Interpretable Aesthetic Analysis Model for Intelligent Photography Guidance Systems
Abstract.
An aesthetics evaluation model is at the heart of predicting users’ aesthetic experience and developing user interfaces with higher quality. However, previous methods on aesthetic evaluation largely ignore the interpretability of the model and are consequently not suitable for many human-computer interaction tasks. We solve this problem by using a hyper-network to learn the overall aesthetic rating as a combination of individual aesthetic attribute scores. We further introduce a specially designed attentional mechanism in attribute score estimators to enable the users to know exactly which parts/elements of visual inputs lead to the estimated score. We demonstrate our idea by designing an intelligent photography guidance system. Computational results and user studies demonstrate the interpretability and effectiveness of our method.
1. Introduction
Aesthetic experience has been celebrated for evoking unusual cognitive and affective emotions for thousands of years (Kant, 1790; Dewey, 1958; Goodman, 1976), and it is not surprising that aesthetics is closely related to our appreciation of the interaction with computers (Tractinsky, 1997; Tullis, 1981; Aspillaga, 1991; Toh, 1998; Szabo and Kanuka, 1999; Heines, 1984; Grabinger, 1993). As a result, predicting users’ aesthetic experience becomes a critical component for many real-world human-computer interaction applications, such as user interface design (Ngo et al., 2003), image retrieval (Westerman et al., 2007), photography guidance (Wu and Jia, 2021), image cropping (Wang and Shen, 2017), photo enhancement (Bhattacharya et al., 2010), photo management (Datta et al., 2007), etc. Central to such a prediction model is an aesthetic quality evaluation algorithm estimating the aesthetic quality for the visual input.
Some previous works base their aesthetic evaluation models on hand-crafted features. For example, image quality is estimated according to basic visual features like global edge distribution (Ke et al., 2006), color distribution (Ke et al., 2006; Aydın et al., 2014), blurriness (Tong et al., 2004), sharpness (Aydın et al., 2014), depth (Aydın et al., 2014), and saliency (Wu et al., 2010; Tang et al., 2013; Zhang et al., 2014), while features like overall density, local density, grouping, and layout complexity (Tullis, 1997; Streveler and Wasserman, 1984; Ngo et al., 2003) are utilized to evaluate user interfaces aesthetically. Hand-crafted features exploit domain and expert knowledge, but it is largely unclear whether these features are effective and powerful enough for modelling the complicated and intertwined human aesthetic standards.
To automatically extract features with a high representational capacity for aesthetic evaluation, deep learning (LeCun et al., 2015) methods have been extensively studied. These methods typically include a convolutional neural network as a learnable feature extractor, followed by several fully-connected layers for aesthetic score prediction. Researchers design special schemes such as multi-column architecture (Lu et al., 2015a; Zhang, 2016; Kao et al., 2016), multi-task training (Kong et al., 2016; Wang et al., 2016a), and adaptive spatial pooling (Mai et al., 2016) and obtain state-of-the-art prediction performance on large-scale aesthetics testbeds (Murray et al., 2012; Kong et al., 2016).
Despite these achievements, existing methods largely lack interpretability and are more like a black box directly mapping inputs to aesthetic scores. These methods may be sufficient for applications like recommendation but become especially problematic when it comes to some human-computer interaction applications, where users care more about why they get the score and how they can improve their work accordingly. For example, a previous photography guidance system (Wu and Jia, 2021, Tumera) evaluates the aesthetic quality of current images in the viewfinder, giving scores for different aesthetic attributes like composition and color vividness. A low score reminds users of poor photo composition or color but contains little information about how to improve it. Similarly, a novice user interface designer may wonder how to redesign the interface when getting feedback saying that the density of the layout can be improved.
Closing this gap between current methods and the expectation is challenging. Detailed suggestions require fine-grained aesthetic analysis of the visual input. We pinpoint the following drawbacks of existing methods that prevent interpretability. First, current methods predict overall and attribute (lighting, composition, etc.) aesthetic scores separately (Kong et al., 2016; Ngo et al., 2003) and cannot judge which attributes contribute more to the overall aesthetic evaluation. Users may focus on minor shortcomings when refining their work. Second, to improve a specific aesthetic attribute, users need to know how different elements or regions in the input contribute to the attribute score. Existing methods cannot provide such information. Consequently, users may modify the wrong part without improving the aesthetic quality.
In this paper, we solve these challenges by proposing an interpretable aesthetic evaluation model. Novelties include: (1) We propose a learnable linear combination and decompose the overall aesthetic score as a combination of individual attribute scores. The advantage is that each attribute will be given a weight quantifying how much it contributes to overall aesthetic quality. Given that different attributes are typically intertwined, we generate the parameters of the linear decomposition by a hyper-network (Ha et al., 2016) conditioned on the global image, which automatically learns the interrelationship between attributes by back-propagation. (2) An attentional module is introduced into the attribute score predictor. In this way, predictors attend to different input regions when evaluating different attributes. The attention mask highlights regions or elements that significantly influence the evaluation result. We further optimize the mutual information between attended regions and attribute scores to obtain more a more accurate attentional model.
We demonstrate our idea by designing an interactive photography guidance system, Tumera+. Tumera+ users get timely feedback during shooting reminding them of the most significant shortcomings of current photos. Aesthetic scores, detailed explanations, and suggestions on how to improve will be given when requested. We provide visualization results to demonstrate that our method enables aesthetic interpretability by synergizing feature extraction, feature attention, and aesthetics regression in a unified model. User studies are carried out and proves that the enhanced interpretability largely improves the quality of photography taken by users.
2. Related Works
Automatically assessing image aesthetic promote many real-world applications like image retrieve (Westerman et al., 2007), photography guidance (Wu and Jia, 2021), image cropping (Wang and Shen, 2017), photo enhancement (Bhattacharya et al., 2010), photo management (Datta et al., 2007), etc. Computationally modelling the process of human aesthetic experience is non-trivial. Challenges in judging the quality of an image include (Deng et al., 2017): (1) computationally analysing and modelling the entangled photographic rules, (2) knowing the aesthetic differences in different images types, such as portrait or scenery, and in different shooting techniques, such as depth of field and high-dynamic range, (3) obtaining a large amount of human-annotated data for training or testing.
