Interpretable Transformer Hawkes Processes: Unveiling Complex Interactions in Social Networks
Abstract.
Social networks represent complex ecosystems where the interactions between users or groups play a pivotal role in information dissemination, opinion formation, and social interactions. Effectively harnessing event sequence data within social networks to unearth interactions among users or groups has persistently posed a challenging frontier within the realm of point processes. Current deep point process models face inherent limitations within the context of social networks, constraining both their interpretability and expressive power. These models encounter challenges in capturing interactions among users or groups and often rely on parameterized extrapolation methods when modeling intensity over non-event intervals, limiting their capacity to capture intricate intensity patterns, particularly beyond observed events. To address these challenges, this study proposes modifications to Transformer Hawkes processes (THP), leading to the development of interpretable Transformer Hawkes processes (ITHP). ITHP inherits the strengths of THP while aligning with statistical nonlinear Hawkes processes, thereby enhancing its interpretability and providing valuable insights into interactions between users or groups. Additionally, ITHP enhances the flexibility of the intensity function over non-event intervals, making it better suited to capture complex event propagation patterns in social networks. Experimental results, both on synthetic and real data, demonstrate the effectiveness of ITHP in overcoming the identified limitations. Moreover, they highlight ITHP’s applicability in the context of exploring the complex impact of users or groups within social networks. Our code is available at https://github.com/waystogetthere/Interpretable-Transformer-Hawkes-Process.git.
1. Introduction
Event sequences are pervasive in social networks (Zhang et al., 2022a; Kong et al., 2023), including platforms such as Stack Overflow, Amazon, and Taobao. Understanding and mining these event sequences to uncover interactions between different users or groups within social networks is a critical research topic (Zipkin et al., 2016; Farajtabar et al., 2015). This analysis can help identify influential users, user groups, and trending topics, offering practical insights for platform optimization and user engagement strategies (Zhao et al., 2015; Zhou et al., 2013). For instance, consider the Stack Overflow platform, where developers ask and answer questions related to programming. Event sequences in this context could consist of events such as question postings, answers, comments, and votes. Analyzing this data can reveal insights into user interactions.
Temporal point processes (TPP) (Daley and Vere-Jones, 2003) play a fundamental role in modeling event sequences. The Poisson process (Daley and Vere-Jones, 2007), a basic temporal point process, assumes that events occur uniformly and independently over time. Besides, the Hawkes process (Hawkes, 1971) is an extension of the Poisson process that allows for event dependencies. While these models have been useful in many scenarios, they may not always capture the complexities present in real-world event sequences, which often exhibit more intricate dependencies and interactions. Therefore, more sophisticated and flexible models are needed.
With the advancement of deep learning, deep architectures have demonstrated remarkable performance in modeling sequence data. For example, models utilizing either vanilla RNN (Du et al., 2016) or long short-term memory (LSTM) networks (Mei and Eisner, 2017) have exhibited improved likelihood fitting and event prediction compared to earlier parameterized models. Moreover, models relying on transformer architectures or self-attention mechanisms (Zuo et al., 2020; Zhang et al., 2020) have shown even better performance. These deep learning approaches have opened up new possibilities for effectively capturing intricate patterns within event sequences, enhancing the overall predictive accuracy and efficiency in various applications.
However, current deep point process models still have some inherent limitations, which restrict the interpretability and expressive power. Firstly, such models are unable to explicitly capture the interactions between different event types. Deep point process models often model interactions between event types implicitly, which may hinder their interpretability due to the lack of explicit representation for these interactions. Understanding the interactions between different event types is crucial in social networks. For example, on Amazon, event sequences encompass a wide range of user activities, which can be considered events of various types, including product searches, purchases, reviews, and recommendations. Analyzing the interactions among these types can yield valuable insights into user-level and product-level interactions, providing Amazon with strategic advantages. Secondly, most existing deep point process models only perform encoding for the positions where events have occurred. For non-event intervals, intensity functions are modelled using parameterized extrapolation methods. For examples, Eq. (11) in Du et al. (2016), Eq. (7) in Mei and Eisner (2017), and Eq. (6) in Zuo et al. (2020). This approach introduces a parameterized assumption, which restricts the model’s expressive power.
In order to address the aforementioned issues, we propose a novel interpretable TPP model based on Transformer Hawkes processes (THP). The proposed model aligns THP perfectly with the statistical nonlinear Hawkes processes, greatly enhancing the interpretability. Thus, we refer to this enhanced model as interpretable Transformer Hawkes processes (ITHP). In ITHP, the attention mechanism’s product of the historical event’s key and the subsequent event’s query corresponds precisely to a time-varying trigger kernel in the statistical nonlinear Hawkes processes. By establishing a clear correspondence with statistical Hawkes processes, ITHP offers valuable insights into the interactions between different event types. This advancement is significant for enhancing the interpretability of THP in social network applications. Meanwhile, for the intensity function over non-event intervals, we do not adopt a simple parameterized extrapolation method. Instead, we utilize a “fully attention mechanism” to express the conditional intensity function at any position. This improvement increases the flexibility of the intensity function over non-event intervals, consequently elevating the model’s expressive power. Specifically, our contributions are as follows:
-
•
ITHP explicitly captures interactions between event types, providing insights into interactions and improving model interpretability;
-
•
ITHP’s fully attention mechanism for the conditional intensity function over non-event intervals enhances model flexibility, allowing it to capture complex intensity patterns beyond the observed events;
-
•
ITHP is validated with synthetic and real social network data, demonstrating its superior ability to interpret event interactions and outperform alternatives in expressiveness.
2. Related Work
Enhancing the expressive power of point process models has long been a challenging endeavor. Currently, mainstream approaches fall into two categories. The first approach entails the utilization of statistical non-parametric methods to augment their expressive capacity. For instance, methodologies grounded in both frequentist and Bayesian nonparametric paradigms are employed to model the intensity function of point processes (Lewis and Mohler, 2011; Zhou et al., 2013; Lloyd et al., 2015; Donner and Opper, 2018; Zhou et al., 2020a, 2021; Pan et al., 2021). The second significant category is deep point process models. These models harness the capabilities of deep learning architectures to infer the intensity function from data, including RNNs (Du et al., 2016), LSTM (Mei and Eisner, 2017; Xiao et al., 2017b), Transformers (Zuo et al., 2020; Zhang et al., 2020, 2022b), normalizing flow (Shchur et al., 2020b), adversarial learning (Xiao et al., 2017a; Noorbakhsh and Rodriguez, 2022), reinforcement learning (Upadhyay et al., 2018), deep kernel (Okawa et al., 2019; Zhu et al., 2021; Dong et al., 2022), and intensity-free frameworks (Shchur et al., 2020a). These architectural choices empower the modeling of temporal dynamics within event sequences and unveil the underlying patterns. However, in contrast to statistical point process models, the enhanced expressive power of deep point process models comes at the cost of losing interpretability, rendering deep point process models akin to “black-box” constructs. To the best of our knowledge, there has been limited exploration into explicitly capturing interactions between event types and enhancing the interpretability of deep point process models (Zhou and Yu, 2023; Wei et al., 2023). This paper introduces an innovative attention-based ITHP model, whose intensity function aligns seamlessly with statistical nonlinear Hawkes processes, substantially enhancing the interpretability. Our work serves as a catalyst for advancing the interpretability of deep point process models, greatly promoting their utility in uncovering interactions between different users or groups within social networks.
3. Preliminary Knowledge
In this section, we provide some background knowledge on some relevant key concepts.
3.1. Hawkes Process
The multivariate Hawkes process (Hawkes, 1971) is a widely used temporal point process model for capturing interactions among multiple event types. The key feature of the multivariate Hawkes process lies in its conditional intensity function. The conditional intensity function for event type at time is defined as the instantaneous event rate conditioned on the historical information :
where is the base rate for event type and is the trigger kernel representing the excitation effect from event with type to with type . It expresses the expected number of occurrences of event type at time given the past history of events.
The interpretability of Hawkes processes stems from its explicit representation of event dependencies through the trigger kernel. The model allows us to quantify the impact of past events with different event types on the occurrence of a specific event, providing insights into the interactions between event types. As a result, the multivariate Hawkes process serves as a powerful tool in social network applications where understanding the interactions between event types (users or groups) is of utmost importance.
3.2. Nonlinear Hawkes Process
In contrast to the original Hawkes process, which assumes only non-negative trigger kernels (excitatory interactions) between events to avoid generating negative intensities, the nonlinear Hawkes process (Brémaud and Massoulié, 1996) offers a more flexible modeling framework by incorporating both excitatory and inhibitory effects among events. In the nonlinear Hawkes process, the conditional intensity function for event type at time is defined as:
where is a nonlinear mapping from to , ensuring the non-negativity of the intensity. Hence this trigger kernel can be positive (excitatory) or negative (inhibitory), thus enabling the modeling of complex interactions between different event types.
In the aforementioned models, the trigger kernel depends solely on the relative time , implying that the trigger kernel is shift-invariant. However, in dynamic Hawkes process models (Zhou et al., 2020b, a; Bhaduri et al., 2021; Zhou et al., 2022), the trigger kernel is further extended to vary with absolute time, denoted as . By incorporating the absolute time, the trigger kernel becomes capable of capturing time-varying patterns, offering the model more degrees of freedom in its representation.
3.3. Transformer Hawkes Process
Our work is built upon THP (Zuo et al., 2020), so we concisely introduce the framework of THP here. Given a sequence where each event is characterized by a timestamp and an event type , THP leverages two types of embeddings, namely temporal embedding and event type embedding, to represent these two kinds of information. To encode event timestamps, THP represents each timestamp using an embedding vector :
where is the -th entry of and . The collection of time embeddings is represented as . For encoding event types, the model utilizes a learnable matrix , where is the number of event types. For each event type , its embedding is computed as:
where is the one-hot encoding of the event type . The collection of type embeddings is . The final embedding is the summation of the temporal and event type embeddings:
| (1) |
where each row of represents the complete embedding of a single event in the sequence .
After embedding, the model focuses on learning the dependence among events using self-attention mechanism. The attention output is computed as:
where , , are the query, key and value matrices. Matrices , and are the learnable parameters. To preserve causality and prevent future events from influencing past events, we mask out the entries in the upper triangular region of .
Finally, the attention output is passed through a two-layer MLP to produce the hidden state :
where , , and are the learnable parameters. The -type conditional intensity function of THP is designed as:
| (2) |
where is the last event before , are learnable parameters, the nonlinear function is chosen to be softplus to ensure that the intensity is non-negative, is the transpose of the -th row of expressing the historical impact on event .
4. Interpretable Transformer Hawkes Processes
As mentioned earlier, THP has two prominent limitations: (1) THP implicitly model the dependency between events, which hinders the explicit representation of interactions between different event types and makes it challenging to understand the interactions among event types. (2) Like many other deep point process models, THP applies attention encoding only to the event occurrence positions, while using parameterized extrapolation methods to model the intensity on non-event intervals (the red term in Eq. 2). This approach introduces a parameterized assumption restricting the model’s expressive power.
