secReferences
Interacted two-stage least squares with treatment effect heterogeneity
Abstract
Treatment effect heterogeneity with respect to covariates is common in instrumental variable (IV) analyses. An intuitive approach, which we term the interacted two-stage least squares (2sls), is to postulate a linear working model of the outcome on the treatment, covariates, and treatment-covariate interactions, and instrument it by the IV, covariates, and IV-covariate interactions. We clarify the causal interpretation of the interacted 2sls under the local average treatment effect (LATE) framework when the IV is valid conditional on the covariates. Our contributions are threefold. First, we show that the interacted 2sls with centered covariates is consistent for estimating the LATE if either of the following conditions holds: (i) the IV-covariate interactions are linear in the covariates; (ii) the linear outcome model underlying the interacted 2sls is correct. In particular, condition (i) is satisfied if either (ia) the covariates are categorical or (ib) the IV is randomly assigned. In contrast, existing 2sls procedures with an additive second stage only recover weighted averages of the conditional LATEs that generally differ from the LATE. Second, we show that the coefficients of the treatment-covariate interactions from the interacted 2sls are consistent for estimating treatment effect heterogeneity with regard to covariates among compliers if either condition (i) or condition (ii) holds. Moreover, we connect the 2sls estimator with the weighting perspective in Abadie (2003) and establish the necessity of condition (i) in the absence of additional assumptions on the outcome model. Third, leveraging the consistency guarantees of the interacted 2sls for categorical covariates, we propose a stratification strategy based on the IV propensity score to approximate the LATE and treatment effect heterogeneity with regard to the IV propensity score when neither condition (i) nor condition (ii) holds.
Keywords: Conditional average treatment effect, instrumental variable, local average treatment effect, potential outcome, treatment effect variation
1 Introduction
Two-stage least squares (2sls) is widely used for estimating treatment effects when instrumental variables (IVs) are available for endogenous treatments. Under the potential outcomes framework, Imbens and Angrist (1994) and Angrist et al. (1996) defined the local average treatment effect (LATE) as the average treatment effect over the subpopulation of compliers whose treatment status is affected by the IV, and formalized the assumptions on the IV that ensure the consistency of 2sls for estimating the LATE.
Often, IVs only satisfy the IV assumptions after conditioning on a set of covariates. Refer to such IVs as conditionally valid IVs hence. A common strategy is to include the corresponding covariates as additional regressors when fitting the 2sls. When treatment effect heterogeneity with regard to covariates is suspected, an intuitive generalization, which we term the interacted 2sls, is to add the IV-covariate and treatment-covariate interactions to the first and second stages, respectively (Angrist and Pischke, 2009, Section 4.5.2).
To our knowledge, theoretical properties of the interacted 2sls have not been discussed under the LATE framework except when the IV is randomly assigned hence unconditionally valid (Ding et al., 2019). Our paper closes this gap and clarifies the properties of the interacted 2sls in the more prevalent setting where the IV is conditionally valid.
Our contributions are threefold. First, we show that the interacted 2sls with centered covariates is consistent for estimating the LATE if either of the following conditions holds:
-
(i)
the IV-covariate interactions are linear in the covariates;
-
(ii)
the linear outcome model underlying the interacted 2sls is correct.
In particular, condition (i) is satisfied if either (ia) the covariates are categorical or (ib) the IV is randomly assigned. In contrast, existing 2sls procedures with an additive second stage only recover weighted averages of the conditional LATEs that generally differ from the LATE (Angrist and Imbens, 1995; Sloczynski, 2022; Blandhol et al., 2022). This illustrates an advantage of including treatment-covariate interactions in the second stage.
Second, define systematic treatment effect variation as the variation in individual treatment effects that can be explained by covariates (Heckman et al., 1997; Djebbari and Smith, 2008). We show that the coefficients of the treatment-covariate interactions from the interacted 2sls are consistent for estimating the systematic treatment effect variation among compliers if either condition (i) or condition (ii) holds. Furthermore, we connect the 2sls estimator with the weighting perspective in Abadie (2003), and establish the necessity of condition (i) in the absence of additional assumptions on the outcome model. The results extend the literature on the connection between regression and weighting for estimating the average treatment effect and LATE (Kline, 2011; Chattopadhyay and Zubizarreta, 2023; Chattopadhyay et al., 2024; Słoczyński et al., 2025; frolich2007nonparametric).
Third, to remedy the possible biases when neither condition (i) nor condition (ii) holds, we propose stratifying based on the estimated propensity score of the IV and using the stratum dummies as the new covariates to fit the interacted 2sls. While propensity score stratification is standard for estimating the average treatment effect (Rosenbaum and Rubin, 1983) and LATE (Cheng and Lin, 2018; Pashley et al., 2024), we highlight its value in approximating treatment effect heterogeneity with respect to the IV propensity score.
Notation.
For a set of tuples with and for , denote by the least squares fit of the component-wise linear regression of on . We allow each to be a scalar or a vector and use + to denote concatenation of regressors. Throughout, we focus on the numeric outputs of least squares without invoking any assumption of the corresponding linear model. For two random vectors and , denote by the linear projection of on in that , where . Let denote the indicator function. Let denote independence.
2 Interacted 2SLS and identifying assumptions
2.1 Interacted 2SLS
Consider a study with two treatment levels, indexed by , and a study population of units, indexed by . For each unit, we observe a treatment status , an outcome of interest , a baseline covariate vector , and a binary IV that is valid conditional on . We assume includes the constant one as the first element unless specified otherwise, and state the IV assumptions in Section 2.2. Let denote the IV propensity score of unit (Rosenbaum and Rubin, 1983).
Definition 1 below reviews the standard 2sls procedure for estimating the causal effect of the treatment on outcome. We call it the additive 2sls to signify the additive regression specifications in both stages.
Definition 1 (Additive 2sls).
-
(i)
First stage: Fit over . Denote the fitted values by for .
-
(ii)
Second stage: Fit over . Estimate the treatment effect by the coefficient of .
The standard 2sls in Definition 1 is motivated by the additive working model , where . The coefficient of , , is the constant treatment effect of interest, and we use to instrument the possibly endogenous . We use the term working model to refer to models that are used to construct estimators but not necessarily correct.
When treatment effect heterogeneity with regard to covariates is suspected, an intuitive generalization is to consider the interacted working model
| (1) |
with representing the covariate-dependent treatment effect. We can then use to instrument the possibly endogenous ; see, e.g., Angrist and Pischke (2009, Section 4.5.2). We term the resulting 2sls procedure the interacted 2sls, formalized in Definition 2 below.
Definition 2 (Interacted 2sls).
-
(i)
First stage: Fit over , as the component-wise regression of on . Denote the fitted values by for .
-
(ii)
Second stage: Fit over . Let denote the coefficient vector of .
Of interest is the causal interpretation of the coefficient vector .
2.2 IV assumptions and causal estimands
We formalize below the IV assumptions and corresponding causal estimands using the potential outcomes framework (Imbens and Angrist, 1994; Angrist et al., 1996).
For , let denote the potential treatment status of unit if , and let denote the potential outcome of unit if and . The observed treatment status and outcome satisfy and .
Following the literature, we classify the units into four compliance types, denoted by , based on the joint values of and . We call unit an always-taker if , denoted by ; a complier if and , denoted by ; a defier if and , denoted by ; and a never-taker if , denoted by .
Assumption 1 below reviews the assumptions for conditionally valid IVs that we assume throughout the paper.
Assumption 1.
are independent and identically distributed across , and satisfy the following conditions:
-
(i)
Selection on observables: .
-
(ii)
Overlap: .
-
(iii)
Exclusion restriction: for , where denotes the common value.
-
(iv)
Relevance: .
-
(v)
Monotonicity: .
Assumption 1(i) ensures is as-if randomly assigned given . Assumption 1(ii) ensures positive probabilities of and at all possible values of . Assumption 1(iii) ensures has no effect on the outcome once we condition on the treatment status. Assumption 1(iv) ensures has a nonzero causal effect on the treatment status at all possible values of . Assumption 1(v) precludes defiers. Assumption 1(iv)–(v) together ensure positive proportion of compliers at all possible values of , i.e., .