Conventional approaches try to solve these problems with handcrafted features. Unsurprisingly, the design of these features requires a large amount of domain knowledge and engineering skill. Hand-designed features generally belong to one of the following four categories. (1) Basic visual features, including global edge distribution (Ke et al., 2006), color distribution (Ke et al., 2006; Aydın et al., 2014), hue count (Ke et al., 2006), low-level contrast (Tong et al., 2004; Ke et al., 2006) and brightness (Ke et al., 2006), blurriness (Tong et al., 2004), sharpness (Aydın et al., 2014), depth (Aydın et al., 2014). Related to our work, previous research introduces visual attention mechanisms into image aesthetics evaluation (Sun et al., 2009; You et al., 2009). However, they apply attention to image saliency and do not model or provide interpretability to other aesthetic attributes and the overall aesthetic score. Aforementioned visual features can also be extracted locally from image regions that are potentially the most attractive to humans (Luo and Tang, 2008; Wong and Low, 2009; Nishiyama et al., 2011; Lo and Chen, 2012). (2) Composition features. Composition is typically related to the position of a salient object in an image. To make an object salient, one can adopt techniques like the rule of third, low depth of field, and opposing colors. Various handcrafted features (Bhattacharya et al., 2010; Dhar et al., 2011; Bhattacharya et al., 2011; Wu et al., 2010, 2010; Tang et al., 2013; Zhang et al., 2014) are designed to model this aesthetic aspect. (3) General-purpose features. These features are not specifically designed for aesthetic evaluation, such as scale-invariant feature transform (SIFT) (Yeh and Cheng, 2012), bag of word (BOV) words, and Fisher vector (FV) (Marchesotti et al., 2011, 2013; Murray et al., 2012). (4) Task-specific features. These features are designed specifically for a category of images. For example, Li et al. (2010) and Lienhard et al. (2015) design features for photos with faces, Su et al. (2011) and Yin et al. (2012) study landscape photos, and Sun et al. (2015) evaluate the visual quality of Chinese calligraphy.
Based on these features, heuristic rules (Aydın et al., 2014), SVMs (Datta et al., 2006; Luo and Tang, 2008; Wong and Low, 2009; Wu et al., 2010; Nishiyama et al., 2011; Dhar et al., 2011; Wu et al., 2010; Yin et al., 2012; Tang et al., 2013; Lienhard et al., 2015), SVR (Bhattacharya et al., 2010; Li et al., 2010; Bhattacharya et al., 2011), naive Bayes classifiers (Ke et al., 2006), boosting (Tong et al., 2004; Su et al., 2011), regression (Sun et al., 2009), and Gaussain mixture model (Marchesotti et al., 2011, 2013; Murray et al., 2012) are used to get the overall aesthetic score estimation. For detailed discussion of these methods, we refer readers to Deng et al. (2017).
Deep aesthetic models. Wang et al. (2016b) modify the AlexNet architecture for aesthetic evaluation. Specifically, the authors replace the fifth convolutional layer of AlexNet by a group of seven convolutional layers. The purpose is to better extract scene-specific features. Each of the seven convolutional layers is dedicated to one category of scene. The output from these layers are averaged and the whole architecture is trained end-to-end with backpropagation.
Tian et al. (2015) train an aesthetic model with a smaller fully-connected layer. They expect the deep model to extract useful features which can be classified by an SVM. Typical deep learning models require the input to have the same size. Therefore, images are usually resized or cropped before fed into the network. Visual features related to image aesthetics may be corrupted during this process. To solve this problem, Lu et al. (2015b) aggregate features of randomly selected image patches that are of the same size. Patches are directly fed into the CNN, so that the original aesthetic information is retained. Another attempt to deal with this information loss problem is adaptive spatial pooling (Mai et al., 2016). Another contribution of (Mai et al., 2016) is to adopt a multi-column CNN structure to deal with images with different scenes. Multi-column neural networks have also been used in aesthetics evaluation for global-local feature combination (Lu et al., 2015a), patch-global input tradeoff (Zhang, 2016), and separate object-scene-texture processing (Kao et al., 2016).
Kong et al. (2016) present a dataset containing around 10,000 images, each with an overall aesthetic score and scores for 11 aesthetic attributes. The authors also propose a Siamese architecture which takes two images as input and outputs a rank of the images. It is shown that such a training scheme can help distinguish images with similar aesthetic quality. Our work is orthogonal to the aforementioned works involving deep learning. One can easily integrate our methods into these model and expect enhanced interpretability. On the other hand, introducing these models into our framework can further improve the accuracy of the proposed learning architecture.
Similar to our work, Wang et al. (2016a) predict different style attributes and use them as the input to a final CNN for predicting the overall score distribution. The difference between this work and ours lies in three aspects. (1) We use a hyper-network to incorporate global information of the image when predicting the overall score, which makes a better use of the interrelationship among attributes. (2) We directly predict attribute scores instead of features to better use label information. (3) We use an attentional mechanism when predicting the attribute scores, improving the interpretability of our model for better interaction experience.
Apart from image aesthetic evaluation, it has been found that interface aesthetics greatly influence system acceptability (Tractinsky, 1997; Kurosu and Kashimura, 1995), comprehensibility (Tullis, 1981, 1984), and productivity (Kelster and Gallaway, 1983; Aspillaga, 1991; Toh, 1998; Szabo and Kanuka, 1999; Heines, 1984; Grabinger, 1993). An aesthetic metric would be an essential aid of screen design. Previous work (Tullis, 1997; Streveler and Wasserman, 1984; Ngo et al., 2003) propose hand-crafted metrics, such as overall density, local density, grouping, and layout complexity, for alphanumeric displays. Sears (1993) proposes the concept of layout User appropriateness to assess whether the spatial layout is in harmony with the task. Rahman et al. (2021); Gupta et al. (2020) use a transformer for refining user interface layout aesthetics. Dou et al. (2019) use CNNs for predicting website aesthetics.