To enhance the model’s interpretability and expressiveness, our work introduces modifications to the THP model. Specifically, we make modifications to (1) the event embedding, (2) the attention module and (3) the conditional intensity function in THP. Interestingly, the modified THP corresponds perfectly to the statistical nonlinear Hawkes processes. This leads to significantly improved interpretability and a better characterization of the interactions between event types. Additionally, new design of the conditional intensity function can avoid the restrictions imposed by parameterized extrapolation, enabling the model to effectively capture complex intensity patterns beyond the observed events.
In following sections, we outline the step-by-step process of modifying THP to achieve the aforementioned goals. For each modification, we provide theoretical proofs to demonstrate the rationality and validity of the respective changes.
4.1. Modified Event Embedding
In ITHP, we maintain the same temporal embedding and event type embedding methods as in THP. However, our modification lies in replacing the summation operation in Eq. 1 with concatenation:
| (3) |
The reason for this modification is that the original summation operation introduces a similarity between timestamps and event types (or vice versa) of the preceding and succeeding events. However, in statistical Hawkes processes, known for their interpretability, the interaction between two events is the magnitude of a kernel determined by the similarity (correlation) between their types and the similarity (distance) between their timestamps. No cross-similarity is introduced. To maintain a similar level of interpretability, we replace summation with concatenation here.
Theorem 4.1.
In Eq. 3, the concatenation operation enables us to explicitly capture the desired temporal and event type similarities, while simultaneously avoiding any cross-similarities between timestamps and event types.
Proof.
Suppose we define using concatenation, and in subsequent attention module computation, it is necessary to calculate the product to measure the similarity between different data points. The similarity between the -th point and the -th point can be expressed as follows:
Instead, if we define using addition, is as follows:
It is evident that by defining through concatenation, temporal and event type similarities are captured separately. Otherwise, the cross-similarities emerge. ∎
4.2. Modified Attention Module
In ITHP, we still use self-attention to capture the influences of historical events on subsequent events. However, unlike THP, in the modified attention module, we use distinct query and key matrices:
| (4) |
where the -th row of , , represents the historical influence on the -th event. The calculation of can be explicitly expressed as the summation over all events preceding event , where the attention weights are normalized by the softmax:
| (5) |
The reason for this modification is that after removing and , the attention weights can be simply represented as . Compared to the original , has a clearer physical meaning. In , the entry in the -th row and -th column can be expressed as a shift-invariant function . This representation allows for a more meaningful interpretation of the relationship between events. In contrast, does not achieve this clarity.
Theorem 4.2.
Proof.
When we use Eq. 3 to obtain and remove and in Eq. 4, the similarity between the -th and -th points, denoted as , is expressed as . If we assume that is even, can be further represented as:
where . It is clear that can be expressed as a shift-invariant function , with originating from , and the subscripts arising from . While retaining and leads to the following expression:
where the introduction of can once again introduce undesired cross-similarities and render the temporal similarity term unable to be expressed in a shift-invariant function form. ∎
Corollary 4.3.
Given Theorem 4.2, we can further simplify Eq. 5 as follows:
| (6) |
where is an dimensional vector function.
Proof.
According to Theorem 4.2, can be expressed as a shift-invariant function . After normalization through softmax in Eq. 5, we obtain satisfying . When multiplied by , yields a vectorized, time-varying and non-normalized function where the additional stems from the introduction of . ∎
4.3. Modified Conditional Intensity Function
The form of Eq. 6 naturally reminds us of the trigger kernel summation in statistical Hawkes processes. The only difference is that in Eq. 6 is a vector, whereas the trigger kernel in statistical Hawkes processes is a scalar function. Taking inspiration from this, we propose a more interpretable conditional intensity function:
| (7) | ||||
where is a learnable parameter used to aggregate the vector into a scalar value and is a learnable bias term. The newly designed conditional intensity aligns perfectly with the nonlinear Hawkes processes with a time-varying trigger kernel. The green term in Eq. 7 corresponds to the base rate in Section 3.2, the yellow term in Eq. 7 corresponds to the time-varying trigger kernel in Section 3.2, and the softplus function serves as a non-linear mapping ensuring the non-negativity of the intensity. This leads to improved interpretability as the trigger kernel can be explicitly expressed in our design, in contrast to the original THP.
4.4. Fully Attention-based Intensity Function
In point process model training with maximum likelihood estimation (MLE), it is vital to compute the intensity integral over the entire time domain, which requires modeling the intensity both at event positions and on non-event intervals. In the RNN-based deep point process models (Du et al., 2016; Mei and Eisner, 2017), due to the limitations of the RNN framework in solely modeling latent representations at event positions, the aforementioned works adopted parameterized extrapolation methods to model the intensity on non-event intervals, see Eq. (11) in (Du et al., 2016) and Eq. (7) in (Mei and Eisner, 2017). THP (Zuo et al., 2020) also adopted the same approach to model the intensity on non-event intervals (the red term in Eq. 2). However, we emphasize that attention-based deep point process models do not necessarily require the parameterized extrapolation methods to model the intensity on non-event intervals. Our design Eq. 7 employs the attention mechanism to model the intensity function whether it is at event positions or not. Therefore, we refer to it as a “fully attention-based intensity function”. The fully attention-based intensity function circumvents the limitations of parameterization and ensures that the model can effectively capture intricate intensity patterns at non-event positions, thus enhancing the model’s expressive power.
4.5. Model Training
For a given sequence on , the point process model training can be performed by the MLE approach. The log-likelihood of a point process is expressed in the following form:
| (8) |
where .
For ITHP, we estimate its parameters by maximizing the log-likelihood. Regarding the first term, we only need to compute the intensity function at event positions using Eq. 7. As for the second term, the intensity integral generally lacks an analytical expression. Here, we employ numerical integration by discretizing the time axis into a sufficiently fine grid and calculating the intensity function at each grid point using Eq. 7.
Complexity: The utilization of a fine grid does not significantly increase computational time. This is because the attention mechanism facilitates parallel computation of attention outputs for each point. This parallelized computation improves the scalability of ITHP. Parallel computation with more grid points would require additional memory. Fortunately, for one-dimensional temporal point processes, a large number of grids is not necessary. In subsequent experiments, all datasets can run smoothly with only 8GB memory.
5. Experiment
We assess the performance of ITHP using both synthetic and public datasets. With the synthetic dataset, our objective is to validate the interpretability of our model by accurately identifying the underlying ground-truth trigger kernel. For the public datasets, we conduct a comprehensive evaluation of ITHP by comparing its performance against popular baseline models. The goal here is twofold: to quantitatively demonstrate the superior expressive power of ITHP and to qualitatively analyze its interpretability on real datasets.
5.1. Synthetic Data
We validate the interpretability of ITHP using two sets of 2-variate Hawkes processes data. Each dataset is simulated from a 2-variate Hawkes processes described in Section 3.1, using the thinning algorithm (Ogata, 1998). Both datasets share a common base rate (), but they possess distinct trigger kernels:
-
•
Exponential Decay Kernel This kernel assumes that the influence of historical events decays exponentially as time elapses. The kernel function is given by: for , where is the source type and is the target type. Specifically, , , and for all .
-
•
Half Sinusoidal Kernel This kernel assumes the influence of historical events follows a sinusoidal pattern as time elapses and disappears when the interval surpasses . The kernel function is given by: for . Likewise, is the source type and is the target type. Specifically, , , and .
Further elaboration on the simulation process and statistical aspects of the synthetic dataset can be found in Appendix A.
 (a) Trigger Kernel Recover (Exp)
(a) Trigger Kernel Recover (Exp)
 (b) Trigger Kernel Recover (Sin)
(b) Trigger Kernel Recover (Sin)
 (c) Intensity Recover (Exp)
(c) Intensity Recover (Exp)
 (d) Intensity Recover (Sin)
(d) Intensity Recover (Sin)
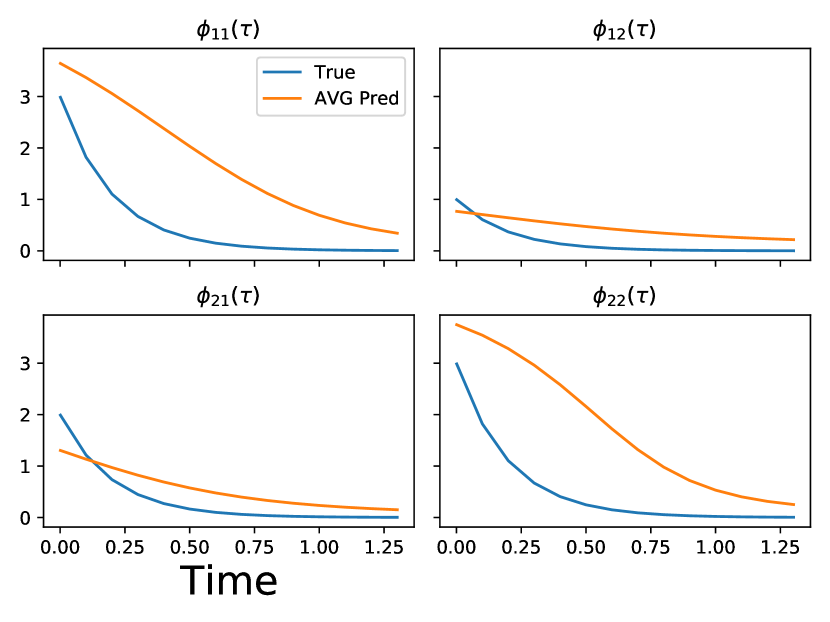
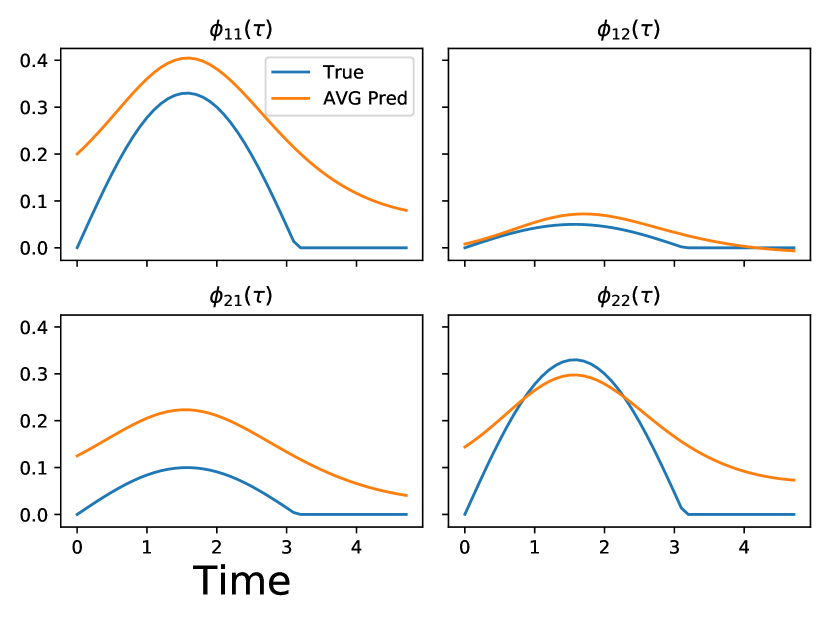
Results: We validate the interpretability of ITHP by reconstructing the trigger kernel. In ITHP, the trigger kernel is represented as , which is time-varying. To uncover the time-invariant trigger kernel inherent in the synthetic dataset, we evaluate trigger kernels at various time points and compute their mean. This approach enables us to extract the desired time-invariant trigger kernel (Zhang et al., 2020). The results are presented in Figs. 1 and 1, revealing a noticeable alignment between the learned kernel trends and the patterns exhibited by the ground-truth kernels. Moreover, as depicted in Figs. 1 and 1, the learned intensity function from ITHP exhibits a striking resemblance to the ground-truth intensity function. This observation underscores ITHP’s capability to accurately capture the true conditional intensity function for both exponential decay and half sinusoidal Hawkes processes.