Recall as the common value of for under Assumption 1(iii). Define as the individual treatment effect of unit . Define
| (2) |
as the local average treatment effect (LATE) on compliers, and define
| (3) |
as the conditional LATE given . The law of iterated expectations ensures .
To quantify treatment effect heterogeneity with regard to covariates, consider the linear projection of on among compliers, denoted by . The coefficient vector equals
| (4) |
By Angrist and Pischke (2009, Theorem 3.1.6), is also the linear projection of the conditional LATE on among compliers with . This ensures is the best linear approximation to both and based on , generalizing the idea of systematic treatment effect variation in Djebbari and Smith (2008) to the IV setting; see also Heckman et al. (1997). We define as the causal estimand for quantifying treatment effect heterogeneity among compliers that is explained by .
Recall as the coefficient vector from the interacted 2sls in Definition 2. Under the finite-population, design-based framework, Ding et al. (2019) showed that is consistent for estimating when is randomly assigned hence valid without conditioning on . We establish in Section 3 the properties of for estimating , , and in the more prevalent setting where is only conditionally valid given .
2.3 Identifying assumptions
We introduce below two assumptions central to our identification results. First, Assumption 2 below restricts the functional form of the IV propensity score, requiring the product of and to be linear in .
Assumption 2 (Linear IV-covariate interactions).
is linear in .
In contrast, Assumption 3 below imposes linearity on the outcome model.
Assumption 3 (Correct interacted outcome model).
The interacted working model (1) is correct.
Proposition 1.
Let denote the dimension of the covariate vector .
-
(i)
Assumption 2 holds if either of the following conditions holds
-
(a)
Categorical covariates: is categorical with levels.
-
(b)
Random assignment of IV: .
-
(a)
- (ii)
- (iii)
Proposition 1(i) provides two important special cases of Assumption 2. Together with Assumption 1, the condition of in Proposition 1(ib) ensures the IV is valid without conditioning on .
3 Identification by interacted 2SLS
We establish in this section the conditions for the interacted 2sls to recover the LATE and treatment effect heterogeneity with regard to covariates in the presence of treatment effect heterogeneity.
3.1 Identification of LATE
We first establish the properties of the interacted 2sls for estimating the LATE and unify the results with the literature. Assume throughout this subsection that has the constant one as the first element.
3.1.1 Interacted 2SLS with centered covariates
Let denote the complier average of for . While is generally unknown, we can consistently estimate it by the method of moments proposed by Imbens and Rubin (1997) or the weighted estimator proposed by Abadie (2003). Definition 3 below formalizes our proposed estimator of the LATE.
Definition 3.
Given , let be a consistent estimate of for . Let be the first element of from the interacted 2sls in Definition 2 that uses as the covariate vector.
We use the subscript to signify the interacted first and second stages in the interacted 2sls. Given , is the coefficient of the fitted value of from the interacted second stage. Let denote the probability limit of as the sample size goes to infinity. Theorem 1 below establishes the conditions for to identify the LATE.
Theorem 1 ensures the consistency of for estimating the LATE when either Assumption 2 or Assumption 3 holds. From Proposition 1, this encompasses (i) categorical covariates, (ii) unconditionally valid IV, and (iii) correct interacted working model as three special cases. In particular, the regression specification of the interacted 2sls is saturated when is categorical, and is therefore a special case of the saturated 2sls discussed by Blandhol et al. (2022).
Recall that is the first element of with centered covariates. We provide intuition for the use of centered covariates in Section 3.2 after presenting the more general theory for , and demonstrate the sufficiency of Assumptions 2 and 3 in Section 4. See Hirano and Imbens (2001) and Lin (2013) for similar uses of centered covariates when using interacted regression to estimate the average treatment effect.
Note that when computing , we use the estimated complier averages to center the covariates, because the true values are unknown. To conduct inference based on , we need to account for the uncertainty in estimating the complier means. This can be achieved by bootstrapping.
3.1.2 Unification with the literature
Theorem 1 contributes to the literature on using 2sls to estimate the LATE in the presence of treatment effect heterogeneity. Previously, Angrist and Imbens (1995) studied a variant of the additive 2sls in Definition 1 for categorical , and showed that the coefficient of recovers a weighted average of the conditional LATEs that generally differs from . Sloczynski (2022) studied the additive 2sls in Definition 1, and showed that when is linear in , the coefficient of recovers a weighted average of the conditional LATEs that generally differs from . Blandhol et al. (2022) studied the additive 2sls and showed that the coefficient of recovers a weighted average of the conditional LATEs when the additive first stage is correctly specified, or saturated. In contrast, Theorem 1 ensures that the interacted 2sls directly recovers if either (i) the covariates are categorical, or (ii) the IV is unconditionally valid, or (iii) the interacted working model (1) is correct. This illustrates an advantage of including the treatment-covariate interactions in the second stage.
We formalize the above overview in Definition 4 and Proposition 2 below. First, Definition 4 states the 2sls procedure considered by Angrist and Imbens (1995) and Sloczynski (2022).
Definition 4 (Interacted-additive 2sls).
-
(i)
First stage: Fit over . Denote the fitted values by for .
-
(ii)
Second stage: Fit over . Estimate the treatment effect by the coefficient of , denoted by .
We use the subscript to signify the interacted first stage and additive second stage. The additive, interacted, and interacted-additive 2sls in Definitions 1–2 and 4 are three variants of 2sls discussed in the LATE literature, summarized in Table 1. The combination of additive first stage and interacted second stage leads to degenerate second stage and is hence omitted.
Let denote the coefficient of from the additive 2sls in Definition 1. Let and denote the probability limits of and , respectively. Proposition 2 below states the conditions for and to identify a weighted average of , and contrasts the results with that of .
Let
with and . Let denote the proportion of compliers given . Let denote the linear projection of on weighted by . That is, with .
Proposition 2.
Assume Assumption 1.
-
(i)
If is linear in , then , where
Further assume that is linear in , i.e., the additive first stage in Definition 1 is correctly specified. Then .
-
(ii)
If Assumption 2 holds, then , where
Further assume that is linear in , i.e., the interacted first stage in Definition 4 is correctly specified. Then .
- (iii)
Proposition 2(i) reviews Sloczynski (2022, Corollary 3.4) and ensures that when the IV propensity score is linear in , recovers a weighted average of that generally differs from . We further show that simplifies to when the additive first stage is correctly specified. See Sloczynski (2022) for a detailed discussion about the deviation of from .
Proposition 2(ii) extends Angrist and Imbens (1995) on categorical covariates to general covariates, and ensures that when is linear in , recovers a weighted average of that generally differs from . A technical subtlety is that may be negative due to , so that some may be negatively weighted. Note that categorical covariates satisfy both Assumption 2 and the condition that is linear in . Proposition 2(ii) then simplifies to the special case in Angrist and Imbens (1995).
Proposition 2(iii) follows from Theorem 1 and ensures that when is linear in , from the interacted 2sls directly recovers .
Together, Proposition 2 illustrates the advantage of over and for estimating the LATE, especially when the covariates are categorical or the IV is unconditionally valid; c.f. Proposition 1. See Table 1 for a summary and Section 6 for a simulated example.
3.2 Identification of treatment effect heterogeneity
We establish in this subsection the properties of the interacted 2sls for estimating that quantifies treatment effect heterogeneity with regard to covariates. Recall as the coefficient vector of from the interacted 2sls in Definition 2. Let denote the probability limit of .
3.2.1 General theory
Let denote the linear projection of on . Let denote the residual from the linear projection of on . Let for compliers, as the residual from the linear projection of on among compliers. Let for compliers and never-takers, and for always-takers. Let
| (8) |
where is the coefficient matrix of in and is the coefficient matrix of in .
Theorem 2 ensures that identifies if and only if , and establishes Assumption 2 and Assumption 3 as two sufficient conditions. We discuss the sufficiency and “almost necessity” of these two assumptions in Section 4.