3. Aesthetic evaluation model
The major aim of our work is to enhance the interpretability of aesthetic evaluation models for a better user interaction experience. To this end, we focus on two novel functions of the evaluation model. (1) We propose to learn the overall aesthetic score as an input-dependent decomposition of individual attribute scores so that users know which attributes contribute the most to the overall aesthetic quality of the image. (2) For each attribute, we learn an attentional mask and let the model attend different input regions.Based on the learned attention mechanism, our model provides detailed explanations and suggestions accompanying the aesthetic evaluation.
In this paper, we focus on the aesthetic assessment of images, but our model can be easily extended to other applications, like user interface design. Fig. 1 shows the architecture of our learning framework.
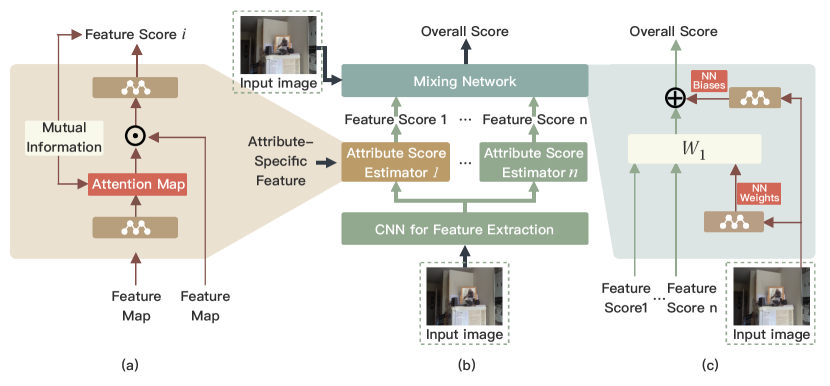
The proposed framework (Fig. 1 (b)) consists of three modules. The first part is a convolutional neural network (CNN) for feature extraction. Since we usually have a limited number of training samples with human-labeled aesthetic scores, it is not practical to learn the feature extractor from scratch. Thus we start from a pre-trained ResNet (He et al., 2016) for its proven ability to learn robust image representations that show ever-improving performance in the task of aesthetic evaluation (McCormack and Lomas, 2020; Jang and Lee, 2021; McCormack and Lomas, 2021). Feature maps extracted by the CNN are fed into attribute score estimators ,which output attribute scores. At the heart of these attribute estimators is a specially designed attentional mechanism that provides better interpretability. Estimated attribute scores are combined with a decomposition network to generate the overall aesthetic evaluation. The whole structure is differentiable and can be trained in an end-to-end fashion. In the following sections, we introduce the detailed structures for attribute score estimators and the decomposition network and also discuss the training scheme of our model.
3.1. Attribute Score Estimator
The aim of an attribute score estimator is to predict a score for one of the aesthetic attributes. In this paper, we consider eleven aesthetic attributes: , , , , , , , , , , and .
The major novelty here is (1) an attention module enabling the model (and the user) to attend different regions or elements when considering different attributes and (2) the way to train the attentional module. A separate attention module is trained for each of the attributes. The attention module is a fully-connected network with SoftMax activation at the last layer, parameterized by , takes the feature map generated by the feature extractor as input and outputs an attention mask , which has the same size as . The attention mask and the feature map are combined together by an element-wise multiplication. This attentional weighted feature map is fed into another network to predict the attribute score. Prediction losses are used to train the attention modules end-to-end (Sec.3.3).
Gradients induced by prediction losses may not contain much supervision information to get accurate attention maps. We thus introduce an information-theoretical regularizer to maximize the mutual information between attentional masks and the corresponding attribute scores:
| (1) |
where , , and are the random variable of attentional maps, attribute scores, and input images, respectively. We have that
| (2) |
While has been approximated by attribute score estimators, needs to be estimated. Therefore, we introduce a variational posterior estimator and get a lower bound of the mutual information objective:
| (3) | ||||
where the inequality holds because of the non-negativity of the KL divergence. The expectation operator here means that images are sampled from the training set and the attentional maps are generated by the attention module . Intuitively, this lower bound quantifies the difference of attribute scores with and without attentional maps, highlighting the influence of attentional masks.
To calculate the KL divergence, the output of the attention module needs to be a distribution over scores. To this end, we introduce a Gaussian distribution
| (4) |
where is a constant covariance matrix. In Sec. 3.3, we describe the training approach in detail.
3.2. Aesthetic Decomposition Network
To learn how much each attribute contributes to the overall aesthetic score, we propose to learn the overall score as a combination of individual attribute scores. Specifically, we propose to learn
| (5) |
where is the overall quality score, and is the score of the i- attribute. In this way, the overall score is represented as a linear combination of attribute scores. The question is how can we get the weights of this linear combination. Intuitively, the interrelationship between attributes is determined by the structure of the original image. Therefore, we adopt a hyper-network (Ha et al., 2016) to learn the linear combination parameters. This network is called ”hyper” because it generates the parameters of another function. Specifically, a network with a SoftMax activation after the last layer processes the input image and outputs a vector whose elements serve as the weights of the linear combination.
It is worth noting that gradients can flow through into the hyper-network, so that its parameters can be updated. On the other hand, gradients can also flow into attribute score estimators through . Therefore, the use of hyper-networks does not influence the end-to-end differentiability of the whole learning framework.
3.3. Training Scheme
Our model is trained by minimizing three losses. The first loss is to minimize the mean square error between the predicted aesthetic quality and the groundtruth :
| (6) |
where the expectation operator means that images are sampled from the training set . Similarly, the loss for minimizing the attribute score prediction error is given by:
| (7) |
where is the groundtruth score of the i- attribute provided by the dataset. In Eq. 6 and 7, attribute scores are sampled from the distribution (Eq. 4). We use the reparameterization trick (Kingma and Welling, 2014) to sample scores so that our framework is end-to-end differentiable.