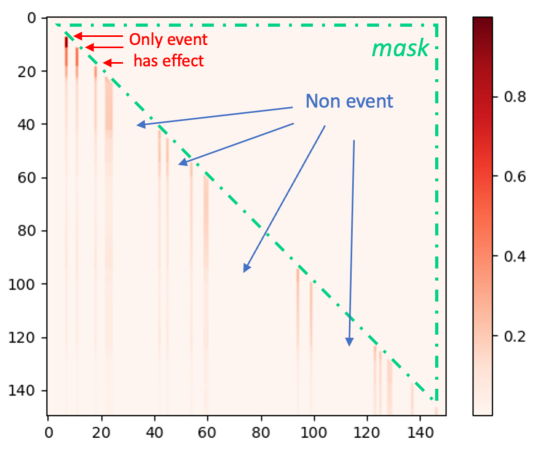
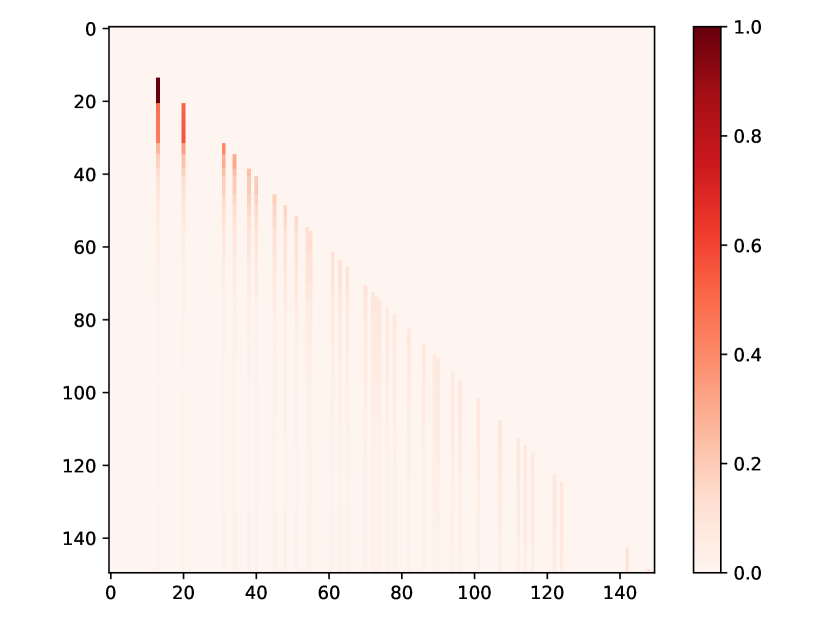
We also visualize the learned attention map of ITHP, which provides a deeper insight into the influence patterns. As depicted in Fig. 2, this is the attention weight matrix of a testing sequence in the context of exponential decay Hawkes process data. The sequence encompasses both event timestamps and grids within the non-event intervals. In the matrix, the rows and columns correspond to events and grids on the sequence (arranged chronologically). The horizontal axis represents the source point, while the vertical axis represents the target point. Only events have the potential to impact subsequent points, whereas grids, lacking actual event occurrences, cannot affect future points. As a result, it is evident that numerous columns corresponding to grids have values of . Due to a masking operation, the upper triangular section, including the diagonal, is set to , which restricts events from influencing the past. Moreover, the color of event columns becomes progressively lighter as time advances, which aligns with the characteristics of the ground-truth exponential decay trigger kernel.
5.2. Public Data
In this section, we extensively evaluate ITHP by comparing it to baseline models across several public datasets. We have selected several network-sequence datasets, including social media (StackOverflow), online shopping (Amazon, Taobao), traffic networks (Taxi), and a widely used public synthetic dataset (Conttime).
5.2.1. Datasets
We investigate five public datasets, each accompanied by a concise description. More details can be found in Appendix B.
-
•
StackOverflow111https://snap.stanford.edu/data/(Leskovec and Krevl, 2014): This dataset has two years of user awards on a question-answering website: StackOverflow. Each user received a sequence of badges (Nice Question, Good Answer, ) and there are kinds of badges.
-
•
Amazon222https://nijianmo.github.io/amazon/(Ni et al., 2019): This dataset includes user online shopping behavior events on Amazon website (browsing, purchasing, ) and there are in total event types.
-
•
Taobao333https://tianchi.aliyun.com/dataset/649(Zhu et al., 2018): This dataset is released for the 2018 Tianchi Big Data Competition and comprises user activities on Taobao website (browsing, purchasing, ) and there are in total event types.
-
•
Taxi444https://chriswhong.com/open-data/foil_nyc_taxi/(Whong, 2014): While our main focus is social networks, our model can also be applied to other domains. This dataset comprises traffic-network sequences, including taxi pick-up and drop-off incidents across five boroughs of New York City. Each borough, whether involved in a pick-up or drop-off event, represents an event type and there are in total event types.
-
•
Conttime(Mei and Eisner, 2017): This dataset is a popular public synthetic dataset designed for Hawkes processes, which comprises ten thousand event sequences with event types .
5.2.2. Baselines
In the experiments, we conduct a comparative analysis against the following popular baseline models:
-
•
RMTPP (Du et al., 2016) is a RNN-based model. It learns the representation of influences from historical events and takes event intervals as input explicitly.
-
•
NHP (Mei and Eisner, 2017) utilizes a continuous-time LSTM network, which incorporates intensity decay, allowing for a more natural representation of temporal dynamics without requiring explicit encoding of event intervals as inputs to the LSTM.
-
•
SAHP (Zhang et al., 2020) uses self-attention to characterize the influence of historical events and enhance its predictive capabilities by capturing intricate dependencies within the data.
-
•
THP (Zuo et al., 2020) is another attention-based model that utilizes Transformer to capture event dependencies while maintaining computational efficiency.
| Model | stackoverflow | amazon | taobao | taxi | conttime | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| TLL() | ACC() | TLL() | ACC() | TLL() | ACC() | TLL() | ACC() | TLL() | ACC() | |
| RMTPP | ||||||||||
| NHP | ||||||||||
| SAHP | ||||||||||
| THP | ||||||||||
| ITHP | ||||||||||
| Ex-ITHP | ||||||||||
5.2.3. Metrics
We assess ITHP and other baseline models using two distinct metrics:
-
•
TLL: the log-likelihood on the test data which quantifies the model’s ability to capture the underlying data distribution and effectively predict future events.
-
•
ACC: the event type prediction accuracy on the test data which characterizes the model’s accuracy in predicting the specific types of events, thereby gauging its capacity to discriminate between different event categories.
5.2.4. Quantitative Analysis
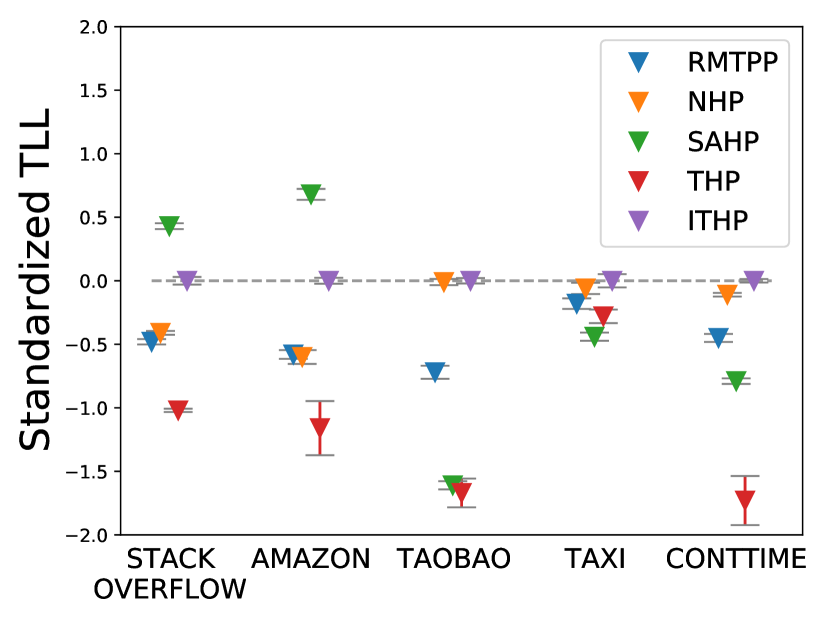
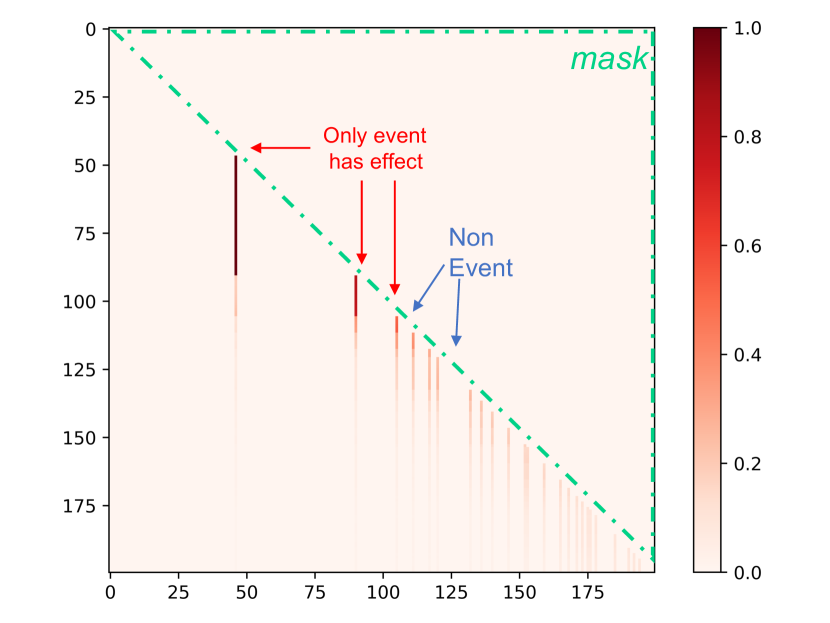
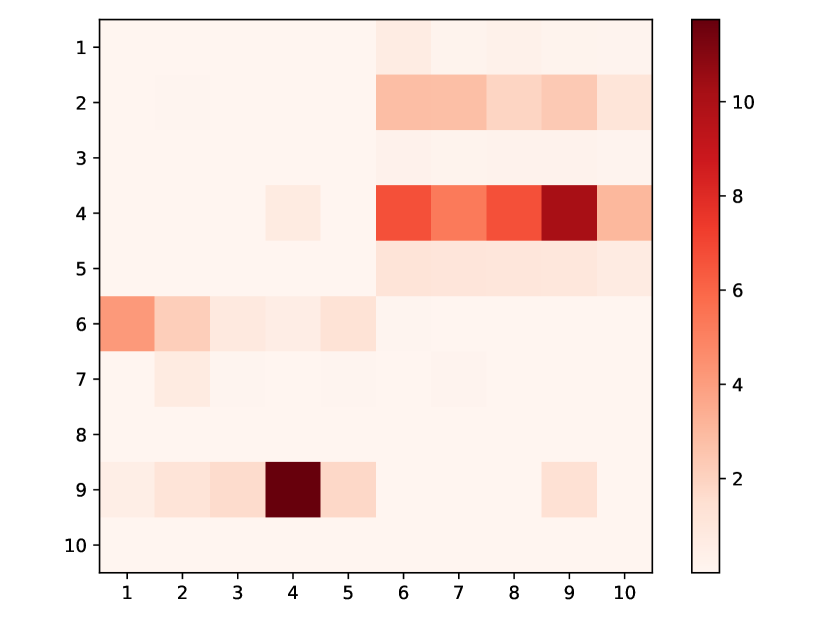
We conduct a comparative experiment across five datasets using all baseline models. The results, as shown in Table 1, demonstrate that ITHP can achieve competitive performance. A more intuitive visualization is presented in Fig. 3, where each model’s TLL is standardized by subtracting the TLL of ITHP. It is worth noting that, to achieve interpretability, ITHP undergoes a certain degree of simplification, resulting in a reduction of its number of parameters. Interestingly, we observe that ITHP achieves comparable performance to other models with larger number of parameters. ITHP can equivalently be regarded as a non-parametric, time-varying, and nonlinear statistical Hawkes process. The results in Fig. 3 provide some reflections: while deep point processes claim to outperform statistical point processes, it is evident that a sufficiently flexible (non-parametric, time-varying, and nonlinear) statistical point process can also achieve competitive performance. Furthermore, ITHP maintains excellent interpretability, both at the event level and the event type level. Fig. 3 displays the attention weight matrix of a testing sequence from StackOverflow, illustrating the impact between events: the influence from past events tends to decrease as time elapsed. Moreover, ITHP can describe the influence functions between event types. Take StackOverflow as an example: Fig. 3 presents the learned influence functions from types 1,3,4,5,9,12 to type 4, which is the most prevalent type. Generally, these influences tend to decay over time.
