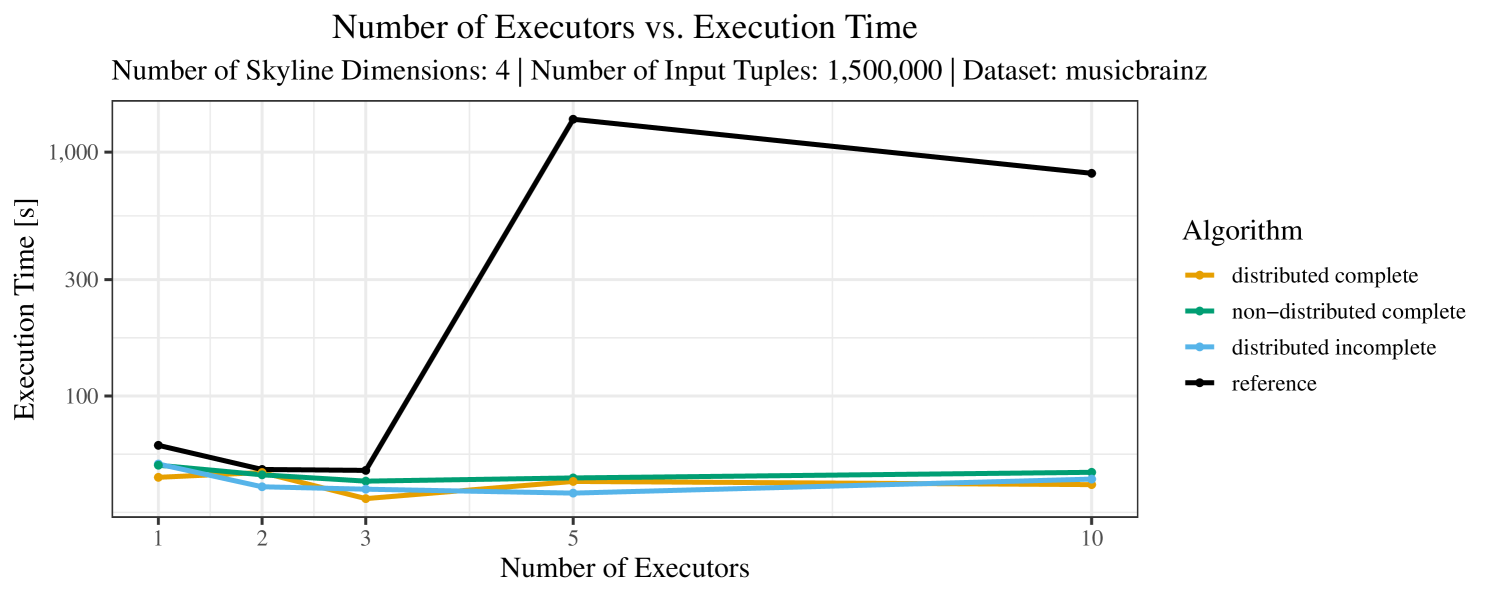
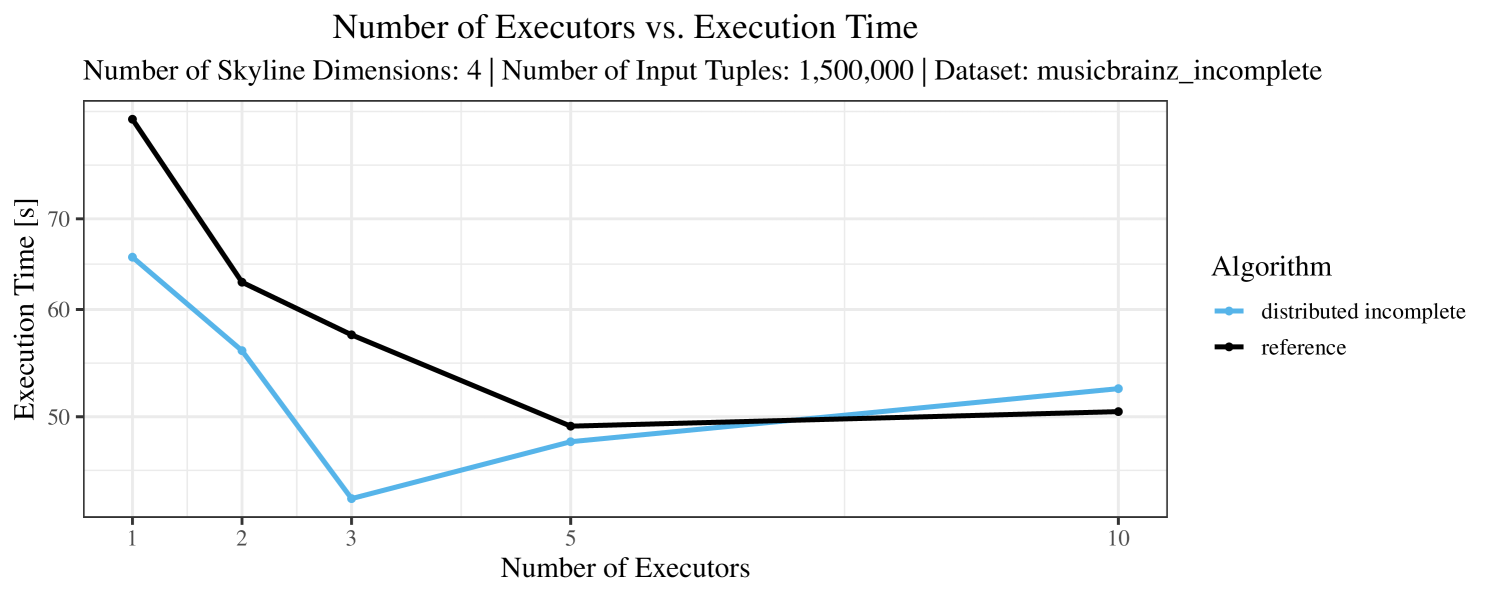
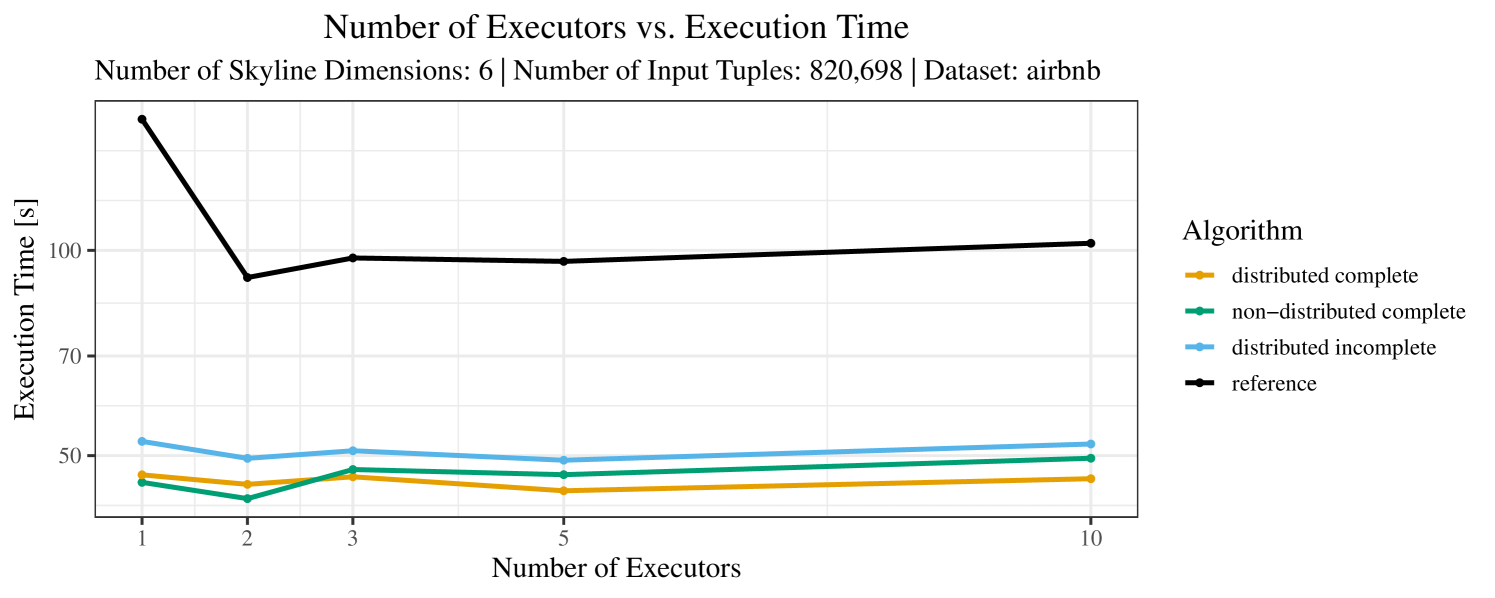
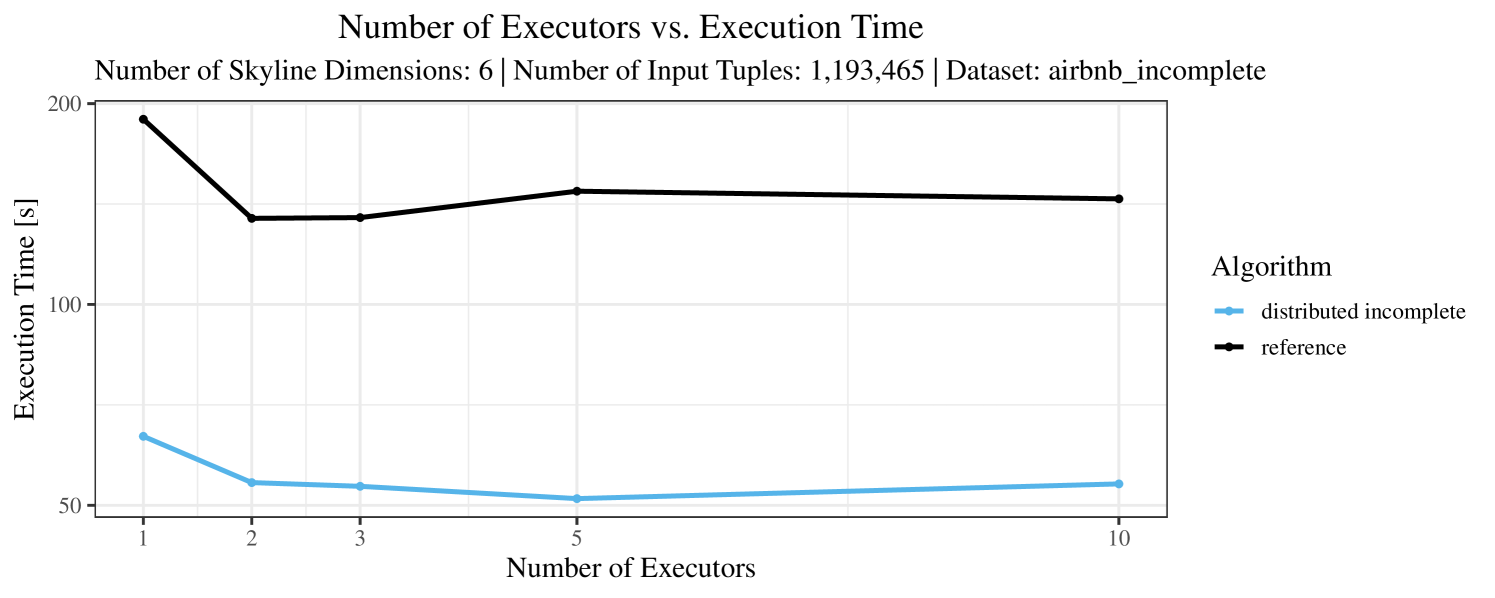
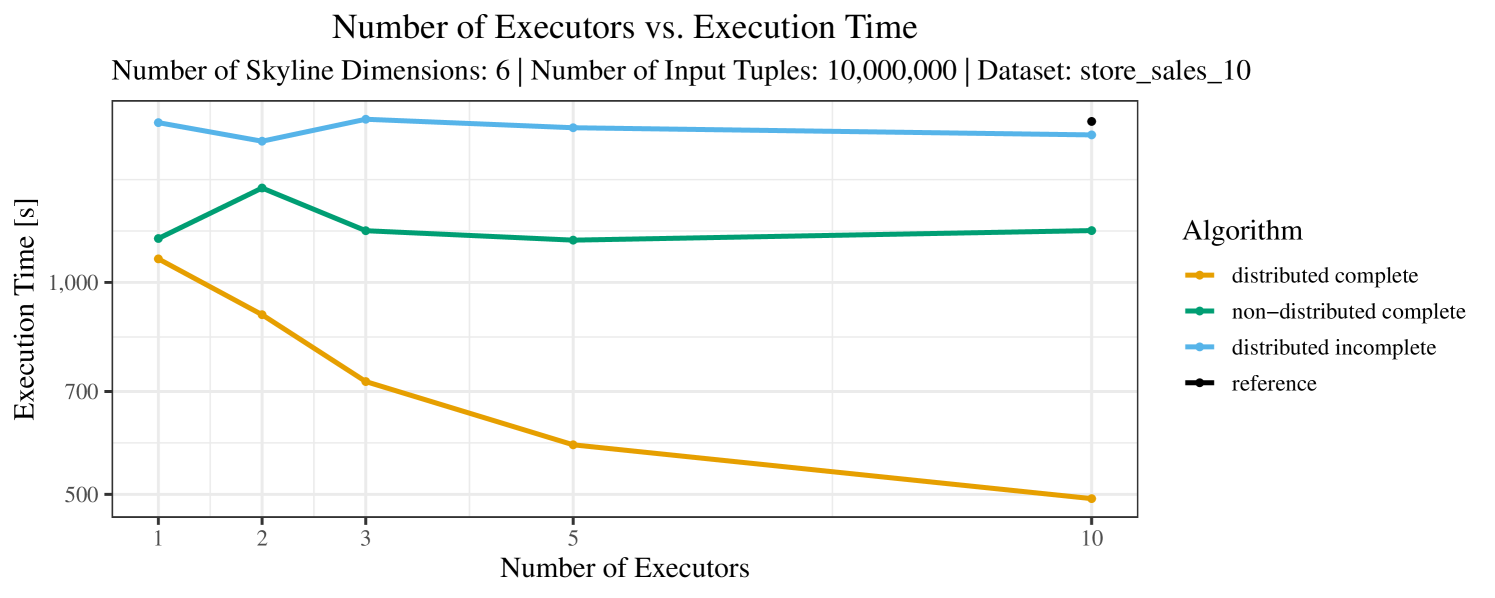
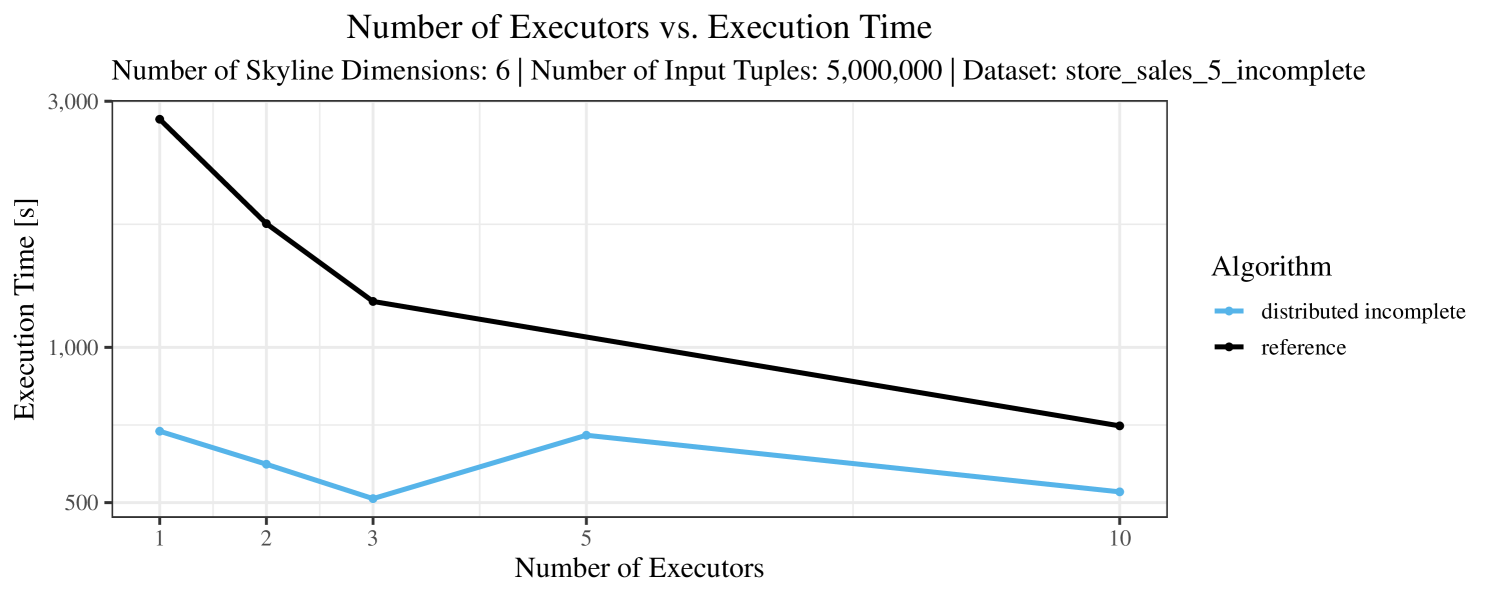
The impact of the number of executors on the performance is shown in Figure 6 for the real-world dataset and in Figure 7 for the synthetic dataset. Ideally, we want the algorithms to be able to use an arbitrary number of executors productively. Here, we use the term “executors” since it is the parameter by which we can instruct Spark how many instances of the code it should run in parallel.
We observe that the benefit of additional executors tapers off after a certain number of executors has been reached. This point is reached sooner, the smaller the dataset is. This behavior, especially in the case of the distributed algorithms, can be explained as follows: As we increase the parallelism of the local skyline computation, the portion of data contained in each partition becomes smaller; this means that more and more dominance relationships get lost and fewer tuples are eliminated from the local skylines. Hence, more work is left to the global skyline computation, which allows for little to no parallelism and, thus, becomes the bottleneck of the entire computation. In other words, there is a sweet spot in terms of the amount of parallelism relative to the size of the input data.
Note that the “reference” algorithm is also able to make (limited) use of parallelism. Indeed, the execution plan generated by Spark from the plain SQL query is still somewhat distributed albeit not as much as the truly distributed and specialized approaches. As in the previous experiments, the “reference” algorithm never outperforms any of the specialized algorithms – not even the non-distributed or quasi-non-distributed (incomplete algorithm on complete dataset) approaches. The discrepancy between the best specialized algorithm and the reference algorithm is constantly above 50% and may even go up to 90% (complete synthetic data, 10 executors).