For maximizing the mutual information objective, we minimize the following loss:
| (8) |
By introducing scaling factor and , the total loss for training our model is:
| (9) |
4. Demo Application: Intelligent Photography Assistant
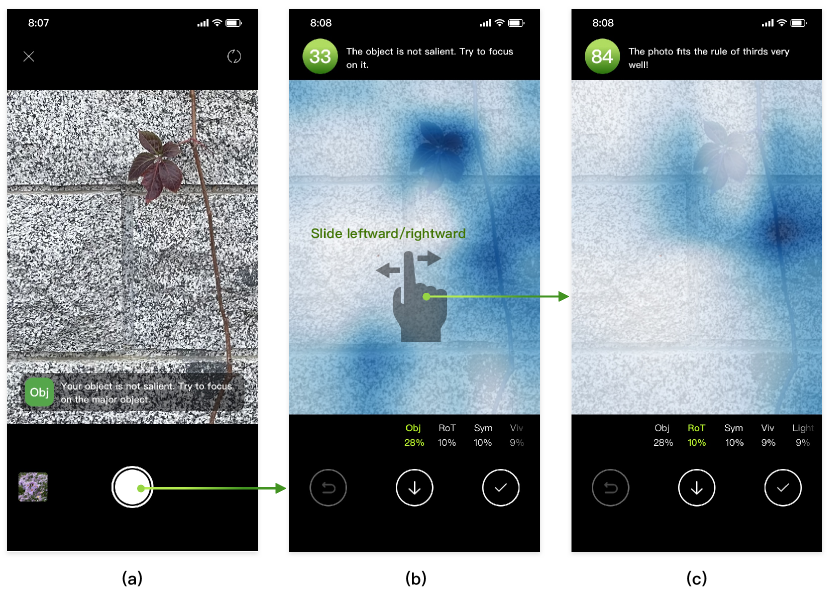
We apply our aesthetic model to an interactive photography guidance system. We also notice that our model can be used for other tasks like user interface design but leave it for future work. In this section, we describe our intelligent user interface for photography guidance. Based on the proposed aesthetic evaluation model, we design heuristics and provide users with brief prompts or detailed scores and suggestions according to their needs. Specifically, we design the following interfaces to provide users with various photography guidance.
4.1. Real-Time Prompts
Real-time prompts are immediate feedback provided during shooting (Fig. 2 left). The proposed aesthetic evaluation model runs asynchronously with the camera, requesting the image in the viewfinder every 0.5 second and evaluating their aesthetic quality. Based on the evaluation, our system prompts users to improve their photography by pointing out the disadvantages of current images. Trying not to be distracting, we select the attribute with the largest weight among all attributes whose score is below the overall score and show the information in the form of pop-up messages.
Messages are based on attribute scores and the image region indicated by the attention map. For example, for the attribute , if its score is below the overall score, we calculate the area to which the attentional module attends. If the area exceeds one-half of the entire image, the prompt would be Your object is too salient. Try to make it small. Otherwise, if the area is less than one-ninth of the entire image, the prompt would be Your object is not salient. Try to focus on the major object. For attribute , we translate the RGB values within the attentional map into HSV values and calculate the average chrominance. If the chrominance is too low, the prompt would be Highlighted color is not vivid. If the chrominance is too high, the prompt would be Highlighted color is too vivid. Similarly, we design heuristics for all the other attributes.
We note than such guidance is only possible with the learned attentional module. Otherwise, we only know whether an attribute contribute positively or negatively to the overall quality, but cannot give accurate messages with detailed explanations.
4.2. Detailed Feedback and Suggestions
Real-time prompts only give hints regarding the attribute that needs the most urgent attention, and users are unaware of the overall quality of the image as well as the information about other attributes. To makeup for this shortage, we provide detailed feedback and suggestion by designing the following interaction interfaces.
(1) Detailed suggestions. When the user presses the shutter button, the current image is sent to the evaluation model. Based on the returned results, we provide detailed feedback and suggestions. Specifically, we sort the attributes according to their weights. Then, users can slide their window leftward or rightward (Fig. 2 (b-c)) to see scores, attentional maps, and corresponding suggestions associated with different attributes. The same as real-time prompts, detailed suggestions are given by heuristics based on attribute scores and attentional maps. Users can better understanding the suggestions by looking at the attentional maps.
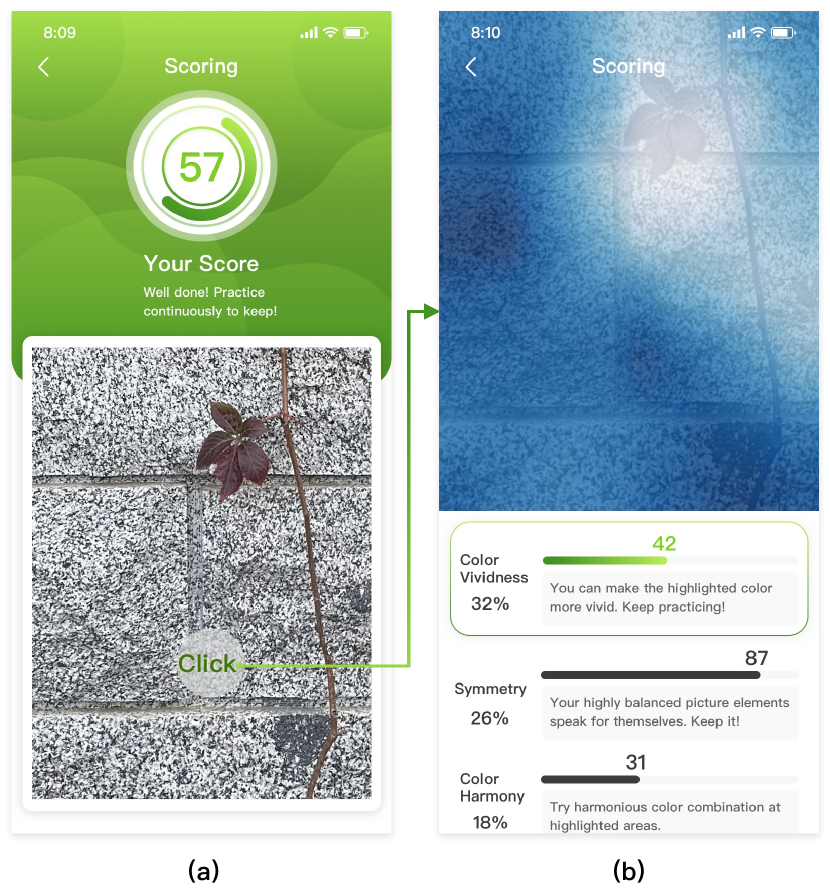
(2) Regional suggestions. To adjust their camera and get a better photo, users may need some regional evaluation. For example, in Fig. 3, a user may want to know whether she should include the wall in the picture. To this end, we design a clicking interaction function. After a user clicks at a specific region of the image, we calculate the average attentional value within the region for each attribute. These average values are sorted so that we know which attributes are attending to this region. If more attributes with a large average attentional value contribute negatively to the overall photo quality, we would suggest the user to remove the region when they shoot the same scene again.