 (a) TLL Comparison
(a) TLL Comparison
 (b) Attention Map (StackOverflow)
(b) Attention Map (StackOverflow)
 (c) Estimated (StackOverflow)
(c) Estimated (StackOverflow)
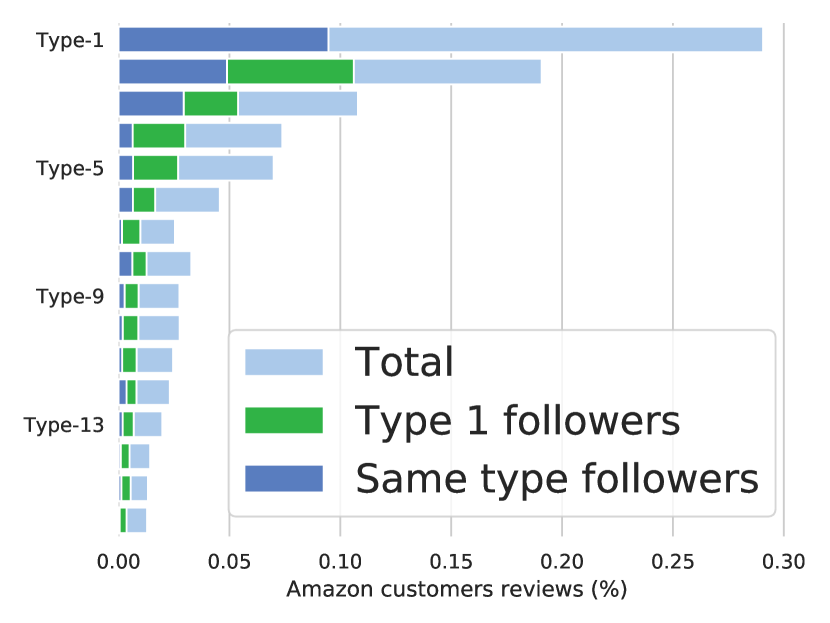 (d) Amazon Statistics
(d) Amazon Statistics
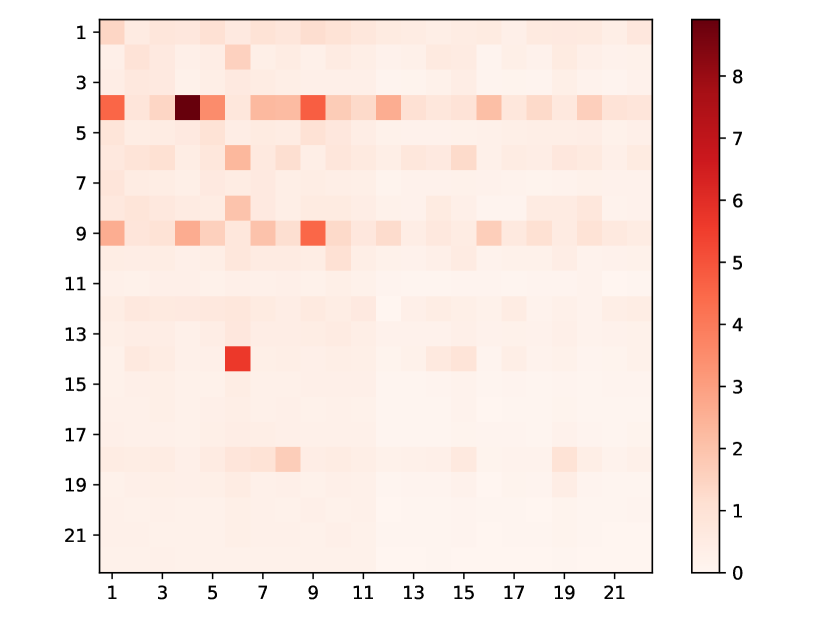 (e) Heatmap of StackOverflow
(e) Heatmap of StackOverflow
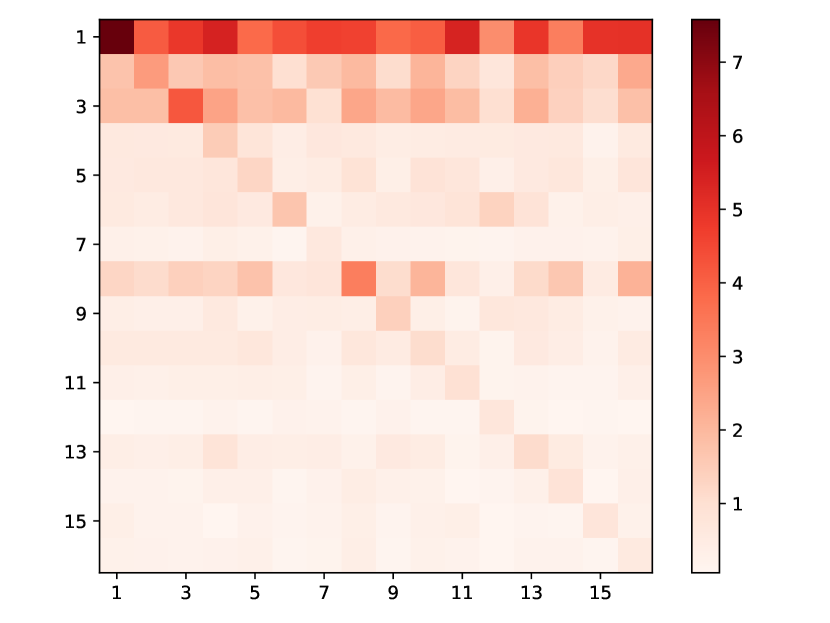 (f) Heatmap of Amazon
(f) Heatmap of Amazon
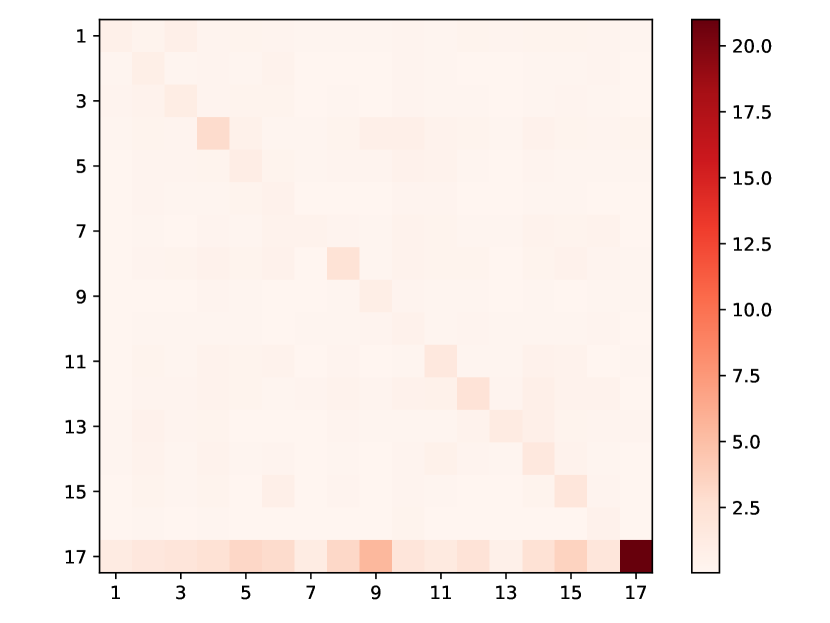 (g) Heatmap of Taobao
(g) Heatmap of Taobao
 (h) Heatmap of Taxi
(h) Heatmap of Taxi
5.2.5. Qualitative Analysis
Our model can provide useful insights into the interaction among event types. To demonstrate this, we first quantify the magnitude of influence between event types. We compute for each influence function, representing the extent of influence from type (source type) to type (target type). Specifically, each learned is a scalar and can be demonstrated in heat maps. In this section, we analyse these datasets by looking into their learned heat maps: Figs. 3, 3, 3 and 3.