Recall that Assumption 2 holds when the IV is randomly assigned. Therefore, Theorem 2 ensures for randomly assigned IVs as a special case. See Ding et al. (2019, Theorem 7) for similar results in the finite-population, design-based framework.
In addition, recall that Assumption 2 holds when the covariates are categorical. Therefore, Theorem 2 ensures for categorical covariates. As it turns out, the elements of equal the category-specific LATEs if we define as the vector of all category dummies, without the constant one. This allows us to recover the conditional LATEs as coefficients of the interacted 2sls for categorical covariates. We formalize the intuition below.
3.2.2 The special case of categorical covariates
Assume throughout this subsection that the covariate vector encodes a -level categorical variable, represented by , using category dummies:
| (9) |
Define
as the conditional LATE on compliers with ; c.f. Eq. (3). Lemma 1 below states the simplified forms of and under (9).
Lemma 1.
Assume (9). Then and .
Lemma 1 has two implications. First, when is the dummy vector, the corresponding has the subgroup LATEs ’s as its elements, which adds interpretability. Second, with categorical , the conditional LATE is linear in and equals the linear projection . This is not true for general , so that linear projection is only an approximation.
3.3 Reconciliation of Theorems 1 and 2
We now clarify the connection between Theorems 1 and 2, and provide intuition for the use of centered covariates in estimating the LATE.
Recall that is the first element of with centered covariates. Theorem 2 ensures that is consistent for estimating when either Assumption 2 or Assumption 3 holds. Therefore, a logical basis for using to estimate is that equals the first element of . Lemma 2 below ensures that this condition is satisfied when the nonconstant covariates are centered by their respective complier averages. This establishes Theorem 1 as a direct consequence of Theorem 2, and justifies the use of centered covariates for estimating the LATE.
Lemma 2.
Assume . If for , then the first element of equals .
4 Discussion of Assumptions 2 and 3
We discuss in this section the sufficiency and “almost necessity” of Assumptions 2 and 3 to ensure in Theorem 2.
4.1 Sufficiency and “almost necessity” of Assumption 2
We discuss below the sufficiency and “almost necessity” of Assumption 2. We first demonstrate the sufficiency of Assumption 2 to ensure , as a sufficient condition for by Theorem 2. We then adopt the weighting perspective in Abadie (2003) and establish the necessity of Assumption 2 to ensure in the absence of additional assumptions on the outcome model beyond Assumption 1.
4.1.1 Sufficiency
Recall the definitions of and from Eq. (8), where denotes the coefficient matrix of in . Assumption 2 ensures
| (10) |
so that .
In addition, recall that is the residual from the linear projection of on among compliers. Properties of linear projection ensure so that the expectation term in satisfies
This ensures and therefore the sufficiency of Assumption 2 to ensure .
4.1.2 Necessity in the absence of additional assumptions on outcome model
Proposition 3 below expresses as a weighted estimator and establishes the necessity of Assumption 2 to ensure in the absence of additional assumptions on the outcome model. Recall that denotes the residual from the linear projection of on .
Proposition 3.
Proposition 3(i) expresses as a weighted average of the outcome . The result is numeric and does not require Assumption 1.
Proposition 3(ii) follows from Abadie (2003) and expresses as a weighted average of when Assumption 1 holds.
4.2 Sufficiency and “almost necessity” of Assumption 3
We discuss below the sufficiency and “almost necessity” of Assumption 3 to ensure in the absence of additional assumptions on beyond Assumption 1.
Without additional assumptions on , the in the definitions of and is arbitrary. To ensure , we generally need , which is equivalent to
| is linear in . | (11) |
In addition, Lemma S4 in the Supplementary Material ensures that is invertible. From Eq. (8), we have if and only if
| (12) |
By the law of iterated expectations, the left-hand side of condition (12) equals
When is arbitrary, condition (12) generally requires , which is equivalent to
| is linear in . | (13) |
The above observations suggest the sufficiency and “almost necessity” of the combination of conditions (11) and (13) to ensure in the absence of additional assumptions on . We further show in Lemma S5 in the Supplementary Material that under Assumption 1, Assumption 3 is equivalent to the combination of conditions (11) and (13). This demonstrates the sufficiency and “almost necessity” of Assumption 3 to ensure in the absence of additional assumptions on .
Remark 1.
From Theorem 2 and Lemma 2, if and only if
| the first dimension of equals 0, | (14) |
which is weaker than the condition of to ensure . Nonetheless, we did not find intuitive relaxations of Assumptions 2 and 3 to satisfy (14), and therefore invoke the same identifying conditions for and in Theorems 1 and 2.
5 Stratification based on IV propensity score
The results in Section 3 suggest that the interacted 2sls may be inconsistent for estimating the LATE and treatment effect heterogeneity when neither Assumption 2 or Assumption 3 holds for the original covariates. When this is the case, we propose stratifying based on the IV propensity score and using the stratum dummies as the new covariates to fit the interacted 2sls. The consistency of the interacted 2sls for categorical covariates provides heuristic justification for using the resulting 2sls coefficients to approximate the LATE and treatment effect heterogeneity with regard to the IV propensity score. We formalize the intuition below. See Cheng and Lin (2018) and Pashley et al. (2024) for other applications of stratification based on the IV propensity score.
Assume that is a general covariate vector that ensures the conditional validity of . Let denote the IV propensity score of unit , and define
as the conditional LATE given ; c.f. Eq. (3). Properties of the propensity score (Rosenbaum and Rubin, 1983) ensure so that is also conditionally valid given . This, together with the consistency guarantees of the interacted 2sls for categorical covariates, motivates viewing as a new covariate that ensures the validity of , and fitting the interacted 2sls with a discretized version of to approximate and . In most applications, is unknown so we need to first estimate using . We formalize the procedure in Algorithm 1 below.
Algorithm 1.
-
(i)
Estimate as .
-
(ii)
Partition into strata, denoted by . Define and , where , as two representations of the stratum of . In practice, we can choose and the cutoffs for based on the realized values of ’s.
-
(iii)
Compute by letting in Definition 3 to approximate the LATE.
Compute by letting in Definition 2. For , use the th element of to approximate for .
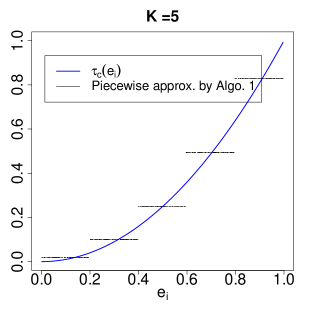
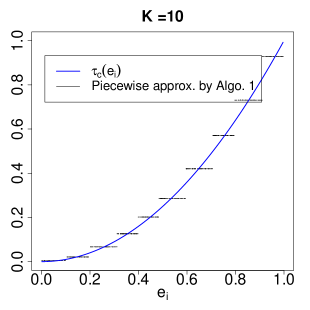
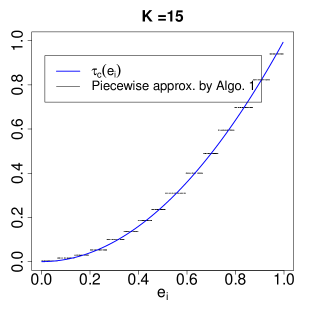
Algorithm 1 transforms arbitrary covariate vector into categorical and to fit the interacted 2sls. Note that and are discretized approximations to the actual . Heuristically, an IV that is conditionally valid given can be viewed as “approximately valid” given or . This, together with Theorem 1 and Corollary 1, provides the heuristic justification of the resulting and to approximate the LATE and subgroup LATEs
| (15) |
respectively. The subgroup LATEs in (15) further provide a piecewise approximation to by assuming for . This is analogous to the idea of regressogram in nonparametric regression (Liero, 1989; Wasserman, 2006).
6 Simulation
6.1 Interacted 2SLS for estimating LATE
We now use a simulated example to illustrate the advantage of the interacted 2sls for estimating the LATE. Assume the following model for :
-
(i)
, where Bernoulli(0.5).