5. Experiments
In this section, we design experiments to answer the following two questions: (1) Whether our model can learn interpretable aesthetic evaluations. (Sec. 5.3) (2) Does the learned evaluation model align with judgements of photography experts. (Sec. 5.4) In Sec. 6, we carry out user studies to test whether our photography guidance system can help improve the quality of users’ photos.
5.1. Image Aesthetic Datasets
We train our model on the public image aesthetic datasets AADB (Kong et al., 2016). This dataset includes 10,000 images in total. Each image in the dataset has an overall aesthetic quality rating and attribute assessments provided by five different individual raters. These attribute assessments cover the 11 attributes considered in this paper. Original images are presented in this dataset with different sizes. To fit our model, we resize the images to . Although we can use previous methods (Lu et al., 2015b; Mai et al., 2016) to avoid image resizing and preserve more original aesthetic-related image features, our focus in this paper is on interpretability and we leave these for future work.
5.2. Training Setups
We set the loss weight to and to and train the model for epochs with a mini-batch of size . Optimization is carried out by an Adam optimizer (Kingma and Ba, 2015) with a learning rate of . An early stop mechanism is adopted to adopt model overfitting – we stop training when the total loss (Eq. 9) does not decrease in consecutive epochs. We clip gradients with a norm larger than 5 to avoid dramatic network changes.
A pre-trained ResNet with 101 layers is used for feature extraction. We do not use the fully-connected layers of the pre-trained model because the downstream task is different. The extracted feature maps are of the size . For the attentional module, we generate the attentional map via a fully-connected neural network with a hidden layer of units and ReLU activation. The extracted image features are also fed into the hyper-network for generating the weights of the linear transformation for individual attribute scores. The hyper-network is a three-layer fully-connected network with ReLU activation. The two hidden layers have and units, respectively.
5.3. Interpretable Aesthetic Model
We show our model’s evaluation of an image from the AADB dataset in Fig. 4. The left column shows the original image and the overall aesthetic score (both overall and attribute scores are in the range in all of our experiments, but they are transformed linearly to the range in our photography guidance system) estimated by our model. The rest columns show the attention masks and scores corresponding to each aesthetic attribute.
We can observe that the rating of this image is not very high. From the attribute weights shown in the right, we can see that four attributes—, , , and —have the most significant influence on the final score by accounting for over of the total weight. Among them, has the largest weight but contribute negatively to the overall score. The corresponding attention mask indicates which part of the image leads to the rating. As the mask highlights the ground and sky, we know that a more salient object will improve the rating of . The attribute has the lowest score among attributes with large weights. The model mainly attends to the sky when estimating this score. The negative score and the attentional mask together suggest that the sky is not interesting and could be removed for better score.
Among the attributes with large weights, and contribute positively to the final score. The attentional masks explain why the attribute scores are positive. We can see that, in the original image, the cloud is clear and free of blur, and the object texture is of good quality, which explain why the model assigns positive scores.
For other attributes with negligible weights, we can see that our model still learns meaningful attentional masks, though the corresponding attribute scores do not influence the final evaluation significantly. For example, our model attends to the salient object in this image when evaluating whether the image conforms to the rule of thirds (attribute ). The attribute attentional mask sits at the horizontal line dividing the lower third of the photo from the upper two thirds.
Similar results generally hold for most pictures in the dataset. In Sec. 6, we further show that our model can also generalize to photos out of the training set by showing cases encountered by our users.
5.4. Expert Evaluation
To further test whether our model learns reasonable aesthetic evaluation metrics, we invite three photography experts, an advertising photographer, a photography graduate student, and a college photography teacher, to evaluate our model. Specifically, we show the experts with 10 pairs of photos and ask them to: (1) For each pair of image, choose the one with better overall aesthetic quality; (2) For each photo, select attributes which they think contribute the most to the overall quality; (3) For each pair of the image and each attribute, select the image with better attribute quality.
| Overall Score | Attribute Scores | Attribute Weights | |
| Expert #1 | 90% | 83.6% | 67.5% |
| Expert #2 | 70% | 73.6% | 62.5% |
| Expert #3 | 90% | 85.5% | 82.5% |
The expert data is then used to evaluate each of the prediction made by our model. (1) For the overall aesthetic score, we check whether the rank given by experts is the same as the one given by our model. Agreement degrees are shown in Table 1 (2) For the attribute weights, we check whether the most important attributes selected by our model align with the ones selected by experts. Overlap rates are shown in Table 1. (3) For the attribute scores, we check whether the rank given by experts agrees with our computational model. Agreement degrees are shown in Table 1.
We can see that the agreement degree is very high in terms of the overall score, with an average of among the three experts. The prediction of attribute scores also is also well aligned with the expert evaluation, achieving an average of among experts. The prediction of the most influential attributes is more challenging than the other two prediction tasks, which is because the aesthetic attributes are typically intertwined with each other. Despite the difficulty, our model achieves an average agreement degree of with the experts. These results verify the effectiveness of our method.
6. User Study
Having described our aesthetic model architecture and the results in terms of computational evaluation, we then carry out user studies to see whether our system can improve the aesthetic quality of photos taken by users.
We recruit volunteers to use our system. The number of male and female volunteers are equal, and they are between 21-60 years old. Since our system aims to provide guidance, volunteers are mainly beginners in photography and do not include professional photographers. Volunteers are asked to photograph a scene for two times, without and with the guidance of our system, respectively. Volunteers can freely decide which scene they want to photograph.
Table 2 shows the scores estimated by our aesthetic model for photos taken by users before and after the guidance of Tumera+. We can see that 9 out of all 10 volunteers are able to improve photo quality with the guidance of Tumera+. The improvements of score distribute from to , with an average of . These results demonstrate that our system can help users obtain photos of higher quality.