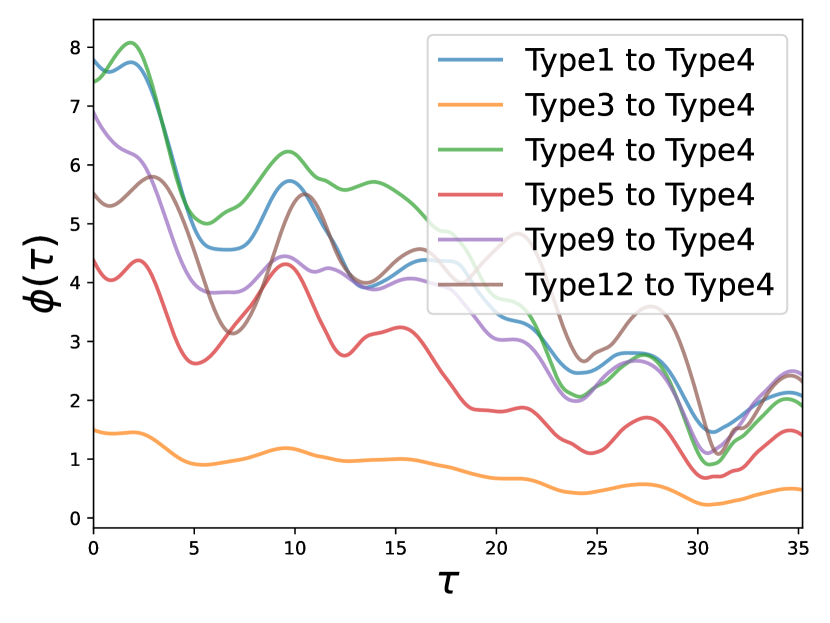
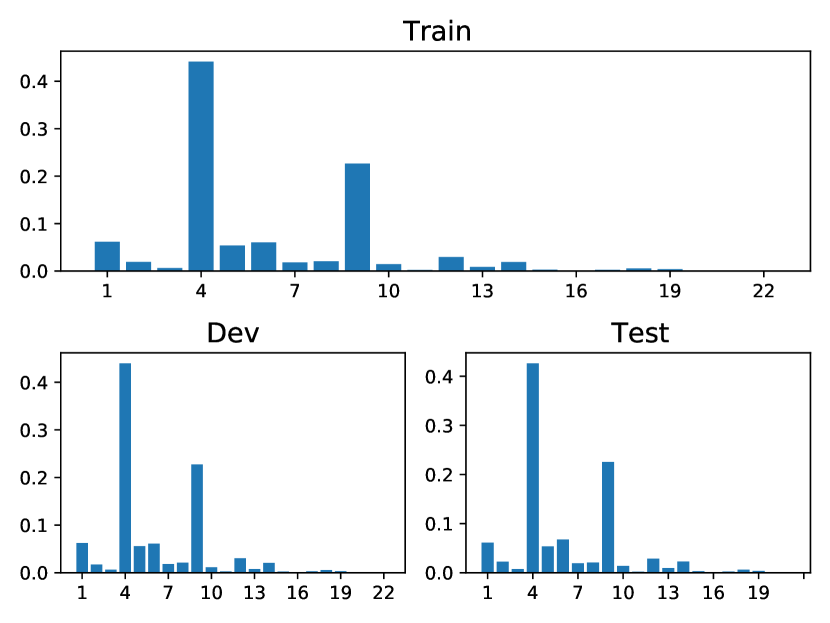
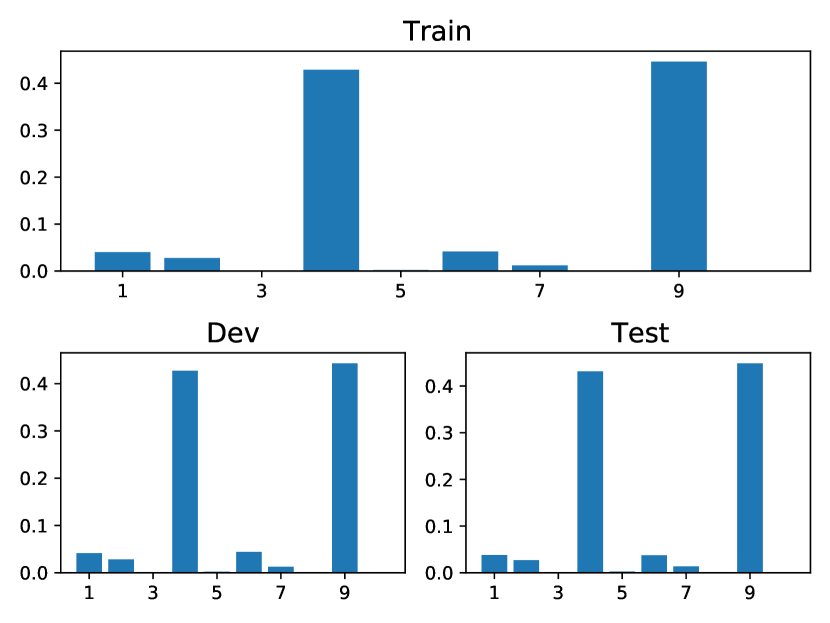
StackOverflow: In this dataset, there are 22 event types related to “badges” awarded to users based on their actions. As depicted in Fig. 3, many of these types have a strong positive influence on both type 4 (“Popular Question”) and type 9 (“Notable Question”). This observation aligns with the fact that “Popular Question” and “Notable Question” are the two most frequent events. Our model captures this trend and associates a significant positive impact from other types to them. Furthermore, a noticeable link between type 6 (“Nice Answer”, awarded when a user’s answer first achieves a score of 10) and type 14 (“Enlighten”, given when a user’s answer reaches a score of 10) is identified, which have nearly identical meanings. This mirrors the real-world progression from receiving a “Nice Answer” badge to later earning an “Enlighten” badge. This congruence demonstrates that our model accurately captures the dataset’s characteristics and effectively highlights the interplay between different event types.
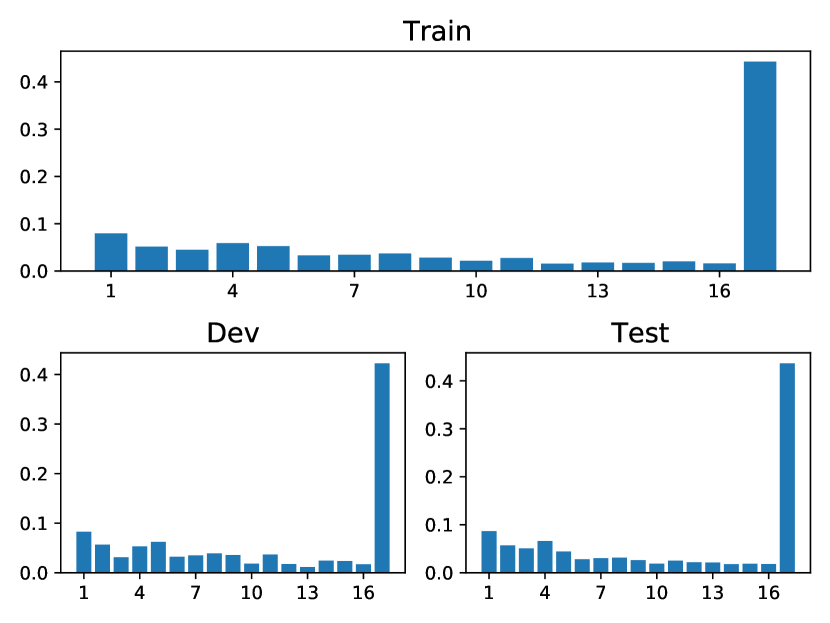
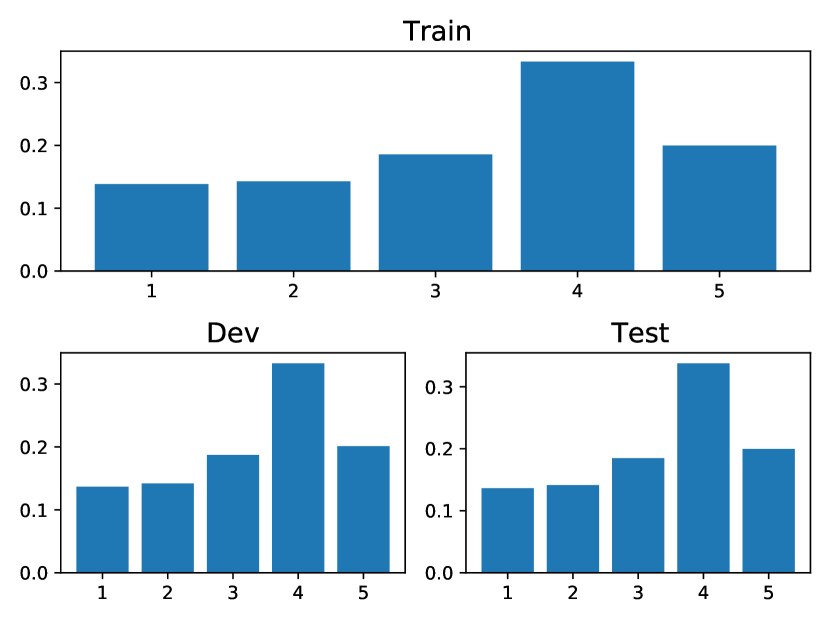
Amazon, Taobao: Both of these datasets pertain to customer behavior on shopping platforms and share some commonalities. Each event type represents a category of the browsing item (Taobao) or purchased item (Amazon), with Taobao having types and Amazon having types. The learned heat maps are presented in Figs. 3 and 3. Interestingly, our model uncovers two common insights: (1) The dark diagonals observed indicate strong self-excitation for each type. This suggests customers tend to browse items of the same category consecutively in a short period. In Taobao and Amazon, with over 15 types in total, there are approximately and of events involving subsequent events of the same type. This behavior reflects how customers often browse items of the same category in a short period to decide which one to purchase. Additionally, Amazon’s subscription purchases exemplify this pattern: vendors offer extra savings to customers who subscribe. These items are then regularly scheduled for delivery. (2) In Figs. 3 and 3, rows 1 and 17 appear the darkest, indicating that these two types receive the most significant excitation from others. In reality, these two categories are the most prevalent in their respective datasets, implying that they should also have the highest intensity. What our model learns aligns empirically with the ground truth patterns in the datasets. Moreover, we conducted a statistical analysis on Amazon in Fig. 3, calculating the percentages of various event types (“Total”), the percentages of the next event being of the same type (“Same type follower”), and the percentages of the next event being of type 1 (“Type 1 follower”). It is evident that the latter two constitute a significant portion (), indicating strong self-excitation effects and a pronounced exciting effect on type 1, which aligns with the learned heatmap in Fig. 3.
Taxi: In this dataset, there are 10 types of events representing taxi pick-up and drop-off across the five boroughs of New York City. Types 1-5 categorize “drop-off” actions, whereas types 6-10 correspond to “pick-up” actions in the respective boroughs. The learned heatmap (Fig. 3) reveals three key insights: (1) Among the “drop-off” actions (types 1-5), type 4 experiences the most significant influence from types 6-10 (“pick-up”). This aligns with the fact that type 4 (drop-off in Manhattan) is the most common drop-off event, accounting for over and thereby possessing the highest intensity. (2) The “pick-up” and “drop-off” events always occur alternately. One driver can’t pick up or drop off consecutively. As Fig. 3 shows, type 6-10 (“pick-up”) have much more excitation on type 1-5 (“drop-off”) rather than on themselves because a “pick-up” action will stimulate a consecutive “drop-off” action rather than another “pick-up” action. Likewise, type 1-5 have much less excitation on themselves. (3) Type 9 and 4, pick-ups and drop-offs in Manhattan, display the most significant mutual influence, as indicated by the two darkest cells in Fig. 3. This is consistent because most pick-up () and drop-off () actions occur in Manhattan. Furthermore, these two types always occur in tandem: of passengers picked up in Manhattan are also dropped off there, and of drivers who complete a trip in Manhattan will pick up their next customer within the same borough. This behavior is a clear short-term pattern captured by our model and is evident in the dataset.