-
(ii)
Bernoulli.
-
(iii)
, where and .
-
(iv)
with and .
The data-generating process ensures , , and . For each replication, we generate independent realizations of and compute , , and from the additive, interacted, and interacted-additive 2sls in Definitions 1–4; c.f. Table 1. We use the method of moments to estimate the complier average of in computing .
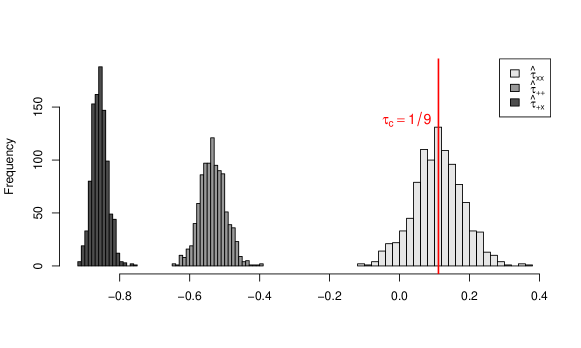
Figure 1 shows the distributions of the three estimators over 1000 replications. Almost all realizations of and are below while the actual is positive. In contrast, the distribution of is approximately centered at the actual , which is coherent with Theorem 1 for categorical covariates.
6.2 Approximation of LATE by Algorithm 1.
We now illustrate the improvement of Algorithm 1 for estimating the LATE. Assume the following model for generating .
-
(i)
, where and are independent standard normals.
-
(ii)
.
-
(iii)
, where and .
-
(iv)
with and .
For each replication, we generate independent realizations of and compute by Algorithm 1. We consider to evaluate the impact of the number of strata on estimation. For comparison, we also compute , , and from the additive, interacted, and interacted-additive 2sls in Definitions 1–4.
Figure 2 shows the violin plot of the deviations of the resulting estimators from the LATE over 1000 replications. The three estimators by Algorithm 1 substantially reduce the biases compared with , , and . In addition, increasing the number of strata further reduces the bias but increases variability. Table 2 summarizes the means and standard deviations of the deviations.
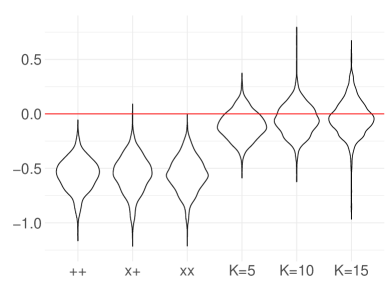
| from Algorithm 1 | ||||||
| Bias | ||||||
| Standard dev. | 0.144 | 0.165 | 0.157 | 0.124 | 0.140 | 0.336 |
6.3 Possible inconsistency for estimating
We now illustrate the possible inconsistency of the interacted 2sls in Theorem 2. Assume the following model for :
-
(i)
, where Uniform(0,1).
-
(ii)
Bernoulli() with .
-
(iii)
, where and .
-
(iv)
with and .
The data-generating process ensures and .
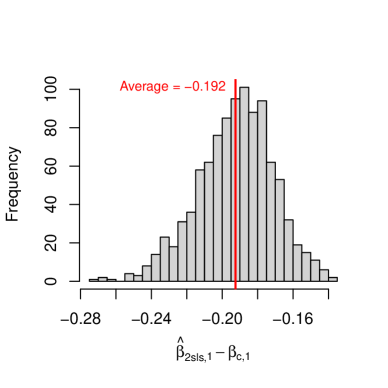
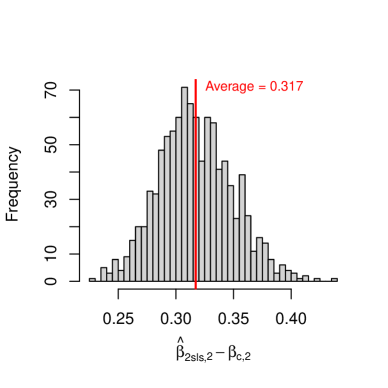
For each replication, we generate independent realizations of and compute from the interacted 2sls in Definition 2. Figure 3 shows the distribution of over 1000 replications, indicating clear empirical biases in both dimensions.
 |
 |
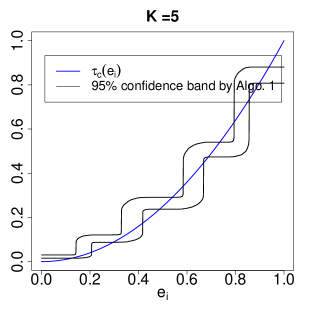
6.4 Approximation of by Algorithm 1.
We now illustrate the utility of Algorithm 1 for approximating the conditional LATEs given the IV propensity score. Assume the same model as in Section 6.3 for generating . The data-generating process ensures with .
To use Algorithm 1 to approximate , we estimate the IV propensity score by the logistic regression of on , and create the strata by dividing into equal-sized bins. Figure 4 shows the results at . The first row is based on one replication to illustrate the evolution of the approximation as increases. The second row shows the 95% confidence bands based on 3000 replications. The coverage of the confidence band improves as increases. Note that the logistic regression for estimating is misspecified in this example. The results suggest the robustness of the method to misspecification of the propensity score model with moderate number of strata.
 |
 |
 |
 |
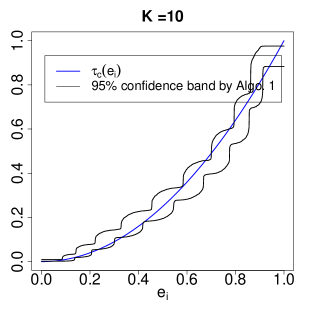 |
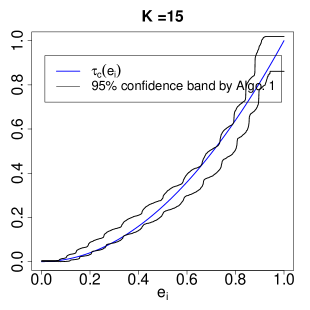 |
7 Application
We now apply Algorithm 1 to the dataset that Abadie (2003) used to study the effects of 401(k) retirement programs on savings. The data contain cross-sectional observations of units on eligibility for and participation in 401(k) plans along with income and demographic information. The outcome of interest is net financial assets. The treatment variable is an indicator of participation in 401(k) plans, and the IV is an indicator of 401(k) eligibility. Based on Abadie (2003), the IV is conditionally valid after controlling for income, age, and marital status.
Table 3 shows the point estimates of the LATE by the additive, interacted, interacted-additive 2sls in Definitions 1–4 and Algorithm 1, along with their respective bootstrap standard deviations. Figure 5 shows the piecewise approximations of based on Algorithm 1 and the 95% confidence bands based on bootstrapping. The result suggests heterogeneity of conditional LATEs across different strata of the propensity score.
| from Algorithm 1 | |||||||
|---|---|---|---|---|---|---|---|
| Point estimate | 9.658 | 11.019 | 9.296 | 12.760 | 12.148 | 12.008 | 12.066 |
| Standard dev. | 2.222 | 2.520 | 1.913 | 2.076 | 2.079 | 2.081 | 2.089 |
 |
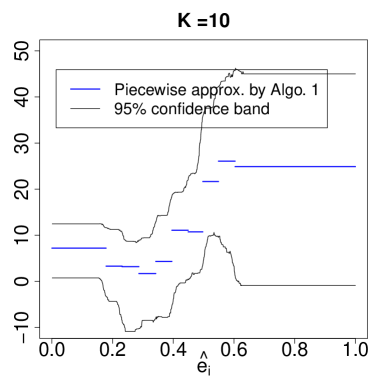 |
8 Extensions
8.1 Extension to partially interacted 2SLS
Let denote the covariate vector that ensures the conditional validity of the IV. The interacted 2sls in Definition 2 includes interactions of and with the whole set of in accommodating treatment effect heterogeneity. When treatment effect heterogeneity is of interest or suspected for only a subset of , denoted by , an intuitive modification is to interact and with only in fitting the 2sls, formalized in Definition 5 below. See Resnjanskij et al. (2024) for a recent application. See also Hirano and Imbens (2001) and Hainmueller et al. (2019) for applications of the partially interacted regression in the ordinary least squares setting.