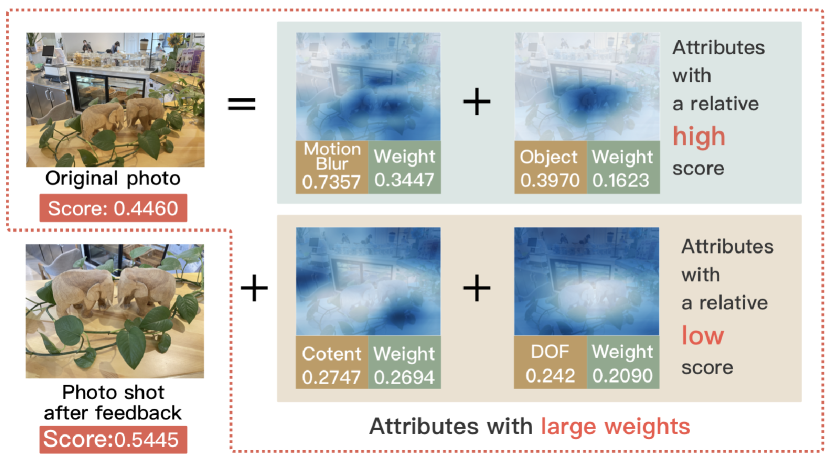
In Fig. 5, we show an example pair of photos shot by one volunteer. At upper-left is the photo shot before using Tumera+. Based on the attribute scores and attentional maps shown in the right, we give the suggestions ”The highlighted content is not very interesting.” and ”Improve the depth of field by blurring or removing the highlighted area”. The suggestions, scores, and attentional maps are shown to the volunteer. Guided by the feedback, the volunteer is able to take a photo (lower-left) of better quality.
We invite three photography experts (the same as who we invite for computational experiments in Sec. 5) to evaluate whether the quality of photos indeed improves. Results are shown in the last three lines of Table 2. We observe a great alignment between expert judgements and the evaluation given by our system. All experts agree that at least 8 photos shot after our system’s guidance are better. We show the detailed results of Tumera+ on the tested photo pairs and the corresponding evaluations of experts and participants online111https://sites.google.com/view/iui1170.
| Volunteer | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| Before | 0.253 | 0.446 | 0.314 | 0.217 | 0.365 | 0.265 | 0.322 | 0.452 | 0.212 | 0.374 |
| After | 0.249 | 0.544 | 0.379 | 0.395 | 0.375 | 0.306 | 0.504 | 0.524 | 0.224 | 0.407 |
| Diff. | -1.58% | 21.97% | 20.70% | 82.03% | 2.74% | 15.47% | 56.52% | 15.93% | 5.66% | 8.82% |
| Expert #1 | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Expert #2 | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||
| Expert #3 | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
7. Conclusion
In this paper, we improve visual aesthetic evaluation models by introducing interpretability so that their applicability to human-computer interaction applications is enhanced. To this end, (1) we learn to decompose the overall aesthetic score as a combination of attribute scores so that we know the contribution of each attribute; (2) we introduce a specially-designed attentional mechanism into predictors so that the contribution of different image regions and elements are explainable. We demonstrate our idea by designing an intelligent photography guidance system. Although we focus on image aesthetic evaluation in this paper, our model is expected to be extended to other tasks like user interface design. We plan to explore this direction in future work.
References
- (1)
- Aspillaga (1991) Macarena Aspillaga. 1991. Screen design: Location of information and its effects on learning. Journal of Computer-Based Instruction 18, 3 (1991), 89–92.
- Aydın et al. (2014) Tunç Ozan Aydın, Aljoscha Smolic, and Markus Gross. 2014. Automated aesthetic analysis of photographic images. IEEE transactions on visualization and computer graphics 21, 1 (2014), 31–42.
- Bhattacharya et al. (2010) Subhabrata Bhattacharya, Rahul Sukthankar, and Mubarak Shah. 2010. A framework for photo-quality assessment and enhancement based on visual aesthetics. In Proceedings of the 18th ACM international conference on Multimedia. 271–280.
- Bhattacharya et al. (2011) Subhabrata Bhattacharya, Rahul Sukthankar, and Mubarak Shah. 2011. A holistic approach to aesthetic enhancement of photographs. ACM Transactions on Multimedia Computing, Communications, and Applications (TOMM) 7, 1 (2011), 1–21.
- Datta et al. (2006) Ritendra Datta, Dhiraj Joshi, Jia Li, and James Z Wang. 2006. Studying aesthetics in photographic images using a computational approach. In European conference on computer vision. Springer, 288–301.
- Datta et al. (2007) Ritendra Datta, Jia Li, and James Z Wang. 2007. Learning the consensus on visual quality for next-generation image management. In Proceedings of the 15th ACM international conference on Multimedia. 533–536.
- Deng et al. (2017) Yubin Deng, Chen Change Loy, and Xiaoou Tang. 2017. Image aesthetic assessment: An experimental survey. IEEE Signal Processing Magazine 34, 4 (2017), 80–106.
- Dewey (1958) John Dewey. 1958. Experience and nature. Vol. 471. Courier Corporation.
- Dhar et al. (2011) Sagnik Dhar, Vicente Ordonez, and Tamara L Berg. 2011. High level describable attributes for predicting aesthetics and interestingness. In CVPR 2011. IEEE, 1657–1664.
- Dou et al. (2019) Qi Dou, Xianjun Sam Zheng, Tongfang Sun, and Pheng-Ann Heng. 2019. Webthetics: quantifying webpage aesthetics with deep learning. International Journal of Human-Computer Studies 124 (2019), 56–66.
- Goodman (1976) Nelson Goodman. 1976. Languages of art: An approach to a theory of symbols. Hackett publishing.
- Grabinger (1993) R Scott Grabinger. 1993. Computer screen designs: Viewer judgments. Educational Technology Research and Development 41, 2 (1993), 35–73.
- Gupta et al. (2020) Kamal Gupta, Alessandro Achille, Justin Lazarow, Larry Davis, Vijay Mahadevan, and Abhinav Shrivastava. 2020. Layout Generation and Completion with Self-attention. arXiv preprint arXiv:2006.14615 (2020).
- Ha et al. (2016) David Ha, Andrew Dai, and Quoc V Le. 2016. Hypernetworks. In Proceedings of the International Conference on Learning Representations (ICLR).