6.5. Further Measurements and Experiments
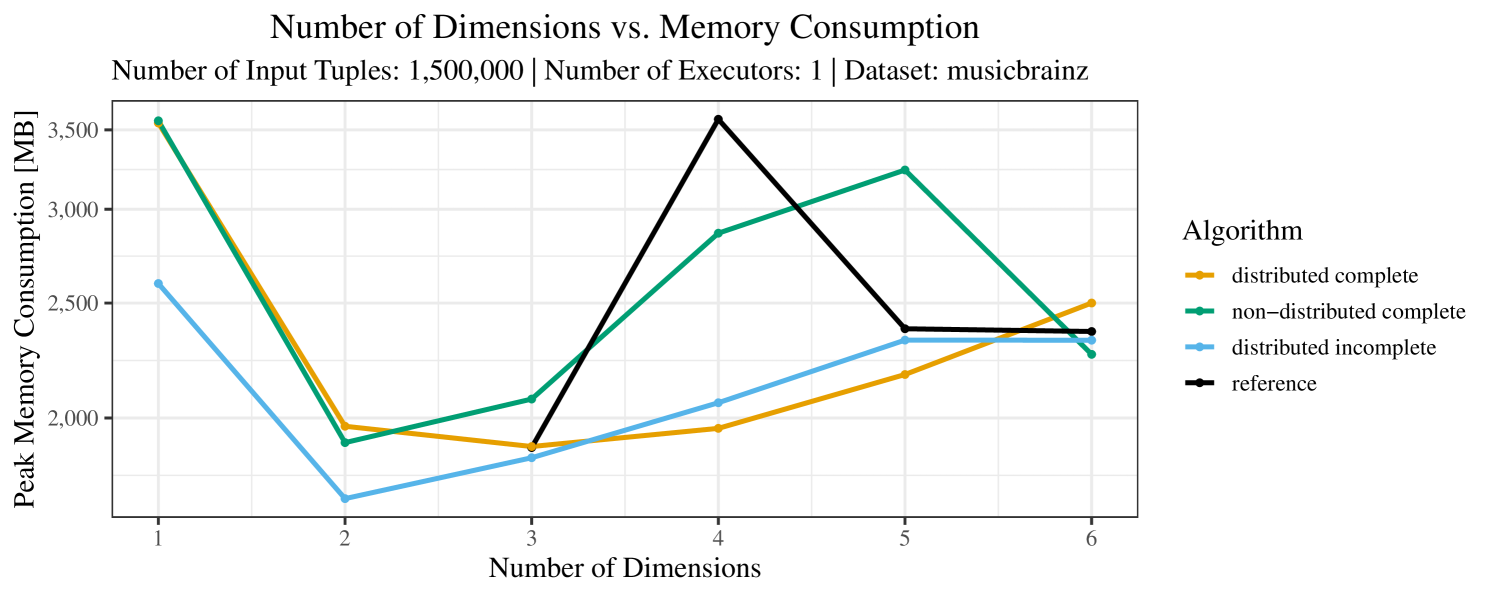
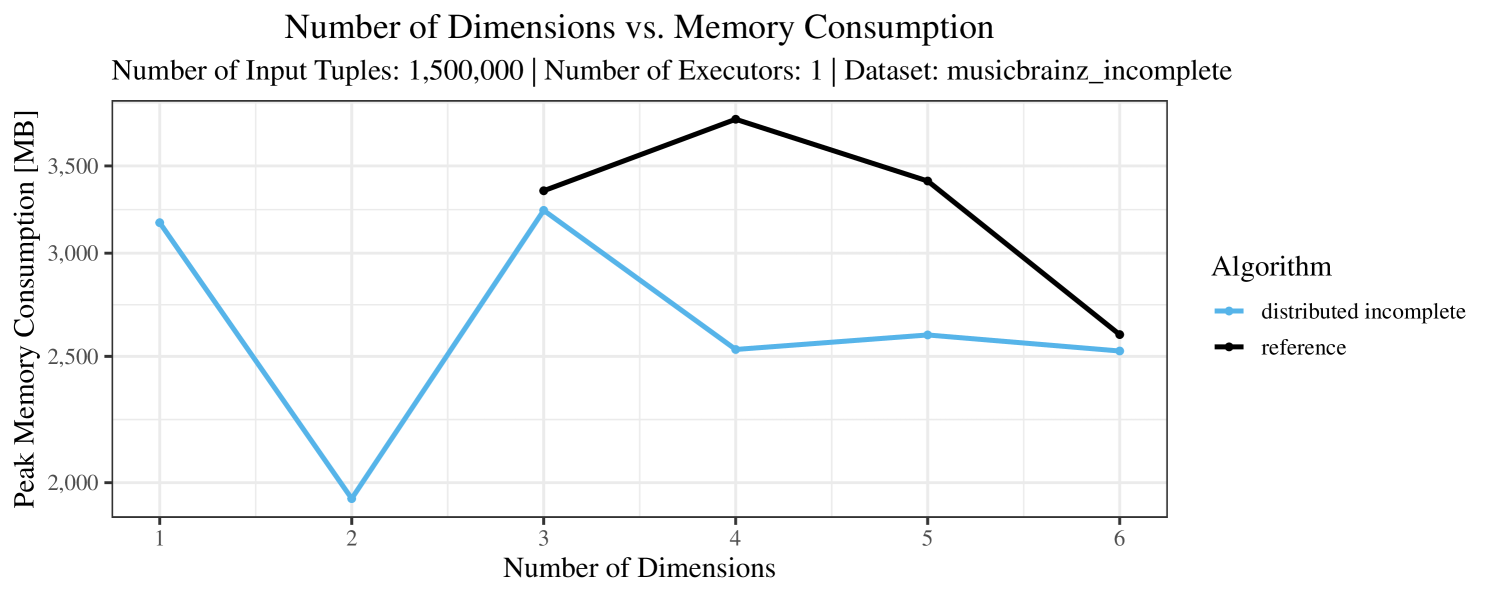
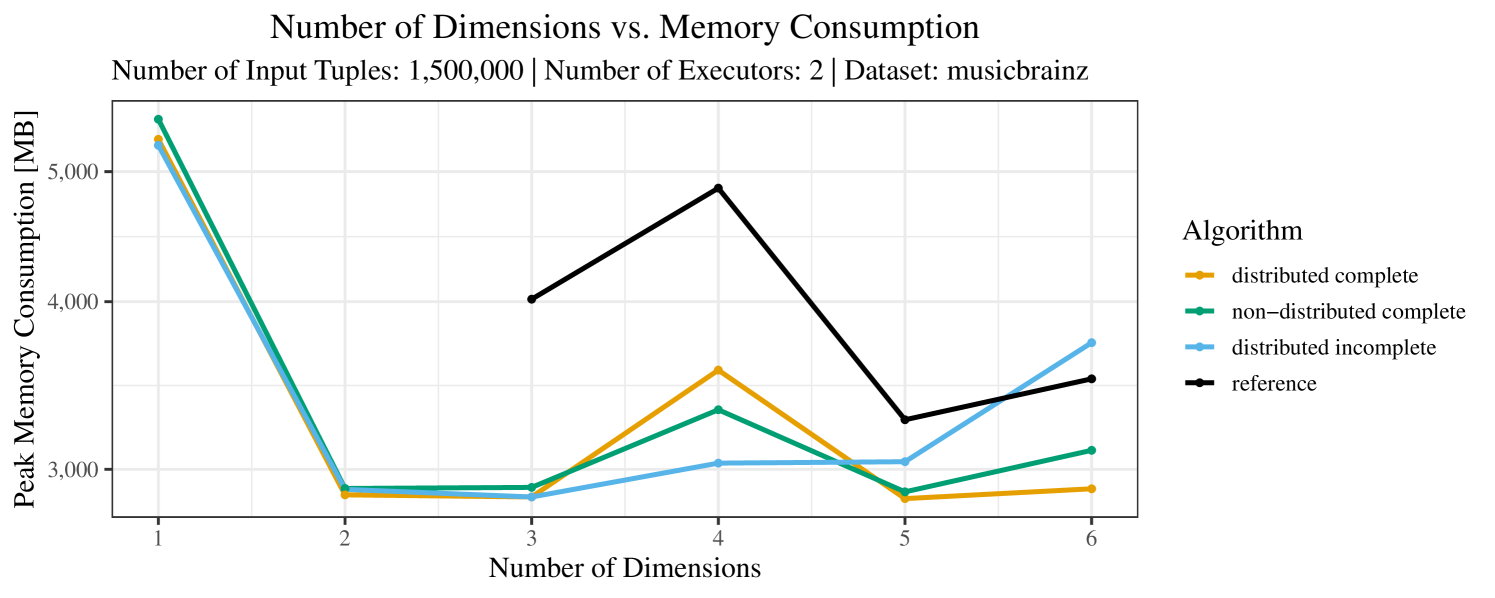
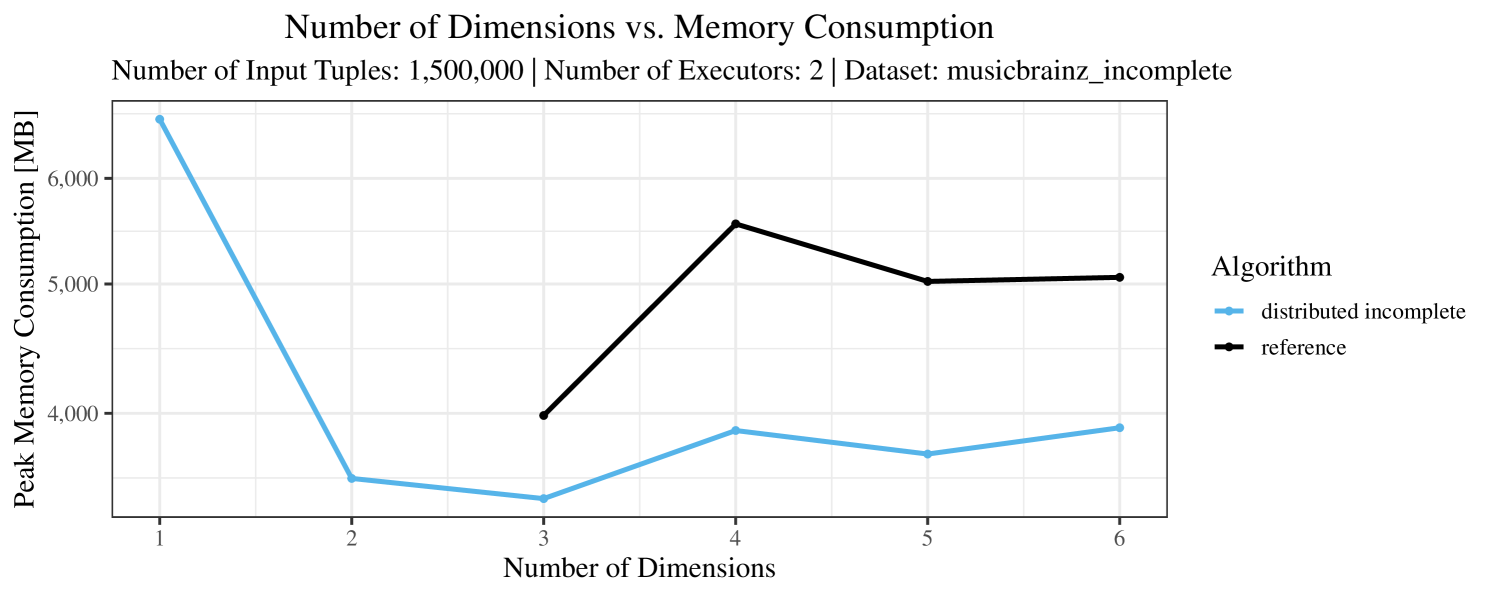
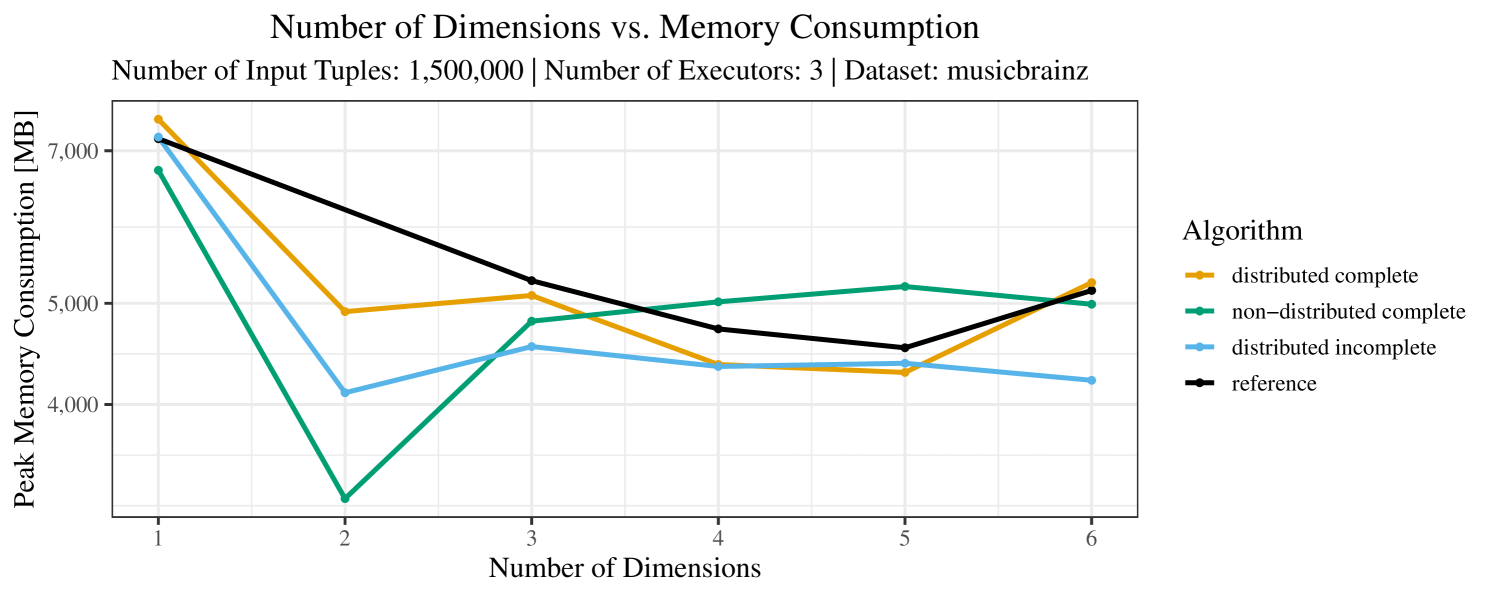
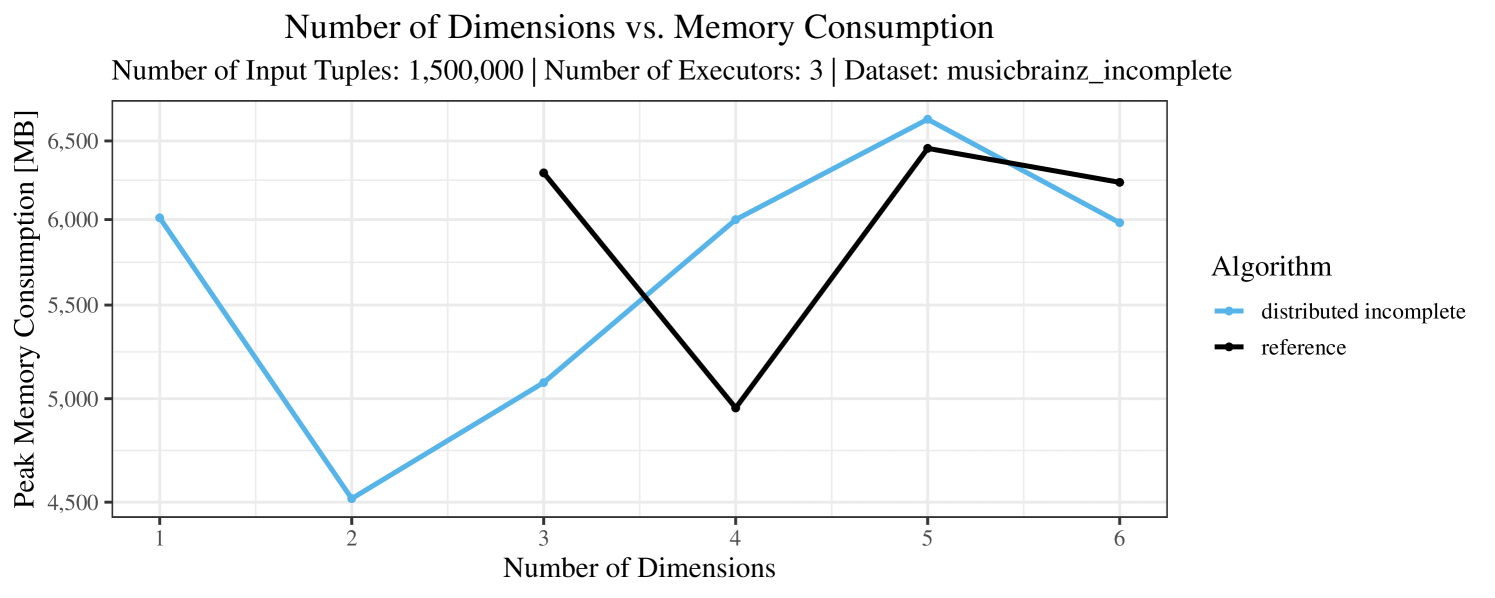
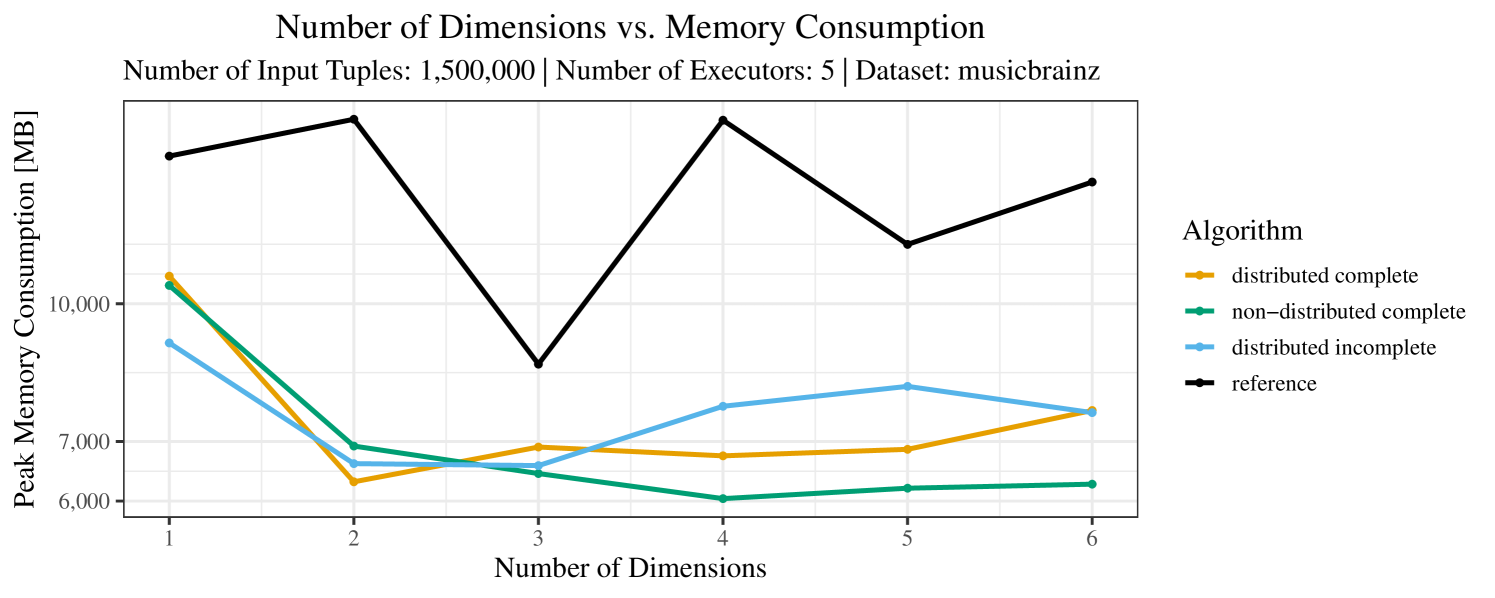
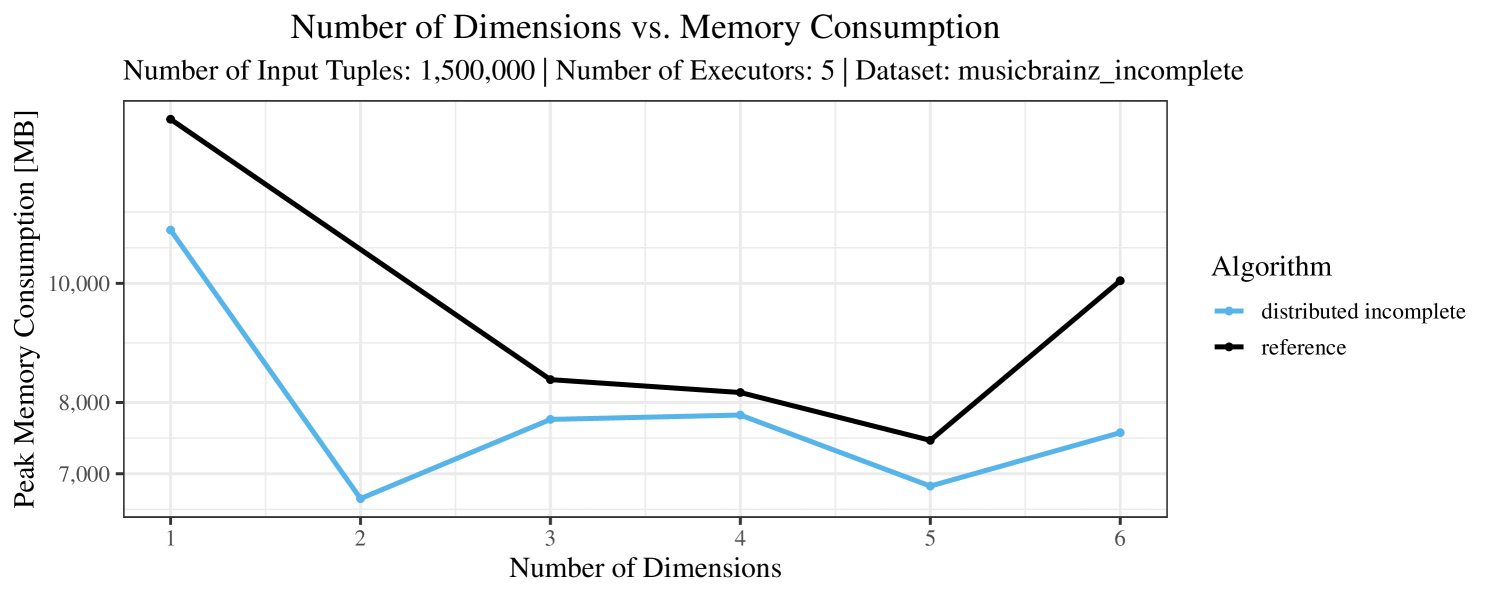
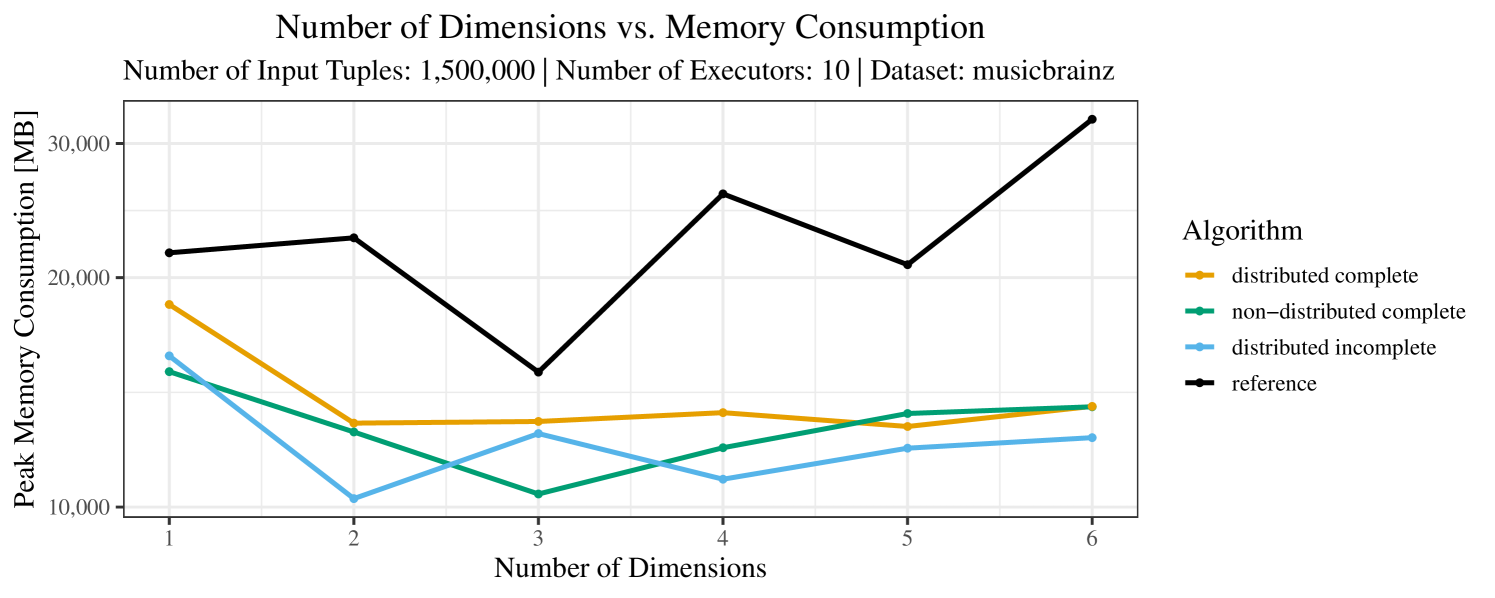
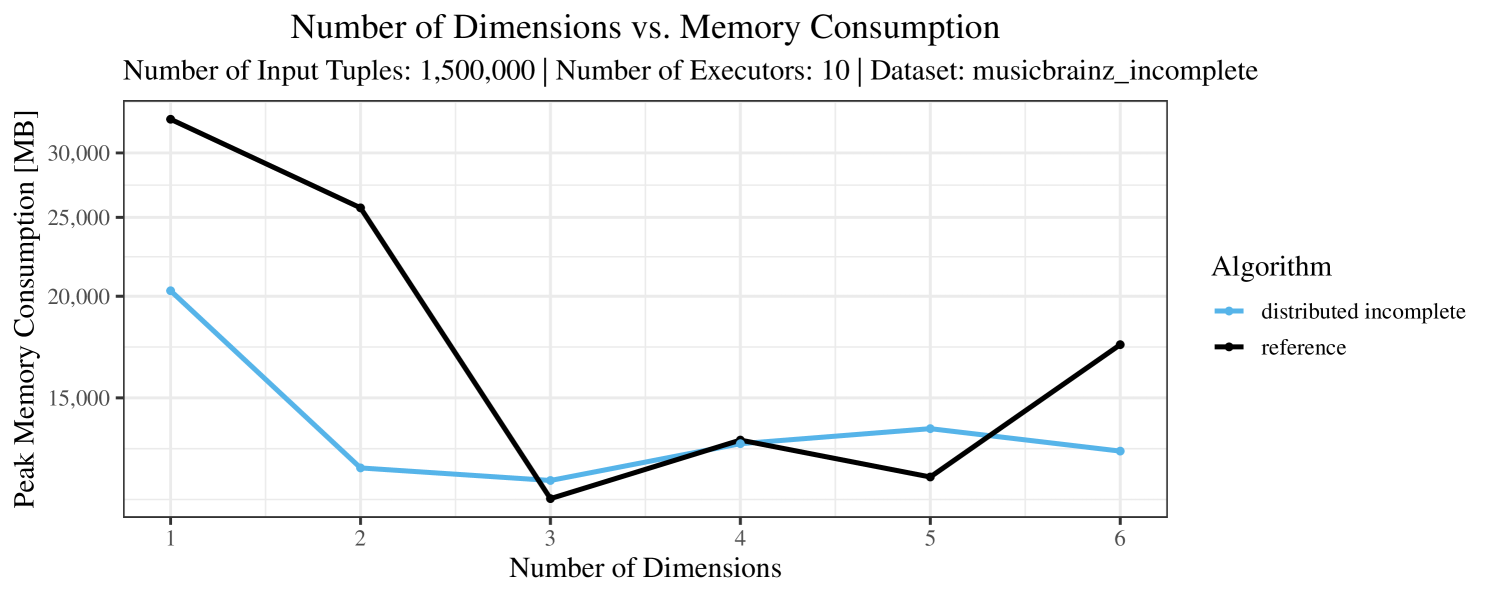
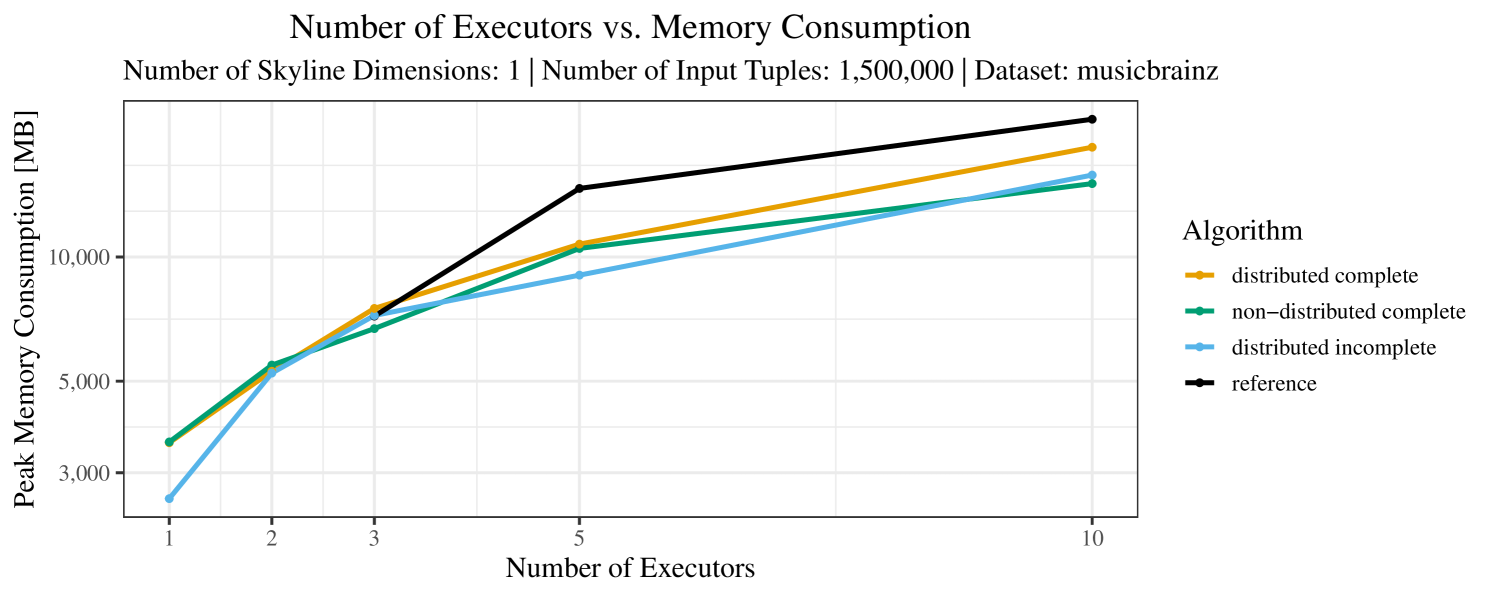
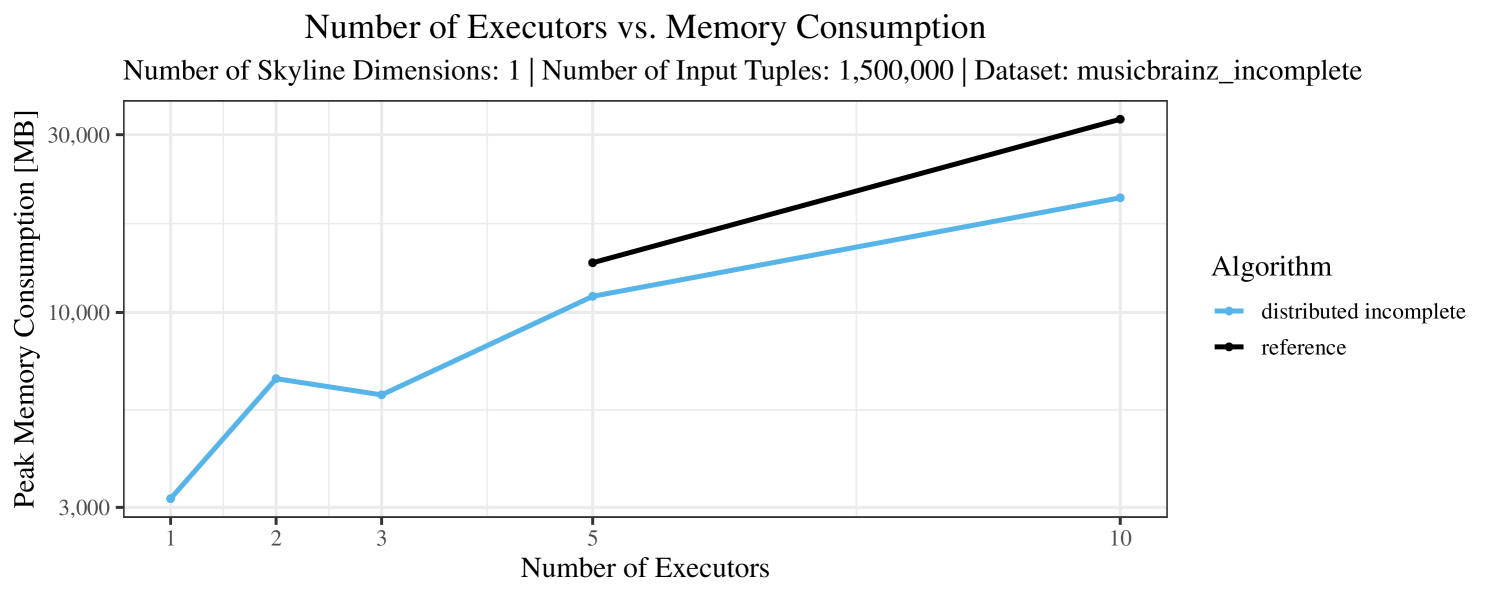
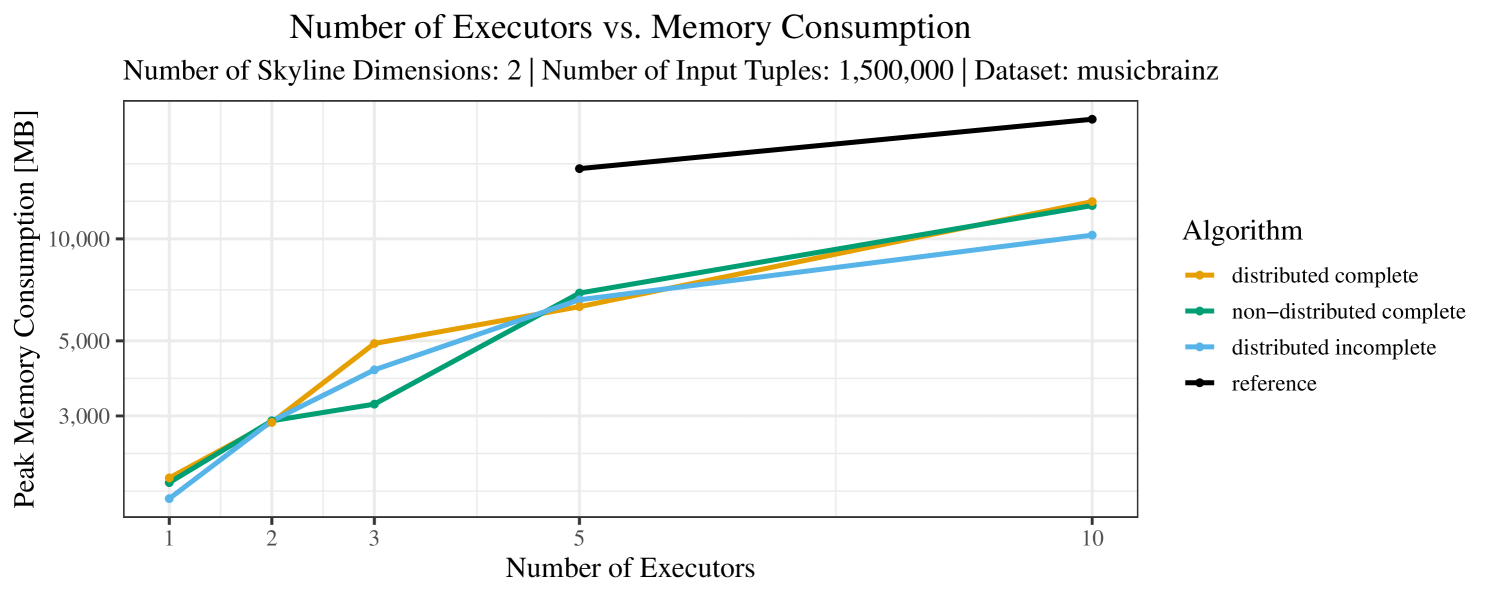
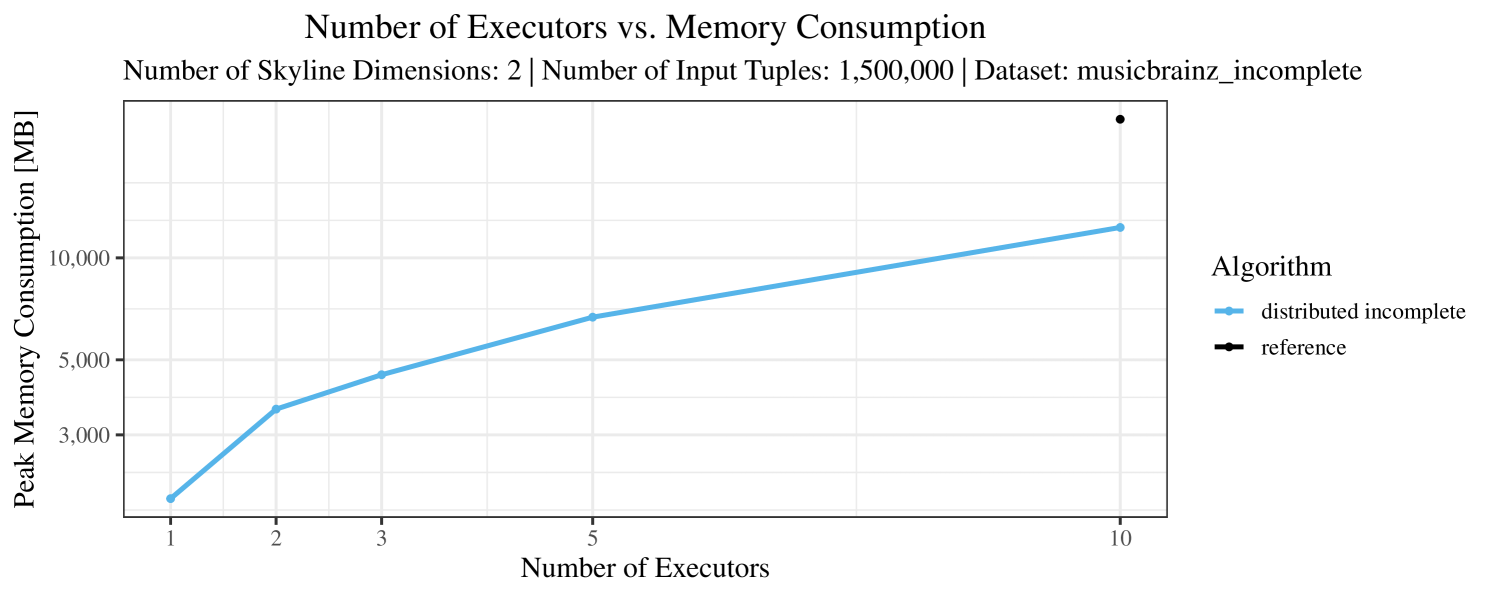
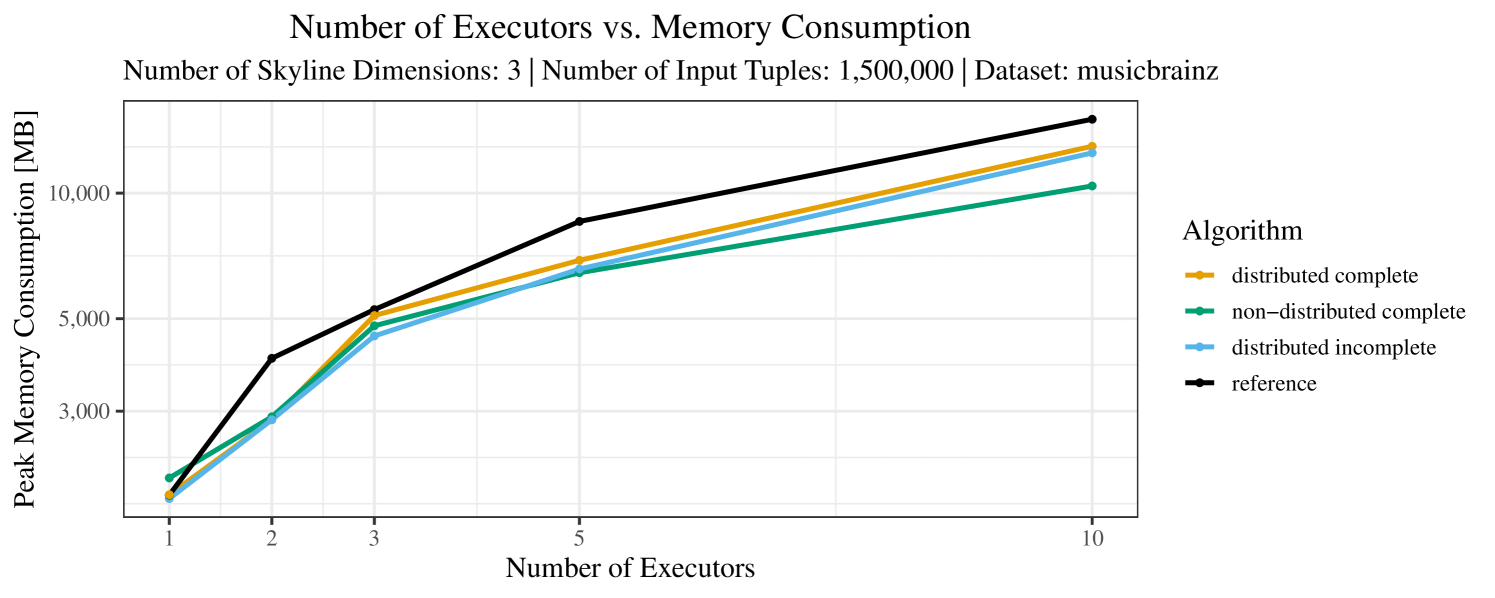
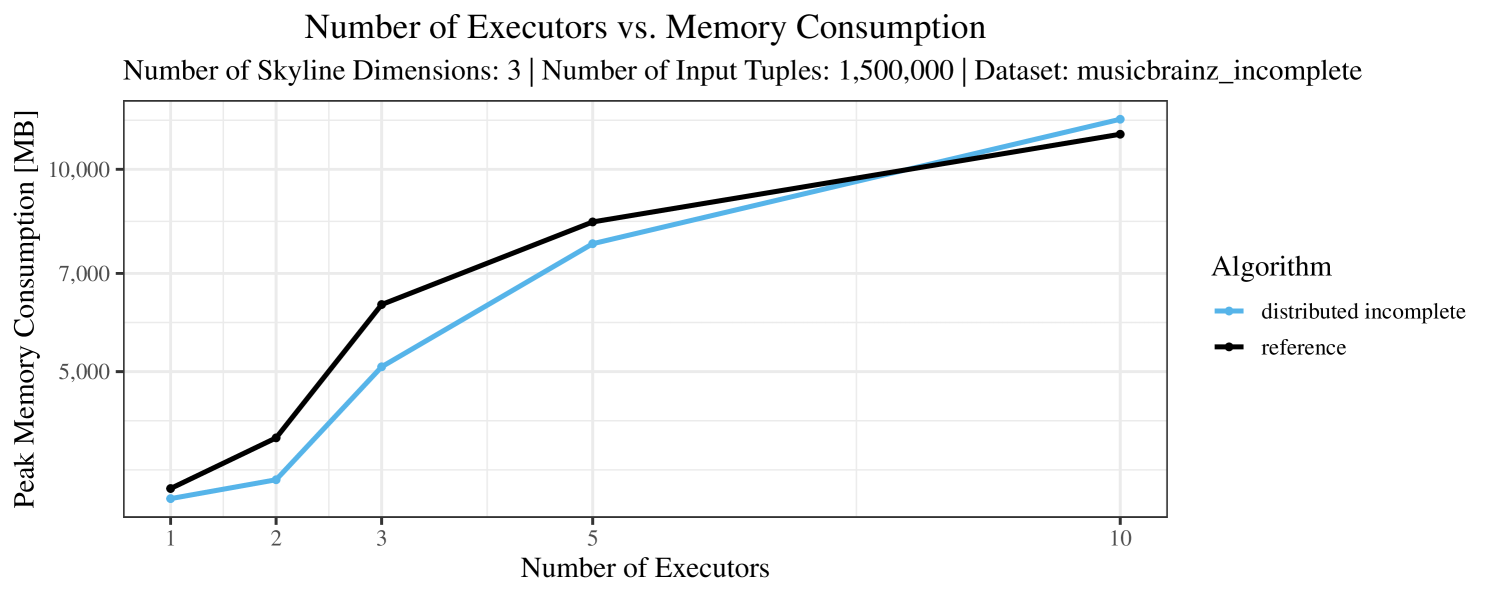
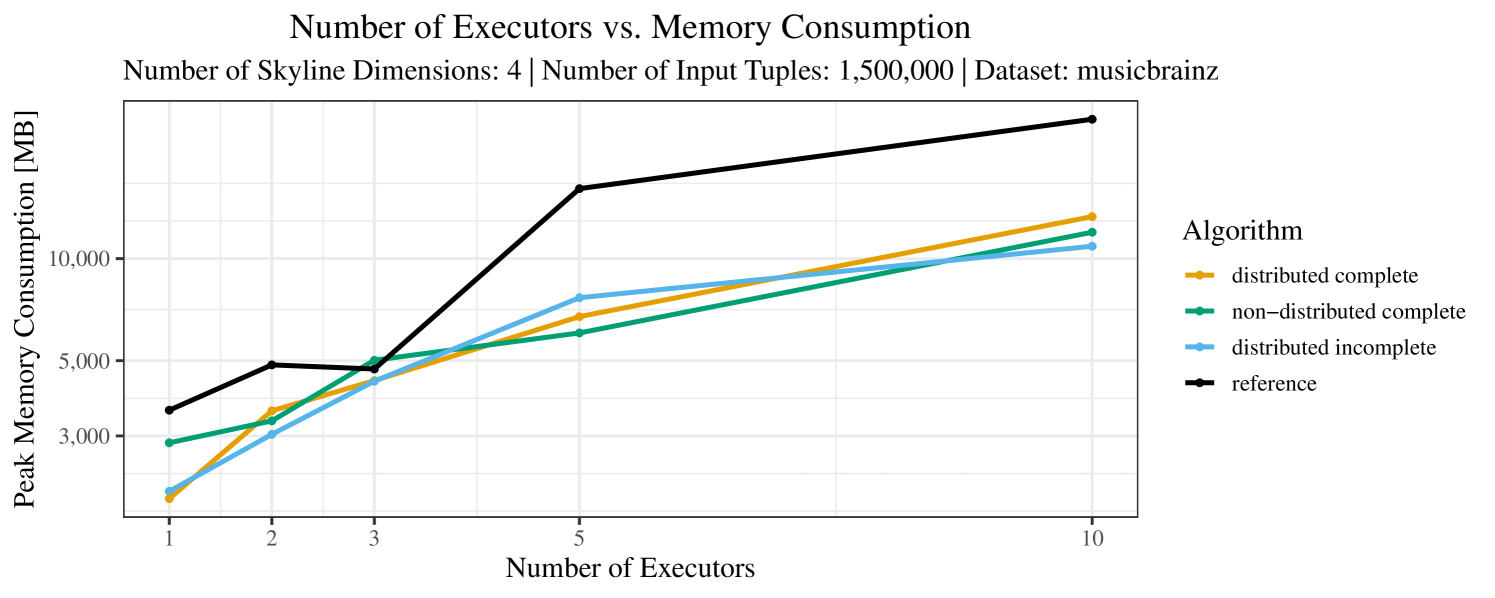
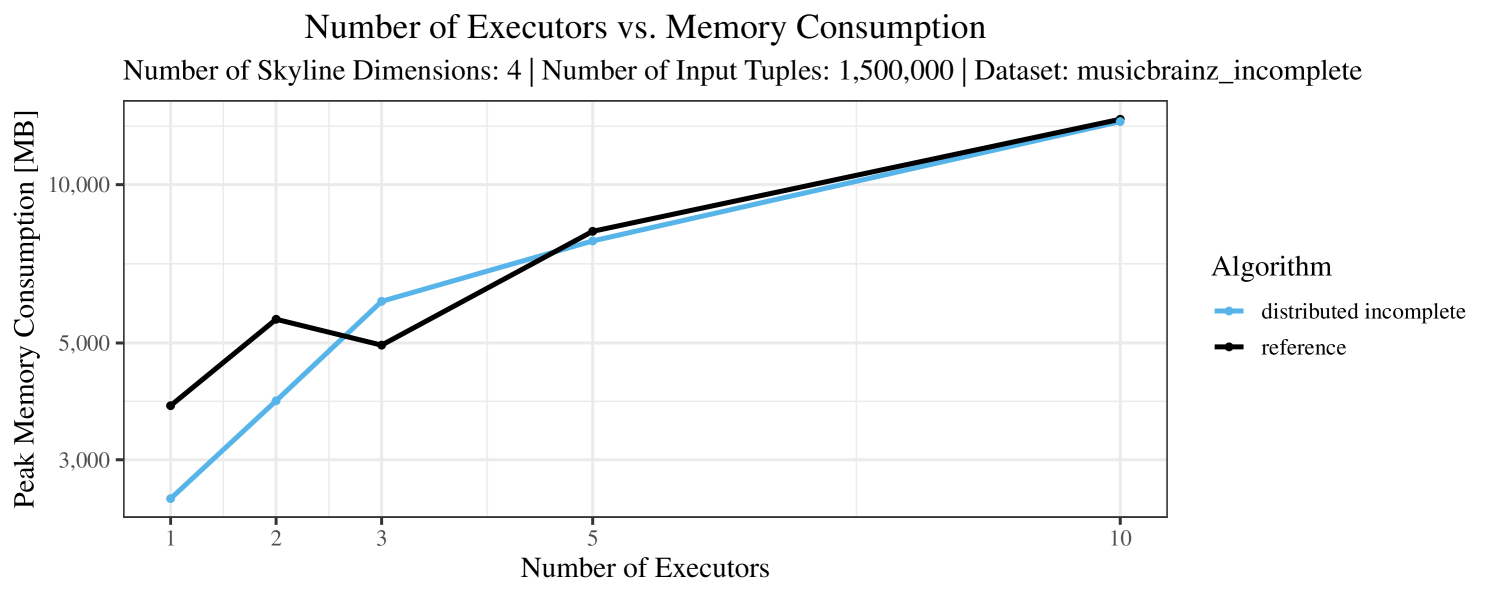
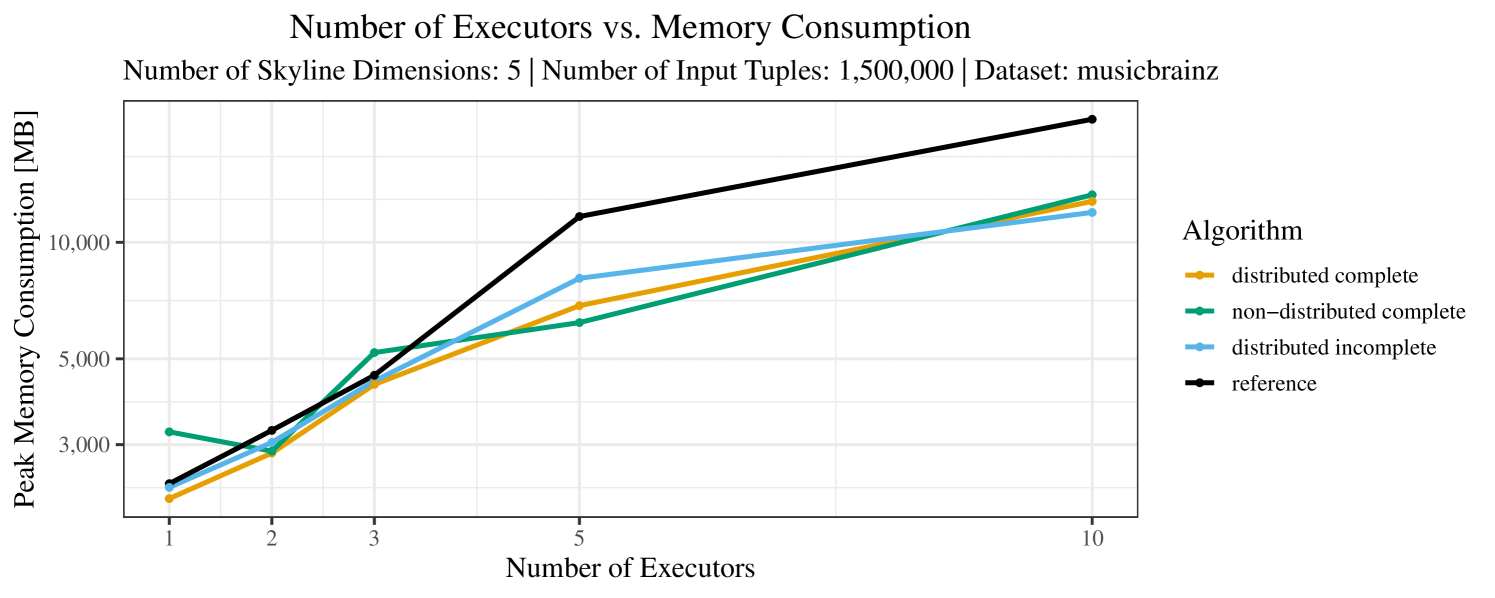
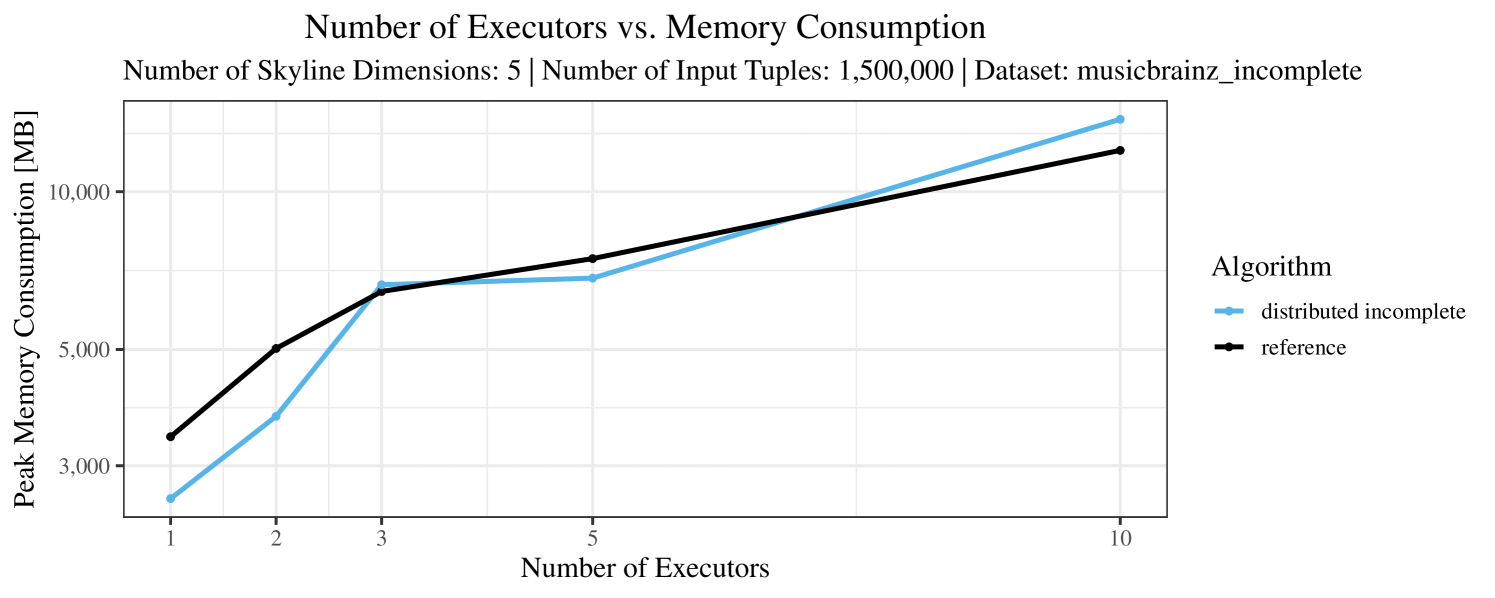
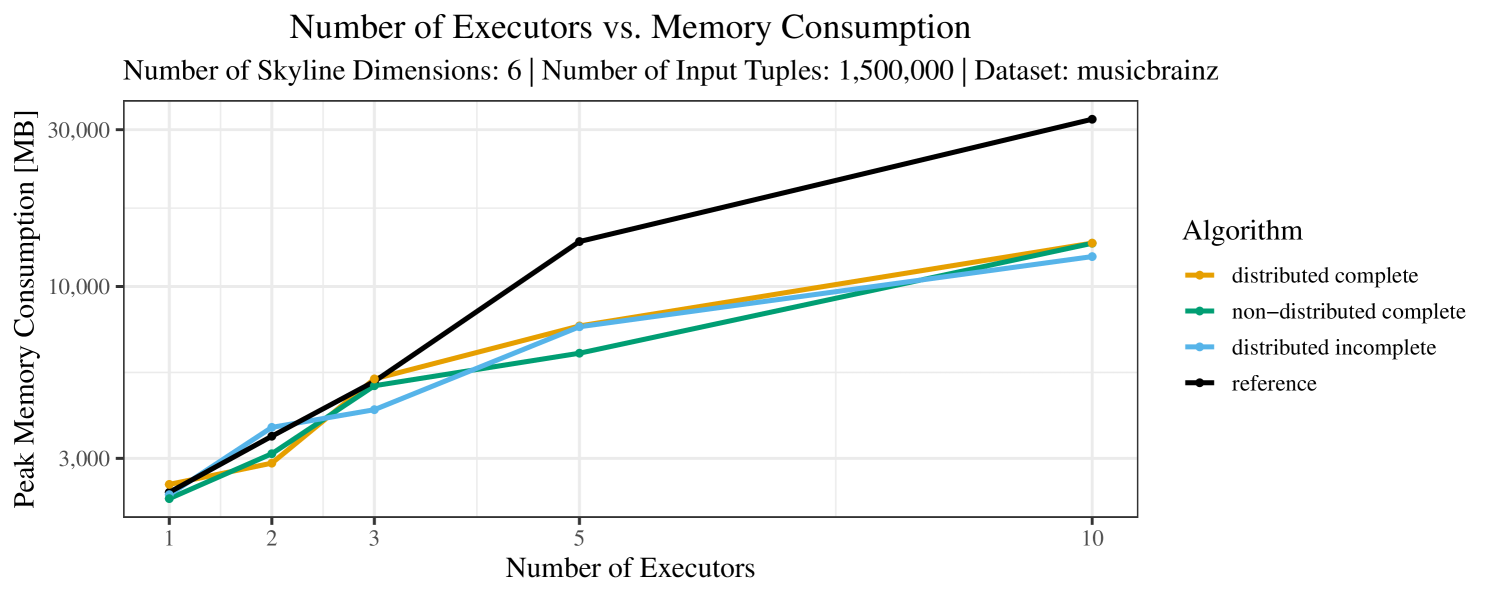
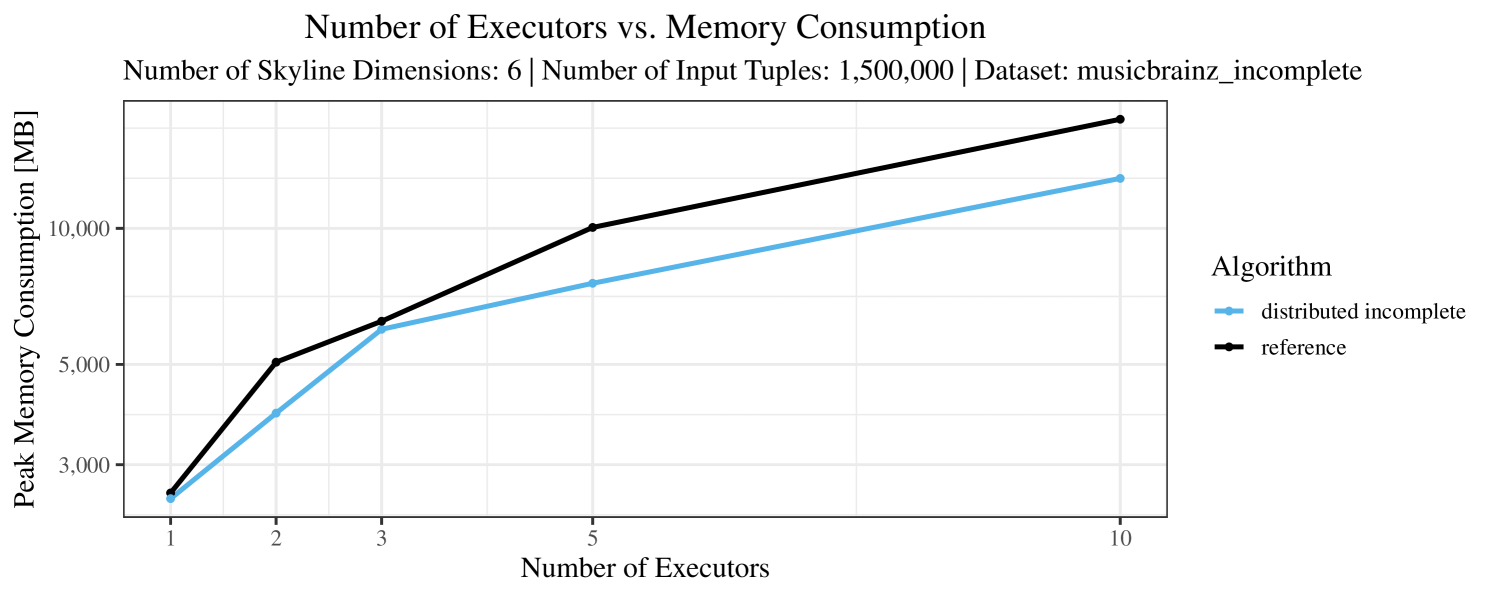
Our main concern with the experiments reported in Section 6.4 was to measure the execution time of our integrated skyline algorithms depending on several factors (number of dimensions/tuples/executors). Apart from the execution time, we made further measurements in our experiments. In particular, we were interested in the memory consumption of the various algorithms in the various settings. In short, the results were unsurprising: the number of dimensions does not influence the memory consumption while the number of executors and, even more so, the number of input tuples does. In the case of the executors this is mainly due to the fact that each executor loads its entire execution environment, including the Java execution framework, into main memory. In the case of the number of tuples, of course, more memory is needed if more tuples are loaded. Importantly, we did not observe any significant difference in memory consumption between the four algorithms studied here. For the sake of completeness, we provide plots with the memory consumption in various scenarios in Appendix C.