Definition 5 (Partially interacted 2sls).
-
(i)
First stage: Fit over . Denote the fitted values by for .
-
(ii)
Second stage: Fit over . Let denote the coefficient vector of .
The partially interacted 2sls in Definition 5 generalizes the interacted 2sls, and reduces to the interacted 2sls when . It is the 2sls procedure corresponding to the working model
| (16) |
with representing the covariate-dependent treatment effect. We establish below the causal interpretation of .
Causal estimand.
Analogous to the definition of in Eq. (4), let denote the linear projection of on among compliers with
Parallel to the discussion after Eq. (4), is also the linear projection of on among compliers with . This ensures is the best linear approximation to both and based on . We define as the causal estimand for quantifying treatment effect heterogeneity with regard to among compliers.
Properties of for estimating .
Let denote the probability limit of . Proposition 4 below generalizes Theorem 2 and states three sufficient conditions for to identify .
Proposition 4.
Assume , where and with . Let denote the residual of the linear projection of on . Let . Assume Assumption 1. Then
where if any of the following conditions holds:
-
(i)
Categorical covariates: is categorical with levels, and satisfies and .
-
(ii)
Random assignment of IV: .
-
(iii)
Correct interacted outcome model: The interacted working model (16) is correct.
Proposition 4(i) parallels the identification of with categorical covariates by Theorem 2, and states a sufficient condition for to identify when is categorical. A special case is when encodes two categorical variables and corresponds to one of them.
Proposition 4(ii) parallels the identification of with randomly assigned IV by Theorem 2, and ensures when is unconditionally valid.
Proposition 4(iii) parallels the identification of under correct interacted working model (1) by Theorem 2, and ensures when the working model (16) underlying the partially interacted 2sls is correct.
We relegate possible relaxations of these three sufficient conditions to Lemma S9 in the Supplementary Material.
8.2 Interacted OLS as a special case
Ordinary least squares (ols) is a special case of 2sls with . Therefore, our theory extends to the ols regression of on when is conditionally randomized. Interestingly, the discussion of interacted ols in observational studies is largely missing except Rosenbaum and Rubin (1983). See Aronow and Samii (2016) and Chattopadhyay and Zubizarreta (2023) for the corresponding discussion of additive ols.
Renew , where , as a variant of centered by covariate means over all units. Let be the coefficient of in , as the ols analog of when . Let be the coefficient vector of in , as the analog of when . We derive below the causal interpretation of and .
First, letting ensures that all units are compliers. The definitions of and in Eqs. (2) and (4) simplify to , as the average treatment effect, and , as the coefficient vector in the linear projection of on , respectively. The IV assumptions in Assumption 1 simplify to the selection on observables and overlap assumptions on , summarized in Assumption 4 below.
Assumption 4.
-
(i)
Selection on observables: ;
-
(ii)
Overlap: .
Proposition 5 below follows from applying Theorems 1–2 with , and establishes the properties of and for estimating and .
Proposition 5.
Let and denote the probability limits of and . Assume Assumption 4. Then and if either of the following conditions holds:
-
(i)
Linear treatment-covariate interactions: is linear in .
-
(ii)
Linear outcome: , where , for some fixed .
Parallel to Proposition 1(i), Proposition 5(i) encompasses (a) categorical covariates and (b) randomly assigned treatment as special cases. Proposition 5(ii) implies that the interacted regression is correctly specified.
Similar results can be obtained for partially interacted ols regression of on by letting in Proposition 4. We omit the details.
9 Discussion
We formalized the interacted 2sls as an intuitive approach for incorporate treatment effect heterogeneity in IV analyses, and established its properties for estimating the LATE and systematic treatment effect variation under the LATE framework. We showed that the coefficients from the interacted 2sls are consistent for estimating the LATE and treatment effect heterogeneity with regard to covariates among compliers if either (i) the IV-covariate interactions are linear in the covariates or (ii) the linear outcome model underlying the interacted 2sls is correct. Condition (i) includes categorical covariates and randomly assigned IV as special cases. When neither condition (i) nor condition (ii) holds, we propose a stratification strategy based on the IV propensity score to approximate the LATE and treatment effect heterogeneity with regard to the IV propensity score. We leave possible relaxations of the identifying conditions for the LATE to future work.
References
- Abadie (2003) Abadie, A. (2003). Semiparametric instrumental variable estimation of treatment response models. Journal of Econometrics 113, 231–263.
- Angrist (1998) Angrist, J. D. (1998). Estimating the labor market impact of voluntary military service using social security data on military applicants. Econometrica 66, 249–288.
- Angrist and Imbens (1995) Angrist, J. D. and G. W. Imbens (1995). Two-stage least squares estimation of average causal effects in models with variable treatment intensity. Journal of the American statistical Association 90, 431–442.
- Angrist et al. (1996) Angrist, J. D., G. W. Imbens, and D. B. Rubin (1996). Identification of causal effects using instrumental variables (with discussion). Journal of the American Statistical Association 91, 444–455.
- Angrist and Pischke (2009) Angrist, J. D. and J.-S. Pischke (2009). Mostly Harmless Econometrics: An Empiricist’s Companion. Princeton: Princeton University Press.
- Aronow and Samii (2016) Aronow, P. M. and C. Samii (2016). Does regression produce representative estimates of causal effects? American Journal of Political Science 60, 250–267.
- Blandhol et al. (2022) Blandhol, C., J. Bonney, M. Mogstad, and A. Torgovitsky (2022). When is tsls actually late? Technical report, National Bureau of Economic Research Cambridge, MA.
- Chattopadhyay et al. (2024) Chattopadhyay, A., N. Greifer, and J. R. Zubizarreta (2024). lmw: Linear model weights for causal inference. Observational Studies 10, 33–62.
- Chattopadhyay and Zubizarreta (2023) Chattopadhyay, A. and J. R. Zubizarreta (2023). On the implied weights of linear regression for causal inference. Biometrika 110, 615–629.
- Cheng and Lin (2018) Cheng, J. and W. Lin (2018). Understanding causal distributional and subgroup effects with the instrumental propensity score. American Journal of Epidemiology 187, 614–622.
- Ding et al. (2019) Ding, P., A. Feller, and L. Miratrix (2019). Decomposing treatment effect variation. Journal of the American Statistical Association 114, 304–317.
- Djebbari and Smith (2008) Djebbari, H. and J. Smith (2008). Heterogeneous impacts in progresa. Journal of Econometrics 145, 64–80.
- Hainmueller et al. (2019) Hainmueller, J., J. Mummolo, and Y. Xu (2019). How much should we trust estimates from multiplicative interaction models? Simple tools to improve empirical practice. Political Analysis 27, 163–192.
- Heckman et al. (1997) Heckman, J. J., J. Smith, and N. Clements (1997). Making the most out of programme evaluations and social experiments: Accounting for heterogeneity in programme impacts. The Review of Economic Studies 64, 487–535.
- Hirano and Imbens (2001) Hirano, K. and G. W. Imbens (2001). Estimation of causal effects using propensity score weighting: An application to data on right heart catheterization. Health Services and Outcomes Research Methodology 2, 259–278.
- Imbens and Angrist (1994) Imbens, G. W. and J. D. Angrist (1994). Identification and estimation of local average treatment effects. Econometrica 62, 467–475.
- Imbens and Rubin (1997) Imbens, G. W. and D. B. Rubin (1997). Estimating outcome distributions for compliers in instrumental variables models. The Review of Economic Studies 64, 555–574.
- Kline (2011) Kline, P. (2011). Oaxaca-Blinder as a reweighting estimator. American Economic Review 101, 532–537.
- Liero (1989) Liero, H. (1989). Strong uniform consistency of nonparametric regression function estimates. Probability Theory and Related Fields 82, 587–614.