5.3. Ablation Study
Our model has reduced the parameter count but still achieves comparable or even better results compared to THP. This improvement is attributed to the “fully attention-based intensity function” (Section 4.4). THP relies on the parameterized extrapolated intensity, assuming that the intensity function on non-event intervals follows an approximately linear pattern (red term in Eq. 2). However, such an assumption does not align with the actual patterns in real data and can impact the expressive capability of the model. We conduct further ablation studies to illustrate the limitations of the parameterized extrapolation method in Table 1. We implement an extra revised model Ex-ITHP which essentially is “interpretable Transformer” + “extrapolated intensity”. More details about Ex-ITHP is provided in Appendix C. THP, ITHP, and Ex-ITHP naturally constitute an ablation study. Ex-ITHP has fewer parameters as it removes the parameters and , and uses a less flexible extrapolated intensity. In Table 1, the Ex-ITHP exhibits the poorest performance due to its fewer parameters and restricted intensity flexibility. THP performs moderately, having more parameters but still restricted intensity flexibility. Conversely, the ITHP, despite having fewer parameters, outperforms THP on most datasets owing to its more flexible intensity expression.
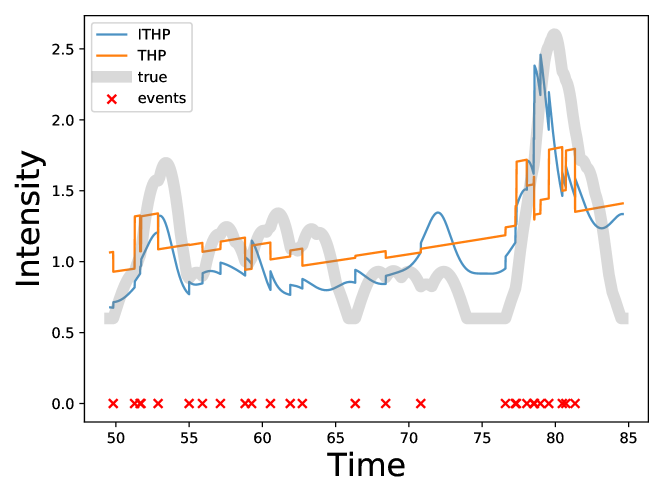
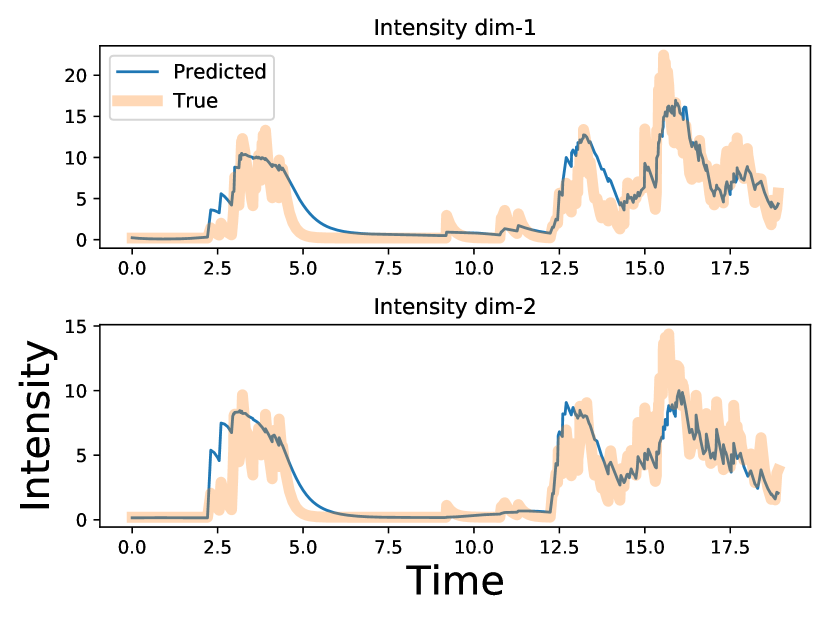
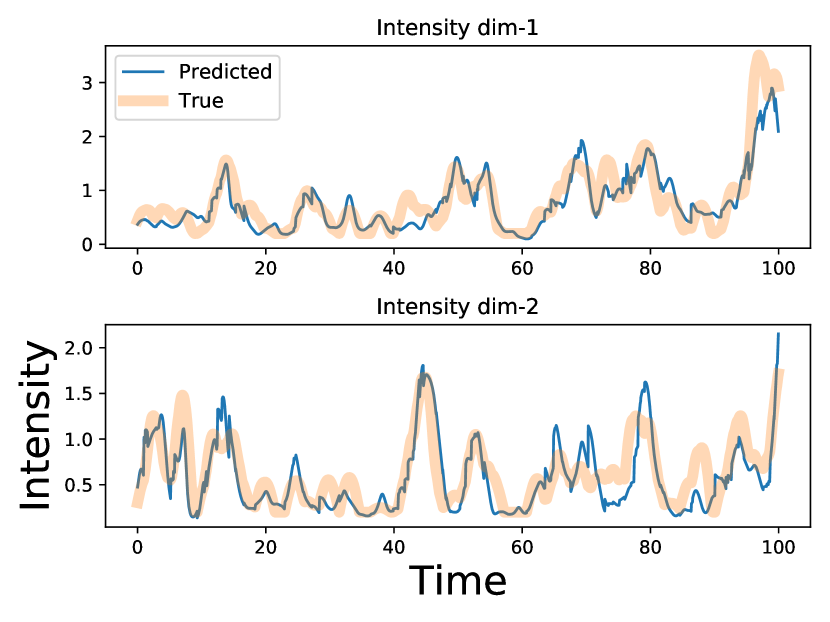
Additionally, we visualize the difference between the learned fully attention-based intensity and the learned extrapolated intensity for a segment of the sequence in Half Sinusoidal Kernel Hawkes Synthetic dataset (Section 5.1). As depicted in Fig. 4, on non-event intervals, THP, constrained by the approximately linear extrapolation, struggles to capture the fluctuating intensity patterns and can only learn an intensity that is approximately linear. Additionally, due to the limited variation in intensity on non-event intervals, large jumps are required when a new event occurs to maintain a height similar to the ground-truth intensity. In contrast, our proposed ITHP demonstrates greater flexibility, successfully capturing the fluctuating pattern on non-event intervals, and accurately fitting the scale level.
5.4. Hyperparameter Analysis
Our model’s configuration primarily encompasses two dimensions: the encoding dimension, denoted as , and the Value dimension, denoted as . We maintain the skip connection within the implementation of the encoder which necessitates that must be equal to . We test the sensitivity of model performance to hyperparameters by using various hyperparameter configurations on one toy dataset and one public dataset: the half-sine and Taxi datasets. The results of our experiments are shown in Table 2. The results indicate that our model is not significantly affected by the hyperparameter variation. Additionally, it can achieve reasonably good performance even with fewer parameters.
| Config | Taxi | Half-Sine | ||
|---|---|---|---|---|
| TLL | ACC | TLL | ACC | |
| , | 0.2513 | 0.97 | -0.7714 | 0.58 |
| , | 0.2501 | 0.97 | -0.7909 | 0.58 |
| , | 0.2520 | 0.97 | -0.7822 | 0.58 |
| , | 0.2498 | 0.97 | -0.7852 | 0.59 |
6. Conclusion
To model interactions in social networks using event sequence data, we introduce ITHP as a novel approach to enhance the interpretability and expressive power of deep point processes model. Specifically, ITHP not only inherits the strengths of Transformer Hawkes processes but also aligns with statistical nonlinear Hawkes processes, offering practical insights into user or group interactions. It further enhances the flexibility of intensity functions over non-event intervals. Our experiments have demonstrated the effectiveness of ITHP in overcoming inherent limitations in existing deep point process models. Our findings open new avenues for research in understanding and modeling the complex dynamics of social ecosystems, ultimately contributing to the broader understanding of these intricate networks.
Acknowledgments
This work was supported by NSFC Project (No. 62106121), the MOE Project of Key Research Institute of Humanities and Social Sciences (22JJD110001), and the Public Computing Cloud, Renmin University of China.
References
- (1)
- Bhaduri et al. (2021) Moinak Bhaduri, Dhruva Rangan, and Anurag Balaji. 2021. Change detection in non-stationary Hawkes processes through sequential testing. In ITM Web of Conferences, Vol. 36. EDP Sciences, 01005.
- Brémaud and Massoulié (1996) Pierre Brémaud and Laurent Massoulié. 1996. Stability of nonlinear Hawkes processes. The Annals of Probability (1996), 1563–1588.
- Daley and Vere-Jones (2003) Daryl J Daley and David Vere-Jones. 2003. An introduction to the theory of point processes. Vol. I. Probability and its Applications.
- Daley and Vere-Jones (2007) Daryl J Daley and David Vere-Jones. 2007. An Introduction to the Theory of Point Processes: Volume II: General Theory and Structure. Springer Science & Business Media.
- Dong et al. (2022) Zheng Dong, Xiuyuan Cheng, and Yao Xie. 2022. Spatio-temporal point processes with deep non-stationary kernels. arXiv preprint arXiv:2211.11179 (2022).
- Donner and Opper (2018) Christian Donner and Manfred Opper. 2018. Efficient Bayesian inference of sigmoidal Gaussian Cox processes. Journal of Machine Learning Research 19, 1 (2018), 2710–2743.
- Du et al. (2016) Nan Du, Hanjun Dai, Rakshit Trivedi, Utkarsh Upadhyay, Manuel Gomez-Rodriguez, and Le Song. 2016. Recurrent marked temporal point processes: embedding event history to vector. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. ACM, 1555–1564.
- Farajtabar et al. (2015) Mehrdad Farajtabar, Yichen Wang, Manuel Gomez Rodriguez, Shuang Li, Hongyuan Zha, and Le Song. 2015. Coevolve: A joint point process model for information diffusion and network co-evolution. Advances in Neural Information Processing Systems 28 (2015).
- Hawkes (1971) Alan G Hawkes. 1971. Spectra of some self-exciting and mutually exciting point processes. Biometrika 58, 1 (1971), 83–90.
- Kong et al. (2023) Quyu Kong, Pio Calderon, Rohit Ram, Olga Boichak, and Marian-Andrei Rizoiu. 2023. Interval-censored transformer hawkes: Detecting information operations using the reaction of social systems. In Proceedings of the ACM Web Conference 2023. 1813–1821.
- Leskovec and Krevl (2014) Jure Leskovec and Andrej Krevl. 2014. SNAP Datasets: Stanford Large Network Dataset Collection. http://snap.stanford.edu/data.
- Lewis and Mohler (2011) Erik Lewis and George Mohler. 2011. A nonparametric EM algorithm for multiscale Hawkes processes. Journal of Nonparametric Statistics 1, 1 (2011), 1–20.