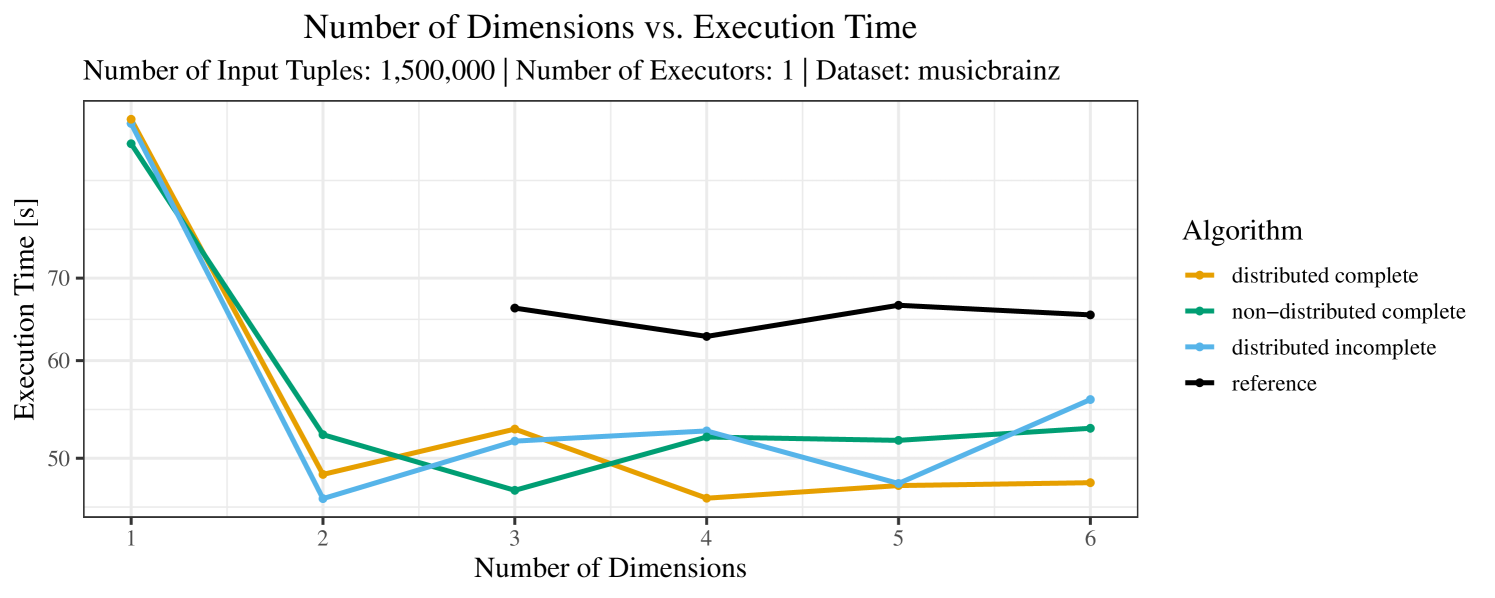
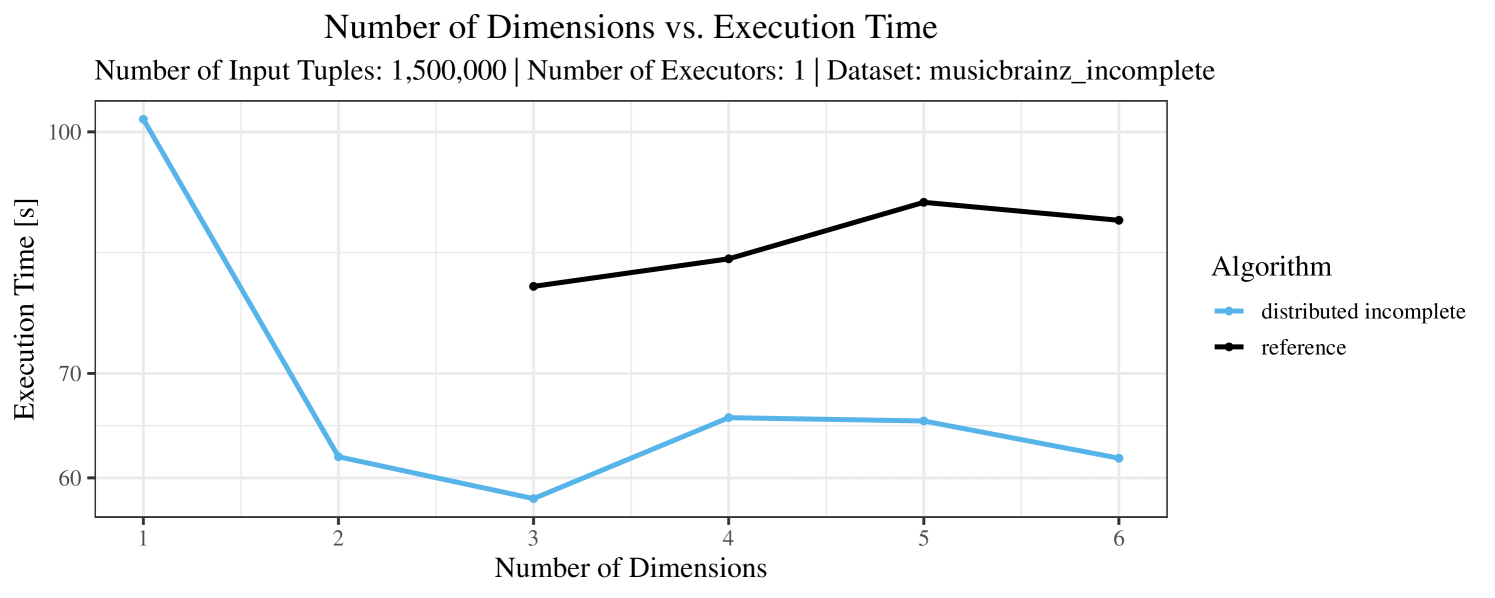
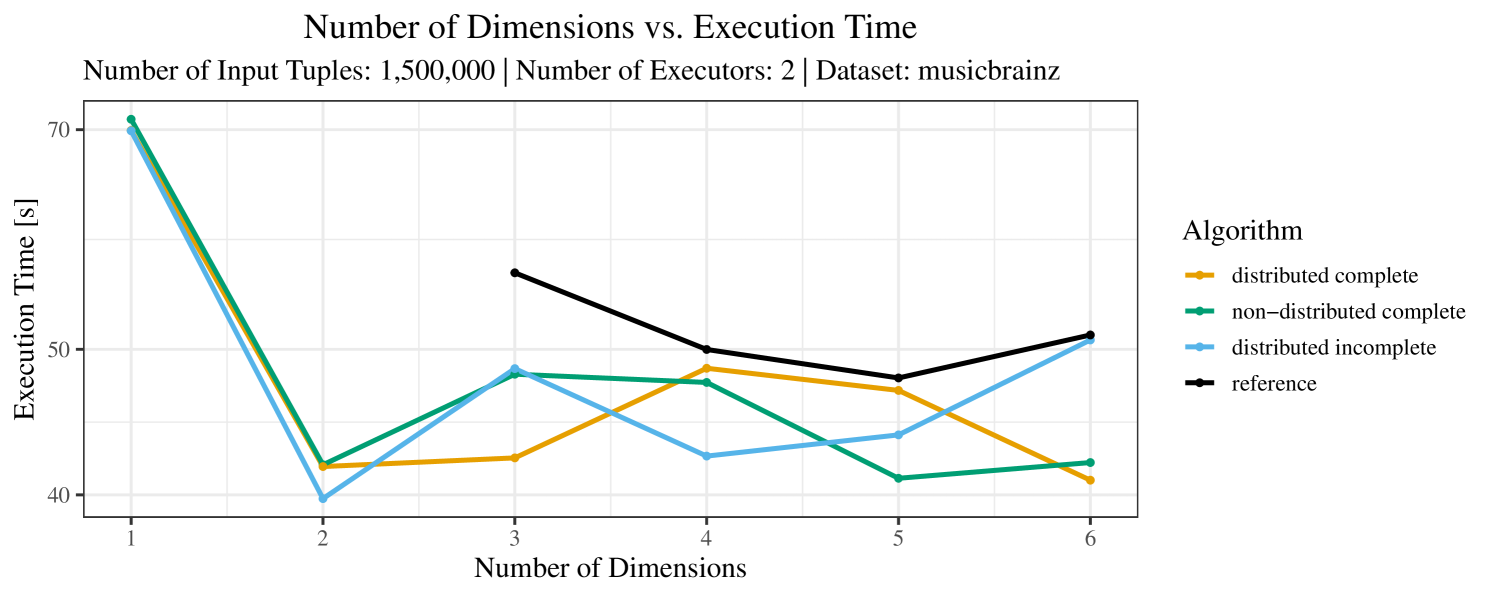
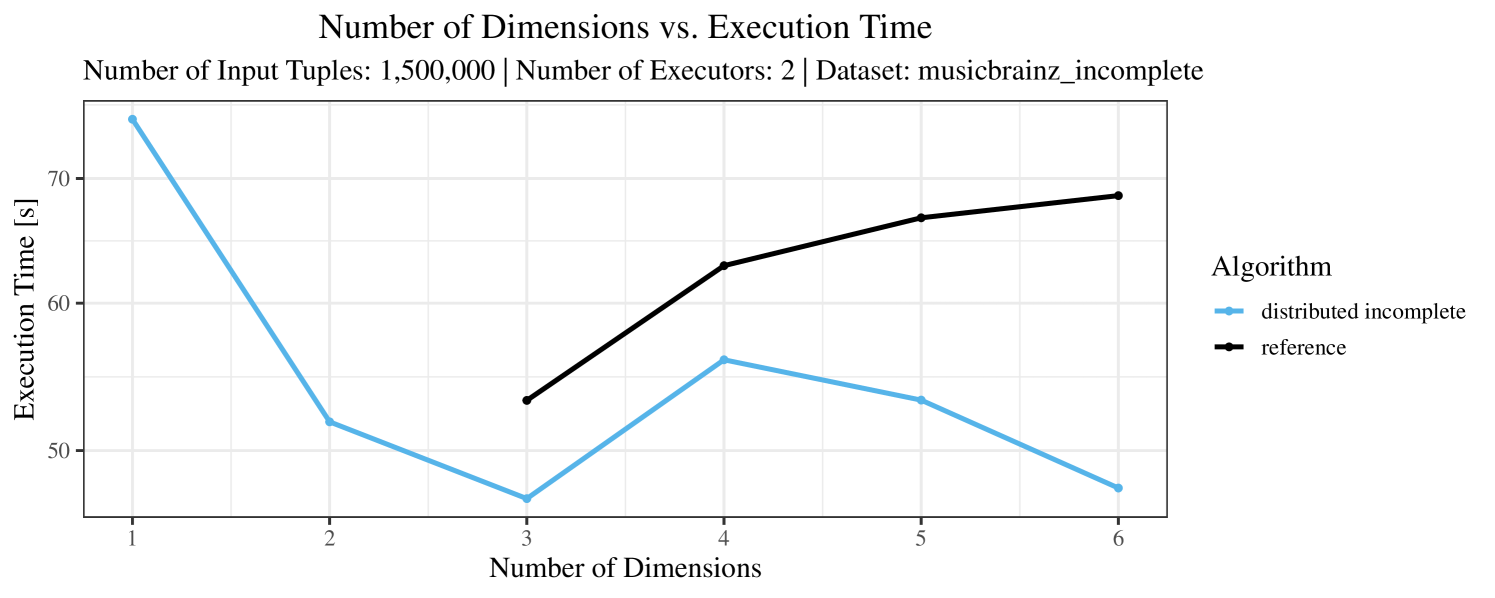
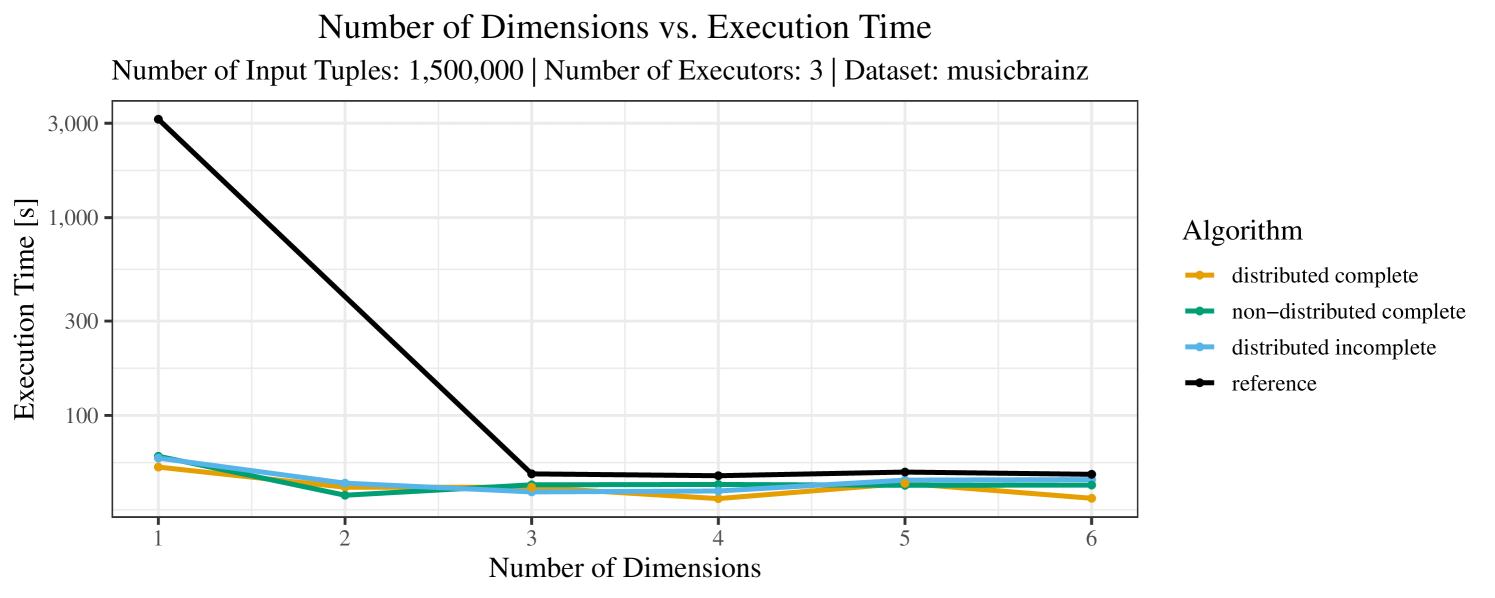
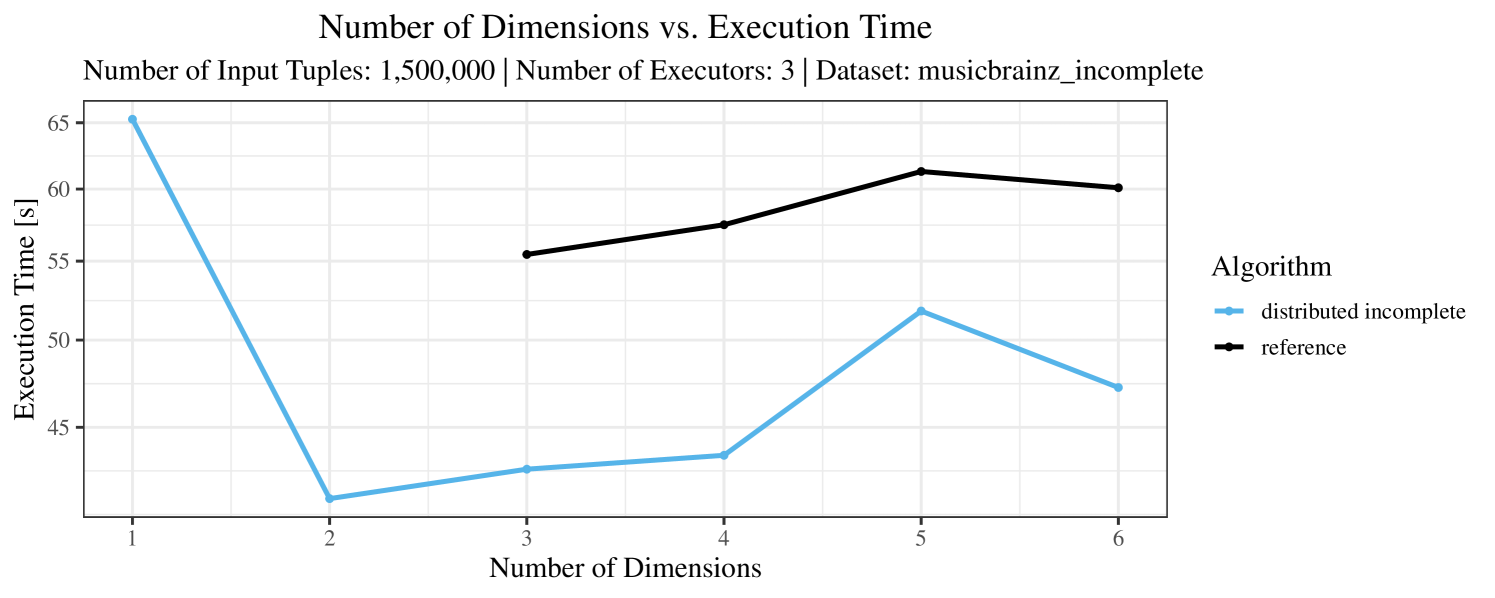
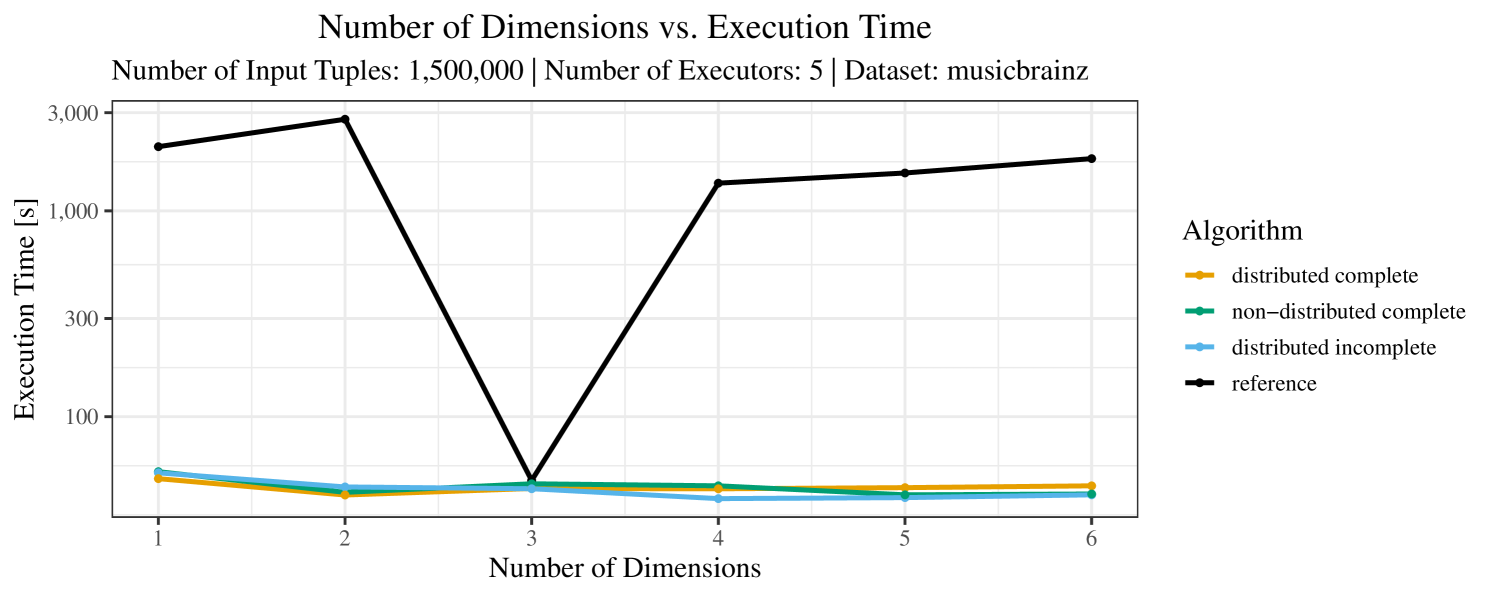
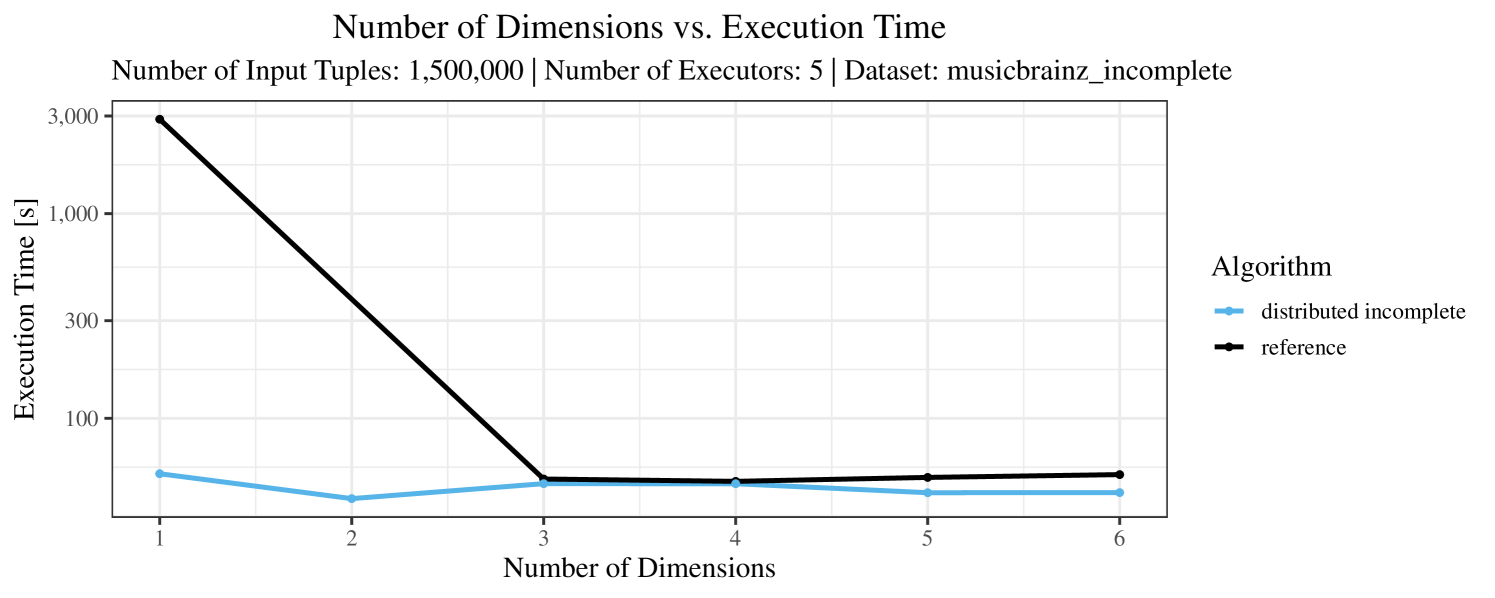
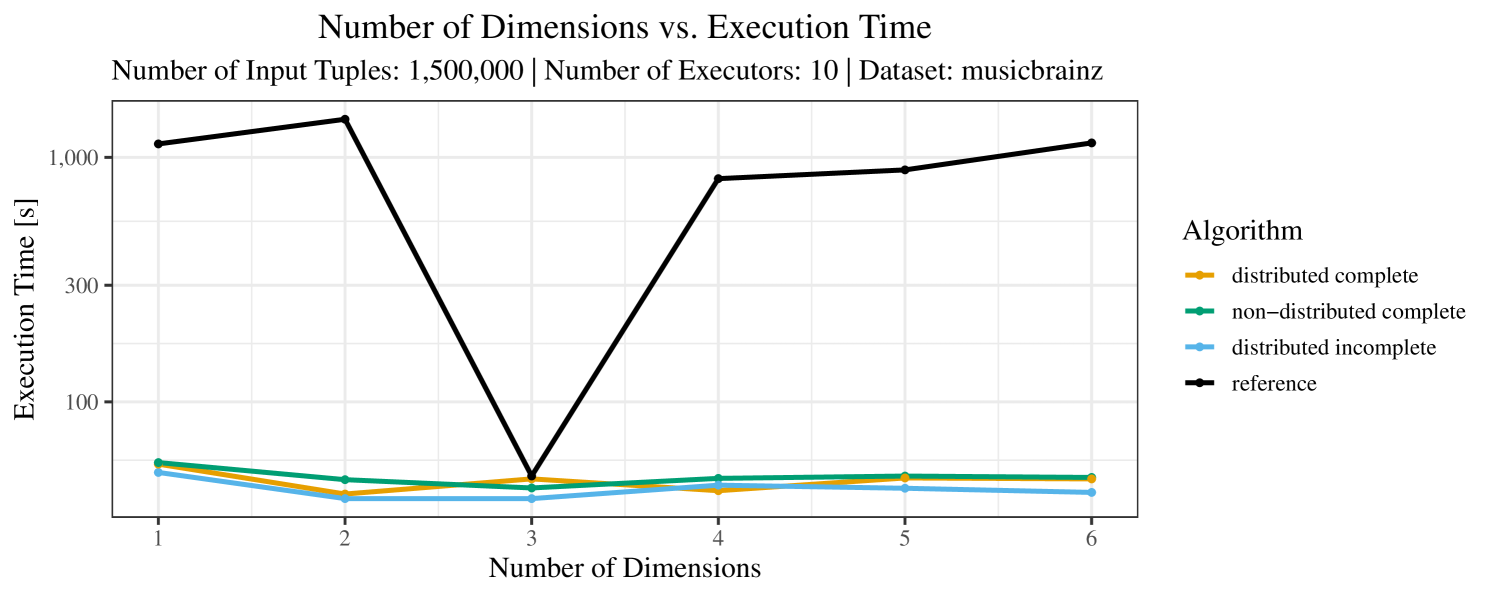
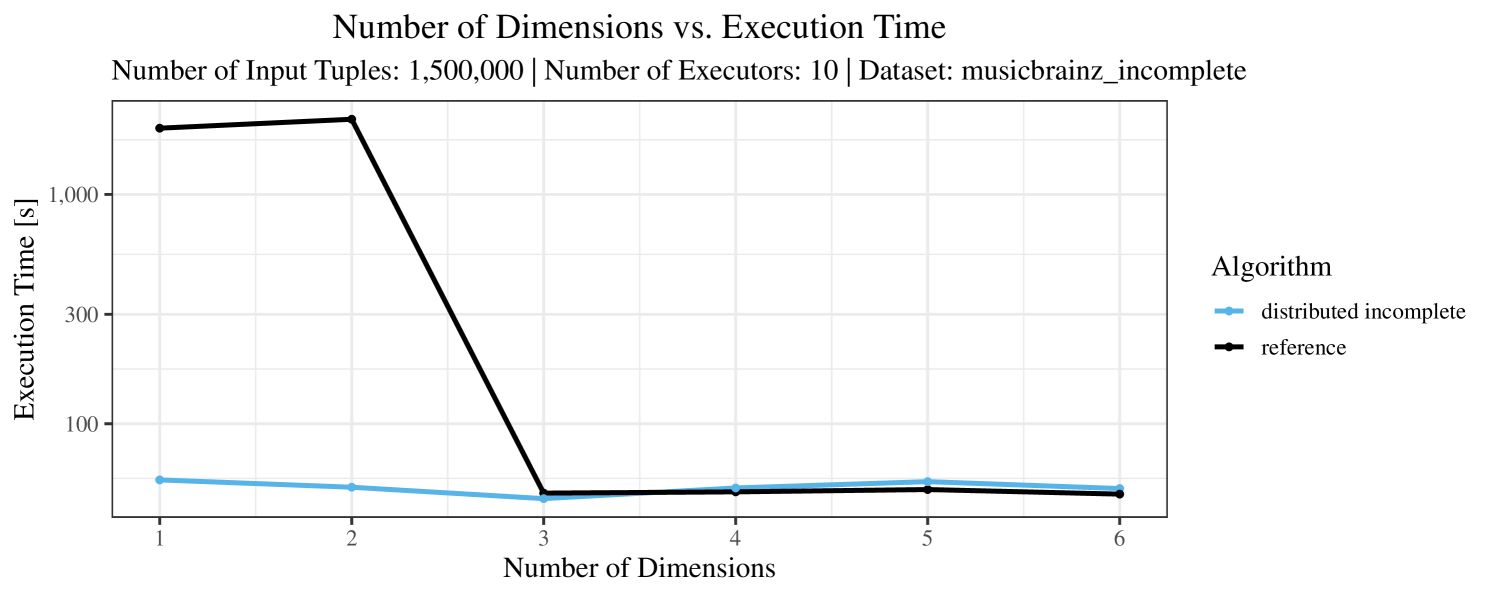
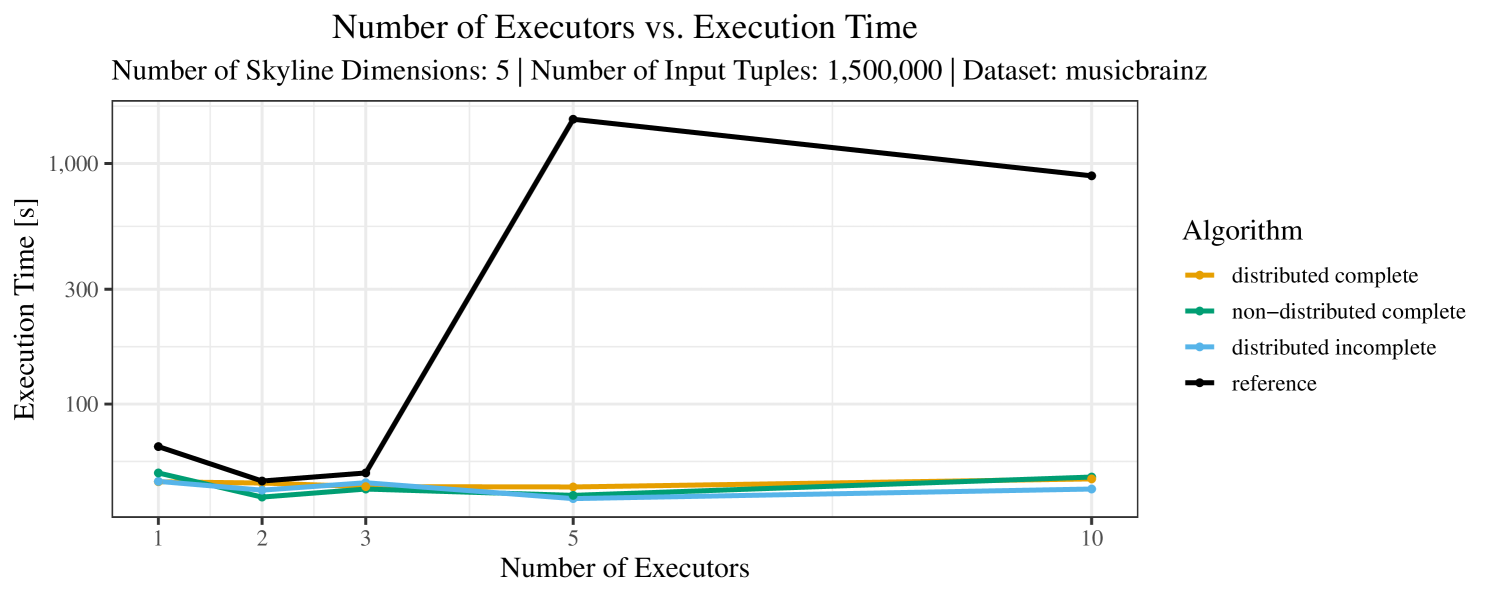
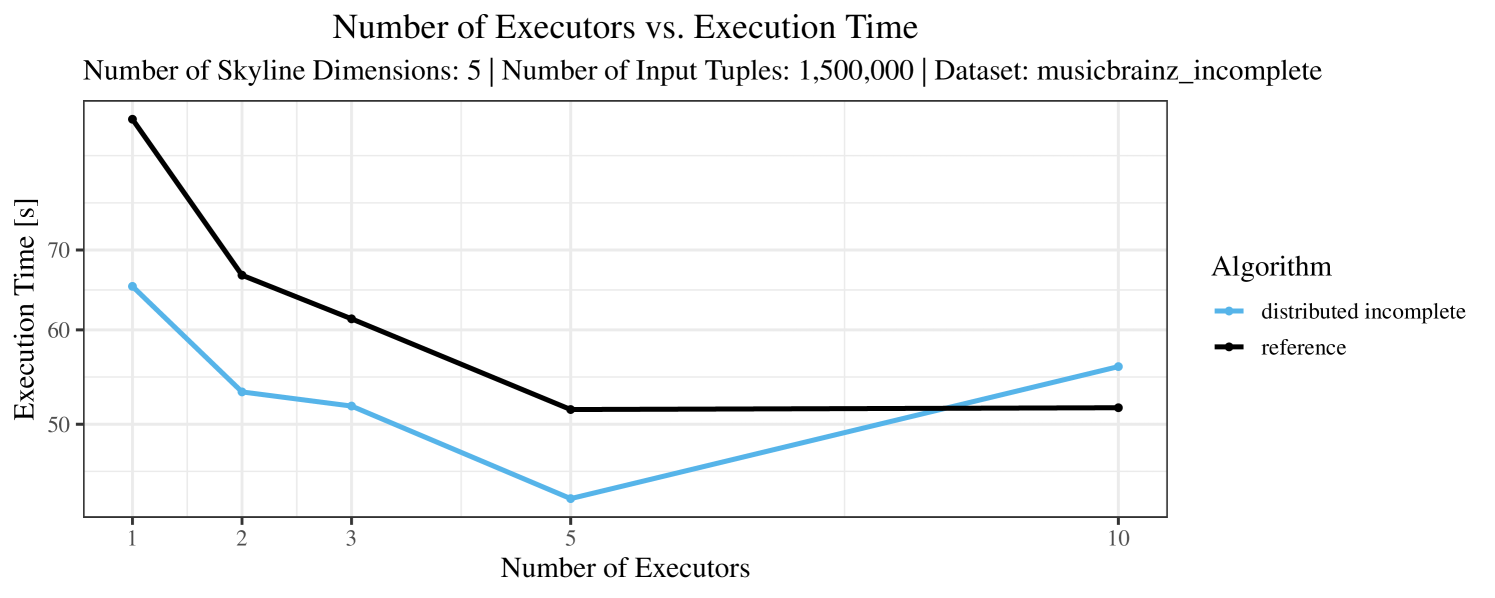
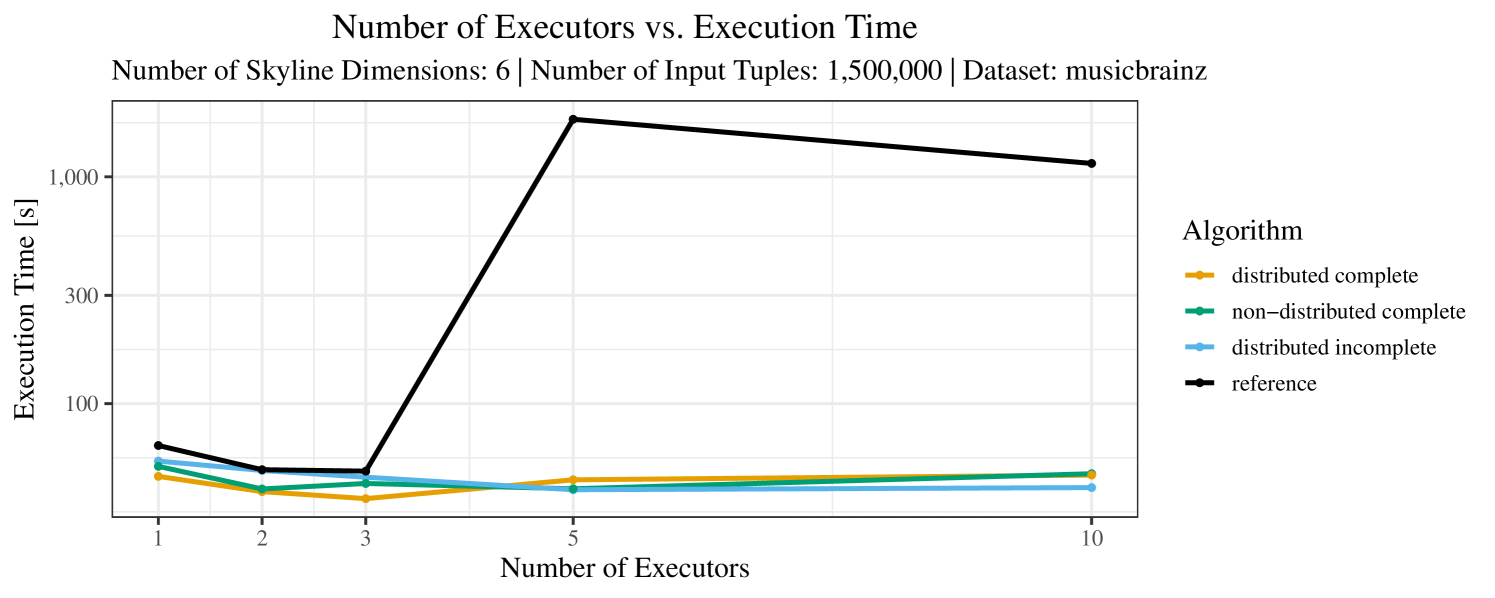
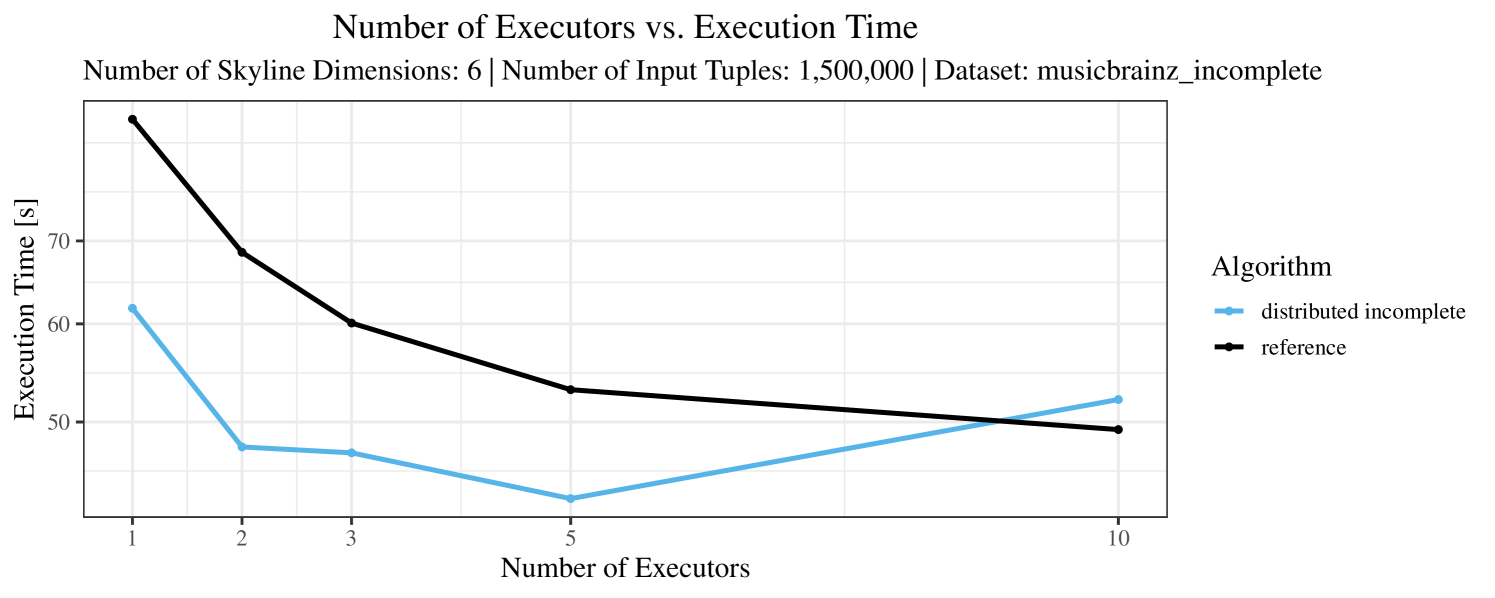
The test setup described in Section 6.2 was intentionally minimalistic in the sense that we applied skyline queries to base tables of the database rather than to the result of (possibly complex) SQL queries. This allowed us to focus on the behavior of our new skyline algorithms vs. the reference queries without having to worry about side-effects of the overall query evaluation. But, of course, it is also interesting to test the behavior of skyline queries on top of complex queries. To this end, we have carried out experiments on the MusicBrainz database (Foundation, 2022) with more complex queries including joins and aggregates. Due to lack of space, the detailed results are given in Appendix E. In a nutshell, the results are quite similar to the ones reported in Section 6.4:
-
•
The execution time of the reference solution is almost always above the time of the specialized algorithms. The only cases where the reference solution performs best are the easiest ones with execution times below 50 seconds. For the harder cases it is always slower and – in contrast to the specialized algorithms – causes several timeouts.