- Lin (2013) Lin, W. (2013). Agnostic notes on regression adjustments to experimental data: Reexamining Freedman’s critique. The Annals of Applied Statistics 7, 295–318.
- Pashley et al. (2024) Pashley, N. E., L. Keele, and L. W. Miratrix (2024, 08). Improving instrumental variable estimators with poststratification. Journal of the Royal Statistical Society Series A: Statistics in Society, qnae073.
- Resnjanskij et al. (2024) Resnjanskij, S., J. Ruhose, S. Wiederhold, L. Woessmann, and K. Wedel (2024). Can mentoring alleviate family disadvantage in adolescence? a field experiment to improve labor market prospects. Journal of Political Economy 132, 000–000.
- Rosenbaum and Rubin (1983) Rosenbaum, P. R. and D. B. Rubin (1983). The central role of the propensity score in observational studies for causal effects. Biometrika 70, 41–55.
- Sloczynski (2022) Sloczynski, T. (2022). When should we (not) interpret linear IV estimands as LATE?
- Słoczyński et al. (2025) Słoczyński, T., S. D. Uysal, and J. M. Wooldridge (2025). Abadie’s kappa and weighting estimators of the local average treatment effect. Journal of Business & Economic Statistics 43, 164–177.
- Strang (2006) Strang, G. (2006). Linear Algebra and Its Applications (4 ed.). Cengage Learning.
- Wasserman (2006) Wasserman, L. (2006). All of Nonparametric Statistics. New York: Springer.
Supplementary Material
Section S1 gives additional results that complement the main paper.
Section S2 gives the lemmas for the proofs. In particular, Section S2.4 gives two linear algebra results that underlie Proposition 1(ii).
Section S3 gives the proofs of the results in the main paper.
Notation.
Recall that for two random vectors and , we use to the linear projection of on . Further let denote the corresponding residual.
Write
| (S1) |
where , , and denote the coefficient matrices. A useful fact for the proofs is
| (S2) | |||||
Recall the definition of and from Theorem 2. Extend the definition of to all units as
A useful fact for the proofs is
| (S7) |
S1 Additional results
Population 2SLS estimand.
Linear projection gives the population analog of least-squares regression. Proposition S1 below formalizes the population analog of the interacted 2sls in Definition 2.
Proposition S1.
Define the population interacted 2sls as the combination of the following two linear projections:
-
(i)
First stage: the linear projection of on , denoted by .
-
(ii)
Second stage: the linear projection of on the concatenation of and .
Then equals the coefficient vector of from the second stage.
Invariance of the interacted 2SLS to nondegenerate linear transformations.
The values of from the interacted 2sls and from Eq. (4) both depend on the choice of the covariate vector . Let , , and denote the values of , , and corresponding to covariate vector . Proposition S2 below states their invariance to nondegenerate linear transformation of .
Proposition S2.
For covariate vectors and an invertible matrix , we have
Generalized additive 2SLS.
Definition S1 below generalizes the additive and interacted-additive 2sls in Definitions 1 and 4 to arbitrary first stage.
Definition S1 (Generalized additive 2sls).
Let be an arbitrary vector function of .
-
(i)
First stage: Fit over . Denote the fitted values by for .
-
(ii)
Second stage: Fit over . Denote the coefficient of by .
We use the subscript to represent the arbitrary first stage and additive second stage. The additive 2sls in Definition 1 is a special case of the generalized additive 2sls with . The interacted-additive 2sls in Definition 4 is a special case with .
Let denote the probability limit of . Proposition S3 below clarifies the causal interpretation of .
Let denote the population fitted value from the first stage of the generalized additive 2sls. Let . Let for compliers and never-takers and for always-takers. Recall
Proposition S3.
Assume Assumption 1. Then , where
In particular,
-
(i)
if either of the following conditions holds:
-
(a)
is linear in .
-
(b)
is linear in .
-
(a)
-
(ii)
if both of the following conditions hold:
-
(a)
is linear in .
-
(b)
; i.e., the arbitrary first stage is correct.
-
(a)
S2 Lemmas
S2.1 Projection and conditional expectation
Lemmas S1–S3 below review some standard results regarding projection and conditional expectation. We omit the proofs.
Lemma S1.
For random vectors and ,
-
(i)
if and only if is linear in ;
-
(ii)
if , then ;
-
(iii)
if is binary, then is constant implies .
Lemma S2.
Let be an random vector with being invertible. Then
-
(i)
for any subvector of , denoted by , is invertible.
-
(ii)
takes at least distinct values.
-
(iii)
If takes exactly distinct values, denoted by , then
-
-
is invertible, and .
-
-
is component-wise linear in .
-
-
for any random vector , is linear in .
Lemma S3 (Population Frisch–Waugh–Lovell (FWL)).
For a random variable , a random vector , and a random vector , let and denote the residuals from the linear projections of and on , respectively. Then the coefficient vector of in the linear projection of on equals the coefficient vector of in the linear projection of or on .
S2.2 Lemmas for the interacted 2SLS
Assumption S1 below states the rank condition for the interacted 2sls, which we assume implicitly throughout the main paper. By the law of large numbers,
Assumption S1.
is invertible.
Lemma S4.
Proof of Lemma S4.
Proof of Lemma S4(i):
We prove the result by contradiction. Note that is positive semidefinite. If is degenerate, then there exists a nonzero vector such that . This implies
such that . As a result, we have
for a nonzero . This contradicts with being invertible.
Proof of Lemma S4(ii).
Proof of Lemma S4(iii):
Properties of linear projection ensure
with
| (S8) |
This ensures .
In addition, note that
To show that and are invertible, it suffices to show that and are invertible. This is ensured by
∎
Sufficiency.
Necessity.
We show below that (S9) implies Assumption 3. Recall from (S7) that . When (S9) holds, we have so that
| (S23) |
This ensures
| (S24) | |||||
Let . We have
so that Assumption 3 holds. ∎
Lemma S6.
Let and denote the fitted values from and
| (S25) |
respectively. Assume that is categorical with levels. Then .
Proof of Lemma S6.
We verify below the result for , where denotes a -level categorical variable. The result for general categorical then follows from the invariance of least squares to nondegenerate linear transformations of the regressor vector.
Given , for , the th element of equals , and the th element of equals the fitted value from
| (S26) |
denoted by . By symmetry, to show that , it suffices to show that the first element of equals the first element of , i.e.,
| (S27) |
We verify (S27) below.
Left-hand side of (S27).
Standard results ensure that (S25) is equivalent to stratum-wise regressions
for , such that equals the sample mean of for units with . This ensures
| (S30) |
Right-hand side of (S27).
S2.3 Lemmas for the partially interacted 2SLS
Assumption S2 below states the rank condition for the partially interacted 2sls.
Assumption S2.
is invertible.
Lemma S7 below generalizes Lemma S4 and states some implications of Assumption S2 useful for the proofs. The proof is similar to that of Lemma S4, hence omitted.
Lemma S7.
Assume Assumption S2. We have
-
(i)
, , and are all invertible with
with
-
(ii)
takes at least distinct values. takes at least distinct values.
-
(iii)
, , and are all invertible.
Lemma S8.
Assume , where with and is invertible. Then is linear in and is linear in if any of the following conditions holds:
-
(i)
is categorical with levels; and .
-
(ii)
.
Proof of Lemma S8.
Proof of Condition (i).
Given is invertible, Lemma S2(i) ensures that is invertible. When is categorical with levels, Lemma S2(iii) ensures that is component-wise linear in and that is linear in . We can write
| (S32) |
for and some constant . This, together with and , ensures
which is linear in when is component-wise linear in .
Proof of Condition (ii).
Lemma S9 below underlies the sufficient conditions in Proposition 4. Renew
| (S36) |
where is the coefficient matrix of in . Renew
The renewed , , and reduce to their original definitions in Theorem 2 when .
Lemma S9.
Proof of Lemma S9.