- He et al. (2016) Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition. 770–778.
- Heines (1984) Jesse M Heines. 1984. Screen design strategies for computer-assisted instruction. Digital Press.
- Jang and Lee (2021) Hyeongnam Jang and Jong-Seok Lee. 2021. Analysis of Deep Features for Image Aesthetic Assessment. IEEE Access 9 (2021), 29850–29861.
- Kant (1790) Immanuel Kant. 2000 [orig. 1790]. Critique of the Power of Judgment. Cambridge University Press.
- Kao et al. (2016) Yueying Kao, Kaiqi Huang, and Steve Maybank. 2016. Hierarchical aesthetic quality assessment using deep convolutional neural networks. Signal Processing: Image Communication 47 (2016), 500–510.
- Ke et al. (2006) Yan Ke, Xiaoou Tang, and Feng Jing. 2006. The design of high-level features for photo quality assessment. In 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), Vol. 1. IEEE, 419–426.
- Kelster and Gallaway (1983) Richard S Kelster and Glen R Gallaway. 1983. Making software user friendly: An assessment of data entry performance. In Proceedings of the Human Factors Society Annual Meeting, Vol. 27. SAGE Publications Sage CA: Los Angeles, CA, 1031–1034.
- Kingma and Ba (2015) Diederik P Kingma and Jimmy Ba. 2015. Adam: A method for stochastic optimization. In Proceedings of the International Conference on Learning Representations (ICLR).
- Kingma and Welling (2014) Diederik P Kingma and Max Welling. 2014. Stochastic gradient VB and the variational auto-encoder. In Second International Conference on Learning Representations, ICLR, Vol. 19. 121.
- Kong et al. (2016) Shu Kong, Xiaohui Shen, Zhe Lin, Radomir Mech, and Charless Fowlkes. 2016. Photo aesthetics ranking network with attributes and content adaptation. In European Conference on Computer Vision. Springer, 662–679.
- Kurosu and Kashimura (1995) Masaaki Kurosu and Kaori Kashimura. 1995. Apparent usability vs. inherent usability: experimental analysis on the determinants of the apparent usability. In Conference companion on Human factors in computing systems. 292–293.
- LeCun et al. (2015) Yann LeCun, Yoshua Bengio, and Geoffrey Hinton. 2015. Deep learning. nature 521, 7553 (2015), 436–444.
- Li et al. (2010) Congcong Li, Andrew Gallagher, Alexander C Loui, and Tsuhan Chen. 2010. Aesthetic quality assessment of consumer photos with faces. In 2010 IEEE International Conference on Image Processing. IEEE, 3221–3224.
- Lienhard et al. (2015) Arnaud Lienhard, Patricia Ladret, and Alice Caplier. 2015. Low level features for quality assessment of facial images. In 10th International Conference on Computer Vision Theory and Applications (VISAPP 2015). 545–552.
- Lo and Chen (2012) Li-Yun Lo and Ju-Chin Chen. 2012. A statistic approach for photo quality assessment. In 2012 International Conference on Information Security and Intelligent Control. IEEE, 107–110.
- Lu et al. (2015a) Xin Lu, Zhe Lin, Hailin Jin, Jianchao Yang, and James Z Wang. 2015a. Rating image aesthetics using deep learning. IEEE Transactions on Multimedia 17, 11 (2015), 2021–2034.
- Lu et al. (2015b) Xin Lu, Zhe Lin, Xiaohui Shen, Radomir Mech, and James Z Wang. 2015b. Deep multi-patch aggregation network for image style, aesthetics, and quality estimation. In Proceedings of the IEEE international conference on computer vision. 990–998.
- Luo and Tang (2008) Yiwen Luo and Xiaoou Tang. 2008. Photo and video quality evaluation: Focusing on the subject. In European Conference on Computer Vision. Springer, 386–399.
- Mai et al. (2016) Long Mai, Hailin Jin, and Feng Liu. 2016. Composition-preserving deep photo aesthetics assessment. In Proceedings of the IEEE conference on computer vision and pattern recognition. 497–506.
- Marchesotti et al. (2011) Luca Marchesotti, Florent Perronnin, Diane Larlus, and Gabriela Csurka. 2011. Assessing the aesthetic quality of photographs using generic image descriptors. In 2011 international conference on computer vision. IEEE, 1784–1791.
- Marchesotti et al. (2013) Luca Marchesotti, Florent Perronnin, and France Meylan. 2013. Learning beautiful (and ugly) attributes.. In BMVC, Vol. 7. 1–11.
- McCormack and Lomas (2020) Jon McCormack and Andy Lomas. 2020. Understanding aesthetic evaluation using deep learning. arXiv preprint arXiv:2004.06874 (2020).
- McCormack and Lomas (2021) Jon McCormack and Andy Lomas. 2021. Deep learning of individual aesthetics. Neural Computing and Applications 33, 1 (2021), 3–17.
- Murray et al. (2012) Naila Murray, Luca Marchesotti, and Florent Perronnin. 2012. AVA: A large-scale database for aesthetic visual analysis. In 2012 IEEE Conference on Computer Vision and Pattern Recognition. IEEE, 2408–2415.
- Ngo et al. (2003) David Chek Ling Ngo, Lian Seng Teo, and John G Byrne. 2003. Modelling interface aesthetics. Information Sciences 152 (2003), 25–46.
- Nishiyama et al. (2011) Masashi Nishiyama, Takahiro Okabe, Imari Sato, and Yoichi Sato. 2011. Aesthetic quality classification of photographs based on color harmony. In CVPR 2011. IEEE, 33–40.
- Rahman et al. (2021) Soliha Rahman, Vinoth Pandian Sermuga Pandian, and Matthias Jarke. 2021. RUITE: Refining UI Layout Aesthetics Using Transformer Encoder. In 26th International Conference on Intelligent User Interfaces. 81–83.
- Sears (1993) Andrew Lee Sears. 1993. Layout appropriateness: guiding user interface design with simple task descriptions. Ph. D. Dissertation. University of Maryland, College Park.