-
•
The memory consumption is comparable for all 4 algorithms. There are, however, some peaks in case of the reference algorithms that do not occur with the specialized algorithm. In general, the behavior of the reference algorithm seems to be less stable than the other algorithms. For instance, with 4, 5, or 6 dimensions, the execution time jumps from below 50 seconds for 3 executors to over 1000 seconds for 5 executors and then slightly decreases again for 10 executors.
-
•
It is also notable, that skyline queries rewritten to plain SQL are much less readable and less intuitive in the context of the entire query.
6.6. Summary of Results
From our experimental evaluation, we conclude that, in almost all cases, our specialized algorithms outperform the “reference” algorithm and they also provide better scalability. Parallelization (if applicable) has proved profitable – but only up to a certain point, that depends on the size of the data. Moreover, it has become clear that using the incomplete distributed algorithm on a complete dataset is not advisable and may perform worse than the non-distributed algorithm. As such, the introduction of additional syntax to select an appropriate algorithm through the keyword COMPLETE may help to significantly boost the performance.
7. Conclusion and Future Work
In this work, we have presented the extension of Spark SQL by the skyline operator. It provides users with a simple, easy to use syntax for formulating skyline queries. To the best of our knowledge, this is the first distributed data processing system with native support of skyline queries. By our extension of the various components of Spark SQL query execution and, in particular, of the Catalyst optimizer, we have obtained an implementation that clearly outperforms the formulation of skyline queries in plain SQL. Nevertheless, there is still ample space for future enhancements:
So far, we have implemented only the Block-Nested-Loop skyline algorithm and variants thereof. It would be interesting to implement additional algorithms based on other paradigms like ordering (Chomicki et al., 2003, 2005; Godfrey et al., 2005, 2007; Bartolini et al., 2006, 2008; Liu and Li, 2020) or index structures (Tan et al., 2001; Lee and Hwang, 2010a, b) and to evaluate their strengths and weaknesses in the Apache Spark context. Also, for the partitioning scheme, further options such as angle-based partitioning (Kim and Kim, 2018; Vlachou et al., 2008) are worth trying. Further specialized algorithms, that require a deeper modification of Spark (such as Z-order partitioning (Tang et al., 2019), which requires the computation of a Z-address for each tuple (Lee et al., 2010)) are more long-term projects.
For our skyline algorithm that can cope with (potentially) incomplete datasets, we have chosen a straightforward extension of the Block-Nested-Loop algorithm. As mentioned in Section 5.7, this may severely limit the potential of parallelism. Moreover, in the worst case, the algorithm may thus have to compare each tuple against any other tuple. Clearly, a more sophisticated algorithm for potentially incomplete datasets would be highly desirable.
We have included rule-based optimizations in our integration of skyline queries. The support of cost-based optimization by Spark SQL is only somewhat rudimentary as of now. Fully integrating skyline queries into a future cost-based optimizer will be an important, highly non-trivial research and development project. However, as soon as further skyline algorithms are implemented, a light-weight form of cost-based optimization should be implemented that selects the best-suited skyline algorithm for a particular query.
Finally, from the user perspective, the integration into different Spark modules such as structured streaming would be desirable.
To conclude, the goal of this work was a full integration of skyline queries into Spark SQL. The favorable experimental results with simple skyline algorithms (Block-Nested-Loops and variants thereof) demonstrate that an integrated solution is clearly superior to a rewriting of the query on SQL level. To leverage the full potential of the integrated solution, the implementation of further (more sophisticated) skyline algorithms is the most important task for future work. It should be noted that, in our implementation, we have paid particular attention to a modular structure of our new software so that the implementation of further algorithms is possible without having to worry about Spark SQL as a whole. Moreover, our code is provided under Apache Spark’s own open-source license, and we explicitly invite other groups to join in this effort of enabling convenient and efficient skyline queries in Spark SQL.
Acknowledgements.
This work was supported by the Austrian Science Fund (FWF): P30930 and by the Vienna Science and Technology Fund (WWTF) grant VRG18-013.References
- (1)
- Airbnb (2022) Inside Airbnb. 2022. Inside Airbnb. Retrieved January 19, 2022 from http://insideairbnb.com/get-the-data.html
- Alrifai et al. (2010) Mohammad Alrifai, Dimitrios Skoutas, and Thomas Risse. 2010. Selecting skyline services for QoS-based web service composition. In Proceedings of the 19th International Conference on World Wide Web, WWW 2010, Raleigh, North Carolina, USA, April 26-30, 2010, Michael Rappa, Paul Jones, Juliana Freire, and Soumen Chakrabarti (Eds.). ACM, 11–20. https://doi.org/10.1145/1772690.1772693
- Bartolini et al. (2006) Ilaria Bartolini, Paolo Ciaccia, and Marco Patella. 2006. SaLSa: computing the skyline without scanning the whole sky. In Proceedings of the 2006 ACM CIKM International Conference on Information and Knowledge Management, Arlington, Virginia, USA, November 6-11, 2006, Philip S. Yu, Vassilis J. Tsotras, Edward A. Fox, and Bing Liu (Eds.). ACM, 405–414. https://doi.org/10.1145/1183614.1183674
- Bartolini et al. (2008) Ilaria Bartolini, Paolo Ciaccia, and Marco Patella. 2008. Efficient sort-based skyline evaluation. ACM Trans. Database Syst. 33, 4 (2008), 31:1–31:49. https://doi.org/10.1145/1412331.1412343
- Börzsönyi et al. (2001) Stephan Börzsönyi, Donald Kossmann, and Konrad Stocker. 2001. The Skyline Operator. In Proceedings of the 17th International Conference on Data Engineering, April 2-6, 2001, Heidelberg, Germany, Dimitrios Georgakopoulos and Alexander Buchmann (Eds.). IEEE Computer Society, 421–430. https://doi.org/10.1109/ICDE.2001.914855
- Carey and Kossmann (1997) Michael J. Carey and Donald Kossmann. 1997. On Saying "Enough Already!" in SQL. In SIGMOD 1997, Proceedings ACM SIGMOD International Conference on Management of Data, May 13-15, 1997, Tucson, Arizona, USA, Joan Peckham (Ed.). ACM Press, 219–230. https://doi.org/10.1145/253260.253302
- Chen et al. (2007) Bee-Chung Chen, Raghu Ramakrishnan, and Kristen LeFevre. 2007. Privacy Skyline: Privacy with Multidimensional Adversarial Knowledge. In Proceedings of the 33rd International Conference on Very Large Data Bases, University of Vienna, Austria, September 23-27, 2007, Christoph Koch, Johannes Gehrke, Minos N. Garofalakis, Divesh Srivastava, Karl Aberer, Anand Deshpande, Daniela Florescu, Chee Yong Chan, Venkatesh Ganti, Carl-Christian Kanne, Wolfgang Klas, and Erich J. Neuhold (Eds.). ACM, 770–781. http://www.vldb.org/conf/2007/papers/research/p770-chen.pdf
- Chen and Lian (2008) Lei Chen and Xiang Lian. 2008. Dynamic skyline queries in metric spaces. In EDBT 2008, 11th International Conference on Extending Database Technology, Nantes, France, March 25-29, 2008, Proceedings (ACM International Conference Proceeding Series), Alfons Kemper, Patrick Valduriez, Noureddine Mouaddib, Jens Teubner, Mokrane Bouzeghoub, Volker Markl, Laurent Amsaleg, and Ioana Manolescu (Eds.), Vol. 261. ACM, 333–343. https://doi.org/10.1145/1353343.1353386
- Chomicki et al. (2013) Jan Chomicki, Paolo Ciaccia, and Niccolò Meneghetti. 2013. Skyline queries, front and back. SIGMOD Rec. 42, 3 (2013), 6–18. https://doi.org/10.1145/2536669.2536671
- Chomicki et al. (2003) Jan Chomicki, Parke Godfrey, Jarek Gryz, and Dongming Liang. 2003. Skyline with Presorting. In Proceedings of the 19th International Conference on Data Engineering, March 5-8, 2003, Bangalore, India, Umeshwar Dayal, Krithi Ramamritham, and T. M. Vijayaraman (Eds.). IEEE Computer Society, 717–719. https://doi.org/10.1109/ICDE.2003.1260846
- Chomicki et al. (2005) Jan Chomicki, Parke Godfrey, Jarek Gryz, and Dongming Liang. 2005. Skyline with Presorting: Theory and Optimizations. In Intelligent Information Processing and Web Mining, Proceedings of the International IIS: IIPWM’05 Conference held in Gdansk, Poland, June 13-16, 2005 (Advances in Soft Computing), Mieczyslaw A. Klopotek, Slawomir T. Wierzchon, and Krzysztof Trojanowski (Eds.), Vol. 31. Springer, 595–604. https://doi.org/10.1007/3-540-32392-9_72
- Cui et al. (2008) Bin Cui, Hua Lu, Quanqing Xu, Lijiang Chen, Yafei Dai, and Yongluan Zhou. 2008. Parallel Distributed Processing of Constrained Skyline Queries by Filtering. In Proceedings of the 24th International Conference on Data Engineering, ICDE 2008, April 7-12, 2008, Cancún, Mexico, Gustavo Alonso, José A. Blakeley, and Arbee L. P. Chen (Eds.). IEEE Computer Society, 546–555. https://doi.org/10.1109/ICDE.2008.4497463
- Dellis and Seeger (2007) Evangelos Dellis and Bernhard Seeger. 2007. Efficient Computation of Reverse Skyline Queries. In Proceedings of the 33rd International Conference on Very Large Data Bases, University of Vienna, Austria, September 23-27, 2007, Christoph Koch, Johannes Gehrke, Minos N. Garofalakis, Divesh Srivastava, Karl Aberer, Anand Deshpande, Daniela Florescu, Chee Yong Chan, Venkatesh Ganti, Carl-Christian Kanne, Wolfgang Klas, and Erich J. Neuhold (Eds.). ACM, 291–302. http://www.vldb.org/conf/2007/papers/research/p291-dellis.pdf
- Ding et al. (2021) Bailu Ding, Surajit Chaudhuri, Johannes Gehrke, and Vivek Narasayya. 2021. DSB: A Decision Support Benchmark for Workload-Driven and Traditional Database Systems. Proc. VLDB Endow. 14, 13 (sep 2021), 3376–3388. https://doi.org/10.14778/3484224.3484234
- Eder (2009) Hannes Eder. 2009. On Extending PostgreSQL with the Skyline Operator. Master’s thesis. Fakultät für Informatik der Technischen Universität Wien.
- Foundation (2022) MetaBrainz Foundation. 2022. MusicBrainz. Retrieved August 30, 2022 from https://musicbrainz.org/
- Godfrey et al. (2005) Parke Godfrey, Ryan Shipley, and Jarek Gryz. 2005. Maximal Vector Computation in Large Data Sets. In Proceedings of the 31st International Conference on Very Large Data Bases, Trondheim, Norway, August 30 - September 2, 2005, Klemens Böhm, Christian S. Jensen, Laura M. Haas, Martin L. Kersten, Per-Åke Larson, and Beng Chin Ooi (Eds.). ACM, 229–240. http://www.vldb.org/archives/website/2005/program/paper/tue/p229-godfrey.pdf
- Godfrey et al. (2007) Parke Godfrey, Ryan Shipley, and Jarek Gryz. 2007. Algorithms and analyses for maximal vector computation. VLDB J. 16, 1 (2007), 5–28. https://doi.org/10.1007/s00778-006-0029-7
- Grasmann et al. (2022) Lukas Grasmann, Reinhard Pichler, and Alexander Selzer. 2022. Integration of Skyline Queries into Spark SQL - Experiment Artifacts. Zenodo. https://doi.org/10.5281/zenodo.7157840
- Gulzar et al. (2019) Yonis Gulzar, Ali Amer Alwan, and Sherzod Turaev. 2019. Optimizing Skyline Query Processing in Incomplete Data. IEEE Access 7 (2019), 178121–178138. https://doi.org/10.1109/ACCESS.2019.2958202
- Hose and Vlachou (2012) Katja Hose and Akrivi Vlachou. 2012. A survey of skyline processing in highly distributed environments. VLDB J. 21, 3 (2012), 359–384. https://doi.org/10.1007/s00778-011-0246-6
- Huang and Jensen (2004) Xuegang Huang and Christian S. Jensen. 2004. In-Route Skyline Querying for Location-Based Services. In Web and Wireless Geographical Information Systems, 4th InternationalWorkshop, W2GIS 2004, Goyang, Korea, November 2004, Revised Selected Papers (Lecture Notes in Computer Science), Yong Jin Kwon, Alain Bouju, and Christophe Claramunt (Eds.), Vol. 3428. Springer, 120–135. https://doi.org/10.1007/11427865_10
- Kalyvas and Tzouramanis (2017) Christos Kalyvas and Theodoros Tzouramanis. 2017. A Survey of Skyline Query Processing. CoRR abs/1704.01788 (2017), 127. arXiv:1704.01788 http://arxiv.org/abs/1704.01788
- Kanellis (2020) Aki Kanellis. 2020. SkySpark. Retrieved November 10, 2020 from https://github.com/AkiKanellis/skyspark
- Kim and Kim (2018) Junsu Kim and Myoung Ho Kim. 2018. An efficient parallel processing method for skyline queries in MapReduce. J. Supercomput. 74, 2 (2018), 886–935. https://doi.org/10.1007/s11227-017-2171-y
- Kossmann et al. (2002) Donald Kossmann, Frank Ramsak, and Steffen Rost. 2002. Shooting Stars in the Sky: An Online Algorithm for Skyline Queries. In Proceedings of 28th International Conference on Very Large Data Bases, VLDB 2002, Hong Kong, August 20-23, 2002. Morgan Kaufmann, 275–286. https://doi.org/10.1016/B978-155860869-6/50032-9
- Kriegel et al. (2010) Hans-Peter Kriegel, Matthias Renz, and Matthias Schubert. 2010. Route skyline queries: A multi-preference path planning approach. In Proceedings of the 26th International Conference on Data Engineering, ICDE 2010, March 1-6, 2010, Long Beach, California, USA, Feifei Li, Mirella M. Moro, Shahram Ghandeharizadeh, Jayant R. Haritsa, Gerhard Weikum, Michael J. Carey, Fabio Casati, Edward Y. Chang, Ioana Manolescu, Sharad Mehrotra, Umeshwar Dayal, and Vassilis J. Tsotras (Eds.). IEEE Computer Society, 261–272. https://doi.org/10.1109/ICDE.2010.5447845
- Lee and Hwang (2010a) Jongwuk Lee and Seung-won Hwang. 2010a. BSkyTree: scalable skyline computation using a balanced pivot selection. In EDBT 2010, 13th International Conference on Extending Database Technology, Lausanne, Switzerland, March 22-26, 2010, Proceedings (ACM International Conference Proceeding Series), Ioana Manolescu, Stefano Spaccapietra, Jens Teubner, Masaru Kitsuregawa, Alain Léger, Felix Naumann, Anastasia Ailamaki, and Fatma Özcan (Eds.), Vol. 426. ACM, 195–206. https://doi.org/10.1145/1739041.1739067
- Lee and Hwang (2010b) Jongwuk Lee and Seung-won Hwang. 2010b. BSkyTree: scalable skyline computation using a balanced pivot selection. In EDBT 2010, 13th International Conference on Extending Database Technology, Lausanne, Switzerland, March 22-26, 2010, Proceedings (ACM International Conference Proceeding Series), Ioana Manolescu, Stefano Spaccapietra, Jens Teubner, Masaru Kitsuregawa, Alain Léger, Felix Naumann, Anastasia Ailamaki, and Fatma Özcan (Eds.), Vol. 426. ACM, 195–206. https://doi.org/10.1145/1739041.1739067
- Lee et al. (2010) Ken C. K. Lee, Wang-Chien Lee, Baihua Zheng, Huajing Li, and Yuan Tian. 2010. Z-SKY: an efficient skyline query processing framework based on Z-order. VLDB J. 19, 3 (2010), 333–362. https://doi.org/10.1007/s00778-009-0166-x
- Lee et al. (2007) Ken C. K. Lee, Baihua Zheng, Huajing Li, and Wang-Chien Lee. 2007. Approaching the Skyline in Z Order. In Proceedings of the 33rd International Conference on Very Large Data Bases, University of Vienna, Austria, September 23-27, 2007, Christoph Koch, Johannes Gehrke, Minos N. Garofalakis, Divesh Srivastava, Karl Aberer, Anand Deshpande, Daniela Florescu, Chee Yong Chan, Venkatesh Ganti, Carl-Christian Kanne, Wolfgang Klas, and Erich J. Neuhold (Eds.). ACM, 279–290. http://www.vldb.org/conf/2007/papers/research/p279-lee.pdf
- Lin et al. (2011) Xin Lin, Jianliang Xu, and Haibo Hu. 2011. Authentication of location-based skyline queries. In Proceedings of the 20th ACM Conference on Information and Knowledge Management, CIKM 2011, Glasgow, United Kingdom, October 24-28, 2011, Craig Macdonald, Iadh Ounis, and Ian Ruthven (Eds.). ACM, 1583–1588. https://doi.org/10.1145/2063576.2063805
- Liu and Li (2020) Rui Liu and Dominique Li. 2020. Efficient Skyline Computation in High-Dimensionality Domains. In Proceedings of the 23rd International Conference on Extending Database Technology, EDBT 2020, Copenhagen, Denmark, March 30 - April 02, 2020, Angela Bonifati, Yongluan Zhou, Marcos Antonio Vaz Salles, Alexander Böhm, Dan Olteanu, George H. L. Fletcher, Arijit Khan, and Bin Yang (Eds.). OpenProceedings.org, 459–462. https://doi.org/10.5441/002/edbt.2020.57
- Morse et al. (2007) Michael D. Morse, Jignesh M. Patel, and H. V. Jagadish. 2007. Efficient Skyline Computation over Low-Cardinality Domains. In Proceedings of the 33rd International Conference on Very Large Data Bases, University of Vienna, Austria, September 23-27, 2007, Christoph Koch, Johannes Gehrke, Minos N. Garofalakis, Divesh Srivastava, Karl Aberer, Anand Deshpande, Daniela Florescu, Chee Yong Chan, Venkatesh Ganti, Carl-Christian Kanne, Wolfgang Klas, and Erich J. Neuhold (Eds.). ACM, 267–278. http://www.vldb.org/conf/2007/papers/research/p267-morse.pdf
- Papadias et al. (2003) Dimitris Papadias, Yufei Tao, Greg Fu, and Bernhard Seeger. 2003. An Optimal and Progressive Algorithm for Skyline Queries. In Proceedings of the 2003 ACM SIGMOD International Conference on Management of Data, San Diego, California, USA, June 9-12, 2003, Alon Y. Halevy, Zachary G. Ives, and AnHai Doan (Eds.). ACM, 467–478. https://doi.org/10.1145/872757.872814
- Papadias et al. (2005) Dimitris Papadias, Yufei Tao, Greg Fu, and Bernhard Seeger. 2005. Progressive skyline computation in database systems. ACM Trans. Database Syst. 30, 1 (2005), 41–82. https://doi.org/10.1145/1061318.1061320
- Papanikolaou (2018) Ioanna Papanikolaou. 2018. Distributed Algorithms for Skyline Computation using Apache Spark. Master’s thesis. INTERNATIONAL HELLENIC UNIVERSITY. https://repository.ihu.edu.gr/xmlui/handle/11544/29524 Accessed on: 23.01.2022.
- Park et al. (2013) Yoonjae Park, Jun-Ki Min, and Kyuseok Shim. 2013. Parallel Computation of Skyline and Reverse Skyline Queries Using MapReduce. Proc. VLDB Endow. 6, 14 (2013), 2002–2013. https://doi.org/10.14778/2556549.2556580
- Sheng and Tao (2012) Cheng Sheng and Yufei Tao. 2012. Worst-Case I/O-Efficient Skyline Algorithms. ACM Trans. Database Syst. 37, 4 (2012), 26:1–26:22. https://doi.org/10.1145/2389241.2389245
- Tan et al. (2001) Kian-Lee Tan, Pin-Kwang Eng, and Beng Chin Ooi. 2001. Efficient Progressive Skyline Computation. In VLDB 2001, Proceedings of 27th International Conference on Very Large Data Bases, September 11-14, 2001, Roma, Italy, Peter M. G. Apers, Paolo Atzeni, Stefano Ceri, Stefano Paraboschi, Kotagiri Ramamohanarao, and Richard T. Snodgrass (Eds.). Morgan Kaufmann, 301–310. http://www.vldb.org/conf/2001/P301.pdf
- Tang et al. (2019) Mingjie Tang, Yongyang Yu, Walid G. Aref, Qutaibah M. Malluhi, and Mourad Ouzzani. 2019. Efficient Parallel Skyline Query Processing for High-Dimensional Data. In 35th IEEE International Conference on Data Engineering, ICDE 2019, Macao, China, April 8-11, 2019. IEEE, 2113–2114. https://doi.org/10.1109/ICDE.2019.00251
- Vlachou et al. (2008) Akrivi Vlachou, Christos Doulkeridis, and Yannis Kotidis. 2008. Angle-based space partitioning for efficient parallel skyline computation. In Proceedings of the ACM SIGMOD International Conference on Management of Data, SIGMOD 2008, Vancouver, BC, Canada, June 10-12, 2008, Jason Tsong-Li Wang (Ed.). ACM, 227–238. https://doi.org/10.1145/1376616.1376642
- Zaharia et al. (2010) Matei Zaharia, Mosharaf Chowdhury, Michael J. Franklin, Scott Shenker, and Ion Stoica. 2010. Spark: Cluster Computing with Working Sets. In 2nd USENIX Workshop on Hot Topics in Cloud Computing, HotCloud’10, Boston, MA, USA, June 22, 2010, Erich M. Nahum and Dongyan Xu (Eds.). USENIX Association, 10. https://www.usenix.org/conference/hotcloud-10/spark-cluster-computing-working-sets
- Zaharia et al. (2016) Matei Zaharia, Reynold S. Xin, Patrick Wendell, Tathagata Das, Michael Armbrust, Ankur Dave, Xiangrui Meng, Josh Rosen, Shivaram Venkataraman, Michael J. Franklin, Ali Ghodsi, Joseph Gonzalez, Scott Shenker, and Ion Stoica. 2016. Apache Spark: a unified engine for big data processing. Commun. ACM 59, 11 (2016), 56–65. https://doi.org/10.1145/2934664
- Zhang et al. (2009) Shiming Zhang, Nikos Mamoulis, and David W. Cheung. 2009. Scalable skyline computation using object-based space partitioning. In Proceedings of the ACM SIGMOD International Conference on Management of Data, SIGMOD 2009, Providence, Rhode Island, USA, June 29 - July 2, 2009, Ugur Çetintemel, Stanley B. Zdonik, Donald Kossmann, and Nesime Tatbul (Eds.). ACM, 483–494. https://doi.org/10.1145/1559845.1559897
Appendix A Problems with Incomplete Datasets
Recall from Section 3 that, in the case of incomplete data, cyclic dominance relationships may arise. Therefore, care is required with deleting dominated tuples, since premature deletion of dominated tuples may prevent us from identifying other tuples as being dominated. Below, we illustrate this problem by revisiting the skyline algorithm from (Gulzar et al., 2019), which behaves incorrectly in the presence of cyclic dominance relationships.
The algorithm in (Gulzar et al., 2019), divides the dataset into clusters (= partitions) according to the occurrence of nulls in skyline dimensions and computes the local skyline in each cluster. It then arranges these clusters, i.e., through , in some order and computes the global skyline by visiting the clusters in this order and carrying out dominance checks for the data points in the local skylines of all clusters. For each data point, the following two steps are applied:
-
•
For the current data point of the iteration, we check for every not yet deleted data point in all subsequent clusters if one dominates the other. For instance, if is the current cluster, we check for all clusters with . Checking in the same cluster is not necessary since dominated data points have already been removed when computing the local skyline. If dominance is detected there are two scenarios:
-
–
If , then is immediately eliminated.
-
–
If , then a domination flag is set for .
-
–
-
•
If after checking against all data points , the domination flag is set for , then is subsequently also eliminated from the candidate list, since it is dominated by another point.
Counterexample. We now argue that the approach of (Gulzar et al., 2019) to compute the global skyline as described above is incorrect. To show this, we give a counterexample with simple data where applying the algorithm does not yield a correct skyline. We thus revisit the example that was used in Section 3 to illustrate the existence of dominance cycles in the case of incomplete data: Suppose that we have 3 dominance dimension and consider the following 3 data points: , , and . Here, “” indicates a null value.
As already discussed, we know that , and in this example under the assumption that all dimensions are minimized in the skyline. From the definition of the dominance relation and the skyline for incomplete data, it follows that the skyline of these values should be empty as every single tuple is dominated by another tuple. We now “execute” the above algorithm to check whether we get the same result.
-
•
For clustering, the tuples correspond to the bitmaps 101, 110, and 011 respectively. It follows that every tuple is in its own cluster according to the algorithm.
-
•
Clearly, each tuple is contained in its local skyline since each cluster contains only a single element.
This leaves the global skyline computation as the only step where tuples are eliminated. We now assume w.l.o.g. that belongs to , belongs to , and belongs to as per the algorithm introduced in (Gulzar et al., 2019). It follows that the algorithm starts by comparing from to which is the only element in . Since , we remove from after which is empty. Next, we go to the cluster and compare to . Since , we set the domination flag for . No further clusters and tuples remain. Therefore, is deleted from since the domination flag is set. For the next iteration, we check the cluster . Since is now empty, no comparisons remain for this cluster. We move on to the last cluster . Since there are no further clusters, we note that still contains after these steps. Hence, the algorithm returns tuple as part of the global skyline, which contradicts our expected result of an empty skyline.
Correct Skyline Computation. As was detailed in Section 5.7, we take over from (Gulzar et al., 2019) the idea of partitioning the data according to the occurrence of nulls for the local skyline computation of incomplete data. However, in our global skyline computation for incomplete data, we compare all pairs of tuples with each other and set a dominance flag if one tuple is dominated. Only after all pairs have been processed in this way, we actually delete the tuples for which the dominance flag is set. In this way, we can guarantee that all dominance relationships are found even if they are cyclic.
Appendix B Spark SQL Error When Sorting on Aggregates With Filter
While integrating the skyline queries into Apache Spark, we have noticed that aggregates are sometimes not resolved correctly by the default rules of Spark. This occurs, for example, when an Aggregate (introduced by a GROUP BY clause) is used in combination with a Filter (introduced by a HAVING clause) as input to the Skyline node. The aggregates are then not correctly resolved since they are either not introduced into the Aggregate node or lost during a projection after the Filter. As part of the implementation, we have taken preventive measures such that these queries can be resolved correctly for skyline queries.
Note, however, that this problem is not skyline-specific. A similar (erroneous) behavior in the Sort node leads to errors with queries in standard Apache Spark SQL. Below we discuss how this error can be fixed for standard Apache Spark SQL. The bugfix in the case of the skyline extension is similar. First, we eliminate Project nodes that may be introduced as part of the Filter caused by a HAVING clause in the query. To achieve this, we introduce a new analyzer rule which can be found in Listing 9.
First, we match the plan that was described above using the matching syntax of Scala (line 3 - 6). We then try to change the plan to not include the filter (line 10 - 14). Only if this allows us to resolve additional attributes (line 16 and 18), then we return the changed plan with the Filter reintroduced as the “parent” node (line 19 - 20). Otherwise, we return the old plan as-is (line 23).
In addition to the new rule introduced above, we also extend the ResolveAggregateFunctions rule such that it can handle plans consisting of Sort, Filter, and Aggregate. This is necessary, since otherwise the aggregates from the Aggregate node may not be resolved correctly in the Sort node. To achieve this, we modify the existing source code from Spark to fit our needs. The modifications can be found in Listing 10.
This code first takes all ordering dimensions (line 2) and subsequently tries to resolve them (line 3 - 7). In this step, we insert the (potentially) resolved dimensions into a new list of sort orders (line 4 - 5) that is used to create a new Sort node that is now (more) resolved than before.
Appendix C Additional Benchmarks
In this section, we provide additional benchmarks and performance data that were left out in Section 6 due to lack of space. First, we look at the peak memory consumption across all nodes in Figure 8 for the real-world dataset and in Figures 9 and 10 for the synthetic data set. As in Section 6, the measurements for complete datasets are shown on the left-hand side, while the results for incomplete datasets are shown on the right-hand side.
In Figures 8 and 9, we are interested in the impact of the number of executors on the memory consumption, while the plots in Figure 10 are about the relationship between data size and memory consumption. In Figures 8 and 9, we observe that the memory consumption mainly increases with the number of executors – but with a considerable amount of jitter. The increase of memory consumption is the expected behavior as every single executor must include the entire execution environment of Spark to be able to execute the code generated by the nodes in the physical plan. However, there are some outliers such as, in Figure 8, for 5 executors in the case of the non-distributed complete algorithm (left plot) and the distributed incomplete algorithm (right plot). The problem here is probably that Spark’s history server sometimes reports the memory consumption inaccurately. These inaccuracies occur since Spark uses periodical “heartbeats” to report the current memory consumption and its beat is then computed by selecting the highest value. If the timing of the heartbeats is off, then the peak memory consumption may not be captured correctly. There is notably less jitter in Figures 9 and 10. This is likely due to the fact that the execution times of the queries are higher and the memory consumption improves the longer each Spark application runs.
To sum up, the plots show that the improved runtime of our specialized algorithms compared with the reference algorithm is not achieved at the expense of significantly higher memory usage. On the contrary, in most cases, the memory consumption of our algorithms is even below that of the reference algorithm. In the remaining cases, the additional memory consumption (in particular, of the distributed complete algorithm) is within a reasonable margin. A comparison among our algorithms shows that the distributed complete algorithm has the highest memory requirements. This is most obvious as the data size increases. Here, the size of the “window” (see Section 5.6 for explanations) maintained in the skyline computation seems to be the predominant cost factor in terms of memory consumption.
In Figures 3 and 4, we have already seen plots depicting the relationship between the number of dimensions and the execution time. Further results – with varying numbers of executors – are shown in Figure 11 for the real-world dataset and in Figure 12 for the synthetic dataset. In the case of the real-world dataset, the plots provide a similar picture as in Section 6. In the case of the synthetic dataset, two observations in Figure 12 seem particularly noteworthy: since the tests with incomplete data were carried out on a bigger dataset than in Figure 4, timeouts (in particular, of the reference algorithm) occur much more frequently. In the case of the tests with complete datasets, the two opposing effects of increasing the number of dimensions are very well visible: first, when moving from 1 dimension to 2 and further to 3 dimensions, apparently the size of the skyline shrinks and, therefore, in particular the reference algorithm requires significantly less time. As further dimensions are added, apparently the size of the skyline increases and, hence, in particular the reference algorithm starts requiring significantly more time again. However, what remains unchanged compared with Figures 3 and 4 in Section 6 is, that in almost all cases, the time needed by our specialized algorithms is (significantly) below the time needed by the reference algorithm.
In Figure 13, we follow up on Figure 5, providing further details on the impact of the size of the dataset on the execution time. In the plots in Figure 13, the number of executors may take the values 2,3,5, or 10. We notice that, only when we increase the number of executors to 5 or even 10, then the reference algorithm can cope with the biggest dataset of size . In all tests with complete data, the distributed complete algorithm performs best and also the other specialized algorithms outperform the reference algorithm. In the case of incomplete data and a higher number of executors, the performance of the reference algorithm is comparable to the distributed incomplete algorithm.
In Figures 6 and 7, we analyzed the relationship between the number of executors and the running time. We report on further experiments in this direction in Figure 14 for the real-world dataset and in Figure 15 for the synthetic dataset. Again, the picture in Figures 14 and 15 is quite similar to the one in Figures 6 and 7. For instance, in almost all cases, all of the specialized algorithms outperform the reference algorithm and, for complete data, in almost all cases, the distributed complete algorithm performs best. Most noteworthy in the case of the tests with the real-world dataset (Figures 14) seems the observation that the distributed complete algorithm (which normally performs best) hardly profits from additional executors. We already discussed in Section 6 that, if the dataset is too small, then the distributed computation of the local skylines loses its effectiveness – leaving more work for the global skyline computation. This is in sharp contrast to the setting in Figure 7, where we considered an almost 10 times bigger dataset and where additional executors were clearly helpful. This effect is still visible but weaker in Figure 15, where we consider the complete dataset with tuples. In the case of the incomplete dataset of this size, the reference algorithm runs into several timeouts and, in all cases, the distributed incomplete algorithm performs better than the reference algorithm.