Observe that
| (S42) |
This ensures
Therefore, it suffices to show that
| (S43) |
for and in Eq. (S36). To simplify the notation, write
where and are well defined by Lemma S7 with being invertible under Assumption S2. We have
This ensures
| (S46) |
Let with . Properties of linear projection ensure such that
| (S47) |
In addition, is a function of , whereas and are both functions of . This ensures
| (S48) |
under Assumption 1.
Proof of in (S43) and sufficient conditions of .
Proof of in (S43) and sufficient conditions of .
S2.4 Two linear algebra propositions
Propositions S4–S5 below state two linear algebra results that underlie Proposition 1(ii). We did not find formal statements or proofs of these results in the literature. We provide our original proofs in Section S5.
Proposition S4.
Assume is an vector such that is linear in . That is, there exists constants such that
| (S50) |
Then takes at most distinct values across all solutions of to (S50).
Proposition S5 below extends Proposition S4 and ensures that if are all linear in , then the whole vector takes at most distinct values.
Proposition S5.
Assume is an vector such that is component-wise linear in . That is, there exists constants such that
Then takes at most distinct values.
Corollary S1.
Let be an vector.
-
(i)
If there exists an constant vector such that is linear in , then takes at most distinct values.
-
(ii)
If is linear in for all constant vectors , then takes at most distinct values.
S3 Proofs of the results in the main paper
S3.1 Proofs of the results in Section 2
Proof of Proposition 1(i).
The sufficiency of categorical covariates follows from Lemma S1. The sufficiency of randomly assigned IV follows from .
Proof of Proposition 1(ii).
Let with . Assumption 2 requires that
| (S51) |
From (S51), there exists constants and so that
| (S52) |
This ensures
| (S53) |
From (S53), for to be linear in as suggested by (S51), we need to be linear in . By Corollary S1(i), this implies that takes at most distinct values, which in turn ensures takes at most distinct values given (S52).
Proof of Proposition 1(iii).
S3.2 Proofs of the results in Section 3.2
Proof of Theorem 2.
With a slight abuse of notation, renew as the population fitted value from the first stage of the interacted 2sls throughout this proof. From Proposition S1, equals the coefficient vector of in . Recall . The population FWL in Lemma S3 ensures
| (S65) |
Write with
This ensures the on the right-hand side of (S65) equals
| (S66) | |||||
where
Plugging (S66) in (S65) ensures
Therefore, it suffices to show that
| (S67) |
The sufficiency of Assumptions 2 and 3 to ensure then follows from Section 4 and Lemma S5.
Proof of in (S67).
Proof of in (S67).
Proof of in (S70).
Proof of in (S70).
Note that is a function of . Assumption 1(i) ensures
| (S77) |
Accordingly, we have
| (S78) | |||||
This, combined with (S73), ensures
∎
Proof of Lemma 1.
Proof of Corollary 1.
Let denote the Wald estimator based on units with . We show in the following that
| (S81) |
which ensures .
Recall the definition of forbidden regression from above Lemma S6. In addition, consider the following stratum-wise 2sls based on units with :
-
(i)
First stage: Fit over . Denote the fitted value by .
-
(ii)
Second stage: Fit over . Denote the coefficient of by .
When ,
-
(a)
properties of least squares ensure that the coefficients of from the forbidden regression equal ;
-
(b)
Lemma S6 ensures the coefficients of from the forbidden regression equal .
These two observations ensure . This, together with by standard theory, ensures (S81). ∎
S3.3 Proofs of the results in Section 3.3
S3.4 Proofs of the results in Section 3.1
Proof of Theorem 1.
Let denote the population analog of . Let and denote the first elements of and , respectively. Then and have the same probability limit.
In addition, Lemma 2 ensures that equals the first element of . This ensures
| (S82) | |||||
| the first element of equals the first element of | |||||
where the last equivalence follows from being a nondegenerate linear transformation of and the invariance of 2sls to nondegenerate linear transformations in Proposition S2. By Theorem 2, the equivalent result in (S82) is ensured by either Assumption 2 or 3. ∎
Proof of Proposition 2(i).
Assume throughout this proof that denotes the population fitted value from the additive first stage , and let denote the residual from the linear projection of on . Given Proposition S3, it suffices to verify that when is linear in , we have
| (S83) |
Write
| (S84) |
Proof of linear in (S83).
From (S84), we have which is linear in when is linear in .
Proof of in (S83).
Proof of linear in (S91).
From (S92), we have , which is linear in when is linear in .
Proof of in (S91).
When is linear in , we just showed that is linear in . This ensures so that
| (S93) | |||||
Note that the last expression in (S93) parallels (S85) after replacing with . Replacing by in the proof of Proposition 2(i) after (S85) ensures that the renewed in (S91) satisfies
| (S94) |
We show below , which completes the proof.
By the population FWL, we have
Therefore, it suffices to show that
| (S95) | |||||
| (S96) |
A useful fact is that when is linear in , we have
with
| (S97) | |||||
| (S98) | |||||
| (S99) |
Proof of (S95).
Proof of (S96).
Let with and . This ensures
| (S101) | |||||
with
| (S102) | |||||
Note that the two terms in (S102) satisfy
| (S107) |
This ensures
∎
S3.5 Proofs of the results in Section 4
S3.6 Proofs of the results in Section 8
Proof of Proposition 4.
Proof of (S112).
With a slight abuse of notation, renew and write
| (S113) |
Note that is by definition a linear combination of . Properties of linear projection ensure
| (S114) |
(S113)–(S114) together ensure (S112) as follows:
∎
S4 Proofs of the results in Section S1
Proof of Proposition S3.
Recall as the regressor vector in the first stage of the generalized additive 2sls in Definition S1. Recall and . The correspondence between least squares and linear projection ensures is the coefficient of in . The population FWL in Lemma S3 ensures
| (S115) |
We simplify below the numerator in (S115).
Compute in (S124).
Compute in (S124).
Compute in (S124).
We have
and therefore
| (S143) |
Plugging (S133), (S139), (S143) into (S124) ensures
which verifies the expression of by (S115).
The sufficient conditions for are straightforward. We verify below the sufficient conditions for .
Conditions for .
Assume that is linear in . We have with
| (S144) |
This, together with being a function of , ensures
| (S145) | |||||
| (S146) | |||||
From (S146), we have
| (S147) | |||||
(S145) and (S147) together ensure
| (S148) |
When , (S148) simplifies to .
∎
S5 Proofs of the results in Section S2.4
S5.1 Lemmas
Lemma S10.
Let be an matrix. Let denote the rank of with . Then there exists an invertible matrix
with , , and such that
Proof of Lemma S10.
The results for and are straightforward by letting and , respectively. We verify below the result for .
Given , the theory of reduced row echelon form (see, e.g., Strang (2006)) ensures that there exists an invertible matrix such that
| (S149) |
Write
| (S150) |
That is invertible ensures has full row rank with . The theory of reduced row echelon form ensures that there exists an invertible matrix such that
| (S151) |
Define
| (S152) |
Let denote a partition of with and . It follows from (S150)–(S151) that
| (S153) |
with
∎
Lemma S11.
Assume the setting of Proposition S4. Let
denote the solution set of (S50). Let
denote the set of values of across all solutions to (S50). Let denote the coefficient vector of in the first equation in (S50). Let denote the coefficient matrix of in the last equations in (S50). Let denote the set of eigenvalues of . Let
denote the set of solutions to (S50) that have not equal to any eigenvalue of . Then
-
(i)
if .
-
(ii)
Each corresponds to a unique solution to (S50) with
-
(iii)
Further assume that . Let denote an eigenvalue of that is also in . Let denote the rank of . Let
denote a partition of , containing solutions to (S50) that have and , respectively.
-
(a)
If , then and there exists constant , , , and such that
-
–
for all with , the corresponding and satisfy
-
–
for all with , the corresponding and satisfy
-
–
-
(b)
If , then
-
–
for all with , we have .
-
–
-
–
-
–
-
(a)
Proof of Lemma S11.