- Lloyd et al. (2015) Chris Lloyd, Tom Gunter, Michael Osborne, and Stephen Roberts. 2015. Variational inference for Gaussian process modulated Poisson processes. In International Conference on Machine Learning. 1814–1822.
- Mei and Eisner (2017) Hongyuan Mei and Jason Eisner. 2017. The Neural Hawkes Process: A Neurally Self-Modulating Multivariate Point Process. In Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4-9, 2017, Long Beach, CA, USA, Isabelle Guyon, Ulrike von Luxburg, Samy Bengio, Hanna M. Wallach, Rob Fergus, S. V. N. Vishwanathan, and Roman Garnett (Eds.). 6754–6764.
- Ni et al. (2019) Jianmo Ni, Jiacheng Li, and Julian McAuley. 2019. Justifying recommendations using distantly-labeled reviews and fine-grained aspects. In Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP). 188–197.
- Noorbakhsh and Rodriguez (2022) Kimia Noorbakhsh and Manuel Rodriguez. 2022. Counterfactual Temporal Point Processes. In Advances in Neural Information Processing Systems, S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh (Eds.), Vol. 35. Curran Associates, Inc., 24810–24823. https://proceedings.neurips.cc/paper_files/paper/2022/file/9d3faa41886997cfc2128b930077fa49-Paper-Conference.pdf
- Ogata (1998) Yosihiko Ogata. 1998. Space-time point-process models for earthquake occurrences. Annals of the Institute of Statistical Mathematics 50, 2 (1998), 379–402.
- Okawa et al. (2019) Maya Okawa, Tomoharu Iwata, Takeshi Kurashima, Yusuke Tanaka, Hiroyuki Toda, and Naonori Ueda. 2019. Deep Mixture Point Processes: Spatio-temporal Event Prediction with Rich Contextual Information. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, KDD 2019, Anchorage, AK, USA, August 4-8, 2019, Ankur Teredesai, Vipin Kumar, Ying Li, Rómer Rosales, Evimaria Terzi, and George Karypis (Eds.). ACM, 373–383.
- Pan et al. (2021) Zhimeng Pan, Zheng Wang, Jeff M Phillips, and Shandian Zhe. 2021. Self-adaptable point processes with nonparametric time decays. Advances in Neural Information Processing Systems 34 (2021), 4594–4606.
- Shchur et al. (2020a) Oleksandr Shchur, Marin Bilos, and Stephan Günnemann. 2020a. Intensity-Free Learning of Temporal Point Processes. In 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, April 26-30, 2020. OpenReview.net.
- Shchur et al. (2020b) Oleksandr Shchur, Nicholas Gao, Marin Biloš, and Stephan Günnemann. 2020b. Fast and flexible temporal point processes with triangular maps. Advances in Neural Information Processing Systems 33 (2020), 73–84.
- Upadhyay et al. (2018) Utkarsh Upadhyay, Abir De, and Manuel Gomez Rodriguez. 2018. Deep reinforcement learning of marked temporal point processes. Advances in Neural Information Processing Systems 31 (2018).
- Wei et al. (2023) Song Wei, Yao Xie, Christopher S Josef, and Rishikesan Kamaleswaran. 2023. Granger Causal Chain Discovery for Sepsis-Associated Derangements via Continuous-Time Hawkes Processes. In Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 2536–2546.
- Whong (2014) Chris Whong. 2014. FOILing NYC’s taxi trip data. FOILing NYCs Taxi Trip Data. Np 18 (2014).
- Xiao et al. (2017a) Shuai Xiao, Mehrdad Farajtabar, Xiaojing Ye, Junchi Yan, Le Song, and Hongyuan Zha. 2017a. Wasserstein learning of deep generative point process models. Advances in neural information processing systems 30 (2017).
- Xiao et al. (2017b) Shuai Xiao, Junchi Yan, Xiaokang Yang, Hongyuan Zha, and Stephen M. Chu. 2017b. Modeling the Intensity Function of Point Process Via Recurrent Neural Networks. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, February 4-9, 2017, San Francisco, California, USA, Satinder Singh and Shaul Markovitch (Eds.). AAAI Press, 1597–1603.
- Zhang et al. (2022b) Lu-ning Zhang, Jian-wei Liu, Zhi-yan Song, and Xin Zuo. 2022b. Temporal attention augmented transformer Hawkes process. Neural Computing and Applications (2022), 1–15.
- Zhang et al. (2020) Qiang Zhang, Aldo Lipani, Ömer Kirnap, and Emine Yilmaz. 2020. Self-Attentive Hawkes Process. In Proceedings of the 37th International Conference on Machine Learning, ICML 2020, 13-18 July 2020, Virtual Event (Proceedings of Machine Learning Research, Vol. 119). PMLR, 11183–11193.
- Zhang et al. (2022a) Yizhou Zhang, Defu Cao, and Yan Liu. 2022a. Counterfactual neural temporal point process for estimating causal influence of misinformation on social media. Advances in Neural Information Processing Systems 35 (2022), 10643–10655.
- Zhao et al. (2015) Qingyuan Zhao, Murat A Erdogdu, Hera Y He, Anand Rajaraman, and Jure Leskovec. 2015. Seismic: A self-exciting point process model for predicting tweet popularity. In Proceedings of the 21th ACM SIGKDD international conference on knowledge discovery and data mining. 1513–1522.
- Zhou et al. (2022) Feng Zhou, Quyu Kong, Zhijie Deng, Jichao Kan, Yixuan Zhang, Cheng Feng, and Jun Zhu. 2022. Efficient Inference for Dynamic Flexible Interactions of Neural Populations. Journal of Machine Learning Research 23, 211 (2022), 1–49.
- Zhou et al. (2020a) Feng Zhou, Zhidong Li, Xuhui Fan, Yang Wang, Arcot Sowmya, and Fang Chen. 2020a. Efficient inference for nonparametric Hawkes processes using auxiliary latent variables. Journal of Machine Learning Research 21, 241 (2020), 1–31.
- Zhou et al. (2020b) Feng Zhou, Zhidong Li, Xuhui Fan, Yang Wang, Arcot Sowmya, and Fang Chen. 2020b. Fast multi-resolution segmentation for nonstationary Hawkes process using cumulants. International Journal of Data Science and Analytics 10 (2020), 321–330.
- Zhou et al. (2021) Feng Zhou, Yixuan Zhang, and Jun Zhu. 2021. Efficient Inference of Flexible Interaction in Spiking-neuron Networks. In 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. OpenReview.net.
- Zhou et al. (2013) Ke Zhou, Hongyuan Zha, and Le Song. 2013. Learning triggering kernels for multi-dimensional Hawkes processes. In International Conference on Machine Learning. 1301–1309.
- Zhou and Yu (2023) Zihao Zhou and Rose Yu. 2023. Automatic Integration for Fast and Interpretable Neural Point Processes. In Learning for Dynamics and Control Conference. PMLR, 573–585.
- Zhu et al. (2018) Han Zhu, Xiang Li, Pengye Zhang, Guozheng Li, Jie He, Han Li, and Kun Gai. 2018. Learning tree-based deep model for recommender systems. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 1079–1088.
- Zhu et al. (2021) Shixiang Zhu, Minghe Zhang, Ruyi Ding, and Yao Xie. 2021. Deep fourier kernel for self-attentive point processes. In International Conference on Artificial Intelligence and Statistics. PMLR, 856–864.
- Zipkin et al. (2016) Joseph R Zipkin, Frederic P Schoenberg, Kathryn Coronges, and Andrea L Bertozzi. 2016. Point-process models of social network interactions: Parameter estimation and missing data recovery. European journal of applied mathematics 27, 3 (2016), 502–529.
- Zuo et al. (2020) Simiao Zuo, Haoming Jiang, Zichong Li, Tuo Zhao, and Hongyuan Zha. 2020. Transformer hawkes process. In International conference on machine learning. PMLR, 11692–11702.
Appendix
Appendix A Toy Data
We simulate two synthetic datasets: the exponential decay Hawkes processes and the half sinusoidal Hawkes processes. In the case of the exponential decay Hawkes processes, we set the maximum observed length as . For the half sinusoidal Hawkes processes, the maximum observed length is set to . To perform simulation, we employ the thinning algorithm (Ogata, 1998) which is outlined in the algorithm below. Note that the kernel function is defined in Section 5.1, where is the target type and is the source type. Note that indicates all kernels whose target type is . The statistics of our toy datasets are listed in Table 3. Additionally, we present the attention weight matrix of a testing sequence in the half-sine toy data, as depicted in Fig. 6.
| Dataset | Split | # of Events | Sequence Length | Event Interval | ||||
|---|---|---|---|---|---|---|---|---|
| Max | Min | Mean(Std) | Max | Min | Mean(Std) | |||
| Exponential-Decay | training | 70644 | 877 | 47 | 282.58 (150.25) | 21.86 | 1.91e-06 | 0.28 (150.25) |
| validation | 36521 | 877 | 47 | 292.17 (153.94) | 20.90 | 1.91e-06 | 0.27 (153.94) | |
| test | 33716 | 894 | 59 | 269.73 (144.97) | 20.31 | 3.81e-06 | 0.29 (144.97) | |
| Half-Sine | training | 95714 | 858 | 158 | 382.86 (96.29) | 21.21 | 3.83e-07 | 0.52 (96.29) |
| validation | 48814 | 858 | 158 | 390.51 (106.12) | 21.21 | 3.83e-07 | 0.51 (106.12) | |
| test | 50376 | 717 | 223 | 403.01 (102.19) | 19.57 | 5.48e-06 | 0.49 (102.19) | |
Appendix B Public Data
B.1. Public Data Statistics
In this section, we cover the main statistics of five public datasets: StackOverflow, Taobao, Amazon, Taxi and Conttime, which is listed in Table 4. Note that all the public data are multivariate. The visualizations of the event percentages in each dataset are depicted in Fig. 5. Each subplot in Fig. 5 displays the distribution of event types in the training, validation, and testing sets, respectively.