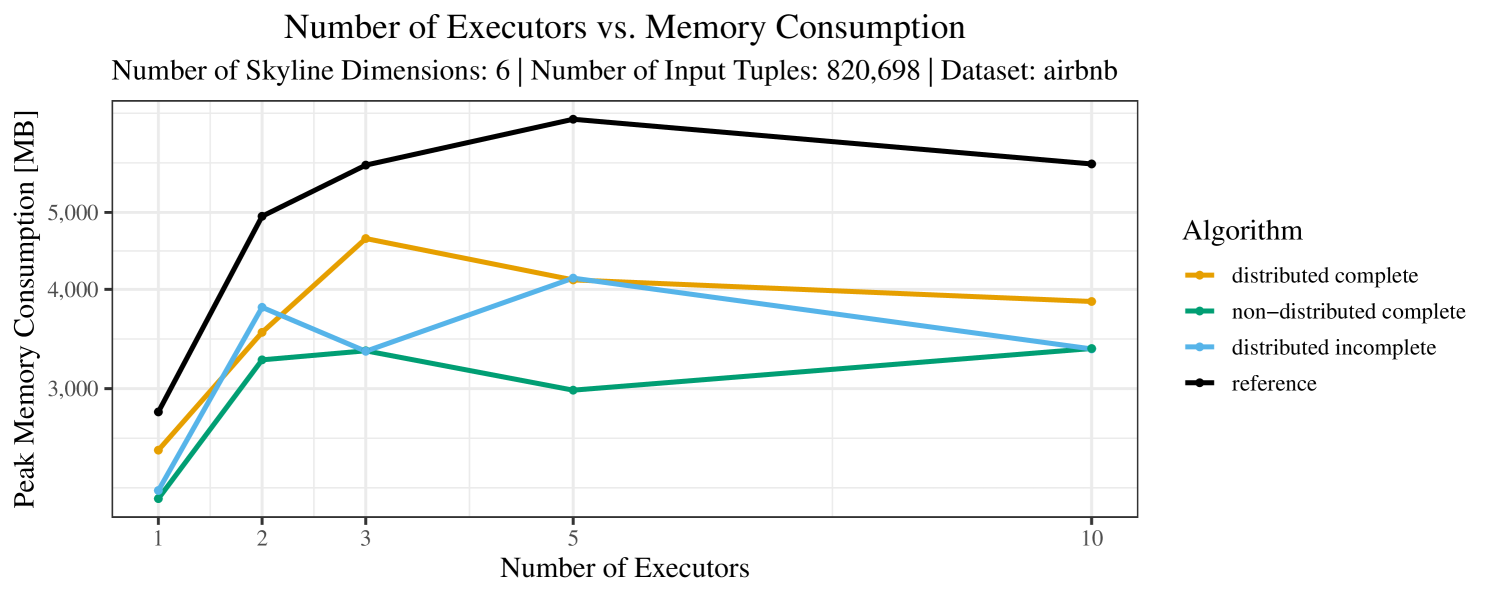
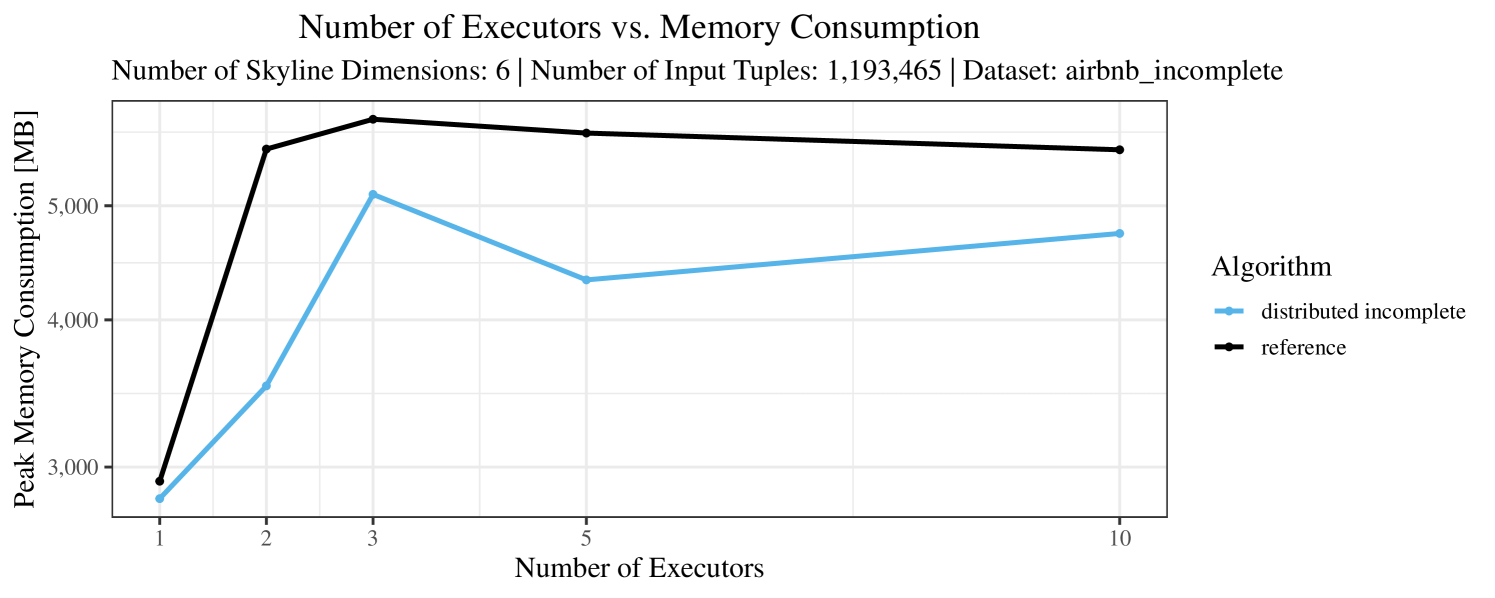
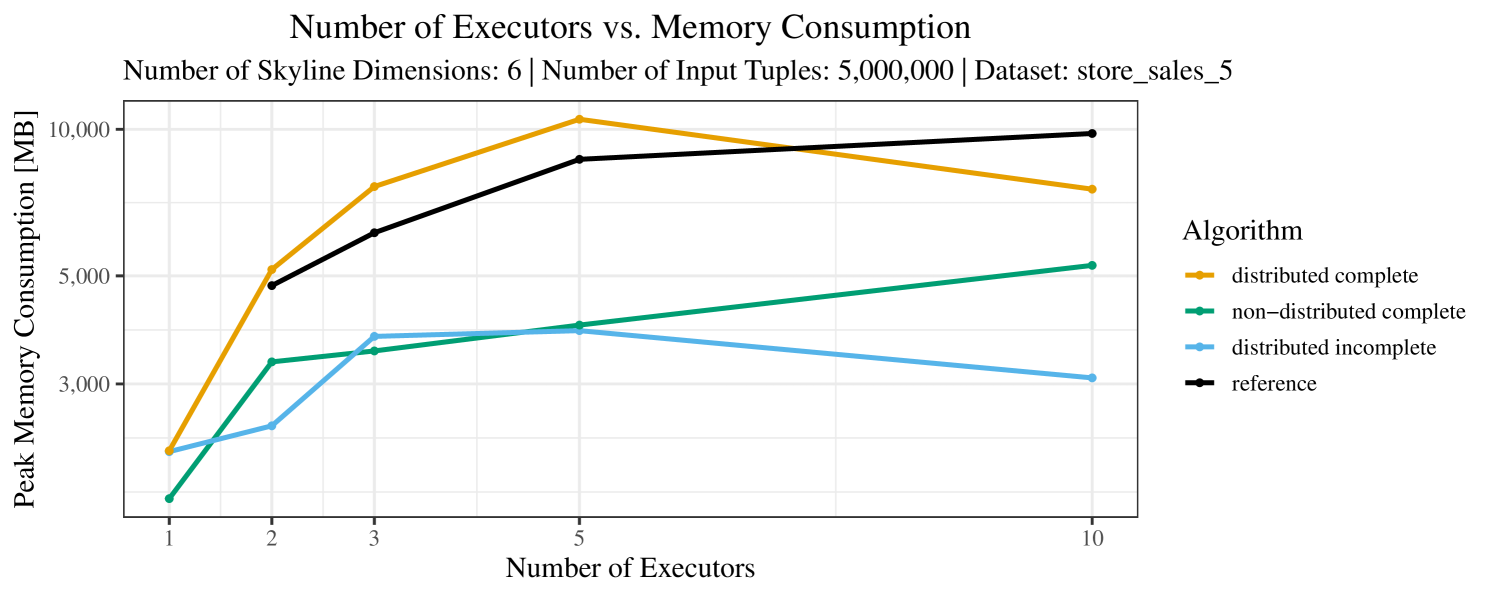
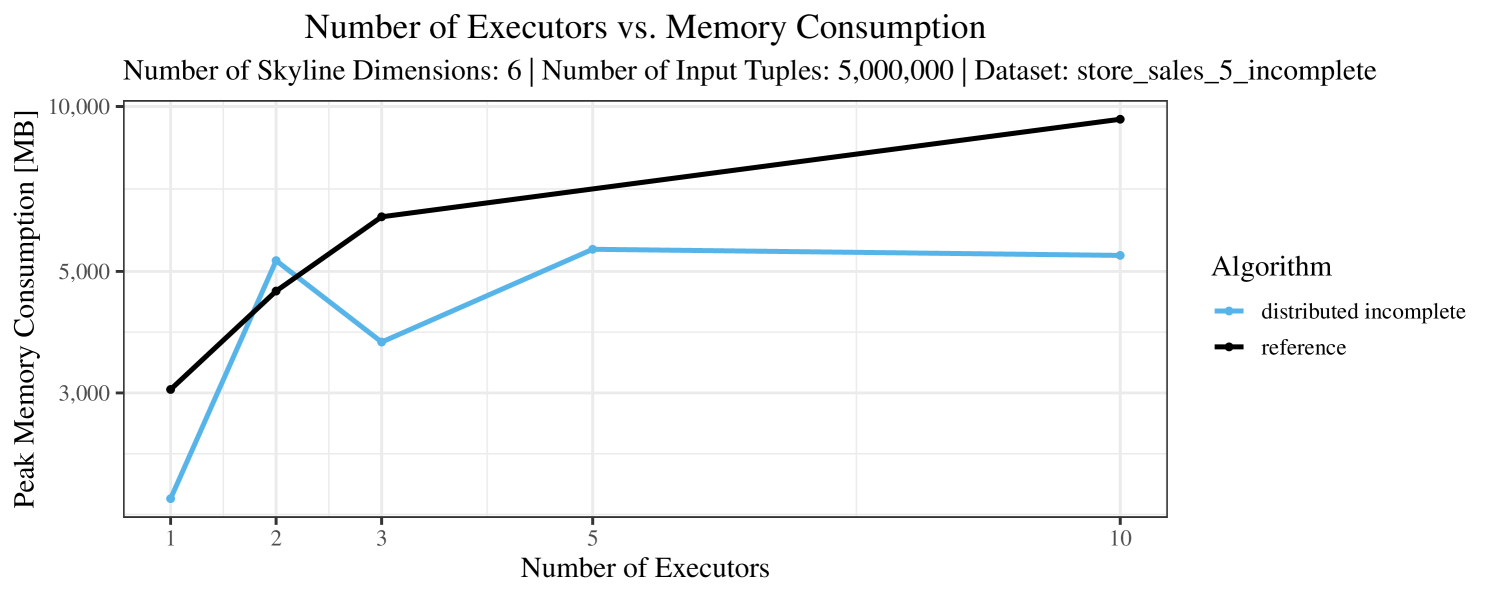
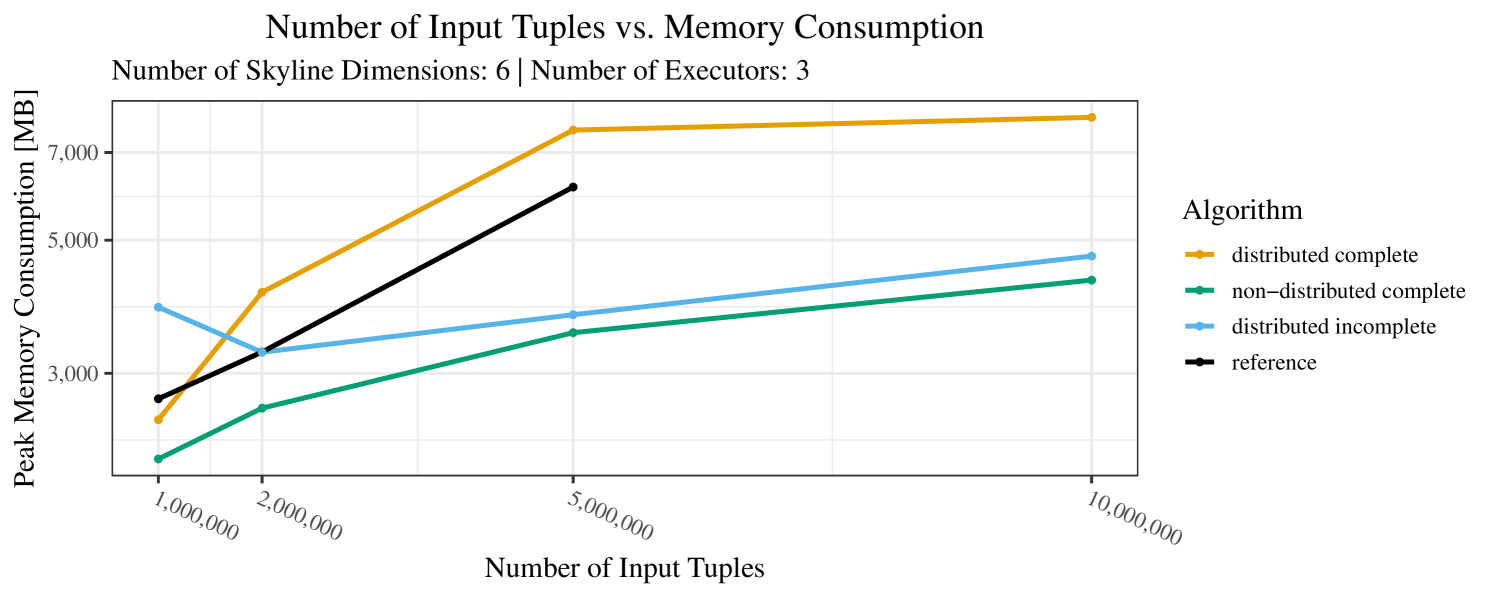
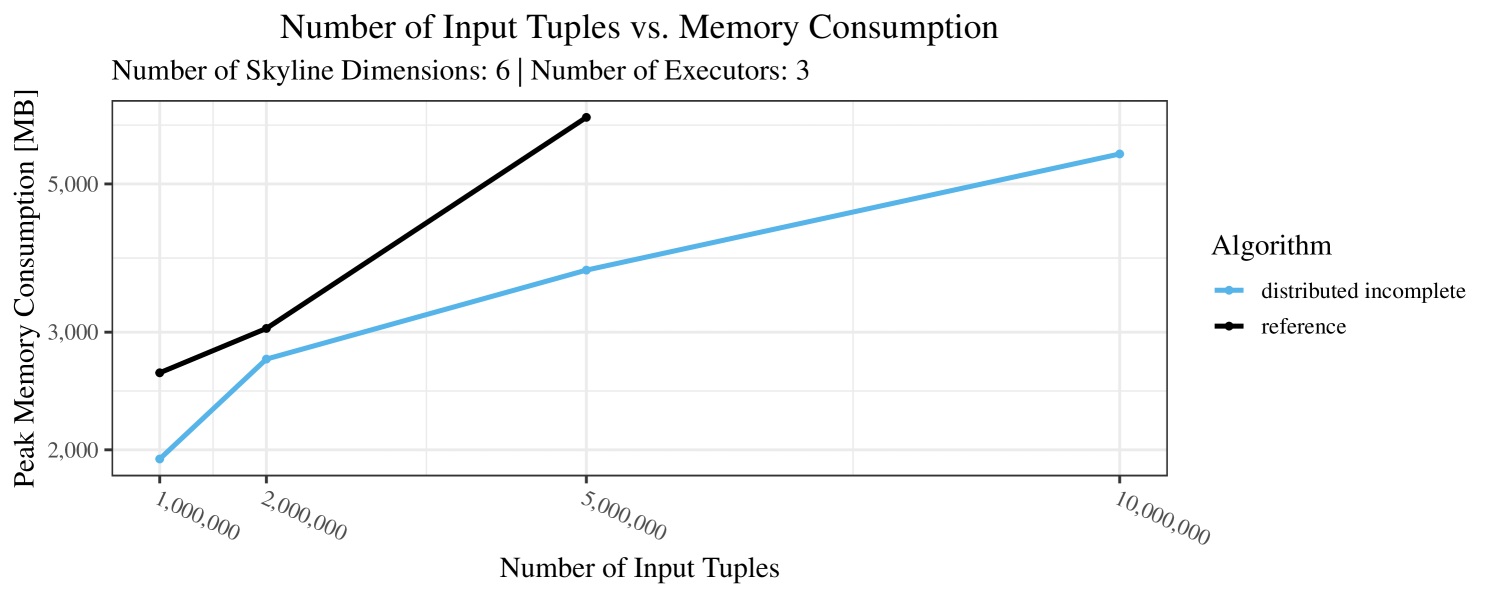
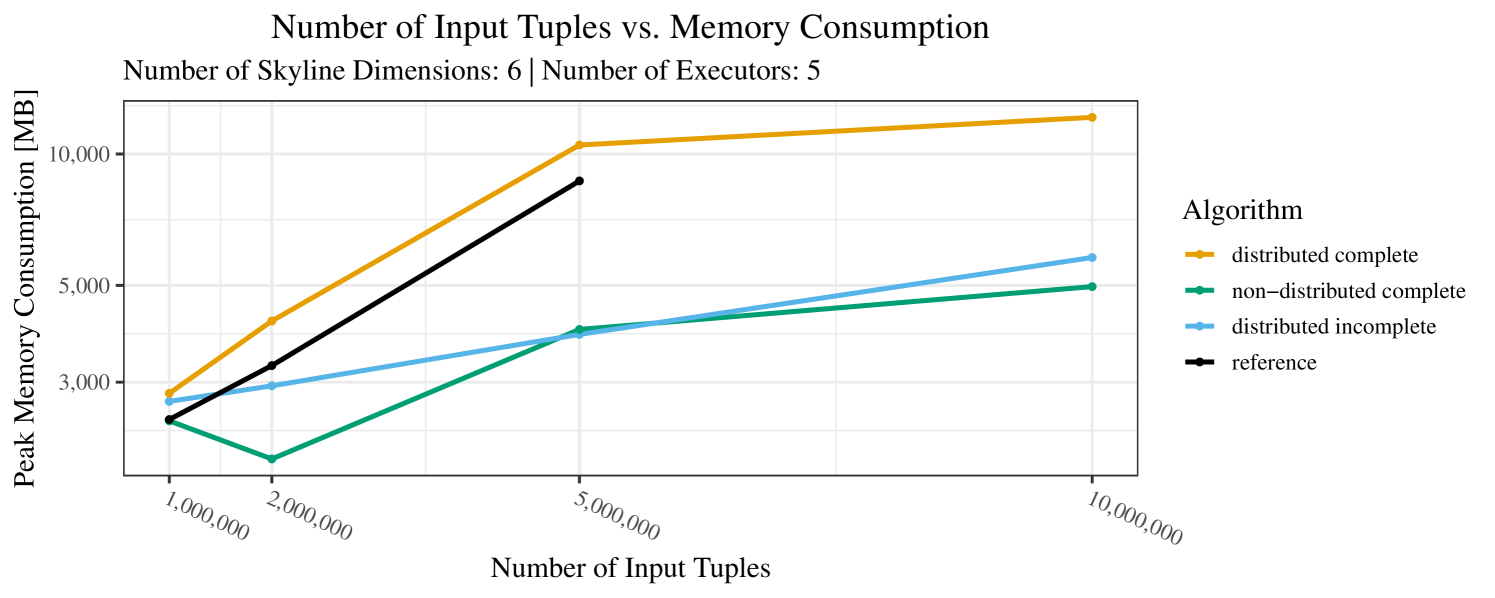
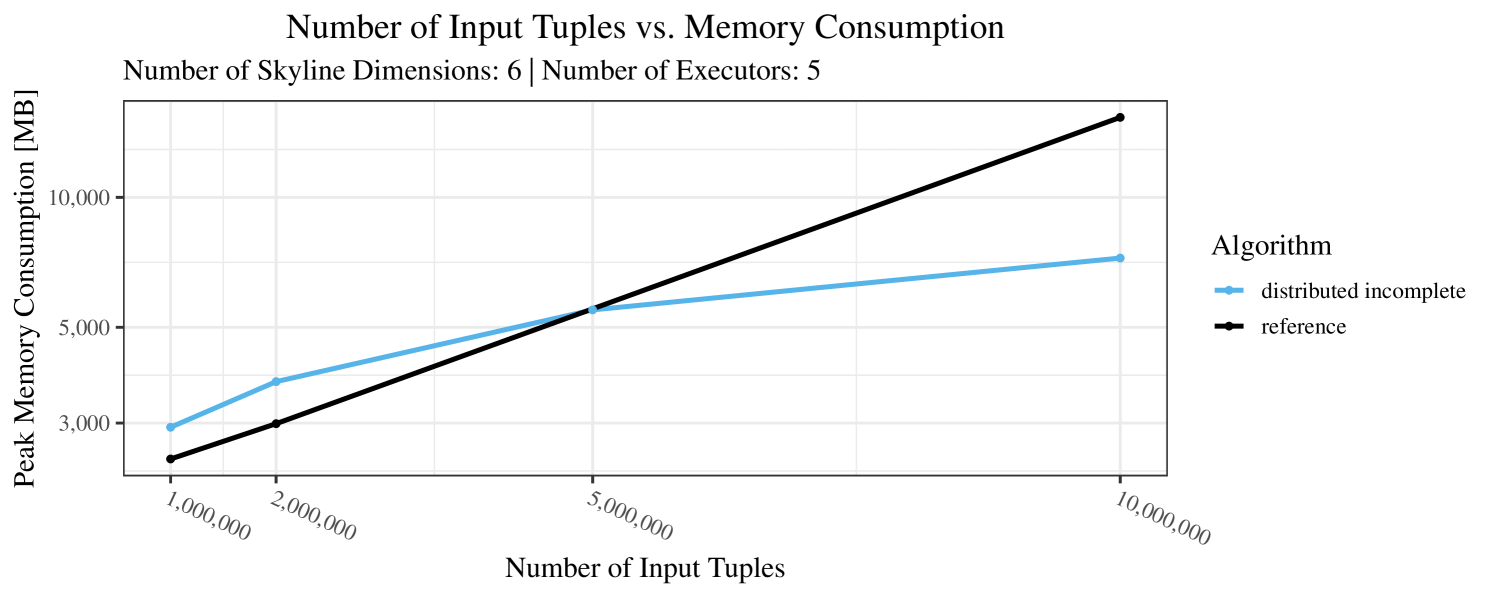
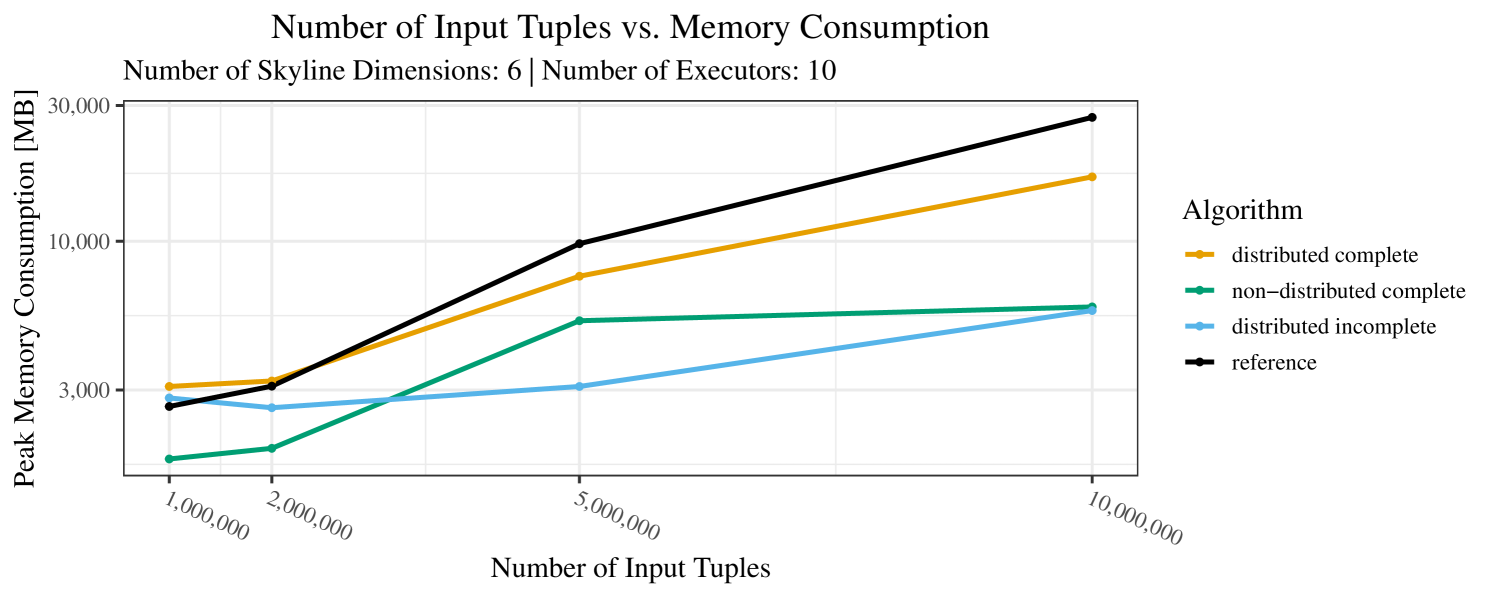
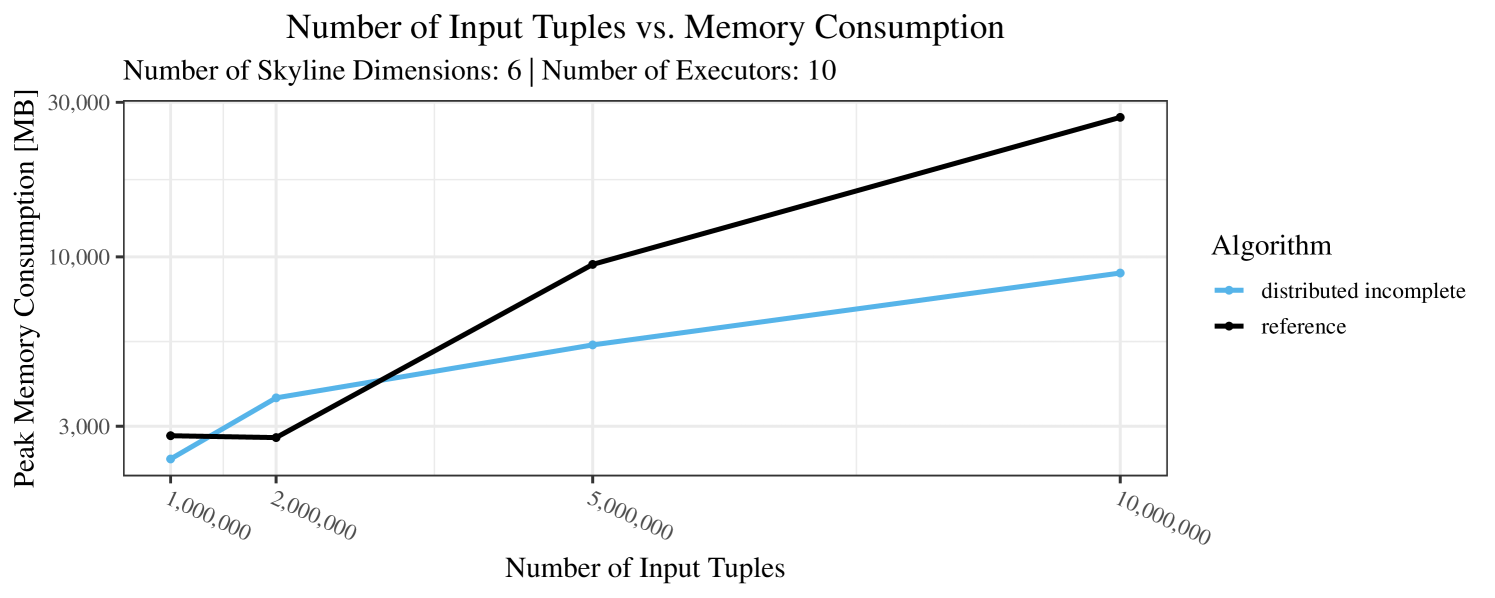
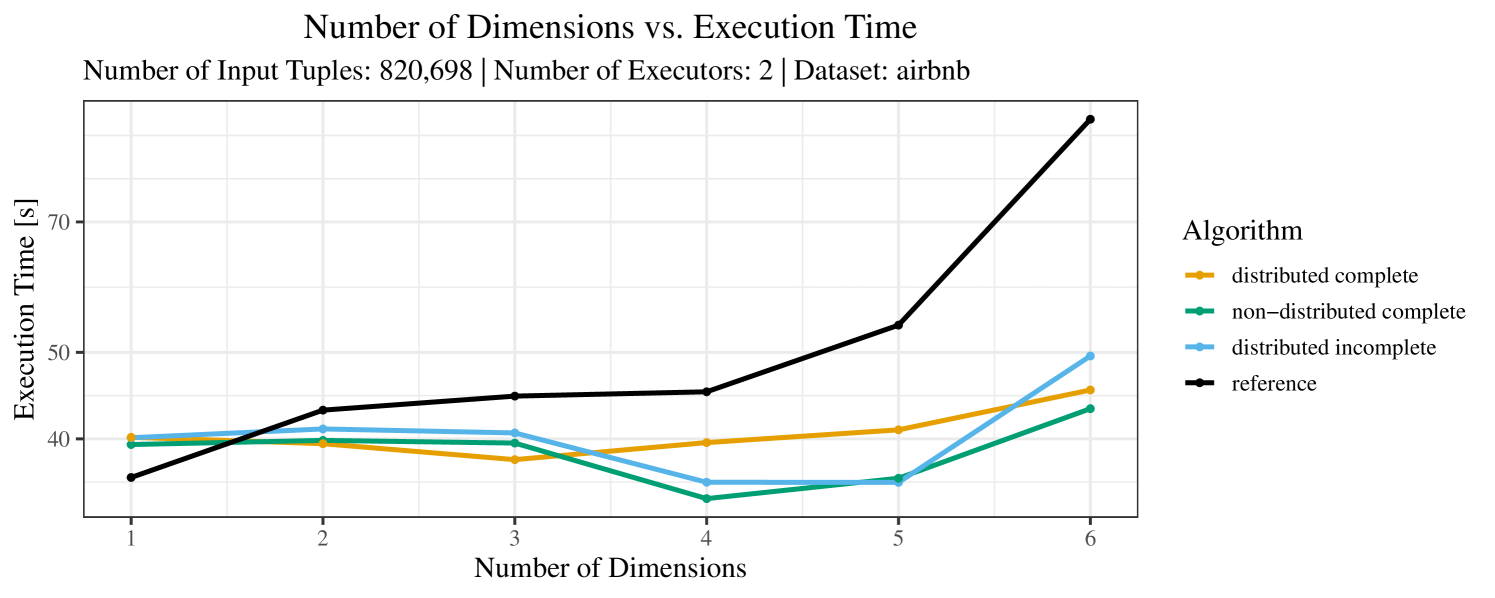
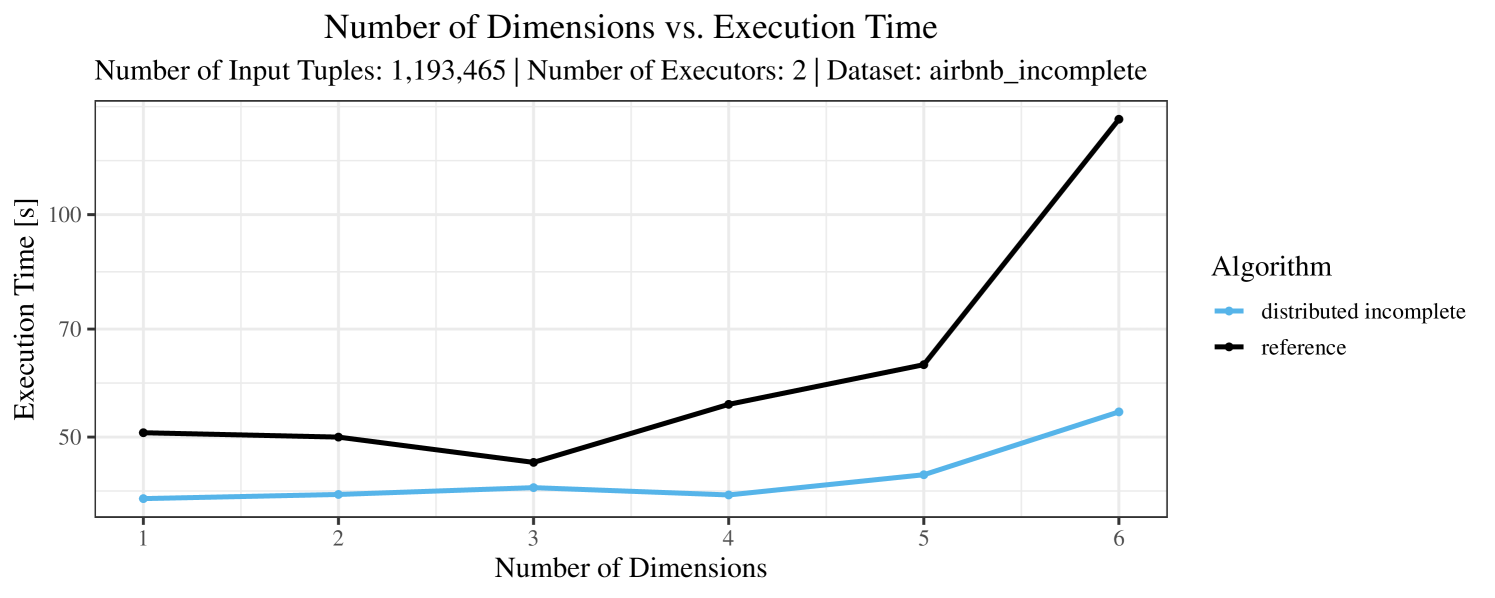
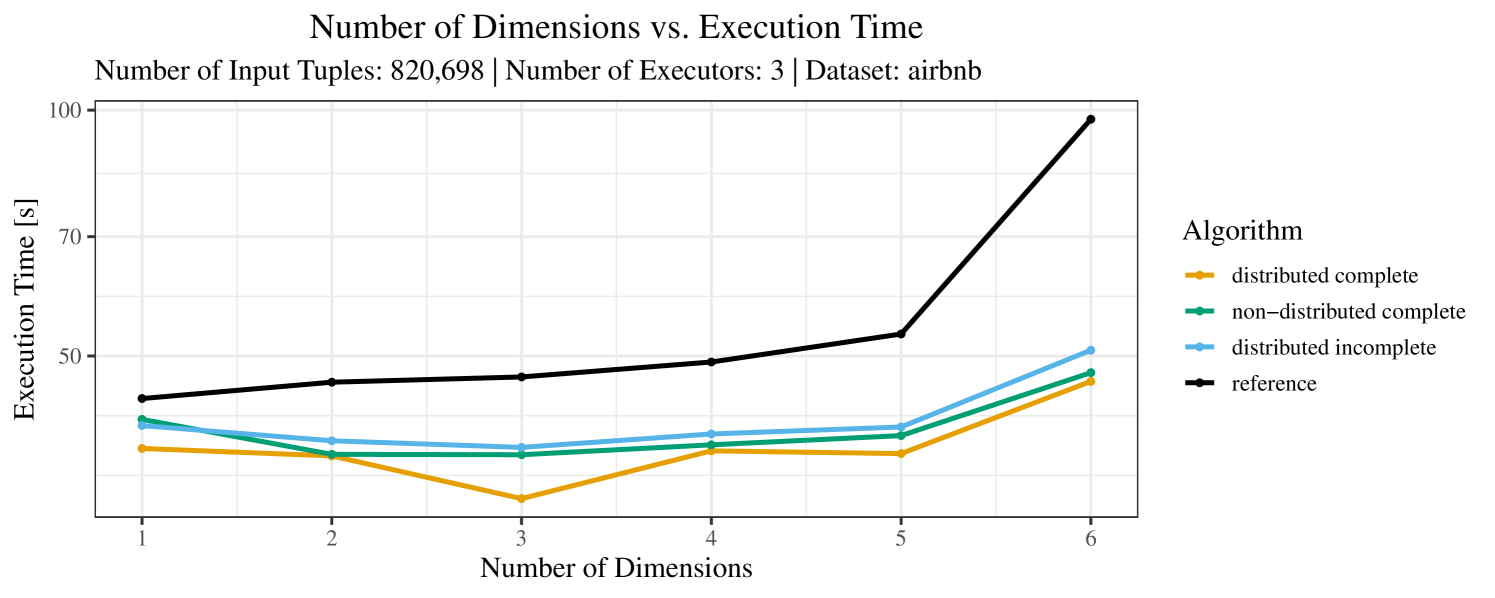
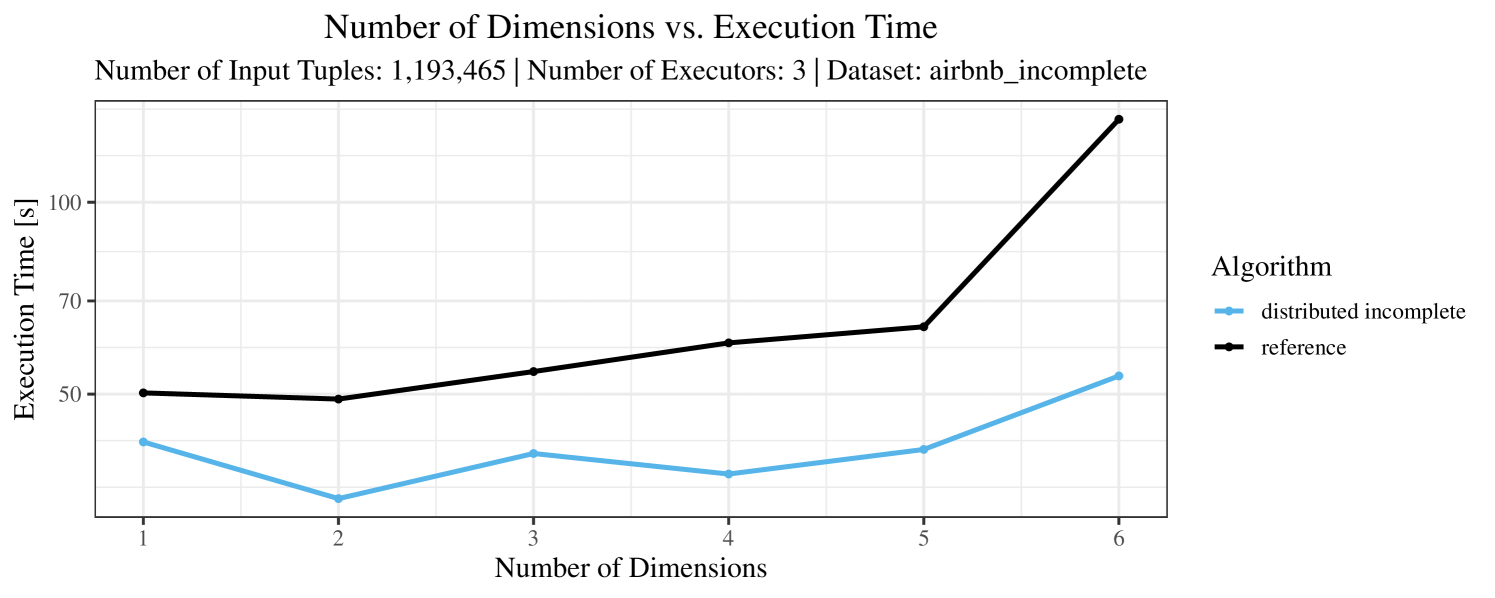
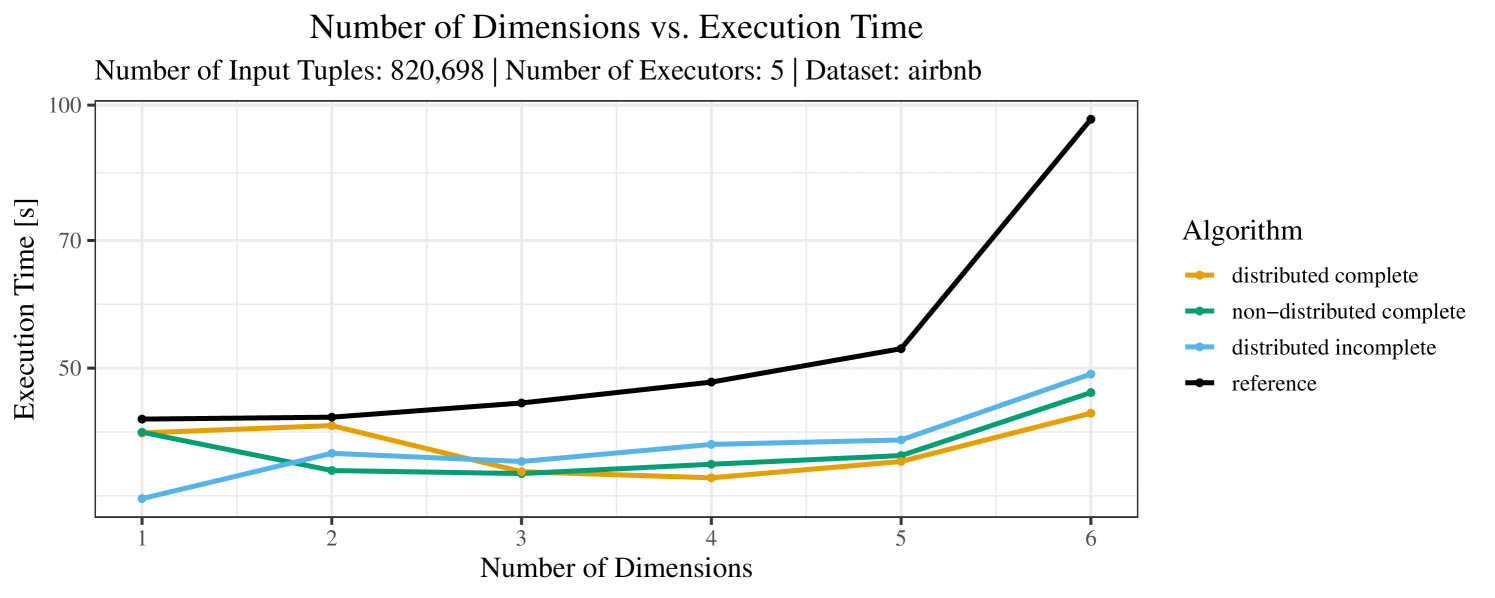
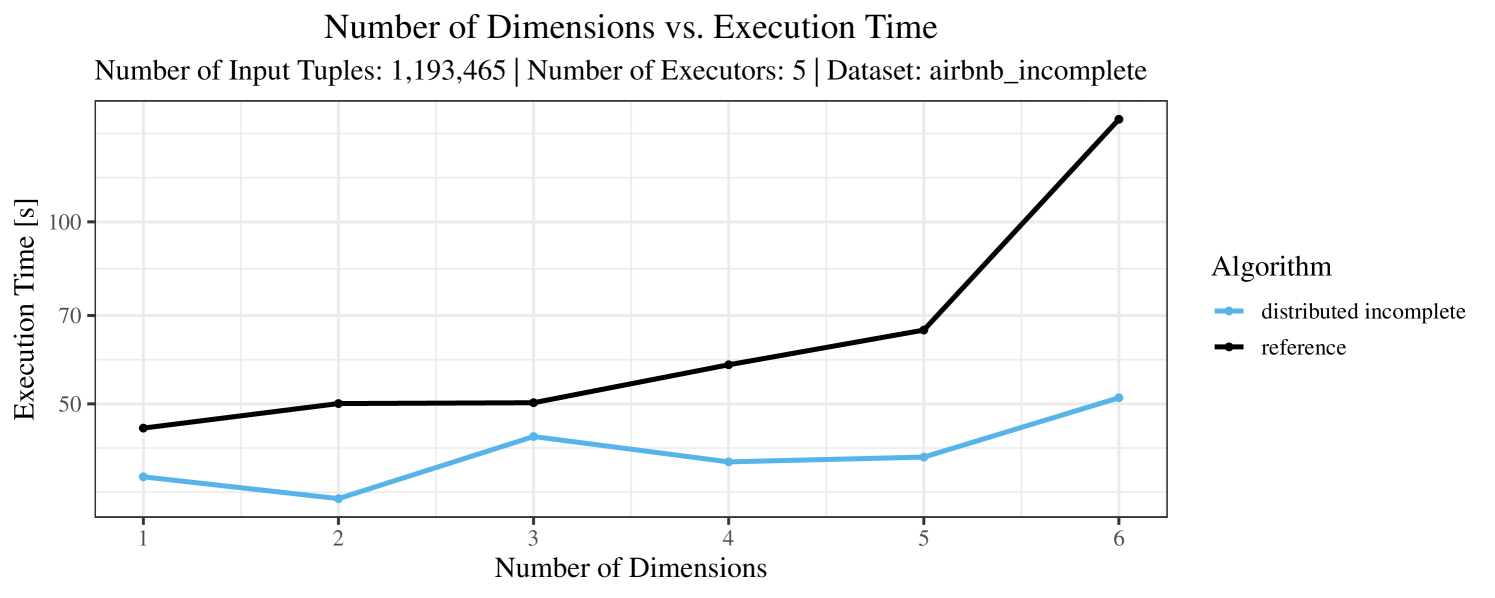
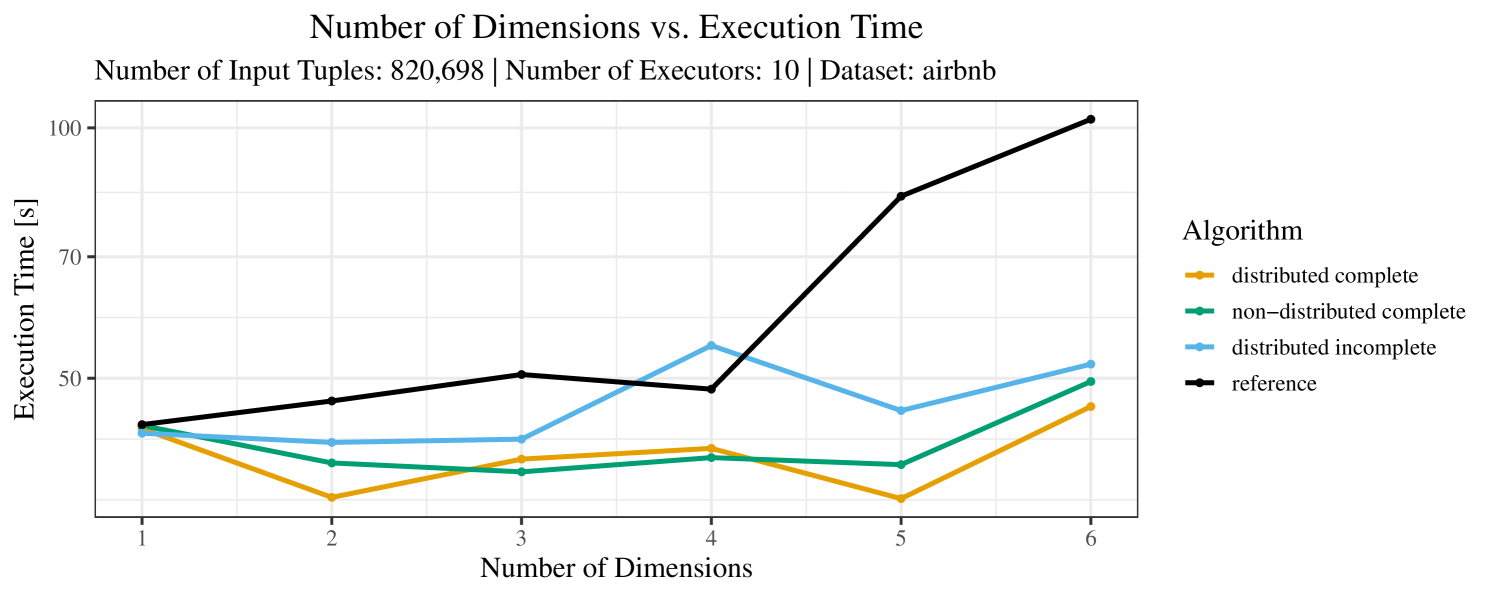
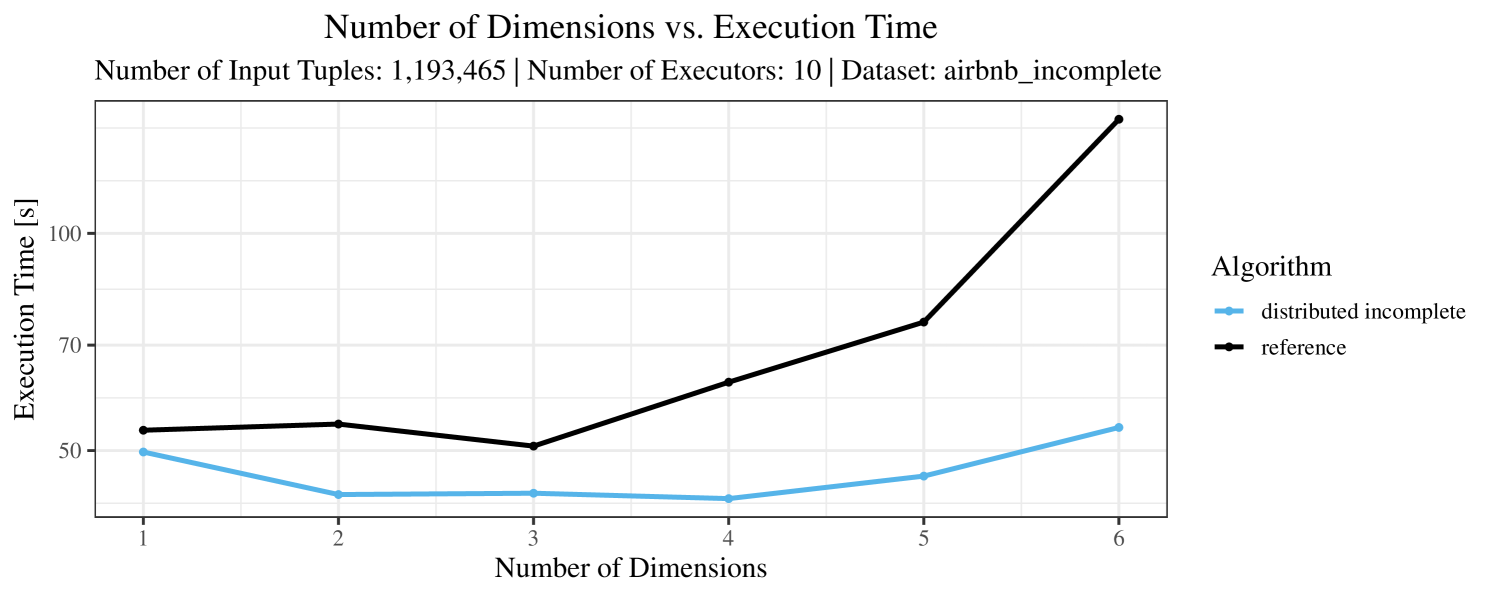
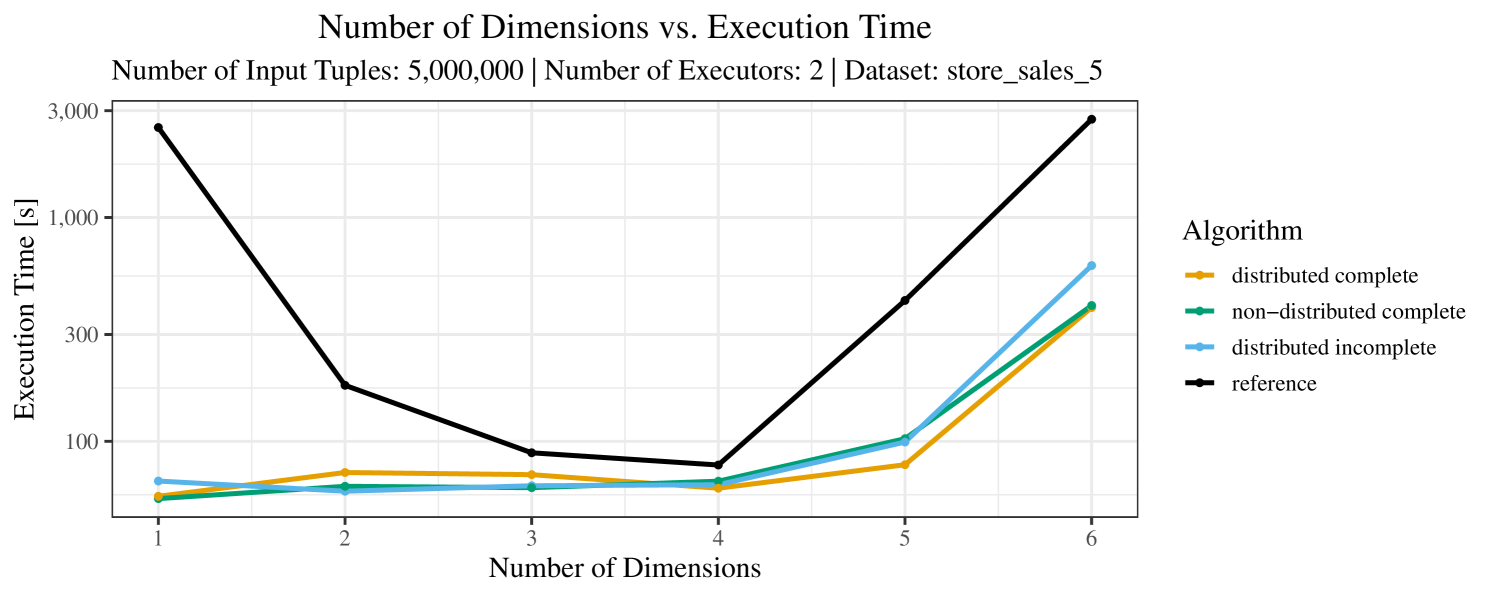
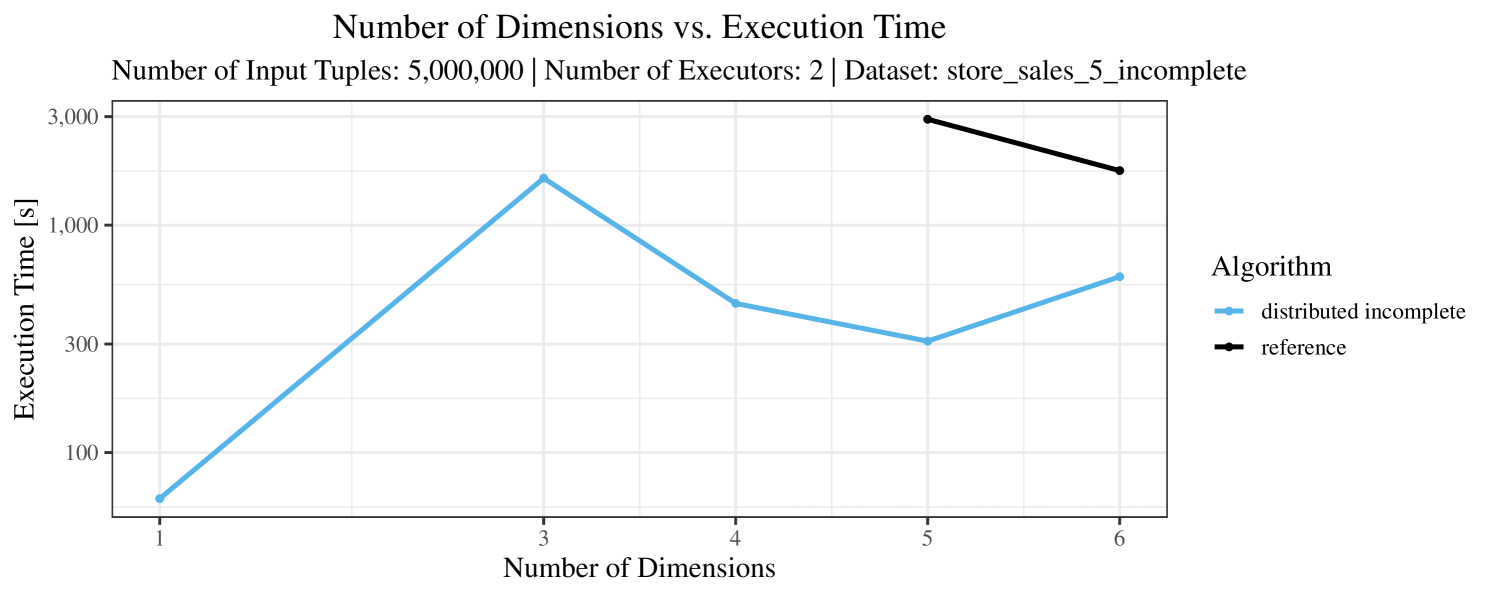
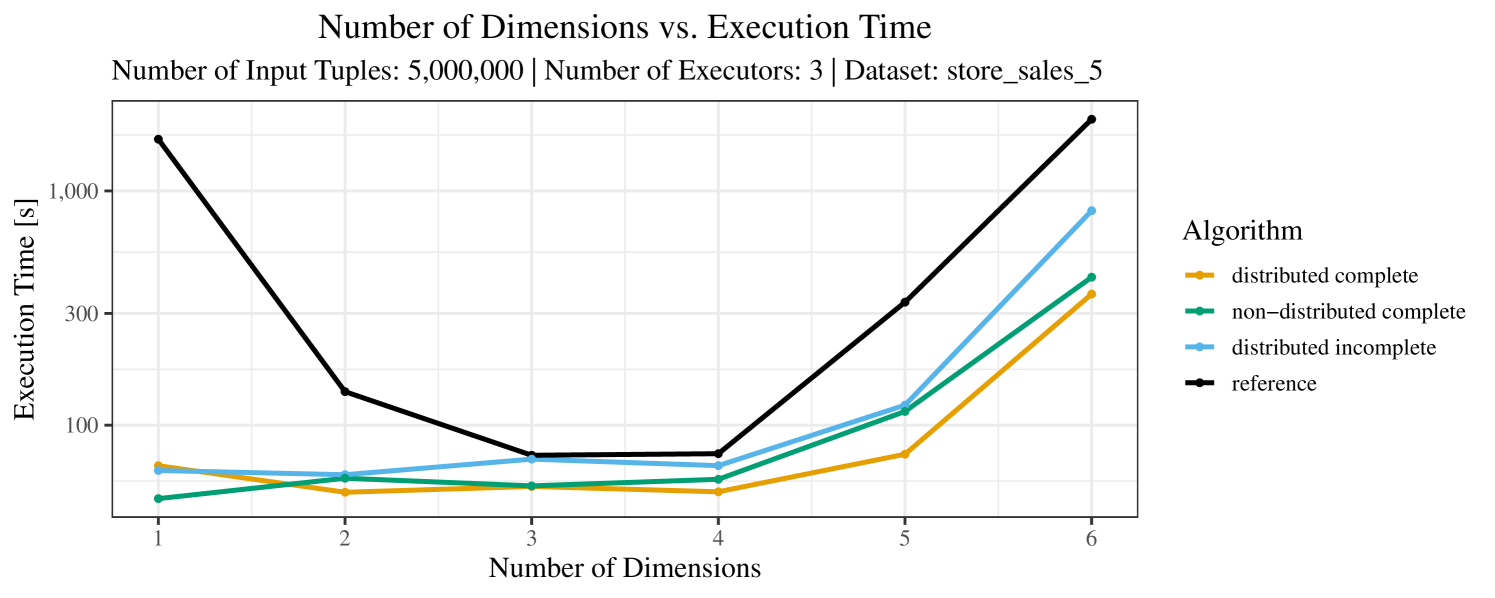
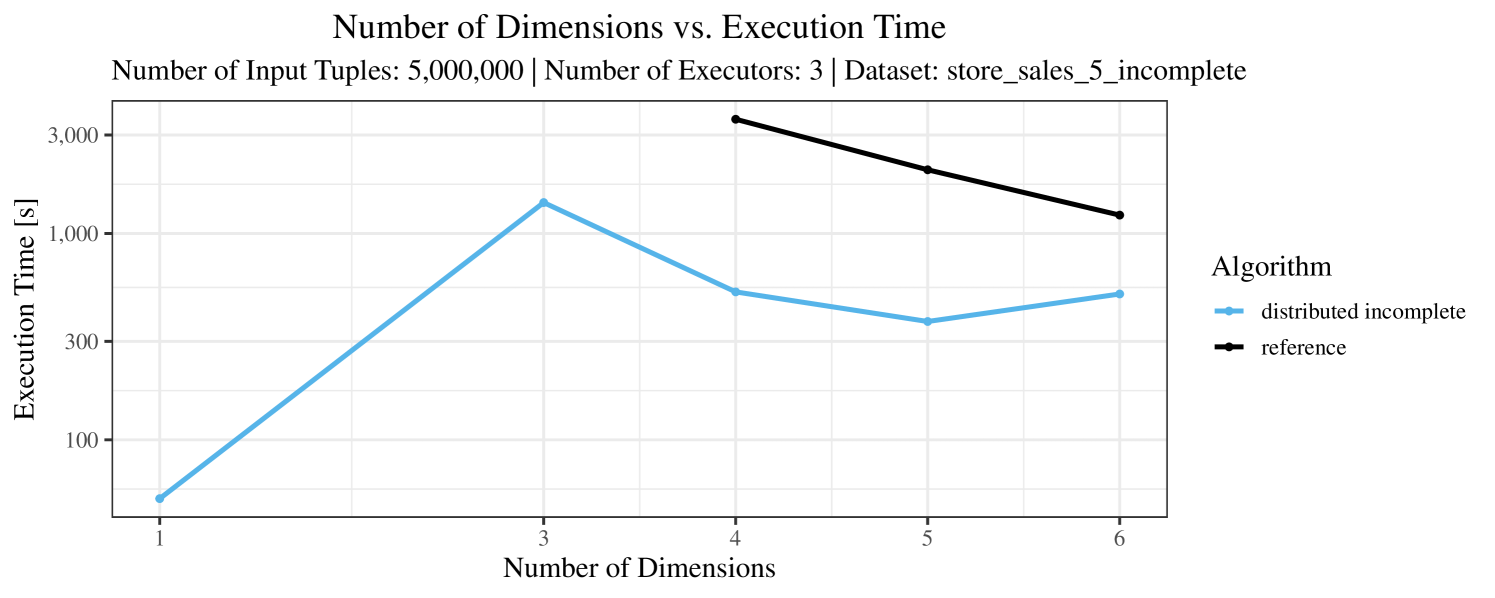
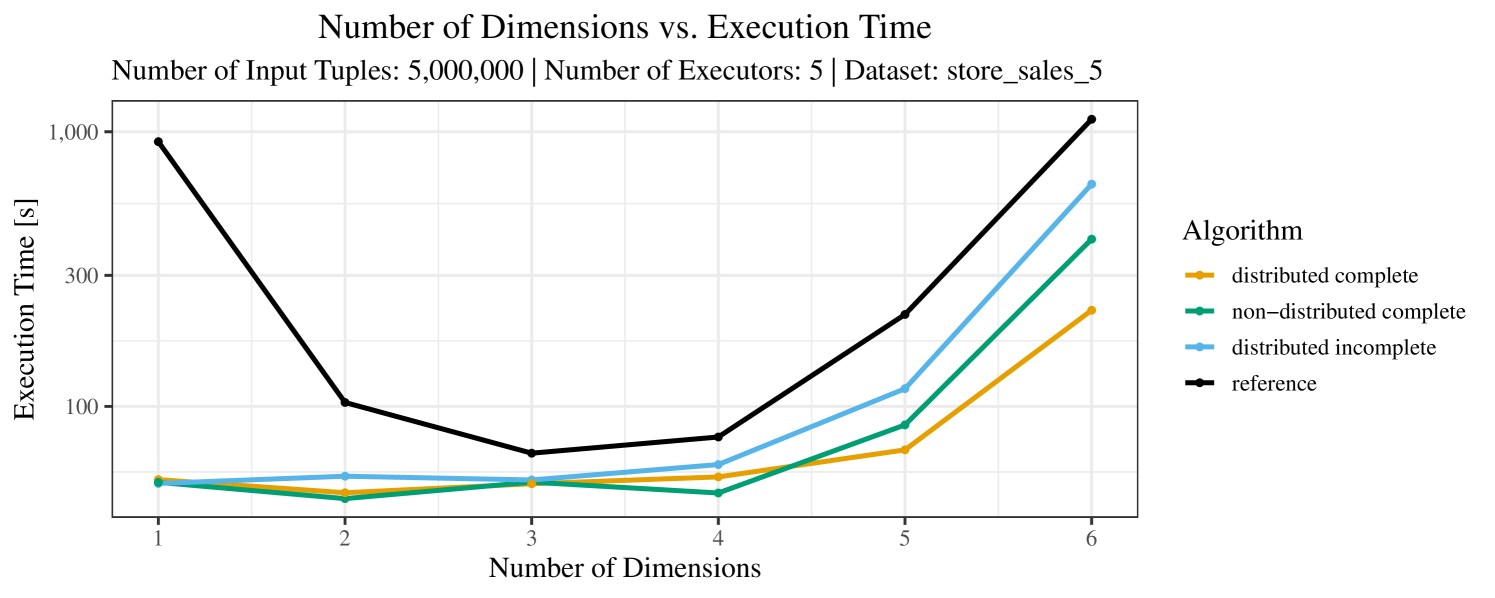
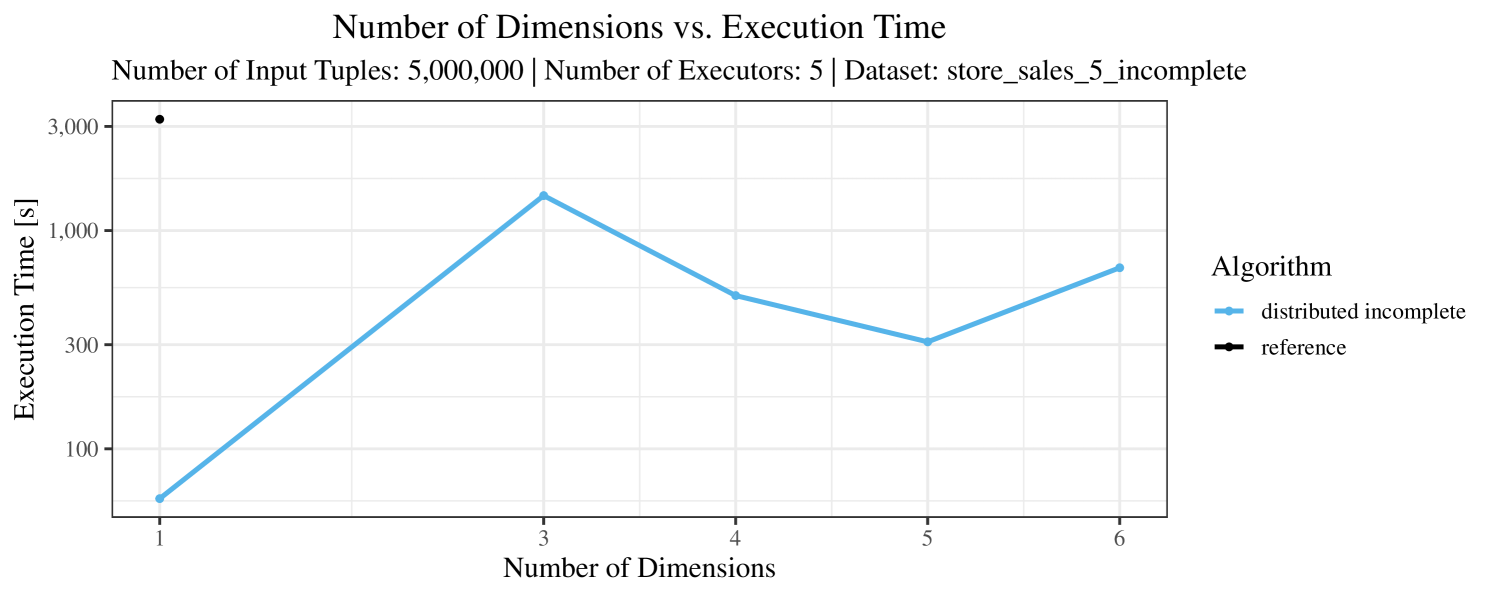
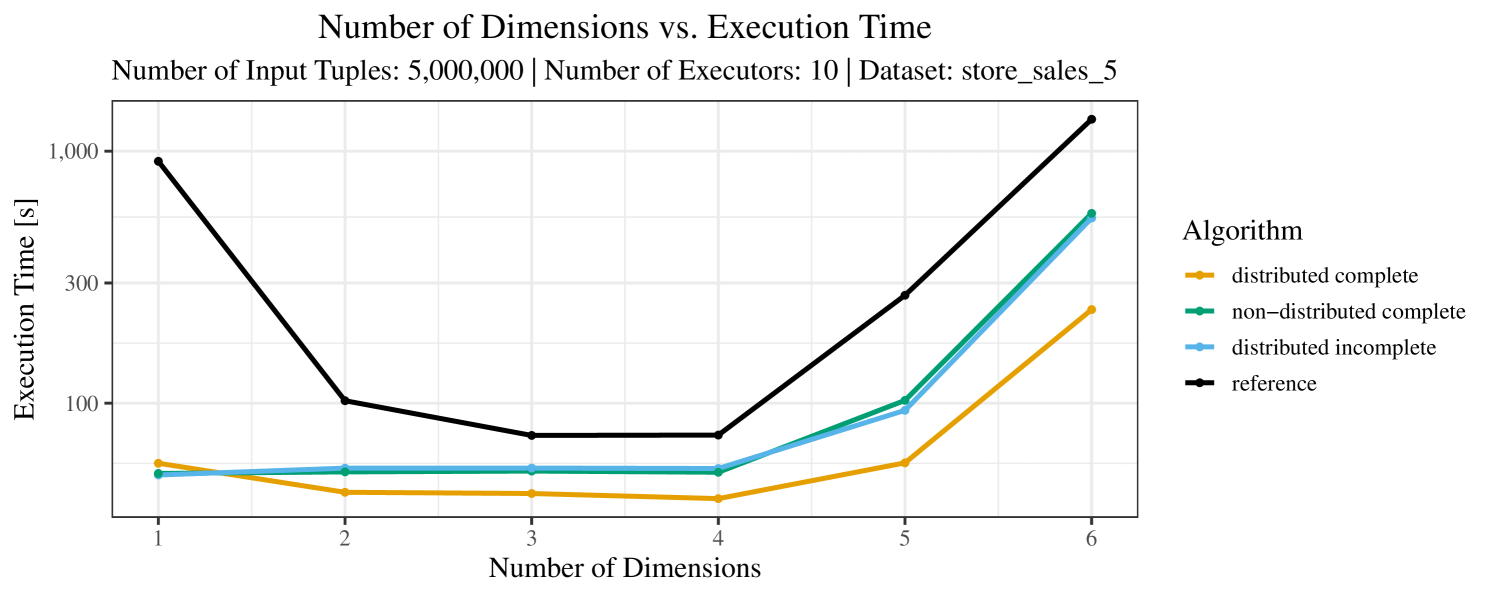
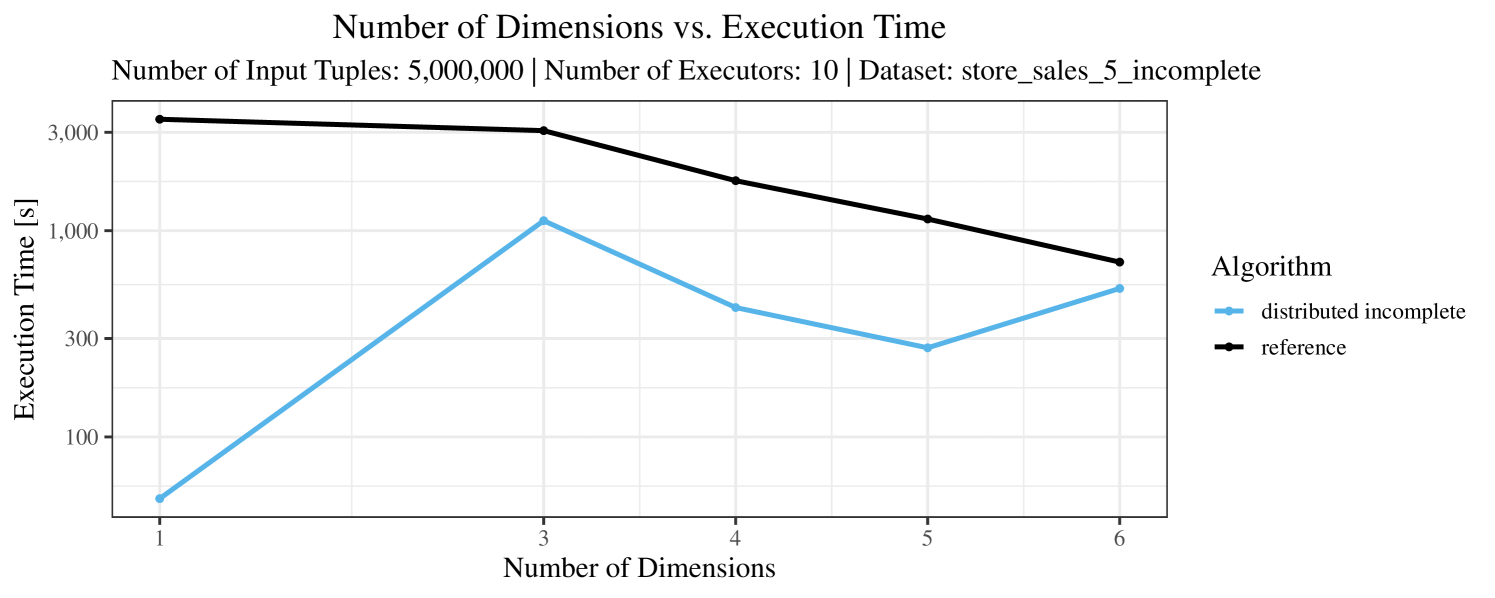
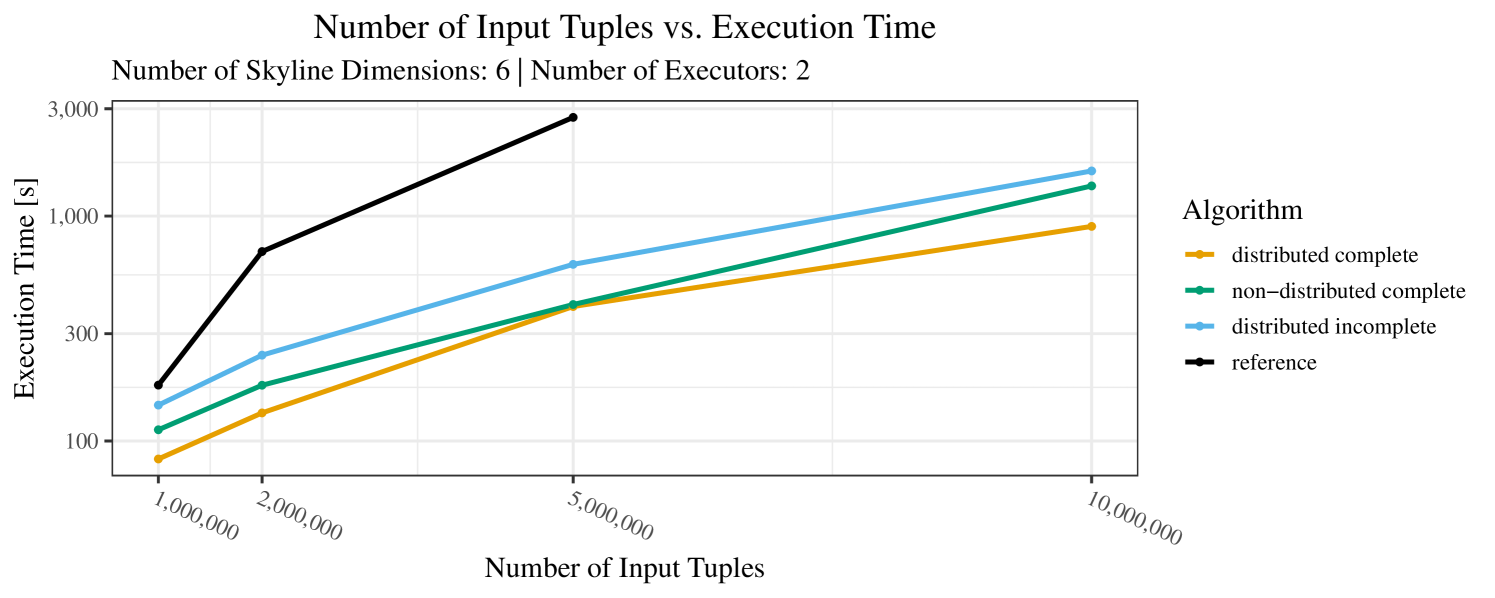
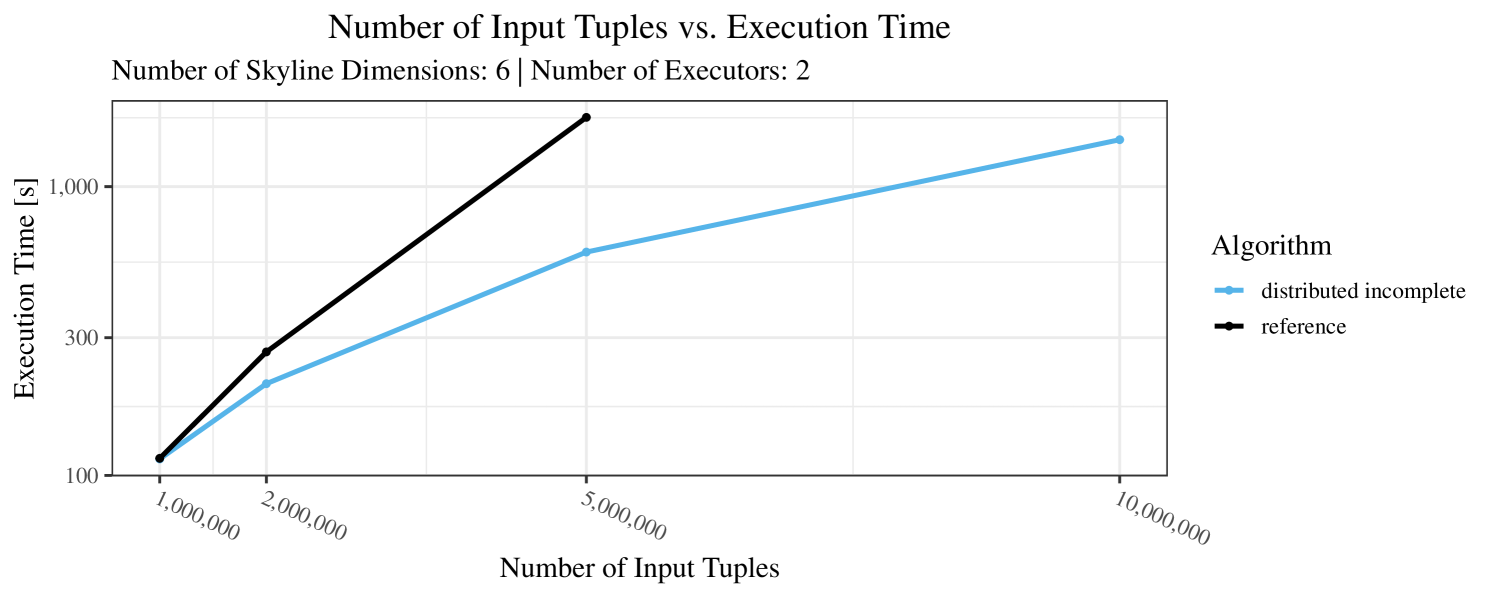
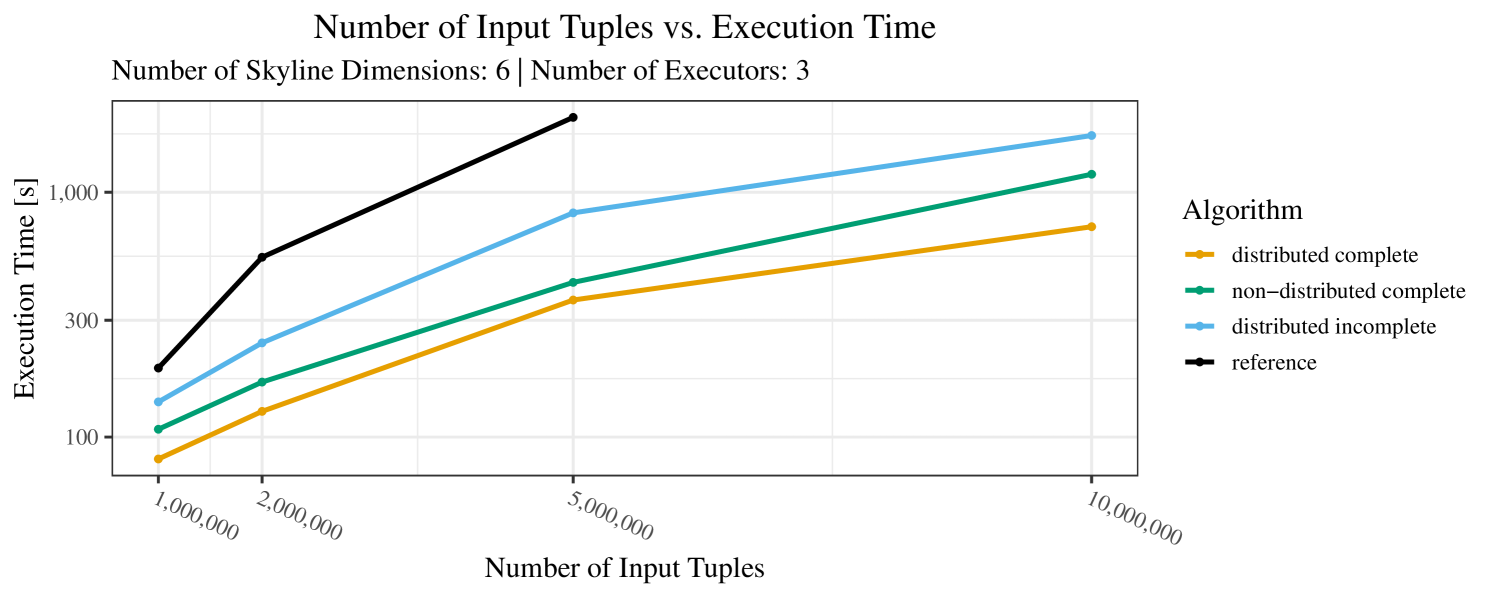
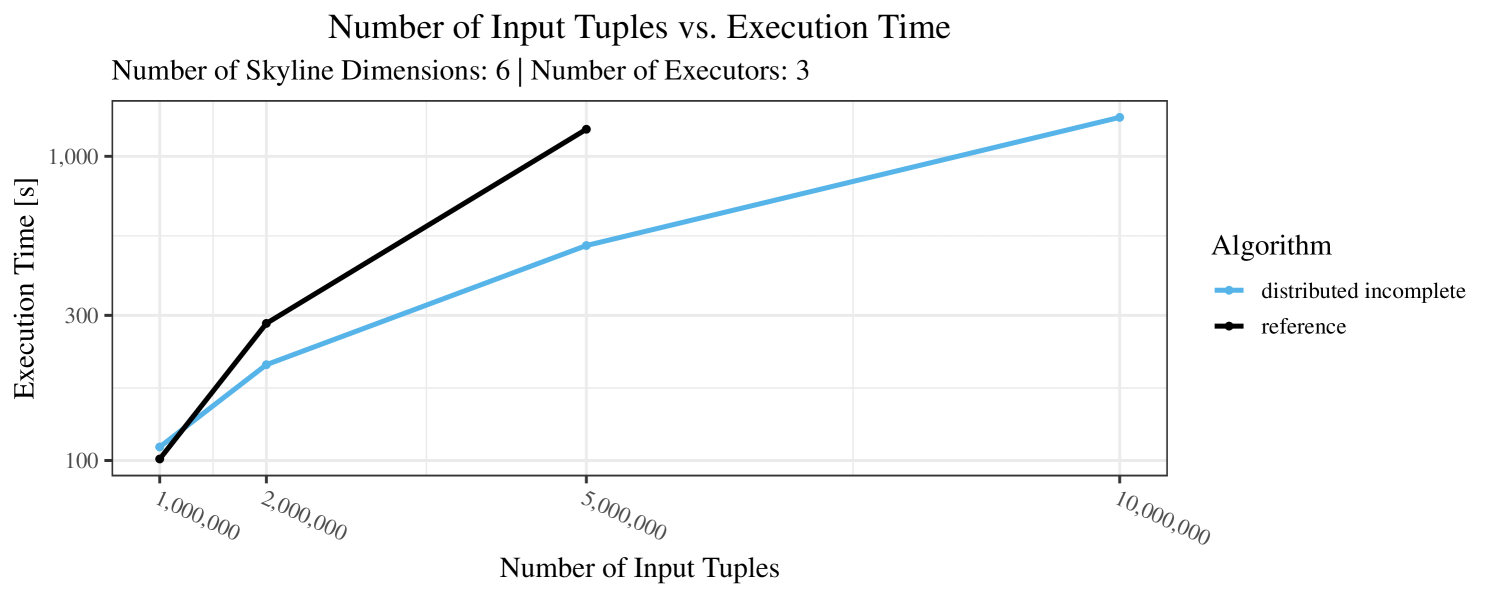
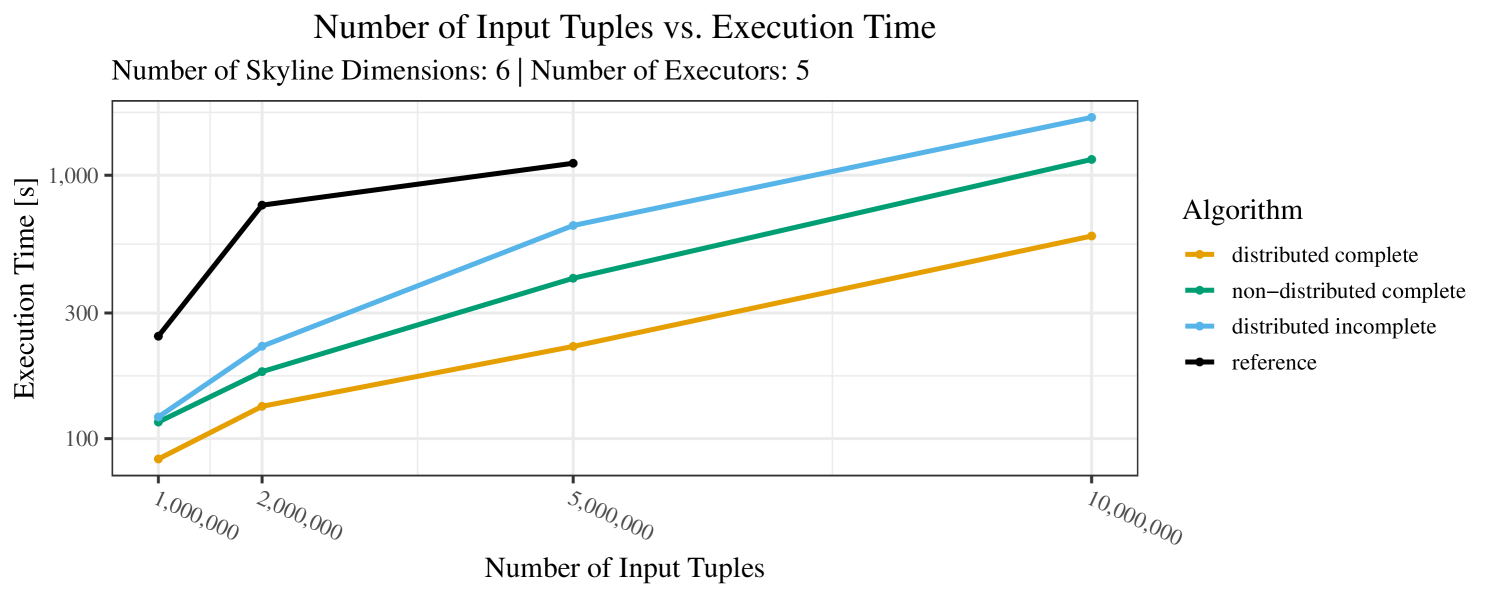
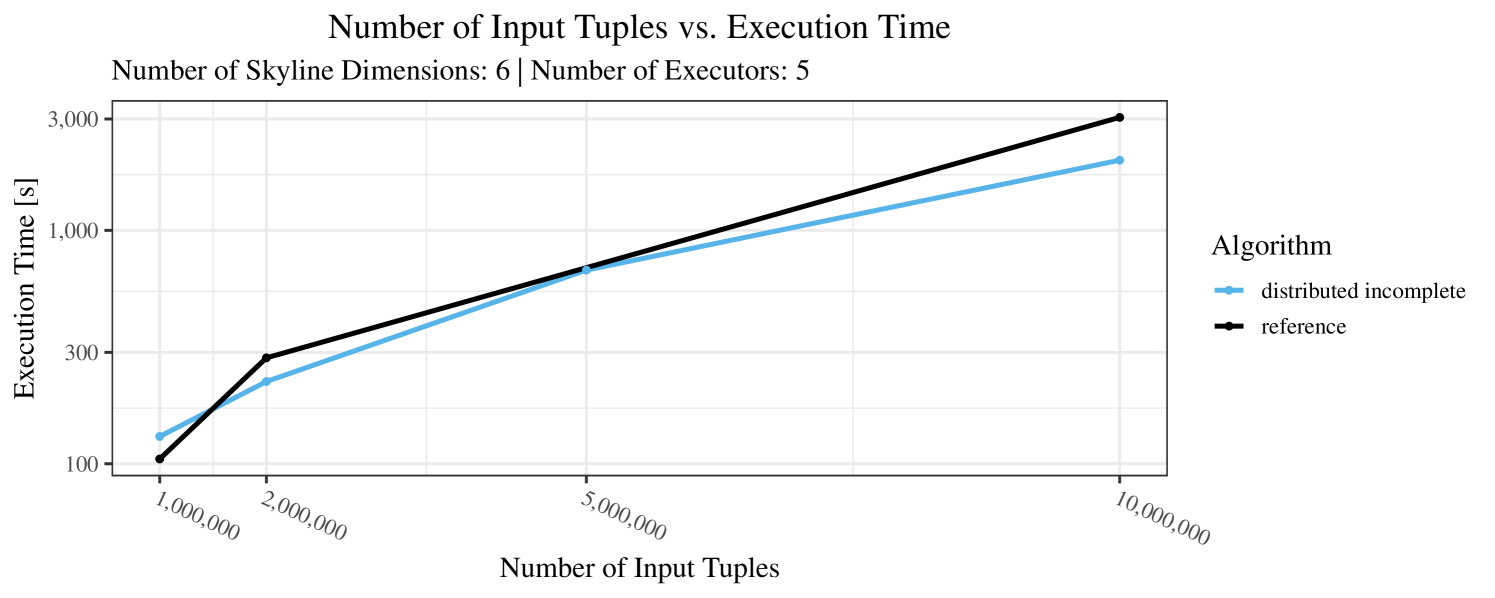
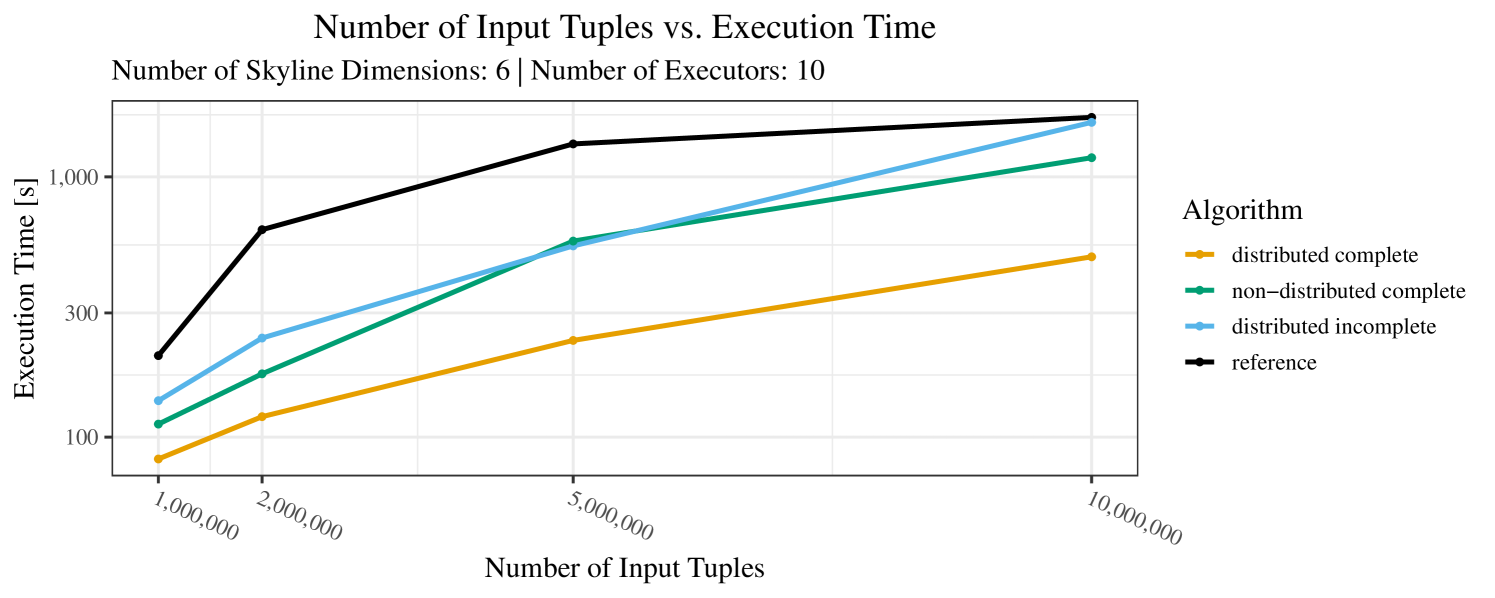
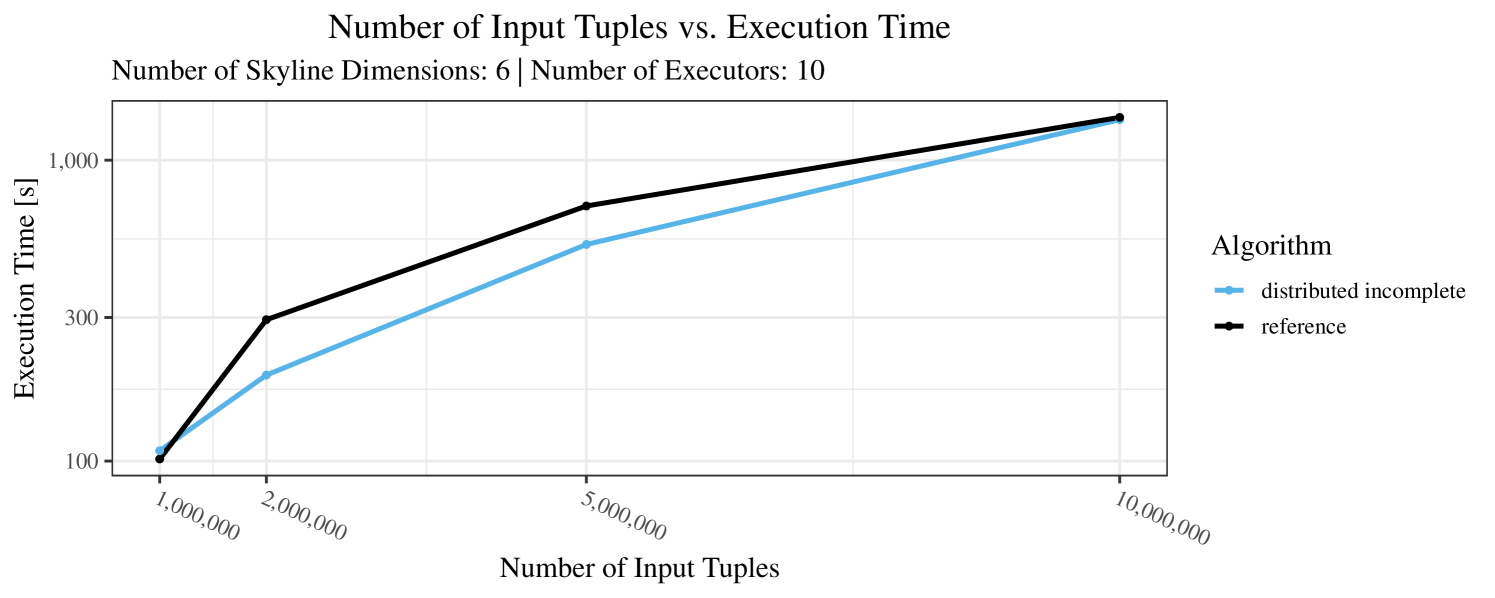
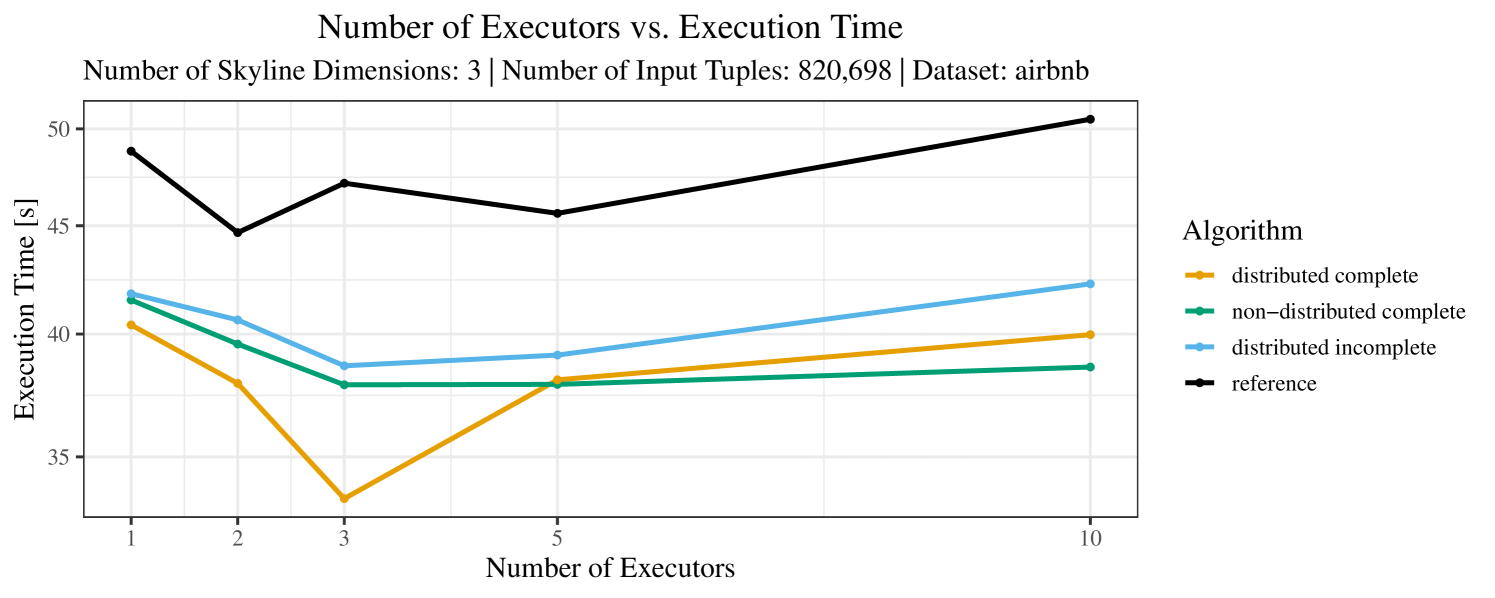
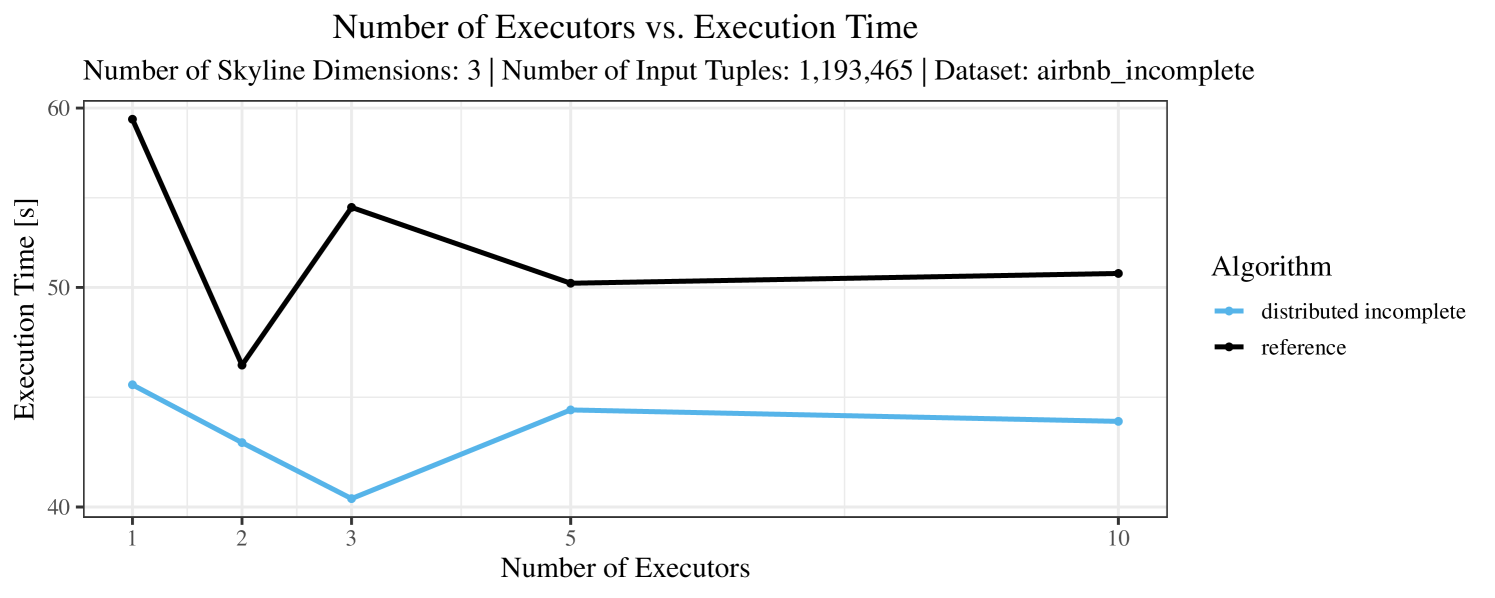
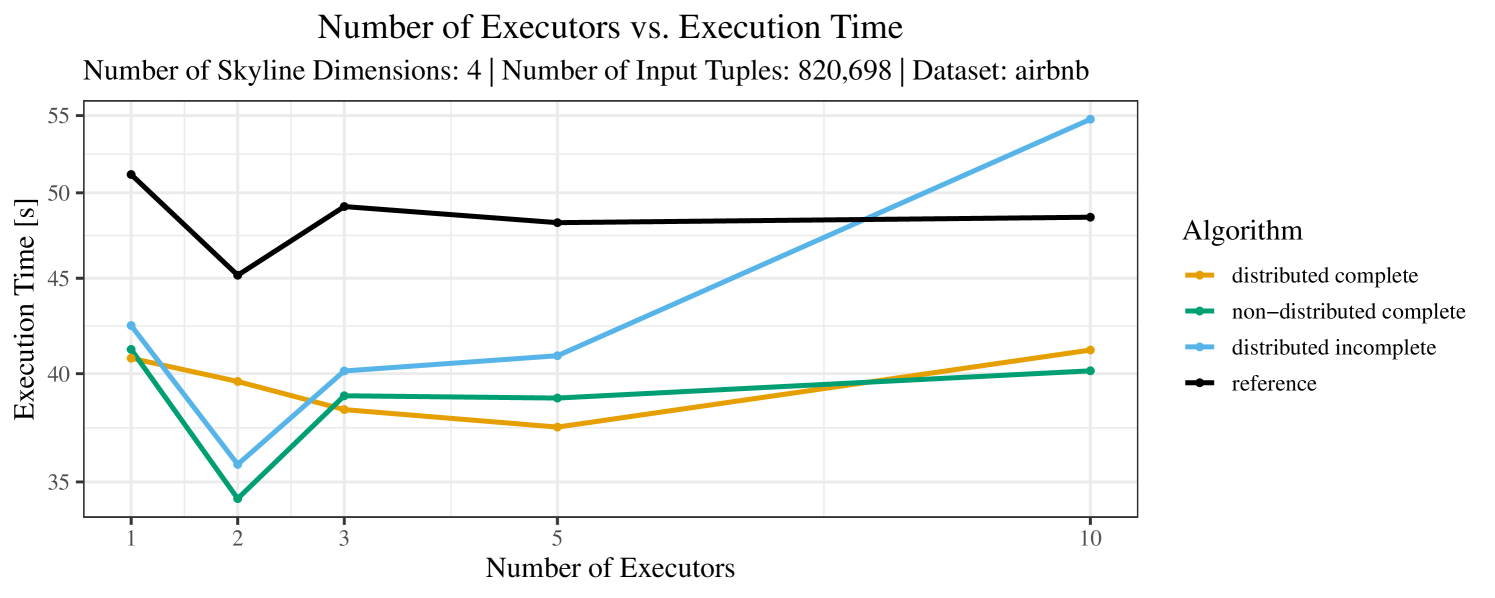
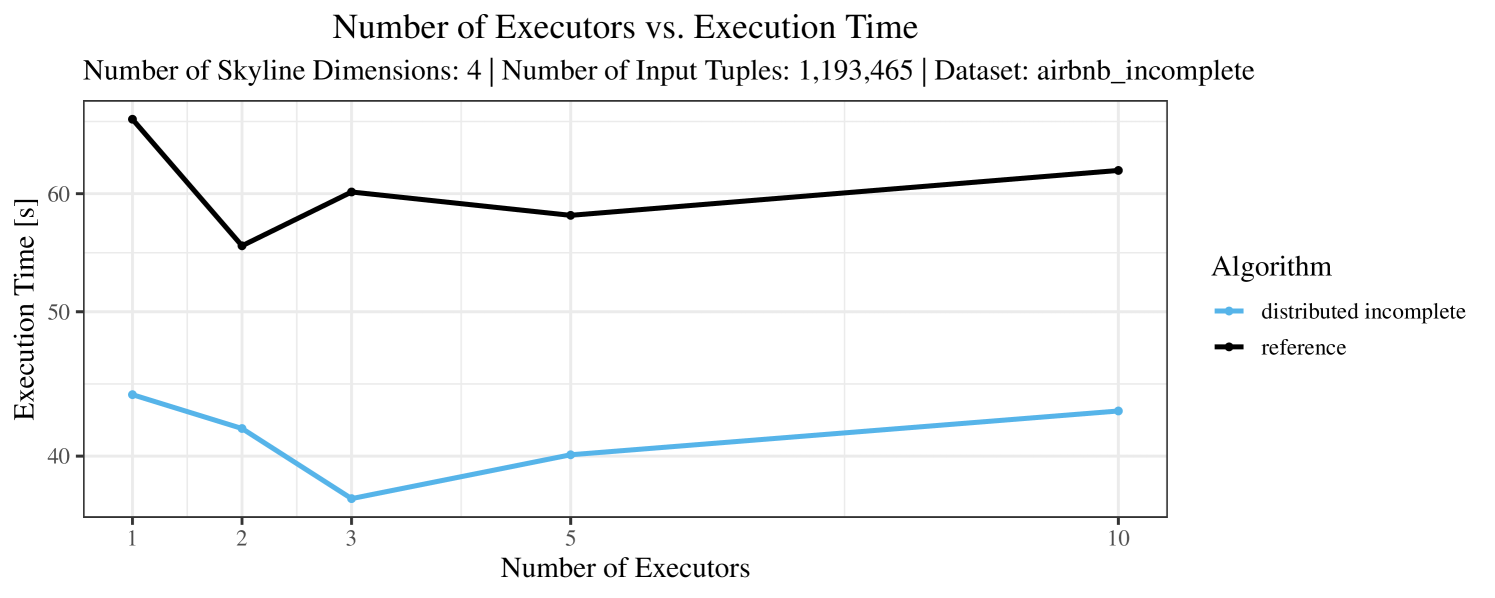
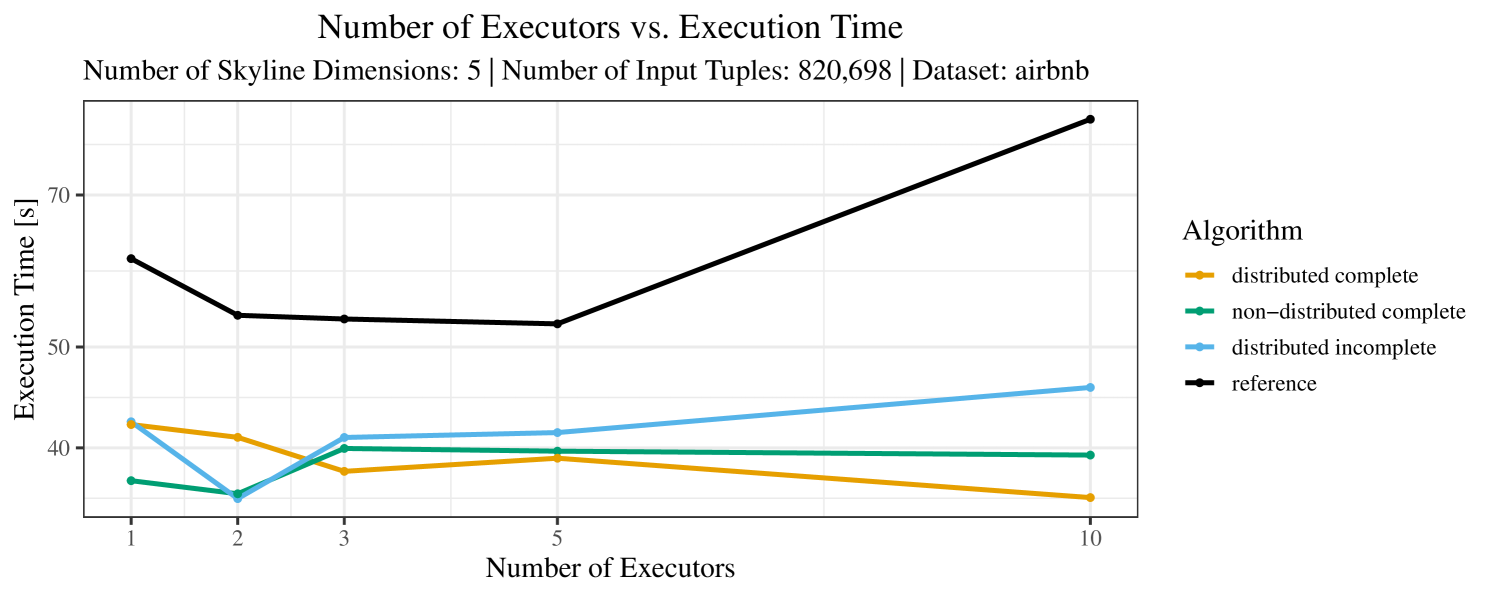
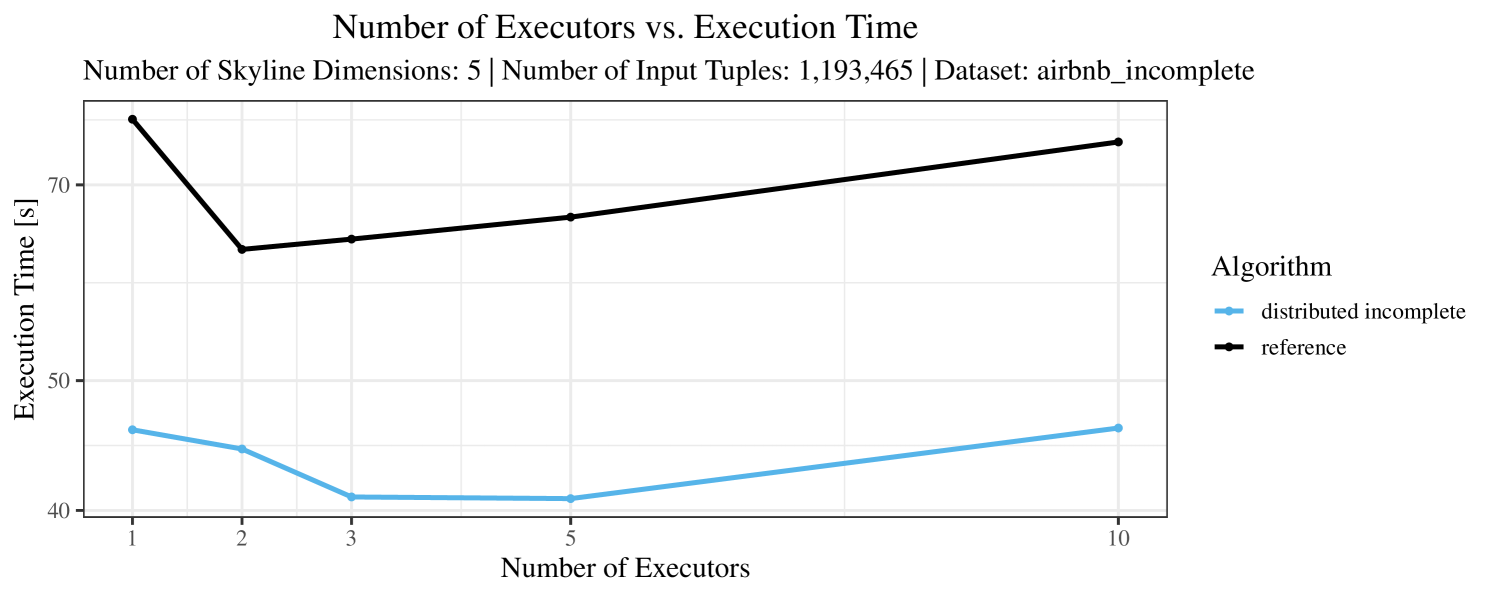
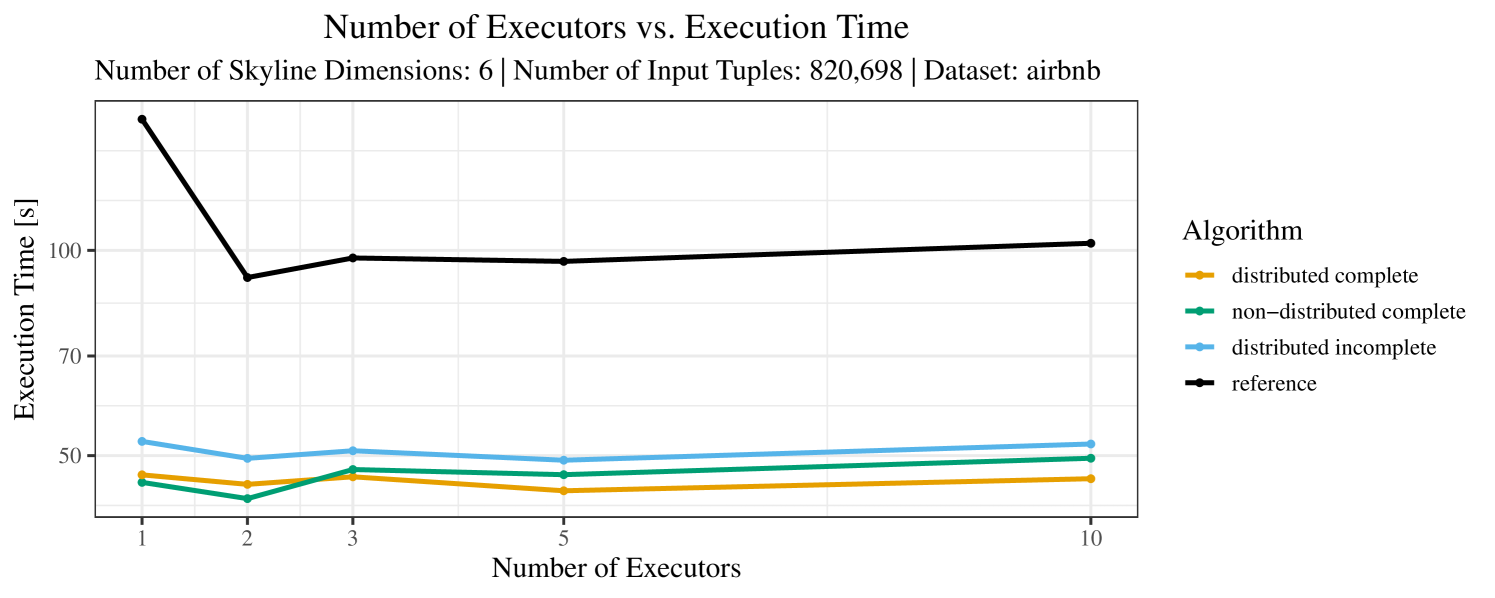
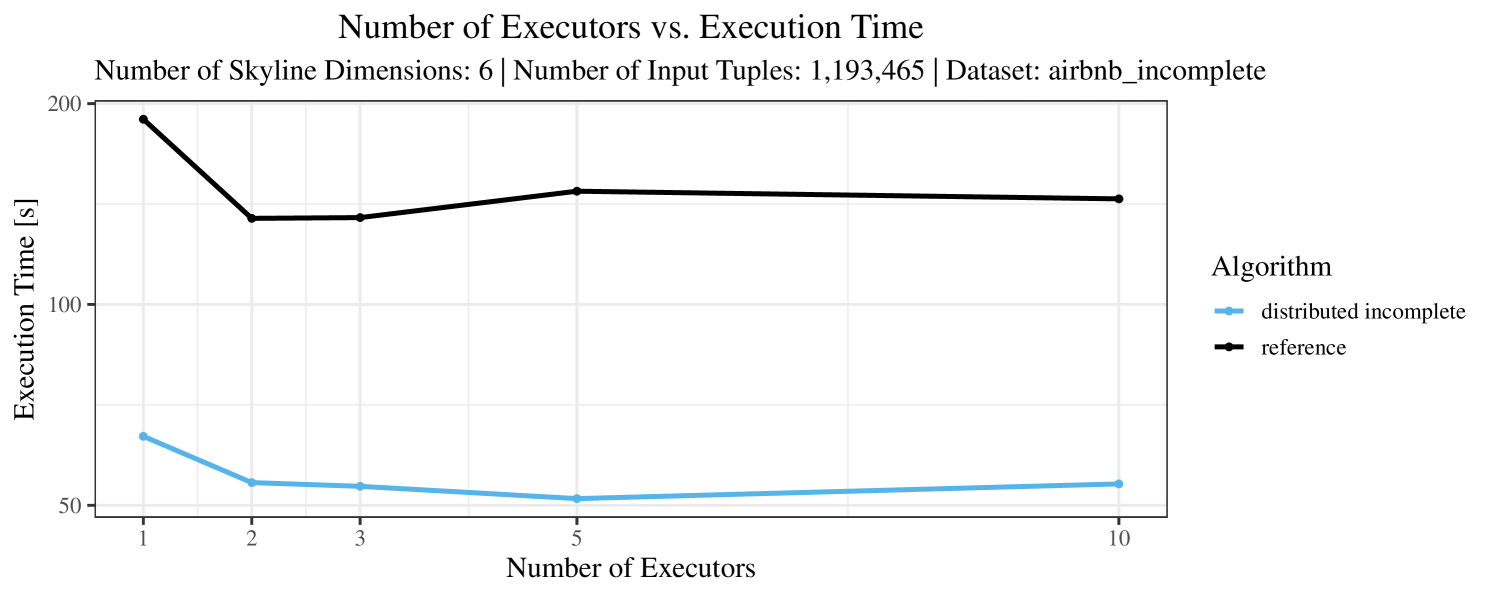
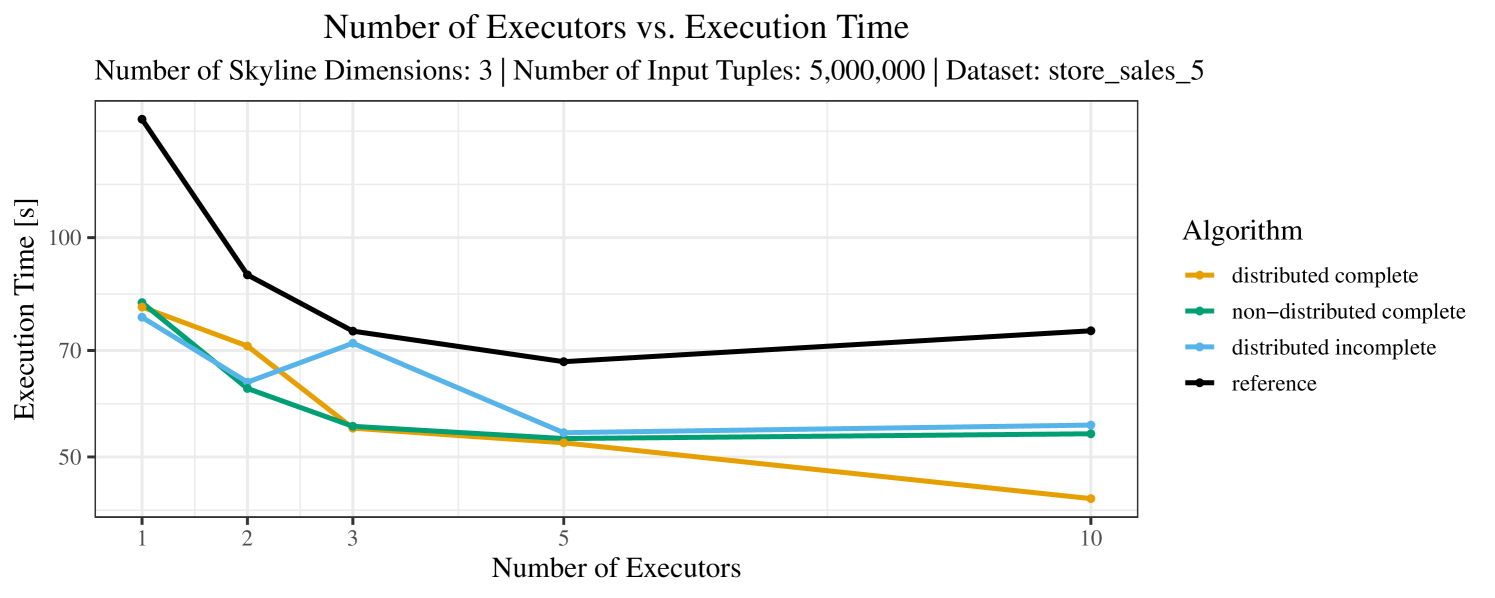
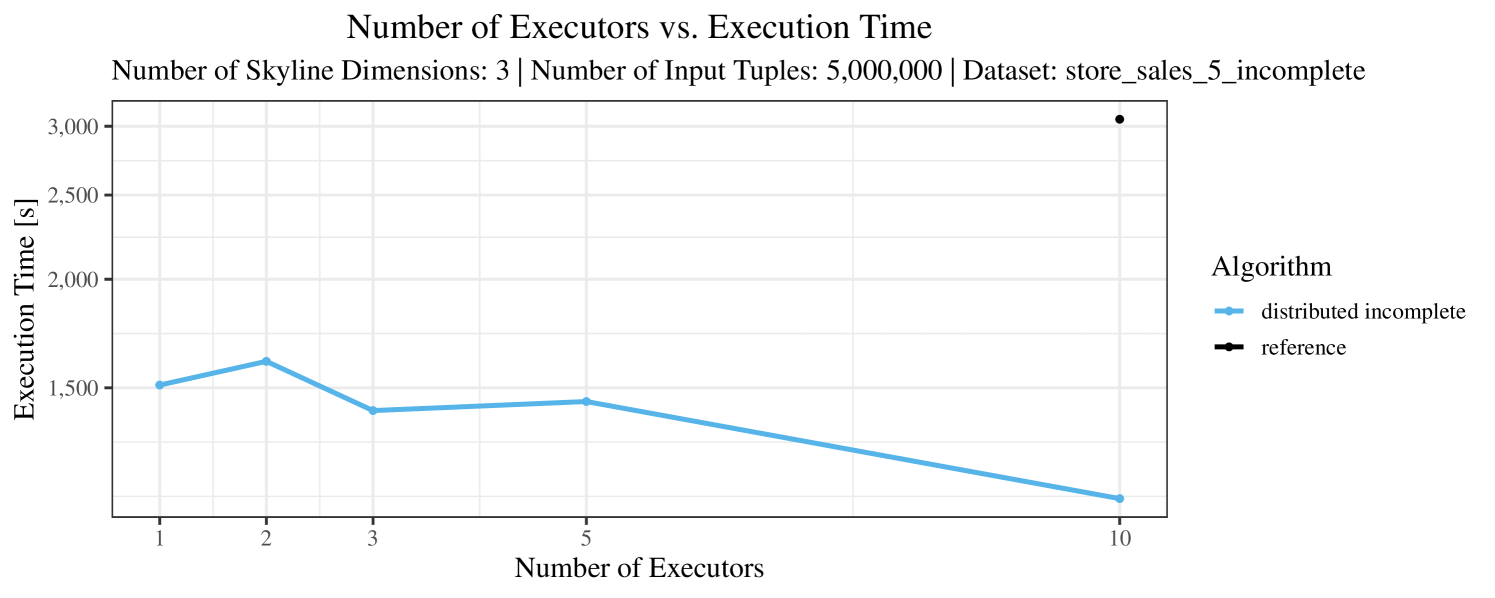
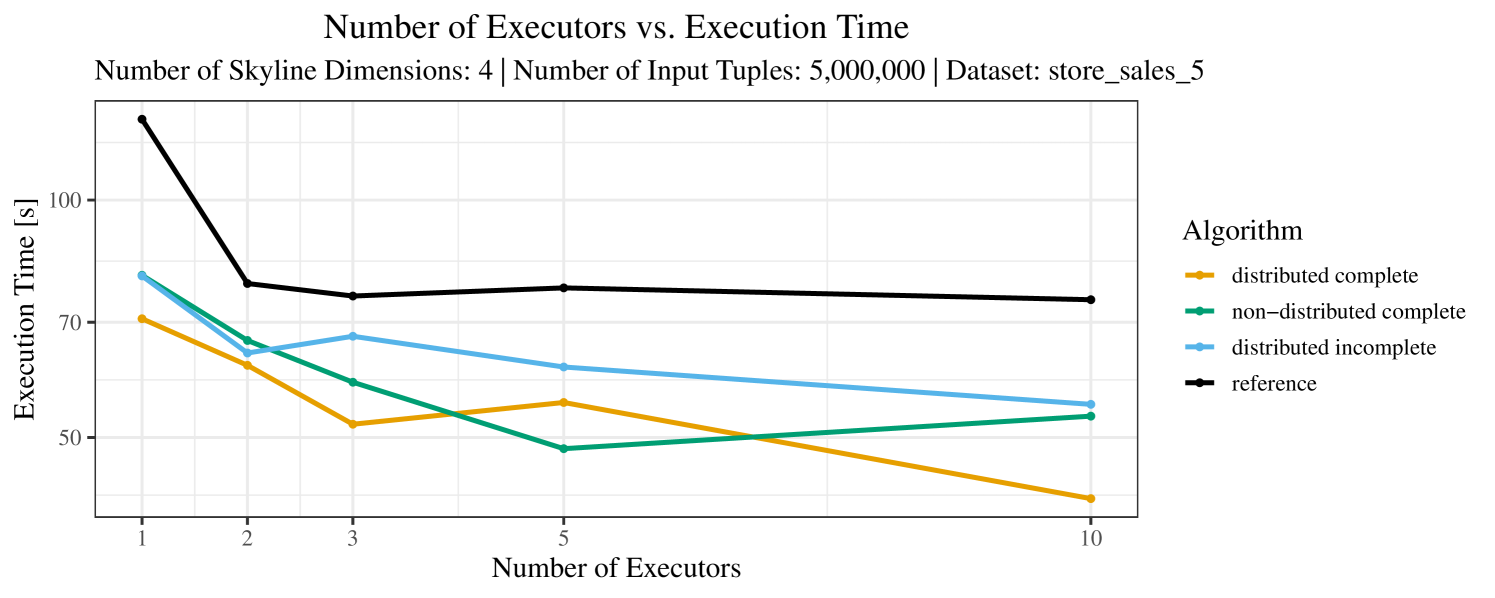
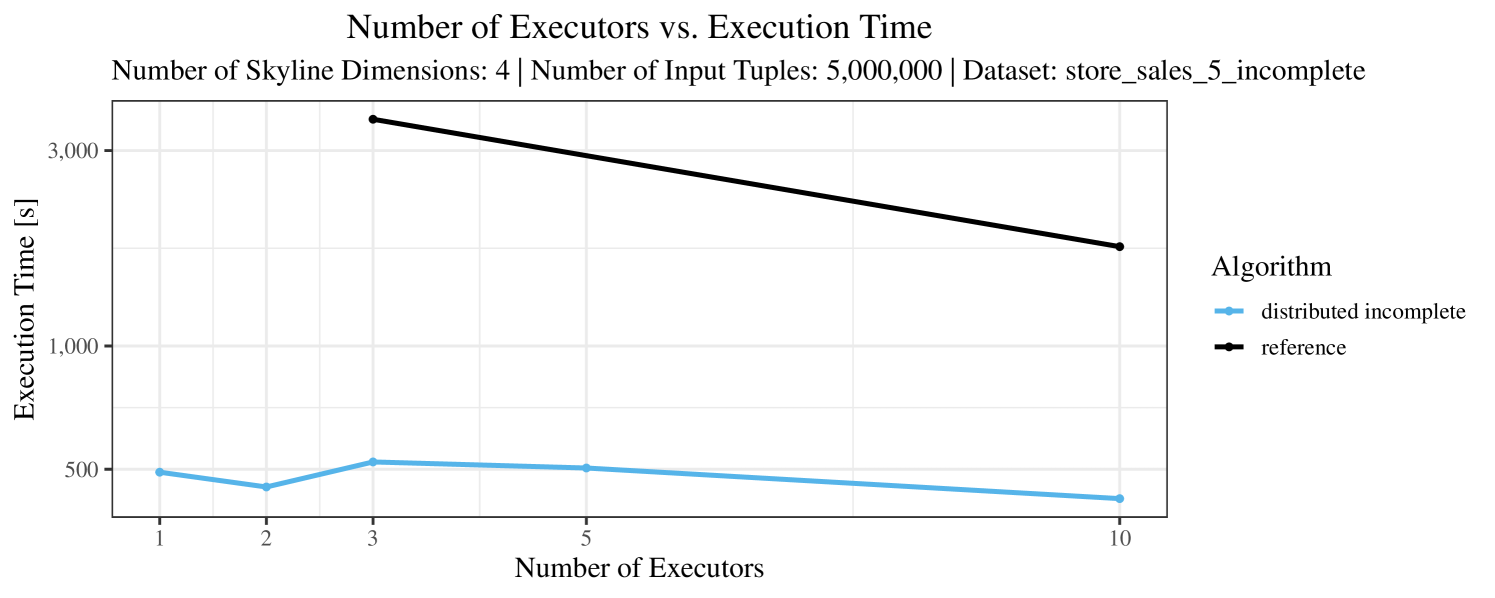
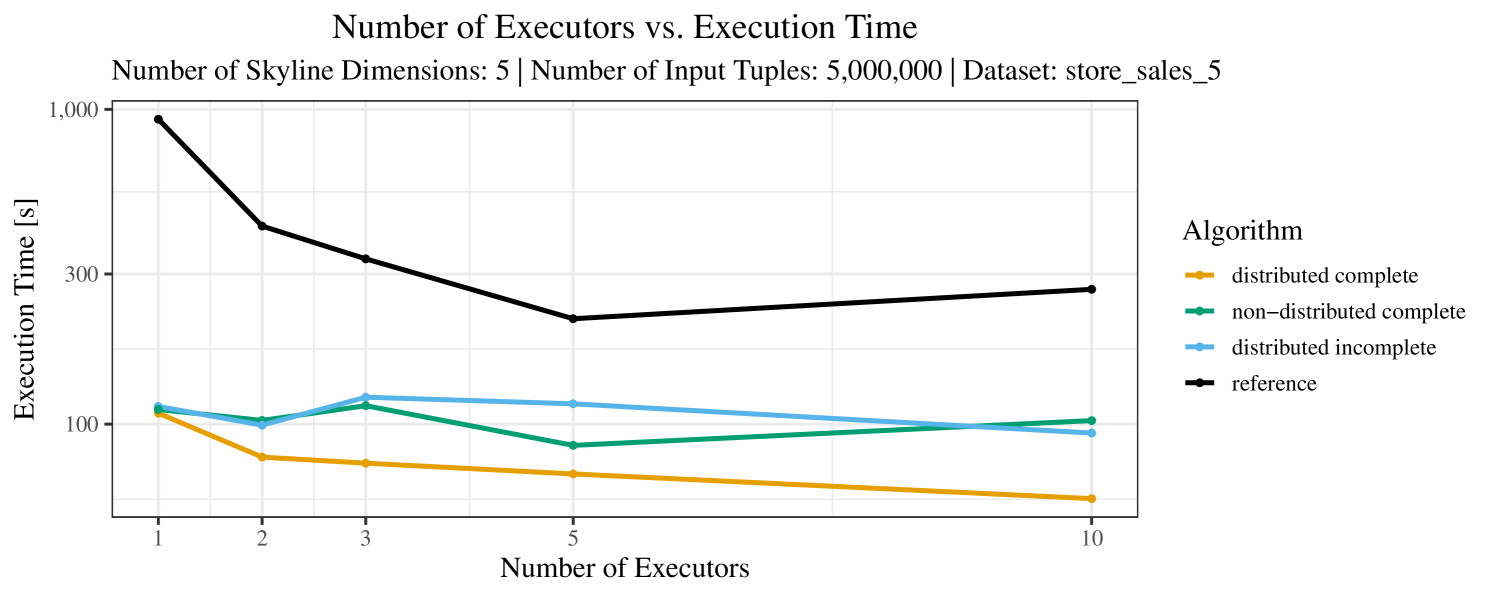
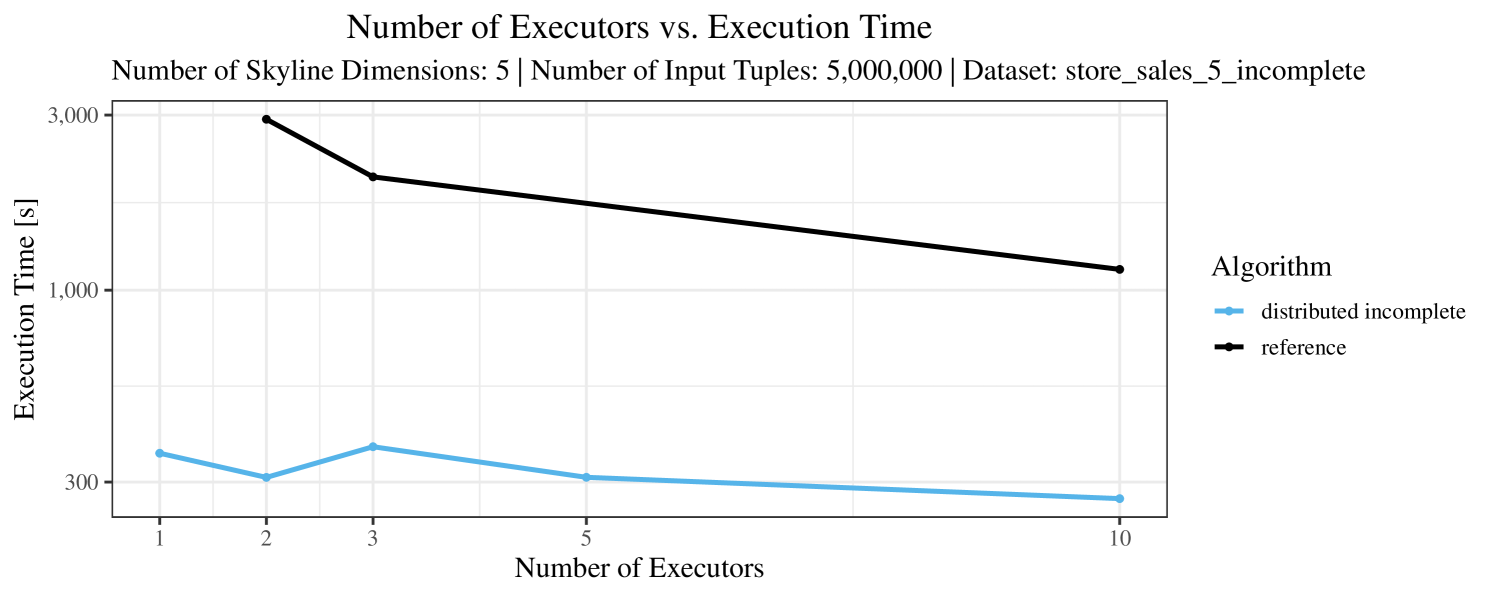
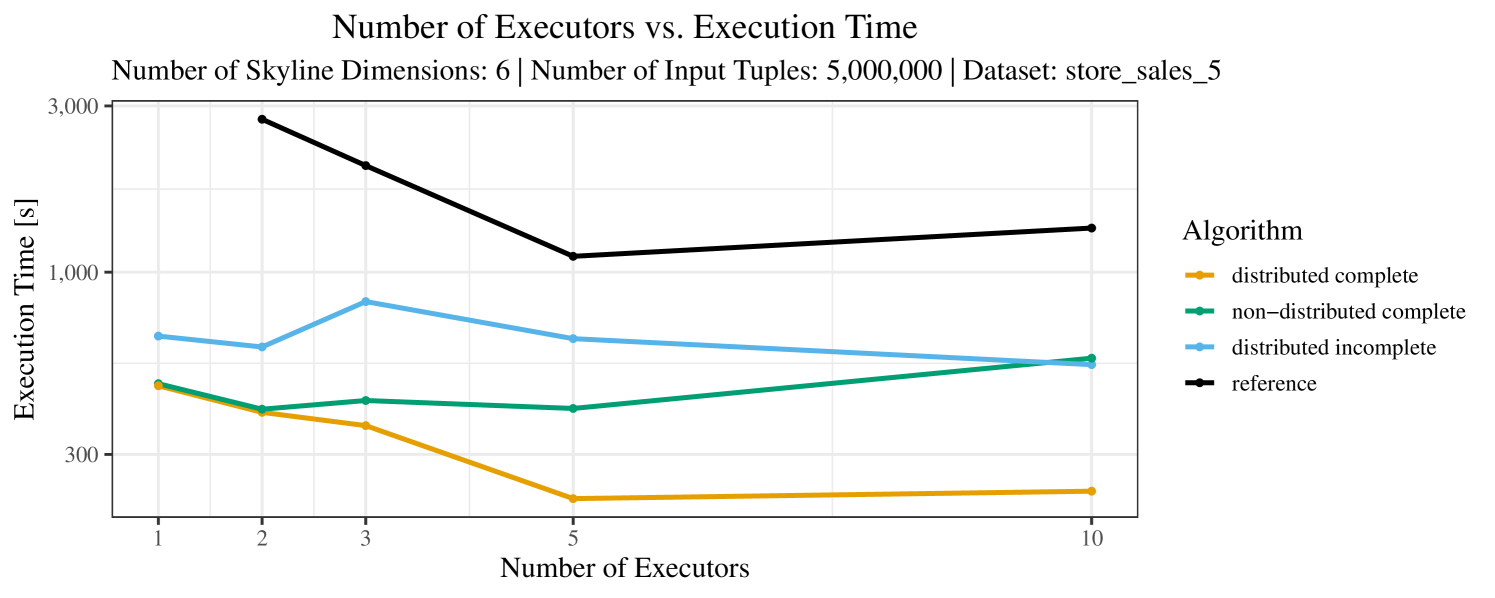
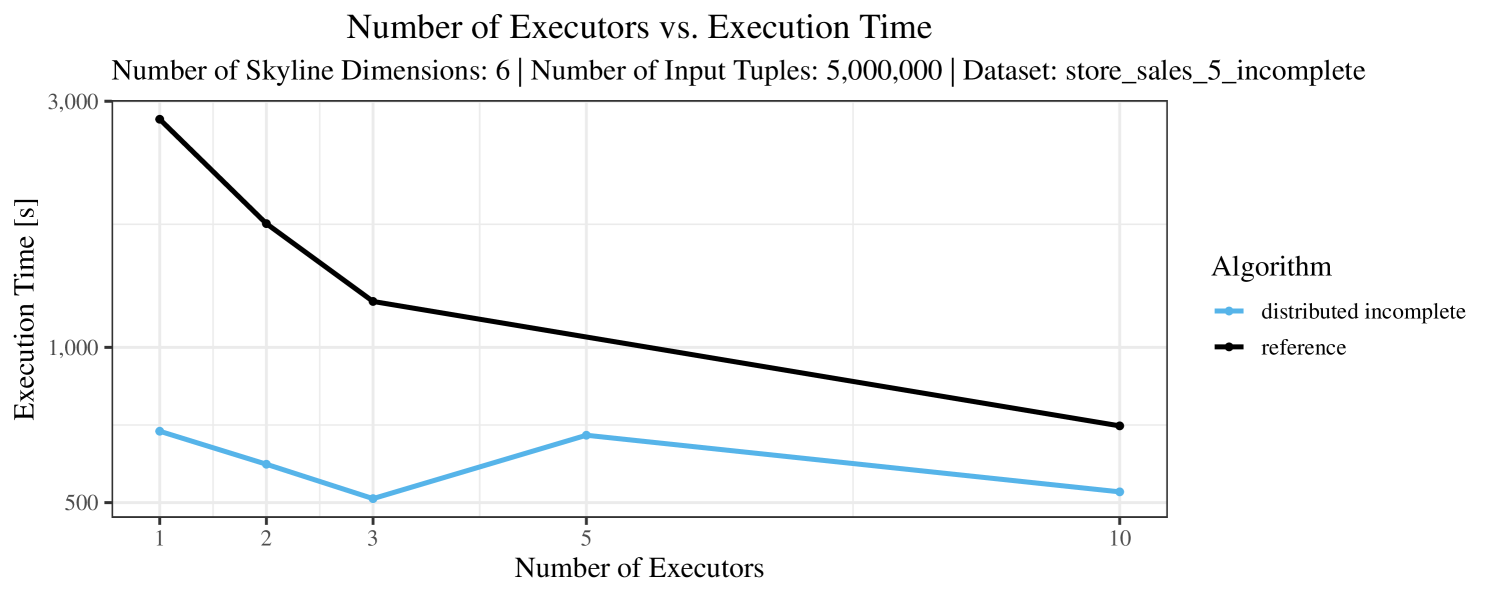
Appendix D Tabulation of Execution Time
In this section, we revisit the experimental evaluation from Section 6.4. In Figures 3 – 7, we presented plots of the execution times depending on the number of dimensions, tuples, and executors, respectively. We now present the same results in table form to make the precise execution times easier to read. Since some queries do not finish in the allotted time frame, we use “t.o.” to mark such timeouts in the tables.
The tables also contain the execution times relative to the reference query. Here, we always denote the time consumed by the reference query as 100%. For the other algorithms, a value below 100% means a speed-up while a value above 100% means a slow-down. If a timeout has occurred, no meaningful percentage value can be given. We use “n.a.” to denote that the calculation of a percentage value is not applicable. In fact, if the reference query has timed out, we use “n.a.” for the entire column since no comparison with the reference value is possible in this case even if the specialized algorithms do not time out. Note that we never have the opposite situation that a specialized algorithm times out but not the reference algorithm.
The results are shown in Tables 3 – 12. The correspondence with the plots in Figures 3 – 7 is as follows:
- •
- •
- •
- •
- •
From these tables, it becomes very apparent that if the reference query can execute the skyline in a reasonable time, then the computation with our specialized algorithms displays a similar or even better behavior. Actually, a notable fact with regards to the results discussed in Section 6.4 can be derived from Table 6. Here, we encounter one of the rare cases where the reference query is better than our implementation. However, we also see that the increase is only seconds or . While this is an interesting result, it is unlikely to ever have an impact on the performance or usability of our integration of the skyline operator.