- Streveler and Wasserman (1984) Dennis J Streveler and Anthony I Wasserman. 1984. Quantitative measures of the spatial properties of screen designs. In Proceedings of the IFIP TC13 First International Conference on Human-Computer Interaction. 81–89.
- Su et al. (2011) Hsiao-Hang Su, Tse-Wei Chen, Chieh-Chi Kao, Winston H Hsu, and Shao-Yi Chien. 2011. Scenic photo quality assessment with bag of aesthetics-preserving features. In Proceedings of the 19th ACM international conference on Multimedia. 1213–1216.
- Sun et al. (2015) Rongju Sun, Zhouhui Lian, Yingmin Tang, and Jianguo Xiao. 2015. Aesthetic visual quality evaluation of Chinese handwritings. In Twenty-Fourth International Joint Conference on Artificial Intelligence.
- Sun et al. (2009) Xiaoshuai Sun, Hongxun Yao, Rongrong Ji, and Shaohui Liu. 2009. Photo assessment based on computational visual attention model. In Proceedings of the 17th ACM international conference on Multimedia. 541–544.
- Szabo and Kanuka (1999) Michael Szabo and Heather Kanuka. 1999. Effects of violating screen design principles of balance, unity, and focus on recall learning, study time, and completion rates. Journal of educational multimedia and hypermedia 8, 1 (1999), 23–42.
- Tang et al. (2013) Xiaoou Tang, Wei Luo, and Xiaogang Wang. 2013. Content-based photo quality assessment. IEEE Transactions on Multimedia 15, 8 (2013), 1930–1943.
- Tian et al. (2015) Xinmei Tian, Zhe Dong, Kuiyuan Yang, and Tao Mei. 2015. Query-dependent aesthetic model with deep learning for photo quality assessment. IEEE Transactions on Multimedia 17, 11 (2015), 2035–2048.
- Toh (1998) SC Toh. 1998. Cognitive and motivational effects of two multimedia simulation presentation modes on science learning. Unpublished Ph. D. thesis, University of Science Malaysia (1998).
- Tong et al. (2004) Hanghang Tong, Mingjing Li, Hong-Jiang Zhang, Jingrui He, and Changshui Zhang. 2004. Classification of digital photos taken by photographers or home users. In Pacific-Rim Conference on Multimedia. Springer, 198–205.
- Tractinsky (1997) Noam Tractinsky. 1997. Aesthetics and apparent usability: empirically assessing cultural and methodological issues. In Proceedings of the ACM SIGCHI Conference on Human factors in computing systems. 115–122.
- Tullis (1981) Thomas S Tullis. 1981. An evaluation of alphanumeric, graphic, and color information displays. Human Factors 23, 5 (1981), 541–550.
- Tullis (1984) Thomas Stuart Tullis. 1984. Predicting the usability of alphanumeric displays. Ph. D. Dissertation. Rice University.
- Tullis (1997) Thomas S Tullis. 1997. Screen design. In Handbook of human-computer interaction. Elsevier, 503–531.
- Wang and Shen (2017) Wenguan Wang and Jianbing Shen. 2017. Deep cropping via attention box prediction and aesthetics assessment. In Proceedings of the IEEE International Conference on Computer Vision. 2186–2194.
- Wang et al. (2016b) Weining Wang, Mingquan Zhao, Li Wang, Jiexiong Huang, Chengjia Cai, and Xiangmin Xu. 2016b. A multi-scene deep learning model for image aesthetic evaluation. Signal Processing: Image Communication 47 (2016), 511–518.
- Wang et al. (2016a) Zhangyang Wang, Shiyu Chang, Florin Dolcos, Diane Beck, Ding Liu, and Thomas S Huang. 2016a. Brain-inspired deep networks for image aesthetics assessment. arXiv preprint arXiv:1601.04155 (2016).
- Westerman et al. (2007) Steve J Westerman, S Kaur, C Dukes, and J Blomfield. 2007. Creative industrial design and computer-based image retrieval: The role of aesthetics and affect. In International Conference on Affective Computing and Intelligent Interaction. Springer, 618–629.
- Wong and Low (2009) Lai-Kuan Wong and Kok-Lim Low. 2009. Saliency-enhanced image aesthetics class prediction. In 2009 16th IEEE International Conference on Image Processing (ICIP). IEEE, 997–1000.
- Wu and Jia (2021) Xiaoran Wu and Jia Jia. 2021. Tumera: Tutor of Photography Beginners. arXiv preprint arXiv:2109.11365 (2021).
- Wu et al. (2010) Yaowen Wu, Christian Bauckhage, and Christian Thurau. 2010. The good, the bad, and the ugly: Predicting aesthetic image labels. In 2010 20th International Conference on Pattern Recognition. IEEE, 1586–1589.
- Yeh and Cheng (2012) Mei-Chen Yeh and Yu-Chen Cheng. 2012. Relative features for photo quality assessment. In 2012 19th IEEE International Conference on Image Processing. IEEE, 2861–2864.
- Yin et al. (2012) Wenyuan Yin, Tao Mei, and Chang Wen Chen. 2012. Assessing photo quality with geo-context and crowdsourced photos. In 2012 Visual Communications and Image Processing. IEEE, 1–6.
- You et al. (2009) Junyong You, Andrew Perkis, Miska M Hannuksela, and Moncef Gabbouj. 2009. Perceptual quality assessment based on visual attention analysis. In Proceedings of the 17th ACM international conference on Multimedia. 561–564.
- Zhang (2016) Luming Zhang. 2016. Describing human aesthetic perception by deeply-learned attributes from flickr. arXiv preprint arXiv 1605 (2016).
- Zhang et al. (2014) Luming Zhang, Yue Gao, Roger Zimmermann, Qi Tian, and Xuelong Li. 2014. Fusion of multichannel local and global structural cues for photo aesthetics evaluation. IEEE Transactions on Image Processing 23, 3 (2014), 1419–1429.
Appendix A Questionnaire for Expert Evaluation
In this section, we present part of the questionnaire completed by Expert #1. The questionnaire requests the expert to compare the two images shown in a row, select five attributes which they think are the most influential to the final aesthetic evaluation, and how these attributes contribute (positively or negatively) to the overall aesthetic quality. These results are used to calculate the agreement degree between the expert evaluations and the assessments provided by our system.