Proof of Lemma S11(i):
Proof of Lemma S11(ii):
Write (S156) as
| (S158) |
For that is not an eigenvalue of , we have is invertible with
| (S159) |
where det and Adj denote the determinant and adjoint matrix, respectively. (S158)–(S159) together ensure that
| (S163) |
(S163) ensures that
| each corresponds to a unique solution to (S50) with . |
It remains to show that
| (S166) |
When , Lemma S11(i) ensures . When , plugging (S163) in (S157) ensures
and therefore
| (S167) |
Note that is at most th-degree in and the elements of are at most ()th-degree in . This, together with , ensures (S167) is at most th-degree in . By the fundamental theorem of algebra, takes at most distinct values beyond the eigenvalues of . This verifies (S166).
Proof of Lemma S11(iii):
Proof of Lemma S11(iiia) for :
Recall . When , we have . From Lemma S10, there exists an invertible matrix
| (S169) |
with , , , , and such that
| (S170) |
Multiplying both sides of (S5.1) by ensures that
| (S173) |
We simplify below the left- and right-hand sides of (S173), respectively.
Write
| (S174) |
with
This, together with (S169)–(S170), ensures
| (S175) |
and
| (S176) | |||||
Given (S169)–(S176), the left-hand side of (S173) equals
| (S177) | |||||
and the right-hand side of (S173) equals
| (S178) | |||||
Given (S173), comparing the first and second rows of (S177) and (S178) ensures that
| for all , we have | |||||
| (S179) | |||||
| (S180) |
Proof of Lemma S11(iiib) for :
When , (S5.1) simplifies to
| (S189) |
Given by assumption, letting in (S189) ensures
| (S190) |
as a constraint on analogous to (S184). Plugging (S190) back in (S189) ensures
| (S191) |
analogous to (S187). This ensures
| for all with , we have , | (S192) |
analogous to (S188).
In addition, that implies with . This, together with Lemma S11(ii), ensures
When , Lemma S11(i) ensures such that . When , plugging (S192) in (S157) ensures that
The fundamental theorem of algebra ensures that takes at most 2 distinct values beyond , i.e., . The bound for then follows from .
∎
Remark S1.
S5.2 Proof of Proposition S4
We verify below Proposition S4 by induction.
Proof of the result for .
When , (S50) suggests
| (S193) | |||||
| (S194) |
for fixed constants . If , then (S193) reduces to so that takes at most distinct values. If , then (S193) implies . Plugging this in (S194) yields
as a cubic equation of . The fundamental theorem of algebra ensures that takes at most distinct values. This verifies the result for .
Proof of the result for .
Assume that the result holds for . We verify below the result for , where (S50) becomes
| (S195) |
Following Lemma S11, renew
The goal is to show that .
Proof of under (S197).
Let denote an element in with . Let denote the rank of with . Let
denote a partition of . The last equations in (S196) equal
| (S198) | |||||
where
S5.3 Proof of Proposition S5
We verify below Proposition S5 by induction.
Proof of the result for .
Assume is a scalar such that is linear in . Then there exists constants such that . By the fundamental theorem of algebra, takes at most distinct values.
Proof of the result for .
Assume that the result holds for . We verify below the result for . Assume is a vector such that all elements of
| (S215) |
are linear in with
| (S216) |
for constants . Without loss of generality, assume the coefficients for and are identical with
| (S217) |
Let
denote the solution set of (S216). To goal is to show that .
To this end, consider the last column of in (S215) that consists of . The corresponding part in (S216) is
and can be summarized in matrix form as
| (S218) | |||||
Let
denote the coefficient matrix of in the last rows of (S218). Let denote the set of eigenvalues of . Let
denote the set of values of across all solutions to (S216). Note that all solutions to (S216) must satisfy (S218). Applying Proposition S4 and Lemma S11(ii) to (S218) with treated as ensures
-
(i)
by Proposition S4.
- (ii)
These two observations together ensure
We show below when .
S5.3.1 when .
Let in (S216) to see
| (S219) |
Condition S1 below states the condition that the coefficients for in (S219) all equal zero. We verify below that
| (S222) | |||||
| (S225) |
These two parts together ensure .
Condition S1.
for .
Part I: Proof of (S222).
Part II: Proof of (S225).
First, (S216) ensures
| (S226) |
Letting in (S226) ensures that
| (S231) |
By induction, applying Proposition S5 to at ensures that
This ensures , and verifies the first line of (S225) when Condition S1 holds.
When Condition S1 does not hold, there exists such that . Without loss of generality, assume that . Letting in (S219) implies
| (S238) |
Plugging the expression of in (S238) back in (S231) ensures
By induction, applying Proposition S5 to at ensures that
| (S242) |
The expression of in (S238) further ensures that
| (S245) |
Observations (S242)–(S245) together ensure in the second line of (S225) when Condition S1 does not hold.
S5.3.2 when .
A reparametrization.
Let denote the th row of for with . Motivated by the first row of (S248), define as a reparametrization of with
| (S251) |
summarized as
Denote by
| (S252) |
the reparameterization of (S216) in terms of . The coefficients in (S252) are constants fully determined by ’s and , and satisfy
| (S253) |
under (S217). We omit their explicit forms because they are irrelevant to the proof. Let
denote the solution set of (S252). Let
denote a partition of , containing solutions to (S252) that have and , respectively. The definition of (S252) ensures
| (S256) |
Eq. (S256) ensures that
This, together with (S248) and from (S251), ensures that
| (S260) |
where denotes the th element of for .
A condition analogous to Condition S1.
Write (S252) as
| (S261) |
Plugging (S260) to the right-hand side of (S261) ensures that
| (S268) |
Divide combinations of for into nine blocks as follows:
| (S273) |
Given (S260), writing out for on the left-hand side of (S268) implies the following for combinations of in blocks (i)–(v) in (S273):
| for all with , we have | (S274) | ||
| (S280) |
Condition S2 below parallels Condition S1, and states the condition that all coefficients of in (S274) are zero. We show below
| (S283) | |||||
| (S286) |
These two parts together ensure .
Condition S2.
All coefficients of in (S274) are zero. That is,
Part I: Proof of (S283).
when Condition S2 holds.
Recall that for from (S253). Condition S2(i), (iii), and (v) together ensure
Therefore, when Condition S2 holds, the coefficients of are all zero in the linear expansions of in (S252). The corresponding part of (S252) reduces to
| (S291) |
In words, (S291) ensures that
By induction, applying Proposition S5 to at ensures that
Given that in at least one solution of to (S252), we have
| (S296) |
In addition, Condition S2(iv) ensures that
The linear expansions of in (S252) reduce to
implying
| (S299) |
In words, (S299) ensures that
This, together with (S296), ensures
| there are at most distinct solutions of to (S252) that | ||
| have , i.e., . |
This ensures from (S256).
when Condition S2 does not hold.
Recall from (S248) that
This ensures that
| for all with , we have | |||
| (S306) |
where and are elements of . Plugging (S5.3) in (S216) ensures that
|
for all with , we have
|
||
In words, this ensures that
By induction, applying Proposition S5 to at ensures
| (S311) |
Part II: Proof of (S286).
Let denote the set of values of across all solutions to (S216) that have . The first line in (S248) ensures that
This ensures such that it suffices to show that
A useful fact is that (S268) ensures
| for all with , we have | |||
| (S315) |
when Condition S2 holds.
In words, (S5.3) implies that
By induction, applying Proposition S5 to at ensures that
This, together with the correspondence of and from (S256), ensures that
We next improve the bound by one when Condition S2 does not hold.
when Condition S2 does not hold.
When Condition S2 does not hold, at least one coefficient of in (S274) is nonzero. This ensures that there exists constants such that
Without loss of generality, assume that such that
| (S321) |
Plugging (S321) in (S5.3) ensures that
| for all with , we have | ||||
| for . |
In words, (S5.3) ensures that
By induction, applying Proposition S5 to at ensures that
| across all with , the corresponding take at most distinct values. | (S329) |
This, together with (S321), ensures that
It then follows from (S256) that .