| algorithm | 1 | 2 | 3 | 4 | 5 | 6 | |
|---|---|---|---|---|---|---|---|
| 1 | reference | 100.00% | 100.00% | 100.00% | 100.00% | 100.00% | 100.00% |
| 2 | non-distributed complete | 96.60% | 86.88% | 83.03% | 80.54% | 75.45% | 48.66% |
| 3 | distributed complete | 96.42% | 97.81% | 83.44% | 77.71% | 74.28% | 46.08% |
| 4 | distributed incomplete | 81.09% | 90.92% | 85.72% | 84.86% | 78.62% | 51.10% |
| algorithm | 1 | 2 | 3 | 4 | 5 | 6 | |
|---|---|---|---|---|---|---|---|
| 1 | reference | 43.72 | 43.94 | 45.61 | 48.19 | 52.63 | 96.34 |
| 2 | non-distributed complete | 42.23 | 38.17 | 37.87 | 38.81 | 39.71 | 46.88 |
| 3 | distributed complete | 42.15 | 42.98 | 38.06 | 37.45 | 39.09 | 44.40 |
| 4 | distributed incomplete | 35.45 | 39.95 | 39.10 | 40.90 | 41.38 | 49.23 |
| algorithm | 1 | 2 | 3 | 4 | 5 | 6 | |
|---|---|---|---|---|---|---|---|
| 1 | reference | 100.00% | 100.00% | 100.00% | 100.00% | 100.00% | 100.00% |
| 2 | distributed incomplete | 83.07% | 69.62% | 87.92% | 69.08% | 61.64% | 34.61% |
| algorithm | 1 | 2 | 3 | 4 | 5 | 6 | |
|---|---|---|---|---|---|---|---|
| 1 | reference | 45.58 | 50.05 | 50.21 | 58.03 | 66.22 | 147.82 |
| 2 | distributed incomplete | 37.87 | 34.85 | 44.15 | 40.08 | 40.82 | 51.17 |
| algorithm | 1 | 2 | 3 | 4 | 5 | 6 | |
|---|---|---|---|---|---|---|---|
| 1 | reference | 100.00% | 100.00% | 100.00% | 100.00% | 100.00% | 100.00% |
| 2 | non-distributed complete | 2.63% | 34.41% | 54.98% | 63.06% | 46.26% | 69.97% |
| 3 | distributed complete | 2.20% | 27.42% | 56.83% | 45.35% | 22.22% | 29.12% |
| 4 | distributed incomplete | 2.30% | 36.12% | 57.33% | 59.74% | 65.95% | 95.69% |
| algorithm | 1 | 2 | 3 | 4 | 5 | 6 | |
|---|---|---|---|---|---|---|---|
| 1 | reference | 2463.29 | 164.18 | 105.44 | 93.86 | 281.42 | 1693.31 |
| 2 | non-distributed complete | 64.77 | 56.50 | 57.97 | 59.18 | 130.17 | 1184.86 |
| 3 | distributed complete | 54.26 | 45.02 | 59.93 | 42.56 | 62.52 | 493.03 |
| 4 | distributed incomplete | 56.58 | 59.29 | 60.45 | 56.06 | 185.60 | 1620.40 |
| algorithm | 1 | 2 | 3 | 4 | 5 | 6 | |
|---|---|---|---|---|---|---|---|
| 1 | reference | 100.00% | 100.00% | 100.00% | 100.00% | 100.00% | 100.00% |
| 2 | distributed incomplete | 14.60% | 47.59% | 33.80% | 25.98% | 36.61% | 106.51% |
| algorithm | 1 | 2 | 3 | 4 | 5 | 6 | |
|---|---|---|---|---|---|---|---|
| 1 | reference | 314.47 | 354.12 | 258.10 | 197.19 | 149.84 | 101.62 |
| 2 | distributed incomplete | 45.92 | 168.53 | 87.23 | 51.23 | 54.86 | 108.23 |
| algorithm | 1000000 | 2000000 | 5000000 | 10000000 | |
|---|---|---|---|---|---|
| 1 | reference | 100.00% | 100.00% | 100.00% | n.a. |
| 2 | non-distributed complete | 56.23% | 30.91% | 21.18% | n.a. |
| 3 | distributed complete | 42.51% | 23.46% | 17.94% | n.a. |
| 4 | distributed incomplete | 72.73% | 44.69% | 40.72% | n.a. |
| algorithm | 1000000 | 2000000 | 5000000 | 10000000 | |
|---|---|---|---|---|---|
| 1 | reference | 191.35 | 542.55 | 2022.67 | t.o. |
| 2 | non-distributed complete | 107.59 | 167.69 | 428.31 | 1184.43 |
| 3 | distributed complete | 81.35 | 127.31 | 362.83 | 723.11 |
| 4 | distributed incomplete | 139.16 | 242.47 | 823.56 | 1705.47 |
| algorithm | 1000000 | 2000000 | 5000000 | 10000000 | |
|---|---|---|---|---|---|
| 1 | reference | 100.00% | 100.00% | 100.00% | n.a. |
| 2 | distributed incomplete | 109.52% | 73.15% | 41.47% | n.a. |
| algorithm | 1000000 | 2000000 | 5000000 | 10000000 | |
|---|---|---|---|---|---|
| 1 | reference | 101.17 | 282.33 | 1227.49 | t.o. |
| 2 | distributed incomplete | 110.80 | 206.53 | 509.06 | 1342.98 |
| algorithm | 1 | 2 | 3 | 5 | 10 | |
|---|---|---|---|---|---|---|
| 1 | reference | 100.00% | 100.00% | 100.00% | 100.00% | 100.00% |
| 2 | non-distributed complete | 29.34% | 47.40% | 48.95% | 48.66% | 48.38% |
| 3 | distributed complete | 30.09% | 49.74% | 47.76% | 46.08% | 45.15% |