| Dataset | Split | # of Events | Sequence Length | Event Interval | ||||
|---|---|---|---|---|---|---|---|---|
| Max | Min | Mean(Std) | Max | Min | Mean(Std) | |||
| STACKOVERFLOW | training | 90497 | 101 | 41 | 64.59 (20.46) | 20.34 | 1.22e-4 | 0.88 (20.46) |
| validation | 25313 | 101 | 41 | 63.12 (19.85) | 16.68 | 1.22e-4 | 0.90 (19.85) | |
| test | 26518 | 101 | 41 | 66.13(20.77) | 17.13 | 1.22e-4 | 0.85 (20.77) | |
| TAOBAO | training | 75205 | 64 | 40 | 57.85 (6.64) | 2.00 | 9.99e-05 | 0.22 (6.64) |
| validation | 11497 | 64 | 40 | 57.49 (6.82) | 1.99 | 9.99e-05 | 0.22 (6.82) | |
| test | 28455 | 64 | 32 | 56.91 (7.82) | 1.00 | 4.21e-06 | 0.05 (7.82) | |
| AMAZON | training | 288377 | 94 | 14 | 44.68 (17.88) | 0.80 | 0.010 | 0.51 (17.88) |
| validation | 40088 | 94 | 15 | 43.48 (16.60) | 0.80 | 0.010 | 0.50 (16.60) | |
| test | 84048 | 94 | 14 | 45.41 (18.19) | 0.80 | 0.010 | 0.51(18.19) | |
| TAXI | training | 51854 | 38 | 36 | 37.04 (1.00) | 5.72 | 2.78e-4 | 0.22 (1.00) |
| validation | 7422 | 38 | 36 | 37.11 (1.00) | 5.52 | 2.78e-4 | 0.22 (1.00) | |
| test | 14820 | 38 | 36 | 37.05 (1.00) | 5.25 | 8.33e-4 | 0.22 (1.00) | |
| CONTTIME | training | 479467 | 100 | 20 | 59.93 (23.13) | 4.03 | 1.91e-06 | 0.24 (23.13) |
| validation | 60141 | 100 | 20 | 60.14 (22.97) | 3.94 | 2.86e-06 | 0.24 (22.97) | |
| test | 61781 | 100 | 20 | 61.78 (23.21) | 4.47 | 9.54e-07 | 0.24 (23.21) | |
 (a) StackOverflow
(a) StackOverflow
 (b) Taobao
(b) Taobao
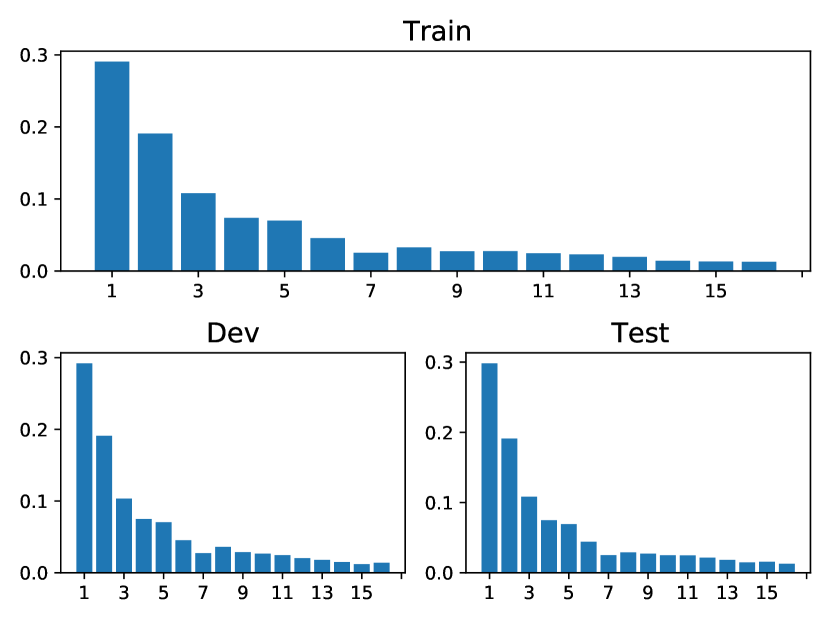 (c) Amazon
(c) Amazon
 (d) Taxi
(d) Taxi
 (e) Conttime
(e) Conttime
B.2. Additional Attention Map
We present additional attention weight matrices for the four public datasets, as depicted in Fig. 6, which is more intuitive to demonstrate how events affect each other in the sequence.
 (a) Half-sine
(a) Half-sine
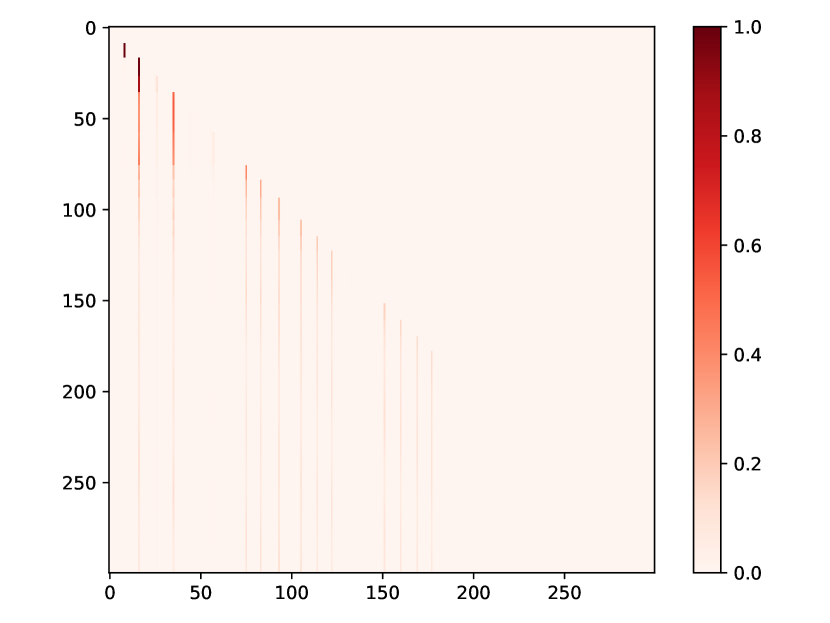 (b) Taobao
(b) Taobao
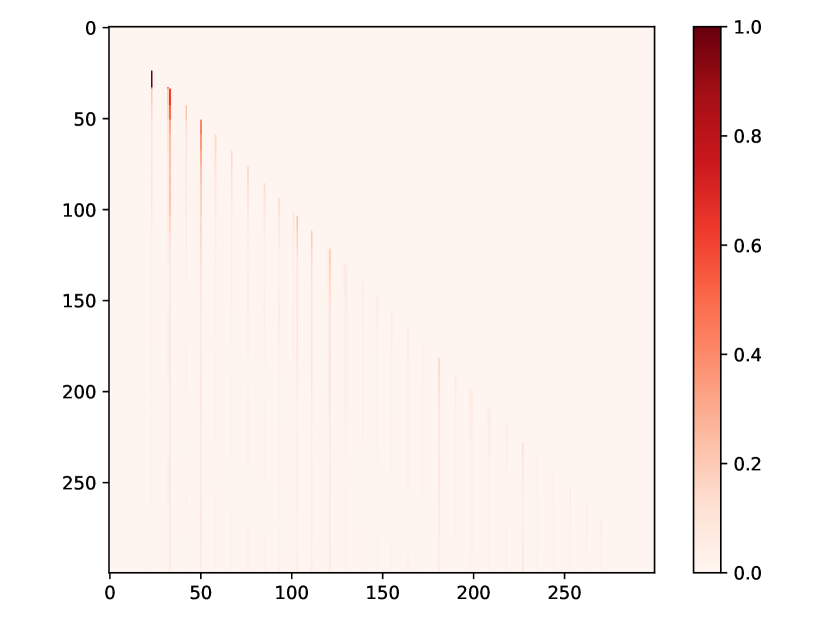 (c) Amazon
(c) Amazon
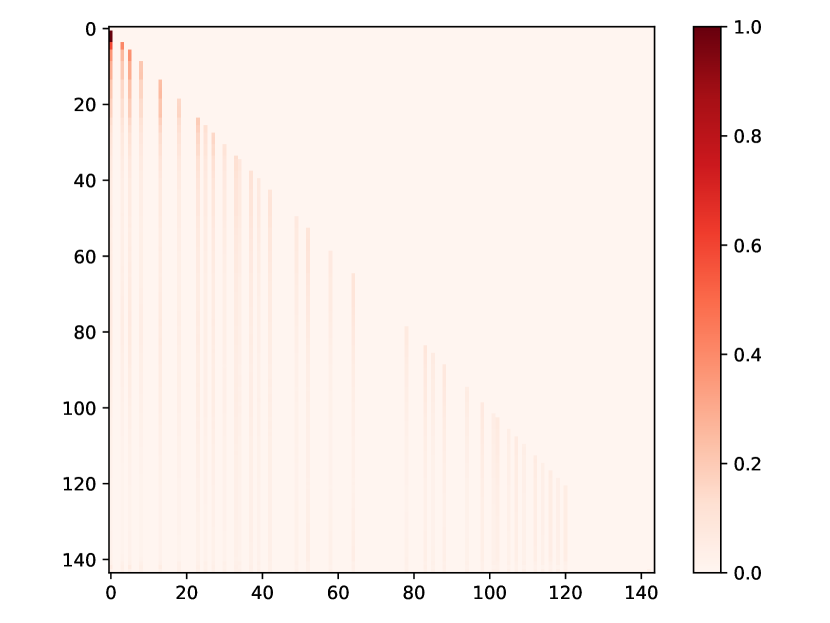 (d) Taxi
(d) Taxi
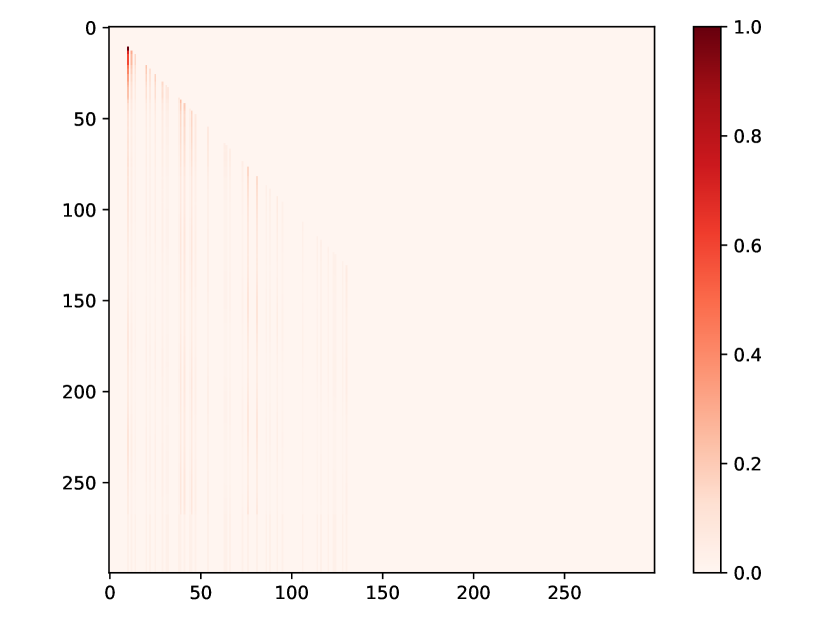 (e) Conttime
(e) Conttime
Appendix C Implementation of Ex-ITHP
The Ex-ITHP, namely, "extrapolation iTHP" is the iTHP(removing parameters , ) utilising ’extrapolation intensity’. In this section, we introduce the implementation of Ex-ITHP. Given a sequence where each event is characterized by a timestamp and an event type , Ex-ITHP utilize the same temporal embedding and type embedding and concatenates them as iTHP does:
| (9) |
where and are the temporal encoding and type encoding of . The encoder output is calculated in the same way as Eq. 4. indicates the -th row of , which is the representation of event :
| (10) |
The encoder output is then passed through a MLP to get the final representation of event :
Then, given a type and time t (), the corresponding intensity is given by the extrapolation method:
| (11) |
Finally, the log-likelihood to be optimized is given by:
| (12) |
In summary, Ex-ITHP employs identical encoding techniques, specifically temporal encoding and event type encoding, while also eliminating the use of and , akin to iTHP. However, it utilizes the extrapolation method to formulate the intensity as THP does.