| 4 | distributed incomplete | 33.69% | 54.30% | 52.15% | 51.10% | 50.77% |
| algorithm | 1 | 2 | 3 | 5 | 10 | |
|---|---|---|---|---|---|---|
| 1 | reference | 155.69 | 91.23 | 97.47 | 96.34 | 102.42 |
| 2 | non-distributed complete | 45.68 | 43.24 | 47.71 | 46.88 | 49.55 |
| 3 | distributed complete | 46.85 | 45.37 | 46.55 | 44.40 | 46.24 |
| 4 | distributed incomplete | 52.46 | 49.54 | 50.82 | 49.23 | 52.00 |
| algorithm | 1 | 2 | 3 | 5 | 10 | |
|---|---|---|---|---|---|---|
| 1 | reference | 100.00% | 100.00% | 100.00% | 100.00% | 100.00% |
| 2 | distributed incomplete | 33.48% | 40.18% | 39.56% | 34.61% | 37.39% |
| algorithm | 1 | 2 | 3 | 5 | 10 | |
|---|---|---|---|---|---|---|
| 1 | reference | 189.48 | 134.60 | 134.95 | 147.82 | 143.96 |
| 2 | distributed incomplete | 63.44 | 54.08 | 53.39 | 51.17 | 53.83 |
| algorithm | 1 | 2 | 3 | 5 | 10 | |
|---|---|---|---|---|---|---|
| 1 | reference | n.a. | n.a. | n.a. | n.a. | 100.00% |
| 2 | non-distributed complete | n.a. | n.a. | n.a. | n.a. | 69.97% |
| 3 | distributed complete | n.a. | n.a. | n.a. | n.a. | 29.12% |
| 4 | distributed incomplete | n.a. | n.a. | n.a. | n.a. | 95.69% |
| algorithm | 1 | 2 | 3 | 5 | 10 | |
|---|---|---|---|---|---|---|
| 1 | reference | t.o. | t.o. | t.o. | t.o. | 1693.31 |
| 2 | non-distributed complete | 1154.56 | 1361.92 | 1184.43 | 1148.37 | 1184.86 |
| 3 | distributed complete | 1080.17 | 899.84 | 723.11 | 587.94 | 493.03 |
| 4 | distributed incomplete | 1686.67 | 1587.29 | 1705.47 | 1658.78 | 1620.40 |
| algorithm | 1 | 2 | 3 | 5 | 10 | |
|---|---|---|---|---|---|---|
| 1 | reference | 100.00% | 100.00% | 100.00% | n.a. | 100.00% |
| 2 | distributed incomplete | 24.85% | 34.17% | 41.47% | n.a. | 74.49% |
| algorithm | 1 | 2 | 3 | 5 | 10 | |
|---|---|---|---|---|---|---|
| 1 | reference | 2768.18 | 1737.20 | 1227.49 | t.o. | 704.39 |
| 2 | distributed incomplete | 687.76 | 593.55 | 509.06 | 675.54 | 524.68 |
Appendix E Skylines of More Complex Queries
We have also evaluated the performance of our skyline implementation using more complex queries. For this purpose, we have adapted a part of the MusicBrainz database (Foundation, 2022) to allow for more complex queries, which contain multiple joins and aggregates.
E.1. Test Data and Queries
We have selected tuples from Musicbrainz’ recordings such that we have a dataset for complete and one for incomplete algorithms. Both datasets contain almost exactly 1.5 million recording tuples, which we will use as the size for both sets. Tuples were selected such that all recordings with ratings () were selected first and the rest () were sampled randomly. To limit the complexity of the joins, we also have limited the tables of the join “partners” in similar ways. For details on the generation of the dataset and the datasets themselves as .csv files, we refer to our collection of supplemental material under (Grasmann et al., 2022).
As opposed to our more simple queries, there are now slight differences between the complete and incomplete queries due to the more complex nature of the queries. Nevertheless, they should still be comparable with regards to both execution time and memory consumption.
Our “base” queries are given in Listing 12 and Listing 11, respectively. They can be easily extended to skyline queries by adding the skyline clause and potentially adding a subquery where applicable. In Table 13, we give the skyline dimensions as we have already done in Section 6.1. The actual skyline queries are then constructed by using the base queries in combination with the skyline dimensions from this table.
| Dimension | Type | Description |
|---|---|---|
| id | KEY | id of the recording |
| rating | MAX | rating of the recording (cumulative) |
| rating_count | MAX | number of ratings |
| length | MIN | length of the recording |
| video | MAX | whether the recording has a video |
| num_tracks | MAX | how many tracks the recording is on |
| min_position | MIN | lowest track number of recording |
Our queries can be described as finding the best and most often rated recordings which are the shortest and have an associated video. Additionally, we also seek recordings, which were on many tracks and had a very low position on the associated album (i.e., at the beginning of the album).
The more complex queries considered in this section clearly demonstrate the advantage of the easy to use skyline syntax. While the queries in skyline syntax are relatively straightforward by only containing the base query and a skyline clause, the corresponding reference queries become quite extensive and unwieldy. As we can see in Listing 13, the rewritten query is not easy to read anymore, even after heavy formatting to balance space restrictions and readability. In comparison, the specialized skyline syntax given in Listing 14, which expresses the same query, is significantly more concise and readable.
E.2. Experimental Results
In this section, we will take a closer look at the performance results and some conclusions we can draw from them. For this, we will again look at both the execution time and the memory consumption depending on the number of dimensions and executors. Since we are using a real-world dataset to do this, considering the number of tuples as a parameter is not applicable here (as was already the case with the Airbnb dataset in Section 6.4). The impact of the number of dimensions on the execution time and on the memory consumption is shown in Figure 16 and in Figure 17, respectively. Likewise, the impact of the number of executors on the execution time and on the memory consumption is shown in Figure 18 and in Figure 19, respectively.
First, we note that more complex queries result in the measurements to be both more oblique and more opaque. The way how joins and aggregates are handled by Spark has a huge influence on the query execution and affects both the execution time and the memory consumption. This can be seen across almost all plots which correspond to the complex queries. In these cases, our implementation works such that it will take the output of the base query and then uses it to compute the skyline (we exclude potential optimizations here). Still, while always yielding the same result, Spark may execute the queries in many different optimized ways heavily affecting the performance. Hence, the results obtained with the simpler queries such as those found in Section 6.4 seem to give a more precise picture of the performance of the various skyline algorithms.
As already mentioned in Section 6.4, there is a limit of how much distribution makes sense for the distributed algorithms. Since joins can also be computed in a distributed fashion, this effect may be amplified by more complex queries. This can, for example, be seen in Figure 18 where executors is the optimum for which the query is executed the fastest. Adding further executors might slow down the query due to additional distribution and synchronization costs. In these benchmarks it is, however, impossible to exactly pinpoint which part of the query causes such loss of performance.
To conclude, for skyline queries on top of complex queries, it is not always clear if a particular increase of execution time or memory consumption is caused by the skyline computation or by peculiarities of the way how Spark processes the complex base query. Nevertheless, the results obtained with the complex queries are consistent with the ones obtained with the simple queries in Section 6.4. Above all, it has again turned out that the reference queries are significantly slower in most cases and, in some cases, they also take significantly more memory than our specialized algorithms. As such, the specialized algorithms are potentially able to handle bigger data and also more complex queries than the “plain” SQL reference solution without running into serious problems.